Слова «проще» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «проще» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «проще» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «проще».
Содержимое:
- 1 Слоги в слове «проще» деление на слоги
- 2 Как перенести слово «проще»
- 3 Морфологический разбор слова «проще»
- 4 Разбор слова «проще» по составу
- 5 Сходные по морфемному строению слова «проще»
- 6 Синонимы слова «проще»
- 7 Антонимы слова «проще»
- 8 Ударение в слове «проще»
- 9 Фонетическая транскрипция слова «проще»
- 10 Фонетический разбор слова «проще» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «проще»
- 12 Сочетаемость слова «проще»
- 13 Значение слова «проще»
- 14 Как правильно пишется слово «проще»
- 15 Ассоциации к слову «проще»
Слоги в слове «проще» деление на слоги
Количество слогов: 2
По слогам: про-ще
Как перенести слово «проще»
про—ще
Морфологический разбор слова «проще»
Часть речи:
Компаратив
Грамматика:
часть речи: компаратив;
остальные признаки: качественное, сравнительная степень на по-;
отвечает на вопрос: Как?
Начальная форма:
проще
Разбор слова «проще» по составу
| прощ | корень |
| е | суффикс |
проще
Сходные по морфемному строению слова «проще»
Сходные по морфемному строению слова
Синонимы слова «проще»
1. элементарнее
элементарнее
2. попроще
3. уймись
4. не задавайся
Антонимы слова «проще»
1. сложный
2. замысловатый
3. причудливый
4. затейливый
5. тоталитарный
6. приобретённый
7. хитрый
8. запутанный
9. неясный
10. непонятный
11. необычный
12. знаменитый
13. знаменательный
14. из ряда вон выходящий
15. прихотливый
Ударение в слове «проще»
про́ще — ударение падает на 1-й слог
Фонетическая транскрипция слова «проще»
[пр`ощ’э]
Фонетический разбор слова «проще» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| п | [п] | согласный, глухой парный, твёрдый, шумный | п |
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| о | [`о] | гласный, ударный | о |
| щ | [щ’] | согласный, глухой непарный, мягкий, шипящий | щ |
| е | [э] | гласный, безударный | е |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 5 букв и 5 звуков.
Буквы: 2 гласных буквы, 3 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «проще»
Её задача — подмечать детали, ускользающие от взгляда простых смертных.
Источник: Лариса Райт, Алая нить, 2012.
И кричала матом, а не простыми обиходными словами.
Источник: Евгения Пёрышкина, Танец двух половинок. Хроники.
Делиться с простым народом своими «спецресурсами» бывшие правители то ли не спешили, то ли просто
Источник: Константин Медведев, Тайна кремлевской фигуромоделирующей гимнастики, 2008.
Сочетаемость слова «проще»
1. вынужденный простой
2. от долгого простоя
от долгого простоя
3. после длительного простоя
4. простой вагонов
5. время простоя
6. в период простоя
7. в случаях простоя
8. простые люди
9. простой народ
10. простые смертные
11. оказаться проще
12. стать проще
13. казаться простым
14. (полная таблица сочетаемости)
Значение слова «проще»
ПРО́ЩЕ см. простой1, просто. (Малый академический словарь, МАС)
Как правильно пишется слово «проще»
