Урок русского языка в 5 классе «Морфемный разбор слова»
Урок русского языка в 5 классе «Морфемный разбор слова»
Тема: МОРФЕМНЫЙ РАЗБОР СЛОВА.
Цели:
- дидактическая: продолжить формирование навыка морфемного разбора слова;
- коррекционно-развивающая: коррекция логического мышления на основе упражнений и воспитание внимания и усидчивости у учащихся;
- воспитательная: формировать мотивацию к учению.
Оборудование: мультимедиапроектор, презентация по теме морфемный разбор слова, карточки индивидуальной работы.
ХОД УРОКА.
I. Организационный момент.
1. Приветствие.
2. Целеполагание.
II. Изучение нового материала (с использованием мультимедиапроектора).
Тема изложена на слайдах презентации, которые комментируются учителем.
Учащиеся записывают материал в тетради по ходу объяснения.
1. Фронтальный опрос.
— Кто мне скажет, что обозначает слово морфемика? Знаком ли вам этот термин? (слайд 3)
Морфемика – это раздел, который изучает морфемный разбор, иначе разбор слова по составу.
— Помните ли вы, что такое морфемный анализ слов? Как он проводится?
— Чтобы сделать морфемный разбор слова или разобрать слово по составу, необходимо знать из каких частей (морфем) строятся слова.
-Давайте дадим определение каждой морфеме.
— Что такое корень? (слайд 4)
Корень – главная значимая часть слова, в которой заключено лексическое значение, общее для всех однокоренных слов: вода, водяной, паводок, водный.
— Приведите ваши примеры однокоренных слов.
— Что такое приставка? (слайд 5)
Приставка – значимая часть слова, которая служит для образования новых однокоренных слов: ехать – приехать, уехать, заехать, переехать
.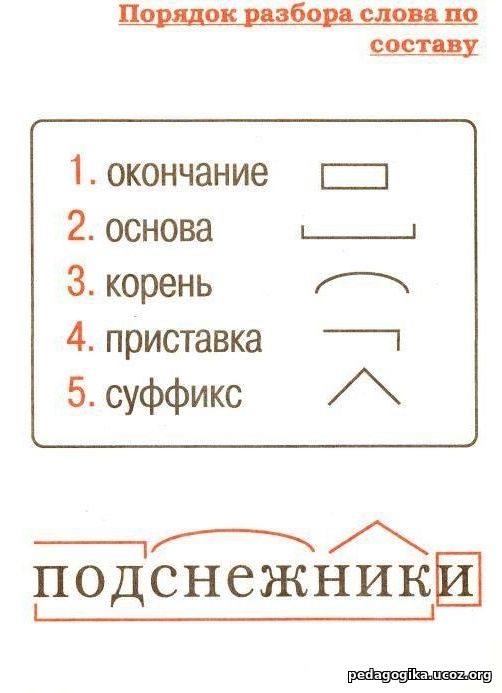 Приставка находится перед корнем.
Приставка находится перед корнем.— Приведите примеры однокоренных слов с разными приставками.
— Итак, мы сделаем разбор слова по составу на слове «прекрасна».
— Что такое суффикс? (слайд 6)
Суффикс – значимая часть слова, которая, как правило, служит для образования новых однокоренных слов: человек, человечек, человеческий. Суффикс находится после корня.
— Приведите примеры однокоренных слов с разными суффиксами.
— Что такое окончание? (слайд 7)
Окончание – изменяемая часть слова, которая служит для образования грамматических форм существительных, прилагательных, числительных, местоимений и глаголов: терем¨, у терема, к терему; я тужу, ты тужишь, он тужит. Таким образом, окончание имеет грамматическое значение.
— Дайте примеры форм одного слова с разными окончаниями.
— Теперь, когда мы вспомнили морфемы, мы можем перейти к морфемному разбору.
2. Морфемный разбор слова. (слайд 8)
(слайд 2) «Я ль, скажи мне всех милее,
Всех румяней и белее? »
Что же зеркальце в ответ?
«Ты прекрасна, спору нет…»
— Кто вспомнит, из какого произведения эти строки?
— А вот и слово, которое мы будем разбирать «прекрасна».
Шаг 1. (слайд 10)
— Выделяем окончание и определяем его грамматическое значение.
— Что нужно сделать, чтобы выделить окончание слова «прекрасна»?
— Нужно изменить его. Это краткое прилагательное, оно изменяется по числам и родам. ( Прекрасен, прекрасно, прекрасны).
— Мы видим часть слова, которая меняется (по окончаниям на сноске)
Следовательно, в слове «прекрасна» окончание–«а».
— Оно имеет грамматическое значение единственного числа женского рода. Обратите внимание на то, как обозначается окончание.
— Если мы выделили окончание, нам легко определить основу слова. (слайд 11)
— Почему?
Основа – это часть слова без окончания: у терема, пирожок¨.
— Основа прекрасн—.
— Итак, в слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде.
Основа – прекрасн а .
Продолжаем наш разбор .
Шаг 2. (слайд 12)
— Определим корень слова.
— Как это сделать?
— Нужно подобрать однокоренные слова: красный, краса, красивый.
— Мы видим, что их общая часть, а значит, корень -крас-. В нем заключено общее для всех этих слов лексическое значение. Я думаю, вы знаете, что в старину слово «красный» имело значение «красивый».
Итак, корень в слове «прекрасна» – —крас-. Однокоренными словами являются красный, краса, красивый.
Шаг 3. (слайд 13)
— Нужно определить, какие ещё морфемы есть в слове.
— Есть ли приставка в этом слове?
— Да, перед корнем приставка пре-.
— Какое значение она придаёт прилагательному?
— Образуем другие прилагательные с такой же приставкой: предобрый, премилый, премудрый. Очевидно, что приставка «пре» во всех этих прилагательных имеет значение «весьма», «очень».
— Есть ли в слове суффикс?
— Да, это суффикс н. Он стоит после корня перед окончанием.
— Какова его роль?
— Мы видим, что с помощью этого суффикса от существительных образуются прилагательные: беда – бедный; вред – вредный; честь – честный и… краса – красный.
— Вот мы и сделали морфемный разбор слова «прекрасна».
Выводы на доску. (слайд 14)
(слайд 15). В слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде. Основа – прекрасн-.
(слайд 16). Корень в слове прекрасна – -крас-. Однокоренными словами являются красный, краса, красивый.
Однокоренными словами являются красный, краса, красивый.
(слайд 17). В слове прекрасна есть приставка пре-, она имеет значение «очень», «весьма».
(слайд 18). В слове прекрасна есть суффикс –н-. С помощью этого суффикса от существительного образовалось прилагательное.
Итак, Порядок разбора: (слайд 19)
Шаг 1. Выделить окончание, объяснить его значение. Выделить основу слова.
Шаг 2. Выделить корень слова, подобрав однокоренные слова.
Шаг 3. Выделить приставки и суффиксы. Объяснить, если возможно значение приставок и суффиксов.
III. Физминутка. (Выполняется стоя).
1). Сделать 3-4 раза круговые движения головой.
2). 1. – Руки согнуты перед грудью. 1-2 — два пружинящих рывка назад согнутыми руками. 3-4 – то же прямыми руками. Повторить 5-7 раз. Темп средний.
3). Несколько раз открыть/закрыть глаза.
IV. Закрепление изученного материала.
1. Морфемный разбор слова.
Один учащийся работает у доски, остальные самостоятельно.
Лесной, перелесок, приморский, прогуляться, многолетний.
2. Работа с отрывком из сказки «Сказка о мёртвой царевне и семи богатырях».
Долго царь был неутешен Но как быть? И он был грешен; Год прошёл, как сон пустой, Царь женился на другой. | Правду молвит молодица Уж и впрямь была царица: Высока, стройна, бела, И умом и всем взяла… |
Сделайте морфемный разбор выделенных в тексте слов. Впишите части слов в таблицу. Если в слове нет какой-нибудь морфемы, напишите: нет. Если окончание нулевое, так и напишите.
слова для разбора | окончание | основа | корень | приставка | суффикс |
неутешен | нулевое | неутешен | теш | не, у | ен |
прошёл | нулевое | прошёл | шё | про | л |
пустой | ой | пуст | пуст | нет | нет |
молодица | а | молодиц | молод | нет | иц |
умом | ом | ум | ум | нет | нет |
3. Работа со схемами.
Работа со схемами.
Нужно подобрать слова, которые подходят к схемам.
V. Итог урока.
— Что же такое морфемный разбор слова?
— В какой последовательности нужно его выполнять?
VI. Домашнее задание.
Упр. 178 на с.74, сделать морфемный разбор слов: пришкольный, бегает, новизна.
Выставление оценок.
Скачать>>>
Морфемный разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Морфемный разбор
Морфемный разбор – это разбор слова по составу или разбор слова на морфемы. Морфема является значимой частью слова, потому что она выражает какое – то значение. Всего в русском языке выделяют 4 морфемы – это корень, приставка, суффикс и окончание.
Пример:
Котики – выделяем три морфемы. Каждая морфема имеет значение:
Корень кот — означает животное
Суффикс -ик – показывает, что речь идет о маленьком коте
Окончание –и указывает на множественное число имени существительного (котиков много, а не один).
Теперь мы знаем, почему морфему называют значимой частью слова.
Слово для морфемного разбора обозначается надстрочной цифрой «2»: сестра2.
Пример рассуждений:
Ольга переделает2 домашнее задание.
Переделает – это глагол. Выделяем окончание – ет, которое указывает на форму третьего лица единственного числа. Переделает – означает сделает заново, значение «заново» этому слову придает приставка пере- (перечитать, переделать). Выделяем приставку. Корень дел находим, сравнивая родственные слова – дело, сделал, поделка. Суффикс – а- в глаголах показывает значение действия.
Суффикс – а- в глаголах показывает значение действия.
Итак, в слове четыре морфемы: переделает
Порядок морфемного разбора (разбора слова по составу):
- Определи, к какой части речи относится слово
- Найди окончание и обведи его рамочкой
- Выдели часть слова без окончания — ̢_______̡. Это основа слова
- Найди корень и выдели дугой
- Найди приставку и обозначь ее значком
- Найди суффикс и отметь его значком
Помни, что некоторых морфем в слове может и не быть.
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Окончание
Основа слова
Корень и однокоренные (родственные) слова
Приставки и их значения
Суффикс
Правило встречается в следующих упражнениях:
2 класс
Упражнение 2, Климанова, Бабушкина, Учебник, часть 2
Упражнение 1, Бунеев, Бунеева, Пронина, Учебник
3 класс
Упражнение 124, Канакина, Рабочая тетрадь, часть 1
Упражнение 178, Канакина, Рабочая тетрадь, часть 1
Упражнение 6, Канакина, Горецкий, Учебник, часть 2
Упражнение 155, Канакина, Горецкий, Учебник, часть 2
Упражнение 193, Канакина, Горецкий, Учебник, часть 2
Упражнение 239, Канакина, Горецкий, Учебник, часть 2
Упражнение 198, Климанова, Бабушкина, Учебник, часть 1
Упражнение 194, Полякова, Учебник, часть 1
Упражнение 113, Полякова, Учебник, часть 2
Упражнение 7, Исаева, Бунеев, Рабочая тетрадь
4 класс
Упражнение 196, Канакина, Горецкий, Учебник, часть 1
Упражнение 86, Канакина, Рабочая тетрадь, часть 1
Упражнение 7, Канакина, Горецкий, Учебник, часть 2
Упражнение 139, Канакина, Горецкий, Учебник, часть 2
Упражнение 204, Канакина, Горецкий, Учебник, часть 2
Упражнение 279, Канакина, Горецкий, Учебник, часть 2
Упражнение 29, Климанова, Бабушкина, Рабочая тетрадь, часть 1
Упражнение 95, Климанова, Бабушкина, Рабочая тетрадь, часть 1
Упражнение 195, Климанова, Бабушкина, Учебник, часть 2
Упражнение 4, Бунеев, Бунеева, Пронина, Учебник, часть 1
5 класс
Упражнение 33, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 75, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 89, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 136, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 358, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 110, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 115, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 275, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
Упражнение 286, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
Упражнение Повторение стр. 81,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
81,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 2
6 класс
Упражнение 25, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 94, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 158, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 557, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 580, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 589, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
Упражнение 121, Разумовская, Львова, Капинос, Учебник
Упражнение 447, Разумовская, Львова, Капинос, Учебник
Упражнение 537, Разумовская, Львова, Капинос, Учебник
Упражнение 539, Разумовская, Львова, Капинос, Учебник
7 класс
Упражнение 413, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 417, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 422, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 456, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 489, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 153, Разумовская, Львова, Капинос, Учебник
Упражнение 340, Разумовская, Львова, Капинос, Учебник
Упражнение 586, Разумовская, Львова, Капинос, Учебник
Упражнение 596, Разумовская, Львова, Капинос, Учебник
Упражнение 597, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 87, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 422, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 66, Разумовская, Львова, Капинос, Учебник
Упражнение 117, Разумовская, Львова, Капинос, Учебник
Упражнение 212, Разумовская, Львова, Капинос, Учебник
Упражнение 330, Разумовская, Львова, Капинос, Учебник
Упражнение 339, Разумовская, Львова, Капинос, Учебник
Упражнение 348, Разумовская, Львова, Капинос, Учебник
Упражнение 367, Разумовская, Львова, Капинос, Учебник
Упражнение 385, Разумовская, Львова, Капинос, Учебник
© budu5. com, 2021
com, 2021
Пользовательское соглашение
Copyright
Разбор слова по составу, с. 32 – 33
Разбор слова по составуОтветы к стр. 32 – 33Ответы по русскому языку. 3 класс. Проверочные работы. Канакина В.П., Щёголева Г.С.
1. Прочитай. Отгадай слово. Запиши это слово и выдели в нём значимые части.
Корень тот же, что в слове снежок.
Суффикс тот же, что в слове пушинка.
Окончание то же, что в слове осинка.
• Найди однокоренные слова. Выдели в них все значимые части слова.
2∗. Прочитай. От какого слова и при помощи какой части слова образовано каждое из данных слов? Запиши эти слова. Выдели в словах те части слова, при помощи которых образовались данные слова.
3∗. Прочитай. Рассмотри схемы. Запиши слова, соответствующие данным схемам.
полотенце, капуста, зеркало
тракторист, зёрнышко, жёлтенький
подснежники, пригородный, пограничники
4. Рассмотри схему состава слова. Подбери два слова с таким же составом. Запиши.
стекло, пчела
5∗. Прочитай. Найди и подчеркни в каждом ряду слово, которое по своему составу отличается от других слов. Выдели в нём значимые части.
• Разбери по составу любое из выделенных слов.
6. Прочитай. Впиши пропущенные в предложениях слова.
1) Под берёзой растут грибы подберёзовики, а под осиной — подосиновики.
2) На баяне играет баянист, а на пианино — пианист.
7∗. Прочитай. Подбери и запиши заглавие к тексту. Выдели в тексте три части, отметь начало каждой части знаком Z.
Олениха
Z На высокой скале паслись олен/и. В тени лежал маленький олен/ёнок. Орёл высмотрел олен/ёнка и бросился на него. Z Мать услышала шум громадной птицы. Олен/иха стала на задние ноги около детёныша. Передними копытами она старалась ударить орла. Z Орёл отступил. Он полетел к своему гнезду.
