Научиться — разбор слова по составу (морфемный разбор) — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Содержание
Морфологический разбор слова «научиться»
Часть речи: Инфинитив
НАУЧИТЬСЯ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАУЧИТЬСЯ»
| Слово | Морфологические признаки |
|---|---|
| НАУЧИТЬСЯ |
|
Все формы слова НАУЧИТЬСЯ
НАУЧИТЬСЯ, НАУЧИЛСЯ, НАУЧИЛАСЬ, НАУЧИЛОСЬ, НАУЧИЛИСЬ, НАУЧУСЬ, НАУЧИМСЯ, НАУЧИШЬСЯ, НАУЧИТЕСЬ, НАУЧИТСЯ, НАУЧАТСЯ, НАУЧАСЬ, НАУЧИВШИСЬ, НАУЧИМТЕСЬ, НАУЧИСЬ, НАУЧИВШИЙСЯ, НАУЧИВШЕГОСЯ, НАУЧИВШЕМУСЯ, НАУЧИВШИМСЯ, НАУЧИВШЕМСЯ, НАУЧИВШАЯСЯ, НАУЧИВШЕЙСЯ, НАУЧИВШУЮСЯ, НАУЧИВШЕЮСЯ, НАУЧИВШЕЕСЯ, НАУЧИВШИЕСЯ, НАУЧИВШИХСЯ, НАУЧИВШИМИСЯ
Разбор слова по составу научиться
научи
ться
| Основа слова | научи |
|---|---|
| Приставка | на |
| Корень | уч |
| Суффикс | и |
| Глагольное окончание | ть |
| Постфикс | ся |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАУЧИТЬСЯ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «научиться»
1
И при этом не давать им чему-то научиться, воевать научиться
: разгрызать по одному, главное, по одному!
Каратели, Алесь Адамович, 1979г.
2
Научиться сидеть на ней верхом – все равно что научиться тому, как покорить Грузию.
Орхан, Роберт Ирвин, 1997г.
3
А если я могу научиться петь, то разве я не могу научиться и многому другому?
Баллада о Максе и Амели, Давид Сафир, 2018г.
4
Но, прежде чем научиться читать на этом языке, надо было научиться различать его буквы.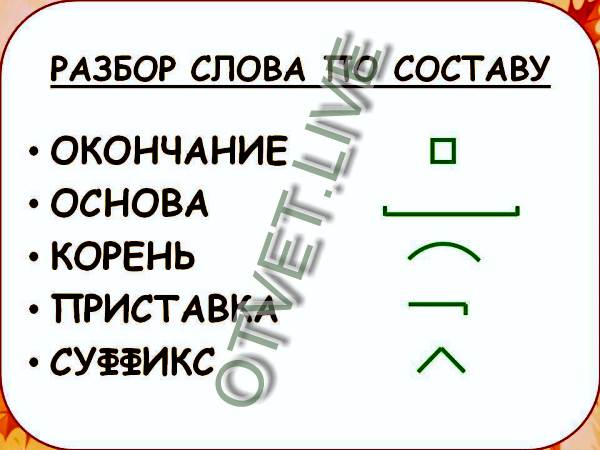
Даниэль Штайн, переводчик, Людмила Улицкая, 2006г.
5
Максимум, чего он мог достичь, – научиться галлюцинациям, а точнее – научиться управлять ими.
Пустые коридоры, Константин Шеметов, 2015г.
Найти еще примеры предложений со словом НАУЧИТЬСЯ
[PDF] Обучение распределенному словесному представлению для анализа межъязыковых зависимостей title={Распределенное обучение представлению слов для анализа межъязыковых зависимостей}, автор={Минь Сяо и Юйхун Го}, название книги={CoNLL}, год = {2014} }
- Мин Сяо, Юхун Го
- Опубликовано в CoNLL 1 июня 2014 г.
- Информатика, лингвистика
В этой статье предлагается изучить языконезависимые представления слов для решения межъязыкового синтаксического анализа зависимостей, целью которого является прогнозирование деревьев синтаксического анализа зависимостей для предложений на целевом языке путем обучения синтаксического анализатора зависимостей помеченными предложениями из исходного языка.
Сначала мы объединяем все предложения из обоих языков, чтобы вызвать распределенное представление слов с действительными значениями в рамках архитектуры глубокой нейронной сети, которая, как ожидается, будет фиксировать семантическое сходство слов, а не…
Представление в ACL
Анализ межъязыковых зависимостей на основе распределенных представлений
В этой статье представлены два алгоритма для создания межъязыковых распределенных представлений слов, которые отображают словари из двух разных языков в общее векторное пространство и устраняют разрыв в лексических признаках с помощью распределенных представлений признаков и их композиции.
Аннотационные проекции Обучение репрезентации для межсового анализа зависимости
для синтаксического анализа межъязыковых зависимостей путем создания скрытых представлений межъязыковых данных посредством завершения матрицы и проекций аннотаций на большое количество немаркированных параллельных предложений.
Основанная на распределенных представлениях структура для анализа межъязыкового переноса
В этой статье представлены два алгоритма для создания межъязыковых распределенных представлений слов, которые отображают словари из двух разных языков в общее векторное пространство и значительно превосходят современные делексикализованные модели, дополненные спроецированным кластером. функции на идентичных данных.
