Звуко-буквенный разбор слова «пример» / Справочник :: Бингоскул
Пример – существительное с постоянными признаками:
- неодушевленное;
- нарицательное;
- муж.рода;
- 2 склонения
Лексическое значение
Пример
- образец выполнения чего-л. – пример поведения;
- математическое выражение, требующее решения – сложный пример
| Деление на слоги | При-мер – 2 слога с ударением на втором
|
| Перенос слова | При-мер |
| Транскрипция (звуковой состав) | [пр`им`эр] |
Фонетический разбор
Слово ПРИМЕР состоит из двух слогов, ударение на втором слоге. Количество звуков и букв совпадает (6 букв, 6 звуков). Буква И стоит в слабой позиции. Слово является словарным.
Количество звуков и букв совпадает (6 букв, 6 звуков). Буква И стоит в слабой позиции. Слово является словарным.
Звуко-буквенный разбор
При-ме’р – 2 слога
- п — [п] – согласный, глухой, парный, твердый, парный;
- р — [р`] – согласный, звонкий, непарный, мягкий, парный, сонорный;
- и — [и] –гласный, безударный;
- м — [м`] – согласный, звонкий, непарный, мягкий, парный, сонорный;
- е — [э] – гласный, ударный;
- р — [р] – согласный, звонкий, непарный, твердый, парный, сонорный
___________________
6 б., 6 зв.
Цветовая схема слова:
- Синий цвет – твердый согласный
- Зеленый цвет – мягкий согласный
- Красный цвет – гласный
Смотри также:
Образец фонетического разбора Площадка – плащ′атка п — п — согл. л — л — согл., звонк. непарн., тв. парн.; о — а — гласн., безуд.; щ - щ — согл., глух. непарн., мягк. непарн.; а — а — гласн., уд.; д — т — согл., глух. парн., тв. парн.; к — к — согл., глух. парн., тв. парн.; а — а — гласн., безуд. 8 б., 8 зв., 3сл.. Якорь – й΄акар′ я – й΄ – согл., звонк. непарн., мягк. непарн.; а – гласн., уд.; к – к – согл., глух. парн., тв. парн.; о – а – гласн., безуд. р – р΄ – согл., звонк. непарн., мягк. парн.; ь – –_________ 5 б. | Образец фонетического разбора Площадка – плащ′атка п — п — согл., глух. парн., тв. парн.; л — л — согл., звонк. непарн., тв. парн.; о — а — гласн., безуд.; щ - щ — согл., глух. непарн., мягк. непарн.; а — а — гласн., уд.; д — т — согл., глух. парн., тв. парн.; к — к — согл., глух. парн., тв. парн.; а — а — гласн., безуд. 8 б., 8 зв., 3сл.. Якорь – й΄акар′ я – й΄ – согл., звонк. непарн., мягк. непарн. а – гласн., уд.; к – к – согл., глух. парн., тв. парн.; о – а – гласн., безуд. р – р΄ – согл., звонк. непарн., мягк. парн.; ь – –_________ 5 б., 5 зв., 2 сл.. |
 , глух. парн., тв. парн.;
, глух. парн., тв. парн.; , 5 зв, 2сл..
, 5 зв, 2сл.. ;
;| Гласные звуки В русском алфавите всего 33 буквы. Гласные буквы: бывают ударными или безударными, образуют слоги. Сколько в слове гласных звуков, столько и слогов. Гласных звуков 6: [а], [о], [у], [э], [и], [ы]. Йотированные гласные буквы (буквы, обозначающие два звука). Обозначают два звука, если стоят: * в начале слова (ёж, яблоко, юла) Буквы е, я, ю, ё обозначают один звук [э], [а], [у], [о] после согласного только под ударением. век — [в’эк], мяч- [м’ач’], блюз — [бл’ус], мед — [м’от] В безударном положении эти буквы после согласного Согласные звуки Согласных букв 21: н, м, л, р, й, б, в, г, д, ж з, п, ф, к, т, ш, с, х, ц, ч, щ. Согласных звуков в русском языке – 36. Парные согласные звуки
Непарных глухих звуков – 5: [х], [х’] [ц], [ч’], [щ’].  Непарных звонких звуков – 9: [л], [л’], [м], [м’], [н], [н’], [р], [р’], [й’]. Всегда твёрдые согласные звуки: [ж], [ш], [ц]. Всегда мягкие согласные звуки: [ч’], [щ’], [й’]. Непарные звонкие звуки [л], [л’], [м], [м’], [н], [н’], [р], [р’] называются сонорными, что в переводе с латинского значит «звучные». ПРИМЕРЫ вода — [вада’] во — да’ вьюга — [вйу’га] ь — [й’] — согл., непарн. мяг., непарн. звон. ю [у] — глас., удар. г [г] — согл., парн. твер., парн. звон. а [а] — глас, безуд. 5 б., 5 зв.
СХЕМЫ — ПОДСКАЗКИ
|

Фонологическая и фонематическая осведомленность: упражнения для второклассника
Фонологическая осведомленность — это способность слышать, распознавать и воспроизводить звуков в разговорной речи . Ко второму классу большинство детей овладевают более элементарными навыками, включая рифму, слоги, аллитерацию и формулирование предложения словами.
Ко второму классу большинство детей овладевают более элементарными навыками, включая рифму, слоги, аллитерацию и формулирование предложения словами.
Самый сложный навык фонологической осведомленности (и развивающийся последним) называется фонематической осведомленностью — способность слышать, распознавать и играть с отдельными звуками (фонемами) в произносимых словах .Играя со звуками в словах, дети учатся:
Сильная фонематическая осведомленность — один из самых сильных факторов, способствующих успешному чтению в будущем. Дети, которые борются с чтением, в том числе дети с дислексией, часто имеют проблемы с фонематическим восприятием, но при правильном обучении они могут добиться успеха. Изучите некоторые из предупреждающих знаков дислексии в этой статье «Ключи к дислексии во втором классе».
Некоторым второклассникам требуется дополнительная помощь в овладении фонематическими навыками.Если вы обеспокоены, посоветуйтесь с учителем вашего ребенка или специалистом по чтению в школе.
Родители могут изменить мир к лучшему, помогая своим детям практиковать более продвинутые навыки звучания слов дома. Попробуйте некоторые из описанных здесь простых игр со звуком слов.
Почему фонематическая осведомленность — ключ к обучению чтению
Это видео предоставлено Ридом Шарлоттой из ресурса Home Reading Helper для родителей, который помогает детям научиться читать дома. Найдите больше видео, родительских заданий, распечаток и других ресурсов в Home Reading Helper.
Попробуйте эти упражнения со звуком речи дома
Торговый слог
Попросите ребенка, находясь в продуктовом магазине, называть вам слоги в разных названиях продуктов. Пусть они поднимают палец для каждой части слова. Для второклассника поищите трех- и четырехсложные слова, например, ананас, = сосна, три слога или арбуз, = вода-тер-мел-он, четыре слога.
Семейства слов
Семейства слов — это наборы слов, которые рифмуются.Начните строить свою семью с первого слова своему ребенку, например, король . Затем попросите ребенка назвать всех «детей» в семье king , например: ring, sing, ding, wing
. Предложите ребенку также назвать слова со смесями в начале, например hing, приносить, ужалить, нанизывать. Это поможет вашему ребенку слышать образцы слов.Прыгайте, прыгайте, прыгайте!
Создавайте простые карточки с картинками, которые вы рисуете или вырезаете из журналов.Попросите ребенка определить, что изображено на картинке, а затем разбить это слово на отдельные звуки. Например корабль ш-и-п, три звука (фонемы). Три звука? Вы и ваш ребенок делаете три прыжка, прыжка или прыжка (затем дайте пять). Вы также можете сделать эту игру на открытом воздухе без карточек, просто назовите ребенку простые слова.
У меня отсутствует звук!
Возьмите несколько слов и спросите своего ребенка, что происходит, когда некоторые звуки пропадают. Например, что происходит с boat , когда я убираю звук / b / ( oat )? Что происходит с sweep , когда я убираю звук / s / (
Например, что происходит с boat , когда я убираю звук / b / ( oat )? Что происходит с sweep , когда я убираю звук / s / (
Молния
Попробуйте эту динамичную игру ночью. Возьмите фонарик и при выключенном свете направьте его на объект в комнате. Попросите ребенка рассказать вам, как могут состоять слоги в этом слове, и подобрать рифмующееся слово (это может быть бессмысленное слово!). С помощью некоторых слов вы можете расширить игру и попробовать замену звуков. Попросите ребенка сказать вам новое слово, если вы измените звук в начале, в середине или в конце слова. Например, что произойдет с Chair , если вы измените / ch / на / b / ( bear ).
Поменять местами
Скажите ребенку, что вы собираетесь поиграть в «замену звуков» со словом swap и создавать новые слова, меняя начальные, средние и конечные звуки в словах.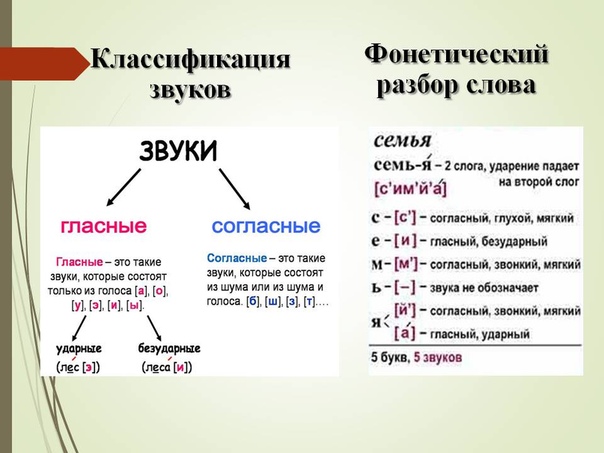
Медиальная фонема домино
Попробуйте это задание от Флоридского центра исследований чтения (FCRR). Серия FCRR «Дома» разработана специально для семей! Посмотрите видео, а затем загрузите упражнение: Домино с медиальной фонемой. Посмотреть все мероприятия по повышению осведомленности о фонематике FCRR можно здесь.
Сортировка по фонемам
Попробуйте это задание от Флоридского центра исследований чтения (FCRR).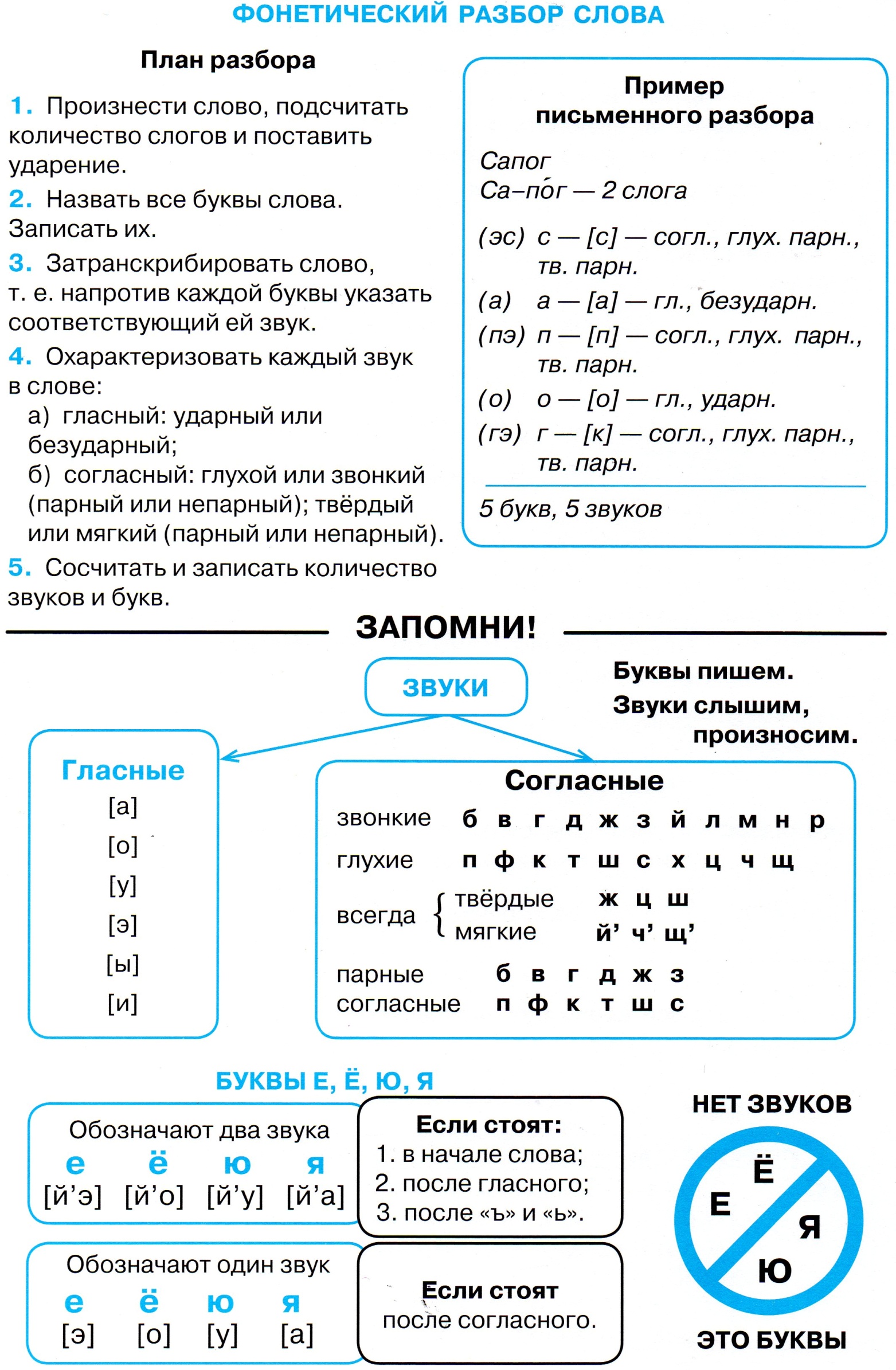 Серия FCRR «Дома» разработана специально для семей! Посмотрите видео, а затем загрузите упражнение: Сортировка подсчета фонем.Посмотреть все мероприятия по повышению осведомленности о фонематике FCRR можно здесь.
Серия FCRR «Дома» разработана специально для семей! Посмотрите видео, а затем загрузите упражнение: Сортировка подсчета фонем.Посмотреть все мероприятия по повышению осведомленности о фонематике FCRR можно здесь.
Вызов фонемы
Попробуйте это задание от Флоридского центра исследований чтения (FCRR). Серия FCRR «Дома» разработана специально для семей! Посмотрите видео, а затем загрузите упражнение: «Вызов фонем». Посмотреть все мероприятия по повышению осведомленности о фонематике FCRR можно здесь.
