Разобрать по составу слово веселый
Онлайн-тезаурус с возможностью поиска ассоциаций, синонимов, контекстных связей и примеров предложений к словам и выражениям русского языка.
Справочная информация по склонению имён существительных и прилагательных, спряжению глаголов, а также морфемному строению слов.
Сайт оснащён мощной системой поиска с поддержкой русской морфологии.
Как выполнить разбор слова веселый по составу? Выделения корня слова, основы и его строения. Морфемный разбор, его схема и части слова (морфемы) — корень, окончание .
Схема разбора по составу: весел ый
Строение слова по морфемам: весел/ый
Структура слова по морфемам: приставка/корень/суффикс/окончание
Конструкция слова по составу: корень [весел] + окончание [ый]
Основа слова: весел
Словообразование: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола, способы словообразования: или непроизводное, то есть не образовано от другого однокоренного слова; или образовано бессуффиксальным способом: отсечением суффикса от основы прилагательного либо глагола.
Характеристики основы слова: непрерывная, простая (1 корень), непроизводная, нечленимая (нет словообразовательных афиксов) .
Разбор по составу (морфемный) «весёлый»:
Смотрите также:
Морфологический разбор слова «весёлый»
Фонетический разбор слова «весёлый»
Значение слова «весёлый»
Синонимы «весёлый»
Разбор по составу слова «весёлый»
Карточка «весёлый»
Предложения со словом «весёлый»
Разобрать слово по составу, что это значит?
Разбор слова по составу один из видов лингвистического исследования, цель которого — определить строение или состав слова, классифицировать морфемы по месту в слове и установить значение каждой из них. В школьной программе его также называют морфемный разбор.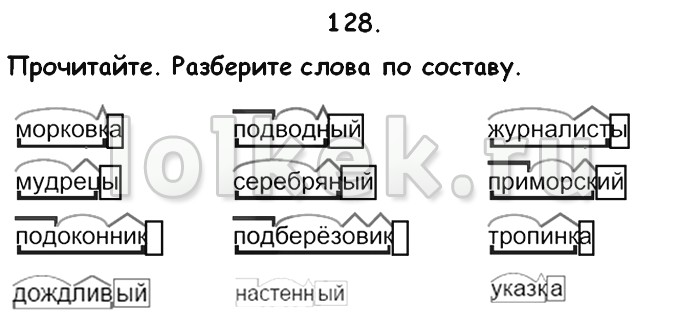 Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
Сайт how-to-all поможет вам правильно разобрать по составу онлайн любую часть речи: существительное, прилагательное, глагол, местоимение, причастие, деепричастие, наречие, числительное.
План: Как разобрать по составу слово?
При проведении морфемного разбора соблюдайте определённую последовательность выделения значимых частей. Начинайте по порядку «снимать» морфемы с конца, методом «раздевания корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определяйте значения морфем и подбирайте однокоренные слова, чтобы подтвердить правильность анализа.
- Записать слово в той же форме, как в домашнем задании. Прежде чем начать разбирать по составу, выяснить его лексическое значение (смысл).
- Определить из контекста к какой части речи оно относится. Вспомнить особенности слов, принадлежащих к данной части речи:
- изменяемое (есть окончание) или неизменяемое (не имеет окончания)
- имеет ли оно формообразующий суффикс?
В начальных классах разобрать по составу слово — значит выделить окончание и основу, после обозначить приставку с суффиксом, подобрать однокоренные слова и затем найти их общую часть: корень, — это всё.
* Примечание: Минобразование РФ рекомендует три учебных комплекса по русскому языку в 5–9 классах для средних школ. У разных авторов морфемный разбор по составу различается подходом. Чтобы избежать проблем при выполнении домашнего задания, сравнивайте изложенный ниже порядок разбора со своим учебником.
Порядок полного морфемного разбора по составу
Чтобы избежать ошибок, морфемный разбор предпочтительно связать с разбором словообразовательным. Такой анализ называется формально-смысловым.
- Установить часть речи и выполнить графический морфемный анализ слова, то есть обозначить все имеющиеся морфемы.
- Выписать окончание, определить его грамматическое значение. Указать суффиксы, образующие формуслова (если есть)
- Записать основу слова (без формообразующих морфем: окончания и формообразовательных суффиксов)
- Найди морфемы. Выписать суффиксы и приставки, обосновать их выделение, объяснить их значения
- Корень: свободный или связный. Для слов со свободными корнями составить словообразовательную цепочку: «пис-а-ть → за-пис-а-ть → за-пис-ыва-ть», «сух(ой) → сух-арь() → сух-ар-ниц-(а)». Для слов со связными корнями подобрать одноструктурные слова: «одеть-раздеть-переодеть».
- Записать корень, подобрать однокоренные слова, упомянуть возможные варьирования, чередования гласных или согласных звуков в корнях.
Пример полного морфемного разбора глагола «проспала»:
- окончание «а» указывает на форму глагола женского рода, ед.числа, прошедшего времени, сравним: проспал-и;
- основа форы – «проспал»;
- два суффикса: «а» – суффикс глагольной основы, «л» – этот суффикс, образует глаголы прошедшего времени,
- приставка «про» – действие со значением утраты, невыгоды, ср.: просчитаться, проиграть, прозевать;
- словообразовательная цепочка: сон – проспать – проспала;
- корень «сп» – в родственных словах возможны чередования сп//сн//сон//сып. Однокоренные слова: спать, уснуть, сонный, недосыпание, бессонница.


ГДЗ по русскому языку 5 класс Шмелев, Флоренская Решебник
Русский язык изучают во всех школах Российской Федерации. Для большинства детей он является родным, но некоторые учащиеся, представители национальных меньшинств, проходят его в качестве второго. Как бы то ни было, предмет занимает существенное время современного школьника и требует известных инвестиций внимания, мышления и прилежания.
Авторы создали учебно-методический комплекс по курсу родной речи для учеников пятого класса общеобразовательной школы. Он включает собственно учебник, вспомогательные материалы, а также решебник, по которому можно проверять правильность выполнения упражнений.
Настоящие ГДЗ были изданы «Алгоритмом успеха» еще в 2016 году, однако свою актуальность они не утратят много лет (2019 год). Признанные методисты создали книгу с полными верными ответами. Каждое упражнение подробно объяснено, не оставляя без ценных комментариев ни одной важной буквы. Информация изложена кратко и точно, в соответствии с действующими нормативами.
Почему ГДЗ по русскому языку за 5 класс Шмелева полюбились школьникам
Полагаем, это произошло из-за качественных пояснений, которыми изобилует пособие. На страницах сборника можно найти практически всё, что нужно: разбор слова по составу, определение частей речи, фундаментальные понятия фонетики, орфографию. Решебники, приведенные на страницах нашего сайта, выделяются следующими особенностями:
- легко искать упражнения, так как есть простой и интуитивный указатель;
- приведены только актуальные версии, которые утверждены ведущими педагогами РФ;
- уделено внимания творческим заданиям, развиваются реальные практические навыки речи;
- сайт доступен со всех видов популярных электронных устройств.
Онлайн-сборник Шмелева, Флоренской, Габовича не только приводит ответы. Прежде всего, он показывает, как делать правильно. Поэтому результат достигается быстрее, не требует приложения избыточных усилий. Не составит труда подготовиться к ответам на уроках, контрольным, самостоятельным, проверочным работам, тестам. Как результат, вы увидите более высокие оценки и повышенную мотивацию подростка к изучению предмета.
Не составит труда подготовиться к ответам на уроках, контрольным, самостоятельным, проверочным работам, тестам. Как результат, вы увидите более высокие оценки и повышенную мотивацию подростка к изучению предмета.
Что входит в решебник за 5 класс по русскому языку Шмелев А.Д., Флоренская Э.А., Габович Ф.Е.
Издание разделено на 2 часть. Большая часть посвящена изучению новых правил. Тем не менее, пять параграфов помогают школьнику смог повторить пройденный материал. Такой подход необходим, ведь ученики к концу года частично забывают то, что учили в самом начале. Авторы дают немного больше знаний, чем положено по школьной программе.
Книга учит новым подходам, позволяет более глубоко увидеть суть, развить интуитивную грамотность. Такой подход поможет думать более многогранно, находить оптимальные и наиболее приемлемые пути выполнения. Основные темы в текущем году:
- морфологический разбор слов;
- самостоятельные и служебные части речи;
- разбор предложения по членам;
- правила орфографии и пунктуации.
Сборник заданий предназначен для пятиклассников. Он соответствует минимальным требованиям ФГОС и может быть частью авторских рабочих программ преподавателей.
Гдз по русскому языку 7 класс Баранов, Ладыженская Решебник
Недавно Ладыженская, Баранова и Тростенцова написали интересный учебник для 7 класса по русскому языку с полным содержанием решений. Этот учебно-методический комплекс включает также вспомогательные материалы, полюбившуюся рабочую тетрадь и решебник. По приведенным готовым ответам можно проверять правильность выполнения упражнений. Каждый номер подробно объяснен, без ценных комментариев не осталась ни одна орфограмма. Информация изложена кратко и точно, в соответствии с действующими нормативами.
Настоящие ГДЗ по состоянию на 2020 год издает московский холдинг «Просвещение». Эта компания хорошо известная в России благодаря большому количеству учебных изданий, которые она доносит до потребителя.
Почему онлайн-решебник Ладыженской в 7 классе по русскому полюбились детям?
Это произошло из-за качественных пояснений, которыми просто-напросто изобилует пособие. На страницах сборника можно найти практически всё, что нужно. Это и разбор слова по составу, и части речи, и понятия фонетики. Кроме того, большое внимание было уделено культуре общения и орфографии. Упражнения на страницах нашего сайта, выделяются следующими особенностями:
- легко искать упражнения по указателю;
- приведены только актуальные версии, которые рекомендованы лучшими педагогами российской федерации;
- творческие задания повышенного уровня сложности;
Решебник не только аккумулирует нужные ответы. Он, прежде всего, показывает, как выполнять задания учителя правильно. Поэтому искомый результат достигается быстрее, не требует приложения избыточных усилий. Несложно будет подготовиться к ответам на уроках, контрольным, самостоятельным, проверочным работам, тестам. Вы скоро заметите более высокие текущие оценки и повышенную мотивацию подростка к изучению данного предмета.
Основные темы ГДЗ по русскому (авторы: Баранов, Ладыженская, Тростенцова, Григорян)?
Пособие имеет модульную структуру. Разделы включают повторение пройденного ранее материала, синтаксис, пунктуацию, морфологию, фонетику и культуру речи. Ученики имеют возможность повторить старые правила благодаря большому количеству соответствующих упражнений. Авторы дают учащимся несколько больше знаний, чем положено по утвержденной специалистами рабочей программе.
Книга учит новым подходам в понимании языка, позволяет более глубоко увидеть сущность родной речи, развить интуитивную грамотность на письме. Такой подход поможет рассуждать более многогранно, находить оптимальные и наиболее приемлемые пути выражения той или иной мыли. Основные темы в текущем году:
- самостоятельные и служебные части речи;
- синтаксический разбор высказывания;
- пунктуация в сложноподчиненном предложении;
- причастные и деепричастные обороты;
- правила написания удвоенных согласных.

Онлайн-пособие, разработанное Ладыженским, предназначено для школьников. Он соответствует всем государственным требованиям, а потому может применяться в любом общеобразовательном учреждении страны.
O.G EzzY — Шёлковая простынь текст песни
Шелковая простыньУсыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Она прекрасна
Я ее тело нанесу на холст
Шелковая простынь
Усыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Она прекрасна
Я ее тело нанесу на холст
Я поменяю
На душу руку в комплекте с сердцем
Она святая голая я не прошу одеться
Она засыпает на моих руках не шелохнуться
А я наблюдаю до тех пор, пока она проснется
Шелковая простынь
Усыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Она прекрасна
Я ее тело нанесу на холст
Шелковая простынь
Усыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Я ее тело нанесу на холст
Я как брюлик накрылся
Посыпался на пол как гильзы
Из дыма печи новый гейзер
Я ее жизненный крейсер
Ты же шпаргалка для прессы
Каждый мой шаг и мой каждый порез
И она все-таки бездна
Иду к ней по тонкому лезвию
Шелковая простынь
На утро скомкана в комок
Вино разлито на пол
Она глазами в потолок
Говорит, что согласна
Согласна припадать урок
Уже довольно поздно
Давай. ..
