Фонетикалық талдау (Фонетический разбор)
Дыбыстар (Звуки)
Қазақ тілінде 42 әріп, 37 дыбыс бар.
В казахском языке 42 буквы и 37 звуков.
| Дауысты дыбыстар түрлері Виды гласных звуков |
|||||
| Тілдің қатынасына қарай По подъему языка |
Жақтың қатынасына қарай По положению челюсти |
Еріннің қатынасына қарай По участию губ |
|||
| жуан твердые |
жіңішке мягкие |
ашық открытые |
қысаң сжатые |
еріндік губные | езулік неогубленные |
| а, о, ы, ұ, э, у | ә, ө, і, ү, е, и | а, ә, е, о, ө, э | ы, и, і, у, ұ, ү | о, ө, у, ұ, ү | а, ә, е, э, ы, і, и |
| Дауыссыз дыбыстар түрлері Виды согласных звуков |
||
| Ұяң Звонкие |
Үнді Сонорные |
Қатаң Глухие |
| б, в, г, ғ, д, ж, з, һ | й, л, м, н, ң, р, у | к, қ, п, с, т, ф, х, ч, ц, ш, щ |
Буындар (Слоги)
- Ашық: A, BA
- Тұйық: AB
- Бітеу: BAB
A – дауысты дыбыс (гласный звук)
B – дауыссыз дыбыс (согласный звук)
Мысалы (Пример фонетического разбора)
Өсімдік1 — 3 буын, ө – ашық, сім – бітеу, дік – бітеу.
Ө – дауысты, ашық, еріндік, жіңішке;
с – дауыссыз, қатаң;
і – дауысты, қысаң, езулік, жіңішке;
м – дауыссыз, үнді;
д – дауыссыз, ұяң;
і – дауысты, қысаң, езулік, жіңішке;
к – дауыссыз, қатаң.
Сөзде 7 әріп, 7 дыбыс бар.
Дополнительно
Кроме фонетического разбора слова на казахском языке, Вам также могут быть интересны следующие темы:
- Синтаксический разбор
- Морфологический разбор
- Разбор слова по составу
Как создать анализатор электронной почты с нуля
Итак, ваш начальник только что попросил вас решить «проблему с электронной почтой», которая тормозит работу компании. Сотни автоматических писем, в которых ввод данных производится вручную, каждое утро, забивая почтовые ящики сотрудников.
Вы, будучи умным и эффективным, сразу видите потенциал для создания системы парсинга электронной почты. Отличная идея! Хотя это может быть немного сложнее, чем просто несколько сценариев и смазка локтя. Вот шесть шагов, чтобы создать анализатор электронной почты и успешно автоматизировать рабочий процесс ввода данных электронной почты.
Отличная идея! Хотя это может быть немного сложнее, чем просто несколько сценариев и смазка локтя. Вот шесть шагов, чтобы создать анализатор электронной почты и успешно автоматизировать рабочий процесс ввода данных электронной почты.
Прежде чем мы начнем: давайте определим синтаксический анализ и что такое синтаксический анализ
В компьютерных науках синтаксический анализ — это действие по разделению текста на части в соответствии с набором правил.
Парсер электронной почты — это способ заставить компьютер читать электронные письма и действовать в соответствии с набором правил. В идеале эта система будет автоматически извлекать соответствующие данные из этих электронных писем и передавать их в ваше бэк-офисное приложение. Ознакомьтесь со следующей статьей о подробном анализе электронной почты.
Бессовестная вилка: вы встречались с Парсером?
Создание собственного анализатора электронной почты — увлекательный проект, позволяющий понять, как все устроено внутри.
Но это отнимает много времени.
Parseur был создан с нуля в конце 2015 года, и только на создание серверной части ушло около 5000 человеко-часов в течение 6 лет. На создание интерфейса (весь пользовательский интерфейс, включая редактор шаблонов) также ушли тысячи человеко-часов. А команда Parseur состоит из опытных разработчиков с более чем 20-летним опытом профессионального кодирования.
Мы еще не закончили и даже не можем оценить, сколько времени уйдет на создание «достаточно хорошего» анализатора текста.
Если вам нужны быстрые результаты, попробуйте Parseur. Parseur — это управляемый и удобный для пользователя анализатор электронной почты , который сэкономит вам часы на настройке собственного решения. Ознакомьтесь с обширным набором функций Parseur.
