What is Google Sans Text?
Browse Eckher Glossary and expand your business and technology vocabulary.
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
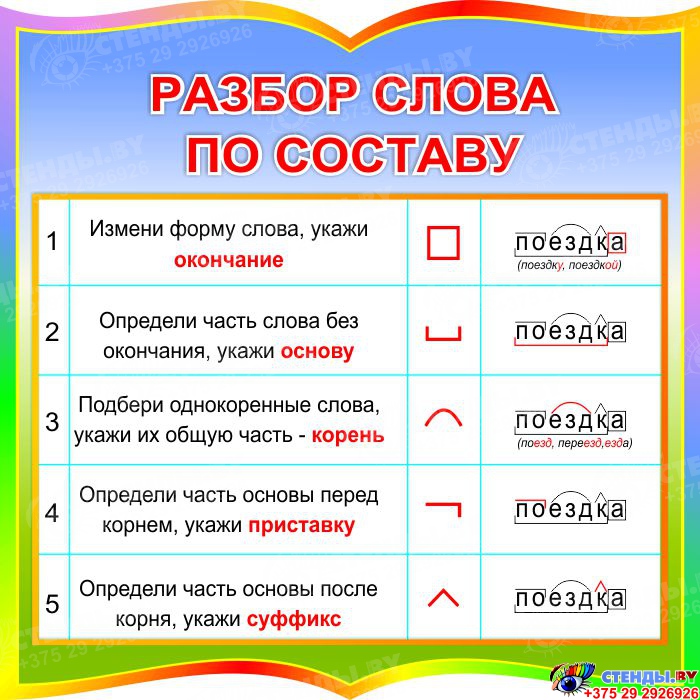
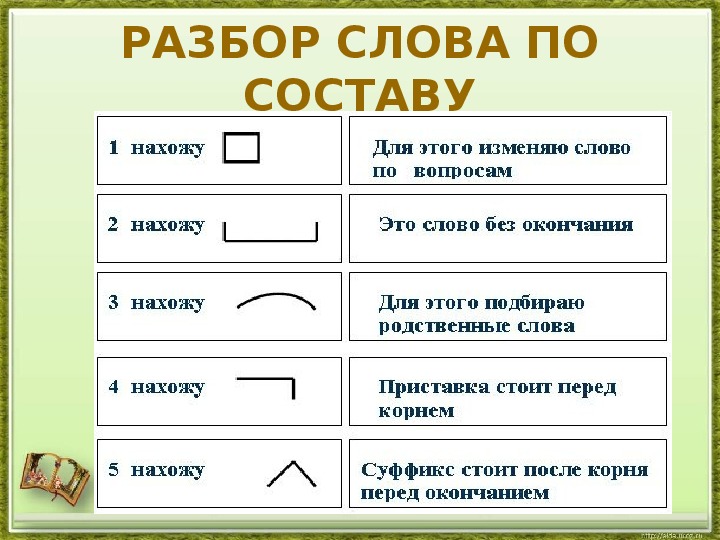
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
How to pronounce «featurize» in English?
How to pronounce «Onehunga» in English?
How to pronounce «Takapuna» in English?
How to pronounce «İzmir» in English?
How to pronounce «Coronaviridae» in English?
How to pronounce «Whanganui» in English?
How to pronounce «Chlöe Swarbrick» in English?
How to pronounce «Kohimarama» in English?
How to pronounce «Tua Tagovailoa» in English?
How to pronounce «Craig Federighi» in English?
How to pronounce «Stefanos Tsitsipas» in English?
How to pronounce «Jacob deGrom» in English?
How to pronounce «myocarditis» in English?
How to pronounce «SZA» in English?
How to pronounce «Cassie Kozyrkov» in English?
Экспертный разбор состава — Angel Lab
Самый известный в России эксперт по натуральным составам @alona_eco разбирает Angel Lab ❤️:
⠀
Лучшее средство против пигментации — профилактика пигментации. Например, с помощью ночного флюида «Ровный тон» от @olga.yanaslova
Например, с помощью ночного флюида «Ровный тон» от @olga.yanaslova
⠀
Это не просто флюид.
⠀
Это интенсивное ароматерапевтическое средство на физиологичной основе без эмульгаторов и других спорных компонентов.
⠀
Ингредиенты этого флюида (как и других средств от Angel Lab) подобраны в соответствии с составом гидролипидной мантии здоровой кожи. У него сильный антиоксидантный эффект, флюид восстанавливает, сглаживает тон кожи, деликатно устраняет пигментные пятна при регулярном использовании.
⠀
🌿В основе лежит корнетерапевтическая композиция липидов и жирных кислот из масел (масло кунжута, гидрированный фосфатидилхолин, фитостеролы, церамиды, масла дыни калахари, макадамии, жожоба, соевый лецитин).
⠀
⠀
🌿Натуральный Увлажняющий Фактор стимулирует синтез церамидов и улучшает барьерную функцию кожи, увлажняет, поддерживает упругость, пластичность и гладкость кожи.

⠀
🌿Масла бораго и комбо, экстракт шиповника — сами по себе сильные активы, а вместе еще и усиливают действие друг друга. Именно они помогают сглаживать пигментацию и постакне (если шрамы новые и неглубокие).
⠀
🌿Бораго и Шиповник подходят только для ночного ухода, так как склонны к окислению, вот почему флюид ночной.
⠀
🌿Экстракты терминалии хебулы, розмарина, солодки, шалфея, ванили, эфирное масло герани, — сильные антиоксиданты, осветляющие и устраняющие нежелательную пигментацию растительные активы с приятным ароматом.
⠀
🌿Лексгард (глицерил каприлат, глицерил ундециленат) и сенсива (фенилэтиловый спирт, этилгексилглицерин) — противомикробные добавки, которые работают с воспалениями и увлажняют кожу.
⠀
🌿Арабиногалактан, ксантан, растительный глицерин, полиглутаминовая кислота, тремеллы полисахарид качественно и глубоко увлажняют кожу. 😇 Angel Lab — этичное 🐰 производство натуральных флюидов.
✅ Финалист Live Organic Awards 2020 и Green Awards 2020
↗ Победитель Live OrganicAwards2019
✅ Финалист Green Awards 2018
🚘 Доставка курьером и в пункты выдачи по РФ, РБ, Казахстану и Армении.

🌹 Консультации: [email protected]
🤗 Заказать в 1й раз — заполните анкету.
✅ Повторный заказ — личный кабинет сайта или почта [email protected]
🌹 Заказать подарочный сертификат — здесь.
👌 Гарантия!
звуко буквенный разбор слова жить
1)Наш грач жил на свободе, разгуливая возле дачи.2) Его проделкам не было конца.3) Из дома он таскал все, что мог унести: наперстки, ножницы, мелкие и
… нструменты, хотя прекрасно знал, что воровать нельзя.4)
Он проказничал, когда его никто не видел, и всегда, недовольно каркнув, поспешно улетал, если его заставали на месте преступления.5) Отлетев на безопасное расстояние, он издали наблюдал, какое впечатление производило его озорство.
6)Грач особенно внимательно следил за работой жены художника, которая увлекалась садоводством и много работала в саду.7) Если производилась прививка растений и место прививки заматывалось изоляционной лентой, он разматывал ее и, довольный, торопливо удалялся.
8)Но, несмотря ни на что, его нельзя было не любить: он сопровождал, перелетая с ветки на ветку, хозяев, если они уходили на прогулки, летал над лодкой, если они катались по реке.
1)Наш грач жил на свободе, разгуливая возле дачи.2) Его проделкам не было конца.3) Из дома он таскал все, что мог унести: наперстки, ножницы, мелкие и
… нструменты, хотя прекрасно знал, что воровать нельзя.4)
Он проказничал, когда его никто не видел, и всегда, недовольно каркнув, поспешно улетал, если его заставали на месте преступления.5) Отлетев на безопасное расстояние, он издали наблюдал, какое впечатление производило его озорство.
1)Наш грач жил на свободе, разгуливая возле дачи. 2) Его проделкам не было конца.3) Из дома он таскал все, что мог унести: наперстки, ножницы, мелкие и
… нструменты, хотя прекрасно знал, что воровать нельзя.4)
Он проказничал, когда его никто не видел, и всегда, недовольно каркнув, поспешно улетал, если его заставали на месте преступления.5) Отлетев на безопасное расстояние, он издали наблюдал, какое впечатление производило его озорство.
6)Грач особенно внимательно следил за работой жены художника, которая увлекалась садоводством и много работала в саду.7) Если производилась прививка растений и место прививки заматывалось изоляционной лентой, он разматывал ее и, довольный, торопливо удалялся.
8)Но, несмотря ни на что, его нельзя было не любить: он сопровождал, перелетая с ветки на ветку, хозяев, если они уходили на прогулки, летал над лодкой, если они катались по реке. 9)Он никогда не пропускал обеденное время, терпеливо ожидая, когда ему дадут что-нибудь вкусненькое, и если был сыт, то лакомые кусочки прятал про запас: засовывал в башмаки, под шкаф или в другие укромные местечки.
2) Его проделкам не было конца.3) Из дома он таскал все, что мог унести: наперстки, ножницы, мелкие и
… нструменты, хотя прекрасно знал, что воровать нельзя.4)
Он проказничал, когда его никто не видел, и всегда, недовольно каркнув, поспешно улетал, если его заставали на месте преступления.5) Отлетев на безопасное расстояние, он издали наблюдал, какое впечатление производило его озорство.
6)Грач особенно внимательно следил за работой жены художника, которая увлекалась садоводством и много работала в саду.7) Если производилась прививка растений и место прививки заматывалось изоляционной лентой, он разматывал ее и, довольный, торопливо удалялся.
8)Но, несмотря ни на что, его нельзя было не любить: он сопровождал, перелетая с ветки на ветку, хозяев, если они уходили на прогулки, летал над лодкой, если они катались по реке. 9)Он никогда не пропускал обеденное время, терпеливо ожидая, когда ему дадут что-нибудь вкусненькое, и если был сыт, то лакомые кусочки прятал про запас: засовывал в башмаки, под шкаф или в другие укромные местечки.
№3. Заменить одним словом. Определить род . Человек, который играет на трубе -….., Человек, который выступает в цирке — …., Очень сильный человек — …, … Человек, который играет на скрипке — …, Житель Москвы — …, Место, где купаются и загорают — … Колючее животное — …., Женское украшение — …,
Выберите правильное утверждение: А) Глагол – это служебная часть речи Б) Глагол – склоняемая часть речи В) В предложении глагол чаще всего бывает сказ … уемым Г) Глагол обозначает признак предмета
Укажите ряд, где во всех словах на месте пропуска пишется Ъ: А) С_экономить, объяснение, пред_явил Б) Пред_юбилейный, меж_этажный, с_ел В) С_ёжился, п … ред_октябрьский, из_украшенный Г) Под_ём, с_ёмка, об_явление
Какое слово написано правильно? А) Гиганский Б) Экскалатор В) Тросник Г) Крепостной
что такое однородные члены предложений
1. выполни звуко-буквеный анализ слов.
выполни звуко-буквеный анализ слов.
Замените предложения синонимичными. Используйте конструкциюсо словом который.Модель: Надень куртку, подаренную тебе мамой!Нарень куритику, которуюmede … парашла сама.1. Ты видел выставку, открытую недавно в Эрмитаже?2. Мы ездим на машине, купленной 10 лет назад.3. Дома, построенные в 1980-е годы, похожи как две капли воды.4. Уха, приготовленная по рецепту моей бабушки, нравится всем,5. Роман «Дети Арбата», написанный А. Рыбаковым в 1987 году, был издантолько после перестройки.6. После фильма «Идиот», снятого режиссером А. Бортко, молодые люди началичитать Ф. Достоевского.7. Гости, приглашённые к 6 часам, почему-то опаздывали,8. Кофе, принесённый официантом, был холодным.
Слова «живем» морфологический и фонетический разбор
1. проживать
2. пребывать
3. пробывать
4. быть
5. жительствовать
6. обретаться
7. водиться
8. обитать
9. населять
10. ютиться
11. гнездиться
12. квартировать
квартировать
13. стоять
14. зимовать
15. проводить молодость
16. век вековать
17. коротать
18. благоденствовать
19. долгоденствовать
20. здравствовать
21. существовать
22. быть в живых
23. не умирать
24. выживать
25. доживать
26. зажиться
27. сожительствовать
28. кормиться
29. пробиваться
30. перебиваться
31. влачить
32. вести жалкую жизнь
33. вести жалкое существование
34. прозябать
35. коснеть
36. дотягивать
37. протягивать до утра
38. довольствоваться
39. роскошествовать
40. нежиться
41. припевать
42. как у Христа за пазухой
43. барствовать
44. кататься как сыр в масле
45. протягивать ножки по одежке
46. питаться
47. иметь половые отношения
48. бредить
49. зарабатывать
50. любиться
51. поживать
52. бараться
53. зависать
54. кантоваться
55. иметься
иметься
56. интересоваться
57. стоять на квартире
58. отдаваться всецело
59. грешить
60. отдаваться со страстью
61. отдаваться целиком
62. отдаваться полностью
63. тесниться
64. добывать пропитание
65. зарабатывать на жизнь
66. зарабатывать на хлеб
67. содержать себя
68. греховодить
69. влачить существование
70. увлекаться
71. добывать средства к жизни
72. коптить небо
73. загораться
74. гореть
75. пробавляться
76. сосуществовать
77. влачить жалкое существование
78. скрипеть
79. коротать век
80. встречаться
81. держаться
82. вести жизнь
83. вести образ жизни
84. жить-поживать
Cedarwood: разбор состава | Журнал Ярмарки Мастеров
Привет! Очень захотелось показать вам из чего же состоит натуральное мыло. И сегодня я решила поближе познакомить вас с составом сорта Cedarwood.
На обратной стороне каждой упаковки с мылом вы всегда найдете его полный состав.
Состав этого сорта выглядит так: омыленные масла ши, оливы, миндаля, кокоса, клещевины; масло кедра, ши баттер; зеленая глина; спирулина; эфирные масла кедра и сосны; слюда.
Прежде, чем перейти к разбору состава, расскажу о том, что же такое «омыленные масла» и само мыло в принципе.)
Натуральное твердое мыло представляет собой смесь натриевых солей жирных кислот, получаемых в результате процесса омыления масел каустической содой (NaOH, гидроксид натрия, едкий натр, натриевая щелочь). Щелочь — неорганическое вещество, однако в готовом мыле ее не остается. Омыление начинается со смешивания масел с щелочным раствором, запускающим процесс превращения жиров в мыло.
Вот так выглядит смесь масел и щелочи:
Натуральное мыло можно готовить двумя способами — горячим и холодным. При холодном способе масла смешиваются с щелочным раствором, разливаются по формам и отправляются зреть под воздействием времени. Процесс омыления и созревания составляет от нескольких недель, до нескольких лет (например, лаврово-оливковое алеппское мыло вызревает 3 года).
При горячем способе омыление происходит под воздействием температуры. Я предпочитаю горячий, поскольку он позволяет обогащать мыло уходовыми компонентами, которые уже не будут контактировать с щелочью, а значит сохранят максимум своей пользы. Еще один приятный бонус горячего способа — мыло полностью готово уже на следующий день. Но я, обычно, даю ему полежать 7-10 дней, прежде чем добавляю его в магазин. Конечно, этот способ немного ограничивает мастера в дизайне, однако, лично для меня — польза в мыле превыше всего.)
А теперь вернемся к составу кедрового мыла и посмотрим на него своими глазами:
Верхний ряд: ши баттер, кокосовое масло, оливковое масло, масло сладкого миндаля.
Нижний ряд: масло клещевины, кедровое масло, щелочь, зеленая глина/спирулина.
А в центре — очищенная вода для щелочного раствора.
Большую часть в этом мыле занимает масло ши (карите). Оно дает нежную кремовую пенку и не позволяет мылу сушить кожу. Оливковое и миндальные масла добавлены для увлажнения и смягчения. Омыленное кокосовое масло делает пену обильной, а также существенно повышает его очищающие свойства. Масло клещевины (касторовое) стабилизирует пену. Его в составе чуть больше, чем эфирных масел.
Омыленное кокосовое масло делает пену обильной, а также существенно повышает его очищающие свойства. Масло клещевины (касторовое) стабилизирует пену. Его в составе чуть больше, чем эфирных масел.
Уходовая часть сорта представлена маслом из кедровых орехов и ши баттером, помогающими устранить сухость и шелушение кожи, улучшить ее общее состояние и цвет. Мягкий скрабирующий эффект мылу придает смесь зеленой глины и спирулины. Чуть позже я расскажу об этих компонентах подробнее.)
На снимке не хватает только эфирных масел и слюды, которую я использую для декора.
На этих же омыленных маслах сделаны еще несколько сортов моего мыла:
— Pink Clay: нежное мыло с розовой глиной, манго и ши баттерами, эфирными маслами дамасской розы и бергамота.
— Lavender: мыло-скраб с манго и ши баттерами, эфирным маслом и пудрой лаванды.
— Turmeric: целебное мыло с облепиховым маслом, куркумой, эфирными маслами душицы, чабреца и чайного дерева.
— Oleum Rusci: дегтярное мыло с маслом ши.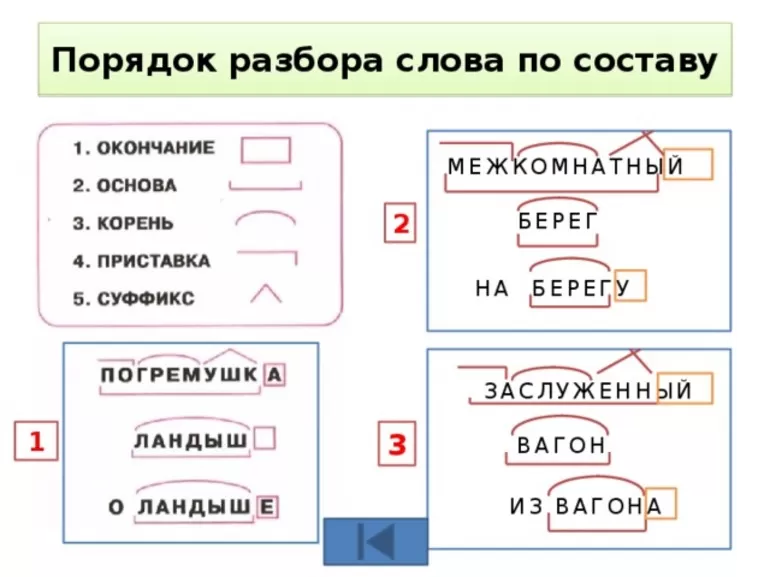
— Menthol: освежающее мыло с манго и ши баттерами, эфирными маслами пихты и эвкалипта, ментолом и спирулиной.
— Charcoal: угольное мыло с ши баттером, эфирными маслами чайного дерева, можжевельника и сосны.
— Sagebrush: ароматное мыло-скраб с ши баттером, пудрой полыни, эфирными маслами полыни и лайма.
Теперь вы узнали о моем мыле чуть больше. А чуть больше о маслах, травах, пудрах и глинах я расскажу в отдельных статьях.)
Статут — Международный Суд
Статут
Статья 1
Международный Суд, учрежденный Уставом Объединенных Наций в качестве главного судебного органа Объединенных Наций, образуется и действует в соответствии с нижеследующими постановлениями настоящего Статута.
ГЛАВА I: Организация Суда
Статья 2
Суд состоит из коллегии независимых судей, избранных, вне зависимости от их гражданства, из числа лиц высоких моральных качеств, удовлетворяющих требованиям, предъявляемым в их странах для назначения на высшие судебные должности, или являющихся юристами с признанным авторитетом в области международного права.
Статья 3
1. Суд состоит из пятнадцати членов, причем в его составе не может быть двух граждан одного и того же государства.
2. Лицо, которое можно рассматривать, в применении к составу Суда, как гражданина более чем одного государства, считается гражданином того государства, в котором он обычно пользуется своими гражданскими и политическими правами.
Статья 4
1. Члены Суда избираются Генеральной Ассамблеей и Советом Безопасности из числа лиц, внесенных в список по предложению национальных групп Постоянной Палаты Третейского Суда, согласно нижеследующим положениям.
2. Что касается Членов Объединенных Наций, не представленных в Постоянной Палате Третейского Суда, то кандидаты выставляются национальными группами, назначенными для этой цели их правительствами, с соблюдением условий, установленных для членов Постоянной Палаты Третейского Суда статьей 44 Гаагской Конвенции 1907 года о мирном решении международных столкновений.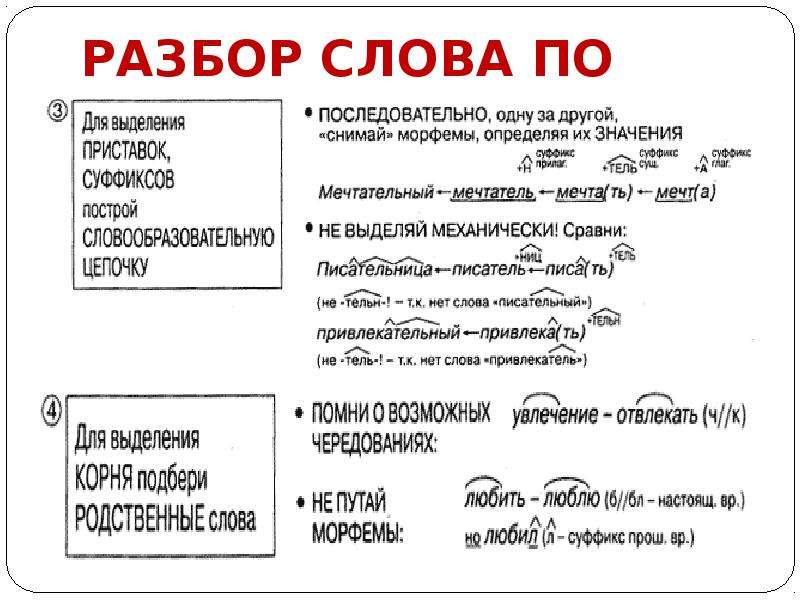
3. Условия, на которых государство — участник настоящего Статута, но не входящее в состав Объединенных Наций, может участвовать в избрании членов Суда, определяются, при отсутствии особого соглашения, Генеральной Ассамблеей по рекомендации Совета Безопасности.
Статья 5
1. Не позднее чем за три месяца до дня выборов Генеральный Секретарь Объединенных Наций обращается к членам Постоянной Палаты Третейского Суда, принадлежащим к государствам — участникам настоящего Статута, и к членам национальных групп, назначенных в порядке пункта 2 статьи 4, с письменным предложением о том, чтобы каждая национальная группа указала, в течение определенного срока, кандидатов, могущих принять на себя обязанности членов Суда.
2. Никакая группа не может выставить более четырех кандидатов, причем не более двух кандидатов могут состоять в гражданстве государства, представляемого группой. Число кандидатов, выставленных группой, ни в коем случае не может превышать более чем вдвое число мест, подлежащих заполнению.
Статья 6
Рекомендуется , чтобы каждая группа до выставления кандидатур запрашивала мнение высших судебных установлений, юридических факультетов, правовых высших учебных заведений и академий своей страны, а также национальных отделений международных академий, занимающихся изучением права.
Статья 7
1. Генеральный Секретарь составляет в алфавитном порядке список всех лиц, чьи кандидатуры были выставлены. Кроме случая, предусмотренного в пункте 2 статьи 12, только лица, внесенные в этот список, могут быть избраны.
2. Генеральный Секретарь представляет этот список Генеральной Ассамблее и Совету Безопасности.
Статья 8
Генеральная Ассамблея и Совет Безопасности приступают к выборам членов Суда независимо друг от друга.
Статья 9
При избрании избиратели должны иметь в виду, что не только каждый избранный в отдельности должен удовлетворять всем предъявляемым требованиям, но и весь состав судей в целом должен обеспечить представительство главнейших форм цивилизации и основных правовых систем мира.
Статья 10
1. Избранными считаются кандидаты, получившие абсолютное большинство голосов и в Генеральной Ассамблее, и в Совете Безопасности.
2. Любое голосование в Совете Безопасности как при выборах судей, так и при назначении членов согласительной комиссии, предусмотренной статьей 12, производится без всякого различия между постоянными и непостоянными членами Совета Безопасности.
3. В случае, если бы абсолютное большинство голосов было подано и в Генеральной Ассамблее, и в Совете Безопасности более чем за одного гражданина того же государства, избранным считается лишь старший по возрасту.
Статья 11
Если после первого заседания, созванного для выборов, одно или несколько мест окажутся незаполненными, состоится второе, а в случае надобности, и третье заседание.
Статья 12
1. Если после третьего заседания одно или несколько мест окажутся незаполненными, то в любое время, по требованию либо Генеральной Ассамблеи, либо Совета Безопасности, может быть созвана согласительная комиссия в составе шести членов: трех по назначению Генеральной Ассамблеи и трех по назначению Совета Безопасности, для избрания абсолютным большинством голосов одного лица на каждое еще свободное место и представления его кандидатуры на усмотрение Генеральной Ассамблеи и Совета Безопасности.
2. Если согласительная комиссия единогласно остановится на кандидатуре какого-либо лица, удовлетворяющего предъявляемым требованиям, его имя может быть включено в список, хотя бы оно и не было внесено в кандидатские списки, предусмотренные статьей 7.
3. Если согласительная комиссия придет к убеждению, что выборы не могут состояться, тогда члены Суда, уже избранные, приступают в срок, определяемый Советом Безопасности, к заполнению свободных мест путем избрания членов Суда из числа кандидатов, за которых были поданы голоса либо в Генеральной Ассамблее, либо в Совете Безопасности.
4. В случае равенства голосов судей голос старшего по возрасту дает перевес.
Статья 13
1. Члены Суда избираются на девять лет и могут быть переизбраны, с тем, однако, что срок полномочий пяти судей первого состава Суда истекает через три года, а срок полномочий еще пяти судей — через шесть лет.
2. Генеральный Секретарь немедленно по окончании первых выборов определяет по жребию, кто из судей считается избранным на указанные выше первоначальные сроки в три года и в шесть лет.
3. Члены Суда продолжают исполнять свою должность впредь до замещения их мест. Даже после замещения они обязаны закончить начатые дела.
4. В случае подачи членом Суда заявления об отставке это заявление адресуется Председателю Суда для передачи Генеральному Секретарю. По получении последним заявления место считается вакантным.
Статья 14
Открывшиеся вакансии заполняются тем же порядком, который установлен для первых выборов, с соблюдением нижеследующего правила: в течение месяца после открытия вакансии Генеральный Секретарь приступает к посылке приглашений, предусмотренных статьей 5, а день выборов устанавливается Советом Безопасности.
Статья 15
Член Суда, избранный взамен члена, срок полномочий которого еще не истек, остается в должности до истечения срока полномочий своего предшественника.
Статья 16
1. Члены Суда не могут исполнять никаких политических или административных обязанностей и не могут посвящать себя никакому другому занятию профессионального характера.
2. Сомнения по настоящему вопросу разрешаются определением Суда.
Статья 17
1. Никто из членов Суда не может исполнять обязанностей представителя, поверенного или адвоката ни в каком деле.
2. Никто из членов Суда не может участвовать в разрешении какого-либо дела, в котором он ранее участвовал в качестве представителя, поверенного или адвоката одной из сторон, или члена национального или международного суда, следственной комиссии или в каком-либо ином качестве.
3. Сомнения по настоящему вопросу разрешаются определением Суда.
Статья 18
1. Член Суда не может быть отрешен от должности, кроме случая, когда, по единогласному мнению прочих членов, он перестает удовлетворять предъявляемым требованиям.
2. Об этом Генеральный Секретарь официально уведомляется Секретарем Суда.
3. По получении этого уведомления место считается вакантным.
Статья 19
Члены Суда при исполнении ими судебных обязанностей пользуются дипломатическими привилегиями и иммунитетами.
Статья 20
Каждый член Суда обязан до вступления в должность сделать в открытом заседании Суда торжественное заявление, что он будет отправлять свою должность беспристрастно и добросовестно.
Статья 21
1. Суд избирает Председателя и Вице-Председателя на три года. Они могут быть переизбраны.
2. Суд назначает своего Секретаря и может принять меры для назначения таких других должностных лиц, которые могут оказаться необходимыми.
Статья 22
1. Местопребыванием Суда является Гаага. Это, однако, не препятствует Суду заседать и выполнять свои функции в других местах во всех случаях, когда Суд найдет это желательным.
2. Председатель и Секретарь Суда должны проживать в месте пребывания Суда.
Статья 23
1. Суд заседает постоянно, за исключением судебных вакаций, сроки и длительность которых устанавливаются Судом.
2. Члены Суда имеют право на периодический отпуск, время и продолжительность которого определяются Судом, причем принимается во внимание расстояние от Гааги до постоянного местожительства каждого судьи на родине.
3. Члены Суда обязаны быть в распоряжении Суда во всякое время, за исключением времени нахождения в отпуске и отсутствия по причине болезни или по иным серьезным основаниям, должным образом объясненным Председателю.
Статья 24
1. Если по какой-либо особой причине член Суда считает, что он не должен участвовать в разрешении определенного дела, он сообщает об этом Председателю.
2. Если Председатель находит, что какой-либо из членов Суда не должен по какой-либо особой причине участвовать в заседании по определенному делу, он предупреждает его об этом.
3. Если при этом возникает разногласие между членом Суда и Председателем, то оно разрешается определением Суда.
Статья 25
1. Кроме случаев, специально предусмотренных в настоящем Статуте, Суд заседает в полном составе.
2. При условии, что число судей, имеющихся налицо для образования Суда, не меньше одиннадцати, Регламент Суда может предусмотреть, что один или несколько судей могут быть, в зависимости от обстоятельств, освобождены по очереди от участия в заседаниях.
3. Кворум в девять судей достаточен для образования судебного присутствия.
Статья 26
1. Суд может, по мере надобности, образовать одну или несколько камер, в составе трех или более судей, по усмотрению Суда, для разбора определенных категорий дел, например, трудовых дел и дел, касающихся транзита и связи.
2. Суд может в любое время образовать камеру для разбора отдельного дела. Число судей, образующих такую камеру, определяется Судом с одобрения сторон.
3. Дела заслушиваются и разрешаются камерами, предусмотренными настоящей статьей, если стороны об этом просят.
Статья 27
Решение, постановленное одной из камер, предусмотренных в статьях 26 и 29, считается вынесенным самим Судом.
Статья 28
Камеры, предусмотренные статьями 26 и 29, могут, с согласия сторон, заседать и выполнять свои функции в других местах, помимо Гааги.
Статья 29
В целях ускорения разрешения дел Суд ежегодно образует камеру в составе пяти судей, которая, по просьбе сторон, может рассматривать и разрешать дела в порядке упрощенного судопроизводства. Для замены судей, которые признают для себя невозможным принять участие в заседаниях, выделяются дополнительно два судьи.
Статья 30
1. Суд составляет Регламент, определяющий порядок выполнения им своих функций. Суд, в частности, устанавливает правила судопроизводства.
2. В Регламенте Суда может быть предусмотрено участие в заседаниях Суда или его камер асессоров без права решающего голоса.
Статья 31
1. Судьи, состоящие в гражданстве каждой из сторон, сохраняют право участвовать в заседаниях по производящемуся в Суде делу.
2. Если в составе судебного присутствия находится судья, состоящий в гражданстве одной стороны, любая другая сторона может избрать для участия в присутствии в качестве судьи лицо по своему выбору. Это лицо избирается преимущественно из числа тех лиц, которые выдвигались в качестве кандидатов, в порядке, предусмотренном в статьях 4 и 5.
3. Если в составе судебного присутствия нет ни одного судьи, состоящего в гражданстве сторон, то каждая из этих сторон может избрать судью в порядке, предусмотренном в пункте 2 настоящей статьи.
4. Постановления настоящей статьи применяются к случаям, предусмотренным в статьях 26 и 29. В таких случаях Председатель просит одного или, в случае надобности, двух членов Суда из состава камеры уступить свое место членам Суда, состоящим в гражданстве заинтересованных сторон, либо, при отсутствии таковых или в случае невозможности присутствовать, судьям, специально избранным сторонами.
5. Если у нескольких сторон имеется общий интерес, то они, поскольку это касается применения предыдущих постановлений, рассматриваются как одна сторона. В случае сомнений по этому вопросу они разрешаются определением Суда.
6. Судьи, избранные согласно изложенному в пунктах 2, 3 и 4 настоящей статьи, должны удовлетворять условиям, требуемым статьей 2 и пунктом 2 статьи 17 и статьями 20 и 24 настоящего Статута. Они участвуют в принятии решений на равных правах с их коллегами.
Статья 32
1. Члены Суда получают годовой оклад.
2. Председатель получает особую годовую прибавку.
3. Вице-Председатель получает особую прибавку за каждый день, когда он исполняет обязанности Председателя.
4. Избранные в порядке статьи 31 судьи, не являющиеся членами Суда, получают вознаграждение за каждый день выполнения ими своих функций.
5. Эти оклады, прибавки и вознаграждение устанавливаются Генеральной Ассамблеей. Они не могут быть уменьшены в течение срока службы.
6. Оклад Секретаря Суда устанавливается Генеральной Ассамблеей по представлению Суда.
7. Правила, установленные Генеральной Ассамблеей, определяют условия, на которых членам Суда и Секретарю Суда назначаются пенсии при выходе их в отставку, равно как и условия, на которых члены и Секретарь Суда получают возмещение своих путевых расходов.
8. Указанные выше оклады, прибавки и вознаграждение освобождаются от всякого обложения.
Статья 33
Объединенные Нации несут расходы Суда в порядке, определяемом Генеральной Ассамблеей.
ГЛАВА II: Компетенция Суда
Статья 34
1. Только государства могут быть сторонами по делам, разбираемым Судом.
2. На условиях своего Регламента и в соответствии с ним, Суд может запрашивать у публичных международных организаций информацию, относящуюся к делам, находящимся на его рассмотрении, а также получает подобную информацию, представляемую указанными организациями по их собственной инициативе.
3. Когда по делу, разбираемому Судом, ему надлежит дать толкование учредительному документу какой-либо публичной международной организации или международной конвенции, заключенной в силу такого документа, Секретарь Суда уведомляет данную публичную международную организацию и препровождает ей копии всего письменного производства.
Статья 35
1. Суд открыт для государств, являющихся участниками настоящего Статута.
2. Условия, на которых Суд открыт для других государств, определяются Советом Безопасности, с соблюдением особых постановлений, содержащихся в действующих договорах; эти условия ни в коем случае не могут поставить стороны в неравное положение перед Судом.
3. Когда государство, не состоящее Членом Объединенных Наций, является стороной в деле, Суд определяет сумму, которую эта сторона должна внести на покрытие расходов Суда. Это постановление не применяется, если данное государство уже участвует в расходах Суда.
Статья 36
1. К ведению Суда относятся все дела, которые будут переданы ему сторонами, и все вопросы, специально предусмотренные Уставом Объединенных Наций или действующими договорами и конвенциями.
2. Государства — участники настоящего Статута могут в любое время заявить, что они признают без особого о том соглашения, ipso facto, в отношении любого иного государства, принявшего такое же обязательство, юрисдикцию Суда обязательной по всем правовым спорам, касающимся:
a) толкования договора;
b) любого вопроса международного права;
c) наличия факта, который, если он будет установлен, представит собой нарушение международного обязательства;
d) характера и размеров возмещения, причитающегося за нарушение международного обязательства.
3. Вышеуказанные заявления могут быть безусловными, или на условиях взаимности со стороны тех или иных государств, или же на определенное время.
4. Такие заявления сдаются на хранение Генеральному Секретарю, который препровождает копии таковых участникам настоящего Статута и Секретарю Суда.
5. Заявления, сделанные на основании статьи 36 Статута Постоянной Палаты Международного Правосудия, продолжающие оставаться в силе, считаются, в отношениях между участниками настоящего Статута, признанием ими юрисдикции Международного Суда для себя обязательной на неистекший срок действия этих заявлений и в соответствии с условиями, в них изложенными.
6. В случае спора о подсудности дела Суду вопрос разрешается определением Суда.
Статья 37
Во всех случаях, когда действующие договор или конвенция предусматривают передачу дела Суду, который должен был быть учрежден Лигой Наций, или Постоянной Палате Международного Правосудия, дело между сторонами — участниками настоящего Статута должно передаваться в Международный Суд.
Статья 38
1. Суд, который обязан решать переданные ему споры на основании международного права, применяет:
а) международные конвенции, как общие, так и специальные, устанавливающие правила, определенно признанные спорящими государствами;
b) международный обычай как доказательство всеобщей практики, признанной в качестве правовой нормы;
с) общие принципы права, признанные цивилизованными нациями;
d) с оговоркой, указанной в статье 59, судебные решения и доктрины наиболее квалифицированных специалистов по публичному праву различных наций в качестве вспомогательного средства для определения правовых норм.
2. Это постановление не ограничивает право Суда разрешать дело ex aequo et bono, если стороны с этим согласны.
ГЛАВА III: Судопроизводство
Статья 39
1. Официальными языками Суда являются французский и английский. Если стороны согласны на ведение дела на французском языке, то решение выносится на французском языке. Если стороны согласны на ведение дела на английском языке, то решение выносится на английском языке.
2. При отсутствии соглашения относительно того, какой язык будет применяться, каждая сторона может в судоговорении пользоваться тем языком, который она предпочитает; решение Суда выносится на французском или английском языках. В этом случае Суд одновременно определяет, какой из двух текстов рассматривается в качестве аутентичного.
3. Суд обязан по ходатайству любой стороны предоставить ей право пользоваться другим языком, помимо французского и английского.
Статья 40
1. Дела возбуждаются в Суде, в зависимости от обстоятельств, или нотификацией специального соглашения, или письменным заявлением на имя Секретаря. В обоих случаях должны быть указаны предмет спора и стороны.
2. Секретарь немедленно сообщает заявление всем заинтересованным лицам.
3. Он также извещает Членов Объединенных Наций, через посредство Генерального Секретаря, а также другие государства, имеющие право доступа к Суду.
Статья 41
1. Суд имеет право указать, если, по его мнению, это требуется обстоятельствами, любые временные меры, которые должны быть приняты для обеспечения прав каждой из сторон.
2. Впредь до окончания решения сообщение о предлагаемых мерах немедленно доводится до сведения сторон и Совета Безопасности.
Статья 42
1. Стороны выступают через представителей.
2. Они могут пользоваться в Суде помощью поверенных или адвокатов.
3. Представители, поверенные и адвокаты, представляющие стороны в Суде, пользуются привилегиями и иммунитетами, необходимыми для самостоятельного выполнения ими своих обязанностей.
Статья 43
1. Судопроизводство состоит из двух частей: письменного и устного судопроизводства.
2. Письменное судопроизводство состоит из сообщения Суду и сторонам меморандумов, контрмеморандумов и, если потребуется, ответов на них, а равно всех подтверждающих их бумаг и документов.
3. Эти сообщения производятся через Секретаря, в порядке и в сроки, установленные Судом.
4. Всякий документ, предъявляемый одной из сторон, должен быть сообщен другой в засвидетельствованной копии.
5. Устное судопроизводство состоит в заслушании Судом свидетелей, экспертов, представителей, поверенных и адвокатов.
Статья 44
1. Для передачи всех извещений иным лицам, кроме представителей, поверенных и адвокатов, Суд обращается непосредственно к правительству государства, на территории которого извещение должно быть вручено.
2. То же правило применяется в случаях, когда необходимо принять меры к получению доказательств на месте.
Статья 45
Слушание дела ведется под руководством Председателя или, если он не может председательствовать, Вице-Председателя; если ни тот, ни другой не могут председательствовать, председательствует старший из присутствующих судей.
Статья 46
Слушание дела в Суде производится публично, если не последовало иного решения Суда или если стороны не требуют, чтобы публика не была допущена.
Статья 47
1. Каждому судебному заседанию ведется протокол, подписываемый Секретарем и Председателем.
2. Лишь этот протокол аутентичен.
Статья 48
Суд распоряжается о направлении дела, определяет формы и сроки, в которые каждая сторона должна окончательно изложить свои доводы, и принимает все меры, относящиеся к собиранию доказательств.
Статья 49
Суд может, даже до начала слушания дела, требовать от представителей предъявления любого документа или объяснений. В случае отказа составляется акт.
Статья 50
Суд может во всякое время поручить производство расследования или экспертизы всякому лицу, коллегии, бюро, комиссии или другой организации по своему выбору.
Статья 51
При слушании дела все относящиеся к делу вопросы предлагаются свидетелям и экспертам с соблюдением условий, определяемых Судом в Регламенте, упомянутом в статье 30.
Статья 52
После получения доказательств в установленные для этого сроки Суд может отказать в принятии всех дальнейших устных и письменных доказательств, которые одна из сторон пожелала бы предъявить без согласия другой.
Статья 53
1. Если одна из сторон не явится в Суд или не представит своих доводов, другая сторона может просить Суд о разрешении дела в свою пользу.
2. Суд обязан, до удовлетворения этого ходатайства, удостовериться не только в подсудности ему дела, согласно статьям 36 и 37, но также и в том, имеет ли это притязание достаточное фактическое и правовое обоснование.
Статья 54
1. Когда представители, адвокаты и поверенные закончили под руководством Суда свои объяснения по делу, Председатель объявляет слушание законченным.
2. Суд удаляется для обсуждения решений.
3. Совещания Суда происходят в закрытом заседании и сохраняются в тайне.
Статья 55
1. Все вопросы разрешаются большинством голосов присутствующих судей.
2. В случае разделения голосов поровну, голос Председателя или замещающего его Судьи дает перевес.
Статья 56
1. В решении должны быть приведены соображения, на которых оно основано.
2. Решение содержит имена судей, участвовавших в его принятии.
Статья 57
Если решение, в целом или в части, не выражает единогласного мнения судей, то каждый судья имеет право представить свое особое мнение.
Статья 58
Решение подписывается Председателем и Секретарем Суда. Оно оглашается в открытом заседании Суда после надлежащего уведомления представителей сторон.
Статья 59
Решение Суда обязательно лишь для участвующих в деле сторон и лишь по данному делу.
Статья 60
Решение окончательно и не подлежит обжалованию. В случае спора о смысле или объеме решения толкование его принадлежит Суду по требованию любой стороны.
Статья 61
1. Просьба о пересмотре решения может быть заявлена лишь на основании вновь открывшихся обстоятельств, которые по своему характеру могут оказать решающее влияние на исход дела и которые при вынесении решения не были известны ни Суду, ни стороне, просящей о пересмотре, при том непременном условии, что такая неосведомленность не была следствием небрежности.
2. Производство по пересмотру открывается определением Суда, в котором определенно устанавливается наличие нового обстоятельства с признанием за последним характера, дающего основание к пересмотру дела, и объявляется о принятии, в силу этого, просьбы о пересмотре.
3. Суд может потребовать, чтобы условия решения были выполнены, прежде чем он откроет производство по пересмотру дела.
4. Просьба о пересмотре должна быть заявлена до истечения шестимесячного срока после открытия новых обстоятельств.
5. Никакие просьбы о пересмотре не могут быть заявлены по истечении десяти лет с момента вынесения решения.
Статья 62
1. Если какое-нибудь государство считает, что решение по делу может затронуть какой-либо его интерес правового характера, то это государство может обратиться в Суд с просьбой о разрешении вступить в дело.
2. Решение по такой просьбе принадлежит Суду.
Статья 63
1. В случае возникновения вопроса о толковании конвенции, в которой, кроме заинтересованных в деле сторон, участвуют и другие государства, Секретарь Суда немедленно извещает все эти государства.
2. Каждое из государств, получивших такое извещение, имеет право вступить в дело, и, если оно воспользуется этим правом, толкование, содержащееся в решении, равным образом обязательно и для него.
Статья 64
При отсутствии иного определения Суда каждая сторона несет свои собственные судебные издержки.
ГЛАВА IV: Консультативные заключения
Статья 65
1. Суд может давать консультативные заключения по любому юридическому вопросу, по запросу любого учреждения, уполномоченного делать такие запросы самим Уставом Объединенных Наций или согласно этому Уставу.
2. Вопросы, по которым испрашивается консультативное заключение Суда, представляются Суду в письменном заявлении, содержащем точное изложение вопроса, по которому требуется заключение; к нему прилагаются все документы, могущие послужить к разъяснению вопроса.
Статья 66
1. Секретарь Суда немедленно сообщает о заявлении, содержащем просьбу о консультативном заключении, всем государствам, имеющим право доступа к Суду.
2. Кроме того, Секретарь Суда посылкою особого и непосредственного уведомления сообщает любому имеющему доступ к Суду государству, а также любой международной организации, которые могут, по мнению Суда (или его Председателя, если Суд не заседает), дать сведения по данному вопросу, что Суд готов принять, в течение устанавливаемого Председателем срока, относящиеся к вопросу письменные доклады или же выслушать такие же устные доклады на открытом заседании, назначаемом с этой целью.
3. Если такое государство, имеющее право доступа к Суду, не получит особого уведомления, упомянутого в пункте 2 настоящей статьи, то оно может выразить желание представить письменный доклад или быть выслушанным; Суд принимает решение по этому вопросу.
4. Государства и организации, которые представили письменные или устные доклады, или и те и другие, допускаются к обсуждению докладов, сделанных другими государствами или организациями, в формах, пределах и в сроки, устанавливаемые в каждом отдельном случае Судом или, если он не заседает, Председателем Суда. Для этой цели Секретарь Суда сообщает в надлежащее время все такие письменные доклады государствам и организациям, которые сами представили подобные доклады.
Статья 67
Суд выносит свои консультативные заключения в открытом заседании, о чем предупреждаются Генеральный Секретарь и представители непосредственно заинтересованных членов Объединенных Наций, других государств и международных организаций.
Статья 68
При осуществлении своих консультативных функций Суд, помимо указанного, руководствуется постановлениями настоящего Статута, относящимися к спорным делам, в той мере, в какой Суд признает их применимыми.
ГЛАВА V: Поправки
Статья 69
Поправки к настоящему Статуту вводятся тем же порядком, какой предусмотрен Уставом Объединенных Наций для поправок к этому Уставу, при соблюдении, однако, всех правил, какие могут быть установлены Генеральной Ассамблеей по рекомендации Совета Безопасности относительно участия государств, не состоящих Членами Объединенных Наций, но являющихся участниками Статута.
Статья 70
Суд имеет право предлагать поправки к настоящему Статуту, какие он признает необходимыми, сообщая их письменно Генеральному Секретарю для дальнейшего рассмотрения сообразно с правилами, изложенными в статье 69.
GeoTools — OSGeo-Live 7.9 Documentation
GeoTools — это Java-библиотека с открытым исходным кодом (LGPL), которая предоставляет стандартные методы для работы с геопространственными данными и использует структуры данных, основанные на спецификациях Open Geospatial Consortium (OGC).
Библиотека GeoTools используется в ряде проектов, включая веб сервисы, утилиты командной строки и настольные приложения. Приложения из состава OSGeo-Live , которые используют GeoTools, включают: 52°North SOS, 52°North WPS, AtlasStyler, Geomajas, Geopublisher, GeoServer, and uDig.
Базовые функции¶
Определение интерфейсов для основных пространственных представлений и структур данных
- Встроенная поддержка геометрии посредством JTS Topology Suite (JTS)
- Атрибутивные и пространственные фильтры с использованием спецификации OGC Filter Encoding
Простой API доступа к данным, поддерживающий доступ к записям; транзакции и блокировки между потоками
- Доступ к ГИС данным в множестве файловых форматах и баз геоданных
- Поддержка систем координат и преобразований между ними
- Работа с широким спектром картографических проекций
- Выборка и анализ данных в терминах пространственных и непространственных атрибутов
Без сохранения состояния отрисовка требует немного памяти, наиболее полезна в серверных средах.
- Создавать и отображать карты со сложными стилями
Мощная технология разбора на основе “схем” с использованием XML для связи с данными в формате GML
- Технология разбора / декодирования предоставляется с привязками ко многим стандартам OGC, включая GML, Filter, KML, SLD и SE.
Плагины GeoTools: открытая система плагинов, позволяющая изучить дополнительные форматы библиотеки
- Плагины для проекта ImageIO-EXT, которые позволяют читать дополнительные растровые форматы из GDAL
Расширения GeoTools
- Предоставляет дополнительные возможности по сборке, используя пространственные возможности базовой библиотеки
- Расширения предоставляют графические и сетевые возможности (поиск кратчайшего пути), возможности валидации, клиент для картографического веб-сервера, привязки к инструментам разбора XML, декодирования и создания палитр.
Поддержка GeoTools
- Библиотека GeoTools поддерживается обширным сообществом, а также выступает в качестве “точки входа” для начала работы и для стимулирования новых талантов и содействия экспериментам.
- Отмечается поддержка swing (по данным руководств по geotools), swt, поддержка локальной и удалённой (веб) обработки, расширенная символика, дополнительные форматы данных, генерация сеток и несколько реализаций ISO Geometry.
Поддерживаемые форматы¶
Растровые форматы и доступ к данным:
ArcSDE, Arc GRID, GeoTIFF, GRASS raster, GTOPO30, растры (JPEG, TIFF, GIF, PNG), imageio-ext-gdal, imagemoasaic, imagepyramid, JP2K, Matlab.
Поддержка баз данных “jdbc-ng”:
DB2, h3, MySQL, Oracle, PostGIS, SpatiaLite, SQL Server.
Векторные форматы и доступ к данным:
app-schema, ArcSDE, CSV, DXF, EDIGEO, Excel, GeoJSON, OGR, shp-файлы, WFS.
Привязки XML:
Структуры данных языка Java и привязки предоставляются для следующих типов: xsd-core (простые типы XML), fes, filter, GML2, GML3, KML, OWS, SLD, WCS, WFS, WMS, WPS, VPF.
Дополнительно парсеры/декодеры для геометрий, фильтров и стилей доступны для приложений DOM и SAX.
Реализованные стандарты¶
Поддержка большого числа стандартов Open Geospatial Consortium (OGC):
- OGC Style Layer Descriptor / Symbology Encoding data structures and rendering engine
- OGC General Feature Model including Simple Feature support
- OGC Grid Coverage representation of raster information
- OGC Filter and Common Constraint Language (CQL)
- Clients for Web Feature Service (WFS), Web Map Service (WMS) и экспериментальная поддержка Web Process Service (WPS)
- ISO 19107 Geometry
Начало работы¶
Лоуренс Тратт: Какой подход к синтаксическому анализу?
Все мы знаем, что синтаксический анализ — важная часть разработки и реализации языков программирования, но это эквивалент брюссельской капусты: подходит для диета, но вкус, который нравится лишь немногим избранным. К сожалению, я пришел в понимаем, что наше общее отвращение к синтаксическому анализу проблематично. Хотя многие из нас думаю, что мы впитали достижения 1960-х годов в нашу коллективную понимание, я боюсь, что мы регрессировали, и что мы часто делаем неуместные решения о парсинге.Если это звучит обвиняюще, я не значит, что это должно быть: я потратил более 20 лет, предполагая что синтаксический анализ прост и что мне не нужно было понимать его должным образом в чтобы использовать это хорошо. Увы, действительность была жестоким учителем, и в этом сообщение Я хочу поделиться некоторыми уроками, которые мне пришлось усвоить медленно, и сознавать. Начнем с основ. Грамматика кодирует правила синтаксиса для данного языка.
Парсинг — это процесс получения входных данных (например,
исходный файл) и определение того, соответствует ли он грамматике и как.На своем
самый базовый уровень, синтаксический анализ просто говорит: «этот ввод не соответствует / не соответствует
грамматика ». Это редко бывает полезно для языков программирования, поэтому обычно
выполнить семантических действий во время синтаксического анализа, что позволяет, например,
построить дерево синтаксического анализа, которое представляет входные данные в виде дерева. Если у меня есть
простой калькулятор грамматики и ввод 2-3 * 4 я мог бы вернуться
дерево, которое выглядит следующим образом:
(2- (3 * 4)) . Я собираюсь предположить
что «синтаксический анализ» означает «проверить соответствие грамматике и построить синтаксический анализ.
дерево». Я также собираюсь упростить другой жаргон синтаксического анализа и терминологию.
всякий раз, когда я могу, стараюсь, чтобы все было в некоторой степени понятным, а продолжительность
в некоторой степени управляемый.Рекурсивный спуск
Существует поразительное количество способов синтаксического анализа ввода, поэтому я начнем с того, что, вероятно, является наиболее распространенным: рукописного синтаксического анализатора.Хотя это может означать что угодно, почти каждый, кто пишет наполовину приличный рукописный синтаксический анализатор, знают они об этом или нет, пишет рекурсивный спуск парсер. В идея относительно проста: нужно написать серию функций, которые исследуют входная строка в заданной позиции и, если они совпадают в этой позиции, продвинуть синтаксический анализ. Например, первая попытка в парсере рекурсивного спуска в Python, который может анализировать простой язык калькулятора, указанный выше, может выглядеть следующим образом:
ЧИСЛА = [«0», «1», «2», «3», «4», «5», «6», «7», «8», «9»]
ОПЕРАТОРЫ = ["-", "*"]
Номер класса:
def __init __ (self, n): себя.п = п
def __str __ (self): вернуть str (self.n)
класс Мул:
def __init __ (self, lhs, rhs):
self.lhs = lhs
self.rhs = rhs
def __str __ (self): return "(% s *% s)"% (str (self.lhs), str (self.rhs))
класс Sub:
def __init __ (self, lhs, rhs):
self.lhs = lhs
self.rhs = rhs
def __str __ (self): return "(% s-% s)"% (str (self.lhs), str (self.rhs))
def parse_expr (s, i):
если s [i] не входит в ЧИСЛА:
возвращаться
j = я
в то время как j Идея относительно проста: у нас есть строка « s », которую мы анализируем,
с переменной « i », которая сообщает нам, как далеко мы проанализировали.Если
он смог проанализировать часть ввода, начиная с « i », затем parse_expr функция возвращает пару (i, tree) , сообщающую
нам, как далеко он проанализировал и вернул нам созданное им дерево; если это не удалось
возвращает Нет . Когда я разбираю 2-3 * 4 , он печатает:
(2- (3 * 4))
Другими словами, если бы мы оценили это дерево, мы получили бы результат -10 -
успех! По общему признанию, за это пришлось заплатить: синтаксический анализатор рекурсивного спуска имеет
довольно много шаблонов, чтобы убедиться, что он не делает глупостей и
что любые обнаруженные синтаксические ошибки вызывают остановку синтаксического анализа.Например, если вы
удалите проверку строк 40 и 41, тогда 2abc успешно проанализирует
возвращая Number (2) , игнорируя тот факт, что abc не может быть проанализирован! Есть способы уменьшить шаблон,
но если вы зарабатываете на жизнь написанием рекурсивных парсеров спуска, вы должны научиться
живи с этим. К сожалению, если я попытаюсь разобрать 2 * 3-4 , я получаю неожиданный
результат:
(2 * (3-4))
Нас всех с юных лет учили, что грамматика математики требует
« * » означает «крепче связывать», чем «–».Говоря более формально,
Считается, что « * » имеет на более высокий приоритет , чем
«–». К сожалению, мой рукописный парсер рекурсивного спуска имеет
дает обоим операторам одинаковый приоритет. Если бы я оценил это дерево, я бы
получить -2 вместо 2, которые мы ожидали от исходного выражения. К счастью, существует довольно стандартный способ кодирования приоритета оператора.
который в стиле вышеупомянутого парсера может быть
написано следующим образом:
def parse_expr (s, i):
r = parse_factor (s, i)
если r равно None:
возвращаться
(i, lhs) = r
если i Если я проанализирую эти выражения:
print (parse ("2-3 * 4"))
print (parse ("2 * 3-4"))
Я вижу, что получаю ожидаемый результат:
(2- (3 * 4))
((2 * 3) -4)
Наконец-то успех! Ну, не совсем так, потому что если разобрать 2-3-4 я
получить еще один удивительный результат:
(2- (3-4))
К сожалению, как показывает этот пример, мы неправильно обрабатываем операторы как правоассоциативно , когда они должны быть левоассоциативными .В
другими словами, когда мы видим последовательность вычитаний, предыдущие вычитания должны
перед последующими вычитаниями. Исправляем это
может показаться, что это легко, но это не так: «очевидный» способ реализации
левая ассоциативность в синтаксическом анализаторе рекурсивного спуска вызывает бесконечный цикл.
Исправить это сложнее, чем я хочу здесь: см.
страницу с доступным обзором решений этой проблемы. Может возникнуть соблазн увидеть эти проблемы в результате действий идиота (меня)
написание парсера для языка, который они недостаточно понимают (математика).я надеюсь
вы можете видеть, что происходит нечто более глубокое. Основная проблема заключается в том, что
грамматика, которую я хотел написать, неоднозначно : 2-3 * 4 можно разобрать как
эквивалент 2- (3 * 4) или (2-3) * 4 . Часто говорят, что
Парсеры рекурсивного спуска по своей сути однозначны. Хотя правда, это
делает добродетель из порока: парсеры рекурсивного спуска однозначны просто
потому что они игнорируют двусмысленность. Другими словами, всякий раз, когда парсер рекурсивного спуска
обнаруживает момент во время выполнения, когда ввод может быть неоднозначно проанализирован, он произвольно
выбирает одну из возможностей и бросается вперед, как если бы другая
возможностей никогда не существовало.Примечательно, что автор парсера не
уведомил, что это произошло. Поскольку синтаксические анализаторы рекурсивного спуска - это просто обычные программы,
маловероятно, что мы когда-нибудь сможем провести статический анализ, который
возьмите такой синтаксический анализатор и достоверно сообщите нам во время компиляции обо всех неоднозначных моментах.
Поэтому, вероятно, не случайно, что парсеры рекурсивного спуска
нет реальной «теории». Примечательно, что они не
иметь какое-либо известное отношение к классу грамматик, который мы понимаем лучше всего
- Без контекста
Грамматики (CFG).Например, мы, как правило, не знаем
язык, который будет принимать синтаксический анализатор рекурсивного спуска: все, что мы можем сделать, это
бросать в него все больше входных данных и наблюдать, если и как он их анализирует, никогда
зная, вызовет ли другой ввод неожиданный синтаксический анализ.
Со временем я стал рассматривать рекурсивный спуск как синтаксический эквивалент
программирование сборки: максимальная гибкость, максимальная производительность и максимум
Опасность. Каждый нетривиальный синтаксический анализатор рекурсивного спуска, который я видел, преобразовал
другой формализм привел к обнаружению неожиданных двусмысленностей.Иногда это приводит к неправильному
анализирует (как указано выше), но так же часто приводит к, казалось бы, правильному вводу, а не
анализируется вообще. Есть веские причины
для использования парсеров с рекурсивным спуском (я вернусь к ним позже), но, на мой взгляд,
если можно использовать другой формализм, обычно так и должно быть.
Обобщенные парсеры
На противоположном конце спектра находятся то, что стали называть обобщенных парсеров . Существуют различные обобщенные алгоритмы парсинга.
(например, Earley, GLL,
и GLR), но из
перспектива этого поста, они все
эквивалент.Каждый может анализировать любой CFG (так что они основаны на твердой теории), даже
неоднозначные (так что вам не нужно беспокоиться об искажении грамматики) и
они гарантируют, что скажут вам, где находятся все неоднозначные моменты в грамматике
во время выполнения (так что вам не нужно беспокоиться о том, что что-то неожиданно
неправильно проанализированы). Эти свойства, кажется, делают обобщенный синтаксический анализ решения
проблемы, отмеченные выше с рекурсивным анализатором спуска. Однако за это приходится платить.
Рассмотрим следующую грамматику, которая снова анализирует небольшое подмножество
математику, которую мы используем в качестве примера:
Expr: Expr "-" Expr
| Выражение "*" Выражение
| "ИНТ"
;
Учитывая эту грамматику, многие читатели заметят очевидную точку
неоднозначность: 2-3 * 4 можно проанализировать как эквивалент (2-3) * 4 или 2- (3 * 4) .Обобщенные парсеры
интересно, потому что они генерируют обе возможности во время выполнения. это
такие парсеры могут возвращать «лес синтаксического анализа» (т. е. показывать все
неоднозначные возможности), но это не очень полезно для языков программирования:
мы ожидаем, что компиляторы придут к единому значению программ
мы кидаем на них. Таким образом, нам нужно устранить неоднозначность неоднозначных возможностей, чтобы
мы получаем одно дерево синтаксического анализа. Легкий способ сделать это - назначить
приоритет продуктам правила, так что если в какой-то момент
синтаксического анализа, более чем одно из его произведений соответствует, мы можем выбрать тот, у которого есть
высший приоритет.Например, я мог бы переписать свою грамматику, чтобы она выглядела следующим образом:
Expr: Expr "-" Expr% приоритет 10
| Выражение "*" Выражение% приоритет 20
| "ИНТ"
;
Предполагая, что «более высокие» приоритеты означают «более плотное связывание», тогда будет выполняться синтаксический анализ 2-3 * 4 как эквивалент 2- (3 * 4) . Мой опыт показывает, что меньше людей (в том числе, из горького опыта,
me) обнаружил вторую двусмысленность в приведенной выше грамматике: 2-3-4 можно проанализировать как левое
(например, (2-3) -4 ) или вправо (т.е.е. 2- (3-4) ) ассоциативный
(из-за таких правил, как « Expr» - «Expr »). К несчастью,
приоритетов недостаточно для устранения неоднозначности между этими двумя возможностями:
нужно либо переписать грамматику, либо использовать другое разрешение неоднозначности
оператор.
Хотя хорошие новости заключаются в том, что обобщенный синтаксический анализатор надежно сообщит нам на
во время выполнения, что возникла двусмысленность, плохие новости заключаются в том, что мы
обычно приходится ждать, пока мы не встретим ввод, который неоднозначно анализируется
чтобы обнаружить, что наша грамматика неоднозначна.Есть некоторые
приличная эвристика, которая статически найдет многие из точек
двусмысленность, но это всего лишь эвристика.
Со временем я стал рассматривать обобщенный синтаксический анализ как эквивалент
динамический набор текста: выразительный и безопасный, но с большим количеством ошибок, чем необходимо
откладывается до времени выполнения. Я потратил годы, пытаясь написать произвольные CFG, но,
Что касается сложных грамматик, я постоянно пытался избавиться от всех двусмысленностей. Я не встречал пользователя
кто был доволен ошибками двусмысленности или чем-то еще, кроме как испугался:
довольно странно слышать, что введенные вами данные действительны, но не могут быть проанализированы.Тем не менее, я думаю, что обобщенно
парсеры играют определенную роль в композиции языка, где
составление разных грамматик по своей сути ведет к двусмысленности. Однако я не
больше полагаю, что обобщенный синтаксический анализ хорошо подходит для «нормального» синтаксического анализа.
Статически однозначный разбор
Есть несколько подходов к синтаксическому анализу, которые статически исключают двусмысленность.
обойдя одну из фундаментальных проблем с обобщенным синтаксическим анализом. Я опишу
два наиболее известных: LL и LR. По сути, эти подходы описывают подмножества
CFG, которые предположительно содержат только однозначные грамматики.Грамматики, принадлежащие к одному из этих подмножеств, принято описывать как
«Действующая грамматика LL» или аналогичный. Однако, насколько нам известно, невозможно определить полное подмножество
однозначных CFG, поэтому есть однозначные грамматики, которые не вписываются в
эти подмножества. Таким образом, мне легче всего рассматривать эти подходы как
аналогично системе статических типов: они являются правильными (т.е. если грамматика является допустимой
Грамматика LL / LR, действительно однозначная), но не полная (некоторые недвусмысленные
грамматики не являются допустимыми грамматиками LL / LR).
LL разбор
Хотя LL-синтаксический анализ встречается реже, чем раньше, он все еще лежит в основе
такие системы, как javacc. Мой личный
предвзятость состоит в том, что парсеры LL в значительной степени непривлекательны из-за отсутствия левых
рекурсия позволяет выразить многие стандартные конструкции языка программирования как
неудобно, как с парсерами с рекурсивным спуском. Однако, как намекает это
общности, LL-грамматики имеют одну важную особенность: они естественным образом сопоставляются
парсеры рекурсивного спуска (но не обязательно наоборот). Поэтому можно
убедитесь, что парсер рекурсивного спуска случайно не запустил
над двусмысленностями, создав грамматику LL и точно сопоставив ее с рекурсивным
парсер спуска. На мой взгляд, комбинация LL и парсера рекурсивного спуска имеет небольшой
но важная ниша: если
вам действительно нужна максимально возможная производительность и / или вы хотите
наилучшие возможные сообщения об ошибках, это, вероятно, лучший путь, который мы знаем. Однако это
требует значительных затрат. Для реалистичной грамматики языка программирования это
обычно требуется много человеко-месяцев усилий, чтобы автоматически победить
сгенерированный парсер. Поэтому я думаю, что это
подход имеет смысл только для небольшого числа проектов (особенно
промышленные компиляторы и IDE).
Разбор LR: prelude
Последний из основных подходов к синтаксическому анализу, который я собираюсь рассмотреть, - это синтаксический анализ LR.
Как и многие люди, я потратил годы, пытаясь избежать синтаксического анализа LR, потому что я
впитал общую идею, что парсинг LR - ужасная вещь.
Вместо этого я бросился к другим подходам к синтаксическому анализу, особенно к синтаксическим анализаторам Эрли.
. Затем, в конце 2008 года, когда мне было скучно на собраниях, я начал писать extsmail, программу, в основном предназначенную для отправки
электронная почта через ssh. Думал будет интересно написать
это в стиле традиционного демона Unix, чего я не пытался
перед.Поэтому для двух файлов конфигурации, необходимых extsmail, я решил использовать
традиционный инструмент анализа демонов Unix Yacc. Я не только раньше не использовал Yacc,
Я не использовал и не изучал парсинг LR - я подозревал, что
довольно сложная задача для меня. Я был весьма удивлен, когда оказалось, что это
легко написать такую грамматику, как externals_parser.y.
Однако я предположил, что мне повезло с этими грамматиками, которые
довольно просто, и вернулся к тому, чтобы избежать синтаксического анализа LR. Осознав, что
общий синтаксический анализ и двусмысленность вызывали у меня проблемы, я потратил довольно много времени
баловаться с синтаксическим анализом PEG (который является замаскированным рекурсивным спуском)
прежде чем, в конце концов, понял, что это приведет меня к другому, но
не менее серьезные проблемы, связанные с обобщенным синтаксическим анализом.
Позже я наткнулся на Тима
Тезис Вагнера об инкрементальном синтаксическом анализе
которые стали основой, на которой Лукас Дикманн построил Eco. Вагнера
в работе используется парсинг LR, но мне удалось немного поработать с Eco без
собственно понимание того, как работает парсинг LR. Затем, в 2015 году, когда мы экспериментировали
как группа с Rust, Лукас написал начало парсера LR как
поэкспериментировал, и я быстро включился и внес несколько изменений. Без
действительно намереваясь, я начал расширять код, пока не понял, что у меня
взят на сопровождение того, что явно могло стать полноценным парсером Rust LR.В
В этот момент я понял, что мне действительно нужно понимать парсинг LR.
Сначала я обнаружил, что объяснения, скрывающиеся в Интернете, немного сбивают с толку, но
алгоритм был достаточно прост, так что вскоре у меня был полный, хотя и базовый, парсер Rust LR
(который стал grmtools).
Почему я рассказываю вам эту длинную, наверное, утомительную личную историю? Так как
Я хочу подчеркнуть, что я старался изо всех сил избегать синтаксического анализа LR, хотя
Я действительно не знал, чего избегаю и почему. Даже после того, как я использовал
LR проанализировал и понял, что это не тот призрак, которого я ожидал, я все равно потратил
несколько лет пробовал альтернативы.Мало того, что это смущает
публично признаться, меня это также беспокоит: как я уловил предвзятость,
так долго преодолевать? Я постепенно пришел к правдоподобному объяснению
из-за общей неприязни нашего сообщества к синтаксическому анализу LR и, как ни странно,
для бакалавриата на курсах компилятора. По причинам, которые, вероятно, имели смысл в
1970-е и 80-е годы, многие курсы компиляторов тратят значительное, возможно чрезмерное, время на
парсинг - в основном парсинг LR. Студенты приходят в ожидании обучения
как сгенерировать машинный код умными способами, но вместо этого нужно изучать всевозможные
анализа фона еще до того, как они дойдут до основного алгоритма LR.Тем
Дело в том, что они полностью устали от синтаксического анализа в целом и от синтаксического анализа LR в
специфический. Это рана, нанесенная самому себе нашим субъектом, поскольку мы
случайно оттолкнул людей от красивого алгоритма.
LR разбор
Давайте рассмотрим некоторые технические детали LR
парсинг. Во-первых, LR строго более мощный, чем LL. Другими словами, каждый
допустимая грамматика LL также является допустимой грамматикой LR (но не обязательно наоборот).
Во-вторых, грамматики LR - это
наибольшее практическое подмножество однозначных CFG, которые мы в настоящее время знаем, как
статически определить.
Давайте попробуем разобрать LR, введя следующую грамматику:
% start Expr
%%
Expr: Expr "-" Expr
| Выражение "*" Выражение
| "ИНТ"
;
в Yacc. Это приведет к тому, что во время компиляции будет напечатано следующее:
expr1.y: yacc обнаруживает 4 конфликта сдвига / уменьшения
К этому моменту я знаю, что некоторые читатели будут в холодном поту на
упоминание «конфликта сдвига / уменьшения». Пока не паникуйте! На данный момент давайте
просто представьте это как парсер LR, статически обнаруживающий двусмысленность (или четыре...)
и говорит нам, что мы должны как-то это исправить. Существуют различные способы более детального изучения этих
двусмысленность. ->.-> Выражение, {'$'}]
'-' -> 3
'*' -> 4
2: [Выражение -> 'INT'., {'-', '*', '$'}]
3: [Выражение -> Выражение '-'. Выражение, {'-', '*', '$'}]
'INT' -> 2
Выражение -> 5
4: [Выражение -> Выражение '*'. Выражение, {'-', '*', '$'}]
Выражение -> 6
'INT' -> 2
5: [Выражение -> Выражение. '-' Выражение, {'-', '*', '$'}]
[Выражение -> Выражение. '*' Выражение, {'-', '*', '$'}]
[Выражение -> Выражение '-' Выражение, {'-', '*', '$'}]
'*' -> 4
'-' -> 3
6: [Выражение -> Выражение. '-' Выражение, {'-', '*', '$'}]
[Выражение -> Выражение.'*' Выражение, {'-', '*', '$'}]
[Выражение -> Выражение '*' Выражение, {'-', '*', '$'}]
'*' -> 4
'-' -> 3
Это показывает нам граф состояний (то есть машину состояний), в которой наша грамматика была
трансформировались и государства, в которых произошли конфликты. Приложив немного усилий, можно понять этот граф состояний и
возникшие конфликты. Однако я не буду здесь вдаваться в подробности,
потому что большинство читателей, вероятно, уже догадались, что это очень
трудно разобраться в конфликтах на больших грамматиках.Я бы сравнил это примерно
говоря, к разрешению ошибок вывода типа всей программы: сообщения об ошибках верны, но не обязательно
соответствуют пунктам вашей программы / грамматики, которые вы считаете необходимыми
фиксация.
Хотя я уверен, что можно улучшить способ устранения конфликтов
сообщил, что, к моему удивлению, я разработал множество грамматик без
очень обеспокоен проблемами с конфликтами. Действительно, единственный раз
Я когда-либо пытался понять конфликты, когда
грамматика нуждается в обновлении в соответствии с новой внешней спецификацией, что встречается нечасто
.В большинстве случаев я разрабатываю новый или настраиваю
существующая, малая грамматика. Затем, как и в случае с языками, использующими вывод типов, я
находят наиболее продуктивным сохранять и компилировать почти после каждого изменения. Если это
выявляет конфликт, я знаю, какое изменение вызвало его, и затем имеет тенденцию
быть достаточно очевидным, что такое правдоподобное исправление. Мало того, что я не беспокоюсь
беспокоясь о том, какое состояние в графе состояний задействовано, я даже не
потрудитесь проверить, являются ли конфликты сдвигом / уменьшением, уменьшением / уменьшением,
или принять / уменьшить.
Честно говоря, я встретил только один реалистичный контрпример:
- подожди - математические выражения. Это удивительно
трудно закодировать это как грамматику LR, потому что правила синтаксиса математики
сложны, и почти каждая наивная грамматика для них неоднозначна. К счастью, потому что
это такой распространенный пример, решения этой проблемы можно найти в Интернете. Вот
классическое решение:
% start Expr
%%
Expr: Expr "-" Срок
| Срок
;
Срок: Срок "*" Фактор
| Фактор
;
Фактор: «ИНТ»
;
У него нет конфликтов, что означает, что Yacc статистически доказал, что он
однозначно! Он обрабатывает приоритет - 2-3 * 4 разбирается как 2- (3 * 4) - и ассоциативность - 2-3-4 анализирует как (2-3) -4 - правильно. Со временем я пришел к выводу, что синтаксический анализ LR эквивалентен статической типизации:
иногда раздражающе ограничительный, но дает достаточно статических гарантий
быть достойным раздражения для важного программного обеспечения. Важно помнить, что LR
не волшебство: оно не остановит вас, если вы напишите неоднозначной грамматики , но не остановит
вы пишете неправильную грамматику для языка, который хотите разобрать.
Например, хотя LR не позволит вам создать правило как слева, так и справа
ассоциативно, вам еще предстоит правильно выбрать, оставить его или
правоассоциативный.
Производительность
Люди часто беспокоятся о производительности синтаксического анализа в целом, а анализ LR
производительность конкретно, хотя почти всегда без причины
на современных компьютерах. Например, если я возьму грамматику Java (что необычно
большой и, следовательно, медленный для синтаксического анализа) и написанная мною система синтаксического анализа LR (в которой
были оптимизированы лишь умеренно) Я с радостью могу разобрать многие десятки
тысячи строк кода в секунду на моем ноутбуке трехлетней давности. Если у вас нет миллиардов
строк исходного кода или миллионы пользователей, это, безусловно, быстро
достаточно. Я подозреваю, что проблемы с производительностью парсинга восходят к тому периоду, когда
методы синтаксического анализа находились в стадии интенсивной разработки. Разбор LR был
изобретен в 1965 году, в то время, когда компьютеры были ужасно медленными и бедными ресурсами. Разбор LR работает путем создания таблица состояний во время компиляции, которая затем интерпретируется во время выполнения.
Эти таблицы состояний были слишком большими, чтобы их можно было использовать на
компьютеров того времени, поэтому было изобретено два решения этой проблемы.
Первый,
алгоритмические подмножества LR (например,грамм. LALR, SLR) были изобретены, уменьшающие размер
таблиц состояний за счет уменьшения количества грамматик, которые они могут принять
(т.е. некоторые грамматики LR не являются допустимыми грамматиками LALR).
На практике использование этих подмножеств раздражает: они вызывают некоторые, казалось бы,
разумные грамматики, которые следует отклонить; и понимание того, почему грамматика была отклонена
может потребоваться
глубокое понимание алгоритма.
Во-вторых, с 1977 года мы знаем
что вы можете значительно уменьшить таблицы состояний LR без
ограничение принятых грамматик.Когда
в сочетании с парой других методов сжатия таблицы состояний
объем памяти, даже самый хилый современный
машина может запускать произвольный парсер LR на впечатляющих скоростях.
Восстановление ошибки
Когда я программирую, я делаю поистине досадное количество синтаксических ошибок. Это
очень важно, чтобы синтаксический анализатор, который я использую, точно сообщал, где я
допустил такую ошибку: большинство парсеров, включая парсеры LR, делают достаточно приличную
работа в этом отношении. Тогда будет хорошо, если парсер восстановит из
моя ошибка, позволяющая продолжить синтаксический анализ. Лучшие парсеры рекурсивного спуска неплохо справляются с исправлением ошибок. Системы анализа LL также обычно делают
сносная работа для произвольных грамматик LL.
К сожалению, можно сказать, что системы парсинга LR такие
как Yacc плохо справляются с работой. Сам Yacc использует токены error , но
результаты настолько плохи, что я нахожу парсеры Yacc с восстановлением ошибок подробнее
разочаровывает в использовании, чем без них. Однако мы можем сделать
намного лучше для произвольных грамматик LR и, надеюсь, больше парсеров LR
будет выдавать хорошие сообщения об ошибках в будущем.
LR разбор: эстетика
Теперь я перейду к более нечеткому фактору: удобочитаемости. Будь то явно или
неявно людям нужно знать правила синтаксиса
языка, который они используют. Некоторые разработчики языков программирования предполагают, или
надеюсь, что предоставление пользователям нескольких примеров кода эквивалентно сообщению им
правила синтаксиса языка. Это работает в большинстве случаев, поскольку мы можем в значительной степени полагаться на общий
культурное понимание того, «как выглядит язык программирования», но
опытные программисты знают об опасности игнорирования сырых углов, таких как
приоритет оператора.На более глубоком уровне те, кто реализует компилятор, или
даже просто точный выделитель синтаксиса, нужно знать точно , что за
правила синтаксиса языка. На мой взгляд, читабельность парсера невысока.
жизненно важный фактор в обеспечении точного инструментария и использования программных
язык.
На мой взгляд, из различных грамматик и синтаксических анализаторов, представленных в
этот пост легче всего прочитать версию для обобщенных парсеров, потому что
это наиболее близко соответствует неформальной математической грамматике, которой меня учили как
ребенок.Однако за такую удобочитаемость приходится платить: потому что грамматика
потенциально неоднозначно. Иногда я неправильно оцениваю, каким образом данный ввод будет
анализироваться после устранения неоднозначности.
Самым трудным для чтения, без тени сомнения, является рекурсивный
парсер спуска. Это самый длинный, самый подробный и лишенный каких-либо
лежащая в основе теория, чтобы направлять читателя.
Отсутствие левой рекурсии при синтаксическом разборе LL затрудняет понимание многих грамматик.
читать. Удивительный способ увидеть это - использовать тот факт, что многие (хотя
не все) LR-грамматики могут быть преобразованы в LL полумеханически (см. e.грамм.
это
перевод примерно той же грамматики LR, которая использовалась в этом посте, на
Эквивалент LL): получившуюся грамматику LL никогда не бывает так легко читать
после преобразования.
LR-грамматики заполняют важную дыру. Они вообще близки
в читаемости произвольной CFG; так как левая ассоциативность так распространена,
их почти всегда легче читать, чем грамматики LL; и, если вы позволите
небольшое количество поэтической лицензии, их бесконечно легче читать, чем
парсер рекурсивного спуска.
Конечно, я явно несколько предвзят, так что, возможно, эти слова Гая Стила могли
быть более убедительным:
[Будьте] уверены, что ваш язык будет разбираться.Кажется глупым ... сесть и
начните проектировать конструкции и не беспокойтесь о том, как они будут сочетаться друг с другом. Ты
может получить язык, который сложно, если вообще возможно, разобрать, не только для
компьютер, но для человека. Я постоянно использую Yacc для проверки всего моего языка
дизайн, но я очень редко использую Yacc в реализации. Я использую это как
тестировщик, чтобы убедиться, что это LR (1) ... потому что, если язык LR (1), это больше
вероятно, что человек сможет с этим справиться. Мастера динамических языков
Серия - Панель по языковому дизайну
Сводка
Потратив годы на попытки практически всех возможных подходов к
синтаксического анализа, теперь я твердо верю, что синтаксический анализ LR - лучший подход для обширных
большинство целей: имеет самые надежные практические гарантии безопасности,
обеспечивает хорошую читаемость грамматики и имеет приличную производительность.В частности, надеюсь на будущее
авторы языков программирования следуют совету Гая Стила, приведенному выше, и делают свои
справочная грамматика LR совместима.
Лично я вкладываю свои деньги туда, где мне говорят: я много поработал в grmtools,
Yacc-совместимая система парсинга LR для Rust. grmtools еще не идеален, или
полная, и ни в коем случае не полностью оптимизирована - но это более чем хорошо
достаточно для многих целей, и я намерен продолжать поддерживать его для некоторых
время приехать. Я надеюсь, что это небольшой шаг к тому, чтобы побудить людей
заново откройте для себя красоту и полезность парсинга LR.
Благодарности: Спасибо Лукасу Дикманну и Навените Васудеван
за комментарии к черновикам этой публикации. Спасибо Роберто Иерусалимши и
Теренс Парр за ответы на мои вопросы. Все мнения и любые ошибки или
неудачи, во многом благодаря мне!
Сноски
[1] Грамматики выражений синтаксического анализа (PEG) и «комбинаторы синтаксического анализа» в некоторых
функциональные языки - это всего лишь замаскированные рекурсивные парсеры спуска. [2] Мой любимый пример этого лучше всего выразить в грамматике синтаксического анализа (PEG):
г <- а / аб
или как рукописный синтаксический анализатор рекурсивного спуска:
def r (s, i):
если i + 1 Оба этих парсера успешно анализируют строку « a », но терпят неудачу.
для синтаксического анализа строки « ab ». Как только " a " будет
совпадает, правило считается успешным, что оставляет " b " несравнимым; ни один
синтаксический анализатор пытается напрямую сопоставить « ab ». [3] Я считаю, что вопрос о том, сколько различных
там должны быть операторы разрешения неоднозначности. [4] В Converge я обманул, кодировал
некоторые правила разрешения неоднозначности по умолчанию в синтаксический анализатор. Когда я это сделал, я не
действительно понимал проблему, с которой столкнулся, и не осознавал, что мои
«Решение» не лечило, а просто отсрочивало боль. Единственное
более удивительным, чем столкновение с неоднозначным синтаксическим анализом, является обнаружение того, что ваш
ввод по умолчанию был устранен неверным способом. [5] Чтобы дать приблизительное представление о масштабе: Rust’s
парсер составляет около 10KLoC, а javac
парсер около 4.5KLoC. [6] Да я написал еще
чем
один. Я больше не рекомендую его, потому что в исходном алгоритме Эрли есть ошибка в
это, и описания исправления кажутся либо неверными, либо уничтожают
красота алгоритма. [7] Майкл Ван Де Вантер первым указал мне на работу Вагнера. Тем не мение,
Я не ценил это за то, что было. Затем я забыл об этом и споткнулся
через это «независимо» позже, прежде чем каким-то образом понять, что это
было то, что Майкл уже предложил.Позже я научился прислушиваться к его советам
более тщательно и извлекли из этого большую пользу! [8] Это также основа Tree-sitter, которая
может быть лучшим долгосрочным аргументом в пользу языков программирования, который я знаю
имея грамматику LR! [9] Возможно, мне посчастливилось самому не изучать курс компиляторов (в моем университете
не предлагать один в тот момент), так как это означало, что я не мог развить
тяжелые аллергические реакции на разбор ЛР. [10] Таким образом, от наименее выразительного к наиболее выразительному: регулярные выражения, LL, LR,
однозначно, CFG. Другими словами, регулярные выражения - это строгое подмножество
LL, LL - строгое подмножество LR и так далее. Наиболее полное описание
известную мне иерархию можно найти на стр. 89 Александра
Разговор Охотина (где стрелки означают «более выразительный», а «обычный» - «ЧФГ»).
Обратите внимание, что рекурсивный спуск не
вообще вписываются в эту иерархию - формально мы знаем, что
принимает непересекающийся набор языков относительно CFG, но, поскольку PEG не имеют
лежащая в основе теории, о которой мы знаем, мы не можем точно определить это множество
способствовать. Еще один интересный случай - алгоритм ALL (*)
который лежит в основе ANTLR. ALL (*) принимает строгий
надмножество LL (включая много неоднозначных грамматик), но не пересекается с LR
поскольку ALL (*) не поддерживает левую рекурсию. Однако ANTLR может удалять прямые
левая рекурсия перед вызовом ALL (*), поэтому некоторые грамматики, которые могут показаться
невозможно выполнить синтаксический анализ с помощью ALL (*), фактически может быть проанализирован им. Подшипник в
помните, что мы говорим о бесконечных множествах, и что я не думаю, что у нас есть
формальное доказательство следующего утверждения, я думаю, было бы справедливо сказать, что
подмножество ВСЕ (*) CFG больше, чем подмножество LR.
[11] Существуют более крупные однозначные подмножества, такие как
LR-Regular (или «LRR»)
грамматики. Однако, насколько я могу судить, это, вероятно, непрактично.
Например, это не
решить, является ли произвольная грамматика LRR или нет. [Обновлять
2020-10-28: предыдущая версия этой сноски предполагала, что Марпа
На основе LRR. Это обобщенный синтаксический анализатор, который также может анализировать LRR
грамматики. Приношу свои извинения за путаницу!] [12] Berkeley Yacc на самом деле реализует LALR, но для этого примера это
неотличим от LR.Я расскажу о LALR немного позже в этом посте. [13] Хотя я представил конфликты как ошибки, в Yacc они на самом деле
предупреждений, потому что у него есть правила «разрешения конфликтов по умолчанию» (см. Раздел 5 Yacc
руководство по эксплуатации). Другими словами, Yacc готов принять двусмысленную грамматику и
автоматически устраняет неоднозначность, чтобы получить однозначную грамматику. В общем,
Я не рекомендую использовать эту функцию. [14] Хотя это редко упоминается, традиционное разделение "синтаксического анализа" на
отдельные фазы лексирования и синтаксического анализа - важная часть истории неоднозначности.Лексеру не только легко идентифицировать для как ключевое слово и лес в качестве идентификатора, но парсер тогда должен только различать
между токеном типа и не токеном значениями . Разбор без сканирования
объединяет эти две фазы, что позволяет выразить больше грамматик, но
вводит больше возможностей для двусмысленности - и, в некоторых случаях, включает результирующий алгоритм синтаксического анализа
принимать контекстно-зависимые грамматики. [15] Представьте себе программу Haskell или RPython, в которой ни одна из функций не имеет явных типов.Проблема при программировании в таких системах заключается в том, что часто возникают ошибки.
сообщили далеко от места, где они были вызваны. Другими словами,
Я мог бы сделать
ошибка статического типа в одной функции, но модуль вывода типов обнаружит
приводящая к ошибке в другой функции. Хотя сообщения об ошибках типа стали намного лучше
со временем они никогда не смогут соответствовать человеческим ожиданиям во всех случаях. [16] Лучшие отчеты о конфликтах, которые я видел, поступают от LALRPOP. [17] Навскидку, я могу вспомнить только один пример: когда Лукас пытался
развить эту Java 7
грамматика на Java 8.До этого момента у grmtools не было возможности
сообщать подробности о конфликтах, потому что мне не нужна была такая функция! Спецификация Java, используемая для гордости
представление простой, проверенной машиной, однозначной грамматики в приложении. К сожалению, в
в какой-то момент кажется, что эта грамматика была исключена из спецификации, и я
подозреваю, что введенный новый синтаксис не был проверен на предмет возможных
двусмысленность. Мы быстро поняли, что грамматика Java 8 недостаточно важна.
нашей работе, чтобы мы вкладывали в это время, поэтому я не знаю,
неоднозначно или нет.
[18] Для ненасытно любопытных типы конфликтов означают примерно:- сдвиг / уменьшение: синтаксический анализатор LR не может быть уверен, должен ли он продвигать
ввод по одному токену, или будет ли правило синтаксического анализа завершено.
- уменьшить / уменьшить: синтаксический анализатор LR не может быть уверен, какое из двух правил будет выполнено.
- принять / уменьшить: синтаксический анализатор LR не может быть уверен, что весь синтаксический анализ
выполнено или выполнено только одно правило.
Последняя возможность настолько редка, что я забыл, что она существует еще до того, как
думал проверить эту сноску! [19] Грубо говоря, самый быстрый
суперкомпьютер в мире в то время работал примерно в 10 000 раз медленнее
чем достойный настольный чип сегодня. [20] SLR особенно ограничен. Однако я не уверен, что когда-нибудь видел, чтобы SLR использовали
на практике (хотя я знаю, что это было в прошлом), но LALR все еще находится в
Berkeley Yacc.Несмотря на то, что LALR менее строгий, чем SLR, он все же может
требуют, чтобы грамматики реальных языков программирования были неприятно искажены
места. [21] Описание пейджера немного неполное; лучше всего в паре с Синь Чен
Тезис. По памяти ни один не упоминает, что алгоритм
недетерминированные и иногда могут создавать недостижимые состояния, которые могут быть
сборщик мусора, чтобы сэкономить немного больше памяти.
grmtool’s
реализация этого алгоритма более подробно описывает такие вопросы и
также имеет бонус в виде бега.Однако алгоритм Пейджера не совсем
работают правильно, если вы используете функцию разрешения конфликтов Yacc. Однажды я должен
реализовать
Алгоритм IELR
Для решения этой проблемы. [22] Например, кодирование разреженных таблиц (например, в Rust с sparsevec crate) и упаковка
векторы небольших целых чисел (например, с упакованным ящиком). Это
Я давно не думал об этих аспектах: по памяти,
можно сделать даже лучше, чем эти методы, но они уже
достаточно эффективно, чтобы мы не чувствовали необходимости углубляться в этот вопрос. [23] В синтаксисах C-ish есть одно важное исключение: отсутствие фигурных скобок. В
результирующие ошибки обычно сообщаются через много строк после точки,
человек будет рассматривать как причину проблемы. [24] rustc выдает лучшие сообщения об ошибках синтаксиса среди всех компиляторов / парсеров, которые я когда-либо делал.
использовал. [25] Последние годы укрепили давнюю тенденцию: программисты не любят
изучать языки с незнакомым синтаксисом.К лучшему или худшему, синтаксис C-ish таков:
вероятно, будет доминирующей культурной силой в языках программирования в течение десятилетий
приходить. [26] Это не означает, что конечный компилятор имеет , чтобы содержать LR.
парсер (хотя я бы начал с парсера LR и подумал о переходе только на
что-то еще, если бы у меня были миллионы пользователей), но парсер, который он содержит
должен полностью соответствовать справочной грамматике LR. К сожалению, в обозримом будущем мы застрянем с
языки программирования, которые использовали другие формализмы синтаксического анализа: пожалейте бедных
Автор IDE, которому приходится иметь дело с еще одним языком только с рекурсивным
синтаксический анализатор спуска вместо грамматики LR!
Дом - nearley.js - набор инструментов парсинга JS
Дом
Синтаксические анализаторы превращают строки символов в значимые структуры данных (например,
Объект JSON!). nearley - быстрый , многофункциональный и современный набор инструментов парсера для JavaScript. Nearley - персонал НПМ
Выбирать.
Nearley 101
- Установка:
$ npm install -g nearley (или попробуйте nearley live в своем браузере
вот!) - Напишите свою грамматику:
# Подберите цвет CSS
# http: // www.w3.org/TR/css3-color/#colorunits
@builtin "whitespace.ne" # `_` означает произвольное количество пробелов
@builtin "number.ne" # примитивы чисел `int`,` decimal` и `процент`
csscolor -> "#" hexdigit hexdigit hexdigit hexdigit hexdigit hexdigit
| "#" шестнадцатеричный разряд шестнадцатеричный шестнадцатеричный
| "rgb" _ "(" _ colnum _ "," _ colnum _ "," _ colnum _ ")"
| "hsl" _ "(" _ colnum _ "," _ colnum _ "," _ colnum _ ")"
| "rgba" _ "(" _ colnum _ "," _ colnum _ "," _ colnum _ "," _ decimal _ ")"
| "hsla" _ "(" _ colnum _ "," _ colnum _ "," _ colnum _ "," _ decimal _ ")"
шестнадцатеричный -> [a-fA-F0-9]
colnum -> int | проценты
- Составьте свою грамматику:
$ nearleyc csscolor.ne -o csscolor.js
- Проверьте свою грамматику:
$ nearley-test -i "# 00ff00" csscolor.js
Результаты синтаксического анализа:
[['#', ['0'], ['0'], ['f'], ['f'], ['0'], ['0']]]
- Превратите свою грамматику в генератор:
$ nearley-unparse -n 3 csscolor.js
# Ab21F2
RGB (-29,889%, 7,8172)
# a40
- Вы попробуете! Введите здесь цвет CSS:
… и здесь появится проанализированный результат!
- Создавайте красивые железнодорожные диаграммы для формального документирования грамматики.
$ nearley-railroad csscolor.ne -o csscolor.html
Смотрите демо здесь.
Характеристики
- nearley - первый парсер JS, использующий алгоритм Earley (вставьте
здесь собственный каламбур "ранней пташки"). Он также реализует оптимизацию Joop Leo для
правая рекурсия, что делает его эффективно линейным временем для грамматик LL (k).
- почти счастливо живет в узле , но не возражает против браузера .
- nearley выводит маленьких файлов.А его выразительный DSL поставляется с
много синтаксического сахара , чтобы ваши исходные файлы были короткими. И сладко.
Грамматический язык- Nearley мощный и выразительный: вы можете использовать макросов , импорт из большой встроенной библиотеки предопределенных
части парсера, используйте токенизатор для дополнительной производительности и многое другое!
- nearley построен на идиоматическом потоковом API . У вас даже есть доступ к
частичный синтаксический анализ для создания пользовательских интерфейсов с прогнозированием .
- Nearley обрабатывает левой рекурсией без задержки. Фактически, рядом будет
разбирать все, что вы в него бросаете, не жалуясь и не дуться
бесконечная петля. - Nearley изящно обрабатывает неоднозначных грамматик . Неоднозначные грамматики могут
анализироваться несколькими способами: вместо того, чтобы запутаться, Nearley дает вам
все синтаксические разборы (в детерминированном порядке!).
- nearley позволяет выполнять отладку с обширным обнаружением ошибок .Когда это
обнаруживает ошибку времени синтаксического анализа, Nearley сообщает вам, что именно пошло не так, и
где.
- Nearley достаточно мощный, чтобы быть загруженным . Это означает, что Nearley использует
Nearley для компиляции частей Nearley. nearleyception!
- парсеров Nearley могут быть инвертированы для формирования генераторов , которые выводят случайные
строки, соответствующие грамматике. Полезно для написания тестовых случаев , фаззеров и Mad-Libs .
- Вы можете экспортировать парсеры Nearley как железнодорожных диаграмм , которые предоставляют
легкая для понимания документация по вашей грамматике.
- nearley поставляется с фантастическим набором инструментов. Вы можете найти плагины редактора для vim , Sublime Text , Atom и VS Code ; это также
плагины для Webpack и gulp .
Проекты с использованием nearley
Искусственный интеллект, НЛП, лингвистика :
Шрдлит - это
проект по программированию в области искусственного интеллекта, курс, читаемый в
Гетеборгский университет и Технологический университет Чалмерса.Он использует nearley
для чтения инструкций на естественном языке (т. е. на английском).
лексикон-грамматики использовались
для синтаксического анализа лексиконов для проекта в Австралийском национальном университете.
Стандартные форматы : node -dmi - это
модуль, который читает метаданные iconstate из файлов BYOND DMI,
edtf.js - это парсер для расширенной даты
Формат времени, node -krl-parser
- парсер KRL для узла,
библиография
Конвертер BibTeX в HTML,
biblatex-csl-конвертер
конвертирует между bibtex / CSL / JSON, скальпель
анализирует селекторы CSS (активизирующий фермент,
Инструмент тестирования Airbnb React),
rfc5545-rrule помогает разобрать
данные iCalendar, мангудаи разбирает RMS
скрипты для Age of Empires II, парсы tf-hcl
и генерирует файлы конфигурации HCL,
CSS-селектор-инспектор
анализирует и токенизирует селекторы CSS3,
css-свойство-парсер
проверяет и расширяет сокращения CSS,
узел-scad-парсер анализирует
3D модели OpenSCAD, js-sql-parse
анализирует операторы SQL, pg-mem - это эмулятор базы данных Postgres в памяти, resp-parser - это
парсер для протокола RESP, celio
разбирает звездные каталоги Селестии, Харака
SMTP-сервер, на котором работает Craigslist (и другие).
Шаблоны и файлы : uPresent - это
система создания презентаций на основе уценки,
saison - это минималистичный язык шаблонов,
Packdown - это инструмент для создания
удобочитаемые архивы из нескольких файлов.
Языки программирования : Углерод - это C
подмножество, которое компилируется в JavaScript, оптимизировано для разработки игр,
эзланг - простой язык,
tlnccuwagnf - забавный универсальный
язык, наналанг - глупая эзотерика
язык, английский менее эзотерический
язык программирования, ecmaless - это
легко расширяемый язык, hm-parser
анализирует сигнатуры типа Хиндли-Милнера, подобные Haskell,
kozily реализует язык Oz,
абстрактная машина проверяет
модели исполнения, fbp-types предоставляет
примитивы проверки типов для потоковых систем,
lp5562 - ассемблер для TI LP5562
Светодиодный драйвер, VSL - это универсальный сценарий
Язык, в то время как машинописный текст
реализация языка WHILE,
lo - это язык для безопасного распределения
систем, jaco - это реализация
Язык обучения C0 CMU, Уолт -
подмножество JavaScript, предназначенное для WebAssembly,
N-lang - это язык общего назначения
разработан группой старшеклассников.
Математика : Растворитель - это
мощный настольный калькулятор,
Таблица истинности - это инструмент для
визуализировать логику высказываний в таблицах истинности, Emunotes
это личная Wiki со встроенными графиками и вычислениями,
анализирует и отображает уравнение реакции
уравнений в React, mLab генерирует
статьи по теории категорий.
Доменные языки : Hexant - это
симулятор клеточного автомата с DSL для пользовательских автоматов,
Dicetower - расширенный плагин для игры в кости
для hubot, deck.zone - это язык для
создавать настольные игры, за секунды - это
калькулятор времени для музыкальных приложений,
website-spec - это инструмент для функциональных
веб-тестирование, pianola позволяет декларативно
композиция функций, идиллия - это разметка
язык для документов, управляемых данными,
virtsecgroup предоставляет виртуальную AWS
группы безопасности, deadfad - шестнадцатеричный редактор
который позволяет вам указывать структуры,
Бишбош помогает тебе творить
интерфейсы командной строки, syso кодифицирует аспекты
французских юридических контрактов,
Sitewap анализирует Siteswap
обозначение паттернов жонглирования, jsgrep
предоставляет синтаксический grep для JavaScript,
электрограмматические синтаксические разборы
описания электронных компонентов, таких как резисторы и конденсаторы,
cicero помогает создавать умные юридические контракты,
Eventbot - это плагин календаря для Slack, используемый
тысяч команд, Obyte - это
криптовалютная платформа OptiCSS - это
Оптимизатор CSS, созданный LinkedIn,
Nestup - это язык для
указание вложенных ритмических кортежей,
htlengine анализирует HTL Adobe
язык шаблона,
fhir-работы
это инструмент, предоставляемый AWS для анализа параметров поиска FHIRPath (FHIR - это
интерфейс для медицинских данных), Penrose - это язык
для выражения математических диаграмм,
sema - это DSL для живого кодирования музыки
выступления.
Другое :
Процедурный
генерирует «случайные эпизоды веселого, но шаблонного шоу»,
parse-vbb-имя-станции
анализирует названия остановок общественного транспорта в Берлине.
Библиотеки синтаксического анализа : nearley - это набор инструментов парсера для
JavaScript. Он имеет почти основанный на DSL интерфейс для определения парсеров.
Отдать nearley
nearley поддерживается волонтерами с 2014 года. Если вы хотите помочь
поддержите нас, свяжитесь с @kach или @tjvr на GitHub.Мы пришлем наши
Информация PayPal - и, может быть, что-нибудь приятное. :-).
Разбор мифов о Панчо Вилья
Жанна Клэр ван Ризин
Жизнь Панчо Вилья - это естественная опера.
Миф о легендарном мексиканском революционном генерале-бандите. Его история скользкая, противоречивая, надуманная и увлекательная.
Помимо подробностей его рождения - он родился Хосе Доротео Аранго Арамбула в 1878 году в семье бедных издольщиков в штате Дуранго на севере Мексики - историки спорят о многих подробностях жизни Панчо Вильи.
Он был чрезвычайно популярен как защитник мексиканских бедняков, символ простых людей и их борьбы против чрезвычайно могущественных владельцев гасиенд. И он остается почитаемым сегодня.
Панчо Вилья также стал чем-то вроде народного героя в Соединенных Штатах. В конце концов, мексиканская революция была одной из первых войн, освещаемых средствами массовой информации, ее события и ее основные участники популяризировались в газетах и первых выпусках немой кинохроники.
Вилла проницательно участвовал в создании мифов в средствах массовой информации, время от времени сознательно выполняя свою жизнь.Голливудские режиссеры и газетные фотографы стекались в Северную Мексику, чтобы снимать его битвы. Вилла, чья армия контролировала районы возле границы с США, подписала соглашение с Mutual Film, предоставляющее киножурналисту привилегированный доступ.
Панчо Вилла на кадре из эксклюзивного фильма Mutual Film 1914 года.
Эта скользкость между фактом и вымыслом истории Виллы вдохновила композитора Грэма Рейнольдса.
«Панчо Вилла с безопасного расстояния» - камерная опера Рейнольда о жизни и смерти народного героя.
«Панчо Вилла - это загадка. Он культовый и при жизни был важнее жизни для людей по обе стороны границы», - говорит Рейнольдс.
Опера, созданная совместно Fusebox и Ballroom Marfa, является заключительной частью The Marfa Triptych , музыкального исследования Рейнольда общей истории и культуры пограничного региона Техас и Мексики.
Фото Алекса Маркса.
Рейнольдс и его партнер и соратник, режиссер Шон Сайдс, отправились в Эль-Пасо и остановились в отеле El Comino Real, где во время мексиканской революции люди собирались на крыше и смотрели, как внизу разыгрываются сражения - большой театр или война.
«У меня все сложилось, когда мы были в Эль-Пасо», - говорит Сайдс, сопродюсер знаменитого театрального коллектива Rude Mechs, художественный руководитель Остина. «Мифология вокруг Панчо Вильи, как люди наблюдали за этой битвой и ее насилием, как если бы это происходило в отдалении».
Панчо Вилья, крайний слева в шляпе на коленях, вкушает мороженое в Elite Confectionary в Эль-Пасо после захвата соседнего города Сьюдад-Хуарес 10 мая 1911 года.
Как жизнь Виллы - это композиция меняющихся повествований, так и либретто оперы.Нелинейное повествование - это коллаж из текстов, взятых из исторических документов.
Рейнольдс обратился к Луизе Пардо и Габино Родригес из Мехико из театральной компании Lagartijas Tiradas al Sol для создания либретто.
Два года назад Лагартихас принес в Fusebox завораживающую «El Rumor del Incendio». Используя смесь документальных материалов и звукозаписей устных историй, исполнители использовали игрушечные фигурки и миниатюрные настольные пейзажи, чтобы пересказать историю молодых мексиканских активистов 1960-х годов.
Как и в случае с «El Rumor», Пардо и Родригес рассматривают свое либретто «Панчо Вилья» как попытку соединить историю и наследие с нюансами современности.
«Иногда нам нужно объяснить себе, что произошло в прошлом, чтобы понять наше настоящее», - написали они в электронном письме.
Следовательно, слово «расстояние» в названии оперы действует на нескольких уровнях. Мы часто держим историю, ее противоречия и сложности на безопасном расстоянии от нашего настоящего.То же самое относится к отношениям Америки с Мексикой, страной к югу от границы, всегда дистанцированной в политическом и культурном отношении и относящейся к категории «других». И все же для приграничного региона история и культура неразрывно связаны и их невозможно отделить друг от друга.
Фото Алекса Маркса.
В исполнении двух певцов - меццо-сопрано Лиз Касс и тенора Пола Санчеса - в сопровождении ансамбля, в состав которого входит удостоенный премии Грэмми продюсер Адриан Кесада на гитаре, «Панчо Вилла с безопасного расстояния» представляет собой типичный музыкальный калейдоскоп Рейнольдса. Работа.Мексиканские корридо, мелодии Теджано, альтернативная классика, американский кантри-вестерн и арт-песня сливаются в 80-минутном произведении, которое исполняется в концертном стиле на фоне проецируемых изображений и видеозаписей.
Хотя Рейнольдс и его сотрудники начали работу над оперой до того, как появились новости о пограничной стене и до эскалации депортации иммигрантов, «Панчо Вилья», тем не менее, проявил своевременность, когда премьера состоялась в Марфе всего через несколько дней после ноябрьских президентских выборов.
«Я не думал, что это будет так своевременно, но это так», - говорит он.«Я хотел безграничный разговор об общей истории Мексики и Техаса».
Построение таблицы синтаксического анализа LL (1)
Предварительное условие - классификация нисходящих синтаксических анализаторов, ПЕРВЫЙ набор, СЛЕДУЮЩИЙ набор
Нисходящий синтаксический анализатор строит дерево синтаксического анализа сверху вниз, начиная с нетерминального начала. Существует два типа нисходящих парсеров:
- нисходящие парсеры с обратным отслеживанием
- нисходящие синтаксические анализаторы без возврата
нисходящие парсеры без возврата могут быть разделены на две части:
В этой статье мы собираемся обсудить нерекурсивный спуск, который также известен как парсер LL (1).
LL (1) Разбор:
Здесь 1-й L представляет, что сканирование входа будет выполняться слева направо, а второй L показывает, что в этом методе анализа мы собираемся использовать Самое левое дерево деривации. И, наконец, 1 представляет количество упреждающих символов, что означает, сколько символов вы увидите, когда захотите принять решение.
Алгоритм построения таблицы анализа LL (1):
Шаг 1: Сначала проверьте левую рекурсию в грамматике, если в грамматике есть левая рекурсия, удалите ее и перейдите к шагу 2.
Шаг 2: Вычислить первый () и последующий () для всех нетерминалов.
- Первый (): Если есть переменная и из этой переменной, если мы пытаемся управлять всеми строками, то начальный Терминальный символ называется Первым.
- Follow (): какой конечный символ следует за переменной в процессе вывода.
Шаг 3: Для каждого производства A -> α. (A стремится к альфа)
- Найдите первый (α) и для каждого терминала в первом (α) сделайте запись A -> α в таблице.
- Если Первый (α) содержит ε (эпсилон) в качестве терминала, то найдите Follow (A) и для каждого терминала в Follow (A) сделайте запись A -> α в таблице.
- Если Первый (α) содержит ε, а Follow (A) содержит $ в качестве терминала, то сделайте запись A -> α в таблице для $.
Для создания таблицы синтаксического анализа у нас есть две функции:
В таблице строки будут содержать нетерминальные элементы, а столбец будет содержать терминальные символы. Все Null Productions Grammars будут находиться под элементами Follow, а остальные производства будут находиться под элементами First set.
Теперь давайте разберемся на примере.