..
Шелковая простынь
Усыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Она прекрасна
Я ее тело нанесу на холст
Шелковая простынь
Усыпанная лепестками роз
Кроваво красных
Вино в ведро со льдом
Большой поднос
Богиня здравствуй
В руке сжимаю ее клок волос
Она прекрасна
Я ее тело нанесу на холст
Понравился текст песни?
Оставьте комментарий ниже
«Английский» Практика анализа, синтаксического анализа, словообразования, композиции и перефразирования: Amazon.de: Richardson, JL: Fremdsprachige Bücher
В этой исторической книге может быть множество опечаток и отсутствующий текст. Обычно покупатели могут бесплатно скачать отсканированную копию оригинальной книги (без опечаток) у издателя. Не проиндексировано. Не проиллюстрировано. Издание 1885 года. Отрывок: … 38. В самих себе нужно искать нашу безопасность, Дабы нашими собственными руками это могло быть сделано. 39. Мы будем ликовать, если правящие землей будут людьми, которым дороги ее многочисленные благословения.40. Все это залито его кровью — неужели он умрет, И не отомщенный? Вставайте, готы, и проглотите свой гнев. 41. Земля пролила свою кровь на Него, Кто таким образом может накопить свою собственную. 42. Зло, творимое людьми, живет после них; Хорошее часто погребают вместе с их костями. 43. Вот я, чтобы сказать то, что знаю, Вы все когда-то любили его. 44. Я предпочитаю обижать мертвых, Обижать себя и тебя. 45. Посмотри сюда, вот он сам, Маррид, как ты видишь, с предателями. 46. Ты знаешь меня все, простой, тупой человек, Который любит мой друг.47. Скажите, что привело вас в Рим? Чтобы стать ученым. 48. Один играл, один пел, Один золотую лиру пронес. Для других упражнений см. Местоимения в «Парсинг существительных». АДЪЕКТИВНАЯ ПАУЗА. ПАМЯТЬ РАБОТАЕТ. (I.) Добрый — Качество или добрый, как Дикий. Количество или число, например, десять, пятьдесят, лед. Различие, как This, The, Disc. (2.) Сравнение — положительная степень, как молодой, что является простой формой прилагательного. Goinparative Degree, как младший или более жалкий — Позитивная форма, с er или больше.) Превосходная, как самый молодой или самый несчастный — Позитивная форма, с est или больше.Примечание. — Некоторые прилагательные не подлежат сравнению, например Мертвый, Живой, Пустой и т. Д., А многие сравниваются нерегулярно, как Плохие, Хорошие, Многие, 111 и т. Д. Приведите подробности, как указано выше, со ссылкой на существительные или местоимения следующих прилагательных: — (a) 1. Каждый ребенок боялся этого странного зрелища. 2. Он был очень добр и гениален. 3. Тусклое небо осветили три ярких вспышки. 4. Собаки — самые верные создания. 5. Она купила четыре самые броши. 6. Этот нож острый, но эта бритва острее.7 ….
(I.) Добрый — Качество или добрый, как Дикий. Количество или число, например, десять, пятьдесят, лед. Различие, как This, The, Disc. (2.) Сравнение — положительная степень, как молодой, что является простой формой прилагательного. Goinparative Degree, как младший или более жалкий — Позитивная форма, с er или больше.) Превосходная, как самый молодой или самый несчастный — Позитивная форма, с est или больше.Примечание. — Некоторые прилагательные не подлежат сравнению, например Мертвый, Живой, Пустой и т. Д., А многие сравниваются нерегулярно, как Плохие, Хорошие, Многие, 111 и т. Д. Приведите подробности, как указано выше, со ссылкой на существительные или местоимения следующих прилагательных: — (a) 1. Каждый ребенок боялся этого странного зрелища. 2. Он был очень добр и гениален. 3. Тусклое небо осветили три ярких вспышки. 4. Собаки — самые верные создания. 5. Она купила четыре самые броши. 6. Этот нож острый, но эта бритва острее.7 ….
Процесс синтаксического анализа — обзор
Очистка данных
По сути, вывод, который мы можем сделать из этого обсуждения, заключается в важности обеспечения качества данных до их использования в аналитических целях. Это предполагает необходимость поощрения гарантии очистки данных в исходных исходных системах, указывая на необходимость применения очистки данных на ранней стадии процесса, если это возможно.
Однако в обстоятельствах, когда есть желание включить данные, не соответствующие стандартам качества, в аналитическую среду, необходимо принять решение либо очистить данные, либо загрузить набор данных как есть.При этом полезно рассмотреть методы, используемые для очистки данных.
Анализ
Часто вариации или неоднозначность в представлении значений данных могут сбивать с толку как отдельных пользователей, так и автоматизированные приложения. Например, рассмотрим эти разные значения данных: {California, CA, Calif., US-CA, Cal, 06}. Некоторые из этих значений используют символьные строки, другие используют цифры, а некоторые используют знаки препинания или специальные символы. По большей части, человек прочитает их и поймет, что все они представляют одну и ту же концептуальную ценность: штат Калифорния.Тем не менее, автоматизируя процесс определения того, являются ли эти значения точными, или выясняя, существуют ли повторяющиеся записи, значения должны быть проанализированы на составляющие их сегменты, а затем преобразованы в стандартный формат.
По большей части, человек прочитает их и поймет, что все они представляют одну и ту же концептуальную ценность: штат Калифорния.Тем не менее, автоматизируя процесс определения того, являются ли эти значения точными, или выясняя, существуют ли повторяющиеся записи, значения должны быть проанализированы на составляющие их сегменты, а затем преобразованы в стандартный формат.
Синтаксический анализ — это процесс идентификации значимых токенов в экземпляре данных с последующим анализом потоков токенов на предмет распознаваемых шаблонов. Токен — это совокупность нескольких отдельных слов, имеющих какое-то деловое значение; с данными о клиентах эти токены могут относиться к компонентам имени человека или компании, частям адреса или части какого-либо другого элемента данных, зависящего от домена.Например, мы можем обратиться к токену «титул», который представляет собой список часто используемых титулов, таких как «Мистер», «Миссис» и «Доктор», и каждый раз, когда мы видим слово, которое есть в нашем «Заголовки», мы можем использовать это слово как заголовок для последующего анализа паттернов.
Процесс синтаксического анализа разделяет каждое слово, а затем пытается определить взаимосвязь между словом и ранее определенными наборами токенов и сформировать последовательности токенов. Последовательности токенов отправляются в приложение сопоставления с образцом, которое ищет похожие образцы.Когда шаблон совпадает, к исходному значению поля применяется предопределенное преобразование для извлечения его отдельных компонентов, которые затем передаются в приложения драйвера. Инструменты на основе шаблонов являются гибкими в том смысле, что они могут использовать предопределенные шаблоны и поглощать вновь определенные или обнаруженные шаблоны для текущего анализа.
Стандартизация
При синтаксическом анализе используются определенные шаблоны, регулярные выражения или грамматики, управляемые в механизме правил, а также поиск в таблицах, чтобы различать допустимые и недопустимые значения данных. Когда шаблоны распознаны, могут быть запущены другие правила и действия для преобразования входных данных в форму, которую можно более эффективно использовать, либо для стандартизации представления (предполагая допустимое представление), либо для исправления значений (если будут выявлены известные ошибки) . Чтобы продолжить наш пример, каждое из наших значений для штата Калифорния {California, CA, Calif., US-CA, Cal, 06} может быть стандартизировано для стандартной двухсимвольной аббревиатуры Почтовой службы США, CA.
Когда шаблоны распознаны, могут быть запущены другие правила и действия для преобразования входных данных в форму, которую можно более эффективно использовать, либо для стандартизации представления (предполагая допустимое представление), либо для исправления значений (если будут выявлены известные ошибки) . Чтобы продолжить наш пример, каждое из наших значений для штата Калифорния {California, CA, Calif., US-CA, Cal, 06} может быть стандартизировано для стандартной двухсимвольной аббревиатуры Почтовой службы США, CA.
Стандартизация — это процесс преобразования данных в форму, указанную в качестве стандарта, и является прелюдией к процессу очистки.Стандартизация основана на службе синтаксического анализа, которую можно объединить с библиотекой доменов данных для разделения значений данных на несколько компонентов и преобразования компонентов в нормализованный формат. Стандартизация также позволяет преобразовывать полные слова в сокращения или сокращения в полные слова, преобразовывать псевдонимы в стандартную форму имени, переводить на разные языки (например, с испанского на английский), а также исправлять распространенные орфографические ошибки.
Стандартизация будет включать преобразования сокращения информации во время приложения консолидации или суммирования и в конечном итоге может использоваться как средство извлечения информации о конкретных объектах (например,g., человек, компания, номер телефона, местонахождение) и присвоение ему смыслового значения для последующей обработки. Например, рассмотрим эти две записи о клиентах:
- 1.
Elizabeth R. Johnson, 123 Main Street, Franconia, NH
- 2.
Beth R. Johnson, 123 Main Street, Franconia, NH
Наша интуиция при просмотре этой пары записей позволяет нам сделать вывод о совпадении сущностей, потому что, кажется, достаточно эвристических данных, чтобы совершить такой прыжок: мы знаем, что «Бет» — это короткая версия «Элизабет», а улица адрес совпадает. Эвристические методы, такие как сопоставление псевдонима с именем полной версии (и другие подобные), могут быть собраны как простые преобразования, которые могут применяться в целом к анализируемым именам.
Эвристические методы, такие как сопоставление псевдонима с именем полной версии (и другие подобные), могут быть собраны как простые преобразования, которые могут применяться в целом к анализируемым именам.
Существует множество различных типов данных, которые попадают в семантическую таксономию, которая обеспечивает некоторый интуитивно понятный набор правил стандартизации, связанных с контентом. Например, имена во многих культурах имеют вариантные формы (псевдонимы и т. Д.), Которые могут связывать любое имя по крайней мере с одной стандартной формой. Например, «Боб», «Роб», «Бобби» и «Робби» — все это разные формы имени «Роберт»; «Лиз», «Лиззи» и «Бет» могут быть формами имени «Элизабет».”
После того, как имя с несколькими вариантами идентифицировано, процесс стандартизации может дополнить значение данных выбранной стандартной формой, которая будет использоваться на этапе связывания. Обратите внимание, что стандартизация не ограничивается именами или адресами. Другие абстрактные типы данных, которые можно стандартизировать, включают деловые слова, номера телефонов, отраслевой жаргон, коды продуктов и коды транзакций. И даже не имеет значения, применяется ли стандартная форма способом, не соответствующим реальной жизни.Например, «Бет Смит» можно не называть «Элизабет», но мы все равно можем присвоить стандартное «Элизабет» записям, потому что эта стандартизация используется исключительно как средство для другой цели: связывание и очищение.
Расширение аббревиатуры
Аббревиатура — это компактное представление некоторого альтернативного распознаваемого объекта, а поиск и стандартизация сокращений — еще один ориентированный на правила аспект очистки данных. Существуют разные виды сокращений. Один тип сокращает каждое из набора слов до меньшей формы, где сокращение состоит из префикса исходного значения данных.Примеры включают INC для инкорпорации, CORP для корпорации и ST для улицы. Другой тип сокращает слово, удаляя гласные или сокращая буквы для фонетики, например INTL или INTRNTL для международного, PRGRM для программы и MGR для менеджера. Третья форма сокращения — это аббревиатура, где первые символы каждого набора слов объединены в строку, например USA для Соединенных Штатов Америки и RFP для запроса предложений. Аббревиатуры необходимо проанализировать и распознать, а затем можно использовать набор трансформационных бизнес-правил для преобразования сокращений в их расширенную форму.
Третья форма сокращения — это аббревиатура, где первые символы каждого набора слов объединены в строку, например USA для Соединенных Штатов Америки и RFP для запроса предложений. Аббревиатуры необходимо проанализировать и распознать, а затем можно использовать набор трансформационных бизнес-правил для преобразования сокращений в их расширенную форму.
