Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «последовательность», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ПОСЛЕДОВАТЕЛЬНОСТЬ, и, ж.
1. см. последовательный.
2. В математике: бесконечный упорядоченный набор чисел.
Фонетический (звуко-буквенный) разбор
после́довательность
последовательность — слово из 6 слогов: по-сле-до-ва-тель-ность. Ударение падает на 2-й слог.
Транскрипция слова: [пасл’эдават’ил’наст’]
п — [п] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
с — [с] — согласный, глухой парный, твёрдый (парный)
л — [л’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
д — [д] — согласный, звонкий парный, твёрдый (парный)
о — [а] — гласный, безударный
в — [в] — согласный, звонкий парный, твёрдый (парный)
а — [а] — гласный, безударный
т — [т’] — согласный, глухой парный, мягкий (парный)
е — [и] — гласный, безударный
л — [л’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
с — [с] — согласный, глухой парный, твёрдый (парный)
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 18 букв и 16 звуков.
Цветовая схема: последовательность
Разбор слова «последовательность» по составу
последовательность
Части слова «последовательность»: по/след/ова/тельн/ость
Часть речи: имя существительное
Состав слова:
по — приставка,
след — корень,
ова, тельн, ость — суффиксы,
последовательность — основа слова.

последовательность
Части слова «последовательность»: по/след/ова/тель/ность
Часть речи: имя существительное
Состав слова:
по — приставка,
след — корень,
ова, тель, ность — суффиксы,
нулевое окончание,
последовательность — основа слова.
Урок русского языка. «Разбор слов по составу». 2-й класс
Урок русского языка.
«Разбор слов по составу». 2-й класс
Цели: рассмотреть алгоритм разбора слова по составу.
Задачи:
Образовательные: добиться понимания и воспроизведения алгоритма разбора слова по составу, развивать умение выделять части слова (корень, окончание, приставку, суффикс).
Воспитательные: воспитывать потребность совершенствовать свою речь, формировать интерес к слову, воспитывать аккуратность, способность к самооценке на основе критерия успешности учебной деятельности (
Развивающие:
Регулятивные УУД: умение определять и формулировать цель на уроке с помощью учителя, проговаривать последовательность действий на уроке, работать по коллективно составленному плану, оценивать правильность выполнения действий, планировать своё действие в соответствии с поставленной задачей, вносить необходимые коррективы в действие после его завершения на основе его оценки и учета характера сделанных ошибок, высказывать свое предположение.
Познавательные УУД: умение ориентироваться в своей системе знаний; отличать новое от уже известного с помощью учителя; добывать новые знания; находить ответы на вопросы, используя учебник, свой жизненный опыт и информацию, полученную на уроке.
Коммуникативные УУД: умение оформлять свои мысли в устной форме, слушать и понимать речь других, совместно договариваться о правилах поведения и общения на уроке и следовать им.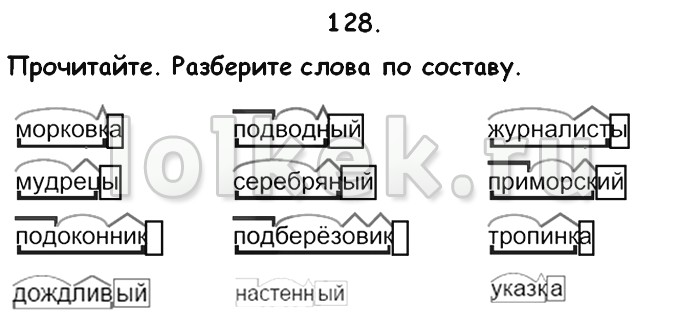
Формировать УУД:
Предметные УУД: понимать и воспроизводить алгоритм разбора слова по составу, выделять части слова, развивать орфографическую зоркость.
Метапредметные: умение определять и формулировать цель на уроке с помощью учителя, проговаривать последовательность действий на уроке, работать по коллективно составленному плану, оценивать правильность выполнения действий на уровне адекватной ретроспективной оценки, планировать своё действие в соответствии с поставленной задачей, вносить необходимые коррективы в действие после его завершения на основе его оценки и учета характера сделанных ошибок, высказывать свое предположение. (регулятивные УУД)
умение оформлять свои мысли в устной форме, слушать и понимать речь других, совместно договариваться о правилах поведения и общения на уроке и следовать им (коммуникативные УУД)
умение ориентироваться в своей системе знаний; отличать новое от уже известного с помощью учителя; добывать новые знания; находить ответы на вопросы, используя учебник, свой жизненный опыт и информацию, полученную на уроке (познавательные УУД).
Личностные УУД: уметь проводить самооценку на основе критерия успешности учебной деятельности.
Ход урока
I. Организационный момент.
Настрой на хорошую работу.
Вдохните… Как хорошо, что мы вместе. Мы все счастливы и здоровы. Мы помогаем друг другу. Улыбнитесь друг другу.
Вот с таким настроением мы и начнём наш урок.
II. Чистописание.
— Откройте тетради и запишите число и предложение «Классная работа».
— Назовите буквы и буквосочетания.
Зз зи за
— Пропишите буквы Зз и буквосочетания.
— Прочитайте слова.
зима Зима зимородок заморозки
— Объясните лексическое значение слов.
Зима́ — город в России, Иркутской области. Расположен в 230 км на северо-запад от областного центра г. Иркутска, на левом берегу реки Оки.
Расположен в 230 км на северо-запад от областного центра г. Иркутска, на левом берегу реки Оки.
Зимородок — это удивительно красивая птица. Он немного крупнее воробья с необычайно ярким оперением. Зимородков можно увидеть и в студеную пору — возле незамерзающих речных родников и стремнин, где пернатые рыболовы, подобно оляпкам, остаются на зиму.
За́морозки — легкие утренние морозы осенью или весной. (С.И. Ожегов, Н.Ю. Шведова «Толковый словарь русского языка»)
— Что заметили? Разделите слова на группы.
— Какие слова называются однокоренными?
— Подчеркните ошибкоопасные буквы в словах.
— Как проверить ошибкоопасные буквы в слове заморозки? Подобрать проверочные слова.
— Какую букву нельзя проверить?
— Как называются слова написание надо запомнить? (словарные слова)
— Запишите слова.
III. Актуализация.
— Подберите однокоренные слова к слову заморозки. Мороз, заморозка, мороженое,
морозец, морозилка, морозильник, Морозко, морозная.
— Ребята, я вам сейчас прочитаю стихотворение, а вы внимательно его послушайте и скажите о чем идет речь в стихотворении?
* Слово делится на части,
Ах какое это счастье!
Может каждый грамотей
Делать слово из частей!
На конце любого слова
Что – то долго ищет Вова
Изменяемая часть
С другим словом держит связь
Все же он его найдет
Даже в рамочку возьмет
Перед главной частью слова
Строго пишется она
И при помощи той части образуются слова
После главной части слова
Обозначен уголком он
Его если заменить
Другое слово можно получить.
Я предлагаю работать по этому плану.
— Так какую часть слова надо находить первой, какую следующей и почему? А в какой последовательности нужно выполнять разбор слова по составу?
V. Открытие нового.
— Я предлагаю вам установить порядок разбора слова по составу, т. е. вывести алгоритм. Вернёмся к нашему слову –
Вывод:
Слово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.
VI. Физминутка.
Пускай снегами все заносит,
(Руки через стороны вверх, опустили)
Пускай лютуют холода,
(Руки на пояс, повороты туловища влево – вправо)
Зима меня не заморозит,
Не напугает никогда.
(Левой рукой плавное движение вверх – вниз, правая на поясе)
Зимою белые снежинки
Танцуют за моим окном.
(Правой рукой плавное движение вверх-вниз, левая на поясе)
А Дед Мороз свои картинки рисует на стекле ночном.
(Плавные движения двумя руками вверх-вниз перед собой)
VII. Первичное закрепление.
— Запишите слова: зимушка, холода, снежинка, прогулка, горка.
(Выполняют ученики разбор слов по составу с комментированием)— А в какой последовательности нужно выполнять разбор слова по составу?
— Какие части слова входят в основу?
Вывод: Начинать разбор по составу нужно с окончания, затем, зная окончание слова, будем выделять основу, потом корень и только после этого приставку и суффикс.
VIII. Закрепление.
1. Соотнеси слово со схемой: (работа в паре)
Песенка
Пенал ^
Подруга ^
Подсказка
2. В каждой группе слов найдите лишнее и разберите по составу.
В каждой группе слов найдите лишнее и разберите по составу.
Водитель, водичка, водить
Пёсик, песок, пёс
Газетный, газ, газовый
IX. Итог урока.
— Подведем итог нашего урока. Какое открытие сделали? (Алгоритм разбора состава слова)
Слово по составу верно разбирай:
Первым, окончание всегда выделяй,
На основу внимательно смотри,
Корень, поскорее, ты у нее найди,
Приставку и суффикс в конце определи.
Рефлексия
Х. Домашнее задание
Выскажите свое мнение по задачам урока по следующим критериям: -Всё понял и могу научить других… -Всё понял… -Понял, но были затруднения.. — Мне ещё трудно… |
Т. С.31, упр.3,5
Камышом корень. Разбор по составу слова «камыш»
А вы знаете, что растение, которое по привычке, мы называем камышом, на самом деле рогоз. Ещё есть тростник, который тоже, совсем не камыш. Тем не менее, все 3 вида похожих растений, в силу какой-то необъяснимой русской традиции, мы продолжаем называть одним словом — камыш. Все три растения не только внешне отличаются, но и принадлежат к разным семействам. То есть, они даже не родственники.
Так кто есть кто, давайте разбираться.
Рогоз.
Вот тот самый, который в народе камыш. Травянистое болотное растение, до 2-х метров высотой, стебель которого венчается красивым и декоративным соцветием-початком. По осени початок распускается, появляется пух-семена. Спутать его с камышом и тростником ну никак не возможно, уж слишком велика разница.
Принадлежит к семейству рогозовые, по данным википедии насчитывает 19 видов только в России. Самые распространенные представители: рогоз узколистный и, соответственно, рогоз широколистный. Разница обозначена в названиях.
Разница обозначена в названиях.
Тростник.
Не сахарный, обыкновенный. У нас встречается повсеместно. И его тоже называют камыш. Может вырастать до 4-х (!) метров. Растение-великан. Стебли кончаются крупной, густой, развесистой метёлкой. Метелка-одно из отличий от камыша.
У тростника метелка массивная и мягкая, у камыша колючая и жесткая.
В целом, тростник и камыш похожи. Их можно спутать, хотя и они принадлежат к разным семействам: тростник- злак. Огромный злак. При этом, агрессивный сорняк, распространяется и семенами и ползучим корневищем.
Камыш.
Его можно спутать с тростником, но не с рогозом- слишком разные. В отличии от тростника, камыш не вырастает таким огромным. 2, ну 2,5 метра-его потолок. Опять же, метёлка-жесткая. Интересно, что у камыша почти нет листьев на стебле.
Поэтому, когда в известной песне шумел камыш, делал это рогоз, у него есть листья и возможность шуршать на ветру. Принадлежит к семейству осоковых. В моей местности, камыш фактически не встречается, всё заглушил тростник.
