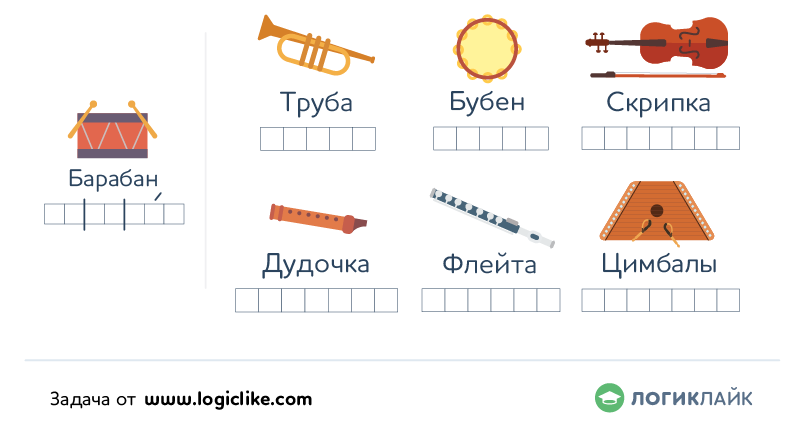
аккорды для гитары, бой, текст песни
Перейти к содержанию
Разбор композиции Виктора Цоя и группы Кино «Восьмиклассница» на гитаре для начинающих: аппликатуры аккордов, схема боя и текст песни.
- Аккорды
- Бой
Кино (В.Цой) — Восьмиклассница: аккорды, бой и текст песни
Бой: ↓↑⇣↑↓↑⇣↑ Вступление: Am | Em x4 Куплет 1: Am Em
Пустынной улицей вдвоём
C G
С тобой куда-то мы идём,
F G C
Я курю, а ты конфетки ешь.
Am Em
И светят фонари давно,
C G
Ты говоришь: «Пойдём в кино»,
F G C Am
А я тебя зову, м-м-м в кабак, конечно. Припев: F G C Am
Ммм-м-м, восьмиклассница а-а-а,
F G
Ммм-м-м. Проигрыш: Am | Em x4 Куплет 2: Am Em
Ты говоришь, что у тебя
C G
По географии трояк,
F G C Am
А мне на это просто наплевать. Am Em
Ты говоришь, из-за тебя
C G
Там кто-то получил синяк
F G
Многозначительно молчу,
C Am
И дальше мы идём гулять. Припев: F G C Am
Ммм-м-м, восьмиклассница а-а-а,
F G
Ммм-м-м. Соло: Am | Em | C | G | F | G | C | C x2 Припев:
Am Em
Ты говоришь, из-за тебя
C G
Там кто-то получил синяк
F G
Многозначительно молчу,
C Am
И дальше мы идём гулять. Припев: F G C Am
Ммм-м-м, восьмиклассница а-а-а,
F G
Ммм-м-м. Соло: Am | Em | C | G | F | G | C | C x2 Припев:
Разбор песни Виктора Цоя «Восьмиклассница» на гитаре для начинающих: аккорды, табы и бой
 Цой) — Восьмиклассница: аккорды, табы и бой (Разбор на гитаре)» src=»https://www.youtube.com/embed/11prNijClrs?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> В этом видео мы разберём, как играть на гитаре песню Виктора Цоя и группы Кино «Восьмиклассница». В песне «Восьмиклассница» всего 5 аккордов: Am, Em, C, G, F. Тут всего один аккорд с баррэ (аккорд F), поэтому никаких трудностей с этой композицией возникнуть не должно. Последовательности аккордов в песне «Восьмиклассница» такие: — вступление и проигрыш: Am – Em; — куплет: Am – Em – C – G – F – G – C – Am; — припев: F – G – C – Am — F – G. Обратите внимание, что в оригинале первая часть первого куплета играется так: Am – Em – C – G – F – G – C – С, т.е. последний аккорд C повторяется два раза, а во второй части первого куплета и остальных куплетах нужно играть вместо последнего аккорда C аккорд Am. Это несущественно, но на студийной версии альбома «45» эта песня звучит именно так.
