Дидактический материал по русскому языку. 3 класс.
Карточка №1 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Повязка, скороход, соринка, темнота, чайник, головоломка, задумчивый, ловушка, моряк, печник.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Весенняя, конь.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Тихий туман стоит на жёлтыми полями.
Берёза красиво рисуется на голубом небе.
…………………………………………………………………………………………………
Карточка №2 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Постройка, лесовоз, теснота, полёт, переезды, прибрежная, выдумка, походка, рыбак, самолёт.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Конёк, боец.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Сквозь бурые сучья деревьев белеет небо.
Тропинка шла вдоль прибрежного обрыва.
…………………………………………………………………………………………………
Карточка №3 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Завязка , громоотвод, разлив, горошек, плясун, снежный, грустная, столовая, лисий, ключик.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Снеговик, лыжи.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
На старой сосне сидел клест.
У дороги росла развесистая берёза.
…………………………………………………………………………………………………
Карточка №4 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Кустик, вырубка, лесопарк, связка, второклассник, сынок, книга, вылет, загадка, снегопады.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Перья, местный.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Около берёзки скачут шустрые воробьи.
На пригорке красовались фиалки.
…………………………………………………………………………………………………
Карточка №5 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Огонёк, выкройка, путь, выставка, первоклассник, карандашик, рассказ, столик, перелесок, поездка.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Съезд, осенний.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
В зоопарке живут белые медведи.
Из кустов я услышал голосок иволги.
…………………………………………………………………………………………………
Карточка № 6 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Разбег, зимушка, дверка, звонок, звоночек, лесок, пробежка, поддержка, лимонный, подосиновики.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Вьюнок, класс.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Завод запустил новые машины.
На небе показалось грозовое облако.
…………………………………………………………………………………………………
Карточка №7 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Книжечка, выставка, дружок, дружочек, листопад, хвостик, пенёк, супница, бессмертный, кирпичный.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Ясень, праздник.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
На поляне красуется белоствольная берёзка.
Корабль ведёт опытный капитан
…………………………………………………………………………………………………
Карточка №8 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Листок, грядочка, веточка, птицевод, грибок, грибочек, наконечник, бесстрашный, маленький, конский.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Крепостной, юноша.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Далеко разносилась песня соловья.
…………………………………………………………………………………………………
Карточка №9 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Поход, нагрузка, скорлупка, садовод, кустик, пыльное, отцовский, берёзовое, смешной, короткий.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Крылья, гигантский.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Дикие животные готовятся к зиме.
Территорию охраняет злая собака.
…………………………………………………………………………………………………
Карточка № 10 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Уговор, разгрузка, гнёздышко, дубовый, оленевод, дворник, бездорожье, подберёзовик, крылатый, молодой.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Пёстрые, счастье.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
На морозе потрескалась кора деревьев.
Мама положила на стол печенье.
…………………………………………………………………………………………………
Карточка № 11 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Запуск, поездка, белый, градусник, корнеплод, снежок, стекляшка, беззвучный, низина, берёзка.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Юрий, звёздный.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
В окно попадает свет луны.
Кошка играла с бантиком на нитке.
…………………………………………………………………………………………………
Карточка № 12 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Отлёт, перевозка, красный, кораблик, бурелом, островок, солонка, сорняк, стеклодув, рыбный.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Ночью, яростно.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Мышь спряталась от лисы в норке.
С дерева осыпались последние листья.
…………………………………………………………………………………………………
Карточка № 13 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Наклейка, подъезд, весёлый, беленький, паровоз, голосок, лыжник, рассада, красный, солёная.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Капустница, ямка.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Папа перешёл из комнаты в комнату.
Туристы вернулись с базы домой.
…………………………………………………………………………………………………
Карточка № 14 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Игрок, дуб, свисток, бабушка, ёжик, ключик, водолаз, слонёнок, рисовый, лесник.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Въезд, тётушка.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Аккуратно стояли плюшевые игрушки.
Спортсмен прыгал с вышки в бассейн.
…………………………………………………………………………………………………
Карточка № 15 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Приезд, глоток, сдвиг, самовар, гвоздик, синенький, сынок, сыночек, слониха, парник.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Поёт, местный.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
На берег накатывались морские волны.
В лес пошли бывалые охотники.
…………………………………………………………………………………………………
Карточка № 16 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Проезд, рыжик, лесник, самокат, шарфик, мостик, денёк, денёчек, холодный, синева.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Линия, подъехал.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Антон хорошо написал диктант.
Солнце осветило опустевшие леса.
…………………………………………………………………………………………………
Карточка № 17 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Вылет, стрелок, школьник, верхолаз, пушок, пенёк, пенёчек, осенний, быстрый, беленький.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Баян, свистнул.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Письмо отправилось в далёкие края.
Туристы с базы отправились в горы.
…………………………………………………………………………………………………
Карточка № 18 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Обход, лучик, черника, поездка, пылесос, грибок, грибочек, дружок, дружочек, весенний.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Вьюга, честная.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Бабушка испекла вкусный пирог.
Крик кукушки доносится из ближнего леса.
…………………………………………………………………………………………………
Карточка № 19 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Забег, слон, подарок, глазок, сгиб, пешеход, уголок, уголочек, кораблики, огоньки.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Юлия, счастливо.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Ёж зарылся в сухую листву.
Ребята идут в лес за ягодой.
…………………………………………………………………………………………………
Карточка № 20 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Полёт, сон, тряска, водопад, дымоход, погремушка, пригородный, головастый, головастик, рассада.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Аллея, ненастно.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Вода у берегов озера замёрзла.
Осенью часто идут холодные дожди.
…………………………………………………………………………………………………
Карточка № 21 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Улов, хлеб, наклон, сдвиг, зверолов, передвижка, поднос, яйцеварка, шагомер, придуманный.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Масса, известный.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
На высокой сосне сидят бельчата.
Скоро в садах зацветёт черёмуха.
…………………………………………………………………………………………………
Карточка № 22 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Переход, час, шалость, глазомер, морозный, прогулка, больной, жидкий, города, орешек.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Группа, доброта.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
Ребята бегут на лыжах по снегу.
В лесу много сочной травы.
…………………………………………………………………………………………………
Карточка № 23 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Побег, дом, шалун, ледокол, подснежник, школьница, дорожка, фруктовые, морской, звёздочка.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Звёздочка, ссора.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
В саду расцвели фруктовые деревья.
По реке плывёт теплоход.
…………………………………………………………………………………………………
Карточка № 24 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Забег, стул, накипь, звёздочка, снегопад, звонкий, сладкая, звонкоголосый, длинное, гладенький.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Ходьба, русский.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
В комнату внесли большую ёлку.
В зоопарке жила ручная обезьянка.
…………………………………………………………………………………………………
Карточка №25 для самостоятельной работы.
1.Выполни морфемный разбор слов (по составу)
Обход, стол, гнёздышко, прорубь, поход, рыболов, длинноногий, дождливая, радостная, широкое.
2.Выполни фонетический разбор слов (звуко-буквенный анализ)
Дорожка, лунная.
3. Выполни синтаксический разбор предложений (по членам предложения, частям речи, выписывая словосочетания)
В весеннем лесу ветер свободно гуляет.
Солнце осветило яркие и пушистые цветы
…………………………………………………………………………………………………
Презентация «Разбор предложения по членам. Характеристика предложения» 3 класс
Разбор предложения по членам. Характеристика предложения Устный и письменный образцы разбора3 класс
Школа России
Автор-составитель: Печенкина Светлана Владимировна,
учитель начальных классов МКОУ «СОШ № 44»
Миасский городской округ
2015г.