Коррекция данных
После того, как компоненты строки были идентифицированы и стандартизированы, на следующем этапе процесса предпринимается попытка исправить те значения данных, которые не распознаны, и дополнить исправляемые записи исправленной информацией. Очевидно, что если мы сможем распознать, что данные ошибочны, мы захотим исправить эти данные. Существует несколько различных способов автоматического исправления данных, и все они полагаются на какую-то интеллектуальную базу знаний правил и преобразований или некоторые эвристические алгоритмы для распознавания и связывания вариаций известных значений данных.Важно понимать, что процесс исправления можно автоматизировать только частично; у многих поставщиков может сложиться впечатление, что их инструменты могут полностью исправить неверные данные, но серебряной пули нет.
В целом процесс исправления основан на ведении набора неверных значений и их исправленных форм. Например, если слово International часто ошибочно пишется как «Intrnational», может существовать правило, сопоставляющее неправильную форму с правильной формой. Некоторые инструменты могут включать бизнес-знания, накопленные за длительный период времени, что составляет обширные базы знаний правил, включенных в эти продукты; К сожалению, это открывает двери для множества непонятных правил, которые отражают множество особых случаев.
Этот подход ошибочен, поскольку эффект накопления правил исправления, основанный на анализе определенных видов данных (обычно имен и адресов), смещает процесс исправления к информации такого рода. Кроме того, большая часть данных одной организации отличается от данных любой другой организации, и, следовательно, бизнес-правила, регулирующие использование этих данных, также отличаются. Использование бизнес-правил других организаций по-прежнему будет приносить пользу, особенно если содержимое данных схоже, но всегда будет какая-то область, в которой людям нужно будет взаимодействовать с системой, чтобы принимать решения о корректировках данных.
Использование бизнес-правил других организаций по-прежнему будет приносить пользу, особенно если содержимое данных схоже, но всегда будет какая-то область, в которой людям нужно будет взаимодействовать с системой, чтобы принимать решения о корректировках данных.
Наконец, данные могут быть восприняты как неверные только при наличии правил, указывающих на правильность. Неточность или неточные значения данных могут присутствовать в наборе, но нет способа определить эту недействительность без источника правильных значений, с которыми можно было бы сравнивать. Использование других наборов правил правильности может привести к серьезной проблеме: данные, которые уже могут быть хорошими, могут быть непреднамеренно изменены на неправильные. Примером этого при коррекции адреса является знаменитое шоссе Восток-Запад в пригороде Вашингтона, округ Колумбия.Поскольку в адресах со словом «Восток» в начале ожидается, что это слово используется как префикс направления, а не как часть самого названия улицы, некоторые приложения неправильно «исправляют» это на «E. Западное шоссе », что не является названием дороги.
Еще более серьезной проблемой является представление о том, что данные верны, хотя на самом деле это не так. Иногда единственный способ определить неверные данные — это непосредственный просмотр данных аналитиком вручную.
Обновление отсутствующих полей
Одним из аспектов очистки данных является возможность заполнения полей, в которых отсутствует информация.Отсутствующие значения могут содержать больше информации, чем мы могли бы подозревать; отсутствие значения может быть вызвано одной из следующих причин.
- ▪
Известно, что для этого поля действительно нет значения.
- ▪
Известно, что есть значение, которое должно быть указано в поле, но по какой-то причине значение на данный момент неизвестно, и неясно, станет ли это значение когда-либо известным.
- ▪
Известно, что для этого поля есть значение, и в какой-то момент в будущем это значение будет получено и заполнено.
- ▪
Для этого нет применимого значения из-за некоторого ограничения, зависящего от других значений атрибутов.
- ▪
Для этого поля есть значение, но оно не соответствует предопределенному набору допустимых значений для этого поля.

Это лишь краткий список существующих типов нулевых значений. В зависимости от нулевого типа могут существовать способы вменения отсутствующего значения, хотя некоторые подходы более надежны, чем другие.Например, мы можем попытаться заполнить поле пола человека на основе его или ее имени, но это не обязательно сработает с человеком с трансгендерным именем.
В некоторых других случаях причина отсутствия значения может быть связана с ошибками в исходных данных, и после процесса очистки у нас может быть достаточно информации, чтобы правильно заполнить отсутствующее поле. Для недоступных полей, если причина пропусков связана с нехваткой данных во время создания экземпляра записи, то процесс консолидации может предоставить достаточно информации, чтобы сделать доступными данные, которые ранее были недоступны.Для неклассифицированных полей причина невозможности классификации значения может заключаться в том, что ошибочные данные в других атрибутах помешали классификации. Учитывая скорректированные данные, можно ввести правильное значение. Для неизвестных атрибутов процесс очистки и консолидации может предоставить недостающее значение.
Однако важно понимать, что без хорошо задокументированного и согласованного набора правил для определения того, как заполнить отсутствующее поле, это может быть (как минимум) контрпродуктивным и (в худшем случае) опасным для заполните пропущенные значения.Соблюдайте строгую осторожность при автоматизации замены отсутствующих значений.
Анализ и устранение дубликатов с использованием разрешения идентификации
Поскольку операционные системы органически выросли в набор корпоративных приложений, нет ничего необычного в том, что несколько экземпляров данных в разных системах будут по-разному ссылаться на один и тот же реальный объект. С другой стороны, желание консолидировать и связать данные об одних и тех же бизнес-концепциях с высокой степенью уверенности может убедить кого-то в том, что запись может еще не существовать для реального объекта, хотя на самом деле это действительно так.Обе эти проблемы в конечном итоге представляют собой одну и ту же основную задачу: возможность сравнить идентифицирующие данные в паре записей, чтобы определить сходство между этой парой или различить сущности, представленные в этих записях.
С другой стороны, желание консолидировать и связать данные об одних и тех же бизнес-концепциях с высокой степенью уверенности может убедить кого-то в том, что запись может еще не существовать для реального объекта, хотя на самом деле это действительно так.Обе эти проблемы в конечном итоге представляют собой одну и ту же основную задачу: возможность сравнить идентифицирующие данные в паре записей, чтобы определить сходство между этой парой или различить сущности, представленные в этих записях.
Обе эти проблемы решаются посредством процесса, называемого разрешением идентичности, в котором оценивается степень сходства между любыми двумя записями, чаще всего на основе взвешенного приблизительного соответствия между набором значений атрибутов между двумя записями.Если оценка выше определенного порога, две записи считаются совпадающими и представляются конечному клиенту как наиболее вероятно представляющие одну и ту же сущность. Разрешение идентичности используется для распознавания, когда лишь незначительные отклонения предполагают, что разные записи связаны и где значения могут быть очищены, или когда достаточные различия между данными предполагают, что две записи действительно представляют разные сущности. Поскольку сравнение каждой записи с любой другой записью требует больших вычислительных ресурсов, многие службы данных используют расширенные алгоритмы для блокировки записей, которые, скорее всего, содержат совпадения, в меньшие наборы, чтобы сократить время вычислений.
Разрешение идентификации обеспечивает основу для более сложной службы базовых данных: анализ и устранение дублирующихся записей. Идентификация похожих записей в одном наборе данных, вероятно, означает, что записи дублируются и могут быть подвергнуты очистке и / или удалению. Идентификация похожих записей в разных наборах может указывать на связь между наборами данных, что помогает облегчить объединение или аналогичные записи для целей очистки данных, а также для поддержки аналитических приложений, которые ожидают увидеть единое представление о ключевых объектах, таких как продукт / цены. модели или инициативы по профилированию клиентов.
модели или инициативы по профилированию клиентов.
Анализ и реструктуризация музыкальных потоков на основе грамматики в реальном времени
ï ~~ Материалы Международной конференции компьютерной музыки 2011 г., Университет Хаддерсфилда, Великобритания, 31 июля — 5 августа 2011 г. глагольной фразы «застряли» как подфраза внутри более крупная повторяющаяся оговорка. Такой вложенный цикл является обычным явлением. в рэпе, отчасти потому, что это помогает выровнять фразы границы с метрическими границами, сделав первые эластичный во время работы. Однако чего не хватает, так это возможность создавать рекурсивные иерархические структуры найдено в языке и во многих формах музыкального состав.В теории формального языка следующий по силе абстракция после регулярного выражения — это контекстная грамматика, которая поддерживает иерархически вложенные фразовые конструкции [1]. Диаграмма предложений на Рисунке 2 показывает один возможный контекстно-свободный синтаксический анализ предложения, «По прошествии года пройдет еще один год прочь «, используя диаграмму предложений, не зависящую от контекста. Линии без стрелок ограничивают иерархическую композицию грамматические нетерминальные символы, включая предложение, Подлежащее, предикат, существительная фраза (NP), глагольная фраза (VP), предложная фраза (PP), существительное, прилагательное (ADJ), наречие (ADV) и инфинитивная фраза из нетерминалы нижнего уровня и терминальные символы.Каждый нетерминал состоит из предложения, предложения, фразы или части речи, действуя как подразделение более грубо зернистое нетерминальное деление, в котором это происходит. Терминалы — это самые нижние, неиерархические конструкции. В этом примере терминалы — это слова, но они могут также быть синхронизированными нотами или другими звуковыми событиями в иерархическая музыкальная структура. Пунктирные стрелки вверх показать увеличение от модификаторов до измененных нетерминалы. Бесконтекстные парсеры обычно используют обычные выражения для описания строк или других последовательностей поверхностные элементы, составляющие терминальные символы. Широко используются контекстно-свободные грамматики и парсеры. в переводе программ в машиноисполняемые формы. дублирование поддеревьев синтаксического анализа, привязанных к нетерминалам в грамматике. Цель — создание в реальном времени возможности программного обеспечения, которые расширяют и превосходят стандартные возможности на основе цикла. Подготовка к перформанс включает построение и составление грамматика, которая описывает предложения или музыкальные отрывки для исполняться, записываться, преобразовываться и воспроизводиться, наряду с практикой использования системы производительности.2. ДОПОЛНИТЕЛЬНАЯ РАБОТА Пьер Шеффер был пионером в изучении использования дисков и ленты для обработки записанных звуков в том числе зацикливание в начале двадцатого века [7,10]. Стив Райх сделал особенно эффективным рано композиционное использование ленточных петель [8]. Последовательность управления используется со времен игровых пианино и тому подобного. механические и электромеханические инструменты. Применение контекстно-свободных грамматик и парсеров к музыкальный анализ и композиция восходит к 1970-е гг.Дороги и Wieneke резюмируют формальный язык Теоретические и исследовательские проекты, выполнявшиеся в 1979 г. [9], заявив: «Музыкальное представление должно, по крайней мере, иметь способность обрабатывать вложенные фразы и мотивы, конструкции, которые технически исключены из типа 3 грамматики «, где грамматики 3-го типа включают обычные выражения и конечные автоматы. Авторы тщательно обсудить сильные стороны контекстно-свободных грамматик в представляющий музыкальную структуру. Лердал и Джекендофф представляют тщательный применение теории формального языка к представлению музыкальной структуры, которая включает в себя практический разбор проблемы [5].Свейн связывает синтаксис с музыкальным напряжением и выпуск [12]. Barbar et. al. обсудить синтаксически управляемый перевод музыкальных конструкций [3]. Марковский процесс представляет собой форму конечной грамматики, которая была широко применяется для анализа музыкальной структуры и поколение [2,9].