Самое интересное, что все 3 растения, имеют/имели огромное хозяйственное значение, из них плетут циновки, делали крыши, мешали с глиной и обмазывали стены. Отличные биофильтры- замечательно очищают воду. Их даже едят. В корнях содержится крахмал и сахар.
Тем не менее, для меня тростник является врагом №1, смертельно опасным, я веду с ним беспощадную борьбу.
Читайте об этом:
Камыш. Как я его побеждаю на своём участке и почему с ним надо бороться. ПожарыКамыш. Как я его побеждаю на своём участке и почему с ним надо бороться. Рекомендуемые способыКамыш. Как я его побеждаю на своём участке и почему с ним надо бороться. Личный опыт.Пожалуйста, поддержите канал подпиской, оцените материал лайком. Спасибо за внимание.Ещё почитать:
Марьин корень или лазоревый цветок?Разбор по составу (морфемный) слова «прилежный.
 «прилежно» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) Морфемный разбор слова прилежный
«прилежно» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание) Морфемный разбор слова прилежныйРазбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.

- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.

Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Разбор слова по составу.
Состав слова «прилежный»:
Морфемный разбор слова прилежный
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова прилежный делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова прилежный – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для прилежный (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для прилежный путем подбора других слов, которые образованы таким же способом, что и прилежный.
Как вы видите, морфемный разбор прилежный делается просто. Теперь давайте определимся с основными морфемами слова прилежный и сделаем его разбор.
См. также в других словарях:
Просклонять слово прилежный по падежам в единственном и множественном числе…. Склонение слова прилежный по падежам
Полный морфологический разбор слова «прилежный»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор прилежный
Ударение в слове прилежный: на какой слог падает ударение и как… Слово «прилежный» правильно пишется как… Ударение в слове прилежный
Синонимы «прилежный». Словарь синонимов онлайн: подобрать синонимы к слову «прилежный». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову прилежный
Разбор слова по составу.
Состав слова «прилежно»:
Морфемный разбор слова прилежно
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова прилежно делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова прилежно – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для прилежно (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для прилежно путем подбора других слов, которые образованы таким же способом, что и прилежно.
Как вы видите, морфемный разбор прилежно делается просто. Теперь давайте определимся с основными морфемами слова прилежно и сделаем его разбор.
См. также в других словарях:
Просклонять слово прилежно по падежам в единственном и множественном числе…. Склонение слова прилежно по падежам
Полный морфологический разбор слова «прилежно»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор прилежно
Ударение в слове прилежно: на какой слог падает ударение и как… Слово «прилежно» правильно пишется как… Ударение в слове прилежно
ДАВИДЮК Л.В.ТЕСТЫ ПО МЕТОДИКЕ ПРЕПОДАВАНИЯ РУССКОГО ЯЗЫКА
ДАВИДЮК Л.В.ТЕСТЫ ПО МЕТОДИКЕ ПРЕПОДАВАНИЯ РУССКОГО ЯЗЫКА
16. Выделите приоритетные методы изучения состава слова и словообразования:
а) слово учителя;
б) наблюдение над языком;
в) анализ образцов;
г) беседа.
17. Определите цифрами последовательность разбора слова по составу:
а) выделите корень, подобрав 2-3 однокоренных слова;
б) запишите слово, дайте толкование его лексического значения, определите, к какой части речи оно относится;
в) выделите суффикс, подберите слова с таким же суффиксом;
г) выделите основу и окончание, укажите грамматическое значение которое выражает окончание;
д) выделите префикс, подберите слова с таким же префиксом.
18. Согласны ли вы с утверждением, что словообразовательные упражнения развивают две группы умений: определять структуру слова и устанавливать структурно-семантические связи родственных слов:
а) да;
б) нет.
19. Определите цифрами последовательность словообразовательного разбора:
а) укажите слово, от которого образовано данное слово;
б) дайте толкование лексического значения слова;
в) укажите способ словообразования;
г) найдите в данном слове производящую основу;
д) выделите те значимые части, с помощью которых образовано данное слово.
20. Согласны ли вы с утверждением, что изучение состава слова и словообразования создаёт основу для усвоения правописания слов, поэтому в связи с темами по составу слова и словообразованию обычно изучаются орфографический правила правописания окончаний существительных, прилагательных и глаголов:
а) да;
б) нет.
Ключи:
1 – а, в, г, д; 2 – а, г, д; 3 – 1 б, 2 а; 4 – 1 б, 2 г, 3 д, 4 в, 5 а; 5 – а; 6 – а, в, г, е, ж; 7 – а 1, б 2, в 1, г 2, д 2, е 1; 8 – а, б, д; 9 – б, г, д, ж; 10 – а, в, г, е; 11 – а; 12 – а; 13 – б; 14 – б; 15 – б, г, е; 16 – б, в; 17 – 1 б, 2 г, 3 а, 4 д, 5 в; 18 – а; 19 – 1 б, 2 а, 3 г, 4 д, 5 в; 20 – б.
ПРИМЕЧАНИЯ:
1. При подготовке тестов была использована следующая литература: Литневская Е. И., Багрянцева В. А. Методика преподавания русского языка в средней школе: Учебное пособие для студентов высших учебных заведений / Под ред. Е. И. Литневской. М., 2006; Теория и практика обучения русскому языку: Учебн. пособие для студ. высш. пед. уч. заведений / Е. А. Архипова, Т. М. Воителева, А. Д. Дейкина и др.; под ред. Р. Б. Сабаткоева. М., 2005; Титов В. А. Методика преподавания русского языка: Конспекты лекций. М., 2005; Методика преподавания русского языка: Учеб. пособие для студентов пед. ин-тов / М. Т. Баранов, Т. А. Ладыженская, М. Р. Львов и др.; Под ред. М. Т. Баранова. М., 1990; Львов М. Р. Словарь-справочник по методике русского языка: Учеб. пособие для студентов пед. ин-тов. М., 1988; Гребёнкина Р. Т. Изучение в школе фонетики и графики русского языка: Книга для учителей. М., 1984; Баранов М. Т. Методика лексики и фразеологии на уроках русского языка: Пособие для учителя. М., 1988; Вознюк Л. В. Изучение состава слова и словообразования в школе: Пособие для учителя. К., 1986.
Т. Методика лексики и фразеологии на уроках русского языка: Пособие для учителя. М., 1988; Вознюк Л. В. Изучение состава слова и словообразования в школе: Пособие для учителя. К., 1986.
Л. В. ДАВИДЮК – канд. пед. наук, доцент кафедры методики преподавания русского языка и мировой литературы Национального педагогического университета имени М. П. Драгоманова
Составление слов по схемам. Порядок разбора слова по составу
Русский язык
РАЗБОР СЛОВА ПО СОСТАВУ
Урок 63 (57).
Тема: Составление слов по схемам. Порядок разбора слова по составу
Цель:
– развитие умений разбора слова по составу на основе словообразовательного анализа, чтение схем состава слова, подбор
слов к заданным схемам.
П – повышенный уровень
М – максимальный уровень
Этапы урока
Ход урока
Ι
. Актуализация
знаний.
– Откройте тетрадь.
– Что надо записать? (Дату.)
Комментированная запись числа.
– Какую запись должны сделать дальше?
– Напишите слова «Классная работа».
3 4
Словарная работа.
Диктант с обозначением орфограмм (на материале слов в рамке
после упр. 204, с. 161).
Цель: проверка знаний словарных слов § 8–15.
Запись: Хозяин, черёмуха, навсегда, галерея, насекомое, всегда,
аромат, заяц, потому_что.
Формирование УУД,
ТОУУ (технология оценивания
учебных успехов)
Познавательные УУД
1. Развиваем умения извлекать
информацию из схем, иллюстраций,
текстов.
2. Представлять информацию в виде
схемы.
3. Выявлять сущность, особенности
объектов.
4. На основе анализа объектов делать
выводы.
5. Обобщать и классифицировать по
признакам.
6. Ориентироваться на развороте
© ООО «Баласс», 2013
1 Самопроверка (сравнение с образцом в рамке).
– Составьте и запишите предложение с одним из слов.
Вопросы к ученику, выполнявшему работу (начало формирования алгоритма
самооценки):
– Что тебе нужно было сделать?
– Удалось тебе выполнить задание?
– Ты сделал всё правильно или были недочёты?
– Ты составил всё сам или с чьейто помощью?
– Какой был уровень задания?
– Какие умения формировались при выполнении этого задания?
– Какую отметку ты бы себе поставил?
– Сейчас мы вместе с… (имя ученика) учились оценивать свою работу. 1 3 3
Игра «Молчанка».
На доске записаны слова в три столбика (по количеству рядов в
классе). Одновременно три ученика выходят к доске и выделяют в
словах окончания, молча садятся, другие ученики – основу, следующие
– суффиксы, приставки, последние – корень. Если допущены ошибки,
их исправляет капитан команды. Какой ряд быстрее разберёт слова,
тот и победил. Слова для разбора:
грязный часовой капустная
перегородка подорожник побелка
листик мосты цепочка
– На основе проведённой игры сформулируйте тему урока. (Разбор слова
по составу.) Запись на доске.
План.
Учитель вместе с детьми составляет план.
учебника.
7. Находить ответы на вопросы в
иллюстрации.
Регулятивные УУД
1. Развиваем умение высказывать
своё предположение на основе
работы с материалом учебника.
2. Оценивать учебные действия в
соответствии с поставленной
задачей.
3. Прогнозировать предстоящую
работу (составлять план).
4. Осуществлять познавательную и
личностную рефлексию.
II.
Формулирование
проблемы,
планирование
деятельности.
Открытие новых
знаний.
© ООО «Баласс», 2013
2 IIΙ . Развитие
умений –
применение
знания.
– Что мы сейчас делали? (Формулировали тему урока, составляли план,
планировали свою деятельность.)
Упр. 199 – развивается умение соотносить части слова и
1 3 5 3 4
1. Составление слов по схемам. Работа в парах.
1.
составлять из них слова.
Самостоятельная работа по вариантам. Коллективная проверка.
– Назовите слова, которые получились у каждого варианта.
– Какие из них называют признак?
– Из скольких частей они состоят?
2. Упр. 200 – составление слов по схемам, разбор их по составу.
Работа в парах. Коллективное обсуждение слов, которые получились
у разных пар.
Обобщающий вопрос: почему возможны разные варианты? (Могут быть
разные суффиксы и окончания у однокоренных слов.
1 3 3
Игра «Молчанка».
На доске записаны слова в три столбика (по количеству рядов в
классе). Одновременно три ученика выходят к доске и выделяют в
словах окончания, молча садятся, другие ученики – основу, следующие
– суффиксы, приставки, последние – корень. Если допущены ошибки,
их исправляет капитан команды. Какой ряд быстрее разберёт слова,
тот и победил. Слова для разбора:
грязный часовой капустная
перегородка подорожник побелка
листик мосты цепочка
– На основе проведённой игры сформулируйте тему урока. (Разбор слова
по составу.) Запись на доске.
План.
Учитель вместе с детьми составляет план.
учебника.
7. Находить ответы на вопросы в
иллюстрации.
