Морфологический разбор слова «подходящий»
Слово можно разобрать в 2 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Прилагательное
ПОДХОДЯЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОДХОДЯЩИЙ»
| Слово | Морфологические признаки |
|---|---|
| ПОДХОДЯЩИЙ |
|
| ПОДХОДЯЩИЙ |
|
Все формы слова ПОДХОДЯЩИЙ
ПОДХОДЯЩИЙ, ПОДХОДЯЩЕГО, ПОДХОДЯЩЕМУ, ПОДХОДЯЩИМ, ПОДХОДЯЩЕМ, ПОДХОДЯЩАЯ, ПОДХОДЯЩЕЙ, ПОДХОДЯЩУЮ, ПОДХОДЯЩЕЮ, ПОДХОДЯЩЕЕ, ПОДХОДЯЩИЕ, ПОДХОДЯЩИХ, ПОДХОДЯЩИМИ, ПОДХОДЯЩ, ПОДХОДЯЩА, ПОДХОДЯЩЕ, ПОДХОДЯЩИ, ПОПОДХОДЯЩЕЕ, ПОПОДХОДЯЩЕЙ
2 вариант разбора
Часть речи: Причастие
ПОДХОДЯЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОДХОДИТЬ»
| Слово | Морфологические признаки |
|---|---|
| ПОДХОДЯЩИЙ |
|
| ПОДХОДЯЩИЙ |
|
Все формы слова ПОДХОДЯЩИЙ
ПОДХОДИТЬ, ПОДХОЖУ, ПОДХОДИМ, ПОДХОДИШЬ, ПОДХОДИТЕ, ПОДХОДИТ, ПОДХОДЯТ, ПОДХОДИЛ, ПОДХОДИЛА, ПОДХОДИЛО, ПОДХОДИЛИ, ПОДХОДЯ, ПОДХОДИВ, ПОДХОДИВШИ, ПОДХОДИ, ПОДХОДЯЩИЙ, ПОДХОДЯЩЕГО, ПОДХОДЯЩЕМУ, ПОДХОДЯЩИМ, ПОДХОДЯЩЕМ, ПОДХОДЯЩАЯ, ПОДХОДЯЩЕЙ, ПОДХОДЯЩУЮ, ПОДХОДЯЩЕЮ, ПОДХОДЯЩЕЕ, ПОДХОДЯЩИЕ, ПОДХОДЯЩИХ, ПОДХОДЯЩИМИ, ПОДХОДИВШИЙ, ПОДХОДИВШЕГО, ПОДХОДИВШЕМУ, ПОДХОДИВШИМ, ПОДХОДИВШЕМ, ПОДХОДИВШАЯ, ПОДХОДИВШЕЙ, ПОДХОДИВШУЮ, ПОДХОДИВШЕЮ, ПОДХОДИВШЕЕ, ПОДХОДИВШИЕ, ПОДХОДИВШИХ, ПОДХОДИВШИМИ
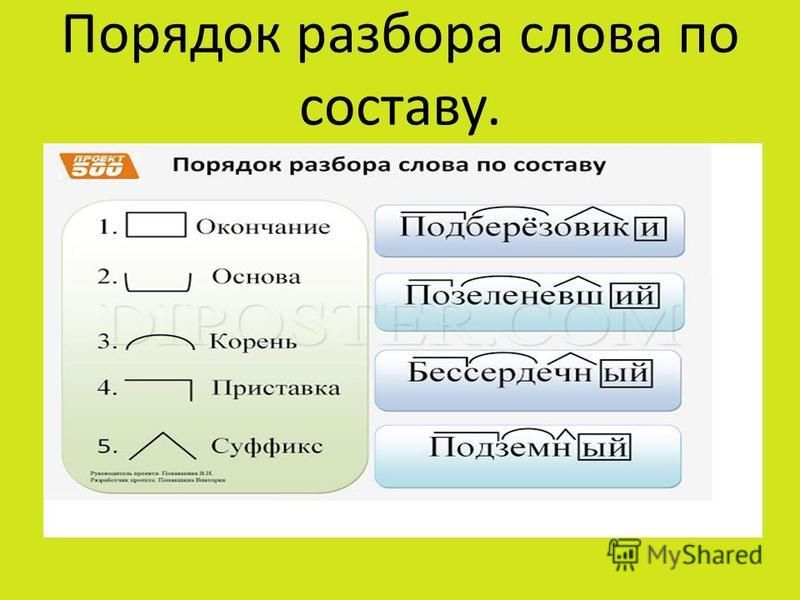
Разбор слова по составу подходящий
подходящ
ий
| Основа слова | подходящ |
|---|---|
| Приставка | под |
| Корень | ход |
| Суффикс | ящ |
| Окончание | ий |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОДХОДЯЩИЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «подходящий»
Примеры предложений со словом «подходящий»
1
Возможно, сказал бы в подходящий момент, настолько подходящий, что…
Взор синих глаз, Томас Харди, 1873г.