Целевой язык с ограниченным ограниченным языком для перекрестного анализа зависимости
It Is Supe. лингвистических знаний для целевых языков может существенно улучшить межъязыковой анализатор зависимостей на основе графа и предложить новые алгоритмы, которые адаптируют два метода, лагранжеву релаксацию и апостериорную регуляризацию, для проведения вывода с ограничениями корпусной статистики.
перекрестная передача для неконтролируемого диапазона зависимости без параллельных данных
- Long Duong, Trevor Cohn, Steven Bird, Paul Cook
Компьютерная наука, лингвистика
СМОРТИЧЕСКИЙ СОВЕРИНС.
 которые обобщают синтаксические контексты двуязычного словаря и включают их в синтаксический анализатор нейронной сети, а также демонстрируют эмпирические улучшения по сравнению с базовым делексикализованным синтаксическим анализатором в наборах данных CoNLL и Universal Dependency Treebank.
которые обобщают синтаксические контексты двуязычного словаря и включают их в синтаксический анализатор нейронной сети, а также демонстрируют эмпирические улучшения по сравнению с базовым делексикализованным синтаксическим анализатором в наборах данных CoNLL и Universal Dependency Treebank.Неконтролируемое перекрестное встроение слов с помощью многоязычных моделей нейронного языка
- Takashi Wada, Tomoharu Iwata
Компьютерная наука, Linguistic
Arxiv
- 2018 9007
- Wasi Uddin Ahmad, Zhisong Zhang, Xuezhe MA, Kai-Wei Chang, Nanyun Peng
Компьютерная наука, лингвистика
Conll
20119
- 111111111111111111118 2011 2011 2011 2011 2011 2011 2011 2011 г. 2011 года. исследует состязательное обучение для изучения контекстных кодировщиков, которые создают инвариантные представления для разных языков, чтобы облегчить межъязыковую передачу, и предлагает использовать неаннотированные предложения из вспомогательных языков, чтобы помочь в изучении языково-независимых представлений.
Неконтролируемая перекрестная адаптация адаптации диапазонов зависимости с использованием CRF AutoEncoders
- Z. Li, Kewei TU
Компьютерная наука
Результаты
- 2020
фреймворк для задачи межъязыковой адаптации парсеров зависимостей без аннотированных целевых корпусов и параллельных корпусов.
Двуязычные вложения слов на основе зависимостей без выравнивания слов
. выравнивания (BilBOWA) с использованием линейных контекстов Bag-of-words и контекстов на основе зависимостей, чтобы предоставить доказательства того, что использование функций зависимости в двуязычных встраиваниях слов имеет различный эффект, основанный на синтаксическом сходстве и сходстве структуры предложения языковой пары.
с показателем 1-10 из 46 ссылок
Sort Byrelevancemost, под влиянием PapersRecency
Селективное совместное использование для многоязычного парирования зависимости
- Tahira Naseem, R. Barzilay, A. Globersing
Computer Science, Linguiste, R. Barzilay, A. Globerson
, Computer Science, Linguiste, R. Barzilay, A. Globerson
, Computer Science, Linguiste, R. Barzilay, A. Globerson
.
Мы представляем новый алгоритм анализа многоязычных зависимостей, который использует аннотации из различных наборов исходных языков для анализа нового языка без аннотаций.
Наша мотивация – расширить…Адаптация и проекция анализатора с квази-синхронной грамматикой
- Дэвид А. Смит, Джейсон Эйснер
Компьютерная наука
EMNLP
- 2009
We Connect Two Scendaries in Structure Learning. одного корпуса в другой стиль аннотаций и проецирование синтаксических аннотаций с одного языка на другой. Мы предлагаем…
Индукция грамматики зависимостей через ограничения проекции битекста
- Кузман Ганчев, Дженнифер Гилленуотер, Б. Таскар
Информатика
ACL
- 2009
ограничивает пространство возможных целевых деревьев и оценивает подход к данным общих задач CoNLL в Болгарии и Испании и показывает, что он последовательно превосходит неконтролируемые методы и может превзойти контролируемое обучение для ограниченных обучающих данных.
Анализ межъязыковых зависимостей с использованием двуязычного лексикона
- Чжао Хай, Ян Сонг, К. Кит, Годун Чжоу
Информатика
ACL
- 2009
Межъязыковые кластеры слов для прямого переноса лингвистической структуры
Показано, что при дополнении систем прямого переноса межъязыковыми кластерными функциями относительная погрешность делексикализованных синтаксических анализаторов зависимостей, обученных на английских банках деревьев и переведенных на иностранные языки, может быть снижен до 13%.
Адаптация к целевому языку анализаторов различительного перевода
- Оскар Тэкстрем, Райан Т. Макдональд, Йоаким Нивре
Информатика
NAACL
- 2013
В этой работе показано, как последние идеи по выборочному совместному использованию параметров могут быть применены к дискриминационному синтаксическому анализатору путем тщательной декомпозиции функций его модели, а также показано, как синтаксический анализатор можно повторно лексизировать и адаптировать с помощью немаркированного целевого объекта.
языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.Передача из нескольких источников делексикализованных синтаксических анализаторов зависимостей
- Райан Т. Макдональд, Слав Петров, Кит Б. Холл
Информатика
EMNLP
- 2011
Эта работа демонстрирует, что парсеры, производящие делексикализованные парсеры, могут быть значительно выше, чем парсеры, производящие делексикализованные парсеры, могут быть напрямую переданы между языками, делексикализованными парсерами и показывает, что простые методы введения нескольких исходных языков могут значительно улучшить общее качество результирующих синтаксических анализаторов.
