Слова «повышение» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «повышение» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «повышение» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «повышение».
Содержимое:
- 1 Слоги в слове «повышение» деление на слоги
- 2 Как перенести слово «повышение»
- 3 Морфологический разбор слова «повышение»
- 4 Разбор слова «повышение» по составу
- 5 Сходные по морфемному строению слова «повышение»
- 6 Синонимы слова «повышение»
- 7 Антонимы слова «повышение»
- 8 Ударение в слове «повышение»
- 9 Фонетическая транскрипция слова «повышение»
- 10 Фонетический разбор слова «повышение» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «повышение»
- 12 Сочетаемость слова «повышение»
- 13 Значение слова «повышение»
- 14 Склонение слова «повышение» по подежам
- 15 Как правильно пишется слово «повышение»
- 16 Ассоциации к слову «повышение»
Слоги в слове «повышение» деление на слоги
Количество слогов: 5
По слогам: по-вы-ше-ни-е
Как перенести слово «повышение»
по—вышение
повы—шение
повыше—ние
Морфологический разбор слова «повышение»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: средний;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
повышение
Разбор слова «повышение» по составу
| по | приставка |
| выш | корень |
| ени | суффикс |
| е | окончание |
повышение
Сходные по морфемному строению слова «повышение»
Сходные по морфемному строению слова
Синонимы слова «повышение»
1. увеличение
увеличение
2. усиление
3. пупинизация
4. ревалоризация
5. ревальвация
6. вздувание
7. выдвижение
8. наращивание
9. нарастание
10. наращение
11. увеличивание
12. поднятие
13. умножение
14. рост
15. возрастание
16. улучшение
17. усовершенствование
18. продвижение
19. овербот
20. подскакивание
21. пригорок
22. увал
23. угор
24. холм
25. горка
26. высота
27. возвышенность
28. бугор
29. возвышение
30. курган
31. нагорье
32. взлобок
33. взгорок
34. взгорье
35. высотка
36. накручивание
37. взвинчивание
38. работа
39. валоризация
Антонимы слова «повышение»
1. регресс
2. понижение
3. снижение
4. спад
5. сужение
6. уменьшение
Ударение в слове «повышение»
повыше́ние — ударение падает на 3-й слог
Фонетическая транскрипция слова «повышение»
[павыш`эн’ий’э]
Фонетический разбор слова «повышение» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| п | [п] | согласный, глухой парный, твёрдый, шумный | п |
| о | [а] | гласный, безударный | о |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| ы | [ы] | гласный, безударный | ы |
| ш | [ш] | согласный, глухой парный, твёрдый, шипящий, шумный | ш |
| е | [`э] | гласный, ударный | е |
| н | [н’] | согласный, звонкий непарный (сонорный), мягкий | н |
| и | [и] | гласный, безударный | и |
| е | [й’] | согласный, звонкий непарный (сонорный), мягкий | е |
| [э] | гласный, безударный |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 9 букв и 10 звуков.
Буквы: 5 гласных букв, 4 согласных букв.
Звуки: 5 гласных звуков, 5 согласных звуков.
Предложения со словом «повышение»
Крупы с низким индексом гликемии вызывают повышение уровня сахара в крови от небольшого до умеренного.
Источник: И. А. Михайлова, Книга о вкусной и здоровой пище. Лучшие рецепты, 2013.
Отмечаются повышение температуры, увеличение числа лейкоцитов в крови, СОЭ.
Источник: Аурика Луковкина, Атеросклероз, 2013.
При отсутствии увеличения объёма спроса на продукцию отдельных отраслей повышение экономической эффективности возможно при развитии без роста.
Источник: И. В. Васильева, Совершенствование эффективности деятельности малых форм хозяйствования как важная часть реализации стратегии развития АПК России, 2015.
Сочетаемость слова «повышение»
1. очередное повышение
2. новое повышение
3. долгожданное повышение
4. повышение квалификации
5. повышение уровня
6. повышение эффективности
7. курсы повышения квалификации
8. с целью повышения
9. в сторону повышения
10. получить повышение
11. пойти на повышение
12. добиться повышения
13. (полная таблица сочетаемости)
Значение слова «повышение»
ПОВЫШЕ́НИЕ , -я, ср. 1. Действие по знач. глаг. повысить—повышать; действие и состояние по знач. глаг. повыситься—повышаться. Повышение урожайности. Повышение зарплаты. Повышение роли первичных партийных организаций. (Малый академический словарь, МАС)
Склонение слова «повышение» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
ИменительныйИм.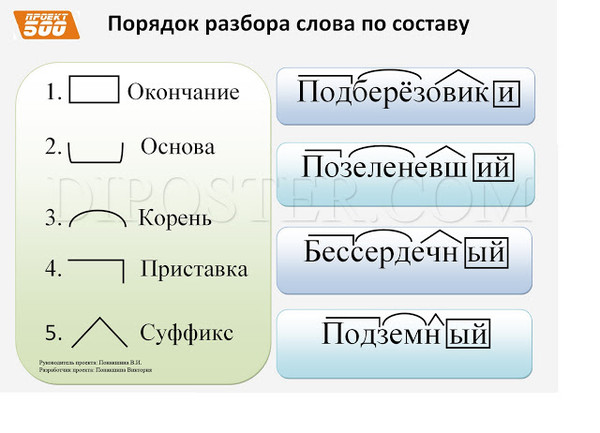 | что? | повышение, повышенье | повышения, повышенья |
| РодительныйРод. | чего? | повышения, повышенья | повышений |
| ДательныйДат. | чему? | повышению, повышенью | повышениям, повышеньям |
| ВинительныйВин. | что? | повышение, повышенье | повышения, повышенья |
| ТворительныйТв. | чем? | повышением, повышеньем | повышениями, повышеньями |
| ПредложныйПред. | о чём? | повышенье, повышении, повышеньи | повышениях, повышеньях |
Как правильно пишется слово «повышение»
Орфография слова «повышение»Правильно слово пишется: повышение
Нумерация букв в слове
Номера букв в слове «повышение» в прямом и обратном порядке:
- 9
п
1 - 8
о
2 - 7
в
3 - 6
ы
4 - 5
ш
5 - 4
е
6 - 3
н
7 - 2
и
8 - 1
е
9
Ассоциации к слову «повышение»
Квалификация
Понижение
Эффективность
Производительность
Снижение
Совершенствование
Тариф
Благосостояние
Улучшение
Увеличение
Уменьшение
Температура
Зарплата
Внедрение
Устойчивость
Концентрация
Модернизация
Оклад
Активность
Престиж
Плат
Сокращение
Усиление
Давление
Рвота
Занятость
Уровень
Чувствительность
Расширение
Поощрение
Энергетик
Смертность
Продукция
Жалованье
Пошлина
Забастовка
Чина
Интенсивность
Функционирование
Выработка
Инвестиция
Потребление
Регулирование
Обеспечение
Чин
Недостаточность
Цена
Привлечение
Стабильность
Реализация
Плазма
Спрос
Азот
Коэффициент
Потенциал
Выплата
Профилактика
Усовершенствование
Тенденция
Аспирантура
Оплата
Вуз
Семинар
Мероприятие
Отрасль
Стимул
Предотвращение
Электроэнергия
Потребитель
Льгота
Способствовать
Повышаться
Стимулировать
Достигаться
Обеспечиваться
Сопровождаться
Содействовать
Русско-английский словарь, перевод на английский язык
wordmap
Русско-английский словарь — показательная эрудиция
Русско-английский словарь — прерогатива воспользоваться вариативным функционалом, насчитывающим несколько сотен тысяч уникальных английских слов.
Русско-английский словарь — автоматизированная система, которая отображает результаты поиска по релевантности. Нужный перевод на английский будет в верхней части списка: альтернативные слова указываются в порядке частоты их применения носителями языка. При нажатии на запрос откроется страница с выборкой фраз: система отобразит примеры использования искомого слова.
Русско-английский словарь содержит строку для поиска, где указывается запрос, а после запускается непосредственный поиск. Система может «предлагать» пользователю примеры по использованию слова: «здравствуйте» на английском языке, «хризантема» на английском языке. Дополнительные опции системы — отображение частей речи (будет выделена соответствующим цветом). В WordMap русско-английский словарь характеризуется наличием функции фильтрации запросов, что позволит «отсеять» ненужные словосочетания.
Применение сервиса и достоинства
Перевод на английский язык с сервисом WordMap — возможность улучшить словарный запас учащегося. Дополнительные преимущества в эксплуатации WordMap:
- Слова с различным значением, которые оптимизированы под любой уровень владения английским языком;
- Русско-английский словарь содержит примеры, позволяющие усовершенствовать практические навыки разговорного английского;
- В списке результатов указаны всевозможные синонимы и паронимы, которые распространены в сложном английском языке.
Онлайн-сервис WordMap предлагает пространство для совершенствования интеллектуальных способностей, способствует результативной подготовке к сдаче экзамена. Быстрый перевод на английский может быть использован с игровой целью: посоревноваться с коллегой или одноклубником; бросить вызов преподавателю, превзойдя ожидания собственного ментора.
Только что искали:
синок только что
изображение божьей матери только что
быстрейшая 2 секунды назад
чтение пьесы 2 секунды назад
мигусева 2 секунды назад
санталпер 3 секунды назад
запуски 4 секунды назад
дарская 4 секунды назад
онемить 4 секунды назад
гиаруфк 5 секунд назад
в образовавшийся промежуток 5 секунд назад
отрезывающийся 5 секунд назад
паленваь 5 секунд назад
отлило 6 секунд назад
экономлю 6 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | лев | 0 слов | 3 часа назад | 178. 120.8.108 120.8.108 |
| Игрок 2 | обкручивание | 42 слова | 4 часа назад | 90.154.46.74 |
| Игрок 3 | залупа | 11 слов | 6 часов назад | 217.114.236.56 |
| Игрок 4 | пиздабол | 0 слов | 6 часов назад | 176.59.144.167 |
| Игрок 5 | сепараторщик | 0 слов | 1 день назад | 178.45.154.184 |
| Игрок 6 | ипнкрзда | 1 слово | 2 дня назад | 176.59.50.37 |
| Игрок 7 | апрапр | 2 слова | 2 дня назад | 51.15.48.52 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | подкосина | 31:30 | 4 минуты назад | 188. 190.88.4 190.88.4 |
| Игрок 2 | комик | 56:55 | 58 минут назад | 93.81.130.5 |
| Игрок 3 | клефт | 46:44 | 1 час назад | 176.59.121.161 |
| Roman_Rain | барон | 35:37 | 1 час назад | 37.145.190.163 |
| Игрок 5 | морда | 56:57 | 1 час назад | 93.81.130.5 |
| Игрок 6 | дачка | 48:46 | 1 час назад | 176.59.121.161 |
| Игрок 7 | барон | 0:0 | 1 час назад | 37.145.190.163 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Оля | На одного | 10 вопросов | 3 часа назад | 109. 60.151.116 60.151.116 |
| Тим | На одного | 10 вопросов | 1 день назад | 217.64.145.174 |
| Виталик | На одного | 10 вопросов | 1 день назад | 176.59.81.79 |
| Виталик | На одного | 20 вопросов | 1 день назад | 176.59.81.79 |
| Полинка | На одного | 20 вопросов | 1 день назад | 178.178.93.154 |
| Полина | На одного | 15 вопросов | 1 день назад | 178.178.93.154 |
| Полина | На одного | 10 вопросов | 1 день назад | 178.178.93.154 |
| Играть в Чепуху! | ||||
Отзывы, благодарности и грамоты | Официальный сайт Научного центра неврологии
Чтобы добавить отзыв, перейдите, пожалуйста,
в раздел отправки отзывов
Курс повышения квалификации «Диагностика и лечение полинейропатий с основами ЭНМГ-исследования»
Проходил 18-22 июля 2022 г.
Прекрасный курс! Демонстрация практического опыта и стратификация нозологий, обсуждение особенностей – ключевые моменты данного курса. Базовые понятий ЭНМГ с практическим уклоном – крайне важный аспект данного курса. Обсуждение в непринужденной обстановке потенцирует усвоенные знания!
Терещенко Николай Михайлович
Огромная благодарность преподавателям за четкие алгоритмы диагностики, современные принципы лечения, которые можно интегрировать в свою практику, и соответственно уменьшить вероятность пропустить курабельные заболевания и улучшить качество своей работы. Намереваюсь вернуться теперь на другой курс и Вам советую.
Власова Ирина Владимировна
Потрясающий курс, благодаря полученным знаниям удалось все систематизировать. Все темы раскрыты в полном объеме, особенно хотелось бы отметить лекции по дизиммунным полинейропатиям. Огромное спасибо хочется сказать за демонстрацию пациентов, наглядные клинические случаи, обучение основам ЭНМГ-исследования.
Рубцов Николай Сергеевич
Все отлично! Квалифицированные преподаватели, доступная форма подачи материала. И почти домашняя атмосфера. Хочется вернуться еще!
Игошкин Александр Владимирович
Темы раскрыты максимально подробно и доступно, спасибо.
Панфилова Анна Алексеевна
Полный восторг! Раньше при попытках самостоятельно разобраться в теме полинейропатий получалась только каша в голове (во многих литературных источниках – просто нагромождение фактов). А после курса в голове сформировалась четкая структура, алгоритмы и установились горизонтальные связи между разными разделами.
Заиграев Владимир Юрьевич
Замечательный курс! Огромное спасибо. Прекрасная подача материала, современная и актуальная информация, интересные клинические случаи.
Сергеенко Елизавета Викторовна
Курс очень понравился. Материал был очень хорошо представлен методологически, в достаточном объеме. Цикл был очень полезен и буду рекомендовать как для врачей, глубоко погруженных в тематику полинейропатий, так и для неврологов общего звена.
Краснов Владимир Сергеевич
Курс помог систематизировать имеющийся материал по дизиммунным хроническим полинейропатиям, недизиммунным полинейропатиям. Курс помог ориентироваться в правильном прочтении протоколов ЭНМГ. Очень наглядными были представленные клинические примеры. А также особого внимания заслуживает живая дискуссия и сравнение опыта НЦН с собственным небольшим опытом в ведении данных пациентов.
Кушнир Яна Богдановна
Курс повышения квалификации «Ультразвуковая диагностика цереброваскулярных заболеваний»
Проходил 06.06.2022 г. – 10.06.2022 г.
Цикл замечательный!! Объем полученной информации в целом достаточный, на все вопросы получены полные ответы, продемонстрирована практическая составляющая, при необходимости, Андрей Олегович «ставит руку». Спасибо за знания.
Павлова Ольга Борисовна
Очень хороший цикл: много теоретического материала в доступной, хорошо понимаемой форме. Появилась осознанность цереброваскулярной патологии, уверенность в проведении методики. Спасибо большое!
Появилась осознанность цереброваскулярной патологии, уверенность в проведении методики. Спасибо большое!
Коваль Нелли Викторовна
Благодарю Андрея Олеговича за его восхитительные лекции с полноценной информацией о самых насущных темах. Особенно отмечу введение в курс спорных вопросов, их оценку и логичное разъяснение возможных решений. Также спасибо за уделенное дополнительное время для постановки руки и возможность визуализации патологий в реальной жизни.
Очень порадовала организация самого курса, четкое распределение графика, сбор документации и выдача удостоверений.
Давыдова Ксения Эдуардовна
Все темы раскрыты очень хорошо. Использованы зарубежные и отечественные источники, проведен анализ данных с дополнением собственных наблюдений и собственных выводов.
Цикл понравился, но хотелось бы побольше посмотреть обследований пациентов, в том числе просто на обычном приеме в отделении диагностики. Большое спасибо за обучение, несмотря на стаж работы 18 лет, узнала и конкретизировала многие моменты.
Боева Наталья Анатольевна
Довольна подачей информации, разборами клинических случаев, цикл получился максимально информативный, узнали много полезных навыков, следили активно за выступлениями лектора за пределами учебного времени на цикле. Желаю плодотворной профессиональной деятельности во благо пациентов и курсантов. Спасибо за знания!
Кабардова Амина Борисовна
«Диагностика и лечение миастении с основами ЭНМГ-исследования»
Проходил 06.06.2022 г.-11.06.2022 г.
Мельник Е.А. осветила все темы касательно миастении, в свою очередь хочу выразить благодарность Мельник Е.А. за проведение данного курса по «Миастении» на высоко профессиональном уровне и доброжелательное отношение к слушателям.
Исаева Аида Муслимовна
Курс интересный. Практически ориентированный.
Стрельникова Инна Анатольевна
Евгения Александровна Мельник – замечательный преподаватель и специалист. Материал прекрасно подан, доступно, понятно. Все, что мне было нужно от этого курса, я получила в полном объеме. Огромное спасибо!
Материал прекрасно подан, доступно, понятно. Все, что мне было нужно от этого курса, я получила в полном объеме. Огромное спасибо!
Титлова Елена Юрьевна
Курс очень полезен, т.к. ранее не часто сталкивалась с пациентами с миастенией.
Кроме того, стала лучше понимать основы ЭНМГ-исследования, не только в том, что касается специфических исследований, но и общих понятий. Большое спасибо!
Сазонова Валерия Юрьевна
Курс повышения квалификации «Индивидуальная стратегия ботулинотерапии при спастичности нижней конечности. Узи-навигационный контроль»
Проходил 17-28 мая 2022 г.
Хочу поблагодарить за представленный материал и возможность общения во время онлайн-обучения на курсе: Ботулинотерапия в лечении спастичности нижней конечности, прошедший 27-28.05.2022 года. Материал,представленный Римкевичус А.А. в процессе обучения, дает возможность использования ботулинотерапию в практике для начинающих специалистов. Поддержка лектора и возможность дальнейшего общения после обучения, дает мне надежду, что я приступлю к использованию этого метода в лечении своих пациентов. Спасибо огромное!
Спасибо огромное!
Шалак Юлия Анатольевна
Курс повышения квалификации «Нейровизуализация»
Проходил 16-20 мая 2022 г.
Прекрасный преподаватель. Курс прочитан доступно, каждая тема разобрана по основным пунктам. Обязательно вернемся для дальнейшего обучения.
Бастрыкина Кристина Васильевна
Хочу выразить огромную благодарность старшему научному сотруднику НИИ Неврологии Коновалову Родиону Николаевичу за высокопрофессиональное проведение курса «Нейровизуализация», доступность и полноту полученного образования. Спасибо!
Леушкин Андрей Владимирович
Очень хорошо!
Мокеев Михаил Валентинович
Курс повышения квалификации «Транскраниальная магнитная стимуляция»
Проходил 16-20 мая 2022 г.
Насыщенная информация с актуальными темами и ресурсами, в доступной форме изложенная программа, активная обратная связь.
Архинчеева Мария Борисовна
Информативный актуальный курс по ТМС, составленный профессионалами. Рекомендую всем слушателям.
Рекомендую всем слушателям.
Бахтерева Елена Владимировна
Хочу поблагодарить весь преподавательский состав за полученные знания, комфортную обстановку.
Джикия Марианна Иликовна
Благодарность всем экспертам, организовавшим и проводившим этот курс! Высокопрофессионально и ценно для дальнейшей самостоятельной практики!
Ратникова Оксана Юрьевна
Все очень понравилось. Спасибо!
Бейшеева Медера Таалайбековна
Курс очень подробный, интересный, затрагивающий самое важное ТМС с азов, включающий методики работ по разным нозологиям. Спасибо за предоставленные знания всему коллективу!
Соколова Софья Алексеевна
Вы – лучшие!!! Спасибо за обучение, все доступно, насыщенно, доброжелательно!!!
Харитонова Светлана Сергеевна
Выражаю благодарность всему коллективу научного центра за профессионализм, внимательность, самоотдачу. Спасибо за полученные знания.
Абрамова Зоя Валерьевна
Курс повышения квалификации по ЭНМГ
Проходил с 05. 04.-20.04.22 г.
04.-20.04.22 г.
Огромное спасибо нашим преподавателям — профессору Касаткиной Л.Ф. и Гришиной Д.А., мегапрофессионалы! Очень много информации, замечательно иллюстрированной, все доступно и практически направленно. Практические навыки по стимуляционной ЭНМГ. Теплая и дружественная обстановка. Дарья Александровна, в Вас я просто влюбилась, Вы вдохновляете на дальнейшую работу! Будем дальше учиться на практике.
Маныкина Анна Александровна
Курс повышения квалификации «Клиническая ЭЭГ. Практический курс»
Проходил с 18.04.–22.04.2022 г.
Очень доброжелательные, внимательные специалисты-преподаватели с высокой мотивацией и огромным объемом знаний, которыми Ваши лектора щедро делятся.
Спасибо. Приедем еще!
Синяева Елена Владимировна
Большая благодарность коллективу кафедры, отделения за подаренные знания. Подробная подача материала, большое количество клинических разборов, примеров, акцент на новые тенденции. Преподавательский состав профессиональный, очень доступно доносит материал!
Преподавательский состав профессиональный, очень доступно доносит материал!
Магомедова Шахризада Ахмедовна
Курс повышения квалификации «Нейровизуализация»
Проходил 21.03-25.03.2022 г.
Выражаю огромную благодарность преподавателю Коновалову Родиону Николаевичу, а также сотрудникам кафедры «Лучевая диагностика» за высокий профессионализм работы, хорошую оснащенность учебного центра обучающими материалами, проведение семинаров организовано на высочайшем уровне, много клинических примеров, разбор которых необходим для грамотного описания томограмм на рабочем месте.
Отдельное спасибо учебному отделу, в частности, Фадеевой Татьяне Николаевне за профессионализм и оперативность в работе.
Макарова Юлия Михайловна
Все понравилось!
Язова Ирина Юрьевна
Замечательно! Спасибо!
Тимошина Татьяна Михайловна
Курс повышения квалификации «Диагностика и лечение миастении с основами ЭНМГ-исследования»
Проходил 21. 03-25.03.2022 г.
03-25.03.2022 г.
Отдельная благодарность Евгении Александровне за доступность изложения, насыщенного материала, интерактивность, также большого количества клинических примеров (практики).
Андреева Анастасия Валентиновна
Отличная систематизация информации. Курс отличный, интересный, актуальный. Мельник Евгения Александровна грамотный, прогрессивный специалист, отличный преподаватель, который доступно доносит информацию до слушателей.
Валеева Анна Александровна
Большое спасибо за полученный опыт.
Панфилова Анна Алексеевна
Актуально, доступно, интересно. Очень полезен для практики и дальнейшего опыта работы с больными миастении. Огромное спасибо!
Макарова Анастасия Евгеньевна
Евгения Александровна дает информацию очень доходчиво, информативно, полно, легко. Благодарю за цикл. Получила больше, чем ожидала. Приехала не зря, это точно. Сочетание теории и практики имеет важное значение. Отмечается заинтересованность в студентах (врачах).
Отмечается заинтересованность в студентах (врачах).
Русина Екатерина Александровна
Очень насыщенная, интересная программа! Очень понравилась подача теоретических знаний, возможность обсуждения кейсов, отработка практических знаний с использованием шкал, инструментальных исследований. Большое количество клинических случаев позволяет расширить свои знания и пообщаться с пациентами!
Юсупова Джамиля Гереевна
Прошла курс обучения по электромиографии.
Хочу сказать большое спасибо за великолепную подачу сложного материала. Я проходила не одно обучение по ЭМГ, и по-моему мнению, это лучший курс. Хочу поблагодарить Гришину Дарью Сергеевну за такой чёткий алгоритм проведения и интерпритации стимуляционной ЭМГ. А Любовь Филипповну Касаткину за очень подробное объяснение, что такое игольчатая ЭМГ. Я очень рада, что попала на этот курс. Знаний очень много, осталось разложить всё в голове по полочкам:)
Матузкова Оксана Евгеньевна
Курс «Ишемический инсульт в молодом возрасте: причины, клиника, диагностика и лечение» (36 часов. )
)
Проходил 24.01-28.01.2022г.
Хочу поблагодарить за очень актуальный и насыщенный образовательный курс по инсульту у молодых. Очень понравилась форма обучения в виде научно-практической стажировки в отделении под руководством Добрыниноной Л. А. и Калашниковой Л. А. Участие в клинических разборах, совместные осмотры пациентов в сочетании с лекциями от ведущих научных сотрудников центра позволяют быстро сформировать правильные алгоритмы диагностики и лечения сложных пациентов. Очень надеюсь, что в ближайшем будущем подобные курсы будут и по другим неврологическим направлениям.