Цой) — Восьмиклассница: аккорды, табы и бой (Разбор на гитаре)» src=»https://www.youtube.com/embed/11prNijClrs?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> В этом видео мы разберём, как играть на гитаре песню Виктора Цоя и группы Кино «Восьмиклассница». В песне «Восьмиклассница» всего 5 аккордов: Am, Em, C, G, F. Тут всего один аккорд с баррэ (аккорд F), поэтому никаких трудностей с этой композицией возникнуть не должно. Последовательности аккордов в песне «Восьмиклассница» такие: — вступление и проигрыш: Am – Em; — куплет: Am – Em – C – G – F – G – C – Am; — припев: F – G – C – Am — F – G. Обратите внимание, что в оригинале первая часть первого куплета играется так: Am – Em – C – G – F – G – C – С, т.е. последний аккорд C повторяется два раза, а во второй части первого куплета и остальных куплетах нужно играть вместо последнего аккорда C аккорд Am. Это несущественно, но на студийной версии альбома «45» эта песня звучит именно так. Схема боя в песне «Восьмиклассница» выглядит так: ↓↑⇣↑↓↑⇣↑. Разбор композиции Виктора Цоя и группы Кино «Восьмиклассница» на гитаре для начинающих: ☛ 00:00 Восьмиклассница на гитаре: аккорды и табы ☛ 00:53 Восьмиклассница на гитаре: вступление (медленно) ☛ 01:24 Восьмиклассница на гитаре: бой (медленно)
Схема боя в песне «Восьмиклассница» выглядит так: ↓↑⇣↑↓↑⇣↑. Разбор композиции Виктора Цоя и группы Кино «Восьмиклассница» на гитаре для начинающих: ☛ 00:00 Восьмиклассница на гитаре: аккорды и табы ☛ 00:53 Восьмиклассница на гитаре: вступление (медленно) ☛ 01:24 Восьмиклассница на гитаре: бой (медленно)Аккорды к другим песням группы Кино
Прокрутить вверхСхема. Почему моя простая грамматика SQL не анализируется в Brag?
спросил
Изменено 3 года, 5 месяцев назад
Просмотрено 151 раз
Я пытаюсь создать парсер для простого подмножества SQL, используя грамматику, написанную с помощью BNF в Brag. Мой код Брэга выглядит так:
#язык похвастаться
оператор: «выбрать» поля «из» исходных объединений* фильтры*
поля : поле ("," поле)*
поле : СЛОВО
источник: СЛОВО
присоединяется : присоединяюсь *
join : "присоединиться" к источнику "on" "("условие")"
фильтры: условие "где" ("и" | "или" условие)*
условие: поле "=" поле
Но когда я пытаюсь использовать эту грамматику для разбора простого оператора SQL, я получаю следующую ошибку:
> (parse-to-datum "select * from table") Обнаружен неожиданный токен типа "s" (значение "s") при синтаксическом анализе "неизвестно [строка=#f, столбец=#f, смещение=#f]
Я совсем новичок в грамматике и хвастовстве. Любые идеи, что я делаю неправильно?
Любые идеи, что я делаю неправильно?
- схема
- ракетка
- хвастовство
1
Сначала вам нужно lex/tokenize строку. Входными данными для parse / parse-to-datum должен быть список токенов. Кроме того, хвастовство чувствительно к регистру, что означает, что ввод должен быть select , а не SELECT . После того, как вы это сделаете, это должно работать:
> (разбор до данных (список "выбрать"
(токен 'WORD "foo")
"от "
(токен 'WORD "bar")
" "
"")))
'(оператор "выбрать" (поля (поле "foo")) "из" (источник "бар") "" " ")
Что касается чувствительности к регистру, это не проблема, так как вы можете выполнить нормализацию на этапе токенизации.
Однако ваша грамматика выглядит странно. Вы, вероятно, не должны иметь дело с пробелами.
См. https://beautifulracket.com/bf/the-tokenizer-and-reader.html для получения дополнительной информации о токенизации.
Альтернативой является использование других анализаторов. https://docs.racket-lang.org/megaparsack/index.html, например, может сразу разобрать строку на данные (или данные синтаксиса), хотя он использует некоторые передовые концепции функционального программирования, поэтому в некотором смысле это может быть сложнее в использовании.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
CS 11: дорожка ocaml: назначение 5
CS 11: дорожка ocaml: назначение 5Голы
Это задание и задание 6 будут включать в себя реализацию интерпретатора
для простого языка программирования. Этот язык будет очень
урезанный диалект Схемы
язык программирования под названием «богосхема». Несмотря на название, язык
по-прежнему будут обладать многими чертами реальной схемы, в том числе первоклассными
функции и правильное лексическое определение. Попутно мы научимся использовать
некоторые из специальных инструментов, которые ocaml предоставляет для использования при построении
языковые парсеры.