Разбор предложения по членам (устный)
Характеристика предложения
(устная)
Образец письменного разбора предложения и его характеристика
Как разобрать предложение по членам
Памятка для 3 класса
1. Читаю предложение. Яркая звезда сверкала над лесом.
2. Нахожу подлежащее. Ставлю вопрос: о чём говорится
в предложении? (О звезде.) В предложении слово звезда
отвечает на вопрос что? Значит, слово звезда – подлежа-
щее. Подчёркиваю одной чертой.
3. Нахожу сказуемое. Ставлю вопрос: что говорится о под-
лежащем, о звезде? (Сверкала). Слово сверкала отвечает
на вопрос что делала? (Звезда (что делала?) сверкала.)
Значит, слово сверкала – сказуемое. Подчёркиваю двумя
чертами.
план разбора
характеристика
письменный разбор
Как разобрать предложение по членам
Памятка для 3 класса
4. Делаю вывод: подлежащее (звезда) и сказуемое
(сверкала) – это главные члены предложения.
5. Нахожу второстепенный член предложения, который
поясняет подлежащее. Ставлю от подлежащего вопрос:
звезда (какая?) яркая.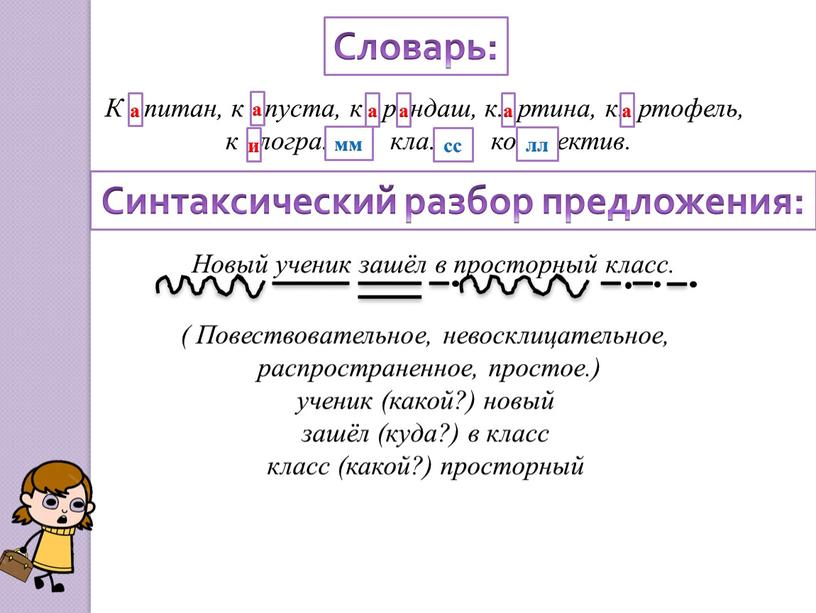 Нахожу второстепенный член
Нахожу второстепенный член
Предложения, который поясняет сказуемое. Ставлю
от сказуемого вопрос сверкала (где?) над лесом.
6. Делаю вывод: в предложении два словосочетания:
яркая звезда, сверкала над лесом.
план разбора
характеристика
письменный разбор
Как дать характеристику предложению
Памятка для 3 класса
1. Прочитай предложение.
2. Определи, какое это предложение по цели
высказывания (повествовательное, вопросительное,
побудительное).
Является ли предложение восклицательным?
3. Определи, простое это предложение или сложное.
Если простое, то какое оно: распространённое или
Нераспространённое. Если сложное, то как соединены
простые предложения в сложное (с помощью интонации
или с помощью союзов и, а, но).
план разбора
характеристика
письменный разбор
Разбор предложения по членам
Образец письменного разбора предложения и его
характеристика. 3 класс
Яркая звезда сверкала над лесом.⁴ ( повест.,
невосклиц., простое, распростр.)
яркая звезда;
сверкала над лесом.
план разбора
сущ.
гл.
какая?
где?
характеристика
письменный разбор
Предложения для грамматического разбора, 3 класс
Предложения для орфографического и грамматического разбора.3 – 4 класс
Под берёзкой белеет пушистый ландыш.
Над зелёным лугом несётся медовый запах травы.
В утренней прохладе разливается горьковатый запах полыни.
Золотой луч солнца заиграл на верхушке молодой берёзки.
На дне глубокого ущелья журчал весёлый ручеёк.
В осеннем лесу ярко горели кисти рябин.
7. Дети собирали еловые шишки в корзины.
Притаился у границы пограничников отряд.
Через сосновый бор вьётся лесная тропинка.
Заунывный ветер гонит стаи туч на край небес.
Золотая осень украсила верхушки деревьев чудесным узором.

Над лесом выплывает яркое солнце.
По лёгкой пороше от ели к берёзке тянется след белочки.
В парке ветки берёзки украсились серебристым инеем.
В осенние дни хлопотливый ёжик готовит себе жилище на зиму.
На моховых кочках ожерельем разрумянилась клюква.
Над болотом с шумом поднялась стая диких уток.
Зимние вьюги намели большие сугробы снега.
С вершины высокой ели хлопьями посыпался лёгкий иней.
По лесной поляне тянется след рыжей лисицы.
Горячее солнце залило окрестность ярким светом.
В солнечный день жемчужная кувшинка нежилась на гладкой поверхности реки.
Белеет парус одинокий в тумане моря голубом.
Озорной ветер устилает жёлтыми листьями мокрую землю.
Зимой около ёлки оставляют следы на снегу обитатели леса.
Под тяжестью плодов гнутся к земле стройные яблоньки.
В густом лесу притаилась пограничная застава.
Пёстрые бабочки весело порхают с цветка на цветок.
С дальних полей доносится шум машин.
В субботу ученики третьего класса меняют книги в библиотеке.
Утром на бледном небосклоне показалась алая полоска зари.
Стеной стоит пшеница золотая по сторонам дорожки полевой.
Липы усыпали золотыми листьями гадкие дорожки сада.
От густого леса к болоту тянутся узкие тропинки.
У беседки полыхают алые гроздья рябины.
Всю ночь поют в пшенице перепёлки.
В зеркало залива сонный лес глядит.
Из тёплых стран прилетели пернатые вестники весны.
В осеннем лесу горели яркие кисти рябин.
Над глухою степью в неизвестный путь бесконечной цепью облака плывут.
От нашей дачи к берёзовой роще тянется узкая тропинка.
Лесов таинственная сень с печальным шумом обнажилась.
В ясный день в голубом небе раздаётся весёлая песенка жаворонка.
Закружилась листва золотая в розоватой воде на пруду.
Кроет уж лист золотой влажную землю в лесу.
Звёзды ярким светом упадут на дно реки.
Через лесное оконце мне открылась поляна в лесу.
Тянутся с юга на север стаи диких уток.

В степной полосе население занимается земледелием.
На траве играют лучи утреннего солнца.
Потемнела полосами белая пелена снега у дороги.
На высокой сосне мелькнул пушистый хвост белочки.
Гибкие веточки берёз покрылись смолистыми почками.
Капли крови густой из груди молодой на зелёные травы сбегали.
На вырубке у дорожки поспела сладкая земляника.
В небе вспыхивали яркие нити молний.
Удары грома оглушили всю местность.
Ласковый май насыпал по овражкам белые сугробы черёмухи.
Берёза кудрявая в старом саду зелёные ветви склонила к пруду.
Зелёные листья трепещут в ветвистой вышине под росистой влагой.
Птицы встречают ликующими песнями ранний луч солнца.
Прозрачный отрезок туч тает у лунного серпа.
С далёкого севера дует холодный ветер.
