Морфологический разбор слова «подобный»
Часть речи: Прилагательное
ПОДОБНЫЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОДОБНЫЙ»
| Слово | Морфологические признаки |
|---|---|
| ПОДОБНЫЙ |
|
| ПОДОБНЫЙ |
|
Все формы слова ПОДОБНЫЙ
ПОДОБНЫЙ, ПОДОБНОГО, ПОДОБНОМУ, ПОДОБНЫМ, ПОДОБНОМ, ПОДОБНАЯ, ПОДОБНОЙ, ПОДОБНУЮ, ПОДОБНОЮ, ПОДОБНОЕ, ПОДОБНЫЕ, ПОДОБНЫХ, ПОДОБНЫМИ, ПОДОБЕН, ПОДОБНА, ПОДОБНО, ПОДОБНЫ, ПОДОБНЕЕ, ПОДОБНЕЙ, ПОПОДОБНЕЕ, ПОПОДОБНЕЙ, ПОДОБНЕЙШИЙ, ПОДОБНЕЙШЕГО, ПОДОБНЕЙШЕМУ, ПОДОБНЕЙШИМ, ПОДОБНЕЙШЕМ, ПОДОБНЕЙШАЯ, ПОДОБНЕЙШЕЙ, ПОДОБНЕЙШУЮ, ПОДОБНЕЙШЕЮ, ПОДОБНЕЙШЕЕ, ПОДОБНЕЙШИЕ, ПОДОБНЕЙШИХ, ПОДОБНЕЙШИМИ
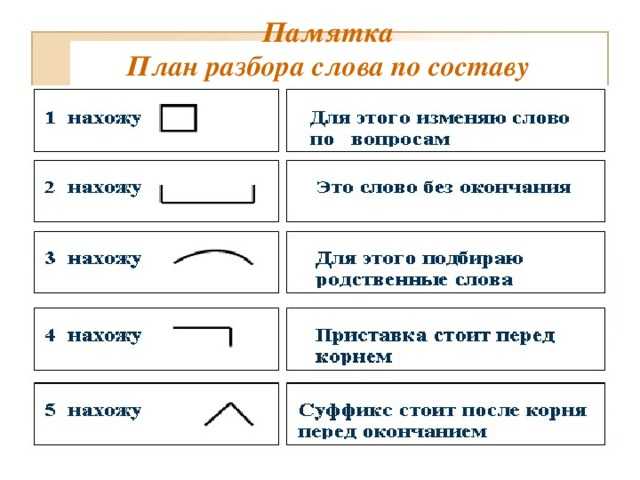
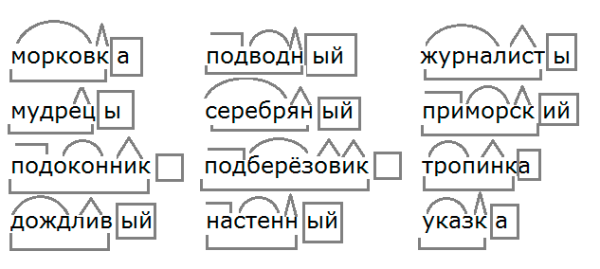
Разбор слова по составу подобный
подобн
ый
| Основа слова | подобн |
|---|---|
| Корень | подоб |
| Суффикс | н |
| Окончание | ый |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОДОБНЫЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «подобный»
Примеры предложений со словом «подобный»
1
Таков был выбранный им текст, и, несомненно, подобное собрание не могло не слушать подобного проповедника, избравшего подобную тему в подобном месте.
Барчестерские башни, Энтони Троллоп, 1857г.
2
Тут он принялся цитировать «Песнь о буревестнике»: пусть сильнее грянет буря, глупый пингвин, чёрной молнии подобный, и тому подобное.
Игрушки, Дмитрий Дейч
3
Говорят же в народе: «подобное притягивает подобное», «скажи мне, кто твой друг», «два сапога пара» и тому подобное.
О’живи, Любовь Бордунос, 2019г.
4
лампа под бледно-голубым колпаком разливала нежный свет, подобный свету луны.
Рекенштейны, Вера Ивановна Крыжановская-Рочестер, 1894г.
5
Подобный пропуск, разумеется, не может быть случайным, так как Одар являлся слишком деятельным лицом и его слишком хорошо знали все главари заговора.
Две жизни, Михаил Волконский, 1914г.
Найти еще примеры предложений со словом ПОДОБНЫЙ
Московский городской педагогический университет
Ежегодный международный симпозиум состоится 18-20 мая
Главные новости
Все новостиУниверситет
Шалва Амонашвили представил полное собрание сочинений
25 апреля в Московском городском педагогическом университете прошла презентация двадцатитомного собрания, в которое вошли труды Шалвы Александровича, создаваемые им на протяжении 67 лет
Бесправны ли учителя? Ректор МГПУ в программе «Агора»
22 апреля в программе Михаила Швыдкого на телеканале «Культура» обсудили то, смогут ли поправки в законодательство защитить педагогов от невоспитанных учеников, нервных родителей и требовательного начальства
«Цифровизацию невозможно остановить, но можно возглавить»
Участники выездного круглого стола Московской городской думы «Цифровые инструменты развития современного высшего педагогического образования: опыт МГПУ» обсудили проблемы и перспективы цифровизации высшего педагогического образования
Конкурсы и стипендии
В МГПУ прошли финалы состязаний «Я — профессионал»
Более сотни лучших будущих педагогов и дефектологов со всей страны собрались в Московском городском педагогическом университете на очный финал Всероссийской олимпиады «Я — профессионал» по своим направлениям
Календарь событий
Все событияУчёные женщины | Спектакль выпускников Мастерской Игоря Яцко в ШДИ
Выпускники МГПУ направления подготовки «Артист драматического театра и кино» (Мастерская Заслуженного артиста России Игоря Яцко) приглашают на свой спектакль в театре «Школа драматического искусства»
27. 04.2023
04.2023
19:00
Конкурс перевода и озвучания документальных фильмов на кафедре языкознания и переводоведения
Кафедра языкознания и переводоведения приглашает студентов направления подготовки «Лингвистика. Перевод и переводоведение (английский язык)» принять участие в конкурсе перевода и озвучания документальных фильмов с применением цифровых инструментов
27.04.2023
12:00
Просмотр и обсуждение фильма «Shakespeare in Love»
Кафедра английской филологии приглашает отметить День рождения Уильяма Шекспира на киновечере
27.04.2023
15:40
Клуб китайской живописи
На кафедре китайского языка состоится очередное собрание Клуба китайской живописи. В этот весенний день мы снова возвращаемся к теме цветов
27.04.2023
15:40
Online
Как привлечь молодежные сообщества к воспитательной работе?
Круглый стол с обсуждением модели привлечения молодежных сообществ к воспитательной работе через социальные сети
27. 04.2023
04.2023
15:00
Студенческая лингвистическая лаборатория «Эврика» «Климат и погода: отражение в фразеологической картине европейских языков»
На очередном заседании студенческой лингвистической лаборатории «Эврика» в рамках проекта «Люди, События, Факты в фразеологических единицах» планируется познакомиться с устойчивыми выражениями, обозначающими обозначающими климатические условия
27.04.2023
18:00
Блажен, кто верует | Спектакль Мастерской Карэна Бадалова
Приглашаем всех желающих на открытые показы студентов 4 курса направления подготовки «Артист драматического театра и кино» Института культуры и искусств МГПУ по «Горю от ума» Грибоедова
28.04.2023
19:00
II Конкурс презентаций туристических маршрутов на китайском языке «Я шагаю по Москве»
Кафедра китайского языка ИИЯ Московского городскогоприглашает студентов 3 и 4 курсов китайского отделения принять участие в студенческом конкурсе презентаций однодневных туристических маршрутов на китайском языке
28. 04.2023
04.2023
15:40
Кружок «Этимологические раскопки»
Апрельская встреча научно-студенческого кружка «Этимологические раскопки» будет посвящена теме «Орудия, оружие и инструменты» в индоевропейских языках
28.04.2023
16:30
Финал конкурса «Miss & Mister МГПУ 2023»
10 финалистов. 10 чувств будущего. Miss & Mister МГПУ 2023. Участники не только раскроют свои чувства, но и помогут тебе пробудить их!
28.04.2023
17:30
Образовательное событие «Научный диалог»
Преподаватели вузов дадут участникам олимпиады школьников «Высокие технологии и материалы будущего» рекомендации и полезные советы, а также проведут интерактивные мастер-классы
28.04.2023
15:00
Поездка к 80-летию Ржевской битвы
28 апреля состоится уже третья поездка за 2 года представителей студенческого актива и ветеранской организации МГПУ в г. Ржев с посещением Ржевского мемориала. Каждый институт может направить своих активных студентов на экскурсию.