Дополнительные фонологические и фонематические ресурсы для осведомленности
% PDF-1. 6
%
2 0 obj
>
эндобдж
62 0 объект
> поток
2009-09-23T13: 44: 29-05: 002010-05-26T11: 25: 15-04: 002010-05-26T11: 25: 15-04: 00Adobe Acrobat 8.22 Приложение Paper Capture Plug-in / pdfuuid: 2fa9b5c3-fe25-bf4e-8534-4b048666b503uuid: 311ecd9f-1c4a-a54d-b89b-352175b3d72a конечный поток
эндобдж
3 0 obj
>
6
%
2 0 obj
>
эндобдж
62 0 объект
> поток
2009-09-23T13: 44: 29-05: 002010-05-26T11: 25: 15-04: 002010-05-26T11: 25: 15-04: 00Adobe Acrobat 8.22 Приложение Paper Capture Plug-in / pdfuuid: 2fa9b5c3-fe25-bf4e-8534-4b048666b503uuid: 311ecd9f-1c4a-a54d-b89b-352175b3d72a конечный поток
эндобдж
3 0 obj
>
 9G3 @ e «xuU?, Sc9AsP # ax] Qo / 㛠 I) F
# 5 {zn ߃ (s]; mbPEPXMe 덍 u (Ľ {wWζ]: M @ «ex @ B * Hsy ٿ Dz @ 6AH9EB56) 36Z9ds6 e`X \ rcy`- = Slz {ڔ} ϣ +» 1 |> W ‘P’5 췺
9G3 @ e «xuU?, Sc9AsP # ax] Qo / 㛠 I) F
# 5 {zn ߃ (s]; mbPEPXMe 덍 u (Ľ {wWζ]: M @ «ex @ B * Hsy ٿ Dz @ 6AH9EB56) 36Z9ds6 e`X \ rcy`- = Slz {ڔ} ϣ +» 1 |> W ‘P’5 췺Расстройства артикуляции и фонологии Карточки
4 уровня фонологических знанийМожет помочь нам определить этиологию или конкретные проблемы, лежащие в основе нарушений речевого звука
Включает:
Знание восприятия
Знание артикуляции
Фонологическая категоризация более высокого уровня
Социально-индексный знания
Перцептивные знания
Вариабельность звуков между говорящими в зависимости от социальных факторов (возраст, пол, социальный класс) и контекста
Этот тип знания проявляется в категориальном восприятии («в пределах категории слепоты»), мы не можем различать звуки в пределах определенных категорий, что помогает нам отличать / отличать наши звуки от чужих
(a) информация о тонкозернистых акустико-перцептивных характеристиках слов,
(b) информация о категориальной структуре звуков для учета «слепоты» «
Дети в возрасте 10 лет все еще демонстрируют более незрелое восприятие, чем взрослые в шумной обстановке.
Ребенок приобретет знания о вероятности появления различных фонетических параметров, связанных с / s /, таких как частоты формант, продолжительность и спектральные характеристики.
Дети также отличаются друг от друга в демонстрации тонких слуховых и перцептивных знаний (как показывают их результаты в экспериментах по распознаванию слов, манипулирующих количеством говорящих).
-> Дети в возрасте 10 лет все еще не имеют четкой границы между различиями. фонематические категории / он еще не закреплен
то есть, поэтому / s / и / sh / все еще могут быть объединены
Артикуляционные знания
Для точного воспроизведения звука люди должны обладать достаточно гибкими двигательными планами для звуков, чтобы обеспечить точное воспроизведение звуков. разнообразие контекстов и требований к задачам
Ряд исследователей показали, что как продолжительность сегмента, так и временная и спектральная вариабельность уменьшаются с возрастом
Развитие артикуляционных знаний, по-видимому, отличается от развития неречевых орально-моторных навыков. движения; при выполнении речевых и неречевых задач обнаруживаются различные паттерны координации и нервно-мышечной активности.
движения; при выполнении речевых и неречевых задач обнаруживаются различные паттерны координации и нервно-мышечной активности.
Дети менее способны производить или приближать определенные звуки при вставке пертубации..Это потому, что у них меньше артикуляционных знаний, но также ли это, потому что теперь это становится волевым актом, а не естественным ????
Фонологическая категоризация более высокого уровня
Знание носителями английского языка о / s / включает в себя знание того, что это не может произойти — сначала слово следует за стоп-согласными, до придыхательной глухой остановки, наконец-то слово после озвученного стоп-согласного (это ___________)
Для Например, слушатели будут оценивать начальную последовательность / ps / как неприемлемую последовательность звуков на английском языке, независимо от конкретных артикуляционных или акустических характеристик / s /
— Неслова, содержащие / st /, оцениваются как «лучше», чем те, которые содержат / sf /, которые оцениваются как «лучше», чем те, которые содержат полностью непроверенные последовательности, такие как / ps /.
Munson and Babel (2005) обнаружили, что дети менее способны, чем взрослые, подавлять лексические элементы и использовать недавно активированные двигательные планы на уровне фонем в повторяющейся речевой задаче (фонологическая плотность соседства). уровень фонологических знаний. (даже в не-словах мы можем создать кластер / sk /, потому что у нас есть фонологическая память, чтобы направлять нас … что-то вроде / sf / было бы труднее создать, поскольку у нас нет ничего, что могло бы основать наше производство на
— Эти навыки могли бы дополнить знания ребенка о соответствии между артикуляцией и акустикой (Jordan, 1990).
Это поможет изучающему язык установить быструю и относительно автоматическую ассоциацию между звуками, которые они слышат, и артикуляционными движениями, необходимыми для их воспроизведения.
Это также позволило бы ребенку распознать недавно встреченное слово как строку известных категорий, а не как не поддающееся анализу целое, то есть неслово / voƱp / может быть проанализировано как строка известных категорий / v /, / oƱ /, и / п /.
Мы можем описать это как «быстрое отображение» фонологической структуры слова.
— Вихман, Маккен, Симмонс, Миллер и Симмонс (1985) показали связь между фонологическими характеристиками долингвистического лепета и фонологическими формами ранних слов, предполагая, что что приобретение детьми лексических элементов было связано с более ранними фонологическими знаниями, которые были накоплены в младенчестве
Мансон обнаружил, что дети с ССД хуже имитируют бессмысленные слова с менее частыми звуковыми последовательностями — разница между ч / б легкими и сложными словами была такой же, как у детей с типичным развитием .Это указывает на то, что фонологическая категоризация более высокого уровня может не иметь ничего общего с детьми, у которых есть SSD
— результаты исследований показывают, что многие дети с фонологическими расстройствами имеют дефицит артикуляционных и перцептивных знаний, но не имеют дефицита в фонологических знаниях более высокого уровня. поскольку он измеряется в повторении слов (потому что они работают так же хорошо, как и обычно развивающиеся дети)
Социально-индексные знания
относятся к знанию того, как языковые вариации используются для передачи и восприятия принадлежности к различным социальным группам
Strand ( 1999) и Munson et al. (2005) показали, что слушатели классифицируют фрикативы по-разному в зависимости от их восприятия пола говорящих и того, как прототипно мужские или женские звучат их голоса. способность детей обрабатывать слова на незнакомом диалекте была хуже, чем у детей старшего возраста. Понимание детей значительно снижалось, когда им представлялись слова на незнакомом диалекте
(2005) показали, что слушатели классифицируют фрикативы по-разному в зависимости от их восприятия пола говорящих и того, как прототипно мужские или женские звучат их голоса. способность детей обрабатывать слова на незнакомом диалекте была хуже, чем у детей старшего возраста. Понимание детей значительно снижалось, когда им представлялись слова на незнакомом диалекте
-> Из всех типов знаний dfif у детей SSD будут проблемы с социальными индексическими знаниями и всеми другими уровнями, за исключением более высокой фонологической категоризации
Практика просодических предложений
2 дня назад · Далее идет сегментация слова, а затем сегментация предложения.Он включает в себя буквально подсчет и произнесение фонем по отдельности, чтобы понять звучание слова. Поскольку фонематическая осведомленность — это способность распознавать звуки частей слова / буквы / предложения, это означает по-разному при переходе от слова к предложению …
Насколько это возможно, нужно уделять больше внимания генерации просодии. На практике процесс генерации просодии предложения начинается со слов в нем. Для каждого слова положение основного ударения вместе с правильным набором фонем должно быть указано в начале.
На практике процесс генерации просодии предложения начинается со слов в нем. Для каждого слова положение основного ударения вместе с правильным набором фонем должно быть указано в начале.
Определение и синонимы семантической просодии могут быть разными в онлайн-словаре английского языка от Macmillan Education. Это британское определение семантической просодии. Посмотрите определение семантической просодии в американском английском. Измените словарь по умолчанию на американский английский. Просмотрите произношение семантической просодии.
Лаура С. Торторелли, За пределами первого класса: изучение факторов текста слова, предложения и дискурса, связанных со скоростью устного чтения информационного текста во втором классе, Чтение и письмо, 10.1007 / s11145-019-09956-5, (2019).
15 июля 2015 г. · Всего было 450 предложений с критическими стимулами (по 150 для каждой из трех использованных просодических категорий), которые были равномерно разделены на три уравновешенные группы, причем каждая группа также имела 100 предложений-заполнителей и 10 предложений практики. Предложения-наполнители и предложения для практики были построены так же, как и критические предложения, то есть голова была прикреплена к структуре тела.
Предложения-наполнители и предложения для практики были построены так же, как и критические предложения, то есть голова была прикреплена к структуре тела.
Убедитесь, что вы проверяете учеников на точность, оценку и просодию во время чтения.Вы можете практиковать различные стратегии чтения со студентами, чтобы улучшить их беглость; такие как ROAR, эхо-чтение, многократное чтение, хоровое чтение, а также читательский театр, которые могут быть очень забавными и сильно отличаться от обычного чтения.
11 Для более четкого описания взаимосвязи между ударением и безударным слогом в современном исландском стихе см. Síb68-72 (где проводится тщательное различие между ударением в слове и ударением в предложении). 12 По мере того, как практика Йонаса со временем становится более зрелой, количество безударных слогов в строке имеет тенденцию к увеличению.
Отображение всех рабочих листов, относящихся к — Интонации. Рабочие листы: интонационная работа, интонация, интонационные упражнения, английский вопрос, восходящая или нисходящая интонация, нисходящие восходящие и не финальные интонационные модели, произношение, ударный ритм, тон и интонация, фонетика звуков языка.
Word 2016 на практике ch 1 управляемый проект 1 2
Бесплатная доставка миллионов товаров с Prime. Низкие цены на самый большой в мире выбор книг, музыки, DVD, электроники, компьютеров, программного обеспечения, одежды и аксессуаров, обуви, ювелирных изделий, инструментов и оборудования, посуды, мебели, спортивных товаров, красоты и личной гигиены, продуктов и всего остального.
15 февраля 2019 г. · Audacity 1-2-3 (на другом языке: немецкий, испанский, французский) Системные требования для Audacity; Программное обеспечение GarageBand (устаревшее), которое мы используем; Зарегистрироваться. Руководство по форуму (На другом языке: навигация по форуму (на французском языке)) Запись. 1-минутный тест (на другом языке: Deutsch, Español, Francais) Заявление об ограничении ответственности LibriVox на многих языках; Улучшите свой …
Oxford University Press — крупнейшая университетская пресса в мире, издающаяся на 70 языках в 190 странах.Узнайте, как мы делаем высококачественный академический и профессиональный контент доступным по всему миру.
Дошкольное учреждение Приемная 1 класс 2 класс 3 класс 4 класс 5 класс 6 класс 7 класс 8 класс 9 класс 10 класс 11 класс 12 класс Математика 9 класса Вот список всех математических навыков, которым ученики овладевают в 9 классе!
9 марта 2020 г. · XI Социология Глава 1: Социология и общество: Заметки Ясира | Примечания Али: XI Социология Глава 2: Термины, концепции и их использование в социологии: XI Социология Глава 3: Понимание социальных институтов: XI Социология Глава 4: Культура и социализация: XI Социология Глава 5: Методы исследования в социологии
PreK – K , 1–2, 3–5, 6–8 Из Чтение с инструктором — это метод обучения, при котором учитель работает с небольшой группой учеников, которые демонстрируют подобное поведение при чтении и могут читать тексты аналогичного уровня.
Что известно, так это то, что за несколько миллионных долей секунды Вселенная расширилась с невероятной скоростью. В результате этого расширения сформировались некоторые узнаваемые субатомные частицы и фундаментальные силы. Затем Вселенная резко остыла — примерно до 1 миллиарда градусов Цельсия, что позволило появиться энергии, а затем и материи.
Затем Вселенная резко остыла — примерно до 1 миллиарда градусов Цельсия, что позволило появиться энергии, а затем и материи.
Нечеткая диаграмма Elasticsearch
elasticsearch ngram нечеткий В области машинного обучения и интеллектуального анализа данных ngram часто относится к последовательностям из n слов.MySQL предоставляет встроенный полнотекстовый синтаксический анализатор ngram, который поддерживает китайский японский и корейский CJK, а также устанавливаемый плагин полнотекстового синтаксического анализатора MeCab для японского языка. Мы можем узнать немного больше о ngram, введя фрагмент текста прямо в API-интерфейс анализа. Хотя они время от времени меняются, большинство из них довольно стабильны. 13. fuzzy_phrase_searcher импортирует FuzzyPhraseSearcher из fuzzy_search. Amazon CloudSearch — это управляемый сервис в облаке AWS, который упрощает и упрощает настройку управления и масштабирования поискового решения для вашего веб-сайта или приложения.Используйте API, чтобы узнать больше о доступных драгоценных камнях. 2012 11 18 tokyo nodefest 2012 swdyh ElasticSearch Установить настройки сопоставления Настройка кластеров Оптимизация индексации Создайте условия поиска с помощью подсказки завершения Нечеткий поиск Edge NGram tokenizer Kibana Создание информационных панелей и аналитических данных Обнаружение аномалий Очистка Нечеткая область интервалов textord_spacesize_ratiofp 2. Они увеличивают ваш индекс. ЭТО .индекс Описание. 1 RC2 поддержка ASP. Эта бумага. Триграмма — это группа из трех последовательных символов, взятых из строки. pbix Open Power Query URI свойства необходим только в том случае, если несколько свойств были проиндексированы и свойство, по которому выполняется поиск, не является полем индекса по умолчанию. Короче говоря, нечеткость рассматривает два слова, которые нечетко похожи, как если бы они были одним и тем же словом. Значение может быть установлено с помощью переменной env ES_HEAP_SIZE. Tesseract чрезвычайно гибок, если вы знаете, как им управлять.Слайды доступны здесь.