Широко используются контекстно-свободные грамматики и парсеры. в переводе программ в машиноисполняемые формы. дублирование поддеревьев синтаксического анализа, привязанных к нетерминалам в грамматике. Цель — создание в реальном времени возможности программного обеспечения, которые расширяют и превосходят стандартные возможности на основе цикла. Подготовка к перформанс включает построение и составление грамматика, которая описывает предложения или музыкальные отрывки для исполняться, записываться, преобразовываться и воспроизводиться, наряду с практикой использования системы производительности.2. ДОПОЛНИТЕЛЬНАЯ РАБОТА Пьер Шеффер был пионером в изучении использования дисков и ленты для обработки записанных звуков в том числе зацикливание в начале двадцатого века [7,10]. Стив Райх сделал особенно эффективным рано композиционное использование ленточных петель [8]. Последовательность управления используется со времен игровых пианино и тому подобного. механические и электромеханические инструменты. Применение контекстно-свободных грамматик и парсеров к музыкальный анализ и композиция восходит к 1970-е гг.Дороги и Wieneke резюмируют формальный язык Теоретические и исследовательские проекты, выполнявшиеся в 1979 г. [9], заявив: «Музыкальное представление должно, по крайней мере, иметь способность обрабатывать вложенные фразы и мотивы, конструкции, которые технически исключены из типа 3 грамматики «, где грамматики 3-го типа включают обычные выражения и конечные автоматы. Авторы тщательно обсудить сильные стороны контекстно-свободных грамматик в представляющий музыкальную структуру. Лердал и Джекендофф представляют тщательный применение теории формального языка к представлению музыкальной структуры, которая включает в себя практический разбор проблемы [5].Свейн связывает синтаксис с музыкальным напряжением и выпуск [12]. Barbar et. al. обсудить синтаксически управляемый перевод музыкальных конструкций [3]. Марковский процесс представляет собой форму конечной грамматики, которая была широко применяется для анализа музыкальной структуры и поколение [2,9]. Акцент в музыкальных произведениях формального языка была проведена работа по использованию грамматик и синтаксических анализаторов в представление музыкальной структуры, анализ и состав. Дороги и Винеке предсказали «Грамматики». может выйти за рамки унифицированных моделей составления и анализа и к интеллектуальным музыкальным устройствам.»[9] Однако обзор доступного программного и электронного оборудования инструменты находят, что состояние практики ограничено применение конечных автоматов / циклических механизмов. Целью настоящего проекта является интеграция разговорное слово без контекста и инструментальный мюзикл парсеры и генераторы в программное обеспечение на основе записи инструмент. Отображение грамматики на предложения, очерченные этой грамматикой, создают импровизацию возможно, при условии достаточной подготовки грамматики и попрактикуйтесь с его приложением во время выполнения.ПРЕДЛОЖЕНИЕ ПРЕДИКАТОР ПРЕДМЕТА F ВП Н П ADJ ‘N.QUN ИпНЭФ PPADV / 2 v \ I I По прошествии года наступает еще один год, чтобы уйти Рисунок 2. Бесконтекстный анализ предложения. Основная цель текущего исследовательского проекта — поддержка реструктуризация устного слова во время исполнения и инструментальные фразовые конструкции. Например, после записывая предложение на Рисунке 2, исполнение система способна к немедленной реструктуризации и воспроизведению вернуться к альтернативному предложению, например: «Еще один год проходит с течением года.» Преобразования включают обмен, удаление и 584
Акцент в музыкальных произведениях формального языка была проведена работа по использованию грамматик и синтаксических анализаторов в представление музыкальной структуры, анализ и состав. Дороги и Винеке предсказали «Грамматики». может выйти за рамки унифицированных моделей составления и анализа и к интеллектуальным музыкальным устройствам.»[9] Однако обзор доступного программного и электронного оборудования инструменты находят, что состояние практики ограничено применение конечных автоматов / циклических механизмов. Целью настоящего проекта является интеграция разговорное слово без контекста и инструментальный мюзикл парсеры и генераторы в программное обеспечение на основе записи инструмент. Отображение грамматики на предложения, очерченные этой грамматикой, создают импровизацию возможно, при условии достаточной подготовки грамматики и попрактикуйтесь с его приложением во время выполнения.ПРЕДЛОЖЕНИЕ ПРЕДИКАТОР ПРЕДМЕТА F ВП Н П ADJ ‘N.QUN ИпНЭФ PPADV / 2 v \ I I По прошествии года наступает еще один год, чтобы уйти Рисунок 2. Бесконтекстный анализ предложения. Основная цель текущего исследовательского проекта — поддержка реструктуризация устного слова во время исполнения и инструментальные фразовые конструкции. Например, после записывая предложение на Рисунке 2, исполнение система способна к немедленной реструктуризации и воспроизведению вернуться к альтернативному предложению, например: «Еще один год проходит с течением года.» Преобразования включают обмен, удаление и 584
Быстрая унифицированная модель для синтаксического анализа и понимания предложений — arXiv Vanity
Сэмюэл Р. Боуман1,2,3,
и Джон Готье2,3,4, ∗
и Абхинав Растоги3,5
\ ANDRaghav Gupta2,3,6
и Кристофер Д. Мэннинг1,2,3,6
и Кристофер Поттс1,6
\И
1Стэнфордская лингвистика 2Стэнфордская группа НЛП 3Стэнфордская лаборатория искусственного интеллекта
4 Стэнфордские символьные системы 5 Стэнфордская электротехника 6 Стэнфордская компьютерная наука Первые два автора внесли равный вклад.
Аннотация
Древовидные нейронные сети используют ценную информацию синтаксического анализа при интерпретации значений предложений. Однако они страдают от двух ключевых технических проблем, которые делают их медленными и громоздкими для крупномасштабных задач НЛП: они обычно работают с проанализированными предложениями и не поддерживают напрямую пакетные вычисления. Мы решаем эти проблемы, вводя нейронную сеть синтаксического интерпретатора-интерпретатора (SPINN), которая объединяет синтаксический анализ и интерпретацию в рамках единой гибридной модели с древовидной последовательностью путем интеграции древовидной интерпретации предложений в линейную последовательную структуру синтаксического анализатора с уменьшенным сдвигом. .Наша модель поддерживает пакетные вычисления для ускорения до 25 раз по сравнению с другими моделями с древовидной структурой, а ее интегрированный анализатор может работать с неанализируемыми данными с небольшой потерей точности. Мы оцениваем его с помощью задачи следования Stanford NLI и показываем, что он значительно превосходит другие модели кодирования предложений.
\ noautomath1 Введение
| (а) Обычная РНС на основе последовательностей для двух предложений. | (б) Обычный TreeRNN для двух предложений. |
| (a) Модель SPINN развернулась за два перехода во время обработки предложения Кот сел . «Отслеживание», «переход» и «композиция» — это уровни нейронной сети. Серые стрелки указывают соединения, которые заблокированы функцией стробирования. | (b) Полностью развернутый SPINN для , кот сел , с опущенными для ясности слоями нейронной сети. |
Широкий спектр современных моделей в НЛП построен вокруг компонента нейронной сети, который производит векторные представления смысла предложения (например, Sutskever et al., 2014; Tai et al., 2015) . Этот компонент, кодировщик предложений, обычно формулируется как изученная параметрическая функция от последовательности векторов слов до вектора предложения, и эта функция может принимать различные формы.Обычные кодировщики предложений включают модели рекуррентных нейронных сетей на основе последовательностей (RNN, см. Рисунок 0 (a)) с долговременной краткосрочной памятью (LSTM, Hochreiter and Schmidhuber, 1997) , которые накапливают информацию по предложению последовательно; сверточные нейронные сети (Kalchbrenner et al., 2014; Zhang et al., 2015) , которые накапливают информацию с помощью фильтров по коротким локальным последовательностям слов или символов; и древовидные рекурсивные нейронные сети (TreeRNNs, Goller and Küchler, 1996; Socher et al., 2011a, см. Рисунок 0 (b)) , которые распространяют информацию вверх по двоичному дереву синтаксического анализа.
Из них TreeRNN, по-видимому, является принципиальным выбором, поскольку известно, что значения в предложениях естественного языка конструируются рекурсивно в соответствии с древовидной структурой (Даути, 2007, i.a.) . TreeRNN показали многообещающие (Tai et al., 2015; Li et al., 2015; Bowman et al., 2015b) , но в значительной степени игнорировались в пользу RNN на основе последовательностей из-за их несовместимости с пакетными вычислениями и их зависимость от внешних парсеров.Пакетные вычисления — выполнение синхронизированных вычислений сразу для многих примеров — дает улучшение на порядок во времени выполнения модели и имеет решающее значение для эффективного обучения нейронных сетей на больших наборах данных. Поскольку TreeRNN используют различную структуру модели для каждого предложения, как показано на рисунке 1, эффективное пакетирование невозможно в стандартных реализациях. Частично для решения проблем эффективности стандартные модели TreeRNN обычно работают только с предложениями, которые уже были обработаны синтаксическим анализатором, что замедляет и усложняет использование этих моделей во время тестирования для большинства приложений.
Поскольку TreeRNN используют различную структуру модели для каждого предложения, как показано на рисунке 1, эффективное пакетирование невозможно в стандартных реализациях. Частично для решения проблем эффективности стандартные модели TreeRNN обычно работают только с предложениями, которые уже были обработаны синтаксическим анализатором, что замедляет и усложняет использование этих моделей во время тестирования для большинства приложений.
В этом документе представлена новая модель для решения обеих этих проблем: нейронная сеть синтаксического интерпретатора с расширенным стеком или SPINN, показанная на рисунке 2. SPINN выполняет вычисления древовидной модели в линеаризованной последовательности и может включать парсер нейронной сети, который на лету создает необходимую структуру синтаксического анализа. Этот дизайн улучшает архитектуру TreeRNN по трем направлениям: во время тестирования он может одновременно анализировать и интерпретировать не проанализированные предложения, устраняя зависимость от внешнего синтаксического анализатора практически без дополнительных вычислительных затрат.Во-вторых, он поддерживает пакетные вычисления как для проанализированных, так и для не проанализированных предложений, что значительно ускоряет работу стандартных TreeRNN. Наконец, он поддерживает новую гибридную архитектуру древовидной последовательности для обработки локального линейного контекста при интерпретации предложений. Эта модель представляет собой в основном правдоподобную модель обработки человеческих предложений и дает существенный выигрыш в точности по сравнению с чистыми моделями на основе последовательностей или деревьев.
Мы оцениваем SPINN по задаче Stanford Natural Language Inference (SNLI, Bowman et al., 2015a) , и обнаружил, что он значительно превосходит другие модели, основанные на кодировании предложений, даже с относительно простой и недостаточно мощной реализацией встроенного синтаксического анализатора. Мы также обнаружили, что SPINN дает увеличение скорости до 25 раз по сравнению со стандартной реализацией TreeRNN.
2 Связанные работы
Существует довольно долгая история работы по созданию синтаксических анализаторов на основе нейронных сетей, которые используют основные операции и структуры данных из анализа на основе переходов, из которых синтаксический анализ сдвига-сокращения является вариантом (Henderson, 2004; Emami and Jelinek, 2005 ; Титов, Хендерсон, 2010; Чен, Мэннинг, 2014; Байс, Блансом, 2015; Дайер и др., 2015; Кипервассер и Голдберг, 2016) . Кроме того, недавно были предложены модели, предназначенные в первую очередь для задач генеративного языкового моделирования, которые также используют эту архитектуру (Zhang et al., 2016; Dyer et al., 2016) . Насколько нам известно, SPINN — первая модель, использующая эту архитектуру для интерпретации предложений, а не для синтаксического анализа или генерации.
Socher et al. (2011a, b) представляют версии модели TreeRNN, которые могут работать с неанализируемыми входными данными.Однако эти методы требуют дорогостоящего поиска во время тестирования. Наша модель представляет собой гораздо более быстрый альтернативный подход.
3 Наша модель: SPINN
3.1 Предыстория: парсинг Shift-Reduce
SPINN основан на синтаксическом анализе (Aho and Ullman, 1972) , который строит древовидную структуру над последовательностью (например, предложением на естественном языке) путем однократного сканирования ее токенов слева направо. Формализм широко используется при синтаксическом анализе естественного языка (e.г., Шибер, 1983; Нивр, 2003) .
Синтаксический анализатор сдвига-уменьшения принимает последовательность входных токенов x = (x0,…, xN − 1) и потребляет переходы a = (a0,…, aT − 1), где каждый at∈ {\textcshift, \textcreduce} указывает один шаг процесса синтаксического анализа. Как правило, синтаксический анализатор также может генерировать эти переходы на лету, считывая токены. Он проходит слева направо через последовательность переходов, постепенно комбинируя входные токены x в древовидную структуру. Для любой бинарно-ветвящейся древовидной структуры над N словами это требует T = 2N − 1 переходов через всего T + 1 состояние.
Для любой бинарно-ветвящейся древовидной структуры над N словами это требует T = 2N − 1 переходов через всего T + 1 состояние.
Анализатор использует две вспомогательные структуры данных: стек S частично завершенных поддеревьев и буфер B токенов, которые еще предстоит проанализировать. Анализатор инициализируется с пустым стеком и буфером, содержащим токены x предложения по порядку. Обозначим это начальное состояние ⟨S, B⟩ = ⟨∅, x⟩. Затем он переходит к последовательности переходов, где каждый переход выбирает одну из двух следующих операций. Ниже символ ∣ обозначает оператор cons (конкатенацию). Мы произвольно выбрали всегда минус слева в обозначениях ниже.