Солнце чёрными кругами в лесу деревья обвело.
Роняет лес багряный свой убор.
По дороге волнистым облаком ложится пыль.
В окно дышит ароматом ветка белых роз.
Песню раннюю запел в лазури жаворонок звонкий.
По дну ущелья протекала быстрая горная речка.
Большие сугробы со всех сторон окружали узкую тропинку.
FђЗаголовок 1FђЗаголовок 2FђЗаголовок 3FђЗаголовок 4FђЗаголовок 5FђЗаголовок 6FђЗаголовок 7FђЗаголовок 8FђЗаголовок 915
Разбор по членам предложения.3 класс
Тема: «Разбор предложений по членам».
Цель: обобщить и закрепить наши знания о членах предложения и о порядке разбора предложения
Задачи:
Систематизируют знания о членах предложения.
Оборудование: индивидуальные карточки
I Орг.момент
Добрый день! Добрый весенний день! Я рада видеть вас на уроке. У вас на партах карточки настроения, покажите какое у вас настроение. Я рада, что у большинства из вас хорошее настроение. А с теми, у кого плохое настроение, мы попытаемся поделиться своим хорошим настроением.
II Целеполагание
Сегодня у нас на уроке будут разные испытания. Чтобы не бояться трудностей, мы произнесём все вместе волшебные слова.
Чтобы не бояться трудностей, мы произнесём все вместе волшебные слова.
Ра-ра-ра, отправляться нам пора,
Ны-ны-ны, нам преграды не страшны.
Желаю всем успеха! А сейчас, я прочитаю загадку, а вы мне отгадку произнесёте хором.
Тает снежок, ожил лужок,
День прибывает, когда это бывает? (весной)
-Конечно же, это весна. Какие признаки весны встретились вам в загадке? Какой национальный праздник мы отмечаем в марте?
Сегодня на урок все задания вам принесла девочка-весна.
Первое задание: Сказка о членах предложения
Послушайте сказку ,которая поможет вам определиться с темой урока.
Сказка о членах предложения
В этой дружной семье есть мама, папа, дочь-старшеклассница, сын и маленький ребенок.
Папа очень любит читать газеты, ему интересно знать кто? и что?
Мама всегда занята домашними делами и спрашивает что делать? что сделать?
Старшая дочь любит повертеться перед зеркалом, задавая вопросы: какое платье надеть? Какиетуфли подойдут? Какая прическа ей к лицу?
Сын-пятиклассник смотрит фильмы и спрашивает:кого? чего? Кому? Чему?..
А малыш интересуется всем вокруг и постоянно задает массу вопросов:где? когда? куда? откуда? как?
О какой дружной семье идёт речь?(предложение)А что такое предложение?(предложение-законченная мысль)
Синквейн –д/з
Проблемная ситуация.
Три ученика сделали разбор одного и того же предложения. Получилось у всех по-разному. Почему? Кто сделал разбор правильно? Какие допущены ошибки? Какой вывод мы сделаем? (надо хорошо знать члены предложения и уметь правильно делать разбор предложения).
1-уч.- Ребята сделали кораблик.
2- уч.- Ребята сделали кораблик.
3-уч. — Ребята сделали кораблик.
Значит, какова цель нашего урока? (обобщить и закрепить наши знания о членах предложения и о порядке разбора предложения).
А что мы должны сделать на уроке, чтобы уметь делать правильный разбор предложения по членам? (повторить части речи, повторить определения членов предложения, вспомнить порядок разбора предложения, хорошо и плодотворно потрудиться).
I I I Орфографическая минутка
Работаем в парах
в-сной в-селые скв-рцы д-лекая стр-на прил-тают
а)вставить пропущенные буквы
б)составить словосочетание
в)на основе словосочетаний составить предложение
Весной из дальних стран прилетают веселые скворцы.
IV Обобщение материала
1.Работа в группах. Кластер «Солнышко»
— Ребята, необходимо из тех утверждений, которые я вам раздала, выбрать только те, что относятся к нашей теме. На работу даю 2 минуты. Затем дети выходят к доске и составляем кластер. Повторяться с утверждениями нельзя.
2.Засели домики Продолжаем работать в группах. Ваше задание – необходимо соотнести второстепенные члены предложения и их вопросы. Работаем на специальных карточках.
Физминутка.
V Работа с текстом.
Работаем в группах. Списать текст.
Весной наши птицы возвращаются на родину из жарких стран. Открывает птичье весеннее расписание март. На полях показались первые проталины. Важно по проталинам расхаживает грач. Скоро прилетят скворцы.
1-группа- Разобрать по членам предложения. (на полях показались первые проталины)Сделать схему предложения.
2-группа – Разобрать по членам предложения. (Открывает птичье весеннее расписание март.)
3-группа – В каждом предложении найти подлежащее и сказуемое.
VI Р Разноуровневая самостоятельная работа (смена состава группы)
1- группа-сильная
Весна гуляла по лесам, по степям и заглянула к нам. А кого она встретила? Грача.
Задание: Продолжить рассказ. Составляем предложения по схемам.
1. _____ =======.
2. Какой? ______ =======.
3. Какой? ______ ======= по чему?
2-группа- средняя Нравится картинка? (картина весны) Составьте небольшой рассказ по картине. Предложения разобрать по членам.
Предложения разобрать по членам.
3-группа-слабая
Прочитать стихотворение. Укажите члены предложения, обозначающие признаки предмета и отвечающие на вопросы какой? какая? какое? какие?
Черёмуха душистая с весною расцвела
И ветки золотистые, что кудри, завила.
V I IТестирование.
Работаем индивидуально.
1.Выберите правильный ответ:
А) обстоятельство отвечает на вопросы кого? чего?
Б) дополнение отвечает на вопросы какой?какие?
В) определение подчёркивается волнистой линией
2. Выберите правильный ответ:
А) дополнение подчёркивается пунктирной линией
б) определение отвечает на вопросы кем?чем?
в)обстоятельство отвечает на вопросы какой?чей?
3.Выбери правильный ответ:
А) определение отвечает на вопрос где?откуда?
б) дополнение отвечает на вопросы какие? какая?
в) обстоятельство отвечает на вопросы почему?где?
4.Из перечисленных, к главным членам относятся?
А) подлежащее
б)определение
в)дополнение
г) обстоятельство
д) сказуемое
5. Выбери варианты ответов, в которых правильно найдены главнее члены предложения:
А) На деревьях набухли почки.
б) Из теплых стран прилетели скворцы.
В) Ребята сделали хорошие скворечники.
VIII Рефлексия
Наш урок подходит к концу. Чему учились? Что нового узнали? О чём вспомнили? Что непонятно было на уроке? Что понравилось на уроке? Как вы оцениваете свою работу? Покажите, какое у вас настроение после завершения урока?
Весна вам тоже делает подарки. Спасибо за урок!
IX выставление оценок
X Домашнее задание
1.стр.184 упр.504
2.Творческая минутка(сочинить стихотворение)
——————весна
——————красна
——————наступает
—————-оживает.
Урок 48. части речи. разбор предложения по частям речи — Русский язык — 3 класс
Русский язык. 3 класс
3 класс
№ 48
Раздел. Части речи (повторение).
Тема. Части речи. Разбор предложения по частям речи
Цель:
обобщить знания о частях речи.
Задачи:
уточнить отличительные признаки изученных частей речи;
научиться различать части речи.
Тезаурус
Часть речи — категория слов языка, определяемая морфологическими и синтаксическими признаками.
Морфология — отдел грамматики, изучающий формы слов.
Имя существительное — часть речи, отвечающая на вопрос кто? что?, обозначает предмет.
