Примеры для 2 класса по математике
Занимательная математика
Дошкольнику | 1 класс | 2 класс | 3 класс | 4 класс
Детям наскучили обычные примеры из учебников. Предложите ребёнку красочные увлекательные задания на сложение и вычитание от ЛогикЛайк.
С занятиями от LogicLike.com дети развивают математические способности, логическое мышление и смело решают олимпиадные задания.
Предлагаем 9 веселых арифметических заданий для второклассников, которые подойдут для дополнительных, факультативных занятий или олимпиад. Решать сейчас эти примеры в уме или в тетради необязательно.
На сайте ЛогикЛайк дети могут выполнять интерактивные задания в своем учебном профиле. В блоге мы приводим примеры заданий для родителей и учителей. Подборка поможет понять, какие задания точно увлекут детей математикой! 😉
Определи, сколько стоит сыр?
Чтобы решать, нажимайте Начать!
Смотреть ответ
Ответ:
7-3=4.
Магический квадрат
Чтобы решать, нажимайте Начать!
В магическом квадрате сумма чисел в любой горизонтали, вертикали и диагонали одинакова.
Определи недостающие числа.
Смотреть ответ
Ответ:
Сумма чисел в каждой горизонтали, вертикали и диагонали равна 12.
На платформе ЛогикЛайк более 2500 заданий для развития логики и математического мышления.
Монстрик Цифроежка
Чтобы решать, нажимайте Начать!
На торте было двузначное число. Монстрик съел цифру 9.
Число уменьшилось на 36. Какое это было число: 36, 63 или 93?
Какое это было число: 36, 63 или 93?
Смотреть решение
Ответ:
39-3=36.
Арифметический ребус
Чтобы решать, нажимайте Начать!
Узнать ответ
6=3+3
11-3=8
Создать аккаунт
и решать задачи с любого устройства!
Заколдованные цифры
Чтобы решать, нажимайте Начать!
Волшебник превратил цифры в геометрические фигуры. Помоги расколдовать
цифры и запиши примеры.
Смотреть решение
Ответ:
10-9=1
9+0=9
Чтобы набрать 22 очка, в какие шары нужно попасть?
Чтобы решать, нажимайте Начать!
Смотреть ответ
Ответ:
16+4+2.
Примеры и задачи ЛогикЛайк повышают интерес к учёбе и развивают навыки нестандартного мышления.
Найди недостающие числа
Чтобы решать, нажимайте Начать!
Каждое верхнее число равно сумме двух чисел под ним.
Узнать ответ
Ответ:
4, 1, 4, 0, 1.
Математический ребус
Чтобы решать, нажимайте Начать!
Верни цифры и знак в пример.
Узнать ответ
Ответ:
32-23=9.
Подключайтесь к ЛогикЛайк!
Более 2 000 000 ребят со всего мира уже занимаются математикой и логикой на LogicLike.com.
Начать обучение! Начать обучение
Темы проектов в начальной школе 2 класс
Внимание! Мы также предлагаем бесплатно скачать нашу обучающую игру-тренажер
Таблица умножения для 2 класса в мультиках.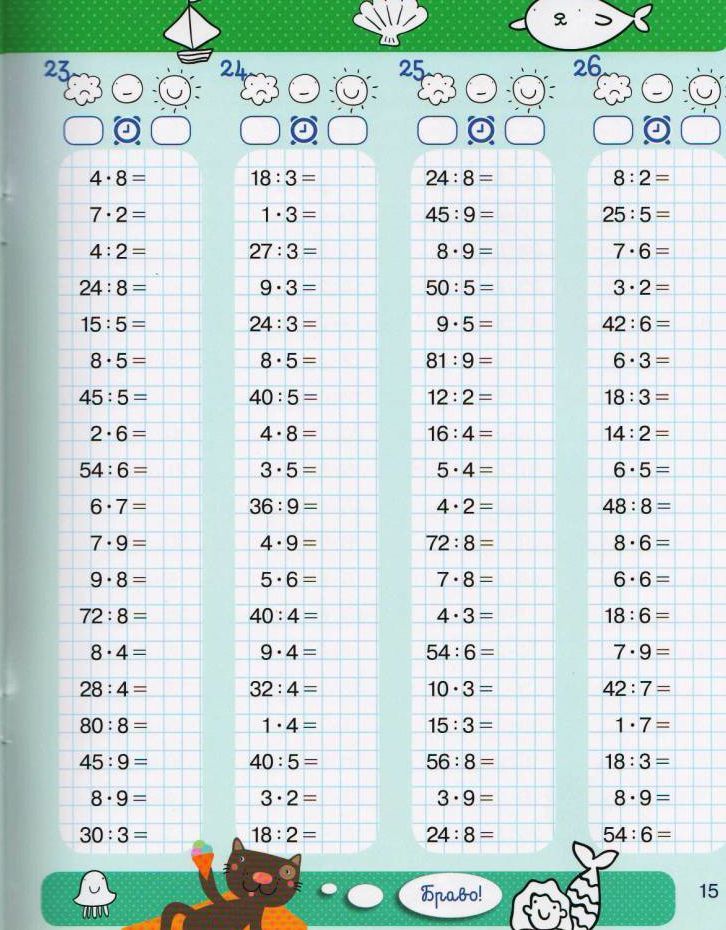
Предлагаем детские темы проектов в начальной школе 2 класс как примеры тем для осуществления исследовательской и проектной деятельности в начальных классах школы.