Общая задача CoNLL-X по анализу многоязычных зависимостей
- S. Buchholz, E. Marsi
Информатика
CoNLL
- 2006
Описано, как деревья деревьев для 13 языков были преобразованы в один и тот же общий формат зависимостей и как анализ производительности был преобразован в один и тот же общий формат зависимостей -языковой разбор.
Парсеры начальной загрузки посредством синтаксической проекции на параллельные тексты
Использование параллельного текста для решения проблемы создания синтаксических аннотаций на других языках путем аннотирования английской стороны параллельного корпуса, перенос анализа на второй язык , и обучить стохастический анализатор на полученных зашумленных аннотациях.
Кросслингвальная индукция смысловых ролей
- Иван Титов, А. Клементьев
Информатика
ACL
- 2012
В этой работе рассматривается неконтролируемая индукция семантических ролей из предложений, аннотированных автоматически прогнозируемыми представлениями синтаксической зависимости, и для этого используется современная генеративная байесовская непараметрическая модель. так.
разбор — Является ли слово «лексер» синонимом слова «парсер»?
спросил
Изменено 11 лет, 6 месяцев назад
Просмотрено 647 раз
В заголовке вопрос: Слова «лексер» и «парсер» синонимы или разные? Похоже, что в Википедии эти слова взаимозаменяемы, но английский не мой родной язык, поэтому я не уверен.
- синтаксический анализ
- язык-агностик
- лексер
- синоним
2
Лексер используется для разделения входных данных на токены, тогда как синтаксический анализатор используется для построения абстрактного синтаксического дерева из этой последовательности токенов.
Теперь вы можете просто сказать, что токены — это просто символы и напрямую использовать синтаксический анализатор, но часто бывает удобно иметь синтаксический анализатор, которому нужно только просмотреть один токен, чтобы определить, что он собирается делать дальше.
Поэтому лексер обычно используется для разделения ввода на токены до того, как его увидит синтаксический анализатор. Лексер обычно описывается с помощью простых правил регулярных выражений, которые проверяются по порядку. Существуют такие инструменты, как
lex, которые могут автоматически генерировать лексеры из такого описания.[0-9]+ Номер [A-Z]+ Идентификатор + Плюс
Анализатор, с другой стороны, обычно описывается путем указания грамматики .
Опять же, существуют инструменты, такие как yacc, которые могут генерировать синтаксические анализаторы из такого описания.выражение ::= выражение Плюс выражение | Число | ИдентификаторНет. Лексер разбивает входной поток на «слова»; парсер обнаруживает синтаксическую структуру между такими «словами». Например, при вводе:
скорость = путь/время;
вывод лексера:
скорость (идентификатор) = (оператор присваивания) путь (идентификатор) / (бинарный оператор) время (идентификатор) ; (разделитель операторов)
и тогда синтаксический анализатор может установить следующую структуру:
= (назначить) lvalue: скорость rvalue: результат / (разделение) дивиденд: содержимое переменной "путь" делитель: содержимое переменной "время"Нет. Лексер разбивает исходный текст на лексемы, тогда как синтаксический анализатор соответствующим образом интерпретирует последовательность лексем.
Они разные.
Лексер принимает поток входных символов в качестве входных данных и создает токены (также известные как «лексемы») в качестве выходных данных.
Синтаксический анализатор принимает токены (лексемы) в качестве входных данных и создает (например) абстрактное синтаксическое дерево, представляющее операторы.
Однако они достаточно похожи, поэтому многие люди (особенно те, кто никогда не писал ничего похожего на компилятор или интерпретатор) рассматривают их как одно и то же или (чаще) используют «анализатор», когда они действительно имеют в виду это «лексер».
Насколько мне известно, лексер и парсер близки по значению, но не являются точными синонимами. Хотя многие источники используют их как аналогичные, лексер (аббревиатура от лексического анализатора) идентифицирует токены, относящиеся к языку, из входных данных; в то время как синтаксические анализаторы определяют, соответствует ли поток токенов грамматике рассматриваемого языка.
. обратные языковые модели, и эти сети являются общими для всех языков, так что встраивания слов каждого языка отображаются в общее скрытое пространство, что позволяет измерять сходство слов в нескольких языках.
О трудностях межъязыкового переноса с разницей в порядке: пример разбора зависимостей
Исследование межъязыкового переноса и утверждение о том, что модель, не зависящая от порядка, будет работать лучше при переносе на далекие иностранные языки, показывает, что архитектуры на основе RNN хорошо переносятся на языки, близкие к английскому, в то время как модели с самостоятельным вниманием лучшую общую межъязыковую переносимость и особенно хорошо работают на далеких языках.
Проповедник по межзобной зависимости с нематборенными вспомогательными языками
 которые обобщают синтаксические контексты двуязычного словаря и включают их в синтаксический анализатор нейронной сети, а также демонстрируют эмпирические улучшения по сравнению с базовым делексикализованным синтаксическим анализатором в наборах данных CoNLL и Universal Dependency Treebank.
которые обобщают синтаксические контексты двуязычного словаря и включают их в синтаксический анализатор нейронной сети, а также демонстрируют эмпирические улучшения по сравнению с базовым делексикализованным синтаксическим анализатором в наборах данных CoNLL и Universal Dependency Treebank.
 Наша мотивация – расширить…
Наша мотивация – расширить… Кит, Годун Чжоу
Кит, Годун Чжоу языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.
языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.

 Опять же, существуют инструменты, такие как
Опять же, существуют инструменты, такие как 
Время, назад: 5 крутых anti-age средств — Красота
Лицо
Отдел красоты WomanHit. ru протестировал антивозрастные бьюти-новинки и бестселлеры. Теперь готовы рассказать, почему и как они работают
ru протестировал антивозрастные бьюти-новинки и бестселлеры. Теперь готовы рассказать, почему и как они работают
Юлия АмелинаОльга Бродзка
29 ноября 2022 18:55
Изучаем новинки anti-age средств
Фото: Unsplash.com
Что: сыворотка для лица и шеи MOLECULA 199
Фото: материалы пресс-служб
Основные ингредиенты: два мощнейших пептида — MATRIBUST-пептид (получен из жожоба, действует на клеточную регенерацию, восстанавливая дермо-эпидермальные соединения) и COHELISS — природный пептид, богат арабиноксиланами, полученными из очищенных семян ржи.
Как это работает:
Еще в прошлом столетии было открыто благотворное действие пептидов, чудо-молекул, которые дают сигнал формироваться коллагеновым волокнам. Сначала пептиды стали активно применять в медицине для заживления и регенерации тканей. Позже эти свойства пептидов взяли на вооружение и создатели косметики. Научные разработки сумели поставить действие этих по истине чудесных ферментов на службу нашей красоте.
Пептидная косметика марки «MOLECULE199» производится в России на основе премиальных ингредиентов, собранных по всему миру — от Бельгии до Китая и Швеции. И занимает свое почетное место в секторе «Премиум», потому что в составе содержится не менее 10% пептидных комплексов. Это необходимый минимум для того, чтобы формула работала. Также в кремах от «MOLECULE199» есть ингредиенты для защиты от УФ, что необходимо в любое время года, витамин С для придания ровного, красивого тона и масла для увлажнения.
Что: крем-филлер против глубоких морщин Deep Lines Filler Cream от Skeyndor
Фото: материалы пресс-служб
Этот крем — мировой бестселлер линии CORRECTIVE. Да и сам бренд Skeyndor достоин отдельной оды. Правительством Испании ему официально присвоен «знак качества», подтверждающий, что эта марка официально является национальным достоянием.
Основные ингредиенты: наши добрые знакомые — пептиды, здесь они представлены пептидами с пресинаптической активностью, обладающие ботулоподобным эффектом, и пептиды в постсинаптической активностью (например, «яд храмовой гадюки»). Вообще состав у этого крема такой насыщенный, что перечислять ингредиенты можно долго (всего их мы насчитали 17). Поскольку какие-то названия понятны только профессионалам, просто поверьте на слово: формула по-настоящему эффективная.
Вообще состав у этого крема такой насыщенный, что перечислять ингредиенты можно долго (всего их мы насчитали 17). Поскольку какие-то названия понятны только профессионалам, просто поверьте на слово: формула по-настоящему эффективная.
Как это работает:
Корректирующий крем-филлер сочетает две техники заполнения морщин — липофиллер и технологию «DRON» для эффективного и глубокого омоложения. Благодаря им расслабляются мимические мышцы и заполняются глубокие морщины. Крем может использоваться для продления действия инъекционных методик или как их альтернатива.
Что: сыворотка в капсулах Physio Radiance Expert от QNET
Фото: материалы пресс-служб
В дополнение к любимой многими серии Physio Radiance бренд выпустил две высокоэффективные сыворотки, которые мгновенно преображают кожу — для лица и для глаз. Средства помещены в удобные капсулы, которые удобно брать с собой в длительные поездки.
Основные ингредиенты: в составе сывороток — мощный коктейль из питательных и увлажняющих ингредиентов, пептидов, пробиотиков и пребиотиков. Из них от 95 до 99 процентов — натуральные ингредиенты без опасных консервантов и аллергенов.
Из них от 95 до 99 процентов — натуральные ингредиенты без опасных консервантов и аллергенов.
Как это работает:
Благодаря своему составу сыворотка является эффективной заменой болезненной процедуры мезотерапии, которую иногда называют «уколами красоты». Согласно клиническим исследования, Physio Radiance Expert всего за две недели уменьшает мелкие морщинки на лице и мешки под глазами, через четыре — разглаживает морщины на лбу, через два месяца делает эпидермис более увлажненным, упругим и подтянутым.
Что: Крем для коррекции морщин Active Repair от Institut Esthederm
Фото: материалы пресс-служб
Этот крем — главный герой гаммы Active Repair, созданной для кожи, которая теряет упругость. Средства восстанавливают структуру кожи, активизируют производство коллагена и эластина в дерме, запускают процесс регенерации в эпидермисе.
Основные ингредиенты: патент «Клеточная вода» (реактивирует клеточную энергию и оптимизирует функционал клеток). патент Time control system (замедляет процесс старения, оптимизируя выработку энергии клетками и усиливая антиоксидантную защиту кожи) и патент Repair technology (оказывает глубокое регенерирующее действие, восстанавливает структуру кожи и активизирует воспроизведение поддерживающих волокон коллагена и эластина).
патент Time control system (замедляет процесс старения, оптимизируя выработку энергии клетками и усиливая антиоксидантную защиту кожи) и патент Repair technology (оказывает глубокое регенерирующее действие, восстанавливает структуру кожи и активизирует воспроизведение поддерживающих волокон коллагена и эластина).
