Морфемный разбор
Разбор слова по составу называют ещё морфемным разбором.
Сначала определяют границы окончания, изменяя форму слова (склоняют или спрягают слово). Затем выясняют часть речи, иначе разбор будет неправильным. Изменяемая часть является окончанием. В нём содержится грамматическое значение слова.
Домик-ом – существительное Т.п. и ед.ч.
Чёрн-ому – прилагательное м.р., ед.ч. и П.п.
Плыл-и – глагол мн.ч.
Окончания могут быть многозначными, одно и то же окончание выражает несколько разных грамматических значений (сравните: стекл-о – сущ. ед.ч. и стекл-о – глаг. ср.р. и ед.ч.).
Полк-а – существительное И.п. и ед.ч.
Знал-а – глагол ж.р. и ед.ч.
Прекрасн-а – прилагательное ж.р. и ед.ч.
Окончание существительного состоит из одной буквы (земл-я, стран-а, арми-я, окн-о, мор-е, собрани-е, подлежаще-е) или бывает нулевым (стол, конь, врач, воробей, гений, мышь, осень).
Окончание прилагательного или причастия в полной форме состоит из двух букв, в краткой форме сокращается на одну букву или становится нулевым в форме мужского рода (син-ий, голуб-ой, син-яя, голуб-ая, син-ее, голуб-ое; нежен, нежн-а, нежн-о, нежн-ы).
Прилагательные синий и лисий внешне похожи, но относятся к разным разрядам (первое качественное, второе притяжательное) и отвечают на разные вопросы. А кроме этого, они еще отличаются своими окончаниями: в слове лисий выделяется суффикс -ий, а окончание нулевое.
Окончание у глаголов выделяется не так просто. Сначала нужно определить его форму. Если это инфинитив (начальная форма), то он не изменяется, то есть не имеет непостоянных признаков, а значит, у него нет никакого окончания. В большинстве случаев он легко узнается по особым приметам: -ть, -ти, -чь (плыть, нести, беречь).
Форма прошедшего времени глагола определяется по суффиксу -л- (пел, пел-а, пел-о, пел-и, смеял-ся, смеял-а-сь, смеял-о-сь, смеял-и-сь). Здесь нужно отбросить постфикс -ся или -сь, потому что окончание стоит перед ним.
Формы настоящего и будущего времени глагола легко вспомнить (буквы Е, У, Ю есть в глаголах I спряжения, а буквы И, А, Я – в глаголах II спряжения): делаешь, делаете, делаем, делают; стоишь, стоите, стоим, стоят.
В повелительном наклонении глагола перед окончанием может быть суффикс И, а окончание ТЕ: ид-и-те, пиш-и-те (или режь, режь-те, возь-ми, стой).
Местоимения не разбираем по составу в школе, слишком странно выглядит их корень (к-ого-нибудь, ч-ем-то).
Числительные имеют не одно окончание, а сразу два, причем одно из них находится в середине слова: семьсот, сем-и-сот, семь-ю-ст-ами, сем-и-ст-ах.
В деепричастиях, наречиях, категории состояния, служебных словах, междометиях и звукоподражаниях окончание искать совсем не будем, так как это неизменяемые части речи.
После окончания выделяем основу слова. Она может совпадать с корнем (берег, гор-а), и это непроизводная основа. Она может включать в себя приставку, суффикс (пере-ход, бес-полез-н-ый, дом-ик) и быть производной основой.
Основа простая, если состоит из одного корня (красн-ый), она становится сложной, если имеет несколько корней (пар-о-ход). В основе содержится лексическое значение слова. В основу входят и постфиксы -ся, -сь.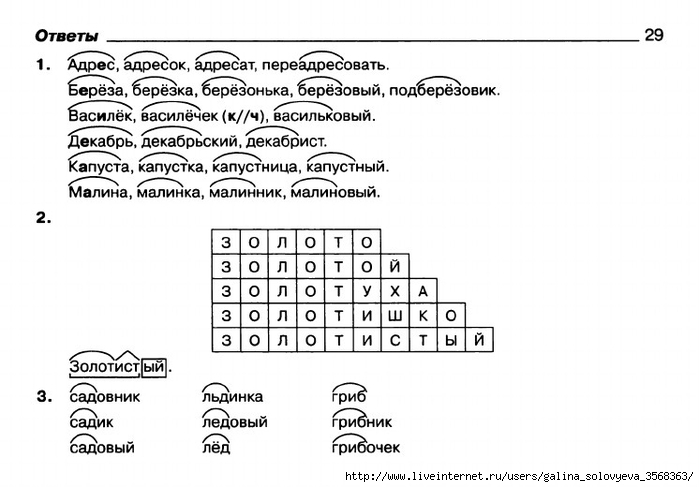 Тогда она становится прерывистой (сме-ёшь-ся – основа смеся). В основу не включаются интерфиксы (соединительные гласные О-Е): тепл-о-ход, птиц-е-фабрика.
Тогда она становится прерывистой (сме-ёшь-ся – основа смеся). В основу не включаются интерфиксы (соединительные гласные О-Е): тепл-о-ход, птиц-е-фабрика.
В каждом слове присутствует корень. Это главная часть слова, в которой заключается общее значение всех однокоренных слов (трав-а, трав-к-а, трав-инк-а, трав-ян-ой, трав-ян-ист-ый). В нём часто видны чередования гласных и согласных звуков (рАсти – срАщение – вырОс; друг – друзья – дружба).
Приставка – знАчимая часть слова, которая находится перед корнем и служит для образования новых слов и форм слов. Приставка состоит из одного звука или нескольких, как гласного, так и согласного (у-нёс, с-петь, по-розовел, при-вкус, сверх-герой). В слове можно найти более одной приставки: без-от-чётный, пере-с-читывать.
Каждая приставка имеет своё значение, может быть многозначной, к ней легко подобрать приставку-синоним или антоним.
Приставка бес- имеет значение отсутствия (бес-порядок, бес-конечность).
Приставка вы- имеет синоним по- (вы-мыть и по-мыть).
Приставка в- имеет антоним вы- (в-толкнуть – вы-толкнуть).
Есть даже приставки-омонимы: по-мёрзли, по-бежали, по-сидели, по-стирали.
Новые слова: не-счастье, ис-писать, бес-полезный.
Формы слова: наи-лучший, с-делать.
И по своему происхождению приставки бывают исконными и иноязычными: под-нести, контр-игра.
Суффикс – знАчимая часть слова, которая находится после корня и служит для образования новых слов и форм слов. Одно слово иногда содержит несколько суффиксов: за-бол-е-ва-ем-ость. Некоторые суффиксы выступают в разных вариантах: буфет-чик, стеколь-щик.
Суффиксы, как и приставки, тоже обладают лексическим значением, есть многозначные суффиксы, есть суффиксы-синонимы и омонимы.
Суффиксы -ек, -ик обладают уменьшительно-ласкательным значением: орех – ореш-ек, дом – дом-ик.
Синонимические суффиксы: стакан-чик и газет-чик; учи-тель и выключа-тель.
Суффиксы-омонимы: свин-ин-а, солом-ин-а, голос-ин-а, царап-ин-а, шир-ин-а.
Новые слова: син-ев-а, дожд-лив-ый, капитан-ск-ий.
Формы слов: тиш-е, красив-ее, пе-ть, прыга-л, бежа-вш-ий, увиде-в.
Порядок разбора слова по составу
- Определить часть речи.
- Обозначить окончание слова (если есть).
- Выделить основу.
- Через ряд однокоренных слов найти корень слова, отметить чередование звуков.
- Установить приставку или приставки.
- Установить суффикс или суффиксы.
Образец разбора слова по составу
Переплетение – сущ. ед.ч., И.п., нет переплетени-я или переплетени-ем, окончание Е.
Основа «переплетени». Однокоренные слова: плету, плеть, плетешь. Корень «плет».
Приставка пере- служит для образования нового слова.
Суффикс -ени[j] служит для образования нового слова.
Пере-плет-ени-е.
Порозовел – глагол, прошедшее время, ед. ч., м.р., окончание нулевое.
ч., м.р., окончание нулевое.
Основа «порозове» (-л – формообразующий суффикс). Однокоренные слова: розовый, розоветь. Корень «роз».
Приставка по- обозначает начало действия, служит для образования нового слова.
Суффикс -ов- служит для образования нового слова.
Суффикс -е- служит для образования нового слова.
По-роз-ов-е-л Ø
Выполните разбор по составу следующих слов:
Побеседовать
Беспорядочный
Невосприимчивость
Избранный
Сгнивший
Усмехаясь
Направо
Проверьте себя!
Урок русского языка в 5 классе «Морфемный разбор слова»
- Главная
- >
- Учителям
- >
- Методическая копилка
- >
- МО учителей русского языка и литературы
- >
- Разработки уроков
Тема: МОРФЕМНЫЙ РАЗБОР СЛОВА.
Цели:
- дидактическая: продолжить формирование навыка морфемного разбора слова;
- коррекционно-развивающая: коррекция логического мышления на основе упражнений и воспитание внимания и усидчивости у учащихся;
- воспитательная: формировать мотивацию к учению.


Оборудование: мультимедиапроектор, презентация по теме морфемный разбор слова, карточки индивидуальной работы.
ХОД УРОКА.
I. Организационный момент.
1. Приветствие.
2. Целеполагание.
II. Изучение нового материала (с использованием мультимедиапроектора).
Тема изложена на слайдах презентации, которые комментируются учителем.
Учащиеся записывают материал в тетради по ходу объяснения.
1. Фронтальный опрос.
— Кто мне скажет, что обозначает слово морфемика? Знаком ли вам этот термин? (слайд 3)
Морфемика – это раздел, который изучает морфемный разбор, иначе разбор слова по составу.
— Помните ли вы, что такое морфемный анализ слов? Как он проводится?
— Чтобы сделать морфемный разбор слова или разобрать слово по составу, необходимо знать из каких частей (морфем) строятся слова.
-Давайте дадим определение каждой морфеме.
— Что такое корень? (слайд 4)
Корень – главная значимая часть слова, в которой заключено лексическое значение, общее для всех однокоренных слов: вода, водяной, паводок, водный.
— Приведите ваши примеры однокоренных слов.
— Что такое приставка? (слайд 5)
Приставка – значимая часть слова, которая служит для образования новых однокоренных слов: ехать – приехать, уехать, заехать, переехать. Приставка находится перед корнем.
— Приведите примеры однокоренных слов с разными приставками.
— Итак, мы сделаем разбор слова по составу на слове «прекрасна».
— Что такое суффикс? (слайд 6)
Суффикс – значимая часть слова, которая, как правило, служит для образования новых однокоренных слов: человек, человечек, человеческий. Суффикс находится после корня.
— Приведите примеры однокоренных слов с разными суффиксами.
— Что такое окончание? (слайд 7)
Окончание – изменяемая часть слова, которая служит для образования грамматических форм существительных, прилагательных, числительных, местоимений и глаголов: терем¨, у терема, к терему; я тужу, ты тужишь, он тужит. Таким образом, окончание имеет грамматическое значение.
— Дайте примеры форм одного слова с разными окончаниями.
— Теперь, когда мы вспомнили морфемы, мы можем перейти к морфемному разбору.
2. Морфемный разбор слова. (слайд 8)
(слайд 2) «Я ль, скажи мне всех милее,
Всех румяней и белее? »
Что же зеркальце в ответ?
«Ты прекрасна, спору нет…»
— Кто вспомнит, из какого произведения эти строки?
— А вот и слово, которое мы будем разбирать «прекрасна».
Шаг 1. (слайд 10)
— Выделяем окончание и определяем его грамматическое значение.
— Что нужно сделать, чтобы выделить окончание слова «прекрасна»?
— Нужно изменить его. Это краткое прилагательное, оно изменяется по числам и родам. ( Прекрасен, прекрасно, прекрасны).
— Мы видим часть слова, которая меняется (по окончаниям на сноске)
Следовательно, в слове «прекрасна» окончание–«а».
— Оно имеет грамматическое значение единственного числа женского рода. Обратите внимание на то, как обозначается окончание.
— Если мы выделили окончание, нам легко определить основу слова. (слайд 11)
— Почему?
Основа – это часть слова без окончания: у терема, пирожок ¨.
— Основа прекрасн—.
— Итак, в слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде.
Основа – прекрасн а .
Продолжаем наш разбор .
Шаг 2. (слайд 12)
— Определим корень слова.
— Как это сделать?
— Нужно подобрать однокоренные слова: красный, краса, красивый.
— Мы видим, что их общая часть, а значит, корень -крас-. В нем заключено общее для всех этих слов лексическое значение. Я думаю, вы знаете, что в старину слово «красный» имело значение «красивый».
Итак, корень в слове «прекрасна» – —крас-. Однокоренными словами являются красный, краса, красивый.
Шаг 3. (слайд 13)
— Нужно определить, какие ещё морфемы есть в слове.
— Есть ли приставка в этом слове?
— Да, перед корнем приставка пре-.
— Какое значение она придаёт прилагательному?
— Образуем другие прилагательные с такой же приставкой: предобрый, премилый, премудрый. Очевидно, что приставка «пре» во всех этих прилагательных имеет значение «весьма», «очень».
— Есть ли в слове суффикс?
— Да, это суффикс н. Он стоит после корня перед окончанием.
— Какова его роль?
— Мы видим, что с помощью этого суффикса от существительных образуются прилагательные: беда – бедный; вред – вредный; честь – честный и… краса – красный.
— Вот мы и сделали морфемный разбор слова «прекрасна».
Выводы на доску. (слайд 14)
(слайд 15). В слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде.
(слайд 16). Корень в слове прекрасна – -крас-. Однокоренными словами являются красный, краса, красивый.
(слайд 17). В слове прекрасна есть приставка пре-, она имеет значение «очень», «весьма».
(слайд 18). В слове прекрасна есть суффикс –н-. С помощью этого суффикса от существительного образовалось прилагательное.
Итак, Порядок разбора: (слайд 19)
Шаг 1. Выделить окончание, объяснить его значение. Выделить основу слова.
Шаг 2. Выделить корень слова, подобрав однокоренные слова.
Шаг 3. Выделить приставки и суффиксы. Объяснить, если возможно значение приставок и суффиксов.
III. Физминутка. (Выполняется стоя).
1). Сделать 3-4 раза круговые движения головой.
2). 1. – Руки согнуты перед грудью. 1-2 — два пружинящих рывка назад согнутыми руками. 3-4 – то же прямыми руками. Повторить 5-7 раз. Темп средний.
3). Несколько раз открыть/закрыть глаза.
IV. Закрепление изученного материала.
1. Морфемный разбор слова.
Один учащийся работает у доски, остальные самостоятельно.
Лесной, перелесок, приморский, прогуляться, многолетний.
2. Работа с отрывком из сказки «Сказка о мёртвой царевне и семи богатырях».
Долго царь был неутешен Но как быть? И он был грешен; Год прошёл, как сон пустой, Царь женился на другой. | Правду молвит молодица Уж и впрямь была царица: Высока, стройна, бела, И умом и всем взяла… |
Сделайте морфемный разбор выделенных в тексте слов. Впишите части слов в таблицу. Если в слове нет какой-нибудь морфемы, напишите: нет. Если окончание нулевое, так и напишите.
слова для разбора | окончание | основа | корень | приставка | суффикс |
неутешен | нулевое | неутешен | теш | не, у | ен |
прошёл | нулевое | прошёл | шё | про | л |
пустой | ой | пуст | пуст | нет | нет |
молодица | а | молодиц | молод | нет | иц |
умом | ом | ум | ум | нет | нет |
3. Работа со схемами.
Работа со схемами.
Нужно подобрать слова, которые подходят к схемам.
V. Итог урока.
— Что же такое морфемный разбор слова?
— В какой последовательности нужно его выполнять?
VI. Домашнее задание.
Упр. 178 на с.74, сделать морфемный разбор слов: пришкольный, бегает, новизна.
Выставление оценок.
Скачать>>>
Разбор слова по составу, морфемный разбор онлайн — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Разбор слова по составу корень суффикс окончание
В значении «как?» при употреблении без предлога. Например, быть онлайн, смотреть онлайн.
Части слова: онлайн
Часть речи: наречие
Состав слова:
онлайн — корень,
нет окончания ,
онлайн — основа слова.
В значении «состояния» или «места» при употреблении с предлогом «в». Например, быть в онлайне.
Части слова: онлайн
Часть речи: имя существительное
Состав слова:
онлайн — корень,
нулевое окончание,
онлайн — основа слова.
В значении «подключенный», «работоспособный».
Части слова: он/-/лайн
Часть речи: наречие
Состав слова:
он — приставка,
лайн — корень,
нет окончания ,
он-лайн — основа слова.
Разобрать слово по составу или сделать его морфемный анализ означает указать, из каких морфем оно состоит. Под морфемой понимается минимально значимая часть слова.
В русском языке существуют следующие морфемы:
- корень — самая главная часть слова, несущая его значение. У однокоренных слов — общий корень. Например, слова «лист», «листочек» и «листва» имеют общий корень —«лист». Бывают слова, которые состоят только из корня — «гриб», «метро», «остров». Бывает, что корня два — «теплоход», «водопад». Бывает, что корней три — не стоит пугаться — «водогрязелечебница». Повтори правило, которое касается соединительных гласных, чтобы не делать ошибки при их написании;
- суффикс — значимая часть слова. Расположена обычно после корня. Используется для образования новых слов. Например, в слове «чайник» «чай» — это корень, «ник» — это суффикс. Суффиксов в слове может не быть. Иногда суффиксов бывает два — например, в слове «подберезовик»;
- приставка — еще одна значимая часть слова. Расположена перед корнем. Назначение такое же, как и у суффикса — с ее помощью образовываются новые слова. В слове «подходит» «ход» — это корень, «под» — это приставка;
- Окончание — изменяемая часть слова. Для чего она нужна? Чтобы связывать слова в предложении;
- Основа — часть слова без окончания.
 Например, в слове «чайник» «чай» — это корень, «ник» — это суффикс. Суффиксов в слове может не быть. Иногда суффиксов бывает два — например, в слове «подберезовик»;
Например, в слове «чайник» «чай» — это корень, «ник» — это суффикс. Суффиксов в слове может не быть. Иногда суффиксов бывает два — например, в слове «подберезовик»;Каждая часть слова имеет графическое обозначение. Посмотреть, как обозначаются части слова, можно в учебнике по русскому языку, в морфемном словаре или в Интернете.
Правила и исключения при разборе по составу
Разбор слова по составу онлайн несложен, если знать правила, по которым он делается. На начальном этапе можно пользоваться морфемно-орфографическим словарем — он поможет не делать ошибок.
Обязательно в слове должен присутствовать только корень — один или несколько. Слов без корня не бывает. Не бывает слов и без основы. А вот слова без суффиксов, приставок или окончаний очень даже бывают. Этому не стоит удивляться.
Слов без корня не бывает. Не бывает слов и без основы. А вот слова без суффиксов, приставок или окончаний очень даже бывают. Этому не стоит удивляться.
Часто бывает, что все слово представляет собой основу. Так бывает, например, у наречий. Они относятся к неизменяемым частям речи. Слово «быстро» не имеет окончания («о» в слове — это суффикс), а потому все слово будет основой.
В проведении морфемного анализа ученику поможет словообразовательный словарь Тихонова. Этот учебник содержит информацию о составе 100 тыс. слов русского языка. Словарем удобно пользоваться, и в период обучения в начальной школе он должен стать твоей настольной книгой.
Тем же, кто обладает навыками работы в сети Интернет, будут полезными ресурсы, на которых можно сделать морфемный разбор слова онлайн. Тренируйся, если занятий в школе на уроках русского языка тебе недостаточно.
Краткая шпаргалка (план) по морфемному разбору слов
Морфемный разбор состоит из следующих этапов:
- Определяем к какой части речи относится слово. Для этого надо задать к нему вопрос. Возьмем для примера слово «поездка». Оно отвечает на вопрос «что?».
- Прежде всего надо найти в слове окончание. Для этого его нужно изменить несколько раз. Изменим его несколько раз — «перед поездкой», «в поездке». Видим, что изменяющаяся часть — «а». Это окончание.
- Разбор слова по составу продолжается определением корня. Подберем однокоренные слова — «поезд», «переезд». Сравним эти слова — не меняется часть «езд». Это и есть корень.
- Выясняем, какая в слове приставка. Для этого анализируем еще раз однокоренные слова — «поезд», «подъезд». Соответственно, в слове «поездка» приставка «по».
- Заключительный этап — это выяснение, где же в слове суффикс. Остается буква «к», которая стоит после корня и служит для образования слова. Это и есть суффикс.
- Обозначаем все части слова соответствующими символами.
 Для этого надо задать к нему вопрос. Возьмем для примера слово «поездка». Оно отвечает на вопрос «что?».
Для этого надо задать к нему вопрос. Возьмем для примера слово «поездка». Оно отвечает на вопрос «что?».Примеры морфемного разбора
Для примера ниже подобраны слова с наиболее интересными вариантами разбора по составу: кляузничать, срываться, поозорничать, стираться, ссаживаться, склоняться, денационализироваться, спрягаться, малодушествовать, срядиться, для выполнения разбора других слов воспользуйтесь формой поиска.
Описание
Как разобрать слово по составу
Морфемный разбор слова или разбор по составу — это нахождение всех необходимых частей слова (корень, суффикс, окончание и т. д). Данный принцип является одним из основных в русскоязычной грамматике, поэтому морфемный разбор имеет немаловажное значение. Например, для того, чтобы определить, какая буква пишется в том или ином слове, нужно сначала узнать, в какой части слова она находится. И в зависимости от этого, использовать нужное написание. Грамотный разбор слова является основой правописания. Для осуществления разбора нужно иметь общее представление о морфемах, а также знать определённый порядок действий.
Какие бывают морфемы
Приставка. Это морфема, при помощи которой образовываются новые слова. Приставка находится перед корнем. При помощи приставочного способа образования слов чаще всего получаются одинаковые части речи. Например: ставить — переставить. На примере видно, что от глагола при помощи приставки пере- образовался новый глагол. В русском языке также присутствуют заимствованные от других языков приставки. Например: анти-, де-, суб- и так далее.
В русском языке также присутствуют заимствованные от других языков приставки. Например: анти-, де-, суб- и так далее.
Корень слова. Корень считается основной частью любого слова. В нем закладывается общее его значение, а также значение однокоренных слов (тех, у которых одинаковый корень). Однокоренных слова не обязательно должны относиться к одной части речи, они могут быть различными (от существительного образовываться в прилагательные и т. д.). Однако встречаются слова, которые имеют созвучные и похожие корни, но в то же время имеют отличные друг от друга значения. В таких случаях слова не считаются однокоренными, а называются омонимами. Для того, чтобы выявить корень слова, необходимо попытаться подобрать к нему однокоренные слова и найти ту общую часть, которая присутствует в каждом слове и остаётся неизменной. Обязательное условие: слова должны иметь похожее лексическое обозначение, а не просто созвучный корень. Например: дом — домик — домашний. Данные слова имеют одинаковую часть слова дом-, а значит она и является корнем.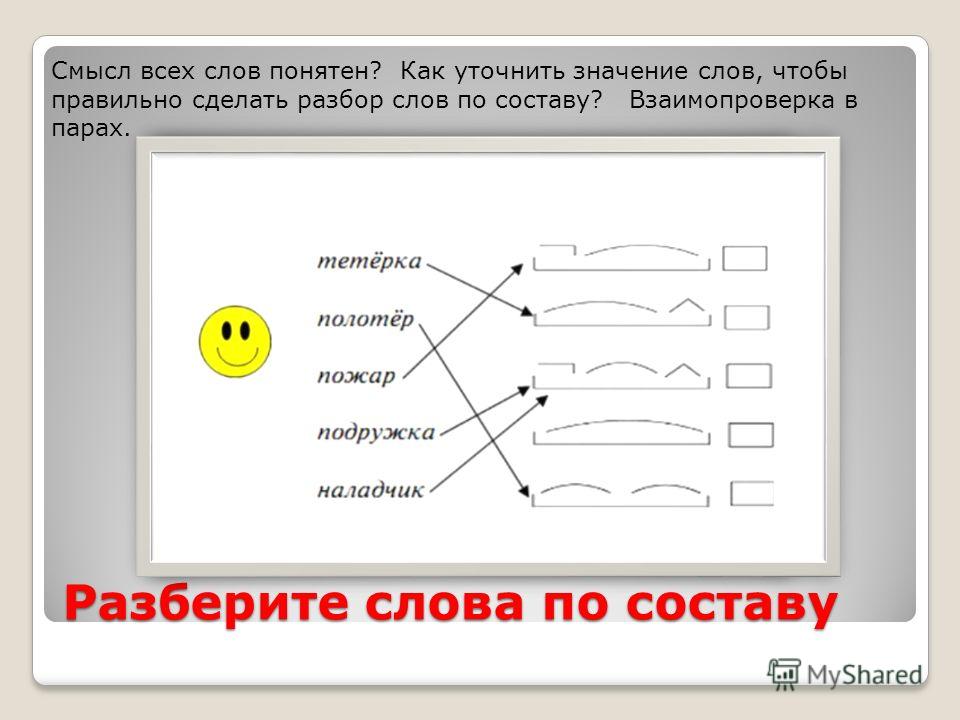
Игра — игровой — играть. В этой цепочке слов общей частью является игр-, значит она также является корнем.
Суффикс. Это также одна из части слов, которая помогает образовывать новые слова. Морфема находит свое расположение после корня слова. Кроме того, суффикс помогает менять саму форму того или иного слова, а также образовывать новые части речи. Чаще всего существительное и прилагательные. Например: лес — лесник. Благодаря суффиксу -ник- образовалось новое существительное. Море — морской. При помощи суффикса -ск- от существительного образовалось новое прилагательное. Стоит заметить, что морфема не считается основной частью слова, суффикса попросту может не быть в составе. Чтобы найти данную морфему, нужно для начала определить корень и окончание слова. То, что останется между ними, и будет суффиксом. Важно знать, что оставшаяся часть слова не всегда является цельным суффиксом. Их может быть и несколько.
Окончание слова. Окончание является изменяем ой частью слова, которая зависит от рода слова, числа и падежа. Данная морфема обычно идёт после корня либо суффикса. Окончание несёт роль связывание слов в предложениях. Как же его определить? Нужно просто просклонять нужное слово и понять, какой части присуще меняться. Это и будет окончанием слова. Например: трава, травы, траве. Просклоняв слово в разных падежах, можно увидеть, что изменяется только последняя буква, а значит она и является окончанием.
Данная морфема обычно идёт после корня либо суффикса. Окончание несёт роль связывание слов в предложениях. Как же его определить? Нужно просто просклонять нужное слово и понять, какой части присуще меняться. Это и будет окончанием слова. Например: трава, травы, траве. Просклоняв слово в разных падежах, можно увидеть, что изменяется только последняя буква, а значит она и является окончанием.
Окончание также может иметь и нулевую форму. Для того, чтобы его определить, нужно также просклонять нужное слово по падежам. Если в падежных формах появляются новые буквы, значит начальная форма слова имеет нулевое окончание. Например: дом, дома, дому. В падежных формах слово приобрело окончание, значит изначально оно являлось нулевым.
Соединительные буквы. Это буквы, которые соединяют несколько корней в сложнообразованных словах. Наиболее распространены сединительные гласные -о- и -е-. Например: птицелов, кровожадный, самолёт.