Макеева Татьяна Николаевна
Курс «Транскраниальная магнитная стимуляция»
Проходил 07.02.2022 – 11.02.2022 г.
Учитывая мой начальный уровень владения материалом, считаю данный курс полным и достаточным для формирования основных понятий, выработки первичного навыка и определения перспектив в работе.
Светличная Евгения Леонтьевна
Курс очень понравился, хотя и очень короткий! Дает полезный старт для дальнейших самостоятельных исследований. Спасибо!
Спасибо!
Некрасова Юлия Юрьевна
Цикл интересный, информативный.
Сорокина Анна Александровна
Спасибо за курс, информацию и материал.
Тихонова Ольга Алексеевна
Насыщенный курс. Единственная проблема малой изученности влияния метода при лечении и диагностики патологий ЦНС. Но, в принципе, думаю, что на данном этапе, мне в моей практике по реабилитации пациентов после ОНМК, полученных знаний будет достаточно.
Тарабаева Дарья Александровна
Интересный цикл, материал изложен в доступной форме, много практических замечаний, что ценно в наше время.
Шевченко Наталия Сергеевна
Курс «Вызванные потенциалы в клинической практике»
Проходил 17.01.22 — 28.01.22 г.
Проходил цикл обучения по теме вызванные потенциалы. Очень понравилось, преподаватель Ольга Станиславовна Корепина крайне подробно дает каждую тему, с примерами и практическими занятиями. Очень много практики, что особенно важно. Буквально каждая тема разобрана по косточкам, и даже по личной просьбе продемонстрировали ряд смежных методик. Крайне рекомендую данные циклы.
Очень много практики, что особенно важно. Буквально каждая тема разобрана по косточкам, и даже по личной просьбе продемонстрировали ряд смежных методик. Крайне рекомендую данные циклы.
Хичев Антон Сергеевич
Курс «Клиническая электроэнцефалография»
Большое впечатление и профессиональное удовлетворение оставил курс «Клиническая электроэнцефалография».
Лекции Амаяка Грачевича Брутяна и Александры Игоревны Беляковой-Бодиной, а также их коллег были не только максимально прибоижены к практике, но включали новые теоретические данные. Огромное спасибо!
Телегина Елена Владимировна
Курс «Ультразвуковая диагностика цереброваскулярных заболеваний»
Проходил с 25.10 по 29.10. 2021 г.
Это лучший курс по ангиологии из всех курсов, что мне приходилось слушать.
Нехаенко Виктория Борисовна
Понравилось все, отдельно спасибо руководителю курса Андрею Олеговичу Чечеткину за четкое и доступное изложение материала и человеческие качества.
Шевелев Вадим Игорьевич
Спасибо за высокий уровень и профессионализм в изложении материала, за новизну и индивидуальность подхода к разным темам.
Жидков Дмитрий Александрович
Пришла конкретно послушать Чечеткина А.О. Не разочаровалась. Все лекции актуальны, приближены к клинике. Очень много примеров, снимков. Получила достаточное количество информации, все буду применять в работе. Огромное спасибо!
Хамитова Альбина Дагиевна
Насыщенный, интересный курс по ультразвуковой диагностике цереброваскулярных заболеваний.
Пестовская Виктория Сергеевна
Очень понравилось. Детальный разбор тем, насыщенный лекционный материал с примерами. Очень благодарна Андрею Олеговичу за возможность поставить руку в практике выведения БЦА, ТКДС.
Новикова Анна Сергеевна
Спасибо за хорошую организацию цикла, интересные лекции, все очень доступно и актуально. Понравилась оценка и сравнение различных методик и данных и свое видение проблем.
Сташук Юлия Борисовна
Большое спасибо, все было хорошо.
Казанцев Сергей Викторович
Спасибо огромное! Интересный курс, насыщенный, много новой информации. Получила огромное удовольствие от обучения.
Богданова Александра Андреевна
Спасибо большое за курс! Очень информативно, объемно и интересно.
Ремизова Екатерина Юрьевна
Спасибо большое за замечательный цикл, на котором получила огромное количество очень нужной для работы информации по ультразвуковому исследованию сосудов, узнала много нового и поняла, где делаю ошибки и как их избежать в работе, что очень ценно. Спасибо большое за доброе отношение, доброжелательное отношение ко всем курсантам, ответы на все вопросы, за проведение мастер-класса по практическим навыкам уважаемому Андрею Олеговичу. В полном восторге от курса, жаль, что он такой короткий, хотелось бы чтобы он был более продолжительным. Спасибо большое Татьяне Николаевна за отличную организацию учебного процесса и работу с документами. Спасибо!
Спасибо!
Сацюк Ольга Владимировна
Понравился курс, очень! Получила мощный толчок для дальнейшего изучения сосудистой системы головы и шеи. Хотела выразить огромную благодарность Андрею Олеговичу за познавательные лекции и Татьяне Николаевне за организацию!
Симакова Елена Анатольевна
Мне очень понравился цикл обучения. Я начинающий специалист в этой области. После прослушивания лекций Андрея Олеговича появилось четкое понимание методики. Особенно понравилась подача материала, упор не на азы, а на конкретные важные вещи, разбор сложнейших тем доступным способом. Спасибо огромное!
Валеева Лилия Рафиковна
Огромнейшая благодарность преподавателю курса д.м.н. Чечеткину А.О. за высочайший профессионализм, искреннее желание делиться накопленным опытом и знаниями с каждым слушателем. Отдельное спасибо Фадеевой Т.Н. за высокий уровень организации сопровождения курса.
Меркулова Лилия Вячеславовна
Курс повышения квалификации по программе «Электронейромиография».
Проходил с 12.10.2021- 28.10.2021 г.
Спасибо огромное, курс очень понравился!
Супер- информативно и полезно!))
Некрасова Юлия Юрьевна
Низкий поклон и благодарность преподавателям и организаторам курса)
Всё было на высшем уровне.
Спасибо за поддержку и сплоченный коллектив коллегам)
«Праздник специальности» и масса положительных эмоций от занятий в НЦН.
Всем — профессиональных успехов, благополучия и хорошего настроения.
Новоселова Екатерина Владимировна
Искренне благодарю Касаткину Любовь Филипповну, Гришину Дарью Александровну и Фадееву Татьяну Николаевну с прекрасной организацией курса! Высокий профессиональный уровень, отличные педагогические навыки, содержательность и доступность подачи учебного материала позволили нам значительно углубить наши теоретические знания, приобрести практические навыки и расширить область применения электронейромиографии в нашей повседневной работе. Хотел пожелать вам крепкого здоровья, поблагодарить за преданность развитию науки и за благородное стремлению служить людям! Желаю успехов и всех благ вам и всему коллективу Научного центра неврологии.
Бейсенбаев Адиль Жумажанович
Проходил курс обусения по Электронейромиографии.
Хотел выразить благадорность Касаткиной Любовь Филлиповне и Гришиной Дарье Александровне!
Шахнович Роман Викторович
Курс повышения квалификации по дополнительной профессиональной программе «Диагностика и лечение миастении с основами ЭНМГ-исследования»
Проходил с 11.10 по 15.10.2021 г.
Понравилась тактика обследования пациента, подбор лечения, интерпретация данных ЭНМГ-исследования. Доброжелательное отношение и высокий профессионализм лектора Евгении Александровны.
Алхимова Татьяна Викторовна
Курс полезен и начинающим, и опытным специалистам. Много практики, отработка и осмотр пациентов, тактика ведения, рекомендации. Учитывались пожелания и во время цикла. Огромное спасибо Евгении Александровне за открытость и желание делиться.
Тихонова Ольга Алексеевна
Однозначно интересный курс, считаю, что врачи-неврологи должны посетить данный курс, так как миастения – диагноз не часто встречающийся и требует тщательного осмотра. Евгения Александровна доступным языком со всеми нюансами научила этому. По содержанию курс интересный, правильно был составлен план занятия.
Евгения Александровна доступным языком со всеми нюансами научила этому. По содержанию курс интересный, правильно был составлен план занятия.
P.S.: Осмотр пациентов с миастенией закрепил полученные мной знания на практике. Планирую посетить другие курсы. Спасибо!
Акимов Виктор Евгеньевич.
Отличный курс! Мне, как молодому врачу, для получения базовых знаний, этот курс много дал. Тактика лечения, сбор анамнеза и тонкости осмотра – будет очень полезно в работе! Евгения Александровна отличный преподаватель и врач.
P.S.: В Новосибирске будем лечить правильно)
Телепова Алена Сергеевна
Мельник Евгения Александровна – высококвалифицированный специалист, доступно объясняет теоретический материал, объясняет на примерах клинических случаев осмотр пациента, сбор анамнеза и жалоб, диагностический поиск, проведение ЭНМГ-исследований. Курс мне дал огромный опыт, интересные знакомства и дальнейшую мотивацию к постижению своих новых целей.
Сопрун Виктория Викторовна
Очень актуальный и интересный курс по миастении. Большая часть курса направлена на практический аспект, что несомненно ценно. За пять дней мы посмотрели более 15 пациентов, разобрались в каждом случае. Евгения Александровна объясняла тонкости диагностики, лечения по каждому пациенту. Считаю, что это один из самых лучших очных курсов. Большое спасибо за то, что делитесь своими знаниями.
Большая часть курса направлена на практический аспект, что несомненно ценно. За пять дней мы посмотрели более 15 пациентов, разобрались в каждом случае. Евгения Александровна объясняла тонкости диагностики, лечения по каждому пациенту. Считаю, что это один из самых лучших очных курсов. Большое спасибо за то, что делитесь своими знаниями.
Тумилович Таисия Александровна
Курс повышения квалификации по дополнительной профессиональной программе «Диагностика и лечение миастении с основами ЭНМГ- исследования»
Проходил с 14.09.21 по 18.09.21 очно.
Огромная благодарность преподавателю Мельник Е.А. за очень насыщенный, подробный курс и за ответы на все-все вопросы. Появилось понимание проблемы, как «подойти» к пациенту. Как всегда ждем новых курсов.
Меркулова Татьяна Борисовна.
Цикл очень понравился своей информативностью и доступностью. Правильное сочетание теоретической и практической частей, много разнообразных клинических примеров. Получила хороший практический опыт в исследовании декремента. Огромное спасибо Евгении Александровне Мельник и всем организаторам за такой прекрасный и важный цикл.
Дунаева Светлана Альбертовна.
Данный курс максимально гармоничен: теоретические знания сразу применяются на практике, обсуждаются все интересующие вопросы. Мельник Е.А. – прекрасный врач и педагог. Хотелось бы продолжить обучение по темам «Миопатии, миодистрофии», «Атипичный паркинсонизм». Сотрудники НЦН — профессионалы, у которых бы хотелось учиться, повышать свой профессиональный уровень.
Скрыпник Ольга Викторовна.
Очень довольна очередным образовательным курсом от Центра заболеваний периферической нервной системы ФГБНУ НЦН. Курс очень полезен с практичной стороны вопроса, готовит доктора не только к выявлению редкого заболевания, но и к ведению пациентов самостоятельно, без привлечения специалистов со стороны НЦН. Обязательно вернемся!
Жидконожкина Екатерина Александровна.
Очень актуальный и интересный курс по миастении осветил нам самые последние достижения науки в диагностике и лечении этого заболевания. Понравились практические занятия с осмотром пациентов, проведением ЭНМГ, что позволило сформировать правильное клиническое мышление и современные алгоритмы лечения.
Макеева Татьяна Николаевна.
Курс повышения квалификации по дополнительной профессиональной программе «Транскраниальная магнитная стимуляция»
Проходил с 20.09-24.09.2021 г.
Хочу поблагодарить организаторов и лекторов этого курса. В максимально короткий срок смогли в простой форме объяснить методику ТМС. Особенно понравились практические занятия. Важно, что после курса любой врач сможет проводить исследование и лечение на своем рабочем месте.
Матузкова Оксана Евгеньевна
Ранее ТМС в своей практике не использовала, пришла на цикл «с нуля». Была приятно удивлена теплому приему. Преподаватели доброжелательные, грамотные, четко и конкретно отвечают на вопросы слушателей цикла. Очень понравилось, что было много практических занятий, удалось все попробовать и самой, и проверить на себе. Большое спасибо нашим преподавателям!
Лапкина Оксана Михайловна
Отличная нацеленность на практические навыки, возможность индивидуального подхода к каждому обучающемуся в зависимости от потребностей. Спасибо Вам огромное, уважаемые Илья Сергеевич, Дмитрий Юрьевич и Александра Георгиевна!
Виноградова Алена Александровна.
Отмечаю прекрасную структурированность и качество лекций. За короткий срок удалось изложить большой объем интереснейшей информации.
Александров Андрей Алексеевич.
Очень кратко, объемно, доступно представлен курс. На все вопросы были даны ответы в понятной форме. «Краткость – сестра таланта». Спасибо всем и каждому по отдельности.
Абдурахманова Мегрибан Алекперовна
Спасибо за бесценный опыт и знания! Я поняла, что многое делаю неправильно. Теперь я более детально понимаю, с чем же я все-таки работаю, какие нюансы и подводные камни есть у метода. Я даже не думала в таких направлениях. Буду посещать курс повторно, если будет такая возможность, поскольку метод современный и развитие методики не стоит на месте. Приятно было пообщаться с коллегами!
Носикова Инна Николаевна
Курс повышения квалификации «Нейровизуализация»
Хочу выразить благодарность Родиону Николаевичу Коновалову, за свои знания, которые он вложил в меня, за свой труд!
Спасибо Вам большое!
С уважением, Лилит Вачагановна Осеян
Курс повышения квалификации по Электронейромиографии
Проходил с 15.06 по 01.07.2021 г.
Уважаемые наши преподаватели Любовь Филипповна, Дарья Александровна, Татьяна Николаевна хотим от чистого сердца сказать вам огромное спасибо за безупречную организацию цикла, за ваше усердие и понимание, за вашу работу и ваши старания, доброту, поддержку и чуткость, за внимание, проявленное терпение и верные знания! Желаем вам оставаться в отличной форме и с крепким здоровьем, спасибо вам за все! От самой дружной группы) всех благ вам!!
Начальник кабинета нейрофизиологических исследований, старший врач функциональной диагностики неврологического отделения ГВКГВНГ РФ
Сохова Фатима Нургалиевна
Выражаю огромную благодарность организаторам цикла по ЭНМГ, Татьяне Николаевне! Особая благодарность преподавателям профессору Касаткиной Любовь Филипповне, это большая честь учиться у того, кто стоит у истоков игольчатой ЭМГ и делится своим огромным опытом, знаниями! Также к. м.н. Гришиной Дарье Александровне, за ее умение все разложить, структурировать и подать в доступной, понятной форме по стимуляционной ЭНМГ, за ее желание научить и демонстрацию насколько важна выверенная методология и четкое следование ей! Эти 16 дней обучения были очень насыщенными. Крепкого здоровья и процветания всем
Невролог
Абрамовских Лейла Эхтибаровна,
Новосибирск
Уважаемые Любовь Филипповна и Дарья Александровна! Благодарю вас за уникальную возможность получения неоценимых знаний, а в недалёком будущем и практических умений. На основе этих знаний, которые помогут мне продолжить начатое вами дело, дело наше общее -правильно понимать и применять на благо наших пациентов полученные знания и умения. Спасибо за кропотливую работу, понимание и великое терпение, любовь к своему делу. Здоровья вам и большое человеческое спасибо.
С глубоким уважением,
кандидат медицинских наук, врач-ревматолог,
врач функциональной диагностики
Костюнина Надежда Викторовна
Вот и закончился цикл по электронейромиографии, 2,5 недели пролетели, как один миг.
Цикл насыщен информацией, лекционный материал фундаментален с одной стороны, а с другой непосредственно связан с практической деятельностью. Я не новичок в ЭНМГ, но с превеликим удовольствием прошла обучение, скучать не приходилось совсем. Вычленяла для себя тонкости методики.
Хочу выразить огромную благодарность нашим лекторам и организаторам. Любовь Филипповна преподносила материал доступно, разжевывала и раскладывала по полочкам законы нейрофизиологии. Дарья Александровна очень структурно и обстоятельно доносила до нас стимуляционную ЭНМГ с ее особенностями и протоколами при разной патологии. Ведь методика неотъемлемая часть искусства Неврологии.
Спасибо и до новой встречи.
Тихонова Ольга Алексеевна
Курс повышения квалификации
«Ультразвуковая диагностика цереброваскулярных заболеваний»
Очень понравилось полное, с акцентами, преподавание теоретического материала в неразрывной связи с практическими навыками. Получила большое удовольствие от общения с сотрудниками, организовавшими цикл. Большое спасибо Чечеткину А.О. за его высокий профессионализм как врача, так и преподавателя.
ФГКУ Поликлиника №2,
врач функциональной диагностики
Жданюк-Нарышкина Татьяна Михайловна
Получила больше, чем ожидала: легко доступный для понимания материал, доступ к ультразвуковому аппарату для закрепления пройденного материала. Спасибо большое преподавателю за честность и желание донести информацию до слушателей.
ГБУЗ «Городская клиническая больница имени В.П. Демихова Департамента здравоохранения города Москвы»,
врач ультразвуковой диагностики
Пинкина Светлана Валентиновна
Все темы, прослушанные на курсе, были очень подробно изложены, понятно для начинающих специалистов, наглядно все показано по всем патологиям. Подробно была показана работа непосредственно за аппаратом УЗИ. Спасибо огромное за прекрасный цикл.
ООО «МЦ ВМЛ «Мой доктор поликлиника»,
врач функциональной диагностики
Лутина Елена Игоревна.
Получила от этого курса все, что ожидала, и даже больше. Материал изложен максимально полно и доступно. Самое главное, что есть возможность отточить практические навыки под контролем преподавателя.
ООО «Панацея»,
врач ультразвуковой диагностики
Любимова Яна Юрьевна
Пройденный курс показался очень насыщенным и по времени недостаточным, хотелось бы, чтобы увеличили время на его прохождение. В целом, очень довольна лекционным материалом и практическими навыками, которые успела получить.
ГБУЗ «Психиатрическая клиническая больница № 1 им. Н.А. Алексеева ДЗМ»,
врач функциональной диагностики
Сварник Людмила Юрьевна
Организация учебного процесса отличная, материал изложен очень доступно, дополнен клинической картиной, динамичными наблюдениями, собственным опытом. Многие темы, а вернее все темы, раскрыты в таком объеме, где больше не встретить.
АУЗ ВО «ВОККДЦ»,
врач функциональной диагностики
Елисеева Надежда Васильевна
Получил большое удовлетворение и практическую пользу.
БУ «Сургутская городская клиническая поликлиника №2»,
заведующий структурного подразделения
Леконцев Александр Юрьевич
Курс очень понравился, получила большой объем информации. Андрей Олегович в очень доступной форме читал свои лекции, подробно отвечал на многочисленные вопросы. Представил интересные клинические случаи, лично показывал практические навыки, помогал каждому с выведением ультразвуковых изображений. Спасибо большое!
ГБУЗ МО «МОЦОМД» ,
врач ультразвуковой диагностики
Багаутдинова Ирина Викторовна
В полном восторге. Очень радует, что информация довелась самая актуальная, было акцентировано внимание на тонкости в УЗ-дуплексном сканировании БЦА.
Спасибо большое! Буду рекомендовать коллегам.
ГКБ № 1 ИМ. Н.И. ПИРОГОВА,
врач функциональной диагностики
Исаева Саида Ходжаевна
Благодарю за предоставленную возможность получить актуальную и всеобъемлющую информацию по интересующей теме. Особенно хотелось бы отметить практическую направленность материала, а также возможность приобрести практические навыки по методике исследования.
ФГАОУ ВО «Российский национальный исследовательский медицинский университет имени Н.И. Пирогова» Минздрава России,
врач функциональной диагностики
Шубина Анна Тимофеевна
Все отлично, но мало времени. Спасибо огромное за цикл.
Поликлиника ру,
врач ультразвуковой диагностики
Шадиева Марина Хасанова
Огромное спасибо за организацию курса. Много нового в допплерографии; пожелание – организовать курсы для оттачивания мастерства отдельно от начинающих врачей.
ООО «УМНАЯ КЛИНИКА»,
врач ультразвуковой диагностики
Габриелян Нонна Амбарцумовна
Очень понравился цикл, помимо насыщенной теоретической части приятна была атмосфера диалога с преподавателем, акцентирование внимания на нюансы, про которые, возможно, не узнала бы, не побывав на этом цикле. Спасибо, что много времени уделялось и практическим занятиям. Результат даже превзошел ожидания. Андрей Олегович, огромное Вам спасибо!
ГБУЗ ЯО «ЯОКГВВ-МЦ «Здоровое долголетие»,
врач функциональной диагностики
Маряшина Инна Викторовна
Спасибо за прекрасное изложение темы курса. Также спасибо за то, что много времени было уделено практическим занятиям с начинающими. Прекрасная атмосфера.
ООО Семейный Доктор,
врач-невролог
Колесникова Ирина Ивановна
Все очень актуально и на высшем уровне, с очень хорошей подачей материала.
АО «Самарский Диагностический Центр»,
заведующий отделом, врач функциональной диагностики
Пичко Геннадий Александрович
2021 г.
Курс повышения квалификации
«Вызванные потенциалы в клинической практике»
Мне очень понравилось обучение, считаю крайне информативной и воспроизводимой методикой. Очень понравился стиль изложения и подача материала О.С. Корепиной.
Врач-невролог
Канарский Михаил Михайлович
2021 г.
Курс повышения квалификации
«ДИАГНОСТИКА И ЛЕЧЕНИЕ ПОЛИНЕЙРОПАТИЙ С ОСНОВАМИ ЭНМГ- ИССЛЕДОВАНИЯ»
Спасибо большое за полученные знания и умения! Данный курс помог узнать тонкости разных патологий, новые методы лабораторной и инструментальной диагностики.
Горбачева Диана Шамилевна
Спасибо большое за курс! Все очень понравилось: наполнение, лекторы, организация. Обязательно приму участие в последующих циклах.
Меркулова Татьяна Борисовна
Курс очень актуален, особенно учитывая рост заболеваемости ПНП. Материал был подобран в хорошем объеме, доступно излагался, не хватило демонстрации пациентов с соответствующими заболеваниями.
Головина Светлана Анатольевна
Очень замечательный и своевременный курс. На основании полученных знаний уверена, что самостоятельно начну разбираться с ЭНМГ-заключениями, критически их оценивать. Особенно полученные знания пригодятся при проведении экспертизы. Спасибо большое всему коллективу.
Скрыпник Ольга Викторовна
Выражаю глубокую благодарность за проведенный цикл, который дал возможность переосмыслить часть своей клинической практики и определить вектор движения для профессионального развития.
Уткина Юлия Владимировна
Своевременный и актуальный курс. Уверена, что информация, полученная на курсе, поможет в практической работе. По окончании курса появился большой интерес к ЭНМГ- исследованию, поэтому, надеюсь, в ближайшее время посетить курс по ЭНМГ в НЦН.
Макеева Татьяна Николаевна
Все лекторы обладают высоким уровнем знаний по нервно-мышечным заболеваниям, в частности, полинейропатиям. Материал представлен доступно, эмоционально; предложены алгоритмы диагностики и лечения ПНП, которые будут полезны для клинической работы.
Блохина Вера Николаевна
Огромная благодарность организаторам и инициаторам этого цикла. Очень нужная и актуальная тема, изучение которой позволило увеличить уровень знаний в области заболеваний периферической нервной системы.
Жидконожкина Екатерина Александровна
Спасибо за цикл, получила ответы на интересующие меня вопросы, особенно по методике и интерпретации ЭНМГ. Все лекторы открыты к общению, дружелюбны, прекрасно владеют информацией. Успехов и процветания Центру заболеваний периферической нервной системы НЦН.
Дунаева Светлана Альбертовна
2021 г.
Учиться всегда интересно! А в нашей врачебной профессии это ещё и необходимость.