Регулятивные УУД
1. Развиваем умение высказывать
своё предположение на основе
работы с материалом учебника.
2. Оценивать учебные действия в
соответствии с поставленной
задачей.
3. Прогнозировать предстоящую
работу (составлять план).
4. Осуществлять познавательную и
личностную рефлексию.
II.
Формулирование
проблемы,
планирование
деятельности.
Открытие новых
знаний.
© ООО «Баласс», 2013
2 IIΙ . Развитие
умений –
применение
знания.
– Что мы сейчас делали? (Формулировали тему урока, составляли план,
планировали свою деятельность.)
Упр. 199 – развивается умение соотносить части слова и
1 3 5 3 4
1. Составление слов по схемам. Работа в парах.
1.
составлять из них слова.
Самостоятельная работа по вариантам. Коллективная проверка.
– Назовите слова, которые получились у каждого варианта.
– Какие из них называют признак?
– Из скольких частей они состоят?
2. Упр. 200 – составление слов по схемам, разбор их по составу.
Работа в парах. Коллективное обсуждение слов, которые получились
у разных пар.
Обобщающий вопрос: почему возможны разные варианты? (Могут быть
разные суффиксы и окончания у однокоренных слов. )
Слова, соответствующие схемам:
– девочка, девушка, девица;
– гнёздышко;
– лисица, лисонька, лисёнок;
– сказка, сказочка;
– подсказка, присказка;
– полоска, полосатый.
2. Освоение алгоритма разбора слова по составу в режиме
проблемного диалога.
1. Самостоятельное выведение алгоритма учениками на основе
Коммуникативные УУД
1. Развиваем умение слушать и
понимать других.
2. Строить речевое высказывание в
соответствии с поставленными
задачами.
3. Оформлять свои мысли в устной
форме.
4. Умение работать в паре.
Личностные результаты
1. Развиваем умения выказывать своё
отношение к героям, выражать свои
эмоции.
2. Оценивать поступки в
соответствии с определённой
ситуацией.
3. Формируем мотивацию к обучению
и целенаправленной познавательной
деятельности.
© ООО «Баласс», 2013
3 наблюдений и рассуждений.
– Запишите слова вазочка, яблочко, бабочка. Их надо разобрать по
составу. Что это значит? (Выделить все части слова.)
– С чего предлагаете начать? (Предположения и объяснения детей.)
– Выделим окончания у слов, изменив их: вазочки, яблочка, бабочки.
Методическая рекомендация: эти этапы обычно не вызывают
сложностей у учащихся. Но можно ещё раз напомнить, что важно
сначала разграничить те части в слове, которые изменяются, и те, в
которых содержится основное значение слова. Окончания часто
бывают одинаковыми у разных слов, их легче всего выделить и
обозначить.
– Что выделим теперь? (Основу.) Что такое основа? Назовите её в наших
словах.
– Что предлагаете выделить в основе сначала, а что потом?
(Предположения детей.)
Методическая рекомендация: на этом этапе нередко предлагают
найти корень в словах. В этом заключается методическая ошибка,
т.к. в корнях слов часто происходят различные изменения
(чередования, усечения, наращения), часто первые компоненты корня
омонимичны приставкам, а последние – суффиксам, существует
опасность «выхода» на этимологические корни (как в слове бабочка).
)
Слова, соответствующие схемам:
– девочка, девушка, девица;
– гнёздышко;
– лисица, лисонька, лисёнок;
– сказка, сказочка;
– подсказка, присказка;
– полоска, полосатый.
2. Освоение алгоритма разбора слова по составу в режиме
проблемного диалога.
1. Самостоятельное выведение алгоритма учениками на основе
Коммуникативные УУД
1. Развиваем умение слушать и
понимать других.
2. Строить речевое высказывание в
соответствии с поставленными
задачами.
3. Оформлять свои мысли в устной
форме.
4. Умение работать в паре.
Личностные результаты
1. Развиваем умения выказывать своё
отношение к героям, выражать свои
эмоции.
2. Оценивать поступки в
соответствии с определённой
ситуацией.
3. Формируем мотивацию к обучению
и целенаправленной познавательной
деятельности.
© ООО «Баласс», 2013
3 наблюдений и рассуждений.
– Запишите слова вазочка, яблочко, бабочка. Их надо разобрать по
составу. Что это значит? (Выделить все части слова.)
– С чего предлагаете начать? (Предположения и объяснения детей.)
– Выделим окончания у слов, изменив их: вазочки, яблочка, бабочки.
Методическая рекомендация: эти этапы обычно не вызывают
сложностей у учащихся. Но можно ещё раз напомнить, что важно
сначала разграничить те части в слове, которые изменяются, и те, в
которых содержится основное значение слова. Окончания часто
бывают одинаковыми у разных слов, их легче всего выделить и
обозначить.
– Что выделим теперь? (Основу.) Что такое основа? Назовите её в наших
словах.
– Что предлагаете выделить в основе сначала, а что потом?
(Предположения детей.)
Методическая рекомендация: на этом этапе нередко предлагают
найти корень в словах. В этом заключается методическая ошибка,
т.к. в корнях слов часто происходят различные изменения
(чередования, усечения, наращения), часто первые компоненты корня
омонимичны приставкам, а последние – суффиксам, существует
опасность «выхода» на этимологические корни (как в слове бабочка). Если ученики предложат ошибочную версию – начнут с корня, то
возможно расхождение в мнениях. Это следует зафиксировать.
– Какой корень выделили в этих словах? У всех ли он один и тот же?
(Возможны расхождения в выделении корня в словах яблочко и
бабочка (ябл, яблоч; баб, бабоч, бабочк).
– Как быть? Может быть, нам поможет другой способ – сначала
© ООО «Баласс», 2013
4 выделить суффикс? Вспомните, как нужно выделять суффикс в слове.
(Объяснить слово через однокоренное.)
Методическая рекомендация: при выделении суффикса обычно
«срабатывает» сформированный навык: знаем, что есть такой
суффикс, как в нашем примере очк, его обычно и выделяют в словах.
Необходимо напомнить ученикам, что поиск суффикса начинаем с
объяснения значения слова через однокоренное.
Предлагаем записать слова в столбик и рядом дать объяснение.
Вазочка – маленькая ваза.
Яблочко – маленькое яблоко.
Бабочка – ?
Примечание: на повышенном уровне можно показать, что яблочко –
это не только маленькое яблоко, но и ласковое, нежное, оценочное (в
сказках – наливное яблочко, не имея в виду его размер).
– Какое слово не смогли объяснить через однокоренное? (Бабочка.)
Учитель помогает: значит, в этом слове нет никаких других частей,
кроме корня. Теперь можно его выделить в слове.
– Выделите основы однокоренных слов, через которые объяснили другие
наши слова – вазочка и яблочко.
– Какие части добавились? Обозначьте их. (Обозначают суффиксы.)
– Что вы обнаружили? (Эти части разные: очк и к.)
– Вам понятно, почему в словах есть эти суффиксы? Мы объясняли
наши слова через однокоренные и сравнивали их основы.
– Что теперь осталось сделать? (Выделить корень.)
– У всех теперь получился одинаковый корень? (Да.)
– Как это можно проверить? (Подобрать однокоренные слова.)
– Сделайте вывод: что нужно найти в основе вначале – корень или
© ООО «Баласс», 2013
5 суффикс? (Суффикс.)
– Проверьте свои предположения, прочитав инструкцию «Как нужно
разбирать слово по составу».
Если ученики предложат ошибочную версию – начнут с корня, то
возможно расхождение в мнениях. Это следует зафиксировать.
– Какой корень выделили в этих словах? У всех ли он один и тот же?
(Возможны расхождения в выделении корня в словах яблочко и
бабочка (ябл, яблоч; баб, бабоч, бабочк).
– Как быть? Может быть, нам поможет другой способ – сначала
© ООО «Баласс», 2013
4 выделить суффикс? Вспомните, как нужно выделять суффикс в слове.
(Объяснить слово через однокоренное.)
Методическая рекомендация: при выделении суффикса обычно
«срабатывает» сформированный навык: знаем, что есть такой
суффикс, как в нашем примере очк, его обычно и выделяют в словах.
Необходимо напомнить ученикам, что поиск суффикса начинаем с
объяснения значения слова через однокоренное.
Предлагаем записать слова в столбик и рядом дать объяснение.
Вазочка – маленькая ваза.
Яблочко – маленькое яблоко.
Бабочка – ?
Примечание: на повышенном уровне можно показать, что яблочко –
это не только маленькое яблоко, но и ласковое, нежное, оценочное (в
сказках – наливное яблочко, не имея в виду его размер).
– Какое слово не смогли объяснить через однокоренное? (Бабочка.)
Учитель помогает: значит, в этом слове нет никаких других частей,
кроме корня. Теперь можно его выделить в слове.
– Выделите основы однокоренных слов, через которые объяснили другие
наши слова – вазочка и яблочко.
– Какие части добавились? Обозначьте их. (Обозначают суффиксы.)
– Что вы обнаружили? (Эти части разные: очк и к.)
– Вам понятно, почему в словах есть эти суффиксы? Мы объясняли
наши слова через однокоренные и сравнивали их основы.
– Что теперь осталось сделать? (Выделить корень.)
– У всех теперь получился одинаковый корень? (Да.)
– Как это можно проверить? (Подобрать однокоренные слова.)
– Сделайте вывод: что нужно найти в основе вначале – корень или
© ООО «Баласс», 2013
5 суффикс? (Суффикс.)
– Проверьте свои предположения, прочитав инструкцию «Как нужно
разбирать слово по составу». 2. Чтение алгоритма разбора по составу в учебнике.
– О какой части слова мы не говорили в разборе слов вазочка, яблочко,
бабочка? Почему? (В них не было приставок.) Установите общую
последовательность разбора, продолжив ряд: окончание, основа, …
(суффикс, приставка, корень).
– Чем заканчивается разбор по составу? (Выделением корня.)
– А когда начинаем искать однокоренные слова? (Сразу после выделения
основы, см. п. 4.)
3. Самопроверка.
Выполнение задания № 9, тема 6 в рабочей тетради.
Ученики называют сначала порядок букв: 1а, …, затем читают
пункты алгоритма в нужной последовательности.
3. Развитие умений работать по алгоритму.
1. Упр. 201.
Дети вслух проговаривают этапы разбора, как в образце.
– Сравните два столбика слов. Какое слово должно было бы быть
первым во 2м столбике: грачиха…? Почему? (Через него можно
объяснить все остальные.)
2. Коллективная работа класса.
На слайде (доске) – стихотворение И. Токмаковой.
Берёза
Если б дали берёзе расчёску,
Изменила б берёза причёску:
В речку, как в зеркало, глядя,
© ООО «Баласс», 2013
6 Расчесала б кудрявые пряди.
И вошло б у неё в привычку
По утрам заплетать косичку.
(И. Токмакова)
– Выпишите однокоренные слова, выделите корень. (Расчёска, причёску,
расчесала.)
– Что ещё общего у этих слов? (У двух одинаковая приставка –
расчёска, расчесала, одинаковый суффикс – расчёска, причёска.)
