Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
| Вопрос 1 из 20 Действие по глаголу обкаливать | |
| осмолка | отделка |
| обкалка | отзолка |
Только что искали: пиоканея сейчас сервер сейчас в ь о е л м р ы е и и н с е е сейчас миягицар сейчас а з а к у б сейчас фреска сейчас кийален сейчас богнлее сейчас г а б о н ь сейчас самохвальской сейчас постройка 1 секунда назад клеперина 1 секунда назад доталог 1 секунда назад шанкваи 1 секунда назад митаногал 1 секунда назад
Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- определить его корректное написание;
- понять, как правильно в нем ставить ударение.


Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
реноеупчи только что
хиылскт только что
реотаксис только что
лоагким 1 секунда назад
зельпоа 1 секунда назад
иватора 1 секунда назад
аиторц 2 секунды назад
подзадоривают 2 секунды назад
вывеивавшемся 3 секунды назад
давить свинцовой тяжестью 3 секунды назад
лачи 3 секунды назад
холвуд 11 секунд назад
рнаукг 12 секунд назад
цокавшем 12 секунд назад
еек 12 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | несуразность | 70 слов | 14 минут назад | 91. 132.23.36 132.23.36 |
| Игрок 2 | исчезновение | 0 слов | 48 минут назад | 178.176.215.226 |
| Игрок 3 | cap | 0 слов | 48 минут назад | 178.176.215.226 |
| Игрок 4 | лесокультура | 117 слов | 3 часа назад | 91.132.23.36 |
| Игрок 5 | назойливость | 77 слов | 3 часа назад | 91.132.23.36 |
| Игрок 6 | избираемость | 81 слово | 4 часа назад | 91.132.23.36 |
| Игрок 7 | подзатыльник | 114 слов | 5 часов назад | 91.132.23.36 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Софи | замша | 39:41 | 56 минут назад | 46. 251.112.98 251.112.98 |
| Адам | сетка | 54:43 | 1 час назад | 89.109.196.236 |
| Игрок 3 | толпа | 9:9 | 2 часа назад | 5.138.195.151 |
| Игрок 4 | проза | 45:51 | 2 часа назад | 5.138.195.151 |
| Игрок 5 | толпа | 46:53 | 2 часа назад | 5.138.195.151 |
| Игрок 6 | страсть | 38:49 | 2 часа назад | 5.138.195.151 |
| Игрок 7 | аграф | 42:50 | 2 часа назад | 2.58.194.132 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Соци | На одного | 10 вопросов | 1 час 40 секунд назад | 46. 251.112.98 251.112.98 |
| П | На одного | 5 вопросов | 4 часа назад | 84.237.54.5 |
| А | На одного | 10 вопросов | 4 часа назад | 84.237.54.5 |
| Ьо | На одного | 5 вопросов | 4 часа назад | 84.237.54.5 |
| Даня | На одного | 10 вопросов | 9 часов назад | 109.165.44.106 |
| Я | На одного | 20 вопросов | 12 часов назад | 188.170.169.224 |
| Олли | На двоих | 5 вопросов | 14 часов назад | 79.98.9.16 |
| Играть в Чепуху! | ||||
‘Close To The Edge’: как Yes прыгнули в прог-рок-бессмертие в начале 1972 года вместе с сопродюсером Эдди Оффордом направились в студию Advision Studios в Фицровии.
 Уже находясь на пороге величия, певец Джон Андерсон, гитарист Стив Хоу, клавишник Рик Уэйкман, басист Крис Сквайр и барабанщик Билл Бруфорд удвоили свой жанр. — бросающий вызов породе звуковых смельчаков, разветвляющихся на более длинные, более джазовые композиции и эзотерические лирические концептуальные пьесы для их определяющего шедевра прогрессивного рока, Близко к краю .
