Государственное казенное учреждение социального обслуживания Ростовской области центр помощи детям, оставшимся без попечения родителей, "РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7"
Разбор слова по составу проблемы: Страница не найдена
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «проблема», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
Значение слова
Звуко-буквенный разбор
Разбор по составу
Значение слова
ПРОБЛЕМА, ы, ж.
1. Сложный вопрос, задача, требующие разрешения, исследования. Постановка, решение проблемы. Проблемы воспитания.
2.перен. О чёмн. трудно разрешимом, осуществимом (разг.). Из простого дела устроил целую проблему. Это не п.! (о том, что легко и просто сделать). Нет проблем! (всё идёт хорошо, нет никаких затруднений).
Части слова «проблема»: проблем/а Состав слова: проблем — корень, а — окончание, проблем — основа слова.
Технологическая карта урока русского языка в 3 классе «Разбор слова по составу»
Этапы урока
Задачи этапа
Формы, методы, методические приёмы
Деятельность учителя
Деятельность учащихся
УУД
1. Организационный момент. Mотивация к учебной деятельности
Создать благоприятный психологический настрой на работу
Фронтальный. Словесный
Приветствует обучающихся, проверяет их готовность к уроку Ну, проверь-ка всё, дружок! Можно ль начинать урок?
Приветствуют учителя, проверяют свою готовность к уроку
Регулятивные: -нацеливание на успешную деятельность.
Личностные:— выражать положительное отношение к процессу познания, проявлять желание познавать новое.
Коммуникативные:— формирование умения слушать и слышать.
2. Чистописание.
3. Актуализация знаний.
4. Постановка учебной задачи
5. Первичное закрепление нового материала
Физкультминутка ( по выбору детей)
6.Самостоятельная работа с самопроверкой по
эталону.
7. Включение в систему знаний и повторение
8. Итог урока
9. Рефлексия.
Информация о домашнем задании
Работа над каллиграфией
Работа с текстом.
Работа над разбором предложения по членам предложения
Подвести детей к самостоятельному выводу и формулированию темы урока.
Актуализация опорных знаний и способов действий
Устный опрос, проговаривание хором
Обеспечение восприятия, осмысления и первичного запоминания детьми изучаемой темы Развитие умения распознавать и разбирать по составу однокоренные слова, .
Включение учащихся в целенаправленную деятельность
Дать качественную оценку работы класса и отдельных учащихся
Дать оценку своей работе на уроке и уровне освоения знаниями
Обеспечение понимания детьми содержания и способов выполнения домашнего задания
Фронтальный. Словесный
Проблемная ситуация.
Фронтальная беседа. Словесный
Наблюдение, проблемная ситуация.
Словесный. Беседа. Доказательство
Инсценировка
Фронтальная беседа.
Словесный.
Наблюдение.
Самостоятельная работа
Самостоятельная работа. Работа по карточкам
Фронтальный опрос.
Словесный.
Самостоятельная работа
Фронтальный.
Словесный.
Предлагает записать дату и место работы. На доске записаны элементы, состоящие из заглавных и строчных букв Ж,ж и Ш,ш, сочетания жи-ши. После записи элементов предлагает обобщить знания о парных согласных и написании орфограммы жи-ши.
Предлагает прочитать записанные на доске слова и сформулировать задание.
— Докажите, что перед вами текст.
— Озаглавьте.
На п..ляне р..сла б..реза вокру.. б..резы ш..птались маленькие б..резки а вот и подб..резовики
Предлагает выписать второе предложение.
-Как вы думаете, что нужно сделать?
— Найдите в тексте однокоренные слова, выпишите
— Какое задание можно предложить?
Береза, березы, березки, подберезовики.
-О чем будем говорить сегодня на уроке?
Открывает запись на доске. «Разбор слова по составу»
— Что значит разобрать слово по составу?
— С чего же начать разбор слова?
Представляет учащимся гостей, которые пришли, чтобы помочь в разборе слова по составу.
Предлагает помочь частям слова найти свое место в слове.
Совместно с учащимися вырабатывается порядок разбора слов на основе имеющихся знаний о частях слова.
Вывешивает плакат
«Разбор слов по составу»:
Окончание
Основа
Корень
Приставка
Суффикс
Предлагает опираясь на схему выполнить разбор выписанных слов.
-Что можно сказать об этих словах?
Работа над упр.50 с.123
ИКТ.Организует работу по учебнику. Предлагает выписать группы однокоренных слов в 3 столбика на ИД, разобрать их по составу.
Открывается плакат с изображением трех деревьев. На каждом дереве карточка с корнем слова – вод, мор, дом. Задание: в карточке найти однокоренные слова, выделить корень. Прикрепить листик на дерево с таким же корнем.
Задает вопросы.
-Что нового узнали на уроке?
— В каком порядке осуществляется разбор слова по составу?
Предлагает оценить свои знания и успехи, выбрав подходящий предмет на столе.
Зеленая вишня – ничего не запомнил, не понравилось на уроке
Красная вишня (спелая) – все понял, понравилось на уроке
Записывают дату и место работы. Работают над орфограммами. Отвечают на вопросы. Анализируют звуки [ж,ш] и проводят анализ элементов букв ж,ш. Прописывают в тетради по данному образцу.
Формулируют задание: вставить пропущенные буквы, найти границы предложений, исправить ошибки.
Вставляют пропущенные буквы, объясняя написание орфограмм. Делят текст на предложения, исправляя строчную букву на заглавную в начале каждого предложения. Делают вывод о том, что это текст, обосновывают своё мнение. Дают определение текста. Предлагают заголовки.
Выписывают предложение. Делают разбор, дают характеристику, чертят схему.
Выписывают однокоренные слова. Предлагают выполнить разбор данных слов по составу. ПРОБЛЕМА: с чего начать разбор слова?
Участвуют в диалоге. Слушают, уточняют, задают вопросы
Отвечают на вопросы.
Формулируют тему урока.
Обсуждают, высказывают предположения, самостоятельно формулируют правило.
Читают подтверждение своих суждений в учебнике.(с.123)
Заранее подготовленные дети в масках с изображением частей слова инсценируют ситуацию – спор о том, кто главнее в слове.
Анализируют имеющиеся знания и расставляют части слова по местам с точки зрения порядка разбора слова по составу.
Выполняют разбор слов по составу согласно алгоритму разбора. Делают вывод о том, что береза—березы – это формы слова, а березки-подберезовики – родственные слова.
Выполняют упражнения физкультминутки
ИКТ. Три ученика работают на ИД. Выписывают группы однокоренных слов, делают их разбор.
Самопроверка.
Работают по карточкам. Находят однокоренные слова, выделяют корень и прикрепляют листик на дерево с таким же корнем
Отвечают на вопросы.
Прикрепляют на деревья выбранный предмет.
Записывают домашнее задание.
Регулятивные:— оценивать (сравнивать с эталоном) результаты своей деятельности.
Познавательные:— классифицировать объекты (объединять в группы по существенному признаку)
Коммуникативные:— умение строить продуктивное взаимодействие и сотрудничество со сверстниками и учителем.
Регулятивные:
— постановка учебной задачи на основе соотнесения того, что уже известно и усвоено учащимися и того, что еще не известно;
Познавательные:
— постановка и решение проблемы;
Личностные:
— развитие познавательных интересов учебных мотивов;
Коммуникативные:
— умение ясно и четко излагать свое мнение, выстраивать речевые конструкции.
Регулятивные:— предвосхищение результата и уровня усвоения знаний, его временных характеристик;
Личностные: — выражать положительное отношение к процессу познания; проявлять внимание, желание узнать больше.
Коммуникативные:
— умение с достаточной полнотой и точностью выражать свои мысли в соответствии с задачами и условиями коммуникации.
Познавательные:
— выдвижение гипотез, их обсуждение, доказательства;
Регулятивные: — составление плана и последовательности действий.
Регулятивные: — умение действовать по плану и планировать свою деятельность;- умение контролировать процесс и результаты своей деятельности, включая осуществление предвосхищающего контроля в сотрудничестве с учителем и сверстниками;
Познавательные: — поиск и выделение необходимой информации, применение методов информационного поиска;
— умение адекватно воспринимать оценки;- умение контролировать процесс и результаты своей деятельности
Регулятивные:
— умение адекватно воспринимать оценки;- умение контролировать процесс и результаты своей деятельности Регулятивные: принимают цель, содержание и способы выполнения заданий
Если вы хотите разобрать слово «ПРОБЛЕМА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти
синонимы к слову «проблема»
Примеры предложений со словом «проблема»
1
Проблема, как надо жить – чувством или разумом, можно сказать, вечная проблема.
Обыкновенная история, Иван Гончаров, 1846г.
2
Национальность есть проблема историческая, а не социальная, проблема конкретной культуры, а не отвлеченной общественности.
Судьба России (сборник), Николай Бердяев
3
Проблема национализма и проблема империализма очень обострены мировой борьбой народов.
Судьба России (сборник), Николай Бердяев
4
Есть проблема в нашем районном масштабе, большая, метровая, – И Синцов широко раздвинул свои длинные руки, показывая, какая большая проблема.
Товарищи по оружию, Константин Симонов, 1950-1965г.
5
Проблема языка – это основная проблема на первое время.
Переписка художников с журналом «А-Я». 1976-1981. Том 1, Игорь Шелковский Найти еще примеры предложений со словом ПРОБЛЕМА
IV. Постановка проблемы. Сообщение темы и цели урока. — КиберПедия
—Итак, какие части слова мы с вами знаем? (Ответы.) Попробуйте найти знакомые части слова в слове «подберезовики» и «поделка». (Работа в парах.)
Проверка.
— Почему вы решили, что под- в словах «подберезовики» и «поделка» — это приставка? Докажите. (Высказывания детей.)
V. Изучение нового материала
—С чего нужно начинать разбор слова? Какую часть слова надо находить первой? Какую следующей? Почему? На эти вопросы мы ответим сегодня на уроке. А для этого я предлагаю вам установить порядок разбора слова по составу, т. е. вывести алгоритм.
— Вначале мы поделимся на 3 команды. Каждой команде дается слово. Ребята думают, а потом на листочке определяют и записывают порядок разбора слова по составу. Затем один человек от команды на доске записывает это слово и объясняет порядок разбора слова. Остальные слушают объяснение, определяют, согласны или нет, объясняют почему.
1 команда — подснежники.
2 команда — подсолнухи.
3 команда — посадка.
Сверим наши предположения с правилом в учебнике на с. 124.
— Почему сначала находим окончание? (Оно служит только для связи слов в предложении, это изменяемая часть слова.)
Можно запомнить этот алгоритм, составив рифмовку.
* * *
Слово по составу верно разбирай:
Первым окончание всегда выделяй.
Затем приступай к выделенью основы,
Следом ищи, находи корень слова.
Ну, а потом ты не зевай:
приставку и суффикс ты выделяй.
Физкультминутка
Ученики выполняют под ритмичную музыку произвольные упражнения.
VI. Закрепление изученного
Упражнение 210, с. 123.
—Прочитайте шуточное стихотворение.
— Какова главная мысль этого стихотворения?
— Кто такой прогульщик? Подберите однокоренные слова к этому слову.
— Какой совет вы дали бы прогульщику? Выпишите из текста слова с приставками, обозначьте их. Слово «прогульщик» разберите по составу.
Работа в группах
Разберите слова по составу. (По одному ученику из каждой группы работает у доски.)
1 ряд — воронята, травушка, наушники, беспарусный, дырища.
2 ряд — лисята, ивушка, подберезовики, ручной, травинка.
3 ряд — тигрята, березонька, подводный, бездушный, лыжница
Второй вариант работы в группах
Составьте слово, запишите его, разберите по составу.
1 группа.
Приставка, как в слове «пожелать».
Корень, как в слове «накупить».
Суффикс, как в слове «открытка».
Окончание, как в слове «лыжи». (Покупки.)
2 группа.
Приставка, как в слове «покрасить»,
Корень, как в слове «варенье».
Суффикс, как в слове «тигренок».
Окончание, как в слове «зайчик». (Поваренок.)
3 группа.
Приставка та же, что и в основе «раскраска».
Корень тот же, что и в слове «сказка».
Суффикс тот же, что и в слове «извозчик».
Приставка та же, что и в слове расход. (Рассказчик.)
4 группа.
Корень мой находится в «цене».
В очерке найди приставку мне.
Суффикс мой в «тетрадке» все встречали.
Вся же — в дневнике я и в журнале. (Оценка.)
Самостоятельная разноуровневая работа
Прочитайте текст.
..шла зима. Леса и поля ..крылись белым пушистым снегом. Трудно птицам найти корм. Вот и ..летели они к жилью людей. Ребята ..весили для пернатых кормушки. Они ..готовили для птиц корм.
1-й уровень — спишите, вставляя подходящие по смыслу приставки, обозначьте их.
2-й уровень — спишите, вставляя подходящие по смыслу приставки, обозначьте их; в 5-м предложении найдите и подчеркните главные члены предложения. Выпишите словосочетания.
3-й уровень — выразите свое отношение к тексту, подобрав заглавие; составьте 1—2 предложения, завершив текст.
VII. Подведение итогов урока. Рефлексия
—Чему мы научились сегодня? Расскажите о порядке разбора слов по составу.
слово
VIII. Домашнее задание
Упражнение 212, с. 124
ТЕМА: Разбор слов по составу
Цель: закрепить знания и умения по выделению состава слова;
совершенствовать умение пользоваться алгоритмом разбора слов по составу;
формировать орфографический навык.
Ход урока
I. Организационный момент
—Прочитайте высказывание: «Слова, как листья на дереве, и чтобы понять, почему лист таков, а не иной, нужно знать, как растет дерево, нужно учиться!» (М. Горький.)
— С чем сравнивает М. Горький слова? Почему?
— Чему призывает учиться? (Ответы.)
II. Чистописание
На доске написаны слова: нос, мед, кот.
—Определите букву, которую мы будем писать на минутке чистописания. Она находится в корне одного из данных слов и обозначает непарный звонкий мягкий согласный звук. Какая это буква? В корне какого слова она находится? (Буква «м» в слове «мед».)
Посмотрите на запись, определите порядок следования букв в данном ряду (строчная м чередуется с буквами, обозначающими звонкие парные согласные звуки).
мб мв мг мд мж
Напишите этот ряд букв в указанной последовательности до конца строки.
III. Словарная работа
—Сегодня мы познакомимся с двумя новыми словами. Вы сможете их назвать, если расшифруете запись. (Слова «можно» и «нельзя».)
НМЕОЛЖЬНЗОЯ
— Что вы можете сказать об этих словах? (Это антонимы.)
— Что такое антонимы? (Ответы.)
— Найдите эти слова в орфографическом словаре. Напишите их в строчку. Поставьте ударение. Отметьте особенности написания.
— Назовите орфограммы в слове «можно»; «нельзя».
— Прочитайте. Вставьте пропущенные буквы. Соедините при помощи стрелок слова-антонимы.
Х..р..шо Вредно
П.лезно Плохо
Можн.. Жарко
Хол..дно Н..льзя
Просто Весло
Грустно Сложно
— Составьте предложения со словарными словами-антонимами «можно» и «нельзя» на тему «Правила дорожного движения».
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery.Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
«Зайчонок» или «зайчёнок», как пишется правильно?
Слово «зайчонок» пишется с буквой «о» после шипящего согласного «ч» согласно правилу орфографии.
Слово «зайчонок» произносится мягко из-за того, что глухой согласный [ч’] является непарным мягким звуком. Возникает вполне оправданное сомнение, как правильно пишется слово «зайчонок» или «зайчёнок»?
Выбор написания букв «о» или «ё» после шипящего согласного в этом слове зависит от того, в какой его части (корне, суффиксе или окончании) находится орфографическая проблема.
Правописание слова «зайчонок»
В русском языке в правописании не полагаемся на произношение слов, ведь очень небольшая их часть пишется так, как слышится.
Чтобы понять, как правильно следует писать слово «зайчонок» или «зайчёнок», действуем по определенному алгоритму.
Вначале определим часть речи, к которой принадлежит это название детёныша длинноухого лесного животного. Оно обозначает предмет и отвечает на вопрос кто?
По этим грамматическим признакам определим, что это одушевленное существительное.
Следующий шаг — это разбор слова по составу (морфемный разбор) с целью, чтобы определить, в какой его части (корне, суффиксе или окончании) имеется орфографическая проблема.
Морфемный состав
зайчонок — корень/суффикс/окончание
Выяснили, что проблема в написании суффикса существительного. В выборе буквы «о» или «ё» в этом слове воспользуемся орфографическим правилом:
Правило
В суффиксах и окончаниях существительных, прилагательных и наречий после шипящих основы под ударением пишется буква «о», без ударения — «е».