– Какие есть ещё слова с суффиксами? (Речку, косичку…)
Вопросы к ученику, выполнявшему работу (начало формирования алгоритма
самооценки):
– Что тебе нужно было сделать?
– Удалось тебе выполнить задание?
– Ты сделал всё правильно или были недочёты?
– Ты составил всё сам или с чьейто помощью?
– Какой был уровень задания?
– Какие умения формировались при выполнении этого задания?
– Какую отметку ты бы себе поставил?
– Сейчас мы вместе с… (имя ученика) учились оценивать свою работу.
– Что мы сейчас делали?
– Какие умения формировали? (Умение работать с информацией.
2. Чтение алгоритма разбора по составу в учебнике.
– О какой части слова мы не говорили в разборе слов вазочка, яблочко,
бабочка? Почему? (В них не было приставок.) Установите общую
последовательность разбора, продолжив ряд: окончание, основа, …
(суффикс, приставка, корень).
– Чем заканчивается разбор по составу? (Выделением корня.)
– А когда начинаем искать однокоренные слова? (Сразу после выделения
основы, см. п. 4.)
3. Самопроверка.
Выполнение задания № 9, тема 6 в рабочей тетради.
Ученики называют сначала порядок букв: 1а, …, затем читают
пункты алгоритма в нужной последовательности.
3. Развитие умений работать по алгоритму.
1. Упр. 201.
Дети вслух проговаривают этапы разбора, как в образце.
– Сравните два столбика слов. Какое слово должно было бы быть
первым во 2м столбике: грачиха…? Почему? (Через него можно
объяснить все остальные.)
2. Коллективная работа класса.
На слайде (доске) – стихотворение И. Токмаковой.
Берёза
Если б дали берёзе расчёску,
Изменила б берёза причёску:
В речку, как в зеркало, глядя,
© ООО «Баласс», 2013
6 Расчесала б кудрявые пряди.
И вошло б у неё в привычку
По утрам заплетать косичку.
(И. Токмакова)
– Выпишите однокоренные слова, выделите корень. (Расчёска, причёску,
расчесала.)
– Что ещё общего у этих слов? (У двух одинаковая приставка –
расчёска, расчесала, одинаковый суффикс – расчёска, причёска.)
– Какие есть ещё слова с суффиксами? (Речку, косичку…)
Вопросы к ученику, выполнявшему работу (начало формирования алгоритма
самооценки):
– Что тебе нужно было сделать?
– Удалось тебе выполнить задание?
– Ты сделал всё правильно или были недочёты?
– Ты составил всё сам или с чьейто помощью?
– Какой был уровень задания?
– Какие умения формировались при выполнении этого задания?
– Какую отметку ты бы себе поставил?
– Сейчас мы вместе с… (имя ученика) учились оценивать свою работу.
– Что мы сейчас делали?
– Какие умения формировали? (Умение работать с информацией. )
4 4
Задание № 5, тема 6 в рабочей тетради.
– Выберите правильный вариант разбора.
– Объясните, в чём ошибка в других вариантах. (Бегун: ун – суффикс,
окончание нулевое; полёты: корень лет, по – приставка; заборишко –
VΙ . Итог урока.
© ООО «Баласс», 2013
7 корень забор, нет приставки, однокоренные слова забор, подзаборный.)
– Что у вас получалось сегодня лучше всего?
– В чём испытали затруднения?
– Кто сегодня получил отметку в дневник?
– За что?
Задание № 8, тема 6 в рабочей тетради.
V. Домашнее
задание.
Деятельность учеников:
– Выделять в слове все части, действовать по алгоритму.
Урок 64 (58).
Тема: Контрольное списывание
Работа выполняется в тетради «Проверочные и контрольные работы по русскому языку. 3й класс» на с. 24–25. Ученики
читают первое задание, выполняют его. Затем списывают, проверяют и выполняют задание после текста. Списывание
оценивается двумя отметками. Первая ставится за правильность и каллиграфию, вторая – за задания: озаглавливание и
выделение орфограмм.
Работу над ошибками учитель при необходимости планирует самостоятельно в соответствии с результатами работы.
© ООО «Баласс», 2013
8
)
4 4
Задание № 5, тема 6 в рабочей тетради.
– Выберите правильный вариант разбора.
– Объясните, в чём ошибка в других вариантах. (Бегун: ун – суффикс,
окончание нулевое; полёты: корень лет, по – приставка; заборишко –
VΙ . Итог урока.
© ООО «Баласс», 2013
7 корень забор, нет приставки, однокоренные слова забор, подзаборный.)
– Что у вас получалось сегодня лучше всего?
– В чём испытали затруднения?
– Кто сегодня получил отметку в дневник?
– За что?
Задание № 8, тема 6 в рабочей тетради.
V. Домашнее
задание.
Деятельность учеников:
– Выделять в слове все части, действовать по алгоритму.
Урок 64 (58).
Тема: Контрольное списывание
Работа выполняется в тетради «Проверочные и контрольные работы по русскому языку. 3й класс» на с. 24–25. Ученики
читают первое задание, выполняют его. Затем списывают, проверяют и выполняют задание после текста. Списывание
оценивается двумя отметками. Первая ставится за правильность и каллиграфию, вторая – за задания: озаглавливание и
выделение орфограмм.
Работу над ошибками учитель при необходимости планирует самостоятельно в соответствии с результатами работы.
© ООО «Баласс», 2013
8
Беспорядок морфемный разбор. «беспорядке» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Разбор слова по составу.
Состав слова «беспорядке»:
Морфемный разбор слова беспорядке
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова беспорядке делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова беспорядке – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для беспорядке (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для беспорядке путем подбора других слов, которые образованы таким же способом, что и беспорядке.
 Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;Как вы видите, морфемный разбор беспорядке делается просто. Теперь давайте определимся с основными морфемами слова беспорядке и сделаем его разбор.
См. также в других словарях:
Просклонять слово беспорядке по падежам в единственном и множественном числе…. Склонение слова беспорядке по падежам
Полный морфологический разбор слова «беспорядке»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор беспорядке
Ударение в слове беспорядке: на какой слог падает ударение и как… Слово «беспорядке» правильно пишется как… Ударение в слове беспорядке
Разбор слова по составу.
Состав слова «беспорядок»:
Морфемный разбор слова беспорядок
Морфемным разбором слова обычно называют разбор слова по составу – это поиск и анализ входящих в заданное слово морфем (частей слова).
Морфемный разбор слова беспорядок делается очень просто. Для этого достаточно соблюсти все правила и порядок разбора.
Сделаем морфемный разбор правильно, а для этого просто пройдем по 5 шагам:
- определение части речи слова беспорядок – это первый шаг;
- второй — выделяем окончание: для изменяемых слов спрягаем или склоняем, для неизменяемых (деепричастие, наречие, некоторые имена существительные и имена прилагательные, служебные части речи) – окончаний нет;
- далее ищем основу. Это самая легкая часть, потому что для определения основы нужно просто отсечь окончание. Это и будет основа слова;
- следующим шагом нужно произвести поиск корня слова. Подбираем родственные слова для беспорядок (еще их называют однокоренными), тогда корень слова будет очевиден;
- Находим остальные морфемы для беспорядок путем подбора других слов, которые образованы таким же способом, что и беспорядок.
 Подбираем родственные слова для беспорядок (еще их называют однокоренными), тогда корень слова будет очевиден;
Подбираем родственные слова для беспорядок (еще их называют однокоренными), тогда корень слова будет очевиден;Как вы видите, морфемный разбор беспорядок делается просто. Теперь давайте определимся с основными морфемами слова беспорядок и сделаем его разбор.
См. также в других словарях:
Однокоренные слова… это слова имеющие корень… принадлежащие к различным частям речи, и при этом близкие по смыслу… Однокоренные слова к слову беспорядок
Просклонять слово беспорядок по падежам в единственном и множественном числе…. Склонение слова беспорядок по падежам
Полный морфологический разбор слова «беспорядок»: Часть речи, начальная форма, морфологические признаки и формы слова. Направление науки о языке, где слово изучается… Морфологический разбор беспорядок
Ударение в слове беспорядок: на какой слог падает ударение и как… Слово «беспорядок» правильно пишется как… Ударение в слове беспорядок
Синонимы «беспорядок». Словарь синонимов онлайн: подобрать синонимы к слову «беспорядок». Слова-синонимы, сходные слова и близкие по смыслу выражения в… Cинонимы к слову беспорядок
Антонимы… имеют противоположное значение, различны по звучанию, но принадлежат к одной и той же части речи… Антонимы к слову беспорядок
бес порядок
Состав слова «беспорядок» :
приставка — [бес] , корень — [порядок] , нулевое окончание —
Предложения со словом «беспорядок»
Порядок старости и обветшания обычно кажется беспорядком , а между тем это именно порядок, имеющий свои отлаженные законы и, очевидно, свой, ускользающий от нас, смысл.
От них и так много беспорядка в мире, и так многие отвращения от образа и подобия.
Бывший президент Фернандо де ла Руа 19 декабря ввел в стране чрезвычайное положение с целью остановить беспорядки
, за время которых погибли 29 человек.
В Мосуле начались массовые беспорядки и акты мародерства.
Кроме того, новое несмертельное оружие может эффективно использоваться для ведения охранных мероприятий, защиты блокпостов, границ и может успешно использоваться полицейскими подразделениями для борьбы с антиправительственными демонстрантами и уличными беспорядками .
У вас там полный беспорядок , а вы… а вы только бумажки читаете.
Неожиданность произошла от полного беспорядка в тогдашних лагерях: власти на материке не знали, что по своему произволу предпринимали начальники на острове.
Мол, активисты компартии, заподозрив неладное, могут установить круглосуточное дежурство на кладбище, возле семейного захоронения Ульяновых, и попытаться устроить беспорядки .
А вот траур в среде тиффози обернулся беспорядками : в Мельбурне, где проживает крупная итальянская община, около 400 футбольных фанатов затеяли ночью массовую драку, стали кидать в полицейских и прохожих бутылки, камни и петарды, разводить на улицах костры.
Традиционные линнеисты опасаются того, что новая система внесёт в мир растений ещё больший беспорядок .
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор . Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
- Найти окончание. Для этого просклонять по падежам, изменить число, род или лицо, проспрягать — изменяемая часть будет окончанием. Помнить про изменяемые слова с нулевым окончанием, обязательно обозначить, если такое имеется: сон(), друг(), слышимость(), благодарность(), покушал().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить в основе приставку (если она есть). Для этого сравнить однокоренные слова с приставками и без.
- Определить суффикс (если он есть). Чтобы проверить, подобрать слова с другими корнями и с таким же суффиксом, чтобы он выражал одинаковое значение.
- Найти в основе корень. Для этого сравнить ряд родственных слов. Их общая часть — это корень. Помнить про однокоренные слова с чередующимися корнями.
- Если в слове два (и более) корня, обозначить соединительную гласную (если она есть): листопад, звездолёт, садовод, пешеход.
- Отметить формообразующие суффиксы и постфиксы (если они есть)
- Перепроверить разбор и значками выделить все значимые части
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы — «проспал»;
- два суффикса: «а» — суффикс глагольной основы, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон — проспать — проспала;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.