Имя прилагательное — часть речи, отвечающая на вопросы какой? какая? какое? какие?, обозначает признак предмета.
Глагол — часть речи, отвечающая на вопросы что делать? что сделать?, обозначают действие предмета.
Местоимение — часть речи, которая указывает на предмет, но не называет его.
Имя числительное — часть речи, отвечающая на вопросы сколько? какой?, обозначает количество или порядок при счёте.
Список литературы
- В.П. Канакина, В.Г. Горецкий. Русский язык. 3 класс Учебник для общеобразовательных организаций. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс Рабочая тетрадь. Пособие для общеобразовательных организаций. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс. Проверочные работы. М.: Просвещение, 2017.
- В.П. Канакина, Русский язык. 3 класс. Тетрадь учебных достижений. М.: Просвещение, 2017.
Планируемые результаты
На этом уроке
Узнаем:
- особенности распознавания различных частей речи;
Научимся:
- различать части речи;
- выполнять разбор по частям речи.
Открытые электронные ресурсы по теме урока (при наличии)
http://resh.edu.ru
https://nsportal.ru
www.prosv.ru
Теоретический материал для самостоятельного изучения
Прочитаем стихотворение О. Высоцкой. Определим, о каких частях речи идёт речь.
Высоцкой. Определим, о каких частях речи идёт речь.
Существительное – школа,
Просыпается – глагол.
С прилагательным весёлый
Новый школьный день пришёл.
Встали мы – местоимение,
Бьёт числительное семь,
За ученье без сомненья,
Приниматься надо всем.
В этом стихотворении можно выделить разные части речи: имя существительное – школа; имя прилагательное – весёлый, глагол – просыпается, местоимение – мы, имя числительное – семь.
Вспомним, для того, чтобы узнать, какой частью речью является то или иное слово, нужно поставить вопрос и определить, что обозначает данное слово.
Имя существительное отвечает на вопрос кто? что?, обозначает предмет.
Имя прилагательное отвечает на вопросы какой? какая? какое? какие?, обозначает признак предмета.
Глагол отвечает на вопросы что делать? что сделать?, обозначают действие предмета.
Местоимение указывают на предметы, но не называют их.
Имя числительное отвечает на вопросы сколько? какой?, обозначает количество или порядок при счете.
В предложении имя существительное, имя прилагательное, имя числительное, глагол, местоимение являются членами предложения.
Выполним разбор по членам предложения и частям речи.
Птицы летят в небе.
(Кто?) Птицы – подлежащее, является именем существительным.
Птицы (что делают?) летят – сказуемое, является глаголом.
Летят (где?) в небе – второстепенный член предложения, является существительным с предлогом.
Дует холодный ветер.
(Что?) Ветер – подлежащее, является существительным.
Ветер (что делает?) дует – сказуемое, является глаголом.
Ветер (какой?) холодный – второстепенный член предложения, является именем прилагательным.
Разбор заданий
Укажите имена существительные.
- Стадион.
- Молодой.
- Раскрасил.
- Семь.
Правильный ответ
Стадион.
Укажите глагол.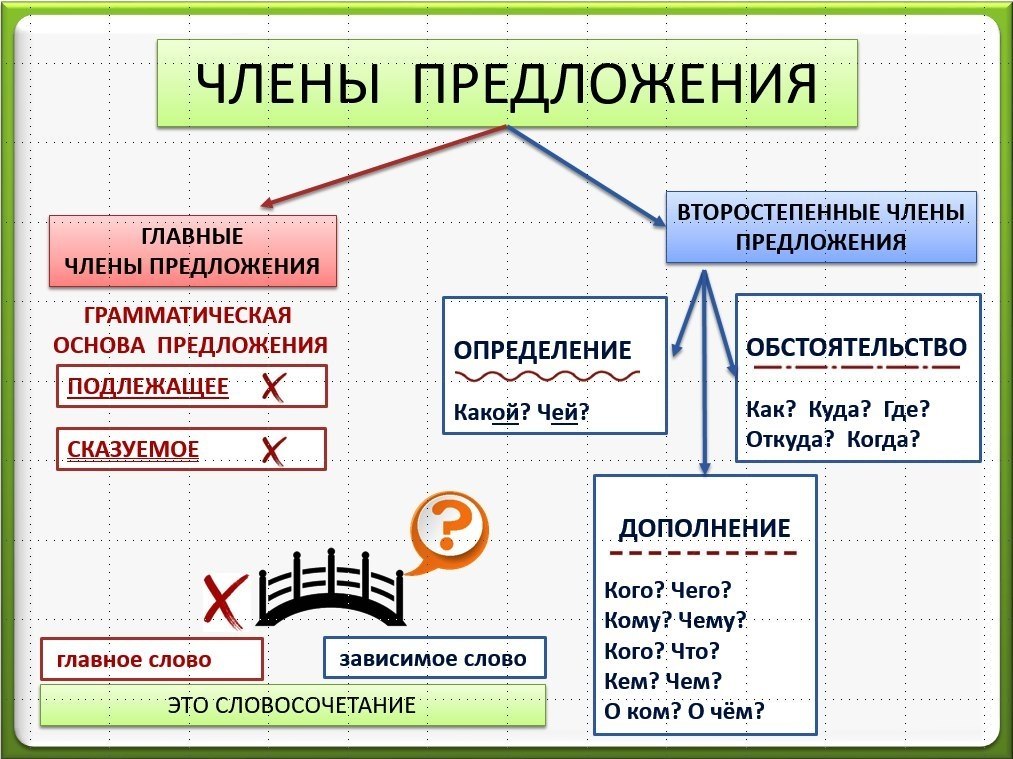
- Медвежий.
- Краски.
- Расстроился.
- Пятый.
Правильный ответ
Расстроился.
Укажите имя прилагательное.
- Военный.
- Осень.
- Маршировать.
- Седьмой.
Правильный ответ
Военный.
Повышенный уровень
Установите соответствия.
Имя существительное | Пятый. |
Имя прилагательное. | Пятёрка. |
Имя числительное. | Пятикратный. |
Правильный ответ
Имя существительное | Пятёрка |
Имя прилагательное. | Пятикратный |
Имя числительное. | Пятый |
Урок 9. главные и второстепенные члены предложения — Русский язык — 3 класс
Название предмета: Русский язык
Класс: Третий класс
Номер урока: № 9
Раздел: Предложение
Тема: Главные и второстепенные члены предложения
Когда слова объединяются в предложение, каждое из них становится одним из членов предложения. У каждого члена предложения своё назначение.
В предложении всегда есть главные члены. Они составляют основу предложения. В ней заключается главный смысл предложения.
Подлежащее ‒ главный член предложения, который обозначает, о ком или о чём говорится в предложении. Подлежащее отвечает на вопрос кто? или что?
Подлежащее в предложении подчеркивается одной чертой.
Сказуемое – главный член предложения, который обозначает, что говорится о подлежащем. Сказуемое отвечает на вопросы что делает? что делают? что делал? что сделал? что сделает? что сделают?
Сказуемое в предложении подчеркивается двумя чертами.
Подлежащее и сказуемое – это главные члены предложения. Они составляют грамматическую основу предложения.
Слова, которые не составляют грамматическую основу предложения, являются второстепенными членами. Второстепенные члены поясняют главные члены предложения, уточняют их.
Предложения могут быть распространёнными и нераспространёнными.
Нераспространённое предложение состоит только из главных членов.
Распространённое предложение состоит из главных и второстепенных членов.
Тезаурус: Предложение; члены предложения; распространённые и нераспространённые предложения; главные и второстепенные члены предложения; подлежащее и сказуемое.
