What is Google Sans Text?
Browse Eckher Glossary and expand your business and technology vocabulary.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments.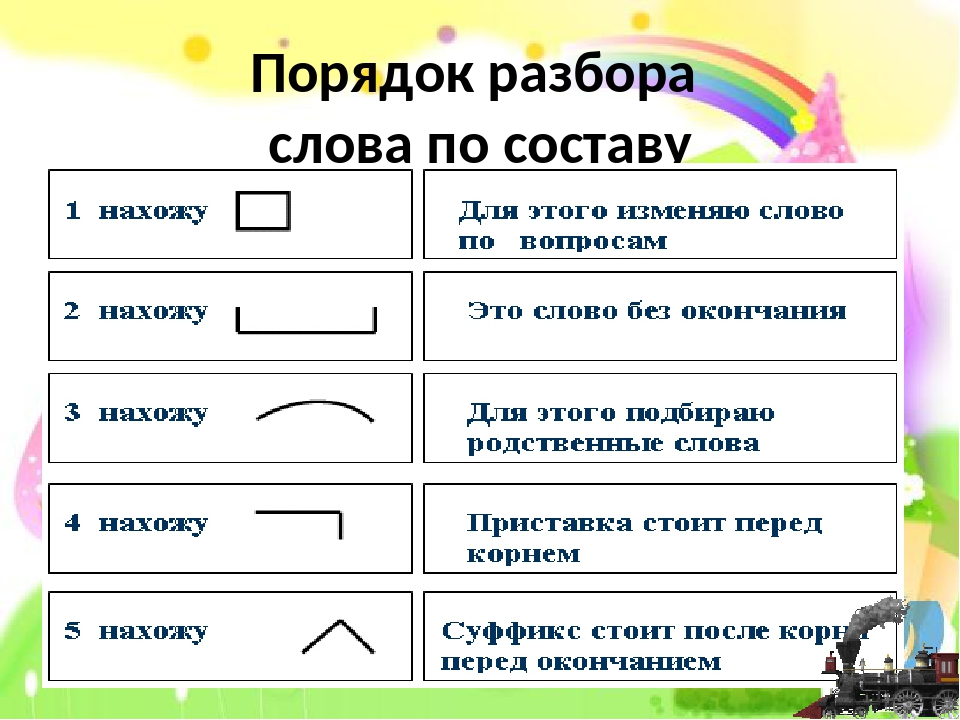 They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «featurize» in English?
How to pronounce «Onehunga» in English?
How to pronounce «Takapuna» in English?
How to pronounce «İzmir» in English?
How to pronounce «Coronaviridae» in English?
How to pronounce «Whanganui» in English?
How to pronounce «Chlöe Swarbrick» in English?
How to pronounce «Kohimarama» in English?
How to pronounce «Tua Tagovailoa» in English?
How to pronounce «Craig Federighi» in English?
How to pronounce «Stefanos Tsitsipas» in English?
How to pronounce «Jacob deGrom» in English?
How to pronounce «myocarditis» in English?
How to pronounce «SZA» in English?
How to pronounce «Cassie Kozyrkov» in English?
Синтаксический разбор предложения
Каждое наше выражение мыслей состоит из логически связанных предложений. Чтобы грамотно составить предложение, которое полностью передаст весь смысл, нужно знать, из чего оно состоит, и какая структура должна быть для правильного понимания. Чем сложнее формулировка, тем больше составных частей, которые сложно уловить и осмыслить с первого раза. Чтобы упростить понимание, существует синтаксический разбор.
Чтобы грамотно составить предложение, которое полностью передаст весь смысл, нужно знать, из чего оно состоит, и какая структура должна быть для правильного понимания. Чем сложнее формулировка, тем больше составных частей, которые сложно уловить и осмыслить с первого раза. Чтобы упростить понимание, существует синтаксический разбор.
Что такое синтаксический разбор предложения?
Синтаксический анализ подразумевает изучение строения текста. Это выражается через выявление взаимосвязей между определенными частями речи. Соединение словосочетаний и предложений между собой также играет важную роль. Синтаксический анализ текста позволяет:
- Разобрать, как построено и из чего состоит каждое отдельное предложение или словосочетание.
- Выявить взаимосвязь между отдельными словами.
- Определить темы, которые относятся к синтаксическим единицам.
- Выявить главные и второстепенные члены предложения.
- Определить грамматические основы.
При таком разборе определяют какого времени и наклонения часть речи, действующие лица, а также количество главных членов предложения.
Какие члены предложения определяют при синтаксическом анализе?
Полный синтаксический разбор выполняется для того, чтобы проанализировать структуру предложения и, тем самым, повысить уровень грамотности в сфере пунктуации. Этот анализ проводится:
- по тексту;
- по предложению;
- по словосочетанию.
Выделяют 5 основных членов предложения:
- Подлежащее
- Сказуемое
- Дополнение
- Обстоятельство
- Определение
Подлежащее и сказуемое являются главными членами предложения (существительное или местоимение + глагол). Остальные 3 части речи являются второстепенными. Определение выражается прилагательным, обстоятельство уточняет место, либо время, а дополнение относится к подлежащему.
Как провести синтаксический разбор предложения онлайн?
Как это работает:
- На сайте нашего сервиса вы вставляете или пишете текст в специальном окне.
- Нажимаете кнопку «Разобрать».

- Сервис производит разбор текста по частям речи и выводит на экран итоговый вариант.

Пользователю будет показано число каждой части речи, содержащейся в тексте. Каждая часть речи выделена в тексте определенным цветом, что наглядно показывает, где в предложении она находится. Наведя на определенную часть речи, всплывает дополнительное окно, где указана информация:
- Какая это часть речи.
- Начальная форма.
- Характеристики (в зависимости от части речи: род, число, падеж, время, изменяемость, вид, одушевленность и т.д.).
Результаты анализа можно сохранить. После каждого разбора, пользователю предоставляется индивидуальная ссылка на результаты анализа введенного текста.
Кому понадобится синтаксический анализ предложений?
В первую очередь, этот инструмент очень полезен для учащихся и студентов. Они могут использовать его как для более подробного разбора темы и улучшения понимания, так и для проверки своих знаний и закрепления. Также его могут использовать копирайтеры и редакторы, это поможет повысить качество текстов и значительно уменьшит количество стилистических ошибок.
Также его могут использовать копирайтеры и редакторы, это поможет повысить качество текстов и значительно уменьшит количество стилистических ошибок.
Деление слов на слоги онлайн
Сайт slogi.su — самый удобный и самый быстрый сервис деления любых русских слов на слоги. Сервис умеет выделять слоги как в отдельных словах, так и в тексте. У нас нет готового словаря слов с заранее выделенными слогами, мы определяем слоги в словах в автоматическом режиме. Это означает, что можно ввести слово русского языка в любом числе, роде, падеже и любой другой форме склонения слова. Дополнительно к разбору мы даём справку по каждому выделенному слогу в слове — вид слога, правило разбиения. Деление на слоги на сайте осуществляется с учётом современных правил русского языка школьной программы (традиционная школа) и программы с углублённым изучением. Если есть разница в делении на слоги двух программ, на странице слова даются пояснения.
Выделить слоги в слове:
Деление осуществляется по правилам школьной программы и углублённого изучения русского языка.
Можно вводить только одно слово и только русскими буквами. Не допускаются иностранные буквы, цифры, пробелы и другие символы.
Если нужно разбить на слоги все слова в тексте, используйте форму ниже. С помощью формы удобно привести текст песни к формату караоке, подготовить детский рассказ для чтения по слогам, разбить слова на слоги для иностранцев и для других полезных нужд.
Выделить слоги в тексте:
Выделяются слоги в русских словах по правилам школьной программы. Цифры, иностранные буквы и другие символы пропускаются.
Слог
Слог является наименьшей цельной произносимой единицей в устной речи. Слоги образуются только за счёт гласных звуков, поэтому число слогов равно числу гласных в слове. Согласные же «примыкают» к той или иной гласной в соответствии с правилами деления на слоги, сложившимися в ходе развития русского языка. Правила деления на слоги описывают правильные способы разбора слов на слоги.
Слоги бывают: открытые и закрытые, прикрытые и неприкрытые. Открытый слог заканчивается на гласный, закрытый слог — на согласный. Прикрытый слог начинается на согласный, неприкрытый слог — на гласный.
Открытый слог заканчивается на гласный, закрытый слог — на согласный. Прикрытый слог начинается на согласный, неприкрытый слог — на гласный.
Выделение слогов
Ниже описаны общие подходы к выделению слогов в словах для традиционной школы и с углублённым изучением. Подробные материалы с объяснениями и примерами смотрите на странице правил деления слов на слоги.
Традиционная школа
Главное правило обычной школьной программы, на которое ориентируется ребёнок: сколько гласных, столько и слогов. При переносе слов ориентируются на правила: слово переносим по слогам, нельзя оставлять одну букву на строчке. Эти правила известны всем.
При делении слова на слоги можно использовать метод толчков: подставляем ладошку ко рту и чувствуем толчки воздуха при проговаривании слова. Или представляем перед собой свечку: сколько раз пламя колыхнется, столько и слогов. Для некоторых слов с течением согласных такой вариант не всегда подходит.
В разных начальных школах принципы обучения делению на слоги различаются.
Школа углублённого изучения
В школах углублённого изучения русского языка и в программах институтов разбираются случаи, когда слова переносятся не по слогам, то есть слог переноса не совпадает с фонетическим слогом.
Деление слова на слоги происходит таким образом, чтобы слог произносился по нарастающей: от глухого произношения к звонкому. Поэтому слоги из нескольких звуков всегда начинаются с глухой согласной и оканчиваются гласной. Например: по-чта (но не поч-та), мо-шка (но не мош-ка). Слог может оканчиваться звонкой согласной (сонорной р, л, м, н), звучит которая менее звонко, чем гласная, но звонче глухой согласной. Например: бул-ка, вар-ка.
Подборки слов
Мы подбираем примеры слов с разбивкой на слоги по различным критериям, которые наибольшим спросом пользуются у посетителей сайта.
По числу слогов
Со слогами
Слова со слогом: -ан-, -бри-, -бы-, -вни-, -гон-, -до-, -доз-, -жи-, -зик-, -кас-, -кос-, -кра-, -мер-, -мол-, -мор-, -нность-, -пра-, -пре-, -при-, -рен-, -ска-, -сли-, -соль-, -тель-, -фи-, -ча-, -чик-, -чу-, -ши-, -ща-, -щик-, -щу-.
Популярные слова
Чаще всего искали слова: русский (17875), Россия (17030), Москва (16364), яблоко (15762), листья (15106), ёжик (14802), медведь (13394), обезьяна (13093), аллея (12986), тетрадь (12929), ягода (12434), якорь (12263), урожай (12190), ученик (11809), змея (10810).
В скобках указано число запросов слова.
Самые необычные варианты сочетания слогов, которые наш сервис обработал, собраны на странице интересных слов. Результат деления на слоги не всегда можно использовать для постановки переносов в слове, так как при переносе используются другие правила. Узнать правила и проверить переносы можно на сайте переноса слов.
Найти тип текущего прочитанного объекта Word во время синтаксического анализа с помощью модуля python-openxml python-docx
Я хочу извлечь текст и таблицы из файла в формате docx. Для этого я использую библиотеку Python 3 python-docx; работает неплохо, текст и таблицы извлекаются правильно.
Однако мой вариант использования требует, чтобы я анализировал текст и таблицы в том же порядке
, в котором они появляются в документе, т.е. во время обработки страницы мне нужно знать тип текущего читаемого объекта (объекты понимаются в смысл слова, т. е.е. абзац, таблица и т. д.), чтобы сохранить порядок в этом документе.
