What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор слова «материи»
Часть речи: Существительное
МАТЕРИИ — неодушевленное
Начальная форма слова: «МАТЕРИЯ»
| Слово | Морфологические признаки |
|---|---|
| МАТЕРИИ |
|
| МАТЕРИИ |
|
| МАТЕРИИ |
|
| МАТЕРИИ |
|
| МАТЕРИИ |
|
Все формы слова МАТЕРИИ
МАТЕРИЯ, МАТЕРИИ, МАТЕРИЮ, МАТЕРИЕЙ, МАТЕРИЕЮ, МАТЕРИЙ, МАТЕРИЯМ, МАТЕРИЯМИ, МАТЕРИЯХ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «МАТЕРИИ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «материи»
1
Далее, согласно этой идее, материейматерии был человек, а материяматерииматерий – это общество.
Конец – мое начало, Тициано Терцани2
Сверху, со второго этажа, свешивались, развеваясь, как знамена, полотнища шерстяной материи и сукон, материи из мериносовой шерсти, шевиот, мольтон;
Дамское счастье, Эмиль Золя, 1883г.3
И вдруг появляется на свет и оказывается таким сгустком именно материи, беспамятной материи.
Поправка Джексона (сборник), Наталия Червинская, 2013г.Поэтому оставим, пока, вопрос о создании самой материи, а сосредоточимся на том, что из этой материи создано.
Откровенно о сокровенном, Владимир Парилов5
То есть: сознание – первично, источник материи, но каждая частица материи им (сознанием) обладает.
Найти еще примеры предложений со словом МАТЕРИИ
Квантовая жизнь. Возможны ли квантовые процессы в живой материи и зачем они там нужны?
Микроскопический мир живет по законам квантовой физики. Электроны вращаются вокруг атомных ядер, атомы собираются в молекулы, а фотоны взаимодействуют с материей, и все это — в соответствии с какими-то загадочными правилами, которые разрешают одной частице быть сразу в нескольких местах. В большом мире такого не происходит. Здесь кот всегда либо жив, либо мертв, метро приходит с интервалом в 2−3 минуты (по вечерам — до 10), а зубы рекомендуют чистить хотя бы два раза — утром и вечером, и это даже странно. Все макроскопические объекты построены из тех же самых атомов и частиц, но квантовые законы для них не властны, они как будто теряют силу где-то в зазоре между микро и макро.
Во многом именно поэтому мы можем жить вполне размеренно и надежно — рассчитывать на гарантированные и предсказуемые результаты своих действий, знать, что метр всегда остается метром, сколько бы его не измеряли, и чувствовать, что пространство вокруг не выкинет фокусов, не породит из небытия какую-нибудь виртуальную частицу. И тем удивительней, что иногда жизнь все-таки использует законы квантового мира.
Квантовая проводка
Нас учат восторгаться фотосинтезу со школы. Еще бы: берем немного света, немного воды, углекислый газ и получаем глюкозу. Настоящее чудо. Человек давно пытается отдаленно воспроизвести этот фокус в солнечных батареях, но получается пока не очень уверенно: хотя они и должны превращать фотоны света всего лишь в электроны, а не органическое топливо, эффективность работы коммерческих фотоэлементов не превышает 30—40%.
Такому низкому КПД есть масса разных причин, и одна из них — это ненадежный транспорт энергии внутри солнечных батарей. Дело в том, что фотоны солнечного света никогда не превращаются напрямую в электроны, питающие наши ноутбуки и телефоны, а проходят вместо этого много промежуточных этапов, сопряженных с неминуемыми потерями.
Дело в том, что фотоны солнечного света никогда не превращаются напрямую в электроны, питающие наши ноутбуки и телефоны, а проходят вместо этого много промежуточных этапов, сопряженных с неминуемыми потерями.
Однако не менее сложна и логика фотосинтеза: там фотоны улавливаются молекулами хлорофилла и порождают энергетические возбуждения, которые по хитросплетению органических молекул должны добраться к отдаленному реакционному центру, где их энергия пойдет на построение органических веществ. Но только в природе такой запутанный перенос заряда идет почти со 100-процентной эффективностью, а в солнечных батареях все гораздо скромнее.
Кроме этого, передача энергии в фотосинтезе происходит не только аномально эффективно, но еще и аномально быстро — настолько, что ученые разглядели в этом след квантовых процессов, а именно квантовой когеренции, сохраняющейся на уровне всего светособирающего комплекса, состоящего из десятков молекул.
Светособирающий комплекс I у высших растений. Вид сверху. Изображение: Wikipedia.Многие скептики тогда не поверили в квантовость фотосинтеза. Живая материя кажется слишком «теплой и влажной», чтобы в ней проявлялись квантовые эффекты: тепловые движения молекул должны вызывать декогеренцию — сбивать своим хаосом все тонкие и гармоничные сонастройки, но в реальности такого не происходит. В 2007 году американские и чешские ученые показали когерентность энергетических возбуждений в фотосинтетических мембранах бактерий: они существуют в виде согласованных, не мешающих друг друг волн, «ищущих» оптимальный путь до реакционного центра и как будто обнюхивающих все возможные траектории.
Эксперименты, показали что когерентные состояния живут в фотосинтезирующих молекулах порядка пикосекунд, что вполне сопоставимо с характерными временами колебаний атомов, которые почему-то не разрушают этой гармонии. Более того, дальнейшие работы уже на фотосинтетических системах растений показали, что колебания атомов даже помогают сохранить квантовую когерентность и увеличивают эффективность передачи энергии: живой природе удается преодолеть эту пропасть между микро и макромиром. Как умелый капитан корабля, она не слепо сопротивляется молекулярному шторму, а умеет подстраиваться под него.
Как умелый капитан корабля, она не слепо сопротивляется молекулярному шторму, а умеет подстраиваться под него.
Квантовый компас
Люди тоже пытаются приручить квантовую механику, и с каждым годом это получается все лучше, но пока квантовые компьютеры или устройства квантового шифрования существуют только в условиях сверхнизких температур или глубокого вакуума, снижающих шум теплых и влажных условий. Природа справляется с этими задачами куда смелей: ей даже удалось встроить в птиц квантовые компасы, позволяющие чувствовать геомагнитные поля настолько хорошо, что это дает возможность ориентироваться на масштабах в тысячи километров.
Сейчас ученые считают, что в основе птичьей магниторецепции лежит явление квантовой запутанности — взаимосвязанности и взаимозависимости характеристик некоторых квантовых объектов, сохраняющейся даже на макроскопических расстояниях.
Работает все это следующими образом: квант света попадает на сетчатку глаза, что запускает каскад реакций, в конце концов приводящих к образованию двух свободных радикалов — очень реакционноспособных молекул, каждая из которых обладает неспаренным электроном. При этом так получается, что эти два электрона перепутаны между собой и чувствуют состояние друг друга даже через расстояние.
Когда спин — собственный магнитный момент одного из этих электронов — ориентируется в направлении внешнего геомагнитного поля, спин второго электрона тоже меняет свою ориентацию, а поскольку от ориентаций спинов зависят и химические свойства радикалов, дальше вступающих в различные биохимические реакции, внешнее магнитное поле, получается, определяет химический состав этой магниточувствительной биосистемы.
Эксперименты показывают, что подобные синтетические системы способны реагировать на магнитные поля вплоть до 50 миллитесла, что сопоставимо с магнитным полем Земли. Никакие искусственные квантовые сенсоры подобной чувствительности пока не добились. Поэтому многие ученые считают, что квантовые явления в живой природе стоит очень внимательно изучать хотя бы для того, чтобы перенести самые удачные наработки в наши несовершенные солнечные батареи, квантовые компьютеры и другие устройства.
Поэтому многие ученые считают, что квантовые явления в живой природе стоит очень внимательно изучать хотя бы для того, чтобы перенести самые удачные наработки в наши несовершенные солнечные батареи, квантовые компьютеры и другие устройства.
Квантовый нос
Общепринятая теория обоняния считает, что запахи рождаются ароматическими молекулами, которые входят в подходящие обонятельные рецепторы по принципу «ключ—замок» и запускают нервные импульсы, убегающие до обонятельных центров головного мозга. У этой теории много подтверждений и сильных сторон, но также есть и свои слабости: например, непонятно, почему очень похожие по своему строению молекулы часто могут обладать совершенно разными запахами, хотя, казалось бы, они должны попадать в одни и те же рецепторы.
Биофизик Лука Турин решил, что здесь замешана квантовая механика: живые организмы, по его мнению, действительно реагируют на летучие ароматические вещества, но только считывают их структуру не за счет взаимодействий по принципу «ключ—замок» (то есть с формы молекулы), а за счет туннельного эффекта, позволяющего живому чувствовать положение электронных уровней молекул.
В 2011 году эта вибрационная теория обоняния даже получила серьезное подтверждение: эксперименты показали, что мухи способны различать легкие и тяжелые изотопы одного и того ароматического вещества, ацетофенона (в легких изотопах были атомы водорода, в тяжелых — атомы дейтерия). Однако работы других научных групп противоречили этим результатам, и в конце концов команда Турина признала свою экспериментальную ошибку.
Квантовое мышление
В индустриальный век люди сравнивали мозг со сложной, запутанной машиной. Потом он стал компьютером, теперь — нейрокомпьютером, и дальше, вероятно, нас ждут все новые сравнения: человеку от природы свойственно уподоблять себя сложной технике, что его окружает. Что-то похожее произошло и с известным английским математиком сэром Роджером Пенроузом. Он долго занимался общей теорией относительности и квантовой теорией, а потом задумался над проблемой сознания и решил, что мышление не может быть только продуктом биохимических вычислений нашей нервной системы, и «методом исключения» дошел до понимания, что сознание может порождаться только квантовыми процессами.
Он долго занимался общей теорией относительности и квантовой теорией, а потом задумался над проблемой сознания и решил, что мышление не может быть только продуктом биохимических вычислений нашей нервной системы, и «методом исключения» дошел до понимания, что сознание может порождаться только квантовыми процессами.
Логика этого построения совершенно туманна, но дальше события развивались примерно следующим образом. Пенроуз предположил, что сознание рождается в акте объективной редукции волновых функций — том самом схлопывании волновой функции, ломающей согласованность квантовых колебаний, и стал искать, где именно это происходит в мозге. Дальше в его веру обратился Стюарт Хамерофф, известный анестезиолог, уверенный, что сознание человека порождается работой микротрубочек — внутриклеточных белковых структур, входящих в состав цитоскелета, и вместе они решили, что сознание и память есть продукт квантовых вычислений, проходящих в этих самых микротрубочках внутри нейронов головного мозга.
Большинство современных ученых считают эту теорию абсолютно маргинальной, но Пенроуз и Хамерофф уверены в своей правоте: микротрубочки, по их мнению, есть очень сложный квантовый компьютер, что-то наподобие фотосинтетического комплекса, но только вычисляют они не оптимальный путь электронного возбуждения до реакционного центра, а всю работу нашего сознания, диктующую в том числе и обычные нервные импульсы, бегущие по нейронам. Никаких надежных экспериментальных подтверждений этой теории пока нет, но последователи Пенроуза уже идут дальше: следы квантовых вычислений они находят уже в шизофрении или в депрессии и даже выпускают свой научный журнал.
Подобные предположения о квантовой сути природных явлений будут звучать еще очень долго — до тех пор, пока передний фронт науки и технологий не переместится еще куда-нибудь, и какие-то из них окажутся верными, какие-то наверняка помогут нам развить свою технику, а большинство, наверное, так и останутся только смелыми идеями, рожденными научной модой.
