Конспект урока «Морфемный разбор слова 5 Класс» по русскому языку для 5 класса
Тема урока: Морфемный разбор слова.
Цели урока: 1. Обучающая: познакомить учащихся с порядком устного и письменного морфемного разбора; повторить орфограмму «Безударные гласные в корне слова».
2. Развивающая: формировать навык выделения значимых частей слова, развивать умение обобщать, сравнивать, систематизировать.
3. Воспитательная: вызывать интерес к изучению языка, воспитывать чувство ответственности при работе в коллективе, любовь к родной природе.
Оборудование: 1. Школьный учебник русского языка под редакцией Т.А. Ладыженской.
2. Плакат с изображением паровоза.
3. Указатели станций.
4. Магнитная доска с материалом.
5. Сигналы с номерами «вагонов».
6. Карточки с заданием.
7. Жетоны.
8. Эпиграф к уроку на доске.
9. Магнитофон, кассеты с аудиозаписью песен.
Тип урока: урок изучения нового материала.
Форма проведения
Ход урока.
I. Организационный момент (2 мин.)
Приветствие. Сообщение темы и целей урока.
II. Повторение ранее пройденного материала как средство подготовки учащихся к усвоению новых знаний (8-10 минут).
1) Выбор капитана-проводника для каждого ряда.
а) Знакомство с эпиграфом урока:
Слово делится на части,
Ах, какое это счастье!
Может каждый грамотей
Делать слово из частей!
«Кто быстрее (за 2 минуты) «соберёт» из морфем слова». По одному ученику с каждого ряда, составившему наибольшее количество слов, будут проводником своего «вагона» (ряда).
Морфемы записаны на доске и на карточках для каждого ученика:
С, за, вы, пере, рас, пре, раз, да, бег, сказ, к, ств, о, ние, а, ыва, ва, ть, тель.
б) Когда закончится время, каждый ученик подсчитывает количество составленных слов и сообщает учителю.
2. Станция «Незабудка» (повторение теоретических сведений о морфемах).
По одной девочке от каждой команды «срывают» искусственные цветы, на обратной стороне которых написан вопрос, и дают на него ответ.
Вопросы:
1) Что изучает морфемика?
2) Назовите морфемы, из которых может состоять основа слова.
3) Как найти окончание в слове?
III. Изучение нового материала (10-12 минут).
1) Станция «Познавательная».
Учитель объясняет на доске на примере слова «проводник» новый материал. Учащиеся принимают активное участие в объяснении: они следят в учебниках за порядком разбора, подбирают проверочные морфемы к анализируемому слову, записывают материал с доски в тетрадь.
IV. Закрепление нового материала (15 минут).
1) Станция «Научный городок».
Всем учащимся даётся текст с заданиями:
1) Выписать слова с безударными гласными в корне слова.
2) Найти слова, состав которых соответствует схемам:
3) Разобрать по составу слова:
Распутаешь, строчки, написать.
Текст
Белые страницы
Свежий след со следами зверей принято называть белой книгой. Издаётся она один раз в году, когда на первой пороше первые звери отпечатают строчки своих следов.
Новый снегопад – новая страница. Новые рассказы пишут на ней лесные жители.
Нет снегопада. А каждый зверь так много пишет, что потом не распутаешь. И всякий норовит поперёк чужой строчки написать своё. Кто с утра до вечера, кто с вечера до утра. Никто не скроется от внимательного глаза до весны, пока не растают страницы белой книги.
3) Проверка выполненного задания у доски:
1 вагон – 1 задание.
2 вагон – 2 задание.
3 вагон – 3 задание.
4) Станция «Игровая».
«Лингвистическая эстафета»
Кто за минимальное количество времени подберёт как можно больше однокоренных слов к корню вод- ( на приз).
5) Станция «Музыкальная».
Звучит песня «Голубой вагон».
Нужно выписать из песни слова с как можно большим количеством (составом) морфем.
6) Станция «Речевая мастерская» (словарная работа).
На доске написаны слова:
Пр…ятно
Пр…рода
Пр…спокойно
Пр…шли
Пр…ветливо
Пр…чудливые
Задание: 1) Назвать те слова, которые образованы приставочным способом.
2) Написать сочинение-миниатюру на тему «Прогулка по зимнему лесу», используя все записанные на доске слова.
Проверка (каждая команда зачитывает по одной работе).
V. Станция «Итоговая».
1) Задание на дом (1-2 минуты):
а) запомнить порядок морфемного разбора слов, § 80.
б) Выполнить упражнение 417.
2) Подведение итогов урока, выставление оценок (2-3 минуты).
Чтение учителем стихотворения из книги А. Милна «Винни-Пух и все-все-все».
Вопросы: — Какую ошибку допускает Винни-Пух, определяя морфемы?
— Для чего нужно знать и изучать строение слова?
Опять ничего не могу я понять,
Опилки мои – в беспорядке.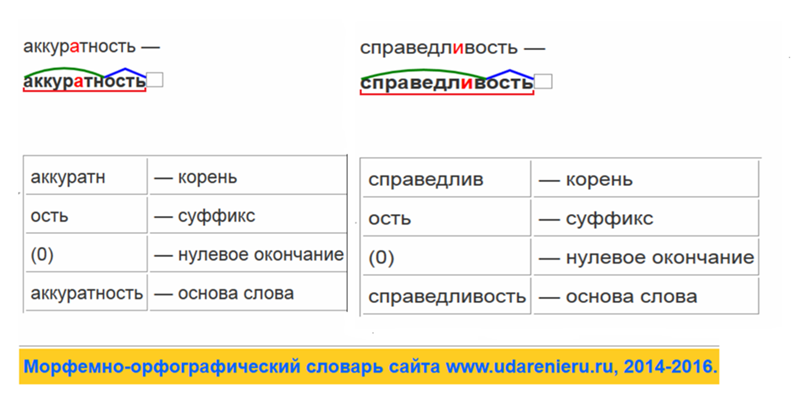
Везде и повсюду, опять и опять
Меня окружают загадки.
Возьмём это самое слово опять.
Зачем мы его произносим,
Когда мы свободно могли бы сказать
Ошесть, и осемь, и овосемь?
Молчит этажерка, молчит и тахта –
У них не добьёшься ответа,
Зачем эта хта – обязательно та,
А жерка, как правило, эта?
Вывод: Морфемы – значимые части слова. Механическое деление слова на части приводит к разрушению смысла.
Приложение: вместо тетрадей работаем на индивидуальных листах –«проездных билетах».
Проездной билет Фамилия, имя пассажира:_____________________________
Класс: ________________________________________________
Дата:_________________________________________________
Наименование работы:__________________________________
Тема:_________________________________________________
Задание 1. Выборы проводника (соберите из данных морфем наибольшее количество слов):
С, за, вы, пере, рас, пре, раз, да, бег, сказ, к, ств, о, ние, а, ыва, ва, ть, тель.
________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Задание 2. Станция «Научный городок»
(Выполнить задания по тексту «Белые страницы»):
1) Выписать слова с безударными гласными в корне слова.
2) Найти слова, состав которых соответствует схемам:
3) Разобрать по составу слова:
Распутаешь, строчки, написать.
Т е к с т
Белые страницы
Свежий след со следами зверей принято называть белой книгой. Издаётся она один раз в году, когда на первой пороше первые звери отпечатают строчки своих следов.
Новый снегопад – новая страница. Новые рассказы пишут на ней лесные жители.