Попробуйте парсер электронной почты Parseur
Для начала бесплатно. Все функции доступны в нашем бесплатном плане!
2. Преобразование электронной почты в правильный формат данных
Электронная почта — это старый формат, «созданный до «Звездных войн», старый, и за десятилетия он накопил несколько недостатков.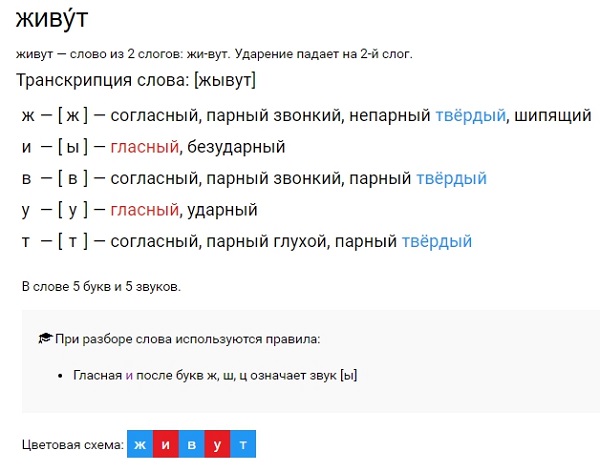 Например, обработка международных (не американских) символов не входила в первоначальную спецификацию. Для обработки специальных символов, таких как €, вам необходимо принять во внимание 3 технических документа (также называемых RFC):
Например, обработка международных (не американских) символов не входила в первоначальную спецификацию. Для обработки специальных символов, таких как €, вам необходимо принять во внимание 3 технических документа (также называемых RFC):
- RFC 2047 обеспечивает поддержку международных имен и строк темы в заголовке электронной почты .
- RFC 5890 обеспечивает поддержку международных доменных имен в системе доменных имен (DNS)
- RFC 6532 позволяет использовать UTF-8 (еще один способ хранения международного текста) в разделе заголовка почты
Опять же, такие сервисы, как Postmark или Mailgun, могут спасти вас и сделать перевод за вас. Можете забыть страшилки про UTF-8, MIME и cp1252 (никогда не слышали про UTF-8, MIME или cp1252? Завидую вашей жизни).
Например, если вы используете mailgun, серверы будут получать электронную почту для вас и преобразовывать ее в простой для обработки документ JSON, заботясь обо всех RFC, известных человечеству.
Для любопытных вот список всех RFC, связанных с SMTP. Пожалуйста.
Например, простое электронное письмо, полученное на Mailgun, придет на ваш сервер в следующем виде:
{
тема: "Мое любимое кафе",
отправитель: "Джон Доу <[email protected]>",
получатель: "Г-н Парсер <[email protected]>",
сообщение: "Это называется Awesome Café! См. инструкции во вложении. До свидания.",
вложения: [
{имя: "directions.pdf", содержимое: "https://url.with.content"},
{название: "cappucino.jpg", содержимое: "https://another.content.url"}
]
[...другие интересные данные здесь (читай документ, Люк)...]
}
Разве это не прекрасно? Сравните это с традиционным форматом электронной почты:
MIME-версия: 1.0 Получено: по 102.29.23.176 с HTTP; Сб, 12 августа 2016 г., 14:13:31 -07:00 (PDT) Дата: сб, 12 августа 2016 г., 14:13:31 -07:00 Доставлено: =?ISO-8859-1?Q?Mr. Парсер <[email protected]> Идентификатор сообщения: <[email protected]om> Тема: =?ISO-8859-1?Q?My=20Favorite=20Caf=E9 От: =?ISO-8859-1?Q?John Doe <[email protected]> Кому: =?ISO-8859-1?Q?Mr. Парсер <[email protected]> Content-Type: составной/смешанный; граница = смешанная == смешанный Content-Type: составной/альтернативный; граница = альтернатива == альтернатива Content-Type: текстовый/обычный; кодировка = "utf-8" Это называется Awesome Caf=C3=A9! См. инструкции в приложении. До свидания. == альтернатива Тип содержимого: текст/html; кодировка = "utf-8" Он называется Отличное кафе=C3=A9! См. указания в приложении =. До свидания. ==альтернативный== ==смешанный Тип содержимого: документ/pdf; имя="направления.pdf" Content-Disposition: вложение; имя_файла="направления.pdf" Контент-передача-кодирование: base64 iVBORw [...все закодированное вложение здесь...] RK5CYII= == смешанный Тип содержимого: изображение/jpg; имя="капучино.jpg" Content-Disposition: вложение; имя_файла="капучино.
