Слова «разница» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «разница» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «разница» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «разница».
Содержимое:
- 1 Слоги в слове «разница» деление на слоги
- 2 Как перенести слово «разница»
- 3 Морфологический разбор слова «разница»
- 4 Разбор слова «разница» по составу
- 5 Сходные по морфемному строению слова «разница»
- 6 Синонимы слова «разница»
- 7 Антонимы слова «разница»
- 8 Ударение в слове «разница»
- 9 Фонетическая транскрипция слова «разница»
- 10 Фонетический разбор слова «разница» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «разница»
- 12 Сочетаемость слова «разница»
- 13 Значение слова «разница»
- 14 Склонение слова «разница» по подежам
- 15 Как правильно пишется слово «разница»
- 16 Ассоциации к слову «разница»
Слоги в слове «разница» деление на слоги
Количество слогов: 3
По слогам: ра-зни-ца
По правилам школьной программы слово «разница» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
раз-ни-ца
По программе института слоги выделяются на основе восходящей звучности:
ра-зни-ца
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
з примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «разница»
ра—зница
раз—ница
разни—ца
Морфологический разбор слова «разница»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: единственное;
падеж: именительный;
отвечает на вопрос: (есть) Что?
Начальная форма:
разница
Разбор слова «разница» по составу
| разн | корень |
| иц | суффикс |
| а | окончание |
разница
Сходные по морфемному строению слова «разница»
Сходные по морфемному строению слова
Синонимы слова «разница»
1. депрессия
депрессия
2. декувер
3. маржа
4. различие
5. разность
6. отличие
7. несоответствие
8. расхождение
9. несходность
10. несходство
11. несхожесть
12. дисконт
13. репорт
14. своп
15. непохожесть
16. неодинаковость
17. отличка
18. различка
19. перепад
Антонимы слова «разница»
1. сходство
Ударение в слове «разница»
ра́зница — ударение падает на 1-й слог
Фонетическая транскрипция слова «разница»
[р`азн’ица]
Фонетический разбор слова «разница» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| а | [`а] | гласный, ударный | а |
| з | [з] | согласный, звонкий парный, твёрдый, шумный | з |
| н | [н’] | согласный, звонкий непарный (сонорный), мягкий | н |
| и | [и] | гласный, безударный | и |
| ц | [ц] | согласный, глухой непарный, твёрдый, шумный | ц |
| а | [а] | гласный, безударный | а |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 7 букв и 7 звуков.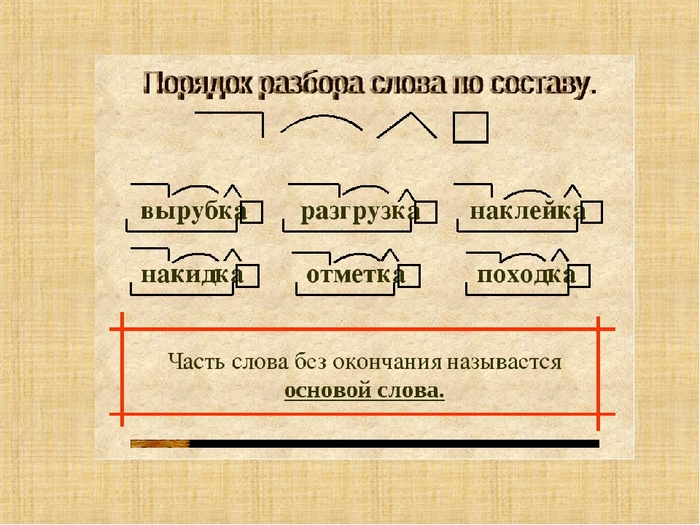
Буквы: 3 гласных буквы, 4 согласных букв.
Звуки: 3 гласных звука, 4 согласных звука.
Предложения со словом «разница»
Не совсем слушались, видишь разницу?
Источник: Тимур Свиридов, Дар Дерзкий, 2009.
Так-то оно так, но в современном понимании богатства и тем, что несёт в себе слово «Бог» существует огромная разница — вы об этом не задумывались?
Источник: Инга Валдинс, Тайна притяжения богатства, 2010.
По-видимому, это очень большая и существенная разница: там, в физиологическом раздражении, раздражители постоянные, а здесь — переменные.
Источник: И. П. Павлов, Об уме вообще, о русском уме в частности. Записки физиолога, 1918.
Сочетаемость слова «разница»
1. большая разница
2.
3. существенная разница
4. разница температур
5. разница давлений
6. разница лет
7. год разницы
8. в случае разницы
9. по большому счёту без разницы
10. разница составляет
11. разница заключалась
12. разница существует
13. не видеть разницы
14. понять разницу
15. почувствовать разницу
16. (полная таблица сочетаемости)
Значение слова «разница»
РА́ЗНИЦА , -ы, ж. 1. Несходство, различие в чем-л. (Малый академический словарь, МАС)
Склонение слова «разница» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | разница | разницы |
| РодительныйРод. | чего? | разницы | разниц |
| ДательныйДат. | чему? | разнице | разницам |
ВинительныйВин. | что? | разницу | разницы |
| ТворительныйТв. | чем? | разницей, разницею | разницами |
| ПредложныйПред. | о чём? | разнице | разницах |
Как правильно пишется слово «разница»
Орфография слова «разница»Правильно слово пишется: ра́зница
Нумерация букв в слове
Номера букв в слове «разница» в прямом и обратном порядке:
- 7
р
1 - 6
а
2 - 5
з
3 - 4
н
4 - 3
и
5 - 2
ц
6 - 1
а
7
Ассоциации к слову «разница»
Велик
Возраст
Шайба
Той
Мяч
Очко
Различие
Особа
Ничья
Налогоплательщик
Сущность
Полова
Температура
Стоимость
Темперамент
Пародия
Проигрыш
Возмещение
Актив
Произношение
Убыток
Явь
Темь
Ровесник
Равенство
Балл
Валюта
Тариф
Потенциал
Мировоззрение
Восприятие
Учёт
Хер
Выигрыш
Хрен
Цена
Выплата
Габарит
Коэффициент
Резка
Платёж
Подлежащее
Принципиальный
Невеликий
Существенный
Забитый
Несущественный
Весовой
Ощутимый
Возрастной
Разительный
Качественный
Очковый
Незначительный
Колоссальный
Имущественный
Заметный
Одинаковый
Двадцатилетний
Очевидный
Идентичный
Номинальный
Субъективный
Биржевой
Кардинальный
Никакой
Уловимый
Неизмеримый
Балловый
Климатический
Теперешний
Значительный
Какать
Улавливать
Заключаться
Сказываться
Компенсировать
Ощущаться
Уяснить
Возместить
Уловить
Определяться
Сгладить
Разъяснять
Отмахнуться
Учитывать
Обусловить
Уплатить
Подчеркнуть
Сравнить
Сравнивать
Отличить
Измерить
Существовать
Состоять
Сказаться
Наглядно
Добром
Собственно
Одинаково
«Длина» или «длинна»: как пишется?
На основании данных из орфографического словаря и один, и второй вариант написания слова «длина» или «длинна» являются верными. Разница между ними состоит только в постановке ударения. С чем же это связано?
Разница между ними состоит только в постановке ударения. С чем же это связано?
Правильное написание многих слов в русском языке состоит в прямой связи с тем, какой смысл в них вкладывается автором и к какой части речи относится данное слово. Это определяется очень легко, с помощью постановки вопроса к слову, вызывающему трудности написания.
Читайте в статье
- «Длина» или «длинна»: как правильно написать?
- Примеры предложений
- «Длиной» или «длинной»: как правильно?
- Примеры предложений
- Заключение
«Длина» или «длинна»: как правильно написать?
Если слово «длина» в предложении отвечает на вопрос «что?», его можно смело писать с одной буквой «н», поскольку это существительное, имеющее несколько разных значений.
Согласно толковым словарям, слово «длина» может означать:
- Расстояние между наиболее отдаленными между собой концами протяженного объекта.
- В математическом значении подразумевает протяженность прямой, образованной из линии или геометрической фигуры путем ее выпрямления.

- Характеризует продолжительность или длительность времени.
- Может быть использована в физике как синоним расстояния.

В русском языке существует правило, что в имени существительном пишутся две буквы «н» в том случае, если одна из них входит в корень слова, а другая − в суффикс.
Сделав разбор слова «длина» по составу, можно определить что:
- «-длин» – это корень;
- «-а» − это окончание.
В нашем случае суффикс отсутствует, поэтому в слове «длина» мы пишем только одну букву «н», которая является частью корня.
Второй пример написания слова «длинна» с двумя буквами «н» будет правильным в том случае, если оно является краткой формой от прилагательного «длинная».
Первоначальная форма − слово «длинный». Его значение определяется, как имеющий большую длину, протяжение.
Также первоначальная полная форма используется для характеристики длительности времени: длинная ночь, для обозначения более длинного предмета – длинное пальто, для сравнения роста – человек был длинным и сутулым.
Если слово «длинна» отвечает на вопрос «какова?», его смело пишем с двумя буквами «н». Это краткая форма имени прилагательного, образованного от слова «длинная».
В этом случае применимо правило, что в краткой форме прилагательного пишется столько «н», сколько их в полной форме. Слово «длинная» имеет в своем составе две буквы «н»: одну − в корне, вторую − в суффиксе. Следовательно, и «длинна» пишется тоже с двумя «н».
Примеры предложений
- Длина комнаты составляла всего три метра.
- Нужно измерить длину и ширину комнаты.
- При такой скорости длина пути не имела значения.
- Хочу купить шарф большой длины.
- В международной системе единицей длины является метр.
- Длина тела новорожденного составляла 53 см.
- Шея жирафа была длинна.
- Продвижение по горной тропе заняло много времени, она была очень длинна.
«Длиной» или «длинной»: как правильно?
«Длина» − это существительное женского рода единственного числа первого склонения, может изменяться по падежам и числам.
Слово «длиной» − это существительное с одной «н», стоящее в творительном падеже и отвечающее на вопрос «чем?».
Например:
| Падежи | Единственное число | Множественное число |
| Именительный | Длина | Длины |
| Родительный | Длины | Длин |
| Дательный | Длине | Длинам |
| Винительный | Длину | Длины |
| Творительный | Длиной | Длинами |
| Предложный | Длине | Длинах |
Как видим, правильное написание слова будет с двумя «н» в любом числе и любых падежах. Ударение во множественном числе всегда падает на первый слог.
Прилагательное «длинная» может изменяться по числам, родам и падежам, в зависимости от основного слова, которым в большинстве случаев является существительное.
| Падежи | |
| Именительный | Длинная ночь |
| Родительный | Длинной ночи |
| Дательный | Длинной ночи |
| Винительный | Длинной ночи |
| Творительный | Длинной ночью |
| Предложный | Длинной ночи |
Как видно, слово «длинная», как и основное слово, практически не изменяется во время склонения, но всегда пишется с двумя буквами «н». Падеж определяется в зависимости от поставленного вопроса.
Примеры предложений
- Аня после окончания школы сразу отрезала косу, она была слишком длинной.
- Для кого-то жизнь будет слишком длинной, а кому-то − короткой.
- Эта ночь была самой длинной в ее жизни.
- Мы не стали ждать, так как очередь была длинной.
- Между длиной этих дорог есть большая разница.
- Дорога длиной в жизнь.
Заключение
Исходя из вышеизложенного, для того, чтобы в дальнейшем у вас больше не возникало вопросов по поводу правильного написания этих слов, нужно запомнить:
Можно воспользоваться еще одним способом: к слову «длинна» можно подобрать антонимы, например, короткая или недолгая. У слова «длина» антонимов нет.
Чем отличается приказ от распоряжения в организации и в каком случае что использовать
Чтобы ставить и решать задачи внутри компании, бизнес использует приказы и распоряжения. Не всегда понятно, когда какой документ нужно издать. Разбираемся, в чем отличия приказа от распоряжения, какой документ нужно издавать в разных ситуациях и кто имеет право это делать.
- Сходства и различия приказа и распоряжения
- Виды приказов и распоряжений
- Порядок издания приказа и распоряжения
- Требования к оформлению приказов и распоряжений
Сходства и различия приказа и распоряжения
В законодательстве нет общих правил, которые регулируют, когда издавать приказ, а когда — распоряжение. Например, в трудовом кодексе эти документы часто уравнивают в правах.
Например, в трудовом кодексе эти документы часто уравнивают в правах.
Так, чтобы принять сотрудника на работу или уволить его, подойдут оба документа.
Как оформить прием на работу — ст. 68 ТК РФ
Чтобы понять, чем отличается приказ от распоряжения, возьмем за основу определения из Единой государственной системы делопроизводства — ЕГСД.
Приказ — правовой акт, который издает руководитель органа государственного управления или его структурного подразделения, чтобы решить основные и оперативные задачи.
Единая государственная система делопроизводства
Распоряжение — правовой акт, который издает руководитель коллегиального органа государственного управления, чтобы решить оперативные вопросы. У распоряжения обычно ограниченный срок действия, и оно касается узкого круга организаций, должностных лиц и граждан.
Главное отличие этих документов в том, что приказ всегда издает руководитель компании или его заместитель, а распоряжение — руководитель компании, заместитель и другие уполномоченные лица, например начальники отделов.
Примерная инструкция по делопроизводству, утвержденная приказом Росархива от 11.04.2018 № 44
Есть также условные отличия приказа от распоряжения. Мы собрали их в таблице.
Виды приказов и распоряжений
В делопроизводстве есть три вида приказов и распоряжений.
По основной деятельности. Цель — решить основные задачи, которые стоят перед компанией. Например, ввести штатное расписание или создать новое подразделение.
По административно-хозяйственным вопросам. Относятся к деятельности, которая связана с транспортным обслуживанием, эксплуатацией и оснащением зданий. Например, приказ или распоряжение о покупке оборудования.
По личному составу. Касаются вопросов взаимодействия сотрудников с компанией. Например, чтобы принять на работу или уволить сотрудника, нужно издать соответствующий приказ или распоряжение.
Порядок издания приказа и распоряжения
Правила не регламентированы законом, но их прописывают в инструкции по делопроизводству. Обычно порядок издания приказов и распоряжений выглядит так:
Обычно порядок издания приказов и распоряжений выглядит так:
Иногда порядок может быть сложнее: ответственный сотрудник сначала готовит проект, согласует его с юристами и руководителем и только потом отдает на подпись.
Например, если руководитель издает приказ о введении системы сохранения коммерческой тайны, лучше сначала подготовить проект и согласовать его с юристом, чтобы документ не противоречил законам.
А вот при издании приказа о приеме на работу можно воспользоваться шаблоном — готовить проект и согласовывать с юристом не обязательно.
Шаблоны документов для бизнеса
Требования к оформлению приказов и распоряжений
В законе нет требований к оформлению приказов и распоряжений, но в государственном стандарте есть рекомендации, примеры и шаблоны распорядительных документов.
