What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
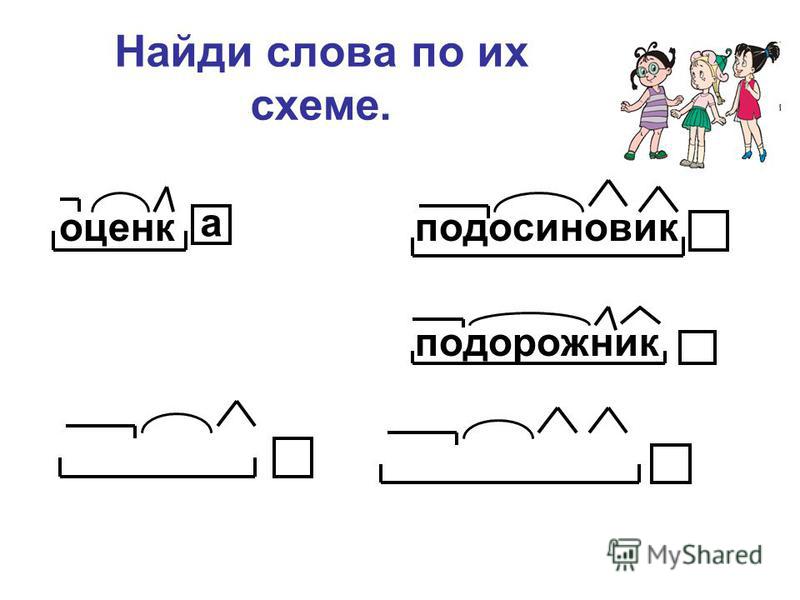
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Сходство и различие служебных слов
Сходство служебных слов
1. Все служебные слова могут быть производными и непроизводными.
Производные служебные слова сохранили в современном русском языке живые словообразовательные и лексико-семантические отношения с мотивирующими знаменательными словами.
Непроизводные (первообразные) служебные слова не имеют словообразовательных и лексико-семантических связей со знаменательными частями речи: в продолжение года, в течение урока, на уроке, об уроке.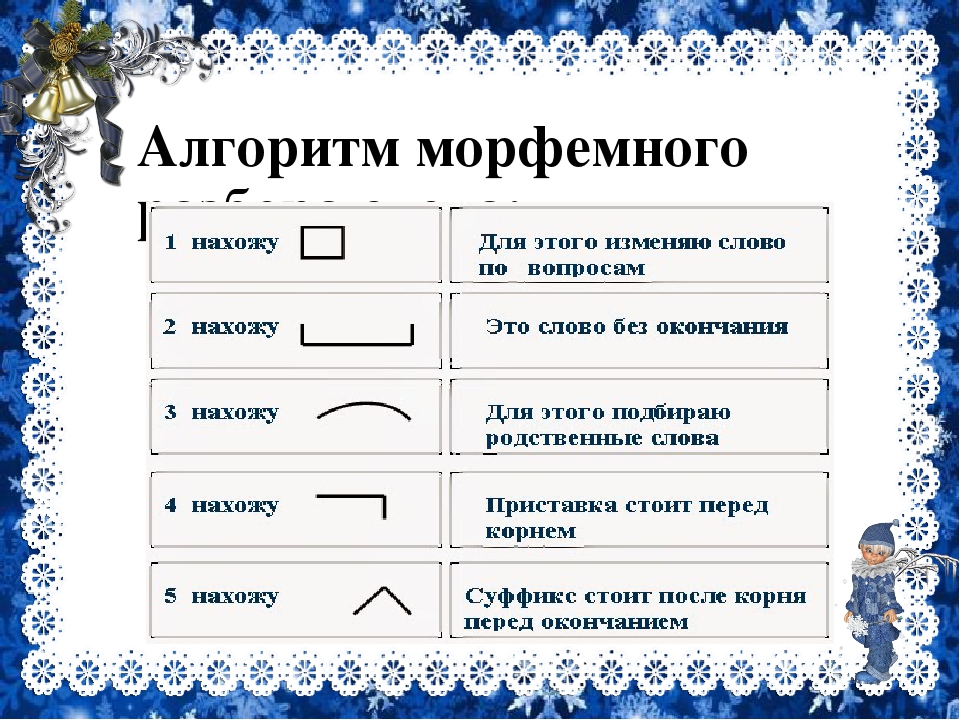
2. По составу все служебные слова делятся на простые (в, к, на, перед) и составные, состоящие из нескольких элементов (несмотря на, потому что, хотя бы).
В отличие от знаменательных, все служебные слова не имеют номинативной функции, не изменяются, не имеют грамматических категорий и не являются членами предложения.
Различие служебных слов
1. Предлоги и союзы отличаются от частиц по функции.
Предлоги и союзы служат для выражения различных семантико-синтаксических отношений между словами, предложениями и частями предложений. Частицы в отличие от них не участвуют в построении структуры предложения или словосочетания. Они выражают смысловые оттенки или участвуют в образовании аналитических форм слов, т. е. выражают объективную и субъективную модальность.
- Только ты меня понимаешь. (Только — частица.)
- Неужели ты был там на самом деле? (Неужели — частица.
 )
) - Я как раз это и хотела спросить. (Как раз — частица.)
 )
)
Сложные моменты
Среди служебных слов много омонимов как по отношению к знаменательным словам, так и по отношению друг к другу.
Скажи, что случилось? (Что — местоимение.) Что так поздно пришёл? (Что — наречие, = кто.) Сказал так тихо, что никто не услышал. (Что — союз.) |
Говорите просто, чтобы было понятно. Чтобы этого больше не было. (Чтобы — частица.)
|
Лес точно сказка. (Точно — союз, = как.) Точно такая же вещь. (Точно — наречие, = совершенно.) Точно я вас где-то встречал. (По Ожегову, точно — частица.) |
 (Чтобы — союз.)
(Чтобы — союз.)
Возможно частичное внешнее совпадение служебных слов.
- Несмотря на мороз, мы пошли гулять. (Несмотря — предлог.)
- Несмотря на то что был мороз… (Несмотря на то что — союз.)
Может происходить перекрещивание функций служебных слов.
- — Не думай об этом.
- — Я и не думаю.
Поделиться публикацией:
Классный урок на «Радио России – Тамбов», эфир 14 мая 2020 года — ВЕСТИ / Тамбов
Этот урок культуры речи будет полезен не только тем, кто готовится к сдаче ЕГЭ. Разговор пойдет, в частности, о паронимах, которые иногда называют «ложными братьями» — словах, сходных по звучанию и морфологическому составу, но различающихся лексическим значением. Омонимы впервые заметил Аристотель. А вот Цицерон утверждал, что «Как в жизни, так и в речи нет ничего труднее, как видеть, что уместно». Сегодняшний урок поможет изучающим русский язык всегда правильно выбирать слова.
Разговор пойдет, в частности, о паронимах, которые иногда называют «ложными братьями» — словах, сходных по звучанию и морфологическому составу, но различающихся лексическим значением. Омонимы впервые заметил Аристотель. А вот Цицерон утверждал, что «Как в жизни, так и в речи нет ничего труднее, как видеть, что уместно». Сегодняшний урок поможет изучающим русский язык всегда правильно выбирать слова.
Урок русского языка в 11 классе «Паронимы»
Здравствуйте, уважаемые слушатели. Тема сегодняшнего урока «Паронимы, употребление паронимов в речи». Приглашаем к разговору тех, кто хочет сделать лингвистические открытия, кто хочет расширить свой лексикон, говорить правильно и повысить культуру речи, кому интересно больше узнать о паронимах. Эта тема будет интересна и полезна учащимся 11 классов, так как задание №5 в ЕГЭ именно на это правило.
Наблюдения над живым словом в повседневном обиходе, на собраниях, лекциях, над речью школьников, особенно в ее письменном выражении (творческие работы), наконец над языком периодической печати, радио и телевидения свидетельствуют о том, что в речи встречается немало ошибок и отклонений от современных литературных норм. Паронимия – один из источников «трудностей» литературной речи.
Паронимия – один из источников «трудностей» литературной речи.
Одна из распространенных ошибок школьников — смешение паронимов. Да и люди, свободно владеющие русским литературным языком, по справедливому замечанию Д. Э. Розенталя, «нередко затрудняются в выборе какого-либо из слов, отмеченных не только сходством в их звучании, но и смысловой близостью, что объясняется их образованием от одного и того же корня».
Однако в школьную программу по русскому языку в 5-9 классах не включен специально вопрос, предполагающий изучение слов-паронимов и употребление их в речи. В программе же для старшей школы количество часов на изучение темы «Паронимы и их употребление» ограничено. Не случайно выпускники испытывают большие трудности на ЕГЭ по русскому языку при выполнении заданий, связанных с употреблением паронимов. А ведь задания по данной теме имеют место во всех типах тестов ЕГЭ.
М. Горький говорил: «Слово — одежда всех фактов, всех мыслей». Значит, эту одежду необходимо подбирать «по мерке» и «со вкусом», следует в первую очередь учитывать присущее каждому слову значение. А знаем ли мы эти значения? Как показывает практика – не всегда.
А знаем ли мы эти значения? Как показывает практика – не всегда.
Ошибки в употреблении паронимов можно услышать очень часто. Бабушка говорит внуку: «Одень пальто – на улице холодно». Кондуктор в автобусе строго обращается к пассажирам: «Вошедшие граждане, оплатите за проезд». А в рекламной листовке парикмахерской можно прочитать: «Мы создадим вам эффективную внешность». Подобные ошибки связаны с тем, что говорящие и пишущие не видят различий в значениях паронимов, неправильно понимают значения слов. Как же избежать подобных ошибок? Что нужно делать, чтобы не допускать лексические недочёты в речи? Попытаемся найти ответы на эти важные вопросы и попробуем выяснить специфику употребления паронимов, причины возникновения их в русском языке, а также типичные ошибки при употреблении слов – паронимов.
Паронимы – это однокоренные слова, принадлежащие к одной части речи, имеющие общие грамматические признаки. Паронимы — это слова, имеющие структурное и звуковое сходство.
Паронимы в большинстве случаев относятся к одной части речи. Например: одеть и надеть, абонент и абонемент, мудреть и мудрить. Иногда паронимы также называют ложными братьями.
Каковы основные ошибки в употреблении паронимов? Близнецы или совсем чужие? Паронимы требуют к себе особого внимания, поскольку в речи недопустимо их смешение.
Итак, с учетом особенностей паронимы бывают по структуре:
Приставочные паронимы – паронимы, имеющие разные приставки. Например: вбежать – взбежать, обсудить – осудить, одеть – надеть и т.д.
Суффиксальные паронимы – паронимы, имеющие разные суффиксы.
Например: грозный – грозовой, белеть – белить, лирический – лиричный и т.д.
Финальные паронимы – паронимы, отличающиеся окончаниями, а также конечными буквами. Например: жар – жара, гарант – гарантия, невежа – невежда, адресат — адресант и т.д.
По значению:
Полные (абсолютные) паронимы – паронимы с ударением на одном и том же слоге, выражающие разные смысловые понятия. Например: осуждение – обсуждение, восход – всход и т.д.
Например: осуждение – обсуждение, восход – всход и т.д.
Неполные паронимы – паронимы, в которых наблюдается неполное разделение объёма значений, что вызывает их сближение.
Например: аристократический – аристократичный, комический – комичный и т.д.
Частичные (приблизительные) паронимы – паронимы, различающиеся местом ударения, характеризующиеся общностью смысловых понятий и возможным совпадением сочетаемости. Например: водный напор – водяной напор, героический подвиг – геройский подвиг и т.д.
Как различать паронимы?
Например, в заявлении директору сотрудник пишет: «Прошу предоставить мне отпуск» (т.е. дать возможность пользоваться отпуском), а директор может начертать на этом заявлении: «Представьте сначала отчёт о работе» (т.е. он велит, приказывает предъявить ему отчёт о работе).
На собрании докладчику предоставляют слово, т. е. разрешают высказаться. А если кого-нибудь признают достойным высокой похвалы, то его могут представить к награде.
е. разрешают высказаться. А если кого-нибудь признают достойным высокой похвалы, то его могут представить к награде.
Гостя собравшимся также представляют (т.е. знакомят, называют его имя), но бывают такие нерадивые хозяева, которые предоставляют гостей самим себе (т.е. не развлекают, не обращают на гостей внимания).
Внешнее различие этих двух глаголов – всего одной буквой, а по смыслу разница весьма существенная.
Паронимы можно различать ещё так:
Вместо каждого паронима подставлять близкое ему по смыслу слово. Эти подстановочные слова никогда не совпадут.
Например, вместо экономная хозяйка можно сказать рачительная хозяйка, а вместо экономичная упаковка – выгодная упаковка. Прилагательное рачительная по значению явно отличается от прилагательного выгодная.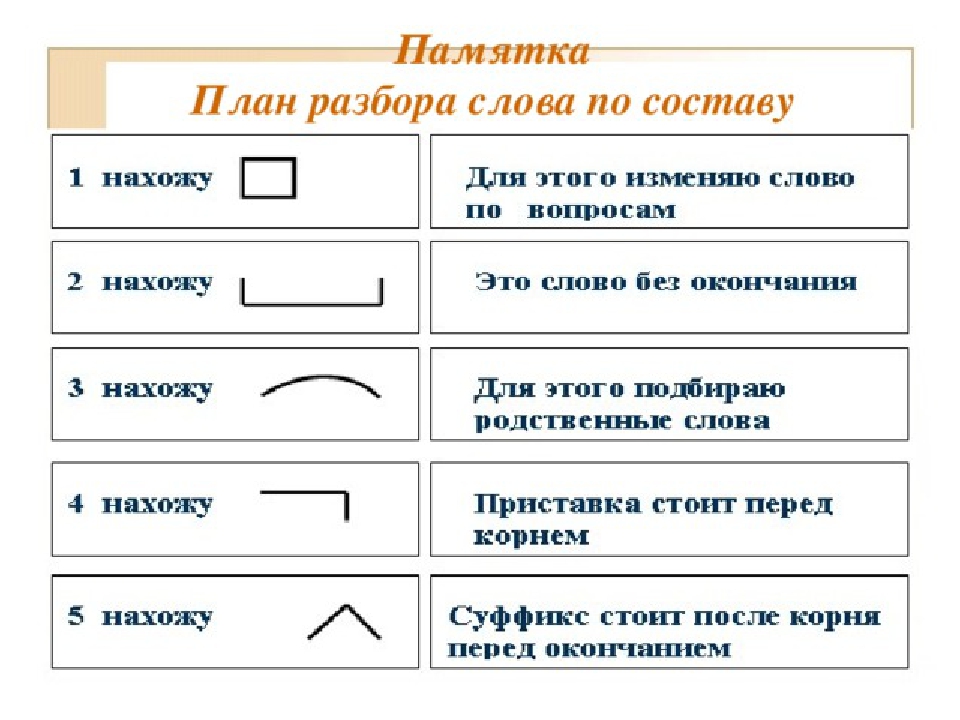 Тем самым делается очевидной разница между паронимами экономная и экономичная.