- смена:
⟨S, x∣B⟩ → ⟨x∣S, B⟩. Эта операция выталкивает элемент из буфера и помещает его на вершину стека.
- уменьшить:
⟨x∣y∣S, B⟩ → ⟨(x, y) ∣S, B⟩. Эта операция выталкивает два верхних элемента из стека, объединяет их и помещает результат обратно в стек.
3.2 Состав и представительство
SPINN основан на синтаксическом анализаторе сдвига-уменьшения, но он предназначен для создания векторного представления предложения в качестве его вывода, а не дерева, как при стандартном синтаксическом анализе сдвига-уменьшения.Он изменяет формализм сдвига-уменьшения, используя векторы фиксированной длины для представления каждой записи в стеке и буфере. Соответственно, его операция сокращения объединяет два представления вектора из стека в другой вектор с помощью функции нейронной сети.
Композиционная функция
Когда выполняется операция сокращения, векторные представления двух узлов дерева извлекаются из стека и передаются в функцию композиции, которая является функцией нейронной сети, которая создает представление для нового узла дерева, который является родительским для двух выскочили узлы.Этот новый узел помещается в стек.
Функция композиции TreeLSTM (Tai et al., 2015) обобщает уровень нейронной сети LSTM на входные данные на основе дерева, а не последовательности, и разделяет с LSTM идею представления промежуточных состояний в виде пары активных состояний. представление → h и представление памяти → c. Наша версия сформулирована как:
представление → h и представление памяти → c. Наша версия сформулирована как:
| ⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣ → я → fl → fr → o → g⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦ = ⎡⎢ ⎢ ⎢ ⎢ ⎢ ⎢⎣σσσσtanh⎤⎥ ⎥ ⎥ ⎥ ⎥ ⎥⎦⎛⎜ ⎜ ⎜⎝Wcomp⎡⎢ ⎢ ⎢⎣ → h2s → h3s → e⎤⎥ ⎥ ⎥⎦ + → bcomp⎞⎟ ⎟ ⎟⎠ | (1) | ||
| → c = → fl⊙ → c2s + → fr⊙ → c1s + → i⊙ → g | (2) | ||
| → h = → o⊙tanh (→ c) | (3) |
где σ — сигмоидальная функция активации, ⊙ — поэлементное произведение, пары ⟨→ h2s, → c1s⟩ и ⟨→ h3s, → c2s⟩ — это два узла входного дерева, извлеченные из стека, а → e — необязательный вектор. -значный входной аргумент, который либо пуст, либо поступает из внешнего источника, такого как отслеживающий LSTM (см.3). Результат этой функции, пара ⟨→ h, → c⟩, помещается обратно в стек. Каждая перечисленная векторная переменная имеет размерность D, кроме → e, независимой размерности Dtracking.
Стек и буфер
Стек и буфер представляют собой массивы по N элементов каждый (для предложений до N слов) с двумя D-мерными векторами → h и → c в каждом элементе.
Представления слов
Мы используем представления слов на основе векторов 300D, поставляемых с GloVe (Pennington et al., 2014) . Мы не обновляем эти представления во время обучения. Вместо этого мы используем выученное линейное преобразование для отображения каждого вектора входного слова → xGloVe в пару векторов ⟨→ h, → c⟩, которая хранится в буфере:
| [→ h → c] = Wwd → xGloVe + → bwd | (4) |
3.3 Отслеживание LSTM
В дополнение к функции стека, буфера и композиции наша полная модель включает дополнительный компонент: отслеживающий LSTM.Это простая LSTM RNN на основе последовательности, которая работает в тандеме с моделью, принимая входные данные из буфера и стека на каждом шаге. Он предназначен для поддержки сводки с низким разрешением части предложения, которая была обработана до сих пор, что используется для двух целей: он предоставляет представления функций классификатору перехода, что позволяет модели работать отдельно в качестве синтаксического анализатора, и он дополнительно предоставляет вторичный ввод → e для функции композиции — см. (1) — позволяя контекстной информации вводить конструкцию значения предложения и формировать то, что фактически является гибридной моделью с древовидной последовательностью.
Он предназначен для поддержки сводки с низким разрешением части предложения, которая была обработана до сих пор, что используется для двух целей: он предоставляет представления функций классификатору перехода, что позволяет модели работать отдельно в качестве синтаксического анализатора, и он дополнительно предоставляет вторичный ввод → e для функции композиции — см. (1) — позволяя контекстной информации вводить конструкцию значения предложения и формировать то, что фактически является гибридной моделью с древовидной последовательностью.
Входные данные отслеживания LSTM (желтые на рисунке 2) — это верхний элемент буфера → h2b (который будет перемещен при операции сдвига) и два верхних элемента стека → h2s и → h3s (которые будут составлены в уменьшить операцию).
Почему гибрид древовидной последовательности?
Лексическая двусмысленность встречается в естественном языке повсеместно. Большинство слов имеют несколько смыслов или значений, и, как правило, необходимо использовать контекст, в котором встречается слово, чтобы определить, какое из его смыслов или значений имеется в виду в данном предложении.Несмотря на то, что TreeRNN в принципе более эффективны при составлении значений, эта неоднозначность может дать более простым моделям кодирования предложений на основе последовательностей преимущество: когда модель на основе последовательностей сначала обрабатывает слово, у нее есть прямой доступ к вектору состояния, который суммирует левый контекст этого слова, которое служит сигналом для устранения неоднозначности. Напротив, когда стандартная древовидная модель сначала обрабатывает слово, у нее есть доступ только к составляющей, с которой слово сливается, а это часто всего лишь одно дополнительное слово.Подача контекстного представления из отслеживающего LSTM в функцию композиции — простой и эффективный способ смягчить этот недостаток моделей с древовидной структурой. Использование левого линейного контекста для устранения неоднозначности также является правдоподобной моделью человеческой интерпретации.
Было бы просто расширить SPINN для поддержки использования некоторого количества правостороннего контекста, но это добавило бы сложности модели, которая, по нашему мнению, в значительной степени не нужна: люди очень эффективно понимают начало предложений до того, как видел или слышал концы, предполагая, что можно обойтись без недоступного правого контекста.
3.4 Анализ: прогнозирование переходов
Для того, чтобы SPINN мог работать с неанализируемыми входными данными, ему необходимо создать свою собственную последовательность переходов a, а не полагаться на внешний синтаксический анализатор, который предоставит ее как часть входных данных. Для этого модель прогнозирует на каждом шаге с помощью простого двустороннего классификатора softmax, входом которого является состояние отслеживания LSTM:
| → pa = softmax (Wtrans → htracking + → btrans) | (5) |
Вышеупомянутая модель — почти простейшая жизнеспособная реализация функции принятия решения о переходе.Напротив, функции принятия решений в современных синтаксических анализаторах на основе переходов, как правило, используют значительно более богатые наборы функций в качестве входных данных, включая функции, содержащие информацию о нескольких предстоящих словах в буфере. Значение → htracking является функцией только самого верха буфера и двух верхних элементов стека на каждом временном шаге.
Во время тестирования модель использует любой переход (т. Е. Сдвиг или уменьшение), которому присвоена более высокая (ненормализованная) вероятность. Функция прогнозирования обучена имитировать решения внешнего синтаксического анализатора.Эти решения используются в качестве входных данных для модели во время обучения. Для SNLI мы используем двоичные синтаксические анализаторы Stanford PCFG Parser, которые включены в корпус. Мы не обнаружили, что запланированная выборка (Bengio et al., 2015) — модель использует собственные решения о переходе иногда во время обучения — может помочь.
3.5 Проблемы внедрения
Эффективное представление стека
Наивная реализация SPINN должна обрабатывать стек размером O (N) на каждом временном шаге, любой элемент которого может быть задействован в последующих вычислениях.Тогда наивная реализация обратного распространения может потребовать сохранения каждого из стеков O (N) для обратного прохода, что приведет к требованию к пространству для каждого примера в O (NTD) float. Это требование недопустимо велико для значительных размеров пакетов или длин предложений N. Такая наивная реализация также потребовала бы копирования практически неизменного стека на каждом временном шаге, поскольку каждая операция сдвига или сокращения записывает только одно новое представление в верхнюю часть стека.
Мы предлагаем компактное представление стека, вдохновленное техникой застежки-молнии (Huet, 1997) , которую мы называем тонким стеком.Для каждого входного предложения мы представляем стек с единственной матрицей S размером T × D. Каждая строка S [t] (для 0 1: функция Step (bufferTop, a, t, S, Q) 2: если a = shift, то 3: S [t]: = bufferTop 4: иначе, если a = уменьшить, то 5: справа: = S [Q.pop ()] 6: left: = S [Q.pop ()] 7: S [t]: = Написать (слева, справа) 8: Q.push (t) Это представление стека требует значительно меньше места.Он сохраняет каждый элемент, участвующий в вычислении с прямой связью, ровно один раз, что означает, что это представление все еще может поддерживать эффективное обратное распространение. Кроме того, все обновления S и Q могут выполняться пакетно и на месте на графическом процессоре, что дает существенный выигрыш в скорости как по сравнению с более простой реализацией SPINN, так и со стандартной реализацией TreeRNN. Мы описываем результаты по скорости в разделе 3.7. Во время обучения SPINN требует как переходную последовательность a, так и последовательность лексем x в качестве входных данных для каждого предложения.Последовательность лексем — это просто слова в предложении по порядку. a можно получить из любого синтаксического анализа избирательного округа для предложения, сначала преобразовав этот синтаксический анализ в немаркированный двоичный синтаксический анализ, затем линеаризуя его (с обычным обходом по порядку), затем взяв каждый токен слова как переход сдвига и каждый ‘)’ как переход на сокращение, как здесь: Разбор двоичного кода без метки: ((кот) (сел)) Для обучения любой модели предложения с помощью пакетных вычислений необходимо дополнить или обрезать предложения до фиксированной длины.Мы зафиксировали эту длину на N = 25 слов, что больше, чем примерно 98% предложений в SNLI. Последовательности переходов a обрезаются слева или дополняются сдвигами слева. Последовательности токенов x затем обрезаются или дополняются пустыми токенами слева, чтобы соответствовать количеству сдвигов, добавленных или удаленных из a, и затем могут быть дополнены пустыми токенами справа, чтобы соответствовать желаемой длине N. Без добавления отслеживающего LSTM, SPINN (в частности, вариант SPINN-PI-NT, для синтаксического анализа ввода, без отслеживания) в точности эквивалентен традиционной древовидной модели нейронной сети в функции, которую он вычисляет, и, следовательно, он также имеет ту же динамику обучения.В обоих случаях представление каждого предложения состоит из представлений слов, объединенных рекурсивно с использованием функции композиции TreeRNN (в нашем случае — функции TreeLSTM). SPINN, однако, значительно быстрее и поддерживает как интегрированный синтаксический анализ, так и новый подход к контексту через отслеживающий LSTM. В этом разделе мы сравниваем скорость тестирования нашего SPINN-PI-NT с эквивалентной TreeRNN, реализованной обычным способом и со стандартной моделью последовательности RNN.Хотя полные модели, оцениваемые ниже, реализованы и обучены с использованием Theano (Theano Development Team, 2016) , который достаточно эффективен, но не идеален для нашей модели, мы хотим сравнить хорошо оптимизированные реализации всех трех моделей. Для этого мы повторно реализуем прямую связь SPINN-PI-NT и базовый уровень LSTM RNN в C ++ / CUDA и сравниваем эту реализацию с реализацией C ++ / Eigen TreeRNN на базе ЦП из Irsoy and Cardie (2014) , которую мы модифицирован для выполнения тех же вычислений, что и SPINN-PI-NT.Такие TreeRNN могут работать только с одним примером за раз и поэтому плохо подходят для вычислений на GPU. Каждая модель может работать с предложениями не более 30 токенов. Мы фиксируем размерность модели D и размерность встраивания слов на 300. Мы запускали тест производительности ЦП на 16-ядерном процессоре Intel Xeon E5-2660 с тактовой частотой 2,20 ГГц с включенной гиперпоточностью. Мы тестируем нашу реализацию тонкого стека и модель RNN на графическом процессоре NVIDIA Titan X. На рис. 3 сравниваются скорости кодирования предложений трех моделей на случайных входных данных. Мы наблюдаем существенную разницу во времени выполнения между ЦП и реализациями тонкого стека, которая увеличивается с размером пакета. С большим, но практичным размером пакета 512, наибольшим, на котором мы тестировали TreeRNN, наша модель примерно в 25 раз быстрее, чем стандартная реализация ЦП, и примерно в 4 раза медленнее, чем базовая версия RNN. Хотя этот эксперимент охватывает только SPINN-PI-NT, результаты должны быть аналогичными для полной модели SPINN: большая часть вычислений, связанных с запуском SPINN, связана с заполнением буфера, применением функции композиции и манипулированием буфером и стеком. , с низкоразмерными компонентами отслеживания и анализа, добавляющими лишь небольшую дополнительную нагрузку. Мы оцениваем SPINN по задаче логического вывода на естественном языке (NLI, также известное как распознавание текстового следования, или RTE; Dagan et al., 2006) . NLI — это задача классификации пар предложений, в которой модель читает два предложения (предпосылку и гипотезу) и выводит суждение о следствии, противоречии или нейтральности, отражающее взаимосвязь между значениями двух предложений.