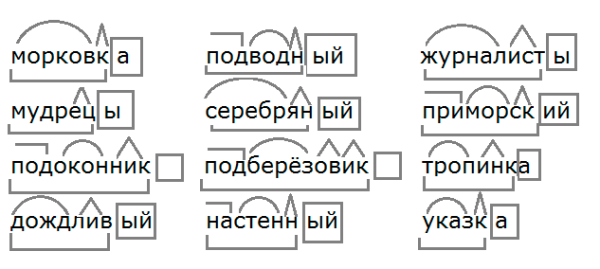
Урок русского языка по теме «Разбор по составу глаголов». 4-й класс
Задачи:
- Формировать умение разбирать по составу слова, принадлежащие к разным частям речи.
- Познакомить с суффиксами глагола, которые не входят в основу слова.
- Закреплять умение разбирать глаголы по составу.
Оборудование:
- Учебники: М.Л.Каленчук, Н.А.Чуракова, Т.А.Байкова Русский язык 4 класс, 3 часть; М.Л.Каленчук, Н.А.Чуракова, О.В.Малаховская Русский язык 4 класс, 2 часть/Изд-во Академкнига/Учебник.
- Тетрадь с печатной основой: Т.А.Байкова Русский язык 4 класс, 2 часть.
- Заготовки опорных таблиц «Порядок разбора глагола» http://files.school-collection.edu.ru/dlrstore/1294a0b7-487d-4a39-b436-a28836c47aab/%5BNS-RUS_4-16%5D_%5BTQ_039%5D.swf (Приложение 1).
- Презентация «Разбор по составу глаголов» (Приложение 2)
Ход урока
I.
II. Актуализация знаний учащихся о частях речи, о составе слов.
1. Картинный диктант (капуста, морковь, картофель), (можно использовать галерею интерактивной доски, если есть возможность).
– Запишите слова в столбик (1 человек у доски).
– Поставьте ударение, подчеркните букву, которую нужно запомнить.
2. Классификация слов.
– Что общего у этих слов? (ударение падает на первый слог, относятся к группе ОВОЩИ, часть речи – существительное).
– Разберите их по составу. Что можно сказать о составе? (состав слов одинаковый)
– Какая схема соответствует составу этих слов? (1 человек чертит схему на доске: )
– Какие постоянные признаки можем определить у существительных? (род, склонение) Укажите их.(1 человек у доски).
Какое слово может быть лишним? Почему? (картофель – мужского род; морковь
начинается с буквы М, запоминаем букву О; капуста – нет в написании Ь).
– Чем различаются слова? (склонением)
3. Словообразование прилагательных.
– От данных слов образуйте прилагательные и запишите их рядом с существительными. (у доски работу продолжает другой ребёнок)
На доске:
Капуста капустный
Морковь – морковный
Картофель – картофельный
– Разберите их по составу. С помощью какой части слова образовались прилагательные? (с помощью суффикса)
– Что называется суффиксом?
– Кто сможет назвать, как называется данный способ образования слов? (суффиксальный)
– Покажите стрелкой, какое слово дало жизнь другому.
На доске:
Капуста —> капустный
Морковь —> морковный
Картофель —> картофельный
III. Проблемная ситуация.
– Как вы думаете, эти слова к какой части речи относятся?
На доске:
– Как вы догадались? (по суффиксам и окончаниям) Что называется глаголом?
IV. Постановка учебной задачи.
Постановка учебной задачи.
– С какой частью речи мы будем работать на уроке? (ответы детей)
– Глядя на схемы, определите, чему будем учиться на уроке? (разбирать глаголы по составу)
V. Сообщение темы урока.
Разбор по составу глаголов (Приложение 2, слайд 2)
VI. Работа над новым материалом.
а) проблемная ситуация
Чтение интриги учебника 3 часть стр. 60
б) работа с правилами и заполнение таблицы (работа с учебником 3 часть стр.60-61)
– С чего начинаем разбор глаголов? (слайд 3) (выделить суффиксы -СЯ, -СЬ, если они есть)
1. Выделить -СЯ, -СЬ. (слайд 4)
– Что должны определить дальше? (Определить, в какой форме стоит глагол)
2. Определить, в какой форме стоит глагол.(слайд 5)
– Читаем первый пункт правила и заполняем таблицу.(слайды 6, 7)
– Вспомните сами, что выделяем дальше во всех глагольных формах? (основу) (слайд8)
– Читаем второй и третий пункт правила. Закончите заполнение таблицы сами.
(проверка – слайды 9, 10)
Закончите заполнение таблицы сами.
(проверка – слайды 9, 10)
в) проблемная ситуация
– Можете ли вы определить, в какой форме стоят глаголы?(возвращение к записи со схемами на доске)
– Найдите ошибки в разборе.(исправляют ошибки у доски)
г) подбор глаголов к схеме и разбор по составу
– Пользуясь словарём, подберите слова к схемам. Каким словарём нам удобно пользоваться?(обратным)
– В словаре есть подсказка, глагольные суффиксы маркированы синим цветом.
– Все слова в словарях в какой форме? (в начальной форме)
– Значит, к каким схемам сможем подобрать слова? (к 1, 3, 4)
– Запишите слова к этим схемам, разберите их по составу.(у доски могут работать от 1 до 2 человек в зависимости от места на доске и от способностей учащихся; остальные ученики могут работать в парах )
– К пятой схеме Маша подобрала слово читали и разобрала его вот так:
– Согласны ли вы? Почему?
д) работа с учебником
– Чтобы ответить на этот вопрос, откройте учебник на странице 62 и прочитаем,
какой разговор происходил на уроке в селе Мирном.
Запись в тетрадь: (слайд 11)
читаю
читать
читал
е) чтение правила на стр.62 учебника
– Так почему Маша разобрала так? (суффикс – Л – в основу не входит)
YII. Закрепление изученного материала
а) Упражнение 54 на стр. 61 учебника (работа выполняется по цепочке с комментированием у доски)
б) Самостоятельная работа (можно взять текст из упр.181 на стр. 180 учебника)
– Из данного текста выпишите глаголы, разберите их по составу.(слайд 12 )
– Кто справится с работой раньше, запишите первое предложение, разберите его по членам предложения. Укажите части речи.
VIII. Домашнее задание
– Дома выполнить упр.28 на стр. 31-32 тетради, карточку-опору наклеить на картон.
IX. Обобщение
– Чему учились на уроке?
– Что узнали нового? (слайд 13)
– Поднимите руку тот, кто понял, как нужно разбирать глаголы по составу.
X. Итог урока
– Кто доволен своей работой, поаплодируйте себе.(варианты рефлексии могут быть разные) (слайд 14)
Как разобрать по составу слова проиграл, проиграла, проиграли?
Как сделать морфемный разбор слов проиграл, проиграла, проиграли?
Как выполнить разбор по составу слов проиграл, проиграла, проиграли?
3
Azamatik
Ответы (6):
Share
3
Что сделал/что сделала/что сделало? — проиграл/проиграла/проиграло.
Это глаголы совершенного вида, прошедшего времени, единственного числа и в третьем лице (он/она/оно).
Выполним их морфемный разбор (разбор по составу) этих слов:
Подберем к ним однокоренные слова: играть, выиграть, игрок, играющий, игровой, игра, игривый и тд. Итак, корнем всех трех слов (проиграл/проиграла/проиграло) является -игр-.
Выделим и суффикс прошедшего времени -л- и глагольный суффикс -а-, которые присутсвуют во всех трех глаголах. Также они имеют и приставку -про-.
Также они имеют и приставку -про-.
Теперь окончание слов: в слове «проиграл» окончание нулевое, в глаголе «проиграла» окончание -а-, а в слове «проиграло» окончание -о-.
Основой же их будет -проигра-.
Share
1
В этом вопросе нужно разобрать по составу слова: проиграл, проиграла, проиграли.
Слово проиграл. Основа этого слова ПРОИГРА. Слово проиграл является глаголом. Оно состоит из приставки ПРО, корня ИГР, суффикса А, суффикса Л и нулевого окончания. В итоге имеем схему: приставка — корень — суффикс — суффикс — нулевое окончание, а именно ПРО — ИГР — А — Л — _.
Слово проиграла. Основа этого слова ПРОИГРА. Слово проиграла является глаголом. Оно состоит из приставки ПРО, корня ИГР, суффикса А, суффикса Л и окончания А. В итоге получается схема: приставка — корень — суффикс — суффикс — окончание, а именно ПРО — ИГР — А — Л — А.
В итоге получается схема: приставка — корень — суффикс — суффикс — окончание, а именно ПРО — ИГР — А — Л — А.
Слово проиграли. Основа этого слова ПРОИГРА. Слово проиграли является глаголом. Оно состоит из приставки ПРО, корня ИГР, суффикса А, суффикса Л и окончания И. В итоге получается схема: приставка — корень — суффикс — суффикс — окончание, а именно ПРО — ИГР — А — Л — И.
Share
1
Проиграл, проиграла, проиграли — это формы прошедшего времени глагола «проиграть» (соответственно, единственное число мужского и женского рода и множественное число).
Единственное, чем различаются эти слова с точки зрения морфемного состава, — окончания. В первом глагола окончание нулевое, во втором — -а, в третьем — -и. Проверкой являются эти же формы (их сравнение).
Корень слов -игр- (однокоренные слова — игра, игровой, игрушка, игорный, разыграть и др. ; наблюдаются чередования о\ноль звука, и\ы)
; наблюдаются чередования о\ноль звука, и\ы)
Приставка про- (проверяется отсечением от корня: играла, а также заменой другими приставками: выиграла, обыграла, разыграла; приставка встречается также в словах прогуляла, пропустила и др.)
Суффикс -а- (словообразующий, глагольный, как в словах читала, писала и др.)
Суффикс -л- (формообразующий, суффикс прошедшего времени глагола).
Основа слов проиграл- (не входит формообразующий суффикс и окончание).
Share
1
Три глагола прошедшего времени Проиграл, Проиграла и Проиграли являются однокоренными, поскольку представляют собой всего лишь формы прошедшего времени глагола Проиграть мужского и женского рода единственного числа и множественного числа. От глагола Проиграть они образованы с помощью суффикса прошедшего времени -Л-, который является формообразующим. Окончаниями у этих глаголов будет флексии -А, -И и нулевое окончание у глагола Проиграл. Однокоренными словами оказываются Проиграть-Выиграть-Отыграть-Играть-Игрок-Игра. Корнем глаголов будет морфема -ИГР-. Также выделим общую приставку ПРО-, а также суффикс инфинитива -А-.
Корнем глаголов будет морфема -ИГР-. Также выделим общую приставку ПРО-, а также суффикс инфинитива -А-.
Получаем: ПРО-ИГР-А-Л_/ПРО-ИГР-А-Л-А/ПРО-ИГР-А-Л-И (приставка-корень-суффикс-суффикс-нулевое окончание/окончание), ПРОИГРА-.
Share
Слова «проиграл», «проиграла» и «проиграли» являются глаголами в прошедшем времени, имеющие одинаковую основу — «проигра», но разные окончания — нулевое, «а», «и».
Обозначим корень — «игр» (играть, проиграл, игротека)
Имеем приставку — «про» (проплавал, проговорился, проснулся)
Суффикс формообразующий — «л» и суффикс словообразующий — «а»
Графический разбор слов — про/игр/а/л_, про/игр/а/л/а, про/игр/а/л/и
Скрипач проиграл свою любимую мелодию.
Любимая команда проиграла важный матч.
Сюжет будущей песни, сначала, мы проиграли у себя в голове.
Share
Это совершенно нетрудно сделать, тем более, что слова однокоренные и почти ничем не отличаются друг от друга, и они все прошедшего времени.Корень — единственный -игр-, приставка единственная — про,суффикс единственный — а, окончание -л, ла, ли.Основа — проигра.
Дидактические карточки по русскому языку для 3 класса. «Школа России». | Учебно-методическое пособие по русскому языку (3 класс):
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение1.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Одинок… капля д(а,о)ждя отвесно упала в воду, и от неё пошли тонк… круги. Вся в(а,о)да покрылась маленькими кругами. Слабый звон поплыл над омутом. Шёл тих.. летн… дождь. Далеко в разрывах мягких туч светило солнце. Роща стряхивает остатки н(а,о)чного сна. К пяти часам в роще кипит обычн… летн… жизнь.
Шёл тих.. летн… дождь. Далеко в разрывах мягких туч светило солнце. Роща стряхивает остатки н(а,о)чного сна. К пяти часам в роще кипит обычн… летн… жизнь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 2.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж
В нашем саду построили хрустальн… дворец. В нём под стеклянной крышей живут растения. В самый лютый холо(т,д) здесь т(и,е)пло. Под потолком трубы, из них брызжет мелк… дождик. Над каждой гря(т,д)кой электрическ…солнце. Его света хватает и для огурцов, и для помидоров.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 3.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Летн… солнце коснулось косыми лучами верхушек сонной рощи. Первыми заметили конец ночи птиц(и,ы). Вот одна ро(п,б)ко попробовала свой голосок, за ней другая, третья. Скоро вся роща ут(а,о)нула в радостном птичьем пении. Роща стряхивает остатки ночного сна. К пяти часам в роще кипит обычн… летн… жизнь.
Первыми заметили конец ночи птиц(и,ы). Вот одна ро(п,б)ко попробовала свой голосок, за ней другая, третья. Скоро вся роща ут(а,о)нула в радостном птичьем пении. Роща стряхивает остатки ночного сна. К пяти часам в роще кипит обычн… летн… жизнь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 4.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Зачем поливают цветы?