Нет снегопада. А каждый зверь так много пишет, что потом не распутаешь. И всякий норовит поперёк чужой строчки написать своё. Кто с утра до вечера, кто с вечера до утра. Никто не скроется от внимательного глаза до весны, пока не растают страницы белой книги.
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
____________________________________________________________________________________________________________________________________________________________________________________
Задание 3. Станция «Игровая»
«Лингвистическая эстафета»
Кто за минимальное количество времени подберёт как можно больше однокоренных слов к корню вод- ( на приз).
____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Задание 4. Станция «Музыкальная».
Станция «Музыкальная».
Звучит песня «Голубой вагон».
Нужно выписать из песни слова с как можно большим количеством (составом) морфем
________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Задание 5. Станция «Речевая мастерская»
Написать сочинение-миниатюру на тему «Прогулка по зимнему лесу», используя все записанные на доске слова.
__________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
Здесь представлен конспект к уроку на тему «Морфемный разбор слова 5 Класс», который Вы можете бесплатно скачать на нашем сайте.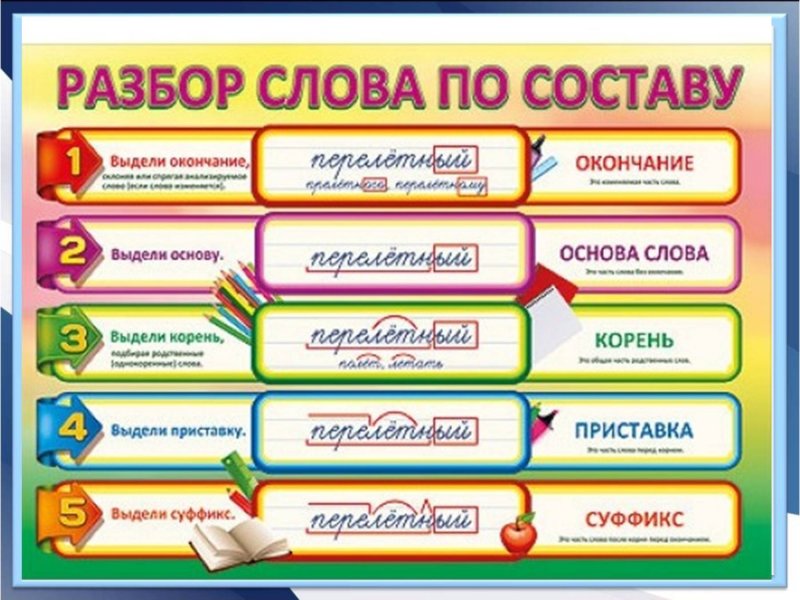 Предмет конспекта: Русский язык (5 класс). Также здесь Вы можете найти дополнительные учебные материалы и презентации по данной теме, используя которые,
Вы сможете еще больше заинтересовать аудиторию и преподнести еще больше полезной информации.
Предмет конспекта: Русский язык (5 класс). Также здесь Вы можете найти дополнительные учебные материалы и презентации по данной теме, используя которые,
Вы сможете еще больше заинтересовать аудиторию и преподнести еще больше полезной информации.
Урок русского языка в 5 классе на тему «Значимые части слова»
Урок русского языка. 5 класс
Тема: «Состав слова. Основа и окончание»
Цель: дать понятие о морфемах, продолжить работу над изучением значимых частей слова, их особенностей, развивать навыки разбора слова по составу, повторить понятие об однородных членах предложения, продолжить работу над изучением словарных слов, развивать навыки составления устных высказываний, воспитывать интерес к изучению русского языка.
Учебник: «Русский язык 5 класс» Авторы: А.Н. Рудяков, Т.Я. Фролова и др., К., «Грамота», 2013
ХОД УРОКА
І Организационный момент. Сообщение темы и цели урока.
ІІ Актуализация опорных знаний.
- Словарная работа. Слайд №1:
- Задание: записать слова в тетрадь, подчеркнуть выделенные буквы, устно составить предложение с одним из данных слов.
- Слайд №2. Вставить пропущенные буквы, поставить знаки препинания, подчеркнуть главные и второстепенные члены предложения.
- Слово учителя. Сегодня, ребята, мы начинаем изучать новую тему. Но прежде, чем мы приступим к её изучению, попробуйте вставить в данный текст пропущенные слова. Думаю, тогда мы сможем определить, что мы будем изучать на этом и следующих уроках. Слайд №3:
ІІ Работа над изучением новой темы. Организационные вопросы. Делим класс на 3 команды, каждая из которых выполняет задание учителя. Кто первым и правильно выполнит задание, тот получает фишку. В конце урока определяется команда-победитель и лучшие игроки.
- Работа с учебником.
 (Стр.138) Дать понятие о морфемах и морфемике. Составляем опорный конспект в тетради.
(Стр.138) Дать понятие о морфемах и морфемике. Составляем опорный конспект в тетради. - Работа с учебником. Знакомство с морфемами. (Стр. 138) Составляем опорный конспект:
 (Стр.138) Дать понятие о морфемах и морфемике. Составляем опорный конспект в тетради.
(Стр.138) Дать понятие о морфемах и морфемике. Составляем опорный конспект в тетради.
1.Как вы думаете, почему корень слова, суффикс и приставку называют значимыми частями слова? Ответ найдите в учебнике на стр. 140.
2. Работа в группах. Заполните таблицу: (слайд №4). Укажите, какие из данных морфем словообразующие, а какие – формообразующие.
- Конкурс капитанов. Выписать в два столбика однокоренные слова и формы одного и того же слова
Вода, водяной, воде, водица, воды, водный, подводный, воду.
Пока капитаны работают самостоятельно, в комондах проводится игра «Эстафета» На первую парту даётся лист с заданием: составить с помощью приставки новое слово и передать следующим членам команды. Кто быстрее и больше составит слов, тот и побеждает
Задание: образовать с помощью приставок новые слова от слова Лить
- Работа с учебником. Основа слова и окончание (стр. 142-143).
- Работа в командах. Кто быстрее? (указать, в каких словах нет окончания)
 Основа слова и окончание (стр. 142-143).
Основа слова и окончание (стр. 142-143).
- Найдите ответ в учебнике на вопрос: какое окончание называется нулевым? (стр. 143) Задание для команд:
ІІІ Подведение итогов.
- Подсчитать фишки. Определить победителя.
- Продолжи предложение:
— Я повторил…
— Я научился…
— я узнал…
ІV Оценивание.
V Домашнее задание : выучить правила в параграфе 32, выполнить упражнение№365
Python BeautifulSoup Парсинг веб-страниц | Pluralsight
Gaurav Singhal
Gaurav Singhal
- декабрь 19, 2019
- 14 мин. Читать
- 339,973 Просмотры
- декабря 19,
- 14 MIN 339,916.
Введение
В настоящее время все говорят о данных и о том, как они помогают изучать скрытые закономерности и новые идеи. Правильный набор данных может помочь бизнесу улучшить свою маркетинговую стратегию и увеличить общий объем продаж. И давайте не будем забывать популярный пример, в котором политик может знать общественное мнение перед выборами. Данные имеют большое значение, но они не предоставляются бесплатно. Сбор правильных данных всегда стоит дорого; подумайте об опросах или маркетинговых кампаниях и т. д.
