Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- понять, как правильно в нем ставить ударение.


Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций. Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
бездельничание 1 секунда назад
ходарева 1 секунда назад
шпыгарева 1 секунда назад
фокарева 1 секунда назад
цумарева 1 секунда назад
усинский 1 секунда назад
год кролика 1 секунда назад
шумарева 2 секунды назад
мринский 2 секунды назад
нежная ласка 2 секунды назад
чемарева 2 секунды назад
шапарева 2 секунды назад
щухарева 3 секунды назад
щипарева 3 секунды назад
едигарева 3 секунды назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | достопримечательность | 37 слов | 5 часов назад | 213.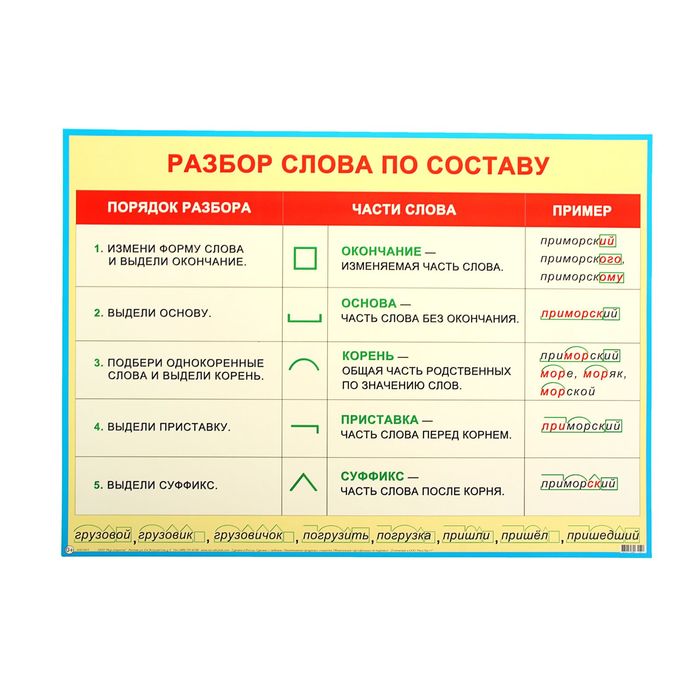 59.248.62 59.248.62 |
| Игрок 2 | воздухонепроницаемость | 67 слов | 5 часов назад | 213.59.248.62 |
| Игрок 3 | фундаментальность | 27 слов | 5 часов назад | 213.59.248.62 |
| Игрок 4 | первооткрывательница | 34 слова | 6 часов назад | 213.59.248.62 |
| Игрок 5 | электролампа | 24 слова | 6 часов назад | 213.59.248.62 |
| Игрок 6 | виноторговля | 21 слово | 6 часов назад | 213.59.248.62 |
| Игрок 7 | океанография | 22 слова | 6 часов назад | 213.59.248.62 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | муковоз | 5:4 | 55 секунд назад | 94. 51.52.160 51.52.160 |
| Игрок 2 | волостель | 0:0 | 1 час назад | 83.220.237.187 |
| Игрок 3 | абрикосик | 218:210 | 1 час назад | 188.190.68.6 |
| Игрок 4 | океан | 51:47 | 2 часа назад | 89.113.136.48 |
| Игрок 5 | таран | 53:53 | 2 часа назад | 89.113.136.48 |
| Игрок 6 | мышка | 47:48 | 2 часа назад | 78.132.206.97 |
| Игрок 7 | мышка | 0:0 | 2 часа назад | 78.132.206.97 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Марина | На одного | 10 вопросов | 5 часов назад | 5. 228.158.31 228.158.31 |
| Ляйля | На одного | 10 вопросов | 6 часов назад | 213.59.248.62 |
| Сладкий пупс | На одного | 10 вопросов | 22 часа назад | 188.186.209.238 |
| Сергей | На одного | 5 вопросов | 1 день назад | 83.234.52.224 |
| Оля | На одного | 5 вопросов | 1 день назад | 83.234.52.224 |
| Пенал | На одного | 20 вопросов | 1 день назад | 178.235.191.115 |
| Настя | На одного | 10 вопросов | 2 дня назад | 212.58.119.40 |
| Играть в Чепуху! | ||||
Морфологический разбор слова «отсутствующий»
Часть речи: Причастие
ОТСУТСТВУЮЩИЙ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ОТСУТСТВОВАТЬ»
| Слово | Морфологические признаки |
|---|---|
| ОТСУТСТВУЮЩИЙ |
|
| ОТСУТСТВУЮЩИЙ |
|
Все формы слова ОТСУТСТВУЮЩИЙ
ОТСУТСТВОВАТЬ, ОТСУТСТВУЮ, ОТСУТСТВУЕМ, ОТСУТСТВУЕШЬ, ОТСУТСТВУЕТЕ, ОТСУТСТВУЕТ, ОТСУТСТВУЮТ, ОТСУТСТВОВАЛ, ОТСУТСТВОВАЛА, ОТСУТСТВОВАЛО, ОТСУТСТВОВАЛИ, ОТСУТСТВУЯ, ОТСУТСТВОВАВШИ, ОТСУТСТВУЙ, ОТСУТСТВУЙТЕ, ОТСУТСТВУЮЩИЙ, ОТСУТСТВУЮЩЕГО, ОТСУТСТВУЮЩЕМУ, ОТСУТСТВУЮЩИМ, ОТСУТСТВУЮЩЕМ, ОТСУТСТВУЮЩАЯ, ОТСУТСТВУЮЩЕЙ, ОТСУТСТВУЮЩУЮ, ОТСУТСТВУЮЩЕЮ, ОТСУТСТВУЮЩЕЕ, ОТСУТСТВУЮЩИЕ, ОТСУТСТВУЮЩИХ, ОТСУТСТВУЮЩИМИ, ОТСУТСТВОВАВШИЙ, ОТСУТСТВОВАВШЕГО, ОТСУТСТВОВАВШЕМУ, ОТСУТСТВОВАВШИМ, ОТСУТСТВОВАВШЕМ, ОТСУТСТВОВАВШАЯ, ОТСУТСТВОВАВШЕЙ, ОТСУТСТВОВАВШУЮ, ОТСУТСТВОВАВШЕЮ, ОТСУТСТВОВАВШЕЕ, ОТСУТСТВОВАВШИЕ, ОТСУТСТВОВАВШИХ, ОТСУТСТВОВАВШИМИ
Разбор слова по составу отсутствующий
отсутствующ
ий
| Основа слова | отсутствующ |
|---|---|
| Приставка | от |
| Корень | сутств |
| Суффикс | у |
| Суффикс | ющ |
| Окончание | ий |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ОТСУТСТВУЮЩИЙ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «отсутствующий»
Примеры предложений со словом «отсутствующий»
1
Отсутствующий зуб на краю улыбки.