Основа. Это часть слова, не входящая в состав окончания и остающаяся неизменной.
Основной принцип разбора слова по составу
Определить, с какой частью речи придётся работать. Это можно сделать путем подбора вопроса к слову.
Теперь нужно определить окончание имеющегося слова. Для этого стоит просклонять его по числам и падежам. Та часть, которая изменилась, обводится в квадрат. Так обозначается окончание. Первоначальный поиск окончания является обязательным правилом для всех школьников. Ведь некоторые из них начинают морфемный разбор именно с выделения корня. Это является одним из самых ошибочных заблуждений, потому что в некоторых словах определить корень довольно сложно, а где-то его и вовсе нет.
Следующее действие — найти основу. Сделать это несложно. Часть слова, оставшаяся после выделения окончания, и является основой. Подчёркивается она одной горизонтальной линией, которая немного приподнимается перед окончанием.
Определить корень слова. Чтобы это осуществить, нужно подобрать однокоренные слова к нужному слову. Они должны быть похожи по лексическому значению, то есть быть похожими по смыслу, а не только по звучанию. Та неизменная часть, которая присутствует во всех словах и будет являться корнем. Обозначается он специальной дугой над нужной буквенной частью.
Та неизменная часть, которая присутствует во всех словах и будет являться корнем. Обозначается он специальной дугой над нужной буквенной частью.
Выделить суффиксы. Для этого нужно сопоставить конкретное слово с его прочими формами. А затем создать словообразовательную цепочку, чтобы понять, какое слово было первоначальным, и какой суффикс использовался в процессе. Обозначается морфема формой полуромба над нужной частью слова.
Найти приставку. К конкретному слову нужно попытаться подобрать другие приставки. Также можно использовать другие слова с применением имеющейся приставки. Если смысл слова не коверкается, значит эта часть слова является приставкой. Выделяется она горизонтальной линией над словом, которая загинается перед корнем.
Слова с приставкой, корнем, суффиксом и окончанием Примеры 10 слов
Для анализа структуры слова мы можем использовать несколько вариантов разбора слова. Наряду со словообразовательным разбором слова, помогающим определить основу слова и производные от него слова, существует также морфемный разбор слова, предполагающий выделение в слове его корня, приставки, суффикса и окончания. В данном материале я расскажу, как выполнить морфемный разбор нужного нам слова, а также укажу на характерные особенности проведения подобного разбора.
В данном материале я расскажу, как выполнить морфемный разбор нужного нам слова, а также укажу на характерные особенности проведения подобного разбора.
Читайте также: Слова без окончания примеры.
Последовательность действий морфемного разбора слова
Выполнение морфемного разбора слова предполагает следование следующему алгоритму:
- Разбираемся, к какой части речи относится анализируемое нами слово;
- Затем выделяем в данном слове его основу и окончание. Для выделения окончания необходимо выполнить склонение нужного слова по падежам. Та часть слова, которая не будет изменяться при склонении, обычно является основой, а изменяемая часть – окончанием. Хотя также бывают ситуации (например, у наречия), когда всё слово будет являться основой без окончания (обычно это бывает тогда, когда слово при склонении не изменяется, например, в случае слов «издали», «тихо» и др.). Чтобы не допустить различных ошибок при выделении основы, почаще заглядывайте в подручный словарь морфем;
- Проанализируйте, входит ли в основу данного слова приставка и суффикс. Для определения суффикса сопоставьте разбираемое слово с однокоренными словами, это позволит выделить формообразующие суффиксы (т.е. суффиксы, которые образуют формы одного и того же слова, например: – время – времени). Затем определитесь с наличием в слове словообразовательных суффиксов (служат для образования новых однокоренных слов, например: — писать – писа-тель). Если затрудняетесь с поиском суффиксов, не стыдитесь обращаться за помощью к уже упомянутому словарю морфем;
- Найдите корень слова. Для нахождения корня подберите однокоренные слова – например, гриб – грибной.
- Теперь отметьте части речи в слове с помощью соответствующих графических обозначений.
 Для определения суффикса сопоставьте разбираемое слово с однокоренными словами, это позволит выделить формообразующие суффиксы (т.е. суффиксы, которые образуют формы одного и того же слова, например: – время – времени). Затем определитесь с наличием в слове словообразовательных суффиксов (служат для образования новых однокоренных слов, например: — писать – писа-тель). Если затрудняетесь с поиском суффиксов, не стыдитесь обращаться за помощью к уже упомянутому словарю морфем;
Для определения суффикса сопоставьте разбираемое слово с однокоренными словами, это позволит выделить формообразующие суффиксы (т.е. суффиксы, которые образуют формы одного и того же слова, например: – время – времени). Затем определитесь с наличием в слове словообразовательных суффиксов (служат для образования новых однокоренных слов, например: — писать – писа-тель). Если затрудняетесь с поиском суффиксов, не стыдитесь обращаться за помощью к уже упомянутому словарю морфем;Смотрите также: Слова с корнем и окончанием примеры 10 слов.

Особенности работы с источниками при морфемных разборах
Помните, что при работе с морфемными словарями (в том числе и в сети) разбор одних и тех же слов может быть выполнен по-разному, в зависимости от конкретной школы русского языка, и специфики используемой ею методологии. Существенно может отличаться морфемный разбор слова в школе и университете (в ВУЗе уделяют пристальное внимание этимологии слова), потому в университете могут выделять нулевой суффикс, фиксировать наличие нулевого корня и так далее.
Также могут существенно отличаться морфемные разборы одних и тех же слов в различных словарях (например, в словарях под ред. Ефремовой Т.Ф, и под ред. Тихонова А.Н. отличается морфемный разбор слова «благодарность»). Поскольку споры о единственно правильном разборе слова ещё ведутся, необходимо считать верными оба варианта разбора слова.
Примеры слов с приставкой, корнем, суффиксом и окончанием
Приведём морфемный разбор некоторых слов:
Слово «яблоко»
Часть речи: имя существительное
Состав слова:
яблок — корень,
о — окончание,
яблок — основа слова.
Слово «каждый»
Часть речи — местоименное прилагательное
Состав слова:
кажд — корень,
ый — окончание,
кажд — основа слова.
Слово «играть»
Часть речи: глагол
Состав слова:
игр — корень,
а, ть — суффиксы,
нет окончания,
игра — основа слова.
Слово «ответ»
Часть речи — существительное
Состав слова:
ответ — корень,
нулевое окончание,
ответ — основа слова.
Слово «работать»
Часть речи: глагол
Состав слова:
работ — корень,
а, ть — суффиксы,
нет окончания,
работа — основа слова.
Слово «гитара»
Часть речи – имя существительное
Состав слова:
гитар — корень,
а — окончание,
гитар — основа слова.
Слово «ель»
Часть речи – существительное
Состав слова:
ель — корень,
нулевое окончание,
ель — основа слова.
Слово «коллекция»
Часть речи — существительное
Состав слова:
коллекци — корень,
я — окончание,
коллекци — основа слова.
Слово «путешествовать»
Часть речи: глагол
Состав слова:
пут, ше — корни,
е — соединительная гласная,
ств, ова, ть — суффиксы,
окончания нет,
путешествова — основа слова.
Помните, что «ть» здесь (и в других аналогичных словах) является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах «ть» отмечается как окончание.
Слово «вперёд»
Данное слово может быть как наречием, так и предлогом.
Состав слова:
в — приставка,
перёд — корень,
нет окончания,
вперёд — основа слова.
Слово «лучший»
Часть речи – слово прилагательное
Состав слова:
лучш — корень,
ий — окончание,
лучш — основа слова.
Перечень сервисов для анализа слов с приставкой, корнем, суффиксом и окончанием
Также хотели бы обратить внимание читателей на сетевые сервисы, где находятся словари морфем, благодаря которым вы сможете получить информацию о выбранном вами слове:
- Russkiy-na-5. ru – на данном сервисе размещена база с 2300 слов, для которых вы можете просмотреть морфемный разбор. Просто введите требуемое слово в поисковую строку, и при нахождении данного слова вы получите образец его морфемного разбора;
- Odnokorennye-slova-k-slovy.ru – данный сайт являет собой справочный ресурс, на котором вы можете просмотреть морфемный разбор большинства слов, а также подобрать к вашему слову однокоренные слова. Работа с сайтом не отличается от аналогов – вы переходите на ресурс, вбиваете нужное слово в строку поиска, и жмёте на кнопку ввода;
- Morphemeonline.ru – ещё один аналогичный сервис, где имеется внушительная база морфемных разборов слов. Работа с сервисом не отличается от работы с сервисами-аналогами.
 ru – на данном сервисе размещена база с 2300 слов, для которых вы можете просмотреть морфемный разбор. Просто введите требуемое слово в поисковую строку, и при нахождении данного слова вы получите образец его морфемного разбора;
ru – на данном сервисе размещена база с 2300 слов, для которых вы можете просмотреть морфемный разбор. Просто введите требуемое слово в поисковую строку, и при нахождении данного слова вы получите образец его морфемного разбора;Заключение
Морфемный разбор слова предполагает следование определённому плану, который был изложен нами выше. Учтите, что специфика результатов подобного разбора может отличаться в зависимости от методологии конкретной школы, дифференциируясь даже в словарях различных авторов. Поскольку споры о правильности того или иного морфемного разбора ещё ведутся, рекомендуем использовать один из имеющихся в словарях вариантов разбора – на базовом уровне он будет считаться правильным в любом случае.
Поскольку споры о правильности того или иного морфемного разбора ещё ведутся, рекомендуем использовать один из имеющихся в словарях вариантов разбора – на базовом уровне он будет считаться правильным в любом случае.
Фонетический разбор слова «Дактилографический». Сколько звуков и букв в слове?
Транскрипция слова: [ дакт’илаграф’ич’иск’ий’ ]
В слове «Дактилографический»: 18 букв, 18 звуков (7 гласных, 11 согласных).
| Буква | Звук | Характеристика звука |
|---|---|---|
| д | [ д ] | согласный, звонкий парный, твёрдый (парный) |
| а | [ а ] | гласный, безударный |
| к | [ к ] | согласный, глухой парный, твёрдый (парный) |
| т | [ т’ ] | согласный, глухой парный, мягкий (парный) |
| и | [ и ] | гласный, безударный |
| л | [ л ] | согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный) |
| о | [ а ] | гласный, безударный |
| г | [ г ] | согласный, звонкий парный, твёрдый (парный) |
| р | [ р ] | согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный) |
| а | [ а ] | гласный, безударный |
| ф | [ ф’ ] | согласный, глухой парный, мягкий (парный) |
| и | [ и ] | гласный, ударный |
| ч | [ ч’ ] | согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий |
| е | [ и ] | гласный, безударный |
| с | [ с ] | согласный, глухой парный, твёрдый (парный) |
| к | [ к’ ] | согласный, глухой парный, мягкий (парный) |
| и | [ и ] | гласный, безударный |
| й | [ й’ ] | согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко) |
Цветовая схема: д а к т и л о г р а ф и ч е с к и й
Естігенді есте сақтау жолдары Абайдың қай қара сөзінде айтылады?
Қамшыны тастай берып домбыра ұстайсын домбырадан босап кетсе қолың тағы тізгенде болады солай.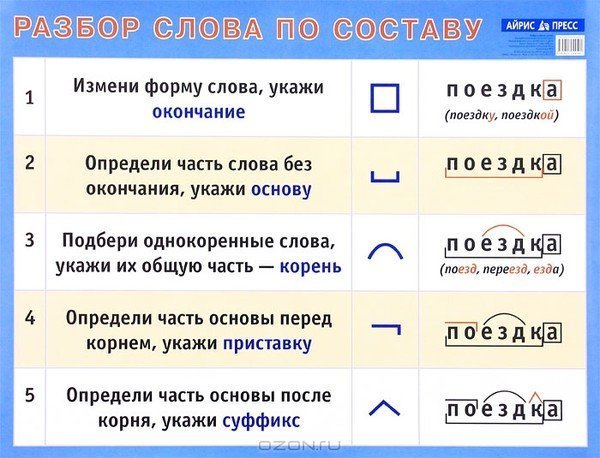 Оразымбет шырағым бұл сөзды айтқан кым
Оразымбет шырағым бұл сөзды айтқан кым
9-тапсырма. Берілген үзінділерге талдау жасаңдар.Әңгімеден үзіндіКөріктеу құралдары… Ұлан асуына қарай созылған | Сиыр жалағандай теңеу.ұзақ жол бет … і сиыр жалағандай. Жып-жылмағай көк — эпи-Жып-жылмағай көк мұз.тет….наурыздың ақша қарын жамы-лып, самарқау жатыр….қалың тұманда адасып қалғанадамдай сандалмас па еді…Автобус тасбақаша төрттағандапілбіп келеді.Ат құлағы көрінбес боран.
Қамшыны тастай берып домбыра ұстайсын домбырадан босап кетсе қолың тағы тізгенде болады солай.Оразымбет шырағым бұл сөзды айтқан кым
Сөйлемді аяқта.A) Интернет желісінде адасып қалмау үшін ……..Ә) Электронды пошта жылдан бастап пайда болған… Б) Электронды пошта ашу үшін ….B) … Интернеттегі ақпаратты іздеу порталдары -… СРОЧНО ПОЖАЛУЙСТА У МЕНЯ УРОК
3. «Әттең, біздің сор маңдайлы ЖайықтаЕрлер аз ғой бара алатын байыпқа!Тым кеш ұқтым,Махамбеттей батырғаБүкіл қазақ ғашық болса, айып па?» – деген ақы … н толғанысын қалай түсіне
Өлеңнен сын есімдер мен зат есімдерді тап. Оларды тіркестіріп, сөйлем кұра.
Мен жастарға сенемін.
Арыстандай айбатты,
Жолбарыстай қайратты –
Қырандай
… күштi қанатты.
Мен жастарға сенемiн!
Көздерiнде от ойнар,
Сөздерiнде жалын бар,
Жаннан қымбат оларға ар,
Мен жастарға сенемiн!
Жас қырандар – балапан,
Жайып қанат ұмтылған.
Көздегенi көк аспан.
Мен жастарға сенемiн!
Жұмсақ мiнез жiбектер.
Сүттей таза жүректер.
Қасиеттi тiлектер –
Мен жастарға сенемiн!
Помогите написать полностью всё пж
Оларды тіркестіріп, сөйлем кұра.
Мен жастарға сенемін.
Арыстандай айбатты,
Жолбарыстай қайратты –
Қырандай
… күштi қанатты.
Мен жастарға сенемiн!
Көздерiнде от ойнар,
Сөздерiнде жалын бар,
Жаннан қымбат оларға ар,
Мен жастарға сенемiн!
Жас қырандар – балапан,
Жайып қанат ұмтылған.
Көздегенi көк аспан.
Мен жастарға сенемiн!
Жұмсақ мiнез жiбектер.
Сүттей таза жүректер.
Қасиеттi тiлектер –
Мен жастарға сенемiн!
Помогите написать полностью всё пж
СРОЧНО ПОЖАЛУЙСТА.Составьте небольшой текст по картинкам
қазақ әдебиеті 5класс 135бет
5 тапсырма 95 бет пожалуйста сделайте срочно
Эссе жазу»Күй аңызы» әңгімесі туралы менің пікірімМенің ойымша:Себебі мен оны ……………………………………………………………. … ………………………………. деп түсіндіремін.Оны мен ………………………………………………………………………………………………….деген дәлелдермен, мысалдармен дәлелдеймін.Осы тақырыпқа байланысты мен ……………………………………………………………..тұжырым жасадым.Осы «ПОПС формуласы әдісін» қолдана отырып, эссені жазамыз. Сөз саны 120-130 сөз.Көмектесыедершы ртынем
nlp — программа для извлечения словесных функций, таких как субъект, предикат, объект и т.
 Д.
Д.Согласно http://nlp.stanford.edu/software/lex-parser.shtml, в Стэнфордском НЛП действительно есть синтаксический анализатор, который может идентифицировать подлежащее и предикат предложения. Вы можете попробовать его на сайте http://nlp.stanford.edu:8080/parser/index.jsp. Вы можете использовать типизированные зависимости для идентификации субъекта, предиката и объекта.
На странице примера предложение Моя собака тоже любит есть колбасу даст вам этот синтаксический анализ:
(КОРЕНЬ
(S
(NP (PRP $ My) (NN собака))
(АДВП (также РБ))
(VP (лайки VBZ)
(S
(ВП (ВБГ ест)
(НП (колбаса НН)))))
(..)))
Парсер также может генерировать зависимости:
посс (собака-2, Мой-1) nsubj (нравится-4, собака-2) advmod (нравится-4, также-3) корень (ROOT-0, нравится-4) xcomp (нравится-4, ест-5) добж (ест-5, колбаса-6)
Зависимость nsubj показывает основной предикат и подлежащее — в данном случае любит и dog . Цифры показывают позицию слова в предложении (по какой-то причине с одним индексом). Зависимость
Цифры показывают позицию слова в предложении (по какой-то причине с одним индексом). Зависимость dobj показывает отношение предиката и объекта.Зависимость xcomp предоставляет внутреннюю информацию о предикате.
Это также работает, когда сказуемое не является глаголом: Моя собака большая и ответственная дает:
посс (собака-2, Мой-1) nsubj (большой-4, собачий-2) полицейский (большой-4, ис-3) корень (ROOT-0, большой-4) cc (большой-4 и-5) con (большой-4, в-6) pobj (ин-6, заряд-7)
Это говорит нам, что large является основным предикатом ( nsubj (large-4, dog-2) ), но была связка ( cop (large-4, is-3) ), а также союз и предлог с объектом.
Я не знаком с API, поэтому не могу назвать точный код. Возможно, это сможет сделать кто-то другой, знакомый с API. Анализатор задокументирован на сайте документации Stanford NLP. Вам также может быть полезен ответ на Инструменты для упрощения текста (Java). Дополнительную информацию о формате зависимостей можно найти в Стэнфордском руководстве по зависимостям.
Дополнительную информацию о формате зависимостей можно найти в Стэнфордском руководстве по зависимостям.
(PDF) Взаимодействие корня, суффикса и частоты всего слова при обработке производных слов
Взаимодействие корня, суффикса и частоты всего слова 185
слова, с другой стороны (всегда p
(p = 0,05).
Двусторонний дисперсионный анализ для четырех производных наборов с корневой частотой
(высокий или низкий) и частотой суффикса (высокий или низкий) в качестве двух факторов,
подтвердил только корневой эффект обоими факторами. участников и заданий, по реакции
раз и ошибок (F1 (1,46) = 129,3, p
14,59, p
p
По времени реакции не было обнаружено суффиксного эффекта (F
(F только
(F1 (1,46) = 9,83, p 0,1, MSE =
30,7), где слова с низкочастотными суффиксами вызывают больше ошибок
, чем слова с высокочастотными суффиксами. Никакого взаимодействия не обнаружено на er-
rors (F
Результаты эксперимента 3 подтвердили основанную на морфемах обработку слов HH
. Как и ожидалось, эти производные слова показали более быстрое время реакции и более высокую точность на
Как и ожидалось, эти производные слова показали более быстрое время реакции и более высокую точность на
из-за включения высокочастотных морфологических компонентов
. Результаты эксперимента 3 также предполагали обработку целого слова для слов, производных от LL — последние слова, составляющие фемы которых были низкочастотными, не показали никакого преимущества по сравнению с
непроизводными словами из словосочетания. такая же поверхностная частота.
Результаты эксперимента 3 не соответствовали прогнозам
, сделанным для слов, производных от HL и LH. В отличие от эксперимента 2, в
, где два набора производных слов, которые включают одну высокочастотную составляющую
, не отличались друг от друга и показали промежуточное время реакции и точность в отношении слов, включая два высокочастотных компонента.
частотных составляющих, с одной стороны, и слов, включающих две низкочастотные составляющие
, с другой, в Эксперименте 3 HL и LH слова
дали противоположные результаты. Очевидно, несовершенный баланс между наборами слов с рейтингом
Очевидно, несовершенный баланс между наборами слов с рейтингом
был ответственен за часть эффектов, обнаруженных в эксперименте
Эксперимент 2. Лучшее соответствие между экспериментальными наборами привело к другому шаблону результатов
в Эксперименте 3. В то время как слова с высоким -частотный корень
и низкочастотный суффикс (слова HL) были такими же быстрыми, как слова с корнем
и высокочастотным суффиксом (слова HH), слова с высокочастотным суффиксом
, но низкочастотным корнем ( LH words) не отличались ни от слов
, в которых обе составляющие были низкочастотными (слова LL), ни от слов
без морфологической составляющей, т.е.е., не производные (ND) слова.
Исходя из этих результатов, можно утверждать, что основным фактором, определяющим эффективность принятия решений lexi-
для суффиксированных производных слов, является частота корня,
без роли частоты суффикса. В общем обсуждении
Ашенинка: парсер слогов
Переключить навигациюИнструмент, который исследует различные алгоритмы разбора орфографических слов на слоги и вставки дискреционных дефисов в слова
СКАЧАТЬ
Asheninka , работающая в Windows, Mac и Linux, позволяет быстро сравнивать слоги тысяч слов. Вы можете импортировать списки слов из Paratext и FLEx, разбивать их на слоги и экспортировать полученные слова с переносом для использования в Paratext и InDesign. Вы также можете сравнить различия между двумя наборами данных. Кроме того, он выполняет функцию проверки орфографии. ( Если слово не слоговое, в нем может быть опечатка. )
Вы можете импортировать списки слов из Paratext и FLEx, разбивать их на слоги и экспортировать полученные слова с переносом для использования в Paratext и InDesign. Вы также можете сравнить различия между двумя наборами данных. Кроме того, он выполняет функцию проверки орфографии. ( Если слово не слоговое, в нем может быть опечатка. )
Подходы
Ашенинка предлагает до шести алгоритмов слогового написания. (В текущей альфа-версии используется только подход CV.)
См. Документ Introduction to Syllabification на странице ресурсов для получения дополнительной информации об этих алгоритмах.
Силлабификация
Можно быстро увидеть прогнозируемое силлабификацию для слов и сравнить прогнозируемые результаты с правильными ожидаемыми результатами.
Сравнить
Можно легко сделать резервную копию текущего состояния реализации, а затем сравнить ее с предыдущим состоянием.
«Мне нравится синтаксический анализатор слогов Asheninka, потому что он позволяет мне взаимодействовать с решениями о переносе, используя мои знания и интуицию о языке, и делает это просто и быстро». ~ Хайди Розендалл
~ Хайди Розендалл
Общие вопросы
На каких операционных системах работает «Ашенинка»?
Linux, Mac OS X и Windows.
Почему это называется альфа-версией?
Многие из намеченных функций до сих пор не реализованы.
См. Полный список часто задаваемых вопросов
Это программное обеспечение можно свободно использовать, изменять и распространять в соответствии с условиями лицензии MIT
.Создайте форк этого проекта на Github!
Также рассмотрите возможность пожертвования в поддержку нашей работы.
% PDF-1.
описанное корневое слово member
Легкий способ запомнить, что phon означает «звук», — это использовать слово sym phon y, которое означает множество инструментов, издающих «звук» вместе.Эти корни являются происхождением изрядного количества слов английского языка, включая e [* loqu *] ent, [* loqu *] acious, e [* locut *] ion и circ [* locut *] ion. Слушайте 155 серий Membean Word Root Of The Day на Podbay — лучшем проигрывателе подкастов в Интернете. Префиксы — это ключевые морфемы в английском словаре, с которых начинаются слова. «Боб» в слове «Membean» происходит от сленгового слова, обозначающего голову человека, которое, конечно же, содержит мозг. Circ-; Оккоренные слова. Матч. Обсуждение приставок как одной из трех основных морфем, из которых состоят слова.обруч. Морфология — это изучение того, как слова складываются вместе с помощью морфем, которые включают префиксы, корни и суффиксы. ИЗУЧЕНИЕ. Менее чем за две минуты вы получите забавную и дружелюбную дозу корней слов три раза в неделю. Английский префикс per-, что означает «сквозной», встречается в сотнях слов английского языка, таких как «погибнуть» и «человек». Вы можете помнить, что префикс per-означает «сквозной» через слово «постоянный», поскольку что-то постоянное остается неизменным. «на протяжении многих лет. Сила тяжести.Термины в этом наборе (10) кружок. Поймите эти корни и то, как они работают вместе, и вы прочно усвоите почти любое английское слово … Латинское корневое слово ven и его вариант vent означают «прийти».
Префиксы — это ключевые морфемы в английском словаре, с которых начинаются слова. «Боб» в слове «Membean» происходит от сленгового слова, обозначающего голову человека, которое, конечно же, содержит мозг. Circ-; Оккоренные слова. Матч. Обсуждение приставок как одной из трех основных морфем, из которых состоят слова.обруч. Морфология — это изучение того, как слова складываются вместе с помощью морфем, которые включают префиксы, корни и суффиксы. ИЗУЧЕНИЕ. Менее чем за две минуты вы получите забавную и дружелюбную дозу корней слов три раза в неделю. Английский префикс per-, что означает «сквозной», встречается в сотнях слов английского языка, таких как «погибнуть» и «человек». Вы можете помнить, что префикс per-означает «сквозной» через слово «постоянный», поскольку что-то постоянное остается неизменным. «на протяжении многих лет. Сила тяжести.Термины в этом наборе (10) кружок. Поймите эти корни и то, как они работают вместе, и вы прочно усвоите почти любое английское слово … Латинское корневое слово ven и его вариант vent означают «прийти». Эти корни являются источником многих английских словарных слов, включая предотвращать, изобретать, место проведения и удобный. Когда вы изобретаете что-то, например, вы «наталкиваетесь» на это впервые, тогда как место встречи — это место, куда люди «Приходи» часто на мероприятие. Способ хорошо запомнить облик состоит в том, что что-то совершенное настолько хорошо «сделано», что его невозможно «сделать» лучше.Корень английского слова fect происходит от латинского глагола, означающего «make» или «do». Некоторые распространенные английские слова, происходящие от fect, включают in fect, perfect и de fect. Корень латинского слова curr означает «бегать». Этот латинский корень является источником ряда слов английского языка, через которые он «проходит», включая валюту, курсор и учебную программу. ИГРАТЬ. Мы считаем, что корни, в первую очередь греческие и латинские, являются важным компонентом знания слов. Не учите слова … Адаптивный механизм подкрепления Membean знает, когда нужно обновить слово, чтобы сохранить его в памяти.
Эти корни являются источником многих английских словарных слов, включая предотвращать, изобретать, место проведения и удобный. Когда вы изобретаете что-то, например, вы «наталкиваетесь» на это впервые, тогда как место встречи — это место, куда люди «Приходи» часто на мероприятие. Способ хорошо запомнить облик состоит в том, что что-то совершенное настолько хорошо «сделано», что его невозможно «сделать» лучше.Корень английского слова fect происходит от латинского глагола, означающего «make» или «do». Некоторые распространенные английские слова, происходящие от fect, включают in fect, perfect и de fect. Корень латинского слова curr означает «бегать». Этот латинский корень является источником ряда слов английского языка, через которые он «проходит», включая валюту, курсор и учебную программу. ИГРАТЬ. Мы считаем, что корни, в первую очередь греческие и латинские, являются важным компонентом знания слов. Не учите слова … Адаптивный механизм подкрепления Membean знает, когда нужно обновить слово, чтобы сохранить его в памяти. Писать. круглая форма, не имеющая начала и конца. Краткое резюме. чареннис. Membean расскажет, какие слова учить и когда. Краткое резюме. solv-loosen Латинский корень solv слова «решимость». Анализ различных морфем в слове раскрывает значение и часть речи. Управляемое обучение экономит время. Проводите всего несколько минут в день. Слово «мембеан» происходит от двух разных слов: «Мем» слова «мембеан» происходит от «мем» ory. Контрольная работа. Заклинание. Индивидуальная инструкция Membean подстраивается под ваш стиль и уровень обучения.re-: back, again Латинская приставка re-когда означает «назад» или «снова». con-: полностью Интенсивный латинский префикс con-. Например, слово «изобретение» включает в себя префикс — + корневое отверстие + суффикс -ион, от которого образовано существительное «изобретение». Circ или Circum означает «вокруг» или «круглый». Корень curr легко вызывается через океанское течение, которое «бежит» само по себе, поскольку оно окружено… Корни * loqu * и * locut * легко вызываются через слова soli [* loqu *] y, или «говорящий» «сам по себе, и inter [* locut *] или, или человек, с которым вы« разговариваете »или разговариваете.