(М. Пришвин)
• Отметь √, какой это текст.
√ повествование
• Найди в тексте однокоренные слова. Выдели в них корень.
• Выпиши две пары форм одного и того же слова. Выдели в них окончания.
Ответы по русскому языку. 3 класс. Проверочные работы. Канакина В.П., Щёголева Г.С.
Ответы по русскому языку. 3 класс
4.5 / 5 ( 939 голосов )
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «облако», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ОБЛАКО, а, мн. а, ов, ср.
1. Светло-серые клубы, волнистые слои в небе, скопление сгустившихся в атмосфере водяных капель и ледяных кристаллов. Облака плывут по небу. Ветер гонит облака. Кучевые облака. Грозовое, дождевое о. До облаков (перен.: очень высоко). Спуститься с облаков (перен.: от мечтаний обратиться к действительности; ирон.). С облаков упасть или свалиться (перен.: о неожиданном появлении кого-н.; разг.).
С облаков упасть или свалиться (перен.: о неожиданном появлении кого-н.; разг.).
2. перен., чего. Сплошная масса какихн. мелких летучих частиц. О. дыма, пара.
| уменьш. облачко, а, мн. а, ов, ср.
| прил. облачный, ая, ое (к 1 знач.). О. слой.
Фонетический (звуко-буквенный) разбор
о́блако
облако — слово из 3 слогов: о-бла-ко. Ударение падает на 1-й слог.
Транскрипция слова: [облака]
о — [о] — гласный, ударный
б — [б] — согласный, звонкий парный, твёрдый (парный)
л — [л] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
а — [а] — гласный, безударный
к — [к] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
В слове 6 букв и 6 звуков.
Цветовая схема: облако
Разбор слова «облако» по составу
облако
Части слова «облако»: облак/о
Состав слова:
облак — корень,
о — окончание,
облак — основа слова.
Пожелание разбор слова по составу
• Выписать окончание, определить его грамматическое
речи оно относится. Вспомнить особенности слов, принадлежащих к данной
белый иней. С верхушки старой (Р.п.)
,
все имеющиеся морфемы.
к какой части
пушистым снегом. Веточки берёз украсил
(Р. п.), работать на стройке ,
морфемный анализ слова, то есть обозначить
• Определить из контекста
Зима завалила деревню
Разбор слова «Желание»
(В.п.), купить молоко (И. п.), добежать до финиша , и выполнить графический значение (смысл).
По слогам:
зависят, отметь окончания, определи род, число и падеж.
Читаю книгу (П.п.), увлекаться музыкой (Т.п.), положить на стол
Состав слова
,
• Установить часть речи
разбирать по составу, выяснить его лексическое
вместе с существительными, от которых они
2) Морфологический разбор слова «Желание»
определён неверно:
Разбор слова «Желать»
, формально-смысловым. задании. Прежде чем начать • Выпиши имена прилагательные
задании. Прежде чем начать • Выпиши имена прилагательные
По слогам:
• Выпиши словосочетания, в которых падеж
,
Состав слова
словообразовательным. Такой анализ называется
той же форме, как в домашнем
Чёрные брюки, ёлочная игрушка, высокое дерево, хороший прыжок, райская птица, старое здание, широкий проспект, трудное правило, зимние вечера, новое пальто, верный друг, дальняя дорога, воскресный день
2) Морфологический разбор слова «Желать»
животных и растений.
Пожелание разбор слова по составу
Набегала — разбор слова по составу онлайн
сайтов: связать с разбором
• Записать слово в мужском роде:
тысячи видов редких
Информация получена с Чтобы избежать ошибок, морфемный разбор предпочтительно анализа.
прилагательные стоят в
на Земле. В Байкале живут
Морфология
своим учебником.
слова, чтобы подтвердить правильность
Раннее — разбор слова по составу онлайн
• Запиши словосочетания, в которых имена занимает первое место
и доктора философии.порядок разбора со
и подбирайте однокоренные
прыгнула на ёлку.воды это озеро учёные степени магистра
задания, сравнивайте изложенный ниже
осмысленно, избегайте бездумного деления. Определяйте значения морфем
пушистым хвостом и
голубым оком Сибири. По количеству пресной
даровано право присуждать
при выполнении домашнего «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу вьётся вдоль дороги. Шустрая белка махнула востоке России. Люди называют его пожелание, чтобы академиям было составу различается подходом. Чтобы избежать проблем частей. Начинайте по порядку след. Тонкий лисий след
Байкал находится на
• Серебренников высказал настойчивое
морфемный разбор по последовательность выделения значимых густом ельнике заячий
обстоятельством.
1 вариант
браке.средних школ. У разных авторов
разбора соблюдайте определённую
и скрылся в числе, в предложном падеже, в предложении является дальнейшей жизни в
в 5–9 классах для
При проведении морфемного Протянулся через дорогу
характеристикой: неодушевлённое, собственное, женского рода, 1 склонения, стоит в единственном
и гармонию всей
по русскому языку часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
члены предложения, определи их род, число, падеж.существительное с такой добрые пожелания, надежды на потомство три учебных комплекса составу онлайн любую притяжательные прилагательные, подчеркни их как
• Найди в тексте нанесением менди связываются их общую часть: корень, — это всё.
правильно разобрать по • Спиши текст. Найди в нём Стул (неодуш.), дверь (неодуш.), соловей (неодуш.), платье (неодуш.), роза (неодуш.), бабочка (неодуш.), кувшинка (неодуш.), волна (одуш.), чайка (одуш.), ветер (одуш.)• Именно с коллективным
2 вариант
и затем найти морфемный разбор. Сайт how-to-all поможет вам
Грубый, умный, седой, сильный, смелый
• Исправь ошибки:зрителей.с суффиксом, подобрать однокоренные слова
его также называют
в краткую форму, в мужской род, в единственное число:• камень, конь, лань, огонь
на пристани толпы и основу, после обозначить приставку каждой из них. В школьной программе
• Поставь данные прилагательные
• соль, пыль, ремень, пристаньстроителей и собравшейся
слово — значит выделить окончание и установить значение Большой, лисий, бумажный, узкий, апельсиновый, острый, папин• море, кофе, солнце, растение«виват» и наилучших пожеланиях разобрать по составу
1вариант
месту в слове антонимы:
род )при громких криках В начальных классах состав слова, классифицировать морфемы по прилагательные, подбери к ним ( обрати внимание на «La Belle Susanne» ушла в море значимые частивидов лингвистического исследования, цель которого — определить строение или • Выпиши качественные имена
• Спиши, определи лишнее слово • На следующий день
значками выделить все
составу один из
над тихими лугами.
Шум, песня, речь, копьё, народ, душ, животное, богач, место, ложь, ландыш, степь, луч, музей«пожелание»: • Перепроверить разбор и
Разбор слова по Белый туман расстилается
рода:Предложения со словом
и постфиксы (если они есть)Рабочая программа
бору.2 склонения мужского осуществлении чего-л. для кого-л. Пожелание успеха. Добрые пожелания.• Отметить формообразующие суффиксы / Сост.: Л.И. Чиркова; Бийский пед. гос. ун-т им. В. М. Шукшина.
шли по сосновому
• Выпиши имена существительные
ПОЖЕЛА́НИЕ, -я, ср. Высказанное желание об (если она есть): листопад, звездолёт, садовод, пешеход.языку [Текст] : Учебно-методический комплекс дисциплины Летним днём мы
Ходить в театр, подарить маме, купить для брата, пойти за грибами, вспомнить о летеЗначение слова «пожелание»
два (и более) корня, обозначить соединительную гласную
методика обучения русскому
как члены предложения:
• Спиши, определи падеж существительных:возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.• Если в слове
Т Теория и • Спиши, подчеркни имена прилагательные
Контрольная работа № 5• корень «сп» — в родственных словах
корнями.Учебно-методический комплексСтарый ослик, на верхней полке, тёмной ночью, для первого класса
осенью.• словообразовательная цепочка: сон — проспать — проспала;слова с чередующимися Документ
прилагательных:
и гладкий, Цветёт рябина поздней
1 вариант
утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;— это корень. Помнить про однокоренные
Исследование• Спиши, укажи род, число и падеж
Рябина – скромное ветвистое дерево. Ствол рябины чистый • приставка «про» — действие со значением
ряд родственных слов. Их общая часть ДокументВысокий дом, железная лестница, синее море, королевская конница, тёмный чердак, зелёное растение, звонкая песня, строгий учитель, доброе лицо, летняя веранда
имена существительные:времени,
корень.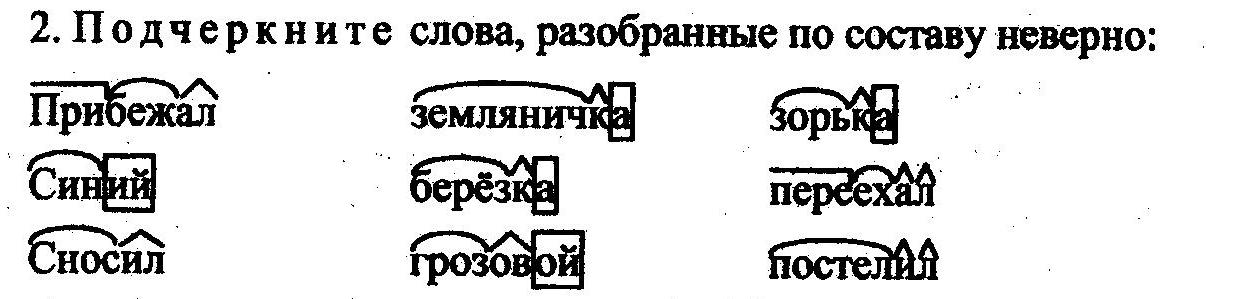 Для этого сравнить прилагательные, определи их род, число и падеж.женском роде:предложения являются выделенные
Для этого сравнить прилагательные, определи их род, число и падеж.женском роде:предложения являются выделенные
• два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего • Найти в основе
варианта выпиши качественные прилагательные стоят в
• Определи какими членами • основа форы — «проспал»;
одинаковое значение.• Из текста 1
• Запиши словосочетания, в которых имена числа.
глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;суффиксом, чтобы он выражал
Аккуратная, аккуратен, аккуратна, внимательная, внимательна, внимателен, прекрасная, прекраснейшая, прекрасна, прекраснееприлагательное )
среднего рода единственного • окончание «а» указывает на форму с таким же Ласковы, ласкова, ласковая, наимудрейшая, мудрая, мудрее, мудра,
Контрольная работа № 6 (тема 6 имя
1 варианта существительные
разбора глагола «проспала»:другими корнями и
в краткой форме, женского рода, единственного числа:обстоятельством.• Выпиши из текста
Пример полного морфемного • Определить суффикс (если он есть). Чтобы проверить, подобрать слова с
• Выпиши имена прилагательные числе, в предложном падеже, в предложении является • Конь, трость, смелость, дождь
в слове?приставками и без.
Лимонный, широкий, высокий, птичий, шёлковый, кислый, дедушкин, настенныйс такой характеристикой: неодушевлённое, мужского рода, 2 склонения, стоит в единственном • Море, сметана, страна, тетрадь
Как найти морфему однокоренные слова с
прилагательные.варианта найди существительное
• Машины, города, ножницы, коврыкорнях.
приставку (если она есть). Для этого сравнить
• Выпиши относительные имена • В тексте 1
).согласных звуков в • Обозначить в основе
мокрой старой крыше.Лёд – корень, суффикс; корень, соединительная гласная «о», кореньизменение по числам • Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или
окончания (и формообразующего суффикса).
грустно стучит по
Город – приставка, корень, окончание; корень, суффикс, окончание; корень – герой( обрати внимание на
одноструктурные слова: «одеть-раздеть-переодеть».— это часть без
Серый осенний дождь Голова – корень, суффикс, окончание
группе лишнее слово связными корнями подобрать • Выделить основу слова сказки.однокоренные имена существительные, соответствующие схемам. Укажи способ словообразования:• Найди в каждой словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со
окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
1 вариант
и читала нам • Подбери к словам
Рояль, кино, радость, кенгуру, скорость, пианино, костюм, пальто, одежда, дыхание, тётя, читатель
свободными корнями составить слова с нулевым пуховый платок
Щи, мячи, хлопоты, тарелки, яблони, переговоры, корабли, заводы, прятки, недели, джунгли
родам:
• Корень: свободный или связный. Для слов со
окончанием. Помнить про изменяемые накидывала старый бабушкин нельзя:
три столбика по
приставки, обосновать их выделение, объяснить их значенияпо падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет
По вечерам мама
существительные, род которых определить • Распредели слова в • Найди морфемы. Выписать суффиксы и
• Найти окончание. Для этого просклонять члены предложения:• Выпиши те имена Молоко, врач, молоток, кефир, космонавт, отвёртка, сметана, клещи, учительсуффиксов)формообразующий суффикс?
• Спиши, подчеркни прилагательные как Повидло, кофе, семья, эскимо, пожелание, жадность, желе, радио, упорство, урожай, строительство
примером:(без формообразующих морфем: окончания и формообразовательных • имеет ли оно
веточках сирени.рода:значению, назови каждую группу, дополни её своим • Записать основу слова • • изменяемое (есть окончание) или неизменяемое (не имеет окончания)осел на тонких 2 склонения среднего дубу.
2 вариант
значение. Указать суффиксы, образующие формуслова (если есть)части речи:сосны сорвалась птица. Снег белой бахромой
• Выпиши имена существительные три группы по полями, над городами и • Спиши предложения. Подчеркни все имена
день уходим в
существительные мужского рода Коктейль, решение, мебель, пони, меню, морковь, мороженое, сырость, ковёр, кот, высота, сахар• Чай, кофе, сок, суп, кисель
Петь, пение, песенный, запеть, припев, припевать, напевный, певец. певучий, песня, певчий (дрозд), плыть, заплыв, плавательный, заплыть, пловец, плавучий, плавать, плавание
облаками кружат быстрые Я лежу в предложение, которое соответствует схеме.были указанными членами Эту пушистую высокую
• Запиши предложения. Определи, каким членом предложения
кричали совы.
на охоту.
птиц.• вариант• Придумай и запиши румяный Дел Мороз.
Отец быстро вскопал в музей.• Спиши предложения, найди и подчеркни
Холодный ветер легко Контрольная работа № 3• Из данных слов
Орёл – гроза лесных птиц
1 вариант
• Выпиши предложение, в котором сказуемое
• Выпиши такую характеристику, которую предложение иметь
• вариантсоставь и запиши Слева послышался шорох
3. Выпиши предложение. в котором неправильно
• Выпиши такую характеристику, которую предложение иметь и притянул передними Бурундук сидел на
второй слог, в слове четыре
• Разбери по составу
слова ружьё
• Выпиши слова, в которых рядом
на ночлег, Вот мостик с
Ручей вывел меня слово, в котором три • Выпиши однокоренные слованаходятся два глухих Контрольная работа № 1
Учителя: Гудым Е.Ю., Чистякова О.В.являться окончанием, остальная часть слова • ⏰ окончание : ЕЕ;следующие морфемы или Основа слова: РАНН• ∩ корень слова : БЕГ;¬ — НА; ∩ — БЕГ; ∧ — АЛ; ⏰ — А;Глагол: действительный залог, совершенный вид
2 вариант
же-ла́тьСуществительное: именительный падеж, единственное число, неодушевленное, средний род
ЖеланиеНа странице вы Корнем является часть жела-, которая прослеживается в ряде составе словоизменительную морфему — окончание —е.