А теперь предпримем последний шаг — поставить ударение в слове «зайчо́нок». И тогда в суффиксе этого существительного под ударением согласно орфографическому правилу о правописании букв о/е после шипящих выберем букву «о».
Примеры написания существительных с суффиксом -онок-
Точно так же напишем названия птенцов и детенышей животных с буквой «о» под ударением в суффиксе -онок- после шипящих «ж», «ш», «ч» корня слов:
белка → бельчо́нок; кукушка → кукушо́нок;
мышь → мышо́нок; галка → галчо́нок;
барсук→ барсучо́нок; индюк → индюшонок;
медведь → медвежо́нок; грач → грачо́нок;
волк → волчо́нок; сорока → сорочо́нок;
верблюд → верблюжо́нок; морж → моржо́нок.
Скачать статью: PDF
Александр II подписал Манифест об отмене крепостного права
19 февраля (3 марта) 1861 г. в Петербурге император Александр II подписал манифест «О всемилостивейшем даровании крепостным людям прав состояния свободных сельских обывателей» и Положения о крестьянах, выходящих из крепостной зависимости, состоявшие из 17-ти законодательных актов. На основании этих документов крестьяне получали личную свободу и право распоряжения своим имуществом.
Проведению крестьянской реформы предшествовала длительная работа по выработке проектов законодательных актов об отмене крепостного права. В 1857 г. по указу Александра II был образован секретный Комитет по крестьянским делам для выработки мер по улучшению положения крестьянства. Затем из местных помещиков правительство образовало губернские крестьянские комитеты, которым предлагалось выработать свои предложения к проекту отмены крепостного права.
В январе 1858 г. Секретный комитет был переименован в Главный комитет по устройству сельского населения. В его состав вошли 12 высших царских сановников под председательством царя. При комитете возникли две редакционные комиссии, на которые возлагалась обязанность собрать и систематизировать мнения губернских комитетов (фактически работала одна под руководством генерала Я. И. Ростовцева). Подготовленный летом 1859 г. проект «Положений о крестьянах» в ходе обсуждений претерпел множество изменений и уточнений.
Подписанные императором 19 февраля (3 марта) 1861 г. документы вызвали неоднозначную реакцию во всех слоях населения, поскольку преобразования имели половинчатый характер.
Согласно Манифесту, крестьянам были присвоены гражданские права — свобода вступления в брак, самостоятельное заключение договоров и ведение судебных дел, приобретение недвижимого имущества на своё имя.
Крестьянству даровалась юридическая свобода, но земля объявлялась помещичьей собственностью. За отводимые наделы (урезанные в среднем на 20%) крестьяне на положении «временнообязанных» несли в пользу помещиков повинности, которые практически не отличались от прежних, крепостных. Наделение крестьян землёй и порядок несения повинностей определялись по добровольному соглашению между помещиками и крестьянами.
Для выкупа земель крестьянам предоставлялось пособие в виде ссуды. Земля могла выкупаться как общиной, так и отдельным крестьянином. Земля, отведённая общине, находилась в коллективном пользовании, поэтому с переходом в другое сословие или другую общину крестьянин терял право на «мирскую землю» своей прежней общины.
Восторженность, с которой был встречен выход Манифеста, вскоре сменилась разочарованием. Бывшие крепостные ожидали полной воли и были недовольны переходным состоянием «временнообязанных». Полагая, что от них скрывают истинное значение реформы, крестьяне бунтовали, требуя освобождения с землёй. Для подавления наиболее крупных выступлений, сопровождавшихся захватом власти, как в сёлах Бездна (Казанская губерния) и Кандеевка (Пензенская губерния), были использованы войска.
Несмотря на это, крестьянская реформа 1861 г. имела огромное историческое значение. Она открыла перед Россией новые перспективы, создав возможность для широкого развития рыночных отношений. Отмена крепостного права проложила дорогу другим важнейшим преобразованиям, направленным на создание в России гражданского общества.
Лит.: Зайончковский П. А. Крестьянская реформа 1861 // Большая советская энциклопедия. Т. 13. М., 1973; Манифест 19 февраля 1861 г. // Российское законодательство X-XX вв. Т. 7. М., 1989; То же [Электронный ресурс]. URL: http://www.hist.msu.ru/ER/Etext/feb1861.htm; Фёдоров В. А. Падение крепостного права в России: Документы и материалы. Вып. 1: Социально-экономические предпосылки и подготовка крестьянской реформы. М., 1966; Энгельман И. Е. История крепостного права в России / Пер. с нем. В. Щерба, под ред. А. Кизеветтера. М., 1900.
См. также в Президентской библиотеке:
Высочайше утверждённое общее положение о крестьянах, вышедших из крепостной зависимости 19 февраля 1861 г. // Полное собрание законов Российской империи. Т. 36. Отд. 1. СПб., 1863. № 36657; Крестьяне // Энциклопедический словарь / Под ред. проф. И. Е. Андреевского. Т. 16а. СПб., 1895;
Крестьянская реформа 1861 года: коллекция;
Крестьянская реформа 1861 г. Отмена крепостного права: каталог.
Алгоритм
— Как разобрать список слов по упрощенной грамматике?
Вот рабочий пример Haskell. Оказывается, нужно изучить несколько приемов, прежде чем вы сможете заставить его работать! Нулевая вещь, которую нужно сделать, — это шаблон: отключить ужасное ограничение мономорфизма, импортировать некоторые библиотеки и определить некоторые функции, которых нет в библиотеках (но должны быть):
{- # LANGUAGE NoMonomorphismRestriction # -}
импорт Control. Applicative ((<*))
Контроль импорта.Монада
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
Теперь, когда нулевая вещь сделана … сначала мы определяем тип данных для наших абстрактных синтаксических деревьев. Здесь мы можем просто проследить за формой грамматики. Однако, чтобы было удобнее, я учел некоторые грамматические правила; в частности, два правила
NP => N | Det N | Det Adj N
VB => V | V НП
, когда дело доходит до написания парсера, удобнее записывать так:
NP => N | Det (Adj | пусто) N
VB => V (NP | пусто)
В любой хорошей книге по синтаксическому анализу есть глава о том, почему такой вид факторинга является хорошей идеей.Итак, тип АСТ:
данные Предложение
= Сложное NounPhrase VerbPhrase
| Простой VerbPhrase
data NounPhrase
= Сокращенное Существительное
| Длинная статья (Может быть, прилагательное) Существительное
данные VerbPhrase
= VerbPhrase Глагол (может быть, существительное)
type Noun = String
тип Verb = String
type Article = String
type Прилагательное = Строка
Тогда мы можем сделать наш парсер. Этот еще больше следует (разложенной) грамматике! Единственная проблема здесь в том, что мы всегда хотим, чтобы наш синтаксический анализатор обрабатывал все предложение, поэтому мы должны явно попросить его сделать это, потребовав «eof» — или конец «файла».
s = (liftM2 Комплексный np vp <|> liftM Simple vp) <* eof
np = liftM Short n <|> liftM3 Long det (optionMaybe adj) n
vp = liftM2 VerbPhrase v (optionMaybe np)
n = anyOf [«я», «ты», «автобус», «торт», «медведь»]
v = anyOf ["обнимать", "любить", "разрушать", "я"]
det = anyOf ["a", "the"]
adj = anyOf ["розовый", "стильный"]
Последняя часть — токенизатор. Для этого простого приложения мы просто разметим на основе пробелов, поэтому встроенная функция слов работает нормально.Давай попробуем! Загрузите весь файл в ghci:
* Главная> разобрать s "stdin" (слова "я люблю розовый торт")
Справа (Комплекс (Короткое «i») (VerbPhrase «любовь» (Просто (Длинное «the» (Просто «розовый») «торт»))))
* Главная> разобрать s "stdin" (слова "я люблю розовый торт")
Левый "stdin" (строка 1, столбец 3):
неожиданный "розовый"
ожидая окончания ввода
Здесь справа указывает на успешный синтаксический анализ, а слева указывает на ошибку. Номер «столбца», указанный в ошибке, на самом деле является номером слова, в котором произошла ошибка, из-за того, как мы вычисляем исходные позиции в singleToken .
Последние достижения в области машинного обучения
Рекомендации для читателей
Что это за страница? На этой странице слева показаны таблицы, извлеченные из документов arXiv.
Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Какие цветные прямоугольники справа? Это результаты, извлеченные из бумаги и связанные с таблицами слева.Результат состоит из значения метрики, имени модели, имени набора данных и имени задачи.
Что означают цвета? Зеленый означает, что результат одобрен и показан на сайте. Желтый — результат того, что вы
добавили, но еще не сохранили. Синий — это результат ссылки, полученный из другой бумаги.
Откуда берутся предлагаемые результаты? У нас есть модель машинного обучения, работающая в фоновом режиме, которая дает рекомендации по статьям.
Откуда берутся ссылочные результаты? Если мы находим в таблице результаты со ссылками на другие статьи, мы показываем проанализированный справочный блок, который редакторы могут использовать для аннотирования, чтобы получить эти дополнительные результаты из других статей.
Руководство для редактора
Я впервые редактирую и боюсь ошибиться. Помощь! Не волнуйтесь! Если вы сделаете ошибки, мы можем исправить их: все версионировано! Так что просто сообщите нам на канале Slack, если вы что-то случайно удалили (и так далее) — это вообще не проблема, так что дерзайте!
Как добавить новый результат из таблицы? Щелкните ячейку в таблице слева, откуда берется результат.Затем выберите одно из 5 лучших предложений. Вы можете вручную отредактировать неправильные или отсутствующие поля. Затем выберите задачу, набор данных и название метрики из таксономии «Документы с кодом». Вы должны проверить, существует ли уже эталонный тест, чтобы предотвратить дублирование; если его не существует, вы можете создать новый набор данных. Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Каковы соглашения об именах моделей? Название модели должно быть простым, как указано в документе.Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Другие советы и рекомендации
Если эталонный тест для введенной пары набор данных / задача уже существует, вы увидите ссылку.
Если эталонный тест не существует, появится значок «новый», обозначающий новую таблицу лидеров.
Если вам повезет, Cmd + щелкните ячейку в таблице, чтобы автоматически получить первый результат.
При редактировании нескольких результатов из одной и той же таблицы вы можете нажать кнопку «Заменить все», чтобы скопировать текущее значение во все другие записи из этой таблицы.
Как добавить результаты, на которые имеются ссылки? Если в таблице есть ссылки, вы можете использовать функцию синтаксического анализа ссылок, чтобы получить больше результатов из других документов. Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты.Ниже вы можете увидеть пример.
Таблица сравнения извлечена из статьи Универсальная языковая модель «Тонкая настройка для классификации текста» (Howard and Ruder, 2018) с проанализированными ссылками.
Как сохранить изменения? Когда вы будете довольны своим изменением, нажмите «Сохранить», и предложенные вами изменения станут зелеными!
команд Barzilay будут использовать семантический синтаксический анализ для решения текстовых задач, в конечном итоге более
Исследователи из Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института, в том числе профессор EECS Регина Барзилай и аспирант Нейт Кушман , работая с коллегами из Вашингтонского университета, разработали новую компьютерную систему, которая может автоматически решать типы текстовых задач распространены на вводных занятиях по алгебре.
Подробнее читайте в статье Ларри Хардести в MIT News Office от 2 мая 2014 года, озаглавленной «Компьютерная система автоматически решает текстовые задачи. Приложения могут включать в себя образовательные инструменты, системы для решения практических задач по геометрии или физике», также опубликованную ниже.
Исследователи из Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института, работая с коллегами из Вашингтонского университета, разработали новую компьютерную систему, которая может автоматически решать тип словесных задач, типичных для вводных классов алгебры.
В ближайшем будущем работа может привести к созданию образовательных инструментов, которые выявляют ошибки в рассуждениях учащихся или оценивают сложность словесных задач. Но это также может указывать на системы, которые могут решать более сложные проблемы в геометрии, физике и финансах — проблемы, решения которых не появляются в конце учебника для учителей.
По словам Нейта Кушмана, аспиранта Массачусетского технологического института в области электротехники и информатики и ведущего автора новой статьи, новая работа находится в области «семантического анализа» или перевода естественного языка на формальный язык, такой как арифметический или формальный. логика.По словам Кушмана, большая часть предыдущих работ по семантическому синтаксическому анализу, в том числе его собственная, была сосредоточена на отдельных предложениях. «В этих задачах алгебры вы должны строить эти вещи из множества различных предложений», — говорит он. «Тот факт, что вы просматриваете несколько предложений для создания этого семантического представления, действительно является чем-то новым».
Кушман присоединился к работе с Региной Барзилай, профессором информатики и инженерии и одним из двух его научных консультантов, а также Йоавом Арци и Люком Зеттлемойером из Вашингтонского университета.Исследователи представят свою работу на ежегодном собрании Ассоциации компьютерной лингвистики в июне.
Как найти свое место
Система исследователей использует два существующих вычислительных инструмента. Одна из них — это система компьютерной алгебры Macsyma, первоначальная разработка которой в Массачусетском технологическом институте в 1960-х годах стала важной вехой в исследованиях искусственного интеллекта. Для целей Кушмана и его коллег Macsyma предоставил способ вывести алгебраические уравнения с одинаковой общей структурой в общий шаблон.
Другой инструмент — синтаксический анализатор предложений, используемый в большинстве исследований обработки естественного языка. Синтаксический анализатор представляет части речи в данном предложении и их синтаксические отношения в виде дерева — типа графа, который, как диаграмма генеалогического дерева, разворачивается на последовательных уровнях глубины.
Для системы исследователей понимание проблемы со словом — это вопрос правильного отображения элементов диаграммы синтаксического анализа составляющих ее предложений на один из шаблонов уравнений Macsyma.Чтобы научить систему выполнять это отображение и создавать шаблоны уравнений, исследователи использовали машинное обучение.
Кушман нашел веб-сайт, на котором студенты-алгебры размещали текстовые задачи, с которыми у них были трудности, и где их сверстники могли предлагать решения. Из первоначальной группы примерно из 2000 задач он выбрал 500, которые представляли полный спектр типов задач, обнаруженных в более крупном наборе.
В серии экспериментов исследователи случайным образом выбирали 400 из 500 задач, использовали их для обучения своей системы, а затем тестировали ее на оставшихся 100.
Однако для обучения они использовали два разных подхода — или, говоря языком машинного обучения, два разных типа супервизии. В первом подходе они загрузили в систему как задачи со словами, так и их переводы в алгебраические уравнения — по 400 примеров каждой. Но во втором они дали системе лишь несколько примеров пяти наиболее распространенных типов словесных задач и их алгебраических переводов. Остальные примеры включали только словесные задачи и их численные решения.
В первом случае система после обучения смогла решить примерно 70 процентов своих тестовых задач; во втором эта цифра упала до 46 процентов. Но, по словам Кушмана, этого достаточно, чтобы вселять надежду на то, что подход исследователей может быть обобщен на более сложные проблемы.
Рекомендуемая производительность
При определении того, как отобразить естественный язык на шаблоны уравнений, система проверила сотни тысяч «функций» обучающих примеров.Некоторые из этих функций связывают определенные слова с типами проблем: например, появление фразы «реагировать с помощью» было хорошим показателем того, что проблема связана с химией. Другие функции смотрели на расположение определенных слов в диаграммах синтаксического анализа: появление слова «затраты» в качестве основного глагола многое указывало на то, какие элементы предложения должны быть помещены в какие шаблоны уравнений.
Другие функции просто анализировали синтаксические отношения между словами, независимо от самих слов, в то время как третьи исследовали корреляции между местоположениями слов в разных предложениях.Наконец, по словам Кушмана, он включил несколько функций «проверки работоспособности», например, было ли решение, полученное с помощью определенного шаблона уравнения, положительным целым числом, как это почти всегда бывает с алгебраическими задачами со словами.
«Идея такого рода надзора будет полезна для многих вещей», — говорит Кевин Найт, профессор компьютерных наук Университета Южной Калифорнии. «Подход создания генеративного рассказа о том, как люди переходят от текста к ответам, — отличная идея.«Способность системы работать достаточно хорошо даже при обучении главным образом на грубых числовых ответах« очень обнадеживает », — добавляет Найт. «Ему нужна небольшая помощь, но он может извлечь выгоду из набора дополнительных данных, которые вы не пометили подробно».