Ученик может легко выбрать интересную тему проекта в начальной школе 2 класс по фгос согласно своим интересам и увлечениям о животных, птицах, насекомых, растениях, грибах, а также о народных играх, комиксах, танцах, игрушках, о всем необычном.
Детям можно выбрать темы детских проектов 2 класс школы и создать проект по выращиванию в домашних условиях растений, по экологии, математике, русскому языку, по музыке и о музыкальных инструментах, любимых журналах и книгах или здоровом питании.
Любой пример темы проекта для начальных классов 2 класс рекомендуется изменять в зависимости от возможностей, заинтересованности ребенка в определенной области исследования и каким-либо объектом или процессом. Во 2 классе учащемуся необходима помощь родителей.
Темы творческих проектов для 2 класса
Интересные темы проектов для учащихся 2 класса начальной школы:
Береги зрение с детства.
Буклет «Автоэрудит»
В какие игры играли наши бабушки и дедушки.
Вальс – король танцев
Грибы-грибочки, весёлые строчки.
Два любимых деда (Санта Клаус и Дед Мороз).
Дорожная азбука второклассника.
Древнее искусство чаепития.
Дымковская игрушка
Её Величество – запятая.
Ежик — самое безобидное существо.
Живи, елочка, живи!
Жизнь маленькой горошины.
Забыта ли игра русская лапта.
Загадки моей бабушки.
Зачем луку луковица
Здоровым быть модно
Зимующие птицы нашего двора.
Исследование слова «Доброта»
История инструмента фортепиано.
История новогодней игрушки.
История светофора
Как появились первые часы.
Как я могу защитить природу
Какой же он, каменный уголь?
Каргаполовская игрушка.

Комиксы — забава или искусство?
Кто такой Кощей Бессмертный?
Кулинарный сюрприз маме
Мое недельное меню домашнего завтрака.
Мое путешествие к родной бабушке.
Мои пушистые питомцы
Мой любимый цветок — роза.
Мой любимый детский журнал — » «.
Моя любимая детская книга — » «.
Мои любимые детские комиксы -» «.
Молоко — это здоровье!
Молоко и молочные продукты.
Молочная история
Морские птицы — охотники моря.
На грибной охоте не промахнись!
Народные художественные промыслы. Гжель.
Не рвите цветы! Это природные лекарства.
Необычные возможности бумаги
Необычные птицы планеты.
Омофоны на Руси
Простейшие приспособления для счёта.
Темы проектов для учащихся 2 класса
Интересные темы исследовательских и творческих проектов для 2 класса:
Путешествие в страну Светофорию
Роль ударения в русском языке.
С пчелой за нектаром
Соберем съедобные грибочки в лукошко.

Старинный народный костюм из бабушкиного сундучка.
У меня дома лесная аптечка
Удивительные животные нашего зоопарка.
Украшения своими руками
Филимоновская игрушка.
Хитрости маскировки у насекомых.
Цветы-инопланетяне
Что удивительного в поваренной соли.
Что я могу сделать из мусора.
Школьные правила этикета
Школьный портфель будущего.