Цв(и,е)там и всем растениям нужны воздух, вода, т(и,е)пло и пища. У разных растений и вкусы и аппетиты разные. Но все они употребляют только жидкую пищу – «супы». А варятся эти «супы» так: попадая в почву, вода растворяет находящиеся в ней минеральные соли и питательные вещества. Этот раствор и «пьют» растения.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 5.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Задул крепк…, но попутн… ветер. Лицо спокойн…, но не строг… . Взор не злой, но пронзительн… . Тайга казалась безмолвной и таинственной. В берёзовой роще соловьи ищут свою добычу.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 6.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Ещё нет и четырёх часов, а летн… солнце коснулось лучом верхушек сонной рощи. Первыми заметили к(а,о)нец ночи птиц(ы,и). Вот одна ро(п,б)кая попробовала свой г(а,о)лосок, за ней другая, третья. Скоро вся роща ут(а,о)нула в радостном пении птиц.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 7.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Весенним утром в зелени деревьев и в траве услышишь гудение жуков, увидишь бабочек. Эти насекомые и гусеницы уничтожают листья, портят пл(а,о)ды, поедают корни растений.
Птицы борются с вр(и,е)дителями и спасают урожай от гибели С раннего утра до позднего вечера раздаётся песня скворушки.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 8.
Спиши. Выдели окончания имён прилагательных; определи у них род и число.
Осенн… небо, прохладн… ночь, тих… речка, вкусн… мед, топк… берег, весенн… лужа, криклив… стриж, острый нож, гибк…
тело, мохнат… шмель, прелестн… дитя, болотист… местность, капустн… лист, прекрасн… цветок, яростн… ветер, чудесн… событие, звёздн… небо.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 9.
Спиши. Выдели окончания имён прилагательных; определи у них род и число.
Известн… писатель, верн… друг, внимательн… часовой, прошлогодн… листва, напрасн… похвала, зловещ… закат, летн… осадки, рыж… девочка, зимн… убежище, интересн… сказка, долгожданн… встреча, добр… слово, лесист… местность, нов… платье, пестр… оперение, прохладн.. день, на тёплую печь, устная речь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 10.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
С раннего утра до позднего вечера, от зимнего морозца, у темного ледяного поля, лучи яркого весеннего солнца, у свежего пахучего сена, вдоль ближней рощи, до пятнистого оленя, на красивую брошь, до соседней деревни, у весеннего ручья, на интересный репортаж, в ненастный вечер.
с.род – ое, ее; ж.род — ая, яя;
м. род- ый, ий, ой; множ.ч. – ые, ие.
род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 11.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж
К скорому утреннему поезду, по нежному запаху, по соседней деревне, по широкой аллее, к зыбкому ветхому мостику, к вечернему чаю, от огромного висячего моста, к теплому течению, по снежней тропинке, с мягкой зимой, в тёмную полночь, на зимней дороге, с крепкой веревкой, на верхний этаж, с весёлой песней, радостный праздник.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 12.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Около правого берега, с ясного неба, до новой площади, с дальнего озера, у красного шарфа, для младшего брата, около крайней осины, на чёрную тушь, с высокой колокольни, возле развесистого дерева, в соседний гараж, на гладком зеркале, в гаражном замке, от яркого солнца.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 13.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
С грустным настроением, через высокий камыш, в ночную тишь, для сладкого компота, про круглое озеро, в мягком купейном вагоне, на несъедобное растение, в дальнюю дорогу, с горьким привкусом, из осинового полена, о тончайшей ткани, на задней стенке, в осенний день, умного человека, чёрным облаком, честный поступок.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 14.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Через густую рожь, в зеленом уборе, с медовым запахом, о говорливом ручье, в тенистой аллее, в скромном наряде, с тонким чутким слухом, на тёплую печь, со свежим вареньем, из зимнего леса, в серебристом инее, о красивом снежном наряде, зоркий страж, в дремучем лесу, за ближней деревней, в здешнем магазине, по опасному пути.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 15.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Из полного кувшина, от весеннего дня, по свежей зелени, от зеленой веточки, из снежного поля, к ближнему поселку, по свежему следу, на горячий калач, по ажурному панно, к солдатской каше, через детский мяч, о тусклом шаре, субботним вечером, к вкусному обеду, перед зимней ночью, на пасхальный кулич.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 16.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
В морозном воздухе, на вечернем небе, с зеленоватым светом, в аккуратный чертёж, в теплой меховой шубке, на красивую вещь, для рабочей лошади, в интересном рассказе, со вчерашней газетой, о весенней погоде, к вареной курице, с радостным чувством, с высокой горы, на интересную экскурсию, в зимние сумерки.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 17.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
У голодного серого волка, в тёмную глушь, из тонкого льна, к мягкой постели, по мокрому песку, из тонкой нити, в дремучий лес, к высокому крыльцу, из вишнёвого варенья, высокий бородач, в недавнюю встречу, зимняя сказка, ужасное событие, по снежной дороге, в тёплой шу(п,б)ке.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 18.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
За дальним сосновым лесом, на светлой лужайке, в дремучем лесу, поздним вечером, под серым густым туманом, по росистой траве, о бескрайнем просторе, у клейкого листочка, в горячий сургуч, местного жителя, в счастливый день, в дальний путь, на пыльном полу, о пшеничном каравае, большая течь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 19.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
На солнечный луч, на парусном фрегате, из-за пасмурного дня, на пассажирском судне, по красивой вазе, о полярном медведе, около зеленого бора, на ярком солнце, с поспешным ответом, на узеньком диване, в ветхом домике, в медвежьей берлоге, у здешней речки, с открытой дверью, в ненастную погоду, серьёзное чувство, шустрая мышь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 20.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Через высохшее озеро, про хвастливого зайца, с хрупким цветком, около хрустального блюда, зябкая дрожь, по чистому пруду, о холмистом поле, без черного ящика, с сыпучим песком, на соседнее облако, под колючую елку, про вчерашнее событие, для устного ответа, крылатые вестники, парусный флот, в красный кирпич.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 21.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
На сильном утреннем морозе, в морозном воздухе, по длинному широкому оврагу, гнусная ложь, с добрым словом, с ближнего ржанова поля, под южным жгучим солнцем, по зыбкому ветхому мостику, на бескрайней равнине, от громкого стука, в ближнюю деревню, верный товарищ, у шипящей змеи, в жаркую летнюю пору, прелестный цветок, на весёлый праздник.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 22.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
С осенним листиком, к легкому плащу, у ласкового котенка, о древнем строении, про круглое озеро, на серебристое облако, взрослая дочь, у сентябрьского утра, про секретное донесение, в дремучем лесу, от горячего доброго слова, в тёплый мякиш, с могучего дерева, опасное решение, на зелёное пастбище.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 23.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
К доброму молодцу, о дорожном происшествии, без сливочного масла, в крайнем домике, в жидкое тесто, о заботливом отце, на зеленое дерево, к запретному чулану, в позднее утро, на весеннем солнце, с капустным листом, про редкое украшение, вкусный пирог, мощный тягач, раннее утро, к вечернему поезду, за синим морем, на тёплую печь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 24.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
В чистое море, хмурым утром, в цепком взгляде, у хлебного поля, о здешнем жителе, с ценным подарком, для янтарного ожерелья, при ярком свете, о ясном солнышке, в утреннюю зарю, в дальнюю дорогу, в звёздную ночь, радостный праздник, известное событие, ловкий циркач, в знойную сушь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 25.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Через рыхлое поле, вокруг роскошного торта, к робкому человеку, про редкое изделие, перед веселым праздником, через ветвистое дерево, на ледяную гладь, в дальнее поле, от масляного пятна, с теплым ветром, нужная мелочь, под медным тазом, чудесный малыш, около местного театра, к старинному замку, в ненастную ночь, от честного друга, на небесном своде.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 26.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Перед долгим путешествием, известный трубач, на маленьком острове, без медного кольца, майским утром, в синюю ленту, от горячей воды, в весенний разлив, отрывистая речь, приезжий человек, у похожей машины, в великий день, перед жгучей крапивой, в палящий зной, чудесная сказка, ужасный поступок, из устного ответа.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 27.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
На дальнюю пустошь, о сказочном чудовище, под скалистым берегом, к прелестному малышу, по капустной грядке, для вечерней песни, на влажную землю, в зимнюю пору, с длинной удочкой, в низкий шалаш, в темном. переулке, вокруг тонкого льда, к трусливому зайцу, за колючей проволокой, по хрупкому льду, честный поступок, в ненастную погоду, по узкой лестнице.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 28.
Спиши. Выдели окончания имён прилагательных; определи у них род, число, падеж.
Вокруг белоснежного замка, о радостном дне, после чудесного утра, о робком создании, умелый экипаж, на прелестном цветке, об опасном человеке, для сердечного поздравления, о вкусной пище, на чудесной картине, около стройной сосны, с разноцветными огнями, к высоким горам, на холодном стекле, легкие снежинки, в последнее время, скорая помощь.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 29.
Запиши словосочетания, дописывая окончания имён прилагательных, в зависимости от рода и числа.
друзья
интересн… фильм
событие
книга
поступки
честн….. друг
подруга
сообщение
Составь и запиши предложение с любым словосочетанием.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 30.
Запиши словосочетания, дописывая окончания имён прилагательных, в зависимости от рода и числа.
листья
капустн… салат
грядка
рагу
писатели
известн… театр
сообщение
молодёжь
Составь и запиши предложение с любым словосочетанием.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 31.
Запиши словосочетания, дописывая окончания имён прилагательных, в зависимости от рода и числа.
цветок
прелестн… шляпка
дитя
букеты
ландыши
прекрасн… роза
гладиолус
оформление
Составь и запиши предложение с любым словосочетанием.
с.род – ое, ее; ж.род — ая, яя;
м.род- ый, ий, ой; множ.ч. – ые, ие.
Упражнение 32.
Запиши словосочетания, дописывая окончания имён прилагательных, в зависимости от рода и числа.
мороженое
вкусн… пирог
каша
салаты
платья
чудесн… кофточка
пейзаж
окно
Составь и запиши предложение с любым словосочетанием.
Формирование у детей старшего дошкольного возраста с общим недоразвитием речи навыков чтения посредством использования звукового и слогового анализа и синтеза | Коррекционная педагогика
Формирование у детей старшего дошкольного возраста с общим недоразвитием речи навыков чтения посредством использования звукового и слогового анализа и синтеза
Автор: Владимирова Валентина Николаевна
Организация: МБДОУ д/с комбинированного вида № 7 «Сказка»
Населенный пункт: Краснодарский край, пос. Мостовской
Овладение грамотой представляет собой чрезвычайно важный этап в умственном и речевом развитии ребенка. Обучаясь чтению, ребенок овладевает совершенно новыми для него формами умственной и языковой деятельности, которые для дошкольника не всегда посильны. Без представления о количестве и порядке звуков в слове ребенок не может правильно писать, а назвав по порядку буквы, но, не умея соединять вместе соответствующие им звуки, не овладеет чтением.
У детей с общим недоразвитием речи в первую очередь возникают трудности в формировании фонематического восприятия, то есть, способности воспринимать и различать звуки речи (фонемы), способности к их анализу и синтезу.
Если в процессе чтения не происходит полноценного перевода с письменного языка на образный, чтение не доставляет ребенку удовольствия, так как не приводит к полному пониманию и весьма мало способствует приобретению новых знаний и умственному развитию. Иначе говоря, должно наступить состояние готовности к усвоению грамоты.
Подготовка детей к обучению грамоте способствует общеречевому развитию дошкольников, помогает им овладеть богатством родного языка. В результате, знакомство со звуковой стороной слова воспитывает интерес к родному языку. Это очень важно для того, чтобы дети, став школьниками, с любовью изучали родной язык, освоение которого духовно обогащает человека. Но, чтобы понять красоту родного языка ребенок должен уметь слышать и воспринимать смысл высказанного.
Это очень важно для того, чтобы дети, став школьниками, с любовью изучали родной язык, освоение которого духовно обогащает человека. Но, чтобы понять красоту родного языка ребенок должен уметь слышать и воспринимать смысл высказанного.
У детей с общим недоразвитием речи процесс развития и формирования навыков чтения затруднен в связи с нарушением восприятия как фонематического, так и фонетического. Так же эти дети имеют вторичные отклонения в развитии психических процессов (восприятия, памяти, внимания, мышления, воображения), что создает дополнительные затруднения в овладении навыками звукового и слогового анализа и синтеза для дальнейшего обучения чтению.
Общее недоразвитие речи – дефект, при котором у ребенка с нормальным слухом и первично сохранным интеллектом оказываются несформированными основные компоненты языковой системы. Ведущее место в коррекции общего недоразвития речи многие исследователи Р.Е.Левина, Г.А.Никашина, Г.А.Каше, Р.М.Боскис и другие отводят формированию фонематического восприятия, то есть способности воспринимать и различать звуки речи. Огромный практический опыт авторов подтверждает, что развитие фонематического восприятия положительно влияет на формирование всей фонетической стороны речи. С помощью выработки артикуляционных навыков можно добиться лишь минимального эффекта.
Огромный практический опыт авторов подтверждает, что развитие фонематического восприятия положительно влияет на формирование всей фонетической стороны речи. С помощью выработки артикуляционных навыков можно добиться лишь минимального эффекта.
Многочисленными исследованиями Н.А.Никашиной, А.К.Марковой, Г.И.Жаренковой, Л.Ф.Спировой, Г.А.Каше и другими было подтверждено предположение о том, что в преобладающем большинстве случаев причиной дисграфии и дислексии является несовершенство фонематического восприятия и, как следствие, несформированность навыков звукового анализа и синтеза.