Будучи неврологом с 39-летним стажем мне удалось вытянуть счастливый билет! Так я могу назвать обучение на цикле по электромиогграфии с 9 по 25 марта 2021 года. Считаю, что это был уникальный цикл! Нас учила Гуру электромиографии в России — Любовь Филипповна Касаткина ! Уникальное сочетание человеческого благородства, высочайшего профессионализма и уважения к своим колегам — всем этим был пронизан цикл обучения профессора Касаткиной Л. Ф.! Стимуляционную ЭМГ нам преподовала Дарья Александровна Гришина. Умница! Высоко профессинальна! И молодость ей в этом не помеха. Наши преподаватели с таким интересом и любовью проводили обучение, что благодаря им все черные непонятные чёрточки, штрихи и импульсы на экране «заговорили и запели», стали понятнее многие сложные диагнозы. Конечно, наша набольшая группа курсантов (нас было 7 человек) не стали сразу выдающимися нейрофизиологами, но то, что мы полюбили электромиографию и поверили в ее уникальные возможности, это можно сказать с уверенностью! Кроме наших преподавателей, нам постоянно помогала Фадеева Татьяна Николаеана, благодаря которой мы не знали проблем с документами, оформлением, возникшими вопросами. Она постоянно держала руку «на пульсе » и помогала нам.
Наши замечательные Учителя, Любовь Филипповна и Дарья Александровна! СПАСИБО ВАМ!
Хотя восхищение Вами не может уместиться в таком коротком слове — спасибо! Удачи Вам во всём! Хочется поблагодарить Михаила Александровича Пирадова, Маринэ Мовсесовну Танашян и Сергея Николаевича Иллариошкина! СПАСИБО ВАМ за ту атмосферу в Научном центре неврологии, которую Вы сохраняете все годы! Даже воздух в Вашем учреждении уникален! Спасибо за это! Спасибо за все » здравствуйте», которыми встречают Ваши сотрудники всех входящих и нуждающихся в Вашей помощи! Поверьте, эта атмосфера есть только В НЦ Неврологии!
Хочу выразить свою безмерную благодарность и Галине Николаевне Бельской, к которой приходится часто обращаться за помощью для сложных больных. Галина Николаевна мгновенно решает все сложные проблемы, помогая не только пациентам, но и родственникам.
Вот это и есть Научный центр неврологии! Вот это и есть сочетание науки, особой человеческой породы и любви к своей профессии! Спасибо, дорогие учителя и коллеги! Учиться надо у лучших!
С огромным уважением и почтением,
Щербоносова Татьяна Анатольевна.
04.04.2021 г.
От всего сердца благодарим уважаемых Касаткину Любовь Филипповну и Гришину Дарью Александровну за пройденный цикл по электромиографии!
Нам повезло учиться у Любовь Филипповны, которая в этом году отметит 50-летний юбилей профессиональной деятельности, автора монографий по исследованию периферического нейромоторного аппарата. На курсе подробно и доступно были изложены методика и возможности использования игольчатой миографии, представлены клинические примеры нервно-мышечных заболеваний и протоколы исследований.
Дарья Александровна познакомила нас со стимуляционной миографией, дифференциально-диагностическими алгоритмами при различных заболеваниях периферической нервной системы. Отлично налажен процесс отработки полученных знаний по стимуляции нервов на практических занятиях.
Курс изложен доступно, со множеством демонстрационного материала и клинических примеров.
Спасибо!
С уважением, группа курсантов (цикл 08.09.2020-23.09.2020)
Хочу выразить благодарность за цикл на рабочем месте «Игольчатая ЭМГ» под руководством Касаткиной Л.Ф.
Любовь Филипповна умеет доступно и понятно отвечать на вопросы, рассказывает все в мелочах и поэтому открывает целую планету под названием МИОГРАФИЯ.
Безусловно, что хочется часами слушать и смотреть на весь процесс, поэтому не экономьте и берите больше часов для познания этой науки.
Бесконечно благодарна Касаткиной Л.Ф. за ее любовь к ЭМГ, к ученикам и пациентам. Любовь Филипповна, долгих лет жизни и благополучия Вам.
Организация циклов всегда очень хорошая, уже не первый раз прохожу обучение на этой базе и проходила другие циклы повышения квалификации. Цена за цикл соответствует качеству. Поэтому благодарность и отделу по организации и оформлению, очень все доброжелательные и идут на встречу.
Веткасова Т.В., 24.03.2020 г.
Сегодня у нас, у студентов, была уникальна возможность посмотреть, как очень опытный и прекрасный человек, логопед-афазиолог, кандидат педагогических наук Бердникович Елена Семёнова работает с пациентами. Она нам также показала и рассказала как нужно работать с людьми разной категории, с разными диагнозами, каким должен быть настрой на работу и много всего другого интересного. Очень надеемся, что мы ещё придём на практику к Елене Семёновне, спасибо Вам большое от имени всех студентов 4 курса МСПИ, логопедов и дефектологов.
Жирнова И.В., 12.12.2019 г.
Многоуважаемая, уникальная Любовь Филипповна и несравненная, замечательная Дарья Александровна!
Хотим выразить Вам огромную благодарность за Ваше мастерство, высокий профессионализм, чуткое отношение к нам при проведении курса обучения по электронейромиографии, проходившем на базе научного центре неврологии с 4 по 20 февраля 2019 года.
Уверены, что Ваш практический опыт и Ваши знания, переданные нам, помогут в дальнейшем освоении этой сложной диагностической методики, которое, в свою очередь, нацелит наших врачей-клиницистов к постановке правильного диагноза и назначению соответсвующего лечения. Спасибо Вам!!!
С уважением, группа докторов,
проходивших курс по программе
«Электронейромиографии»
05.03.2019 г
Хочу выразить огромную благодарность д.м.н. Андрею Олеговичу Чечеткину и всему коллективу научно-координационного и образовательного отдела ФГБНУ НЦН за профессионализм, доброжелательное и гостеприимное отношение, желание поделиться знаниями и опытом, поздравить их с наступающим Новым 2019 годом и пожелать здоровья, благополучия и больших успехов в их трудной и очень нужной работе!
С уважением, группа курсантов
(цикл 24.09.18 — 29.09.18)
врач УЗДГ ГУЗ «Елецкая городская больница № 2» Малютина Ирина Александровна
29.12.2018 г.
Хочется от себя лично и от всей группы обучавшихся по программе «Электронейромиография» в декабре 2018 года выразить глубокую искреннюю благодарность нашим замечательным преподавателям – доктору биологических наук, профессору Касаткиной Любови Филипповне и кандидату медицинских наук Гришиной Дарье Александровне.
Любовь Филипповна – не просто специалист высочайшего класса, стоявший у истоков метода электромиографии в нашей стране, но и невероятно увлеченный своей работой и увлекающий других виртуоз. Она щедро делится с врачами богатством своих знаний и навыков. Такое немногим дано! После занятий с ней чувствуешь подъем и большое желание включиться в самостоятельную работу, потому что знаешь, что в случае неизбежных вопросов и трудностей всегда найдется мудрый советчик. Нельзя не сказать также, что Любовь Филипповну — человек огромного обаяния, очень доброжелательная и располагающая к себе с первых минут общения.
Дарью Александровну, несмотря на молодость, характеризует ответственный и серьезный подход к делу. Она настоящий врач и педагог от бога, обладает настолько системным мышлением, что даже сложные вопросы умеет представить доходчиво и понятно каждому курсанту. Занятия с ней были интересным сочетанием освоения теории и отработки практических навыков стимуляционной электронейромиографии.
Всем, кто решил овладеть этим непростым, но таким интересным и диагностически значимым методом, с полной убежденностью рекомендуем сделать это в стенах Научного центра неврологии! Особенно хочется призвать к этому врачей-неврологов, стремящихся к повышению своего профессионального уровня. Поверьте, что дни, проведенные на цикле, станут незабываемыми, обогатят знаниями и подарят возможность общения с замечательными людьми.
В преддверии Нового года хочется пожелать нашим глубокоуважаемым и дорогим преподавателям Любови Филипповне Касаткиной и Дарье Александровне Гришиной, всему коллективу Научного центра неврологии здоровья, благополучия, оптимизма и огромных творческих успехов!
С уважением и признательностью,
от группы курсантов
Сааркоппель Людмила Мейнхардовна —
врач-невролог, главный врач
клиники Федерального
научного центра гигиены им.Ф.Ф.Эрисмана
20.12.2018 г.
Регулярно прохожу курсы повышения квалификации в этом замечательной Центре, хочу поблагодарить Касаткину Любовь Филлиповну за обучение ЭМГ и Гришину Дарью Александровну за обучение ЭНМГ! Все прошло на высшем уровне, с подачей большого и интересного материала! Спасибо Вам!
Дмирий И.
03.11.2018 г.
Хочу выразить огромную благодарность Гришиной Д.А. за высокий профессионализм. Проходила курсы повышения квалификации по стимуляционной электронейромиографии и осталась очень довольной!
С уважением,
Ваша ученица из Киргизии
Мамадумарова
22.07.2018 г.
Выражаю огоромную благодарность профессору Касаткиной Любовь Филипповне, у которой я проходил повышение квалификации по теме «Игольчатая электромиография». Мастер активно и с душой делится своими многочисленными знаниями и огромным опытом. Любовь Филипповна влюблена в свою профессию и заражает этим других нейрофизиологов. Спасибо за Ваш труд!
Врач нейрофизиолог
Матвеев Евгений,
г. Тюмень.
08.04.2018
Уважаемая Любовь Филипповна!
Громадное спасибо за те знания с которыми Вы так легко делитесь с врачами, за доступность и их практичность!!!
Вы — МОЗГ!!! Долгих лет Вам жизни!!!
Я хочу, чтобы как можно больше врачей, занимающихся ЭМГ, познакомилось с Вами и приобрело Ваш многолетний уникальный опыт! И весь Ваш опыт, все знания, Вы сами продолжите жить в нас — врачах! А мы будем стараться совершенствоваться и помогать нашим пациентам!!!
Еще раз громадное спасибо!
Штаймец С. В.
05.04.2018
Огромная благодарность Центру неврологии, нашим учителям: Касаткиной Л.Ф. и Гришиной Д.А..
Мы получили огромное удовольствие от общения с профессионалами такого высокого уровня, которые поделились с нами своим бесценным опытом, вложили в нас частичку своей души, «заразили» любовью к этому замечательному методу.
Курсанты циклов электронейромиографии
25.05.2017-09.06.2017
Выражаю огромную благодарность Центру неврологии, в особенности моим наставникам Екатерине Николаевне Михайловой и Наталье Владимировне Полькиной, а также отдельную благодарность Ларисе Николаевне Яковлевой без участия которых, я бы не смогла осуществить и воплотить в реальность мои планы.
Спасибо за дружескую, семейную атмосферу, за обучение, за встречи с профессорами опыт которых передался мне, и который я буду использовать в своей врачебной деятельности! Спасибо огромнейшее!
С наилучшими пожеланиями клинике ФГБНУ НЦН.
Врач Микаелян Л. В.
Цикл нейроофтальмологии
15.05.2017-26.05.2017
Огромная благодарность Гнездицкому В.В. и Корепиной О.С. за полученные знания во время прохождения цикла по ВП! Благодаря огромному опыту проф. Гнездицкого В.В. в Центре неврологии — это единственная нейрофизиологическая лаборатория в стране, где можно получить качественные знания в области клинической нейрофизиологии!
Отдельное спасибо Корепиной О.С. за внимательное отношение к отработке практических навыков, за терпение и отзывчивость!
С большим удовольствием посещали занятия, получили доступное объяснение на все интересующие вопросы, а так же получили огромную мотивацию к дальнейшей работе!
С уважением и благодарностью, курсанты циклов по ВП
10.04.2017-21.04.2017
В самом начале хочется поблагодарить коллектив Научного центра за организацию и возможность получить новые знания и навыки по нейроурологии.
Особые слова благодарности руководителю лаборатории нейроурологии — Шварцу Павлу Геннадьевичу.
Умелое сочетание фундаментальных знаний, биохимии… и смежных дисциплин — неврологии, психиатрии, урологии, позволяют по-новому взглянуть на нейроурологические заболевания пациентов. Широкий кругозор, высокая эрудиция, оригинальный подход к различным ситуациям вызывают живой интерес и желание учиться. Открывая новые горизонты, формируем новую реальность.
Курсанты цикла Нейроурологии
14.03.2016-25.03.2016
Шварцу Павлу Геннадьевичу
Пытливый ум, желание иль был заказ!
Ну что гадать? Необходимость нас на курсы привела.
А, если хорошо подумать и понять —
Всевышнего рука!
Мотивация к учебе велика.
Задачи у всех равнозначные,
Потому, как на рабочих местах
Решения придется принимать неоднозначные.
К счастью, не утрачена способность к обучению.
Павел Геннадьевич — Вы, конечно же, Гуру!
Вашу наблюдательность, абстракцию и склонность к обобщению
Постигали ежедневно по утру.
В подаче материала методичность,
Логика и доказательность мышления,
Глубокий ум, критичность.
Доверительность и легкость общения.
Нейроурология — не «хилая» наука,
Две недели мозгового штурма да дедукция —
Аппетит умерился, пропала скука,
Но сработала IQ — индукция…
Уносит ветер с легкостью снежинки,
Луч солнечный слизал последний наст,
Чудесен март: ожившие природные картинки,
Но главное — он познакомил с Вами нас!
Курсанты «Нейроурология»
март 2016
Выражаем огромную благодарность Гнездицкому В.В. и Корепиной О.С. за изложение практического и теоретического материала на высоком уровне и в доступной форме. За доброжелательную атмосферу, царившую во время лекций и занятий. Желаем коллективу кафедры творческих успехов в дальнейшей научной деятельности. Хотелось бы продолжить дальнейшее сотрудничество с Вами!
Цикл по клинической ЭЭГ
Группа слушателей
14.03.2016-26.03.2016
Жизни бывает свойственно неожиданно преподносить бесценные подарки-встречи с потрясающими интересными людьми неординарного ума, позволяющие расширить горизонты твоего познания, восприятия и мироощущения, светом науки озарить тесную каморку косного мышления и примитивных представлений, ибо мы не видим лишь то, чего мы не знаем.
Несомненно, курс нейроурологии восхитительного Шварца Павла Геннадьевича относится к таким возможностям.
Нестандартность передачи материала, индивидуальный подход, наглядность, доказательность и неиссякаемая пища как для ума, так и для души — вот что отличает этот обучающий цикл. Поэтому пользуясь случаем, выражаю огромную благодарность коллективу лаборатории нейроурологии и уродинамики, а в особенности Шварцу Павлу Геннадьевичу, за радушный прием, дружеское отношение, горячий бабушкин самовар и чай с печеньками, шикарную коллекцию книг и удивительных вещей на полках, уютную располагающую атмосферу и осязаемую ауру интригующей таинственности и иных времени и пространства в лаборатории.
Желаю Вашей интереснейшей и важной работе невероятной плодотворности и дальнейшего роста и развития вопреки всему и всем. И надеюсь и верю, что посеянные зерна светлого знания дадут желаемые всходы. Хотелось бы когда-нибудь побывать у Вас снова.
С чувством глубокого почтения и уважения,
Ермакова А. И., врач-невролог
г. Калуга, 16.04.2015
Коллектив учащихся курса ЭМГ выражает благодарность профессору Касаткиной Л.Ф. и её сотрудникам за прекрасное качество материала и уникальный стиль учебного процесса.
Цикл по электронейромиографии
апрель 2014
Совершенно уникальный цикл обучения с принципиально новой интересной и систематизированной подачей информации.
Данный цикл очень полезен для неврологов и нейрохирургов. Большое спасибо учителю!
Цикл по нейроурологии
апрель 2014
Бородулина И.В.
Большое спасибо за интересный цикл, позволяющий систематизировать имеющиеся знания и усилить их более глубоким погружением в тайны энцефалографии.
Отдельное спасибо Ольге Станиславовне Корепиной за её профессиональные и человеческие качества.
Курсанты цикла по клинической ЭЭГ
10.12.2012-21.12.2012
Единственное место, где можно обучиться ВП это в Научном центре неврологии, в лаборатории профессора В. В. Гнездицкого. Атлас В.В. Гнездицкого и О.С. Корепиной очень помогает в практической деятельности.
Цикл по вызванным потенциалам
12.11.2012-25.11.2012
Моллаева К.Ю.
Огромная благодарность НЦ неврологии за возможность пройти обучение по нейроурологии. За время прохождения цикла получила глубокие систематизированные знания, благодаря одаренному, талантливому педагогу и нейроурологу Шварцу Павлу Геннадьевичу.
Большое ему спасибо и глубокое уважение!
Цикл по нейроурологии
12 октября 2012
Галкина Н.Г.
Глубокое уважение и огромная благодарность Гнездицкому В.В. и Корепиной О.С. за внимание, большое количество важной информации, доброжелательное отношение, наглядное проведение занятий и просто хорошее настроение! Получили большое удовольствие и незаменимые знания! Большое спасибо и самые наилучшие пожелания!
Курсанты цикла ЭЭГ
14.05.2012-25.05.2012
В ноябре 2011 г. проходила курс повышения квалификации по ЭМГ у профессора Касаткиной Л. Ф. Приехала в Москву и не могла не зайти к ней и ещё раз выразить благодарность.
Всю жизнь буду гордиться, что я училась у самой Л.Ф. Касаткиной. Благодаря ей я освоила такой сложный метод и получаю огромное удовольствие от своей работы.
Цикл по ЭМГ
21.12.2012
г. Краснодар,Т.А. Смирнова
Уникальный цикл, который посвящен актуальным междисциплинарным проблемам.
Всем доволен, спасибо!
Цикл по нейроурологии
16.01.2012-30.01.2012
Лобкарев А.О.
Решение ученого совета об участии проекта в конкурсном отборе Цели инновационного образовательного проекта. Подготовка студентов, выпускников вуза и молодых специалистов к работе в школе с освоением современных навыков учителя, знакомством со спецификой определенной школы, в которой они будут работать, обучением работе в команде для более эффективного решения задач образовательной организации по развитию.
Задачи инновационного образовательного проекта. 1. Разработка концепции проекта; 2. Создание локальной нормативно-правовой базы для реализации проекта; 3. Поиск и утверждение образовательных организаций, которые станут базами для реализации проекта с участием Комитета по образованию г. Санкт-Петербурга и Комитета по общему и профессиональному образованию Ленинградской области; 4. Разработка диагностического инструментария для измерения профессиональных и личностных характеристик участников проекта, а также методов мониторинга эффективности проекта; 5. Ежегодный отбор участников проекта: студентов, начиная с 3 курса, выпускников и молодых специалистов; 6. Диагностика профессиональных и личностных характеристик участников проекта; 7. Разработка и утверждение плана мероприятий ежегодно с учетом проведенной диагностики; 8. Проведение мероприятий с участием студентов и молодых специалистов с целью создания команды педагогов «под ключ»; 9. 10. Трудоустройство участников проекта в составе команды педагогов в образовательные организации; 11. Научно-методическое и организационное сопровождение молодых специалистов, трудоустроенных в образовательные организации проекта, в том числе повышение квалификации, супервизорские мероприятия, научное кураторство и пр.; 12. Разработка и внедрение сетевых образовательных программ с участием работодателей.
Обоснование актуальности выполнения инновационного образовательного проекта: — основание выбора тематики; В связи с подписанием Федерального закона «О внесении изменений в статьи 46 и 108 Федерального закона «Об образовании в Российской Федерации» президентом РФ В.В. Путиным 8 июня 2020 г. и тем, что студенты педагогических вузов 3-5 курсов получили возможность трудоустройства в общеобразовательные организации, считаем целесообразным рассматривать проект по подготовке команды педагогов «под ключ» как одну из возможностей подготовки студентов педагогических вузов для будущей работы в школе. Более того, трудоустройство в образовательную организацию – лишь первый шаг в профессиональном развитии молодого педагога. Для полноценного профессионального и личностного развития участники проекта получат соответствующее научно-методическое сопровождение со стороны вуза на первых этапах вхождения в профессию: дополнительное профессиональное образование, семинары, мастер-классы, кураторство, супервизия. — новизна, инновационность предлагаемых решений.
Проекты по созданию целостных команд педагогов не реализуются на территории России. Данный факт позволяет отнести проект к инновационному, тем более реализация проекта позволит решить ряд задач: — практическая и индивидуализированная подготовка студентов педагогических вузов к работе в образовательной организации; — освоение студентами педагогических направлений компетенций, не входящих в ООП; — знакомство и взаимодействие с будущим работодателем еще на этапе обучения в вузе; — ранняя диагностика профессиональных и личностных характеристик студентов для построения индивидуального образовательного маршрута при подготовке к трудоустройству; — выявление педагогически одаренных студентов и молодых специалистов, способных внести большой вклад в развитие образовательной организации; — распространение инновационного опыта в регионе и РФ путем внедрения сетевых образовательных программ с привлечением работодателей; — научно-методическое сопровождение молодых специалистов со стороны вуза на первых этапах вхождения в профессию.
ГОДОВОЙ ОТЧЕТ О ДЕЯТЕЛЬНОСТИ ИННОВАЦИОННОГО ОБРАЗОВАТЕЛЬНОГО ПРОЕКТА «КОМАНДА ШКОЛЬНЫХ ПЕДАГОГОВ «ПОД КЛЮЧ»
ПРИКАЗ ОБ УТВЕРЖДЕНИИ СПИСКА ИСПОЛНИТЕЛЕЙ ПРОЕКТА
План-график реализации инновационного образовательного проекта в 2022 г.
Контакты по проекту: Отдел карьерных траекторий «Центр Мост» e-mail: [email protected], тел.: 643-77-67 (доб. 26-69, 26-71)
Новости о проекте на 2022 г. 01.09. В День знаний свою работу в ГБОУ СОШ № 604 Пушкинского района Санкт-Петербурга начали 12 выпускников Герценовского университета в рамках проекта «Команда педагогов под ключ». Поздравить новоиспечённых учителей-герценовцев в жилой район Славянка приехали сотрудники отдела карьерных траекторий «Центр Мост»: начальник отдела Светлана Владимирова и ведущий аналитик Ольга Заболоцкая. Они пожелали коллегам лёгкого вхождения в профессию, дружного коллектива и любознательных учеников. С вступлением в новую должность молодых педагогов также поздравили учителя и директор школы Елена Дерипаска. В актовом зале нового здания школы прошёл праздничный концерт для учеников и преподавателей с участием почётных гостей. С приветствием к участникам праздника обратился вице-губернатор Санкт-Петербурга Николай Линченко. «Нет ни одной сферы деятельности, в которой не были бы востребованы глубокие знания. Именно знания являются основой социально-экономического развития и основой созидательного процесса любого общества. С Днём знаний присутствующих поздравил депутат Государственной думы Виталий Милонов и дал напутствие школьникам: «Самые успешные страны — те, которые вкладываются в знания и в развитие. У нас нет другого выбора, за нас делать никто ничего не будет. Вы сейчас как инвесторы — инвестируете в собственное будущее. Делайте сегодня то, что хотите сделать завтра, а не наоборот». Депутат законодательного собрания Дмитрий Павлов также выступил с поздравлением к 1 сентября. Торжественная часть праздника завершилась вручением символического ключа от нового здания школы её директору Елене Дерипаска. Генеральный директор группы компаний «КВС» Сергей Ярошенко поблагодарил правительство Санкт-Петербурга за возможность воплотить такой замечательный проект. Он отметил, что компания через 2 месяца сдаст новое здание детского сада. В завершение праздничного дня директор Елена Дерипаска провела экскурсию по новому зданию школы для представителей законодательной и исполнительной власти, а также для представителей Герценовского университета. Она показала учебные классы и помещения для внеклассных занятий. Гости оценили оснащённость учебного корпуса и отметили, что ученикам школы очень повезло здесь учиться. 01.07.2022 «Путёвка в жизнь» выпускникам проекта «Команда педагогов «под ключ» Поздравляя студентов с окончанием вуза, Ирина Потехина отметила, что за последнее десятилетие ежегодно в первые классы города приходят по 20 тысяч учеников: «Мы каждый год вводим в эксплуатацию по 10-12 школ и до тридцати детских садов, испытываем колоссальную потребность в педагогах и с огромным нетерпением ждем в наши учебные заведения герценовцев». Награды за лучшие из них были вручены Елизавете Кисловой, Марии Ковковой и Виктору Богдановичу. Выступая от имени выпускников, Елизавета Пряслова поблагодарила руководство вуза, городской комитет по образованию и лично Вице-губернатора Санкт-Петербурга Ирину Потехину за предоставленную возможность стать участниками проекта «Команда педагогов «под ключ» и заверила, что герценовцы приложат все силы, чтобы оправдать возложенное на них доверие.
