Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: кров тин 1 секунда назад коленка 1 секунда назад еимпдгн 2 секунды назад маркоо 2 секунды назад тьнриеег 2 секунды назад срльое 2 секунды назад тамкпяа 2 секунды назад трактве 2 секунды назад ш и р о т а 3 секунды назад лаедикт 3 секунды назад ситерсп 3 секунды назад миксирпа 3 секунды назад деминерализация 3 секунды назад пласировка 4 секунды назад плктиа 4 секунды назад
Морфологический разбор слова «преодолевать»
Часть речи: Инфинитив
ПРЕОДОЛЕВАТЬ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПРЕОДОЛЕВАТЬ»
| Слово | Морфологические признаки |
|---|---|
| ПРЕОДОЛЕВАТЬ |
|
Все формы слова ПРЕОДОЛЕВАТЬ
ПРЕОДОЛЕВАТЬ, ПРЕОДОЛЕВАЮ, ПРЕОДОЛЕВАЕМ, ПРЕОДОЛЕВАЕШЬ, ПРЕОДОЛЕВАЕТЕ, ПРЕОДОЛЕВАЕТ, ПРЕОДОЛЕВАЮТ, ПРЕОДОЛЕВАЛ, ПРЕОДОЛЕВАЛА, ПРЕОДОЛЕВАЛО, ПРЕОДОЛЕВАЛИ, ПРЕОДОЛЕВАЯ, ПРЕОДОЛЕВАВ, ПРЕОДОЛЕВАВШИ, ПРЕОДОЛЕВАЙ, ПРЕОДОЛЕВАЙТЕ, ПРЕОДОЛЕВАЮЩИЙ, ПРЕОДОЛЕВАЮЩЕГО, ПРЕОДОЛЕВАЮЩЕМУ, ПРЕОДОЛЕВАЮЩИМ, ПРЕОДОЛЕВАЮЩЕМ, ПРЕОДОЛЕВАЮЩАЯ, ПРЕОДОЛЕВАЮЩЕЙ, ПРЕОДОЛЕВАЮЩУЮ, ПРЕОДОЛЕВАЮЩЕЮ, ПРЕОДОЛЕВАЮЩЕЕ, ПРЕОДОЛЕВАЮЩИЕ, ПРЕОДОЛЕВАЮЩИХ, ПРЕОДОЛЕВАЮЩИМИ, ПРЕОДОЛЕВАВШИЙ, ПРЕОДОЛЕВАВШЕГО, ПРЕОДОЛЕВАВШЕМУ, ПРЕОДОЛЕВАВШИМ, ПРЕОДОЛЕВАВШЕМ, ПРЕОДОЛЕВАВШАЯ, ПРЕОДОЛЕВАВШЕЙ, ПРЕОДОЛЕВАВШУЮ, ПРЕОДОЛЕВАВШЕЮ, ПРЕОДОЛЕВАВШЕЕ, ПРЕОДОЛЕВАВШИЕ, ПРЕОДОЛЕВАВШИХ, ПРЕОДОЛЕВАВШИМИ, ПРЕОДОЛЕВАЕМЫЙ, ПРЕОДОЛЕВАЕМОГО, ПРЕОДОЛЕВАЕМОМУ, ПРЕОДОЛЕВАЕМЫМ, ПРЕОДОЛЕВАЕМОМ, ПРЕОДОЛЕВАЕМАЯ, ПРЕОДОЛЕВАЕМОЙ, ПРЕОДОЛЕВАЕМУЮ, ПРЕОДОЛЕВАЕМОЮ, ПРЕОДОЛЕВАЕМА, ПРЕОДОЛЕВАЕМОЕ, ПРЕОДОЛЕВАЕМО, ПРЕОДОЛЕВАЕМЫЕ, ПРЕОДОЛЕВАЕМЫХ, ПРЕОДОЛЕВАЕМЫМИ, ПРЕОДОЛЕВАЕМЫ
Разбор слова по составу преодолевать
преодолева
ть
| Основа слова | преодолева |
|---|---|
| Приставка | пре |
| Корень | одол |
| Суффикс | е |
| Суффикс | ва |
| Глагольное окончание | ть |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПРЕОДОЛЕВАТЬ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «преодолевать»
1
Преодолевать трудности, преодолевать себя – самую главную трудность.
Вектор ненависти, Анатолий Александрович Страхов, 2019г.
2
Привыкнешь, военнослужащий должен стойко преодолевать тяготы и невзгоды военной службы, вот и иди, преодолевай.
Распад, Ак – патр Алибабаевич Чугашвили, 2017г.
3
Преодолеть меня мною же, то есть вовсе не преодолевать.
