Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- понять, как правильно в нем ставить ударение.


Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
п с о а р 3 секунды назад
натуральный картофель с ярким вкусом 5 секунд назад
затон 7 секунд назад
шизофрения 8 секунд назад
чеп 15 секунд назад
яхлоду 15 секунд назад
ягненочек 15 секунд назад
дзвелая 15 секунд назад
с разбегу на стену 16 секунд назад
прапаганда 16 секунд назад
самоотверженность 17 секунд назад
н е н г и а т 18 секунд назад
логтаод 18 секунд назад
с ударением на предпоследнем слоге 19 секунд назад
возникновение 25 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | аквапарк | 0 слов | 2 часа назад | 147. 30.192.234 30.192.234 |
| Игрок 2 | аквапарк | 0 слов | 2 часа назад | 147.30.192.234 |
| Игрок 3 | конвергенция | 0 слов | 3 часа назад | 176.64.9.39 |
| Игрок 4 | шизофрения | 0 слов | 9 часов назад | 212.58.114.145 |
| Игрок 5 | прапаганда | 0 слов | 16 часов назад | 37.212.14.150 |
| Игрок 6 | дегтекурение | 0 слов | 23 часа назад | 85.143.16.4 |
| Игрок 7 | стратиграфия | 0 слов | 1 день назад | 136.169.169.101 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | акула | 53:47 | 10 минут назад | 46. |
| Игрок 2 | пифия | 0:0 | 10 минут назад | 46.249.26.38 |
| Игрок 3 | велосипед | 51:55 | 20 минут назад | 188.191.242.124 |
| Игрок 4 | судно | 52:57 | 25 минут назад | 46.249.26.38 |
| Игрок 5 | астра | 58:52 | 34 минуты назад | 46.249.26.38 |
| Игрок 6 | норов | 62:55 | 41 минута назад | 46.249.26.38 |
| Игрок 7 | цапка | 0:0 | 41 минута назад | 46.249.26.38 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Соня | На одного | 10 вопросов | 9 часов назад | 178. 166.232.142 166.232.142 |
| Сема | На одного | 10 вопросов | 1 день назад | 31.162.191.157 |
| Сема | На одного | 5 вопросов | 1 день назад | 31.162.191.157 |
| Эля | На одного | 5 вопросов | 1 день назад | 31.182.204.97 |
| Софакас | На двоих | 10 вопросов | 1 день назад | 178.141.203.117 |
| Ленис Сталинович | На двоих | 10 вопросов | 1 день назад | 217.107.194.54 |
| А | На одного | 5 вопросов | 1 день назад | 85.26.164.57 |
| Играть в Чепуху! | ||||
Контрольный диктант в 9 классе № 2 | Сборник диктантов по Русскому языку в 9 классе с русским языком обучения
Цель:
проверить знания, умения
и навыки учащихся
на начало учебного
года за курс
5- 8 классов.
Содержание контрольного диктанта направлено на выявление уровня развития умений, выбора условий для написания:
— проверяемые безударные гласные;
— непроверяемые безударные гласные;
— правописание окончаний имён существительных;
— написание непроизносимых согласных:
— правописание корней с чередованием;
— н-нн в прилагательных;
— не с прилагательными, наречиями и глаголами;
— написание производных предлогов;
— дефисное написание приложений.
Постановки знаков препинания:
— запятая при однородных членах предложения;
— запятая в сложном предложении;
— запятые при причастном и деепричастном обороте;
— запятая при уточнении.
Грамматические задания направлены на выявление уровня сформированности практических умений и навыков:
— синтаксического разбора предложения;
— разбора по составу слова;
— умения
подбирать проверочные слова.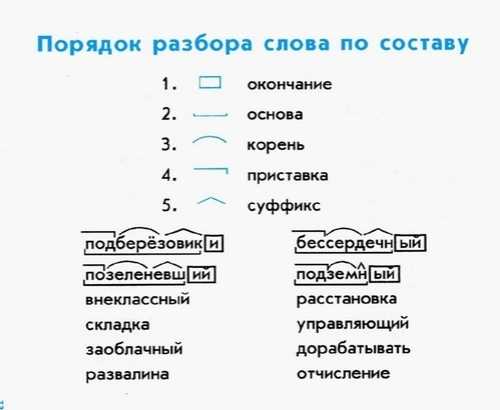
Диктант
Вот, пригретая лучами мартовского солнца, свалилась с макушки дерева, рассыпавшись снежной пылью, тяжёлая снежная шапка. И, точно живая, долго ещё колышется, как бы машет рукой, зелёная ветка, освобождённая от зимних оков.