Правописание слова «проще»
Орфография слова «проще»
Правильно слово пишется: про́ще
Нумерация букв в слове
Номера букв в слове «проще» в прямом и обратном порядке:
- 5
п
1 - 4
р
2 - 3
о
3 - 2
щ
4 - 1
е
5
Ассоциации к слову «проще»
Убыток
Вычисление
Конвейер
Производительность
Возмещение
Процессор
Оплата
Уменьшение
Задержка
Сокращение
Загрузка
Издержка
Графика
Работодатель
Ремонт
Снижение
Локомотив
Затрата
Обслуживание
Причина
Задача
Оборудование
Люд
Разгон
Увеличение
Цех
Штраф
Репа
Пластик
Депо
Планирование
Продукция
Пользователь
Эксплуатация
Компенсация
Расход
Стоимость
Заказчик
Плат
Люда
Совпадение
Зарплата
Крестьянка
Съёмка
Потеря
Перерыв
Работяга
Ущерб
Заработок
Режим
Работник
Предприятие
Производство
Депрессия
Обыватель
График
Формальность
Сутки
Период
-
Рубль
Перевозка
Переезд
Мощность
Договор
Норма
Вагон
Заработный
Длительный
Вынужденный
Исправный
Плановый
Производственный
Бесхитростный
Смертный
Предусмотренный
Минимальный
Творческий
Престижный
Технологический
Трудовой
Дополнительный
Рабочий
Технический
Временной
Указанный
Понятный
Приостановить
Сократить
Обходиться
Уменьшать
Снижать
Поручать
Оплатить
Запланировать
Оплачивать
Покроить
Снизить
Возобновить
Сказываться
Предельно
Опубликовано: 2020-08-06
Популярные слова
воспитанник , беседами , взбежавшие , взъерошив , выскребу , высчитанною , вытравлявшей , вячеславом , гемолизом , геннадиевичи , гимнастерочку , домоустройство , завибрируют , завинчивающимся , павлиньего , парабеллумами , парковавшемся , перебираемыми , плакатная , подающее , подлетать , подросту , положительнейшего , помпонах , поохотившимся , пражского , прогульном , прокашливаться , проституируя , противогазовые , развернувшее , разделе , раскрутилось , раскусывают , расторгну , резервированного , реорганизовавшем , респонсорною , сильванер , солея
Разбор слов по составу
Разбор слова по составу
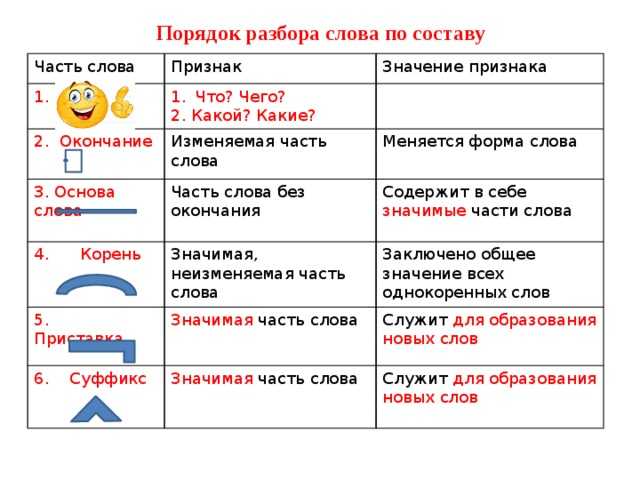
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок».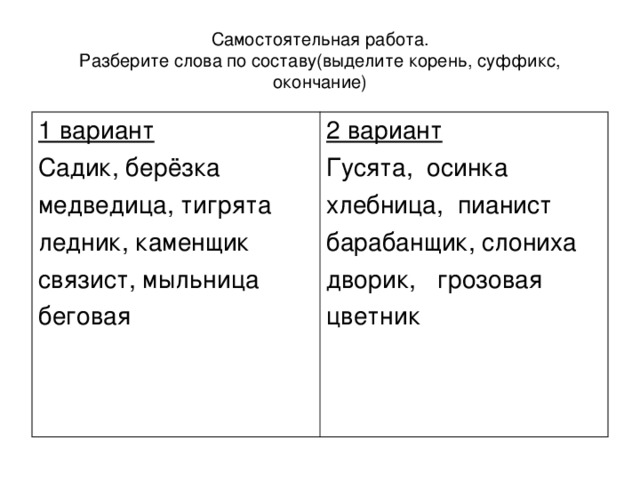 Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н., Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т. д.
д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: субъект 1 секунда назад процесс 1 секунда назад очкораз 1 секунда назад х р м и а а з 1 секунда назад аолугнб 1 секунда назад п о л к о в н и к 1 секунда назад ркали 1 секунда назад п а т о к а 1 секунда назад л я р ы 1 секунда назад аецочкп 2 секунды назад низюксо 2 секунды назад розоратне 2 секунды назад н а р г е б 2 секунды назад к о в е р д 2 секунды назад лаврёо 2 секунды назад
Введение в парсеры. Синтаксический анализ является удивительно сложным… | Chet Corcos
Синтаксический анализ — удивительно сложная задача. Неудивительно, что я часто вижу простые проблемы синтаксического анализа в качестве вопросов для собеседования. В своих собственных проектах я мучил себя, пытаясь найти надежные и эффективные способы очистки данных с веб-сайтов. Я не мог найти много помощи в Интернете, за исключением людей, говорящих, что с использованием регулярных выражений — это плохой подход .