е.е. абзац, таблица и т. д.), чтобы сохранить порядок в этом документе.Возможно, мои объяснения сбивают с толку, поэтому я позволю вам взглянуть на код, который я написал, непосредственно вдохновленный этой частью документации:
def readLines (самостоятельно): # Загрузить парсер документов DOCX. docxDocument = docx.Document (self._fileHandle) # Добавить каждую строку абзаца в строку. pagesLines = [] для абзаца в docxDocument.paragraphs: для строки в paragraph.text.split ('\ n'): pagesLines.append (кортеж ([строка, 0])) # Добавить каждую строку из таблиц. для таблицы в docxDocument.tables: для строки в таблице. строк: для ячейки в row.cells: для абзаца в ячейке. абзацы: для строки в paragraph.text.split ('\ n'): pagesLines.append (кортеж ([строка, 0])) # Вернуть список строк. вернуть страницы
(Пожалуйста, не учитывайте добавленный кортеж к списку pagesLines , поскольку они используются только для хранения метаданных, используемых моим синтаксическим анализатором, но документ docx не может предоставить: кортеж добавляется только для обеспечения совместимости с парсер и удален в вызывающей функции).
Как видите, проблема в том, что я должен прочитать сначала весь текст, содержащийся в абзацах, объектах , затем весь текст, содержащийся в таблицах объектов.
Наконец, мой вопрос: существует ли метод для синтаксического анализа docx на уровне объекта Word, определяющий во время синтаксического анализа тип объекта (абзац, таблица и т. Д.), Чтобы иметь возможность вызвать правильный метод извлечения текста?
Другими словами, можно ли написать что-то, что циклически повторяется в документе и позволяет узнать тип текущего объекта, чтобы иметь возможность правильно анализировать эту часть документа?
Помощь будет принята с благодарностью!
Спасибо!
python — парсинг уникальных слов из текстового файла
Одна проблема заключается в том, что тест в для списка работает медленно.Вероятно, вам следует держать набор , чтобы отслеживать, какие слова вы видели, потому что в тесте для набора набора очень быстр.
Пример:
report_set = set ()
для строки в отчете:
на слово в line.split ():
если we_want_to_keep_word (слово):
report_set.add (слово)
Затем, когда вы закончите: report_list = список (report_set)
В любое время, когда вам нужно принудительно поместить набор в список , вы можете.Но если вам просто нужно перебрать его или выполнить в тестах , вы можете оставить его как набор ; разрешено делать для x в report_set:
Другая проблема, которая может иметь значение, а может и не иметь значения, заключается в том, что вы проглатываете все строки из файла за один раз, используя метод .readlines () . Для действительно больших файлов лучше просто использовать открытый объект дескриптора файла в качестве итератора, например:
с open ("filename", "r") как f:
для строки в f:
... # обработать каждую строку здесь
Большая проблема в том, что я даже не понимаю, как может работать этот код:
а 1:
lines = report. readlines ()
если не строки:
перерыв
 readlines ()
если не строки:
перерыв
readlines ()
если не строки:
перерыв
Это будет повторяться вечно. Первый оператор заполняет все входные строки с помощью .readlines () , затем мы снова зацикливаемся, затем при следующем вызове .readlines () уже исчерпан отчет , поэтому вызов .readlines () возвращает пустой список, который вырывается из бесконечного цикла.Но теперь потеряны все строки, которые мы только что прочитали, и остальной код должен довольствоваться пустой переменной lines . Как это вообще работает?
Итак, избавьтесь от всего этого цикла , а 1 - и измените следующий цикл на для строки в отчете: .
Кроме того, вам действительно не нужно хранить переменную count . Вы можете использовать len (report_set) в любое время, чтобы узнать, сколько слов в наборе .
Кроме того, с набором вам фактически не нужно проверять, соответствует ли слово в наборе ; вы всегда можете просто позвонить report_set., и если он уже находится в  add (word)
add (word) , установите , он больше не будет добавлен!
Кроме того, у вас нет , у вас нет , чтобы делать это по-моему, но мне нравится делать генератор, который выполняет всю обработку. Разделите строку, переведите ее, разделите на пробелы и выделите слова, готовые к использованию. Я бы также заставил слова писать в нижнем регистре, но я не знаю, важно ли, чтобы FOOTNOTES определялись только в верхнем регистре.
Итак, сложите все вместе, и вы получите:
стандартных слов (объект_файла):
для строки в file_object:
линия = линия.strip (). translate (Нет, строка. пунктуация)
на слово в line.split ():
уступить слово
report_set = set ()
с open (fullpath, 'r') в качестве отчета:
за слово в словах (отчет):
если слово == "СНОСКИ":
перерыв
word = word.lower ()
если len (word)> 2 и слово отсутствует в dict_file:
report_set. add (слово)
print ("Слова в report_set:% d"% len (report_set))
 add (слово)
print ("Слова в report_set:% d"% len (report_set))
add (слово)
print ("Слова в report_set:% d"% len (report_set))
Перевод и синтаксический анализ латинских слов
Часть речи — ПрилагательноеНаречиеСоединениеИнтеръекцияСуществительноеЧисловоеПредставлениеПроноунГлагол
Возраст — Современный — неологизмы Классический (~ 150 г. до н.э. — 200 г. н.э.) Архаический — очень ранние формы, устаревшие к классическим временам Раннее — ранняя латынь, доклассическая, использовалась для эффекта / поэзии Позднее — латынь не использовалась в классические времена (6-10) Христианское Средневековье — Средневековье (XI-XV вв.) Ученый — Латинский пост 15-й — Научный / Научный (16-18) Поздний — Поздний, постклассический (III-V вв.) Все / Другое
Область — Сельское хозяйство, Флора, Фауна, Земля, Оборудование, Сельский, Биологический, Медицинский, Части тела, Грамматика, Реторика, Логика, Литература, Школы, Юридическое, Государственное, Налоговое, Финансовое, Политическое, Названия, Драма, Музыка, Театр, Искусство, Живопись, Скульптура, Мифология, Духовное, Библейское, РелигиозноеВойна, Военное дело, Военно-морской флот, Корабли, ДоспехиВсе или нетПоэтическиеТехнические, Архитектура, Топография, ГеодезияНаука, Философия, Математика, Единицы / меры
Locale — ПерсияИталия, Рим, Россия, Африка, Британия, Нидерланды, Восточная Европа, Все или ничего, Индия, Греция, Китай, Египет, Балканы, Ближний Восток, Франция, Галлия, Германия, Скандинавия, Испания, Иберия,
.
Частота — Граффити Только надписи Обычное — 10 000 первых слов Очень часто: 1000 первых слов Часто: 3000 первых слов Нечасто: 2 или 3 цитирования Очень редко (hapax legomenon) Только в естественной истории Плиния Меньше распространенных — 20 000 первых слов Неизвестно или не указано
Источник
— Оксфордский латинский словарь, 1982 (СТАРЫЙ) Другой Рой Дж.Деферрари, Словарь Св. Фомы Аквинского, 1960 (DeF) Отправлено пользователем — нет словарной ссылки Colatinus Dictionary by Yves Ouvrard Vademecum in opus Saxonis — Franz Blatt (Saxo) Уважаемый WhitakerOther, цитируемые или неуказанные словари Латам, Revised Medieval Word List, 1980 (Latham ) Gildersleeve + Lodge, Latin Grammar 1895 (G + L) Найдено в переводе — нет словарной ссылки Lewis and Short, A Latin Dictionary, 1879 (L + S) Plater + White, A Grammar of the Vulgate, Oxford 1926 (Plater) Ч. Бисон, Букварь средневековой латыни, 1925 (Пчела) Леверетт, Ф.P., Lexicon of the Latin Language, Boston 1845Souter, A Glossary of Later Latin to 600 AD, Oxford 1949 (Souter) Lewis, CS, Elementary Latin Dictionary 1891 General or unknown или слишком распространенный, чтобы сказать Брактон: De Legibus Et Consuetudinibus AngliaeCharles Beard, Cassell’s Латинский словарь 1892 (Cas) LFStelten, Словарь Экклеса. Латинский, 1995 (Ecc) Calepinus Novus, современная латынь, Гай Ликоппе (Cal) Линн Нельсон, Wordlist (Nel) Дж. Н. Адамс, Latin Sexual Vocabulary, 1982 (Sex)
Латинский, 1995 (Ecc) Calepinus Novus, современная латынь, Гай Ликоппе (Cal) Линн Нельсон, Wordlist (Nel) Дж. Н. Адамс, Latin Sexual Vocabulary, 1982 (Sex)
Автоматизируйте скучную работу с Python
Документы PDF и Word представляют собой двоичные файлы, что делает их намного более сложными, чем файлы с открытым текстом.Помимо текста, они хранят много информации о шрифтах, цвете и макете. Если вы хотите, чтобы ваши программы могли читать или писать в PDF-файлы или документы Word, вам нужно сделать больше, чем просто передать их имена файлов в open () .
К счастью, есть модули Python, которые упрощают взаимодействие с документами PDF и Word. В этой главе будут рассмотрены два таких модуля: PyPDF2 и Python-Docx.
PDF означает Portable Document Format и использует .pdf расширение файла. Хотя PDF-файлы поддерживают множество функций, в этой главе основное внимание будет уделено двум вещам, которые вы будете с ними делать чаще всего: чтению текстового содержимого из PDF-файлов и созданию новых PDF-файлов из существующих документов.
Модуль, который вы будете использовать для работы с PDF, — PyPDF2. Чтобы установить его, запустите pip install PyPDF2 из командной строки. Это имя модуля чувствительно к регистру, поэтому убедитесь, что y строчные, а все остальное — прописные. (См. Приложение A для получения полной информации об установке сторонних модулей.) Если модуль был установлен правильно, запуск import PyPDF2 в интерактивной оболочке не должен отображать никаких ошибок.
Извлечение текста из PDF-файлов
PyPDF2 не имеет способа извлекать изображения, диаграммы или другие носители из документов PDF, но он может извлекать текст и возвращать его как строку Python. Чтобы начать изучение того, как работает PyPDF2, мы воспользуемся им в примере PDF, показанном на рисунке 13-1.