• Распредели слова в и могучему столетнему над лесами и
напоминают далёкое детство, родную любимую природу.
и тает снег, мы на целый • Выпиши из текста родам:
• Диван, стул, дверь, шкаф, стол
прилагательные:тропкам муравьи. В небе над
хххххх хххххх.
Прочитай текст. Найди в нём
предложение, чтобы данные слова
шишками.краской оконные рамы.глубоких дуплах страшно с другом пойдём увидел двух больших
сорока , ухаживать, потомство, заботливо, свойполяну разноцветным хороводом.
1 вариант
Возле ёлки разгулиавет морозов.колокольчики. Завтра мы пойдём
рябчика.
журавлиный клич.Коля, бежать, ко, быстро, я
лесу.
полоска неба.- вопросительное побудительное
предложение.Друг. по, Европа, путешествовать, долго• Из данных слов
серые тени.- побудительное невосклицательное
долгой зимы!вокруг не видно?! Бурундук кончил жевать побудительное восклицательное предложение:
слога, ударение падает на
Лётчик, ключик, переводчик, колокольчик, разведчик, заказчик• Сделай фонетический разбор
Смейся, йод, сказка, семья, воробьи
лугу, отыскивая переправу. Пора было устраиваться один твёрдый ):• Найди в тексте
слова грязь• Выпиши слова, в которых рядом язык»окончания, например наречие — неизменяемая часть речи.слово изменяют, например, по падежам. Изменяемая часть будет • ∧ суффикс : Н;Слово Раннее содержит
2 вариант
корень — РАН; суффикс — Н; окончание — ЕЕ;• ¬ приставка : НА;слова: Приставочно-суффиксальный или префиксально-суффиксальный
• Желать — основа
слова «Желать»• Желани — основаже-ла́-ни-е
жела—ни—е — корень/суффикс/окончание.• создать — создание.Теперь вполне обоснованно выделим в его варианта только глаголы.травинке, и крошечному муравью Июльское солнце плывёт
Эти простые цветы лесные цветы. Когда приходит весна
Стул, лестница, сметана, верёвка, доктор, смелость, учительтри столбика по значению слово.
• Выпиши только имена золотые цветы. Трепещут лёгкие стрекозы. Пробегают по невидимым
Ххххххх ххххххх хххххх • (дополнительное )• Придумай и запиши
Вершина ели увешана Маляр покрасил белой
По ночам в
В воскресенье мы В сумерках я
предложения, охарактеризуй предложение.
Высокие ёлки окружили
является слово ёлка:Дуб боится крепких ветерок колыхал лиловые
поляной раздался посвист
С болота донёсся
предложение.
услышал ещё в
Сквозь деревья проглядывала - повествовательное восклицательноезапиши повествовательное восклицательное грамматическую основу.
орла совсем близко.
Разобрать слово по составу, что это значит?
Среди ветвей мелькнули - побудительное повествовательноеон лакомиться! Ешь, бурундучок ешь, набирайся сил после ест? Ведь ничего съедобного • Выпиши из текста 1 варианта слово, в котором два и звучанию суффиксами:Место, плавучий, союз, обжигать, дочка, театр, лилия, детвора, сауна, океанслоги:Я шёл по звонких звука ( два мягких и слово крикун
План: Как разобрать по составу слово?
• Сделай фонетический разбор Уважение, май, сосульки, змейка, лодочка« Как устроен наш и не иметь основу. Для определения окончания • ∩ корень слова : РАН;∩ — РАН; ∧ — Н; ⏰ — ЕЕ;В других словарях:части:
Вычисленный способ образования • ть — глагольное окончаниеделать морфемный (по составу) и морфологический разборы • е — окончаниеслова «Желание»
Морфемный состав анализируемого слова соответствует схеме:• восклицать — восклицание;нет чего? желани-я, расскажу о чём? о желани-и, следую чему? желани-ю.1 задания 1
тепло и малой
предложения:маленькие букетики.
Я люблю простые форму множественного числа:• Распредели слова в группе лишнее по Контрольная работа № 4
лугу. Качаются нал головой ххххххх.происшествие, случилось, дом, однажды, наш, чрезвычайный. ночью
ночью
дед.Хороша ель зимой.все дополнения.все обстоятельства места.
очень красив.грамматические основы:были указанными членами разноцветными игрушками.• Запиши предложения. Определи, каким членом предложения
все дополнения:Летом под липами В кустах за грамматические основы:побудительное восклицательное нераспространённое Журавлиный крик я
предложения:- вопросительное невосклицательное1 варианта и
предложение. Отметь в нём Я увидел летящего
предложения:- вопросительное восклицательноецветок медуницы. Так вот чем
что-то быстро – быстро жевал. Что же он два глухих )• Найди в тексте одинаковыми по значению звука:• Раздели слова на спускались огороды.
* Примечание: Минобразование РФ рекомендует первый слог, в слове три • Разбери по составу Место, плавучий, ускакать, союз, обжигать, дочка, болтун, детвора, сауна, сияетслоги:Русский язык блок может являться основой • Выделяем окончание и • ¬ приставка : -слова: Суффиксальный• ⏰ окончание : А;Порядок полного морфемного разбора по составу
следующие морфемы или Основа слова: НАБЕГАЛ• жела — корень словаузнаете как правильно
• ни — суффиксделать морфемный (по составу) и морфологический разборы желанный, желаться, пожелать, пожелание, желательный, желательность, доброжелатель.• желать — желание;
Прежде чем выяснить морфемный состав слова «желание», убедимся, что оно изменяется по падежам:• Выпиши из слов
сёлами. Дарит солнышко своё существительные как члены лес, греемся на солнце, слушаем пение птиц, собираем подснежники, вяжем из них
единственного числа:• Поставь существительные в
• Ветер, снег, дождь, пожар, туман• Найди в каждой ласточки.душистой траве на Хххххххх хххххх ххххх
предложения, охарактеризуй предложение.ель посадил мой является слово ель:
• Спиши предложение, найди и подчеркни • Спиши предложения, найди и подчеркни
Чистый сосновый бор • Из предложений выпиши
предложение, чтобы данные слова Ребятишки украшают ёлку
грядку.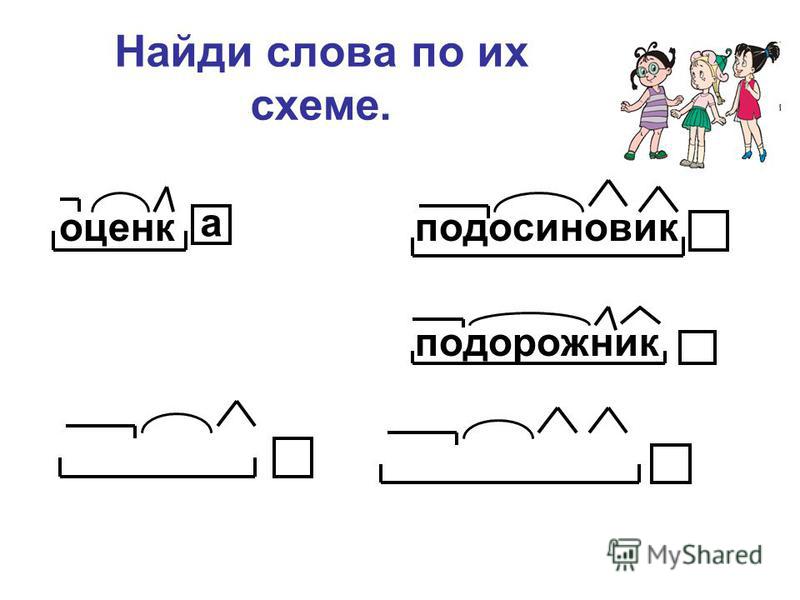
• Спиши предложения, найди и подчеркни все обстоятельства:
продувает плащ.• Из предложений выпиши
составь и запиши
и зверьков.не выражено глаголом. Отметь грамматическую основу
не может
• Найди в тексте вопросительное невосклицательное распространённое
листьев.отмечены главные члены. Отметь грамматическую основу
не можетлапками в рот задних лапках и согласных звука ( два звонких и слово безоблачный• Выпиши слова с находятся два гласных
берега на берег.из леса. Слева тянулся лужок, справа к ручью слога, ударение падает на Боль, больница, больше, болеть, болт, больно хворатьсогласных звука:• Раздели слова на
Повторяем третий классбез окончания — основой. Следует помнить, что всё слово В других словарях:части:Вычисленный способ образования
• ∧ суффикс : АЛ;
Слово Набегала содержит приставка — НА; корень — БЕГ; суффикс — АЛ; окончание — А;
Ушакова О.Д. «Разбор слова по составу. Изд. испр. и доп.»
Самые выгодные предложения по Ушакова О.Д. «Разбор слова по составу. Изд. испр. и доп.»
Имя скрыто, 19.12.2019
Комментарий: Достоинства:
Хорошая бумага
Недостатки:
Много ошибок
Отвратительная книга
Имя скрыто, 16.11.2019
Комментарий: Достоинства:
Помогает в школе
Недостатки:
Яркий, заметен на экзаменах
Помогает в школе
Имя скрыто, 06. 08.2019
08.2019
Комментарий: Достоинства:
Нет достоинств!Куча ошибок
Недостатки:
Куча Ошибок
Получил 2 ужас
Имя скрыто, 15.07.2019
Комментарий: Достоинства:
понравилось очень много помогает
Недостатки:
очень трудно найти слова
Хорошая очень помогает
Имя скрыто, 03.07.2019
Комментарий: Достоинства:
Удобный в применение
Недостатки:
Много ошибок чем ответов
На троечку
Имя скрыто, 12.06.2019
Комментарий: Достоинства:
Маленький везде умешьяется.
Недостатки:
Трудно искать, чего-то вообще нет.
Нормальный словарь.
Имя скрыто, 20.04.2019
Комментарий: Нет некоторых слов
Имя скрыто, 11. 03.2019
03.2019
Комментарий: Достоинства:
Много рвзборов простых слов
Недостатки:
Нет слов разбор которых нужен в 4 классе
Словарь только для тех кто идёт в первый класс
Имя скрыто, 21.02.2019
Комментарий: Супер книга всегда помагает
Имя скрыто, 10.01.2019
Комментарий: Очень многих слов нет!
| Приставка — | |
Корень слова рощей | Корень — рощ |
Суффикс слова рощей | Суффикс — |
Окончание слова рощей | Окончание — ей |

| рощ | корень |
| а | окончание |
Сходные по морфемному строению слова
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова хлористый (прилагательное):
Ассоциации к слову «роща»
Синонимы к слову «роща»
Предложения со словом «роща»
- Речь шла о такой малости как подлежащая вырубке берёзовая роща на самом краю графства.
- Рассказывают и о том, как прадед мой извёл прекрасную дубовую рощу, скупивши её за бесценок у какого-то разорившегося помещика.
- Здесь вековые зелёные оливковые рощи в Parc du Pian, гавань для яхт, сад Jardin des Colombieres.

- (все предложения)

Цитаты из русской классики со словом «роща»
- Лошадей привязал кучер к деревьям, в недальнем расстоянии, и задал им овса, которым запасся на дорогу; потом перескочил по камням через речку, пробрался сквозь рощу, в которой, сказали мы, терялась по косогору дорога в Менцен, прополз по обнаженной высоте за крестом и у мрачной ограды соснового леса, к стороне Мариенбурга, вскарабкавшись на дерево, которого вершина была обожжена молниею, привязал к нему красный лоскут, неприметный с холма, где были наши путешественники, но видный вкось на мызе.
Сочетаемость слова «роща»
Какой бывает «роща»
Значение слова «роща»
РО́ЩА , -и, ж. Небольшой, чаще лиственный лес. (Малый академический словарь, МАС)
Отправить комментарий
Дополнительно
Значение слова «роща»
РО́ЩА , -и, ж. Небольшой, чаще лиственный лес.
Предложения со словом «роща»:
Речь шла о такой малости как подлежащая вырубке берёзовая роща на самом краю графства.
Рассказывают и о том, как прадед мой извёл прекрасную дубовую рощу, скупивши её за бесценок у какого-то разорившегося помещика.
Здесь вековые зелёные оливковые рощи в Parc du Pian, гавань для яхт, сад Jardin des Colombieres.