Как это работает:
В составе этого крема — сразу несколько запатентованных формул, которые и позволяют ему активно бороться с возрастными изменениями. Клетки обновляются, в результате чего морщинки буквально разглаживаются, а кожа визуально подтягивается, становится упругой и сияющей.
Что: бифазная сыворотка Neovadiol от VICHY
Фото: материалы пресс-служб
Еще в начале этого года Vichy представила реновацию гаммы NEOVADIOL. Теперь в гамме есть две линейки, которые точно отвечают потребностям женщин на разных этапах менопаузального периода:
– Для ухода за кожей в период пред-менопаузы.
– Для ухода за кожей в период менопаузы и постменопаузы.
А сейчас, под занавес года, появилась бифазная менопаузальная сыворотка, которая дополнит оба этих ухода.
Основные ингредиенты: в составе сыворотки — микс из пяти активных ингредиентов. Это — проксилан (производное ксилозы, стимулирует синтез коллагена и гиалуроновой кислоты в коже), ниацинамид (водорастворимый витамин В3 с сильными антиоксидантными, восстанавливающими и противовоспалительныеми свойствам), Омега 6—9 (восстанавливает уровень липидов, устраняет сухость кожи), гликолиевая кислота (выравнивает тон кожи, ускоряет ее обновление) и вулканическая вода Vichy (укрепляет защитный барьер кожи).
Как это работает:
Благодаря этим пяти активным ингредиентам сыворотка оказывает 5 целенаправленных действий на кожу в период пред- и постменопаузы:
– повышает упругость;
– выравнивает тон;
– сокращает морщины;
– ремоделирует контуры лица;
– питает кожу.
Подписывайтесь на наш канал в Телеграм
уход за лицом, антивозрастной уход, бьюти-обзор
Как научиться плакать по команде
Если вы ищете советы и техники, как это осуществить, актер театр и кино Семен Якубов готов поделиться профессиональными секретами
Стала известна причина смерти актрисы Наталии Стешенко
Она внезапно потеряла сознание
Молодая жена Прилучного похвасталась оголенной грудью в мокром бикини
Зепюр Брутян начала прятать живот, что спровоцировало слухи о ее беременности
Как правильно подбирать зимнюю одежду для ребенка — основные правила
Модельер Наз Маер советует, что выбрать из громадного многообразия одежды, обуви и аксессуаров для грядущих холодов
Продлить молодость кожи: зачем нам коллаген и гиалуроновая кислота
WomanHit. ru — о том, почему необходимо поддерживать и восполнять их естественное количество в коже
ru — о том, почему необходимо поддерживать и восполнять их естественное количество в коже
Восточная Швейцария: почему Пакистан — это открытие для путешественника
Эту страну редко рассматривают в качестве места для отпуска. И зря! Ведь тут есть и горы, и теплое море, а еще — древние руины и уникальная архитектура
Седокова похвасталась огромной грудью после занятий спортом
Также артистка рассказала о своем питании
Календарь ретроградного Сатурна 2023
Как мы будем жить в следующем году, рассказывает Мирелла Гасанова — ясновидящая, биоэнерготерапевт
Как провести весело новогоднюю ночь всей семьей
Актуальные советы специально для WomanHit.ru от певца и композитора Алекса Анохина
Кадры недели: Бузова вышла в свет с новым мужчиной, выздоравливающий Юдашкин появился в театре
Самые интересные события из мира шоу-бизнеса — в новом эксклюзивном видеообзоре WomanHit.ru
Золотой стандарт, кислородный коктейль и кокосовый рай: изучаем бьюти-новинки начала осени
Бьюти-отдел WomanHit. ru протестировал новые косметические коллекции и делится своими впечатлениями
ru протестировал новые косметические коллекции и делится своими впечатлениями
Кадры недели: брутальный Нагиев обнажил пресс, Киркоров поцеловался с Михеевой
Самые интересные события из мира шоу-бизнеса — в новом эксклюзивном видеообзоре WomanHit.ru
Нина Шацкая: «Кто-то не пережил моего счастья»
Певица в беседе с нашим обозревателем рассказала, насколько ей важен бытовой комфорт, почему она так любит Индию и Ахматову, что главное в общении со зрителем и способна ли она соврать для пользы дела
Как можно похудеть, если вечером приходит жрун. Советы о способах эффективного похудения от эксперта
Синдром ночного питания и способы борьбы с ним, в том числе лучшие таблетки и диеты для похудения
Обойдемся без уколов: курс на омоложение
WomanHit.ru собрал бьюти-средства, которые вполне могут заменить «инъекции красоты»
Милана Тюльпанова возмутила голой грудью в топе без нижнего белья
Поклонники считают, что звезда выбрала неуместный наряд
Большая грудь Равшаны Курковой еле уместилась в откровенном купальнике
Звезда выложила фото с пляжа
Композитные пломбы или керамические вкладки: чему отдать предпочтение
Врач-ортопед Роман Бирюков рассказывает про плюсы и минусы пломб и коронок
машин, которые изучают язык как дети | MIT News
Дети изучают язык, наблюдая за своим окружением, слушая окружающих их людей и связывая точки между тем, что они видят и слышат. Среди прочего, это помогает детям установить порядок слов в своем языке, например, где в предложении находятся подлежащие и глаголы.
Среди прочего, это помогает детям установить порядок слов в своем языке, например, где в предложении находятся подлежащие и глаголы.