ГОСТ Р 7.0.97-2016
Компаниям и ИП не обязательно оформлять документы строго по ГОСТу, но чтобы они имели юридическую силу, нужно указать следующие реквизиты:
| Реквизит | Требование к реквизиту |
|---|---|
| Название компании | Должно соответствовать названию, которое прописано в уставе. Например, ООО «Компания» |
| Имя и должность автора документа | Должность указывают так, как она прописана в распорядительном документе о назначении на должность. Например, генеральный директор ООО «Компания» Петров П. П. |
| Вид документа | «Приказ» или «Распоряжение» |
| Номер документа | Указывают номер, который присвоен при регистрации документа |
| Дата | Должна соответствовать дате подписания или издания документа |
| Населенный пункт | Нужно указать город или другой населенный пункт, в котором издан документ |
| Заголовок | То, о чем пойдет речь в документе. Например, приказ «Об утверждении штатного расписания» |
| Подпись руководителя | Руководитель ставит подпись, а расшифровку печатают в документе |
| Контроль за исполнением приказа или распоряжения | Чтобы назначить сотрудника, который будет отвечать за исполнение документа, последним пунктом в тексте указывают фамилию и должность ответственного. Например: «Контроль за исполнением возложить на начальника отдела Петрова П. П.» |
Кроме реквизитов, есть и другие рекомендации по оформлению распорядительных документов.
Оформление приказа. Текст приказа состоит из двух частей: первая — это основания или причины создания документа, вторая — решение руководителя, которое начинается со слова «Приказываю».
Ввести штатное расписание — это основная задача компанииОформление распоряжения. В отличие от приказа, в распоряжении оснований и причин для издания документа может не быть. В таком случае оно начинается сразу с решения руководителя — например, со слова «Обязываю».
Провести анализ рекламной кампании — это текущая задачаКоротко
- Приказ издает только руководитель или его заместитель для решения основных задач компании и кадровых вопросов.
- Распоряжение издает руководитель, его заместитель и начальники отделов для решения текущих задач компании.
- Компании и ИП могут использовать только один из этих документов — разница между приказом и распоряжением условна.
- Если хотите использовать оба документа, пропишите в инструкции по делопроизводству, кто имеет право издавать распорядительные документы и какие вопросы решает каждый из них.
Отличие слов категории состояния от других частей речи
Слова категории состояния
- не склоняются и не изменяются (иногда могут иметь сравнительную степень) – морфологическое отличие,
- выполняют функцию сказуемого в безличном предложении – синтаксическое отличие,
- обозначают состояния предмета – лексическое отличие.
Многие имена состояния по звуковому и буквенному составу совпадают с краткими именами прилагательными среднего рода и наречиями на -о, т.е. звучат и пишутся одинаково.
Различие между формами определяется в контексте. При выделении слов категории состояния надо учитывать семантику слов, морфологическое и синтаксическое значение.
Различия и сходство с наречиями на -о-
Основной способ отделения наречий от слов категории состояния – определить, каким членом предложения является слово. Слова категории состояния обозначают состояние и могут быть только сказуемым безличного предложения или его частью, а наречие называет признак действия (лексическое отличие), а в предложении является обстоятельством (синтакическое отличие). .
- С наречием имя состояния сближает неизменяемость и возможность в некоторых случаях образовывать степени сравнения.
Здесь слишком мрачно. Здесь еще мрачнее. – слова категории состояния, сказуемое в безличном предложении.
Он мрачно усмехнулся. Его лицо выглядит мрачнее при свете свечи. – наречие, обстоятельство, относится к глаголу-сказуемому “усмехнулся”, “выглядит” .Всем было весело. Всем стало веселее. – слово категории состояния, именная часть сказуемого “было весело”, “стало веселее” в односоставном безличном предложении.
Мы весело рассмеялись. Он смеется веселее, чем мы. – наречие, обстоятельство образа действия, относится к глаголу-сказуемому “рассмеялись”, “смеется”.

С краткими прилагательными
- С прилагательным имя состояния сближает функция сказуемого в предложении.
прилагательное выполняет функцию сказуемого в предложении с подлежащим, а имя состояния в безличном предложении, т.е. без подлежащего.
Прилагательное согласуется с подлежащим в роде и числе, т.е. изменяется.
Прилагательное обозначает признак предмета.Лицо её грустно.
Лицо -подлежащее, грустно -прилагательное ср.р., обозначает признак предмета (лица), выполняет функцию сказуемого в предложении с подлежащим, согласуется с подлежащим лицо в среднем роде единственного числа, на что указывает окончание –о .Она грустна.
Он грустен. Они грустны. –
краткие прилагательные ж., м. рода, мн. числа., обозначают признак предмета, сказуемые в предложении с подлежащим, согласуются с подлежащим по роду и числу.Сравнительная степень прилагательного в предложении обычно является именной частью сказуемого и поясняет признак подлежащего (выделено сказуемое):
Он был грустным, но стал грустнее.
Сравните:
- Она поет грустно.
– наречие, которое обозначает признак действия (поет (как?) грустно), выполняет функцию обстоятельства образа действия, –о – суффикс. - Мне грустно. – имя состояния, так как обозначает состояние человека, выполняет функцию сказуемого в предложении без подлежащего, -о – суффикс.
- Всем было грустно. – слово категории состояния, функция именной части сказуемого было грустно в односоставном безличном предложении
Краткое прилагательное грустно, наречие грустно, имя состояния грустно – это разные слова, которые выступают как функциональные омонимы (родственные по происхождению слова, которые звучат одинаково, но относятся к разным частям речи).
 Он грустен. Они грустны. –
Он грустен. Они грустны. –
С существительными
- Функциональными омонимами являются некоторые существительные и слова категории состояния: пора, охота, лень, грех и др.
Существительные выполняют в предложении функцию подлежащего, дополнения или обстоятельства, а имена состояния – функцию сказуемого в безличном предложении (синтаксические отличия). Существительные склоняются, имеют категории рода, падежа, числа (морфологические отличия) и называют субъект или объект действия (лексическое отличие), а слова состояния не изменяются.
Мне лень двигаться. – категория состояния, часть сказуемого “лень двигаться”.
Лень портит человека. – существительное, подлежащее.Мне пора. – слово категории состояния, сказуемое в безличном предложении.
Была смутная пора. – имя существительное, функция подлежащего .Охота вам спорить! – категория состояния, часть сказуемого.
На охоте надо быть внимательным. – существительное, обстоятельство места.

С безличными глаголами
- Список использованной литературы.
- Справочник школьника под ред. В.Славкина, “Слово”, 1994
- Бабайцева В.В. Русский язык. Теорияю 5-9 кл., М.:Дрофа,2208, – 414 с.
- Панова Е.А., Позднякова А.А. Справочные материалы по русскому языку для подготовки к экзаменам. – М.: – ООО “Издательство Астрель”, 2004.-462 с.
Синонимы и антонимы «разница» — анализ и ассоциации к слову разница.
 Морфологический разбор и склонение слов
Морфологический разбор и склонение слов- Перевод
- Ассоциации
- Анаграммы
- Антонимы
- Синонимы
- Гиперонимы
- Морфологический разбор
- Склонения
- Спряжения
Перевод слова разница
Мы предлагаем Вам перевод слова разница на английский, немецкий и французский языки.
Реализовано с помощью сервиса «Яндекс.Словарь»
- На английский
- На немецкий
- На французский
- difference — различие, дифференциал
- разница во времени — time difference
- значительная разница — significant distinction
- разница в цене — price differential
- margin — маржа
- минимальная разница — minimum margin
- variance — отклонение
- spread — спред
- odds — шансы
- inequality — неравенство
- Unterschied — различие
- единственная разница заключается — einziger Unterschied
- значение разницы — Wert der Differenz
- Unterschiedsbetrag — разность
- Delta
- Gefälle — перепад
- Spanne — разрыв
- différence — различие, расхождение, разность, разброс
- разница в стоимости — différence de valeur
- разница в цене — différentiel de prix
- Ecart
- déséquilibre — дисбаланс
- discrimination — дискриминация
- plage — разрыв
Какой бывает разница (прилагательные)?
Подбор прилагательных к слову на основе русского языка.
большейогромнойединственнойсущественнойвеликойнебольшойневеликойпринципиальнойзаметнойбольшойзначительнойгромаднойнеуловимойглавнойосновноймаленькойизвестнойколоссальнойвиднойособойнезначительнойопределеннойпонятнойочевиднойрезкойнемалойтаковойощутимойкачественнойреальнойважнойкурсовойвозрастнойвременнойнекойгигантскойдесятилетнейкардинальнойдьявольскойпсихологическойвсякойсерьезноймалейшейпоразительнойглубокойподобнойнесущественнойяснойколичественнойуловимойничтожнойизряднойкореннойфундаментальнойгеографическойдругойпотрясающейразительноймалойневероятнойчудовищнойвеличайшейидеологическоймаксимальной
Что может разница? Что можно сделать с разницей (глаголы)?
Подбор глаголов к слову на основе русского языка.
заключатьсясостоятьоказатьсясоставлятьказатьсясоставитьсуществоватьощущатьсястановитьсяпридаватьбросатьсяделатьидтисводитьсячувствоватьсясказыватьсяоказыватьсяобнажитьсяпроисходитьиметьсявозвращатьсянайтинаблюдатьсяполучатьсяпредставлятьсяусилитьдойтиопределятьсяобъяснятьсяудручатькрытьсястиратьсяпоказатьсяисчезнутьполучитьсядоставлятьсократитьсядостигатькластьтратитьуказыватьставитьдостичьчувствоватьвнушатьзамечатьсяпонятьсвестисьбеспокоитьвызыватьсгладитьсяпроявитьсяброситьсяподаритьудивлятьвоспитыватьложитьсядостатьсяомрачатьпревыситьзаставитьозначатьпокрытьпролечь
Ассоциации к слову разница
возрасттемаростгодценаположениемужчинаскоростьчеловекжизньразмервестемпературатемьхарактеруровеньцветсловодавлениесилаотношениевысотапонятиестоимостьповедениелюбовьколичествосравнениевосприятиеженщинапроисхождениеоттеноккурсдоходсонубийствосуммакачествозваниеполобразправдавремядлинавашингтонмассаподходощущениерезультатвойнасостояниечисложеланиесоставреальностьсчетвыражениесмыслопытоценкамирязыкмальчикзнание
Анаграммы слова разница
зарница
Синонимы слова разница
знакнесходствонесхожестьотличиепредпочтениеразличиеразность
Антонимы слова разница
сходство
Гипонимы слова разница
- контраст
- плечо
Сфера употребления слова разница
ЭкономикаОбщая лексикаБанковское делоSAPДеловая лексика
Морфологический разбор (часть речи) слова разница
Часть речи:
существительное
Род:
женский
Число:
единственное
Одушевленность:
неодушевленное
Падеж:
именительный
Склонение существительного разница
| Падеж | Вопрос | Ед. число число | Мн. число |
|---|---|---|---|
| Именительный | (кто, что?) | разница | разницы |
| Родительный | (кого, чего?) | разницы | разниц |
| Дательный | (кому, чему?) | разнице | разницам |
| Винительный | (кого, что?) | разницу | разницы |
| Творительный | (кем, чем?) | разницей | разницами |
| Предложный | (о ком, о чём?) | разнице | разницах |
Предложения со словом разница
Пожалуйста, помогите нашему роботу осознать ошибки. Их пока много, но с вашей помощью их станет гораздо меньше. Вот несколько предложений, которые он сделал.
1. Явная разница неплохо сохранилась в любой тайне
0
0
2. Потрясающая разница точно составляла на белый пол
0
0
3. Существенная разница неизменно наблюдалась при серьезной поражении
Существенная разница неизменно наблюдалась при серьезной поражении
0
0
4. Неуловимая разница живо чувствовалась на тонкий вкус
0
0
Понимание деловой репутации и других нематериальных активов: в чем разница?
Оглавление
Содержание
Обзор
Деловая репутация
Прочие нематериальные активы
Ключевые отличия
Особые соображения
Что такое деловая репутация?
Часто задаваемые вопросы
По
Пралин Баджпай
Полная биография
Праблин Баджпай — основатель FinFix and Analytics Private Limited. У нее более 10 лет опыта работы в качестве эксперта по финансам, криптовалютам и торговым стратегиям.
Узнайте о нашем редакционная политика
Обновлено 23 апреля 2022 г.
Рассмотрено
Чип Стэплтон
Рассмотрено Чип Стэплтон
Полная биография
Чип Стэплтон является обладателем лицензий Серии 7 и Серии 66, сдал экзамен CFA уровня 1 и в настоящее время имеет лицензию на жизнь, несчастный случай и здоровье в Индиане. Он имеет 8-летний опыт работы в области финансов, от финансового планирования и управления активами до корпоративных финансов и планирования и анализа.
Узнайте о нашем Совет по финансовому обзору
Деловая репутация и другие нематериальные активы: обзор
Одной из концепций, которая может помочь деловым людям, не занимающимся бухгалтерией (и даже некоторым бухгалтерам), является различие между деловой репутацией и другими нематериальными активами в финансовой отчетности компании.
Возможно, следует ожидать путаницы. В конце концов, деловая репутация обозначает стоимость определенных неденежных, нефизических ресурсов, и это звучит как нематериальный актив.
В конце концов, деловая репутация обозначает стоимость определенных неденежных, нефизических ресурсов, и это звучит как нематериальный актив.
Однако многие факторы отделяют деловую репутацию от других нематериальных активов, и эти два термина представляют собой отдельные статьи в балансе.
Ключевые выводы
- Лояльность клиентов, репутация бренда и другие активы, не поддающиеся количественной оценке, считаются деловой репутацией.
- Нематериальные активы – это активы, которые не являются физическими, но поддаются идентификации.
- К ним относятся запатентованные технологии компании (компьютерное программное обеспечение и т. д.), авторские права, патенты, лицензионные соглашения и доменные имена веб-сайтов.
- Хотя термины «гудвил» и «нематериальные активы» иногда используются взаимозаменяемо, между ними существуют существенные различия.
- В бухгалтерском балансе «гудвил» и «нематериальные активы» представляют собой отдельные статьи.

Деловая репутация
Деловая репутация — это разная категория нематериальных активов, которые сложнее анализировать по отдельности или измерять напрямую. Лояльность клиентов, репутация бренда и другие активы, не поддающиеся количественной оценке, считаются деловой репутацией.
Деловая репутация не может существовать независимо от бизнеса, а также не может быть продана, куплена или передана отдельно. Часто также включаются достижения компании в области инноваций, исследований и разработок, а также опыт ее управленческой команды. В результате гудвилл имеет неопределенный срок полезного использования, в отличие от большинства нематериальных активов.
Деловая репутация появляется в балансе только тогда, когда две компании завершают слияние или поглощение. Когда компания покупает другую фирму, все, что она платит сверх чистой стоимости идентифицируемых активов цели, становится деловой репутацией в балансе. Скажем, компания по производству безалкогольных напитков была продана за 120 миллионов долларов; у него были активы на сумму 100 миллионов долларов и обязательства на 20 миллионов долларов. Сумма в 40 миллионов долларов, которая была выплачена сверх 80 миллионов долларов (стоимость активов за вычетом обязательств), представляет собой гудвил и отражается в бухгалтерских книгах как таковая.
Сумма в 40 миллионов долларов, которая была выплачена сверх 80 миллионов долларов (стоимость активов за вычетом обязательств), представляет собой гудвил и отражается в бухгалтерских книгах как таковая.