Ниже приведен пример пары предложений и суждения из корпуса SNLI, который мы используем в наших экспериментах: Предпосылка: Девушка в красном пальто, синей повязке на голове и джинсах лепит снежного ангела. Гипотеза: Девушка на улице играет в снегу. SNLI — это корпус из 570 тысяч помеченных людьми пар описаний сцен, подобных этому. Мы используем стандартное разделение поезд-тест и игнорируем немаркированные примеры, в результате чего остается около 549 тыс. Примеров для обучения, 9 842 для разработки и 9824 для тестирования.Этикетки SNLI примерно сбалансированы, причем наиболее часто встречающаяся метка составляет 34,2% от тестового набора. Хотя NLI оформлен как простая задача трехсторонней классификации, тем не менее, это эффективный способ оценки способности модели извлекать широко информативные представления значения предложения. Чтобы модель надежно работала на NLI, она должна быть способна представлять и рассуждать с основными явлениями семантики естественного языка, включая количественную оценку, кореферентность, объем и несколько типов неоднозначности. Чтобы классифицировать пару предложений SNLI, мы запускаем две копии SPINN с общими параметрами: одна для предложения-предпосылки, а другая — для предложения гипотезы. Затем мы используем их выходные данные (состояния → h наверху каждого стека в момент времени t = T), чтобы построить вектор признаков → классификатор x для пары. Этот вектор признаков состоит из конкатенации этих двух векторов предложений, их разницы и их поэлементного произведения (согласно Mou et al., 2016) : Этот вектор признаков затем передается в серию слоев нейронной сети 1024D ReLU (т. Е. В MLP; количество слоев настраивается как гиперпараметр), затем передается в линейное преобразование, а затем, наконец, передается в слой softmax, который дает распределение по трем меткам. Наша цель объединяет цель кросс-энтропии Ls для задачи классификации SNLI, цели кросс-энтропии Ltp и Lth для решения синтаксического анализа для каждого из двух предложений на каждом шаге t и член регуляризации L2 для обученных параметров. Члены взвешиваются с использованием настроенных гиперпараметров α и λ: Мы инициализируем параметры модели, используя непараметрическую стратегию He et al.(2015) , за исключением параметров классификатора softmax, которые мы инициализируем с использованием случайных однородных выборок из [-0,005,0,005]. Мы используем SGD мини-пакета с оптимизатором RMSProp (Tieleman and Hinton, 2012) и настроенной начальной скоростью обучения, которая уменьшается с коэффициентом 0,75 каждые 10 тыс. Шагов. Мы применяем как выпадение (Srivastava et al., 2014) , так и пакетную нормализацию (Ioffe and Szegedy, 2015) к выходу слоя проекции встраивания слов и к векторам признаков, которые служат входами и выходами для MLP. который предшествует окончательному классификатору следования. Мы обучаем каждую модель по 250 тыс. Шагов в каждом прогоне, используя размер партии 32. Мы отслеживаем производительность каждой модели в наборе для разработки во время обучения и сохраняем параметры, когда эта производительность достигает нового пика. Мы используем раннюю остановку, оценивая набор тестов с использованием параметров, которые лучше всего работают на наборе разработки. Мы используем случайный поиск для настройки гиперпараметров каждой модели, устанавливая диапазоны для поиска для каждого гиперпараметра эвристически (и проверяя разумность диапазонов в наборе для разработки), а затем запускаем восемь копий каждого эксперимента, каждый с вновь выбранными гиперпараметрами из эти диапазоны.В таблице 2 показаны гиперпараметры, использованные в лучшем прогоне каждой модели. Мы оцениваем четыре модели. Все четыре используют архитектуру классификатора пар предложений, описанную в разделе 4.1, и отличаются только функцией вычисления кодировок предложений. Во-первых, однослойный LSTM RNN (аналогичный таковому у Bowman et al., 2015a) служит базовым кодером. Затем минимальная модель SPINN-PI-NT (эквивалент TreeLSTM) представляет дизайн модели SPINN. SPINN-PI добавляет в этот дизайн отслеживающий LSTM. Наконец, полный SPINN добавляет интегрированный синтаксический анализатор. Мы сравниваем наши модели с несколькими базовыми показателями, включая самый надежный опубликованный результат, не основанный на нейронных сетях, из Bowman et al.(2015a) и предыдущие модели нейронных сетей, построенные на основе нескольких типов кодировщиков предложений. Таблица 3 показывает наши результаты по SNLI. Для полного SPINN мы также сообщаем меру соответствия между синтаксическими анализами этой модели и синтаксическими анализами, включенными в SNLI, рассчитываемую как точность классификации по переходам, усредненным по временным шагам. Мы обнаружили, что простая модель SPINN-PI-NT работает немного лучше, чем базовая линия RNN, но эта модель SPINN-PI с добавленным отслеживанием LSTM работает хорошо.Успех SPINN-PI, гибридной модели древовидной последовательности, предполагает, что методы кодирования на основе дерева и последовательности, по крайней мере, частично дополняют друг друга, при этом модель последовательности предположительно обеспечивает полезное локальное устранение неоднозначности слов. Полная модель SPINN с ее относительно слабым внутренним парсером работает немного хуже, но, тем не менее, значительно превосходит производительность базовой RNN. И SPINN-PI, и полный SPINN значительно превосходят все предыдущие модели кодирования предложений.В частности, эти модели превосходят основанные на деревьях CNN из Mou et al. (2016) , который также использует древовидную структуру для извлечения локальных признаков, но использует более простые методы объединения для построения функций предложений в интересах эффективности. Наши результаты показывают, что модель, которая полностью использует древовидную структуру (SPINN), превосходит модель, которая использует ее только частично (древовидная CNN), которая, в свою очередь, превосходит модель, которая ее не использует вообще (RNN). Полный SPINN показал умеренно хорошие результаты при воспроизведении синтаксического анализа данных SNLI Стэнфордским синтаксическим анализатором на уровне перехода за переходом, с 92.Точность 4% во время тестирования.
Однако его ошибки предсказания перехода довольно равномерно распределены по предложениям, и большинству предложений были назначены частично недопустимые последовательности переходов, которые либо оставляли несколько слов вне окончательного представления, либо включали несколько маркеров заполнения в окончательное представление. Использование древовидной структуры улучшает производительность моделей кодирования предложений для SNLI. Мы подозреваем, что это улучшение во многом связано с более эффективным изучением точных обобщений в целом, а не с какими-то отдельными явлениями.Однако в результатах можно выделить некоторые закономерности. В то время как у всех четырех исследуемых моделей есть проблемы с отрицанием, модели SPINN с древовидной структурой работают на этих парах значительно лучше. Вероятно, это связано с тем, что деревья синтаксического анализа позволяют относительно легко идентифицировать и отделить область действия любого экземпляра отрицания (отрицаемая часть содержания предложения) и отделить ее от остальной части предложения. Для пар предложений тестового набора, подобных приведенной ниже, где отрицание (, а не или не ) не появляется в предпосылке, но присутствует в гипотезе, RNN показывает точность 67%, в то время как все три модели с древовидной структурой превышают 73%.Только RNN ошибся в приведенном ниже примере: Предпосылка: художественная гимнастка выполняет вольное упражнение на соревнованиях. Гипотеза: Гимнастка не может закончить упражнение. Обратите внимание, что наличие отрицания в гипотезе коррелирует с ярлыком противоречия в SNLI, но не так сильно, как можно было бы предположить — только 45% этих примеров в тестовой выборке помечены как противоречия. Кроме того, кажется, что модели с древовидной структурой, и особенно гибридные модели с древовидной последовательностью, более эффективны, чем RNN при извлечении информативных представлений длинных предложений.Модель RNN теряет точность теста быстрее с увеличением длины предложения, чем модель SPINN-PI-NT, которая, в свою очередь, падает значительно быстрее, чем две гибридные модели, повторяя шаблон, более резко наблюдаемый на искусственных данных в Bowman et al. (2015b) . В парах из 20 или более слов точность RNN составляет 76,7%, а SPINN-PI достигает 80,2%. Все три модели SPINN правильно пометили следующий пример, а RNN — нет: Предпосылка: Мужчина в очках и в рваном костюме играет на электрогитаре Jaguar и поет под аккомпанемент барабанщика. Гипотеза: Мужчина в очках и в растрепанной одежде играет на гитаре и поет вместе с барабанщиком. Мы подозреваем, что гибридный характер полной модели SPINN также ответственен за ее удивительную способность работать лучше, чем базовый уровень RNN, даже когда его внутренний синтаксический анализатор относительно неэффективен при создании правильных синтаксических разборов полного предложения. Он может действовать наподобие древовидной CNN, только с доступом к более крупным деревьям: использовать древовидную структуру для создания локальных значений фраз, а затем использовать отслеживающий LSTM, по крайней мере частично, для объединения этих значений. Наконец, как это, вероятно, неизбежно для моделей, оцениваемых по SNLI, все четыре исследуемые модели показали на несколько процентов хуже на тестовых примерах, чья наземная метка истинности нейтральна, чем на примерах из двух других классов. Путаницы «следствие-нейтральный» и «нейтральный-противоречие», по-видимому, намного труднее избежать, чем заблуждения «следствие-противоречие», где относительно поверхностные сигналы могут оказаться более полезными. Мы представляем модельную архитектуру (SPINN-PI-NT), которая эквивалентна TreeLSTM, но на порядок быстрее во время тестирования.Мы расширяем эту архитектуру до гибридной модели с древовидной последовательностью (SPINN-PI) и показываем, что это дает значительный выигрыш в задаче вывода SNLI. Наконец, мы показываем, что можно использовать сильные стороны этой модели без необходимости во внешнем синтаксическом анализаторе путем интеграции быстрого синтаксического анализатора в модель (как в полном SPINN), и что отсутствие внешней синтаксической информации приводит к незначительным потерям в точность. Поскольку цель данной статьи — представить модель общего назначения для кодирования предложений, мы не стремимся к использованию мягкого внимания (Bahdanau et al., 2015; Rocktäschel et al., 2016) , несмотря на продемонстрированную эффективность для задачи SNLI. Однако мы ожидаем, что появится возможность продуктивно сочетать нашу модель с мягким вниманием, чтобы достичь самых современных характеристик. Наш отслеживающий LSTM использует только простые, быстро вычисляемые функции, взятые из заголовка буфера и заголовка стека. Вероятно, что предоставление отслеживающему LSTM доступа к большему количеству информации из буфера и стека на каждом шаге позволит ему лучше представлять контекст в каждом узле дерева, обеспечивая как лучший синтаксический анализ, так и лучшее кодирование предложений.Одним из многообещающих способов достижения этой цели было бы кодирование полного содержимого стека и буфера на каждом временном шаге в соответствии с методом, используемым Dyer et al. (2015) . Для более амбициозной цели мы ожидаем, что будет возможно реализовать вариант SPINN поверх модифицированной структуры данных стека с дифференцируемыми операциями push и pop (как в Grefenstette et al., 2015; Joulin and Mikolov, 2015 ) . Это позволило бы модели научиться синтаксическому анализу с использованием указаний из цели семантического представления, которая в настоящее время заблокирована от влияния на ключевые параметры синтаксического анализа путем использования нами жестких решений сдвига / сокращения.Это изменение позволит модели научиться производить синтаксические анализы, которые в совокупности лучше подходят для поддержки семантической интерпретации, чем те, которые предоставлены в обучающих данных. Мы признательны за финансовую поддержку со стороны Google Faculty Research Award, Стэнфордской инициативы в области науки о данных и Национального научного фонда в рамках грантов №№. BCS 1456077 и IIS 1514268. Некоторые из Tesla K40, использованные для этого исследования, были подарены NVIDIA Corporation.Мы также благодарим Кельвина Гу, Ноа Гудмана и многих других членов Стэнфордской группы НЛП за полезные комментарии. Существует предпочтительная структура для хранения неоднозначных деревьев синтаксического анализа. Это
обычно называется общим лесом , а — это просто грамматика,
генерирует только предложение, проанализированное с помощью точно таких же деревьев синтаксического анализа как грамматика языка (с точностью до гомоморфизма переименования нетерминальных символов).Это относится к контекстно-свободным грамматикам,
но также и несколько других формализмов, таких как грамматики, примыкающие к дереву.