Наталья Гончарова (жизнь и творчество), Марина Цветаева, 1929г.
4
Тогда придется преодолевать изгородь.
Дожить до рассвета; Сотников; Обелиск; Журавлиный крик; Знак беды (сборник), Василь Быков
5
Сил было достаточно, но и преодолевать приходилось немало, с раннего детства, довольно сурового.
Чехов, Борис Зайцев, 1954г.
Найти еще примеры предложений со словом ПРЕОДОЛЕВАТЬ
Нелинейное обучение подобия для композиционности
%PDF-1.3 % 207 0 объект >/OCGs[210 0 R]>>/OutputIntents[204 0 R]/PageLabels 202 0 R/Pages 19 0 R/Тип/Каталог>> эндообъект 209 0 объект >/Шрифт>>>/Поля 214 0 R>> эндообъект 206 0 объект >поток 2016-01-23T20:05:39-08:00TeX2016-01-31T20:21:55-08:002016-01-31T20:21:55-08:00Это pdfTeX, версия 3.14159265-2.6-1.40.16 (TeX Live 2015) kpathsea версия 6.2.1PDF/X-1a:2001PDF/X-1:2001Acrobat Distiller 15.0 (Macintosh)FalseТехнические документы: обработка естественного языка и машинное обучениеPDF/X-1a:2001PDF/X-1:2001application/pdf
 aaai.orguuid:755e8387-ab39-234b-81b4-3a48dad6857cuuid:a84bff79-3248-d24c-9910-530b8c58dc801PDF/X-1:2001 конечный поток
эндообъект
202 0 объект
>
aaai.orguuid:755e8387-ab39-234b-81b4-3a48dad6857cuuid:a84bff79-3248-d24c-9910-530b8c58dc801PDF/X-1:2001 конечный поток
эндообъект
202 0 объект
> Реализация языка предметной области для бедняков – Подход к встроенному синтаксическому анализу и оценке
Как языковой инженер вы, по сути, должны иметь дело с синтаксическим анализом и семантическим анализом языков (программирования). Вы пачкаете руки, тщательно разрабатывая компиляторы, интерпретаторы, генераторы кода, инструменты рефакторинга и статические анализаторы кода.
Вы пачкаете руки, тщательно разрабатывая компиляторы, интерпретаторы, генераторы кода, инструменты рефакторинга и статические анализаторы кода.
Мощные языковые инструменты, напр. Xtext или MPS очень помогут вам в решении этих драгоценных задач, предлагая генерацию:
- сканер и парсер вашей EBNF-подобной грамматики,
- метамодель, представляющая результирующее абстрактное синтаксическое дерево (AST),
- встроенный редактор (например, для Eclipse или Intellij) с подсветкой синтаксиса и завершением кода,
- заглушки для генерации кода или преобразования метамодели в целом и
- заглушки для переводчиков.
Таким образом, у вас очень хорошая поддержка для всех необходимых дел, которые возникают после синтаксического анализа. Но что делать, если вы не хотите столкнуться с гигантской задачей изучения этих инструментов? Или если вам приходится работать в техническом пространстве с ограниченными ресурсами?
В этой статье демонстрируется встроенный синтаксический анализ и оценка, применимые к небольшим встроенным предметно-ориентированным языкам (DSL), с использованием трех концепций.
Во-первых, чистое встраивание в мощный статически типизированный базовый язык Scala. Это обеспечивает высокую совместимость не только с существующим кодом Scala общего назначения, но и с другими языками, работающими на виртуальной машине Java (JVM). Нет необходимости в собственном препроцессоре или языковом расширении.
Во-вторых, комбинаторы парсеров. Они обеспечивают компактное интегрированное в язык сканирование и синтаксический анализ. Кроме того, предоставляются удобные синтаксические анализаторы для Java или часто используемые регулярные выражения, синтаксис с очень небольшим количеством операторов синтаксического анализа довольно прост, и они могут быть легко расширены посредством наследования. С другой стороны, производительность может быть не на высшем уровне из-за использования возврата при синтаксическом анализе.
И последнее, но не менее важное: используются ссылочные грамматики атрибутов (RAG). Эта устаревшая концепция каким-то образом застряла в научных кругах (в качестве хорошего введения заинтересованному читателю рекомендуется прочитать, например, эту статью), но она полезна при попытке рассуждать о языках. Атрибутные грамматики расширяют контекстно-свободные грамматики с помощью декларативных уравнений, которые связывают друг с другом значения атрибутов грамматических символов. Большинство систем грамматики атрибутов переводят уравнения в реализацию, написанную на языке программирования общего назначения. Преобразование принимает решения о порядке оценки и хранения атрибутов, устраняя необходимость в ручных методах обхода дерева, таких как посетители. Таким образом, разработчик может сосредоточиться на свойствах языка, представленных атрибутами. На стороне реализации используется Kiama. Библиотека грамматики атрибутов Kiama поддерживает ряд функций RAG, включая кэшированные, некэшированные атрибуты, атрибуты более высокого порядка, параметризованные и циклические атрибуты. Киама также реализует методы динамического расширения и изменения уравнений атрибутов.