Посмотрите на этот пример раздела активов баланса. Деловая репутация является отдельной строкой от нематериальных активов.
| Текущие активы | |
| Наличные | 300 000 долларов США |
| Инвестиции | 200 000 долларов |
| Инвентарь | 150 000 долларов США |
| Внеоборотные активы | |
| Основные средства | 600 000 долларов |
| Деловая репутация | 200 000 долларов |
| Нематериальные активы | 150 000 долларов США |
Прочие нематериальные активы
Нематериальные активы – это те, которые не являются физическими, но идентифицируемыми. Подумайте о собственной технологии компании (компьютерное программное обеспечение и т. д.), авторских правах, патентах, лицензионных соглашениях и доменных именах веб-сайтов. Это не то, что можно потрогать, но можно оценить их ценность для предприятия. Нематериальные активы можно покупать и продавать независимо от самого бизнеса.
Подумайте о собственной технологии компании (компьютерное программное обеспечение и т. д.), авторских правах, патентах, лицензионных соглашениях и доменных именах веб-сайтов. Это не то, что можно потрогать, но можно оценить их ценность для предприятия. Нематериальные активы можно покупать и продавать независимо от самого бизнеса.
Также есть ключевое различие в том, как вносятся поправки в два класса активов после их регистрации. Поскольку активы, как правило, со временем теряют часть своей стоимости, компаниям иногда приходится периодически их списывать.
Нематериальные активы амортизируются, что означает, что фиксированная сумма снижается каждый год, что приводит к одновременному списанию прибыли. Сумма амортизации корректируется, если стоимость актива обесценивается в какой-то момент после его приобретения или разработки.
Ключевые отличия
Хотя «гудвилл» и «нематериальные активы» иногда используются как синонимы, в мире бухгалтерского учета между ними существуют существенные различия.
Деловая репутация — это надбавка к справедливой стоимости активов при покупке компании. Следовательно, он помечен для компании или бизнеса и не может быть продан или куплен отдельно. Напротив, другие нематериальные активы, такие как лицензии, патенты и т. д., можно продавать и покупать отдельно.
Считается, что деловая репутация имеет неопределенный срок службы (пока компания работает), в то время как другие нематериальные активы имеют определенный срок полезного использования.
При отсутствии обесценения гудвил может оставаться на балансе компании на неопределенный срок.
Особые указания
Совет по стандартам финансовой отчетности (FASB) недавно предложил новое альтернативное правило учета деловой репутации. Долгое время он мог амортизироваться в течение 40 лет. Постановление 2001 г. постановило, что деловая репутация не может амортизироваться, но должна ежегодно оцениваться для определения убытка от обесценения; этот ежегодный процесс оценки был дорогостоящим и отнимал много времени.
В соответствии с альтернативным правилом FASB для частных компаний гудвил может амортизироваться линейным методом в течение периода, не превышающего 10 лет. Необходимость тестирования на обесценение уменьшилась; вместо этого убыток от обесценения отражается, когда событие сигнализирует о том, что справедливая стоимость могла стать ниже балансовой стоимости.
Эти правила применяются к предприятиям, соответствующим общепринятым принципам бухгалтерского учета (GAAP) с использованием полного метода учета по методу начисления. Если условия указывают на то, что балансовая стоимость не может быть возмещена, проводятся тесты на обесценение.
Малые предприятия, использующие кассовый учет или модифицированный кассовый учет, могут использовать установленные законом ставки, установленные Налоговой службой (IRS). IRS допускает 15-летний период списания нематериальных активов, которые были приобретены. Отчеты IRS и GAAP во многом совпадают и контрастируют.
Что такое деловая репутация?
С точки зрения бизнеса, «гудвилл» — это всеобъемлющая категория для активов, которые не могут быть монетизированы напрямую или оценены по отдельности. Такие активы, как лояльность клиентов, репутация бренда и общественное доверие, квалифицируются как «гудвил» и не подлежат квалификации.
Такие активы, как лояльность клиентов, репутация бренда и общественное доверие, квалифицируются как «гудвил» и не подлежат квалификации.
Что такое GAAP?
GAAP означает общепринятые принципы бухгалтерского учета.
Можно ли списать нематериальные активы?
Да. Вы можете списать нематериальные активы (на 15-летний период списания), которые были приобретены, используя установленные законодательством ставки, установленные Налоговой службой (IRS).
Что такое нематериальный актив?
Патенты, товарные знаки, лицензии и авторские права — все это примеры нематериальных активов.
Статья Источники
Investopedia требует, чтобы авторы использовали первоисточники для поддержки своей работы. К ним относятся официальные документы, правительственные данные, оригинальные отчеты и интервью с отраслевыми экспертами. Мы также при необходимости ссылаемся на оригинальные исследования других авторитетных издателей. Вы можете узнать больше о стандартах, которым мы следуем при создании точного и беспристрастного контента, в нашем
редакционная политика.
Бухгалтерский журнал. «Попрощайтесь с объединением и амортизацией деловой репутации».
Совет по пересмотру стандартов финансового учета. «Выпуск новостей от 20.07.01 — FASB выпускает два заявления о своем проекте по объединению бизнеса».
Совет по стандартам финансового учета. «№ 2021-03-март 2021: Нематериальные активы — деловая репутация и прочее (тема 350)», страницы 13–14.
Налоговая служба. «Нематериальные активы».
Разница между синтаксисом и грамматикой (со сравнительной таблицей)
Многие думают, что синтаксис и грамматика — одно и то же, но на самом деле синтаксис — это всего лишь часть грамматики. В отличие от этого, грамматика — это вся система правил, которая позволяет людям формировать и интерпретировать слова, предложения, фразы и предложения на их языке.
Синтаксис можно понимать как набор принципов, определяющих порядок слов, предложений и фраз для формирования правильного предложения на конкретном языке.
Напротив, Грамматика подразумевает абстрактную систему, содержащую набор правил, регулирующих основы языка, такие как форма, структура и порядок слов. Давайте посмотрим на статью, приведенную ниже, чтобы подробно понять разницу между синтаксисом и грамматикой.
Содержание: синтаксис и грамматика
- Сравнительная таблица
- Определение
- Ключевые отличия
- Заключение
Сравнительная таблица
| Основание для сравнения | Синтаксис | Грамматика |
|---|---|---|
| Значение | Синтаксис относится к системе, которая указывает, как слова могут быть соединены вместе, чтобы составить предложение. | Грамматика — это не что иное, как раздел лингвистики, занимающийся синтаксисом и морфологией. |
| Что это? | Это часть грамматики. | Это лингвистическая дисциплина. |
| Сообщает вам | Как сформулировано и структурировано предложение. | Как создаются логичные и осмысленные предложения и как работает язык. |
| Обозначает | Правила расположения слов. | Языковое право |
Определение синтаксиса
Синтаксис — это часть грамматики, которая касается порядка слов и фраз для формирования правильного предложения на конкретном языке. Это система правил, которые сообщают вам, какое слово стоит перед другим словом в предложении и после него, чтобы оно имело полный смысл.
В простых словах формат, с помощью которого слова и фразы структурированы, чтобы составить предложение, называется синтаксисом. Это означает, что он решает, как следует расположить подлежащее, глагол и дополнение, чтобы сформировать правильное предложение. Это то, что может иметь огромное значение в контексте предложения, как вы можете видеть в примере ниже:
- Щенок радостно бежал .
- Щенок радостно побежал.
- Радостно , щенок побежал.

В приведенном примере вы могли заметить, что мы только что изменили порядок слов «радостно» и изменился весь контекст предложения, и в этом сила «синтаксиса».
В творческом письме синтаксис играет очень важную роль, так как он может сделать текст более интересным и увлекательным, а также помогает подчеркнуть определенный момент.
Определение грамматики
Грамматика – это методическое изучение и объяснение определенного языка. Это подразумевает систему, состоящую из набора структурных правил, определяющих, как строить предложения на конкретном языке. Правила могут быть связаны с синтаксисом, морфологией, фонологией и семантикой. Эти правила помогают систематизировать слова для составления правильных предложений.
Синтаксис занимается порядком слов, т. е. обычным расположением слов, тогда как морфология занимается формами и структурой слов, фонология занимается звуками языка, а семантика занимается значениями. Эти правила определяют состав слов, фраз и предложений.
В более широком смысле грамматика изучает классы слов, их спряжение, функции и отношения. Следовательно, он также охватывает акцидентность (изменение слов), орфографию (систему правописания) и синтаксис (расположение слов и фраз в предложениях). В общем, есть два типа грамматики, обсуждаемые ниже:
- Предписывающая грамматика : содержит набор правил, определяющих правильное или предпочтительное использование языка, таких как произношение, словарный запас, правописание, синтаксис и семантика.
- Описательная грамматика : Он направлен на логическое исследование и объяснение того, как язык фактически используется или как он ранее использовался группой людей со схожими языковыми нормами.
Ключевые различия между синтаксисом и грамматикой
Разницу между синтаксисом и грамматикой можно четко определить по следующим основаниям:
- Синтаксис подразумевает набор правил, определяющих способ организации слов и фраз для создания связных предложений. С другой стороны, грамматика относится к изучению классов слов, их спряжения, функций и отношений в конкретном предложении.
- Грамматика — это раздел языкознания, который занимается синтаксисом, морфологией, семантикой и фонологией. Напротив, синтаксис является частью грамматики, указывающей способ, которым слова упорядочиваются для создания предложений.
- В то время как синтаксис говорит вам, как расположить слова в предложении, основываясь на повествовательном, вопросительном, отрицательном, утвердительном или восклицательном предложении. И наоборот, грамматика — это создание логического и осмысленного предложения. Он расскажет вам, как работает язык и как используются слова.
- Синтаксис — это изучение принципов и процессов, посредством которых слова и другие компоненты структуры предложения объединяются для создания грамматически правильных предложений. Напротив, грамматика помогает вам понять законы языка и правильный способ использования языка как в устной, так и в письменной форме.
 С другой стороны, грамматика относится к изучению классов слов, их спряжения, функций и отношений в конкретном предложении.
С другой стороны, грамматика относится к изучению классов слов, их спряжения, функций и отношений в конкретном предложении.
Заключение
Когда что-то говорят или пишут, синтаксис, то есть порядок слов, может изменить смысл предложения.
Точно так же грамматика играет очень важную роль в процессе общения, потому что без нее язык не будет правильно понят. Следовательно, получатель не сможет правильно интерпретировать сообщение, поскольку и говорящий, и слушающий должны знать язык друг друга, чтобы обмениваться словами.
Введение
PLoS ONEplosplosonePLoS ONE1932-6203Public Library of Science, Сан-Франциско, USAPONE-D-13-1820410.1371/journal.pone.0073949Исследовательская статьяГибкая композиция: доказательство использования основных комбинаторных лингвистических механизмов в ответ на требования задачи. PylkkänenLiina a b c * a Факультет психологии, Нью-Йоркский университет, Нью-Йорк, Нью-Йорк, СШАb Факультет лингвистики, Нью-Йоркский университет, Нью-Йорк, Нью-Йорк, Соединенные Штаты АмерикиcNYU Абу-Даби Институт Нью-Йоркского университета Абу-Даби, Абу-Даби, Объединенные Арабские ЭмиратыБарнсГарет РобертРедакторЛондонский университетский колледж – Институт неврологии, Великобритания* Электронная почта: liina. [email protected]
[email protected]Авторы заявили об отсутствии конкурирующих интересов.
Придумал и спроектировал эксперименты: ДКБ ЛП. Выполняли опыты: ДКБ. Проанализированы данные: ДКБ. Предоставленные реагенты/материалы/инструменты для анализа: DKB. Написал статью: ДКБ ЛП.
2013129201389e7394925201325720132013Bemis, PylkkanenЭто статья с открытым доступом, распространяемая в соответствии с условиями лицензии Creative Commons Attribution, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника. В настоящем исследовании исследуется, могут ли минимальные манипуляции в требованиях задания вызвать выход основных лингвистических комбинаторных механизмов за пределы нормальных грамматических фраз. Используя магнитоэнцефалографию, мы измерили нейронную активность, вызванную обработкой словосочетаний прилагательное-существительное в каноническом (красная чашка) и обратном порядке (красная чашка). При выполнении задачи, не требующей композиции (проверка по цветному пятну и контуру формы), мы наблюдали значительную комбинаторную активность только во время канонических фраз, что определялось минимальной активностью источника нормы, локализованной в левой передней височной доле на 200–250 мс (ср. 1], [2]). Когда были введены требования к комбинаторным задачам (путем простого объединения капли и контура в одну цветную фигуру), мы также наблюдали значительную комбинаторную активность во время обратных последовательностей. Эти результаты демонстрируют первое прямое доказательство того, что основные лингвистические комбинаторные механизмы могут быть задействованы за пределами обычных грамматических выражений в ответ на требования задачи, независимо от изменений в лексических факторах или факторах внимания.
1], [2]). Когда были введены требования к комбинаторным задачам (путем простого объединения капли и контура в одну цветную фигуру), мы также наблюдали значительную комбинаторную активность во время обратных последовательностей. Эти результаты демонстрируют первое прямое доказательство того, что основные лингвистические комбинаторные механизмы могут быть задействованы за пределами обычных грамматических выражений в ответ на требования задачи, независимо от изменений в лексических факторах или факторах внимания.
Человеческий язык черпает свою выразительную силу из способности творчески создавать сложные значения из отдельных частей. Хотя это творчество ясно видно при разборе грамматических выражений, например, при построении значения для фиолетовых горилл, неуклюже поющих Вивальди, неясно, в какой степени комбинаторный механизм языка может быть применен за пределами нормальной языковой обработки; вопрос актуален как для оценки модульности в языковой архитектуре [3], [4], так и для определения взаимодействия между лингвистическими комбинаторными механизмами и когнитивной сферой в целом [5]. В настоящем исследовании мы исследуем, достаточно ли простого изменения требований к задаче, независимо от изменений в лексических требованиях или требованиях к вниманию, чтобы спровоцировать задействование основных комбинаторных лингвистических механизмов — тех, которые лежат в основе языка и составляют сложные значения из отдельные элементы – за пределами их естественной, грамматической области. В частности, мы стремились оценить, могут ли комбинаторные механизмы, которые составляют простые фразы, такие как красная чашка, также работать с выражениями, не соответствующими родной грамматике, такими как обратная последовательность чашка красная, в ситуациях, в которых есть некоторое давление, чтобы интерпретировать последовательность комбинаторным способом.
Хотя это творчество ясно видно при разборе грамматических выражений, например, при построении значения для фиолетовых горилл, неуклюже поющих Вивальди, неясно, в какой степени комбинаторный механизм языка может быть применен за пределами нормальной языковой обработки; вопрос актуален как для оценки модульности в языковой архитектуре [3], [4], так и для определения взаимодействия между лингвистическими комбинаторными механизмами и когнитивной сферой в целом [5]. В настоящем исследовании мы исследуем, достаточно ли простого изменения требований к задаче, независимо от изменений в лексических требованиях или требованиях к вниманию, чтобы спровоцировать задействование основных комбинаторных лингвистических механизмов — тех, которые лежат в основе языка и составляют сложные значения из отдельные элементы – за пределами их естественной, грамматической области. В частности, мы стремились оценить, могут ли комбинаторные механизмы, которые составляют простые фразы, такие как красная чашка, также работать с выражениями, не соответствующими родной грамматике, такими как обратная последовательность чашка красная, в ситуациях, в которых есть некоторое давление, чтобы интерпретировать последовательность комбинаторным способом. Интуитивно комбинаторный механизм действительно обладает такой гибкостью, учитывая, что понимание неносителей языка может быть достаточно хорошим даже при наличии множества грамматических ошибок, таких как такой тип изменения порядка слов. Но интуиция еще не говорит нам, является ли механизм, используемый для построения сложных представлений из неграмматического ввода, тем же самым, что и при обработке грамматического материала. В текущем исследовании мы оценили это, записав активность магнитоэнцефалографии (МЭГ) во время обработки грамматических и неграмматических фраз в условиях выполнения комбинаторных и некомбинаторных задач. Полученные в результате пространственно-временные карты нейронной активности позволили нам оценить, могут ли базовые комбинаторные нейронные механизмы, работающие во время обычной грамматической обработки, быть развернуты в новых контекстах в ответ на незначительное изменение требований задачи.