Ищу человека (сборник), Сергей Довлатов
2
У вас такой отсутствующий взгляд, господин Нагель, вы что, не разделяете моего мнения?
Мистерии, Кнут Гамсун, 1892г.
3
У Лолы был отсутствующий вид, Бориса охватило желание причинить ей боль, и, чтобы уязвить ее, он добавил:
Возраст зрелости, Жан-Поль Сартр, 1945г.
4
черные волосы, мечтательно-отсутствующий взгляд;
Антон Райзер, Карл Филипп Мориц, 1790г.
5
Тот сидел и меланхолично ел овсянку, взгляд его был какой-то отсутствующий, полный тоски.
Мартин Иден, Джек Лондон, 1909г.
Найти еще примеры предложений со словом ОТСУТСТВУЮЩИЙ
NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики (книга)
NEWCAT: Разбор естественного языка с помощью левоассоциативной грамматики (книга) | ОСТИ.GOVперейти к основному содержанию
- Полная запись
- Другое связанное исследование
 Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на построении и сокращении валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа удваивается как лингвистический анализ. Левоассоциативная грамматика иллюстрируется двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.
Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на построении и сокращении валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа удваивается как лингвистический анализ. Левоассоциативная грамматика иллюстрируется двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.- Авторов:
- Хауссер, Р.
- Дата публикации:
- Идентификатор ОСТИ:
- 6721611
- Тип ресурса:
- Книга
- Страна публикации:
- США
- Язык:
- Английский
- Тема:
- 99 ОБЩИЕ И РАЗНЫЕ // МАТЕМАТИКА, ВЫЧИСЛИТЕЛЬНАЯ И ИНФОРМАЦИОННАЯ НАУКА; ЕСТЕСТВЕННЫЙ ЯЗЫК; АЛГОРИТМЫ; КОМПЬЮТЕРНЫЕ РАСЧЕТЫ; ЭФФЕКТИВНОСТЬ; N КОДОВ; СТАНДАРТНАЯ ТЕРМИНОЛОГИЯ; КОМПЬЮТЕРНЫЕ КОДЫ; МАТЕМАТИЧЕСКАЯ ЛОГИКА; ЯЗЫКИ ПРОГРАММИРОВАНИЯ; 990200* — Математика и компьютеры
Форматы цитирования
- MLA
- АПА
- Чикаго
- БибТекс
Хауссер, Р. NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики . США: Н. П., 1986.
Веб.
NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики . США: Н. П., 1986.
Веб.
Копировать в буфер обмена
Хауссер, Р. NEWCAT: Разбор естественного языка с использованием левоассоциативной грамматики . Соединенные Штаты.
Копировать в буфер обмена
Хауссер, Р. 1986.
«NEWCAT: анализ естественного языка с использованием левоассоциативной грамматики». Соединенные Штаты.
Копировать в буфер обмена
@статья{osti_6721611,
title = {NEWCAT: анализ естественного языка с использованием левоассоциативной грамматики},
автор = {Хауссер, Р},
abstractNote = {Эта книга показывает, что анализ составной структуры приводит к нерегулярному порядку линейной композиции, что является прямой причиной крайней неэффективности вычислений. Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на построении и сокращении валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа удваивается как лингвистический анализ. Левоассоциативная грамматика иллюстрируется двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.},
Он предлагает альтернативную левоассоциативную грамматику, которая работает с регулярным порядком линейных композиций. Левоассоциативная грамматика основана на построении и сокращении валентностей. Левоассоциативные синтаксические анализаторы отличаются от всех других систем тем, что история синтаксического анализа удваивается как лингвистический анализ. Левоассоциативная грамматика иллюстрируется двумя левоассоциативными синтаксическими анализаторами естественного языка: одним для немецкого и одним для английского.},
дои = {},
URL = {https://www.osti.gov/biblio/6721611},
журнал = {},
номер =,
объем = ,
место = {США},
год = {1986},
месяц = {1}
}
Копировать в буфер обмена
Дополнительную информацию о получении полнотекстового документа см. в разделе «Доступность документа». Постоянные посетители библиотек могут искать в WorldCat библиотеки, в которых хранится эта книга.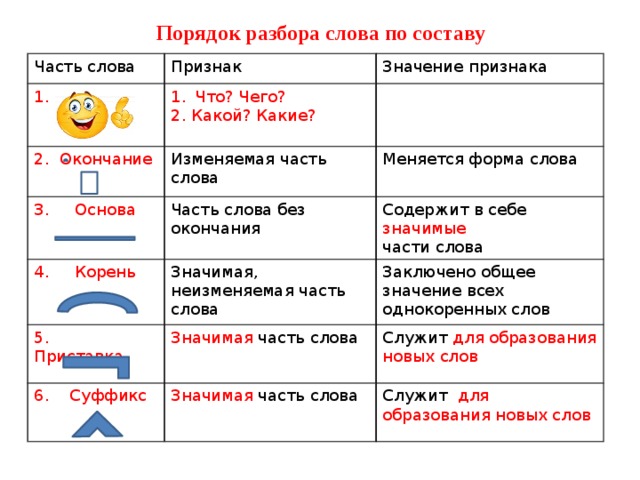
Экспорт метаданных
Сохранить в мою библиотеку
Вы должны войти в систему или создать учетную запись, чтобы сохранять документы в своей библиотеке.
Аналогичных записей в сборниках OSTI.GOV:
- Аналогичные записи
chempy.util.parsing — документация chempy 0.4.1
# -*- кодировка: utf-8 -*- """ Функции для химических формул и реакций """ из __future__ import (absolute_import, Division, print_function) из коллекций импортировать defaultdict импортировать повторно предупреждения об импорте из .pyutil import ChemPyDeprecationWarning, memoize parsing_library = 'pyparsing' # информация, используемая для выборочного тестирования. @memoize() защита _get_formula_parser(): """ Создать прямой анализатор химических формул BNF для простой химической формулы (без вложения) целое :: '0'.[документы] def атомный_номер (имя): пытаться: возврат символов.индекс (имя) + 1 кроме ValueError: вернуть нижние_имена.индекс(имя.нижний()) + 1 # Данные в '_relative_atomic_masses' находятся под лицензией CC-SA. # https://en.wikipedia.org/w/index.php?title=List_of_elements&oldid=700476748
_relative_atomic_masses = ( "1,008 4,002602(2) 6,94 9,0121831(5) 10,81 12,011 14,007 15,999" " 18,998403163(6) 20,1797(6) 22,98976928(2) 24,305 26,9815385(7) 28,085" 30,973761998(5) 32,06 35,45 39,948(1) 39,0983(1) 40,078(4)" " 44,955908(5) 47,867(1) 50,9415(1) 51,9961(6) 54,938044(3) 55,845(2)" " 58,933194(4) 58,6934(4) 63,546(3) 65,38(2) 69,723(1) 72,630(8)" " 74,921595(6) 78,971(8) 79,904 83,798(2) 85,4678(3) 87,62(1)" " 88,90584(2) 91,224(2) 92,90637(2) 95,95(1) [98] 101,07(2) 102,90550(2)" " 106,42(1) 107,8682(2) 112,414(4) 114,818(1) 118,710(7) 121,760(1)" " 127,60(3) 126,90447(3) 131,293(6) 132,90545196(6) 137,327(7)" " 138,90547(7) 140,116(1) 140,90766(2) 144.[документы] def mass_from_composition (состав): """ Расчет молекулярной массы по атомным весам Параметры ---------- состав: дикт.