Оглядываясь назад, могу сказать, что это был один из тех случаев, когда я просто не знал правильных ключевых слов для поиска. Наконец-то я чувствую, что во всем разобрался, но это был долгий путь, наполненный академическим жаргоном, который было трудно понять и которым часто злоупотребляли. Цель этой статьи — сделать теорию и практику парсеров более доступными.
Я собираюсь начать с теории о формальных грамматиках, потому что считаю очень полезным понимать, когда люди начинают разбрасываться причудливыми словами, такими как контекстно-свободная грамматика и тому подобное. Во второй половине этой статьи мы создадим синтаксический анализатор с нуля, чтобы вы могли использовать его в своем следующем интервью. Это не быстрое чтение, поэтому убедитесь, что у вас есть хорошая чашка кофе и свежие мысли, прежде чем продолжить.
Теория синтаксических анализаторов уходит своими корнями в 1956 основополагающая статья Ноама Хомского, Три модели описания языка . В этой статье он описывает иерархию Хомского четырех классов формальных грамматик. Каждый из них является подмножеством другого, отличающимся сложностью алгоритма, необходимого для их проверки. Мы рассмотрим их один за другим.
В этой статье он описывает иерархию Хомского четырех классов формальных грамматик. Каждый из них является подмножеством другого, отличающимся сложностью алгоритма, необходимого для их проверки. Мы рассмотрим их один за другим.
Тип 3 — обычные языки
Языки типа 3 называются обычными языками . Все, что вы можете сопоставить с регулярным выражением, является прекрасным примером регулярного языка — отсюда и название «обычное» выражение. Любой регулярный язык можно решить с помощью детерминированных конечных автоматов (DFA). Для тех, кто менее знаком, DFA — это программа, которую можно представить в виде фиксированного набора состояний (узлов) и переходов (ребер). На основе этого понимания есть несколько замечательных инструментов визуализации регулярных выражений. Например, посмотрите на это:
Детерминированный конечный автомат, представляющий следующее регулярное выражение: /-?[0–9]+\.?[0–9]*/John : Некоторые механизмы регулярных выражений на самом деле более мощные чем интерпретация только обычных языков.
Прекрасным примером является движок Oniguruma, который использует Ruby.
Я: Вау!
 Прекрасным примером является движок Oniguruma, который использует Ruby.
Прекрасным примером является движок Oniguruma, который использует Ruby.Тип 2 — контекстно-свободные языки
Языки типа 2 называются контекстно-свободными (он же CFG для контекстно-свободной грамматики) и может быть представлен как автомат выталкивания вниз, который является автоматом, который может поддерживать некоторое состояние со стеком. Эта часть иерархии привлекает наибольшее внимание, поскольку большинство языков программирования и предметно-ориентированных языков не зависят от контекста. Прекрасным примером языка, который является контекстно-свободным , но не обычным , является язык, определяемый « n 0, за которыми следует n 1 для любого n» . Математики определили бы эту грамматику с помощью следующих обозначений: 9н | n >= 0 }
Если бы нам нужно было попробовать , чтобы записать это как регулярное выражение, мы бы начали с записи чего-то вроде 0{n}1{n} . Но это недопустимое регулярное выражение, потому что нам нужно было бы точно указать, что такое
Но это недопустимое регулярное выражение, потому что нам нужно было бы точно указать, что такое и , следовательно, это не обычный язык. Однако мы можем проверить эту грамматику с помощью автомата выталкивания, используя следующую процедуру:
- Если вы видите 0, поместите его в стек и вернитесь к (1).
- Если вы видите 1, извлеките элемент из стека и вернитесь к (2).
- Если стек пуст, мы убедились, что входная строка «на языке».
John : У меня было много ситуаций, когда мне нужно было разобрать сбалансированные скобки, и я думаю, что это более приятный случай для программистов.
Я: Хороший вопрос! Это простой случай проблемы сбалансированных скобок.
Распространенным способом определения контекстно-свободных грамматик является форма Бэкуса-Наура (BNF). Это отличная статья, объясняющая, как работает BNF, распространенные расширения BNF (обычно называемые EBNF или ABNF), а также объясняет, как работают синтаксические анализаторы «сверху вниз» (LL) и «снизу вверх» (LR). Некоторые другие распространенные термины, которые вы можете услышать, это SLR, CLR, LALR, и этот комментарий StackOverflow хорошо разъясняет их.
Некоторые другие распространенные термины, которые вы можете услышать, это SLR, CLR, LALR, и этот комментарий StackOverflow хорошо разъясняет их.