Интуитивно комбинаторный механизм действительно обладает такой гибкостью, учитывая, что понимание неносителей языка может быть достаточно хорошим даже при наличии множества грамматических ошибок, таких как такой тип изменения порядка слов. Но интуиция еще не говорит нам, является ли механизм, используемый для построения сложных представлений из неграмматического ввода, тем же самым, что и при обработке грамматического материала. В текущем исследовании мы оценили это, записав активность магнитоэнцефалографии (МЭГ) во время обработки грамматических и неграмматических фраз в условиях выполнения комбинаторных и некомбинаторных задач. Полученные в результате пространственно-временные карты нейронной активности позволили нам оценить, могут ли базовые комбинаторные нейронные механизмы, работающие во время обычной грамматической обработки, быть развернуты в новых контекстах в ответ на незначительное изменение требований задачи.
Несколько предыдущих исследований напрямую исследовали степень, в которой комбинаторные лингвистические механизмы могут быть гибко развернуты в новых контекстах, хотя во многих работах этот вопрос затрагивается косвенно. Ясно, что на каком-то уровне комбинаторные лингвистические процессы могут быть применены к новым контекстам, поскольку люди способны научиться извлекать смысл из письменных слов и иностранных языков, ни один из которых не вызывает успешной комбинаторной лингвистической обработки без обучения. Нейролингвистические исследования обоих типов обработки, хотя и не окончательные, указывают на большое совпадение нейронных сигнатур, связанных с комбинаторным пониманием речи, и теми, которые возникают как при чтении [2], [6], [7], так и при обработке иностранного языка [8]. [9], [10]. Что еще более важно, большое количество данных свидетельствует о том, что лингвистические механизмы в широком смысле могут быть распространены и на обработку искусственных «языков». В парадигме канонического обучения искусственной грамматике (AGL) [11] наборы произвольных символов, начиная от иностранных слов [12], до строк букв [13] и визуальных объектов [14], генерируются с помощью конечного автомата таким образом, что они подчиняться различным синтаксическим ограничениям.
Ясно, что на каком-то уровне комбинаторные лингвистические процессы могут быть применены к новым контекстам, поскольку люди способны научиться извлекать смысл из письменных слов и иностранных языков, ни один из которых не вызывает успешной комбинаторной лингвистической обработки без обучения. Нейролингвистические исследования обоих типов обработки, хотя и не окончательные, указывают на большое совпадение нейронных сигнатур, связанных с комбинаторным пониманием речи, и теми, которые возникают как при чтении [2], [6], [7], так и при обработке иностранного языка [8]. [9], [10]. Что еще более важно, большое количество данных свидетельствует о том, что лингвистические механизмы в широком смысле могут быть распространены и на обработку искусственных «языков». В парадигме канонического обучения искусственной грамматике (AGL) [11] наборы произвольных символов, начиная от иностранных слов [12], до строк букв [13] и визуальных объектов [14], генерируются с помощью конечного автомата таким образом, что они подчиняться различным синтаксическим ограничениям. Затем испытуемым показывают образцы из этих наборов в течение периода обучения, а затем просят оценить «грамматичность» тестового набора строк, некоторые из которых генерируются автоматом, а некоторые нет. Существует бесчисленное множество вариаций этой парадигмы с точки зрения синтаксических ограничений, «языковых» символов, методов обучения и т. д. (см. нейронных исследований [18], [12], [13] заключается в том, что обработка таких искусственных грамматик может во многих отношениях оказаться похожей на обработку естественного языка. Таким образом, в общих чертах исследования AGL предоставляют доказательства того, что лингвистические механизмы могут быть развернуты в новых контекстах с учетом соответствующих требований задачи.
Затем испытуемым показывают образцы из этих наборов в течение периода обучения, а затем просят оценить «грамматичность» тестового набора строк, некоторые из которых генерируются автоматом, а некоторые нет. Существует бесчисленное множество вариаций этой парадигмы с точки зрения синтаксических ограничений, «языковых» символов, методов обучения и т. д. (см. нейронных исследований [18], [12], [13] заключается в том, что обработка таких искусственных грамматик может во многих отношениях оказаться похожей на обработку естественного языка. Таким образом, в общих чертах исследования AGL предоставляют доказательства того, что лингвистические механизмы могут быть развернуты в новых контекстах с учетом соответствующих требований задачи.
Тем не менее, несколько факторов не позволяют этим результатам напрямую обратиться к задаче настоящего исследования, которая состоит в том, чтобы определить, в какой степени базовые лингвистические комбинаторные механизмы могут быть гибко и быстро развернуты в новых контекстах. Во-первых, в парадигмах AGL, хотя испытуемые обычно способны отличать «грамматические» строки от «неграмматических» с большей точностью, чем случайная [15], их работа редко бывает идеальной [19], и в некоторых обстоятельствах лежащие в основе грамматические правила не могут быть изменены. вообще не освоены, несмотря на их кажущуюся схожесть с ограничениями естественного языка [20], [21]. Во-вторых, по замыслу эти исследования почти исключительно измеряют обработку, связанную со сложными правилами, такими как иерархические, вложенные структуры [22], [14] и нежесткие зависимости от расстояния [23], и часто оценивают нейронную активность, вызванную нарушением этих правил. (например, [13]). Таким образом, пресловутые трудности в распутывании бесчисленного множества механизмов, лежащих в основе такой сложной обработки в естественном языке [24], [25], преувеличиваются при работе с искусственными языками (ср. [26]). Следовательно, существуют обширные разногласия относительно природы нейронных механизмов, которые управляют эффектами, наблюдаемыми в парадигмах AGL [27], [28], [29].
Во-первых, в парадигмах AGL, хотя испытуемые обычно способны отличать «грамматические» строки от «неграмматических» с большей точностью, чем случайная [15], их работа редко бывает идеальной [19], и в некоторых обстоятельствах лежащие в основе грамматические правила не могут быть изменены. вообще не освоены, несмотря на их кажущуюся схожесть с ограничениями естественного языка [20], [21]. Во-вторых, по замыслу эти исследования почти исключительно измеряют обработку, связанную со сложными правилами, такими как иерархические, вложенные структуры [22], [14] и нежесткие зависимости от расстояния [23], и часто оценивают нейронную активность, вызванную нарушением этих правил. (например, [13]). Таким образом, пресловутые трудности в распутывании бесчисленного множества механизмов, лежащих в основе такой сложной обработки в естественном языке [24], [25], преувеличиваются при работе с искусственными языками (ср. [26]). Следовательно, существуют обширные разногласия относительно природы нейронных механизмов, которые управляют эффектами, наблюдаемыми в парадигмах AGL [27], [28], [29]. ], [30], [23] или даже были ли изучены предполагаемые правила вообще [20]. Таким образом, в то время как результаты парадигм AGL предполагают возможность развертывания лингвистических механизмов в новых контекстах, их связь с базовыми лингвистическими комбинаторными процессами, с одной стороны, и нарушением ожидания [30], рекурсией [19] и механизмами иерархической последовательности, с другой [14]. ], [27] до конца еще не решен.
], [30], [23] или даже были ли изучены предполагаемые правила вообще [20]. Таким образом, в то время как результаты парадигм AGL предполагают возможность развертывания лингвистических механизмов в новых контекстах, их связь с базовыми лингвистическими комбинаторными процессами, с одной стороны, и нарушением ожидания [30], рекурсией [19] и механизмами иерархической последовательности, с другой [14]. ], [27] до конца еще не решен.
В парадигмах, более прямо направленных на исследование взаимодействия между требованиями задачи и лингвистическими механизмами, основное внимание уделялось определению влияния манипуляций вниманием на языковую обработку. В этих исследованиях внимание часто вообще отвлекается от языковых стимулов либо пассивно, например, при просмотре немого фильма во время прослушивания речи [31], [32], либо активно, например, выполняя задание на слуховое различение во время прослушивания речи [31, 32]. 33] В качестве альтернативы внимание может быть направлено на различные аспекты стимулов или от них, например, путем выполнения задачи обнаружения шрифта [34] или выборочного отслеживания синтаксических или семантических нарушений [35]. Грубо говоря, эти исследования выявили градуированное влияние внимания на обработку, так что ранние стадии обработки оказываются в значительной степени инвариантными при манипулировании вниманием [36], [37], [38], [33], промежуточные стадии обработки часто можно модулировать. но обычно не устраняется полностью [39], [40], [41], а более поздняя обработка может приходить и уходить в зависимости от задачи [34], [42], [37], [43], [44] для обзора.
Грубо говоря, эти исследования выявили градуированное влияние внимания на обработку, так что ранние стадии обработки оказываются в значительной степени инвариантными при манипулировании вниманием [36], [37], [38], [33], промежуточные стадии обработки часто можно модулировать. но обычно не устраняется полностью [39], [40], [41], а более поздняя обработка может приходить и уходить в зависимости от задачи [34], [42], [37], [43], [44] для обзора.
Этот последний результат, конечно, потенциально предполагает гибкое развертывание лингвистических механизмов. Недавняя работа действительно показала, что более поздние этапы лингвистического разбора, часто связанные с синтаксическим повторным анализом и разрешением неоднозначности, в некоторой степени зависят от задачи и не всегда происходят во время обычной языковой обработки [45], [46], [47], [48]. ]. Эти результаты, однако, были в первую очередь связаны с глубиной обработки лингвистических стимулов и, следовательно, подпадают под рубрику «достаточно хорошего» синтаксического анализа, т. е. данные указывают на то, что при нормальном понимании языка обработка должна быть «достаточно хорошей», чтобы решить поставленную задачу. С нейрофизиологической точки зрения обычная мера этой обработки, компонент ERP P600, сильно зависит от того, требует ли данная задача суждения о правдоподобии (см. [44]). Таким образом, вместо того, чтобы отражать гибкое развертывание процессов вне их естественного контекста, эти результаты, по-видимому, указывают на то, что синтаксический анализ может останавливаться до полного задействования механизмов, связанных с разрешением неоднозначности или синтаксическим повторным анализом [47]. На сегодняшний день нет никаких данных, непосредственно касающихся того, действуют ли лингвистические комбинаторные механизмы только на грамматический ввод, за исключением, возможно, работы над грамматическими иллюзиями, в которых синтаксический анализатор сбивается с толку выражениями, которые кажутся грамматическими, несмотря на то, что репрезентативно неправильно сформированы [49]. ]. Таким образом, результаты, относящиеся к «достаточно хорошему» синтаксическому анализу, не предполагают гибкого использования языковых процессов за пределами их нормальных границ, а скорее говорят об их автоматизме в рамках нормальной грамматической области.
е. данные указывают на то, что при нормальном понимании языка обработка должна быть «достаточно хорошей», чтобы решить поставленную задачу. С нейрофизиологической точки зрения обычная мера этой обработки, компонент ERP P600, сильно зависит от того, требует ли данная задача суждения о правдоподобии (см. [44]). Таким образом, вместо того, чтобы отражать гибкое развертывание процессов вне их естественного контекста, эти результаты, по-видимому, указывают на то, что синтаксический анализ может останавливаться до полного задействования механизмов, связанных с разрешением неоднозначности или синтаксическим повторным анализом [47]. На сегодняшний день нет никаких данных, непосредственно касающихся того, действуют ли лингвистические комбинаторные механизмы только на грамматический ввод, за исключением, возможно, работы над грамматическими иллюзиями, в которых синтаксический анализатор сбивается с толку выражениями, которые кажутся грамматическими, несмотря на то, что репрезентативно неправильно сформированы [49]. ]. Таким образом, результаты, относящиеся к «достаточно хорошему» синтаксическому анализу, не предполагают гибкого использования языковых процессов за пределами их нормальных границ, а скорее говорят об их автоматизме в рамках нормальной грамматической области.
. В настоящем исследовании, напротив, мы изучаем, могут ли основные комбинаторные лингвистические механизмы быть быстро развернуты вне их естественного контекста в родной грамматике, и, кроме того, может ли это развертывание быть ускорено простым манипулированием задачами, не зависящими от изменений в сложности. или внимание. Иными словами, в какой степени базовые комбинаторные языковые механизмы могут быть использованы в качестве гибкого познавательного инструмента при решении задач? В частности, мы исследовали, можно ли гибко использовать комбинаторные механизмы, действующие при составлении простых именных словосочетаний, для интерпретации минимально контрастных неграмматических последовательностей, если этого требует задача. В нашей предыдущей работе мы охарактеризовали комбинаторную нейронную активность, вызванную пониманием простых комбинаций прилагательных и существительных, таких как красная чашка, обнаружив надежное увеличение активности в левой передней височной доле (LATL) примерно на 200–250 мс по сравнению с некомбинаторным контролем. [1], [2]. В настоящем исследовании (рис. 1) мы сравнили такие сочетания прилагательных и существительных с их перевернутыми аналогами, cup red, которые нарушают канонический порядок слов английского языка для таких фраз. Это манипулирование стимулом затем было встроено в манипулирование заданием, которое варьировало необходимость объединения прилагательного и существительного в единое семантическое представление. В комбинаторном (сочинении) задании испытуемые оценивали, соответствует ли словесный стимул изображению цветного предмета. В задании «Не составление» изображение задания вместо этого изображало отдельный цветной шарик и контур формы, что позволяло испытуемым обрабатывать значения существительных и прилагательных полностью в виде списка, без композиции. Активность LATL, предположительно отражающая состав, измеряли путем последовательного предъявления каждого слова и сравнения активности, генерируемой при втором слове, с активностью, вызванной при обработке соответствующего некомбинаторного контроля из одного слова (frw red или xtp cup).
В канонических условиях (верхние ряды) стимулами были словосочетания с прилагательными и существительными (красная чашка) и соответствующие им однословные элементы управления (чашка xhl). В обратных условиях (нижние ряды) стимулами были последовательности существительное-прилагательное (чашка красная) и соответствующие им однословные элементы управления (frw красный). В задании «Составить» (левое изображение задания) целевые изображения содержали одну цветную фигуру. В задаче без составления (правое изображение задачи) целевые изображения содержали цветную каплю и контур фигуры. Каждый испытуемый выполнял только одно задание, а канонические и обратные испытания блокировались отдельно.
Для стимулов канонического порядка слов мы ожидали, что комбинаторная обработка будет происходить автоматически в обеих задачах, учитывая, что почти все модели синтаксического анализа предполагают, что грамматические лингвистические выражения автоматически в некоторой степени задействуют комбинаторные механизмы, независимо от задачи (например, [50], [51 ]). Это теоретическое утверждение было подтверждено многочисленными нейролингвистическими исследованиями, демонстрирующими, что ранние электрофизиологические компоненты, связанные с комбинаторной обработкой, инвариантны как к задачам [36], [37], так и к манипуляциям с вниманием [43], [33], [31]. Кроме того, гемодинамические эффекты, связанные с комбинаторной обработкой, в том числе эффекты LATL, вызванные обработкой предложений, остаются наблюдаемыми даже во время задач, специально разработанных для минимизации комбинаторной обработки [52], [53], [54].