jpg" Контент-передача-кодирование: base64 G+aHAAAA [... другое вложение, закодированное здесь ...] ORK5CYII= == смешанный ==
 , 14:13:31 -07:00
Доставлено: =?ISO-8859-1?Q?Mr. Парсер <[email protected]>
Идентификатор сообщения: <[email protected]om>
Тема: =?ISO-8859-1?Q?My=20Favorite=20Caf=E9
От: =?ISO-8859-1?Q?John Doe <[email protected]>
Кому: =?ISO-8859-1?Q?Mr. Парсер <[email protected]>
Content-Type: составной/смешанный; граница = смешанная
== смешанный
Content-Type: составной/альтернативный; граница = альтернатива
== альтернатива
Content-Type: текстовый/обычный; кодировка = "utf-8"
Это называется Awesome Caf=C3=A9! См. инструкции в приложении. До свидания.
== альтернатива
Тип содержимого: текст/html; кодировка = "utf-8"
Он называется Отличное кафе=C3=A9! См. указания в приложении =. До свидания. ==альтернативный== ==смешанный
Тип содержимого: документ/pdf; имя="направления.pdf"
Content-Disposition: вложение; имя_файла="направления.pdf"
Контент-передача-кодирование: base64
iVBORw [...все закодированное вложение здесь...] RK5CYII=
== смешанный
Тип содержимого: изображение/jpg; имя="капучино.jpg"
Content-Disposition: вложение; имя_файла="капучино.
, 14:13:31 -07:00
Доставлено: =?ISO-8859-1?Q?Mr. Парсер <[email protected]>
Идентификатор сообщения: <[email protected]om>
Тема: =?ISO-8859-1?Q?My=20Favorite=20Caf=E9
От: =?ISO-8859-1?Q?John Doe <[email protected]>
Кому: =?ISO-8859-1?Q?Mr. Парсер <[email protected]>
Content-Type: составной/смешанный; граница = смешанная
== смешанный
Content-Type: составной/альтернативный; граница = альтернатива
== альтернатива
Content-Type: текстовый/обычный; кодировка = "utf-8"
Это называется Awesome Caf=C3=A9! См. инструкции в приложении. До свидания.
== альтернатива
Тип содержимого: текст/html; кодировка = "utf-8"
Он называется Отличное кафе=C3=A9! См. указания в приложении =. До свидания. ==альтернативный== ==смешанный
Тип содержимого: документ/pdf; имя="направления.pdf"
Content-Disposition: вложение; имя_файла="направления.pdf"
Контент-передача-кодирование: base64
iVBORw [...все закодированное вложение здесь...] RK5CYII=
== смешанный
Тип содержимого: изображение/jpg; имя="капучино.jpg"
Content-Disposition: вложение; имя_файла="капучино.
К счастью, большинство приличных языков программирования поставляются с библиотекой для расшифровки электронной почты, такой как модуль электронной почты для Python или библиотека Ruby для RubyMail.
3. Загрузите данные в базу данных
С этого момента вы можете рассчитывать на свои навыки кодирования, чтобы обрабатывать все эти HTTP-запросы и превращать их в красивые записи в выбранной вами базе данных.
Вот несколько популярных языков программирования и фреймворков, которые помогут вам в решении этой задачи, в порядке возрастания популярности:
- PHP Symfony или Zend
- Django, Tornado или Flask для Python
- Руби на рельсах
- И многие, многие другие…
Используемый код должен быть тривиальным, если вы не ориентируетесь на какой-либо конкретный формат. Но вам, возможно, придется узнать, какой формат принимает ваше программное обеспечение для бизнеса, а затем преобразовать в этот формат. Популярные форматы обмена включают CSV и JSON, но некоторые бизнес-приложения используют более малоизвестные двоичные форматы.
Популярные форматы обмена включают CSV и JSON, но некоторые бизнес-приложения используют более малоизвестные двоичные форматы.
Если все, что вам нужно, это хранилище (возможно, для вашего собственного бизнес-приложения), вам просто нужно выбрать, как вы будете хранить данные.