Фотографии: Педагогические вести 24.05.2022 Герценовцы, ставшие участниками проекта «Команда педагогов под ключ», продолжили защиту выпускных работ 24 мая в Гербовом зале, где с презентациями своих разработок выступили 19 студентов. В состав комиссии вошли заведующая кафедрой дидактики института педагогики Елена Пискунова, начальник отдела карьерных траекторий «Центр Мост» Светлана Владимирова, директор инженерно-технологической школы Ломоносовского района Ксения Елистратова, заместитель директора по учебно-воспитательной работе школы № 353 Московского района Елена Козловская и председатель методического объединения естественно-научного цикла школы № 353 Московского района Полина Батова. Студенты представляли проекты, отвечающие запросам учебных заведений, в которые в случае успешного прохождения отбора им предстоит выйти на работу: школы № 353 Московского района, школа № 604 Пушкинского района и инженерно-технологической школы Ломоносовского района. Выпускные работы, направленные на решение конкретных задач, охватывали широкий круг тем: инновационные формы организации домашней работы, внеурочная деятельность, эстетическое развитие школьников, волонтёрство. Студентки факультета физики Анастасия Бердникова, Лариса Комелева, Дарья Липей и Алёна Сбоева представили проект «Внеурочная деятельность как ресурс развития общего образования». О своей идее они рассказали: «В рамках нашего предмета, физики, мы решили предложить такую форму внеурочной деятельности, как кружок под названием “Физика в гостях у художников”. В кружке мы планируем рассматривать с детьми различные картины и искать там физические закономерности, чтобы решить проблему эстетического воспитания и повысить их интерес как к искусству, так и к естественным наукам». Студентка факультета химии Эрика Моклуз подняла актуальную тему использования электронных ресурсов в школьном образовании: «Мой проект посвящён управлению учебной деятельностью в цифровой среде. Проекты очень заинтересовали слушателей и заслужили высокую оценку членов комиссии, которые пожелали участникам проекта профессиональной реализации. Проект по созданию команды педагогов под ключ позволяет увеличить число студентов и выпускников педагогических вузов, выбирающих профессию педагога, так как специализированная подготовка к работе учителя, сопровождение молодого специалиста на начальных этапах вхождения в профессию снимают психологические ограничения при освоении такой сложной и ответственной профессии, как учитель, а также может снизить кадровый дефицит в российских школах.
23. После двух месяцев активной работы студенты РГПУ им. А. И. Герцена, ставшие участниками «Команды педагогов под ключ», в Гербовом зале представили на суд комиссии свои проектные разработки — как индивидуальные, так и групповые. В первый день успешную защиту прошло пять проектов, тематика которых была определена запросами конкретного учебного заведения — школы № 604. В состав комиссии вошли заведующая кафедрой дидактики института педагогики Елена Пискунова, заместитель начальника управления межрегионального сотрудничества в сфере образования, доцент кафедры психологии профессиональной деятельности института психологии Юлия Проект, начальник отдела карьерных траекторий «Центр Мост» Светлана Владимирова, заместитель директора по воспитательной работе школы № 604 Алена Телух. Елена Витальевна отметила: «Сегодняшняя защита — это важное событие не только для вас. Для нас это тоже своеобразный экзамен: насколько мы смогли подготовить выпускников к будущей работе. Тематика представленных проектов была крайне разнообразной. Студентка 3 курса института психологии Александра Коваленко подняла актуальную проблематику профилактики кибербуллинга, ее коллега Мария Хорошева разработала проект, нацеленный на сплочение школьного коллектива. Виктор Богданович, студент 4 курса института истории и социальных наук, предложил проект «Забытые игры нашего двора». Идею зимнего сада как специальной зоны в школьном пространстве развила в своем проекте студентка 3 курса факультета географии Анастасия Рыбакова. Задачу превращения выполнения домашних заданий в интересную увлекательную игру поставили участники группового проекта — студентки 4 курса института художественного образования Диана Кикосова и Дарья Чиркова, студентка 3 курса института иностранных языков Елизавета Пряслова. Проекты вызвали неподдельный интерес слушателей и активную дискуссию. Разработки заслужили высокую оценку членов комиссии, которые пожелали участникам проекта профессиональной реализации. Со стороны школьного руководства Алена Телух поддержала ребят: «Мы верим, что вы воплотите ваши идеи, как никто лучше, поэтому мы ждем вас, наши дети ждут вас — с вашими идеями, с вашей молодостью, с вашим талантом и неиссякаемой энергией». Ребята пояснили выбор темы своего проекта и поделились впечатлениями от участия в «Команде педагогов под ключ». Виктор Богданович (студент 4 курса института истории и социальных наук): «Я вижу сколько времени современные школьники проводят с гаджетами. Детям необходимо показать другие игровые практики, в том числе, используя опыт прошлого, ведь методического материала предостаточно. Игры прошлого рассчитаны на обширное пространство, например, большой крестьянский двор. Подвижные игры во дворе были отдушиной в трудовой жизни. Современные дворовые игры проходят в гораздо более замкнутом пространстве и, по сути, являются единственной альтернативой гаджетам. Студентка 4 курса института художественного образования Диана Кикосова и студентка 3 курса института иностранных языков Елизавета Пряслова рассказали, что их знакомство состоялось во время первой встречи участников и идея создания общего проекта возникла в ходе экскурсии в школу № 604. Участники мини-команды поделились: «Для начала мы определились, что домашнее задание мы оставляем. Затем стали думать, как его модернизировать. Мы сами не любили его в школе, потому что неинтересно было организовано. В разработке мы опираемся на ролевые игры и проектную деятельность, где есть игровое начало. В ходе участия в проекте «Команда педагогов под ключ» мы познакомились с теми, кто действительно хотят стать учителями. Мы здесь нашли единомышленников и получили обратную связь от ведущих педагогов Санкт-Петербурга — это очень ценно. Студентка 3 курса факультета географии Анастасия Рыбакова: «По моей задумке зимний сад в школе может стать не только местом релаксации и совместного времяпрепровождения учеников, учителей и родителей, но и научной базой для проведения различных работ по биологии, экологии, а также площадкой сотрудничества с вузами и Ботаническим садом. Здесь могут взаимодействовать ученики разного возраста, например, старшие ученики химико-биологических классов могут проводить экскурсии и показывать правила ухода за растениями. К созданию дизайна зимнего сада в форме конкурса можно привлечь всех участников учебного процесса. Проект «Команда педагогов под ключ» включил в себя очень интересные тренинги, где опытными педагогами раскрывались практические навыки — общения, поведения, даже умения одеваться и многого другого».
22. 22 апреля начальник отдела карьерных траекторий «Центр Мост» Светлана Владимирова и студенты из проекта «Команда школьных педагогов «под ключ» стали участниками международной акции «Сад памяти». Её цель – увековечить память каждого, кто погиб в годы Великой Отечественной войны. За первые два года к акции присоединилось более 2 миллионов человек из всех 85 регионов России. Более 50 стран ближнего и дальнего зарубежья поддержали масштабную инициативу. На территории «Инженерно-технологической школы» Ломоносовского района Санкт-Петербурга участники акции посадили именные деревья в память о своих предках, а также преподавателях и сотрудниках РГПУ им. А.И. Герцена, внесших вклад в Победу нашей страны в Великой Отечественной войне. «Инженерно-технологическая школа» откроет свои двери с 1 сентября 2022 года. В состав педагогического коллектива войдет команда молодых учителей, выпускников Герценовского университета. Подготовка команды ведется в рамках партнерского соглашения между РГПУ им. 19.04.2022 19 апреля в Дискуссионном зале РГПУ им. А. И. Герцена в рамках реализации проекта «Команда школьных педагогов «под ключ»» прошли открытые лекции заместителя директора по научной деятельности ГБНОУ «Академия цифровых технологий» Валерия Волкова и заместителя председателя Комитета по образованию Михаила Пучкова. Спикеры поделились знаниями из своего многолетнего опыта о том, как можно использовать информационные системы в работе учителя, и рассказали о возможностях профессионального развития педагога в современных условиях. Валерий Волков поговорил со слушателями о глобальных вызовах системе образования в XXI веке, месте учителя в современном мире и о путях развития его профессионализма. В ходе лекции он сопоставил формы профессионального развития и условия труда учителей в разных странах, в частности, в России, Японии и США. Михаил Пучков побеседовал с будущими учителями о профессиональных ценностях педагога, показал, куда движется сфера образования в целом. Он задавал вопросы слушателям и просил отрефлексировать. «Учитель умирает, когда перестает развиваться. Как только что-то вам становится неинтересно делать для себя с точки зрения собственного развития, то и ученикам перестает быть интересно с вами. И, соответственно, вам с ними. Образование — это сфера, которая заряжает. Она классическая, но в ней постоянно появляется что-то новое», — отметил Михаил Юрьевич. Он рассказал о том, что такое цифровая трансформация в сфере образования: «Это эффективная информационная поддержка всех участников образовательных отношений. Отдать информацию для родителя, учителя и ребёнка, чтобы получив эту информацию, они стали более эффективны для развития ребёнка — идеальная цель для цифровой трансформации». 11.04.2022 В Точке кипения Герценовского университета 11 апреля прошли занятия курсов повышения квалификации «Навыки учителя XXI века» в рамках проекта «Команда школьных педагогов «под ключ»», реализуемого отделом карьерных траекторий «Центр Мост» под руководством Светланы Владимировой. Участники проекта были разделены на две группы. Первая группа отправилась в зал «Коменский». Там прошел психологический тренинг «Разбор сложных случаев в поведении учащихся». В роли модераторов выступили преподаватели кафедры психологии профессиональной деятельности РГПУ им. А. И. Герцена Александра Кошелева и Виолетта Луговая. На встрече присутствовали учащиеся психолого-педагогических классов школы № 2065 г. Москвы и школы № 47 г. Санкт-Петербурга. На тренинге гости и студенты университета постарались представить образ идеального учителя, проанализировали современные проблемы, с которыми сталкивается молодой педагог.
04.04.2022 и 06.04.2022 В Герценовском университете прошла вторая неделя занятий проекта «Команда педагогов под ключ»
Екатерина Дмитриевна поделилась с аудиторией советами на основе своего многолетнего опыта работы в школе. Студенты узнали о философии принятия профессии, о преимуществах внеурочной деятельности и доп.образования, о важности оценивания школьника относительно его самого в развитии, и хитростях в повышении мотивации учащихся, о тонкостях общения с администрацией школы, коллегами и родителями учеников, о том, как сплотить «сложный» класс, почему так важно прийти в школу не посторонним и учиться профессии с первого летнего педсовета, после того, как определился с ответами на два основных вопроса – чему учить и как учить, постепенно привыкая к новому пространству, особому ритму жизни, оставаясь честным с собой и передавая детям знания, как мыслить критически, делать выбор, расти над собой, уважать интеллектуальную собственность, закладывать фундамент для будущей учёбы.
28-29.03.2022 В Герценовском университете стартовали занятия проекта «Команда педагогов под ключ» 28-29 марта в Герценовском университете прошли первые занятия курсов повышения квалификации «Навыки учителя XXI века» в рамках проекта «Команда школьных педагогов под ключ». Начальник управления межрегионального сотрудничества в сфере образования Елена Спасская торжественно открыла мероприятие вдохновенными напутственными словами участникам проекта. Первую лекцию курсов повышения квалификации «Учитель будущего или будущее учителя» герценовцам прочла Елена Казакова, профессор, доктор педагогических наук, директор института педагогики СПбГУ, член-корреспондент Российской академии образования. Основное внимание в ходе обсуждения уделялось трём вопросам: методологии, включающей в себя персонализированное образование, цифровизации и личностному потенциалу. Второго выступающего, Анастасию Микляеву, профессора, доктора психологических наук РГПУ им. А. И. Герцена, аудитории представила Светлана Владимирова, начальник отдела карьерных траекторий «Центр Мост». Анастасия Владимировна прочла лекцию «Психолого-педагогические технологии профилактики буллинга в образовательных учреждениях», в которой подробно рассказала о тонкостях понимания определений «буллер», «жертва», «наблюдатели», о мифах и признаках буллинга, принципиальной важности различения конфликта и буллинга, и их распространённости в школах. Елена Николаева, профессор, доктор биологических наук РГПУ им. А. И. Герцена представила две лекции «Чтение как изменение мозга и личности ребенка» и «Двойная исключительность – основная проблема начальной школы». Обе лекции были наполнены множеством увлекательных фактов из точных наук. Елена Ивановна в своём выступлении охватила целый ряд актуальных проблем: обучение чтению, развитие модели психического, влияние стресса на организм человека, важность допущения ошибок, связь музыки и работы нейронов мозга, а также поделилась методиками помощи детям с дислексией. 24.03.2022 Состоялся установочный семинар по проекту «Команда школьных педагогов под ключ». Начальник Управления межрегионального сотрудничества в сфере образования РГПУ им. А. И. Герцена Елена Спасская приветствовала участников семинара — студентов старших курсов университета. «За вашими достижениями в рамках проекта очень внимательно наблюдает руководство Герценовского университета, Комитет по образованию и администрации районов, — отметила Елена Борисовна. — Для нас очень ценно ваше время и ваше внимание к проекту. Учителю важно видеть новые горизонты и новые возможности, ведь чем шире будет ваш кругозор, тем продуктивнее станет работа». Семинар был посвящен специальной программе, созданной специально для участников проекта. Елена Спасская представила преподавателей курсов, в число которых вошли представители Комитета по образованию и Герценовского университета. Начальник Отдела карьерных траекторий «Центр Мост» Светлана Владимирова рассказала студентам, как будут проходить обучение, а также поделилась информацией о дисциплинах, экскурсиях и грядущих встречах в рамках проекта «Команда школьных педагогов под ключ». В семинаре приняли участие представители школ-участниц проекта: заместитель директора по воспитательной работе школы № 604 Алена Телух, заместитель директора школы № 353 Елена Козловская и директор Инженерно-технической школы Ксения Елистратова. Они представили темы проектных работ: «Формирование комфортной среды образовательного учреждения», «Система работы в школе в области изобретательства и патентования продуктов интеллектуальной деятельности» и многие другие. Кроме того, семинар посетили представители Республики Тыва: первый заместитель министра образования Республики Тыва Ирина Сарагашева, ректор ГАОУ ДПО «Тувинский институт развития образования и повышения квалификации» Жанна Уважа, директор ГБУ «Институт оценки качества образования Республики Тыва Виктория Донгак. 18.02.2022 18 марта прошла встреча студентов РГПУ им. А. И. Герцена с педагогическим коллективом школы № 604 Пушкинского района Санкт-Петербурга в рамках проекта «Команда школьных педагогов под ключ». После презентации деятельности школы и перспектив её развития студенты посетили экскурсию по школьным помещениям. Герценовцы высоко оценили многообразие спортивных секций: от водного поло и обучения плаванию учащихся младших классов до командно-тактического фехтования и спортивных единоборств. Кроме того, студентов воодушевил диапазон возможностей, предоставленных школой для развития творческих способностей учащихся: хореографическая студия «Акварель», музыкальный ансамбль «Нитриты», глиняная мастерская и множество других кружков и секций по интересам. В школе № 604 Пушкинского района Санкт-Петербурга обучается более 2000 школьников, педагогический коллектив состоит из 186 человек. В сентябре 2022 года планируется введение в эксплуатацию второго здания школы, рассчитанного на 1375 мест. Благодаря такому расширению педагогического состава студенты Герценовского университета приглашаются в школу после окончания вуза для работы учителями разных предметов. В школе уже активно развиваются и продолжат укрепляться такие направления, как: патриотическое воспитание, инновационная деятельность, формирование педагогического коллектива и культурно-досуговая деятельность микрорайона Славянка. 28.02.2022 «Давайте познакомимся»: студенты-герценовцы встретились с представителями школ в рамках проекта «Команда педагогов под ключ». В Герценовском университете продолжается реализация проекта «Команда педагогов под ключ» — инновационной технологии подготовки выпускников педагогического вуза к реализации актуальных задач современной школы. В Гербовом зале университета состоялась презентация школ-участников проекта «Давайте познакомимся». Студенты узнали условия обучения по программе повышения квалификации с выдачей сертификата установленного образца и получили исчерпывающую информацию о школах, в которые предстоит выйти на работу её выпускникам. И. о. проректора по образовательной деятельности и цифровой трансформации Виктория Снегурова отметила: «Этот проект — замечательная инициатива, которой Герценовский университет в очередной раз доказал, что он — не только флагман педагогического образования в России, но и источник очень ярких и продуктивных инноваций в сфере подготовки молодых педагогических кадров». Начальник управления межрегионального сотрудничества в сфере образования Герценовского университета Елена Спасская обратилась к студентам: «Сегодняшняя встреча поможет вам понять, чего ожидать, когда вы будете готовиться к самостоятельной работе в образовательном учреждении. Также во встрече приняли участие главный специалист отдела аттестации и повышения квалификации педагогических кадров Комитета по образованию Санкт-Петербурга Наталья Михайлова, председатель Комитета по образованию Ломоносовского района Ленинградской области Ирина Засухина и главный специалист Комитета общего и профессионального образования Ленинградской области Марина Орлова. Свои учебные заведения представили заместитель директора по учебно-воспитательной работе школы № 353 Московского района Елена Козловская, директор школы № 604 Пушкинского района Елена Дерипаска и директор инженерно-технологической школы Ломоносовского района Ленинградской области Ксения Елестратова. Студенты с интересом выслушали представителей школ и проявили большую мотивированность, задав многочисленные вопросы об условиях и перспективах работы. Студент института психологии Роман поделился: «На мой взгляд, на старших курсах очень важно иметь чёткое представление о будущем месте работы. Я хочу работать в школе, поэтому было интересно послушать потенциальных работодателей». Проект по созданию команды педагогов под ключ позволяет увеличить число студентов и выпускников педагогических вузов, выбирающих профессию педагога, так как специализированная подготовка к работе учителя, сопровождение молодого специалиста на начальных этапах вхождения в профессию снимают психологические ограничения при освоении такой сложной и ответственной профессии, как учитель, а также может снизить кадровый дефицит в школах РФ.
Презентация о проекте Команда школьных педагогов «под ключ», включающая в себя результаты 2020-2021 гг. Скачать файл Концепция проекта Команда школьных педагогов «под ключ».
План-график реализации инновационного образовательного проекта в 2021 г.
Для отбора студентам необходимо пройти ряд психодиагностических методик для измерения профессиональных и личностных характеристик участников проекта: 1. Методика «Ценностные ориентации» М. Рокича; 2. Методика Е.А. Климова «Определение типа будущей профессии»; 3. Методика «Оценка профессиональной направленности личности учителя». Кроме того, необходимо заполнить авторскую анкету для оценки мотивации студента для участия в проекте, включающую сведения об академической успеваемости. Для связи нужно обратиться по телефону (812) 643-77-67 (доб. н. 26-36) или электронной почте [email protected]
Скачать файл Скачать файл Расписание занятий по программе повышения квалификации 20-31 мая 2021 г.
Новости о проекте
12.02.21 Герценовскому университету присвоен статус федеральной инновационной площадки В конце декабря ушедшего года Министерством науки и высшего образования был издан приказ «Об утверждении перечня организаций, отнесенным к федеральным инновационным площадкам, составляющим инновационную инфраструктуру в сфере высшего образования и соответствующего дополнительного профессионального образования». Статус федеральной инновационной площадки получили 127 университетов и институтов России. РГПУ им. А. И. Герцена вошел в перечень организаций, отнесенных к федеральным инновационным площадкам, составляющим инновационную инфраструктуру в сфере высшего образования и соответствующего дополнительного профессионального образования. В университете начинают функционировать сразу две федеральные инновационные площадки:
Новость на официальном сайте РГПУ им. А. И. Герцена о присвоении статуса ФИП от 12.02.21: https://www.herzen.spb.ru/news/12-02-2021_1/
20.03.21 Начинается подготовка новой «команды педагогов «под ключ» для дошкольного отделения МОБУ «Бугровская СОШ №2» В 2021 г. в пос. Бугры Ленинградской области откроется новый детский сад в МОБУ «Бугровская СОШ №2». С просьбой подготовить команду педагогов для новой образовательной организации обратилась директор школы Панкрева Анна. В апреле 2021 г. студенты-выпускники и магистранты института детства, института музыки, театра и хореографии, а также института физической культуры и спорта приступят к обучению по новой программе дополнительного профессионального образования «Навыки педагога XXI века: дошкольное образование», которая была разработана специально для проекта. Трудоустройство студентов в Бугровскую СОШ №2 является уникальным проектом подготовки команды педагогов «под ключ» — одним из этапов масштабного проекта по сопровождению развития новой школы Ленинградской области, реализуемого совместно с Правительством Ленинградской области и Комитетом общего и профессионального образования Ленинградской области. В 2020 г. в рамках проекта в среднюю школу уже была внедрена команда из молодых педагогов-выпускников РГПУ им. А. И. Герцена в составе 17 человек. В 2021 г. РГПУ им. А. И. Герцена получил статус Федеральной инновационной площадки для продолжения реализации проекта под названием ««Команда школьных педагогов «под ключ». Новость на официальном сайте РГПУ им. А. И. Герцена о начале подготовки новой «команды педагогов «под ключ» для дошкольного отделения МОБУ «Бугровская СОШ №2» от 20.03.21: https://www.herzen.spb.ru/news/20-03-2021_1/
21.06.21 Студенты РГПУ им. А. И. Герцена посетили дошкольное отделение МОБУ «Бугровская СОШ №2» В РГПУ им. А. И. Герцена завершилась реализация программы дополнительного профессионального образования «Навыки педагога XXI века: дошкольное образование» (72 ак.ч.), предназначенная для студентов-выпускников и магистрантов РГПУ им. А. И. Герцена, которые будут в составе команды трудоустроены в дошкольное отделение МОБУ «Бугровская СОШ №2». По итогам программы студентам необходимо выполнить задания по проектированию дополнительных занятий для воспитанников детского сада – это станет критерием оценки их успеваемости при обучении. Новый детский сад рассчитан на 14 групп детей, имеет большую территорию, спортивный и хореографический залы. Здание детского сада находится по соседству с школой, что позволяет реализовывать дополнительные возможности с целью преемственности образования. В сентябре в дошкольное отделение МОБУ «Бугровская СОШ №2» уже придут воспитанники. Студенты РГПУ им. А. И. Герцена познакомились с территорией и зданием нового детского сада. После небольшой экскурсии в здании МОБУ «Бугровская СОШ №2» было проведено совещание с будущими педагогами о миссии нового образовательного учреждения, условиях работы в детском саду. Директор МОБУ «Бугровская СОШ №2» Анна Панкрева ответила на вопросы студентов. На встрече также присутствовали начальник управления обеспечения сотрудничества с образовательными организациями Анна Обласова, доцент кафедры дошкольной педагогики Лидия Ничипоренко. Новость на официальном сайте РГПУ им. А. И. Герцена о посещении студентами-участниками проекта дошкольного отделения МОБУ «Бугровская СОШ №2» от 21.06.21 https://herzen.spb.ru/news/21-06-2021_2/
20.09.21 В РГПУ им. А. И. Герцена продолжается реализация проекта «Команда педагогов «под ключ» В 2021 г. РГПУ им. А. И. Герцена получил статус Федеральной инновационной площадки для продолжения реализации проекта под названием ««Команда школьных педагогов «под ключ». Инновационная технология подготовки выпускников педагогического вуза к реализации актуальных задач современной школы и сопровождения молодых учителей на этапе «входа» в профессию». Проект предполагает создание не отдельных педагогических кадров, но целого педагогического коллектива, характеризующегося высоким профессионализмом и инициативностью, для работы в новых образовательных организациях, а также в образовательных организациях, в которых требуются кадровые преобразования. Проект по созданию команды педагогов «под ключ» позволяет увеличить число студентов и выпускников педагогических вузов, выбирающих профессию педагога, т.к. специализированная подготовка к работе учителя, сопровождение молодого специалиста на начальных этапах вхождения в профессию снимают психологические ограничения при освоении такой сложной и ответственной профессии, как учитель, а также может снизить кадровый дефицит в школах РФ. В рамках данного проекта РГПУ им. А. И. Герцена уже успешно подготовил 2 команды педагогов для новой школы МОБУ «Бугровская СОШ №2» в 2020 г. и дошкольного отделения этой же школы в 2021 г. Всего в комплексе МОБУ «Бугровская СОШ №2» на данный момент работают 20 выпускников РГПУ им. А. И. Герцена, из них 3 в течение первого года работы уже получили 1 квалификационную категорию, а их ученики стали победителями олимпиад и конкурсов. В МОБУ «Бугровская СОШ №2» в этом году также открывается психолого-педагогический 8 класс, в котором осуществляется предпрофильная подготовка учеников. В новом учебном году программа подготовки команды педагогов «под ключ» открывается вновь. На данный момент осуществляется поиск базовой образовательной организации для реализации проекта. При этом продолжается работа с уже трудоустроенными командами по научно-методическому сопровождению их деятельности в образовательных организациях. Новость на официальном сайте РГПУ им. А. И. Герцена о продолжении реализации проекта «Команда педагогов «под ключ» от 20.09.21 https://www.herzen.spb.ru/news/20-09-2021_7/
Контакты по проекту (в 2021 г.) E-mail: [email protected] Тел. (812) 643-77-67 (доб. н. 26-36)
| ||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение: 5 сентября 2022 г. в 12:28:07 |
MCV в анализе крови: показания, подготовка, норма
Содержание:
- Описание анализа
- Подготовка к анализу
- Расшифровка анализа крови mcv
- MCV в анализе крови повышен
- MCV понижен
MCV в анализе крови это один из важнейших эритроцитарных индексов. Он отражает средний объем эритроцита, высчитывается путем деления показателя гематокрита на число эритроцитов. Результат выражается в кубических микронах либо фемтолитрах.