Во время обработки стимулов обратного порядка (красная чашка), напротив, мы не ожидали автоматического запуска комбинаторной обработки. Важно отметить, что мы разработали наши задачи так, чтобы они требовали суждений об обозначениях объектов, тем самым удерживая испытуемых от интерпретации этих последовательностей как измененных цветов (например, винно-красный — это определенный оттенок красного, связанный с вином). Кроме того, мы отобрали словосочетания, которые не имели знакомых цветов существительное-прилагательное (например, красный цвет свеклы не использовался). Следует отметить, что в более широком контексте прилагательные, конечно, могут изменять существительные постноминально, например Я видел красную от краски чашку, однако такое употребление обычно требует, чтобы прилагательное было достаточно «тяжелым», и часто требует интонационной паузы после существительного [55]. Таким образом, мы ожидали, что эти обратные последовательности не должны задействовать комбинаторную обработку, если задача не требует этого. Следовательно, мы ожидали контраста между канонической и обратной последовательностями с точки зрения комбинаторной обработки во время задачи «Не составление». Наш основной вопрос заключался в том, чтобы определить, в какой степени обратные последовательности могут задействовать комбинаторную обработку во время задачи «Составить».
Чтобы манипулирование заданием было как можно более чистым, два задания были назначены отдельным группам участников. В частности, мы хотели избежать возможности того, что после обработки стимулов комбинаторным образом испытуемым будет трудно отключиться от комбинаторного способа обработки. Другими словами, такая стоимость переключения задач может привести к комбинаторной обработке канонических порядков слов во время задачи «Не составление» не потому, что композиция для них выполняется автоматически, а из-за помех от недавно выполненной задачи композиции.
В нашей предыдущей работе над последовательностями грамматических прилагательных и существительных (красная чашка) [1], [2] полный паттерн активности, связанный с комбинаторной обработкой, состоял из раннего эффекта в чаше, локализованного в LATL примерно через 200–250 мс, за которым следовал более вариабельные эффекты позже в эпоху (~ 400 мс), локализованные как в вентромедиальной префронтальной коре [1]), так и в угловой извилине (AG-[2]). В настоящем исследовании мы решили использовать активность MEG, локализованную в LATL, в качестве нашего основного показателя базовой комбинаторной обработки по двум причинам. Во-первых, довольно обширная гемодинамическая литература предполагает, что эта область играет решающую роль в комбинаторной лингвистической обработке [56], [57], [58], [59].], [54], и обе предыдущие версии этой парадигмы, при визуальном и слуховом представлении, надежно производили комбинаторную активность, локализованную в LATL [1], [2]. Более поздние эффекты были более разнообразными. Во-вторых, как обсуждалось выше, более поздние компоненты обработки, особенно те, которые возникают во временном окне, окружающем ранее наблюдаемые эффекты vmPFC и AG (350–450 мс), могут сильно зависеть от манипуляций с задачами независимо от каких-либо изменений в комбинаторной обработке (см. 41]). Таким образом, более ранние компоненты являются лучшими кандидатами для показателей, которые могут более непосредственно отражать комбинаторную обработку при выполнении задач.
Подводя итог, если наши предположения верны и канонические сочетания прилагательных и существительных действительно задействуют комбинаторные механизмы независимо от требований задачи, а обратные последовательности существительных и прилагательных — нет, то мы ожидаем, что активность LATL в задаче «Не составить» демонстрирует взаимодействие между обратная (красная чашка) и каноническая последовательности (красная чашка) по сравнению с соответствующими им однословными контролями (красная чашка xhl и чашка frw соответственно), с повышенной активностью LATL, присутствующей только во время канонического состояния из двух слов. Если затем задача Compose вызывает гибкое задействование основных комбинаторных механизмов во время обработки обратных последовательностей, мы ожидаем увидеть основной эффект количества слов в этой задаче с повышенной активностью LATL, присутствующей в обеих последовательностях из двух слов по сравнению с их совпадающими последовательностями. контролирует. С другой стороны, если манипуляции с заданием недостаточно, чтобы вызвать комбинаторную обработку в обратной последовательности, то мы снова ожидаем наблюдать взаимодействие между порядком и количеством слов и в этом задании. Чтобы максимизировать силу манипуляции, мы давали каждое задание отдельно разным испытуемым.
15 испытуемых выполнили задание «Не сочинить» (8 женщин; средний возраст 22,4 года). Задание «Составить» выполнил 21 человек (14 женщин, средний возраст 21,4 года). Все испытуемые были правшами, носителями английского языка без дальтонизма, с нормальным или скорректированным до нормального зрением. Все процедуры были одобрены Комитетом Нью-Йоркского университета по деятельности с участием людей, и от каждого участника было получено информированное письменное согласие. Участники получали вознаграждение или кредит курса за свое участие.
Материалы В каждой пробе последовательно предъявлялись четыре стимула: фиксационный крест, начальное слово или не слово, существительное или прилагательное и целевая картинка (рис. 1). Испытуемым предлагалось игнорировать все несловесные стимулы и указывать, содержит ли целевое изображение изображение всех предшествующих лексических элементов. В задаче «Создать» целевое изображение содержало одну цветную фигуру. В задаче без составления цвет и форма были представлены отдельно в виде круглого пятна и белого контура соответственно. Лингвистические стимулы варьировались в зависимости от условия: канонические испытания из двух слов представляли прилагательное, за которым следовало существительное (красная чашка), обратные испытания из двух слов представляли существительное, за которым следовало прилагательное (красная чашка), а испытания из одного слова заменяли начальные слова непроизносимыми. согласные строки (xhl чашка, frw красный). Таким образом, второй, критический стимул оставался неизменным между парными одно- и двухсловными условиями. Во время эксперимента Non-Compose испытуемые также выполняли вариант списка каждого задания, в котором они оценивали, соответствует ли целевое изображение одному из двух предшествующих существительных или прилагательных. Поскольку это противопоставление не имеет отношения к гипотезам настоящего исследования, оно было исключено из последующего обсуждения.
Во всех состояниях использовались девять односложных прилагательных общего цвета (красный, коричневый, бирюзовый, синий, розовый, черный, коричневый, белый, зеленый). Каждому прилагательному было присвоено соответствующее по длине существительное (чашка, машина, замок, обувь, лист, дом, сердце, самолет, крест) и соответствующая по длине непроизносимая цепочка согласных (xkq, kjw, qxsw, mtpv, vbnw, rjdnw). , wvcnz, zbxlv, vtzkn). Существительные и прилагательные также были сопоставлены по частоте (p = 0,74; логарифмическая частота HAL; парный t-критерий). Каждое слово было напечатано непропорциональным шрифтом Courier с наклоном примерно 3°. В задании «Составить» целевые изображения представляли собой созданные вручную канонические изображения каждой формы, раскрашенные одним из девяти цветов и отображаемые в центре экрана под углом примерно 8°. В задаче «Не составление» круглые капли и очертания (взятые из цветных фигур) были случайным образом размещены в одном из четырех мест с центром на +/-2° как по горизонтали, так и по вертикали от центра экрана, при этом никакие два объекта не занимали одно и то же место в любом испытании. Для этих стимулов каждый объект сам по себе стягивался примерно на 4°. Все стимулы предъявлялись с помощью psychtoolbox [60], [61] и проецировались на экран примерно в 45 см от глаза испытуемого.
В каждом задании канонические и обратные испытания были заблокированы отдельно, с уравновешенным порядком для каждой группы испытуемых. В каждом условии критические элементы (т. е. существительные для канонических испытаний, прилагательные для обратных испытаний) предъявлялись четыре раза в совпадающих испытаниях и четыре раза в несоответствующих испытаниях, в результате чего в каждом условии было 72 испытания и 144 испытания на блок. В испытаниях с несовпадением двух слов целевые изображения совпадали либо с предыдущим термином цвета, либо с формой, но не с обоими одновременно. Для каждого субъекта были созданы обратные испытания из двух слов путем простого изменения порядка стимулов в канонических испытаниях из двух слов. Затем из всех двухсловных испытаний были созданы однословные испытания путем замены совпадающей строки согласных для каждого начального стимула и перетасовки целевых изображений, чтобы они соответствовали или не соответствовали оставшемуся слову по мере необходимости. Списки стимулов были рандомизированы для каждого субъекта.
Перед экспериментом испытуемые практиковали свой первый блок за пределами комнаты МЭГ. Перед записью формы головы испытуемых были оцифрованы с помощью дигитайзера Polhemus Fastrak 3D (Polhemus, VT, USA). Оцифрованная форма головы затем использовалась для ограничения локализации источника во время анализа путем совместной регистрации пяти катушек, расположенных вокруг лица по отношению к датчикам МЭГ. Кроме того, на 1 см справа и на 1 см ниже середины правого глаза были прикреплены электроды для записи вертикальной и горизонтальной электроокулограммы (ЭОГ) и обнаружения моргания. Оба электрода были привязаны к левому сосцевидному отростку.
Данные MEG были собраны с использованием 157-канальной осевой градиентометрической системы для всей головы (Технологический институт Канадзавы, Токио, Япония) с частотой дискретизации 1000 Гц с фильтром нижних частот на частоте 200 Гц и режекторным фильтром на частоте 60 Гц. Все стимулы, кроме изображений-мишеней, предъявлялись в течение 300 мс, после чего следовал пустой экран в течение 300 мс. Картинки-мишени появлялись в конце каждого испытания и оставались на экране до тех пор, пока испытуемый не принял решение. Последующие испытания начинались после того, как в течение переменного периода времени демонстрировался пустой экран в соответствии с нормальным распределением со средним значением 500 мс и стандартным отклонением 100 мс (см. рис. 1). Весь сеанс записи длился примерно 50 минут для задания без составления и 25 минут для задания для составления (разница связана с блоками списка, включенными в задание без составления; см. материалы выше).
Данные МЭГ записывались непрерывно, с шумоподавлением с использованием непрерывно корректируемого метода наименьших квадратов (CALM; [62]) и с периодичностью от 100 мс до начала каждого критического элемента до 600 мс после начала. Необработанные данные сначала очищали от потенциальных артефактов, отбрасывая испытания, в которых: а) испытуемый отвечал либо неправильно, либо слишком медленно (определялось как более 2,5 секунд после появления целевой формы), б) максимальная амплитуда превышала 3000 фТл, или в) испытуемый моргал в пределах критического временного интервала, что определялось ручной проверкой записей ЭОГ. Один испытуемый в задаче «Не сочинить» случайно выполнил односложное обратное условие и поэтому был исключен из дальнейшего анализа. Затем оставшиеся данные усреднялись для каждого субъекта для каждого состояния и подвергались полосовой фильтрации в диапазоне от 1 до 40 Гц. Для включения в дальнейший анализ мы требовали, чтобы испытуемые демонстрировали качественно канонический профиль вызванных ответов во время обработки критических заданий. Этот профиль определялся как появление устойчивых и заметных первоначальных зрительных ответов, т. е. картина поля М100 или М170 [63, 64] должна была четко присутствовать во временном окне от 100 до 200 мс после критических стимулов. Пять испытуемых в целом не соответствовали этому требованию (три в задании на составление и два в задании без составления) и были исключены из дальнейшего анализа.
В качестве нашей основной зависимой меры мы создали распределенные оценки источника минимальной нормы для записанных данных датчика МЭГ. Эта мера обеспечивает оценку кортикальной локализации электрической активности, лежащей в основе наблюдаемых магнитных полей, регистрируемых вне головы. Исходная оценка была построена для каждого среднего состояния с использованием оценок минимальной нормы L2, рассчитанных с использованием BESA 5.1 (MEGIS Software GmbH, Мюнхен, Германия). Ковариационная матрица шума канала для каждой оценки была основана на 100 мс до появления критического элемента в каждом среднем условии. Каждая оценка минимальной нормы основывалась на активности 1426 региональных источников, равномерно распределенных в двух оболочках на 10% и 30% ниже сглаженной стандартной поверхности мозга. Региональные источники в МЭГ можно рассматривать как источники с двумя одиночными диполями в одном и том же месте, но с ортогональной ориентацией. Общая активность каждого регионального источника затем вычислялась как среднеквадратичное значение активности источника двух его компонентов. Пары диполей в каждом месте сначала усреднялись, а затем выбиралось большее значение из каждой пары источников, создавая 713 ненаправленных источников, активацию которых можно было сравнить для разных субъектов и условий. Изображения минимальной нормы были взвешены по глубине, а также пространственно-временно взвешены с использованием меры корреляции сигнального подпространства [65]. Дисперсионный анализ повторных измерений в рамках каждой задачи с факторами Порядок (канонический, обратный) и Количество слов (два, одно) не выявил достоверных основных эффектов или взаимодействий в отношении сигнал/шум оценок минимальной нормы (все p > .15).
Чтобы оценить комбинаторную активность, наш первичный анализ изучал исходную активность, локализованную в LATL, как определено ROI, используемой в наших предыдущих экспериментах [1], [2]. Граница этого ROI была первоначально основана на гемодинамических результатах, демонстрирующих повышенную активность в LATL во время понимания предложений по сравнению со списками слов [57], [56], [54]. Мы проанализировали активность, локализованную в этой области интереса, от 0 до 600 мс после предъявления второго слова, используя тест перестановок на основе кластеров [66], предназначенный для выявления значительных эффектов в любой момент в течение эпохи анализа. Этот тест контролирует множественные сравнения в течение всего интервала времени с помощью следующей обобщенной процедуры. Сначала для наблюдаемых данных рассчитывается статистика кластерного теста. Затем эта же тестовая статистика вычисляется для многих перестановок фактических данных, каждая из которых создается путем случайного перетасовки меток условий внутри каждого участника. Затем значение p наблюдаемой тестовой статистики вычисляется относительно распределения, созданного из 10 000 перестановок исходных данных, и устанавливается равным доле переставленных наборов данных, которые дают тестовую статистику, более экстремальную, чем у фактических данных.
Одним из преимуществ этого теста является то, что статистика кластерного теста может быть построена специально для соответствия конкретной гипотезе (см. [1]; [66]). В настоящем эксперименте каждая статистика была рассчитана путем определения смежных моментов времени, для которых статистический точечный тест достиг определенного порога (установленного на p = 0,30, чтобы соответствовать нашим предыдущим анализам), а затем расчета одной тестовой статистики из полученного кластера. точек. Чтобы проверить взаимодействие, предсказанное в некомбинаторной задаче, мы использовали ту же тестовую статистику, что и в нашей предыдущей статье (подробности см. в [1]). Таким образом, каждый кластер был идентифицирован с использованием значения взаимодействия p из точечных 2×2 повторных измерений ANOVA с количеством слов (один, два) и порядком слов (канонический, обратный) в качестве факторов. Затем итоговая тестовая статистика была рассчитана путем суммирования значений t, полученных в результате точечных t-тестов между каноническими условиями, и вычитания значений t, полученных в результате точечных t-тестов между обратными условиями. Чтобы проверить основной эффект, предсказанный в комбинаторной задаче, мы идентифицировали кластеры, используя значение p из поточечного дисперсионного анализа с повторными измерениями 2 × 2, которое соответствовало основному эффекту количества слов, и мы включили только те точки, для которых значение p взаимодействия также не превышало порогового значения. Затем мы просто суммировали t-статистику всех t-тестов, выполненных в двух парах условий, чтобы вычислить окончательную статистику теста.