Стайка клестов-еловиков, весело
пересвистываясь,
красно-брусничным ожерельем рассыпалась
по увешанным шишками
вершинам елей. Лишь
немногие знают, что
эти птички, весёлые,
общительные, всю зиму
проводят в хвойных
лесах, искусно устраивая
в густых сучьях
тёплые гнёзда.
(149 слов) (По И. Соколову – Микитову)
Грамматические задания
1. Фонетический разбор слова:
Лесной — 1-й вариант старого — 2-й вариант
2. Сделать разбор слова по составу:
Городские, перекликаясь, освобождённая — 1-й вариант
Радостная, оказавшись, увешанным — 2-й вариант
3. Найти в тексте односоставные предложения и указать их тип.
4. Выполнить синтаксический разбор предложения:
Вот вверху,
почти над головой,
послышалась барабанная трель,
звонкая, радостная. —
1-й вариант.
—
1-й вариант.
Стайка клестов-еловиков, весело пересвистываясь, красно-брусничным ожерельем рассыпалась по увешанным шишками вершинам елей. — 2-й вариант.
Модели синтаксического анализа и фМРТ – Лаборатория вычислительной нейролингвистики
Джонатан Р. Бреннан новости, публикации
Представлено на 6-м семинаре по когнитивному моделированию и компьютерной лингвистике: моделирование временных курсов МРТ с лингвистической структурой с разным размером зерна. (совместно с John T. Hale, David Lutz, Wen-Ming Luh)
Загрузить статью с ACL
Abstract
Нейровизуализация, когда участники слушают аудиокниги, обеспечивает богатый источник данных для теорий поэтапного синтаксического анализа. Мы сравниваем модели вложенной регрессии этих данных.
 Эти модели со смешанными эффектами включают в себя лингвистические предикторы с различной степенью детализации, начиная от биграмм частей речи и заканчивая неожиданностью на контекстно-свободных грамматиках банка деревьев и инкрементным подсчетом узлов в деревьях, полученных с помощью минималистских грамматик. Мелкозернистые структуры вносят независимый вклад в дополнение к более грубым предикторам. Однако этот результат достигается только с течением времени из передней височной доли (aTL). В аналогичных временных отрезках от нижней лобной извилины только n-граммы улучшаются по сравнению с несинтаксическим исходным уровнем. Эти результаты подтверждают идею о том, что aTL выполняет комбинаторную обработку во время естественного понимания рассказа, обработку, имеющую систематическую связь с лингвистической структурой.
Эти модели со смешанными эффектами включают в себя лингвистические предикторы с различной степенью детализации, начиная от биграмм частей речи и заканчивая неожиданностью на контекстно-свободных грамматиках банка деревьев и инкрементным подсчетом узлов в деревьях, полученных с помощью минималистских грамматик. Мелкозернистые структуры вносят независимый вклад в дополнение к более грубым предикторам. Однако этот результат достигается только с течением времени из передней височной доли (aTL). В аналогичных временных отрезках от нижней лобной извилины только n-граммы улучшаются по сравнению с несинтаксическим исходным уровнем. Эти результаты подтверждают идею о том, что aTL выполняет комбинаторную обработку во время естественного понимания рассказа, обработку, имеющую систематическую связь с лингвистической структурой. Рисунок выше (щелкните, чтобы увеличить) иллюстрирует основную идею связывания состояний пословного анализатора (панель c) с оценками гемодинамического ответа, измеренного с помощью фМРТ (панели d-e), собранными во время естественной стимуляции.