Если вы знаете, что вам никогда не понадобится выполнять статистику или непоследовательные операции с этими сохраненными электронными письмами, вы можете, например, рассмотреть возможность использования MongoDB. Тем не менее, я буду советовать вам против этого, используя аргументы из этого замечательного поста в блоге.
Любая система управления реляционными базами данных, основанная на SQL, прекрасно сохранит вашу электронную почту. Как минимум, вы определите 2 таблицы, одну для электронных писем, а другую для их вложений, если вы решите их хранить.
Любой механизм базы данных SQL должен справиться с этим, если ваш объем и нагрузка соответствуют серверу. В настоящее время существует несколько популярных вариантов реляционных баз данных:
- MySQL и рекомендуемый, но неофициальный форк MariaDB являются базовыми и по-прежнему популярными вариантами серверов баз данных. Обратите внимание, что с тех пор, как Oracle купила MySQL, поддержка не так сильна, как раньше. Сюрприз.
- Postgresql — это более крупный, многофункциональный движок базы данных с большим количеством опций для масштабирования и более сложной настройкой, чем MySQL.
- Помимо этих бесплатных баз данных с открытым исходным кодом, есть, конечно же, Oracle с множеством функций, отвечающих потребностям крупных компаний. Очень большой, сложный и дорогой. Вы уверены, что вашему простому решению для хранения электронной почты нужна такая масштабируемость?
- Кроме того, с коммерческой точки зрения Microsoft SQL Server значительно улучшился за последние годы и теперь является достойным конкурентом Oracle.
 Обратите внимание, что с тех пор, как Oracle купила MySQL, поддержка не так сильна, как раньше. Сюрприз.
Обратите внимание, что с тех пор, как Oracle купила MySQL, поддержка не так сильна, как раньше. Сюрприз.Вот и мы. Если вы хотите поместить содержимое ваших электронных писем как есть в базу данных вашего приложения, вы в основном закончили.
Но зачем останавливаться на достигнутом? Теперь у вас под рукой много интересных данных. Этот набор данных очень интересен, потому что он имеет отношение к вашему основному бизнесу. Ваши электронные письма, вероятно, полны счетов-фактур, командировочных расходов, оценок, потенциальных клиентов и клиентов.
Ваши электронные письма, вероятно, полны счетов-фактур, командировочных расходов, оценок, потенциальных клиентов и клиентов.
Как насчет того, чтобы сделать еще один шаг и извлечь соответствующие данные из этих писем? Уточнение имеющихся у вас данных может помочь вам автоматизировать бизнес-процессы, экономя время вам и вашим сотрудникам.
5. Управляемое решение? Парсер поможет!
Было бы неплохо просто получить нужные данные, отсортированные по нужным столбцам электронной таблицы или базы данных Excel?
Ну, это наша цель в Parseur. Мы предоставляем вам простой интерфейс «укажи и щелкни», чтобы определить, какие данные важны для вас, раз и навсегда. Затем вы можете отправлять аналогичные электронные письма, и их данные будут извлечены и автоматически помещены в электронную таблицу Excel.
Вам не нужно создавать парсер электронной почты с нуля самостоятельно. Вам не нужно выполнять какую-либо ручную обработку после первого короткого сеанса указания и нажатия. Каждое электронное письмо само по себе превращается в строку Excel.
Каждое электронное письмо само по себе превращается в строку Excel.
Попробуйте Parseur!
Бесплатно для начала. Все функции включены в наш план «Бесплатно навсегда»!
6. Интеграция в ваше бизнес-программное обеспечение
После того, как ваши извлеченные данные будут аккуратно размещены в вашей электронной таблице Excel, вам «просто» нужно получить их там, где это необходимо: в ваше бизнес-приложение.
Такие инструменты, как Zapier или Integromat, могут вам в этом очень помочь, поскольку они могут связать ваше собственное почтовое приложение с вашим бизнес-приложением. Все, что вам нужно сделать, это написать коннектор для этих служб. Затем вы можете пользоваться многими другими соединителями, которые являются частью их экосистемы.
Parseur интегрируется с Google Sheets, Zapier, Integromat, Microsoft Flow, Getswift, открывая проанализированные данные тысячам приложений всего за несколько кликов.
Удачи!
