Национальный корпус русского языка
Подробнее о Корпусе
05.10.2022
Акцентологический корпус пополнен до 133,8 млн словоупотреблений.
Устный корпус пополнен до 13,9 млн словоупотреблений.
16.09.2022
В наших больших корпусах появились новые типы разметки с использованием нейросетевых методов — это лексико-грамматическая разметка с автоматическим разрешением омонимии и автоматическая синтаксическая разметка. Сегодня поиск по такой разметке открыт в Газетном корпусе региональных СМИ, на следующем этапе он станет доступен для основного и газетного корпусов.
На всем объёме регионального корпуса автоматически разведены морфологические омонимы: например, существительное печь теперь размечено иначе, чем глагол печь, а дательный падеж — чем предложный. Можно искать такие синтаксические параметры, как разные типы сложных предложений, предикативных групп (клауз), дополнения, связки, обращения и многое другое. Синтаксическая разметка в региональном корпусе устроена иначе, чем в отдельном синтаксическом корпусе, и сильнее ориентирована на синтаксис составляющих.
Синтаксическая разметка в региональном корпусе устроена иначе, чем в отдельном синтаксическом корпусе, и сильнее ориентирована на синтаксис составляющих.
Просим вас активно пользоваться новыми возможностями поиска и сообщать нам о всех замеченных ошибках.
В синтаксическом корпусе существенно пополнена информация о текстах: теперь пользователю показываются пол автора, сфера функционирования, тема и тип текста, издание и дата разметки. Для предложений с неоднословными оборотами (например, потому что или по меньшей мере) показывается два варианта структуры предложения: с пословным разбором и с разбором, где оборот представлен как одно слово. Объем корпуса вырос до 1,5 млн словоупотреблений.
16.09.2022
Существенно обновлен интерфейс поиска по основному корпусу. Мы постарались сделать поиск более современным и учесть пожелания, связанные с удобством работы.
Для тех пользователей, которые только знакомятся с новым интерфейсом или с корпусом, на главной странице появился новый функционал «Обзор возможностей». Задав слово или словосочетание, вы увидите, какие виды результатов поиска можно получить в НКРЯ, узнаете о возможных ошибках при задании запроса и сможете перейти к поиску по корпусу.
Задав слово или словосочетание, вы увидите, какие виды результатов поиска можно получить в НКРЯ, узнаете о возможных ошибках при задании запроса и сможете перейти к поиску по корпусу.
В интерфейсе основного корпуса произошли следующие изменения:
В форме лексико-грамматического поиска по основному корпусу блоки с условиями на слово теперь расположены не сверху вниз, а слева направо. Это позволяет самостоятельно добавить нужное количество слов и для каждого из них задать только те условия, которые необходимы для исследования. В наборе условий, доступных в основном корпусе, теперь появилось отдельное поле «Словоформа».
В верхней части всплывающего окна при выборе значений атрибутов появляется формула поиска, объединяющая выбранные значения. Во всплывающих окнах для выбора атрибутов текстов списки значений теперь учитывают изменения в разметке текстов: тексты с новым атрибутом сразу можно найти, а атрибуты, тексты с которыми отсутствуют в корпусе, не отображаются в списке.
Подкорпус теперь можно задать как до, так и после задания запроса, а вместо всплывающих окон с большим количеством значений для художественных и нехудожественных текстов сделан компактный выбор из списков.
Как параметры запроса, так и параметры подкорпуса запоминаются, их можно отредактировать в любой момент.
На странице с результатами поиска отображаются все параметры запроса и параметры подкорпуса (если он задан). Все настройки и выбор способа сортировки теперь сосредоточены в верхней части страницы и сохраняются в браузере пользователя.
Этот список изменений далеко не полон, подробнее об изменениях можно почитать в руководстве пользователя.
Существенно изменилось также внутреннее устройство системы. Основной корпус переведен на корпусную платформу нового поколения, разработанную в рамках гранта МОН № 075-15-2020-793. Корпусная платформа, конфигурация корпусов и пользовательский интерфейс теперь представляют собой отдельные, но системно связанные посредством API части НКРЯ.
Планируется постепенный перевод остальных корпусов на новый интерфейс и новую платформу.
Просим вас активно пользоваться новой версией сайта и сообщать нам о всех замеченных ошибках.
31.08.2022
Пополнен Параллельный корпус. В чешско-русскую часть включены материалы современных чешских СМИ, а также художественная проза и публицистика XIX—XXI веков. Во французско-русскую часть включены художественные и научные тексты. Объем параллельного корпуса вырос до 166 млн словоформ.
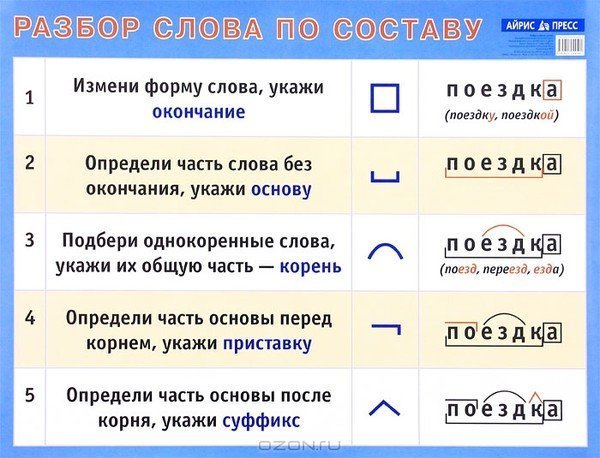
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «читать», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ЧИТАТЬ, аю, аешь; читанный; несов.