Правильный набор данных может помочь бизнесу улучшить свою маркетинговую стратегию и увеличить общий объем продаж. И давайте не будем забывать популярный пример, в котором политик может знать общественное мнение перед выборами. Данные имеют большое значение, но они не предоставляются бесплатно. Сбор правильных данных всегда стоит дорого; подумайте об опросах или маркетинговых кампаниях и т. д.
Интернет — это хранилище данных, и при наличии соответствующих навыков можно использовать эти данные для получения большого количества новой информации. Вы всегда можете скопировать и вставить данные в свой файл Excel или CSV, но это также требует много времени и денег. Почему бы не нанять разработчика программного обеспечения, который может привести данные в читаемый формат, написав какой-нибудь бред? Да, можно извлекать данные из Интернета, и этот «тарабарщина» называется Web Scraping.
Согласно Википедии, Web Scraping:
Веб-скрапинг, веб-сбор или извлечение веб-данных — это парсинг данных, используемый для извлечения данных с веб-сайтов.

BeautifulSoup — одна из популярных библиотек, предоставляемая Python для сбора данных из Интернета. Чтобы получить максимальную отдачу от этого, нужно иметь только базовые знания HTML, которые описаны в руководстве.
Компоненты веб-страницы
Если вы знаете основы HTML, вы можете пропустить эту часть.
Основной синтаксис любой веб-страницы:
1 2 3 <голова> 4 <метакодировка="utf-8" /> 5 6 7 <тело> 8Мой первый веб-скрейпинг с Beautiful Soup
9Давайте удалим сайт с помощью Python.
10 <тело> 11
html
Каждый тег в HTML может иметь атрибутивную информацию (например, класс, идентификатор, href и другую полезную информацию), которая помогает однозначно идентифицировать элемент.
Дополнительные сведения об основных тегах HTML см. на сайте w3schools.
Действия по очистке любого веб-сайта
Чтобы очистить веб-сайт с помощью Python, вам необходимо выполнить следующие четыре основных шага:
Отправка запроса HTTP GET на URL-адрес веб-страницы, которую вы хотите HTML-контент.
Мы можем сделать это, используя библиотеку Python Request .Получение и анализ данных с помощью Beautifulsoup и хранить данные в некоторой структуре данных, например Dict или List .
Анализ тегов HTML и их атрибутов, таких как класс, идентификатор и другие атрибуты тегов HTML. Кроме того, определение тегов HTML, в которых находится ваш контент.
- Вывод данных в любой файловый формат, такой как CSV, XLSX, JSON и т. д.
 Мы можем сделать это, используя библиотеку Python Request .
Мы можем сделать это, используя библиотеку Python Request .Понимание и проверка данных страницу, которую вы хотите очистить. Инспекция — самая важная работа в веб-скрейпинге; не зная структуры веб-страницы, очень сложно получить необходимую информацию. Чтобы облегчить проверку, каждый браузер, такой как Google Chrome или Mozilla Firefox, поставляется с удобным инструментом, называемым инструментами разработчика.
В этом руководстве мы будем работать с wikipedia , чтобы удалить некоторые из его табличных данных со страницы Список стран по ВВП (номинальному). Эта страница содержит заголовок Lists , который содержит три таблицы стран, отсортированных по их рейтингу и значению ВВП в соответствии с «Международным валютным фондом», «Всемирным банком» и «Организацией Объединенных Наций». Обратите внимание, что эти три таблицы заключены во внешнюю таблицу.
Эта страница содержит заголовок Lists , который содержит три таблицы стран, отсортированных по их рейтингу и значению ВВП в соответствии с «Международным валютным фондом», «Всемирным банком» и «Организацией Объединенных Наций». Обратите внимание, что эти три таблицы заключены во внешнюю таблицу.
Чтобы узнать о любом элементе, который вы хотите очистить, просто щелкните правой кнопкой мыши этот текст и просмотрите теги и атрибуты элемента.
Перейти к коду
В этом руководстве мы узнаем, как сделать простой веб-скрапинг, используя Python и BeautifulSoup .
Установка основных библиотек Python
1pip3 запросы на установку BeautifulSoup4
оболочка
Примечание. Если вы используете Windows, используйте pip вместо pip3
Импорт основных библиотек
6
3 fetch содержимое страницы и bs4 (Beautiful Soup) для разбора содержимого HTML-страницы.
1из импорта bs4 BeautifulSoup 2импортные запросы
python
Сбор и анализ веб-страницы
На следующем шаге мы сделаем GET-запрос к URL-адресу и создадим объект дерева анализа (суп) с помощью BeautifulSoup и встроенного Python «lxml «парсер.
1# импорт библиотек 2из bs4 импортировать BeautifulSoup 3запроса на импорт 4 5url="https://en.wikipedia.org/wiki/Список_стран_по_ВВП_(номинальный)" 6 7# Сделайте запрос GET для получения необработанного HTML-контента 8html_content = запросы.получить(url).текст 910# Разбираем html-контент 11soup = BeautifulSoup(html_content, "lxml") 12print(soup.prettify()) # вывести проанализированные данные html
python
С нашим объектом BeautifulSoup, т. е. суп , мы можем двигаться дальше и собирать необходимые данные таблицы.
Прежде чем перейти к коду, давайте сначала поиграем с объектом супа и напечатаем из него некоторую базовую информацию:
Пример 1:
Давайте сначала напечатаем заголовок веб-страницы.
1print(суп.название)
python
Он выдаст следующий вывод:
1Список стран по ВВП (номинальному) - Википедия
Чтобы получить текст без тегов HTML, мы просто используем .text :
1print(soup.title.text)
python
В результате получится:
1Список стран по ВВП (номинальному) - Википедия
Пример 2:
Теперь давайте получим все ссылки в страница вместе с ее атрибутами, такими как href , title и его внутренний текст.
1для ссылки в супе.find_all("a"):
2 print("Внутренний текст: {}".format(link.text))
3 print("Название: {}".format(link.get("название")))
4 print("href: {}".format(link.get("href"))) python
Это выведет все доступные ссылки вместе с указанными атрибутами со страницы.
Теперь вернемся к треку и найдем нашу таблицу целей.
Анализируя внешнюю таблицу, мы видим, что она имеет специальные атрибуты, которые включают класс wikitable и имеет два тега tr внутри tbody.
Если вы развернете тег tr , вы обнаружите, что первый тег tr предназначен для заголовков всех трех таблиц, а следующий тег tr предназначен для табличных данных для всех трех внутренних таблиц.
Давайте сначала получим все три заголовка таблицы:
Обратите внимание, что мы удаляем символы новой строки и пробелы слева и справа от текста с помощью простых строковых методов, доступных в Python.
1gdp_table = суп.найти("стол", attrs={"класс": "викитаблица"})
2gdp_table_data = gdp_table.tbody.find_all("tr") # содержит 2 строки
3
4 # Получить все заголовки списков
5 заголовков = []
6для td в gdp_table_data[0].find_all("td"):
7 # удалить все символы новой строки и лишние пробелы слева и справа
8 заголовков.append(td.b.text.replace('\n', ' ').strip())
9
10print(headings) python
Результат будет выглядеть следующим образом:
1['Согласно Международному валютному фонду (2018 г.
 )', 'Согласно Всемирному банку (2017 г.)', 'Согласно Организации Объединенных Наций (2017 г.)' ]
)', 'Согласно Всемирному банку (2017 г.)', 'Согласно Организации Объединенных Наций (2017 г.)' ] Переходя ко второму тегу tr внешней таблицы, давайте получим содержимое всех трех таблиц, перебирая каждую таблицу и ее строки.