Еще один способ получения данного показателя – умножение гематокрита на 10 и деление полученного числа на количество красных кровяных клеток, содержащихся в одном кубическом миллиметре крови.
Важно учитывать, что в некоторых случаях анализ на mcv будет давать недействительные данные. Например, при серповидно-клеточной анемии в кровотоке циркулирует большое количество аномальных, деформированных эритроцитов. Поэтому полученные расчетным путем индексы будут в таком случае неинформативными.
Описание анализа
Показатель mcv вычисляется на основании данных, полученных из общего анализа крови. Это одно из наиболее массовых и часто назначаемых лабораторных исследований. Он позволяет комплексно оценить состояние всей системы кроветворения.
Эритроцитарные индексы, которые входят в состав общего анализа крови позволяют с достаточно высокой точностью диагностировать и классифицировать различные анемии.
Благодаря этому врач сможет поставить точный диагноз и назначить правильную схему лечения.
Так как анализ прост, недорог и общедоступен его используют в качестве скрининговой методики выявления нарушений в системе кроветворения. Еще одно преимущество методики – возможность динамического контроля эффективности проводимого лечения и своевременная корректировка дозировок назначенных пациенту препаратов.
На результат исследования могут повлиять наличие выраженного лейкоцитоза, большое количество ретикулоцитов, значительное превышение нормального уровня глюкозы. Все эти состояния приводят увеличению среднего размера эритроцита.
Также нужно учитывать, что одновременное увеличение макроцитарных (крупных) и микроцитарных (мелких) эритроцитов может создать видимость нормы. Это связано с тем, что mcv – расчетный показатель, который не всегда отражает объективное состояние клеток крови. Для выявления нарушений в таких случаях требуется прямая микроскопия мазка крови, взятой у обследуемого.
Подготовка к анализу
В большинстве случаев кровь для анализа забирается из вены. Допустимо взятие капиллярной крови у детей до 3 лет и у взрослых по особым показаниям. Анализ берется утром, натощак, период голодания должен составлять не менее 8 часов.
Перед забором крови запрещается употреблять пищу и любые напитки, можно пить простую воду. Соблюдать диету за несколько дней до анализа нет необходимости, но стоит исключить спиртные напитки, жирную пищу. Нежелательно подвергаться высоким физическим и психоэмоциональным нагрузкам, которые могут повлиять на достоверность результатов анализа.
В процессе подготовки к процедуре забора крови пациента нужно предупредить о возможных неприятных ощущениях при наложении жгута и в процессе пункции вены.
Расшифровка анализа крови mcv
Нормальным значением показателя mcv для людей от 18 до 45 лет считается диапазон от 84 до 99 мкм3. Норма mcv в течение жизни человека достаточно сильно изменяется. Для новорожденных нормальным показателем считается до 112 мкм3, затем, по мере взросления средний объем эритроцита быстро уменьшается. Поэтому уже для подростков 12-15 лет нормальным значением считается диапазон от 73 до 95 кубических микрометров.
В целом, можно сказать, что объем эритроцитов максимален у новорожденных и медленно снижается на протяжении всей жизни. При этом то, что большая часть эритроцитов имеет нормальный объем, но не исключает наличия патологий, связанных с кроветворной системой. Например, достаточно часто встречаются нормоцитарные анемии – заболевания крови, которые не влияют на средний объем эритроцитов.
Чаще всего такая анемия возникает после серьезной кровопотери, в процессе восстановления после состояний связанных с недостатком железа. Нередко нормоцитарная анемия свидетельствует об угнетении функций красного костного мозга, тяжелых заболеваниях печени и почек. Реже она является проявлениями других патологических процессов, таких как гемоглобинопатия. Но не стоит путать MCV и MCHC, так как это два разных показателя.
MCV в анализе крови повышен
Если расшифровка mcv анализа крови показала увеличение показателя выше 100 мкм3 это признак развития анемии, связанной с недостатком фолиевой кислоты либо витамина В12. В результате происходит нарушение процессов формирования эритроцитов. Они увеличиваются в объеме, но плохо справляются с функцией транспортировки кислорода. Одновременно с ростом размеров красных кровяных клеток часто снижает уровень гемоглобина. Такое сочетание признаков хорошо выявляется при общем анализе крови и служит достаточно надежным фактором диагностики.
Повышение mcv может служить проявлением и других заболеваний, в том числе очень серьезных. В их число входят заболевания печени и костного мозга, гемолитические состояния, миелодиспластические состояния.
Не всегда повышение mcv в анализе крови свидетельствует о развитии анемии либо других серьезных патологий. Значения выше 100 мкм3 могут наблюдаться у людей, длительно злоупотребляющих алкоголем, курильщиков с многолетним стажем, а также при хроническом нарушении функций щитовидной железы.
MCV понижен
Снижение среднего объема эритроцитов чаще всего возникает при развитии железодефицитных анемий. Они могут развиваться в результате воздействия различных факторов, таких как:
- Хронические кровопотери.
- Недостаток железа в пищевом рационе.
- Нарушение всасывания железа в кишечнике.
Снижение объема эритроцитов наблюдается при разнообразных хронических заболеваниях – длительные инфекции, онкологические патологии. Изредка возможно врожденное уменьшение mcv, например, при талассемии. Это группа генетических патологий, возникающих при нарушении синтеза глобиновых цепей гемоглобина.
Если нарушен синтез альфа цепи, развивается альфа-талассемия. Это относительно нетяжелая патология, характеризуется снижением показателя гемоглобина до 70-90 г/л и снижением индекса mcv. Эта форма заболевания часто никак не проявляет себя и выявляется случайно, при изучении лабораторных показателей крови.
Значительно тяжелее протекает бета-талассемия, которая возникает при нарушении синтеза бета-цепи гемоглобина. Если дефектные гены были унаследованы от одного из родителей – она проявляется снижением mcv-индекса и уровня гемоглобина. При передаче дефектных генов от обоих родителей развивается анемия Кули. Она отличается крайне тяжелым течением, эритроциты не только резко снижаются в объеме, но и быстро разрушаются. Это приводит к увеличению печени и селезенки, нарушению их функций. Для поддержания жизни такие пациенты требуют регулярных переливаний крови, возможно и полное излечение при проведении пересадки костного мозга.
Как расширять словарный запас студента: направления и приемы работы
Фесенко Ольга Петровна,доктор филологическихнаук, профессор кафедры иностранных и русского языков Омского автобронетанкового инженерного института, г. Омск[email protected]
Как расширять словарный запас студента: направления и приемы работы
Аннотация.В статье рассматривается проблема расширения словарного запаса студентов вуза. Анализируются существующие подходы в решении этой проблемы, предлагающиеся приемы и упражнения, определяются наиболее подходящиеи продуктивные для вузовского образования в рамках дисциплины «Русский язык и культура речи». Ключевые слова:словарный запас, лексикон, студенты вуза, способы расширения словарного запаса.
До недавнего времени проблема расширения словарного запаса волновала методистов исключительно при анализе коммуникации тех, кто изучает иностранные языки, или детей, осваивающих родной язык в дошкольном и школьном возрасте. В современной методической науке встал вопрос о необходимости измерения и расширения лексикона современной учащейся молодежи, пришедшей в вузы получать образование и столкнувшейся с определенными сложностями освоения стандартов. И сложности эти во многомсвязаны с сократившимся за последние десятилетия словарным запасом обучающихся, препятствующим пониманию и осмыслению материала дисциплин высшей школы.Как организовать работу по расширению лексикона студентов вот главный вопрос, который встает перед педагогами в условиях сокращения учебных часов на обучение гуманитарныхдисциплин (в т.ч. на обучение русскомуязыкуи культуреречи). В науке достаточно давно ведется работа по совершенствованию систематизации методов и приемов расширения словарного запаса обучающихся. Если подходить с самых широких позиций, то можноговорить о наличии двух групп методов освоения словарного составаязыка: I. Методы накопления содержания речи обучающихся:1) непосредственного ознакомления с окружающим и обогащение словаря,2) опосредованного ознакомления с окружающим и обогащение словаря.II. Методы, направленные на закрепление и активизацию словаря, развития его смысловой стороны. Это различные дидактические (словарные) задания [Акулова 2016, с. 220].По сути, перед нами два этапа расширения объема словарного запаса. Один (первый)обеспечивает накопление словарного материала, другой использование его в речи. Это не единственный подход к проблеме. В научной литературе ряд исследователей выделяет несколько главных линий работы по обогащению словарного состава обучающихся: «обогащение, уточнение, активизация словаря, устранение нелитературных слов, разъяснение значений слов, в том числе уточнение значения слова по толковому словарю, подбор синонимичной (антонимичной) пары по словарю» [Артеменко 2014, с. 56].Также всовременной методике имеются точки зрения, согласно которым выделяются несколько иные направления расширения объема лексикона: непроизвольное запоминание в процессе коммуникации и чтения,произвольное заучивание слов [Вепрева 2015].Стоит отметить, что простое заучивание не обеспечивает увеличение словаря обучающегося. Поскольку лексемы, которые выучены, но не включены в речь, в коммуникацию, быстро забываются, уходят в пассивныйсловарь и перестают быть продуктивно используемыми. Несмотря на очевидность данного утверждения, довольно часто методисты ограничиваются работой со словом без его включения в коммуникацию. Расширение словарного запаса обучающегося можно осуществлять в рамках различных подходов и направлений: 1. Грамматикоорфографическое направление в словарной работе, объединяющее «морфологическую, орфографическую, морфемную работу над словом» [см. об этом: Артеменко 2014, с. 55].2. Семантическое направление,объединяющеесемантическую и стилистическую работу над словом», которая,по мнению М. Т. Баранова, «составляет основу обогащения лексикона» [см. об этом: Артеменко 2014, с. 55].Это направление весьма популярно на сегодняшний день и поддерживается как отечественными, так и зарубежными методистами. Исследователи предлагают изучать значения слова в тексте. 3. Лексикографический подход. Лексикографический подход может быть весьма актуальным в школе. Но в вузе словарная работа сама по себе не расширяет словарный запас. Кроме того, она не проводится автономно, а обязательно опираетсяна освоение грамматики и фонетики, на что в системе высшего образования просто нет времени.В рамках вузовского обучение лексикографический подход может быть только вспомогательным. 4. Коммуникативный подход освоение словарного запаса в процессе коммуникации, с использованием «коммуникативных приемов и методов в специально организованной последовательности и взаимосвязи» [Акулова 2016, с. 205]. Коммуникативный подход опирается на создание ситуации общения, т.е. «новое слово должно быть включено в речь» [см. об этом: Фетисова 2011, с. 78; Масленникова 2011, с. 196]. Коммуникативный подход обеспечивает освоение словарного состава языка без отрыва от использования слов в речи (как в устной, так и в письменной), в процессе построение связного высказывания. Мы придерживаемся точки зрения, согласно которой именно коммуникативный подход является наиболее эффективным в системе высшего образования.Тем более что в стандартах высшего образования акцент делается именно на речевое поведение, на коммуникацию, на умение выстраивать диалог и монолог с учетом требований речевой культуры и речевого этикета. Однако приоритеткоммуникативного подходане исключает возможности использования упражнений грамматикоорфографической, семантической или лексикографическойнаправленности. В совокупности и при рациональном использованииэлементы каждого подхода должныоказаться весьма продуктивными в процессе расширения словаря обучающихся, поскольку главное не расширение лексикона само по себе, а формирование у студентов способности порождать речь с использованиемсвободных контекстуальных замен с целью «уточнения мысли и избегания повторов, создания образности и стилистической адекватности» [цит. По Елизарова 2015, с. 18].Коммуникативный подход это высшая ступень в освоении лексики. Подняться на нее невозможно без восприятия и понимания смысла слова, без умения объяснять его значение. Только при формировании этих навыков имеет смысл утверждать, что обучающийся будет способен адекватно, грамматически(грамматикоорфографический подход), семантическии стилистическиверно(семантический подход), с учетом коммуникативной ситуации использовать слово в речи.В этом случае работа над орфографией уходит на второй план, что вполне возможно при освоении курса «Русский язык и культура речи» в вузе (не в школе!).
Рассмотрим, какими конкретно приемамии видами упражненийнаполняется работа по расширению словарногозапаса обучающихся. Чаще всего в методической литературе дается перечень видов упражнений без учета выбранного педагогом подхода к расширению словаря. Этот перечень традиционно охватывает следующие виды работ:использование обобщающих таблиц по стилистике [Камуз 2008, с. 43],работа с искаженными текстами [Камуз 2008, с. 43].публичные выступления с последующим анализом и оценкой [Камуз 2008, с. 44],работа с текстом образцом, его анализ [Камуз 2008, с. 4445],составление словарных карт (слово и примеры его употребления) [Вепрева 2015],составление словообразовательных цепочек [Вепрева 2015],подбор синонимов и антонимов [Вепрева 2015],запоминание слов в группе [Вепрева 2015],сочинения и изложения [Колесова 2010, с. 79],работа со словарем [Колесова 2010, с. 78],понимание значение слова с опорой на контекст (при условии, что слово многократно употреблено в тексте) с последующей проверкой по словарю [Масленникова 2011, с. 197],общение, чтение вслух, пересказ близко к тексту, заучивание наизусть [Колесова 2010, с. 7980],упражнения на развитие лексической памяти и создание когнитивного образа слова (назовите слова с удвоенной буквой, с чередование согласного и нуля звука…) [Масленникова 2011, с. 197],упражнения на развитие лингвокреативного мышления (составьте как можно больше глагольных словосочетаний с глаголом…, выберите слова, которые могут сочетаться с глаголом…, составьте словосочетания со словами…) [Масленникова 2011, с. 197],упражнение на прогнозирование (угадывание) слов и словосочетаний (продолжите предложение) [Масленникова 2011, с. 197198],сочинение по ключевым словам, дающее «возможность приобретать навыки писателя, не беспокоясь о выборе тем, стиля или формы» [Юшкевич 2015, с. 73],таксономия [Юшкевич 2015, с. 73] многоаспектный анализ и группировка слов по их смысловому наполнению. Анализ должен включать в себя не только работу с лексическим значением слова, но и с его формой, со стилистической окраской, с употреблением и т.д. При этом не рекомендуется пользоваться традиционными словарями, поскольку значение слова в них не адаптировано для детей. В зарубежной литературе такой анализ слова называют «словарным осознанием» (wordconsciousness) [Юшкевич 2015, с. 73],практическое изучение генетического анализа лексики [Акулова 2016, с. 209],применение фразеологизмов как средство выразительности речи [Акулова 2016, с. 209],изучение исторического, стилистического и социального анализа словарного состава языка [Акулова 2016, с. 209],изучение семантической системы языка [Акулова 2016, с. 209]изучение заимствованной лексики [Акулова 2016, с. 209].восстановление, реконструкция отдельных неполных высказываний или преднамеренно деформированного текста (заполнение пропусков, дополнение, перегруппировка) [Акулова 2016, с. 224],игровое моделирование, драматизация (используются в коммуникативных играх), методические приемы драматизации вырабатывают у студентов умение варьировать форму своего высказывания, выбирать официальный или неофициальный стиль речи, исходя из оценки говорящим условий речевого общения [Акулова 2016, с. 225],лингвистический анализ художественного и публицистического текстов [Егорова 2010, с. 148],Как видно из приведенного достаточно подробного перечня, абсолютное большинствоупражнений не может быть применено в рамках коммуникативного подхода в вузе. Это объясняется следующими причинами.Вопервых, курс «Русский язык и культура речи» крайне мал по количеству учебных часов, чтобы уделять внимание всем предложенным видам работ, какими бы полезными они не казались преподавателю.
Вовторых, такие задания будут требовать от обучающихся примерно одинакового уровняязыковой подготовки, что весьма проблематично, поскольку студенты / курсанты приезжают учиться в вуз из разных регионов России, из села и из города. Эта проблема требуетдифференцированного подхода к обучению культуре речи.Втретьих, некоторые рекомендации педагогов по расширению словарного запаса кажутся не совсем удачными, поскольку сложность заданий и целесообразность их применения вызывают вопросы. С одной стороны, мы говорим о том, что у студентов недостаточный словарный запас и в условиях небольшого объема учебных часов крайне сложно организовать работу по его расширению. С другой стороны, в научной литературе встречаются упражнения, выполнение которых требует от студентов уже сформированного лингвистического мышления, навыка работы со словарями и с художественным текстом, умения различать стилистические фигуры и тропы и т.д. [Егорова 2010, с. 149]. Мало того, что такие задания не могут быть вписаны в контекст обучения по дисциплине «Русский язык и культура речи» (на занятиях нет времени на то, чтобы анализировать отрывки из произведений русских классиков, как советуют педагоги, т. к. объем учебного материала с трудом распределяется между 1618 учебными парами), так еще и для студентов технических специальностей это «неподъемный материал», поскольку у большинства из них не сформировано лингвистической мышление. Итак, все перечисленное обусловливает специфику расширения словарного запаса в вузе тремя важнейшими факторами: 1) недостаток учебного времени в сочетании с большим объемом информации, необходимой для освоения курса; 2) разный уровень подготовки обучающихся и отсутствие достаточно хорошо сформированного лингвистического мышления у студентов / курсантов технических специальностей и направленийподготовки; 3) сложность и нецелесообразность некоторых заданий, направленных на расширения словаря.Все это заставляет педагога не изучать содержание программы по дисциплине «Русский язык и культура речи», а осваивать его «на практике», т.е. делать изучение необходимого для выполнения упражнений теоретического материала частью практической работы, которая станет этапом или элементов коммуникативного процесса (как устного, так и письменного). Иными словами, главная цель курса «Русский язык и культура речи» это «повышение уровнявладениясовременным русским литературным языком в разных сферах общения» [Камуз 2008, с. 42]. Для овладения языкомследует отдать приоритет реальной практической речевой и коммуникативной деятельности, т.е. отказаться от языковой теории ради теории и обратиться к общению (как устному, так и письменному), в рамках которого выпускник будет после окончания вуза демонстрировать свои коммуникативные навыки. В каких формах возможна реализация такого подхода? Прежде всего, в форме тренинга. Например, если темой занятия становится официальноделовой стиль и его языковые особенности, то после учебного занятия обучающийся должен выти не с представлением о том, какие языковые единицы должны встретиться в документах, а с навыком составления текстов официальноделовогостиля. При этом студенту в процессе практического занятия необходимо предоставить возможность для составления таких текстов, чтобы в тетради у каждого из них были автобиография, рапорт, характеристика или какиелибо иные документы (согласно учебной программе). В таком случае можно подключить и «искаженные тексты», и упражнения на прогнозирование (угадывание) слов и словосочетаний (продолжите предложение), и упражнения на развитие лингвокреативного мышления и т.д.Если, скажем,речь идет о видах устной деловой коммуникации, то следует организовать сам процесс общения в рамках предложенных в программе жанров (деловой беседы, дискуссии и пр.). Безусловно, это требует огромной предварительной подготовки как со стороны преподавателя, так и со стороны обучающихся. Проходить подобныезанятия могут в виде тренинга, игрового моделирования, драматизации, организованныхв формате деловой игры со всей учебной группой или в микро группах. Кигре имеет смысл подключить «экспертов» из числа студентов, заранее получивших домашнее задание по освоению требований оформления конкретных видов документов или проведения деловых бесед и т.д. Игра даст возможность реализовать и дифференцированный подходк обучению, позволил выбирать роли с учетом языковой подготовки. Данноеобучение культуре речи будет проходить «с опорой на формирование коммуникативной и культуроведческой компетенций, которые, являясь ведущими, подчиняют себе компетенции языковую»[Камуз 2008, с. 41]. Именно такие требования предъявляют новые образовательные стандарты вузов к освоению русского языка и культуры речи, поскольку сформированная языковая компетенция сама по себе не дает возможности человеку вступать в эффективный коммуникативный процессонапредставляет собой лишь набор знаний и умений, обеспечивающих владение различными языковыми ресурсами без учета ситуации.
Ссылки на источники1.Акулова Л.П. Обогащение словарного запаса студентов в процессе обучения русскому языку на коммуникативной основе / Л.П. Акулова // Профессиональное образование и общество. 2016. № 2 (18). С. 2022262.Артеменко Н.А. Обогащение словарного запаса учащихся с опорой на идеографический подход / Н.А. Артеменко // Научнопедагогическое обозрение. 2014. № 1 (3). С. 53593.Вепрева Т.Б. Как расширить свой вокабуляр / Т.Б. Вепрева // Международный информационноаналитический журнал CredeExperto: транспорт, общество, образование, язык». 2015. № 4. Режим доступа: http://ce.ifmstuca.ru4.Егорова М. М.О методике совершенствования речевой культуры студентов / М.М. Егорова // Высшее образование в России. 2010. № 1. С. 1461505.Елизарова Е.Р. Как оценить словарный запас современного школьника: содержание и технология констатирующего эксперимента / Е.Р. Елизарова // Международный студенческий научный вестник. 2015. № 51. С. 18196.Камуз В.В. Развитие культуры речи студентов в процессе профессиональной подготовки (на примере сельскохозяйственного вуза) / В.В. Камуз // Педагогика и психология. Филология и искусствоведение. 2008. № 1. С. 41457.Колесова Т.В. Как увеличить словарный запас / Т.В. Колесова // Актуальные проблемы гуманитарных и социальноэкономических наук. 2010. №34. 77808.Масленникова Н.Л. Коммуникативнокогнитивный подход как инновационный способ обучения курсантов внутренних войск МВД России иностранному языку / Н.Л. Масленникова // Вестник СанктПетербургского университета МВД России. 2011. Т. 52. № 4. С. 1951989.Фетисова А.А. К вопросу об объеме лексического запаса студентов языкового педагогического вуза / А. А. Фетисова // Вестник Московского городского педагогического университета. Серия Филология. Теория языка. Языковое образование. 2011. № 1. С. 758010.Юшкевич Е.В. Стратегии развития личностного тезаурусаучащихся в современной зарубежной образовательной практике / Е.В. Юшкевич // Непрерывное образование. 2015. № 3 (13). С. 7174.
Значение для обучения и понимания расширения словарного запаса в JSTOR
журнальная статья
Морфологический анализ: значение для обучения и понимания роста словарного запасаТомас Г. Уайт, Майкл А. Пауэр и Шейда Уайт
Reading Research Quarterly
Vol. 24, № 3 (лето 1989 г.), стр. 283-304 (22 страницы)
Опубликовано: Международная ассоциация грамотности
https://doi.org/10.2307/747771https://www.jstor.org/stable/747771
Читать и скачивать
Войти через школу или библиотеку
Альтернативные варианты доступа
Для независимых исследователей
Подписаться на JPASS
Неограниченное чтение + 10 загрузок
Артикул покупки
46,00 $ — Загрузить сейчас и позже
Ежемесячный план- Доступ ко всему в коллекции JPASS
- Читать полный текст каждой статьи
- Загрузите до 10 статей в формате PDF, чтобы сохранить и сохранить
- Доступ ко всему в коллекции JPASS
- Читать полный текст каждой статьи
- Загрузите до 120 статей в формате PDF, чтобы сохранить и сохранить
Приобрести PDF-файл
Купите эту статью за 46,00 долларов США.
Как это работает?
- Выберите покупку вариант.
- Оплатить с помощью кредитной карты или банковского счета с PayPal.