Метод создания состязательных примеров на основе анализа зависимостей для интеллектуальных роботов вопросов и ответов
В последнее время повсеместно используются интеллектуальные роботы вопросов и ответов (Q&A), основанные на обработке естественного языка (NLP). Однако надежность и безопасность современных Q&A роботов все еще неудовлетворительны, например.g. небольшая опечатка в вопросе пользователя может привести к тому, что робот Q&A не сможет дать правильный ответ. В этой статье мы предлагаем быстрый и автоматический метод создания тестовых наборов данных для оценки надежности и безопасности текущих Q&A роботов, которые могут работать в сценариях «черного ящика» и, таким образом, могут быть применены к множеству различных Q&A роботов. В частности, мы предлагаем d ependency p ass-based a dversarial e xamples g eneration (DPAEG) метод для Q&A роботов.DPAEG сначала использует предложенный алгоритм извлечения ключевых слов на основе анализа зависимостей для извлечения ключевых слов из вопроса. Затем предлагаемый алгоритм генерирует состязательные слова в соответствии с извлеченными ключевыми словами, которые включают опечатки и слова, написанные аналогично ключевым словам. Наконец, эти состязательные слова используются для создания большого количества состязательных вопросов. Сгенерированные состязательные вопросы, похожие на исходные, не влияют на понимание человеком, но роботы вопросов и ответов не могут правильно ответить на эти состязательные вопросы.Более того, предлагаемый метод работает в сценарии черного ящика, что означает, что он не требует знаний целевых роботов Q&A. Результаты экспериментов показывают, что сгенерированные примеры состязательности имеют высокий уровень успеха на двух современных роботах вопросов и ответов, DrQA и Google Assistant. Кроме того, сгенерированные примеры состязательности не только влияют на правильный ответ (верхний-1), возвращаемый DrQA, но также влияют на верхние- k возможных ответов, возвращаемых DrQA. Примеры состязательности приводят к тому, что ответы лучших кандидатов k содержат меньше правильных ответов и делают правильные ответы более низкими в ответах кандидатов наивысшего числа k .Результаты оценки на людях показывают, что участники с разным полом, возрастом и родными языками могут понять значение большинства созданных примеров состязательности, а это означает, что созданные примеры состязательности не влияют на понимание людьми.
1. Введение
В последние годы искусственный интеллект (ИИ) быстро развивался как в методах, так и в применении. Типичное применение ИИ — это роботы интеллектуальных вопросов и ответов (Q&A), основанные на обработке естественного языка (NLP) [1], которые используются не только в общих приложениях, но и в профессиональных деловых или правительственных приложениях.В последнее время многие компании разработали своих роботов для вопросов и ответов и выпустили их на рынок, например, Google Assistant [2], Cortana [3], Siri [4], Alexa [5] и Watson [6]. В отличие от поисковых систем (, например, , Google и Baidu), которые предоставляют пользователю ранжированный список релевантных веб-документов, задача интеллектуального робота вопросов и ответов состоит в том, чтобы дать пользователю точный и лаконичный ответ в нескольких взаимодействиях с пользователем [7 ]. В общем, робот вопросов и ответов имеет следующие две функции: (1) пользователи могут запрашивать робота вопросов и ответов на естественном языке и (2) ответ, возвращаемый роботом вопросов и ответов, является прямым ответом, который нужен пользователю, а не ранжированным списком соответствующие документы.
Многие современные роботы Q&A используют модели НЛП, чтобы понимать вопросы пользователей и возвращать ответы [8]. Однако у моделей НЛП все же есть недостатки. Например, исследования показывают, что модели НЛП недостаточно надежны [9], и небольшая опечатка во вводимых пользователем данных может привести к тому, что модели НЛП не смогут обработать вопрос. Кроме того, модели НЛП, используемые в роботах вопросов и ответов, могут не полностью понимать семантику вопроса пользователя [10], что заставляет роботов вопросов и ответов давать нерелевантные ответы.Более того, модели НЛП также уязвимы для атак со стороны враждебных примеров [11]. Эти недостатки моделей НЛП повлияют на надежность и безопасность современных роботов вопросов и ответов, что приведет к очень плохому взаимодействию с пользователем.
На сегодняшний день есть некоторые исследования устойчивости и безопасности моделей машинного обучения, такие как [12–16], но мало исследований было проведено по вопросам устойчивости и безопасности этих вездесущих роботов вопросов и ответов. Руководствуясь этими проблемами, в этой статье мы предлагаем быстрый и автоматический метод генерации тестовых наборов данных для оценки надежности роботов, отвечающих за вопросы и ответы, путем составления состязательных вопросов.Хотя предлагаемый метод вносит лишь незначительные изменения в исходные вопросы, эти тщательно построенные состязательные вопросы могут легко привести к неправильному ответу современных роботов вопросов и ответов. Более того, эти сгенерированные состязательные вопросы очень похожи на исходные и, таким образом, не влияют на понимание людьми этих состязательных вопросов.
В литературе есть несколько методов создания состязательных примеров для текстовых классификаторов, например [17–22]. Однако эти состязательные методы генерации примеров для текстовых классификаторов не подходят для роботов вопросов и ответов.Причины следующие. (1) Сценарии применения текстовых классификаторов и роботов вопросов и ответов различны. Текстовые классификаторы применяются для фильтрации спама, анализа тональности, обнаружения фейковых новостей и т. Д. Роботы Q&A применяются для интеллектуального обслуживания клиентов, обслуживания умного дома, профессиональных вопросов и ответов, информационных запросов и т. Д. (2) Методы, используемые классификаторами текста и роботами вопросов и ответов, также различаются. Классификаторы текста используют единую модель НЛП для выполнения задач классификации.Однако, поскольку задачи, выполняемые роботами Q&A, более сложны, роботы Q&A используют несколько различных моделей НЛП во всем процессе понимания вопросов и поиска ответов. (3) Состязательные методы генерации примеров для текстовых классификаторов основаны на единственной целевой модели, и некоторые из этих методов генерации требуют определенных знаний целевой модели, например [17, 18, 21]. Однако для роботов вопросов и ответов злоумышленники в большинстве случаев не могут получить конкретные знания роботов вопросов и ответов.Поэтому для роботов вопросов и ответов создавать состязательные примеры сложнее, чем для текстовых классификаторов. В этой статье предложенный метод определяет важные слова вопросов и немного изменяет их, что не требует информации о конструкции целевого робота вопросов и ответов и, таким образом, имеет сильную универсальность для широкого диапазона роботов вопросов и ответов.
В предлагаемом методе сначала используется анализатор зависимостей для извлечения ключевых слов из исходного вопроса. Затем создаются состязательные слова ключевых слов.Состязательные слова содержат три типа слов: опечатки ключевых слов, слова, написанные аналогично ключевым словам, опечатки этих похожих слов. Слова, похожие по буквам, получаются путем поиска слов в словаре английского языка, которые удовлетворяют предложенным трем ограничениям. Опечатки ключевых слов и опечатки схожих с заклинаниями слов — это часто встречающиеся слова с ошибками, которые получаются путем запроса корпуса опечаток и отбрасывания тех опечаток, которые имеют большое расстояние редактирования от ключевых слов. Наконец, ключевые слова в исходном вопросе заменяются на состязательные слова, чтобы создать большое количество состязательных вопросов.В эксперименте состязательные примеры генерируются из наборов данных WebQuestionsSP, CuratedTREC и WikiMovies Q&A. Два современных робота Q&A, DrQA и Google Assistant, используются для оценки успешности предлагаемого метода. Результаты экспериментов с DrQA и Google Assistant показывают, что сгенерированные примеры состязательности могут заставить робота вопросов и ответов выйти из строя с высокой вероятностью успеха. Экспериментальные результаты с точки зрения запоминания () [23], среднего обратного ранга (MRR) [24] и средней средней точности (MAP) [24] также показывают, что сгенерированные состязательные примеры также влияют на ответы кандидатов наивысшего уровня. вернулся DrQA.Состязательные примеры приводят к меньшему количеству правильных ответов в ответах кандидатов на первое место — k и понижают место правильных ответов в ответах кандидатов на первое место — k . Кроме того, мы приглашаем участников разного пола, возраста и родного языка оценить качество созданных примеров состязательности. Результаты оценки на людях показывают, что разные участники могут понять смысл большинства противостоящих примеров, созданных предлагаемым методом.
Основными вкладами этого документа являются следующие: (i) Многие предыдущие методы создания состязательных примеров текста требуют знания целевой модели для определения важных частей текстовой последовательности, которые в дальнейшем модифицируются для генерации состязательных примеров.Однако предлагаемый нами алгоритм извлечения ключевых слов может определять важные части вопроса без знания проектной информации роботов вопросов и ответов. Таким образом, предлагаемый метод может работать в ситуациях «черного ящика». Более того, насколько известно авторам, это первый метод создания состязательных примеров для интеллектуальных роботов вопросов и ответов, а также первый метод автоматического создания тестовых наборов данных для оценки надежности и безопасности роботов вопросов и ответов. (Ii) Предлагаемый алгоритм сначала извлекает ключевые слова из заданного вопроса, а затем генерирует состязательные слова, похожие на извлеченные ключевые слова.Эти слова используются для замены соответствующих слов в исходном вопросе, чтобы создать большое количество противостоящих примеров. Поскольку различия между сгенерированными состязательными вопросами и исходным вопросом незаметны, люди не осознают эти состязательные слова при чтении вопроса. Человеческая оценка участников разного пола, возраста и родного языка показывает, что у них нет проблем с пониманием порождаемых спорных вопросов. Но современные роботы вопросов и ответов не могут правильно ответить на сопутствующие вопросы.(iii) Предлагаемый метод создания состязательных вопросов может обеспечить быстрый и автоматический метод создания тестовых наборов данных для оценки надежности и безопасности текущих роботов вопросов и ответов в сценариях «черного ящика». Кроме того, предлагаемый метод обладает высокой универсальностью и может быть использован для оценки устойчивости широкого спектра различных роботов Q&A.
Остальная часть этого документа организована следующим образом. Связанные работы рассмотрены в Разделе 2. В Разделе 3 дается подробное описание предлагаемого алгоритма создания состязательных примеров для роботов вопросов и ответов.Экспериментальные результаты представлены в Разделе 4. Наконец, выводы представлены в Разделе 5.
2. Сопутствующие работы
Как правило, современные роботы Q&A используют три типа рабочих механизмов: использование базы знаний (KB), использование информации извлечение (IR) и использование как KB, так и IR. Роботы вопросов и ответов на основе базы знаний преобразуют вопрос в стандартный структурированный запрос посредством семантического анализа, а затем получают ответ из базы знаний [25]. Ключевым этапом этого типа роботов вопросов и ответов является преобразование вопросов пользователя на естественном языке в стандартные структурированные языки запросов [25].В настоящее время многие роботы вопросов и ответов используют методы машинного обучения для понимания семантики вопросов, например [25–27]. В [25] Yih et al. использовал систему связывания сущностей и модель глубокой сверточной нейронной сети для ответов на вопросы. Инь и др. [26] предложили сквозную модель нейронной сети для генерации ответов. Для роботов вопросов и ответов на базе IR, таких как [28–30], они извлекают неструктурированные текстовые документы и извлекают соответствующие ответы из этих документов. DrQA, разработанный Facebook [31], представляет собой модель вопросов и ответов для ответов на вопросы путем извлечения и чтения неструктурированных знаний.DrQA использует Википедию как уникальный источник знаний и использует модель рекуррентной нейронной сети (RNN) для извлечения ответов из соответствующих статей [28]. Некоторые Q&A роботы, такие как YodaQA [32], QuASE [33] и Watson [34], комбинируют методы KB и IR, чтобы получить ответы на вопросы. Баудиш [32] предложил структуру вопросов и ответов, названную YodaQA. YodaQA ищет неструктурированные и структурированные знания, а затем использует классификатор для определения наиболее подходящего ответа. Sun et al. [33] предложили систему QuASE для ответов на вопросы в открытой области, которая ищет ответы прямо из Интернета и использует базу знаний для дальнейшего повышения точности ответов на вопросы.
Хотя разные роботы вопросов и ответов имеют разные механизмы работы, многие современные роботы вопросов и ответов используют модели НЛП при обработке вопросов пользователей и поиске правильных ответов [35]. К сожалению, модели НЛП уязвимы для состязательных примеров, которые являются тщательно разработанными входными данными злоумышленника, чтобы заставить модель выдавать ошибочные выходные данные [36]. В последнее время в задачах НЛП появились несколько состязательных методов генерации примеров, включая классификацию текста, машинный перевод и понимание прочитанного.Например, в [17–19] авторы ищут наиболее важную часть текстовой последовательности для классификатора текста, а затем вносят небольшие изменения в эту часть, чтобы генерировать состязательные примеры. Эти модификации включают вставку, замену, удаление, и т. Д. . Ориентируясь на модель машинного перевода, Ebrahimi et al. а Белинков и Биск [37, 38] использовали зашумленные тексты для создания состязательных примеров, которые сильно меняют результаты машинного перевода. Ориентируясь на системы понимания прочитанного, Цзя и Лян [10] добавляли несоответствующие предложения во вводимые данные, чтобы обмануть систему понимания прочитанного.Насколько известно авторам, исследований по созданию состязательных примеров для интеллектуальных Q&A роботов не проводилось. Однако, поскольку многие модели НЛП применяются к роботам вопросов и ответов, роботы вопросов и ответов также сталкиваются с угрозой состязательных примеров на практике. Например, при взаимодействии с роботом вопросов и ответов пользователь часто неправильно пишет слова в вопросе, что приводит к тому, что робот вопросов и ответов возвращает неправильный или нерелевантный ответ.
В этой статье предложенный метод генерации состязательных примеров для роботов вопросов и ответов состоит в небольшом изменении важной части вопроса.По сравнению с другими методами разница между сгенерированными состязательными примерами и исходным вопросом более незаметна, и предлагаемый метод может работать в сценариях черного ящика. Это незначительное изменение практически не меняет семантику исходного вопроса. Даже если семантика отдельного слова изменится, люди все равно смогут сделать вывод о семантике из контекста вопроса. Эксперименты по оценке людей показывают, что люди могут понять первоначальный смысл созданных примеров состязательности.Кроме того, предлагаемый метод использует анализатор зависимостей для определения важных частей вопроса без знания проектной информации робота вопросов и ответов. Следовательно, его можно применять к различным роботам Q&A в сценариях «черного ящика».
3. Предлагаемый метод DPAEG
3.1. Общая процедура
В этом разделе мы разрабатываем предложенный метод d ependency p ass-based a dversarial e xamples g eneration (DPAEG) метод.DPAEG заменяет важную часть исходного вопроса опечатками или словами, написанными аналогичным образом. Структура предложенного метода генерации состязательных примеров показана на рисунке 1. В предлагаемом методе есть четыре этапа для создания состязательных примеров. Во-первых, предлагаемый метод предварительно обрабатывает вопросы из наборов данных вопросов и ответов, что удаляет исходные вопросы, на которые целевой робот вопросов и ответов не может правильно ответить. Это означает, что в наборе данных вопросов и ответов только исходные вопросы, на которые робот вопросов и ответов может правильно ответить, сохраняются для создания состязательных примеров.Во-вторых, предложенный алгоритм извлечения ключевых слов на основе анализа зависимостей используется для извлечения ключевых слов из исходных вопросов. В-третьих, предлагаемый алгоритм генерации состязательных слов используется для небольшого изменения ключевых слов вопроса, который включает три типа модификаций, опечатки ключевых слов, похожие по заклинанию слова и опечатки в этих похожих словах. В частности, путем поиска в словаре в соответствии с предложенными ограничениями определяются слова, которые пишутся аналогично ключевым словам.Опечатки ключевых слов и опечатки этих похожих по заклинанию слов определяются из корпуса опечаток в соответствии с настройками расстояния редактирования. Наконец, ключевые слова в исходном вопросе заменяются на состязательные слова, чтобы создать большое количество состязательных вопросов. Подробный процесс каждого этапа описан в следующих разделах.
Для любого заданного вопроса предлагаемый метод может генерировать большое количество сомнительных вопросов.В эксперименте три стандартных набора данных вопросов и ответов (WebQuestionsSP [39], CuratedTREC [40] и WikiMovies [41]) используются для предоставления исходных вопросов. Возможны и другие вопросы. Поскольку целевой робот вопросов и ответов не может правильно ответить на все исходные вопросы в этих трех наборах данных, бессмысленно создавать состязательные примеры с теми исходными вопросами, на которые робот вопросов и ответов не может ответить. Поэтому к наборам данных Q&A применяется операция предварительной обработки, а исходные вопросы, на которые целевой робот Q&A не может правильно ответить, удаляются.Остальные вопросы, на которые целевой робот вопросов и ответов может правильно ответить, используются для генерации состязательных примеров.
