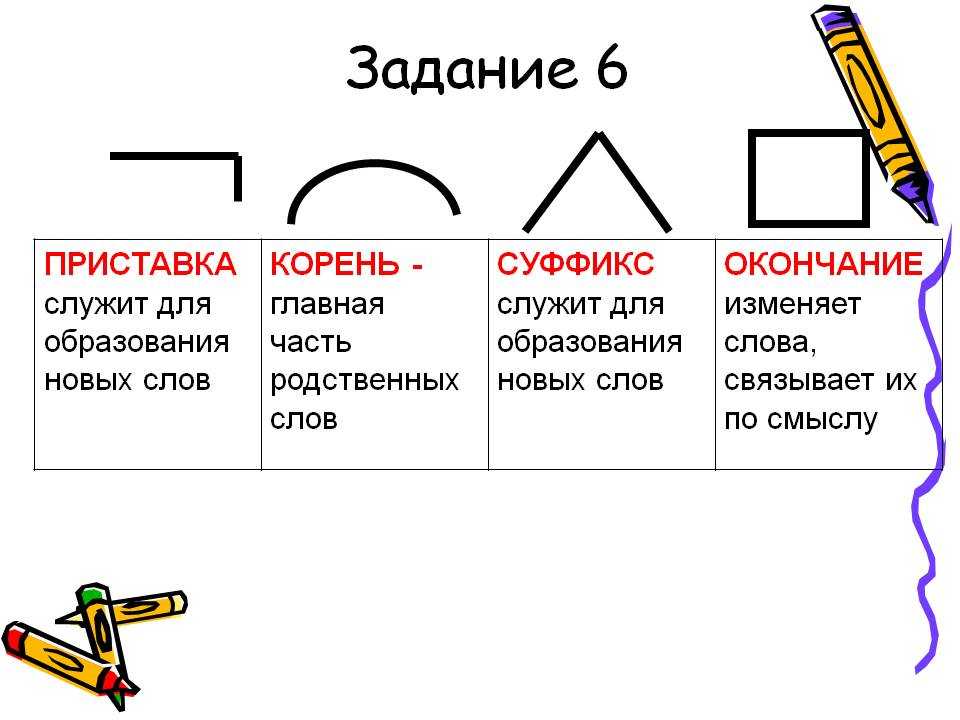
Окончание – что это такое и как правильно находить окончания в словах
Окончание – это изменяемая часть слова.
Окончание – это морфема, часть слова. Это единственная морфема, которая изменяется при изменении слова. То есть то, что изменяется, и есть окончание. То, что не изменяется – это основа слова.
Например: красивый – красивая, красивое, красивые – -ый, -ая, -ое, -ые – окончания.
Окончания есть только у изменяемых слов. У депо, пальто, бюро, очень, вверху, вдрызг, ой-ой, ах, мяу окончаний нет.
Как найти окончание слова
Если учительница говорит: «Найдите окончание слова», вам надо это слово изменить. Если хотите выпендриться, скажите: «Хорошо, тогда проспрягаем слово» (если у вас глагол) или «Ок, тогда я просклоняю слово» (если у вас ИМЯ существительное, прилагательное, числительное или местоимение, причастие).
Склоняем имя существительное «курица» – нет курицы, даю курице, виню курицу – окончание «а».
Спрягаем глагол «звонит» – звоню, звонишь – окончание «ет».
Помните про [j]
Проспрягаем слово «работает». Обратите внимание, там «е» после гласного и обозначает два звука – «jэ» или «йэ»: работаjэт – работаjу, работаjут. «Работаj» не изменился, поэтому окончание здесь только «-эт».
Просклоняем существительное «вдохновение»: вдохновениjэ – вдохновениjа – вдохновениjу – основа «вдохновениj», окончение «-э».
Бывает так, что в очень слабых классах учителя этого не требуют. И если вы просто выделите «е» в слове «вдохновение» или «ет» в слове «работает» – ошибки не будет.
Но правильнее все-таки выделять так, как показал я.