Атрибутные грамматики расширяют контекстно-свободные грамматики с помощью декларативных уравнений, которые связывают друг с другом значения атрибутов грамматических символов. Большинство систем грамматики атрибутов переводят уравнения в реализацию, написанную на языке программирования общего назначения. Преобразование принимает решения о порядке оценки и хранения атрибутов, устраняя необходимость в ручных методах обхода дерева, таких как посетители. Таким образом, разработчик может сосредоточиться на свойствах языка, представленных атрибутами. На стороне реализации используется Kiama. Библиотека грамматики атрибутов Kiama поддерживает ряд функций RAG, включая кэшированные, некэшированные атрибуты, атрибуты более высокого порядка, параметризованные и циклические атрибуты. Киама также реализует методы динамического расширения и изменения уравнений атрибутов.
В целом язык программирования Scala используется из-за его поддержки нотаций, специфичных для предметной области, и акцента на масштабируемость. В отличие от генераторов со специальной нотацией, грамматики атрибутов Kiama используют стандартные концепции
В отличие от генераторов со специальной нотацией, грамматики атрибутов Kiama используют стандартные концепции
Scala, такие как классы case, функции сопоставления с образцом для уравнений, трейты и примеси для композиции и неявные параметры для пересылки.
Далее показаны основные принципы реализации встроенного синтаксического анализатора с использованием комбинаторов синтаксических анализаторов и оценки результатов синтаксического анализа.
Очень простой математический язык
Простые математические выражения, например, 1 + 2 + 3 * 0 должны быть правильно проанализированы и оценены. Kiama использовала простые классы Scala для построения AST и представления метамодели за один прием:
запечатанный абстрактный класс Exp extends Product класс case Num(i: Double) расширяет Exp класс case Add(l: Exp, r: Exp) расширяет Exp класс case Sub(l: Exp, r: Exp) расширяет Exp класс case Mul(l: Exp, r: Exp) расширяет Exp класс case Div(l: Exp, r: Exp) расширяет Exp
Синтаксический анализ
В качестве первого шага анализ теперь выполняется с помощью следующего:
import org.{ case t ~ ts => ts.foldLeft(t) { case (t1, "*" ~ t2) => Mul(t1, t2) case (t1, "/" ~ t2) => Div(t1, t2) } } lazy val factor = "(" ~> expr <~ ")" | число ленивый val число = регулярное выражение ("[0-9(s => Num(s.toDouble)) }
 {
case t ~ ts => ts.foldLeft(t) {
case (t1, "*" ~ t2) => Mul(t1, t2)
case (t1, "/" ~ t2) => Div(t1, t2)
}
}
lazy val factor = "(" ~> expr <~ ")" | число
ленивый val число = регулярное выражение ("[0-9(s => Num(s.toDouble))
}
{
case t ~ ts => ts.foldLeft(t) {
case (t1, "*" ~ t2) => Mul(t1, t2)
case (t1, "/" ~ t2) => Div(t1, t2)
}
}
lazy val factor = "(" ~> expr <~ ")" | число
ленивый val число = регулярное выражение ("[0-9(s => Num(s.toDouble))
}
Исполняемые грамматики создаются из композиций синтаксических анализаторов. Эти композиции описываются как функциональные отображения. Композиционная целостность типов парсера гарантируется реализацией их классов с помощью монад.