Этот язык будет очень
урезанный диалект Схемы
язык программирования под названием «богосхема». Несмотря на название, язык
по-прежнему будут обладать многими чертами реальной схемы, в том числе первоклассными
функции и правильное лексическое определение. Попутно мы научимся использовать
некоторые из специальных инструментов, которые ocaml предоставляет для использования при построении
языковые парсеры.
Если вы никогда раньше не видели Scheme, попробуйте ознакомиться с основами языка, прежде чем пытаться выполнить эту лабораторную работу. К счастью, вы не нужно будет знать много Схемы, чтобы написать эту лабораторную работу.
Концепции, рассмотренные на этой неделе
- Генераторы Lexer
- Генераторы парсеров
- S-выражения
- Абстрактные синтаксические деревья
Языковые средства, охватываемые на этой неделе
-
окамллекс -
окамлякк
Чтение
Читать стандарт ocamllex и ocamlyacc документация здесь.
Еще один отличный ресурс — это ocamlyacc учебник, который значительно углубляется в материал
больше глубины, чем руководство от разработчиков языка. Обратите особое внимание на это
страница с правилами рекурсивной грамматики — мы гарантируем, что она будет полезна
ты.
Еще один полезный ocamllex туториал
здесь.
Обзор
Базовая последовательность интерпретации
Процесс написания интерпретатора языка программирования состоит из последовательность шагов, которые ведут нас от исходного исходного кода (который обрабатывается как большая длинная строка символов) к результату выполнение программы. Хотя конкретные шаги могут варьироваться в зависимости от сложности интерпретатора, для наших целей шаги будут включает:
Lexing: Преобразование исходного кода в поток токенов , которые являются примитивными синтаксическими объектами, такими как числа, знаки препинания и идентификаторы.
Этот этап называется «лексический анализ». или «лексинг» для краткости, а программы/функции, которые это делают, называются «лексеры».
Разбор: Преобразование потока токенов в реферат представление программы, обычно называемое абстрактным синтаксисом дерево или АСТ . Этот этап называется «разбор» и программы/функции, которые это делают, называются «парсерами». Иногда люди неофициально использовать слово «парсинг» для обозначения комбинации лексического и синтаксический анализ, но мы будем использовать более ограниченную форму слова в том, что следует.
Интерпретация: Выполнение абстрактного представления программа.
Компиляторы (и более сложные интерпретаторы) всегда имеют гораздо больше этапов, чем это, хотя они также начинаются с лексирования и синтаксического анализа, так же, как мы будем делать.
Генераторы лексеров и парсеров
Лексеры и парсеры были написаны с первых дней программирования
языках, и существует обширная литература, связанная с теорией
позади них. В какой-то момент кто-то понял, что
В какой-то момент кто-то понял, что
- Писать лексеры и парсеры очень скучно.
- Большую часть этой скучной работы можно автоматизировать.
В итоге люди начали писать генераторы лексеров и парсер генераторы , то есть программы, которые читают какой-то текстовый
спецификация того, что должен делать лексер или синтаксический анализатор, и сгенерировать
код, чтобы сделать это. Это похоже на то, что делают компиляторы, но это
гораздо более ограниченным. Самый известный генератор лексеров называется lex и генерирует код C для лексера (есть лучший
версию этой программы под названием flex , которая доступна на
большинство систем Linux). Самый известный генератор синтаксических анализаторов называется yacc (сокращение от «Еще один компилятор-компилятор», а также
самоуничижительное имя) и генерирует код C для синтаксического анализатора (есть лучший
версии эта программа называется bison (имя
каламбур на «yacc», а также «gnu», так как это программа GNU), что
доступны в большинстве систем Linux).
Эти программы очень популярны, но они генерируют только код C, поэтому
незадолго до того, как люди начали писать версии, которые могли генерировать код
на других языках. Теперь во многих языках есть эквивалент lex и yacc . Окамль, в частности, имеет
программы ocamlyacc которые генерируют
код окамла. Это программы, которые мы будем использовать. Их использование будет
описано в лекциях, а также описано в руководстве по ocaml (но не
в учебнике Джейсона Хики!).
Цель следующих двух лабораторий
Целью следующих двух лабораторных работ является написание программы, которая позволит нам интерпретировать следующий код схемы, который вычисляет факториал 10:
;; bogoscheme программа для вычисления факториалов.
(определить факториал
(лямбда (сущ.)
(если (= п 0)
1
(* n (факториал (- n 1)))))
(печать (факториал 10))
Обратите внимание, что "печать" не является стандартной схемой; он просто печатает
его аргумент на терминал, за которым следует новая строка.