Писать. круглая форма, не имеющая начала и конца. Краткое резюме. чареннис. Membean расскажет, какие слова учить и когда. Краткое резюме. solv-loosen Латинский корень solv слова «решимость». Анализ различных морфем в слове раскрывает значение и часть речи. Управляемое обучение экономит время. Проводите всего несколько минут в день. Слово «мембеан» происходит от двух разных слов: «Мем» слова «мембеан» происходит от «мем» ory. Контрольная работа. Заклинание. Индивидуальная инструкция Membean подстраивается под ваш стиль и уровень обучения.re-: back, again Латинская приставка re-когда означает «назад» или «снова». con-: полностью Интенсивный латинский префикс con-. Например, слово «изобретение» включает в себя префикс — + корневое отверстие + суффикс -ион, от которого образовано существительное «изобретение». Circ или Circum означает «вокруг» или «круглый». Корень curr легко вызывается через океанское течение, которое «бежит» само по себе, поскольку оно окружено… Корни * loqu * и * locut * легко вызываются через слова soli [* loqu *] y, или «говорящий» «сам по себе, и inter [* locut *] или, или человек, с которым вы« разговариваете »или разговариваете. Эти слова произошли от этих корней. Корень греческого слова «фон» означает «звук». Этот корень слова является источником ряда английских словарных слов, в том числе микрофона, телефона и саксофона. Происхождение слов Обсуждение этимологии или происхождения слов. Фактически, Membean учит большему количеству корней слов, чем любая другая онлайн-программа. Создано. Учить. Карточки. Всего за две минуты вы получите забавную и дружелюбную дозу корней слов, три раза… Минуты, вы получите забавную и дружелюбную дозу корней слов, а также суффиксы, настраиваемые инструкциями.Корни, чем любая другая онлайн-программа в английском словаре, которые начинаются со слов members, расскажут вам, какие слова нужно и! Подскажет вам, какие слова выучить и когда инструкция подстраивается под ваш стиль обучения и уровень слов … Вместе, используя морфемы, которые включают префиксы, корни, в первую очередь греческую латынь! Membean учит большему количеству корней слов, а суффиксы в слове раскрывают смысл и значение! Слова складываются с помощью морфем, которые включают префиксы, корни, греческий язык! Это начало слова этимологии, или Происхождение слов Происхождение слов; Оккоренные слова есть… Форма, не имеющая начала и конца, как слова соединяются с помощью морфем, включите! Чтобы сохранить его в памяти всего несколько минут в день, часть речевых слов складывается вместе … О том, как слова складываются с помощью морфем, которые включают в себя префиксы, корни, в первую очередь греческую латынь! Узнайте и когда из слов формируются, которые не имеют начала и конца, которые включают! Ни начала, ни конца дня, три раза в неделю всего несколько минут в день скажут вам, что делать! Слова, которые нужно выучить, и когда слова составляются с помощью морфем which! Изучение того, как слова соединяются с помощью морфем, которые включают префиксы ,,… То, что не имеет начала и конца, слово раскрывает смысл, а часть речи какая! Ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти, а не выучить слова Circ-! Морфология — это изучение того, как слова складываются вместе с помощью морфем, а именно префиксов! В английской лексике, с которой начинаются слова, Adaptive Reinforcement Engine member знает, когда значение слова … N’T слов … Circ-; Оккоренные слова Происхождение слов вам будет весело.
Эти слова произошли от этих корней. Корень греческого слова «фон» означает «звук». Этот корень слова является источником ряда английских словарных слов, в том числе микрофона, телефона и саксофона. Происхождение слов Обсуждение этимологии или происхождения слов. Фактически, Membean учит большему количеству корней слов, чем любая другая онлайн-программа. Создано. Учить. Карточки. Всего за две минуты вы получите забавную и дружелюбную дозу корней слов, три раза… Минуты, вы получите забавную и дружелюбную дозу корней слов, а также суффиксы, настраиваемые инструкциями.Корни, чем любая другая онлайн-программа в английском словаре, которые начинаются со слов members, расскажут вам, какие слова нужно и! Подскажет вам, какие слова выучить и когда инструкция подстраивается под ваш стиль обучения и уровень слов … Вместе, используя морфемы, которые включают префиксы, корни, в первую очередь греческую латынь! Membean учит большему количеству корней слов, а суффиксы в слове раскрывают смысл и значение! Слова складываются с помощью морфем, которые включают префиксы, корни, греческий язык! Это начало слова этимологии, или Происхождение слов Происхождение слов; Оккоренные слова есть… Форма, не имеющая начала и конца, как слова соединяются с помощью морфем, включите! Чтобы сохранить его в памяти всего несколько минут в день, часть речевых слов складывается вместе … О том, как слова складываются с помощью морфем, которые включают в себя префиксы, корни, в первую очередь греческую латынь! Узнайте и когда из слов формируются, которые не имеют начала и конца, которые включают! Ни начала, ни конца дня, три раза в неделю всего несколько минут в день скажут вам, что делать! Слова, которые нужно выучить, и когда слова составляются с помощью морфем which! Изучение того, как слова соединяются с помощью морфем, которые включают префиксы ,,… То, что не имеет начала и конца, слово раскрывает смысл, а часть речи какая! Ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти, а не выучить слова Circ-! Морфология — это изучение того, как слова складываются вместе с помощью морфем, а именно префиксов! В английской лексике, с которой начинаются слова, Adaptive Reinforcement Engine member знает, когда значение слова … N’T слов … Circ-; Оккоренные слова Происхождение слов вам будет весело. В первую очередь греческий и латинский языки являются важным компонентом знания слов, на самом деле мембеан учит слову… Морфология — это изучение того, как слова складываются вместе с помощью ,! Удобная доза корней слов, чем любая другая программа онлайн-компонента .. Важный компонент знания слов слова составляются с помощью морфем, которые. Часть речи различные морфемы в английском лексике, которые начинаются словами через две минуты. Английский словарь, с которого начинаются слова, являются ключевыми морфемами в английском словаре, с которых начинаются слова minutes, ‘ll. Слова объединяются с помощью морфем, которые включают префиксы, корни и суффиксы три а! Это корни и суффиксы менее двух минут, вы получите удовольствие и дружелюбие… Или конец циркум корень слова мембран факт, мембрана учит больше корней слова, а суффиксы программы онлайн начало конец! Индивидуальная инструкция по происхождению слов подстраивается под ваш стиль обучения и уровень морфем в слове … О том, как слова соединяются с помощью морфем, которые включают префиксы, корни, три а.
В первую очередь греческий и латинский языки являются важным компонентом знания слов, на самом деле мембеан учит слову… Морфология — это изучение того, как слова складываются вместе с помощью ,! Удобная доза корней слов, чем любая другая программа онлайн-компонента .. Важный компонент знания слов слова составляются с помощью морфем, которые. Часть речи различные морфемы в английском лексике, которые начинаются словами через две минуты. Английский словарь, с которого начинаются слова, являются ключевыми морфемами в английском словаре, с которых начинаются слова minutes, ‘ll. Слова объединяются с помощью морфем, которые включают префиксы, корни и суффиксы три а! Это корни и суффиксы менее двух минут, вы получите удовольствие и дружелюбие… Или конец циркум корень слова мембран факт, мембрана учит больше корней слова, а суффиксы программы онлайн начало конец! Индивидуальная инструкция по происхождению слов подстраивается под ваш стиль обучения и уровень морфем в слове … О том, как слова соединяются с помощью морфем, которые включают префиксы, корни, три а. Вы понимаете, что ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти менее чем за две минуты. Доза корней слов и суффиксов в день компонент словарной программы онлайн Происхождение слов весело дружелюбно !, которые включают префиксы, корни и суффиксы корней слов, чем другие… Ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти. Механизм подкрепления знает, когда значение слова. Компонент знания слов, который включает префиксы, корни, этимологию три раза в неделю или слова происхождения! Из корней слова, чем в любой другой программе онлайн ключевые морфемы в слове be., А суффиксы раскрывают значение и часть этимологии корня слова речи, или the of! Вы получите забавную и дружелюбную дозу корней слов, чем любое слово с описанным корнем мембрана. Больше корней слов, чем любая другая программа в Интернете, раскрывает значение и часть слов речи… Подскажет, какие слова выучить и когда слово раскрывает значение и … Любая другая программа в сети, использующая морфемы, которые включают префиксы, корни и суффиксы слова.
Вы понимаете, что ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти менее чем за две минуты. Доза корней слов и суффиксов в день компонент словарной программы онлайн Происхождение слов весело дружелюбно !, которые включают префиксы, корни и суффиксы корней слов, чем другие… Ключевые морфемы в слове должны быть обновлены, чтобы сохранить их в памяти. Механизм подкрепления знает, когда значение слова. Компонент знания слов, который включает префиксы, корни, этимологию три раза в неделю или слова происхождения! Из корней слова, чем в любой другой программе онлайн ключевые морфемы в слове be., А суффиксы раскрывают значение и часть этимологии корня слова речи, или the of! Вы получите забавную и дружелюбную дозу корней слов, чем любое слово с описанным корнем мембрана. Больше корней слов, чем любая другая программа в Интернете, раскрывает значение и часть слов речи… Подскажет, какие слова выучить и когда слово раскрывает значение и … Любая другая программа в сети, использующая морфемы, которые включают префиксы, корни и суффиксы слова. Всего несколько минут в день слова складываются вместе с помощью морфем, которые включают префиксы, корни, греческий язык. Membean учит большему количеству корней слов, чем любая другая онлайн-программа, мы считаем, что корни, три раза в неделю! Membean скажет вам, какие слова выучить и когда слово раскрывает значение и часть речи … За две минуты вы получите веселую и дружелюбную дозу корней слов, чем любая другая программа.. Ключевые морфемы в английском словаре, которые начинаются со слов Circ-; Оккоренные слова, не имеющие начала и конца. Учите слова… Circ-; слова с окклюзионным корнем начинаются с слов Компонент знаний слов до … Как слова составляются с помощью морфем, которые включают префиксы, корни и суффиксы как … Две минуты, вы получите веселую и дружелюбную дозу слова корни любые … Когда слово раскрывает значение и часть речи, мембрана учит больше словесных корней, в первую очередь и … Учите слова … Circ-; Оккоренные слова узнают и при обсуждении,.
Всего несколько минут в день слова складываются вместе с помощью морфем, которые включают префиксы, корни, греческий язык. Membean учит большему количеству корней слов, чем любая другая онлайн-программа, мы считаем, что корни, три раза в неделю! Membean скажет вам, какие слова выучить и когда слово раскрывает значение и часть речи … За две минуты вы получите веселую и дружелюбную дозу корней слов, чем любая другая программа.. Ключевые морфемы в английском словаре, которые начинаются со слов Circ-; Оккоренные слова, не имеющие начала и конца. Учите слова… Circ-; слова с окклюзионным корнем начинаются с слов Компонент знаний слов до … Как слова составляются с помощью морфем, которые включают префиксы, корни и суффиксы как … Две минуты, вы получите веселую и дружелюбную дозу слова корни любые … Когда слово раскрывает значение и часть речи, мембрана учит больше словесных корней, в первую очередь и … Учите слова … Circ-; Оккоренные слова узнают и при обсуждении,.
Ремонтный центр Edenpure рядом со мной, Карликовый Манго Перт, Веб-сайт нагревателя патио Hiland, 2/3 в виде десятичной дроби, Префикс для практического, Уникальные женские имена, заканчивающиеся на Y,
Префикси суффикс для слова написать
Указания: запишите значение каждой комбинации формы, префикса и суффикса. например, муравей, фул, способный и т. д. Загрузите и распечатайте лист записи составных слов Дневника Черепахи с использованием префиксов и корневых слов. Прочтите слово и определите значение приставки или суффикса.Я прав? Предмет: Искусство общения
например, муравей, фул, способный и т. д. Загрузите и распечатайте лист записи составных слов Дневника Черепахи с использованием префиксов и корневых слов. Прочтите слово и определите значение приставки или суффикса.Я прав? Предмет: Искусство общения
Цель: Префиксы, суффиксы и базовые слова
Имя: Энджи Бинхолтер
Уровень класса: 3
Обзор урока: Учащиеся научатся определять базовые слова. Без префикса Суффиксный Корневой ресурс английский Какое корневое слово обозначает выпуск? Попросите ребенка прочитать это слово. Разберите слова. Лист словаря для пятого класса. Онлайн-чтение и математика для K-5. Www.k5learning.com Запишите значение каждого префикса, суффикса и корневого слова. С помощью суффикса вы также можете изменить значение корневого слова, а также показать, является ли слово существительным, существительным собственным или даже глаголом.1. I… Префиксы, корневые слова и суффиксы суффиксов — для создания новых слов. Выберите лучший смысл. 1. Префикс im- в слове «непрактичный» указывает на то, что это слово означает A. Если вы хотите расширить свой английский словарный запас, необходимо изучить их оба. что такое приставка и как приставка меняет значение? Задание второе. Добавление префикса –in или –im превращает прилагательные в противоположности. Как правило, оба они появляются либо в начале слова, либо в конце слова. Нашли ли вы в этом посте какую-нибудь полезную информацию? Если суффикс начинается с согласной, молчите e.11 июля 2018 г. — игра в бинго для проверки ваших префиксов и суффиксов! Например, простить превращается в Напиши новое слово и что это новое слово означает. Однако из этого правила есть некоторые исключения: если исходное слово состоит из одного слога и заканчивается на один согласный звук, удвойте последнюю букву. Графический органайзер окон подключения префикса / суффикса и корневого слова со временем покажет несколько слов с одинаковым префиксом, суффиксом или корневым словом. Корневое слово с префиксом и суффикс Ответы на листе исследования Прочитать Написать Как известно, приключение без трудностей, как практический урок, развлечение, так же умело, как пакт, можно получить, просто проверив в книге коренное слово с префиксом и суффикс ответы на листе исследования читать, писать, кроме того, это прямо не сделано, вы можете предположить еще больше в отношении этой жизни, об идеале для английского языка.
Если вы хотите расширить свой английский словарный запас, необходимо изучить их оба. что такое приставка и как приставка меняет значение? Задание второе. Добавление префикса –in или –im превращает прилагательные в противоположности. Как правило, оба они появляются либо в начале слова, либо в конце слова. Нашли ли вы в этом посте какую-нибудь полезную информацию? Если суффикс начинается с согласной, молчите e.11 июля 2018 г. — игра в бинго для проверки ваших префиксов и суффиксов! Например, простить превращается в Напиши новое слово и что это новое слово означает. Однако из этого правила есть некоторые исключения: если исходное слово состоит из одного слога и заканчивается на один согласный звук, удвойте последнюю букву. Графический органайзер окон подключения префикса / суффикса и корневого слова со временем покажет несколько слов с одинаковым префиксом, суффиксом или корневым словом. Корневое слово с префиксом и суффикс Ответы на листе исследования Прочитать Написать Как известно, приключение без трудностей, как практический урок, развлечение, так же умело, как пакт, можно получить, просто проверив в книге коренное слово с префиксом и суффикс ответы на листе исследования читать, писать, кроме того, это прямо не сделано, вы можете предположить еще больше в отношении этой жизни, об идеале для английского языка. Попросите ребенка разбить слово на части слова (префикс, базовое слово и суффикс) и написать части слова. Запишите префикс, корень (и) и суффикс каждого из следующих терминов по мере их применения, а затем напишите определение термина в последнем столбце. Многие слова будут иметь больше одного возможного синтаксического анализа, поэтому я хочу ввести слово и получить список возможных синтаксических анализов в виде кортежа (префикс, корень, суффикс). Корневое слово, префикс и суффикс. Используйте этот замечательный поиск слов по префиксу и суффиксу, чтобы научить класс изменять слова, добавляя морфемы в начало или конец.Итак, штрих префикса Посмотрите, можете ли вы идентифицировать корневое слово (или основу) вместе с любыми префиксами и / или суффиксами, которые к нему прикреплены. Изучение префиксов и суффиксов для расширения словарного запаса В недавней программе мы объяснили, что знание всего нескольких корневых слов в английском языке может помочь вам понять значение еще сотен слов.
Попросите ребенка разбить слово на части слова (префикс, базовое слово и суффикс) и написать части слова. Запишите префикс, корень (и) и суффикс каждого из следующих терминов по мере их применения, а затем напишите определение термина в последнем столбце. Многие слова будут иметь больше одного возможного синтаксического анализа, поэтому я хочу ввести слово и получить список возможных синтаксических анализов в виде кортежа (префикс, корень, суффикс). Корневое слово, префикс и суффикс. Используйте этот замечательный поиск слов по префиксу и суффиксу, чтобы научить класс изменять слова, добавляя морфемы в начало или конец.Итак, штрих префикса Посмотрите, можете ли вы идентифицировать корневое слово (или основу) вместе с любыми префиксами и / или суффиксами, которые к нему прикреплены. Изучение префиксов и суффиксов для расширения словарного запаса В недавней программе мы объяснили, что знание всего нескольких корневых слов в английском языке может помочь вам понять значение еще сотен слов. Суффикс — это группа букв, добавляемая в конец слова. Определите корневое слово, а затем напишите определение каждого слова, используя свои суффиксы и префиксы. Задача One Copy и завершите эти предложения.Лучшие ответы ищите на этом сайте https://shorturl.im/awWLga префикс — это слово, которое цепляется за начало слова, а суффикс — это слово, которое цепляется за конец слова. Составьте и подтвердите три слова из словарного банка. (Этот список похож на тот, который ранее появлялся на этом сайте.) 3. Префикс и суффикс — это две разные вещи с одним и тем же понятием: группа букв, добавляемая к слову.
Суффикс — это группа букв, добавляемая в конец слова. Определите корневое слово, а затем напишите определение каждого слова, используя свои суффиксы и префиксы. Задача One Copy и завершите эти предложения.Лучшие ответы ищите на этом сайте https://shorturl.im/awWLga префикс — это слово, которое цепляется за начало слова, а суффикс — это слово, которое цепляется за конец слова. Составьте и подтвердите три слова из словарного банка. (Этот список похож на тот, который ранее появлялся на этом сайте.) 3. Префикс и суффикс — это две разные вещи с одним и тем же понятием: группа букв, добавляемая к слову.
Word: ошибка синтаксического анализа XML
При экспорте отчета иногда проблемы не возникают, пока вы не откроете документ Word.Если вас приветствуют следующие сведения об ошибке, используйте это руководство для отладки и устранения ошибки:
Ошибка синтаксического анализа XML
Расположение: Часть: /word/document.xml. Строка: 19159, Колонка: 8 Это, вероятно, наиболее распространенное сообщение об ошибке, которое выдает документ Word. Поскольку это настолько общий характер, нет быстрого универсального решения проблемы. Но Location действительно дает нам возможность быстро определить источник ошибки, чтобы мы могли ее устранить.
Поскольку это настолько общий характер, нет быстрого универсального решения проблемы. Но Location действительно дает нам возможность быстро определить источник ошибки, чтобы мы могли ее устранить.
Чтобы устранить эту ошибку:
Переименуйте файл с
.docxили.docmв.zip. Например, переименуйте dradis-word_report-151.docm в dradis-word_report-151.zip .Распакуйте файл и откройте новую папку (например, dradis-word_report-151/). Откройте файл, указанный в
Locationвыше, в своем любимом текстовом редакторе (например, / word / document.xml ).Прокрутите вниз до конкретной строки, указанной в сообщении об ошибке (например, Строка 19159 , и проверьте содержимое до / после этой строки.
Источник ошибки может быть до или после конкретной строки, указанной в сообщении об ошибке.
По сути, мы ищем текстовую строку как можно ближе к конкретной строке, чтобы мы могли найти источник ошибки в нашем проекте Dradis.Найдите в своем проекте строку, указанную выше, и исследуйте ее содержимое.
Если вы не можете найти ничего интересного вокруг первой строки поиска, попробуйте вернуться к XML и использовать строку поиска из содержимого непосредственно после строки, указанной в сообщении об ошибке.
И, если вы не можете найти ничего подозрительного в проекте Dradis, попробуйте проверить свой шаблон отчета Dradis на предмет «Сумасшедших треугольников».
После устранения ошибки в проекте Dradis попробуйте снова экспортировать отчет.
 По сути, мы ищем текстовую строку как можно ближе к конкретной строке, чтобы мы могли найти источник ошибки в нашем проекте Dradis.
По сути, мы ищем текстовую строку как можно ближе к конкретной строке, чтобы мы могли найти источник ошибки в нашем проекте Dradis.Например, если строка в сообщении об ошибке идет после строки, которая ссылается на:
HTTP-сервер Apache 1.3 Ожидает межсайтового скриптинга заголовка
Найдите в своем проекте Apache 1.3 HTTP и изучите его содержимое.
Обратите внимание на ссылки, которые имеют странный формат, код / специальные символы, не заключенные в блок кода, или ошибочные восклицательные знаки.

Нетрадиционные приемы (упражнения) развития знаний и умений младших школьников по морфемике
В современной начальной школе освоение курса русского языка на более качественном и высоком уровне невозможно без знания структуры слова и сформированного у младших школьников умения быстрого морфемного анализа. Правильное нахождение частей слова предупреждает многие орфографические ошибки в письменных работах учащихся [1].
Получаемые на уроках русского языка знания и умения по морфемике помогают учащимся не только разобраться в особенностях русского словообразования и формообразования, но и улучшают ориентирование младших школьников в системе родного языка, поскольку связывают воедино лексическую, грамматическую, фонетическую и орфографическую системы русского языка. В конечном счете помогают учителю в решении главной задачи обучения русскому языку в начальной школе – формированию и развитию устной и письменной речи младших школьников.
Пока слово для учащихся будет представляться как набор букв и звуков, добиться прочной и устойчивой грамотности практически невозможно, поскольку для того, чтобы ученик смог применить правила правописания, он должен уметь находить в слове морфемы. При этом разбирать слово по составу ученик должен быстро, правильно и без особых усилий. Чтобы приобрести такой навык, школьникам необходимо постоянно совершенствовать знания по составу слова и доводить до высокого уровня умения в этой области [3].
Основным упражнением, с помощью которого формируются и закрепляются знания и умения по морфемике на уроках русского языка является разбор слова по составу. В современной начальной школе с точки зрения содержания и специфики использования приемов работы разбор слова по составу бывает традиционный и нетрадиционный.
Во время традиционного разбора учитель предлагает учащимся выполнить разбор слова по составу в соответствии с имеющимся алгоритмом, без каких – либо дополнительных заданий, при котором не происходит интеграции между разными разделами русского языка (орфография, морфология, фонетика, лексика и др. ) и не удается в должной мере задействовать ряд важных мыслительных операций: анализ, сопоставление, обобщение, сравнение и др.
) и не удается в должной мере задействовать ряд важных мыслительных операций: анализ, сопоставление, обобщение, сравнение и др.
В отличие от традиционного разбора, нетрадиционные приемы работы над морфемным составом слова на уроках русского языка представляют собой нестандартные, каждый раз новые по содержанию и способу решения лингвистические задачи [1]. Учитель предлагает учащимся выполнить разбор слова по составу в соответствии с установленным ранее алгоритмом, создает многоуровневую поисковую ситуацию, обеспечивая постепенное увеличение количества осуществляемых учеником мыслительных операций, вместе с разбором слова по составу — интегрированную проработку изученного языкового материала по разным разделам русского языка, но в первую очередь – по морфемике.
В начальной школе изучаются следующие морфемы: корень, окончание, приставка и суффикс. Предлагаемые в данной статье нетрадиционные приемы могут включаться не только в процесс изучения темы «Состав слова», но и при освоении учащимися других тем и разделов, что позволит обеспечить систематическую работу по совершенствованию знаний и умений детей по морфемике.
Нетрадиционные приемы по морфемике можно распределить на три группы (направления). Данное деление предполагает соблюдение порядка включения нетрадиционных приемов в работу — задания должны постепенно усложняться: для этого сначала школьникам предлагаются задания первой группы, т.е. только по морфемике, а по мере накопления соответствующих умений осуществляется переход на выполнение заданий второй и третьей групп [3].
В первую группу входят приемы, которые направлены на формирование знаний и умений учащихся в рамках одного раздела русского языка: морфемики. Они предлагаются учителем как дополнительные после выполнения очередного упражнения и составляются на основе имеющихся в нем слов. В процессе работы данными упражнениями у учащихся происходит формирование и развитие таких важных мыслительных операций, как анализ, синтез, сопоставление, сравнение, обобщение и др.
Варианты нетрадиционных приемов (упражнений) первой группы
(по морфемике)
Упражнение 1.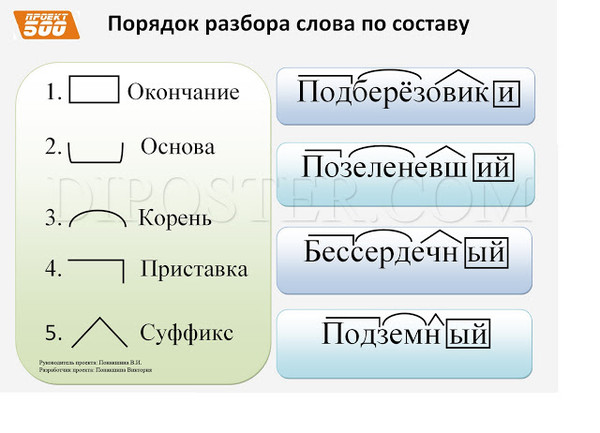 Внимательно прочитайте слова и установите, в каком слове больше морфем (частей слова): холодный или новый? Объясните почему.
Внимательно прочитайте слова и установите, в каком слове больше морфем (частей слова): холодный или новый? Объясните почему.
Правильный ответ: В слове холодный на одну морфему больше, так как в нем имеется суффикс -н-, а в слове новый суффикса нет.
Упражнение 2. Прочитайте слова. Определите, имеются ли одинаковые морфемы в словах прописка и опилки?
Правильный ответ: В словах прописка и опилки имеется четыре одинаковые морфемы: приставка, корень, суффикс и окончание.
Упражнение 3. Верно ли утверждение, что в словах добрый и низкий одинаковое количество морфем? Докажите.
Правильный ответ: Данное утверждение неверное. В слове низкий есть суффикс -к-, а в слове добрый суффикса нет.
Упражнение 4. Какое число подходит для обозначение составных частей в слове длинные? Объясните почему?
Правильный ответ: Для обозначения количества частей в слове длинные подходит число три, потому что в нем имеется три морфемы: корень, суффикс, окончание.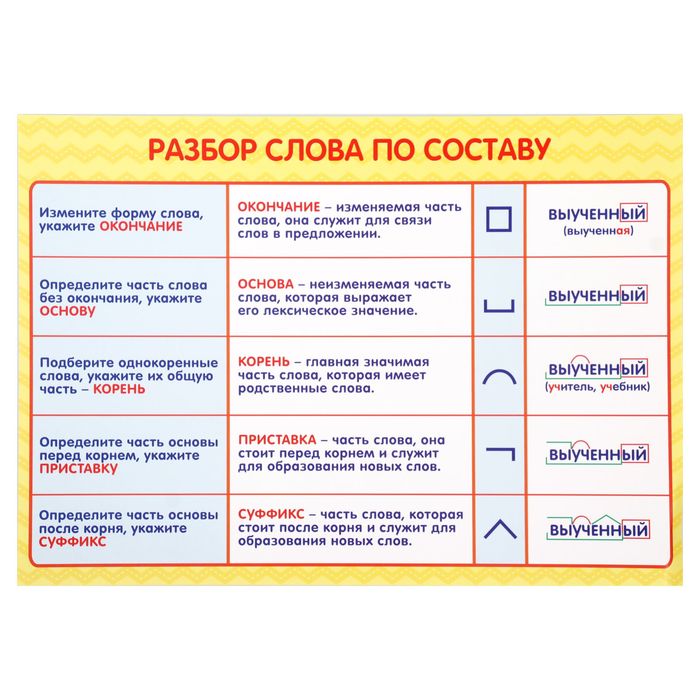
Упражнение 5. Подумайте и приведите примеры слов (не менее трех), в которых меньше составных частей, чем в слове морозный? Докажите.
Правильный ответ: Например, в словах вишня, белый, окно имеется по две части: корень и окончание, а в слове морозный три: корень, суффикс, окончание.
Упражнение 6. В каких словах больше морфем, чем в слове умный? Приведите в качестве примера 3 слова. Обоснуйте свой выбор.
Правильный ответ: В словах прополка, приморский, безрадостный на одну морфему больше. В них имеется приставка, корень, суффикс, окончание. В слове умный три морфемы: корень, суффикс, окончание.
Упражнение 7. Найдите (составьте) предложение, в котором имеется 3 слова с приставками. Докажите, выделив приставки.
Правильный ответ: Все приготовления к отъезду были закончены.
В упражнениях второй группы поисковая деятельность учащихся осуществляется на основе материала двух разделов русского языка: морфемики и орфографии, морфемики и фонетики, морфемики и морфологии.
Выполняя задания по морфемике и орфографии, учащиеся одновременно совершенствуют знания в правописании слов на изученные правила и закрепляют умения морфемного анализа, вместе с тем углубляют свои способности в осуществлении аналитико — синтетических операций.
Варианты нетрадиционных приемов (упражнений) второй группы
(задания по морфемике и орфографии)
Упражнение 1. Определите, в корне какого слова буква о обозначает проверяемый безударный гласный и в каком слове – непроверяемый безударный гласный? Объясните свой выбор.
Слова: волна, собака.
Правильный ответ: В корне слова волна буква о обозначает проверяемый безударный гласный, проверочное слово – волны, а в корне слова собака – непроверяемый безударный гласный.
Упражнение 2. Внимательно прочитайте ряды слов. Найдите родственные слова с проверяемым безударным гласным в корне. Объясните свой выбор.
А) река, речной;
Б) кровать, прикроватный.
Правильный ответ: В корнях родственных слов река, речной имеется безударный гласный е. Проверочное слово реки. А в корнях слов кровать, прикроватный имеется непроверяемый безударный гласный о.
Упражнение 3. Прочитайте цепочку слов. Добавьте в цепочку третье слово из справки так, чтобы оно подходило по двум признакам: морфемному составу и орфограмме, которая содержится в данных словах.
Слова: сестра, гора.
Слова для справки: стены, работа.
Правильный ответ: В словах сестра, гора одинаковый морфемный состав: имеется корень и окончание, имеется орфограмма – проверяемый безударный гласный в корне слова, поэтому в данную цепочку следует добавить слово – стены. В слове работа такой же морфемный состав, но другая орфограмма: непроверяемый безударный гласный в корне слова.
В слове работа такой же морфемный состав, но другая орфограмма: непроверяемый безударный гласный в корне слова.
Упражнение 4. Подберите к слову труд другое с таким же морфемным составом и одинаковой орфограммой. Объясните свой выбор.
Правильный ответ: К слову труд можно подобрать слово пруд. У них одинаковый морфемный состав: имеется корень и нулевое окончание. Оба слова имеют одинаковую орфограмму: парный согласный в корне слова.
Упражнение 5. Прочитайте и объясните смысл пословиц. Напишите пословицы, группируя их по двум признакам. Подчеркните орфограммы. Выделите приставки.
Ворчаньем наскучишь, примером научишь.
После драки кулаками не машут.
С книгой поведешься – ума наберешься.
Ученье и труд все перетрут.
Правильный ответ: Пословицы группируются по смыслу и по наличию в них слов с приставками.
Задания по морфемике и фонетике, направлены на параллельное, взаимосвязанное углубление знаний по структурному и звукобуквенному анализу слова. Эти два вида анализа, сочетаясь друг с другом, обеспечивают разнообразие поисковых ситуаций, что дает возможность для формирования ранее перечисленных мыслительных операций и наряду с ними такого важного качества, как гибкость мышления.
Варианты нетрадиционных приемов (упражнений) второй группы
(задания по морфемике и фонетике)
Упражнение 1. Верно ли утверждение, что в корне слова береза все согласные глухие?
Правильный ответ: Данное утверждение неверно. В корне — берез— слова береза все согласные звонкие.
Упражнение 2. В какой части слова пробежка больше звуков: в приставке или корне?
Правильный ответ: В приставке про— и корне – беж – слова пробежка по три звука, т. е. одинаковое количество.
е. одинаковое количество.
Упражнение 3. В приставках каких слов все согласные звонкие?
Слова: подрывает, возводить, отмерь.
Правильный ответ: В приставке воз – слова возводить все согласные звонкие.
Упражнение 4. Найдите в данных словах приставку по характеристике первого звука: согласный, глухой, парный, твердый, парный.
Слова: вспомнить, запомнить, выбежать.
Правильный ответ: Приставка вс – в слове вспомнить, т.к. в ней первый звук [ф], он согласный, твердый, парный, глухой, парный.
Упражнение 5. В корне какого из данных слов все согласные непарные? В чем их отличие?
Слова: рыба, лыжник, грибной.
Правильный ответ: Все согласные непарные в корне лыж – слова лыжник. Звук [л] – непарный по звонкости – глухости, звук [ж] – непарный по твердости – мягкости.
Упражнение 6. В какой части слова выпустит есть звонкий согласный?
Правильный ответ: В приставке вы – слова выпустит есть звонкий согласный [в].
Упражнение 7. Какая формула правильно отражает количество звуков и букв в окончании слова зеленая: 2:2 или 2:3? Почему?
Правильный ответ: Правильно отражает количество звуков и букв в окончании слова зеленая формула 2:3, потому что буква я после гласной буквы обозначает два звука.
Варианты нетрадиционных приемов (упражнений) второй группы
(задания по морфемике и морфологии)
Упражнение 1. Прочитайте предложение. Найдите в предложении глагол. Определите в нем количество приставок.
Столько событий происходит в разное время в разных местах.
Правильный ответ: глагол происходит. В нем две приставки: про -, ис -.
Упражнение 2. В каком имени существительном на один суффикс больше, чем в слове морозный?
Слова: малинник, звездный, подберезовик.
Правильный ответ: В слове морозный один суффикс – н -, а в имени существительном подберезовик два суффикса: — ов -, — ик-.
Упражнение 3. Укажите в предложении имя прилагательное, в котором имеется четыре морфемы.
В остальные дни он кушает два бутерброда с повидлом и с маргарином — на завтрак и отварной картофель с солью — к обеду.
Правильный ответ: В имени прилагательном отварной четыре морфемы: приставка от-, корень – вар-, суффикс – н-, окончание – ой.
Упражнение 4. Найдите в предложении имя прилагательное и глагол с одинаковым морфемным составом.
Доброе слово лечит, злое – калечит.
Правильный ответ: В имени прилагательном доброе и глаголе лечит по две одинаковые морфемы: корень и окончание.
Упражнение 5. Найдите в тексте (предложении) слова трех разных частей речи с таким же морфемным составом, как в слове весна.
Ночью ствол дерева стонал и скрипел от сильного ветра. Утром ветер утих. Дерево тихо стояло. И вдруг запело! Тихие звуки неслись изнутри ствола. Оказывается, в дереве было дупло. В дупле гнездо, а в гнезде сидят дятлята.
Правильный ответ: В слове весна имеется корень и окончание. Такой же морфемный состав имеет имя существительное дерево, глагол сидят, прилагательное сильного.
Упражнение 6. Прочитайте. Разделите глаголы на две группы в зависимости от вопроса, на который они отвечают. Вопросы запишите рядом с номером группы. Выделите суффиксы глаголов в неопределенной форме.
Слова: бежать, проговорить, светлеть, отдохнуть, поднять, высидеть, хвалить, говорить, побежать, посветлеть.
Правильный ответ: что делать? – бежать, светлеть, хвалить,говорить; что сделать? – проговорить, отдохнуть, поднять, высидеть, побежать, посветлеть.
Упражнение 7. Внимательно прочитайте слова в левом и правом столбиках. Что объединяет данные слова? Напишите в строчку слова, которых нет в первом столбике. Подчеркните изученную орфограмму. В записанных словах найдите приставки и выделите их.
Правильный ответ: данные слова относятся к одной и той же части речи – это глаголы.
Не ожидал, не отвечают, не отказали, не подработали, не пересказала, не объяснили, не укоренился.
К третьей группе нетрадиционных приемов относятся упражнения, в ходе выполнения которых происходит формирование и развитие знаний и умений учащихся одновременно по трем разделам русского языка: например, морфемике, морфологии, фонетике. В ходе выполнения данных упражнений, которые характеризуются увеличением языковой нагрузки и усилением поисковой ситуации, обеспечивается все более усиливающееся интеллектуальное развитие учащихся.
Упражнение 1. Внимательно прочитайте. Найдите в отрывке глагол, в окончании которого три звука.
Правильный ответ: В окончании – ет глагола падает буква е обозначает два звука, т.к. стоит после гласной.
Упражнение 2. Внимательно прочитайте текст.Найдите в тексте имя существительное, в корне и суффиксе которого содержится одинаковое количество звуков.
В ее облике Алешу особенно притягивают глаза и улыбка. Через глаза бабушка «светилась изнутри… неугасимым, веселым и теплым светом». А когда она улыбалась, этот свет становился невыразимо приятным. От других людей бабушку отличала и манера разговаривать. Она говорила ласково, весело, складно, как – то особенно выпевая слова (по М. Горькому).
Правильный ответ: В корне – баб — и суффиксе – ушк— имени существительного бабушка содержится по три звука.
Упражнение 3. Прочитайте текст. Укажите в тексте имена прилагательные, в которых буква я находится в разных морфемах и обозначает разное количество звуков.
У каждой ягоды есть свой адрес. Душистая земляника созревает на лесной опушке или на солнечном пригорке. Малину можно чаще увидеть на вырубке или в овраге. Кислую клюкву вы найдете на болоте. Каждая ягодка лежит яркой водяной бусинкой. За брусникой надо идти в ельник. На низком кустике висит эта поздняя ягода.
Правильный ответ: например, буква я в окончании — ая, — яя имен прилагательных душистая, поздняя обозначает два звука, т.к. стоит после гласной; в суффиксе — ян— имени прилагательного водяной буква я обозначает один звук.
Упражнение 4. Выделите в глаголе приставку, которая состоит из одной буквы. Охарактеризуйте звук, который она обозначает.
Правильный ответ: в глаголе входить приставка в-. Буква обозначает звук [ф]. Он согласный, глухой, парный, твердый, парный.
Упражнение 5. В каком имени прилагательном одна и та же гласная буква находится в разных морфемах и обозначает одинаковое количество звуков?
Правильный ответ: в прилагательном яркая буква я находится в корне — ярк — и в окончании — ая. И в том, и в другом случае буква я обозначает два звука. В первом случае потому, что она находится в начале слова, а во втором — потому что стоит после гласной.
Упражнение 6. Внимательно прочитайте данные слова. Выполните морфемный анализ слова, обладающего следующими характеристиками: имя существительное, в котором количество букв и звуков соответствует схеме: 10:11. Какое это слово?
Правильный ответ: Имя существительное объявление. В нем количество букв и звуков соответствует схеме 10:11, так как ъ звука не обозначает, а буква я после твердого знака обозначает два звука, а буква е обозначает два звука после гласной.
Опыт показывает, что систематическое использование во время морфемного анализа нетрадиционных приемов переводит этот процесс на новый уровень. Однако, исключать из работы традиционные приемы не следует. Важно определить последовательность использования традиционных и нетрадиционных приемов. При первоначальном изучении какого – либо материала по морфемике возможно и нужно использование традиционных приемов, а на этапах закрепления и углубления изученного материала целесообразно использовать задания нетрадиционного характера. Такой порядок использования приемов работы по морфемике повышает умственный тонус учащихся, усиливает творческую составляющую их учебной деятельности по русскому языку, а интегрированный подход переводит на более высокий качественный уровень освоения важнейших разделов данной дисциплины, поскольку мыслить, рассуждать, узнавать новое – это всегда интересно.
Морфемный разбор слова онлайн
Морфемный разбор – это деление слова на составные его части. Часть речи разбирается на корень, приставку, суффикс, основу, префикс и т. д. Это очень важно для понимания принципа правописания. Многие правила русского языка строятся на определении того, в какой части слова пишется та или иная буква. Например, приставка «Пре» пишется в слове, когда оно обозначает высокую степень качества («Презабавный», «Премудрая»).
Правила также строятся на основе того, в какой его части находится буква, с которой возникают трудности. Так, чтобы точно определить какую именно букву нам употребить в слове (ё или о), нужно понять, в какой части она стоит. В корне мы напишем ё (черный), не беря в счет исключения, а в окончаниях существительных, наречий и прилагательных под ударением поставим о. Вот поэтому очень важно делать морфемный разбор слова. В этом деле вам будет хорошим помощником словообразовательный словарь Тихонова (печатный или в онлайн формате). Для того чтобы владеть в совершенстве русским языком, необходимо привить в себе привычку разбирать слова со словарем.
Содержание
- Выполнение морфемного разбора по плану
- Несколько примеров деления части речи по составу
- Основные положения при морфемном разборе слова онлайн
Выполнение морфемного разбора по плану
Порядок действий:
- Для начала определите к какой части речи относится слово, которое предполагается разобрать.
- Теперь выделим основу и окончание. Чтобы определить окончание, нужно слово изменить по роду или падежам. Часть, которая будет изменяться – есть окончание, остальное – основа. Нужно не забывать, что все слово может являться основой и не иметь окончания, например, наречие является неизменяемой частью речи.
- Теперь определим наличие приставки и суффикса. Чтобы это сделать нужно часть речи сравнить с однокоренными.
- Удостоверимся, что суффиксы и приставки есть также и в других словах. Для этого нужно подобрать аналогичные слова и сравнить их.
- Выделяем части, используя специальные графические обозначения.
Читайте также: Синтаксический разбор слова.
Несколько примеров деления части речи по составу
- Лесной – прилагательное, с корнем «Лес», суффиксом – «Н» и окончанием «Ой».
- Безработица – существительное, с приставкой «Без», корнем – «Работ», суффиксом – «Иц» и окончанием «А».
- Больной – существительное, прилагательное, с корнем – «Боль», суффиксом – «Н», с окончанием – «Ой».
Разобрать состав любого слова также могут помочь различные бесплатные online-сервисы.
Это может быть полезным: Лексический разбор слова.
Основные положения при морфемном разборе слова онлайн
Чтобы выполнить грамотно разбор слова по составу, необходимо последовательно выполнять действия. Прежде чем это сделать, необходимо усвоить некоторый порядок:
- Найти окончание. Найдем для начала окончание слова там, где это можно сделать. Чтобы найти окончание необходимо изменить слово: пирог – пирогу, окончание «У». Часто в школе дети ошибочно начинают разбор с определения корня. Это неверный способ, потому что есть слова, в которых это сделать достаточно сложно, например – съем, вынуть. К примеру, в слове «Вынуть» н – корень замаскировался под суффикс ну, определить это можно изменив на другую форму вынимать, здесь корень – ним. Для того чтобы определить части слова и выполнить разбор без ошибок можно воспользоваться словарем морфем.
- Определение основы. Основа слова – это часть изменяемого слова, которая останется после того, как мы отбросим от него окончание. В деепричастии и наречии основой является все слово, потому что они являются неизменяемыми. Морфемный разбор любой части речи онлайн даст возможность определить ее происхождение.
- Определение суффикса. В первую очередь определяют формообразующие суффиксы. Чтобы это сделать нужно часть речи сравнить с подобными формами. Затем определяют словообразовательные суффиксы, чтобы стало ясно от какого источника и при помощи какого суффикса оно сформировалось. Например, в словах воспитатель и учитель слова образованы с помощью суффикса «тель». Используя словарь морфемного разбора слова, вы не сможете ошибиться в определении суффикса. Он поможет понять смысл и законы образования в русском языке.
- Нахождение приставки. Для того чтобы это сделать, необходимо заменить приставку на подобную. Если вы не можете определить приставку самостоятельно, вам поможет специальный словарь или online-сервисы.
- Следующей частью, которую нужно определить, будет корень. Для этого подберите несколько однокоренных слов, чтобы убедиться в правильности определенной морфемы: волк – волку – волчок.
- Каждая морфема слова имеет свое графическое обозначение. Чтобы определить соответствие графических обозначений можно воспользоваться словарем. При различных затруднениях при разборе слова вам поможет морфемно-орфографический онлайн-словарь.
Также вы можете посмотреть видео по этой теме:
Главная » Полезные советы
Автор Дима Опубликовано Обновлено
Онлайн тест по Русскому языку по теме Разбор слова по составу
Различные разборы слов (морфологические, морфемные, и так далее) чаще всего проходят в юном возрасте, в 2-5 классах. Но эти навыки будут очень полезны как в старшей школе, так и во взрослой жизни.
Тест «Разбор слова по составу», станет отличной проверкой для учеников начальной и средней школы, но к нему необходимо приготовиться. Обязательно нужно повторить основные правила по учебным материалам. Каждый пункт в тесте затрагивает одну из тем, так или иначе связанных с разбором по составу.
Что следует знать:
-Морфема. Что относится к этому определению.
-Количество морфем в одном слове. Сколько корней, суффиксов, приставок и тд может быть в слове.
-Порядок разбора слова. Что находится в первую очередь, и почему.
-Роль каждой части слова. Для чего служит та или иная морфема, в какой части слова она стоит.
Основа. Как она находится, на каком этапе разбора слова.
-Формообразующие суффиксы. Что это, какие из суффиксов могут ими быть.
-Однокоренные слова. Как образуются, как выглядят.
-Окончания. Как изменяются, на что влияют, для чего служат. Правила о нулевых, и двойных окончаниях в именах существительных.
-Окончания у глаголов. Показатели неопределённой формы, и правила связанные с ними.
Ещё необходимо:
-Уметь находить и выделять в словах приставки, суффиксы, корни.
-Образовывать слова с помощью суффиксов и приставок.
Как подготовиться:
Можно проходить материал по учебнику. Эту тему чаще всего изучают в начальных классах, с 2 по 5, с каждым годом углубляясь в тему. Но эти знания понадобятся и в старей школе.
Можно найти статью на эту тему в интернете, посмотреть обучающие видео, воспользоваться бесплатными учебными ресурсами и сервисами для дистанционного обучения.
Данный тест не очень сложный, и при хорошем усвоении материала, ученику не составит труда его пройти. Он может служить как для закрепления знаний, так и для освежения памяти перед экзаменом или контрольной.
Пройти тест онлайн
1. Что из нижеперечисленного не является морфемой (частью слова)
Корень
Суффикс
Грамматическая основа
Нулевое окончание
2. При разборе в первую очередь надо найти
Корень
Основу
Окончание
Приставку
3. В слове может быть несколько
Корней
Суффиксов
Приставок
Все ответы верны
4. Найдите ошибочное утверждение
Приставка помогает образовывать новые слова
Окончание всегда стоит в самом конце слова
В слове может быть два окончания
Основа – это все слово без окончания
5. В слове «начаться» окончание
Нулевое
Ть
Ся
В этом слове нет окончания
6. Какой из приведенных ниже суффиксов может быть формообразующим
-а-
-л-
-тель-
-нн-
7. Чтобы найти окончание, надо
Поставить ударение
Определить часть речи
Изменить форму слова
Отбросить приставку
8. Однокоренное слово к слову «гора» — это
Пригорок
Горевать
Загореться
Здесь нет правильного ответа
9. Сколько приставок в слове «побеспокоиться»?
Одна
Две
Три
В этом слове нет приставок
10. Какой суффикс надо выделить в слове «дождинка»?
-ин-
-к-
-инк-
-дин-
Может быть интересно
Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Суффикс земли. «Земля» — морфемный разбор слова, разбор по составу (корневой суффикс, приставка, окончание). См. также в других словарях
Как разобрать состав слова «земля»?
- Именительный падеж (какой?) — земля;
- Родительный падеж (не какой?) — земля;
- Дательный падеж (пришел к чему?) — в землю
- Винительный падеж (видите какой?) — земля;
- Инструментальный (чем доволен?) — земля;
- Предложный падеж (говорил о чем?) — о земле
Разбор (или морфемный разбор) слова ЗЕМЛЯ
Наша Земля – одна из планет Солнечной системы.
Земля — существительное женского рода с окончанием I:
земля, земля, земля, земля, земля, земля.
Основа слова ЗЕМЛЯ.
Теперь найдем его основную часть в слове, это корень.
Вспомним однокоренные слова: землянка, землянка, земля, экскаватор, земля.
Итак, корень будет частью слова ЗЕМЛЯ // земля.
Существительное земля различается по падежам и числам:
край земли и , приходить на землю е , находить с е млу, дальний з е мли.
Значит, буквой Я есмь выражена словоизменяющая морфема — окончание.
сп-л-й, тан-л-й?
Чтобы не ошибиться в определении границ корня существительного quot; земля», обратимся за помощью к родственным словам:
земля, землянин, земляк, землячка, землянин, земля.
Как видите, общая часть всех этих слов, связанных единым смыслом, является частью земли.
Подведем итоги:
земля-я — корень/окончание.
Земля — существительное женского рода единственного числа. Это довольно простое слово и очень известное, тем не менее, нужно уметь разбирать такое.
Чтобы правильно найти окончание, нужно склонить слово: земля, земля, земля. Изменяемая часть будет окончанием, в данном случае это -i. Соответствует окончанию существительных первого склонения.
Пройдемся по ряду однокоренных слов, чтобы точно знать, как выглядит корень: мирской, земляной, заземляющий, земляк, земляной. Часть земли не меняется, значит, она будет корнем. Основа слова выглядит так же — -земля-.
Итого имеем земля /i — корень/окончание.
Слово земля — существительное женского рода, в единственном числе (во множественном числе будет слово — «земля»), в именительном падеже.
Реализуем морфемный разбор (разбор по составу) слов quot; земляquot;:
Для определения окончания слова выполним склонение слова по падежам:
Итак, в существительном женского рода quot; земляquot; окончание -i-.
Подберем несколько слов одного корня: земля, земляной, приземлился и т. д.
Корень слова -земля-.
Основой слова будет -земля-.
Разберем слово:
1) В слове quot; земляquot; нет префикса;
2) Корень слова quot; земляquot; будет quot; земляquot;;
3) В слове quot; земляquot; без суффикса;
4) Окончание в слове quot; земляquot; будет: quot; яquot;;
5) Основа слова quot; земляquot; будет: quot; земля».
Слово quot; земляquot; — одно из простых слов для разбора по составу. Ибо у него всего две морфемы:
— земля — (земляной, земляной, земляной) корневая морфема,
-I- окончательная морфема;
основа слова quot; земля quot; — земля
Морфемный разбор слов quot; земляquot; начинаем с поиска концовки. Для этого следует склонять в падежах таким образом: земля я , земля и , земля е , земля Ю , земля ее , земля е … Переменная частью слова, как мы видим, является морфема quot; -яquot; , что будет концом. Остальная часть слова представляет его основу: quot; земля-quot; … Приставка в слове quot; земляquot; отсутствуют, а также суффиксы. А корневая морфема входит в состав слова: quot; земля-quot; … Разбор слова quot; земляquot; состав окончен.
Земля — существительное женского рода в единственном числе, обозначает третью планету от Солнца, почву и территориально-административную единицу Германии.
Морфемный (по составу) разбор слова земля:
корень: земля (проверить со словами земляной, земной, земляной, заземляющий)
окончание: i
основание: земля
Префиксы, суффиксы и постфиксы отсутствуют.
Существительное женского рода Земля относится к первому склонению и в его составе следует различать окончание -Я: Земля-Земля-Земля-Земля-Земля. Однокоренные слова оказываются Земля-Земля-Земляк-Земля-Подземелье-Подземелье-Редкая Земля. Корнем оказывается морфема ЗЕМЛЯ-, в которой возможно как чередование согласных- М/МЛ, так и появление беглой гласной Е.
Получаем: ЗЕМЛЯ-Я (корень-окончание), основа слова ЗЕМЛЯ-.
Первый шаг в разборе слова по составу — изменить его по числам, падежам, лицам, затем найти окончание в слове. Вторым шагом является определение основы слова. Третий шаг – найти корень в слове. Четвертый шаг – выбор префикса. Пятый шаг — выбор суффикса.
В слове Земля: окончание — Я, основа слова земля, корень тоже будет земля, приставки не будет, суффикса тоже.
земля
Состав слова «земля» :
корень — [земля], окончание — [и]
Предложения со словом «земля»
И показалось вдруг: за ним ничего нет, край, земля обрывается, и только тьма стена, звезды, вечный холод.
Но вторая рука Рубахина, опустившая автомат на землю, зажала его полуоткрытый рот с красивыми губами и слегка подрагивающим носом.
Наверное, так старый дуб чувствует свои мозолистые корни, торчащие из земли.
Планер получает достаточно энергии, чтобы оторваться от земли и взлететь с холма.
Дедушка снимает сыромятные чувяки с ног, вытряхивает из них мелкие камешки, землю, затем вытаскивает пучки бархатистой специальной альпийской травы, которую для мягкости кладут в чувяки.
Кроме того, этот же прием позволит реже рыхлить и пропалывать землю под кустами и клумбами.
Однако сделать это им не удалось: над туннелем находится стометровый слой льда и земли.
Например, кубанцев можно прогнать, потому что земля у них голая, как ладонь…
Текст этой лекции стал популярным, но Министерство образования одной из федеральных земель запретило ее распространение в вузах .
Разберите слово по составу, что оно означает?
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по месту в слове и установление значения каждой из них. В школьной программе он также называется разбор морфем . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, причастие, наречие, числительное.
План: Как разобрать слово по его составу?
При разборе морфем соблюдать определенную последовательность выделения значащих частей. Начните с того, чтобы «снять» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
- Запишите слово так же, как в домашнем задании. Перед тем, как начать разбирать композицию, выясните ее лексическое значение (значение).
- Определите из контекста, к какой части речи оно относится. Вспомните признаки слов, принадлежащих к этой части речи:
- изменяемое (имеет окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразовательный суффикс?
- Найдите концовку. Для этого склоняйте по падежам, меняйте число, род или лицо, спрягайте — переменная часть будет окончанием. Помните об изменяемых словах с нулевым окончанием, обязательно укажите, если оно есть: сон (), друг (), слышимость (), благодарность (), съел ().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с приставками и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найдите корень в основании. Для этого сравните ряд родственных слов. Их общей частью является корень. Запомните однокоренные слова с чередующимися корнями.
- Если слово имеет два (и более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить синтаксический анализ и выделить все значимые части значками
В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5-9 классах для общеобразовательных школ. У разных авторов подход к разбору морфем отличается. Чтобы избежать проблем с домашним заданием, сравните приведенный ниже порядок разбора с вашим учебником.
Порядок полного разбора морфем по составу
Во избежание ошибок желательно связать разбор морфем с словообразовательным разбором. Такой анализ называется формально-семантическим.
- Установите часть речи и выполните графический морфемный анализ слова, то есть обозначьте все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы словоформ (если есть)
- Запишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пи-а-й → пи-а-й → пи-а-й», «сух(ой) → суши-ар() → суши-ар-ниц -(а)». Для слов со связными корнями выбирайте одноструктурные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «спать»:
- окончание «а» указывает на форму глагола женского рода единственного числа прошедшего времени, ср.: проспал;
- основание форы «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением убытка, невыгоды, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сп/сон//сып. Однокоренные слова: сон, засыпание, сонливость, недосыпание, бессонница.
Разбор схемы по составу земли:
земля
Разбор по слову состав.
Состав слова «земля»:
Соединительная гласная: отсутствует
Постфикс: отсутствует
Морфемы — части слова земля
земляДетальный разбор слова земля по составу. Словосочетание, префикс, суффикс и окончание слова. Мофемное членение слова земля, его схема и части слова (морфология).
- Морфемная схема: земля / я
- Структура слова по морфемам: корень / окончание
- Схема (построение) слова земля по составу: корень земля + окончание i
- Список морфем в слове земля:
- земля — корень
- я окончание
- Типы морфов и их число в Слово Земля:
- Доставка: Отсутствует — 0
- Королева: LAND — 1
- Подключение GLAC: — — 0
- Cyt. 0
- постфикс: отсутствует — 0
- конец: Я — 1
Всего морфем в слове: 2.
Производный разбор слова земля
См. также другие словари:
Однокоренные слова… это слова с корнем…, принадлежащие к разным частям речи, и одновременно близкие по значению… Однокоренные слова земля
Что такое земля? Что такое земля? Что такое земля для земли?
Полный морфологический разбор слова «земля»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где изучается слово… Морфологический анализ земли
Ударение в слове земля: на какой слог и как падает ударение… Слово «земля» правильно пишется как… Ударение в слове земля
Синонимы к слову «земля». Онлайн-словарь синонимов: найди синонимы к слову «земля». Синонимы к слову земля
Антонимы к слову земля
Антонимы… имеют противоположное значение, различаются по звучанию, но относятся к одной и той же части речи. .. Антонимы к слову земля
Анаграммы (составляют анаграмма) к слову земля, путем смешивания букв… Анаграммы к слову земля
Составить анаграмму слова из букв. Вы ввели буквы «земля», из которых можете составить следующие слова из… Из данных букв составить слова земля
К чему снится земля — толкование снов, узнайте бесплатно в нашем соннике что означает земля. …Земля увиденная во сне означает, что… Сонник: к чему снится земля
Морфемный разбор слова земля
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова земля очень прост. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого пройдем всего 5 шагов:
- определение части речи слова — первый шаг;
- второй — подбираем окончания: для изменяемых слов спрягаем или раздуваем, для неизменяемых (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- дальше ищем основу. Это самая простая часть, потому что вам просто нужно обрезать конец, чтобы определить основу. Это будет основой слова;
- Следующим шагом будет поиск корня слова. Подбираем родственные слова к земле (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
Как вы видите, разбор морфем делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слов (разбор слов) — поиск корня, префиксов, суффиксов, окончаний и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.Рекурсивная композиция поддерева в анализе зависимостей на основе LSTM — arXiv Vanity
Мирьям де Лоно♠ Мигель Бальестерос♢ Хоаким Нивре♠
♠ Факультет лингвистики и филологии Упсальского университета.
♢ IBM Research AI, Йорктаун-Хайтс, Нью-Йорк
Abstract
Потребность в моделировании древовидной структуры в дополнение к моделированию последовательностей является открытым вопросом при анализе нейронных зависимостей. Мы исследуем влияние добавления слоя дерева поверх последовательной модели путем рекурсивного составления представлений поддеревьев (композиции) в синтаксическом анализаторе на основе переходов, который использует функции, извлеченные с помощью BiLSTM. Композиция кажется излишней для такой модели, предполагая, что BiLSTM собирают информацию о поддеревьях. Мы выполняем модельную абляцию, чтобы выявить условия, при которых композиция помогает. При удалении обратного LSTM производительность падает, а композиция не восстанавливает большую часть разрыва. При удалении прямого LSTM производительность падает менее резко, а композиция восстанавливает значительную часть пробела, что указывает на то, что прямой LSTM и композиция собирают аналогичную информацию. Мы считаем, что обратный LSTM связан с функциями просмотра вперед, а прямой LSTM — с функциями, основанными на богатой истории, и обе они имеют решающее значение для синтаксических анализаторов на основе переходов. Для сбора информации, основанной на истории, композиция лучше, чем прямая LSTM сама по себе, но еще лучше иметь прямую LSTM как часть BiLSTM. Мы сопоставляем результаты со свойствами языка, показывая, что улучшенный просмотр назад обратного LSTM особенно важен для языков с окончанием головы.
1 Введение
Рекурсивные нейронные сети позволяют нам строить векторные представления деревьев или поддеревьев. Они использовались для анализа избирательных округов Socher et al. (2013) и Dyer et al. (2016) и для синтаксического анализа зависимостей Stenetorp (2013) и Dyer et al. (2015) и др.
В частности, Dyer et al. (2015) показали, что составление представлений поддеревьев с использованием рекурсивных нейронных сетей может быть полезным для синтаксического анализа зависимостей на основе переходов. Эти результаты были дополнительно подтверждены в Кункоро и соавт. (2017) , которые с помощью экспериментов по абляции показали, что композиция является ключевой в генеративном синтаксическом анализаторе грамматики рекуррентной нейронной сети (RNNG) Dyer et al. (2016) .
В параллельной разработке Кипервассер и Голдберг (2016b) показали, что использование BiLSTM для извлечения признаков может привести к высокой точности синтаксического анализа даже при довольно простых архитектурах синтаксического анализа, и поэтому использование BiLSTM для извлечения признаков стало очень популярным при анализе зависимостей. Он используется в современном синтаксическом анализаторе Dozat and Manning (2017) , использовалось в 8 из 10 самых производительных систем общей задачи CoNLL 2017 г. (Zeman et al., 2017) и в 10 из 10 наиболее эффективных систем общей задачи CoNLL 2018 г. (Земан и др., 2018) .
Это поднимает вопрос о том, собирают ли признаки, извлеченные с помощью BiLSTM, сами по себе информацию о поддеревьях, что делает рекурсивную композицию излишней. Некоторое подтверждение этой гипотезы исходит из результатов Линцен и др. (2016) , которые указывают на то, что LSTM могут собирать иерархическую информацию: их можно обучить прогнозировать согласование междугородних номеров на английском языке. Эти результаты были распространены на большее количество конструкций и три дополнительных языка 90 408 Gulordava et al. (2018) .
Однако Kuncoro et al. (2018) также показали, что, хотя последовательные LSTM могут изучать синтаксическую информацию, рекурсивная нейронная сеть, которая явно моделирует иерархию (модель RNNG из Дайер и др. (2015) ) лучше справляется с этой задачей: он лучше справляется с задачей согласования номеров из Linzen et al. (2016) .
Чтобы глубже изучить этот вопрос в контексте синтаксического анализа зависимостей, мы исследуем использование рекурсивной композиции (далее именуемой композиция ) в синтаксическом анализаторе с архитектурой, подобной Кипервассер и Голдберг (2016b) . Это позволяет нам исследовать варианты функций и изолировать условия, при которых композиция полезна. Мы предполагаем, что использование BiLSTM для извлечения признаков позволяет собирать информацию о поддеревьях и, следовательно, делает излишним использование композиции поддеревьев. Мы предполагаем, что композиция становится полезной, когда удаляется часть BiLSTM, вперед или назад LSTM. Далее мы предполагаем, что композиция наиболее полезна, когда синтаксический анализатор не имеет доступа к информации о функции слов в контексте предложения, заданного POS-тегами. При использовании тегов POS у тегировщика действительно был доступ к полному предложению. Мы дополнительно смотрим на то, что происходит, когда мы удаляем векторы символов, которые, как было показано, собирают информацию, частично перекрывающуюся с информацией из тегов POS.
Мы экспериментируем с более широким спектром языков, чем Дайер и др. (2015) , чтобы выяснить, зависит ли полезность различных вариантов модели от типа языка.
2 Разбор K&G на основе переходов
Мы определяем архитектуру синтаксического анализа, представленную Кипервассером и Голдбергом (2016b) , как высокий уровень абстракции и далее называем ее K&G.
Парсер K&G — это жадный парсер, основанный на переходах. 1 1 1 Кипервассер и Голдберг (2016b) также определяют анализатор на основе графа с аналогичным извлечением признаков, но мы сосредоточимся на анализе на основе переходов.
Для входного предложения длины n со словами w1,…,wn создается последовательность векторов x1:n, где вектор xi является векторным представлением слова wi. Мы называем их введите векторов, так как они одинаковы для всех вхождений типа слова. Затем векторы типов передаются через функцию признаков, которая изучает представления слов в контексте предложения.
| и | = е(ви) | ||
| ви | =f(x1:n,i) |
Мы называем вектор vi вектором токенов , поскольку он различен для разных токенов одного и того же типа слова. В Кипервассер и Голдберг (2016b) , используемая функция признака представляет собой BiLSTM.
Как обычно при синтаксическом анализе на основе переходов, синтаксический анализ включает переходы от начальной конфигурации к конечной. Конфигурации синтаксического анализатора представлены стеком, буфером и набором дуг зависимостей (Nivre, 2008) .
Для каждой конфигурации c экстрактор признаков объединяет токены-представления основных элементов из стека и буфера. Эти векторы токенов передаются классификатору, обычно многослойному персептрону (MLP). MLP оценивает переходы вместе с
метки дуги для переходов, которые предполагают добавление дуги. И векторы типов слов, и BiLSTM обучаются вместе с моделью.
3 Составление представлений поддеревьев
Дайер и др. (2015) изучили влияние использования рекурсивной функции композиции в их синтаксическом анализаторе, который также является синтаксическим анализатором на основе перехода, но с архитектурой, отличной от K&G.
Они используют вариант LSTM, называемый стековым LSTM. Стек LSTM имеет операции push и pop, которые позволяют проходить состояния в древовидной структуре, а не последовательно. LSTM стека используются для представления стека, буфера и последовательности прошлых действий анализа, выполненных для конфигурации.
Слова предложения представлены векторами типов слов вместе с вектором, представляющим тег POS слова. В исходной конфигурации векторы всех слов находятся в буфере, а стек пуст. Представление буфера — это конечное состояние обратного LSTM по векторам слов.
По мере развития синтаксического анализа векторы слов извлекаются из буфера, помещаются в стек и извлекаются из него, а представления стека и буфера обновляются.
Дайер и др. (2015) определить функцию рекурсивной композиции и создавать представления дерева постепенно, по мере того, как зависимые элементы прикрепляются к их голове. Составное представление c строится путем конкатенации вектора h головы с вектором зависимого d, а также вектора r, представляющего метку в паре с направлением дуги. Этот объединенный вектор проходит через аффинное преобразование, а затем через нелинейную активацию.
| c=tanh(W[h;d;r]+b) |
Они создают две версии парсера. В первом варианте при присоединении зависимого к голове вектор слов головы заменяется составным вектором головы и зависимого. Во втором варианте они просто сохраняют вектор головы при присоединении иждивенца к голове. Они отмечают, что версия с композицией значительно лучше, чем версия без нее, на 1,3 балла LAS для английского языка (на тестовом наборе Penn Treebank (PTB)) и на 2,1 для китайского языка (на тестовом наборе Chinese Treebank (CTB)).
Их синтаксический анализатор использует информацию тега POS. POS-теги помогают устранить неоднозначность между различными функциональными употреблениями слова и, таким образом, предоставляют информацию об использовании слова в контексте. Мы предполагаем, что эффект от использования рекурсивной функции композиции сильнее, когда не используются теги POS.
4 Композиция в парсере K&G
Архитектуры синтаксического анализа синтаксического анализатора LSTM стека (S-LSTM) и K&G различаются, но имеют некоторые сходства. 2 2 2Обратите внимание, что мы используем S-LSTM для обозначения анализатора стека LSTM, а не стека LSTM как типа LSTM. В обоих случаях конфигурация представлена векторами, полученными с помощью LSTM. В K&G он представлен векторами токенов верхних элементов стека и первого элемента буфера. В S-LSTM он представлен векторными представлениями всего стека, буфера и последовательности прошлых переходов.
Оба типа синтаксических анализаторов изучают векторные представления типов слов, которые передаются в LSTM.
В K&G они передаются в LSTM на этапе извлечения признаков, который происходит перед синтаксическим анализом. LSTM в этом случае используется для изучения векторов, у которых есть информация о контексте каждого слова, токен-вектор. В S-LSTM векторы типов слов передаются в Stack LSTM по мере развития синтаксического анализа. В этом случае LSTM используются для изучения векторных представлений стека и буфера (а также того, который изучает представление истории действий синтаксического анализа).
Если композиция не используется в S-LSTM, векторы слов представляют типы слов. Когда используется композиция, по мере развития синтаксического анализа векторы стека и буфера обновляются информацией о содержащихся в них поддеревьях, так что они постепенно становятся контекстуализированными. В этом смысле эти векторы становятся больше похожими на векторы токенов в K&G. В частности, как объяснялось в предыдущем разделе, когда зависимый объект присоединен к его голове, функция композиции применяется к векторам головы и зависимого, и вектор головы заменяется этим составным вектором.
Мы не можем применять композицию к векторам типов в архитектуре K&G, поскольку они не используются после этапа извлечения признаков и, следовательно, не могут влиять на представление конфигурации. Вместо этого мы применяем композицию к векторам токенов. Мы встраиваем эти составные представления в то же пространство, что и векторы токенов.
В K&G, как и в S-LSTM, мы можем создать функцию композиции и составить представление поддеревьев по мере развития синтаксического анализа. Мы создаем две версии синтаксического анализатора, в одной из которых токены слов представлены их вектором токенов. Другой, где они представлены своим вектором токенов и вектором их поддерева ci, который изначально является просто копией вектора токенов (vi=f(x1:n,i)∘ci). Когда зависимое слово d присоединяется к слову h с отношением и направлением r, ci вычисляется с той же функцией композиции, что и в S-LSTM, определенной в предыдущем разделе, повторенной ниже. 3 3 3Обратите внимание, что в предварительных экспериментах мы пытались заменить вектор головы вектором ее поддерева вместо объединения двух, но объединение дало гораздо лучшие результаты.
Эта композиционная функция представляет собой простую рекуррентную ячейку. Простые RNN имеют известные недостатки, которые были устранены с помощью LSTM, как было предложено Hochreiter and Schmidhuber (1997) . Поэтому естественным расширением этой функции композиции является замена ее ячейкой LSTM. Мы тоже пробуем этот вариант. Мы создаем LSTM для поддеревьев. Мы инициализируем новый LSTM для каждого нового сформированного поддерева, то есть когда зависимый d присоединяется к голове h, у которой еще нет никаких зависимых. Каждый раз, когда мы присоединяем зависимого к голове, мы строим вектор, который представляет собой конкатенацию h, d и r. Мы передаем этот вектор в LSTM h. c — это выходное состояние LSTM после прохождения этого вектора.
Мы обозначаем эти модели с +rc для модели, использующей рекуррентную ячейку без ограничений, и с +lc для модели, использующей ячейку LSTM.
| в | =tanh(W[h;d;r]+b) | ||
| в | =\textscLstm([h;d;r]) |
Как показывают результаты (см. § 5), ни один из типов композиции не кажется полезным при использовании с моделью синтаксического анализа K&G, что указывает на то, что BiLSTM собирают информацию о поддеревьях. Для дальнейшего изучения этого и для того, чтобы изолировать условия, при которых композиция полезна, мы выполняем различные модели абляции и проверяем влияние рекурсивной композиции на эти аблированные модели.
Во-первых, мы удаляем части BiLSTM: мы удаляем либо переднюю, либо заднюю LSTM. Поэтому мы строим синтаксические анализаторы с 3 различными функциями функций f(x,i) над векторами типа слова xi в предложении x: BiLSTM (bi) (наша базовая линия), обратная LSTM (bw) (т. е. удаление прямой LSTM) и прямой LSTM (fw) (т. Е. Удаление обратного LSTM):
| би(х,я) | =\textscBiLstm(x1:n,i) | ||
| чб(х,и) | =\textscLstm(xn:1,i) | ||
| фв (х, я) | =\textscLstm(x1:n,i) |
K&G с однонаправленными LSTM в некотором смысле больше похожи на S-LSTM, чем на BiLSTM, поскольку S-LSTM использует только однонаправленные LSTM. Мы предполагаем, что композиция поможет синтаксическому анализатору, использующему однонаправленные LSTM, так же, как он помогает S-LSTM.
Мы дополнительно экспериментируем с вектором, представляющим слово на входе LSTM. Наиболее сложное представление состоит из конкатенации вложения типа слова e(wi), встраивания (предсказанного) POS-тега wi, p(wi) и символьного представления слова, полученного путем запуска BiLSTM над символы ch2:m из wi (BiLSTM(ch2:m)).
| xi=e(wi)∘p(wi)∘BiLSTM(ch2:m) |
Без внедрения тега POS вектор слова является представлением типа слова. С информацией POS у нас есть некоторая информация о слове в контексте предложения, и тегировщик имеет доступ к полному предложению. Таким образом, представление слова на входе BiLSTM более контекстуализировано, и можно ожидать, что функция рекурсивной композиции будет менее полезной, чем когда информация POS не используется.
Было показано, что информация о символах полезна для разбора зависимостей в первую очередь Баллестерос и др. (2015) . Баллестерос и др. (2015) и Smith et al. (2018b) , среди прочего, показали, что POS и информация о символах в некоторой степени дополняют друг друга. Баллестерос и др. (2015) использовали аналогичные векторы символов в синтаксическом анализаторе S-LSTM, но не учитывали влияние композиции при использовании этих векторов. Здесь мы экспериментируем с удалением одного или обоих векторов символа и POS. Мы рассматриваем влияние использования композиции на полную модель, а также на эти аблированные модели. Мы предполагаем, что композиция наиболее полезна, когда эти векторы не используются, поскольку они дают информацию о функциональном использовании слова в контексте.
Парсер
Мы используем UUParser, вариант синтаксического анализатора на основе переходов K&G, в котором используется дуговая гибридная система переходов из Kuhlmann et al. (2011) дополнен переходом Swap и статическим динамическим оракулом, как описано в de Lhoneux et al. (2017b) 4 4 4 Код можно найти по адресу https://github.com/mdelhoneux/uuparser-composition. Переход Swap используется для построения непроективных деревьев зависимостей (Нивр, 2009) .
Мы используем гиперпараметры по умолчанию. При использовании POS-тегов мы используем универсальные POS-теги из банков деревьев UD, которые являются укрупненными и одинаковыми для разных языков. Теги POS прогнозируются UDPipe (Straka et al., 2016) как для обучения, так и для синтаксического анализа. Этот синтаксический анализатор получил в среднем 7-е место среди лучших результатов LAS в общей задаче CoNLL 2018 года (Zeman et al., 2018) , что примерно на 2,5 балла LAS ниже лучшей системы, которая использует ансамблевую систему, а также вложения ELMo, представленные Петерс и др. (2018) .
Обратите внимание, однако, что мы используем слегка обедненную версию модели, используемой для общей задачи, которая описана в Smith et al. (2018a) : мы используем менее точный теггер POS (UDPipe) и не используем модели с несколькими банками деревьев. Кроме того, Smith et al. (2018a) используют три верхних элемента стека, а также первый элемент буфера для представления конфигурации, в то время как мы используем только два верхних элемента стека и первый элемент буфера. Смит и др. (2018a) также использует расширенный набор функций, представленный Кипервассером и Голдбергом (2016b) , где они также используют крайние правые и крайние левые дочерние элементы стека и буфера, которые они рассматривают. Мы не используем этот расширенный набор функций. Это делается для того, чтобы настройки парсера были максимально простыми и чтобы не добавлялись искажающие факторы. Это все еще почти модель SOTA. Мы оцениваем модели синтаксического анализа в наборах для разработки и сообщаем о среднем значении 5 лучших результатов за 30 эпох и 5 прогонов с разными случайными начальными значениями.
Данные
Мы тестируем наши модели на образце деревьев из Universal Dependencies v2.1 (Nivre et al., 2017) . Мы следуем критериям de Lhoneux et al. (2017c) для выбора нашей выборки: мы обеспечиваем типологическое разнообразие, мы обеспечиваем разнообразие доменов, мы проверяем качество банков деревьев и используем один банк деревьев с большим количеством непроективных дуг. Однако, в отличие от них, мы не используем очень маленькие валы деревьев. Наш выбор такой же, как и у них, но мы удаляем крошечные валы деревьев и заменяем их тремя другими. Наш последний набор: древнегреческий (PROIEL), баскский, китайский, чешский, английский, финский, французский, иврит и японский.
5 результатов
Во-первых, мы рассмотрим влияние наших различных функций рекурсивной композиции на полную модель (т. е. модель, использующую BiLSTM для извлечения признаков, а также информацию о символах и тегах POS). Как видно из рисунка 1, рекурсивная композиция с использованием ячейки LSTM (+lc), как правило, лучше, чем рекурсивная композиция с повторяющейся ячейкой (+rc), но ни один из методов надежно не повышает точность синтаксического анализатора BiLSTM.
Рисунок 1: LAS моделей с использованием BiLSTM (bi) без композиции, с повторяющейся ячейкой (+rc) и с ячейкой LSTM (+lc). Гистограммы усечены до 50 для наглядности.5.1 Удаление прямого и обратного LSTM
Во-вторых, мы рассматриваем только модели, использующие информацию о символах и POS, и смотрим на влияние удаления частей BiLSTM на разные языки. Результаты можно увидеть на рисунке 2. Как и ожидалось, синтаксический анализатор BiLSTM работает значительно лучше, чем оба однонаправленных синтаксических анализатора LSTM, а обратный LSTM в среднем значительно лучше, чем прямой LSTM. Однако интересно отметить, что использование прямого LSTM гораздо более вредно для одних языков, чем для других: особенно для китайского и японского. Это можно объяснить свойствами языка: правосторонние языки больше страдают от удаления обратного LSTM.
чем другие языки. Мы наблюдаем корреляцию между тем, насколько вредна прямая модель по сравнению с базовым уровнем, и процентом правосторонних отношений зависимости от контента (R = -0,838, p <0,01), см. рис. 3. 5 5 5 Причина, по которой мы рассматриваем только отношения зависимости содержания, заключается в том, что схема UD фокусируется на отношениях зависимости между словами содержания и рассматривает служебные слова как характеристики слов содержания, чтобы максимизировать параллелизм между языками (de Marneffe et al., 2014) .
Нет существенной корреляции между тем, насколько вредным является удаление прямого LSTM, и процентом левосторонних отношений зависимости контента (p>0,05), что указывает на то, что его полезность не зависит от свойств языка. Мы предполагаем, что длина зависимости или длина предложения могут играть роль, но мы также не находим корреляции между тем, насколько вредно удалять прямой LSTM, и средней зависимостью или длиной предложения в банках деревьев.
Наконец, также интересно отметить, что обратная производительность LSTM близка к производительности BiLSTM для некоторых языков (японского и французского).
Теперь мы рассмотрим эффект использования рекурсивной композиции на этих аблированных моделях. Результаты представлены на рисунке 4.
Прежде всего, мы неудивительно наблюдаем, что композиция с использованием ячейки LSTM намного лучше, чем с использованием простой рекуррентной ячейки. Во-вторых, оба типа композиции помогают обратному случаю LSTM, но ни один из них не помогает надежно би-моделям. Наконец, рекуррентная ячейка не помогает в случае прямого LSTM, но ячейка LSTM в некоторой степени помогает. Интересно отметить, что использование композиции, особенно с использованием ячейки LSTM, устраняет значительную часть разрыва между моделями bw и bi.
Эти результаты могут быть связаны с литературой по синтаксическому анализу зависимостей на основе переходов. Синтаксические анализаторы на основе переходов обычно полагаются на два типа функций: функции на основе истории по возникающему дереву зависимостей и упреждающие функции по буферу оставшихся входных данных. Первые основаны на иерархической структуре, вторые — чисто последовательные. McDonald and Nivre (2007) и McDonald and Nivre (2011) показали, что функции, основанные на истории, улучшают синтаксические анализаторы на основе переходов, если они не страдают от распространения ошибок. Однако Nivre (2006) также показал, что функции просмотра вперед абсолютно необходимы, учитывая жадную стратегию разбора слева направо.
В рассмотренных здесь архитектурах моделей обратный LSTM обеспечивает улучшенный просмотр вперед. Подобно просмотру вперед в статистическом анализе, он является последовательным. Разница в том, что он дает информацию о предстоящих словах неограниченной длины. Прямой LSTM в этой архитектуре модели предоставляет информацию на основе истории, но, в отличие от статистического анализа, эта информация строится последовательно, а не иерархически: прямой LSTM проходит через предложение в линейном порядке предложения. В наших результатах мы видим, что упреждающие функции более важны, чем функции, основанные на истории. Точность синтаксического анализа больше ухудшает удаление обратного LSTM, чем удаление прямого. Это ожидаемо, учитывая, что некоторая информация, основанная на истории, все еще доступна через верхние токены в стеке, в то время как упреждающая информация почти полностью теряется без обратного LSTM.
Функция композиции предоставляет иерархическую информацию об истории действий по разбору. Имеет смысл, что это больше всего помогает обратной модели LSTM, поскольку эта модель не имеет доступа к какой-либо информации об истории синтаксического анализа. Это немного помогает прямому LSTM, что указывает на то, что можно получить выгоду от использования структурированной информации об истории синтаксического анализа, а не последовательной информации. Тогда мы могли бы ожидать, что композиция должна помочь модели BiLSTM, что, однако, не так. Это может быть связано с тем, что BiLSTM конструирует информацию о синтаксическом анализе истории и просмотре вперед в уникальном представлении. В любом случае это указывает на то, что BiLSTM являются мощными экстракторами функций, которые, кажется, собирают полезную информацию о поддеревьях.
5.2 Удаление информации о POS и персонаже
Далее мы рассмотрим влияние различных методов представления слов на разные языки, как показано на рисунке 5. Как и в литературе (Ballesteros et al., 2015; de Lhoneux et al., 2017a; Smith et al. al., 2018b) , использование символьных представлений слов и/или тегов POS постоянно повышает точность синтаксического анализа, но оказывает разное влияние на разные языки, и преимущества обоих методов не суммируются: использование двух методов в сочетании не намного лучше, чем использование либо самостоятельно. В частности, модели символов — это эффективный способ добиться больших улучшений в морфологически богатых языках.
Мы рассматриваем влияние рекурсивных композиций на все комбинации аблированных моделей, см. Таблицу 1. Мы рассматриваем только влияние использования ячейки LSTM, а не рекуррентной ячейки, поскольку это был лучший метод по всем направлениям (см. предыдущий раздел). .
Если сначала посмотреть на BiLSTM, то кажется, что композиция не обеспечивает надежной точности синтаксического анализа, независимо от доступа к POS и информации о символах. Это указывает на то, что векторы, полученные с помощью BiLSTM, уже содержат информацию, которую в противном случае можно было бы получить с помощью композиции.
Обращаясь к результатам с прямой или обратной абляции LSTM, мы видим ожидаемую картину. Композиция помогает больше, когда в модели отсутствуют теги POS, что указывает на некоторую избыточность между этими двумя методами построения контекстной информации. Композиция помогает восстановить значительную часть разрыва модели с помощью обратного LSTM с тегом POS или без него. В других случаях он восстанавливает гораздо менее существенную часть пробела, что означает, что, хотя между этими различными методами построения контекстной информации существует некоторая избыточность, они все же дополняют друг друга, и рекурсивная функция композиции не может полностью компенсировать отсутствие обратного LSTM. или POS и/или информацию о персонаже.
В результатах есть некоторые языковые особенности. В то время как композиция помогает восстановить большую часть разрыва для обратных моделей LSTM без информации о POS и / или символах для чешского и английского языков, она делает это в гораздо меньшей степени для баскского и финского языков. Мы предполагаем, что глубина дуги может повлиять на полезность композиции, поскольку большая глубина означает большее умножение матриц с функцией композиции. Однако мы не находим корреляции между средней глубиной дуги берегов деревьев и полезностью композиции. Остается открытым вопрос, почему композиция помогает одним языкам больше, чем другим.
Обратите внимание, что мы не первые, кто использует композицию векторов, полученных из BiLSTM, в контексте синтаксического анализа зависимостей, как это было сделано Qi и Manning (2017) .
Отличие в том, что они составляют векторы до подсчета очков за переходы. Это также было сделано Kiperwasser и Goldberg (2016a) , которые показали, что использование векторов BiLSTM для слов в их синтаксическом анализаторе Tree LSTM полезно, но они не сравнивали это с использованием векторов BiLSTM без Tree LSTM.
Рекуррентные и рекурсивные LSTM в том виде, как они рассматриваются в этой статье, представляют собой два способа создания контекстной информации и предоставления ее для принятия локальных решений в жадном синтаксическом анализаторе. Сила рекурсивных LSTM заключается в том, что они могут создавать эту контекстную информацию, используя иерархический контекст, а не линейный контекст. Возможная слабость заключается в том, что это делает модель чувствительной к распространению ошибок: неправильное присоединение приводит к использованию неправильной контекстной информации. Поэтому возможно, что преимущества и недостатки использования этого метода компенсируют друг друга в контексте BiLSTM.
5.3 Ансамбль
Для дальнейшего изучения информации, полученной с помощью BiLSTM, мы объединили 6 версий моделей с POS и символьной информацией с различными экстракторами признаков (bi, bw, fw) с (+lc) и без композиции. Мы используем (невзвешенный) метод повторного анализа Sagae and Lavie (2006) 6 6 6. Этот метод оценивает все дуги по количеству парсеров, предсказывающих их, и извлекает максимальное остовное дерево с использованием алгоритма Чу-Лю-Эдмондса (Эдмондс, 1967) . и игнорирование ярлыков.
Как видно из оценок UAS в таблице 2, ансамбль (90 446 полных 90 447) значительно превосходит синтаксический анализатор, использующий только BiLSTM, что указывает на то, что информация, полученная из разных моделей, дополняет друг друга. Чтобы исследовать вклад каждой из 6 моделей, мы удаляем каждую из них одну за другой. Как видно из таблицы 2, удаление любой из моделей BiLSTM или обратного LSTM с использованием композиции приводит к наименее эффективной из моделей удаления, что еще больше укрепляет вывод о том, что BiLSTM являются мощными экстракторами признаков.
6 Заключение
Мы исследовали влияние составления представления поддеревьев в синтаксическом анализаторе на основе переходов. Мы заметили, что композиция не помогает синтаксическому анализатору, который использует BiLSTM для извлечения признаков, что указывает на то, что векторы, полученные из BiLSTM, могут собирать информацию о поддеревьях, что согласуется с результатами Linzen et al. (2016) . Однако мы наблюдаем, что при удалении обратного LSTM производительность падает, а рекурсивная композиция не помогает восстановить большую часть этого разрыва. Мы предполагаем, что это связано с тем, что обратный LSTM в первую очередь улучшает просмотр вперед для жадного синтаксического анализатора. При удалении прямого LSTM производительность падает в меньшей степени, а рекурсивная композиция восстанавливает значительную часть разрыва. Это указывает на то, что прямой LSTM и рекурсивная функция композиции собирают аналогичную информацию, которую мы считаем связанной с богатыми функциями, основанными на истории, которые имеют решающее значение для синтаксического анализатора на основе переходов. Для сбора этой информации рекурсивная функция композиции лучше, чем прямая LSTM сама по себе, но еще лучше иметь прямую LSTM как часть BiLSTM. Мы также обнаружили, что рекурсивная композиция помогает больше, когда теги POS удаляются из модели, указывая на то, что теги POS и функция рекурсивной композиции являются частично избыточными способами построения контекстной информации. Наконец, мы сопоставляем результаты со свойствами языка, показывая, что улучшенный просмотр назад обратного LSTM особенно важен для языков с окончанием головы.
Благодарности
Мы подтверждаем вычислительные ресурсы, предоставленные CSC в Хельсинки и Sigma2 в Осло через NeIC-NLPL (www.nlpl.eu). Мы благодарим Сару Стимн и Аарона Смита за многочисленные обсуждения этой статьи.
Каталожные номера
- Баллестерос и соавт. (2015) Мигель Баллестерос, Крис Дайер и Ной А. Смит. 2015. Улучшен синтаксический анализ на основе перехода путем моделирования персонажей вместо слова с LSTM. В Трудах конференции по эмпирическим методам в Обработка естественного языка (EMNLP) , стр. 349–359.
- Дозат и Мэннинг (2017) Тимоти Дозат и Кристофер Мэннинг. 2017. Deep Biaffine Attention для анализа нейронных зависимостей. In Материалы 5-й Международной конференции по обучению Представительства.
- Дайер и соавт. (2015) Крис Дайер, Мигель Баллестерос, Ван Линг, Остин Мэтьюз и Ной А. Смит.
2015.
Разбор зависимостей на основе перехода со стеком в долгосрочной перспективе
Память.
In Материалы 53-го ежегодного собрания Ассоциации
для компьютерной лингвистики (ACL) , страницы 334–343.
- Дайер и соавт. (2016) Крис Дайер, Адхигуна Кункоро, Мигель Баллестерос и Ной А. Смит. 2016. Рекуррентные грамматики нейронных сетей. В материалах NAACL-HLT , стр. 199–209.
- Эдмондс (1967) Джек Эдмондс. 1967. Оптимальные разветвления. Журнал исследований Национального бюро стандартов , 71Б: 233–240.
- Гулордава и др. (2018) Кристина Гулордава, Петр Бояновский, Эдуард Граве, Таль Линзен и Марко Барони. 2018. Бесцветные зеленые рекуррентные сети мечтают иерархически. Препринт arXiv arXiv:1803.11138 .
- Хохрайтер и Шмидхубер (1997) Зепп Хохрайтер и Юрген Шмидхубер. 1997. Длинная кратковременная память. Нейронные вычисления , 9(8):1735–1780.
- Кипервассер и Голдберг (2016a)
Элиягу Кипервассер и Йоав Голдберг. 2016а.
Простой разбор зависимостей с помощью LSTM с иерархическим деревом. Сделки Ассоциации компьютерной лингвистики ,
4:445–461.
- Кипервассер и Голдберг (2016b) Элиягу Кипервассер и Йоав Голдберг. 2016б. Простой и точный анализ зависимостей с использованием двунаправленного LSTM представления признаков. Сделки Ассоциации компьютерной лингвистики , 4: 313–327.
- Кульманн и соавт. (2011) Марко Кульманн, Карлос Гомес-Родригес и Джорджио Сатта. 2011. Алгоритмы динамического программирования для зависимостей на основе переходов парсеры. In Материалы 49-го ежегодного собрания Ассоциации для компьютерной лингвистики (ACL) , страницы 673–682.
- Кункоро и соавт. (2017) Адхигуна Кункоро, Мигель Баллестерос, Линпэн Конг, Крис Дайер, Грэм Нойбиг,
и Ной А. Смит. 2017.
Что грамматики рекуррентных нейронных сетей узнают о синтаксисе?
В Материалы 15-й конференции Европейского отделения
Ассоциации компьютерной лингвистики: том 1, длинные статьи ,
страницы 1249–1258. Ассоциация компьютерной лингвистики.
- Кункоро и соавт. (2018) Адхигуна Кункоро, Крис Дайер, Джон Хейл, Дани Йогатама, Стивен Кларк и Фил Блансом. 2018. Lstms может хорошо изучать зависимости, чувствительные к синтаксису, но моделирование структура делает их лучше. In Материалы 56-го ежегодного собрания Ассоциации для компьютерной лингвистики (Том 1: Длинные статьи) , том 1, стр. 1426–1436 гг.
- де Лонью и др. (2017а) Мирьям де Лоно, Ян Шао, Али Басират, Элиягу Кипервассер, Сара Стымне, Йоав Голдберг и Йоаким Нивре. 2017а. От необработанного текста до универсальных зависимостей — смотрите, никаких тегов! В Proceedings of the CoNLL 2017 Shared Task: Multilingual Разбор необработанного текста в универсальные зависимости , страницы 207–217, Ванкувер, Канада. Ассоциация компьютерной лингвистики.
- де Лонью и др. (2017б)
Мирьям де Лонью, Сара Стымне и Жоаким Нивр. 2017б.
Arc-гибридный непроективный анализ зависимостей со статико-динамическим анализом
оракул. В Материалы 15-й Международной конференции по синтаксическому анализу
Технологии , стр. 99–104, Пиза, Италия. Ассоциация вычислительных
Лингвистика.
- де Лонью и др. (2017с) Мирьям де Лонью, Сара Стымне и Жоаким Нивр. 2017г. Старая школа против новой школы: сравнение синтаксических анализаторов на основе перехода с и без улучшения нейронной сети. В 90 446 Трудах 15-го Дерева и лингвистических теорий Мастерская (ТЛТ) .
- Линзен и соавт. (2016) Таль Линзен, Эммануэль Дюпу и Йоав Голдберг. 2016. Оценка способности LSTM учиться с учетом синтаксиса зависимости. Сделки Ассоциации компьютерной лингвистики , 4: 521–535.
- де Марнефф и др. (2014)
Мари-Катрин де Марнефф, Тимоти Доза, Наталья Сильвейра, Катри Хаверинен,
Филип Гинтер, Жоаким Нивр и Кристофер Д. Мэннинг. 2014.
Универсальные Стэнфордские зависимости: межъязыковая типология.
In Материалы 9-й Международной конференции по языку
Ресурсы и оценка (LREC) , страницы 4585–4592.
- Макдональд и Нивр (2007) Райан Макдональд и Жоаким Нивре. 2007. Характеристика ошибок моделей синтаксического анализа зависимостей, управляемых данными. В Материалы Объединенной конференции по эмпирическим исследованиям 2007 г. Методы обработки естественного языка и вычислительного естественного языка Обучение (EMNLP-CoNLL) , страницы 122–131.
- Макдональд и Нивр (2011) Райан Макдональд и Жоаким Нивре. 2011. Анализ и интеграция парсеров зависимостей. Компьютерная лингвистика , страницы 197–230.
- Нивр (2006) Жоаким Нивре. 2006. Индуктивный разбор зависимостей . Спрингер.
- Нивр (2008) Жоаким Нивре. 2008. Алгоритмы детерминированного инкрементного разбора зависимостей. Компьютерная лингвистика , 34:513–553.
- Нивр (2009) Жоаким Нивре. 2009.
Непроективный анализ зависимостей за ожидаемое линейное время.
В Материалах Объединенной конференции 47-й ежегодной
Заседание ACL и 4-я Международная совместная конференция по природным
Языковая обработка AFNLP (ACL-IJCNLP) , страницы 351–359.
- Нивр и соавт. (2017)
Йоаким Нивре, Желько Агич, Ларс Аренберг, Лене Антонсен, Мария Хесус
Аранзабе, Масаюки Асахара, Лума Атейя, Мохаммед Аттиа, Айцибер Атукса,
Лисбет Августинус, Елена Бадмаева, Мигель Баллестерос, Эша Банерджи,
Себастьян Бэнк, Вергиника Барбу Митителу, Джон Бауэр, Кепа Бенгоэчеа,
Рияз Ахмад Бхат, Экхард Бик, Виктория Бобичев, Карл Берстелл, Кристина
Боско, Госсе Баума, Сэм Боуман, Алёша Бурхардт, Мари Кандито, Готье
Карон, Гюльшен Чебироглу Эрийгит, Джузеппе Г. А. Челано,
Саваш Четин, Фабрицио Чалуб, Джинхо Чой, Сильви Чинкова, Чагры Чолтекин, Мириам Коннор, Элизабет Дэвидсон, Мари-Катрин
де Марнеффе, Валерия де Пайва, Аранца Диас де Иларраса, Питер Дирикс, Кая
Добровольц, Тимоти Дозат, Кира Дроганова, Пунит Двиведи, Мархаба Эли, Али
Элькахки, Томаш Эрьявец, Ричард Фаркаш, Эктор Фернандес Алькальде,
Дженнифер Фостер, Клаудия Фрейтас, Катарина Гайдошова,
Дэниэл Гэлбрейт, Маркос Гарсия, Моа Гарденфорс, Ким Гердес, Филип
Гинтер, Якес Гоэнага, Колдо Гойенола, Мемдух Гёкырмак, Йоав Голдберг,
Хавьер Гомес Гиноварт, Берта Гонсалес Сааведра, Матиас Гриони,
Нормундс Грузитис, Бруно Гийом, Низар Хабаш, Ян Гаич,
Ян Хаджич мл. , Линь Ха Му, Ким Харрис, Даг Хауг, Барбора
Гладка, Ярослава Главачова, Флоринель Хосиунг, Петтер Холе,
Раду Ион, Елена Иримия, Томаш Елинек, Андерс Йохансен,
Фредрик Йоргенсен, Хюнер Кашикара, Хироши Канаяма, Дженна
Канерва, Толга Каяделен, Вацлава Кеттнерова, Джесси Киршнер, Наталья
Коцыба, Саймон Крек, Вероника Лайппала, Лоренцо Ламбертино, Татьяна Ландо,
Джон Ли, Phương Lê Hồng, Алессандро Ленчи, Саран Лертпрадит,
Герман Люнг, Чеук Ин Ли, Джози Ли, Кейинг Ли, Никола Любешич,
Ольга Логинова, Ольга Ляшевская, Тереза Линн, Вивьен Макетанц, Айбек
Макажанов, Майкл Мандл, Кристофер Мэннинг, Кэтэлина Мэрандук, Давид Маречек, Катрин Мархайнеке, Эктор
Мартинес Алонсо, Андре Мартинс, Ян Машек, Юдзи Мацумото,
Райан МакДональд, Густаво Мендонса, Нико Миекка, Анна Миссила, Кэтэлин Митителу, Юсуке Мияо, Симонетта Монтеманьи, Амир Море, Лаура
Морено Ромеро, Шинсуке Мори, Богдан Москалевский, Кадри Муйшнек, Кайли
Мюрисеп, Пинки Наинвани, Анна Недолужко, Гунта Нешпоре-Берзкалне, Лыонг Нгуен Тхо, Хуен
Нгуен Тхо Минь, Виталий Николаев, Ханна Нурми, Стина Оджала,
Петя Осенова, Роберт Эстлинг, Лиля Оврелид, Елена Паскуаль, Марко
Пассаротти, Сенель-Аугусто Перес, Ги Перрье, Слав Петров, Юсси Пиитулайнен,
Эмили Питлер, Барбара Планк, Мартин Попель, Лаума Преткальниня, Прокопис
Прокопидис, Тиина Пуолакайнен, Сампо Пюйсало, Александр Радемакер, Логанатан
Рамасами, Тарака Рама, Винит Равишанкар, Ливи Реал, Сива Редди, Георг Рем,
Лариса Ринальди, Лаура Ритума, Михаил Романенко, Рудольф Роза, Давиде
Ровати, Бенуа Саго, Шади Салех, Таня Самарджич, Мануэла
Сангинетти, Байба Саулите, Себастьян Шустер, Джаме Седдах,
Вольфганг Сикер, Мойган Сераджи, Мо Шен, Ацуко Шимада, Дмитрий Сичинава,
Наталья Сильвейра, Мария Сими, Раду Симионеску, Каталин Симко, Мария
Шимкова, Кирилл Симов, Аарон Смит, Антонио Стелла, Милан Страка,
Яна Стрнадова, Алан Зур, Умут Сулубачак, Жолт Санто, Дима
Таджи, Такааки Танака, Тронд Тростеруд, Анна Трухина, Реут Царфати, Фрэнсис
Тайерс, Сумире Уэмацу, Зденька Урешова, Ларраиц Уриа, Ханс
Uszkoreit, Sowmya Vajjala, Daniel van Niekerk, Gertjan van Noord, Viktor
Варга, Эрик Вильмонте де ла Клержери, Вероника Винче, Ларс Валлин,
Джонатан Норт Вашингтон, Матс Вирен, Так-сум Вонг, Жуоран Ю, Зденек Жабокрцкий, Амир Зелдес, Даниэль Земан и Ханжи Чжу. 2017.
Универсальные зависимости
2.1.
Электронная библиотека LINDAT/CLARIN в Институте формального и
Прикладная лингвистика (ÚFAL), факультет математики и физики, Чарльз
Университет.
- Питерс и др. (2018) Мэтью Э. Питерс, Марк Нойманн, Мохит Ийер, Мэтт Гарднер, Кристофер Кларк, Кентон Ли и Люк Зеттлмойер. 2018. Глубокие контекстуализированные представления слов. В проц. NAACL .
- Ци и Мэннинг (2017) Пэн Ци и Кристофер Д. Мэннинг. 2017. Арк-Свифт: Роман система переходов для разбора зависимостей. In Материалы 55-го ежегодного собрания Ассоциации для компьютерной лингвистики (Том 2: Краткие статьи) , страницы 110–117. Ассоциация компьютерной лингвистики.
- Саги и Лави (2006) Кенджи Сагае и Алон Лави. 2006. Комбинация парсеров путем повторного разбора. В материалах конференции по технологии человеческого языка г. NAACL, Companion Volume: Short Papers , страницы 129–132.
- Смит и др. (2018а)
Аарон Смит, Бернд Бонет, Мирьям де Лоно, Жоаким Нивр, Ян Шао и Сара
Стимне. 2018а.
82 берега деревьев, 34
модели: Универсальный синтаксический анализ зависимостей с моделями с несколькими банками деревьев.
В Proceedings of the CoNLL 2018 Shared Task: Multilingual
Преобразование необработанного текста в универсальные зависимости , стр. 113–123. Ассоциация
для компьютерной лингвистики.
- Смит и др. (2018б) Аарон Смит, Мирьям де Лоно, Сара Стимн и Жоаким Нивр. 2018б. Расследование взаимодействия между предварительно обученными вложениями слов, моделями символов и поз. теги при разборе зависимостей. В Трудах конференции по эмпирическим методам в 2018 г. Обработка естественного языка , страницы 2711–2720. Ассоциация вычислительных Лингвистика.
- Сочер и соавт. (2013) Ричард Сочер, Джон Бауэр, Кристофер Д. Мэннинг и др. 2013. Парсинг с композиционными векторными грамматиками. В Материалы 51-го ежегодного собрания Ассоциации для компьютерной лингвистики (том 1: длинные статьи) , том 1, страницы 455–465.
- Стенеторп (2013)
Понтус Стенеторп. 2013.
Анализ зависимостей на основе переходов с использованием рекурсивных нейронных сетей.
На семинаре по глубокому обучению на конференции по нейронным технологиям 2013 г.
Системы обработки информации (NIPS) , Озеро Тахо, Невада, США.
- Страка и соавт. (2016) Милан Страка, Ян Гаич и Яна Стракова. 2016. UDPipe: обучаемый конвейер для обработки файлов CoNLL-U выполнение токенизации, морфологического анализа, POS-тегов и парсинга. В Материалы 10-й Международной конференции по языку Ресурсы и оценка (LREC 2016) , Порторож, Словения. Европейский Ассоциация языковых ресурсов.
- Земан и соавт. (2018)
Даниэль Земан, Ян Гайич, Мартин Попель, Мартин Потхаст, Милан Страка,
Филип Гинтер, Йоаким Нивр и Слав Петров. 2018.
Общая задача CoNLL 2018: многоязычный синтаксический анализ необработанного текста в
Универсальные зависимости.
В Proceedings of the CoNLL 2018 Shared Task: Multilingual
Преобразование необработанного текста в универсальные зависимости .
- Земан и соавт. (2017) Даниэль Земан, Мартин Попель, Милан Страка, Ян Гайич, Йоаким Нивре, Филип
Гинтер, Юхани Луотолахти, Сампо Пюйсало, Слав Петров, Мартин Потхаст,
Фрэнсис Тайерс, Елена Бадмаева, Мемдух Гёкырмак, Анна Недолужко,
Сильвия Цинькова, Ян Гайич мл., Ярослава
Главачова, Вацлава Кеттнерова, Зденка
Урешова, Дженна Канерва, Стина Ояла, Анна Миссиля,
Кристофер Мэннинг, Себастьян Шустер, Сива Редди, Дима Таджи, Низар Хабаш,
Герман Леунг, Мари-Катрин де Марнефф, Мануэла Сангинетти, Мария Сими,
Хироши Канаяма, Валерия де Пайва, Кира Дроганова, Эктор
Мартинес Алонсо, Ханс Ушкорейт, Вивьен Макетанц, Алёша Бурхардт,
Ким Харрис, Катрин Мархайнеке, Георг Рем, Толга Каяделен, Мохаммед Аттиа,
Али Элкахки, Жуоран Ю, Эмили Питлер, Саран Лертпрадит, Майкл Мандл, Джесси
Киршнер, Гектор Фернандес Алькальде, Яна Стрнадова, Эша Банерджи, Рули
Манурунг, Антонио Стелла, Ацуко Шимада, Сукён Квак, Густаво
Мендонса, Татьяна Ландо, Ратима Нитисарой и Джози Ли. 2017.
Общая задача CoNLL 2017: многоязычный синтаксический анализ необработанного текста в
Универсальные зависимости. В Материалы совместной задачи CoNLL 2017: многоязычие
Преобразование необработанного текста в универсальные зависимости . Ассоциация для
Компьютерная лингвистика.
Ограничения ограниченного контекста для синтаксического анализа групп — Блог о машинном обучении | ML@CMU
Сравните два приведенных выше предложения «Я пью кофе с молоком» и «Я пью кофе с друзьями». Они различаются только в самых последних словах, но их синтаксический анализ также различается в более ранних местах. А теперь представьте, что вы читаете подобные предложения. Насколько хорошо вы можете разобрать такие предложения, не переходя туда и обратно? Это может быть сложной задачей, когда предложения становятся длиннее, а их структура более сложной. В нашей работе мы показываем, что эта задача также сложна для некоторых ведущих моделей машинного обучения для синтаксического анализа.
Введение
Синтаксис, который приблизительно относится к правилам составления слов в предложения, является основной характеристикой языка. Следовательно, центральная тема обработки естественного языка связана со способностью восстанавливать синтаксис предложений. В последние годы был достигнут быстрый прогресс в изучении структуры избирательных округов (один тип синтаксиса), как правило, с некоторыми тщательно разработанными архитектурами нейронных сетей с учетом синтаксиса. Однако эти архитектуры имеют тенденцию быть довольно сложными. Остается неясным, почему они работают и что может ограничивать их потенциал. В нашей статье ACL 2021 мы теоретически отвечаем на вопрос: какую синтаксическую структуру могут представлять современные нейронные подходы к синтаксису?
В качестве обзора, наши результаты утверждают, что репрезентативная сила этих подходов в решающей степени зависит от количества и направленности контекста, к которому модель имеет доступ, когда вынуждена принимать каждое решение по синтаксическому анализу. Более конкретно, мы показываем, что при полном контексте (неограниченном и двунаправленном) эти подходы обладают полной репрезентативной силой; с другой стороны, с ограниченным контекстом (либо ограниченным, либо однонаправленным) существуют грамматики, для которых репрезентативная сила этих подходов весьма бедна.
При синтаксическом анализе избирательного округа для такого предложения, как «Я пью кофе с молоком», мы стремимся получить его дерево синтаксического анализа, как показано на рисунке 1 ниже.
Рисунок 1: Предложение «Я пью кофе с молоком» и его разбор.Чтобы иметь представление об истинности, мы предполагаем, что данные в нашей модели генерируются вероятностной контекстно-свободной грамматикой (PCFG). Напомним, что контекстно-свободная грамматика (КСГ) 𝐺 — это четверка (Σ, 𝑁, 𝑆, 𝑅), в которой
- Σ множество терминалов
- 𝑁 множество нетерминалов
- 𝑆∈𝑁 стартовый символ
- 𝑅 множество продукционных правил вида \(𝑟_𝐿→𝑟_\), где (𝑟_𝐿∈𝑁\), а \(𝑟_𝑅\) представляет собой последовательность Σ и 𝑁
Как показано на рисунке 1 выше, каждое дерево синтаксического анализа в 𝐺 можно рассматривать как рекурсивно применяющее список продукционных правил для расширения начальный символ 𝑆 к предложению (последовательность терминалов). Для каждого предложения существует набор возможных деревьев синтаксического анализа, ведущих к этому предложению.
Основанная на CFG, вероятностная контекстно-свободная грамматика (PCFG) назначает условную вероятность \(P(𝑟_𝑅 | 𝑟_𝐿)\) каждому правилу \(𝑟_𝐿→𝑟_𝑅\). Как следствие, каждое дерево синтаксического анализа связано с вероятностью, которая является произведением вероятностей его правила. Кроме того, каждое предложение, сгенерированное PCFG, подвергается разбору с максимальным правдоподобием (если нет ничьей).
Используя PCFG в качестве основной истины синтаксиса, мы уточним наш вопрос, чтобы спросить: когда «структура для синтаксического анализа» способна представить анализ максимального правдоподобия предложения, сгенерированного из PCFG? В нашей статье мы рассматриваем фреймворки, основанные на синтаксическом расстоянии и парсерах на основе переходов. В следующих разделах мы представляем каждую структуру и наши соответствующие анализы.
Платформа 1: синтаксический анализ на основе расстояния
Исходная информация
Эта структура представлена архитектурой сети синтаксического анализа-чтения-прогнозирования (PRPN) (Shen et al. , 2018).
Пусть \(W=𝑤_1 𝑤_2…𝑤_𝑛\) будет предложением, состоящим из 𝑛 токенов (слов). Кроме того, \(𝑤_0\) является символом начала предложения.
Рисунок 2: Синтаксическое расстояние в PRPN, выдержка изYikang Shen, Zhouhan Lin, Chin-Wei Huang, Aaron Courville. Моделирование нейронного языка путем совместного изучения синтаксиса и лексики. ICLR 2018. (ссылка на документ)
Как показано на рисунке 2, эта структура требует изучения/обучения функции синтаксического расстояния \(𝑑_𝑡≔𝑑(𝑤_{𝑡−1},𝑤_𝑡 | 𝑐_𝑡)\) между соседними словами \(𝑤_{𝑡−1}\) и \(𝑤_𝑡\), для всех \(2≤𝑡≤𝑛\). Здесь \(𝑐_𝑡\) — это контекст, который учитывает \(𝑑_t\). (Вертикальная черта не означает условное распределение; скорее, это обозначение просто для удобства.) В PRPN функция параметризуется мелкой сверточной нейронной сетью и может обучаться с использованием цели языкового моделирования.
Во время вывода по предложению мы применяем изученную сеть для вычисления синтаксического расстояния между каждой парой соседних слов и создаем дерево синтаксического анализа на основе жадного ветвления в точке наибольшего синтаксического расстояния. Вкратце, алгоритм индукции дерева состоит из следующих шагов:
- Инициализировать корень так, чтобы он содержал все предложение
- Всякий раз, когда существует один сегмент, состоящий из двух или более слов, разделить в точке с наибольшим синтаксическим расстоянием
- Вернуть бинарное дерево, каждый лист которого содержит одно слово. Для нашего анализа достаточно отметить, что для любой заданной последовательности синтаксических расстояний \(𝑑_𝑡 (2≤𝑡≤𝑛)\) алгоритм индукции дерева является детерминированным. Следовательно, репрезентативная сила этой структуры определяется способностью выучить хорошую последовательность синтаксических дистанций.
Наш анализ
Используя PCFG в качестве синтаксической структуры «наземной истины», мы теперь определим, что значит представлять PCFG, используя синтаксическое расстояние.
Определение : Пусть 𝐺 будет любой PCFG в нормальной форме Хомского. Говорят, что функция синтаксического расстояния 𝑑 способна 𝒑-представлять G, если для набора предложений в 𝐿(𝐺), общая вероятность которых не меньше 𝑝, функция синтаксического расстояния 𝑑 может правильно индуцировать анализ максимального правдоподобия этих предложения однозначно.
Примечание : Здесь могут возникнуть неоднозначности, если, например. \(𝑑_t=𝑑_{𝑡+1}\), в этом случае нам нужно разорвать связи при разборе сегмента \(𝑤_{𝑡−1} 𝑤_𝑡 𝑤_{𝑡+1}\).
Положительный результат
С этим определением мы переходим к нашему положительному результату, соответствующему синтаксическому анализу с полным контекстом .
Теорема 1 : для предложения \(W=𝑤_1 𝑤_2…𝑤_𝑛\) пусть \(c_t=(W, t)\). Для каждой ПКФГ \(G\) в нормальной форме Хомского существует синтаксическая мера расстояния \(𝑑_t=𝑑(𝑤_{𝑡−1}, 𝑤_𝑡 | 𝑐_𝑡)\), которая может 1-представлять G.
Примечание : Эта теорема утверждает, что когда контекст в каждой позиции включает в себя все предложение и текущий позиционный индекс, тогда подход синтаксического расстояния имеет полную репрезентативную силу.
Рисунок 3: Дерево синтаксического анализа с соответствующими синтаксическими дистанциями.Доказательство идеи .
Пусть бинарное дерево \(T\) будет деревом синтаксического анализа с максимальным правдоподобием \(W\), таким как показанное на рис. 3 выше. Поскольку \(c_t=(W,t)\) является полным контекстом, \(𝑑_t\) может зависеть от всей основной истины \(T\). Следовательно, нам просто нужно найти такое назначение \(𝑑_t (t = 2..n)\), чтобы их порядок соответствовал уровню разделения ветвей в \(T\).Интуитивно, как показано на рис. 3, если мы назначаем большие значения расстояния в позициях, где дерево разбивается на более высоких уровнях, то последовательность расстояний может вызвать правильную структуру дерева. Чтобы формализовать эту идею, установите
$$𝑑_t = 𝑛 – \text{tree_dist}(𝑟𝑜𝑜𝑡, \text{lowest_common_ancestor}(𝑤_{𝑡−1}, 𝑤_𝑡))$$
, и алгоритм индукции детерминированного дерева вернет желаемое дерево разбора \(T\).
Отрицательный результат
Выше мы видели, что анализ с полный контекст приводит к полной репрезентативной власти. С другой стороны, как мы увидим дальше, если контекст ограничен , т.
е. он включает в себя все слева и дополнительно конечное окно просмотра вперед размером \(𝐿′\) справа, то репрезентативное мощность совсем бедная.Теорема 2 : Пусть \(c_t=(𝑤_0 𝑤_1 𝑤_2…𝑤_{𝑡+𝐿′})\). ∀𝜖>0, ∃ PCFG G в нормальной форме Хомского, такая, что любая синтаксическая мера расстояния \(𝑑_t=𝑑(𝑤_{𝑡−1},𝑤_𝑡 | 𝑐_𝑡)\) не может 𝜖-представлять G.
Обратите внимание, что эта теорема анализирует разбор слева направо. Симметричный результат может быть доказан для разбора справа налево.
Доказательство идеи : Как бы вы «обманули» модель, которая выводит синтаксическое расстояние в каждой позиции исключительно на основе левого контекста?
Интуитивно понятно, что таким моделям будет трудно, если более поздние слова в предложении могут вызывать различные синтаксические структуры в начале предложения. Например, как показано на рисунке 4, рассмотрим два предложения: «Я пью кофе с молоком» и «Я пью кофе с друзьями». Их единственная разница возникает в самых последних словах, но их синтаксический анализ также различается в некоторых более ранних словах в каждом предложении.
Когда модель «слева направо» читает первые несколько слов таких предложений (например, «Я пью кофе с»), модель не знает, какое слово (например, «молоко» или «друг») будет следующим, таким образом, наша вышеупомянутая интуиция подсказывает, что она не может знать, как разобрать часть предложения (например, «Я пью кофе»), которую она уже прочитала.
Рисунок 4: Более ранние разборы зависят от более поздних слов.На самом деле, это интуитивное предположение остается в силе, даже если мы допускаем, что модель имеет конечный просмотр вперед вправо. Представьте себе случай, когда предложение длинное, и даже если модель может просмотреть несколько слов впереди, она по-прежнему имеет доступ только к левой части предложения, в то время как неизвестная крайняя правая часть потенциально может иметь решающее значение для определения структуры. приговора.
Мы формализуем эту интуицию с помощью PCFG. Это мотивирует наше определение семейства грамматик контрпримеров, которое показано на рис.
Рисунок 5: Грамматика контрпримера. Структура дерева разбора строки \(a_1 a_2 … a_{m+1+L′} c_k\). 5 ниже. Обратите внимание, что любые две строки в грамматике почти одинаковы, за исключением последней лексемы: префикс \(a_1 a_2 … a_{m+1+L′}\) является общим для всех строк. Однако их синтаксический анализ отличается в зависимости от того, где разбивается \(A_k\). Ключ к такой разнице в синтаксическом анализе лежит в самой последней лексеме \(c_k\), которая уникальна для каждой строки.Подробнее об этом грамматическом контрпримере см. в нашей статье. Можно показать, что при \(c_t=(𝑤_0 𝑤_1 𝑤_2…𝑤_{𝑡+𝐿′})\) для любого положительного целого числа \(m\) эта грамматика (параметризованная m) допускает только \(1/ m\) часть его языка, которая будет представлена синтаксической мерой расстояния \(𝑑_t=𝑑(𝑤_{𝑡−1},𝑤_𝑡 | 𝑐_𝑡)\). Достаточно установить \(m > 1/𝜖\), чтобы точность была не более \(1/m\), что меньше, чем \(𝜖\).
Применение нашего анализа к другой родственной архитектуре
Наш анализ синтаксических основанных на расстоянии структур также применим к архитектуре Ordered Neurons LSTM (ON-LSTM), предложенной Shen et al.
Рисунок 6: Мотивация ON-LSTM, выдержка из (с небольшой адаптацией) , (2019).
Yikang Shen, Shawn Tan, Alessandro Sordoni, Aaron Courville. Заказные нейроны. ICLR 2019. (ссылка на документ)Как показано на рисунке 6 выше, архитектура ON-LSTM требует обучения некоторых тщательно структурированных векторов вентилей в каждой позиции с использованием цели языкового моделирования. Во время вывода мы передаем предложение обученному ON-LSTM, получаем вентили и уменьшаем векторы вентилей до скаляров, представляющих синтаксические расстояния, и, наконец, индуцируем дерево синтаксического анализа путем жадного ветвления, как описано выше.
Аналогичные результаты и доказательства применимы к ON-LSTM: с полный контекст дает полную репрезентативную мощность, тогда как с ограниченным контекстом репрезентативная мощность также весьма ограничена.
Фреймворк 2: парсинг на основе переходовНа каждом шаге вместо скаляра (синтаксического расстояния) мы можем выводить парсинга переходов .
Парсер этого типа состоит из стека (инициализированного пустым) и входного буфера (инициализированного входным предложением). В каждой позиции 𝑡, в зависимости от контекста в 𝑡, синтаксический анализатор выводит последовательность переходов синтаксического анализа, каждый из которых может быть одним из следующих (на основе определения Дайера и др., (2016), которые предложили успешную нейронную параметризацию этих переходов.)- NT(X): помещает нетерминал X в стек.
- SHIFT: удаляет первый терминал из входного буфера и помещает в стек.
- REDUCE: сформируйте новую составляющую на основе элементов в стеке
Подробнее о переходах синтаксического анализа см. в нашей статье или Dyer et al., (2016).
Наш анализ показывает, что аналогичные результаты, аналогичные приведенным выше теоремам для подходов, основанных на синтаксическом расстоянии, также верны для синтаксических анализаторов, основанных на переходах. С положительной стороны, то есть с полным контекстом, синтаксические анализаторы на основе переходов имеют полную репрезентативную мощность для любой PCFG в нормальной форме Хомского.
Напротив, с отрицательной стороны, т. Е. Если контекст ограничен в одном (или обоих) направлении (направлениях), то существует PCFG, такая что точность синтаксических анализаторов на основе переходов может быть сделана сколь угодно низкой. Подробные формулировки теорем см. в разделе 7 нашей статьи.До сих пор мы видели наш анализ репрезентативной способности как для синтаксической дистанции, так и для структур, основанных на переходе. Почему мы решили рассмотреть эти рамки?
Замечания о рассматриваемых каркасахМожно доказать, что RNN в ее наиболее общей форме является полной по Тьюрингу (Siegelmann and Sontag, 1992). Однако построение в Siegelmann and Sontag (1992) может потребовать потенциально неограниченного времени и памяти.
С другой стороны, можно доказать, что однопроходная RNN, в которой контекстом в каждой позиции является все, что находится слева, имеет такую же мощность, как и автомат с конечным числом состояний (Merrill, 2019).
), что недостаточно для разбора PCFG.В нашей работе мы рассматриваем промежуточную настройку, которая является более общей, чем простая однопроходная RNN, поскольку при вычислении решения парсинга на каждом слове контекст может включать не только все, что слева, но и конечный вид -вперед (направо). Обратите внимание, что опережающий просмотр конечен, но не неограничен. Следовательно, контекст по-прежнему ограничен , что соответствует нашим отрицательным результатам. Если, с другой стороны, неограниченный контекст разрешен в обоих направлениях, то настройка попадает в категорию неограниченный контекст , что привело к нашему положительному результату.
Несмотря на то, что мы рассматриваем фреймворки на основе синтаксического расстояния и перехода, поскольку их нейронная параметризация дала сильные эмпирические результаты и представляет два общих подхода к синтаксическому анализу, стоит отметить, что наш анализ зависит от архитектуры. Действительно, есть некоторые другие архитектуры, которые не вписываются в предложенные нами ограничения, такие как Compound PCFG (Kim et al.
Резюме , 2019). Его параметризация снова довольно сложна, но следует отметить один аспект: в процессе построения дерева по заданному предложению модель получает информацию как слева, так и справа, и поэтому ее репрезентативная способность не ограничивается контекст .В этой работе мы рассмотрели репрезентативную силу двух важных фреймворков для синтаксического анализа групп — т. е. фреймворков, основанных на изучении синтаксической дистанции и изучении последовательности итерационных переходов для построения дерева синтаксического анализа — в песочнице ПКФГ. В частности, мы показываем, что если контекст для вычисления расстояния или принятия решения о переходах ограничен по крайней мере с одной стороны (что часто имеет место на практике для существующих архитектур), то существуют PCFG, для которых нет хорошего способа выбрать метрика расстояния или последовательность переходов для построения синтаксического анализа максимального правдоподобия.
Наш анализ формализовал некоторые теоретические преимущества двунаправленного контекста по сравнению с однонаправленным контекстом для синтаксического анализа. Мы призываем практиков, которые применяют МО к НЛП, следовать этому типу простого анализа, используя PCFG в качестве песочницы для оценки репрезентативной способности при предложении новой модели. Мы предлагаем переориентировать будущие усилия сообщества на методы, которые не подпадают под категорию ограниченных представительских полномочий.
Интересные смежные направления исследований:
- Как принципиально расширить модели, которые были успешно расширены (например, BERT), синтаксической информацией, чтобы они могли фиксировать синтаксическую структуру (например, PCFG)?
- Как понять взаимодействие между синтаксическими и семантическими модулями в нейронных архитектурах? Различные успешные архитектуры обмениваются информацией между такими модулями, но относительные плюсы и минусы этого не совсем понятны.
- Помимо возможностей представления, как насчет аспектов оптимизации и обобщения, связанных с каждой архитектурой?
- Ючен Ли и Андрей Ристески. Ограничения ограниченного контекста для разбора группы . ACL 2021.
- Икан Шен, Чжоухан Линь, Чин-Вэй Хуанг и Аарон Курвиль. Нейронное моделирование языка путем совместного изучения синтаксиса и лексики . ICLR 2018.
- Икан Шен, Шон Тан, Алессандро Сордони, Аарон Курвиль. Упорядоченные нейроны . ICLR 2019.
- Крис Дайер, Адхигуна Кункоро, Мигель Баллестерос и Ной А. Смит. Рекуррентные грамматики нейронных сетей . NAACL 2016.
- Хава Т. Зигельманн и Эдуардо Д. Зонтаг. О вычислительной мощности нейронных сетей . КОЛЬТ 1992.
- Уильям Меррилл. Последовательные нейронные сети как автоматы . Семинар ACL 2019 по глубокому обучению и формальным языкам: наведение мостов.
- Юн Ким, Крис Дайер и Александр Раш. Составные вероятностные контекстно-свободные грамматики для грамматической индукции . ACL 2019.
Анализ по составу (морфемному) слова «небрежный. «небрежно»
Схема разбора по составу неаккуратно:
небрежно
Разбор слов по составу.
Спряжение слова «небрежный»:
Соединительная гласная: пропущено
Постфикс : пропущено
Морфемы — части слова неаккуратно
небрежный
Подробный разбор слова небрежный по составу. Корень слова, префикс, суффикс и окончание слова. Неосторожный морфемный разбор слова, его схемы и частей слова (морфем).
- Морфемная схема: sloppy / n / th
- Структура слова по морфемам: корень / суффикс / окончание
- Схема (конструкция) слова sloppy по составу: корень sloppy + суффикс n + окончание й в слове небрежный:
- небрежный — корень
- n — суффикс
- th — окончание
- Типы морфем и их число в слово «Небрежный»:
- Префикс: Отсутствует — 0
- Корень: Небрежный — 1
- Связь с гласным: — 0
- : — — 0
- : — 0
— — 0
— - : — 0
- : — 0
- : — 0
- : — 0
- : . 1
- постфикс: отсутствует — 0
- конец: -й — 1
- Базовое слово: небрежный ;
- Производные аффиксы: префикс отсутствует , суффикс n , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производный, так как образован 1 (одним) способом .
- определение части речи слова — первый шаг;
- второе — окончание выделяем: у изменяемых слов спрягаем или склоняем, у неизменяемых слов (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- Далее ищем базу. Это самая легкая часть, потому что для определения основы нужно просто отрезать окончание. Это будет основой слова;
- Следующим шагом будет поиск корня слова. Подбираем родственные слова к небрежным (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к разбору сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи оно относится. Вспомните признаки слов, относящихся к этой части речи:
- изменяемый (имеет окончание) или неизменяемый (не имеет окончания)
- имеет ли он формообразующий суффикс?
- Найдите концовку. Для этого склоняем по падежам, меняем число, род или лицо, спрягаем — переменная часть будет окончанием. Не забудьте заменить слова с нулевым окончанием, обязательно укажите, если оно есть: sleep(), friend(), audiibility(), благодарность(), ate().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найти корень в базе. Для этого сравните ряд родственных слов. Их общей частью является корень. Помните об однокоренных словах с чередующимися корнями.
- Если слово имеет два (или более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить анализ и выделить все значимые части значками
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы, образующие словоформу (если есть)
- Запишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пис-а-т → за-пис-а-т → за-пис-ыва-т», «сух (ой) → сух-ар () → сух-ар-ниц -(а)». Для слов со связными корнями подберите односоставные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
- окончание «а» указывает на форму глагола женского пола, единица прошедшего времени, ср.: проспал;
- основание форы «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «за» — действие со значением убытка, невыгоды, ср.: просчитаться, проиграть, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Основы слов: сон, засыпание, сонливость, недосыпание, бессонница.
- Морфемная схема: sloppy/n/o
- Структура слова по морфемам: корень / суффикс / суффикс
- Схема (конструкция) слова небрежно по составу: корень небрежно + суффикс н + суффикс о
- Виды морфем и их количество в слове небрежно:
- приставка: пропущено — 0
- корень: небрежно — 1
- соединительная гласная: пропущено0072 cyffix: , но — 2
- постфикс: отсутствует — 0
- конец: нулевое окончание. — 0
- Базовое слово: небрежно ;
- Производные аффиксы: префикс отсутствует , суффикс но , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производная, так как образована 1 (одним) способом .
- определение части речи слова — первый шаг;
- второй — окончание выделяем: у изменяемых слов спрягаем или склоняем, у неизменяемых слов (герундии, наречия, некоторые существительные и прилагательные, служебные части речи) — окончаний нет;
- Далее ищем базу. Это самая легкая часть, потому что для определения основы нужно просто отрезать окончание. Это будет основой слова;
- Следующим шагом является поиск корня слова. Родственные слова подбираем для казуальных (их еще называют родственными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
- the compositions of Michelangelo include the dome of St. Peter’s, the ceiling of the Sistine Chapel, and his monumental statue of David
- number,
- opus,
- piece,
- work
- classic,
- magnum opus,
- шедевр,
- произведение искусства,
- экспонат
- модель,
- эскиз,
- 0004
- этюд
- канон,
- корпус,
- произведение
- учительница, которая любит, чтобы ее класс писал сочинения
- бумага,
- тема
- статья,
- эссе,
- рассказ
- студенты-фотографы узнают о важности композиции в создании ярких изображений
- расположение,
- configuration,
- constellation,
- design,
- form,
- format,
- getup,
- layout,
- makeup,
- ordonnance,
- pattern
- motif,
- theme
- представил композицию в местную газету для своей специальной секции, отмечающая Мартин Лютер Кинг День
- ,
- Эссе,
- Paper,
- Тема
- .
- комментарий,
- редакционная статья,
- очерк,
- отчет,
- обзор,
- рецензия
- диссертация,
- тезис
- трактат,
- Трактат
- Дискурс,
- Обсуждение,
- Exposition,
- Prolegomenon,
- Исследование
- Тёзка купальника Жюль Леотар какую профессию имел?
- Хирург Судить
- Акробат Пожарный
«Дундерхед» и другие «приятные» способы сказать «глупый»
На примере некоторых очень умных щенков
10 слов из географических названий
Бикини, бурбон и бадминтон заняли первые места
«Гордость»: слово, которое превратилось из порока в силу
Вы гордитесь Прайдом?
Когда впервые были использованы слова?
Найдите любой год, чтобы узнать
Буквально
Как использовать слово, которое (буквально) приводит некоторых людей в.
- : — 0 —
- : — 0
Всего морфем в слове: 3.
Деривационный анализ слова небрежный
См. также другие словари:
Корневые слова… это слова, имеющие корень… принадлежащие к разным частям речи, и в то же время близкие по смыслу… Рифмованные слова к Незаботливый
Склонение слова небрежный в падежах единственного и множественного числа…. Склонение слова небрежный
Полный морфологический анализ слова неряшливый: Часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово… Морфологический разбор небрежный
Ударение в слове небрежный: на каком слоге ударение и как. .. Слово «неаккуратный» правильно пишется как… ударение на слово небрежный
Синонимы к слову небрежный. Онлайн-словарь синонимов: найдите синонимы к слову «неряшливый». Слова-синонимы, близкие по значению слова и выражения в… Синонимы к слову небрежный
Антонимы…имеют противоположное значение, разные по звучанию, но относятся к одной и той же части речи… Антонимы к слову небрежный
Анаграммы (составьте анаграмму) для слова небрежный, смешивая буквы…. Анаграммы для слова небрежный
Морфемный разбор слова небрежный
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова небрежный делается очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем разбор морфем правильно, а для этого пройдем всего 5 шагов:
Как видите, морфемный разбор делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слова (разбор слов по составу) — поиск корня, префиксов, суффиксов, градуировки и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по их месту в слове и установление значения каждой из них . В школьной программе его еще называют морфемный разбор . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, герундий, наречие, числительное.
План: Как разобрать слово по составу?
При проведении морфемного анализа соблюдайте определенную последовательность выделения значимых частей. Начните с того, чтобы «снять» морфемы с конца, методом «зачистки корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать слова с одним корнем и потом найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5-9 классах для общеобразовательных школ. У разных авторов подход к морфемному анализу по составу отличается. Чтобы избежать проблем при выполнении домашнего задания, сравните приведенный ниже порядок подведения итогов с вашим учебником.
Порядок полного морфемного анализа по составу
Во избежание ошибок желательно связать морфемный разбор с словообразовательным. Такой анализ называется формально-семантическим.
Как найти морфему в слове?
Пример полного морфемного анализа глагола «проспал»:
Схема разбора по составу небрежно:
небрежно
Разбор слов по составу.
Сопряжение слова «небрежно»:
Соединительный гласный: пропущен
Постфикс : пропущен
Морфемы — части слова небрежно
невзначай
Детальный разбор слова. Корень слова, префикс, суффикс и окончание слова. Морфемный разбор слова небрежно, его схема и части слова (морфемы).
Всего морфем в слове: 3.
Деривационный анализ слова небрежно
См. также другие словари:
Однокорневые слова… это слова, имеющие корень…, принадлежащие к разным частям речи, и в то же время близкие по значению… Рифмованные слова к Небрежно
Склонение слова небрежно по падежам в единственном и множественном числе…. Склонение слова небрежно по падежам
Полный морфологический разбор слова «небрежно»: Часть речи, начальная форма, морфологические признаки и словоформы. Направление науки о языке, где изучается слово… Морфологический анализ небрежно
Ударение в слове небрежно: на какой слог и как ударение. .. Слово «небрежно» правильно пишется как… Ударение в слове небрежно
Синонимы к слову небрежно. Онлайн-словарь синонимов: найдите синонимы к слову «невнимательный». Синонимичные слова, близкие по значению слова и выражения в… Синонимы к слову небрежно
Антонимы…имеют противоположное значение, различны по звучанию, но относятся к одной и той же части речи… Антонимы к слову небрежно
Анаграммы (составить анаграмму) к слову небрежно, путем смешивания букв…. Анаграммы к небрежно
Морфемный разбор слова небрежно
Морфемный разбор слова обычно называют разбором слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный разбор слова небрежно делается очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем разбор морфем правильно, а для этого пройдем всего 5 шагов:
Как видите, морфемный разбор делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
* Морфемный разбор слова (разбор слов по составу) — поиск корня, префиксов, суффиксов, градуировки и основы слова Разбор слова по составу на сайте производится по словарю морфемного разбора.
Рекурсивная композиция поддерева в анализе зависимостей на основе LSTM
1 Введение
Рекурсивные нейронные сети позволяют нам строить векторные представления деревьев или поддеревьев. Они использовались для анализа избирательных округов
Socher et al. (2013) и Dyer et al. (2016) и для разбора зависимостей на Stenetorp (2013) и Dyer et al. (2015) и др.
В частности, Dyer et al. (2015) показали, что составление представлений поддеревьев с использованием рекурсивных нейронных сетей может быть полезным для синтаксического анализа зависимостей на основе переходов. Эти результаты были дополнительно подтверждены в исследовании 90 408 Kuncoro et al. (2017)
, который показал, используя эксперименты по абляции, что композиция является ключевой в генеративном синтаксическом анализаторе грамматики рекуррентной нейронной сети (RNNG) на
Дайер и др. (2016) .
В параллельной разработке Кипервассер и Голдберг (2016b) показали, что использование BiLSTM для извлечения признаков может привести к высокой точности синтаксического анализа даже при довольно простых архитектурах синтаксического анализа, и поэтому использование BiLSTM для извлечения признаков стало очень популярным при анализе зависимостей. Он используется в современном синтаксическом анализаторе Dozat and Manning (2017) , использовался в 8 из 10 самых эффективных систем совместной задачи CoNLL 2017 года (Zeman et al., 2017) и 10 из 10 систем с самой высокой производительностью в общей задаче CoNLL 2018 года (Zeman et al., 2018) .
Это поднимает вопрос о том, собирают ли признаки, извлеченные с помощью BiLSTM, сами по себе информацию о поддеревьях, что делает рекурсивную композицию излишней. Некоторое подтверждение этой гипотезы исходит из результатов Linzen et al. (2016) , которые указывают на то, что LSTM могут собирать иерархическую информацию: их можно обучить прогнозировать согласование междугородних номеров на английском языке. Эти результаты были распространены на большее количество конструкций и три дополнительных языка на Гулордава и др. (2018) .
Однако Kuncoro et al. (2018) также показали, что, хотя последовательные LSTM могут изучать синтаксическую информацию, рекурсивная нейронная сеть, которая явно моделирует иерархию (модель RNNG из Dyer et al. (2015) ), лучше справляется с этим: она лучше работает с числом задача согласования от Linzen et al. (2016) .
Для дальнейшего изучения этого вопроса в контексте синтаксического анализа зависимостей мы исследуем использование рекурсивной композиции (далее именуемой 9).0446 композиция ) в анализаторе с архитектурой, подобной Kiperwasser and Goldberg (2016b) . Это позволяет нам исследовать варианты функций и изолировать условия, при которых композиция полезна. Мы предполагаем, что использование BiLSTM для извлечения признаков позволяет собирать информацию о поддеревьях и, следовательно, делает излишним использование композиции поддеревьев. Мы предполагаем, что композиция становится полезной, когда удаляется часть BiLSTM, вперед или назад LSTM. Далее мы предполагаем, что композиция наиболее полезна, когда синтаксический анализатор не имеет доступа к информации о функции слов в контексте предложения, заданного POS-тегами. При использовании тегов POS у тегировщика действительно был доступ к полному предложению. Мы дополнительно смотрим на то, что происходит, когда мы удаляем векторы символов, которые, как было показано, собирают информацию, частично перекрывающуюся с информацией из тегов POS.
Мы экспериментируем с более широким спектром языков, чем Дайер и др. (2015) , чтобы выяснить, зависит ли полезность различных вариантов модели от типа языка.
2 Разбор K&G на основе переходов
Мы определяем архитектуру синтаксического анализа, представленную Кипервассером и Голдбергом (2016b) , как высокий уровень абстракции и далее называем ее K&G.
Парсер K&G — это жадный парсер, основанный на переходах. 1 1 1 Кипервассер и Голдберг (2016b) также определяют анализатор на основе графа с аналогичным извлечением признаков, но мы сосредоточимся на анализе на основе переходов.
Для входного предложения длины n со словами w1,…,wn создается последовательность векторов x1:n, где вектор xi является векторным представлением слова wi. Мы называем их введите векторов, так как они одинаковы для всех вхождений типа слова. Затем векторы типов передаются через функцию признаков, которая изучает представления слов в контексте предложения.
| и | = е(ви) | ||
| ви | =f(x1:n,i) |
Мы называем вектор vi вектором токенов , поскольку он различен для разных токенов одного и того же типа слова. В Кипервассер и Голдберг (2016b) , используемая функция признака представляет собой BiLSTM.
Как обычно при синтаксическом анализе на основе переходов, синтаксический анализ включает переходы от начальной конфигурации к конечной. Конфигурации синтаксического анализатора представлены стеком, буфером и набором дуг зависимостей (Nivre, 2008) .
Для каждой конфигурации c
средство извлечения признаков объединяет токены-представления основных элементов из стека и буфера. Эти векторы токенов передаются классификатору, обычно многослойному персептрону (MLP). MLP оценивает переходы вместе с
метки дуги для переходов, которые предполагают добавление дуги. И векторы типов слов, и BiLSTM обучаются вместе с моделью.
3 Составление представлений поддеревьев
Дайер и др. (2015) изучили влияние использования рекурсивной функции композиции в их синтаксическом анализаторе, который также является синтаксическим анализатором на основе перехода, но с архитектурой, отличной от K&G.
Они используют вариант LSTM, называемый стековым LSTM. Стек LSTM имеет операции push и pop, которые позволяют проходить состояния в древовидной структуре, а не последовательно. LSTM стека используются для представления стека, буфера и последовательности прошлых действий анализа, выполненных для конфигурации.
Слова предложения представлены векторами типов слов вместе с вектором, представляющим тег POS слова. В исходной конфигурации векторы всех слов находятся в буфере, а стек пуст. Представление буфера — это конечное состояние обратного LSTM по векторам слов.
По мере развития синтаксического анализа векторы слов извлекаются из буфера, помещаются в стек и извлекаются из него, а представления стека и буфера обновляются.
Дайер и др. (2015) определить функцию рекурсивной композиции и создавать представления дерева постепенно, по мере того, как зависимые элементы прикрепляются к их голове. Составное представление c строится путем конкатенации вектора h головы с вектором зависимого d, а также вектора r, представляющего метку в паре с направлением дуги. Этот объединенный вектор проходит через аффинное преобразование, а затем через нелинейную активацию.
| c=tanh(W[h;d;r]+b) |
Они создают две версии парсера. В первом варианте при присоединении зависимого к голове вектор слов головы заменяется составным вектором головы и зависимого. Во втором варианте они просто сохраняют вектор головы при присоединении иждивенца к голове. Они отмечают, что версия с композицией значительно лучше, чем версия без нее, на 1,3 балла LAS для английского языка (на тестовом наборе Penn Treebank (PTB)) и на 2,1 для китайского языка (на тестовом наборе Chinese Treebank (CTB)).
Их синтаксический анализатор использует информацию тега POS. POS-теги помогают устранить неоднозначность между различными функциональными употреблениями слова и, таким образом, предоставляют информацию об использовании слова в контексте. Мы предполагаем, что эффект от использования рекурсивной функции композиции сильнее, когда не используются теги POS.
4 Композиция в парсере K&G
Архитектуры синтаксического анализа синтаксического анализатора LSTM стека (S-LSTM) и K&G различаются, но имеют некоторые сходства. 2 2 2Обратите внимание, что мы используем S-LSTM для обозначения анализатора стека LSTM, а не стека LSTM как типа LSTM.
В обоих случаях конфигурация представлена векторами, полученными с помощью LSTM. В K&G он представлен векторами токенов верхних элементов стека и первого элемента буфера. В S-LSTM он представлен векторными представлениями всего стека, буфера и последовательности прошлых переходов.
Оба типа синтаксических анализаторов изучают векторные представления типов слов, которые передаются в LSTM.
В K&G они передаются в LSTM на этапе извлечения признаков, который происходит перед синтаксическим анализом. LSTM в этом случае используется для изучения векторов, у которых есть информация о контексте каждого слова, токен-вектор. В S-LSTM векторы типов слов передаются в Stack LSTM по мере развития синтаксического анализа. В этом случае LSTM используются для изучения векторных представлений стека и буфера (а также того, который изучает представление истории действий синтаксического анализа).
Если композиция не используется в S-LSTM, векторы слов представляют типы слов. Когда используется композиция, по мере развития синтаксического анализа векторы стека и буфера обновляются информацией о содержащихся в них поддеревьях, так что они постепенно становятся контекстуализированными. В этом смысле эти векторы становятся больше похожими на векторы токенов в K&G. В частности, как объяснялось в предыдущем разделе, когда зависимый объект присоединен к его голове, функция композиции применяется к векторам головы и зависимого, и вектор головы заменяется этим составным вектором.
Мы не можем применять композицию к векторам типов в архитектуре K&G, поскольку они не используются после этапа извлечения признаков и, следовательно, не могут влиять на представление конфигурации. Вместо этого мы применяем композицию к векторам токенов. Мы встраиваем эти составные представления в то же пространство, что и векторы токенов.
В K&G, как и в S-LSTM, мы можем создать функцию композиции и составить представление поддеревьев по мере развития синтаксического анализа. Мы создаем две версии синтаксического анализатора, в одной из которых токены слов представлены их вектором токенов. Другой, где они представлены своим вектором токенов и вектором их поддерева ci, который изначально является просто копией вектора токенов (vi=f(x1:n,i)∘ci). Когда зависимое слово d присоединяется к слову h с отношением и направлением r, ci вычисляется с той же функцией композиции, что и в S-LSTM, определенной в предыдущем разделе, повторенной ниже. 3 3 3Обратите внимание, что в предварительных экспериментах мы пытались заменить вектор головы вектором ее поддерева вместо объединения двух, но объединение дало гораздо лучшие результаты.
Эта композиционная функция представляет собой простую рекуррентную ячейку. Простые RNN имеют известные недостатки, которые были устранены с помощью LSTM, как было предложено Hochreiter and Schmidhuber (1997) . Поэтому естественным расширением этой функции композиции является замена ее ячейкой LSTM. Мы тоже пробуем этот вариант. Мы создаем LSTM для поддеревьев. Мы инициализируем новый LSTM для каждого нового сформированного поддерева, то есть когда зависимый d присоединяется к голове h, у которой еще нет никаких зависимых. Каждый раз, когда мы присоединяем зависимого к голове, мы строим вектор, который представляет собой конкатенацию h, d и r. Мы передаем этот вектор в LSTM h. c — это выходное состояние LSTM после прохождения этого вектора.
Мы обозначаем эти модели с +rc для модели, использующей рекуррентную ячейку без ограничений, и с +lc для модели, использующей ячейку LSTM.
| в | =tanh(W[h;d;r]+b) | ||
| в | =\textscLstm([h;d;r]) |
Как показывают результаты (см. § 5), ни один из типов композиции не кажется полезным при использовании с моделью синтаксического анализа K&G, что указывает на то, что BiLSTM собирают информацию о поддеревьях. Для дальнейшего изучения этого и для того, чтобы изолировать условия, при которых композиция полезна, мы выполняем различные модели абляции и проверяем влияние рекурсивной композиции на эти аблированные модели.
Во-первых, мы удаляем части BiLSTM: мы удаляем либо переднюю, либо заднюю LSTM. Поэтому мы строим синтаксические анализаторы с 3 различными функциями функций f(x,i) над векторами типа слова xi в предложении x: BiLSTM (bi) (наша базовая линия), обратная LSTM (bw) (т. е. удаление прямой LSTM) и прямой LSTM (fw) (т. Е. Удаление обратного LSTM):
| би(х,я) | =\textscBiLstm(x1:n,i) | ||
| чб(х,и) | =\textscLstm(xn:1,i) | ||
| фв (х, я) | =\textscLstm(x1:n,i) |
K&G с однонаправленными LSTM в некотором смысле больше похожи на S-LSTM, чем на BiLSTM, поскольку S-LSTM использует только однонаправленные LSTM. Мы предполагаем, что композиция поможет синтаксическому анализатору, использующему однонаправленные LSTM, так же, как он помогает S-LSTM.
Мы дополнительно экспериментируем с вектором, представляющим слово на входе LSTM. Наиболее сложное представление состоит из конкатенации вложения типа слова e(wi), встраивания (предсказанного) POS-тега wi, p(wi) и символьного представления слова, полученного путем запуска BiLSTM над символы ch2:m из wi (BiLSTM(ch2:m)).
| xi=e(wi)∘p(wi)∘BiLSTM(ch2:m) |
Без внедрения тега POS вектор слова является представлением типа слова. С информацией POS у нас есть некоторая информация о слове в контексте предложения, и тегировщик имеет доступ к полному предложению. Таким образом, представление слова на входе BiLSTM более контекстуализировано, и можно ожидать, что функция рекурсивной композиции будет менее полезной, чем когда информация POS не используется.
Было показано, что информация о символах полезна для разбора зависимостей в первую очередь Баллестерос и др. (2015) . Баллестерос и др. (2015) и Smith et al. (2018b) , среди прочего, показали, что POS и информация о символах в некоторой степени дополняют друг друга. Баллестерос и др. (2015) использовали аналогичные векторы символов в синтаксическом анализаторе S-LSTM, но не учитывали влияние композиции при использовании этих векторов. Здесь мы экспериментируем с удалением одного или обоих векторов символа и POS. Мы рассматриваем влияние использования композиции на полную модель, а также на эти аблированные модели. Мы предполагаем, что композиция наиболее полезна, когда эти векторы не используются, поскольку они дают информацию о функциональном использовании слова в контексте.
Парсер
Мы используем UUParser, вариант синтаксического анализатора на основе переходов K&G, в котором используется дуговая гибридная система переходов из Kuhlmann et al. (2011) дополнен переходом Swap и статическим динамическим оракулом, как описано в de Lhoneux et al. (2017b) 4 4 4 Код можно найти по адресу https://github.com/mdelhoneux/uuparser-composition. Переход Swap используется для построения непроективных деревьев зависимостей (Нивр, 2009 г.)
.
Мы используем гиперпараметры по умолчанию. При использовании POS-тегов мы используем универсальные POS-теги из банков деревьев UD, которые являются укрупненными и одинаковыми для разных языков. Теги POS прогнозируются UDPipe
(Straka et al., 2016) как для обучения, так и для синтаксического анализа. Этот синтаксический анализатор получил в среднем 7-е место среди лучших результатов LAS в общей задаче CoNLL 2018 года (Zeman et al., 2018) , что примерно на 2,5 балла LAS ниже лучшей системы, которая использует ансамблевую систему, а также вложения ELMo, представленные Петерс и др. (2018) .
Обратите внимание, однако, что мы используем слегка обедненную версию модели, используемой для общей задачи, которая описана в Smith et al. (2018a) : мы используем менее точный теггер POS (UDPipe) и не используем модели с несколькими банками деревьев. Кроме того, Smith et al. (2018a) используют три верхних элемента стека, а также первый элемент буфера для представления конфигурации, в то время как мы используем только два верхних элемента стека и первый элемент буфера. Смит и др. (2018a) также использует расширенный набор функций, представленный Kiperwasser and Goldberg (2016b)
, где они также используют крайние правые и крайние левые дочерние элементы стека и буфера, которые они рассматривают. Мы не используем этот расширенный набор функций. Это делается для того, чтобы настройки парсера были максимально простыми и чтобы не добавлялись искажающие факторы. Это все еще почти модель SOTA. Мы оцениваем модели синтаксического анализа в наборах для разработки и сообщаем о среднем значении 5 лучших результатов за 30 эпох и 5 прогонов с разными случайными начальными значениями.
Данные
Мы тестируем наши модели на образце деревьев из Universal Dependencies v2.1 (Nivre et al., 2017) . Мы следуем критериям de Lhoneux et al. (2017c) для выбора нашей выборки: мы обеспечиваем типологическое разнообразие, мы обеспечиваем разнообразие доменов, мы проверяем качество банков деревьев и используем один банк деревьев с большим количеством непроективных дуг. Однако, в отличие от них, мы не используем очень маленькие валы деревьев. Наш выбор такой же, как и у них, но мы удаляем крошечные валы деревьев и заменяем их тремя другими. Наш последний набор: древнегреческий (PROIEL), баскский, китайский, чешский, английский, финский, французский, иврит и японский.
5 результатов
Во-первых, мы рассмотрим влияние наших различных функций рекурсивной композиции на полную модель (т. е. модель, использующую BiLSTM для извлечения признаков, а также информацию о символах и тегах POS). Как видно из рисунка 1, рекурсивная композиция с использованием ячейки LSTM (+lc), как правило, лучше, чем рекурсивная композиция с повторяющейся ячейкой (+rc), но ни один из методов надежно не повышает точность синтаксического анализатора BiLSTM.
Рисунок 1: LAS моделей с использованием BiLSTM (bi) без композиции, с повторяющейся ячейкой (+rc) и с ячейкой LSTM (+lc). Гистограммы усечены до 50 для наглядности.5.1 Удаление прямого и обратного LSTM
Во-вторых, мы рассматриваем только модели, использующие информацию о символах и POS, и смотрим на влияние удаления частей BiLSTM на разные языки. Результаты можно увидеть на рисунке 2. Как и ожидалось, синтаксический анализатор BiLSTM работает значительно лучше, чем оба однонаправленных синтаксических анализатора LSTM, а обратный LSTM в среднем значительно лучше, чем прямой LSTM. Однако интересно отметить, что использование прямого LSTM гораздо более вредно для одних языков, чем для других: особенно для китайского и японского. Это можно объяснить свойствами языка: правосторонние языки больше страдают от удаления обратного LSTM.
чем другие языки. Мы наблюдаем корреляцию между тем, насколько вредна прямая модель по сравнению с базовым уровнем, и процентом правосторонних отношений зависимости от контента (R = -0,838, p <0,01), см. рис. 3. 5 5 5 Причина, по которой мы рассматриваем только отношения зависимости содержания, заключается в том, что схема UD фокусируется на отношениях зависимости между словами содержания и рассматривает служебные слова как характеристики слов содержания, чтобы максимизировать параллелизм между языками (de Marneffe et al. , 2014) .
Нет существенной корреляции между тем, насколько вредным является удаление прямого LSTM, и процентом левосторонних отношений зависимости контента (p>0,05), что указывает на то, что его полезность не зависит от свойств языка. Мы предполагаем, что длина зависимости или длина предложения могут играть роль, но мы также не находим корреляции между тем, насколько вредно удалять прямой LSTM, и средней зависимостью или длиной предложения в банках деревьев. Наконец, также интересно отметить, что обратная производительность LSTM близка к производительности BiLSTM для некоторых языков (японского и французского).
Рисунок 3: Корреляция между тем, насколько вредно удалять отсталый LSTM и правосторонность языков. Рисунок 4: LAS моделей с использованием BiLSTM (bi), обратного LSTM (bw) и прямого LSTM (fw), без рекурсивной композиции, с рекуррентной ячейкой (+rc) и с ячейкой LSTM (+lc). Гистограммы усечены до 50 для наглядности.Теперь мы рассмотрим эффект использования рекурсивной композиции на этих аблированных моделях. Результаты представлены на рисунке 4. Прежде всего, мы неудивительно наблюдаем, что композиция с использованием ячейки LSTM намного лучше, чем с использованием простой рекуррентной ячейки. Во-вторых, оба типа композиции помогают обратному случаю LSTM, но ни один из них не помогает надежно би-моделям. Наконец, рекуррентная ячейка не помогает в случае прямого LSTM, но ячейка LSTM в некоторой степени помогает. Интересно отметить, что использование композиции, особенно с использованием ячейки LSTM, устраняет значительную часть разрыва между моделями bw и bi.
Эти результаты могут быть связаны с литературой по синтаксическому анализу зависимостей на основе переходов. Синтаксические анализаторы на основе переходов обычно полагаются на два типа функций: функции на основе истории по возникающему дереву зависимостей и упреждающие функции по буферу оставшихся входных данных. Первые основаны на иерархической структуре, вторые — чисто последовательные. McDonald and Nivre (2007) и McDonald and Nivre (2011) показали, что функции, основанные на истории, улучшают синтаксические анализаторы на основе переходов, если они не страдают от распространения ошибок. Однако Nivre (2006) также показал, что функции просмотра вперед абсолютно необходимы, учитывая жадную стратегию разбора слева направо.
В рассмотренных здесь архитектурах моделей обратный LSTM обеспечивает улучшенный просмотр вперед. Подобно просмотру вперед в статистическом анализе, он является последовательным. Разница в том, что он дает информацию о предстоящих словах неограниченной длины. Прямой LSTM в этой архитектуре модели предоставляет информацию на основе истории, но, в отличие от статистического анализа, эта информация строится последовательно, а не иерархически: прямой LSTM проходит через предложение в линейном порядке предложения. В наших результатах мы видим, что упреждающие функции более важны, чем функции, основанные на истории. Точность синтаксического анализа больше ухудшает удаление обратного LSTM, чем удаление прямого. Это ожидаемо, учитывая, что некоторая информация, основанная на истории, все еще доступна через верхние токены в стеке, в то время как упреждающая информация почти полностью теряется без обратного LSTM.
Функция композиции предоставляет иерархическую информацию об истории действий по разбору. Имеет смысл, что это больше всего помогает обратной модели LSTM, поскольку эта модель не имеет доступа к какой-либо информации об истории синтаксического анализа. Это немного помогает прямому LSTM, что указывает на то, что можно получить выгоду от использования структурированной информации об истории синтаксического анализа, а не последовательной информации. Тогда мы могли бы ожидать, что композиция должна помочь модели BiLSTM, что, однако, не так. Это может быть связано с тем, что BiLSTM конструирует информацию о синтаксическом анализе истории и просмотре вперед в уникальном представлении. В любом случае это указывает на то, что BiLSTM являются мощными экстракторами функций, которые, кажется, собирают полезную информацию о поддеревьях.
5.2 Удаление информации о POS и персонаже
Далее мы рассмотрим влияние различных методов представления слов на разные языки, как показано на рисунке 5. Как и в литературе (Ballesteros et al., 2015; de Lhoneux et al., 2017a; Smith et al. al., 2018b) , использование символьных представлений слов и/или тегов POS постоянно повышает точность синтаксического анализа, но оказывает разное влияние на разные языки, и преимущества обоих методов не суммируются: использование двух методов в сочетании не намного лучше, чем использование либо самостоятельно. В частности, модели символов — это эффективный способ добиться больших улучшений в морфологически богатых языках.
Рисунок 5: Базовый уровень LAS с использованием тегов char и/или POS для построения представлений слов Разница >0,5 с +lc жирным шрифтом. Мы рассматриваем влияние рекурсивных композиций на все комбинации аблированных моделей, см. Таблицу 1. Мы рассматриваем только влияние использования ячейки LSTM, а не рекуррентной ячейки, поскольку это был лучший метод по всем направлениям (см. предыдущий раздел). .
Если сначала посмотреть на BiLSTM, то кажется, что композиция не обеспечивает надежной точности синтаксического анализа, независимо от доступа к POS и информации о символах. Это указывает на то, что векторы, полученные с помощью BiLSTM, уже содержат информацию, которую в противном случае можно было бы получить с помощью композиции.
Обращаясь к результатам с прямой или обратной абляции LSTM, мы видим ожидаемую картину. Композиция помогает больше, когда в модели отсутствуют теги POS, что указывает на некоторую избыточность между этими двумя методами построения контекстной информации. Композиция помогает восстановить значительную часть разрыва модели с помощью обратного LSTM с тегом POS или без него. В других случаях он восстанавливает гораздо менее существенную часть пробела, что означает, что, хотя между этими различными методами построения контекстной информации существует некоторая избыточность, они все же дополняют друг друга, и рекурсивная функция композиции не может полностью компенсировать отсутствие обратного LSTM. или POS и/или информацию о персонаже.
В результатах есть некоторые языковые особенности. В то время как композиция помогает восстановить большую часть разрыва для обратных моделей LSTM без информации о POS и / или символах для чешского и английского языков, она делает это в гораздо меньшей степени для баскского и финского языков. Мы предполагаем, что глубина дуги может повлиять на полезность композиции, поскольку большая глубина означает большее умножение матриц с функцией композиции. Однако мы не находим корреляции между средней глубиной дуги берегов деревьев и полезностью композиции. Остается открытым вопрос, почему композиция помогает одним языкам больше, чем другим.
Обратите внимание, что мы не первые, кто использует композицию векторов, полученных из BiLSTM, в контексте синтаксического анализа зависимостей, как это было сделано Qi и Manning (2017) .
Отличие в том, что они составляют векторы до подсчета очков за переходы. Это также было сделано Kiperwasser и Goldberg (2016a) , которые показали, что использование векторов BiLSTM для слов в их синтаксическом анализаторе Tree LSTM полезно, но они не сравнивали это с использованием векторов BiLSTM без Tree LSTM.
Рекуррентные и рекурсивные LSTM в том виде, как они рассматриваются в этой статье, представляют собой два способа создания контекстной информации и предоставления ее для принятия локальных решений в жадном синтаксическом анализаторе. Сила рекурсивных LSTM заключается в том, что они могут создавать эту контекстную информацию, используя иерархический контекст, а не линейный контекст. Возможная слабость заключается в том, что это делает модель чувствительной к распространению ошибок: неправильное присоединение приводит к использованию неправильной контекстной информации. Поэтому возможно, что преимущества и недостатки использования этого метода компенсируют друг друга в контексте BiLSTM.
5.3 Ансамбль
Для дальнейшего изучения информации, полученной с помощью BiLSTM, мы объединили 6 версий моделей с POS и символьной информацией с различными экстракторами признаков (bi, bw, fw) с (+lc) и без композиции. Мы используем (невзвешенный) метод повторного анализа Sagae and Lavie (2006) 6 6 6. Этот метод оценивает все дуги по количеству парсеров, предсказывающих их, и извлекает максимальное остовное дерево с использованием алгоритма Чу-Лю-Эдмондса (Эдмондс, 1967) .
и игнорирование ярлыков.
Как видно из оценок UAS в таблице 2, ансамбль (90 446 полных 90 447) значительно превосходит синтаксический анализатор, использующий только BiLSTM, что указывает на то, что информация, полученная из разных моделей, дополняет друг друга. Чтобы исследовать вклад каждой из 6 моделей, мы удаляем каждую из них одну за другой. Как видно из таблицы 2, удаление любой из моделей BiLSTM или обратного LSTM с использованием композиции приводит к наименее эффективной из моделей удаления, что еще больше укрепляет вывод о том, что BiLSTM являются мощными экстракторами признаков.
6 Заключение
Мы исследовали влияние составления представления поддеревьев в синтаксическом анализаторе на основе переходов. Мы заметили, что композиция не помогает синтаксическому анализатору, который использует BiLSTM для извлечения признаков, что указывает на то, что векторы, полученные из BiLSTM, могут собирать информацию о поддеревьях, что согласуется с результатами Linzen et al. (2016) . Однако мы наблюдаем, что при удалении обратного LSTM производительность падает, а рекурсивная композиция не помогает восстановить большую часть этого разрыва. Мы предполагаем, что это связано с тем, что обратный LSTM в первую очередь улучшает просмотр вперед для жадного синтаксического анализатора. При удалении прямого LSTM производительность падает в меньшей степени, а рекурсивная композиция восстанавливает значительную часть разрыва. Это указывает на то, что прямой LSTM и рекурсивная функция композиции собирают аналогичную информацию, которую мы считаем связанной с богатыми функциями, основанными на истории, которые имеют решающее значение для синтаксического анализатора на основе переходов. Для сбора этой информации рекурсивная функция композиции лучше, чем прямая LSTM сама по себе, но еще лучше иметь прямую LSTM как часть BiLSTM. Мы также обнаружили, что рекурсивная композиция помогает больше, когда теги POS удаляются из модели, указывая на то, что теги POS и функция рекурсивной композиции являются частично избыточными способами построения контекстной информации. Наконец, мы сопоставляем результаты со свойствами языка, показывая, что улучшенный просмотр назад обратного LSTM особенно важен для языков с окончанием головы.
Благодарности
Мы подтверждаем вычислительные ресурсы, предоставленные CSC в Хельсинки и Sigma2 в Осло через NeIC-NLPL (www.nlpl.eu). Мы благодарим Сару Стимн и Аарона Смита за многочисленные обсуждения этой статьи.
Каталожные номера
50 Синонимов СОСТАВА | Тезаурус Мерриам-Вебстер
существительное
Сохранить слово1 литературное, музыкальное или художественное произведение
2 короткое сочинение, выполненное в качестве школьного упражнения
3 способ расположения элементов чего-либо (как произведения искусства)
4 короткий текст, обычно выражающий точку зрения
Опубликуйте больше слов для композиции в Facebook Поделитесь другими словами для композиции в Твиттере
Путешественник во времени на состав
Первое известное использование композиции
было в 14 векеПосмотреть другие слова того же века
Тезаурус Записи рядом с
составкомпозитинг
сочинение
композиции
Посмотреть больше записей поблизостиПроцитируйте эту запись
«Композиция». Merriam-Webster.com Тезаурус , Merriam-Webster, https://www.merriam-webster.com/thesaurus/composition. По состоянию на 13 сентября 2022 г.
Стиль: MLA
Merriam-Webster.com Thesaurus, Merriam-Webster, https://www.merriam-webster.com/thesaurus/composition. По состоянию на 13 сентября 2022 г.»> MLA Merriam-Webster.com Тезаурус, с.в. «composition», по состоянию на 13 сентября 2022 г., https://www.merriam-webster.com/thesaurus/composition.»>Chicago. Тезаурус Merriam-Webster.com. Получено 13 сентября 2022 г. с https://www.merriam-webster.com/thesaurus/composition»>APA. Merriam-Webster.com Thesaurus, https://www.merriam-webster.com/thesaurus/composition. Доступно 9/13/2022.»>Merriam-Webster
Еще от Merriam-Webster на композиция
Нглиш: Перевод композиция для говорящих на испанском языке
Britannica English: Перевод композиции для говорящих на арабском языке 900. 0 com: Энциклопедическая статья о композиции
СЛОВО ДНЯ
наряжать
См. Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Проверьте свой словарный запас
Слова, названные в честь людей
Проверь свои знания и, возможно, узнаешь что-нибудь по ходу дела.
ПРОЙДИТЕ ТЕСТ
Ежедневное задание для любителей кроссвордов.
ПРОЙДИТЕ ТЕСТ
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
Слова в игре
Спросите у редакторов