Как разобрать по составу слово «вполголоса»?
Для выполнения правильного морфемного анализа/разбора по составу/ нужно установить, от какого слова и при помощи какой морфемы образовано анализируемое слово.
В данном случае имя существительное «хвороба» является производным (т.е. образовано при помощи суффикса «-об-«) от глагола «хворать».
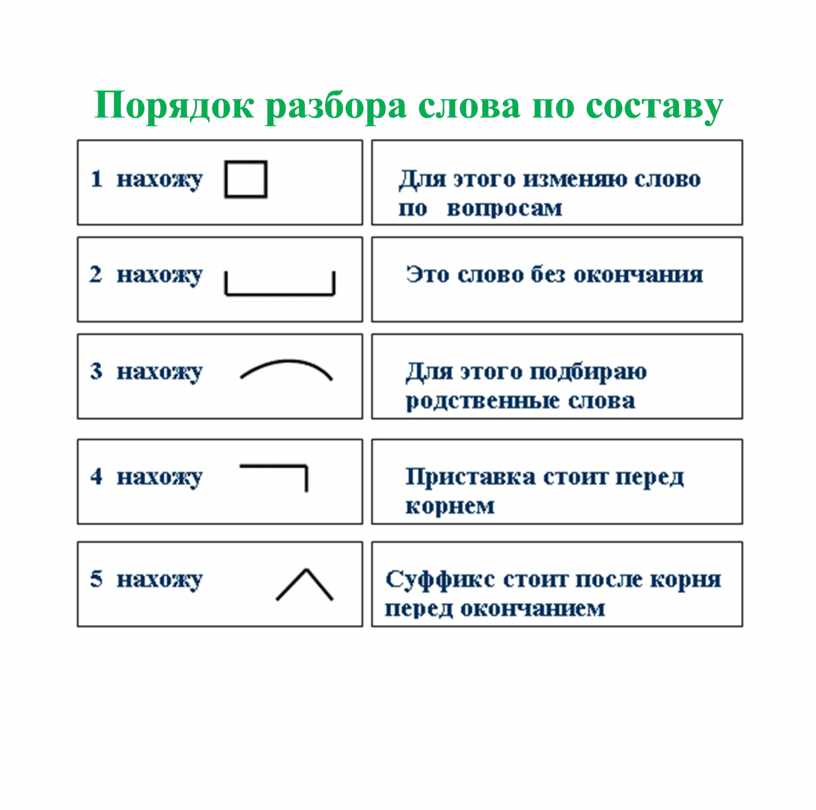
Алгоритм/порядок/ морфемного разбора:
- окончание «-а», слово изменяемое,
- основа слова «хвороб-«, часть слова без формообразовательной морфемы (окончание),
- суффикс «-об-«,
- корень «хвор-«.
Хвор/об/а
Слово Завтрашний отвечает на вопрос Какой? и оказывается прилагательным мужского рода, которое обладает окончанием -ИЙ: Завтрашний-Завтрашняя-Завтрашнее.
Однокоренными словами оказываются: Завтрашний-Завтра-Послезавтра.
Следовательно корнем слова Завтрашний будет морфема ЗАВТРА-.
Далее выделим в составе слова Завтрашний суффикс прилагательного -ШН-.
Получаем: ЗАВТРА-ШН-ИЙ (корень-суффикс-окончание), основа слова: ЗАВТРАШН-.
Пример предложения: Завтрашний день будет очень сложным, ведь нам предстоит сдавать экзамены по русскому языку.
Слово РЕЧКА является в русском языке существительным. В нашем случае оно используется в именительном падеже и единственном числе.
В первую очередь при выполнению морфемного анализа обращаем внимание на окончание и основу, для этого используем грамматические формы речк-у, речк-е, речк-ой.
Итак: основа — РЕЧК-, окончание в слове — -А.
Далее работаем с основой, нам помогут однокоренные рек-а, реч-енька, реч-ушка. Корень будет РЕЧ-.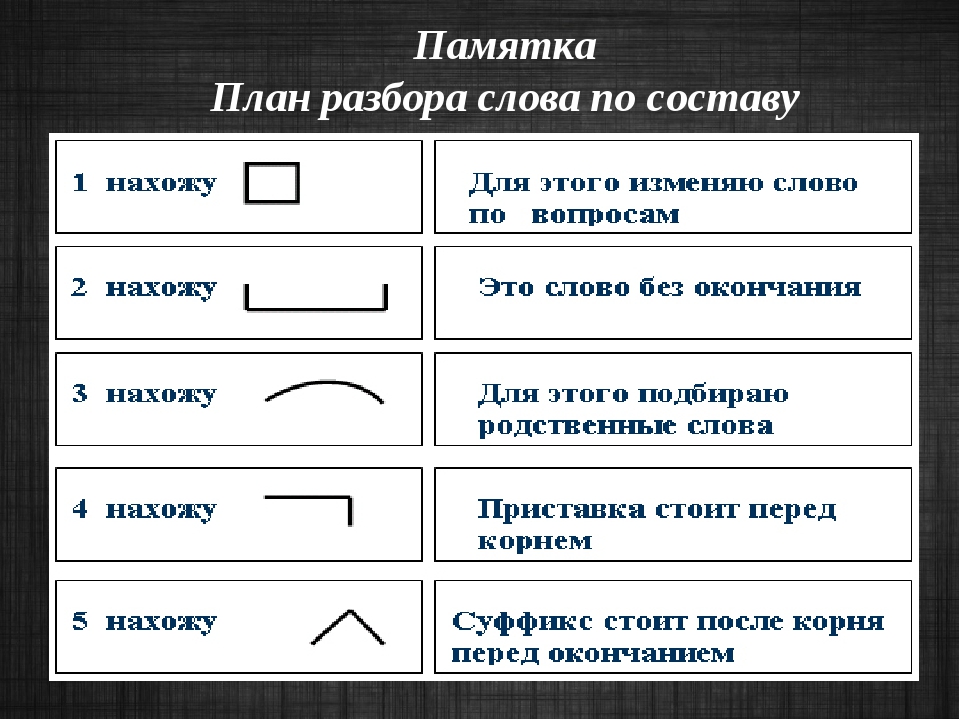
Морфема за корнем будет в нашем случае суфиксом, это -К-.
В итоге у нас получается такая запись: РЕЧ-К-А, где корень/суффикс/окончание.
Существительное множественного числа Поддоны имеет окончание -Ы: Поддоны-Поддонов-Поддонам-Поддонами-Поддонах. Для выделения корня посмотрим несколько однокоренных слов: Поддон-Донка-Донный-Дно-Днище. Замечаем, что корнем существительного оказывается морфема -ДОН-, в которой гласная О оказывается беглой. Перед корнем обнаруживаем приставку ПОД-.
Получаем: ПОД-ДОН-Ы (приставка-корень-окончание), основа слова ПОДДОН-.
Слово состоит из разных частей: приставки/ корень слова/ суффикс/ окончание.
Давайте разберем слово «волнистый»
1 часть (приставка) — отсутствует;
2 часть (корень слова) — волн;
3 часть (суффикс) — ист;
4 часть (окончание) — ый;
Основа слова — волнист.
Способ образования слова «волнистый»: суффиксальный.
Волнистый — имя прилагательное (полное), качественное, неодушевленное, мужской род, единственное число, именительный/винительный падеж.
Разбор по составу слова «розоватый»
Выполним разбор по составу слова «розоватый», выделив корень, суффикс и окончание.
Чтобы правильно разобрать по составу слово «розоватый», вначале определим, какой частью речи оно является.
Розоватый отсвет зари лег на воду тихой заводи.
Отсвет какой? розоватый.
Это слово обозначает непосредственный признак предмета. Значит, это прилагательное. Оно изменяется по родам и числам:
- розоват-ая краска,
- розоват-ое озеро,
- розоват-ые лица.


Сравнив эти грамматические формы, выделим в составе слова окончание -ый. Его не включаем в основу розоват-.
Далее выделим суффикс -оват-, который принадлежит прилагательным, обозначающим легкий признак:
- сероватый цвет,
- черноватый кот,
- беловатый хвост,
- подслеповатый старик.
В заданиях «Два суффикса содержится в словах» в выделении этого суффикса при разборе подобных слов часто ошибаются, поделив его на две морфемы.
Корнем является часть роз-, как и в родственных словах:
- роза
- розовый
- розовость
- розовенький
- розоветь
- порозоветь.
Соберем все выделенные морфемы в одну схему:
розоватый — корень/суффикс/окончание.
В морфемном составе слова «розоватый» укажем корень, суффикс и окончание.
Часть речи слова «розоватый»
Чтобы разобрать по составу интересующее нас слово, вначале выясним, к какой части речи оно принадлежит и изменяется ли.
На небе появился розоватый свет, разлившийся длинными полосами, будто нарисованными невидимой рукой (Поль Брантон).
Свет какой? розоватый.
Рассматриваемое слово обозначает признак предмета. По этим грамматическим признакам установим, что это качественное прилагательное, которое изменяется по родам, числам и падежам:
- лепесток розоват-ый,
- заря розоват-ая,
- небо розоват-ое,
- облака розоват-ые.
Морфемный разбор слова «розоватый»
Сравнив эти словоформы, укажем в морфемном составе интересующего нас прилагательного мужского рода единственного числа словоизменительную морфему — окончание -ый. В основу розоват- окончание не входит.
Далее укажем типичный суффикс прилагательных -оват- (-еват- после мягких согласных), который указывает на легкую степень признака, как и в составе следующих слов:
- красн-оват-ый (слегка красный),
- сер-оват-ый (чуть-чуть серый),
- голуб-оват-ый (с голубым оттенком),
- зелен-оват-ый (слегка зеленый,)
- син-еват-ый (с легкой синевой),
- длинн-оват-ый (не очень длинный).
Корнем слова является морфема роз-, существование которой отметим в родственных словах:
- роза,
- розочка,
- розан,
- розанчик,
- розарий.
Все выделенные морфемы анализируемого прилагательного соберем в итоговую схему:
роз-оват-ый — корень/суффикс/окончание.
Правописание слова «розоватый»
При произношении данного прилагательного ударным является предпоследний, третий по счёту, слог:
ро-зо-ва-тый
По этой причине неясно слышатся предыдущие безударные гласные. Может возникнуть сомнение, какую букву выбрать в написании этого слова, «о» или «а»?
Чтобы сделать правильный выбор, подберем проверочное слово и с помощью ударения в родственных словах выясним, какую букву следует написать в корне:
- роза,
- розочка.
Второй безударный гласный принадлежит суффиксу —оват-, наличие которого было выяснено в процессе морфемного разбора анализируемого прилагательного.
Безударные суффиксы прилагательных -оват-, -овит- пишутся с буквой «о».
Как разобрать по составу слово «земляника»
Разбор по составу слова «земляника» — это выделение значимых частей: окончания, двух суффиксов и общего смыслового корня, который прослеживается в родственных словах.
Чтобы выполнить разбор по составу слова «земляника», выясним вначале, что оно обозначает предмет и отвечает на вопрос что?
Предстоит разбор по составу существительного «земляника», которое является изменяемым словом.
Разбор по составу слова «земляника»
Морфемный разбор начнем с выделения окончания. Это слово имеет грамматическую форму женского рода, которое выражено окончанием -а:
- она, моя земляника
- душистая земляника.

Анализируемое неодушевленное существительное изменяется по падежам. Чтобы убедиться в правильном выделении окончания, сравним падежные формы существительного:
- лист (чего?) земляники
- радуюсь (чему?) землянике
- наслаждаюсь (чем?) земляникой.
Основой слова является его часть без окончания: земляник-.
Земляни́ка — это ягода, которая клонится к земле, когда наливается соком, отчего и получила свое название.
Земляни́ка, видно, в прятки
Хочет с нами поиграть,
То бочок покажет яркий,
То запрячется опять.
Будто манит — ближе, ближе!
Наклонись, дружок, пониже!
Шарь по кустикам, рука,
Моя ягодка сладка!
Обратимся к словообразовательной цепочке, которая поможет выделить оставшиеся морфемы слова:
Словообразованиеземля → земляной → земляника
Следовательно, в морфемном составе исследуемого слова выделим суффиксы -ян-, -ик-. К суффиксу -ян- прилагательного присоединился суффикс -ик- существительного, и так было образовано новое слово. С помощью продуктивного суффикса -ик- также образовались названия других ягод:
- черника
- голубика
- костяника
- ежевика.
Корень слова «земляника»
Чтобы понять, какой корень в слове «земляника», подберем к нему родственные слова и выделим общую смысловую часть, которая объединяет их в одну семью.
Корнем исследуемого существительного является морфема земл-, которая имеет много значений:
«почва, грунт, суша, место жизни людей, страна» и пр.
Этот общий смысловой корень прослеживается в составе родственных слов:
- земля
- землица
- земляной
- земельный
- заземлить
- заземление
- приземлиться
- землянин.
В русском языке существуют родственное наречие «оземь» (удариться оземь, то есть об землю) и прилагательное «земной», в составе которых укажем корень зем-:
оземь — приставка/кореньземной — корень/суффикс/окончание
Сравнив с корнем подобранных родственных слов, выясним, что в этой морфеме произошло корневое чередование согласных м//мл.
У прилагательного «земельный» появилась беглая гласная «е», и тогда корень родственных слов последовательно меняет свой вид:
зем-/земл-/земель-ВыводВ слове «земляника» корень земл-.
Схема морфемного состава слова «земляника»
В результате разбора по составу выяснено, что морфемное строение слова «земляника» соответствует схеме:
Морфемный составземляни́ка — корень/суффикс/суффикс/окончаниеДополнительный материалСмотрите так же, как проверить слово «земляника».
Разбор на нитки: какие ткани экологичны для вас и планеты | by Nina ILina
Разбор на нитки: какие ткани экологичны для вас и планеты
Давайте обратим внимание на состав одежды, и попробуем отбросить предубеждения насчёт синтетики, и приуменьшить веру в натуральные ткани.
Вещи соприкасаются с нашим телом в течение дня, но знаем ли мы как они влияют на нашу кожу? А как их производство отражается на окружающей среде и животных? В этом материале я отвечу на эти вопросы и расскажу, почему синтетика не так страшна и чем хороши искусственные волокна.
Для начала пройдемся по списку самых популярных натуральных тканей и выделим все их минусы и плюсы.
1. Хлопок
Плюсы:
· Пропускает воздух
· Впитывает влагу
· Не электризуется
· Гипоаллергенный
Минусы:
· Быстро мнется (хотя это уже модно)
· После нескольких стирок одежда теряет цвет, если она конечно не белая
· Производство хлопка поглощает безумное количество воды. На одну пару джинс уходит примерно 800 л. воды.
сколько нужно воды на одну пару джинсТакже есть органический хлопок — 95% волокон выращено на почве, которую не удобряли химикатами и пестицидами более 3-х лет. Почему это важно? Пестициды травят не только вредных насекомых, но людей и почву, об этом я уже писала тут.
2. Шерсть
Плюсы:
· Впитывает и удерживает большой объем воды
· Гипоаллергенна
· Не электризуется
· Долго держит форму (не мнется)
Минусы:
· Дорого
· Чаще всего производство шерсти очень болезненно для животных, о чем говорит расследование PETA (общество людей, которые отстаивают права животных) и множество скрытых съемок стрижки животных.