Ржев с посещением Ржевского мемориала. Каждый институт может направить своих активных студентов на экскурсию.
28.04.2023
Танцевальный конкурс «SHAKE IT OFF»
Межвузовский танцевальный конкурс «SHAKE IT OFF» — проект, объединяющий лучших танцоров Москвы в стенах Московского городского29.04.2023
17:00
Конкурс проектов «Russian-Chinese-English center
Кафедра языкознания и переводоведения ИИЯ МГПУ приглашает студентов 4 курсов направления подготовки «Перевод и переводоведение — китайский язык» на конкурс проектов «Russian-Chinese-English center»
29.04.2023
11:00
Online
Мастер-класс, посвященный решению задач ЕГЭ по физике, пройдет в ИЦО
Институт цифрового образования приглашает учащихся 10-11 классов на мастер-класс, посвященный решению задач ЕГЭ по физике (разбор заданий №№ 28, 29)
06.05.2023
12:00
Online
Презентации программ магистратуры ИЦО 2023 года
Институт цифрового образования приглашает всех желающих на презентацию магистерских программ, реализуемых в 2023 году
11.
18:00
О мероприятии
В театре «Школа драматического искусства» продолжает идти спектакль, в котором заняты исключительно молодые артисты, выпускники 2021 года Мастерской Заслуженного артиста РФ Игоря Яцко в Институте культуры и искусств МГПУ. Даты ближайших спектаклей — 27 и 28 апреля, затем 23 и 24 мая, 7 июня
Создатели спектакля «Учёные женщины» по комедии Ж.-Б. Мольера:
Режиссёр — Заслуженный артист РФ Игорь Яцко
Художник — Лауреат премии города Москвы Кирилл Федоров
Художник по свету — Михаил Глейкин
Помощник режиссёра — Карина Заварина
В ролях:
Галина Селякова Александр Стасеев
Арина Федосенко Сергей Атрощенко
Анастасия Фурсова Антон Ромм
Ксения Копылова Роман Клепченко
Алина Чеченкова Максим Бойко
Премьера спектакля состоялась 29 июня в Тау-зале ШДИ.
Билеты можно приобрести в театральных кассах и на сайте театра
Рецензии на спектакль:
Ученые женщины. Зачем вам философия? (Театральная афиша столицы)
Смех без слез: Мольер и Островский на московских сценах (РИА Новости)
«Мольер. Экспромт» и «Ученые женщины»: выпускники МГПУ покоряют сцены Москвы (seldon)
Смех и много блесток. Из чего состоит спектакль «Ученые женщины» (mos.ru)
Химеры тщеславия витают над «Учеными женщинами» Мольера в «Школе драматического искусства» (Закулисье)
Между умными и красивыми: выбор делают «Учёные женщины» Игоря Яцко (Театр to go)
Премьера «Учёных женщин» выпускников МГПУ в Школе драматического искусства (Московский городской университет)
Игорь Яцко поставил пьесу Мольера со своими учениками (Театрал)
Les Femmes Savantes à l’école de Drame (О театре и не только)
В “Школе драматического искусства” прошла премьера комедии “Ученые женщины” (РИА новости)
Премьера спектакля “Ученые женщины” по Мольеру в Школе драматического искусства (Телеканал «Культура»)
«Ученые женщины» поступят в «Школу драматического искусства» (Театрал)
От комедии Шекспира до спектакля без слов. Что смотреть в театрах до конца сезона (mos.ru)
Что смотреть в театрах до конца сезона (mos.ru)
О мероприятии
Кафедра языкознания и переводоведения приглашает студентов 2 курса направления подготовки «Лингвистика. Перевод и переводоведение (английский язык)» принять участие в конкурсе перевода и озвучания документальных фильмов с применением цифровых инструментов.
К участию в конкурсе принимаются групповые и индивидуальные проекты.
Файлы проекта, включающие в себя файл скрипта фильма на оригинальном языке (word), диалоговый (речевой) лист на языке перевода (word) и видеофайл с озвученным фильмом (вариант закадровый перевод, полудубляж) необходимо разместить в облаке Mail.ru или Яндекс Диск. Ссылку на проект необходимо в срок до 24 апреля прислать по адресу электронной почты [email protected] для оценки жюри.
Состав жюри:
к.ф.н., доц. Анна Иванова
к.ф.н., доц. Вероника Никитина
асс. Анна Шестопалова
Подведение итогов и объявление победителей — 27 апреля в 12. 00, ауд. 106.
00, ауд. 106.
О мероприятии
Приглашаем отметить День рождения У. Шекспира на нашем киновечере. В это раз смотрим один из самых титулованных фильмов – «Влюбленный Шекспир». Вместе погрузимся в атмосферу конца XVI века, чтобы потом обсудить личность и творчество великого драматурга.
О мероприятии
27 апреля в 15.40 на кафедре китайского языка состоится очередное собрание Клуба китайской живописи. В этот весенний день мы снова возвращаемся к теме цветов. Приглашаем всех желающих!
Информация для тех, кто присоединится к нам в первый раз. Для занятий живописью вам потребуются следующие материалы:
- Кисть для сеи
- Бумага: бумага должна быть тоже для сеи. Обратите внимание на размер листов, которые продают обычно в магазинах — этот лист необходимо нарезать, они довольно большие.
- Коврик
- Тушь
- Краски для китайской живописи
Если кто-то не успеет приобрести материалы к назначенному дню, у нас есть тушь, запасные кисти и бумага, но материалов не так много.
О мероприятии
27 апреля 2023 года с 15:00 до 16:30 на платформе Microsoft Teams пройдет круглый стол «Обсуждение модели привлечения молодежных сообществ к воспитательной работе через социальные сети».
В ходе мероприятия, которое станет частью общеуниверситетской научной сессии «Дни науки МГПУ», сотрудники Лаборатории образовательных инфраструктур НИИ урбанистики и глобального образования МГПУ расскажут:
- как функционируют молодежные сообщества и организации в социальных сетях;
- какие существуют механизмы привлечения сообществ к воспитательной работе через социальные сети;
- как использовать социальные сети в воспитательном процессе и организовать работу с молодежными сообществами через них.
Для участия в мероприятии необходимо зарегистрироваться.
О мероприятии
На очередном заседании студенческой лингвистической лаборатории «Эврика» в рамках проекта «Люди, События, Факты в фразеологических единицах» планируется познакомиться с устойчивыми выражениями (пословицами, поговорками, идиомами), обозначающими климатические и погодные условия в европейских странах.
Участники заседания сделают попытку выявить особенности восприятия климата и погоды носителями романских, германских и славянских языков, нашедшие отражение в фразеологической картине указанных языков.
Подключение к мероприятию возможно по ссылке.
О мероприятии
Приглашаем на премьерный открытый показ студентов 4 курса направления подготовки «Артист драматического театра и кино» Института культуры и искусств МГПУ.
Спектакль «Блажен, кто верует» по пьесе А.С. Грибоедова «Горе от ума»
.
Режиссёр-постановщик: Карэн Бадалов
Роли исполняют:
София — Глафира Дощечкина
Лиза — Елизавета Газана
Чацкий- Тагир Шамсутдинов
Молчалин — Артем Штукатуров
Буфетчик Петруша — Фотис Келепурис
Регистрация:
Спектакль 28 апреля 2023 г.
Спектакль 29 апреля 2023 г.
Условия посещения спектакля:
• Бесплатно, по регистрации
• Наличие паспорта обязательно
• Количество мест ограничено (25 человек)
О мероприятии
Кафедра китайского языка института иностранных языков Московского городского педагогического университета приглашает студентов 3 и 4 курсов китайского отделения принять участие в студенческом конкурсе презентаций однодневных туристических маршрутов на китайском языке, который состоится 28 апреля2023 г. в смешанном формате.
в смешанном формате.
Цель конкурса: развитие и совершенствование общекультурных и профессиональных компетенций обучающихся бакалавриата, связанных с профессиональной организационной и переводческой деятельностью в сфере туризма на китайском языке.
Рабочие языки конкурса: русский, китайский.
Все участники конкурса получат сертификаты об участии, а победители – дипломы и призы.
Для участия необходимо зарегистрироваться до 23 апреля 2023 г.
Требования к оформлению и содержанию, а также критерии оценивания представлены в информационном письме.
Оглашение результатов Конкурса состоится 29.04.2023 г. Итоги Конкурса будут размещены на сайте ИИЯ МГПУ в разделе «Новости». Адрес электронной почты оргкомитета конкурса: [email protected]
О мероприятии
Апрельская встреча научно-студенческого кружка «Этимологические раскопки» будет посвящена теме «Орудия, оружие и инструменты» в индоевропейских языках. На встрече рассмотрим этимологию слов, обозначающих разные орудия, от наиболее базовых (рука, плуг, молот, hammer, bow, arrow), до более вычурных (Единорог, циркуль, автомат). Конечно, при этом обсудим языковую репрезентацию представлений об инструментальности, в том числе и соответствующий падеж.