Чтобы определить эффекты за пределами LATL, мы также провели анализ всего мозга, в котором сравнивались показатели активности из двух и одного слова в каждой задаче, выборка за выборкой для каждой исходной точки времени с использованием парного t-критерия. Различие считалось значимым в этом тесте только в том случае, если оно превышало критерии значимости и размера, так что оно оставалось достоверным (p<0,05) по крайней мере для 10 образцов (10 мс), наблюдалось по крайней мере в 10 соседних корковых источниках и было по крайней мере 1,5 нАм по амплитуде. В приведенных ниже результатах и рисунках мы обсуждаем только эффекты, связанные с увеличением активности двух слов.
РезультатыПоведенческие результаты Поведенческие данные, изображенные на рис. 2, были проанализированы на скорость и точность с помощью дисперсионного анализа 2×2×2 с Заданием (Составление, Несоставление) в качестве переменной между субъектами и Порядок (канонический, обратный) × Количество слова (два, один) как внутри предметных переменных. За этим последовали запланированные повторные измерения 2 × 2 ANOVA на влияние порядка и количества слов в каждой задаче.
Для каждой задачи данные о времени реакции и точности были представлены для 2×2 повторных измерений ANOVA с порядком (канонический, обратный) и количеством слов (один, два) в качестве факторов. В задаче без составления (A) мы наблюдали значительное взаимодействие между двумя факторами для точности и не обнаружили значительного влияния на время реакции. В задании «Составить» (B) мы наблюдали значительное влияние количества слов на точность и значительное взаимодействие между двумя факторами на время реакции. нс, несущественный; ***р<0,001; **р<0,01.
Для точности дисперсионный анализ 2×2×2 выявил значительное трехстороннее взаимодействие между задачей (составить, не составить), порядком (канонический, обратный) и количеством слов (два, один) (F(1, 28) = 6,62; p = 0,016). Последующий дисперсионный анализ 2×2 в задаче «Не составить» показал значительную взаимосвязь между порядком и количеством слов для точности (F(1,11) = 9,03, p = 0,012) с последующими парными t-тестами между одним- и пары условий из двух слов показали, что этот эффект был вызван значительно более низкой точностью канонического условия из двух слов по сравнению с согласованным контрольным условием из одного слова (p = 0,007; два слова: 91,9% в среднем [1,8% станд.]; одно слово: 96,8% в среднем. [0,7% станд.]), и нет статистической разницы в точности для условий обратного порядка (p = 0,39; два слова: 97,9% в среднем [0,8% станд.]; одно слово: 97,2% в среднем [0,7% станд.]). С другой стороны, соответствующий дисперсионный анализ 2 × 2 в задаче «Составление» не дал основного эффекта порядка или взаимодействия между двумя факторами (оба Fs <1), но значительный основной эффект количества слов (F (1,17) = 13,94; p = 0,0017), с более низкой точностью в обоих условиях с двумя словами по сравнению с их соответствующими элементами управления (канонические два слова: 96,4% в среднем [0,8% станд. ]; каноническое однословие: 98,1% в среднем. [0,5% стандарт.]; перевернутые два слова: 97,1% в среднем. [0,4% станд.]; перевернутое одно слово: 98,0% в среднем. [0,4% станд.]). Таким образом, взаимодействие, наблюдаемое в исходном дисперсионном анализе 2×2×2, было вызвано значительным влиянием задачи на взаимодействие между количеством слов и порядком точности.
Для времени реакции дисперсионный анализ 2×2×2 показал основной эффект задачи (F(1,28) = 6,96; p<0,01), при этом ответы в задаче «Составление» были быстрее, чем в задаче «Не составление» (622 мс). в среднем [139мс станд.] т. 745 мс в среднем. [349 мс станд.]). Не было значимого трехстороннего взаимодействия (F(1,28) = 1,88, p = 0,18), хотя восемь условий снова демонстрировали тот же качественный образец, что и для точности, причем каждое условие из двух слов отличалось от его парного контроля из одного слова. таким же образом (здесь, с более быстрыми ответами), за исключением перевернутого условия из двух слов в задаче без составления, которая не отличалась от соответствующего контрольного слова из одного слова (и фактически имела несколько более медленные ответы). Дисперсионный анализ 2 × 2 в задаче «Не составление» не показал значительного влияния на время реакции на порядок, количество слов или их взаимодействие (все значения F <1; канонический: два слова: 727 мс в среднем [86 мс стандартное ]; одно слово: 739мс сред. [98 мс стандарт]; перевернутое: два слова: 759 мс в среднем. [113 мс стандарт]; одно слово: 757 мс в среднем. [116 мс станд.]). Однако соответствующий 2×2 ANOVA в задаче «Составь» показал значительную взаимосвязь между порядком и количеством слов (F(1,17) = 8,39; p = 0,01). Последующие парные t-тесты показали, что этот эффект был обусловлен значительно более быстрыми ответами в каноническом условии из двух слов по сравнению с согласованным контролем (p<0,001; два слова: 579 мс в среднем [30 мс стандарт]; одно -слово: 644 мс в среднем [38 мс стандарт]) и отсутствие статистической разницы между условиями обратного порядка (p = 0,40; два слова: 625 мс в среднем [36 мс стандарт]; одно слово: 640 мс в среднем [33 мс стандарт]).
Таким образом, в целом наши поведенческие показатели указывают на четкую диссоциацию между всеми условиями, состоящими из двух слов, и их контрольными значениями, состоящими из одного слова, за исключением перевернутого условия из двух слов в задании без составления, которое вместо этого близко соответствовало его однословному условию. контроль. Этот шаблон результатов, конечно, точно такой же, как предсказан для комбинаторной обработки, если комбинаторные механизмы могут быть гибко развернуты в перевернутых последовательностях из двух слов, когда задача требует композиции, и не задействуются автоматически, когда задача этого не требует. Кроме того, более быстрое время отклика при составлении условий из двух слов перекликается с эффектом облегчения, ранее наблюдаемым для составленных фраз в этом задании (Bemis & Pylkkänen, 2011). Хотя причина сопутствующего снижения точности для этих условий неясна и предполагает ненаблюдаемый ранее компромисс между скоростью и точностью, в целом поведенческие результаты показывают, что обработка была одинаковой во время канонических и перевернутых последовательностей из двух слов, когда задача требовала композиции. и непохожие, когда не требовалось никакого состава.
В задаче Non-Compose тест перестановок взаимодействия выявил значительный кластер активности, локализованный в LATL (рис. 3) от 215 до 266 мс (p = 0,023; 10 000 перестановок). Повторные измерения ANOVA 2 × 2, выполненные для активности LATL, усредненной в этом временном окне, подтвердили этот результат и продемонстрировали значительную взаимосвязь между порядком и количеством слов (F (1,11) = 7,361; p = 0,020) с активностью в двух- каноническое условие слова значительно выше, чем в совпавшем однословном контроле (p = 0,009; парные выборки t-критерий; два слова: 4,25 нАм в среднем. [2,14 нАм станд.]; одно слово: 2,86 нАм в среднем. [1,23 нАм станд.]), и отсутствие статистической разницы между активностью в обращенных условиях (p = 0,732; t-критерий для парных образцов; два слова: 3,70 нАм в среднем [1,95 нАм станд.]; одно слово: 3,51 нАм в среднем [0,86 нАм станд.]).
Локализованная активность показана для LATL ROI во время обработки критических элементов (существительные в канонической последовательности, прилагательные в обратной последовательности), усредненные по субъектам. Заштрихованные области обозначают значительные кластеры комбинаторной активности, определенные с помощью непараметрического теста перестановок на основе кластеров (Maris & Oostenveld, 2007), примененного ко всей эпохе, от 0 до 600 мс после представления критического элемента. Мы наблюдали значительную взаимосвязь между порядком и количеством слов в задаче «Не составить» (A) и значительный основной эффект количества слов в задаче «Составить» (B) для активности, генерируемой между 200 и 300 мс. нс, несущественный; **р<0,01; *р<0,05.
Мы не обнаружили доказательств повышенной активности LATL во время обработки обращенных последовательностей в этой задаче. Как тест перестановки основного эффекта, так и апостериорный кластерный тест, проведенный только между двумя обратными условиями, не смогли найти каких-либо значимых кластеров активности (все кластеры p>0,8). Таким образом, в задаче Non-Compose мы наблюдали значительный комбинаторный эффект при обработке канонических фраз в то же время, что и в наших предыдущих экспериментах (Bemis & Pylkkänen, 2011, 2012), и никаких доказательств каких-либо комбинаторных эффектов LATL во время обработки. обработка обратных последовательностей в любое время.
В задаче Compose тест перестановок, предназначенный для выявления повышенной активности в обоих состояниях двух слов, выявил значительный кластер активности, локализованный в LATL (рис. 3) от 201 до 269 мс (p = 0,029; 10 000 перестановок). . ANOVA с повторными измерениями 2 × 2, выполненный для активности, усредненной по этому кластеру, подтвердил этот результат и выявил значительный основной эффект количества слов (F (1,17) = 4,52; p = 0,0385) с повышенной активностью в двух словах. условиях по сравнению с их парными контролями из одного слова (канонический из двух слов: в среднем 4,00 нАм [1,93 нАм станд.]; однословный канонический: 3,37 нАм в среднем. [0,97 нАм станд.]; перевернутое из двух слов: 4,17 нАм в среднем. [2,43 нАм станд.]; перевернутое одно слово: 3,39 нАм в среднем. [1,61 нАм станд.]). Ни основной эффект порядка, ни взаимодействие между двумя факторами не были значимыми в этом тесте (оба Fs <1).
Этот тест перестановок также выявил предельно значимый кластер активности от 380 до 430 мс (p = 0,075; 10 000 перестановок), что подтверждается предельным основным эффектом количества слов в соответствии с ANOVA с повторными измерениями 2×2 на активность в течение этого периода. временное окно (F(1,17) = 3,52; p = 0,078; канонический из двух слов: 3,72 нАм в среднем [1,96 нАм станд.]; однословный канонический: 3,13 нм в среднем. [1,20 нАм станд.]; перевернутое из двух слов: 3,80 нАм в среднем. [2,32 нАм станд.]; перевернутое одно слово: 2,95 нАм в среднем. [1,33 нАм станд.]). Опять же, в этом временном окне не было эффекта порядка и взаимодействия между двумя факторами (оба Fs <1). Этот результат снова близко соответствует нашим предыдущим выводам, в которых мы наблюдали незначительное увеличение комбинаторной активности в LATL примерно с 350 до 400 мс (Bemis & Pylkkänen, 2011).
Единственным эффектом, идентифицированным тестом перестановки взаимодействия в этой задаче, был незначительно значимый кластер активности от 469 до 505 мс (p = 0,079; 10 000 перестановок), в котором активность LATL увеличивалась только во время канонического условия из двух слов (двухсловное канонический: 3,77 нАм в среднем [1,43 нАм стандарт]; однословный канонический: 2,70 нАм в среднем [0,87 нАм стандарт]; двухсловный перевернутый: 2,72 нАм в среднем [2,12 нАм стандарт]; однословный перевернутый: 2,83 нАм в среднем [1,52 нАм станд. ]). Это взаимодействие было значимым в соответствии с повторным дисперсионным анализом 2 × 2 для активности в течение этого временного окна (F (1,17) = 6,79).; р = 0,019). Никакие другие значимые эффекты не были выявлены в любой момент эпохи анализа с использованием любого теста.
Таким образом, в целом, результаты нашего анализа LATL ROI убедительно указывают на группировку обработки канонической и обратной последовательности во время задачи Compose и диссоциацию между ними во время задачи Non-Compose.
Результаты с полным мозгом Несоставные результаты с полным мозгом Для канонического упорядочения можно увидеть явное увеличение активности (рис. 4) со 150 до 250 мс в LATL, что подтверждает приведенный выше анализ ROI. Дополнительные эффекты также видны в вентромедиальной префронтальной коре (vmPFC) и правой передней височной доле (RATL) от 450 до 550 мс. Повышенная активность в обеих этих областях также наблюдалась во время обработки словосочетаний прилагательное-существительное в нашем предыдущем исследовании, хотя в этих результатах оба эффекта начались немного раньше, и только активность в vmPFC, по-видимому, отражала комбинаторную обработку, при этом активность RATL, по-видимому, зависела от задачу (подробнее см. [1]).
Области графика обозначают разницу в средней амплитуде между двумя словами и одним словом для всех областей пространства-времени, в которых активность двух слов была достоверно выше, чем активность одного слова (p<0,05, без поправки) в течение по крайней мере 10 мс в течение 10 пространственных соседей, а амплитуда различий не менее 1,5 нАм. Для ясности некортикальные источники были удалены. В целом, результаты как в задаче «Не составить» (A), так и в задаче «Составить» (B) соответствуют нашему анализу ROI, обнаруживая четкие эффекты LATL в более раннем временном окне, примерно от 200 до 300 мс. Более поздние эффекты также видны в RATL и vmPFC как для канонических фраз в задаче Non-Compose, так и для обратных последовательностей в задаче Compose.
В перевернутых последовательностях мы наблюдали очень небольшое увеличение активности во время обработки двух слов, что еще раз подтверждает анализ LATL ROI и поведенческие результаты, указывающие на то, что обработка в обратном условии двух слов не отличалась от согласованного контроля одного слова. в этой задаче.
В задаче Compose можно наблюдать явное увеличение активности LATL (рис. 4) во время обработки канонических фраз из двух слов от 250 до 550 мс. Это хорошо согласуется с нашим анализом ROI, который выявил повышенную активность в этой области на протяжении второй половины эпохи анализа. Никаких других заметных эффектов в этом сравнении не видно.
Для обратных выражений сравнение всего мозга снова соответствовало нашему анализу ROI, обнаруживая явное увеличение активности LATL со 150 до 250 мс. За пределами этого ROI эффекты снова были четко видны в RATL одновременно с эффектом LATL и в vmPFC после эффекта LATL. Как упоминалось ранее, этот образец активности очень близко согласуется с нашими предыдущими результатами для канонических словосочетаний прилагательное-существительное в той же парадигме [1].
Обсуждение В настоящем исследовании мы исследовали, можно ли гибко применить базовую комбинаторную лингвистическую обработку к новым выражениям при минимальном изменении требований задачи. Мы регистрировали активность МЭГ, когда испытуемые читали простые последовательности прилагательных и существительных в каноническом или обратном порядке (красная чашка, красная чашка), и измеряли комбинаторную обработку, сравнивая активность, вызванную предъявлением второго слова, с активностью, вызванной во время обработки совпадающих, не- комбинаторные элементы управления (чашка xhl, красный цвет frw). Мы использовали нейронную активность, локализованную в LATL, во время обработки совпадающих критических слов в качестве нашей основной меры комбинаторной активности. Предыдущие исследования МЭГ с использованием аналогичной парадигмы наблюдали последовательные и надежные комбинаторные эффекты в этой области во время понимания простых словосочетаний «прилагательное-существительное» [1], [2], а во многих гемодинамических исследованиях наблюдалась повышенная активность в LATL во время понимания предложений. по сравнению со списками слов [57], [59], [54] В настоящем исследовании, когда испытуемым требовалось оценить, соответствуют ли данные лингвистические стимулы следующему цветному пятну и контуру формы, комбинаторная активность LATL не наблюдалась для обратных последовательностей, но четко присутствовала для канонических фраз. Когда вместо этого следующая мишень была представлена в виде одной цветной формы, для обоих типов последовательностей наблюдалась значительная комбинаторная активность. Эта модель результатов была отражена в наших поведенческих показателях, которые продемонстрировали устойчивые различия между всеми ответами из двух слов и одним словом, за исключением двухсловных перевернутых последовательностей в задаче без составления, которые вместо этого повторяли свои контрольные ответы из одного слова. . Таким образом, настоящие данные, как поведенческие, так и нейронные, показывают, что перевернутые последовательности существительное-прилагательное обрабатывались аналогично каноническим словосочетаниям прилагательное-существительное, когда задача требовала композиции, и аналогично некомбинаторному контролю, когда этого не требовалось.