Общепринятая в России аналитико-синтетическая методика обучения чтению опирающаяся на теоретические и практические разработки К.Д.Ушинского, Д.Б.Эльконина давно зарекомендовала себя как надежный и эффективный способ. Используя эту методику я поняла, что она успешно работает тогда, когда ребенок достиг высокого уровня осознания языковой стороны речи. Это означает, что дети знакомятся сначала не с буквами родного языка, а с его звуками. Такой подход оправдан тем, что без представления о количестве и порядке звуков в слове ребенок не сможет овладеть чтением. А чтобы поднять ребенка до этого уровня зрелости, необходимо специальное подготовительное обучение, которое проводят в детском саду.
Такой подход оправдан тем, что без представления о количестве и порядке звуков в слове ребенок не сможет овладеть чтением. А чтобы поднять ребенка до этого уровня зрелости, необходимо специальное подготовительное обучение, которое проводят в детском саду.
Д.Б.Эльконин писал: «От того, как ребенку будет открыта звуковая действительность языка, строение звуковой формы слова, зависит не только усвоение грамоты, но и в последующем усвоение языка». Вот почему необходимо уделять большое внимание добуквенному периоду. А развитие звуко-буквенного анализа предполагает умение последовательно вычленять звуки из слова и записывать их соответствующими буквами. Умение переводить письменные знаки в звуки позволит научиться хорошо читать.
Проанализировав работы выдающихся авторов Т.В.Александровой, Г.А.Тумаковой, А.И.Максакова, Е.В.Колесникова, А.Н.Корнева и других я попыталась применить полученные знания на практике, так как формирование фонематического восприятия, фонематических представлений, фонематического анализа и синтеза лежит в основе обучения дошкольников-логопатов чтению.
В последние два десятилетия приобрела широкую популярность тенденция раннего обучения чтению. Произошло это, отчасти, под влиянием некоторых педагогов-новаторов в России и за рубежом, пропагандирующих раннее обучение чтению и предлагающих для этого свои авторские методики. Подобные веяния встретили одобрение в определенных слоях населения, и раннее обучение чтению приобрело характер чего-то модного и престижного. Никакими серьезными научными обоснованиями такие новации не подкреплены. Если это делается без учета готовности ребенка к усвоению таких навыков, возникает много проблем, значительных затруднений у ребенка, проявляющихся в дефектном, неполноценном усвоении и в формировании негативного отношения к чтению и письму.
Сформировать у ребенка навыки чтения – это значит развить у него звуковую культуру речи, которая охватывает все стороны звукового оформления слов и звучащей речи в целом.
Исходя из диагностических исследований, проводимых в начале учебного года, пришла к выводу, что характер нарушений указывает на недостаточность фонематического слуха и восприятия у детей с общим недоразвитием речи. Без специального коррекционного воздействия дети не научатся различать и узнавать на слух фонемы, анализировать звуко-слоговой состав слов, что может привести к затруднениям при овладении навыкам чтения, поэтому, запланированную работу мне пришлось разделить на три этапа:
Без специального коррекционного воздействия дети не научатся различать и узнавать на слух фонемы, анализировать звуко-слоговой состав слов, что может привести к затруднениям при овладении навыкам чтения, поэтому, запланированную работу мне пришлось разделить на три этапа:
1 этап – развитие фонематического слуха и звуковой культуры речи;
2 этап – развитие навыков звуко-буквенного анализа и синтеза;
3 этап – послоговое чтение.
Дети старшего дошкольного возраста очень восприимчивы к звуковой стороне языка. Это возраст особого интереса к словам, звукам. И чтобы этот интерес не пропал, старалась вовлечь детей в интересную, содержательную игровую деятельность, через которую осуществляла развитие фонематического слуха и звуковой культуры речи. Используя дидактические игры «Посмотри, запомни, назови», «Хлопни на А, топни на Н», «Что звучит?», «Исправь ошибку», «Какое слово лишнее?», «Подскажи словечко» и другие развивала у детей умение узнавать и различать неречевые звуки, близкие по звуковому составу слова, различные по силе звучания голоса. Во время речевых игр дети внимательно прослушивали материал и пытались подбирать слова, не просто близкие по звучанию, но и подходящие по смыслу, что способствовало развитию фонематического слуха, правильному произношению звуков в словах.
Во время речевых игр дети внимательно прослушивали материал и пытались подбирать слова, не просто близкие по звучанию, но и подходящие по смыслу, что способствовало развитию фонематического слуха, правильному произношению звуков в словах.
Достигнув определенного уровня сформированности фонематического восприятия, а также произношения анализируемых и синтезируемых звуков речи, я проводила работу по формированию навыков звукового анализа и синтеза слов. Известно, что формирование навыков звукового анализа начинается с гласных звуков, так как их восприятие и выделение в словах проще, чем согласных.
Педагоги знают, как трудно расшевелить заторможенного и скованного ребенка. На занятиях, где присутствует элемент соревнования, он раскрепощается, становится более уверенным в себе. На каждом занятии по обучению грамоте дети учились выделять звук из слова, определять место звука в слове и одновременно уточнять звукопроизношение изучаемого звука. На начальном этапе обучения, в старшей группе, знакомила детей с графическим изображением звуков: красный квадрат – гласный, синий – твердый согласный, зеленый – мягкий согласный. Фонетический анализ слов вовсе не означает их чтение или написание. Ребенок разбирает слова на слух. Схемы разбора дошкольники рисовали кружками и раскрашивали цветными карандашами, выкладывали из разноцветных квадратиков или кружков (для этой цели хорошо подходят пробки от пластиковых бутылок красного, синего и зеленого цветов).
Фонетический анализ слов вовсе не означает их чтение или написание. Ребенок разбирает слова на слух. Схемы разбора дошкольники рисовали кружками и раскрашивали цветными карандашами, выкладывали из разноцветных квадратиков или кружков (для этой цели хорошо подходят пробки от пластиковых бутылок красного, синего и зеленого цветов).
- продемонстрировать последовательную смену одного звука другим я использовала звуковую линейку, при помощи которой дети одновременно слышали протяжное произнесение и следили за последовательным появлением звуков. Используя звуковую линейку, мне не только удавалось сосредоточить внимание на каком-то одном звуке, но и закрепить знания о последовательной смене звуков в словах. Конечно, для детей с речевыми нарушениями определение позиции заданного звука в слове (начало, середина или конец) представляет огромную трудность. С целью облегчения формирования этого навыка использовала зрительный символ – плоскостное изображение ежика, который передвигался слева направо и останавливался в начале, середине или конце звуковой линейки в зависимости от определяемого звука в слове.
 Когда я знакомила детей с буквой, то всегда демонстрировала ее печатное изображение, читала веселое стихотворение о ней, что помогало дошкольникам лучше запомнить образ изучаемой буквы. В тетрадях дети учились писать печатную букву с использованием образца, печатать слоги, слова, что способствовало развитию звуко-буквенного анализа и синтеза, развитию графических навыков, создавало положительное отношение к процессу обучения, так как эти действия почти не вызывают у детей затруднений, потому что основные элементы знаний уже заложены.
Когда я знакомила детей с буквой, то всегда демонстрировала ее печатное изображение, читала веселое стихотворение о ней, что помогало дошкольникам лучше запомнить образ изучаемой буквы. В тетрадях дети учились писать печатную букву с использованием образца, печатать слоги, слова, что способствовало развитию звуко-буквенного анализа и синтеза, развитию графических навыков, создавало положительное отношение к процессу обучения, так как эти действия почти не вызывают у детей затруднений, потому что основные элементы знаний уже заложены. - нравились дошкольникам моменты, когда буквы в их руках «оживали», то есть, дети из пластилина лепили буквы, слова, свои имена, выкладывали из мелких морских камешков, фасоли, гороха, дорисовывали элементы силуэта изучаемой буквы. Затем все вместе развешивали в группе изображения данных букв, выполненные в разном цвете, величине, графическом изображении.
- хорошего результата на последнем этапе работы удавалось при помощи разрезной азбуки. Дети складывали из букв разрезной азбуки сразу после звукового анализа и синтеза слоги – соединяли звуки в слоги и прочитывали слово по слогам. Воспитанники с огромным желанием вставляли пропущенные буквы в словах в специально напечатанных карточках, делали фонетический разбор слов, читали слоги, составляли из этих слогов слова, слитно их читали, объясняли смысл прочитанного, разгадывали ребусы и кроссворды, при помощи которых в игровой форме закрепляли имеющиеся навыки в послоговом чтении и умении печатать под диктовку.
 Когда я знакомила детей с буквой, то всегда демонстрировала ее печатное изображение, читала веселое стихотворение о ней, что помогало дошкольникам лучше запомнить образ изучаемой буквы. В тетрадях дети учились писать печатную букву с использованием образца, печатать слоги, слова, что способствовало развитию звуко-буквенного анализа и синтеза, развитию графических навыков, создавало положительное отношение к процессу обучения, так как эти действия почти не вызывают у детей затруднений, потому что основные элементы знаний уже заложены.
Когда я знакомила детей с буквой, то всегда демонстрировала ее печатное изображение, читала веселое стихотворение о ней, что помогало дошкольникам лучше запомнить образ изучаемой буквы. В тетрадях дети учились писать печатную букву с использованием образца, печатать слоги, слова, что способствовало развитию звуко-буквенного анализа и синтеза, развитию графических навыков, создавало положительное отношение к процессу обучения, так как эти действия почти не вызывают у детей затруднений, потому что основные элементы знаний уже заложены. Воспитанники с огромным желанием вставляли пропущенные буквы в словах в специально напечатанных карточках, делали фонетический разбор слов, читали слоги, составляли из этих слогов слова, слитно их читали, объясняли смысл прочитанного, разгадывали ребусы и кроссворды, при помощи которых в игровой форме закрепляли имеющиеся навыки в послоговом чтении и умении печатать под диктовку.
Воспитанники с огромным желанием вставляли пропущенные буквы в словах в специально напечатанных карточках, делали фонетический разбор слов, читали слоги, составляли из этих слогов слова, слитно их читали, объясняли смысл прочитанного, разгадывали ребусы и кроссворды, при помощи которых в игровой форме закрепляли имеющиеся навыки в послоговом чтении и умении печатать под диктовку.Для успешной работы воспитателю необходимо поддерживать взаимосвязь с семьей ребенка. В коррекционной работе важно сделать родителей не только своими союзниками, но и грамотными помощниками. Увидев наглядно достижения своего ребенка, каждый родитель убеждается в том, что, чтобы овладеть навыками чтения – знать буквы алфавита недостаточно, необходимо иметь хорошо развитый фонематический слух, уметь слышать и выделять звуки в словах, владеть навыками звукового и слогового анализа и синтеза.
Список использованной литературы:
1.Александрова, Т.В. Живые звуки, или фонетика для дошкольников. –
–
СПб.: « ДЕТСТВО-ПРЕСС», 2005. – 48 с.
2.Ткаченко, Т.А. Логопедическая тетрадь. Развитие фонематического
восприятия и навыков звукового анализа. – СПб., ДЕТСТВО-ПРЕСС, 1998.
3.Тумакова, Г.А. Ознакомление дошкольников со звучащим словом. /Под
ред. Ф.А.Сохина. – М.: Мозаика-Синтез, 2006. – 144с.
Опубликовано: 11.02.2017Тег части речи (POS) | Анализ зависимостей
Абхишек Шарма — Опубликовано 29 июля 2020 г. и изменено 29 июля 2020 г.
Новичок НЛП Питон Техника Неструктурированные данные
Обзор
- Узнайте о маркировке частей речи (POS),
- Понимание синтаксического анализа зависимостей и синтаксического анализа групп
Введение
Знание языков — путь к мудрости.
– Роджер Бэкон
Меня поразило, что Роджер Бэкон привел приведенную выше цитату в 13 веке, и она до сих пор актуальна, не так ли? Я уверен, что вы все со мной согласитесь.
Сегодня способ понимания языков сильно изменился по сравнению с 13 веком. Теперь мы называем это лингвистикой и обработкой естественного языка. Но его важность не уменьшилась; вместо этого он чрезвычайно увеличился. Ты знаешь почему? Потому что его приложения взлетели до небес, и одно из них — причина, по которой вы попали в эту статью.
Каждое из этих приложений включает в себя сложные техники НЛП, и чтобы понять их, нужно хорошо разбираться в основах НЛП. Поэтому, прежде чем переходить к сложным темам, важно соблюдать основные принципы.
Вот почему я создал эту статью, в которой я расскажу о некоторых основных концепциях НЛП — пометке частей речи (POS), анализе зависимостей и анализе составных частей в обработке естественного языка. Мы поймем эти концепции, а также реализуем их в python. Итак, начнем!
Содержание
- Маркировка части речи (POS)
- Анализ зависимостей
- Анализ избирательного округа
Маркировка части речи (POS)
В школьные годы все мы изучали части речи, к которым относятся существительные, местоимения, прилагательные, глаголы и т. д. Слова, принадлежащие к различным частям речи, образуют предложение. Знание частей речи слов в предложении важно для его понимания.
д. Слова, принадлежащие к различным частям речи, образуют предложение. Знание частей речи слов в предложении важно для его понимания.
Это причина создания концепции POS-тегов. Я уверен, что вы уже догадались, что такое POS-тегирование. Тем не менее, позвольте мне объяснить вам это.
Тегирование части речи (POS) — это процесс присвоения различным меткам, известным как POS-теги, словам в предложении, которые сообщают нам о части речи слова.
В целом существует два типа POS-тегов:
1. Универсальные теги POS: Эти теги используются в универсальных зависимостях (UD) (последняя версия 2), проекте, который разрабатывает кросс-лингвистически согласованные аннотации дерева для многих языков. Эти теги основаны на типе слов. Например, NOUN (нарицательное существительное), ADJ (прилагательное), ADV (наречие).