Уже находясь на пороге величия, певец Джон Андерсон, гитарист Стив Хоу, клавишник Рик Уэйкман, басист Крис Сквайр и барабанщик Билл Бруфорд удвоили свой жанр. — бросающий вызов породе звуковых смельчаков, разветвляющихся на более длинные, более джазовые композиции и эзотерические лирические концептуальные пьесы для их определяющего шедевра прогрессивного рока, Близко к краю .Послушайте «Close To The Edge» здесь.
«По сути, у нас нет направления. Мы можем отправиться куда угодно, — с гордостью заявил Джон Андерсон. «Мы просто надеемся, что это та музыка, в которой все барьеры рухнули». Играя с магнитофонными лупами длиной до 40 футов и заставляя барабанщика Билла Бруфорда целыми днями проходить через его окровавленные пальцы, Yes решили не демо своих новых песен и вместо этого сосредоточились на оттачивании грубых идей для того, что станет их пятым альбомом.
«Речь идет о невероятном дисбалансе человеческого опыта на планете»
Литературное влияние варьируется от духовных основ романа Германа Гессе 1922 года « Сиддхартха » до фантастического миростроительства романа Дж. Р. Р. Толкина « Повелитель Мира». Rings , Close To The Edge Сложный 18-минутный заглавный трек открыл альбом и показал, как Yes с головой нырнул в головокружительный пейзаж прог-рока.
Р. Р. Толкина « Повелитель Мира». Rings , Close To The Edge Сложный 18-минутный заглавный трек открыл альбом и показал, как Yes с головой нырнул в головокружительный пейзаж прог-рока.
Со структурой из четырех частей, которая имеет больше общего с классической музыкой, чем с готовым для радио роком, песня с самого начала амбициозна, ослепляя слушателя фрагментарной гитарной игрой Стива Хоу и барабанными партиями произвольной формы Билла Бруфорда. От пения птиц до джаз-роковой тренировки песня переходит в возвышенный рапсодический рифф, прежде чем группа бросается в неистовый ритм с хлюпающими басовыми партиями Криса Сквайра, в то время как Джон Андерсон поет, как средневековый раб во власти волшебницы («A опытная ведьма могла бы призвать тебя из глубины твоего позора»).
После заклинания космических клавишных тонов Рика Уэйкмана и паучьих гитарных партий Хоу появляется повторяющийся вокальный мотив («Я встаю, я спускаюсь»). «Эта песня появилась потому, что однажды Стив взял эти аккорды, — сказал Андерсон, — и я начал петь: «Два миллиона человек едва удовлетворяют». Она о невероятном дисбалансе человеческого опыта на планете». Задавая тон неустанным амбициям Close To The Edge , заглавный трек уже поставил группу на грань нового рубежа.
Она о невероятном дисбалансе человеческого опыта на планете». Задавая тон неустанным амбициям Close To The Edge , заглавный трек уже поставил группу на грань нового рубежа.
«Вся комната была так наполнена музыкой, которую мы сочиняли»
Возможно, это одна из самых загадочных песен о любви, когда-либо написанных. -минутное поэтическое размышление о паре влюбленных, живущих вместе, поражающих слушателей стрелой Купидона с помощью 12-струнной акустической гитары Стива Хоу. «Это должна была быть очень красивая народная песня, которую я написал со Стивом», — сказал Джон Андерсон. «Вскоре мы решили, что это должно быть окружено очень большими темами».
