What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Разбор слова Болезнь по составу!!!
спишите текст.Укажите спряжение глаголов в неопределённой форме
Помогите пожалуйста очень срочно пришлите фото что бы я смогла переписать с вашего фото а если не можете то напишите так что бы я смогла переписать с … вашего ответа
Помогите пожалуйста очень срочно и пришлите фото что бы я смогла переписать с вашего фото а если не можете то напишите так что бы я смогла переписать … с вашего ответа
1.Запишите все существительные в родительном падеже единственного числа.
2.Укажите строку, в которой все местоимения употреблены правильно:
А поговори
… ть с ей, подойти к ему, ихние друзья;
Б сказать мне, думать о ней, той дом;
В учиться с ней, помогать им, за тем домом. Запишите словосочетания с ошибками в исправленном виде.
Запишите словосочетания с ошибками в исправленном виде.
1.Подберите два родственных слова к слову ШКОЛА и разберите одно из них по составу. 2.Приведите три примера местоимений (личное, указательное, притяжа … тельное)
5. Укажите строку, в которой все местоимения употреблены правильно: А поговорить с ей, подойти к ему, ихние друзья; Б сказать мне, думать о ней, той д … ом; В учиться с ней, помогать им, за тем домом. Запишите словосочетания с ошибками в исправленном виде. 6. Укажите имя числительное: А двойня Б двое В дважды Г двойной 7. В каких числительных на месте пропуска не пишется Ь? А cем(?)десят Б девят(?)надцать В девят(?)сот Г шест(?)надцать ПоМоГиТе☹️
Укажите предложение с обращением (знаки препинания не расставлены). А Я люблю тебя мой город. Б Я люблю мой город. В Любим мною мой город. Запишите да … нные словосочетания в творительном падеже: Пушистый снег, высокий тополь, лохматая собака.
говори правильно! начал, начали, начала. понял, поняли, поняла. принял, приняли, приняла. на какую часть слова падает ударение в женском роде? прочита
… й. 1) ребята нашего класса приняли участие в математической олимпиаде. 2) катя приняла участие в соревнованиях по гимнастике. составь предложения со словами начал и начала.
понял, поняли, поняла. принял, приняли, приняла. на какую часть слова падает ударение в женском роде? прочита
… й. 1) ребята нашего класса приняли участие в математической олимпиаде. 2) катя приняла участие в соревнованиях по гимнастике. составь предложения со словами начал и начала.
Какое из слов является формой слова море обведи номер правильного ответа 1) море 2) морской 3) Приморье 4)моряк
Упр 476 5 клас морфологический разбор слов существительные по Самый большой в мире остров — это Гренландия. Высочайшая гора мира Джомолунгма, каторая … возвышается на границе между Тибетом и Непалом. Учёные спорят, какую реку назвать самой длинной- Нил или Амазонку. Самой короткой речкой является Роу, приток Миссури. Её длина — шестьдесят один метр
Дерипаска назвал бедными больше половины населения России
По мнению миллиардера Олега Дерипаски, в России около 80 миллионов жителей находятся за чертой бедности, а официальные данные Росстата не соответствуют действительности.
Миллиардер Олег Дерипаска заявил, что более половины жителей РФ имеют доходы ниже прожиточного минимума, и обвинил Росстат в «жонглировании цифрами». Пост соответствующего содержания бизнесмен опубликовал в своём Telegram-канале.
По мнению Дерипаски, к числу бедных можно отнести 80 миллионов россиян, а не 17,8 миллиона, как сообщает Росстат. При этом он добавил, что никакого сокращения уровня бедности до минимума с 2014 года не было.
По слова миллиардера, за прошедшие несколько лет ведомство «научилось виртуозно манипулировать статистикой». Как считает Дерипаска, лишь благодаря этому умению появляются «бравые» отчёты об успехах в борьбе с бедностью. Говоря об этом, бизнесмен особо отметил, что все достижения имеют место только на бумаге.
На прошлой неделе в Росстате сообщили об успехе в борьбе с бедностью. В частности, по данным ведомства, в минувшем году её уровень снизился до 12,1%, что на 300 тыс. меньше, нежели годом ранее.
Ранее в текущем месяце глава Счётной палаты Алексей Кудрин сообщил, что российский кабмин обсуждает новые критерии для подсчёта бедного населения. Новая методика должна способствовать достижению задачи по сокращению уровня бедности в РФ.
Напомним, ранее президент России Владимир Путин поставил цель добиться снижения уровня бедности в стране в два раза к 2030 году. К этому времени, согласно указу главы государства, в стране должно насчитываться не больше 6,5% бедного населения.
DEXTER: Извлечение связи между заболеванием и выражением из текста | База данных
Аннотация
 Характеристика профилей экспрессии полезна для клинических исследований, диагностики и прогнозирования заболеваний. В настоящее время существует несколько высококачественных баз данных, которые фиксируют информацию об экспрессии генов, полученную в основном в результате крупномасштабных исследований, таких как микроматрицы и технологии секвенирования нового поколения, в контексте болезни.Научная литература — еще один богатый источник информации о взаимосвязи между экспрессией генов и заболеванием, которая не только была получена в результате крупномасштабных исследований, но также наблюдалась в тысячах небольших исследований. Информация о экспрессии, полученная из литературы путем ручного курирования, может расширить базы данных экспрессии. Хотя многие из существующих баз данных включают информацию из литературы, они ограничены трудоемкостью ручного курирования и с трудом справляются с ростом публикаций в области биомедицины.В этой работе мы описываем автоматизированный инструмент интеллектуального анализа текста, извлечение связи между заболеванием и выражением из текста (DEXTER) для извлечения информации из литературы по экспрессии генов и микроРНК в контексте болезни.
Характеристика профилей экспрессии полезна для клинических исследований, диагностики и прогнозирования заболеваний. В настоящее время существует несколько высококачественных баз данных, которые фиксируют информацию об экспрессии генов, полученную в основном в результате крупномасштабных исследований, таких как микроматрицы и технологии секвенирования нового поколения, в контексте болезни.Научная литература — еще один богатый источник информации о взаимосвязи между экспрессией генов и заболеванием, которая не только была получена в результате крупномасштабных исследований, но также наблюдалась в тысячах небольших исследований. Информация о экспрессии, полученная из литературы путем ручного курирования, может расширить базы данных экспрессии. Хотя многие из существующих баз данных включают информацию из литературы, они ограничены трудоемкостью ручного курирования и с трудом справляются с ростом публикаций в области биомедицины.В этой работе мы описываем автоматизированный инструмент интеллектуального анализа текста, извлечение связи между заболеванием и выражением из текста (DEXTER) для извлечения информации из литературы по экспрессии генов и микроРНК в контексте болезни. Одним из мотивов разработки DEXTER было расширение базы данных BioXpress, базы данных по экспрессии генов, ориентированной на рак, которая включает данные, полученные в результате крупномасштабных экспериментов и ручного редактирования публикаций. Литературная часть BioXpress значительно отстает от информации о экспрессии, полученной в результате крупномасштабных исследований, и может извлечь выгоду из наших текстовых результатов.Мы провели две разные оценки, чтобы измерить точность нашего инструмента для интеллектуального анализа текста, и получили в среднем
Одним из мотивов разработки DEXTER было расширение базы данных BioXpress, базы данных по экспрессии генов, ориентированной на рак, которая включает данные, полученные в результате крупномасштабных экспериментов и ручного редактирования публикаций. Литературная часть BioXpress значительно отстает от информации о экспрессии, полученной в результате крупномасштабных исследований, и может извлечь выгоду из наших текстовых результатов.Мы провели две разные оценки, чтобы измерить точность нашего инструмента для интеллектуального анализа текста, и получили в среднем 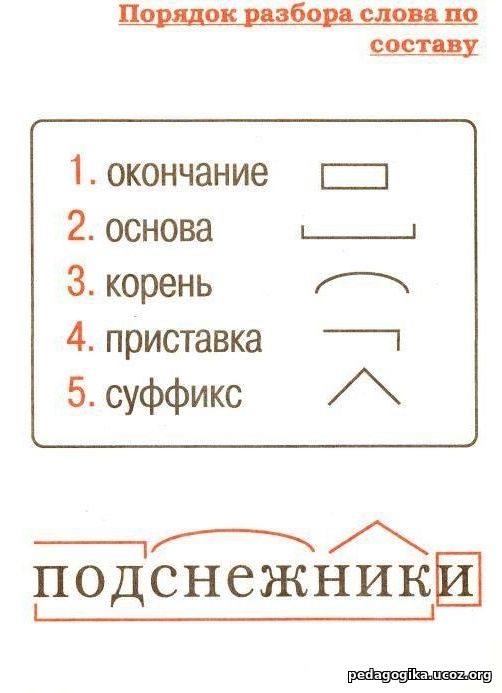
URL базы данных: http://biotm.cis.udel.edu/DEXTER
Введение
Гены содержат информацию, необходимую для создания белков и определения функций клеток; однако именно характер экспрессии генов определяет фенотип клетки. Экспрессия генов очень динамична и широко варьирует в разных тканях, условиях окружающей среды и болезненных состояниях. Транскрипция контролируется сложным взаимодействием активаторов, репрессоров и факторов ремоделирования хроматина, а нарушения в программе транскрипции хорошо известны как движущие силы заболевания (1).Более того, критическая роль, которую играют miRNAs, небольшие РНК, которые посттранскрипционно регулируют экспрессию своих генов-мишеней, становится все более очевидной в последние годы (2), а аномалии экспрессии miRNA были связаны со многими заболеваниями (3-8). Идентификация генов и miRNA, уровни экспрессии которых могут определять диагноз заболевания, оценивать прогноз или предсказывать реакцию на терапию, является ключевым аспектом точной медицины (9).
Развитие микрочипов и технологий секвенирования нового поколения привело к появлению большого количества данных об экспрессии генов в масштабе всего транскриптома.Большая часть этих данных общедоступна через общие репозитории, такие как Gene Expression Omnibus (GEO) (10) и Array Express (11), а также через более специализированные ресурсы, такие как International Cancer Genome Consortium (ICGC) (12) и Атлас генома рака (13) (TCGA: http://cancergenome.nih.gov/), в котором основное внимание уделяется данным о раке, а также тканеспецифической экспрессии и регуляции генов (TiGER) (14), в котором данные об экспрессии генов систематизируются по типу ткани. . Высокопроизводительная масс-спектрометрия (МС) предоставляет данные об экспрессии на уровне белка.Эти данные собраны в таких ресурсах, как база данных dbDEPC (15, 16), содержащая более 4000 дифференциально экспрессируемых белков для 20 видов рака, полученных в результате 331 эксперимента MS. Хотя эти наборы данных дают представление о биологических процессах и путях, на которые влияют изменения в профиле экспрессии гена / белка, они, как известно, содержат много шума и поэтому имеют ограниченную полезность для оценки поведения отдельных генов или белков.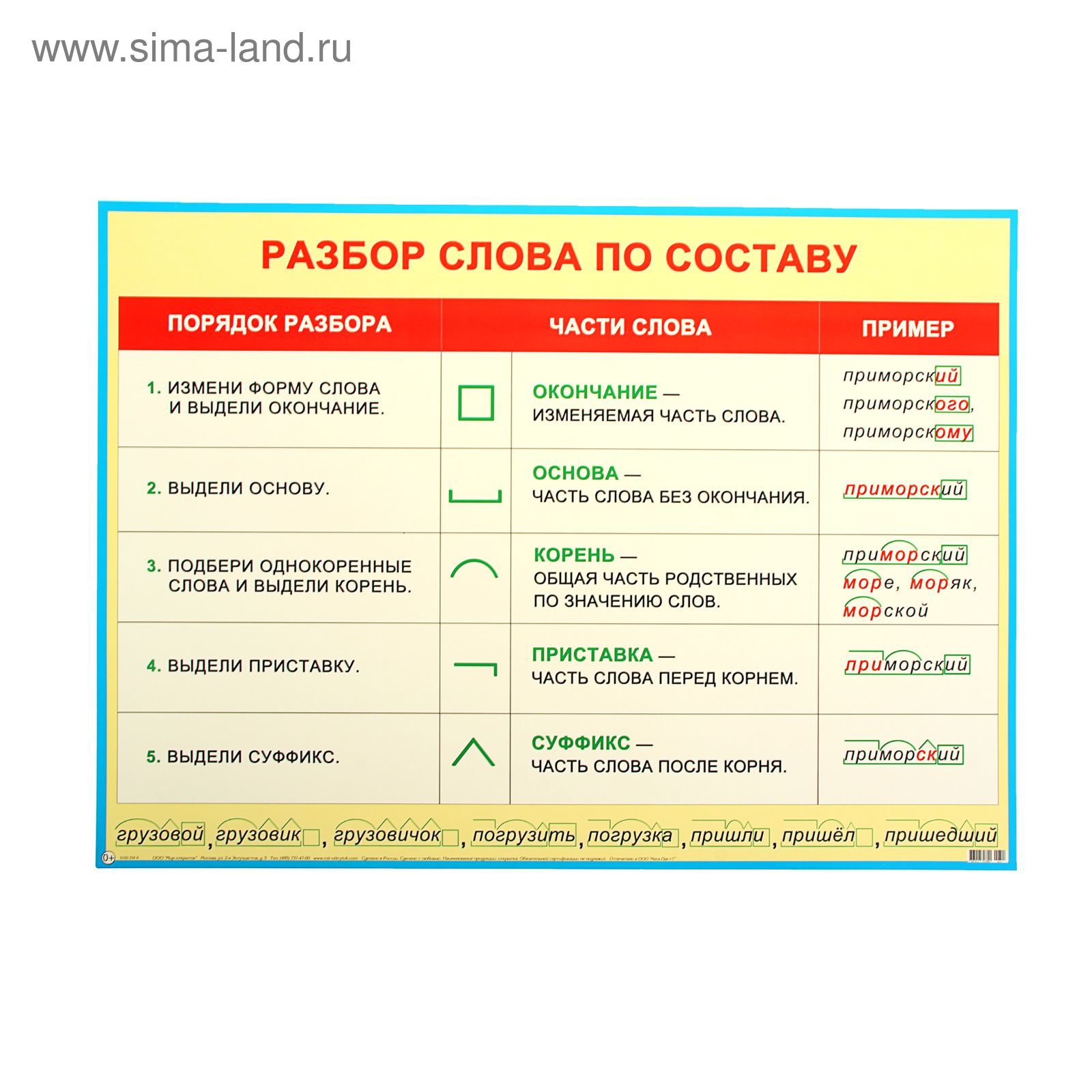
Научная литература является богатым источником информации о взаимосвязях между экспрессией гена и заболеванием, которые наблюдались в тысячах небольших исследований.В общем, эти результаты доступны только при кропотливой ручной обработке; однако инструменты автоматического анализа текста начинают снижать барьеры на пути систематического сбора этих данных. Некоторые ресурсы сосредоточены на вручную собранных данных из публикаций по экспрессии генов, связанных с заболеванием, и miRNA. DisGeNET (17, 18) — это комплексная платформа, посвященная взаимосвязям генотип-фенотип человека, которая объединяет данные из баз данных, созданных экспертами, с информацией, собранной путем интеллектуального анализа текста научной литературы.miR2Disease (19) — это управляемая вручную база данных, цель которой — предоставить исчерпывающий ресурс по дисрегуляции микроРНК при различных заболеваниях человека на основе опубликованной литературы. OncomiRDB (20) — это база данных экспериментально подтвержденных связанных с раком микроРНК, собранных вручную из литературы.