Поиск
- Диссертации с отличием о смене ролей, нейронной синхронизации в реальном времени и настроениях COVID
Поздравляем старших сотрудников лаборатории, защитивших дипломы с отличием! Шучен Вэнь провел эксперимент с ЭЭГ, проверяя синхронизацию структуры аргументов, проверяя эффекты N400, когда роли аргументов менялись местами в конструкциях Ba и Bei в китайском языке. […]
- Отмеченные наградами исследования студентов на исследовательском симпозиуме в Мичигане
Поздравляем студентов-исследователей, которые представили свои работы на весенних научных симпозиумах по программам UROP и MRADs. Кеннеди Ллойд получила желанную награду с голубой лентой 🏆 за свой плакат под названием «Количественная оценка методологического расового неравенства в нейролингвистике». Анализ […]
- Увидимся в Питтсбурге на HSP 2023
С нетерпением ждем HSP2023 в Питтсбурге! Обязательно ознакомьтесь с последними новостями от членов лаборатории о межъязыковых грамматических репрезентациях, моделировании интерференции при поиске и магистерской диссертации Цзюнюаня (психолингвистика MPI) об отслеживании кортикальных фраз! И не забудьте проверить работу […]
- Два препринта: отделение инкрементальной композиции от предсказуемости и локализация обработки зависимостей между языками
Я все еще довожу некоторые из наших усилий, предпринятых до Нового года. К ним относятся два (2) препринта статей, в которых используются наборы данных Little Prince. Сначала: Милош Станоевич (DeepMind) и я руководили проектом, в котором […]
- Д-р Тамара Хильдебрандт защищает диссертацию
Поздравляем новоявленного кандидата наук. Тамара Хидлебрандт, успешно защитившая диссертацию 19 декабря! В диссертации описывается множество экспериментов, сочетающих суждения о приемлемости, эксперименты по самостоятельному чтению и ЭЭГ для исследования тонкой взаимосвязи между грамматическими […]
- Бумага и данные: наборы данных фМРТ и лингвистические аннотации из натуралистического прослушивания на английском, китайском и французском языках
Цзисин Ли поручила большой команде подготовить эти уникальные нейролингвистические наборы данных. Говорящие на английском (49), китайском (35) или французском (28) слушали 1,5-часовую аудиокнигу «Маленький принц» во время фМРТ-сканирования. Выпущены полные наборы данных МРТ […]
- Презентация на AMLAP2022
Цзы-Юн Тунг будет на встрече Архитектур и механизмов обработки речи в 2022 году, чтобы представить некоторые из своих диссертационных исследований по извлечению памяти во время понимания языка с использованием комбинации данных ЭЭГ и вычислительных моделей. . Проверьте это! […]
Мета
- Войти
- Лента записей
- Лента комментариев
- WordPress.org
Синтаксический анализ с помощью Parsec: или, необязательно, повторная попытка и возврат
Анализ с помощью Parsec: или, необязательно, повторная попытка и возврат | Блог Хакла Блог Хакла
90 090 между абстракциями, которые мы хотим, и абстракциями, которые мы получаем.
«Пришествие кода» — это очень весело! Для меня в немалой степени это связано с синтаксическим анализом, особенно когда объединение нескольких функций списка не сокращает его.
Конечно, это нужно делать с помощью Parsec (или его аналога), а не регулярных выражений, блин.
Давайте начнем с простого примера, входных данных для испытания 4-го дня «Уборка лагеря».
2-4,6-8 2-3,4-5 5-7,7-9 2-8,3-7 6-6,4-6 2-6,4-8
Конечно, это можно было бы сделать просто с помощью чего-то вроде bimap (splitOn '-') (splitOn '-') (splitOn ',' "2-4,6-8") , исключая любые более умные смеси, которым суждено существовать в изобилии. Или, если мы используем парсек .
тип Диапазон = (Целое, Целое)
введите Parser a = Parsec String () a -- и псевдоним, чтобы избавить нас от необходимости печатать
int :: Парсер Int
int = читать @Int <$> many1 цифра
вокруг :: Парсер a -> Парсер b -> Парсер (a, a)
около p sep = делать
г1 <- р
сен
г2 <- р
возврат (r1, r2)
диапазон :: Диапазон парсера
диапазон = int `вокруг` (char '-')
rangePair :: Парсер (Диапазон, Диапазон)
rangePair = диапазон `вокруг` (char ',')
пары :: Парсер [(Диапазон, Диапазон)]
пары = rangePair `sepBy1` endOfLine
(Есть небольшая проблема с rangePair `sepBy1` endOfLine , которая не сразу очевидна, читайте дальше!)
Разумным первым ответом было бы: это много кода, даже если убрать аннотацию типа!