От открытия родственной души (Cord Of Life) до супружеского союза (Eclipse) песня снова была разделена на четыре части, используя небесные метафоры так же выразительно, как гравюры поэта-романтика Уильяма Блейка. В музыкальном плане And You And I порхает от задумчивого мелодизма к необычному тактовому размеру, отражая сумеречные годы влюбленных, состарившихся вместе (Проповедник, Учитель), прежде чем полностью сбросить эту смертную оболочку (Апокалипсис).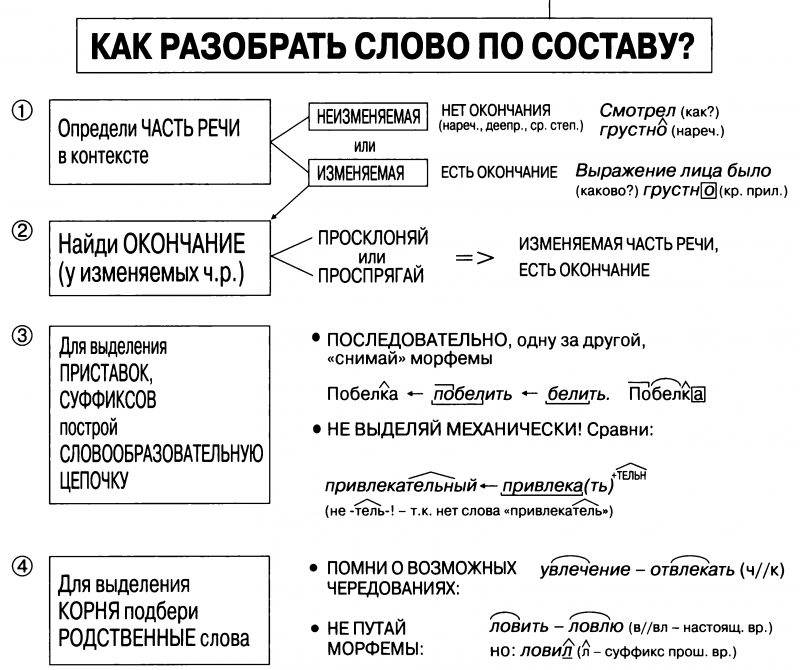 Смерть, в данном случае, является просто символом трансцендентности, подобно тому, как священники в Средние века описывали ее религиозным приверженцам.
Смерть, в данном случае, является просто символом трансцендентности, подобно тому, как священники в Средние века описывали ее религиозным приверженцам.
Однако только когда Yes сыграли эту песню вживую, они поняли, насколько захватывающим был And You And I. «Я помню, как мы впервые выступили And You And I в Spectrum в Филадельфии, — сказал Андерсон. «Вся комната была настолько наполнена музыкой, которую мы делали, это было действительно ошеломляюще». Поистине демонстрируя музыкальную изобретательность Yes, And You And I создали впечатление, будто они срывают с небес какую-то древнюю истину.
«Я продолжал петь это слово снова и снова, хотя понятия не имел, что оно означает»
Начавшись с гитарного вступления Стива Хоу, почти в стиле Джими Хендрикса, а затем очаровав слушателей крутящимися клавишными Рика Уэйкмана, Close To The Edge, эпическое завершение , Siberian Khatru, разворачивается в своеобразный R&B-стиль, сочетающийся с головокружительным бессвязный рок-рифф. В песне, наполненной тоном электрического ситара и лихорадочным клавесином, Джон Андерсон снова вступает на философскую территорию.
В песне, наполненной тоном электрического ситара и лихорадочным клавесином, Джон Андерсон снова вступает на философскую территорию.
«Khatru в переводе с йеменского означает «как хочешь», — сказал певец. «Я продолжал петь это слово снова и снова, хотя понятия не имел, что оно означает». Загадочный, как всегда, текст песни может быть как размышлением о географической дистанции, так и квазирелигиозной притчей. Стремясь к лихорадочным и драматическим крайностям, Siberian Khatru была восьмиминутным рокером, в отличие от любой другой из лучших песен Yes, переходя от выигрышных моментов гипнотических басовых грувов к пассажу, похожему на скат, среди кружащихся звуков, которые были захвачены качанием микрофона. вокруг студии для создания эффекта Доплера.
Собранный в первой половине 1972 года, Close To The Edge довел каждого музыканта до предела, но результат того стоил. «Это было все равно что стиснуть зубы, чтобы сделать Close To The Edge », — сказал барабанщик Билл Бруфорд. «И все же получилось очень хорошо! Это был отличный альбом. Как так получилось, просто чудо».