1. что. Воспринимать написанное, произнося или воспроизводя про себя. Ч. книгу. Ч. вслух. Ч. про себя (не вслух). Ч. по слогам. Ч. бегло. Ч. на двух языках. Ч. с губ (у глухонемых: воспринимать словесную речь по движениям губ).
2. кого-что. Воспринимать зрительно и интеллектуально какое-н. произведение. Юноша много читает. Ничего не читает кто-н. Ч. ноты (перен.: различать их и воспроизводить их голосом или на музыкальном инструменте). Ч. географические карты, чертежи (перен.: уметь пользоваться).
3. перен., что. Воспринимать, угадывать что-н. по внешним проявлениям. Ч. настроения по лицам. Ч. в сердцах (угадывать чьин. мысли, желания). Ч. сомнение на лице у кого-н.
4. кого-что. Произносить, декламировать (какой-н. текст). Ч. стихи с эстрады. Ч. наизусть басни Крылова.
5. что. Произносить с целью поучения, наставления. Ч. нотации, нравоучения.
Произносить с целью поучения, наставления. Ч. нотации, нравоучения.
6. что. Излагать устно перед аудиторией. Ч. лекцию. Ч. курс русской литературы.
7. читай(те). употр. в знач.: это нужно понимать так-то, это значит то-то. Нежелание вмешиваться читай равнодушие.
| сов. прочесть, чту, чтёшь; чтённый (ён, ена) (к 1, 2, 3, 4, 5 и 6 знач.) и прочитать, аю, аешь; итанный (к 1, 2, 3, 4, 5 и 6 знач.).
| многокр. читывать, наст. не употр. (ко 2 и 4 знач.).
| сущ. чтение, я, ср. (к 1, 2, 3, 4, 5 и 6 знач.), читание, я, ср. (ко 2 и 5 знач.) и прочтение, я, ср. (к 1, 4 и 6 знач.). Взять книгу для прочтения.
| прил. читальный, ая, ое (ко 2 знач.).
читальный, ая, ое (ко 2 знач.).
Фонетический (звуко-буквенный) разбор
чи́тать
читать — слово из 2 слогов: чи-тать. Ударение падает на 1-й слог.
Транскрипция слова: [ч’итат’]
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
и — [и] — гласный, ударный
т — [т] — согласный, глухой парный, твёрдый (парный)
а — [а] — гласный, безударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 6 букв и 5 звуков.
Цветовая схема: читать
Разбор слова «читать» по составу
читать (программа института)
читать (школьная программа)
Части слова «читать»: чит/а/ть
Часть речи: глагол
Состав слова:
чит — корень,
а, ть — суффиксы,
нет окончания,
чита — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Parser Combinators: прохождение
04 декабря, 2020 | 14 минут чтения
Или: Напишите вам парсек во имя великого добра
Большинство людей на пути к Haskell проходят одни и те же первые шаги. Во-первых, вам нужно познакомиться с самим языком, особенно если вы приходите к нему без каких-либо знаний функционального программирования: его необычный синтаксис, ленивость, отсутствие изменяемого состояния… Оттуда вы можете перейти к функциям и объявлениям типов, ознакомиться освойте функции Prelude (и их известные недостатки) и начните писать свои первые программы. Следующий большой шаг — это, конечно же, монады, печально известное слово на букву «м» 9.0009 [1] и как мы их используем для структурирования наших программ.
Но потом, когда ты начал развивать интуицию для монад… Путь становится неясным. Можно было бы охватить гораздо больше, но ничто из этого не является столь фундаментальным. Есть примерно три категории тем, которые можно изучить:
- Идем дальше с самим языком: изучаем языковые расширения, теорию, лежащую в их основе, и расширенные функции, которые они предоставляют.

- Узнайте больше о различных способах структурирования программы (таких как преобразователи монад или системы эффектов).
- Изучение некоторых из наиболее часто используемых библиотек и понимание того, что делает их такими вездесущими: QuickCheck, Lens… и Parsec.
Сегодня я хочу изучить Parsec, а особенно как работает Parsec . Синтаксический анализ используется повсеместно, и большинство программ на Haskell будут использовать Parsec или один из его вариантов (мегапарсек или аттопарсек). Хотя можно использовать эти библиотеки, не заботясь о том, как они работают, мне кажется интересным разработать ментальную модель их внутреннего устройства; а именно комбинаторы монадических синтаксических анализаторов , так как это простая и элегантная техника, которая полезна не только в случае использования синтаксического анализа необработанного текста. В Hasura мы недавно использовали эту технику, чтобы переписать код, который генерирует схему GraphQL и проверяет по ней входящий запрос GraphQL.
Чтобы лучше понять эту технику, в ходе этой статьи мы сначала повторно реализуем упрощенную версию Parsec , а затем используем ее для написания парсера для значений JSON [2] . Наша цель здесь не будет заключаться в разработке полноценной библиотеки, как раз наоборот: мы реализуем строгий минимум, который нам нужен, чтобы сосредоточиться на основных идеях.