Возможно, вы также слышали о так называемой грамматике синтаксического анализа (PEG). PEG — это то же самое, что и CFG, за исключением того, что это однозначное и жадное — если вы программист, а не математик, чаще всего PEG — это то, что вы думаете.
Неоднозначность болезненна. Markdown — хороший пример неоднозначной грамматики, и это основная причина, по которой синтаксические анализаторы Markdown не имеют формального определения грамматики BNF. В следующих примерах представлены ожидаемые результаты синтаксического анализа, основанные на последней спецификации CommonMark.
***жирный**курсив* => жирныйкурсив***italic*bold** => курсивполужирный *курсив**не полужирный* => курсив**не полужирный
Математик может определить CFG для Markdown с помощью BNF следующим образом:
Математик сказал бы, что это допустимая CFG определения и убедитесь, что три приведенных выше примера соответствуют языку. Однако, если бы вы были программистом, пытающимся написать анализатор уценки, это определение CFG для вас практически бесполезно. Если бы вы интерпретировали это определение в реальном синтаксическом анализаторе, он потерпел бы неудачу, потому что программа не может быть двусмысленной. PEG будет охотно сопоставлять токены, как если бы это была настоящая программа, тогда как математика на самом деле это не волнует.
Однако, если бы вы были программистом, пытающимся написать анализатор уценки, это определение CFG для вас практически бесполезно. Если бы вы интерпретировали это определение в реальном синтаксическом анализаторе, он потерпел бы неудачу, потому что программа не может быть двусмысленной. PEG будет охотно сопоставлять токены, как если бы это была настоящая программа, тогда как математика на самом деле это не волнует.
John : Парсер Markdown — отличный пример, а двусмысленность грамматики — боль. Уценка стала слабым размытым стандартом.
Я: Я думаю, что на самом деле может быть наоборот. Ознакомьтесь с последней спецификацией о том, как работает полужирный шрифт и курсив. Смею вас потратить 15 минут на чтение этой спецификации, пытаясь понять ее, и написать простой синтаксический анализатор жирного шрифта и выделения, удовлетворяющий примерам 328–455. Может быть, проблема в том, что CommonMark настолько переопределен и нелеп, что никто на самом деле не соответствует ему.
Для однозначных контекстно-свободных языков, таких как C, есть всевозможные инструменты. Наиболее популярными являются ANTLR, Bison и YACC. На самом деле их называют компиляторами-компиляторами , потому что они не просто проверяют грамматику, но и предоставляют инструменты для создания компиляторов для этих грамматик. Есть репозиторий с кучей примеров грамматики ANTLR, которые довольно интересно проверить. В мире JavaScript вы также можете проверить PEG.js и Jison.
Тип 1 — Контекстно-зависимые языки 9н | n >= 0 }
Мы можем проверить, что строка написана на этом языке, используя автомат со следующей процедурой:
- Считайте первые a и перезапишите их x.
- Перейти к первому b и перезаписать его x.
- Перейти к первому c и перезаписать его x.
- Затем вернитесь к началу и вернитесь к (1).
- Если вы дойдете до конца строки, ища первые a , и все они равны x’ s, тогда мы проверили строку.

Здесь следует признать, что по сравнению с предыдущим примером этот синтаксический анализатор имеет состояние, поддерживаемое путем изменения входной памяти, которая не является просто стеком.
Тип 0 — R
Рекурсивно перечисляемые языкаЯзыки типа 0 называются рекурсивно перечислимыми и представляют собой все, что может быть решено компьютером, то есть не проблема остановки. Простое, но досадно сложное математическое доказательство того, что язык относится к типу 0, но не к типу 1, — это язык, который считывает два регулярных выражения и определяет, представляют ли они один и тот же язык. Это хорошо известная проблема EXPSPACE, поэтому она явно не может быть типом 1.
Нерешенная гипотеза
Обычный вопрос: как мы можем анализировать неоднозначные контекстно-свободные грамматики . Что ж, если вы сможете доказать, что не можете написать PEG для какой-то CFG, тогда вы будете титулованным математиком!
«Предполагается, что существуют контекстно-свободные языки, которые не могут быть проанализированы PEG, но это еще не доказано».
 — Википедия , ACM
— Википедия , ACMВ противном случае, для всех ваших потребностей в синтаксическом анализе, комбинаторы синтаксических анализаторов — это универсальное элегантное решение, и об этом мы поговорим далее.