В вычислительной технике изучение языка является задачей синтаксических и семантических парсеров. Эти системы обучаются на предложениях, аннотированных людьми, которые описывают структуру и значение слов. Парсеры становятся все более важными для веб-поиска, запросов к базам данных на естественном языке и систем распознавания голоса, таких как Alexa и Siri. Вскоре их также можно будет использовать для домашней робототехники.
Но сбор данных аннотаций может занять много времени и быть сложным для менее распространенных языков. Кроме того, люди не всегда согласны с аннотациями, а сами аннотации могут не точно отражать то, как люди говорят естественно.
В статье, представленной на конференции «Эмпирические методы обработки естественного языка» на этой неделе, исследователи Массачусетского технологического института описывают синтаксический анализатор, который учится посредством наблюдения, чтобы более точно имитировать процесс овладения языком ребенком, что может значительно расширить возможности синтаксического анализатора. Чтобы изучить структуру языка, синтаксический анализатор наблюдает видео с субтитрами без какой-либо другой информации и связывает слова с записанными объектами и действиями. Получив новое предложение, синтаксический анализатор может затем использовать то, что он узнал о структуре языка, чтобы точно предсказать значение предложения без видео.
Чтобы изучить структуру языка, синтаксический анализатор наблюдает видео с субтитрами без какой-либо другой информации и связывает слова с записанными объектами и действиями. Получив новое предложение, синтаксический анализатор может затем использовать то, что он узнал о структуре языка, чтобы точно предсказать значение предложения без видео.
Этот «слабо контролируемый» подход — то есть он требует ограниченных данных для обучения — имитирует то, как дети могут наблюдать за окружающим миром и изучать язык, без предоставления прямого контекста. По словам исследователей, этот подход может расширить типы данных и сократить усилия, необходимые для обучения парсеров. Например, несколько предложений с прямыми аннотациями можно объединить с большим количеством видео с субтитрами, которые легче найти, чтобы повысить производительность.
В будущем синтаксический анализатор можно будет использовать для улучшения естественного взаимодействия между людьми и личными роботами. Например, робот, оснащенный синтаксическим анализатором, может постоянно наблюдать за окружающей средой, чтобы лучше понимать произнесенные команды, в том числе когда произносимые предложения не полностью грамматически правильны или ясны. «Люди разговаривают друг с другом неполными предложениями, обтекаемыми мыслями и путаной речью. Вы хотите, чтобы в вашем доме был робот, который адаптируется к их особой манере говорить… и при этом понимать, что они имеют в виду», — говорит соавтор Андрей Барбу, научный сотрудник Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) и Центра Мозги, разум и машины (CBMM) в Институте Макговерна Массачусетского технологического института.
«Люди разговаривают друг с другом неполными предложениями, обтекаемыми мыслями и путаной речью. Вы хотите, чтобы в вашем доме был робот, который адаптируется к их особой манере говорить… и при этом понимать, что они имеют в виду», — говорит соавтор Андрей Барбу, научный сотрудник Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) и Центра Мозги, разум и машины (CBMM) в Институте Макговерна Массачусетского технологического института.
Синтаксический анализатор также может помочь исследователям лучше понять, как маленькие дети изучают язык. «Ребенок имеет доступ к избыточной, дополнительной информации из разных модальностей, включая слух родителей, братьев и сестер, говорящих о мире, а также к тактильной и визуальной информации, [которые помогают ему или ей] понять мир», — говорит соавтор. Борис Кац, главный научный сотрудник и руководитель группы InfoLab в CSAIL. «Это удивительная головоломка — обрабатывать все эти одновременные сенсорные данные. Эта работа является частью более крупной работы, направленной на то, чтобы понять, как такое обучение происходит в мире».
Соавторами статьи являются: первый автор Кэндис Росс, аспирант кафедры электротехники и компьютерных наук и CSAIL, исследователь CBMM; Евгений Берзак PhD ’17, постдоктор в группе вычислительной психолингвистики в отделе мозга и когнитивных наук; и аспирант CSAIL Баттушиг Мьянганбаяр.
Визуальный ученик
Для своей работы исследователи объединили семантический парсер с компонентом компьютерного зрения, обученным распознаванию объектов, людей и действий в видео. Семантические синтаксические анализаторы обычно обучаются на предложениях, аннотированных кодом, который приписывает значение каждому слову и связи между словами. Некоторые обучались на неподвижных изображениях или компьютерных симуляциях.
Росс говорит, что новый синтаксический анализатор впервые обучается с использованием видео. Отчасти видео более полезно для уменьшения двусмысленности. Если синтаксический анализатор не уверен, скажем, в действии или объекте в предложении, он может обратиться к видео, чтобы прояснить ситуацию. «Есть временные компоненты — объекты, взаимодействующие друг с другом и с людьми — и свойства высокого уровня, которые вы не увидите в неподвижном изображении или просто в языке», — говорит Росс.
«Есть временные компоненты — объекты, взаимодействующие друг с другом и с людьми — и свойства высокого уровня, которые вы не увидите в неподвижном изображении или просто в языке», — говорит Росс.
Исследователи собрали набор данных из примерно 400 видеороликов, на которых изображены люди, выполняющие ряд действий, в том числе поднимающие или опускающие предмет и идущие к нему. Затем участники краудсорсинговой платформы Mechanical Turk предоставили 1200 подписей к этим видео. Они выделили 840 примеров видеотитров для обучения и настройки и использовали 360 для тестирования. Одним из преимуществ использования синтаксического анализа на основе зрения является то, что «вам не нужно почти столько же данных, хотя, если бы у вас были [данные], вы могли бы масштабироваться до огромных наборов данных», — говорит Барбу.