защита _get_charge (chgstr): если chgstr == '+': вернуть 1 Элиф chgstr == '-': возврат -1 для токена, анти, знака zip('+-', '-+', (1, -1)): если токен в chgstr: если анти в chgstr: поднять ValueError("Неверное описание платежа (+ и - присутствует)") до, после = chgstr.split(токен) если len(до) > 0 и len(после) > 0: поднять ValueError("Значения как до, так и после токена оплаты") если len(до) > 0: # will_be_missing_in='0.[docs]def Formula_to_composition(формула, префиксы=Нет, суффиксы=('(s)', '(l)', '(g)', '(aq)')): """ Составление разбора формулы, представляющей химическую формулу Композиция представлена как отображение словаря int -> int (atomic число -> кратность). «Атомный номер» 0 представляет собой чистый заряд. Параметры ---------- формула: ул. Химическая формула, например «h3O», «Fe+3», «Cl-» префиксы: итерируемые строки Префиксы для игнорирования, например. ('.', 'альфа-') суффиксы: кортеж строк Суффиксы, которые следует игнорировать, например. ('(г)', '(с)') Примеры -------- >>> Formula_to_composition('Nh5+') == {0:1, 1:4, 7:1} Истинный >>> Formula_to_composition('.NHO-(водн.)') == {0:-1, 1:1, 7:1, 8:1} Истинный >>> Formula_to_composition('Na2CO3.
def _subs (строка, шаблоны): для patt, repl в Patterns.items(): строка = строка.заменить (patt, repl) возвращаемая строка def _parse_multiplicity (строки, essential_keys = нет): """ Примеры -------- >>> _parse_multiplicity(['2 h3O2', 'O2']) == {'h3O2': 2, 'O2': 1} Истинный >>> _parse_multiplicity(['2 * h3O2', 'O2']) == {'h3O2': 2, 'O2': 1} Истинный >>> _parse_multiplicity(['']) == {} Истинный """ результат = {} для элементов в [re.[docs]def to_reaction(line, essential_keys, token, Cls, globals_=None, **kwargs): """ Разбирает строку на объект реакции и вещества Reac1 + 2 Reac2 + (2 Reac1) -> Prod1 + Prod2; 10**3,7; ссылка='doi:12/ab' Reac1 = Prod1; 2.1; Параметры ---------- строка: ул. строковое представление для анализа substant_keys: итерация строк Допустимые имена, например. ('h3O', 'H+', 'OH-') жетон: ул. токен-разделитель между реагентом и продуктом Класс: класс например подкласс реакции globals_: словарь (необязательно) Глобальные переменные передаются :func:`eval`, когда ``None``: `chempy.
def _formula_to_format (sub, sup, формула, префиксы = нет, инфиксы = нет, суффиксы = ('(s)', '(l)', '(g)', '(aq)')): части = _formula_to_parts (формула, префиксы.ключи(), суффиксы) стехи = части[0].[docs]def Formula_to_latex(формула, префиксы=Нет, инфиксы=Нет, **kwargs): r""" Преобразование строки формулы в латексное представление Параметры ---------- формула: ул. Химическая формула, например «h3O», «Fe+3», «Cl-» префиксы: дикт Префиксные преобразования, по умолчанию: греческие буквы и .
_unicode_sub = {} для k, v в enumerate(u"₀₁₂₃₄₅₆₇₈₉"): _unicode_sub[str(k)] = v _unicode_sup = { '+': у'⁺', '-': у'⁻', } для k, v в enumerate(u"⁰¹²³⁴⁵⁶⁷⁸⁹"): _unicode_sup[str(k)] = v[docs]def Formula_to_Unicode(формула, префиксы=Нет, инфиксы=Нет, **kwargs): u""" Преобразование строки формулы в строковое представление Unicode Параметры ---------- формула: ул. Химическая формула, например «h3O», «Fe+3», «Cl-» префиксы: дикт Префиксные преобразования, по умолчанию: греческие буквы и . инфиксы: дикт Инфиксные преобразования, по умолчанию: . суффиксы: кортеж строк Суффиксы, которые нужно сохранить, например. ('(г)', '(с)') Примеры -------- >>> Formula_to_unicode('Nh5+') == u'NH₄⁺' Истинный >>> Formula_to_unicode('Fe(CN)6+2') == u'Fe(CN)₆²⁺' Истинный >>> Formula_to_unicode('Fe(CN)6+2(водн.
[docs]def number_to_scientific_unicode(число, fmt='%.3g'): ты""" Примеры -------- >>> number_to_scientific_unicode(3.14) == u'3.14' Истинный >>> number_to_scientific_unicode(3.14159265e-7) == u'3.14·10⁻⁷' Истинный >>> количество импорта как pq >>> number_to_scientific_html(2**0,5 * pq.m / pq.s) «1,41 м/с» """ пытаться: единица измерения = ' ' + число.размерность.юникод число = число.величина кроме AttributeError: единица = '' s = fmt% число если 'e' в s: префикс, суффикс = s.
[docs]def Formula_to_html(формула, префиксы=Нет, инфиксы=Нет, **kwargs): u""" Преобразование строки формулы в строковое представление html Параметры ---------- формула: ул. Химическая формула, например «h3O», «Fe+3», «Cl-» префиксы: дикт Префиксные преобразования, по умолчанию: греческие буквы и . инфиксы: дикт Инфиксные преобразования, по умолчанию: . суффиксы: кортеж строк Суффиксы, которые нужно сохранить, например. ('(г)', '(с)') Примеры -------- >>> Formula_to_html('Nh5+') 'NH4+' >>> Formula_to_html('Fe(CN)6+2') 'Fe(CN)62+' >>> Formula_to_html('Fe(CN)6+2(водн.)') 'Fe(CN)62+(водн.)' >>> Formula_to_html('.NHO-(водн.)') '⋅NHO-(aq)' >>> Formula_to_html('альфа-FeOOH(s)') 'α-FeOOH(s)' """ если префиксы None: префиксы = _html_mapping если инфиксы равны None: инфиксы = _html_infix_mapping вернуть _formula_to_format(лямбда x: '%s' % x, лямбда x: '%s' % x, формула, префиксы, инфиксы, **kwargs)
[docs]def number_to_scientific_html(число, fmt='%.