Тем самым делается очевидной разница между паронимами экономная и экономичная.
Невежа-невежда
Чтобы научиться различать паронимы НЕВЕЖА — НЕВЕЖДА и научиться правильно их употреблять, стоит подробнее изучить лексическое значение и этимологию.
Оба слова могут описывать человека любого пола, возраста и социального статуса. Они не только звучат похоже, но и часто применяются в одинаковом контексте, что затрудняет понимание.
Рассматриваемые паронимы образуют необычную пару, имеющую разные корни. Разбор слова невежда по составу показывает основу «невежд» и окончание «а». Происходит от древнеславянского слова «ведать», то есть «знать». Слово отражает необразованность, недостаточную осведомлённость человека о предмете. Невежа имеет другой корень — «невеж», Это намекает на его родство со словом «невежливость» — отсутствие манер. Эти два паронима взаимосвязаны, поскольку в обществе малообразованность и незнание правил поведения часто идут рука об руку.
Похожесть слов объясняется их происхождением. Во времена Пушкина они относились к одному и тому же понятию и представляли собой разные формы одного существительного. Принципиальное различие между ними впервые было указано в «Толковом словаре живого великорусского языка» В. И. Даля.
В современной разговорной речи понятия продолжают путать, несмотря на то что даже самый воспитанный и вежливый человек может быть необразованным и наоборот.
Запомнить эти паронимы помогут приемы мнемотехники, например, стихи:
Этот человек – НЕВЕЖДА,
Так как разум не разбужен,
А сосед его – НЕВЕЖА,
Что во много раз похуже.
Одеть-надеть
Тонкий знаток русского языка А.Т. Твардовский, обращая внимание на ошибки в употреблении паронимов, заметил: «Я сам, как песчинку в хлебе, попадающую на зуб, не выношу слова – одел шапку, а так упорно почему-то пишется вместо надел.» В речи, действительно, смешивают эти паронимы: «Одень пальто, на улице холодно»; «На мебель одели чехлы». Глагол надеть, который следовало употребить в этих случаях, как правило, имеет при себе предлог на или позволяет нам мысленно его подставить: надень пальто (на сына), надень очки (на нос). Дополнение при этом глаголе обычно выражено неодушевленным существительным. Слово одеть обычно имеет дополнения без предлога, оно часто выражено одушевленным существительным.
Глагол надеть, который следовало употребить в этих случаях, как правило, имеет при себе предлог на или позволяет нам мысленно его подставить: надень пальто (на сына), надень очки (на нос). Дополнение при этом глаголе обычно выражено неодушевленным существительным. Слово одеть обычно имеет дополнения без предлога, оно часто выражено одушевленным существительным.
Об ошибках употребления этих паронимов пишет Новелла Матвеева:
Одень, надень…Два слова
Мы путаем так бестолково!
Морозный выдался рассвет,
Оделся в шубу старый дед.
А шуба, стало быть, надета…
Компания и кампания
Различать и правильно употреблять слова компания и кампания помогает стихотворение А.Т. Твардовского:
Но со страстью неизменной
Дед судил, рядил, гадал
О кампании военной,
Как в отставке генерал.
Шел наш брат, худой, голодный,
Потерявший связь и часть,
Шел поротно и повзводно,
И компанией свободной,
И один, как перст, подчас.
АДРЕСАТ – АДРЕСАНТ
Слова «адресат» и «адресант» должны быть знакомы любителям писать письма. Без них и переписки не получится, ведь это два взаимодействующих лица. Они очень похожи, за что и попали в словари паронимов.
Адресат (он же получатель, на конвертах отмечен словом «Кому») — это тот, кому адресовано сообщение, то есть тот, кто его получит.
Адресант (он же отправитель, на конверте обозначается кодовым словом «От кого») — тот, кто отправляет сообщение.
Много слов написал АДРЕСАНТ,
Только сбивчиво, очень невнятно.
И сидит над письмом АДРЕСАТ –
Половина ему лишь понятна!
Эти слова входят в профессиональную речь служителей почты в составе таких оборотов, как «адресат выбыл», «уточните адресата».
В литературе можно встретить примеры использования в одном предложении одновременно двух слов-паронимов Они служат для задания бинарной стилистической фигуры — парономазии.
Парономазия (от греч. para — возле, onomazo — называю) или паронимическая аттракция — стилистический приём с использованием обоих паронимов в одном предложении. Так как задействованы сразу два слова, приём иногда также называют бинарной стилистической фигурой.
para — возле, onomazo — называю) или паронимическая аттракция — стилистический приём с использованием обоих паронимов в одном предложении. Так как задействованы сразу два слова, приём иногда также называют бинарной стилистической фигурой.
С помощью парономазии добиваются выразительности авторской мысли и образности высказывания. Парономазия используется в поэзии, фольклоре (пословицах, скороговорках, сказках), публицистики.
В приеме парономазии, как правило, используются родственные слова: «Служить бы рад, прислуживаться тошно» (А. С. Грибоедов, «Горе от ума»), «Нечего их ни жалеть, ни жаловать» (А. С. Пушкин, «Капитанская дочка»). Пары таких слов, органично встроенные в художественный текст, усиливают смысл высказывания, способствуют акцентированию внимания читателя, заставляют его лучше запомнить эффектную фразу.
Заключение
Проблема овладения лексическими нормами русского языка, проблема устранения и предупреждения речевых ошибок сегодня стоит остро. Поэтому каждый из нас должен стремиться увеличению своего словарного запаса, к грамотному использованию слов, ведь наша речь – это показатель нашей образованности.
Поэтому каждый из нас должен стремиться увеличению своего словарного запаса, к грамотному использованию слов, ведь наша речь – это показатель нашей образованности.
Какой совет можно дать учащимся? Чтобы повысить уровень культуры речи по употреблению паронимов, необходимо:
— читать научную и художественную литературу;
— проводить постоянные языковые тренировки;
— пополнять словарный запас;
— иметь специальный словарик паронимов и интенсивно его пополнять, поскольку языковой состав постоянно изменяется.
Наша речь – это показатель нашей культуры и образованности. Надеемся, что сегодняшний радиоурок поможет школьникам правильно употреблять паронимы в речи и успешно выполнить задание №5 на ЕГЭ по русскому языку.
| Приставка — | |
Корень слова рощей | Корень — рощ |
Суффикс слова рощей | Суффикс — |
Окончание слова рощей | Окончание — ей |

 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;| рощ | корень |
| а | окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова хлористый (прилагательное):
Ассоциации к слову «роща»
Синонимы к слову «роща»
Предложения со словом «роща»
- Речь шла о такой малости как подлежащая вырубке берёзовая роща на самом краю графства.
- Рассказывают и о том, как прадед мой извёл прекрасную дубовую рощу, скупивши её за бесценок у какого-то разорившегося помещика.
- Здесь вековые зелёные оливковые рощи в Parc du Pian, гавань для яхт, сад Jardin des Colombieres.
- (все предложения)
Цитаты из русской классики со словом «роща»
- Лошадей привязал кучер к деревьям, в недальнем расстоянии, и задал им овса, которым запасся на дорогу; потом перескочил по камням через речку, пробрался сквозь рощу, в которой, сказали мы, терялась по косогору дорога в Менцен, прополз по обнаженной высоте за крестом и у мрачной ограды соснового леса, к стороне Мариенбурга, вскарабкавшись на дерево, которого вершина была обожжена молниею, привязал к нему красный лоскут, неприметный с холма, где были наши путешественники, но видный вкось на мызе.
Сочетаемость слова «роща»
Какой бывает «роща»
Значение слова «роща»
РО́ЩА , -и, ж. Небольшой, чаще лиственный лес. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «роща»
РО́ЩА , -и, ж. Небольшой, чаще лиственный лес.
Предложения со словом «роща»:
Речь шла о такой малости как подлежащая вырубке берёзовая роща на самом краю графства.
Рассказывают и о том, как прадед мой извёл прекрасную дубовую рощу, скупивши её за бесценок у какого-то разорившегося помещика.
Здесь вековые зелёные оливковые рощи в Parc du Pian, гавань для яхт, сад Jardin des Colombieres.
Синонимы к слову «роща»
Ассоциации к слову «роща»
Сочетаемость слова «роща»
Какой бывает «роща»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
★ Юный — чечерский район .. Информация
Пользователи также искали:
не юный,
юный часть речи,
юный или юнный,
юный морфемный разбор,
юный натуралист,
юный правописание,
юный разбор по составу,
юный синоним,
юный,
Юный,
разбор,
не юный,
юный разбор по составу,
юный морфемный разбор,
юный синоним,
юный натуралист,
юный часть речи,
юный правописание,
речи,
правописание,
составу,
морфемный,
синоним,
натуралист,
часть,
юнный,
юный или юнный,
чечерский район.
…
Как сделать фонетический разбор слова юный?
Этот текст можно озаглавить «Как рождался словарь Даля».
Составим план пересказа этого текста:
- Детство, юность, отрочество Даля
- Полвека на службе родному языку
- Четыре тома словаря
- Отношение Пушкина к словарю
- Значение словаря в современности.
Выпишем прилагательные, которые в тексте используется с отсутствующим окончанием, вставим нужные формы окончания, укажем определяемые существительные.
Известного толкового Словаря; морским офицером, военным врачом; по родному краю; русского народа.
Русской речи в разнообразных проявлениях; русского языка; в народной речи, меткие русские пословицы, интересные загадки.
Огромный труд, с большим интересом.
Почетное, прочное место.
«Олицетворять» (что делать?) является инфинитивом/неопреде
Сначала определимся с местом этого слова в словарном гнезде: исходное (непроизводное) или производное.
В словаре А. Тихонова мы обнаруживаем, что глагол «олицетворять» занимает первую позицию и является суффиксальным производным от глагола совершенного вида «олицетворить».
Это важно для выделения основы.
Особый разговор об элементе «-ть», поскольку в разных учебных программах (имею в виду школьный курс русского языка) он определяется по-разному: как окончание инфинитива (УМК Т. Ладыженской, УМК М. Разумовской) или как суффикс инфинитива (УМК В. Бабайцевой). В обоих случаях «-ть» не входит в основу слова, т.к. является формообразующей/форм
Сам морфемный анализ может быть таким:
- ть — суффикс инфинитива/окончание инфинитива,
- олицетворя- основа слова,
- я — суффикс,
- олицетвор- корень.

Олицетвор/я/ть
Разобрать слово по составу значит выделить в нем приставку , корень , суффикс , окончание и основу слова . В слове Кролик корень слова кролик , окончание нулевое , основа слова кролик. В слове Учитель , корень уч , суффикс и , суффикс тель , окончание нулевое , основа слова учитель. В слове подушка , корень подушк , окончание а , основа слова подушк. В слове Привлекательность , приставка при , корень влек , суффикс а , тель, ность , основа слова привлекательность.
В слове ОБРАЗОВАЛОСЬ в современном языке корень -образ-. Словом ОБРАЗ мы и проверим первую безударную гласную О. Исторически в этом слове корень -раз-. Этот же корень имели раньше слова: БЕЗОБРАЗНЫЙ, РАЗНООБРАЗНЫЙ. Они и будут проверочными для буквы А.
Добрый день.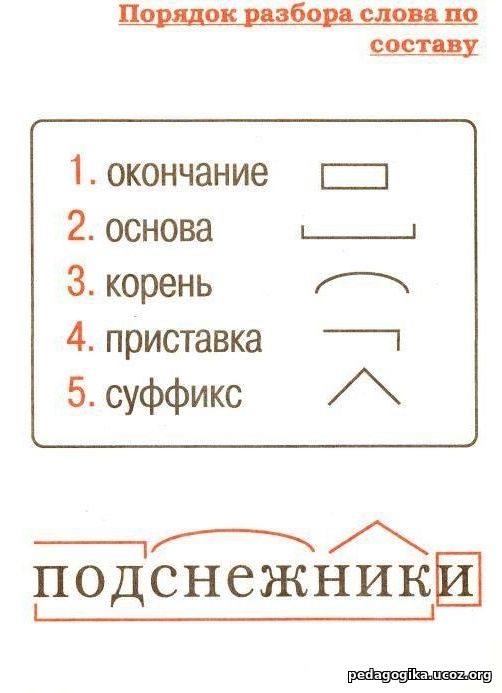 Давайте определим, нужен ли дефис в словосочетание «(темно)голубой».
Давайте определим, нужен ли дефис в словосочетание «(темно)голубой».
Предлагаю обратиться к правилам русского языка, но для этого определим часть речи этого слова.
Слово «(темно)голубой» отвечает на вопрос «Какой?», а, следовательно, является прилагательным.