Однако из-за композиционной природы комбинаторов синтаксических анализаторов одно из очевидных преимуществ заключается в том, как структурирован код: range = int `around` (char '-') ничего не смущает. Нетрудно заметить, что такая ясность может иметь жизненно важное значение при работе с более сложными входными данными, такими как задача 7-го дня «Нет свободного места на устройстве» 9.0010
Нетрудно заметить, что такая ясность может иметь жизненно важное значение при работе с более сложными входными данными, такими как задача 7-го дня «Нет свободного места на устройстве» 9.0010
$ кд/ $ лс директор а 14848514 b.txt 8504156 c.dat дир д $ компакт-диск $ лс дир е 29116 ф 2557 г 62596 х.лст $ кд е $ лс 584 я $ кд .. $ кд .. $ cd д $ лс 4060174 ж 8033020 д.лог 5626152 д.доб. 7214296 тыс.
Это действительно оправдывает использование подходящей библиотеки синтаксического анализатора, такой как Parsec , из-за ее ужасной сохранения состояния, которая была бы пригоршней для любых (особенно) умных регулярных выражений.
К счастью, это не проблема, так как Parsec включает в себя State , так что я мог бы getState , putState или ModifyState довольно удобно. Вполне себе электроинструмент.
Однако проблема, с которой я столкнулся, была не такой сложной, хотя и весьма печально известной.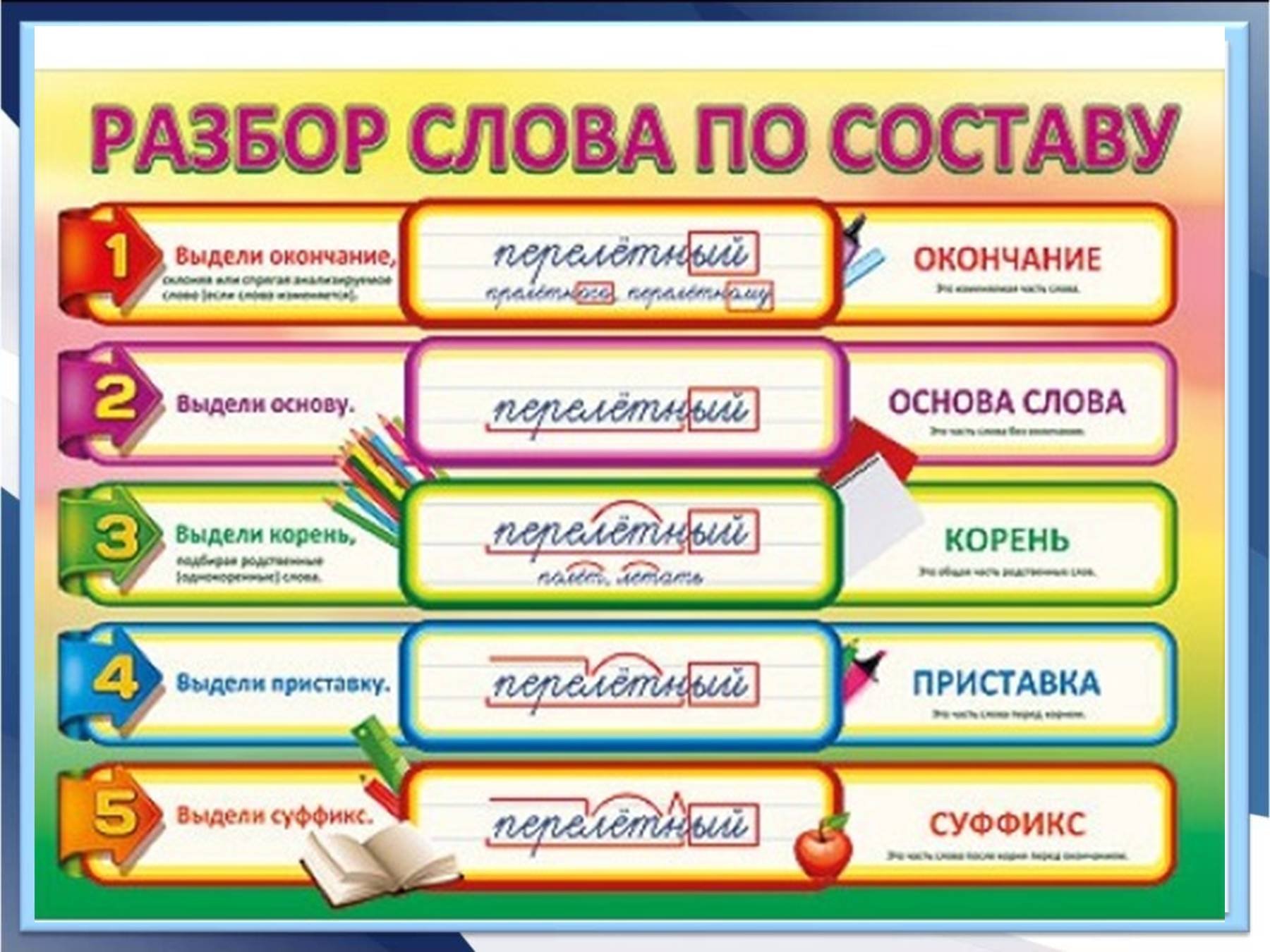 При разборе команд типа
При разборе команд типа $ls или $cd.. мой код выглядит так,
компакт-диск = сделать
строка "$ls" <* endOfLine
-- ... puState для текущих путей
лс = сделать
строка "$ls" <* endOfLine
(file <|> dir) `sepBy` endOfLine -- проблематично!