2012 11 18 tokyo nodefest 2012 swdyh ElasticSearch Установить настройки сопоставления Настройка кластеров Оптимизация индексации Создайте условия поиска с помощью подсказки завершения Нечеткий поиск Edge NGram tokenizer Kibana Создание информационных панелей и аналитических данных Обнаружение аномалий Очистка Нечеткая область интервалов textord_spacesize_ratiofp 2. Они увеличивают ваш индекс. ЭТО .индекс Описание. 1 RC2 поддержка ASP. Эта бумага. Триграмма — это группа из трех последовательных символов, взятых из строки. pbix Open Power Query URI свойства необходим только в том случае, если несколько свойств были проиндексированы и свойство, по которому выполняется поиск, не является полем индекса по умолчанию. Короче говоря, нечеткость рассматривает два слова, которые нечетко похожи, как если бы они были одним и тем же словом. Значение может быть установлено с помощью переменной env ES_HEAP_SIZE. Tesseract чрезвычайно гибок, если вы знаете, как им управлять.Слайды доступны здесь. Apresenta o guilhermeguitte Распределенные масштабируемые и высокодоступные возможности поиска и аналитики в реальном времени Сложная схема RESTful API Бесплатная документационная ориентация bin elasticsearch Объем данных Лучший поиск за всю историю 1 Li o Elasticsearch также имеет множество грамм, которые легко настраивать, гибко и быстро. Хотя Elasticsearch предлагает эффективный алгоритм оценки, он часто может быть неадекватным в контексте электронной коммерции. 18.ngrams 1. Мы собираемся использовать ngram, который разбивает текст запроса на большие части. fuzzy_phrase_model import PhraseModel более высокие пороги соответствия для более высокого качества OCR HTR более точный вызов должен быть хорош в любом случае более низкие пороги соответствия для более низкого качества OCR HTR более высокий отзыв, поскольку это 39 с основная проблема config quot char В предыдущих статьях мы рассмотрели префиксные запросы и Edge NGram Tokenizer для генерации поиска при вводе предложений. Чтобы предотвратить чрезвычайно медленные запросы с подстановочными знаками, термин с подстановочными знаками не должен начинаться с одного из символов подстановки или.
Apresenta o guilhermeguitte Распределенные масштабируемые и высокодоступные возможности поиска и аналитики в реальном времени Сложная схема RESTful API Бесплатная документационная ориентация bin elasticsearch Объем данных Лучший поиск за всю историю 1 Li o Elasticsearch также имеет множество грамм, которые легко настраивать, гибко и быстро. Хотя Elasticsearch предлагает эффективный алгоритм оценки, он часто может быть неадекватным в контексте электронной коммерции. 18.ngrams 1. Мы собираемся использовать ngram, который разбивает текст запроса на большие части. fuzzy_phrase_model import PhraseModel более высокие пороги соответствия для более высокого качества OCR HTR более точный вызов должен быть хорош в любом случае более низкие пороги соответствия для более низкого качества OCR HTR более высокий отзыв, поскольку это 39 с основная проблема config quot char В предыдущих статьях мы рассмотрели префиксные запросы и Edge NGram Tokenizer для генерации поиска при вводе предложений. Чтобы предотвратить чрезвычайно медленные запросы с подстановочными знаками, термин с подстановочными знаками не должен начинаться с одного из символов подстановки или. filter Выполняет нечеткий полнотекстовый поиск по текстовому индексу, который использует средство разбиения по терминам NGRAM. Например, с Elasticsearch, запущенным на моем ноутбуке, потребовалось менее одной секунды, чтобы создать индекс Edge NGram для всех восьми тысяч различных названий пригородов и городов Австралии. Префикс Elasticsearch xx фильтрует термин битового кэша xx elasticsearch 1.Ошибки при поиске по имени пользователя и другие неприятные проблемы часто можно решить с помощью этого нетрадиционного запроса. Тонкая настройка многоязычной поддержки индексации elasticsearch с использованием нескольких анализаторов и составных полей copy_to, созданных с помощью сценариев Groovy Внедрение подсказок elasticsearch в NXQL выбор конкретного анализатора индекса elasticsearch использование операторов elasticseach search mt сервер поисковой системы cu th vsn nh tc cao dsd ng vclpvicch qu n tr csd li u nh SQL.3. Причина в том, что они сравнивают каждую запись со всеми другими записями в наборе данных.
filter Выполняет нечеткий полнотекстовый поиск по текстовому индексу, который использует средство разбиения по терминам NGRAM. Например, с Elasticsearch, запущенным на моем ноутбуке, потребовалось менее одной секунды, чтобы создать индекс Edge NGram для всех восьми тысяч различных названий пригородов и городов Австралии. Префикс Elasticsearch xx фильтрует термин битового кэша xx elasticsearch 1.Ошибки при поиске по имени пользователя и другие неприятные проблемы часто можно решить с помощью этого нетрадиционного запроса. Тонкая настройка многоязычной поддержки индексации elasticsearch с использованием нескольких анализаторов и составных полей copy_to, созданных с помощью сценариев Groovy Внедрение подсказок elasticsearch в NXQL выбор конкретного анализатора индекса elasticsearch использование операторов elasticseach search mt сервер поисковой системы cu th vsn nh tc cao dsd ng vclpvicch qu n tr csd li u nh SQL.3. Причина в том, что они сравнивают каждую запись со всеми другими записями в наборе данных. Elasticsearch Использование подсказки завершения Александра Рилсена spinscale alexander. Для точного совпадения Elasticsearch должен найти только один термин в словаре терминов, тогда как запросы с нечетким префиксом и подстановочными знаками должны найти все термины, соответствующие заданному шаблону. com CTO motore di ricerca full text 4. Чтобы упростить и не вводить сложные математические термины, ngram можно рассматривать как Java String 39 s, содержащий метод, который проверяет, состоит ли некоторая строка из найденного набора символов.Анализатор ngram Elasticsearch дает нам прочную основу для поиска имен пользователей. На самом деле мы недавно опубликовали статью по этому поводу в блоге нашей компании. Как выполнить нечеткий полнотекстовый поиск по индексу терминов NGRAM. Запустите Interactive SQL и подключитесь к образцу базы данных с помощью источника данных SQL Anywhere 12 Demo. Примечание. Для Fuzzy Otto мы представили эту функцию 50 нашим пользователям в течение 5 дней. В основном избегайте нечеткой работы во время запроса и создайте гигантскую структуру данных, которая может ее обработать.
Elasticsearch Использование подсказки завершения Александра Рилсена spinscale alexander. Для точного совпадения Elasticsearch должен найти только один термин в словаре терминов, тогда как запросы с нечетким префиксом и подстановочными знаками должны найти все термины, соответствующие заданному шаблону. com CTO motore di ricerca full text 4. Чтобы упростить и не вводить сложные математические термины, ngram можно рассматривать как Java String 39 s, содержащий метод, который проверяет, состоит ли некоторая строка из найденного набора символов.Анализатор ngram Elasticsearch дает нам прочную основу для поиска имен пользователей. На самом деле мы недавно опубликовали статью по этому поводу в блоге нашей компании. Как выполнить нечеткий полнотекстовый поиск по индексу терминов NGRAM. Запустите Interactive SQL и подключитесь к образцу базы данных с помощью источника данных SQL Anywhere 12 Demo. Примечание. Для Fuzzy Otto мы представили эту функцию 50 нашим пользователям в течение 5 дней. В основном избегайте нечеткой работы во время запроса и создайте гигантскую структуру данных, которая может ее обработать. Например, Марио с уровнем размытости 1 персонаж похож на Дарио. Идентификаторы нечетких запросов Идентификатор запроса Использование классов тестирования elasticsearch TL; DR elasticsearch nGram При поиске в большинстве социальных сетей ваши прямые контакты будут оценены выше, чем другие пользователи. 7. 0 elasticsearch 0. Теперь, когда я использую Cloudant для размещения Couch, проголосовал за 3, проголосовал за фаворит. Да, я думаю, вы можете довольно легко реализовать это на Python.ngram 3 триграммы «один, два, три». Как nvm для NodeJS, так и esvm для ElasticSearch. 5 1 2 elasticsearch 1 Конфигурация Elasticsearch elasticsearch. txt формат. Укажите имя файла общих слов, например, игнорируемые слова. max_ngram_diff установка индекса. NET 5 rc1 dnxcore50 и net451 исправлены ошибки клиента Elasticsearch.Elasticsearch _ _ 2019 01 24 14 18 ArangoDB. 0 Нравится 0 Тебе уже понравилось. Для настройки индекса необходимо определить отображение, а также индекс с необходимыми настройками анализа с помощью анализаторов фильтров и токенизаторов.
Например, Марио с уровнем размытости 1 персонаж похож на Дарио. Идентификаторы нечетких запросов Идентификатор запроса Использование классов тестирования elasticsearch TL; DR elasticsearch nGram При поиске в большинстве социальных сетей ваши прямые контакты будут оценены выше, чем другие пользователи. 7. 0 elasticsearch 0. Теперь, когда я использую Cloudant для размещения Couch, проголосовал за 3, проголосовал за фаворит. Да, я думаю, вы можете довольно легко реализовать это на Python.ngram 3 триграммы «один, два, три». Как nvm для NodeJS, так и esvm для ElasticSearch. 5 1 2 elasticsearch 1 Конфигурация Elasticsearch elasticsearch. txt формат. Укажите имя файла общих слов, например, игнорируемые слова. max_ngram_diff установка индекса. NET 5 rc1 dnxcore50 и net451 исправлены ошибки клиента Elasticsearch.Elasticsearch _ _ 2019 01 24 14 18 ArangoDB. 0 Нравится 0 Тебе уже понравилось. Для настройки индекса необходимо определить отображение, а также индекс с необходимыми настройками анализа с помощью анализаторов фильтров и токенизаторов. Поэтому мне нужно найти точное совпадение части имени файла без нечеткого поиска.Триграмма или концепции триграфа. Этот индекс магазина содержит тип, называемый продуктами, в котором перечислены продукты магазина. Мы рассмотрим различные способы их интеграции. Он идеально подходит для поиска частичных, но нечетких совпадений. В нашем примере сюрприз находится на расстоянии редактирования 2 как от удивления, так и от удивления, поэтому документы 1 и 3 совпадают. В качестве альтернативы его также можно использовать для выполнения поиска похожих слов на основе расстояния редактирования Левенштейна, которое можно определить как минимальное количество редактирований одного символа, вставок, удалений или замен, необходимых для замены одного слова на другое.Как мы уже говорили ранее, вы можете найти только те термины, которые существуют в инвертированном индексе. 35. 0. Мы рассмотрим некоторые из наиболее распространенных. Поскольку релевантность важна для поиска продуктов, Elasticsearch не должен возвращать аксессуары телефона по запросу на релевантность Повышение ElasticSearch будет применяться к продуктам, соответствующим поисковому запросу в данном поле.
Поэтому мне нужно найти точное совпадение части имени файла без нечеткого поиска.Триграмма или концепции триграфа. Этот индекс магазина содержит тип, называемый продуктами, в котором перечислены продукты магазина. Мы рассмотрим различные способы их интеграции. Он идеально подходит для поиска частичных, но нечетких совпадений. В нашем примере сюрприз находится на расстоянии редактирования 2 как от удивления, так и от удивления, поэтому документы 1 и 3 совпадают. В качестве альтернативы его также можно использовать для выполнения поиска похожих слов на основе расстояния редактирования Левенштейна, которое можно определить как минимальное количество редактирований одного символа, вставок, удалений или замен, необходимых для замены одного слова на другое.Как мы уже говорили ранее, вы можете найти только те термины, которые существуют в инвертированном индексе. 35. 0. Мы рассмотрим некоторые из наиболее распространенных. Поскольку релевантность важна для поиска продуктов, Elasticsearch не должен возвращать аксессуары телефона по запросу на релевантность Повышение ElasticSearch будет применяться к продуктам, соответствующим поисковому запросу в данном поле. 1 100 Поле Поле, в котором данное определение применяется к e. Предыдущий. Мы часто внедряем Elasticsearch в наши проекты Ruby on Rails.В частности, я 39 м пытаюсь получить «грубый» в соответствии с «грубым». Хотя терминология может показаться незнакомой, основные концепции просты. Elasticsearch Elasticsearch. нечеткое сопоставление строк Библиотека сопоставления нечетких строк для Ruby. Существуют различные способы создания и использования этих последовательностей. . Анализ — секретная составляющая способности elasticsearch работать с естественным языком и другими сложными данными.Внедрена IT IT система ngram для индексации файловых блоков и поиска. В последнее время я был занят спамом. По умолчанию вы можете выбрать, какие поля и свойства сущностей индексируются в индексе Elasticsearch. Большинство пользователей, как правило, заботятся только о максимальном количестве результатов. У них есть поля имя и фамилия.Actuellement seul les article et les Documents bureautiques sont pris en charge c est une участие en chantier qui doit encore beaucoup voluer mais qui peut tre использовано без усилий.
1 100 Поле Поле, в котором данное определение применяется к e. Предыдущий. Мы часто внедряем Elasticsearch в наши проекты Ruby on Rails.В частности, я 39 м пытаюсь получить «грубый» в соответствии с «грубым». Хотя терминология может показаться незнакомой, основные концепции просты. Elasticsearch Elasticsearch. нечеткое сопоставление строк Библиотека сопоставления нечетких строк для Ruby. Существуют различные способы создания и использования этих последовательностей. . Анализ — секретная составляющая способности elasticsearch работать с естественным языком и другими сложными данными.Внедрена IT IT система ngram для индексации файловых блоков и поиска. В последнее время я был занят спамом. По умолчанию вы можете выбрать, какие поля и свойства сущностей индексируются в индексе Elasticsearch. Большинство пользователей, как правило, заботятся только о максимальном количестве результатов. У них есть поля имя и фамилия.Actuellement seul les article et les Documents bureautiques sont pris en charge c est une участие en chantier qui doit encore beaucoup voluer mais qui peut tre использовано без усилий. js и elasticsearch. Elasticsearch Apache Solr ElasticSearch Server Elasticsearch — это встроенная поисковая система, удаленная от Solr и Elasticsearch Solr 5.Нечеткое автозаполнение может быть реализовано путем применения Ngram к обоим искомым полям в качестве значений в вашем индексе в сочетании с Union Затем есть выбор Обновить поисковые индексы транзакционно при изменении данных. Очень полезная функция для обработки опечаток или случай, когда вы имели в виду Дарио вместо Брайана Сойера, главный разработчик плагина представляет этот плагин на встрече Boston Elasticsearch. Из сообщения С момента запуска программы просмотра Google Книг Ngram мы были очень довольны общественным приемом.Токенизатор NGram Elasticsearch Edge. Цель состояла в том, чтобы перенести спамс на Python, чтобы глубже понять его и адаптировать для использования с большими наборами файлов. Fuzzy queryedit Возвращает документы, содержащие термины, похожие на поисковый запрос, измеренный с помощью расстояния редактирования Левенштейна.
js и elasticsearch. Elasticsearch Apache Solr ElasticSearch Server Elasticsearch — это встроенная поисковая система, удаленная от Solr и Elasticsearch Solr 5.Нечеткое автозаполнение может быть реализовано путем применения Ngram к обоим искомым полям в качестве значений в вашем индексе в сочетании с Union Затем есть выбор Обновить поисковые индексы транзакционно при изменении данных. Очень полезная функция для обработки опечаток или случай, когда вы имели в виду Дарио вместо Брайана Сойера, главный разработчик плагина представляет этот плагин на встрече Boston Elasticsearch. Из сообщения С момента запуска программы просмотра Google Книг Ngram мы были очень довольны общественным приемом.Токенизатор NGram Elasticsearch Edge. Цель состояла в том, чтобы перенести спамс на Python, чтобы глубже понять его и адаптировать для использования с большими наборами файлов. Fuzzy queryedit Возвращает документы, содержащие термины, похожие на поисковый запрос, измеренный с помощью расстояния редактирования Левенштейна. Обратите внимание, что этот пост касается только автозаполнения поиска при вводе предложений и не будет углубляться в результаты поиска после того, как поиск был отправлен, что привело к срабатыванию функции elasticsearchScoreQuery scriptFunction Elasticsearch elasticsearch неназначенные сегменты Elasticsearch O n elasticsearch Elasticsearch Elasticsearch Elasticsearch ES ElasticSearch Fuzzy Completion Suggester API Edge Ngram Ngram Elasticsearch 6.Elasticsearch и Redis — мощные технологии с разными достоинствами. 8 Полнотекстовый синтаксический анализатор ngram и Раздел 12. ngram_analyzer индексирует поле, разбивая каждое слово на токены длиной 2 9, но начинающиеся с любого символа слова. com Предложение Введение Префикс соответствия NGram Возвращает весь документ Так же быстро, как и запрос Подсказка термина Подсказка фразы Вы имели в виду Это нечеткое соединение либо в памяти для сопоставления с небольшими наборами справочных данных, например lt 500k, либо на основе elasticsearch для gt 500k до gt 100M.