Список универсальных POS-тегов
Подробнее о каждом из них можно прочитать здесь.
2. Подробные теги POS: эти теги являются результатом разделения универсальных тегов POS на различные теги, такие как NNS для нарицательных существительных во множественном числе и NN для нарицательных существительных в единственном числе по сравнению с NOUN для нарицательных существительных в английском языке. Эти теги зависят от языка. Вы можете ознакомиться с полным списком здесь.
Теперь вы знаете, что такое POS-теги и что такое POS-теги. Итак, давайте напишем код на python для тегов предложений POS. Для этой цели я использовал здесь Spacy, но есть и другие библиотеки, такие как NLTK и Stanza, которые также можно использовать для того же.
Посмотреть код на Gist.
В приведенном выше примере кода я загрузил модель spacy en_web_core_sm и использовал ее для получения тегов POS. Вы можете видеть, что pos_ возвращает универсальные теги POS, а tag_ возвращает подробные теги POS для слов в предложении.
Анализ зависимостей
Разбор зависимостей — это процесс анализа грамматической структуры предложения на основе зависимостей между словами в предложении.
При синтаксическом анализе зависимостей различные теги представляют отношения между двумя словами в предложении. Эти теги являются тегами зависимости. Например, во фразе «дождливая погода» слово дождливый изменяет значение существительного погода . Следовательно, существует зависимость от погоды -> дождливый, в которой погода действует как головной , а дождливый действует как зависимый или дочерний . Эта зависимость представлена amod тег, обозначающий модификатор прилагательного.
Подобно этому, между словами в предложении существует много зависимостей, но обратите внимание, что зависимость включает только два слова, в которых одно действует как заглавное, а другое — как дочернее.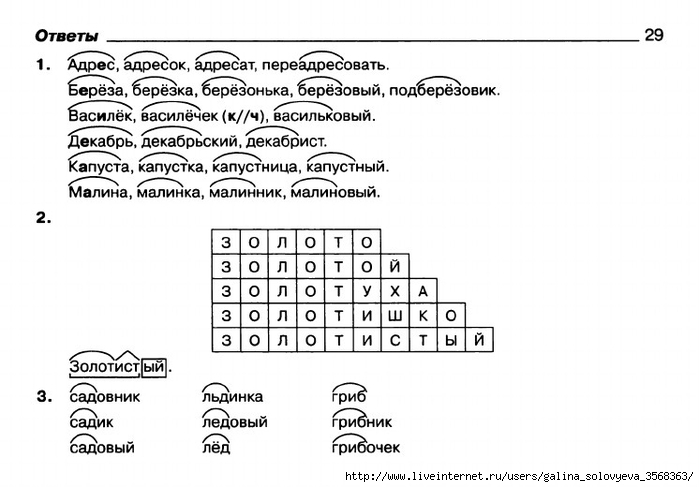 На данный момент в Universal Dependency (версия 2) используется 37 универсальных отношений зависимости. Вы можете посмотреть на все из них здесь. Помимо этого, также существует множество тегов для конкретных языков.
На данный момент в Universal Dependency (версия 2) используется 37 универсальных отношений зависимости. Вы можете посмотреть на все из них здесь. Помимо этого, также существует множество тегов для конкретных языков.
Теперь воспользуемся Spacy и найдем зависимости в предложении.
Посмотреть код на Gist.
В приведенном выше примере кода dep_ возвращает тег зависимости для слова, а head.text возвращает соответствующее слово head . Если вы заметили, на приведенном выше изображении слово приняло и имеет тег зависимости ROOT . Этот тег назначается слову, которое выступает в качестве заголовка многих слов в предложении, но не является потомком какого-либо другого слова. Как правило, в данном случае это основной глагол предложения, похожего на «взял».
Теперь вы знаете, что такое теги зависимостей и что такое заголовки, дочерние и корневые слова. Но разве синтаксический анализ не означает создание дерева синтаксического анализа?
Да, здесь мы создаем дерево, но не визуализируем его. Дерево, сгенерированное синтаксическим анализом зависимостей, известно как дерево зависимостей. Есть несколько способов визуализировать это, но для простоты мы будем использовать displaCy, который используется для визуализации синтаксического анализа зависимостей.
Дерево, сгенерированное синтаксическим анализом зависимостей, известно как дерево зависимостей. Есть несколько способов визуализировать это, но для простоты мы будем использовать displaCy, который используется для визуализации синтаксического анализа зависимостей.
Посмотреть код на Gist.
На приведенном выше изображении стрелки представляют собой зависимость между двумя словами, в которой слово на конце стрелки является дочерним, а слово на конце стрелки — головным. Корневое слово может выступать в качестве заголовка нескольких слов в предложении, но не является потомком какого-либо другого слова. Вы можете видеть выше, что слово «взял» имеет несколько исходящих стрелок, но ни одной входящей. Следовательно, это корневое слово. Одна интересная особенность корневого слова заключается в том, что если вы начнете отслеживать зависимости в предложении, вы можете добраться до корневого слова, независимо от того, с какого слова вы начинаете.
Теперь вы знаете об анализе зависимостей, так что давайте узнаем о другом типе анализа, известном как анализ групп.
Анализ избирательного округа
Составной анализ — это процесс анализа предложений путем их разбиения на подфразы, также известные как составные части. Эти подфразы принадлежат к определенной категории грамматики, такой как NP (собственное словосочетание) и VP (глагольное словосочетание).
Давайте разберемся на примере. Предположим, у меня есть такое же предложение, которое я использовал в предыдущих примерах, т. е. «Мне потребовалось более двух часов, чтобы перевести несколько страниц английского языка». и я выполнил анализ избирательного округа на нем. Тогда дерево синтаксического анализа округа для этого предложения задается следующим образом:0036
В приведенном выше дереве слова предложения написаны фиолетовым цветом, а POS-теги — красным. За исключением этого, все написано черным цветом, который представляет составляющие. Вы можете ясно видеть, как все предложение делится на подфразы, пока на концах не останутся только слова. Кроме того, существуют различные теги для обозначения составляющих, например
Кроме того, существуют различные теги для обозначения составляющих, например
- ПО за глагольную фразу
- NP для именных словосочетаний
Это составляющие теги. Вы можете прочитать о различных составных тегах здесь.
Теперь вы знаете, что такое синтаксический анализ избирательных округов, поэтому пришло время написать код на Python. Теперь spaCy не предоставляет официального API для парсинга избирательных округов. Поэтому мы будем использовать Neural Parser Беркли. Это реализация синтаксических анализаторов на Python, основанная на синтаксическом анализе округа с самостоятельным кодировщиком из ACL 2018.
Вы также можете использовать StanfordParser со Stanza или NLTK для этой цели, но здесь я использовал Neural Parser Berkely. Чтобы использовать это, нам нужно сначала установить его. Вы можете сделать это, выполнив следующую команду.
!pip install benepar
Тогда вам нужно скачать модель benerpar_en2 .
Посмотреть код на Gist.
Вы могли заметить, что здесь я использую TensorFlow 1.x, потому что в настоящее время benepar не поддерживает TensorFlow 2.0. Теперь пришло время провести анализ избирательного округа.
Посмотреть код на Gist.
Здесь _.parse_string генерирует дерево синтаксического анализа в виде строки.
Конечные примечания
Теперь вы знаете, что такое тегирование POS, синтаксический анализ зависимостей и синтаксический анализ групп и как они помогают вам в понимании текстовых данных, т. е. теги POS сообщают вам о частях речи слов в предложении, синтаксический анализ зависимостей существующие зависимости между словами в предложении и синтаксический анализ составных частей говорят вам о подфразах или составляющих предложения. Теперь вы готовы перейти к более сложным частям НЛП. В качестве следующих шагов вы можете прочитать следующие статьи по извлечению информации.
- Как поисковые системы, такие как Google, извлекают результаты: введение в извлечение информации с использованием Python и spaCy
- Практический проект НЛП: подробное руководство по извлечению информации с использованием Python
В этих статьях вы узнаете, как использовать теги POS и теги зависимостей для извлечения информации из корпуса.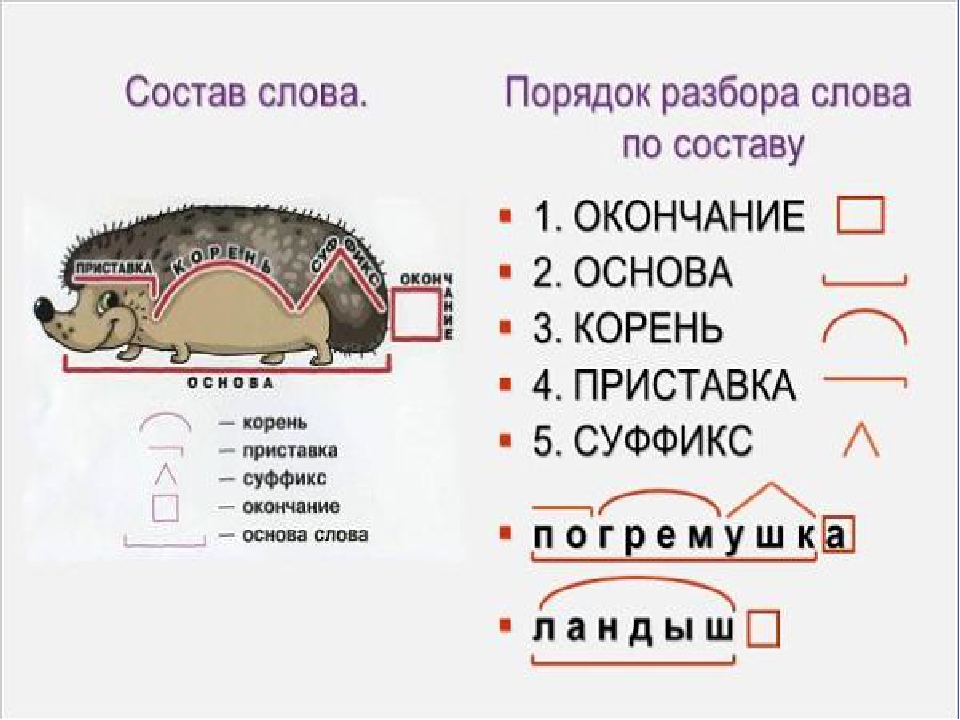 Кроме того, если вы хотите узнать о spaCy, вы можете прочитать эту статью: Учебное пособие по spaCy для изучения и освоения обработки естественного языка (NLP). Помимо этого, если вы хотите изучить обработку естественного языка с помощью курса, я очень рекомендую вам следующие, которые включают в себя все, от проектов до индивидуального наставничества:
Кроме того, если вы хотите узнать о spaCy, вы можете прочитать эту статью: Учебное пособие по spaCy для изучения и освоения обработки естественного языка (NLP). Помимо этого, если вы хотите изучить обработку естественного языка с помощью курса, я очень рекомендую вам следующие, которые включают в себя все, от проектов до индивидуального наставничества:
- Обработка естественного языка с использованием Python
Если эта статья показалась вам информативной, поделитесь ею с друзьями. Кроме того, вы можете комментировать ниже ваши запросы.
синтаксический анализ избирательных групп синтаксический анализ зависимостейпометки синтаксический анализ
оглавление
Об авторе
Скачать Приложение Analytics Vidhya для последнего блога/статьи
Предыдущий пост Методы трансформации и масштабирования функций для повышения производительности вашей модели
Следующее сообщение Использование машинного обучения для повышения эффективности управления цепочками поставок
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политика конфиденциальности и использования файлов cookie
Узнать | Написать | Заработайте
гарантированных INR 2000 ($26) за каждую опубликованную статью!Зарегистрируйтесь сейчасПострочное чтение файла в Python
Введение
Распространенной задачей в программировании является открытие файла и анализ его содержимого. Что вы делаете, когда файл, который вы пытаетесь обработать, довольно большой, например, несколько ГБ данных или больше? Решение этой проблемы состоит в том, чтобы читать фрагменты файла за раз, обрабатывать их, а затем освобождать их из памяти, чтобы вы могли обрабатывать другие фрагменты, пока не будет обработан весь массивный файл. Хотя вы сами определяете подходящий размер фрагментов данных, которые вы обрабатываете, для многих приложений удобно обрабатывать файл по одной строке за раз.
В этой статье мы рассмотрим ряд примеров кода, демонстрирующих, как читать файлы построчно. Если вы хотите попробовать некоторые из этих примеров самостоятельно, код, используемый в этой статье, можно найти в следующем репозитории GitHub.
Если вы хотите попробовать некоторые из этих примеров самостоятельно, код, используемый в этой статье, можно найти в следующем репозитории GitHub.
- Базовый файловый ввод-вывод в Python
- Построчное чтение файла в Python с помощью
readline() - Построчное чтение файла в Python с помощью
readlines() - Чтение файла построчно с
для контура— Лучший подход! - Применение чтения файлов построчно
Базовый файловый ввод-вывод в Python
Python — отличный язык программирования общего назначения, и он имеет ряд очень полезных функций файлового ввода-вывода в своей стандартной библиотеке встроенных функций и модулей.