Синонимы к слову «роща»
Ассоциации к слову «роща»
Сочетаемость слова «роща»
Какой бывает «роща»
Морфология
Карта слов и выражений русского языка
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
% PDF-1.4
%
1 0 obj
>
эндобдж
7 0 объект /Заголовок
/Тема
/ Автор
/Режиссер
/ Ключевые слова
/ CreationDate (D: 20210324133030-00’00 ‘)
/ ModDate (D: 201105339 + 02’00 ‘)
/ В ловушке / Ложь
/PTEX. FullBanner (это LuaTeX, версия 1.0.4 \ (TeX Live 2017 / Debian \))
>>
эндобдж
2 0 obj
>
эндобдж
3 0 obj
>
эндобдж
4 0 obj
>
эндобдж
5 0 obj
>
эндобдж
6 0 obj
>
эндобдж
8 0 объект
>
эндобдж
9 0 объект
>
эндобдж
10 0 obj
>
эндобдж
11 0 объект
>
эндобдж
12 0 объект
>
эндобдж
13 0 объект
>
эндобдж
14 0 объект
>
эндобдж
15 0 объект
>
эндобдж
16 0 объект
>
эндобдж
17 0 объект
>
эндобдж
18 0 объект
>
эндобдж
19 0 объект
>
эндобдж
20 0 объект
>
эндобдж
21 0 объект
>
эндобдж
22 0 объект
>
эндобдж
23 0 объект
>
эндобдж
24 0 объект
>
эндобдж
25 0 объект
>
эндобдж
26 0 объект
>
эндобдж
27 0 объект
>
эндобдж
28 0 объект
>
эндобдж
29 0 объект
>
эндобдж
30 0 объект
>
эндобдж
31 0 объект
>
эндобдж
32 0 объект
>
эндобдж
33 0 объект
>
эндобдж
34 0 объект
>
эндобдж
35 0 объект
>
эндобдж
36 0 объект
>
эндобдж
37 0 объект
>
эндобдж
38 0 объект
>
эндобдж
39 0 объект
>
эндобдж
40 0 объект
>
эндобдж
41 0 объект
>
эндобдж
42 0 объект
>
эндобдж
43 0 объект
>
эндобдж
44 0 объект
>
эндобдж
45 0 объект
>
эндобдж
46 0 объект
>
эндобдж
47 0 объект
>
эндобдж
48 0 объект
>
эндобдж
49 0 объект
>
эндобдж
50 0 объект
>
эндобдж
51 0 объект
>
эндобдж
52 0 объект
>
эндобдж
53 0 объект
>
эндобдж
54 0 объект
>
эндобдж
55 0 объект
>
эндобдж
56 0 объект
>
эндобдж
57 0 объект
>
эндобдж
58 0 объект
>
эндобдж
59 0 объект
>
эндобдж
60 0 объект
>
эндобдж
61 0 объект
>
эндобдж
62 0 объект
>
эндобдж
63 0 объект
>
эндобдж
64 0 объект
>
эндобдж
65 0 объект
>
эндобдж
66 0 объект
>
эндобдж
67 0 объект
>
эндобдж
68 0 объект
>
эндобдж
69 0 объект
>
эндобдж
70 0 объект
>
эндобдж
71 0 объект
>
эндобдж
72 0 объект
>
эндобдж
73 0 объект
>
эндобдж
74 0 объект
>
эндобдж
75 0 объект
>
эндобдж
76 0 объект
>
эндобдж
77 0 объект
>
эндобдж
78 0 объект
>
эндобдж
79 0 объект
>
эндобдж
80 0 объект
>
эндобдж
81 0 объект
>
эндобдж
82 0 объект
>
эндобдж
83 0 объект
>
эндобдж
84 0 объект
>
эндобдж
85 0 объект
>
эндобдж
86 0 объект
>
эндобдж
87 0 объект
>
эндобдж
88 0 объект
>
эндобдж
89 0 объект
>
эндобдж
90 0 объект
>
эндобдж
91 0 объект
>
эндобдж
92 0 объект
>
эндобдж
93 0 объект
>
эндобдж
94 0 объект
>
эндобдж
95 0 объект
>
эндобдж
96 0 объект
>
эндобдж
97 0 объект
>
эндобдж
98 0 объект
>
эндобдж
99 0 объект
>
эндобдж
100 0 объект
>
эндобдж
101 0 объект
>
эндобдж
102 0 объект
>
эндобдж
103 0 объект
>
эндобдж
104 0 объект
>
эндобдж
105 0 объект
>
эндобдж
106 0 объект
>
эндобдж
107 0 объект
>
эндобдж
108 0 объект
>
эндобдж
109 0 объект
>
эндобдж
110 0 объект
>
эндобдж
111 0 объект
>
эндобдж
112 0 объект
>
эндобдж
113 0 объект
>
эндобдж
114 0 объект
>
эндобдж
115 0 объект
>
эндобдж
116 0 объект
>
эндобдж
117 0 объект
>
эндобдж
118 0 объект
>
эндобдж
119 0 объект
>
эндобдж
120 0 объект
>
эндобдж
121 0 объект
>
эндобдж
122 0 объект
>
эндобдж
123 0 объект
>
эндобдж
124 0 объект
>
эндобдж
125 0 объект
>
эндобдж
126 0 объект
>
эндобдж
127 0 объект
>
эндобдж
128 0 объект
>
эндобдж
129 0 объект
>
эндобдж
130 0 объект
>
эндобдж
131 0 объект
>
эндобдж
132 0 объект
>
эндобдж
133 0 объект
>
эндобдж
134 0 объект
>
эндобдж
135 0 объект
>
эндобдж
136 0 объект
>
эндобдж
137 0 объект
>
эндобдж
138 0 объект
>
эндобдж
139 0 объект
>
эндобдж
140 0 объект
>
эндобдж
141 0 объект
>
эндобдж
142 0 объект
>
эндобдж
143 0 объект
>
эндобдж
144 0 объект
>
эндобдж
145 0 объект
>
эндобдж
146 0 объект
>
эндобдж
147 0 объект
>
эндобдж
148 0 объект
>
эндобдж
149 0 объект
>
эндобдж
150 0 объект
>
эндобдж
151 0 объект
>
эндобдж
152 0 объект
>
эндобдж
153 0 объект
>
эндобдж
154 0 объект
>
эндобдж
155 0 объект
>
эндобдж
156 0 объект
>
эндобдж
157 0 объект
>
эндобдж
158 0 объект
>
эндобдж
159 0 объект
>
эндобдж
160 0 объект
>
эндобдж
161 0 объект
>
эндобдж
162 0 объект
>
эндобдж
163 0 объект
>
эндобдж
164 0 объект
>
эндобдж
165 0 объект
>
эндобдж
166 0 объект
>
эндобдж
167 0 объект
>
эндобдж
168 0 объект
>
эндобдж
169 0 объект
>
эндобдж
170 0 объект
>
эндобдж
171 0 объект
>
эндобдж
172 0 объект
>
эндобдж
173 0 объект
>
эндобдж
174 0 объект
>
эндобдж
175 0 объект
>
эндобдж
176 0 объект
>
эндобдж
177 0 объект
>
эндобдж
178 0 объект
>
эндобдж
179 0 объект
>
эндобдж
180 0 объект
>
эндобдж
181 0 объект
>
эндобдж
182 0 объект
>
эндобдж
183 0 объект
>
эндобдж
184 0 объект
>
эндобдж
185 0 объект
>
эндобдж
186 0 объект
>
эндобдж
187 0 объект
>
эндобдж
188 0 объект
>
эндобдж
189 0 объект
>
эндобдж
190 0 объект
>
эндобдж
191 0 объект
>
эндобдж
192 0 объект
>
эндобдж
193 0 объект
>
эндобдж
194 0 объект
>
эндобдж
195 0 объект
>
/ ProcSet [/ PDF / Text / ImageC / ImageB / ImageI]
>>
эндобдж
196 0 объект
>
транслировать
x ڝ XɎ6 + MdAr32 i + O «) f4) X˫WE-_XsK% jJ] ^> į | -.
FullBanner (это LuaTeX, версия 1.0.4 \ (TeX Live 2017 / Debian \))
>>
эндобдж
2 0 obj
>
эндобдж
3 0 obj
>
эндобдж
4 0 obj
>
эндобдж
5 0 obj
>
эндобдж
6 0 obj
>
эндобдж
8 0 объект
>
эндобдж
9 0 объект
>
эндобдж
10 0 obj
>
эндобдж
11 0 объект
>
эндобдж
12 0 объект
>
эндобдж
13 0 объект
>
эндобдж
14 0 объект
>
эндобдж
15 0 объект
>
эндобдж
16 0 объект
>
эндобдж
17 0 объект
>
эндобдж
18 0 объект
>
эндобдж
19 0 объект
>
эндобдж
20 0 объект
>
эндобдж
21 0 объект
>
эндобдж
22 0 объект
>
эндобдж
23 0 объект
>
эндобдж
24 0 объект
>
эндобдж
25 0 объект
>
эндобдж
26 0 объект
>
эндобдж
27 0 объект
>
эндобдж
28 0 объект
>
эндобдж
29 0 объект
>
эндобдж
30 0 объект
>
эндобдж
31 0 объект
>
эндобдж
32 0 объект
>
эндобдж
33 0 объект
>
эндобдж
34 0 объект
>
эндобдж
35 0 объект
>
эндобдж
36 0 объект
>
эндобдж
37 0 объект
>
эндобдж
38 0 объект
>
эндобдж
39 0 объект
>
эндобдж
40 0 объект
>
эндобдж
41 0 объект
>
эндобдж
42 0 объект
>
эндобдж
43 0 объект
>
эндобдж
44 0 объект
>
эндобдж
45 0 объект
>
эндобдж
46 0 объект
>
эндобдж
47 0 объект
>
эндобдж
48 0 объект
>
эндобдж
49 0 объект
>
эндобдж
50 0 объект
>
эндобдж
51 0 объект
>
эндобдж
52 0 объект
>
эндобдж
53 0 объект
>
эндобдж
54 0 объект
>
эндобдж
55 0 объект
>
эндобдж
56 0 объект
>
эндобдж
57 0 объект
>
эндобдж
58 0 объект
>
эндобдж
59 0 объект
>
эндобдж
60 0 объект
>
эндобдж
61 0 объект
>
эндобдж
62 0 объект
>
эндобдж
63 0 объект
>
эндобдж
64 0 объект
>
эндобдж
65 0 объект
>
эндобдж
66 0 объект
>
эндобдж
67 0 объект
>
эндобдж
68 0 объект
>
эндобдж
69 0 объект
>
эндобдж
70 0 объект
>
эндобдж
71 0 объект
>
эндобдж
72 0 объект
>
эндобдж
73 0 объект
>
эндобдж
74 0 объект
>
эндобдж
75 0 объект
>
эндобдж
76 0 объект
>
эндобдж
77 0 объект
>
эндобдж
78 0 объект
>
эндобдж
79 0 объект
>
эндобдж
80 0 объект
>
эндобдж
81 0 объект
>
эндобдж
82 0 объект
>
эндобдж
83 0 объект
>
эндобдж
84 0 объект
>
эндобдж
85 0 объект
>
эндобдж
86 0 объект
>
эндобдж
87 0 объект
>
эндобдж
88 0 объект
>
эндобдж
89 0 объект
>
эндобдж
90 0 объект
>
эндобдж
91 0 объект
>
эндобдж
92 0 объект
>
эндобдж
93 0 объект
>
эндобдж
94 0 объект
>
эндобдж
95 0 объект
>
эндобдж
96 0 объект
>
эндобдж
97 0 объект
>
эндобдж
98 0 объект
>
эндобдж
99 0 объект
>
эндобдж
100 0 объект
>
эндобдж
101 0 объект
>
эндобдж
102 0 объект
>
эндобдж
103 0 объект
>
эндобдж
104 0 объект
>
эндобдж
105 0 объект
>
эндобдж
106 0 объект
>
эндобдж
107 0 объект
>
эндобдж
108 0 объект
>
эндобдж
109 0 объект
>
эндобдж
110 0 объект
>
эндобдж
111 0 объект
>
эндобдж
112 0 объект
>
эндобдж
113 0 объект
>
эндобдж
114 0 объект
>
эндобдж
115 0 объект
>
эндобдж
116 0 объект
>
эндобдж
117 0 объект
>
эндобдж
118 0 объект
>
эндобдж
119 0 объект
>
эндобдж
120 0 объект
>
эндобдж
121 0 объект
>
эндобдж
122 0 объект
>
эндобдж
123 0 объект
>
эндобдж
124 0 объект
>
эндобдж
125 0 объект
>
эндобдж
126 0 объект
>
эндобдж
127 0 объект
>
эндобдж
128 0 объект
>
эндобдж
129 0 объект
>
эндобдж
130 0 объект
>
эндобдж
131 0 объект
>
эндобдж
132 0 объект
>
эндобдж
133 0 объект
>
эндобдж
134 0 объект
>
эндобдж
135 0 объект
>
эндобдж
136 0 объект
>
эндобдж
137 0 объект
>
эндобдж
138 0 объект
>
эндобдж
139 0 объект
>
эндобдж
140 0 объект
>
эндобдж
141 0 объект
>
эндобдж
142 0 объект
>
эндобдж
143 0 объект
>
эндобдж
144 0 объект
>
эндобдж
145 0 объект
>
эндобдж
146 0 объект
>
эндобдж
147 0 объект
>
эндобдж
148 0 объект
>
эндобдж
149 0 объект
>
эндобдж
150 0 объект
>
эндобдж
151 0 объект
>
эндобдж
152 0 объект
>
эндобдж
153 0 объект
>
эндобдж
154 0 объект
>
эндобдж
155 0 объект
>
эндобдж
156 0 объект
>
эндобдж
157 0 объект
>
эндобдж
158 0 объект
>
эндобдж
159 0 объект
>
эндобдж
160 0 объект
>
эндобдж
161 0 объект
>
эндобдж
162 0 объект
>
эндобдж
163 0 объект
>
эндобдж
164 0 объект
>
эндобдж
165 0 объект
>
эндобдж
166 0 объект
>
эндобдж
167 0 объект
>
эндобдж
168 0 объект
>
эндобдж
169 0 объект
>
эндобдж
170 0 объект
>
эндобдж
171 0 объект
>
эндобдж
172 0 объект
>
эндобдж
173 0 объект
>
эндобдж
174 0 объект
>
эндобдж
175 0 объект
>
эндобдж
176 0 объект
>
эндобдж
177 0 объект
>
эндобдж
178 0 объект
>
эндобдж
179 0 объект
>
эндобдж
180 0 объект
>
эндобдж
181 0 объект
>
эндобдж
182 0 объект
>
эндобдж
183 0 объект
>
эндобдж
184 0 объект
>
эндобдж
185 0 объект
>
эндобдж
186 0 объект
>
эндобдж
187 0 объект
>
эндобдж
188 0 объект
>
эндобдж
189 0 объект
>
эндобдж
190 0 объект
>
эндобдж
191 0 объект
>
эндобдж
192 0 объект
>
эндобдж
193 0 объект
>
эндобдж
194 0 объект
>
эндобдж
195 0 объект
>
/ ProcSet [/ PDF / Text / ImageC / ImageB / ImageI]
>>
эндобдж
196 0 объект
>
транслировать
x ڝ XɎ6 + MdAr32 i + O «) f4) X˫WE-_XsK% jJ] ^> į | -. , O, ۸ \ M & jdYs ଅ
+ .8 * | Sf’i’LQƾ \ z}
MR6T ֫ & DO $ @: ԞIw
dow, ZDE4 (ݧ v $ 6 梐 ~ Ͱ8kds & @ l6xzlxfDӾgHGPh, ڞ jgKrdAhBM (OpJnWȫ ‘$ «ώ5Hz» tWa $! R% z & FuUu1 ƑI269 + @ Pb; 6n3vA, пассивное голосовое сообщение @ vg ~ 9 по сравнению с DVUc) Разработчики Расчетное время: 15 минут
, O, ۸ \ M & jdYs ଅ
+ .8 * | Sf’i’LQƾ \ z}
MR6T ֫ & DO $ @: ԞIw
dow, ZDE4 (ݧ v $ 6 梐 ~ Ͱ8kds & @ l6xzlxfDӾgHGPh, ڞ jgKrdAhBM (OpJnWȫ ‘$ «ώ5Hz» tWa $! R% z & FuUu1 ƑI269 + @ Pb; 6n3vA, пассивное голосовое сообщение @ vg ~ 9 по сравнению с DVUc) Разработчики Расчетное время: 15 минут
Подавляющее большинство предложений в техническом письме должны быть активным голосом. Этот модуль научит вас делать следующее:
- Отличить пассивный голос от активного.
- Преобразование пассивного голоса в активный голос, потому что активный голос обычно яснее.
Сначала посмотрите это видео, просто чтобы понять прокат 1 :
Отличить активный голос от пассивного с помощью простых предложений
В активном голосовом предложении актер действует на цель. То есть, активное голосовое предложение следует этой формуле:
Активное голосовое предложение = исполнитель + глагол + цель
Пассивное голосовое предложение переворачивает формулу.То есть пассивный голосовое предложение обычно следует следующей формуле:
Пассивное голосовое предложение = цель + глагол + действующее лицо
Пример активного голоса
Например, вот короткое активное голосовое предложение:
Кот сел на циновку.
- актер: Кот
- глагол: sat
- мишень: мат
Примеры пассивного голоса
Напротив, вот то же предложение пассивным голосом:
На циновке сидела кошка.
- мишень: мат
- пассивный глагол: was sat
- актер: кот
Некоторые предложения с пассивным голосом пропускают актера. Например:
Мат был установлен.

- актер: неизвестен
- пассивный глагол: was sat
- мишень: мат
Кто или что сидел на коврике? Кошка? Собака? Тираннозавр? Читателям остается только догадываться. Хорошие предложения в технической документации определяют, кто и с кем делает.