Выбор представления типа для синтаксических анализаторов
С точки зрения высокого уровня синтаксический анализатор можно рассматривать как функцию перевода: он принимает в качестве входных данных некоторые слабоструктурированные данные (чаще всего это текст) и пытается преобразовать их в структурированные данные, следуя правилам формальная грамматика. Компилятор преобразует последовательность символов в абстрактное синтаксическое дерево, анализатор JSON преобразует последовательность символов в эквивалентное представление значения JSON в Haskell. Есть несколько алгоритмических подходов к этой проблеме; комбинаторы парсера являются примером рекурсивный спуск : мы анализируем каждый термин нашей грамматики, рекурсивно вызывая синтаксические анализаторы для каждого подтермина.
Это означает, что под «парсером» мы оба подразумеваем общее высокоуровневое преобразование и каждый из его отдельных шагов, поскольку каждый парсер рекурсивно выражается как комбинация других парсеров.
Минимальная жизнеспособная реализация
Давайте шаг за шагом разберемся с типом парсера. Во-первых, мы установили, что синтаксический анализатор — это функция от некоторого заданного ввода до того, что мы пытаемся проанализировать. В этом проекте мы будем использовать
тип Parser a = String -> a
Но этого типа недостаточно для нашего варианта использования. Прежде всего: синтаксический анализатор может дать сбой, если входные данные не соответствуют тому, что диктует наша грамматика. Нам нужно будет определить соответствующий тип для представления ошибок, и синтаксический анализатор должен включить эту возможность на уровне типа.
тип Parser a = String -> либо ParseError a
Кроме того, синтаксический анализ представляет собой последовательную операцию: для анализа объекта JSON необходимо сначала проанализировать открывающую фигурную скобку, затем проанализировать записи, а затем проанализировать закрывающую фигурную скобку; рекурсивно, чтобы проанализировать запись, нужно сначала проанализировать ключ, затем двоеточие, а затем значение. Наш тип синтаксического анализатора будет использоваться для представления каждого из этих шагов, и мы не ожидаем, что каждый шаг будет полностью потреблять входную строку: поэтому каждый синтаксический анализатор должен также возвращать что-то, указывающее, где мы находимся во входном потоке, сколько его было израсходовано или что осталось обработать.
Поскольку мы используем String в качестве нашего входного потока, каждому синтаксическому анализатору достаточно просто вернуть то, что осталось от входной строки [4] . Тип Parser , который мы будем использовать, будет следующим:
Тип Parser , который мы будем использовать, будет следующим:
Парсер нового типа a = Парсер {
runParser :: String -> (String, либо ParseError a)
}
Написание элементарных парсеров
любой :: Parser Char
any = Parser $ \input -> ввод регистра
-- осталось немного ввода: мы распаковываем и возвращаем первый символ
(x:xs) -> (xs, справа x)
-- ничего не осталось: анализатор не работает
[] -> ("", Left $ ParseError
"любой символ" -- ожидается
"конец ввода" -- встречается
)
eof::Парсер()
eof = Parser $ \input -> регистр ввода
-- никаких входных данных не осталось: синтаксический анализатор прошел успешно
[] -> ("", Право ())
-- оставшиеся данные: синтаксический анализатор не работает
(c:_) -> (ввод, Left $ ParseError
"конец ввода" -- ожидается
[с] -- встречается
)
Это только два основных парсера которые нам нужны! Они охватывают два основных случая: у нас есть символ для разбора или нет. Все остальное можно выразить с помощью этих двух и с помощью комбинаторов.
Все остальное можно выразить с помощью этих двух и с помощью комбинаторов.
Анализаторы последовательности
Как упоминалось ранее, синтаксический анализ последовательный . Нам часто нужно будет выразить что-то вроде: я хочу применить какой-то парсер A , затем какой-нибудь парсер B и использовать их результаты. Давайте посмотрим, как мы реализуем синтаксический анализатор для записи объекта JSON, например: нам нужно проанализировать строку json, затем двоеточие, затем значение json (мы будем предполагать, что эти отдельные синтаксические анализаторы уже существуют). Полученный код… неоптимален: повторяющийся, подверженный ошибкам и трудно читаемый:
jsonEntry :: Parser (String, JValue)
jsonEntry = Парсер $\ввод ->
-- разобрать строку json
case runParser jsonString ввод
(вход2, левая ошибка) -> (вход2, левая ошибка)
(вход2, правая клавиша) ->
-- в случае успеха: разобрать одно двоеточие
case runParser (char ':') input2 of
(input3, левая ошибка) -> (input3, левая ошибка)
(вход3, справа _) ->
-- в случае успеха: анализировать значение json
case runParser jsonValue input3 of
(input4, левая ошибка) -> (input4, левая ошибка)
(вход4, правильное значение) ->
-- в случае успеха: вернуть результат
(вход4, справа (ключ, значение))
Это делается довольно громоздко как из-за того, что каждый шаг может завершиться ошибкой, так и из-за того, что каждый шаг возвращает входные данные для следующего.
andThen :: Парсер a -> (a -> Парсер b) -> Парсер b
parserA `andThen` f = Parser $ \input ->
case runParser parserA ввод
(restOfInput, Right a) -> runParser (f a) restOfInput
(restOfInput, Left e) -> (restOfInput, Left e)
Эта функция позволяет нам переписать наш синтаксический анализатор записей JSON таким образом, что больше не требуется явного самоанализа каждого синтаксического анализатора на этом пути.
jsonEntry :: Parser (String, JValue)
jsonEntry =
-- разобрать строку json
jsonString `andThen` \key ->
-- разобрать одно двоеточие
char ‘:’ `иЗатем` \_ ->
-- разобрать значение JSON
jsonValue `andThen` \value ->
-- создать постоянный анализатор, который не потребляет входных данных
constParser (ключ, значение)
Силой монад!