Какое окончание у начальной формы глагола, или инфинитива
«Ть». Читать, писать, слушать, орать, хихикать, улюлюкать, вздыхать, мять – везде «ть».
Но в глаголах «беречь», «печь», «стеречь» и других окончания нет. Оно как бы есть – «чь», но оно входит в корень, поэтому мы его не выделяем.
«Ся» – это не окончание!
Это постфикс, то есть то, что находится после окончания.
В слове «подготовиться» окончание «ть», а «-ся» – постфикс. Выделять его надо треугольничком, как суффикс.
 В слове «подготовиться» окончание «ть», а «-ся» – постфикс. Выделять его надо треугольничком, как суффикс.
В слове «подготовиться» окончание «ть», а «-ся» – постфикс. Выделять его надо треугольничком, как суффикс.Что такое нулевое окончание
Вот здесь ученики всегда тупят.
Нулевое окончание – это когда окончания нет, но при изменении слова оно появляется. Например, «муж» – нулевое окончание. Если мы начнем слово склонять, то окончание появится: «мужа» – «а», «мужу» – «у», «с мужем» – «ем».
Когда вы делаете морфемный разбор слова «муж» надо обязательно после него нарисовать пустой квадрат – показать, что окончание нулевое.
У каких слов нет окончания
В русском языке есть неизменяемые слова, у них окончания вообще нет, то есть нет даже нулевого.
В первую очередь, это иноязычные слова. Например, вот слово «пальто». Как его не изменяй – оно так и будет «пальто». То же самое с «депо», «мсье» и другими иноязычными словами. Не надо в них даже квадратик рисовать – окончания просто нет.
Другие слова, у которых нет окончаний:
- Все служебные слова: предлоги (на, за, в, вследствие, благодаря), союзы (и, а, но, чтобы, что), частицы (не, ни, же).
- Междометия (ах, ой, блин, ура).
- Звукоподражания (гав-гав, мяу-мяу, квак-квак, курлык-курлык).
- Наречия (вверх, громко, сразу, утром, весной).
- Деепричастия (вспоминая, изучив, выпросив, спустив, открывая).
- Категория состояния (холодно, тепло, одиноко, страшно).
- Некоторые заимствованные прилагательные (хаки, беж, меланж).
Вот мое видео про окончания в словах, посмотрите на досуге.
Помогите мне сделать этот материал лучше. Напишите в комментариях, какие трудности у вас вызывают окончания, я их разберу в статье.
ЕЖЕНЕДЕЛЬНАЯ РАССЫЛКА
Получайте самые интересные статьи по почте и подписывайтесь на наши социальные сети
ПОДПИСАТЬСЯВаш браузер устарел рекомендуем обновить его до последней версии
или использовать другой более современный.
python — отделять только суффиксы от строки
спросил
Изменено 1 год, 6 месяцев назад
Просмотрено 348 раз
У меня есть список суффиксов слов, моя цель состоит в том, чтобы разделить введенное предложение на суффиксы в списке.
Моя проблема в том, что суффиксы в этом списке разделяют слова даже в корне. Например:
(международно) >> должно быть >> (interna _tion _al _ly), вывод моего кода >> (int _erna _tion _al _ly)
Примечание: в моем списке есть «er»
Одним из решений может быть поиск слов, начинающихся с конца предложения. Например, код сначала добавляет букву «y», если она соответствует списку, разделяет ее, если нет, продолжает добавлять >
Если искать таким образом, проблема исчезает, но я не нашел, как это сделать.
Буду очень рад, если вы мне покажете дорогу.
предложение = ввод ()
суффиксы = ["acy", "ance", "ence", "dom", "er", "or", "ism", "ist",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
для x в суффиксах:
у = "_" + х
предложение = предложение. заменить(х, у)
 заменить(х, у)
заменить(х, у)
- питон
- суффикс
11
str.replace() проблема. Он заменяет подстроку в любом месте , а не только в конце. Вместо этого вы можете использовать str.endswith() или, если вы используете 3.9+, str.removesuffix() . Вот итеративная реализация с использованием str.endswith() .
def remove_suffixes (строка, суффиксы):
"""
Удалить все суффиксы из строки. Вернуть корень и суффиксы.