Рисунок 13-1. Страница PDF, из которой мы будем извлекать текст из
Загрузите этот PDF-файл с сайта http: // nostarch.com / automatestuff / и введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFileObj = open ('meetingminutes. pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ ' pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ '
pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ ' Сначала импортируйте модуль PyPDF2 . Затем откройте meetingminutes.pdf в двоичном режиме чтения и сохраните его в pdfFileObj . Чтобы получить объект PdfFileReader , представляющий этот PDF-файл, вызовите PyPDF2.PdfFileReader () и передайте ему pdfFileObj . Сохраните этот объект PdfFileReader в pdfReader .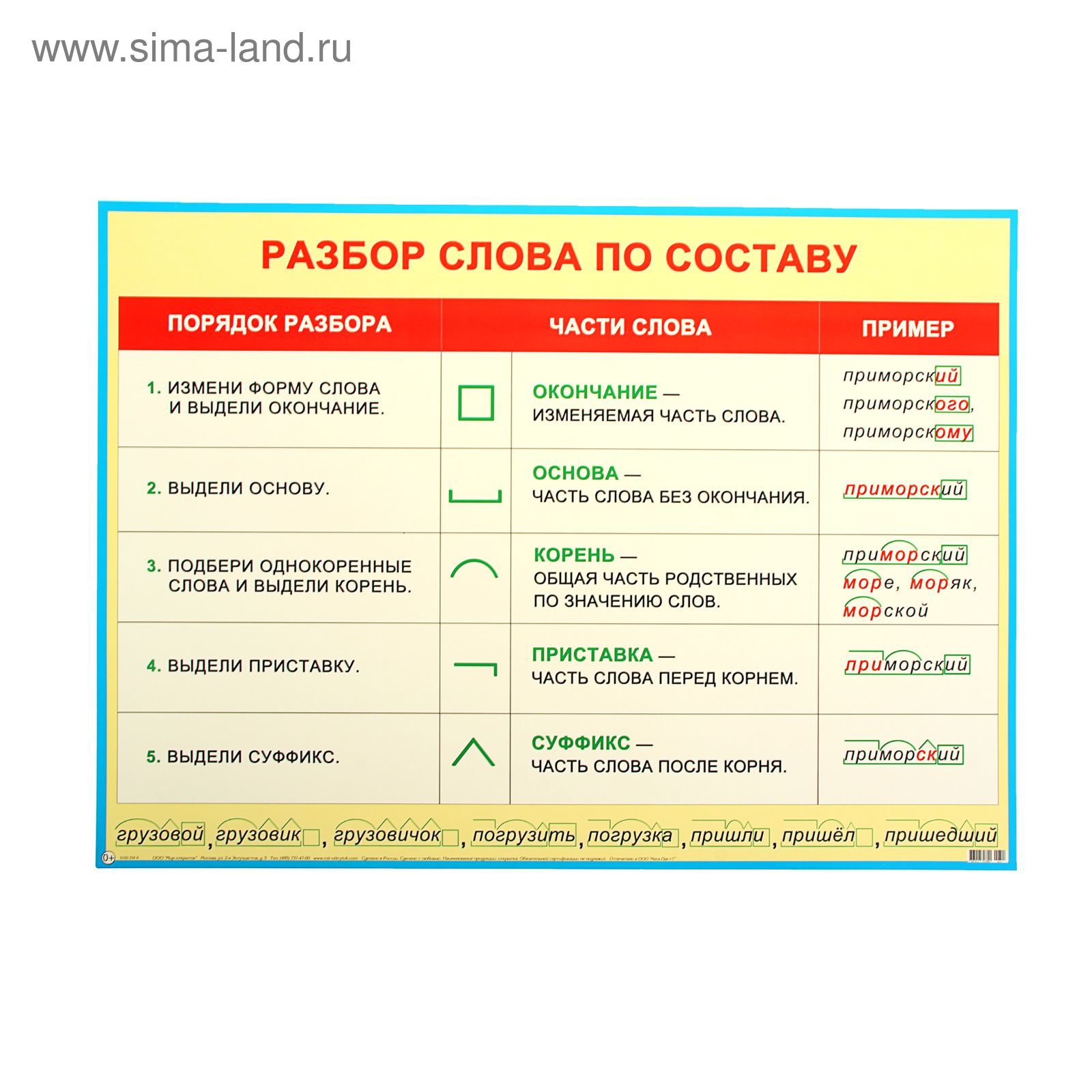
Общее количество страниц в документе хранится в атрибуте numPages объекта PdfFileReader ❶.В примере PDF 19 страниц, но давайте извлечем текст только с первой страницы.
Чтобы извлечь текст со страницы, вам необходимо получить объект Page , который представляет одну страницу PDF-файла, из объекта PdfFileReader . Вы можете получить объект Page , вызвав метод getPage () ❷ для объекта PdfFileReader и передав ему номер страницы интересующей вас страницы — в нашем случае 0.
PyPDF2 использует для получения страниц индекс с отсчетом от нуля : первая страница — это страница 0, вторая — это Введение и так далее.Это всегда так, даже если страницы в документе пронумерованы по-разному. Например, предположим, что ваш PDF-файл представляет собой трехстраничный отрывок из более длинного отчета, а его страницы пронумерованы 42, 43 и 44. Чтобы получить первую страницу этого документа, вам нужно вызвать pdfReader., а не  getPage (0)
getPage (0) getPage (42) или getPage (1) .
Получив объект Page , вызовите его метод extractText () , чтобы вернуть строку текста страницы ❸.Извлечение текста не идеально: текст Charles E. «Chas» Roemer, President из PDF-файла отсутствует в строке, возвращаемой функцией extractText () , а интервалы иногда отсутствуют. Тем не менее, этого приближения к текстовому содержимому PDF может быть достаточно для вашей программы.
Некоторые PDF-документы имеют функцию шифрования, которая предотвращает их чтение до тех пор, пока открывающий документ не предоставит пароль. Введите в интерактивную оболочку следующее с загруженным PDF-файлом, который был зашифрован паролем rosebud :
>>> импорт PyPDF2
>>> pdfReader = PyPDF2.PdfFileReader (открытый ('encrypted.pdf', 'rb'))
❶ >>> pdfReader.isЗашифрованный
Правда
>>> pdfReader. getPage (0)
❷ Отслеживание (последний звонок последний):
Файл "", строка 1, в
pdfReader.getPage ()
- снип -
Файл "C: \ Python34 \ lib \ site-packages \ PyPDF2 \ pdf.py", строка 1173, в getObject
поднять utils.PdfReadError («файл не расшифрован»)
PyPDF2.utils.PdfReadError: файл не расшифрован
❸ >>> pdfReader.decrypt ('бутон розы')
1
>>> pageObj = pdfReader.getPage (0)  getPage (0)
❷ Отслеживание (последний звонок последний):
Файл "
getPage (0)
❷ Отслеживание (последний звонок последний):
Файл " Все объекты PdfFileReader имеют атрибут isEncrypted , который имеет значение True , если PDF-файл зашифрован, и False , если это не так. Любая попытка вызвать функцию, которая читает файл до того, как он был расшифрован с помощью правильного пароля, приведет к ошибке ❷.
Чтобы прочитать зашифрованный PDF-файл, вызовите функцию decrypt () и передайте пароль в виде строки ❸. После того, как вы вызовете decrypt () с правильным паролем, вы увидите, что вызов getPage () больше не вызывает ошибки. Если задан неправильный пароль, функция
Если задан неправильный пароль, функция decrypt () вернет 0 , а getPage () продолжит сбой. Обратите внимание, что метод decrypt () расшифровывает только объект PdfFileReader , а не фактический файл PDF.После завершения вашей программы файл на вашем жестком диске остается зашифрованным. Ваша программа должна будет снова вызвать decrypt () при следующем запуске.
PyPDF2 объектам PdfFileReader являются объекты PdfFileWriter , которые могут создавать новые файлы PDF. Но PyPDF2 не может записывать произвольный текст в PDF, как Python может делать с файлами с открытым текстом. Вместо этого возможности PyPDF2 по написанию PDF-файлов ограничиваются копированием страниц из других PDF-файлов, поворотом страниц, наложением страниц и шифрованием файлов.
PyPDF2 не позволяет напрямую редактировать PDF. Вместо этого вам нужно создать новый PDF-файл, а затем скопировать содержимое из существующего документа. Примеры в этом разделе будут следовать этому общему подходу:
Примеры в этом разделе будут следовать этому общему подходу:
Откройте один или несколько существующих PDF-файлов (исходных PDF-файлов) в объектах
PdfFileReader.Создайте новый объект
PdfFileWriter.Копирование страниц из объектов
PdfFileReaderв объектPdfFileWriter.Наконец, используйте объект
PdfFileWriterдля записи выходного PDF-файла.
Создание объекта PdfFileWriter создает только значение, представляющее документ PDF в Python. Он не создает фактический файл PDF. Для этого вы должны вызвать метод PdfFileWriter write () .
Метод write () принимает обычный объект File , который был открыт в режиме с двоичной записью .Вы можете получить такой объект File , вызвав функцию Python open () с двумя аргументами: строка того, что вы хотите, чтобы имя файла PDF было, и 'wb' , чтобы указать, что файл должен быть открыт в двоичном формате записи. режим.
режим.
Если это звучит немного запутанно, не волнуйтесь — вы увидите, как это работает, в следующих примерах кода.
PyPDF2 можно использовать для копирования страниц из одного документа PDF в другой. Это позволяет объединить несколько файлов PDF, вырезать ненужные страницы или изменить порядок страниц.
Загрузите meetingminutes.pdf и meetingminutes2.pdf с сайта http://nostarch.com/automatestuff/ и поместите файлы PDF в текущий рабочий каталог. Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdf1File = open ('meetingminutes.pdf', 'rb')
>>> pdf2File = open ('meetingminutes2.pdf', 'rb')
❶ >>> pdf1Reader = PyPDF2.PdfFileReader (pdf1File)
❷ >>> pdf2Reader = PyPDF2.PdfFileReader (pdf2File)
❸ >>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdf1Reader. numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close ()  numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close ()
numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close () Откройте оба файла PDF в двоичном режиме чтения и сохраните два результирующих объекта File в файлах pdf1File и pdf2File .Вызовите PyPDF2.PdfFileReader () и передайте ему pdf1File , чтобы получить объект PdfFileReader для минут встречи.pdf ❶. Вызовите его снова и передайте pdf2File , чтобы получить объект PdfFileReader для meetingminutes2. pdf ❷. Затем создайте новый объект
pdf ❷. Затем создайте новый объект PdfFileWriter , который представляет собой пустой документ PDF ❸.
Затем скопируйте все страницы из двух исходных PDF-файлов и добавьте их в объект PdfFileWriter .Получите объект Page , вызвав getPage () для объекта PdfFileReader ❹. Затем передайте этот объект Page в метод addPage () вашего PdfFileWriter ❺. Эти шаги выполняются сначала для pdf1Reader , а затем снова для pdf2Reader . Когда вы закончите копировать страницы, напишите новый PDF-файл с именем commonutes.pdf , передав объект File методу PdfFileWriter write () ❻.
Примечание
PyPDF2 не может вставлять страницы в середину объекта PdfFileWriter ; метод addPage () добавит страницы только в конец.
Вы создали новый файл PDF, который объединяет страницы из meetingminutes. pdf и meetingminutes2.pdf в один документ. Помните, что объект
pdf и meetingminutes2.pdf в один документ. Помните, что объект File , переданный в PyPDF2.PdfFileReader () , необходимо открыть в двоичном режиме чтения, передав 'rb' в качестве второго аргумента в open () . Аналогичным образом, объект File , переданный в PyPDF2.PdfFileWriter () , необходимо открыть в двоичном режиме записи с помощью 'wb' .
Страницы PDF-файла также можно поворачивать с шагом 90 градусов с помощью методов rotateClockwise () и rotateCounterClockwise () . Передайте в эти методы одно из целых чисел 90 , 180 или 270 . Введите в интерактивную оболочку следующее, с файлом meetingminutes.pdf в текущем рабочем каталоге:
>>> импорт PyPDF2
>>> minutesFile = open ('meetingminutes.pdf ',' rb ')
>>> pdfReader = PyPDF2. PdfFileReader (minutesFile)
❶ >>> стр. = PdfReader.getPage (0)
❷ >>> стр. Поворот по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (страница)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> результатPdfFile.close ()
>>> минутFile.close ()  PdfFileReader (minutesFile)
❶ >>> стр. = PdfReader.getPage (0)
❷ >>> стр. Поворот по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (страница)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> результатPdfFile.close ()
>>> минутFile.close ()
PdfFileReader (minutesFile)
❶ >>> стр. = PdfReader.getPage (0)
❷ >>> стр. Поворот по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (страница)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> результатPdfFile.close ()
>>> минутFile.close () Здесь мы используем getPage (0) для выбора первой страницы PDF ❶, а затем вызываем rotateClockwise (90) на этой странице ❷. Мы пишем новый PDF-файл с повернутой страницей и сохраняем его как rotatedPage.pdf ❸.