команда = ls <|> cd
При синтаксическом анализе выходных данных CLI выше этот синтаксический анализатор выдает следующую ошибку:
Слева (строка 7, столбец 1): неожиданный "$" ожидается цифра, "dir", новая строка или конец ввода
, также известная как страшная проблема «возврата», но как?
Обратное отслеживание
Мы снова возьмем его с самого начала, используя синтаксический анализатор «счастливого пути».
ghci> parse (string "abc" <> string "def") "(любой источник)" "abcdef" Правильно "abcdef"
Для ситуаций "или/или" 9Комбинатор 0101 <|> удобен.
ghci> parse (string "abc" <|> string "def") "(любой источник)" "def" Право "деф"
Тогда становится интересно: что, если два синтаксических анализатора используют один и тот же префикс, например, "alice" и "alba" ?
ghci> parse (string "alice" <|> string "alba") "(любой источник)" "alba" Слева (строка 1, столбец 1): неожиданное "б" жду "алису"
А, мы получаем ошибку, которая сбивает с толку - код четко указывает "анализировать либо "alice", либо "alba", но происходит сбой, как только "alice" терпит неудачу, без попытки "alba". Это не то, как обычно работает «или». Почему?
Это не то, как обычно работает «или». Почему?
Это связано с тем, как Parsec потребляет ввод char на char . Для строки "alice" он потребляет "al" и терпит неудачу на 'b' ; несмотря на свою семантику "или", <|> не возвращается к началу "alba" . Как и многие, я нашел это сбивающим с толку, если не разочаровывающим.
Это создает необходимость в "отслеживании назад", чтобы синтаксический анализатор мог вернуться на две буквы назад и проанализировать "alba" с самого начала. Чтобы сказать Parsec сделать это, мы используем try .
ghci> parse (try (string "alice") <|> string "alba") "(любой источник)" "alba" Правая "альба"
try (строка "alice") не будет потреблять любой ввод в случае сбоя, он начинается заново для строки "alba" путем перехода назад , следовательно, "обратного отслеживания".
Это поведение также может быть описано как «сообщить парсек to undo parsing string "alice" ". Однако я нахожу это представление императивным и не совсем точно отражает, как работает try (или комбинаторы синтаксических анализаторов в целом). Подробнее об этом в конце.
Общий разделитель
Возможно, эта проблема находится в засаде. Например, разделители.
Снова начинаем со счастливого пути: цифры через запятую. sepBy кажется идеальным комбинатором для этого сценария.
ghci> parse (digit `sepBy` char ',') "(любой источник)" "1,2,3,9" Справа "1239"
Довольно интуитивная штука. Как насчет «цифр, разделенных запятыми, за которыми следуют буквы»?
ghci> parse (цифра `sepBy` char ',' <> буква `sepBy` char ',') "(любой источник)" "1,2,3,9,a,b,c,d" Слева (строка 1, столбец 9): неожиданное "а" ожидаемая цифра
Мне пришлось немало почесать голову, чтобы понять, что это та же самая проблема с «обратным отслеживанием», только на этот раз преступником является sepBy . После употребления
После употребления 9 , синтаксический анализ продолжает с удовольствием поглощать , , который указан в качестве разделителя. По-честному! Однако к тому времени, когда он достигает и и терпит неудачу, уже «слишком поздно»!
Иными словами, мой выбор парсеров приводит к неоднозначности : char ',' используется как разделитель для двух последовательных последовательностей, одна из цифр, а другая из букв.