2
Чтобы рассказать ей о том, что случилось, он подождет подходящего момента, если для этого вообще может быть подходящий момент.
Допустимые потери, Ирвин Шоу, 1982г.
3
Подходящий рост, подходящая фигура, каучуковое лицо…
Театр, Уильям Сомерсет Моэм, 1937г.
4
Подходящее время, подходящий момент: человеку свойственно потакать своим желаниям, даже если они идут не от сердца.
Солдатики Гауди и другие невероятные истории, Анджей Ласки, 2017г.
5
Вы – именно вполне подходящий для нашего дела человек.
Две жизни, Михаил Волконский, 1914г.
Найти еще примеры предложений со словом ПОДХОДЯЩИЙ
Морфологический разбор слова «подходить»
Часть речи: Инфинитив
ПОДХОДИТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПОДХОДИТЬ»
| Слово | Морфологические признаки |
|---|---|
| ПОДХОДИТЬ |
|
Все формы слова ПОДХОДИТЬ
ПОДХОДИТЬ, ПОДХОЖУ, ПОДХОДИМ, ПОДХОДИШЬ, ПОДХОДИТЕ, ПОДХОДИТ, ПОДХОДЯТ, ПОДХОДИЛ, ПОДХОДИЛА, ПОДХОДИЛО, ПОДХОДИЛИ, ПОДХОДЯ, ПОДХОДИВ, ПОДХОДИВШИ, ПОДХОДИ, ПОДХОДЯЩИЙ, ПОДХОДЯЩЕГО, ПОДХОДЯЩЕМУ, ПОДХОДЯЩИМ, ПОДХОДЯЩЕМ, ПОДХОДЯЩАЯ, ПОДХОДЯЩЕЙ, ПОДХОДЯЩУЮ, ПОДХОДЯЩЕЮ, ПОДХОДЯЩЕЕ, ПОДХОДЯЩИЕ, ПОДХОДЯЩИХ, ПОДХОДЯЩИМИ, ПОДХОДИВШИЙ, ПОДХОДИВШЕГО, ПОДХОДИВШЕМУ, ПОДХОДИВШИМ, ПОДХОДИВШЕМ, ПОДХОДИВШАЯ, ПОДХОДИВШЕЙ, ПОДХОДИВШУЮ, ПОДХОДИВШЕЮ, ПОДХОДИВШЕЕ, ПОДХОДИВШИЕ, ПОДХОДИВШИХ, ПОДХОДИВШИМИ
Разбор слова по составу подходить
подходи
ть
| Основа слова | подходи |
|---|---|
| Приставка | под |
| Корень | ход |
| Суффикс | и |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПОДХОДИТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «подходить»
1
Народ же всё будет подходить и подходить, расспрашивая ранее стоявших о том, что же произошло.
Колючки иголки, Несахар, 2017г.
2
Шурик не знал, подходить – не подходить, стоял в проходе между станками , нервничал, кусал губы.
Истина, Владимир Чихнов, 2018г.
3
и как он может не подходить мне теперь, если прекрасно подходил раньше?
Взор синих глаз, Томас Харди, 1873г.
4
Не подхожу ей, все это время подходил, а сейчас не подхожу.