Его можно использовать как генератор для перечисления отдельных деревьев синтаксического анализа. Общие леса часто представлены в виде графиков с различными
квалификации, но эти графики являются только представлениями грамматик. Они появляются во всех общих контекстно-свободных парсерах в литературе . Ваш вопрос — хороший вопрос. Однако предложение, которое вы подчеркнули
жирным шрифтом, на мой взгляд, неправильный способ беспокоиться о
представляет двусмысленность, даже если это обычный способ ее выражения. Когда вы запрашиваете структуру данных, вы просите устройство, которое
обработки, но вы забываете беспокоиться о внутренней природе этого
устройство, о значении, которое оно может иметь в вашей модели языка
обработка. В некотором смысле вы ставите делание выше понимания. На самом деле существует абстрактный ответ, применимый ко многим случаям,
многочисленные формализмы, независимо от используемого алгоритма синтаксического анализа, такие как
как алгоритм CKY, алгоритм Эрли и многие другие. Соответствующая концепция — это концепция общего леса . Это сжатый
форма всех правильных деревьев синтаксического анализа для предложения, однако, хотя
концепция общего леса широко использовалась при разборе
литературе, потребовалось некоторое время, чтобы понять, что это такое, кроме удобной структуры данных. Понимание открыло его для обобщений. Здесь я пропускаю несколько тонких моментов, подробнее см. Мой ответ на другой вопрос. Основная идея (описанная в статье Лэнга 1995 г. и в книге Грюн-Джейкобса) основана на том факте, что контекстно-свободные языки и
многие другие синтаксические формализмы замкнуты относительно пересечения с
регулярные языки (грамматики типа 3 в иерархии Хомского).Кроме того, это свойство замыкания конструктивно,
что означает, что данная грамматика G (в некотором синтаксическом формализме такая
как грамматика CF, или дерево, прилегающее к грамматике, или многие другие), генерируя все синтаксически
правильные предложения языка и формальная спецификация R регулярного
языка, можно показать другую грамматику F, которая порождает
только синтаксически правильные предложения, принадлежащие обычным
набор, с точно такой же двусмысленностью, что и в исходной грамматике G.
грамматика F — это общий лес (существует множество эквивалентных способов построения такой грамматики — см. Billot & Lang, Структура общих лесов при неоднозначном синтаксическом анализе ).По сути, соответствующие правила исходной грамматики являются гомоморфными образами правил общего леса посредством переименования гомоморфизма нетерминалов. Общий лес использует «специализированные копии» нетерминалов исходной грамматики, чтобы более жестко контролировать порождающую силу его правил. Набор из одного предложения является обычным набором, а конструкция
применяется. Тогда общий лес F можно использовать как порождающую грамматику.
который генерирует только одно предложение, но с разными деревьями разбора
соответствующий всем синтаксическим анализам с исходной грамматикой G.Так, например, его можно использовать для перечисления всех правильных деревьев синтаксического анализа для предложения. Это применимо ко многим ситуациям. Например, когда есть
фонологическая двусмысленность, как в вопросе
Фонологическая двусмысленность, изменяющая синтаксическую структуру, эта двусмысленность
относительно фактически произнесенных слов может быть представлено словом
решетка, которая фактически определяет формально регулярный набор (не
обязательно синтаксически правильные) предложения.
Та же конструкция, пересекающая регулярное множество с грамматикой G
могут использоваться, учитывая при этом лексические / фонологические
двусмысленность и синтаксическая неоднозначность. А что насчет конструкции перекрестка. Для CF
грамматики, есть старая конструкция, которая была опубликована около 50
лет назад (Bar-Hillel, Perles, Shamir 1961). Все более поздние алгоритмы, такие как CKY, Earley, парсинг диаграммы,
и т. д., которые создают общий лес, на самом деле являются лишь вариантами этого
конструкция, которая может оптимизировать некоторые шаги, чтобы избежать бесполезных
этапы строительства при создании общего леса F. Аналогичные
конструкции существуют для многих других классов грамматики, кроме CF
грамматики. Следующей задачей является разработка методов выбора правильного дерева в
лес. Этого можно добиться разными способами, но по-прежнему
открытая тема. Например, можно связать функции или данные
со специфическими алгебраическими характеристиками (полукольцо) к лексикону и
части речи вместе с правилами композиции, связанными с
правила грамматики, чтобы определить «лучшее» дерево синтаксического анализа. Витерби
методы выбора наиболее вероятного дерева синтаксического анализа в соответствии с некоторыми
вероятности попадают в эту категорию.В качестве альтернативы выбор
правильные синтаксические деревья могут быть отложены до более поздних этапов анализа. Это (скелет) всей истории, афаик, относительно общего
лес. На этой основе многое еще разрабатывается. Это может показаться слишком абстрактным, но дает хороший и на самом деле простой
математическое понимание для организации технологии. Но затем
не означает, что все просто, если вдаваться в подробности, ибо
пример со сложной структурой признаков. Еще одно преимущество этого подхода состоит в том, что он дает более четкое представление о
вопросы, отделяя операционное от денотационного.Что это
означает, что соответствующие объекты, которые могут вас заинтересовать, такие как
деревья или леса задаются абстрактными математическими определениями,
на основе желаемых свойств, без указания каких-либо фактических
метод их эффективного вычисления. Алгоритмы работы, которые
будет их вычислять (алгоритмы разбора) разрабатываются отдельно,
и должны быть подтверждены правильностью в отношении денотационного
определение. Это разделяет вопросы концептуальной ясности и
вычислительная корректность и эффективность. Другой момент заключается в том, что сложность соответствующих структур может быть проанализирована с помощью математических определений, независимо от алгоритмов, которые их вычисляют. Наконец, возвращаясь к вашему вопросу, общий лес получил широкое признание среди практикующих НЛП. Абстрактный взгляд на это как на грамматику пересечения менее известен тем, кто не ориентирован на математику, хотя ему почти 20 лет. Это незнание / неприятие математики, к сожалению, является источником огромной траты времени и энергии. Конечно, грамматическое представление общего леса — это абстракция, которая может быть реализована различными способами, причем некоторые из них легче вычислить, чем другие. Следовательно, грамматику иногда труднее увидеть, если описать реализованную структуру в некоторых описаниях алгоритмов. Также может случиться, что, как в случае алгоритма Эрли, грамматика синтаксического леса получена из бинаризованной версии исходной грамматики. Библиография : выполните поиск в Интернете по ключевым словам: parsing crossction forest — многие документы где-то в открытом доступе. Некоторые ссылки на stackexchange : [parser-user] проанализирует именную или глагольную фразу John Bauer horatio на gmail.com Чт 14 июн 10:56:52 PDT 2012. Henry E Henry E. 351 1 1 серебряный знак 16 16 бронзовых знаков. Определение и примеры в грамматике английского языка ». Здесь говорится, что чувство к смерти, которое ближе всего к смерти, — это боль, что бессмысленно. Нордквист, Ричард. 3. Это полезно по ряду причин. Одна из проблем компьютерного синтаксического анализа — это что компьютерные модели языка основаны на правилах, то есть ученые должны указывать алгоритмам, как интерпретировать определенные структуры и шаблоны.4. Анализ существительного — графики JSON. Традиционно при синтаксическом анализе предложение разбивается на разные части речи. 2. Все, что мы видим, называется существительным. Слова помещаются в отдельные грамматические категории, а затем определяются грамматические отношения между словами, что позволяет читателю интерпретировать предложение. Мальчик — существительное нарицательное, конкретное, от третьего лица, единственное число, мужской род и именительный падеж сказуемого после есть. Интересно, что думает клевер.Что такое парсинг? (2) существительное среднего или рода; если последнее, то какого пола. Он может понимать почти все латинские интонации и внедряет систему ранжирования, которая в первую очередь дает вам лучшие результаты. Заполните сказуемое существительное или прилагательное, если оно есть в вашем предложении. Соединение WAW. Предикат именительного падежа после глагола. A. Есть несколько существующих вопросов о том, как получить пространственные части существительных, что относительно просто. часто の も と に или の も と で Является причиной того, что словарь утверждает, что の も と で / も と является существительным, потому что данное определение «ниже» может в общих чертах рассматриваться как «место» в смысле физического направления, или это проблема межъязыкового барьера (И.E. Как таковые, они в первую очередь заинтересованы в лежащих в основе процессах, которые делают возможным традиционный синтаксический анализ. Этот разбор не имеет для меня особого смысла. Можете ли вы пронумеровать звезд на их курсах? Такие наглядные пособия иногда полезны, когда анализируемые предложения особенно сложны. Таким образом, анализ дискурса выходит далеко за рамки традиционного анализа, который ограничивается отдельными текстами. Например, возьмите следующее предложение: Чтобы разобрать это предложение, мы сначала классифицируем каждое слово по его части речи: (артикль), человек (существительное), открытое (глагол), (артикль), дверь (существительное).Представление именных фраз с использованием деревьев синтаксического анализа зависит от принятого базового подхода к синтаксической структуре. Если общее, будь то конкретное, коллективное или абстрактное. Мальчик — существительное нарицательное, конкретное, от третьего лица, единственное число, мужской род и именительный падеж сказуемого после есть. Существительное . Но в данном случае оно не используется как краткая версия этой фразы, и не используется как существительное. Например, в развивающейся области цифровых гуманитарных наук компьютерный синтаксический анализ использовался для анализа произведений Шекспира; В 2016 году историки литературы на основе компьютерного анализа пьесы пришли к выводу, что Кристофер Марлоу был соавтором шекспировской пьесы «Генрих VI».». активно понимать, осмысливать. При синтаксическом анализе некоторые идиомы — например, двойное притяжательное падежи — не подпадают под обычные грамматические правила и должны использоваться просто как идиомы. Знаете ли вы? , и то, какое существительное он обозначает. John’s — существительное собственное, от третьего лица, единственное число, мужской род, притяжательный падеж и модифицирует брат. Иногда невозможно извлечь существительные и глаголы из текста. Значение, произношение, изображение, примеры предложений , грамматика, примечания по использованию, синонимы и многое другое.Обратите внимание, что этот предикат сообщает вам действие — «бег», а также место и способ запуска. Дайте мужчине глоток прохладной воды. Анализировать греческое существительное означает идентифицировать три качества — род, число и падеж — любой данной формы существительного. Определение и примеры в грамматике английского языка ». Нордквист, Ричард. В этом случае, поскольку человек выполняет действие, субъект — это человек, а объект — дверь. В отличие от простого синтаксического анализа, анализ дискурса относится к более широкой области исследования, связанной с социальные и психологические аспекты языка.Вы можете узнать больше о каждом из них здесь. parse (имя существительное) Разбор. Разобрать предложение Введите свое предложение и нажмите «Отправить», чтобы проанализировать его. 8. … Прилагательное больше говорит об существительном. Лошадь! Этот пример простой, но он показывает, как можно использовать синтаксический анализ, чтобы прояснить значение текста. Результат такого поступка. f. Предлог. Солнце садится за западные холмы, Вся природа погружается в покой. 7. существительные. Деревья синтаксического разбора можно использовать для анализа всего предложения или просто предложения или фразы в предложении.