>>> remove_suffixes('умно', ['y', 'ly'])
('умный', ['лай'])
"""
# Сортируем так, чтобы самые длинные совпадали первыми
суффиксы = отсортированы (суффиксы, ключ = длина, реверс = истина)
удалено = []
prev = None # Переменная цикла
while prev != string: # т.е. прервать, если не изменилось
prev = string # Копировать для следующего цикла
для суффикса в суффиксах:
если string. endswith(суффикс):
удалено.дополнение(суффикс)
строка = строка[:-len(суффикс)]
возвращаемая строка, удаленная[::-1]
суффиксы = [
"acy", "ance", "ence", "dom", "er", "or", "ism", "ist",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
s_out, found = remove_suffixes('международно', суффиксы)
# > 'внутренняя', ['ция', 'аль', 'лы']
print(s_out, *found, sep=' _') # -> внутренний _tion _al _ly
 endswith(суффикс):
удалено.дополнение(суффикс)
строка = строка[:-len(суффикс)]
возвращаемая строка, удаленная[::-1]
суффиксы = [
"acy", "ance", "ence", "dom", "er", "or", "ism", "ist",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
s_out, found = remove_suffixes('международно', суффиксы)
# >
endswith(суффикс):
удалено.дополнение(суффикс)
строка = строка[:-len(суффикс)]
возвращаемая строка, удаленная[::-1]
суффиксы = [
"acy", "ance", "ence", "dom", "er", "or", "ism", "ist",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
s_out, found = remove_suffixes('международно', суффиксы)
# > Вот способ использования endwith() и нарезки строк:
suffixes = ["acy", "ance", "ence", "dom", "er", "or", "ism", " ист",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
определение find_suffix (слово):
для суффикса в суффиксах:
если word. endswith(суффикс):
suffix_removed = word[:-len(suffix)] # часть перед суффиксом
return find_suffix(suffix_removed) + f' _{suffix}' # recurse
return word # если суффикс не найден, вернуть слово как есть
print(find_suffix('международно')) # международный _tion _al _ly
print(find_suffix('эгоистично')) # ego _ist _ic _al _ly
 endswith(суффикс):
suffix_removed = word[:-len(suffix)] # часть перед суффиксом
return find_suffix(suffix_removed) + f' _{suffix}' # recurse
return word # если суффикс не найден, вернуть слово как есть
print(find_suffix('международно')) # международный _tion _al _ly
print(find_suffix('эгоистично')) # ego _ist _ic _al _ly
endswith(суффикс):
suffix_removed = word[:-len(suffix)] # часть перед суффиксом
return find_suffix(suffix_removed) + f' _{suffix}' # recurse
return word # если суффикс не найден, вернуть слово как есть
print(find_suffix('международно')) # международный _tion _al _ly
print(find_suffix('эгоистично')) # ego _ist _ic _al _ly
Рекурсия не обязательна; то же самое можно сделать только с циклом на .
В Python 3.9 они представили метод removesuffix() для строки, который определяется в основном так же, как код выше. Если вы используете Python 3.9+, вы можете вместо этого использовать suffix_removed = word.removesuffix(suffix) для удобочитаемости (хотя я не проверял это, так как использую 3.8).
По запросу OP ниже приведена функция, которая применяет вышеуказанное к каждому слову в предложении.