Во время обучения исследователи поставили парсеру задачу определить, точно ли предложение описывает данное видео. Они скормили парсеру видео и соответствующий заголовок. Анализатор извлекает возможные значения подписи в виде логических математических выражений. Предложение «Женщина собирает яблоко», например, может быть выражено как: λxy. женщина x, пикап x y , яблоко y .
Анализатор извлекает возможные значения подписи в виде логических математических выражений. Предложение «Женщина собирает яблоко», например, может быть выражено как: λxy. женщина x, пикап x y , яблоко y .
Эти выражения и видео вводятся в алгоритм компьютерного зрения, называемый «Отслеживание предложений», разработанный Барбу и другими исследователями. Алгоритм просматривает каждый видеокадр, чтобы отслеживать, как объекты и люди трансформируются с течением времени, чтобы определить, воспроизводятся ли действия, как описано. Таким образом, он определяет, возможно ли значение видео.
Соединение точек
Выражение с наиболее близкими представлениями для объектов, людей и действий становится наиболее вероятным значением подписи. Первоначально выражение может относиться ко многим различным объектам и действиям в видео, но набор возможных значений служит обучающим сигналом, который помогает синтаксическому анализатору постоянно отсеивать возможности. «Предполагая, что все предложения должны следовать одним и тем же правилам, что все они взяты из одного и того же языка, и просматривая множество видео с субтитрами, вы можете еще больше сузить значения», — говорит Барбу.
«Предполагая, что все предложения должны следовать одним и тем же правилам, что все они взяты из одного и того же языка, и просматривая множество видео с субтитрами, вы можете еще больше сузить значения», — говорит Барбу.
Короче говоря, синтаксический анализатор учится посредством пассивного наблюдения: чтобы определить, верна ли подпись к видео, синтаксический анализатор по необходимости должен идентифицировать наиболее вероятное значение заголовка. «Единственный способ выяснить, является ли предложение верным для видео, [это] пройти через этот промежуточный этап: «Что означает предложение?» В противном случае вы понятия не имеете, как их связать», — объясняет Барбу. «Мы не придаем системе значение предложения. Мы говорим: «Есть предложение и видео. Предложение должно быть верным для видео. Придумайте какое-нибудь промежуточное представление, которое сделает его верным для видео»9.0003
В ходе обучения вырабатывается синтаксическая и семантическая грамматика для выученных слов. Получив новое предложение, синтаксический анализатор больше не требует видео, а использует свою грамматику и лексику для определения структуры и значения предложения.
Получив новое предложение, синтаксический анализатор больше не требует видео, а использует свою грамматику и лексику для определения структуры и значения предложения.
В конечном счете, этот процесс представляет собой обучение «как если бы вы были ребенком», — говорит Барбу. «Вы видите мир вокруг себя и слышите, как люди говорят, чтобы понять смысл. Однажды я могу дать вам предложение и спросить, что оно означает, и даже без наглядного изображения вы поймете его значение».
«Это исследование является правильным направлением для обработки естественного языка», — говорит Стефани Теллекс, профессор компьютерных наук в Университете Брауна, которая помогает роботам использовать естественный язык для общения с людьми. «Чтобы интерпретировать обоснованный язык, нам нужны семантические представления, но практически невозможно сделать их доступными во время обучения. Вместо этого эта работа фиксирует представления композиционной структуры, используя контекст из видео с субтитрами. Вот газета, которую я ждал!»
Вот газета, которую я ждал!»
В будущей работе исследователи заинтересованы в моделировании взаимодействий, а не только в пассивных наблюдениях. «Дети взаимодействуют с окружающей средой во время обучения. Наша идея состоит в том, чтобы создать модель, которая также будет использовать восприятие для обучения», — говорит Росс.
Эта работа была частично поддержана CBMM, Национальным научным фондом, стипендией для выпускников Фонда Форда, Исследовательским институтом Toyota и проектом MIT-IBM Brain-Inspired Multimedia Comprehension.
Фрагментирование в НЛП: расшифровано. Когда я начал изучать обработку текста… | by Nikita Bachani
Какую роль он играет в обработке текста
Когда я начал изучать обработку текста, единственной темой, на которой я долго застревал, было создание фрагментов. (Я знаю, в это странно верить🙆) Обычно мы можем найти в Интернете много статей от простых до сложных тем, но когда дело доходит до этой конкретной темы, я чувствовал, что нет ни одной статьи, которая дает общее представление о фрагментации, однако ниже часть Написание представляет собой объединение всех статей или видео, которые я изучил до сих пор, связанных с темой.
Итак, вот как я понимаю фрагментацию.
Разбиение на фрагменты — это процесс извлечения фраз из неструктурированного текста, что означает анализ предложения для выявления составляющих (групп существительных, глаголов, групп глаголов и т. д.). Однако он не определяет ни их внутреннюю структуру, ни их роль в основном приговор.
Работает поверх тегов POS. Он использует POS-теги в качестве входных данных и предоставляет фрагменты в качестве выходных данных.