Твой дом там, где я, Кадрия Расиловна Хабибуллина
5
Гитлеровцев сдерживали уставшие до предела войска, подходившие и подходившие к линии фронта подкрепления командование пока в бой не вводило.
Вечный зов. Том 2, Анатолий Иванов, 1976г.
Найти еще примеры предложений со словом ПОДХОДИТЬ
[PDF] Двухэтапный гибридный подход на основе ограничений к анализу языковых зависимостей со свободным порядком слов
- title={Двухэтапный гибридный подход на основе ограничений к синтаксическому анализу языковых зависимостей со свободным порядком слов},
автор = {Акшар Бхарати и Самар Хусейн и Дипти Мишра Шарма и Раджив Сангал},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {2009}
}
В документе описывается общий дизайн нового двухэтапного гибридного подхода к анализу зависимостей на основе ограничений.
 Мы определяем два этапа и показываем, как разбираются различные грамматические конструкции на соответствующих этапах. Это разделение приводит к выборочной идентификации и разрешению конкретных отношений зависимости на двух этапах. Кроме того, мы показываем, как использование жестких и мягких ограничений помогает нам создать эффективный и надежный гибридный синтаксический анализатор. Наконец, мы оцениваем реализованные…
Мы определяем два этапа и показываем, как разбираются различные грамматические конструкции на соответствующих этапах. Это разделение приводит к выборочной идентификации и разрешению конкретных отношений зависимости на двух этапах. Кроме того, мы показываем, как использование жестких и мягких ограничений помогает нам создать эффективный и надежный гибридный синтаксический анализатор. Наконец, мы оцениваем реализованные… View on ACL
dl.acm.orgA Two Stage Constraint Based Hybrid Dependency Parser for Telugu
- Sruthilaya Reddy Kesidi, Prudhvi Kosaraju, Meher Vijay, Samar Husain
Computer Science
- 2010
A Представлен двухэтапный синтаксический анализ зависимостей телугу и обсуждается стратегия ранжирования, которая использует S-ограничения, чтобы дать нам лучший синтаксический анализ.
Гибридный синтаксический анализатор зависимостей на основе ограничений для телугу
- Шрутилая Редди Кесиди, Прудхви Косараджу, Мехер Виджай, Самар Хусейн
Информатика
Междунар.
Дж. Вычисл. Лингвистика Appl.- 2011
Обсуждается двухэтапный подход к анализу зависимостей на основе ограничений на телугу и стратегия ранжирования, которая использует Sconstraints для обеспечения наилучшего анализа.
Улучшение разбора зависимостей, управляемых данными, с использованием информации о клаузальной информации
- Фани Гадде, Каран Джиндал, Самар Хусейн, Д. Шарма, Р. Сангал
Информатика
NAACL
- 2010
Подход к анализу зависимостей, управляемый данными, который использует клаузальную информацию предложения для повышения производительности синтаксического анализатора и демонстрирует эксперименты с хинди, языком с относительно богатой системой маркировки регистра и бесплатным -порядок слов.
Анализаторы и подходы к анализу: классификация и современное состояние
- А. Рани, Комал Мела, А. Джангра
Информатика
2015 Международная конференция по футуристическим тенденциям в области вычислительного анализа и управления знаниями (ABLAZE)
- 2015
В этой статье для лучшего анализа предлагается сравнительная таблица различных синтаксических анализаторов, основанных на различной методологии синтаксического анализа для разных языков.
Два метода включения «локальных морфосинтаксических» признаков в синтаксический анализ зависимостей хинди
- Бхарат Рам Амбати, Самар Хусейн, Самбхав Джайн, Д. Шарма, Р. Сангал
Информатика
SPMRL@NAACL-HLT
- 2010
В этой статье сначала исследуется, какая информация, предоставляемая поверхностным синтаксическим анализатором, является наиболее информация о начале, информация о границе фрагмента, расстояние до конца фрагмента и конкатенация суффиксов очень важны при анализе зависимостей хинди.
Анализ зависимостей на языке Bangla
- Утпал Гарайн, Санкар Де
Информатика
- 2013
Для бангла (бенгали) была предпринята попытка разбора зависимостей на основе грамматики, чтобы упростить сложные и составные предложения, а затем разобрать простые предложения, удовлетворяя требованиям карака групп запросов (групп глаголов).