 .'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: элемент [целое число]
формула :: срок+
BNF для вложенной химической формулы
целое :: '0'..'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: (элемент | '(' формула ')') [целое число]
формула :: срок+
Заметки
-----
Код этой функции взят из ответа на StackOverflow:
http://stackoverflow.com/a/18555142/790973
написано:
Пол Макгуайр, http://stackoverflow.com/users/165216/paul-mcguire
в ответ на вопрос, сформулированный:
Thales MG, http://stackoverflow.com/users/2708711/thales-mg
код находится под лицензией «CC-WIKI».
(см.: http://blog.stackoverflow.com/2009/06/требуется указание авторства/)
"""
_p = __import__(parsing_library)
Вперед, Группа, Один или несколько = _p.Forward, _p.Group, _p.OneOrMore
Необязательно, ParseResults, Regex = _p.Optional, _p.ParseResults, _p.Regex
Подавить, Word, nums = _p.Suppress, _p.
.'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: элемент [целое число]
формула :: срок+
BNF для вложенной химической формулы
целое :: '0'..'9'+
элемент :: 'A'..'Z' 'a'..'z'*
термин :: (элемент | '(' формула ')') [целое число]
формула :: срок+
Заметки
-----
Код этой функции взят из ответа на StackOverflow:
http://stackoverflow.com/a/18555142/790973
написано:
Пол Макгуайр, http://stackoverflow.com/users/165216/paul-mcguire
в ответ на вопрос, сформулированный:
Thales MG, http://stackoverflow.com/users/2708711/thales-mg
код находится под лицензией «CC-WIKI».
(см.: http://blog.stackoverflow.com/2009/06/требуется указание авторства/)
"""
_p = __import__(parsing_library)
Вперед, Группа, Один или несколько = _p.Forward, _p.Group, _p.OneOrMore
Необязательно, ParseResults, Regex = _p.Optional, _p.ParseResults, _p.Regex
Подавить, Word, nums = _p.Suppress, _p.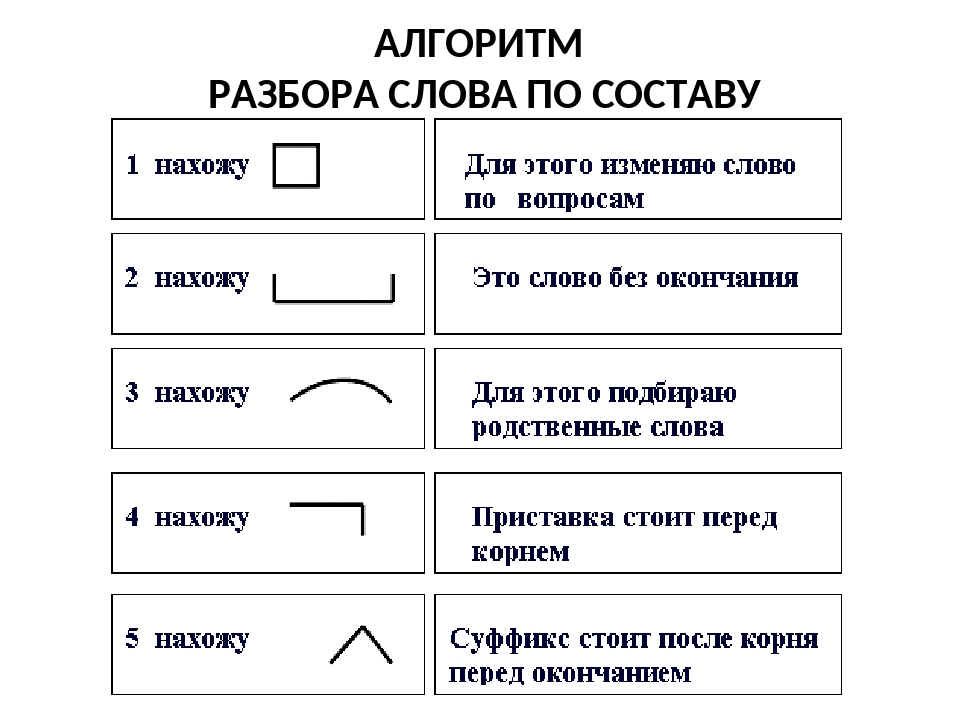 Word, _p.nums
LPAR, RPAR = карта (подавить, "()")
целое число = слово (числа)
# добавить действие синтаксического анализа для преобразования целых чисел в целые, чтобы поддерживать сложение
# и умножение во время разбора
integer.setParseAction (лямбда t: int (t [0]))
# element = Word(alphas.upper(), alphas.lower())
# или, если вы хотите быть более конкретным, используйте это регулярное выражение
элемент = регулярное выражение (
r"A[cglmrstu]|B[aehikr]?|C[adeflmorsu]?|D[bsy]|E[rsu]|F[emr]?|"
"G[ade]|H[efgos]?|I[nr]?|Kr?|L[airu]|M[dgnot]|N[abdeiop]?|"
"Os?|P[abdmortu]?|R[abefghnu]|S[bcegimnr]?|T[abcehilm]|"
"Uu[bhopqst]|U|V|W|Xe|Yb?|Z[nr]")
# вперед объявить 'формулу', чтобы ее можно было использовать в определении 'термина'
формула = Вперед()
термин = Группа((элемент | Группа(LPAR + формула + RPAR)("подгруппа")) +
Необязательно (целое число, по умолчанию = 1) ("несколько"))
# определить содержимое формулы как один или несколько терминов
формула << Один или больше (термин)
# добавить действия парсинга для обработки во время разбора
# действие синтаксического анализа для умножения подгрупп
def multiContents (токены):
т = токены [0]
# если эти токены содержат подгруппу, то используйте множитель для
# увеличить количество всех элементов в подгруппе
если t.