Конечно, при этом обсудим языковую репрезентацию представлений об инструментальности, в том числе и соответствующий падеж.
Подключение по ссылке.
О мероприятии
28 апреля состоится финал конкурса Miss & Mister МГПУ, на котором 10 финалистов продемонстрируют свои творческие номера.
Главной темой конкурса в этом году стали чувства – каждый участник станет олицетворением одного из них.
В финал конкурса вышли студенты из 5 институтов:
- Елизавета Белинская (ИКИ, 2 курс)
- Медеа Гиоргадзе (ИИЯ, 3 курс)
- Руслан Джумагалеев (ИЭУиП, 1 курс)
- Анна Коровина (ИГН, 1 курс)
- Лаура Маркарян (ИГН, 1 курс)
- Елена Мошенина (ИЦО, 3 курс)
- Михаил Мякинин (ИЭУиП, 1 курс)
- Иван Пищеров (ИИЯ, 2 курс)
- Никита Работа (ИЦО, 2 курс)
- Богдан Рогачев (ИИЯ, 3 курс)
Жюри определит тех, кто станет Мисс и Мистером МГПУ 2023, а также Вице-Мисс и Вице-Мистером. Победителей в разных номинациях будут выбирать зрители. Не упусти шанс пробудить в себе чувства!
Не упусти шанс пробудить в себе чувства!
17:30 – welcome-зона
18:00 – начало мероприятия
О мероприятии
28 апреля в институте естествознания и спортивных технологий МГПУ пройдет образовательное событие для школьников «Научный диалог». В актовый зал института приглашаются участники очного этапа олимпиады «Высокие технологии и материалы будущего», участники заочной научно-технологической школы, олимпиад Московского городского по биологии и химии.
В первой части мероприятия преподаватели вузов интерпретируют результаты олимпиады, обозначат наиболее проблемные зоны заданий, дадут ученикам рекомендации и полезные советы.
Спикеры
- Евгений Гудилин, д. х. н., член-корреспондент РАН, профессор химического факультета, зам. декана факультета наук о материалах МГУ имени М.В. Ломоносова
- Юлия Кропова, кбн, доцент института естествознания и спортивных технологий МГПУ
Вторая часть образовательного события будет построена в формате интерактивных мастер-классов для участников.
Основы биомиметики (биомиметика своими руками). Спикер – Юлия Кропова, кандидат биологических наук, доцент института естествознания и спортивных технологий Московского городского педагогического университета
Методы мониторинга состояния окружающей среды. Спикер – Ольга Кукушкина, кандидат биологических наук, доцент института естествознания и спортивных технологий Московского городского педагогического университета
Секреты побед в естественнонаучных конкурсах и олимпиадах школьников. Спикер – Наталья Жукова, кандидат химических наук, доцент института естествознания и спортивных технологий Московского городского педагогического университета.
Тайминг встречи: 28 апреля (пятница), 15:00-17:00. Открыта предварительная регистрация по ссылке.
О мероприятии
28 апреля состоится уже третья поездка за 2 года представителей студенческого актива и ветеранской организации МГПУ в г. Ржев с посещением Ржевского мемориала. В марте 2023 года исполнилось 80 лет освобождения г. Ржева и окончания Ржевской битвы. Чтобы посетить этот город и увидеть величественный мемориал, каждый институт может направить группу активных студентов на экскурсию.
Ржев с посещением Ржевского мемориала. В марте 2023 года исполнилось 80 лет освобождения г. Ржева и окончания Ржевской битвы. Чтобы посетить этот город и увидеть величественный мемориал, каждый институт может направить группу активных студентов на экскурсию.
О мероприятии
29 апреля состоится финальное шоу межвузовского танцевального конкурса SHAKE IT OFF. 6 солистов, 6 дуэтов и 12 команд покажут свои номера на сцене Московского городского.
В конкурсе принимают участие 14 вузов столицы:
- МГПУ
- МГУ им. Ломоносова
- РГУ им. Косыгина
- МТУСИ
- РГАУ-МСХА
- ФУ при Правительстве РФ
- ПМГМУ им. Сеченова
- НИЯУ МИФИ
- Синергия
- РХТУ им. Менделеева
- РАНХиГС
- РТУ МИРЭА
- МГМСУ им. Евдокимова
- РУДН
Жюри определит лучшие номера в различных номинациях, а гости смогут отдать свои голоса для определения тех, кто получит приз зрительских симпатий.
Не упусти возможность увидеть лучших танцоров Москвы!
О мероприятии
Кафедра языкознания и переводоведения ИИЯ МГПУ приглашает студентов 4 курсов направления подготовки «Перевод и переводоведение — китайский язык» на конкурс проектов «Russian-Chinese-English center», который состоится в субботу 29 апреля в 11.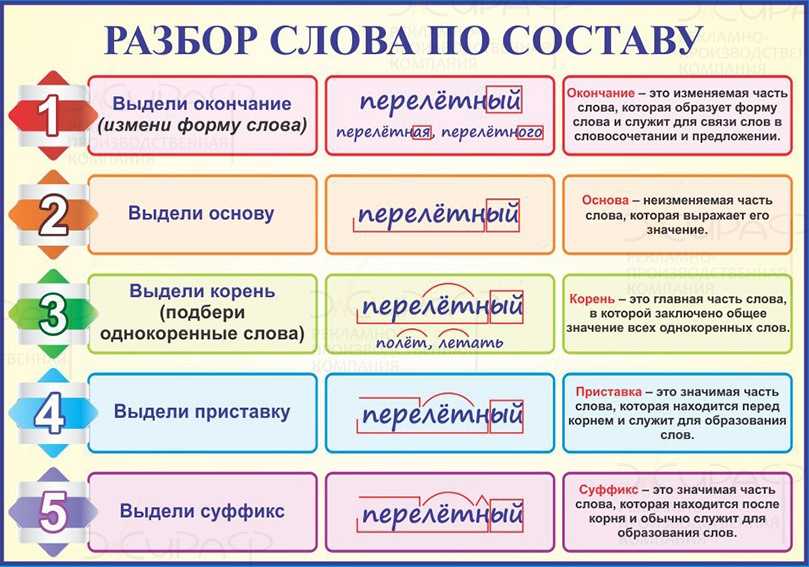 00. Конкурс проводится с целью повышения мотивации к изучению английского языка; создания среды творческого общения и обмена опытом участников конкурса; развития коммуникативных и организаторских способностей обучающихся; развития у обучающихся мотивации и интереса к актуальным проблемам в профессиональной сфере.
00. Конкурс проводится с целью повышения мотивации к изучению английского языка; создания среды творческого общения и обмена опытом участников конкурса; развития коммуникативных и организаторских способностей обучающихся; развития у обучающихся мотивации и интереса к актуальным проблемам в профессиональной сфере.
Жюри: преподаватели кафедры языкознания и переводоведения ИИЯ МГПУ, студенты 4 курсов направления подготовки «Перевод и переводоведение — китайский язык»
Заявки на участие просим направлять по электронной почте Айгуль Батыровой ([email protected]).
О мероприятии
Институт цифрового образования МГПУ приглашает учащихся 10-11 классов на мастер-класс, посвященный решению задач ЕГЭ по физике (разбор заданиq №№ 28, 29).
Мастер-класс направлен на оказание практической помощи выпускникам школы в подготовке к ЕГЭ по физике. В рамках мастер-класса будут рассмотрены задачи 28-29-го номера из перечня заданий ЕГЭ по данному предмету. Предлагается рассмотрение и анализ расчетных задач высокого уровня по электродинамике.
Данное мероприятие поможет слушателям улучшить свои знания в данных разделах и позволит понять и разобраться в решении подобных задач на экзамене.

О мероприятии
Институт цифрового образования МГПУ приглашает студентов, учителей, директоров школ и колледжей на вебинар, в ходе которого Вам расскажут о программах магистратуры, реализуемых в ИЦО МГПУ в 2023 году.
Московский городской открывает свои двери онлайн для поступающих на программы магистратуры!
Подключившись к вебинару вы сможете узнать нюансы учебного процесса, познакомиться с дисциплинами, базами практик, методиками преподавания, задать вопросы руководителям программ и ведущим преподавателям. Вас ждут презентации магистерских программ педагогического образования:
— Математическое образование и подготовка учителя на основе цифровой дидактики;
— Интернет вещей в образовании;
— Современные цифровые технологии в образовании;
— Международный бакалавриат: теория и технологии.
А также презентации на такие направления как бизнес-информатика, информационные системы и технологии:
— Бизнес-аналитика и большие данные;
— Архитектор цифрового пространства.