Кем работают мои родные.
Профессии моего рода.
Кем я хочу быть?
Опасные профессии.
Добрые профессии.
Сладкие профессии.
Строгие профессии.
Музыкальные профессии.
Рекомендуем перейти к:
Темам проектов в начальной школе
Готовым проектам в начальной школе
Если Вы хотите разместить ссылку на страницу с Темами проектов в начальной школе 2 класс
, установите у себя на сайте, блоге или форуме один из кодов:Код ссылки на страницу Темы проектов для начальной школы 2 класс:
<a href=»http://tvorcheskie-proekty.ru/node/518″ target=»_blank»>Темы проектов в начальной школе 2 класс</a>
Код ссылки на ваш форум:
[URL=http://tvorcheskie-proekty. ru/node/518]Темы детских проектов для начальной школы 2 класс[/URL]
ru/node/518]Темы детских проектов для начальной школы 2 класс[/URL]
Если страница Вам понравилась, поделитесь в социальных сетях:
Множественное наследование Python (с примерами)
В этом руководстве мы узнаем о множественном наследовании в Python с помощью примеров.
Класс может быть получен более чем из одного суперкласса в Python. Это называется множественным наследованием.
Например, класс A Летучая мышь является производным от надклассов Млекопитающее и Крылатое животное . Это имеет смысл, потому что летучая мышь — это не только крылатое животное, но и млекопитающее.
Синтаксис множественного наследования Python
class SuperClass1:
# особенности SuperClass1
класс суперкласс2:
# особенности SuperClass2
класс MultiDerived (SuperClass1, SuperClass2):
# Особенности класса SuperClass1 + SuperClass2 + MultiDerived class Здесь класс MultiDerived является производным от классов SuperClass1
SuperClass2 .
Пример: множественное наследование Python
класс млекопитающих:
def млекопитающее_информация (я):
print("Млекопитающие могут рожать напрямую.")
класс крылатое животное:
Def winged_animal_info (я):
print("Крылатые животные умеют махать крыльями.")
класс летучая мышь (млекопитающее, крылатое животное):
проходить
# создаем объект класса Bat
b1 = летучая мышь ()
b1.mammal_info()
b1.winged_animal_info() Выход
Млекопитающие могут рожать напрямую. Крылатые животные могут махать крыльями.
В приведенном выше примере класс Летучая мышь является производным от двух надклассов: Млекопитающее и Крылатое животное . Обратите внимание на операторы,
b1 = Bat() b1.mammal_info() b1.winged_animal_info()
Здесь мы используем b1 (объект Летучая мышь ) для доступа к млекопитающее_информация() и winged_animal_info() классов Mammal и WingedAnimal соответственно.
Многоуровневое наследование Python
В Python мы можем не только получить класс от суперкласса, но вы также можете получить класс от производного класса. Эта форма наследования известна как многоуровневое наследование .
Вот синтаксис многоуровневого наследования,
класс SuperClass:
# Здесь код суперкласса
класс DerivedClass1 (суперкласс):
# Здесь производный код класса 1
класс DerivedClass2 (DerivedClass1):
# Производный код класса 2 здесь Здесь класс DerivedClass1 является производным от класса SuperClass , а класс DerivedClass2 является производным от класса DerivedClass1 .
Многоуровневое наследование в PythonПример: Многоуровневое наследование Python
class SuperClass:
определение super_method(я):
print("Вызван метод суперкласса")
# определить класс, производный от SuperClass
класс DerivedClass1 (суперкласс):
деф производный1_метод (я):
print("Вызван метод производного класса 1")
# определить класс, производный от DerivedClass1
класс DerivedClass2 (DerivedClass1):
деф производный2_метод (я):
print("Вызван метод производного класса 2")
# создать объект DerivedClass2
d2 = производный класс2()
d2. super_method() # Вывод: "Вызван метод суперкласса"
d2.derived1_method() # Вывод: "Вызван метод производного класса 1"
d2.derived2_method() # Вывод: "Вызван метод производного класса 2"
super_method() # Вывод: "Вызван метод суперкласса"
d2.derived1_method() # Вывод: "Вызван метод производного класса 1"
d2.derived2_method() # Вывод: "Вызван метод производного класса 2"  super_method() # Вывод: "Вызван метод суперкласса"
d2.derived1_method() # Вывод: "Вызван метод производного класса 1"
d2.derived2_method() # Вывод: "Вызван метод производного класса 2"
super_method() # Вывод: "Вызван метод суперкласса"
d2.derived1_method() # Вывод: "Вызван метод производного класса 1"
d2.derived2_method() # Вывод: "Вызван метод производного класса 2" Выход
Вызван метод суперкласса Производный метод класса 1 называется Производный метод класса 2 с именем
В приведенном выше примере DerivedClass2 является производным от DerivedClass1 , который является производным от SuperClass .
Это означает, что DerivedClass2 наследует все атрибуты и методы обоих DerivedClass1 и SuperClass .
Следовательно, мы используем d2 (объект DerivedClass2 ) для вызова методов из SuperClass , DerivedClass1 и DerivedClass2 .
Порядок разрешения методов (MRO) в Python
Если два суперкласса имеют одинаковое имя метода и производный класс вызывает этот метод, Python использует MRO для поиска нужного метода для вызова. Например,
Например,
класс SuperClass1:
информация о защите (я):
print("Вызван метод суперкласса 1")
класс суперкласс2:
информация о защите (я):
print("Вызван метод суперкласса 2")
Производный класс (SuperClass1, SuperClass2):
проходить
d1 = Производный ()
d1.info()
# Вывод: "Вызван метод суперкласса 1" Здесь SuperClass1 и SuperClass2 оба этих класса определяют метод info() .
Итак, когда info() вызывается с использованием объекта d1 класса Derived , Python использует MRO , чтобы определить, какой метод вызывать.
В этом случае MRO указывает, что методы должны сначала наследоваться от самого левого надкласса, поэтому info() из SuperClass1 вызывается, а не из СуперКласс2 .
Машинное обучение — многоклассовая классификация с несбалансированным набором данных | by Javaid Nabi
Проблемы классификации и методы повышения производительности
источник [Unsplash] Проблемы классификации, имеющие несколько классов с несбалансированным набором данных, представляют собой другую проблему, чем проблема бинарной классификации. Асимметричное распределение делает многие традиционные алгоритмы машинного обучения менее эффективными, особенно при прогнозировании примеров класса меньшинства. Для этого давайте сначала поймем проблему, а затем обсудим способы ее преодоления.
Асимметричное распределение делает многие традиционные алгоритмы машинного обучения менее эффективными, особенно при прогнозировании примеров класса меньшинства. Для этого давайте сначала поймем проблему, а затем обсудим способы ее преодоления.
- Многоклассовая классификация: Задача классификации с более чем двумя классами; например, классифицировать набор изображений фруктов, которые могут быть апельсинами, яблоками или грушами. Мультиклассовая классификация предполагает, что каждому образцу присваивается одна и только одна этикетка: фрукт может быть либо яблоком, либо грушей, но не тем и другим одновременно.
- Несбалансированный набор данных: Несбалансированные данные обычно относятся к проблемам с классификацией, когда классы не представлены одинаково. Например, у вас может быть задача классификации 3-х классов набора фруктов, которые нужно классифицировать как апельсины, яблоки или груши, всего 100 экземпляров. В общей сложности 80 экземпляров имеют класс 1 (апельсины), 10 экземпляров — класс 2 (яблоки), а остальные 10 экземпляров — класс 3 (груши). Это несбалансированный набор данных и соотношение 8:1:1. Большинство наборов классификационных данных не имеют точно одинакового количества экземпляров в каждом классе, но небольшая разница часто не имеет значения. Есть проблемы, когда дисбаланс классов не просто распространен, он ожидаем. Например, наборы данных, подобные тем, которые характеризуют мошеннические транзакции, несбалансированы. Подавляющее большинство транзакций будет относиться к классу «Без мошенничества», и очень небольшое меньшинство будет к классу «Мошенничество».
 Это несбалансированный набор данных и соотношение 8:1:1. Большинство наборов классификационных данных не имеют точно одинакового количества экземпляров в каждом классе, но небольшая разница часто не имеет значения. Есть проблемы, когда дисбаланс классов не просто распространен, он ожидаем. Например, наборы данных, подобные тем, которые характеризуют мошеннические транзакции, несбалансированы. Подавляющее большинство транзакций будет относиться к классу «Без мошенничества», и очень небольшое меньшинство будет к классу «Мошенничество».
Это несбалансированный набор данных и соотношение 8:1:1. Большинство наборов классификационных данных не имеют точно одинакового количества экземпляров в каждом классе, но небольшая разница часто не имеет значения. Есть проблемы, когда дисбаланс классов не просто распространен, он ожидаем. Например, наборы данных, подобные тем, которые характеризуют мошеннические транзакции, несбалансированы. Подавляющее большинство транзакций будет относиться к классу «Без мошенничества», и очень небольшое меньшинство будет к классу «Мошенничество». Набор данных, который мы будем использовать в этом примере, — это знаменитый набор данных «20 групп новостей». Набор данных 20 групп новостей представляет собой набор примерно из 20 000 документов групп новостей, разделенных (почти) равномерно по 20 различным группам новостей. Коллекция из 20 групп новостей стала популярным набором данных для экспериментов с текстовыми приложениями методов машинного обучения, таких как классификация текста и кластеризация текста.
scikit-learn предоставляет инструменты для предварительной обработки набора данных. Дополнительные сведения см. здесь. Количество статей для каждой группы новостей, приведенное ниже, примерно одинаково.
Удаление некоторых новостных статей из некоторых групп, чтобы сделать общий набор данных несбалансированным, как показано ниже.
Теперь наш несбалансированный набор данных с 20 классами готов для дальнейшего анализа.
Поскольку это проблема классификации, мы будем использовать аналогичный подход, описанный в моей предыдущей статье для анализа настроений. Единственная разница в том, что здесь мы имеем дело с проблемой мультиклассовой классификации.
Последний слой в модели Плотный (количество меток, активация = ‘softmax’) , с классами num_labels=20 вместо «сигмоид» используется «softmax». Другое изменение в модели связано с изменением функции потерь на loss = ‘categorical_crossentropy’, , которая подходит для задач с несколькими классами.
Обучение модели с 20% набором проверки validation_split=20 и использованием verbose=2, мы видим точность проверки после каждой эпохи. Сразу после 10 эпох мы достигаем точности проверки 90%.
Похоже, очень хорошая точность, но действительно ли модель хороша?
Как измерить производительность модели? Предположим, что мы обучаем нашу модель на несбалансированных данных из более раннего примера фруктов, и, поскольку данные сильно смещены в сторону класса 1 (апельсины), модель соответствует этикетке класса 1 и предсказывает ее в большинстве случаев. и мы достигаем точности 80%, что на первый взгляд кажется очень хорошим, но при ближайшем рассмотрении может никогда не быть в состоянии правильно классифицировать яблоки или груши. Теперь возникает вопрос, если точность в данном случае не является подходящей метрикой для выбора, то какие метрики использовать для измерения производительности модели?
С несбалансированными классами легко получить высокую точность, фактически не делая полезных прогнозов. Таким образом, точность как оценочная метрика имеет смысл только в том случае, если метки классов распределены равномерно. В случае несбалансированных классов матрица путаницы является хорошим методом для подведения итогов производительности алгоритма классификации.
Таким образом, точность как оценочная метрика имеет смысл только в том случае, если метки классов распределены равномерно. В случае несбалансированных классов матрица путаницы является хорошим методом для подведения итогов производительности алгоритма классификации.
ось x=прогнозируемая метка, ось y, истинная меткаМатрица путаницы — это измерение производительности алгоритма классификации, в котором выходные данные могут быть двух или более классов.
Когда мы внимательно смотрим на матрицу путаницы, мы видим, что классы [ alt.athiesm, talk.politics.misc, soc.religion.christian ], которые имеют очень меньше выборок [65, 53, 86] соответственно действительно имеют очень меньше баллов [0,42, 0,56, 0,65] по сравнению с классами с большим количеством выборок, таких как [ rec.sport.hockey, rec.motorcycles ]. Таким образом, глядя на матрицу путаницы, можно ясно увидеть, как модель работает при классификации различных классов.
Существуют различные методы повышения производительности несбалансированных наборов данных.
Повторная выборка набора данных
Чтобы сделать наш набор данных сбалансированным, есть два способа сделать это:
- Недостаточная выборка: Удалить выборки из чрезмерно представленных классов ; используйте это, если у вас есть огромный набор данных
- Избыточная выборка: Добавьте больше выборок из недостаточно представленных классов; используйте это, если у вас небольшой набор данных
SMOTE (метод передискретизации синтетического меньшинства)
SMOTE — это метод избыточной выборки. Он создает синтетические образцы класса меньшинства. Мы используем пакет Python imblearn для избыточной выборки классов меньшинств.
у нас есть 4197 образцов до и 4646 образцов после применения SMOTE, похоже, что SMOTE увеличил выборки классов меньшинств. Мы проверим производительность модели с новым набором данных.
Повышена точность проверки с 90 до 94%. Проверим модель:
Небольшое улучшение точности теста по сравнению с предыдущим (с 87 до 88%). Давайте теперь посмотрим на матрицу путаницы.
Мы видим, что классы [ alt.athiesm , talk.politics.misc , sci.electronics , soc.religion.christian ] улучшили показатели [0,76, 0,58, 0,72], чем раньше 0,75, . Таким образом, модель работает лучше, чем раньше, при классификации классов, хотя точность аналогична.
Еще одна хитрость: Поскольку классы несбалансированы, как насчет того, чтобы дать некоторую предвзятость классам меньшинств? Мы можем оценить веса классов в scikit_learn, используя calculate_class_weight и используйте параметр ‘class_weight’ при обучении модели. Это может помочь обеспечить некоторую предвзятость в отношении классов меньшинств при обучении модели и, таким образом, помочь улучшить производительность модели при классификации различных классов.
Precision-Recall — полезная мера успеха предсказания, когда классы сильно несбалансированы. Точность является мерой способности модели классификации идентифицировать только соответствующие точки данных, в то время как вспомнить i s мера способности модели найти все соответствующие наблюдения в наборе данных .
Кривая точности-отзыва показывает компромисс между точностью и полнотой для различных пороговых значений. Большая площадь под кривой представляет как высокую полноту, так и высокую точность, где высокая точность связана с низким уровнем ложноположительных результатов, а высокая полнота связана с низким уровнем ложноотрицательных результатов.
Высокие баллы для обоих точность и отзыв показывают, что классификатор возвращает точные результаты (точность), а также возвращает большинство всех положительных результатов (отзыв).
 Идеальная система с высокой точностью и высоким отзывом будет возвращать множество результатов, причем все результаты будут помечены правильно.
Идеальная система с высокой точностью и высоким отзывом будет возвращать множество результатов, причем все результаты будут помечены правильно. Ниже приведен график точного отзыва для набора данных 20 групп новостей с использованием scikit-learn.
Кривая Precision-RecallМы хотели бы, чтобы площадь кривой P-R для каждого класса была близка к 1. За исключением классов 0, 3 и 18, остальные классы имеют площадь выше 0,75. Вы можете попробовать разные модели классификации и методы настройки гиперпараметров, чтобы еще больше улучшить результат.
Мы обсудили проблемы, связанные с классификацией мультиклассов в несбалансированном наборе данных. Мы также продемонстрировали, как использование правильных инструментов и методов помогает нам разрабатывать лучшие модели классификации.
Спасибо за внимание. Код можно найти на Github.
8 тактик по борьбе с несбалансированными классами в вашем наборе данных машинного обучения
Это случилось с вами? Вы работаете со своим набором данных.
 Вы создаете классификационную модель и получаете 9Точность 0%…
Вы создаете классификационную модель и получаете 9Точность 0%…machinelearningmastery.com
Как справиться с проблемами несбалансированной классификации в машинном обучении?
Введение Если вы занимались машинным обучением и наукой о данных, вы наверняка сталкивались с…
www.analyticsvidhya.com
Три метода повышения производительности модели машинного обучения с использованием несбалансированных наборов данных
Этот проект был частью моего недавнего теста навыков собеседования на должность «Инженер по машинному обучению». Пришлось…
в направлении datascience.com
Понимание матрицы путаницы
Когда мы получаем данные, после их очистки, предварительной обработки и обработки, первым шагом, который мы делаем, является передача их в…
в направлении datascience.com
3 9001 Простая классификация текста с использованием библиотеки Python для глубокого обучения Keras — opencodezГлубокое обучение повсюду.