Комбинаторы синтаксических анализаторов — это элегантный и мощный способ определения синтаксических анализаторов. Parsec — популярная библиотека Haskell и де-факто решение для комбинаторов синтаксических анализаторов. Практически все другие решения на других языках вдохновлены Parsec — Parsatron для Clojure, Parsec.py для Python и Parsimmon для JavaScript. Поначалу комбинаторы парсера могут показаться немного сложными, но на самом деле они относительно просты. Итак, давайте разберем его и создадим небольшой игрушечный пример.
Если вы знакомы с функциональным программированием и теорией категорий, вы по достоинству оцените элегантность комбинаторов парсеров. Если нет, то продолжать чтение не обязательно, но я настоятельно рекомендую ознакомиться с курсом Брайана Лонсдорфа на Egghead.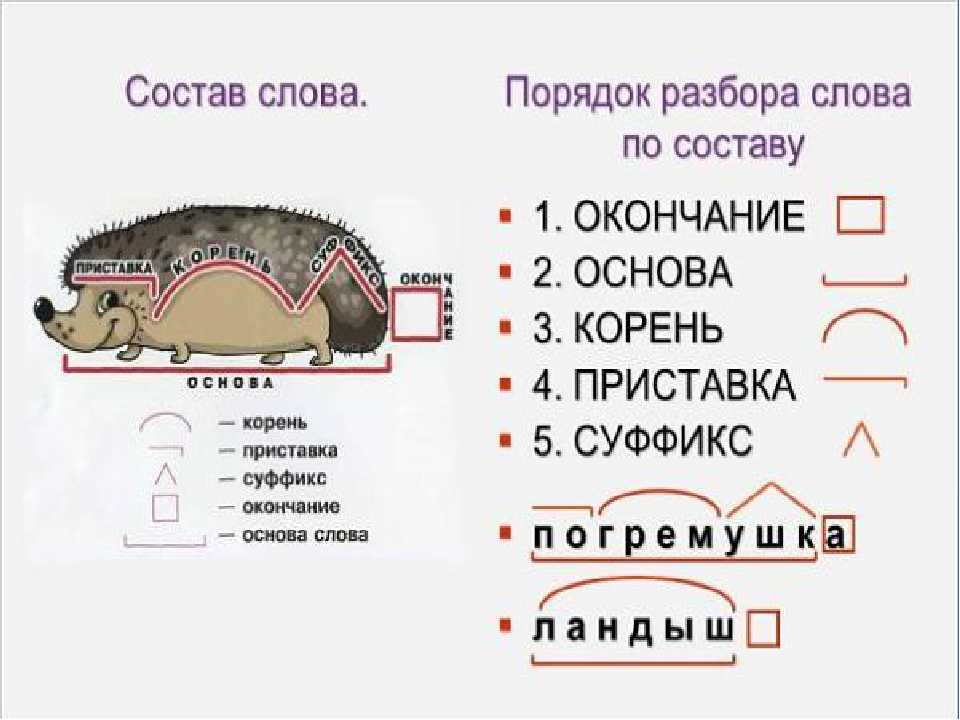
Наивный подход
Целью комбинаторов синтаксических анализаторов является создание мини-парсеров, которые объединяют вместе в более крупные анализаторы. Это означает, что когда мы что-то анализируем, последующие парсеры могут анализировать что-то еще. Итак, давайте определим синтаксический анализатор, который анализирует только один символ.
Если мы видим искомый символ, мы потребляем один символ из ввода и возвращаем сообщение об успехе, а остальную часть ввода необходимо проанализировать.
Мы можем комбинировать эти синтаксические анализаторы вместе с некоторыми функциями более высокого порядка, называемыми комбинаторами . Давайте создадим комбинатор с именем sequence , который принимает список синтаксических анализаторов и будет анализировать ввод с использованием этих синтаксических анализаторов по порядку.
Одна вещь, которая довольно крутая, это то, что, когда синтаксический анализатор дает сбой, мы можем видеть, где именно он сбой. Давайте воспользуемся этим комбинатором последовательностей для создания синтаксического анализатора строк .
Давайте воспользуемся этим комбинатором последовательностей для создания синтаксического анализатора строк .
Вы заметите, что мы даже не коснулись введите аргумент — это потому, что эти функции каррируются! Вы уже можете видеть, насколько краткими могут быть синтаксические анализаторы, использующие эти комбинаторы. Вот еще один очень полезный комбинатор, который пробует каждый из синтаксических анализаторов в списке, пока не сработает один или пока все не выйдет из строя.