Для этой части речи есть замечательное правило – оттенок цвета пишут через дефис всегда.
Правильный ответ: «темно-голубой».
Пример предложения.
На полу в гостиной лежал в темно-голубой ковролин.
Темно-голубой цвет в данном доме был в фаворитах, где мы его только не видели.
Выбор мы делали между темно-голубым и ярко-синим цветом.
Всем удачи.
Паронимы — определение, классификация, примеры
Паронимы — определение, классификация, примерыСловарь паронимов русского языка
Определение
Паронимы (от греч. para «возле, рядом» + onyma «имя») — слова, схожие по звучанию, близкие по произношению, лексико-грамматической принадлежности и по родству корней, но имеющие разное значение. Паронимы в большинстве случаев относятся к одной части речи. Например: одеть и надеть, абонент и абонемент, мудреть и мудрить. Иногда паронимы также называют ложными братьями.
Паронимы в большинстве случаев относятся к одной части речи. Например: одеть и надеть, абонент и абонемент, мудреть и мудрить. Иногда паронимы также называют ложными братьями.
Паронимов в современном русском языке насчитывается сравнительно немного (О. В. Вишняковой составлено около 1000 паронимических рядов), но их роль нельзя недооценивать, необходимо верно понимать значение и смысл слов из паронимической пары, чтобы избегать речевых ошибок. Лексические значения компонентов пары всегда разграничены, нельзя заменять любой пароним его парным компонентом. Ошибочная взаимозамена делает контекст бессмысленным или относящимся к иной предметной области. Паронимы можно встретить в разговорной речи, художественной литературе, поэзии, научных журналах.
Морфологическое деление
Выделяют три группы паронимов.
- Суффиксальные паронимы
- Образованы с помощью суффиксов -н-/-лив-, -чат-/-очн-, -ат-/-аст- и друхих. Самая большая и активно пополняемая группа паронимов. Большая часть паронимов из этой группы относится к прилагательным, образованных суффиксами -ическ-/-ичн-, -еск-/-н-.
Примеры: зри́тельский и зри́тельный, изобрета́тельный и изобрета́тельский, цвета́стый и цвети́стый. - Префиксальные паронимы
- Образуются за счёт присоединения к корню созвучных префиксов: о-/от-, по-/про- и других. Образованные однокорневые созвучные слова имеют ударение на том же слоге.
Примеры: опеча́тать и отпеча́тать, поглоти́ть и проглоти́ть, опи́ски и отпи́ски. - Корневые паронимы
- Созвучные слова, имеющие различные корни. Отсутствует семантическая связь. Незначительная по численности группа паронимов, главным образом состоящая из существительных.
Примеры: вака́нсия и вака́ция, неве́жа и неве́жда, моро́женый и моро́зный.
 Большая часть паронимов из этой группы относится к прилагательным, образованных суффиксами -ическ-/-ичн-, -еск-/-н-.
Большая часть паронимов из этой группы относится к прилагательным, образованных суффиксами -ическ-/-ичн-, -еск-/-н-. Лексико-семантическое деление
- Корневые паронимы
- Разные корни, общая семантическая связь отсутствует, сходство случайное.
Пример: экскаватор и эскалатор. - Аффиксальные паронимы
- Общий корень, но разные созвучные аффиксы (приставки, суффиксы).
Пример: экономический и экономный. - Этимологические паронимы
- Внимание уделяется происхождению слов. В группу входят одни и те же слова, заимствованные из разных близкородственных языков, многократно заимствованных в разных значениях, сформированных под влиянием народной этимологии.
Пример: ординарный и одинарный.

Примеры паронимов
Наш словарь paronymonline.ru содержит примеры паронимов. Они сгруппированы по буквам, с которых начинаются, и по частям речи. Для просмотра примеров выберите часть речи или букву в алфавитном указателе.
(PDF) Изучение подобия предложений посредством лексической декомпозиции и композиции
3.4 Функция оценки подобия
Функция оценки подобия f
sim
в уравнении. (4)
предсказывает оценку сходства, принимая в качестве входных данных два вектора признаков. Мы используем линейную функцию для суммирования
всех функций и применяем сигмовидную функцию к
, чтобы ограничить подобие в пределах диапазона [0, 1].
3.5 Обучение
Мы обучаем нашу подобную модель предложения, максимизируя вероятность на обучающей выборке.Каждый обучающий экземпляр
в обучающем наборе представлен как тройка
(S
i
, T
i
, L
i
), где S
i
и T
i
— это пара предложений,
и L
i
∈ {0, 1} указывает на сходство между ними
. Мы присваиваем L
i
= 1, если T
i
является перефразированием S
i
для задачи определения перефразирования, или T
i
является правильным ответом
для S
i
для выбора предложения ответа
задача.В противном случае мы присваиваем L
i
= 0. Мы реализуем
математических выражений с помощью Theano (Bastien
et al., 2012) и используем Adam (Kingma and Ba, 2014)
для оптимизации.
4 Эксперимент
4.1 Экспериментальная установка
Мы оцениваем нашу модель по двум задачам: выбор отправителя ответа
и идентификация перефразирования. Задача выбора предложения ответа
Задача выбора предложения ответа
состоит в том, чтобы ранжировать список из
ответов кандидата на основе их сходства с предложением вопроса
, а эффективность измеряется
с помощью средней средней точности (MAP) и среднего получателя —
rocal rank (MRR).Мы экспериментируем с двумя наборами данных:
,QASent и WikiQA. Таблица 2 суммирует статистику —
тиков двух наборов данных, где QASent (Wang et al.,
,и др., 2007) был создан из трека QA TREC,
и WikiQA (Ян и др., 2015) построен из
.реальных запроса Bing и Википедии. Задача идентификации фраз из параграфа
состоит в том, чтобы определить, являются ли два предложения
пересказами на основе сходства между ними
. Метрики включают точность
и положительный результат класса F
1
.Мы экспериментируем с
в корпусе Microsoft Research Paraphrase (MSRP)
(Dolan et al., 2004), который включает 2753 истинных и
1323 ложных экземпляра в обучающей выборке, а также 1147
истинных и 578 ложных экземпляров в обучающем наборе. набор тестов. Мы строим
набор тестов. Мы строим
набор разработки, случайным образом выбирая 100 истинных
и 100 ложных экземпляров из обучающего набора. Во всех экспериментах
мы устанавливали размер вектора слова dimen-
sion как d = 300 и предварительно обучили векторы с
Set Questions QA Pairs
QASent
train 1,229 53,417
dev 65 1,117
test 68 1,442
WikiQA
train 2,118 20,360
dev 296 2,733
test 633 6,165
Таблица 2: Статистика наборов данных для выбора предложений ответа.
набор инструментов word2vec (Миколов и др., 2013) на En-
glish Gigaword (LDC2011T07).
4.2 Свойства модели
В нашей модели есть несколько альтернативных вариантов,
, например, функции семантического сопоставления, операции разложения
и типы фильтров. Выбор
из этих опций может повлиять на конечную производительность.
В этом подразделе мы представляем некоторые эксперименты для
, демонстрирующие свойства нашей модели и находим хорошую конфигурацию
, которую мы используем для оценки нашей окончательной модели
. Все эксперименты в этом подразделе были
Все эксперименты в этом подразделе были
, выполненными на наборе данных QASent и оцененными на
наборе для разработки.
Сначала мы оценили эффективность различных функций мантического сопоставления. Мы переключили функции сопоставления seman-
на {max, global, local-
l}, где l ∈ {1, 2, 3, 4}, и зафиксировали другие параметры
как: линейное разложение, Типы фильтров включают
{униграмма, биграмма, триграмма} и 500 фильтров по
каждого типа.На рисунке 2 представлены результаты. Мы обнаружили, что функция
работает лучше, чем глобальная функция
как для MAP, так и для MRR. За счет увеличения размера окна
функция local-l получила ряд улучшений, когда размер окна меньше
, чем 4. Но после того, как мы увеличили размер окна до
4, производительность упала. Функция local-3
работала лучше, чем функция max в терминах
MAP, а также получила сопоставимый MRR.Следовательно,
мы используем функцию local-3 в следующих экспериментах:
.
Во-вторых, мы изучили влияние различных операций разложения
позиции. Мы варьировали операцию разложения
на {жесткую, линейную, ортогональную}, а
оставили другие параметры неизменными. На рисунке 3 показана производительность
. Мы обнаружили, что жесткая операция
дала худший результат. Это разумно, потому что
Основанный на грамматике алгоритм семантического сходства для предложений естественного языка
В этой статье представлен алгоритм подобия на основе грамматики и семантического корпуса для предложений естественного языка.Естественный язык, в отличие от «искусственного языка», такого как языки компьютерного программирования, — это язык, используемый широкой публикой для повседневного общения. Традиционные подходы к поиску информации, такие как векторные модели, LSA, HAL, или даже подходы на основе онтологий, которые расширяются и включают сравнение сходства понятий вместо совпадения терминов / слов, не всегда могут определять идеальное соответствие, пока нет очевидной связи или концепции. перекрываются между двумя предложениями на естественном языке.В этой статье предлагается алгоритм подобия предложений, который использует онтологию на основе корпуса и грамматические правила для преодоления решаемых проблем. Эксперименты на двух известных тестах показывают, что предложенный алгоритм имеет значительное улучшение производительности в предложениях / коротких текстах с произвольным синтаксисом и структурой.
перекрываются между двумя предложениями на естественном языке.В этой статье предлагается алгоритм подобия предложений, который использует онтологию на основе корпуса и грамматические правила для преодоления решаемых проблем. Эксперименты на двух известных тестах показывают, что предложенный алгоритм имеет значительное улучшение производительности в предложениях / коротких текстах с произвольным синтаксисом и структурой.
1. Введение
Естественный язык, термин, противоположный искусственному языку, — это язык, используемый широкой публикой для повседневного общения.Искусственный язык часто характеризуется самостоятельно созданными словарями, строгой грамматикой и ограниченным идеографическим диапазоном и, следовательно, относится к лингвистической категории, к которой труднее привыкнуть, но не сложно освоить широкой публикой. Естественный язык неотделим от всей социальной культуры и постоянно меняется с течением времени; люди могут легко развить чувство этого первого языка во время взросления. Кроме того, синтаксическая и семантическая гибкость естественного языка позволяет этому типу языка быть естественным для людей.Однако из-за бесконечных исключений, изменений и указаний естественный язык также становится типом языка, который труднее всего освоить.
Кроме того, синтаксическая и семантическая гибкость естественного языка позволяет этому типу языка быть естественным для людей.Однако из-за бесконечных исключений, изменений и указаний естественный язык также становится типом языка, который труднее всего освоить.
Обработка естественного языка (NLP) изучает, как позволить компьютеру обрабатывать и понимать язык, используемый людьми в их повседневной жизни, понимать человеческие знания и общаться с людьми на естественном языке. Приложения НЛП включают поиск информации (IR), извлечение знаний, системы вопросов и ответов (QA), категоризацию текста, машинный перевод, помощь в написании, идентификацию голоса, композицию и так далее.Развитие Интернета и массовое производство цифровых документов привело к острой необходимости в интеллектуальной обработке текста, и поэтому теория, а также навыки НЛП стали более важными.
Традиционно методы обнаружения сходства между текстами сосредоточены на разработке моделей документов. В последние годы было создано несколько типов моделей документов, таких как логическая модель, векторная модель и статистическая вероятностная модель.Булевская модель обеспечивает охват ключевых слов с помощью пересечения и объединения множеств. Логический алгоритм склонен к неправильному использованию, и поэтому метод поиска, приближенный к естественному языку, является направлением для дальнейшего улучшения. Солтон и Леск впервые предложили поисковую систему модели векторного пространства (VSM) [1–3], которая была не только методом двоичного сравнения. Основной вклад этого метода заключался в предложении концепций частичного сравнения и подобия, чтобы система могла вычислять сходство между документом и запросом на основе различных весов терминов индекса и в дальнейшем выводить результат ранжирования поиска.Что касается актуализации векторной модели, запросы и документы первых пользователей в базе данных должны быть преобразованы в векторы в том же измерении. Хотя и документы, и запросы представлены одним и тем же измерением векторного пространства, наиболее распространенной оценкой семантического сходства в многомерном пространстве является вычисление сходства между двумя векторами с использованием косинуса, значение которого должно находиться в диапазоне от 0 до 1. В целом, К преимуществам модели векторного пространства можно отнести следующее. (1) При заданных весах VSM может лучше выбирать характеристики, а эффективность поиска в значительной степени улучшается по сравнению с булевой моделью.(2) VSM предоставляет механизм частичного сравнения, который позволяет находить документы с наиболее похожим распределением. Wu et al. представить систему поиска FAQ на основе VSM. Элементы вектора состоят из сегмента категории вопроса и сегмента ключевого слова [4]. Мера сходства документов на основе фраз предложена Чимом и Денгом [5]. В [5] взвешенные фазы TF-IDF в суффиксном дереве [6, 7] отображаются в многомерное пространство терминов VSM. Совсем недавно Ли и др. [8] представили новую меру вычисления сходства предложений.Их мера, учитывающая семантическую информацию и порядок слов, которая показала хорошие результаты при измерении, в основном представляет собой модель на основе VSM.