Список литературы:
Канакина В. П., Горецкий В. Г. Русский язык. Учебник. 3 класс. В 2 ч. Ч. 1. — М.: Просвещение, 2018. – С. 26-30.
Канакина В. П. Русский язык. Рабочая тетрадь. 3 класс. В 2 ч. Ч. 1. — М.: Просвещение, 2018. – С. 13-15.
Канакина В.П. Русский язык. Раздаточный материал. 3 класс. – М.: Просвещение, 2019. – С. 8.
Канакина В. П. и др. Русский язык. 3 класс. Электронное приложение. — М.: Просвещение, 2011.
Открытые электронные ресурсы по теме урока (при наличии):
http://resh.edu.ru
www.prosv.ru
Теоретический материал для самостоятельного изучения.
Мы уже знаем, что предложение – это слово или несколько слов, которые выражают законченную мысль. Слова в предложении связаны между собой по смыслу и грамматически.
Когда слова объединяются в предложение, каждое из них становится одним из членов предложения. У каждого члена предложения своё назначение.
В предложении всегда есть главные члены. Они составляют основу предложения. В ней заключается главный смысл предложения.
Подлежащее ‒ главный член предложения, который обозначает, о ком или о чём говорится в предложении. Подлежащее отвечает на вопрос кто? или что?
Подлежащее в предложении подчеркивается одной чертой.
Птицы летят. Ветер дует.
Ветер дует.
Сказуемое – главный член предложения, который обозначает, что говорится о подлежащем. Сказуемое отвечает на вопросы что делает? что делают? что делал? что сделал? что сделает? что сделают?
Сказуемое в предложении подчеркивается двумя чертами.
Дети играют. Дождь льёт.
Подлежащее и сказуемое – это главные члены предложения. Они составляют грамматическую основу предложения.
Слова, которые не составляют грамматическую основу предложения, являются второстепенными членами. Второстепенные члены поясняют главные члены предложения, уточняют их.
Птицы летят в небе.
Птицы – подлежащее
Летят – сказуемое
Летят (где?) в небе – второстепенный член предложения
Дует холодный ветер.
Ветер – подлежащее
Дует – сказуемое
Ветер (какой?) холодный – второстепенный член предложения
Предложения могут быть распространёнными и нераспространёнными.
Нераспространённое предложение состоит только из главных членов.
Жужжит пчела. Пищит комар. Шумит река.
Распространённое предложение состоит из главных и второстепенных членов.
Жужжит пчела на цветке. Пищит громко комар. Шумит бурная река.
Обратим внимание, что в учебниках по русскому языку принято определённым образом обозначать определённые виды разборов. Цифра 4 у последнего слова предложения показывает, что данное предложение надо разобрать по членам предложения.
Например,
Румяной зарёю покрылся восток.4
Приведем пример разбора по членам предложения.
- Читаю предложение:
Яркое солнце взошло на востоке.
- Нахожу подлежащее. Ставлю вопрос: о чём говорится в предложении (о солнце). В предложении слово солнце отвечает на вопрос что? Значит, слово солнце – подлежащее. Подчёркиваю одной чертой.
- Нахожу сказуемое. Ставлю вопрос: что говорится о подлежащем, о солнце? (Взошло.
 ) Слово взошло отвечает на вопрос что сделало? (Солнце (что сделало?) взошло.) Значит слово взошло – сказуемое. Подчёркиваю двумя чертами.
) Слово взошло отвечает на вопрос что сделало? (Солнце (что сделало?) взошло.) Значит слово взошло – сказуемое. Подчёркиваю двумя чертами. - Делаю вывод: подлежащее (солнце) и сказуемое (взошло) – это главные члены предложения.
- Нахожу второстепенный член предложения, который поясняет подлежащее. Ставлю вопрос от подлежащего: солнце (какое?) яркое. Нахожу второстепенный член предложения, который поясняет сказуемое. Ставлю от сказуемого вопрос: взошло (где?) на востоке.
 ) Слово взошло отвечает на вопрос что сделало? (Солнце (что сделало?) взошло.) Значит слово взошло – сказуемое. Подчёркиваю двумя чертами.
) Слово взошло отвечает на вопрос что сделало? (Солнце (что сделало?) взошло.) Значит слово взошло – сказуемое. Подчёркиваю двумя чертами.Делаю вывод: в предложении два словосочетания: яркое солнце, взошло на востоке
- Разбор типового тренировочного задания
ТВ – 1. базовый уровень сложности.
Тип – подстановка элементов в пропуски таблицы.
Текст вопроса
Заполните схему. Впишите слова.
Члены предложения
Правильный ответ.
Члены предложения
главнче члены предложения
подлежащее
сказуемое
второстепенные члены предложения
Алгоритм выполнения задания:
- Прочитайте задание.
- Определите опорные слова задания.
- Расскажите, как вы будете выполнять задание.
- Проверьте, правильно ли рассказали.
- Вспомните, какие есть члены предложения, как называются главные члены предложения.
- Заполните схему.
7. Проверьте, правильно ли выполнили задание.
- Разбор типового тренировочного задания
ТВ – 2. Базовый уровень сложности.
Тип – ребус – соответствие.
Текст вопроса
Пользуясь словами для справок, распространите предложения. Запишите вопросы к второстепенным членам.
Подул ( ?) _________ ветер.
Белка тащит ( ?) ______________ .
( ?) ____________ каркает ворона.
Медведь спит ( ?) _____________ .
Слова для справок: в берлоге, громко, орешки, резкий.
Правильный ответ
Подул (какой?) резкий ветер.
Белка тащит ( что?) орешки .
( Как?) Громко каркает ворона.
Медведь спит ( где?) в берлоге .
Алгоритм выполнения задания:
- Прочитайте задание.
- Определите опорные слова задания.
- Расскажите, как вы будете выполнять задание.
- Проверьте, правильно ли рассказали.
- Прочитайте предложения.
- Определите в предложении главные члены предложения.
- Дополните предложения второстепенными членами предложения.
- Запишите вопросы.
- Проверьте, правильно ли выполнили задание.
Тренажёр «Разбор предложений» — русский язык, разное
Выполни синтаксический разбор предложения (разбери по членам предложения и по частям речи)
- Из березовой рощи доносилась соловьиная2 трель1.
- К дальнему3 лесу вела узкая тропинка2.
- По сторонам3 дороги1 тянутся поля спелой пшеницы.
- Кругом раскинулся2 необъятный зеленый3 простор.
- После снегопада2 лес был3 удивительным и сказочным.
- Деревья1, поля, сады укутаны в снежные3 одеяла.
- Пчела летит3 за медом в сады, в поля1, на луга.
- Ночью1 месяц сверкает2 и всё освещает.
- Охотник сделал3 себе укрытие2 и с вечера залёг в засаду.
- Дунет ветер1, и поднимутся вверх парашютики одуванчика3.
Выполни синтаксический разбор предложения (разбери по членам предложения и по частям речи)
-
Из березовой рощи доносилась соловьиная2 трель1.
- К дальнему3 лесу вела узкая тропинка2.
- По сторонам3 дороги1 тянутся поля спелой пшеницы.
- Кругом раскинулся2 необъятный зеленый3 простор.
- После снегопада2 лес был3 удивительным и сказочным.
- Деревья1, поля, сады укутаны в снежные3 одеяла.
- Пчела летит3 за медом в сады, в поля1, на луга.
- Ночью1 месяц сверкает2 и всё освещает.
- Охотник сделал3 себе укрытие2 и с вечера залёг в засаду.
- Дунет ветер1, и поднимутся вверх парашютики одуванчика3.