С помощью этого подхода мы можем встроить их в более сложные синтаксические анализаторы, и я рекомендую перейти к CodePen ниже и реализовать несколько других комбинаторов, таких как nOrMore и , возможно, .
Нажмите «Редактировать на CodePen» в правом верхнем углу, чтобы изменить код. Хотя такой подход немного наивен. Одна важная часть, которой не хватает, заключается в том, что эти синтаксические анализаторы не выводят никаких значений! Это важно, если мы действительно хотим что-то сделать со строкой, которую мы только что проанализировали. Другая проблема связана с производительностью — каждый раз, когда мы создаем строку rest , мы отсекаем только один символ и копируем остальную часть строки в другую переменную в памяти. Это будет проблемой, если мы анализируем большую входную строку.
Другая проблема связана с производительностью — каждый раз, когда мы создаем строку rest , мы отсекаем только один символ и копируем остальную часть строки в другую переменную в памяти. Это будет проблемой, если мы анализируем большую входную строку.
Раунд 2
Во-первых, давайте решим проблему производительности, связанную с измельчением входной строки. Мы собираемся создать новый тип данных, который содержит всю строку вместе с курсором, чтобы отслеживать, где мы находимся внутри строки. Я буду называть это Stream , хотя это может быть неправильным.
Обратите внимание, что этот Stream может обрабатывать как массивы, так и строки — это довольно мило! Далее мы собираемся создать типы данных Success и Failure , которые отслеживают остальное потока, а также значение , которое может быть выдано парсером. Эти типы данных представляют собой тегированное объединение, очень похожее на типы Maybe или Both. Я также добавил несколько методов-прототипов для map , bimap , chain и fold. (Если вы не слишком знакомы с функциональным программированием, это совершенно нормально, и не беспокойтесь о следующем предложении.) Эти методы представляют собой алгебраическую структуру для четко определенных категорий для функтора, бифунктора, цепочки и складной на основе Спецификация FantasyLand.
Я также добавил несколько методов-прототипов для map , bimap , chain и fold. (Если вы не слишком знакомы с функциональным программированием, это совершенно нормально, и не беспокойтесь о следующем предложении.) Эти методы представляют собой алгебраическую структуру для четко определенных категорий для функтора, бифунктора, цепочки и складной на основе Спецификация FantasyLand.
А теперь последняя часть головоломки. Парсер содержит функцию, которая анализирует поток , но имеет методы для сопоставления и связывания результатов анализа .
Теперь мы можем создать функцию char заново, только на этот раз мы выдадим этот символ с результатом .
Но помните, что Stream не всегда должен быть String ? Давайте обобщим это немного больше, чтобы работать с Массив тоже.
Итак, что у нас здесь? Что ж, давайте что-нибудь разберем, а затем сложите , чтобы получить результат.
Мы можем использовать карту , если мы хотим изменить выходное значение при успешном разборе.
И мы можем использовать bimap для улучшения сообщений об ошибках.
Последняя часть головоломки — это цепочка , которую мы можем использовать для последовательного объединения парсеров.
Обратите внимание, что мы получили только последнее значение из синтаксического анализатора. Мы можем объединить все значения вместе в выводе так же, как мы могли бы сделать это, если бы мы объединяли Promise вместе в последовательности:
Итак, теперь давайте создадим некоторые из тех полезных комбинаторов, которые были раньше. Мы можем начать с нашего комбинатора или .
Мы можем очень аккуратно создать наш комбинатор последовательности , но было бы неплохо, если бы мы также определили некоторые другие вспомогательные функции.
Теперь намного чище! Я надеюсь, вы действительно начинаете понимать, почему они называются комбинаторами . Другой интересный пример с этим новым подходом, который мы использовали, — это может быть комбинатор .
Другой интересный пример с этим новым подходом, который мы использовали, — это может быть комбинатор .
Мне очень нравится этот пример, потому что в нем есть очень явная тонкость: когда синтаксический анализатор дает сбой, мы возвращаем Success с null значением и исходным Stream , переданным синтаксическому анализатору. То есть мы ничего не потребляли из потока при неудачном разборе. Это называется с возвратом , который обсуждался в статье, на которую я ссылался в начале, о парсерах LL(1) . Если синтаксический анализатор анализирует 10 символов, а затем дает сбой, мы хотим продолжить синтаксический анализ с того места, где он начал синтаксический анализатор. Однако у этого есть свои недостатки производительности, если вы анализируете более одного символа и заключаете их все в 9 символов.0003 может быть .