Некоторым читателям этот шаблон и затем покажется знакомым; это потому, что andThen в точности совпадает с оператором привязки Monad :
(>>=) :: Парсер a -> (a -> Парсер b) -> Парсер b
Сделав наш Parser тип экземпляром Monad , мы можем использовать мощь всех функций, которые поставляются с ним, и гораздо более удобный синтаксис нотации do для наших парсеров [5] . Наконец, нашу функцию jsonEntry можно переписать лаконично и просто:
Наконец, нашу функцию jsonEntry можно переписать лаконично и просто:
jsonEntry :: Parser (String, JValue) jsonEntry = сделать ключ <- jsonString _ <- символ ‘:’ значение <- jsonValue возврат (ключ, значение)
В качестве примечания стоит упомянуть, что, хотя нотация do делает последовательность явной, мы также будем использовать операторы по всему коду (иначе это не был бы «настоящий Haskell» :P). В частности, следующие Функтор и Прикладные операторы :
(*>) :: Парсер a -> Парсер b -> Парсер b (<*) :: Парсер a -> Парсер b -> Парсер a (<$) :: a -> Парсер b -> Парсер a -- игнорировать начальные пробелы пробелы *> значение -- игнорировать конечные пробелы значение <* пробелы -- подставить значение Истина <$ строка «истина»
Резюме
На данный момент мы определили два наших элементарных парсера и увидели, что цепочка является монадической операцией. Все готово: наши основные потребности удовлетворены. Теперь мы можем начать создавать более интересные парсеры. Для начала представим удовлетворяет : небольшая оболочка вокруг любого , которая позволяет нам проверить, соответствует ли следующий символ во входных данных некоторому произвольному требованию.
Теперь мы можем начать создавать более интересные парсеры. Для начала представим удовлетворяет : небольшая оболочка вокруг любого , которая позволяет нам проверить, соответствует ли следующий символ во входных данных некоторому произвольному требованию.
удовлетворять :: String -> (Char -> Bool) -> Parser Char
выполнить предикат описания = попытаться $ сделать
с <- любой
если предикат c
затем вернитесь с
описание else parseError [c]
Эта функция, хотя и проста, использует другие функции, с которыми мы еще не сталкивались, такие как try . Это наш первый комбинатор!
Объединение парсеров
Формально комбинатор — это функция, которая не полагается ни на что, кроме своих аргументов, например (.) оператор композиции функций:
(ф. г) х = ж (г х)
Но неформально… комбинатор — это то, что объединяет другие вещи . И именно в этом неформальном смысле мы используем его здесь! В нашем контексте комбинаторы синтаксических анализаторов — это функции на синтаксических анализаторах : функции, которые объединяют и преобразуют синтаксические анализаторы в другие синтаксические анализаторы для обработки таких вещей, как поиск с возвратом или повторение.
Выбор, ошибки и возврат
Мы знаем, что синтаксические анализаторы могут дать сбой: поэтому у нас есть или в их типе. Но не все ошибки фатальны: от некоторых из них можно восстановиться. Представьте, например, что вы пытаетесь проанализировать значение JSON: это может быть объект, или массив, или строка… Чтобы проанализировать такое значение, вы можете попробовать проанализировать открывающие фигурные скобки объекта: если это успешно, вы можете продолжить синтаксический анализ объекта; но если это сразу не удается, вы можете вместо этого попытаться разобрать открывающую скобку массива и так далее. Именно с ошибкой и возвратом мы можем реализовать нашу первую «продвинутую» функцию: выбор.
Чтобы отличить реальную ошибку, которая произошла дальше по линии, или что-то, что просто было неправильным выбором, мы проводим различие между синтаксическими анализаторами, которые терпят неудачу без использования каких-либо входных данных , которые терпят неудачу немедленно, и парсеры, которые терпят неудачу позже: мы предполагаем что если какой-либо ввод был потреблен, то мы были на правильной «ветви».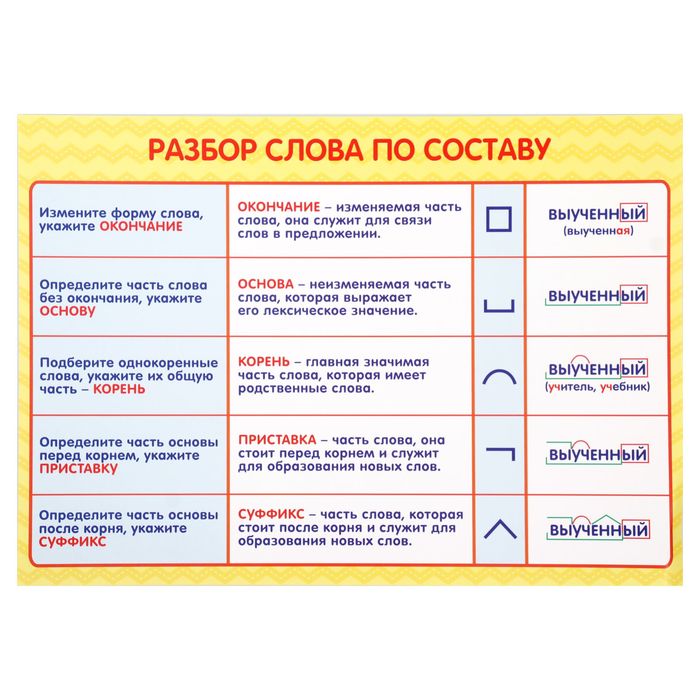 Но просмотра только одного символа вперед не всегда будет достаточно, чтобы решить, является ли ветвь правильной, и в этом случае нам нужно иметь возможность вернуться назад, если ветвь не удалась: нам нужен комбинатор возврата. вот что try делает: он превращает анализатор в анализатор с возвратом: тот, который не использует входные данные в случае сбоя, который восстанавливает состояние до того, что было. Имеет смысл использовать его для удовлетворения : если предикат не работает, мы не встретили ни одного символа, который можно было бы распаковать, и мы должны оставить входную строку без изменений.