Фотогалерeи
Все галереиДвадцатый «Тотальный диктант»
Первый этап Открытой лиги КВН МГПУ
Встреча Министра просвещения РФ Сергея Кравцова со студентами МГПУ
День открытых дверей — 2022
Фестиваль #ДружбаМГПУ 2022
Школа КВН МГПУ 2022
Школа волонтеров 2022
Встреча бывших активистов МГПУ «Выпускники. Внеучебка»
Всероссийский исторический кроссворд — 2022
Кубок КВН МГПУ 2022
Битва молодых учёных Science Slam
Первая встреча выпускников МГПУ
Фестиваль вожатых МГПУ 2022
ANTI-SUMMIT 2022
Start Day в Московском городском
Абитуриенты-2022
RED BRICK FEST 2022
Премия «Люди МГПУ» 2022
Miss & Mister МГПУ 2022
Полуфинал конкурса «Флагманы образования. Студенты»
Студенты»
«Тотальный диктант» — 2022
Видеоблог
Все видеоДень открытых дверей: причины выбрать МГПУ
Карэн Бадалов о подготовке актеров в МГПУ
Кубок КВН МГПУ 2022
МГПУ Alumni: первая встреча выпускников
Иностранные языки в Московском городском
28 лет МГПУ
Финал университетского конкурса «Талант»
Серебряный университет от МГПУ
Как задать вопрос приёмной комиссии МГПУ?
Правильно + Эффективно + Красиво
Содержание
Вы можете написать свой собственный лексер и парсер с нуля. Но многие языки включают инструменты для автоматического создания лексеров и парсеров из формальных описаний синтаксиса языка. Предки многие из этих инструментов — lex и yacc, которые генерируют лексеры и парсеры соответственно; lex и yacc были разработаны в 1970-е годы для C.
Как часть стандартного дистрибутива, OCaml предоставляет лексер и синтаксический анализатор. генераторы с именами ocamllex и ocamlyacc. есть еще
современный генератор парсеров по имени менгир, доступный через opam;
менгир – это «90% совместим» с ocamlyacc и обеспечивает значительно
улучшена поддержка отладки сгенерированных парсеров.
генераторы с именами ocamllex и ocamlyacc. есть еще
современный генератор парсеров по имени менгир, доступный через opam;
менгир – это «90% совместим» с ocamlyacc и обеспечивает значительно
улучшена поддержка отладки сгенерированных парсеров.
9.2.1. Lexers
Генераторы Lexer, такие как lex и ocamllex, построены на теории детерминированные конечные автоматы, которые обычно рассматриваются в дискретной математике или курс теории вычислений. Такие автоматы принимают обычных языков , которые можно описать с помощью регулярных выражений . Итак, вход в генератор лексеров представляет собой набор регулярных выражений, описывающих токены языка. На выходе — автомат, реализованный на языке высокого уровня, таком как C (для lex) или OCaml (для ocamllex).
Сам этот автомат принимает на вход файлы (или строки), и каждый символ
файл становится входом для автомата. В конце концов автомат либо распознает последовательность символов, которую он получил как действительный токен в
язык, и в этом случае автомат производит вывод этого токена и
сбрасывает себя на распознавание следующего маркера, или отклоняет последовательность
символов как недопустимый токен.
9.2.2. Парсеры
Генераторы парсеров, такие как yacc и menhir, аналогичным образом построены на теории автоматы. Но они используют автоматы с выталкиванием вниз , похожие на конечные автоматы, которые также поддерживать стек, в который они могут помещать и извлекать символы. Стек позволяет им принять более широкий класс языков, известных как контекстно-свободных языков (CFL). Одно из больших улучшений КЛЛ по сравнению с обычные языки, заключается в том, что CFL могут выражать идею о том, что разделители должны быть сбалансированный — например, что каждая открывающая скобка должна быть уравновешена закрывающая скобка.
Точно так же, как обычные языки могут быть выражены специальной записью (обычные
выражения), то же самое можно сказать и о КЛЛ. Контекстно-свободные грамматики используются для описания CFL. А
контекстно-свободная грамматика представляет собой набор из продукционных правил , которые описывают, как один символ
могут быть заменены другими символами. Например, язык сбалансированного
круглые скобки, которые включают такие строки, как
Например, язык сбалансированного
круглые скобки, которые включают такие строки, как (()) и ()() и (()()) , но
не такие строки, как ) или (() , генерируется по следующим правилам:
\(S \rightarrow (S)\)
\(S \стрелка вправо\)
\(S \стрелка вправо \эпсилон\)
В этих правилах встречаются символы \(S\), \((\) и \()\). \(\эпсилон\) обозначает пустую строку. Каждый символ является либо нетерминалом , либо терминал в зависимости от того, является ли он токеном описываемого языка. \(S\) является нетерминалом в приведенном выше примере, а ( и ) являются терминалами.
В следующем разделе мы изучим Бэкуса-Наура Форма (BNF), который является стандартным
обозначения для контекстно-свободных грамматик. Входные данные для генератора синтаксического анализатора обычно
BNF-описание синтаксиса языка. Вывод генератора парсера
это программа, которая распознает язык грамматики. В качестве входных данных эта программа
ожидает вывод лексера. На выходе программа выдает значение
Тип AST, представляющий принятую строку. Программы, выводимые
таким образом, генератор синтаксического анализатора и генератор лексера зависят от другого и
по типу АСТ.
В качестве входных данных эта программа
ожидает вывод лексера. На выходе программа выдает значение
Тип AST, представляющий принятую строку. Программы, выводимые
таким образом, генератор синтаксического анализатора и генератор лексера зависят от другого и
по типу АСТ.
9.2.3. Форма Бэкуса-Наура
Стандартный способ описания синтаксиса языка — математический обозначение под названием Backus-Naur form (BNF), названное в честь его изобретателя Джона Бэкуса. и Питер Наур. Существует множество вариантов БНФ. Здесь мы не будем слишком придирчивы о приверженности тому или иному варианту. Наша цель состоит в том, чтобы иметь разумную хорошая нотация для описания синтаксиса языка.
BNF использует набор правил вывода для описания синтаксиса языка. Давайте
начни с примера. Вот описание BNF крошечного языка
выражения, которые включают только целые числа и сложение:
Давайте
начни с примера. Вот описание BNF крошечного языка
выражения, которые включают только целые числа и сложение:
е ::= я | е + е я ::= <целые числа>
Эти правила говорят, что выражение e является либо целым числом i , либо двумя
выражения, между которыми стоит символ + . Синтаксис «целых чисел»
не определяется этими правилами.
Каждое правило имеет вид
метапеременная ::= символы | ... | символы
Метапеременная — это переменная, используемая в правилах BNF, а не переменная в
описываемого языка. ::= и | , которые появляются в правилах, метасинтаксис : синтаксис BNF, используемый для описания синтаксиса языка. Символы есть
последовательности, которые могут включать метапеременные (например, i и e ), а также токены
языка (например, + ). Пробелы в этих правилах неуместны.
Иногда нам может понадобиться легко сослаться на отдельные вхождения
метапеременные. Мы делаем это, добавляя некоторый отличительный знак к
метапеременная (ы). Например, мы могли бы переписать первое правило выше как
Мы делаем это, добавляя некоторый отличительный знак к
метапеременная (ы). Например, мы могли бы переписать первое правило выше как
е ::= я | е1 + е2
или как
e ::= i | е + е'
Теперь мы можем говорить о e2 или e' вместо того, чтобы говорить « e на
правая часть + ”.
Если сам язык содержит один из токенов ::= или | — и
OCaml действительно содержит последнее — тогда написание BNF может стать немного затруднительным.
сбивает с толку. Некоторые нотации BNF пытаются справиться с этим, используя дополнительные
разделители, чтобы отличить синтаксис от метасинтаксиса. Мы будем более расслабленными и
предположим, что читатель может их различить.
9.2.4. Пример: SimPL
В качестве рабочего примера мы будем использовать очень простой язык программирования, который мы называем СимПЛ. Вот его синтаксис в BNF:
e ::= x | я | б | e1 боп e2
| если е1 то е2 иначе е3
| пусть x = e1 в e2
боп ::= + | * | <=
х ::= <идентификаторы>
я ::= <целые числа>
б ::= истина | ЛОЖЬ
Очевидно, что в этом языке многого не хватает, особенно функций. Но
этого достаточно для изучения важных понятий интерпретаторов
не слишком отвлекаясь на множество языковых функций. Позже мы
рассмотрим более крупный фрагмент OCaml.
Но
этого достаточно для изучения важных понятий интерпретаторов
не слишком отвлекаясь на множество языковых функций. Позже мы
рассмотрим более крупный фрагмент OCaml.
Мы собираемся разработать полноценный интерпретатор SimPL. Вы можете скачать готовый интерпретатор здесь: simpl.zip. Или просто следуйте за тем, как мы строим каждую его часть.