по определению suffixify_sentence(предложение):
return ' '.join(find_suffix(word) для слова в предложении. split())
предложение = 'человечество на международном уровне искренне живописно'
print(suffixify_sentence(sentence)) # Humani _ty interna _tion _al _ly вера _ful _ly pictur _esque
 split())
предложение = 'человечество на международном уровне искренне живописно'
print(suffixify_sentence(sentence)) # Humani _ty interna _tion _al _ly вера _ful _ly pictur _esque
split())
предложение = 'человечество на международном уровне искренне живописно'
print(suffixify_sentence(sentence)) # Humani _ty interna _tion _al _ly вера _ful _ly pictur _esque
9
Я не уверен, что ваш алгоритм будет работать во всех случаях, но мне показалось забавным реализовать его, так что вот оно:
предложение = 'международно'
предложение = список (предложение)
стек = []
результаты = []
для i в предложении[::-1]:
стек.insert(0,i)
угадать = ''.join(стек)
если угадать в суффиксах:
results.insert(0, f'_{догадка}')
стек = []
results.insert(0, предположение)
печать(''.присоединиться(результаты))
# международный_al_ly
вы по существу реализуете стек и строите его в обратном порядке
вы можете сделать
max_length = max(len(suffix) для суффикса в суффиксе)
для suffix_length в диапазоне (max_length):
если suffix_length >= len(word):
сломать
если слово[-suffix_length:] в суффиксах:
#разделить суффикс
Другая тактика заключается в повторении суффиксов по возрастающей длине. Вы можете сделать это, имея
Вы можете сделать это, имея суффиксов = отсортированных (суффиксы, ключ = длина) , прежде чем перебирать суффиксы. То есть:
предложение = ввод ()
суффиксы = ["acy", "ance", "ence", "dom", "er", "or", "ism", "ist",
"ты", "мент", "несс", "корабль", "сион", "ция", "ели",
"en", "fy", "ize", "able", "ible", "al",
"esque", "ful", "ic", "ous", "ish", "ive",
«меньше», «ред», «инг», «лы», «подопечный», «мудрый»]
суффиксы = отсортированы (суффиксы, ключ = длина)
для x в суффиксах:
у = "_" + х
предложение = предложение.заменить(х, у)
1
Объединение суффикса или префикса с корневыми словами — обратитесь за помощью
Обнаружено отключение Javascript
В настоящее время у вас отключен JavaScript. Некоторые функции могут не работать. Пожалуйста, повторно включите JavaScript, чтобы получить доступ ко всем функциям.
Привет,
Может ли кто-нибудь помочь мне, как объединить префикс и суффикс с их корневыми словами?
корневые слова, префиксы и суффиксы разделены в разных файлах, и цель состоит в том, чтобы объединить их с корневыми словами.
В настоящее время я получил только примитивный код для слияния с простыми суффиксами или префиксами
FileReadLine, var, suffix.txt, 1 FileReadLine, var1, root.txt, 1 FileAppend, %var1%%var%, final.txt
Теперь проблема заключается в том, как мне зациклить это, чтобы получить каждую комбинацию суффикса (или префикса) с корнем? Так, например, если я получил 3 суффикса и 3 корневых слова, в моем окончательном тексте должно быть 9 слов. В сложном случае, если я получил 3 суффикса, 3 префикса и 3 корневых слова, я думаю, что у меня должно быть 81 слово.
Будем признательны за любую помощь, заранее спасибо.
#1 —
Опубликовано 29 ноября 2009 г. — 10:51
— 10:51
- Наверх
FileRead,префикс,префикс.txt
FileRead,корень,root.txt
FileRead,суффикс,суффикс.txt
FileDelete, final.txt
цикл, разбор, префикс, `n, `r
{
слово = %A_LoopField%; сохранить в другом var
цикл, разбор, корень, `n, `r
{
слово2 = %слово%%A_LoopField% ; сохранить в другом var
петля, разбор, суффикс, `n, `r
{
FileAppend, %word2%%A_LoopField%`n, final.txt
}
}
} #2 — Опубликовано 29 ноября 2009 г. — 11:26
Динамические строки быстрого доступа на основе регулярных выражений
COM
AutoHotkey 2
- Вернуться к началу
Вот демонстрация со строкой. Его легче понять и протестировать:
слов = AutoHotkey, Programming, Scripting префиксы = A_, B_, C_ суффиксы = 1, 2, 3 ; Списки представляют собой значения, разделенные запятыми.