Важность этих результатов двояка. Во-первых, устойчивая активность LATL, наблюдаемая во время канонических фраз в задаче Non-Compose, дополнительно подтверждает эту меру как показатель базовой комбинаторной обработки. Многие предыдущие исследования автоматизма механизмов лингвистического синтаксического анализа показывают, что гемодинамические комбинаторные эффекты, локализованные в LATL [54], и ранние электрофизиологические компоненты, связанные с разбором грамматических выражений [37], [33], остаются устойчивыми даже при явно не комбинаторных задачах. . Таким образом, если ранняя активность, локализованная в LATL в настоящей парадигме, действительно отражает базовую комбинаторную обработку, можно было бы ожидать, что она будет демонстрировать наблюдаемый профиль и оставаться устойчивой во время манипуляций с нашей задачей. Во-вторых, идентификация этого эффекта при обработке перевернутых последовательностей в задаче «Составить», а не в задаче «Не составить», указывает на то, что комбинаторные лингвистические механизмы, индексируемые этой мерой, могут гибко задействоваться вне их обычного контекста при минимальной нагрузке. изменение требований к задаче. Интересно, что наблюдаемый эффект в перевернутых последовательностях совпадал по времени с эффектом в канонических фразах (оба произошли примерно через 200–250 мс), что свидетельствует об аналогичном временном ходе этого комбинаторного механизма для разных типов последовательностей. Хотя эта очевидная легкость распространения комбинаторной обработки на новый контекст может быть потенциально нелогичной, она могла быть облегчена заблокированной природой настоящей парадигмы. Дальнейшая работа может показать, что более неожиданное изменение требований к задачам приводит к более отложенному включению комбинаторной обработки.
Прошлые исследования влияния требований задачи на языковую обработку были сосредоточены почти исключительно на манипулировании вниманием, явно [33] или имплицитно [32]. Даже те немногие исследования, в которых использовались задачи, потенциально способные решить проблему гибкости комбинаторной обработки (например, [67]), вместо этого по-прежнему были явно сосредоточены на измерении эффекта внимания. Напротив, в настоящем исследовании стремились свести к минимуму изменения внимания, манипулируя только необходимой комбинаторной обработкой. В обеих наших задачах испытуемые должны были получить семантическое представление всех слов, чтобы определить, содержит ли целевое изображение их денотат. Таким образом, обработка, связанная с лексическим доступом и вниманием, должна быть относительно эквивалентна между двумя задачами. Поэтому трудно приписать увеличение активности LATL, наблюдаемое во время обработки обращенных последовательностей в задаче «Составить», изменениям внимания, тем более что такая же активность четко присутствовала для канонических фраз и во время задачи «Не составление». Таким образом, в отличие от предыдущих исследований, настоящее исследование демонстрирует гибкое использование комбинаторных лингвистических механизмов, вызванное изменением требований к задаче, которое не связано с явным манипулированием вниманием.
Мы также обнаружили дополнительные доказательства гибкого использования комбинаторной обработки вне ранней активности LATL. Во время обработки обращенных последовательностей в задаче Compose мы наблюдали незначительное увеличение активности LATL примерно с 350 до 400 мс и дополнительную комбинаторную активность, локализованную в vmPFC, с 400 до 500 мс — картина эффектов, поразительно похожая на наблюдаемую ранее. для канонических фраз [1]. В задаче Non-Compose таких эффектов не наблюдалось. Таким образом, результаты более поздней обработки также подтверждают вывод о том, что основные комбинаторные механизмы были задействованы при обработке обращенных последовательностей в задаче «Составить».
Это доказательство, однако, не столь убедительно, как для более ранних эффектов LATL, поскольку эти более поздние результаты не были воспроизведены в настоящем эксперименте с такой точностью для канонических фраз. Хотя мы наблюдали повышенную активность, локализованную в vmPFC, во время обработки канонических фраз в задаче Non-Compose примерно с 450 до 550 мс, этот эффект не повторялся и в задаче Compose. Вместо этого комбинаторная активность оставалась локализованной в LATL до конца эпохи в этой задаче и не мигрировала в другие регионы, такие как vmPFC [1] или AG [2]. Этот отклоняющийся результат был особенно неожиданным, учитывая, что этот конкретный контраст не отличался структурным образом от того, который использовался в наших предыдущих исследованиях. Одним из возможных объяснений наблюдаемой разницы может быть то, что в настоящем исследовании использовалось только девять критических элементов, тогда как в обоих предыдущих исследованиях использовалось не менее 20. Это снижение лексической изменчивости могло способствовать относительно приглушенному и изменчивому характеру более поздних эффектов в этом контрасте, поскольку снижение лексической изменчивости часто связывают со снижением нервной активности (например, [68]). Однако устойчивая природа более поздних эффектов, наблюдаемых во время обратных последовательностей в этой задаче, предполагает, что это объяснение является неполным. Очевидно, что требуется дополнительная работа, чтобы распутать различные механизмы, лежащие в основе этой более поздней стадии обработки, особенно с учетом изменчивости, наблюдаемой для таких эффектов и в наших предыдущих результатах.
Хотя настоящие результаты говорят о том, как работает комбинаторный механизм, заключенный в LATL, наши результаты совместимы с несколькими функциональными гипотезами о том, что именно вычисляет этот механизм. Предполагается, что даже самая простая грамматическая обработка включает как синтаксические, так и семантические механизмы, ответственные за формирование структурных отношений и построение сложных значений из отдельных элементов. Ранее [1], [2] мы предложили предварительное сопоставление синтаксических и семантических процессов с ранними эффектами LATL и поздними vmPFC соответственно. Это предположение было основано на предыдущей работе, связывающей гемодинамическую активность в LATL с комбинаторной синтаксической обработкой [69].], [70], MEG работают, связывая повышенную активность vmPFC с семантической композицией [71], [72], и модели нейролингвистической обработки, которые постулируют синтаксическую комбинацию до семантической композиции [73]. С одной стороны, настоящие результаты можно рассматривать как поддержку этого предложенного разграничения, поскольку многие прошлые исследования связывают ранние автоматические электрофизиологические компоненты с синтаксическими процессами [36], [32], [33], а более поздние компоненты, более зависящие от задачи, с семантическими процессами. обработки [41], [40]. Таким образом, наш вывод о том, что ранняя комбинаторная активность в LATL остается устойчивой во всех задачах во время обработки канонических фраз, может подтвердить предположение, что этот компонент отражает синтаксическую обработку.
С другой стороны, устойчивые к задачам ранние электрофизиологические компоненты также приписывались семантической обработке [74], а недавняя гемодинамическая работа утверждает, что повышенная активность в LATL во время понимания предложений отражает семантическую, а не синтаксическую, комбинаторную обработку [59]. ], [35]. В настоящем исследовании характер манипулирования заданием также предполагает семантическую, а не синтаксическую роль LATL, поскольку единственная разница между двумя заданиями заключается в том, что в задании Compose испытуемые должны создать единственное семантическое представление из индивидуальной формы. и цветовые представления. Никаких очевидных синтаксических манипуляций не происходит, поскольку языковые стимулы остаются постоянными между задачами. Таким образом, трудно дать простое функциональное объяснение того, как или почему синтаксическая фраза может быть образована для перевернутых последовательностей в этой задаче. Конечно, может случиться так, что синтаксический анализатор формирует такую составляющую, несмотря на обратный порядок составляющих — и некоторые утверждали, что это должно иметь место для того, чтобы семантическая композиция продолжалась (например, [36]) — однако это кажется более вероятным. вполне вероятно, что комбинаторная активность, наблюдаемая во время задания на составление, просто отражает требования задания, то есть смысловую композицию двух элементов. Более конкретно, эта деятельность может отражать тип процесса спецификации, в котором базовое концептуальное представление объекта трансформируется в более сложную форму, представляющую более конкретную концепцию цветной формы. Такая операция, возможно, может происходить независимо от порядка, в котором встречаются элементы, и такая симметрия фактически является формальным свойством теоретических представлений о модификации [75]. Кроме того, несколько предыдущих исследований связывали активность в LATL именно с этим типом операции спецификации, хотя и при обработке отдельных слов [76], [77]. Если эта гипотеза верна, то более поздние комбинаторные эффекты могут составлять вторую стадию семантической композиции, соответствующую нескольким моделям концептуальной модификации, основанным на психолингвистических результатах (например, [78], [79].]. Однако на данный момент этот вывод должен оставаться предварительным, поскольку настоящая манипуляция не была специально разработана для того, чтобы распутать эти функциональные гипотезы.
. В настоящем исследовании мы демонстрируем, что основные комбинаторные лингвистические механизмы могут быть гибко развернуты в контексте за пределами их естественной грамматической области. В отличие от предыдущих исследований, которые манипулируют вниманием или используют длительные имплицитные парадигмы обучения, мы показываем здесь, что простое введение релевантности комбинации при неизменности факторов внимания и лексики достаточно для того, чтобы вызвать базовую комбинаторную обработку между двумя лексическими единицами, которые естественным образом не задействуются. такая обработка. Будущая работа теперь может опираться на этот результат, чтобы определить степень этой гибкости как с точки зрения лингвистических механизмов, так и когнитивных областей.
Мы благодарим Анну Бемис за помощь в создании рисунков, Ребекку Эгберт за помощь в сборе данных, Пола Дель Прато за помощь в анализе данных и Джона Бреннана за советы по анализу.
Ссылки1 BemisDK, PylkkänenL (2011) Простая композиция: магнитоэнцефалографическое исследование понимания минимальных лингвистических фраз. J Neurosci31: 2801–2814.2 BemisDK, PylkkanenL (2013) Базовая лингвистическая композиция задействует левую переднюю височную долю и левую угловую извилину во время прослушивания и чтения. Кора головного мозга 23: 1859 г.–1873,3 CarruthersP (2002) Когнитивные функции языка. Behav Brain Sci25: 657–674.4 Фодор Дж. А. (1983) Модульность разума. Кембридж, Массачусетс: MIT Press.5 Спелке Э.С. (2003) Что делает нас умными? Основные знания и естественный язык. В: Gentner D, Goldin-Meadow S, редакторы. Язык в уме: достижения в изучении языка и мышления. Кембридж, Массачусетс: MIT Press. 277–311,6
JobardG, VigneauM, MazoyerB, Tzourio-MazoyerN (2007)Влияние модальности и лингвистической сложности на чтение и аудирование. Нейроизображение34: 784–800,7
ConstableRT, PughKR, BerroyaE, MenclWE, WesterveldM и др. (2004)Сложность предложений и влияние модальности ввода на понимание предложений: исследование фМРТ. Нейроизображение22: 11–21,8
PeraniD, PaulesuE, GallesNS, DupouxE, DehaeneS и др. (1998) Двуязычный мозг. Уровень владения и возраст овладения вторым языком. Мозг 121: 1841–1852.9
RossiS, GuglerMF, FriedericiAD, HahneA (2006) Влияние уровня владения немецким и итальянским языками на синтаксическую обработку второго языка: данные потенциальных возможностей, связанных с событиями. J Cogn Neurosci18: 2030–2048.10
KotzSA (2009) Критический обзор данных ERP и fMRI по синтаксической обработке L2. Брейн Ланг109: 68–74.11
ReberAS (1967) Неявное изучение искусственных грамматик. J Вербальное обучение вербальному поведению6: 855–863. 12
MussoM, MoroA, GlaucheV, RijntjesM, ReichenbachJ, et al. (2003) Зона Брока и языковой инстинкт. Нат Невроци6: 774–781,14
Бахлманн Дж., Шуботц Р.И., Мюллер Дж. Л., Кестер Д., Фридеричи А. Д. (2009 г.) Нейронные схемы обработки иерархических зрительно-пространственных последовательностей. Разрешение мозга 1298: 161–170,15
PothosEM (2007) Теории искусственного обучения грамматике. Психол Булл 133: 227–244,16
AmatoMS, MacDonaldMC (2010) Обработка предложений на искусственном языке: изучение и использование комбинаторных ограничений. Познание 116: 143–148,17
MisyakJB, ChristiansenMH, Bruce TomblinJ (2010) Последовательные ожидания: роль обучения языку на основе прогнозов. Top Cogn Sci2: 138–153,18
FriedericiAD, SteinhauerK, PfeiferE (2002)Мозговые сигнатуры обработки искусственного языка: доказательства, бросающие вызов гипотезе критического периода. Proc Natl Acad Sci U S A99: 529–534.19
Федор А., Варга М., Сатмари Э. (2012)Семантика улучшает синтаксис в задачах обучения искусственной грамматике с помощью рекурсии. J Exp Psychol Learn Mem Cogn.20
де Врис М.Х., Монаган П., Кнехт С., Звитсерлод П. (2008) Синтаксическая структура и искусственное изучение грамматики: обучаемость встроенных иерархических структур. Познание 107: 763–774,21
PerruchetP, ReyA (2005) Отличает ли мастерство встроенных в центр лингвистических структур людей от нечеловеческих приматов? Psychon Bull Rev12: 307–313.22
BahlmannJ, SchubotzRI, FriedericiAD (2008)Иерархическая обработка искусственной грамматики задействует область Брока. Нейроизображение42: 525–534,23