Выполни синтаксический разбор предложения (разбери по членам предложения и по частям речи)
- Из березовой рощи доносилась соловьиная2 трель1.
- К дальнему3 лесу вела узкая тропинка2.
- По сторонам3 дороги1 тянутся поля спелой пшеницы.
- Кругом раскинулся2 необъятный зеленый3 простор.
- После снегопада2 лес был3 удивительным и сказочным.
- Деревья1, поля, сады укутаны в снежные3 одеяла.
- Пчела летит3 за медом в сады, в поля1, на луга.
-
Ночью1 месяц сверкает2 и всё освещает.
- Охотник сделал3 себе укрытие2 и с вечера залёг в засаду.
- Дунет ветер1, и поднимутся вверх парашютики одуванчика3.

— доступ к деревьям синтаксического анализа Python — документация Python 3.9.3
Модуль синтаксического анализатора предоставляет интерфейс для внутреннего синтаксического анализатора Python и
компилятор байт-кода. Основная цель этого интерфейса — позволить Python
код для редактирования дерева синтаксического анализа выражения Python и создания исполняемого кода
из этого. Это лучше, чем пытаться разобрать и изменить произвольный Python.
фрагмент кода в виде строки, поскольку синтаксический анализ выполняется аналогично
код, образующий приложение.Это также быстрее.
Предупреждение
Модуль синтаксического анализатора устарел и будет удален в будущих версиях
Python. Для большинства случаев использования вы можете использовать абстрактный синтаксис.
Этап генерации и компиляции дерева (AST) с использованием модуля ast .
Следует отметить несколько важных моментов, связанных с этим модулем.
использование созданных структур данных. Это не руководство по редактированию синтаксического анализа.
деревья для кода Python, но некоторые примеры использования модуля парсера :
представлен.
Самое главное, хорошее понимание грамматики Python, обрабатываемой
требуется внутренний парсер. Для получения полной информации о синтаксисе языка см.
к Справочнику по языку Python. Парсер
сам создается из спецификации грамматики, определенной в файле Грамматика / Грамматика в стандартном дистрибутиве Python. Деревья синтаксического анализа
сохраненные в объектах ST, созданных этим модулем, являются фактическим выходом из
внутренний парсер при создании функциями expr () или suite () ,
описано ниже.Объекты ST, созданные sequence2st () , точно
моделируйте эти структуры. Имейте в виду, что значения последовательностей, которые
считается «правильным», будет варьироваться от одной версии Python к другой, поскольку
пересмотрена формальная грамматика языка. Однако перенос кода из одного
Версия Python для другой в качестве исходного текста всегда будет позволять правильные деревья синтаксического анализа
быть созданным в целевой версии, с единственным ограничением:
переход на более старую версию интерпретатора не будет поддерживать более свежие
языковые конструкции.Деревья синтаксического анализа обычно несовместимы с одним
версия к другой, хотя исходный код обычно был совместим с продвижением в пределах
основная серия релизов.
Каждый элемент последовательностей, возвращаемых функцией st2list () или st2tuple () имеет простую форму. Последовательности, представляющие нетерминальные элементы грамматики
всегда иметь длину больше единицы. Первый элемент — это целое число, которое
определяет продукцию в грамматике. Этим целым числам даны символические имена.
в заголовочном файле C Include / graminit.h и модуль Python символ . Каждый дополнительный элемент последовательности представляет собой компонент
продукции, как распознано во входной строке: это всегда последовательности
которые имеют ту же форму, что и родительские. Важный аспект этой структуры
Следует отметить, что ключевые слова, используемые для идентификации типа родительского узла,
такие как ключевое слово , если в if_stmt , включены в
дерево узлов без какой-либо специальной обработки. Например, , если ключевое слово представлен кортежем (1, 'if') , где 1 — числовое значение
связаны со всеми токенами NAME , включая имена переменных и функций
определяется пользователем.В альтернативной форме возвращается, когда информация о номере строки
запрашивается, тот же токен может быть представлен как (1, 'if', 12) , где 12 представляет собой номер строки, в которой был найден символ терминала.
Терминальные элементы представлены примерно так же, но без дочерних элементов.
элементы и добавление исходного текста, который был идентифицирован. Пример
из , если ключевое слово выше репрезентативно. Различные типы
терминальные символы определены в заголовочном файле C Include / token.h и
модуль Python , токен .
Объекты ST не требуются для поддержки функциональности этого модуля, но предназначены для трех целей: позволить приложению амортизировать стоимость обработки сложных деревьев синтаксического анализа, чтобы обеспечить представление дерева синтаксического анализа что экономит место в памяти по сравнению со списком или кортежем Python представление, и для облегчения создания дополнительных модулей в C, которые манипулировать деревьями синтаксического анализа. В Python можно создать простой класс-оболочку, чтобы скрыть использование объектов ST.
Модуль синтаксического анализатора определяет функции для нескольких различных целей. В
наиболее важными целями являются создание объектов ST и преобразование объектов ST в
другие представления, такие как деревья синтаксического анализа и объекты скомпилированного кода, но есть
также являются функциями, которые служат для запроса типа дерева синтаксического анализа, представленного
СТ объект.
См. Также
- Модуль
символ Полезные константы, представляющие внутренние узлы дерева синтаксического анализа.
- Модуль
токен Полезные константы, представляющие конечные узлы дерева синтаксического анализа и функции для значения узлов тестирования.
Создание объектов ST
Объекты ST могут быть созданы из исходного кода или из дерева синтаксического анализа. При создании
объект ST из источника, различные функции используются для создания 'eval' и 'exec' форм.
-
парсер.expr( источник ) Функция
expr ()анализирует параметр source , как если бы это был вход для компиляции(исходный код, 'file.py ',' eval '). Если синтаксический анализ успешен, объект ST создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае возникает соответствующее исключение.
-
парсер.люкс( источник ) Функция
suite ()анализирует параметр source , как если бы это был вход для компиляции(исходный код, 'file.py', 'exec'). Если синтаксический анализ успешен, объект ST создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае возникает соответствующее исключение.
-
парсер.последовательность 2-я( последовательность ) Эта функция принимает дерево синтаксического анализа, представленное как последовательность, и строит внутреннее представительство, если возможно. Если он может подтвердить, что дерево соответствует к грамматике Python, и все узлы являются допустимыми типами узлов в версии узла Python, объект ST создается из внутреннего представления и возвращается к вызываемому. Если есть проблема с созданием внутреннего представления, или если дерево не может быть проверено, возникает исключение
ParserError.An Не следует предполагать, что объект ST, созданный таким образом, правильно компилируется; обычный исключения, вызванные компиляцией, все еще могут быть инициированы, когда объект ST передано вcompilest (). Это может указывать на проблемы, не связанные с синтаксисом. (например, исключениеMemoryError), но также может быть вызвано такими конструкциями в результате синтаксического анализаdel f (0), который ускользает от синтаксического анализатора Python, но является проверяется компилятором байт-кода.Последовательности, представляющие токены терминала, могут быть представлены как двухэлементные списки формы
(1, 'имя')или трехэлементные списки формы(1, 'имя', 56).Если присутствует третий элемент, предполагается, что это действительный номер строчки. Номер строки может быть указан для любого подмножества терминала. символы во входном дереве.
-
парсер.tuple2st( последовательность ) Это та же функция, что и
sequence2st (). Эта точка входа поддерживается для обратной совместимости.
Преобразование объектов ST
объектов ST, независимо от входных данных, используемых для их создания, могут быть преобразованы в деревья синтаксического анализа, представленные в виде деревьев списков или кортежей, или могут быть скомпилированы в объекты исполняемого кода.Деревья синтаксического анализа могут быть извлечены с линией или без нее информация о нумерации.