Разбор предложений на языке с различным порядком слов: пословные вариации требований к обработке выявляются на основе связанных с событиями потенциалов мозга в котором систематически менялся порядок элементов предложения: субъект, косвенный объект и прямой объект.
 Все предложения были законными грамматическими конструкциями. Предложения были представлены дословно, и на вопрос о назначении ролей нужно было ответить через 5 секунд после представления последнего слова каждого предложения.Поведенческие данные подтвердили предыдущие результаты, показывающие, что предложения, порядок слов которых отклоняется от канонической последовательности подлежащего, косвенного и прямого объекта, труднее обрабатывать. ERP выявили несколько эффектов, которые различались по своим предшествующим условиям, топографии и времени: (1) Предвидение вопроса, от которого зависит эпизодическое вербальное знание, сопровождалось выраженным тоническим негативным сдвигом с левым передним максимумом. (2) Артикли, которые в немецком языке функционируют как падежные знаки, вызывают временную левую переднюю негативность всякий раз, когда они указывают, что последовательность именных фраз не будет продолжаться в ее каноническом порядке.(3) Существительные, которые следуют за падежными маркерами в неканонических позициях, сопровождались повышенной временной задней положительностью. (4) Обработка слов в конечных позициях в предложениях с неканоническим порядком слов сопровождалась рядом эффектов: медленной апостериорной позитивностью, временной передней негативностью и временной задней негативностью, соответственно. Эти эффекты обсуждаются в отношении функционально различных механизмов синтаксического анализа. Они показывают, что ERP могут помочь разделить функционально различные процессы во время понимания языка, даже если участник не генерирует никаких поведенческих результатов.
Все предложения были законными грамматическими конструкциями. Предложения были представлены дословно, и на вопрос о назначении ролей нужно было ответить через 5 секунд после представления последнего слова каждого предложения.Поведенческие данные подтвердили предыдущие результаты, показывающие, что предложения, порядок слов которых отклоняется от канонической последовательности подлежащего, косвенного и прямого объекта, труднее обрабатывать. ERP выявили несколько эффектов, которые различались по своим предшествующим условиям, топографии и времени: (1) Предвидение вопроса, от которого зависит эпизодическое вербальное знание, сопровождалось выраженным тоническим негативным сдвигом с левым передним максимумом. (2) Артикли, которые в немецком языке функционируют как падежные знаки, вызывают временную левую переднюю негативность всякий раз, когда они указывают, что последовательность именных фраз не будет продолжаться в ее каноническом порядке.(3) Существительные, которые следуют за падежными маркерами в неканонических позициях, сопровождались повышенной временной задней положительностью. (4) Обработка слов в конечных позициях в предложениях с неканоническим порядком слов сопровождалась рядом эффектов: медленной апостериорной позитивностью, временной передней негативностью и временной задней негативностью, соответственно. Эти эффекты обсуждаются в отношении функционально различных механизмов синтаксического анализа. Они показывают, что ERP могут помочь разделить функционально различные процессы во время понимания языка, даже если участник не генерирует никаких поведенческих результатов.Ключевые слова
Язык
синтаксический анализ предложений
ERP
левая передняя отрицательность (LAN)
P300
синтаксический положительный сдвиг (SPS)
N400
Рекомендуемые статьи Цитирующие статьи (0)
1998 Academic Press. Все права защищены.
Рекомендуемые статьи
Цитирующие статьи
Страница не найдена
К сожалению, страница, которую вы искали на веб-сайте AAAI, не находится по URL-адресу, который вы щелкнули или ввели:
https: // www. aaai.org/papers/aaai/1990/aaai90-147.pdf  aaai.org/papers/aaai/1990/aaai90-147.pdf
aaai.org/papers/aaai/1990/aaai90-147.pdf Если указанный выше URL заканчивается на «.html», попробуйте заменить «.html:» на «.php» и посмотрите, решит ли это проблему.
Если вы ищете конкретную тему, попробуйте следующие ссылки или введите тему в поле поиска на этой странице:
- Выберите темы AI, чтобы узнать больше об искусственном интеллекте.
- Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство».
- Выберите «Публикации», чтобы узнать больше о AAAI Press и журналах AAAI.
- Для рефератов (а иногда и полного текста) технических документов по ИИ выберите Библиотека
- Выберите AI Magazine, чтобы узнать больше о флагманском издании AAAI.
- Чтобы узнать больше о конференциях и встречах AAAI, выберите Conferences
- Для ссылок на симпозиумы AAAI выберите «Симпозиумы».
- Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «Организация».
Помогите исправить страницу, которая вызывает проблему
Интернет-страница
, который направил вас сюда, должен быть обновлен, чтобы он больше не указывал на эту страницу.Вы поможете нам избавиться от старых ссылок? Напишите веб-мастеру ссылающейся страницы или воспользуйтесь его формой, чтобы сообщить о неработающих ссылках. Это может не помочь вам найти нужную страницу, но, по крайней мере, вы можете избавить других людей от неприятностей. Большинство поисковых систем и каталогов имеют простой способ сообщить о неработающих ссылках.
Если это кажется уместным, мы были бы признательны, если бы вы связались с веб-мастером AAAI, указав, как вы сюда попали (то есть URL-адрес страницы, которую вы искали, и URL-адрес ссылки, если он доступен).Спасибо!
Содержание сайта
К основным разделам этого сайта (и некоторым популярным страницам) можно перейти по ссылкам на этой странице. Если вы хотите узнать больше об искусственном интеллекте, вам следует посетить страницу AI Topics. Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство». Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека».Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»). Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
Чтобы присоединиться или узнать больше о членстве в AAAI, выберите «Членство». Выберите «Публикации», чтобы узнать больше о AAAI Press, AI Magazine, и журналах AAAI. Чтобы получить доступ к цифровой библиотеке AAAI, содержащей более 10 000 технических статей по ИИ, выберите «Библиотека».Выберите Награды, чтобы узнать больше о программе наград и наград AAAI. Чтобы узнать больше о конференциях и встречах AAAI, выберите «Встречи». Для ссылок на программные документы, президентские обращения и внешние ресурсы ИИ выберите «Ресурсы». Для получения информации об организации AAAI, включая ее должностных лиц и сотрудников, выберите «О нас» (также «Организация»). Окно поиска, созданное Google, будет возвращать результаты, ограниченные сайтом AAAI.
— эффективный алгоритм синтаксического анализа для обнаружения слов.
2068
Парсер BTH, способный эффективно анализировать решетку ключевых слов
, содержащую большое количество ложных срабатываний. В этом разделе
описаны его функции и методы.
2.1. Проблема синтаксического анализа ключевого слова и решетки
Один из методов анализа структуры решетки, которая получается при распознавании речи / рукописного текста
, заключается в последовательном применении синтаксического анализатора естественного языка
одно за другим к предложениям-кандидатам, которые
сгенерированы путем разворачивания решетки.TOSBURG-II использовал
обобщенный парсер LR [3], который анализирует решетку ключевых слов
, генерируя промежуточных кандидатов и отсекая безнадежные пути [1,2].
Решетка ключевых слов, однако, сгенерированная распознавателем речи
с большим объемом словаря и грамматики, содержит
сложной структуры с множеством узлов и форм в падежах.
сложно проанализировать каждого кандидата, созданного разворачиванием решетки
, с учетом как времени вычислений, так и памяти.
Для разработки речевого интерфейса практического приложения необходимо получить огромное количество словаря и
грамматики.
Мы собрали 389 примеров произнесения предложений, которые являются естественными
и необходимы водителям, которые используют автомобильные навигационные системы с распознаванием речи
. Они включают в себя фактические высказывания, сделанные одним из
из нас во время вождения автомобиля и в то время как пассажир в автомобиле.
Затем мы проанализировали их и составили грамматические правила, которые применяют
к этим примерам.Мы также разработали структуры намерений пользователей
, классифицируя собранные высказывания на 5W
(Где, Что, Что, Когда, Почему) и 2H (Как, Сколько).
Параллельно с анализом моделей предложений и грамматики,
мы подобрали ключевые слова из примеров высказываний. Для экземпляра
предложение
«Deguchi-no-mae-no-saigo-no-service-area-ha-doko? (Где
последняя зона обслуживания перед выходом?) »Был отнесен к группе типов предложений
« Где », и пять слов, т.е.e., deguchi
(выход), mae (до), saigo (последний), service-area и doko
(где) были выбраны в качестве ключевых слов. В результате анализа
около 700 слов были выбраны как распознанные ключевые слова, а
были классифицированы примерно на 110 классов слов (частей речи).
Рисунок 1. Пример решетки ключевых слов, полученной из механизма определения слов
.
По мере увеличения словаря для распознавания речи число ложных тревог
в результате распознавания увеличивается, а соответствующая решетка ключевых слов
становится огромной.На рисунке 1 изображен пример решетки ключевых слов
, который получается как результат распознавания речи
, когда пользователь произносит предложение выше
(«Дегучи-но-маэ-но-сайго-но-сервис-ареал-ха-доко? »). В этом примере было обнаружено 36
ключевых слов, то есть 5 правильных и 31 ложная тревога. Когда применяются только подключаемые временные ограничения
, может быть сгенерировано более 4 миллионов правдоподобных последовательностей слов
, каждая из которых представляет собой отдельный путь от начального узла
к конечному узлу, если решетка развернута. Таким образом, требуется синтаксический анализатор решетки,
Таким образом, требуется синтаксический анализатор решетки,
, который способен выполнять синтаксический анализ без развертывания заданной решетки ключевых слов
и генерировать набор приемлемых слов
кандидатов на последовательность по заданной грамматике.
2.2. Анализ ключевого слова-решетки с помощью
шаблонных хэш-таблиц
На основе следующих точек зрения мы разработали парсер BTH
(Bun [означает «предложение» на японском языке] Template Hash),
, который является эффективным синтаксическим анализатором решетки для выделение слов, что
удовлетворяет вышеупомянутым требованиям:
Обработка в реальном времени в масштабе практических приложений
на традиционных вычислительных мощностях: Для разработки практического речевого интерфейса
требуется как больший словарный запас
, так и меньше вычислений .Мы стремились реализовать парсер
, работающий в режиме реального времени на RISC MPU со скоростью 70-80 MIPS, то есть с MPU
, которые, как ожидается, будут применяться в автомобильных навигационных системах следующего поколения
.
Грамматическое представление с учетом как метода распознавания
, так и приложения:
сложно построить исчерпывающую и точную грамматику для
фактического высказывания, даже если задача, к которой оно применяется,
ограничено, потому что слово порядок и синтаксис в реальном высказывании
очень разнообразны.Требуется слабо ограниченное грамматическое представление
, чтобы справиться с заметными явлениями
в речи, такими как инверсии. С другой стороны, для синтаксического анализатора
бессмысленно принимать предложения
, которые прикладная программа не может выполнить. Грамматическое представление
, которое генерирует очень
сложных предложений, например, использующее рекурсивные правила,
было бы слишком выразительным для практического использования.
Разбор без разворачивания заданной решетки: в случае большого словаря
решетка результатов распознавания от механизма определения слов
включает в себя множество ложных тревог, как упомянуто выше
.Если парсер
анализирует развернутые кандидаты один за другим, это требует огромных затрат времени на вычисления.