Короче говоря, фрагментация означает группировку слов/токенов в фрагменты
Раньше я думал, что обычно обработка текста выполняется путем простого разбиения предложения на слова, прежде чем я познакомился с такими темами. так что простое разбиение на слова не очень полезно. Очень важно знать, что в предложении есть человек, дата, места и т. д. (разные сущности). так что одни они бесполезны.
Фрагментирование может разбивать предложения на фразы, которые более полезны, чем отдельные слова, и дают значимые результаты.
Фрагментирование очень важно, когда вы хотите извлечь информацию из текста, такую как местонахождение, имена людей. (извлечение сущности)

Давайте разберемся с нуля.
Предложение обычно следует иерархической структуре, состоящей из следующих компонентов.
предложение → предложения → фразы → слова
Группы слов составляют фразы, и существует пять основных категорий.
- Фраза существительного (NP)
- Фраза глагола (VP)
- Фраза прилагательного (ADJP)
- Фраза наречия (ADVP)
- Фраза предлога (PP)
S -> NP VP
NP -> {Det N,Pro,PN}
VP -> V (NP) (PP) (Adv)
PP -> P NP
AP -> A (PP)
Разбиение на фрагменты: фразы, разделенные на фрагменты (Источник: https://www.nltk.org)Прежде чем углубляться в фрагментирование, хорошо иметь краткое представление о синтаксическом дереве и правилах грамматики.

Как мы видим, здесь все предложение разделено на две разные части, которые представляют собой NP (именное словосочетание).
Теперь давайте разберемся с этой концепцией в эксперименте с Python.
- Фрагментирование на основе регулярных выражений
Фрагмент кода для фрагментирования на основе шаблона регулярных выражений
Дерево синтаксического анализа (фраза существительного генерируется на основе заданного регулярного выражения) Здесь мы ввели грамматику.
, в котором NP (именная группа) сочетается с
DT? → один или нулевой определитель
JJ* → ноль или более прилагательных
NN → существительное
, и мы анализируем эту грамматику с помощью анализатора регулярных выражений, определенного NLTK. Как мы видим, все предложение S разделено на куски и представлено в виде древовидной структуры. На основе определенной грамматики создается внутренняя древовидная структура. Таким образом, вы можете определить свою грамматику, основываясь на том, что предложение будет разбито на части.
2. Обучающий чанкер на основе тегов
Я использовал корпус conll2000 для обучения чанкеру. Корпус conll2000 определяет фрагменты с помощью тегов IOB.
Указывает, где начинается и заканчивается фрагмент, а также его типы.
Теггер POS может быть обучен этим тегам IOB
Теги фрагментов используют формат IOB.
IOB : Inside,Outside,Beginning
Префикс B перед тегом указывает, что это начало фрагмента
Префикс I указывает, что он находится внутри фрагмента
O-тег указывает, что токен не принадлежит ни к одному фрагменту :10900]
test_data=data[10900:]print(len(train_data),len(test_data))
print(train_data[1]) Запись набора данных ‘conll2000’
tree2conlltags,conlltags2tree являются служебными функциями фрагментации.
→ ` tree2conlltags `, чтобы получить тройки (слово, тег, фрагмент тегов для каждого токена). Эти кортежи затем, наконец, используются для обучения тегировщика, и он изучает теги IOB для тегов POS.
→ ` conlltags2tree ` для создания дерева синтаксического анализа из этих троек токенов.
Conlltags2tree() является обращением к tree2conlltags(). conlltags2treewtc=tree2conlltags(train_data[1])
wtc
tree=conlltags2tree(wtc)
print(tree)
def conll_tag_chunks(chunk_sents):
tagged_sents = [tree2conlltags(tree)] для дерева в chunk0_sents[137] t, c) для (w, t, c) в отправленных] для отправленных в tagged_sents]def Combined_Tagger(train_data, taggers, backoff=None):
для tagger в taggers:
backoff = tagger(train_data, backoff=backoff)
return backoff
Он читает текст и присваивает POS-тег каждому слову. (слово, тег)
Теггер Unigram : Для определения POS используется только одно слово. (теггер на основе контекста одного слова)
UnigramTagger , BigramTagger и TrigramTagger являются классами, которые наследуются от базового класса ContextTagger класс, который наследуется от класса SequentialBackoffTagger
Теперь мы определим класс NGramTagChunker , который будет принимать помеченные предложения в качестве входных данных для обучения, получать их (слово, тег POS, тег фрагмента) WTC, тройные и обучите BigramTagger с UnigramTagger в качестве резервного теггера.
Мы также определим функцию parse() для поверхностного разбора нового предложения.
из nltk.tag импортировать UnigramTagger, BigramTagger
из nltk.chunk import ChunkParserI#Определить класс чанкера train_sent_tags,tagger_classes)def parse(self,tagged_sentence):
если не tagged_sentence:
return None
pos_tags=[тег для слова, тег в tagged_sentence]
chunk_pos_tags=self.chunk_tagger.tag(pos_tags) 9# модель чанкера train
ntc=NGramTagChunker(train_data)#evaluate производительность модели чанкера
print(ntc.evaluate(test_data))
Теперь мы воспользуемся этой моделью для неглубокого синтаксического анализа и разбиения на фрагменты нашего примера заголовка новостной статьи.
импортировать панд как предложение pd
= «Новые смайлики не могут быть выпущены в 2021 году из-за COVID-19».пандемическое слово'
nltk_pos_tagged=nltk.pos_tag(sentence.split())
pd.DataFrame(nltk_pos_tagged,columns=['word','POS tag'])
chunk_tree=ntc.