).О роли морфосинтаксических признаков в анализе зависимостей хинди
- Бхарат Рам Амбати, Самар Хусейн, Джоаким Нивре, Р. Сангал
Информатика, лингвистика
SPMRL@NAACL-HLT
- 2010
Анализ показывает, что наибольший прирост точности достигается за счет добавления морфо-синтаксических функций, связанных с падежом, временем, аспектом и модальностью, при анализе зависимостей хинди на основе данных. .
Синтаксические ядра в диапазоне зависимостей — многоязычное исследование
- A. Basirat, Joakim Nivre
Усовершенствование компьютерных наук
EACL
- 2021
Эксперименты на 12 -я языках показывают, что на ноклереалистских композициях. Показывает на ноклере, что на ноклереатюре приводит к тому, что на ноклереалистских композициях. Показывает, что на ноклереалисных натуральных композициях. точность и в основном касается небольшого числа отношений зависимости, включая именные модификаторы, отношения согласования, главные предикаты и прямые объекты.
Использование языковых вариантов посредством грамматического анализа, имеющего морфологически богатую информацию
- Qaiser Abbas
Компьютерная наука, лингвистика
EMNLP 2014
- 2014
. Парсер -path shift-reduce для урду и простой парсер зависимостей хинди с увеличением отзыва на 4,8% и 22% соответственно.
Улучшение синтаксического анализа зависимостей индийского языка путем объединения синтаксических анализаторов на основе переходов и графов
- B. VenkataSeshuKumari, R. R. Rao
Информатика
- 2015
Разработан гибридный подход, объединяющий выходные данные этих двух парсеров интуитивно понятным образом, а именно парсер Malt и парсер MST для анализа зависимостей. два индийских языка, телугу и хинди.
ПОКАЗАНЫ 1–10 ИЗ 18 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантность Наиболее влиятельные документыНедавность
MaltParser: независимая от языка система для анализа зависимостей на основе данных
- Юдзи Мацумото
Информатика
- 2005
Экспериментальная оценка подтверждает, что MaltParser может обеспечить надежный, эффективный и точный синтаксический анализ для широкого спектра языков без специальных языковых усовершенствований и с довольно ограниченным объемом обучающих данных.
Два семантических признака определяют точность синтаксического анализа
- Самар Хусейн, Бхарат Рам Амбати, Самбхав Джайн, Д. Шарма
Информатика
- 2008
В заключение отметим, что окончательная производительность, полученная при анализе хинди, обнадеживает: лучшие оценки прикрепления с пометкой и прикрепления без пометки составляют 69,64% и 88,67% соответственно в банке деревьев размером всего 1200 предложений.
Схема аннотации зависимостей для индийских языков
- Рафия Бегум, Самар Хусейн, Арун Дуадж, Д. Шарма, Лакшми Бай, Р. Сангал
Лингвистика, информатика
IJCNLP
- 2008
Представлена мотивация для следования схеме Панина в качестве схемы аннотаций, и утверждается, что структура Панина лучше подходит для моделирования различных лингвистических явлений, проявляющихся в индийских языках.
Односолодовый или купажированный? Исследование по оптимизации многоязычного парсера
- Йохан Холл, Йенс Нильссон, Йоаким Нивре
Информатика
EMNLP
- 2007
Двухэтапная оптимизация системы MaltParser для десяти языков в многоязычном треке общей задачи CoNLL 2007 по синтаксическому анализу зависимостей приводит к созданию ансамблевой системы, которая объединяет шесть различных стратегий синтаксического анализа, экстраполируя оптимальные настройки параметров для каждого языка.
Синтаксический анализ языков со свободным порядком слов в панинианской структуре
- Акшар Бхарати, Р. Сангал
Информатика, лингвистика
ACL
- 1993
В этой статье показано, что панинианская структура, примененная к современным индийским языкам, дает элегантное описание отношения между поверхностной формой (вибхакти) и семантическими (карака) ролями, что предполагает, что решение не просто случайное, но имеет более глубокий смысл.