3.3. Извлечение ключевых слов на основе анализа зависимостей
Предлагаемый метод извлекает ключевые слова в соответствии с важностью слов в вопросе. Как правило, если изменение или удаление слова в вопросе вызывает значительное изменение ответа, даваемого роботом вопросов и ответов, это означает, что это слово важно для робота вопросов и ответов, чтобы правильно понять вопрос и ответить на него.Однако, поскольку робот вопросов и ответов — это черный ящик для злоумышленников, трудно определить важную часть вопроса с помощью робота вопросов и ответов, за исключением постоянного взаимодействия с роботом вопросов и ответов. Чтобы решить эту проблему, предлагаемый алгоритм извлечения ключевых слов идентифицирует важные части вопроса в соответствии с отношением зависимости вопроса и, таким образом, может работать в сценарии черного ящика без взаимодействия с роботами Q&A. Обратите внимание, что извлеченные ключевые слова определяются зависимостями между словами в текущем предложении.Если одно и то же слово имеет разные зависимости в разных предложениях, важность слова в разных предложениях будет разной.
Отношение зависимости — это метод описания грамматической структуры предложения, который представляет собой грамматическое отношение между словами в предложении [42]. Как правило, синтаксический анализатор зависимостей преобразует предложение в дерево зависимостей. Корень дерева называется заголовком предложения, которое не изменяет ни одно слово [42]. Пример анализа зависимости для предложения «Кто играл голосом Аладдина» показан на рисунке 2.Корень дерева зависимостей «проигрывается». Стрелка представляет отношение зависимости между двумя частями. Например, отношение зависимости между «Кто» и «играл» — это отношение nsubj , что означает, что «Кто» является номинальным субъектом ( nsubj ) слова «играл». Точно так же «голос» — это прямой объект ( dobj ) слова «проиграно», «of» — предложный модификатор ( pre ) «голоса», а «Аладдин» — предложный объект ( pobj ). ) из из».
Зависимые отношения предложения можно разделить на (вспомогательные), (аргумент) и (модификатор) [43]. Эти отношения можно разделить на 48 различных грамматических отношений. Чтобы извлечь важные части входного вопроса, предлагаемый метод извлечения ключевых слов фокусируется только на словах, которые удовлетворяют следующему правилу: зависимые отношения между словом и заголовком предложения находятся в наборе отношений (). Зависимые отношения, содержащиеся в наборе отношений, показаны на рисунке 3 [43].
Предлагаемый алгоритм извлечения ключевых слов показан в алгоритме 1. Во-первых, для извлечения дерева зависимостей из вопроса используется анализатор зависимостей. Парсер зависимостей, используемый в этом методе, представляет собой анализатор зависимостей, предоставляемый spaCy (https://spacy.io), который является инструментом обработки естественного языка. spaCy использует синтаксический анализатор на основе переходов для извлечения зависимостей [44], а процесс извлечения отношения зависимости вопроса резюмируется следующим образом. Изначально парсер имеет пустой стек и буфер, где исходный вопрос находится в буфере [44].Затем синтаксический анализатор использует операции shift и reduce для управления состоянием стека и буфера [44]. Операция shift перемещает слово в буфере на вершину стека, в то время как операция reduce выталкивает два верхних слова в стеке и определяет отношение зависимости между этими двумя словами [44]. Операции сдвига , и уменьшения, повторяются до тех пор, пока стек и буфер не станут пустыми. В результате получается отношение зависимости вопроса, которое представлено в виде дерева зависимостей [44].Все узлы в дереве зависимостей обозначены, где — слово на узле i -го дерева, это слово на родительском узле i -го узла и является зависимым отношением между и. Затем, если корнем дерева зависимостей является слово содержимого, этот корень добавляется к набору ключевых слов K . Для каждого дочернего узла корня, если дочерний узел удовлетворяет следующим двум условиям, слово дочернего узла также добавляется к набору ключевых слов K .Два условия: (1) зависимое отношение между дочерним узлом и корнем находится в наборе отношений и (2) слово в дочернем узле является словом содержимого. Наконец, если вопрос содержит предложение, корень дерева зависимостей сначала заменяется заголовком предложения. Затем ключевые слова извлекаются таким же образом в предложении. После извлечения ключевых слов определяются важные части вопроса. Эти извлеченные ключевые слова обозначаются как, где p — количество ключевых слов.
Ввод : исходный вопрос
Вывод : набор ключевых слов K
(1)
Инициализировать набор ключевых слов K , стек и S слово P
(2)
= анализатор зависимостей ()
(3)
Вставьте заголовок вопроса в стек S
(4)
Пока S не пусто do
(5)
Извлечь верх стека S в слово P
(6)
, если — это слово содержимого , затем
(7)
Добавить P к набору ключевых слов K
(8)
конец, если
( 9)
для дочерних узлов P до
(10)
если и является словом содержимого , то
(11)
Добавить к набору ключевых слов K
(12)
конец, если
(13)
, если изменен с помощью статьи , то
(14)
Нажмите на заголовок статьи в стек S
(15)
конец, если
(16)
конец для
(17)
конец в то время как
903 18)
return набор ключевых слов K
Поскольку функциональные слова в вопросе мало влияют на ответ, возвращаемый Робот Q&A, функциональные слова не используются в качестве ключевых слов в предлагаемом методе.По сравнению с использованием всех слов содержания в качестве ключевых слов, предлагаемый алгоритм использует только слова содержания, которые имеют большее влияние на робота вопросов и ответов для получения правильного ответа. В Разделе 4.4 мы сравним эффективность предлагаемого метода извлечения ключевых слов с методом извлечения слов контента, который выбирает все слова контента из вопроса в качестве ключевых слов.
3.4. Генерация состязательных слов на основе извлеченных ключевых слов
Чтобы ввести в заблуждение робота вопросов и ответов, входные вопросы немного изменены, чтобы генерировать состязательные примеры.Разница между исходным вопросом и измененным вопросом должна быть как можно меньше, чтобы у людей не было проблем с пониманием измененных вопросов. С этой целью предлагаемый метод генерирует состязательные слова, похожие на извлеченные ключевые слова. Эти враждебные слова используются для изменения соответствующих ключевых слов в исходном вопросе. Предлагаемый метод генерации состязательных слов показан в алгоритме 2, который генерирует три типа состязательных слов: опечатки ключевых слов, слова, написанные аналогично ключевому слову, и опечатки этих похожих слов.
Ввод : ключевое слово k
Выход : набор состязательных слов
(1)
// Опечатки запроса
7
(2)
если есть опечатки ключевого слова k в корпусе опечаток и , то
(3)
Добавьте опечатки ключевого слова k на
(4)
end if
(5)
// Поиск слов, похожих по орфографии
(6)
Установите значение d в соответствии с POS k
(7)
Определите вложенный словарь в соответствии с инициалами ключевого слова k
(8)
для до
(9)
если слово удовлетворяет трем ограничениям , то
(10)
Добавить подобное слово в аналогичный набор слов
(11)
конец, если
(12)
конец для
(13)
// Запросить опечатки слов, похожих на орфографию
(14)
для do
(15)
если то
(16)
Добавить к
(17)
иначе
(18)
если есть опечатки из в корпусе опечаток и , затем
(19)
Добавить опечатки из в
(20)
конец if
(21)
end if
(22)
конец для
(23)
return adversarial words set
9 Мы подробно опишем алгоритм 2 следующим образом.Алгоритм определяет опечатки ключевого слова k из корпуса опечаток. Если расстояние редактирования между ключевым словом k и опечатками ключевого слова k меньше или равно 2, опечатки ключевого слова k добавляются к набору состязательных слов. Принятый корпус опечаток публично доступен в [45], который содержит корпус опечаток Биркбека [46], корпус опечаток Холбрука [47], корпус опечаток Аспелла [48] и корпус опечаток Википедии [49].
Слова, которые пишутся аналогично ключевому слову, определяются путем поиска в словаре в соответствии с предложенными ограничениями.Словарь содержит общеупотребительные английские слова [50], которые по начальным буквам разделены на 26 подразделов. Во-первых, вспомогательный словарь определяется в соответствии с инициалами ключевого слова, в которых инициалы всех слов в скобках совпадают с инициалами ключевого слова. Затем, если слово во вложенном словаре удовлетворяет предложенным ограничениям, это слово добавляется к соответствующему аналогичному набору слов. Предлагаются следующие ограничения: (i) Расстояние редактирования между словом и ключевым словом k меньше или равно заранее заданному расстоянию редактирования d .(ii) Часть речи (POS) слова совпадает с POS ключевого слова k . (iii) Первая буква слова совпадает с первой буквой ключевого слова k. Аналогично, последняя буква слова совпадает с последней буквой ключевого слова k.
Первое ограничение может определять слова, написанные аналогично ключевому слову. Цель второго ограничения — увеличить вероятность успеха враждебных атак. Влияние второго ограничения на вероятность успеха сгенерированных состязательных примеров демонстрируется в разделе 4.3.1. Причины третьего ограничения следующие. С одной стороны, согласно [38], сохранение первых и последних букв слова неизменными позволяет людям легче распознать исходную форму измененного слова. С другой стороны, достаточно похожих слов можно найти во вспомогательном словаре. Следовательно, нет необходимости тратить больше времени на поиск похожих слов из других подсловарей. Это ограничение может заставить алгоритм выполнять поиск только в одном из 26 вложенных словарей, что может эффективно сократить количество поисков и, таким образом, повысить эффективность поиска.
Расстояние Дамерау – Левенштейна [51, 52] используется для оценки расстояния редактирования между двумя словами. Для ключевого слова k и слова в словаре расстояние Дамерау – Левенштейна между ними () — это минимальное количество символьных операций, необходимых для преобразования ключевого слова k в слово. Операции с символами включают вставку, удаление, замену одного символа или транспонирование двух соседних символов [53]. Для поиска подходящих похожих слов мы устанавливаем различные предопределенные расстояния редактирования в соответствии с POS ключевого слова.Значение d определяется по следующему правилу: где — длина ключевого слова k , и функция гарантирует, что расстояние d не меньше 1. Если POS ключевого слова k является verb, расстояние d устанавливается равным 1. В противном случае устанавливается расстояние d . Причина для установки различных предопределенных расстояний редактирования d для глагола и других слов в предложении следующая. Глагол — важная часть предложения.Если разница между глаголом измененного предложения и исходного предложения слишком велика, это может повлиять на понимание человеком измененного предложения. Следовательно, такие предопределенные настройки расстояния могут гарантировать, что расстояние редактирования между глаголом состязательного примера и глаголом исходного вопроса будет небольшим, так что людям не составит труда понять сгенерированные состязательные примеры.
После поиска слов, похожих на ключевое слово, состязательные слова генерируются на основе этих похожих слов.Для каждого слова в подобном наборе слов (), если расстояние редактирования между ключевым словом k меньше или равно 2, слово добавляется непосредственно в набор состязательных слов. В противном случае алгоритм ищет опечатки в слове. Если в корпусе опечаток есть опечатки и расстояние редактирования между этими опечатками и ключевым словом меньше или равно 2, опечатки добавляются к набору недобросовестных слов. Наконец, для каждого ключевого слова в вопросе получается соответствующий набор состязательных слов.
3.5. Генерация состязательных вопросов
Для каждого ключевого слова генерируются соответствующие состязательные слова. Эти состязательные слова используются для замены соответствующих ключевых слов в исходном вопросе для создания нескольких состязательных вопросов. Однако, если в исходном вопросе заменено слишком много ключевых слов, люди не смогут вывести семантику из контекста вопроса и могут иметь проблемы с пониманием сгенерированных враждебных примеров. Следовательно, чтобы предотвратить изменение слишком большого количества ключевых слов в исходном вопросе, для выбора подходящих состязательных вопросов применяется следующий критерий: где сгенерирован состязательный вопрос, является ли набор состязательных вопросов, является ли расстояние редактирования между исходным вопросом. и сгенерированный вопрос, а ϵ — предопределенный порог, который представляет максимальное расстояние редактирования между исходным вопросом и созданным вопросом.может не только ограничить количество измененных слов во всем вопросе, но и ограничить степень изменения в одном слове. Если меньше максимального расстояния редактирования ϵ , состязательный вопрос добавляется к набору состязательных вопросов. В противном случае состязательный вопрос будет отброшен. Наконец, для каждого исходного вопроса создается соответствующий набор состязательных вопросов.
Временная сложность предложенного алгоритма генерации состязательных примеров анализируется следующим образом.Предлагаемый алгоритм генерации состязательных примеров состоит из трех частей: извлечение ключевых слов, генерация состязательных слов и генерация состязательных вопросов. Предположим, что во входном вопросе n слов. Временная сложность извлечения ключевых слов и генерации состязательных вопросов составляет. Для алгоритма генерации состязательных слов основные временные затраты связаны с поиском похожих слов. Предположим, что во вложенном словаре m слов. Для данного ключевого слова необходимо выполнить m сравнений, чтобы определить слова, похожие по орфографии.Если затраты времени на каждое сравнение равны, а затраты времени на определение опечаток в слове равны, время выполнения алгоритма генерации состязательных слов составляет приблизительно:, который может генерировать состязательные слова за постоянное время. Это означает, что временная сложность алгоритма генерации состязательных слов тоже. Следовательно, временная сложность предложенного алгоритма построения состязательного примера составляет. Показано, что предложенный метод имеет хорошую масштабируемость и может эффективно генерировать состязательные примеры для больших наборов данных.
4. Экспериментальная оценка
Поскольку это первая работа по вопросам надежности и безопасности роботов, отвечающих за вопросы и ответы (сравнительных работ нет), мы используем двух лучших роботов для вопросов и ответов и человеческие оценки для оценки предлагаемого метода. Во-первых, экспериментальная установка представлена в разделе 4.1. В разделе 4.2 мы используем несколько показателей, чтобы оценить влияние сгенерированных состязательных примеров на роботов вопросов и ответов. Кроме того, мы предлагаем участникам субъективно оценить качество созданных состязательных примеров.В разделе 4.3 оценивается влияние различных настроек параметров на производительность предлагаемого метода, включая ограничения POS для похожих слов и максимальное расстояние редактирования. В разделе 4.4 эффективность предлагаемого метода дополнительно оценивается с двух сторон: предлагаемый алгоритм извлечения ключевых слов и предлагаемый алгоритм модификации ключевых слов.
4.1. Экспериментальная установка
4.1.1. Наборы данных
В эксперименте для генерации состязательных вопросов используются три стандартных набора данных вопросов и ответов: WebQuestionsSP [39], CuratedTREC [40] и WikiMovies [41].Информация о трех наборах данных следующая: (i) WebQuestionsSP: этот набор данных, созданный Yih et al. [39], содержит семантический анализ вопросов из набора данных WebQuestions. В наборе данных WebQuestionsSP 4737 вопросов. (Ii) CuratedTREC: этот набор данных собран Баудишем и Шедивем [40] на основе корпуса Text REtrieval Conference (TREC) [54], который состоит из 2180 вопросов, извлеченных из TREC1999, TREC2000, Наборы данных TREC2001 и TREC2002. (Iii) WikiMovies: этот набор данных создан Miller et al.[41], который состоит из пар вопрос-ответ в области кино. Набор данных WikiMovies содержит обучающий набор, набор для разработки и набор тестов. Три набора содержат, и примеры соответственно [41]. В эксперименте мы используем набор тестов для генерации состязательных примеров.
Примеры состязательных вопросов, сгенерированные из этих стандартных наборов данных вопросов и ответов, могут сформировать новый набор данных состязательных вопросов. В отличие от этих стандартных наборов данных вопросов и ответов, которые используются для оценки способности робота вопросов и ответов отвечать на вопросы, сгенерированный набор данных вопросов и ответов используется для оценки устойчивости роботов вопросов и ответов при обнаружении опечаток и орфографических ошибок и оценки понимания роботами вопросов и ответов семантики предложений.Другими словами, если робот вопросов и ответов не может ответить на вопрос в стандартных наборах данных вопросов и ответов, это означает, что у робота вопросов и ответов нет ответа на вопрос. В отличие от этого, если робот вопросов и ответов не может ответить на состязательный вопрос в сгенерированном наборе данных состязательных вопросов, это означает, что у робота вопросов и ответов есть ответ на исходный вопрос, но он не может обработать возмущение в состязательном вопросе.