TettamantiM, RotondiI, PeraniD, ScottiG, FazioF и др. (2009 г.) Синтаксис без языка: нейробиологические доказательства междоменных синтаксических вычислений. Кортекс45: 825–838,24
Гродзинский, СантиА (2008) Битва за область Брока. Тенденции Cogn Sci12: 474–480,25
WillemsRM, HagoortP (2009) Область Брока: битвы не выигрываются за счет игнорирования половины фактов. Тенденции Cogn Sci13: 101–101.26
MarcusGF, VouloumanosA, SagIA (2003) Играет ли Брока по правилам? Nat Neurosci6: 651–652. 27
де Вриес М.Х., Кристиансен М., Петерссон К.М. (2011) Рекурсия обучения: множественные вложенные и перекрестные зависимости. Биолингвистика5: 10–035.28
FriedericiAD, BahlmannJ, HeimS, SchubotzRI, AnwanderA (2006) Мозг различает человеческие и нечеловеческие грамматики: функциональная локализация и структурная связь. Proc Natl Acad Sci U S A103: 2458–2463.31
ShtyrovY, PulvermüllerF, NäätänenR, IlmoniemiRJ (2003) Обработка грамматики вне фокуса внимания: исследование MEG. J Cogn Neurosci15: 1195–1206.32
HastingAS, KotzSA (2008) Ускорение синтаксиса: об относительном времени и автоматизме локальной структуры фразы и морфосинтаксической обработки, как это отражено в связанных с событиями потенциалах мозга. J Cogn Neurosci20: 1207–1219.33
PulvermüllerF, ShtyrovY, HastingAS, CarlyonRP (2008) Синтаксис как рефлекс: нейрофизиологические доказательства раннего автоматизма грамматической обработки. Брейн Ланг104: 244–253,34
GunterTC, FriedericiAD (1999) Относительно автоматизма синтаксической обработки. Психофизиология36: 126–137.35
РогальскийC, HickokG (2009) Избирательное внимание к семантическим и синтаксическим функциям модулирует сети обработки предложений в передней височной коре. Кора головного мозга 19: 786–796,36
HahneA, FriedericiAD (2002) Дифференциальные эффекты задач на семантические и синтаксические процессы, выявленные ERP. Cogn Brain Res13: 339–356,37
HahneA, FriedericiAD (1999) Электрофизиологические доказательства двух этапов синтаксического анализа: ранние автоматические и поздние контролируемые процессы. J Cogn Neurosci11: 194–205.38
MaidhofC, KoelschS (2011) Влияние избирательного внимания на синтаксическую обработку в музыке и языке. J Cogn Neurosci23: 2252–2267,39McCarthyG, NobreAC (1993) Модуляция семантической обработки пространственным избирательным вниманием. Электроэнцефалогр Клин Нейрофизиол88: 210–219,40
HolcombPJ (1988) Автоматическая обработка и обработка внимания: анализ потенциала мозга, связанного с событием, семантического прайминга. Брейн Ланг35: 66–85,41
DeaconD, Shelley-TremblayJ (2000) Как автоматически осуществляется доступ к смыслу: обзор влияния внимания на семантическую обработку. Front Biosci5: 82–94,42
GunterTC, FriedericiAD, SchriefersH (2000) Синтаксический пол и семантическое ожидание: ERP выявляют раннюю автономию и позднее взаимодействие. J Cogn Neurosci12: 556–568.43
Hasting AS (2008) Синтаксис в мгновение ока: ранняя и автоматическая обработка синтаксических правил, выявленная потенциалом мозга, связанным с событиями: Институт Макса Планка по когнитивным наукам и наукам о мозге. 44
KuperbergGR (2007) Нейронные механизмы понимания языка: вызовы синтаксису. Мозг Res1146: 23–49.45
FerreiraF (2003) Неправильное толкование неканонических предложений. Cogn Psychol47: 164–203,46
FerreiraF, BaileyKGD, FerraroV (2002) Достаточно хорошие представления в понимании языка. Crr Dir Psychol Sci11: 11–15.47
SanfordAJ, SturtP (2002) Глубина обработки в понимании языка: не замечая доказательств. Тенденции Cogn Sci6: 382–386,48
SturtP, SanfordAJ, StewartA, DawydiakE (2004) Лингвистическая направленность и достаточно хорошие представления: применение парадигмы обнаружения изменений. Psychon Bull Rev11: 882–888,49Филлипс С., Вейджерс М.В., Лау Э.Ф. (2011) 5 Грамматические иллюзии и выборочная ошибочность в понимании языка в реальном времени. В: Runner J, редактор. Эксперименты с интерфейсами, синтаксисом и семантикой: Emerald Group Publishing Limited.50
FrazierL, Clifton JrC (1989) Последовательная цикличность в грамматике и парсере. Lang Cogn Process4: 93–126,51
MacDonaldMC, Pearlmutter NJ, SeidenbergMS (1994) Лексическая природа разрешения синтаксической неоднозначности. Psychol Rev101: 676–703.52
CaplanD (2010) Влияние задачи на корреляты сигнала BOLD неявной синтаксической обработки. Ланг Когн Процесс 25: 866–86901.53
CaplanD, ChenE, WatersG (2008) Зависимые от задач и независимые от задач нервно-сосудистые реакции на синтаксическую обработку. Кортекс44: 257–275,54
VandenbergheR, NobreA, PriceC (2002) Реакция левой височной коры на предложения. J Cogn Neurosci14: 550–560,55
SadlerL, ArnoldDJ (1994) Предименные прилагательные и различие между фразовыми и лексическими терминами. J Лингвист30: 187–226,56
MazoyerBM, TzourioN, FrakV, SyrotaA, MurayamaN, et al. (1993) Корковое представление речи. J Cogn Neurosci5: 467–479,57
FriedericiAD, MeyerM, Von CramonDY (2000) Слуховое понимание языка: связанное с событием исследование фМРТ обработки синтаксической и лексической информации. Брэйн Ланг74: 289–300,58
HumphriesC, LoveT, SwinneyD, HickokG (2005) Реакция передней височной коры на синтаксические и просодические манипуляции во время обработки предложений. Hum Brain Map 26: 128–138,59
PallierC, DevauchelleAD, DehaeneS (2011)Корковое представление составной структуры предложений. Proc Natl Acad Sci U S A108: 2522–2527.60
PelliDG (1997) Программное обеспечение VideoToolbox для визуальной психофизики: преобразование чисел в фильмы. Споты Vis10: 437-442,61
BrainardDH (1997) Набор инструментов для психофизики. Споты Vis10: 433-436,62
AdachiY, ShimogawaraM, HiguchiM, HarutaY, OchiaiM (2001) Снижение непериодического магнитного шума окружающей среды при измерении МЭГ с помощью непрерывно настраиваемого метода наименьших квадратов. Приложение IEEE Trans Supercond11(1): 669–672,63
Таркиайнен А., Хелениус П., Хансен П., Корнелиссен П., Салмелин Р. (1999)Динамика восприятия цепочки букв в затылочно-височной коре головного мозга человека. Мозг122: 2119–2132,64
PylkkänenL, MarantzA (2003) Отслеживание динамики распознавания слов с помощью MEG. Тенденции Cogn Sci7: 187–189,65
MosherJC, LeahyRM (1998) Recursive MUSIC: Framework для локализации источников ЭЭГ и МЭГ. IEEE Trans Biomed Eng45: 1342–1354.66
MarisE, OostenveldR (2007) Непараметрическое статистическое тестирование данных ЭЭГ и МЭГ. Методы J Neurosci 164: 177–19.0,67
GravesWW, BinderJR, DesaiRH, ConantLL, SeidenbergMS (2010) Нейронные корреляты неявной и явной комбинаторной семантической обработки. Нейроизображение53: 638–646,68
GabrieliJDE, DesmondJE, DembJB, WagnerAD, StoneMV и др. (1996) Функциональная магнитно-резонансная томография процессов семантической памяти в лобных долях. Психология 7: 278–283,69
NoppeneyU, PriceCJ (2004) Исследование синтаксической адаптации с помощью фМРТ. J Cogn Neurosci16: 702–713,70
BrennanJ, NirY, HassonU, MalachR, HeegerDJ и др. (2012)Построение синтаксической структуры в передней височной доле во время естественного прослушивания истории. Брейн Ланг120: 163–173,71
PylkkänenL, McElreeB (2007) Исследование молчаливого значения MEG. J Cogn Neurosci19: 1905–1921.72
BrennanJ, PylkkänenL (2008) Обработка событий: поведенческие и нейромагнитные корреляты аспектного принуждения. Брейн Ланг106: 132–143,73
FriedericiAD (2002) На пути к нейронной основе обработки слуховых предложений. Тенденции Cogn Sci6: 78–84,74
HinojosaJA, Martin-LoechesM, MuñozF, CasadoP, PozoMA (2004) Электрофизиологические доказательства автоматической ранней семантической обработки. Брэйн Ланг88: 39–46,75
Heim I, Kratzer K (1998) Семантика в генеративной грамматике: Blackwell Publishers Ltd.76
PattersonK, NestorPJ, RogersTT (2007) Откуда вы знаете то, что знаете? Представление семантических знаний в мозгу человека. Нат Рев Невроци8: 976–988,77
RogersTT, HockingJ, NoppeneyU, MechelliA, Gorno-TempiniML, et al. (2006) Передняя височная кора и семантическая память: согласование результатов нейропсихологии и функциональной визуализации. Cogn Affect Behav Neurosci6: 201–213,78
MurphyGL (1988) Понимание сложных концепций. Cogn Sci12: 529–562,79
Мерфи Г.Л. (2002) Большая книга понятий. Кембридж, Массачусетс: MIT Press.Guardian Quiptic 1191 Hectence – Fifteensquared
Спасибо Hectence. Определения подчеркнуты в подсказках.
Поперек
7. Катера с кораблем, обходящим мыс острова Росс, перевернулись (8)
НОЖНИЦЫ : SS (аббревиатура от «steamship» в названиях судов) 9029 9 9098 9028 902 ) переворот (… опрокинулся) [Росс + I (аббревиатура от «остров») + C (аббревиатура от «мыс», как в названиях таких географических объектов на картах) ].
9. Токсический шок после экстази нехарактерен (6)
ЭКЗОТИЧЕСКИЙ : Анаграмма (… шок) ТОКСИЧНЫЙ стоит после (после) E (аббревиатура от наркотика, экстази).
10. Юнайтед удерживал лидерство в Чемпионате ранее (4)
ОДИН РАЗ : ОДИН (объединенный/в целом) содержащий (удерживающий) 1-я буква «Чемпион» (лидерство) .
11. Покровительствует лекция муниципальной партии Спунера? (4,4,2)
ДО : РАЗГОВОР (неформальная лекция/выступление) плюс (от) Spoonerism of (Spooner’s) [«город»(муниципальный/относящийся к городу) «делать»(вечеринка/общественная функция) ].
12. Уйти нездоровым во время теста — это хитро (6)
ТРИКИЙ : 1-я буква удалена из (Уход) «больной» (нездоровый/больной) (во время) ПОПРОБОВАТЬ (испытывать/испытывать).
14. Пудинг кажется недоваренным (4,4)
ETON MESS : Анаграмма (…приготовить) НЕ КАЖЕТСЯ.
Defn: …/десерт.
… ака …
15. Собака маленькой девочки с поводком, странно комичная (7)
ШУТКА : JO(сокращенная форма/маленькая «Жозефина», имя девочки) + CUR(агрессивный или неряшливый собака, например дворняга) содержащий (несущий) 1-я и 3-я буквы (…, как ни странно) «свинец».
17. Противодействие получению прибыли каким-либо образом (7)
ПРОТИВ : ПРИБЫЛЬ (для получения прибыли/получения финансовой выгоды) содержится в (in) [A + ST (аббревиатура от «улица /путь/проезжая часть)].
20. Удар по идеальному возвращению к сладкой беседе (6,2)
МАСЛО ВВЕРХ : BUTT(ударить/ударить головой) плюс (на) 299 разворот
299 (… возвращение) PURE (идеальный/неиспорченный).
Defn: …/льстить или хвалить кого-то, чтобы получить его/ее помощь.
22. Снасть случайного мошенничества с серьезностью (6)
ЖЕСТКОСТЬ : RIG(снасти/оборудование специального назначения) + 2-я, 4-я и 6-я буквы («случайное»).
23. Прекрасные ночи в море с рыболовными снастями (7,3)
РЫБОЛОВНАЯ СЕТЬ : Анаграмма (… в море) ПРЕКРАСНЫЕ НОЧИ.
24. Свободный ключ подъемника (4)
RIDE : RID(освободить/снять ненужную вещь) плюс (с) E(одна из мажорных тональностей в музыке).
Defn: …, например, «он подвезет меня домой».
25. В последней букве есть девушка и английский мальчик, описывающие любовь в летнем домике (6)
БЕСЕДКА : [A + Z(последняя буква английского алфавита)] содержится в (имеет… описание) Г, Е, Б (соответственно аббревиатуры от «девушка» плюс ( и ) «английский мальчик») + O (буква, обозначающая 0/любовь в теннисных счетах).
В качестве аббревиатур в текстовых сообщениях я использую «G» и «B» (если не пропущен 1-й буквенный указатель?).
26. Здесь происходит развитие, когда корабль входит в мертвое пространство (4,4)
ТЕМНАЯ КОМНАТА : КОВЧЕГ(корабль или лодка, например Ноев ковчег) содержится в D (входит) [входит] (аббревиатура от «мертвая») + ROOM(пространство/незанятая область).
Определ.: …, т.е. Разработка фотографической пленки… и, возможно, больше:
DOWN
1. Последовательность возможных событий со спутником Cranes Moving (8)
Сценарий : ANAGRAM (…… 140098 из (…… 140098 из (…… из (…… из (…… из (…… . + IO(спутник/спутник Юпитера).
Defn: …, как в романе, пьесе или фильме.
2. Приземление в воде, когда человек остается подвешенным в середине (4)
ОСТРОВ : I (римская цифра «один») ‘S + L (сокращение от «левый») + средняя буква (… в середине) «подвешенный».
3. Выкинуть неизвестного сановника (6)
ДОСТОЙНЫЙ : Анаграмма (… вон) Выбросить + Y(символ неизвестной величины в математике).
4. Опрометчиво, у лидера есть точка, внесенная в официальный отчет (8)
ГОЛОВА : ГОЛОВА (лидер/вождь) плюс (имеет) [ N (аббревиатура от «север», компас) точка) содержится в (вставлено в) ЖУРНАЛ (официальный отчет/журнал)].
5. Выезд, чтобы забрать небольшую женскую группу, даже не мам, чтобы искупаться (2,8)
ПОПЛАВАТЬСЯ : ИДТИ(отъезд/отправление) содержащий (для сбора) [ S (аббревиатура от «маленький») + WI (аббревиатура от Женского института, группа/организация женщин) + 2-я и 4-я буквы удалены из (не четные) «мамы».
6. Открытие грунта, разрешение на добычу руды (6)
HIATUS : Анаграмма (земля) [«разрешить» минус (… быть извлеченным) «руда»].
Defn: Естественная …/расщелина в анатомии.
8. Расстроенный викарий, собирающий один фунт монетами (6)
СЕРЕБРО : Отмена (расстроенный…, неверный ключ) REV(форма обращения викария)’S , содержащий (коллекционирование) [ I (римская цифра «один») + L (или £, символ фунта стерлингов)].
Defn: …, все вместе, сделаны из серебра или выглядят так, как будто они сделаны из серебра.
13. Попробуйте заснуть в куче дворянина, слышим (5,5)
СЧЁТ ОВЕЦ : СЧЁТ(дворянин, конкретно европейский эквивалент графа)’S + омофон (…, мы слышим) «куча» (куча/набор предметов, сложенных друг на друга).
16. Новый матадор бегает бессистемно (2,6)
НА СЛУЧАЙНОМ : Анаграмма (… бегает) [ N (аббревиатура от «новый») + MATADOR].
18. Войсковая часть – одна из четырех обстрелянных на Южном фронте (8)
ЭСКАРДОН : СЧЕТВЕРЕНКА (сокращение от «четверка», один из четырех детей от одной матери в одной поставке) содержится в (в) [ S (аббревиатура от «южный») + «передний» минус его 1-я и последняя буквы (это лущеный)].
19. Разблокирована отчаянная потребность продолжать работу (6)
ОТКРЫТЫЙ : Анаграмма (отчаянный) NEED стоит после (преследовать) OP (аббревиатура от «opus»/музыкальная композиция/произведение).
21. Шофер в лимузине показан куда идти (6)
ПИССУАР : Спрятан в (… показан) «Шофер в лимузине».