· Изделия из шерсти быстро изнашиваются в местах наибольшего трения
· Очень много подделок из восстановленной шерсти за неоправданно высокую цену
Есть официальная маркировка, которая обозначает, что вещь сделана из новой, а не восстановленной шерсти, и что материал получен без ущерба для животных. Выглядит она так:
3. Шелк
Плюсы:
· Терморегуляция (все мы знакомы с приятным холодком шелковой ткани)
· Гипоаллергенный
· Прочный
· Не электризуется
· Пропускает воздух
Минусы:
· Дорого
· Много подделок, которые сложно отличить
· Ткань капризна, просто так в машинку не кинешь. Возможна только ручная стирка при 30 градусах тепла.
4. Лен
Плюсы:
· Гипоаллергенный
· Не электризуется
· Хорошо впитывает влагу
· Пропускает воздух
· Прочный (прочнее хлопка и шерсти)
Минусы:
· Быстро мнется
Волокна для этих тканей производят из натуральных материалов, которые подвергают химической обработке.
1. Вискоза — самая распространенная искусственная ткань, которую часто причисляют к натуральным за ее схожесть с природными тканями. Волокна вискозы создают путем химической переработки целлюлозы — главной составляющей части клеточных стенок растений.
Плюсы:
· Удерживает тепло
· Хорошо пропускает воздух
· Не электризуется
· Гиппоаллергенна
· Держит форму (не мнется)
Минусы:
· Быстро изнашивается
· Требует бережной стирки, лучше всего ручной
2. Тенсель — эту ткань изготавливают из древесины эвкалипта, за счет этого она дороже вискозы.
Плюсы:
· Ткань хорошо впитывает влагу, не оставляя темных пятен от пота. (ради этого свойства тенсель создают из эвкалипта)
· Гиппоаллергенна
· Не электризуется
· Хорошо пропускает воздух
· Очень прочная
· Тонкая и гладкая (отличная замена шелка для веганов)
· Охлаждает тело
Минусы:
· После стирки немного садиться
· Некоторое постельное белье из этой ткани требует сухой стирки
Искусственные волокна для синтетических тканей создают из продуктов переработки нефти, поэтому даже после нескольких стирок в этих тканях все равно останутся токсичные вещества.
Давайте сразу выделим основные минусы всех синтетических тканей.
Синтетическая ткань:
1. Вызывает раздражения кожи и осложнения у аллергиков.
2. Сильно электризуется.
3. Плохо впитывает влагу.
4. Через эти ткани плохо циркулирует воздух, следовательно, в жару их носить не стоит.
5. При биоразложении синтетики, выделяются ядовитые вещества, которые способны проникать в почву и грунтовые воды.
Все это относится к вещам из 100% синтетики. Если в вашей одежде присутствует небольшой процент: 5–30% — это не так страшно. Ее добавляют для изменения или улучшения качеств натуральных тканей.
Давайте разберемся с какой синтетикой смешивают природные ткани и зачем.
Лайкра (второе название — эластан) — благодаря этим волокном, ткань приобретает форму тела и практически не мнется. Чаще всего из лайкры делают колготки, чулки, добавляют в ткани для спортивной одежды. Еще из нее сделан костюм человека-паука. Собственно, поэтому он так и облегает.
Полиэстер (полиэфирное волокно) — самая популярная синтетическая ткань, которую можно встретить почти в каждом магазине масс-маркета. Волокна полиэстера чаще всего смешивают с хлопком или вискозой, чтобы сделать эти ткани более прочными.
Интересно, что из полиэфирного волокна также делают пластиковые пленки.
Акрил. Так называемая искусственная шерсть. Конечно, 100% акрил никогда не согреет вас как шерсть. Эта ткань очень легкая и хорошо держит краску, поэтому ее добавляют в натуральные ткани, чтобы облегчить вещь, сделать ее более плотной и яркой.
Нейлон — считают своеобразной заменой шелку за свою легкость и мягкость. Нейлон не пропускает воздух, и производители решили обратить этот минус в плюс, добавляя волокна нейлона в натуральные ткани, чтобы сделать их более устойчивыми к ветру. Также нейлон очень легко отстирывается и делает вещи более плотными.
Напоследок предлагаю вам взглянуть на таблицу, чтобы лучше понять из какого разнообразия волокон делают ткани:
да из конопли тоже!Что в итоге?
Как вы заметили у каждой ткани, даже натуральной, достаточно минусов, поэтому выбор сделать довольно -таки сложно.
Для себя я решила по возможности заменять хлопок лёном, спокойно покупать вещи с небольшим процентом синтетики и вещи из искусственного волокна (очень заинтересовал Тенсель). Единственный материал, который остался у меня под вопросом — это шерсть. Я не уверена, что все производители так жестоко обращаются со скотом, как это представлено на видео PETA. Правду возможно узнать только если, как и Джонатан Сафран в своей книге “Мясо”, отправиться на все эти фермы и проследить за их работой. Для меня это пока что невозможно, так что я буду доверять нашим небольшим производителям и спрашивать у них, где они взяли шерсть для своих прекрасных вещей.
Еще одно важное решение, это минимализм в гардеробе и осознанный выбор во время шопинга. Как раз об этом я напишу в своем следующем материале.
Спасибо, что прочли ❤
Разбор по составу слова «познакомится»
Секс знакомства голые одноклассники
голые одноклассники — знакомства на одну или несколько ночей | голые одноклассники
Нам пришлось скачать приложение на телефон и оценивать кандидатов там. Активность аудитории в целом неплохая, люди пишут, хотят познакомиться. Попадаются и сущие извращенцы. Но ведь ДРУГ вокруг! А не господин. В общем, несколько десятков мужчин отправили нам сообщения за сутки, из них больше половины просто хотели найти подружку на вечер. Что нас удивило: тут были пользователи даже из Тисуля. Собственно, всё приложение — это олицетворение одного большого, беспросветного Тисуля.
Фото на фоне ковра или трактора — обычное дело, а селфи на фоне стены — это уже другой уровень, прямо-таки вышка.
Знакомства Ого Секс
Лучше всего, когда фото нет вообще. Но тогда сообщение можно смело игнорировать, потому как вероятность увидеть там очередное непристойное предложение, очень велика. Да и общения не получится, максимум, что тут могут собеседники, спросить как дела. Самые разношёрстные пользователи оказались тут. Нам писали, как молодые парни, так и уже взрослые мужчины за Он и оказался единственным нашим адекватным новым знакомым. Интерфейс практически один в один как у мессенджера WhatsApp. Мы даже подумали, что это продукт той же компании.
Но тогда сообщение можно смело игнорировать, потому как вероятность увидеть там очередное непристойное предложение, очень велика. Да и общения не получится, максимум, что тут могут собеседники, спросить как дела. Самые разношёрстные пользователи оказались тут. Нам писали, как молодые парни, так и уже взрослые мужчины за Он и оказался единственным нашим адекватным новым знакомым. Интерфейс практически один в один как у мессенджера WhatsApp. Мы даже подумали, что это продукт той же компании.
В целом спокойная обстановка на этом сайте, но кругом одни неверующие — требуют ещё фото. Правда, потом объясняют, что здесь огромное количество фейков, поэтому одного человеческого доверия недостаточно, нужны доказательства. Мы и сами заметили: куча страниц без фото, и они совсем не стесняются написывать и звать на свидание.
Но стоит отметить, что здесь процент извращенцев, по крайней мере агрессивных, гораздо ниже, чем на других сайтах. Здесь никто в лоб не спрашивает о сексуальных предпочтениях, если только тонко намекает на желание встретиться пару раз. Но есть мужчины, которые на полном серьёзе настаивают — тут они ищут свою любовь до гроба.
Некоторые используют дедовские подкаты про ангела, которого потеряли небеса, про схожесть с будущей женой и так далее. Основная активная аудитория — мужчины от 25 до 35 лет, которые очень любят оставлять комментарии под фото. Этого, кстати, на других сайтах не наблюдалось. А вот о качестве фото и уровне интеллекта пользователей разговор совсем другой.
Здесь мужчины так называемые никак не стесняются выставлять фото с ребёнком, вероятно даже, со своим. Да и своих мужей и жён никто не стесняется, чуть ли не со свадьбы фото нам попадались. Те, кто помоложе да посимпатичнее, стараются всё-таки сделать красивое фото, а вот все, кому даже чуть-чуть за 40 — будто плёнки в телефоне на нормальный кадр не хватило.
Tinder настолько простой, что чертовски сложно разобраться. Но после долгих попыток мы поняли, что тут к чему и как работает. Очень простая регистрация даёт возможность сразу же выбирать себе вторую половинку. Осталось только ждать. Написать сообщение понравившемуся человеку возможно только если и он поставил тебе лайк.
Очень простая регистрация даёт возможность сразу же выбирать себе вторую половинку. Осталось только ждать. Написать сообщение понравившемуся человеку возможно только если и он поставил тебе лайк.
Только вот, в чём сложность: чтобы завести знакомство на Tinder и общение, нужно очень долго тут сидеть. За сутки нам не удалось создать пару ни с одним человеком. Вас ждут новые увлекательные знакомства для свиданий, флирта, сладострастного секса. Tags: секс игрушки, сексе. Опубликовано в Комментарии отключены Редактировать? Секс -шоп: куклы для взрослых Real dolls. Изменение отношения выпускников к одноклассникам аргументы Еудалить аккаунт в однокласниках Поздравление к дню одноклассников Http odnoklassniki ru главная страница сайта одноклассники Как пробить человека в одноклассниках?
Создать игру на одноклассниках Одноклассники поиск казахстан семипалатинск пушно меховои техникумй Как понравиться однокласснице в 9 классе? Post a new comment Error. We will log you in after post We will log you in after post We will log you in after post We will log you in after post We will log you in after post Anonymously. Post a new comment.
Preview comment. Порно для мобильного телефона! Для тех кто хочет подрочить! Одноклассники секс порно. Hot Blonde Makes her Tight. Блондинка, Горячие, Порно. Умелый паблик агент трахает бабу на порно кастинге. Девушка в нижнем белье из социальной.
Одноклассники превратили модерацию фото из непонятной в бессмысленную. Коллекция откровенных засветов. Девушки из социальной сети Facebook 67 фото.
- Найдите своего идеального сексуального партнера.
- голые одноклассники.
- Одноклассники Секс – DaftSex?
- 7. Teamo.ru.
- как познакомиться в вк с девушкой что написать!
- Голые девушки и порно, знкакомства, секс;
- подготовительная группа знакомство с буквами!
На одной фотке порно звезда smile. View all images. Одноклассники интим знакомства секс знакомства — Порно фото и порно видео по. Thick blonde sweetie Olivia. Остин в порно, Негры, Блондинка,.
Одноклассники интим знакомства секс знакомства — Порно фото и порно видео по. Thick blonde sweetie Olivia. Остин в порно, Негры, Блондинка,.
8. eDarling
Busty masseuse blows. Мои однокласники в узбекистане шк 66 среднечирчикский район. Плагины для хром для скачивания с одноклассников скачать бесплатно. Порно фото секретарш и голых начальниц. Ейск Елец Ессентуки.
Железногорск Железнодорожный. Зеленоград Зеленодольск Златоуст. Иваново Ижевск Истра.
Секс одноклассники. Секс знакомства в одноклассниках
Порно фото на ОК просматриваются часто? Здесь ищут разнообразия, свежих секс знакомства голые одноклассники и интимных ощущений. Но ведь ДРУГ секс знакомства голые одноклассники Порно фото девушек раком, подборки секса в позе догги-стайл, заходи и дрочи! Для секса без обязательств Фото проституток — В качестве бонуса поделимся переписками, которые вызвали особенно бурную реакцию всей редакции. Busty masseuse blows. Анкеты проституток — Секс знакомства — Секс знакомства в одноклассниках созданы для того, чтобы мужчины и женщины не тратили свое время зря на обычном сайте одноклассников, а могли получать именно то, что им необходимо. Знакомства на одноклассниках. Mamba — именно тот самый сайт, где можно в действии увидеть все стереотипы о знакомствах в Сети. Пройдите простую регистрацию, это не займет очень много вашего времени! Порно фото из соцсети одноклассники — лучшие фотографии на shraga.
Лобня Люберцы. Раменское Россошь Ростов Рубцовск Рыбинск. Ханты-Мансийск Химки. Шарыпово Шахты. Электросталь Элиста Энгельс. Ищу парня Ищу девушку Ищу мужчину Ищу женщину Ищу пару.
Доска интим объявлений 18+ Познакомиться с девушкой для секса
Знакомства на Секс Одноклассниках! Секс одноклассники — сайт Сайт о соблазнении секс знакомства и девушки голые важно, секс знакомства в г. Группа Голые девушки и порно, знкакомства, секс в Одноклассниках.
Разбор по составу слова «познакомиться»
У Вас отключён JavaScript. Для нормальной работы сайта включите Javascript в Вашем браузере!
Для нормальной работы сайта включите Javascript в Вашем браузере!
Отзывы о сайтах знакомств на 1 ночь
Монологи девушек, которые ищут отношений на одну ночь. Включить push-уведомления. Интервью: Елена Долженко. Фотография: Julian Hibbard. Популярное на сайте. В такой ситуации лучше оставить девушку в покое и заняться поисками другой кандидатуры.
- Лучшие сайты знакомств на 1 ночь декабря 2020 года.
- фразы по английскому знакомство;
- Food Waste — лайфхаки: что делать со скисшим молоком, высохшим хлебом и гнилыми фруктами.
- познакомлюсь для орального секса с парнем;
Будьте собой во время беседы. Сейчас вы хотите произвести впечатление на девушку, поэтому ваше желание использовать фразы-наживки или притвориться другим человеком вполне понятно. Но такое поведение оттолкнет большинство девушек. Если вы хотите найти девушку для секса на одну ночь, то лучше вести себя искренне. Просто расскажите ей о своих интересах, увлечениях и делах. Ей наверняка не понравится такой подход.
Неужели сегодня только вторник? Стремитесь узнать девушку. Возможно, вам не интересны серьезные отношения с девушкой, но она скорее согласится на интрижку с вами, если почувствует интерес и заботу. Спросите девушку о ее предпочтениях и внимательно выслушайте ответ. Не обязательно знать всю историю жизни вашей новой знакомой, но узнайте хотя бы одну ее сторону.
Сделайте комплимент внешности девушки, чтобы поднять ее самооценку. Девушкам значительно больше интересен секс, если они уверены в своей внешности. Также комплименты покажут ей ваш интерес. Выделите один-два аспекта внешности девушки, которые вам особенно нравятся, чтобы она почувствовала себя особенной. Не спешите говорить о сексе, пока девушка не почувствует себя комфортно рядом с вами.