Но просмотра только одного символа вперед не всегда будет достаточно, чтобы решить, является ли ветвь правильной, и в этом случае нам нужно иметь возможность вернуться назад, если ветвь не удалась: нам нужен комбинатор возврата. вот что try делает: он превращает анализатор в анализатор с возвратом: тот, который не использует входные данные в случае сбоя, который восстанавливает состояние до того, что было. Имеет смысл использовать его для удовлетворения : если предикат не работает, мы не встретили ни одного символа, который можно было бы распаковать, и мы должны оставить входную строку без изменений.
попытка :: Парсер a -> Парсер a try p = Parser $ \state -> case runParser p состояние (_newState, левая ошибка) -> (состояние, левая ошибка) успех -> успех
В этом проекте мы называем наши комбинаторы точно так же, как Parsec. Оператор, который Parsec использует для представления выбора, совпадает с оператором, определенным классом типов Alternative : (<|>) . Его семантика проста: если первый синтаксический анализатор дал сбой, не приняв никаких входных данных [6] , попробуйте второй; в противном случае распространите ошибку:
Его семантика проста: если первый синтаксический анализатор дал сбой, не приняв никаких входных данных [6] , попробуйте второй; в противном случае распространите ошибку:
(<|>) :: Парсер а -> Парсер а -> Парсер а
p1 <|> p2 = Parser $ \s -> case runParser p1 s из
(с', левая ошибка)
| s' == s -> runParser p2 s
| иначе -> (s', левая ошибка)
успех -> успех
С помощью этого оператора мы, наконец, можем реализовать гораздо более удобный комбинатор: выбор . Имея список синтаксических анализаторов, попробуйте их все, пока один из них не добьется успеха.
выбор :: Строка -> [Парсер а] -> Парсер а описание выбора = папка (<|>) noMatch где noMatch = описание parseError "нет совпадения"
Повторение
Последняя группа комбинаторов, которая нам понадобится для нашего проекта, — это комбинаторы повторения. Они не требуют каких-либо внутренних знаний наших Parser и являются хорошим примером того, какую высокоуровневую абстракцию мы теперь можем писать. Как обычно, мы используем те же имена, что и Parsec: many эквивалентно звездочке регулярного выражения и соответствует нулю или более вхождений данного парсера, а many1 эквивалентно плюсу: соответствует одному или нескольким вхождениям:
Как обычно, мы используем те же имена, что и Parsec: many эквивалентно звездочке регулярного выражения и соответствует нулю или более вхождений данного парсера, а many1 эквивалентно плюсу: соответствует одному или нескольким вхождениям:
много, много1 :: Парсер а -> Парсер [а] много p = много1 p <|> вернуть [] много1 р = делать первый <- р остальные <- много р вернуться (первый: отдых)
Благодаря им мы также можем реализовать sepBy и sepBy1 , которые сопоставляют повторяющиеся вхождения данного синтаксического анализатора с заданным разделителем между ними:
sepBy, sepBy1 :: Парсер a -> Парсер s -> Парсер [a] sepBy p s = sepBy1 p s <|> return [] sepBy1 p s = делать первый <- р остальное <- много (s >> p) вернуться (первый: отдых)
Резюме
Вот и все: эти семь комбинаторов — все, что нам нужно для реализации синтаксического анализатора JSON с нуля; на данный момент у нас уже есть достаточно хорошая минимальная повторная реализация библиотеки комбинаторов синтаксических анализаторов, подобной Parsec!
Конечно, полноценная библиотека реализовывала бы гораздо больше: больше примитивов для обработки символов, комбинаторов для необязательных парсеров, более специфичных комбинаторов повторения, поддержки улучшенных сообщений об ошибках… Но это выходит за рамки данного упражнения.
Парсеры на практике: разбор JSON
Чтобы собрать воедино все, что мы видели до сих пор, давайте шаг за шагом рассмотрим процесс построения грамматики парсера JSON. Мы будем делать это снизу вверх: начнем с парсеров для отдельных символов, затем перейдем к парсерам для синтаксиса, затем для скаляров… пока, наконец, мы не сможем выразить парсер для произвольного значения JSON. Цель здесь — продемонстрировать, как на каждом этапе мы можем использовать более простые абстракции, которые мы построили, чтобы составить что-то более сложное. В этом разделе немного больше кода, но я надеюсь, что если вы до сих пор следили за всем, вам будет так же приятно читать, как и мне!