Таким образом, комбинатор синтаксического анализатора обычно представляет собой набор правил производства. Они используют операторы, определенные в классе Scala Parser, для составления результатов парсера, как показано в следующей таблице:
| Оператор | Назначение | Пример сверху |
|---|---|---|
"..." | Определение литерала | "+" |
"...".р | Определение регулярного выражения | "[+-]". |
Р <~ Q | Состав парсеров P и Q, сохраняется только результат P | выражение <~ ")" |
П ~> В | Состав парсера P и Q, сохраняется только результат Q | "(" ~> выражение |
П ~ В | Состав синтаксического анализатора P и Q, оба результата P и Q сохраняются | "[*/]".r ~ фактор |
П | Вопрос | Альтернативный анализатор P и Q | "(" ~> выражение <~ ")" | номер | 9(s => Num(s.toDouble))
 r
r Оценка
В качестве второго шага оценка теперь очень проста:
import org.bitbucket.inkytonik.kiama.attribution.Attribution
класс MathExample расширяет атрибут {
значение val: CachedAttribute[Exp, Double] = attr {
случай Num(i) => i
case Add(l, r) => значение(l) + значение(r)
case Sub(l, r) => значение(l) - значение(r)
case Mul(l, r) => значение(l) * значение(r)
case Div(l, r) => значение(l) / значение(r)
}
}
Функция высшего порядка attr из библиотеки Kiama автоматически кэширует оценку. Следовательно, расчеты с интенсивными вычислениями на построенном AST выполняются не более одного раза для каждого элемента. Кроме того, разработчику не нужно думать о деталях обхода AST, разрешения ссылок и пересылки. Это все сделано Киамой и умной конструкцией AST из классов case (поддерживающих все типы коллекций в качестве полей) с наложенным графом.
Следовательно, расчеты с интенсивными вычислениями на построенном AST выполняются не более одного раза для каждого элемента. Кроме того, разработчику не нужно думать о деталях обхода AST, разрешения ссылок и пересылки. Это все сделано Киамой и умной конструкцией AST из классов case (поддерживающих все типы коллекций в качестве полей) с наложенным графом.
Перезапись
Перезапись в домене RAG позволяет обновлять модель с точки зрения перезаписи графа, что, в свою очередь, обновляет анализ. Например, может потребоваться оптимизировать выражения, такие как 3 * 0 до 0 или 0 - 1 до -1 перед их фактическим вычислением. Этого можно добиться с помощью следующего расширения класса MathExample , показанного выше:
import org.bitbucket.inkytonik.kiama.attribution.Attribution.
импортировать org.bitbucket.inkytonik.kiama.rewriting.Rewriter
класс MathExample расширяет атрибуцию с помощью Rewriter[Exp, Exp] {
значение val: CachedAttribute[Exp, Double] = attr {
случай Num(i) => i
case Add(l, r) => значение(l) + значение(r)
case Sub(l, r) => значение(l) - значение(r)
case Mul(l, r) => значение(l) * значение(r)
case Div(l, r) => значение(l) / значение(r)
}
def optimise(e: Exp): Exp = переписать(оптимизатор)(e)
lazy val оптимизатор = снизу вверх (попытка (упрощение))
ленивый val simplifier =
правило[выражение] {
case Add(Num(0), e) => e
случай Add(e, Num(0)) => e
case Sub(Num(0), Num(v)) => Num(-v)
случай Sub(e, Num(0)) => e
случай Mul(Num(1), e) => e
случай Mul(e, Num(1)) => e
случай Mul(z@Num(0), _) => z
случай Mul(_, z@Num(0)) => z
случай Div(e, Num(1)) => e
case Div(_, Num(0)) => throw new IllegalArgumentException("Деление на 0!")
}
}
Можно использовать различные стратегии перезаписи и обхода (например, снизу вверх , попытка ). Это абстрагируется от необходимости думать о прохождении специфичного для DSL AST.
Это абстрагируется от необходимости думать о прохождении специфичного для DSL AST.
Но смешивается ли?
Настройте небольшой проект Scala с SBT и добавьте необходимую библиотеку:
libraryDependencies += "org.bitbucket.inkytonik.kiama" % "kiama_2.12" % "2.2.0"
Затем запустите:
val someMath = new MathExample()
val resultFunc: Exp => Double = someMath.value
значение: Exp = новый MathParser().parse("1+2+3*0")
println("АСТ: " + АСТ)
результат var = resultFunc(ast)
println("Результат до оптимизации: " + результат)
значение optimiseAst: Exp = someMath.optimise(ast)
println("Оптимизированный AST: " + оптимизированныйAst)
результат = результатFunc (оптимизированный Ast)
println("Результат после оптимизации: " + результат)
утверждать (3 == результат)
Упражнение 1:
Удалите Kiama и все библиотечные вызовы для еще большей чистоты. Что требуется для сохранения кэширования оценки и перезаписи атрибутов? Какие классические дизайн-паттерны можно было бы использовать и каковы их недостатки?
TL;DR
Scala упрощает создание встроенных предметно-ориентированных языков. Справочные грамматики атрибутов — это удобный инструмент для рассуждения о результирующей модели. Композиция монад потрясающая.
Справочные грамматики атрибутов — это удобный инструмент для рассуждения о результирующей модели. Композиция монад потрясающая.
Более реалистичный пример
Некоторое время назад, во время процесса подачи заявки на работу в немецкой сети универмагов, передо мной стояла задача написать небольшой анализатор логов на Scala. Он должен потреблять журналы и производить статистику. Запись в журнале успеха имеет следующую структуру:
ЧЧ:мм:сс:СС УРОВЕНЬ - выборка http://www.server/endpoint.json заняла: timeInMilliseconds ms
Запись в журнале сбоев имеет следующую структуру:
ЧЧ:мм:сс:СС УРОВЕНЬ - ошибка при получении http://www.server/endpoint.json после timeInMilliseconds мс
Вывод должен выглядеть следующим образом:
http://srv1.host.de: avg: 215 мс 478x успех: 79% конечные точки: продукты в среднем: 217 мс количество: 168x успех: 81% (32 из 168 неудачных) тизер в среднем: 210 мс количество: 154 успеха: 76% (37 из 154 неудачных) среднее значение профиля: 220 мс количество: 156x успех: 81% (31 из 156 неудач) http://srv2.
 host.de:
...
host.de:
...
Я не хотел использовать простые регулярные выражения и вложенные функции оценки для статистики, поскольку это невозможно ни прочитать, ни расширить, ни протестировать.
Следовательно, я придумал следующую метамодель и AST:
объект LogTree {
Журнал класса case (записи: List [LogEntry]) расширяет продукт
запечатанный абстрактный класс LogEntry расширяет продукт {
уровень значения: строка
val сообщение: строка
дата проверки: строка
сервер val: строка
конечная точка val: строка
val принял: Строка
val URL: String = s"http://$server/$endpoint.json"
переопределить def toString: String = s"$date $level - $msg"
}
Информация о классе case (дата: строка, сервер: строка, конечная точка: строка, взято: строка) extends LogEntry {
уровень val: String = "INFO"
val msg: String = s"fetch $url взял: $взял мс"
}
case class Предупреждение (дата: строка, сервер: строка, конечная точка: строка, взятие: строка) extends LogEntry {
уровень val: String = "ПРЕДУПРЕЖДЕНИЕ"
val msg: String = s"ошибка при получении $url после того, как $took ms"
}
} Анализ
импорт java.
 net.URL
импортировать java.text.SimpleDateFormat
import org.bitbucket.inkytonik.kiama.parsing.{Ошибка, Ошибка, Парсеры, Успех}
импортировать org.bitbucket.inkytonik.kiama.util.{Позиции, StringSource}
класс LogParser расширяет парсеры (новые позиции) {
частное значение Info = "INFO"
частный val Предупреждение = "ПРЕДУПРЕЖДЕНИЕ"
приватный разделитель val = "-"
частный val Fetch = "выборка"
частный val Взял = "взял:"
private val ErrorWhileFetching = "ошибка при загрузке"
частное значение После = "после"
частный val DateFormat = "ЧЧ: мм: сс: СС"
частный val Json = ".json"
частное значение Url = "[a-zA-Z0-9:/\\.]*\\.json"
частное значение Ms = "мс"
частное значение Дата = "[a-zA-Z0-9:]*"
частное значение Число = "[0-9]*"
импортировать LogTree._
def parseAll(in: List[String]): Log = Log(in.map(parse))
private def parse(in: String): LogEntry = parse(expr, StringSource(in)) match {
case Success(s, _) => s
case Failure(f, _) => throw new RuntimeException("Ошибка синтаксического анализа: " + f)
case Error(e, _) => throw new RuntimeException("Ошибка синтаксического анализа: " + e)
}
private lazy val expr: Parser[LogEntry] = дата ~ уровень ~ разделитель ~ msg ^^ {
case d ~ Info ~ Separator ~ m => new Info(d, m.
net.URL
импортировать java.text.SimpleDateFormat
import org.bitbucket.inkytonik.kiama.parsing.{Ошибка, Ошибка, Парсеры, Успех}
импортировать org.bitbucket.inkytonik.kiama.util.{Позиции, StringSource}
класс LogParser расширяет парсеры (новые позиции) {
частное значение Info = "INFO"
частный val Предупреждение = "ПРЕДУПРЕЖДЕНИЕ"
приватный разделитель val = "-"
частный val Fetch = "выборка"
частный val Взял = "взял:"
private val ErrorWhileFetching = "ошибка при загрузке"
частное значение После = "после"
частный val DateFormat = "ЧЧ: мм: сс: СС"
частный val Json = ".json"
частное значение Url = "[a-zA-Z0-9:/\\.]*\\.json"
частное значение Ms = "мс"
частное значение Дата = "[a-zA-Z0-9:]*"
частное значение Число = "[0-9]*"
импортировать LogTree._
def parseAll(in: List[String]): Log = Log(in.map(parse))
private def parse(in: String): LogEntry = parse(expr, StringSource(in)) match {
case Success(s, _) => s
case Failure(f, _) => throw new RuntimeException("Ошибка синтаксического анализа: " + f)
case Error(e, _) => throw new RuntimeException("Ошибка синтаксического анализа: " + e)
}
private lazy val expr: Parser[LogEntry] = дата ~ уровень ~ разделитель ~ msg ^^ {
case d ~ Info ~ Separator ~ m => new Info(d, m.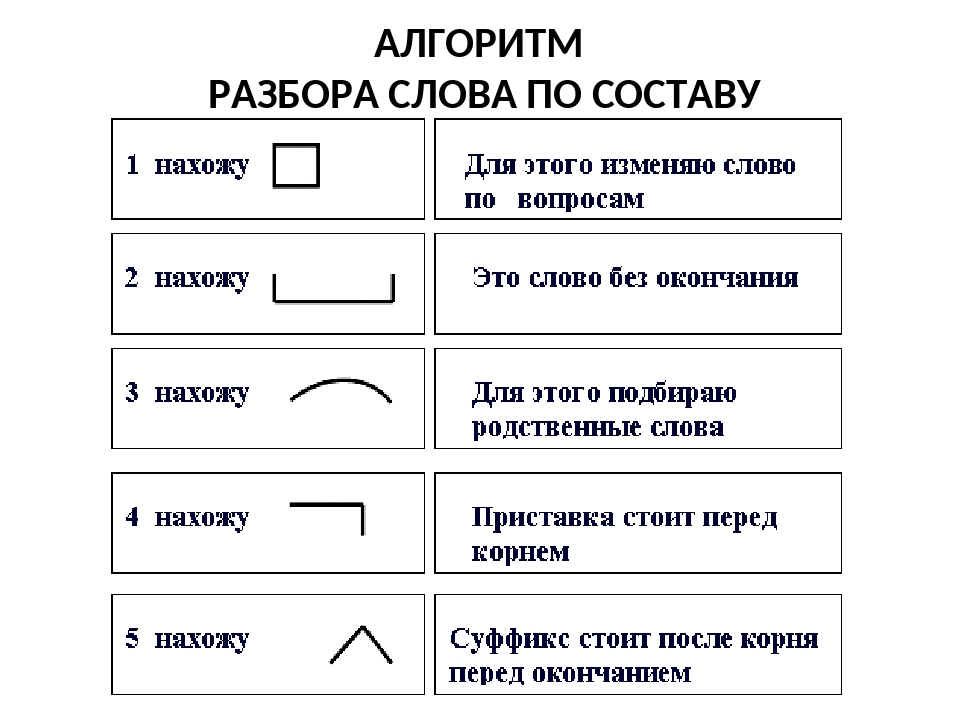 (s => formatter.format(formatter.parse(s)))
}
(s => formatter.format(formatter.parse(s)))
}
Как вы могли заметить, написание комбинаторов синтаксических анализаторов определенно не является святым Граалем, как только ваша грамматика усложняется. Здесь все еще существуют некоторые неприятные регулярные выражения, и приближение к датам вручную - это не та задача, которую вы хотите, прежде чем выпить свой первый (три) кофе.
Оценка
С другой стороны, оценка теперь довольно проста благодаря строгой декомпозиции на более мелкие единицы работы. Это приводит к лучшей тестируемости и расширяемости.
импорт LogTree.{Информация, Журнал, LogEntry, Предупреждение}
импортировать org.bitbucket.inkytonik.kiama.attribution.Attribution
класс LogTreeAnalyzer (журнал: журнал) {
def printAllStatistics(): Unit = {
uniqueServers(log).foreach(s => {
val имя_сервера = s
val avg = avgForServer(имя_сервера)(журнал)
val numEntries = numEntriesForServer(имя_сервера)(журнал)
val succ = succRateForServer (serverName) (журнал)
println(s"$s: avg: ${avg}ms ${numEntries}x Success: $succ%")
println("\тенденции:")
val uniqueEndpoints = uniqueEndpointsForServer(имя_сервера)(журнал)
uniqueEndpoints. foreach(ep => {
val endpointName = ep
val avgEP = avgForEndpoint((serverName, endpointName))(журнал)
val numEntriesEP = numEntriesForEndpoint((serverName, endpointName))(log)
val succEP = succRateForEndpoint((serverName, endpointName))(журнал)
val numFailedEP = numFailuresForEndpoint((serverName, endpointName))(log)
println(s"\t\t$endpointName avg: ${avgEP}ms count: ${numEntriesEP}x Success: $succEP% ($numFailedEP из $numEntriesEP не удалось)")
})
})
}
val uniqueServers: (Log) => List[String] = attr {
l => l.entries.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.server) acc else next.server :: acc }
}
val entryForServer: (String) => (Log) => List[LogEntry] = paramAttr {
сервер => {
l => l.entries.filter(_.server == сервер)
}
}
val avgForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
записи.карта(_. взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForServer: (String) => (Log) => Int = paramAttr {
сервер => {
l => entryForServer(сервер)(l).size
}
}
val succRateForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
val totalEntries = numEntriesForServer(сервер)(l)
val успешные записи = записи для сервера (сервер) (l). count {
случай _: информация => истина
случай _: предупреждение => ложь
}
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
val uniqueEndpointsForServer: (String) => (Log) => List[String] = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
posts.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.endpoint) acc else next.endpoint :: acc }
}
}
}
val avgForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr. _2
записи val = записи для сервера (сервер) (l). фильтр (_. конечная точка == конечная точка)
записи.карта(_.взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
entryForServer(сервер)(l).count(_.endpoint == конечная точка)
}
}
}
val numFailuresForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
ЗаписиForServer(сервер)(l).count {
case i: Предупреждать, если i.endpoint == endpoint => true
случай _ => ложь
}
}
}
}
val succRateForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
val успешные записи = записи для сервера (сервер) (l). count {
случай i: информация, если i.endpoint == endpoint => true
случай _ => ложь
}
val totalEntries = numEntriesForEndpoint((сервер, конечная точка))(l)
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
}
 foreach(ep => {
val endpointName = ep
val avgEP = avgForEndpoint((serverName, endpointName))(журнал)
val numEntriesEP = numEntriesForEndpoint((serverName, endpointName))(log)
val succEP = succRateForEndpoint((serverName, endpointName))(журнал)
val numFailedEP = numFailuresForEndpoint((serverName, endpointName))(log)
println(s"\t\t$endpointName avg: ${avgEP}ms count: ${numEntriesEP}x Success: $succEP% ($numFailedEP из $numEntriesEP не удалось)")
})
})
}
val uniqueServers: (Log) => List[String] = attr {
l => l.entries.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.server) acc else next.server :: acc }
}
val entryForServer: (String) => (Log) => List[LogEntry] = paramAttr {
сервер => {
l => l.entries.filter(_.server == сервер)
}
}
val avgForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
записи.карта(_.
foreach(ep => {
val endpointName = ep
val avgEP = avgForEndpoint((serverName, endpointName))(журнал)
val numEntriesEP = numEntriesForEndpoint((serverName, endpointName))(log)
val succEP = succRateForEndpoint((serverName, endpointName))(журнал)
val numFailedEP = numFailuresForEndpoint((serverName, endpointName))(log)
println(s"\t\t$endpointName avg: ${avgEP}ms count: ${numEntriesEP}x Success: $succEP% ($numFailedEP из $numEntriesEP не удалось)")
})
})
}
val uniqueServers: (Log) => List[String] = attr {
l => l.entries.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.server) acc else next.server :: acc }
}
val entryForServer: (String) => (Log) => List[LogEntry] = paramAttr {
сервер => {
l => l.entries.filter(_.server == сервер)
}
}
val avgForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
записи.карта(_. взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForServer: (String) => (Log) => Int = paramAttr {
сервер => {
l => entryForServer(сервер)(l).size
}
}
val succRateForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
val totalEntries = numEntriesForServer(сервер)(l)
val успешные записи = записи для сервера (сервер) (l). count {
случай _: информация => истина
случай _: предупреждение => ложь
}
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
val uniqueEndpointsForServer: (String) => (Log) => List[String] = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
posts.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.endpoint) acc else next.endpoint :: acc }
}
}
}
val avgForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr.
взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForServer: (String) => (Log) => Int = paramAttr {
сервер => {
l => entryForServer(сервер)(l).size
}
}
val succRateForServer: (String) => (Log) => Int = paramAttr {
сервер => {
л => {
val totalEntries = numEntriesForServer(сервер)(l)
val успешные записи = записи для сервера (сервер) (l). count {
случай _: информация => истина
случай _: предупреждение => ложь
}
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
val uniqueEndpointsForServer: (String) => (Log) => List[String] = paramAttr {
сервер => {
л => {
записи val = записи для сервера (сервер) (l)
posts.foldLeft(Nil: List[String]) { (acc, next) => if (acc содержит next.endpoint) acc else next.endpoint :: acc }
}
}
}
val avgForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr.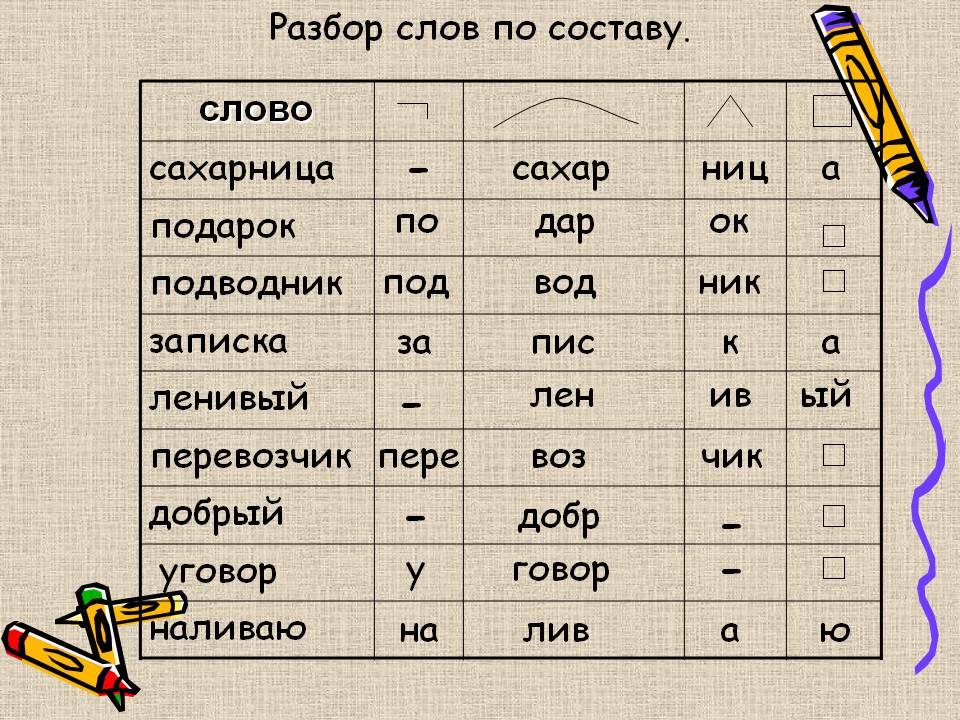 _2
записи val = записи для сервера (сервер) (l). фильтр (_. конечная точка == конечная точка)
записи.карта(_.взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
entryForServer(сервер)(l).count(_.endpoint == конечная точка)
}
}
}
val numFailuresForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
ЗаписиForServer(сервер)(l).count {
case i: Предупреждать, если i.endpoint == endpoint => true
случай _ => ложь
}
}
}
}
val succRateForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
val успешные записи = записи для сервера (сервер) (l).
_2
записи val = записи для сервера (сервер) (l). фильтр (_. конечная точка == конечная точка)
записи.карта(_.взял.toInt).сумма / записи.длина
}
}
}
val numEntriesForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
entryForServer(сервер)(l).count(_.endpoint == конечная точка)
}
}
}
val numFailuresForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
ЗаписиForServer(сервер)(l).count {
case i: Предупреждать, если i.endpoint == endpoint => true
случай _ => ложь
}
}
}
}
val succRateForEndpoint: ((String, String)) => (Log) => Int = paramAttr {
адрес => {
л => {
val сервер = адрес_1
конечная точка val = addr._2
val успешные записи = записи для сервера (сервер) (l). count {
случай i: информация, если i.endpoint == endpoint => true
случай _ => ложь
}
val totalEntries = numEntriesForEndpoint((сервер, конечная точка))(l)
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
}
count {
случай i: информация, если i.endpoint == endpoint => true
случай _ => ложь
}
val totalEntries = numEntriesForEndpoint((сервер, конечная точка))(l)
val rate = успешные записи * 100f / totalEntries
Math.round(скорость)
}
}
}
}
Упражнение 2:
Реализуйте такой анализатор журнала с помощью Xtext. Реализуйте такой анализатор логов с помощью MPS. Как можно реализовать оценку/печать статистики в этих инструментах? Обсудите преимущества и недостатки наличия полноценной метамодели (например, в рамках Xtext как модели Ecore).
Резюме или Что мы узнали?
Работа с разбором и семантическим анализом языков требует от языкового инженера тщательной разработки компиляторов, интерпретаторов, генераторов кода, инструментов рефакторинга и статических анализаторов кода. Языковые рабочие места, например, Xtext или MPS, помогут вам в решении этих задач, предлагая создание важных компонентов (парсеры, AST, редакторы, генераторы кода).