В результате PDF-файл будет содержать одну страницу, повернутую на 90 градусов по часовой стрелке, как показано на рисунке 13-2. Возвращаемые значения
Возвращаемые значения rotateClockwise () и rotateCounterClockwise () содержат много информации, которую вы можете игнорировать.
Рисунок 13-2. Файл rotatedPage.pdf со страницей, повернутой на 90 градусов по часовой стрелке
PyPDF2 также может накладывать содержимое одной страницы на другую, что полезно для добавления на страницу логотипа, отметки времени или водяного знака. С Python легко добавлять водяные знаки в несколько файлов и только на страницы, указанные в вашей программе.
Загрузите watermark.pdf из http://nostarch.com/automatestuff/ и поместите PDF-файл в текущий рабочий каталог вместе с meetingminutes.pdf . Затем введите в интерактивную оболочку следующее:
>>> импортировать PyPDF2
>>> minutesFile = open ('meetingminutes.pdf', 'rb')
❷ >>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❷ >>> minutesFirstPage = pdfReader.getPage (0)
❸ >>> pdfWatermarkReader = PyPDF2. PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close ()  PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close ()
PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close () Здесь мы создаем объект PdfFileReader из meetingminutes.pdf ❶. Мы вызываем getPage (0) , чтобы получить объект Page для первой страницы и сохранить этот объект через minutesFirstPage ❷. Затем мы создаем объект PdfFileReader для watermark.pdf ❸ и вызываем mergePage () на minutesFirstPage ❹.Аргумент, который мы передаем в mergePage () , является объектом Page для первой страницы watermark.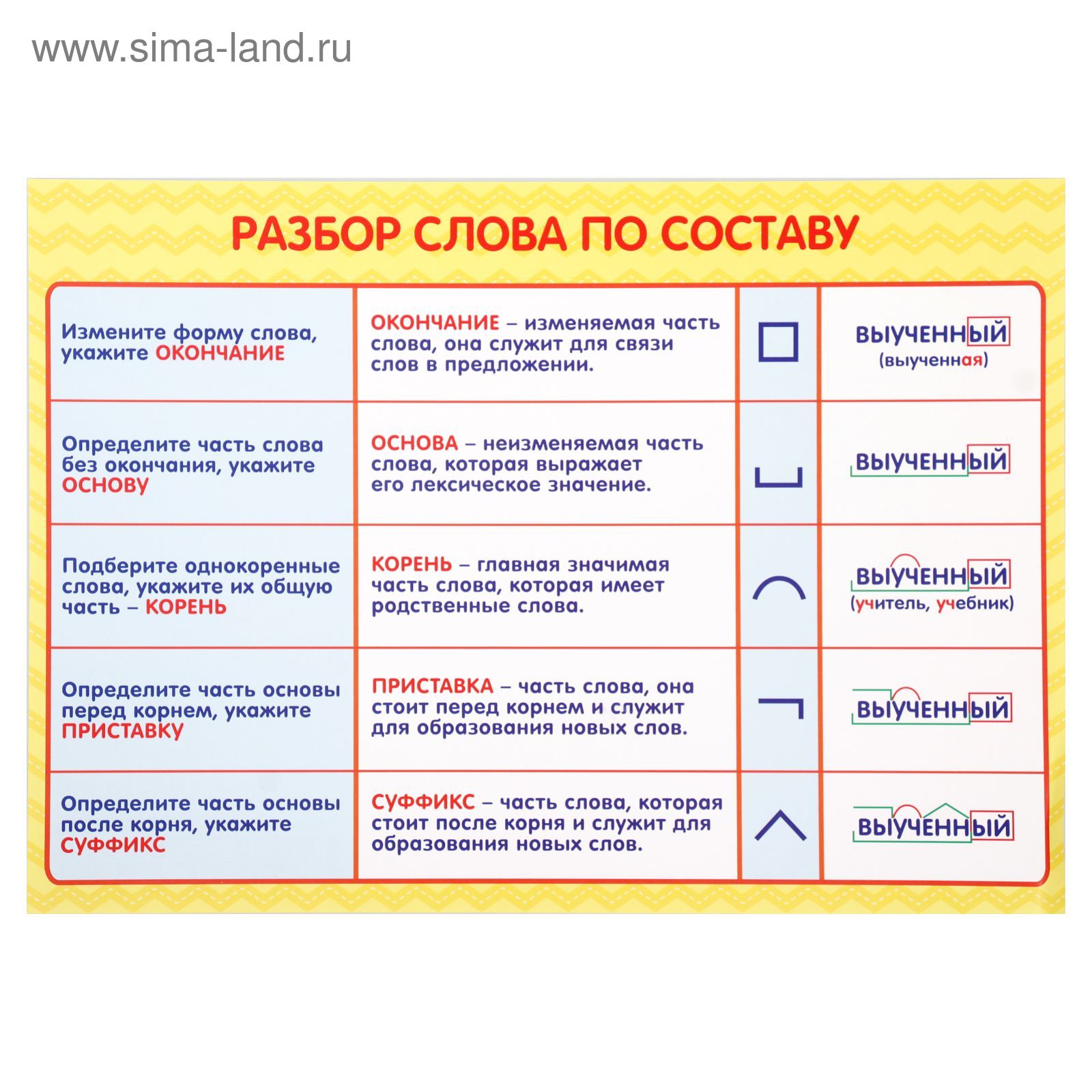 pdf .
pdf .
Теперь, когда мы вызвали mergePage () на minutesFirstPage , minutesFirstPage представляет первую страницу с водяными знаками. Мы создаем объект PdfFileWriter ❺ и добавляем первую страницу с водяным знаком ❻. Затем мы просматриваем остальные страницы в meetingminutes.pdf и добавляем их в объект PdfFileWriter ❼.Наконец, мы открываем новый PDF-файл с именем watermarkedCover.pdf и записываем содержимое PdfFileWriter в новый PDF-файл.
Рисунок 13-3 показывает результаты. Наш новый PDF-файл watermarkedCover.pdf содержит все содержимое файла meetingminutes.pdf , а первая страница снабжена водяными знаками.
Рисунок 13-3. Исходный PDF-файл (слева), PDF-файл с водяным знаком (в центре) и объединенный PDF-файл (справа)
Объект PdfFileWriter также может добавлять шифрование в документ PDF.Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFile = open ('meetingminutes. pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close ()  pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close ()
pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close () Перед вызовом метода write () для сохранения в файл вызовите метод encrypt () и передайте ему строку пароля ❶. PDF-файлы могут иметь пароль пользователя (позволяющий просматривать PDF-файлы) и пароль владельца (позволяющий устанавливать разрешения на печать, комментирование, извлечение текста и другие функции).Пароль пользователя и пароль владельца являются первым и вторым аргументами функции encrypt () соответственно. Если в
Если в encrypt () передан только один строковый аргумент, он будет использоваться для обоих паролей.
В этом примере мы скопировали страницы meetingminutes.pdf в объект PdfFileWriter . Мы зашифровали PdfFileWriter с паролем swordfish , открыли новый PDF-файл с именем encryptedminutes.pdf и записали содержимое PdfFileWriter в новый PDF-файл.Прежде чем кто-либо сможет просмотреть encryptedminutes.pdf , им нужно будет ввести этот пароль. Вы можете удалить исходный незашифрованный файл meetingminutes.pdf , убедившись, что его копия была правильно зашифрована.
Допустим, у вас скучная работа по объединению нескольких десятков PDF-документов в один PDF-файл. Каждая из них имеет титульный лист в качестве первой страницы, но вы не хотите, чтобы титульный лист повторялся в конечном результате. Несмотря на то, что существует множество бесплатных программ для объединения PDF-файлов, многие из них просто объединяют целые файлы вместе. Давайте напишем программу на Python, чтобы настроить, какие страницы вы хотите объединить в PDF.
Давайте напишем программу на Python, чтобы настроить, какие страницы вы хотите объединить в PDF.
На высоком уровне вот что будет делать программа:
Найти все файлы PDF в текущем рабочем каталоге.
Отсортируйте имена файлов, чтобы файлы PDF добавлялись по порядку.
Записать каждую страницу, кроме первой, каждого PDF-файла в выходной файл.
С точки зрения реализации ваш код должен будет сделать следующее:
Позвоните по телефону
os.listdir (), чтобы найти все файлы в рабочем каталоге и удалить все файлы, отличные от PDF.Вызовите метод списка
sort ()Python, чтобы расположить имена файлов в алфавитном порядке.Создайте объект
PdfFileWriterдля выходного PDF.Перебирайте каждый PDF-файл, создавая для него объект
PdfFileReader.Прокрутите каждую страницу (кроме первой) в каждом файле PDF.
Добавьте страницы в выходной PDF-файл.
Запишите выходной PDF-файл в файл с именем allminutes.pdf .

Для этого проекта откройте новое окно редактора файлов и сохраните его как commonPdfs.py .
Шаг 1. Найдите все файлы PDF
Во-первых, ваша программа должна получить список всех файлов с расширением .pdf в текущем рабочем каталоге и отсортировать их.Сделайте так, чтобы ваш код выглядел следующим образом:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# в один PDF-файл.
❶ импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
для имени файла в os.listdir ('.'):
если filename.endswith ('. pdf'):
❷ pdfFiles.append (имя файла)
❸ pdfFiles.sort (ключ = str.lower)
❹ pdfWriter = PyPDF2.PdfFileWriter ()
# TODO: просмотреть все файлы PDF.# TODO: просмотреть все страницы (кроме первой) и добавить их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. После строки shebang и описательного комментария о том, что делает программа, этот код импортирует модули os и PyPDF2 ❶. Вызов os.listdir ('.') вернет список всех файлов в текущем рабочем каталоге. Код проходит по этому списку и добавляет только файлы с расширением .pdf в pdfFiles ❷.После этого этот список сортируется в алфавитном порядке с аргументом ключевого слова key = str.lower до sort () ❸.
Создается объект PdfFileWriter для хранения объединенных страниц PDF ❹. Наконец, несколько комментариев обрисовывают остальную часть программы.
Теперь программа должна читать каждый файл PDF в pdfFiles . Добавьте в свою программу следующее:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdf Файлы:
pdfFileObj = open (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
# TODO: просмотреть все страницы (кроме первой) и добавить их.
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Для каждого PDF-файла цикл открывает имя файла в двоичном режиме чтения, вызывая open () с 'rb' в качестве второго аргумента.Вызов open () возвращает объект File , который передается в PyPDF2.PdfFileReader () для создания объекта PdfFileReader для этого файла PDF.
Для каждого PDF-файла вы захотите перебрать каждую страницу, кроме первой. Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.для имени файла в pdfFiles:
- снип -
# Просмотрите все страницы (кроме первой) и добавьте их.
❶ за pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
# ЗАДАЧА: сохранить полученный PDF-файл в файл. Код внутри цикла для копирует каждый объект Page индивидуально в объект PdfFileWriter .Помните, вы хотите пропустить первую страницу. Поскольку PyPDF2 считает 0 первой страницей, ваш цикл должен начинаться с 1 ❶, а затем увеличиваться, но не включать целое число в pdfReader.numPages .
После того, как эти вложенные циклы для будут выполнены в цикле, переменная pdfWriter будет содержать объект PdfFileWriter со страницами для всех объединенных PDF-файлов. Последний шаг — записать это содержимое в файл на жестком диске.Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdfFiles:
- снип -
# Прокрутите все страницы (кроме первой) и добавьте их.
для pageNum в диапазоне (1, pdfReader.numPages):
- снип -
# Сохраните полученный PDF-файл в файл.
pdfOutput = open ('allminutes.pdf', 'wb')
pdfWriter.write (pdfOutput)
pdfOutput.close () Передача 'wb' в open () открывает выходной PDF-файл allminutes.pdf в двоичном режиме записи. Затем передача результирующего объекта File методу write () создает фактический файл PDF. Вызов метода close () завершает программу.