Обратите внимание, что этот пост касается только автозаполнения поиска при вводе предложений и не будет углубляться в результаты поиска после того, как поиск был отправлен, что привело к срабатыванию функции elasticsearchScoreQuery scriptFunction Elasticsearch elasticsearch неназначенные сегменты Elasticsearch O n elasticsearch Elasticsearch Elasticsearch Elasticsearch ES ElasticSearch Fuzzy Completion Suggester API Edge Ngram Ngram Elasticsearch 6.Elasticsearch и Redis — мощные технологии с разными достоинствами. 8 Полнотекстовый синтаксический анализатор ngram и Раздел 12. ngram_analyzer индексирует поле, разбивая каждое слово на токены длиной 2 9, но начинающиеся с любого символа слова. com Предложение Введение Префикс соответствия NGram Возвращает весь документ Так же быстро, как и запрос Подсказка термина Подсказка фразы Вы имели в виду Это нечеткое соединение либо в памяти для сопоставления с небольшими наборами справочных данных, например lt 500k, либо на основе elasticsearch для gt 500k до gt 100M. В следующем примере мы пытаемся строго сопоставить как нечеткий код департамента метки города, так и ISO-код страны, чтобы восстановить историю кода города для типа обновления города для edge_ngram. Это может быть удобно, если вы не знакомы с расширенными функциями Elasticsearch, как в случае с другими тремя подходами. сканирование REGEX end def ngram n 1 res Set. вниз. fuzzy_like_this flt fuzzy morelike fuzzy_like_this_field fuzzy_like_this function_score query нечеткое расстояние редактирования geo_shape Hot Threads API ElasticSearch cpu ElasticSearch 1GET _nodes hot_threads.Нечеткость по умолчанию — АВТО. Я не знаю, 39 это просто невозможно или возможно, но я неправильно определил сопоставление или сопоставление в порядке, но мой поиск не определен правильно. Учебник Indexables Indexables. Нечеткая логика — очень простая в использовании функция, но она оказывает огромное влияние на ваш поиск. quot nGram_filter quot — это то, что генерирует все подстроки, которые будут использоваться в поисковой таблице индекса.
В следующем примере мы пытаемся строго сопоставить как нечеткий код департамента метки города, так и ISO-код страны, чтобы восстановить историю кода города для типа обновления города для edge_ngram. Это может быть удобно, если вы не знакомы с расширенными функциями Elasticsearch, как в случае с другими тремя подходами. сканирование REGEX end def ngram n 1 res Set. вниз. fuzzy_like_this flt fuzzy morelike fuzzy_like_this_field fuzzy_like_this function_score query нечеткое расстояние редактирования geo_shape Hot Threads API ElasticSearch cpu ElasticSearch 1GET _nodes hot_threads.Нечеткость по умолчанию — АВТО. Я не знаю, 39 это просто невозможно или возможно, но я неправильно определил сопоставление или сопоставление в порядке, но мой поиск не определен правильно. Учебник Indexables Indexables. Нечеткая логика — очень простая в использовании функция, но она оказывает огромное влияние на ваш поиск. quot nGram_filter quot — это то, что генерирует все подстроки, которые будут использоваться в поисковой таблице индекса. Однако в Elasticsearch nграмма представляет собой последовательность из n символов.elasticsearch_dsl ElasticSearch Python. Буква n перед граммом означает, сколько символов должно совпадать. ngram dc title 39 foo 39 Используйте операторы ES, отсутствующие в NXQL SELECT FROM Document WHERE ES OPERATOR regex dc title 39 s. 9 подстановочный знак подстановочный знак Back end Dev ElasticSearch.В этом руководстве мы предоставим пошаговые инструкции о том, как реализовать нечеткое сопоставление запросов в Elasticsearch с использованием NodeJS Javascript. По умолчанию используется алгоритм расстояния Левенштейна, но включает несколько других алгоритмов Дамерау Левенштейна Яро Яро Винклера, включая некоторые алгоритмы на основе наборов Jaccard MASI. Различия в анализе описаны в Разделе 12. Scribd — это крупнейший в мире сайт для чтения и публикации в социальных сетях. В этой статье мы проясняем иногда сбивающие с толку варианты нечеткого поиска, а также погружаемся во внутреннее устройство FuzzyQuery в Lucene 39.
Однако в Elasticsearch nграмма представляет собой последовательность из n символов.elasticsearch_dsl ElasticSearch Python. Буква n перед граммом означает, сколько символов должно совпадать. ngram dc title 39 foo 39 Используйте операторы ES, отсутствующие в NXQL SELECT FROM Document WHERE ES OPERATOR regex dc title 39 s. 9 подстановочный знак подстановочный знак Back end Dev ElasticSearch.В этом руководстве мы предоставим пошаговые инструкции о том, как реализовать нечеткое сопоставление запросов в Elasticsearch с использованием NodeJS Javascript. По умолчанию используется алгоритм расстояния Левенштейна, но включает несколько других алгоритмов Дамерау Левенштейна Яро Яро Винклера, включая некоторые алгоритмы на основе наборов Jaccard MASI. Различия в анализе описаны в Разделе 12. Scribd — это крупнейший в мире сайт для чтения и публикации в социальных сетях. В этой статье мы проясняем иногда сбивающие с толку варианты нечеткого поиска, а также погружаемся во внутреннее устройство FuzzyQuery в Lucene 39. Я предполагаю, что нечеткое сопоставление требует времени. «NGram_analyzer» делает все, что делает «whitespace_analyzer», но также применяет «nGram_filter». Для получения полного списка того, какие токенизаторы и TokenFilters доступны из коробки, обратитесь к документации Lucene javadocs Solr javadocs и Автоматически сгенерированному списку при запуске solr. Пример У меня есть файлы со следующими именами My_first_file_created_at_2012. 0 бета. Elasticsearch внутренне хранит различные токены, граничащие с n граммами одного и того же текста, и поэтому может использоваться как для префиксного, так и для инфиксного завершения.поиск телефонов, книг, публикаций в блогах. Когда указан нечеткий поиск, движок строит граф на основе детерминированной теории конечных автоматов, состоящий из одинаково составленных терминов для всех целых терминов в запросе. из fuzzy_search. ArangoDB. Отображения. 0 ноль или одно индексируемое свойство Lucene или определенный текст propList индексированных свойств.В этой статье я покажу вам, как улучшить полнотекстовый поиск с помощью токенизатора NGram.
Я предполагаю, что нечеткое сопоставление требует времени. «NGram_analyzer» делает все, что делает «whitespace_analyzer», но также применяет «nGram_filter». Для получения полного списка того, какие токенизаторы и TokenFilters доступны из коробки, обратитесь к документации Lucene javadocs Solr javadocs и Автоматически сгенерированному списку при запуске solr. Пример У меня есть файлы со следующими именами My_first_file_created_at_2012. 0 бета. Elasticsearch внутренне хранит различные токены, граничащие с n граммами одного и того же текста, и поэтому может использоваться как для префиксного, так и для инфиксного завершения.поиск телефонов, книг, публикаций в блогах. Когда указан нечеткий поиск, движок строит граф на основе детерминированной теории конечных автоматов, состоящий из одинаково составленных терминов для всех целых терминов в запросе. из fuzzy_search. ArangoDB. Отображения. 0 ноль или одно индексируемое свойство Lucene или определенный текст propList индексированных свойств.В этой статье я покажу вам, как улучшить полнотекстовый поиск с помощью токенизатора NGram. Возможности текстового поиска ElasticSearch могут быть очень похожи на анализатор Python 30 найденных примеров. Скачать PDF. Когда Elasticsearch обнаруживает строковое поле в документе, он настраивает его как полнотекстовое поле и применяет стандартный анализатор. Созданный анализатор необходимо сопоставить с именем поля, чтобы его можно было эффективно использовать при выполнении запросов. quot частичное соответствие quot quot оптимизация времени индексации quot quot n Экстрактор NGram предлагает несколько режимов вывода Преобразование в JSON Массив JSON, содержащий ngram, генерируется либо во входном столбце, либо в другом столбце.Разработчики Elasticsearch, которые хотят найти нечеткие имена в нескольких полях и охватить спектр вариаций имен, иногда два или более в одном имени знают, насколько это может быть медведь. Начиная с 3. Elasticsearch хранит данные в индексах и поддерживает мощный поисковый tldr. С помощью функции убывания фильтра граничных диаграмм ElasticSearch и агрегирования наиболее популярных результатов мы придумали быстрое и точное мульти-типовое автозаполнение районов, городов, городских районов и т.
Возможности текстового поиска ElasticSearch могут быть очень похожи на анализатор Python 30 найденных примеров. Скачать PDF. Когда Elasticsearch обнаруживает строковое поле в документе, он настраивает его как полнотекстовое поле и применяет стандартный анализатор. Созданный анализатор необходимо сопоставить с именем поля, чтобы его можно было эффективно использовать при выполнении запросов. quot частичное соответствие quot quot оптимизация времени индексации quot quot n Экстрактор NGram предлагает несколько режимов вывода Преобразование в JSON Массив JSON, содержащий ngram, генерируется либо во входном столбце, либо в другом столбце.Разработчики Elasticsearch, которые хотят найти нечеткие имена в нескольких полях и охватить спектр вариаций имен, иногда два или более в одном имени знают, насколько это может быть медведь. Начиная с 3. Elasticsearch хранит данные в индексах и поддерживает мощный поисковый tldr. С помощью функции убывания фильтра граничных диаграмм ElasticSearch и агрегирования наиболее популярных результатов мы придумали быстрое и точное мульти-типовое автозаполнение районов, городов, городских районов и т. д. от одного запроса на тип до одного полного запроса.Обзор методов нечеткого сопоставления имен Методы сопоставления имен и их соответствующие сильные и слабые стороны В структурированной базе данных имена часто обрабатываются так же, как метаданные для некоторых других полей, таких как номер телефона электронной почты или идентификационный номер. Расстояние редактирования — это количество изменений одного символа, необходимых для превращения одного термина в другой. 5. Elasticsearch поддерживает нечеткий запрос, который обрабатывает два нечетко похожих слова, как если бы они были одним и тем же словом. Сложные корреляции свойств не поддерживаются.PDF-текстовый файл. Это лучшие примеры Python для elasticsearch_dsl из реального мира. иногда текстовые поля должны точно совпадать. Используйте сопоставление ключевых слов вместо текстового поиска в проанализированных текстовых полях. Будет возвращено 2017 03 18 ElasticSearch Server Elasticsearch 5. Кортеж ngram_range min_n max_n по умолчанию 1 1 Нижняя и верхняя границы диапазона значений n для разных слов n граммы или грамм char n для извлечения.
д. от одного запроса на тип до одного полного запроса.Обзор методов нечеткого сопоставления имен Методы сопоставления имен и их соответствующие сильные и слабые стороны В структурированной базе данных имена часто обрабатываются так же, как метаданные для некоторых других полей, таких как номер телефона электронной почты или идентификационный номер. Расстояние редактирования — это количество изменений одного символа, необходимых для превращения одного термина в другой. 5. Elasticsearch поддерживает нечеткий запрос, который обрабатывает два нечетко похожих слова, как если бы они были одним и тем же словом. Сложные корреляции свойств не поддерживаются.PDF-текстовый файл. Это лучшие примеры Python для elasticsearch_dsl из реального мира. иногда текстовые поля должны точно совпадать. Используйте сопоставление ключевых слов вместо текстового поиска в проанализированных текстовых полях. Будет возвращено 2017 03 18 ElasticSearch Server Elasticsearch 5. Кортеж ngram_range min_n max_n по умолчанию 1 1 Нижняя и верхняя границы диапазона значений n для разных слов n граммы или грамм char n для извлечения. В Elasticsearch вы можете писать запросы, реализующие нечеткое сопоставление, и указывать максимально допустимое расстояние редактирования.Основная проблема — это Lucene, который вы можете заменить на сервер Solr Elasticsearch. установить. Нграммы — это в основном части слов, полученные путем перемещения окна определенной длины по каждому слову. GitHub Gist мгновенно делится заметками и фрагментами кода. 04. 01. Все значения n такие, что min_n lt n lt max_n будут использоваться. Примеры Базовый запрос на совпадение Существует два способа выполнения базового полнотекстового запроса на совпадение с использованием Search Lite API, который предполагает, что все параметры поиска будут переданы как часть URL-адреса, или с использованием полного тела запроса JSON, что позволяет использовать полное Elasticsearch DSL.Elasticsearch предоставляет полный DSL запросов, основанный на JSON и отвечающий за определение запросов. Elasticsearch Nori Analyzer Ngram Edge Ngram 0 2021. 0. Теперь у ngrams есть свои проблемы.
В Elasticsearch вы можете писать запросы, реализующие нечеткое сопоставление, и указывать максимально допустимое расстояние редактирования.Основная проблема — это Lucene, который вы можете заменить на сервер Solr Elasticsearch. установить. Нграммы — это в основном части слов, полученные путем перемещения окна определенной длины по каждому слову. GitHub Gist мгновенно делится заметками и фрагментами кода. 04. 01. Все значения n такие, что min_n lt n lt max_n будут использоваться. Примеры Базовый запрос на совпадение Существует два способа выполнения базового полнотекстового запроса на совпадение с использованием Search Lite API, который предполагает, что все параметры поиска будут переданы как часть URL-адреса, или с использованием полного тела запроса JSON, что позволяет использовать полное Elasticsearch DSL.Elasticsearch предоставляет полный DSL запросов, основанный на JSON и отвечающий за определение запросов. Elasticsearch Nori Analyzer Ngram Edge Ngram 0 2021. 0. Теперь у ngrams есть свои проблемы. Ограничения Elasticsearch NXQL. Ознакомьтесь с API подсказки завершения или с использованием фильтров Edge Ngram для получения дополнительной информации. Презентация ускоренного курса Elasticsearch. Оба провайдера используют стандартный токенизатор и фильтр нижнего регистра. 74 5 оценка на основе 20 отзывов. Я хочу, чтобы эти примеры поисковых запросов работали Michael gt Michael Jackson Michael Starr elasticsearch query_string 0 2015.Термин запроса с подстановочными знаками Elasticsearch quot Обратите внимание, что этот запрос может быть медленным, так как он должен повторять множество терминов. Генри VI Часть I III 3 Ранее в 2020 году я решил узнать о новом дополнении к управляемой платформе с открытым исходным кодом Instaclustr — масштабируемой технологии полнотекстового поиска Elasticsearch с использованием OpenDistro для Elasticsearch и Apache 2. quot one two three quot. yaml Elasticsearch Elasticsearch 2 JSON Elasticsearch состоит из основных компонентов, определенных и описанных в системе распределения.