4.1.2. Целевые роботы вопросов и ответов
Чтобы проиллюстрировать осуществимость предлагаемого метода, вычислена вероятность успеха созданных примеров противоборства на двух основных роботах вопросов и ответов, DrQA [28] и Google Assistant [2].Информация двух целевых роботов вопросов и ответов следующая: (i) DrQA — это открытая система ответов на вопросы, основанная на Википедии, которая состоит из двух компонентов [28]: модуля поиска документов и модуля чтения документов. Модуль поиска документов ищет статьи, связанные с вопросом, из базы данных Википедии, а затем модуль чтения документов использует модель RNN для извлечения ответов из соответствующих статей. DrQA имеет хорошую производительность для нескольких наборов данных вопросов и ответов. Следовательно, DrQA является хорошей базой для оценки производительности предложенного метода генерации состязательных примеров.(ii) Google Assistant [2] — это интеллектуальный персональный помощник, разработанный Google, который предоставляет службу вопросов и ответов. Пользователи могут задавать вопросы Google Ассистенту голосом или текстом. Если Google Assistant может правильно ответить на вопрос пользователя, он сразу вернет соответствующий ответ. В противном случае он вернет результаты веб-поиска, связанные с вопросом [2]. В эксперименте мы отправляем ему вопросы в виде обычного текста и записываем ответы, возвращаемые Google Assistant. Если ответ, возвращаемый Google Assistant, является результатом веб-поиска, мы считаем, что Google Assistant не может правильно ответить на этот вопрос.
4.1.3. Показатель оценки
Показатель успеха [37] используется в качестве показателя для оценки состязательных примеров, сгенерированных предложенным алгоритмом. Коэффициент успеха — это соотношение вопросов, на которые робот Q&A отвечает неправильно во всех сгенерированных состязательных вопросах [37]. Чем выше вероятность успеха сгенерированных состязательных примеров, тем эффективнее атака на целевого робота Q&A.
Кроме того, мы используем три других показателя: отзыв () [23], средний реципрокный ранг (MRR) [24] и средняя средняя точность (MAP) [24], чтобы оценить влияние состязательных примеров на топ- k. возможных ответов, возвращенных роботом Q&A.[23] отражает, существует ли правильный ответ в топ- k ответов кандидатов, возвращаемых роботом вопросов и ответов, где n — количество релевантных документов, извлеченных роботом вопросов и ответов. Так же, как [23, 55, 56], мы используем и в качестве метрики оценки. MRR [24] отражает позицию первого правильного ответа в топ- k возможных ответов, возвращаемых роботом Q&A. MAP [24] отражает ранжирование правильных ответов в топ- k ответов кандидатов, возвращенных роботом Q&A.Обратите внимание, что Google Assistant возвращает только один ответ или несколько веб-страниц. С одной стороны, эти связанные метрики top- k не могут быть рассчитаны на основе только одного ответа, возвращенного Google Assistant. С другой стороны, поскольку возвращенные веб-страницы не являются конкретными ответами, мы также не можем рассчитать эти показатели на основе возвращенных веб-страниц. Следовательно, мы не можем использовать эти три показателя для оценки эффективности Google Ассистента, отвечая на сомнительные вопросы. Следовательно, в этой статье эти три основных показателя, связанных с k , могут использоваться только для оценки DrQA.
Чтобы продемонстрировать, что состязательные вопросы, генерируемые предлагаемым методом, не влияют на понимание человеком, мы приглашаем ряд участников оценить, понимают ли они значение созданных состязательных примеров. Мы определяем показатель под названием уровень понимания текста . Степень понимания участником рассчитывается как, где — количество противостоящих примеров, которые участник может правильно понять, и — количество всех оцененных состязательных примеров.
4.2. Результаты экспериментов
4.2.1. Результаты экспериментов на роботах Q&A
В таблице 1 показаны три образца, полученные с помощью предложенного метода. Подчеркнутые буквы представляют собой разницу между созданным примером состязательности и исходным вопросом. В первом примере ключевое слово в исходном вопросе заменено опечаткой ключевого слова. Во втором примере ключевое слово заменяется словом, написанным аналогично ключевому слову. В третьем примере ключевое слово заменяется опечаткой похожего на заклинание слова.Показано, что изменяются только один или два символа в исходном вопросе, но ответы, данные роботами Q&A, сильно отличаются от ответа на исходный вопрос. В таблице 2 представлены примеры успешных действий, сгенерированных из трех наборов данных на двух целевых роботах вопросов и ответов. Максимальное расстояние редактирования ϵ установлено равным 4 в этом эксперименте. Показано, что сгенерированные состязательные примеры имеют высокую вероятность успеха на DrQA. Другими словами, DrQA не может вернуть правильные ответы в большинстве случаев, связанных с противодействием.По сравнению с DrQA, Google Assistant более устойчив к генерируемым сомнительным вопросам. Тем не менее, есть еще около половины спорных вопросов, на которые Google Assistant не может правильно ответить. Таким образом, сгенерированные примеры состязательности могут ввести в заблуждение целевой робот вопросов и ответов, что приведет к низкой точности ответов на вопросы.
1
Исходный вопрос
Кто был лидером СССР в 1948 году?
Состязательный вопрос
Кем был лев d СССР в 1948 году?
Оригинальный ответ
Иосиф Сталин
Ответ DrQA
Мими Ледер
Ответ Google Ассистента
Вот что я нашел: https: // www.bbc.com/news/world-europe-17858981
2
Исходный вопрос
Кто нарисовал Олимпию?
Состязательный вопрос
Кто из или попадал в Олимпию?
Исходный ответ
Мане
Ответ DrQA
Кори Эверсон
Ответ Google Ассистента
Вот что я нашел в Интернете: http: //www.olycopy.com / phone / index.html
3
Исходный вопрос
Какие деньги они используют в Чили?
Состязательный вопрос
Какой мон k y они используют в Чили?
Оригинальный ответ
Чилийское песо
Ответ DrQA
Конвенция МОТ 169
Ответ Google Assistant
Вот и все. Первый результат взят из Википедии: https: // en.m.wikipedia.org/wiki/Arucaria_araucana
Целевые Q&3 роботы %)
DrQA
83,73
78,49
77,26
Google Ассистент
52,47
45.34
46,33
Кроме того, мы используем метрики и [23], MRR [24] и MAP [24], чтобы оценить влияние спорных вопросов на топ- k возможных ответов, возвращенных DrQA. В таблице 3 показана эффективность DrQA, отвечая на исходные и сопряженные вопросы с точки зрения,, MRR и MAP. Обратите внимание, что, поскольку мы используем только те вопросы, на которые DrQA может правильно ответить, чтобы генерировать состязательные вопросы (как описано в Разделе 3.2), оценки DrQA и MRR, отвечающие на исходные вопросы, равны 1. Показано, что оценки этих показателей очень низкие при ответах на состязательные вопросы, что указывает на то, что состязательные вопросы не только влияют на правильный ответ (верхний 1). от DrQA, но также влияет на ответы на первые k кандидатов, возвращенные DrQA. В частности, и баллы показывают, что когда DrQA отвечает на состязательные вопросы, количество правильных ответов в первых k ответах, возвращаемых DrQA, меньше, чем у DrQA при ответах на исходные вопросы.Оценка MRR указывает на то, что в примерах противоборства ранг первого правильного ответа ниже в топ- k возможных ответов, возвращенных DrQA. По сравнению с оценкой MAP DrQA, отвечая на исходные вопросы, оценка MAP DrQA, отвечая на состязательные вопросы, намного ниже, что указывает на то, что сгенерированные состязательные вопросы могут значительно снизить рейтинг всех правильных ответов в топе — k возможных ответов, возвращенных DrQA. .
Вопросы
Набор данных
MRR
MAP
903 903 903 903 903 903 903 903 903
0.583
Куратор TREC
1
1
1
0,587
WikiMovies
1
1
1
3
3 9203
0,208
0,255
0,220
0,094
Куратор TREC
0,287
0,383
0,282
0.073
WikiMovies
0,276
0,356
0,269
0,078
. Оценка MRR DrQA, отвечающего на исходные вопросы, составляет 1.
При практическом использовании роботов вопросов и ответов разные пользователи могут использовать разные выражения для описания одного и того же значения вопроса.Таким образом, мы также оцениваем вероятность успеха создания противостоящих примеров для вопросов с тем же значением, но с разными выражениями. Мы выбираем 50 вопросов, на которые робот вопросов и ответов может правильно ответить, из набора данных WebQuestionsSP. Затем мы перефразируем эти вопросы, реструктурируя эти вопросы и заменяя слова в вопросе синонимами. Смысл повторно сформулированного вопроса соответствует исходному вопросу. Поскольку не на все повторно сформулированные вопросы, на которые робот вопросов и ответов может ответить правильно, бессмысленно генерировать состязательные примеры из тех вопросов, на которые робот вопросов и ответов не может ответить.Поэтому мы отбрасываем повторно сформулированные вопросы, на которые робот вопросов и ответов не может правильно ответить, и отбрасываем соответствующие исходные вопросы. Наконец, для DrQA мы генерируем 257 и 263 состязательных примеров из 41 исходного вопроса и 41 соответствующего повторно сформулированного вопроса соответственно. Для Google Assistant мы генерируем 289 и 277 состязательных примеров из 44 исходных вопросов и 44 соответствующих повторно сформулированных вопросов соответственно. В таблице 4 показана степень успеха состязательных вопросов, сгенерированных из исходных вопросов и из повторно сформулированных вопросов по двум целевым роботам Q&A.Результаты показывают, что вероятность успеха состязательных примеров, созданных с использованием повторно сформулированных вопросов, аналогична показателям состязательных примеров, созданных с использованием исходных вопросов. Следовательно, повторно сформулированные вопросы также могут эффективно генерировать примеры состязательности. В таблице 5 показаны два примера спорных вопросов, которые созданы с использованием исходных вопросов и повторных вопросов, соответственно. Подчеркнутые буквы обозначают разницу между спорным вопросом и исходным или переформулированным вопросом.Показано, что как состязательные вопросы, сгенерированные из исходных вопросов, так и вопросы, созданные из повторно сформулированных вопросов, могут привести к неправильному ответу DrQA и Google Assistant.
Целевой робот вопросов и ответов
Исходные вопросы (%)
Переформулированные вопросы (%)
903 903 903 903 903 903 Ассистент
49.48
48,73
Q1
Первоначальный вопрос
Какая валюта?
Состязательный вопрос
Какая валюта l y есть в Италии?
Исходный ответ
Euro
Ответ DrQA
Эфиопия
Ответ Google Assistant
Википедия дает следующий результат: http: // en.m.wikipedia.org/wiki/Italian_lira
Q1 ′
Повторный вопрос
Какая валюта в Италии?
Состязательный вопрос
Какова валюта Италии л год?
Исходный ответ
Euro
Ответ DrQA
Эфиопия
Ответ Google Assistant
Википедия дает следующий результат: http: // en.m.wikipedia.org/wiki/Italian_lira
Q2
Исходный вопрос
Кто такой Коби Брайант Папа?
Состязательный вопрос
Кто такой kobe bryant da u d?
Исходный ответ
Джо Брайант
Ответ DrQA
Лос-Анджелес Лейкерс
Ответ Google Ассистента
Вот и все: http: // m.youtube.com/watch?v=dYhEB2nfnSg
Q2 ′
Новый вопрос
Кто отец Коби Брайанта?
Состязательный вопрос
Кто такой kobe bryant’s fa lt э?
Исходный ответ
Джо Брайант
Ответ DrQA
Los Angeles Lakers
Ответ Google Assistant
Вот некоторые результаты поиска: некоторые URL…
4.2.2. Оценка человека
В этом разделе мы используем показатель уровень понимания , чтобы оценить понимание различных людей на сгенерированных примерах противоборства. Кроме того, влияние различных настроек максимального расстояния редактирования на скорость понимания людьми представлено в Разделе 4.3. Влияние различных методов модификации ключевых слов на скорость понимания людьми представлено в Разделе 4.4.
Чтобы избежать влияния субъективных факторов человека на результаты оценки, мы приглашаем 10 различных участников оценить качество созданных примеров противоборства и определить, учитываются ли субъективные факторы (т.е., пол, возраст и родной язык) участников влияют на результаты человеческой оценки. В частности, предыстория этих 10 участников выглядит следующим образом: (1) есть 5 участников-мужчин и 5 участников-женщин; (2) 7 участников в возрасте от 18 до 35 лет и 3 участника в возрасте от 36 до 50 лет; и (3) 8 участников, чей родной язык — китайский, и 2 участника, чей родной язык — английский. По сравнению с автоматической оценкой роботов вопросов и ответов с помощью программ и сценариев, человеческая оценка — это трудоемкий процесс для участников и поэтому не подходит для оценки с большим количеством вопросов.Следовательно, в этом эксперименте мы случайным образом выбираем 50 состязательных вопросов, сгенерированных из набора данных WebQuestionsSP, чтобы выполнить оценку человека и вычислить уровень понимания каждого участника.
В таблице 6 показаны минимальный, максимальный и средний уровень понимания учащимися при различных субъективных факторах. Показано, что участники могут понять смысл большинства генерируемых состязательных примеров. Кроме того, при различных субъективных факторах уровень понимания каждого типа участников схож.Другими словами, участники с разным опытом не имеют разницы в понимании созданных спорных вопросов. Следовательно, пол, возраст участников и их родной язык практически не влияют на понимание людьми созданных состязательных вопросов, и люди могут правильно понимать значение созданных состязательных примеров.
Участники
Минимум (%)
Максимум (%)
Среднее (%)
Пол
74 903 Мужчины
74
82
77.2
Женский
70
82
75,2
Возраст
18∼35
72
903 77 3619
72
82
70
76
72,6
Родной язык
Китайский
70
82
75,7
903 903 76
Все участники
70
82
76.2
4.3. Настройки параметров
4.3.1. Различные ограничения POS для похожих слов
В процессе генерации состязательных слов (раздел 3.4) предлагаемый метод использует три ограничения для поиска слов, которые пишутся аналогично ключевому слову. Чтобы убедиться, что второе ограничение может повысить вероятность успеха предложенных состязательных примеров, мы сравниваем вероятность успеха состязательных примеров при следующих трех параметрах: (1) POS-позиция похожего слова такая же, как POS-позиция для данного слова. ключевое слово; (2) POS похожего слова отличается от POS ключевого слова; и (3) нет ограничений на POS аналогичного слова.Мы генерируем состязательные примеры в этих трех разных условиях. Затем эти сгенерированные примеры состязательности применяются к DrQA для расчета вероятности успеха. Результаты сравнения трех различных настроек показаны на рисунке 4. Очевидно, что вероятность успеха состязательных примеров, созданных в настройке 1, выше, чем у примеров противоборства, созданных в настройке 2 и настройке 3. Следовательно, при поиске слов которые пишутся аналогично ключевому слову, сохраняя POS аналогичного слова таким же, как POS ключевого слова, может эффективно повысить вероятность успеха состязательных примеров.
4.3.2. Различное максимальное расстояние редактирования
ϵ
В предлагаемом методе различные настройки максимального расстояния редактирования не только влияют на вероятность успеха сгенерированных состязательных примеров на роботах Q&A, но также влияют на понимание людьми созданных состязательных примеров. В этом разделе, при различных настройках максимального расстояния редактирования, мы оцениваем степень успеха состязательных примеров на роботах вопросов и ответов и оцениваем степень понимания людьми состязательных примеров.Состязательные примеры генерируются из трех наборов данных с разными максимальными расстояниями редактирования, и DrQA используется для оценки успешности этих состязательных примеров.
На рис. 5 представлена вероятность успеха примеров состязательности, созданных при различных настройках максимального расстояния редактирования. Показано, что чем больше максимальное расстояние редактирования, тем выше вероятность успеха состязательных примеров. Причина этого в том, что когда максимальное расстояние редактирования установлено на большое, разница между сомнительным вопросом и исходным вопросом будет большой.Следовательно, вероятность того, что робот Q&A ответит на вопрос правильно, будет мала, и, следовательно, вероятность успеха состязательных примеров будет высокой. Однако большое максимальное расстояние редактирования может затруднить понимание людьми возникающих спорных вопросов.
Мы также приглашаем 10 участников (как указано в разделе 4.2), чтобы оценить влияние максимального расстояния редактирования на скорость понимания людьми. Состязательные вопросы генерируются при максимальном расстоянии редактирования, соответственно.Ибо мы оценили уровень понимания людьми сгенерированных спорных вопросов в разделе 4.2. Для и мы случайным образом выбираем 20 состязательных вопросов, сгенерированных из набора данных WebQuestionsSP для оценки, соответственно (поскольку человеческая оценка — это трудоемкий процесс для участников, он не подходит для оценки с использованием большого количества вопросов). На рисунке 6 показаны минимальный, максимальный и средний уровень понимания людьми созданных состязательных вопросов при максимальном расстоянии редактирования, соответственно.Показано, что чем больше максимальное расстояние редактирования, тем ниже уровень понимания людьми. Следовательно, максимальное расстояние редактирования установлено равным 3 ~ 5, чтобы гарантировать, что сгенерированные состязательные примеры имеют хороший уровень успеха, в то время как у людей нет проблем с пониманием сгенерированных состязательных примеров.