Идеи для похожих программ
Возможность создавать PDF-файлы из страниц других PDF-файлов позволит вам создавать программы, которые могут выполнять следующие действия:
Вырезайте определенные страницы из PDF-файлов.
Изменение порядка страниц в PDF.
Создайте PDF-файл только из тех страниц, на которых есть определенный текст, обозначенный
extractText ().
Python может создавать и изменять документы Word с расширением файла .docx с помощью модуля python-docx . Вы можете установить модуль, запустив pip install python-docx . (Приложение A содержит полную информацию об установке сторонних модулей.)
Примечание
При использовании pip для первой установки Python-Docx обязательно установите python-docx , а не docx . Имя установки docx относится к другому модулю, который не рассматривается в этой книге. Однако, когда вы собираетесь импортировать модуль python-docx , вам нужно будет запустить import docx , а не import python-docx .
Если у вас нет Word, LibreOffice Writer и OpenOffice Writer — это бесплатные альтернативные приложения для Windows, OS X и Linux, которые можно использовать для открытия .docx файлов. Вы можете скачать их с https://www.libreoffice.org и http://openoffice.org соответственно. Полная документация по Python-Docx доступна по адресу https://python-docx.readthedocs.org/ . Хотя существует версия Word для OS X, в этой главе основное внимание будет уделено Word для Windows.
По сравнению с обычным текстом файлы .docx имеют большую структуру. Эта структура представлена в Python-Docx тремя разными типами данных.На самом высоком уровне объект Document представляет весь документ. Объект Document содержит список объектов Paragraph для абзацев в документе. (Новый абзац начинается всякий раз, когда пользователь нажимает ENTER или RETURN при вводе документа Word.) Каждый из этих объектов Paragraph содержит список из одного или нескольких объектов Run . Абзац из одного предложения на рис. 13-4 состоит из четырех частей.
Рисунок 13-4.Объекты Run , идентифицированные в объекте Paragraph
Текст в документе Word — это больше, чем просто строка. С ним связаны шрифт, размер, цвет и другая информация о стиле. Стиль в Word представляет собой набор этих атрибутов. Объект Run — это непрерывный ряд текста с одинаковым стилем. При изменении стиля текста требуется новый объект Run .
Давайте поэкспериментируем с модулем python-docx .Загрузите demo.docx из http://nostarch.com/automatestuff/ и сохраните документ в рабочем каталоге. Затем введите в интерактивную оболочку следующее:
>>> импорт docx
❶ >>> doc = docx.Document ('demo.docx')
❷ >>> len (док. Абзацы)
7
❸ >>> док. Абзацы [0]. Текст
'Заголовок документа'
❹ >>> док. Абзацев [1].текст
'Простой абзац с полужирным шрифтом и курсивом'
❺ >>> len (док. Параграфы [1] .runs)
4
❻ >>> doc.paragraphs [1] .runs [0] .text
'Простой абзац с некоторыми'
❼ >>> док. Параграфы [1] .runs [1] .text
'смелый'
❽ >>> док. Параграфы [1] .runs [2] .text
' и немного '
➒ >>> док. Параграфы [1] .runs [3] .text
'курсив' В ❶ мы открываем .docx в Python, вызовите docx.Document () и передайте имя файла demo.docx . Это вернет объект Document , который имеет атрибут Paragraph , который представляет собой список объектов Paragraph . Когда мы вызываем len () в doc.paragraphs , он возвращает 7 , что говорит нам о семи объектах Paragraph в этом документе ❷. Каждый из этих объектов Paragraph имеет атрибут text , который содержит строку текста в этом абзаце (без информации о стиле).Здесь первый текстовый атрибут содержит 'DocumentTitle' ❸, а второй содержит 'Простой абзац с некоторым полужирным и некоторым курсивом' ❹.
Каждый объект Paragraph также имеет атрибут Run , который представляет собой список объектов Run . Run Объекты также имеют атрибут text , содержащий только текст в этом конкретном прогоне. Давайте посмотрим на атрибут text во втором объекте Paragraph : 'Простой абзац с полужирным шрифтом и курсивом' .Вызов len () для этого объекта Paragraph сообщает нам, что существует четыре объекта Run ❺. Объект первого запуска содержит 'Простой абзац с некоторым' ❻. Затем текст меняется на полужирный, поэтому «полужирный» запускает новый объект Run ❼. После этого текст возвращается к стилю без полужирного шрифта, что приводит к появлению третьего объекта Run , 'и некоторого количества' ❽. Наконец, четвертый и последний объект Run содержит «курсив» курсивом ➒.
Благодаря Python-Docx ваши программы Python теперь смогут читать текст из файла .docx и использовать его, как любое другое строковое значение.
Получение полного текста из файла .docx
Если вас интересует только текст, а не информация о стилях в документе Word, вы можете использовать функцию getText () . Он принимает имя файла .docx и возвращает одно строковое значение его текста. Откройте новое окно редактора файлов и введите следующий код, сохранив его как readDocx.py :
#! python3
импорт docx
def getText (имя файла):
doc = docx.Document (имя файла)
fullText = []
для пункта в пунктах документа:
fullText.append (параграф)
return '\ n'.join (fullText) Функция getText () открывает документ Word, перебирает все объекты Paragraph в списке абзацев , а затем добавляет их текст в список в fullText . После цикла строки в fullText объединяются с помощью символов новой строки.
Программа readDocx.py может быть импортирована как любой другой модуль. Теперь, если вам просто нужен текст из документа Word, вы можете ввести следующее:
>>> импорт чтения Docx
>>> печать (readDocx.getText ('demo.docx'))
Заголовок документа
Простой абзац с жирным шрифтом и курсивом
Заголовок, уровень 1
Интенсивная цитата
первый элемент в неупорядоченном списке
первая позиция в заказанном списке Вы также можете настроить getText () , чтобы изменить строку перед ее возвратом.Например, чтобы сделать отступ в каждом абзаце, замените вызов append () в readDocx.py следующим:
fullText.append ( '' + параграф текста)
Чтобы добавить двойной пробел между абзацами, измените код вызова join () на следующий:
return '\ n \ n ' .join (fullText)
Как видите, требуется всего несколько строк кода для написания функций, которые будут читать файл .docx и возвращать строку его содержимого по вашему вкусу.
Стилизация абзацев и объектов бега
В Word для Windows стили можно просмотреть, нажав CTRL-ALT-SHIFT-S, чтобы отобразить панель «Стили», которая выглядит, как на рис. 13-5. В OS X вы можете просмотреть панель стилей, щелкнув пункт меню View ▸ Styles .
Рисунок 13-5. Откройте панель стилей, нажав CTRL-ALT-SHIFT -S в Windows.
Word и другие текстовые процессоры используют стили, чтобы визуальное представление похожих типов текста было согласованным и легко изменяемым.Например, возможно, вы хотите установить основные абзацы шрифтом Times New Roman 11 кеглями, с выравниванием по левому краю и неровным правым текстом. Вы можете создать стиль с этими настройками и назначить его всем абзацам основного текста. Затем, если вы позже захотите изменить представление всех основных абзацев в документе, вы можете просто изменить стиль, и все эти абзацы будут автоматически обновлены.
Для документов Word существует три типа стилей: Стили абзаца могут применяться к объектам Paragraph , стили символов могут применяться к объектам Run , а связанные стили могут применяться к обоим типам объекты.Вы можете задать стили объектам Paragraph и Run , установив их атрибут style в строку. Эта строка должна быть именем стиля. Если для стиля задано значение Нет , то не будет стиля, связанного с объектом Параграф или Выполнить .
Строковые значения для стилей Word по умолчанию следующие:
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | |
При установке атрибута стиля не используйте пробелы в имени стиля.Например, хотя имя стиля может быть «Тонкое выделение», вы должны установить для атрибута стиля строковое значение «SubtleEmphasis» вместо «Тонкое выделение» . Включение пробелов приведет к тому, что Word неправильно прочитает имя стиля и не применит его.
При использовании связанного стиля для объекта Run вам нужно будет добавить 'Char' в конец его имени. Например, чтобы установить связанный стиль Quote для объекта Paragraph , вы должны использовать paragraphObj.style = 'Quote' , но для объекта Run вы должны использовать runObj.style = 'QuoteChar' .
В текущей версии Python-Docx (0.7.4) можно использовать только стили Word по умолчанию и стили в открытом .docx . Новые стили не могут быть созданы, хотя это может измениться в будущих версиях Python-Docx.
Создание документов Word со стилями не по умолчанию
Если вы хотите создать документы Word, в которых используются стили помимо стандартных, вам нужно будет открыть Word в пустой документ Word и самостоятельно создать стили, нажав кнопку New Style в нижней части панели стилей (рис. -6 показывает это в Windows).
Откроется диалоговое окно «Создать новый стиль из форматирования», в котором можно ввести новый стиль. Затем вернитесь в интерактивную оболочку и откройте этот пустой документ Word с помощью docx.Document () , используя его в качестве основы для документа Word. Имя, которое вы дали этому стилю, теперь будет доступно для использования с Python-Docx.
Рисунок 13-6. Кнопка «Новый стиль» (слева) и диалоговое окно «Создать новый стиль из форматирования» (справа)
Прогонам можно дополнительно стилизовать с помощью атрибутов текст .Каждому атрибуту можно присвоить одно из трех значений: True (атрибут всегда включен, независимо от того, какие другие стили применяются к запуску), False (атрибут всегда отключен) или None (по умолчанию независимо от того, какой стиль выполнения задан).
В таблице 13-1 перечислены атрибуты text , которые можно установить для объектов Run .
Таблица 13-1. Выполнить Объект текст Атрибуты
Атрибут | Описание |
|---|---|
| Текст выделен жирным шрифтом. |
| Текст выделен курсивом. |
| Текст подчеркнут. |
| Текст зачеркивается. |
| Текст выделен двойным зачеркиванием. |
| Текст отображается заглавными буквами. |
| Текст отображается заглавными буквами, а строчные буквы на два пункта меньше. |
| Текст отображается с тенью. |
| Текст выглядит обведенным, а не сплошным. |
| Текст пишется справа налево. |
| Текст кажется вдавленным на страницу. |
| Текст выглядит рельефно приподнятым над страницей. |
Например, чтобы изменить стили demo.docx , введите в интерактивную оболочку следующее:
>>> doc = docx.Document ('demo.docx')
>>> док. Абзацы [0]. Текст
'Заголовок документа'
>>> док. Абзацы [0]. Стиль
'Заголовок'
>>> doc.paragraphs [0] .style = 'Normal'
>>> док. Абзацы [1]. Текст
'Простой абзац с полужирным шрифтом и курсивом'
>>> (док.параграфы [1] .runs [0] .text, doc.paragraphs [1] .runs [1] .text, doc.
абзацев [1] .runs [2] .text, doc.paragraphs [1] .runs [3] .text)
(«Простой абзац с некоторыми», «полужирным», «и некоторыми», «курсивом»)
>>> doc.paragraphs [1] .runs [0] .style = 'QuoteChar'
>>> doc.paragraphs [1] .runs [1] .underline = True
>>> doc.paragraphs [1] .runs [3] .underline = True
>>> doc.save ('restyled.docx') Здесь мы используем атрибуты text и style , чтобы легко увидеть, что находится в абзацах в нашем документе.Мы видим, что разделить абзац на запуски и получить доступ к каждому запуску индивидуально просто. Итак, мы получаем первое, второе и четвертое прогоны во втором абзаце, стилизуем каждый прогон и сохраняем результаты в новом документе.