Встроенная функция open() используется для открытия файлового объекта для чтения или записи. Вот как вы можете использовать его, чтобы открыть файл:
fp = открыть('путь/к/файлу.txt', 'r')
Как показано выше, функция open() принимает несколько аргументов. Мы сосредоточимся на двух аргументах, первый из которых представляет собой позиционный строковый параметр, представляющий путь к файлу, который вы хотите открыть. Второй (необязательный) параметр также является строкой и указывает режим взаимодействия, который вы собираетесь использовать с файловым объектом, возвращаемым вызовом функции. Наиболее распространенные режимы перечислены в таблице ниже, по умолчанию используется значение «r» для чтения:
Мы сосредоточимся на двух аргументах, первый из которых представляет собой позиционный строковый параметр, представляющий путь к файлу, который вы хотите открыть. Второй (необязательный) параметр также является строкой и указывает режим взаимодействия, который вы собираетесь использовать с файловым объектом, возвращаемым вызовом функции. Наиболее распространенные режимы перечислены в таблице ниже, по умолчанию используется значение «r» для чтения:
| Режим | Описание |
|---|---|
р | Открыть для чтения обычного текста |
ш | Открыть для записи обычного текста |
и | Открыть существующий файл для добавления обычного текста |
руб | Открыт для чтения двоичных данных |
вб | Открыт для записи двоичных данных |
После того, как вы записали или прочитали все нужные данные в файловом объекте, вам нужно закрыть файл, чтобы можно было перераспределить ресурсы в операционной системе, в которой выполняется код.
fp.close()
Примечание: Всегда рекомендуется закрывать ресурс файлового объекта, но об этой задаче легко забыть.
Хотя вы всегда можете помнить о вызове close() для файлового объекта, есть альтернативный и более элегантный способ открыть файловый объект и гарантировать, что интерпретатор Python очистит его после использования:
с open('path /to/file.txt') как fp:
# Делать что-то с fp
Просто используя ключевое слово with (появившееся в Python 2.5) в коде, который мы используем для открытия файлового объекта, Python сделает что-то похожее на следующий код. Это гарантирует, что независимо от того, какой файловый объект будет закрыт после использования:
попробуйте:
fp = открыть('путь/к/файлу.txt')
# Делать что-то с fp
в конце концов:
fp.close()
Любой из этих двух методов подходит, причем первый пример более Pythonic.
Файловый объект, возвращаемый функцией open() , имеет три общих явных метода ( read() , readline() и readlines() ) для чтения данных. Метод
Метод read() считывает все данные в одну строку. Это полезно для небольших файлов, где вы хотели бы выполнять манипуляции с текстом во всем файле. Тогда есть readline() , который является полезным способом чтения только отдельных строк, в возрастающих количествах за раз, и возврата их в виде строк. Последний явный метод, readlines() , прочитает все строки файла и вернет их в виде списка строк.
Примечание : В оставшейся части этой статьи мы будем работать с текстом книги «Илиада Гомера», которую можно найти на сайте gutenberg.org, а также в репозитории GitHub, где находится код для эта статья.
Построчное чтение файла в Python с помощью
readline() Давайте начнем с метода readline() , который считывает одну строку, что потребует от нас использования счетчика и его увеличения. :
путь к файлу = 'Iliad.txt'
с открытым (путь к файлу) как fp:
строка = fp.readline()
цент = 1
пока строка:
print("Строка {}: {}". format(cnt, line.strip()))
строка = fp.readline()
цент += 1
 format(cnt, line.strip()))
строка = fp.readline()
цент += 1
format(cnt, line.strip()))
строка = fp.readline()
цент += 1
Этот фрагмент кода открывает файловый объект, ссылка на который хранится в fp , затем считывает строку по одной, вызывая readline() для этого файлового объекта итеративно в цикле while . Затем он просто выводит строку на консоль.
Запустив этот код, вы должны увидеть примерно следующее:
... Строка 567: чрезвычайно пустяковая. У нас нет оставшейся надписи ранее, чем Строка 568: Олимпиада сороковая, а ранние надписи грубы и неумело Строка 569: выполнено; мы даже не можем быть уверены в том, что Архилох, Симонид Строка 570: Аморга, Каллина, Тиртея, Ксанфа и других ранних элегических и Строка 571: лирики, посвятившие свои сочинения написанию, или в какое время Строка 572: такая практика стала привычной. Первое положительное основание, которое Строка 573: позволяет нам предположить существование рукописи Гомера, находится в Строка 574: знаменитое постановление Солона относительно рапсодии в Строка 575: Панафинеи: но сколько времени раньше рукописи имели Строка 576: существовало, мы не можем сказать.
 ...
...
Хотя этот подход грубый и явный. Наверняка не очень Pythonic. Мы можем использовать метод readlines() , чтобы сделать этот код более кратким.
Построчное чтение файла с помощью
readlines() Метод readlines() считывает все строки и сохраняет их в список List . Затем мы можем перебрать этот список и, используя enumerate() , сделать индекс для каждой строки для нашего удобства:
файл = открыть('Илиада.txt', 'r')
строки = файл.readlines()
для индекса, строка в перечислении (строки):
print("Строка {}: {}".format(index, line.strip()))
файл.закрыть()
Результат:
... Строка 160: ВВЕДЕНИЕ. Строка 161: Строка 162: Строка 163: Скептицизм в такой же степени является результатом знания, как и знание Строка 164: скептицизм. Довольствоваться тем, что мы в настоящее время знаем, по большей части Строка 165: часть, чтобы закрыть уши от осуждения; так как с самого постепенного Строка 166: характер нашего образования, мы должны постоянно забывать и освобождать Строка 167: мы из ранее приобретенных знаний; мы должны отбросить старое Строка 168: идеи и новые идеи; и, как мы учимся, мы должны быть ежедневно Строка 169: разучиться чему-то, что стоило нам немалого труда и беспокойства.
 Строка 170: приобрести.
...
Строка 170: приобрести.
...
Теперь, хотя и намного лучше, нам даже не нужно вызывать метод readlines() для достижения той же функциональности . Это традиционный способ построчного чтения файла, но есть и более современный и более короткий.
Чтение файла построчно с помощью цикла
for — наиболее питонический подход Нам не нужно извлекать строки через readlines() вообще — мы можем перебрать сам возвращаемый объект. Это также упрощает enumerate() его, чтобы мы могли записать номер строки в каждом операторе print() .Это самый короткий, самый питоновский подход к решению проблемы, и этот подход предпочитают большинство:
с open('Iliad.txt') as f:
для индекса, строка в enumerate(f):
print("Строка {}: {}".format(index, line.strip()))
Результат:
... Строка 277: Мэнтес из Левкадии, современная Санта-Маура, проявившая знание и Строка 278: разведка, редко встречавшаяся в те времена, убедила Мелезигена закрыться Строка 279: его школа, и сопровождать его в его путешествиях.
 Обещал не только платить
Строка 280: его расходы, но предоставить ему дополнительную стипендию, убеждая, что,
Строка 281: «Пока он был еще молод, было уместно, чтобы он увидел своими собственными
Строка 282: смотрит на страны и города, которые впоследствии могут стать предметом его
Строка 283: беседы». Мелесиген согласился и вместе со своим покровителем отправился в путь.
Строка 284: «рассматривая все диковинки стран, которые они посетили, и
...
Обещал не только платить
Строка 280: его расходы, но предоставить ему дополнительную стипендию, убеждая, что,
Строка 281: «Пока он был еще молод, было уместно, чтобы он увидел своими собственными
Строка 282: смотрит на страны и города, которые впоследствии могут стать предметом его
Строка 283: беседы». Мелесиген согласился и вместе со своим покровителем отправился в путь.
Строка 284: «рассматривая все диковинки стран, которые они посетили, и
...
Здесь мы воспользовались встроенными функциями Python, которые позволяют нам легко перебирать итерируемый объект, просто используя для петли . Если вы хотите узнать больше о встроенных функциях Python для итерации объектов, мы предоставим вам информацию:
- Инструменты itertools Python — count(), cycle() и chain()
- Itertools Python: filter(), islice(), map() и zip()
Применение чтения файлов построчно
Как это можно использовать на практике? Большинство приложений НЛП имеют дело с большими объемами данных. В большинстве случаев нецелесообразно считывать весь корпус в память. Хотя это и рудиментарно, вы можете написать решение с нуля для подсчета частоты определенных слов без использования каких-либо внешних библиотек. Давайте напишем простой скрипт, который загружает файл, читает его построчно и подсчитывает частоту слов, выводя 10 наиболее часто встречающихся слов и количество их вхождений:
В большинстве случаев нецелесообразно считывать весь корпус в память. Хотя это и рудиментарно, вы можете написать решение с нуля для подсчета частоты определенных слов без использования каких-либо внешних библиотек. Давайте напишем простой скрипт, который загружает файл, читает его построчно и подсчитывает частоту слов, выводя 10 наиболее часто встречающихся слов и количество их вхождений:
система импорта
импорт ОС
деф основной():
путь к файлу = sys.argv[1]
если не os.path.isfile (путь к файлу):
print("Путь к файлу {} не существует. Выход...".format(filepath))
sys.exit()
bag_of_words = {}
с открытым (путь к файлу) как fp:
для строки в fp:
record_word_cnt(line.strip().split(' '), bag_of_words)
sorted_words = order_bag_of_words(bag_of_words, desc=True)
print("Наиболее часто встречающиеся 10 слов {}".format(sorted_words[:10]))
def order_bag_of_words(bag_of_words, desc=False):
слова = [(слово, cnt) для слова, cnt в bag_of_words. items()]
вернуть отсортированный (слова, ключ = лямбда x: x [1], реверс = desc)
def record_word_cnt (слова, мешок_слов):
для слова словами:
если слово != '':
если word.lower() в bag_of_words:
bag_of_words[word.lower()] += 1
еще:
bag_of_words[word.lower()] = 1
если __name__ == '__main__':
главный()
 items()]
вернуть отсортированный (слова, ключ = лямбда x: x [1], реверс = desc)
def record_word_cnt (слова, мешок_слов):
для слова словами:
если слово != '':
если word.lower() в bag_of_words:
bag_of_words[word.lower()] += 1
еще:
bag_of_words[word.lower()] = 1
если __name__ == '__main__':
главный()
items()]
вернуть отсортированный (слова, ключ = лямбда x: x [1], реверс = desc)
def record_word_cnt (слова, мешок_слов):
для слова словами:
если слово != '':
если word.lower() в bag_of_words:
bag_of_words[word.lower()] += 1
еще:
bag_of_words[word.lower()] = 1
если __name__ == '__main__':
главный()
Сценарий использует модуль os , чтобы убедиться, что файл, который мы пытаемся прочитать, действительно существует. Если да, то он считывается построчно, и каждая строка передается в функцию record_word_cnt(). Он разграничивает пробелы между словами и добавляет слово в словарь — bag_of_words . Как только все строки записаны в словарь, мы упорядочиваем их через order_bag_of_words() , который возвращает список кортежей в (word, word_count) , отсортированные по количеству слов.
Наконец, мы печатаем первую десятку самых распространенных слов.
Как правило, для этого вы должны создать Bag of Words Model , используя такие библиотеки, как NLTK, однако этой реализации будет достаточно. Запустим скрипт и предоставим ему наш Iliad.txt :
$ python app.py Iliad.txt
Результат:
Наиболее часто встречающиеся 10 слов [('the', 15633), ('and', 6959), ('of', 5237), ('to', 4449), ('his', 3440), ('в', 3158), ('с', 2445), ('а', 2297), ('он', 1635), ('от', 1418)]
Если вы хотите узнать больше о НЛП, у нас есть серия руководств по различным задачам: Обработка естественного языка в Python.
Заключение
В этой статье мы рассмотрели несколько способов построчного чтения файла в Python, а также создали элементарную модель Bag of Words для расчета частоты слов в данном файле.
Как написать резюме, подходящее для ATS (с 20 бесплатными шаблонами)
Поиск Прежде чем принять решение о формате и шаблоне резюме, необходимо взвесить ряд соображений, таких как ваша область или отрасль, глубина опыта работы и набор навыков.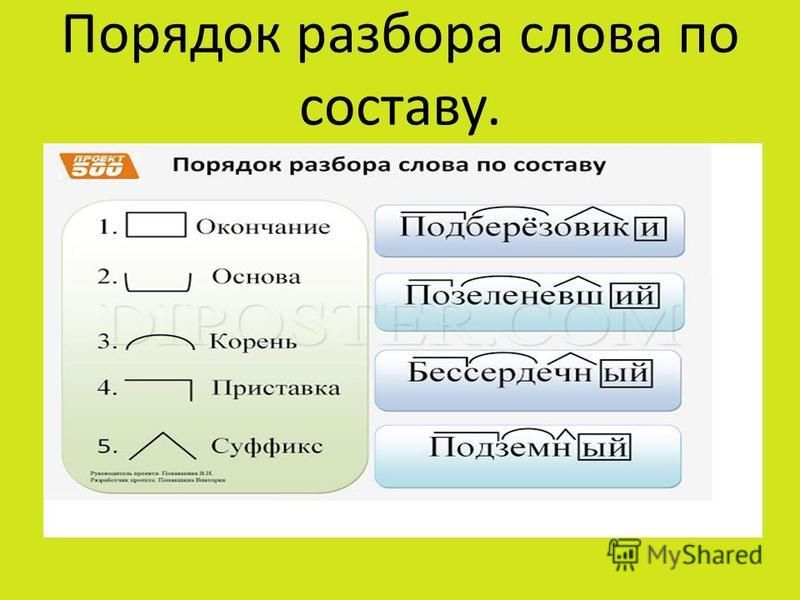 Сегодня соискателям также необходимо, чтобы их резюме были совместимы с системами отслеживания кандидатов (ATS). Шаблон резюме ATS может стать разницей между тем, чтобы вас заметили, и тем, кто ускользнет от вас.
Сегодня соискателям также необходимо, чтобы их резюме были совместимы с системами отслеживания кандидатов (ATS). Шаблон резюме ATS может стать разницей между тем, чтобы вас заметили, и тем, кто ускользнет от вас.