1данные = {}
2для таблицы, заголовок в zip(gdp_table_data[1].find_all("таблица"), заголовки):
3 # Получить заголовки таблицы, например, Rank, Country, GDP.
4 t_headers = []
5 для th в table.find_all("th"):
6 # удалить все символы новой строки и лишние пробелы слева и справа
7 t_headers.append(th.text.replace('\n', ' ').strip())
8 # Получить все строки таблицы
9table_data = []
10 for tr in table.tbody.find_all("tr"): # найти все tr из tbody таблицы
11 t_row = {}
12 # Каждая строка таблицы хранится в виде
13 # t_row = {'Рейтинг': '', 'Страна/территория': '', 'ВВП (млн долларов США)': ''}
14
15 # найти все td(3) в tr и заархивировать с помощью t_header
16 для тд, й в zip(tr.find_all("тд"), t_headers):
17 t_row[th] = td.text.replace('\n', ''). strip()
18 table_data.append(t_row)
19
20 # Поместите данные для таблицы со своим заголовком.
21 данные[заголовок] = table_data
22
23print(данные)  strip()
18 table_data.append(t_row)
19
20 # Поместите данные для таблицы со своим заголовком.
21 данные[заголовок] = table_data
22
23print(данные)
strip()
18 table_data.append(t_row)
19
20 # Поместите данные для таблицы со своим заголовком.
21 данные[заголовок] = table_data
22
23print(данные) python
Запись данных в CSV
Теперь, когда мы создали нашу структуру данных, мы можем экспортировать ее в файл CSV, просто перебирая ее.
1импорт CSV
2
3для темы, таблица в data.items():
4 # Создать файл csv для каждой таблицы
5 с open(f"{topic}.csv", 'w') как out_file:
6 # Каждая 3 таблица имеет следующие заголовки
7 заголовков = [
8 «Страна/территория»,
9 "ВВП (млн долларов США)",
10 «Ранг»
11 ] # == t_headers
12 писатель = csv.DictWriter (out_file, заголовки)
13 # пишем заголовок
14 писатель.writeheader()
15 для строки в таблице:
16, если ряд:
17 писатель.писательряд(строка) python
Собираем вместе
Давайте объединим все приведенные выше фрагменты кода.
Полный код выглядит так:
1# импорт библиотек 2из bs4 импортировать BeautifulSoup 3запроса на импорт 4импорт CSV 5 6 7# Шаг 1: Отправка HTTP-запроса на URL-адрес 8url = "https://en.
 wikipedia.org/wiki/Список_стран_по_ВВП_(номинальный)"
9# Сделайте запрос GET для получения необработанного HTML-контента
10html_content = запросы.получить(url).текст
11
12
13# Шаг 2: Разберите html-контент
14soup = BeautifulSoup(html_content, "lxml")
15# print(soup.prettify()) # вывести проанализированные данные html
16
17
18# Шаг 3. Проанализируйте HTML-тег, в котором находится ваш контент
19# Создайте словарь данных для хранения данных.
20данные = {}
21#Получить таблицу с классом wikitable
22gdp_table = суп.найти("таблица", attrs={"класс": "викитаблица"})
23gdp_table_data = gdp_table.tbody.find_all("tr") # содержит 2 строки
24
25# Получить все заголовки списков
26заголовков = []
27для td в gdp_table_data[0].find_all("td"):
28 # удалить все символы новой строки и лишние пробелы слева и справа
29 заголовков.append(td.b.text.replace('\n', ' ').strip())
30
31# Получить все 3 таблицы, содержащиеся в "gdp_table"
32для таблицы, заголовок в zip(gdp_table_data[1].find_all("таблица"), заголовки):
33 # Получить заголовки таблицы, например, Rank, Country, GDP.
wikipedia.org/wiki/Список_стран_по_ВВП_(номинальный)"
9# Сделайте запрос GET для получения необработанного HTML-контента
10html_content = запросы.получить(url).текст
11
12
13# Шаг 2: Разберите html-контент
14soup = BeautifulSoup(html_content, "lxml")
15# print(soup.prettify()) # вывести проанализированные данные html
16
17
18# Шаг 3. Проанализируйте HTML-тег, в котором находится ваш контент
19# Создайте словарь данных для хранения данных.
20данные = {}
21#Получить таблицу с классом wikitable
22gdp_table = суп.найти("таблица", attrs={"класс": "викитаблица"})
23gdp_table_data = gdp_table.tbody.find_all("tr") # содержит 2 строки
24
25# Получить все заголовки списков
26заголовков = []
27для td в gdp_table_data[0].find_all("td"):
28 # удалить все символы новой строки и лишние пробелы слева и справа
29 заголовков.append(td.b.text.replace('\n', ' ').strip())
30
31# Получить все 3 таблицы, содержащиеся в "gdp_table"
32для таблицы, заголовок в zip(gdp_table_data[1].find_all("таблица"), заголовки):
33 # Получить заголовки таблицы, например, Rank, Country, GDP. 34 t_headers = []
35 для th в table.find_all("th"):
36 # удалить все символы новой строки и лишние пробелы слева и справа
37 t_headers.append(th.text.replace('\n', ' ').strip())
38
39# Получить все строки таблицы
40 table_data = []
41 for tr in table.tbody.find_all("tr"): # найти все tr из tbody таблицы
42 т_ряд = {}
43 # Каждая строка таблицы хранится в виде
44 # t_row = {'Рейтинг': '', 'Страна/территория': '', 'ВВП (млн долларов США)': ''}
45
46 # найти все файлы td(3) в tr и заархивировать их с помощью t_header
47 для тд, й в zip(tr.find_all("тд"), t_headers):
48 t_row[th] = td.text.replace('\n', '').strip()
49 table_data.append(t_row)
50
51 # Поместите данные для таблицы со своим заголовком.
52 данные[заголовок] = table_data
53
54
55# Шаг 4: Экспорт данных в csv
56"""
57Для этого примера давайте создадим 3 отдельных CSV для
583 стола соответственно
59"""
60 для темы, таблица в data.items():
61 # Создать файл csv для каждой таблицы
62 с open(f"{topic}.csv", 'w') в качестве out_file:
63 # Каждая 3 таблица имеет следующие заголовки
64 заголовка = [
65 «Страна/территория»,
66 "ВВП (млн долларов США)",
67 "Ранг"
68 ] # == t_headers
69 писатель = csv.
34 t_headers = []
35 для th в table.find_all("th"):
36 # удалить все символы новой строки и лишние пробелы слева и справа
37 t_headers.append(th.text.replace('\n', ' ').strip())
38
39# Получить все строки таблицы
40 table_data = []
41 for tr in table.tbody.find_all("tr"): # найти все tr из tbody таблицы
42 т_ряд = {}
43 # Каждая строка таблицы хранится в виде
44 # t_row = {'Рейтинг': '', 'Страна/территория': '', 'ВВП (млн долларов США)': ''}
45
46 # найти все файлы td(3) в tr и заархивировать их с помощью t_header
47 для тд, й в zip(tr.find_all("тд"), t_headers):
48 t_row[th] = td.text.replace('\n', '').strip()
49 table_data.append(t_row)
50
51 # Поместите данные для таблицы со своим заголовком.