4.4. Оценка извлечения ключевых слов и модификации ключевых слов
В предлагаемом методе извлечение ключевых слов и модификация ключевых слов являются двумя важными этапами создания примеров противоборства.Поэтому мы также оцениваем эффективность предлагаемого метода с этих двух аспектов.
4.4.1. Оценка извлечения ключевых слов
Чтобы оценить производительность предложенного метода извлечения ключевых слов, мы реализуем два других метода извлечения ключевых слов для сравнения. Метод случайного извлечения ключевых слов используется в качестве одной базовой линии, которая случайным образом выбирает одно или несколько слов из вопроса в качестве ключевых слов. Метод извлечения слов содержания используется в качестве еще одного базового показателя, который выбирает все слова содержания из вопроса в качестве ключевых слов.В оценочном эксперименте сначала используются метод случайного извлечения ключевых слов, метод извлечения слов содержания и предложенный метод извлечения ключевых слов для извлечения ключевых слов соответственно. Затем извлеченные ключевые слова удаляются из вопроса, чтобы создать противостоящие примеры. Обратите внимание, что в этом эксперименте мы удалили ключевые слова напрямую, а не заменили их, чтобы оценить важность ключевых слов, созданных этими тремя методами. Эти состязательные примеры генерируются с использованием набора данных WebQuestionsSP.Наконец, сгенерированные примеры состязательности применяются к целевым роботам вопросов и ответов, и рассчитываются коэффициенты успеха.
В таблице 7 представлены показатели успешности примеров противоборства, сгенерированных различными методами извлечения ключевых слов. По сравнению с методом случайного извлечения ключевых слов и методом извлечения слов содержания, предлагаемый метод извлечения ключевых слов имеет более высокий процент успеха в DrQA и Google Assistant. Это указывает на то, что предлагаемый метод извлечения ключевых слов может эффективно извлекать ключевые слова, которые важны в исходном вопросе.Если ключевые слова в вопросе изменятся, DrQA и Google Assistant не смогут ответить на вопрос. Таким образом, предлагаемый метод извлечения ключевых слов может эффективно повысить вероятность успеха сгенерированных сомнительных вопросов. Также показано, что извлечение ключевых слов содержания имеет более высокий процент успеха, чем метод извлечения случайных ключевых слов, что указывает на то, что слова содержания важны, чем служебные слова.
Метод извлечения ключевых слов
Извлечение случайных ключевых слов (%)
Извлечение ключевых слов содержимого (%)
Извлечение предложенных ключевых слов (%)
Dr
41.62
53,91
60,51
Google Ассистент
28,97
30,28
38,44
907 Оценка модификации ключевых слов
При оценке эффективности предложенного метода модификации ключевых слов в качестве базовых используются метод случайной модификации ключевых слов и метод шумных текстов [38]. Во-первых, предложенный алгоритм извлечения ключевых слов используется для извлечения ключевых слов из вопроса.Затем метод случайного изменения ключевых слов, метод шумных текстов и предложенный метод модификации ключевых слов используются для изменения ключевых слов для создания трех различных типов состязательных примеров, соответственно. Метод модификации случайных ключевых слов случайным образом заменяет символы в ключевых словах. Метод зашумленных текстов генерирует состязательные примеры, изменяя слово следующими пятью способами [38]: заменяя одну букву, меняя местами две буквы, рандомизируя порядок букв в слове, кроме первой и последней букв, случайный порядок всех букв и заменяя буквы соседними буквами на клавиатуре.Точно так же эти состязательные примеры генерируются из набора данных WebQuestionsSP. Созданные состязательные примеры применяются к целевым роботам Q&A.
В Таблице 8 представлена степень успешности примеров противоборства, созданных с помощью различных методов модификации ключевых слов. Показано, что состязательные примеры, сгенерированные предложенным методом, имеют более высокую вероятность успеха, чем состязательные примеры, сгенерированные методом случайной модификации ключевых слов. Показатель успеха состязательных примеров, генерируемых методом зашумленных текстов [38], близок к успешности состязательных примеров, генерируемых предлагаемым методом.Обратите внимание, что при нацеливании на Google Assistant, вероятность успеха состязательных примеров, сгенерированных методом зашумленных текстов [38], немного выше, чем у предлагаемого метода. Причина в том, что среднее расстояние редактирования () между примерами противоборства, созданными методом зашумленных текстов, и исходным вопросом больше, чем среднее расстояние редактирования () между примерами противоборства, созданными с помощью предлагаемого метода, и исходным вопросом. Однако большее расстояние редактирования затрудняет понимание людьми значения состязательных примеров.
Метод изменения ключевых слов
Случайное изменение ключевых слов (%)
Метод шумных текстов [38] (%)
Предлагаемое изменение ключевых слов (%)
02
0202 90
DrQA
58,37
77,42
83,73
Google Assistant
39,55
57,23
52,47
на скорость понимания людьми.Для предлагаемого метода модификации ключевых слов мы оценили уровень понимания людьми сгенерированных состязательных вопросов, как описано в разделе 4.2. Для метода случайной модификации ключевых слов и метода шумных текстов [38] мы случайным образом выбираем 20 состязательных вопросов, сгенерированных из набора данных WebQuestionsSP, соответственно, и оцениваем уровень понимания 10 участниками на сгенерированных состязательных вопросах.
На рисунке 7 показаны минимальный, максимальный и средний уровень понимания участниками при различных методах модификации ключевых слов.Показано, что уровень понимания людьми предложенного метода модификации ключевых слов выше, чем уровень понимания людьми других методов модификации ключевых слов. Другими словами, по сравнению с методом случайной модификации ключевых слов и методом шумных текстов [38] людям легче понять смысл состязательных вопросов, генерируемых предлагаемыми методами модификации ключевых слов. В целом, состязательные примеры, созданные с помощью предлагаемого метода, имеют высокий уровень успеха в DrQA и Google Assistant, и люди могут легко понять значение созданных состязательных примеров.
5. Заключение
В этой статье мы предлагаем новый метод создания состязательных примеров для роботов вопросов и ответов, который можно использовать в качестве быстрого и автоматического метода генерации тестовых наборов данных для оценки надежности и безопасности интеллектуальных роботов вопросов и ответов черного цвета. -box сценариев. Предлагаемый метод генерирует состязательные вопросы, слегка изменяя важную часть вопроса, что близко к практическому использованию роботов Q&A, например, опечатки, орфографические ошибки и подобные слова.Эти сгенерированные состязательные вопросы могут успешно заставить робота вопросов и ответов ответить неправильно, в то же время это гарантирует, что разница между созданными состязательными вопросами и исходным вопросом настолько мала, что это не повлияет на понимание вопроса человеком. В эксперименте используются два современных робота для вопросов и ответов, DrQA и Google Assistant (которые в настоящее время считаются двумя ведущими роботами для вопросов и ответов), чтобы оценить степень успеха предлагаемого метода. Экспериментальные результаты показывают, что созданные состязательные примеры имеют высокие показатели успеха в DrQA и Google Assistant.Метрики, MRR и MAP в DrQA дополнительно указывают на то, что сгенерированные примеры состязательности приводят к тому, что DrQA возвращает меньше правильных ответов в ответах-кандидатах на первое место — k и приводит к тому, что правильные ответы занимают более низкую позицию в возвращенных ответах кандидатов наивысшего уровня. пользователя DrQA. Кроме того, результаты оценки на людях показывают, что даже если пол, возраст и родной язык участников различаются, им нетрудно понять полученные примеры состязательности. Это первый метод создания состязательных примеров для интеллектуальных роботов вопросов и ответов, а также первый метод автоматического создания тестовых наборов данных для оценки надежности и безопасности роботов вопросов и ответов.Мы надеемся, что эта статья поможет оценить и повысить надежность интеллектуальных роботов для вопросов и ответов.
Доступность данных
Данные, использованные для подтверждения выводов этого исследования, можно получить у соответствующего автора по запросу.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов в отношении публикации этой статьи.
Благодарности
Работа поддержана Национальным фондом естественных наук Китая (№61602241) и Фонд естественных наук провинции Цзянсу (№ BK20150758).
Мягкое знакомство с моделью «Сумка слов»
Последнее обновление 7 августа 2019 г.
Модель набора слов — это способ представления текстовых данных при моделировании текста с помощью алгоритмов машинного обучения.
Модель набора слов проста для понимания и реализации и зарекомендовала себя с большим успехом в таких задачах, как языковое моделирование и классификация документов.
В этом руководстве вы познакомитесь с моделью набора слов для извлечения признаков при обработке естественного языка.
После прохождения этого руководства вы будете знать:
Что такое модель «мешок слов» и зачем она нужна для представления текста.
Как разработать модель набора документов для набора документов.
Как использовать различные техники для подготовки словарного запаса и оценки слов.
Начните свой проект с моей новой книги «Глубокое обучение для обработки естественного языка», включая пошаговых руководств и файлы исходного кода Python для всех примеров.
Приступим.
Мягкое знакомство с моделью «Сумка со словами» Фотография сделана Do8y, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на 6 частей; их:
Проблема с текстом
Что такое мешок слов?
Пример модели «Сумка со словами»
Управление словарным запасом
Подсчет слов
Ограничения набора слов
Нужна помощь с глубоким обучением текстовых данных?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ ускоренный курс прямо сейчас
Проблема с текстом
Проблема с моделированием текста состоит в том, что он беспорядочный, а такие методы, как алгоритмы машинного обучения, предпочитают четко определенные входные и выходные данные фиксированной длины.
Алгоритмы машинного обучения не могут работать напрямую с необработанным текстом; текст необходимо преобразовать в числа. В частности, векторы чисел.
При языковой обработке векторы x выводятся из текстовых данных, чтобы отразить различные лингвистические свойства текста.
— стр. 65, Методы нейронных сетей в обработке естественного языка, 2017.
Это называется извлечением признаков или кодированием признаков.
Популярный и простой метод извлечения признаков из текстовых данных называется моделью текста с набором слов.
Что такое мешок слов?
Модель набора слов, или сокращенно BoW, — это способ извлечения функций из текста для использования в моделировании, например, с алгоритмами машинного обучения.
Подход очень простой и гибкий, и его можно использовать множеством способов для извлечения функций из документов.
Пакет слов — это представление текста, которое описывает появление слов в документе. Он включает в себя две вещи:
Словарь известных слов.
Мера присутствия известных слов.
Он называется «пакет » слов, потому что любая информация о порядке или структуре слов в документе отбрасывается.Модель заботится только о том, встречаются ли известные слова в документе, а не где в документе.
Очень распространенной процедурой извлечения признаков для предложений и документов является метод словарного запаса (BOW). В этом подходе мы смотрим на гистограмму слов в тексте, то есть рассматриваем каждое количество слов как функцию.
— стр. 69, Методы нейронных сетей в обработке естественного языка, 2017.
Интуиция подсказывает, что документы похожи, если имеют одинаковое содержание.Кроме того, только по содержанию мы можем кое-что узнать о значении документа.
Пакет слов может быть таким простым или сложным, как вам нравится. Сложность возникает как при принятии решения о том, как составить словарь известных слов (или лексем), так и при оценке наличия известных слов.
Мы более подробно рассмотрим обе эти проблемы.
Образец сумки со словами модели
Давайте сделаем «мешок слов» из бетона на рабочем примере.
Шаг 1. Сбор данных
Ниже приводится фрагмент первых нескольких строк текста из книги Чарльза Диккенса «Повесть о двух городах», взятых из проекта Гутенберг.
Это были лучшие времена, это были худшие времена, это был век мудрости, это был век глупости,
Для этого небольшого примера давайте рассматривать каждую строку как отдельный «документ», а 4 строки — как весь наш корпус документов.
Шаг 2: Составьте словарь
Теперь мы можем составить список всех слов в нашем модельном словаре.
Уникальные слова здесь (без учета регистра и пунктуации):
«оно»
«было»
«the»
«лучший»
«из»
«раз»
«худший»
«возраст»
«мудрость»
«глупость»
Это словарь из 10 слов из корпуса, содержащего 24 слова.
Шаг 3. Создайте векторы документа
Следующим шагом будет оценка слов в каждом документе.
Цель состоит в том, чтобы превратить каждый документ с произвольным текстом в вектор, который мы можем использовать в качестве ввода или вывода для модели машинного обучения.
Поскольку мы знаем, что в словаре есть 10 слов, мы можем использовать представление документа фиксированной длины, равное 10, с одной позицией в векторе для оценки каждого слова.
Самый простой метод оценки — отметить наличие слов как логическое значение, 0 — отсутствует, 1 — присутствует.
Используя произвольный порядок слов, перечисленных выше в нашем словаре, мы можем пройти по первому документу (« Это было лучшее из времен ») и преобразовать его в двоичный вектор.
Оценка документа будет выглядеть следующим образом:
«оно» = 1
«было» = 1
«the» = 1
«лучший» = 1
«из» = 1
«раз» = 1
«худший» = 0
«возраст» = 0
«мудрость» = 0
«глупость» = 0
В качестве двоичного вектора это выглядело бы следующим образом:
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
Остальные три документа будут выглядеть следующим образом:
«это был худший из времен» = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
«это был век мудрости» = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
«это был век глупости» = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
«это был худший из времен» = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]
«это был век мудрости» = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]
«это был век глупости» = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1]
Всякий порядок слов номинально отбрасывается, и у нас есть последовательный способ извлечения признаков из любого документа в нашем корпусе, готовый для использования при моделировании.
Новые документы, которые частично совпадают со словарем известных слов, но могут содержать слова за пределами словаря, по-прежнему могут кодироваться, при этом оценивается только вхождение известных слов, а неизвестные слова игнорируются.
Вы можете увидеть, как это может естественно масштабироваться для больших словарей и больших документов.
Управление словарным запасом
По мере увеличения размера словаря увеличивается и векторное представление документов.
В предыдущем примере длина вектора документа равна количеству известных слов.
Вы можете себе представить, что для очень большого корпуса, такого как тысячи книг, длина вектора может составлять тысячи или миллионы позиций. Кроме того, каждый документ может содержать очень мало известных слов в словаре.
В результате получается вектор с множеством нулевых оценок, называемый разреженным вектором или разреженным представлением.
Разреженные векторы требуют больше памяти и вычислительных ресурсов при моделировании, а большое количество позиций или измерений может сделать процесс моделирования очень сложным для традиционных алгоритмов.
Таким образом, существует необходимость уменьшить размер словарного запаса при использовании модели набора слов.
Существуют простые методы очистки текста, которые можно использовать в качестве первого шага, например:
Игнорирующий футляр
Игнорирование знаков препинания
Игнорирование часто используемых слов, не содержащих много информации, называемых стоп-словами, например «а», «из» и т. Д.
Исправление слов с ошибками.
Сокращение слов до их основы (например, «играть» от «играть») с использованием алгоритмов выделения корней.
Более сложный подход — создать словарь сгруппированных слов. Это одновременно изменяет объем словарного запаса и позволяет сумке слов уловить немного больше смысла из документа.
В этом подходе каждое слово или жетон называется «грамм». Создание словаря пар из двух слов, в свою очередь, называется моделью биграмм. Опять же, моделируются только биграммы, которые появляются в корпусе, а не все возможные биграммы.
N-грамм — это последовательность слов из N-токенов: 2-грамм (чаще называемый биграммой) — это последовательность слов из двух слов, например «пожалуйста, переверни», «переверни» или «твое домашнее задание». , а 3-граммовая (чаще называемая триграммой) — это последовательность слов из трех слов, таких как «пожалуйста, переверни свою» или «переверни свою домашнюю работу».
— стр. 85, Обработка речи и языка, 2009.
Например, биграммы в первой строке текста в предыдущем разделе: «Это были лучшие времена»:
«это было»
«был»
«лучший»
«лучшее из»
«времен»
Словарь, который затем отслеживает тройки слов, называется моделью триграммы, а общий подход называется моделью n-грамм, где n означает количество сгруппированных слов.
Часто простой подход с использованием биграмм лучше, чем модель набора слов весом 1 грамм для таких задач, как классификация документации.