9.2.4.1. AST
Поскольку AST является самой важной структурой данных в интерпретаторе, давайте
спроектируйте его в первую очередь. Мы поместим этот код в файл с именем ast.ml :
type bop = | Добавлять | Мульт | Лек введите выражение = | Var строки | Целое число | Бул из бул | Binop of bop * expr * expr | Пусть строки * expr * expr | Если expr * expr * expr
Для каждой синтаксической формы выражения в
БНФ. Для базовых примитивных синтаксических классов идентификаторов, целых чисел,
и логические, мы используем собственные типы OCaml
Для базовых примитивных синтаксических классов идентификаторов, целых чисел,
и логические, мы используем собственные типы OCaml string , int и bool .
Вместо определения типа bop и одного конструктора Binop мы могли бы
определили три отдельных конструктора для трех бинарных операторов:
type expr = ... | Добавление expr * expr | Множественное выражение * выражение | Leq expr * expr ...
Но, исключив тип bop , мы сможем избежать большого количества кода.
дублирование позже в нашей реализации.
9.2.4.2. Парсер Menhir
Давайте начнем с разбора, а затем вернемся к лексическому анализу. Мы поставим все Менгиры
код, который мы пишем ниже в файле с именем parser.. Расширение  mly
mly .mly указывает
что этот файл предназначен для входа в Menhir. («y» намекает на yacc.) Это
файл содержит определение грамматики для языка, который мы хотим разобрать.
синтаксис определений грамматики описан на примере ниже. Будьте предупреждены, что это
может быть немного странным, но это потому, что он основан на инструментах (таких как yacc), которые
были разработаны довольно давно. Menhir обработает этот файл и создаст
файл с именем parser.ml в качестве вывода; он содержит программу OCaml, которая анализирует
язык. (Здесь нет ничего особенного в названии парсера ; это просто
описательный.)
Определение грамматики состоит из четырех частей: заголовка, объявлений, правил и трейлер.
Заголовок. Заголовок появляется между %{ и %} . Это код, который будет
скопировано буквально в сгенерированный parser.ml . Здесь мы используем его только для открытия Модуль Ast , чтобы позже в определении грамматики мы могли написать
такие выражения, как Int i вместо Ast. . Если бы мы хотели, мы могли бы также
определить некоторые функции OCaml в заголовке.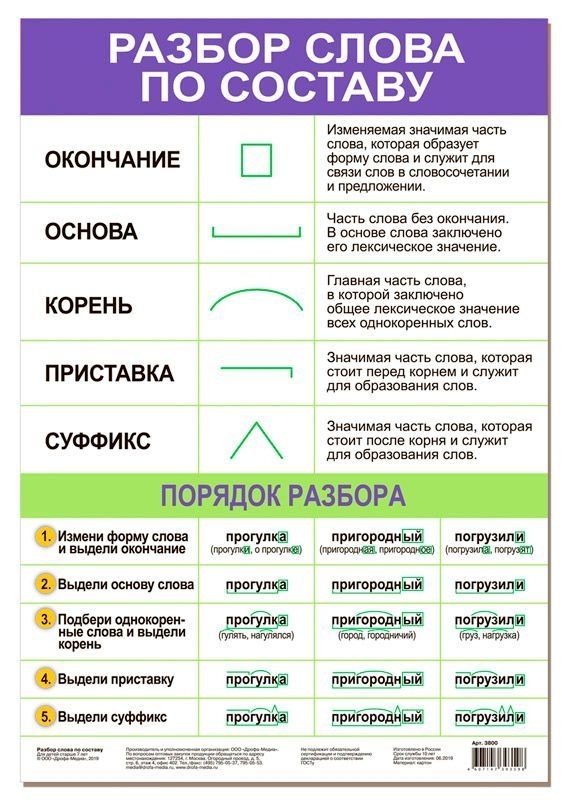 Int i
Int i
%{
открыть Аст
%}
Декларации. Раздел объявлений начинается с того, что лексический токенов языка есть. Вот объявления токенов для SimPL:
%tokenINT %token <строка> ID %токен ИСТИНА %токен ЛОЖЬ %токен LEQ %токен РАЗ %токен ПЛЮС %токен LPAREN %токен RPAREN %токен ПОЗВОЛЬТЕ %токен РАВНО %токен ВХОДИТ %токен ЕСЛИ %токен ТОГДА %токен ИНАЧЕ %токен EOF
Каждое из них — просто описательное имя токена. Ничто пока не говорит об этом LPAREN действительно соответствует ( , например. Мы позаботимся об этом, когда будем
определить лексер.
Токен EOF — это специальный токен конца файла , который лексер вернет, когда
он подходит к концу потока символов. В этот момент мы знаем полную
программа прочитана.
Токены, в которых есть аннотация , заявляют, что
они будут нести некоторые дополнительные данные вместе с ними. В случае
В случае ИНТ ,
это OCaml int . В случае ID это строка OCaml .
После объявления токенов мы должны предоставить некоторую дополнительную информацию о старшинство и ассоциативность . В следующих декларациях говорится, что PLUS является
левоассоциативный, IN не ассоциативен, а PLUS имеет более высокий приоритет, чем В (поскольку ПЛЮС появляется в строке после В ).
%nonassoc IN %nonassoc ИНАЧЕ % левый LEQ % осталось ПЛЮС % осталось РАЗ
Поскольку PLUS является левой ассоциативностью, 1 + 2 + 3 будет проанализировано как (1 + 2) + 3 и
не как 1 + (2 + 3) . Поскольку PLUS имеет более высокий приоритет, чем IN ,
выражение пусть x = 1 в x + 2 будет анализироваться как пусть x = 1 в (x + 2) , а не как (пусть х = 1 в х) + 2 . Другие объявления имеют аналогичный эффект.
Правильное определение приоритета и ассоциативности является одним из более сложные части разработки определения грамматики. Он помогает развивать определение грамматики постепенно, добавляя всего пару токенов (и их связанные правила, обсуждаемые ниже) одновременно с языком. Менгир позволит вы знаете, когда вы добавили токен (и правило), для которого он запутался что вы предполагаете, что приоритет и ассоциативность должны быть. Затем вы можете добавить декларации и проверить, чтобы убедиться, что вы поняли их правильно.
После объявления ассоциативности и приоритета нам нужно объявить, что
отправной точкой является разбор языка. Следующее объявление говорит
начните с правила (определенного ниже) с именем prog . В декларации также говорится, что
анализ программы вернет значение OCaml типа Ast.expr .
%startпрог
Наконец, %% завершает раздел объявлений.
Правила. Правила 9Раздел 0008 содержит продукционные правила, напоминающие BNF, хотя там, где в BNF мы бы написали «::=», эти правила просто пишут «:». формат правила
название:
| производство1 { действие1 }
| производство2 { действие2 }
| ...
;
Произведение — это последовательность из символов , которым соответствует правило. Символ либо токен, либо имя другого правила. Действие — это значение OCaml для вернуть, если соответствует . Каждое производство может bind значение, переносимое символ и использовать это значение в своем действии. Это, пожалуй, лучше всего понимают Например, давайте углубимся.
Первое правило с именем prog имеет только одну продукцию. В нем говорится, что prog — это expr , за которым следует EOF . Первая часть производства, e=expr , говорит, что нужно сопоставить expr и связать полученное значение с e . действие просто говорит вернуть это значение
действие просто говорит вернуть это значение е .
прог:
| е = выражение; EOF {е}
;
Второе и последнее правило, названное expr , содержит продукцию для всех выражений
в СимПЛ.
выражение:
| я = INT {целое я}
| х = ID {Вар х}
| ИСТИНА { логическая истина }
| FALSE { Логическое значение false }
| e1 = выражение; ЛЭК; e2 = выражение {Binop (Leq, e1, e2)}
| e1 = выражение; РАЗ; e2 = expr {Binop (Mult, e1, e2)}
| e1 = выражение; ПЛЮС; e2 = expr {Binop (Добавить, e1, e2)}
| ПОЗВОЛЯТЬ; х = идентификатор; РАВНО; e1 = выражение; В; e2 = expr { Пусть (x, e1, e2) }
| ЕСЛИ; e1 = выражение; ЗАТЕМ; e2 = выражение; ЕЩЕ; e3 = выражение {Если (e1, e2, e3)}
| ЛПАРЕН; е=выражение; РАРЕН {е}
;
Первая продукция,
i = INT, говорит, что для сопоставления токенаINTнеобходимо привязать результирующее значение OCamlintвiи вернуть узел ASTInt i.Вторая продукция,
x = ID, говорит, что для сопоставления токенаIDнеобходимо привязать результирующее значение строки OCamlвxи возврат узла ASTVar x.Третье и четвертое произведения соответствуют
TRUEилиFALSEтокен и возврат соответствующий узел AST.Пятая, шестая и седьмая продукции обрабатывают бинарные операторы. Для например,
e1 = выражение; ПЛЮС; e2 = exprговорит, что соответствуетexpr, за которым следует ТокенPLUS, за которым следует еще одинexpr. Первыйexprпривязан кe1и второй доe2. Возвращаемый узел AST —Binop (Add, e1, e2).Восьмое производство,
ЛЕТ; х = идентификатор; РАВНО; e1 = выражение; В; e2 = expr, говорит чтобы соответствовать токенуLET, за которым следует токенID, за которым следует токенEQUALSза которым следуетexpr, за которым следует токенIN, за которым следует ещеexpr. Строка, содержащаяся в идентификаторе ID, привязана кx, и два выражения привязан кe1иe2. Возвращенный узел AST равен 9.0039 Пусть (x, e1, e2) .Последнее производство,
LPAREN; е = выражение; RPARENговорит, что соответствуетLPARENтокен, за которым следуетexpr, за которым следуетRPAREN. Выражение связано наeи вернулся.