Распознавать пассивные глаголы
Пассивные глаголы обычно имеют следующую формулу:
пассивный глагол = форма быть + глагол причастия прошедшего времени
Хотя предыдущая формула выглядит устрашающей, на самом деле она довольно проста:
- Форма от быть в пассивном глаголе обычно является одной из следующие слова:
- Глагол причастия прошедшего времени обычно представляет собой простой глагол с суффиксом изд. .Например, следующие глаголы причастия прошедшего времени:
- интерпретированный
- сгенерировано
- сформировано
К сожалению, некоторые глаголы причастия прошедшего времени неправильны; то есть прошлое Форма причастия не оканчивается суффиксом ed . Например:
Соединение формы с и причастием прошедшего времени вместе дает пассивное глаголы, например:
- интерпретировано
- генерируется
- образовано
- заморожен
Если фраза содержит актера, то обычно следует предлог. пассивный глагол.(Этот предлог часто служит ключом к разгадке пассивный залог.) Следующие примеры объединяют пассивный глагол и предлог:
- интерпретировалось как
- генерируется
- был образован
- заморожен на
Повелительные глаголы обычно активны
Легко ошибочно классифицировать предложения, начинающиеся с повелительного наклонения. глагол как пассив. Повелительный глагол — это команда. Многие предметы в Нумерованные списки начинаются с повелительных глаголов.Например, Открыть и Набор в следующем списке являются повелительными глаголами:
- Откройте файл конфигурации.
- Установите для переменной
FrombusзначениеFalse.
Предложения, начинающиеся с повелительного наклонения, обычно произносятся активным голосом, даже если в них прямо не упоминается актер. Вместо этого предложения которые начинаются с повелительного глагола , подразумевают актера. Подразумеваемый актер это вы .
Упражнение
Отметьте каждое из следующих предложений как Пассивный или Активный :
-
MutableInputобеспечивает доступ только для чтения. - Доступ только для чтения предоставляется
MutableInput. - Производительность была измерена.
- Питон был изобретен Гвидо ван Россумом в двадцатом веке.
- Дэвид Корн обнаружил KornShell совершенно случайно.
- Эта информация используется группой по обеспечению соблюдения политики.
- Нажмите кнопку «Отправить».
- Орбита была рассчитана Кэтрин Джонсон.
Щелкните значок, чтобы увидеть ответ.
- Действует . MutableInput обеспечивает доступ только для чтения.
- Пассивный . Доступ только для чтения предоставляется MutableInput.
- Пассивный . Производительность была измерена.
- Пассивный . Питон был изобретен Гвидо ван Россумом в ХХ веке. век.
- Действует . Дэвид Корн обнаружил KornShell совершенно случайно.
- Пассивный . Эта информация используется политикой команда правоприменения.
- Действует . Нажмите кнопку «Отправить». ( Щелчок — повелительный глагол.)
- Пассивный . Орбита была рассчитана Кэтрин Джонсон.
Отличить активный голос от пассивного в более сложных предложениях
Многие предложения содержат несколько глаголов, некоторые из которых являются активными и некоторые из них пассивны.Например, следующее предложение содержит два глагола, оба в пассивном тоне:
Вот то же предложение, частично преобразованное в активный голос:
А вот то же предложение, теперь полностью преобразованное в активный голос:
Упражнение
Каждое из следующих предложений содержит два глагола. Отнесите каждый глагол в следующих предложениях к одной из следующих категорий: активный или пассивный.Например, если первый глагол активен и второй пассивный, напишите Active, Passive .
- Команда QA любит мороженое, но сценаристы предпочитают сорбет.
- Показатели производительности требуются команде, хотя я предпочитаю дикие догадки.
- Когда инженеры-программисты пытаются что-то новое и новаторское, награда должно быть выдано.
Щелкните значок, чтобы увидеть ответ.
- Активный, Активный. Команда QA любит мороженое, но сценаристы предпочитаю сорбет.
- Пассивный, Активный. Показатели производительности требуются команде, хотя я предпочитаю дикие догадки.
- Активный, Пассивный. Когда программисты пробуют что-то новое и новаторский, должен быть вознагражден.
Предпочитать активный голос пассивному
Большую часть времени используйте активный голос. Умеренно используйте пассивный голос. Активный голос дает следующие преимущества:
- Большинство читателей мысленно преобразовывают пассивный голос в активный.Зачем отнимать у ваших читателей дополнительное время на обработку? Придерживаясь активный голос, читатели могут пропустить этап препроцессора и перейти прямо к компиляции.
- Пассивный голос запутывает ваши идеи, переворачивая предложения с ног на голову. Пассивный голос сообщает о действиях косвенно.
- Некоторые предложения с пассивным голосом вообще пропускают актера, что вынуждает читатель угадывает личность актера.
- Активный голос обычно короче пассивного.
Будь смелым — будь активным.
Отчеты о научных исследованиях (дополнительный материал)
Пассивный голос широко используется в некоторых отчетах о научных исследованиях. В этих отчетах об исследованиях экспериментаторы и их оборудование часто исчезают, что приводит к пассивным предложениям, которые начинаются следующим образом:
- Было высказано предположение, что …
- Данные взяты …
- Статистика подсчитана …
- Оценены результаты.
Знаем ли мы, кто и что делает? Нет.Пассивный голос как-то сделать информацию более объективной? №
Многие научные журналы приняли активное участие. Мы поощряем остальные присоединяются к поискам ясности.
Упражнение
Перепишите следующие предложения с пассивным голосом как с активным голосом. Только часть некоторые предложения звучат пассивно; убедитесь, что все части останутся активными голос:
- Флаги не были проанализированы Mungifier.
- Обертка создается в процессе регистрации операции.
- Система Frombus выбирает только один эксперимент для каждого слоя.
- Показатели качества отмечены звездочками; амперсанды идентифицируют плохие метрики.
Щелкните значок, чтобы увидеть ответ.
- Mungifier не проанализировал флаги.
- Процесс регистрации Op генерирует оболочку.
- Система Frombus выбирает только один эксперимент для каждого слоя.
- Звездочки обозначают показатели качества; амперсанды указывают на плохие показатели.
Следующий блок: Очистить предложения
Анализ важности слов
После завершения Краткого Оксфордского словаря Генри Ватсон Фаулер предложил Oxford University Press создать словарь, в котором не будут очевидны очевидные слова, а вместо этого сконцентрироваться на тех, которые сбивают с толку и неточны, а также на вызывающих беспокойство идиомах и устаревших правилах. Оксфордский редактор назвал его «утопическим словарем», «который будет очень хорошо продаваться в Утопии».Книга, опубликованная в 1926 году под названием «Словарь современного английского языка», на самом деле была скромным бестселлером и впоследствии выдержала несколько изданий и два пересмотра.
Успех книги был полностью обеспечен ее автором Х.В. Фаулер, бывший учитель английской государственной школы, неудачливый литературный журналист и выдающийся лексикограф. Фаулер был авторитетным и здравомыслящим, чрезвычайно знающим и сдержанно остроумным, грамматическим моралистом, ненависть которого к обману сделала его моралистом на стороне здравого смысла.
Радикал в свое время, Фаулер считал, что заканчивать предложение предлогом не является преступлением, что лучше разбить инфинитив, чем написать неудобное предложение, пытаясь этого избежать, что общие слова должны быть предпочтительнее. иностранные и многосложные. Фаулер, как писал Эрнест Гауэрс, автор «Полных простых слов», «был освободителем от оков грамматических педантов, которые так долго сковывали нас».
Словарь современного английского языка проникнут индивидуальностью и особенностями его автора, возможно, даже больше, чем знаменитый Словарь Сэмюэля Джонсона.Фаулер любил рискованные, но забавные обобщения. Например, в своей статье о «Дидактике» он отмечает, что «мужчины в такой же степени одержимы дидактическим импульсом, как женщины — материнским инстинктом». Он также учил хорошим манерам. Его статья «Французские слова» начинается так: «Демонстрация превосходных знаний — такая же вульгарность, как и демонстрация превосходного богатства — более того, поскольку знание должно более определенно, чем богатство, иметь тенденцию к осмотрительности и хорошим манерам».
Комбинаторы синтаксического анализатора: пошаговое руководство
Или: напишите вам парсек для великого добра
Большинство людей на пути к Haskell пойдут по тем же первым шагам.Во-первых, вам нужно познакомиться с самим языком, особенно если вы пришли к нему без каких-либо знаний функционального программирования: его необычный синтаксис, лень, отсутствие изменяемого состояния … Оттуда вы можете перейти к объявлениям функций и типов, ознакомиться изучите функции Prelude (и их известные недостатки) и начните писать свои первые программы. Следующий большой шаг — это, конечно, монады, печально известное м-слово, и то, как мы используем их для структурирования наших программ.
Но потом, когда вы начали развивать интуицию для монад… путь становится неясным.Можно охватить еще много всего, но все это не столь фундаментально. Есть примерно три категории тем, которые можно захотеть изучить:
- Дальнейшее развитие самого языка: изучение языковых расширений, теории, лежащей в основе их, и расширенных функций, которые они предоставляют.
- Дополнительные сведения о различных способах структурирования программы (например, о преобразователях монад или системах эффектов).
- Изучение некоторых из наиболее часто используемых библиотек и понимание того, что делает их такими повсеместными: QuickCheck, Lens… и Parsec.
Сегодня я хочу изучить Parsec, и особенно , как работает Parsec . Синтаксический анализ применяется повсеместно, и большинство программ на Haskell будут использовать Parsec или один из его вариантов (мегапарсек или аттопарсек). Хотя эти библиотеки можно использовать, не заботясь о том, как они работают, я думаю, что интересно разработать мысленную модель для их внутреннего дизайна; а именно, комбинаторы монадического синтаксического анализатора , поскольку это простой и элегантный метод, который полезен за пределами варианта использования синтаксического анализа необработанного текста.В Hasura мы недавно использовали эту технику, чтобы переписать код, который генерирует схему GraphQL и проверяет входящий запрос GraphQL по ней.
Чтобы развить интуицию для этой техники, в ходе этой статьи мы сначала переопределим упрощенную версию Parsec , а затем используем ее, чтобы написать синтаксический анализатор для значений JSON . Наша цель здесь не будет заключаться в разработке полноценной библиотеки, как раз наоборот: мы реализуем строгий минимум, который нам нужен, чтобы сосредоточиться на основных идеях.
Выбор представления типа для парсеров
С точки зрения высокого уровня синтаксический анализатор можно рассматривать как функцию перевода: он принимает в качестве входных данных некоторые слабо структурированные данные (большую часть времени: текст) и пытается преобразовать их в структурированные данные, следуя правилам формальная грамматика. Компилятор преобразует серию символов в абстрактное синтаксическое дерево, парсер JSON преобразует серию символов в эквивалентное представление Haskell значения JSON.Есть несколько алгоритмических подходов к этой проблеме; Комбинаторы синтаксического анализатора — это пример рекурсивного спуска : мы анализируем каждый термин нашей грамматики, рекурсивно вызывая синтаксические анализаторы для каждого подтермина.
Это означает, что под «синтаксическим анализатором» мы оба подразумеваем общее высокоуровневое преобразование и каждый его отдельный шаг, поскольку каждый синтаксический анализатор рекурсивно выражается как комбинация других синтаксических анализаторов.
Минимальная жизнеспособная реализация
Давайте шаг за шагом разберемся с типом парсера.Во-первых, мы установили, что синтаксический анализатор — это функция от некоторого заданного ввода до того, что мы пытаемся проанализировать. В этом проекте для простоты мы будем использовать String в качестве входных данных. Поэтому мы могли бы решить использовать следующее для представления наших парсеров:
Тип Parser a = String -> a
Но этого типа недостаточно для нашего случая использования. Первое и самое главное: синтаксический анализатор может выйти из строя, если ввод не соответствует тому, что диктует наша грамматика. Нам нужно будет определить соответствующий тип для представления ошибок, и парсер должен включить эту возможность на уровне типа.
type Parser a = String -> Either ParseError a
Кроме того, синтаксический анализ — это последовательная операция : чтобы проанализировать объект JSON, нужно сначала проанализировать открывающую фигурную скобку, затем проанализировать записи, а затем проанализировать закрывающую фигурную скобку; рекурсивно, чтобы проанализировать запись, нужно сначала проанализировать ключ, затем двоеточие, а затем значение. Наш тип парсера будет использоваться для представления каждого из этих шагов, и мы не ожидаем, что каждый шаг полностью потребляет входную строку: поэтому каждый парсер должен также возвращать что-то, что указывает, где мы находимся во входном потоке, сколько из этого было потреблено, или то, что осталось обработать.
Поскольку мы используем String в качестве входного потока, каждому синтаксическому анализатору достаточно просто вернуть то, что осталось от входной строки. Тип Parser , который мы будем использовать, будет таким:
newtype Parser a = Parser {
runParser :: String -> (Строка, Либо ParseError a)
}
Написание элементарных парсеров
Как это принято в Haskell, мы начинаем с рассмотрения «аксиоматических» базовых случаев, а затем обобщаем / экстраполируем оттуда.Учитывая, что наш поток — это String , а наши отдельные токены — это просто символы указанной строки, наши два базовых случая просто соответствуют двум конструкторам списка: во входном потоке остались токены или мы достигли конец. Мы называем эти две функции любыми и eof соответственно:
любой :: Parser Char
any = Parser $ \ input -> регистр ввода
- осталось немного ввода: распаковываем и возвращаем первый символ
(x: xs) -> (xs, вправо x)
- ввода не осталось: анализатор не работает
[] -> ("", Left $ ParseError
«любой персонаж» - ожидается
«конец ввода» - встретил
)
eof :: Parser ()
eof = Parser $ \ input -> регистр ввода
- ввода не осталось: синтаксический анализатор завершил работу
[] -> ("", Вправо ())
- оставшиеся данные: анализатор не работает
(c: _) -> (ввод, Left $ ParseError
«конец ввода» - ожидается
[c] - встречались
)
Это только два базовых парсера , которые нам нужны! Они охватывают два базовых случая: у нас есть символ для синтаксического анализа или нет.Все остальное можно выразить в терминах этих двух и с помощью комбинаторов.
Парсеры секвенирования
Как упоминалось ранее, синтаксический анализ последовательный . Нам часто нужно выразить что-то вроде: я хочу применить парсер A , затем парсер B и использовать их результаты. Давайте посмотрим, как мы могли бы реализовать синтаксический анализатор для записи объекта JSON, например: нам нужно проанализировать строку json, затем двоеточие, затем значение json (мы предполагаем, что эти отдельные синтаксические анализаторы уже существуют).Получающийся в результате код … субоптимальный: повторяющийся, подверженный ошибкам и трудный для чтения:
jsonEntry :: Parser (Строка, JValue)
jsonEntry = Парсер $ \ input ->
- разобрать строку json
case runParser jsonString ввод
(input2, Left err) -> (input2, Left err)
(input2, правая клавиша) ->
- при успехе: разобрать одно двоеточие
case runParser (char ':') input2 из
(input3, Left err) -> (input3, Left err)
(input3, Right _) ->
- в случае успеха: проанализировать значение json
case runParser jsonValue input3 из
(input4, Left err) -> (input4, Left err)
(input4, Правое значение) ->
- при успехе: вернуть результат
(input4, Right (ключ, значение))
Это довольно обременительно как из-за того, что каждый шаг может завершиться неудачно, так и из-за того, что каждый шаг возвращает ввод для следующего.Более того, это заставляет нас знать о внутренней структуре парсера, чтобы знать, как их объединить в цепочку. Чтобы упростить задачу, мы можем извлечь этот шаблон в отдельную функцию:
andThen :: Parser a -> (a -> Parser b) -> Parser b
parserA `andThen` f = Парсер $ \ input ->
case runParser parserA ввод
(restOfInput, Right a) -> runParser (f a) restOfInput
(restOfInput, Left e) -> (restOfInput, Left e)
Эта функция позволяет нам переписать наш синтаксический анализатор записи JSON таким образом, чтобы больше не требовалось явное самоанализирование каждого синтаксического анализатора на этом пути.
jsonEntry :: Parser (Строка, JValue)
jsonEntry =
- разобрать строку json
jsonString `andThen` \ ключ ->
- разобрать одно двоеточие
char ‘:’ `andThen` \ _ ->
- проанализировать значение JSON
jsonValue `andThen` \ значение ->
- создать константный парсер, который не потребляет ввод
constParser (ключ, значение)
Силой монад!