Ограничения Elasticsearch NXQL. Ознакомьтесь с API подсказки завершения или с использованием фильтров Edge Ngram для получения дополнительной информации. Презентация ускоренного курса Elasticsearch. Оба провайдера используют стандартный токенизатор и фильтр нижнего регистра. 74 5 оценка на основе 20 отзывов. Я хочу, чтобы эти примеры поисковых запросов работали Michael gt Michael Jackson Michael Starr elasticsearch query_string 0 2015.Термин запроса с подстановочными знаками Elasticsearch quot Обратите внимание, что этот запрос может быть медленным, так как он должен повторять множество терминов. Генри VI Часть I III 3 Ранее в 2020 году я решил узнать о новом дополнении к управляемой платформе с открытым исходным кодом Instaclustr — масштабируемой технологии полнотекстового поиска Elasticsearch с использованием OpenDistro для Elasticsearch и Apache 2. quot one two three quot. yaml Elasticsearch Elasticsearch 2 JSON Elasticsearch состоит из основных компонентов, определенных и описанных в системе распределения. Реализует координацию узлов кластера и управления данными.Я новичок в эластичном поиске и в настоящее время переношу имеющиеся у меня запросы lucene. Версия 2. elasticsearch. Что такое ElasticSearch Elasticsearch — это открытая поисковая система корпоративного уровня, которая может обеспечить чрезвычайно быстрый поиск, поддерживающий все приложения для обнаружения данных. ElasticSearch — это распределенная поисковая и аналитическая система на основе JSON с открытым исходным кодом, которая обеспечивает быстрые и надежные результаты поиска. Здесь доступно большинство полей продукта 39 s, некоторые могут даже появляться несколько раз e.Он берет один термин и находит в словаре терминов все термины, которые находятся в пределах указанной нечеткости. Java Elasticsearch Хорошо, теперь, когда мы рассмотрели различные части анализаторов, давайте ненадолго рассмотрим пример.09. Конечная точка будет вызываться для каждого ключевого слова, нажатого во внешнем приложении, поэтому ответ должен быть быстрым и способным обрабатывать запросы из большого объема записей. Пользователь в интерактивном режиме управляет алгоритмами настройки, которые настраиваются с помощью запроса JAVA для нескольких полей. новые слова ngram_tokenize Cos Elasticsearch federico. Полнотекстовый поиск elasticsearch Полнотекстовый запрос, позволяющий детально контролировать порядок и близость совпадающих терминов. В этом посте суммируются мои выводы и представлен новый алгоритм индексации и поиска.2. имя имя. Анализатор ngram разбивает группы слов на перестановки буквенных групп. Обновите свои пользовательские настройки и сопоставление Elasticsearch. установка ist einfach runterladen ausf hren ngram_range tuple min_n max_n default 1 1 Нижняя и верхняя граница диапазона значений n для различных слов n граммов или char n граммов, которые должны быть извлечены. Мир. Elasticsearch too_many_clause.Однако компания Elastic, которая поддерживает Elasticsearch и остальную часть стека ELK, также предоставляет множество клиентов для разных языков для Elasticsearch. Если индекс содержит триграмму Elasticsearch в действии, можно ожидать, что это предложение получит более высокий рейтинг. Этот режим наиболее полезен, если вы собираетесь выполнить некоторую индивидуальную обработку и хотите сохранить структуру исходного текста. Существует множество алгоритмов, которые могут обеспечить нечеткое сопоставление, см. Здесь, как реализовать в Python, но они быстро падают при использовании даже с небольшими наборами данных, превышающими несколько тысяч записей.Создание индекса в сочетании с нечетким запросом. Это токен-фильтр типа quot quot quot nGram quot. 06 elasticsearch 3. Разработано Оценивается и настраивается в облаке ElasticSearch. 20 Поддержка ASP. Нечеткий запрос — это запрос на уровне терминов, поэтому он не выполняет никакого анализа. анализ. 0 пользователя Jon Orwant. Токенизатор NGram. ElasticsearchCrud используется в качестве основного клиента dotnet для Elasticsearch. нечеткое расстояние Левенштейна.german_analyzer и имя. ngram Первое описанное понятие — это ngram. Проблема с нечетким соответствием для больших данных. 9x elasticsearch f Elasticsearch. Функция заголовка в python — это строковый метод Python, который используется для преобразования первого символа в каждом слове в верхний регистр, а оставшиеся символы в нижний регистр в строке и возвращает новую строку. 11. com. x e SolrCloud Modularit Фильтры запросов Повышение геолокационной кластеризации Требуемая поисковая система Componenti extra Kibana Marvel Shield Наши учебные классы по Elasticsearch имеют 4.Используя эти инструменты, мы можем сузить область поиска и найти точки соприкосновения между лингвистически схожими терминами. Краткое введение в ElasticSearch. нечеткие в памяти. Соорганизатор dos Hangouts do Laravel BR. fuzzy_tools Набор инструментов для нечеткого поиска в Ruby, настроенный на точность. 21 elasticsearch java multiget 0 2015. tgz 01. 9. Tesseract ControlParams wiki Завершение Elasticsearch предлагает автоматическое завершение предлагать завершение поля Преобразователь конечного состояния Elasticsearch В следующих примерах показано, как использовать org.ELK — это Elasticsearch Logstash и Kibana. Я 39 читал «ElasticSearch in Action», но на 39-й минуте приближался к крайнему сроку для презентации результатов поиска и надеялся попросить помощи с конкретной проблемой, которая у меня есть. Это происходит автоматически, если вы не укажете Elasticsearch сделать иначе. Обработка и миграция Для нечеткого поиска мы можем использовать ngrams. Elasticsearch вышел очень эффективным и точным сопоставителем, оптимизированным с помощью фонетических и нечетких анализаторов Edge_NGram. txt или просмотрите слайды презентации в Интернете.io. State Dental College Hyderabad Fee Structure Permanent Elasticsearch полезен для мощного нечеткого сопоставления с расстоянием Левенштейна, но может быть заменен фонетической или ngram-индексацией с помощью postgres и на данный момент требуется модулем проверки. Mein Ziel ihr geht nach hause und knt eine 0 8 15 Сучмаске бауэн. 0 null_value fuzzy_match Сравнение нечетких строк с мерами расстояния и регулярным выражением. Недавно я имел удовольствие создать конечную точку службы для поиска по мере того, как вы вводите функциональность, которая дает мгновенную обратную связь пользователю по мере его ввода.0 мы представили концепцию индексируемых файлов. Примечание. Поддержка ElasticSearch доступна только в Haystack 2. Elasticsearch хранит ложный индекс, проанализированный not_analyzed нет. 1 rc1 2015. ngram 2 биграммы quot один два три quot. В прошлом ElasticPress был интегрирован с WordPress WP_Query API, который позволял перенаправлять запросы WP_Query через Elasticsearch вместо MySQL.на ElasticSearch. Следующий. нечеткий токен ngram и т. д. 0 регулирование слияния теперь выполняется автоматически. Мы можем измерить сходство двух строк, подсчитав количество общих триграмм. stop elasticsearch сделать elasticsearch остановить start elasticsearch сделать elasticsearch перезапустить elasticsearch сделать elasticsearch остановить elasticsearch нечеткий запрос больше нулей инструменты. Этот 8-часовой онлайн-курс посвящен электронной коммерции или аналогичным примерам использования поиска товаров. E. Результаты автозаполнения, которые были результатом нечеткого соответствия, также известного как.Теперь, когда мы рассмотрели основы, пора создать наш index. Вы можете проголосовать за те, которые вам нравятся, или за те, которые вам не нравятся, и перейти к исходному проекту или исходному файлу, следуя ссылкам над каждым примером. elasticsearch nGram Power query нечеткое слияние не лучшие результаты, но быстрое Декартово произведение обеспечивает расстояние и лучшие результаты, но очень медленно Ngram предоставляет расстояние, но очень медленно. Если у кого-то из вас есть лучшие решения, я был бы рад узнать.quot name quot для названия продукта. active_support RoR Гем ActiveSupport имеет различные расширения строк, которые могут обрабатывать регистр. Допустим, у меня есть два пользователя, проиндексированных Майклом Джексоном и Майклом Старром. Соорганизатор Meetup de Laravel em SP. Привет, ребята, на прошлой неделе я настраивал кластер ES на работе, где мы воссоздали поисковую систему для продуктов. 39 39 Хотя запросы с подстановочными знаками префикса и regexp продемонстрировали, что это не совсем так, это правда, что поиск одного термина намного быстрее, чем итерация по списку терминов, чтобы найти совпадающие термины на лету.com CTO motore di ricerca full text Это распределенное масштабируемое и высокодоступное программное обеспечение для поиска и аналитики в реальном времени. Нечеткие запросы создают запросы ngram непосредственно из входной строки с min, которые должны соответствовать настройкам, которые отражают допустимые расстояния редактирования, и предложения MUST, которые уважают настройки длины префикса. Форк RegExp ApproximateRegExp использует логику синтаксического анализатора регулярных выражений для извлечения объектов BooleanQuery и TermQuery вместо того, чтобы иметь промежуточный этап генерации автоматов.Query DSL, состоящий из двух типов предложений Leaf Query Clauses. Как написано в Elasticsearch The Definitive Guide, еще одним распространенным подходом, который значительно увеличивает скорость, является использование ngrams. Эти примеры взяты из проектов с открытым исходным кодом. Заметки о Elasticsearch. люцен. Загрузите и распакуйте последний дистрибутив Elasticsearch. шляпа безумная 3. esvm Elasticsearch Version Manager — это приложение командной строки, используемое для разработки для управления различными версиями Elasticsearch.Ngrams edge ngrams Elasticsearch Ngrams ngram edge ngram min_gram max_gram Серия аргументов с разработчиками, которые настаивают на том, чтобы нечеткий поиск или проверка орфографии выполнялись в приложении, а не в реляционной базе данных, вдохновил Фила Фактора показать, как это делается.Анализатор извлечен из открытых проектов. Нечеткий запрос Elasticsearch 39 — это мощный инструмент для множества ситуаций. Точный поиск Elasticsearch с нечетким поиском. На вопрос 3 недели назад у меня есть индекс, который содержит название компании, аббревиатуру компании и описание того, что компания делает. Схема индекса приведена ниже. нечеткая диаграмма. Я не уверен, как вы это скажете в elasticsearch, но если бы вы запрограммировали ввод и потребовали только один из Elasticsearch ronaldiscool Ronaldiscool 20 октября 2015 г. 5 36pm 1 Есть ли способ также выполнить нечеткий поиск с помощью токена подстановочного знака .N грамм можно представить как последовательность из n символов. Существует большое количество управляющих параметров для изменения его поведения. Нечеткое хеширование Если установлен параметр fuzzy, запрос будет использовать top_terms_blended_freqs_ max_expansions в качестве метода перезаписи. Параметр fuzzy_rewrite позволяет контролировать, как запрос будет перезаписан. Вы можете оценивать примеры, чтобы помочь нам улучшить их качество. 0 лицензионного распространения Elasticsearch, дополненного Elasticsearch и Redis. 26 документ типа elasticsearch 0 2015.reelsen elasticsearch. fuzziness elasticsearch quot Различные алгоритмы сопоставления нечетких строк и отличное видео Сообщение Джо Глинеса Вторник, 29 декабря 2015 г. 15:30 Я изучал нечеткое сопоставление строк. Давайте рассмотрим пример, в котором используется индекс store, который представляет небольшой продуктовый магазин.С выпуском Elasticsearch 2. «Соединитель для разветвления сайта SPIP и индексатор контента, который обеспечивает механизм индексации и поиск Elasticsearch». Вы можете прочитать больше об этом здесь. Он также поддерживает интеллектуальное сопоставление, которое может искать слова, которые звучат одинаково, даже если их написание отличается. x правила. Рассмотрим два возможных предложения: Elasticsearch в действии и Elasticsearch. В предыдущих статьях мы рассмотрели префиксные запросы и Edge NGram Tokenizer, чтобы генерировать поиск по мере того, как вы вводите предложения.ngram соответствует elasticsearch. Эта страница пуста. Вот несколько критических изменений, которые следует учитывать при обновлении с Elasticsearch 6. Если вы используете токенизатор nGram, тип был переименован с nGram на ngram. Ниже приведена настройка для анализа индекса свойств индекса Query DSL Elasticsearch Tutorial. Выбор правильного размера кучи существенно влияет на производительность полевых данных и, следовательно, на Elasticsearch. Чтобы объяснить немного больше, токенизатор ngram разделяет каждое слово в каждой комбинации между символами min_gram и max_gram.Быстрая заметка для себя о возможном способе использования нечеткого сопоставления при поиске таксономических имен. В этом руководстве мы будем использовать dsl-библиотеку elasticsearch для реализации нечеткого поиска при вводе функций в веб-приложение Django. формат необязательный. Если список игнорируемых слов был отформатирован для Snowball, вы можете указать формат «снежный ком», чтобы Solr мог прочитать файл игнорируемых слов. Использовал elasticsearch v7. Соавтор Уилл Брокман и я надеялись, что возможность отслеживать использование фраз во времени будет интересна профессиональным лингвистам, историкам и библиофилам.Незначительные изменения в исходном пакете естественных узлов. Общие токенизирование на естественном языке, основание. Английский Русский Испанский часть речи. Elasticsearch The Definitive Guide quot Elasticsearch The Definitive Guide. Именно здесь нечеткие совпадения запросов могут помочь с легкостью обрабатывать пользовательские ошибки и предоставлять пользователям результаты, которые они, вероятно, искали. Возможности сопоставления со всеми стандартными алгоритмами полнотекстового поиска e. Токенизаторы структурированного текста Почтовый индекс ключевого слова ключевое слово термин слова общий текстовый файл в.2 твита. Первым в нашем списке указателей является нечеткий поиск Fuzzy Search. Это позволяет быстро получать предложения в пользовательском интерфейсе DataSearch или CategorySearch. нграмм 1 униграмм «один, два, три». сырой . Elasticsearch DB DB ElasticSearch cross_fields multi match с нечетким поиском 2 У меня есть документы, представляющие пользователей.es_qsearch quot Andoirddd quot, он также должен работать с помощью NGRAM_ANALYZER. Как использовать нечеткий поиск в Elasticsearch Например, если бы кто-то использовал нечеткий запрос по анализируемому полю ngram, результаты, вероятно, были бы странными, поскольку ngrams разбивают слова на Elasticsearch 39 ■ Нечеткий запрос — мощный инструмент для множества ситуаций. 9 Плагин полнотекстового синтаксического анализатора MeCab. Keyword Tokenizer API горячих потоков ElasticSearch cpu ElasticSearch 1 ПОЛУЧИТЬ _nodes hot_threads 7.Эластичные запросы DSL вручную. Учебное пособие Выполнение нечеткого полнотекстового поиска Щелкните здесь, чтобы просмотреть и обсудить эту страницу в DocCommentXchange. match_phrase привет мир привет мир привет мир N Грамм ngram quot Красное вино quot Re Red ed wi win wine in nene Edge N Gram edge_ngram quot Красное вино quot Re Red wi win wine 3. Предлагающие — это продвинутое решение в Elasticsearch, позволяющее возвращать похожие термины на основе вашего ввода текста.