 Строка, содержащаяся в идентификаторе
Строка, содержащаяся в идентификаторе Окончательная продукция может удивить, потому что она не была включена в БНФ мы писали для SimPL. Эта БНФ была предназначена для описания абстрактного синтаксиса языка, поэтому он не включал конкретных деталей того, как выражения могут быть сгруппированы скобками. Но определение грамматики, которое мы писали, нужно описать конкретный синтаксис , включая такие детали, как круглые скобки.
После правил также может быть раздел трейлер , который, как и заголовок,
Код OCaml, который копируется непосредственно в выходной файл parser.. ml
ml
9.2.4.3. Ocamllex Lexer
Теперь давайте посмотрим, как используется генератор лексеров. Многое покажется знакомым
из нашего обсуждения генератора парсеров. Мы поместим весь код ocamllex, который мы
пропишите ниже в файл с именем lexer.mll . Расширение .mll указывает, что
этот файл предназначен для ввода в ocamllex. (буква «l» намекает на лексику.) Это
файл содержит определение лексера для языка, который мы хотим лексировать. Менгир
обработает этот файл и создаст на выходе файл с именем lexer.ml ; это
содержит программу OCaml, которая лексизирует язык. (ничего особенного
про имя lexer здесь; это просто описание.)
Определение лексера состоит из четырех частей: заголовка, идентификаторов, правил и трейлер.
Заголовок. Заголовок появляется между { и } . Это код, который будет
просто скопируйте буквально в сгенерированный lexer. . ml
ml
{
открыть парсер
}
Здесь мы открыли модуль Parser , который представляет собой код в parser.ml , который
был произведен Menhir из parser.mly . Причина, по которой мы открываем его, заключается в том, что мы
может использовать объявленные в нем имена токенов, например, TRUE , LET и INT внутри
наше определение лексера. В противном случае нам пришлось бы писать Parser.TRUE и т. д.
Идентификаторы. Следующий раздел определения лексера содержит идентификаторов , которые называются регулярными выражениями. Они будут использоваться в раздел правил, далее.
Вот идентификаторы, которые мы будем использовать с SimPL:
let white = [' ' '\t']+ пусть цифра = ['0'-'9'] пусть int = '-'? цифра+ пусть буква = ['a'-'z' 'A'-'Z'] пусть id = буква+
Приведенные выше регулярные выражения предназначены для пробелов (пробелов и табуляции), цифр (0
до 9), целые числа (непустые последовательности цифр, которым может предшествовать
знак минус), буквы (от a до z и от A до Z) и имена переменных SimPL. (непустые последовательности букв), также известные как идентификаторы или «идентификаторы», хотя сейчас мы
употребляя это слово в двух разных смыслах.
(непустые последовательности букв), также известные как идентификаторы или «идентификаторы», хотя сейчас мы
употребляя это слово в двух разных смыслах.
К вашему сведению, это не совсем то же самое, что определения целых чисел в OCaml и идентификаторы.
Раздел идентификаторов фактически не требуется; вместо того, чтобы писать белый дюймов
правила, мы могли бы просто написать регулярное выражение для него. Но
идентификаторы помогают сделать определение лексера более самодокументируемым.
Правила. Раздел правил определения лексера написан в нотации, которая также напоминает BNF. Правило имеет вид
имя правила =
разобрать
| регулярное выражение1 { действие1 }
| регулярное выражение2 { действие2 }
| ...
Здесь правило и разбор являются ключевыми словами. Сгенерированный лексер попытается
для сопоставления с регулярными выражениями в порядке их перечисления. Когда
соответствует регулярному выражению, лексер создает токен, указанный его действие .
Вот (единственное) правило для лексера SimPL:
правило чтения =
разобрать
| белый { читать lexbuf }
| "правда правда }
| "ложь" {ЛОЖЬ}
| "<=" {LEQ}
| "*" {РАЗ}
| "+" {ПЛЮС}
| "(" {ЛПАРЕН}
| ")" {RPAREN}
| "Пусть" {ПУСТЬ}
| "=" {РАВНО}
| "в" {В}
| "если если }
| "потом" {ТО}
| "иначе" { ИНАЧЕ }
| id { ID (Lexing.lexeme lexbuf) }
| int { INT (int_of_string (Lexing.lexeme lexbuf)) }
| конец {конец}
Большинство регулярных выражений и действий говорят сами за себя, но пара нет:
Первое,
white { read lexbuf }, означает, что если пробелы совпадают, вместо того, чтобы возвращать токен, лексер должен просто снова вызвать правилоreadи вернуть любые результаты токена. Другими словами, пробелы будут пропущены.Для идентификаторов и целых чисел используется выражение
Lexing.lexeme lexbuf. Это вызывает функциялексема, определенная в модулеLexing, и возвращает строку которое соответствует регулярному выражению. Например, в idправило, это будет вернуть последовательность прописных и строчных букв, которые образуют переменную имя.Регулярное выражение
eof— это специальное выражение, которое соответствует концу файла (или строка) лексируется.
 Например, в
Например, в Обратите внимание, важно, чтобы регулярное выражение id встречалось почти последним в
список. В противном случае ключевые слова, такие как true и , если будут лексироваться как переменные.
имена, а не Токены TRUE и IF .
9.2.4.4. Генерация синтаксического анализатора и лексера
Теперь, когда мы завершили определения синтаксического анализатора и лексера в parser.mly и lexer.mll , мы можем запустить Menhir и ocamllex для создания парсера и лексера
от них. Давайте организуем наш код следующим образом:
- <какая-то корневая папка>
- дюна-проект
- источник
- аст. мл
- дюна
- лексер.млл
- парсер.mly
 мл
- дюна
- лексер.млл
- парсер.mly
мл
- дюна
- лексер.млл
- парсер.mly
В src/dune напишите следующее:
(библиотека (вставка имени)) (менгир (парсер модулей)) (окамлекс лексер)
Это организует всю папку src в библиотеку с именем Interp .
parser и lexer будут модулями Interp.Parser и Interp.Lexer в этом
библиотека.
Запустите dune build , чтобы скомпилировать код, сгенерировав парсер и лексер. Если
вы хотите увидеть сгенерированный код, посмотрите в _build/default/src/ для parser.ml и lexer.ml .
9.2.4.5. Драйвер
Наконец, мы можем объединить лексер и синтаксический анализатор для преобразования строки в
АСТ. Поместите этот код в файл с именем src/main.ml :
open Ast let parse (s : string) : expr = пусть lexbuf = Lexing.from_string s в let ast = Parser.prog Lexer.read lexbuf в аст
Эта функция принимает строку s и использует модуль стандартной библиотеки Lexing . чтобы создать лексер буфер из него. Думайте об этом буфере как о потоке маркеров.
Затем функция лексизирует и анализирует строку в AST, используя
чтобы создать лексер буфер из него. Думайте об этом буфере как о потоке маркеров.
Затем функция лексизирует и анализирует строку в AST, используя Lexer.read и Parser.prog . Функция Lexer.read соответствует правилу с именем читать в нашем определении лексера, а функция Parser.prog в правиле с именем прог в нашем определении парсера.
Обратите внимание, как этот код выполняет лексический анализ строки; есть соответствующая функция from_channel для чтения из файла.
Теперь мы можем использовать parse в интерактивном режиме для разбора некоторых строк. Начать сверху
и загрузите библиотеку, объявленную в src , с помощью этой команды:
$ dune utop src
Теперь Interp.Main.parse доступен для использования:
# Interp.Main.parse "let x = 3110 in x + x";;
- : Interp.Ast.expr =
Interp.Ast.Let("x", Interp. Ast.Int 3110,
Interp.Ast.Binop (Interp.Ast.Add, Interp.Ast.Var "x", Interp.Ast.Var "x"))
 Ast.Int 3110,
Interp.Ast.Binop (Interp.Ast.Add, Interp.Ast.Var "x", Interp.Ast.Var "x"))
Ast.Int 3110,
Interp.Ast.Binop (Interp.Ast.Add, Interp.Ast.Var "x", Interp.Ast.Var "x"))
На этом лексирование и синтаксический анализ SimPL завершены.