-
парсер.st2list( st , line_info = False , col_info = False ) Эта функция принимает объект ST от вызывающего в st и возвращает Список Python, представляющий эквивалентное дерево синтаксического анализа. Результирующий список представление может использоваться для проверки или создания нового дерева синтаксического анализа в форма списка. Эта функция не дает сбоев, пока доступна память для сборки. представление списка.Если дерево синтаксического анализа будет использоваться только для проверки,
st2tuple ()следует использовать вместо этого, чтобы уменьшить потребление памяти и фрагментация. Когда требуется представление списка, эта функция значительно быстрее, чем получение представления кортежа и преобразование этого во вложенные списки.Если line_info истинно, информация о номере строки будет включена для всех токены терминала как третий элемент списка, представляющего токен. Примечание что предоставленный номер строки указывает строку, на которой заканчивается токен .Эта информация опускается, если флаг ложный или опущен.
-
парсер.st2tuple( st , line_info = False , col_info = False ) Эта функция принимает объект ST от вызывающего в st и возвращает Кортеж Python, представляющий эквивалентное дерево синтаксического анализа. Помимо возврата кортеж вместо списка, эта функция идентична
st2list ().Если line_info истинно, информация о номере строки будет включена для всех токены терминала как третий элемент списка, представляющего токен.Этот информация опускается, если флаг ложный или опущен.
-
парсер.compilest( st , filename = '' ) Компилятор байтов Python может быть вызван для объекта ST для создания объектов кода который может использоваться как часть вызова встроенной функции
exec ()илиeval ()функции. Эта функция предоставляет интерфейс компилятору, передавая внутреннее дерево синтаксического анализа от st до анализатора, используя имя исходного файла задается параметром filename .Значение по умолчанию предоставляется для имя файла указывает, что источником был объект ST.Компиляция объекта ST может привести к исключениям, связанным с компиляцией; ан Примером может быть
SyntaxError, вызванная деревом синтаксического анализа дляdel f (0): это утверждение считается допустимым в формальной грамматике Python, но является не юридическая языковая конструкция.SyntaxError, вызванный для этого Условие на самом деле обычно генерируется байтовым компилятором Python, то есть почему он может быть поднят в этот момент модулем парсера.Большинство причин Ошибка компиляции может быть диагностирована программно путем проверки синтаксического анализа дерево.
Запросы к объектам ST
Предусмотрены две функции, которые позволяют приложению определять, был ли ЗБ
создано как выражение или набор. Ни одну из этих функций нельзя использовать для
определить, был ли ST был создан из исходного кода с помощью expr () или suite () или из дерева синтаксического анализа через sequence2st () .
-
парсер.исэкспр( ст ) Когда st представляет форму
'eval', эта функция возвращаетTrue, в противном случае он возвращаетЛожь. Это полезно, поскольку объекты кода обычно не могут быть запрошены. для этой информации используются существующие встроенные функции. Обратите внимание, что код объекты, созданныеcompilest (), тоже не могут быть запрошены таким образом, и идентичны тем, которые созданы встроенной функциейcompile ().
-
парсер.выпуск( ул ) Эта функция отражает
isexpr ()в том смысле, что она сообщает, представляет собой форму'exec', широко известную как «набор». Это небезопасно Предположим, что эта функция эквивалентна, а не isexpr (st), в качестве дополнительной синтаксические фрагменты могут поддерживаться в будущем.
Исключения и обработка ошибок
Модуль синтаксического анализатора определяет одно исключение, но может также передавать другие встроенные исключения из других частей среды выполнения Python.Увидеть каждый для получения информации об исключениях, которые она может вызвать.
- исключение
синтаксический анализатор.ParserError Исключительная ситуация возникает при сбое в модуле синтаксического анализатора. Это обычно производится для сбоев валидации, а не для встроенных
SyntaxErrorвозникает во время обычного синтаксического анализа. Аргумент исключения либо строка, описывающая причину сбоя, либо кортеж, содержащий последовательность, вызывающая сбой из дерева синтаксического анализа, передана вsequence2st ()и пояснительная строка.Звонки наsequence2st ()должны иметь возможность обрабатывать любой тип исключения, в то время как вызовы других функций в модуле нужно будет знать только о простых строковых значениях.
Обратите внимание, что функции compilest () , expr () и suite () могут
вызывать исключения, которые обычно возникают при синтаксическом анализе и компиляции
процесс. К ним относятся встроенные исключения MemoryError , OverflowError , SyntaxError и SystemError .В этих
случаях эти исключения несут все значение, обычно связанное с ними.
Обратитесь к описанию каждой функции для получения подробной информации.
СТ Объекты
Поддерживаются упорядоченные сравнения и сравнения на равенство между объектами ST. Травление
Также поддерживаются объекты ST (с использованием модуля pickle ).
-
парсер.ST Тип Тип объектов, возвращаемых
expr (),suite ()иsequence2st ().
Объекты СТ имеют следующие методы:
-
ST.компиляция( filename = '' ) То же, что и
compilest (st, filename).
-
ST.исэкспр() То же, что
isexpr (st).
-
ST.выпуск() То же, что и
, выпуск (st).
-
ST.tolist( line_info = False , col_info = False ) То же, что и
st2list (st, line_info, col_info).
-
ST.всего( line_info = False , col_info = False ) То же, что и
st2tuple (st, line_info, col_info).
Пример: Эмуляция
compile () Хотя между синтаксическим анализом и байт-кодом может происходить множество полезных операций
генерации, самая простая операция - ничего не делать.Для этого используя
модуль парсера для создания промежуточной структуры данных эквивалентен
на код
>>> code = compile ('a + 5', 'file.py', 'eval')
>>> а = 5
>>> eval (код)
10
Эквивалентная операция с использованием модуля парсера несколько длиннее, и
позволяет сохранить промежуточное внутреннее дерево синтаксического анализа как объект ST:
>>> синтаксический анализатор импорта
>>> st = parser.expr ('а + 5')
>>> код = ул.компилировать ('file.py')
>>> а = 5
>>> eval (код)
10
Приложение, которому нужны как ST, так и объекты кода, может упаковать этот код в готовые функции:
синтаксический анализатор импорта
def load_suite (исходная_строка):
st = parser.suite (исходная_строка)
вернуть st, st.compile ()
def load_expression (исходная_строка):
st = parser.expr (исходная_строка)
вернуть st, st.compile ()
Персонализированное обучение: анализ истины из возможностей
Является ли персонализированное обучение будущим образования? Это зависит от того, кого вы спрашиваете.Как и почти все, что касается обучения, концепция персонализированного обучения имеет свои преимущества и свои проблемы. Истинная ценность индивидуального подхода может проявиться только после того, как преподаватели найдут правильный способ реализовать его с помощью имеющихся у них инструкций.
В статье в Education Week Бенджамин Херольд сообщил, что Министерство образования США выделило округам полмиллиарда долларов на индивидуальное обучение. Херольд также отмечает отсутствие исследований или доказательств, которые поддержали бы такие серьезные инвестиции.Согласно статье, «состояние исследований реальных реализаций моделей персонализированного обучения остается запутанным и спорным».
Кажется, что для каждого исследования, в котором приводятся доказательства в поддержку персонализированного обучения, можно найти другое исследование, которое опровергает эти аргументы.
