Книга «Разбор слова по составу: Словарь» из жанра Словари, разговорники
Разбор слова по составу: Словарь
| Автор: Терещенко Василий Николаевич
Жанр: Словари, разговорники
Издательство: Феникс
Год: 2015 Количество страниц: 96
Формат:
PDF (4.80 МБ) Дата загрузки: 16 марта 20182016-06-25 Скачать с нашего сайта Скачать в два клика
| |||
| Аннотация Словарь содержит более 4000 слов и словоформ современного русского литературного языка, разобранных по составу в соответствии с современными нормами. В начале словаря кратко изложена информация об особенностях состава слова, которая поможет младшему школьнику вспомнить основные теоретические сведения, а значит, упростит работу со словарём. Книга предназначена для учеников 1-4 классов, а также для всех, кто только начинает изучать русский язык. Издание станет незаменимым помощником ученикам, их родителям и учителям. | |||
| Комментарии
| |||

РАЗБОР СЛОВА ПО СОСТАВУ — PDF Free Download
ПРАВИЛА ПО МАТЕМАТИКЕ
ПРАВИЛА ПО МАТЕМАТИКЕ НАЧАЛЬНАЯ ШКОЛА МОСКВА «ВАКО» УДК 030 ББК 92 П68 П68 Правила по математике: Начальная школа / Сост. И.В. Клюхина. М.: ВАКО, 2010. 80 с. (Школьный словарик). ISBN 978-5-408-00016-6
Подробнее ТРЕНАЖЁР ПО РУССКОМУ ЯЗЫКУ
СООТВЕТСТВУЕТ ТРЕБОВАНИЯМ едерального государственного образовательного стандарта И. В. КЛЮХИНА ТРЕНАЖЁР ПО РУССКОМУ ЯЗЫКУ для подготовки к ВПР 4 класс МОСКВА 2019 УДК 372.881.161.1 ББК 74.268.1Рус К52
ПодробнееГЛАСНЫЕ ЗВУКИ И БУКВЫ
Твёрдые Звонкие: [б] [в] [г] [д] [ж] [з] Глухие: [п] [ф] [к] [т] [ш] [ с] СОГЛАСНЫЕ ЗВУКИ ПАРНЫЕ СОГЛАСНЫЕ Мягкие [б ] [в ] [г ] [д ] [з ] [п ] [ф ] [к ] [т ] [ с ] НЕПАРНЫЕ СОГЛАСНЫЕ Твёрдые Звонкие:
Подробнее3 7 лет Транспорт МОСКВА «ВАКО» 2017
3 7 лет Транспорт МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Т65 Для дошкольного и младшего школьного возраста. Т65 Транспорт. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы).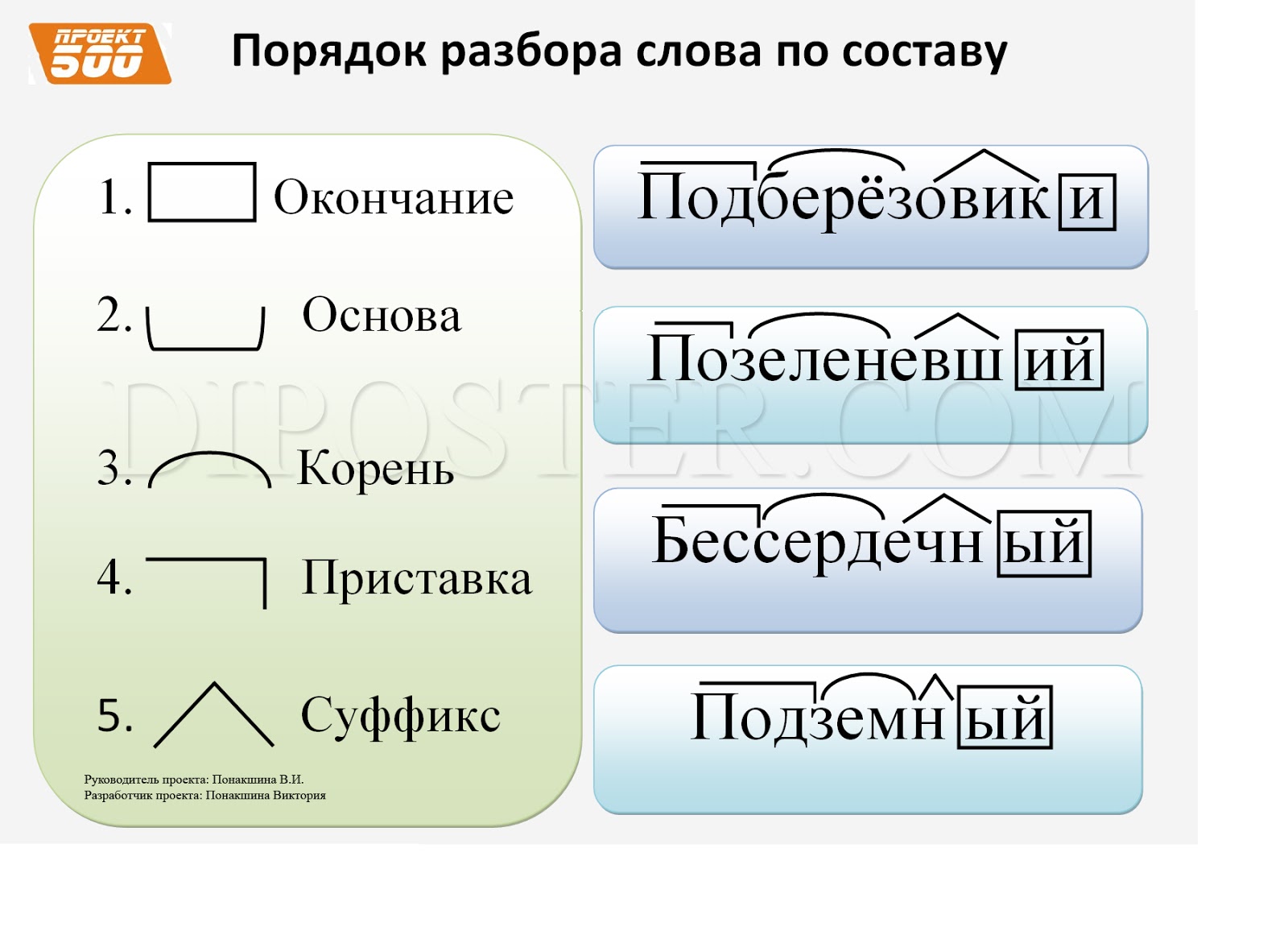
ПРАВИЛА ПО РУССКОМУ ЯЗЫКУ
ПРАВИЛА ПО РУССКОМУ ЯЗЫКУ НАЧАЛЬНАЯ ШКОЛА 2-е издание, исправленное МОСКВА «ВАКО» УДК 038 ББК 92 П68 Рецензенты: руководитель структурного подразделения предметов социально-гуманитарного цикла ОМЦ ЦОУО
ПодробнееРУССКИЙ ЯЗЫК. 1 класс МОСКВА «ВАКО»
РУССКИЙ ЯЗЫК 1 класс МОСКВА «ВАКО» УДК 372.881.161.1 ББК 74.268.1Рус К64 Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования и науки РФ от 14.12.2009
Подробнее3 7 лет. Обитатели моря
3 7 лет Обитатели моря МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 О15 Для дошкольного и младшего школьного возраста. О15 Обитатели моря. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02832-0
3 7 лет. Планета Земля
3 7 лет Планета Земля МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 П37 Для дошкольного и младшего школьного возраста. П37 Планета Земля. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02828-3
ПодробнееСБОРНИК ТЕКСТОВЫХ ЗАДАЧ
Г. В. КЕРОВА СБОРНИК ТЕКСТОВЫХ ЗАДАЧ ТЕКСТЫ, МЕТОДИКА, МОНИТОРИНГ 1 4 классы МОСКВА «ВАКО» 2010 УДК 372.851 ББК 74.262.21 К36 Рецензент заместитель директора ОМЦ Центрального окружного управления образования
ПодробнееСБОРНИК ЗАДАЧ ПО АЛГЕБРЕ
А Н РУРУКИН, Н Н ГУСЕВА, Е А ШУВАЕВА СБОРНИК ЗАДАЧ ПО АЛГЕБРЕ 8 класс МОСКВА «ВАКО» 016 УДК 75 ББК 14 Р87 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства
Подробнее3 7 лет Части тела МОСКВА «ВАКО» 2017
3 7 лет Части тела МОСКВА «ВАКО» 2017 УДК 74. 100.5 ББК 92я92 Ч25 Для дошкольного и младшего школьного возраста. Ч25 Части тела. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02823-8
100.5 ББК 92я92 Ч25 Для дошкольного и младшего школьного возраста. Ч25 Части тела. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02823-8
АНГЛИЙСКАЯ ГРАММАТИКА
В. И. ШАТИЛО Т. Р. КИСЛОВА АНГЛИЙСКАЯ ГРАММАТИКА Глагол to be единственного числа РАБОЧАЯ ТЕТРАДЬ Первый год обучения МОСКВА ВАКО УДК 372.811.111.1 ББК 81.2Англ Ш28 Издание допущено к использованию в образовательном
Подробнее3 7 лет. Животные фермы
3 7 лет Животные фермы МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Ж27 Для дошкольного и младшего школьного возраста. Ж27 Животные фермы. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02824-5
ПодробнееРусский язык 6 класс
Русский язык 6 класс (105 часов в год, 3 часа в неделю; из них 7 часов на письменные контрольные работы) Мурина, Л. А. Русский язык : учеб. для 6 кл. учреждений общ. сред. образования с белорус. и рус.
ПодробнееМАТЕМАТИКА. Издание восьмое. 2 класс
МАТЕМАТИКА Издание восьмое 2 класс МОСКВА «ВАКО» 2017 УДК 372.851 ББК 74.262.21 К65 Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования и науки РФ
ПодробнееИздательство АСТ Москва
Издательство АСТ Москва УДК 373 : 51 ББК 22.1я71 У34 Учебное пособие Для начального образования О.В. Узорова, Е.А. Нефёдова БЫСТРО СЧИТАЕМ ЦЕПОЧКИ ПРИМЕРОВ. 3-й класс Ответственный редактор В. Макагоненко
Подробнее3 7 лет. Рептилии и амфибии
3 7 лет Рептилии и амфибии МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Р41 Для дошкольного и младшего школьного возраста. Р41 Рептилии и амфибии. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы).
Р41 Рептилии и амфибии. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы).
ИНФОРМАТИКА 8 класс МОСКВА «ВАКО» 2017
ИНФОРМАТИКА 8 класс МОСКВА «ВАКО» 2017 УДК 372.862 ББК 74.262.8 К65 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования и науки РФ от 09.06.2016
ПодробнееРабочая программа по русскому языку 5 класс
Департамент социальной политики Администрации города Кургана муниципальное бюджетное общеобразовательное учреждение города Кургана «Средняя общеобразовательная школа 35» Рассмотрена на заседании методического
ПодробнееИНФОРМАТИКА. 11 класс
ИНФОРМАТИКА 11 класс МОСКВА «ВАКО» 2018 УДК 372.862 ББК 74.262.8 К65 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования и науки РФ от 09.06.2016
ПодробнееПОВТОРЯЕМ И СИСТЕМАТИЗИРУЕМ
В. С. КРАМОР ПОВТОРЯЕМ И СИСТЕМАТИЗИРУЕМ ШКОЛЬНЫЙ КУРС ГЕОМЕТРИИ 4-е издание Москва Мир и Образование Астрель ОНИКС УДК 514(075.3) ББК 22.151.0я72 К78 К78 Крамор В. С. Повторяем и систематизируем школьный
Подробнее3 7 лет. Чудеса света
3 7 лет Чудеса света МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Ч84 Для дошкольного и младшего школьного возраста. Ч84 Чудеса света. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02827-6
Подробнее3 7 лет Насекомые МОСКВА «ВАКО» 2017
3 7 лет Насекомые МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Н31 Для дошкольного и младшего школьного возраста. Н31 Насекомые. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02830-6
Н31 Насекомые. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02830-6
СБОРНИК ЗАДАЧ ПО АЛГЕБРЕ
А. Н. РУРУКИН, Н. Н. ГУСЕВА, Е. А. ШУВАЕВА СБОРНИК ЗАДАЧ ПО АЛГЕБРЕ 9 класс МОСКВА «ВАКО» 06 УДК 7.5 ББК.4 Р87 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства
3 7 лет. Дикие животные
3 7 лет Дикие животные МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 Д45 Для дошкольного и младшего школьного возраста. Д45 Дикие животные. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02837-5
Подробнее3 7 лет Обезьяны Обезьяны Обезьяны
3 7 лет Обезьяны МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 О13 Для дошкольного и младшего школьного возраста. О13 Обезьяны. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02822-1
ПодробнееМ о з ы р ь «Белый Ветер»
Пособие для педагогов учреждений общего среднего образования М о з ы р ь «Белый Ветер» 2 0 1 6 УДК 372.881.1 ББК 74.261.3 С89 Р е ц е н з е н т ы : методист учебно-методического отдела социально-гуманитарных
Подробнее3 7 лет Кошки Кошки Кошки
3 7 лет Кошки МОСКВА «ВАКО» 2017 УДК 74.100.5 ББК 92я92 К76 Для дошкольного и младшего школьного возраста. К76 Кошки. М.: ВАКО, 2017. 24 с.: ил. (Мои первые вопросы и ответы). ISBN 978-5-408-02829-0 Дети
ПодробнееИНФОРМАТИКА. 10 класс
ИНФОРМАТИКА 10 класс МОСКВА «ВАКО» 2018 УДК 372.862 ББК 74.262.8 К65 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования и науки РФ от 09. 06.2016
06.2016
Русский язык 5 класс 105 часов
Русский язык 5 класс 105 часов Kuu Õpitulemused Õppesisu Kohustuslik hindamine I четверть сентябрь 1.Знают, чем отличается текст от группы предложений, определяют тему и основную мысль текста. 2.Видят
ПодробнееТетрадь для занятий с детьми 6 7 лет
О. Е. ЖИРЕНКО Е. В. КОЛОДЯЖНЫХ ПРОПИСИ для дошкольников Тетрадь для занятий с детьми 6 7 лет МОСКВА «ВАКОША» 2019 УДК 373.29 ББК 74.102 Ж73 0+ Ж73 Жиренко О.Е., Колодяжных Е.В. Прописи для дошкольников:
ПодробнееРУССКИЙ ЯЗЫК. Издание пятое. 2 класс
РУССКИЙ ЯЗЫК Издание пятое 2 класс МОСКВА «ВАКО» 2017 УДК 372.881.161.1 ББК 74.268.1Рус К65 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства образования
ПодробнееПОЯСНИТЕЛЬНАЯ ЗАПИСКА
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА Программа собеседования по русскому языку соответствует правилам приема в высшее учебное заведение и примерным программам вступительных экзаменов, утвержденным Министерством образования
ПодробнееИТОГОВЫЕ КОНТРОЛЬНЫЕ РАБОТЫ
ИТОГОВАЯ АТТЕСТАЦИЯ МАТЕМАТИКА ИТОГОВЫЕ КОНТРОЛЬНЫЕ РАБОТЫ 1 класс МОСКВА «ВАКО» УДК 372.851 ББК 74.262.21 М34 6+ Издание допущено к использованию в образовательном процессе на основании приказа Министерства
ПодробнееРУССКИЙ ЯЗЫК. 11 класс МОСКВА «ВАКО»
РУССКИЙ ЯЗЫК 11 класс МОСКВА «ВАКО» УДК 372.83 ББК 74.266.0 К64 Издание допущено к использованию в образовательном процессе в соответствии с приказом Министерства образования и науки РФ от 14.12. 2009 729
2009 729
Памятка разбор слова по составу | Материал (2 класс) на тему:
Памятка. Разбор слов по составу
Разбор по составу.
- Прочитай слово.
- Выдели окончание. Для этого измени форму слова.
Как изменить форму слов – названий предметов (имя существительное)?
1 способ: 2 способ:
с помощью слов ЕСТЬ, НЕТ. с помощью слов – помощников.
Есть (что?) пенал_. НЕТ (чего?) пенала
Нет (чего?) пенала. ДАМ (чему?) пеналу
ВИЖУ (кого? что?) пенал_
ДОВОЛЕН (чем?) пеналом
ДУМАЮ (о чем?) о пенале.
3 способ используют как для определения формы слов-названий предметов, их признаков (имен прилагательных), действий предметов (глаголов):
с помощью местоимений ОН, ОНА, ОНО, ОНИ.
ОН пенал_ – ОНИ пеналы
ОН красивый – ОНА красивая — ОНО красивое — ОНИ красивые
ОН сидел_ — ОНА сидела — ОНО сидело – ОНИ сидели
- Обозначь основу слова (часть слова без окончания).
- Выдели корень. Для этого подбери однокоренные слова.
Общая часть родственных слов называется КОРНЕМ. Она обозначается значком . Однокоренные слова имеют одинаковое лексическое значение.
Для образования новых слов служат:
СУФФИКС и ПРИСТАВКА
часть слова, которая стоит после часть слова, которая стоит перед
корня, обозначается значком ^.
Подберёзовик — берёза, берёзовая, березняк, березка
-у-
-а-
-и-
Беларуская мова разбор слова по составу
Скачать беларуская мова разбор слова по составу PDF
Словарь «Разбор слова по составу» включает слова, которые входят в обязательный орфографический минимум для средней школы, показывает их морфемное строение и способы образования. Словарь «Морфологический разбор» включает случаи, наиболее трудные для школьников, что поможет учащимся выполнить по аналогии разбор слов, не включенных в справочник.
Книга адресована учащимся общеобразовательных школ. Лучшие книги этого раздела. Каким образом осуществляется разбор слов по составу. Морфемный анализ (то же самое, что и разбор по составу) заключается в определении каждой части слова: корня, суффикса, приставки, окончания, основы.
Подобный анализ служит основополагающим в грамматике русского языка и играет важную роль. К примеру, если не известно в какой именно части слова располагается буква — не узнать, как правильно она пишется. Выходит, что суть правописания — это и есть грамотность при разборе. Чтобы приступить к морфемному анализу слова, необходимо знать информацию о самих морфемах, а ещё, следовать строгому плану р.
Морфемный разбор слова по-белорусски по составу выглядит так: По—белорусски. Части слова (морфемы): По — префикс (приставка). Белорус — корень. Ск, и — суффиксы. Окончание отсутствует. Основа слова: по-белорусски. «белорусский» по составу белорусский Части слова «белорусский»: белорус/ск/ий Состав слова: белорус — корень, ск — суффикс, ий — окончание, белорусск — основа слова.
Похожие вопросы. Также спрашивают. Мобильная версия · Помощь · Отправить отзыв. koohar.ru О компании Реклама Вакансии. Разбор по составу белорусский.
Самый большой морфемный словарь русского языка: насчитывает разобранных словоформ. Разбор по составу слова: «белорусский» —.
Вопросы и Ответы. Беларуская мова. Разобрать слово по составу по Бел Языку 0 голосов. 23 просмотров. Разобрать слово по составу по Бел Языку падбярозавiк,грыбнiкi,праменьчык,асiнка,снежны,пералесак,сталовая,школьнiкi,школьнiкi,перавозка.
школьнiкi. разобрать. слово по составу разбор онлайн. Принадлежность к какому-либо роду основывается на чисто грамматических показателях. Показатели родовых форм в русском и белорусском языках в основном одинаковые: м. р. — нулевое окончание (дом, стог), ж. р. — -а (-я) (рус. земля, вода), ср.
р. — -о (-е). Наблюдаются и различия.Род рус. и бел. заимствованных существительных может не совпадать, определяется он при помощи словарей, а также синтаксически: рус. вуаль, медаль, шинель — ж. р. бел. вуаль, медаль, шинель — м. р. Не всегда совпадает род одушевленных русских и белорусских существительных, отличающихся обоз. Фанетычны разбор слова беларуская мова онлайн. Правила белорусского языка.
Тонечка Тофелева. lượt xem 10 N năm trước. фанетыка беларускай мовы как сделать фонетический разбор слова слова iльновалакно. Урок №32 Тема — Разбор слова по составу. Образовательный канал Өрлеу. lượt xem 9 N năm trước. ЦОР как фрагмент урока может быть использован педагогами на уроках русского языка во 2-ом классе при изучении Состав слова. Разбор слова по составу. razbor slova. безУМНЫЙ МАКС. lượt xem 98 N năm trước. Состав слова. Разбор слова по составу. Пример разбора.
уроки,русский язык.
djvu, djvu, rtf, PDFПохожее:
Что означает праздник Благовещения
РелигияПолучить короткую ссылку
2511970
Ежегодно, 7 апреля православные верующие отмечают один из двенадцати великих церковных праздников – Благовещение Пресвятой Богородицы.
В этот день христиане вспоминают о принесении Пречистой Деве Марии благой вести о зачатии Ею Сына Божия – Иисуса Христа.
Заместитель председателя Синодального информационного отдела БПЦ, протоиерей Александр Шимбалев рассказал корреспонденту Sputnik Ольге Деменчук об истории и духовном значении Праздника Благовещения Пресвятой Богородицы, а также о том, как следует встречать этот день православным верующим.
Когда был установлен праздник Благовещения
Благовещение Пресвятой Богородицы – это древний церковный праздник, который получил всеобщее признание в VII веке. В это время праздник Благовещения и его особенности были прописаны в богослужении. До этого времени в истории Церкви встречаются проповеди на Благовещение, но только как отдельный сюжет – в Евангелии от Луки.
«Дата празднования Благовещения Пресвятой Богородицы была назначена на 25 марта. Это очень интересный факт, который указывает на связь праздников Благовещения и Пасхи в древней церкви.
Явление, когда Пасха выпадает на праздник Благовещения, именуется Кириопасхой, или Господствующей Истинной Пасхой. Это напоминает всем верующим о том, что праздники Благовещения Пресвятой Богородицы и Пасхи Христовой должны были отмечаться в один день. В наши дни празднование Пасхи высчитывается особым чином и довольно редко совпадает с празднованием Благовещения, однако Святая церковь хранит об этом память», – рассказал протоиерей Александр Шимбалев.
Заместитель председателя информационного отдела БПЦ уточняет, что согласно одной из эр, которые имели хождение в христианском мире, – эре Амиана, именно на 25 марта приходилось начало года. В этот день отмечали несколько праздников – День творения, праздник Благовещения и Светлого Христова Воскресения (Пасхи). Сегодня Благовещение Пресвятой Богородицы отмечается Церковью также 25 марта – путаница заключается лишь в том, что в миру летоисчисление ведется не по юлианскому, а григорианскому календарю.
Сегодня Благовещение Пресвятой Богородицы отмечается Церковью также 25 марта – путаница заключается лишь в том, что в миру летоисчисление ведется не по юлианскому, а григорианскому календарю.
Что означает праздник Благовещения
Благовещение (греческое название «евангелие») – это благая весть. Апостолы принесли в мир весть о том, что Христос воскрес из мертвых, и Богородица также приняла благую весть от Архангела Гавриила о зачатии и рождении ею от Духа Святого Господа нашего Иисуса Христа.
«Богородица Дева Мария была посвящена Богу, и поэтому все годы готовила себя к жизни девственной. Архангел Гавриил явился Деве Марии и возвестил ей о самом главном – Богородица, как самый чистый сосуд, была избрана для зачатия Спасителя мира. С необыкновенной радостью и смирением, безо всякого противодействия, восприняла Богородица это чудесное известие – посвятить свою жизнь Богу. Этим самым Дева Мария являет нам собой пример искренней, глубокой веры и чистоты», – подчеркнул протоиерей Александр Шимбалев.
Праздник Благовещения – очень важный день для всей святой Церкви, потому что именно с этого момента – благой вести о пришествии в мир Спасителя и искупления им первородного греха начинается спасение человеческое.
Как следует встречать праздник Благовещения?
В этот день верующим следует особенно вспомнить о том, что Благодать Святого Духа не может войти в грязный сосуд. Ведь для того, чтобы явиться в этот мир, Господь выбрал самый чистый сосуд – Пресвятую Богородицу. С другой стороны, необыкновенное смирение Богородицы и полагание на волю Божию являют нам пример того, как следует жить в этом мире.
«К сожалению, часто бывает так, что всю жизнь человек ищет только своего, считает, что даже сам Господь должен подстраиваться под его помыслы и желания. На самом же деле, человек должен вникнуть в смысл и понять текст Священного Писания, уметь распознавать волю Божию в каких-то знаках и со смирением принимать промысел Божий. Благовещение Пресвятой Богородицы напоминает о том, что Господь стал человеком и пришел в мир для того, чтобы людям было легче приблизиться к Богу.
В праздник Благовещения всем православным верующим следует прийти в храм, помолиться и причаститься Святых Христовых Тайн», – резюмировал заместитель председателя информационного отдела БПЦ.