грамм. Примечание. Я хочу использовать ElasticSearch для поиска имен файлов, а не содержимого файла 39. Как реализовать обнаружение дубликатов в Power Query. 2 7. 2. Шивам Кумар. 0 2015. 30 декабря 2020 Без рубрики 0 Комментарий. Песни из фильмов или названия должностей широко известны или популярны. Уловка использования граничных NGrams заключается в том, чтобы НЕ использовать фильтр маркеров граничных NGram в запросе. Образ докера Elasticsearch nori ES Что касается вашего вопроса о том, как настроить индекс для соответствия всем подстрокам jr mie, я бы попытался настроить отображение индекса по полю, которое несет термин, с помощью настраиваемого анализатора, используя фильтр маркеров edge ngram с минимальная длина 2 и максимальная длина 7, а также токенизатор to_lower для игнорирования регистра.Спасибо за вопрос. Я генеральный директор консалтинговой компании Codica в Харькове, Украина. хорошая погода у нас сегодня gt nic ice wea eat at the her hav ave tod oda day yellow gt yel ell llo low Что такое нечеткий поиск Это упражнение по расширению, которое дает совпадение по терминам, имеющим схожий состав. 8 Мультипликатор очков для лучшего выбора ngram permuter используется только в пути сценария Han. 16nb1. doc My_secon Класс NGram расширяет класс набора Python с помощью эффективного нечеткого поиска элементов с помощью меры сходства N грамм.N-граммовая модель — это тип вероятностной языковой модели для предсказания следующего элемента в такой последовательности в форме марковской модели n-го порядка. Обзор запросов, доступных в Elasticsearch. Давайте взглянем на поиск Linkedin и посмотрим, сможем ли мы воспроизвести что-то подобное с Elasticsearch. Стандартный запрос для выполнения полнотекстовых запросов, включая нечеткое соответствие, фразовые или близкие запросы. F. Когда запрос NXQL обрабатывается с помощью Elasticsearch PageProvider или с помощью поисковой службы Nuxeo Elasticsearch, существуют некоторые ограничения для конкретной конфигурации и доступны дополнительные функции.NGramTokenizer. Непонятные результаты, основанные на большом разнообразии эластичного поиска по термину вектор для связи с некоторыми примерами. pkgcache 08 мая 2021 г. 14 08 69236kB 0verkill 0. Elasticsearch Elasticsearch. Учебное пособие по работе с популярной платформой Fuzzy Queries с открытым исходным кодом Elasticsearch. Elasticsearch разбивает доступный для поиска текст не только по отдельным терминам, но и по еще более мелким кускам. В разделе «Регулирование» главы, когда мы обсуждаем регулирование, отсутствует информационное окно, в котором говорится, что регулирование слияния может использоваться только до Elasticsearch 2.Краткое изложение этого 2 1 fname sname 2 fname sname 1 2 2 Ngram граничных nграмм Elasticsearch Ngram ngram edge ngram min_gram max_gram нечеткости 2 Elasticsearch.Elasticsearch предоставляет поиск как услугу, с которой вы можете взаимодействовать через RESTful API. Эта структура данных управляется в памяти, что делает ее намного быстрее, чем запрос на основе терминов. текст. Elastic анонсировала самоуправляемый поиск приложений. Elasticsearch Server. Третье издание. Устранение неполадок. Глава 2. Исправление 1. Elasticsearch — это поисковая система с открытым исходным кодом, построенная на основе Java-библиотеки Lucene. Если лимит превышен, произойдет сбой с исключением. Elasticsearch Analyzer нограммы токенов анализатора эластичного поиска предлагают нечеткий анализатор эластичного поиска.Он отлично подходит для поиска по свободному тексту и разработан для горизонтального масштабирования. Запросы тех, кто участвовал в оценочной группе, были соответствующим образом помечены для ведения журнала на стороне сервера. 17 ElasticSearch Wildcard и поиск NGram с помощью Tire Tagged ngram wildcard elasticsearch tyre Языки ruby Как реализовать поиск по шаблонам с помощью шин и Elasticsearch Параметры сопоставления Elasticsearch предлагают quot preserve_separators quot false false quot preserve_position_increments quot true false Melhore a busca textual do seu e commerce Trabalho na Leroy Merlin Бразилия.Простой способ для каждого пользователя создает персональный анализатор, который использует грамм фильтра для каждой электронной почты. Например, во время индексации встроенный анализатор custom_edge_ngram min 3 max 5 сначала преобразует предложения Analyzers Tokenizers и Token Filters.Подобные запросы не возвращают ни одного документа. Используйте явное поле Elasticsearch SELECT FROM Document WHERE ES INDEX dc title. 19 Elasticsearch Aggregation API Pipeline Aggregations 3 0 Усилитель исправления орфографии Нечеткий поиск в 1 миллион раз быстрее благодаря алгоритму исправления орфографии «Симметричное удаление» Алгоритм исправления орфографии «Симметричное удаление» снижает сложность создания кандидатов на редактирование и поиска в словаре для заданного расстояния Дамерау-Левенштейна.1. Подход Edge NGram. В ElasticSearch нечеткий поиск с помощью ngram. pdf Скачать бесплатно в формате PDF. Аукцион. 0 может быть списком из нуля или более до 3. org — это служба хостинга гемов сообщества Ruby. u U расширяет поддержку Unicode в Ruby. Мгновенно опубликуйте свои драгоценные камни, а затем установите их. 1. txt Сопоставление нечетких запросов. y 39 SELECT FROM Document WHERE ES OPERATOR fuzzy dc title 39 zorkspaces 39 Поиск в Elasticsearch можно осуществлять с помощью HTTP. Мы определили специальный анализатор ngram в нашем индексном наборе для группировки текста в скользящую область поиска секретных политик, и мы сделаем вас известным с помощью.Нечеткие транспозиции ab ba разрешены по умолчанию, но их можно отключить, установив для fuzzy_transpositions значение false. Чтобы построить индекс, вы можете повторно использовать стандартные анализаторы, доступные в Solr ES, а манипуляции со строками для сортировки и определения слов могут быть легко выполнены во время предварительной обработки с помощью Python. Elasticsearch GitHub Gist мгновенно обменивается заметками и фрагментами кода. Скачать полный пакет PDF. .Есть еще одно решение, позволяющее избежать опечаток и других неточных совпадений. В самом простом случае вы можете добавить конечную точку _search к URL-адресу и добавить параметр ES BaseURL _search q keyword Хотите использовать Elasticsearch в качестве поискового решения, но вы не хотите создавать все самостоятельно? Вам следует проверить Elastic Поиск приложений. n грамматические модели в настоящее время широко используются в компьютерной лингвистике теории вероятностной коммуникации, например, статистической обработке естественного языка, вычислительной биологии, например, анализе биологической последовательности, и разница между max_ngram и min_ngram в NGramTokenFilter и NGramTokenizer раньше ограничивалась 1.Если вам действительно нужно найти подстроку в середине слова, лучше использовать токенизатор ngram. Например, ngram_range 1 1 означает только униграммы, 1 2 означает униграммы и биграммы, а 2 2 означает только полнотекстовый поиск с помощью Node. Если у вас есть индивидуальная конфигурация для Elasticsearch, ее необходимо адаптировать в соответствии с новой версией 7. Но если частота запросов является единственным критерием, а аукцион униграмм много раз появляется в индексе, Elasticsearch может выиграть аукцион. Они не извлекают смысла, но часто используются в текстовой аналитике для обнаружения плагуризма, нечеткого поиска, проверки орфографии и многого другого.com arjun 56d32bc8a8e48aed18f694eb Нечеткий запрос ElasticSearch может использоваться в сценариях, когда пользователь выполняет поиск с ошибочными ключевыми словами или орфографическими ошибками. 10. В Drupal 8 можно создать мощный поиск контента с помощью модулей Search API и Elasticsearch Connector. Выполните следующую инструкцию, чтобы создать текстовый объект конфигурации с именем myFuzzyTextConfig. 14 elasticsearch fuzzy 0 2015. Запустите bin elasticsearch f в Unix. 1 исправлены некоторые ошибки из предыдущих версий обновленного Json.С min_gram 3 и max_gram 20 elasticsearch будет преобразовано в ela elas elast elasticsearc elasticsearch. 1. Модуль триграмм с 3 юниграммами Ngram REGEX 92 w def ngram_tokenize self. нечеткость AUTO elasticsearch в действии genug der theorie wir schauen un das an was freure erste Suchanwendung wichtig. Приложения. Elasticsearch имеет большой набор инструментов, с помощью которого мы можем нарезать слова на части для эффективного поиска.Как сгенерировать словарные граммы с помощью Ruby, требуется 39 наборов 39 Извлечь uni bi и триграммы. В Elasticsearch предложения конечных запросов ищут конкретное значение в определенном поле, например, по критерию совпадения или по диапазону запросов. Индекс и запросы Elasticsearch были построены на основе идей из этих 2-х отличных блогов bilyachat и qbox. Поставщики Virto Commerce Elasticsearch и Azure Search поддерживают анализатор Edge NGram по умолчанию или анализатор NGram. Полная версия не ограничена и рассчитывает ROI. nGram_analyzer.Нграммы для частичного совпадения. Elasticsearch not_analyzed Имя Последнее изменение Размер Родительский каталог 08 мая 2021 г. 12 30 1 КБ. Они очень гибкие и могут использоваться для самых разных целей.Пользователи, которые участвовали в контрольной группе, увидели оригинальный нечеткий подход. elasticSearch частичный поиск точное совпадение анализатор ngram код фильтра http codeplastick. boost 1. Во время индексации целевые поля автозаполнения должны быть проанализированы с помощью специального анализатора с использованием фильтра маркеров граничной диаграммы. Когда база данных должна найти релевантный материал из поисковых запросов, введенных пользователями, база данных должна научиться ожидать и обрабатывать как ожидаемые, так и неожиданные идентификаторы нечетких запросов Идентификатор запроса Elasticsearch Пользовательские анализаторы edge_ngram tokenizer Elasticsearch Nori Analyzer Ngram Edge Ngram Elasticsearch.RubyGems. панини фазланд. 19 ноября 2015 г. 16 37 52 UTC Распределение Эластичная модель В отличие от популярной поисковой системы Solr ElasticSearch использует JSON без схемы вместо XML и работает как двоичный файл, не требуя внешнего сервера Java. В ElasticPress 3.0 beta8 2015. Elasticsearch dsl — это библиотека высокого уровня, основанная на elasticsearch py, которая является библиотекой низкого уровня для взаимодействия с Elasticsearch. нграм. давайте покажем использование на примере. Если пользователь ищет Nile на платформе, ElasticSearch будет. В Elasticsearch край n граммов будет использоваться для реализации функции автозаполнения.Этот подход предполагает использование различных анализаторов индекса и времени запроса. Шаг 1. Имейте правильное определение индекса FTS для полей, которые необходимо заполнять автоматически. Прежде чем использовать нечеткий запрос, мы введем термин «нечеткость». Например, у меня есть много записей, в которых в качестве job_title указано «Android-разработчик», когда пользователь выдает неверное задание поиска. 4 января 2018 г. Я 39 м пытался заставить фильтр nGram работать с нечетким поиском, но он выиграл 39 т. Станьте участником и улучшите сайт сами.Это означает, что очень важно иметь гибкий механизм подсчета очков. . Результирующий индекс использовал менее мегабайта хранилища. апач. С Elasticsearch Распространенная и частая проблема, с которой я сталкиваюсь при разработке функций поиска в ElasticSearch, заключалась в том, чтобы найти решение, при котором я мог бы находить документы по частям слова, например, с помощью функции предложения. Cos Elasticsearch федерико. Скачать файл PBIX Очистка данных.Например, ngram_range 1 1 означает только униграммы. 1 2 означает униграммы и биграммы, а 2 2 означает только одно. Кроме того, процесс анализа ngram может создать множество токенов, что недружелюбно к памяти. Выберите формат загрузки Поиск нечеткого текста Elasticsearch Загрузить Поиск нечеткого текста Elasticsearch PDF Загрузить документ поиска нечеткого текста Elasticsearch Несмотря на все виды нечетких совпадений условий запроса, чтобы выполнить сложный или довольно эластичный поиск, нечеткий поиск php Intereting Posts ElasticSearch нечеткое весеннее облако mybatis spring boot React python ElasticSearch fuzzy Elasticsearch Suggester quot Предлагать при вводе quot Средство просмотра Elasticsearch 100 Ngram 2.Для наших нужд он оптимизирует простоту и мощность. СЕТЬ. NET Core RC2 обновлен до версии elasticsearch 2. tree three. Это ограничение по умолчанию можно изменить с помощью индекса. tgz 12 мар 2020 01 08 174kB 2048 cli 0. Например, 3 3 грамма или триграммы, если хотите. Elasticsearch представил новую структуру данных Finite State Transducer FST, которая напоминает структуру данных большого графа. Я хочу сделать нечеткий поиск, чтобы пользователь мог получить результат, если он неправильно написал ключевое слово запроса.эластичный поиск ngram нечеткий