Word, _p.nums
LPAR, RPAR = карта (подавить, "()")
целое число = слово (числа)
# добавить действие синтаксического анализа для преобразования целых чисел в целые, чтобы поддерживать сложение
# и умножение во время разбора
integer.setParseAction (лямбда t: int (t [0]))
# element = Word(alphas.upper(), alphas.lower())
# или, если вы хотите быть более конкретным, используйте это регулярное выражение
элемент = регулярное выражение (
r"A[cglmrstu]|B[aehikr]?|C[adeflmorsu]?|D[bsy]|E[rsu]|F[emr]?|"
"G[ade]|H[efgos]?|I[nr]?|Kr?|L[airu]|M[dgnot]|N[abdeiop]?|"
"Os?|P[abdmortu]?|R[abefghnu]|S[bcegimnr]?|T[abcehilm]|"
"Uu[bhopqst]|U|V|W|Xe|Yb?|Z[nr]")
# вперед объявить 'формулу', чтобы ее можно было использовать в определении 'термина'
формула = Вперед()
термин = Группа((элемент | Группа(LPAR + формула + RPAR)("подгруппа")) +
Необязательно (целое число, по умолчанию = 1) ("несколько"))
# определить содержимое формулы как один или несколько терминов
формула << Один или больше (термин)
# добавить действия парсинга для обработки во время разбора
# действие синтаксического анализа для умножения подгрупп
def multiContents (токены):
т = токены [0]
# если эти токены содержат подгруппу, то используйте множитель для
# увеличить количество всех элементов в подгруппе
если t. подгруппа:
мульт = t.мульт
для срока в т.подгруппе:
термин[1] *= несколько
вернуть t.subgroup
term.setParseAction (умножить содержимое)
# добавить действие синтаксического анализа для суммирования нескольких ссылок на один и тот же элемент
def sumByElement (токены):
elementsList = [t[0] для t в токенах]
# набор конструкций для проверки наличия дубликатов
дубликаты = len (список элементов) > len (набор (список элементов))
# если есть повторяющиеся имена элементов, суммировать по элементам и
# вернуть новый вложенный ParseResults
если дубликаты:
ctr = defaultdict (целое число)
для t в токенах:
ctr[t[0]] += t[1]
вернуть ParseResults([ParseResults([k, v]) для k, v в ctr.items()])
формула.setParseAction (sumByElement)
формула возврата
символы = (
«H», «He», «Li», «Be», «B», «C», «N», «O», «F», «Ne», «Na», «Mg», «Al». ',
«Si», «P», «S», «Cl», «Ar», «K», «Ca», «Sc», «Ti», «V», «Cr», «Mn», «Fe ',
«Co», «Ni», «Cu», «Zn», «Ga», «Ge», «As», «Se», «Br», «Kr», «Rb», «Sr»,
«Y», «Zr», «Nb», «Mo», «Tc», «Ru», «Rh», «Pd», «Ag», «Cd», «In», «Sn»,
«Sb», «Te», «I», «Xe», «Cs», «Ba», «La», «Ce», «Pr», «Nd», «Pm», «Sm»,
«Eu», «Gd», «Tb», «Dy», «Ho», «Er», «Tm», «Yb», «Lu», «Hf», «Ta», «W»,
«Re», «Os», «Ir», «Pt», «Au», «Hg», «Tl», «Pb», «Bi», «Po», «At», «Rn»,
«Fr», «Ra», «Ac», «Th», «Pa», «U», «Np», «Pu», «Am», «Cm», «Bk», «Cf»,
«Es», «Fm», «Md», «No», «Lr», «Rf», «Db», «Sg», «Bh», «Hs», «Mt», «Ds»,
«Rg», «Cn», «Uut», «Fl», «Uup», «Lv», «Uus», «Uuo»
)
имена = (
«Водород», «Гелий», «Литий», «Бериллий»,
«Бор», «Углерод», «Азот», «Кислород», «Фтор», «Неон», «Натрий»,
«Магний», «Алюминий», «Кремний», «Фосфор», «Сера»,
«Хлор», «Аргон», «Калий», «Кальций», «Скандий», «Титан»,
«Ванадий», «Хром», «Марганец», «Железо», «Кобальт», «Никель»,
«Медь», «Цинк», «Галлий», «Германий», «Мышьяк», «Селен»,
«Бром», «Криптон», «Рубидий», «Стронций», «Иттрий», «Цирконий»,
«Ниобий», «Молибден», «Технеций», «Рутений», «Родий»,
«Палладий», «Серебро», «Кадмий», «Индий», «Олово», «Сурьма»,
«Теллур», «Йод», «Ксенон», «Цезий», «Барий», «Лантан»,
«Церий», «Празеодим», «Неодим», «Прометий», «Самарий»,
«Европий», «Гадолиний», «Тербий», «Диспрозий», «Гольмий»,
«Эрбий», «Тулий», «Иттербий», «Лютеций», «Гафний», «Тантал»,
«Вольфрам», «Рений», «Осмий», «Иридий», «Платина», «Золото»,
«Ртуть», «Таллий», «Свинец», «Висмут», «Полоний», «Астатин»,
«Радон», «Франций», «Радий», «Актиний», «Торий», «Протактиний»,
«Уран», «Нептуний», «Плутоний», «Америций», «Кюрий»,
«Берклиум», «Калифорний», «Эйнштейниум», «Фермиум», «Менделевий»,
«Нобелий», «Лавренций», «Резерфордий», «Дубний», «Сиборгий»,
«борий», «хассиум», «мейтнерий», «дармштадтий», «рентгений»,
«Копернициум», «(Унунтриум)», «Флеровиум», «(Унунпентий)»,
'Ливермориум', '(Унунсептиум)', '(Унуноктиум)'
)
lower_names = tuple(n.