Михаил Петров
Что с вами произойдет внутри черной дыры?
- Аманда Гефтер
- BBC Earth
Автор фото, Thinkstock
Возможно, вы думаете, что человека, попавшего в черную дыру, ждет мгновенная смерть. В действительности же его судьба может оказаться намного более удивительной, рассказывает корреспондент BBC Earth.
Что произойдет с вами, если вы попадете внутрь черной дыры? Может быть, вы думаете, что вас раздавит — или, наоборот, разорвет на клочки? Но в действительности все гораздо страннее.
В тот момент, когда вы попадете в черную дыру, реальность разделится надвое. В одной реальности вас мгновенно испепелит, в другой же — вы нырнете вглубь черной дыры живым и невредимым.
Внутри черной дыры не действуют привычные нам законы физики. Согласно Альберту Эйнштейну, гравитация искривляет пространство. Таким образом, при наличии объекта достаточной плотности пространственно-временной континуум вокруг него может деформироваться настолько, что в самой реальности образуется прореха.
Массивная звезда, израсходовавшая все топливо, может превратиться именно в тот тип сверхплотной материи, который необходим для возникновения подобного искривленного участка Вселенной. Звезда, схлопывающаяся под собственной тяжестью, увлекает за собой пространственно-временной континуум вокруг нее. Гравитационное поле становится настолько сильным, что даже свет больше не может из него вырваться. В результате область, в которой ранее находилась звезда, становится абсолютно черной — это и есть черная дыра.
Автор фото, Thinkstock
Подпись к фото,Никто точно не знает, что происходит внутри черной дыры
Внешняя поверхность черной дыры называется горизонтом событий. Это сферическая граница, на которой достигается баланс между силой гравитационного поля и усилиями света, пытающегося покинуть черную дыру.
Горизонт событий лучится энергией. Благодаря квантовым эффектам, на нем возникают потоки горячих частиц, излучаемых во Вселенную. Это явление называется излучением Хокинга — в честь описавшего его британского физика-теоретика Стивена Хокинга. Несмотря на то, что материя не может вырваться за пределы горизонта событий, черная дыра, тем не менее, «испаряется» — со временем она окончательно потеряет свою массу и исчезнет.
По мере продвижения вглубь черной дыры пространство-время продолжает искривляться и в центре становится бесконечно искривленным. Эта точка известна как гравитационная сингулярность. Пространство и время в ней перестают иметь какое-либо значение, а все известные нам законы физики, для описания которых необходимы эти два понятия, больше не действуют.
Никто не знает, что именно ждет человека, попавшего в центр черной дыры. Иная вселенная? Забвение? Задняя стенка книжного шкафа, как в американском научно-фантастическом фильме «Интерстеллар»? Это загадка.
Давайте порассуждаем — на вашем примере — о том, что произойдет, если случайно попасть в черную дыру. Компанию в этом эксперименте вам составит внешний наблюдатель — назовем его Анной. Итак, Анна, находящаяся на безопасном расстоянии, в ужасе наблюдает за тем, как вы приближаетесь к границе черной дыры. С ее точки зрения события будут развиваться весьма странным образом.
По мере вашего приближения к горизонту событий Анна будет видеть, как вы вытягиваетесь в длину и сужаетесь в ширину, будто она рассматривает вас в гигантскую лупу. Кроме того, чем ближе вы будете подлетать к горизонту событий, тем больше Анне будет казаться, что ваша скорость падает.
Автор фото, Thinkstock
Подпись к фото,В центре черной дыры пространство бесконечно искривлено
Вы не сможете докричаться до Анны (поскольку в безвоздушном пространстве звук не передается), но можете попытаться подать ей знак азбукой Морзе при помощи фонарика в вашем iPhone. Однако ваши сигналы будут достигать ее со все возрастающими интервалами, а частота света, испускаемого фонариком, будет смещаться в сторону красного (длинноволнового) участка спектра. Вот как это будет выглядеть: «Порядок, п о р я д о к, п о р я…».
Однако ваши сигналы будут достигать ее со все возрастающими интервалами, а частота света, испускаемого фонариком, будет смещаться в сторону красного (длинноволнового) участка спектра. Вот как это будет выглядеть: «Порядок, п о р я д о к, п о р я…».
Когда вы достигнете горизонта событий, то, с точки зрения Анны, замрете на месте, как если бы кто-то поставил воспроизведение на паузу. Вы останетесь в неподвижности, растянутым по поверхности горизонта событий, и вас начнет охватывать все возрастающий жар.
С точки зрения Анны, вас будут медленно убивать растяжение пространства, остановка времени и жар излучения Хокинга. Прежде чем вы пересечете горизонт событий и углубитесь в недра черной дыры, от вас останется один пепел.
Но не спешите заказывать панихиду — давайте на время забудем об Анне и посмотрим на эту ужасную сцену с вашей точки зрения. А с вашей точки зрения будет происходить нечто еще более странное, то есть ровным счетом ничего особенного.
Вы летите прямиком в одну из самых зловещих точек Вселенной, не испытывая при этом ни малейшей тряски — не говоря уже о растяжении пространства, замедлении времени или жаре излучения. Все потому, что вы находитесь в состоянии свободного падения и поэтому не чувствуете своего веса — именно это Эйнштейн назвал «самой удачной идеей» своей жизни.
Действительно, горизонт событий — это не кирпичная стена в космосе, а явление, обусловленное точкой зрения наблюдающего. Наблюдатель, остающийся снаружи черной дыры, не может заглянуть внутрь сквозь горизонт событий, но это его проблема, а не ваша. С вашей точки зрения никакого горизонта не существует.
Если бы размеры нашей черной дыры были меньше, вы и правда столкнулись бы с проблемой — гравитация действовала бы на ваше тело неравномерно, и вас вытянуло бы в макаронину. Но, по счастью для вас, данная черная дыра велика — она в миллионы раз массивнее Солнца, так что гравитационная сила достаточно слаба, чтобы можно было ею пренебречь.
Автор фото, Thinkstock
Подпись к фото,Вы не можете вернуться и выбраться из черной дыры — точно так же, как никто из нас не способен на путешествие в прошлое
Внутри достаточно крупной черной дыры вы даже сможете вполне нормально прожить остаток жизни, пока не умрете в гравитационной сингулярности.
Вы можете спросить, насколько нормальной может быть жизнь человека, помимо воли увлекаемого к дыре в пространственно-временном континууме без шанса на то, чтобы когда-нибудь выбраться наружу?
Но если вдуматься, нам всем знакомо это ощущение — только применительно ко времени, а не к пространству. Время идет только вперед и никогда вспять, и оно действительно влечет нас за собою помимо нашей воли, не оставляя нам шанса на возвращение в прошлое.
Это не просто аналогия. Черные дыры искривляют пространственно-временной континуум до такой степени, что внутри горизонта событий время и пространство меняются местами. В каком-то смысле вас влечет к сингулярности не пространство, а время. Вы не можете вернуться назад и выбраться из черной дыры — точно так же, как никто из нас не способен на путешествие в прошлое.
Возможно, теперь вы задаетесь вопросом, что же не так с Анной. Вы летите себе в пустом пространстве черной дыры и с вами все в порядке, а она оплакивает вашу гибель, утверждая, что вас испепелило излучение Хокинга с внешней стороны горизонта событий. Уж не галлюцинирует ли она?
В действительности утверждение Анны совершенно справедливо. С ее точки зрения, вас действительно поджарило на горизонте событий. И это не иллюзия. Анна может даже собрать ваш пепел и отослать его вашим родным.
Автор фото, Thinkstock
Подпись к фото,Горизонт событий — не кирпичная стена, он проницаем
Дело в том, что, в соответствии с законами квантовой физики, с точки зрения Анны вы не можете пересечь горизонт событий и должны остаться с внешней стороны черной дыры, поскольку информация никогда не теряется безвозвратно. Каждый бит информации, отвечающий за ваше существование, обязан оставаться на внешней поверхности горизонта событий — иначе с точки зрения Анны, будут нарушены законы физики.
Каждый бит информации, отвечающий за ваше существование, обязан оставаться на внешней поверхности горизонта событий — иначе с точки зрения Анны, будут нарушены законы физики.
С другой стороны, законы физики также требуют, чтобы вы пролетели сквозь горизонт событий живыми и невредимыми, не повстречав на своем пути ни горячих частиц, ни каких-либо иных необычных явлений. В противном случае будет нарушена общая теория относительности.
Итак, законы физики хотят, чтобы вы одновременно находились снаружи черной дыры (в виде горстки пепла) и внутри нее (в целости и сохранности). И еще один немаловажный момент: согласно общим принципам квантовой механики, информацию нельзя клонировать. Вам нужно находиться в двух местах одновременно, но при этом лишь в одном экземпляре.
Такое парадоксальное явление физики называют термином «исчезновение информации в черной дыре». По счастью, в 1990-х гг. ученым удалось этот парадокс разрешить.
Американский физик Леонард Зюсскинд понял, что никакого парадокса на самом деле нет, поскольку никто не увидит вашего клонирования. Анна будет наблюдать за одним вашим экземпляром, а вы — за другим. Вы с Анной никогда больше не встретитесь и не сможете сравнить наблюдения. А третьего наблюдателя, который мог бы наблюдать за вами как снаружи, так и изнутри черной дыры одновременно, не существует. Таким образом, законы физики не нарушаются.
Разве что вы захотите узнать, какой из ваших экземпляров реален, а какой нет. Живы вы в действительности или умерли?
Автор фото, Thinkstock
Подпись к фото,Пролетит ли человек сквозь горизонт событий целым и невредимым или врежется в огненную стену?
Дело в том, что никакого «в действительности» нет. Реальность зависит от наблюдателя. Существует «в действительности» с точки зрения Анны и «в действительности» с вашей точки зрения. Вот и всё.
Почти всё. Летом 2012 г. физики Ахмед Альмхеири, Дональд Маролф, Джо Полчински и Джеймс Салли, коллективно известные под английской аббревиатурой из первых букв своих фамилий как AMPS, предложили мысленный эксперимент, который грозил перевернуть наше представление о черных дырах.
По словам ученых, разрешение противоречия, предложенное Зюсскиндом, основывается на том, что разногласие в оценке происходящего между вами и Анной опосредовано горизонтом событий. Неважно, действительно ли Анна видела, как один из двух ваших экземпляров погиб в огне излучения Хокинга, поскольку горизонт событий не давал ей увидеть ваш второй экземпляр, улетающей вглубь черной дыры.
Но что, если бы у Анны имелся способ узнать, что происходит по ту сторону горизонта событий, не пересекая его?
Общая теория относительности говорит нам, что это невозможно, но квантовая механика слегка размывает жесткие правила. Анна могла бы одним глазком заглянуть за горизонт событий при помощи того, что Эйнштейн называл «жутким дальнодействием».
Речь идет о квантовой запутанности — явлении, при котором квантовые состояния двух или более частиц, разделенных пространством, загадочным образом оказываются взаимозависимыми. Эти частицы теперь формируют единое и неделимое целое, а информация, необходимая для описания этого целого, заключена не в той или иной частице, а во взаимосвязи между ними.
Идея, выдвинутая AMPS, звучит следующим образом. Предположим, Анна берет частицу поблизости от горизонта событий — назовем ее частицей A.