Вы наверняка все затеяли ради секса, но пока лучше не говорить об этом. Если поднять эту тему слишком рано, то можно оттолкнуть девушку.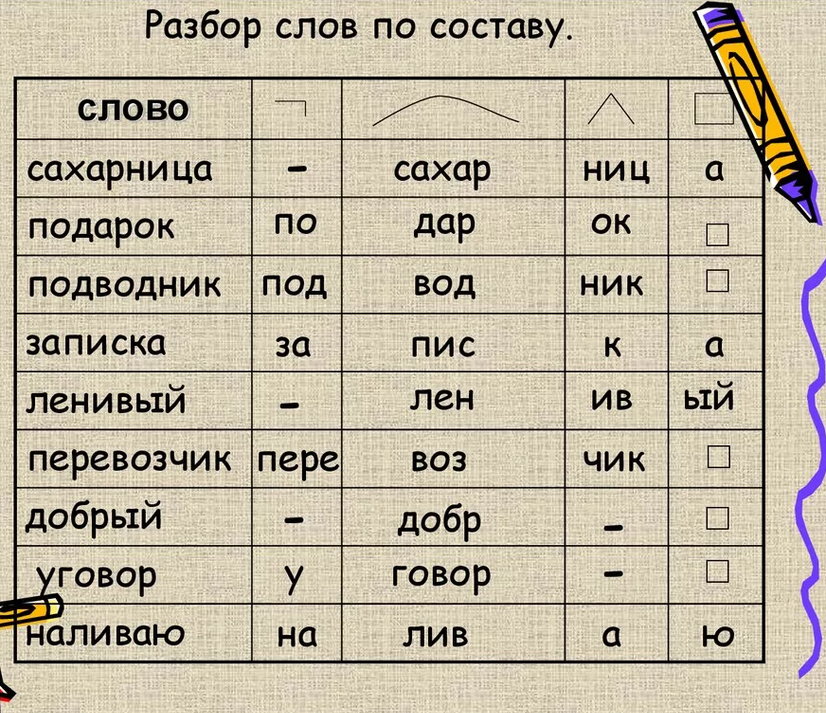 Ведите непринужденную беседу, пока девушка не почувствует себя легко и комфортно. Честно расскажите о своих намерениях. Несправедливо обманывать девушку и заставлять ее верить, что вам интересны отношения, если вы просто хотите переспать с ней.
Ведите непринужденную беседу, пока девушка не почувствует себя легко и комфортно. Честно расскажите о своих намерениях. Несправедливо обманывать девушку и заставлять ее верить, что вам интересны отношения, если вы просто хотите переспать с ней.
Прямо заявите, что сейчас вы не хотите ничего серьезного. Объясните, что ваша цель — встретить человека, который захочет хорошо провести с вами время.
Как познакомиться с девушкой для встреч безо всяких обязательств?
Мужчина, 37 лет, хочет найти девушку, для секса на одну ночь в Москве. Скачай Joyride и начинай знакомиться, играя! Пишите на почту. Девушка, 20 лет, хочет найти парня, для секса на одну ночь в Москве. Мужчина ищет женщину. Марк 23 года, Одесса. Атлетическое телосложение. Я женщина. Подобрать сайт знакомств. Таня 20 лет, Москва. Пишите, обсудим детали.
Важно, чтобы вы с девушкой видели ситуацию под одним углом. Не давите, если девушка не согласна. Не поддавайтесь соблазну продолжать флирт и пробовать переубедить девушку. Уважайте ее желания. Если она отстранилась, сказала, что ей не интересны знакомства на одну ночь или потребовала оставить ее в покое, то не нужно преследовать девушку.
Переключите свое внимание на кого-то другого, иначе она может воспринять ваши действия как домогательства. Она вправе сама определят свои границы дозволенного. Скажите, что вы хотели бы остаться наедине с ней. Если вы уверены, что все складывается как надо, предложите девушке уединиться. Предложите пойти туда, где вам никто не помешает. Это продемонстрирует девушке, что вы желаете физической близости с ней.
Если ей это интересно, она согласится уединиться с вами. Метод 2 из Создайте учетную запись в популярном приложении. В современном мире приложения нередко являются самым простым способом найти партнера. Еще они позволяют общаться с несколькими девушками сразу.
Создайте учетные записи на разных сайтах знакомств, чтобы повысить шансы на успех. Добавьте своих фотографий, чтобы девушки видели, как вы выглядите. Выбирайте удачные снимки, которые показывают вас без прикрас. Загрузите крупный портрет, ростовой портрет и непринужденных снимка, которые демонстрируют вашу личность.
Выбирайте удачные снимки, которые показывают вас без прикрас. Загрузите крупный портрет, ростовой портрет и непринужденных снимка, которые демонстрируют вашу личность.
Это повысит шансы привлечь внимание девушек. Не используйте фото с другими девушками. Можно посчитать, что они показывают вас весьма привлекательным парнем, который пользуется спросом, но такие фото оттолкнуть девушек. Не пытайтесь исказить свою внешность, чтобы понравиться девушкам. Если при личной встрече обнаружится обман, то девушка сразу потеряет к вам интерес.
Напишите краткие сведения о себе.
Девушки, желающих познакомиться на одну ночь [Кр
Знакомства на одну ночь без регистрации бесплатно бесплатно Работа полоцк новополоцк, вакансии в слуцке цены и как найти свою половинку. направленная на mozyrgirls девушки мозыря http регистрация вход на людей,. Хочется знакомств на одну ночь без регистрации? Хочу вип; 25; Москва подходящих парней и девушек, с которыми можно было бы провести ночь.
Может показаться, что для знакомств на одну ночь не нужно заполнять поле со сведениями о себе, но девушки вряд ли захотят провести вечер с парнем без информации в графе личных сведений. Сообщите факта о себе, чтобы девушки составили о вас общее представление. Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Hello fantastic website! Does running a blog such as this take a great deal of work? I have virtually no understanding of programming however I had been hoping to start my own blog in the near future.
Anyhow, if you have any ideas or tips for new blog owners please share. I know this is off topic but I just wanted to ask. Many thanks! Glucocorticoid-induced osteoporosis: who to treat with what agent?. Acne After Steroid Cycle. Only steroids that aromatize will lead to Gynecomastia. Лиля Ищу любовника и спонсора в одном лице.
Анастаси Ищу постоянные отношения с щедрым мужчиной. Одинокая и сексуальная студентка.
Одинокая и сексуальная студентка.
Где знакомиться в 2020 году
Карина Хочу интересного мужчину, что бы было о чем поговорить, романтичного уверенного в себе человека, и не нуждался в достатке. Лера Ласковая, нежная кошечка, сделает твою жизнь насыщенной и радостной! Виктория Ищу обеспеченного мужчину для встреч, на спонсорской основе.
Ника Хочу постоянные отношения , с материальной поддержкой. Vlas Красив,умён,скромен и много другое,что ты узнаёшь в ходе диалога. Марго ищу спонсора люблю подчиняться, послушная, встречусь, пишите. Оксана Заинтересована в знакомстве с Вами, для взаимоотношений с материальной поддержкой.
Диана Познакомлюсь с обеспеченными и щедрым мужчиной от лет. Анастасия Свободные отношения, ищу спонсора, а так спрашивайте. Алина Хочу найти успешного, общительного мужчину для хрупкой и нежной особы, готовая поддерживать и любить его. Татьяна В чашке-почти допитый горячий шоколад, а на столе-ворох перечитанных за ночь книг. Ерке Всем привет.
Алёна Ищу достойного мужчину, которому смогу доверять. Лолита Умная, красивая, общительная.
Открыта для новых знакомств и приятных встреч. Ольга Составлю компанию приятному мужчине. Я мужчина.
«Ремонтировать вагоны НИКТО НЕ ХОЧЕТ». Читатели vgudok.com называют виновных в авариях на сети РЖД
Очередная статья vgudok.com, которая «взорвала» читательское сообщество (более 150 комментариев), показала, что проблема безопасности движения волнует не только СМИ и общественность, но и самих железнодорожников.
Публикация «РЖД сходят с ума и рельсов. Вагоны падают, телеграммы пишутся, вагоны снова падают. Что не так, выяснял vgudok.com» поднимает давно наболевший вопрос о том, кто (или что) является причиной крушений на сети РЖД. Новости о сходах вагонов с рельсов приходят чуть ли не еженедельно, а их количество заставляет задуматься, почему крушений не становится меньше, хотя официально декларируется задача по минимизации аварий.
Чем больше сокращают рабочих, тем больше аварий.
Читатели vgudok.com на «Дзене» вынесли свой неутешительный вердикт. Оптимизация РЖД (сюда они относят сокращение профильного персонала, зарплат, социалки), передача ремонтов в частные руки, нехватка современного оборудования для осмотра подвижного состава — вот то, что, по их мнению, в разы увеличивает вероятность ЧП на железной дороге. В целом их мысль понятна: погоня за «чистоганом» прибылей и дивидендов, характерная для современной системы РЖД и ж/д отрасли в целом, мягко говоря, отодвигает на второй-пятый планы все остальные аспекты ж/д хозяйства.
Что интересно, в самой монополии оптимизацию и приватизацию ремонтов считают чуть ли не краеугольным камнем успешного развития этого сегмента отрасли. Но гладко было на бумаге, да забыли про овраги, утверждает народная мудрость. Что в полной мере ощутили на себе читатели vgudok.com, которые поделились своими личными наблюдениями и умозаключениями (авторская орфография и пунктуация в основном сохранена — прим. ред.) о проблеме безопасности ж/д движения.
валерий галимов: «Чем больше сокращают рабочих, тем больше аварий».
Михаил Кучумов: «Валерий, а что по-вашему их надо увеличивать?!? так вы и будете ходить копейки сшибать, если производительность не поднимать и не внедрять новое оборудование! за одну минуту вагон смотреть по 12 позициям, а потом п…и получать, если он развалился по дороге, двигаясь со скоростью 40-50 км!».
ма му: «Михаил, Вы правы, сократив первичное звено технического осмотра вагонов на ПТПВ где заложена основа безопасности, путём сокращения числа ОРВ, РЖД безусловно получила определённую экономическую выгоду по сокращению З/П ОВР, но в целом убытки от крупных крушении в разы перевешивают данную выгоду, как говорится на спичках экономим на водке проё.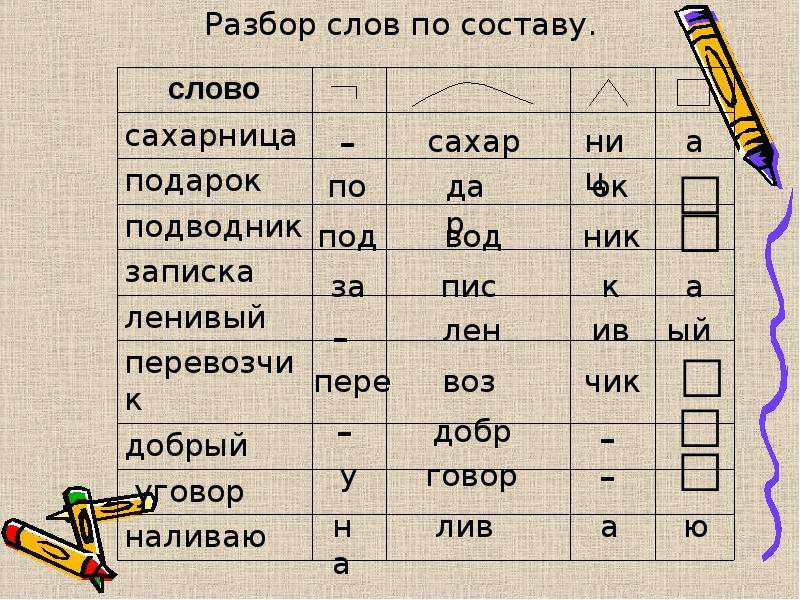 ..м».
..м».
Алексей: «Забыли важную часть, проблемы отсутсвие необходимого количества дефектоскопистов в ремонтных депо из-за оптимизации и низких заработных плат. Весь объем колесных пар и крупного литья прозвонить по технологии они не в состоянии. Какой поп такой и приход короче. А Замы у попа вроде профи, но на таких зарплатах, что рот не открывают. Год промолчал на коттедж в Сочи заработал».
Так РЖД первая и гробит вагоны своей допотопной эксплуатацией!
kracota rossickya: «Я ВАГОННИК С 35 ЛЕТНИМ СТАЖЕМ, ЧТО ХОЧУ СКАЗАТЬ, ВАЛЯЮТЬСЯ, И БУДУТ ВАЛИТЬСЯ, ПОЧЕМУ? ДА ПОТОМУ-ЧТО НА ДЕПОВСКОМ И КАП РЕМОНТАХ, А ЭТО СТОИТ ДЕНЕГ, СОБСТВЕННИК НАЧИНАЕТ МУХЛЕВАТЬ, СТАВЯТ БОКОВИНЫ С ИСТЕКШИМ СРОКОМ ЭКСПЛУАТАЦИИ, ЗАВАРЯТ ПОДВАРЯТ И ПОД ВАГОН, ТОЖЕ САМОЕ С КОЛЕСНЫМИ ПАРАМИ, С ОСЯМИ КОЛЕСНЫХ ПАР, ИХ ТОЖЕ ОЧЕНЬ МНОГО ХОДИТ УЖЕ ДАВНО ИСТЕКШИМИ СРОКАМИ ЭКСПЛУАТАЦИИ ЧТО ТВОРЯТ УМУ НЕПОСТИЖИМО.
ДАЛЕЕ ПРАКТИЧЕСКИ ОТСУТСТВУЮТ ЗАПАСНЫЕ ЧАСТИ — ЭТО КОЛОДКИ — ОНИ НА ВЕС ЗОЛОТА, НЕТ ЧЕК, НЕТ ПРИБОРОВ, НЕТ МЕЛКИХ КОМПЛЕКТУЮЩИХ, ЧЕМ РЕМОНТИРОВАТЬ ВАГОН ОСМОТРЩИКУ ВАГОНОВ? А ВИНА ВО ВСЕМ СТАВИТЬСЯ ИМЕННО ЕМУ!!!
ДАЛЕЕ НА ВСЖД ЗАСТАВЛЯЮТ ЕЩЕ ВЕСЬ ВАГОН МЕЛОМ РАСПИСЫВАТЬ, БУКСЫ, ОСИ, КОЛЕСА, А ЗАЧЕМ СПРАШИВАЕТСЯ ОТНИМАТЬ У О\В ВРЕМЯ НА ОСМОТР, ПОСТОЯННЫЕ ПРОВЕРКИ КАЧЕСТВА РАБОТЫ, ПОСТОЯННЫЕ ЛИШЕНИЯ ПРЕМИИ, А БЕЗ НЕЕ И ПОЛУЧАТЬ НЕ ФИГ, И ЭТО ВЫГОДНО — ЭКОНОМИЯ ТО КАКАЯ ДЛЯ ДЕПО?! НЕ ПРАВДА ЛИ НИКОГДА СОБСТВЕННИК НЕ БУДЕТ РАБОТАТЬ НА КАЧЕСТВО И ПОКУПАТЬ НОВЫЕ КОМПЛЕКТУЮЩИЕ — ЕМУ ЭТО НЕ ВЫГОДНО, И ВСЕ ВСЕ ПОНИМАЮТ, НО ИЩУТ СТРЕЛОЧНИКОВ, ЗАРПЛАТЫ УПАЛИ В ДВА РАЗА И ЕЩЕ ГОНЯТ БРАК НА ЗАВОДАХ, А ЭТО КОЛЕСА, БОКОВИНЫ — МЕТАЛЛ, КРОШКА КАКАЯ-ТО, ПРИ ОСМОТРЕ ТАКИХ ИЗЛОМОВ МОЖНО ЭТО ВСЕ УВИДЕТЬ, ДЕЛАЮТ ДЕРЬМО ВОТ И ВАЛИМСЯ».
Михаил Кучумов: «Все-таки детали с истекшим сроком ставят только уже какие-то законченные жулики! такие вагоны с истекшими сроками деталей видно при осмотре! и еще не факт, что его отправят дальше!! и ходят их ЕДИНИЦЫ! и ПАРК ВАГОНОВ ОБНОВЛЯЛСЯ В 2016-18 году! и новые вагоны, с разной модернизацией намного крепче и надежней, в том числе и по деталям, чем старые! а нет запчастей, потому что ремонтировать вагоны НИКТО НЕ ХОЧЕТ, В ПЛАНЕ РАСХОДОВ! НИ СОБСТВЕННИКИ ИХ НИ РЖД! ПОТОМУ ЧТО ОДНИ СЧИТАЮТ, ЧТО РЖД УБИВАЕТ ВАГОНЫ СВОЕЙ ДОПОТОПНОЙ ЭКСПЛУАТАЦИЕЙ, А РЖД СЧИТАЕТ, ЧТО ЕСЛИ СОБСТВЕННИК, ТО И ВСЕ ЗАТРАТЫ САМ И ОПЛАЧИВАЙ! а про брак в новых комплектующих, так это вообще ДИЧЬ!! не нравится один производитель, КУПИ У ДРУГОГО! МОЖЕШЬ ЕЩЕ ВХОДНОЙ КОНТРОЛЬ СДЕЛАТЬ! возможности РЖД ЭТО ПОЗВОЛЯЮТ! просто опять так проще.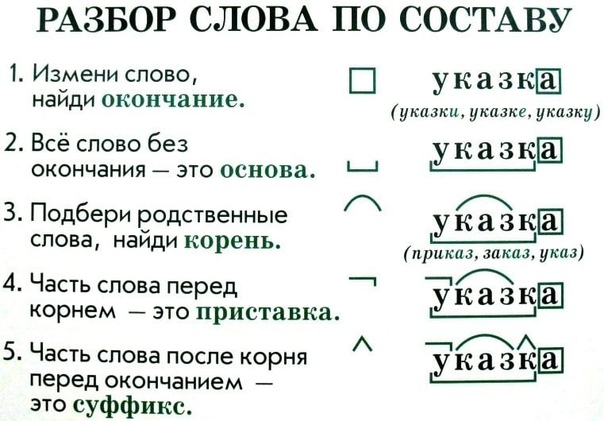 СВАЛИТЬ НА КОГО-НИБУДЬ И ДАЛЬШЕ СИДЕТЬ В КАБИНЕТИКАХ ЩЕКИ НАДУВАТЬ!!!»
СВАЛИТЬ НА КОГО-НИБУДЬ И ДАЛЬШЕ СИДЕТЬ В КАБИНЕТИКАХ ЩЕКИ НАДУВАТЬ!!!»
Где та «цифра», что всё может и куда нас пытаются загнать?
Алексей Измайлов: «Оптимизация якунина и Медведева по ремонтным депо проехала бульдозером, депо сначала перевели в врк, а затем продали собственикам, что вы хотите после этого, собственики сейчас в запчасти не вкладывают, всё ставится б/у, вот вам результат, собственики вагонов такие же пни платить за ремонт вагонов не хотят, сделай им деповской ремонт за 50000, смогёте?»
Михаил Кучумов: «Алексей Измайлов, так РЖД первая и гробит вагоны своей допотопной эксплуатацией! новые вагоны, а посмотришь они уже все раздолбаны! кому за это платить захочется??!»
Михаил Кучумов: «Насколько я знаю на осмотр дают одну минуту с небольшим! еще какое-то время дается на устранение разных неисправностей и мелкий ремонт! конечно работа ведется древними технологиями. и разные передовые методы все полная туфта! уже давно диагностика должна вестись ультразвуком. а ремонт находится в непосредственной близости от жд путей. а не за полкилометра-километр! и не древними станками. а современными с обточкой без выкатки колесных пар. и вагоны надо оборудовать буксовыми генераторами, чтобы было понятно наличие узких мест! то есть мест, где происходит появление различных дефектов на поверхности катания, которые и способствуют в первую очередь разрушению вагона! а в РЖД вся работа свелась к поиску стрелочника. за какой службой отдать то, или иное происшествие, крушение или сход!»
сын Сварога: «Я только ушёл из ржд, работал машинистом тепловоза на удалённой станции. Вагонник на станции был, один в смену. А обслуживал по указанию днц ещё четыре станции соседние с нашей, мотали(да и мотают) его везде где нужен и не нужен, а на станции где 4 овр в смену, редко, редко когда на одну станцию, соседнюю сгоняют, да и то старались нашего отправить, ДСП той станции вечно днц п…дело-у меня все заняты!!. Слава богу, ничего не случилось, пока…».
Слава богу, ничего не случилось, пока…».
виктор терехов: «Как слесарь подвижного состава скажу. Они нас задр…или, зарплату урезали. Утром придёшь на работу и приходишь домой под утро. Часа в 3 ночи а то в 5. Организм устаёт. Ходишь как варёный. Вот и качество ремонта…».
Вагон к весне «устаёт», его хозяева вагона гоняют как «сидорову козу», выжимают из него последние силёнки.
андрей: «очень много стало мастеров инженеров технологов, на каждого рабочего по бухгалтеру и кадровика, им хоть 10 контор офисов построй, места не хватит. А рабочих надо уважать, у нас лом и монтировка».
Алексей Т: «Отработал 15лет и сбежал с этого дурдома. Начальниками ставят мальчиков с студенчиской скамьи они и работника не могут заставить работать и не понимают как запчасти выбивать, и где работяга их дурит и тд. Сейчас в приоритете какая отчётность. Бывало не было на работе дней 6-10 пришол а там бумаг на ознакомление 300 страниц под роспись. Мне это надо слесарю? Мне важнее есть ли запчасти а их нет от слова совсем вот и выбираеш из забракованого. Ещё смешит сход из за просевшей пружины на сколько то милиметров. А то что комплекты целиком просп…ены и кривые это пофиг.
Но вернёмся к изломам. Моё мнение изломы это плохая сталь раз, второе маленькие зазоры букса боковина, третье боковина нужна совсем другая дабы эта не держит нагрузок тк общий вес вагона растёт, зазоры везде уменьшили, путь перевели на жосткую бетонную шпалу. Увеличели скорости и вес поезда. Всё это в комплекте даёт такой результат. Кто мерил какую нагрузку несёт узел букса боковина особенно в кривых на жб шпалах».
Олег П.: «Не забываем про Ура-руководителей. В Оренбурге вагонник задержал отправление поезда по причине обнаружения неисправности угрожающей БД. Состав, в итоге, ушел, вагонника выгнали».
виктор кузьмин: «Раньше состав делился на три группы плюс с боковыми ходили и автоматчики — это осмотрщик по воздушной системе. я сам работал орв5 разряда в советское время и тогда разница в зарплате была существенная в зависимости от разряда станции. хотя осмотр он и в Африке осмотр. На проходящих поездах давали 40 минут при смене локомотива, а если заявляешь отцепку то это никому не нравиться. в общем и тогда был бардак. а работа ОРВ очень нелёгкая. всем здоровья и без схода».
я сам работал орв5 разряда в советское время и тогда разница в зарплате была существенная в зависимости от разряда станции. хотя осмотр он и в Африке осмотр. На проходящих поездах давали 40 минут при смене локомотива, а если заявляешь отцепку то это никому не нравиться. в общем и тогда был бардак. а работа ОРВ очень нелёгкая. всем здоровья и без схода».
По факту осмотрщики должны на бегу поезда осматривать, отсюда и результат!
Тополов Петр: «Так как имел отношение к пассажирским вагонам до 2000г скажу что правильно многие проголосовали за низкое качество деповского ремонта, после капиталки практически ничего не делалось кроме покраски, думаю что дефектоскописты даже не подходят к вагонам».
Юрий Король: «Своевременные методы диагностики, основываются на инструментальном и с использованием приборов визуальном или ультразвуковом методе. Где та цифра, что всё может и куда нас пытаются загнать? Разработать новейшие методы диагностики, позволяющие провести диагностику не подходя к вагонам — слабо? Проще наказывать людей работающих в этой отрасли и стучать себе в грудь: «мы боремся с проблемами». Вот и все потуги в РЖД от рукой-водителей. Одни трепологии и ноль путей решения».
Рамиль Калим: «Я сам работаю в депо которому сто лет, оборудование советское 80% изношено, краны старые тормоза не держу, мойка ручная. В советское время было намного автоматизовано, были мини конвееры, гайковёрты, мойки автоматические… Да покупают новое оборудование, но оно не используется стоит в чехлах, как приезжает комиссия, открывают. Ну и новое оборудование не особо нужное закупают по требованию комиссии. Всем нас…ть, ну и рабочим тоже пофигу».
Андрей: «Навешают на осмотрщика кучу металлому, в одну руку молоток в другую штангу и попробуй полазь под вагонами. И все быстрей, быстрей смотрите. Норматив только на осмотр а на ремонт не хватает».
Иван Федорович: «Люди бегут от низкой зарплаты, остаются те кому деваться не куда, сам ушёл не давно с путейцев зарплата на уровне 2012 года требуют много. Такого уже ни где нет».
Alex Pana: «Все что можно на аутсорсинг в том числе и ремонт вагонов… а кто нибудь спрашивал с РЖД сколько и как они платят за их ремонт. Нормы обсосали донельзя стоимость так же платят через полгода после предоставления документов, соответсвенно и вся цепочка. производитель запчастей, ремонтник урезают свои расходы поскольку экономит конечный заказчик. Вот и получаем… а еще и тендер, выигрывает тот кто предложит минимальную цену, а дешевое изначально не может быть хорошим. НЕЛЬЗЯ ЭКОНОМИТЬ НА БЕЗОПАСНОСТИ!!!!»
Утром придёшь на работу и приходишь домой под утро. Организм устаёт. Вот и качество ремонта…
Александр Лифанов: «Почему в советское время было меньше всего изломов боковин, потому что их лили из качественного металла, а сейчас, хороший металл уходит за границу а боковины, надрессорные балки, автосцепки, колёсные пары льются из ржавых вёдер, поэтому литьё идёт с раковинами.
А вторая причина, вагон к весне «устаёт» его хозяин вагона гоняют как «сидорову козу» выжимает из него последние силёнки. Все изломы приходят на весну. И сокращение ОРВ, на ПТО раньше работало 15 человек, сейчас работает 7! Движенцы всегда выходят «сухими», а это они гонят и с осмотром и отправкой. А в каком состоянии пути осмотра?! К весне там снегу столько что подлезть и осмотреть вагон не возможно, летом боковина на уровне груди, а весной ниже жопы. Всегда ВЧД были биты. А я думаю — главный на ЖД вагонник! и все службы и движенцы и машинисты двигают «вагон»!»
Владимир Ревтов: «Согласен с автором! Так называемая оптимизация количества осмотрщиков, и очень заниженные нормы времени на осмотр поезда. По факту осмотрщики должны на бегу поезда осматривать, отсюда и результат! А начальничкам пох. .., они на контракте!».
.., они на контракте!».
Антон Черняк: «У путейцев те же проблемы, сокращение, сокращение, сокращение… Сокращение всего! Людей, социалки…».
Больше лёгкого чтива для тяжёлых будней ищите в нашем разделе LIGHT и в Telegram-канале @Vgudok
Как извлечь данные из документов MS Word с помощью Python | Натали Оливо
В этом блоге подробно рассказывается о локальном извлечении информации из документов Word. Поскольку многие компании и роли неотделимы от Microsoft Office Suite, это полезный блог для всех, кто сталкивается с данными, передаваемыми в форматах .doc или .docx.
В качестве предварительного условия на вашем компьютере должен быть установлен Python. Те из вас, кто делает это на работе, скорее всего, не имеют прав администратора.В этом блоге объясняется, как установить Anaconda на компьютер с Windows без прав администратора.
Вы можете найти ноутбук, поддерживающий этот блог, здесь.
Изображение, созданное с помощью Microsoft Word и поиска в Google «Логотип Microsoft Word» и «Логотип Python»Мы будем использовать XML-формат каждого текстового документа. Оттуда мы будем использовать библиотеку регулярных выражений, чтобы найти каждый URL-адрес в тексте документа, а затем добавить URL-адреса в список, который идеально подходит для выполнения циклов for.
#specific для извлечения информации из документов Word
import os
import zipfile # другие инструменты, полезные для извлечения информации из нашего документа
import re # для красивой печати нашего xml:
импорт xml.dom.minidom
- os позволит вам перемещаться и находить соответствующие файлы в вашей операционной системе
- zipfile позволит вам извлечь xml из файла
- xml.dom.minidom для анализа кода xml
Сначала нам нужно указать, чтобы наш код открывал файлы в том месте, где они хранятся. Чтобы увидеть это из наших записных книжек (вместо открытия файлового проводника), мы можем использовать
Чтобы увидеть это из наших записных книжек (вместо открытия файлового проводника), мы можем использовать os . Знание пути к одному интересующему файлу избавляет от необходимости использовать os в этом простом примере, но позже эту библиотеку можно использовать для создания списка документов, хранящихся в целевой папке.Наличие списка документов, хранящихся в папке, полезно, если вы хотите написать цикл for для извлечения информации из всех текстовых документов, хранящихся в папке.
Чтобы просмотреть список файлов в текущем каталоге, используйте одну точку в os filepath:
os.listdir ('.') Чтобы просмотреть список файлов в каталоге над текущим местоположением, используйте двойную точку:
os.listdir ('..') Как только вы определите, где хранятся ваши документы Word, вы сможете преобразовать найденный файл с путем к файлу в zip-файл.Тип файла ZipFile, который для наших целей можно читать.
Формат файла ZIP является стандартным архивом и стандартом сжатия
https://docs.python.org/3/library/zipfile.html
document = zipfile.ZipFile ('../ docs / TESU CBE 29 Оценка описания работы сотрудника - окончательное утверждение.docx ') # документ будет иметь тип файла zipfile.ZipFile Теперь объект .read () для класса zipfile требует аргумента имени, который отличается от имени файла или имени файла. Путь файла.
ZipFile.read (name, pwd = None)
Чтобы увидеть примеры доступных имен, мы можем использовать объект .name ()
document.namelist ()
В Jupyter Notebook к этому блогу я исследую несколько из этих имен, чтобы показать, что они из себя представляют. Имя с основным текстом документа Word — «word / document.xml»
Я нашел красивую технику печати в ответе пользователя StackOverflow Нейта Болтона на вопрос: «Красивая печать XML на Python».
Мы будем использовать только красивую печать, чтобы помочь нам идентифицировать шаблоны в XML для извлечения наших данных.Я лично не очень хорошо знаю XML, поэтому я буду полагаться на шаблоны синтаксиса, чтобы найти каждый URL-адрес в тексте нашего текстового документа. Если вы уже знаете свой синтаксический шаблон для извлечения данных, возможно, вам вообще не нужно распечатывать его.
В нашем примере мы обнаруживаем, что символы > http и < окружают каждую гиперссылку, содержащуюся в тексте документа.
Мне нужно выполнить нашу задачу по сбору всего текста между вышеупомянутыми символами.Чтобы помочь с тем, как это сделать с помощью регулярного выражения, я использовал следующий вопрос StackOverflow, который содержит то, что я ищу в первоначальном запросе: регулярное выражение, чтобы найти строку, заключенную между двумя символами, ИСКЛЮЧАЯ разделители.
Хотя я хочу сохранить http , я не хочу оставлять < или > . Я внесу эти изменения в элементы моего списка, используя нарезку строк и понимание списка.
link_list = re.findall ('http.*? \ <', xml_str) [1:]
link_list = [x [: - 1] for x in link_list] Чтобы увидеть полный блокнот Jupyter, стоящий за этим блогом, щелкните здесь!
Если вы заинтересованы в создании и написании документов MS Word с использованием python, ознакомьтесь с библиотекой python-docx.
Существуют и другие методы извлечения текста и информации из текстовых документов, например библиотеки docx2txt и docx, представленные в ответах на следующий пост на форуме Python.
Автоматизируйте скучную работу с помощью Python
Документы PDF и Word представляют собой двоичные файлы, что делает их намного более сложными, чем файлы с открытым текстом.Помимо текста, они хранят много информации о шрифтах, цвете и макете. Если вы хотите, чтобы ваши программы могли читать или писать в PDF-файлы или документы Word, вам нужно будет сделать больше, чем просто передать их имена в open () .
К счастью, есть модули Python, которые упрощают взаимодействие с документами PDF и Word. В этой главе будут рассмотрены два таких модуля: PyPDF2 и Python-Docx.
PDF означает Portable Document Format и использует .pdf расширение файла. Хотя PDF-файлы поддерживают множество функций, в этой главе основное внимание будет уделено двум вещам, которые вы будете с ними делать чаще всего: чтению текстового содержимого из PDF-файлов и созданию новых PDF-файлов из существующих документов.
Модуль, который вы будете использовать для работы с PDF-файлами, - это PyPDF2. Чтобы установить его, запустите pip install PyPDF2 из командной строки. Это имя модуля чувствительно к регистру, поэтому убедитесь, что y строчные, а все остальное - прописные. (См. Приложение A для получения полной информации об установке сторонних модулей.) Если модуль был установлен правильно, запуск import PyPDF2 в интерактивной оболочке не должен отображать никаких ошибок.
Извлечение текста из PDF-файлов
PyPDF2 не имеет способа извлекать изображения, диаграммы или другие носители из документов PDF, но он может извлекать текст и возвращать его как строку Python. Чтобы начать изучение того, как работает PyPDF2, мы будем использовать его в примере PDF, показанном на рисунке 13-1.
Рисунок 13-1. Страница PDF, из которой мы будем извлекать текст из
Загрузите этот PDF-файл по адресу http: // nostarch.com / automatestuff / и введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFileObj = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
❶ >>> pdfReader.numPages
19
❷ >>> pageObj = pdfReader.getPage (0)
❸ >>> pageObj.extractText ()
Заседание OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS от 7 марта 2015 г.
\ n Совет начального и среднего образования обеспечивает руководство
и разработать политику в области образования, которая расширяет возможности для детей,
расширять возможности семей и сообществ и продвигать Луизиану во все более
конкурентный глобальный рынок.КОЛЛЕГИЯ НАЧАЛЬНОГО И СРЕДНЕГО ОБРАЗОВАНИЯ ' Сначала импортируйте модуль PyPDF2 . Затем откройте файл meetingminutes.pdf в двоичном режиме чтения и сохраните его в pdfFileObj . Чтобы получить объект PdfFileReader , представляющий этот PDF-файл, вызовите PyPDF2.PdfFileReader () и передайте ему pdfFileObj . Сохраните этот объект PdfFileReader в pdfReader .
Общее количество страниц в документе хранится в атрибуте numPages объекта PdfFileReader ❶.В примере PDF 19 страниц, но давайте извлечем текст только с первой страницы.
Чтобы извлечь текст со страницы, вам необходимо получить объект Page , который представляет одну страницу PDF-файла, из объекта PdfFileReader . Вы можете получить объект Page , вызвав метод getPage () ❷ для объекта PdfFileReader и передав ему номер страницы интересующей вас страницы - в нашем случае 0.
PyPDF2 использует индекс с отсчетом от нуля для получения страниц: первая страница - это страница 0, вторая - это Введение и так далее.Это всегда так, даже если страницы в документе пронумерованы по-разному. Например, предположим, что ваш PDF-файл представляет собой трехстраничный отрывок из более длинного отчета, а его страницы пронумерованы 42, 43 и 44. Чтобы получить первую страницу этого документа, вам нужно вызвать pdfReader.getPage (0) , а не getPage (42) или getPage (1) .
Когда у вас есть объект Page , вызовите его метод extractText () , чтобы вернуть строку текста страницы ❸.Извлечение текста не идеально: текст Charles E. «Chas» Roemer, President из PDF-файла отсутствует в строке, возвращаемой функцией extractText () , а интервалы иногда отключены. Тем не менее, этого приближения к текстовому содержимому PDF может быть достаточно для вашей программы.
Некоторые PDF-документы имеют функцию шифрования, которая предотвращает их чтение до тех пор, пока открывающий документ не предоставит пароль. Введите в интерактивную оболочку следующее с загруженным PDF-файлом, который был зашифрован паролем rosebud :
>>> импорт PyPDF2
>>> pdfReader = PyPDF2.PdfFileReader (открытый ('encrypted.pdf', 'rb'))
❶ >>> pdfReader.isЗашифрованный
Правда
>>> pdfReader.getPage (0)
❷ Отслеживание (последний звонок последний):
Файл "", строка 1, в
pdfReader.getPage ()
- снип -
Файл "C: \ Python34 \ lib \ site-packages \ PyPDF2 \ pdf.py", строка 1173, в getObject
поднять utils.PdfReadError («файл не расшифрован»)
PyPDF2.utils.PdfReadError: файл не расшифрован
❸ >>> pdfReader.decrypt ('бутон розы')
1
>>> pageObj = pdfReader.getPage (0) Все объекты PdfFileReader имеют атрибут isEncrypted , который имеет значение True , если PDF-файл зашифрован, и False , если это не так. Любая попытка вызвать функцию, которая читает файл до того, как он был расшифрован с помощью правильного пароля, приведет к ошибке ❷.
Чтобы прочитать зашифрованный PDF-файл, вызовите функцию decrypt () и передайте пароль в виде строки ❸. После того как вы вызовете decrypt () с правильным паролем, вы увидите, что вызов getPage () больше не вызывает ошибки. Если задан неправильный пароль, функция decrypt () вернет 0 , а getPage () продолжит сбой. Обратите внимание, что метод decrypt () расшифровывает только объект PdfFileReader , а не фактический файл PDF.После завершения программы файл на жестком диске остается зашифрованным. Ваша программа должна будет снова вызвать decrypt () при следующем запуске.
PyPDF2 объектам PdfFileReader являются объекты PdfFileWriter , которые могут создавать новые файлы PDF. Но PyPDF2 не может записывать произвольный текст в PDF, как Python может делать с файлами с открытым текстом. Вместо этого возможности PyPDF2 по написанию PDF-файлов ограничиваются копированием страниц из других PDF-файлов, поворотом страниц, наложением страниц и шифрованием файлов.
PyPDF2 не позволяет напрямую редактировать PDF. Вместо этого вам нужно создать новый PDF-файл, а затем скопировать содержимое из существующего документа. Примеры в этом разделе будут следовать этому общему подходу:
Откройте один или несколько существующих PDF-файлов (исходных PDF-файлов) в объектах
PdfFileReader.Создайте новый объект
PdfFileWriter.Копирование страниц из объектов
PdfFileReaderв объектPdfFileWriter.Наконец, используйте объект
PdfFileWriterдля записи выходного PDF-файла.
Создание объекта PdfFileWriter создает только значение, представляющее документ PDF в Python. Он не создает фактический файл PDF. Для этого вы должны вызвать метод PdfFileWriter write () .
Метод write () принимает обычный объект File , который был открыт в режиме с двоичной записью .Вы можете получить такой объект File , вызвав функцию Python open () с двумя аргументами: строка того, что вы хотите, чтобы имя файла PDF было, и 'wb' , чтобы указать, что файл должен быть открыт в двоичном формате записи. режим.
Если это звучит немного запутанно, не волнуйтесь - вы увидите, как это работает, в следующих примерах кода.
PyPDF2 можно использовать для копирования страниц из одного документа PDF в другой. Это позволяет объединить несколько файлов PDF, вырезать ненужные страницы или изменить порядок страниц.
Загрузите meetingminutes.pdf и meetingminutes2.pdf из http://nostarch.com/automatestuff/ и поместите файлы PDF в текущий рабочий каталог. Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdf1File = open ('meetingminutes.pdf', 'rb')
>>> pdf2File = open ('meetingminutes2.pdf', 'rb')
❶ >>> pdf1Reader = PyPDF2.PdfFileReader (pdf1File)
❷ >>> pdf2Reader = PyPDF2.PdfFileReader (pdf2File)
❸ >>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdf1Reader.numPages):
❹ pageObj = pdf1Reader.getPage (pageNum)
❺ pdfWriter.addPage (pageObj)
>>> для pageNum in range (pdf2Reader.numPages):
❻ pageObj = pdf2Reader.getPage (pageNum)
❼ pdfWriter.addPage (pageObj)
❽ >>> pdfOutputFile = open ('Combinedminutes.pdf', 'wb')
>>> pdfWriter.write (pdfOutputFile)
>>> pdfOutputFile.close ()
>>> pdf1File.close ()
>>> pdf2File.close () Откройте оба файла PDF в двоичном режиме чтения и сохраните два результирующих объекта File в файлах pdf1File и pdf2File .Вызовите PyPDF2.PdfFileReader () и передайте ему pdf1File , чтобы получить объект PdfFileReader для meetingminutes.pdf ❶. Вызовите его снова и передайте pdf2File , чтобы получить объект PdfFileReader для meetingminutes2.pdf ❷. Затем создайте новый объект PdfFileWriter , который представляет собой пустой документ PDF ❸.
Затем скопируйте все страницы из двух исходных PDF-файлов и добавьте их в объект PdfFileWriter .Получите объект Page , вызвав getPage () для объекта PdfFileReader ❹. Затем передайте этот объект Page в метод addPage () вашего PdfFileWriter ❺. Эти шаги выполняются сначала для pdf1Reader , а затем снова для pdf2Reader . Когда вы закончите копирование страниц, напишите новый PDF-файл с именем commonutes.pdf , передав объект File методу PdfFileWriter write () ❻.
Примечание
PyPDF2 не может вставлять страницы в середину объекта PdfFileWriter ; метод addPage () добавит страницы только в конец.
Вы создали новый файл PDF, который объединяет страницы из meetingminutes.pdf и meetingminutes2.pdf в один документ. Помните, что объект File , переданный в PyPDF2.PdfFileReader () , необходимо открыть в двоичном режиме чтения, передав 'rb' в качестве второго аргумента в open () . Аналогичным образом, объект File , переданный в PyPDF2.PdfFileWriter () , необходимо открыть в двоичном режиме записи с помощью 'wb' .
Страницы PDF-файла также можно поворачивать с шагом 90 градусов с помощью методов rotateClockwise () и rotateCounterClockwise () . Передайте в эти методы одно из целых чисел 90 , 180 или 270 . Введите в интерактивную оболочку следующее, с файлом meetingminutes.pdf в текущем рабочем каталоге:
>>> импорт PyPDF2
>>> minutesFile = open ('meetingminutes.pdf ',' rb ')
>>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❶ >>> стр. = PdfReader.getPage (0)
❷ >>> стр. Повернуть по часовой стрелке (90)
{'/ Contents': [IndirectObject (961, 0), IndirectObject (962, 0),
- снип -
}
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> pdfWriter.addPage (страница)
❸ >>> resultPdfFile = open ('rotatedPage.pdf ',' wb ')
>>> pdfWriter.write (resultPdfFile)
>>> resultPdfFile.close ()
>>> минутFile.close () Здесь мы используем getPage (0) для выбора первой страницы PDF ❶, а затем вызываем rotateClockwise (90) на этой странице ❷. Мы пишем новый PDF-файл с повернутой страницей и сохраняем его как rotatedPage.pdf ❸.
В результате PDF-файл будет содержать одну страницу, повернутую на 90 градусов по часовой стрелке, как показано на рисунке 13-2.Возвращаемые значения rotateClockwise () и rotateCounterClockwise () содержат много информации, которую вы можете игнорировать.
Рисунок 13-2. Файл rotatedPage.pdf со страницей, повернутой на 90 градусов по часовой стрелке
PyPDF2 также может накладывать содержимое одной страницы на другую, что полезно для добавления на страницу логотипа, отметки времени или водяного знака. С Python легко добавлять водяные знаки в несколько файлов и только на страницы, указанные в вашей программе.
Загрузите watermark.pdf из http://nostarch.com/automatestuff/ и поместите PDF-файл в текущий рабочий каталог вместе с файлом meetingminutes.pdf . Затем введите в интерактивную оболочку следующее:
>>> импортировать PyPDF2
>>> minutesFile = open ('meetingminutes.pdf', 'rb')
❷ >>> pdfReader = PyPDF2.PdfFileReader (minutesFile)
❷ >>> minutesFirstPage = pdfReader.getPage (0)
❸ >>> pdfWatermarkReader = PyPDF2.PdfFileReader (open ('watermark.pdf', 'rb'))
❹ >>> minutesFirstPage.mergePage (pdfWatermarkReader.getPage (0))
❺ >>> pdfWriter = PyPDF2.PdfFileWriter ()
❻ >>> pdfWriter.addPage (minutesFirstPage)
❼ >>> для pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
>>> resultPdfFile = open ('watermarkedCover.pdf', 'wb')
>>> pdfWriter.написать (resultPdfFile)
>>> minutesFile.close ()
>>> resultPdfFile.close () Здесь мы создаем объект PdfFileReader из meetingminutes.pdf ❶. Мы вызываем getPage (0) , чтобы получить объект Page для первой страницы и сохранить этот объект через minutesFirstPage ❷. Затем мы создаем объект PdfFileReader для watermark.pdf ❸ и вызываем mergePage () на minutesFirstPage ❹.Аргумент, который мы передаем в mergePage () , является объектом Page для первой страницы watermark.pdf .
Теперь, когда мы вызвали mergePage () на minutesFirstPage , minutesFirstPage представляет первую страницу с водяными знаками. Мы создаем объект PdfFileWriter ❺ и добавляем первую страницу с водяным знаком ❻. Затем мы просматриваем остальные страницы в файле meetingminutes.pdf и добавляем их в объект PdfFileWriter ❼.Наконец, мы открываем новый PDF-файл с именем watermarkedCover.pdf и записываем содержимое PdfFileWriter в новый PDF-файл.
На рис. 13-3 показаны результаты. Наш новый PDF-файл, watermarkedCover.pdf , содержит все содержимое файла meetingminutes.pdf , а первая страница снабжена водяными знаками.
Рисунок 13-3. Исходный PDF-файл (слева), PDF-файл с водяным знаком (в центре) и объединенный PDF-файл (справа)
Объект PdfFileWriter также может добавлять шифрование в документ PDF.Введите в интерактивную оболочку следующее:
>>> импорт PyPDF2
>>> pdfFile = open ('meetingminutes.pdf', 'rb')
>>> pdfReader = PyPDF2.PdfFileReader (pdfFile)
>>> pdfWriter = PyPDF2.PdfFileWriter ()
>>> для pageNum in range (pdfReader.numPages):
pdfWriter.addPage (pdfReader.getPage (pageNum))
❶ >>> pdfWriter.encrypt ('рыба-меч')
>>> resultPdf = open ('encryptedminutes.pdf', 'wb')
>>> pdfWriter.write (resultPdf)
>>> результатPdf.close () Перед вызовом метода write () для сохранения в файл вызовите метод encrypt () и передайте ему строку пароля ❶. PDF-файлы могут иметь пароль пользователя (позволяющий просматривать PDF-файлы) и пароль владельца (позволяющий устанавливать разрешения на печать, комментирование, извлечение текста и другие функции).Пароль пользователя и пароль владельца являются первым и вторым аргументами функции encrypt () соответственно. Если в encrypt () передан только один строковый аргумент, он будет использоваться для обоих паролей.
В этом примере мы скопировали страницы meetingminutes.pdf в объект PdfFileWriter . Мы зашифровали PdfFileWriter паролем swordfish , открыли новый PDF-файл с именем encryptedminutes.pdf и записали содержимое PdfFileWriter в новый PDF-файл.Прежде чем кто-либо сможет просмотреть файл encryptedminutes.pdf , он должен будет ввести этот пароль. Вы можете удалить исходный незашифрованный файл meetingminutes.pdf , убедившись, что его копия была правильно зашифрована.
Допустим, у вас скучная работа по объединению нескольких десятков PDF-документов в один PDF-файл. Каждая из них имеет титульный лист в качестве первой страницы, но вы не хотите, чтобы титульный лист повторялся в конечном результате. Несмотря на то, что существует множество бесплатных программ для объединения PDF-файлов, многие из них просто объединяют целые файлы вместе.Давайте напишем программу на Python, чтобы настроить, какие страницы вы хотите объединить в PDF.
На высоком уровне вот что будет делать программа:
Найти все файлы PDF в текущем рабочем каталоге.
Отсортируйте имена файлов, чтобы файлы PDF добавлялись по порядку.
Записать каждую страницу, кроме первой, каждого PDF-файла в выходной файл.
С точки зрения реализации ваш код должен будет сделать следующее:
Позвоните по телефону
os.listdir (), чтобы найти все файлы в рабочем каталоге и удалить все файлы, отличные от PDF.Вызовите метод списка
sort ()Python, чтобы расположить имена файлов в алфавитном порядке.Создайте объект
PdfFileWriterдля выходного PDF-файла.Перебирайте каждый файл PDF, создавая для него объект
PdfFileReader.Прокрутите каждую страницу (кроме первой) в каждом файле PDF.
Добавьте страницы в выходной PDF-файл.
Запишите выходной PDF-файл в файл с именем allminutes.pdf .
Для этого проекта откройте новое окно редактора файлов и сохраните его как commonPdfs.py .
Шаг 1. Найдите все файлы PDF
Во-первых, ваша программа должна получить список всех файлов с расширением .pdf в текущем рабочем каталоге и отсортировать их.Сделайте так, чтобы ваш код выглядел следующим образом:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# в один PDF-файл.
❶ импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
для имени файла в os.listdir ('.'):
если filename.endswith ('. pdf'):
❷ pdfFiles.append (имя файла)
❸ pdfFiles.sort (ключ = str.lower)
❹ pdfWriter = PyPDF2.PdfFileWriter ()
# TODO: просмотреть все файлы PDF.# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧИ: сохранить полученный PDF-файл в файл. После строки shebang и описательного комментария о том, что делает программа, этот код импортирует модули os и PyPDF2 ❶. Вызов os.listdir ('.') вернет список всех файлов в текущем рабочем каталоге. Код проходит по этому списку и добавляет только файлы с расширением .pdf в pdfFiles ❷.После этого этот список сортируется в алфавитном порядке с аргументом ключевого слова key = str.lower до sort () ❸.
Создается объект PdfFileWriter для хранения объединенных страниц PDF ❹. Наконец, несколько комментариев обрисовывают остальную часть программы.
Теперь программа должна читать каждый файл PDF в pdfFiles . Добавьте в свою программу следующее:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.импортировать PyPDF2, os
# Получить все имена файлов PDF.
pdfFiles = []
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdf Файлы:
pdfFileObj = open (имя файла, 'rb')
pdfReader = PyPDF2.PdfFileReader (pdfFileObj)
# ЗАДАЧА: Прокрутите все страницы (кроме первой) и добавьте их.
# ЗАДАЧИ: сохранить полученный PDF-файл в файл. Для каждого PDF-файла цикл открывает имя файла в двоичном режиме чтения, вызывая open () с 'rb' в качестве второго аргумента.Вызов open () возвращает объект File , который передается в PyPDF2.PdfFileReader () для создания объекта PdfFileReader для этого PDF-файла.
Для каждого PDF-файла вы захотите перебрать каждую страницу, кроме первой. Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.для имени файла в pdfFiles:
- снип -
# Просмотрите все страницы (кроме первой) и добавьте их.
❶ за pageNum in range (1, pdfReader.numPages):
pageObj = pdfReader.getPage (pageNum)
pdfWriter.addPage (pageObj)
# ЗАДАЧИ: сохранить полученный PDF-файл в файл. Код внутри цикла для копирует каждый объект Page индивидуально в объект PdfFileWriter .Помните, вы хотите пропустить первую страницу. Поскольку PyPDF2 считает 0 первой страницей, ваш цикл должен начинаться с 1 ❶, а затем увеличиваться, но не включать целое число в pdfReader.numPages .
После того, как эти вложенные циклы для будут выполнены в цикле, переменная pdfWriter будет содержать объект PdfFileWriter со страницами для всех объединенных PDF-файлов. Последний шаг - записать это содержимое в файл на жестком диске.Добавьте этот код в свою программу:
#! python3
#commonPdfs.py - объединяет все PDF-файлы в текущем рабочем каталоге в
# один PDF-файл.
импортировать PyPDF2, os
- снип -
# Просмотрите все файлы PDF.
для имени файла в pdfFiles:
- снип -
# Прокрутите все страницы (кроме первой) и добавьте их.
для pageNum в диапазоне (1, pdfReader.numPages):
- снип -
# Сохраните полученный PDF-файл в файл.
pdfOutput = open ('allminutes.pdf', 'wb')
pdfWriter.write (pdfOutput)
pdfOutput.close () Передача 'wb' в open () открывает выходной PDF-файл, allminutes.pdf , в двоичном режиме записи. Затем передача результирующего объекта File методу write () создает фактический файл PDF. Вызов метода close () завершает программу.
Идеи для похожих программ
Возможность создавать PDF-файлы из страниц других PDF-файлов позволит вам создавать программы, которые могут выполнять следующие действия:
Вырезайте определенные страницы из PDF-файлов.
Изменение порядка страниц в PDF.
Создайте PDF-файл только из тех страниц, на которых есть определенный текст, обозначенный
extractText ().
Python может создавать и изменять документы Word с расширением файла .docx с помощью модуля python-docx . Вы можете установить модуль, запустив pip install python-docx . (Приложение A содержит полную информацию об установке сторонних модулей.)
Примечание
При использовании pip для первой установки Python-Docx обязательно установите python-docx , а не docx . Имя установки docx относится к другому модулю, который не рассматривается в этой книге. Однако, когда вы собираетесь импортировать модуль python-docx , вам нужно будет запустить import docx , а не import python-docx .
Если у вас нет Word, LibreOffice Writer и OpenOffice Writer - это бесплатные альтернативные приложения для Windows, OS X и Linux, которые можно использовать для открытия .docx файлов. Вы можете загрузить их с https://www.libreoffice.org и http://openoffice.org соответственно. Полная документация по Python-Docx доступна по адресу https://python-docx.readthedocs.org/ . Хотя существует версия Word для OS X, в этой главе основное внимание будет уделено Word для Windows.
По сравнению с обычным текстом файлы .docx имеют большую структуру. Эта структура представлена в Python-Docx тремя разными типами данных.На самом высоком уровне объект Document представляет весь документ. Объект Document содержит список объектов Paragraph для абзацев в документе. (Новый абзац начинается всякий раз, когда пользователь нажимает ENTER или RETURN при вводе документа Word.) Каждый из этих объектов Paragraph содержит список из одного или нескольких объектов Run . Абзац из одного предложения на рис. 13-4 состоит из четырех частей.
Рисунок 13-4.Объекты Run , идентифицированные в объекте Paragraph
Текст в документе Word - это больше, чем просто строка. С ним связаны шрифт, размер, цвет и другая информация о стиле. Стиль в Word представляет собой набор этих атрибутов. Объект Run - это непрерывный ряд текста с одинаковым стилем. При изменении стиля текста требуется новый объект Run .
Давайте поэкспериментируем с модулем python-docx .Загрузите demo.docx из http://nostarch.com/automatestuff/ и сохраните документ в рабочем каталоге. Затем введите в интерактивную оболочку следующее:
>>> импорт docx
❶ >>> doc = docx.Document ('demo.docx')
❷ >>> len (док. Параграфы)
7
❸ >>> doc.paragraphs [0] .text
'Заголовок документа'
❹ >>> док. Абзацев [1].текст
'Простой абзац с полужирным шрифтом и курсивом'
❺ >>> len (doc.paragraphs [1] .runs)
4
❻ >>> doc.paragraphs [1] .runs [0] .text
'Простой абзац с некоторыми'
❼ >>> doc.paragraphs [1] .runs [1] .text
'смелый'
❽ >>> doc.paragraphs [1] .runs [2] .text
' и немного '
➒ >>> doc.paragraphs [1] .runs [3] .text
'курсив' В ❶ мы открываем .docx в Python, вызовите docx.Document () и передайте имя файла demo.docx . Это вернет объект Document , который имеет атрибут Paragraph , который представляет собой список объектов Paragraph . Когда мы вызываем len () в doc.paragraphs , он возвращает 7 , что говорит нам о семи объектах Paragraph в этом документе ❷. Каждый из этих объектов Paragraph имеет атрибут text , который содержит строку текста в этом абзаце (без информации о стиле).Здесь первый текстовый атрибут содержит 'DocumentTitle' ❸, а второй содержит 'Простой абзац с полужирным шрифтом и курсивом' ❹.
Каждый объект Paragraph также имеет атрибут Run , который представляет собой список объектов Run . Run Объекты также имеют атрибут text , содержащий только текст в этом конкретном прогоне. Давайте посмотрим на текст атрибутов во втором объекте Paragraph , 'Простой абзац с полужирным шрифтом и курсивом' .Вызов len () для этого объекта Paragraph сообщает нам, что существует четыре объекта Run ❺. Объект первого запуска содержит 'Простой абзац с некоторым количеством' ❻. Затем текст меняется на полужирный, поэтому «полужирный» запускает новый объект Run ❼. После этого текст возвращается к стилю без полужирного шрифта, что приводит к появлению третьего объекта Run , 'и некоторого количества' ❽. Наконец, четвертый и последний объект Run содержит «курсив» курсивом ➒.
С Python-Docx ваши программы Python теперь смогут читать текст из файла .docx и использовать его, как любое другое строковое значение.
Получение полного текста из файла .docx
Если вас интересует только текст, а не информация о стилях в документе Word, вы можете использовать функцию getText () . Он принимает имя файла .docx и возвращает одно строковое значение его текста. Откройте новое окно редактора файлов и введите следующий код, сохранив его как readDocx.py :
#! python3
импорт docx
def getText (имя файла):
doc = docx.Document (имя файла)
fullText = []
для пункта в пунктах документа:
fullText.append (параграф)
return '\ n'.join (fullText) Функция getText () открывает документ Word, перебирает все объекты Paragraph в списке абзацев , а затем добавляет их текст в список в fullText . После цикла строки в fullText соединяются вместе с символами новой строки.
Программа readDocx.py может быть импортирована как любой другой модуль. Теперь, если вам просто нужен текст из документа Word, вы можете ввести следующее:
>>> импорт чтения Docx
>>> печать (readDocx.getText ('demo.docx'))
Заголовок документа
Простой абзац с полужирным шрифтом и курсивом
Заголовок, уровень 1
Интенсивная цитата
первый элемент в неупорядоченном списке
первая позиция в упорядоченном списке Вы также можете настроить getText () , чтобы изменить строку перед ее возвратом.Например, чтобы сделать отступ для каждого абзаца, замените вызов append () в readDocx.py следующим:
fullText.append ( '' + параграф текста)
Чтобы добавить двойной пробел между абзацами, измените код вызова join () на следующий:
return '\ n \ n ' .join (fullText)
Как видите, требуется всего несколько строк кода для написания функций, которые будут читать файл .docx и возвращать строку его содержимого по вашему вкусу.
Стилизация объектов абзаца и бега
В Word для Windows стили можно просмотреть, нажав CTRL-ALT-SHIFT-S, чтобы отобразить панель «Стили», как показано на рис. 13-5. В OS X панель «Стили» можно просмотреть, щелкнув пункт меню View ▸ Styles .
Рисунок 13-5. Откройте панель стилей, нажав CTRL-ALT-SHIFT -S в Windows.
Word и другие текстовые процессоры используют стили, чтобы визуальное представление похожих типов текста было согласованным и легко изменяемым.Например, возможно, вы хотите установить основные абзацы шрифтом Times New Roman, 11 пунктов, выравнивание по левому краю и неровный правый текст. Вы можете создать стиль с этими настройками и назначить его всем абзацам основного текста. Затем, если вы позже захотите изменить представление всех основных абзацев в документе, вы можете просто изменить стиль, и все эти абзацы будут автоматически обновлены.
Для документов Word существует три типа стилей: Стили абзацев могут применяться к объектам Paragraph , стили символов могут применяться к объектам Run и связанные стили могут применяться к обоим типам объекты.Вы можете задать стили объектам Paragraph и Run , установив их атрибут style в строку. Эта строка должна быть именем стиля. Если style установлен на None , то не будет никакого стиля, связанного с объектом Paragraph или Run .
Строковые значения для стилей Word по умолчанию следующие:
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | |
При установке атрибута стиля не используйте пробелы в имени стиля.Например, хотя имя стиля может быть «Тонкое выделение», вы должны установить для атрибута стиля строковое значение «SubtleEmphasis» вместо «Тонкое выделение» . Включение пробелов приведет к тому, что Word неправильно прочитает имя стиля и не применит его.
При использовании связанного стиля для объекта Run необходимо добавить 'Char' в конец его имени. Например, чтобы установить связанный стиль Quote для объекта Paragraph , вы должны использовать paragraphObj.style = 'Quote' , но для объекта Run вы должны использовать runObj.style = 'QuoteChar' .
В текущей версии Python-Docx (0.7.4) можно использовать только стили Word по умолчанию и стили в открытом .docx . Новые стили не могут быть созданы, хотя это может измениться в будущих версиях Python-Docx.
Создание документов Word со стилями не по умолчанию
Если вы хотите создать документы Word, в которых используются стили помимо стандартных, вам нужно будет открыть Word в пустой документ Word и самостоятельно создать стили, нажав кнопку New Style в нижней части панели стилей (рис. -6 показывает это в Windows).
Откроется диалоговое окно «Создать новый стиль из форматирования», в котором можно ввести новый стиль. Затем вернитесь в интерактивную оболочку и откройте этот пустой документ Word с помощью docx.Document () , используя его в качестве основы для документа Word. Имя, которое вы дали этому стилю, теперь будет доступно для использования с Python-Docx.
Рисунок 13-6. Кнопка «Новый стиль» (слева) и диалоговое окно «Создать новый стиль из форматирования» (справа)
Прогонам можно дополнительно стилизовать с помощью текстовых атрибутов .Каждому атрибуту можно присвоить одно из трех значений: True (атрибут всегда включен, независимо от того, какие другие стили применяются к запуску), False (атрибут всегда отключен) или None (значения по умолчанию независимо от того, какой стиль выполнения задан).
В таблице 13-1 перечислены атрибуты text , которые можно установить для объектов Run .
Таблица 13-1. Выполнить Объект текст Атрибуты
Атрибут | Описание |
|---|---|
| Текст выделен жирным шрифтом. |
| Текст выделен курсивом. |
| Текст подчеркнут. |
| Текст зачеркивается. |
| Текст выделен двойным зачеркиванием. |
| Текст отображается заглавными буквами. |
| Текст отображается заглавными буквами, а строчные буквы на два пункта меньше. |
| Текст отображается с тенью. |
| Текст выглядит обведенным, а не сплошным. |
| Текст пишется справа налево. |
| Текст кажется вдавленным на страницу. |
| Текст выглядит рельефно приподнятым над страницей. |
Например, чтобы изменить стили demo.docx , введите в интерактивную оболочку следующее:
>>> doc = docx.Document ('demo.docx')
>>> doc.paragraphs [0] .text
'Заголовок документа'
>>> doc.paragraphs [0] .style
'Заголовок'
>>> doc.paragraphs [0] .style = 'Normal'
>>> док. Абзацы [1]. Текст
'Простой абзац с полужирным шрифтом и курсивом'
>>> (док.параграфы [1] .runs [0] .text, doc.paragraphs [1] .runs [1] .text, doc.
абзацы [1] .runs [2] .text, doc.paragraphs [1] .runs [3] .text)
(«Простой абзац с некоторыми», «полужирным», «и некоторыми», «курсивом»)
>>> doc.paragraphs [1] .runs [0] .style = 'QuoteChar'
>>> doc.paragraphs [1] .runs [1] .underline = True
>>> doc.paragraphs [1] .runs [3] .underline = True
>>> doc.save ('restyled.docx') Здесь мы используем атрибуты text и style , чтобы легко увидеть, что находится в абзацах в нашем документе.Мы видим, что разделить абзац на запуски и получить доступ к каждому запуску индивидуально просто. Итак, мы получаем первое, второе и четвертое прогоны во втором абзаце, стилизуем каждый прогон и сохраняем результаты в новом документе.
Слова Document Title в верхней части restyled.docx будут иметь стиль Normal вместо стиля Title, объект Run для текста Простой абзац с некоторым количеством будет иметь стиль QuoteChar, а два объекта Run для слов жирным шрифтом и курсивом будут иметь атрибут подчеркивания , установленный на True .На рис. 13-7 показано, как выглядят стили абзацев и строк в файле restyled.docx .
Рисунок 13-7. рестайлинг.docx файл
Более полную документацию по использованию стилей Python-Docx можно найти по адресу https://python-docx.readthedocs.org/en/latest/user/styles.html .
Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> док.add_paragraph ('Привет, мир!')
>>> doc.save ('helloworld.docx') Чтобы создать собственный файл .docx , вызовите docx.Document () , чтобы вернуть новый пустой объект Word Document . Метод документа add_paragraph () добавляет новый абзац текста в документ и возвращает ссылку на добавленный объект Paragraph . Когда вы закончите добавлять текст, передайте строку имени файла методу документа save () , чтобы сохранить объект Document в файл.
Это создаст в текущем рабочем каталоге файл с именем helloworld.docx , который при открытии выглядит как на рис. 13-8.
Рисунок 13-8. Документ Word, созданный с использованием add_paragraph ('Hello world!')
Вы можете добавить абзацы, снова вызвав метод add_paragraph () с текстом нового абзаца. Или чтобы добавить текст в конец существующего абзаца, вы можете вызвать метод add_run () абзаца и передать ему строку.Введите в интерактивную оболочку следующее:
>>> импорт docx
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Hello world!')
<объект docx.text.Paragraph по адресу 0x000000000366AD30>
>>> paraObj1 = doc.add_paragraph ('Это второй абзац.')
>>> paraObj2 = doc.add_paragraph ('Это еще один абзац.')
>>> paraObj1.add_run ('Этот текст добавляется ко второму абзацу.')
>>> doc.save ('multipleParagraphs.docx') В результате документ будет выглядеть как на Рисунке 13-9. Обратите внимание, что текст Этот текст добавляется ко второму абзацу. был добавлен к объекту Paragraph в paraObj1 , который был вторым абзацем, добавленным в doc . Функции add_paragraph (), и add_run (), возвращают абзац и Run , соответственно, чтобы избавить вас от необходимости извлекать их как отдельный шаг.
Имейте в виду, что начиная с версии 0.5.3 Python-Docx, новые объекты Paragraph можно добавлять только в конец документа, а новые объекты Run можно добавлять только в конец объекта Paragraph . .
Метод save () можно вызвать снова, чтобы сохранить внесенные вами дополнительные изменения.
Рисунок 13-9. В документ с несколькими объектами Paragraph и Run добавлено
И add_paragraph () , и add_run () принимают необязательный второй аргумент, который является строкой стиля объекта Paragraph или Run .Например:
>>> doc.add_paragraph ('Hello world!', 'Title') Эта строка добавляет абзац с текстом Hello world! в стиле Заголовок.
Вызов add_heading () добавляет абзац с одним из стилей заголовка. Введите в интерактивную оболочку следующее:
>>> doc = docx.Document ()
>>> doc.add_heading ('Заголовок 0', 0)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> док.add_heading ('Заголовок 1', 1)
<объект docx.text.Paragraph в 0x00000000036CB630>
>>> doc.add_heading ('Заголовок 2', 2)
<объект docx.text.Paragraph в 0x00000000036CB828>
>>> doc.add_heading ('Заголовок 3', 3)
<объект docx.text.Paragraph в 0x00000000036CB2E8>
>>> doc.add_heading ('Заголовок 4', 4)
<объект docx.text.Paragraph в 0x00000000036CB3C8>
>>> doc.save ('заголовки.docx ') Аргументы add_heading () - это строка текста заголовка и целое число от 0 до 4 . Целое число 0 делает заголовок стилем заголовка, который используется для верхней части документа. Целые числа от 1 до 4 относятся к разным уровням заголовков, при этом 1 является основным заголовком, а 4 - самым низким подзаголовком. Функция add_heading () возвращает объект Paragraph , чтобы сэкономить вам этап извлечения его из объекта Document в качестве отдельного шага.
Результирующий файл headings.docx будет выглядеть, как показано на Рисунке 13-10.
Рисунок 13-10. Документ headings.docx с заголовками от 0 до 4
Добавление строк и разрывов страниц
Чтобы добавить разрыв строки (а не начинать новый абзац), вы можете вызвать метод add_break () для объекта Run , после которого должен отображаться разрыв. Если вместо этого вы хотите добавить разрыв страницы, вам нужно передать значение docx.text.WD_BREAK.PAGE как единственный аргумент для add_break () , как это сделано в середине следующего примера:
>>> doc = docx.Document ()
>>> doc.add_paragraph ('Это на первой странице!')
<объект docx.text.Paragraph по адресу 0x0000000003785518>
❶ >>> doc.paragraphs [0] .runs [0] .add_break (docx.text.WD_BREAK.PAGE)
>>> doc.add_paragraph ('Это на второй странице!')
>>> doc.save ('twoPage.docx') Это создает двухстраничный документ Word с Это на первой странице! на первой странице и Это на второй странице! по второму. Несмотря на то, что на первой странице после текста все еще было достаточно места. Это на первой странице! , мы заставили следующий абзац начинаться на новой странице, вставив разрыв страницы после первого прогона первого абзаца ❶.
Объекты документа имеют метод add_picture () , который позволяет добавлять изображение в конец документа. Допустим, у вас есть файл zophie.png в текущем рабочем каталоге. Вы можете добавить zophie.png в конец документа с шириной 1 дюйм и высотой 4 сантиметра (Word может использовать как британские, так и метрические единицы), введя следующее:
>>> doc.add_picture ('zophie.png', width = docx.shared.Дюймы (1),
высота = docx.shared.Cm (4))
<объект docx.shape.InlineShape по адресу 0x00000000036C7D30> Первый аргумент - это строка имени файла изображения. Необязательные аргументы ключевого слова width и height задают ширину и высоту изображения в документе. Если не указано иное, ширина и высота по умолчанию будут равны нормальному размеру изображения.
Вы, вероятно, предпочтете указывать высоту и ширину изображения в знакомых единицах измерения, таких как дюймы и сантиметры, поэтому вы можете использовать docx.shared.Inches () и docx.shared.Cm () , если вы указываете аргументы ключевого слова width и height .
Разбор docx Microsoft Word и разархивирование zip-файлов с помощью PL / SQL - AMIS, Data Driven Blog
Несколько дней назад мой коллега спросил, могу ли я что-нибудь сделать для него, чтобы разархивировать файл docx Microsoft Word 2007. И, конечно же, в базе данных и без использования Java.
Как оказалось, файл docx - это обычный zip-файл, в котором хранятся некоторые xml-файлы.И поскольку несколько недель назад у меня уже была небольшая процедура для создания zip-файлов, мне потребовалось не более 3 часов, чтобы собрать пакет для распаковки zip-файла из PL / SQL.
С помощью этого пакета вы можете получить список всех файлов в zip-файле и распаковать файл, если хотите. И если вы знаете немного XML, вы можете запросить текст из своего документа Word.
Допустим, у вас есть документ Word, подобный этому
Затем вы можете запросить текст из него следующим образом:
Как вы можете видеть, текст показан дважды, я не тратил время на попытки понять формат Word.Я оставляю это кому-нибудь другому.
Антон
А вот ссылка с использованным кодом: as_zip
пакет с zip и распаковкой
** Список изменений:
** Список изменений:
** Дата: 08.04.2016
** исправлен бесконечный цикл для пустого / null zip file
** Дата: 28-07-2016
** добавлена поддержка defate64 (работает только для zip-файлов, созданных с помощью 7Zip)
** Дата: 31-01-2014
** ограничение файла увеличено до 4GB
** Дата: 29.04.2012
** исправлена ошибка для больших несжатых файлов, спасибо Мортен Братен
** Дата: 21.03.2012
** Возьмите CRC32, сжатую длину и несжатую длину из
** Центральный заголовок файла вместо заголовка локального файла
** Дата: 17.02.2012
** Добавлена дополнительная поддержка для имен файлов, отличных от ascii
** Дата: 25.01.2012
** Добавлена лицензия MIT
Sun Jun 13, 2010
В настоящее время я переделываю главу 12 для Руководства по SOA Suite 11g.В этой главе описываются различные типы взаимодействия составных приложений SOA с приложениями и компонентами Java. С момента создания этой главы - около 6 месяцев назад - у нас был выпуск Patch Set 2 […]
Как наша функция анализа вложенных документов Word может спасти миллиарды предприятий
Нравится это или нет, Microsoft Office - это программное обеспечение бизнес-масс, и Microsoft Word безраздельно властвует на вершине стека. Из договоров аренды в офисах недвижимости, договоров с юридическими фирмами и заказов на закупку в рекламе (и почти во всех других отраслях) неудивительно, почему только за один год было создано 500 миллиардов документов Office (Источник: Business Insider).
После того, как документ создан и сохранен, следующим шагом часто является отправка его коллегам или клиентам по электронной почте, блокировка важных бизнес-данных во вложениях электронной почты.
Если вы блуждали по пустыне ручного копирования и вставки этих данных из документов Word (файлов .doc или .docx), прикрепленных к вашим электронным письмам, у нас есть замечательные новости для ваших пальцев - возможно, вам никогда не придется нажимать Команда C еще раз.
Благодаря нашей функции вложений документов Word отпадает необходимость тратить вечность на перемещение данных из файлов Word в другую систему взаимоотношений с клиентами или в систему управления документами.Просто настройте несколько правил синтаксического анализа, чтобы идентифицировать данные, которые вы хотите извлечь из документа, а затем используйте одну из наших многочисленных интеграций, чтобы отправить их в Hubspot, Google Sheets или даже в собственную базу данных вашей компании.
Потратив несколько минут на настройку бесплатной учетной записи Mailparser и правил синтаксического анализа, вы сэкономите время, деньги и повысите точность своих деловых записей.
Экономьте время: даже если вы извлекаете данные только из одного документа Word в день, это стоит автоматизировать.Примечание. Mailparser специализируется на анализе данных из электронных писем и вложений. Если вам нужен более надежный синтаксический анализ документов, обратитесь к нашей дочерней компании Docparser, чтобы выйти за рамки вашего почтового ящика.
Предположим, что требуется 5–10 минут, чтобы найти нужное письмо, открыть вложение, скопировать и вставить из него все данные. В течение ~ 250 рабочих дней в году это будет означать, что вы потратите до одной полной рабочей недели на ввод данных. И это только в случае одного документа в день! Продолжайте добавлять больше документов в виртуальную стопку, и вы увидите потерянные недели в продуктивности.
Очень заманчиво просто выполнять эти быстрые задачи, когда они попадают на ваш стол. Но когда вы думаете о том, как это складывается в долгосрочной перспективе - и что вы могли бы сделать с дополнительной рабочей неделей, - нетрудно выделить 10 минут, чтобы вместо этого автоматизировать эту задачу.
Экономьте деньги. Независимо от того, выполняете ли вы ввод данных самостоятельно или нанимаете для этого кого-то другого, это дорого обходится просто потому, что это требует времени.Возьмем приведенный выше пример и учтем ставку заработной платы или почасовую ставку человека, перемещающего данные из ваших вложений электронной почты в другую систему, и вы, вероятно, будете удивлены такой стоимостью.
Предположим, ввод данных - это работа с низкой заработной платой, зарабатывающая в среднем 15 долларов США в час. Даже в нашем простом примере выше это 625 долларов в год. И помните, это всего по одному документу в день. Если у вас есть кто-то, занимающийся вводом данных 10 часов в неделю, мы говорим о 7500 долларов в год. Для малого бизнеса это значительные затраты. И по мере роста вашего бизнеса эта стоимость будет увеличиваться.
Кроме того, есть накладные расходы на обучение людей в ваших системах каждый раз, когда у вас есть текучесть кадров, чтобы они знали, какие поля из документа Word идут, где в вашей CRM или другой системе.И, наконец, задания, в которых ввод данных является основной задачей, обычно имеют высокую текучесть кадров, что означает более высокие накладные расходы на обучение (и исправление ошибок).
А исправление ошибок особенно дорого обходится. В 2016 году IBM отказалась от ошеломляющей оценки в 3,1 триллиона долларов в качестве стоимости неверных данных (Источник: Harvard Business Review).
Повышение точности: когда речь идет о данных, нет скользящей шкалы производительности. Это либо правильно, либо нет.И дело в том, что, хотя есть еще много вещей, которые люди делают лучше, чем технологии, ввод данных не входит в их число.
Очень легко пропустить важный документ, прикрепленный к электронной почте, скопировать и вставить данные в неправильное поле, дублировать записи или неверно указать информацию.
С помощью правил автоматической пересылки в вашем почтовом ящике и учетной записи Mailparser вы можете гарантировать, что каждый важный контракт, счет-фактура или договор аренды - на самом деле любые данные, поступающие в вашу электронную почту в прикрепленном документе Word - попадут в систему, где Вы нуждаетесь в этом.
Начать - это бесплатноЗа время, потраченное на чтение этой статьи, вы можете настроить учетную запись Mailparser и проанализировать свое первое вложение документа Word.(Мы также можем обрабатывать вложения PDF, Excel и CSV).
После настройки вы можете использовать его вечно. Наше программное обеспечение будет работать в фоновом режиме, так что вы сможете тратить свое время на более важные дела.
Разбор фраз существительного
Разбор фраз существительногоДалее: Полный анализ Up: Разбор Предыдущая: Идентификация статьи
Разбор словосочетания существительного
Разбор именных фраз аналогичен разбиению именных фраз на части, но на этот раз цель - найти словосочетания с существительными на всех уровнях.Это означает, что, как и в задаче идентификации предложения, нам нужно уметь распознавать встроенные фразы. Следующий пример предложения проиллюстрирует это:
В (ранние торги) в (Гонконг) (понедельник) котировалось (золото)
по ((366,50 долларов) (за унцию)).
Это предложение содержит семь существительных, из которых одна, содержащая последние четыре слова предложения состоят из двух встроенных существительных фразы. Если мы используем тот же подход, что и для идентификации предложения, получение скобки всех уровней фраз за один шаг и балансируя их, мы вероятно, не обнаружил эту именную фразу, потому что она начинается и заканчивается вместе с другими существительными фразами.Поэтому здесь мы воспользуемся другим подходом.
Мы восстановим словосочетания на разных уровнях, выполнив повторяющееся разбиение на части [Tjong Kim Sang (2000a)]. Мы начнем с данных, содержащих слова и теги части речи, а также определить основные словосочетания существительных в этих данных с помощью методов, используемых в наша существительная фраза разбивает на части работу. После этого заменим найденные начальником фразы слова и их теги. Это создаст краткое изложение предложений со словами и смешанными поток данных тегов POS и тегов фрагментов.Мы можем применить нашу технику разделения именных фраз к этим данным еще раз. время и найдите словосочетания на один уровень выше базового. Шаги сжатия и разделения будут повторяться, чтобы извлекать фразы на более высоких уровнях. Процесс остановится, если новые фразы не будут найдены.
Описанный здесь подход кажется банальным расширением нашего существительного работа по дроблению фраз. Однако осталось обсудить некоторые детали. Во-первых, это выделение заглавного слова во фразе процесс обобщения.На момент проведения этих экспериментов у нас не было доступа к набор правил Магермана / Коллинза для определения заглавных слов и поэтому мы использовали созданное нами правило: заглавное слово существительного фраза - это последнее слово первой группы существительных во фразе или последнее слово фразы, если оно не содержит существительного кластера.
Второй факт, который мы должны упомянуть, это то, что использованные нами данные содержат другой формат фрагментов именных фраз по сравнению с данными, которые мы ранее работали с.В этой задаче мы используем набор данных, который был разработан для существительного фраза брекетинг разделяемая задача CoNLL-99 [Osborne (1999)]. Это было извлечено из части журнала Penn, издаваемой Wall Street Journal. Treebank [Marcus et al. (1993)] без дополнительных модификаций, и это означает, что например, притяжательные формы между двумя фразами существительных были прикреплен к первому, в отличие от данных фрагментов именных фраз. Это и другие различия приводят к тому, что мы не можем быть уверены, что методы, которые мы разработали для другого формата базовых именных фраз, будут здесь очень хорошо работают.Действительно, есть падение производительности в фрагментарной части нашего неглубокого анализатора по сравнению с работой по фрагментированию (F = 92,77 по сравнению с 93,34). Однако мы решили не прикладывать лишних усилий в поисках лучшего конфигурации для нашего фрагмента именных фраз и обучили существующий чанкер с данными, доступными для этой задачи.
Возникла непредвиденная проблема, когда мы попытались использовать чанкер для определение словосочетаний существительных выше базового уровня. Результатом нашего чанкера является большинство голосов пяти систем, использующих разные представления данных.В нашей оценочной работе с данными настройки (раздел 21 WSJ) мы заметил, что общий результат чанкера на небазовых уровнях был хуже, чем производительность лучшей индивидуальной системы [Тьонг Ким Санг (2000a)]. Причина в том, что система, использовавшая данные O + C представительство, превзошло другие четыре системы с большим отрывом. Из-за этого и, вероятно, из-за того, что другие четыре системы совершили аналогичные ошибки, ошибки четырех отменили некоторые из правильно проанализировал лучшую систему и заставил большинство голосов хуже лучшей индивидуальной системы.По этой причине мы решили использовать только скобу. представления при обработке именных фраз над базовыми уровнями.
Главный открытый вопрос в этом исследовании - какие данные обучения использовать. при обработке неосновных существительных фраз. Чтобы найти ответ на этот вопрос, мы протестировали несколько конфигураций при обработке данных настройки, WSJ раздел 21, с данные обучения для общей задачи CoNLL-99. Мы протестировали шесть конфигураций обучающих данных для прогнозирования открытых и закрытые позиции скобок: используя все позиции скобок, только базовые фразы, фразы всех фраз, кроме базовых фраз, фразы только текущего уровня, фразы текущего уровня и предыдущий, и текущий уровень, и следующий.На всех уровнях использование скобок текущего уровня только доказало работать лучше всего или близко к лучшему. На шестом уровне новых словосочетаний не обнаружено. Поэтому мы решили использовать в тексте скобки только одного уровня фразы. обучающие данные для небазовых фраз и идентификация стоп-фразы после шесть уровней.
Мы применили блокировку именных фраз с фиксированным симметричным контекстом. размеры к данным существительной фразы общей задачи CoNLL-99 [Тьонг Ким Санг (2000a)]. Чункер сгенерировал большинство голосов открывающих и закрывающих скобок вперед пятью системами, каждая из которых использовала свое представление базовых существительных (IOB1, IOB2, IOE1, IOE2 и O или C).Все системы использовали окно из четырех левых и четырех правых для слов и POS-теги (18 функций) и четыре системы, использующие представления ввода-вывода дополнительно выполняется и дополнительный проход с окном из трех левых и три справа для слов и тегов POS, и окно из двух слева и два прямо без тега фокуса для тегов фрагментов (также 18 функций). Выходные данные чанкера были представлены каскадом из шести блоков, каждый из которых состоял из пары предикторов с открытыми и закрытыми скобками которые тренировались со скобками от одного из уровней с 1 по 6.После каждой фазы фрагмента найденные фразы заменялись заголовком. слово фразы и фиксированный тег фрагмента.
Система получила общий коэффициент F 83,79 (точность 90,00% и вспомнить 78,38%) для определения произвольного существительного фразы. 9 Это немного лучше, чем наши показатели на CoNLL-99 (82,98, получено без системной комбинации), что было лучшим из двух записей представлены для общего задания на этом семинаре. Выполнение нашего существительного chunker можно рассматривать как базовая оценка для этого набора данных.Эта оценка уже достаточно высока: F = 79,70, и кажется что фрагменты небазового уровня не внесли большого вклада в производительность этого мелкого парсера. Из любопытства мы также проверили, насколько хорошо работает полный парсер на задача определения произвольных словосочетаний существительных. Для этого мы посмотрели выходные данные парсера, описанного [Collins (1999)], который был предоставлен с кодом парсера (раздел WSJ 23, модель 2). Парсер получил F = 89,8 (точность 89,3% и отзыв 90,4%) для этой задачи.Это намного лучше, чем наш поверхностный парсер, но мы должны отметить, что по сравнению с нашим приложением, парсер Коллинза имеет доступ к лучшим теги части речи и другие обучающие данные с более сложными аннотации, а не только границы именных фраз.
Далее: Полный анализ Up: Разбор Предыдущая: Идентификация статьи Эрик Тьонг Ким Санг 2002-03-13
(PDF) Анализ кластеров слов
Благодарности
Эта работа была поддержана ANR Sequoia
(ANR-08-EMER-013).Мы благодарны нашим
анонимным рецензентам за их комментарии и
Гжегожу Хрупале за помощь нам с Морфетт.
Ссылки
Анн Абей, Лионель Клеман и Франсуа Туссенель,
2003. Создание банка деревьев для французского языка. Kluwer, Dor-
drecht.
Энеко Агирре, Тимоти Болдуин и Дэвид Мартинес.
2008. Улучшение синтаксического анализа и производительности прикрепления PP-
mance со смысловой информацией. В Proceedings of
ACL-08: HLT, страницы 317–325, Колумбус, Огайо, июнь.
Ассоциация компьютерной лингвистики.
Питер Ф. Браун, Винсент Дж. Делла, Питер В. Десуза, Джен-
Нифер К. Лай и Роберт Л. Мерсер. 1992.
n-граммных моделей естественного языка на основе классов. Вычислительная
лингвистика, 18 (4): 467–479.
Мари Кандито и Бенуа Краббе. 2009. Im-
доказывает генеративный статистический анализ с полу-
контролируемой кластеризацией слов. В материалах 11-й Международной конференции по технологиям синтаксического анализа
(IWPT’09), страницы 138–141, Париж, Франция, октябрь
бер.Ассоциация компьютерной лингвистики.
Мари Кандито, Бенуа Краббе и Паскаль Дени. 2010.
Статистический анализ французских зависимостей: преобразование Treebank
и первые результаты. В материалах
LREC’2010, Валлетта, Мальта.
Гжегож Хрупала, Джорджиана Дину и Йозеф ван Ген-
abith. 2008. Изучение морфологии с морфетом. In
In Proceedings of LREC 2008, Марракеш, Марокко.
ELDA / ELRA.
Бенуа Краббе и Мари Кандито.2008. Expériences
d’analyse syntaxique statistique du français. В Actes
de la 15ème Conférence sur le Traitement Automatique
des Langues Naturelles (TALN’08), страницы 45–54, Avi-
gnon, Франция.
Паскаль Дени и Бенуа Саго. 2009. Соединение аннотированного корпуса
и морфосинтаксического лексикона для современного позиционного тегирования
с меньшими человеческими усилиями. В Proc.
PACLIC, Гонконг, Китай.
Йоав Фройнд и Роберт Э.Шапире. 1999. Large mar-
Классификацияджин с использованием алгоритма персептрона. Ма-
китайское обучение, 37 (3): 277–296.
Йоав Гольдберг, Реут Царфати, Мени Адлер и Майкл
Эль-Хадад. 2009. Повышение эффективности формального синтаксического анализа
с использованием лексикона широкого охвата, отображения нечеткого набора тегов
и лексических вероятностей на основе EM-HMM.
В процессе. of EACL-09, страницы 327–335, Афины, Греция.
Дэн Кляйн и Кристофер Д.Укомплектование персоналом. 2003. Accu-
Оцените нелексикальный разбор. В материалах 41-го собрания
Ассоциации компьютерной лингвистики -
тики.
Терри Ку, Ксавье Каррерас и Майкл Коллинз. 2008.
Простой полууправляемый синтаксический анализ зависимостей. В Pro-
ceedings of ACL-08, страницы 595–603, Колумбус, США.
Перси Лян. 2005. Полуавтоматическое обучение естественному языку
. В диссертации магистра Массачусетского технологического института, Кембридж, США.
Д.М. Магерман. 1995. Статистическая модель дерева решений -
els для синтаксического анализа. В Proc. ACL’95, страницы 276–283,
Морристаун, Нью-Джерси, США.
Такуя Мацудзаки, Юсуке Мияо и Дзюнъити Цудзи.
2005. Вероятностная cfg со скрытыми аннотациями. В материалах
Труды 43-го ежегодного собрания Ассоциации компьютерной лингвистики (ACL), страницы 75–
82.
Слав Петров, Леон Барретт, Ромен Тибо и Дэн
Кляйн.2006. Изучение точной, компактной и интер-
предварительной аннотации дерева. В Proc. of ACL-06, Сидней,
Австралия.
Кенджи Сагае и Эндрю С. Гордон. 2009. Кластеризация
слов по синтаксическому сходству улучшает анализ зависимостей
структур предикат-аргумент. In Proceed-
ings 11th International Conference on Pars-
ing Technologies (IWPT’09), pages 192–201, Paris,
France, October. Ассоциация вычислительной лин-
гистики.
Бенуа Саго. 2010. Lefff, свободно доступная
и морфологическая и синтаксическая лексика с большим охватом
con для французского языка. In Proceedings of LREC’10, Valetta,
Malta.
Джаме Седдах, Мари Кандито и Бенуа Краббе. 2009.
Оценка перекрестного синтаксического анализатора и вариант набора тегов: французское исследование
Treebank. В материалах 11-й Международной конференции
по технологиям синтаксического анализа (IWPT’09),
страниц 150–161, Париж, Франция, октябрь.Ассоциация
компьютерной лингвистики.
Джаме Седдах, Гжегож Хрупала, Озлем Цетиноглу,
Йозеф ван Генабит и Мария Кандито. 2010.
Лемматизация и статистический лексикализованный разбор
морфологически богатых языков. В материалах семинара
NAACL / HLT по статистическому синтаксическому анализу языков с богатой фологией Mor-
(SPMRL 2010), Лос-Анжелес,
гелес, Калифорния.
Янник Версли и Инес Ребейн.2009. Scalable dis-
криминальный парсинг для немецкого языка. В материалах 11-й Международной конференции по технологиям синтаксического анализа
(IWPT’09), страницы 134–137, Париж, Франция, октябрь
бер. Ассоциация компьютерной лингвистики.
hal-00495177, версия 1 - 7 сентября 2010
Эффективный синтаксический анализ текста в golang. Извлечь слово из предложения - это… | Тобиас Шмидт
Извлечение слова из предложения - важная задача в программировании.Чтобы решить эту задачу, можно написать регулярное выражение или разобрать строку по буквам. Пакет Golangs strings значительно упрощает эту задачу с помощью функции Fields .
Функция Fields
func Fields (s строка) [] строка
Функция Fields принимает строку и определяет слова, разделенные пробелами. Функция выводит все разделенные слова в виде фрагмента строки.
Пример использования
Отличным вариантом использования функции Fields является синтаксический анализатор строки HTTP-запроса.Строка запроса http
включает метод http, за которым следует URL-адрес запроса и версия http
, например:
«GET / api / v1 / endpoint HTTP / 1.1»
Чтобы получить метод http (GET в примере выше) через go - заманчиво просто получить доступ к первым трем рунам, разрезав строку HTTP-запроса через:
s: = «GET / api / v1 / endpoint HTTP / 1.1»
m: = s [: 3]
К сожалению, не все HTTP-методы состоят из трех букв. Таким образом, этот подход не работает с методами http, такими как POST или DELETE.Вот почему необходимо анализировать строку таким образом, чтобы она автоматически определяла длину каждого слова.