Наконец, была разработана база данных BioXpress (22, 23), чтобы удовлетворить потребность в интегрированном представлении данных об экспрессии гена рака и miRNA, полученных в различных исследованиях, как крупных, так и мелкомасштабных.BioXpress собирает данные об экспрессии из общедоступных источников, таких как TCGA (13) и ICGC (12), и использует стандартизированный статистический метод для определения значимости дифференциальной экспрессии генов и микроРНК между опухолью и соседними неопухолевыми образцами от одного и того же пациента. Кроме того, BioXpress сообщает о дифференциальной экспрессии генов, вручную выделенных и отобранных из публикаций и дополнительных материалов, что позволяет исследователям и клиницистам легко сравнивать данные экспрессии пациентов с существующими знаниями из литературы.Хотя имеется значительная информация об экспрессии, полученная в результате крупномасштабных исследований в BioXpress (18 626 генов и 710 микроРНК от 33 типов рака и 667 пациентов), вручную отобранные аннотации, основанные на информации из литературы (138 генов-аннотаций PMID), значительно отстают. Внедрение автоматизированных инструментов интеллектуального анализа текста может упростить и ускорить процесс курирования BioXpress.
Внедрение автоматизированных инструментов интеллектуального анализа текста может упростить и ускорить процесс курирования BioXpress.
В этой работе мы описываем автоматизированный инструмент интеллектуального анализа текста DEXTER для извлечения информации об экспрессии генов / микроРНК в контексте заболеваний.DEXTER извлекает ген или miRNA, ассоциированное заболевание, уровень экспрессии (например, высокий или низкий), экспериментальный контекст (например, ткань или клеточную линию) и сравниваемые условия. Результаты поиска текста DEXTER могут быть использованы для расширения баз данных экспрессии, таких как BioXpress, miR2Disease и dbDEMC (24, 25). Однако для BioXpress необходимо учитывать дополнительные ограничения, поскольку BioXpress сообщает только о дифференциальной экспрессии генов и микроРНК между опухолевыми и нормальными (не опухолевыми) образцами. Таким образом, с учетом критериев BioXpress, экстракты DEXTER будут включены в основанную на литературе часть базы данных в случаях, когда сравниваются опухолевые и нормальные ткани.
Одним из мотивов разработки DEXTER было расширение базы данных BioXpress. Фактически, DEXTER использовался в трех случаях [рак легких, гены гликозилтрансферазы (GT) и отрывки, связанные с микроРНК], и результаты были интегрированы в литературную часть BioXpress (https: //hive.biochemistry.gwu. edu / bioxpress / about). Мы запустили DEXTER на 88 431, 27 516 и 28 067 рефератах по раку легкого, GT и рефератам, связанным с микроРНК, соответственно. Информация о дифференциальной экспрессии для 2024 генов, 115 GT и 826 микроРНК была извлечена из баз данных экспрессии рака легких, GT и микроРНК соответственно.
Мы также провели две разные оценки для измерения эффективности DEXTER. Первая оценка фокусируется не только на точности Dexter, но и на способности гарантировать, что потребности в курировании базы данных BioXpress удовлетворяются, то есть обнаружение дифференциально экспрессируемых генов в раковых тканях по сравнению с нормальными. В этой оценке система получила точность 94% и отзывчивость 84%. Вторая оценка была сосредоточена на общем извлечении данных экспрессии при заболеваниях из текста и не ограничивалась специфическими для BioXpress требованиями к сравнению образцов.В этой оценке система достигла показателей точности и запоминания 90 и 75% соответственно.
Вторая оценка была сосредоточена на общем извлечении данных экспрессии при заболеваниях из текста и не ограничивалась специфическими для BioXpress требованиями к сравнению образцов.В этой оценке система достигла показателей точности и запоминания 90 и 75% соответственно.
Материалы и методы
В следующих разделах мы опишем наш подход к разработке системы DEXTER. Сначала мы представим типы информации о выражениях, которые обычно можно найти в литературе, и обсудим те, которые мы считаем подходящими для этой задачи. Затем мы формально описываем задачу и различные типы информации, которую мы извлекаем.Наконец, мы представляем архитектуру нашей системы и подробно рассказываем о процессе извлечения.
Типы информации о выражениях
Среди бесчисленных утверждений в литературе относительно экспрессии генов при заболевании мы наблюдаем три широкие категории:
Тип A: В первую категорию входят предложения, которые предоставляют прямые доказательства экспрессии гена в двух различных сценариях, по крайней мере в одном из которых влечет за собой болезнь. Эти предложения обычно сравнительные; я.е. экспрессия гена контрастирует между двумя сценариями (Пример 1). Такие предложения часто встречаются в биомедицинской литературе, потому что эксперименты часто проводятся для сравнения двух разных образцов или условий. В подмножестве этих случаев сравниваемые группы представляют собой раковые и нормальные ткани; вот те предложения, которые представляют интерес для BioXpress.
Эти предложения обычно сравнительные; я.е. экспрессия гена контрастирует между двумя сценариями (Пример 1). Такие предложения часто встречаются в биомедицинской литературе, потому что эксперименты часто проводятся для сравнения двух разных образцов или условий. В подмножестве этих случаев сравниваемые группы представляют собой раковые и нормальные ткани; вот те предложения, которые представляют интерес для BioXpress.
Пример 1. Экспрессия белка Shp2 была значительно повышена в тканях плоскоклеточной карциномы полости рта (OSCC) по сравнению с нормальными тканями….[PMID: 24439919]
Тип B: Ко второй категории относятся предложения, которые указывают уровень экспрессии гена в болезненном состоянии, но без явного сравнения. В примере 2 сообщается, что экспрессия miR-155 является высокой в образце заболевания («ткани рака поджелудочной железы») без какого-либо явного упоминания исходного уровня.
Пример 2: экспрессия miR-155 была высокой в тканях рака поджелудочной железы.
[PMID: 23817566]
 [PMID: 23817566]
[PMID: 23817566] Тип C: К третьей категории относятся предложения, которые устанавливают связь между уровнем экспрессии гена и различными концепциями, связанными с заболеванием, такими как исходы заболевания (например,грамм. «Плохая выживаемость») или болезненные процессы (например, «метастаз», «пролиферация раковых клеток»). Пример 3 представляет такой случай. Хотя такие предложения часто встречаются в литературе и информируют нас о последствиях экспрессии гена, они не затрагивают связь между экспрессией гена и заболеванием. Например, из Примера 3 мы не знаем, наблюдается ли обычно сверхэкспрессия C1GALT1 при раке груди; все, что мы знаем, это то, что , когда C1GALT1 чрезмерно экспрессируется при раке груди, рост, миграция и инвазия клеток усиливаются.Более того, в этих случаях возможно, что экспрессия гена подвергается экспериментальным манипуляциям и вообще не является естественным свойством болезнетворных клеток. Поэтому мы не извлекаем информацию из таких предложений.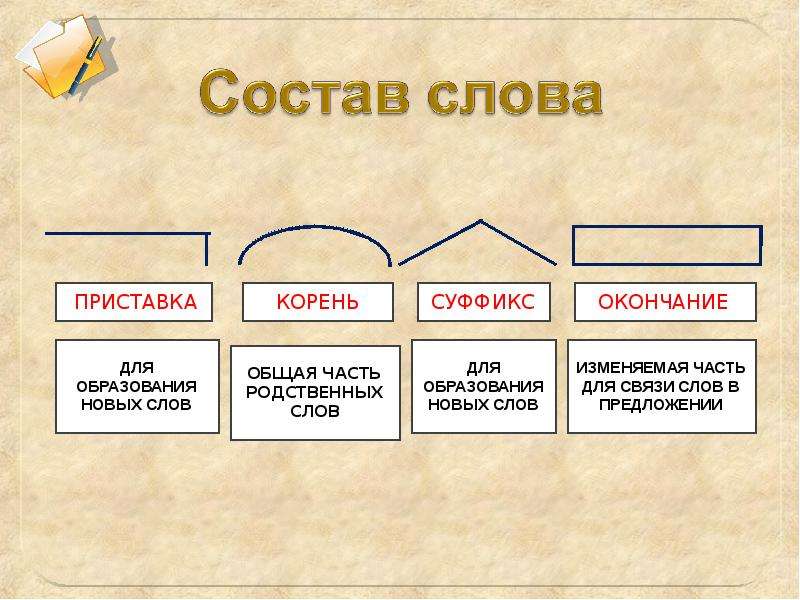
Пример 3. Сверхэкспрессия C1GALT1 усиливала рост, миграцию и инвазию клеток рака молочной железы in vitro , а также рост опухоли in vivo . [PMID: 25762620]
Определение задачи
Основываясь на обсуждении выше, мы сосредоточились на извлечении информации из предложений типа A и типа B.Для обоих типов DEXTER извлекает экспрессированный ген / микроРНК, уровень экспрессии и ассоциированное заболевание. Для предложений типа A, где выражение противопоставляется в двух сценариях, оно также извлекает сравниваемые сценарии. Если один из сравниваемых сценариев — нормальные ткани (например, пример 1), результаты помечаются как относящиеся к BioXpress. Информация, извлеченная из предложений типа A, описывающих другие сравниваемые сценарии (например, в примере 4, опухоли высокой и низкой степени злокачественности) и предложений типа B, также сохраняется, поскольку представляет потенциальный интерес для исследователей, клиницистов и кураторов других ресурсов по заболеваниям, таких как dbDEMC.
Пример 4: уровни экспрессии miR-454-3p были выше в глиомах высокой степени злокачественности, чем в глиомах низкой степени злокачественности. [PMID: 251]
Подводя итог, с учетом текста, наш инструмент DEXTER извлекает:
Экспрессируемый ген / микроРНК: дифференциально экспрессируемый ген (нормализованный по идентификатору гена NCBI) / микроРНК.
Ассоциированное заболевание: заболевание, связанное с образцом, в котором экспрессируется ген. Заболевание нормализовано по идентификатору онтологии заболевания (26) (DOID).
Уровень экспрессии: уровень экспрессии, нормализованный до «высокого» или «низкого».
Образец заболевания: образец (например, ткань, клетка, линия клеток и т. Д.), Упомянутый в предложении, где экспрессируется ген.
Сравненный образец: второй образец, который используется в качестве контраста с образцом на (d). Эта информация доступна в предложениях типа A, но не типа B.

Рассмотрим предложение в примере 1. Из этого предложения мы извлечем следующее:
Shp2 (идентификатор гена NCBI: 5781), (b) OSCC (DOID: 0050866), (c) усиленный (высокий) , (d) ткани OSCC и (e) нормальные ткани.
Обратите внимание, что одним из мотивов разработки DEXTER было расширение литературной части BioXpress. Поскольку DEXTER может собирать информацию в сценариях, выходящих за рамки рекомендаций BioXpress, мы должны рассмотреть дополнительные ограничения, прежде чем выходные данные DEXTER могут быть интегрированы в BioXpress. Например, сравниваемый образец (e) полезен для определения включения в BioXpress, поскольку рекомендации BioXpress требуют сравнения с нормальными или контрольными образцами. Таким образом, основываясь на информации в (e), мы определяем, что Пример 1 будет соответствовать рекомендациям BioXpress, тогда как Пример 4 — нет, поскольку сравниваемый образец представляет собой «нормальные ткани» в Примере 1 и «глиомы низкой степени злокачественности» в Примере 4. .
.
Образец заболевания (d) — это фраза, используемая в тексте, где упоминается, где экспрессируется ген. Например, образец заболевания — это «ткани OSCC» в Примере 1 и «глиомы высокой степени злокачественности» в Примере 4. Как видно из этих двух примеров, образец заболевания (d) позволяет нам часто вывести ассоциированное заболевание (b), которое нормализуется с помощью DOID.
Архитектура системы
Различные этапы системы DEXTER изображены на рисунке 1. На первом этапе (модуль обработки текста на рисунке 1) заголовок и текст аннотации Medline разбиваются на предложения и токенизируются.Затем эти предложения анализируются, чтобы получить синтаксические зависимости между словами и фразами. Поскольку мы рассматриваем эту задачу как задачу извлечения отношений (RE), применяется модуль RE, в котором извлекаются два типа отношений, соответствующие информации типа A и типа B. Эта фаза RE основывается на синтаксических зависимостях, определенных на предыдущем шаге.
Рисунок 1.
Обзор конвейера системы.
Рисунок 1.
Обзор конвейера системы.
Выходные данные компонента обработки текста также являются входными данными для компонента обнаружения и ввода объектов. Этот компонент обнаруживает названия генов, термины болезней и фразы, в которых упоминается информация об экспрессии. Таким образом, словосочетания существительных (NP), которые были идентифицированы синтаксическим анализатором, могут быть проверены, чтобы установить, являются ли они одним из этих типов сущностей. После шага RE нам нужно убедиться, что аргументы имеют ожидаемый тип. Например, аргументом, соответствующим сравниваемому сценарию, должна быть выборка болезни или болезни.Таким образом, мы можем отфильтровать отношения на основе информации о типе их аргументов. После фильтрации может потребоваться дополнительная обработка для извлечения некоторой информации. Например, информация о заболевании не может быть указана в предложении, и ее может потребоваться извлечь из другого места в аннотации. DEXTER разработан в основном с использованием языков программирования Python и Java. Подробности каждого шага архитектуры системы описаны в следующих подразделах.