подгруппа:
мульт = t.мульт
для срока в т.подгруппе:
термин[1] *= несколько
вернуть t.subgroup
term.setParseAction (умножить содержимое)
# добавить действие синтаксического анализа для суммирования нескольких ссылок на один и тот же элемент
def sumByElement (токены):
elementsList = [t[0] для t в токенах]
# набор конструкций для проверки наличия дубликатов
дубликаты = len (список элементов) > len (набор (список элементов))
# если есть повторяющиеся имена элементов, суммировать по элементам и
# вернуть новый вложенный ParseResults
если дубликаты:
ctr = defaultdict (целое число)
для t в токенах:
ctr[t[0]] += t[1]
вернуть ParseResults([ParseResults([k, v]) для k, v в ctr.items()])
формула.setParseAction (sumByElement)
формула возврата
символы = (
«H», «He», «Li», «Be», «B», «C», «N», «O», «F», «Ne», «Na», «Mg», «Al». ',
«Si», «P», «S», «Cl», «Ar», «K», «Ca», «Sc», «Ti», «V», «Cr», «Mn», «Fe ',
«Co», «Ni», «Cu», «Zn», «Ga», «Ge», «As», «Se», «Br», «Kr», «Rb», «Sr»,
«Y», «Zr», «Nb», «Mo», «Tc», «Ru», «Rh», «Pd», «Ag», «Cd», «In», «Sn»,
«Sb», «Te», «I», «Xe», «Cs», «Ba», «La», «Ce», «Pr», «Nd», «Pm», «Sm»,
«Eu», «Gd», «Tb», «Dy», «Ho», «Er», «Tm», «Yb», «Lu», «Hf», «Ta», «W»,
«Re», «Os», «Ir», «Pt», «Au», «Hg», «Tl», «Pb», «Bi», «Po», «At», «Rn»,
«Fr», «Ra», «Ac», «Th», «Pa», «U», «Np», «Pu», «Am», «Cm», «Bk», «Cf»,
«Es», «Fm», «Md», «No», «Lr», «Rf», «Db», «Sg», «Bh», «Hs», «Mt», «Ds»,
«Rg», «Cn», «Uut», «Fl», «Uup», «Lv», «Uus», «Uuo»
)
имена = (
«Водород», «Гелий», «Литий», «Бериллий»,
«Бор», «Углерод», «Азот», «Кислород», «Фтор», «Неон», «Натрий»,
«Магний», «Алюминий», «Кремний», «Фосфор», «Сера»,
«Хлор», «Аргон», «Калий», «Кальций», «Скандий», «Титан»,
«Ванадий», «Хром», «Марганец», «Железо», «Кобальт», «Никель»,
«Медь», «Цинк», «Галлий», «Германий», «Мышьяк», «Селен»,
«Бром», «Криптон», «Рубидий», «Стронций», «Иттрий», «Цирконий»,
«Ниобий», «Молибден», «Технеций», «Рутений», «Родий»,
«Палладий», «Серебро», «Кадмий», «Индий», «Олово», «Сурьма»,
«Теллур», «Йод», «Ксенон», «Цезий», «Барий», «Лантан»,
«Церий», «Празеодим», «Неодим», «Прометий», «Самарий»,
«Европий», «Гадолиний», «Тербий», «Диспрозий», «Гольмий»,
«Эрбий», «Тулий», «Иттербий», «Лютеций», «Гафний», «Тантал»,
«Вольфрам», «Рений», «Осмий», «Иридий», «Платина», «Золото»,
«Ртуть», «Таллий», «Свинец», «Висмут», «Полоний», «Астатин»,
«Радон», «Франций», «Радий», «Актиний», «Торий», «Протактиний»,
«Уран», «Нептуний», «Плутоний», «Америций», «Кюрий»,
«Берклиум», «Калифорний», «Эйнштейниум», «Фермиум», «Менделевий»,
«Нобелий», «Лавренций», «Резерфордий», «Дубний», «Сиборгий»,
«борий», «хассиум», «мейтнерий», «дармштадтий», «рентгений»,
«Копернициум», «(Унунтриум)», «Флеровиум», «(Унунпентий)»,
'Ливермориум', '(Унунсептиум)', '(Унуноктиум)'
)
lower_names = tuple(n. lower().lstrip('(').rstrip(')') для n в именах)
lower().lstrip('(').rstrip(')') для n в именах) 242(3) [145] 150.36(2)"
" 151,964(1) 157,25(3) 158,92535(2) 162,500(1) 164,93033(2) 167,259(3)"
" 168,93422(2) 173,045(10) 174,9668(1) 178,49(2) 180,94788(2) 183,84(1)"
" 186,207(1) 190,23(3) 192,217(3) 195,084(9) 196,966569(5) 200,592(3)"
" 204,38 207,2(1) 208,98040(1) [209] [210] [222] [223] [226] [227]"
" 232.0377(4) 231.03588(2) 238.02891(3) [237] [244] [243] [247] [247]"
"[251] [252] [257] [258] [259] [266] [267] [268] [269] [270] [269]"
"[278] [281] [282] [285] [286] [289] [289] [293] [294] [294]"
)
защита _get_relative_atomic_masses():
для массы в _relative_atomic_masses.split():
если mass.startswith('[') и mass.endswith(']'):
выход с плавающей запятой (масса [1: -1])
элиф '(' по массе:
выход с плавающей запятой (mass.split ('(') [0])
еще:
доходность (плавающая (масса))
относительные_атомные_массы = кортеж (_get_relative_atomic_masses())
242(3) [145] 150.36(2)"
" 151,964(1) 157,25(3) 158,92535(2) 162,500(1) 164,93033(2) 167,259(3)"
" 168,93422(2) 173,045(10) 174,9668(1) 178,49(2) 180,94788(2) 183,84(1)"
" 186,207(1) 190,23(3) 192,217(3) 195,084(9) 196,966569(5) 200,592(3)"
" 204,38 207,2(1) 208,98040(1) [209] [210] [222] [223] [226] [227]"
" 232.0377(4) 231.03588(2) 238.02891(3) [237] [244] [243] [247] [247]"
"[251] [252] [257] [258] [259] [266] [267] [268] [269] [270] [269]"
"[278] [281] [282] [285] [286] [289] [289] [293] [294] [294]"
)
защита _get_relative_atomic_masses():
для массы в _relative_atomic_masses.split():
если mass.startswith('[') и mass.endswith(']'):
выход с плавающей запятой (масса [1: -1])
элиф '(' по массе:
выход с плавающей запятой (mass.split ('(') [0])
еще:
доходность (плавающая (масса))
относительные_атомные_массы = кортеж (_get_relative_atomic_masses()) Словарь, отображающий int (атомный номер) в int (коэффициент)
Возвращает
-------
плавать
молекулярная масса в атомных единицах массы
Заметки
-----
Атомный номер 0 обозначает заряд или «чистый электронный дефицит».
Примеры
--------
>>> '%.2f' % mass_from_composition({0:-1, 1:1, 8:1})
'17.01'
"""
масса = 0,0
для k, v в композиции.items():
если k == 0: # электрон
масса -= v*5,489е-4
еще:
масса += v*relative_atomic_masses[k-1]
масса возврата
Словарь, отображающий int (атомный номер) в int (коэффициент)
Возвращает
-------
плавать
молекулярная масса в атомных единицах массы
Заметки
-----
Атомный номер 0 обозначает заряд или «чистый электронный дефицит».
Примеры
--------
>>> '%.2f' % mass_from_composition({0:-1, 1:1, 8:1})
'17.01'
"""
масса = 0,0
для k, v в композиции.items():
если k == 0: # электрон
масса -= v*5,489е-4
еще:
масса += v*relative_atomic_masses[k-1]
масса возврата 5.0'
warnings.warn("'Fe/3+' устарело, используйте, например, 'Fe+3'",
ChemPyDeprecationWarning, уровень стека = 3)
знак возврата * int (1, если раньше == '' еще раньше)
если длина (после) > 0:
знак возврата * int (1, если после == '' еще после)
поднять ValueError("Неверное описание платежа (+ или - отсутствует)")
def _formula_to_parts (формула, префиксы, суффиксы):
# Отбросить префиксы и суффиксы
drop_pref, drop_suff = [], []
для ign в префиксах:
если формула.startswith(ign):
drop_pref.append(ign)
формула = формула[len(ign):]
для ign в суффиксах:
если формула.заканчивается(ign):
drop_suff.append(ign)
формула = формула[:-len(ign)]
# Добыча заряда
если '/' в формуле:
# will_be_missing_in='0.5.0'
warnings.warn("/ depr. (до 0.5.0): используйте 'Fe+3' вместо 'Fe/3+'",
ChemPyDeprecationWarning, уровень стека = 3)
части = формула.