В последние годы в области приложений НЛП постепенно возникла потребность в методе семантического анализа более коротких документов или предложений [9]. Что касается приложений в интеллектуальном анализе текста, метод семантического анализа коротких текстов / предложений также может применяться в базах данных в качестве определенного стандарта оценки для поиска неоткрытых знаний [10].Кроме того, метод семантического анализа коротких текстов / предложений может быть использован в других областях, таких как реферирование текста [11], категоризация текста [12] и машинный перевод [13]. Недавно в разрабатываемой концепции подчеркивается, что сходство между текстами — это «скрытый семантический анализ (LSA), который основан на статистических данных лексики в большом корпусе». LSA и гиперпространственный аналог языка (HAL) являются известными корпусными алгоритмами [14–16]. LSA, также известная как латентно-семантическое индексирование (LSI), представляет собой полностью автоматический математический / статистический метод, который анализирует большой корпус текста на естественном языке и представление сходства слов и отрывков текста.В LSA группа терминов, представляющих статью, была извлечена путем оценки из множества контекстов, и была построена матрица термин-документ для описания частоты встречаемости терминов в документах. Пусть будет матрица термин-документ, где element () обычно описывает вес термина TF-IDF в документе. Затем матрица, представляющая товар, делится методом разложения по сингулярным числам (SVD) на три матрицы, включая диагональную матрицу SVD [15]. Посредством процедуры SVD можно исключить меньшие сингулярные значения, а также уменьшить размер диагональной матрицы.Размерность слагаемых, включенных в исходную матрицу, может быть уменьшена путем реконструкции SVD. Посредством процессов декомпозиции и реконструкции LSA может получить сведения о терминах, выраженных в статье. Когда LSA применяется для вычисления сходства между текстами, вектор каждого текста преобразуется в пространство уменьшенной размерности, в то время как сходство между двумя текстами получается путем вычисления двух векторов уменьшенной размерности [14].Разница между векторной моделью и LSA заключается в том, что LSA преобразует термины и документы в скрытое семантическое пространство и устраняет некоторый шум в исходном векторном пространстве.
Одной из стандартных вероятностных моделей LSA является вероятностный скрытый семантический анализ (PLSA), который также известен как вероятностное скрытое семантическое индексирование (PLSI) [17]. PLSA использует смешанную декомпозицию для моделирования слов и документов совпадения, где вероятности получаются выпуклой комбинацией аспектов.LSA и PLSA широко применяются в системах обработки информации и других приложениях [18–24].
Другое важное исследование, основанное на корпусе, — это гиперпространственный аналог языка (HAL) [25]. HAL и LSA имеют очень похожие атрибуты: они оба используют параллельные словари для извлечения значения термина. В отличие от LSA, HAL использует абзац или документ как часть документа для создания информационной матрицы термина. HAL устанавливает оконную матрицу общего термина в качестве основы и сдвигает ширину окна, не выходя за пределы исходного определения оконной матрицы.Окно просматривает весь корпус, используя термины как ширину окна терминов (обычно ширину 10 терминов), и далее формирует матрицу. Когда окно сдвигается и сканирует документы во всем корпусе, элементы в матрице могут записывать вес каждого общего термина (количество вхождений / частота). Размерный вектор термина может быть получен путем объединения строк и строк матрицы, соответствующей термину, а сходство между двумя текстами может быть вычислено с помощью приблизительного евклидова расстояния.Однако при расчете коротких текстов HAL дает менее удовлетворительные результаты, чем LSA.
В заключение, вышеупомянутые подходы вычисляют сходство на основе количества общих терминов в статьях, а не игнорируют синтаксическую структуру предложений. Если применить обычные методы для вычисления сходства между короткими текстами / предложениями напрямую, могут возникнуть некоторые недостатки. (1) Традиционные методы предполагают, что документ имеет сотни или тысячи измерений, переводя короткие тексты / предложения в очень большие размеры. пространство и очень разреженные векторы могут привести к менее точному результату вычислений.(2) Алгоритмы, основанные на общих терминах, подходят для поиска средних и более длинных текстов, которые содержат больше информации. Напротив, информация об общих терминах в коротких текстах или предложениях редка и даже недоступна. Это может привести к тому, что система будет генерировать очень низкую оценку семантического сходства, и этот результат не может быть скорректирован с помощью общей функции сглаживания. (3) Стоп-слова обычно не принимаются во внимание при индексировании обычных IR-систем. Стоп-слова не имеют особого значения при вычислении сходства между более длинными текстами.Однако они являются неизбежными частями в отношении сходства между предложениями, поскольку они предоставляют информацию о структуре предложений, которая в определенной степени влияет на объяснение значений предложений. (4) Подобные предложения могут состоять из синонимов; обильные общие термины не нужны. Текущие исследования оценивают сходство в соответствии с совпадающими терминами в текстах и игнорируют синтаксическую информацию. Предлагаемый алгоритм семантического сходства устраняет ограничения этих существующих подходов за счет использования грамматических правил и онтологии WordNet.Набор грамматических матриц создан для представления отношений между парами предложений. Размер набора ограничен максимальным количеством выбранных грамматических ссылок. Скрытая семантика слов рассчитывается с помощью меры сходства WordNet. Остальная часть этой статьи организована следующим образом. Раздел 2 знакомит с соответствующими технологиями, принятыми в нашем алгоритме. Раздел 3 описывает предлагаемый алгоритм и основные функции. В разделе 4 приведены некоторые примеры, иллюстрирующие наш метод. Результаты экспериментов на двух известных тестах показаны в Разделе 5, а окончательный вывод дает заключение.
2. Справочная информация
2.1. Онтология и WordNet
Проблема семантической осведомленности среди текстов / естественных языков все чаще указывает на технологии семантической паутины в целом и онтологию в частности в качестве решения. Онтология — это философская теория о природе бытия. Исследователи искусственного интеллекта, особенно в области получения и представления знаний, реинкарнируют термин, чтобы выразить « общее и общее понимание некоторой области, которая может передаваться между людьми и прикладными системами » [26, 27].Типичная онтология — это таксономия, определяющая классы в определенной области и их отношения, а также набор правил вывода, обеспечивающих ее функции рассуждений [28]. Онтология теперь признана в семантическом веб-сообществе как термин, который относится к общему пониманию знаний в некоторых областях, представляющих интерес [29–31], которое часто понимается как набор понятий, отношений, функций, аксиом и примеров. Гуарино провел всестороннее исследование для определения онтологии из различных высоко цитируемых работ в сообществе обмена знаниями [32–37].Семантическая сеть — это развивающееся расширение Всемирной паутины, в которой веб-контент может быть выражен на естественных языках и в форме, понятной, интерпретируемой и используемой программными агентами. Элементы семантической сети выражаются в формальных спецификациях, которые включают структуру описания ресурсов [38], различные форматы обмена данными (такие как RDF / XML, N3, Turtle и N-Triples) [39, 40] и такие нотации, как язык веб-онтологий [41] и схема RDF.
В последние годы WordNet [42] стал наиболее широко используемой лексической онтологией английского языка.WordNet был разработан и поддерживается Лабораторией когнитивных наук Принстонского университета в 1990-х годах. Существительные, глаголы, прилагательные и наречия сгруппированы в когнитивные синонимы, называемые «синсеты», и каждый синоним выражает отдельное понятие. Как обычный онлайн-словарь, WordNet перечисляет предметы вместе с объяснениями в алфавитном порядке. Кроме того, он также показывает семантические отношения между словами и понятиями. Последняя версия WordNet — 3.0, которая содержит более 150 000 слов и 110 000 синсетов.В WordNet лексикализованные синсеты существительных и глаголов организованы иерархически с помощью гиперонима / гипернимии и гипонима / гипонимии. Гипонимы — это концепции, которые описывают вещи более конкретно, а гиперонимы относятся к концепциям, которые описывают вещи в более общем плане. Другими словами, это гипероним if every — это разновидность, и гипоним if every — разновидность. Например, птица является гипонимом позвоночное животное , а позвоночное животное является гиперонимом птица .Иерархия понятий WordNet превратилась в полезную основу для открытия и извлечения знаний [43–49]. В этом исследовании мы используем меру сходства Ву и Палмера [50], которая стала своего рода стандартом для измерения сходства между словами в лексической онтологии. Как показано в где — глубина самого нижнего общего гиперонима () в лексической таксономии, и обозначает количество переходов от до и, соответственно.
2.2. Грамматика ссылок
Грамматика ссылок (LG) [51], разработанная Дэви Темперли, Джоном Лафферти и Дэниелом Слейтором, представляет собой синтаксический синтаксический анализатор английского языка, который строит отношения между парами слов.Для данного предложения LG создает соответствующую синтаксическую структуру, которая состоит из набора помеченных ссылок, соединяющих пары слов. Последняя версия LG также создает «составное представление» (дерево фраз в стиле банка Пенна) предложения (словосочетания с существительными, словосочетания с глаголами и т. Д.). Парсер использует словарь из более чем 6000 словоформ и охватывает широкий спектр синтаксических конструкций. LG в настоящее время поддерживается под эгидой проекта Abiword [52]. Основная идея LG — рассматривать слова как блоки с соединителями, которые образуют отношения, или называемые ссылками.Эти ссылки используются не только для определения части речи слов, но и для подробного описания функций этих слов в предложении. LG может объяснить отношения модификации между различными частями речи и рассматривает предложение как последовательность слов и состоит из набора помеченных связей, соединяющих пары слов. Все слова в словаре LG были определены для описания того, как они используются в предложениях, и такая система называется «лексической системой».
Лексическая система может легко построить большую грамматическую структуру, поскольку изменение определения слова влияет только на грамматику предложения, в котором это слово находится.Кроме того, выразить грамматику неправильных глаголов просто, поскольку система определяет каждый из них индивидуально. Что касается грамматики различных структур фраз, связи, которые являются гладкими и соответствуют семантической структуре, могут быть установлены для каждого слова, используя слова грамматики ссылок для анализа грамматики предложения.
Все созданные связи между словами подчиняются трем основным правилам [51]. (1) Планарность: связи не пересекаются друг с другом. (2) Связность: ссылок достаточно, чтобы соединить все слова последовательности вместе.(3) Удовлетворение: ссылки удовлетворяют требованиям связывания каждого слова в последовательности.
В предложении « канадские официальные лица согласились провести дополнительные упражнения по реагированию на угрозы .», Например, есть ссылки AN , соединяющие модификаторы существительного « официальный » с существительным « канадский, » «» упражнение »на« ответ, »и« упражнение »на« угроза », как показано на рисунке 1. Основные слова отмечены« .n »,« .v »,« .a »для обозначения существительных, глаголов и прилагательных. Ссылка A соединяет предыстительные (атрибутивные) прилагательные с существительными. Ссылка D соединяет определители с существительными. Есть много слов, которые могут действовать как определители или словосочетания, такие как « a » (помечены как « Ds »), « many » (« DmC ») и « some ». (« Dm »), и каждый из них соответствует подтипу типа связи D .Ссылка O соединяет переходные глаголы с прямыми или косвенными объектами, в которых Os является подтипом O , который соединяет существительные как единственное число. PP связывает формы «иметь» с причастиями прошедшего времени (« согласовали »), Sp — это подтип S , который связывает множественное число существительных с формами множественного числа глаголов ( S связывает подлежащие-существительные с конечными глаголами. ), и так далее.
Этот простой пример показывает, что связи подразумевают определенную степень семантических корреляций в предложении.LG определяет более 100 ссылок; однако в нашем дизайне семантическое сходство извлекается из специально разработанной матрицы связей и оценивается с помощью меры сходства WordNet; таким образом, зарезервированы только соединительные элементы, содержащие неспецифические существительные и глаголы. Другие ссылки, такие как AL (который связывает несколько определителей со следующими определителями, такими как « и » и « все ») и EC (который связывает наречия и сравнительные прилагательные, например « много более ”), игнорируются.
3. Алгоритм грамматического семантического сходства
В этом разделе подробно показан предлагаемый алгоритм грамматического сходства. Этот алгоритм может быть подключаемым модулем обычных английских систем обработки естественного языка и экспертных систем. Наш подход получает сходство из семантической и синтаксической информации, содержащейся в сравниваемых предложениях естественного языка. Предложение на естественном языке рассматривается как последовательность ссылок вместо отдельных слов, каждое из которых содержит определенное значение.В отличие от существующих подходов, использующих фиксированный набор терминов из словаря, совпадающих терминов [1–3] или даже порядков слов [8], предлагаемый подход напрямую извлекает скрытую семантику из одних и тех же или похожих ссылок.
3.1. Типы ссылок
Предлагаемый алгоритм определяет схожесть двух предложений естественного языка на основе грамматической информации и семантическое сходство слов, содержащихся в ссылках. В таблице 1 показаны выбранные ссылки, подтипы ссылок и соответствующие описания, используемые в нашем подходе.Первый столбец — это выбранные основные типы связи LG . Во втором столбце показаны выбранные подтипы основных типов ссылок. Если были выбраны все подтипы конкретной ссылки, она обозначается «*». Пунктирная линия указывает на то, что ни один подтип не выбран или не существует. Этот метод разделен на три функции. Первая часть — это извлечение типа связывания. Алгоритм 1 принимает предложение и набор выбранных типов связывания и возвращает набор оставшихся типов связывания и соответствующую информацию для каждой ссылки.Это этап предварительной обработки; элементы возвращенного набора — это структуры, которые записывают ссылки, подтипы ссылок, а также существительные или глаголы каждой ссылки.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OUTPUT : | |||
| (1) ← link_grammar 378 () | (2) ДЛЯ ВСЕХ DO | ||
| (3) IF . тип THEN | |||
| (4) ← — | |||
| (5) END IF | |||
| (6) END FOR |
После предварительной обработки алгоритм 2 вычисляет показатель семантического сходства входных предложений. Алгоритм принимает два предложения и набор выбранных типов ссылок и возвращает показатель семантического сходства, который формализован до 0 ~ 1.В алгоритме 2 строки 1 и 2 вызывают алгоритм 1 для записи ссылок и информации слов предложений и в наборах и. Если, это означает, что существуют некоторые общие или похожие связи между и, которые можно рассматривать как корреляции фраз между двумя предложениями. В нашем проекте общие основные ссылки с похожими подтипами образуют матрицу с именем Grammar_Matrix ( GM ). Каждый GM подразумевает определенную степень корреляции между фразами; значение каждого члена в GM вычисляется с помощью алгоритма Ву и Палмера.Алгоритм 3 отображает детали процесса оценки. В алгоритме 3 GM был составлен из общих ссылок. Поскольку количество подтипов варьируется от каждой ссылки, мы устанавливаем ссылки с меньшим количеством подтипов в качестве строк, а другие в качестве столбцов. Для каждой строки был зарезервирован максимальный термин, который составляет Grammar_Vector ( GV ), который представляет максимальное семантическое включение конкретной связи между и.
| ||||||||||||||||||
| ||||||||||||||||||||||||
На рисунке 2 показана структура GMs и G и сравниваются первые предложения общая ссылка и, и так далее, являются подтипами и.Каждый GM представляет собой корреляцию определенных фраз, поскольку в предложении может существовать несколько похожих подссылок, в которых соответствующий GV количественно определяет информацию и извлекает скрытую семантику между этими фразами. Алгоритм 1 вызывает функцию LG и создает связи, как показано на рисунках 3, 4 и 5.