Мы будем использовать следующее представление для значений JSON, которое очень близко к тому, что определяет Aeson [7] :
данные JValue = JObject (JValue строки HashMap) | JArray [JValue] | JString Строка | Двойной номер JNumber | JBool Bool | JNull
Распознавание символов
Используя функции Data. Char , давайте начнем определение нашей грамматики с определения типа символов, которые мы хотим распознавать: это прямое использование нашего удовлетворяет функции :
Char , давайте начнем определение нашей грамматики с определения типа символов, которые мы хотим распознавать: это прямое использование нашего удовлетворяет функции :
char c = выполнить [c] (== c) пробел = удовлетворить "пробел" isSpace цифра = удовлетворить "цифра" isDigit
Синтаксис языка
Чтобы пойти дальше, мы можем определить удобные синтаксические функции, используя вышеупомянутые аппликационные операторы:
строка = символ пересечения
пробелы = много пробелов
символ s = строка s <* пробелы
между открытым закрытым значением = открытым *> значением <* закрытым
скобки = между (символ "[") (символ "]")
фигурные скобки = между (символ "{") (символ "}")
Реализация символа здесь основана на определении Parsec лексемы (в их библиотеке определений языка), которая всегда пропускает конечные пробелы; Таким образом, каждый синтаксический анализатор может быть безопасно написан с предположением, что нет начальных пробелов, которые он должен учитывать. Благодаря такому подходу в нашей грамматике JSON очень мало явных упоминаний о пробелах.
Благодаря такому подходу в нашей грамматике JSON очень мало явных упоминаний о пробелах.
Скаляры
Здесь наша реализация будет отличаться от стандарта JSON. Для простоты наш анализатор чисел будет сопоставлять только натуральные числа:
jsonNumber = читать <$> много1 цифра
Для логических значений мы просто сопоставляем два возможных случая:
jsonBool = выбор "JSON boolean" [ True <$ символ "true" , Ложь <$ символ "ложь" ]
Что касается строк, мы сопоставляем последовательность символов между двумя двойными кавычками, но мы должны обрабатывать возможность того, что некоторые символы могут быть экранированы. Мы обрабатываем только небольшое подмножество экранированных символов, реализация остальной части спецификации предоставляется читателю в качестве упражнения. 🙂
jsonString =
между (char '"') (char '"') (много jsonChar) <* пробелов
куда
jsonChar = выбор "Строковый символ JSON"
[ попробуйте $ '\n' <$ строка "\\n"
, попробуйте $ '\t' <$ строка "\\t"
, попробуйте $ '"' <$ строка "\\\""
, попробуйте $ '\\' <$ строка "\\\\"
, удовлетворять "не кавычки" (/= '"')
]
Массивы и объекты
Значения JSON по определению являются рекурсивными: массивы и объекты содержат другие значения JSON… Чтобы продолжить наш восходящий подход, мы будем предполагать существование верхнего уровня jsonValue парсер, который будет определен последним.
Объект JSON представляет собой группу отдельных записей, разделенных запятыми. Сначала мы анализируем их как список, используя наш комбинатор повторений, а затем преобразуем указанный список ассоциаций в HashMap :
. jsonObject = сделать
assocList <- фигурные скобки $ jsonEntry `sepBy` символ ","
вернуть $ fromList asocList
куда
jsonEntry = сделать
к <- jsonString
символ ":"
v <- jsonValue
возврат (к, в)
Наконец, массив — это просто группа значений, заключенных в скобки и разделенных запятыми:
jsonArray = скобки $ jsonValue `sepBy` символ ","
Собираем все вместе
Наконец, мы можем выразить анализатор верхнего уровня для значения JSON:
jsonValue = выбор "значение JSON" [JObject <$> jsonObject , JArray <$> jsonArray , JString <$> jsonString , JNumber <$> jsonNumber , JBool <$> jsonBool , JNull <$ символ "нуль" ]
И… все!
Завершение
Эта статья является результатом моего личного опыта попыток понять внутреннюю работу Parsec после многих лет его использования. Я попробовал свои силы в написании небольшого синтаксического анализатора JSON с нуля, на стороне, когда я изучал, что заставляет Parsec работать, чтобы лучше понять, применив его на практике. Когда я это сделал, я был поражен тем, насколько маленьким и лаконичным получился код, и насколько простой была грамматика JSON. Я искренне надеюсь, что это пошаговое руководство окажется для вас полезным и даст вам представление о красоте комбинаторов парсеров!
Я попробовал свои силы в написании небольшого синтаксического анализатора JSON с нуля, на стороне, когда я изучал, что заставляет Parsec работать, чтобы лучше понять, применив его на практике. Когда я это сделал, я был поражен тем, насколько маленьким и лаконичным получился код, и насколько простой была грамматика JSON. Я искренне надеюсь, что это пошаговое руководство окажется для вас полезным и даст вам представление о красоте комбинаторов парсеров!
Весь код в этой статье можно найти в этом списке GitHub.
Для более сложного примера использования комбинаторов синтаксического анализатора, если вы хотите узнать больше о том, как мы использовали эту технику для повторной реализации нашего поколения схемы GraphQL, вы можете взглянуть на описание PR, которое представило ее.