DEXTER разработан в основном с использованием языков программирования Python и Java. Подробности каждого шага архитектуры системы описаны в следующих подразделах.
Обработка текста
Предварительная обработка
На этом этапе предварительной обработки мы токенизируем и разбиваем текст, как правило, аннотацию в Medline, на предложения с помощью инструментария Stanford CoreNLP (27).После разделения предложения мы проверяем, содержит ли предложение определенные слова, так называемые триггерные слова для отношений типа A и типа B (как описано ниже). Предложения, не содержащие триггерных слов, дальше не обрабатываются. Полный список триггерных слов, которые мы используем для выражения и сравнительных отношений, можно найти в дополнительном файле S1.
Синтаксическая обработка
Задача RE часто определяется как идентификация структур предикат-аргумент. Мы используем общий подход для извлечения отношений предикат – аргумент на основе синтаксического анализа. Далее мы преобразуем синтаксическое дерево синтаксического анализа в зависимости, чтобы получить результат, более близкий к отношениям предикат – аргумент. Стандартный граф зависимостей (SDG) (28) обеспечивает представление грамматических отношений между словами в предложении. На рисунке 2 показана SDG, использующая нотацию универсальной зависимости для предложения «MicroRNA-224 часто сверхэкспрессируется при колоректальном раке». Один из представленных триплетов зависимостей — это nsubjpass (MicroRNA-224, сверхэкспрессия), где отношение равно , nsubjpass (номинальный субъект пассивный), а регулятор и зависимый от отношения являются «сверхэкспрессируемыми» и «MicroRNA-224» , соответственно.
Мы используем общий подход для извлечения отношений предикат – аргумент на основе синтаксического анализа. Далее мы преобразуем синтаксическое дерево синтаксического анализа в зависимости, чтобы получить результат, более близкий к отношениям предикат – аргумент. Стандартный граф зависимостей (SDG) (28) обеспечивает представление грамматических отношений между словами в предложении. На рисунке 2 показана SDG, использующая нотацию универсальной зависимости для предложения «MicroRNA-224 часто сверхэкспрессируется при колоректальном раке». Один из представленных триплетов зависимостей — это nsubjpass (MicroRNA-224, сверхэкспрессия), где отношение равно , nsubjpass (номинальный субъект пассивный), а регулятор и зависимый от отношения являются «сверхэкспрессируемыми» и «MicroRNA-224» , соответственно.
Рисунок 2.
Рисунок 2.
Мы используем синтаксический анализатор Чарняка – Джонсона (29, 30) с адаптацией Дэвида МакКлоски к биомедицинской области (31), чтобы получить деревья синтаксического анализа избирательных округов для каждого предложения. Затем мы используем инструмент преобразования Стэнфорда (27, 28), чтобы преобразовать дерево синтаксического анализа в синтаксический граф зависимостей. Мы используем опцию «CCProcessed», которая сворачивает и распространяет зависимости, позволяя надлежащим образом обрабатывать предложения, содержащие союзы.Обратите внимание, что «CCProcessed» полезно, поскольку зависимости, включающие предлог, союзы, а также референт относительных предложений, «сворачиваются», чтобы получить прямые зависимости между контекстными словами.
Затем мы используем инструмент преобразования Стэнфорда (27, 28), чтобы преобразовать дерево синтаксического анализа в синтаксический граф зависимостей. Мы используем опцию «CCProcessed», которая сворачивает и распространяет зависимости, позволяя надлежащим образом обрабатывать предложения, содержащие союзы.Обратите внимание, что «CCProcessed» полезно, поскольку зависимости, включающие предлог, союзы, а также референт относительных предложений, «сворачиваются», чтобы получить прямые зависимости между контекстными словами.
Наш подход к извлечению информации основан на определении шаблонов на синтаксических зависимостях, полученных после синтаксического анализа. Эти шаблоны написаны на Semgrex, который является частью Stanford NLP Toolkit. Semgrex позволяет нам указывать шаблоны как регулярные выражения на основе лемм, тегов частей речи и меток зависимостей, которые будут автоматически совпадать со структурой зависимостей.
Текст в биомедицинской литературе часто бывает сложным и насыщенным информацией. Хотя синтаксический синтаксический анализ дает возможность абстрагироваться от некоторых текстовых вариаций, существуют некоторые синтаксические вариации, которые обеспечивают различные структуры зависимостей (активные, пассивные и номинальные). Однако эти вариации носят систематический характер и нашли отражение в различных лингвистических теориях, а также в грамматических рамках [например, древовидные семейства лексикализованных древовидных грамматик (LTAG)] (32, 33).При разработке наших паттернов мы учитываем такие синтаксические вариации, мотивированные принципами, используемыми в расширенном графе зависимостей (EDG) (34) и iXtractR (35).
Хотя синтаксический синтаксический анализ дает возможность абстрагироваться от некоторых текстовых вариаций, существуют некоторые синтаксические вариации, которые обеспечивают различные структуры зависимостей (активные, пассивные и номинальные). Однако эти вариации носят систематический характер и нашли отражение в различных лингвистических теориях, а также в грамматических рамках [например, древовидные семейства лексикализованных древовидных грамматик (LTAG)] (32, 33).При разработке наших паттернов мы учитываем такие синтаксические вариации, мотивированные принципами, используемыми в расширенном графе зависимостей (EDG) (34) и iXtractR (35).
Отношение извлечения
Как обсуждалось ранее, мы заинтересованы в извлечении информации из предложений с явными сравнениями между группами и без них (тип A и тип B соответственно). В следующих двух подразделах обсуждается обработка двух разных типов предложений.
Соотношения для типа A: сравнительные конструкции
Напомним, что экспрессия в образцах болезней для информации типа A присутствует в сравнительных предложениях, где экспрессия гена / микроРНК сравнивается в двух или более сценариях. Диапазон сравнений в биомедицинской литературе разнообразен и обширен и, очевидно, не ограничивается дифференциальным выражением. В предыдущей работе (36) мы разработали систему, которая идентифицирует и извлекает информацию (компоненты) из сравнений в целом. Хотя мы ссылаемся на нашу более раннюю работу для получения подробной информации об извлечении компонентов сравнения, мы кратко обсуждаем здесь компоненты сравнения и то, как они связаны с нашей задачей.
Диапазон сравнений в биомедицинской литературе разнообразен и обширен и, очевидно, не ограничивается дифференциальным выражением. В предыдущей работе (36) мы разработали систему, которая идентифицирует и извлекает информацию (компоненты) из сравнений в целом. Хотя мы ссылаемся на нашу более раннюю работу для получения подробной информации об извлечении компонентов сравнения, мы кратко обсуждаем здесь компоненты сравнения и то, как они связаны с нашей задачей.
Компоненты сравнения
Рассмотрим предложение в примере 5, в котором сравнивается уровень экспрессии гена в раковых и злокачественных опухолях.незлокачественные ткани. Сравниваемый аспект (CA) — это аспект, по которому производится сравнение двух сущностей. В этом предложении CA обозначается фразой «Экспрессия гена GPC5». Сравниваемые сценарии будут называться сравниваемыми объектами (CE) и обычно относятся к одному типу. В этом примере сравниваемыми объектами являются «ткани рака легких» и «смежные доброкачественные образования». Кроме того, в сравнительных предложениях есть две части, которые указывают на сравнение. Первый — это наличие слова, которое указывает масштаб сравнения, а второй — разделяет два CE.Первое часто является сравнительным прилагательным или наречием (например, «выше», «ниже», «лучше» и т. Д.), В то время как последнее может быть выражено фразами или словами (например, «чем», «по сравнению с», » по сравнению с ‘и т. д.). Мы будем называть сравнительное слово, обозначающее шкалу, индикатором шкалы (SI), а последнее, разделяющее сущности, — разделителем сущностей (ES). В примере 5 они обозначены как «ниже» и «чем» соответственно. Хотя ES полезен для идентификации двух объектов и, следовательно, полезен в нашей обработке, мы не извлекаем его в качестве аргумента, а вместо этого извлекаем только CA, два CE и SI.
Кроме того, в сравнительных предложениях есть две части, которые указывают на сравнение. Первый — это наличие слова, которое указывает масштаб сравнения, а второй — разделяет два CE.Первое часто является сравнительным прилагательным или наречием (например, «выше», «ниже», «лучше» и т. Д.), В то время как последнее может быть выражено фразами или словами (например, «чем», «по сравнению с», » по сравнению с ‘и т. д.). Мы будем называть сравнительное слово, обозначающее шкалу, индикатором шкалы (SI), а последнее, разделяющее сущности, — разделителем сущностей (ES). В примере 5 они обозначены как «ниже» и «чем» соответственно. Хотя ES полезен для идентификации двух объектов и, следовательно, полезен в нашей обработке, мы не извлекаем его в качестве аргумента, а вместо этого извлекаем только CA, два CE и SI.
Пример 5: Экспрессия гена GPC5 CA была ниже SI в тканях рака легкого CE , чем ES в соседних доброкачественных тканях CE .

Сравнительные предложения написаны в различных текстовых и синтаксических формах. Несмотря на вариации, наш ранее разработанный метод (36) эффективно извлекает компоненты этих сравнений, определяя шаблоны на основе синтаксических зависимостей, тем самым абстрагируясь от вариаций.Пример 6 состоит из семи предложений, которые иллюстрируют некоторое разнообразие сравнительных предложений в литературе; компоненты сравнений, извлеченные нашей системой, показаны в таблице 1. В первых трех предложениях СИ является основным предикатом предложения. СИ в первых двух предложениях является сравнительным прилагательным, тогда как в третьем предложении СИ является глаголом. Тем не менее, во всех трех предложениях CA является субъектом главного предиката.
Таблица 1.Компонентов, извлеченных из предложений типа A (Пример 6)
| Предложение # . | Индикатор шкалы . | В сравнении
. | Объект сравнения 1 . | Сравниваемая организация 2 . | |||
|---|---|---|---|---|---|---|---|
| (SI) . | (Калифорния) . | (CE1) . | (CE2) . | ||||
| 1 | Высшее | Плазма miR-187 | Пациенты с OSCC | Нормальные люди | |||
| 2 | Низшие | miR-181a экспрессия | клеток He6196 9019клеток He6 3 | Выше | экспрессия miR-210 | Метастатические опухоли | Первичные опухоли |
| 4 | Повышенные | уровни miR-95 | Образцы рака простаты человека | Нормальные ткани Нормальные ткани | Экспрессия TP | Рак яичников | Нормальные яичники |
| 6 | Снижение | Экспрессия FOXD3 | Ткани HGG | Нормальные ткани головного мозга | |||
| Элементы управления |
Предложение #
. | Индикатор шкалы . | В сравнении . | Объект сравнения 1 . | Сравниваемая организация 2 . | |||
|---|---|---|---|---|---|---|---|
| (SI) . | (Калифорния) . | (CE1) . | (CE2) . | ||||
| 1 | Высшее | Плазма miR-187 | Пациенты с OSCC | Нормальные люди | |||
| 2 | Низшие | miR-181a экспрессия | клеток He6196 9019клеток He6 3 | Выше | экспрессия miR-210 | Метастатические опухоли | Первичные опухоли |
| 4 | Повышенные | уровни miR-95 | Образцы рака простаты человека | Нормальные ткани Нормальные ткани | Экспрессия TP | Рак яичников | Нормальные яичники |
| 6 | Снижение | Экспрессия FOXD3 | Ткани HGG | Нормальные ткани головного мозга | |||
| Элементы управления |

Компонентов, извлеченных из предложений типа A (Пример 6)
| Предложение # . | Индикатор шкалы . | В сравнении . | Объект сравнения 1 . | Сравниваемая организация 2 . | |||
|---|---|---|---|---|---|---|---|
| (SI) . | (Калифорния) . | (CE1) . | (CE2) . | ||||
| 1 | Высшее | Плазма miR-187 | Пациенты с OSCC | Нормальные люди | |||
| 2 | Низшие | miR-181a экспрессия | клеток He6196 9019клеток He6 3 | Выше | экспрессия miR-210 | Метастатические опухоли | Первичные опухоли |
| 4 | Повышенные | уровни miR-95 | Образцы рака простаты человека | Нормальные ткани Нормальные ткани | Экспрессия TP | Рак яичников | Нормальные яичники |
| 6 | Снижение | Экспрессия FOXD3 | Ткани HGG | Нормальные ткани головного мозга | |||
| Элементы управления |
Предложение #
. | Индикатор шкалы . | В сравнении . | Объект сравнения 1 . | Сравниваемая организация 2 . | |||
|---|---|---|---|---|---|---|---|
| (SI) . | (Калифорния) . | (CE1) . | (CE2) . | ||||
| 1 | Высшее | Плазма miR-187 | Пациенты с OSCC | Нормальные люди | |||
| 2 | Низшие | miR-181a экспрессия | клеток He6196 9019клеток He6 3 | Выше | экспрессия miR-210 | Метастатические опухоли | Первичные опухоли |
| 4 | Повышенные | уровни miR-95 | Образцы рака простаты человека | Нормальные ткани Нормальные ткани | Экспрессия TP | Рак яичников | Нормальные яичники |
| 6 | Снижение | Экспрессия FOXD3 | Ткани HGG | Нормальные ткани головного мозга | |||
| Элементы управления |
Напротив, в следующих двух предложениях (4 и 5) SI не является основным предикатом, а вместо этого является модификатором существительного, изменяющим CA. Однако, как и в случае с первыми тремя предложениями, подлежащее основного сказуемого (и предложения) обеспечивает CA.
Однако, как и в случае с первыми тремя предложениями, подлежащее основного сказуемого (и предложения) обеспечивает CA.
До сих пор мы наблюдали, что CA появляется как субъект основного предиката и что SI действует как главный предикат предложения или присоединяется как модификатор CA NP. Один из CE появляется после основного предиката и синтаксически присоединяется к предикату с помощью предлога «in». Второй CE обнаружен позже и разделен ES.
Шестое и седьмое предложения отличаются, поскольку структура сравнения начинается с фразы ES, которая включает в себя второй CE. Помимо этого различия, шестое предложение соответствует условиям, обсужденным выше в отношении CA, первого CE и SI. Однако в седьмом предложении один из CE («пациенты с ХЛЛ») является субъектом основного сказуемого. CA («уровень экспрессии мРНК PTEN») является объектом предиката, с SI («нижний»), присоединенным к как модификатор существительного.
Все образцы сравнения перечислены в дополнительном файле S1.
Пример 6:
Уровень miR-187 в плазме был значительно выше у пациентов с OSCC, чем у здоровых людей.
Экспрессия miR-181a была ниже в клетках HepG2 по сравнению с клетками Hep3B.
Уровни miR-95 были увеличены в образцах рака простаты человека по сравнению с нормальными тканями.
Более высокая экспрессия miR-210 была обнаружена в метастатических опухолях по сравнению с первичными опухолями.
Повышенная экспрессия TP наблюдалась при раке яичников, чем при нормальных яичниках.
По сравнению с нормальными тканями мозга, экспрессия FOXD3 была значительно снижена в тканях HGG как на уровне мРНК, так и на уровне белка.
По сравнению с контрольной группой, пациенты с ХЛЛ имели более низкий уровень экспрессии мРНК PTEN ( P <0,001).
Извлечение компонентов из предложений типа A (сравнительные)
Хотя мы отсылаем читателя к (36) за полным описанием нашей системы, мы кратко опишем процесс извлечения ниже и приведем пример.
Напомним, что наш подход к извлечению компонентов из сравнительных предложений основан на определении шаблонов с помощью Semgrex на синтаксических зависимостях, полученных после синтаксического анализа. Мы используем ребра зависимости из слов SI и ES для извлечения CA и CE. Пример такого шаблона сравнения описан ниже.
На рисунке 3 показан график зависимости сравнительного предложения, где SI («высший») сравнительное прилагательное (JJR) служит основным предикатом предложения. Обратите внимание, мы обычно ожидаем, что субъектом SI в таких случаях будет CA.Таким образом, мы следуем за ребром nsubj от JJR («выше»), чтобы получить голову CA («miR-187»). Мы отслеживаем все исходящие ребра из головки CA, чтобы извлечь NP NP («Plasma miR-187»). Как обсуждалось ранее, в таких случаях один из CE будет добавлен к SI с помощью предлога «in». Таким образом, мы используем nmod: в ребрах из JJR для извлечения CE («пациенты OSCC» и «нормальные люди»). Мы также проверяем, что извлеченные CE разделены ES («чем»).
Рисунок 3.
Рисунок 3.
Извлечение связи для типа B
Предложения типа B указывают уровень экспрессии объекта (например, гена) в некоторой выборке болезни, без явного противопоставления его другому состоянию. Важно отметить, что упоминается уровень выражения сущности, а не только сама сущность. Следовательно, нас интересует (i) выраженный аспект (EA): выражаемая сущность, (ii) выраженная локализация (EL): биологический контекст экспрессируемой сущности, которым могут быть образцы болезни, клетки, ткани и т. Д.и (iii) Индикатор уровня (LI): фраза, указывающая уровень выражения.
Несколько предложений типа B показаны в примере 7, изображая возможные синтаксические и текстовые вариации. Мы показываем результат нашей системы извлечения отношений для этих предложений в Таблице 2. В первых трех предложениях LI является основным предикатом предложения, задаваемым глаголом, сравнительным прилагательным и прилагательным, соответственно. Независимо от типа LI, в этих случаях субъект основного предиката предоставляет нам EA.
Независимо от типа LI, в этих случаях субъект основного предиката предоставляет нам EA.
Компонентов, извлеченных из предложений типа B (Пример 7)
| Предложение # . | Индикатор уровня . | Выраженный аспект . | Расположение выражения . | Неявное сравнение . | |||||
|---|---|---|---|---|---|---|---|---|---|
| (LI) . | (EA) . | (EL) . | |||||||
| 1 | Сверхэкспрессия | GALNT2 | OSCC | Да | |||||
| 2 | Более высокий | Уровни экспрессии IGF1R | Низкий уровень | Опухоль надпочечников | Уровни экспрессии miR-373 | Клеточные линии рака поджелудочной железы | Нет | ||
| 4 | Более высокий | Более высокий уровень экспрессии BRF2 | Ткани NSCLC | Да | Высокий Уровни экспрессии | Ткани рака желудка | Нет | ||
| 6 | Высокие | Уровни экспрессии FKBP51 | Клетки меланомы | Нет |
. | Индикатор уровня . | Выраженный аспект . | Расположение выражения . | Неявное сравнение . | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (LI) . | (EA) . | (EL) . | |||||||||
| 1 | Сверхэкспрессия | GALNT2 | OSCC | Да | |||||||
| 2 | Более высокий | Уровни экспрессии IGF1R | Низкий | Опухоль правого надпочечника | Правая опухоль | Уровни экспрессии miR-373 | Клеточные линии рака поджелудочной железы | Нет | |||
| 4 | Более высокий | Более высокий уровень экспрессии BRF2 | Ткани NSCLC | Да | Уровни экспрессии | Ткани рака желудка | Нет | ||||
| 6 | Высокие | Уровни экспрессии FKBP51 | Клетки меланомы | Нет |

Компоненты, извлеченные из предложений типа B (Пример 7)
| Предложение # . | Индикатор уровня . | Выраженный аспект . | Расположение выражения . | Неявное сравнение . | |||||
|---|---|---|---|---|---|---|---|---|---|
| (LI) . | (EA) . | (EL) . | |||||||
| 1 | Сверхэкспрессия | GALNT2 | OSCC | Да | |||||
| 2 | Более высокий | Уровни экспрессии IGF1R | Низкий уровень | Опухоль надпочечников | Уровни экспрессии miR-373 | Клеточные линии рака поджелудочной железы | Нет | ||
| 4 | Более высокий | Более высокий уровень экспрессии BRF2 | Ткани NSCLC | Да | Высокий Уровни экспрессии | Ткани рака желудка | Нет | ||
| 6 | Высокие | Уровни экспрессии FKBP51 | Клетки меланомы | Нет |
. | Индикатор уровня . | Выраженный аспект . | Расположение выражения . | Неявное сравнение . | |||||
|---|---|---|---|---|---|---|---|---|---|
| (LI) . | (EA) . | (EL) . | |||||||
| 1 | Сверхэкспрессия | GALNT2 | OSCC | Да | |||||
| 2 | Более высокий | Уровни экспрессии IGF1R | Низкий уровень | Опухоль надпочечников | Уровни экспрессии miR-373 | Клеточные линии рака поджелудочной железы | Нет | ||
| 4 | Более высокий | Более высокий уровень экспрессии BRF2 | Ткани NSCLC | Да | Уровни экспрессии | Ткани рака желудка | Нет | ||
| 6 | Высокий | Уровни экспрессии FKBP51 | Клетки меланомы | Нет |
Напротив, в следующих двух предложениях (4 и 5), главное сказуемое предложения начинается с таких глаголов, как ‘f «обнаружено», «обнаружено», «отмечено», «обнаружено» и т. д.В этих случаях LI присоединяется как модификатор существительного, модифицируя EA. Но, как и в случае с первыми тремя предложениями, субъект главного предиката дает EA. EL во всех этих предложениях (1–5) появляется после основного предиката и синтаксически присоединяется к предикату через предлог «in». В шестом предложении подлежащим основного сказуемого («найдено») является «мы», а не фраза EA. В таких случаях, когда предметом являются такие слова, как «мы», «авторы», «исследование» и т. Д., Объект предиката предоставляет нам EA, а EL присоединяется к EA через предлог «in».Как показано в предложениях 4 и 5, LI («высокий») в этом случае также присоединяется к EA как модификатор существительного.
д.В этих случаях LI присоединяется как модификатор существительного, модифицируя EA. Но, как и в случае с первыми тремя предложениями, субъект главного предиката дает EA. EL во всех этих предложениях (1–5) появляется после основного предиката и синтаксически присоединяется к предикату через предлог «in». В шестом предложении подлежащим основного сказуемого («найдено») является «мы», а не фраза EA. В таких случаях, когда предметом являются такие слова, как «мы», «авторы», «исследование» и т. Д., Объект предиката предоставляет нам EA, а EL присоединяется к EA через предлог «in».Как показано в предложениях 4 и 5, LI («высокий») в этом случае также присоединяется к EA как модификатор существительного.
Пример 7:
GALNT2 часто сверхэкспрессируется в OSCC, особенно в клетках карциномы на инвазивном фронте. [PMID: 24582885]
Уровни экспрессии IGF1R были выше в опухоли правого надпочечника. [PMID: 21468523]
Уровни экспрессии miR-373 были низкими в клеточных линиях рака поджелудочной железы.
[PMID: 24748127]Более высокий уровень экспрессии BRF2 был обнаружен в тканях NSCLC. [PMID: 24523874]
Высокие уровни экспрессии TRIM32 были обнаружены в тканях рака желудка. [PMID: 28521418]
Мы обнаружили высокие уровни экспрессии FKBP51 в клетках меланомы. [15571967]
 [PMID: 24748127]
[PMID: 24748127]Обратите внимание, что определенные слова и фразы LI, такие как «чрезмерно / недооценено», «увеличено», «уменьшено» и «увеличено», указывают на неявное сравнение с неустановленным исходным уровнем.Например, в предложении 7.1 использование предиката «чрезмерно выражено» не имеет смысла, если уровень выражения («высокий») не относится к некоторой базовой линии. Таким образом, мы отмечаем флаг «Неявное сравнение» (последний столбец в Таблице 2) в дополнение к аргументам EA, EL, LI в зависимости от типа фразы LI. Актуальность этого флага дополнительно обсуждается в разделе «Определение типа сравниваемой сущности».
Извлечение компонентов из предложений типа B
Обратите внимание, что, как обсуждалось ранее, существует два класса предикатов, которые запускают такие отношения типа B. Первый класс содержит LI (например, «избыточно выражено в», «недостаточно выражено в», «усилено в» и «усилено»). Второй класс включает слова или триггеры, состоящие из нескольких слов, например: «находится в», «обнаруживается в», «увеличивается в» и т. Д .; в этих случаях LI модифицирует советник. Наши шаблоны для извлечения аргументов отношений типа B основаны на этих двух типах классов предикатов. Рассмотрим граф зависимостей, показанный на рисунке 4a для предложения 7.1. Здесь LI — это главное сказуемое предложения.Поскольку в этих случаях EA является объектом LI, мы следуем ребру nsubjpass из предиката (LI), чтобы получить EA («GALNT2»). Мы следуем правилу nmod: in edge для извлечения EL («плоскоклеточный рак полости рта»). Пример графа зависимостей, где LI не является основным предикатом предложения, показан на рисунке 4b. Здесь главный предикат «найден» и аналогичен 4a nsubj и nmod: в ребра используются для извлечения EA и EL. LI («высокий») модифицирует EA в этих случаях, и поэтому мы прослеживаем ребро amod от заголовка EA, чтобы получить LI.
Первый класс содержит LI (например, «избыточно выражено в», «недостаточно выражено в», «усилено в» и «усилено»). Второй класс включает слова или триггеры, состоящие из нескольких слов, например: «находится в», «обнаруживается в», «увеличивается в» и т. Д .; в этих случаях LI модифицирует советник. Наши шаблоны для извлечения аргументов отношений типа B основаны на этих двух типах классов предикатов. Рассмотрим граф зависимостей, показанный на рисунке 4a для предложения 7.1. Здесь LI — это главное сказуемое предложения.Поскольку в этих случаях EA является объектом LI, мы следуем ребру nsubjpass из предиката (LI), чтобы получить EA («GALNT2»). Мы следуем правилу nmod: in edge для извлечения EL («плоскоклеточный рак полости рта»). Пример графа зависимостей, где LI не является основным предикатом предложения, показан на рисунке 4b. Здесь главный предикат «найден» и аналогичен 4a nsubj и nmod: в ребра используются для извлечения EA и EL. LI («высокий») модифицирует EA в этих случаях, и поэтому мы прослеживаем ребро amod от заголовка EA, чтобы получить LI. Полный список шаблонов и триггеров можно найти в дополнительном файле S1.
Полный список шаблонов и триггеров можно найти в дополнительном файле S1.
Рисунок 4.
(a) Пример ЦУР типа B 1. (b) Пример ЦУР типа B 2.
Рисунок 4.
(a) Пример ЦУР типа B 1. (b) Пример ЦУР типа B 2.
Обнаружение сущностей и набор фраз
Поскольку мы заинтересованы в извлечении информации о выражениях в контексте болезни, аргументы / компоненты наших отношений должны удовлетворять определенным ограничениям типа.Например, в сравнительной конструкции CA должен иметь тип , экспрессия гена . Кроме того, наша задача требует извлечения экспрессируемого гена, уровня экспрессии и ассоциированного заболевания. Следовательно, нам необходимо определить тип аргументной фразы. На этом этапе, который принимает проанализированные предложения в качестве входных данных из модуля обработки текста, мы смотрим на NP и определяем, содержат ли они термины, которые относятся к объектам типа : ген / miRNA, экспрессия или болезнь /, образец болезни .
Обратите внимание, что на этом этапе мы помечаем только все гены, микроРНК и заболевания, выражения и фразы-образцы болезней в тексте; подробности о том, как извлекается конкретный экспрессируемый ген и связанное с ним заболевание, будут описаны в разделе «Фильтрация и извлечение аргументов». Упоминания генов (на этом этапе мы не делаем различий между генами и белками) обнаруживаются с помощью PubTator (37), общедоступного инструмента, который помогает биодокументации путем пометки различных биологических объектов. Мы загрузили и использовали предварительно рассчитанные аннотации из PubTator, которые содержат упоминания генов в аннотациях, нормализованные по идентификаторам генов NCBI.Для обнаружения микроРНК мы используем регулярные выражения, которые фиксируют способы их упоминания в тексте (например, miR-1, microRNA1, miRNA-1 и т. Д.). При разработке регулярных выражений мы использовали устоявшееся соглашение об именах, как описано в miRBase (38), включая обнаружение префиксов, обозначающих виды или суффиксы, как в miR-1a, miR-1-5p и hsa-miR-1- 3п. Чтобы определить, относится ли фраза к типу « Expression », мы сравниваем заглавное существительное фразы со списком триггеров выражения, таких как «выражение», «уровень», «сверхвыражение» и т. Д.Обратите внимание, что ген, экспрессия которого определяется такой фразой Expression , будет либо находиться в той же фразе NP, указывающей фразу Expression , либо присоединяться к ней через предложную фразу. В обоих случаях экспрессируемый ген будет изменять фразу экспрессии, такую как «экспрессия X» или «экспрессия X», где X — название гена.
Чтобы определить, относится ли фраза к типу « Expression », мы сравниваем заглавное существительное фразы со списком триггеров выражения, таких как «выражение», «уровень», «сверхвыражение» и т. Д.Обратите внимание, что ген, экспрессия которого определяется такой фразой Expression , будет либо находиться в той же фразе NP, указывающей фразу Expression , либо присоединяться к ней через предложную фразу. В обоих случаях экспрессируемый ген будет изменять фразу экспрессии, такую как «экспрессия X» или «экспрессия X», где X — название гена.
Для выявления заболеваний мы также используем PubTator (37), где упоминания о заболеваниях нормализованы до идентификаторов MEDIC (39). Эти идентификаторы сопоставляются с DOID с помощью таблицы, предоставленной Disease Ontology (DO) (26), которая сопоставляет идентификаторы MEDIC с DOID.Выбор нормализации болезней к DOID был сделан, чтобы облегчить интеграцию с BioXpress, который использует только DOID. Обратите внимание, что аргументы нашего отношения могут быть болезнью (как обнаружено PubTator) или содержать заболевание, заголовок которого соответствует определенным триггерам выборки болезней , таким как «ткани», «клетки», «пациенты», «образцы». ‘,’ опухоли ‘и т. д. Полный список триггеров экспрессии и выборки заболеваний можно найти в дополнительном файле S2.
‘,’ опухоли ‘и т. д. Полный список триггеров экспрессии и выборки заболеваний можно найти в дополнительном файле S2.
Фильтрация и извлечение аргументов
На этом этапе есть два основных шага: (i) проверка соответствия аргументов, найденных модулями RE, ограничениям типа и соответствующая фильтрация, и (ii) извлечение окончательного отношения, которое может быть помещено в базу данных.
Как показано на рисунке 1, вводом в модуль RE является проанализированное предложение, которое также вводится в модуль ввода сущностей и фраз. Основная причина такого дизайна заключается в том, что мы используем отдельно разработанную систему общего назначения для извлечения сравнений. На этом этапе мы проверяем, что аргументы из модуля RE имеют правильный тип, где информация о типировании была определена модулем ввода. Рассмотрим случай сравнения: мы проверяем, что фраза, идентифицированная как CA, относится к типу , выражению и что два CE относятся к типу болезнь / образец болезни . Аналогичным образом мы проверяем ограничения типа для типа B: т.е. EA имеет тип , ген или , экспрессия гена , а EL — тип , образец болезни .
Аналогичным образом мы проверяем ограничения типа для типа B: т.е. EA имеет тип , ген или , экспрессия гена , а EL — тип , образец болезни .
Далее мы обсудим, как извлечь всю необходимую информацию для заполнения базы данных. Сначала мы обсудим извлечение гена и уровня, а затем обсудим извлечение болезни. Ген и уровень всегда извлекаются из предложения, тогда как болезнь может быть извлечена из какой-либо другой части аннотации или его названия.
Экспрессируемый ген и извлечение уровня экспрессии
Напомним, что аргументы CA и EA для типа A и типа B — это NP типа « Expression » или иногда сам ген. Таким образом, эти NP будут либо напрямую содержать имя гена, который мы захватываем, либо имя гена будет присоединено к фразе выражения в качестве модификатора. Мы используем упоминания генов / микроРНК, обнаруженные в модуле обнаружения и типирования сущностей, описанном в разделе «Выявление сущностей и типирование фраз», для извлечения конкретного экспрессированного гена / микроРНК из сравниваемых аргументов / EA.
Помимо выделения экспрессированного гена, нам также необходимо отметить уровень экспрессии (высокий или низкий). Как указывалось ранее во фразах, уровень выражения может быть предикатом извлеченных отношений (например, X выше в Y, чем Z, X перевыражен в Y) или присоединен к сравниваемым фразам / EA в качестве модификаторов существительных (например, ниже экспрессии X было обнаружено в Y). Эти фразы уже фиксируются нашей системой RE как аргументы SI или LI для отношений типа A и типа B соответственно.Затем они нормализуются до высокого или низкого уровня путем сопоставления их со списком триггеров. Мы используем триггеры, такие как «чрезмерно выраженный», «высокий», «повышенный» и т. Д., Чтобы назначить высокий уровень выражения, и триггеры, такие как «недовыраженный», «низкий», «пониженный» и т. Д., Чтобы назначить низкий. Полный список этих триггеров приведен в дополнительном файле S2.
Вылечить болезнь
В большинстве случаев заболевание упоминается в NP, соответствующих аргументам CE или EL отношений типа A / B, или присоединяется к нему предложной фразой. Таким образом, при определении ассоциированного заболевания мы проверяем, упоминается ли заболевание, обнаруженное PubTator (описанное в разделе «Извлечение отношений»), в одном из CE или в аргументе EL. В некоторых случаях аргументы отношений могут содержать только общие фразы о заболевании, такие как «опухоль», «рак», «болезнь», или популяционные фразы, такие как «пациенты», «мужчины» и т. Д. (Как в CE в Примере 6). . В этих случаях мы предполагаем, что указанное заболевание может быть выведено из контекста, а связанное заболевание извлечено из другого места в том же аннотации.
Таким образом, при определении ассоциированного заболевания мы проверяем, упоминается ли заболевание, обнаруженное PubTator (описанное в разделе «Извлечение отношений»), в одном из CE или в аргументе EL. В некоторых случаях аргументы отношений могут содержать только общие фразы о заболевании, такие как «опухоль», «рак», «болезнь», или популяционные фразы, такие как «пациенты», «мужчины» и т. Д. (Как в CE в Примере 6). . В этих случаях мы предполагаем, что указанное заболевание может быть выведено из контекста, а связанное заболевание извлечено из другого места в том же аннотации.
Вывод болезни из контекста
Основываясь на предварительном исследовании, мы заметили, что есть определенные места, где указано связанное заболевание. В некоторых случаях предложения заголовок / первое / заключение могут содержать указанное заболевание. Это места, где авторы склонны делать выводы или описывать характер проделанной работы. Таким образом, любая болезнь, упомянутая в этих местах, скорее всего, будет болезнью, изучаемой в представленной работе. Например, рассмотрим предложение в примере 8.Аргумент CE, извлеченный из этого предложения, является общей фразой о заболевании «раковые ткани». Здесь упоминается рак желудка, который упоминается в нескольких местах аннотации, включая заголовок.
Например, рассмотрим предложение в примере 8.Аргумент CE, извлеченный из этого предложения, является общей фразой о заболевании «раковые ткани». Здесь упоминается рак желудка, который упоминается в нескольких местах аннотации, включая заголовок.
Пример 8: Напротив, экспрессия miR-143 и -195 в раковых тканях была значительно ниже по сравнению с таковой в нормальных тканях. [PMID: 24649051]
В качестве альтернативы болезнь и образцы, которые были изучены, описаны в разделе «методы» аннотации, где описаны исследовательские цели исследования или его установка.Мы разработали определенные шаблоны для идентификации таких предложений, которые описаны ниже.
Предложения, в которых обсуждаются исследовательские цели статьи, содержат определенные расследования триггеров, таких как «исследовано», «изучено», «проанализировано», «оценено», «изучено», «сравнено» и т. Д. Наличие таких триггеров недостаточно для выявления таких предложений об изучении / расследовании. Нам необходимо дополнительно убедиться, что у триггера расследования есть соответствующий агент. Агент (субъект предложения) может быть авторами статьи, обозначенными такими словами, как «мы» или «авторы» (Пример 9a).В качестве альтернативы агент может быть причиной расследования, обозначенной такими словами, как «цель», «цель» или «цель» (Пример 9b). Наконец, триггер расследования может быть в пассивной форме с необязательным агентом, как в Примере 9c.
Нам необходимо дополнительно убедиться, что у триггера расследования есть соответствующий агент. Агент (субъект предложения) может быть авторами статьи, обозначенными такими словами, как «мы» или «авторы» (Пример 9a).В качестве альтернативы агент может быть причиной расследования, обозначенной такими словами, как «цель», «цель» или «цель» (Пример 9b). Наконец, триггер расследования может быть в пассивной форме с необязательным агентом, как в Примере 9c.
Пример 9a: Итак, авторы исследовали экспрессию TP при раке мочевого пузыря.
Пример 9b: Целью этого исследования было изучить, модулируют ли полифенолы из яблок экспрессию генов, связанных с профилактикой рака толстой кишки, в предопухолевых клетках, полученных из аденомы толстой кишки (LT97).
Пример 9c: Предпосылки. Исследовали связь между активностью фермента, связанного с 5-фторурацилом (5-FU), и чувствительностью уротелиальной карциномы мочевого пузыря (BUC) к 5-FU, и проанализировали способы повышения чувствительности к 5-FU.

Названия болезней также можно найти в предложениях, описывающих экспериментальную установку. Эти предложения содержат определенные проанализированных триггерных слов, таких как «проверено», «зарегистрировано», «собрано», «проанализировано», «измерено», «изучено», «оценено» и т. Д.Шаблоны для обнаружения таких предложений аналогичны шаблонам для расследования предложений. Разница в том, что темой этих слов (то есть кто был зачислен / протестирован) будут пациенты или образцы и обычно упоминается изучаемое заболевание. Мы заметили, что большинство из проанализированных конструкций триггеров находятся в пассивной форме, и поэтому мы ищем границу nusbjpass , которая предоставляет нам тему (примеры 10a и 10b). Субъект NP (подчеркнут в примерах ниже) указывает образец , который тестируется / изучается (тема) в эксперименте.Мы ищем число, которое часто указывает, сколько пациентов / образцов было протестировано, в аргументе sample , чтобы дополнительно проверить обнаружение предложений установки эксперимента.
Пример 10а: МЕТОДЫ. Всего было включено 140 пациентов с колоректальным раком и 280 не страдающих раком пациентов контрольной группы с подобранной частотой из группы наблюдения, созданной в 1989 году.
Пример 10b: Сыворотки 9 пациентов с хроническим гепатитом B и 32 пациентов с HCC, связанной с вирусом гепатита B (HBV), тестировали на уровень AFP-L3 с использованием гликанового микрочипа.
Определение типа сравниваемой сущности
КЭ, извлеченные из сравнительных конструкций в предложениях типа A, должны быть образцом болезни, такой как болезненная клетка, ткань, клеточная линия, опухоль, пациенты и т. Д. Поскольку руководящие принципы базы данных BioXpress требуют данных экспрессии, которые включают прямые доказательства различий в экспрессии генов между опухолью и соседние неопухолевые ткани (контроль), мы различаем сравнение с Control и Not-Control , добавляя флажок рамки сравнения. Если один из NP CE содержит такие слова, как «контроль», «нормальный», «здоровый», «смежный» и т. Д. В качестве модификатора существительного, мы обнаруживаем систему отсчета как Control (Пример 11), указывающую дифференциальная экспрессия при заболевании по сравнению с нормальным. Если такая фраза не обнаруживается в CE, мы устанавливаем флаг Not-Control , как в Примере 12, где сравниваются два подтипа заболевания («карцинома мочевого пузыря T1» и «карцинома Ta»).
Если один из NP CE содержит такие слова, как «контроль», «нормальный», «здоровый», «смежный» и т. Д. В качестве модификатора существительного, мы обнаруживаем систему отсчета как Control (Пример 11), указывающую дифференциальная экспрессия при заболевании по сравнению с нормальным. Если такая фраза не обнаруживается в CE, мы устанавливаем флаг Not-Control , как в Примере 12, где сравниваются два подтипа заболевания («карцинома мочевого пузыря T1» и «карцинома Ta»).
Пример 11: Более высокая экспрессия TP наблюдалась при раке яичников, чем при нормальных яичниках.[PMID: 15628771]
Пример 12: «… .экспрессия PDECGF при карциноме мочевого пузыря T1 была вдвое выше, чем при карциноме Ta». [PMID:97]
Примечание. через определенные предикатные триггеры отношений типа B, такие как «чрезмерно / недостаточно выражено», «увеличено», «уменьшено», «повышено» и «уменьшено» («чрезмерно выражено», как на рисунке 4a). Помимо указания на высокую / низкую экспрессию гена в раковых клетках, эти предложения также предполагают неявное сравнение с контролем . Использование предиката «сверхэкспрессия», используемого для обнаружения высокого уровня экспрессии в болезненном состоянии, не имеет смысла, если оно не относится к некоторому исходному уровню. В таких случаях мы предполагаем, что эталон для сравнения является нормальным (состояние, не связанное с заболеванием), и назначаем контрольный флаг Control_Implicit . С другой стороны, триггеры предикатов, такие как «высокий», «низкий» и т. Д., Указывают информацию о выражении, но не обязательно подразумевают дифференциальное выражение. В таких случаях мы назначаем none в качестве системы отсчета, как в Примере 13.
Использование предиката «сверхэкспрессия», используемого для обнаружения высокого уровня экспрессии в болезненном состоянии, не имеет смысла, если оно не относится к некоторому исходному уровню. В таких случаях мы предполагаем, что эталон для сравнения является нормальным (состояние, не связанное с заболеванием), и назначаем контрольный флаг Control_Implicit . С другой стороны, триггеры предикатов, такие как «высокий», «низкий» и т. Д., Указывают информацию о выражении, но не обязательно подразумевают дифференциальное выражение. В таких случаях мы назначаем none в качестве системы отсчета, как в Примере 13.
Пример 13: Экспрессия GCS была высокой в образцах, положительных по рецепторам эстрогена (ER) и отрицательных по HER-2. [PMID: 24456584]
Результаты
Одной из наших мотиваций при разработке DEXTER была помощь в курировании базы данных BioXpress. В этом разделе сначала обсуждаются три варианта использования, предназначенные для расширения литературной части базы данных BioXpress. Кроме того, мы обсуждаем результаты запуска DEXTER на большом наборе рефератов PubMed, связанных с раком.Затем мы рассмотрим оценку DEXTER с использованием стандартных мер точности и отзыва. Наша первая оценка сосредоточена на результатах, относящихся к BioXpress, и поэтому мы рассматриваем только случаи, в которых экспрессия гена в образце рака сравнивается с нормальным исходным уровнем. Мы также провели вторую оценку, чтобы проверить способность DEXTER извлекать данные о проявлениях болезней из текста без ограничений, налагаемых руководящими принципами BioXpress. Обе оценки основаны на сравнении вывода DEXTER с наборами данных, аннотированными вручную.Наборы данных были аннотированы соавторами, которые являются экспертами в предметной области и не участвовали в разработке и внедрении системы DEXTER. В первой оценке использовались аннотации двух исследователей, которые участвовали в разработке базы данных BioXpress. Вторая оценка была основана на аннотациях исследователя, имеющего значительный опыт в области биологического кураторства и аннотации.
Кроме того, мы обсуждаем результаты запуска DEXTER на большом наборе рефератов PubMed, связанных с раком.Затем мы рассмотрим оценку DEXTER с использованием стандартных мер точности и отзыва. Наша первая оценка сосредоточена на результатах, относящихся к BioXpress, и поэтому мы рассматриваем только случаи, в которых экспрессия гена в образце рака сравнивается с нормальным исходным уровнем. Мы также провели вторую оценку, чтобы проверить способность DEXTER извлекать данные о проявлениях болезней из текста без ограничений, налагаемых руководящими принципами BioXpress. Обе оценки основаны на сравнении вывода DEXTER с наборами данных, аннотированными вручную.Наборы данных были аннотированы соавторами, которые являются экспертами в предметной области и не участвовали в разработке и внедрении системы DEXTER. В первой оценке использовались аннотации двух исследователей, которые участвовали в разработке базы данных BioXpress. Вторая оценка была основана на аннотациях исследователя, имеющего значительный опыт в области биологического кураторства и аннотации.
Сценарии использования
Напомним, что одним из мотивов разработки DEXTER было расширение литературной части базы данных BioXpress.Вывод DEXTER подходит для BioXpress, если: (i) заболевание является раком (как определено DO) и (ii) имеется явное / неявное сравнение экспрессии в образцах рака с нормальными образцами. Результаты этого раздела показывают, что DEXTER можно масштабировать для обработки и извлечения информации о выражениях из большого набора рефератов. Мы обсуждаем обработку трех больших наборов рефератов, охватывающих различные варианты использования, для включения в BioXpress. Обработанные результаты поиска текста для этих трех наборов были интегрированы в базу данных BioXpress (https: // hive.biochemistry.gwu.edu/bioxpress/about).
Чтобы рассмотреть вариант использования, в котором исследователь хочет изучить конкретное заболевание, мы обработали набор отрывков, связанных с раком легких. Во-вторых, мы сосредоточились на наборе отрывков, относящихся к группе генов, а именно GT, которые представляют собой набор ферментов, которые играют важную роль в основных посттрансляционных модификациях в клеточном развитии. Изменение гликановых структур или статуса гликозилирования может играть важную роль в развитии неопластического характера в клетках пролиферации.Последний набор отрывков был выбран, чтобы продемонстрировать, что наш метод расширяется, чтобы позволить всестороннее исследование, в данном случае для исследователей, заинтересованных в роли микроРНК в развитии рака. Значительный объем данных, которые мы извлекли для этих трех сценариев использования, указывает на то, что в литературе содержится огромное количество информации, которую DEXTER может извлечь. Методология отбора рефератов и некоторые ключевые характеристики трех разработанных наборов данных обсуждаются ниже.
Изменение гликановых структур или статуса гликозилирования может играть важную роль в развитии неопластического характера в клетках пролиферации.Последний набор отрывков был выбран, чтобы продемонстрировать, что наш метод расширяется, чтобы позволить всестороннее исследование, в данном случае для исследователей, заинтересованных в роли микроРНК в развитии рака. Значительный объем данных, которые мы извлекли для этих трех сценариев использования, указывает на то, что в литературе содержится огромное количество информации, которую DEXTER может извлечь. Методология отбора рефератов и некоторые ключевые характеристики трех разработанных наборов данных обсуждаются ниже.
Вариант использования 1: рак легких
В нашем первом наборе рефератов мы сосредоточились на конкретном раке.Из-за проекта OncoMX (https://hive.biochemistry.gwu.edu/bioxpress; веб-сайт OncoMX, который на основе BioXpress находится в стадии разработки), который опирается на BioXpress, мы выбрали «рак легких» в качестве представляющего интерес рака. Мы использовали DO, чтобы получить все термины рака легких, то есть все термины в иерархии DO с раком легких в качестве корня, что привело к 47 терминам DO рака. Мы использовали синонимы, предоставленные DO для каждого термина рака легких, в результате чего получился набор терминов, относящихся к раку легких. Мы запросили PubMed с этим списком терминов (т.е. «Рак легких» ИЛИ «карцинома легких» ИЛИ «немелкоклеточная карцинома»…) для получения всех рефератов, связанных с раком легких, что дало 151 618 рефератов. Затем мы выбрали только те рефераты, которые содержат определенные слова-выражения / фразы, такие как «выражение», «уровень» и т. Д., Что уменьшило количество рефератов до 88 431 рефератов.
Мы использовали DO, чтобы получить все термины рака легких, то есть все термины в иерархии DO с раком легких в качестве корня, что привело к 47 терминам DO рака. Мы использовали синонимы, предоставленные DO для каждого термина рака легких, в результате чего получился набор терминов, относящихся к раку легких. Мы запросили PubMed с этим списком терминов (т.е. «Рак легких» ИЛИ «карцинома легких» ИЛИ «немелкоклеточная карцинома»…) для получения всех рефератов, связанных с раком легких, что дало 151 618 рефератов. Затем мы выбрали только те рефераты, которые содержат определенные слова-выражения / фразы, такие как «выражение», «уровень» и т. Д., Что уменьшило количество рефератов до 88 431 рефератов.
Мы запустили DEXTER для этих отрывков и выбрали только те результаты, в которых извлеченный рак был одним из 47 DOID рака легких. В таблице 3 (строка 1) перечислены некоторые ключевые характеристики набора данных по экспрессии рака легких.Обратите внимание, что количество рефератов, обработанных DEXTER (88 431), отражает количество рефератов, в которых упоминается как рак легкого, так и словесное выражение (и еще несколько альтернативных вариантов) где-то в реферате. Таким образом, во многих случаях эти два понятия не связаны между собой и могут быть разделены на несколько предложений. Даже среди случаев, которые они появляются в одном предложении, DEXTER занимается только упоминаниями о различном выражении в образцах болезни по сравнению с выборкой, не связанной с заболеванием. Мы извлекли информацию типа A из 742 рефератов и информацию типа B из 1448 рефератов.Всего из информации об экспрессии типа A и типа B было извлечено 642 и 1383 гена соответственно. На рисунке 5 показаны 10 основных генов, извлеченных с наибольшим количеством литературных данных (количество отрывков, синие столбцы), в дополнение к количеству различных терминов рака легких, которые были связаны с каждым геном (оранжевые столбцы). Например, дифференциальная экспрессия верхнего гена рецептора эпидермального фактора роста (EGFR) была извлечена из 62 отрывков, и было обнаружено, что она экспрессируется в «немелкоклеточной карциноме легкого», «раке легких», «овсяноклеточной карциноме легкого», мелкоклеточная карцинома легких »и« аденокарцинома легких ».
Таким образом, во многих случаях эти два понятия не связаны между собой и могут быть разделены на несколько предложений. Даже среди случаев, которые они появляются в одном предложении, DEXTER занимается только упоминаниями о различном выражении в образцах болезни по сравнению с выборкой, не связанной с заболеванием. Мы извлекли информацию типа A из 742 рефератов и информацию типа B из 1448 рефератов.Всего из информации об экспрессии типа A и типа B было извлечено 642 и 1383 гена соответственно. На рисунке 5 показаны 10 основных генов, извлеченных с наибольшим количеством литературных данных (количество отрывков, синие столбцы), в дополнение к количеству различных терминов рака легких, которые были связаны с каждым геном (оранжевые столбцы). Например, дифференциальная экспрессия верхнего гена рецептора эпидермального фактора роста (EGFR) была извлечена из 62 отрывков, и было обнаружено, что она экспрессируется в «немелкоклеточной карциноме легкого», «раке легких», «овсяноклеточной карциноме легкого», мелкоклеточная карцинома легких »и« аденокарцинома легких ».
Результаты крупномасштабной обработки
| . | # тезисов обработано . | Количество извлеченных рефератов . | Количество записей . | Количество экспрессируемых генов . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| . | . | Тип А . | Тип B . | Тип А . | Тип B . | Тип А . | Тип B . | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Набор для рака легких | 88 431 | 742 | 1448 | 985 | 2019 | 642 | 1383 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9019 106 | 236 | 42 | 73 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| набор микроРНК | 28 067 | 1650 | 3575 | 2522 | 6437 | 477 | 9018 9018 9018 | 9018 9018 9018 9018
. | # тезисов обработано . | Количество извлеченных рефератов . | Количество записей . | Количество экспрессируемых генов . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| . | . | Тип А . | Тип B . | Тип А . | Тип B . | Тип А . | Тип B . | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Набор для рака легкого | 88431 | 742 | 1448 | 985 | 2019 | 642 | 1383 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9019 106 | 236 | 42 | 73 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| набор микроРНК | 28067 | 1650 | 3575 | 2522 | 6437 | 477 | 721 Таблица | 721 Результаты крупномасштабной обработки
3.3. Основные функцииФункции играют незаменимую роль в задаче извлечения отношений, особенно для китайских текстов EMR. В этой статье сначала представлены основные особенности извлечения отношений сущностей для китайских EMR и даны ссылки на функции открытого текста для извлечения отношений, которые в основном делятся на лексические, контекстные, сущностные и местоположения. (1) Лексические: это касается самих двух сущностей, которые играют определенную роль в извлечении связи между ними, потому что даже если две конкретные сущности появляются в разных местах, отношения между ними могут быть одинаковыми.Например, отношение между «感冒 (простуда)» и «发烧 (лихорадка)» в «患者 因 感冒 而 发烧 (у пациентов повышается температура из-за простуды)» обычно является «DCS (болезнь вызывает симптомы)», поэтому в этой статье также принимает две сущности как функцию. (2) Контекстуальный: в китайских текстах EMR набор слов и часть речи в определенном диапазоне до и после двух сущностей играют ключевую роль в извлечении отношения между двумя объектами. Отношение сущностей оценивается по контекстной информации, которая относится к трем пакетам слов и части речи до и после двух сущностей в этой статье.(3) Сущность: характеристика сущности относится к типу сущности, что является чрезвычайно важной характеристикой, поскольку связь сущностей в этом документе классифицируется по двум типам сущностей. Среди них объекты типа «тест» и «лечение» связаны только с двумя типами объектов, а именно с болезнью и симптомом, и существует связь между болезнью и симптомом, а не между тестом и лечением. Эта особенность имеет важное руководящее значение для суждения о границах и особого типа суждения об отношениях сущностей.(4) Относительное положение: относительное положение двух сущностей, E1 и E2, имеет определенную индикативную функцию для извлечения отношения сущностей в предложении китайских текстов EMR. Для большинства предложений в китайском наборе данных EMR этой статьи сущности болезни и сущности симптомов появляются перед сущностями тестирования и сущностями лечения, тогда как сущности болезни обычно появляются перед сущностями симптомов. Например, заболевание «胆结石 (желчный камень)» находится перед объектами лечения «全 胆囊 切除 术 (тотальная холецистэктомия)» в китайском тексте EMR «1974 年 因 胆结石 于 瑞金 医院 全 术 ( в 1974 году в больнице Жуйджин была проведена тотальная холецистэктомия из-за камней в желчном пузыре », и связь между двумя объектами называется« TrAD (лечение, применяемое к болезни) ».В этой статье есть четыре категории взаимного расположения двух объектов: E1 находится слева от E2, E1 находится справа от E2, E1 находится в E2, а E2 находится в E1. (5) Расстояние: расстояние между двумя сущности относятся к количеству слов между ними. В общем, чем больше слов между двумя объектами, тем дальше они друг от друга и тем менее вероятно, что между ними существует связь. Расстояние между двумя объектами выражается путем измерения количества слов между двумя объектами после сегментации слов, в которой слова содержат знаки препинания. 3.4. Расширенные возможностиДля более точного решения задачи по извлечению связи сущностей китайских EMR, после анализа текстов китайских EMR, в этой статье расширены возможности EMR на основе базовых функций, которые называются расширенными функциями, которые в основном разделены в медицинские записи, индикаторы и расширенные контекстные функции. (1) Медицинская карта: глава, в которой находится объект, оказывает определенное влияние на извлечение связи между объектами из китайских EMR.Например, в главе «出院 情况 (ситуация с разгрузкой)» сводки по разрядам в китайских EMR вероятность связи, связанной с улучшением, выше, чем связанная с ухудшением. Кроме того, информация о модификации объекта также является уникальной информацией в EMR, которая является описанием объекта. Подводя итог, можно сказать, что характеристики медицинской карты относятся к главам и модификациям сущностей. (2) Индикатор: отображение контекстных слов сущности и базы слов-индикаторов для связи сущностей рассматриваются как характеристики индикатора в китайских MER.Согласно характеристикам китайских MER, суждение об отношении сущности связано с контекстными словами двух сущностей. Есть несколько индикаторов, которые могут напрямую классифицировать отношения между двумя объектами. Если есть такие индикаторы, как «好转 (улучшено)», «有所 缓解 (облегчено)», «明显 好转 (очевидно, улучшено)» и «控制 稳定 (стабильный контроль)», отношение сущности обычно является «TrID» или «Трис». Если есть такие индикаторы, как «控制 不佳 (плохой контроль)», «效果 一般 (общий эффект)», «未见 明显 变化 (без очевидных изменений)», то связь сущности обычно бывает «TrWD» или «TrWS».«После анализа и статистики устанавливается база слов индикатора для всех отношений сущностей, и отображение слов двух сущностей в базе слов индикатора рассматривается как расширенная функция. (3) Расширенный контекст: в предложении много сопоставление сущностей, что делает невозможным найти слова с указательным значением отношения в контексте сущности. Например, в предложении «患者 7 天 前 无 明显 诱因 出现» (у пациента не было явных побуждений к развитию вздутия живота) 伴 右上腹 钝痛 (сопровождалась тупой болью в правой верхней части живота), 伴 乏力, 食欲减退 (усталость и анорексия), 伴 皮肤, 巩膜 黄 染 (пожелтение кожи и склеры), 无 腹泻, 黑 便 (отсутствие диареи или черного стула), 无 寒战 (отсутствие дрожи), 高热 (лихорадка), 恶心 (тошнота ) и 呕吐 (рвота) », есть много слов, которые бесполезны для извлечения отношения в определенном диапазоне рядом с сущностью.Таким образом, эта статья расширяет функцию общего контекста и выбирает глаголы рядом с сущностью в качестве расширенной функции контекста. 3.5. Анализ зависимостейБольшинство китайских EMR являются длинными предложениями, и содержание и форма предложений относительно шаблонны, особенно структура предложений, которые в основном похожи. Поэтому стоит добавить информацию о структуре предложений к задаче извлечения связи сущностей из китайских EMR. Анализ зависимостей выявляет синтаксическую структуру предложения путем анализа зависимости между его компонентами.Одним словом, это распознавание грамматических компонентов, таких как «объект-предикат субъекта» и «атрибутивно-наречное дополнение», и анализ отношений между ними. Он утверждает, что доминирующим элементом предложения является основной глагол [21], и что все доминаторы так или иначе зависят от основного глагола. Платформа языковых технологий (http://ltp.ai/) (LTP) Харбинского технологического университета представляет собой полный набор систем обработки китайского языка, разработанных исследовательским центром социальных вычислений и информационного поиска Харбинского технологического университета. .Он предоставляет богатые, эффективные и точные технологии обработки естественного языка, включая сегментацию китайских слов, тегирование части речи, синтаксический анализ зависимостей и тегирование семантических ролей. Использование LTP для анализа зависимости предложения «пациенту с симптомами свистящего дыхания и лихорадки было назначено противоинфекционное лечение, и ему стало легче после лечения противоастматическим средством (患者 出现 喘息, 伴 发热, 予 抗 感染, 平喘 治疗 后 缓解) . » Результаты показаны на рисунке 3. Анализ зависимостей предназначен для анализа структурной информации предложения, распознавания «объекта-предиката субъекта» и «атрибутивного наречия» и анализа отношений между компонентами.Согласно синтаксическому анализу зависимостей примеров предложений на рисунке 3, основной предикат предложения — «出现 (имеет)», зависимость сущности «喘息 (хрипит)» и «出现 (имеет)» — это VOB, а зависимость сущность «抗 感染 (антиинфекция)» также является VOB. В таблице 2 показано отношение аннотации, полученное в результате анализа зависимостей с помощью LTP.
3.6. Синтаксические особенности зависимостейВ этом разделе будут объединены структура и функции предложения, чтобы получить синтаксические особенности зависимостей для лучшего синтаксического построения и семантических функций, где структура предложения отражается в синтаксическом анализе зависимостей и вычислении сходства предложений с использованием алгоритма редактировать расстояние. Специфические синтаксические особенности зависимости определяются следующим образом: (1) Отношение зависимости предложения бинарных объектов: это относится к синтаксическим отношениям между двумя объектами в синтаксической структуре предложения после синтаксического анализа зависимости.Например, отношение зависимости сущности «(свистящее дыхание)» после синтаксического анализа — это VOB в приведенном выше примере (рисунок 3), а отношение зависимости сущности «(лихорадка)» — это COO. Таким образом, в данном документе значение анализа зависимостей каждой сущности в парах сущностей рассматривается как характеристика. (2) Комбинация отношений зависимости пары сущностей: последняя функция состоит в том, чтобы принять отношение зависимости пары сущностей в качестве входных данных, в то время как эта функция относится к комбинации отношений зависимости пары сущностей, которая является последовательной.Благодаря этой последовательности синтаксическая структура пар сущностей в предложениях может быть показана более четко путем анализа комбинаторного признака, чем анализа признака независимого отношения зависимости. Например, отношение зависимости пары сущностей <喘息 (свистящее дыхание), 抗 感染 (защита от инфекции)> в приведенном выше примере (рисунок 3) — это VOB-VOB, что указывает на то, что оба объекта действуют как объект в VOB. Различные типы отношений имеют разные комбинации отношений зависимости, поэтому эта синтаксическая функция зависимости может лучше отражать различия типов отношений между разными объектами.(3) Расстояние между двоичной сущностью и основным предикатом: после множества исследований и экспериментов по синтаксическому анализу зависимостей было обнаружено, что основной предикат играет важную роль в извлечении границ сущностей и отношений сущностей. В предложении расстояние между сущностью и основным предикатом, очевидно, отличается от расстояния между сущностью и общим предикатом, поэтому в данной статье первый рассматривается как особенность. После того, как основной предикат предложения получен путем анализа зависимостей, расстояние между сущностью и основным предикатом вычисляется путем вычисления количества слов между ними на основе местоположения основного предиката. 3,7. SVM ModelЗадача модели машины опорных векторов [22] состоит в том, чтобы найти гиперплоскость в N-мерном пространстве (N — количество функций), которая четко классифицирует точки данных. Чтобы разделить два класса точек данных, можно выбрать множество возможных гиперплоскостей. Чтобы найти плоскость, которая имеет максимальный запас, то есть максимальное расстояние между точками данных обоих классов, мы превращаем ее в задачу выпуклого квадратичного программирования. Для данного набора обучающих выборок, где — вектор -й признак и — метка классов, обозначенная как, гиперплоскость определяется следующим образом: где — вектор нормали гиперплоскости и определяет направление гиперплоскости, а — перехват, который определяет расстояние между гиперплоскостью и началом координат.Поскольку правильность классификации оценивается путем наблюдения за положительными или отрицательными числами, функция запаса должна быть определена следующим образом: Чтобы унифицировать измерения, к вектору нормали добавляются ограничения: Идея SVM заключается в максимальном увеличении запаса, чтобы расстояние от всех точек до гиперплоскости было больше или равно определенному расстоянию; то все точки классификации классифицируются по обе стороны от вектора поддержки, я.е., Если функция запаса, то уравнение (4) сокращается до Учитывая, что максимизация равняется минимизации, модель SVM для решения задачи гиперплоскости максимального разбиения может быть выражена как следующая задача оптимизации с ограничениями : 4. РезультатыВ этом разделе мы проводим три сравнительных эксперимента, основанных на основных функциях, расширенных функциях и синтаксических функциях зависимостей. Результаты экспериментов показывают, что структурная информация очень важна для извлечения отношений сущностей из китайских EMR, незаменимая роль в задаче извлечения отношений, особенно для китайских текстов EMR. 4.1. Набор данныхМы оцениваем наш подход к извлечению связи сущностей на медицинском наборе данных из существующего исследования [23]; этот набор данных является полуавтоматическим и аннотирован на основе китайских EMR больницы общего профиля третьего класса в Шанхае за целый год, а набор сущностей получен с помощью метода распознавания сущностей с расширенными функциями. Подробная информация о наборе данных показана в таблице 3. Мы используем 70% набора данных в качестве обучающих данных и 30% для тестирования. Читателям, интересующимся этим набором данных, рекомендуется прочитать академическое исследование [23].
4.2. Базовый планВ этой статье задача извлечения связи сущностей может быть преобразована в задачу мультиклассификации. Инструмент машинного обучения LibSVM [24] используется для автоматического построения нескольких двоичных классификаторов в соответствии с количеством категорий, которые можно напрямую использовать для многозначной классификации. Поэтому в этой статье используется инструмент LibSVM для обучения и тестирования модели SVM, которая имеет определенные требования к формату данных для обучения и набора тестовых данных, а формат данных входных файлов показан на рисунке 4.Каждая строка данных на рисунке 4 представляет собой обучающий вектор, а «метка» представляет собой идентификацию каждой классификационной метки в этой мультиклассификации, «индекс» — это количество функций, а «значение» — это ценность функций. В этой статье все наборы данных, обученные и протестированные с помощью LibSVM, преобразуются в файлы данных этого формата для экспериментов после извлечения признаков и построения вектора признаков. Для того, чтобы сравнить влияние расширенных функций и информации о структуре предложения на экспериментальные результаты извлечения отношений сущностей в китайских EMR, в этой статье проводятся три контрастных эксперимента.Первый эксперимент — это базовый эксперимент, в ходе которого выбираются базовые характеристики, включая лексическую функцию, контекстную функцию, функцию объекта и функцию местоположения. И второй эксперимент добавляет расширенные функции, основанные на основных функциях, в то время как последний эксперимент добавляет синтаксический анализ зависимостей к функциям для формирования синтаксических функций зависимостей. Результаты экспериментов оцениваются тремя типами индикаторов [25]: Precision (P), Recall (R) и F1. 4.3. Результаты и анализЭкспериментальные результаты извлечения отношений на основе различных характеристик набора данных показаны в таблице 4.Как мы и ожидали, метод синтаксического анализа зависимостей превосходит метод извлечения отношений, основанный на базовых или расширенных функциях. Для базовой линии эффект извлечения взаимосвязей сущностей TrCD, TrNAD и TrNAS является слабым. Это связано с тем, что эти три типа отношений встречаются реже (менее 5 раз) в корпусе тегов. Хотя точность TeRS высока, не только потому, что этот тип отношения чаще встречается в тренировочном корпусе, но и потому, что характеристики этого отношения очевидны, в котором паттерн предложения в основном состоит из «胸片 shows» (рентгенограмма грудной клетки показывает):双 肺纹理 增多 (двусторонняя маркировка легких увеличена) и 模糊 (размыто) ».Кроме того, эффект извлечения SID и TeRD лучше, что также связано с очевидными особенностями поверхности и большим количеством обучающих данных. Однако точность извлечения отношений TrID, TrIS, TrWd и TrWS невысока из-за наличия длинных предложений в китайских EMR, и только контекстные особенности слов до и после не очевидны.
Хотя после добавления расширенных функций, предложенных в этой статье, в дополнение к трем невыделенным типам отношений TrCD, TrNAD и TrNAS, точность и скорость отзыва всех других типов отношений были улучшены, среди которых Эффект улучшения четырех типов сильнее: TrID, TrWd, TrIS и TrWS. Это связано с тем, что особенности медицинской карты в расширенных функциях (включая информацию о главах и информацию о модификации объекта) имеют некоторое влияние на расположение связи между объектами.Например, в главе «出院 情况 (ситуация с выпиской)» степень отношения сущности к улучшению выше, чем отношение к ухудшению. Признаки индикатора в расширенных характеристиках более эффективны для типов отношений улучшения и ухудшения, потому что есть связанные демонстративные признаки (好转 (улучшение), 稳定 (стабильность), 一般 (общее), 不佳 (плохое) и т. Д.) До и после сущности улучшения и ухудшения. Глагольные особенности сущности вперед и назад в расширенных характеристиках также имеют большое значение для извлечения отношения сущности из китайских EMR.Из-за длинного предложения в текстах китайского EMR слова до и после многих пар сущностей не имеют смысла для извлечения отношений сущностей, в то время как глаголы до и после пар сущностей обычно имеют определенные ориентировочные значения. Как показано в таблице 4, точность и скорость отзыва всех отношений сущностей были значительно улучшены после добавления синтаксических функций зависимостей. Анализ зависимостей в основном предназначен для поиска более глубокой структурной информации предложений на основе поверхностных семантических характеристик.Очевидно, что три синтаксических функции зависимостей, добавленные в этот документ, по-прежнему значительно улучшают точность TrID, TrWd, TrIS и TrWS, а также улучшают TeRD и TeRS. Причина в том, что модели предложений «лечение обнаруживают симптомы» и «лечение подтвержденных заболеваний» очень похожи и унифицированы. Многие предложения представляют собой шаблоны «определенный тест: описание симптома или описание заболевания» или «тест показывает: описание симптома или описание заболевания», поэтому эта характеристика может быть обнаружена с помощью анализа зависимостей. Значения F1 для извлечения отношения на основе различных функций показывают тенденцию эффектов извлечения отношения сущности. В случае ограниченного обучающего корпуса производительность каждого отношения сущностей улучшается после объединения расширенных функций и синтаксических функций зависимостей. В частности, он более эффективен для нескольких типов отношений (TrID, TrWD и т. Д.), Которых относительно мало в корпусе. Однако наш метод не очень эффективен при извлечении трех типов отношений TrCD, TrNAD и TrNAS, поскольку количество этих трех типов отношений в корпусе слишком мало.Будущее направление исследований может быть сосредоточено на том, как сгенерировать соответствующий корпус или найти более глубокие особенности, когда количество корпусов невелико. 5. ВыводыВ этом документе реализуется извлечение отношений сущностей в китайских EMR. Типы извлечения отношений включают отношения между лечением и заболеванием, лечением и симптомом, тестом и заболеванием, тестом и симптомом и заболеванием и симптомом. А метод машинного обучения используется для преобразования задачи извлечения отношений в классификацию пар сущностей, которая в основном использует модель SVM для обучения и тестирования.Сходство предложений дает много намеков на отношение сущностей, то есть, как правило, отношения между двумя сущностями в предложениях с аналогичными структурами и семантикой предложений одинаковы. Во-первых, в этой статье предлагаются четыре основных характеристики общего текста, такие как лексическая характеристика и функция расположения. Во-вторых, из-за сопоставления многих сущностей или слов в китайских текстах EMR простая контекстная информация является избыточной и зашумленной, поэтому предлагается расширенная функция, которая состоит из информации о главах и функции индикатора.Кроме того, поскольку основные функции и расширенные функции являются единственными поверхностными семантическими функциями, но игнорируют информацию о структуре предложения, инструмент LTP используется для анализа синтаксического анализа зависимостей китайских текстов EMR и введения синтаксических функций зависимостей. В этой статье модель SVM применяется для обучения и тестирования извлечения отношений сущностей. Три сравнительных эксперимента предназначены для трех вышеупомянутых типов функций. Результаты показывают, что расширенные функции и синтаксические функции зависимостей, предложенные в этой статье, в определенной степени повышают точность и скорость отзыва при извлечении связи сущностей из китайских EMR.Однако обучающий набор и набор тестов, используемые в этой статье, имеют ограниченный масштаб. В будущем необходимо изучить метод глубокого обучения для крупномасштабного корпуса, чтобы более эффективно извлекать связи сущностей. Конфликт интересовАвторы заявляют об отсутствии конфликта интересов. БлагодарностиАвторы хотели бы поблагодарить больницу за ее вклад, который предоставляет электронные медицинские записи, которые используются в качестве набора данных для экспериментов в этой статье.Это исследование финансировалось Национальной программой ключевых исследований и разработок Китая (№ 2019YFB2101600). Дополнительные материалыИз-за конфиденциальности набора данных наших медицинских EMR мы выбрали некоторые экспериментальные данные в качестве образцов. Подробности файла дополнительных материалов следующие: (1) папка выписки — это данные сводки выписки, которая включает данные обучения, теста, сводки выписки и сущность сводки выписки. Файлы в папках train и test представляют собой выписки пациентов, которые используются для обучения и тестирования моделей, включая условия госпитализации, признание диагноза, диагностику и процесс лечения, диагностику выписки, выписку из больницы и приказы о выписке.Файлы в папках с именем разрядаEntity являются медицинскими объектами выписок. Каждая строка в файлах соответствует информации об объекте в сводках по выписке, которые помечены тегом « C = объект P = начало: конец T = тип объекта A = утверждение объекта», где C представляет собой концепции сущностей в сводках выписки, P означает начальную и конечную позицию сущностей в медицинских текстах EMR, а T и A обозначают тип сущностей и модификацию сущностей соответственно.Файлы в папках с именем разрядаRelation являются отношениями сущностей сводок выписок. Каждая строка в файлах соответствует отношениям между объектами в сводках медицинских выписок, которые помечены тегами E = {entity [strat-end] entity type; …;} ‖ R = ‖ E = { entity [strat-end] тип объекта; …;}, где первый E представляет первый объект, включая концепцию объекта, позицию начала-конца и тип объекта. Точно так же второй E представляет вторую сущность.А средний R представляет тип отношения между двумя объектами. (2) Папка прогресса — это данные записи прогресса, которые включают данные обучения, теста, отношения записей прогресса и сущность записи прогресса. Файлы в папках train и test представляют собой записи о прогрессе пациентов, которые используются для обучения и тестирования моделей, включая характеристики случая, предварительный диагноз и план диагностики. Файлы в папках с именем progress Entity являются медицинскими объектами записей прогресса.Каждая строка в файлах соответствует информации об объекте в текущих записях, которые помечены тегом « C = объект P = начало: конец T = тип объекта A = утверждение объекта», где C представляет собой концепции сущностей в записях о прогрессе, P означает начальную и конечную позицию сущностей в записях о состоянии здоровья, T и A обозначает тип сущностей и модификацию сущностей соответственно.Файлы в папках с именем progressRelation являются отношениями сущностей записей прогресса. Каждая строка в файлах соответствует отношению между сущностями в записях о ходе выполнения, которые помечены тегами E = {entity [strat-end] entity type; …;} ‖ R = ‖ E = {entity [strat-end] тип объекта; …;}, где первый E представляет первый объект, включая концепцию объекта, позицию начала-конца и тип объекта. Точно так же второй E представляет вторую сущность.А средний R представляет тип отношения между двумя объектами. (Дополнительные материалы) Определение болезни по Merriam-Websterболезнь | \ di-ˈzēz \ 1 : состояние живого тела животного или растения или одной из его частей, которое нарушает нормальное функционирование и обычно проявляется отличительными признаками и симптомами. : болезнь, недомогание. инфекционные заболевания — редкое генетическое заболевание, болезнь сердца.2 : вредное развитие (как в социальном институте) рассматривает преступность города как болезнь
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
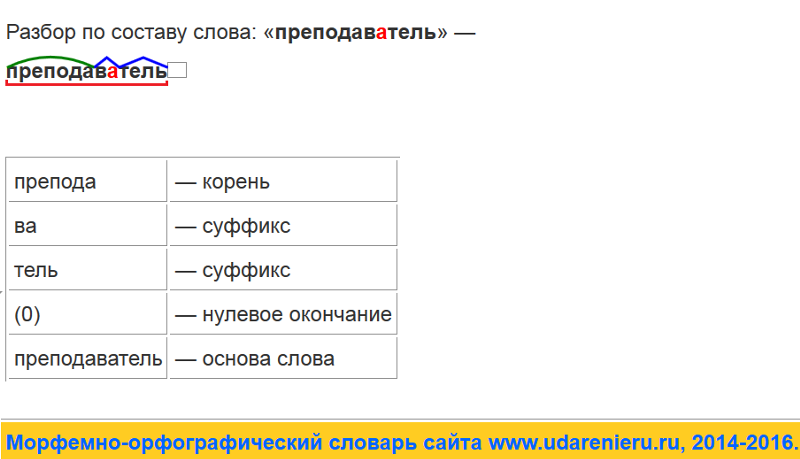


 Как и в наборе рака легких, мы выбрали только те отрывки, которые содержали экспрессивные слова / фразы. Кроме того, мы выбрали только те отрывки, которые содержали упоминание рака, выбрав те рефераты, в которых упоминается заболевание (как обнаружено PubTator) и чей MESH ID может быть сопоставлен с любым из 2100 терминов DOID рака [термины DOID рака — все узлы в Иерархия DO с раком (DOID: 162) в качестве корня], используя файл сопоставления DOID. Эти этапы фильтрации дали 27 516 рефератов, на которых мы запустили DEXTER и извлекли информацию, относящуюся к BioXpress, где экспрессируемым геном был GT.
Как и в наборе рака легких, мы выбрали только те отрывки, которые содержали экспрессивные слова / фразы. Кроме того, мы выбрали только те отрывки, которые содержали упоминание рака, выбрав те рефераты, в которых упоминается заболевание (как обнаружено PubTator) и чей MESH ID может быть сопоставлен с любым из 2100 терминов DOID рака [термины DOID рака — все узлы в Иерархия DO с раком (DOID: 162) в качестве корня], используя файл сопоставления DOID. Эти этапы фильтрации дали 27 516 рефератов, на которых мы запустили DEXTER и извлекли информацию, относящуюся к BioXpress, где экспрессируемым геном был GT. Например, дифференциальная экспрессия для высших GT, никотинамидфосфорибозилтрансферазы (NAMPT) была извлечена из 30 отрывков, и было обнаружено, что она экспрессируется при 20 раковых заболеваниях, таких как «рак желудка», «рак груди», «рак эндометрия», «b- клеточная лимфома и папиллярная карцинома щитовидной железы.
Например, дифференциальная экспрессия для высших GT, никотинамидфосфорибозилтрансферазы (NAMPT) была извлечена из 30 отрывков, и было обнаружено, что она экспрессируется при 20 раковых заболеваниях, таких как «рак желудка», «рак груди», «рак эндометрия», «b- клеточная лимфома и папиллярная карцинома щитовидной железы. Мы выполнили DEXTER для этих отрывков, и в таблице 3 (строка 3) перечислены некоторые ключевые характеристики набора данных экспрессии микроРНК.
Мы выполнили DEXTER для этих отрывков, и в таблице 3 (строка 3) перечислены некоторые ключевые характеристики набора данных экспрессии микроРНК.
 В настоящее время интерфейс принимает запросы, подобные PubMed, в качестве входных данных, таким образом поддерживая такие запросы, как название гена, название болезни или любое биологическое понятие.Например, пользователь, интересующийся геном egfr и заболеванием «рак легких», может отправить такой запрос, как « egfr » И « рак легких ». Затем система отправляет запрос в PubMed, который возвращает все PMID, удовлетворяющие запросу. Система отображает результаты этих PMID, которые ранее были обработаны DEXTER. Поскольку этот список PMID был возвращен PubMed для данного запроса, результаты могут также содержать результаты для генов, отличных от egfr, и / или для других видов рака.По этой причине интерфейс позволяет фильтровать результаты с помощью раскрывающихся меню. Интерфейс доступен по адресу: http://biotm.cis.udel.edu/DEXTER. На рисунке 8 представлен снимок экрана интерфейса после отправки запроса «egfr» И «рак легких».
В настоящее время интерфейс принимает запросы, подобные PubMed, в качестве входных данных, таким образом поддерживая такие запросы, как название гена, название болезни или любое биологическое понятие.Например, пользователь, интересующийся геном egfr и заболеванием «рак легких», может отправить такой запрос, как « egfr » И « рак легких ». Затем система отправляет запрос в PubMed, который возвращает все PMID, удовлетворяющие запросу. Система отображает результаты этих PMID, которые ранее были обработаны DEXTER. Поскольку этот список PMID был возвращен PubMed для данного запроса, результаты могут также содержать результаты для генов, отличных от egfr, и / или для других видов рака.По этой причине интерфейс позволяет фильтровать результаты с помощью раскрывающихся меню. Интерфейс доступен по адресу: http://biotm.cis.udel.edu/DEXTER. На рисунке 8 представлен снимок экрана интерфейса после отправки запроса «egfr» И «рак легких».
 Чтобы удовлетворить потребности BioXpress, нам необходимо извлечь информацию об экспрессии генов / микроРНК, где рак прямо или неявно сравнивается с контролем. Таким образом, наша система идентифицирует предложения типа A, в которых один из CE содержит модифицирующую фразу, предполагающую, что это контрольный образец (флаг системы отсчета Control ), и предложения типа B, где есть неявное сравнение для контроля ( флаг кадра ссылки Control_Implicit ).Поскольку BioXpress занимается только информацией об экспрессии в контексте рака, а не других заболеваний, отрывки из этого оценочного набора были выбраны, если они содержат какой-либо термин, который может указывать на рак (например, опухоль, злокачественный, рак, карцинома и т. Д.).
Чтобы удовлетворить потребности BioXpress, нам необходимо извлечь информацию об экспрессии генов / микроРНК, где рак прямо или неявно сравнивается с контролем. Таким образом, наша система идентифицирует предложения типа A, в которых один из CE содержит модифицирующую фразу, предполагающую, что это контрольный образец (флаг системы отсчета Control ), и предложения типа B, где есть неявное сравнение для контроля ( флаг кадра ссылки Control_Implicit ).Поскольку BioXpress занимается только информацией об экспрессии в контексте рака, а не других заболеваний, отрывки из этого оценочного набора были выбраны, если они содержат какой-либо термин, который может указывать на рак (например, опухоль, злокачественный, рак, карцинома и т. Д.). Затем мы выбираем только те рефераты, которые содержат определенные слова / фразы-выражения, такие как «выражение», «уровень» и т. Д., Что сокращает количество рефератов до 28 067 рефератов. Для выбора абстрактов GT, вместо использования запроса PubMed, как в случае с микроРНК, мы идентифицировали абстракты, в которых упоминается любая из GT, используя базу данных генов PubTator. Затем, как и раньше, мы выбрали подмножество рефератов, которые содержали слова / фразы-выражения и упоминание о болезни, что дало 10 278 рефератов. Наконец, мы случайным образом выбрали 200 рефератов из этих двух наборов с равным количеством из каждого набора.
Затем мы выбираем только те рефераты, которые содержат определенные слова / фразы-выражения, такие как «выражение», «уровень» и т. Д., Что сокращает количество рефератов до 28 067 рефератов. Для выбора абстрактов GT, вместо использования запроса PubMed, как в случае с микроРНК, мы идентифицировали абстракты, в которых упоминается любая из GT, используя базу данных генов PubTator. Затем, как и раньше, мы выбрали подмножество рефератов, которые содержали слова / фразы-выражения и упоминание о болезни, что дало 10 278 рефератов. Наконец, мы случайным образом выбрали 200 рефератов из этих двух наборов с равным количеством из каждого набора.


 Мы случайным образом выбрали 100 абстрактов (поровну разделенных между генами и микроРНК) в качестве набора для оценки, следуя той же процедуре для отбора абстрактов, которая использовалась при первой оценке. На этот раз набор отрывков, связанных с генами, не ограничивался генами GT, а рассматривался любой ген. Как и раньше, аннотатор пометил всю информацию об экспрессии: экспрессируемый ген / микроРНК, уровень экспрессии и ассоциированное заболевание, в результате чего было получено 169 аннотированных экземпляров.Кроме того, если аннотатор считал, что это было явное сравнение уровня выражения между двумя разными сценариями, то аннотатор также отмечал два CE.
Мы случайным образом выбрали 100 абстрактов (поровну разделенных между генами и микроРНК) в качестве набора для оценки, следуя той же процедуре для отбора абстрактов, которая использовалась при первой оценке. На этот раз набор отрывков, связанных с генами, не ограничивался генами GT, а рассматривался любой ген. Как и раньше, аннотатор пометил всю информацию об экспрессии: экспрессируемый ген / микроРНК, уровень экспрессии и ассоциированное заболевание, в результате чего было получено 169 аннотированных экземпляров.Кроме того, если аннотатор считал, что это было явное сравнение уровня выражения между двумя разными сценариями, то аннотатор также отмечал два CE.

 Пример последнего типа показан в примере 14. Нам не удалось зафиксировать этот случай как отношение типа A, потому что в этом случае сравнение охватывает два отдельных предложения. Поскольку наш текущий набор шаблонов полностью зависит от синтаксического анализа, существующая система не может фиксировать сравнения (следовательно, отношения типа A), где два CE появляются в разных разделах.
Пример последнего типа показан в примере 14. Нам не удалось зафиксировать этот случай как отношение типа A, потому что в этом случае сравнение охватывает два отдельных предложения. Поскольку наш текущий набор шаблонов полностью зависит от синтаксического анализа, существующая система не может фиксировать сравнения (следовательно, отношения типа A), где два CE появляются в разных разделах.