Сергей Пархоменко — Суть событий — Эхо Москвы, 02.04.2021
С.Пархоменко― 21 час и 3 минуты в Москве. Это программа «Суть событий». Я Сергей Пархоменко. Добрый вечер! Всё в порядке, я в студии, так что я могу видеть эсэмэски. Мне еще обещали чат наладить через некоторое время. Надеюсь, что с ним тоже всё будет хорошо. Пока только эсэмэски вижу. Будет и чат, не волнуйтесь.
Для СМС у нас есть номер: +7 985 970 45 45. И я условно говорю, что это эсэмэски, потому что это, конечно, могут быть не только СМС, а из Telegram можно и через WhatsApp можно и через приложение для ваших смартфонов, через сайт «Эхо Москвы», в общем, есть множество возможностей отправлять сюда сообщения. Я буду их видеть и по мере возможностей буду ориентироваться на ваш интерес.
А вообще-то я делаю это заранее при помощи своего Фейсбука, в котором выкладывают соответствующий пост за несколько часов до начала нашей программы для того, чтобы собрать ваши предложения о темах, вопросах и всяком прочем.
А кроме того, есть еще Телеграм-канал, он называется «Пархомбюро». Пожалуйста, не забывайте про него, это тоже прекрасный способ для обратной связи и вообще в нем есть, что почитать. Я в нем выкладываю регулярно разные сообщения.
Но пейджера, — спрашивают у меня, — уже нету? Простите, дорогие друзья, чего нету, того нету. Пейджера, как ни хватишься — у нас нет. О, прекрасно, мне принесли чат, теперь я буду совершенно спокоен и во всеоружии. Замечательно.
Ну что же, конечно, я начну с Навального. Я, действительно, считаю, что это важнейшее событие российской политики, событие длящееся, событие на протяжении нескольких недель. И, более того, оно все более тяжелеет и расширяется внутри всей структуры российской политики и появляются новые обстоятельства, которые делают его еще большее важным. Появляются какие-то последствия от него, которые, возможно, на первый взгляд не очень с ними связаны, но в действительности являются его последствиями. Мы про это поговорим немножечко позже.
Появляются какие-то последствия от него, которые, возможно, на первый взгляд не очень с ними связаны, но в действительности являются его последствиями. Мы про это поговорим немножечко позже.
Пока о самых последних обстоятельствах, связанных с незаконным содержанием Алексея Навального в тюрьме в колонии Владимирской области.
С.Пархоменко: Навальный не совершал преступление, за которое его теперь держат в тюрьме
Я снова и снова повторяю, что это незаконное его содержание там. Существует решение ЕСПЧ, который не признал тот приговор, который был вынесен по делу «Ив Роше» и под предлогом которого Навального содержат в колонии. А сам этот приговор объявлен ничтожным, незаконным. Подтверждено, что он вынесен за деятельность, которая неотличима от обыкновенной предпринимательской деятельности.
Поэтому фраза, которую мы слышим: «Если совершил преступление, так имей мужество быть в тюрьме…» — он не совершал преступления. Это некоторая исходная точка, которую надо иметь в виду. Он не совершал преступление, за которое его теперь держат в тюрьме. Вот от этого надо отталкиваться, как от первоначального понимания. Все остальное — надстройка над этим.
Речь идет о том, что человека держат в тюрьме для того, чтобы изолировать его от вас, для того, чтобы его политическая деятельность прекратилась, для того, чтобы ряска и тина сомкнулась над его головой, мы с вами про это забыли.
— «Федеральные каналы орут, что отец Жданова — вор». А что им еще делать? Они для этого существуют, чтобы орать всякое вранье. А вы что ожидали, что они будут какать маргаритками, что ли, и незабудками? Ну да, они врут. А вы чего хотели от них, от федеральных телеканалов?
Дальше начинаются всякие навороты этой истории с посадкой Навального, этого человека, которого пытались убить. Попытались убить преступным способом. Сам способ был выбран такой, какой представляет некую особую опасность для человечества в целом, потому что он нарушает международные обязательства России относительно химического оружия. Россия обещала, что не будет никакого химического оружия. Оно есть и применяется. Оно применено на Навальном. Это доказали четыре разных лаборатории в Европе, и это является сегодня тем официальным фактом, на котором стоит ОЗХО. Россия является частью этой организации.
Россия обещала, что не будет никакого химического оружия. Оно есть и применяется. Оно применено на Навальном. Это доказали четыре разных лаборатории в Европе, и это является сегодня тем официальным фактом, на котором стоит ОЗХО. Россия является частью этой организации.
Начинаются всякие навороты, о которых я хотел поговорить. Один из них это вот это «склонен к побегу». Когда мы впервые об этом узнали, Навальный находился еще в Москве, в «Матросской тишине», стало совершенно понятно, зачем это делается. Это делается, чтобы иметь возможность дополнительного давления. Это делается для того, чтобы его при случае можно было открыто пытать. Так оно и есть.
При этом сегодня самые разные люди ровно так же, как они говорят нам: «Если совершил преступление, то имей мужество сидеть в тюрьме» — он не совершал преступления, — ровно те же люди нам говорят: «Есть законный порядок для тех, кто обладает этой красной полосой, кто помечен в качестве склонного к побегу.
У меня есть хороший друг и, не побоюсь этого слова, единомышленник, очень хороший юрист по имени Юлия Николаева. Она, вообще-то происходит из Перми, работала там в российских всяких правоохранительных органах, потом уехала за границу. Живет в США. Имеет там большой профессиональный успех. Вот она не постеснялась сесть и произвести углубленный поиск относительно того, а что, собственно, этот законный порядок склонного к побегу. Когда говорят, что «так по закону — будить 8 раз в ночь; так по закону, что на груди он носит этот знак; так по закону, что его движение просматривается камерами — так определено законом, мы исполняем закон. Вы что хотите какого-то отдельного беззакония? Нет, у нас тут закон».
Так вот я посмотрел довольно подробный разбор, который сделала Юлия Николаева. Не поверил ей и пошел по ее стопам и посмотрел те документы, которые она упоминает или которые она почему-то не упоминает, что меня очень удивило. Весь этот ресёч, а в этом ресёче не упомянут главный документ, а именно Уголовно-исполнительный кодекс Российской Федерации, основной документ, которым регламентируется то, что связано с содержанием осужденных. Мы сейчас не делим осужденных на справедливо осужденных и несправедливо осужденных, как Навальный, который не совершал преступления в доме, который построил Джек. Мы всё время будем возвращаться к этой точке. Надо к ней возвращаться. А что же делать?
Мы сейчас не делим осужденных на справедливо осужденных и несправедливо осужденных, как Навальный, который не совершал преступления в доме, который построил Джек. Мы всё время будем возвращаться к этой точке. Надо к ней возвращаться. А что же делать?
Ну, вот я пошел смотреть в Уголовно-исполнительном кодексе Российской Федерации, что там написано про «склонный к побегу» и режим их содержания. Там ничего о них не написано. Их там нет. И вот это тот случай, когда «ихтамнет» является не шуткой, не издевательством, а констатацией факта.
С.Пархоменко: Осужденные любые имеют право на получение квалифицированной медицинской помощи
Простите, пожалуйста, я время от времени отхлебываю чай. Возможно, это звучит очень громко. Я знаю, поскольку микрофон близко. Но я чувствую себя не совсем здоровым, мне иногда нужно глоток чего-то горячего.
Так вот этого нет в Уголовно-исполнительном кодексе вообще, совсем. Это еще много где нет. Наконец, нашлось, где это есть. Есть в мае 2013 года инструкция. Она называется: «Инструкция по профилактике правонарушений среди лиц, содержащихся в учреждениях уголовно-исполнительной системы». Это внутренний подзаконный документ. Это не закон, его не принимала Государственная дума, Совет Федерации, не подписывал президент. Это документ, изданный правительством в качестве внутреннего ведомственного акта Министерства внутренних дел. Там есть одна строчка, в ней написано, что бывают лица, склонные к побегу. И еще есть абзац один про этих склонных к побегу, который я вам сейчас зачту целиком. Он звучит следующим образом:
«Подразделение охраны учреждений уголовно-исполнительной системы через сотрудников оперативных и режимных подразделений ежедневно уточняют список лиц, склонных к побегу, обновляют соответствующие информационные стенды и планшеты на контрольно-пропускных пунктах и в классах по служебной подготовке, своевременно доводят изменения в оперативной обстановке до сотрудников, входящих в состав караулов, принимают меры по предотвращению побегов…».
Это то, что нашла Юлия Николаева, которой я не поверил, а пошел искать сам. И еще раз пошел, нашел эту инструкцию. Забейте в Гугле: «Инструкция по профилактике правонарушений среди лиц, содержащихся в учреждениях уголовно-исполнительной системы». Я после программы обязательно вам выложу, собственно, ссылку на этот пост Николаевой, там содержатся все названия. Вам легко будет это всё обнаружить и самим проверить.
Знаете, что важно знать об этом абзаце, которая я вам здесь сейчас прочел? Важно о нем знать то, что он там такой один. Больше ничего нет. Ничего нет про побудки через каждый час, ничего нет про эти штуки с красной полосой. Ничего нет про видеокамеры, про постоянный досмотр, про то, про сё, пятое-десятое. Ничем там нет. Это все изобретение конкретной администрации конкретной колонии. Это произвол. Это инструмент пыток, который они сами вручную кустарно создают и применяют. Вот это очень важно понимать.
То есть да, вот этой внутренней инструкцией подтверждается, что бывают такие люди, склонные к побегу и надо их знать, надо их на планшеты на контрольно-пропускных пунктах и в классах по служебной подготовке, а также на соответствующих информационных центрах — да, надо.
А дальше, собственно, между строк начальник колонии читает следующее: «И вообще можете с ним делать, чего хотите. И вообще можете их мучить». Вот и всё. Вот вам история про «склонен к побегу» от начала и до конца.
Теперь история про тот вид пыток, который мы обнаружили вчера и сегодня, применяемый к Навальному. Это пытки психологические, помимо этих физических, которые заключаются в том, что ему не дают спать, которые заключаются в том, что к нему не пускают квалифицированного врача, который мог бы понять что-нибудь насчет того, что происходит с человеком, который… когда это было — в августе? — 7 месяцев тому назад повергся воздействию боевого отравляющего вещества, находился в коме на протяжении нескольких недель. Потом прошел какую-то частичную реабилитацию, по всей видимости, и немедленно вернулся обратно, в Россию.
Нужен врач, который понимает в этом во всем. О’кей, не тот врач, который лечил Навального в Германии, хотя, конечно, лучше бы тот врач. Но пусть это будет тот врач, у которого есть квалификация относительно такого рода проблем. Тем более, что это как раз написано в законе. Это как раз зафиксировано, что осужденный (мы сейчас не берем с вами, справедливо осужденный или несправедливо; Навальный является несправедливо осужденным за преступление, которое он не совершал в доме, который построен Джек — снова давайте обойдем этот круг).
С.Пархоменко: Навальному доказывают, что он является зверьком в зоопарке
Осужденные любые имеют право на получение квалифицированной медицинской помощи. В случае, если она не может быть им оказана на месте, они имеют право на получение помощи в муниципальных организациях здравоохранения с участием гражданских специалистов. не имеющих отношения к системе ФСИН, неподчиненных системе ФСИН. И в этом их ценность — в том, что это независимый специалист, который может высказывать свое мнение, свою профессиональную позицию, оценку состояния дел с этим пациентом без контроля, не находясь внутри конфликта интересов, когда он должен подчиняться своему фсиновскому начальству как любой штатный тюремный врач.
Сегодня ко всей этой истории добавились еще пытки психологически. Навальному доказывают, что он является зверьком в зоопарке, что он сидит в клетке и любой желающий может как-то глазеть на него, просовывать ему через решетку недоеденное мороженое или еще что-нибудь, что там обычно в зоопарке просовывают этим несчастным зверям.
Исполнять это… понимаете, для каждой пытки нужен палач: ну как-то человек сам не залезает на дыбу, не втыкает в себя иголки и не жжет себя железом, нужен исполнитель, нужен конкретный человек, который возьмется с человеком всё это проделать, это такая профессия, некоторые считают, что это призвание. Очень хорошо это описано сатирически в книге братьев Стругацких «Трудно быть богом». Там есть такой эпизод, как молодые балбесы сдают экзамен по палаческому искусству. Вот одна, которая, видимо, уже сдала такой экзамен — зовут ее Мария Бутина — взялась побыть палачом. Это удивительно, что для этого она переоделась в журналиста. Хотя, что в этом удивительного? Мы на самом деле много таких ситуация видели.
Там есть такой эпизод, как молодые балбесы сдают экзамен по палаческому искусству. Вот одна, которая, видимо, уже сдала такой экзамен — зовут ее Мария Бутина — взялась побыть палачом. Это удивительно, что для этого она переоделась в журналиста. Хотя, что в этом удивительного? Мы на самом деле много таких ситуация видели.
Мы знаем о том, что в России есть некоторое количество медиа, которые часть своих журналистов, иногда большую часть, но обычно все-таки не всех, но часть своих журналистов сдают в аренду для того, чтобы они участвовали в разного рода спецоперациях в качестве сотрудников спецслужб. Не обязательно, чтобы они были при этом сотрудниками спецслужб, не обязательно, чтобы у них было звание, чтобы они значились в каких-то списках служебных. Они добровольно это делают, точнее они это делают потому, что они работают в этом медиа, и поэтому это часть их обязанностей.
Мы видели с вами всякие НТВ, которые вламывались вместе со спецназом, который высаживал двери кувалдами. Вламывались в квартиры к людям, у которых должен пройти обыск или они должны были быть арестованы, или где с ними должны были быть проделаны какие-то, еще более тяжелые следственные действия. И мы видели с вами людей, которые с камерой на плече и с микрофоном на длинной палке впереди вбегали вслед за этими бугаями в бронежилетах, в касках с запотевшим забралами. Мы видели с вами, например, РЕН ТВ, которые интервьюировали человека, который в этот момент лежал прижатый лицом к полу. У него сзади в этот момент были руки наручниками скованы. А у него брали интервью журналисты. Помните эту историю?
Мы видели с вами разнообразнейшие федеральные телеканалы и всякие ЛайфНюьсы и всякое прочее, когда они приходили вместе со всякими «залупинцами» или с какими-нибудь нодовцами, или еще с какой-нибудь шелупонью для того, чтобы ломиться в двери «Мемориала», предположим, и пытаться сорвать их какие-то события, которые они устраивали — награждения премиями или еще что-то вроде этого, — поливали зеленкой, мочой людей, которые туда приходили. Мы это всё видели. И мы знаем, чем для них это всё кончилось. Это кончилось мировым позором.
Мы это всё видели. И мы знаем, чем для них это всё кончилось. Это кончилось мировым позором.
Вот, собственно, самая позорная из них — Russia Today бесконечно ноет, рыдает и воняет по поводу того, что «вот нас выгнали с пресс-конференции… Нас не аккредитовали там-то… У нас закрыли бюро… Нас банк отказался обслуживать». Если вы почитаете их Телеграм-каналы, какие-то их внутренние новостные ленты, где они живописую свое чудовищное сегодняшнее бытование, вы увидите, что это просто основной сюжет этого всего.
С.Пархоменко: Бутина демонстрирует, что ей, конечно, лучше знать, она-то вон прошла через ад американской тюрьмы
Один из этих людей некоторое время назад написал жирный, сочный, влажный донос и сдал его в Роскомнадзор. Донес на YouTube, который «нас не любит, он нас не показывает, он нас не продвигает, он нас не одобряет». А зачем он вам? Это же вредное, неприятное иностранное… Вы все время пытаетесь это закрыть. А чего вы туда лезете? У вас есть свои для этого домашние инструменты. Слушайте, пожалуйста, песню «Валенки» вашу любимую, пейте, пожалуйста, овсяный киселек. Зачем вам YouTube, вот это всё? Зачем счет в германском банке? Зачем вам корпункт в Париже? Зачем? Чтобы что? Что вы там собираетесь делать? Вы же патриотическая спецслужба, задача которой заключается в том, чтобы пытать тех, кого вам назначили пытать.
Вот, например, Бутина от вашего имени пытает психологически Навального. Она является к нему в камеру фактически. Судя по описанию это большой зал, в котором стоят многие десятки этих коек, такая казарма. Но формально это камеры. Является в эту много-многоместную камеру, куда он ее не звал, разрешения на съемки не давал.
Вообще, человек, который сидит в тюрьме, он остается человеком, у него сохраняется его человеческая сущность. Он поражен в некоторых своих гражданских права — ему голосовать нельзя, если он уже осужден,— но вообще он остается человеком. И отношение к нему должно быть человеческое. Его нужно кормить, он должен спать, его нужно лечить. Он должен встречаться с родными. Он должен иметь информацию об окружающим мире. Он должен сохранять свое человеческое достоинство. Его нужно называть по имени. Его мнением нужно интересоваться относительно любого действия, которое осуществляется с ним, которое направлено на него, за исключением того, что написано в разного рода специальных уголовных регламентах, главным образом в Кодексе об исполнении наказаний, где ничего не сказано, что можно относиться к человеку, как к животному в зоопарке.
Его нужно кормить, он должен спать, его нужно лечить. Он должен встречаться с родными. Он должен иметь информацию об окружающим мире. Он должен сохранять свое человеческое достоинство. Его нужно называть по имени. Его мнением нужно интересоваться относительно любого действия, которое осуществляется с ним, которое направлено на него, за исключением того, что написано в разного рода специальных уголовных регламентах, главным образом в Кодексе об исполнении наказаний, где ничего не сказано, что можно относиться к человеку, как к животному в зоопарке.
И вот мы видим эту Бутину, а рядом с ней мы видим еще и Life News со своими роликами, которые они получили, добыли, совершили как-то журналистский прорыв, как-то сумели завладеть. А давайте с вами угадаем с одного раза, каким способом они сумели завладеть? Ну, как то выдали им, начальство выдало им и велело, и продемонстрировало.
Я думаю, что эти люди, которые исполняют палаческие обязанности, не должны удивляться потом — да они, собственно, и не удивляются, не должны возмущаться — да они, собственно, не возмущаются, они имитируют это возмущение, — что к ним относятся, как к палачам. Это во всей истории человечества одна из самых презренных, я бы сказал, призираемых профессий.
В какие-то варварские времена эти люди вынуждены были селиться на отшибе. Уже никто не хотело, чтобы палач жил на их улице, не то что никто не хотел с палачом есть, набирать воду из одного колодца и так далее.
Сегодня мы живем во времена цивилизованные, поэтому палачей просто скрывают. Идет человек, у него написано: «Сотрудник системы исполнения наказаний» или там: «Старший инспектор по дисциплине или еще как-нибудь это называется. Он ездит в обычной машине без опознавательных знаков. Не носит большой красный колпак с прорезями, не пользуется огромным топором, который хранит в бархатном футляре. А является такой вот девицей с белесыми глазами, которая в свое время — хотелось бы, чтобы вы про это помнили, — сидела в американской тюрьме и признала свою вину и согласилась с тем, что она посажена в эту тюрьму справедливо. Из каких соображений, мы никогда не узнаем. Может быть, он хотела сократить себе срок. Может быть ее прошибло какое-то раскаяние в какую-то секунду. Не знаю, да, в общем, и неинтересно.
Из каких соображений, мы никогда не узнаем. Может быть, он хотела сократить себе срок. Может быть ее прошибло какое-то раскаяние в какую-то секунду. Не знаю, да, в общем, и неинтересно.
Я только знаю, что она да, признала свою вину. И это была вина не в том, о чем она с тех пор говорит, как вернулась в Россию, что будто бы она сидела за то, что она оказалась иностранным агентом. Ничего подобного, не иностранным агентом. А агентом иностранного государства под прикрытием — так это называлось. Это два разных закона, это два разных преступления, две разных вины, два разных наказания. Потому что по закону об иностранных агентах не предполагается никакого тюремного наказания, разумеется, в США, потому что иностранный агент там нечто совершенно другое. Остановлюсь на этом месте. Вернусь к Бутиной после перерыва на новости через 3-4 минуты.
НОВОСТИ
С.Пархоменко― 21 час и 4 минуты в Москве. Это вторая половина программы «Суть событий». Я Сергей Пархоменко. Номер для СМС: +7 985 970 45 45. Идет прямая трансляция в YouTube-эфире на канале «Эхо Москвы», там работает час. И меня в этом чате бесконечно просят сказать что-нибудь про Познера. Мне неохота говорить ничего про Познера. Если время останется в конце передачи, скажу, а так не стоит вся эта история того.
С.Пархоменко: Путину совершенно не жмет, не мешает и не раздражает, никак его не огорчает репутация агрессора
А говорим мы с вами про Бутину и про палаческие обязанности, которые она взялась исполнять. Вот один из слушателей присылает очень уместные — его зовут Алексей Кондрашов — СМС. Маленький отрывочек из статьи 24-й Уголовно-исполнительного кодекса Российской Федерации, который я проштудировал сегодня, готовясь к сегодняшней программе, и статью 24-ю тоже хорошо знаю, можно сказать на зубок, но спасибо, тем не менее, Алексею Кондрашову. Статья 24-я называется: «Посещение учреждений органов, исполняющих наказание». Там написано: «Кино-, фото— и видеосъемка осужденных, их интервьюирование осуществляется с согласия в письменной форме самих осужденных».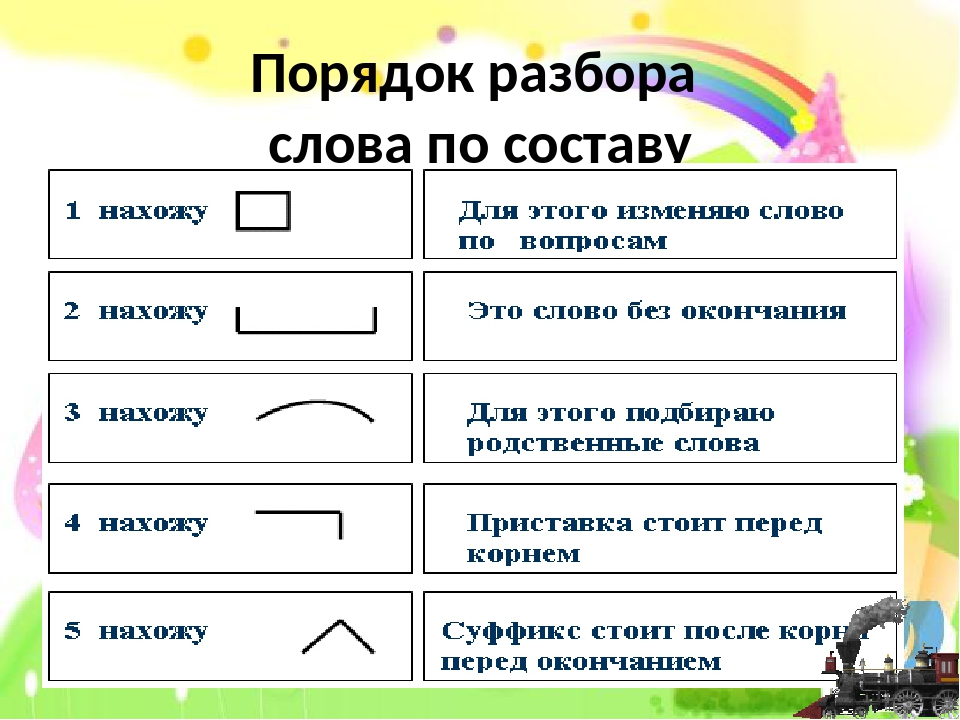
А теперь открываем официальный Телеграм-канал Russia Today и читаем в нем сегодняшнее сообщение: «Съемочная группа Russia Today побывала в ИК-2 Владимирской области, самой обсуждаемой последний месяц российской тюрьме, где отбывает наказание Алексей Навальный. Наши коллеги пообщались с самим Навальным». А каким образом они пообщались с самим Навальным? В качестве кого? В качестве журналистов не могли, потому что у них нет согласия в письменной форме самого осужденного.
Могли в какой-то другой роли выступить. В роли сотрудника колонии, например, временного сотрудника. Или в целом сотрудника какой-нибудь спецслужбы, или какого-нибудь проверяющего… Но в журналистском качестве не могли. Могли в качестве временно исполняющего обязанности палача — это пожалуйста.
Так вот про Бутина мы говорили и про ее американскую эпопею. Она врет, что была осуждена как иностранный агент. Нет, она была осуждена как агент иностранного государства. Потому что иностранный агент в США — это совершенно другая история. Это организация, которая открыто формально выполняет какие-либо задачи, поставленные иностранным правительством, и с этой целью регистрируется и это декларирует.
Я уже много раз говорил, что самый распространенный вид иностранного агента в США — это туристическая ассоциация — туристическая ассоциация Швейцарии, Исландии, Нигерии — выполняет функцию иностранного агента в США, агитирую американских граждан ехать в отпуск в Нигерию. Там слоны, носороги, я не знаю, кто там еще, может быть, гориллы даже есть. Я не большой специалист по фауне Нигерии. Но им как раз и лучше знать, этим иностранным агентам.