Если ее версия произошедшего с вами соответствует действительности, то есть вас убило излучение Хокинга с внешней стороны черной дыры, значит, частица A должна быть взаимосвязана с другой частицей — B, которая также должна находиться с внешней стороны горизонта событий.
Автор фото, Thinkstock
Подпись к фото,Черные дыры могут притягивать к себе материю близлежащих звезд
Если действительности соответствует ваше видение событий, и вы живы-здоровы с внутренней стороны, тогда частица A должна быть взаимосвязана с частицей C, находящейся где-то внутри черной дыры.
Прелесть этой теории заключается в том, что каждая из частиц может быть взаимосвязана только с одной другой частицей.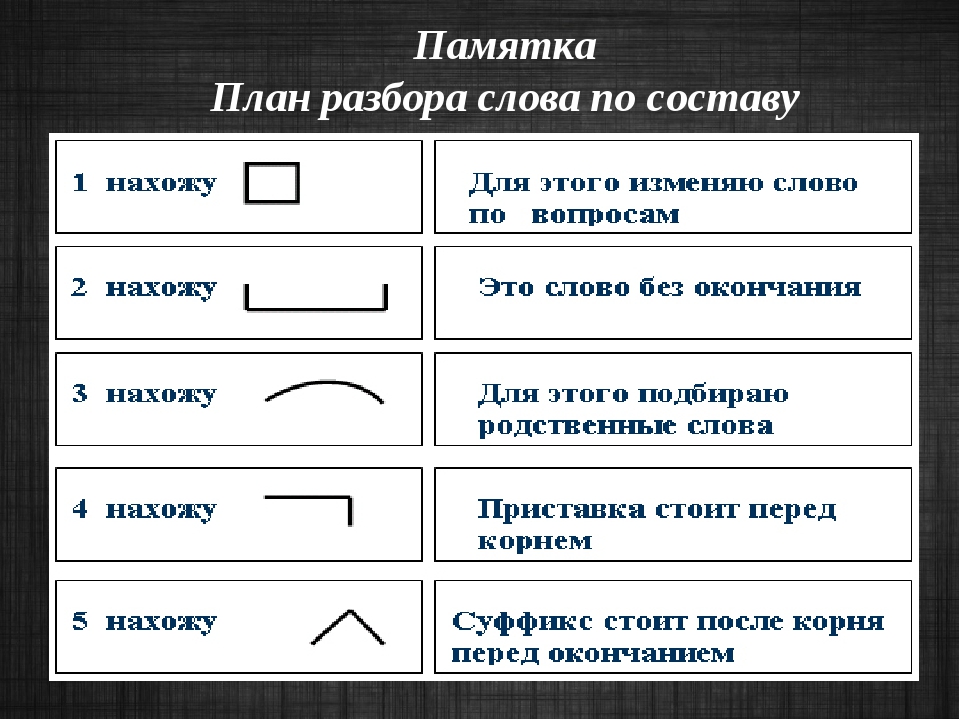 Это значит, что частица A связана или с частицей B, или с частицей C, но не с обеими одновременно.
Это значит, что частица A связана или с частицей B, или с частицей C, но не с обеими одновременно.
Итак, Анна берет свою частицу A и пропускает ее через имеющуюся у нее машинку для расшифровки запутанности, которая дает ответ — связана ли эта частица с частицей B или с частицей C.
Если ответ — C, ваша точка зрения восторжествовала в нарушение законов квантовой механики. Если частица A связана с частицей C, находящейся в недрах черной дыры, то информация, описывающая их взаимозависимость, оказывается навсегда утерянной для Анны, что противоречит квантовому закону, согласно которому информация никогда не теряется.
Если же ответ — B, то, вопреки принципам общей теории относительности, права Анна. Если частица A связана с частицей B, вас действительно испепелило излучение Хокинга. Вместо того, чтобы пролететь сквозь горизонт событий, как того требует теория относительности, вы врезались в стену огня.
Итак, мы вернулись к вопросу, с которого начинали — что произойдет с человеком, попавшим внутрь черной дыры? Пролетит ли он сквозь горизонт событий целым и невредимым благодаря реальности, которая удивительным образом зависит от наблюдателя, или врежется в огненную стену (black holes firewall, не путать с компьютерным термином firewall, «брандмауэр», программным обеспечением, защищающим ваш компьютер в сети от несанкционированного вторжения – Ред.)?
Никто не знает ответа на этот вопрос, один из самых спорных вопросов теоретической физики.
Уже свыше 100 лет ученые пытаются примирить принципы общей теории относительности и квантовой физики в надежде на то, что в конце концов та или другая возобладает. Разрешение парадокса «огненной стены» должно ответить на вопрос, какие из принципов взяли верх, и помочь физикам создать всеобъемлющую теорию.
Автор фото, Thinkstock
Подпись к фото,А может, в следующий раз отправить в черную дыру Анну?
Решение парадокса исчезновения информации может крыться в дешифровальной машинке Анны. Определить, с какой именно другой частицей взаимосвязана частица A, чрезвычайно трудно. Физики Дэниэл Харлоу из Принстонского университета в Нью-Джерси и Патрик Хайден, который сейчас работает в калифорнийском Стэнфордском университете в Калифорнии, задались вопросом, сколько на это потребуется времени.
Определить, с какой именно другой частицей взаимосвязана частица A, чрезвычайно трудно. Физики Дэниэл Харлоу из Принстонского университета в Нью-Джерси и Патрик Хайден, который сейчас работает в калифорнийском Стэнфордском университете в Калифорнии, задались вопросом, сколько на это потребуется времени.
В 2013 г. они подсчитали, что даже при помощи наибыстрейшего компьютера, который возможно создать в соответствии с физическими законами, Анне потребовалось бы чрезвычайно много времени на то, чтобы расшифровать взаимосвязь между частицами — настолько много, что к тому моменту, как она получит ответ, черная дыра давным-давно испарится.
Если это так, вероятно, Анне просто не суждено когда-либо узнать, чья точка зрения соответствует действительности. В этом случае обе истории останутся одновременно правдивыми, реальность — зависящей от наблюдателя, и ни один из законов физики не будет нарушен.
Кроме того, связь между сверхсложными вычислениями (на которые наш наблюдатель, по всей видимости, не способен) и пространственно-временным континуумом может натолкнуть физиков на какие-то новые теоретические размышления.
Таким образом, черные дыры — не просто опасные объекты на пути межзвездных экспедиций, но и теоретические лаборатории, в которых малейшие вариации в физических законах вырастают до таких размеров, что ими уже невозможно пренебречь.
Если где-то и таится истинная природа реальности, искать ее лучше всего в черных дырах. Но пока у нас нет четкого понимания того, насколько безопасен для человека горизонт событий, наблюдать за поисками безопаснее все же снаружи. В крайнем случае можно в следующий раз отправить в черную дыру Анну — теперь ее очередь.
3.4: Классификация вещества по его составу
Цели обучения
- Объясните разницу между чистым веществом и смесью.
- Объясните разницу между элементом и соединением.
- Объясните разницу между гомогенной смесью и гетерогенной смесью.


Один из полезных способов упорядочить наше понимание материи — подумать об иерархии, которая простирается от самых общих и сложных до самых простых и фундаментальных (рисунок \ (\ PageIndex {1} \)).Материю можно разделить на две большие категории: чистые вещества и смеси. Чистое вещество — это форма вещества, которая имеет постоянный состав (это означает, что он везде одинаков) и свойства, которые постоянны во всем образце (это означает, что существует только один набор свойств, таких как точка плавления, цвет, кипение точка и т. д. по всему делу). Материал, состоящий из двух или более веществ, представляет собой смесь . Элементы и соединения являются примерами чистых веществ.Вещество, которое не может быть разбито на химически более простые компоненты, — это элемент . Алюминий, который используется в банках с газировкой, является элементом. Вещество, которое можно разбить на химически более простые компоненты (поскольку оно состоит из более чем одного элемента), представляет собой соединение . Например, вода представляет собой соединение, состоящее из элементов водорода и кислорода. Сегодня в известной нам вселенной около 118 элементов. Напротив, на сегодняшний день ученые идентифицировали десятки миллионов различных соединений.
Рисунок \ (\ PageIndex {1} \): Взаимосвязь между типами веществ и методами, используемыми для разделения смесей Обычная поваренная соль называется хлоридом натрия. Он считается веществом , потому что он имеет однородный и определенный состав. Все образцы хлорида натрия химически идентичны. Вода — тоже чистое вещество. Соль легко растворяется в воде, но соленую воду нельзя классифицировать как вещество, поскольку ее состав может варьироваться. Вы можете растворить небольшое или большое количество соли в определенном количестве воды.Смесь представляет собой физическую смесь двух или более компонентов, каждый из которых сохраняет свою индивидуальность и свойства в смеси . Меняется только форма соли, когда она растворяется в воде. Он сохраняет свой состав и свойства.
Меняется только форма соли, когда она растворяется в воде. Он сохраняет свой состав и свойства.
Гомогенная смесь представляет собой смесь, состав которой однороден по всей смеси. Вышеописанная соленая вода является однородной, поскольку растворенная соль равномерно распределяется по всей пробе соленой воды.Часто легко спутать однородную смесь с чистым веществом, потому что они оба однородны. Разница в том, что состав вещества всегда одинаковый. Количество соли в соленой воде может варьироваться от одного образца к другому. Все растворы считаются однородными, поскольку растворенный материал присутствует в одинаковом количестве во всем растворе.
Гетерогенная смесь представляет собой смесь, состав которой неоднороден по всей смеси.Овощной суп — это неоднородная смесь. Любая данная ложка супа будет содержать различное количество различных овощей и других компонентов супа.
Этап
Фаза — это любая часть образца, имеющая однородный состав и свойства. По определению, чистое вещество или гомогенная смесь состоит из одной фазы. Гетерогенная смесь состоит из двух или более фаз. Когда масло и вода смешиваются, они не смешиваются равномерно, а образуют два отдельных слоя.Каждый из слоев называется фазой.
Пример \ (\ PageIndex {1} \)
Определите каждое вещество как соединение, элемент, гетерогенную смесь или гомогенную смесь (раствор).
- фильтрованный чай
- свежевыжатый апельсиновый сок
- компакт-диск
- оксид алюминия, белый порошок с соотношением атомов алюминия и кислорода 2: 3
- селен
Дано : химическое вещество
Запрошен : его классификация
Стратегия:
- Определите, является ли вещество химически чистым.Если оно чистое, это либо элемент, либо соединение. Если вещество можно разделить на элементы, это соединение.
- Если вещество не является химически чистым, это либо гетерогенная смесь, либо гомогенная смесь. Если его состав однороден во всем, это однородная смесь.

Решение
- A) Чай представляет собой раствор соединений в воде, поэтому он не является химически чистым. Обычно его отделяют от чайных листьев фильтрацией.
B) Поскольку состав раствора однороден повсюду, это однородная смесь . - A) Апельсиновый сок содержит твердые частицы (мякоть), а также жидкость; он не является химически чистым.
B) Апельсиновый сок, потому что его состав неоднороден, является гетерогенной смесью . - A) Компакт-диск — это твердый материал, содержащий более одного элемента, с видимыми по краю участками разного состава.Следовательно, компакт-диск не является химически чистым.
B) Области разного состава указывают на то, что компакт-диск представляет собой гетерогенную смесь. - A) Оксид алюминия представляет собой отдельное химически чистое соединение .