Чтение, посещение и анализ: нейронный анализ неструктурированного текста с помощью преобразователей на основе внимания — часть 1 | by Ninjacart
Преобразование неструктурированного текста в структурированный каталог — один из важных шагов по созданию и обновлению каталогов для наших покупателей на платформе.
Например, продавец таких артикулов, как сахар, создаст короткое сообщение с информацией о различных запасах различного качества и цен соответственно. Затем он поделится сообщением во многих группах WhatsApp.
Выше приведен пример сообщения, созданного производителем сахара, которое он будет транслировать по своей сети. Он может обновлять некоторые детали в сообщении, например, цену, доступность и т. д. каждый раз, когда происходит изменение, и снова транслировать его, пока не найдет подходящего покупателя.
Ninjacart ежедневно получает тысячи таких сообщений от поставщиков, и для обеспечения легкого обнаружения на платформе мы должны создать структурированный каталог из этих сообщений в режиме реального времени без какого-либо вмешательства человека.
В данном примере изображения содержимое записано в виде неструктурированного текста. Чтобы сделать его листингом каталога на рынке, нам нужно, чтобы он был в форме структурированных сущностей, таких как вариант и цена, все взаимосвязаны друг с другом. Изображение ниже — это структурированный вывод, который нам нужен.
Изображение ниже — это структурированный вывод, который нам нужен.
Для данного образца текста похоже, что простое регулярное выражение с нечеткой логикой должно решить постановку задачи.
Но подождите, давайте посмотрим еще несколько примеров:
Теперь давайте добавим в смесь местный контент.
Это не выглядит просто!
Поскольку разработать сквозную модель машинного обучения, которая могла бы решить все в нашем случае, довольно маловероятно, мы разбили всю эту постановку задачи на несколько классических постановок задачи НЛП, которые передают данные по конвейерам для получения конечного результата.
Мы использовали модуль идентификации языка fasttext, который работал у нас без каких-либо изменений в их существующей модели.
В приведенной постановке задачи мы не можем полностью выполнить языковой перевод, потому что смысл слова сильно меняется, если выполняется дословный перевод.
В одном из примеров «हल्के फुल्के» является вариантом качества, но, если сделать перевод на это, получится «легко», что может не соответствовать цели сообщения. Таким образом, в этих случаях транслитерация очень помогает нам сохранить словарь рынка нетронутым.
Таким образом, в этих случаях транслитерация очень помогает нам сохранить словарь рынка нетронутым.
Точно так же мы не можем просто использовать языковую транслитерацию, потому что мы хотим понять намерение контента, чтобы извлечь из него некоторые значимые сущности. Например, «बुधवार» — это день недели, поэтому перевод этого слова дает нам больше информации о дне, в который происходит сделка. Даже цены иногда указываются на местных языках.
Итак, какой текстовый контент нужно перевести, а какой транслитерировать — еще одна активная проблема, над которой мы работаем.
Это немного более сложная часть конвейера, если ее правильно понять, но в первую очередь следует учитывать визуальную структуру текста. Нам нужно добавить уникальные токены для представления нескольких визуальных подсказок, которые представляют отношения между сущностями. Подробнее об этом мы расскажем во второй части этого поста.
Это классический подход к распознаванию именованных объектов, при котором мы обучаем roBERTa на нашем пользовательском наборе данных с пользовательскими объектами. Сущности в этом случае скорее адаптированы к нашей постановке задачи. Это может быть артикул, или вариация внутри артикула, цена и многое другое.
Сущности в этом случае скорее адаптированы к нашей постановке задачи. Это может быть артикул, или вариация внутри артикула, цена и многое другое.
После того, как сущности идентифицированы, определение связи между этими различными сущностями представляет собой сложную постановку задачи. Например, если текст содержит два сорта лука, то цены на разные сорта должны точно совпадать. Подробнее об этом мы расскажем во второй части этого поста.
В очень очевидных случаях ключевое слово SKU присутствует в содержании. Но есть много случаев, когда в контенте нет информации о том, для какого типа SKU предназначены эти слова. В этих случаях мы строим классификационную модель для прогнозирования SKU по всем ключевым словам.
Для аннотации данных мы используем модифицированную версию doccano внутри компании. Для всех задач, упомянутых выше, у нас есть собственные аннотации, созданные на базе doccano.
Мы постараемся подробно рассказать о каждом модуле в следующей части нашего блога.