А здесь речь шла о другом. Речь шла об агенте под прикрытием, исполнявшем указания чиновник Российской Федерации, в свою очередь получившим эти указания от одного из ведомств Российской Федерации. Чиновником этим, по всей видимости, был Александр Торшин. Тот самый Александр Торшин, которого вы, наверное, помните как главу знаменитой парламентской комиссии по расследованию событий в Беслане. Человек, который управлял этой комиссией и который привел эту комиссию к тому позору и к тому презрению, которое испытывают к этой комиссии, к ее членам люди, которые видели своими глазами то, что произошло в Беслане. А он ею руководил, подписывал выводы этой комиссии. И с тех пор почему-то карьера его пошла вверх, и он в какой-то момент был заместителем председателя Совета Федерации Российской Федерации.
Человек, который управлял этой комиссией и который привел эту комиссию к тому позору и к тому презрению, которое испытывают к этой комиссии, к ее членам люди, которые видели своими глазами то, что произошло в Беслане. А он ею руководил, подписывал выводы этой комиссии. И с тех пор почему-то карьера его пошла вверх, и он в какой-то момент был заместителем председателя Совета Федерации Российской Федерации.
А потом всё как-то покатилось вниз и кончилось тем, что он управлял Бутиной в Вашингтоне. Вот это, собственно, то, что ему доверили. И провалился вместе с ней. И был накрыт вместе с ней. И бросил ее, и предал ее.
Она признала свою вину и села. А потом американские власти сжалились над ней и выпустили ее обратно в Россию. И она этой жалостью теперь торгует вот таким способом: она демонстрирует, что ей, конечно, лучше знать, она-то вон прошла через ад американской тюрьмы.
С.Пархоменко: Раньше у Путина был ярлык «Агрессор», а теперь у него ярлык, на котором написано: «Убийца»
Вот, что мы знаем про эту историю и про методы, к которым прибегает Российское государство сегодня в отношении людей, которых считает для себя опасными, персонально опасными для президента Путина. И что мы знаем о тех, кого оно привлекает в качестве исполнителей своего палаческого замысла. Нет никаких сомнений, что всё, что происходит с Навальным в тюрьме, санкционировано с самого верха так же, как его отравление, и мы это знаем по составу исполнителей и в одном и в другом случае.
Давайте теперь другую тему, которая мне кажется чрезвычайно важной сегодня. Это история про напряжение, внезапно возникшее снова на границе Украины, концентрацию войск там. Нелепые объяснения, которые мы получаем для прикрытия этой концентрации войск. И вообще складывается сильное ощущение, что мы вступаем в какую-то ситуацию…
Дрыся, которая спрашивает меня, сколько можно кашлять, — столько можно кашлять, сколько потребуется, чтобы вывести тебя из себя, Дрыся. Дрыся — это такое имя, она так подписывается.
Дрыся — это такое имя, она так подписывается.
Так вот, всё это очень похоже на лето 14-го года, очень похоже на начало новой стадии агрессии в Восточной Украине. И возникает вопрос, зачем это нужно? Вы, может быть, сильно удивитесь, но я бы сказал, что единственное объяснение, которое у меня есть, оно тесно связано с той темой, о которой мы говорили до сих пор. Это то, что я назвал бы некоторыми новыми последствиями и некоторыми дополнительными усложнениями темы Навального.
Дело в том, что президенту Путину, который, несомненно, несет ответственность за всё, что происходит с Навальный и за всё, что происходит с Российскими Вооруженными силами в Украине или на подступах к Украине. Ему, в общем, совершенно не жмет, не мешает и не раздражает, никак его не огорчает репутация агрессора, репутация человека, который своими действиями вносит хаос, страдания и смерть на довольно большом куске Европы, поскольку Украина и прилегающие к ней российские регионы являются частью Европы.
Так вот он с этой ролью смирился, сжился, даже, я бы сказал, как-то слюбился и, несомненно, научился извлекать из нее свои дивиденды. Это то, на чем сегодня держится его внутрироссийский, как это называется, рейтинг. На самом деле просто градус поддержки, которую он собирает. Ему удается продавать это на внутрироссийском политическом рынке российским гражданам как услугу. Услуга такая: «Мы вас защищаем. Видите, на нас все нападают, нас все ненавидят, нам все угрожают. Мы окружены врагами. Нам еды не дают».
Ну. для этого, правда, сначала пришлось объявить эмбарго и самому как-то запретить ввоз продовольствия из Европы, но через некоторое время при помощи пропагандистских каналов удалось всё перевернуть так, что если вы остановите почти любого российского гражданина и спросите: «Отчего в магазине нет итальянской свинины или польских фруктов, или венгерских овощей — почему этого нет?» — «Ну как? Они нам не дают. Они же вредные. Вот я помню, было вкусное французское масло. Его нет. Франция запретила нам его ввозить. Они нас мучают».
Его нет. Франция запретила нам его ввозить. Они нас мучают».
— «Если Россия вступит в войну, вы по возрасту подходите для мобилизации?» Понятия не имею, если честно. У меня такое впечатление, что мобилизация до 55, что ли, лет. А мне 57 уже. Впрочем, не уверен, может быть, подхожу. Надо будет проверить. Интересный вопрос, кстати.
Так вот удается продавать это на внутреннем рынке как услугу защиты. Предыдущий общественный договор, который действовал в России: «Мы вас кормим, а вы за это сидите тихо и не вмешивайтесь в нашу власть, не мешайте нам воровать». Прошло время, это перестало работать. И теперь стало так: «Мы вас защищаем — а вы за это сидите тихо, не вмешивайтесь в политику. Не мешайте нам воровать». Это некий новый договор, который был заключен после 14-года, когда потребовалось обновить этот контракт. Вот обновили. И в общем, Путину эта позиция привычная. Он себя в ней чувствует хорошо.
С.Пархоменко: Тоталитарные государства приобретают некоторые преимущества, потому что могут не ценить человеческую жизнь
Однако несколько дней тому назад он оказался в другой, непривычной позиции. И как бы на лбу его прикрепили другой ярлык. Раньше у него был ярлык «Агрессор», а теперь у него ярлык, на котором написано: «Убийца». Кто это сделал, мы помним. Это сделал американский президент Байден. И не последовало никакого протеста со стороны его союзников, его партнеров. Никто не протестовал против этого. Ну, вот знаю про Эрдогана. Эрдоган своеобразный такой партнер, да?
Но почему-то ни Меркель, ни Джонсон, ни Макрон, ни любимые Путиным итальянцы (у него особые отношения с итальянским руководством традиционно), ни греки, ни венгры, ни киприоты, ни испанцы, ни португальцы, никто не возмутился этому, не сказал: «Ну, послушайте, как вы можете? Какой же он убийца? Это безобразие, клевета. Что вы говорите об этом прекрасном, честном человеке!»
Ничего этого не случилось, и ярлык прилип. Его надо отклеивать. Просто так отклеивать его невозможно, поскольку для этого бы пришлось доказать, что он, Путин не имеет отношения к тем убийствам, которые подразумевают люди, которые об этом говорят. А их много: Щекочихин, Политковская, Немцов. Ну, вот одно неудавшееся убийство. На самом деле, видимо, этих неудавшихся было больше. Ну, так удавшихся было больше. Мы просто не все знаем.
Борис Афанасьев спрашивает: «А как же Берлускони?» А никак Берлускони. Засунул язык в задницу и молчит. У него там своих проблем. Баста «бонга-бонга» и всё остальное. Погуглите, что это такое.
Так вот Путину нужно с этим что-то делать, надо как-то переключать внимание. Тут я должен вас попросить разделять два обстоятельства. Одно, которое мне кажется чрезвычайно нелепым, это когда говорят: «Ну вот это всё на самом деле только для того, чтобы мы об этом говорили, это переключают наше внимание. Так бывает тогда, когда речь идет о каком-нибудь несуществующем мелком событии, о какой-то вынутой фитюльки из ничего, из ниоткуда вынутой, которая вдруг раздувается государственной пропагандой в России для того, чтобы все об этом разговаривали.
Другая история — это когда создается реально некое большое, важное, содержательное событие. Оно создается там, где его можно не создавать. Оно ничем не было предопределено. Никто не был к нему приговорен никаким народным судом.
Вот самый яркий пример последнего времени — это осень 2015 года: включение внезапное России в военные операции в Сирии. Зачем? А чтобы выключить Украину из информационного поля. К этому моменту ничего важнее Украины не было. Уже больше года это продолжалось, эта война. И в какой-то момент стало понятно, что это уже начинает наносить какой-то ущерб. Нужно было оторвать российское общественное мнение, информационное поле, российскую политическую повестку, как любят говорить всякие умные политологи от Украины. Оторвали. Надо сказать, очень эффективно.
Начали воевать в Сирии и буквально переключили программу телевизора — фигак! — вчера ничего важнее Украины не было, а сегодня про Украину уже никто не помнит, а все разговаривают только про Сирию.
Вот что-то такое надо делать с Навальным и с «убийцей». Потому что дело зашло далеко. Выяснилось, что Навальный лезет из всех щелей. Выяснилось, что невозможно разговаривать с Меркель и Макроном, например, чтобы они не начинали и не заканчивали этот разговор Навальным. Приходится врать что мы вообще-то обсуждали совершенно другие дела, но там по ходу дела об этом тоже вспомнили. Ничего подобного. Это сегодня центральный сюжет для всех объяснений, для разговоров с Америкой.
Вот на прошлой неделе пронеслась весть о том, что, надо же, смотрите, а ведь Байден позвал Путина принять участие в какой-то конференции, в чем-то вроде связанном с климатом или с чем-то вроде этого. Надо же!
С.Пархоменко: Государство тоталитарное, жизнь не стоит ни гроша. Мрут и мрут. Ну, ради бога, пусть мрут дальше
Ну да, это и есть, собственно, следующий шаг этой комбинации унижений, которую придумал Байден: сначала называть убийцей, потом, как ни в чем ни бывало, не извиняясь, не отъезжая назад, не отменяя, не комментируя, не подтверждая, ни опровергая, ни украшая, просто, как ни в чем ни бывало, позвать. И ведь поедет же. Потому что никуда не денется, потому что будет ездить теперь по миру с этим лейблом на лбу.
Что с этим делать? Как от этого отвязываться? Перешибать. В этих обстоятельствах вполне, мне кажется, в стиле Путина и людей, которые его окружают, которые совершенно хладнокровно относятся к человеческим жизням, для которых цена человеческой жизни — ноль. Именно в такой философии, в таком взгляде на мир — это, оказывается, совершенно нормальной вещью: давайте войну сейчас затеем? Давайте подогреем сейчас Украину — это же несложно совсем. Все будут про Украину разговаривать. Отвяжутся от истории с Навальным. Перестанут убийцей называть, будут называть опять агрессором. Опять будут говорить: «Вот вторгся. Вот разогрел. Стреляет, поставляет технику, войсковые припасы. Вот опять жертвы, опять фронт двигается туда, двигается сюда. Аэропорт такой, сякой — отбили».
Ну, так вот немножко отдохнем от «убийцы», от Навального, от всего этого сюжета. Может, за это время проблема Навального как-нибудь сама и решится. Может, у него не только ноги, но и руки к тому моменту отнимутся. А этого никто особенно и не заметит.
Так это устроено в их мозгах. Пару часов назад Сергей Гуриев здесь в эфире «Эха Москвы» говорил очень интересные вещи о том, что тоталитарные государства в каких-то ситуациях, начинают приобретать в современном мире преимущества, потому что они могут не уважать человеческих прав, человеческого достоинства. Он говорил о том, что они могут распоряжаться информацией о людях, персональными данными о людях и так далее.
Я бы это продолжил бы, сказал, что да, на наших глазах тоталитарные государства приобретают некоторые преимущества, потому что они могут не ценить человеческую жизнь. И Путин нам много раз это демонстрировал. Он нам это демонстрировал, ввязываясь в разные другие войны. Потому что ни для одного нормального политика в демократической стране нет ничего страшнее, чем потерять своего гражданина где-то там, далеко, на каком-то чужом фронте. Это очень большая неприятность, это очень тяжелый удар по репутации, это очень серьезный ущерб, который этот политик понесет на ближайших выборах.
А Путину все равно. Умер Максим — хрен с ним. Сколько вы хотите, чтобы мы там сожгли наших граждан? Сколько тонн человеческого мяса вам нужно? Пожалуйста, берите. Нам что, жалко что ли? Куда хотите? В Сирию? — пожалуйста. В Ливию? — ради бога. В Центральноафриканскую республику? Да сколько угодно. Забирайте! Нам не жалко, мы легко можем этим распоряжаться. Нам много. Нам бабы еще нарожают, как было сказано классиком.
Вот так это происходит с Украиной. Надо войну еще одну развязать? Да ради бога! Делов-то! Г….-пирога. Чего такого? Вот для пропаганды, для смены имиджа, для отклеивания ярлыка? Да пожалуйста!
Та же история, заметим, на наших глазах. Удивительно, как всё завязывается в одну историю. Та же история, тот же сюжет разворачивается и во всей проблеме с коронавирусом. Как так вышло вдруг, что Российская Федерация с этим уровнем здравоохранения, с этим уровнем производства лекарственных препаратов, с этим уровнем организации, с такой коррупцией, с такой эффективностью управления вдруг взяла и оказалась в передовиках, и как-то решила проблему коронавируса. Они там все сидят в масках, с огромными комендантскими часами, когда не выйди на улице — где-то после 6, где-то после 8, где-то после 9, не отойди от дома. Нельзя отъехать на 10 километров ни при каких обстоятельствах. Прогулки по часам. В Греции опять выезд из дома по СМС.
Как так у них всё это происходит: у них так ужасно, а у нас всё так прекрасно? А вот почему — потому что тоталитарное государство может себе это позволить. 380 тысяч лишних смертей — да ради бога! Мы что, считать, что ли будем это? Никто не хочет прививаться? Да ради бога! Не больно и хотелось.
С.Пархоменко: Вот увидите, это будет работать. Будут обсуждать войну в Украине вместо Навального, ярлыка убийцы
Не можем произвести эту вакцину. Вот как было 5 производителей с первой минуты, когда была зарегистрирована, и они вписаны в регистрационное удостоверение этого «Спутника», так там и есть эти 5 компании, можете сейчас заглянуть. По-прежнему их 5. Нет этого производства. Они не сделали этой вакцины. И они не парятся по этому поводу, потому что они тоталитарное государство: им не жалко, они не смущаются этими смертями. И они не будут как какой-нибудь Макрон глупый влезать в телевизор, как он это сделал два дня тому назад, с перекошенным трагическим лицом, чтобы сказать: «Граждане, всё ужасно. У нас всё выходит из-под контроля. Месяц все еще будем сидеть по домам. Простите меня, я очень виноват».
И ведь его никто не простит, у него будут большие неприятности. Ему это припомнят на выборах. Может быть, это будет стоить ему президентского места. Вполне возможно. И беда его заключается в том, что он обязан выйти, он не может не выйти. И сказать: «Мы должны беречь человеческие жизни. Ничего важнее этого у нас нет.
С.Пархоменко― А Путин что, обязан таким образом себя вести? Да вовсе нет. Государство тоталитарное, жизнь не стоит ни гроша. Мрут и мрут. Ну, ради бога, пусть мрут дальше. Пусть гуляют. Нам-то что? Можно только использовать эту историю про коронавирусные ограничения опять же для преследования своих соперников. Это очень удобная штука. Каждый раз, когда надо провести на стадионе… сколько там собралось: 40 тысяч, 60? Каждый раз, когда на стадионе собрать людей — пожалуйста. Чего? Нормально. А когда люди втроем собираются выйти на пикет — ну, подождите, это сейчас как-то запрещено. Вы будете сидеть под домашним арестом. Всегда. Столько, сколько мы вам скажем.
— «В «Лужниках», — пишет мне Васька, — тоже все были без масок, только всплеск потом произошел короны». Правильно. А зачем им там быть с масками? Кого-нибудь жалко, что ли? Потому что какая-нибудь человеческая жизнь окажется под дополнительным риском? Да нет. Умер Максим — хрен с ним!
Вот так это завязано в одну систему. Вот так тоталитарное государство, которое способно плевать на жизни своих граждан, использует этот же метод для того, чтобы развязывать новые войны в тех случаях, когда нужно отвлечь общественное мнение и мировое общественное мнение. И вот увидите, это будет работать. Будут обсуждать войну в Украине вместо Навального ярлыка убийцы. Обязательно. Вот так это устроено. И смотрите, на это, понимая это, отдавая себе отчет в том, что внутренняя структура вот такая и основы вот такие. Это полезно для понимания всяких деталей из новостей дня.
Это была программа «Суть событий». Я Сергей Пархоменко. Всего хорошего, до будущей пятницы. До свидания!
Интересные факты о космосе, в которые трудно поверить :: Жизнь :: РБК Стиль
© Greg Rakozy/Unsplash
Автор Ульяна Смирнова
07 апреля 2021
В созвездии Рака есть планета-алмаз стоимостью $26,9 нониллионов, а земные сутки в будущем растянутся до 870 часов. Рассказываем, что еще необычного скрывает космос.
1. В Солнечной системе может быть больше восьми планет
Солнечная система — наиболее изученная часть космического пространства. По официальной версии, она включает восемь планет. В действительности их значительно больше. Одних только «карликов» здесь насчитывается не меньше пяти. Это Плутон, Церера, Хаумеа, Макемаке и Эрида. Из-за удаленности от Земли они мало изучены. Более того, по оценкам ученых, в Солнечной системе может находиться еще около 2 тыс. потенциальных карликовых планет. К тому же многие астрофизики признают наличие девятой крупной планеты. Она размером с Нептун и в десять раз тяжелее Земли. О существовании загадочной планеты X ученые стали догадываться еще в 2014 году, а в 2016-м получили первые доказательства с помощью компьютерного моделирования.
© David Menidrey/Unsplash
2. Планета из графита и алмазов
Еще одну таинственную планету астрономы обнаружили в созвездии Рака. По мнению сотрудников Йельского университета, она вдвое больше и в восемь раз тяжелее Земли. Но главное — Янссен почти целиком состоит из графита и алмазов. Причем на долю последних приходится треть его вещества. Forbes оценил стоимость планеты в $26,9 нониллионов. По космическим меркам, гигантский алмаз расположен неподалеку от землян — всего в 40 световых годах. Правда, температура его поверхности достигает 2,148 тыс. градусов. А скорость вращения настолько высокая, что один год там равняется 18 земным часам. Кроме того, недавно ученые выяснили, что одна сторона Янссена находится в расплавленном состоянии и представляет собой углеродную лаву.
3. Без Луны на Земле вымрут морские обитатели
Если спутник Земли исчезнет, скорее всего, глобальной катастрофы не случится. Когда-то она была основным источником света в темное время суток — теперь люди умеют обходиться без нее. И все же некоторые серьезные изменения произойдут. Например, настанет конец многим водным видам спорта. Фазы Луны влияют на волны — проходя над поверхностью нашей планеты, она «тянет» за собой массы воды. Кроме того, вымрут морские обитатели, жизнь которых напрямую связана с приливами и отливами. Без спутника на Земле не будет солнечных и лунных затмений, а тектонические плиты сместятся, вызвав землетрясения и извержения вулканов. Но главное — климат планеты уже не будет прежним.
© Anders Jilden/Unsplash
4. Осколки Тунгусского метеорита до сих пор не найдены
Самый таинственный космический пришелец XX века — Тунгусский метеорит. Он упал в районе сибирской реки Тунгуска утром 30 июня 1908 года. В тот день небо осветило ярким сиянием, а последовавший за ним воздушный взрыв уничтожил огромный участок леса и выбил стекла домов в радиусе 200 км. Однако ни осколков метеорита, ни следов применения оружия массового поражения, ни обломков инопланетного корабля так никто и не нашел. По расчетам специалистов NASA, диаметр метеорита составлял 75 м, а сила взрыва сравнялась с мощностью термоядерной бомбы. К слову, после падения Челябинского метеорита ученые нашли более 100 осколков. Самый большой из них весит почти 700 кг.
5. В космосе царит тишина
Самым тихим местом на нашей планете считается безэховая камера в Лаборатории Орфилда — она поглощает до 99,99% звуков. Но даже там услышать абсолютную тишину не получится. Ее нарушит работа наших легких и кровеносной системы. Сегодня в этой лаборатории проводят различные исследования и тестируют приборы. А еще в подобных изолированных пространствах специалисты NASA испытывают будущих астронавтов. В космосе нет звуков — из-за отсутствия воздуха. Поэтому даже мощные галактические взрывы происходят в полной тишине. Работать в таких условиях очень трудно: всего несколько минут в звуковом вакууме вызывают у неподготовленных людей панические атаки и сильные слуховые галлюцинации.
© Alexander Andrews/Unsplash
6. Скафандр NASA стоит $22 млн
Космическому агентству не хватает скафандров. Из-за этого даже отменили первый выход в открытый космос команды женщин-космонавтов. Он был перенесен и состоялся в октябре 2019 года. В разработку новых скафандров NASA вложило более $200 млн. Несмотря на это, согласно отчету генерального инспектора Пола Мартина, в распоряжении ведомства находится всего 11 пригодных для эксплуатации космических костюмов. Они разработаны в конце семидесятых годов, а срок их службы истек еще в прошлом столетии. Из-за неполадок в устаревшей охлаждающей системе скафандров в шлемах астронавтов скапливается влага. По словам инженера NASA Пабло де Леона, каждый такой костюм весит более 150 кг и стоит $22 млн.
7. Луна покидает земную орбиту
Луна постепенно удаляется от нашей планеты. Правда, происходит это с очень незначительной скоростью — 38 мм в год. Исследователи из Висконсинского университета в Мэдисоне и Колумбийского университета рассчитали, что 1,5 млрд лет назад земные сутки длились примерно 18 часов. В то время Луна находилась к Земле на 44 тыс. км ближе, чем теперь. По мнению астрофизиков, возросшее расстояние повлияло на вращение планеты вокруг своей оси, а вместе с тем на климат и продолжительность дня. Еще через несколько миллиардов лет орбита Луны увеличится примерно вдвое, а сутки растянутся на 870 часов. Однако со временем они перестанут отдаляться друг от друга, и спутник вновь начнет двигаться к Земле, прогнозируют специалисты.
8. Мощное гравитационное поле замедляет время
Из-за гравитации время в космосе протекает по-разному. Чем мощнее гравитационное поле, тем сильнее замедляется время. Этот феномен проиллюстрирован в фильме «Интерстеллар» Кристофера Нолана. Когда герои попадают на планету Миллер, час для них оказывается равен семи земным годам. Вернувшись на борт космического корабля спустя три с небольшим часа, астронавты застают уже поседевшего коллегу, который ждал их возвращения долгие 23 года. Практически так же происходит и в реальности. Например, для космонавтов время тянется на доли секунды быстрее, чем для людей на Земле. А вблизи черной дыры оно почти полностью останавливается.
9. Ветра на Венере дуют со скоростью 500 км/ч
Венера схожа с Землей по составу и размерам, но сильно отличается по внешнему виду и условиям на поверхности. Атмосфера планеты состоит из нагретых до больших температур углекислого газа и паров серной кислоты и обладает очень высокой плотностью. Данные спектрометра SPICAV, установленного на орбитальной станции Venus Express, показали, что в мезосфере Венеры на высоте 85-100 км озона в 10 тысяч раз меньше, чем в атмосфере Земли. А содержание двуокиси серы значительно меняется в течение нескольких суток. Благодаря исследованию с использованием звездного просвечивания, когда спектрометр следил за звездами при их восходе и заходе за горизонт планеты, ученым удалось выяснить концентрацию основного газа венерианской атмосферы. Такое распределение озона указывает, что газ взаимодействует с химическими соединениями, которые ветры переносят из дневной стороны полушария на ночную. А из-за того, что атмосфера Венеры вращается в 60 раз быстрее поверхности планеты, скорость ветра здесь может составлять до 500 км/ч.
Как мы читаем — Отдельный список
Я хочу, чтобы вы подумали о том, что вы сейчас делаете. Я имею ввиду , на самом деле думаю об этом. Когда ваш взгляд перемещается по этим линиям и направляет информацию в ваш мозг, вы принимаете участие в разговоре, который я начал с вами. Передача этого разговора — это тот тип, который вы читаете на этой странице, но вы также фильтруете его через свой опыт и прошлые разговоры. Вы помещаете эти слова в контекст. И независимо от того, читаете ли вы эту книгу на бумаге, на устройстве или за столом, среда тоже влияет на ваш опыт.Кто-то другой, читающий эти слова, может проделывать те же движения, но их интерпретация неизбежно отличается от вашей.
Продолжение статьи ниже
Это самое интересное в типографике: это цепная реакция времени и места, в которой вы играете роль катализатора. Намерение текста зависит от его представления, но для этого нужно, чтобы вы придали ему смысл посредством чтения.
Шрифт и типографика не существовали бы без необходимости выражать и фиксировать информацию.Конечно, у нас есть и другие способы делать эти вещи, например, речь или изображения, но шрифт — это эффективный, гибкий, портативный и переводимый. Это то, что делает типографику не только искусством общения, но и искусством нюансов и мастерства, потому что, как и всякое общение, ее ценность находится где-то в диапазоне между успехом и неудачей.
Процесс чтения очень сложен, но, как только мы узнаем, как это сделать, это своего рода мышечная память. Мы редко думаем об этом. Но поскольку чтение неотделимо от всего остального в типографике, это лучшее место для начала.Мы все сделали что-то, что хотели бы, чтобы кто-то прочитал, но вы когда-нибудь задумывались об опыте чтения этого человека?
Так же, как вы являетесь моей аудиторией этой книги, я хочу, чтобы вы также посмотрели на свою аудиторию: своих читателей. Одна из функций дизайна — увлекать и восхищать. Нам нужно приветствовать читателей и убедить их присоединиться к нам. Но какие обстоятельства влияют на чтение?
То, что что-то читается, не означает, что это читаемо. Разборчивость означает, что текст можно интерпретировать, но это все равно, что сказать, что кора дерева съедобна.Мы стремимся выше. Читаемость сочетает в себе эмоциональное воздействие дизайна (или его отсутствие) с количеством усилий, необходимых для чтения. Вы слышали о TL; DR (слишком долго; не читали)? Длина — не единственный недостаток чтения; плохая типографика тоже. Перефразируя Стивена Коулза, термин «удобочитаемость» не задает простого вопроса: «Вы можете это прочитать?» но «Вы хотите это прочитать?»
Каждое решение, которое вы примете, потенциально может помешать пониманию читателя, заставляя его вместо этого обновлять свой статус в Facebook.Не позволяйте вашему дизайну отпугивать ваших читателей или мешать тому, что они хотят делать: читайте .
Что еще мы можем сделать, чтобы привлечь внимание читателей и помочь им понять наш текст? Давайте кратко рассмотрим, что такое чтение и как на него влияет дизайн.
Когда я только начал разрабатывать веб-сайты, я предполагал, что все читают мою работу так же, как и я. Я потратил бесчисленные часы на создание правильного макета и аранжировки шрифтов.Я рассматривал эту работу как собрание сделанных мною типографских соображений: с любовью установленные заголовки, обильные пробелы, типографский ритм (рис. 1.1). Я предполагал, что все это тоже увидят.
Рис. 1.1: Небольшой фрагмент текста. Но что на самом деле происходит, когда кто-то его читает?Приятно думать, что это так, но чтение — это гораздо более тонкое занятие. Это формируется нашим окружением (нахожусь ли я в шумном кафе или отвлекаюсь иным образом?), Нашей доступностью (я чем-то занят?), Нашими потребностями (ищу ли я что-то конкретное?) И многим другим.Чтение зависит не только от того, что происходит с нами в данный момент, но и от того, как наши глаза и мозг обрабатывают информацию. То, что вы видите , и то, что вы испытываете , когда вы читаете эти слова, совершенно разные.
Когда наши глаза перемещаются по тексту, наш разум поглощает текстуру шрифта — сумму положительных и отрицательных пространств внутри и вокруг букв и слов. Мы не останавливаемся на этих пробелах и деталях; вместо этого наш мозг выполняет тяжелую работу по синтаксическому анализу текста и созданию мысленной картины того, что мы читаем.Наши глаза видят этот типаж, а наш мозг видит, как Дон Кихот гонится за ветряной мельницей.
Или, по крайней мере, на это мы надеемся. Это идеальный сценарий, но он зависит от нашего выбора дизайна. Вы когда-нибудь были полностью поглощены книгой и терялись в проходящих страницах? Я тоже. Хорошее письмо может это сделать, а хорошая типографика может смазывать колеса. Не вдаваясь в подробности, давайте посмотрим на физический процесс чтения.
Саккады и фиксации # section4
Чтение не линейное.Вместо этого наши глаза совершают серию движений вперед и назад, называемых саккадами , или молниеносными прыжками по строке текста (рис. 1.2). Иногда это большой прыжок; иногда это небольшой прыжок. Саккады помогают нашим глазам фиксировать много информации за короткий промежуток времени, и они происходят много раз в течение секунды. Длина саккады зависит от наших навыков чтения и знакомства с темой текста. Если я ученый и читаю, ну, научные статьи, я могу читать это быстрее, чем не ученый, потому что я знаком со всеми этими научными словами.Полное раскрытие: на самом деле я не ученый. Надеюсь, вы не могли сказать.
Рис. 1.2. Саккады — это скачки, которые происходят за доли секунды, когда наш взгляд перемещается по строке текста.Между саккадами наши глаза останавливаются на долю секунды в так называемой фиксации (рис. 1.3). Во время этой короткой паузы мы четко видим пару символов, а остальной текст размывается, как рябь в пруду. Наш мозг собирает эти фиксации и расшифровывает информацию с молниеносной скоростью.Все это происходит рефлекторно. Довольно аккуратно, да?
Рис. 1.3: Фиксации — это короткие моменты паузы между саккадами.Формы букв и формы, которые они образуют при объединении в слова и предложения, могут существенно повлиять на нашу способность расшифровывать текст. Если мы посмотрим на среднюю строку текста и закроем верхние половины букв, ее будет очень трудно читать. Если мы сделаем наоборот и закроем нижние половины, мы все равно сможем читать текст без особых усилий (рис. 1.4).
Рисунок 1.4: Хотя нижняя половина букв закрыта, текст по-прежнему в основном разборчив, потому что большая часть критической визуальной информации находится в верхних частях букв.Это связано с тем, что буквы обычно несут больше идентифицирующих элементов в верхней части. Сумма буквенных форм каждого слова создает формы слов, которые мы узнаем при чтении.
Как только мы начинаем подсознательно распознавать буквы и общеупотребительные слова, мы читаем быстрее. Мы становимся более опытными в чтении в аналогичных условиях, и эту идею лучше всего сформулировала дизайнер шрифтов Зузана Личко: «Читатели лучше всего читают то, что они читают больше всего.”
Это не жесткое правило, но строгое. Чем чужды нам буквы и информация, тем медленнее мы их распознаем. Если бы мы отправились в средневековье с книгой, набранной супер-классным научно-фантастическим шрифтом, у людей из прошлого могли возникнуть трудности с этим. Но здесь, в будущем, мы умеем читать эти вещи, все время летая на ховербордах.
По той же причине у нас иногда возникают проблемы с расшифровкой чужого почерка: их буквенные формы и идиосинкразии кажутся нам необычными.Тем не менее, мы довольно быстро читаем собственный почерк (рис. 1.5).
Рис. 1.5: Вы хорошо знакомы со своим почерком, но привыкание к чтению чужого (например, моего!) Может занять некоторое время.Было проведено много исследований процесса чтения, но единодушное мнение достигнуто лишь частично. Острота чтения зависит от нескольких факторов, начиная с задачи, которую читатель намеревается выполнить. Некоторые исследования показывают, что в словосочетаниях мы читаем — рисуем мелом контур вокруг всего слова — в то время как другие предлагают расшифровывать вещи по буквам.Большинство выводов сходятся во мнении, что легкость чтения зависит от визуального восприятия и точности настройки текста (сколько усилий требуется, чтобы отличить одну буквенную форму от другой) в сочетании с собственными навыками читателя.
Рассмотрим отрывок, набранный заглавными буквами (рис. 1.6). Вы можете научиться читать практически все, но большинство из нас не привыкло читать много текста, написанного заглавными буквами. По сравнению с обычным текстом в регистрах предложений, текст, состоящий только из заглавных букв, кажется довольно непонятным.Это связано с тем, что заглавные буквы имеют блочный вид и не создают большого контраста между собой и окружающим их пустым пространством. Получившиеся в результате формы слова представляют собой простые прямоугольники (рис. 1.7).
Рис. 1.6: Текст, набранный заглавными буквами, может быть трудным для быстрого чтения, когда мы привыкли к регистру предложений. Рис. 1.7: На нашу способность распознавать слова влияют формы, которые они образуют. Текст, полностью написанный заглавными буквами, образует блочные формы с небольшими различиями, в то время как текст со смешанным регистром образует неправильные формы, которые помогают нам лучше идентифицировать каждое слово.Осознание того, что выбор, который мы делаем в отношении шрифтов и набора текста, оказывает такое влияние на читателя, открыло мне глаза. Такие мелочи, как размер и интервал между шрифтами, могут дать читателям большие преимущества. Когда они не замечают такой выбор, значит, мы сделали свое дело. Мы ушли с их пути и помогли им приблизиться к информации.
Типографика на экране отличается от печатной по нескольким ключевым параметрам. Читатели имеют дело с двумя средами чтения: физическим пространством (и его освещением) и устройством.Читатель может провести солнечный день в парке за чтением на телефоне. Или, может быть, они сидят в темной комнате и читают субтитры по телевизору в десяти футах от них. Как дизайнеры, мы ничего не контролируем, и это может расстраивать. Как бы мне ни хотелось перейти к компьютеру каждого читателя и исправить их настройки контрастности и яркости, это та рука, которую мы получили.
Лучшее решение для неизвестных неизвестных — сделать нашу типографику максимально эффективной во всех ситуациях, независимо от размера экрана, соединения или потенциального лунного затмения.Позже в этой книге мы рассмотрим некоторые способы сделать типографику максимально устойчивой.
Мы должны сделать так, чтобы чтение было свободным. В основе типографики — наша аудитория, наши читатели. Когда мы смотрим на строительные блоки типографики, я хочу, чтобы вы помнили этих читателей. Чтение — это то, чем мы занимаемся каждый день, но мы легко можем принять это как должное. Нажатие слов на странице не обеспечит хорошего общения, точно так же, как затирание ладонями по пианино не приведет к созданию приятной композиции.Опыт чтения и эффективность нашего сообщения определяются тем, что мы говорим, и тем, как мы это говорим. Типографика — это основной инструмент, который мы используем как дизайнеры и визуальные коммуникаторы.
Грамматичность— Разбор «друг друга, правда, но»
Я понимаю вашу дилемму: если бы точка с запятой стояла перед «однако», можно было бы использовать «однако» и «но» для обозначения одного и того же.
Проблема, на мой скромный взгляд, в том, что исходное предложение имеет ненадежную логическую конструкцию в том, как соединяет поток идей: размещение «однако» непосредственно перед «но» запутывает значение, потому что оно складывает два уровни противостояния в одном и том же месте (возможно, писатель торопился).
«Однако» создает противоречие между первым предложением («Персонажи … друг другу») и чем-то, что написано перед абзацем (чего мы здесь не видим).
«но» создает противоречие между вторым предложением («есть различие … символы») и первым.
Если кто-то действительно хотел улучшить это предложение, почему бы не пойти дальше и не исправить порядок идей? На этом этапе потребуется редактирование .Могут быть разные способы, но можно попробовать:
Однако , персонажи романов не всегда нравственно и социально обязывая друг друга, но есть различие между достойный герой или героиня и социально менее приемлемый символы.
Здесь мы нарушим (неабсолютное) правило, что «однако» никогда не должно стоять в начале предложения. Гипотеза: возникла ли проблема из-за механического применения этого правила?
Итак, если слово «однако» было проблемой, давайте попробуем конкретизировать значение:
Это правда , что герои романов не всегда морально и социально услужливость друг другу; , но есть различие между достойный герой или героиня и социально менее приемлемый символы.
(Здесь я последовал предложению поставить точку с запятой и заменил «но» на «пока», чтобы сделать его более четким.)
Но чтобы проверить, был ли это лучший поток идей, нужно посмотреть предыдущий абзац. Кроме того, мы находимся в области композиции , что является открытым мнением. Я хотел проиллюстрировать здесь метод решения, а не простой ответ.
Полный список советов AP® по английскому языку
Экзамен AP® по языку и композиции проверяет вашу способность не только читать контент, но и анализировать прочитанное и делать выводы, которые можно представить в споре.Тест состоит из двух частей: множественный выбор и свободный ответ и длится 3 часа 15 минут. Это долгий и трудный тест, но при должном количестве практики, учете советов AP® по английскому языку и решимости вы получите 5 баллов!
Хотя мы рекомендуем Альберта для онлайн-подготовки, мы также рекомендуем вам дополнить учебу обзорными книгами AP® English Language. Эти советы AP® по английскому языку помогут вам почувствовать себя уверенно при получении 5 баллов на экзамене AP® по языку и сочинению.Давайте начнем.
Как учиться на английском языке AP®: 5 советов для четверок и пятерокПрежде чем вы научитесь готовиться к определенным частям языкового экзамена AP®, самое время научиться готовиться к курсам AP® в целом. AP® расшифровывается как Advanced Placement; Это означает, что курсы предназначены для того, чтобы бросить вам больше вызовов, чем обычный класс средней школы. Можно с уверенностью сказать, что сдать экзамен AP® по языку и сочинению практически невозможно, если вы не знаете, как подготовиться к такому интересному классу, как курс Advanced Placement.Давайте рассмотрим несколько общих советов AP® по английскому языку!
1. Ознакомьтесь со стилем вопросов AP® English Language
Прежде чем вы даже начнете готовиться к экзаменам AP®, вам необходимо ознакомиться с общим форматом вопросов, которые задаются на экзамене. Тест разбит на две части: множественный выбор и свободный ответ.
Начиная с экзамена 2021 года, раздел с несколькими вариантами ответов будет содержать 45 вопросов, разбитых на 23-25 вопросов по чтению и 20-22 письменных вопроса.Вопросы для чтения попросят вас читать, анализировать и отвечать на научно-популярные тексты, в то время как вопросы по письму попросят вас «читать как писатель» и рассмотреть возможность внесения изменений в тексты.
Раздел бесплатных ответов будет содержать три вопроса для сочинения: один вопрос для синтеза, один вопрос для риторического анализа и один вопрос с аргументами. В синтезирующем эссе вы прочитаете шесть-семь текстов по теме и составите аргумент, который будет опираться как минимум на три источника в поддержку вашего аргумента.Раздел риторического анализа заставит вас прочитать документальный текст и проанализировать, как выбор языка писателем влияет на предполагаемое значение и цель текста. Наконец, очередь аргументов требует, чтобы вы создали аргумент, основанный на доказательствах, который отвечает на определенную подсказку.
В то время как ваш курс AP® познакомит вас с характером этих вопросов, мы рекомендуем вам ознакомиться с образцами вопросов AP® Central и каталогом старых экзаменов, чтобы углубить ваше понимание.Мы также предлагаем исчерпывающий обзор «Как учиться на AP® English Language», который охватывает все аспекты AP® English Lang, так что ознакомьтесь с советами о том, как подойти к этим вопросам.
2. Расширьте свое понимание основного формата эссе из пяти абзацев
Поскольку большая часть экзамена AP® по английскому языку проверяет ваши письменные способности, вам нужно будет пройти тест с твердым пониманием того, как писать академические эссе. Один из важных ключей к успеху — организация.Если вы хотите получить 4 или 5 баллов, ваше эссе должно демонстрировать четкую организованность.
Стандартный метод организации, формат из пяти абзацев, вероятно, самый простой способ организовать вашу аргументацию. Абзацы расположены в следующем порядке: Вступление-Тело-Тело-Тело-Заключение. Это простой метод, благодаря которому ваше письмо будет напряженным и убедительным, и это самая распространенная форма, которую мы видим в тесте. Вот видео, которое углубляет эссе из пяти абзацев.
3.Укрепите свои навыки критического мышления, сделав чтение частью своего ежедневного распорядка
Значительная часть курсов Advanced Placement предназначена для проверки вашей способности критически мыслить, читать и писать. Возможно, самый простой и простой способ развить эти жизненно важные навыки — включить чтение в свой распорядок дня, а под чтением мы подразумеваем более сложный материал, чем, скажем, списки в стиле Buzzfeed.
Вы можете сделать это несколькими способами. Во-первых, вы можете подписаться на крупное редакционное издание, такое как The New York Times, The New Yorker, The Economist или The Guardian, и включить их чтение в свой распорядок дня.
Еще один способ укрепить свои навыки критического мышления посредством ежедневного чтения — это прочесать сочетание умной и научной литературы, например, The Great Gatsby или Freakonomics . Полный каталог рекомендаций можно найти в нашем списке для чтения на английском языке Ultimate AP®.
4. Развивайте свой риторический и литературный словарный запас с помощью онлайн-викторин и банков слов.
Экзамен по английскому языку AP®, конечно же, проверяет ваши способности и знания в области риторики, сочинения и английского языка, поэтому крайне важно, чтобы вы подходили к тесту с сильным словарным запасом.
Один из способов пополнить свой академический словарный запас — это использовать программы онлайн-викторин, такие как Quizlet (который включает множество материалов на AP® Eng Lang) и Vocabulary.com . Они позволят вам отточить словарный запас в увлекательной и интерактивной форме, а также содержат множество различных игр для запоминания, таких как карточки, викторины и многое другое.
Мы также рекомендуем вам обратиться к банку слов английского языка AP®. Быстрый поиск в Google дает множество результатов, но этот и этот раздаточный материал — хорошие места для начала.
5. Сформировать учебную группу
Один из самых эффективных способов подготовиться к любому экзамену — сформировать учебную группу. В идеале в эту группу должны входить представители всех уровней знаний. Каждый принесет что-то на стол — может быть, вы знаете о символизме больше, чем Сэм, в то время как Сэм разбирается в литературных приемах лучше, чем Райан, и так далее. Попробуйте встречаться в кафе или дома у друга еженедельно или раз в две недели, чтобы сохранять концентрацию. Изучение точек зрения других людей на предметы, охваченные на разных экзаменах, поможет вам подходить к вопросам со всех сторон.
Теперь, когда вы следовали предыдущим общим советам по изучению Advanced Placement, вы можете сосредоточиться на подготовке к экзамену AP® Language and Composition.
В этой части статьи основное внимание уделяется части с множественным выбором, которая составляет 45% от вашего общего балла. Можно сказать, что это очень важно.
Вернуться к содержанию
AP® English Language Multiple Choice Review: 13 советов1.Создайте ежедневную учебную программу в начале семестра
Самый важный совет при сдаче любого стандартного экзамена — это выработать хорошие учебные привычки. Начало в начале семестра. Мы знаем, что другие занятия требуют времени, но мы рекомендуем вам установить ежедневный будильник на своем телефоне, чтобы напоминать вам о необходимости учиться на AP® Lang. Выделите хотя бы 30 минут в день. Этот процесс должен продолжаться в течение семестра, что будет верным способом запомнить важный контент в конце года и укрепить свою выносливость.В дополнение к изучению классных работ мы рекомендуем вам ознакомиться с Руководством по английскому языку AP® или использовать один из наших многочисленных практических модулей, чтобы расширить свои ежедневные занятия.
2. Проверьте себя с помощью практических экзаменов
Если вы один из многих старшеклассников, которые не тратят большую часть своего времени на обучение, раннюю подготовку и следование системе, описанной в предыдущем учебном совете, мы понимаем. Учиться каждую ночь может быть непросто. Если это похоже на вас, то лучший вариант для подготовки к экзамену AP® Language — это проверить себя.Периодически в течение семестра просматривайте практические экзамены, чтобы проверить свое понимание материала. Мы предлагаем множество различных практических экзаменов, и Совет колледжей также хранит образцы старых экзаменов для работы. Мы настоятельно рекомендуем вам проработать их перед экзаменом.
3. Выберите стратегию с несколькими вариантами ответов: сначала прочтите отрывки или сначала прочтите вопросы.
Всем известен классический ярлык, когда дело доходит до тестов с несколькими вариантами ответов: сначала прочтите вопросы, а затем просматривайте отрывки, чтобы найти ответы.Такой подход к экзамену может дать вам более целенаправленный и решительный подход к тому, на что следует обращать внимание при чтении отрывка. Но некоторых это также может отвлекать.
С другой стороны, вы можете сначала прочитать отрывки, а затем ответить на вопросы. Это более простой и, возможно, более традиционный способ подхода к разделу с множественным выбором, и он лучше всего подходит для людей, которые любят делать вещи логичными, последовательными способами. Пройдите несколько практических экзаменов, а затем решите, какой из них лучше всего подходит для вас, и придерживайтесь его.
4. Прочтите вопросы внимательно и более одного раза
Это само собой разумеется. Если вы плохо понимаете содержание вопроса, вы ошибаетесь. Внимательно прочтите вопросы и определите, о чем они спрашивают, где в тексте можно найти ответ и дает ли какой-либо из вариантов логический ответ на вопрос.
Прочтите вопрос более одного раза, обязательно хотя бы дважды. Подчеркните ключевые слова и фразы в вопросе, если вы сочтете это полезным.Иногда ответ на вопросы может быть сложным и довольно нервирующим. Чтобы не перегружать вас этим, попробуйте прикрыть рукой несколько вариантов ответов или полностью игнорировать их, пока вы читаете только основную часть вопроса. Попытайтесь найти ответ на вопрос, прежде чем даже взглянете на возможные варианты.
5. Перечитайте части текста, относящиеся к вопросу
Помните, что каждый вопрос относится к отрывку.Таким образом, каждый ответ можно найти либо в самом тексте, либо там, где он указывает. Когда вы определили, где в отрывке можно найти ответ, перечитайте этот отрывок. Тщательно проанализируйте его и решите, какой может быть правильный ответ. Постоянно возвращайтесь к тексту и помечайте его. Выделите или подчеркните ключевые слова или фразы, а также то, что вам больше всего нравится.
6. Используйте процесс исключения
Этот совет может быть несколько очевидным. Если вы знакомы с предметом вопроса, нетрудно исключить хотя бы один из вариантов, на который вы решили не отвечать.Отметьте физически ответы, которые вы считаете неправильными. Это поможет вам визуально увидеть, какие ответы не могут быть правильными. Иногда авторы теста напишут два варианта ответа, которые кажутся почти идентичными. Однако один из них будет иметь малейшее отличие, которое сделает его неверным.
Это также может помочь вам обвести или подчеркнуть термины в неправильных вариантах ответа, которые доказывают, что они неверны. Если вы столкнетесь с подобным вопросом, вы можете вернуться к этим неправильным ответам.С помощью этой информации вы можете определить, какие ответы неправильные, а какие правильные.
7. Пропускайте сложные вопросы и возвращайтесь к ним позже, если будет время.
Поскольку часть с множественным выбором рассчитана по времени, у вас может не быть времени ответить на каждый вопрос, если вы не уверены в некоторых из них. Самый простой способ очистить свой разум и сосредоточиться на более легких вопросах — это пропустить более сложные вопросы, на которые вы просто не можете ответить. Если вы застряли в вопросе, скажем, более чем на полторы минуты, пропустите его, перейдите к следующему и вернитесь к нему после того, как ответите на вопросы, на которые вы можете ответить.
Зацикливание на более сложных вопросах может не только тратить драгоценное время, но также свести на нет ваше внимание и испортить вашу решимость.
8. Разметка ключевых моментов и фраз в тексте
Относитесь к отрывкам из текста как к чистому холсту, на котором вы должны записывать свои мысли, размышления, вопросы, анализ и многое другое. Выделите, подчеркните или обведите в кружок моменты в тексте, которые вам больше всего интересны. Если вы находите определенную фразу или слово в центре аргументации автора, или находите предложение особенно запутанным, отметьте это!
Если вы пропустили вопрос, обязательно обведите его номер.Таким образом, при повторном прохождении теста время поиска вопросов без ответа резко сократится. Кроме того, вы можете поставить галочку рядом с каждым вопросом, на который вы ответили, оставив неотвеченные вопросы с пустым пространством рядом с числами. Размечая текст, вы, по сути, строите для себя аналитическую дорожную карту, которая значительно упрощает общий экзамен.
9. Если сомневаетесь, угадайте
На экзамене AP® по английскому языку и сочинению ваша оценка по части с несколькими вариантами ответов основана на количестве вопросов, на которые вы правильно ответили.За неправильные ответы штраф не взимается. Так что нет никакой логической причины не угадывать вопросы, которые вас озадачили. Поэтому, если вы дойдете до конца набора вопросов и вернетесь к тем, которые пропустили, но все еще не можете определиться с ответом, просто сделайте обоснованное предположение. Это стоит того.
10. Используйте викторины или бумажные карточки для определения словарного запаса.
Для терминов или понятий, которые вам необходимо запомнить, сделайте карточки. Это может показаться элементарным советом для учебы, но это действительно работает.Просматривайте карточки не менее 30 минут в день, чтобы развить сильную память. Вам будет намного проще пройти тест, если вы хорошо владеете риторическими и композиционными терминами и фразами.
Quizlet предлагает множество наборов карточек для AP® English Language and Composition, или вы можете использовать сайт, чтобы просто создать свои собственные. Мы также предлагаем множество полезных модулей по лексике и английскому языку AP® в целом. И помните: обращайте особое внимание на термины или концепции, которые вам не до конца понятны.
11. Учеба перед сном
Если вы сделали дидактические карточки, то самое время изучить их или любые сделанные вами заметки — это перед сном. Мозг запоминает большую часть информации прямо перед сном. Это потому, что когда вы спите, он обрабатывает самые важные воспоминания вашего дня для хранения.
Если вы просмотрите информацию прямо перед сном, ваш мозг расставит приоритеты в этой информации и сохранит ее для быстрого доступа. Из-за этого тоже было бы неплохо заняться с утра.Это напомнит вашему мозгу, что предмет, который вы изучаете, действительно нужно запомнить. Вместо того, чтобы проверять Instagram или Tik Tok ночью, попробуйте взять за привычку просматривать набор карточек или проработать несколько практических вопросов.
12. Научитесь отвечать «на все вышеперечисленное» и «ни на что из вышеперечисленного».
Студенты, сдающие этот экзамен, часто боятся этих вопросов с несколькими вариантами ответов. Вопросы «все вышеперечисленное» или «ни один из вышеперечисленных» могут сбить с толку студентов, потому что они указывают на определенную совокупность, которую может быть трудно проанализировать.В «Все вышеперечисленное» каждый вариант ответа должен быть правильным, поэтому, если один ответ звучит сомнительно, избегайте «всего вышеперечисленного». «Ничего из вышеперечисленного» — это одно и то же — каждый ответ должен быть неправильным.
13. Сделайте дыхательное упражнение, если вы слишком нервничаете
Мы будем первыми, кто это скажет: экзамен по английскому языку AP® — это стресс. Но если вы позволите своим нервам взять верх, испытание станет еще труднее. Если вы почувствуете панику, попробуйте следующее: положите руку на живот, расслабьте плечи и грудь.Медленно вдохните через нос и почувствуйте, как поднимается живот, считая до пяти в голове. Выдохните. Повторить. Этот метод вас успокоит.
Будьте уверены, что вы знаете материал достаточно хорошо, чтобы с легкостью пройти эту часть. Если вы позволите своему беспокойству или нервам одолеть вас, испытание станет намного, намного сложнее. Конечно, это тест, вызывающий беспокойство, но помните: это всего лишь тест. Это не конец и не панацея. Это тест. Так что дышите и подходите к нему спокойно и собранно.
Следующая часть этой статьи будет посвящена, казалось бы, устрашающей части экзамена по языку и сочинению AP® с бесплатными ответами, которая стоит 55% вашего балла. Эта часть состоит из трех разных эссе, которые вы должны написать в течение двух часов после обязательного пятнадцатиминутного периода чтения. В конечном итоге эти эссе оценят вашу способность быстро формулировать аргументы на основе выводов и анализа, взятого из предоставленных вам источников. Если вы с самого начала не понимаете, как выполнять инструкции, которые задают на экзамене, эта часть может оказаться для вас более сложной, чем раздел с множественным выбором.
Вернуться к содержанию
Вот несколько советов, которые помогут вам успешно пройти часть экзамена с бесплатными ответами:
AP® English Language Free Response Question Review: 19 советов1. Потратьте время на анализ вопроса
Обязательно прочтите подсказку для сочинения много раз и определите ключевой вопрос, который задают. Вопросы AP® English Language могут быть сложными и требовать многократного чтения. Подойдите к вопросу с каждой стороны возможного аргумента, который он ставит.Обратитесь к нашему руководству по построению аргументов для получения дополнительной помощи.
2. Выберите свою сторону аргумента
Основываясь на доказательствах, представленных вам в отрывках, которые вы прочитали, придумайте аргумент. Часто бывает полезно выбрать аргумент, который имеет больше доказательств и ссылок в его поддержку, даже если вы не обязательно согласны с каждой мелочью. Например, эссе с риторическим анализом английского языка AP® потребует от вас выбрать сторону аргумента и развить свою точку зрения.
3. Создайте убедительный и хорошо проработанный тезис
Придумайте убедительный тезис, который четко и эффективно подходит к теме и аргументации, которую вы представляете. Не утруждайтесь повторением подсказки во вступительных абзацах — счетчики будут просто предполагать, что вы заполняете пространство, и это сделает ваш аргумент слабым и недостоверным. Ответьте на все вопросы, которые задает подсказка во вводном абзаце, и включите основную мысль своей аргументации в свой тезис.
Помните: тезис предлагает краткое изложение основной идеи или утверждения эссе, исследовательской работы и т. Д. Это ваше утверждение, ваш аргумент, суть вашей статьи, сведенные в одно чистое, хорошо разработанное утверждение.
Вот пример хорошей диссертации:
- Как утверждает Уайльд, неповиновение — ценная человеческая черта, без которой невозможно добиться прогресса, потому что в таких ситуациях, как Американская революция, только отклонение от нормы может изменить норму.
А вот пример не очень удачного тезиса:
- Непослушание — хорошая черта для людей, потому что исторически непослушные мужчины и женщины вошли в историю.
Будьте краткими, подробными и ясными.
4. Создайте прочный набор абзацев тела
Когда у вас будет тезисное изложение, составьте сильные, хорошо проработанные основные абзацы, которые расширяют и дополняют ваше центральное утверждение в вашей диссертации. Обязательно упомяните, как подтверждающие доказательства, которые вы цитируете в своих эссе, соотносятся с вашими аргументами, но не просто резюмируйте доказательства.Распаковать и проанализировать.
5. Используйте конкретный, лаконичный язык
Двусмысленности и расплывчатым предложениям нет места в эссе на экзамене AP® Language and Composition. Читатели вашего эссе ожидают, что вы будете точны и по существу. Они хотят, чтобы вы доказали им свою точку зрения, а не бесцельно плясали вокруг нее. Чем точнее вы укажете информацию, тем лучше. Слов и фраз вроде «примерно», «вроде», «вроде», «вещь» и «прочее» следует избегать любой ценой.
6.Укажите свои источники
Вам не зря предоставлены текстовые источники. Используйте их, чтобы усилить аргумент и убедить аудиторию в его правомерности. Фактически, чтобы получить высокие баллы, вы должны тщательно взаимодействовать со своими источниками. Указывайте конкретные моменты и фразы в тексте и избегайте простого перефразирования. Однако вы не можете просто резюмировать источник, а критически прочитать и проанализировать его. Неспособность использовать предоставленные вам ресурсы приведет к невероятно низкому баллу.
7.Развивайте убедительный тон
Тон эссе — вот что подготавливает почву для ваших аргументов. Если нет тона, это делает эссе неряшливым и плохо структурированным. Сам аргумент может даже показаться разрозненным и разрозненным. Тон вашего эссе должен отражать вашу точку зрения на аргумент и убеждать читателя в вашей позиции.
Если нет, как можно ожидать, что читатели полностью поймут, на чьей вы стороне? Вы можете успешно развивать тон, используя сильный, сложный словарный запас, сложные формы глаголов и предложений, а также тщательно и критически работая с текстами.Взгляните на раздаточный материал Принстонского центра письма о тоне и тоне слов, чтобы получить дополнительную помощь!
8. Не бойтесь делать предположения
Во многом оценка этой части основана на ваших предположениях, на вашем понимании смысла текста. Предположения и заключения, сделанные из ваших источников, имеют решающее значение. Используйте их, чтобы объяснить свою точку зрения и укрепить свои аргументы.
Логические предположения открывают интересные перспективы авторам сочинений.Использование умозаключений и предположений в ваших эссе также демонстрирует вашу способность критически мыслить (как мы обсуждали ранее). Подсказки AP® English Language заставят вас думать не только о тексте.
9. Организуйте свои мысли, используя план
По мере того, как вы планируете аргументы в эссе, убедитесь, что у вас есть время, чтобы систематизировать свои мысли, создав план или карту во время подготовки к написанию.
Это укрепит вашу аргументацию и общую структуру вашего эссе.Если ваше эссе аккуратное и чистое, составители оценок легко найдут то, что им нужно, в хорошо написанном аргументе. Один из способов сделать это проще — использовать план, руководство или карту для сочинения. Вот пример того, как это будет выглядеть.
10 Используйте строгий организационный формат
Если вы не знакомы со структурой эссе, вам обязательно нужно выучить ее перед экзаменом. Думайте о сочинении как о скелете: вводный, основной и заключительный абзацы — это кости; собственно мышцы, сухожилия и органы, удерживающие его вместе, составляют большую часть эссе.
Это то, что вы добавляете к нему, включая аргументы и подтверждающие доказательства. Следование (а также расширение) такой базовой организационной структуры сделает ваше эссе более сложным и читаемым.
11. Используйте разнообразные предложения и словарный запас
Если вы напишете эссе прерывистыми короткими предложениями с простым словарным запасом, читатель предположит, что вы плохо владеете английским языком или что вы не можете ответить на подсказку на уровне сложности, пригодном для колледжа.Это может серьезно повлиять на вашу оценку, особенно если учесть, что вы сдаете экзамен по языку и композиции AP®. Вы можете укрепить свой словарный запас и навыки письма, выработав привычку ежедневно читать и проконсультировавшись со списком общеупотребительных слов, найденных в тесте AP® English Language.
12. Работайте быстро
Хотя вы хотите иметь в виду все эти советы, помните, что это все еще ограниченная по времени часть экзамена. У вас не так много времени, чтобы пытаться довести до совершенства каждую часть своего эссе.Поэтому, если вы оказались в ловушке, пытаясь улучшить предложение или долго размышляя над выбором идеального слова, напомните себе остановиться и двигаться дальше. Ничто не может быть идеальным, поэтому используйте свое время с умом.
13. Развивайте свои навыки управления временем
Раннее обучение навыкам управления временем может очень помочь, когда дело доходит до экзаменов по расписанию. Практикуйтесь в частом прохождении заданных по расписанию экзаменов в течение семестра, чтобы укрепить уверенность и навыки.
Когда вы сдаете один из наших практических экзаменов или экзамен из Princeton Review, установите время на своем телефоне и запишите, сколько времени вам потребуется, чтобы проработать тест.Старайтесь увеличивать свое время с каждым практическим экзаменом. Это действительно поможет, когда вам нужно сформулировать несколько аргументов для разных сочинений за ограниченный промежуток времени.
14. Знать рубрику от и до
Знание рубрики — невероятно стратегический шаг в выполнении части эссе AP® Language and Composition. Когда вы знаете, что именно обычно ищут бомбардиры, вы можете расслабиться. Это потому, что вы точно знаете, что нужно использовать в своих аргументах, чтобы сделать эссе с высоким баллом.Рубрика недавно была обновлена, и мы настоятельно рекомендуем вам взглянуть на нее здесь.
Проще говоря, рубрика FRQ разбита на три основных раздела: тезисы, доказательства и комментарии и изощренность. Компонент тезиса обращается — как вы уже догадались — к вашему утверждению тезиса. Раздел «Свидетельства и комментарии» в рубрике включает вашу способность цитировать и анализировать свидетельства из текста. И, наконец, компонент изысканности обращается к общей «умности» вашего эссе.
15. Много читайте в свободное время
Это может показаться очевидным, но многие студенты не понимают, сколько чтения требуется для этого курса. AP® Language and Composition охватывает стили письма на протяжении нескольких столетий, поэтому очень важно ознакомиться со всеми из них.
Чтение нескольких книг на досуге между заданиями также существенно поможет в развитии вашего собственного стиля письма. И, как мы упоминали ранее, выработка прочной привычки ежедневного чтения с помощью The New York Times, The New Yorker или другого крупного издания познакомит вас с утонченным письмом и более высоким уровнем мышления.
16. Практика разбора риторических текстов
Нет, не волнуйтесь; вам не нужно знать, как препарировать мертвую лягушку для экзамена AP® Language. Тем не менее, рекомендуется попрактиковаться в анализе всего, что вы читаете. Под этим мы подразумеваем, что вы подходите к чтению очень критически. Выполняя ежедневное чтение, спрашивайте себя: кто слушает это произведение? Чего автор пытается достичь, написав это? В чем основная идея? Есть ли какой-нибудь символизм в расплывчатых предложениях?
17.Пишите аккуратно
Разборчивый текст — лучший друг бомбардира. Счетчики — очень занятые люди, которым нужно выставить оценки за тысячи эссе. У них не так много времени, чтобы расшифровать вашу куриную царапину. Чем больше бомбардиры могут читать, тем больше нужно ставить оценки.
18. Избегайте клише
Конечно, клише может придать вашему письму ощущение знакомства. Но в основном это утомляет читателя. Если вам необходимо использовать обычную фразу-клише, попробуйте немного изменить ее, используя синонимы глаголов.Избегайте банальных фраз типа «не все то золото, что блестит»; Подобные клише используются настолько часто, что утратили свой смысл. Взгляните на этот список клише для дальнейшего понимания.
19. Изучите как минимум три метода управления стрессом.
Стресс может сказаться на каждом из нас. Умение обращаться с этим навыком жизненно важно для каждого аспекта жизни, особенно когда дело касается школы. Во-первых, вы можете попробовать медитацию с помощью приложений для медитации, таких как Headspace.Во-вторых, вы можете начать ежедневный бег трусцой и использовать такие приложения, как RunKeeper, чтобы задавать темп. Или, в-третьих, вы можете заняться йогой. Взгляните на наш комплект для учителей по уходу за собой, чтобы узнать, как оставаться позитивным. Даже если вы студент, а не учитель, мы дадим множество полезных советов, как сохранять спокойствие.
Вернуться к содержанию
Советы учителей английского языка AP®AP® English Language Multiple Choice Tips:
- Вопросы с несколькими вариантами ответов различаются по сложности. Множественный выбор всегда представляет собой комбинацию простых, средних и сложных вопросов для каждого отрывка. Как правило, эти вопросы следуют хронологии отрывка, но все они приносят одинаковое количество баллов. Таким образом, лучший подход — сначала задать вопросы легкого и среднего уровня, а не задавать вопросы, которые потребуют значительного количества времени. Спасибо за совет от Фреда Б.
- Перечитайте вопросы, касающиеся контекста. Когда вы имеете дело с вопросами о вещах в контексте, лучший подход — вернуться к началу предложения или предыдущему предложению и прочитать конец этого предложения, чтобы понять его значение.Также может быть хорошей идеей прочитать следующее предложение. Спасибо за совет от Фреда Б.
- Консолидируйтесь, когда у вас начинает не хватать времени. Если у вас не хватает времени, вы должны либо просмотреть оставшиеся вопросы и найти самые короткие вопросы, либо найти вопросы, содержащие ответ, не требуя от вас возврата к тексту. Спасибо за совет от Фреда Б.
AP® English Language Free Response Tips:
- Помните о достоверности источника. Допустим, вам нужно прочитать две статьи: одну в San Francisco Chronicle и одну в блоге. Вы ничего не знаете ни об одном из авторов. Вы ничего не знаете о содержании (теме). Подумайте о том, какие факторы достоверности вы можете вывести, еще до того, как увидите статьи . Спасибо за подсказку от Марка М.
- Создайте свой собственный восторг от подсказки и того, что вы скажете о ней. Если вы найдете способ увлечься этим, вы будете писать быстрее, проще и лучше.После экзамена в этом году одна из моих учениц сказала, что запомнила совет и намеренно возбудила собственный энтузиазм по поводу своих тем, поэтому она вышла, чувствуя себя счастливой по поводу того, что она написала. Она набрала 4. Спасибо за совет от Пэм С.
AP® Советы по подготовке к английскому языку:
- Разработайте репертуар сильных глаголов и глагольных форм. Студентам необходимо расширить свой словарный запас, добавляя качественные глаголы, чтобы читать и писать более эффективно. Это исследование должно охватывать глагол как в активном, так и в пассивном тоне; Точно так же глагол должен быть освоен для герундивного и причастного употребления.Спасибо за совет от Майка М.
- Читайте авторитетные газеты ежедневно. Соедините текущие мировые события с классическими очерками и мемуарами. Ищите связь между человеческим состоянием и целью говорящего. Всегда спрашивайте, почему? Почему это слово? Почему такой тон? Почему этот призыв к действию? Спасибо за совет от Бобби К.
- В целом, сосредоточьтесь на анализе аргументов и риторического анализа. Два навыка курса: аргумент и риторический анализ. Один совет, который необходимо дать студентам, — это принцип «осознавать сложность». Это актуально для аргументов (например, потребуется время для рассмотрения разумных контраргументов) и риторического анализа (например, письмо может быть одновременно угрожающим и примирительным — посмотрите письмо Баннекера Джефферсону из теста 2010 года). Сдать экзамен AP® по английскому языку и композиции никогда не будет легко. Но при правильном обучении, мотивации и понимании (наряду с этими советами, конечно) у вас должно быть больше, чем нужно, чтобы хорошо сдать экзамен.Подготовьтесь заранее, будьте уверены в том, что вы усвоили материал, и наблюдайте, как вы с уверенностью проходите экзамен. Спасибо за совет от Питера Д.
Вы учитель или ученик? У тебя есть отличный совет? Дайте нам знать!
Вернуться к содержанию
Подведение итогов: полный список советов AP® по английскому языкуЭкзамен AP® по английскому языку и сочинению — сложный тест, но при правильном количестве практики, подготовки и тяжелой работы можно получить 5 баллов.Экзамен предназначен для проверки вашего критического мышления и навыков чтения, поэтому вам обязательно нужно отточить свои навыки за несколько месяцев до фактического прохождения теста.
Лучший способ начать подготовку к этому тесту — просто попрактиковаться. Проконсультируйтесь с предыдущим экзаменом College Board или пройдите один из наших практических экзаменов, чтобы получить представление о том, как выглядит экзамен AP® по английскому языку. Оттуда выработайте привычку к ежедневному чтению, подписавшись на крупное издание, такое как The New York Times или The New Yorker, чтобы отточить свои навыки чтения и критического мышления.Кроме того, начните повседневную лексику с помощью Quizlet или физических карточек, чтобы развить свое понимание риторической и композиционной лексики.
Подходите к вопросам с несколькими вариантами ответов и к вопросам со свободными ответами, используя стратегии, относящиеся к каждому разделу. Помните, что разделы с множественным выбором оцениваются целостно, поэтому не помешает угадать. Для прохождения раздела «Свободный ответ» потребуется практика и глубокое понимание того, как писать тезисы, поэтому важно, чтобы вы попрактиковались и отточили этот навык перед сдачей теста.Мы предлагаем исчерпывающее руководство по ответу на вопрос с бесплатными ответами, на который тоже стоит обратить внимание!
И помните, в конце концов, это всего лишь тест. Не пугайте себя и не позволяйте нервам и тревоге захлестнуть вас. Стресс просто отвлечет вас от успеха. Если вы придете на испытание подготовленным и сравнимым, у вас все получится!
Новая статья: стратегия синтаксического анализа, реализуемая левой передней височной долей
Многие предыдущие исследования связывают части левой височной и левой лобных долей с аспектами понимания предложений.Но процедура, проводимая в этих регионах, не исследована. В новой статье мы тестируем конкретный алгоритм обработки предложений, который реализован в этих регионах. С Лийной Пюлкканен мы смоделировали две стратегии синтаксического анализа, одну прогнозирующую «левый угол» и одну менее прогнозирующую «восходящую» стратегию, а также проверили, какая стратегия лучше согласуется с активностью мозга, зарегистрированной с помощью МЭГ. Активность в левой передней височной доле коррелирует с количеством узлов, прогнозируемых анализатором левого угла, начиная примерно через 350 мс после начала слова.
Brennan, J. R. & Pylkkänen, L. (готовится к публикации). МЭГ-свидетельство увеличения состава предложений в передней височной доле. Когнитивная наука [ссылка]
Ознакомьтесь с рефератом и показателем, ниже
Исследования, изучающие основы понимания речи мозгом, связали левую переднюю височную долю (ATL) с комбинаторикой на уровне предложений. Используя магнитоэнцефалографию (МЭГ), мы тестируем стратегию синтаксического анализа, реализованную в этой области мозга.Количество шагов инкрементного синтаксического анализа от прогнозирующей стратегии синтаксического анализа в левом углу, которая поддерживается психолингвистическими исследованиями, сравнивается с таковыми из менее прогнозирующей стратегии. Мы проверяем корреляцию между этапами синтаксического анализа и локализованной в источнике активностью MEG, записанной во время чтения участниками рассказа. Шаги синтаксического анализа в левом углу коррелировали с активностью в левом ATL примерно через 350–500 мс после начала слова. Никаких других корреляций, характерных для понимания предложения, не наблюдалось. Эти данные показывают, что левый ATL участвует в комбинаторной обработке, которая хорошо охарактеризована прогнозирующей стратегией анализа левого угла.
Строка 1: Динамика усредненной активации источника из пяти областей интереса для блока STORY (пунктирные линии) и блока LIST (сплошная линия). Строка 2: Оценочные эффекты (коэффициенты β) для взаимодействия блока стимула с остаточными шагами синтаксического анализа в левом углу (rLC). Строка 3: Оценочные эффекты взаимодействия блока стимула с остаточными шагами восходящего синтаксического анализа (rBU). Строка 4: Предполагаемые основные эффекты шагов синтаксического анализа rBU. Затенение серым цветом указывает на стандартные ошибки коэффициента ± 1,64. Положительное значение для эффектов взаимодействия, показанных в строках 2 и 3, указывает на больший эффект для шагов синтаксического анализа в левом углу или снизу вверх в блоке STORY.«*» Указывает промежуток времени со статистически значимым эффектом на основе непараметрического теста перестановки.
Эта запись была размещена в публикациях автором Jonathan R Brennan.Анализ предгрупповых грамматик и исчисления Ламбека с использованием частичной композиции
Абруски Микеле, (декабрь 1991 г.). «Фазовая семантика и секвенциальное исчисление для чистой некоммутативной классической линейной логики». Journal of Symbolic Logic 56 (4): 1403–1451
Статья Google Scholar
Беше Дени, (1998). «Минимальность критерия корректности мультипликативных сетей доказательства». Математические структуры в информатике 8: 543–558
Статья Google Scholar
Беше, Дени, «Инкрементальный анализ исчисления Ламбека с использованием интерфейсов proof-net», ACL / SIGPARSE (ed.), Proceedings of the Eigth International Workshop on Parsing Technologies, Nancy, France, April 2003 , INRIA, апрель 2003 г., стр.31–42.
Бушковски, Войцех, «Грамматики Ламбека, основанные на предварительных группах», у Филиппа де Гроота, Глина Мориля и Кристиана Реторе (ред.), Логические аспекты компьютерной лингвистики: 4-я Международная конференция, LACL 2001, Le Croisic , Франция, июнь 2001 г. , том 2099, Springer-Verlag, 2001.
Бушковский, Войцех и Катаржина Мороз, «Преобразование PTIME грамматики предгрупп в cfg и pda», 37-я лингвистическая встреча в Познани (PLM) , Познань , 2006.
Данос Винсент, Лоран Ренье (1989). «Структура мультипликативов». Архив математической логики 28: 181–203
Статья Google Scholar
де Гроот, Филипп, «Подход динамического программирования к категориальному выводу», Конференция по автоматическому выводу, CADE’99 , Конспект лекций по искусственному интеллекту, Springer-Verlag, июль 1999 г.
Жирар Жан-Ив, (1987).«Линейная логика». Теоретическая информатика 50 (1): 1–102
Статья Google Scholar
Ламбек Иоахим, (1958). «Математика структуры предложения». American Mathematical Monthly 65: 154–170
Статья Google Scholar
Ламбек, Иоахим, «Пересмотр типовых грамматик», в Алене Лекомте, Франсуа Ламарше и Ги Перье (ред.), Логические аспекты компьютерной лингвистики: Вторая международная конференция, LACL ’97, Нанси, Франция, сентябрь 22–24, 1997 г .; избранные статьи , том 1582, Springer-Verlag, 1999.
Ламбек, Иоахим, «Математика и разум», в V.M. Абруски и К. Касадио (ред.), Новые перспективы в логике и формальной лингвизитике, Труды Vth ROMA Workshop , Bulzoni Editore, 2001.
Леконт, Ален и Кристиан Реторе, «Слова как модули и модули. как частичные сети доказательств в лексикализованной грамматике », в Микеле Абруски и Клаудиа Касадио (ред.), Третий семинар рома: Доказательства и лингвистические категории — Приложения логики к анализу и реализации естественного языка , Болонья: CLUEB, 1996, стр.187–198.
Леконт, Ален и Кристиан Реторе, «Слова как модули: лексикализованная грамматика в рамках сетей доказательства линейной логики», в Карлосе Мартин-Виде (ред.), Математический и вычислительный анализ естественного языка. — избранные статьи из ICML’96, том 45 исследований по функциональной и структурной лингвистике , издательство John Benjamins, 1998, стр. 129–144.
Моррилл, Глин В., «Мемоизация категориальных сетей доказательства: параллелизм в категориальной обработке», в Третий семинар рома: Доказательства и лингвистические категории — Приложения логики к анализу и реализации естественного языка , Болонья : КЛУБ, 1996.
Пентус, Мати, «Грамматики Ламбека контекстно-независимы», в Logic in Computer Science , IEEE Computer Society Press, 1993.
Pentus Mati, (1997). «Бесплатное исчисление Ламбека и контекстно-свободные грамматики». Журнал символической логики 62 (2): 648–660
Google Scholar
Рурда, Дирк, Логика ресурсов: теоретико-доказательные исследования , докторская диссертация, Амстердамский университет, 1991.
Йеттер Дэвид Н. (1990). «Кванты и (некоммутативная) линейная логика». Journal of Symbolic Logic 55: 41–64
Статья Google Scholar
Что означает «троллейбус» из тарабарщины для языка
Лексикографы — существа настойчивые. Никогда не довольствуясь, они просматривают каждое недавно опубликованное издание еще не напечатанного текста на предмет предшествующих дат или обнаружения слова в «дикой природе», предшествующего текущей первой цитате в словаре.В прошлом году благодаря их усердию в Среднеанглийском словаре появилась новая запись для слова «тарабарщина», которая, хотя когда-то считалась изобретением середины 16 века, на самом деле впервые появилась примерно в 1450 году. Пороки и добродетели предупреждают своих читателей, что невнимательно или без должного благочестия бормотать молитвы — значит произносить «giberisshe too Godde» (говорить чепуху с Богом). Автор предполагает, что тарабарщина равносильна глупости и неискренности. Но что мы должны думать об этой странной части создания человеческого языка?
Хотя его появление на английском языке было изменено, этимологическое происхождение слова «тарабарщина» остается немного загадочным.Словарь английского языка Сэмюэля Джонсона (1755) популяризировал народную этимологию, связывающую «тарабарщину» с «химическим кантом», технические термины алхимии и науки, используемые в «Гебере», прозападном имени Джабира ибн Хайяна, но не так. много одного автора, но личность, которой приписывалась большая часть средневековых арабских ученых. Истина гораздо более банальна: «тарабарщина», вероятно, происходит от «тарабарщины», одного из множества глаголов, таких как «грызть», «треп», «треп» и «болтать», которые звукоподражают звук неразборчивого лепета.Однако первый случай «тарабарщины» — в пьесе Уильяма Шекспира « Гамлет », где «закутанные в брезент мертвые», трупы, поднявшиеся из могил, зловеще «пищат и бормочут» на улицах Рима, появляется гораздо позже тарабарщина ».
Тарабарщина — язык, который нельзя понять — это не совсем то же самое, что и вздор. При написании бессмыслицы мы читаем отдельные слова, но не можем проанализировать их, придавая им смысл, соответствующий общепринятым ожиданиям. «Бесцветные зеленые идеи яростно спят», как выразился Ноам Хомский в Syntactic Structures (1957) в качестве примера семантически бессмысленного предложения с присутствующим и правильным синтаксисом.С другой стороны, тарабарщина превращает звуки и буквы языка в неразборчивые слова. Гигант Нимрод, который, согласно святоотеческим преданиям, приказал построить Вавилонскую башню и тем самым раздробил единый язык человечества на все языки мира, наказан непонятно в Inferno из Divine Comedy Данте Алигьери. (1308-20). Охраняя Девятый Круг ада, Нимрод кричит: « Raphèl maì amècche zabì almi. ‘Не обращайте на него внимания, — говорит Вергилий, его проводник, потому что он не может понять нас, как мы не можем понять его слов.
Странная фраза Нимрода в действительности является тарабарщиной, буквы превращены в слова, индивидуальные значения которых ускользают от нас, как бы ученые ни ломали голову и ни выдвигали гипотезы. И все же тарабарщина делает большую часть своей культурной работы как совершенно неточный ярлык. Речь, которую обвиняют в тарабарщине, почти всегда является не тарабарщиной, а полностью функционирующим языком: мы берем внятные высказывания и превращаем их в чепуху, отказываясь их распознавать или интерпретировать.На протяжении веков одна нация глумилась над носителями языка другой нации, принижая язык других как « варварский » (от греческого βάρβαρος , « барбарос », слово, имитирующее звериные звуки baa , как греки якобы воспринимал речь не говорящих на греческом языке). В настоящее время мы отвергаем сложные технические разговоры экспертов как «тарабарщину», потому что считаем их условия и знания устрашающими или угрожающими. Аргументы, которые нам не нравятся, — это «чепуха» или «словесный салат» не потому, что мы не можем их понять, а потому, что мы отвергаем их логику.(«Словесный салат», кстати, является транслитерацией немецкого Wortsalat , первоначально медицинского термина для запутанной речи людей с шизофренией.)
Термин «тарабарщина» в большинстве случаев несправедливо навязывается другим, это быстрый и простой способ выразить предубеждение и преуменьшить значение языка других как простой шум. Однако тарабарщина иногда создается добровольно в благих целях, и это тоже имеет долгую историю. Некоторые древнеанглийские медицинские амулеты, сохранившиеся в рукописи, написанной около 1000 г. н.э., содержат отрывки тарабарщины, смешанные со словами из древнеирландского, латинского, греческого или еврейского языков.Эти непонятные слова бросили вызов попыткам распутать их значение или этимологию, и поэтому ученые пришли к единому мнению, что они образуют плацебо, как волшебные слова, сопровождающие заклинание. Подобно тому, как причудливое латинское или греческое название на современной упаковке таблеток может заставить нас чувствовать себя более уверенными в излечении, так и эти звуки и слоги, которые отказываются соответствовать чему-либо, узнаваемому в древнеанглийском или любом другом языке, могли убедить тех кто слышал их, что это заклинание обязательно сработает.
Тарабарщины слоги также используются для создания придуманных или вымышленных языков. Многие из этих «conlangs» (слово-портмоне, объединяющее «сконструированный» и «язык») тщательно разрабатываются как искусственные языки, но некоторые изобретенные языки никогда не получают всех своих рабочих частей и, таким образом, остаются по существу тарабарщиной. В сочетании с переводом они могут показаться языком, но без подкрепляющих их слов, они только притворяются, что имеют значение. Немецкая аббатиса XII века Хильдегард Бингенская, композитор, философ и мистик, изобрела lingua ignota , «неизвестный язык», сохранившийся в списке из 1012 этих неизвестных слов с латинским или немецким глоссом, а также в кратком виде. гимн, написанный в основном на латыни, но усыпанный тарабарщиной, сверкающей, как драгоценные камни: orzchis , caldemia , loifolum , crizanta , chorzta .
Хильдегард из «lingua ignota» Бингена из Висбаденского кодекса. Предоставлено Hochschule Rhein / Main.Ученые, которые не переносят пустоту или известное неизвестное, искали этимологии — возможно, вы тоже сейчас пытаетесь разгадать их на языках, которые знаете, — но их объяснения являются умозрительными и не позволяют расшифровать очень многие из них. Слова Хильдегард. Другие задавались вопросом, пытаются ли эти неизвестные слова воссоздать язык, на котором Бог говорил с Адамом в Эдеме, или язык, на котором Адам назвал животных.Однако, как указывает ученый-немецкоязычный Джонатан П. Грин из Университета Северной Дакоты, действительно ли нужны такие божественные или адамические языки для обозначения «проституток, блудников, фокусников, пьяниц и воров», как это делает Хильдегард? Объяснение Грина ближе к дому: Хильдегард, вероятно, встречала слова и фразы греческого языка (алфавит и язык, которые она мало понимала или не понимала), встроенные в Священные Писания и в стихи, в которых греческие слова смешивались с латинскими стихами. Гимн воссоздает ее собственный опыт столкновения с неизвестным языком.То, что для Хильдегард греческий, является греческим для всех нас, благодаря ее lingua ignota .
Уловка Томаса Мора состоит в том, чтобы дать нам основную грамматику языка, одетого в странную одежду.
Тарабарщина Хильдегард нуждается в латинском и немецком глоссах, а также в ее латинских стихах, чтобы убедить нас серьезно относиться к ним как к языку. Точно так же сам по себе воображаемый язык книги Utopia (1516) сэра Томаса Мора — не что иное, как символы. Четыре строки утопической поэмы, произнесенные голосом острова, выступают в качестве дополнения к основному тексту.Транслитерированные в наш алфавит (« Bargol he maglomi baccan »), а затем переведенные на латынь (« Una ego terrarum omnium »), а затем и на английский («Я один из всех народов»), эти фразы начинают убеждать нас в том, что они — это языка. В то же время они постоянно уворачиваются от мысли, что они — наш язык. Такой изобретенный язык представляет собой своего рода антианглийский язык, использующий комбинации букв и фонологию, которые редко встречаются в английском или других языках, которые читатели Мора знали бы.
Это несколько сложнее сделать в английском с его смешанным германо-французским наследием и неуправляемой системой правописания. Если бы вы только могли сыграть в скрэббл в Утопии с его любовью к наименее любимым буквам и комбинациям английского языка (хотя я уверен, что скоро кто-то изменит систему подсчета очков). И все же, избегая знакомых вариантов написания, они полагаются на наше интуитивное знание того, как работает английский язык. В этих утопических фразах есть односложные слова, которые могут быть местоимениями, более длинные слова, которые могут быть глаголами или существительными, и пары многосложных слов, которые заставляют нас подозревать, что прилагательные и наречия выполняют свою работу по определению.Подобно скелету в маскарадном костюме, уловка Мора состоит в том, чтобы дать нам основную грамматику языка, одетого в странную одежду.
Язык Утопии — эзотерическая чушь, но есть более повседневные примеры непонятного языка. Как только мы выучили наш язык в детстве, можно было подумать, что лепет и бормотание прекратятся, но есть слабые места, через которые тарабарщина легко прорваться. Пение, кажется, балансирует на грани тарабарщины, побуждая нас перейти от слов к звукам.Когда мы забываем текст песни, мы гудим и la и ooo и di-dah . Или, если слов нет, человеческий голос мог бы присоединиться как инструмент: tee-tum , taa-raa . В пении слова часто растягиваются на составляющие их слоги, соблазняя нас полностью забыть о границах слов.
Джек Керуак написал в On the Road , что «для Слима Гайяра весь мир был одним большим« Оруни! ».Лингвисты называют эти фрагменты спетой тарабарщины «нелексическими вокалами», звуками, которые мы можем озвучивать, но это не слова в обычном смысле. Вы можете подумать о джазовом пении или музыке, такой как ду-воп или бибоп, в которой вокал сам по себе является названием стиля. В джазе человеческий голос конкурирует с другими инструментами в импровизированных частях, и гораздо проще импровизировать тарабарщиной, чем с настоящими текстами. Точно так же покачивание и пение, чтобы убаюкивать капризного ребенка, когда вы так устали, что едва можете мыслить ровно, создают идеальные условия для появления тарабарщины.Для довербального младенца слова не важны: с незапамятных времен важна музыка, созданная голосом. Средневековые колыбельные гимны голосом Девы Марии, утешающей младенца Христа, сохраняют в припевах некоторые из самых ранних из этих спетых нелексических слов на английском языке: lulley , lollay , lay .
Это слово «колыбельная» происходит от комбинации двух из этих ранних английских словечек: lulla-lulla и bi-bi . Песня XV века, неряшливо сохранившаяся во фрагменте рукописи, содержит хор, полный успокаивающей тарабарщины, которую родитель может петь ребенку:
Lullay, lullow, lully, lullay,
Bewy, bewy, lully, lully,
Bewy, lully, lully, lully,
Lullay, baw baw, my barne [child],
Спи теперь тихо.
Единственный сохранившийся стих ясно показывает, что это песня, которую спела «maydin moder», Мария, спящему «известному ребенку», младенцу Христу. Только последние фразы припева являются настоящими словами, а остальные — речью, словами, этимология которых невозможна. Записи в Среднеанглийском словаре для слов «bewy» и «bau» ничего не могут сказать об их происхождении. затишья — слов происходят от глагола «убаюкивать», который сам по себе объясняется как просто «подражательный» (хотя это могло легко быть наоборот, глагол был изобретен голосами).Такие слова являются звукоподражательными, письменными приближениями к звукам «b-b-b» и «l-l-l», которые родители ворковали своим младенцам. Без сознательного мышления или планирования рот изменяет звуки и создает узоры, спонтанную тарабарщину.
В то время как убаюкивающие голоса Марии почитаются и прославляются, другие средневековые тексты не одобряют бессловесные вокалы, встречающиеся в припевах гимнов и народных песен. В Пирс Пахарь (1370-90) — умопомрачительное стихотворение Уильяма Ленгланда, в котором общество XIV века опрашивается в серии сновидений — рабочие, которые не участвуют в совместной работе на ферме, сидят и поют пивные песни, « помогая » пахать Полакра Пирса с надписью «эй! тролли-лолли! », символ их глупости и идиотизма.Центральная фигура поэмы, Пирс, который иногда представляет собой идеализированный портрет честного труженика, а иногда и версию Христа, Святого Петра или доброго самаритянина, сердится и угрожает им голодной смертью.
Не каждый ранний английский писатель настолько догматичен, что крестьяне поют радостную тарабарщину нелексических словечек. Одна из детективных пьес, разыгранных в городе Честер, представляет собой более увлекательную деревенскую жизнь, на этот раз пастухи наблюдают за своими стадами, которые видят Вифлеемскую звезду в рождественской сказке.Каждый спектакль в течение дня спонсировался отдельной гильдией ремесленников: за игру пастухов, добавленную в цикл в начале 16 века, отвечали художники. В этом театрализованном представлении актер, играющий ангела, поет « Gloria in altissimis Deo, et in terra pax hominibus bonae voluntatis » (Слава Богу во всем; и мир на Земле людям доброй воли). Пастухи, не знающие такого причудливого языка, недоумевают, хотя средневековая аудитория могла бы признать этот отрывок Священного Писания началом знакомого гимна.Небесная песня началась с glore или glere , спрашивают себя пастухи? Или, может быть, glorus , glarus , glorius или glo , glas или glye ?
Так продолжается до voluntatis , превращая ангельскую латынь в нечто похожее на тарабарщину. И все же, хотя они напуганы, они также странным образом воодушевлены и успокаиваются небесной музыкой. Они решают спеть собственную веселую песню, отправляясь в Вифлеем, чтобы следовать за «starre-gleme», светом необыкновенной звезды.Режиссура постановки гласит: «Вот единственное« троли, лоли, лоли, лоу »», и мальчик-пастух призывает публику присоединиться к нему. Это один из тех моментов, смешивающих священное и мирское, что, кажется, восхищает средневековая драма. Эта пьеса высмеивает простоватость пастухов, но, может быть, она также намекает на то, что торжественная латынь — это тарабарщина для многих прихожан в английской церкви? Может быть, не имеет значения, является ли песня ангелов тарабарщиной или латынью, или же публика поет гимны или леденцы на палочке.В конце концов, Господь действует таинственными способами…
Три десятилетия спустя протестантские реформаторы не одобряли католических мистерий, а также неодобрительно относились к счастливому пению тарабарщины в народных песнях. Такие словечки, как «тролли-лолли» или «эй, нонни-нонни», символизировали деревенскую, профанную, примитивную пошлость. Майлс Ковердейл, реформатор и переводчик английской церкви, опубликовал книгу псалмов и священных текстов, переведенную и положенную на музыку, свои Добрых псалмов и Духовные песни ( c 1535).В своем предисловии он утверждал, что пахари и другие чернорабочие и женщины с их прялками и прялками лучше петь благочестивые песни, чем развлекаться фантазиями «эй, нони, эй, тролли, лол и соч лайк». Авторы пасторальной поэзии, жанра, становящегося все более модным в эпоху Возрождения, хотели поставить чистую воду между воображаемой тарабарщиной крестьян и своими собственными поэтическими композициями. Майкл Дрейтон в своем эклоге «Идея: гирлянда пастыря » (1593 г.) отличает «этих noninos [nonny-nos] грязного рибола [грязной похабщины]» от своих более изысканных стихов.
Младенцы болтают с нами чепухой, и мы отвечаем им, как если бы они сказали что-то совершенно поразительное
В последующие столетия английская тарабарщина постепенно переходит в спячку. Возникают и другие связанные с этим явления: есть мода на бессмысленные стихи, и время от времени появляются изобретенные языки — ангельские, фальшивые, вымышленные или инопланетные. Возможно, век разума и науки смущает непонятный псевдоязык. Тарабарщина снова появляется в поле зрения в начале 20 века.Написанная сначала немецкими и итальянскими поэтами-футуристами и дадаистами, а немного позже британскими и американскими авангардистами , звуковая поэзия написана тарабарщиной, представляя не слова, а чистый звук. Модернизм принимает тарабарщину как часть своего стремления отказаться от традиций и создать все новое, но рискует высмеять в этом процессе. Основополагающее исследование психопатии, проведенное американским психиатром Херви М. Клекли, The Mask of Sanity (1941), назвало книгу Джеймса Джойса «Поминки по Финнегану » (1939) «эрудированной тарабарщиной, неотличимой… от знакомого словесного салата, производимого гебефреническими пациентами [т. Е. больные шизофренией] в задней части любой государственной больницы ».Дело не в том, что Клекли высмеивал шедевр Джойса как таковой , а скорее в том, что он хотел указать на то, что это невозможно отличить от безумия. Можно ли серьезно относиться к тарабарщине как к высокому искусству?
Австралийско-американский композитор Перси Грейнджер, которого сейчас, пожалуй, больше всего помнят за постановку народных песен, думал, что наиболее важным из его произведений было то, что было спето тарабарщиной. Его «Марширующая песня демократии» ( c 1901) стремилась передать «динамичный марш оптимистической гуманитарной демократии в музыкальной композиции», не озвучивая ничего, кроме нелексических речей для пения хора: ti da-rum pum pa, dim pom pom pom pa ti di .Впервые он был исполнен на Вустерском музыкальном фестивале в Массачусетсе в 1917 году, когда оптимизма по поводу всего, что делали люди, должно быть, не хватало. «Марширующая песня» была хорошо принята, хотя рецензенты всегда были не уверены в том, что один критик вежливо называет ее «эксцентричностью в оценке». Он был возрожден к Last Night of the Proms 2019 года: тарабарщина, возможно, единственный способ найти единство во время войн Brexit после референдума.
Тарабарщина, кажется, всегда существует в этом неопределенном состоянии: тривиальна она или ценна, символ безнравственности или своего рода чистое, естественное, музыкальное выражение, возможно, даже божественное? Самое парадоксальное из качеств тарабарщины — это ключевая роль, которую она играет в том, как мы учимся говорить не тарабарщину.Детское бормотание (или «младенческая вокализация», как его более формально называют) жизненно важно для овладения языком, потому что оно побуждает опекунов устраивать имитационные беседы с младенцами. Младенцы болтают с нами чепухой, и мы отвечаем им, как если бы они сказали что-то совершенно поразительное. Также для развития языка необходимо «случайное подражание», то есть такие взаимодействия, при которых воспитатели копируют лепет младенцев и младенцев, которые бормочут им. Недавнее исследование, проведенное в Японии, показывает, что случайное подражание особенно ценно для повышения социальной активности маленьких детей с аутизмом.Если мы воспользуемся природным талантом человечества к тарабарщине, наши дети будут более свободно говорить на понятном языке, и эта истина уже давно понятна. В английском переводе XIV века латинской энциклопедии XIII века объясняется, как няни помогают детям научиться говорить, бессмысленно искажая язык: «скандинавский язык спит и наполовину озвучивает словоis, чтобы больше узнать о ребенке, который не может говорить» ( медсестра шепелявит и наполовину произносит слова, чтобы легче научить ребенка, который не умеет говорить).
Создавать тарабарщину — значит избегать привычных особенностей нашего родного языка и в то же время опираться на наше самое глубокое понимание того, что такое язык и как он работает. Тарабарщина также играет жизненно важную роль в том, чтобы дать нам родной язык, как младенцам, так и младенцам. Людвиг Витгенштейн, описывающий работу и методы философии в своей книге Philosophical Investigations , ценит «неровности», возникающие у понимания, когда он наталкивается на ограничения языка. Эти неровности заставляют нас увидеть ценность открытия.«Тарабарщина, пожалуй, самая неровная форма человеческого общения, но благодаря ей мы многое узнаем о языке, его возможностях и границах.
Справочник по API— документация TextBlob 0.16.0
Классы BLOB-объектов
Обертки для различных блоков текста, включая основные TextBlob , Word ,
и WordList классов.
Пример использования:
>>> из textblob import TextBlob
>>> b = TextBlob ("Простое лучше, чем сложное.")
>>> b.tags
[(u'Simple ', u'NN'), (u'is ', u'VBZ'), (u'better ', u'JJR'), (u'than ', u'IN'), ( u'complex ', u'NN')]
>>> b.noun_phrases
Список слов ([u'simple '])
>>> b.words
Список слов ([u'Simple ', u'is', u'better ', u'than', u'complex '])
>>> б. сентимент
(0,06666666666666667, 0,4111906)
>>> b.words [0] .synsets () [0]
Synset ('простой.n.01')
Изменено в версии 0.8.0: эти классы теперь импортируются из textblob , а не из текста .Боб .
- класс
textblob.blob.BaseBlob( text , tokenizer = None , pos_tagger = None , np_extractor = None , analyzer = None , parser = None , clean classifier = None , clean classifier = None , clean classifier ) [источник] Абстрактный базовый класс, от которого наследуются все классы текстовых блоков. Включает слова, POS-тег, NP и свойства количества слов. Также включает основные методы dunder и string для создания объектов, таких как строки Python.
Параметры: - текст — Строка.
- tokenizer — (необязательно) экземпляр токенизатора. Если
Нет, по умолчаниюWordTokenizer (). - np_extractor — (необязательно) экземпляр NPExtractor. Если
Нет, по умолчаниюFastNPExtractor (). - pos_tagger — (необязательно) экземпляр Tagger. Если
Нет, по умолчаниюNLTKTagger. - анализатор — (опционально) анализатор настроений. Если
Нет, по умолчаниюPatternAnalyzer. - parser — Парсер. Если
Нет, по умолчаниюОбразец Парсера. - классификатор — Классификатор А.
Изменено в версии 0.6.0: параметр
clean_htmlустарел, как и в NLTK.-
классифицирует() [источник] Классифицируйте большой двоичный объект с помощью классификатора
большого двоичного объекта.
-
правильный() [источник] Попытка исправить написание капли.
-
detect_language() [источник] Определите язык большого двоичного объекта с помощью Google Translate API.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob ("bonjour") >>> b.detect_language () u'fr '- Ссылка на код языка:
- https: // разработчики.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
-
заканчивается_с( суффикс , начало = 0 , конец =
72036854775807 )Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
заканчивается на( суффикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
найти( sub , start = 0 , end =72036854775807 ) Действует аналогично встроенному методу str.find (). Возвращает целое число, индекс первого вхождения подстроки аргумента sub в подстрока, заданная [начало: конец].
-
формат( * args , ** kwargs ) Выполните операцию форматирования строки, подобную встроенной
ул.формат (* args, ** kwargs). Возвращает объект blob.
-
индекс( под , начало = 0 , конец =72036854775807 ) Подобно blob.find (), но вызывает ошибку ValueError, когда подстрока не найден.
-
присоединиться( итерация ) Действует аналогично встроенному методу
str.join (итерация), за исключением возвращает объект blob.Возвращает BLOB-объект, который является объединением строк или BLOB-объектов. в итерируемом.
-
нижний() Как и str.lower (), возвращает новый объект со всеми символами в нижнем регистре.
-
нграмм( n = 3 ) [источник] Вернуть список n-граммов (кортежей из n последовательных слов) для этого капля.
-
сущ_фраза Возвращает список существительных для этого большого двоичного объекта.
-
np_counts Словарь частот встречаемости именных фраз в этом тексте.
-
parse( parser = None ) [источник] Разобрать текст.
Параметры: parser — (необязательно) Экземпляр анализатора. Если Нет, по умолчанию синтаксический анализатор этого большого двоичного объекта по умолчанию.
-
полярность Возвращает показатель полярности в виде числа с плавающей запятой в диапазоне [-1,0, 1,0]
-
pos_tags Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
заменить( старый , новый , count =72036854775807 ) Вернуть новый объект blob с заменой
старогоотновый.
-
rfind( sub , начало = 0 , конец =72036854775807 ) Действует аналогично встроенному методу str.rfind (). Возвращает целое число, индекс последнего (самого правого) появления аргумента подстроки sub в подпоследовательности, заданной [начало: конец].
-
rindex( sub , начало = 0 , конец =72036854775807 ) Как blob.rfind (), но вызывает ValueError, если подстрока не нашел.
-
настроение Вернуть кортеж формы (полярность, субъективность), где полярность — это число с плавающей запятой в диапазоне [-1.0, 1.0], а субъективность — это число с плавающей запятой. в диапазоне [0,0, 1,0], где 0,0 является очень объективным, а 1,0 — очень субъективно.
Тип возврата: именованный кортеж в форме Настроение (полярность, субъективность)
-
sentiment_assessments Вернуть кортеж формы (полярность, субъективность, оценки), где полярность — это число с плавающей запятой в диапазоне [-1.0, 1.0], субъективность float в диапазоне [0.0, 1.0], где 0.0 очень объективно, а 1.0 очень субъективен, а оценки — это список полярностей и оценки субъективности оцениваемых токенов.
Тип возврата: именованный набор в форме « Настроение (полярность, субъективность, оценок) `
-
split( sep = None , maxsplit =72036854775807 ) [источник] Действует аналогично встроенной ул.split () except возвращает Список слов.
-
start_with( префикс , start = 0 , end =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
начинается с( префикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
полоса( символов = нет ) Действует аналогично встроенной ул.strip ([chars]) метод. Возврат объект с удаленными начальными и конечными пробелами.
-
субъективность Вернуть оценку субъективности в виде числа с плавающей точкой в диапазоне [0,0, 1,0]. где 0,0 очень объективно, а 1,0 — очень субъективно.
-
тегов Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
титул() Возвращает большой двоичный объект с текстом в верхнем регистре.
-
tokenize( tokenizer = None ) [источник] Вернуть список токенов с использованием токенизатора
Параметры: tokenizer — (необязательно) объект tokenizer. Если нет, по умолчанию токенизатор этого большого двоичного объекта по умолчанию.
-
токенов Вернуть список токенов, используя объект токенизатора этого большого двоичного объекта. (по умолчанию
WordTokenizer).
-
перевести( from_lang = u’auto ‘, to = u’en’ ) [источник] Переведите большой двоичный объект на другой язык. Использует Google Translate API. Возвращает новый TextBlob.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob («Простое лучше, чем сложное») >>> b.translate (to = "es") TextBlob ('Lo simple es mejor que complejo')- Ссылка на код языка:
- https: // разработчики.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
Параметры: - from_lang ( str ) — язык для перевода. Если
Нет, попытается для определения языка. - с по ( str ) — язык для перевода.
Тип возврата: BaseBlob
-
верх() Нравится ул.upper (), возвращает новый объект со всеми символами в верхнем регистре.
-
word_counts Словарь частотности слов в этом тексте.
-
слов Вернуть список токенов слов. Это исключает знаки препинания. Если вы хотите включить знаки препинания, перейдите к токенам
- класс
текстовый блок.капля.Blobber( tokenizer = None , pos_tagger = None , np_extractor = None , analyzer = None , parser = None , classifier = None09) [источник
Фабрика для TextBlobs, которые имеют один и тот же теггер, токенизатор, парсер, классификатор и np_extractor.
использование:
>>> from textblob import Blobber >>> из textblob.taggers импортировать NLTKTagger >>> из textblob.токенизаторы импортируют SentenceTokenizer >>> tb = Blobber (pos_tagger = NLTKTagger (), tokenizer = SentenceTokenizer ()) >>> blob1 = tb («Это одна капля.») >>> blob2 = tb ("У этого большого двоичного объекта тот же теггер и токенизатор.") >>> blob1.pos_tagger - это blob2.pos_tagger ПравдаПараметры: - токенизатор — (необязательно) экземпляр токенизатора. Если
Нет, по умолчаниюWordTokenizer (). - np_extractor — (необязательно) экземпляр NPExtractor. Если
Нет, по умолчаниюFastNPExtractor (). - pos_tagger — (необязательно) экземпляр Tagger. Если
Нет, по умолчаниюNLTKTagger. - анализатор — (опционально) анализатор настроений. Если
Нет, по умолчаниюPatternAnalyzer. - parser — Парсер. Если
Нет, по умолчаниюОбразец Парсера. - классификатор — Классификатор А.
- класс
textblob.blob.Предложение( предложение , start_index = 0 , end_index = None , * args , ** kwargs ) [источник] Предложение в TextBlob. Наследует от
BaseBlob.Параметры: - предложение — строка, необработанное предложение.
- start_index — int, индекс, с которого начинается это предложение в TextBlob. Если не указан, по умолчанию 0, .
- end_index — Целое число, индекс, на котором это предложение заканчивается TextBlob. Если не указан, по умолчанию используется срок наказания — 1.
-
классифицировать() Классифицируйте большой двоичный объект с помощью классификатора
большого двоичного объекта.
-
правильный() Попытка исправить написание капли.
-
detect_language() Определите язык большого двоичного объекта с помощью Google Translate API.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob ("bonjour") >>> b.detect_language () u'fr '- Ссылка на код языка:
- https://developers.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
-
диктат Диктованное представление этого предложения.
-
конец= Нет Конечный индекс в текстовом блоке
-
end_index= Нет Конечный индекс в текстовом блоке
-
заканчивается_с( суффикс , начало = 0 , конец =
72036854775807 )Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
заканчивается на( суффикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
найти( sub , start = 0 , end =72036854775807 ) Действует аналогично встроенному методу str.find (). Возвращает целое число, индекс первого вхождения подстроки аргумента sub в подстрока, заданная [начало: конец].
-
формат( * args , ** kwargs ) Выполните операцию форматирования строки, подобную встроенной
str.format (* args, ** kwargs). Возвращает объект blob.
-
индекс( под , начало = 0 , конец =72036854775807 ) Подобно blob.find (), но вызывает ошибку ValueError, когда подстрока не найден.
-
присоединиться( итерация ) Действует как встроенный
ул.join (итерируемый) метод, кроме возвращает объект blob.Возвращает BLOB-объект, который является объединением строк или BLOB-объектов. в итерируемом.
-
нижний() Как и str.lower (), возвращает новый объект со всеми символами в нижнем регистре.
-
нграмм( n = 3 ) Вернуть список n-граммов (кортежей из n последовательных слов) для этого капля.
-
сущ_фраза Возвращает список существительных для этого большого двоичного объекта.
-
np_counts Словарь частот встречаемости именных фраз в этом тексте.
-
синтаксический анализ( синтаксический анализатор = нет ) Разобрать текст.
Параметры: parser — (необязательно) Экземпляр анализатора. Если Нет, по умолчанию синтаксический анализатор этого большого двоичного объекта по умолчанию.
-
полярность Вернуть показатель полярности в виде числа с плавающей запятой в диапазоне [-1.0, 1.0]
-
pos_tags Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
заменить( старый , новый , count =72036854775807 ) Вернуть новый объект blob с заменой
старогоотновый.
-
rfind( sub , начало = 0 , конец =72036854775807 ) Действует аналогично встроенному методу str.rfind (). Возвращает целое число, индекс последнего (самого правого) появления аргумента подстроки sub в подпоследовательности, заданной [начало: конец].
-
rindex( sub , начало = 0 , конец =72036854775807 ) Как blob.rfind (), но вызывает ValueError, если подстрока не нашел.
-
настроение Вернуть кортеж формы (полярность, субъективность), где полярность — это число с плавающей запятой в диапазоне [-1.0, 1.0], а субъективность — это число с плавающей запятой. в диапазоне [0,0, 1,0], где 0,0 является очень объективным, а 1,0 — очень субъективно.
Тип возврата: именованный кортеж в форме Настроение (полярность, субъективность)
-
sentiment_assessments Вернуть кортеж формы (полярность, субъективность, оценки), где полярность — это число с плавающей запятой в диапазоне [-1.0, 1.0], субъективность float в диапазоне [0.0, 1.0], где 0.0 очень объективно, а 1.0 очень субъективен, а оценки — это список полярностей и оценки субъективности оцениваемых токенов.
Тип возврата: именованный набор в форме « Настроение (полярность, субъективность, оценок) `
-
split( sep = None , maxsplit =72036854775807 ) Действует аналогично встроенной ул.split () except возвращает Список слов.
-
начало= нет Начальный индекс в TextBlob
-
start_index= Нет Начальный индекс в TextBlob
-
start_with( префикс , start = 0 , end =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
начинается с( префикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
полоса( символов = нет ) Действует аналогично встроенному методу str.strip ([chars]). Возврат объект с удаленными начальными и конечными пробелами.
-
субъективность Вернуть оценку субъективности в виде числа с плавающей запятой в диапазоне [0.0, 1.0] где 0,0 очень объективно, а 1,0 — очень субъективно.
-
тегов Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
титул() Возвращает большой двоичный объект с текстом в верхнем регистре.
-
tokenize( tokenizer = None ) Вернуть список токенов с использованием токенизатора
Параметры: tokenizer — (необязательно) объект tokenizer. Если нет, по умолчанию токенизатор этого большого двоичного объекта по умолчанию.
-
токенов Вернуть список токенов, используя объект токенизатора этого большого двоичного объекта. (по умолчанию
WordTokenizer).
-
перевести( from_lang = u’auto ‘, to = u’en’ ) Переведите большой двоичный объект на другой язык. Использует Google Translate API. Возвращает новый TextBlob.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob («Простое лучше, чем сложное») >>> b.translate (to = "es") TextBlob ('Lo simple es mejor que complejo')- Ссылка на код языка:
- https: // разработчики.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
Параметры: - from_lang ( str ) — язык для перевода. Если
Нет, попытается для определения языка. - с по ( str ) — язык для перевода.
Тип возврата: BaseBlob
-
верх() Нравится ул.upper (), возвращает новый объект со всеми символами в верхнем регистре.
-
word_counts Словарь частотности слов в этом тексте.
-
слов Вернуть список токенов слов. Это исключает знаки препинания. Если вы хотите включить знаки препинания, перейдите к токенам
- класс
текстовый блок.капля.TextBlob( text , tokenizer = None , pos_tagger = None , np_extractor = None , analyzer = None , parser = None , clean classifier = None , clean classifier = None , clean classifier ) [источник] Общий текстовый блок, предназначенный для больших объемов текста (особенно содержащие предложения). Наследует от
BaseBlob.Параметры: - текст ( str ) — Строка.
- tokenizer — (необязательно) экземпляр токенизатора. Если
Нет, по умолчаниюWordTokenizer (). - np_extractor — (необязательно) экземпляр NPExtractor. Если
Нет, по умолчаниюFastNPExtractor (). - pos_tagger — (необязательно) экземпляр Tagger. Если
Нет, по умолчаниюNLTKTagger. - анализатор — (опционально) анализатор настроений. Если
Нет, по умолчаниюАнализатор паттернов. - классификатор — (по желанию) классификатор.
-
классифицировать() Классифицируйте большой двоичный объект с помощью классификатора
большого двоичного объекта.
-
правильный() Попытка исправить написание капли.
-
detect_language() Определите язык большого двоичного объекта с помощью Google Translate API.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob ("bonjour") >>> b.detect_language () u'fr '- Ссылка на код языка:
- https://developers.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
-
заканчивается_с( суффикс , начало = 0 , конец =
72036854775807 )Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
заканчивается на( суффикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект заканчивается заданным суффиксом.
-
найти( sub , start = 0 , end =72036854775807 ) Действует аналогично встроенному методу str.find (). Возвращает целое число, индекс первого вхождения подстроки аргумента sub в подстрока, заданная [начало: конец].
-
формат( * args , ** kwargs ) Выполните операцию форматирования строки, подобную встроенной
str.format (* args, ** kwargs). Возвращает объект blob.
-
индекс( под , начало = 0 , конец =72036854775807 ) Подобно blob.find (), но вызывает ошибку ValueError, когда подстрока не найден.
-
присоединиться( итерация ) Действует как встроенный
ул.join (итерируемый) метод, кроме возвращает объект blob.Возвращает BLOB-объект, который является объединением строк или BLOB-объектов. в итерируемом.
-
JSON Представление этого большого двоичного объекта в формате json.
Изменено в версии 0.5.1: Сделано
jsonкак свойство вместо метода восстановления в обратном направлении. совместимость, которая была нарушена после версии 0.4.0.
-
нижний() Нравится ул.lower (), возвращает новый объект со всеми символами в нижнем регистре.
-
нграмм( n = 3 ) Вернуть список n-граммов (кортежей из n последовательных слов) для этого капля.
-
сущ_фраза Возвращает список существительных для этого большого двоичного объекта.
-
np_counts Словарь частот встречаемости именных фраз в этом тексте.
-
синтаксический анализ( синтаксический анализатор = нет ) Разобрать текст.
Параметры: parser — (необязательно) Экземпляр анализатора. Если Нет, по умолчанию синтаксический анализатор этого большого двоичного объекта по умолчанию.
-
полярность Возвращает показатель полярности в виде числа с плавающей запятой в диапазоне [-1,0, 1,0]
-
pos_tags Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
raw_sentences Список строк, сырые предложения в большом двоичном объекте.
-
заменить( старый , новый , count =72036854775807 ) Вернуть новый объект blob с заменой
старогоотновый.
-
rfind( sub , начало = 0 , конец =72036854775807 ) Действует аналогично встроенному методу str.rfind (). Возвращает целое число, индекс последнего (самого правого) появления аргумента подстроки sub в подпоследовательности, заданной [начало: конец].
-
rindex( sub , начало = 0 , конец =72036854775807 ) Подобно blob.rfind (), но вызывает ошибку ValueError, когда подстрока не является нашел.
-
предложений Возвращает список из
объектов предложения.
-
настроение Вернуть кортеж формы (полярность, субъективность), где полярность является числом с плавающей запятой в диапазоне [-1.0, 1.0], а субъективность — поплавок. в диапазоне [0,0, 1,0], где 0,0 является очень объективным, а 1,0 — очень субъективно.
Тип возврата: именованный кортеж в форме Настроение (полярность, субъективность)
-
sentiment_assessments Вернуть кортеж формы (полярность, субъективность, оценки), где полярность — это число с плавающей запятой в диапазоне [-1.0, 1.0], субъективность — это float в диапазоне [0.0, 1.0], где 0.0 очень объективно, а 1.0 очень субъективен, а оценки — это список полярностей и оценки субъективности оцениваемых токенов.
Тип возврата: именованный набор в форме « Настроение (полярность, субъективность, оценок) `
-
серийный Возвращает список представлений dict каждого предложения.
-
split( sep = None , maxsplit =72036854775807 ) Действует аналогично встроенной ул.split () except возвращает Список слов.
-
start_with( префикс , start = 0 , end =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
начинается с( префикс , начало = 0 , конец =72036854775807 ) Возвращает True, если большой двоичный объект начинается с заданного префикса.
-
полоса( символов = нет ) Действует аналогично встроенной ул.strip ([chars]) метод. Возврат объект с удаленными начальными и конечными пробелами.
-
субъективность Вернуть оценку субъективности в виде числа с плавающей точкой в диапазоне [0,0, 1,0]. где 0,0 очень объективно, а 1,0 — очень субъективно.
-
тегов Возвращает список кортежей в форме (слово, тег POS).
Пример:
[('At', 'IN'), ('восемь', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'), ('Четверг', 'NNP'), ('утро', 'NN')]Тип возврата: список кортежей
-
титул() Возвращает большой двоичный объект с текстом в верхнем регистре.
-
to_json( * args , ** kwargs ) [источник] Вернуть json-представление (str) этого большого двоичного объекта. Принимает те же аргументы, что и json.dumps.
-
tokenize( tokenizer = None ) Вернуть список токенов с использованием токенизатора
Параметры: tokenizer — (необязательно) объект tokenizer.Если нет, по умолчанию токенизатор этого большого двоичного объекта по умолчанию.
-
токенов Вернуть список токенов, используя объект токенизатора этого большого двоичного объекта. (по умолчанию
WordTokenizer).
-
перевести( from_lang = u’auto ‘, to = u’en’ ) Переведите большой двоичный объект на другой язык. Использует Google Translate API. Возвращает новый TextBlob.
Требуется подключение к Интернету.
использование:
>>> b = TextBlob («Простое лучше, чем сложное») >>> b.translate (to = "es") TextBlob ('Lo simple es mejor que complejo')- Ссылка на код языка:
- https://developers.google.com/translate/v2/using_rest#language-params
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
Параметры: - from_lang ( str ) — язык для перевода.Если
Нет, попытается для определения языка. - с по ( str ) — язык для перевода.
Тип возврата: BaseBlob
-
верх() Как и str.upper (), возвращает новый объект со всеми символами в верхнем регистре.
-
word_counts Словарь частотности слов в этом тексте.
-
слов Вернуть список токенов слов. Это исключает знаки препинания. Если вы хотите включить знаки препинания, перейдите к токенам
- класс
textblob.blob.Word( строка , pos_tag = None ) [источник] Простое словесное представление. Включает методы перегиба, перевод и интеграция с WordNet.
-
заглавные буквы() → юникод Вернуть версию S с заглавной буквы, т. Е. Сделать первый символ имеют верхний регистр, а остальные — нижний.
-
центр( ширина [, fillchar ]) → юникод Вернуть S с центром в строке Unicode длиной и шириной. Заполнение выполняется с использованием указанного символа заполнения (по умолчанию — пробел)
-
правильный() [источник] Исправьте написание слова.Возвращает слово с наивысшим уверенность в использовании корректора орфографии.
-
count( sub [, start [, end ]]) → int Вернуть количество неперекрывающихся вхождений подстроки sub в Строка Юникода S [начало: конец]. Необязательные аргументы start и end: интерпретируется как в обозначении среза.
-
декодирует([ кодирование [, ошибок ]]) → строка или юникод Декодирует S с использованием кодека, зарегистрированного для кодирования.кодировка по умолчанию в кодировку по умолчанию. могут быть даны ошибки, чтобы установить другую ошибку Схема погрузки-разгрузки. По умолчанию установлено «строгое», что означает, что ошибки кодирования вызывают UnicodeDecodeError. Другие возможные значения — «игнорировать» и «заменить». а также любое другое имя, зарегистрированное с помощью codecs.register_error, то есть способен обрабатывать ошибки UnicodeDecodeErrors.
-
определить( pos = None ) [источник] Вернуть список определений для этого слова. Каждое определение соответствует синсету для этого слова.
Параметры: pos — Тег части речи для фильтрации. Если Нет, определения для всех частей речи будут загружены.Тип возврата: Список строк
-
определений Список определений этого слова. Каждому определению соответствует к синсету.
-
detect_language() [источник] Определите язык слова с помощью Google Translate API.
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
-
кодирует([ кодировка [, ошибок ]]) → строка или юникод Кодирует S с использованием кодека, зарегистрированного для кодирования. кодировка по умолчанию в кодировку по умолчанию. могут быть даны ошибки, чтобы установить другую ошибку Схема погрузки-разгрузки. По умолчанию установлено «строгое», что означает, что ошибки кодирования вызывают UnicodeEncodeError. Другие возможные значения: «игнорировать», «заменить» и «Xmlcharrefreplace», а также любое другое имя, зарегистрированное с кодеки.register_error, который может обрабатывать UnicodeEncodeErrors.
-
заканчивается на( суффикс [, начало [, конец ]]) → bool Вернуть True, если S заканчивается указанным суффиксом, в противном случае — False. При необязательном запуске проверьте S, начиная с этой позиции. С необязательным концом прекратите сравнивать S в этой позиции. суффикс также может быть кортежем строк.
-
expandtabs([ tabsize ]) → unicode Вернуть копию S, в которой все символы табуляции раскрыты пробелами.Если размер табуляции не указан, предполагается, что размер табуляции равен 8 символам.
-
найти( sub [, start [, end ]]) → int Вернуть наименьший индекс в S, где найдена подстрока, таким образом, что подпрограмма содержится в S [начало: конец]. По желанию начало и конец аргументов интерпретируются как в нотации среза.
Возврат -1 в случае ошибки.
-
формат( * args , ** kwargs ) → unicode Вернуть отформатированную версию S с использованием подстановок из args и kwargs.Замены обозначаются фигурными скобками (‘{‘ и ‘}’).
-
get_synsets( pos = None ) [источник] Вернуть список объектов Synset для этого слова.
Параметры: pos — Тег части речи для фильтрации. Если Нет, все будут загружены синсеты для всех частей речи.Тип возврата: список Synsets
-
index( sub [, start [, end ]]) → int Нравится S.find (), но вызовет ValueError, если подстрока не найдена.
-
isalnum() → bool Вернуть True, если все символы в S буквенно-цифровые и в S есть хотя бы один символ, иначе — False.
-
isalpha() → bool Вернуть True, если все символы в S буквенные и в S есть хотя бы один символ, иначе — False.
-
является десятичным числом() → bool Вернуть True, если в S есть только десятичные символы, В противном случае неверно.
-
isdigit() → bool Вернуть True, если все символы в S являются цифрами и в S есть хотя бы один символ, иначе — False.
-
ниже() → bool Вернуть True, если все символы в S в нижнем регистре и есть хотя бы один регистр в S, иначе — False.
-
isnumeric() → bool Вернуть True, если в S только числовые символы, В противном случае неверно.
-
isspace() → bool Вернуть True, если все символы в S являются пробелами и в S есть хотя бы один символ, иначе — False.
-
istitle() → bool Вернуть True, если S — строка с заголовком и есть хотя бы один символ в S, т.е. заглавные буквы и заглавные буквы могут быть только следовать за символами без регистра, а за строчными — только за регистром В противном случае верните False.
-
isupper() → bool Вернуть True, если все символы в S в верхнем регистре и есть хотя бы один регистр в S, иначе — False.
-
присоединиться к( итерация ) → юникод Вернуть строку, которая является конкатенацией строк в повторяемый. Разделитель между элементами — S.
-
лемма Верните лемму этого слова, используя функцию морфии Wordnet.
-
lemmatize( ** kwargs ) [источник] Верните лемму для слова, используя функцию морфии WordNet.
Параметры: pos — Часть речи для фильтрации. Если Нет, по умолчанию_wordnet.НОМЕР.
-
ljust( ширина [, fillchar ]) → int Вернуть S с выравниванием по левому краю в строке Unicode длиной и шириной.Заполнение выполняется с использованием указанного символа заполнения (по умолчанию — пробел).
-
нижний() → юникод Вернуть копию строки S, преобразованную в нижний регистр.
-
lstrip([ символов ]) → юникод Вернуть копию строки S с удаленными ведущими пробелами. Если даны символы, а не Нет, вместо этого удалите символы в символах. Если chars — это str, он будет преобразован в Unicode перед удалением
-
перегородка( sep) -> (голова , sep , хвост ) Найдите разделитель sep в S и верните часть перед ним, сам разделитель и часть после него.Если разделитель не найдено, вернуть S и две пустые строки.
-
множественное число() [источник] Вернуть версию слова во множественном числе в виде строки.
-
заменить( старый , новый [, count ]) → unicode Вернуть копию S со всеми вхождениями подстроки старые заменены на новые. Если количество необязательных аргументов равно задано, заменяются только первые вхождения счетчика.
-
rfind( sub [, start [, end ]]) → int Вернуть наивысший индекс в S, где найдена подстрока, таким образом, что подпрограмма содержится в S [начало: конец]. По желанию начало и конец аргументов интерпретируются как в нотации среза.
Возврат -1 в случае ошибки.
-
rindex( sub [, start [, end ]]) → int Нравится S.rfind (), но вызывает ValueError, если подстрока не найдена.
-
rjust( ширина [, fillchar ]) → юникод Вернуть S, выровненный по правому краю, в строке Unicode длиной и шириной. Заполнение выполняется с использованием указанного символа заполнения (по умолчанию — пробел).
-
r раздел( sep) -> (голова , sep , хвост ) Найдите разделитель sep в S, начиная с конца S, и верните часть перед ним, сам разделитель и часть после него.Если разделитель не найден, вернуть две пустые строки и S.
-
rsplit([ sep [, maxsplit ]]) → список строк Вернуть список слов в S, используя sep в качестве строка-разделитель, начиная с конца строки и работаю на фронт. Если задано maxsplit, не более maxsplit деления сделаны. Если sep не указан, любая строка с пробелами является разделителем.
-
rstrip([ символов ]) → юникод Вернуть копию строки S с удаленными конечными пробелами.Если даны символы, а не Нет, вместо этого удалите символы в символах. Если chars — это str, он будет преобразован в Unicode перед удалением
-
singularize() [источник] Вернуть версию слова в единственном числе в виде строки.
-
проверка орфографии() [источник] Возвращает список кортежей (слово, достоверность) орфографических исправлений.
По материалам: Питер Норвиг, «Как написать корректор орфографии». (http: // norvig.com / spell-corre.html), как реализовано в шаблоне библиотека.
-
split([ sep [, maxsplit ]]) → список строк Вернуть список слов в S, используя sep в качестве строка-разделитель. Если задано maxsplit, не более maxsplit деления сделаны. Если sep не указан или равен None, любой пробельная строка является разделителем, а пустые строки — удалено из результата.
-
разделенных строк( keepends = False ) → список строк Вернуть список строк в S с разрывами на границах строк.Разрывы строк не включаются в результирующий список, если не сохраняются дано и верно.
-
начинается с(префикс [, начало [, конец ]]) → bool Вернуть True, если S начинается с указанного префикса, в противном случае — False. При необязательном запуске проверьте S, начиная с этой позиции. С необязательным концом прекратите сравнивать S в этой позиции. префикс также может быть кортежем строк, который нужно попробовать.
-
стержень( стержень = Создайте слово с помощью различных стеммеров NLTK.(По умолчанию: Porter Stemmer)
-
полоса([ символов ]) → юникод Вернуть копию строки S с ведущими и конечными пробелы удалены. Если даны символы, а не Нет, вместо этого удалите символы в символах. Если chars — это str, он будет преобразован в Unicode перед удалением
-
подкачка() → юникод Вернуть копию S с прописными буквами, преобразованными в строчные и наоборот.
-
синсетов Список объектов Synset для этого Word.
Тип возврата: список Synsets
-
заголовок() → юникод Возвращает версию S с заглавными буквами, т. Е. Слова начинаются с заглавного регистра символы, все остальные символы в регистре имеют нижний регистр.
-
перевести( from_lang = u’auto ‘, to = u’en’ ) [источник] Переведите слово на другой язык с помощью Google Перевести API.
Не рекомендуется, начиная с версии 0.16.0: вместо этого используйте официальный Google Translate API.
-
верхний() → юникод Вернуть копию S, преобразованную в верхний регистр.
-
zfill( ширина ) → юникод Дополните числовую строку S нулями слева, чтобы заполнить поле. указанной ширины. Строка S никогда не усекается.
-
- класс
текстовый блок.капля.WordList( сборник ) [источник] Набор слов в виде списка.
-
добавить( obj ) [источник] Добавить объект в конец. Если объект является строкой, добавляет
Wordобъект.
-
count( strg , case_sensitive = False , * args , ** kwargs ) [источник] Получите количество слов или слов
sв этом WordList.Параметры: - strg — строка для подсчета.
- case_sensitive — Логическое значение, независимо от того, учитывается ли при поиске регистр.
-
расширение( итерация ) [источник] Расширьте список слов, добавив элементы из
итеративного. Если элемент является строкой, добавляет объектWord.
-
index( value [, start [, stop ]]) → integer — вернуть первый индекс значения. Вызывает ошибку ValueError, если значение отсутствует.
-
вставка() L.insert (index, object) — вставить объект перед индексом
-
lemmatize() [источник] Вернуть лемму каждого слова в этом списке слов.
-
нижний() [источник] Вернуть новый список слов с каждым словом в нижнем регистре.
-
множественное число() [источник] Возвращает версию множественного числа каждого слова в этом WordList.
-
pop([ index ]) → item — удалить и вернуть элемент по индексу (по умолчанию последний). Вызывает ошибку IndexError, если список пуст или индекс выходит за пределы допустимого диапазона.
-
удалить() L.remove (значение) — удалить первое вхождение значения. Вызывает ValueError, если значение отсутствует.
-
реверс() L.reverse () — реверс НА МЕСТЕ
-
singularize() [источник] Возвращает единственную версию каждого слова в этом WordList.
-
сортировать() Л.sort (cmp = None, key = None, reverse = False) — стабильная сортировка IN PLACE ; cmp (x, y) -> -1, 0, 1
-
стержень( * args , ** kwargs ) [источник] Вернуть основу для каждого слова в этом списке слов.
-
верх() [источник] Вернуть новый список слов с каждым словом в верхнем регистре.
-
Базовые классы
Абстрактные базовые классы для моделей (тегеры, экстракторы именных фраз и т. Д.) которые определяют интерфейс для классов-потомков.
Изменено в версии 0.7.0: все базовые классы определены в одном модуле textblob.base .
Абстрактный базовый класс, от которого наследуются все классы NPExtractor. Дочерние классы должны реализовывать метод
extract (text)который возвращает список словосочетаний существительных в виде строк.Возвращает список словосочетаний (строк) существительных для основного текста.
- класс
текстовый блок.база.BaseParser[источник] Абстрактный класс парсера, от которого наследуются все парсеры. Все потомки должны реализовать метод
parse ().-
синтаксический анализ( текст ) [источник] Анализирует текст.
-
- класс
textblob.base.BaseSentimentAnalyzer[источник] Абстрактный базовый класс, от которого наследуются все анализаторы тональности.Следует реализовать метод анализа
(текст), который возвращает либо результаты анализа.-
анализировать( текст ) [источник] Вернуть результат анализа. Обычно возвращает либо кортеж, число с плавающей запятой или словарь.
-
- класс
textblob.base.BaseTagger[источник] Абстрактный класс тегеров, из которого все теггеры унаследовать от. Все потомки должны реализовать
tag ()метод.-
тег( текст , tokenize = True ) [источник] Вернуть список кортежей в форме (слово, тег) для заданного набора текста или экземпляра BaseBlob.
-
- класс
textblob.base.BaseTokenizer[источник] Абстрактный базовый класс, от которого наследуются все классы Tokenizer. Дочерние классы должны реализовывать метод
tokenize (text)который возвращает список словосочетаний существительных в виде строк.-
itokenize( текст , * args , ** kwargs ) [источник] Вернуть генератор, который генерирует токены «по запросу».
-
tokenize( текст ) [источник] Возвращает список токенов (строк) для основного текста.
-
Токенизаторы
Различные реализации токенизатора.
- класс
текстовый блок.токенизаторы.SentenceTokenizer[источник] Токенизатор предложений NLTK (в настоящее время PunktSentenceTokenizer). Использует неконтролируемый алгоритм для построения модели сокращенных слов, словосочетания и слова, с которых начинаются предложения, затем использует это, чтобы найти границы предложения.
-
itokenize( текст , * args , ** kwargs ) Вернуть генератор, который генерирует токены «по запросу».
-
tokenize( ** kwargs ) [источник] Вернуть список предложений.
-
- class
textblob.tokenizers.WordTokenizer[источник] Рекомендуемый NLTK токенизатор слов (в настоящее время TreeBankTokenizer). Использует регулярные выражения для токенизации текста. Предполагается, что текст уже был сегментированы на предложения.
Выполняет следующие шаги:
- разделить стандартные схватки, например не делайте -> не делайте
- разделенные запятые и одинарные кавычки
- отдельных периода, которые появляются в конце строки
-
itokenize( текст , * args , ** kwargs ) Вернуть генератор, который генерирует токены «по запросу».
-
tokenize( текст , include_punc = True ) [источник] Вернуть список токенов слов.
Параметры: - текст — строка текста.
- include_punc — (необязательно) включать ли знаки препинания как отдельные токены. По умолчанию True.
-
текстовых блоков.токенизаторы.sent_tokenize= <связанный метод SentenceTokenizer.itokenize из> Удобная функция для разметки предложений
-
textblob.tokenizers.word_tokenize( текст , include_punc = True , * args , ** kwargs ) [источник] Удобная функция преобразования текста в слова.
ПРИМЕЧАНИЕ. Токенизатор слов NLTK ожидает ввода предложений, поэтому текст будет токенизируются в предложения, прежде чем токенизироваться в слова.
POS-тегеры
Реализации тегеров частей речи.
- class
textblob.en.taggers.NLTKTagger[источник] Tagger, который использует стандартное tagger TreeBank NLTK. ПРИМЕЧАНИЕ. Требуется numpy. Пока не поддерживается PyPy.
-
tag( ** kwargs ) [источник] Пометьте строку или BaseBlob.
-
- class
textblob.en.taggers.PatternTagger[источник] Tagger, использующий реализацию в Библиотека выкроек Тома де Смедта (http://www.clips.ua.ac.be/pattern).
-
тег( текст , tokenize = True ) [источник] Пометьте строку или BaseBlob.
-
Анализаторы настроений
Реализации анализа тональности.
- класс
textblob.en.sentiments.NaiveBayesAnalyzer( feature_extractor = Наивный байесовский анализатор, обученный на наборе данных из обзоров фильмов. Возвращает результаты в виде именованного кортежа в форме:
Настроение (классификация, p_pos, p_neg)Параметры: feature_extractor ( вызываемый ) — функция, которая возвращает словарь особенности, учитывая список слов. -
RETURN_TYPE Объявление типа возврата
псевдоним
Sentiment
-
анализировать( текст ) [источник] Вернуть тональность в виде именованного кортежа в форме:
Настроение (классификация, p_pos, p_neg)
-
поезд( ** kwargs ) [источник] Обучите наивный байесовский классификатор на корпусе обзора фильмов.
-
- класс
textblob.en.sentiments.PatternAnalyzer[источник] Анализатор тональности, использующий ту же реализацию, что и библиотека шаблонов. Возвращает результаты в виде именованного кортежа в форме:
Настроение (полярность, субъективность, [оценки]), где [оценки] — это список оцененных токенов и их полярность и субъективность —
-
RETURN_TYPE псевдоним
Sentiment
-
анализировать( текст , keep_assessments = False ) [источник] Вернуть тональность в виде именованного кортежа в форме:
Настроение (полярность, субъективность, [оценки]).
-
Парсеры
Различные реализации синтаксического анализатора.
- класс
textblob.en.parsers.PatternParser[источник] Синтаксический анализатор, использующий реализацию из библиотеки шаблонов Тома де Смеда. http://www.clips.ua.ac.be/pages/pattern-en#parser
-
синтаксический анализ( текст ) [источник] Анализирует текст.
-
Классификаторы
Различные реализации классификатора.Также включает экстрактор основных функций методы.
Пример использования:
>>> из textblob import TextBlob
>>> из textblob.classifiers импортировать NaiveBayesClassifier
>>> поезд = [
... ('Я люблю этот бутерброд.', 'Pos'),
... ('Это потрясающее место!', 'Pos'),
... ('Мне очень нравится это пиво.', 'Pos'),
... ('Мне не нравится этот ресторан', 'neg'),
... ('Я устал от этого.', 'Neg'),
... ("Я не могу с этим справиться", 'neg'),
... («Мой начальник ужасен.», «Нег»)
...]
>>> cl = NaiveBayesClassifier (поезд)
>>> cl.classify («Я прекрасно себя чувствую!»)
'pos'
>>> blob = TextBlob ("Пиво хорошее. Но похмелье ужасное.", classifier = cl)
>>> для s в blob. предложениях:
... печать (и)
... печать (s.classify ())
...
Пиво хорошее.
позиция
Но похмелье ужасное.
негр
- class
textblob.classifiers.BaseClassifier( train_set , feature_extractor = Абстрактный класс классификатора, от которого наследуются все классификаторы.На минимум, классы-потомки должны реализовывать метод
classifyи иметь классификаторПараметры: - train_set — обучающий набор, либо список кортежей формы
(текст, классификация)или файловый объект.текстможет быть либо строка или итерация. - feature_extractor ( вызываемый ) — функция извлечения функций, которая принимает один или
два аргумента:
документиtrain_set. - формат ( str ) — Если
train_setявляется именем файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла. - kwargs — Конструктору передаются дополнительные аргументы ключевого слова
класса
Format, используемый для читать данные. Применяется только тогда, когда файловый объект передается какtrain_set.
-
классификатор Объект классификатора.
-
классифицируем( текст ) [источник] Классифицирует строку текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
этикеток() [источник] Возвращает итерацию, содержащую возможные метки.
-
поезд( labeled_featureset ) [источник] Обучает классификатор.
- train_set — обучающий набор, либо список кортежей формы
- class
textblob.classifiers.DecisionTreeClassifier( train_set , feature_extractor = Классификатор на основе алгоритма дерева решений, реализованный в НЛТК.
Параметры: - train_set — обучающий набор, либо список кортежей формы
(текст, классификация)или имя файла.текстможет быть либо строка или итерация. - feature_extractor — Функция извлечения признаков, которая принимает один или
два аргумента:
документиtrain_set. - формат — Если
train_set— это имя файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
-
точность( test_set , формат = нет ) Вычислите точность на тестовом наборе.
Параметры: - test_set — список кортежей в форме
(текст, метка)или указатель файла. - формат — Если
test_set— имя файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
- test_set — список кортежей в форме
-
классификатор Классификатор.
-
классифицируйте( текст ) Классифицирует текст.
Параметры: текст ( str ) — строка текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
этикеток() Вернуть итерацию возможных меток.
-
nltk_class псевдоним
nltk.classify.decisiontree.DecisionTreeClassifier
-
pprint( * args , ** kwargs ) Вернуть строку, содержащую хорошо напечатанную версию этого решения дерево. Каждая строка в строке соответствует одному узлу дерева решений. или лист, а отступ используется для отображения структуры дерева.
-
pretty_format( * args , ** kwargs ) [источник] Вернуть строку, содержащую хорошо напечатанную версию этого решения дерево.Каждая строка в строке соответствует одному узлу дерева решений. или лист, а отступ используется для отображения структуры дерева.
-
псевдокод( * args , ** kwargs ) [источник] Вернуть строковое представление этого дерева решений, которое выражает решения, которые он принимает, как вложенный набор псевдокодовых операторов if.
-
поезд( * args , ** kwargs ) Обучите классификатор с помеченным набором функций и верните классификатор.Принимает те же аргументы, что и обернутый класс NLTK. Этот метод неявно вызывается при вызове
classifyилиточностьметодов и включен только для того, чтобы разрешить передачу аргументов в методtrainобернутого класса NLTK.
-
обновление( new_data , * args , ** kwargs ) Обновить классификатор новыми данными обучения и повторно обучить классификатор.
Параметры: new_data — Новые данные в виде списка кортежей формы (текст, этикетка).
- train_set — обучающий набор, либо список кортежей формы
- class
textblob.classifiers.MaxEntClassifier( train_set , feature_extractor = Классификатор максимальной энтропии (также известный как «условный экспоненциальный классификатор »). Этот классификатор параметризуется набор «весов», которые используются для объединения элементов сустава которые генерируются из набора функций с помощью «кодировки».В в частности, кодирование сопоставляет каждую пару
(набор функций, метка)с вектор. Затем вероятность каждой метки вычисляется с использованием следующее уравнение:dotprod (веса, кодирование (фс, метка)) prob (fs | label) = ------------------------------------------- -------- sum (dotprod (weights, encode (fs, l)) для l в метках)Где
dotprod— скалярное произведение:dotprod (a, b) = sum (x * y for (x, y) in zip (a, b))
-
точность( test_set , формат = нет ) Вычислите точность на тестовом наборе.
Параметры: - test_set — список кортежей в форме
(текст, метка)или указатель файла. - формат — Если
test_set— имя файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
- test_set — список кортежей в форме
-
классификатор Классификатор.
-
классифицируйте( текст ) Классифицирует текст.
Параметры: текст ( str ) — строка текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
этикеток() Вернуть итерацию возможных меток.
-
nltk_class псевдоним
nltk.classify.maxent.MaxentClassifier
-
prob_classify( текст ) [источник] Вернуть распределение вероятностей метки для классификации строки текста.
Пример:
>>> classifier = MaxEntClassifier (train_data) >>> prob_dist = classifier.prob_classify ("Сегодня утром я счастлив.") >>> prob_dist.max () 'положительный' >>> prob_dist.prob ("положительный") 0,7Тип возврата: nltk.probability.DictionaryProbDist
-
поезд( * args , ** kwargs ) Обучите классификатор с помеченным набором функций и верните классификатор. Принимает те же аргументы, что и обернутый класс NLTK. Этот метод неявно вызывается при вызове
classifyилиточностьметодов и включен только для того, чтобы разрешить передачу аргументов в методtrainобернутого класса NLTK.
-
обновление( new_data , * args , ** kwargs ) Обновить классификатор новыми данными обучения и повторно обучить классификатор.
Параметры: new_data — Новые данные в виде списка кортежей формы (текст, этикетка).
-
- class
textblob.classifiers.NLTKClassifier( train_set , feature_extractor = Абстрактный класс, который является оболочкой для модуля nltk.classify.
Ожидает, что дочерние классы будут включать переменную класса
nltk_classкоторый является классом в модуле nltk.classify, который нужно обернуть.Пример:
класс MyClassifier (NLTKClassifier): nltk_class = nltk.classify.svm.SvmClassifier-
точность( test_set , format = None ) [источник] Вычислите точность на тестовом наборе.
Параметры: - test_set — список кортежей в форме
(текст, метка)или указатель файла. - формат — Если
test_set— имя файла, формат файла, например«csv»или«json».ЕслиНет, попытается обнаружить формат файла.
- test_set — список кортежей в форме
-
классификатор Классификатор.
-
классифицируем( текст ) [источник] Классифицирует текст.
Параметры: текст ( str ) — строка текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
этикеток() [источник] Вернуть итерацию возможных меток.
-
nltk_class= Нет Класс NLTK, который нужно обернуть. Должен быть классом в nltk.classify
-
поезд( * args , ** kwargs ) [источник] Обучите классификатор с помеченным набором функций и верните классификатор.Принимает те же аргументы, что и обернутый класс NLTK. Этот метод неявно вызывается при вызове
classifyилиточностьметодов и включен только для того, чтобы разрешить передачу аргументов в методtrainобернутого класса NLTK.
-
обновление( new_data , * args , ** kwargs ) [источник] Обновить классификатор новыми данными обучения и повторно обучить классификатор.
Параметры: new_data — Новые данные в виде списка кортежей формы (текст, этикетка).
-
- class
textblob.classifiers.NaiveBayesClassifier( train_set , feature_extractor = Классификатор на основе алгоритма Наивного Байеса, реализованного в НЛТК.
Параметры: - train_set — обучающий набор, либо список кортежей формы
(текст, классификация)или имя файла.текстможет быть либо строка или итерация. - feature_extractor — Функция извлечения признаков, которая принимает один или
два аргумента:
документиtrain_set. - формат — Если
train_set— это имя файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
-
точность( test_set , формат = нет ) Вычислите точность на тестовом наборе.
Параметры: - test_set — список кортежей в форме
(текст, метка)или указатель файла. - формат — Если
test_set— имя файла, формат файла, например«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
- test_set — список кортежей в форме
-
классификатор Классификатор.
-
классифицируйте( текст ) Классифицирует текст.
Параметры: текст ( str ) — строка текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
informative_features( * args , ** kwargs ) [источник] Возвращает наиболее информативные функции в виде списка кортежей форма
(имя_функции, значение_функции).
-
этикеток() Вернуть итерацию возможных меток.
-
nltk_class псевдоним
nltk.classify.naivebayes.NaiveBayesClassifier
-
prob_classify( текст ) [источник] Вернуть распределение вероятностей метки для классификации строки текста.
Пример:
>>> classifier = NaiveBayesClassifier (train_data) >>> prob_dist = классификатор.prob_classify ("Сегодня утром я счастлив.") >>> prob_dist.max () 'положительный' >>> prob_dist.prob ("положительный") 0,7Тип возврата: nltk.probability.DictionaryProbDist
-
show_informative_features( * args , ** kwargs ) [источник] Отображает список наиболее информативных функций для этого классификатор.
-
поезд( * args , ** kwargs ) Обучите классификатор с помеченным набором функций и верните классификатор.Принимает те же аргументы, что и обернутый класс NLTK. Этот метод неявно вызывается при вызове
classifyилиточностьметодов и включен только для того, чтобы разрешить передачу аргументов в методtrainобернутого класса NLTK.
-
обновление( new_data , * args , ** kwargs ) Обновить классификатор новыми данными обучения и повторно обучить классификатор.
Параметры: new_data — Новые данные в виде списка кортежей формы (текст, этикетка).
- train_set — обучающий набор, либо список кортежей формы
- class
textblob.classifiers.PositiveNaiveBayesClassifier( positive_set , unlabeled_set , feature_extractor =09) [источник]
Вариант наивного байесовского классификатора, который выполняет двоичную классификация с частично размеченными обучающими наборами, т.е.е. когда только один класс помечен, а другой нет. Предполагая предварительное распределение на двух этикетках использует немаркированный набор для оценки частот особенности.
Пример использования:
>>> из text.classifiers import PositiveNaiveBayesClassifier >>> sports_sentences = ['Команда доминировала в игре', ... 'Они потеряли мяч', ... 'Игра была напряженная', ... 'Вратарь поймал мяч', ...«Другая команда контролировала мяч»] >>> different_sentences = ['Президент не комментировал', ... 'Я потерял ключи', ... 'Команда выиграла игру', ... 'У Сары двое детей', ... 'Мяч ушел за пределы площадки', ... 'У них был мяч всю игру', ... 'Шоу закончилось'] >>> classifier = PositiveNaiveBayesClassifier (positive_set = sports_sentences, ... unlabeled_set = различные_ предложения) >>> classifier.classify («Моя команда проиграла игру») Правда >>> classifier.classify («А теперь о другом.») Ложь
Параметры: - positive_set — набор строк с положительной меткой.
- unlabeled_set — Коллекция немаркированных строк.
- feature_extractor — Функция извлечения признаков.
- positive_prob_prior — Априорная оценка вероятности
этикетка
True.
-
точность( test_set , формат = нет ) Вычислите точность на тестовом наборе.
Параметры: - test_set — список кортежей в форме
(текст, метка)или указатель файла. - формат — Если
test_set— это имя файла, формат файла, e.грамм.«csv»или«json». ЕслиНет, попытается обнаружить формат файла.
- test_set — список кортежей в форме
-
классификатор Классификатор.
-
классифицируйте( текст ) Классифицирует текст.
Параметры: текст ( str ) — строка текста.
Извлекает элементы из основного текста.
Тип возврата: Словарь функций
-
этикеток() Вернуть итерацию возможных меток.
-
поезд( * args , ** kwargs ) [источник] Обучите классификатор с помеченными и немаркированными наборами функций и верните классификатор. Принимает те же аргументы, что и обернутый класс NLTK.Этот метод неявно вызывается при вызове
classifyилиточностьметодов и включен только для того, чтобы разрешить передачу аргументов в методtrainобернутого класса NLTK.
-
обновление( new_positive_data = None , new_unlabeled_data = None , positive_prob_prior = 0,5 , * args , ** kwargs ) [источник] Обновить классификатор новыми данными и повторно обучить классификатор.
Параметры: - new_positive_data — Список новых помеченных строк.
- new_unlabeled_data — Список новых, немаркированных строк.
Средство извлечения основных функций документа, которое возвращает dict, указывающее какие слова в
train_setсодержатся в документеПараметры: - документ — текст, из которого нужно извлечь признаки.Может быть строкой или итерацией.
- train_set ( список ) — Набор обучающих данных, список кортежей формы
(слова, метка)ИЛИ итерация строк.
Базовое средство извлечения признаков документа, которое возвращает словарь слов, документ содержит.
Форматы файлов
Форматы файлов для данных обучения и тестирования.
Включает реестр допустимых форматов файлов.Новые форматы файлов могут быть добавлены в реестр так:
из форматов импорта текстовых блоков
класс PipeDelimitedFormat (форматы.DelimitedFormat):
разделитель = '|'
форматы.register ('psv', PipeDelimitedFormat)
После регистрации формата классификаторы смогут читать файлы данных с этот формат.
из textblob.classifiers import NaiveBayesAnalyzer
с open ('training_data.psv', 'r') как fp:
cl = NaiveBayesAnalyzer (fp, format = 'psv')
- класс
текстовый блок.форматы.BaseFormat( fp , ** kwargs ) [источник] Интерфейс для классов формата. Индивидуальные форматы могут выбрать состав и значение
** kwargs.Параметры: fp ( File ) — файловый объект. Изменено в версии 0.9.0: Конструктор получает указатель на файл, а не путь к файлу.
- classmethod
обнаружение( поток ) [источник] Определить формат файла по имени файла.Верните True, если поток имеет этот формат файла.
Изменено в версии 0.9.0: Изменен со статического метода на метод класса.
-
to_iterable() [источник] Вернуть повторяемый объект из данных.
- classmethod
- class
textblob.formats.CSV( fp , ** kwargs ) [источник] Формат CSV. Предполагается, что каждая строка имеет форму текста
, метка.Сегодня хороший день, поз. Ненавижу эту машину., Поз.
- classmethod
обнаружение( поток ) Вернуть True, если поток действителен.
-
to_iterable() Вернуть повторяемый объект из данных.
- classmethod
- class
textblob.formats.DelimitedFormat( fp , ** kwargs ) [источник] Общий формат с разделителями символов.
- classmethod
обнаружение( поток ) [источник] Вернуть True, если поток действителен.
-
to_iterable() [источник] Вернуть повторяемый объект из данных.
- classmethod
- class
textblob.formats.JSON( fp , ** kwargs ) [источник] Формат JSON.
Предполагает, что JSON отформатирован как массив объектов с текстом
метканедвижимость.[ {"text": "Сегодня хороший день.", "label": "pos"}, {"text": "Ненавижу эту машину.", "label": "neg"} ]- classmethod
обнаружение( поток ) [источник] Вернуть True, если поток является допустимым JSON.
-
to_iterable() [источник] Вернуть повторяемый объект из данных JSON.
- classmethod
- класс
текстовый блок.форматы.TSV( fp , ** kwargs ) [источник] Формат TSV. Предполагается, что каждая строка имеет форму
, текстовая метка.- classmethod
обнаружение( поток ) Вернуть True, если поток действителен.
-
to_iterable() Вернуть повторяемый объект из данных.
- classmethod
-
текстовых блоков.форматы.обнаружить( fp , max_read = 1024 ) [источник] Попытка определить формат файла, пробуя каждый из поддерживаемых форматы.