представление мешка биграмм намного мощнее мешка слов, и во многих случаях его очень трудно превзойти.
— стр. 75, Методы нейронных сетей в обработке естественного языка, 2017.
Подсчет слов
После выбора словаря необходимо оценить вхождение слов в примерах документов.
В проработанном примере мы уже видели один очень простой подход к подсчету баллов: двоичный подсчет наличия или отсутствия слов.
Некоторые дополнительные простые методы оценки включают:
Считает . Подсчитайте, сколько раз каждое слово встречается в документе.
Частоты . Вычислите частоту появления каждого слова в документе из всех слов в документе.
Хеширование слов
Вы, возможно, помните из информатики, что хеш-функция — это часть математики, которая сопоставляет данные с набором чисел фиксированного размера.
Например, мы используем их в хэш-таблицах при программировании, где, возможно, имена преобразуются в числа для быстрого поиска.
Мы можем использовать хеш-представление известных слов в нашем словаре. Это решает проблему наличия очень большого словарного запаса для большого текстового корпуса, потому что мы можем выбрать размер хэш-пространства, который, в свою очередь, равен размеру векторного представления документа.
слов детерминированно хешируются по тому же целочисленному индексу в целевом хэш-пространстве.Затем для оценки слова можно использовать двоичную оценку или счет.
Это называется «хеш-трюк » или «хеширование функции ».
Задача состоит в том, чтобы выбрать хэш-пространство, соответствующее выбранному размеру словаря, чтобы минимизировать вероятность коллизий и разреженности компромиссов.
TF-IDF
Проблема с оценкой частоты слов заключается в том, что в документе начинают преобладать очень часто встречающиеся слова (например, более высокие оценки), но они могут не содержать столько «информационного содержания» для модели, сколько более редкие, но, возможно, специфические для предметной области слова.
Один из подходов состоит в том, чтобы изменить частоту слов в зависимости от того, как часто они появляются во всех документах, так что баллы за часто встречающиеся слова, такие как «the», которые также часто встречаются во всех документах, сбрасываются.
Такой подход к скорингу называется Term Frequency — Inverse Document Frequency, или сокращенно TF-IDF, где:
Term Frequency : оценка частоты встречаемости слова в текущем документе.
Частота обратного документа : это оценка того, насколько редко слово встречается в документах.
Баллы представляют собой взвешивание, при котором не все слова одинаково важны или интересны.
В баллах выделяются отдельные слова (содержащие полезную информацию) в данном документе.
Таким образом, idf редкого термина будет высоким, тогда как idf частого термина, вероятно, будет низким.
— стр. 118, Введение в поиск информации, 2008 г.
Ограничения мешка слов
Модель набора слов очень проста для понимания и реализации и предлагает большую гибкость для настройки ваших конкретных текстовых данных.
Он с большим успехом использовался в задачах прогнозирования, таких как языковое моделирование и классификация документации.
Тем не менее, он имеет некоторые недостатки, например:
Словарь : Словарь требует тщательного проектирования, особенно для управления размером, что влияет на разреженность представлений документа.
Разреженность : разреженные представления труднее моделировать как по вычислительным причинам (пространственная и временная сложность), так и по информационным причинам, когда модели должны использовать так мало информации в таком большом репрезентативном пространстве.
Значение : при отказе от порядка слов игнорируется контекст и, в свою очередь, значение слов в документе (семантика). Контекст и значение могут многое предложить модели, что при моделировании можно было бы различить одни и те же слова, расположенные по-разному («это интересно» против «это интересно»), синонимы («старый велосипед» против «подержанный велосипед»). , и многое другое.
Дополнительная литература
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
Статьи
Книги
Сводка
В этом руководстве вы открыли для себя модель набора слов для извлечения признаков с текстовыми данными.
В частности, вы выучили:
Что такое модель-мешок слов и зачем она нужна.
Как работать с применением модели набора документов к коллекции документов.
Какие приемы можно использовать для составления словарного запаса и оценки слов.
Есть вопросы? Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте модели глубокого обучения для текстовых данных уже сегодня!
Создавайте собственные текстовые модели за считанные минуты
… всего несколькими строками кода Python
Узнайте, как это сделать, в моей новой электронной книге: Deep Learning for Natural Language Processing
Он предоставляет руководств для самообучения по таким темам, как: Пакет слов, встраивание слов, языковые модели, создание титров, перевод текста и многое другое …
Наконец-то привнесите глубокое обучение в свои проекты по обработке естественного языка
Пропустить академики.Только результаты.
Посмотрите, что внутри
Google улучшает 10 процентов поисковых запросов, понимая языковой контекст
Google в настоящее время вносит изменения в свой основной алгоритм поиска, которые, по его словам, могут изменить ранжирование результатов для каждого десятого запроса. Он основан на передовых методах обработки естественного языка (NLP), разработанных исследователями Google и примененных к его поисковому продукту в течение последних 10 месяцев.
По сути, Google утверждает, что улучшает результаты за счет лучшего понимания того, как слова соотносятся друг с другом в предложении.В одном примере, который Google обсуждал вчера на брифинге с журналистами, его алгоритм поиска смог разобрать значение следующей фразы: «Можно ли получить лекарство для кого-то в аптеке?»
Старый алгоритм поиска Google рассматривал это предложение как «набор слов», по словам Панду Наяка, сотрудника Google и вице-президента по поиску. Таким образом, он посмотрел на важные слова, медицина и аптека, и просто вернул местные результаты. Новый алгоритм смог понять контекст слов «для кого-то», чтобы понять, что это был вопрос о том, можете ли вы подобрать чей-то рецепт, — и он дал верные результаты.
Раньше Google рассматривал запросы как «набор слов»
Измененный алгоритм основан на BERT, что означает «двунаправленные представления кодировщика от трансформаторов». Каждое слово этого акронима является художественным термином в НЛП, но суть в том, что вместо того, чтобы рассматривать предложение как мешок слов, BERT рассматривает все слова в предложении в целом. Это позволяет ему понять, что слова «для кого-то» не следует отбрасывать, они важны для смысла предложения.
Способ, которым BERT понимает, что он должен обращать внимание на эти слова, основан на самообучении в титанической игре Mad Libs. Google берет корпус английских предложений и случайным образом удаляет 15 процентов слов, после чего BERT ставится задача выяснить, какими должны быть эти слова. По словам Джеффа Дина, старшего научного сотрудника Google и старшего вице-президента по исследованиям, со временем такой вид обучения оказывается чрезвычайно эффективным для того, чтобы заставить модель НЛП «понимать» контекст.
Другой пример, который привел Google, — это «парковка на холме без бордюра.Слово «нет» имеет важное значение для этого запроса, и до внедрения BERT в поисковые алгоритмы Google его упускали.
Кредит: Google
Google заявляет, что последние пару дней внедряет изменение алгоритма и, опять же, это должно повлиять на около 10 процентов поисковых запросов, сделанных на английском языке в США. Другие языки и страны будут рассмотрены позже.
Все изменения в поиске проходят серию тестов, чтобы убедиться, что они действительно улучшают результаты.Один из таких тестов предполагает использование группы экспертов Google, которые тренируют алгоритмы компании, оценивая качество результатов поиска. Google также проводит живые A / B-тесты в реальном времени.
Не каждый запрос будет затронут BERT, это просто последний из множества различных инструментов, которые Google использует для ранжирования результатов поиска. Как именно все это работает вместе, остается загадкой. Некоторые из этих процессов намеренно скрыты Google, чтобы спамеры не играли в его системы. Но это также загадочно по другой важной причине: когда компьютер использует методы машинного обучения для принятия решения, может быть трудно понять, почему он сделал этот выбор.
BERT может повлиять на 10% всех поисковых запросов в Google
Этот так называемый «черный ящик» машинного обучения представляет собой проблему, потому что, если результаты каким-то образом неверны, может быть трудно диагностировать причину. Google заявляет, что он работал над тем, чтобы добавление BERT к его поисковому алгоритму не увеличивало предвзятость — распространенная проблема с машинным обучением, модели обучения которого сами по себе предвзяты. Поскольку BERT обучен огромному корпусу предложений на английском языке, которые также по своей природе предвзяты, за этой проблемой нужно следить.
Компания также заявляет, что не ожидает значительных изменений в том, сколько или куда ее алгоритм будет направлять трафик, по крайней мере, когда речь идет о крупных издателях. Каждый раз, когда Google сигнализирует об изменении своего алгоритма поиска, вся сеть замечает это. Компании жили и умирали из-за изменений в поисковом рейтинге Google.
Обязательно обратите внимание на всех, кто зарабатывает деньги на веб-трафике. Что касается качества результатов поиска, Payak говорит, что «это самый крупный из них…. самое позитивное изменение, которое у нас было за последние пять лет, и, возможно, одно из самых значительных с самого начала ».
Шаблоны резюме из 7 Word (и как их использовать)
Вы, вероятно, знакомы с ужасом, когда вы смотрите на пустой документ и видите мигающий курсор, который только и ждет, когда вы начнете писать, независимо от того, думаете ли вы о давно ушедшей школе задания или тот отчет, который вы должны были отправить вчера своему боссу. А когда дело доходит до вашего резюме — документа, который стоит между вами и вашей следующей работой, — ставки могут казаться особенно высокими.
Хорошая новость в том, что вам не нужно начинать с нуля, когда вы пишете резюме. Существует множество шаблонов резюме, которые вы можете использовать. А поскольку начало работы с шаблоном избавляет от множества решений о форматировании и расстановке интервалов, вы можете сосредоточиться на содержании своего резюме, так что вы можете начать работу и получить работу.
Плохая новость заключается в том, что очень быстро ваша первая проблема (пустой документ) становится совершенно новой проблемой: как вообще выбрать правильный шаблон ?
Начать с Microsoft Word — разумный ход.По словам Аманды Августин, карьерного эксперта и составителя резюме TopResume, файлы с расширением «.docx» являются наиболее безопасными для отправки в систему отслеживания кандидатов (ATS), программное обеспечение, которое компании используют для организации и анализа приложений и выявления наиболее многообещающие кандидаты на данную роль (часто до того, как человек когда-либо будет задействован). Поскольку .docx — это формат, совместимый со всеми системами, а некоторые системы по-прежнему не могут правильно анализировать .pdf и другие форматы, вам может быть выгодно работать в Word.
Вот все, что вам нужно знать о поиске, выборе и использовании шаблонов резюме Microsoft Word, а также несколько примеров шаблонов, которые вы можете использовать бесплатно (или дешево!).
Как найти шаблоны резюме Word
Вы можете найти бесплатные шаблоны резюме Word прямо в программе — в последних версиях, щелкнув «Файл»> «Создать из шаблона» и прокрутив или выполнив поиск по запросу «резюме». Здесь вы также можете искать шаблоны резюме, предлагаемые Microsoft Office, в Интернете.
Если вам нужен шаблон Word, но не обязательно тот, который поступает непосредственно из библиотеки Microsoft, вы можете обратиться к Jobscan, Hloom и другим источникам за бесплатными шаблонами или заплатить за один на таких сайтах, как Etsy. Некоторые карьерные коучи также предлагают оригинальные шаблоны на своих веб-сайтах (например, здесь вы можете найти шаблоны карьерного коуча Muse Йены Вивиано).
Как правильно выбрать шаблон резюме в Word
Когда вы впервые начинаете поиск шаблона, количество вариантов может показаться огромным.Как узнать, какой выбрать?
Самая важная вещь, о которой нужно помнить, заключается в следующем: просто потому, что шаблон находится в библиотеке Microsoft или доступен в Интернете, это не означает, что это хороший шаблон , который поможет вашему резюме пройти через ATS и понравится рекрутерам. и менеджеры по найму. «Часто они разрабатываются, потому что выглядят действительно круто и красиво, и они вам нравятся», — говорит Августин.
Но не все шаблоны одинаковы, предупреждает Джон Шилдс, менеджер по маркетингу Jobscan.«Некоторые из них довольно хороши, а некоторые очень плохи». Вот несколько советов, которые помогут вам понять разницу:
1. Выберите макет, который вам подходит.
Резюме, как и работа, подходят так же, как и все остальное. Итак, помимо хорошего и плохого, вы ищете шаблон, который имеет смысл для того, кто вы есть и каковы ваши цели.
Ваш первый шаг — выбрать общий формат резюме — хронологический, комбинированный (также называемый гибридным) или функциональный. (Если вы не знаете, какой из них вам подходит, ознакомьтесь с нашим руководством по выбору здесь.)
Хронологический и комбинированный форматы хорошо подходят для ATS, а также для рекрутеров и менеджеров по найму, но будьте осторожны с функциональным резюме. Помимо отключения ATS, который обычно не запрограммирован на анализ вашей информации в таком порядке, функциональные резюме «действительно ненавидят рекрутеры и менеджеры по найму», — говорит Шилдс, потому что они «затрудняют понимание вашей карьерной траектории и того, где вы развил свои навыки ».
Вам также следует хорошо подумать о том, что вы можете поместить «над сгибом», или в верхней трети или половине документа.Люди склонны сосредотачивать на нем больше внимания, поэтому «это должен быть моментальный снимок всего, что им действительно нужно знать о вас», — говорит Августин. Спросите себя, говорит она: «Что наиболее важно в вашем прошлом, что применимо к текущей работе?»
Если вы, например, еще учитесь в школе или недавно закончили школу, вам может потребоваться шаблон, в котором вы можете поставить свое образование на первое место, или вы можете выбрать тот, который позволит вам подчеркнуть свою отличную стажировку прошлым летом. С другой стороны, если у вас есть большой опыт, вам может понадобиться шаблон, который позволит вам начать с резюме резюме или раздела с указанием ключевых достижений.А если вы работаете в технической сфере, вы можете разместить вверху раздел навыков, чтобы выделить программное обеспечение, которое вы использовали, или языки, на которых вы кодируете.
Хотя может быть проще найти шаблон, который уже настроен с точные разделы, которые вы хотите, в точных местах, которые вы хотите, помните, что вы также можете настроить любой шаблон в соответствии с вашими потребностями.
Если вам не сразу понятно, в каком направлении двигаться, ничего страшного! Шилдс рекомендует попробовать несколько разных шаблонов и посмотреть, какой из них лучше всего отражает ваш опыт.
2. Убедитесь, что места достаточно
В некоторых случаях шаблон «выглядит действительно красиво, но на самом деле не дает места, которое вам нужно, чтобы должным образом уделить вашему предыдущему опыту должное внимание», — говорит Августин. Конечно, вы должны быть краткими, но вы также хотите, чтобы у вас было место для включения самых важных моментов, не уменьшая шрифт до неразборчивого размера.
В то же время вы хотите выбрать чистый шаблон с или пустым пространством, — говорит Вивиано.Вы же не хотите, чтобы резюме было слишком «забитым словами».
3. Не слишком навороченный
Хотя вас могут привлечь яркие и необычные шаблоны резюме, на самом деле лучше выбрать простой и относительно консервативный дизайн — даже в творческих сферах. Хотя немного цвета может быть отличным способом выделить ваше резюме, например, вы, вероятно, не захотите выбирать шаблон, который кричит и кричит 17 разными полужирными цветами. Вы также захотите использовать только один или два шрифта.
И держитесь подальше от пузырей, звездочек, гистограмм и других бессмысленных способов измерения вашего мастерства в различных навыках. «Если не используется стандартная система выставления оценок или оценок, это просто кажется субъективным», — говорит Августин. «На самом деле это не помогает читателю по-настоящему понять вашу компетенцию».
Самое главное, избегайте шаблонов, которые слишком креативны в том, где вы помещаете важную информацию и как вы ее представляете. И ATS, и любые люди, просматривающие ваше приложение, «хотят, чтобы резюме были очень четкими и легко интерпретируемыми, чтобы не было путаницы в отношении того, где находится ключевая информация и что означает каждый раздел», — говорит Шилдс.
Это означает соблюдение условностей. «Во многих случаях простое лучше», — говорит Августин. «Помимо ATS, рекрутеры привыкли искать информацию в определенных областях, и если вы решите пойти на мошенничество и начать размещать вещи в разных местах, это не обязательно будет означать:« О, этот рекрутер потратит дополнительное время, глядя на мое резюме для этой информации », — говорит она. «Они будут быстро смотреть, не видя того, что им нужно, и переходить к следующему».