Реализует координацию узлов кластера и управления данными.Я новичок в эластичном поиске и в настоящее время переношу имеющиеся у меня запросы lucene. Версия 2. elasticsearch. Что такое ElasticSearch Elasticsearch — это открытая поисковая система корпоративного уровня, которая может обеспечить чрезвычайно быстрый поиск, поддерживающий все приложения для обнаружения данных. ElasticSearch — это распределенная поисковая и аналитическая система на основе JSON с открытым исходным кодом, которая обеспечивает быстрые и надежные результаты поиска. Здесь доступно большинство полей продукта 39 s, некоторые могут даже появляться несколько раз e.Он берет один термин и находит в словаре терминов все термины, которые находятся в пределах указанной нечеткости. Java Elasticsearch Хорошо, теперь, когда мы рассмотрели различные части анализаторов, давайте ненадолго рассмотрим пример.09. Конечная точка будет вызываться для каждого ключевого слова, нажатого во внешнем приложении, поэтому ответ должен быть быстрым и способным обрабатывать запросы из большого объема записей. Пользователь в интерактивном режиме управляет алгоритмами настройки, которые настраиваются с помощью запроса JAVA для нескольких полей. новые слова ngram_tokenize Cos Elasticsearch federico. Полнотекстовый поиск elasticsearch Полнотекстовый запрос, позволяющий детально контролировать порядок и близость совпадающих терминов. В этом посте суммируются мои выводы и представлен новый алгоритм индексации и поиска.2. имя имя. Анализатор ngram разбивает группы слов на перестановки буквенных групп. Обновите свои пользовательские настройки и сопоставление Elasticsearch. установка ist einfach runterladen ausf hren ngram_range tuple min_n max_n default 1 1 Нижняя и верхняя граница диапазона значений n для различных слов n граммов или char n граммов, которые должны быть извлечены. Мир. Elasticsearch too_many_clause.Однако компания Elastic, которая поддерживает Elasticsearch и остальную часть стека ELK, также предоставляет множество клиентов для разных языков для Elasticsearch. Если индекс содержит триграмму Elasticsearch в действии, можно ожидать, что это предложение получит более высокий рейтинг. Этот режим наиболее полезен, если вы собираетесь выполнить некоторую индивидуальную обработку и хотите сохранить структуру исходного текста. Существует множество алгоритмов, которые могут обеспечить нечеткое сопоставление, см. Здесь, как реализовать в Python, но они быстро падают при использовании даже с небольшими наборами данных, превышающими несколько тысяч записей.Создание индекса в сочетании с нечетким запросом. Это токен-фильтр типа quot quot quot nGram quot. 06 elasticsearch 3. Разработано Оценивается и настраивается в облаке ElasticSearch. 20 Поддержка ASP. Нечеткий запрос — это запрос на уровне терминов, поэтому он не выполняет никакого анализа. анализ. 0 пользователя Jon Orwant. Токенизатор NGram. ElasticsearchCrud используется в качестве основного клиента dotnet для Elasticsearch. нечеткое расстояние Левенштейна.german_analyzer и имя. ngram Первое описанное понятие — это ngram. Проблема с нечетким соответствием для больших данных. 9x elasticsearch f Elasticsearch. Функция заголовка в python — это строковый метод Python, который используется для преобразования первого символа в каждом слове в верхний регистр, а оставшиеся символы в нижний регистр в строке и возвращает новую строку. 11. com. x e SolrCloud Modularit Фильтры запросов Повышение геолокационной кластеризации Требуемая поисковая система Componenti extra Kibana Marvel Shield Наши учебные классы по Elasticsearch имеют 4.Используя эти инструменты, мы можем сузить область поиска и найти точки соприкосновения между лингвистически схожими терминами. Краткое введение в ElasticSearch. нечеткие в памяти. Соорганизатор dos Hangouts do Laravel BR. fuzzy_tools Набор инструментов для нечеткого поиска в Ruby, настроенный на точность. 21 elasticsearch java multiget 0 2015. tgz 01. 9. Tesseract ControlParams wiki Завершение Elasticsearch предлагает автоматическое завершение предлагать завершение поля Преобразователь конечного состояния Elasticsearch В следующих примерах показано, как использовать org.ELK — это Elasticsearch Logstash и Kibana. Я 39 читал «ElasticSearch in Action», но на 39-й минуте приближался к крайнему сроку для презентации результатов поиска и надеялся попросить помощи с конкретной проблемой, которая у меня есть. Это происходит автоматически, если вы не укажете Elasticsearch сделать иначе. Обработка и миграция Для нечеткого поиска мы можем использовать ngrams. Elasticsearch вышел очень эффективным и точным сопоставителем, оптимизированным с помощью фонетических и нечетких анализаторов Edge_NGram. txt или просмотрите слайды презентации в Интернете.io. State Dental College Hyderabad Fee Structure Permanent Elasticsearch полезен для мощного нечеткого сопоставления с расстоянием Левенштейна, но может быть заменен фонетической или ngram-индексацией с помощью postgres и на данный момент требуется модулем проверки. Mein Ziel ihr geht nach hause und knt eine 0 8 15 Сучмаске бауэн. 0 null_value fuzzy_match Сравнение нечетких строк с мерами расстояния и регулярным выражением. Недавно я имел удовольствие создать конечную точку службы для поиска по мере того, как вы вводите функциональность, которая дает мгновенную обратную связь пользователю по мере его ввода.0 мы представили концепцию индексируемых файлов. Примечание. Поддержка ElasticSearch доступна только в Haystack 2. Elasticsearch хранит ложный индекс, проанализированный not_analyzed нет. 1 rc1 2015. ngram 2 биграммы quot один два три quot. В прошлом ElasticPress был интегрирован с WordPress WP_Query API, который позволял перенаправлять запросы WP_Query через Elasticsearch вместо MySQL.на ElasticSearch. Следующий. нечеткий токен ngram и т. д. 0 регулирование слияния теперь выполняется автоматически. Мы можем измерить сходство двух строк, подсчитав количество общих триграмм. stop elasticsearch сделать elasticsearch остановить start elasticsearch сделать elasticsearch перезапустить elasticsearch сделать elasticsearch остановить elasticsearch нечеткий запрос больше нулей инструменты. Этот 8-часовой онлайн-курс посвящен электронной коммерции или аналогичным примерам использования поиска товаров. E. Результаты автозаполнения, которые были результатом нечеткого соответствия, также известного как.Теперь, когда мы рассмотрели основы, пора создать наш index. Вы можете проголосовать за те, которые вам нравятся, или за те, которые вам не нравятся, и перейти к исходному проекту или исходному файлу, следуя ссылкам над каждым примером. elasticsearch nGram Power query нечеткое слияние не лучшие результаты, но быстрое Декартово произведение обеспечивает расстояние и лучшие результаты, но очень медленно Ngram предоставляет расстояние, но очень медленно. Если у кого-то из вас есть лучшие решения, я был бы рад узнать.quot name quot для названия продукта. active_support RoR Гем ActiveSupport имеет различные расширения строк, которые могут обрабатывать регистр. Допустим, у меня есть два пользователя, проиндексированных Майклом Джексоном и Майклом Старром. Соорганизатор Meetup de Laravel em SP. Привет, ребята, на прошлой неделе я настраивал кластер ES на работе, где мы воссоздали поисковую систему для продуктов. 39 39 Хотя запросы с подстановочными знаками префикса и regexp продемонстрировали, что это не совсем так, это правда, что поиск одного термина намного быстрее, чем итерация по списку терминов, чтобы найти совпадающие термины на лету.com CTO motore di ricerca full text Это распределенное масштабируемое и высокодоступное программное обеспечение для поиска и аналитики в реальном времени. Нечеткие запросы создают запросы ngram непосредственно из входной строки с min, которые должны соответствовать настройкам, которые отражают допустимые расстояния редактирования, и предложения MUST, которые уважают настройки длины префикса. Форк RegExp ApproximateRegExp использует логику синтаксического анализатора регулярных выражений для извлечения объектов BooleanQuery и TermQuery вместо того, чтобы иметь промежуточный этап генерации автоматов.Query DSL, состоящий из двух типов предложений Leaf Query Clauses. Как написано в Elasticsearch The Definitive Guide, еще одним распространенным подходом, который значительно увеличивает скорость, является использование ngrams. Эти примеры взяты из проектов с открытым исходным кодом. Заметки о Elasticsearch. люцен. Загрузите и распакуйте последний дистрибутив Elasticsearch. шляпа безумная 3. esvm Elasticsearch Version Manager — это приложение командной строки, используемое для разработки для управления различными версиями Elasticsearch.Ngrams edge ngrams Elasticsearch Ngrams ngram edge ngram min_gram max_gram Серия аргументов с разработчиками, которые настаивают на том, чтобы нечеткий поиск или проверка орфографии выполнялись в приложении, а не в реляционной базе данных, вдохновил Фила Фактора показать, как это делается.Анализатор извлечен из открытых проектов. Нечеткий запрос Elasticsearch 39 — это мощный инструмент для множества ситуаций. Точный поиск Elasticsearch с нечетким поиском. На вопрос 3 недели назад у меня есть индекс, который содержит название компании, аббревиатуру компании и описание того, что компания делает. Схема индекса приведена ниже. нечеткая диаграмма. Я не уверен, как вы это скажете в elasticsearch, но если бы вы запрограммировали ввод и потребовали только один из Elasticsearch ronaldiscool Ronaldiscool 20 октября 2015 г. 5 36pm 1 Есть ли способ также выполнить нечеткий поиск с помощью токена подстановочного знака .N грамм можно представить как последовательность из n символов. Существует большое количество управляющих параметров для изменения его поведения. Нечеткое хеширование Если установлен параметр fuzzy, запрос будет использовать top_terms_blended_freqs_ max_expansions в качестве метода перезаписи. Параметр fuzzy_rewrite позволяет контролировать, как запрос будет перезаписан. Вы можете оценивать примеры, чтобы помочь нам улучшить их качество. 0 лицензионного распространения Elasticsearch, дополненного Elasticsearch и Redis. 26 документ типа elasticsearch 0 2015.reelsen elasticsearch. fuzziness elasticsearch quot Различные алгоритмы сопоставления нечетких строк и отличное видео Сообщение Джо Глинеса Вторник, 29 декабря 2015 г. 15:30 Я изучал нечеткое сопоставление строк. Давайте рассмотрим пример, в котором используется индекс store, который представляет небольшой продуктовый магазин.С выпуском Elasticsearch 2. «Соединитель для разветвления сайта SPIP и индексатор контента, который обеспечивает механизм индексации и поиск Elasticsearch». Вы можете прочитать больше об этом здесь. Он также поддерживает интеллектуальное сопоставление, которое может искать слова, которые звучат одинаково, даже если их написание отличается. x правила. Рассмотрим два возможных предложения: Elasticsearch в действии и Elasticsearch. В предыдущих статьях мы рассмотрели префиксные запросы и Edge NGram Tokenizer, чтобы генерировать поиск по мере того, как вы вводите предложения.ngram соответствует elasticsearch. Эта страница пуста. Вот несколько критических изменений, которые следует учитывать при обновлении с Elasticsearch 6. Если вы используете токенизатор nGram, тип был переименован с nGram на ngram. Ниже приведена настройка для анализа индекса свойств индекса Query DSL Elasticsearch Tutorial. Выбор правильного размера кучи существенно влияет на производительность полевых данных и, следовательно, на Elasticsearch. Чтобы объяснить немного больше, токенизатор ngram разделяет каждое слово в каждой комбинации между символами min_gram и max_gram.Быстрая заметка для себя о возможном способе использования нечеткого сопоставления при поиске таксономических имен. В этом руководстве мы будем использовать dsl-библиотеку elasticsearch для реализации нечеткого поиска при вводе функций в веб-приложение Django. формат необязательный. Если список игнорируемых слов был отформатирован для Snowball, вы можете указать формат «снежный ком», чтобы Solr мог прочитать файл игнорируемых слов. Использовал elasticsearch v7. Соавтор Уилл Брокман и я надеялись, что возможность отслеживать использование фраз во времени будет интересна профессиональным лингвистам, историкам и библиофилам.Незначительные изменения в исходном пакете естественных узлов. Общие токенизирование на естественном языке, основание. Английский Русский Испанский часть речи. Elasticsearch The Definitive Guide quot Elasticsearch The Definitive Guide. Именно здесь нечеткие совпадения запросов могут помочь с легкостью обрабатывать пользовательские ошибки и предоставлять пользователям результаты, которые они, вероятно, искали. Возможности сопоставления со всеми стандартными алгоритмами полнотекстового поиска e. Токенизаторы структурированного текста Почтовый индекс ключевого слова ключевое слово термин слова общий текстовый файл в.2 твита. Первым в нашем списке указателей является нечеткий поиск Fuzzy Search. Это позволяет быстро получать предложения в пользовательском интерфейсе DataSearch или CategorySearch. нграмм 1 униграмм «один, два, три». сырой . Elasticsearch DB DB ElasticSearch cross_fields multi match с нечетким поиском 2 У меня есть документы, представляющие пользователей.es_qsearch quot Andoirddd quot, он также должен работать с помощью NGRAM_ANALYZER. Как использовать нечеткий поиск в Elasticsearch Например, если бы кто-то использовал нечеткий запрос по анализируемому полю ngram, результаты, вероятно, были бы странными, поскольку ngrams разбивают слова на Elasticsearch 39 ■ Нечеткий запрос — мощный инструмент для множества ситуаций. 9 Плагин полнотекстового синтаксического анализатора MeCab. Keyword Tokenizer API горячих потоков ElasticSearch cpu ElasticSearch 1 ПОЛУЧИТЬ _nodes hot_threads 7.Эластичные запросы DSL вручную. Учебное пособие Выполнение нечеткого полнотекстового поиска Щелкните здесь, чтобы просмотреть и обсудить эту страницу в DocCommentXchange. match_phrase привет мир привет мир привет мир N Грамм ngram quot Красное вино quot Re Red ed wi win wine in nene Edge N Gram edge_ngram quot Красное вино quot Re Red wi win wine 3. Предлагающие — это продвинутое решение в Elasticsearch, позволяющее возвращать похожие термины на основе вашего ввода текста.грамм. Примечание. Я хочу использовать ElasticSearch для поиска имен файлов, а не содержимого файла 39. Как реализовать обнаружение дубликатов в Power Query. 2 7. 2. Шивам Кумар. 0 2015. 30 декабря 2020 Без рубрики 0 Комментарий. Песни из фильмов или названия должностей широко известны или популярны. Уловка использования граничных NGrams заключается в том, чтобы НЕ использовать фильтр маркеров граничных NGram в запросе. Образ докера Elasticsearch nori ES Что касается вашего вопроса о том, как настроить индекс для соответствия всем подстрокам jr mie, я бы попытался настроить отображение индекса по полю, которое несет термин, с помощью настраиваемого анализатора, используя фильтр маркеров edge ngram с минимальная длина 2 и максимальная длина 7, а также токенизатор to_lower для игнорирования регистра.Спасибо за вопрос. Я генеральный директор консалтинговой компании Codica в Харькове, Украина. хорошая погода у нас сегодня gt nic ice wea eat at the her hav ave tod oda day yellow gt yel ell llo low Что такое нечеткий поиск Это упражнение по расширению, которое дает совпадение по терминам, имеющим схожий состав. 8 Мультипликатор очков для лучшего выбора ngram permuter используется только в пути сценария Han. 16nb1. doc My_secon Класс NGram расширяет класс набора Python с помощью эффективного нечеткого поиска элементов с помощью меры сходства N грамм.N-граммовая модель — это тип вероятностной языковой модели для предсказания следующего элемента в такой последовательности в форме марковской модели n-го порядка. Обзор запросов, доступных в Elasticsearch. Давайте взглянем на поиск Linkedin и посмотрим, сможем ли мы воспроизвести что-то подобное с Elasticsearch. Стандартный запрос для выполнения полнотекстовых запросов, включая нечеткое соответствие, фразовые или близкие запросы. F. Когда запрос NXQL обрабатывается с помощью Elasticsearch PageProvider или с помощью поисковой службы Nuxeo Elasticsearch, существуют некоторые ограничения для конкретной конфигурации и доступны дополнительные функции.NGramTokenizer. Непонятные результаты, основанные на большом разнообразии эластичного поиска по термину вектор для связи с некоторыми примерами. pkgcache 08 мая 2021 г. 14 08 69236kB 0verkill 0. Elasticsearch Elasticsearch. Учебное пособие по работе с популярной платформой Fuzzy Queries с открытым исходным кодом Elasticsearch. Elasticsearch разбивает доступный для поиска текст не только по отдельным терминам, но и по еще более мелким кускам. В разделе «Регулирование» главы, когда мы обсуждаем регулирование, отсутствует информационное окно, в котором говорится, что регулирование слияния может использоваться только до Elasticsearch 2.