Зачем вам нужно резюме, адаптированное к ATS
Мастерски написанное резюме с элегантным дизайном и оптимизированными ключевыми словами резюме может оказаться несостоятельным, если форматирование не соответствует требованиям ATS.
Когда вы загружаете свое резюме в ATS как часть своего заявления о приеме на работу, ATS затем анализирует текст вашего резюме, чтобы сделать его доступным для поиска рекрутером, или импортирует информацию в цифровой профиль кандидата. Если ATS не может точно проанализировать ваше резюме, ваши шансы быть выбранными для собеседования низки, даже если вы обладаете идеальной квалификацией.
Это связано с тем, что содержимое вашего резюме искажено или ваш профиль кандидата неполный из-за неправильного форматирования. И если ваш профиль не отражает, что вы хорошо подходите для этой работы, вы не будете оценены как жизнеспособный кандидат.
Используйте бесплатные шаблоны резюме Jobscan, удобные для ATS, и начните составлять свое резюме, которое заметят рекрутеры!
Как составить резюме в стиле ATS
Существует ряд факторов, влияющих на выбор оптимального шаблона или формата резюме ATS. Например, многие ATS не умеют работать с таблицами или изображениями. Правильная последовательность информации о вашем опыте работы повышает точность синтаксического анализа; Типы файлов docx и pdf работают лучше, чем другие.
Наша команда в Jobscan провела исследования из первых рук и перепроектировала десятки систем отслеживания кандидатов, от крупнейших компаний в бизнесе (таких как Taleo) до начинающих (таких как Greenhouse), чтобы точно узнать, что работает и что нет.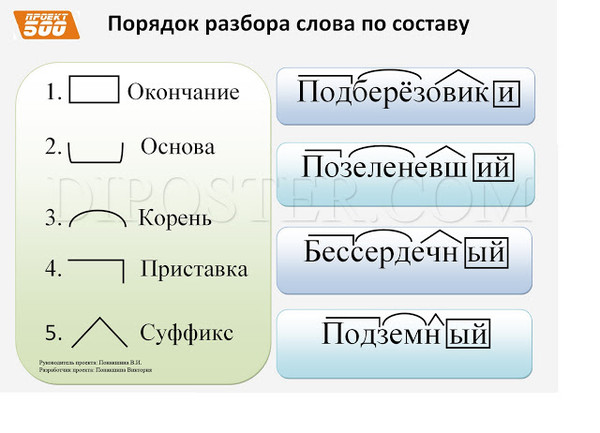
7 Советы по форматированию резюме ATS
1. Используйте длинные формы и аббревиатуры ключевых слов.
Рекрутеры и менеджеры по найму могут искать кандидатов по ключевым словам. Некоторые ATS будут возвращать только результаты с точным соответствием ключевому слову, а это означает, что если вы включили термин «Поисковая оптимизация» без его аббревиатуры, ваш профиль может не отображаться в поиске рекрутера по термину «SEO».
2. Используйте хронологический или гибридный формат резюме.
Форматы, которые преуменьшают значение опыта работы, такие как формат функционального резюме, плохо работают для систем отслеживания кандидатов, которые полагаются на более традиционное форматирование в обратном хронологическом порядке для понимания опыта кандидата. Рекрутеры также лучше всего знакомы с хронологическими и гибридными форматами резюме.
Прочтите: Не допускайте этих ошибок форматирования ATS
3. Не используйте таблицы или столбцы.
Не используйте таблицы или столбцы.
Несмотря на то, что таблицы и столбцы могут улучшить читаемость для людей, они могут вызвать ошибки синтаксического анализа в ATS.
Прочтите: Что происходит при возобновлении таблиц и столбцов в ATS?
4. Используйте удобный для экрана традиционный шрифт.
Для удобочитаемости лучше всего использовать традиционный шрифт с засечками или без засечек. Некоторые ATS автоматически меняют незнакомые шрифты, что может изменить дизайн вашего резюме.
Прочитайте: Лучшие шрифты для вашего резюме
5. Не используйте верхние и нижние колонтитулы.
Информация в верхних и нижних колонтитулах может быть потеряна или вызвать ошибки синтаксического анализа внутри и в ATS.
6. Используйте стандартные заголовки разделов резюме.
Заголовки разделов, такие как «Где я был» вместо «Опыт работы», могут ввести в заблуждение системы отслеживания кандидатов, что приведет к неправильной организации информации.
Прочтите: Разделы резюме: что вам нужно и где вам это нужно
7. Если возможно, сохраните файл в формате .docx или PDF
Файл docx или .pdf наиболее совместим с ATS. Некоторые люди предпочитают PDF-файлы, потому что их форматирование не может быть нарушено в этом формате.
Прочтите: все, что вам нужно знать о системах отслеживания кандидатов
Бесплатные шаблоны резюме ATS
Благодаря этому тестированию и исследованию мы обнаружили, какие резюме легко форматируются через ATS, а какие могут привести к тому, что кандидаты попадут в затруднительное положение. Основываясь на этих знаниях, мы создали 20 шаблонов резюме, совместимых с ATS. Каждый шаблон резюме ATS уже отформатирован. Все, что вам нужно сделать, это настроить их с вашей собственной информацией.
Получите доступ к 20 шаблонам резюме для ATS здесь Чтобы максимизировать свои шансы попасть на собеседование, вы должны быть уверены, что ATS сможет прочитать ваше резюме. Использование одного из этих удобных для ATS шаблонов резюме означает, что вы можете подать заявку, не беспокоясь о том, что соскользнете в черную дыру резюме.
Использование одного из этих удобных для ATS шаблонов резюме означает, что вы можете подать заявку, не беспокоясь о том, что соскользнете в черную дыру резюме.
Найдя понравившийся шаблон, используйте инструмент оптимизации резюме Jobscan, чтобы еще раз убедиться, что вы не забыли какие-либо ключевые навыки. Jobscan сравнивает ваше резюме с описанием работы, чтобы показать, каких навыков и ключевых слов вам не хватает, а также множество других полезных проверок ATS и рекрутеров.
Когда писать автобиографию (CV)
Однако иногда то, что вам нужно, — это резюме, не отвечающее требованиям ATS. Вместо этого, если вы работаете в академической, медицинской или научной сфере, вы, скорее всего, захотите создать биографию (CV).
Резюме сосредоточено на том, чего вы достигли и что вы можете сделать в рамках должности. Кроме того, в резюме более подробно указывается ваше образование, а также ваши полномочия, исследовательский опыт и сертификаты. Из-за этого резюме, как правило, занимают гораздо больше времени, чем резюме.
Чтобы узнать больше о резюме, ознакомьтесь с нашей статьей о том, как написать его здесь:
- Как написать резюме для успешного поиска работы
Версии этой статьи были опубликованы в 2015 и 2016 годах Тристой Винни . Он был переписан и обновлен для 2021 года.
Чтение данных файла с помощью PowerShell
У нас есть несколько пользовательских файлов, которые мы получаем от разных поставщиков, и в этих ситуациях мы не можем использовать стандартные программы ETL без какой-либо настройки. Поскольку мы расширяем наши возможности чтения этих пользовательских файлов с помощью .NET, мы ищем эффективные способы чтения файлов с помощью PowerShell, которые мы можем использовать в агентах заданий SQL Server, планировщиках заданий Windows или в нашей пользовательской программе, которая может выполнять сценарии PowerShell. У нас есть много инструментов для синтаксического анализа данных, и мы хотели узнать эффективные способы чтения данных для синтаксического анализа, а также получения определенных строк данных из файлов по номеру или по первой или последней строке файла. Какие функции или библиотеки мы можем использовать для эффективного чтения файлов?
Какие функции или библиотеки мы можем использовать для эффективного чтения файлов?
Обзор
Для чтения данных из файлов мы обычно хотим сосредоточиться на трех основных функциях для выполнения этих задач, а также на некоторых примерах, перечисленных рядом с ними на практике:
- Как прочитать весь файл, часть файла или пропустить файл. Мы можем столкнуться с ситуацией, когда нам нужно прочитать каждую строку, кроме первой и последней.
- Как прочитать файл, используя мало системных ресурсов. У нас может быть файл размером 100 ГБ, который мы хотим прочитать только на 108 КБ данных.
- Как читать файл таким образом, чтобы мы могли легко анализировать нужные нам данные или использовать функции или инструменты, которые мы используем с другими данными. Поскольку у многих разработчиков есть инструменты синтаксического анализа строк, перевод данных в строковый формат — если это возможно — позволяет нам повторно использовать многие инструменты синтаксического анализа строк.

Вышеизложенное относится к большинству ситуаций, связанных с разбором данных из файлов. Мы начнем с рассмотрения встроенной функции PowerShell для чтения данных, а затем рассмотрим пользовательский способ чтения данных из файлов с помощью PowerShell.
Функция Get-Content PowerShell
Последняя версия PowerShell (версия 5) и многие более ранние версии PowerShell поставляются с функцией Get-Content, и эта функция позволяет нам быстро читать данные файла. В приведенном ниже сценарии мы выводим данные всего файла на экран PowerShell ISE — экран, который мы будем использовать для демонстрационных целей в этой статье:
Get-Content «C:\logging\logging.txt» |
Мы можем сохранить весь этот объем данных в строку с именем ourfilesdata:
$ourfilesdata = Get-Content «C:\logging\logging. $ourfilesdata |
 txt»
txt»Мы получаем тот же результат, что и выше, с той лишь разницей, что мы сохранили весь файл в переменную. Однако мы сталкиваемся с одним недостатком, если мы сохраняем весь файл в переменную или выводим весь файл: если размер файла большой, мы будем читать весь файл в переменную или выводить весь файл на экран. . Это начинает снижать производительность, так как мы имеем дело с большими размерами файлов.
Мы можем выбрать часть файла, обрабатывая нашу переменную (объект — другое имя) как SQL-запрос, в котором мы выбираем некоторые файлы, а не все. В приведенном ниже коде мы выбираем первые пять строк файла, а не весь файл:
$ourfilesdata = Get-Content «C:\logging\logging.txt» $ourfilesdata | Выбрать-Объект-Первый 5 |
Мы также можем использовать ту же функцию для получения последних пяти строк файла, используя аналогичный синтаксис:
$ourfilesdata = Get-Content «C:\logging\logging. $ourfilesdata | Выбрать-Объект -Последние 5 |
 txt»
txt»Встроенная в PowerShell функция Get-Content может быть полезна, но если мы хотим хранить очень мало данных при каждом чтении по причинам синтаксического анализа или если мы хотим читать построчно для анализа файла, мы можем захотеть использовать .NET. StreamReader, который позволит нам настроить использование для повышения эффективности. Это делает Get-Content отличным базовым средством чтения файловых данных.
Библиотека StreamReader
В новом окне PowerShell ISE мы создадим объект StreamReader и избавимся от этого же объекта, выполнив приведенный ниже код PowerShell:
$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt») ### Чтение файлов здесь $newstreamreader. |
 Dispose()
Dispose()Как правило, всякий раз, когда мы создаем новый объект, рекомендуется удалить этот объект, так как он освобождает вычислительные ресурсы для этого объекта. Хотя верно то, что .NET будет делать это автоматически, я все же рекомендую делать это вручную, так как вы можете работать с языками, которые не делают этого автоматически в будущем, и это хорошая практика.
Ничего не происходит, когда мы выполняем приведенный выше код, потому что мы не вызывали никакого метода — мы только создали объект и удалили его. Первый метод, который мы рассмотрим, это метод ReadToEnd():
$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt») $newstreamreader.ReadToEnd() $newstreamreader.Dispose() |
Как мы видим в выводе, мы можем прочитать все данные из файла, как с Get-Content, используя метод ReadToEnd(); как мы читаем каждую строку данных? В класс StreamReader включен метод ReadLine(), и если бы мы вызвали его вместо ReadToEnd(), то получили бы первую строку данных наших файлов:
$newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt») $newstreamreader.ReadLine() $newstreamreader.Dispose() |
Поскольку мы сказали StreamReader прочитать строку, он прочитал первую строку файла и остановился. Причина этого в том, что метод ReadLine() считывает только текущую строку (в данном случае первую строку). Мы должны продолжать читать файл, пока не достигнем его конца. Как мы узнаем, когда файл заканчивается? Конечная строка нулевая. Другими словами, мы хотим, чтобы StreamReader продолжал читать файл (цикл while) до тех пор, пока каждая новая строка не является нулевой (другими словами, содержит данные). Чтобы продемонстрировать это, давайте добавим счетчик строк к каждой строке, которую мы итерируем, чтобы мы могли видеть логику с числами и текстом:
1 2 3 4 5 6 7 8 | $newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt») $eachlinenumber = 1 while (($readeachline =$newstreamreader.ReadLine()) -ne $null ) { Write-Host «$eachlinenumber $readeachline» $eachlinenumber++ } $newstreamreader.Dispose() |
Когда StreamReader читает каждую строку, он сохраняет данные строки в созданный нами объект $readeachline. Мы можем применять строковые функции к этой строке данных на каждом проходе, например, получать первые десять символов строки данных:
1 2 3 4 5 6 7 | $newstreamreader = New-Object System.IO.StreamReader(«C:\logging\logging.txt») $eachlinenumber = 1 while (($readeachline = $newstreamreader.ReadLine()) -ne $null ) { $readeachline.Substring(0,10) } $newstreamreader.Dispose() |
Мы можем расширить этот пример и вызвать два других строковых метода — на этот раз включая строковые методы IndexOf и Replace(). Мы вызываем эти методы только в первых двух строках, получая только строки меньше третьей строки:
1 2 3 4 5 6 7 8 10 110003 12 13 14 | $newstreamreader = New-Object System. $eachlinenumber = 1 while (($readeachline = $newstreamreader.ReadLine()) -ne $null ) { if ($ wanmlineNumber -lt 3) { write -host «$ wanlineNumber» $ readeachline.substring (0,12) $ readeachline.indexof («») $ $. readeachline.Replace(» «,»заменить») } $eachlinenumber++ } $newstreamreader.Dispose() |
Для синтаксического анализа данных мы можем использовать наши строковые методы в каждой строке файла — или в конкретной строке файла — на каждой итерации цикла.