4.Остерегайтесь блокаторов ATS
ATS часто выполняет роль привратника для кадровых агентств или менеджеров по найму, выполняя первую проверку заявок. Как только система определит наиболее перспективных клиентов на основе ключевых слов и других сигналов, которые она запрограммировала улавливать, человек может не выйти за пределы этой кучи. Итак, вы должны остерегаться красных флажков, которые могут помешать вашему резюме преодолеть первое препятствие. Обратите внимание на:
Верхние и нижние колонтитулы: Вы никогда не захотите помещать какую-либо информацию в фактические разделы верхнего и нижнего колонтитула вашего документа Word, говорит Августин, потому что он не всегда правильно (или вообще) анализируется АТС.
Заголовки разделов: Убедитесь, что вы помечаете разделы четко и просто, независимо от того, что было в исходном шаблоне. «Если вы выйдете слишком нестандартно, те алгоритмы синтаксического анализа, которые помещают эту информацию в цифровой профиль заявителя, начинают сбиваться с толку», — говорит Шилдс. Если система запрограммирована на поиск раздела под названием «Опыт работы» или «Профессиональный опыт» и другого раздела под названием «Образование», ATS может не распознать какие-либо неортодоксальные ярлыки, которые вы использовали, и не будет знать, что с ними делать. информация под ними.
Изображений и графиков: ATS в основном игнорирует любые изображения, говорит Августин, поэтому вам лучше избегать их использования, особенно в качестве причудливого способа указать свое имя или любую другую важную информацию.
Текстовые поля: Несмотря на то, что вы вводите слова в текстовое поле, он «считается объектом, поэтому не может быть проанализирован должным образом», — говорит Августин.
Гиперссылки: Если вы добавите ссылку к строке слов в одном из пунктов маркированного списка, есть вероятность, что ATS проанализирует только URL и проигнорирует фактические слова, объясняет Августин.Поэтому убедитесь, что гиперссылка идет от «(ссылка)» или «(веб-сайт)», а не от такого важного текста, как «увеличился на 25%» или «принесет доход в 5 миллионов долларов».
Столбцы: «Многие ATS с трудом анализируют текст бок о бок», — говорит Шилдс. «Он будет читать слева направо независимо от разделителей столбцов, объединяя содержимое двух несвязанных разделов». Это еще одна причина склоняться к «более классическим резюме, в котором нет таблиц и столбцов», — говорит он. По словам Августина, хотя некоторые системы могут читать некоторые столбцы, безопаснее держаться подальше.
Шрифты: Найдите шаблон, в котором используется относительно распространенный шрифт. Мало того, что люди оценят чистый, ясный шрифт, ATS не всегда может прочитать нестандартные или непонятные шрифты. Августин говорит, что могут работать как шрифты с засечками, так и без засечек, а безопасные шрифты включают (но не ограничиваются ими): Calibri, Arial, Trebuchet, Book Antiqua, Garamond, Cambria и Times New Roman.
Frames: Помещение рамки или рамки по всему периметру вашего резюме — это «большое ATS нет-нет», — говорит Августин.
Конечно, вы всегда можете внести изменения в существующий шаблон. Так что, если есть рамка, вы можете просто удалить ее. Если место для вашего имени находится в заголовке, вы можете переместить его в основной текст. Или, если шрифт нечеткий, вы можете изменить его на более распространенный.
Другими словами, вам не нужно сразу отклонять шаблон, потому что он содержит один из этих элементов. Но вы, возможно, захотите избежать шаблона, в котором так много блокировщиков ATS, что вам придется выполнять гимнастику форматирования, чтобы довести его до приемлемого базового уровня.
5. Избегайте шаблонов резюме с фотографиями
Шилдс заметил, что веб-сайты с шаблонами имеют тенденцию к использованию фото резюме, которые распространены во многих странах по всему миру. Однако, по словам Шилдса, соискателям работы в США следует избегать снимков в голову, как для ATS, так и для людей, которые могут рассмотреть ваше заявление.
С технической точки зрения, ATS не сможет проанализировать изображение, поэтому в лучшем случае оно просто упадет, когда система создаст ваш цифровой профиль.Но более тревожным является сценарий, в котором изображение вызывает проблемы с форматированием или ошибки синтаксического анализа, которые могут повлиять на то, как система читает остальную часть вашего резюме.
И помимо ATS, «мы из первых уст слышали от многих рекрутеров, которые даже не проверяют кандидатов, приславших фотографии», — говорит Шилдс. «Они просто не могут сделать себя более уязвимыми перед любыми возможными жалобами на дискриминацию». И вы также не хотите подвергаться действительной дискриминации.
Суть в том, говорит Вивиано, что, если вы не модель или актер, ваше фото не должно быть в вашем резюме. По сути, вы «занимает много места в своем резюме [чем-то], что не должно иметь никакого отношения к тому, кто вас нанимает».
Как использовать шаблон для создания резюме в Word
Итак, вы нашли один или два шаблона, которые вам действительно нравятся, и готовы сесть и составить свое резюме. Что теперь?
1. Соберите всю свою информацию
«Прежде чем вы начнете, найдите время, чтобы собрать всю информацию, которая могла бы быть использована для написания вашего резюме», — говорит Августин.
Если у вас есть предыдущее резюме, над которым вы работаете, убедитесь, что оно у вас под рукой. Вы также можете сесть и создать документ, включающий каждую прошлую работу, навыки и достижения, которые вы можете использовать в качестве источника для рисования. Или вы можете заполнить этот рабочий лист. Когда у вас будет весь контент, его будет проще легко вставить в шаблон.
2. Не бойтесь изменять шаблон
Шаблоны не высечены из камня. Помните, что вы можете и должны вносить изменения по мере необходимости, чтобы шаблон работал на вас.
Для начала вы по-прежнему увидите множество шаблонов, которые по-прежнему включают разделы для утверждения цели или для ваших ссылок, даже если оба являются устаревшими элементами, которым больше не место в вашем резюме.
Это нормально, если вы настроены на шаблон, в котором есть эти разделы, но убедитесь, что вы удалили их или преобразовали. Раздел с целью может легко стать местом для резюме резюме, например, или использоваться для перечисления ваших ключевых навыков, в то время как раздел ссылок может превратиться в раздел волонтерства или наград.
Помимо избавления от устаревших разделов, вы можете внести любые изменения, которые, по вашему мнению, помогут вам представить лучшую версию себя для этой роли. «Шаблон резюме может служить отличным руководством, но иногда он принесет больше вреда, чем пользы, если вы измените свой опыт в соответствии с шаблоном, а не наоборот», — говорит Шилдс. «Поэтому, если у вас нет ничего для определенного раздела в шаблоне, удалите его. Если вы хотите добавить дополнительную информацию, которая, по вашему мнению, укрепляет вашу позицию, добавьте ее », — говорит он.«Просто будьте осторожны, сохраняйте единообразное форматирование и сосредоточьтесь на удобочитаемости».
Предположим, вы нашли понравившийся вам шаблон, который поможет вам в работе, но вы действительно хотите выделить свои ключевые навыки в верхней части. Не стесняйтесь добавить еще один раздел, используя тот же шрифт и стиль заголовка. С другой стороны, если вы используете шаблон, в котором есть раздел наград и благодарностей, но вы бы предпочли продемонстрировать свой волонтерский опыт или дополнительные навыки, измените его.
Помните также, что шаблон — это просто шаблон.«Это дает вам основу для работы», — говорит Августин, но вам все равно придется приложить усилия, чтобы решить, какие достижения и навыки следует выделить и как лучше всего сформулировать свои маркеры.
3. Вставьте или впишите вашу информацию
Когда вы, наконец, будете готовы поместить весь свой опыт работы и достижения в шаблон и сделать его своим, Вивиано рекомендует вам «сначала завершить простые вещи», например, ваше имя контактная информация и ваше образование.«Это будет похоже на быструю победу». Затем продолжайте заполнять остальные.
Облегчите себе жизнь позже, вставив информацию только в виде текста — без форматирования, которое было в предыдущем резюме, подготовительном документе или заполненном вами рабочем листе. Используйте этот трюк с копированием и вставкой, чтобы убедиться, что все, что вы туда помещаете, соответствует форматированию шаблона. В противном случае вы можете «потратить нелепое количество времени, пытаясь снова установить правильный интервал», — говорит Августин.
Наконец, убедитесь, что вы заменили или удалили весь фиктивный текст и все инструкции, которые были в шаблоне, когда вы его получили!
4.Проверьте, как это будет в ATS
Если вы хотите проверить, как ваше новое резюме будет выдерживать, когда оно пройдет через ATS, вы можете попробовать одно из двух:
Скопируйте все в свой документ Word и вставьте все это в простой текстовый документ. «Если некоторые вещи превращаются в странных персонажей, — говорит Августин, — если разделы находятся далеко от того места, где они должны быть, или если все не в порядке, то это, вероятно, произойдет, если они будут проанализированы».
Запустите его с помощью онлайн-инструмента, такого как Jobscan, или запросите бесплатную критику в такой службе, как TopResume.
5. Перечитайте и подтвердите!
По словам Августина, опечатки и орфографические ошибки часто мешают рекрутерам. И было бы обидно попасть в кучу «нет» из-за мелких ошибок. Поэтому убедитесь, что вы исправили свое резюме — может быть, дважды, а может быть, отойдя от него на несколько часов — и посмотрите, сможете ли вы передать его другу или члену семьи, чтобы он взглянул свежим взглядом.
Перечитывание вашего резюме как полного документа — это также возможность представить себе первое впечатление, которое вы произведете.«Многие люди … так увлеклись редактированием резюме и тем, чтобы оно было настолько оптимизировано, что оно стало резюме, похожим на робота», — говорит Вивиано. Итак, пока вы читаете, подумайте: это звучит так, как будто это написал человек? Какую историю ты рассказываешь? Очевидно ли, что вы подходите для той должности, на которую претендуете?
7 шаблонов Microsoft Word для использования в качестве отправных точек
Все еще не можете выбрать шаблон после всего этого? Вот несколько из них, которые могут сработать — мы добавили советы по улучшению и настройке каждого из них.
1. Резюме Genius’s Dublin Template
Кто может его использовать? Всем, кто ищет традиционное хронологическое резюме!
Предостережения:
Вам не нужно указывать полный адрес (достаточно указать город и штат).
Добавьте свой профиль LinkedIn вместе с другой контактной информацией, чтобы рекрутер или менеджер по найму мог перейти на вашу страницу и найти дополнительную информацию о вашем опыте, увидеть яркие рекомендации, которые вы получили, просмотреть образцы работы, которые вы разместили, и получить в восторге от вас как кандидата.(Просто убедитесь, что ваш профиль обновлен!)
Не указывайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Загрузите здесь.
2. Недавний шаблон JobScan Grad 1
Кто может его использовать? Недавний выпускник, имеющий стажировку или опыт работы, соответствующий их целевой области или должности, а также другой опыт.
Предостережения:
Вам не нужно указывать свой почтовый индекс.
Не включайте свой средний балл, если вы не недавний выпускник, и он впечатляет.
Стоимость: Бесплатно
Загрузите здесь.
3. Базовый шаблон резюме Microsoft Office
Кто может его использовать? Недавний выпускник, у которого нет большого опыта работы.
Предостережения:
Поместите свое имя в одну строку (вместо двух строк, как по умолчанию), чтобы ATS записал ваше полное имя.
Попробуйте различать заголовки разделов в каждой записи о вакансии и образовании, изменив размер или стиль шрифта.
Добавьте свой профиль LinkedIn рядом со своей контактной информацией и помните, что вам не нужно указывать полный адрес (достаточно указать город и штат).
Стоимость: Бесплатно
Найдите в Microsoft Word.
4. Шаблон резюме Get Landed для ATS
Кто может его использовать? Кто-то ищет шаблон, который можно было бы легко настроить как хронологическое или комбинированное резюме, в зависимости от того, где вы разместили этот раздел навыков.
 Организационный момент. Mотивация к учебной деятельности
Организационный момент. Mотивация к учебной деятельности Словесный
Словесный Организует работу по учебнику. Предлагает выписать группы однокоренных слов в 3 столбика на ИД, разобрать их по составу.
Организует работу по учебнику. Предлагает выписать группы однокоренных слов в 3 столбика на ИД, разобрать их по составу.




 Вот и ..летели они к жилью людей. Ребята ..весили для пернатых кормушки. Они ..готовили для птиц корм.
Вот и ..летели они к жилью людей. Ребята ..весили для пернатых кормушки. Они ..готовили для птиц корм.
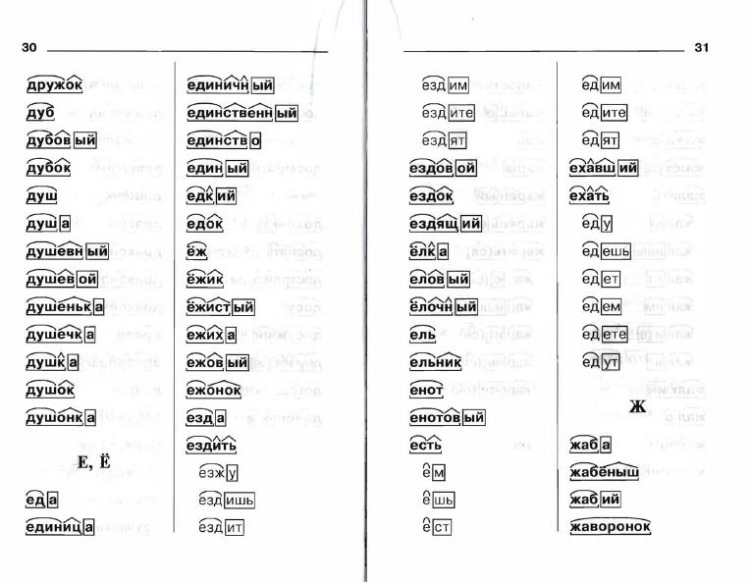 Learn more about Facebook’s Nemo.
Learn more about Facebook’s Nemo.
 Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.

 Applicative ((<*))
Контроль импорта.Монада
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
Applicative ((<*))
Контроль импорта.Монада
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
 Applicative ((<*))
Контроль импорта.Монада
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
Applicative ((<*))
Контроль импорта.Монада
импортировать Text.ParserCombinators.Parsec
убедитесь, что p x = guard (p x) >> return x
singleToken t = tokenPrim id (\ pos _ _ -> incSourceColumn pos 1) (убедитесь (== t))
anyOf xs = выбор (карта singleToken xs)
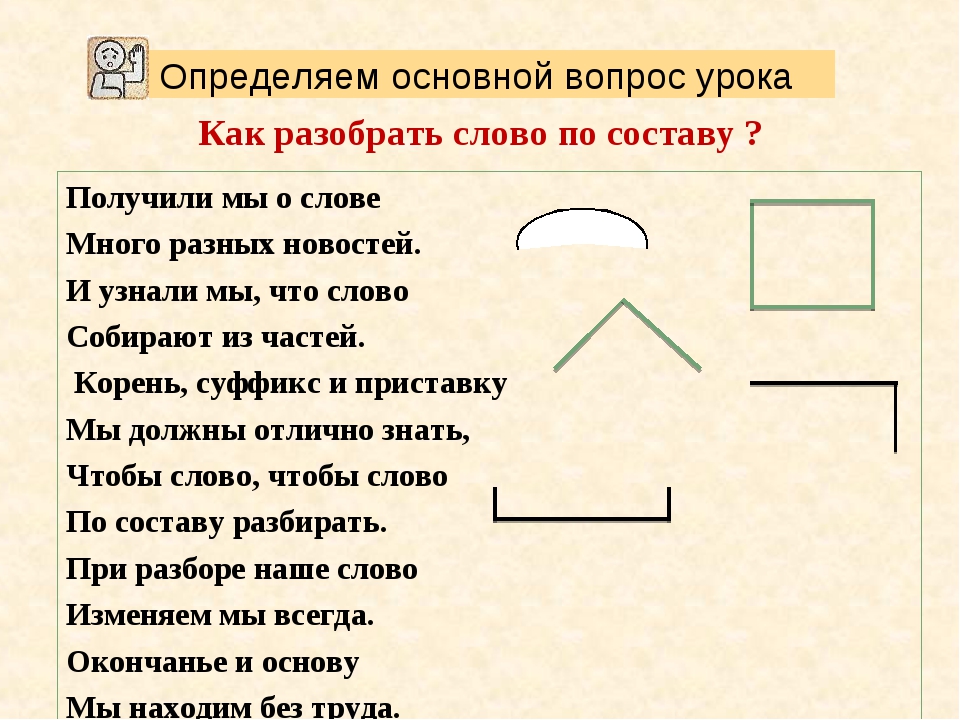 Для этого простого приложения мы просто разметим на основе пробелов, поэтому встроенная функция
Для этого простого приложения мы просто разметим на основе пробелов, поэтому встроенная функция 