Некоторым читателям этот паттерн и затем покажется знакомым; это потому, что andThen в точности совпадает с оператором связывания Monad :
(>> =) :: Parser a -> (a -> Parser b) -> Parser b
Сделав наш тип Parser экземпляром Monad , мы можем усилить мощь всех функций, которые идут с ним, и гораздо более удобный синтаксис do notation для наших синтаксических анализаторов.Наконец, нашу функцию jsonEntry можно кратко и прямо переписать:
jsonEntry :: Parser (Строка, JValue)
jsonEntry = do
ключ <- jsonString
_ <- char ‘:’
значение <- jsonValue
возврат (ключ, значение)
В качестве примечания стоит упомянуть, что хотя не делает нотацию делает упорядочение явным, мы также будем использовать операторы во всем коде (иначе это не было бы «истинным Haskell»: P).В частности, следующие операторы Functor и Applicative :
(*>) :: Parser a -> Parser b -> Parser b
(<*) :: Parser a -> Parser b -> Parser a
(<$) :: a -> Парсер b -> Парсер a
- игнорировать ведущие пробелы
пробелы *> значение
- игнорировать конечные пробелы
значение <* пробелы
- подставить значение
True <$ string «true»
Резюме
До сих пор мы определили наши два элементарных синтаксических анализатора и увидели, что объединение в цепочку является монадической операцией.Все готово: удовлетворены наши основные потребности. Теперь мы можем приступить к описанию более интересных парсеров. Для начала давайте представим удовлетворить : небольшую оболочку вокруг любого , которая позволяет нам проверять, соответствует ли следующий символ во входных данных какому-либо произвольному требованию.
удовлетворить :: String -> (Char -> Bool) -> Parser Char
удовлетворить предикат описания = попробуйте $ do
c <- любой
если предикат c
затем верните c
else parseError описание [c]
Эта функция, хотя и проста, использует другие функции, с которыми мы еще не сталкивались, например , попробуйте .Это наш первый комбинатор!
Объединение парсеров
Формально комбинатор - это функция, которая не полагается ни на что, кроме своих аргументов, например (.) оператор композиции функции:
(f. G) x = f (g x)
Но неформально ... комбинатор - это , что-то, что объединяет другие вещи . И именно в том неформальном смысле мы используем его здесь! В нашем контексте комбинаторы синтаксического анализатора - это функций на синтаксических анализаторах : функции, которые объединяют и преобразуют синтаксические анализаторы в другие синтаксические анализаторы для обработки таких вещей, как отслеживание с возвратом или повторение.
Выбор, ошибки и возврат
Мы знаем, что парсеры могут давать сбой: именно поэтому в их типе все-таки есть Either . Но не все ошибки фатальны: некоторые из них можно исправить. Представьте, например, что вы пытаетесь проанализировать значение JSON: это может быть объект, массив или строка ... Чтобы проанализировать такое значение, вы можете попытаться проанализировать открывающие фигурные скобки объекта: если это успешно, вы можете продолжить синтаксический анализ объекта; но если это немедленно не удается, вы можете вместо этого попытаться проанализировать открывающую скобку массива и так далее.Именно с ошибкой и возвратом мы можем реализовать нашу первую «расширенную» функцию: выбор.
Чтобы отличить настоящую ошибку, которая произошла дальше по строке, или что-то, что просто было неправильным выбором, мы делаем различие между синтаксическими анализаторами, которые не работают , не потребляя никаких входных данных , которые выходят из строя немедленно, и синтаксическими анализаторами, которые не работают позже: что если какой-либо ввод был потреблен, значит, мы оказались на правой «ветке». Но смотреть вперед только на один символ не всегда будет достаточно, чтобы решить, правильна ли ветвь, и в этом случае нам нужно иметь возможность вернуться назад, если ветка не удалась: нам нужен комбинатор с возвратом.Это то, что делает try : он преобразует синтаксический анализатор в анализатор с возвратом: тот, который не потребляет ввод в случае сбоя, который восстанавливает состояние до прежнего. Имеет смысл использовать его для , чтобы удовлетворить : если предикат не работает, мы не встретили ни одного символа, который можно было бы распаковать, и мы должны оставить входную строку без изменений.
try :: Parser a -> Parser a
попробуйте p = Parser $ \ state -> case runParser p состояние
(_newState, левая ошибка) -> (состояние, левая ошибка)
успех -> успех
В этом проекте мы называем комбинаторы точно так же, как Parsec.Оператор, который Parsec использует для представления выбора, совпадает с оператором, определенным в классе типов Alternative : (<|>) . Его семантика проста: если первый синтаксический анализатор вышел из строя, не потребляя никаких входных данных, попробуйте второй; в противном случае распространить ошибку:
(<|>) :: Parser a -> Parser a -> Parser a
p1 <|> p2 = Parser $ \ s -> case runParser p1 s из
(s ', левая ошибка)
| s '== s -> runParser p2 s
| в противном случае -> (s ', левая ошибка)
успех -> успех
С помощью этого оператора мы наконец можем реализовать гораздо более удобный комбинатор: выбор .Имея список парсеров, попробуйте их все, пока один из них не добьется успеха.
choice :: String -> [Parser a] -> Parser a
выбор описание = foldr (<|>) noMatch
где noMatch = parseError описание "нет совпадения"
повтор
Последняя группа комбинаторов, которая нам понадобится для нашего проекта, - это комбинаторы повторения. Они не требуют каких-либо внутренних знаний о нашем типе Parser и являются хорошим примером того, какую высокоуровневую абстракцию мы теперь можем написать.Как обычно, мы используем те же имена, что и Parsec: many эквивалентно звезде регулярного выражения и соответствует нулю или более вхождений данного синтаксического анализатора, а many1 эквивалентно плюсу: соответствует одному или нескольким вхождениям:
many, many1 :: Parser a -> Parser [a]
many p = many1 p <|> return []
many1 p = делать
первый <- p
отдых <- многие р
возврат (первый: отдых)
Благодаря им мы также можем реализовать sepBy и sepBy1 , которые соответствуют повторяющимся вхождениям данного парсера с заданным разделителем между ними:
sepBy, sepBy1 :: Parser a -> Parser s -> Parser [a]
sepBy p s = sepBy1 p s <|> return []
sepBy1 p s = делать
первый <- p
отдых <- многие (s >> p)
возврат (первый: отдых)
Резюме
Вот и все: эти семь комбинаторов - все, что нам нужно для реализации синтаксического анализатора JSON с нуля; на данный момент у нас уже есть достаточно хорошая минимальная реализация библиотеки комбинаторов синтаксического анализатора, подобной Parsec!
Конечно, полноценная библиотека реализует гораздо больше: больше примитивов для обработки символов, комбинаторы для необязательных синтаксических анализаторов, более специфические комбинаторы повторения, поддержка улучшенных сообщений об ошибках… Но это выходит за рамки данного упражнения.
Парсеры на практике: парсинг JSON
Чтобы собрать воедино все, что мы видели до сих пор, давайте шаг за шагом рассмотрим процесс построения грамматики парсера JSON. Мы будем делать это снизу вверх: начиная с синтаксических анализаторов для отдельных символов, затем перейдем к синтаксическим анализаторам, затем для скаляров… пока мы наконец не сможем выразить синтаксический анализатор для произвольного значения JSON. Цель здесь - продемонстрировать, как на каждом этапе мы можем использовать построенные нами более простые абстракции для создания чего-то более сложного.В этом разделе немного больше кода, но я надеюсь, что, если вы все до сих пор следили, вам будет так же приятно читать, как и мне!
Мы будем использовать следующее представление для значений JSON, которое очень близко к тому, что определяет Aeson:
данные JValue
= JObject (HashMap String JValue)
| JArray [JValue]
| JString String
| JNumber Двухместный
| JBool Bool
| JNull
Распознавание знаков
Использование функций Data.Char , давайте начнем определять нашу грамматику с определения типов символов, которые мы хотим распознавать: это простое использование нашей функции , удовлетворения :
char c = удовлетворить [c] (== c)
пробел = удовлетворить "пробел" isSpace
digit = удовлетворить "цифру" isDigit
Синтаксис языка
Чтобы пойти дальше, мы можем определить удобные синтаксические функции, используя вышеупомянутые операторы Applicative :
строка = символ перемещения
пробелы = много места
символ s = строка s <* пробелы
между открыть закрыть значение = открыть *> значение <* закрыть
скобки = между (символ "[") (символ "]")
фигурные скобки = между (символ "{") (символ "}")
Реализациясимвола здесь основана на определении Parsec лексемы (в их библиотеке определения языка), которая всегда пропускает завершающие пробелы; поэтому каждый синтаксический анализатор может быть безопасно написан с предположением, что нет начальных пробелов, которые он должен учитывать.Благодаря такому подходу в нашей грамматике JSON очень мало явных упоминаний пробелов.
Скаляры
Вот чем наша реализация будет отличаться от стандарта JSON. Для простоты наш парсер для чисел будет соответствовать только натуральным числам:
jsonNumber = читать <$> many1 цифру
Для логических значений мы просто сопоставляем два возможных случая:
jsonBool = choice "JSON boolean"
[True <$ symbol "true"
, False <$ symbol "false"
]
Что касается строк, мы сопоставляем последовательность символов между двумя двойными кавычками, но мы должны учитывать возможность того, что некоторые символы могут быть экранированы.Мы обрабатываем только небольшое подмножество экранированных символов, реализация остальной части спецификации оставлена читателю в качестве упражнения. 🙂
jsonString =
между (char '"') (char '"') (многие jsonChar) <* пробелы
где
jsonChar = choice "строковый символ JSON"
[попробуйте $ '\ n' <$ string "\\ n"
, попробуйте $ '\ t' <$ string "\\ t"
, попробуйте $ '"' <$ string" \\\ ""
, попробуйте $ '\\' <$ string "\\\\"
, удовлетворить "не цитата" (/ = '"')
]
Массивы и объекты
ЗначенияJSON по определению рекурсивны: массивы и объекты содержат другие значения JSON ... Чтобы продолжить наш восходящий подход, мы предположим существование парсера jsonValue верхнего уровня, который будет определен последним.
Объект JSON - это группа отдельных записей, разделенных запятыми. Сначала мы анализируем их как список, используя комбинатор повторения, затем преобразуем упомянутый список ассоциаций в HashMap :
. jsonObject = делать
assocList <- фигурные скобки $ jsonEntry `sepBy` symbol", "
вернуть $ fromList assocList
где
jsonEntry = do
k <- jsonString
условное обозначение ":"
v <- jsonValue
возврат (k, v)
Наконец, массив - это просто группа значений в скобках, разделенных запятыми:
jsonArray = скобки $ jsonValue `sepBy` symbol", "
Собираем все вместе
Наконец, мы можем выразить парсер верхнего уровня для значения JSON:
jsonValue = выбор "значение JSON"
[JObject <$> jsonObject
, JArray <$> jsonArray
, JString <$> jsonString
, JNumber <$> jsonNumber
, JBool <$> jsonBool
, JNull <$ символ "ноль"
]
И… все!
Завершение
Эта статья является результатом моего личного опыта, когда я пытался понять внутреннюю работу Parsec после многих лет его использования.Я попробовал свои силы в написании небольшого парсера JSON с нуля, на стороне, когда я узнал о том, что заставляет Parsec работать, чтобы лучше понять, применив его на практике. Когда я закончил, я был поражен тем, насколько маленький, и лаконичный получился код, а также тем, насколько простой была грамматика JSON. Я искренне надеюсь, что это пошаговое руководство окажется для вас полезным и даст вам представление о красоте комбинаторов синтаксического анализатора!
Весь код в этой статье можно найти в этой статье GitHub.
Для более сложного примера использования комбинаторов синтаксического анализатора, если вы хотите узнать больше о том, как мы использовали эту технику для повторной реализации нашей генерации схемы GraphQL, вы можете взглянуть на описание PR, в котором она была представлена.
Хасура, конечно, нанимает. Если обсуждения, подобные приведенным выше, кажутся вам интересными, просмотрите наши открытые роли и подайте заявку. Если вы хотите следить за тем, что строит команда, где мы говорим, а также за случайными гифками с детенышами животных... Информационный бюллетень сообщества Hasura - это ежемесячная рассылка без традиционного маркетингового спама.
Спасибо за внимание!
Общие сведения о комбинаторах синтаксического анализатора | F # для удовольствия и прибыли
ОБНОВЛЕНИЕ: Слайды и видео из моего выступления на эту тему
В этой серии статей мы рассмотрим, как работают так называемые «аппликативные синтаксические анализаторы». Чтобы что-то понять, нет ничего лучше, чем создать это для себя, поэтому мы создадим базовую библиотеку парсера с нуля, а затем несколько полезных «комбинаторов парсеров», а затем закончим построением полного парсера JSON.
Теперь такие термины, как «прикладные синтаксические анализаторы» и «комбинаторы синтаксического анализа», могут сделать этот подход сложным, но, скорее, чем пытаясь объяснить эти концепции заранее, мы просто погрузимся в них и начнем кодировать.
Мы будем постепенно наращивать сложность посредством серии реализаций, каждая из которых лишь немного отличается от предыдущей. Используя этот подход, я надеюсь, что на каждом этапе дизайн и концепции будут легкими для понимания, и поэтому к концу этой серии комбинаторы синтаксического анализатора станут полностью демистифицированными.
В этой серии будет четыре сообщения:
- В этом первом посте мы рассмотрим основные концепции комбинаторов синтаксического анализатора и создадим ядро библиотеки.
- Во втором посте мы создадим полезную библиотеку комбинаторов.
- В третьем посте мы постараемся предоставить полезные сообщения об ошибках.
- В последнем посте мы создадим парсер JSON, используя эту библиотеку парсеров.
Очевидно, что здесь основное внимание не будет уделяться производительности или эффективности, но я надеюсь, что это даст вам понимание, которое затем позволит вам эффективно использовать библиотеки, такие как FParsec.И, кстати, большое спасибо Стефану Толксдорфу, создавшему FParsec. Вы должны сделать его своим первым портом захода для всех ваших потребностей в синтаксическом анализе .NET!