Еще один забавный комбинатор — с опережением . Это плохо для производительности, но действительно полезно, когда вам это нужно. По сути, он делает утверждение о том, что будет дальше, но на самом деле ничего не потребляет из потока. Это полезно, например, для неоднозначных случаев в Markdown. Если вы хотите, чтобы
По сути, он делает утверждение о том, что будет дальше, но на самом деле ничего не потребляет из потока. Это полезно, например, для неоднозначных случаев в Markdown. Если вы хотите, чтобы *italic** преобразовывался в italic* , тогда, когда вы столкнетесь со второй звездочкой, вам нужно будет выполнить lookahead , чтобы убедиться, что другой звездочки нет.
Последний пример: предположим, мы хотим разобрать текст между двумя токенами. Может быть, это теги HTML или что-то в этом роде. Мы подойдем к этой проблеме, определив несколько комбинаторов, чтобы определение нашего синтаксического анализатора было действительно семантическим и выразительным.
Сначала мы собираемся определить zeroOrMore , что очень похоже на * в регулярных выражениях. Нам понадобится этот комбинатор, чтобы проанализировать все, что находится в середине двух HTML-тегов.
Если мы хотим все между и , было бы неплохо иметь функцию строки , как у нас раньше. На самом деле, это то же точное определение!
На самом деле, это то же точное определение!
Теперь сложная часть: как только мы проанализируем , нам нужно выражение для того, что считается действительным токеном, пока мы не доберемся до . Для этого я создал комбинатор , а не , который утверждает, что какой-то синтаксический анализатор не будет анализировать, а затем продвигает поток на один символ.
Последняя часть, и мы готовы: мы можем определить комбинатор между , который принимает три синтаксических анализатора и возвращает проанализированный бит между ними.
Итак, теперь мы готовы определить наш синтаксический анализатор, который анализирует все, что находится между двумя HTML-тегами:
Вот и все! Ознакомьтесь с CodePen ниже и поиграйте сами. И если вы готовы принять вызов, создайте функцию sepBy , которая анализирует значения, разделенные другими значениями. Это полезно, например, для разбора элементов в списке.
Нажмите «Редактировать на CodePen» в правом верхнем углу, чтобы изменить код.
Если вы хотите увидеть более сложные комбинаторы синтаксического анализатора в действии, ознакомьтесь с примерами Parsimmon — пример JSON должен быть достаточно простым для понимания.
Другие библиотеки
Есть еще некоторые вещи, которые мы еще не обработали в этой мини-библиотеке. Одна существенная проблема заключается в том, что мы определили множество функций рекурсивно, но JavaScript не поддерживает устранение хвостовых вызовов. Таким образом, вам пришлось бы реализовать трамплининг, если бы вы использовали этот код для разбора больших файлов. Тем не менее, существуют существующие библиотеки комбинаторов синтаксических анализаторов для JavaScript. Парсиммон выглядит довольно хорошо, а Бенну отлично выглядит, несмотря на то, что он написан каким-то странным языком.
Давайте повторим некоторые важные выводы из этой статьи:
- Иерархия Хомского определяет четыре класса формальных языков, которые можно отличить по сложности программы, необходимой для синтаксического анализа и проверки строки.
- Большинство языков программирования не зависят от контекста и, возможно, где-то определена грамматика BNF. Хорошее место для начала поиска — обширный список примеров ANTLR.
- В некоторых языках, таких как Markdown, много неясностей. Даже если они не зависят от контекста, чрезвычайно сложно определить выражение синтаксического анализа с использованием BNF.
- Комбинаторы синтаксического анализа — это элегантное решение общего назначения для всех ваших потребностей в синтаксическом анализе.

Спасибо за чтение и, пожалуйста, дайте мне знать, что вы думаете! Если вам понравилась эта статья, возможно, вас заинтересует мой еженедельный информационный бюллетень, в котором я отбираю статьи, которые нахожу интересными.
Я также хочу упомянуть и поблагодарить Эллиота Маркса за то, что он помог мне понять все, что я написал в разделе теории, и Брайана Лонсдорфа за то, что он сказал мне, что комбинаторы синтаксических анализаторов — это вещь!