о синтаксическом анализе - PowerShell | Microsoft Learn
- Статья
Краткое описание
Описывает, как PowerShell анализирует команды.
Подробное описание
При вводе команды в командной строке PowerShell прерывает выполнение команды текст на серию сегментов, называемых токенов , а затем определяет, как интерпретировать каждый токен.
Например, если вы наберете:
Write-Host book
PowerShell разбивает команду на два токена: Write-Host и book и
интерпретирует каждый токен независимо, используя один из двух основных режимов синтаксического анализа:
режим выражения и режим аргумента.
Примечание
Поскольку PowerShell анализирует ввод команды, он пытается преобразовать имена команд в
командлеты или собственные исполняемые файлы. Если имя команды не имеет точного
совпадение, PowerShell добавляет Get- в команду как глагол по умолчанию. Для
Например, PowerShell анализирует Service как Get-Service . Это не
рекомендуется использовать эту функцию по следующим причинам:
- Неэффективно. Это заставляет PowerShell выполнять поиск несколько раз.
- Внешние программы с тем же именем разрешаются первыми, поэтому вы не можете выполнить предполагаемый командлет.
-
Get-HelpиGet-Commandне распознают имена без глаголов. - Имя команды может быть зарезервированным словом или ключевым словом языка.
Процессэто оба, и не могут быть разрешены доGet-Process.
Режим выражения
Режим выражения предназначен для объединения выражений, необходимых для значения
манипулирование на языке сценариев. Выражения — это представления значений
в синтаксисе PowerShell и может быть простым или составным, например:
Выражения — это представления значений
в синтаксисе PowerShell и может быть простым или составным, например:
Литеральные выражения являются прямым представлением их значений:
'привет' 32
Переменные выражения содержат значение переменной, на которую они ссылаются:
$x $скрипт:путь
Операторы объединяют другие выражения для оценки:
-12 -не $ Тихо 3 + 7 $input.Length -gt 1
- Строковые литералы символов должны заключаться в кавычки.
- Числа обрабатываются как числовые значения, а не как ряды символы (если не экранированы).
- Операторы , включая унарные операторы типа
-и- неи бинарные такие операторы, как+и-gt, интерпретируются как операторы и применяют их соответствующие операции над своими аргументами (операндами). - Атрибуты и выражения преобразования анализируются как выражения и применяются
к подчиненным выражениям. Например:
[число] '7'. - Ссылки на переменные оцениваются по их значениям, но разбрызгиваются это запрещено и вызывает ошибку парсера.
- Все остальное рассматривается как вызываемая команда.
 Например:
Например: Режим аргумента
При синтаксическом анализе PowerShell сначала пытается интерпретировать ввод как выражение. Но когда встречается вызов команды, синтаксический анализ продолжается в режиме аргумента. Если у вас есть аргументы, содержащие пробелы, такие как пути, то вы должны заключите эти значения аргументов в кавычки.
Режим аргументов предназначен для разбора аргументов и параметров команд в среда оболочки. Весь ввод обрабатывается как расширяемая строка, если только он не использует один из следующих синтаксисов:
Знак доллара (
$), за которым следует имя переменной, начинает ссылку на переменную, в противном случае он интерпретируется как часть расширяемой строки. Переменная ссылка может включать доступ к членам или индексацию.- Дополнительные символы после ссылок на простые переменные, например
$HOMEсчитаются частью одного и того же аргумента. Заключите переменную имя в фигурных скобках ({}), чтобы отделить его от последующих символов. Для например,${ДОМ}. - Если ссылка на переменную включает доступ к члену, первая из
дополнительные символы считаются началом нового аргумента. Для
пример
$HOME.Length-moreприводит к двум аргументам: значение$HOME.Lengthи строковый литерал-more.
- Дополнительные символы после ссылок на простые переменные, например
Кавычки (
'и") начинают строкиФигурные скобки (
{}) начинают новые блоки сценарияЗапятые (
,) вводят списки, передаваемые как массивы, если только команда не называется собственным приложением, и в этом случае они интерпретируются как часть расширяемая строка. Начальные, последовательные или конечные запятые не поддерживается.Скобки (
()) начинают новое выражениеОператор подвыражения (
$()) начинает встроенное выражениеНачальный знак (
@) начинает синтаксис выражения, такой как splatting (@args), массивы (@(1,2,3)) и литералы хеш-таблиц (@{a=1;b=2}).(),$()и@()в начале токена создают новый контекст синтаксического анализа которые могут содержать выражения или вложенные команды.- Когда следуют дополнительные символы, первый дополнительный символ считается началом нового, отдельного спора.
- Если перед литералом без кавычек
$()работает как расширяемая строка,()запускает новый аргумент, который является выражением, а@()воспринимается как литерал@с(), начиная с нового аргумента, который является выражением.
Все остальное рассматривается как расширяемая строка, кроме метасимволов что все еще нужно бежать. См. раздел Обработка специальных символов.
- Метасимволы режима аргумента (символы со специальным синтаксическим
значение) являются:
' " ` , ; ( ) { } | & < > @ # < > @ #являются специальными только в начале токена.
- Метасимволы режима аргумента (символы со специальным синтаксическим
значение) являются:
Маркер остановки анализа (
--%) изменяет интерпретацию всех оставшихся аргументы. Дополнительные сведения см. в разделе маркер остановки синтаксического анализа. ниже.



Примеры
В следующей таблице приведены несколько примеров токенов, обработанных в выражении
режим и режим аргумента, а также оценку этих токенов. Для этих примеров
значение переменной $a равно 4 .
| Пример | Режим | Результат |
|---|---|---|
2 | Выражение | 2 (целое) |
`2 | Выражение | "2" (команда) |
Запись-вывод 2 | Выражение | 2 (целое) |
2+2 | Выражение | 4 (целое) |
Запись-вывод 2+2 | Аргумент | "2+2" (цепочка) |
Запись-Вывод(2+2) | Выражение | 4 (целое) |
$a | Выражение | 4 (целое) |
Запись-вывод $a | Выражение | 4 (целое) |
$a+2 | Выражение | 6 (целое число) |
Запись-вывод $a+2 | Аргумент | "4+2" (цепочка) |
$- | Аргумент | "$-" (команда) |
Запись-вывод $- | Аргумент | "$-" (строка) |
| Выражение | "а$а" (команда) |
Запись-вывод a$a | Аргумент | "а4" (строка) |
| Выражение | "а$а" (команда) |
Запись-вывод a'$a' | Аргумент | "a$a" (строка) |
а"$а" | Выражение | "а$а" (команда) |
Запись-вывод a"$a" | Аргумент | "а4" (строка) |
$(2) | Выражение | "a$(2)" (команда) |
Запись-вывод a$(2) | Аргумент | "а2" (строка) |
Каждый токен можно интерпретировать как некоторый тип объекта, например Boolean или Строка . PowerShell пытается определить тип объекта из
выражение. Тип объекта зависит от типа параметра, ожидаемого командой.
и от того, знает ли PowerShell, как преобразовать аргумент в правильный
тип. В следующей таблице показано несколько примеров типов, присвоенных
значения, возвращаемые выражениями.
PowerShell пытается определить тип объекта из
выражение. Тип объекта зависит от типа параметра, ожидаемого командой.
и от того, знает ли PowerShell, как преобразовать аргумент в правильный
тип. В следующей таблице показано несколько примеров типов, присвоенных
значения, возвращаемые выражениями.
| Пример | Режим | Результат |
|---|---|---|
Запись-вывод !1 | аргумент | "!1" (строка) |
Запись-вывод (!1) | выражение | Ложь (логическое значение) |
Запись-вывод (2) | выражение | 2 (целое) |
Набор переменных AB A,B | аргумент | 'А', 'В' (массив) |
CMD/CECHO A,B | аргумент | 'А, В' (строка) |
CMD/CECHO $AB | выражение | 'AB' (массив) |
CMD/CECHO :$AB | аргумент | ':AB' (строка) |
Обработка специальных символов
Символ обратной кавычки ( `) может использоваться для экранирования любого специального символа в
выражение. Это наиболее полезно для выхода из режима аргумента
метасимволы, которые вы хотите использовать как буквальные символы, а не как
метасимвол. Например, чтобы использовать знак доллара (
Это наиболее полезно для выхода из режима аргумента
метасимволы, которые вы хотите использовать как буквальные символы, а не как
метасимвол. Например, чтобы использовать знак доллара ( $ ) как литерал в
расширяемая строка:
"Значение `$ErrorActionPreference равно '$ErrorActionPreference'."
Значение $ErrorActionPreference — «Продолжить».