- A) Селен — один из известных элементов .
Упражнение \ (\ PageIndex {1} \)
Определите каждое вещество как соединение, элемент, гетерогенную смесь или гомогенную смесь (раствор).
- белое вино
- ртуть
- заправка для салата в стиле ранчо
- сахар столовый (сахароза)
- Ответ:
- гомогенная смесь (раствор)
- Ответ b:
- элемент
- Ответ c:
- гетерогенная смесь
- Ответ d:
- соединение
Пример \ (\ PageIndex {2} \)
Как химик классифицирует каждый образец вещества?
- соленая вода
- почва
- вода
- кислород
Решение
- Морская вода действует так, как если бы она была единым веществом, даже если она содержит два вещества — соль и воду. Морская вода — это однородная смесь или раствор.
- Почва состоит из маленьких кусочков различных материалов, поэтому представляет собой неоднородную смесь.
- Вода — это вещество. Более конкретно, поскольку вода состоит из водорода и кислорода, она представляет собой соединение.
- Кислород, вещество, это элемент.
 Морская вода — это однородная смесь или раствор.
Морская вода — это однородная смесь или раствор.Упражнение \ (\ PageIndex {2} \)
Как химик классифицирует каждый образец вещества?
- кофе
- водород
- яйцо
- Ответ:
- однородная смесь (раствор), если это фильтрованный кофе
- Ответ b:
- элемент
- Ответ c:
- гетерогенная смесь
Сводка
Вещество можно разделить на две большие категории: чистые вещества и смеси.Чистое вещество — это форма вещества, имеющая постоянный состав и постоянные свойства во всем образце. Смеси представляют собой физические комбинации двух или более элементов и / или соединений. Смеси можно разделить на однородные и гетерогенные. Элементы и соединения являются примерами чистых веществ. Соединения — это вещества, состоящие из более чем одного типа атомов. Элементы — это простейшие вещества, состоящие только из одного типа атомов.
Словарь
- Элемент: вещество, состоящее только из одного типа атомов.
- Соединение: вещество, состоящее из более чем одного типа атомов, связанных вместе.
- Смесь: комбинация двух или более элементов или соединений, которые не вступили в реакцию с целью связывания друг с другом; каждая часть смеси сохраняет свои свойства.
Материалы и авторство
Эта страница была создана на основе содержимого следующими участниками и отредактирована (тематически или широко) командой разработчиков LibreTexts в соответствии со стилем, представлением и качеством платформы:
Классификация веществ по составу | Протокол
1.
 4: Классификация материалов по составу
4: Классификация материалов по составуМатерия: чистые вещества и смеси
По своему составу вещество можно разделить на две большие категории — чистые вещества и смеси.
Чистое вещество — это форма материи, которая имеет постоянный состав с одинаковыми свойствами. Например, любой образец сахарозы имеет одинаковый состав и одинаковые физические свойства, такие как температура плавления, цвет и сладость, независимо от источника, из которого он выделен.
Смесь состоит из двух или более типов веществ, которые могут присутствовать в различных количествах и могут быть разделены физическими изменениями, такими как испарение. Компоненты смеси сохраняют свою индивидуальность.
Чистые вещества: элементы и соединения
Чистые вещества можно разделить на два класса: элементы и соединения. Чистые вещества, которые не могут быть разложены на более простые химические изменения, называются элементами. Железо, серебро, золото, алюминий, сера, кислород и медь — элементы.
Чистые вещества, разлагаемые химическими изменениями, называются соединениями. В результате этого разложения могут образовываться элементы или другие соединения, или и то, и другое. Оксид ртути (II), оранжевое кристаллическое твердое вещество, под действием тепла может распадаться на элементы ртуть и кислород. При нагревании в отсутствие воздуха сахароза расщепляется на углерод и воду. Хлорид серебра (I) — это белое твердое вещество, которое можно разделить на элементы, серебро и хлор, путем поглощения света.
Свойства комбинированных элементов отличаются от свойств в свободном или несоединенном состоянии. Например, белый кристаллический сахар (сахароза) представляет собой соединение, полученное в результате химической комбинации элемента углерода, который представляет собой черное твердое вещество в одной из его несвязанных форм, и двух элементов, водорода и кислорода, которые в несоединении являются бесцветными газами. Свободный натрий, элемент, который представляет собой мягкое, блестящее, металлическое твердое вещество, и свободный хлор, элемент, представляющий собой желто-зеленый газ, объединяются с образованием хлорида натрия (поваренной соли), соединения, которое представляет собой белое кристаллическое твердое вещество.
Смеси: однородные и неоднородные
Гомогенная смесь, также называемая раствором, имеет однородный состав и визуально выглядит одинаково во всем. Примером раствора является спортивный напиток, состоящий из воды, сахара, красителя, ароматизатора и электролитов, равномерно смешанных вместе. Каждая капля спортивного напитка имеет одинаковый вкус, потому что каждая капля содержит одинаковое количество воды, сахара и других компонентов. Обратите внимание, что состав спортивного напитка может быть разным — он может быть сделан с несколько большим или меньшим содержанием сахара, ароматизатора или других компонентов, и при этом он будет спортивным напитком.Другие примеры гомогенных смесей включают воздух, кленовый сироп, бензин и раствор соли в воде.
Смесь, состав которой меняется от точки к точке, называется гетерогенной смесью. Итальянская заправка — пример неоднородной смеси. Его состав может быть разным, поскольку он может быть приготовлен из разного количества масла, уксуса и трав. В разных частях смеси это не одно и то же — одна капля может быть в основном уксусом, тогда как другая капля может быть в основном маслом или травами, потому что масло и уксус разделяются, а травы оседают.Другими примерами гетерогенных смесей являются печенье с шоколадной крошкой (мы можем видеть отдельные кусочки шоколада, орехов и теста для печенья) и гранит (мы можем видеть кварц, слюду, полевой шпат и многое другое).
Любая смесь, гомогенная или гетерогенная, может быть разделена на чистые компоненты физическими средствами без изменения идентичности компонентов. Хотя существует чуть более 100 элементов, десятки миллионов химических соединений являются результатом различных комбинаций этих элементов.Каждое соединение имеет определенный состав и обладает определенными химическими и физическими свойствами, которые отличают его от всех других соединений. И, конечно же, существует бесчисленное множество способов комбинировать элементы и соединения для образования различных смесей.
Этот текст адаптирован из Openstax, Chemistry 2e, Section 1.2: Phases and Classification of Matter.
Что такое смесь? Определение, типы, свойства и примеры
Введение
Скорее всего, вы в повседневной жизни сталкиваетесь с одним или разными типами смеси.Воздух, который вы вдыхаете, — это самая распространенная форма смеси. Вы это понимали? Сегодня мы рассмотрим нечистые вещества или смеси, как их обычно называют.
Состав материи
Вы знаете, что, помимо всего прочего, вы можете разделить материю на два вида:
Чистые вещества: они снова организованы в элементы и соединения.
Загрязненные вещества: Все смеси считаются нечистыми веществами.
Что такое смесь?
Смеси — это вещества, состоящие из двух или более форм материи.Вы можете разделить их физическими методами. Такие примеры включают смесь соли и воды, смесь сахара и воды, различные газы, воздух и т. Д. В любой смеси различные компоненты не образуются в результате каких-либо химических изменений. Таким образом, отдельные свойства компонентов остаются неизменными.
Другими словами, смесь — это вещь, которую вы получаете, когда соединяете два вещества так, чтобы между ними не происходила химическая реакция, и вы могли снова разделить их. В смеси каждый компонент сохраняет свою химическую идентичность.Обычно механическое смешивание объединяет компоненты смеси, различные процедуры могут дать смесь (например, диффузия, осмос).
Несмотря на то, что компонент смеси не изменяется, смесь может иметь неожиданные физические свойства по сравнению с обоими ее компонентами. Например, если вы объедините спирт и воду, смесь будет иметь другую точку плавления и температуру кипения, чем любой из компонентов.
Несколько примеров смесей, которые мы находим в нашей повседневной жизни.
Несколько примеров, которые мы находим в нашей повседневной жизни, которые не являются смесями.
Типы смесей
В зависимости от состава смесей их можно разделить на два типа:
Гомогенная смесь
Смеси, имеющие однородный состав по всему веществу, называются гомогенными смесями. Например, смесь соли и воды, смесь сахара и воды, воздух, лимонад, прохладительная вода и так далее. Вот классический пример — смесь соли с водой.Причина в том, что здесь никогда нельзя разделить предел между солью и водой. В момент, когда луч света падает на смесь соли и воды, путь света не виден.
Свойства
Все растворы являются экземплярами однородной смеси.
Размер частиц в этом случае меньше одного нанометра.
Они не демонстрируют влияние Тиндаля.
Вы не можете разделить границы частиц.
Здесь нельзя разделить составляющие частицы с помощью центрифугирования или декантации.
Сплавы — примеры решения.
Гетерогенная смесь
Неоднородные смеси на всем протяжении называются гетерогенными смесями. Таким образом, смесь почвы и песка, серной и железной опилок, нефти и воды и так далее неоднородна, поскольку не имеет однородного состава. Это происходит на том основании, что в таком случае он состоит из двух или более различных фаз.
Свойства
Большинство смесей, за исключением растворов и сплавов, неоднородны.
Составляющие частицы здесь присутствуют неравномерно.
Вы можете эффективно различать компоненты.
Обычно в гетерогенной смеси доступны по крайней мере две ступени.
Размер частиц здесь находится в диапазоне от одного нанометра до одного микрометра.
Они демонстрируют удар Тиндаля.
В зависимости от размера частиц компонентов или веществ, смеси подразделяются на раствор, коллоид и суспензию.
Раствор
Раствор содержит крошечные частицы, размер которых при измерении составляет менее 1 нанометра. Компоненты раствора нельзя выделить центрифугированием или декантацией смеси. Случай этого — воздух.
Коллоиды
Коллоидная смесь выглядит однородной без увеличения, однако, когда вы видите ее под микроскопом; вы можете видеть, что это не однородная смесь.Размеры молекул коллоидов составляют от 1 нанометра до 1 микрометра. Различные вещества в коллоиде можно разделить с помощью центрифуги. Коллоид — это лак для волос, в котором жидкость находится в воздухе и соединяется с газом.
Суспензия
Суспензия имеет более крупные частицы, чем две вышеуказанные смеси. Иногда смесь кажется неоднородной. Суспензии содержат стабилизирующие агенты, которые препятствуют нормальной изоляции частиц друг от друга. И декантация, и центрифугирование могут изолировать компоненты суспензий.Случай суспензии — подача заправки для салата с уксусом и водой. Более тяжелое вещество повязки изолируется и направляется к основанию отсека, в то время как вода дрейфует, чтобы все закончить.
Некоторые тривиальные факты о смесях
Дым — это смесь частиц, взвешенных в воздухе.
Водопроводная вода представляет собой смесь воды и других частиц. Чистую воду или h3O обычно называют дистиллированной водой.
Многие вещества, с которыми мы контактируем каждый день, представляют собой смеси, включая воздух, которым мы дышим, который представляет собой смесь газов, таких как кислород и азот.
Кровь — это смесь, которую можно разделить с помощью центрифуги на две основные части: плазму и эритроциты.
Гомогенная смесь
Смеси, имеющие однородный состав во всем веществе, называются гомогенными смесями. Например, смесь соли и воды, смесь сахара и воды, воздух, лимонад, прохладительная вода и так далее.