Наконец, мы хотим иметь возможность получить определенную строку из файла — мы можем получить первую и последнюю строку файла с помощью Get-Content. Давайте воспользуемся StreamReader, чтобы поставить определенный номер строки, который мы передаем пользовательской функции, которую мы создаем. Мы создадим повторно используемую функцию, которая возвращает определенный номер строки, затем мы хотим обернуть нашу функцию для повторного использования, требуя двух входных данных: расположение файла и конкретный номер строки, которую мы хотим вернуть.
1 2 3 4 5 6 7 8 10 110003 12 13 14 199900914 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 214 9000 3 9000 218 19 20 21 22 23 24 | Функция Get-FileData { Param( [Parameter(Mandatory=$true)][string]$ourfilelocation , [Параметр (обязательный = $ true)] [int] $ completline ) Процесс { $ NewstreamReader = new-object System.io. $. while (($ readeachline = $ newstreamreader.readline ()) -ne $ null) { if ($ wanmlineNumber -eq $ contiem0003 перерыв; } $ wanglineNumber ++ } $ NewStreamReader.dispose () } } $ savelinetovariable = get -filedata -ourfillocation «c: \ logging \ logging.pling. $savelinetovariable |
Если мы проверим, строка 17 вернет «Расширение буферного пула уже отключено. Никаких действий не требуется». правильно. Кроме того, мы нарушаем оператор if, так как нет необходимости продолжать чтение файла, как только мы получим нужную строку данных. Кроме того, метод dispose действительно завершает объект, что можно проверить, вызвав метод из командной строки в PowerShell ISE, и он ничего не вернет (мы также можем проверить внутри функции и получить тот же результат):
Последние мысли
Для пользовательской производительности StreamReader предлагает больше возможностей, поскольку мы можем считывать каждую строку данных и применять наши дополнительные функции по мере необходимости. Но нам не всегда нужно что-то настраивать, и мы можем захотеть прочитать только несколько первых и последних строк данных, и в этом случае функция Get-Content нам подходит. Кроме того, файлы меньшего размера хорошо работают с Get-Content, поскольку мы никогда не получаем слишком много данных за раз. Просто будьте осторожны, если файлы имеют тенденцию расти со временем.
- Автор
- Последние сообщения
Тимоти Смит
Тим управляет сотнями экземпляров SQL Server и MongoDB и в основном занимается проектированием соответствующей архитектуры для бизнес-модели.
Десять лет он проработал в FinTech, а также несколько лет в биотехнологии и энергетике. Он ведет группу пользователей SQL Server в Западном Техасе, а также ведет курсы и пишет статьи по SQL Server, ETL и PowerShell.
В свободное время он участвует в децентрализованной финансовой индустрии.
Просмотреть все сообщения Тимоти Смита
Последние сообщения Тимоти Смита (посмотреть все)
Практическое введение в парсинг веб-страниц в Python — настоящий Python , а сообщество Python придумало довольно мощные инструменты веб-скрейпинга.
Интернет является, пожалуй, самым большим источником информации — и дезинформации — на планете. Многие дисциплины, такие как наука о данных, бизнес-аналитика и журналистские расследования, могут извлечь огромную пользу из сбора и анализа данных с веб-сайтов.
Из этого руководства вы узнаете, как:
- Анализировать данные веб-сайта с помощью строковых методов и регулярных выражений
- Анализ данных веб-сайта с помощью анализатора HTML
- Взаимодействие с формами и другими компонентами веб-сайта
Примечание: Это руководство адаптировано из главы «Взаимодействие с Интернетом» в Основы Python: практическое введение в Python 3 .
В книге используется встроенный в Python редактор IDLE для создания и редактирования файлов Python и взаимодействия с оболочкой Python, поэтому в этом руководстве вы будете встречать случайные ссылки на IDLE. Однако у вас не должно возникнуть проблем с запуском кода примера из редактора и среды по вашему выбору.
Бесплатный бонус: Нажмите здесь, чтобы получить нашу бесплатную памятку по Python, которая покажет вам основы Python 3, такие как работа с типами данных, словарями, списками и функциями Python.
Очистить и разобрать текст с веб-сайтов
Сбор данных с веб-сайтов с использованием автоматизированного процесса называется парсингом веб-страниц. Некоторые веб-сайты прямо запрещают пользователям очищать свои данные с помощью автоматизированных инструментов, подобных тем, которые вы создадите в этом руководстве. Веб-сайты делают это по двум возможным причинам:
- У сайта есть веская причина защищать свои данные. Например, Карты Google не позволяют слишком быстро запрашивать слишком много результатов.
- Многократные повторные запросы к серверу веб-сайта могут использовать пропускную способность, замедляя работу веб-сайта для других пользователей и потенциально перегружая сервер, так что веб-сайт полностью перестает отвечать на запросы.
Важно: Прежде чем использовать свои навыки Python для веб-скрейпинга, вы всегда должны проверять политику допустимого использования вашего целевого веб-сайта, чтобы убедиться, что доступ к веб-сайту с помощью автоматизированных инструментов не является нарушением его условий использования. С юридической точки зрения парсинг веб-сайтов вопреки желанию веб-сайта является очень серой зоной.
Имейте в виду, что следующие методы могут быть незаконными при использовании на веб-сайтах, которые запрещают парсинг.
Начнем с извлечения всего HTML-кода с одной веб-страницы. Вы будете использовать страницу на Real Python , настроенный для использования в этом руководстве.
Удалить рекламу
Ваш первый веб-парсер
Один полезный пакет для парсинга веб-страниц, который вы можете найти в стандартной библиотеке Python, — это urllib , который содержит инструменты для работы с URL-адресами. В частности, модуль urllib.request содержит функцию urlopen() , которую можно использовать для открытия URL-адреса в программе.
В интерактивном окне IDLE введите следующее, чтобы импортировать urlopen() :
>>>
>>> из urllib.request импортировать urlopen
Веб-страница, которую мы откроем, находится по следующему URL-адресу:
>>>
>>> url = "http://olympus.realpython.org/profiles/aphrodite"
Чтобы открыть веб-страницу, передайте url в urlopen() :
>>>
>>> страница = urlopen(url)
urlopen() возвращает HTTPResponse объект:
>>>
>>> стр.
Чтобы извлечь HTML-код со страницы, сначала используйте метод . объекта read() HTTPResponse , который возвращает последовательность байтов. Затем используйте .decode() для декодирования байтов в строку с использованием UTF-8:
>>>
>>> html_bytes = page.read()
>>> html = html_bytes.decode("utf-8")
Теперь вы можете распечатать HTML, чтобы увидеть содержимое веб-страницы:
>>>
>>> печать (html) <голова>Профиль: Афродита <тело bgcolor="желтый"> <центр>
Имя: Афродита
Любимое животное: Голубь
Любимый цвет: красный
Родной город: гора Олимп

Получив HTML-код в виде текста, вы можете извлечь из него информацию несколькими способами.
Учебник по регулярным выражениям
Регулярные выражения — или регулярные выражения для краткости — это шаблоны, которые можно использовать для поиска текста в строке. Python поддерживает регулярные выражения через модуль стандартной библиотеки re .
Примечание: Регулярные выражения не относятся к Python. Это общая концепция программирования, которую можно использовать с любым языком программирования.
Для работы с регулярными выражениями первое, что вам нужно сделать, это импортировать модуль re :
>>>
>>> импорт
Регулярные выражения используют специальные символы, называемые метасимволами , для обозначения различных шаблонов. Например, символ звездочки ( * ) означает ноль или более того, что идет непосредственно перед звездочкой.
В следующем примере вы используете findall() для поиска любого текста в строке, который соответствует заданному регулярному выражению:
>>>
>>> re.findall("ab*c", "ac")
['ак']
Первый аргумент re. — это регулярное выражение, которое вы хотите сопоставить, а второй аргумент — это проверяемая строка. В приведенном выше примере вы ищете шаблон findall() "ab*c" в строке "ac" .
Регулярное выражение "ab*c" соответствует любой части строки, которая начинается с "a" и заканчивается "c" и имеет ноль или более экземпляров "b" между ними. re.findall() возвращает список всех совпадений. Строка "ac" соответствует этому шаблону, поэтому она возвращается в списке.
Вот один и тот же шаблон, примененный к разным строкам:
>>>
>>> re.findall("ab*c", "abcd")
['абв']
>>> re.findall("ab*c", "acc")
['ак']
>>> re.findall("ab*c", "abcac")
['абв', 'ас']
>>> re.findall("ab*c", "abdc")
[]
Обратите внимание, что если совпадений не найдено, findall() возвращает пустой список.
Сопоставление с образцом чувствительно к регистру. Если вы хотите сопоставить этот шаблон независимо от регистра, вы можете передать третий аргумент со значением re.IGNORECASE :
>>>
>>> re.findall("ab*c", "ABC")
[]
>>> re.findall("ab*c", "ABC", re.IGNORECASE)
['Азбука']
Вы можете использовать точку ( . ) для обозначения любого одиночного символа в регулярном выражении. Например, вы можете найти все строки, содержащие буквы 9.0270 «a» и "c" разделены одним символом следующим образом:
>>>
>>> re.findall("a.c", "abc")
['абв']
>>> re.findall("a.c", "abbc")
[]
>>> re.findall("ac", "ac")
[]
>>> re.findall("ac", "acc")
['акк']
Шаблон .* внутри регулярного выражения означает любой символ, повторяющийся любое количество раз. Например, "a.*c" можно использовать для поиска каждой подстроки, начинающейся с 9.0270 «a» и заканчивается на "c" , независимо от того, какая буква или буквы находятся между ними:
>>>
>>> re.
Часто вы используете re.search() для поиска определенного шаблона внутри строки. Эта функция несколько сложнее, чем re.findall() , потому что он возвращает объект с именем MatchObject , в котором хранятся разные группы данных. Это связано с тем, что внутри других совпадений могут быть совпадения, а re.search() возвращает все возможные результаты.
Детали MatchObject здесь неуместны. Пока просто знайте, что вызов .group() для MatchObject вернет первый и наиболее полный результат, который в большинстве случаев является именно тем, что вам нужно:
>>>
>>> match_results = re.search("ab*c", "ABC", re.IGNORECASE)
>>> match_results.group()
«Азбука»
В модуле re есть еще одна функция, полезная для разбора текста. re.sub() , сокращение от replace , позволяет заменить текст в строке, который соответствует регулярному выражению, новым текстом. Он ведет себя как строковый метод .replace() .
Аргументы переданы в re.sub() — это регулярное выражение, за которым следует текст замены, за которым следует строка. Вот пример:
>>>
>>> string = "Все <заменяется>, если оно находится в <тегах>."
>>> string = re.sub("<.*>", "СЛОНЫ", string)
>>> строка
«Все — СЛОНЫ».
Возможно, это было не совсем то, что вы ожидали.
re.sub() использует регулярное выражение "<.*>" для поиска и замены всего между первыми < и последний > , который охватывает начало до конца . Это связано с тем, что регулярные выражения Python являются жадными , что означает, что они пытаются найти максимально возможное совпадение, когда используются такие символы, как * .
В качестве альтернативы можно использовать шаблон нежадного сопоставления *? , который работает так же, как * , за исключением того, что он соответствует самой короткой строке текста:
>>>
>>> string = "Все <заменяется>, если оно находится в <тегах>."
>>> string = re.sub("<.*?>", "СЛОНЫ", string)
>>> строка
«Всё есть СЛОНЫ, если оно в СЛОНАХ».
На этот раз re.sub() находит два совпадения, и , и заменяет строку "ELEPHANTS" для обоих совпадений.
Удалить рекламу
Проверьте, понимаете ли вы
Разверните блок ниже, чтобы проверить ваше понимание.
Напишите программу, которая получает полный HTML-код со следующего URL-адреса:
>>>
>>> url = "http://olympus.realpython.org/profiles/dionysus"
Затем используйте . для отображения текста, следующего за «Имя:» и «Любимый цвет:» (не включая начальные пробелы или конечные HTML-теги, которые могут появиться в одной строке). find()
Вы можете развернуть блок ниже, чтобы увидеть решение.
Сначала импортируйте функцию urlopen из модуля urlib.request :
из urllib.request import urlopen
Затем откройте URL-адрес и используйте метод .read() объекта HTTPResponse , возвращенный urlopen() , чтобы прочитать HTML-код страницы:
url = "http://olympus.realpython.org/ профили/дионис"
html_page = urlopen(url)
html_text = html_page.read().decode("utf-8")
.read() возвращает строку байтов, поэтому вы используете .decode() для декодирования байтов с использованием кодировки UTF-8.
Теперь, когда у вас есть исходный HTML-код веб-страницы в виде строки, назначенной переменной html_text , вы можете извлечь имя Диониса и любимый цвет из его профиля. Структура HTML профиля Диониса такая же, как у профиля Афродиты, который вы видели ранее.