Слова Заголовок документа в верхней части restyled.docx будут иметь стиль Обычный вместо стиля Заголовка, объект Run для текста Простой абзац с некоторым будет иметь стиль QuoteChar, а два объекта Run для слов жирным шрифтом и курсивом будут иметь атрибут подчеркивания , установленный на True .На рис. 13-7 показано, как выглядят стили абзацев и прогонов в restyled.docx .
Рисунок 13-7. рестайлинг.docx файл
Более полную документацию по использованию стилей Python-Docx можно найти на странице https://python-docx.readthedocs.org/en/latest/user/styles.html .
Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> док.add_paragraph ('Привет, мир!')
>>> doc.save ('helloworld.docx') Чтобы создать собственный файл .docx , вызовите docx.Document () , чтобы вернуть новый пустой объект Word Document . Метод документа add_paragraph () добавляет в документ новый абзац текста и возвращает ссылку на добавленный объект Paragraph . Когда вы закончите добавлять текст, передайте строку имени файла методу документа save () , чтобы сохранить объект Document в файл.
Это создаст файл с именем helloworld.docx в текущем рабочем каталоге, который при открытии выглядит как на рис. 13-8.
Рисунок 13-8. Документ Word, созданный с использованием add_paragraph ('Hello world!')
Вы можете добавить абзацы, снова вызвав метод add_paragraph () с текстом нового абзаца. Или чтобы добавить текст в конец существующего абзаца, вы можете вызвать метод add_run () абзаца и передать ему строку.Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Hello world!')
<объект docx.text.Paragraph по адресу 0x000000000366AD30>
>>> paraObj1 = doc.add_paragraph ('Это второй абзац.')
>>> paraObj2 = doc.add_paragraph ('Это еще один абзац.')
>>> paraObj1.add_run ('Этот текст добавляется ко второму абзацу.')
>>> doc.save ('multipleParagraphs.docx') В результате документ будет выглядеть как на Рисунке 13-9. Обратите внимание, что текст Этот текст добавляется ко второму абзацу. был добавлен к объекту Paragraph в paraObj1 , который был вторым абзацем, добавленным в doc . Функции add_paragraph (), и add_run (), возвращают абзац и объекты Run соответственно, чтобы избавить вас от необходимости извлекать их как отдельный шаг.
Имейте в виду, что начиная с версии 0.5.3 Python-Docx, новые объекты Paragraph можно добавлять только в конец документа, а новые объекты Run можно добавлять только в конец объекта Paragraph .
Метод save () можно вызвать снова, чтобы сохранить внесенные вами дополнительные изменения.
Рисунок 13-9. В документ с несколькими объектами Paragraph и Run добавлено
И add_paragraph (), , и add_run () принимают необязательный второй аргумент, который является строкой стиля объекта Paragraph или Run .Например:
>>> doc.add_paragraph ('Hello world!', 'Title') Эта строка добавляет абзац с текстом Hello world! в стиле Заголовок.
Вызов add_heading () добавляет абзац с одним из стилей заголовка. Введите в интерактивную оболочку следующее:
>>> doc = docx.Document ()
>>> doc.add_heading ('Заголовок 0', 0)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> док.add_heading ('Заголовок 1', 1)
<объект docx.text.Paragraph в 0x00000000036CB630>
>>> doc.add_heading ('Заголовок 2', 2)
<объект docx.text.Paragraph в 0x00000000036CB828>
>>> doc.add_heading ('Заголовок 3', 3)
<объект docx.text.Paragraph в 0x00000000036CB2E8>
>>> doc.add_heading ('Заголовок 4', 4)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> doc.save ('заголовки.docx ') Аргументы add_heading () - это строка текста заголовка и целое число от 0 до 4 . Целое число 0 делает заголовок стилем заголовка, который используется для верхней части документа. Целые числа от 1 до 4 относятся к разным уровням заголовков, при этом 1 является основным заголовком, а 4 - самым низким подзаголовком. Функция add_heading () возвращает объект Paragraph , чтобы сэкономить вам этап извлечения его из объекта Document в качестве отдельного шага.
Результирующий файл headings.docx будет выглядеть, как показано на Рисунке 13-10.
Рисунок 13-10. Документ headings.docx с заголовками от 0 до 4
Добавление строк и разрывов страниц
Чтобы добавить разрыв строки (а не начинать новый абзац), вы можете вызвать метод add_break () для объекта Run , после которого должен отображаться разрыв. Если вместо этого вы хотите добавить разрыв страницы, вам нужно передать значение docx.text.WD_BREAK.PAGE как единственный аргумент для add_break () , как это сделано в середине следующего примера:
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Это на первой странице!')
<объект docx.text.Paragraph по адресу 0x0000000003785518>
❶ >>> doc.paragraphs [0] .runs [0] .add_break (docx.text.WD_BREAK.PAGE)
>>> doc.add_paragraph ('Это на второй странице!')
>>> doc.save ('twoPage.docx') Это создает двухстраничный документ Word с Это на первой странице! на первой странице и Это на второй странице! на втором. Несмотря на то, что на первой странице после текста было еще много места. Это на первой странице! , мы заставили следующий абзац начинаться на новой странице, вставив разрыв страницы после первого прогона первого абзаца ❶.
Объекты документа имеют метод add_picture () , который позволяет добавлять изображение в конец документа. Допустим, у вас есть файл zophie.png в текущем рабочем каталоге. Вы можете добавить zophie.png в конец документа с шириной 1 дюйм и высотой 4 сантиметра (Word может использовать как британские, так и метрические единицы измерения), введя следующее:
>>> doc.add_picture ('zophie.png', width = docx.shared.Дюймы (1),
высота = docx.shared.Cm (4))
<объект docx.shape.InlineShape по адресу 0x00000000036C7D30> Первый аргумент - это строка имени файла изображения. Необязательные аргументы ключевого слова width и height задают ширину и высоту изображения в документе. Если не указано иное, ширина и высота по умолчанию будут равны нормальному размеру изображения.
Вы, вероятно, предпочтете указывать высоту и ширину изображения в знакомых единицах измерения, таких как дюймы и сантиметры, поэтому вы можете использовать docx.shared.Inches () и docx.shared.Cm () функции, когда вы указываете аргументы ключевого слова width и height .
WORD: используйте poi для анализа doc и docx
1. зависимость от помпов
<зависимость>
org.apache.poi
poi
4.1.1
<зависимость>
org.apache.poi
poi-ooxml
4.1.1
<зависимость>
org.apache.poi
электронный блокнот
4.1.1
Примечание: старая версия word оканчивается на doc, а новая версия word оканчивается на docx.Если возникает это исключение: org.apache.poi.openxml4j.exceptions.OLE2NotOfficeXmlFileException: предоставленные данные имеют формат OLE2. Вы вызываете часть POI, которая занимается документами OOXML (Office Open XML). Вам необходимо вызвать другую часть POI для обработки этих данных (например, HSSF вместо XSSF). j означает, что текущая проанализированная версия неверна. Использовать старую версию парсера слов
2. Создайте текстовый документ
1. Создайте тест.doc и test.docx и напишите следующее:
3. Создайте общий метод синтаксического анализа для анализа текущего документа Word
Поскольку текущие классы docx и doc несовместимы и нет единого интерфейса, их нужно обрабатывать по-другому
public void handlerWordFile (File file) выдает исключение {
Строка fileName = file.getName ();
int lastIndexOf = имя_файла .lastIndexOf (".");
if (lastIndexOf == - 1) {
throw new IllegalArgumentException («Формат входящего файла недопустим!»);
}
Строка suffex = имя_файла.подстрока (lastIndexOf + 1, fileName.length ());
try (InputStream is = new FileInputStream (файл)) {
switch (suffex) {
case "doc":
handlerByDocFile (есть);
перерыв;
case "docx":
handlerByDocxFile (есть);
перерыв;
По умолчанию:
throw new IllegalArgumentException («Тип документа, который не может быть проанализирован, введите правильный текстовый файл типа документа!»);
}
} catch (Exception e) {
бросить е;
}
}
4. Создайте метод для синтаксического анализа docx
Документ Word (docx) можно проанализировать с помощью объекта XWPFDocument
public void handlerByDocxFile (InputStream is) выдает исключение IOException, InvalidFormatException {
XWPFDocument xwpfDocument = новый XWPFDocument (есть);
Итератор bodyElementsIterator = xwpfDocument.getBodyElementsIterator ();
Список 5.Протестируйте разобранный test.docx
public static void main (String [] args) выдает исключение {
WordTest test = новый WordTest ();
URL-адрес ресурса = Thread.currentThread (). GetContextClassLoader (). GetResource ("test.docx");
Файл файл = новый файл (resource.getFile ());
test.handlerWordFile (файл);
}
Результат выполнения:
6. Создайте метод анализа документов doc
Класс HWPFDocument требуется для анализа файлов документов
public void handlerByDocFile (InputStream is) {
String content = null;
HWPFDocument hwpfDocument = null;
пытаться {
hwpfDocument = новый HWPFDocument (есть);
content = getAllDocText (hwpfDocument);
} catch (IOException e) {
е.printStackTrace ();
}наконец-то {
closeDocFile (hwpfDocument);
}
System.out.println (контент);
}
public String getAllDocText (HWPFDocument hwpfDocument) {
return hwpfDocument.getDocumentText ();
}
public void closeDocFile (HWPFDocument hwpfDocument) {
пытаться {
если (hwpfDocument! = ноль)
hwpfDocument.close ();
} catch (IOException e) {
e.printStackTrace ();
}
}
Вы можете напрямую получить все текстовое содержимое в текущем текстовом документе через HWPFDocument.getDocumentText ()!
Результат:
Было обнаружено, что проанализированный контент содержит символы [?], Что имеет недостатки
7. Резюме
1. При использовании poi для синтаксического анализа docx и doc обратите внимание на текущую версию и класс Incompatible, поэтому вам необходимо разделить его Rationale, Parsing docx requires XWPFDocument , and HWPFDocument is required to parse doc
2.Используйте Старая версия может легко анализировать все текстовое содержимое текущего слова и Новая версия должна вынести суждение и текущий тип для получения данных , В новой версии этой проблемы не будет [?] !
Вышесказанное является сугубо личным мнением, если возникнут вопросы, пишите мне!
Шаблоны резюме из 7 Word (и как их использовать)
Вы, вероятно, знакомы с ужасом, когда вы смотрите на пустой документ и видите мигающий курсор, который только и ждет, когда вы начнете писать, думаете ли вы о давно ушедшей школе задания или тот отчет, который вы должны были отправить своему боссу вчера.А когда дело доходит до вашего резюме - документа, который стоит между вами и вашей следующей работой - ставки могут казаться особенно высокими.
Хорошая новость в том, что вам не нужно начинать с нуля, когда вы пишете резюме. Существует множество шаблонов резюме, которые вы можете использовать. А поскольку начало работы с шаблоном избавляет от множества решений о форматировании и расстановке интервалов, вы можете сосредоточиться на содержании своего резюме, так что вы можете начать работу и получить работу.
Плохая новость в том, что тогда очень быстро ваша первая проблема (пустой документ) становится совершенно новой проблемой: как вообще выбрать правильный шаблон ?
Начать с Microsoft Word - разумный ход.По словам Аманды Августин, карьерного эксперта и составителя резюме TopResume, файлы с расширением «.docx» являются наиболее безопасными для отправки в систему отслеживания кандидатов (ATS), программное обеспечение, которое компании используют для организации и анализа приложений и выявления наиболее многообещающие кандидаты на данную роль (часто до того, как человек когда-либо будет задействован). Поскольку .docx - это формат, совместимый со всеми системами, а некоторые системы по-прежнему не могут правильно анализировать .pdf и другие форматы, вам может быть выгодно работать в Word.