Пример-1:
Рассмотрим грамматику:
E -> TE '
E '-> + TE' | ε
Т -> FT '
T '-> * FT' | ε
F -> id | (E)
* ε обозначает эпсилон
Найти их первый и последующий наборы:
Первый Следовать E -> TE ' , (} )} E '-> + TE' / ε {+, ε} {$,)} T -> FT ' {id, (} {+, $,)} T '-> * FT' / ε {*, ε} {+, $,)} F -> id / ( E) {id, (} {*, +, $,)}
Теперь таблица синтаксического анализа LL (1):
id + * ( ) $ E E -> TE ' E -> TE' E ' E' -> + TE ' E' -> ε E '-> ε T -> FT ' T -> FT' T ' T' -> ε T '-> * FT' T '-> ε T' -> ε F F -> id F -> (E) Примечание: Не все грамматики подходят для таблицы синтаксического анализа LL (1). Возможно, что одна ячейка может содержать более одной продукции.
Давайте посмотрим на примере.
Пример-2:
Рассмотрим грамматику
S -> A | а
A -> a
Найдите их первые и последующие наборы:
Первый Следуйте S -> A / a {a} {$} A -> a {a} {$}
Таблица синтаксического анализа:
a a 40 40 40 902 S -> A, S -> a A A -> a
Здесь мы видим, что в одной ячейке есть два производства.Следовательно, эта грамматика невозможна для LL (1) Parser.
Вниманию читателя! Не прекращайте учиться сейчас. Практикуйте экзамен GATE задолго до самого экзамена с помощью предметных и общих викторин, доступных в курсе серии тестов GATE .
Изучите все концепции GATE CS с бесплатными живыми классами на нашем канале YouTube.
python - Элегантный разбор структурированного текстового файла
Вот два парсера на основе библиотеки генератора парсеров lepl .Оба они дают одинаковый результат.
из pprint import pprint
from lepl import AnyBut, Drop, Eos, Newline, Separator, SkipTo, Space
# field = name, ":", value
имя, значение = AnyBut (': \ n') [1:, ...], AnyBut ('\ n') [:: 'n', ...]
с разделителем (~ Пробел () [:]):
field = name & Drop (':') & value & ~ (Newline () | Eos ())> кортеж
header_start = SkipTo ('Стенограмма чата' и новая строка () [2])
header = ~ header_start и поле [1:]> dict
server_message = Drop ('*') & AnyBut ('\ n') [:,...] & ~ Новая строка ()> 'Сервер'
беседа = (сообщение_сервера | поле) [1:]> список
footer_start = 'Сведения о посетителе' и новая строка () & '-' * 15 и новая строка ()
footer = ~ footer_start & field [1:]> dict
chat_log = заголовок & ~ Новая строка () и беседа & ~ Новая строка () и нижний колонтитул
pprint (chat_log.parse_file (open ('chat.log')))
Более строгий синтаксический анализатор
из pprint import pprint
из импорта lepl And, Drop, Newline, Or, Regexp, SkipTo
def Поле (имя, значение = Regexp (r '\ s * (.\ * (. *?) \ n ')>' Сервер '
footer_fields = Fields (("Ваше имя, ваш вопрос, IP-адрес,"
"Имя хоста, реферер, браузер / ОС"). Split (','))
с open ('chat.log') как f:
# анализируем заголовок, чтобы найти имена посетителя и оператора
заголовки, = (~ заголовок_старт и заголовочные_поля> dict) .parse_file (f)
# только Посетитель, Оператор и Сервер могут принимать участие в разговоре
сообщение = уменьшить (Или, [Поле (заголовки [имя])
на имя в «Оператор-посетитель».расколоть()])
беседа = (сообщение | сообщение_сервера) [1:]
сообщения, нижние колонтитулы = ((беседа> список)
& Drop ('\ nДанные о посетителе \ n --------------- \ n')
& (footer_fields> dict)). parse_file (f)
pprint ((заголовки, сообщения, нижние колонтитулы))
Выход:
({'Компания': 'Инитек',
'Finished': '16 Oct 2008 9:45:44 ',
«Оператор»: «Милтон»,
'Начато': '16 Oct 2008 9:13:58 ',
«Посетитель»: «Случайный посетитель веб-сайта»},
[('Случайный посетитель веб-сайта',
«Где взять титульный лист для отчета TPS?»),
('Сервер',
«В данный момент нет доступных операторов.Если вы хотите оставить сообщение, введите его в поле ввода ниже и нажмите кнопку «Отправить» '),
('Сервер',
«Вызов принят оператором Милтон. В настоящее время в комнате: Милтон, случайный посетитель веб-сайта. '),
('Милтон', 'Д ... Извините. Вы ... Я полагаю, у вас есть мой степлер?'),
(«Случайный посетитель веб-сайта», «Мне действительно нужен титульный лист, хорошо?»),
('Милтон',
«это не нормально, потому что если они заберут мой степлер, то я, я, я подожгу здание ...»),
(«Случайный посетитель веб-сайта», «О, я нашел его, все равно спасибо.'),
('Сервер',
«Случайный посетитель веб-сайта теперь не в сети и не может отвечать. В настоящее время в комнате: Милтон. '),
(«Милтон», «Ну, ладно. Но… это последняя капля».)
('Сервер',
Милтон ушел из разговора. В настоящее время в комнате: комната пуста. ')],
{'Браузер / ОС': 'Mozilla / 4.0 (совместимый; MSIE 7.0; Windows NT 5.2; .NET CLR 1.1.4322; InfoPath.1; .NET CLR 2.0.50727)',
'Имя хоста': '255.255.255.255',
'IP-адрес': '255.255.255.255',
"Реферер": "Неизвестно",
«Ваше имя»: «Случайный посетитель веб-сайта»,
«Ваш вопрос»: «Где мне взять титульный лист для отчета TPS?»})
Анализируя B.История Симоны Плагиат
Обновление: Незадолго до того, как этот пост был готов к публикации (но после его написания), Б. Симона ответила в Instagram, повторив, что плагиат совершила команда, с которой она работала, но признала, что она «бросила мяч". Она также говорит, что берет на себя полную ответственность как генеральный директор своего бренда.
Б. Симона, возможно, наиболее известная своей ролью в Wild ‘N Out , певица, актриса и комик, которая стремилась добавить еще одно название в свой растущий список: Автор.
Однако все прошло не так гладко, как она, вероятно, надеялась. В марте она опубликовала свою книгу Baby Girl: Manifest The Life You Want , руководство, которое, как она надеялась, поможет другим найти свой собственный путь к успеху.
Продвигая книгу, она охарактеризовала ее как «личную» и сказала: «Я вложила все свое сердце в эту книгу и знаю, что она поможет многим людям во всем мире!»
Однако 13 июня стали появляться обвинения в том, что части книги были изъяты у других, менее известных авторов.Первым залпом выступил Элл Дюкло из Boss Girl Bloggers, который в своем твите подчеркнул, что список из книги Б. Симоне идентичен тому, что она опубликовала ранее.
Мне бы очень хотелось, чтобы @TheBSimone ПРЕКРАСНО брала труд мелких создателей контента и продавала его как свой собственный !!!
Отвратительно. Это не предпринимательство. Это плагиат. pic.twitter.com/CCSQ88A85e
- Ell // BossGirlBloggers (@BGbloggers) 13 июня 2020 г.
Вскоре другие также отметили дополнительные совпадения, всегда уделяя внимание спискам, руководствам и другим элементам книги.
Это вызвало бурю споров вокруг Б. Симона, который уже столкнулся с негативной реакцией на более ранние заявления о продолжающихся гражданских беспорядках в Соединенных Штатах и о том, следует ли предпринимателям встречаться с не предпринимателями.
Менеджер Б. Симоне, Мэри Сидс, вмешалась и сказала, что проблема не в письме Б. Симоне, а в дизайнерской фирме, которую они наняли для завершения работы. Далее они заявили, что участвуют в судебном процессе с фирмой и «пытаются с этим разобраться.
https://twitter.com/lady_luck45/status/1271884625237938178
Другие также защищали Б. Симон, особенно рэпер Мик Миллс, сказав в одном твите: «Би Симона отменила, потому что она нашла книгу и ускользнула от нее. внизу, смеется, какие крупные компании вы отменяете за то, что подрывают нашу культуру? »
Однако позже он добавил, что никогда не разбирался в том, в чем ее обвиняли, а вместо этого пытался сделать более широкую точку зрения.
Я даже не проверил, что она на самом деле делала. Я просто устал видеть, как черные отменяют черных… они поставили нас на последнее место, и так мы уже охвачены этим дерьмом https: // t.co / YEjZVrqxoO
- Meek Mill (@MeekMill) 14 июня 2020 г.
В конце концов, сама книга больше не продается на веб-сайте Б. Симоне. Поскольку он доступен на Amazon и других розничных магазинах, они не являются официальными релизами.
Хотя это не похоже, что это будет конец истории, есть еще многое, что нужно распаковать и изучить.
Анализ плагиата
Сам факт плагиата чрезвычайно очевиден. Приведенные примеры указывают на то, что в книге есть построчное и дословное копирование / вставка.Один даже включал элементы дизайна из оригинала. Если эти страницы не были скопированы из предоставленных источников, то они явно имеют общий источник. Короче говоря, это никак не могло быть словами Б. Симона.
Однако это не то, что отрицает Б. Симона или, по крайней мере, ее менеджер. Похоже, они признают, что в книге есть плагиат, и вместо этого возлагают вину на дизайнерскую компанию, с которой они работали над изданием книги.
Такое объяснение действительно возможно.Хотя мы, как сторонние наблюдатели, не имеем возможности точно знать, какие части книги были написаны кем, это не является диковинкой, если списки, вставки и другие элементы были написаны третьей стороной.
Я столкнулся с этим в своей консультационной практике. Меня вызвали для расследования предполагаемого плагиата в учебнике, и я обнаружил, что он был изолирован от подписей и вопросов, элементов, написанных не названными авторами. Они работали со сторонней фирмой над дизайном и редактированием книги, и эти элементы были от этой компании.
Тем не менее, если будет показано, что контент является плагиатом, то есть из основного текста работы, это будет совсем другое дело. Но на данный момент все обвинения сосредоточены вокруг списков и действий, о которых Б. Симона вполне могла не писать.
Однако это не полностью оправдывает Б. Симоне в данном случае. Каждый раз, когда вы публикуете книгу со своим именем и утверждаете, что работа принадлежит вам, вы несете ответственность за ее честность. Даже если эта работа написана писателем-призраком, вы все равно несете за нее ответственность, поскольку на кону стоит ваша репутация и ваш бренд.
Мы уже видели это раньше. Еще в 2013 году Джейн Гудолл обвинили в плагиате в своей книге Seeds of Hope , но Гудолл возложила вину на своего соавтора. В более недавнем случае, в скандале с плагиатом Кристины Серруя фигурировал автор романа-плагиата, который, в свою очередь, возложил вину на своего писателя-призрака. Было много предупреждений о том, что что-то подобное может произойти, но это предупреждение не было учтено.
Очевидно, Б. Симона и никто из ее команды не проявили должной осмотрительности с этой книгой.Беглая проверка на плагиат, вероятно, позволила бы обнаружить эти проблемы и решить вопрос до того, как он был бы опубликован. Хотя это услуга, которую я предоставляю на своем консультационном сайте, это то, что почти любой издатель должен уметь делать самостоятельно.
Даже если Б. Симона не была тем, кто вставил плагиатные разделы, отсутствие должной осмотрительности не освещает ее или эту работу в лучшем свете. Для человека, чье послание - упорный труд и его приверженность, эта история сильно подрывает ее послание.
Bottom Line
Для ясности, в этой истории есть элементы, на которых я не заостряю внимания, но считаю, что они чрезвычайно важны. Например, чернокожая Б. Симона обвиняется в плагиате как от белых, так и от черных авторов. Частью этой истории стала негативная реакция на негативную реакцию и вопрос о том, должны ли чернокожие женщины «отменять» других чернокожих женщин.
Это было подчеркнуто в твитах Мика Милла, в котором говорилось, что не существует аналогичного стимула для отмены компаний, грабящих черную культуру.Это, безусловно, важный момент, и его стоит обсудить, но я не тот, у кого он есть. Я не являюсь экспертом в этой области и не имею личного опыта в этих вопросах. В этом пространстве есть гораздо более важные голоса, и я не хочу их отнимать.
Однако, с точки зрения чистого плагиата, довольно ясно, что книга Б. Симоне содержала значительные фрагменты плагиата. Хотя обвинение в ошибках сторонней дизайнерской фирмы может показаться оправданием, очень легко это может оказаться правдой.
Учитывая, что перекрывающийся контент на момент написания этой статьи ограничен списками и викторинами, весьма вероятно, что они были написаны не самой Б. Симон, а, напротив, были написаны издателем, редактором или дизайнером. Это очень распространенный способ сборки таких книг.
Тем не менее, это вызывает вопросы о тщательности, которая была вложена в книгу, и о том, выполнили ли Б. Симона или ее команда необходимые проверки, чтобы убедиться, что посторонний контент не был плагиатом. Это важный шаг, но многие издатели отказываются от него.
Если бы я был членом команды Б. Симоне, я бы начал забегать вперед. Поделитесь поданным иском и подробно объясните, как это произошло. Прозрачность - единственный реальный путь вперед. В противном случае эти обвинения будут продолжать преследовать ее и, учитывая ее упорный труд и настойчивость, будут подрывать ее на каждом шагу.
Люди склонны прощать прошлые ошибки, когда дело касается плагиата, но только тогда, когда это прощение было заслужено.
Parsing Paradise - повседневные прозрения из Милтонского Эдема и за его пределами
После уроков я не мог не посмотреть, что такое cerastes.По-видимому, это змей из греческой легенды, который, скорее всего, основан на повадках рогатой гадюки. На самом деле это не существо, которое можно найти в Книге VII творения, но появляется в Книге X, когда сатана и другие падшие ангелы превращаются в разные вариации змей:
Но шипение за шипение с раздвоенным языком
В раздвоенный язык, пока все были преобразованы
Подобно Змеям все как аксессуары
Его смелому бунту: ужасен был шум
Шипение по Залу, теперь густое скопление
Со сложной головой и хвостом монстров,
Scorpion and Asp и Amphisbaena dire,
Cerastes hornd, Hyrdus и Ellops (517-525)
Что мне очень интересно в этом, так это то, что это событие, которое мой любимый автор К.С. Льюис упоминает в своей книге Screwtape Letters . Это одна из моих любимых работ Льюиса, который играет роль демона по имени Винтовка, который пишет письма своему племяннику Полынь, демону и обучающемуся искусителю. Доктор С. упоминал Льюиса раньше в классе, и ясно, что его написание, особенно Screwtape Letters , находится под влиянием эпоса Милтона, которого он явно упоминает в Письме 22:
. «В пылу композиции я обнаружил, что случайно позволил себе принять форму большой сороконожки.Остальное я соответственно диктую своему секретарю. Теперь, когда трансформация завершена, я осознаю это как периодическое явление. Некоторые слухи об этом дошли до людей, и искаженное описание этого появляется в поэте Милтон с нелепым добавлением, что такие изменения формы являются «наказанием», наложенным на нас Врагом. Однако более современный писатель - человек с таким именем, как Пшоу - понял истину. Преобразование происходит изнутри и является великолепным проявлением той жизненной силы, которой поклонялся бы наш Отец, если бы он поклонялся кому-либо, кроме себя.