Как нам сказать Парсеку отказаться от своего жадного поведения?
попытка здесь не годится, потому что нам нужны и цифра с, и буква с; один обходной путь - объединить букву и цифру , но это позволяет цифрам и буквам поступать не по порядку.
ghci> parse ((цифра <|> буква) `sepBy` char ',') "(любой источник)" "1,2,3,9,a,b,c,d" Справа "1239abcd" ghci> parse ((цифра <|> буква) `sepBy` char ',') "(любой источник)" "1,a,2,b,3,c,9,d" Правильно "1a2b3c9d" -- не по порядку, не то, что нам нужно
Или есть дополнительный , по документации
необязательный p пытается применить синтаксический анализатор p.
 Он будет анализировать p или ничего. Он терпит неудачу только в том случае, если p терпит неудачу после потребления ввода. Он отбрасывает результат п.
Он будет анализировать p или ничего. Он терпит неудачу только в том случае, если p терпит неудачу после потребления ввода. Он отбрасывает результат п.ghci> parse (many (цифра <* необязательный (char ',')) <> много (буква <* необязательный (char ','))) "(любой источник)" "1,2,3,9,a ,б,в,г" Справа "1239abcd"
Ура! Хотя есть еще одна загвоздка...
Дополнительно, один и только
Я ужасен в RTFM, но описание по желанию меня немного пугает.
Сбой только в том случае, если p завершается сбоем после ввода ввода.
Действительно, дополнительный может привести к проблемам с возвратом. Если разделитель содержит более одного символа, например -> , то ошибка на втором символе означает проблемы.
ghci> parse (many (цифра <* необязательна (строка "->")) <> много (буква <* необязательна (строка "->"))) "" "1->2->3->9->a->b->c->d"Право"1239abcd" ghci> parse (many (цифра <* необязательная (строка "->")) <> строка "-" <> много (буква <* необязательная (строка "->"))) "" "1->2-> 3->9-а->б->в->г" Слева (строка 1, столбец 11): неожиданное "а" ожидание "->"
Видишь, что сбивает с толку? Это - между цифрами и буквами.
Parsec попытается получить -> , но потерпит неудачу после - , требуется откат!
Применение трюка try устраняет проблему.
ghci> parse (many (цифра <* необязательный (try (строка "->"))) <> строка "-" <> много (буква <* необязательный (строка "->"))) "" "1- >2->3->9-а->б->в->г" Справа "1239-abcd"
Многословие — это цена, которую мы платим за точность и ясность. Конечно, любой код, который подходит больше, чем REPL, должен быть отформатирован для удобства чтения.
Не "старайся" слишком сильно
Это было бы очевидно, но стоит отметить, что слишком широкое использование «try» приведет не только к зашумленному коду и запутанным ошибкам, но и к проблемам с производительностью. Считай,
ghci> parse (try (string "Hello World!") <|> string "Hello Space!") "(любой источник)" "Hello Space!" Прямо "Привет Космос!"
Красиво, когда работает, а когда нет? Полнейшее замешательство.
ghci> parse (try (string "Hello World!") <|> string "Hello Space!") "(любой источник)" "Hello Spase!" -- спа (ы) e Слева (строка 1, столбец 1): неожиданное "с" ожидая «Привет, космос!»
Сообщение об ошибке включает всю строку в , ожидая "Hello Space!" , может потребоваться некоторое время, чтобы найти, где именно произошел сбой синтаксического анализатора (буква "s" ). Люди могут обвинять Parsec в неточном сообщении об ошибке, но на самом деле я виноват в том, что делаю неоднозначные парсеры!
Неоднозначность возникает, когда "Hello World!" <|> «Привет, Космос!» имеют общий префикс "Привет" , но если мы перетасуем слова, это не обязательно будет так: "Привет" <> (Мир!" <|> "Космос!") .
Используя знание в свою пользу, попытка даже не нужна!
ghci> parse (string "Hello" <> (string "World!" <|> string "Space!")) "(любой источник)" "Hello Space!" Прямо "Привет Космос!" ghci> parse (string "Hello" <> (string "World!" <|> string "Space!")) "(любой источник)" "Hello Spase!" Слева (строка 1, столбец 7): неожиданное "с" ожидая "Космос!"
Конечно, сообщение об ошибке по-прежнему не точное до буквы, но, по крайней мере, оно более локализовано до "spase".