Следовательно, требуется синтаксический анализатор решетки, способный анализировать
без развертывания заданной решетки ключевых слов.
Синтаксический анализатор BTH включает в себя следующие функции:
Грамматическое представление на основе шаблонов
последовательностей классов слов: Грамматика представлена как набор шаблонов
, каждый из которых образует последовательность классов слов
.Дизайнер интерфейса собирает предложения в задаче
и классифицирует их по типам предложений, то есть класс слов
Речевой ввод: Deguchi-no-mae-no-saigo-no-service-area-wa-doko?
ima
osoi
5
kono
dono
saigo
iku
komu
ano sou
Start End
9000 nai uaima
ima-no
7deguchi
5
iku
eki
uchi
deguchi
are
kore doko
yado
9000 9000yado
yado
e
itsu
u
e
hai
зона обслуживания
Num.пятнистых слов : 36
Num. дуг : 1,646
Кол. путей : 4,562,925
2.2.Последовательности разбора
Общей чертой в грамматиках является последовательность конкретный синтаксический элемент. В EBNF мы бы написали что-нибудь
например n + для представления последовательности из одного или нескольких n s и n * для нуля или более.
Happy не поддерживает этот синтаксис явно, но
вы можете определить эквивалентные последовательности, используя простые
постановки.
Например, грамматика самого Happy содержит такое правило:
prods: prod {[$ 1]}
| prods prod {$ 2: $ 1}
Другими словами, последовательность производств — это либо отдельное производство или последовательность постановок, за которыми следует разовое производство. Это рекурсивное правило определяет последовательность одно или несколько постановок.
Следует отметить, что в отношении этого правила мы использовали левая рекурсия , чтобы определить его — мы могли бы написать это так:
prods: prod {[$ 1]}
| подсказки {$ 1: $ 2}
Единственная причина, по которой мы использовали левую рекурсию, заключается в том, что Happy более эффективен при леворекурсивном разборе правила; они приводят к постоянному синтаксическому анализатору пространства стека, тогда как праворекурсивные правила требуют пространства стека, пропорционального длина анализируемого списка.Это может быть чрезвычайно важно там, где используются длинные последовательности, например, в автоматически сгенерированный вывод. Например, парсер в GHC использовался для использования правой рекурсии для анализа списков, и в результате не удалось проанализировать некоторые Happy-сгенерированные модули из-за к нехватке места в стеке!
Одним из следствий использования левой рекурсии является то, что в результате список выходит перевернутым, и вам нужно перевернуть его снова, чтобы получить это в исходном порядке. Взгляните на Удачная грамматика для Haskell для многих примеров это.
Для анализа последовательностей из нуля или более элементов требуется тривиальное изменение вышеприведенного шаблона:
подсказки: {- пусто -} {[]}
| prods prod {$ 2: $ 1}
Да — пустые производства разрешены. Нормальный
соглашение должно включать комментарий {- пусто -} к
сделать более очевидным для читателя кода, что происходит
на.
2.2.1. Последовательности с разделителями
Распространенным типом последовательности является последовательность с разделитель : например, тела функций в C состоят из операторов, разделенных точкой с запятой.Чтобы разобрать это вид последовательности мы используем такую продукцию:
stmts: stmt {[$ 1]}
| stmts ';' stmt {$ 3: $ 1}
Если ; должен быть терминатором а не разделитель (т.е. должен быть один следующий
каждый оператор), мы можем удалить точку с запятой из приведенного выше
Править и переопределить stmt как
stmt: stmt1 ';' {$ 1}
, где stmt1 — реальное определение операторов.
Мы можем разрешить дополнительные точки с запятой между заявления, чтобы быть немного более либеральными в том, что мы разрешаем в качестве законных синтаксис. Вероятно, мы просто хотим, чтобы синтаксический анализатор игнорировал эти лишние точки с запятой и не генерировать значение « нулевой оператор » или что-то. Следующее правило анализирует последовательность либо ноль, либо больше операторов, разделенных точкой с запятой, в которых операторы могут быть пустыми:
stmts: stmts ';' stmt {$ 3: $ 1}
| stmts ';' {$ 1}
| stmt {[$ 1]}
| {- пустой -} { [] }
Последовательности синтаксического анализа одного или более возможно Нулевые операторы оставлены в качестве упражнения для читателя…
CS440 Лекции
CS440 Лекции CS 440 / ECE 448
Осень 2019
Маргарет Флек
Лекция 19: НЛП 2
Боути Макбоутфейс (от BBC)
На последнем занятии мы набросали процесс получения из речи или сырого (потенциально
беспорядочный) ввод текста в чистую последовательность слов. Под словом я подразумеваю кусок
размера, удобного для последующих алгоритмов (например, синтаксический анализ, перевод).
Часто это стандартное письменное слово.Но это может быть объединением стандартных слов, если они неудобно короткие (например, китайский) или частичное слово на языках (например, турецком, немецком), слова которых неудобно долго. Это может означать морфему, т.е. минимальная смысловая единица, что они обычно считаются слишком короткими.
Найдите слова, морфемы
Модели понимания человеческого языка обычно предполагают, что первый этап, который производит достаточно точную последовательность телефонов. (На практике это не всегда так.) Последовательность телефонов должна затем сегментируется на последовательность слов с помощью алгоритма «сегментации слов». Процесс может выглядеть так, где # обозначает буквальная пауза в речи (например, говорящий переводит дыхание).
ВХОД: ohlThikidsinner # ahrpiyp @ lThA? HAvkids # ohrThADurHAviynqkids
ВЫХОД: ohl Thi kids inner # ahr piyp @ l ThA? HAv kids # ohr ThADur HAviynq kids
В стандартном письменном английском это будет «все дети там # — это люди, у которых есть дети # или у которых есть дети».
Затем эти слова необходимо разделить на морфемы с помощью алгоритма «морфологии». Слова на некоторых языках могут быть очень длинными (например, турецкий), что затрудняет для дальнейшей обработки, если они (хотя бы частично) не разделены в морфемы. Например:
без ответа -> без ответа
предварительных условий -> предварительные условия
Системы, начинающиеся с текстового ввода, могут столкнуться с аналогичной проблемой сегментации. Некоторые системы письма не ставят пробелы между словами.
Системам NLP также может потребоваться объединить входные блоки в более крупные.
Например, системы распознавания речи могут быть настроены на
преобразовать в последовательность коротких слов (например, «база», «мяч», «компьютер»,
«наука»)
даже когда они образуют узкую смысловую единицу («бейсбол» или «информатика»). Это особенно важная проблема для таких систем письма, как
Китайский. Рассмотрим эту хорошо известную последовательность из двух символов:
Это особенно важная проблема для таких систем письма, как
Китайский. Рассмотрим эту хорошо известную последовательность из двух символов:
Чжун + гуу
Исторически это два слова («середина» и «страна») и два символы появляются в письменной форме без явного указания на то, что они образуют единицу.Но на самом деле это одно слово, означающее Китай. Группирование входных последовательностей символов в одинаковые смысловые единицы — важный первый шаг в обработке китайского текста.
Фонология
В приведенном выше примере сегментации обратите внимание, что «там» слилось во «внутреннее» с «ым» звук меняется, чтобы стать похожим на предшествующее ему «n». Этот вид «фонологическое» изменение звука делает и распознавание речи, и слово сегментация намного сложнее. На практике на ранних этапах распознавания речи возникают ошибки. последовательности фонем, которые необходимо исправить при дальнейшей обработке.
Сочетание проблем обработки сигналов и фонологических изменений означает, что на практике современные распознаватели речи не могут транскрибировать речь в последовательности телефонов без какого-либо более широкого контекста. Большинство распознавателей используют простую (ngram) модель слов и слов. чтобы исправить необработанное распознавание телефона и, следовательно, произвести слово последовательности напрямую. Таким образом, фактическая последовательность этапов обработки зависит от приложения и говорите ли вы о производственных компьютерных системах или моделях понимание человеческого языка.
POS-теги
Чтобы сгруппировать слова в более крупные единицы (например, предложные фразы), Первым шагом обычно является присвоение тега «части речи» (POS) каждому слову. Вот пример текста из корпуса Брауна, который содержит очень чистые письменный текст.
Северные либералы — главные сторонники гражданских прав и интеграция. Они также привели нацию к государство всеобщего благосостояния.

Вот версия с тегами. Например, «либералы» — это ННС, которая существительное во множественном числе.«Северный» — прилагательное (JJ). Наборы тегов должны различать основные типы слов (например, существительные и прилагательные) и основные варианты, например единственное и множественное число существительных, настоящее и прошедшее время глаголы. Также есть несколько специальных тегов ключевые функциональные слова, такие как HV для «иметь», и пунктуация (например, точка).
Северные / jj либералы / nns являются / ber сторонниками / at вождя / jjs / nns из / в гражданских / jj прав / nns и / cc of / в интеграции / nn ./. Они / ppss есть / hv также / rb led / vbn the / at nation / nn in / in / at / at направлении / nn в / в а / в благосостоянии / нн государстве / нн./.
На чистом тексте хорошо настроенный POS-теггер может обеспечить точность около 97%. Другими словами, POS-тегеры достаточно надежны и в основном используются в качестве стабильная отправная точка для дальнейшего анализа.
Разбор
Если у нас есть теги POS для слов, мы можем собрать слова в дерево разбора. Есть много стилей построения деревьев синтаксического анализа. Здесь — это дерево избирательных округов из Penn treebank (от Mitch Marcus).
Дерево синтаксического анализа в стиле Penn treebank (от Митча Маркуса)
Альтернативой является дерево зависимостей , подобное приведенным ниже из Лаборатории Google.Достаточно недавний парсер из них называется «Парси МакПарсфейс» после Великобритании Боути Макбоутфейс, показанный выше.
В этом примере левое дерево показывает правильное вложение для слов «в ее машине», то есть изменение слова «водил». Правое дерево показывает интерпретацию, в которой улица находится в машине.
Лингвисты (вычислительные и другие) вели длительные споры по поводу
лучший способ нарисовать эти деревья. Однако закодированная информация
всегда довольно похожи и в первую очередь связаны с объединением слов
образуют связные фразы e. грамм. «государство всеобщего благосостояния». Это довольно похоже
к разбору языков программирования, кроме программирования
языки были разработаны, чтобы упростить синтаксический анализ.
грамм. «государство всеобщего благосостояния». Это довольно похоже
к разбору языков программирования, кроме программирования
языки были разработаны, чтобы упростить синтаксический анализ.
Парсеры делятся на две категории
- Несексикал: используйте только теги POS для построения дерева.
- Классы слов: вне части речи определить общий тип объект или действие (например, человек против транспортного средства)
- Lexicalized: также включить некоторую информацию о слове идентичность / значение
Ценность лексической информации иллюстрируется предложениями. как это, в котором изменение существительная фраза меняет предложную фразу изменяет:
Она шла по улице..в ее грузовике. (изменяет идущий)
в новом наряде. (изменяет тему)
в Южном Чикаго. (изменяет улицу)
Лексикализованы лучшие парсеры (точность до 94% от Google). Парсер «Parsey McParseface»). Но неясно, сколько информации о слова и их значения. Например, должна ли «машина» всегда вести себя как «грузовик»? Более подробная информация помогает принимать решения (особенно вложение) но требует больше данных для обучения.