- Прочтите свою статью в Интернете и загрузите PDF-файл из своей электронной почты или своей учетной записи.
Предварительный просмотр
Предварительный просмотр
Аннотация Стоит ли тратить время на обучение детей в средних классах выводить значение слов с помощью морфологического анализа? Сколько новых слов они смогут понять, используя морфологические знания? Авторы рассмотрели эти вопросы в двух исследованиях. В исследовании 1 они исследовали распространенность на разных уровнях чтения слов с одним из четырех частых префиксов, долю этих слов, которые могут привести к «вводящему в заблуждение анализу», и долю, в которой наблюдаются изменения правописания и произношения в суффиксах. В исследовании 2 они проверили знание учащимися префиксов, суффиксов и корневых слов. Была предложена поэтапная модель морфологического анализа, которая использовалась для получения оценок количества слов с префиксами, которые учащиеся третьего и четвертого классов должны правильно проанализировать через год, учитывая определенные предположения о чтении, знании корней и знании аффиксов. . Полученные оценки подтверждают практику преподавания морфологии в 4 классе и выше и помогают объяснить быстрый рост словарного запаса, происходящий в начальных классах. /// [французский] Les deux études présentées avaient pour but d’évaluer les pratiques d’enseignement de la morphologie et de comprendre le rôle exercé par la morphologie dans l’acquisition du vocabulaire. La première etude allow de vérifier la présence доминирующий de quatre префиксы frequents dans les mots apparaissant dans les methodes de lection à différents niveaux scolaires, де калькулятор ла пропорция d’erreurs d’analyse sur ces mots и ла пропорция де изменения consécutifs à l’ajout де суффиксы, soit au niveau de l’epellation ou de la prononciation. La deuxième étude porta sur les connaissances des élèves americains в отношении avec les префиксы, суффиксы и др. racines des mots. L’élaboration d’un modele hiérarchique d’analyse morphologique allow de prédire la progression d’éves de troisieme et de quatrième annee dans l’analyse morphologic de mots préfixés. Les résultats, подтверждающие важность морфологического анализа à partir de la quatrième année et permettent d’expliquer l’accroissement rapide du vocabulaire durant la scolarité primaire. /// [испанский] Se llevaron a cabo dos estudios para evaluar la práctica de la enseñanza morfológica e incrementar la comprensión del rol de la morfología en el aumento del vocabulario. El estudio 1 Investigó la prevalencia, en varios niveles de lectura, de palabras con uno de cuatro prefijos usados frecuentemente, la proporción de estas palabras que podrían resultar en un análisis quivocado, y la proporción que exhiben cambios de ortografía y pronunciación en el uso de лос суфихос. El estudio 2 examinó эль conocimiento де лос estudiantes norteamericanos де prefijos, sufijos у palabras raíz. Se propuso y se usó un modelo de análisis morfológico para derivar estimados del número de palabras con prefijos que se esperaba que los alumnos de tercero y cuarto grado analizarían correctamente en un año, dadas ciertas presuposiciones acerca de la lectura, conocimiento de conocimiento de raíces y афихос. Los estimados apoyan la práctica de la enseñanza morphológica del grado 4 en adelante, y facilitan la explicación del rápido aumento en vocabulario que ocurre durante los años de enseñanza elemental. /// [немецкий] Zwei studien wurden durchgeführt, um die Praxis des morphologischen Unterrichtens zu untersuchen und um ein Verständnis der Role der Morphologie beim Wortschatzzuwachs zu verbessern. Die erste Studie untersuchte das Vorherrschen von Wörtern, die eins von vier oft vorkommenden Präfixen aufwiesen und auf verschiedenen Lesestufen anzutreffen waren, ferner den Anteil dieser Wörter, der zu einer Fehlanalyse führen könnte, und den Anteil der Schungreibender Auffrender bei einer Sufferwendner Шляпа Aussprache zur Folge. Die zweite Studie untersuchte das Wissen der Americanische Schüler über Präfixe, Suffixe und Wurzelwörter. Daraufhin wurde ein Stufenmodell der morphologischen Analyse vorgeschlagen und verwendet, um Abschätzungen über die Anzahl der mit einem Präfix verbundenen Wörter vorzunehmen, die von Schülern der dritten und vierten Klasse innerhalb eines Jahres richtig eingeordnet werden, wobei bestimmte Voraussetzungen über Lese-, Wurzel- und Affixkenntnisse ангеноммен вурден. Die Schätzwerte unterstützen die Praxis des morphologischen Unterrichtens, beginnend mit der vierten Klasse, und sie sind gut dafür geeignet, den schnellen Wortschatzzuwachs zu erklären, der in den ersten vier Schuljahren stattfindet.
Reading Research Quarterly (RRQ) — ведущий рецензируемый профессиональный исследовательский журнал для тех, кто занимается изучением вопросов грамотности среди учащихся всех возрастов. RRQ поддерживает дух исследования, который необходим для постоянного развития исследований в области грамотности, и предоставляет форум для междисциплинарных исследований, альтернативных методов исследования и различных точек зрения на природу практики и политики в области грамотности различных групп людей во всем мире. RRQ доступен для физических лиц в качестве преимущества членства в Международной ассоциации чтения. Текущие выпуски доступны в ассоциации как в печатной, так и в онлайн-формах.
Международная ассоциация грамотности является профессиональной членской организацией. направлена на повышение уровня грамотности для всех путем повышения качества обучения чтению, распространения исследований и информации о чтении, и поощрять пожизненную привычку к чтению. Среди участников классные руководители, специалисты по чтению, консультанты, администраторы, супервайзеры, преподаватели университетов, исследователи, психологи, библиотекари, специалисты по СМИ и родители. Ассоциация издает несколько рецензируемых журналов и множество книг, предлагает ряд профессиональных встреч по всему миру, а также предоставляет множество других услуги образовательному сообществу.
Права и использование Этот предмет является частью коллекции JSTOR.
Условия использования см. в наших Условиях использования
Чтение исследований ежеквартально
© 1989 Уайли
Запросить разрешения
Расширение словарного запаса | English Composition 1
Цель обучения
- Описать стратегии расширения словарного запаса
- Используйте структурный анализ, чтобы понять значения слов
Изучение общих корней и этимологии слов
Современный английский язык представляет собой изобилие различных языков. На самом деле, если бы вы ограничились словами только специфически «английского» происхождения, у вас был бы довольно маленький словарный запас.
Если вы выучите основные корневые слова, особенно латинские и греческие корни, вы сможете разбивать слова на части, чтобы понять, что они означают. Взгляните на этот список греческих и латинских корней в английском языке. Вы можете быть удивлены.
учиться на практике: изучать латинские корни
Понимание структурного анализа
Структурный анализ — это процесс разложения слов на их основные части для определения значения слова. Структурный анализ является мощным словарным инструментом, поскольку знание нескольких частей слова может дать ключ к пониманию значения большого количества слов. Хотя значение, предлагаемое частями слова, может быть неточным, этот процесс часто может помочь вам понять слово достаточно хорошо, чтобы вы могли продолжать чтение без значительных перерывов.
При структурном анализе читатель разбивает слова на их основные части:
- Префиксы – части слова, расположенные в начале слова для изменения значения
- Корни – основная значимая часть слова
- Суффиксы – части слова, присоединяемые к концу слова; суффиксы часто изменяют часть речи слова
Например, слово велосипедист можно разбить следующим образом:
- bi – префикс, означающий два
- цикл — корень означает колесо
- ist — суффикс существительного, означающий «человек, который»
Таким образом, структурный анализ предполагает, что велосипедист — это человек на двух колесах, что близко к формальному определению слова.
Например, когда вы понимаете, что приставка «орто» означает «прямо» или «правильно», вы начинаете находить связи между, казалось бы, не связанными между собой словами, такими как ортодонт (специалист, выпрямляющий зубы) и орфографией (правильный, или прямой). , способ письма).
Понимание логики слов всегда окупается с точки зрения обучения и запоминания. Рассмотрим эти примеры: «завтрак» означает «прервать ночной пост», а «радуга» означает «дуга или дуга, вызванная дождем». Хотя эти значения могут быть тривиальными для носителей английского языка, такое понимание слов, иностранных или иных, всегда укрепляет вашу связь с ними.
Рассмотрим часть слова –cide. Хотя оно не может стоять как слово само по себе, оно имеет значение: , чтобы убить . Подумайте о многих словах в нашем языке, в состав которых входит слово -cide. Знание этой части слова дает нам знания о многих словах.
Инфиксы
В английском языке есть только суффиксы и префиксы (часть более крупного класса, называемого аффиксами). В других языках есть вещи, называемые инфиксами. Они идут в середине слова. Фортепиано , пианиссимо , пианиссиссимо, и т. д.
Английский язык имеет только один инфикс:
- «Абсолютно черт возьми»
- «соберись-ка черт возьми»
Приготовьтесь к работе
Для дальнейшего развития этого навыка обратитесь к удобному справочному листу «Структурный анализ: общие части слов», где приведен список некоторых распространенных префиксов, корней и суффиксов, а также их значения и примеры слов, в которых они используются. .
Чтобы попрактиковаться в этом навыке, попробуйте упражнения по структурному анализу от Летбриджского колледжа.
Хотя структурный анализ — это метод, который может использовать каждый, определенно есть определенные дисциплины, в которых он используется более широко. Медицина, в частности, использует терминологию, основанную на структурном анализе. Посетите следующие сайты, чтобы узнать некоторые общие части слова, встречающиеся в области медицины:
- Создание медицинских терминов: пищеварительная система. Этот сайт поможет вам составить и выучить термины, связанные с пищеварительной системой.
- Медицинская терминология от SweetHaven Publishing Services
- Медицинские терминологические системы, шестое издание, аудиоупражнения. Этот сайт поможет вам выучить различные части слова, связанные с медицинской терминологией.
- Ресурсы Medword. Основы медицинской терминологии. Этот сайт содержит списки медицинских префиксов, суффиксов, комбинированных форм, кроссвордов и многого другого.
- Медицинская терминология в Sheppard Software
Ведение личного лексикона
Ведя персонализированный список выученных слов, вы будете иметь удобный справочник, который вы сможете использовать для повторения этих слов позже. Скорее всего, вам захочется вернуться и освежить в памяти последние слова, поэтому хранить их в собственном списке намного эффективнее, чем каждый раз возвращаться к словарю.
Даже если вы больше никогда не вернетесь к своему лексикону, запись слов хотя бы один раз значительно повысит вашу способность закрепить их в постоянной памяти. Еще одно отличное средство обучения — написать оригинальное предложение, содержащее это слово, и использовать для этого свой словарный запас — отличный способ укрепить эту привычку. Вы также можете добавить много других деталей по своему усмотрению, таких как дата, когда вы впервые встретили слово, или, может быть, порядковый номер, чтобы помочь вам достичь определенной квоты слов, которую вы определяете.
Существует множество способов вести личный список слов; у каждого есть свои преимущества и недостатки, поэтому обязательно выберите формат, который лучше всего подходит для вас. Вы можете хранить его в виде простого текстового файла на компьютере, или в обычной бумажной тетради, или, может быть, в виде карточек в обувной коробке.
Одним из вариантов является компьютерная электронная таблица с ее удобными функциями, такими как поиск, сортировка и фильтрация.
Watch It
Одно дело знакомиться с новыми словами, и совсем другое — усвоить эти новые слова и сделать их частью своего рабочего словаря.
Наслаждайтесь видео общественной службы, опубликованным ниже, первоначально снятым в 1948 году. Не стесняйтесь смеяться над его более искусственными элементами.
Вы можете просмотреть стенограмму для «Build Your Vocabulary-1948» здесь (скачать).
Несмотря на то, что это видео устарело, оно предлагает хорошие советы о том, как расширить рабочий словарный запас. Как бы вы обновили эти советы для двадцать первого века?
Следуйте процессу
Чтобы расширение словарного запаса стало постоянной привычкой в вашей повседневной жизни, вы должны сделать это настолько привычным, автоматическим и тесно интегрированным в ваш ежедневный рабочий процесс, иначе вы не будете делать это, когда ваши дни станут слишком занятый.
В этом отношении особенно полезной является концепция ведения «Входящих» Word. Имея предварительно определенное место, которое вы используете для записи слов, с которыми вы сталкиваетесь, вы можете обрабатывать их намного эффективнее.
Ваш процесс может быть настолько простым, насколько вы пожелаете — ключ в том, чтобы указать его заранее, а затем следовать ему. Точно зная, как и как часто обрабатывать входящие сообщения, вы будете в курсе процесса улучшения своего словарного запаса, даже когда есть другие насущные вопросы, требующие вашего внимания.
Используйте все возможные ресурсы
Интернет — это кладезь ресурсов для пополнения словарного запаса. Вот некоторые из них, которые помогут вам начать работу, хотя существует множество других:
Существует множество словарных приложений, которые вы можете попробовать. Есть много книг, связанных со словарным запасом, которые вы можете изучить. На таких сайтах, как Project Gutenberg, есть множество бесплатной литературы. Если вы используете браузер Firefox, существует множество способов интегрировать функции поиска в словаре, например подключаемые модули Answers.com и DictionarySearch. Вы можете найти специализированные списки словарного запаса, такие как эти слова для чувств или описательные слова. Вы даже можете выучить классные шекспировские оскорбления!
Дело в том, что вы ограничены только своей готовностью учиться: пусть любопытство будет вашим проводником, и у вас никогда не закончатся ресурсы для обучения.
Попробуйте
Внесите свой вклад!
У вас есть идеи по улучшению этого контента? Мы будем признательны за ваш вклад.
Улучшить эту страницуПодробнее
Важность выбора слов в письме
У всех сильных писателей есть нечто общее: они понимают ценность выбора слов в письме. Выбор сильных слов максимально эффективно использует словарный запас и язык, создавая четкие настроения и образы и делая ваши истории и стихи более сильными и яркими.
Значение слова «выбор слова» может показаться самоочевидным, но для того, чтобы по-настоящему изменить ваш стиль и письмо, нам нужно проанализировать элементы выбора правильного слова. В этой статье мы рассмотрим, что такое выбор слов, и предложим несколько примеров эффективного выбора слов, прежде чем дать вам 5 упражнений на выбор слов, которые вы можете попробовать сами.
Определение выбора слова: четыре элемента выбора слова
Определение выбора слова выходит далеко за рамки простого «выбора правильных слов». При выборе правильного слова учитывается множество различных факторов, и для того, чтобы найти наиболее эффектное слово, требуется как большой словарный запас, так и отличное понимание нюансов английского языка.
Выбор правильного слова зависит от следующих четырех соображений с примерами выбора слов.
1. Значение
Слова могут иметь одно из двух значений: денотативное значение или коннотативное значение. Обозначение относится к основному, буквальному словарному определению и использованию слова. Напротив, коннотация относится к тому, как слово используется в данном контексте: какие из многих употреблений, ассоциаций и связей этого слова используются.
Денотативное значение слова является его буквальным словарным определением, в то время как его коннотативное значение представляет собой сеть употреблений и ассоциаций, которые оно несет в контексте.
Мы все время играем с обозначениями и коннотациями в разговорном английском. Простой пример: когда кто-то саркастически произносит «здоровоооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооо. В контексте слово «великий» означает его противоположность: что-то настолько плохое, что называть это «великим» намеренно смешно. Когда мы используем слова коннотативно, мы позволяем контексту определять значение предложения.
Богатая паутина коннотаций в языке имеет решающее значение для всего письма и, возможно, особенно для поэзии, как в следующих строках из эпической поэмы Дерека Уолкотта, удостоенной Нобелевской премии Омерос :
В горных городах, из Сан Фернандо в Маягуэс,
тот же восход солнца шевелил пернатые копья тростника
по дорогам архипелага. Первый ветерок
загрохотал копьями, и их шум был подобен далекому дождю
, марширующему с холмов, словно снаряд у ушей.
Сахарный тростник буквально не состоит из «пернатых копий», что буквально означает «длинные металлические копья, украшенные птичьими перьями»; но пернатый означает «ветвящийся», как сахарный тростник, а пики означает что-то высокое, прямое и заостренное, как сахарный тростник. Вместе эти два слова создают сильно правдивый визуальный образ сахарного тростника — в дополнение к военному языку («копья», «марш»), используемому в другом месте отрывка.
Будь то в поэзии или в прозе, правильный выбор слов может открыть образы, эмоции и многое другое в читателе, и ассоциации и коннотации, которые слова несут с собой, играют решающую роль в этом.
Посетите наши онлайн-курсы письма!
«Радость поэзии: семинар для начинающих»
с Джой Рулье Сойер
14 сентября 2022 г.
Вы хотели заняться поэзией, но не знаете, с чего начать? Научитесь ремеслу у самой Радости поэзии в этом гостеприимном мастер-классе.
Творческая документальная литература и личное эссе
с Гретхен Кларк
14 сентября 2022 г.
Гретхен Кларк прокладывает свой путь к вулканическому союзу реальной жизни и вымысла. Еженедельное письмо с острой обратной связью.
Наблюдение за тем, что ярко в прозе и поэзии
с Марком Олмстедом
21 сентября 2022 г.
Узнайте, как подчеркнуть красоту с помощью свежего, яркого и удивительного языка, в этом четырехнедельном курсе письма по осознанности.
Анатомия предпосылки: как использовать историю и развитие предпосылок для успеха письма , независимо от того, будет ли ваша история «работать». На этом занятии участники узнают, как освоить процесс разработки сюжетной линии — важный первый шаг в процессе разработки любой книги или сценария.
Создание визуального журнала
с Лиссой Дженсен
21 сентября 2022 г.
Выйдите за рамки узких определений «ведения журнала», чтобы включить визуальные изображения и позволить письму озвучить увиденное. Удивите себя.
Просмотрите наш полный календарь курсов »
2.
СпецификаИспользуйте слова, которые являются правильными по смыслу и конкретными по описанию
В разросшемся английском языке одно слово может иметь десятки синонимов Вот почему важно использовать слова, которые оба являются правильными по смыслу Такие слова, как «хороший», «средний» и «ужасный», гораздо менее информативны и конкретный , чем такие слова, как «освобождающий» (не просто хороший, но хороший и освобождающий ), «троечник» (не просто средний, а академический средний) и «презренный» (не просто ужасный, а морально ужасный) . Эти последние слова содержат больше смысла, чем их более мягкие аналоги.
Поскольку более точные слова дают читателю дополнительный контекст, специфичность также открывает двери для более поэтических возможностей. Возьмите короткое стихотворение «[Ты мне подходишь]» Маргарет Этвуд.
Ты вписываешься в меня
как крючок в глаз
Рыболовный крючок
Открытый глаз
Первая строфа кажется почти романтичной, пока мы не читаем вторую строфу. Проясняя свой язык, Этвуд создает простую, но очень эмоциональную двойственность.
Именно поэтому такие писатели, как Стивен Кинг, выступают против использования наречий (прилагательных, которые изменяют глаголы или другие прилагательные, например «очень»). Если ваш язык точен, вам не нужны наречия для изменения глаголов или прилагательных, поскольку эти слова уже выполняют достаточно работы. Рассмотрим следующее сравнение:
Слабое описание с наречиями: Он очень плохо готовит; еда почти всегда очень пережарена.
Сильное описание, без наречий: Он сжигает пищу.
Конечно, неконкретные слова иногда тоже самое лучшее слово! Эти слова часто используются в разговорной речи, поэтому они отлично подходят для написания описания, написания повествования от первого лица или для переходных отрывков прозы.
3. Аудитория
Правильный выбор слов принимает во внимание читателя. Вы, вероятно, не будете использовать такие слова, как «мрачный» или «светлый» в романе для молодых взрослых, и вы не будете использовать такие слова, как «глупый» или «шаткий» в юридическом документе.
Это еще один способ сказать, что выбор слова передает не только прямое значение, но и паутину ассоциаций и чувств, которые способствуют построению мира читателя. Какой мир помогает построить слово «шаткий» для вашего читателя, и какой мир помогает построить слово «мятежный»? В зависимости от общей среды, которую вы создаете для читателя, любое слово может быть идеальным или совершенно неуместным.
4. Стиль
Считайте, что выбранное вами слово является отпечатком вашего письма.
Считайте, что выбранное вами слово является отпечатком вашего письма. Каждый писатель использует слова по-своему, и поскольку из этих слов складываются стихи, рассказы и книги, ваше уникальное владение английским языком будет узнаваемо всеми вашими читателями.
Стиль — это не то, на что можно указать, а скорее способ описать, как писатель пишет. Эрнест Хемингуэй, например, известен своим кратким, серьезным и точным стилем описания. Вирджиния Вульф, напротив, известна своим поэтичным, интенсивным и мелодраматическим письмом, а Джеймс Джойс — своим возвышенным, избыточным стилем письма.
Вот абзац из Джойса:
Если бы Пирр не пал от руки бельдама в Аргосе или Юлий Цезарь не был бы зарезан ножом. Их не следует отбрасывать. Время заклеймило их и заковало в комнату бесконечных возможностей, которые они вытеснили.
А вот и от Хемингуэя:
Билл ушел в бар. Он стоял и разговаривал с Бретт, которая сидела на высоком табурете, скрестив ноги. На ней не было чулок.
Стиль лучше всего проявляется и развивается через портфолио письма. По мере того, как вы будете больше писать и формируете личность писателя, элементы стиля в вашем письме будут складываться в созвездия.
Выбор слов в письменной речи: важность глаголов
Прежде чем мы предложим несколько упражнений на выбор слов, чтобы расширить ваши горизонты письма, мы сначала хотим упомянуть о важности глаголов. Глаголы, как вы помните, являются «действием» предложения — они описывают то, что на самом деле делает субъект предложения. Если вы намеренно не нарушаете правила грамматики, во всех предложениях должен быть глагол, иначе они мало что сообщат читателю.
Поскольку глаголы являются самой важной частью предложения, именно на них следует обращать внимание при расширении возможностей выбора слов. Глаголы являются наиболее разнообразными единицами языка; чем больше «вещей» вы можете делать в мире, тем больше глаголов для их описания, что делает их отличным средством как для образного языка, так и для яркого описания.
Рассмотрим следующие три предложения:
- Дорога проходит через холмы.
- Дорога петляет среди холмов.
- Дорога петляет среди холмов.
Какое предложение является наиболее описательным? Хотя в каждом из них одно и то же подлежащее, дополнение и количество слов, третье предложение создает наиболее четкий образ. Читатель может представить себе дорогу, изгибающуюся влево и вправо через холмистую местность, в то время как первые два предложения требуют больше размышлений, чтобы ясно видеть.
Наконец, этот ресурс по использованию глаголов прекрасно показывает, как изобретать и расширять выбор глаголов.
Выбор слов при написании: экономия и лаконичность
Выбор сильных слов означает, что каждое слово, которое вы пишете, несет в себе удар. Как мы видели с наречиями выше, вы можете обнаружить, что ваше письмо становится более кратким и экономичным, оказывая большее влияние на каждое слово. Прежде всего, вы можете обнаружить, что опускаете ненужные слова .
Опустить лишние слова , по сути, является общим приказом, изданным Strunk and White в их классическом Elements of Style . Как они это объясняют:
Энергичное письмо лаконично. В предложении не должно быть ненужных слов, в абзаце — ненужных предложений по той же причине, по которой в чертеже не должно быть ненужных линий, а в машине — ненужных частей. Это требует не того, чтобы писатель делал все свои предложения короткими или чтобы он избегал всех подробностей и рассматривал свои предметы только в общих чертах, но чтобы каждое слово говорило.
Стоит повторить, что это означает не , что ваше письмо становится отрывистым или кратким, а просто означает, что «каждое слово говорит». По мере улучшения нашего выбора слов — по мере того, как мы опускаем ненужные слова и выражаемся точнее — наше письмо становится богаче, пишем ли мы длинные или короткие предложения.
В качестве примера, вот вступительное предложение случайного личного эссе из справочника по подготовке к экзаменам для старшей школы:
В мире много студентов-спортсменов, у которых где-то в будущем может быть блестящее будущее.
Большинство слов в этом предложении не нужны. Его можно сократить до:
У многих студентов-спортсменов может быть блестящее будущее.
Теперь давайте возьмем несколько известных строк из шекспировского Макбета . Можете ли вы удалить одно слово, не жертвуя огромным богатством смысла?
Прочь, прочь, короткая свеча!
Жизнь — всего лишь тень ходячая, плохой игрок,
Который с важным видом бродит по сцене,
И больше не слышно. это сказка
Рассказанный идиотом, полный шума и ярости,
Ничего не значащий.