Вот все, что вам нужно знать о поиске, выборе и использовании шаблонов резюме Microsoft Word, а также несколько примеров шаблонов, которые вы можете использовать бесплатно (или дешево!).
Как найти шаблоны резюме Word
Вы можете найти бесплатные шаблоны резюме Word прямо в программе - в последних версиях, щелкнув «Файл»> «Создать из шаблона» и прокрутив или выполнив поиск по запросу «резюме». Здесь вы также можете искать шаблоны резюме, предлагаемые Microsoft Office, в Интернете.
Если вам нужен шаблон Word, но не обязательно тот, который поступает непосредственно из библиотеки Microsoft, вы можете обратиться к Jobscan, Hloom и другим источникам за бесплатными шаблонами или заплатить за один на таких сайтах, как Etsy. Некоторые карьерные коучи также предлагают оригинальные шаблоны на своих веб-сайтах (например, здесь вы можете найти шаблоны карьерного коуча Muse Йены Вивиано).
Как правильно выбрать шаблон резюме в Word
Когда вы впервые начинаете поиск шаблона, количество вариантов может показаться огромным.Как узнать, какой выбрать?
Самая важная вещь, о которой нужно помнить, заключается в следующем: просто потому, что шаблон находится в библиотеке Microsoft или доступен в Интернете, это не значит, что это хороший шаблон , который поможет вашему резюме пройти через ATS и понравится рекрутерам. и менеджеры по найму. «Часто они разрабатываются, потому что выглядят действительно круто и красиво, и они вам нравятся», - говорит Августин.
Но не все шаблоны одинаковы, предупреждает Джон Шилдс, менеджер по маркетингу Jobscan.«Некоторые из них довольно хороши, а некоторые очень плохи». Вот несколько советов, которые помогут вам понять разницу:
1. Выберите макет, который вам подходит
Резюме, как и работа, подходят так же, как и все остальное. Итак, помимо хорошего и плохого, вы ищете шаблон, который имеет смысл для того, кто вы есть и каковы ваши цели.
Ваш первый шаг - выбрать общий формат резюме - хронологический, комбинированный (также называемый гибридным) или функциональный. (Если вы не знаете, какой из них вам подходит, ознакомьтесь с нашим руководством по выбору здесь.)
Хронологический и комбинированный форматы хорошо подходят для ATS, а также для рекрутеров и менеджеров по найму, но будьте осторожны с функциональным резюме. Помимо отключения ATS, который обычно не запрограммирован на анализ вашей информации в таком порядке, функциональные резюме «действительно ненавидят рекрутеры и менеджеры по найму», - говорит Шилдс, потому что они «затрудняют понимание вашей карьерной траектории и того, где вы развил свои навыки ».
Вам также следует хорошо подумать о том, что вы можете поместить «над сгибом», или в верхней трети или половине документа.Люди склонны сосредотачивать на нем больше внимания, поэтому «это должен быть моментальный снимок всего, что им действительно нужно знать о вас», - говорит Августин. Спросите себя, говорит она: «Что наиболее важно в вашем прошлом, что применимо к текущей работе?»
Если вы, например, еще учитесь в школе или недавно закончили школу, вам может понадобиться шаблон, в котором вы можете поставить свое образование на первое место, или вы можете выбрать тот, который позволит вам подчеркнуть свою отличную стажировку прошлым летом. С другой стороны, если у вас есть большой опыт, вам может понадобиться шаблон, который позволит вам начать с резюме резюме или раздела с указанием ключевых достижений.А если вы работаете в технической сфере, вы можете разместить вверху раздел навыков, чтобы выделить программное обеспечение, которое вы использовали, или языки, на которых вы кодируете.
Хотя может быть проще найти шаблон, который уже настроен с точные разделы, которые вы хотите, в точных местах, которые вы хотите, помните, что вы также можете настроить любой шаблон в соответствии с вашими потребностями.
Если вам не сразу понятно, в каком направлении двигаться, ничего страшного! Шилдс рекомендует попробовать несколько разных шаблонов и посмотреть, какой из них лучше всего представляет ваш опыт.
2. Убедитесь, что места достаточно
В некоторых случаях шаблон «выглядит действительно красиво, но на самом деле не дает места, которое вам нужно, чтобы должным образом уделить предыдущему опыту должное внимание», - говорит Августин. Конечно, вы должны быть краткими, но вы также хотите, чтобы у вас было место для включения самых важных моментов, не уменьшая шрифт до неразборчивого размера.
В то же время вы хотите выбрать чистый шаблон с или пустым пространством, - говорит Вивиано.Вы же не хотите, чтобы резюме было слишком "забитым словами".
3. Не слишком навороченный
Хотя вас могут привлечь яркие и необычные шаблоны резюме, на самом деле лучше выбрать простой и относительно консервативный дизайн - даже в творческих сферах. Хотя немного цвета может быть отличным способом выделить ваше резюме, например, вы, вероятно, не захотите выбирать шаблон, который кричит и кричит 17 различными яркими цветами. Вы также захотите использовать только один или два шрифта.
И держитесь подальше от пузырей, звездочек, гистограмм и других бессмысленных способов измерения вашего мастерства в различных навыках. «Если не используется стандартная система выставления оценок или оценок, это просто кажется субъективным», - говорит Августин. «На самом деле это не помогает читателю по-настоящему понять вашу компетенцию».
Самое главное, избегайте шаблонов, которые слишком креативны в том, где вы помещаете важную информацию и как вы ее представляете. И ATS, и любые люди, просматривающие ваше приложение, «хотят, чтобы резюме были очень четкими и легко интерпретируемыми, чтобы не было путаницы в отношении того, где находится ключевая информация и что означает каждый раздел», - говорит Шилдс.
Это означает соблюдение условностей. «Во многих случаях простое лучше», - говорит Августин. «Помимо ATS, рекрутеры привыкли искать информацию в определенных областях, и если вы решите пойти на мошенничество и начать размещать вещи в разных местах, это не обязательно будет означать:« О, этот рекрутер потратит дополнительное время, глядя на мое резюме для этой информации », - говорит она. «Они собираются быстро взглянуть, не видя того, чего хотят, и перейти к следующему».
4.Следите за блокировщиками ATS
ATS часто действует как привратник для кадровых агентств или менеджеров по найму, выполняя первую проверку заявок. Как только система определит наиболее перспективных клиентов на основе ключевых слов и других сигналов, которые она запрограммировала улавливать, человек может не выйти за пределы этой кучи. Так что вы должны обратить внимание на красные флажки, которые могут помешать вашему резюме преодолеть первое препятствие. Обратите внимание на:
- Верхние и нижние колонтитулы: Вы никогда не захотите помещать какую-либо информацию в фактические разделы верхнего и нижнего колонтитула документа Word, говорит Августин, потому что он не всегда анализируется правильно (или вообще) АТС.
- Заголовки разделов: Убедитесь, что вы помечаете разделы четко и просто, независимо от того, что было в исходном шаблоне. «Если вы выйдете слишком нестандартно, те алгоритмы синтаксического анализа, которые помещают эту информацию в цифровой профиль заявителя, начинают сбиваться с толку», - говорит Шилдс. Если система запрограммирована на поиск раздела под названием «Опыт работы» или «Профессиональный опыт» и другого раздела под названием «Образование», ATS может не распознать какие-либо неортодоксальные ярлыки, которые вы использовали, и не будет знать, что с ними делать. информация под ними.
- Изображений и графиков: ATS в основном игнорирует любые изображения, говорит Августин, поэтому вам лучше избегать их использования, особенно в качестве причудливого способа указать свое имя или любую другую важную информацию.
- Текстовые поля: Несмотря на то, что вы вводите слова в текстовое поле, оно «считается объектом, поэтому не может быть проанализировано должным образом», - говорит Августин.
- Гиперссылки: Если вы добавите ссылку к строке слов в одном из пунктов маркированного списка, есть вероятность, что ATS проанализирует только URL и проигнорирует фактические слова, объясняет Августин.Поэтому убедитесь, что гиперссылка идет от «(ссылка)» или «(веб-сайт)», а не от такого важного текста, как «увеличено на 25%» или «приносит доход в размере 5 миллионов долларов».
- Столбцы: «Многие ATS с трудом анализируют текст бок о бок», - говорит Шилдс. «Он будет читаться слева направо независимо от разделителей столбцов, объединяя содержимое двух несвязанных разделов». Это еще одна причина склоняться к «более классическим резюме, в котором нет таблиц и столбцов», - говорит он. По словам Августина, хотя некоторые системы могут читать некоторые столбцы, безопаснее держаться подальше.
- Шрифты: Найдите шаблон, в котором используется относительно общий шрифт. Мало того, что люди оценят чистый, ясный шрифт, ATS не всегда может прочитать нестандартные или непонятные шрифты. Августин говорит, что могут работать как шрифты с засечками, так и без засечек, а безопасные шрифты включают (но не ограничиваются ими): Calibri, Arial, Trebuchet, Book Antiqua, Garamond, Cambria и Times New Roman.
- Frames: Помещение рамки или рамки по всему периметру вашего резюме - это «большое ATS нет-нет», - говорит Августин.
Конечно, вы всегда можете внести изменения в существующий шаблон. Так что, если есть рамка, вы можете просто удалить ее. Если место для вашего имени находится в заголовке, вы можете переместить его в основной текст. Или, если шрифт нечеткий, вы можете изменить его на более распространенный.
Другими словами, вам не нужно сразу отклонять шаблон, потому что он содержит один из этих элементов. Но вы можете избежать шаблона, в котором так много блокировщиков ATS, что вам придется выполнять гимнастику форматирования, чтобы довести его до приемлемого базового уровня.
5. Избегайте шаблонов резюме с фотографиями
Шилдс заметил, что веб-сайты с шаблонами имеют тенденцию к использованию фото резюме, которые распространены во многих странах по всему миру. Однако, по словам Шилдса, соискателям работы в США следует избегать снимков в голову, как для ATS, так и для людей, которые могут рассмотреть ваше заявление.
С технической точки зрения, ATS не сможет проанализировать изображение, поэтому в лучшем случае оно просто упадет, когда система создаст ваш цифровой профиль.Но более тревожным является сценарий, когда изображение вызывает проблемы с форматированием или ошибки синтаксического анализа, которые могут повлиять на то, как система читает остальную часть вашего резюме.
И помимо ATS, «мы слышали из первых уст от множества рекрутеров, которые даже не проверяют кандидатов, приславших фотографии», - говорит Шилдс. «Они просто не могут сделать себя более уязвимыми перед любыми возможными жалобами на дискриминацию». И вы также не хотите подвергаться действительной дискриминации.
Суть в том, говорит Вивиано, что, если вы не модель или актер, ваше фото не должно быть в вашем резюме. По сути, вы «занимает много места в своем резюме [чем-то], что не должно иметь никакого отношения к тому, кто вас нанимает».
Как использовать шаблон для создания резюме в Word
Итак, вы нашли один или два шаблона, которые вам действительно нравятся, и готовы сесть и составить свое резюме. Что теперь?
1. Соберите всю свою информацию
«Прежде чем вы начнете, найдите время, чтобы собрать всю информацию, которая могла бы быть использована для написания вашего резюме», - говорит Августин.
Если у вас есть предыдущее резюме, над которым вы работаете, убедитесь, что оно у вас под рукой. Вы также можете сесть и создать документ, включающий каждую прошлую работу, навыки и достижения, которые вы можете использовать в качестве источника для рисования. Или вы можете заполнить этот рабочий лист. Когда у вас будет весь контент, будет проще легко вставить его в шаблон.
2. Не бойтесь изменять шаблон
Шаблоны не высечены в камне. Помните, что вы можете и должны вносить изменения по мере необходимости, чтобы шаблон работал на вас.