Хасура, конечно же, нанимает. Если обсуждения, подобные приведенным выше, кажутся вам убедительными, посмотрите на наши открытые роли и подайте заявку. Если вы хотите следить за тем, что строит команда, где мы говорим, и иногда получать гифки с детёнышами животных. .. Информационный бюллетень сообщества Hasura — это ежемесячная рассылка без традиционного маркетингового спама.
.. Информационный бюллетень сообщества Hasura — это ежемесячная рассылка без традиционного маркетингового спама.
Спасибо за прочтение!
От себя лично: холм, за который я готов умереть, заключается в том, что монады не сложны, но часто плохо преподаются или преподаются способом, который не предназначен должным образом для аудитории. Я серьезно рассматриваю возможность запустить какую-то программу «интуиция для монад, если вы уже знаете хотя бы один другой язык программирования, менее чем за 15 минут или ваши деньги обратно». ↩︎
Для простоты код в этой статье не будет полностью соответствовать стандарту: мы будем обрабатывать только натуральные числа и сокращенный набор экранируемых символов. ↩︎
Библиотеки комбинаторов синтаксического анализатора не используют напрямую String в качестве входных данных; отчасти потому, что для представления текста доступны лучшие типы, такие как Text , но также и потому, что синтаксический анализатор не всегда является первым шагом перевода: часто, например, в случае компилятора, лексер или токенизатор уже преобразовывают вводимый текст в последовательность лексем или токенов.
Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎Большинство библиотек предпочитают передавать запись State , которая упаковывает входные потоки и несет дополнительную информацию, такую как текущая позиция, что позволяет (помимо других преимуществ) гораздо лучше отображать сообщения об ошибках. ↩︎
Хотя Parsec и его производные используют этот монадический подход, можно создавать синтаксические анализаторы, которые полагаются только на Прикладной . Это компромисс: монадические синтаксические анализаторы более мощные, поскольку синтаксический анализ может разветвляться в зависимости от того, что было проанализировано ранее, но более ограниченные аппликативные синтаксические анализаторы допускают статическую интроспекцию значений. ↩︎
Выполнение сравнения строк для проверки того, не смог ли синтаксический анализатор использовать какие-либо входные данные, крайне неэффективно и является досадным следствием нашего упрощенного дизайна.
Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎Aeson — наиболее широко используемая библиотека Haskell для работы с JSON. ↩︎
 Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎
Для синтаксического анализатора важно, чтобы входные данные можно было линейно повторять; Парсек называет это Stream : String представляет собой поток Char , и вывод токенизатора также будет потоком токенов. ↩︎ Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎
Если вместо того, чтобы просто передавать String в качестве состояния, мы должны были использовать правильный Запись состояния , мы могли бы реализовать это более эффективно, например, сравнив значение, которое представляет нашу позицию во входном потоке. ↩︎#Engineering#Haskell
Antoine Leblanc
Как внимательно читать |
Процесс написания эссе обычно начинается с внимательного чтения текста. Конечно, в эссе иногда может фигурировать личный опыт автора, и все эссе зависят от собственных наблюдений и знаний автора. Но большинство эссе, особенно академических эссе, начинаются с внимательного прочтения какого-либо текста — картины, фильма, события — и обычно с прочтения письменный текст. Когда вы внимательно читаете, вы наблюдаете факты и детали текста. Вы можете сосредоточиться на конкретном отрывке или на тексте в целом. Ваша цель может состоять в том, чтобы заметить все яркие особенности текста, включая риторические особенности, структурные элементы, культурные отсылки; или ваша цель может заключаться в том, чтобы заметить только выбранных особенностей текста, например, противопоставления и соответствия или конкретные исторические ссылки. В любом случае, эти наблюдения представляют собой первый шаг в процессе внимательного чтения.
Второй шаг — интерпретация ваших наблюдений. То, о чем мы в основном говорим здесь, — это индуктивное рассуждение: переход от наблюдения конкретных фактов и деталей к заключению или интерпретации, основанной на этих наблюдениях. И, как и в случае индуктивных рассуждений, внимательное чтение требует тщательного сбора данных (ваших наблюдений) и тщательного обдумывания того, к чему эти данные добавляются.
Как начать:
1. Читайте с карандашом в руке и комментируйте текст.
«Аннотировать» означает подчеркивать или выделять ключевые слова и фразы — все, что кажется вам удивительным или важным или вызывает вопросы, — а также делать пометки на полях. Когда мы таким образом реагируем на текст, мы не только заставляем себя внимательно прислушиваться, но и начинаем думать вместе с автором о доказательствах — первый шаг на пути от читателя к писателю.
Когда мы таким образом реагируем на текст, мы не только заставляем себя внимательно прислушиваться, но и начинаем думать вместе с автором о доказательствах — первый шаг на пути от читателя к писателю.
Вот пример отрывка антрополога и натуралиста Лорен Эйсели. Это из его эссе под названием «Скрытый учитель».