Гетерогенная смесь
Смеси, которые не являются однородными на всем протяжении, называются гетерогенными смесями.Вдоль этих линий смесь почвы и песка, серной и железной опилок, нефти и воды и так далее неоднородна.
1. Что из следующего является примером химической смеси?
Состав, состоящий из различных элементов.
Вещество, образованное за счет химической связи.
Когда два вещества объединены, но не связаны химически.
Все вышеперечисленное.
Ничего из вышеперечисленного.
2. Молоко — это смесь, которая называется ……………….
Сплав
Раствор
Соединение
Коллоид
Суспензия
3. Смесь 903 между твердым веществом4 и 9000 не растворяется в 919
Сплав
Раствор
Соединение
Коллоид
Суспензия
4.Сталь — это тип смеси, который называется ………………
Сплав
Раствор
Соединение
Коллоид
Суспензия
Растворы представляют собой гетерогенные смеси.
Раствор — это смесь.
Все смеси являются растворами.
Все вышеперечисленное.
Ничего из вышеперечисленного.
6. Какое утверждение о смесях и растворах верно?
Растворы представляют собой гетерогенные смеси.
Раствор — это смесь.
Все смеси являются растворами.
Все вышеперечисленное.
Ничего из вышеперечисленного.
7. Какой тип смеси бывает соленая вода?
Сплав
Подвеска
Раствор
Коллоид
Гетерогенный
8.Вещество, растворяющееся в растворе, называется?
Растворитель
Сплав
Суспензия
Растворитель
Коллоид
9. Тип смеси, в которой равномерно распределены вещества?
Однородный.
Неоднородный.
Все виды смесей.
Без видов смесей.
10. Что из следующего неверно?
Компоненты легко разделяются.
Изменены исходные свойства комбинированных веществ.
Соотношение компонентов варьируется.
Два или более веществ объединяются.
Все вышеперечисленное.
11. Пример не является однородной смесью?
Морская вода
Кровь
Металлические сплавы
Воздух
Ни один из вышеперечисленных
12.Что из следующего является примером химической смеси?
Состав, состоящий из различных элементов.
Вещество, образованное за счет химической связи.
Когда два вещества объединены, но не связаны химически.
13. Смеси всегда представляют собой комбинации соединений, находящихся в различных состояниях материи.
Верно
Ложно
14.Фильтрация используется для разделения:
15. Пример того, где раствор содержит две жидкости:
16. Если смесь содержит нерастворенные частицы, которые равномерно перемешаны по всей жидкости, это:
Суспензия
Решение
Преципитат
Нет
(PDF) Разбор нормальной формы для комбинаторных категориальных грамматик с обобщенным составом и набором текста.
Ссылки
Боксвелл, Стивен, Деннис Мехей и Крис Брю.
2009. Brutus: Система обозначения семантических ролей в
, объединяющая функции CCG, CFG и зависимостей.
В материалах 47-го ACL / 4-го IJCNLP, страницы
37–45.
Кларк, Стивен и Джеймс Р. Карран. 2007. Широкий охват
Эффективный статистический анализ с CCG
и лог-линейными моделями. Компьютерная лингвистика,
33 (4): 493–552.
Карран, Джеймс, Стивен Кларк и Йохан Бос.
2007. Лингвистически мотивированное крупномасштабное НЛП
с C&C и боксером. In Proceedings of the 45th
ACL Companion Volume (Demo and Poster Ses-
sions), страницы 33–36, Прага, Чешская Республика.
Эйснер, Джейсон. 1996. Эффективный анализ нормальной формы —
для комбинаторной категориальной грамматики. В Pro-
заседаниях 34-й ACL, страницы 79–86, Santa
Cruz, CA.
Эспиноза, Доминик, Майкл Уайт и Деннис
Мехей.2008. Hypertagging: Supertagging для реализации поверхности
с CCG. В Proceedings of
ACL-08: HLT, страницы 183–191, Колумбус, Огайо.
Гильдеа, Даниэль и Джулия Хокенмайер. 2003. Определение семантических ролей
с использованием Combinatory Catego-
риальной грамматики. В материалах EMNLP, Sap-
poro, Япония.
Хеппл, Марк и Глин Морриллы. 1989. Анализ
и деривационная эквивалентность. In Proceedings of the
Fourth EACL, pages 10–18, Manchester, UK.
Хокенмайер, Джулия и Марк Стидман. 2007.
CCGbank: Корпус производных CCG и зависимых структур
, извлеченных из вымпельного дерева —
банк. Компьютерная лингвистика, 33 (3): 355–396.
Хоккенмайер, Юлия. 2003. Данные и модели для статистического анализа
с комбинаторно-категориальной грамматикой
. Кандидат наук. докторская диссертация, Школа информатики,
Эдинбургский университет.
Хоффман, Берил. 1995. Вычислительный анализ
Синтаксис и интерпретация «свободного» порядка слов
на турецком языке.Кандидат наук. докторская диссертация, Университет Пенсыльвы —
ния. Отчет IRCS 95-17.
Хойт, Фредерик и Джейсон Болдриджи. 2008. Логарифмический базис для комбинатора D и нормальная форма
в CCG. В Proceedings of ACL-08: HLT, pages
326–334, Колумбус, Огайо.
Карттунен, Лаури. 1989. Радикальный лексикализм. В
Балтин М.Р. и А.С. Крох, редакторы, Альтернатива
Концепции структуры фраз. Чикагский университет —
sity Press, Чикаго.
Koehn, Philipp. 2005. Europarl: параллельный корпус
pus для статистического машинного перевода. В 10-м Саммите MT
, страницы 79–86, Пхукет, Таиланд.
Комагата, Нобо. 1997. Генерирующая мощность
ПГУ с обобщенными типо-повышенными категориями. В
ACL35 / EACL8 (Студенческая сессия), страницы 513–515.
Комагата, Нобо. 2004. Решение проблемы ложной неоднозначности
для практических комбинаторных синтаксических анализаторов грамматики класса
.Компьютерная речь и язык —
, 18 (1): 91 — 103.
Нив, Майкл. 1994. Психолингвистически мотивированный парсер для CCG. In Proceedings of The 32nd
ACL, Las Cruces, NM, pages 125–132.
Парески, Ремо и Марк Стидман. 1987. Ленивый
способ разбора диаграмм с категориальной грамматикой. In
Proceedings of the 25th ACL, pages 81–88, Stan-
ford, CA.
Шибер, Стюарт М., Ив Шабес и Фернандо
С.Н. Перейра. 1995. Принципы и реализация —
дедуктивного синтаксического анализа. Журнал Logic Pro —
граммирования, 24 (1-2): 3–36, июль – август.
Стидман, Марк. 2000. Синтаксический процесс. MIT
Press, Кембридж, Массачусетс.
Виджай-Шанкер, К. и Дэвид Дж. Вейр. 1993. Разбор
некоторых формализмов ограниченной грамматики. Компьютерная лингвистика,
, 19 (4): 591–636.
Уир, Дэвид. 1988. Характеризуя умеренно контекст —
чувствительных грамматических формализмов.Кандидат наук. диссертация, Университет
, Пенсильвания. Tech. Отчет CIS-88-74.
Виттенбург, Кент Б. 1986. Анализ естественного языка —
с комбинаторной категориальной грамматикой в формализме, основанном на графической унификации
. Доктор философии —
sis, Техасский университет в Остине.
Зеттлемойер, Люк С. и Майкл Коллинз. 2005.
Обучение отображению предложений в логическую форму: Структурная классификация
с вероятностно-категориальной
грамматиками.In Proceedings of the 21st UAI, pages
658–666, Эдинбург, Великобритания.
Зеттлемойер, Люк и Майкл Коллинз. 2007. On-
строковое изучение расслабленных грамматик CCG для пар-
ингтологической формы. InProceedings of EMNLP-
CoNLL, страницы 678–687, Прага, Чешская Республика.
Благодарности
Мы хотели бы поблагодарить Марка Стидмана за полезные обсуждения и Джейсона Эйснера за его очень щедрые отзывы, которые помогли
доказать эту статью.За все оставшиеся ошибки и упущения мы несем ответственность. J.H поддерживается
грантом NSF IIS 08-03603 INT2-Medium.
Подходы к разрыву строки
Подходы к разрыву строкиЦелевая аудитория: разработчики браузеров, разработчики спецификаций и все, кто хотел бы получить лучшее представление о том, чем различаются полные разрывы строк и перенос текста в системах письма по всему миру.
В этой статье дается общий обзор различных типографских стратегий для переноса текста в конец строки для различных сценариев.
Разрыв строки часто предшествует выравниванию текста. Для аналогичного обобщения подходов к обоснованию см. Подходы к полному обоснованию.
В этой статье представлен широкий обзор различных стратегий, используемых разными системами письма, но это только обзор. Особые правила применяются практически ко всем сценариям, влияющим на то, какие символы могут начинать или заканчивать строку, а какие — нет. Некоторые системы письма позволяют переносить слова, а другие — нет. Мы будем приводить только примеры основных отличий, а не исчерпывающе перечислять все детали.
Для получения более подробной информации о том, как происходит разрыв строк в различных сценариях, см. Международный указатель макета текста и типографики.
Самый фундаментальный алгоритм, используемый для переноса текста в конец строки, зависит от слияния двух факторов:
- разделены ли в тексте «слова» или слоги, и если да, то как, и
- независимо от того, переносит ли система письма слова, слоги или символы в следующую строку.
Что такое слово?
Очень сложно дать четкое определение термина « слово », и тем не менее различие между словами и слогами имеет важное значение в некоторых языках для разрыва строки.
Часто приложения и алгоритмы предполагают, что слово представляет собой последовательность символов, разделенных пробелом, или иногда какой-либо другой знак пунктуации. Некоторые языки, однако, написаны с использованием сценариев, которые только разграничивают слоги, но все же рассматривают слова как единицы, состоящие из одного или нескольких слогов (например, тибетский и вьетнамский). Другие вообще не определяют визуально границы слов или слогов, но поддерживают различие между словами и слогами (например, кхмерский, который обычно не разделяет визуально ни то, ни другое внутри фразы, но сильно склонен рассматривать слова как базовую единицу. при переносе строк, а не слогов или символов).
Даже если слово предполагается для определенного набора языков как последовательность букв, ограниченных пробелами, с лингвистической точки зрения это скрывает некоторые существенные основные различия и сложности. Состав этих слов может значительно отличаться от языка к языку. Например,
- слов в финском языке могут оканчиваться несколькими предложными или другими суффиксами, прикрепленными к основному слову (talo означает «дом», а talostani — «из моего дома»),
- слов в немецком языке могут быть составными, состоящими из последовательности меньших слов, таких как Eingabeverarbeitungsfunktionen, которое является составным из слов Eingabe, Verarbeitung и Funktion, за которыми следует маркер множественного числа,
- на арабском языке маленькие слова, такие как ‘и’ (و), пишутся рядом со следующим словом без пробелов (например,الجامعات والكليات означает «университеты и колледжи», но есть только одно место).
Когда «разделители слов» отсутствуют в таких языках, как кхмерский, тайский, японский и т. Д., Определение того, что составляет слово, может быть субъективным, если речь идет о составных существительных или грамматических частицах. Например, тайский перевод слова «письмо» การ เขียน можно рассматривать как одно слово (kānkhīan) или как два (kān khīan).