3.2. Работа с примером
В этом разделе дается пример, демонстрирующий предложенный алгоритм подобия.Пусть A = « Выручка в первом квартале года упала на 15 процентов по сравнению с тем же периодом годом ранее. », B = « Со скандалом, нависшим над компанией Стюарта, выручка за первый квартал года упала на 15 процентов по сравнению с тем же периодом годом ранее. », и C =« . Результатом является общий пакет, который обеспечит значительный экономический рост для наших сотрудников в течение следующих четырех лет ». Этот пример взят из Microsoft Research Paraphrase Corpus (MRPC) [53], который будет представлен более подробно в следующем разделе.В этом примере мы сравниваем семантическое сходство между A-B , A-C и B-C . Алгоритм 1 сначала генерирует соответствующие связи для каждого предложения, и результаты показаны на рисунках 3–5. Всего имеется 17, 26 и 20 исходных ссылок, созданных LG . После этапа предварительной обработки оставшиеся связи (подробная структура данных здесь опущена), и, соответственно. В алгоритме 2 сравниваемая пара предложений была отправлена в матрицу грамматики (т.е., алгоритм 3) в соответствии с их общими типами связывания, и каждый тип связывания со своими подтипами образует Grammar_Matrix . Таблицы 2, 3 и 4 показывают GMs и их дословное сходство пар A-B , A-C и B-C . В таблице 2 типы связи: Wd , S , Mp , D и J ; следовательно, в паре A-B имеется пять GM . Первый GM представляет собой матрицу с и, второй GM также является матрицей с и, третий GM представляет собой матрицу с и, четвертый GM представляет собой матрицу с и и т. Д.На шаге 5 алгоритма 3 мы оцениваем сходство отдельных слов с помощью онтологии WordNet и метода Wu & Palmer . Результаты также показаны в таблицах 2–4. На этом этапе оценивается вся возможная семантика между похожими ссылками, и очевидно, что слово может быть связано дважды или даже больше в общем случае. Следующая фаза сокращает каждый GM до Grammar_Vector ( GV ), сохраняя максимальное значение каждой строки. Таким образом, в паре A-B ,,,, и.В паре A-C ,,, и,, и в паре B-C . На заключительном этапе все элементы ГВ принимают число мощности элементов для уравновешивания эффектов неоцененных подтипов. Окончательные оценки A против B = 0,987, A против C = 0,817 и B против C = 0,651 соответственно.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
4. Эксперименты
4.1. Эксперимент с тестом Li’s Benchmark
Основываясь на понятии семантической и синтаксической информации, способствовавшей пониманию предложений естественного языка, Li et al. [8] определили меру сходства предложений как линейную комбинацию, основанную на сходстве семантического вектора и порядка слов. Предварительный набор данных был построен Ли и др. с оценками человеческого сходства, предоставленными 32 добровольцами, которые являются носителями английского языка.В наборе данных Ли использовалось 65 пар слов, которые первоначально были предоставлены Рубенштейном и Гуденафом [60] и были заменены определениями из словаря Collins Cobuild [61]. Словарь Collins Cobuild был построен на основе большого корпуса, содержащего более 400 миллионов слов. Каждая пара была оценена по шкале от 0,0 до 4,0 в соответствии с их смысловым сходством. Мы использовали подмножество из 65 пар, чтобы получить более равномерное распределение по диапазону сходства. Это подмножество содержит 30 пар из исходных 65 пар, из которых 10 пар были взяты из диапазона 3 ~ 4, 10 пар из диапазона 1 ~ 3 и 10 пар из диапазона 0 ~ 1.Мы перечисляем полный набор данных Ли в Таблице 7. Таблица 5 показывает оценки человеческого сходства вместе с Ли и др. [8], подход на основе LSA, описанный O’Shea et al. [54], STS Meth. предложенный Islam и Inkpen [55], SyMSS, основанная на синтаксисе мера, предложенная Oliva et al. [56], Омиотис, предложенный Цацаронисом и соавт. [57], и наша семантическая мера, основанная на грамматике. Результаты показывают, что наш подход, основанный на грамматике, обеспечивает лучшую производительность в парах предложений с низким и средним сходством (уровни 0 ~ 1 и 1 ~ 3).Среднее отклонение от человеческих суждений на уровне 0 ~ 1 составляет 0,2, что лучше, чем у большинства подходов. (Ли и др. Среднее значение = 0,356, среднее значение LSA = 0,496 и среднее значение SyMSS = 0,266). Среднее отклонение на уровне 1 ~ 3 составляет 0,208, что также лучше, чем у Li et al. и LSA. Результат показывает, что наша мера семантического сходства на основе грамматики достигла достаточно хороших результатов, и наблюдение состоит в том, что наш подход пытается идентифицировать и количественно оценить потенциальную семантическую связь между синтаксисами и словами, хотя общих слов сравниваемых пар предложений мало или даже никто.
Как признается Ислам и Инкпен [55] и Корли и Михалча [72] мера семантического сходства необходимый шаг в задаче распознавания перефразирования, но не всегда достаточный.В Microsoft Research Paraphrase Corpus пары предложений, признанные непарафразами, могут по-прежнему существенно перекрываться по информационному содержанию и даже по формулировкам. Например, корпус Microsoft Research Paraphrase Corpus содержит следующие пары предложений. Пример 1. ( 1) « Принято в 1999 году, но так и не вступило в силу, закон сделал бы незаконным зажигание для посетителей баров и ресторанов». Пример 2. ( 1) « Хотя из-за того, что более медленные расходы заставили 2003 год выглядеть лучше, многие из расходов фактически будут произведены в 2004 году ». Предложения в каждой паре сильно связаны друг с другом общими словами и синтаксисами, однако они не считаются пересказами и помечаются в корпусе цифрой 0 (парафразы помечаются как 1).По этой причине мы считаем, что количество ложноположительных (FP) и истинно отрицательных (TN) не совсем правильное и может повлиять на правильность точности, измерения, но на точность и отзыв. Результат показывает, что предлагаемый подход на основе грамматики превосходит результат Ислама и Инкпена [55] с порогами 0,6 ~ 1,0 (0,91 против 0,89 и 0,88 против 0,68 отзыва с порогами 0,6 и 0,7; 0,71 против 0,72, 0,70 против 0,68 и 0,59 против 0,57 точности при порогах 0,6, 0,7 и 0.8, соответственно), что является разумным диапазоном для определения того, является ли пара предложений пересказом или нет. 5. ВыводыВ данной статье представлен алгоритм подобия, основанный на грамматике и семантическом корпусе, для предложений на естественном языке. Традиционные ИК-технологии не всегда могут определить идеальное соответствие без очевидной связи или пересечения концепций между двумя предложениями на естественном языке. Некоторые подходы решают эту проблему путем определения порядка слов и оценки семантических векторов; однако их было трудно применять для сравнения предложений со сложным синтаксисом, а также длинных предложений и предложений с произвольными шаблонами и грамматиками.Предлагаемый подход использует онтологию корпусов и грамматические правила для решения этой проблемы. Вклад этой работы можно резюмировать следующим образом: (1) насколько нам известно, предложенный алгоритм является первой мерой семантического сходства между предложениями, которая объединяет дословную оценку с грамматическими правилами, (2) специально разработанный Grammar_Matrix будет количественно определять корреляции между фразами вместо того, чтобы рассматривать общие слова или порядок слов, и (3) использование семантических деревьев, предлагаемых WordNet, увеличивает шансы найти семантическую связь между любыми существительными и глаголами, и (4) Результаты показывают, что предложенный метод очень хорошо показал себя как с точки зрения сходства предложений, так и с точки зрения распознавания парафраз.Наш подход обеспечивает хорошее среднее отклонение для 30 пар предложений и превосходит результаты, полученные Li et al. [8] и LSA [54]. Для задачи распознавания перефразирования наш метод, основанный на грамматике, превосходит большинство существующих подходов и ограничивает лучшую производительность в разумном диапазоне пороговых значений. Конфликт интересовАвторы заявляют об отсутствии конфликта интересов в отношении публикации данной статьи. Изучение подобия предложений посредством лексической декомпозиции и композиции1 ВведениеСходство предложений — это фундаментальный показатель для измерения степени правдоподобия между парой предложений.Он играет важную роль для множества задач как в НЛП, так и в IR сообществах. Например, в задаче идентификации перефразирования, Сходство предложений используется, чтобы определить, являются ли два предложения перефразированием или нет [Yin and Schütze2015, He et al.2015] . Для ответов на вопросы и задач поиска информации, сходство предложений между парами запрос-ответ используется для оценки релевантности и ранжирование всех ответов кандидатов [Severyn and Moschitti2015, Wang and Ittycheriah3015] .
Однако изучение сходства предложений имеет следующие проблемы:
Для решения вышеперечисленных проблем исследователи долгое время работали над алгоритмами сходства предложений. Чтобы преодолеть лексический пробел (проблема 1), были предложены некоторые метрики сходства слов для совпадать с разными, но семантически связанными словами. Примеры включают метрики, основанные на знаниях [Resnik1995] и показатели на основе корпуса [Jiang and Conrath2997, Yin and Schütze2015, He et al.2015] . Чтобы измерить сходство предложений с различной степенью детализации (проблема 2), исследователи изучили особенности, извлеченные из н-граммов, непрерывных фраз, прерывистые фразы и деревья синтаксического анализа [Yin and Schütze2015, He et al., 2015, Heilman and Smith3010] . Раньше третий вопрос не привлекал особого внимания, единственная связанная работа qiu2006paraphrase исследовали различие между предложениями в паре для задачи идентификации перефразирования, но им нужны человеческие аннотации для обучения классификатора, и их производительность по-прежнему ниже современного уровня.В этой статье мы предлагаем новую модель для совместного решения всех этих проблем. путем декомпозиции и составления лексической семантики по предложениям. Учитывая пару предложений, модель представляет каждое слово как вектор малой размерности (проблема 1), и вычисляет вектор семантического соответствия для каждого слова на основе всех слов в другом предложении (проблема 2). Затем на основе вектора семантического соответствия каждый вектор слов разбивается на две составляющие: подобный компонент и непохожий компонент (выпуск 3).Мы используем похожие компоненты всех слов, чтобы представить похожие части пары предложений, и несходные компоненты каждого слова для явного моделирования несходных частей. После этого выполняется двухканальная операция CNN, чтобы объединить похожие и разнородные компоненты в вектор признаков (вопросы 2 и 3). Наконец, составной вектор признаков используется для прогнозирования сходства предложений. Результаты экспериментов по двум задачам показывают, что наша модель современного выполнения задачи выбора предложения ответа, и достигает сопоставимого результата в задаче идентификации перефразирования. В следующих частях мы начнем с краткого обзора нашей модели (Раздел 2), за которыми следуют детали нашей сквозной реализации (раздел 3). Затем мы оцениваем нашу модель по выбору предложения ответа. и перефразируйте задачи идентификации (Раздел 4). 2 Обзор моделиНа рисунке 1 показан обзор нашей модели подобия предложений. Для пары предложений S и T наша задача — вычислить оценку подобия sim (S, T) в следующие шаги: Рисунок 1: Обзор модели.Представление слов. Вложение слова mikolov2013efficient — эффективный способ справиться с проблемой лексического пробела в задаче на сходство предложений, поскольку он представляет каждое слово с распределенным вектором, и слова, встречающиеся в схожих контекстах, как правило, имеют схожие значения [Миколов и др., 2013] . С помощью этих предварительно обученных встраиваний мы преобразуем S и T в матрицы предложений S = [s1, …, si, …, sm] и T = [t1, …, tj, …, tn], где si и tj — d -мерные векторы соответствующих слов, а m и n — длина предложения S и T соответственно.tj), на два компонента: аналогичный компонент s + i (или t + j) и разный компонент s − i (или t − j). Формально мы определяем функцию разложения как: Состав. Учитывая аналогичную матрицу компонентов S + = [s + 1, …, s + m] (или T + = [t + 1, …, t + n]) и разная матрица компонентов S — = [s − 1, …, s − m] (или T — = [t − 1, …, t − n]), наша цель на этом этапе — как использовать эту информацию. Помимо предположения из парафраза qiu2006 о том, что значение только несходных частей между двумя предложениями имеет большое влияние на их сходство, мы также думаем, что разнородные и похожие компоненты имеют сильные связи.Например, в таблице 1 если мы смотрим только на непохожую или похожую часть, трудно судить, какой из E4 или E5 больше похож на E3. Мы можем легко определить, что E5 больше похож на E3, если рассматривать как похожие, так и несходные части. Таким образом, наша модель состоит из одинаковой матрицы компонентов и разнородной матрицы компонентов. в вектор признаков → S (или → T) с композиционной функцией:
Оценка сходства.На заключительном этапе мы объединяем два вектора признаков (→ S и → T) и прогнозируем окончательную оценку сходства:
5 Связанные работыФункции семантического сопоставления в подразделе 3.1 созданы на основе нейронного машинного перевода на основе внимания [Bahdanau et al., 2014, Luong et al., 2015] . Однако большая часть предыдущей работы использовала механизм внимания только в моделях LSTM.В то время как наша модель вводит механизм внимания в модель CNN. Похожая работа — это модель CNN, основанная на внимании, предложенная yin2015abcnn. Сначала они создают матрицу внимания для пары предложений, а затем непосредственно принимают матрицу внимания как новый канал модели CNN. Иными словами, наша модель использует матрицу внимания (или матрицу сходства) для разложения исходной матрицы предложения на аналогичную матрицу компонентов и несходную матрицу компонентов, а затем передает эти две матрицы в двухканальную модель CNN.Затем модель может сосредоточиться на взаимодействии между похожими и разными частями пары предложений.6 ЗаключениеВ этой работе мы предложили модель для оценки сходства предложений путем декомпозиции и составления лексической семантики. Чтобы устранить проблему лексического разрыва, наша модель представляет каждое слово с его вектором контекста. Чтобы извлечь черты как из сходства, так и из несходства пары предложений, мы разработали несколько методов разложения вектора слова на аналогичный компонент и несходный компонент.Чтобы извлечь функции на нескольких уровнях детализации, мы использовали двухканальную модель CNN и оснастили ее несколькими типами фильтров ngram. Экспериментальные результаты показывают, что наша модель достаточно эффективна как в задаче выбора предложения ответа, так и в задаче идентификации перефразирования. Сходствослов с использованием spacyВведение:В алгоритмах интеллектуального анализа текста, а также при моделировании данных на основе nlp сходство слов является очень распространенной особенностью.Сходство слов в контексте nlp относится к семантическому сходству между двумя словами, фразами или даже двумя документами. Мы обсудим, как вычислить сходство слов с помощью библиотеки spacy. что такое сходство в НЛП и как оно рассчитывается? В НЛП под лексическим сходством между двумя текстами понимается степень, в которой тексты имеют одинаковое буквальное и семантическое значение. т.е. насколько похожи тексты; рассчитывается по метрикам сходства в НЛП. Есть много разных способов создать признаки сходства слов; но основная логика в основном одинакова во всех случаях.Основная логика во всех этих случаях — создать два репрезентативных вектора двух элементов; с использованием либо универсальных векторов, созданных из предварительно обученных моделей, таких как word2vec, glove, fasttext, bart и другие; или используя настоящий документ и используя различные методы, такие как соответствие tf-idf, процедуры ранжирования страниц и т.д. Наиболее распространенной процедурой сравнения является косинусное сходство, но менее популярные методы включают рассмотрение различных разновидностей косинусного сходства, корреляции и других сложных методов. Обычно сходство слов находится в диапазоне от -1 до 1 или может быть также нормализовано от 0 до 1. Меньшие значения означают низкую релевантность; и по мере увеличения релевантности увеличивается семантическое сходство между словами. Теперь давайте посмотрим, как spacy решает эту очень распространенную проблему вычисления сходства между словами / документами. Вычисление подобия с использованием spacy:Здесь и далее я предполагаю, что читатели знают базовые техники spacy; и если вы не знакомы с этим, пожалуйста, прочтите это введение в spacy и продолжайте. Прежде всего, давайте просто вспомним тот факт, что в пространстве есть 3 типа словарных объектов; (1) документы (2) токены и (3) промежутки. Документы относятся к объектам документов, созданным из текстов, аналогичных абзацам или полным документам; в то время как токены относятся к подобным словам фрагментам, которые представляют собой наиболее атомарные части документа. промежутки — это непрерывный список этих токенов; т.е. аналог фразы. Теперь каждый из этих объектов, doc, token и span имеет Обратите внимание на предупреждение. Это предупреждение говорит о том, что, поскольку мы загрузили небольшую просторную модель; поэтому здесь не загружен действительный вектор, и мера сходства создается с использованием тегов ner, pos и подобных знаков. Причина этого в том, что для оптимизации использования памяти spacy не загружает встраивание реальных слов для словаря, который он использует при загрузке меньших моделей. Следовательно, чтобы использовать фактические векторы и получить лучшую точность, нам нужно загрузить либо модель среды i.е. en_core_web_md или большая модель, например Теперь, используя большую модель, можно загружать векторы напрямую. В таком случае атрибуты Есть векторы для большинства употребительных слов. Но для необычных слов и слов, для которых нет обученного вектора, в этой настройке им присваивается нулевой вектор. т.е. это означает, что они слишком необычны и в смысле похожести ни на кого не похожи. Есть еще несколько атрибутов, например Существуют способы настройки векторов слов и использование различных методов для создания этих пользовательских векторов для большего удобства использования. Это несколько выходит за рамки данной статьи. Об этом мы поговорим в другой статье. Вы можете прочитать его на официальном сайте для дальнейшего понимания. Итак, в заключение, чтобы вычислить сходство с использованием spacy для двух частей текста, вы должны создать из них документы, используя nlp (текст), а затем использовать Анализ семантического сходства текста с помощью TensorFlow Hub и Dataflow Эта статья является второй из серии, в которой описывается, как выполнять документ
анализ семантического сходства с использованием встраивания текста. Вложения
извлечен с помощью модуля Подробнее о концепциях встраивания и вариантах использования см. Обзор: извлечение и обслуживание встроенных функций для машинного обучения. ВведениеЧтобы найти связанные документы в коллекции, вы можете использовать различные поиск информации техники.Один из подходов — извлекать ключевые слова и сопоставлять документы на основе количество общих терминов в документах. Однако этот подход не учитывает документы, в которых используются похожие, но не идентичные термины. Другой подход — анализ семантического сходства, который обсуждается в этом статья. С помощью анализа схожести текстов вы можете получить релевантные документы, даже если у вас нет подходящих ключевых слов для поиска. Вместо этого вы можете найти статьи, книги, статьи и отзывы клиентов с помощью поиска через представителя документы. Эта статья посвящена анализу сходства текстов на основе встраиваний. Однако вы также можете использовать аналогичный подход для других типов контента, например изображения, аудио и видео, если вы можете преобразовать целевое содержимое в вложения. В этой статье объясняется следующее:
Архитектура решения На рисунке 1 показана общая архитектура анализа текстового сходства.
решение. Для текстовых данных решение использует Reuters-21578, который является
сборник общедоступных статей. Набор данных описан в разделе
Набор данных Reuters
позже в этой статье.Примеры документов загружены в облачное хранилище. В
конвейер обработки реализован с использованием Apache Beam и В конвейере документы обрабатываются для извлечения заголовка каждой статьи,
темы и содержание. Конвейер обработки использует универсальный кодировщик предложений.
модуль в Ключевые концепцииВ следующем списке поясняются концепции, показанные на Рисунке 1.
Набор данных ReutersРешение, описанное в этой статье, использует Рейтер-21587, Распространение 1.0, который представляет собой сборник общедоступных новостных статей. В статьи из набора данных появились в ленте новостей Рейтер в 1987 году. собраны и проиндексированы по категориям по персоналу Reuters Ltd. и Carnegie Group, Inc. в 1987 году. В 1990 году документы были предоставлены Reuters и CGI для исследовательских целей в Лабораторию поиска информации Кафедра компьютерных и информационных наук Университета Массачусетс в Амхерсте. Полное описание набора данных можно найти в коллекции файл readme.txt. Ключевые атрибуты набора данных следующие:
Из нескольких тегов для каждой статьи решение извлекает следующее:
Создание конвейера ETL с Apache BeamКод конвейера находится в трубопровод.ру Модуль Python в репозитории GitHub для этого решения. Конвейер ETL состоит из следующих общих шагов, которые подробно описаны ниже. разделы:
Чтение и анализ файлов статей Как отмечалось ранее, исходные данные состоят из нескольких файлов Метод Это решение использует Python
Красивый суп (bs4)
библиотека для анализа Реализация метода preprocess_fn После того, как статьи были прочитаны, проанализированы и извлечены, следующий шаг в Beam
Конвейер ETL предназначен для создания встраиваемого текста для заголовка и содержимого каждого
статья. В этом решении логика преобразования реализована в Метод Методы Преимущества использования
Подробнее о предварительной обработке данных и преобразовании TensorFlow см. Предварительная обработка данных для машинного обучения: варианты и рекомендации а также Предварительная обработка данных для машинного обучения с использованием TensorFlow Transform в документации Google Cloud. Создание вложений с использованием TensorFlow Hub Как обсуждалось ранее в разделе «Основные понятия», Следующий код для метода Чтобы сгенерировать вектор встраивания для содержания данной статьи, код делает следующее:
Код создает один вектор признаков для представления встраивания для данного
содержание, независимо от того, сколько предложений в содержании
статья.Это показано в следующем коде для Запись вывода в BigQueryПоследним шагом в конвейере Beam ETL является запись вывода предыдущего шаг обработки в таблицу BigQuery. Это показано в следующий код: Конвейер создает таблицу, если не существует, и усекает таблицу, если
таблица включает предыдущие данные. (Вы можете изменить это поведение, установив Для создания таблицы BigQuery решению требуется
В следующем коде показано, как создать объект Запустить конвейер в потоке данных Чтобы запустить конвейер Beam ETL, вам нужно выполнить только На рисунке 2 показано выполнение конвейера потока данных в Облачная консоль. Рисунок 2. График выполнения потока данных конвейера tf.Transform Изучите похожие статьи в BigQuery После запуска конвейера и загрузки выходных данных Reuters
обработки статьи, вы найдете набор данных с именем Здесь n — количество элементов в векторе.(В этом примере вложение
вектор имеет 512 измерений.) Эта формула косинусного подобия может быть реализована в
сценарий BigQuery SQL, чтобы найти статью, которая больше всего похожа на
данный. Например, возможно, вы хотите чаще всего находить статьи Reuters.
аналогично названному «Сильный ветер удерживает суда в ловушке во льдах Балтийского моря». Ты
найти 10 самых похожих статей на основе вложений заголовков
( Вы видите результаты, подобные листингу на Рисунке 4. Рисунок 4. Результаты запроса при использовании вложений заголовков для сравнения сходства Если вы используете Как показано в результатах, хотя заголовок ввода не включал слово «корабль» или «шторм», по запросу были найдены статьи о кораблях и аварии, потому что они относятся к терминам «сильный ветер», «суда» и «в ловушке» в заголовке ввода. Что дальшеПрикладные науки | Бесплатный полнотекстовый | Пополнение базы знаний шаблоном дерева синтаксического анализа и семантическим фильтром1. ВведениеВсемирная паутина содержит обширные знания благодаря вкладу большого числа пользователей, и эти знания используются в различных областях. Поскольку обычные пользователи Интернета обычно используют естественный язык в качестве основного представления для генерации и приобретения знаний, неструктурированные тексты составляют огромную часть Интернета.Хотя люди естественно относятся к неструктурированным текстам, такие тексты не позволяют машинам обрабатывать или понимать содержащиеся в них знания. Следовательно, эти неструктурированные тексты должны быть преобразованы в структурное представление, чтобы позволить их машинную обработку. Цель пополнения базы знаний состоит в том, чтобы превратить небольшую исходную базу знаний в большую. В общем, база знаний состоит из троек: субъект, объект и их отношение. Существующие базы знаний несовершены в двух отношениях — отношениях и троек (экземплярах).Обратите внимание, что даже обширная база знаний, такая как DBpedia, freebase или YAGO, не идеальна для описания всех отношений между сущностями в реальном мире. Однако эта проблема часто решается путем ограничения целевых приложений или областей знаний [1,2]. Еще одна проблема — отсутствие троек. Хотя существующие базы знаний содержат огромное количество троек, они все еще далеки от совершенства по сравнению с бесконечным количеством фактов из реального мира. Решить эту проблему можно только бесконечным созданием троек. В частности, согласно работе Paulheim [3], стоимость изготовления тройки вручную в 15-250 раз дороже, чем стоимость автоматического метода.Таким образом, очень важно автоматически генерировать тройки.Как упоминалось выше, база знаний использует тройное представление для выражения фактов, но новые знания обычно приходят из неструктурированных текстов, написанных на естественном языке. Таким образом, обогащение знаний направлено на извлечение как можно большего количества пар сущностей для конкретного отношения из неструктурированных текстов. С этой точки зрения обогащение знаний на основе шаблонов является одним из самых популярных методов среди различных реализаций обогащения знаний.Его популярность объясняется тем, что он может управлять различными типами отношений, а шаблоны можно легко интерпретировать. При обогащении знаний на основе шаблонов, когда отношение и пара сущностей, связанных этим отношением, задаются как начальные знания, предполагается, что предложение, в котором упоминается пара исходных сущностей, содержит лексическое выражение для отношения, и это выражение становится образцом для извлечение новых знаний для отношений. Поскольку на качество вновь извлеченных знаний сильно влияет качество шаблонов, важно создавать высококачественные шаблоны. Качество шаблонов зависит в первую очередь от метода, используемого для извлечения токенов в предложении и для измерения уверенности кандидатов в шаблоны. Многие предыдущие исследования, такие как NELL [4], ReVerb [5] и BOA [6], используют информацию о лексической последовательности для генерации паттернов [7,8]. То есть, когда исходное знание выражается как тройка из двух сущностей и их отношения, промежуточная лексическая последовательность между двумя сущностями в предложении становится кандидатом в образец. Сообщалось, что такие лексические шаблоны демонстрируют разумную работу во многих системах обогащения знаний [4,6].Однако у них есть очевидные ограничения: (i) они не могут обнаружить зависимости между словами в предложении на большом расстоянии и (ii) лексическая последовательность не всегда передает правильное значение отношения. Предположим, что предложение «Ева — дочь» Селены и Майкла ». дано. Простой генератор лексических шаблонов, такой как BOA, извлекает из этого предложения шаблоны, показанные в таблице 1, путем извлечения лексической последовательности между двумя объектами. Первый шаблон предназначен для отношения childOf и подходит для выражения значения отношения родитель-потомок.Таким образом, его можно использовать для извлечения новых троек для childOf из других предложений. Однако второй шаблон «{arg1} и {arg2}» не может передать смысл отношения spouseOf. Чтобы передать правильное значение spouseOf, необходимо создать образец «дочь {arg1} и {arg2}». Поскольку фраза «дочь» происходит от слов «Селена» и «Майкл», такой образец не может быть получен из предложения. Следовательно, необходимо более эффективное представление шаблонов для выражения зависимостей слов, которые не находятся внутри сущностей.Обычно пара сущностей может иметь более двух отношений. Таким образом, предложение, в котором упоминаются обе сущности в исходной тройке, может выражать другие отношения, отличные от отношения исходной тройки. Затем паттерны, извлеченные из таких предложений, становятся бесполезными для сбора новых знаний об отношении семенной тройки. Например, предположим, что тройная Ева, workFor, Селена дана как семя знания. Поскольку при создании паттернов учитываются только сущности, «{arg1} является дочерью {arg2}» из предложения «Ева — дочь Селены и Майкла.”Становится образцом для отношения workFor, в то время как образец вообще не передает значения workFor. Следовательно, для генерации высококачественных шаблонов важно отфильтровать кандидатов в шаблоны, которые не передают смысл отношения в исходной тройке. Одним из возможных решений этой проблемы является определение достоверности кандидата в шаблон в соответствии с родством между кандидатом в шаблон и целевым отношением. Статистическая информация, такая как частота кандидатов в шаблоны или информация о совместном появлении кандидатов в шаблоны и некоторых предопределенных функций, обычно использовалась в качестве достоверности шаблона в предыдущей работе [6,9].Однако такая основанная на статистике достоверность не отражает напрямую семантическую связь между шаблоном и целевым отношением. То есть, даже когда две сущности очень часто встречаются вместе, чтобы выразить значение отношения, может быть также много случаев, в которых сущности имеют другие отношения. Следовательно, чтобы определить, правильно ли семантически выражает шаблон отношение значение отношения, следует исследовать семантическую взаимосвязь между шаблоном и отношением.В этой статье мы предлагаем новую, но простую систему для начальной загрузки базы знаний, выраженной в троек, из большого объема неструктурированных документов.В частности, мы показываем, что зависимости между сущностями и семантической информацией могут улучшить производительность по сравнению с предыдущими подходами без особых усилий. Для преодоления ограничений шаблонов лексической последовательности система выражает шаблон как дерево синтаксического анализа, а не как лексическую последовательность. Поскольку дерево синтаксического анализа предложения представляет собой глубокий лингвистический анализ предложения и легко выражает зависимости на большом расстоянии, использование шаблонов дерева синтаксического анализа приводит к более высокой производительности в обогащении знаний, чем лексические последовательности.Кроме того, использование семантической уверенности для шаблонов дерева синтаксического анализа позволяет отфильтровывать нерелевантные кандидаты в шаблоны. Семантическая достоверность между шаблоном и отношением в исходных знаниях определяется как среднее сходство между словами шаблона и словами отношения. Среди различных измерений сходства мы применяем два общих семантических измерения сходства: сходство на основе WordNet и сходство встраивания слов. Как правило, подобие WordNet дает правдоподобные результаты, но иногда возникает проблема отсутствия словарного запаса (OOV) [10].Поскольку шаблоны могут содержать много слов, не перечисленных в WordNet, сходство дополняется сходством слов в пространстве для встраивания слов. Таким образом, последнее сходство слов — это сочетание сходства по WordNet и в пространстве встраивания слов. В конечном итоге семантическая достоверность между шаблоном и отношением в исходных знаниях определяется как среднее сходство между словами шаблона и словами отношения.3. Общая структура обогащения знанийНа рисунке 1 изображена общая структура предлагаемой системы обогащения знаний.Для каждого отношения r в исходной базе знаний мы сначала генерируем набор шаблонов P (r) для отношения r. Когда исходное знание задано как тройка e1, r, e2 с двумя объектами (e1 и e2) и отношением (r), шаблон для исходных знаний определяется как поддерево дерева синтаксического анализа предложения, которое содержит оба e1 и e2. Чтобы получить P (r), сначала выбираются предложения, в которых одновременно упоминаются e1 и e2. Поскольку наш шаблон представляет собой дерево синтаксического анализа, выбранные предложения анализируются синтаксическим анализатором естественного языка, а затем преобразуются в шаблоны дерева синтаксического анализа.Затем мы исключаем шаблоны дерева синтаксического анализа, которые не передают значение отношения r. После фильтрации таких нерелевантных шаблонов дерева оставшиеся становятся P (r).После подготовки P (r) он используется для создания новых троек для r из набора документов. Если предложение в наборе документов совпадает с шаблоном дерева синтаксического анализа в P (r), новая тройка, извлеченная из предложения, добавляется в исходную исходную базу знаний. Поскольку шаблон имеет древовидную структуру, все предложения в наборе документов также заранее анализируются анализатором естественного языка.Новая тройка извлекается из дерева синтаксического анализа, когда шаблон точно соответствует дереву синтаксического анализа. Наконец, в базу знаний добавляются новые тройки. 5. Извлечение новых знанийПосле того, как P (r), набор шаблонов для отношения r, подготовлен, новые тройки извлекаются из большого набора документов с помощью P (r). Когда дерево синтаксического анализа предложения полностью совпадает с шаблоном для r, из предложения создается новая тройка для r. Алгоритм 2 объясняет, как создаются новые тройки. В качестве входных данных алгоритм принимает предложение s из набора документов, целевое отношение r и образец p∈P (r).Для простого сопоставления деревьев шаблон p преобразуется в строковое представление Strp функцией ConvertToString. Эта функция преобразует дерево в длинную одиночную строку, просматривая дерево по порядку. Метки ребер рассматриваются как узлы, поскольку они играют важную роль в передаче смысла отношения. Давайте, например, рассмотрим паттерны на рисунках 2b и 3b. Образец на рисунке 2b выражается в виде строки [Тема] ← nsubj ← [дочь] → подготовка → [Объект], тогда как на рисунке 3b шаблон становится [Тема] ← nsubj ← [работает] → подготовка → [компания ] → возможно → [Объект].
Предложение s преобразовано в дерево синтаксического анализа t синтаксическим анализатором естественного языка, и все объекты в s извлекаются в E. Для каждой комбинации (es, eo) пар сущностей в E, поддерево p ‘t, которое включает в себя пару сущностей, сопоставляется с шаблоном p. Если p ‘соответствует p, p’ рассматривается как дерево синтаксического анализа, которое имеет то же значение, что и p. Для сопоставления p ‘и p узлы, соответствующие es и eo в t, сначала идентифицируются как n1 и n2.Затем поддерево p ‘, которое включает n1 и n2, извлекается функцией subtree_extract, используемой в алгоритме 1. После этого p’ также преобразуется в строковое представление Strp ‘с помощью ConvertToString. Если Strp и Strp ‘одинаковы, тройка es, r, eo, как полагают, соответствует значению шаблона p. Таким образом, он добавляется в набор знаний K как новая тройка для отношения r. 6. ЭкспериментыЧтобы оценить предложенный метод, мы проводим эксперименты с двумя наборами данных. Первый набор данных состоит из Википедии и DBpedia.Онтология DBpedia используется как база знаний, а корпус Википедии используется как корпус для генерации шаблонов и извлечения новых троек знаний. Для количественной оценки принят эталонный набор данных QALD-3 (задача лексикализации онтологий), где набор данных состоит из 30 предикатов, которые являются подмножеством DBpedia. Второй набор данных — это набор эталонных данных NYT (New York Times Corpus), который был принят во многих предыдущих исследованиях [36].В эксперименте с Википедией и DBpedia вспомнить шаблоны и новые тройки невозможно рассчитать, потому что нет ответов золотого стандарта на шаблоны и новые тройки в корпусе.Таким образом, измеряется только точность (прецизионность) шаблонов и троек. Однако, чтобы косвенно показать взаимосвязь между отзывом и точностью, используется точность (прецизионность) в точке K по отношению к ранжированным тройным спискам. Все оценки выполняются вручную двумя оценщиками. В каждом суждении правильными считаются только те прогнозы, которые оба эксперта определили как истинные. С другой стороны, в эксперименте с NYT мы также представляем точность высочайшего качества, которая автоматически оценивается с помощью тестовых данных. Предложенный метод оценен с помощью четырех экспериментов. Цель первых двух экспериментов — показать эффективность нашего шага генерации паттернов. В первом эксперименте предложенный шаблон дерева синтаксического анализа сравнивается с шаблоном лексической последовательности, а эффективность предложенного семантического фильтра исследуется во втором эксперименте. Новые тройки, извлеченные с помощью наших шаблонов дерева синтаксического анализа, оцениваются в третьем эксперименте. В заключительном эксперименте предложенный метод сравнивается с предыдущими исследованиями с использованием другого набора контрольных данных, NYT. 6.1. Оценка шаблонов дерева синтаксического анализаМы показываем превосходство представления шаблонов в виде дерева синтаксического анализа, сравнивая его с лексическим представлением. Для оценки паттернов из 30 отношений выбираются десять наиболее часто встречающихся отношений. Десять используемых отношений: художник, доска, кресты, место смерти, поле, местоположение, издатель, религия, супруга и команда. Хотя используется только треть отношений DBpedia, десять отношений могут охватывать большинство кандидатов в шаблоны.То есть 63 704 уникальных кандидата в шаблоны генерируются из 30 отношений, но 75% из них охватываются десятью отношениями. Все тройки онтологии DBpedia, соответствующие десяти предикатам, используются как начальные тройки. Чтобы сгенерировать оба типа шаблонов, из корпуса Википедии случайным образом выбирается 100 предложений для каждого отношения. Поскольку один шаблон генерируется из предложения, каждое отношение имеет 100 шаблонов для представления дерева синтаксического анализа и лексического представления соответственно.Чтобы получить шаблоны лексической последовательности, которые использовались в предыдущих работах, таких как BOA или OLLIE, мы следуем только этапу поиска шаблонов BOA. Правильность каждого шаблона оценивают два человека-оценщика. Для каждого образца отношения оценщики определяют, точно ли слова в образце передают значение отношения. Наконец, правильными считаются только те модели, с которыми оба эксперта согласны как истинные. На рисунке 4 показан результат сравнения дерева синтаксического анализа и шаблонов лексической последовательности.Ось X этого рисунка представляет отношения, а ось Y — точность шаблонов. Предлагаемые шаблоны дерева синтаксического анализа показывают более высокую точность, чем шаблоны лексической последовательности для всех отношений. Средняя точность шаблонов дерева синтаксического анализа составляет 68%, в то время как точность шаблонов лексической последовательности составляет всего 52%. Максимальная разница в точности между двумя представлениями паттернов составляет 35% для издателя отношения. Поскольку деревья синтаксического анализа представляют отношения зависимости между словами и, таким образом, могут выявить зависимости между словами, не входящими в состав слов, более точные шаблоны генерируются деревьями синтаксического анализа.