Подробнее о наборах ярлыков
Обратите внимание, что набор тегов для корпуса Brown был несколько специализированным.
для английского языка, в котором формы «иметь» и «быть»
играют важную синтаксическую роль.
Для наборов тегов для других языков потребуются некоторые из тех же тегов (например, для
существительные), но и категории для
типы служебных слов, которые не используются в английском языке.
Например, для набора тегов для китайцев или майя потребуется тег для числовых значений.
классификаторы, то есть слова, которые идут с числами (например, «три»).
для обозначения примерного типа перечисляемого объекта (например,грамм.
«table» может потребоваться классификатор для больших плоских объектов).
Непонятно, лучше ли иметь специализированные наборы тегов. для определенных языков или один универсальный набор тегов, который включает
основные функциональные категории для всех языков.
для определенных языков или один универсальный набор тегов, который включает
основные функциональные категории для всех языков.
Наборы тегов различаются по размеру в зависимости от теоретических предубеждений люди, создающие аннотированные данные. Меньшие наборы этикеток передают только основная информация о типе слова. Более крупные наборы включают информацию о том, какую роль играет слово в окружающем контексте.Образец размеры
- Penn treebank 36
- Коричневый корпус 87
- «универсал» 12
Разговорный разговорный язык также включает в себя функции, которых нет в письменной речи. В приведенном ниже примере (из корпуса Switchboard) вы можете увидеть заполненную паузу «э-э», а также обрыванное слово «т-». Также обратите внимание на то, что первое предложение разбито на парантийный комментарий («вы знаете»), и третье предложение обрывается в конце. Такие функции усложняют анализ разговорной речи, чем письменный текст.
Я был бы очень осторожен и проверял их. Нашей, пришлось поместить мою мать в дом престарелых. У нее был довольно массивный инсульт о … о …
Я / PRP ‘d / MD быть / VB очень / RB очень / RB осторожно / JJ и / CC, /, ээ / UH, /, вы / PRP знаете / VBP, /, проверяете / VBG them / PRP out / RP ./. Э-э / э-э, /, наш / PRP $, /, имел / VBD t- / TO, /, place / VB my / PRP $ mother / NN in / IN a / DT сестринский уход / NN дом / NN ./. Она / ПРП была / ВБД а / ДТ скорее / РБ массивная / JJ ход / НН о / РБ, /, ух / УХ, /, об / РБ — /:
Перевод
Еще одно низкоуровневое приложение — это перевод.Чтобы узнать, как делать перевод, мы можем выровнять пары предложений на разных языках, сопоставляя соответствующие слова.
Английский: 18-летние не могут покупать алкоголь.
французский язык: Les 18 ans ne peuvent pas acheter d’alcool
| 18 | год | лет | банка | ‘т | купить | спирт | |||
| Лес | 18 | и | ne | peuvent | па | ахетер | г | спирт |
Обратите внимание, что некоторые слова не имеют совпадений на другом языке. Для других пар
в языках могут быть радикальные изменения в порядке слов.
Для других пар
в языках могут быть радикальные изменения в порядке слов.
Корпус совпадающих пар предложений может использоваться для создания словарей переводов (для фразы, а также слова) и извлекать общие сведения об изменениях в порядке слов.
Низкоуровневые алгоритмы
Большинство вкусов, которые мы видели до сих пор, используют простые модели последовательности ввода, предполагая, что только последние несколько пунктов имеют значение для следующего решения («Марковское предположение»).
- Решаете, вставлять ли границу слова? Посмотрите на последние 5-7 символов.
- Решаете, какой тег POS поставить на следующее слово? Посмотрите на последние 1-3 слова.
Конкретные методы включают конечные автоматы, скрытые марковские модели (HMM) и повторяющиеся нейронные сети (РНС).
Алгоритмы синтаксического анализа имеют аналогичную структуру, но их предыдущий контекст включает целые куски дерева. Например, «юную леди» можно считать единый блок.Алгоритмы синтаксического анализа обычно имеют гораздо больше возможностей для рассмотрения, то есть много частично застроенных деревьев. Это заставляет их использовать поиск луча, т.е. сохранение фиксированного количества гипотез с наилучшей оценкой. Новые методы также попробуйте разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование) чтобы они могли хранить больше гипотез и избегать дублирования работы.
Семантика
Представление смысла менее понятно, поэтому во многих методах работы используются поверхностные представления, основанные на модели мешка слов (см. наше обсуждение наивного Байеса) или локальные группы слов (например,грамм. существительные фразы). Приложения, которые могут хорошо работать с ограниченным пониманием включают
- группирование документов по темам, разделение документов в местах, где они меняют тему
- анализ настроений: сценаристу нравится этот фильм или этот ресторан?
Очень немногие системы пытаются понять
сложные конструкции, включающие кванторы
(«Сколько стрел не попало в цель?»)
или относительные предложения (см.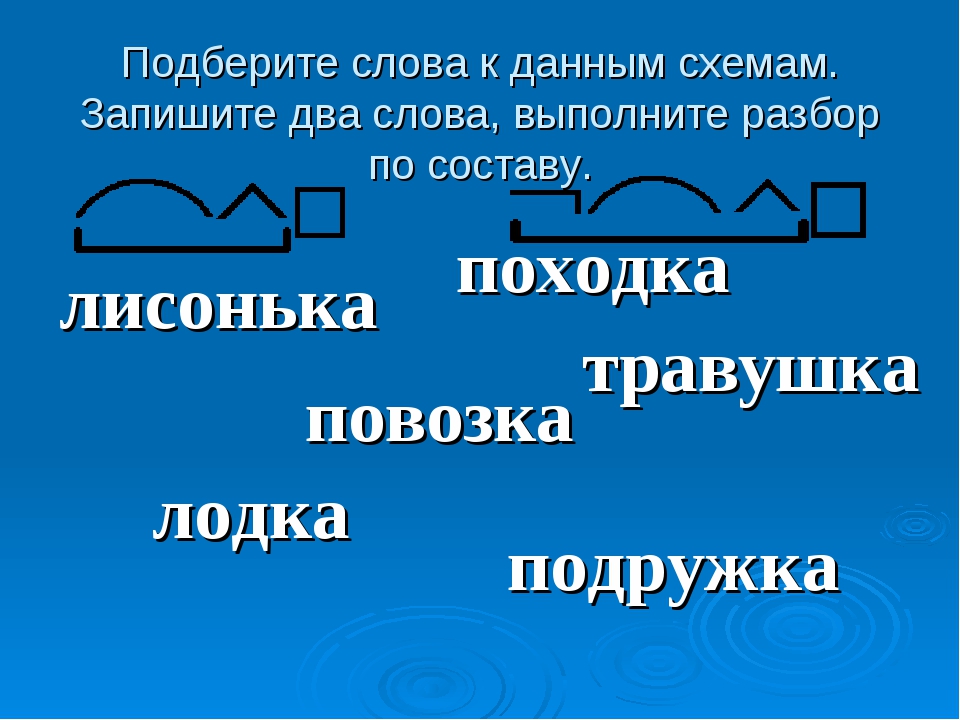 пример синтаксического анализа банка дерева Penn выше).Отрицание сложнее, чем кажется. Например,
запрос Google по запросу «Африка, а не франкоязычный» возвращает информацию
о франкоязычных частях Африки. И это
пример циркулярного перевода
показывает, что Google преобразует «упс на X» в «попробуйте X», т. е. обратное
полярность совета.
пример синтаксического анализа банка дерева Penn выше).Отрицание сложнее, чем кажется. Например,
запрос Google по запросу «Африка, а не франкоязычный» возвращает информацию
о франкоязычных частях Африки. И это
пример циркулярного перевода
показывает, что Google преобразует «упс на X» в «попробуйте X», т. е. обратное
полярность совета.
Три типа поверхностного семантического анализа оказались полезными и почти в пределах имеющихся возможностей:
- обозначение семантических ролей: мы знаем, что именная фраза X связана к глаголу Y.X — субъект / актер? объект, который действие было сделано? инструмент, используемый для помощи в действии?
- классов слов: какие слова похожи друг на друга.
- разрешение сопутствующего образца (см. Ниже)
Разметка семантических ролей включает в себя определение того, как основные словосочетания предложение относится к глаголу. Например, в «Джон вел машину» «Джон» — это субъект / агент, а «машина» — это управляемый объект. Эти отношения не всегда являются объектом, например.грамм. кто ест кто в «мост поедания грузовиков»? (Поищи в Гугле.)
В настоящее время наиболее популярным представлением классов слов является «вложение слов». Вложения слов дают каждому слову уникальное расположение в многомерном евклидовом пространстве, настроенном так, чтобы похожие слова близко друг к другу. Подробности увидим позже. Популярный алгоритм — word2vec.
Текущий текст содержит ряд «именованных сущностей», то есть существительных, местоимений и
существительные, относящиеся к людям, организациям и местам.Совместное разрешение пытается идентифицировать
какие именованные сущности относятся к одному и тому же.
Например, в этом тексте из Википедии у нас есть
определила три сущности, относящиеся к Мишель Обаме,
два как Барак Обама, и три как места, которые ни то, ни другое
из них. Один из источников сложности — это такие предметы, как
последний «Обама», который внешне выглядит так, будто мог бы быть
любой из них.
[Мишель ЛаВон Робинсон Обама] (родился 17 января 1964 г.) американский юрист, администратор университета и писатель. кто служил [Первая леди США] из С 2009 по 2017 гг.Она замужем за [44-й президент США], [Барак Обама], и была первой афроамериканской первой леди. Поднят на южной стороне [Чикаго, Иллинойс], [Обама] является выпускник [Университет Принстона] и [Гарвардская школа права].
AI в действии
Успехи и фейсплантаты от экспериментальные чат-боты.