Этот фрагмент кода (который будет находиться в файле с именем "factorial.bs" ) содержит только несколько конструкций Scheme:
- константы (числа)
- переменные (идентификаторы)
-
определить -
лямбда -
если - функциональное приложение
Абстрактные синтаксические деревья
Цель текущей лаборатории более скромная; мы просто хотим написать
программа, которая возьмет приведенный выше код и преобразует его в промежуточный
представление, называемое «абстрактным синтаксическим деревом» или сокращенно AST. АСТ это
представление программы (или части программы) в терминах ocaml
тип данных. Одна из причин, по которой ocaml является таким прекрасным языком для написания компиляторов на
заключается в том, что его типы объединения (также известные как алгебраические типы данных) идеально
подходит для представления абстрактных синтаксических деревьев. Например, АСТ
представление нашего языка Scheme будет следующим:
Например, АСТ
представление нашего языка Scheme будет следующим:
(* Идентификаторы типа схемы. *) идентификатор типа = строка (* Тип выражения схемы. *) введите выражение = | Expr_unit | Expr_bool логического значения | Expr_int из int | Expr_id идентификатора | Expr_define из id * expr | Expr_if из expr * expr * expr | Expr_lambda списка идентификаторов * expr list | Expr_apply of expr * список expr
Этот код говорит о том, что тип id (для «идентификатор») является просто
псевдоним для строки типа и типа expr имеет
восемь различных случаев. Три из них представляют значения данных (значение единицы,
логические значения и целочисленные значения). Один представляет идентификаторы. По одному
представляют схему , определяют , , если , и лямбда выражения. Наконец, один представляет применение
функцию своим аргументам. Тип агрегата (который также не является стандартным
Scheme) будет использоваться как возвращаемый тип для любого выражения, которое не
вернуть любое значимое значение. Обратите внимание, что единственное значение, имеющее тип единицы измерения
является значением единицы, как и в ocaml (название «единица» означает «тип, который имеет
только одно (бессмысленное) значение»). В нашей программе
Обратите внимание, что единственное значение, имеющее тип единицы измерения
является значением единицы, как и в ocaml (название «единица» означает «тип, который имеет
только одно (бессмысленное) значение»). В нашей программе напечатать функция вернет единичное значение.
AST содержит полное описание синтаксиса любой допустимой части кода, который мы могли бы прочитать, в форме, которую программе ocaml легко воспроизвести. манипулировать. Таким образом, наша цель для этой лабораторной работы состоит в том, чтобы взять факториальную программу приведенный выше, и преобразовать его в этот AST. В следующей лаборатории мы увидим, как интерпретировать AST для вычисления ответа.
S-выражения
В разделе выше я сказал, что сначала обрабатываются интерпретируемые языки. лексированием, затем разбором, затем интерпретацией. Это верно для большинства языки. Однако языки, производные от Lisp (такие как Scheme), требуют большего внимания. непрямой подход:
Во-первых, они используют лексер для преобразования входной строки ( т.
е. содержимое файла) в токены. Это ничем не отличается от подхода, который мы
описано выше.Затем они преобразуют поток токенов в промежуточный представление, называемое «S-выражением» (что первоначально означало «символическое выражение»). Я опишу это ниже.
Затем S-выражение преобразуется в «абстрактное синтаксическое дерево». (АСТ), которые мы описали выше.
Наконец, AST передается функции оценки, которая оценивает это и возвращает результат.
 е. содержимое файла) в токены. Это ничем не отличается от подхода, который мы
описано выше.
е. содержимое файла) в токены. Это ничем не отличается от подхода, который мы
описано выше.Большинство языковых переводчиков пропускают второй шаг и сразу переходят к поток токенов в AST. Это то, что обычно называют «разбором». Мы тут используйте слово «разбор» для обозначения процесса перехода от потока токенов к S-выражение. Преобразование из S-выражения в AST является последующим шаг.
Преимущество S-выражений в том, что они гораздо более общие, чем
АСТ. Если вы когда-нибудь решите добавить в свой язык новую фундаментальную форму, для
Например, вам почти наверняка придется изменить свой AST, а это
обычно означает изменение парсера. Но с нашим подходом мы обычно не придется менять парсер; нам нужно только изменить
функции, которые преобразуют S-выражения в AST, и это обычно проще
(иногда гораздо проще ).
Но с нашим подходом мы обычно не придется менять парсер; нам нужно только изменить
функции, которые преобразуют S-выражения в AST, и это обычно проще
(иногда гораздо проще ).
Тип данных S-выражения очень прост:
(* Тип атомарных выражений. *) тип атом = | Атомная_единица | Atom_bool логического значения | Atom_int из int | Atom_id строки (* Тип всех S-выражений. *) введите выражение = | Expr_atom атома | Expr_list списка expr
Короче говоря, S-выражение является либо «атомом», то есть одиночным скаляром, значение, такое как число, логическое значение, значение единицы или идентификатор, или это список S-выражений. Обратите внимание, что это означает, что S-выражение может содержать вложенные списки (списки списков, или списки списков списков и т. д.).
Обратите внимание, что тип данных S-expression называется expr , как и
тип данных АСТ. Это нормально, потому что они будут в разных модулях, поэтому
полное имя типа S-выражения будет Sexpr. , и
Выражения AST будут иметь тип  expr
expr Ast.expr .
Программа для записи
Вы напишете программу, которая возьмет входной файл и преобразует его в AST и распечатайте представление AST. Результат, который вы должны получить, будет выглядеть примерно так:
ОПРЕДЕЛИТЬ [факториал
ЛЯМБДА[(n)
ЕСЛИ[
ПРИМЕНЯТЬ[
ID[=]
ID[n]
ЦЕЛОЕ[0]]
ЦЕЛОЕ [ 1 ]
ПРИМЕНЯТЬ[
ИДЕНТИФИКАТОР[ * ]
ID[n]
ПРИМЕНЯТЬ[
ID [ факториал ]
ПРИМЕНЯТЬ[
ИДЕНТИФИКАТОР[ - ]
ID[n]
ЦЕЛОЕ[ 1 ] ] ] ] ] ]
ПРИМЕНЯТЬ[
ID[ печать ]
ПРИМЕНЯТЬ[
ID [ факториал ]
ЦЕЛОЕ[10]]]
Вы также должны написать две другие программы, которые помогут вам при отладке ваша программа:
Программа, которая будет выполнять только лексирование, а затем распечатывать токены, которые были прочитаны.
Программа, которая будет выполнять лексирование, а также синтаксический анализ для создания представление S-выражения программы, которое затем распечатает S-выражение.
Основное внимание в этой программе уделяется написанию лексера и синтаксического анализатора.
lexer войдет в файл с именем lexer.mll и синтаксический анализатор
зайдите в файл под названием parser.mll . Кроме того, вам придется
напишите код для преобразования S-выражения в выражение AST. Этот
всего не более 80 строк. Весь остальной код, включая
код для преобразования S-выражений и выражений AST в строки, будет
поставляется для вас.
Места в файле, куда вы должны добавить код, помечены комментарии, включающие слово «TODO». Вы должны удалить эти комментарии, поскольку вы заполните код.
Лексер
Это будет сделано в файле лексер.млл . Это ocamllex файл, который не совпадает с настоящим исходным кодом ocaml
файл; вместо этого ocamllex будет использовать содержимое этого файла для создания
реальный файл ocaml lexer.ml . Вы должны заполнить часть файла
после строки
правило lex = разбор
(* введите здесь код *)
Ваш лексер должен преобразовывать фрагменты входной строки в один из
токены, определенные в парсере (см. ниже). В частности, ваш лексер должен
ручка:
ниже). В частности, ваш лексер должен
ручка:
Однострочные комментарии, начинающиеся с ; и идем до конца линия. От них следует отказаться. Полезный трюк здесь состоит в том, чтобы просто вызвать lexer рекурсивно, чтобы получить другой токен, если встречается комментарий. Примечание что для этого нужно понимать, что лексер
lex(тот идет после словаправиловlexer.mll) есть преобразованоocamllexв функцию ocaml с одним аргументом; в аргументом является лексический буфер, называемыйлексбуф. Знание этого будет позволяют вам вызывать лексер рекурсивно из действия части лексирования правило.Пробелы, которые также следует отбросить (используйте тот же трюк, что и используется с комментариями).
Левая и правая круглые скобки, каждая из которых представляет собой отдельный тип токена (TOK_LPAREN и TOK_RPAREN).
Конец файла, что даст токен типа TOK_EOF.
Единицы измерения, которые записываются как «#u». Это даст токен введите TOK_UNIT.
Логические значения, которые записываются как «#t» (для истинного) и «#f» (для ЛОЖЬ). Они станут токенами типа TOK_BOOL. Токены TOK_BOOL имеют связанное значение (истина или ложь).
Целочисленные значения (возможно, включая предшествующий знак минус). Это будет становятся токенами типа TOK_INT, которые также имеют ассоциированное (целочисленное) значение. Не забудьте преобразовать токен строки в целое число перед созданием Значение TOK_INT.
Идентификаторы, которые станут токенами типа TOK_ID. К ним относятся строка, представляющая идентификатор.
Все остальное является ошибкой.
Парсер
Цель синтаксического анализатора — взять последовательность токенов и преобразовать ее
в S-выражения. Каждый раз, когда вы вызываете синтаксический анализатор, он возвращает новый
S-выражение. Если вы нажмете EOF, синтаксический анализатор вернет None . Таким образом, парсер возвращает тип
Таким образом, парсер возвращает тип Sexpr.expr option .
Типы токенов определены для вас в файле parser.mly . Смотреть
в этом файле, и вы увидите, что есть токены для левого и правого
круглые скобки, значения единиц, логические значения, целые числа и т. д. Обратите внимание, что некоторые
токены имеют связанные данные, а другие нет.
Мы также предоставили заглушки для пяти нетерминалов грамматики:
разбор : представляет S-выражение или
Нет, если Встречается EOF.sexpr : представляет собой S-выражение, которое может быть атом или список S-выражений.
атом : представляет собой атом, который может быть единицей значение, логическое значение, целочисленное значение или идентификатор.
список : представляет собой список S-выражений, окруженных круглые скобки.
sexpr_list : Представляет содержимое списка S-выражения, без скобок.
Обратите внимание, что пустые списки допустимы
S-выражения.
 Обратите внимание, что пустые списки допустимы
S-выражения.
Обратите внимание, что пустые списки допустимы
S-выражения.Все типы каждого из вышеперечисленных нетерминалов приведены в файле.
Этот синтаксический анализатор является едва ли не самым тривиальным языковым синтаксическим анализатором, который только можно себе представить; ты нужно всего лишь заполнить 11 строк кода. Несмотря на это, S-выражения очень гибкие и являются полезным способом структурирования синтаксиса. Фактически XML-документы часто считаются S-выражениями на стероидах.
Преобразование S-выражения в AST
Это нужно сделать в файле ast.ml , в вызываемой функции ast_of_sexpr . Вам нужно будет сопоставить шаблон на
S-выражение, чтобы выяснить, какому выражению AST оно соответствует, или повысить
исключение, если оно не соответствует ни одному допустимому выражению AST. Это будет
быть самой сложной частью лаборатории, поэтому убедитесь, что ваш парсер работает
правильно (используя программу parser_test ), прежде чем пытаться это сделать.
Вспомогательные файлы
Поскольку для этой лабораторной работы имеется много вспомогательных файлов, мы подготовили tarball всех файлов, который находится здесь. К распаковать его, сделать:
% смола xvf lab5.tar
Затем отредактируйте файлы lexer.mll , parser.mly и ast.ml для завершения лабораторной работы. Остальные файлы должны
остаться в покое.
Обратите внимание, что мы предоставляем Makefile , который будет компилировать весь код
для лаборатории, так что вам не придется вызывать окамллекс или ocamlyacc вручную. Тем не менее, не стесняйтесь делать это в любом случае, чтобы увидеть, что
оно делает.
Проверка кода
Крайне рекомендуется протестировать код в нескольких точках, чтобы сделать
Убедитесь, что каждый этап работает правильно. С этой целью Makefile , который мы поставляем, имеет цели для программ, называемых lexer_test , parser_test и ast_test . Вы должны скомпилировать все эти программы (набрав
Вы должны скомпилировать все эти программы (набрав сделать сделает это), запустите их все в файле factorial.bs ,
и убедитесь, что результат соответствует вашим ожиданиям. Простой способ сделать
это набрать make test_lexer (чтобы протестировать лексер), make test_parser (чтобы протестировать синтаксический анализатор) и make test_ast (для проверки ast). лексер тест
использует файл с именем tokens.bs , который включает в себя содержимое factorial.bs плюс несколько других токенов в конце
файл.
Ввод make clean удалит все файлы,
были сгенерированы компилятором.
Обратите внимание, что синтаксический анализатор и лексический анализатор взаимозависимы, поэтому вы не можете проверить
лексер, пока синтаксический анализатор не заработает (точнее, синтаксический анализатор должен
работать достаточно хорошо, чтобы он мог пройти через ocamlyacc без
вызывает ошибку, хотя лексеру не нужно правильно анализировать
работать должным образом).