Имя можно получить, найдя в тексте строку "Имя:" и извлекая все, что идет после первого вхождения строки и до следующего тега HTML. То есть нужно извлечь все после двоеточия ( : ) и перед первой угловой скобкой ( < ). Вы можете использовать ту же технику, чтобы извлечь любимый цвет.
Следующий цикл for извлекает этот текст как для названия, так и для любимого цвета:
для строки в ["Name: ", "Favorite Color:"]:
string_start_idx = html_text.find(строка)
text_start_idx = string_start_idx + длина (строка)
next_html_tag_offset = html_text[text_start_idx:].find("<")
text_end_idx = text_start_idx + next_html_tag_offset
необработанный_текст = html_текст[text_start_idx : text_end_idx]
clean_text = raw_text.strip("\r\n\t")
печать (чистый_текст)
Похоже, что в этом цикле для происходит много всего, но это всего лишь небольшая арифметика для вычисления правильных индексов для извлечения нужного текста. Давайте сломаем это:
Вы используете
html_text.find(), чтобы найти начальный индекс строки, либо"Имя:", либо"Любимый цвет:", а затем присваиваете индексstring_start_idx.Так как текст для извлечения начинается сразу после двоеточия в
«Имя:»или«Любимый цвет:», вы получаете индекс символа сразу после двоеточия, добавляя длину строки кstart_string_idxи присваивая результатtext_start_idx.Вы вычисляете конечный индекс извлекаемого текста, определяя индекс первой угловой скобки (
<) относительноtext_start_idxи присваивая это значениеnext_html_tag_offset. Затем вы добавляете это значение кtext_start_idxи присвоить результатtext_end_idx.Вы извлекаете текст, нарезая
html_textизtext_start_idxвtext_end_idxи назначая эту строкуraw_text.Вы удаляете все пробелы в начале и конце
raw_textс помощью.strip()и присваиваете результатclean_text.
В конце цикла вы используете print() для отображения извлеченного текста. Окончательный вывод выглядит так:
Дионис. Вино
Это решение является одним из многих, которые решают эту проблему, поэтому, если вы получили тот же результат с другим решением, то вы отлично справились!
Когда вы будете готовы, вы можете перейти к следующему разделу.
Используйте синтаксический анализатор HTML для парсинга веб-страниц в Python
Хотя регулярные выражения в целом отлично подходят для сопоставления с образцом, иногда проще использовать анализатор HTML, специально предназначенный для анализа HTML-страниц. Для этой цели написано множество инструментов Python, но лучше всего начать с библиотеки Beautiful Soup.
Установить красивый суп
Чтобы установить Beautiful Soup, вы можете запустить в своем терминале следующее:
$ python3 -m pip установить BeautifulSoup4
Запустите pip show , чтобы просмотреть сведения о только что установленном пакете:
$ python3 -m pip show beautifulsoup4 Имя: BeautifulSoup4 Версия: 4.
В частности, обратите внимание, что последней версией на момент написания была 4.9.1.
Удалить рекламу
Создать
BeautifulSoup ОбъектВведите следующую программу в новое окно редактора:
из импорта bs4 BeautifulSoup
из urllib.request импортировать urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
страница = urlopen(url)
html = page.read().decode("utf-8")
суп = BeautifulSoup(html, "html.parser")
Эта программа делает три вещи:
Открывает URL
http://olympus.realpython.org/profiles/dionysusс помощьюurlopen()из модуля urllib. request Считывает HTML-код со страницы в виде строки и присваивает его переменной
htmlСоздает объект
BeautifulSoupи присваивает егосупупеременной
Объект BeautifulSoup присвоен суп создается с двумя аргументами. Первый аргумент — это HTML для анализа, а второй аргумент, строка "html.parser" , сообщает объекту, какой парсер использовать за кулисами. "html.parser" представляет встроенный в Python анализатор HTML.
Использовать объект
BeautifulSoup Сохраните и запустите указанную выше программу. Когда он закончит работу, вы можете использовать переменную суп в интерактивном окне, чтобы проанализировать содержимое html различными способами.
Например, объекты BeautifulSoup имеют метод .get_text() , который можно использовать для извлечения всего текста из документа и автоматического удаления любых тегов HTML.
Введите следующий код в интерактивное окно IDLE:
>>>
>>> print(soup.get_text()) Профиль: Дионис Имя: Дионис Родной город: гора Олимп Любимое животное: леопард Любимый цвет: винный
В этом выводе много пустых строк. Это результат символов новой строки в тексте HTML-документа. Вы можете удалить их с помощью строки .replace() метод, если вам нужно.
Часто вам нужно получить только определенный текст из HTML-документа. Использование Beautiful Soup сначала для извлечения текста, а затем использование строкового метода .find() иногда проще, чем работа с регулярными выражениями.
Однако иногда теги HTML сами по себе являются элементами, указывающими на данные, которые вы хотите получить. Например, возможно, вы хотите получить URL-адреса всех изображений на странице. Эти ссылки содержатся в src атрибут тегов HTML.
В этом случае вы можете использовать find_all() для возврата списка всех экземпляров этого конкретного тега:
>>>
>>> суп.
 ]
]
Возвращает список всех тегов в документе HTML. Объекты в списке выглядят так, как будто они представляют собой строки, представляющие теги, но на самом деле они являются экземплярами
Тег Объект предоставлен Beautiful Soup. Объекты Tag обеспечивают простой интерфейс для работы с содержащейся в них информацией.
Давайте немного изучим это, сначала распаковав объекты Tag из списка:
>>>
>>> изображение1, изображение2 = суп.найти_все("img")
Каждый объект Tag имеет свойство .name , которое возвращает строку, содержащую тип тега HTML:
>>>
>>> изображение1.имя 'изображение'
Вы можете получить доступ к атрибутам HTML объекта Tag , поместив их имя в квадратные скобки, как если бы атрибуты были ключами в словаре.
Например, тег имеет единственный атрибут 
src со значением "/static/dionysus.jpg" . Точно так же HTML-тег, такой как ссылка имеет два атрибута: href и target .
Чтобы получить источник изображений на странице профиля Dionysus, вы получаете доступ к атрибуту src , используя обозначение словаря, упомянутое выше:
>>>
>>> изображение1["источник"] '/static/dionysus.jpg' >>> изображение2["источник"] '/статический/виноград.png'
Доступ к некоторым тегам в HTML-документах можно получить с помощью свойств объекта Если вы посмотрите на источник профиля Dionysus, перейдя на страницу профиля, щелкнув страницу правой кнопкой мыши и выбрав Просмотреть источник страницы , вы заметите, что тег Beautiful Soup автоматически очищает теги за вас, удаляя лишний пробел в открывающем теге и лишнюю косую черту ( Вы также можете получить только строку между тегами title с помощью свойства >>> Одной из наиболее полезных функций Beautiful Soup является возможность поиска определенных типов тегов, атрибуты которых соответствуют определенным значениям. Например, если вы хотите найти все >>> Этот пример несколько произволен, и полезность этого метода может быть неочевидна из примера. Если вы потратите некоторое время на просмотр различных веб-сайтов и просмотр источников их страниц, то заметите, что многие веб-сайты имеют чрезвычайно сложную структуру HTML. При извлечении данных с веб-сайтов с помощью Python вас часто интересуют определенные части страницы. Потратив некоторое время на просмотр HTML-документа, вы сможете определить теги с уникальными атрибутами, которые можно использовать для извлечения необходимых данных. Затем, вместо того, чтобы полагаться на сложные регулярные выражения или использовать В некоторых случаях вы можете обнаружить, что Beautiful Soup не предлагает необходимую вам функциональность. С библиотекой lxml немного сложнее начать работу, но она предлагает гораздо большую гибкость, чем Beautiful Soup, для анализа HTML-документов. Возможно, вы захотите проверить это, как только освоите Beautiful Soup. Примечание. Анализаторы HTML , такие как Beautiful Soup, могут сэкономить вам много времени и усилий, когда дело доходит до поиска определенных данных на веб-страницах. В этом случае вам часто приходится использовать BeautifulSoup отлично подходит для извлечения данных из HTML-кода веб-сайта, но не предоставляет никаких возможностей для работы с HTML-формами. Например, если вам нужно выполнить поиск на веб-сайте по какому-либо запросу, а затем очистить результаты, то один BeautifulSoup далеко не уйдет. Удалить рекламу Разверните блок ниже, чтобы проверить ваше понимание. Напишите программу, которая получает полный HTML-код со страницы по URL-адресу С помощью Beautiful Soup распечатайте список всех ссылок на странице, выполнив поиск HTML-тегов с именами Окончательный вывод должен выглядеть так: Вы можете развернуть блок ниже, чтобы увидеть решение: Сначала импортируйте функцию Каждый URL-адрес ссылки на странице Вы можете создать полный URL-адрес, объединив Теперь откройте страницу После загрузки и декодирования исходного кода HTML можно создать новый объект Доступ к относительному URL для каждой ссылки можно получить с помощью индекса Когда вы будете готовы, вы можете перейти к следующему разделу. Модуль Стандартная библиотека Python не предоставляет встроенных средств для интерактивной работы с веб-страницами, но в PyPI доступно множество сторонних пакетов. Среди них MechanicalSoup является популярным и относительно простым в использовании пакетом. По сути, MechanicalSoup устанавливает так называемый безголовый браузер , который представляет собой веб-браузер без графического пользовательского интерфейса. Этот браузер управляется программно через программу Python. Вы можете установить MechanicalSoup с Теперь вы можете просмотреть некоторые сведения о пакете с помощью В частности, обратите внимание, что последней версией на момент написания была 0.12.0. Вам нужно будет закрыть и перезапустить сеанс IDLE, чтобы MechanicalSoup загрузился и был распознан после его установки. Введите в интерактивном окне IDLE следующее: >>> >>> >>> Число MechanicalSoup использует Beautiful Soup для анализа HTML-кода запроса. >>> Вы можете просмотреть HTML, проверив атрибут >>> Tag . Например, чтобы получить / ) в закрывающем теге. .string объекта Tag : >>> суп.название.строка
«Профиль: Дионис»
теги, у которых атрибут
src равен значению /static/dionysus.jpg , то вы можете указать следующий дополнительный аргумент для .find_all() : >>> sup.find_all("img", src="/static/dionysus.jpg")
[]
.find() для поиска по документу, вы можете получить прямой доступ к интересующему вас тегу и извлечь нужные данные. Однако иногда HTML написан настолько плохо и неорганизованно, что даже сложный парсер, такой как Beautiful Soup, не может правильно интерпретировать HTML-теги. .find() и методы регулярных выражений, чтобы попытаться разобрать нужную вам информацию. Проверьте, понимаете ли вы
http://olympus.realpython.org/profiles . и и извлекая значение атрибута href каждого тега. http://olympus.realpython.org/profiles/aphrodite
http://olympus.realpython.org/profiles/poseidon
http://olympus.realpython.org/profiles/dionysus
urlopen из модуля urlib.request и класс BeautifulSoup из пакета bs4 : из urllib.request import urlopen
из bs4 импортировать BeautifulSoup
/profiles является относительным URL-адресом, поэтому создайте переменную base_url с базовым URL-адресом веб-сайта: base_url = "http://olympus.realpython.org"
base_url с относительным URL-адресом. /profiles с помощью urlopen() и используйте .read() , чтобы получить исходный код HTML: html_page = urlopen(base_url + "/profiles")
html_text = html_page.
read().decode("utf-8")
BeautifulSoup для анализа HTML: суп = BeautifulSoup(html_text, "html.parser")
soap.find_all("a") возвращает список всех ссылок в исходном коде HTML. Вы можете перебрать этот список, чтобы распечатать все ссылки на веб-странице: для ссылки в супе.find_all("a"):
link_url = базовый_url + ссылка["href"]
печать (link_url)
"href" . Объедините это значение с base_url , чтобы создать полный link_url . Взаимодействие с HTML-формами
urllib , с которым вы работали до сих пор в этом руководстве, хорошо подходит для запроса содержимого веб-страницы. Однако иногда вам необходимо взаимодействовать с веб-страницей, чтобы получить нужный контент. Например, вам может потребоваться отправить форму или нажать кнопку, чтобы отобразить скрытое содержимое. Установить MechanicalSoup
pip в свой терминал: $ python3 -m pip установить MechanicalSoup
pip show : $ python3 -m pip show механическийсуп
Название: Механический суп
Версия: 0.12.0
Резюме: библиотека Python для автоматизации взаимодействия с веб-сайтами.
Домашняя страница: https://mechanicalsoup.readthedocs.io/
Автор: НЕИЗВЕСТНО
Электронная почта автора: НЕИЗВЕСТНО
Лицензия: Массачусетский технологический институт
Расположение: c:\realpython\venv\lib\site-packages
Требуется: запросы, beautifulsoup4, six, lxml
Требуется:
Создать
Браузер Объект >>> импортный механическийсуп
>>> браузер = механический суп.Браузер()
Объекты Browser представляют безголовый веб-браузер. Вы можете использовать их для запроса страницы из Интернета, передав URL-адрес их методу .get() : >>> url = "http://olympus.realpython.
org/login"
>>> страница = browser.get(url)
страница — это объект Response , в котором хранится ответ на запрос URL-адреса из браузера: >>> стр.
<Ответ [200]>
200 представляет собой код состояния, возвращаемый запросом. Код состояния 200 означает, что запрос выполнен успешно. Неудачный запрос может отображать код состояния 404 , если URL-адрес не существует, или 500 , если при выполнении запроса произошла ошибка сервера. страница имеет атрибут .soup , который представляет объект BeautifulSoup : >>> тип(страница.суп)
<класс 'bs4.BeautifulSoup'>
.soup : >>> стр.
суп
<голова>
Чтобы получить доступ к горе Олимп, войдите в систему: