Конспект урока по теме » Морфемный разбор слова» 5 класс | План-конспект урока по русскому языку (5 класс) на тему:
Урок « Морфемный разбор слова»
Цель урока: Закрепить понятие о порядке морфемного разбора;развивать навыки устного и письменного морфемного разбора ; научить проводить морфемный разбор слова; формировать навыки самоконтроля, рефлексии.
Тип урока : Комбинированный урок
Формы обучения: индивидуальная, групповая.
Задачи: научиться выделять в слове разные морфемы, определять часть речи, придумывать слова по схемам, собирать слова из разных морфем, отработать устный разбор слов, воспитывать любовь к русскому языку.
Планируемые результаты: учащиеся научатся понимать связь между морфемикой и орфографией; проводить морфемный анализ слова, морфемный разбор; применять полученные знания и умения на практике.
I. Организационый момент.
Приветствие. Проверка готовности к уроку. Выявление отсутствующих.
II. Актуализация знаний.
— Что такое морфема?
-Назовите морфемы, из которых может состоять основа слова.
— С помощью каких морфем образуются новые слова? Приведите примеры.
— Чем отличаются формы одного и того же слова от однокоренных слов? Приведите примеры.
III. Работа по теме урока.
1. Разберите по составу слова устно: трактористы, привозим, вносишь, сварщик, синеватая (даль), парашютистка, и письменно : (в) сарафанчике,уходит, щерстяным (шарфом) , тихая, безлунная (ночь). К какой части речи относятся данные слова.
Образец рассуждения:
Сварщик — сварщика. В слове нулевое окончание. Основа – сварщик – указывает , что имя существительное стоит в Им.п. ед.ч. Суффикс –чик-, он обозначает лиц по роду занятий. В слове есть приставка с-. Она имеет значение сближения, соединения, скрепления чего-либо.
Сварщик –варить , сварка, сваривать. Корень –вар -.
Комментарий
Детям необходимо напомнить, что корень в слове определяем в последнюю очередь. После выделения основы определяем суффикс и приставку, подбираем однокоренные слова с другими суффиксами и приставками, чтобы яснее выделить корень.
После выделения основы определяем суффикс и приставку, подбираем однокоренные слова с другими суффиксами и приставками, чтобы яснее выделить корень.
2. Тестовое задание
В каком слове не корня с чередующимися согласными ?
1)газета 2) снеговик 3) бегу 4) редкость
3.Придумать и записать по два слова к каждой схеме. Выполнить морфемный разбор. Схемы записаны на доске.
IV . Закрепление изученного материала.
Выпишите из любого литературного произведения ( учебник литературы) существительное, прилагательное, глагол и произведите их морфемный разбор.( Самостоятельное выполнение с последующей проверкой).
V. Занимательная лингвистика.
а) от глагола ОБГОВОРИТЬ –приставку, от ДУМАТЬ – корень, от глагола ЧИТАТЬ – суффикс , от глагола ПЕТЬ –окончание.
(ОБДУМАТЬ)
б) от прилагательного ПРЕДУТРЕННИЙ –приставку, от глагола ПОГОВОРИТЬ – тоже приставку, от слова СЛАГАЕМОЕ –корень, от глагола РЕШАТЬ – глагольный суффикс, от глагола ПИСАЛ- суффикс прошедшего времени, от СОБИРАЛА –окончание.
( предполагала)
2. Кроссворд
Ключевое слово: Раздел науки о языке, в котором изучаются наименьшие значимые части слова.
- Окончание – значимая часть слова, которая образует … слова.
- Окончание, не выраженное звуками.
- Часть речи, которая не имеет окончания.
- Суффикс, стоящий после окончания.
- Замена одних звуков другими в одной и той же части слова.
- Наименьшая значимая часть слова.
- Значимая часть слова, которая находится перед корнем и служит для образования слов.
- Главная значимая часть слова.
- Часть изменяемого слова без окончания.
2.
Рефлексия.
1. Что нового узнали на уроке?
2. Расскажите о порядке морфемного разбора слова.
2. Какие части слов могут иметь разный звуковой состав?
4.Приведите примеры чередований при образовании слов.
5. Могут ли чередоваться звонкие и глухие согласные в одной морфеме? Если могут, приведите примеры.
(Звонкие и глухие согласные могут чередоваться: в снегу – снег, бегу-бег)
Домашнее задание
1. Пар.81.
Пар.81.
2. Упр. 416 – устный и письменный разбор слов.
Для чего нужен морфемный разбор слов?
Вы здесь
Проведение морфемного разбора слова позволяет определить, к какой части речи относится слово, механизм словообразования, подобрать родственные значения. Полученная информация во время такого анализа не позволит совершать орфографические ошибки во время письма. Провести анализ можно самостоятельно или сделать морфемный разбор слова онлайн, последний вариант будет более точным, быстрым и надежным.
Морфемный разбор слова
Морфемный разбор слова – это вид лингвистического анализа слова, во время которого определяется его состав. Простыми словами – это разбор, который помогает понять, из каких частей состоит слово (корень, суффиксы, приставки, окончания). Систематический анализ позволяет повышать уровень грамотности письма. Это происходит благодаря выработке навыка осмысления каждого слова и выбора единственного правильного варианта написания.
При морфемном разборе очень важно руководствоваться современными нормами языка, так как в последние годы он претерпел много изменений. Также не стоит забывать, что во время разбора нужно соблюдать определенный порядок действий, ни в коем случае нельзя начинать его с определения корня, даже если он кажется очевидным.
Порядок проведения морфемного разбора слова
Морфемный разбор необходимо проводить в следующем порядке:
- Определение части речи, к которой относится слово.
- Определение формы, в которой слово употреблено.
- Выделение формообразовательных морфем (если слово изменяется).
- Выделение основы слова, корня, словообразовательных морфем.
На практике это происходит следующим образом:
- выбранное слово изменяется, чтобы найти окончание и обозначить основу;
- с помощью однокорневых слов определяется и выделяется корень;
- обозначается суффиксы (может быть один или несколько) и приставки.
Сам по себе морфемный разбор не является трудным, но даже в нем часто происходят ошибки из-за невнимательности или спорных моментов, с которыми нужно разбираться детальнее. Именно поэтому онлайн сервис для морфемного разбора – лучшее решение для тех, кому важна грамотность и точность анализа.
Именно поэтому онлайн сервис для морфемного разбора – лучшее решение для тех, кому важна грамотность и точность анализа.
Версия для печати
Опубликовано:
Лучшие Android-приложения января
Страховой фонд на $1 млн, ежегодный аудит и выгодные комиссии. Как создавался первый легальный криптообменник в СНГ
Выглядит как флагман, а стоит дешевле. В чем секрет смартфона HONOR X9a?
-
Строгая классика в современной обертке. Обзор смартфона HONOR X8a
Афиша IT-мероприятий в марте
Резюме по оценке композиции в векторных представлениях предложений | Чайтанья Прамод Касула
Фото Патрика из Unsplash Источник: https://www. aclweb.org/anthology/C18-1152.pdf (Эттингер и др., 2018)
aclweb.org/anthology/C18-1152.pdf (Эттингер и др., 2018)
Предыстория: Чтобы понять что такое вложения предложений, необходимо понимать вложения слов. Вложения слов стали очень известными из-за их способности представлять слово в виде вектора, который можно использовать повсеместно. Известные вложения включают word2vec, Glove и т. д.
Та же концепция встраивания слов может быть распространена на предложения таким образом, чтобы каждое предложение было представлено вектором. Такие задачи, как «выяснение того, являются ли два вопроса переполнения стека дубликатами или нет», создают необходимость использования вложений предложений.
Введение: Чтобы понять язык, необходимо понимать значение и состав предложения. Большинство современных моделей нейронных сетей по своей природе являются черными ящиками. Следовательно, трудно понять, какие вложения предложений фиксируются как часть их обучения, которое в конечном итоге их генерирует.
В статье обсуждаются конкретные задачи, предназначенные исключительно для проверки того, отражают ли вложения предложений состав и значение предложения. Настоящая статья основана на другой статье (Ади и др., 2016 г.), в которой авторы (Ади и др., 2016 г.) проводят аналогичные эксперименты с моделью BOW и автокодировщиком. Однако их результаты весьма сомнительны из-за непреднамеренной систематической ошибки в наборе данных. Например, они показывают, что в задачах с порядком слов модель BOW достигает производительности 70%, даже если для такой модели логически невозможно сохранить информацию, связанную с порядком слов. Итак, авторы настоящей статьи считают, что такая производительность модели BOW была случайным событием из-за смещения, присутствующего в наборе данных.
Настоящая статья основана на другой статье (Ади и др., 2016 г.), в которой авторы (Ади и др., 2016 г.) проводят аналогичные эксперименты с моделью BOW и автокодировщиком. Однако их результаты весьма сомнительны из-за непреднамеренной систематической ошибки в наборе данных. Например, они показывают, что в задачах с порядком слов модель BOW достигает производительности 70%, даже если для такой модели логически невозможно сохранить информацию, связанную с порядком слов. Итак, авторы настоящей статьи считают, что такая производительность модели BOW была случайным событием из-за смещения, присутствующего в наборе данных.
В текущей статье предлагается устранить/уменьшить такую предвзятость и протестировать другие модели глубокого обучения. Они также вводят дополнительные задачи, которые подробно обсуждаются ниже. Вклад статьи включает в себя набор для генерации предложений, проверенную модель для проверки того, действительно ли композиция и значение встроены во вложения, система генерации и наборы данных, используемые для классификации, предоставляются другим в качестве открытого исходного кода для дальнейшего изучения. и анализ.
и анализ.
Исследовательские вопросы: Исследовательские вопросы, на которые пытается ответить статья:
1. Насколько хорошо современные нейронные модули встраивания предложений улавливают смысл и состав предложения в своих вложениях предложений?
2. Можем ли мы предложить метод и структуру для оценки вложений предложений и их моделей с точки зрения того, насколько хорошо они отражают смысл и состав предложения?
Значение и композиция: Элементы, из которых состоит предложение, доносят смысл до читателя. Обычно он содержит агента, пациента и событие. Композиция — это способ расположения элементов, который помогает передать смысл. Различные части предложения можно комбинировать, чтобы получить его значение.
Подготовка набора данных: Авторы предлагают новую систему генерации предложений, которая уменьшает систематическую ошибку в наборе данных. Например, он генерирует разнообразные и полностью аннотированные предложения, следуя синтаксическим, семантическим и лексическим правилам английского языка. Он состоит из трех частей.
Он состоит из трех частей.
Представления событий/предложений: Это частичные представления предложения, которые принимают такие аргументы, как агент, пациент, переходные и непереходные глаголы, а также наличие или отсутствие придаточного предложения. Эти представления предоставляются в качестве входных данных для системы генерации событий. Например, рассмотрим предложение, как показано ниже.
Население события: Система получает ввод из системы представления предложений и заполняет событие заданной информацией. Он использует наречия и 17 слов в своем словарном запасе. Количество слов ограничено, чтобы сохранить контроль над сгенерированными предложениями. Он перебирает наречия и существительные, чтобы генерировать предложения.
Синтаксические реализации: Он использует метод, основанный на правилах, чтобы изменить слова в сгенерированном предложении, чтобы следовать морфологии. Они используют структуру NLTK, как указано в (Bird et al. , 2009).), а перегибы извлекаются из базы данных морфологии XTAG (Doran et al., 1994).
, 2009).), а перегибы извлекаются из базы данных морфологии XTAG (Doran et al., 1994).
Задания на классификацию: Различные задания предназначены для проверки того, сохраняют ли вложения предложений состав и значение предложения. В целом их можно разделить на два типа: SemRole и Negation . Задача SemRole предназначена для проверки того, отражают ли вложения предложений смысл. Вопрос, на который нужно ответить, состоит в том, что для данного существительного (n), глагола (v) и вложения предложения (s) является ли n агентом v в s?
Задача на отрицание — это тест, позволяющий узнать, отражают ли вложения предложения отрицание глагола или нет. То есть, учитывая глагол (v) и вложение предложения (s), инвертируется ли v в s или нет? Сгенерированные предложения содержат наречия, заполненные между глаголом и отрицанием, так что не очевидно, что глагол идет после отрицания, и модель может легко изучить и обнаружить этот шаблон.
Три другие задачи связаны с содержанием и порядком слов. Первое задание, Content1Probe создается для проверки того, содержат ли вложения предложений глагол, учитывая, что глагол присутствует во входном предложении. Content2Probe похож на Content1Probe и проверяет, содержат ли вложения предложений и существительное, и глагол, учитывая, что оба они представлены в качестве входных данных до создания вложений предложений.
Задача Order предназначена для проверки того, фиксируют ли результирующие вложения предложений информацию о порядке слов в предложении. Возникает ли тогда существительное (n) перед глаголом (v), учитывая вложение предложения (s), которое содержит как глагол (v), так и существительное (n).
Классификационные эксперименты: Авторы строят модель нейронной сети/многослойного персептрона, размер входных данных которой равен размеру вложений предложений. ReLU используется в качестве функции активации для нейронов. Приведенные выше задачи классификации носят бинарный характер. Следовательно, для сгенерированных предложений присваивается метка для каждой задачи (да или нет). Генерируется 5000 таких предложений, из которых 4000 предложений с соответствующими метками используются в качестве обучающего набора, а остальные 1000 предложений (с соответствующими метками) используются в качестве тестового набора. Настройка гиперпараметров не требуется, поскольку спецификации сети упоминаются в (Adi et. al., 2016). Авторы не проводят никакого обучения для создания вложений предложений. Они также не разрабатывают алгоритм встраивания предложений. Они используют алгоритмы встраивания, которые уже доступны в качестве предварительно обученных моделей в их собственных корпусах. Эти модели используются для создания вложений предложений для сгенерированных 5000 предложений. Вложения предложения и соответствующие им метки для задачи образуют набор данных для модели нейронной сети. Модель обучается на наборе поездов и тестируется на тестовом наборе.
Приведенные выше задачи классификации носят бинарный характер. Следовательно, для сгенерированных предложений присваивается метка для каждой задачи (да или нет). Генерируется 5000 таких предложений, из которых 4000 предложений с соответствующими метками используются в качестве обучающего набора, а остальные 1000 предложений (с соответствующими метками) используются в качестве тестового набора. Настройка гиперпараметров не требуется, поскольку спецификации сети упоминаются в (Adi et. al., 2016). Авторы не проводят никакого обучения для создания вложений предложений. Они также не разрабатывают алгоритм встраивания предложений. Они используют алгоритмы встраивания, которые уже доступны в качестве предварительно обученных моделей в их собственных корпусах. Эти модели используются для создания вложений предложений для сгенерированных 5000 предложений. Вложения предложения и соответствующие им метки для задачи образуют набор данных для модели нейронной сети. Модель обучается на наборе поездов и тестируется на тестовом наборе.
Модели внедрения предложений: Различные используемые модели внедрения предложений описаны ниже:
BOW: Модель BOW — это простая модель, которая использует вектор для представления каждого слова в предложении. Он усредняет эти вложения и использует их как вложения предложений.
Автоэнкодер с последовательным шумоподавлением: Это метод обучения без учителя, в котором используется автоэнкодер на основе LSTM.
Пропустить вложения мыслей: Они используют ГРУ для создания вложений предложений. Доступны два варианта: uni-skip (ST-UNI) и bi-skip (ST-BI). Кодировщики Uni-skip отвечают на прямой проход, тогда как bi-skip использует как прямой, так и обратный проходы в нейронной сети.
InferSent: InferSent — это самая продвинутая модель, которая использует многоуровневый двунаправленный LSTM для создания вложений предложений.
Результаты:
Таблица. 1 (Из исходного документа )
1 (Из исходного документа ) Результаты моделей для различных задач представлены в таблице выше. Он взят из Ettinger et al. (2018).
Модель Bag of Words (BOW) хорошо справляется с задачами, основанными на содержании. Это говорит о том, что модель BOW идеально кодирует значение слова. Ожидается, что он будет плохо работать с задачами Order, SemRole и Negation, и он это сделал. Это служит проверкой набора данных, и он удовлетворяет этим критериям. Это также может быть связано с очень ограниченным словарным набором из 17 слов, используемых в модуле генерации данных.
Для задачи отрицания все модели, кроме ST-BI, показали себя хорошо. Вероятно, это связано с тем, что при прямом проходе сначала встречается отрицание, за которым следует глагол, а при обратном проходе эта последовательность обратная. Следовательно, информация могла быть плохо зафиксирована. Другие модели показали себя хорошо, даже когда трудно уловить отношения, даже если это трудно сделать при наличии наречий между отрицанием и глаголом. Это также может быть связано с уменьшением размерности вложений с 1200 до 300.
Это также может быть связано с уменьшением размерности вложений с 1200 до 300.
Для задачи семантической роли (SemRole) InferSent работает случайно, а другие модели также не работают хорошо. Как утверждают авторы текущей статьи (Ettinger et al., 2018), модели встраивания предложений не предоставляют убедительных доказательств того, что они в значительной степени отражают семантическую роль.
Можно также сделать вывод, что разные модели встраивания предложений, имеющие разную архитектуру и цели, не оказали существенного влияния на значение и состав предложения при оценке через их встраивания. Все модели отражают почти одинаковый уровень смысла и композиции в своих вложениях.
Результат также доказывает, что предложенный подход надежен для определения того, в какой степени или в какой степени смысл и композиция охватываются вложениями предложений. Можно определить больше задач, чтобы лучше понять информацию, захваченную во вложениях предложений.
Авторы планируют протестировать другие модели, явно внедрив синтаксическую структуру, упомянутую в e (Bowman et al., 2016; Dyer et al., 2016; Socher et al., 2013), в свою будущую работу.
Ссылки
Эттингер, А., Элгохари, А., Филлипс, К., и Резник, П. (2018). Оценка композиции в векторных представлениях предложений. архив: 1809.03992.
Йосси Ади, Эйнат Кермани, Йонатан Белинков, Офер Лави и Йоав Голдберг. 2016. Детальный анализ вложений предложений с использованием вспомогательных задач прогнозирования. Препринт arXiv arXiv: 1608.04207.
Стивен Бёрд, Юэн Кляйн и Эдвард Лопер. 2009. Обработка естественного языка с помощью Python: анализ текста с помощью набора инструментов для естественного языка. О’Рейли Медиа, Инк.
Кристи Доран, Дания Эгеди, Бет Энн Хоккей, Бангалор Шринивас и Мартин Зайдель. 1994. Система XTAG: обширная грамматика английского языка. В материалах 15-й конференции по компьютерной лингвистике, том 2, страницы 922–928. Ассоциация компьютерной лингвистики.
Ассоциация компьютерной лингвистики.
Сэмюэл Р. Боуман, Габор Анджели, Кристофер Поттс и Кристофер Д. Мэннинг. 2015. Большой аннотированный корпус для изучения естественного языка. В ЭМНЛП.
Крис Дайер, Адхигуна Кункоро, Мигель Баллестерос и Ной А. Смит. 2016. Рекуррентные грамматики нейронных сетей. НААКЛ.
Ричард Сочер, Алекс Перелыгин, Джин Ву, Джейсон Чуанг, Кристофер Д. Мэннинг, Эндрю Нг и Кристофер Поттс. 2013. Рекурсивные глубокие модели семантической композиционности в банке деревьев настроений. В материалах конференции 2013 г. по эмпирическим методам обработки естественного языка, стр. 1631–1642.
Структурный анализ | Английский для развития: Введение в композицию колледжа |
Структурный анализ — это процесс разбиения слов на их основные части для определения значения слова. Структурный анализ является мощным словарным инструментом, поскольку знание нескольких частей слова может дать ключ к пониманию значения большого количества слов. Хотя значение, предлагаемое частями слова, может быть неточным, этот процесс часто может помочь вам понять слово достаточно хорошо, чтобы вы могли продолжать чтение без значительных перерывов.
При структурном анализе читатель разбивает слова на их основные части:
- Префиксы – части слова, расположенные в начале слова для изменения значения
- Корни – основная значимая часть слова
- Суффиксы — части слова, присоединяемые к концу слова; суффиксы часто изменяют часть речи слова
Например, слово велосипедист можно разбить следующим образом:
- би — префикс, означающий два
- цикл — корень означает колесо
- ist — суффикс существительного, означающий «человек, который»
Таким образом, структурный анализ предполагает, что велосипедист — это человек на двух колесах, что близко к формальному определению слова.
Рассмотрим часть слова –cide. Хотя оно не может стоять как слово само по себе, оно имеет значение: убить . Подумайте о многих словах в нашем языке, в состав которых входит слово -cide. Знание этой части слова дает нам знания о многих словах.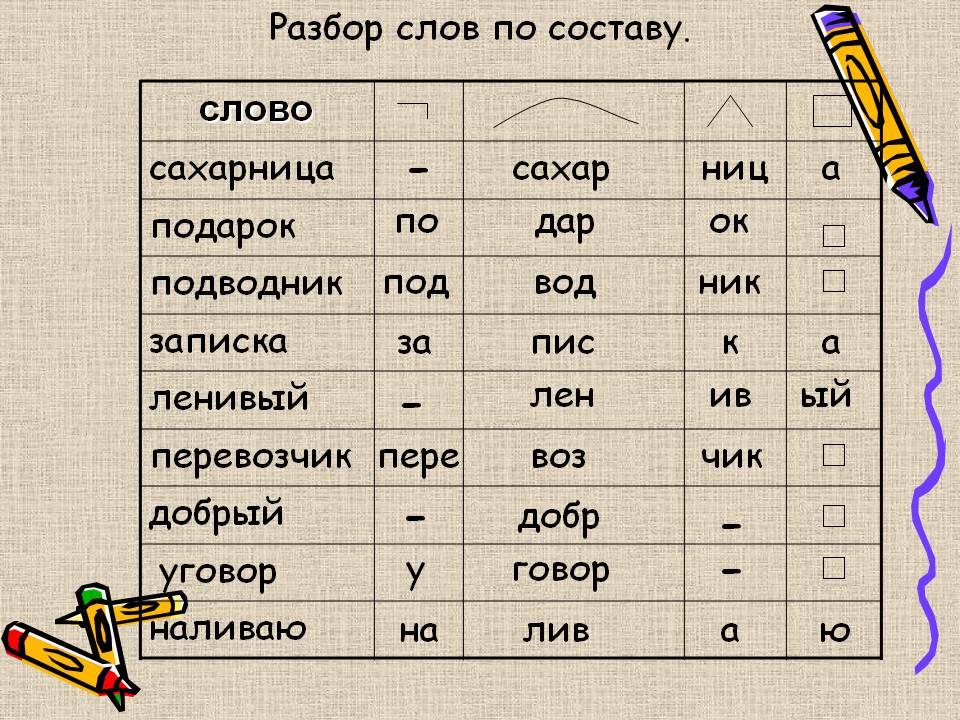
Инфиксы
В английском языке действительно есть только суффиксы и префиксы (часть более крупного класса, называемого аффиксами). В других языках есть вещи, называемые инфиксами. Они идут в середине слова. Piano , pianisimo , pianisisimo, и т. д.
Английский язык имеет только один инфикс:
- «abso-friggin-lutely»
- «соберись-ка черт возьми»
Для дальнейшего развития этого навыка обратитесь к удобному справочному листу «Структурный анализ: общие части слов», где приведен список некоторых распространенных префиксов, корней и суффиксов, а также их значения и примеры слов, в которых они используются.
Заставьте это работать
Чтобы отработать этот навык, попробуйте упражнения по структурному анализу от Летбриджского колледжа.
Хотя структурный анализ — это метод, который может использовать каждый, определенно есть определенные дисциплины, в которых он используется более широко.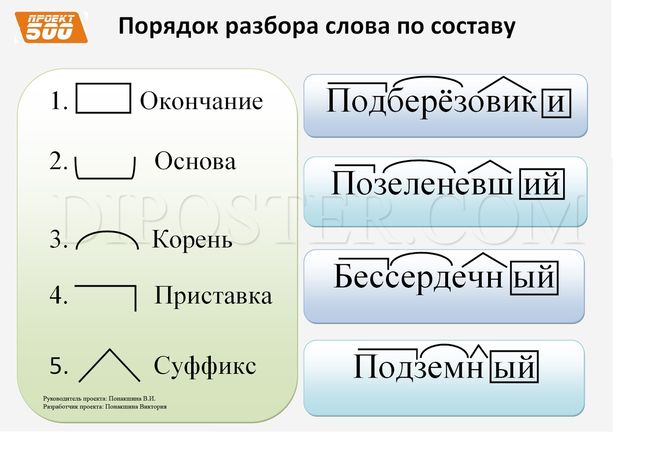
- Построение медицинских терминов: пищеварительная система. Этот сайт поможет вам составить и выучить термины, относящиеся к пищеварительной системе.
- Медицинская терминология от SweetHaven Publishing Services
- Медицинские терминологические системы, шестое издание, аудиоупражнения. Этот сайт поможет вам выучить различные части слова, связанные с медицинской терминологией.
- Ресурсы Medword. Основы медицинской терминологии. Этот сайт содержит списки медицинских префиксов, суффиксов, комбинированных форм, кроссвордов и многого другого.
- Медицинская терминология в Sheppard Software
Лицензии и атрибуты
Содержимое по лицензии CC, совместное использование ранее
- Развитие словарного запаса: структурный анализ. Предоставлено : Летбриджский колледж.