После исследования всех 1000 (= 100 шаблонов · 10 отношений) шаблонов дерева синтаксического анализа было обнаружено, что около 34% слов, встречающихся в шаблонах, являются неперемешивающимися словами, а около 45% шаблонов содержат по крайней мере одно непереходящее слово. Тот факт, что многие шаблоны содержат неперемешивающиеся слова, подразумевает, что предложенный шаблон дерева синтаксического анализа эффективно представляет зависимости между словами на большом расстоянии. Например, рассмотрим следующее предложение и тройной FloatingintotheNight, artist, JuleeCruise. Из этого предложения лексический образец извлекает первые два альбома (ы) как образец, а образец содержит бессмысленные слова, такие как первый и два. Однако следующий образец дерева синтаксического анализа исключает такие непересекающиеся слова. [Тема] ← appos ← [альбом] → возможности → [Object]. 6.2. Производительность семантического фильтраПредлагаемый семантический фильтр основан на совокупном подобии подобия на основе WordNet и подобия встраивания слов.Таким образом, мы сравниваем составное подобие с каждым базовым подобием, чтобы увидеть превосходство семантического фильтра. Кроме того, многие представления шаблонов лексической последовательностью удаляют нерелевантные шаблоны на основе частоты шаблонов. Таким образом, частотный фильтр также сравнивается с предложенным семантическим фильтром. Для каждого отношения шаблоны дерева синтаксического анализа генерируются с использованием всех исходных троек и корпуса Википедии. В результате сгенерировано 47 390 шаблонов дерева синтаксического анализа. Таким образом, одно отношение имеет в среднем 4739 паттернов.Затем были применены четыре фильтра для сортировки паттернов по их сходству или частоте. Поскольку нецелесообразно исследовать правильность 47 390 паттернов вручную, проверяется правильность 100 лучших паттернов по каждому фильтру. На рис. 5 показаны средние значения точности top-K для четырех фильтров. На этом рисунке «WordNet + Word Embedding» — это предлагаемый семантический фильтр, «WordNet Only» и «Word Embedding Only» — два базовых фильтра, а «Frequency-Based» — частотный фильтр, используемый в OLLIE [9].«Встраивание WordNet + Word» превосходит все другие фильтры для всех k. Кроме того, разница между «встраиванием WordNet + Word» и другими фильтрами увеличивается с увеличением k. Эти результаты означают, что предложенный семантический фильтр сохраняет высококачественные паттерны и эффективно удаляет нерелевантные паттерны. Среди десяти отношений результаты для deathPlace показывают самую низкую точность. Как показано на рисунке 6a, точность deathPlace ниже 50% для всех фильтров. В базе знаний понятия Person и Location обычно используются как область и диапазон deathPlace соответственно.Однако они часто используются для многих других отношений, таких как место рождения и национальность. Таким образом, даже если ряд паттернов генерируется из предложений с Человеком в качестве субъекта и Местоположение в качестве объекта, многие из них вообще не связаны с deathPlace. Например, шаблон дерева синтаксического анализа[Тема] ← nsubj ← [live] → подготовка → [Объект]. образовано из предложения «Каспар Хаузер жил в Ансбахе с 1830 по 1833 год». с семенной тройкой KasparHauser, deathPlace, Ansbach. Этот паттерн высоко ценится в нашей системе, но его значение — «Субъект живет в объекте».Таким образом, он не передает значение места смерти. Когда сходство встраивания слов сравнивается со сходством на основе WordNet, оно оказывается более точным, чем сходство на основе WordNet. Как видно на рисунке 5, его точность всегда выше, чем точность подобия на основе WordNet для всех k. Однако его точность чрезвычайно низка для родственников, как показано на рисунке 6b. Такая крайне низкая точность бывает, когда похожие слова отношения в пространстве вложения слов не являются синонимами отношения.Подобные слова супруга в WordNet являются его синонимами, такими как «жена» и «муж», но в месте вложения слова используются «ребенок» и «бабушка и дедушка». Даже если «ребенок» и «дедушка и бабушка» подразумевают семейные отношения, они не соответствуют супругу. Поскольку предлагаемый семантический фильтр использует комбинацию подобия на основе WordNet и подобия внедрения слов, проблема пространства для встраивания слов компенсируется подобием на основе WordNet. На рисунках 7 и 8 показаны точности Top-K для всех отношений, кроме deathPlace и супруга.Для большинства отношений оценка на основе семантики обеспечивает более высокую производительность, чем оценка на основе частоты.6.3. Оценка недавно извлеченных знанийЧтобы исследовать, создают ли шаблоны дерева синтаксического анализа и семантические фильтры точные новые тройки, тройки, извлеченные с помощью шаблонов «дерево синтаксического анализа + семантический фильтр», сравниваются с образцами, извлеченными с помощью «лексического + частотного фильтра», « лексический + семантический фильтр »и шаблоны« дерево синтаксического анализа + частотный фильтр ». Поскольку корпус Википедии чрезмерно велик, из корпуса случайным образом выбираются 15 миллионов предложений, а из предложений извлекаются новые тройки. Таблица 2 показывает подробную статистику количества совпадающих шаблонов и троек, извлеченных вместе с шаблонами. Согласно этой таблице количество совпадающих шаблонов лексической последовательности составляет 255, а количество шаблонов дерева синтаксического анализа — 713. В результате количество новых троек, извлеченных шаблонами лексической последовательности и шаблонами дерева синтаксического анализа, составляет 32 113 и 104 311 соответственно. Хотя шаблоны лексической последовательности и шаблоны дерева синтаксического анализа генерируются из идентичного набора данных и применяются к нему, шаблоны дерева синтаксического анализа извлекают на 72198 троек больше, чем шаблоны лексической последовательности, что означает, что охват шаблонов дерева синтаксического анализа намного шире, чем охват шаблонов лексических последовательностей. .При оценке новых троек для каждого отношения выбираются 100 лучших троек в соответствии с рангами, а правильность 4000 (= 100 троек · 10 отношений · 4 типа образцов) троек проверяется вручную двумя экспертами. Как и в предыдущих экспериментах, правильными считаются только тройки, отмеченные обоими экспертами как истинные. Таблица 3 суммирует точность троек, извлеченных с помощью шаблонов «дерево синтаксического анализа + семантический фильтр» и троек с помощью шаблонов «лексический + частотный фильтр», «лексический + семантический фильтр» и «дерево синтаксического анализа + частотный фильтр».Тройки, извлеченные с помощью шаблонов «дерево синтаксического анализа + семантический фильтр», достигают 60,1% точности, тогда как тройки, полученные с помощью шаблонов «дерево синтаксического анализа + частотный фильтр», «лексический + семантический фильтр» и «лексический + частотный фильтр», достигают 53,9%, 38,2% и 32,4% точности соответственно. Тройки, извлеченные с помощью шаблонов «дерево синтаксического анализа + семантический фильтр», превосходят аналогичные по шаблонам «лексический + частотный фильтр» на 27,7%. Они также на 21 превосходят тройки, извлеченные с помощью шаблонов «лексический + семантический фильтр» и «дерево синтаксического анализа + частотный фильтр».9% и 6,2% соответственно. Эти результаты доказывают, что обогащение знаний значительно улучшается при использовании шаблонов дерева синтаксического анализа и предлагаемого семантического фильтра.Большинство неправильных троек по образцам дерева синтаксического анализа происходят из трех отношений: место смерти, поле и религия. Точность новых троек без соотношений достигает 74,0%. Причина, по которой deathPlace производит много неправильных троек, объяснена выше. Для отношений поля и религии было обнаружено, что несколько неправильных шаблонов, которые высоко ранжируются семантическим фильтром, порождают большинство новых троек.Поэтому решать проблемы — это наша будущая работа. После создания всех возможных кандидатов дерева шаблонов нерелевантные кандидаты удаляются с помощью уравнения (1). θr каждого отношения r, используемого для фильтрации нерелевантных кандидатов, приведены в таблице 4. В среднем 71 шаблон каждого отношения сопоставляется с предложениями Википедии, но только 37 шаблонов остаются после семантической фильтрации. Затем из 104 311 троек тройки, извлеченные из удаленных шаблонов, исключаются из результатов.В результате 12 522 новых тройки извлекаются и добавляются к семенным знаниям.6.4. Сравнение с предыдущей работойЧтобы показать правдоподобность предлагаемого метода, мы проводим дополнительный эксперимент с новым набором данных тестов, NYT, который генерируется с помощью отношений Freebase и корпуса New York Times [36]. Сущности и отношения Freebase согласованы с предложениями корпуса в 2005–2006 годах. Тройки, сгенерированные этим выравниванием, считаются обучающими данными, а тройки, согласованными с предложениями 2007 года, считаются тестовыми данными.Обучающие данные содержат 570 088 экземпляров с 63 428 уникальными сущностями и 53 отношениями со специальным отношением «NA», которое указывает на отсутствие связи между сущностями субъекта и объекта. Тестовые данные содержат 172 448 экземпляров с 16 705 объектами и 32 отношениями, включая «NA». Обратите внимание, что «NA» используется для обозначения отрицательных случаев. Таким образом, тройки с отношением «NA» фактически не несут никакой информации. Без троек с отношением «NA» остается 156 664 и 6444 троек в обучающих и тестовых данных.Таблица 5 показывает простую статистику по набору данных NYT. Предлагаемый метод сравнивается с четырьмя вариантами PCNN (кусочно-сверточной нейронной сети), которые использовали набор данных NYT для их оценки [19,20,21,22]. Эти модели перечислены в таблице 6, в которой ATT подразумевает метод внимания, предложенный Lin et al. [19], nc и cond_opt обозначают преобразователь шума и условный оптимальный селектор Wu et al. [20] soft-label означает метод soft-label по Liu et al. [21], а ATT_RA и BAG_ATT — это метод внимания внутри пакета с учетом отношений и метод внимания между пакетами, предложенный Ye et al.[22]. Мы измеряем точность top-K ([email protected] K), где K равно 100, 200 и 300. В таблице 6 приведены результаты сравнения производительности набора данных NYT. Согласно этой таблице, предлагаемый метод достигает производительности, сопоставимой с методами на основе нейронных сетей. PCNN + ATT_RA + BAG_ATT показывает наивысшую среднюю точность 84,8%, в то время как предлагаемый метод достигает 79,2%. Таким образом, разница между ними составляет всего 5,6%. Предлагаемый метод, однако, не противоречит изменению K. Все методы на основе нейронных сетей показывают разницу примерно в 10% между K = 100 и K = 300.С другой стороны, разница в предлагаемом методе составляет всего 5,4%, что означает, что предложенный подход к генерации шаблонов и оценке подходит для этой задачи. Кроме того, шаблоны, созданные с помощью предлагаемого метода, можно легко интерпретировать, и, таким образом, ошибки рисунка могут быть исправлены без особых усилий.7. Выводы и дальнейшая работаГенерация точных шаблонов является ключевым фактором обогащения знаний на основе шаблонов. В этой статье были предложены шаблон дерева синтаксического анализа и семантический фильтр для удаления нерелевантных кандидатов в шаблоны.Преимущество использования представления дерева синтаксического анализа для шаблонов состоит в том, что зависимости слов на большом расстоянии хорошо выражаются деревом синтаксического анализа. Таким образом, шаблоны дерева синтаксического анализа содержат много слов, которые не расположены между двумя словами сущности. Кроме того, преимуществом семантического фильтра является то, что он находит нерелевантные шаблоны более точно, чем частотный фильтр, поскольку он напрямую отражает смысл отношений. Преимущества нашей системы были эмпирически подтверждены экспериментами с использованием онтологии DBpedia и корпуса Википедии.Предложенная система достигла 68% точности генерации шаблонов, что на 16% выше, чем у лексических шаблонов. Кроме того, знания, извлеченные заново с помощью шаблонов дерева синтаксического анализа, показали точность 60,1%, что на 27,7% выше, чем точность данных, извлеченных с помощью лексических шаблонов и статистической оценки. Хотя по сравнению с предыдущими методами, основанными на нейронных сетях, предложенный метод не смог обеспечить современную производительность, он показал отличную производительность, учитывая простоту модели.В частности, это доказывает, что предлагаемый нами подход надежно подходит для задачи обогащения знаний. Эти результаты означают, что предлагаемый метод обогащения знаний эффективно заполняет новые знания. В качестве нашей будущей работы мы найдем более подходящую метрику сходства между шаблоном и отношением. В ходе нескольких экспериментов мы показали, что WordNet и встраивание слов подходят для этой задачи без дополнительных огромных усилий. Тем не менее, есть еще кое-что для улучшения производительности.Таким образом, мы исследуем новое семантическое сходство, чтобы хорошо уловить взаимосвязь между отношением и шаблоном в будущем. Еще одна слабость предлагаемого метода состоит в том, что он не может обрабатывать невидимые отношения. Очень важно обнаруживать невидимые отношения, чтобы сделать базу знаний как можно более совершенной. Недавно встраивание баз знаний на основе переводов показало некоторый потенциал для поиска отсутствующих связей [37,38]. Поэтому в будущем мы будем исследовать способ обнаружения отсутствующих отношений и обогащения базы знаний, применяя их к базе знаний.python — Вычислить косинусное сходство по 2 строкам предложенийКороткий ответ: «нет, это невозможно сделать принципиальным способом, который работал бы даже удаленно». Это нерешенная проблема в исследовании обработки естественного языка, а также тема моей докторской работы. Я очень кратко резюмирую, где мы находимся, и укажу вам несколько публикаций: Значение слов Наиболее важным предположением здесь является то, что можно получить вектор, который представляет каждое слово в предложении в вопросе.Этот вектор обычно выбирается для захвата контекстов, в которых может появляться слово. Например, если мы рассматриваем только три контекста «есть», «красный» и «пушистый», слово «кошка» может быть представлено как [98, 1 , 87], потому что, если бы вы прочитали очень-очень длинный отрывок текста (несколько миллиардов слов — не редкость по сегодняшним стандартам), слово «кошка» очень часто появлялось бы в контексте «пушистый» и «съесть». , но не так часто в контексте «красных». Таким же образом, «собака» может быть представлена как [87,2,34], а «зонтик» — как [1,13,0].Представляя эти векторы как точки в трехмерном пространстве, «кошка» явно ближе к «собаке», чем к «зонтику», поэтому «кошка» также означает нечто более похожее на «собаку», чем на «зонтик». Это направление работ исследовалось с начала 90-х (например, эта работа Греффенстетта) и дало несколько удивительно хороших результатов. Например, вот несколько случайных записей в тезаурусе, который я недавно построил, прочитав на моем компьютере википедию: Эти списки похожих слов были получены полностью без вмешательства человека — вы вводите текст и возвращаетесь через несколько часов. Проблема с фразами Вы можете спросить, почему мы не делаем то же самое для длинных фраз, таких как «рыжие лисы любят фрукты». Это потому, что у нас не хватает текста. Чтобы мы могли точно определить , на что похож X, нам нужно увидеть много примеров того, как X используется в контексте. Когда X — это одно слово, такое как «голос», это не так уж сложно. Однако по мере того, как X становится длиннее, шансы найти естественные вхождения X экспоненциально снижаются.Для сравнения: в Google есть около 1 млрд страниц, содержащих слово «лиса», и ни одна страница не содержит «имбирные лисы любят фрукты», несмотря на то, что это совершенно правильное английское предложение, и все мы понимаем, что оно означает. Состав Чтобы решить проблему разреженности данных, мы хотим выполнить композицию, то есть взять векторы для слов, которые легко получить из реального текста, и соединить их таким образом, чтобы уловить их значение. Плохая новость в том, что до сих пор никому не удавалось добиться этого. Самый простой и очевидный способ — сложить или умножить отдельные векторы слов вместе. Это приводит к нежелательному побочному эффекту: «кошки преследуют собак» и «собаки преследуют кошек» будут означать то же самое для вашей системы. Кроме того, если вы умножаете, вы должны быть особенно осторожны, иначе каждое предложение будет представлено в виде [0,0,0, …, 0], что лишает смысла. Дополнительная литература Я не буду обсуждать более сложные методы композиции, которые были предложены до сих пор.Предлагаю вам прочитать книгу Катрин Эрк «Векторные пространственные модели значения слов и значений фраз: обзор». Это очень хороший обзор высокого уровня, который поможет вам начать работу. К сожалению, его нет в свободном доступе на веб-сайте издателя, напишите автору напрямую, чтобы получить копию. В этой статье вы найдете ссылки на многие другие конкретные методы. Более понятные — Митчел и Лапата (2008) и Барони и Зампарелли (2010). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||