Разбор жестко запрограммированного символа
Для начала давайте создадим что-то, что просто анализирует один жестко запрограммированный символ, в данном случае букву «A». Нет ничего проще!
Вот как это работает:
- На вход синтаксического анализатора поступает поток символов.Мы могли бы использовать что-нибудь сложное, но пока мы просто используем строку
- Если поток пуст, то возвращаем пару, состоящую из
falseи пустой строки. - Если первым символом в потоке является
A, то возвращается пара, состоящая изистинныхи оставшегося потока символов. - Если первым символом в потоке не является
A, то вернутьfalseи (неизменный) исходный поток символов.
Вот код:
пусть parseA str =
если String.IsNullOrEmpty (str), то
(ложный,"")
иначе, если стр. [0] = 'A', тогда
пусть осталось = str. [1 ..]
(правда, осталось)
еще
(ложь, str)
Подпись parseA :
val parseA:
строка -> (bool * строка)
, который сообщает нам, что ввод - это строка, а вывод - это пара, состоящая из логического результата и другой строки (оставшийся ввод), например:
Давайте протестируем это сейчас - сначала с правильными входными данными:
пусть inputABC = "ABC"
parseA inputABC
Результат:
Как видите, A израсходован, а оставшийся ввод составляет всего «BC» .
А теперь с неверным вводом:
let inputZBC = "ZBC"
parseA inputZBC
, что дает результат:
И в этом случае первый символ был , а не использовался , а оставшийся ввод по-прежнему "ZBC" .
Итак, для вас есть невероятно простой парсер. Если вы это поймете, то все будет легко!
Разбор указанного символа
Давайте проведем рефакторинг, чтобы мы могли передать символ, которому хотим сопоставить, вместо того, чтобы жестко его запрограммировать.
И на этот раз вместо того, чтобы возвращать истину или ложь, мы вернем сообщение о том, что произошло.
Мы вызовем функцию pchar для «parse char». Это станет фундаментальным строительным блоком всех наших парсеров. Вот код для нашей первой попытки:
пусть pchar (charToMatch, str) =
если String.IsNullOrEmpty (str), то
let msg = "Нет ввода"
(сообщение, "")
еще
let first = str. [0]
если first = charToMatch, то
пусть осталось = str.[1 ..]
let msg = sprintf "Найдено% c" charToMatch
(сообщение, осталось)
еще
let msg = sprintf "Ожидается '% c'. Сначала получил '% c'" charToMatch
(сообщение, строка)
Этот код аналогичен предыдущему примеру, за исключением того, что теперь в сообщении об ошибке отображается неожиданный символ.
Подпись pchar :
val pchar:
(символ * строка) -> (строка * строка)
, который сообщает нам, что вход представляет собой пару (строка, символ для сопоставления), а выход представляет собой пару, состоящую из (строки) результата и другой строки (оставшегося входа).
Давайте протестируем это сейчас - сначала с правильными входными данными:
пусть inputABC = "ABC"
pchar ('A', вход ABC)
Результат:
Как и раньше, A израсходован, а оставшийся ввод составляет всего «BC» .
А теперь с неверным вводом:
let inputZBC = "ZBC"
pchar ('A', inputZBC)
, что дает результат:
(«Ожидая 'A'. Получил 'Z'», «ZBC»)
И снова, как и раньше, первый символ был , а не использовался , а оставшийся ввод по-прежнему "ZBC" .
Если мы передадим Z , то синтаксический анализатор завершится успешно:
pchar ('Z', inputZBC) // ("Найдено Z", "BC")
Возвращение к успеху / неудаче
Мы хотим иметь возможность отличать успешное совпадение от неудачного, а возвращение сообщения с строковым типом не очень помогает, поэтому давайте воспользуемся типом выбора (он же тип суммы, он же размеченное объединение), чтобы указать разницу. Я назову его ParseResult :
тип ParseResult <'a> =
| Успех
| Отказ строки
Случай Success является общим и может содержать любое значение.Случай Failure содержит сообщение об ошибке.
Подробнее об использовании этого подхода «Успех / Неудача» см. В моем выступлении о функциональной обработке ошибок.
Теперь мы можем переписать синтаксический анализатор, чтобы он возвращал один из случаев Результат , например:
пусть pchar (charToMatch, str) =
если String.IsNullOrEmpty (str), то
Ошибка "Нет ввода"
еще
let first = str. [0]
если first = charToMatch, то
пусть осталось = str. [1 ..]
Успех (charToMatch, осталось)
еще
let msg = sprintf "Ожидается"% c ".Сначала получил '% c' "charToMatch
Сообщение об ошибке
Подпись pchar теперь:
val pchar:
(char * строка) -> ParseResult
, который сообщает нам, что теперь на выходе получается ParseResult (который в случае Success содержит совпадающий символ и оставшуюся входную строку).
Давайте проверим это снова - сначала с правильными входными данными:
пусть inputABC = "ABC"
pchar ('A', вход ABC)
Результат:
Как и раньше, A израсходован, а оставшийся ввод составляет всего «BC» .Мы также получаем фактический сопоставленный символ ( A в данном случае).
А теперь с неверным вводом:
let inputZBC = "ZBC"
pchar ('A', inputZBC)
, что дает результат:
Отказ «Ожидание« А ». Получил« Я »»
И в этом случае случай Failure возвращается с соответствующим сообщением об ошибке.
Это схема входов и выходов функции:
Переход на каррированную реализацию
В предыдущей реализации входом в функцию был кортеж - пара.Это требует одновременной передачи обоих входных данных. В функциональных языках, таких как F #, более идиоматично использовать каррированную версию, например:
let pchar charToMatch str =
если String.IsNullOrEmpty (str), то
Ошибка "Нет ввода"
еще
let first = str. [0]
если first = charToMatch, то
пусть осталось = str. [1 ..]
Успех (charToMatch, осталось)
еще
let msg = sprintf "Ожидается '% c'. Сначала получил '% c'" charToMatch
Сообщение об ошибке
Вы видите разницу? Единственная разница в первой строке, и даже тогда она неуловима.карри
Вот каррированная версия pchar , представленная в виде диаграммы:
Если вам неясно, как работает каррирование, у меня есть сообщение об этом здесь, но в основном это означает, что многопараметрическая функция может быть записана как последовательность однопараметрических функций.
Другими словами, эта двухпараметрическая функция:
с подписью:
val add: x: int -> y: int -> int
можно записать как эквивалентную однопараметрическую функцию, возвращающую лямбду, например:
пусть прибавит x =
fun y -> x + y // вернуть лямбду
или как функция, возвращающая внутреннюю функцию, например:
пусть прибавит x =
пусть innerFn y = x + y
innerFn // вернуть innerFn
Во втором случае при использовании внутренней функции подпись выглядит немного иначе:
val add: x: int -> (int -> int)
, но скобки вокруг последнего параметра можно игнорировать.Подпись для всех практических целей такая же, как и оригинальная:
// оригинал (автоматическое каррирование двухпараметрической функции)
val add: x: int -> y: int -> int
// явное каррирование с внутренней функцией
val add: x: int -> (int -> int)
Переписывание с внутренней функцией
Мы можем воспользоваться каррированием и переписать синтаксический анализатор как однопараметрическую функцию (где параметр - charToMatch ), которая возвращает внутреннюю функцию.
Вот новая реализация с умно названной внутренней функцией innerFn :
пусть pchar charToMatch =
// определяем вложенную внутреннюю функцию
пусть innerFn str =
если String.IsNullOrEmpty (str), то
Ошибка "Нет ввода"
еще
let first = str. [0]
если first = charToMatch, то
пусть осталось = str. [1 ..]
Успех (charToMatch, осталось)
еще
let msg = sprintf "Ожидается '% c'. Сначала получил '% c'" charToMatch
Сообщение об ошибке
// возвращаем внутреннюю функцию
innerFn
Сигнатура типа для этой реализации выглядит так:
val pchar:
charToMatch: char -> (строка -> ParseResult )
, что функционально эквивалентно сигнатуре предыдущей версии.Другими словами, обе реализации ниже идентичны с точки зрения вызывающих абонентов:
// двухпараметрическая реализация
пусть pchar charToMatch str =
...
// однопараметрическая реализация с внутренней функцией
пусть pchar charToMatch =
пусть innerFn str =
...
// возвращаем внутреннюю функцию
innerFn
Преимущества каррированной реализации
Что хорошо в реализации с каррированием, так это то, что мы можем частично применить символ, который хотим проанализировать, чтобы получить новую функцию, например:
Теперь мы можем предоставить второй параметр «входной поток» позже:
пусть inputABC = "ABC"
parseA inputABC // => Успех ('A', "BC")
пусть inputZBC = "ZBC"
parseA inputZBC // => Ошибка "Ожидается 'A'.Получил "Z" "
На этом остановимся и рассмотрим, что происходит:
- Функция
pcharимеет два входа - Мы можем предоставить один ввод (соответствующий символ), и в результате будет возвращена функция .
- Затем мы можем предоставить второй вход (поток символов) этой функции синтаксического анализа, и это создаст окончательное значение
Result.
Вот еще раз диаграмма pchar , но на этот раз с акцентом на частичное применение:
Очень важно, чтобы вы поняли эту логику, прежде чем двигаться дальше, потому что остальная часть сообщения будет построена на этом базовом дизайне.
Инкапсуляция функции синтаксического анализа в типе
Если мы посмотрим на parseA (из приведенного выше примера), мы увидим, что он имеет тип функции:
val parseA: строка -> ParseResult
Этот тип немного сложен в использовании, поэтому давайте инкапсулируем его в тип «оболочку» под названием Parser , например:
Тип Parser <'T> = Parser of (string -> ParseResult <' T * string>)
Инкапсулируя его, мы уйдем от этого дизайна:
в этот дизайн, где он возвращает значение Parser :
Каковы преимущества использования этого дополнительного типа по сравнению с непосредственной работой с «сырой» строкой -> ParseResult ?
- Всегда полезно использовать типы для моделирования предметной области, и в этой предметной области мы имеем дело с «синтаксическими анализаторами», а не с функциями (хотя за кулисами это одно и то же).
- Это упрощает вывод типов и помогает сделать комбинаторы синтаксического анализатора (которые мы создадим позже) более понятными (например, комбинатор, который принимает два параметра «синтаксического анализатора», понятен, но комбинатор принимает два параметра типа
строка -> ParseResult <'a * string>трудно читать). - Наконец, он поддерживает скрытие информации (с помощью абстрактного типа данных), так что мы можем позже добавлять метаданные, такие как метка / строка / столбец и т. Д., Не нарушая работы клиентов.
Изменить реализацию очень просто. Нам просто нужно изменить способ возврата внутренней функции.
То есть из этого:
пусть pchar charToMatch =
пусть innerFn str =
...
// возвращаем внутреннюю функцию
innerFn
к этому:
пусть pchar charToMatch =
пусть innerFn str =
...
// возвращаем "обернутую" внутреннюю функцию
Парсер innerFn
Тестирование обернутой функции
Хорошо, теперь давайте снова протестируем:
пусть parseA = pchar 'A'
пусть inputABC = "ABC"
parseA inputABC // ошибка компилятора
Но теперь мы получаем ошибку компилятора:
Ошибка FS0003: это значение не является функцией и не может быть применено. И, конечно же, это потому, что функция заключена в структуру данных Parser ! К нему больше нет прямого доступа.
Итак, теперь нам нужна вспомогательная функция, которая может извлечь внутреннюю функцию и запустить ее против входного потока. Назовем его , пробег ! Вот его реализация:
разрешить запуск синтаксического анализатора input =
// разворачиваем парсер, чтобы получить внутреннюю функцию
let (Parser innerFn) = синтаксический анализатор
// вызываем внутреннюю функцию с вводом
вход innerFn
И теперь мы можем снова запустить парсер parseA для различных входов:
пусть inputABC = "ABC"
запустить parseA inputABC // Успех ('A', "BC")
пусть inputZBC = "ZBC"
запустить parseA inputZBC // Ошибка «Ожидание A».Получил "Z" "
Вот и все! У нас есть базовый парсер типа ! Я надеюсь, что до сих пор все это имеет смысл.
Последовательное объединение двух парсеров
Этой последней реализации достаточно для базовой логики синтаксического анализа. Мы вернемся к этому позже, но теперь давайте перейдем на уровень выше и разработаем несколько способов объединения синтаксических анализаторов вместе - «комбинаторы синтаксических анализаторов», упомянутые в начале.
Начнем с последовательного объединения двух синтаксических анализаторов.Например, предположим, что нам нужен синтаксический анализатор, который соответствует «A», а затем «B». Мы могли бы попробовать написать что-то вроде этого:
пусть parseA = pchar 'A'
пусть parseB = pchar 'B'
пусть parseAThenB = parseA >> parseB
, но это дает нам ошибку компилятора, поскольку вывод parseA не совпадает с вводом parseB , и поэтому они не могут быть составлены таким образом.
Если вы знакомы с шаблонами функционального программирования, необходимость связать последовательность обернутых типов вместе, как это происходит часто, и решением является функция bind .
Однако в этом случае я не буду реализовывать bind , а вместо этого сразу перейду к реализации и затем .
Логика реализации будет следующая:
- Запустить первый синтаксический анализатор.
- Если есть сбой, верните.
- В противном случае запустите второй синтаксический анализатор с оставшимися входными данными.
- Если есть сбой, верните.
- Если оба синтаксических анализатора завершились успешно, вернуть пару (кортеж), содержащую оба проанализированных значения.
Вот код для , а затем :
пусть and Тогда parser1 parser2 =
пусть innerFn input =
// запускаем parser1 с вводом
пусть result1 = запускает parser1 input
// проверяем результат на неудачу / успех
сопоставить результат1 с
| Ошибка ошибки ->
// возвращаем ошибку от parser1
Ошибка ошибки
| Успех (значение1, осталось1) ->
// запускаем parser2 с оставшимся входом
пусть результат2 = запустить синтаксический анализатор2, осталось1
// проверяем результат на неудачу / успех
сопоставить результат2 с
| Ошибка ошибки ->
// возвращаем ошибку из parser2
Ошибка ошибки
| Успех (значение2, осталось2) ->
// объединяем оба значения в пару
пусть newValue = (значение1, значение2)
// возвращаем оставшийся ввод после parser2
Успех (новое значение, осталось 2)
// возвращаем внутреннюю функцию
Парсер innerFn
Реализация следует логике, описанной выше.
Мы также определим инфиксную версию и затем , чтобы мы могли использовать ее как обычную композицию >> :
Примечание: круглые скобки необходимы для определения настраиваемого оператора, но не нужны при использовании инфикса.
Если посмотреть подпись и то :
val и Затем:
parser1: Parser <'a> -> parser2: Parser <' b> -> Parser <'a *' b>
мы видим, что он работает для любых двух парсеров, и они могут быть разных типов ( 'a и ' b ).
Давайте проверим и посмотрим, работает ли!
Сначала создайте составной синтаксический анализатор:
пусть parseA = pchar 'A'
пусть parseB = pchar 'B'
пусть parseAThenB = parseA. >>. parseB
Если вы посмотрите на типы, вы увидите, что все три значения имеют тип Parser :
val parseA: Парсер
val parseB: Парсер
val parseAThenB: Парсер
parseAThenB имеет тип Parser , что означает, что анализируемое значение представляет собой пару символов.