Анализ Определение и значение | Dictionary.
 com
com- Лучшие определения
- Тест
- Связанный контент
- Примеры
- Британский
Показывает уровень сложности слова.
[pahrs, особенно британский, pahrz]
/ pɑrs, особенно британский, pɑrz /
Сохранить это слово!
См. синонимы для разбора на Thesaurus.com
Показывает уровень оценки в зависимости от сложности слова.
глагол (используется с объектом), анализируется, анализируется.
проанализировать (предложение) с точки зрения грамматических составляющих, определить части речи, синтаксические отношения и т. д.
грамматически описать (слово в предложении), определить часть речи, форму словоизменения, синтаксическую функцию, и т.д.
анализировать (что-то, как речь или поведение), чтобы обнаружить его последствия или раскрыть более глубокий смысл: Политические обозреватели были в своей славе, разбирая речь президента об экономике в мельчайших деталях.
Компьютеры. анализировать (строку символов), чтобы связать группы символов с синтаксическими единицами базовой грамматики.
глагол (используется без объекта), разбор, разбор.
для анализа; поддается разбору: Извините, но ваш заключительный абзац просто не разбирается.
ВИКТОРИНА
ВСЕ ЗА(U)R ЭТОГО БРИТАНСКОГО ПРОТИВ. ВИКТОРИНА ПО АМЕРИКАНСКОМУ АНГЛИЙСКОМУ
Существует огромная разница между тем, как люди говорят по-английски в США и Великобритании. Способны ли ваши языковые навыки определить разницу? Давай выясним!
Вопрос 1 из 7
Правда или ложь? Британский английский и американский английский различаются только сленговыми словами.
Происхождение разбора
Впервые записано в 1545–1555 гг.; от латинского pars «часть», как и в pars ōrātiōnis «часть речи»
ДРУГИЕ СЛОВА ИЗ parse
pars·a·ble, прилагательноеpars·er, существительное·parse, глагол (используется с дополнением), mis·parsed, mis ·pars·ing. un·parsed, прилагательное
un·parsed, прилагательноеСлова рядом parse
поганка попугая, попугай тюльпан, парри, Парри Канал, парс, разбор, парсек, Парси, Парсеизм, парсер, Парша
Dictionary.com Полный текст На основе Random House Unabridged Dictionary, © Random House, Inc. 2023
Слова, относящиеся к разбору
определять, анализировать, разрешать, определять, делать выводы, интерпретировать, переводить, проверять, проверять, проверять, рассматривать, критиковать, исследовать, осматривать, исследовать, обдумывать, корпеть над, исследовать, читать, исследовать
Как использовать синтаксический анализ в предложении
Тогда стоит потратить некоторое время на разбор того, что именно говорится в отчете, что конкретно отрицания и то, как они соотносятся с фактами, какими мы их знаем.
Трамп назвал погибших в войне США «неудачниками» и «лохами»? Объяснение противоречия.|Алекс Уорд|4 сентября 2020 г.|Vox
В новой колонке главный редактор VOSD Скотт Льюис анализирует решение и критикует чиновников за отказ уделить первоочередное внимание физическому открытию школ.
Утренний отчет: Барриос не сообщил о доходах|Голос Сан-Диего|1 сентября 2020 г.|Голос Сан-Диего
Нам просто нужно проанализировать, что означает «победа» с точки зрения биологии.
Секрет долгой и здоровой жизни кроется в генах самых старых людей|Шелли Фан|10 августа 2020 г.|Центр Singularity предоставляет способ разобрать мозг на области, которые можно дополнительно изучить.
Эти ученые только что завершили 3D-проект «Google Планета Земля» для мозга|Веер Шелли|5 августа 2020 г.|Центр Singularity

Чтобы понять последствия Covid-19однако в дальнейшем экономисты внутри и вне правительства США анализируют очень разные наборы данных.
Данные, на которые следует обратить внимание вместо ВВП, чтобы понять, куда движется экономика|Карен Хо|31 июля 2020 г.|Quartz грамматика
придавать составляющую структуру (предложению или словам в предложении)
(вступление) (слова или языкового элемента) играть определенную роль в структуре предложения
вычисления для анализа исходного кода компьютерной программы, чтобы убедиться, что она структурно правильна, прежде чем она будет скомпилирована и преобразована в машинный код C16: от латинского pars (orātionis) часть (речи)
Словарь английского языка Коллинза — полное и полное цифровое издание 2012 г.