Для целей этой статьи мы не будем пытаться давать слишком точное определение термину «слово».Вместо этого мы просто будем использовать его для обозначения нечетко определенной семантической единицы, которая может включать один или несколько слогов.
Широкие типы
В следующей таблице представлен общий обзор факторов, влияющих на то, как система письма переносит текст в конец строки. Комбинации языка и алфавита, перечисленные в таблице, являются лишь примерами и относятся только к системам письма, которые используются в настоящее время. Если за именем языка не следует имя сценария, и язык, и сценарий имеют одно и то же имя.Обратите внимание, что для данного языка обычно используется более одного сценария.
Обратите также внимание на то, что некоторые комбинации языка и сценария (со звездочками) появляются более чем в одном месте в таблице, указывая на то, что существуют альтернативные подходы. Причины этого описаны позже.
| Пробел как разделитель слов | Разделитель других слов | Разделитель слогов | Без разделителя | |
|---|---|---|---|---|
| Обертывание слов | Амхарский (эфиопский) *, арабский, армянский, бенгальский, чероки, дивехи (тхана), английский (латинский), английский (десерет), фула (адлам), грузинский, греческий, гуджарати, иврит, хинди (деванагари), инуктитут ( UCAS), каннада, корейский (хангыль) *, малаялам, мандайский, мандинка (нько), ория, панджаби (гурмухи), русский (кириллица), сингальский, сирийский, тамильский, тедим (пау чин хау), телугу | Самаритянин | Кхмерский, Лаос, Мьянма, Тайский | |
| Обертывание слогов | Восточно-чамский, корейский (хангыль) *, сунданский | Вьетнамский (латиница), тибетский | балийский, батакский, китайский, яванский, западно-чамский | |
| Обертывание символов | Амхарский (эфиопский) * | Японский, Вай |
В архаичных сценариях гораздо больше шансов использовать подход scriptiocontina (т. Е.без разрывов слов или слогов), хотя в современных текстах, описывающих их, вы можете встретить пробелы, разделяющие единицы текста. В более старых версиях упомянутых скриптов также могут использоваться другие правила для разделения слов и разрыва строки.
В следующих разделах мы дадим примеры основных альтернатив и упомянем некоторые последствия. Мы сосредоточимся только на современном использовании, и отложим упоминание о переносах на потом.
Слова, разделенные пробелами
Это подход, с которым знакомо большинство людей, и именно так работает английский текст в этой статье.Когда достигается конец строки, приложение обычно ищет предыдущий пробел, который считается разделителем слов, и переносит все после него на следующую строку *.
Многие скрипты работают именно так. Среди прочего, они включают скрипты, используемые для всех основных европейских языков, включая кириллицу и греческий; скрипты, используемые для основных индийских языков, таких как деванагари, гуджарати и тамильский; скрипты, используемые для современных семитских языков, таких как арабский, иврит и сирийский; и сценарии, используемые для американских языков, такие как Cherokee и Unified Canadian Syllabic (UCAS).
Возможности разрыва строки в тексте на хинди (сценарий деванагари).Языки, написанные справа налево, например арабский, иврит или дивехи, также обычно переносят полные слова на следующую строку. Однако они делают это, конечно, в противоположном направлении, скажем, от английского.
Возможности разрыва строки для арабского текста.Однако текст на таких языках, как арабский, иврит или дивехи, значительно усложняется, если он содержит двунаправленный текст.Если мы сделаем текст «… في this is English لك …» в приведенном выше примере, мы получим следующее.
Перенос встроенного текста противоположного направления на арабском языке.Посмотрев на приведенный выше пример, вы заметите, что относительный порядок английских слов был изменен на разрыв строки. Это связано с тем, что горизонтальный двунаправленный текст никогда не читается вверх, от строки к строке. Этот вывод управляется процессом двунаправленного переупорядочения до того, как рассчитываются возможности разрыва строки, и влияет только на расположение глифов шрифта.Символы в памяти идут в порядке произношения и не меняются.
Вертикально установленные китайский, японский, корейский и традиционный монгольский языки переносят слова вверх, но новая строка появляется слева для CJK и справа для монгольского.
Юго-Восточная Азия: без разделителя слов
Тайский, лаосский и кхмерский — это языки, в которых нет пробелов между словами. Пробелы встречаются, но они служат в качестве разделителей фраз, а не слов. Однако, когда текст на тайском, лаосском или кхмерском достигает конца строки, ожидается, что текст будет переноситься по слову за раз.Для людей это не слишком сложно (если вы говорите на этом языке), но приложения должны найти способ понять текст, чтобы определить, где находятся границы слов.
Возможности разрыва строки в кхмерском тексте.Большинство приложений делают это с помощью поиска по словарю. Он не идеален на 100%, и авторам может потребоваться время от времени что-то корректировать. Например, вот два альтернативных набора возможностей разрыва строки в тайской фразе.
Альтернативные возможности разрыва строки для тайского текста.Разница здесь не только в ошибочных реализациях. Как упоминалось ранее, понятие слова в системах письма, которые не разграничивают их четко, довольно подвижно. Вышеупомянутые различия возникают из-за различных субъективных мнений о том, следует ли переносить составные слова целиком или нет на следующую строку.
Раньше символ Юникода U + 200B ZERO WIDTH SPACE (ZWSP) использовался для обозначения границ слов для этих сценариев, а некоторые стандартные клавиатуры, такие как кхмерский NIDA, по-прежнему генерируют ZWSP с помощью клавиши пробела, но в последнее время в основных языках есть строчные- в их распоряжении есть ломающие реализации, что означает, что ZWSP не важен.Крупномасштабный ручной ввод ZWSP также не очень практичен, потому что пользователь не может видеть разделитель в большинстве сценариев; это приводит к проблемам с ZWSP, вставленным в неправильном месте или несколько раз. Однако ZWSP можно использовать для ручной работы и исправления аспектов поведения при переносе строки.
Также важно иметь в виду, что упомянутые здесь скрипты могут использоваться для написания языков, отличных от упомянутых, в частности языков меньшинств, для которых необходимы другие словари.Поскольку такие словари могут быть недоступны в данном браузере или другом приложении, существует тенденция использовать ZWSP для компенсации.
Некоторые системы письма переносят в следующую строку не только слова, но и слоги. Часто предпочтительнее переносить слова целиком, но вместо этого текст также может быть разбит на границы слога.
Как правило, требуется некоторый анализ текста, чтобы определить, где встречаются границы слогов. Часто конец слога обозначается последним согласным, который является комбинированным символом, или конец слога может быть обозначен специальным знаком, однако в некоторых случаях расположение границ слога может быть визуально неоднозначным.Более того, рассматриваемый слог может быть орфографическим, а не фонетическим слогом (см. Ниже).
Сюда включеныкитайского и корейского языков, хотя они немного необычны тем, что слог обычно соответствует одному символу, а не последовательности. (Хотя в редких случаях, когда корейский язык хранится как хамос, а не как слоговые символы, присутствует последовательность.)
Тибетский: видимые разделители слогов
Хорошим примером системы письма, которая регулярно ломается на границах слога, является тибетский, в котором для обозначения конца слога используется ་ [U + 0F0B TIBETAN MARK INTERSYLLABIC TSHEG] (произносится как цек).
Тибетский оборачивается путем переноса полных слогов на следующую строку, так что исходная строка заканчивается знаком цек. Тибетские слова могут состоять из нескольких слогов, и хотя желательно избегать разрывов строки в середине слова, это не обязательно. С другой стороны, слог всегда следует сохранять нетронутым.
Возможности разрыва строки на тибетском языкеКорейский хангыль: альтернативы
Корейский необычен тем, что слова в современном тексте хангыль обычно разделяются пробелами, но система письма позволяет авторам контента выбирать один из двух способов переноса этого текста.
Перенос по слогам является обычным явлением, особенно в полностью выровненном по ширине тексте (что чаще встречается в системах письма CJK , чем в западных), но абзацы с рваным правым краем часто переносят целые слова. Однако выбор мотивирован предпочтениями автора, а не каким-либо жестким правилом.
Вы также можете встретить хангыль, написанный без пробелов между словами (например, китайский и японский), особенно в старых текстах.
Альтернативные возможности разрыва строки для корейского текста хангыль.Мы могли бы охарактеризовать хангыль как обертку на основе символов, а не слогов. Слоговая система особенно подходит, когда корейский текст хранится как джамо, однако подавляющее большинство корейского текста хранится как слоговые символы.
Суданский язык, восточно-чамский язык: пробел как разделитель слов
Мы видели, что в корейском тексте используются пробелы между словами, но не обязательно использовать эти пробелы для обозначения возможности переноса строки. Есть и другие системы письма, которые также разделяют слова пробелами, но могут переносить слоговые единицы.В отличие от корейского, в котором обычно используется символ за символом, в этих системах письма в качестве единицы текста используется последовательность символов, соответствующая слогу.
Возможности разрыва строки в сунданском тексте.Больше из Юго-Восточной Азии: без разделителя слов
Ряд других письменностей Юго-Восточной Азии написаны без пробелов между словами. В этих системах письма вы также можете обнаружить, что текст переносится по границам слогов в дополнение к границам слов.
Возможности разрыва строки в яванском тексте.Возможности разрыва, показанные выше для яванского языка, соответствуют орфографическим слогам, а не фонетическим. Например, если один фонетический слог заканчивается согласной, а следующий слог начинается с согласной, они могут быть сложены или соединены особым образом. Эти комбинации не разделяются. Во многих сценариях эти особые союзы могут встречаться только внутри слов, но в других (таких как яванский и балийский) они могут фактически перекрывать границы слов.
Разные цвета представляют два яванских слова pangan и dika , но возможность разрыва (красная линия) появляется перед стеком, отсекая последнее n от предыдущего слова.В тех случаях, когда система письма может представлять согласные в конце слога с помощью комбинированного символа, они обычно рассматриваются как часть предшествующего орфографического слога.
В этих языках обычно символы переносятся на следующую строку, независимо от границ слога или слова.Однако это небольшое упрощение, как мы увидим здесь и в следующих разделах, потому что обычно существуют правила о том, где может отображаться пунктуация, которые влияют на возможность переноса строки, и некоторые соседние символы могут оставаться вместе.
Японский и вайский: упаковка на основе мора
Японский и вайский обычно переносят отдельные символы в следующую строку, независимо от границ слова или слога.
Возможности разрыва строки в японском тексте.Этот тип переноса иногда называют слоговым, но на самом деле японский язык основан на морали, а не на слогах. Например, можно найти текст, заключенный в один слог き ょ う (произносится kyō, что означает «сегодня»).
Тем не менее, все (как всегда) не так однозначно. Хотя принято переносить последний из трех символов в слове き ょ う независимо от следующей строки, некоторые авторы контента предпочитают всегда оставлять маленький второй символ вместе с первым.CSS предоставляет strict и free значений для свойства разрыва строки , чтобы авторы контента могли контролировать это поведение. Последнее значение допускает перенос строки между ними. Это часто может быть полезно для текста в узких столбцах, например газет.
Кроме того, иногда возникают ситуации, например, в заголовках, когда автор контента может предпочесть заключить в перенос, не разделяя то, что воспринимается как «слова». Однако обратите внимание, что в японском языке составные слова часто строятся из отдельных слов, а японский добавляет грамматические частицы после слов, которые могут или не могут рассматриваться как тесно связанные со словом.Таким образом, что касается тайского языка, это может быть довольно субъективным в отношении того, что составляет границу слова в японском языке.