52 данные[заголовок] = table_data
53
54
55# Шаг 4: Экспорт данных в csv
56"""
57Для этого примера давайте создадим 3 отдельных CSV для
583 стола соответственно
59"""
60 для темы, таблица в data.items():
61 # Создать файл csv для каждой таблицы
62 с open(f"{topic}.csv", 'w') в качестве out_file:
63 # Каждая 3 таблица имеет следующие заголовки
64 заголовка = [
65 «Страна/территория»,
66 "ВВП (млн долларов США)",
67 "Ранг"
68 ] # == t_headers
69 писатель = csv. DictWriter (out_file, заголовки)
70 # пишем заголовок
71 писатель.writeheader()
72 для строки в таблице:
73, если ряд:
74 писатель.писательряд(строка)
DictWriter (out_file, заголовки)
70 # пишем заголовок
71 писатель.writeheader()
72 для строки в таблице:
73, если ряд:
74 писатель.писательряд(строка) python
ВНИМАНИЕ -> Правила парсинга
Теперь, когда у вас есть общее представление о парсинге с помощью Python, важно знать законность веб-парсинга, прежде чем начинать парсинг веб-сайта. Как правило, если вы используете очищенные данные для личного использования и не планируете повторно публиковать эти данные, это может не вызвать никаких проблем. Прочтите Условия использования, Условия использования, а также файл robots.txt перед очисткой веб-сайта. Вы должны следовать правилам robots.txt перед парсингом, в противном случае владелец сайта имеет полное право взять судебный иск против вас.
Заключение
В приведенном выше руководстве описан процесс очистки страницы Википедии с помощью Python3 и Beautiful Soup и, наконец, экспорт ее в файл CSV. Мы научились очищать базовый веб-сайт и получать все полезные данные всего за пару минут.
Мы научились очищать базовый веб-сайт и получать все полезные данные всего за пару минут.
Вы можете и дальше расширять возможности искусства парсинга, переходя на новые веб-сайты. Вот несколько хороших примеров парсинга данных:
Beautiful Soup удобен для мелкомасштабного парсинга веб-страниц. Если вы хотите парсить веб-страницы в больших масштабах, вы можете рассмотреть более продвинутые методы, такие как Scrapy и Selenium.
Вот некоторые из моих руководств по парсингу:
- Сканирование Интернета с помощью Python и Scrapy
- Усовершенствованная тактика веб-скрейпинга
- Лучшие практики и рекомендации по парсингу вам понравится это руководство 9002. Если у вас есть какие-либо вопросы по этой теме, не стесняйтесь обращаться ко мне в CodeAlphabet.
- Красивый суп Документация
- W3 School HTML введение
- List_of_countries_by_GDP
- Всплывающее сообщение об ошибке анализа формулы не позволяет мне ввести формулу
- Я получаю сообщение об ошибке #Н/Д
- Я получаю #DIV/0! сообщение об ошибке
- Я получаю #ЗНАЧ! сообщение об ошибке
- Я получаю #REF! сообщение об ошибке
- Я получаю #NAME? сообщение об ошибке
- Я получаю #ЧИСЛО! сообщение об ошибке
- Я получаю сообщение #ОШИБКА! сообщение об ошибке
- Я получаю #NULL! сообщение об ошибке
- Другие стратегии обработки ошибок
- Функции для устранения ошибок в формулах в Google Таблицах
- Помогите! Моя формула ВСЕ ЕЩЕ не работает
- 1 для #NULL!
- 2 для #DIV/0!
- 3 за #ЗНАЧ!
- 4 за #ССЫЛКА!
- 5 для #ИМЯ?
- 6 за #ЧИСЛО!
- 7 для #Н/Д
- 8 для всех остальных ошибок
Полезные ссылки
Ошибки анализа формул в Google Sheets и способы их исправления
Если вы только начинаете работать с Google Sheets или являетесь опытным профессионалом, рано или поздно одна из ваших формул выдаст вам сообщение об ошибке анализа формулы.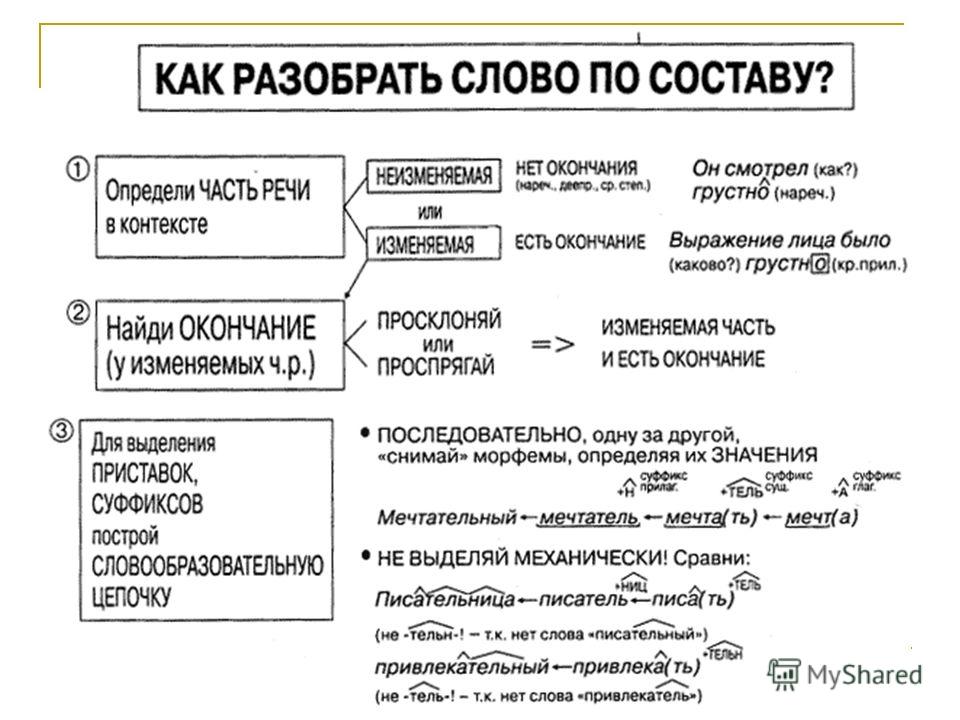 чем желаемый результат.
чем желаемый результат.
Это может быть неприятно, особенно если это более длинная формула, где ошибка анализа формулы может быть неочевидной.
В этом посте я объясню, что такое ошибка синтаксического анализа формулы Google Sheets, как определить причину проблемы и как ее исправить.
Что такое ошибка разбора формулы?
Прежде чем мы перейдем к различным типам ошибок, вам может быть интересно, что означает ошибка синтаксического анализа формулы?
По сути, это означает, что Google Таблицы не могут интерпретировать вашу формулу. Он не может выполнить запрос формулы, поэтому возвращает сообщение об ошибке.
Это может произойти по-разному — от опечаток до математических невозможностей — и мы подробно рассмотрим их все ниже.
Понимание смысла сообщений об ошибках и изучение способов их исправления — важный шаг к тому, чтобы стать профессионалом в области формул в Google Таблицах.
Аудит и отладка ошибок синтаксического анализа формул в Google Sheets
Сопоставьте сообщение об ошибке в Google Sheet с приведенными ниже разделами и узнайте, что может быть причиной вашей ошибки.
Вот таблица Google со всеми этими примерами.
1. Всплывающее сообщение об ошибке анализа формулы не позволяет мне ввести формулу
Вы думаете, что закончили свою формулу, поэтому нажимаете Enter и бум! Вы получаете пощечину всплывающим окном сообщения «Хьюстон, у нас проблема» или аналогичный:
Такое случается достаточно редко, и обычно это указывает на какую-то фундаментальную проблему с вашей формулой.