Продолжение строки
Символ обратной галочки также можно использовать в конце строки, чтобы вы могли продолжить ввод на следующей строке. Это улучшает читаемость команда, которая принимает несколько параметров с длинными именами и значениями аргументов. Для пример:
Новый-AzVm `
-ResourceGroupName "myResourceGroupVM" `
-Имя "мояВМ" `
-Расположение "EastUS" `
-VirtualNetworkName "myVnet" `
-SubnetName "моя подсеть" `
-SecurityGroupName "myNetworkSecurityGroup" `
-PublicIpAddressName "myPublicIpAddress" `
-Учетные данные $cred
Однако следует избегать использования продолжения строки.
- Обратные кавычки бывает трудно увидеть и легко забыть.
- Дополнительный пробел после обратной галочки прерывает продолжение строки. Поскольку пространство трудно увидеть, может быть трудно найти ошибку.
PowerShell предоставляет несколько способов разрыва строк в естественных точках синтаксиса.
- После вертикальной черты (
|) - После бинарных операторов (
+,-,-eqи т. д.) - После запятых (
,) в массиве - После открытия таких символов, как
[,{,(
Для большого набора параметров вместо этого используйте разбрызгивание. Например:
$параметры = @{
ResourceGroupName = "myResourceGroupVM"
Имя = "моя ВМ"
Местоположение = "Восток США"
ИмяВиртуальной Сети = "myVnet"
имя подсети = "моя подсеть"
SecurityGroupName = "myNetworkSecurityGroup"
PublicIpAddressName = "myPublicIpAddress"
Учетные данные = $cred
}
New-AzVm @параметры
Передача аргументов собственным командам
При запуске собственных команд из PowerShell аргументы сначала анализируются
PowerShell. Затем проанализированные аргументы объединяются в одну строку с каждым
параметр, разделенный пробелом.
Затем проанализированные аргументы объединяются в одну строку с каждым
параметр, разделенный пробелом.
Например, следующая команда вызывает программу icacls.exe .
icacls X:\VMS /grant Dom\HVAdmin:(CI)(OI)F
Чтобы запустить эту команду в PowerShell 2.0, необходимо использовать escape-символы для предотвратить неправильное толкование скобок PowerShell.
icacls X:\VMS /grant Dom\HVAdmin:`(CI`)`(OI`)F
Маркер остановки анализа
Начиная с PowerShell 3.0, вы можете использовать маркер остановки анализа ( --% ) для
запретить PowerShell интерпретировать входные данные как команды или выражения PowerShell.
Примечание
Маркер остановки анализа предназначен только для использования на платформах Windows.
При вызове собственной команды поместите токен остановки синтаксического анализа перед программой
аргументы. Этот метод намного проще, чем использование escape-символов для
предотвратить неправильное толкование.
При обнаружении маркера остановки разбора PowerShell обрабатывает оставшиеся
символов в строке как литерал. Единственная интерпретация, которую он выполняет, состоит в том, чтобы
замените значения переменных среды, которые используют стандартную нотацию Windows,
например %USERPROFILE% .
icacls X:\VMS --% /grant Dom\HVAdmin:(CI)(OI)F
PowerShell отправляет следующую командную строку программе icacls.exe :
X:\VMS /grant Dom\HVAdmin:(CI)(OI)F
Маркер остановки анализа действует только до следующей новой строки или конвейера
характер. Вы не можете использовать символ продолжения строки ( ` ) для расширения
его действие или используйте разделитель команд ( ; ), чтобы прекратить его действие.
Кроме %variable% ссылок на переменные окружения, вы не можете внедрить
другие динамические элементы в команде. Экранирование символа % как %% ,
способ, который вы можете сделать внутри пакетных файлов, не поддерживается.
%<имя>% токенов
неизменно расширялся. Если <имя> не относится к определенной среде
переменная, через которую токен передается как есть.
Вы не можете использовать перенаправление потока (например, >file.txt ), потому что они переданы
дословно в качестве аргументов целевой команды.
В следующем примере на первом шаге выполняется команда без использования
токен остановки парсинга. PowerShell оценивает строку в кавычках и передает значение
(без кавычек) до cmd.exe , что приводит к ошибке.
PS> cmd /c echo "a|b" 'b' не распознается как внутренняя или внешняя команда, работающая программа или командный файл. PS> cmd /c --% echo "a|b" "а|б"
Примечание
Некоторые команды в системах Windows реализованы в виде пакетного файла Windows. Для
Например, команда az для Azure CLI — это пакетный файл Windows.
Передача аргументов, содержащих кавычки
Некоторые собственные команды ожидают аргументы, содержащие кавычки. PowerShell
В версии 7.3 изменен способ анализа командной строки для нативных команд.
PowerShell
В версии 7.3 изменен способ анализа командной строки для нативных команд.
Предупреждение
Новое поведение является критическим изменением из Window PowerShell 5.1
поведение. Это может привести к поломке сценариев и автоматизации, которые обходят различные
проблемы при вызове собственных приложений. Используйте токен остановки разбора ( --% )
или командлет Start-Process , чтобы избежать передачи собственного аргумента при
нужный.
Новая переменная предпочтения $PSNativeCommandArgumentPassing управляет этим
поведение. Эта переменная позволяет выбрать поведение во время выполнения. действительный
значения Legacy , Standard и Windows . Поведение по умолчанию
специфическая для платформы. На платформах Windows значение по умолчанию — Windows и
Платформы, отличные от Windows, по умолчанию используют Standard .
Наследие — это историческое поведение. Поведение
Поведение Windows и Standard режим такой же, за исключением того, что в режиме Windows вызовы следующих файлов
автоматически использовать передачу аргумента в стиле Legacy .
-
cmd.exe -
cscript.exe -
wscript.exe - , заканчивающийся на
.bat - , заканчивающийся на
.cmd - , заканчивающийся на
.js - , заканчивающийся на
.vbs - , заканчивающийся на
.wsf
Если для параметра $PSNativeCommandArgumentPassing установлено значение Legacy или Стандартный , синтаксический анализатор не проверяет эти файлы.
Примечание
В следующих примерах используется средство TestExe.exe . Вы можете собрать TestExe из исходного кода. См. TestExe в исходном репозитории PowerShell.
Благодаря этому изменению стали доступны новые варианты поведения:
Литеральные или расширяемые строки со встроенными кавычками. сохранилось:
PS> $а = 'а" "б" PS> TestExe -echoargs $a 'c" "d' e" "f Аргумент 0 равен
Пустые строки в качестве аргументов теперь сохраняются:
PS> TestExe -echoargs ''a b'' Аргумент 0 равен <> Аргумент 1 — это <а> Аргумент 2 равен Аргумент 3 равен <>
Целью этих примеров является передача пути к каталогу (с пробелами и
кавычки) "C:\Program Files (x86)\Microsoft\" в собственную команду, чтобы она
получил путь в виде строки в кавычках.
В режиме Windows или Standard следующие примеры приводят к ожидаемому результату.
результаты:
TestExe -echoargs """${env:ProgramFiles(x86)}\Microsoft\"""
TestExe -echoargs '"C:\Program Files (x86)\Microsoft\"'
Чтобы получить те же результаты в режиме Legacy , необходимо снять кавычки или использовать
токен остановки анализа ( --% ):
TestExe -echoargs """""${env:ProgramFiles(x86)}\Microsoft\\"""""
TestExe -echoargs "\""C:\Program Files (x86)\Microsoft\\"""
TestExe -echoargs --% ""\""C:\Program Files (x86)\Microsoft\\"\"""
TestExe -echoargs --% """C:\Program Files (x86)\Microsoft\\""
TestExe -echoargs --% """%ProgramFiles(x86)%\Microsoft\\""
Примечание
Символ обратной косой черты ( \ ) не распознается как управляющий символ
PowerShell. Это escape-символ, используемый базовым API для
ProcessStartInfo.СписокАргументов.
Это escape-символ, используемый базовым API для
ProcessStartInfo.СписокАргументов.
В PowerShell 7.3 также добавлена возможность отслеживать привязку параметров для собственного команды. Для получения дополнительной информации см. Команда трассировки.
Передача аргументов командам PowerShell
Начиная с PowerShell 3.0, вы можете использовать токен конца параметров ( -- )
чтобы PowerShell не интерпретировал входные данные как параметры PowerShell. Это
соглашение, указанное в спецификации POSIX Shell and Utilities.
Маркер конца параметров
Маркер конца параметров ( -- ) указывает, что все аргументы, следующие за ним
должны быть переданы в их фактической форме, как если бы они были помещены в двойные кавычки
вокруг них. Например, используя -- , вы можете вывести строку -InputObject .
без использования кавычек или интерпретации его как параметра:
Запись-вывод -- -InputObject
- Объект ввода
В отличие от маркера остановки анализа ( --% ), любые значения, следующие за маркером -- , могут
интерпретироваться PowerShell как выражения.