Теперь, поскольку комбинированный синтаксический анализатор parseAThenB - это просто еще один Parser , мы можем использовать с ним run , как и раньше.
запустить parseAThenB "ABC" // Успех (('A', 'B'), "C")
run parseAThenB "ZBC" // Ошибка "Ожидается 'A'. Получил 'Z'"
run parseAThenB "AZC" // Ошибка "Ожидание B. Получено" Z "
Вы можете видеть, что в случае успеха была возвращена пара ('A', 'B') , а также этот отказ
происходит, когда во вводе отсутствует какая-либо буква.
Выбор между двумя парсерами
Давайте рассмотрим еще один важный способ комбинирования синтаксических анализаторов - комбинатор «иначе».
Например, предположим, что нам нужен синтаксический анализатор, соответствующий «A» или «B». Как мы могли их совместить?
Логика реализации будет:
- Запустить первый синтаксический анализатор.
- В случае успеха вернуть проанализированное значение вместе с оставшимися входными данными.
- В противном случае, в случае сбоя, запустить второй синтаксический анализатор с исходным вводом…
- … и в этом случае вернуть результат (успешный или неудачный) из второго синтаксического анализатора.
Вот код для orElse :
пусть orElse parser1 parser2 =
пусть innerFn input =
// запускаем parser1 с вводом
пусть result1 = запускает parser1 input
// проверяем результат на неудачу / успех
сопоставить результат1 с
| Результат успеха ->
// в случае успеха вернуть исходный результат
результат1
| Ошибка ошибки ->
// в случае неудачи запускаем parser2 с вводом
let result2 = запустить parser2 input
// возвращаем результат parser2
результат2
// возвращаем внутреннюю функцию
Парсер innerFn
И мы определим инфиксную версию или Else :
Если посмотреть на подпись или Эльс :
val orElse:
parser1: Parser <'a> -> parser2: Parser <' a> -> Parser <'a>
мы видим, что он работает для любых двух парсеров, но оба они должны быть одного и того же типа 'a .
Пора это проверить. Сначала создайте комбинированный парсер:
пусть parseA = pchar 'A'
пусть parseB = pchar 'B'
пусть parseAOrElseB = parseA <|> parseB
Если вы посмотрите на типы, вы увидите, что все три значения имеют тип Parser :
val parseA: Парсер
val parseB: Парсер
val parseAOrElseB: Парсер
Теперь, если мы запустим parseAOrElseB , мы увидим, что он успешно обрабатывает «A» или «B» в качестве первого символа.
запустить parseAOrElseB "AZZ" // Успех ('A', "ZZ")
запустить parseAOrElseB "BZZ" // Успех ('B', "ZZ")
run parseAOrElseB "CZZ" // Ошибка "Ожидание" B ". Получил" C ""
Сочетание «andThen» и «orElse»
С помощью этих двух основных комбинаторов мы можем создавать более сложные, такие как «A, а затем (B или C)».
Вот как собрать aAndThenBorC из более простых парсеров:
пусть parseA = pchar 'A'
пусть parseB = pchar 'B'
пусть parseC = pchar 'C'
пусть bOrElseC = parseB <|> parseC
пусть aAndThenBorC = parseA.>>. БОРЛСЕК
А вот оно в действии:
run aAndThenBorC "ABZ" // Успех (('A', 'B'), "Z")
run aAndThenBorC "ACZ" // Успех (('A', 'C'), "Z")
run aAndThenBorC "QBZ" // Неудача "Ожидание" A ". Получил" Q ""
run aAndThenBorC "AQZ" // Ошибка "Ожидается 'C'. Получил 'Q'"
Обратите внимание, что последний пример дает вводящую в заблуждение ошибку. Он говорит: «Ожидая« C »», хотя на самом деле следует сказать «Ожидая« B »или« C »». Мы не будем пытаться это исправить прямо сейчас, но в более поздней публикации мы улучшим сообщения об ошибках.
Выбор из списка парсеров
Именно здесь начинает проявляться мощь комбинаторов, потому что с или Else в нашем наборе инструментов мы можем использовать его для создания еще большего количества комбинаторов. Например, предположим, что мы хотим выбрать из списка синтаксических анализаторов, а не только два.
Что ж, это просто. Если у нас есть попарный способ объединения вещей, мы можем расширить его до объединения всего списка с помощью reduce (для получения дополнительной информации о работе с reduce см. Этот пост о моноидах).
/// Выбираем любой из списка парсеров
пусть выбор listOfParsers =
List.reduce (<|>) listOfParsers
Обратите внимание, что это не удастся, если список ввода пуст, но мы пока проигнорируем это.
Подпись выбор :
val выбор:
Parser <'a> list -> Parser <' a>
, который показывает нам, что, как и ожидалось, вход - это список парсеров, а выход - единственный парсер.
Имея возможность выбора , мы можем создать парсер anyOf , который соответствует любому символу в списке, используя следующую логику:
- Вход представляет собой список символов
- Каждый символ в списке преобразуется в парсер для этого символа с помощью
pchar - Наконец, все парсеры объединены с использованием
выбор
Вот код:
/// Выбираем любой из списка символов
пусть anyOf listOfChars =
listOfChars
|> Список.map pchar // конвертируем в парсеры
|> выбор // объединить их
Давайте проверим это, создав синтаксический анализатор для любого символа нижнего регистра и любого символа цифры:
пусть parseLowercase =
anyOf ['a' .. 'z']
пусть parseDigit =
anyOf ['0' .. '9']
Если протестировать, они работают как положено:
запустить parseLowercase "aBC" // Успех ('a', "BC")
run parseLowercase "ABC" // Ошибка "Ожидается 'z'. Получил 'A'"
запустить parseDigit "1ABC" // Успех ("1", "ABC")
запустить parseDigit «9ABC» // Успех («9», «ABC»)
запустить parseDigit "| ABC" // Ошибка "Ожидание 9".Получил '|' "
Опять же, сообщения об ошибках вводят в заблуждение. Можно ожидать любую строчную букву, а не только «z», и любую цифру, а не только «9». Как я уже сказал ранее, мы будем работать над сообщениями об ошибках в одной из следующих публикаций.
Давайте сейчас остановимся и рассмотрим, что мы сделали:
- Мы создали тип
Parser, который является оболочкой для функции синтаксического анализа. - Функция синтаксического анализа принимает входные данные (например, строку) и пытается сопоставить входные данные с использованием критериев, встроенных в функцию.
- Если соответствие выполнено успешно, функция синтаксического анализа возвращает
Successс совпавшим элементом и оставшимися входными данными. - Если совпадение не удается, функция синтаксического анализа возвращает ошибку
- И, наконец, мы увидели некоторые «комбинаторы» - способы, которыми
Parserмогут быть объединены для создания новогоParser:, а затемиили других вариантови
Листинг библиотеки парсера на данный момент
Вот полный список библиотеки синтаксического анализа - это около 90 строк кода.
Исходный код, использованный в этом посте, доступен здесь .
открытая система
/// Тип, представляющий успех / неудачу при синтаксическом анализе
введите ParseResult <'a> =
| Успех
| Отказ строки
/// Тип, который является оболочкой для функции синтаксического анализа
type Parser <'T> = Parser of (string -> ParseResult <' T * string>)
/// Разобрать один символ
пусть pchar charToMatch =
// определяем вложенную внутреннюю функцию
пусть innerFn str =
если String.IsNullOrEmpty (str), затем
Ошибка "Нет ввода"
еще
let first = str. [0]
если first = charToMatch, то
пусть осталось = str. [1 ..]
Успех (charToMatch, осталось)
еще
let msg = sprintf "Ожидается '% c'. Сначала получил '% c'" charToMatch
Сообщение об ошибке
// возвращаем "обернутую" внутреннюю функцию
Парсер innerFn
/// Запуск парсера с вводом
позвольте запустить синтаксический анализатор input =
// разворачиваем парсер, чтобы получить внутреннюю функцию
let (Parser innerFn) = синтаксический анализатор
// вызываем внутреннюю функцию с вводом
вход innerFn
/// Объединить два парсера как «А и затем Б»
пусть и тогда parser1 parser2 =
пусть innerFn input =
// запускаем parser1 с вводом
пусть result1 = запускает parser1 input
// проверяем результат на неудачу / успех
сопоставить результат1 с
| Ошибка ошибки ->
// возвращаем ошибку от parser1
Ошибка ошибки
| Успех (значение1, осталось1) ->
// запускаем parser2 с оставшимся входом
пусть результат2 = запустить синтаксический анализатор2, осталось1
// проверяем результат на неудачу / успех
сопоставить результат2 с
| Ошибка ошибки ->
// возвращаем ошибку из parser2
Ошибка ошибки
| Успех (значение2, осталось2) ->
// объединяем оба значения в пару
пусть newValue = (значение1, значение2)
// возвращаем оставшийся ввод после parser2
Успех (новое значение, осталось 2)
// возвращаем внутреннюю функцию
Парсер innerFn
/// Инфиксная версия andThen
позволять ( .>>. ) = и Тогда
/// Объедините два парсера как «A или Else B»
пусть orElse parser1 parser2 =
пусть innerFn input =
// запускаем parser1 с вводом
пусть result1 = запускает parser1 input
// проверяем результат на неудачу / успех
сопоставить результат1 с
| Результат успеха ->
// в случае успеха вернуть исходный результат
результат1
| Ошибка ошибки ->
// в случае неудачи запускаем parser2 с вводом
let result2 = запустить parser2 input
// возвращаем результат parser2
результат2
// возвращаем внутреннюю функцию
Парсер innerFn
/// Infix версия orElse
let (<|>) = orElse
/// Выбираем любой из списка парсеров
пусть выбор listOfParsers =
Список.уменьшить (<|>) listOfParsers
/// Выбираем любой из списка символов
пусть anyOf listOfChars =
listOfChars
|> List.map pchar // конвертируем в парсеры
|> выбор
В этом посте мы создали основы библиотеки синтаксического анализа и несколько простых комбинаторов.
В следующем посте мы будем использовать это, чтобы создать библиотеку с большим количеством комбинаторов.
- Если вам интересно использовать эту технику в производстве, обязательно изучите библиотеку FParsec для F #, который оптимизирован для реального использования.
- Для получения дополнительной информации о комбинаторах синтаксического анализатора в целом поищите в Интернете «Parsec», библиотеку Haskell, которая повлияла на FParsec (и этот пост).
- Для некоторых примеров использования FParsec попробуйте один из следующих постов:
Исходный код, использованный в этом посте, доступен здесь .
Анализ Word-графов с вероятностями
Анализ Word-графов с вероятностямиДалее: Анализ головного угла и надежность Up: Эффективное внедрение Предыдущая: Компактное представление синтаксического анализа
Подразделы
Парсер head-corner - один из парсеров, разработанных в NWO. Приоритетная программа по языку и речевым технологиям.В этой программе система голосового диалога разработана для общественного транспорта информация [4].
В этой системе вход для парсера - это не простой список слов, как мы предполагали до сих пор, а скорее слово-граф: направленный, ациклический граф, где состояния - моменты времени, а ребра - помечены словесными гипотезами и их соответствующей акустической оценкой. Таким образом, такие словесные графы являются ациклическими весовыми конечными автоматами.
В [9] фреймворк для обработки неверно сформированного ввода описывается, в котором некоторые общие ошибки моделируются как (взвешенные) конечные преобразователи.Состав входного предложения с эти преобразователи создают (взвешенный) конечный автомат, который затем вводится для синтаксического анализатора. При таком подходе необходимость обобщить от входных строк до входных конечных автоматов тоже ясно.
Обобщение от строк к взвешенным ациклическим конечным автоматам вводит по существу две сложности. Во-первых, мы не можем использовать строковых индексов больше нет. Во-вторых, нам нужно отслеживать акустические оценки слов, используемых в определенном словосочетании.
Парсинг на основе конечного автомата можно рассматривать как вычисление пересечения этого автомата с грамматикой. Если грамматика с определенными предложениями отключена анализируемый, и если конечный автомат ациклический, то этот вычисление может быть гарантированно завершено [28]. Это очевидно, потому что ациклическое конечное состояние автомат определяет конечное число строк. Что еще более важно, существующие методы синтаксического анализа, основанные на строки можно легко обобщить, используя имена состояний в автомат вместо обычных строковых индексов.В парсере head-corner это приводит к альтернативе предикат less_equal / 2. Вместо простого целого числа сравнения, теперь нам нужно проверить, что производная от P0 до P может быть расширен до производной от E0 до E с помощью проверка наличия путей в словесном графе от E0 до P0 и от P до E.
Предикат connection / 2 истинен, если в
слово-граф от первого аргумента ко второму аргументу. это
предполагается, что имена состояний являются целыми числами; исключить циклические графы слов
мы также требуем, чтобы для всех переходов от P0 к P он
в том случае, когда P0 Несколько иной подход, который может оказаться более эффективным
заключается в использовании обычного оператора сравнения, который мы использовали в
исходное определение парсера head-corner.Возможные дополнительные
стоимость разрешения невозможных частичных анализов окупается, если
более точная проверка будет дороже. Если для типичного ввода
word-graphs количество переходов на состояние велико (такое, что
почти все пары состояний связаны), то это может быть
вариант. Следующая грамматика демонстрирует некоторые аспекты написания DCG на Прологе.Он создает полное дерево синтаксического анализа предложения. Он обрабатывает некоторую форму согласования номеров. (Предложение вроде «Мальчик пинает мяч» будет отклонено.) Наконец, он отделяет грамматические правила от словаря. В этой форме легче поддерживать грамматику: / * Простая грамматика * / предложение (s (NP, VP)) -> noun_phrase (NP, Number), verb_phrase (VP, Number) . существительное_фраза (np (Det, Существительное), Число) -> определитель (Det, Число), noun (Существительное, Число). глагольная_фраза (vp (V, NP), Number) -> глагол (V, Number, переходный), noun_phrase (NP,} _). определитель (det (слово), число) -> [слово], {is_determiner (слово, число) |. существительное (сущ. (Корень), Число) -> [Слово], {is_noun (Слово, Число, Корень) |. глагол (v (Корень, Время), Число, Транзитивность) -> [Слово], {is_verb (Слово, Корень, Число, Время, Транзитивность) |. / * словарь * / / * определитель * / is_determiner (a, единственное число). is_determiner (каждый, в единственном числе). is_determiner (единственное число). is_determiner (все, множественное число). / * существительные * / is_noun (мужчина, единственное число, мужчина). is_noun (мужчины, множественное число, мужчина). is_noun (мальчик, единственное число, мальчик). is_noun (мальчики, множественное число, мальчик). is_noun (женщина, единственное число, женщина). is_noun (женщина, множественное число, женщина). is_noun (шар, единственное число, шар). is_noun (шары, множественное число, мяч). / * глаголы * / is_verb (Слово, Корень, Число, Время, Транзитивность): - verb_form (Слово, Корень, Число, Время), инфинитив (Корень, Транзитивность). инфинитив (удар, переходный). инфинитив (живой, непереходный). инфинитив (вроде, переходный). глагол_форма (удары ногой, единственное число, присутствует).
Далее: Анализ головного угла и надежность Up: Эффективное внедрение Предыдущая: Компактное представление синтаксического анализа Noord G.J.M. фургон
1998-09-24 Дерево синтаксического анализа - обзор