В ярком письме каждое слово выбрано для максимального воздействия. В этом истинное значение краткого или экономного письма.
5 упражнений на выбор слов, чтобы отточить ваше письмо
Имея в виду наше определение выбора слов, а также наши обсуждения использования глаголов и краткости, давайте рассмотрим следующие упражнения, чтобы применить теорию на практике. Когда вы играете со словами в следующих упражнениях по выбору слов, обязательно учитывайте значение, специфичность, стиль и (если применимо) аудиторию.
1. Создавайте настроение с помощью выбора слов
Писатели точно настраивают свои слова, потому что правильный словарный запас создает пышные, эмоциональные миры. По мере того, как вы расширяете свой выбор слов и учитываете вес каждого слова, сосредоточьтесь на точных эмоциях в своих описаниях и образном языке.
Такую точку зрения лучше всего иллюстрируют примеры выбора слов. Примером великолепного языка является стихотворение «В защиту малых городов» Оливера де ла Паса. Двойственное отношение стихотворения к малым родным городам проявляется через настроение письма.
Стихотворение наполнено напряженными описаниями, такими как «смерть животных и закаленное сено» и «штаны, пропитанные маслом и дизельным топливом», которые представляют маленький городок как стоический и мужественный. Это, подкрепленное краткими строфами и редкими «шансами на прощение», предлагает нам мрачную картину города; но все же это город, где важно все, от «очертания каждого листа» до невесомого полета семян рогоза.
Сжатое, тяжелое настроение письма возникает из-за сопоставления в стихотворении мужских и женских слов. Задача создания настроения создает серьезность и искренность этого стихотворения.
Попробуйте написать стихотворение или даже предложение, которое вызывает определенное настроение с помощью слов, вызывающих в памяти это слово. Вот пример:
- Какое настроение вы хотите вызвать? взбалмошный
- Какие слова вызывают такое настроение? не уверен, что угодно, может быть, возможно, завтра, иногда, вздох
- Попробуйте это в предложении: «Может быть, завтра мы сможем посмотреть результаты лабораторных исследований». Она вздохнула. «Возможно.»
2. Изобретайте новые слова и термины
Авторы часто задают вопрос: «Какой способ изменить выбор слова?» Один из трюков, который стоит попробовать, — придумать новый язык в своих ревизиях.
Если вы создадите язык в решающий момент, вы сможете выделить что-то, чего не может наш текущий язык.
Точно так же, как необычные глаголы подчеркивают действие и стиль вашего рассказа, придумывание несуществующих слов также может создать сильную речь. Конечно, ваше письмо не должно быть переполнено выдуманными словами и претенциозными портмоне, но если вы создадите язык в решающий момент, вы сможете выделить то, что наш нынешний язык не может.
Отличным примером выдуманного слова является фраза «винно-темное море». Понимание этого изобретения требует немного истории; Короче говоря, Гомер описывает море как «οἶνοψ πόντος», или «винное лицо». Таким образом, «винно-темное» — это поэтический перевод, своего рода кеннинг тайны моря.
Почему именно «винно-темное»? Может быть, потому, что, как и море, вино меняет нас; может быть, глаза моря темны, как глаза часто темнеют от вина; возможно, море похоже на лицо, инверсию, отражение себя. В его бесконечности мы видим то, что обычно не видим.
Таким образом, «винно-темное» — это поэтическое сочетание слов, подталкивающее к интенсивному литературному анализу. Менее исторический пример: в настоящее время я работаю над диссертацией по поэзии, где монстры поп-культуры являются центральной темой стихов. В одном стихотворении я описываю любовь как «франкенштейн». Использование этого чудовищного выдуманного глагола вместо «сшитого» делает отношение стихотворения к любви намного яснее.
Попробуйте придумать слово или фразу, смысл которых будет так же понятен читателю, как «винно-темное море». Вот пример:
- Что вы хотите описать? жалко себя из-за того, что вы долгое время находились в состоянии стресса
- Какие слова вызывает это чувство? жалость к себе, сочувствие, печаль, стресс, сострадание, занятость, любовь, тревога, жалость, жалость к себе
- Какие есть забавные способы сочетания этих слов? грусть, любовь к стрессу
- Попробуйте это в предложении: По мере того, как тянулась бессонная ночь, моя тревога смягчилась до грусти: все еще резкой, но мягкой в середине.
3. Используйте только слова определенной этимологии
Одна из причин того, что английский язык такой большой и непоследовательный, заключается в том, что он заимствует слова из всех языков. Когда вы копаетесь в истории заимствований, английский язык невероятно интересен!
(Например, многие наши юридические термины, такие как судья , присяжный и истец , происходят из французского языка. Когда норманны [старые франкоговорящие жители Северной Франции] завоевали Англию, их язык стал язык власти и знати, так что мы сохранили многие из наших юридических терминов из того времени, когда французы правили Британскими островами.)
Занудная лингвистика в сторону, этимология также представляет собой забавное упражнение по выбору слов. Попробуйте заставить себя написать стихотворение или рассказ, используя только слова одной этимологии и избегая других. Например, если вам разрешено использовать только существительные и глаголы, заимствованные из французского языка, вы не можете использовать англосаксонские существительные, такие как «корова», «свинья» или «курица», но вы можете использовать французские заимствованные слова, такие как «говядина», «свинина» и «птица».
Поэкспериментируйте с этимологией слов и посмотрите, как она повлияет на настроение вашего письма. Возможно, вы обнаружите, что это важный аспект вашего выбора слов. Вы можете использовать Google «__ этимология» для любого слова, чтобы увидеть его происхождение, и «__ синоним», чтобы увидеть синонимы.
Попробуйте написать предложение только с корнями одного происхождения. (Вы можете игнорировать распространенные слова, такие как «the», «a», «of» и т. д.)
- Что вы хотите написать? Яблоко скатилось со стола.
- Попробуйте первую этимологию: Немецкий: яблоко качнулось со скамейки.
- Попробуй секунду: Латынь: Румяный фрукт скатился со стола.
4. Пишите в E-Prime
E-Prime Письмо описывает стиль письма, при котором вы пишете только активным залогом. Избегая всех форм глагола «быть» — используя такие слова, как «есть», «ам», «есть», «был» и другие глаголы «существования», — ваше письмо должно казаться более ясным, активным и точным. !
E-Prime не только удаляет страдательный залог («Бутылка была поднята Джеймсом»), но и показывает реальность того, что многие предложения, в которых используется вместо , построены слабо, даже если технически они находятся в активном залоге. голос.
Конечно, письмо E-Prime — не лучший способ письма для каждого проекта. Приведенный выше абзац написан на E-Prime, но растянуть его на всю статью будет сложно. Цель письма E-Prime состоит в том, чтобы сделать все ваши предметы активными и сделать ваши глаголы более действенными. Хотя это забавное упражнение по выбору слов и отличный способ создать запоминающийся язык, оно, вероятно, не подходит для длительного письменного проекта.
Попробуйте написать абзац в E-Prime:
- Что вы хотите написать? Конечно, письмо E-Prime — не лучший способ письма для каждого проекта. Приведенный выше абзац написан на E-Prime, но растянуть его на всю статью будет сложно. Цель письма E-Prime состоит в том, чтобы сделать все ваши предметы активными и сделать ваши глаголы более действенными. Хотя это забавное упражнение по выбору слов и отличный способ создать запоминающийся язык, оно, вероятно, не подходит для длительного письменного проекта.
- Преобразовано в E-Prime: Конечно, письмо E-Prime подходит не для каждого проекта. В приведенном выше абзаце используется E-Prime, но его распространение на всю статью может вызвать проблемы. Письмо E-Prime стремится сделать все ваши предметы активными, а ваши глаголы более эффектными. Хотя это упражнение по выбору слов может доставить удовольствие и создать запоминающийся язык, вы, вероятно, не сможете выдержать его в течение длительного письменного проекта.
5. Напишите стихи для затемнения
Blackout Poetry, также известная как «Найденная поэзия», представляет собой визуальный творческий писательский проект. Вы берете страницу из опубликованного источника и создаете стихотворение, зачеркивая другие слова, пока ваши обведенные слова не создадут новое стихотворение. Проблема в том, что вы ограничены количеством слов на странице, поэтому вам нужно заряженно использовать как пространство, так и язык, чтобы написать убедительное затемненное стихотворение.
Поэзия затемнения завершает наш список замечательных упражнений по выбору слов, потому что заставляет вас учитывать элементы выбора слов. В стихотворениях с затемнением определенные слова могут быть прочитаны коннотативно, а не денотативно, или вы можете изменить значение и специфику слова, используя другие слова рядом. Язык наиболее подвижен и интерпретативен в стихах затемнения!
Отличный пример подбора слов с использованием затемненной поэзии можно найти в книге Ханифа Уиллиса-Абдурракиба «Автор пишет первый черновик своих свадебных клятв». Вот это визуально:
Источник: https://decreation.tumblr.com/post/620222983530807296/from-the-crown-aint-worth-much-by-hanifВыберите свое любимое стихотворение и сочините что-то совершенно новое из этого, используя затемненную поэзию.
Как расширить свой словарный запас
Словарный запас — последняя тема в выборе слов. Чем больше слов в вашем арсенале, тем лучше. Хороший выбор слов не зависит от большого словарного запаса, но знание большего количества слов всегда поможет! Итак, как расширить свой словарный запас?
Самый простой способ расширить свой словарный запас — это читать.
Самый простой ответ, который вы услышите чаще всего, — это чтение. Чем больше литературы вы прочитаете, тем больше примеров хороших слов, использующих четыре элемента выбора слов, вы увидите.
Конечно, есть и отличные программы для расширения словарного запаса. Если вы хотите использовать в предложении такие слова, как «плаксивость», взгляните на следующие словари:
- Word of the Day от Dictionary.com
- Игры Vocabulary.com
- Викторины по словарному запасу Merriam Webster
Усовершенствуйте свой выбор слов с помощью онлайн-курсов письма на Writers.com
Ищете дополнительные письменные упражнения? Нужна дополнительная помощь в выборе правильных слов? Преподаватели Writers.com — мастера своего дела. Взгляните на наши предстоящие курсы и присоединяйтесь к нашему сообществу!
Риторический анализ | Успехи студентов
Университет Арканзаса
Ссылки на важные страницы Университета Арканзаса
- U из А
- Успех студента
- Получить помощь
- Самопомощь
- Риторический анализ
Что такое риторический анализ?
Очерк риторического анализа разбивает научно-популярную работу, такую как эссе, речь,
мультфильм, реклама или представление, на части и объясняет, как работают части
вместе, чтобы убедить, развлечь или проинформировать аудиторию. При выявлении этих частей
важно, оценивая их эффективность в достижении цели(ей) автора
одинаково необходимо.
Части любого текста включают риторические стратегии, призывы и/или приемы. У каждого есть отчетливая цель. В зависимости от риторической ситуации (автор, тема, цель, потребность, аудитория), авторы предпочтут использовать определенные риторические стратегии, призывы, и устройства для повышения вероятности того, что их сообщение будет эффективно передано своей аудитории. Первым шагом в написании эссе по риторическому анализу является чтение работу документальной литературы близко и определить стратегии, призывы и приемы.
Риторические стратегии:
Способы, которыми авторы организуют доказательства и устанавливают связи между своей аудиторией и
информацию, которую они предоставляют. Вот некоторые примеры:
- Причина и следствие
- Сравнение и противопоставление
- Классификация и деление
- Определение
- Описание
- Объяснение процесса
- Рассказывает
Риторические призывы:
Стратегии убеждения, которые авторы используют для поддержки своих заявлений или ответов на аргументы. Четыре риторических призыва — это логос, пафос, этос и кайрос.
- Логос — взывает к логике
- Пафос — взывает к эмоциям
- Этос — призывы к этике
- Кайрос — призывы ко времени/своевременности аргумента
Риторические приемы:
Техники, приемы и образный язык, используемые для передачи информации. Вот десять часто используемых риторических приемов, определения которых взяты из Literary Devices:
- Аллитерация: литературный прием, отражающий повторение в двух или более соседних словах начального согласные звуки.
- Аналогия: фигура речи, которая создает сравнение, показывая, как два, казалось бы, разных сущности похожи
- Анафора: риторический прием, заключающийся в повторении слова или фразы в начале последовательных предложений, фраз или предложений.
- Эпифора: стилистический прием, в котором слово или фраза повторяются в конце последовательных
оговорки. Хиазм: риторический прием, в котором два или более предложения уравновешиваются
друг друга путем перестановки их структур для создания художественного
- Эвфемизм: фигура речи, обычно используемая для замены слова или фразы, связанной с концепция, которая может вызвать дискомфорт у других.
- Идиома: устойчивое выражение или фраза, состоящая из двух или более слов; фраза понятна означать нечто совершенно отличное от того, что подразумевают отдельные слова фразы.
- Метафора: фигура речи, которая делает сравнение между двумя непохожими вещами.
- Олицетворение: фигура речи, в которой неодушевленным предметам и идеям придаются человеческие атрибуты.
- Сравнения: фигура речи, в которой два по существу непохожих объекта или понятия явно выражены. сравниваются друг с другом с помощью слов «подобно» или «как».
Оценка эффективности
После определения риторических стратегий, призывов и приемов определите их эффективность при передаче информации и достижении цели (целей) автора, задав следующие вопросы: вопросы:
- С какой целью автор пишет?
- Стремится ли автор убедить, развлечь или проинформировать свою аудиторию?
- Последовательно ли риторические стратегии, призывы и приемы поддерживают цель(и)?
- Использует ли автор какие-либо риторические приемы, призывы и приемы неуместно? Если да, то как?
- Существуют ли какие-либо другие риторические стратегии, призывы и приемы, которые автор должен использовать? использовали, чтобы передать свое сообщение и достичь своей цели (целей)?
Написание эссе по риторическому анализу
Эссе по риторическому анализу очень похоже на другие эссе. Должно
включают введение, основную часть и заключение.
Введение должно сообщить вашим читателям, что вы будете делать в своем эссе, предоставить соответствующую справочную информацию и представить свой тезис.
В основной части вы предоставляете анализ того, как автор передал свое сообщение. Этот
можно сделать, представляя различные части или риторические стратегии, призывы,
и устройства, а затем описание того, насколько эффективно (или неэффективно) автор использует
эти методы, чтобы передать свое сообщение и достичь своей цели (целей). Только список и
проанализируйте наиболее важные части. Вы также можете описать в этой части эссе
риторическая стратегия, призыв или прием, которым автор не воспользовался,
помогли им более эффективно достигать своих целей.
В заключении должен быть повторен основной аргумент и резюмирован анализ. Воздержаться от дословное повторение и стремление оставить положительное впечатление.
Чем НЕ является эссе по риторическому анализу
Хотя вы можете использовать в своем эссе фрагменты текста из научно-популярной как автор использует риторическую стратегию, призыв или прием и как работают эти части вместе взятые, риторическое аналитическое эссе не является кратким изложением. это тоже не аргумент сочинение; вы не должны занимать позицию по представленному аргументу. Вы должны исследовать как построено эссе и эффективны ли части эссе при представлении информацию и достижение цели (целей) автора для сообщения.
Ссылки
Более 30 риторических приемов, которые ДОЛЖЕН знать каждый. Ридси. (2019, 11 января). https://blog.reedsy.com/rhetorical-devices/.
Колфилд, Дж. (2020, 10 декабря). Как написать риторический анализ: ключевые понятия и примеры. Скриббр. https://www.scribbr.com/academic-essay/rhetorical-analysis/.
Литературные приемы и литературные термины. Полный список. Литературные приемы. (2020, 8 августа). https://literarydevices.net/.
Панель инструментов Norton Reader. (н.д.). https://wwnorton.com/college/english/write/read12/toolbar/set02.aspx.
Составитель:
Джессика Алли
Консультант студии письма
2021
Глоссарий демографических терминов | ПРБ
Глоссарий демографических терминов
— А —
Коэффициент абортов Количество абортов на 1000 женщин в возрасте 15–44 или 15–49 лет в указанном году.
Коэффициент абортов Количество абортов на 1000 живорождений в данном году.
Синдром приобретенного иммунодефицита (СПИД) Относится к наиболее поздним стадиям ВИЧ-инфекции. Это определяется возникновением любой из более чем 20 оппортунистических инфекций или рака, связанного с ВИЧ.
Коэффициент возрастной зависимости Соотношение лиц в возрасте, определяемом как иждивенец (до 15 лет и старше 64 лет), и лиц в возрасте, определяемом как экономически продуктивный (15-64 года) в населении.
Возрастная структура Доля от общей численности населения в каждой возрастной группе.
Половозрастная структура Состав населения, определяемый количеством или соотношением мужчин и женщин в каждой возрастной категории. Половозрастная структура населения является совокупным результатом прошлых тенденций рождаемости, смертности и миграции. Информация о половозрастном составе необходима для описания и анализа многих других типов демографических данных. См. также пирамиду населения.
Повозрастной коэффициент Коэффициент, полученный для определенных возрастных групп (например, повозрастной коэффициент рождаемости, коэффициент смертности, коэффициент брачности, уровень неграмотности или уровень охвата школьным образованием).
Старение населения Процесс, при котором доля взрослых и пожилых людей в популяции увеличивается, а доля детей и подростков уменьшается. Этот процесс приводит к увеличению среднего возраста населения. Старение происходит, когда показатели рождаемости снижаются, а ожидаемая продолжительность жизни остается постоянной или увеличивается в более старшем возрасте.
Антинаталистская политика Политика правительства, общества или социальной группы, направленная на замедление роста населения путем ограничения числа рождений.
Антиретровирусная терапия (АРТ) Лечение людей, инфицированных вирусом иммунодефицита человека (ВИЧ), с помощью препаратов против ВИЧ. Стандартное лечение состоит из комбинации как минимум трех препаратов (часто называемых «высокоактивной антиретровирусной терапией» или ВААРТ), которые подавляют репликацию ВИЧ. Три препарата используются для снижения вероятности развития резистентности вируса. АРТ может как снизить смертность и заболеваемость среди ВИЧ-инфицированных, так и улучшить качество их жизни.
– B –
Бэби-бум Резкий рост показателей рождаемости и абсолютного числа рождений в США, Канаде, Австралии и Новой Зеландии в период после Второй мировой войны (1947–1961).
Бэби-бум Быстрое снижение рождаемости в США до рекордно низкого уровня в период сразу после бэби-бума.
Уравнение баланса Основная демографическая формула, используемая для оценки общего изменения численности населения между двумя моментами времени или для оценки любого неизвестного компонента изменения численности населения при условии, что другие компоненты известны. Уравнение баланса включает все компоненты изменения населения: рождаемость, смертность, иммиграцию, эмиграцию, приток и отток.
Противозачаточные средства Методы, применяемые парами, позволяющие вступать в половую связь с меньшей вероятностью зачатия и родов. Термин «контроль над рождаемостью» часто используется как синоним таких терминов, как контрацепция, контроль над рождаемостью и планирование семьи. Но контроль над рождаемостью включает аборт для предотвращения рождения ребенка, тогда как методы планирования семьи явно не включают аборт.
Коэффициент рождаемости (или общий коэффициент рождаемости) Количество живорождений на 1000 человек населения в данном году. Не путать с темпом роста.
Коэффициент рождаемости для незамужних женщин Количество живорождений на 1000 незамужних женщин (никогда не состоявших в браке, овдовевших или разведенных) в возрасте 15–49 лет в данном году.
Утечка мозгов Эмиграция значительной части высококвалифицированного, высокообразованного профессионального населения страны, как правило, в другие страны, предлагающие лучшие экономические и социальные возможности (например, врачи уезжают из развивающейся страны, чтобы практиковать медицину в развитой стране) .
– C –
Несущая способность Максимально устойчивый размер постоянного населения в данной экосистеме.
Коэффициент летальности Доля лиц, заразившихся болезнью, которые умирают от нее в течение определенного периода времени.
Показатель заболеваемости Количество зарегистрированных случаев определенного заболевания на 100 000 населения в данном году.
Коэффициент смертности от конкретных причин Количество смертей, связанных с конкретной причиной, на 100 000 населения в данном году.
Перепись Обзор определенной территории, результатом которого является подсчет всего населения и часто сбор другой демографической, социальной и экономической информации, относящейся к этому населению в определенное время. См. также опрос.
Годы деторождения Диапазон репродуктивного возраста женщин, принятый для статистических целей как 15–44 или 15–49 лет.
Соотношение детей и женщин Количество детей в возрасте до 5 лет на 1000 женщин в возрасте 15–44 или 15–49 лет.в популяции в данный год. Этот грубый показатель рождаемости, основанный на основных данных переписи населения, иногда используется, когда более конкретная информация о рождаемости недоступна.
Закрытая популяция Население, не имеющее ни входящего, ни исходящего миграционного потока, так что изменения в численности населения происходят только за счет рождений и смертей.
Когорта Группа людей, имеющих общий временной демографический опыт, за которыми наблюдают во времени. Например, возрастная группа 19 лет.00 — это люди, родившиеся в этом году. Есть также когорты брака, когорты школьного класса и так далее.
Когортный анализ Наблюдение за демографическим поведением когорты на протяжении всей жизни или на протяжении многих периодов; например, изучение поведения фертильности когорты людей, родившихся между 1940 и 1945 годами, на протяжении всего их детородного возраста. Показатели, полученные в результате такого когортного анализа, являются когортными показателями. Сравните с анализом периода.
Завершенный коэффициент рождаемости Количество детей, рожденных на одну женщину в когорте женщин к концу их детородного возраста.
Консенсуальный союз Сожительство не состоящей в браке пары в течение длительного периода времени. Хотя такие союзы могут быть достаточно устойчивыми, в официальной статистике они не считаются законными браками.
Распространенность противозачаточных средств Процент пар, использующих в настоящее время метод контрацепции.
Использование противозачаточных средств Процент замужних или находящихся в браке женщин (если не указано иное) репродуктивного возраста, которые в настоящее время используют какие-либо формы контрацепции. Современные методы включают клинические методы и методы снабжения, включая таблетки, инъекции, имплантаты, ВМС, презервативы и стерилизацию.
Общий коэффициент Коэффициент любого демографического события, рассчитанный для всего населения.
– D –
Коэффициент смертности (или общий коэффициент смертности) Количество смертей на 1000 человек населения в данном году.
Демографический переход Историческое смещение уровней рождаемости и смертности населения с высокого на низкий уровень. Снижение смертности обычно предшествует снижению рождаемости, что приводит к быстрому росту населения в переходный период.
Демография Научное изучение человеческих популяций, включая их размеры, состав, распределение, плотность, рост и другие характеристики, а также причины и последствия изменения этих факторов.
Коэффициент демографической нагрузки Коэффициент демографической нагрузки – это отношение числа людей в зависимой возрастной группе (лица в возрасте до 15 лет или в возрасте 65 лет и старше) к числу лиц в экономически продуктивной возрастной группе (в возрасте от 15 до 64 лет) населения. Например, коэффициент демографической нагрузки на детей, равный 0,45, означает, что на каждые 100 взрослых трудоспособного возраста приходится 45 детей.
Депопуляция Состояние сокращения популяции.
Коэффициент разводов (или общий коэффициент разводов) Количество разводов на 1000 человек населения в данном году.
Двойная зависимость Умеренная зависимость детей и относительно высокая зависимость пожилых людей отражают фертильность выше или близкую к уровню воспроизводства и снижающуюся смертность.
Время удвоения Количество лет, необходимое для того, чтобы население области удвоило свой нынешний размер, учитывая текущие темпы роста населения.
– E –
Экономическая инфраструктура Экономическая инфраструктура включает внутренние объекты страны, которые делают возможной деловую и финансовую деятельность, такие как связь, транспорт и распределительные сети; финансовые учреждения и рынки; и системы энергоснабжения.
Экономическая безопасность Условие наличия стабильного дохода или других ресурсов для поддержания уровня жизни в настоящее время и в обозримом будущем.
Эмиграция Процесс выезда из одной страны для постоянного или полупостоянного проживания в другой.
Уровень эмиграции Количество эмигрантов, покидающих район происхождения, на 1000 человек населения в этом районе происхождения в данном году.
Этническая принадлежность Культурные обычаи, язык, кухня и традиции — а не биологические или физические различия — используются для различения групп людей.
– Ж –
Семья Обычно два или более человека, живущих вместе и связанных рождением, браком или усыновлением. Семьи могут состоять из братьев и сестер или других родственников, а также из супружеских пар и любых детей, которые у них есть.
