Как разобрать по составу слово «изображение»? — 4 info
Как разобрать по составу слово «изображение»?
В данном вопросе требуется разобрать по составу слово изображение.
Вот так мы это сделаем ниже.
Слово изображение. Основа этого слова ИЗОБРАЖЕНИ. Слово изображение является существительным. Оно состоит из корня ИЗОБРАЖ, суффикса ЕНИ и окончания Е. В итоге получается корень-суффикс-окончание, а именно ИЗОБРАЖ — ЕНИ — Е.
Слово Изображение отвечает на вопрос Что? и оказывается существительным среднего рода (Изображение — оно мое), которое обладает окончанием -Е: Изображение-Изображения-Изображению-Изображение-Изображением-Изображении.
Однокоренными словами оказываются: Изображение-Изображать-Отображать-Образ.
Следовательно корнем слова будет морфема -ОБРАЖ-/ОБРАЗ-, часто выделяется корень ИЗОБРАЖ-.
Далее выделим в составе слова приставку ИЗ- и суффикс существительного -ЕНИ-.
Получаем: ИЗ-ОБРАЖ-ЕНИ-Е (приставка-корень-суффикс-окончание), основа слова: ИЗОБРАЖЕНИ-.
Пример предложения: Изображение было получено с помощью фотоаппарата, который был напечатан с помощью принтера.
Слово «изображение» имя существительное (Что?), неодушевлнное, среднего рода единственного числа, винительный падеж.
Части слова изображение имеет вид: изображ/ени/е.
Разбор по составу слова:
изображ это корень;
ени суффикс;
е окончание.
Основа слова является изображени .
Слово «нововведение» — это имя существительное второго склонения, среднего рода, употреблено в форме именительного или винительного падежа, единственного числа.
Окончание выделяется по-разному. В упрощенном виде должно быть выделено -е (ср.: изображени-я, изображени-ю, изображени-ем и др.). Но для профессионально или углубленно изучающих русский язык должно быть ясно, что буква е здесь обозначает два звука: jэ (йэ), из них только второй ходит в окончание, а j остается в основе: изображениj-а (изображения), изображениj-у (изображению), изображениj-эм (изображением) и т. д.
д.
Корень слова -ображ- (родственные слова — образ, изобразить, изображенный, преобразить, образец, образчик, вообразить и др.; присутствует чередование зж).
Приставка из- (значение внешнего выражения; присутствует также в словах «исходить», «изложить», «исполнить» и др.; присутствует чередование сз).
Суффикс (в зависимости от выбора окончания -ени- (-ениj-).
Основа изображени(j).
Морфемная структура слова следующая: приставкакореньсуффиксокончание. Из-ображ-ени(j)-э.
Слово «изображение» является существительным среднего рода в единственном числе.
Разбор по составу слова «изображение»:
Части слова изображение: изображ/ени/е
Состав слова:
изображ корень,
ени суффикс,
е окончание,
изображени основа слова.
Урока русского языка «Разбор слова по составу»
Приложение 2
ЗАЯВКА
участника конкурса для учителей начальных классов
«Новое качество урока.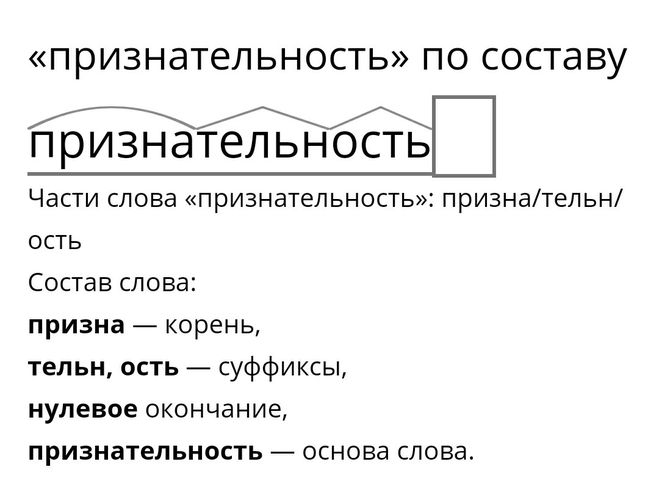 Работаем по ФГОС»
Работаем по ФГОС»
Приложение 3
Форма технологической карты урока
Анисимова Ольга Борисовна
ФИО участника
Невский район, ГБОУ СОШ№20
Район, название ОУ (кратко)
Начальная школа XXI века
Используемый УМК (учебно-методический комплекс)
русский язык
Учебный предмет
3
Класс
«Лучший урок русского языка»
Номинация, подноминация
Тип: урок отработки умений и рефлексииЦель урока: отработать алгоритм разбора слова по составу
Планируемые результаты
Предметные: разбирать слово по составу, определять способ словообразования, составление слова из заданных морфем
Метапредметные: составлять план работы над упражнением, работать по алгоритму, осуществлять самопроверку результата учебных действий
Личностные: интерес к происхождению слов
Ресурсы урока: интерактивная доска, анимированные изображения в PowerPoint, ЭФУ, учебник
Ход урока:
Содержание деятельности учителя
Содержание деятельности обучающихся
Мотивация к деятельности
На экране изображения: ягода и конфета (подписи под изображениями «ягода», «конфета») под изображениями суффиксы
-К-, -ИЩ-
Задает вопрос классу: «Какой суффикс надо выбрать, чтобы уменьшить изображение?. .. А для того чтобы увеличить?»
.. А для того чтобы увеличить?»
— Как с помощью суффикса изменялось значение слов?
— Зачем нужны суффиксы? (Помогает сформулировать ответ)
Уточняет название темы урока: «Состав слова и словообразование»
Дети отвечают, что суффикс –к- уменьшит предмет, а суффикс –ищ- — увеличит.
Подходят к интерактивной доске и выбирают суффикс.
Если выбран суффикс -к- на экране появляется уменьшенное изображение и запись: например: «ягодка», затем «конфетка»
Для того, чтобы увеличить изображение нужно выбрать суффикс –ищ-, тогда появится увеличенное изображение и запись «ягодища», затем «конфетища».
— Суффиксы –к- и –ищ- изменяли значения слов: большой предмет или маленький предмет. Суффиксы нужны для образования новых слов
Приводят примеры: рыбка дорожка, волчище, медведище
Предлагают варианты темы урока. Формулируют цели урока: повторить как разбирать слово по составу, узнать о том, как образуются новые слова
Актуализация необходимых знаний
Организует письменную работу детей, при необходимости напоминает о правильности посадки при письме, о правильном оформлении числа, записи «Классная работа».

Вызывает к доске трех сильных учеников, для написания однокоренных слов на доске.

— Приведите примеры других слов с использованными суффиксами
Предлагает разобрать слово загородный по составу. Для этого нужно вспомнить алгоритм разбора слова, изученного на уроке 8.