«И все же получилось очень хорошо! Это был отличный альбом. Как так получилось, просто чудо».
«Мы рассказывали истории и создавали настроение. Все это было очень смело и прекрасно».
Было продано более миллиона копий после его выпуска, 13 сентября 1972, Close To The Edge занял 3-е место в США и 4-е место в Великобритании, намного превзойдя коммерческий успех своего предшественника, Fragile . Альбом, ставший высшей точкой подъема прогрессивного рока, также доказал, что глобальная аудитория стремится выйти за рамки основанных на поп-музыке формул и готова открыть свой разум для более экспериментального звучания. Поставив себя на порог возвышенных амбиций и бесстрашной музыкальности, Yes выпустили знаменательную работу, которая сразу же заняла свое место среди лучших альбомов 70-х.
«Я могу только предполагать, что фанатов привлек смелый подход и наше путешествие в царство длинных аранжировок, воплощенных в этом альбоме», — позже сказал басист Крис Сквайр. Джон Андерсон также чувствовал, что их мужество плыть против течения модной поп-музыки и глэм-рока окупилось. «Мы рассказывали истории и создавали настроение», — заметил он. «Все это было очень смело и прекрасно».
Джон Андерсон также чувствовал, что их мужество плыть против течения модной поп-музыки и глэм-рока окупилось. «Мы рассказывали истории и создавали настроение», — заметил он. «Все это было очень смело и прекрасно».
В 2019 году опрос читателей журнала Prog объявил Close To The Edge , чтобы стать величайшим альбомом прогрессивного рока всех времен, обогнав такие записи, как King Crimson, Genesis и Pink Floyd. Вряд ли это должно вызывать удивление. Сегодня альбом остается заманчивым произведением симфонического чуда от группы, которая расширяла горизонты рок-н-ролла так, как немногие музыканты когда-либо мечтали.
Купить винил Да и автографы на раскопках! хранить.
Глубокое и широкое изучение мотивов связывания в данных ChIP-Seq | Биоинформатика
Статья журнала
Кулаковский И.В.,
И. В. Кулаковский *
1 Научно-исследовательский институт генетики и селекции промышленных микроорганизмов, Москва 117545, Россия, 2 Институт Кюри, улица Ульм, 26, 3 INSERM, U900, 4 INSERM, Париж F724, U833 , 5 Mines ParisTech, Фонтенбло F-77300, Франция, 6 Университет Джона Хопкинса, Балтимор, Мэриленд 21205, США и 7 Институт молекулярной биологии им. Энгельгардта РАН, Москва 119991, Россия
Энгельгардта РАН, Москва 119991, Россия
Ищите другие работы этого автора на:
Оксфордский академический
пабмед
Google ученый
Боева В.А.,
В. А. Боева
1 Научно-исследовательский институт генетики и селекции промышленных микроорганизмов, Москва 117545, Россия, 2 Institut Curie, 26 rue d’Ulm, 3 INSERM, U900, 4 INSERM, U830, Paris F-75248, 5 Mines ParisTech, Fontainebleau F-77300, France, University , Балтимор, Мэриленд 21205, США и 7 Институт молекулярной биологии им. Энгельгардта РАН, Москва 119991, Россия
Ищите другие работы этого автора на:
Оксфордский академический
пабмед
Google ученый
Фаворов А.В.,
А. В. Фаворов
1 Научно-исследовательский институт генетики и селекции промышленных микроорганизмов, Москва 117545, Россия, 2 Институт Кюри, улица Ульм, 26, 3 INSERM, U900, 4 INSERM, Париж F724, U833 , 5 Mines ParisTech, Фонтенбло F-77300, Франция, 6 Университет Джона Хопкинса, Балтимор, Мэриленд 21205, США и 7 Институт молекулярной биологии им. Энгельгардта РАН, Москва 119991, Россия
Ищите другие работы этого автора на:
Оксфордский академический
пабмед
Google ученый
Макеев В.Ю.
В. Ю. Макеев
1 Научно-исследовательский институт генетики и селекции промышленных микроорганизмов, Москва 117545, Россия, 2 Institut Curie, 26 rue d’Ulm, 3 INSERM, U900, 4 INSERM, U830, Paris F-75248, 5 Mines ParisTech, Fontainebleau F-77300, France, University , Балтимор, Мэриленд 21205, США и 7 Институт молекулярной биологии им. Энгельгардта РАН, Москва 119991, Россия
Ищите другие работы этого автора на:
Оксфордский академический
пабмед
Google ученый
Авторы Примечания
Bioinformatics , том 26, выпуск 20, 15 октября 2010 г., стр. 2622–2623, https://doi.org/10.1093/bioinformatics/btq488
Опубликовано:
20 октябрь 2010
88
. История статьи
Получено:
25 мая 2010 г.
Получена редакция:
07 августа 2010 г.
Принято:
18 августа 2010 г.
Опубликовано:
20 октября 2010 г.
- Разделенный вид
- Содержание статьи
- Рисунки и таблицы
- видео
- Аудио
- Дополнительные данные
Цитировать
Cite
И.
В. Кулаковский, В. А. Боева, А. В. Фаворов, В. Ю. Макеев, Глубокое и широкое исследование мотивов связывания в данных ChIP-Seq, Биоинформатика , том 26, выпуск 20, 15 октября 2010 г., страницы 2622–2623, https://doi.org/10.1093/bioinformatics/btq488Выберите формат Выберите format.ris (Mendeley, Papers, Zotero).enw (EndNote).bibtex (BibTex).txt (Medlars, RefWorks)
Закрыть
Разрешения
- Электронная почта
- Твиттер
- Фейсбук
- Подробнее
Фильтр поиска панели навигации БиоинформатикаЭтот выпускЖурналы по биоинформатикеБиоинформатика и вычислительная биологияКнигиЖурналыOxford Academic Термин поиска мобильного микросайта
Закрыть
Фильтр поиска панели навигации БиоинформатикаЭтот выпускЖурналы по биоинформатикеБиоинформатика и вычислительная биологияКнигиЖурналыOxford Academic Термин поиска на микросайте
Advanced Search
Abstract
Резюме: Данные ChIP-Seq представляют собой новую проблему для обнаружения мотивов. Такие данные обычно состоят из тысяч сегментов ДНК с базовыми значениями покрытия. Мы представляем новую версию нашего программного обеспечения для обнаружения мотивов ДНК ChIPMunk, адаптированного для данных ChIP-Seq. ChIPMunk — это итеративный алгоритм, сочетающий жадную оптимизацию с начальной загрузкой и использующий профили покрытия в качестве позиционных предпочтений мотива. ChIPMunk не требует усечения длинных сегментов ДНК и удобен для обработки до десятков тысяч последовательностей данных. Сравнение с традиционными (MEME) или ориентированными на ChIP-Seq (HMS) инструментами обнаружения мотивов показывает, что ChIPMunk идентифицирует правильные мотивы с таким же или лучшим качеством, но работает значительно быстрее.
Наличие и реализация: ChIPMunk находится в свободном доступе в составе Java-пакета ru_genetika: http://line.imb.ac.ru/ChIPMunk. Также доступна веб-версия.
Контактное лицо: [email protected]
Дополнительная информация: Дополнительные данные доступны по адресу Биоинформатика онлайн.
1 ВВЕДЕНИЕ
ChIP-Seq (Valouev et al. , 2008 г.) представляет собой эффективную технологию для идентификации ДНК-сайтов связывания специфического белка. В сочетании с алгоритмами поиска пиков (Fejes и др. , 2008), он дает набор сегментов ДНК, где каждое положение последовательности имеет вес, отражающий, как часто близлежащая ДНК была сшита с интересующим белком на стадии ChIP (так называемые пики). Могут быть десятки тысяч сегментов ДНК, некоторые из которых длиннее 1000 п.н. Классические инструменты, такие как Weeder (Pavesi et al. , 2001), Gibbs Sampler (Lawrence et al. , 1993) или MEME (Bailey et al. , 2009), были протестированы на обнаружение мотивов в сегментах ChIP-Seq. но оказалось неэффективным для всего объема данных. Поэтому обычно брали часть верхних сегментов ДНК (Chen и др. , 2008) и/или сегменты были усечены вокруг максимумов пиков (Ji и др. , 2008). Такие инструменты, как cERMIT (Georgiev et al. , 2010) и HMS (Hu et al. , 2010), были разработаны для обнаружения мотивов из данных ChIP-Seq. В этой заметке мы представляем алгоритм обнаружения мотива, который может извлекать единственный оптимальный мотив из больших наборов данных, таких как ChIP-Seq, без какой-либо предварительной обработки, принимая во внимание форму пика.
2 МЕТОДЫ
Базовая реализация ChIPMunk (Кулаковский и Макеев, 2009, см. также раздел 1 дополнительного текста, STS1) была дополнена тремя функциями, необходимыми для обнаружения мотивов из данных ChIP-Seq: учет фонового нуклеотидного состава (через концепцию KDIC), режим нулевого или одного вхождения на последовательность (ZOOPS) и позиционные профили в исходных данных (необходимо учитывать базовое покрытие в данных ChIP-Seq).
2.1 Концепция KDIC
Базовая версия алгоритма ChIPMunk осуществляет поиск мотива с наибольшей дискретной информативностью (DIC) (Кулаковский и др. , 2009). ДИК не учитывает фоновый нуклеотидный состав. Для учета фона используем дискретный аналог дивергенции Кульбака–Лейблера (Kullback DIC, KDIC) (Kullback and Leibler, 1951):
, где x α, j — элементы матрицы подсчета позиций (т. е. количество букв), w — длина мотива, а q α — фоновые вероятности нуклеотидов. Пожалуйста, обратитесь к STS 2 для математических подробностей, связанных с KDIC.
2.2 Режим ZOOPS
ChIPMunk ищет множественное локальное выравнивание без пропусков, которое имеет максимальное значение KDIC. Затем строится позиционная весовая матрица (ШИМ), и все выровненные слова сортируются по их значениям ШИМ. Они подразделяются на подсписки «сигнал» и «шум». Чтобы найти граничное слово, мы строим серию ШИМ, состоящую из первых 1, 2,…, n слов. Идея состоит в том, что для «сигнала» оценка n -го слова, рассчитанная с помощью n -й ШИМ должен быть заметно больше, чем рассчитанный с помощью N -й ШИМ (где N — общее количество слов). Подробности см. в STS 3.
2.3 Позиционные профили
Существует два типа весов, присвоенных исходным данным последовательности. Последовательности взвешиваются в целом; также веса назначаются каждой позиции последовательности, формирующей профили последовательности. Источником всех весов являются данные о форме пика. Вес Вт i для i -й последовательности — ее нормированное максимальное пиковое значение; по нормализации сумма W i по всем i равна общему количеству последовательностей. Профили последовательности нормализованы, чтобы они соответствовали интервалу [0,1].
Оптимизация ШИМ включает два чередующихся шага: (i) выравнивание восстанавливается из слов с максимальным значением ШИМ в каждой последовательности данных и (ii) ШИМ восстанавливается из новых вхождений мотива. Оценки PWM для предполагаемых попаданий взвешиваются по профилям последовательностей:
, где w — длина слова, а S word[ j ], j — элемент ШИМ для j -й буквы в слове. Таким образом, позиции с более высокими значениями профиля вносят больший (положительный или отрицательный) вклад в оценку PWM. Затем рассчитываются позиционные счетные веса x α, j для буквы α в позиции мотива j :
Здесь профиль i [ j ] — значение профиля последовательности i в положении j , а N обозначает букву «неизвестный нуклеотид». После сбора данных из всех слов x N , J Значения равномерно разделены между x α, J (α ∈ A , C , G, A , C , G, α ∈ A T ), поэтому общая сумма равна количеству слов.
Сходимость зависит от данных. Если области высокого профиля не могут быть выровнены или их состав похож на фон, разные мотивы могут иметь очень близкие значения KDIC, что ухудшает сходимость. Тем не менее, для реальных данных ChIP-Seq сходимость улучшается после сглаживания профиля за счет замены значений профиля на их максимумы в скользящем окне с длиной, равной длине мотива.
3 РЕЗУЛЬТАТЫ
Мы взяли три набора данных ChIP-Seq: NRSF (Johnson et al. , 2007), GABP (Valouev et al. , 2008) и EWS-FLI1 (Guillon , 20007 0 8. al. ). Мы использовали FindPeaks (Fejes et al. , 2008) для получения обогащенных областей (пиков). Сегменты со строгими повторами типа GGAA были исключены из набора данных EWS-FLI1. Длины мотивов были зафиксированы на уровне 21, 12 и 11 для NRSF, GABP и EWS-FLI1 соответственно.
Топ-100 (NRSF, GABP) и топ-500 (EWS-FLI1) пиков были взяты для тестирования нескольких инструментов обнаружения мотивов, включая MEME (Bailey и др. , 2009), SeSiMCMC (Favorov et al. , 2005) и HMS, новый пробоотборник Гиббса, ориентированный на ChIP-Seq (Hu et al. , 2010). Мы использовали наборы сегментов, которые были усечены от 10% до 100% длины пиков и центрированы по максимумам пиков.
В качестве меры качества мотива использовали долю пиков, усеченных до 10% от исходной длины с центром в максимуме пика, с совпадениями мотива, имеющими баллы, превышающие среднее + 3 SD распределения баллов по всем w -мерам. Мы оценили временную эффективность обнаружения мотива и результирующее качество мотивов, идентифицированных по 500 пикам EWS-FLI1 (рис. 1). На коротких участках, покрывающих лишь 10% пиков, все протестированные инструменты показали себя одинаково хорошо. При увеличении длины сегмента MEME и SeSiMCMC, не учитывающие форму пика, идентифицировали неправильные мотивы. Напротив, ChIPMunk (в пиковом режиме) всегда определял правильный мотив. В режиме, не учитывающем формы пиков, ChIPMunk не смог определить правильный мотив в более длинных сегментах. Тем не менее, в обоих режимах ЧИПМанк явно выигрывал у ГМС с учетом формы пиков как по скорости, так и по качеству. Для NRSF и GABP правильные мотивы были извлечены всеми инструментами в более широком диапазоне длин последовательностей, что, вероятно, указывает на лучшее качество данных (см. STS 4).
Рис. 1.
Открыть в новой вкладкеСкачать слайд
Эффективность времени обнаружения мотива и результирующее качество мотивов, идентифицированных в 500 лучших пиках EWS-FLI1. Подробнее см. в тексте. Консенсус правильного мотива gacaGGAAatg подобен таковому в Guillon et al. (2009).
В общем, здесь мы представили расширенную версию нашего инструмента для обнаружения мотивов ChIPMunk, который позволяет использовать информацию как с сильных, так и с более слабых сайтов (см. STS 10). ChIPMunk достаточно быстр и практически может обрабатывать наборы данных из тысяч последовательностей (см. STS 8) даже на персональном компьютере, используя преимущества современных многоядерных процессоров.
БЛАГОДАРНОСТИ
Мы благодарим Biobase и лично Александра Келя за предоставление нам бесплатного доступа к базе данных TRANSFAC.
Финансирование: Федеральное агентство по науке и инновациям России Государственный контракт [02.531.11.9003, 02.740.11.5008]; Проект Российского фонда фундаментальных исследований [10-04-92663 для VJM].
Конфликт интересов : не объявлено.
ССЫЛКИ
Bailey
TL
, и др.
MEME SUITE: инструменты для обнаружения и поиска мотивов
,
Nucleic Acids Res.
,
2009
, том.
37
(стр.
W202
—
W208
)
, и др.
Интеграция внешних сигнальных путей с основной транскрипционной сетью в эмбриональных стволовых клетках
133
(стр.
1106
—
1117
)
Фаворов
АВ
, и др.
Пробоотборник Гиббса для идентификации симметрично структурированных разнесенных мотивов ДНК с улучшенной оценкой длины сигнала
21
(стр.
2240
—
2245
)
Фейес
AP
и др.
FindPeaks 3.1: инструмент для выявления областей обогащения с помощью технологии массивно-параллельного секвенирования с коротким считыванием
24
(стр.
1729
—
1730
)
Георгиев
S
etal.
Идентификация мотива с доказательностью
,
Геном Биол.
,
2010
, том.
11
стр.
R19
Guillon
N
, и др.
Онкогенный белок EWS-FLI1 связывает in vivo микросателлитные последовательности GGAA с потенциальной функцией активации транскрипции
4
стр.
e4932
и др.
Об обнаружении и уточнении сайтов связывания факторов транскрипции с использованием данных ChIP-Seq
,
Nucleic Acids Res.
,
2010
, том.
38
(стр.
2154
—
2167
)
, и др.
Интегрированная программная система для анализа данных ChIP-chip и ChIP-seq
,
Нац. Биотехнолог.
,
2008
, том.
26
(стр.
1293
—
1300
)
Johnson
DS
8 etal.
Полногеномное картирование взаимодействий белок-ДНК in vivo
316
(стр.
1497
—
1502
)
Кулаковский
IV
,
Макеев
В.Ж.
.
Открытие мотивов ДНК, распознаваемых транскрипционными факторами, путем интеграции различных экспериментальных источников
54
(стр.
667
—
674
)
Кулаковский
2 ИВ
8 и др.
Обнаружение мотива и обнаружение мотива на основе данных следов ДНКазы, нанесенных на карту генома
,
Биоинформатика
,
2009
, том.
25
(стр.
2318
—
2325
)
Kullback
S
,
Leibler
RA
.
Об информации и достаточности
,
Анн. Мат. Стат.
,
1951
, том.
22
(стр.
79
—
86
)
Лоуренс
CE
, и др.
Обнаружение малозаметных сигналов последовательности: стратегия выборки Гиббса для множественного выравнивания
262
(стр.
208
—
214
)
Pavesi
G
8 et al.
Алгоритм поиска сигналов неизвестной длины в последовательностях ДНК
,
Биоинформатика
,
2001
, том.
17
Доп. 1
(стр.
S207
—
S214
)
Валоуев
A
, и др.
Полногеномный анализ сайтов связывания факторов транскрипции на основе данных ChIP-Seq
,
Nat. Методы
,
2008
, том.
5
(стр.
829
—
834
)
Примечания автора
Автор Заместитель редактора: Джон Квакенбуш
0 Опубликовано Oxford University. Все права защищены. Для получения разрешений обращайтесь по электронной почте: [email protected]
Раздел выпуска:
Анализ последовательности
Скачать все слайды
Дополнительные данные
Дополнительные данные
Дополнительные данные — zip-файл
Реклама
Цитаты
Альтметрика
Дополнительная информация о метриках
Оповещения по электронной почте
Оповещение об активности статьи
Предварительные уведомления о статьях
Оповещение о новой проблеме
Оповещение о текущей проблеме
Получайте эксклюзивные предложения и обновления от Oxford Academic
Ссылки на статьи по телефону
Последний
Самые читаемые
Самые цитируемые
Не найдено совпадений для настроенного запроса.