. . . Однажды я получил неожиданный урок от паука. Это случилось далеко дождливым утром на Западе. Я поднялся по длинному ущелью в поисках окаменелостей, и там, прямо на уровне глаз, притаился огромный желто-черный паук-шар, чья паутина была привязана к высоким копьям бизоньей травы на краю арройо. Это была ее вселенная, и ее чувства не простирались дальше линий и спиц огромного колеса, в котором она обитала. Ее вытянутые когти чувствовали каждую вибрацию этой тонкой структуры. Она знала дуновение ветра, падение дождевой капли, трепет крыла пойманной мотылька. Вдоль одной спицы паутины тянулась толстая лента из паутины, по которой она могла поторопиться, чтобы исследовать свою добычу. Заинтересовавшись, я достал из кармана карандаш и коснулся пряди паутины. Сразу же последовал ответ. Паутина, сорванная угрожающим обитателем, начала вибрировать, пока не превратилась в размытое пятно. Все, что задевало когтями или крыльями эту удивительную ловушку, попадало в ловушку. По мере того как вибрации замедлялись, я мог видеть, как владелица перебирала свои ориентиры в поисках признаков борьбы. Острие карандаша было беспрецедентным вторжением в эту вселенную. Паук был ограничен паучьими идеями; его вселенная была вселенной паука. Все внешнее было иррациональным, посторонним, в лучшем случае сырьем для паука. Продолжая свой путь по оврагу, словно огромная невозможная тень, я понял, что в мире пауков я не существую. |
2. Найдите закономерности в том, что вы заметили в тексте: повторения, противоречия, сходства.
Что мы видим в предыдущем отрывке? Во-первых, Эйсели говорит нам, что паук-шар преподал ему урок, тем самым предлагая нам подумать, каким может быть этот урок. Но пока оставим этот более широкий вопрос и сосредоточимся на частностях — мы работаем индуктивно. В следующем предложении Эйсели мы обнаруживаем, что эта встреча «произошла далеко дождливым утром на Западе». Этот опенинг переносит нас в другое время, в другое место и имеет отголоски традиционного сказочного опенинга: «Жили-были...». Что это значит? Зачем Эйсели напоминать нам о сказках и мифах? Мы пока не знаем, но это любопытно. Делаем заметку.
Но пока оставим этот более широкий вопрос и сосредоточимся на частностях — мы работаем индуктивно. В следующем предложении Эйсели мы обнаруживаем, что эта встреча «произошла далеко дождливым утром на Западе». Этот опенинг переносит нас в другое время, в другое место и имеет отголоски традиционного сказочного опенинга: «Жили-были...». Что это значит? Зачем Эйсели напоминать нам о сказках и мифах? Мы пока не знаем, но это любопытно. Делаем заметку.
Детали языка убеждают нас в том, что мы находимся «на Западе» — ущелье, арройо, и трава буйвола. Помимо этого, однако, Эйсели называет паутину "своей вселенной" и "великим колесом, в котором она обитает", как и великое небесное колесо, галактики. Таким образом, метафорически паутина становится вселенной, «вселенной паука». А паук, «она», чьи «чувства не простирались дальше» ее вселенной, знает «трепет крыла пойманной мотылька» и спешит «исследовать свою добычу». Эйсели говорит, что видел, как она «ощупывает свои ориентиры в поисках признаков борьбы». Эти детали языка и другие характеризуют «владельца» сети как мыслящего, чувствующего, стремящегося — существо, очень похожее на нас. Но что с того?
Эти детали языка и другие характеризуют «владельца» сети как мыслящего, чувствующего, стремящегося — существо, очень похожее на нас. Но что с того?
3. Задавайте вопросы о закономерностях, которые вы заметили, особенно о том, как и почему.
Чтобы ответить на некоторые из наших собственных вопросов, мы должны оглянуться на текст и посмотреть, что еще происходит. Например, когда Эйсели касается кончиком карандаша паутины — событие, «для которого не существовало прецедента», — паук, естественно, не может понять феномен карандаша: «Паук был описан паучьими идеями». Конечно, у пауков нет идей, но у нас они есть. И если мы начнем рассматривать этот отрывок с точки зрения человека, рассматривая ситуацию паука в «ее вселенной» как аналогичную нашей ситуации в нашей вселенной (которую мы думаем как вселенная), тогда мы можем решить, что Эйзели предполагает, что наша вселенная ( вселенная) также конечна, что наши идеи ограничены и что за пределами нашей вселенной могут быть явления, столь же совершенно запредельные. наше знание самого Эйсели — этой «огромной невозможной тени» — было за пределами понимания паука.
наше знание самого Эйсели — этой «огромной невозможной тени» — было за пределами понимания паука.
Но почему огромный и невозможный, почему тень? Эйсели имеет в виду Бога, инопланетян? Или что-то другое, что мы не можем назвать или даже представить? Это урок? Теперь мы видим, что ощущение сказки или мифа в начале отрывка плюс эта ссылка на что-то огромное и невидимое перевешивают простой инопланетянин. своеобразная интерпретация. И хотя паук не может объяснить или даже уловить точку карандаша Эйсели, эта точка карандаша это объяснимое, в конце концов, рациональное. Так что, может, и не Бог. Нам нужно больше доказательств, поэтому мы возвращаемся к тексту — теперь ко всему эссе, а не только к этому отрывку — и ищем дополнительные подсказки. И по мере того, как мы действуем таким образом, уделяя пристальное внимание свидетельствам, задавая вопросы, формулируя интерпретации, мы участвуем в процессе, который является центральным для написания эссе и всей академической деятельности: другими словами, мы рассуждаем в соответствии со своими собственными идеями.