Вызывает к доске сильного ученика, помогает ему сформулировать алгоритм разбора слова.
Записывает на доске схематичный порядок разбора слова по составу.
На дороге суффикс –ищ-
Там за деревом волчище
На тропинке суффикс –к-
В норке спряталась лисичка
На ладошку мне упал суффикс –инк-
А с ним дождинка
Пролетает суффикс –ок-
Это легкий ветерок.
Подобрать слово с заданным корнем, подходящее по значению
Записать в тетрадь
Выделить корень и суффикс
Один из сильных учеников разбирает слово загородный у доски, комментируя свои действия.
Находим окончание, изменяя форму слова, с помощью вспомогательных слов: нет загородного, любуюсь загородным, выделяем основу слова – часть слова без окончания
Находим корень слова, подбирая однокоренные слова город, городок. Выделяем корень.
Выделяем суффикс – часть слова между корнем и окончанием, приводим примеры слов с таким же суффиксом
Выделяем приставку, приводим примеры слов с такой же приставкой.
Шагают, при слове суффикс, ладошки домиком над головой
Повторяют движения за учителем
Организация познавательной деятельности
Предлагает самостоятельно разобрать по составу слова березка и стирка, пользуясь алгоритмом написанным на доске.
Организует фронтальную проверку
Задает вопрос о значении суффикса –к- в слове берзка, называя слова с таким же суффиксом – конфетка, ямка, кроватка.

Спрашивает о значении суффикса –к- в слове стирка, называя слова с этим суффиксом: варка, глажка, засолка. Поясняет, что в этих словах значение суффикса не уменьшительное, а произведенное действие.
Предлагает детям проверить как Вова справился с заданием, найти ошибки в его работе. Придумать и записать по два своих примера. Упражнение 4 на с.30.
Проводит фронтальную проверку, придуманных примеров.
Задание выделить синим цветом слова с приставками.
Нажимает на кнопку «Проверить». Если верно, появляется надпись «Молодец», если есть ошибки, предлагает их найти.
Задает домашнее задание: записать в тетрадь и разобрать по составу слова: настольный, пальто, начало, старушка, ручка, строитель, кенгуру. Слова напечатаны на листочках.
Отвечают, что в слове «березка», суффикс –к- имеет значение «маленький», а в слове стирка, суффикс –к- имеет другое значение
Находят ошибки в работе Вовы, устно, фронтальная работа.
Придумывают и записывают свои примеры. Желающие пишут на доске. Остальные по очереди читают свои примеры слов.

Выходят к доске по цепочке, выделяя синим цветом, слова с приставками.
Рефлексия деятельности
-Чему сегодня научились?
-Что было интересным на уроке?
Предлагает оценить свою работу на уроке:
С помощью цветного кружка.
«зеленый» — не возникло затруднений
«желтый» — возникли трудности
«красный» — было трудно и непонятно
Отвечают на вопросы.
Поднимают цветные кружки.
Приложение 4
Форма экспертного заключения
(первый этап Конкурса)
_____________________________________________________________________________
ФИО участника
_____________________________________________________________________________номинация, подноминация
Баллы:
0 – отсутствие данного критерия
1 – частичное наличие данного критерия
2 – наличие данного критерия
Баллы выставляются по каждому критерию
Член жюри:______________________/____________________________/ Дата ___________
Приложение 5
Форма экспертного заключения
по итогам проведения мастер-класса
_____________________________________________________________________________
ФИО участника
_____________________________________________________________________________номинация, подноминация
Баллы:
0 – отсутствие данного критерия
1 – частичное наличие данного критерия
2 – наличие данного критерия
Баллы выставляются по каждому критерию
Член жюри:______________________/____________________________/ Дата ___________
«знакомстве» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Оля Бережная. Екатерина Майская запись закреплена три часа назад. Ищу компанию на погулять в выходные. Нина Королькова. Екатерина Майская. Нина , может Сокольники,может Измайловский. Сколько карандашей на фото? Сначала старые. Bahtiyor Boboev. Светлана Светлана запись закреплена три часа назад.
Екатерина Майская запись закреплена три часа назад. Ищу компанию на погулять в выходные. Нина Королькова. Екатерина Майская. Нина , может Сокольники,может Измайловский. Сколько карандашей на фото? Сначала старые. Bahtiyor Boboev. Светлана Светлана запись закреплена три часа назад.
Истинная любовь приходит случайно, там где ты её не ждёшь. И она может быть не идеальная, как и сам человек. И все мы не идеальны, но встречаем друг друга.. Я бы всем пожелала искать отношения сердцем, а не умом по списку качеств. Юлия Антонова.
Знакомства после 40. Тренд современности: женщина старше мужчины
А я вообще не могу понять, как можно искать любовь она или есть или ее нет. Это непредсказуемо, вообще Виктория Чел. Юлия , думаю, имеется в виду как-то заявить о себе не сидеть дома и не ждать. Но в то же время и на Берлин не идти. Юлия Антонова ответила Виктории.
Виктория , наверное. Красивые слова!. Екатерина Майская запись закреплена вчера в Мужчины,что должна уметь или обладать какими качествами женщина,чтобы вы влюбились в неё? Евгений Лисицын ответил 9 ответов Показать следующие комментарии. Алексей Велесов. Екатерина Майская ответила 3 ответа Показать следующие комментарии. Доброго времени суток познакомлюсь с девушкой лет для серьезных отношений!!! Андрей Сутягин запись закреплена вчера в Только девушки. Что сегодня Вас заставило улыбнуться?
Владимир Крузо. Ольга Сукач ответила 10 ответов Показать следующие комментарии. Евгения Родина. Сегодня у меня все плохо.
Знакомства от 40 до 50
Евгения , тогда вам срочно необходимы обнимашки со слоненком Евгения Родина ответила Евгению. Евгений , да мне срочно нужны обнимашки. Ольга Сукач. Её записи проданы тиражом млн альбомов и более 55 миллионов синглов по всему миру «Чем меньше думаешь о годах, чем меньше смотришься в зеркало, тем лучше выглядишь. Mireille Mathieu. Tous les enfants chantent avec moi.
Tous les enfants chantent avec moi.
Мирей Матье. Sous Le siel De Paris. Ciao, Bambino, Sorry Пока, милый, прости. La Paloma adieu. Une Femme Amoureuse Der Pariser Tango. Я уже долго тебя ищу, моя милая, дорогая женщина.
Так как я ни разу тебя не видел и не знаю. Возможно мы уже не раз проходили мимо друг- друга, В нашем городе, мы может быть живём, с тобой на одной улице, а может на разных берегах, нашего могучего Енисея.
Женщины за 40, не старайтесь подстраиваться под мужчину!
Показать полностью… Пусть я не знаю, как ты выглядишь, но для меня ты самая красивая и желанная. Ты умная, начитана, с хорошим вкусом и чёткой жизненной позицией. У тебя правильная система ценностей, ты ненавидишь ложь, предательство. Возможно тебя уже предавали, твой самый близкий для тебя человек, возможно потушил в тебе веру в мужчин. Жив будь доселе царь Додон, одной тобой он был бы опьянён. Ему б не нужно было ни сребра ни злата, но ты одна была бы виновата. Что он не устерёг своих границ пока перед тобою падал ниц!
Анатолий 2 года назад. Ты очень красивая! Может познакомимся? Батыр Гулматов 2 года назад. Александр Докукин 2 года назад. Сергей 2 года назад. Arthur 2 года назад. Оксана Гирич 2 года назад. Сергей Трусов 2 года назад.
Ты очень красивая! Может познакомимся? Батыр Гулматов 2 года назад. Александр Докукин 2 года назад. Сергей 2 года назад. Arthur 2 года назад. Оксана Гирич 2 года назад. Сергей Трусов 2 года назад.
Артур Хачатурян 3 года назад. Александр Кузнецов 4 года назад. Артур Хачатурян Александр Кузнецов 3 года назад. Комментарий удален. Селиван Осьмаков 4 года назад.
Первые «Быстрые свидания» в Баку: как это было?
Зарабатывай реальные деньги в играх онлайн. Без ограничений. Serg Thirteenth 4 года назад. Mishqa 4 года назад. Михаил 4 года назад. Показать ещё 24 комментария из Российские Флинстоуны: по Челябинску ездит маршрутка с дырой в полу.
Узбекские знакомства | стр.3
Хотите познакомиться с женщиной лет в Москве? 35–40 лет для представительниц слабого пола – возраст достижения духовной зрелости. Знакомства женщин от 40 до 50 лет из любого города для серьёзных отношений, брака или дружбы, я страница результатов поиска.
Вот это разворот! В Ейске пострадала автомобилистка. Инвалиды, потерявшие конечности, но не чувство юмора. Почему в армии нельзя носить бороду? Подборка демотиваторов на злобу дня. Распродажа квартир в новостройках: в чем обман? Стань лицом с обложки диска!
Инвалиды, потерявшие конечности, но не чувство юмора. Почему в армии нельзя носить бороду? Подборка демотиваторов на злобу дня. Распродажа квартир в новостройках: в чем обман? Стань лицом с обложки диска!
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.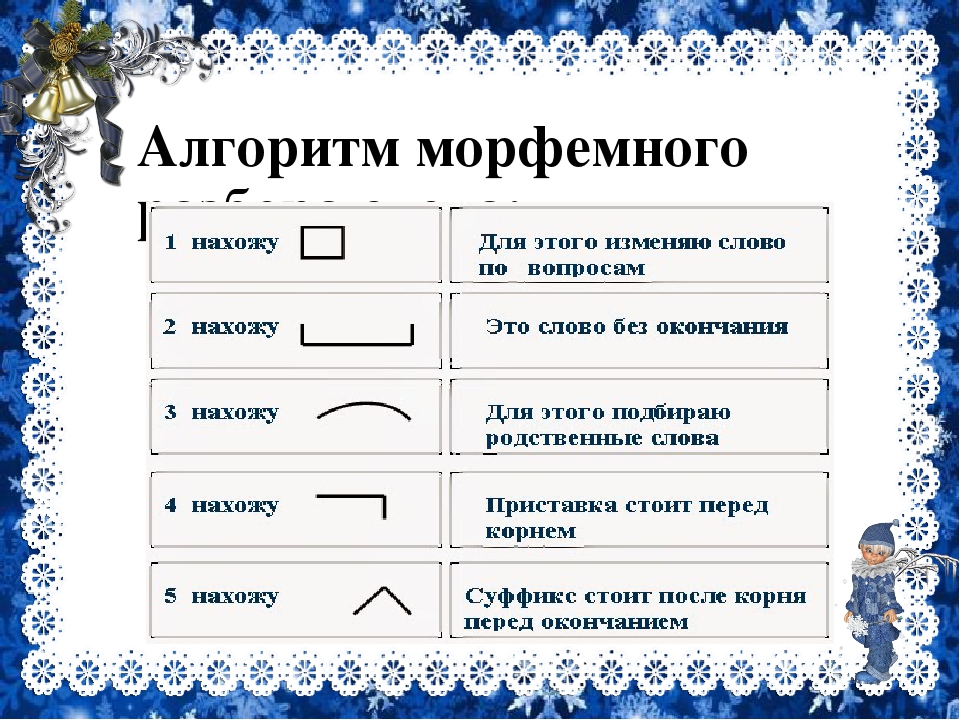
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Сделайте морфемный разбор слов (разобрать слова по составу) : Учительница, пришкольный,
Определи вариант где верно образованные личные формы глагола.Определи вариант, где верно образованы личные формы глаголов. дарить – дарю, даришь, даюл
… юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
дарить – дарю, даришь, даюл
… юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
Распределительная работа. Раскрывая скобки, запишите данные выражения группами, исходя из часте-речной принадлежности слова. Объясните правила написан … ия частиц не.
РЕБЯТА ДАЮ 50 БАЛОВ!!!!!!!!! НАПИСАТЬ СОЧИНЕНИЕ С ОТВЕТОМ НА ВОПРОС «ПРАВИЛЬНО ЛИ ПОСТУПИЛ БОРИС, КОТОРЫЙ ОСТАВИЛ РЫСЬ?» ПО РАССКАЗУ Е.МАРЫСЕВУ
Упражнение 500. Назовите стороны света, запишите их.Образец: Юго-запад.быстрее кто ответить тому лучший ответтт
Русский язык сор 7 класс 4 четверть, срочно.Вот мой номер:87074206310 напишите
Определите, к каким частям речи относятся слова из текста, и расположите их в следующей последовательности: А) прилагательное, Б) существительное, В) … глагол, Г) местоимение, Д) существительное, Е) предлог, Ж) наречие, З) прилагательное, К) существительное 1) животными, 2) количествах, 3) растительная, 4) пища, 5) используется 6) в, 7) небольших, 8) очень, 9) этими
Читательская грамотностьПрочитай текст «Про ежей» и ответы на вопросы. Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
прочитайте. Назовите лишние слова. Можно ли их заменить?пожалуйста помогите ❣
Слово в прямом значении: a) Добрая семечка b) Добрые книжки c) Добрая девочка d) Добрый вечер e) Доброе утро
Можете ответить на вопрос пожалуйста
Разобрать по составу слова:рыбка, тишина, лесною.

Определи вариант где верно образованные личные формы глагола.Определи вариант, где верно образованы личные формы глаголов.дарить – дарю, даришь, даюл … юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
Распределительная работа. Раскрывая скобки, запишите данные выражения группами, исходя из часте-речной принадлежности слова. Объясните правила написан … ия частиц не.
РЕБЯТА ДАЮ 50 БАЛОВ!!!!!!!!! НАПИСАТЬ СОЧИНЕНИЕ С ОТВЕТОМ НА ВОПРОС «ПРАВИЛЬНО ЛИ ПОСТУПИЛ БОРИС, КОТОРЫЙ ОСТАВИЛ РЫСЬ?» ПО РАССКАЗУ Е.МАРЫСЕВУ
Упражнение 500. Назовите стороны света, запишите их.Образец: Юго-запад.быстрее кто ответить тому лучший ответтт
Русский язык сор 7 класс 4 четверть, срочно.Вот мой номер:87074206310 напишите
Определите, к каким частям речи относятся слова из текста, и расположите их в следующей последовательности: А) прилагательное, Б) существительное, В) … глагол, Г) местоимение, Д) существительное, Е) предлог, Ж) наречие, З) прилагательное, К) существительное 1) животными, 2) количествах, 3) растительная, 4) пища, 5) используется 6) в, 7) небольших, 8) очень, 9) этими
Читательская грамотностьПрочитай текст «Про ежей» и ответы на вопросы.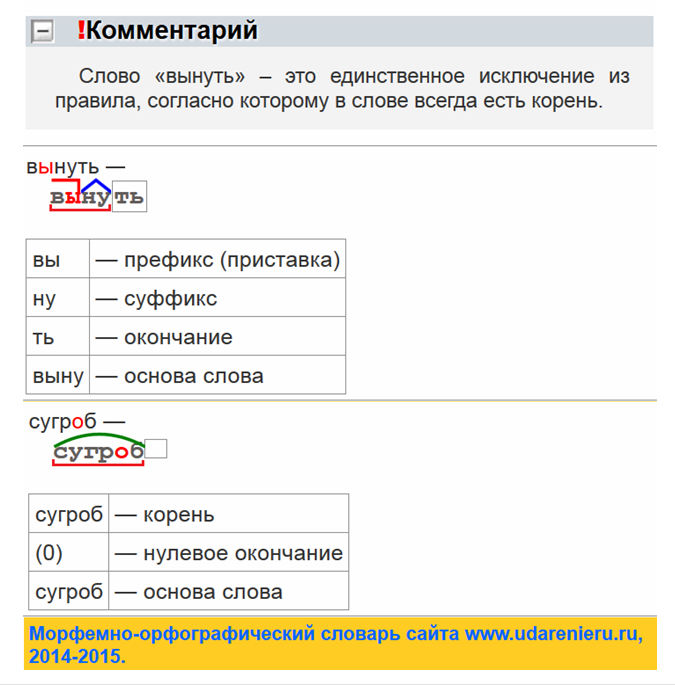 Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
прочитайте. Назовите лишние слова. Можно ли их заменить?пожалуйста помогите ❣
Слово в прямом значении: a) Добрая семечка b) Добрые книжки c) Добрая девочка d) Добрый вечер e) Доброе утро
Можете ответить на вопрос пожалуйста
Два изображения, три слова и отпечатки пальцев обнаружили под «Черным квадратом»
Информация о том, что под красочным слоем «Черного квадрата» Казимира Малевича обнаружено изображение и три слова, неделю назад стала сенсацией. Тогда сотрудники Третьяковской галереи, где и прошло исследование картины, отложили комментарии до официальной презентации. Об этом «Ведомости», получившие разъяснения от музея, писали 12 ноября.
Тогда сотрудники Третьяковской галереи, где и прошло исследование картины, отложили комментарии до официальной презентации. Об этом «Ведомости», получившие разъяснения от музея, писали 12 ноября.
Несмотря на то что мир волнуют уже другие, очень далекие от искусства проблемы, в здании Третьяковской галереи на Крымском Валу в зале Малевича собралось очень много журналистов. Им показали, как выглядит рентгенограмма картины, что видно на холсте при макрофотосъемке с помощью бинокулярного микроскопа и что получается, если «скомпоновать результаты съемок на рентгеновских пленках в единую композицию».
Получаются очень, надо сказать, эффектные изображения. Интригующе выглядит как черно-белая рентгенограмма, так и цветная реконструкция первоначальной композиции, поверх которой и написан черный квадрат. Причем и эти краски были наложены не одновременно, так что, возможно, изображений два. Также исследователи предполагают, что возникшие на холсте кракелюры являются следствием толщины красочного слоя. Очевидно поэтому картина постепенно теряла также свою черноту. На полотне, что было известно и раньше, до нынешнего исследования, оставались следы авторской реставрации. Через 14 лет после написания «иконы супрематизма» (это случилось, как доказала Александра Шатских, 8 июня 1915 г.) картина должна была быть выставлена на персональной выставке Малевича в Третьяковской галерее. Очевидно, тогда заведующий отделом нового русского искусства Алексей Федоров-Давыдов и попросил художника написать авторскую копию картины. Легко предположить, что физическое состояние оригинала казалось ему не слишком надежным.
Очевидно поэтому картина постепенно теряла также свою черноту. На полотне, что было известно и раньше, до нынешнего исследования, оставались следы авторской реставрации. Через 14 лет после написания «иконы супрематизма» (это случилось, как доказала Александра Шатских, 8 июня 1915 г.) картина должна была быть выставлена на персональной выставке Малевича в Третьяковской галерее. Очевидно, тогда заведующий отделом нового русского искусства Алексей Федоров-Давыдов и попросил художника написать авторскую копию картины. Легко предположить, что физическое состояние оригинала казалось ему не слишком надежным.
Кроме того, в результате исследований было обнаружено, что квадрат написан двумя черными красками, разными по составу. То есть, насколько и как черен черный квадрат, Малевичу было небезразлично. Другое дело, что исследуемый «Черный супрематический квадрат», который впервые был выставлен в декабре 1915 г., могут видеть только посетители Третьяковской галереи. На многочисленные выставки посылается как раз вариант 1929 г. этого самого востребованного произведения музея, потому что первый нетранспортабелен.
этого самого востребованного произведения музея, потому что первый нетранспортабелен.
Что же касается надписи из трех слов, которая так заинтриговала публику, то она была сделана поверх окончательного красочного слоя карандашом и могла, как сказала научный сотрудник музея Ирина Вакар, быть сделана кем угодно, например посетителем выставки. Хотя исследователи склонны к заключению, что, судя по почерку, написал ее сам Малевич. Почему и зачем – неизвестно. Из трех слов два прочитаны сотрудниками музея как «Битва негров…», третье разобрать трудно. Но, как и писали «Ведомости», нельзя точно сказать, знал ли художник о том, что французский остроумец Альфонс Алле выставил в 1882 г. черный прямоугольник в раме, названный «Битва негров в пещере ночью». Вакар также напомнила, что шуточные надписи на полях были популярны в то время у художников-футуристов.
Еще при исследовании на картине обнаружены отпечатки пальцев Малевича, что вполне естественно. Как ни пытали журналисты вопросами научных сотрудников Третьяковской галереи и ее директора Зельфиру Трегулову, никаких однозначных выводов, сделанных по результатам исследования, они не высказали. Разве что окрепла уверенность, что «Черный квадрат» был написан художником не случайно, а в результате размышлений и поисков, что, впрочем, было известно и без высокотехнологичной аппаратуры.
«Черному супрематическому квадрату» Казимира Малевича исполнилось в этом году 100 лет. И, как показали последние события, он до сих пор способен вызвать сенсацию. Которой, к слову, не было, когда его впервые показали публике на выставке «0,10». Но что, в сущности, такого – под красочным слоем знаменитой картины нашли ранние изображения, три слова и отпечатки пальцев художника? Никак это причины славы произведения не проясняет, а хотелось бы.
Image to Text: как извлечь текст из изображения
Представьте, что существует простой способ получить или извлечь текст из изображения, отсканированного документа или файла PDF и быстро вставить его в другой документ.
Хорошая новость заключается в том, что вам больше не нужно тратить время на ввод всего текста, потому что есть программы, использующие оптическое распознавание символов (OCR) для анализа букв и слов на изображении, а затем их преобразования в текст.
Существует ряд причин, по которым вы можете захотеть использовать функцию OCR для копирования текста из изображения или PDF.
- Вставьте текст с изображения или снимка экрана в Microsoft Office или другой документ.
- Сохранение текста в сообщении об ошибке, всплывающем окне или меню, где текст не может быть выделен.
- Захватить текст в каталоге файлов (имя файла, размер файла, дата изменения).
Независимо от вашей ситуации, этот тип функциональности может быть полезен, особенно когда вам нужно скопировать информацию из папки с файлами или снимка экрана веб-сайта, что обычно требует от вас значительного количества времени для повторного ввода всего текста.
К счастью, есть чрезвычайно простой способ сохранить текст или преобразовать изображение текста в редактируемый текст. С Snagit достаточно всего нескольких шагов, чтобы быстро извлечь текст с изображения.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Вот все, что вам нужно знать о том, как снимать текст с экрана компьютера или извлекать текст из изображения.
Как записать текст в Windows или Mac
Шаг 1. Настройте параметры захвата.
Чтобы захватить текст, откройте окно захвата, выберите вкладку «Изображение» и установите для выбора значение «Захватить текст».
Вы также можете ускорить процесс с помощью предустановки «Захват текста».
Шаг 2. Сделайте снимок экрана
Начните захват, затем с помощью перекрестия выберите область экрана с нужным текстом.
Snagit анализирует выбранный вами текст и отображает отформатированный текст.
Если указанный шрифт не установлен на вашем компьютере, Snagit заменит его системным шрифтом аналогичного стиля.
Выделите текст, который хотите скопировать, или нажмите «Копировать все…», чтобы скопировать весь текст в буфер обмена.
Шаг 3. Вставьте текст
Наконец, вы можете вставить текст в документ, презентацию или любое другое место назначения.
Изображение в текст: как извлечь текст из изображения с помощью OCR
Шаг 1. Найдите свое изображение
Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.
Шаг 2. Откройте текст для захвата в Snagit
Открыв изображение в редакторе Snagit, перейдите в меню «Правка» и выберите «Захватить текст».
Или просто щелкните изображение правой кнопкой мыши или щелкните изображение и выберите «Захватить текст».
Шаг 3. Скопируйте текст
Затем скопируйте текст и вставьте его в другие программы и приложения.
И все. Извлечение текста из изображений, PDF-файлов или отсканированных документов не требует особых усилий.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Часто задаваемые вопросы
Как преобразовать изображение в текст?Загрузите ваше изображение в Snagit. Затем щелкните правой кнопкой мыши в любом месте изображения и выберите «Захватить текст». Это сканирует ваше изображение и преобразует его в текст.
Как извлечь текст из изображения в Windows?Сначала используйте Snagit, чтобы сделать снимок экрана своего изображения или загрузить его в редактор.
Snagit использует программное обеспечение оптического распознавания символов, или OCR, для распознавания и извлечения текста из изображения на компьютере с Windows.
Как извлечь текст из отсканированного PDF-файла?Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе. Затем просто щелкните изображение правой кнопкой мыши и выберите «Захватить текст».
Текст из отсканированного PDF-файла можно затем скопировать и вставить в другие программы и приложения.
Как скопировать текст с изображения?Воспользуйтесь окном захвата изображения Snagit. Затем в раскрывающемся списке выберите «Захватить текст». По завершении появится окно со всем текстом, готовым для копирования и вставки.
Примечание редактора. Этот пост был первоначально опубликован в 2017 году и был обновлен для обеспечения точности и полноты.
Копирование текста с изображений и распечаток файлов с помощью OCR в OneNote
OneNote поддерживает оптическое распознавание символов (OCR), инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки, чтобы вы могли вносить изменения в слова.Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или в другую программу, например Outlook или Word.
Извлечь текст из одного изображения
Щелкните изображение правой кнопкой мыши и выберите Копировать текст с изображения .
Примечание. В зависимости от сложности, разборчивости и количества текста, отображаемого на вставленном вами рисунке, эта команда может быть недоступна сразу в меню, которое появляется при щелчке правой кнопкой мыши на изображении.Если OneNote все еще читает и преобразует текст на изображении, подождите несколько секунд и повторите попытку.
Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Извлечь текст из изображений распечатанного многостраничного файла
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
Нажмите Копировать текст с этой страницы распечатки , чтобы скопировать текст только с текущего выбранного изображения (страницы).
Нажмите Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех изображений (страниц).
Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Примечание. Эффективность оптического распознавания символов зависит от качества изображения, с которым вы работаете.После вставки текста с изображения или распечатки файла рекомендуется просмотреть его и убедиться, что текст распознан правильно.
Пусть этот AI-бот превратит ваши слова в расплывчатые картинки
Лаборатория
Интерпретация ИИ фразы: «лаборатория».Искусственный интеллект уже влияет на большую часть нашей жизни разными способами, например, помогает водить машину, украшает наши фото в Instagram с едой и даже помогает диагностировать болезни.ИИ обрабатывает данные иначе, чем люди, поэтому общение с ним на нашем странном, непоследовательном языке может привести к таким дурацким результатам. Последняя коллекция странных творений искусственного интеллекта поступает из сети Attentional Generative Adversarial Network, которая переводит напечатанные слова в визуальное изображение.
Кристобаль Валенсуэла, создающий инструменты машинного обучения, создал сайт, чтобы продемонстрировать, как ИИ может анализировать слова и пытаться передать их значение визуально.
Впервые он был замечен в отличном блоге AI Weirdness, который кратко описывает весь процесс как «визуальный чат-бот в обратном порядке.«Вместо того, чтобы пытаться рассказать вам, что изображено на картинке, алгоритм пытается создать картинку из того, что вы ему рассказываете. Концепция основана на исследовании из опубликованной в прошлом году статьи под названием AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
.Бот рисует из набора объектов, на которых он был обучен. В результате он намного точнее работает с повседневными предметами, которые легко переводятся в картинку. Вещи становятся намного более абстрактными, когда вы начинаете кормить их туманными терминами, сложными концепциями или, как мне кажется, дурацкой чепухой.
Мы ввели в инструмент некоторые научные термины, чтобы увидеть, на что он способен. Результаты предсказуемо странные, по крайней мере, для моего мозга, не являющегося роботом.
Вы можете попробовать свои собственные фразы здесь, но имейте в виду, что большой трафик из Twitter сделал службу немного ненадежной.
Вторичные материалы
Интерпретация AI фразы: «Вторичные материалы».Химическая реакция
Интерпретация AI фразы: «Химическая реакция.”Марсоход
Интерпретация ИИ фразы: «Марсоход».Поле астероидов
Интерпретация ИИ фразы: «Поле астероидов».Большой взрыв
Интерпретация ИИ фразы: «Большой взрыв».Внеземная жизнь
Интерпретация ИИ фразы: «Внеземная жизнь».Изменение климата
Интерпретация AI фразы: «Изменение климата».Космический корабль
Интерпретация AI фразы: «Космический корабль.”Как Evernote делает текст внутри изображений доступным для поиска — справочный центр Evernote
Как Evernote делает текст внутри изображений доступным для поиска
Знаете ли вы, что когда вы делаете снимок или прикрепляете изображение к заметке, Evernote может найти и идентифицировать текст, включая рукописный текст, внутри этого изображения?
Как это работает
Машинописный текст и рукописные заметки в формате JPG, PNG или GIF оцениваются нашей системой индексирования.Текст, найденный в изображении, будет оцениваться, если он соответствует одной из следующих ориентаций в пределах нескольких градусов:
- 0 ° — нормальная горизонтальная ориентация
- 90 ° — вертикальная ориентация
- 270 ° — вертикальная ориентация
Текст, не соответствующий одной из этих ориентаций, будет проигнорирован (включая диагональный и инвертированный текст). Когда изображения индексируются, они могут показывать несколько результатов. Например, система индексации может взглянуть на слово и решить, что это «кошка», «летучая мышь» или «3at».
Лучший способ убедиться, что почерк, в частности, найден и проиндексирован, — это следовать этим рекомендациям:
- Изображения, содержащие рукописный текст, следует добавлять в Evernote как изображения JPG, а не в формате PDF. Файлы PDF являются предпочтительным форматом для машинописных документов или отсканированных страниц, содержащих машинописный текст. Рукописный ввод не индексируется в файлах PDF.
- Чем четче почерк, тем больше вероятность, что он будет точно проиндексирован для поиска. Если почерк трудно читается, то Evernote будет труднее различать написанные слова.
- Имейте в виду, что вместо того, чтобы генерировать одно совпадение для данного рукописного слова, Evernote будет генерировать несколько возможных совпадений для этого слова. Например, слово «плоский» в формате JPG может быть проиндексировано как «плоский», «плавающий» или «фиатный».
В настоящее время Evernote может индексировать 28 машинописных языков и 11 рукописных языков. Вы можете выбрать, какой язык будет использоваться при индексировании, изменив параметр «Язык распознавания» в настройках своей учетной записи.
Подробнее о том, как работает распознавание изображений Evernote
Примеры
- Делайте снимки меню ресторана (включая меню на вынос) и сохраняйте их в своей учетной записи Evernote для использования в будущем.
- Делайте фотографии винных и пивных этикеток, чтобы отслеживать свои любимые товары и любые дегустационные заметки.
- Делайте фотографии подарочных карт и подарочных сертификатов, чтобы всегда знать, где можно потратить лишние деньги.
- Делайте снимки рукописных поздравительных открыток и просматривайте их, когда душе угодно.
- Фотографируйте гарантии, инструкции по уходу за продуктами и любую другую полезную информацию, которую вы встретите в бумажной форме.
LANGUAGES_SUPPORT LANGUAGES_INCLUDE = ms
Ключевые слова:
- текстовый поиск
- поисковый текст
- текст в изображениях
- индекс
- индексирование изображений
- окр
- распознавание изображений
- распознавание текста
- индексных изображений
- почерк
- рукописный
— Ruby: синтаксический анализ / извлечение изображений и объектов из файла docx
Я пытаюсь открыть и прочитать.docx с помощью Ruby, извлеките части текста и объектов / изображений и сохраните их в другом (не .docx) файле.
Используя Nokogiri, я могу правильно извлекать текст и разбивать документ на разделы, которые мне нужны через:
zip = Zip :: File.open file_path
doc = zip.find_entry ("word / document.xml")
xml = Nokogiri :: XML.parse (doc.get_input_stream)
wt = xml.root.xpath ("// w: t", {"w" =>
"http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
Если я сделаю это вместо этого:
xml.root.xpath ("// w: body", {"w" => "http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
Я вижу объекты в xml как:
, но не знаю, как преобразовать это во что-то, что позже можно будет использовать для отображения в html. Преобразование в svg таким образом, чтобы его можно было отображать вместе с текстом в html, было бы идеальным.
Спасибо за любую помощь.
python — как реализовать макет для анализа значений и получения файла взамен?
После более чем 30-часовой попытки реализовать python_-docx и docxtpl для определенных функций (и при этом совершенно неуспешно) я решил зайти сюда за советом.
Мой текущий проект состоит из различных изображений (.png), форматированного текста (т.е. полужирный, тень, шрифт, цвет и т. Д.) И т. Д. — теперь эти элементы нужно расположить / вписать в аккуратный шаблон. Сначала я попробовал подушка , создав холст и добавив все эти элементы каждый. Само решение чрезвычайно подвержено ошибкам и не поддерживает все функции, касающиеся текста. Затем я создал шаблон .docx (расположение изображений, текста, включая шрифт, стиль и т. Д.)) и реализовать ценности таким образом — это сработало! … кроме того, что он не поддерживает более одного элемента изображения / мультимедиа на странице Word!)
В демонстрационных целях я попытался набросать рабочий процесс:
Теперь должно быть очевидно, почему я попробовал Word — простую программу для редактирования слов, в которой я смог отформатировать все по своему желанию (хотя Python API не работал, следовательно, он бесполезен) — в демонстрационных целях, вот фрагмент псевдокода:
# КОД ПСЕВДО
из docxtpl import DocxTemplate
tpl = DocxTemplate ('файл.docx ')
tpl.replace_media ('dummy.png', 'pic1.png')
tpl.replace_media ('dummy2.png', 'pic2.png')
tpl.save ('out.docx')
В зависимости от настройки он либо заменяет None, либо оба изображения одним из них. Согласно различным вопросам и темам StackOverflow, более одного изображения невозможно ! Поэтому слово «подход» бесполезно.
Во всяком случае, я ничего не знаю. Любые предложения о том, как достичь такого рабочего процесса, то есть иметь простой редактируемый макет, в котором мне просто нужно проанализировать определенные значения и получить .docx , .png , .pdf , что угодно ..
Извлечение текста из изображений с помощью Tesseract OCR, OpenCV и Python
Людям легко понять содержимое изображения, просто взглянув на него. Вы можете распознать текст на изображении и без особого труда понять его. Однако компьютеры работают иначе. Они понимают только организованную информацию. И именно здесь на сцену выходит оптическое распознавание символов.В моем предыдущем блоге я объяснил основы OCR и 3 важные вещи, о которых вам следует знать. Как и обещал моим читателям, я вернулся со своим вторым блогом. На этот раз я собираюсь подробнее рассказать об оптическом распознавании текста, особенно об извлечении информации из изображения. И, как всегда, с автоматизацией вы можете вывести это на новый уровень. Автоматизация задачи извлечения текста из изображений поможет вам вести и анализировать записи. В этом блоге основное внимание уделяется областям приложений OCR с использованием Tesseract OCR, OpenCV, установке и настройке среды, кодированию и ограничениям Tesseract.Итак, приступим.
Тессеракт OCR
Tesseract — это движок распознавания текста с открытым исходным кодом, доступный по лицензии Apache 2.0, и его разработка спонсируется Google с 2006 года. В 2006 году Tesseract считался одним из самых точных движков OCR с открытым исходным кодом. Вы можете использовать его напрямую или можете использовать API для извлечения печатного текста из изображений. Самое приятное то, что он поддерживает большое количество языков. Именно через оболочки Tesseract можно сделать совместимым с различными языками программирования и фреймворками.В этом блоге я буду использовать оболочку Python под названием pytesseract. Он используется для распознавания текста из большого документа или его также можно использовать для распознавания текста из изображения одной текстовой строки. Ниже представлено визуальное представление архитектуры Tesseract OCR, представленной в исследовательском документе по системе OCR на основе голосования.
Говоря о Tesseract 4.00, он имеет настроенный распознаватель текстовых строк в своей новой подсистеме нейронной сети. В наши дни люди обычно используют сверточную нейронную сеть (CNN) для распознавания изображения, содержащего один символ.Текст произвольной длины и последовательность символов решается с использованием рекуррентной нейронной сети (RNN) и долговременной краткосрочной памяти (LSTM), где LSTM является популярной формой RNN. Входное изображение Tesseract в LSM обрабатывается построчно в прямоугольниках, которые вставляются в модель LSTM и выдают выходные данные.
По умолчанию Tesseract рассматривает входное изображение как страницу текста в сегментах. Вы можете настроить различные сегменты Tesseract, если хотите захватить небольшую область текста с изображения.Вы можете сделать это, назначив ему режим —psm . Tesseract полностью автоматизирует сегментацию страниц, но не выполняет ориентацию и обнаружение скриптов. Различные параметры конфигурации для Tesseract упомянуты ниже:
Режим сегментации страниц (—psm): Настроив это, вы можете помочь Tesseract в том, как он должен разделять изображение в форме текста. Справка командной строки имеет 11 режимов. Вы можете выбрать тот, который лучше всего подходит для ваших требований, из приведенной ниже таблицы:
| режим | Рабочее описание |
| 0psm | Только ориентация и обнаружение сценария (OSD) |
| 1 | Автоматическая сегментация страниц с помощью экранного меню |
| 2 | Автоматическая сегментация страниц без экранного меню или OCR |
| 3 | Полностью автоматическая сегментация страниц, без экранного меню (по умолчанию) |
| 4 | Предположим, что один столбец текста переменного размера |
| 5 | Предположим, что это один однородный блок с вертикально выровненным текстом |
| 6 | Предположим, что один однородный блок текста |
| 7 | Обрабатывать изображение как одну текстовую строку |
| 8 | Обрабатывать изображение как одно слово |
| 9 | Для обработки изображения как отдельного слова в круге |
| 10 | Считать изображение одним символом |
| 11 | Разрезанный текст.Найдите как можно больше текста не в определенном порядке |
| 12 | Разреженный текст с экранным меню |
| 13 | Сырая линия. Рассматривайте изображение как одну текстовую строку, избегайте взлома, специфичного для Tesseract. |
Engine Mode (—oem): Tesseract имеет несколько режимов двигателя с разной производительностью и скоростью. Tesseract 4 представил дополнительный режим нейтральной сети LSTM, который работает лучше всего. Следуйте таблице, приведенной ниже, для различных режимов двигателя OCR:
| Режим двигателя OCR | Рабочее описание |
| 0 | Только устаревший двигатель |
| 1 | Только нейронная сеть LSTM |
| 2 | Legacy + только режим LSTM |
| 3 | По умолчанию, в зависимости от того, что в настоящее время доступно |
OpenCV
OpenCV (библиотека компьютерного зрения с открытым исходным кодом), как следует из названия, представляет собой компьютерное зрение с открытым исходным кодом и библиотеку программного обеспечения для машинного обучения.OpenCV был создан для предоставления общей инфраструктуры для приложений компьютерного зрения. Помимо этого, это также ускоряет использование машинного восприятия в коммерческих продуктах. OpenCV является продуктом с лицензией BSD, поэтому он может пригодиться компаниям для использования и модификации кода. Библиотека включает более 2500 оптимизированных алгоритмов, которые имеют полный набор как классического, так и современного компьютерного зрения, а также алгоритмы машинного обучения. Эти алгоритмы могут использоваться для обнаружения и распознавания лиц, классификации действий человека в видео, извлечения 3D-моделей объектов и многого другого.Здесь я буду использовать его для предварительной обработки, чтобы определить текст из файла изображения. Tesseract требует чистого изображения для обнаружения текста, здесь OpenCV играет важную роль, поскольку он выполняет операции с изображением, такие как преобразование цветного изображения в двоичное изображение, регулировка контрастности изображения, обнаружение краев и многое другое.
Теперь переходим к следующему разделу, который посвящен установке и настройке среды для выполнения задачи распознавания текста.
Установка и настройка среды
Здесь я буду использовать Python в качестве языка программирования для выполнения задачи распознавания текста.Я проведу вас через процедуру настройки среды для Python OCR и установки библиотек в вашей системе Linux.
Во-первых, настройте среду Python в Ubuntu с помощью команды, приведенной ниже:
virtualenv -p python3 ocr_env
Примечание: Убедитесь, что в вашей системе установлен Python версии 3 или более поздней версии.
Теперь активируйте свою среду с помощью следующей команды в терминале:
источник ocr_env / bin / activate
Теперь вы готовы к установке OCR и Tesseract, используйте команды, указанные ниже, одну за другой:
pip install opencv-python
pip install pytesseract
Теперь, когда установка и настройка среды, наконец, завершены, перейдем к части кодирования.
Кодирование
Здесь я буду использовать следующий образец изображения квитанции:
Образец изображения чека
Первая часть — это пороговая обработка изображений. Ниже приведен код, который можно использовать для определения порога:
.1 | # импорт модулей
2 | импорт cv2
3 | импортный питессеракт
5 | # чтение изображения с помощью opencv
6 | image = cv2.imread (sample_image.png ’)
7 | # преобразование изображения в изображение в оттенках серого
8 | gray_image = cv2.cvtColor (изображение, cv2.COLOR_BGR2GRAY)
9 | # преобразование его в двоичное изображение с помощью Thresholding
10 | # этот шаг требуется, если у вас есть цветное изображение, потому что если вы пропустите эту часть
11 | # тогда tesseract не сможет правильно определить текст, и это даст неверный результат
11 | threshold_img = cv2.threshold (gray_image, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) [1]
12 | # отобразить изображение
13 | cv2.imshow («пороговое изображение», threshold_img)
14 | # Сохранять окно вывода, пока пользователь не нажмет клавишу
15 | cv2.waitKey (0)
16 | # Уничтожение текущих окон на экране
17 | cv2.destroyAllWindows ()
После установки порога изображения выходное изображение будет таким:
Изображение после порога
Теперь вы можете увидеть разницу между исходным изображением и изображением с пороговым значением. Изображение с пороговым значением показывает четкое разделение между белыми и черными пикселями. Таким образом, если вы доставите это изображение в Tesseract, он легко обнаружит текстовую область и даст более точные результаты.Для этого следуйте командам, приведенным ниже:
13 | # настройка параметров для tesseract
14 | custom_config = r '- oem 3 --psm 6'
15 | # теперь загружаем изображение в тессеракт
16 | details = pytesseract.image_to_data (threshold_img, output_type = Output.DICT, config = custom_config, lang = ’eng’)
17 | печать (details.keys ())
Если вы распечатываете детали, это ключи словаря, которые будут содержать соответствующие детали:
dict_keys ([‘level’, ‘page_num’, ‘block_num’, ‘par_num’, ‘line_num’, ‘word_num’, ‘left’ , ‘верх’, ‘ширина’, ‘высота’, ‘conf’, ‘текст’])
В приведенном выше словаре содержится информация о вашем входном изображении, такая как обнаруженная текстовая область, информация о положении, высота, ширина, оценка достоверности и т. Д.Теперь нарисуйте ограничивающую рамку на исходном изображении, используя приведенный выше словарь, чтобы узнать, насколько точно Tesseract работает как сканер текста для обнаружения текстовой области. Следуйте приведенному ниже коду:
18 | total_boxes = len (подробности ['текст'])
19 | для sequence_number в диапазоне (total_boxes):
20 | if int (подробности ['conf'] [sequence_number])> 30:
21 | (x, y, w, h) = (подробности ['left'] [sequence_number], details ['top'] [sequence_number], details ['width'] [sequence_number], подробности ['height'] [sequence_number] )
22 | threshold_img = cv2.прямоугольник (threshold_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
23 | # отобразить изображение
24 | cv2.imshow («захваченный текст», threshold_img)
25 | # Сохранять окно вывода, пока пользователь не нажмет клавишу
26 | cv2.waitKey (0)
27 | # Уничтожение текущих окон на экране
28 | cv2.destroyAllWindows ()
Примечание: На шаге 20 учитывайте только те изображения, для которых показатель достоверности больше 30. Получите это значение, вручную просмотрев сведения о текстовом файле словаря и показатель достоверности.После этого убедитесь, что все текстовые результаты верны, даже если их оценка достоверности находится между 30-40. Вам необходимо проверить это, потому что изображения состоят из цифр, других символов и текста. И в Tesseract не указано, что поле содержит только текст или только цифры. Предоставьте весь документ как есть в Tesseract и дождитесь, пока он покажет результаты в зависимости от значения, принадлежит ли он тексту или цифрам.
Изображение после рисования ограничительной рамки
Теперь, когда у вас есть изображение с ограничивающей рамкой, вы можете перейти к следующей части, которая должна упорядочить захваченный текст в файл с форматированием, чтобы легко отслеживать значения.
Примечание: Здесь я написал код на основе текущего формата изображения и вывода из Tesseract. Если вы используете какой-либо другой формат изображения, вам необходимо написать код в соответствии с этим форматом изображения.
Приведенный ниже код предназначен для преобразования результирующего текста в формат, соответствующий текущему изображению:
29 | parse_text = []
30 | word_list = []
31 | last_word = ''
32 | на слово в деталях ['текст]:
33 | если слово! = '':
34 | список слов.добавить (слово)
35 | last_word = word
36 | if (last_word! = '' и word == '') или (word == details ['text'] [- 1]):
37 | parse_text.append (список_слов)
38 | word_list = []
Следующий код преобразует текст результата в файл:
39 | импорт csv
40 | с open (result_text.txt ',' w ', newline = "") как файл:
41 | csv.writer (файл, delimiter = "") .writerows (parse_text)
Пришло время сравнить выходной текстовый файл и входное изображение.
Теперь, если вы сравните оба изображения, можно сделать вывод, что почти все значения верны. Таким образом, можно сказать, что в данном тестовом примере Tesseract дал точный результат около 95%, что весьма впечатляет.
Однако у Tesseract есть некоторые ограничения, давайте посмотрим, что это такое.
Ограничения Tesseract
- Точность распознавания текста не так высока по сравнению с некоторыми коммерческими решениями, доступными в настоящее время.
- Не распознает рукописный текст.
- Если документ содержит языки, которые не поддерживаются Tesseract, результаты будут плохими.
- Требуется четкое изображение на входе. Сканирование низкого качества может привести к плохим результатам при распознавании текста.
- Он не дает точных результатов для изображений, на которые влияют артефакты, включая частичное перекрытие, искаженную перспективу и сложный фон.
- Не подходит для анализа нормального порядка чтения документов. Например, вы можете не распознать, что документ содержит два столбца, и можете попытаться объединить текст в этих столбцах.
- Не раскрывает текстовую информацию о семействе шрифтов.
В итоге можно сделать вывод, что Tesseract идеально подходит для сканирования чистых документов, и вы можете легко преобразовать текст изображения из OCR в word, pdf в word или в любой другой требуемый формат. Имеет довольно высокую точность и вариативность шрифтов. Это очень полезно в случае учреждений, где задействовано много документации, таких как правительственные учреждения, больницы, учебные заведения и т. Д.