В некоторых случаях перенос на основе символов, используемый для китайского и японского языков, также применяется к встроенному латинскому тексту. Когда такой встроенный текст переносится, границы слогов и переносов не принимаются во внимание. Аналогичным образом, можно ожидать, что текст на японском и китайском, встроенный в латинский текст, будет переноситься как единое целое. (Этим поведением можно управлять с помощью свойств CSS.)
Эфиопский язык: разделитель слов без пробела
В современном эфиопском тексте могут использоваться пробелы между словами, и в этом случае ожидается, что все слово будет перенесено на следующую строку как единое целое.
Возможности разрыва строки на амхарском языке, когда слова разделены пробелами.Тем не менее, эфиопский текст может также использовать традиционный символ пространства слов ፡ [U + 1361 ETHIOPIC WORDSPACE] для обозначения границ слов. В этом случае слово Ethiopic переносится после любого символа, если пробел не появляется в начале строки.
Непробельные разделители слов также часто встречаются в архаичных сценариях.
Возможности разрыва строки на амхарском языке, когда слова разделены эфиопским символом пробела.Конечно, как и в случае с другими символами переноса строки, есть и другие правила, которые следует учитывать. Например, предпочтительно ставить перед пробелом слова как минимум два символа в начале строки, а знаки препинания в начале и конце строки могут повлиять на поведение разрыва строки по умолчанию (см. Ниже).
Расстановка переносов — это механизм, который помогает лучше уместить текст в строке. Только подмножество систем письма поддерживает расстановку переносов, но в основном это необходимо для разбиения слов на более мелкие единицы для переноса.
Важно отметить, что правила расстановки переносов в одном и том же сценарии различаются от языка к языку. Хотя оба используют латинский шрифт, правила орфографии на немецком и английском языках могут сильно отличаться. Контент на арабском языке обычно не допускает переносов, в отличие от уйгурского, хотя оба они используют арабскую графику. (Обратите внимание, что арабский язык предоставляет ряд альтернативных методов удлинения или сокращения линий во время выравнивания.)
Механизм расстановки переносов также различается.Для некоторых языков дефис (который может не выглядеть как «-») появляется в начале следующей строки, в других — в обеих строках. В некоторых случаях написание слова изменяется вокруг расстановки переносов, например, в голландском cafeetje → cafe-tje и skiërs → ski-ers , а в венгерском Összeg → Ösz-szeg .
В других сценариях текст может иногда прерываться внутри слова, но дефис не используется для обозначения разрыва.
Пунктуация
Приведенный выше пример на японском языке ясно показывает, как часто запрещается перенос строки перед определенными знаками препинания. Для большинства скриптов характерно, что содержимое не должно начинаться с строки со знаком препинания, который показывает конец фразы или раздела.
Другие знаки препинания обычно не должны завершать строку. К ним относятся открывающие круглые скобки или квадратные скобки.
В этих обстоятельствах приложение обычно ищет возможность переноса предыдущей строки и переносит знак препинания и предшествующий текст в следующую строку вместе.
Возможно, нет необходимости переносить символ пунктуации в следующую строку, если можно сократить пространство вокруг других символов в строке во время выравнивания, тем самым оставляя место для его размещения.
Если это невозможно, альтернативная стратегия, которую иногда можно встретить в таких языках, как японский и китайский, заключается в том, чтобы оставить знаки препинания за пределами поля в конце строки. (Очевидно, это работает только при наличии видимого поля.)
Висячие знаки препинания в японском тексте.Предотвращение разрывов строк
В некоторых ситуациях требуется механизм для предотвращения разрывов строк. Это может быть особенно полезно, когда последовательность символов в очень короткой строке не имеет возможности естественного разрыва строки, но это также может быть полезно в других ситуациях, когда вы хотите настроить поведение .
Unicode имеет набор правил для определения кластеров графем по умолчанию, которые указывают последовательности символов, которые обычно не должны разделяться разрывом строки.Например, сюда входит любой комбинированный символ, следующий за базовым символом. Однако его также можно расширить, чтобы предотвратить разрывы в многосимвольных слогах, например, в индийских алфавитах или шрифтах Юго-Восточной Азии.
В Юникоде также есть символы, которые склеивают смежные символы, включая такие символы, как U + 00A0 NO-BREAK SPACE и U + 2011 NON-BREAKING HYPHEN, а также для ситуаций, когда вы хотите предотвратить разрыв строки, невидимое СЛОВО U + 2060 СОСТАВНИК.
Мы уже упоминали о строгом режиме , который используется для объединения определенных символов в японском языке.Разметка или стили также могут использоваться для отмены нормального поведения при нарушении правил. Например, в заголовках иногда предпочтительнее разрывать границы слов на японском языке, чтобы избежать появления небольшого количества символов на новой строке. Для этого можно использовать укладку.
Другие особые правила
В дополнение к правилам о том, какой символ может или не может появляться в конце / начале строки, могут быть более сложные правила, связанные с процессом переноса текста.
Здесь мы приводим в качестве примера некоторые подробности о переносе строк в традиционных тибетских форматах.В тибетском языке U + 0F0D TIBETAN MARK SHAD 1 используется как разделитель фраз, а двойной шай — разделитель темы. Если только один слог перед шаем переходит в новую строку, шай (или первый шай, когда их два) заменяется на U + 0F11 TIBETAN MARK RIN CHEN SPUNGS SHAD 2 . В конце темы правила гласят, что конвертировать следует только один шай, однако умеренно популярно конвертировать оба. Это изменение служит оптическим указанием на то, что в начале строки есть оставшийся слог, который фактически принадлежит предыдущей строке.
1) ТЕНЬ (произносится как шай)
2) RIN CHEN SPUNGS SHAD
.1)
2)
Двойная насадка рядом с концом лески в (1) превращается в двойную рин чен спанг, когда она завернута в (2).Различается в следующих случаях:
- когда строка начинается с le’u 3 , не будет использоваться rin chen spungs shad , поскольку le’u произносится как два слога.
- иногда, если заменяется только первый из двух шей, этот стиль считается менее привлекательным.
- в некоторых печатных книгах не используются замены rin chen spungs shad , однако в большинстве книг, похоже, применяются те же правила, что и для pechas.
3) лей
В заключение, иллюстрация особого поведения в яванском сценарии. Когда новая строка начинается с U + A9BA JAVANESE VOWEL SIGN TALING 4 , идентичный глиф интервала помещается в конец предыдущей строки. Важно отметить, что в памяти есть только один символ таллинга: первый глиф — это просто призрак.
4) РАССКАЗ
Глиф таллинга появляется в конце и начале строки, когда слово кавон разделяется до того, как выиграть.Это не часто встречается в современном тексте, хотя это не так уж удивительно, поскольку для его создания необходим довольно специальный алгоритм. При использовании старых методов установки шрифтов это (и тибетский пример выше) было бы относительно легко создать, добавив некоторый тип в конец статической строки типа. Однако веб-страницы являются динамическими, и ширина строки может измениться в любое время, поскольку пользователь изменяет размеры окна браузера.Показанное поведение должно быть реализовано только тогда, когда разрыв оказывается точно в нужном месте: по мере перекомпоновки текста при изменении ширины окна браузера лишний тейлинг должен исчезнуть.
5 Подготовка учителей чтения | Подготовка учителей: доказательства в пользу разумной политики
Учащиеся также должны развить беглость речи или способность «читать устно с быстротой, точностью и правильным выражением» (стр. 11). Свободное владение языком увеличивается с практикой устного и немого чтения.
Как алфавитные навыки, так и беглость необходимы учащимся для достижения цели чтения и понимания. Понимание, рассматриваемое как «необходимое не только для академического обучения во всех предметных областях, но и для непрерывного обучения» (стр. 13), в NRP описывается как «сложный когнитивный процесс», требующий адекватного словарного запаса, целенаправленного «взаимодействия с текстом. , »И способность соотносить идеи в тексте с личными знаниями и опытом (Национальный институт здоровья детей и развития человека, 2000, стр.13).
Поскольку они перекрываются, лежащие в основе навыки могут быть сгруппированы по-разному (например, фонематическая осведомленность и фонетика могут рассматриваться как один или два навыка), чем те, которые используются в отчете NRP. Тем не менее, специалисты достигли консенсуса по основным компонентам того, что «знает» успешный читатель. Эти элементы — фонематическая осведомленность, фонетика, беглость, словарный запас и понимание — все чаще считаются наиболее важным содержанием курсов подготовки учителей (Август и Шанахан, 2006, ) .
Международная ассоциация чтенияМеждународная ассоциация чтения (IRA) синтезировала литературу по чтению с целью предложить руководство по подготовке учителей чтения. Его результаты представлены в форме многокомпонентного исследования эффективных практик (2003a), стандартов для профессионалов в области чтения (2003b) и обобщенного исследования (2007). Исследование практики (2003a) включало опрос преподавателей преподавателей чтения, углубленный анализ нескольких программ, признанных образцовыми, и анализ эффективности выпускников этих программ.Стандарты IRA (2003b) используются факультетами программ подготовки учителей и государственными департаментами образования при планировании подготовки учителей чтения в классе, парапрофессионалов, специалистов по чтению и тренеров, воспитателей учителей чтения и администраторов. Они также используются для оценки как кандидатов, так и программ. Пересмотренная версия (которая будет включать новые комментарии групп экспертов и рецензентов) намечена к публикации в 2010 году.
В отчете IRA за 2007 год были обобщены результаты исследования 2003 года, а также обзор эмпирических исследований Риско и его коллег (2008) (обсуждаются ниже).Многие из его выводов больше подходят для вопросов 2, 3 и 4 комитета, чем для вопроса 1, но что касается того, что знают успешные читатели, он по существу следует NRP в определении того, что он называет основными компонентами чтения. Целью IRA в этих трех документах является руководство инструктажем и подготовкой учителей, поэтому в нем обсуждаются навыки в контексте стратегий для учителей.
Текстовый набор данных рецептов синтеза неорганических материалов
Точность экстракции
Общий выход экстракции трубопровода составляет 28%, что означает, что из 53 538 параграфов в твердом состоянии только 15 144 из них вызывают сбалансированную химическую реакцию.В качестве теста полного конвейера извлечения мы случайным образом извлекли 100 абзацев из набора абзацев, классифицированных как твердотельный синтез, и проверили их на полноту извлеченных данных. Из 100 абзацев мы нашли 30, которые не содержали полного набора исходных материалов и конечных продуктов, а это означает, что эксперт-человек не сможет восстановить реакцию по этим абзацам. Остальные 70 абзацев потенциально могут внести свой вклад в набор данных, поскольку они предоставляют всю информацию о исходных материалах и конечных продуктах.Проверка этих 70 параграфов показала, что 42 потенциальных реакции не были реконструированы из-за неполного или слишком полного набора извлеченных материалов-предшественников / мишеней или невозможности проанализировать химический состав, что делает невозможным балансировку реакции. Первая потеря возникает из-за более низкого повторного вызова алгоритма MER, который мы обменяли на более высокую точность, в то время как проблема синтаксического анализа возникает из-за сложной записи, используемой для объекта материалов.