5.0'
warnings.warn("'Fe/3+' устарело, используйте, например, 'Fe+3'",
ChemPyDeprecationWarning, уровень стека = 3)
знак возврата * int (1, если раньше == '' еще раньше)
если длина (после) > 0:
знак возврата * int (1, если после == '' еще после)
поднять ValueError("Неверное описание платежа (+ или - отсутствует)")
def _formula_to_parts (формула, префиксы, суффиксы):
# Отбросить префиксы и суффиксы
drop_pref, drop_suff = [], []
для ign в префиксах:
если формула.startswith(ign):
drop_pref.append(ign)
формула = формула[len(ign):]
для ign в суффиксах:
если формула.заканчивается(ign):
drop_suff.append(ign)
формула = формула[:-len(ign)]
# Добыча заряда
если '/' в формуле:
# will_be_missing_in='0.5.0'
warnings.warn("/ depr. (до 0.5.0): используйте 'Fe+3' вместо 'Fe/3+'",
ChemPyDeprecationWarning, уровень стека = 3)
части = формула. split('/')
если «+» в частях [0] или «-» в частях [0]:
поднять ValueError("Заряд необходимо разделить с помощью /")
если parts[1] не None:
wo_pm = части[1].replace('+', '').replace('-', '')
если wo_pm != '' а не str.isdigit(wo_pm):
поднять ValueError("Нецифровой спецификатор заряда")
если len(parts) > 2:
поднять ValueError("В формуле допускается не более одного '/'")
еще:
для токена в «+-»:
если токен в формуле:
если формула.счет(токен) > 1:
поднять ValueError("Несколько токенов: %s" % токен)
части = формула.split(токен)
части[1] = токен + части[1]
ломать
еще:
части = [формула, нет]
части возврата + [кортеж (drop_pref), кортеж (drop_suff [::-1])]
def _parse_stoich (стоич):
if stich == 'e': # частный случай, электрон не является элементом
возвращаться {}
return {symbols.
split('/')
если «+» в частях [0] или «-» в частях [0]:
поднять ValueError("Заряд необходимо разделить с помощью /")
если parts[1] не None:
wo_pm = части[1].replace('+', '').replace('-', '')
если wo_pm != '' а не str.isdigit(wo_pm):
поднять ValueError("Нецифровой спецификатор заряда")
если len(parts) > 2:
поднять ValueError("В формуле допускается не более одного '/'")
еще:
для токена в «+-»:
если токен в формуле:
если формула.счет(токен) > 1:
поднять ValueError("Несколько токенов: %s" % токен)
части = формула.split(токен)
части[1] = токен + части[1]
ломать
еще:
части = [формула, нет]
части возврата + [кортеж (drop_pref), кортеж (drop_suff [::-1])]
def _parse_stoich (стоич):
if stich == 'e': # частный случай, электрон не является элементом
возвращаться {}
return {symbols. \d+', s)
если len(m) == 0:
м = 1
Элиф лен(м) == 1:
с = с [лен (м [0]):]
м = интервал (м [0])
еще:
поднять ValueError("Не удалось разобрать: %s" % s)
возврат м, с
\d+', s)
если len(m) == 0:
м = 1
Элиф лен(м) == 1:
с = с [лен (м [0]):]
м = интервал (м [0])
еще:
поднять ValueError("Не удалось разобрать: %s" % s)
возврат м, с 7h3O') == {11:2, 6:1, 8:10, 1:14}
Истинный
"""
если префиксы None:
префиксы = _latex_mapping.keys()
stoich_tok, chg_tok = _formula_to_parts(формула, префиксы, суффиксы)[:2]
tot_comp = {}
части = stoich_tok.split('.')
для idx, стоич в перечислении (частях):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
comp = _parse_stoich(stoich)
для k, v в comp.items():
если k не в tot_comp:
tot_comp[k] = m*v
еще:
tot_comp[k] += m*v
если chg_tok не None:
tot_comp[0] = _get_charge(chg_tok)
вернуть tot_comp
7h3O') == {11:2, 6:1, 8:10, 1:14}
Истинный
"""
если префиксы None:
префиксы = _latex_mapping.keys()
stoich_tok, chg_tok = _formula_to_parts(формула, префиксы, суффиксы)[:2]
tot_comp = {}
части = stoich_tok.split('.')
для idx, стоич в перечислении (частях):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
comp = _parse_stoich(stoich)
для k, v в comp.items():
если k не в tot_comp:
tot_comp[k] = m*v
еще:
tot_comp[k] += m*v
если chg_tok не None:
tot_comp[0] = _get_charge(chg_tok)
вернуть tot_comp split(' \* | ', s) для s в строках]:
если len(items) == 1:
если элементы [0] == '':
Продолжать
результат[элементы[0]] = 1
Элиф Лен (предметы) == 2:
результат [предметы [1]] = int (предметы [0])
еще:
поднять ValueError("На много частей в подстроке")
если substant_keys не None:
для k в результате:
если k не в веществе_ключей:
поднять ValueError("Неизвестный ключ_вещества: %s" % k)
вернуть результат
split(' \* | ', s) для s в строках]:
если len(items) == 1:
если элементы [0] == '':
Продолжать
результат[элементы[0]] = 1
Элиф Лен (предметы) == 2:
результат [предметы [1]] = int (предметы [0])
еще:
поднять ValueError("На много частей в подстроке")
если substant_keys не None:
для k в результате:
если k не в веществе_ключей:
поднять ValueError("Неизвестный ключ_вещества: %s" % k)
вернуть результат units.default_units` используется с 'chempy'
и дополнительные записи default_units.
Заметки
-----
Эта функция вызывает :func:`eval`, поэтому существуют серьезные проблемы с безопасностью.
с запуском этого на ненадежных данных.