О шумном пространственно-топическом кодировании позиций слов во время чтения: данные из задачи обнаружения изменений Meeter, & Grainger, 2017; Snell, van Leipsig, Grainger, & Meeter, 2018).Пространственные координаты обеспечивают опорный кадр для представления местоположения объекта в визуальной сцене
независимо, , от того, куда смотрят глаза зрителя. Адаптированные к случаю чтения, пространственно-топические координаты написанных слов определяются как представление местоположения слова в строке текста, который читается, независимо от положения взгляда читателя на этой строке текста. Пространственно-топические местоположения определяются низкоуровневой визуальной информацией, предоставляемой пробелами между словами, и по мере того, как читатели перемещают глаза вдоль строки текста, этим местоположениям постепенно присваиваются идентификаторы слов.В общем, читатели воспринимают серию визуальных «капель», когда они обрабатывают текстовые идентификаторы во время чтения, и они связывают разные словесные идентификаторы с разными местоположениями капель (Reilly & Radach, 2006; Snell et al., 2018). Согласно гипотезе параллельной обработки текста (Snell & Grainger, 2019a), центральным ингредиентом этой теоретической основы является то, что именно восходящая ассоциация идентичностей слов с пространственно-топическими местоположениями дает важную информацию, из которой можно вывести порядок слов и впоследствии используется для синтаксической обработки. Footnote 1
Footnote 1 Известно, что кодирование относительного положения визуальных объектов подвержено шуму. Явные доказательства этого были предоставлены для массивов букв, цифр и других простых визуальных стимулов с использованием одной и той же задачи сопоставления (например, Gómez, Ratcliff, & Perea, 2008; Massol, Duñabetia, Carreiras, & Grainger, 2013). В этом задании участникам просто нужно как можно быстрее и точнее определить, являются ли два последовательных массива стимулов одинаковыми или разными.Каждый массив обычно представлен кратко, чтобы усложнить задачу и сделать акцент на визуальной обработке (задачу иногда называют задачей «перцептивного сопоставления», например, Ratcliff, 1981). Один из ключевых выводов, полученных с помощью этой задачи (см. Gómez et al., 2008; Massol et al., 2013), заключается в том, что участникам сложнее судить о том, что две строки элементов различаются, когда разница создается путем транспонирования двух элементов (например , ПФГХК — ПФХГК) по сравнению с заменой двух элементов на разные (например.г., ПФГХК — ПФМДК). Это было воспринято как доказательство того, что кодирование позиционной информации подвержено определенному уровню шума, так что свидетельство для данного объекта в данном месте также может быть принято как свидетельство для этого объекта в соседних местах.
Основываясь на предыдущей работе по выявлению эффектов транспонированного слова в задаче грамматического принятия решения (Mirault, Snell, & Grainger, 2018; Snell & Grainger, 2019b), в более поздних работах мы сообщили об эффекте транспонированного слова при одинаковом и другом сопоставлении. задача (Pegado & Grainger, 2019, 2020).То есть нашим участникам было труднее решить, что две последовательности слов были разными, когда это различие было создано путем транспонирования двух слов (например, он хочет эти зеленые яблоки / он хочет зеленые яблоки) по сравнению с заменой двух слов разными словами (например, Разговаривает своими зелеными яблоками). Важно отметить, что эти эффекты транспонированных слов были также обнаружены с неконграмматическими последовательностями слов (например, зеленый хочет эти яблоки / зеленый — этим хочет яблоки), и эффекты, обнаруженные с неграмматическими последовательностями слов, были значительно выше, чем с последовательностями не слов (например, .g., ergen twans shete eh lapeps / ergen shete twans eh lapeps). Общая картина эффектов позволила нам сделать вывод, что восходящая вверх шумная ассоциация идентичностей слов с пространственно-топическими местоположениями является одним из ключевых механизмов, лежащих в основе эффектов транспонированного слова.
Важно отметить, что эти эффекты транспонированных слов были также обнаружены с неконграмматическими последовательностями слов (например, зеленый хочет эти яблоки / зеленый — этим хочет яблоки), и эффекты, обнаруженные с неграмматическими последовательностями слов, были значительно выше, чем с последовательностями не слов (например, .g., ergen twans shete eh lapeps / ergen shete twans eh lapeps). Общая картина эффектов позволила нам сделать вывод, что восходящая вверх шумная ассоциация идентичностей слов с пространственно-топическими местоположениями является одним из ключевых механизмов, лежащих в основе эффектов транспонированного слова.
В настоящем исследовании мы ищем более прямые доказательства пространственной природы кодирования положения слова снизу вверх. Для этого мы используем парадигму, которая была предпочтительной парадигмой для исследования кратковременной зрительной памяти (VSTM) и пространственной природы кодирования местоположения в VSTM (Luck, 2008; Luck & Hollingworth, 2008) — обнаружение изменений парадигма.Обнаружение изменений отличается от немедленной задачи сопоставления того же самого-другого с точки зрения задержки между эталонным и целевым стимулами, которая обычно составляет около 1 с, и считается достаточно длинной, чтобы исключить влияние знаковой памяти (Фогель, Вудман и Удача, 2001). Мы также ограничиваем любой вклад активной репетиции, используя параллельную артикуляцию (Baddeley, 1986; см. Ktori, Grainger, & Dufau, 2012, для применения этой процедуры с массивами букв и цифр в задаче обнаружения изменений).Одно из ключевых различий между парадигмой обнаружения изменений и парадигмами, используемыми для изучения других форм кратковременной памяти, таких как словесная кратковременная память (vSTM, не путать с VSTM), заключается в кратком одновременном представлении — запоминание стимулов по сравнению с более длительным последовательным представлением, используемым в задачах vSTM. Более длительное последовательное представление, используемое в парадигмах vSTM, позволило бы фонологически перекодировать визуальные стимулы, что привело бы к общему мнению о том, что фонологические представления участвуют в кратковременном хранении вербальной информации независимо от модальности представления (например,г. , Баддели, 1986). Напротив, мы предполагаем, что орфографические представления в первую очередь участвуют в хранении слов в VSTM. Доказательства в поддержку этой гипотезы были недавно представлены Cauchi, Lété и Grainger (2020). Используя фланкерную задачу Эриксена с горизонтально выровненными мишенью и фланкерами, Cauchi et al. обнаружили, что орфографическое совпадение целевого и фланкерного стимулов, но не фонологическое, влияет на идентификацию целевого слова. В общем, мы считаем, что комбинация процедуры обнаружения изменений и одновременной артикуляции обеспечивает идеальное средство для исследования параллельной ассоциации орфографических идентичностей слов с пространственным расположением.
, Баддели, 1986). Напротив, мы предполагаем, что орфографические представления в первую очередь участвуют в хранении слов в VSTM. Доказательства в поддержку этой гипотезы были недавно представлены Cauchi, Lété и Grainger (2020). Используя фланкерную задачу Эриксена с горизонтально выровненными мишенью и фланкерами, Cauchi et al. обнаружили, что орфографическое совпадение целевого и фланкерного стимулов, но не фонологическое, влияет на идентификацию целевого слова. В общем, мы считаем, что комбинация процедуры обнаружения изменений и одновременной артикуляции обеспечивает идеальное средство для исследования параллельной ассоциации орфографических идентичностей слов с пространственным расположением.
Помимо нашей предыдущей работы с немедленным сопоставлением одинаковых и разных (Pegado & Grainger, 2019, 2020), настоящее исследование было мотивировано выводами Mirault и Grainger (2020). В этом исследовании грамматические и грамматические последовательности из пяти слов были представлены в случайном порядке в течение произвольно изменяющейся продолжительности (с последующим маскирующим стимулом), и 87% точность определения грамматичности уже была достигнута при экспозиции стимула длительностью 300 мс. Мы объяснили эту производительность параллельной обработкой нескольких идентификаторов слов и их поддержанием в VSTM во время вычисления синтаксической информации.Учитывая наше объяснение эффектов транспонированного слова как отражения зашумленной ассоциации идентичностей слов с пространственными местоположениями в VSTM, мы поэтому ожидали найти аналогичные эффекты в задаче обнаружения изменений, и мы ожидали, что эти эффекты будут больше для последовательностей слов, чем для последовательностей без слов. . Однако выводы Миро и Грейнджер (2020) могут быть приспособлены к модели последовательной обработки (например, EZ Reader: Reichle, Pollatsek, Fisher, & Rayner, 1998), если предположить, что это не словесные идентичности, а скорее визуальные представления более низкого уровня. или орфографическая информация, которая хранится в краткосрочном хранилище.Учитывая ограничения емкости VSTM (например, Cowan, 2001), это должно было бы включать другую форму краткосрочного хранения, которая обеспечила бы последовательную обработку текста при отсутствии визуального ввода. То есть, в исследовании Mirault and Grainger (2020) у участников было достаточно времени для хранения сублексической информации о нескольких словах, которая позволила бы продолжить лексическую обработку и обработку на уровне предложений после представления обратной маски. Учитывая ограничения последовательного чтения слов, это хранилище может включать только сублексические представления (которые, в отличие от лексических представлений, могут обрабатываться параллельно), и, следовательно, эффекты транспонирования должны быть одинаковыми для последовательностей слов и неслов в этой учетной записи.
или орфографическая информация, которая хранится в краткосрочном хранилище.Учитывая ограничения емкости VSTM (например, Cowan, 2001), это должно было бы включать другую форму краткосрочного хранения, которая обеспечила бы последовательную обработку текста при отсутствии визуального ввода. То есть, в исследовании Mirault and Grainger (2020) у участников было достаточно времени для хранения сублексической информации о нескольких словах, которая позволила бы продолжить лексическую обработку и обработку на уровне предложений после представления обратной маски. Учитывая ограничения последовательного чтения слов, это хранилище может включать только сублексические представления (которые, в отличие от лексических представлений, могут обрабатываться параллельно), и, следовательно, эффекты транспонирования должны быть одинаковыми для последовательностей слов и неслов в этой учетной записи.
Наконец, мы отмечаем, что, хотя может показаться очевидным, что обнаружение изменений должно быть проще для последовательностей слов, чем для последовательностей без слов, например, из-за механизмов фрагментирования или повторной интеграции, влияющих на кратковременную память, ключевой прогноз, который мы тестируем, это что, согласно нашей учетной записи параллельного текстового редактора, именно природа изменения (транспонирование или замена) должна по-разному влиять на способность обнаруживать эти изменения в последовательностях слов и несловесных последовательностей.Мы считаем, что это нетривиальный прогноз.
Понимание критерия успеха 1.3.2: значимая последовательность
Намерение
Цель этого критерия успеха — дать возможность пользовательскому агенту предоставить альтернативный
представление контента с сохранением порядка чтения, необходимого для понимания
смысл. Важно, чтобы можно было программно определить хотя бы
одна последовательность содержания, которая имеет смысл.Контент, который не соответствует этому успеху
Criterion может сбивать с толку или дезориентировать пользователей, когда вспомогательные технологии читают контент. в неправильном порядке, или когда альтернативные таблицы стилей или другие изменения форматирования
применяемый.
в неправильном порядке, или когда альтернативные таблицы стилей или другие изменения форматирования
применяемый.
Последовательность имеет значение , если порядок содержимого в последовательности не может быть изменен, не влияя на его значение. Например, если страница содержит две независимые статьи, относительный порядок статьи не могут влиять на их значение, пока они не чередуются.В таком ситуация, сами статьи могут иметь значимую последовательность, но контейнер , который содержит статьи, может не иметь смысловой последовательности.
Семантика некоторых элементов определяет, является ли их содержание значимым. последовательность. Например, в HTML текст всегда представляет собой значимую последовательность. Таблицы и упорядоченные списки представляют собой значимые последовательности, а неупорядоченные списки — нет.
Порядок содержимого в последовательности не всегда имеет значение. Например, относительный порядок основного раздела веб-страницы и раздела навигации не влияет на их смысл. Они могут появляться в любом порядке в программно определяемом чтении. последовательность. Другой пример: статья в журнале содержит несколько боковых панелей с выносками. Порядок статьи и боковых панелей не влияет на их значение.В этих случаях существует ряд различных порядков чтения веб-страницы, которые могут удовлетворить Критерий успеха.
Для наглядности:
- Указание определенного линейного порядка требуется только там, где это влияет на значение.
- Может быть более одного «правильного» порядка (согласно определению WCAG 2.