Краткое изложение этого 2 1 fname sname 2 fname sname 1 2 2 Ngram граничных nграмм Elasticsearch Ngram ngram edge ngram min_gram max_gram нечеткости 2 Elasticsearch.Elasticsearch предоставляет поиск как услугу, с которой вы можете взаимодействовать через RESTful API. Эта структура данных управляется в памяти, что делает ее намного быстрее, чем запрос на основе терминов. текст. Elastic анонсировала самоуправляемый поиск приложений. Elasticsearch Server. Третье издание. Устранение неполадок. Глава 2. Исправление 1. Elasticsearch — это поисковая система с открытым исходным кодом, построенная на основе Java-библиотеки Lucene. Если лимит превышен, произойдет сбой с исключением. Elasticsearch Analyzer нограммы токенов анализатора эластичного поиска предлагают нечеткий анализатор эластичного поиска.Он отлично подходит для поиска по свободному тексту и разработан для горизонтального масштабирования. Запросы тех, кто участвовал в оценочной группе, были соответствующим образом помечены для ведения журнала на стороне сервера. 17 ElasticSearch Wildcard и поиск NGram с помощью Tire Tagged ngram wildcard elasticsearch tyre Языки ruby Как реализовать поиск по шаблонам с помощью шин и Elasticsearch Параметры сопоставления Elasticsearch предлагают quot preserve_separators quot false false quot preserve_position_increments quot true false Melhore a busca textual do seu e commerce Trabalho na Leroy Merlin Бразилия.Простой способ для каждого пользователя создает персональный анализатор, который использует грамм фильтра для каждой электронной почты. Например, во время индексации встроенный анализатор custom_edge_ngram min 3 max 5 сначала преобразует предложения Analyzers Tokenizers и Token Filters.Подобные запросы не возвращают ни одного документа. Используйте явное поле Elasticsearch SELECT FROM Document WHERE ES INDEX dc title. 19 Elasticsearch Aggregation API Pipeline Aggregations 3 0 Усилитель исправления орфографии Нечеткий поиск в 1 миллион раз быстрее благодаря алгоритму исправления орфографии «Симметричное удаление» Алгоритм исправления орфографии «Симметричное удаление» снижает сложность создания кандидатов на редактирование и поиска в словаре для заданного расстояния Дамерау-Левенштейна.1. Подход Edge NGram. В ElasticSearch нечеткий поиск с помощью ngram. pdf Скачать бесплатно в формате PDF. Аукцион. 0 может быть списком из нуля или более до 3. org — это служба хостинга гемов сообщества Ruby. u U расширяет поддержку Unicode в Ruby. Мгновенно опубликуйте свои драгоценные камни, а затем установите их. 1. txt Сопоставление нечетких запросов. y 39 SELECT FROM Document WHERE ES OPERATOR fuzzy dc title 39 zorkspaces 39 Поиск в Elasticsearch можно осуществлять с помощью HTTP. Мы определили специальный анализатор ngram в нашем индексном наборе для группировки текста в скользящую область поиска секретных политик, и мы сделаем вас известным с помощью.Нечеткие транспозиции ab ba разрешены по умолчанию, но их можно отключить, установив для fuzzy_transpositions значение false. Чтобы построить индекс, вы можете повторно использовать стандартные анализаторы, доступные в Solr ES, а манипуляции со строками для сортировки и определения слов могут быть легко выполнены во время предварительной обработки с помощью Python. Elasticsearch GitHub Gist мгновенно обменивается заметками и фрагментами кода. Скачать полный пакет PDF. .Есть еще одно решение, позволяющее избежать опечаток и других неточных совпадений. В самом простом случае вы можете добавить конечную точку _search к URL-адресу и добавить параметр ES BaseURL _search q keyword Хотите использовать Elasticsearch в качестве поискового решения, но вы не хотите создавать все самостоятельно? Вам следует проверить Elastic Поиск приложений. n грамматические модели в настоящее время широко используются в компьютерной лингвистике теории вероятностной коммуникации, например, статистической обработке естественного языка, вычислительной биологии, например, анализе биологической последовательности, и разница между max_ngram и min_ngram в NGramTokenFilter и NGramTokenizer раньше ограничивалась 1.Если вам действительно нужно найти подстроку в середине слова, лучше использовать токенизатор ngram. Например, ngram_range 1 1 означает только униграммы, 1 2 означает униграммы и биграммы, а 2 2 означает только полнотекстовый поиск с помощью Node. Если у вас есть индивидуальная конфигурация для Elasticsearch, ее необходимо адаптировать в соответствии с новой версией 7. Но если частота запросов является единственным критерием, а аукцион униграмм много раз появляется в индексе, Elasticsearch может выиграть аукцион. Они не извлекают смысла, но часто используются в текстовой аналитике для обнаружения плагуризма, нечеткого поиска, проверки орфографии и многого другого.com arjun 56d32bc8a8e48aed18f694eb Нечеткий запрос ElasticSearch может использоваться в сценариях, когда пользователь выполняет поиск с ошибочными ключевыми словами или орфографическими ошибками. 10. В Drupal 8 можно создать мощный поиск контента с помощью модулей Search API и Elasticsearch Connector. Выполните следующую инструкцию, чтобы создать текстовый объект конфигурации с именем myFuzzyTextConfig. 14 elasticsearch fuzzy 0 2015. Запустите bin elasticsearch f в Unix. 1 исправлены некоторые ошибки из предыдущих версий обновленного Json.С min_gram 3 и max_gram 20 elasticsearch будет преобразовано в ela elas elast elasticsearc elasticsearch. 1. Модуль триграмм с 3 юниграммами Ngram REGEX 92 w def ngram_tokenize self. нечеткость AUTO elasticsearch в действии genug der theorie wir schauen un das an was freure erste Suchanwendung wichtig. Приложения. Elasticsearch имеет большой набор инструментов, с помощью которого мы можем нарезать слова на части для эффективного поиска.Как сгенерировать словарные граммы с помощью Ruby, требуется 39 наборов 39 Извлечь uni bi и триграммы. В Elasticsearch предложения конечных запросов ищут конкретное значение в определенном поле, например, по критерию совпадения или по диапазону запросов. Индекс и запросы Elasticsearch были построены на основе идей из этих 2-х отличных блогов bilyachat и qbox. Поставщики Virto Commerce Elasticsearch и Azure Search поддерживают анализатор Edge NGram по умолчанию или анализатор NGram. Полная версия не ограничена и рассчитывает ROI. nGram_analyzer.Нграммы для частичного совпадения. Elasticsearch not_analyzed Имя Последнее изменение Размер Родительский каталог 08 мая 2021 г. 12 30 1 КБ. Они очень гибкие и могут использоваться для самых разных целей.Пользователи, которые участвовали в контрольной группе, увидели оригинальный нечеткий подход. elasticSearch частичный поиск точное совпадение анализатор ngram код фильтра http codeplastick. boost 1. Во время индексации целевые поля автозаполнения должны быть проанализированы с помощью специального анализатора с использованием фильтра маркеров граничной диаграммы. Когда база данных должна найти релевантный материал из поисковых запросов, введенных пользователями, база данных должна научиться ожидать и обрабатывать как ожидаемые, так и неожиданные идентификаторы нечетких запросов Идентификатор запроса Elasticsearch Пользовательские анализаторы edge_ngram tokenizer Elasticsearch Nori Analyzer Ngram Edge Ngram Elasticsearch.RubyGems. панини фазланд. 19 ноября 2015 г. 16 37 52 UTC Распределение Эластичная модель В отличие от популярной поисковой системы Solr ElasticSearch использует JSON без схемы вместо XML и работает как двоичный файл, не требуя внешнего сервера Java. В ElasticPress 3.0 beta8 2015. Elasticsearch dsl — это библиотека высокого уровня, основанная на elasticsearch py, которая является библиотекой низкого уровня для взаимодействия с Elasticsearch. нграм. давайте покажем использование на примере. Если пользователь ищет Nile на платформе, ElasticSearch будет. В Elasticsearch край n граммов будет использоваться для реализации функции автозаполнения.Этот подход предполагает использование различных анализаторов индекса и времени запроса. Шаг 1. Имейте правильное определение индекса FTS для полей, которые необходимо заполнять автоматически. Прежде чем использовать нечеткий запрос, мы введем термин «нечеткость». Например, у меня есть много записей, в которых в качестве job_title указано «Android-разработчик», когда пользователь выдает неверное задание поиска. 4 января 2018 г. Я 39 м пытался заставить фильтр nGram работать с нечетким поиском, но он выиграл 39 т. Станьте участником и улучшите сайт сами.Это означает, что очень важно иметь гибкий механизм подсчета очков. . Результирующий индекс использовал менее мегабайта хранилища. апач. С Elasticsearch Распространенная и частая проблема, с которой я сталкиваюсь при разработке функций поиска в ElasticSearch, заключалась в том, чтобы найти решение, при котором я мог бы находить документы по частям слова, например, с помощью функции предложения. Cos Elasticsearch федерико. Скачать файл PBIX Очистка данных.Например, ngram_range 1 1 означает только униграммы. 1 2 означает униграммы и биграммы, а 2 2 означает только одно. Кроме того, процесс анализа ngram может создать множество токенов, что недружелюбно к памяти. Выберите формат загрузки Поиск нечеткого текста Elasticsearch Загрузить Поиск нечеткого текста Elasticsearch PDF Загрузить документ поиска нечеткого текста Elasticsearch Несмотря на все виды нечетких совпадений условий запроса, чтобы выполнить сложный или довольно эластичный поиск, нечеткий поиск php Intereting Posts ElasticSearch нечеткое весеннее облако mybatis spring boot React python ElasticSearch fuzzy Elasticsearch Suggester quot Предлагать при вводе quot Средство просмотра Elasticsearch 100 Ngram 2.Для наших нужд он оптимизирует простоту и мощность. СЕТЬ. NET Core RC2 обновлен до версии elasticsearch 2. tree three. Это ограничение по умолчанию можно изменить с помощью индекса. tgz 12 мар 2020 01 08 174kB 2048 cli 0. Например, 3 3 грамма или триграммы, если хотите. Elasticsearch представил новую структуру данных Finite State Transducer FST, которая напоминает структуру данных большого графа. Я хочу сделать нечеткий поиск, чтобы пользователь мог получить результат, если он неправильно написал ключевое слово запроса.эластичный поиск ngram нечеткий
Звук, беглость речи, словарный запас и понимание для второклассников
Ко времени начала второго класса большинство детей уже умеют читать. Часто к этому моменту дети и родители перестают читать вместе, но чтение вслух по-прежнему является отличным способом развить его навыки и весело провести время вместе.
Если ваш ребенок плохо читает во втором классе, примите меры. Поговорите с его учителем о том, что вас беспокоит, и посмотрите, что рекомендует школа.Исследования показывают, что во втором классе дети должны уверенно и свободно читать. Если этого еще не произошло с вашим ребенком, не ждите. Обратитесь в школу за помощью и информацией. Подумайте о том, чтобы выполнять дополнительную систематическую работу дома, либо с вами, либо через репетитора, который использует основанные на исследованиях методы обучения акустике, подобные тем, которые используются в продуктах и мобильных приложениях Hooked on Phonics.
Обучение чтению — огромная работа, которая включает в себя несколько ключевых частей. Вот обзор того, что входит в этот процесс и чего следует ожидать от своего второклассника.
Фонематическая осведомленность
Что это?
- Фонематическая осведомленность — это знание того, что произносимые слова можно разбить на более мелкие звуковые фрагменты. Эти звуковые единицы называются фонемами .
- Вот пример: слово летучая мышь состоит из трех фонем: звуков / b /, / a / и / t /. Когда дети знают, что эти три звука являются частью слова летучая мышь , они показывают, что у них есть фонематическая осведомленность.
Что должен знать мой второклассник?
- Ваш ребенок должен уверенно знать все звуки букв.Если она этого не делает, поговорите с ее учителем, если школа еще не связалась с вами.
Как я могу помочь своему ребенку развиваться в этой сфере?
Звук
Что это?
- Фонетика связывает знание звуков (также называемых фонем ) с буквенными символами.
- Вот пример: буква X выглядит как «X» и издает звук « ks ».
- Акустика также должна быть сильной стороной вашего второклассника.Она должна уметь произносить слова без особого труда.
- Напишите абзацы более подробно. Правописание должно приближаться к правильному на более регулярной основе во втором классе.
Как я могу помочь своему ребенку развиваться в этой сфере?
- Если акустика — проблема во втором классе, важно действовать. Поговорите с его учителем и подумайте о том, чтобы провести структурированную практику дома с помощью продуктов Hooked on Phonics или мобильных приложений с вами и / или с репетитором.
- Поощряйте ребенка брать на себя большую ответственность при озвучивании и написании слов, особенно если слова, с которыми он работает, соответствуют правилам фонетики. (Если она спросит: «Как произносится« спальня »?» «Ну, какой звук вы слышите в начале? Хорошая köpa priligy. Продолжайте». Если он застрянет — например, как написать « oo » — тогда выручайте.)
Свободное владение
Что это?
- Беглость — это способность читать слова плавно, в хорошем темпе и с выражением.
o Вот пример: если персонаж очень взволнован, голос читателя тоже должен звучать взволнованно. Ребенку не нужно останавливаться, чтобы произнести каждое слово; слова должны течь плавно.
Что должен знать мой второклассник?
- Второклассники должны читать уверенно и в хорошем темпе. Конечно, они запинаются на нескольких словах, но должны уметь обработать большинство слов в рассказе второго класса.
Как я могу помочь своему ребенку развиваться в этой сфере?
- Читайте вместе как можно чаще.
- Если ваш второклассник испытывает трудности со свободным владением языком, выбирайте рассказы, в которых используются предсказуемые рифмы и более простой выбор слов.
Словарь
Что это?
- Словарь — это словарь в голове вашего ребенка. Чем больше значений слов знает ваш ребенок, тем больше у него словарный запас.
Что должен знать мой второклассник?
- Если вы не знаете, что означает слово или как его озвучить, вы можете поискать подсказки на картинках или в остальной части предложения, чтобы понять это.
- Ваш ребенок может понимать гораздо больше значений слов, чем он может использовать в своей устной и письменной речи. Продолжайте говорить о новых словах и их значениях.
Как я могу помочь своему ребенку развиваться в этой сфере?
- Поощряйте вашего ребенка использовать более широкий диапазон слов и поощряйте его ясно и подробно выражать свои мысли. («Как прошла школа сегодня?» «Хорошо». «Расскажи поподробнее. Что-нибудь интересное произошло на перемене?»)
- Чаще читайте своему ребенку.Исследования показывают, что детские книги знакомят детей с гораздо более широким набором словарных слов, чем они обычно слышали бы в разговоре.
Понимание
Что это?
- Понимание — это понимание сути истории.
- Вот пример: способность идентифицировать главных героев рассказа, говорить о том, что они делают и что чувствуют, а также объяснять, что происходит в начале, середине и конце рассказа, — все это важные составляющие понимания прочитанного.
Что должен знать мой второклассник?
- Перескажите прочитанные им истории, включая важные детали, главное сообщение или урок.