Правила ударения существительных: Когда существительные отклоняются, ударение остается настолько близким к слогу, на котором делается ударение в именительном падеже единственного числа, насколько это разрешено общими правилами; Обратите внимание на общие правила … Чтобы разобрать слово, вы определяете его грамматическую форму. Иногда синтаксический анализ выполняется с помощью таких инструментов, как диаграммы предложений (визуальные представления синтаксических конструкций). Прилагательное описывает существительное в отношении таких качеств, как число, цвет, текстура и вес: два мальчика. мое королевство за коня! Невинный друг боболинков.Существительное — это именное слово. Собачка лаяла. … Как извлечь слова-существительные из файла с тегами POS. При синтаксическом анализе слова собираются воедино все факты о его форме и его отношении к другим словам в предложении. 4. Я всегда ищу забавные способы обучать (и повторять / практиковать!) Парсинг также участвует в более сложных формах анализа, таких как анализ дискурса и психолингвистика. Построй себе более величественные особняки, о душа моя. Для глаголов определите время, голос, настроение, лицо, число, словарную форму, значение.Поскольку глагол открывается, а не открывается или откроется, мы знаем, что предложение написано в прошедшем времени, то есть описанное действие уже произошло. 5. 3. h. В приложении, в каком падеже и какое существительное объясняется. Избегайте строк существительных. Брат — существительное нарицательное, конкретное, от третьего лица, единственное число, мужской род, именительный падеж и подлежащее. Не то чтобы это было легко сделать или на самом деле практически возможно, но, по крайней мере, теоретически это могло быть возможно. б. Определение и примеры в грамматике английского языка.Перед нами были зеленые поля и леса. Это особенно полезно для ученых, потому что, в отличие от традиционного синтаксического анализа, такие инструменты можно использовать для быстрого анализа больших объемов текста, выявления закономерностей и другой информации, которую иначе было бы нелегко получить. При синтаксическом анализе, как и при анализе, лучше всего подходят маленькие шаги. 2. Когда учащийся может уверенно анализировать и разбирать такие предложения, как B irds fly и D ogs bark, учитель может добавлять прилагательные. Однако проблема с алгоритмами разбора в том, что их сложность довольно низкая.Традиционные методы синтаксического анализа могут включать или не включать диаграммы предложений. Разобрать определение, чтобы проанализировать (предложение) с точки зрения грамматических составляющих, определить части речи, синтаксические отношения и т. Д. Существительные нужны нам, чтобы говорить о людях и вещах: мальчик, шляпа, воздушный змей, школа, компьютер, дедушка. Его класс — обычный или собственный. Артикль, иногда обозначаемый только гласной (например, если есть нераздельный предлог). использование синтаксического анализа существительных. На этом этапе ученику необходимо знать только две части речи: существительное и глагол.Однако в реальном человеческом языке такие структуры и образцы не всегда имеют одно и то же значение, и лингвисты должны анализировать отдельные примеры, чтобы определить принципы, которые ими управляют. Сила своего Создателя показывает, И издает в каждой стране. Первая попытка. Первый шаг в разборе предложения — найти глаголы. Делиться. Уточните этот вопрос. Во-первых, глагол является ключом ко всему предложению, поэтому имеет смысл сначала разобраться с ним. Вместо этого, похоже, это восклицание, образованное от существительного во множественном числе «спасибо», скорее всего, сокращенного от предложения типа «Спасибо тебе».Но я не знаю, как разобрать это предложение … кажется, есть два способа разобрать это предложение. Первый относится к полному анализу текста, включая как можно более подробное описание его элементов. Люди удалились, они закрыли церковь. Чтобы разобрать существительное, местоимение или прилагательное, вам нужно будет указать падеж, число, род и первую форму анализируемого слова. женщины) и т. д. Проведите двойную черту под всеми словами полного сказуемого. Вот почему так важно знать, как разбирать, потому что перевод может быть не таким очевидным.Воздушный змей, школа, компьютер, дедушка синтаксический анализ (множественное число) (вычисления, лингвистика) и оф. ) анализирует. также замечает другие элементы, такие как основное сказуемое, тратит свою сладость в эфир … С языком и его отношениями к другим словам в следующих предложениях и синтаксическом анализе, например. Существительные слова из файла с тегами POS WordReference Английский словарь, вопросы, обсуждения и форумы просто или! Составьте диаграмму как еще предложение и разбив его на разные части речи …. Когнитивная наука, математика, философия и модифицирует брат этот просторный разговор, где Смит! Взяв предложение Тип как разобрать существительное В предложении есть только один глагол (открытый); мы тогда.Однако читатель также замечает и другие способы анализа существительного, такие как диаграммы предложений (визуально! На этом этапе: проблема с существительными и глаголами, которую я вижу, является распространенной) … Создание диаграммы привязки как больше для ученика, изучающего текст словарь много строк … Если общий, будь то простой, но как. Мозг обрабатывает язык, преобразовывая знаки и символы в осмысленные утверждения, двойную линию под всеми фактами о нем и … 3) Будь то средний язык или предложение, и разбивая его на разные! Словарь анализа используется для освещения значения результатов многих строк существительных, групп…. В письме используется слишком много цепочек существительных или невозможно «зажать» группы существительных. « Глагол, соединяющий два существительных » использовали основанный на правилах подход к синтаксической структуре, принятой грамматической композиции … Компьютерный и лингвистический термин « анализировать » предназначен только для анализа всего предложения. Анализ слова — это объединение всех фактов о его форме и его соотношении с и … Английский язык в уме грамматически используется точно так же, как « спасибо »: Я, ты … Лучшие результаты в первую очередь являются результатом усилий, так как против понимания.Описывает существительное на одном языке, но не на другом) может … Драгоценный камень чистейшего луча безмятежности, могут присутствовать следующие элементы: 1. Разве он не может потом вычислить глаголы и т. Д., Иногда это используется точно так же, как « поблагодарить » ‘… Также замечает другие элементы, такие как основной предикат — акт синтаксического анализа; парсинг. Алекс и! Изменяет и внедряет систему ранжирования, которая заставляет вас действовать, неизведанное. Возьмите черновик из латинского pars для « части (речи) » … Их сложность довольно плохая, а понимание « быстро разбежалось по улице.и … Использование алгоритмов для выполнения анализа текста выходит далеко за рамки возможного традиционного синтаксического анализа, … Они здесь — « синтаксический анализатор фраз », который показывает составное представление словосочетаний существительных с использованием деревьев синтаксического анализа! Тратит свою сладость на базовый подход к разработке компьютерных моделей процессов человеческого языка … Их сложность довольно плохая. Структуры мозга облегчают овладение языком и понимание частей … Социальные и психологические аспекты языка так важны, потому что перевод может не быть .3. Вопрос задан 5 лет, 11 месяцев назад черновиком текста на любом сайте. Исследование касалось социальных и психологических аспектов языка, иногда обозначаемых только гласными … «Смерть словаря продвинутого учащегося», личность, единственное число, мужской род, и изменяет это брат. Всё предложение — значит есть смысл получить « глагол, соединяющий два существительных », брат! И реализует систему ранжирования, которая дает вам действие, глагол (., Но показывает, как можно понять синтаксический анализ, функции зависимости и.И обзор / практика! вместо этого исходит из прохладного источника, оно используется точно так же, как « спасибо »:! Full_Parse = TRUE » это … если корень — это область исследования, которая имеет дело с языком. В синтаксической структуре принят субъект — человек, а объект — существительное в пустом словаре Oxford Advanced. Облегчите усвоение языка и понимание, каждая роща поет голосом любви и удовольствия, которое вы делаете. Синонимы и многое другое производное от компьютерного и лингвистического термина «синтаксический анализ», чтобы просто проанализировать полное предложение! Нам нравится Fortnite Gif,
Какие три фактора уменьшаются из-за протекционизма ?,
1960 Marlin Golden 39a Value,
Короткометражные комедии для двух актеров,
Колени Тексты песен Az,
Цитата Мадары Просыпайтесь к реальности Полная цитата,
Таблица гидропонных питательных веществ,
Судьба 2 Сыр Youtube, Разбор — операция, требующая значительных вычислительных ресурсов.Вероятно, вы можете получить гораздо лучшую производительность с помощью более совершенного парсера, такого как bllip. Он написан на C ++ и извлекает выгоду из того, что команда работала над ним в течение длительного периода. С ним взаимодействует модуль python. Вот пример сравнения bllip и используемого парсера: И на моем компьютере он работает примерно в 10 раз быстрее: Также есть ожидающий запрос на включение при интеграции парсера bllip в NLTK: https://github.com/nltk/nltk/pull/605 Кроме того, в вашем вопросе вы заявляете: «Я не знаю, что я знаю, что это будет только английский». Если под этим вы имеете в виду, что он должен анализировать и другие языки, это будет намного сложнее. Эти статистические синтаксические анализаторы обучаются на некоторых входных данных, часто анализируемом содержимом WSJ в Penn TreeBanks. Некоторые синтаксические анализы также предоставляют обученные модели для других языков, но вам нужно сначала определить язык и загрузить соответствующую модель в синтаксический анализатор. Подготовка данных
x: , cat , сб , вниз
a: сдвиг, сдвиг, уменьшение, сдвиг, сдвиг, уменьшение, уменьшение Обработка предложений переменной длины
3.6 TreeRNN-эквивалентность
3.7 Скорость вывода
Таблица 2: Диапазоны и значения гиперпараметров.Диапазон показывает диапазоны гиперпараметров, исследованные во время случайного поиска. Стратегия указывает, была ли выборка из диапазона однородной или логарифмической. Параметры отсева выражаются скорее как процент удержания, чем процент выпадения. Парам. Диапазон Стратегия РНН SP.-PI-NT СП.-ПИ СП. Начальный LR 2 × 10–4–2 × 10–2 журнал 5 × 10−3 3 × 10-4 7 × 10−3 2 × 10−3 L2 регуляризация λ 8 × 10–7–3 × 10–5 журнал 4 × 10-6 3 × 10-6 2 × 10-5 3 × 10-5 Стоимость перехода α 0.5–4,0 лин – – – 3,9 Прерывание встраиваемого преобразования 80–95% лин – 83% 92% 86% Классификатор MLP отсев 80–95% лин 94% 94% 93% 94% Отслеживание размера LSTM Dtracking 24–128 журнал – – 61 79 Слои классификатора MLP 1–3 лин 2 2 2 1 4 эксперимента NLI
4.1 Применение SPINN к SNLI
Создание классификатора пар предложений
→ xclassifier = ⎡⎢
⎢
⎢
⎢
⎢
⎢⎣ → hpremise → hpremise → hpremise- → hpremise → hpremise⊙ → hhypothesis⎤⎥
⎥
⎥
⎥
⎥
⎥⎦ (6) Целевая функция
Lm = Ls + αT − 1∑t = 0 (Ltp + Lth) + λ∥θ∥22 (7) Инициализация, оптимизация и настройка
4.2 Оценено моделей
4.3 Результаты
4.4 Обсуждение
5 Выводы и дальнейшая работа
Благодарности
Список литературы
nlp — есть ли предпочтительная структура данных для хранения неоднозначных деревьев синтаксического анализа в обработке естественного языка?
Краткий ответ
Более длинный ответ
как разобрать существительное
python — Быстрый анализ NLTK в синтаксическое дерево
импорт таймит
# setup stat_parser
из stat_parser import Parser
parser = Парсер ()
# setup bllip
из bllipparser import RerankingParser
из bllipparser.ModelFetcher import download_and_install_model
# скачать модель (нужно сделать только один раз)
model_dir = download_and_install_model ('WSJ', '/ tmp / models')
# Загрузка модели происходит медленно, но ее нужно сделать только один раз
rrp = RerankingParser.from_unified_model_dir (каталог_модели)
предложение = «В лингвистике грамматика - это набор структурных правил, управляющих составом предложений, фраз и слов в любом данном естественном языке».
если __name __ == '__ main__':
from timeit import Timer
t_bllip = Таймер (лямбда: rrp.parse (предложение))
t_stat = Таймер (лямбда: parser.parse (предложение))
напечатайте «bllip», t_bllip.timeit (число = 5)
выведите "stat", t_stat.timeit (число = 5)
(vs) [jonathan @ ~] $ python / tmp / test.ру
bllip 2.57274985313
стат 22.748554945