Для начала вы по-прежнему увидите множество шаблонов, которые по-прежнему включают разделы для утверждения цели или для ваших ссылок, даже если оба являются устаревшими элементами, которым больше не место в вашем резюме.
Это нормально, если вы настроены на шаблон, в котором есть эти разделы, но убедитесь, что вы удалили или преобразовали их. Раздел с целью может легко стать местом для резюме резюме, например, или использоваться для перечисления ваших ключевых навыков, в то время как раздел ссылок может превратиться в раздел волонтерства или наград.
Помимо избавления от устаревших разделов, вы можете внести любые изменения, которые, по вашему мнению, помогут вам представить лучшую версию себя для этой роли. «Шаблон резюме может служить отличным руководством, но иногда он принесет больше вреда, чем пользы, если вы измените свой опыт в соответствии с шаблоном, а не наоборот», - говорит Шилдс. «Поэтому, если у вас нет ничего для определенного раздела в шаблоне, удалите его. Если вы хотите добавить дополнительную информацию, которая, по вашему мнению, укрепляет вашу позицию, добавьте ее », - говорит он.«Просто будьте осторожны, сохраняйте единообразное форматирование и сосредоточьтесь на удобочитаемости».
Предположим, вы нашли понравившийся вам шаблон, который поможет вам в работе, но вы действительно хотите выделить свои ключевые навыки в верхней части. Не стесняйтесь добавить еще один раздел, используя тот же шрифт и стиль заголовка. С другой стороны, если вы используете шаблон, в котором есть раздел наград и благодарностей, но вы бы предпочли продемонстрировать свой волонтерский опыт или дополнительные навыки, измените его.
Помните также, что шаблон - это просто шаблон.«Это дает вам основу для работы», - говорит Августин, но вам все равно придется приложить усилия, чтобы решить, какие достижения и навыки следует выделить и как лучше всего сформулировать свои маркеры.
3. Вставьте или впишите вашу информацию
Когда вы, наконец, будете готовы поместить весь свой опыт работы и достижения в шаблон и сделать его своим, Вивиано рекомендует вам «сначала завершить простые вещи», например ваше имя контактная информация и ваше образование.«Это будет похоже на быструю победу». Затем продолжайте заполнять остальные.
Облегчите себе жизнь позже, вставив информацию только в виде текста - без форматирования, которое было в предыдущем резюме, подготовительном документе или заполненном вами рабочем листе. Используйте этот трюк с копированием и вставкой, чтобы убедиться, что все, что вы туда помещаете, соответствует форматированию шаблона. В противном случае вы можете «потратить невероятное количество времени, пытаясь снова установить правильный интервал», - говорит Августин.
Наконец, убедитесь, что вы заменили или удалили весь фиктивный текст и все инструкции, которые были в шаблоне, когда вы его получили!
4.Проверьте, как это будет в ATS
Если вы хотите проверить, как ваше новое резюме будет работать, когда оно пройдет через ATS, вы можете попробовать одно из двух:
Скопируйте все в свой документ Word и вставьте все это в простой текстовый документ. «Если некоторые вещи превращаются в странных персонажей, - говорит Августин, - если разделы находятся далеко от того места, где они должны быть, или если все не в порядке, то это, вероятно, произойдет, если они будут проанализированы».
Запустите его с помощью онлайн-инструмента, такого как сканирование вакансий, или запросите бесплатную критику в такой службе, как TopResume.
5. Перечитайте и подтвердите!
По словам Августина, опечатки и орфографические ошибки часто мешают рекрутерам. И было бы обидно попасть в кучу «нет» из-за мелких ошибок. Поэтому убедитесь, что вы исправили свое резюме - может быть, дважды, а может быть, отойдя от него на несколько часов - и посмотрите, сможете ли вы передать его другу или члену семьи, чтобы он взглянул свежим взглядом.
Перечитывание вашего резюме как полного документа - это также возможность представить себе первое впечатление, которое вы произведете.«Многие люди ... так увлекаются редактированием резюме и тем, чтобы оно было настолько оптимизировано, что оно становится похожим на роботизированное резюме», - говорит Вивиано. Итак, пока вы читаете, подумайте: это звучит так, как будто это написал человек? Какую историю ты рассказываешь? Очевидно ли, что вы подходите для той должности, на которую претендуете?
7 шаблонов Microsoft Word для использования в качестве отправных точек
Все еще не можете выбрать шаблон после всего этого? Вот несколько из них, которые могут сработать - мы добавили советы по улучшению и настройке каждого из них.
1. Резюме Genius’s Dublin Template
Кто может его использовать? Всем, кто ищет традиционное хронологическое резюме!
Предостережения:
- Вам не нужно указывать полный адрес (достаточно указать город и штат).
- Добавьте свой профиль LinkedIn вместе с другой контактной информацией, чтобы рекрутер или менеджер по найму могли перейти на вашу страницу и найти дополнительную информацию о вашем опыте, увидеть яркие рекомендации, которые вы получили, просмотреть образцы работы, которые вы разместили, и получить в восторге от вас как кандидата.(Просто убедитесь, что ваш профиль обновлен!)
- Не указывайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Скачайте здесь.
2. Недавний шаблон Grad 1 от JobScan
Кто может его использовать? Недавний выпускник, имеющий стажировку или опыт работы, соответствующий их целевой области или должности, а также другой опыт.
Предупреждения:
- Вам не нужно указывать свой почтовый индекс.
- Не включайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Скачайте здесь.
3. Базовый шаблон резюме Microsoft Office
Кто может его использовать? Недавний выпускник, у которого нет большого опыта работы.
Предостережения:
- Поместите свое имя в одну строку (вместо двух строк, как по умолчанию), чтобы ATS записал ваше полное имя.
- Попробуйте различать заголовки разделов в каждой записи о вакансиях и образовании, изменив размер или стиль шрифта.
- Добавьте свой профиль LinkedIn рядом со своей контактной информацией и помните, что вам не нужно указывать полный адрес (достаточно указать город и штат).
Стоимость: Бесплатно
Найдите в Microsoft Word.
4. Шаблон резюме Get Landed для ATS
Кто может его использовать? Кто-то ищет шаблон, который можно было бы легко настроить как хронологическое или комбинированное резюме, в зависимости от того, где вы разместили этот раздел навыков.
Предостережения:
- Если вы не недавний выпускник, вам, вероятно, не следует получать такое высокое образование.
Стоимость: $ 10
Скачайте здесь.
5. ResumeByRecruiters 'ATS Resume на Etsy
Кто может его использовать? Кто-то ищет шаблон, который можно было бы легко настроить как хронологическое или комбинированное резюме (переместив раздел навыков наверх).
Предостережения:
- Добавьте свой профиль LinkedIn вместе со своей контактной информацией.
Стоимость: Около 12 долларов США
Загрузите его здесь.
6. Классические хронологические и гибридные шаблоны JobScan
Кто может им воспользоваться? Кто-то ищет простой шаблон без излишеств.
Предупреждения:
- Вам не нужно указывать свой почтовый индекс.
- Постарайтесь уместить все на одной странице.
Стоимость: Бесплатно
Скачайте их здесь.
7. Резюме шаблона Белого дома Genius
Кто может его использовать? Кто-то ищет шаблон с большим количеством белого пространства.
Предостережения:
- Вам не нужен полный адрес; города и штата достаточно.
- Добавьте свой профиль в LinkedIn.
- Не используйте ли , а не раздел цели резюме. Вы можете заменить это резюме или полностью избавиться от него.
Стоимость: Бесплатно
Скачайте здесь.
Как наша функция анализа вложений документов Word может спасти миллиарды предприятий
Нравится это вам или нет, но Microsoft Office - это программное обеспечение для деловых масс, а Microsoft Word безраздельно занимает первое место в списке. Из договоров аренды в офисах недвижимости, договоров с юридическими фирмами и заказов на закупку в рекламе (и почти во всех других отраслях) неудивительно, почему только за один год было создано 500 миллиардов документов Office (Источник: Business Insider).
После того, как документ создан и сохранен, следующим шагом часто является отправка его коллегам или клиентам по электронной почте, блокировка важных бизнес-данных во вложениях электронной почты.
Если вы блуждали по пустыне ручного копирования и вставки этих данных из документов Word (файлов .doc или .docx), прикрепленных к вашим электронным письмам, у нас есть замечательные новости для ваших пальцев - возможно, вам никогда не придется нажимать Команда C еще раз.
Благодаря нашей функции вложений документов Word отпадает необходимость тратить вечность на перемещение данных из файлов Word в другую систему взаимодействия с клиентами или систему управления документами.Просто настройте несколько правил синтаксического анализа, чтобы идентифицировать данные, которые вы хотите извлечь из документа, а затем используйте одну из наших многочисленных интеграций, чтобы отправить их в Hubspot, Google Sheets или даже в собственную базу данных вашей компании.
Потратив несколько минут на настройку бесплатной учетной записи Mailparser и ваших правил синтаксического анализа, вы можете сэкономить время, деньги и повысить точность своих деловых записей.
Экономьте время: даже если вы извлекаете данные только из одного документа Word в день, стоит автоматизировать его.Примечание. Mailparser специализируется на анализе данных из электронных писем и вложений. Если вам нужен более надежный анализ документов, обратите внимание на нашу дочернюю компанию, Docparser, которая не ограничивается вашим почтовым ящиком.
Предположим, что требуется 5–10 минут, чтобы найти нужное письмо, открыть вложение, скопировать и вставить из него все данные. В течение ~ 250 рабочих дней в году это будет означать, что вы потратите до одной полной рабочей недели на ввод данных. И это только в случае одного документа в день! Продолжайте добавлять больше документов в виртуальную стопку, и вы увидите потерянные недели в продуктивности.
Очень заманчиво просто выполнять эти быстрые задачи, когда они попадают на ваш стол. Но когда вы думаете о том, как это складывается в долгосрочной перспективе - и что вы могли бы сделать с дополнительной рабочей неделей, - нетрудно выделить 10 минут, чтобы вместо этого автоматизировать эту задачу.
Экономьте деньги. Независимо от того, выполняете ли вы ввод данных самостоятельно или нанимаете для этого кого-то другого, это дорого обходится просто потому, что это требует времени.Возьмем приведенный выше пример и учтем ставку заработной платы или почасовую ставку человека, перемещающего данные из ваших вложений электронной почты в другую систему, и вы, вероятно, будете удивлены такой стоимостью.
Предположим, ввод данных - это работа с низкой заработной платой, зарабатывающая в среднем 15 долларов в час. Даже в нашем простом примере выше это 625 долларов в год. И помните, это всего по одному документу в день. Если у вас есть кто-то, занимающийся вводом данных 10 часов в неделю, мы говорим о 7500 долларов в год. Для малого бизнеса это значительные затраты. И по мере роста вашего бизнеса эта стоимость будет увеличиваться.
Кроме того, есть накладные расходы на обучение людей в ваших системах каждый раз, когда у вас есть текучесть кадров, чтобы они знали, какие поля из документа Word идут, где в вашей CRM или другой системе.И, наконец, задания, в которых ввод данных является основной задачей, обычно имеют высокую текучесть кадров, что означает более высокие накладные расходы на обучение (и исправление ошибок).
А исправление ошибок особенно дорого обходится. В 2016 году IBM отказалась от ошеломляющей оценки в 3,1 триллиона долларов в качестве стоимости неверных данных (Источник: Harvard Business Review).
Повышение точности: когда речь идет о данных, нет скользящей шкалы производительности. Это либо правильно, либо нет.И дело в том, что, хотя есть еще много вещей, которые люди делают лучше, чем технологии, ввод данных не входит в их число.