лежащее в основе единство.Разбор естественного языка с градуированными ограничениями
- Инго Шредер
Информатика
- 2002
Большой набор экспериментальных результатов подтверждает, что устойчивость и градация естественного языка хорошо подходят для обработки: наличие характеристик конфликтов ограничений делает синтаксический анализатор WCDG подходящим кандидатом на роль компонента диагностики в приложениях для компьютерного изучения языков.
Непроективная зависимость зависимости с использованием алгоритмов Spanning Tree
- Ryan T. McDonald, Fernando C Pereira, Kiril Ribarov, Jan Hajic
Компьютерная наука
HLT
HLT
HLT
- 6
. Эйснера (1996) достаточно для поиска по всем проективным деревьям за время O(n3) и естественным образом расширяется до непроективного синтаксического анализа с использованием алгоритма MST Чу-Лю-Эдмондса (Чу и Лю, 1965; Эдмондс, 1967), что дает O( n2) алгоритм разбора.
Расширяемая грамматика зависимостей: новая методология
В этом документе представлен новый грамматический формализм Extensible Dependency Grammar (XDG) и подчеркнуты преимущества его методологии объяснения сложных явлений путем взаимодействия простых…
Доказательства против контекстной независимости естественного языка
- С. Шибер
Лингвистика, информатика
- 1985
, который интерпретируется как сильно, так и слабо как способ характеристики наборов структур и даже слабо для характеристики наборов строк.
Синтаксис зависимостей: теория и практика
- И. Мельчук
Лингвистика
- 1987
Что такое парсинг данных? — Определение парсера данных
Спасибо! Ваша заявка принята!
Ой! Что-то пошло не так при отправке формы.
Синтаксический анализ данных используется для сканирования информации из больших наборов данных и ее структурирования в понятном для человека виде.
Что такое анализ данных? Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь. Синтаксический анализ данных — это процесс преобразования строки данных из одного формата в другой. Если вы читаете данные в необработанном HTML, анализатор данных поможет вам преобразовать их в более читаемый формат, например, в обычный текст. Не вся информация преобразуется в процессе синтаксического анализа, и программы имеют свои собственные наборы правил, когда речь идет о синтаксическом анализе информации.
Короче говоря, программа анализа данных используется для преобразования неструктурированных данных в JSON, CSV и другие форматы файлов и добавляет структуру к указанной информации.
Определение синтаксического анализаВ области компьютерного программирования синтаксический анализ определяется как анализ строки символов, специальных символов и структур данных с использованием обработки естественного языка (NLP). Когда вы определяете извлечение при синтаксическом анализе, это относится к структурированию информации из наборов данных и приданию ей значения путем ее организации на основе определенных пользователем правил.
Синтаксический анализ имеет разные определения для лингвистов и программистов, но общее мнение состоит в том, что он используется для анализа предложений и отображения семантических отношений между ними. Другими словами, вы определяете извлечение информации из файлов и их фильтрацию как синтаксический анализ.
Типы анализа данныхАнализ данных использует два подхода, когда речь идет о семантическом анализе анализа данных, управляемого текстовой грамматикой, и анализа данных, управляемого данными.
Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.Вот как работают эти два подхода:
1. Анализ данных на основе грамматикиАнализ данных на основе грамматики означает, что анализатор использует набор правил формальной грамматики для процесса анализа. Это работает так: предложения из неструктурированных данных фрагментируются и преобразуются в структурированный формат. Проблема анализа данных на основе грамматики заключается в том, что моделям не хватает надежности. Это преодолевается путем ослабления грамматических ограничений, так что предложения, выходящие за рамки грамматических правил, могут быть исключены для последующего анализа. Синтаксический анализ текста является подмножеством анализа грамматики и назначает ряд анализов для данной строки. Он также решает проблемы устранения неоднозначности, с которыми сталкиваются традиционные методы синтаксического анализа.
2. Анализ данных на основе данныхАнализ данных на основе данных использует вероятностную модель и обходит дедуктивные подходы к анализу текста, которые часто используются в моделях на основе грамматики. В этом типе синтаксического анализа программа синтаксического анализа применяет методы, основанные на правилах, семантические уравнения и обработку естественного языка (NLP) для структурирования и анализа предложений. В отличие от синтаксического анализа на основе грамматики, синтаксический анализ данных на основе данных использует статистические синтаксические анализаторы и современные банки деревьев для получения широкого охвата языков. Анализ разговорных языков и предложений, требующих точности, с немаркированными данными, относящимися к предметной области, подпадает под область анализа данных на основе данных.
Варианты использования синтаксического анализатора данныхЧто делает синтаксический анализатор? Он извлекает данные из документов, структурирует их и фильтрует детали.
Синтаксический анализ данных используется различными отраслевыми вертикалями для преобразования информации в электронные форматы из документов. Ниже приведены наиболее популярные варианты использования синтаксического анализа в отраслях:
1. Оптимизация бизнес-процессовАнализаторы данных используются компаниями для структурирования неструктурированных наборов данных в полезную информацию. Предприятия используют синтаксический анализ данных для оптимизации своих рабочих процессов, связанных с извлечением данных. Синтаксический анализ используется в области инвестиционного анализа, маркетинга, управления социальными сетями и других бизнес-приложений.
2. Финансы и бухгалтерский учетБанки и NBFC используют анализ данных для очистки миллиардов данных клиентов и извлечения ключевой информации из приложений. Анализ данных используется для анализа кредитных отчетов, инвестиционных портфелей, проверки доходов и получения более полных сведений о клиентах.
3. Доставка и логистика Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.Предприятия, предоставляющие товары/услуги в режиме онлайн, используют синтаксические анализаторы данных для получения сведений о платежах и доставке. Парсеры используются для упорядочивания отгрузочных этикеток и обеспечения правильного форматирования данных.
4. Сфера недвижимостиДанные о потенциальных клиентах извлекаются из электронных писем владельцев недвижимости и строителей. Технологии парсинга используются для извлечения данных для платформ CRM и обработки документации для передачи агентам по недвижимости. Благодаря контактным данным, адресам собственности, данным о денежных потоках и источникам потенциальных клиентов, парсеры очень полезны для компаний, занимающихся недвижимостью, когда речь идет о покупках, аренде и продажах.
Стоит ли создавать собственный парсер?Распространенный вопрос, который постоянно возникает при обработке документов в организациях, заключается в том, следует ли создавать собственный анализатор данных.
Специальное программное обеспечение для синтаксического анализа текста, созданное для внутренних команд, определенно создано с учетом конкретных требований к синтаксическому анализу в организациях.Однако недостатком является то, что весь персонал должен быть обучен тому, как им пользоваться. Затраты на создание пользовательской программы синтаксического анализа могут быть высокими, поскольку требуется больше времени и ресурсов. Кроме того, эти решения требуют тщательного планирования и собственных выделенных серверов для более быстрого анализа. Если вы переносите системы, они могут быть несовместимы с новыми технологиями и потребуют обновления.
Идеальным сценарием является использование анализатора данных, совместимого с устаревшими системами и предназначенного для различных вариантов использования. Парсер данных Docsumo дает вам полный контроль над извлечением данных и предназначен для работы со всеми типами предприятий, будь то стартапы, предприятия или крупные организации.
 Мы определяем два этапа и показываем, как разбираются различные грамматические конструкции на соответствующих этапах. Это разделение приводит к выборочной идентификации и разрешению конкретных отношений зависимости на двух этапах. Кроме того, мы показываем, как использование жестких и мягких ограничений помогает нам создать эффективный и надежный гибридный синтаксический анализатор. Наконец, мы оцениваем реализованные…
Мы определяем два этапа и показываем, как разбираются различные грамматические конструкции на соответствующих этапах. Это разделение приводит к выборочной идентификации и разрешению конкретных отношений зависимости на двух этапах. Кроме того, мы показываем, как использование жестких и мягких ограничений помогает нам создать эффективный и надежный гибридный синтаксический анализатор. Наконец, мы оцениваем реализованные…  Дж. Вычисл. Лингвистика Appl.
Дж. Вычисл. Лингвистика Appl.
 ).
).


 лежащее в основе единство.
лежащее в основе единство.
 Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь.
Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь. 
 Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.
Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.
 Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.
Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.