"""
# TODO: добавить обработку юнитов.
если globals_ равен None:
импортный химический
тарифы на импорт от chempy.kinetics
из chempy.units импортировать default_units
globals_ = {k: getattr(rates, k) для k в dir(rates)}
globals_.update({'chempy': chempy, 'default_units': default_units})
если default_units не None:
globals_.update(default_units.as_dict())
пытаться:
stoich, param, kw = map(str.strip, line.rstrip('\n').split(';'))
кроме ValueError:
если ';' в соответствии:
stoich, param = map(str.strip, line.rstrip('\n').split(';'))
еще:
stoich, param = line.strip(), kwargs.pop('param', 'Нет')
еще:
kwargs.update({} если globals_ равно False else eval('dict('+kw+')', globals_))
если isinstance (параметр, строка):
param = None, если globals_ имеет значение False, иначе eval(param, globals_)
если токен не в stich:
поднять ValueError ("Отсутствует токен: %s" % токен)
reac_prod = [[y.
units.default_units` используется с 'chempy'
и дополнительные записи default_units.
Заметки
-----
Эта функция вызывает :func:`eval`, поэтому существуют серьезные проблемы с безопасностью.
с запуском этого на ненадежных данных.
"""
# TODO: добавить обработку юнитов.
если globals_ равен None:
импортный химический
тарифы на импорт от chempy.kinetics
из chempy.units импортировать default_units
globals_ = {k: getattr(rates, k) для k в dir(rates)}
globals_.update({'chempy': chempy, 'default_units': default_units})
если default_units не None:
globals_.update(default_units.as_dict())
пытаться:
stoich, param, kw = map(str.strip, line.rstrip('\n').split(';'))
кроме ValueError:
если ';' в соответствии:
stoich, param = map(str.strip, line.rstrip('\n').split(';'))
еще:
stoich, param = line.strip(), kwargs.pop('param', 'Нет')
еще:
kwargs.update({} если globals_ равно False else eval('dict('+kw+')', globals_))
если isinstance (параметр, строка):
param = None, если globals_ имеет значение False, иначе eval(param, globals_)
если токен не в stich:
поднять ValueError ("Отсутствует токен: %s" % токен)
reac_prod = [[y. strip() для y в x.split(' + ')] для
x в stoich.split(токен)]
действовать, бездействовать = [], []
для стороны в reac_prod:
если сторона[-1].startswith('('):
если не сторона[-1].endswith(')'):
поднять ValueError("Неверный формат (отсутствует закрывающая скобка)")
inact.append(_parse_multiplicity(сторона[-1][1:-1].split(' + '),
вещества_ключи))
act.append(_parse_multiplicity(сторона[:-1],substance_keys))
еще:
inact.append({})
act.append(_parse_multiplicity(сторона, essential_keys))
# stich coeff -> dict
вернуть Cls(действие[0], действие[1], параметр, inact_reac=inact[0],
inact_prod=inact[1], **kwargs)
strip() для y в x.split(' + ')] для
x в stoich.split(токен)]
действовать, бездействовать = [], []
для стороны в reac_prod:
если сторона[-1].startswith('('):
если не сторона[-1].endswith(')'):
поднять ValueError("Неверный формат (отсутствует закрывающая скобка)")
inact.append(_parse_multiplicity(сторона[-1][1:-1].split(' + '),
вещества_ключи))
act.append(_parse_multiplicity(сторона[:-1],substance_keys))
еще:
inact.append({})
act.append(_parse_multiplicity(сторона, essential_keys))
# stich coeff -> dict
вернуть Cls(действие[0], действие[1], параметр, inact_reac=inact[0],
inact_prod=inact[1], **kwargs) split('.')
строка = ''
для idx, stoich в перечислении (stoichs):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
строка += _subs('.', инфиксы)
если м != 1:
строка += строка(м)
строка += re.sub(r'([0-9]+)', lambda m: sub(m.group(1)), stoich)
если parts[1] не None:
chg = _get_charge (части [1])
если изменение < 0:
токен = '-' если chg == -1 иначе '%d-' % -chg
если изм > 0:
token = '+', если chg == 1, иначе '%d+' % chg
строка += поддержка (токен)
если len(parts) > 4:
поднять ValueError("Неверная формула")
pre_str = ''.join (карта (лямбда x: _subs (x, префиксы), части [2]))
вернуть pre_str + string + ''.join(parts[3])
split('.')
строка = ''
для idx, stoich в перечислении (stoichs):
если idx == 0:
м = 1
еще:
м, стех = _get_leading_integer (стоич)
строка += _subs('.', инфиксы)
если м != 1:
строка += строка(м)
строка += re.sub(r'([0-9]+)', lambda m: sub(m.group(1)), stoich)
если parts[1] не None:
chg = _get_charge (части [1])
если изменение < 0:
токен = '-' если chg == -1 иначе '%d-' % -chg
если изм > 0:
token = '+', если chg == 1, иначе '%d+' % chg
строка += поддержка (токен)
если len(parts) > 4:
поднять ValueError("Неверная формула")
pre_str = ''.join (карта (лямбда x: _subs (x, префиксы), части [2]))
вернуть pre_str + string + ''.join(parts[3]) {%s}' % x,
формула, префиксы, инфиксы, **kwargs) 9{%s}' % str(int(суффикс)) + единица измерения
еще:
возврат с + единица
{%s}' % x,
формула, префиксы, инфиксы, **kwargs) 9{%s}' % str(int(суффикс)) + единица измерения
еще:
возврат с + единица )') == u'Fe(CN)₆²⁺(водн.)'
Истинный
>>> Formula_to_unicode('.NHO-(водн.)') == u'⋅NHO⁻(водн.)'
Истинный
>>> Formula_to_unicode('альфа-FeOOH(s)') == u'α-FeOOH(s)'
Истинный
"""
если префиксы None:
префиксы = _unicode_mapping
если инфиксы равны None:
инфиксы = _unicode_infix_mapping
вернуть _formula_to_format(
лямбда x: ''.join(_unicode_sub[str(_)] для _ в x),
лямбда x: ''.join(_unicode_sup[str(_)] для _ в x),
формула, префиксы, инфиксы, **kwargs)
)') == u'Fe(CN)₆²⁺(водн.)'
Истинный
>>> Formula_to_unicode('.NHO-(водн.)') == u'⋅NHO⁻(водн.)'
Истинный
>>> Formula_to_unicode('альфа-FeOOH(s)') == u'α-FeOOH(s)'
Истинный
"""
если префиксы None:
префиксы = _unicode_mapping
если инфиксы равны None:
инфиксы = _unicode_infix_mapping
вернуть _formula_to_format(
лямбда x: ''.join(_unicode_sub[str(_)] для _ в x),
лямбда x: ''.join(_unicode_sup[str(_)] для _ в x),
формула, префиксы, инфиксы, **kwargs) split('e')
возвращаемый префикс + u'·10' + u''.join(map(_unicode_sup.get, str(int(suffix)))) + unit
еще:
возврат с + единица
split('e')
возвращаемый префикс + u'·10' + u''.join(map(_unicode_sup.get, str(int(suffix)))) + unit
еще:
возврат с + единица