Например, представьте, что при нажатии клавиши Enter вы также случайно нажали клавишу «\» (которая находится прямо над клавишей Enter) и непреднамеренно добавили ее в конец формулы:
Это приведет к во всплывающем сообщении об ошибке. Это легко исправить, удалив ненужный символ.
Как исправить эту ошибку?
Во-первых, старайтесь избегать их, проверяя свою формулу перед нажатием Enter. Убедитесь, что вы не пропустили ссылку на ячейку и у вас нет скрытых нежелательных символов.
2. Я получаю сообщение об ошибке #Н/Д. Как это исправить?
Ошибка синтаксического анализа формулы #N/A означает, что значение равно недоступен .
Чаще всего это происходит, когда вы используете функцию поиска (например, функцию ВПР), а условие поиска не найдено. Это именно то, что произошло при точном совпадении VLOOKUP на изображении выше. Критерий поиска A-051 отсутствует в нашей таблице данных, поэтому формула возвращает #N/A.
Эта формула не является неправильной или сломанной, поэтому мы не хотим ее удалять. Однако было бы здорово, если бы вы могли отображать собственное сообщение, что-то вроде «Результат не найден», вместо сообщения об ошибке #N/A, особенно если у вас много таких ошибок. Это дает пользователю электронной таблицы гораздо больше информации и уменьшает путаницу.
К счастью, мы можем:
Как исправить ошибку #Н/Д?
В Google Таблицах есть очень удобная функция ЕСЛИОШИБКА:
=ЕСЛИОШИБКА( исходная формула, значение для отображения, если исходная формула дает ошибку )
В этом примере ВПР полная формула будет выглядеть следующим образом:
=ЕСЛИОШИБКА(ВПР(Поиск, Таблица, Индекс столбца, FALSE), «Поиск не найден»)
, как показано в этом примере:
Вместо отображения ошибки синтаксического анализа формулы #Н/Д, когда значение не найдено, формула будет выводить наше пользовательское сообщение вместо «Поиск термин не найден».
3. Я получаю #DIV/0! сообщение об ошибке
Эта ошибка синтаксического анализа формулы возникает, когда число делится на ноль, что может произойти, если в знаменателе есть нулевая или пустая ссылка на ячейку.
Проще говоря, это означает, что мы пытаемся вычислить что-то вроде этого:
= A / 0
, что не имеет смысла, потому что вы не можете делить на 0.
Подробнее о делении на 0 здесь, хотя это очень быстро становится супертехническим.
Другой пример — использование формулы типа СРЗНАЧ с пустым диапазоном.
= СРЗНАЧ(A1:A10)
вызовет #DIV/0! ошибка, если диапазон A1:A10 не содержит числовых значений.
Как исправить #DIV/0! ошибка?
Итак, первое, что нужно сделать, это определить, почему ваш знаменатель равен нулю.
Вы можете выбрать знаменатель и посмотреть, что он оценивает, выделив его в строке формул и увидев результат в маленьком всплывающем окне, как показано на этом рисунке:
В этом случае формула в знаменателе СУММ(A1:A7) дает 0, что вызывает ошибку.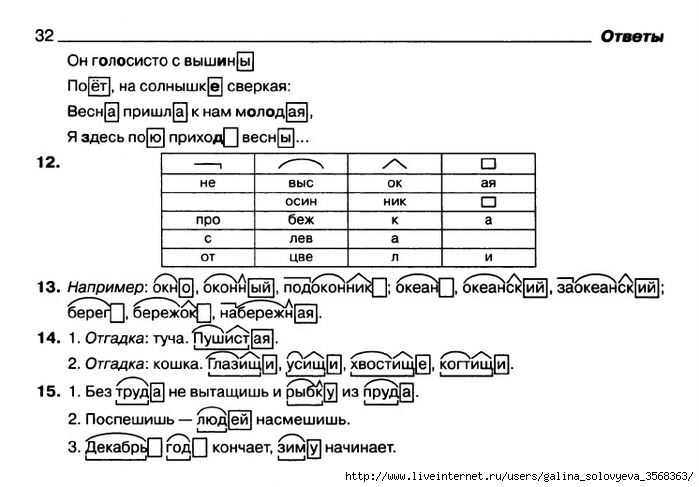 Поэтому проверьте, равен ли результат в знаменателе 0.
Поэтому проверьте, равен ли результат в знаменателе 0.
Затем проверьте, связаны ли вы с пустыми ячейками или пустым диапазоном в знаменателе. Затем вы можете либо заполнить пустую ячейку или диапазон, либо выбрать другую ячейку или диапазон для своей формулы.
Если ваша формула верна и ваши ячейки/диапазоны не являются непреднамеренно пустыми, вам нужно обработать #DIV/0! ошибка. Это выглядит неприглядно и делает вашу электронную таблицу незавершенной, если вы оставляете эти ошибки плавающими.
Как и в примере с ошибкой #Н/Д, используйте формулу ЕСЛИОШИБКА, чтобы обернуть текущую формулу и указать результат, когда #ДЕЛ/0! возникает ошибка. Возможно, вы захотите вывести сообщение об ошибке, например. «Ошибка деления на 0» или, может быть, конкретное значение, например. 0:
4. Я получаю #ЗНАЧ! сообщение об ошибке
Эта ошибка синтаксического анализа формулы обычно возникает, когда ваша формула ожидает определенного типа данных в качестве входных данных, но получает неправильный тип, например, при попытке выполнить математические операции с текстовым значением вместо числового значения.
Пробелы в ячейках также могут вызывать это сообщение об ошибке.
В этом примере ячейка B1 содержит пробел, который является строковым значением и вызывает ошибку #ЗНАЧ! ошибка, потому что Google Sheets не может выполнить над ним математическую операцию, как видно из этого сообщения об ошибке:
В общем, Google Sheets довольно хорошо справляется с преобразованием текста в числа, когда это необходимо. Если вы введете значение в ячейку с некоторыми пробелами, отформатируете его как текст, а затем попытаетесь выполнить над ним математические операции, Google Sheets на самом деле превратит текст в число и все равно выполнит расчет.
Еще одна причина #VALUE! ошибки смешивают форматы даты США и остального мира.
Даты в США имеют формат ММ/ДД/ГГГГ, в то время как для остального мира используется формат ДД/ММ/ГГГГ. Если у вас есть сочетание двух и попытаться вычесть их, например, чтобы получить количество дней между ними, вы получите #ЗНАЧ! ошибка.
(На самом деле, это та же самая проблема с текстом/числом, которая происходит под поверхностью. Даты хранятся в виде чисел, но если ваша дата имеет неправильный формат для настройки страны для вашей электронной таблицы, она будет сохранена как текстовая строка, и Google не узнает, что это дата.)
Здесь правильным ответом должно было быть 59, количество дней между 28 февраля 2017 года и 31 декабря 2016 года.
Как исправить #ЗНАЧ! ошибка?
В сообщении об ошибке должна содержаться информация о том, какая часть формулы вызывает проблему.
Поиск любых возможных несоответствий текста/чисел или ячеек, содержащих ошибочные пробелы. Если вы щелкнете по ячейке, и у мигающего курсора будет пробел между собой и элементом, рядом с которым он находится, тогда у вас будет пробел.
Ячейки могут выглядеть пустыми, но содержать пробелы:
Даты с пробелами посередине тоже не работают:
5. Я получаю #REF! сообщение об ошибке
#REF! ошибка синтаксического анализа формулы возникает, когда у вас есть недопустимая ссылка.
Отсутствует ссылка: Например, когда вы ссылаетесь на ячейку в своей формуле, которая с тех пор была удалена (удалено не значение внутри ячейки, а вся ячейка, как правило, когда вы удалили строку или столбец в своей рабочий лист).
В этом примере исходная формула была
= A1 * B1
, но когда я удалил столбец A, формула вышла из строя из-за отсутствующей ссылки:
ссылки — это когда вы копируете формулу с относительным диапазоном на краю листа. При копировании и вставке относительный диапазон может перемещаться так, как если бы он находился за пределами листа, что недопустимо и приведет к ошибке #ССЫЛКА! ошибка.
В этом примере функция суммирования складывает ячейки в 3 строках выше. Когда я пытаюсь скопировать и вставить функцию суммы в новую ячейку с менее чем 3 строками выше, она даст мне #ССЫЛКА! ошибка:
Поиск за пределами: Вы, наверное, видели #ССЫЛКА! ошибка, если вы часто используете формулы поиска, когда вы пытались вернуть значение за пределами указанных вами диапазонов. В этом примере ВПР я пытаюсь вернуть ответ из 3-го столбца таблицы поиска, в которой всего 2 столбца:
В этом примере ВПР я пытаюсь вернуть ответ из 3-го столбца таблицы поиска, в которой всего 2 столбца:
Круговая зависимость: Вы также получите #REF! ошибка при обнаружении циклической зависимости (когда формула ссылается сама на себя).
В этом примере у меня есть числа в диапазоне от A1 до A3, но формула СУММ в ячейке A4 пытается суммировать от A1 до A4, включая себя. Следовательно, у нас есть циклический аргумент, в котором ячейка A4 пытается быть как входной, так и выходной ячейкой, что недопустимо.
Как исправить ошибку #REF! ошибка?
Прежде всего, прочитайте сообщение об ошибке, чтобы определить тип #REF! ошибка, с которой вы имеете дело. Это должно дать вам большую подсказку о том, как исправить ошибку.
Для удаленных ссылок ищите #REF! ошибка находится внутри вашей формулы, и замените #ССЫЛКА! с правильной ссылкой на ячейку или диапазон.
В случае ошибок поиска вне границ внимательно просмотрите формулу и проверьте размеры диапазонов по любым индексам строк или столбцов, которые вы используете.
Для циклических зависимостей найдите ссылку, которая вызывает проблему (т. е. там, где вы также ссылаетесь на текущую ячейку в формуле), и измените ее.
6. Я получаю #ИМЯ? сообщение об ошибке
#ИМЯ? ошибка синтаксического анализа формулы означает проблему с синтаксисом формулы.
Наиболее распространенной причиной этой ошибки является опечатка в одном из имен функций.
В этом примере я неправильно написал функцию СУММ как СУМММ, которую Google Таблицы не распознали, поэтому вернул ошибку:
Еще одна причина для #ИМЯ? ошибка ссылается на именованный диапазон, который на самом деле не существует или написан с ошибкой.
Так
=СУММ(прибыль)
даст вам #ИМЯ? ошибка, если именованный диапазон прибыль не существует
Отсутствие кавычек вокруг текстового значения, как показано в этой простой формуле, также приведет к ошибке #NAME? ошибка:
=CONCAT("Первый",Второй)
(В слове Второй отсутствуют кавычки.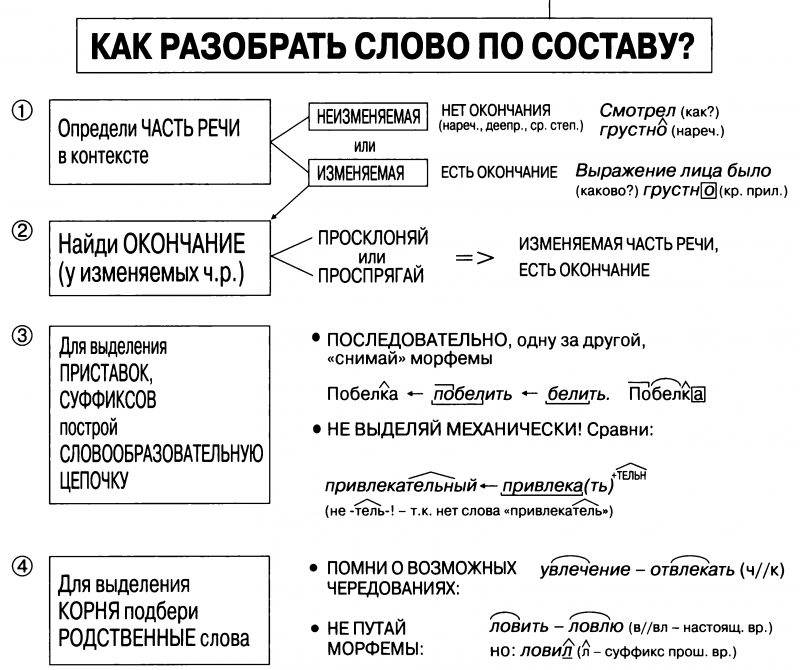 )
)
Как исправить #ИМЯ? ошибка?
Проверьте правильность имен функций. Используйте мастер помощника по функциям, чтобы уменьшить вероятность возникновения ошибок, особенно для функций с более длинными именами. Когда вы начнете вводить формулу, вы увидите меню функций, которое вы можете выбрать с помощью стрелок вверх и вниз и Tab.
Убедитесь, что вы определили все именованные диапазоны, прежде чем использовать их в своих формулах, и что все они имеют правильное написание.
Убедитесь, что все текстовые значения введены с обязательными кавычками.
Наконец, не пропустили ли вы двоеточие в ссылках на диапазоны? Это будет очевидно, потому что оно не будет выделено правильно.
В этой формуле
=СУММ(A1A10)
отсутствует двоеточие между A1 и A10, и она выдаст ошибку #NAME? ошибка.
Конечно, следует читать:
=СУММ(A1:A10)
7.
 Я получаю #ЧИСЛО! сообщение об ошибке
Я получаю #ЧИСЛО! сообщение об ошибке#ЧИСЛО! Ошибка синтаксического анализа формулы отображается, когда ваша формула содержит недопустимые числовые значения.
Классический пример — попытка найти квадратный корень из отрицательного числа, что недопустимо:
(Любой знаток математики знает, что квадратный корень из отрицательного числа можно найти с помощью комплексные (мнимые) числа.)
Некоторые другие функции, которые могут привести к ошибке #ЧИСЛО! сообщениями об ошибках являются функция SMALL и функция LARGE. Если вы попытаетесь найти наименьшее n-е значение в вашем наборе данных, где n выходит за пределы количества значений в вашем наборе данных, вы получите #ЧИСЛО! ошибка.
Например, вы просите Google Таблицы найти 10-е наименьшее число в наборе данных, в котором всего 5 значений:
(почему это не возвращает ошибку #ССЫЛКА!, как в примере с ВПР за пределами границ, не знаю)
Как исправить #ЧИСЛО! ошибка?
Вам необходимо проверить числовые аргументы в формуле.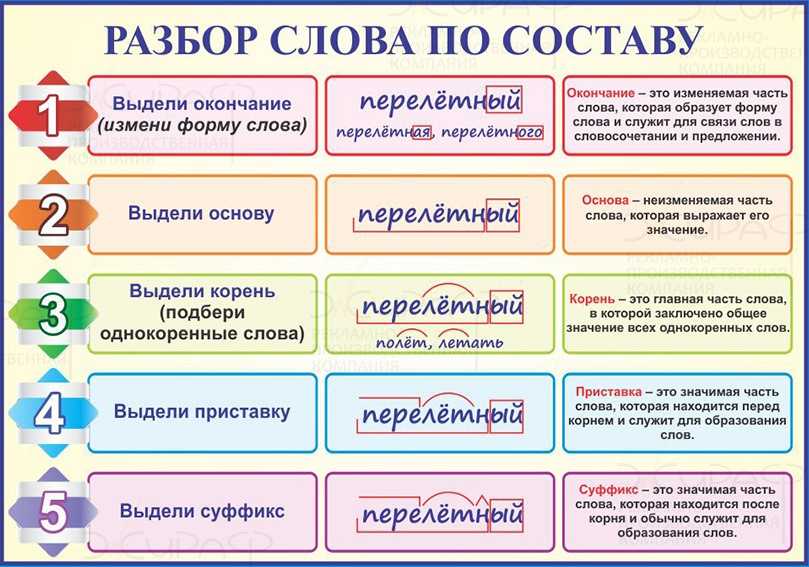 Сообщение об ошибке должно дать вам некоторые подсказки о том, какая часть формулы вызывает проблему.
Сообщение об ошибке должно дать вам некоторые подсказки о том, какая часть формулы вызывает проблему.
8. Я получаю сообщение #ОШИБКА! сообщение об ошибке синтаксического анализа формулы
Это сообщение об ошибке синтаксического анализа формулы уникально для Google Sheets и не имеет прямого эквивалента в Excel. Это означает, что Google Таблицы не могут понять введенную вами формулу, потому что не могут разобрать формулу для ее выполнения.
Например, если вы вручную вводите символ $ для обозначения суммы, но Google Sheets считает, что вы имеете в виду абсолютную ссылку:
или вы пропустили «&» при объединении текста и числа значения:
В этом случае формула должна быть:
="Всего" & сумма(A1:A3)
Другой случай, вызванный тем, что мы перепутали закрывающие скобки формулы:
Как исправить ошибку #ERROR! ошибка?
Внимательно проверьте правильность формулы.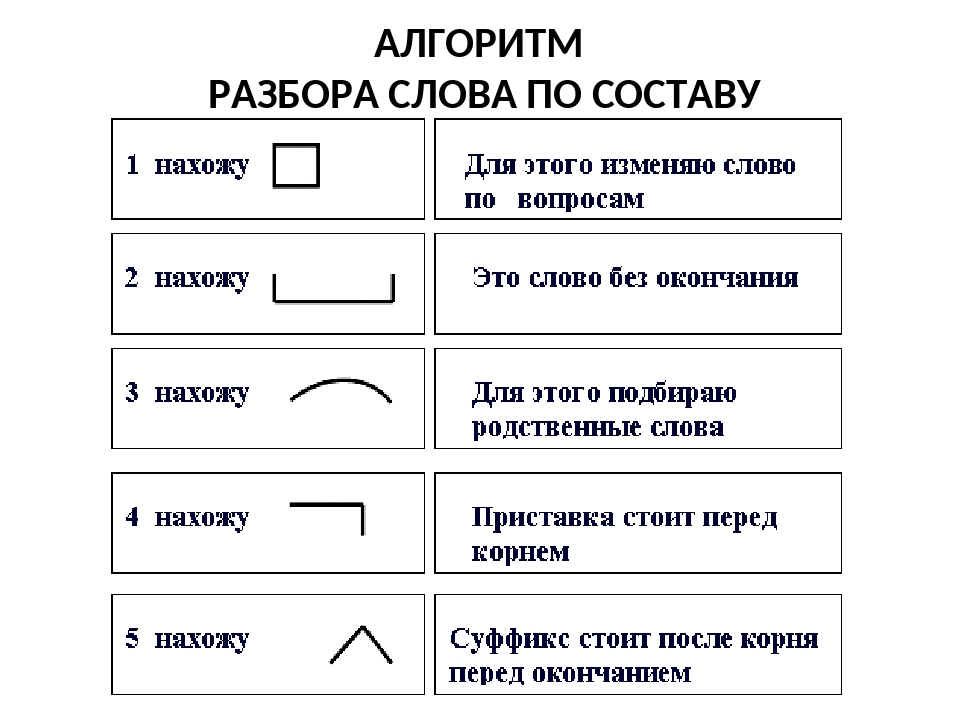
Вы хотите убедиться, что у вас есть правильное количество квадратных скобок и правильный синтаксис соединения между текстом и числовыми значениями (например, с помощью «&»).
Если вы хотите отобразить значения с символами валюты или в процентах, не вводите вручную «$» или «%». Вместо этого введите простое число, а затем используйте параметры форматирования, чтобы изменить его на нужный стиль.
9. Я получаю #NULL! сообщение об ошибке
Мне не удалось воссоздать #NULL! ошибка синтаксического анализа формулы в дикой природе, но теоретически она существует!
(Если у вас есть такая запись на вашем листе, дайте мне знать! Я хотел бы обновить эту статью с примером здесь.)
10. Другие стратегии для работы с ошибкой синтаксического анализа формулы
Посмотрите для красного выделения в вашей формуле, так как это поможет определить источник вашей ошибки, например. в случае слишком большого количества скобок лишние, лишние будут выделены красным цветом.
Отшелушивание луковицы: структура луковицы — это метод устранения ошибок в длинных сложных формулах. Разворачивайте внешние функции в формуле одну за другой, пока она снова не заработает. Затем вы можете начать добавлять их обратно один за другим, и точно увидеть, какой шаг вызывает проблему, и исправить это.
Различный синтаксис в разных странах : В некоторых европейских странах используется точка с запятой «;» вместо запятых «», так что это может быть причиной вашей ошибки. Сравните эти две формулы, которые имеют одинаковые входные и выходные данные, но синтаксис отличается для пользователей в разных странах (регионах).
=ФормулаМассива(ВПР(A1;Лист2!A:I;{2\3\4\5\6\7\8};ЛОЖЬ))
это та же формула, что и эта:
=ФормулаМассива(ВПР( A1,Sheet2!A:I,{2,3,4,5,6,7,8},FALSE))
(Это пример функции ВПР, возвращающей несколько значений (массив) вместо одного значения .)
Совет для профессионалов:
Используйте апостроф в начале формулы, чтобы превратить ее в текстовую строку, которая не будет выполняться. Иногда это полезно для просмотра всей вашей формулы для отладки, сохранения копии вашей формулы, чтобы вы могли копировать и вставлять ее фрагменты в другое место для тестирования.
Иногда это полезно для просмотра всей вашей формулы для отладки, сохранения копии вашей формулы, чтобы вы могли копировать и вставлять ее фрагменты в другое место для тестирования.
11. Функции, помогающие справляться с ошибками синтаксического анализа формул в Google Таблицах
Стоит знать о некоторых других функциях, связанных с ошибками синтаксического анализа формул.
На самом деле, есть даже функция для генерации ошибок #Н/Д. Он имеет ограниченное применение, но может быть полезен для проверки данных в более сложных формулах.
=NA()
выведет ошибку #N/A. (Справка Google Docs для Северной Америки)
=ERROR.TYPE(value)
вернет число, соответствующее типу ошибки:
(Справка Google Docs по ОШИБКЕ.