Оценка точности записей набора данных была проведена путем случайного отбора 100 записей и ручной проверки каждого извлеченного поля на соответствие исходному абзацу.Расчетная точность, полнота и оценка F1 для каждого атрибута ввода данных приведены в таблице 2. В целом мы достигли высокой точности при извлечении целей (точность 97%), предшественников (оценка F1 99%), операций ( F1-оценка 90%) и уравновешивающие реакции (точность 95%). Более низкая точность условий нагрева (оценка F1 <90%) в основном вызвана случаями, когда этап нагрева пропускается алгоритмом извлечения операций. Восстановление условий смешивания показывает относительно низкую точность с оценкой F1 65%.Это в значительной степени связано с неправильной идентификацией MER материала устройства или вещества среды, используемой для смешивания, а также потому, что эти условия часто не упоминаются в том же предложении, что и процедура смешивания.
Таблица 2 Производительность извлечения данных для записей набора данных.Этот анализ приводит нас к выводу, что на химическом уровне (правильные прекурсоры, мишени, реакции) точность набора данных составляет 93%. При включении всех операций и их условий точность извлечения и правильного назначения всех элементов рецепта (химии, операций и атрибутов операций) составляет 51%, что является низким показателем из-за низкой производительности при извлечении атрибутов смешивания.Для многих твердотельных рецептов особенности смешивания прекурсоров менее важны, поэтому этот сбой экстракции менее критичен. При рассмотрении только правильности рецепта без условий нагрева и смешивания (т.е. химии, операций и реакций) точность возрастает до 64%.
Стоит отметить, что для этого набора данных мы стремились достичь более высокой точности извлечения данных за счет более низкого отзыва (т.е. лучше пропустить запись данных, чем предоставить неправильную), поэтому скорость извлечения низкая.Тем не менее, построение сбалансированного химического уравнения устанавливает дополнительные ограничения для целей и прекурсоров и помогает уменьшить потенциальные ошибки, которые могли быть вызваны анализом состава. Это приводит к смещению показателей в сторону более высокой точности идентификации целей и предвестников по сравнению с операциями.
Анализ набора данных
Чтобы проверить разнообразие записей, представляющих набор данных, мы сначала получили список уникальных материалов (целей и прекурсоров) и реакций.Набор данных содержит 13 009 уникальных целей, 1845 уникальных предшественников и 16 290 уникальных реакций. Почти в 10 раз меньшее разнообразие прекурсоров по сравнению с мишенями можно объяснить тем фактом, что в целом исследователи работают с набором общеизвестных прекурсоров. В таблице 3 представлены десять наиболее частых целей, предшественников и реакций в наборе данных. Целевые соединения точно охватывают типы материалов, наиболее часто изучаемые в последние два десятилетия с помощью твердотельного синтеза. Это катодные материалы для литий-ионных аккумуляторов (LiFePO 4 , LiMn 2 O 4 и LiNi 0.5 Mn 1,5 O 4 ), а также перовскиты для мультиферроиков, светодиодов и КМОП-приложений (BaTiO 3 , BiFeO 3 , SrTiO 3 , Y 3 Al 5 12305 ). Возможно, что этот список «первой десятки» материалов смещен из-за набора издателей, которые дали нам разрешение на доступ к их научному корпусу. Например, Американское физическое общество не было включено и, возможно, внесло в список другие соединения.
Таблица 3 Десять наиболее распространенных целей, предшественников и реакций, присутствующих в наборе данных.Затем мы оцениваем химическое пространство, охватываемое набором данных. Для каждого химического элемента мы вычислили количество реакций, которые включают данный элемент в мишень. Результаты отображены на рис. 2 в рамке с градиентом от желтого к зеленому в верхней части окна каждого элемента. В базе данных преобладают целевые материалы, содержащие Ti, Sr, Ba, La, Fe -> 3000 реакций включают эти мишени с этими элементами. Это также отражено в списке из десяти наиболее часто встречающихся целевых материалов, появляющихся в наборе данных (Таблица 3).Следующими по распространенности мишенями являются материалы с Li, Ca, Nb, Mn, Bi — 2 000–3 000 реакций с этими элементами в мишенях. Наименее распространенными элементами являются Au, Pt, Os, Be — <13 реакций в наборе данных содержат эти элементы. Редкие и радиоактивные элементы, такие как франций, радий, технеций или прометий, не представлены в целевых материалах набора данных.
Рис. 2Карта химического пространства, охваченного набором данных. Для каждого элемента рамка, окрашенная в градиент от желтого к зеленому, представляет собой общее количество реакций, в результате которых образуется целевое соединение, содержащее элемент.Гистограмма под каждым элементом показывает список ионов, сопряженных с элементом в соединениях-предшественниках. Длина полоски соответствует средней температуре обжига по всем реакциям с использованием данного прекурсора (т. Е. Элемент + противоион). Элементы, встречающиеся в пяти и менее целях, отображаются серым цветом. «Ас» означает ацетатный радикал CH 3 COO — в формуле соединения.
Мы также исследовали совместное присутствие химических элементов и наиболее типичных противоионов в материалах-прекурсорах и определили среднюю температуру обжига, используемую с каждым из этих прекурсоров.Здесь мы оперативно определяем температуру обжига как температуру, используемую на последнем этапе нагрева в последовательности операций синтеза. Результаты показаны на рис. 2 в виде гистограмм для каждого элемента. Цвет полоски соответствует определенному противоиону. Чистый элемент в качестве предшественника показан пурпурным цветом. Длина полосы обозначает среднюю температуру обжига.
В этом представлении мы видим, что набор данных точно отображает известные аспекты химии твердого тела.Например, катионы щелочных и переходных металлов часто вводятся в реакцию через различные предшественники, включая бинарные оксиды, нитриды, сульфиды и т.д .; или простые соли, такие как карбонаты, фосфаты и нитраты. В то же время некоторые катионы в соединениях-предшественниках можно найти только в форме оксидов или чистых элементов (например, Be, Sc, Hf, Ru, Os, Rh, Pb, Nb, Pt, Au,…).
В твердотельном синтезе противоион управляет температурой плавления или разложения предшественника и может определять, когда предшественник становится активным во время синтеза.Распределение температур обжига на рис. 2 очень хорошо согласуется с этим утверждением и показывает, как разные прекурсоры используются в разных температурных режимах во время твердотельного синтеза. Например, синие полосы обычно имеют большую длину (высокая средняя температура), чем красные, потому что бориды, карбиды и нитриды переходных металлов часто имеют более высокие температуры реакции, чем их соответствующие оксиды, из-за тугоплавкой природы их предшественников. С другой стороны, зеленые полосы относительно короче (более низкая средняя температура обжига), чем красные, потому что, по сравнению с оксидами и сложными оксидными анионами (карбонаты, фосфаты и т. Д.), Синтез с гидроксидами, оксалатами и ацетатами способствует более низкотемпературным реакциям. поскольку они часто гомогенно смешиваются путем осаждения из раствора.Этот анализ температуры на основе данных основан на прекурсоре, и мы признаем, что температуры реакции также зависят от термической стабильности и реакционной способности целевых соединений. Тем не менее, эта цифра представляет собой полуколичественную отправную точку для исследователей: если целевой материал разлагается при относительно низкой температуре, может быть лучше выбрать прекурсор, который имеет тенденцию становиться активным при более низкой температуре.
Чтобы продемонстрировать разнообразие маршрутов синтеза, представленных в наборе данных, мы отсортировали последовательность шагов синтеза в соответствии со следующими заранее заданными шаблонами (таблица на рис.3):
одностадийный синтез состоит только из операций перемешивания / измельчения твердых веществ и не более одного этапа нагрева (окончательный обжиг) без доизмельчения,
синтез с измельчением в жидкой среде для гомогенизации ( без растворения) исходные материалы в любой жидкой среде,
синтез на основе раствора содержит любой тип растворения исходных материалов в растворителе,
синтез с промежуточным нагревом имеет одну или несколько стадий нагрева (не включая сушку после смешивания с жидкой частью) перед окончательным обжигом материалов.
Соответствие между выбором пути синтеза и противоионами прекурсоров. В верхней таблице приведен пример четырех определенных типов синтеза: одностадийный синтез, на основе раствора, синтез с промежуточными стадиями нагрева, синтез, включая измельчение прекурсоров в жидких средах. Круговые диаграммы справа отображают долю каждого маршрута синтеза в наборе данных. Диаграммы в виде пончиков представляют собой доли четырех маршрутов синтеза (приведенных в таблице) для каждого противоиона, используемого в прекурсорах.«Ас» означает ацетатный радикал CH 3 COO — в формуле соединения. «Org» означает органический радикал (–CH–) в формуле соединения.
Во-первых, мы обнаружили, что различные типы синтеза представлены в базе данных почти равномерно (верхняя круговая диаграмма на рис. 3): 26% материалов синтезируются в один этап, 25% маршрутов синтеза выполняются с промежуточным нагревом. стадия (и) перед окончательным обжигом, 21% синтезов содержат измельчение (гомогенизацию) в жидкости, а 14% требуют растворения прекурсоров в растворителе.Остальные рецепты (14%) либо не содержат детальной процедуры синтеза (6%), либо путь более сложен (8%).
Поскольку выбор противоиона, используемого в прекурсоре, часто сильно зависит от метода синтеза, мы рассмотрели, какой тип синтеза является общим для конкретного иона в прекурсоре. Мы запросили подмножество реакций, которые включают данный противоион в соединении-предшественнике, и вычислили долю каждого типа синтеза в этом подмножестве. Полученные круговые диаграммы показаны на рис.3. Возникающая картина согласуется с известными аспектами твердотельного синтеза. Например, при осаждении твердых веществ во время синтеза предшественник растворяется в растворе. Как показано на рис. 3, в синтезе на основе раствора (оранжевая фракция) часто используются растворимые предшественники с нитратами, ацетатами и органическими (СН-содержащими) радикалами. Некоторые противоионы более поддаются одностадийному синтезу, чем другие, например, хлориды, сульфиды и гидриды не требуют дополнительной обработки.С другой стороны, относительно стабильные предшественники, такие как оксиды и карбонаты, обрабатываются различными способами, часто требующими промежуточного нагрева и измельчения. Это, вероятно, связано с обычным образованием реакционных примесей и неравновесных промежуточных продуктов во время последовательностей реакций 45,46 .
Разработанный нами конвейер экстракции позволяет автоматически обрабатывать научные абзацы и определять оттуда ключевую информацию о твердотельном синтезе. Однако конвейер по-прежнему страдает от некоторых проблем с интеллектуальным анализом текста.Во-первых, большинство ошибок в конвейере возникает из-за неправильной токенизации абзацев и предложений. Хотя токенизатор ChemDataExtractor 22 значительно превосходит другие пакеты НЛП в текстах, связанных с химией, он по-прежнему не может правильно обрабатывать формулы больших смесей и твердых растворов, а также химические названия, состоящие из нескольких слов. Мы связываем эту проблему с тем, что ChemDataExtractor был обучен на органических химических объектах, и его использование для распознавания неорганических токенов требует модификации алгоритмов.Во-вторых, не существует установленного шаблона или шаблона для описания процедуры синтеза, что приводит к значительной неоднозначности и трудностям, когда метод синтеза интерпретируется даже экспертом 47 . Это требует разработки более совершенных моделей извлечения текста, учитывающих особенности научного потока текста. В-третьих, хотя набор данных был создан из параграфов, описывающих твердотельный синтез (как определено алгоритмом классификации), он также содержит реакции для синтеза прекурсоров на основе раствора, такие как золь-гель (рис.3). Тем не менее, эти записи в основном выпадали позже, потому что в большинстве из них используются органические предшественники со сложными радикалами, и балансирование таких химических уравнений становится сложным.