Планирование семьи Сознательные усилия пар по регулированию количества рождений и интервалов между родами с помощью искусственных и естественных методов контрацепции. Планирование семьи означает контроль над зачатием, чтобы избежать беременности и абортов, но оно также включает в себя усилия пар по индуцированию беременности.
Плодовитость Физиологическая способность женщины производить на свет ребенка.
Фертильность Фактическая репродуктивная способность человека, пары, группы или населения. См. общий коэффициент рождаемости.
– G –
Пол относится к экономическим, социальным, политическим и культурным атрибутам, ограничениям и возможностям, связанным с принадлежностью к женщине или мужчине. Социальные определения того, что значит быть женщиной или мужчиной, различаются в разных культурах и меняются со временем. Гендер — это социокультурное выражение определенных характеристик и ролей, связанных с определенными группами людей в отношении их пола и сексуальности.
Гендерное равенство это процесс справедливого отношения к женщинам и мужчинам. Для обеспечения справедливости необходимо принять меры для компенсации исторических и социальных неблагоприятных условий, которые мешают женщинам и мужчинам действовать на равных.
Гендерное равенство это состояние или условие, которое дает женщинам и мужчинам равное пользование правами человека, социально ценными благами, возможностями и ресурсами.
Общий коэффициент фертильности Количество живорождений на 1000 женщин в возрасте 15–44 или 15–49 лет.лет в данном году.
Валовой национальный доход (ВНД) ВНД (ранее ВНП) представляет собой сумму добавленной стоимости всех производителей-резидентов плюс любые налоги на продукцию (за вычетом субсидий), не включенные в оценку выпуска, плюс чистые поступления первичного дохода (оплата труда и доходы от собственности) из-за рубежа. Данные указаны в текущих долларах США. ВНД, рассчитанный в национальной валюте, обычно конвертируется в доллары США по официальному обменному курсу для сравнения между странами, хотя альтернативный курс используется, когда считается, что официальный обменный курс отличается исключительно большим отрывом от курса, фактически применяемого в международных сделках. .
Общий коэффициент воспроизводства (GRR) Среднее число дочерей, которые родились бы живыми у женщины (или группы женщин) в течение ее жизни, если бы ее детородный возраст соответствовал возрастным коэффициентам рождаемости данного год. См. также чистый коэффициент воспроизводства и общий коэффициент рождаемости.
Темпы прироста Количество людей, прибавляющихся (или вычитаемых) из населения за год в результате естественного прироста и чистой миграции, выраженное в процентах от населения на начало периода времени.
– H –
Высокий уровень детской зависимости Высокая рождаемость и относительно высокая смертность способствуют большому количеству молодого населения и небольшой численности населения пожилого возраста.
Беременность с высоким риском Беременность, происходящая при следующих условиях: слишком тесное пространство, слишком частые, слишком молодая или слишком старая мать, или сопровождающаяся такими факторами высокого риска, как высокое кровяное давление или диабет.
Высокий уровень зависимости от пожилых людей Умеренный уровень детской зависимости и относительно высокий уровень зависимости от пожилых людей отражают рождаемость выше или близкую к уровню воспроизводства и снижающуюся смертность.
Домохозяйство Одно или несколько лиц, проживающих в жилой единице.
Вирус иммунодефицита человека (ВИЧ) Ретровирус, который поражает клетки иммунной системы, разрушая или нарушая их функцию. По мере прогрессирования инфекции иммунная система ослабевает, и человек становится более восприимчивым к инфекциям.
ВИЧ передается при незащищенном половом акте, переливании зараженной крови, совместном использовании зараженных игл, а также между матерью и ребенком во время беременности, родов и грудного вскармливания.
– I –
Иммиграция Процесс въезда в одну страну из другой с целью постоянного или полупостоянного проживания.
Коэффициент иммиграции Количество иммигрантов, прибывающих в пункт назначения на 1000 человек населения в данном пункте назначения в данном году.
Уровень заболеваемости Количество людей, заразившихся заболеванием, на 1000 человек, подвергающихся риску, за определенный период времени.
Коэффициент младенческой смертности Количество смертей младенцев в возрасте до 1 года на 1000 живорождений в данном году.
Иммиграция Процесс въезда в одну административную единицу страны (например, провинции или штата) из другой единицы с целью поселения.
– L –
Наименее развитые страны В соответствии с определениями Организации Объединенных Наций термин «наименее развитые страны» включает по состоянию на март 2018 года: Афганистан, Анголу, Бангладеш, Бенин, Бутан, Буркина-Фасо, Бурунди, Камбоджу, Центральноафриканскую Республику , Чад, Коморские острова, Демократическая Республика Конго, Джибути, Эритрия, Эфиопия, Гамбия, Гвинея, Гвинея-Бисау, Гаити, Кирибати, Лаосская Народно-Демократическая Республика, Лесото, Либерия, Мадагаскар, Малави, Мали, Мавритания, Мозамбик, Мьянма, Непал, Нигер, Руанда, Сан-Томе и Принсипи, Сенегал, Сьерра-Леоне, Соломоновы Острова, Сомали, Судан, Тимор-Лешти, Того, Тувалу, Уганда, Вануату, Йемен и Замбия. Эти страны также являются «менее развитыми» в терминологии ООН.
Менее развитые страны Согласно определениям Организации Объединенных Наций, термин «менее развитые страны» (или регионы) относится к странам Африки, Азии (кроме Японии), Латинской Америки и Карибского бассейна и Океании (кроме Австралии и Новой Зеландии). ).
Ожидаемая продолжительность жизни Среднее количество дополнительных лет, которые человек мог бы прожить, если бы текущие тенденции смертности сохранялись до конца жизни этого человека. Чаще всего упоминается как ожидаемая продолжительность жизни при рождении.
Продолжительность жизни Максимальный возраст, которого могут достичь люди при оптимальных условиях.
Таблица продолжительности жизни Табличное отображение ожидаемой продолжительности жизни и вероятности смерти в каждом возрасте (или возрастной группе) для данного населения в соответствии с повозрастными коэффициентами смертности, преобладающими в то время. Таблица дожития дает систематизированную полную картину смертности населения.
Низкая общая зависимость Устойчивая иммиграция взрослых трудоспособного возраста с небольшой долей населения в возрасте 65+ приводит к низкой общей зависимости.
– M –
Вовлечение мужчин означает вовлечение мужчин в активное продвижение гендерного равенства в отношении репродуктивного здоровья, усиление поддержки мужчинами репродуктивного здоровья женщин и благополучия детей, а также укрепление репродуктивного здоровья как мужчин, так и женщин.
Мальтус, Томас Р. (1766-1834) английский священник и экономист, прославившийся своей теорией (изложенной в «Эссе о принципе народонаселения») о том, что население мира имеет тенденцию увеличиваться быстрее, чем запасы продовольствия, и что если рождаемость контролируется (поздним браком или безбрачием), голод, болезни и войны должны служить естественными ограничениями численности населения. См. неомальтузианство.
Коэффициент рождаемости в браке Количество живорождений у замужних женщин на 1000 замужних женщин в возрасте 15–44 или 15–49 лет в данном году.
Коэффициент брачности (или общий коэффициент брачности) Количество браков на 1000 человек населения в данном году.
Коэффициент материнской смертности Количество женщин, умерших в результате осложнений беременности и родов, на 100 000 живорождений в данном году.
Средний возраст Математический средний возраст всех членов населения.
Медианный возраст Возраст, который делит население на две численно равные группы; то есть половина людей моложе этого возраста, а половина старше.
Мегаполис Термин, обозначающий взаимосвязанную группу городов и соединяющих урбанизированные полосы.
Страны БВСА Ближний Восток и Северная Африка (БВСА) — это экономически разнообразный регион, который включает как богатые нефтью страны Персидского залива, так и страны с ограниченными ресурсами по отношению к населению. На экономическое благополучие региона на протяжении большей части последней четверти века сильно влияли два фактора: цена на нефть и наследие экономической политики и структур, которые подчеркивали ведущую роль государства. В регион MENA входят: Алжир, Бахрейн, Джибути, Египет, Иран, Ирак, Израиль, Иордания, Кувейт, Ливан, Ливия, Мальта, Марокко. Оман, Катар, Саудовская Аравия, Сирия, Тунис, Объединенные Арабские Эмираты, Западный берег реки Иордан и Газа, а также Йемен.
Агломерация Большая концентрация населения, обычно это район с населением 100 000 и более человек. Район обычно включает важный город с населением 50 000 и более человек и административные районы, граничащие с городом, которые социально и экономически интегрированы с ним.
Миграция Перемещение людей через определенную границу с целью обустройства нового или полупостоянного места жительства. Делится на международную миграцию (миграцию между странами) и внутреннюю миграцию (миграцию внутри страны).
Цели развития тысячелетия (ЦРТ) Цели развития тысячелетия Организации Объединенных Наций — это восемь целей, которые все 191 государство-член ООН договорились попытаться достичь к 2015 году. Декларация тысячелетия Организации Объединенных Наций, подписанная в сентябре 2000 года, обязывает мировых лидеров для борьбы с нищетой, голодом, болезнями, неграмотностью, ухудшением состояния окружающей среды и дискриминацией в отношении женщин. ЦРТ вытекают из этой декларации, и все они имеют конкретные задачи и индикаторы.
Мобильность Географическое перемещение людей.
Умеренная зависимость от детей Снижение фертильности снижает зависимость от детей до умеренного уровня; относительно высокая смертность снижает зависимость пожилых людей.
Более развитые страны Согласно определениям ООН, «более развитые страны» или промышленно развитые страны (или регионы) включают Европу (включая всю Россию), США, Канаду, Австралию, Новую Зеландию и Японию.
Смертность Смерти как компонент изменения численности населения.
– N –
Натальность Рождения как компонент изменения численности населения.
Естественный прирост (или убыль) Избыток (или дефицит) рождаемости над смертностью населения в данный период времени.
Неомальтузианец Сторонник ограничения роста населения с помощью контроля над рождаемостью. (Сам Томас Мальтус не выступал за контроль над рождаемостью как средство от быстрого роста населения.)
Коэффициент неонатальной смертности Количество смертей младенцев в возрасте до 28 дней в данном году на 1000 живорождений в этом году.
Чистая миграция Расчетный уровень чистой миграции (иммиграция минус эмиграция) на 1000 человек населения. Для некоторых стран данные получены как остаток от расчетных показателей рождаемости, смертности и прироста населения.
Коэффициент чистой миграции Чистое влияние иммиграции и эмиграции на население области, выраженное как увеличение или уменьшение на 1000 человек населения области в данном году.
Чистый коэффициент воспроизводства (NRR) Среднее число дочерей, которое родилось бы у женщины (или группы женщин), если бы ее жизнь соответствовала возрастным коэффициентам рождаемости и смертности в данном году. Этот коэффициент аналогичен валовому коэффициенту воспроизводства, но учитывает, что некоторые женщины умрут, не дожив до детородного возраста. NRR, равный единице, означает, что каждое поколение матерей имеет ровно столько дочерей, чтобы заменить себя в популяции. См. также общий коэффициент рождаемости и рождаемость на уровне воспроизводства.
Брачность Частота, характеристики и расторжение браков среди населения.
– O –
«Старое» население Население с относительно высокой долей людей среднего и пожилого возраста, высоким средним возрастом и, следовательно, более низким потенциалом роста.
Эмиграция Процесс выезда из одной части страны для поселения в другой.
– P –
Паритет Количество детей, ранее родившихся живыми у женщины; например, «женщины с двумя родами» — это женщины, у которых было двое детей, а «женщины с нулевым паритетом» не имели живорождений.
Процент городского Процент от общей численности населения, проживающего в районах, которые эта страна или ООН называют «городскими».
Коэффициент перинатальной смертности Количество внутриутробных смертей после 28 недель беременности (поздние внутриутробные смерти) плюс число смертей младенцев в возрасте до 7 дней на 1000 живорождений.
Анализ периода Наблюдение за населением в определенный период времени. Такой анализ фактически делает «моментальный снимок» населения за относительно короткий период времени — например, за один год. Большинство ставок получены из данных за период и, следовательно, являются ставками за период. Сравните с когортным анализом.
Популяция Группа объектов или организмов одного вида.
Контроль рождаемости Общее понятие, которое касается взаимосвязи между рождаемостью, смертностью и миграцией, но чаще всего используется для обозначения усилий по замедлению роста населения посредством действий по снижению рождаемости. Не следует путать с планированием семьи. См. также планирование семьи.
Плотность населения Население на единицу площади; например, человек на квадратную милю или человек на квадратный километр пахотной земли.
Распределение населения Схемы расселения и расселения населения.
«Демографический взрыв» (или «демографическая бомба») Выражения, используемые для описания мировой тенденции быстрого роста населения в 20-м веке в результате того, что уровень рождаемости в мире намного превышает уровень смертности в мире.
Прирост населения Общий прирост населения в результате взаимодействия рождений, смертей и миграции населения за определенный период времени.
Импульс населения Тенденция роста населения сохраняется после того, как был достигнут уровень воспроизводства рождаемости из-за относительно высокой концентрации людей детородного возраста.
Демографическая политика Явные или неявные меры, принимаемые правительством для воздействия на численность, рост, распределение или состав населения.
Прогноз численности населения Расчет будущих изменений численности населения с учетом определенных предположений о будущих тенденциях показателей рождаемости, смертности и миграции. Демографы часто дают низкие, средние и высокие прогнозы для одного и того же населения, исходя из разных предположений о том, как эти показатели изменятся в будущем.
Пирамида населения Вертикальная гистограмма, показывающая распределение населения по возрасту и полу. По соглашению младшие возрасты находятся внизу, мужчины слева, а женщины справа.
Регистр населения Государственная система сбора данных, в которой постоянно регистрируются демографические и социально-экономические характеристики всего населения или его части. Дания, Швеция и Израиль входят в число стран, которые ведут универсальные регистры для демографических целей, регистрируя основные события (рождения, браки, переезды, смерть), которые происходят с каждым человеком, чтобы можно было легко получить актуальную информацию обо всем населении. доступный. В других странах, например в США, для административных целей ведутся частичные регистры, такие как регистрация социального обеспечения и избирателей.
Постнеонатальная смертность Годовое число смертей младенцев в возрасте от 28 дней до 1 года на 1000 живорождений в данном году.
Коэффициент распространенности Количество людей, страдающих определенным заболеванием в данный момент времени, на 1000 человек, подвергающихся риску.
Пронаталистская политика Политика правительства, общества или социальной группы, направленная на увеличение прироста населения за счет увеличения числа рождений.
Покупательная способность Способность потребителей приобретать товары и услуги на основе наличия у них денег и/или использования кредита.
Гипотеза «тяни-толкай» Теория миграции, которая предполагает, что обстоятельства в месте происхождения (например, бедность и безработица) отталкивают или выталкивают людей из этого места в другие места, которые оказывают положительное притяжение или притяжение (например, высокий уровень жизни или возможности трудоустройства).
– R –
Раса Раса определяется прежде всего обществом, а не генетикой, и не существует общепринятых категорий.
Коэффициент естественного прироста (или убыли) Скорость, с которой население увеличивается (или уменьшается) в данном году из-за превышения (или дефицита) рождаемости над смертностью, выраженная в процентах от базовой численности населения.
Коэффициент повторных браков Количество повторных браков на 1000 ранее состоявших в браке (то есть овдовевших или разведенных) мужчин или женщин в данном году.
Уровень замещения – фертильность Уровень фертильности, при котором пара имеет достаточно детей, чтобы заменить себя, или около двух детей на пару.
Репродуктивный возраст См. детородный возраст.
Репродуктивное здоровье Репродуктивное здоровье — это состояние полного физического, психического и социального благополучия, а не просто отсутствие болезней или физических дефектов во всех вопросах, касающихся репродуктивной системы, ее функций и процессов.
– S –
Соотношение полов Количество мужчин на 100 женщин в популяции.
Социальная мобильность Смена статуса (например, смена профессии).
Стабильное население Население с неизменной скоростью роста и неизменным возрастным составом в результате возрастных коэффициентов рождаемости и смертности, которые оставались постоянными в течение достаточного периода времени.
Опрос Опрос отдельных лиц или домохозяйств в населении, обычно используемый для определения демографических характеристик или тенденций для более крупного сегмента или всего населения. См. также перепись.
Коэффициент выживаемости Доля лиц в определенной группе (возраст, пол или состояние здоровья), живущих в начале интервала (например, пятилетнего периода), которые доживают до конца интервала.
– T –
Общий коэффициент фертильности (СКР) Среднее число детей, которые родились бы живыми у женщины (или группы женщин) в течение ее жизни, если бы ее детородный возраст соответствовал возрасту -удельные коэффициенты рождаемости данного года. Этот показатель иногда указывается как количество детей, которых женщины рожают сегодня. См. также общий коэффициент воспроизводства и чистый коэффициент воспроизводства.
– U –
До 5 лет (U5) Детская смертность Вероятность смерти ребенка, родившегося в определенный год или период, до достижения им 5-летнего возраста.
Иммигрант без документов Иностранец, въехавший в страну без проверки или без надлежащих документов, либо нарушивший условия легального въезда в страну страну, например, за превышение срока действия туристической или студенческой визы.
Неудовлетворенная потребность Женщины с неудовлетворенной потребностью в интервалах между рождениями — это те, кто способен забеременеть и ведет активную половую жизнь, но не использует никаких методов контрацепции (современных или традиционных) и сообщает о желании отложить рождение следующего ребенка или ограничить их количество рождений. Концепция неудовлетворенной потребности указывает на разрыв между репродуктивными намерениями женщин и их контрацептивным поведением.
Городское Страны различаются по тому, как они классифицируют население как «городское» или «сельское». Как правило, сообщество или поселение с населением 2000 или более человек считается городским. Список определений стран ежегодно публикуется в Демографическом ежегоднике Организации Объединенных Наций.
Урбанизация Рост доли населения, проживающего в городских районах.
– V –
Статистика естественного движения населения Демографические данные о рождениях, смертях, внутриутробных смертях, браках и разводах.
– W –
Расширение прав и возможностей женщин означает улучшение положения женщин для повышения их способности принимать решения на всех уровнях, особенно в том, что касается их сексуальности и репродуктивного здоровья.
– Y –
«Молодое» население Население с относительно высокой долей детей, подростков и молодых людей; низкий средний возраст; и, следовательно, высокий потенциал роста.
– Z –
Нулевой прирост населения Население в равновесии с нулевым темпом прироста достигается, когда рождаемость плюс иммиграция равна смертности плюс эмиграция.
Ресурсы
Просмотреть всеText Inspector: Analyse the Difficulty Level of English Texts
Menu
- Start New Text Analysis
- View Current Analysis
- My Account
- Home
- About
- Help
- Pricing
- Features
- Analyse Text
- Разработчики
- Блог Text Inspector
- Контакты
Попробуйте Text Inspector сейчас
Проанализируйте до 250 слов бесплатно — прямо здесь
Просто скопируйте и вставьте любой текст в это поле и нажмите «анализировать», чтобы получить мгновенный результат.
Вам нужны дополнительные функции или анализ более длинного документа?
Обновите подписку до полной, чтобы анализировать более длинные тексты, экспортировать свои данные, получать доступ к эксклюзивным инструментам только для подписчиков и пользоваться полной безопасностью данных.
Цены начинаются всего от 2,99 фунтов стерлингов в месяц (около 4,50 долларов США, примерно столько же, сколько чашка кофе)
Расширенные параметры
Тарифные планы
Детальный анализ любого текста/Изучение любого текста в деталях
Посмотрите наше короткое поясняющее видео ниже, чтобы узнать, как работает Text Inspector.
Удостоенный наград инструмент, созданный ведущими экспертами в области лингвистики
Text Inspector был создан известным профессором прикладной лингвистики Стивеном Баксом и стал лауреатом премии Британского совета ELTons Digital Innovation Award 2017. Text Inspector также поддерживается академическими партнерами The Center for Research in English Language Learning and Assessment (CRELLA).
Благодаря последним исследованиям в области прикладной лингвистики нашему инструменту доверяют университеты, колледжи и организации по всему миру, в том числе:
Узнайте, кто еще использует Text Inspector
Зачем анализировать словарный запас?
Словарный запас формирует основные строительные блоки языка.
Богатый словарный запас облегчает четыре основных навыка говорения, аудирования, чтения и письма, а без этого учащиеся не могут понимать язык, выражать свои мысли или быть понятыми.
По словам известного британского лингвиста, Дэвида Уилкинса ; «…тогда как без грамматики можно передать очень немногое, без лексики невозможно передать ничего»
Подробнее
Особенности
Статистика и удобочитаемость
Получите подробный обзор уровня языка и сложности текст
Лексическое разнообразие
Узнайте, насколько разнообразен язык, используемый в тексте
Британский национальный корпус
Понимание реального использования в британско-англоязычном мире
Корпус американского английского
Анализ текстов в соответствии с их употреблением в американском англоязычном мире
Академические списки слов Фразы
Изучите словарный запас, необходимый для успешной учебы, и улучшите учебные материалы для TOEFL и IELTS
English Vocabulary Profile
Понимать тексты с точки зрения их уровня CEFR (Общая европейская система координат)
Система показателей
Получить лексический профиль © Оценка и подробная информация о ключевых языковых метриках, используемых в тексте
Проанализируйте текст и обозначьте роль, которую он играет в предложении
Маркеры метадискурса
Найдите переходные слова, которые добавляют дополнительную информацию к тексту
Зачем использовать Text Inspector?
- Проверка уровня текстов учащихся
- Разработка и создание лучших учебных материалов
- Определение уровня CEFR текста
- Упрощение оценки письменных текстов понимание использования языка в реальной жизни
- Выбор лучших учебных материалов для учащихся, изучающих английский как английский язык
- Понимание использования английского языка в реальной жизни
- Сравните уровни сложности различных текстов
См. примеры Text Inspector в действии
Что говорят наши пользователи
Элейн, учительница и студентка магистратуры в Испании
регионе, где я живу, чтобы увидеть, сколько ключевого словарного запаса у них общего. Благодаря Text Inspector я обнаружил, что их словарный запас относится к непропорционально широкому диапазону уровней, от A1 до C2. Я также обнаружил, что большая часть словарного запаса не указана. Спасибо! Text Inspector стал важной частью расследования.
Уильямс, Сара. Инспектор текстов [онлайн]. Английский австралийский журнал, Vol. 33, № 2, 2018. С. 80-83.
Эта система идеально подходит для лингвистов, ученых и студентов, проводящих
лингвистических исследований. В целом, я нашел Text Inspector увлекательным инструментом для изучения. Он быстрый и всеобъемлющий, создание страниц данных занимает считанные секунды, и он позволяет пользователям анализировать чтение, написание и прослушивание текстов с большой точностью и надежностью. Я рекомендую всем англоязычным учреждениям и преподавателям, желающим убедиться, что их материалы представлены на правильном уровне, используйте Text Inspector.
Subscriptions pricing
Free
For occasional users
Price per month/year
FREE
Price per month/year
FREE
Word limit:
250
Extras:
–
Безопасность:
Автоматически удаляет данные с сервера через 6 часов.
Зарегистрироваться
Стандарт
Для частых пользователей, которые хотят анализировать большие тексты, загрузить свои данные и использовать EVP
Цена в месяц / год
£ 5,99 / £ 32,00
Цена в месяц / год
$ 8,25 / 44,00 долл. США
Word Limit:
10 000
33373 Word. Доступ к профилю английской лексики, академическому списку слов и оценочной таблице.Безопасность:
Автоматически удаляет данные с сервера через 6 часов.
Ручная очистка данных.
Подписка
Организация
Для организаций до 10 человек, которые хотят анализировать большие тексты, загружать свои данные и использовать EVP
Цена за месяц/год
25,99 фунтов стерлингов / 270,00 фунтов стерлингов
Цена за месяц/год
36 долларов США / $370.00
Максимальное количество слов:
13 000
Дополнительно:
Можно экспортировать данные. Доступ к профилю английской лексики, академическому списку слов и оценочной таблице.
Безопасность:
Автоматически удаляет данные с сервера через 6 часов.
Ручная очистка данных.
Подписаться
Индивидуальный анализ
Для исследователей или студентов, анализирующих большие тексты или корпуса.
Цена в месяц/год
Связаться с США
Цена в месяц/год
Связаться с US
Word Limit:
Unlimited
.