Определяемый как учебный подход, который «ставит интересы и способности учащихся в центр их образовательного опыта», персонализированное обучение набирает обороты в классах, собирая критику в образовательном мире.В поддержку персонализированного обучения выступают отдельные лица и организации, которые полностью вложили свои усилия в этот подход. Например, Джим Рикабо и Кристина Спейдер, члены Института персонализированного обучения, вместе с Джеймсом Мюрреем документально подтверждают несколько преимуществ этой концепции обучения, ориентированной на учащихся:
- Воспитывает сильных учеников , а не просто опытных учеников.
- Позиционирует учащихся в качестве партнеров с преподавателями для определения целей обучения, разработки траекторий обучения, создания опыта обучения и разделения ответственности за прогресс и успех обучения.
- Основан на компетенциях , поскольку прогресс основан на обучении, а не на времени, затраченном на учебную деятельность. Студенты участвуют в мониторинге роста своих компетенций и прогресса в непрерывном обучении, часто в нескольких предметных областях.
Однако некоторые преподаватели не согласны с этим подходом. Дэн Мейер, учитель математики и блогер по популярному образованию, ставит под сомнение интерпретацию Рикабо, Мюррея и Спейдера. В частности, он спрашивает, как сидение студентов перед экраном для получения персонализированных инструкций из программного обеспечения и предварительно записанных видеоуроков улучшает их образовательный опыт.
«Быстрая перемотка вперед, перемотка назад и приостановка обучающих видеороликов часто упоминаются как преимущества персонализированного обучения не потому, что это обязательно хорошая инструкция, а потому, что это то, что позволяет технология», - написал Мейер.
Эффективность персонализированного обучения, по-видимому, во многом зависит от того, как оно реализовано. В настоящее время не существует формализованного стандарта, поэтому восприятие этого учебного подхода может быть разным. Даже когда элементы персонализированного обучения могут быть согласованы, включая голос и выбор, соответствующий уровень сложности и реальную аудиторию для аутентичной работы, уровень реализации может варьироваться.
Вместо того, чтобы предлагать другое определение персонализированного обучения, давайте исследуем, что возможно в контексте реальности сегодняшнего класса.
Три реальности - три возможности
Чтобы что-либо было действительно инновационным, включая персонализированное обучение, оно должно отличаться на каком-то уровне от своего предшественника, независимо от того, является ли это различие повторяющимся или фундаментальным. Персонализированное обучение в идеальной ситуации должно предлагать то, чего раньше не было в образовании.
Один из элементов - у каждого ученика есть право голоса и выбор того, что они хотят изучать. При необходимости учащиеся должны управлять постановкой целей с помощью учителя. Без голоса и выбора обучение перестает быть личным. Оно возвращается к традиционному образованию, включая оценки и достижения. Это отсутствие вовлеченности приводит к отключению от процесса обучения.
Как заметил один ученик средней школы: «Так как же изменилась моя любовь к школе? Все просто: школа перестала быть предметом обучения.”
Вот несколько примеров школ, которые предоставляют голос и выбор в классе:
- Ученики 2-го класса выбирают тему , которая их интересует. Учитель подсказывает ученикам, как задать главный вопрос и разработать цель для своего времени.
- Учащимся 5-го класса поручено провести исследование по важному вопросу в их сообществе. Это проект, рассчитанный на год. Учитель выделяет студентам время и ресурсы по 40 минут три раза в неделю, чтобы они могли участвовать в этом личном опросе.
- Студенты могут участвовать в самостоятельном обучении , что дает им возможность реализовать идею или навык, о которых они хотят узнать больше.
Эти примеры несложно представить в классе. Что сдерживает учителей? .
Реальность: Время - враг.
Учителя никогда не сталкивались с большим количеством стандартов, требований учебной программы или оценок, чем сегодня. В Common Core существует 44 стандарта грамотности для учащихся 3-х классов, и некоторые из них имеют невысокие стандарты.Когда учителям поручено разработать учебную программу, некоторые консультанты по образованию ожидают, что преподаватели будут учитывать все стандарты при подготовке инструкций. Не рекомендуется просить преподавателей выделять для этой работы больше времени в их забитые дни.
Возможность: определить стандарты в рамках обучения, ориентированного на учащихся.
Тот факт, что ученик может выбрать тему обучения или навык, не означает, что стандарты не соблюдаются. Немного воображения со стороны учителя может иметь большое значение.Например, в примере с 5-м классом следует ожидать, что учащиеся будут заниматься информативным письмом (CCSS.ELA-LITERACY.W.5.2), использовать технологии для передачи своего обучения (CCSS.ELA-LITERACY.W.5.6) и эффективно представить свои выводы для аутентичной аудитории (CCSS.ELA-LITERACY.SL.5.4). Используя этот подход, учащиеся могут соответствовать стандартам и для самостоятельного обучения.
Второй элемент персонализированного обучения, соответствующий уровень сложности, требует осознания текущих способностей учащихся - их сильных сторон и потребностей, а также их интересов.Эта информация может определять, над чем студент должен работать и как проводить этот процесс. Например, второклассники, которые задают ведущий вопрос по теме или навыку, которые они хотят изучить, могут пройти самооценку, чтобы выявить свои сильные стороны, предпочтения и области роста. Они могут использовать эти знания при планировании и участии в индивидуальных учебных проектах.
Реальность: Каждый ученик уникален.
Как педагог может узнать подробности каждого ребенка в классе, а затем организовать индивидуальное обучение на основе этой информации? Учителю нереально следить за 25-30 индивидуальными планами обучения.Требования сегодняшнего класса оставляют учителям мало времени для подготовки инструкций, которые бросают вызов каждому ученику на должном уровне.
Возможность: Используйте систему управления обучающими отношениями.
Учителя слишком много работают. Мы изо всех сил пытаемся передать ответственность за обучение учащимся отчасти из-за многих стандартов, которым мы должны соответствовать. Тем не менее, всегда есть возможности для процветания в рамках ограничений.
Среди наиболее инновационных технологий, помогающих учащимся решать свои собственные задачи, можно назвать системы управления учебными отношениями (LRMS).Они отличаются от систем управления обучением (LMS), таких как Edmodo и Schoology, в которых учитель облегчает задание и выполнение работы. LRMS ставит студентов на место водителя.
Голос и выбор учащимся предлагается в изучении чего-то нового и интересного, должно быть в контексте реальной аудитории для аутентичной работы . Учащиеся должны иметь возможность публиковать свои выводы в Интернете и представлять свои окончательные проекты семьям и даже сообществу.Инструменты цифрового портфолио, блоги, веб-сайты и социальные сети могут облегчить общение и отметить работу студентов в рамках их индивидуальных учебных проектов.
Реальность: Настоящая публика не всегда доступна.
Иногда бывает трудно найти или создать возможности для подлинной работы. Младшим ученикам, которые все еще учатся читать и писать, может потребоваться несколько учебных циклов с усвоением базовой информации, чтобы понять процесс.Кроме того, учащимся нужны возможности для практики в рамках индивидуального учебного проекта в классе. Как часто мы даем студентам возможность публично совершать ошибки, не беспокоясь о том, кто оценит результаты, отличные или нет?
Возможность: создать сообщество учащихся, изменив дизайн классной комнаты.
Учителя могут создать настоящую аудиторию для реальной работы в своих классах, переосмыслив, как они обустраивают свои классы. Столы, стулья и табуреты могут заменить парты.Удобные сиденья могут стать предпочтительным местом для студентов, чтобы неформально рассказать о своей работе и тем самым разработать новые идеи и стратегии. Педагоги не должны упускать из виду то, что сверстники выступают в качестве партнеров в мозговом штурме и разработке возможных учебных проектов.
Студентов также можно научить обеспечивать обратную связь друг с другом, работая над достижением успешного результата обучения. Истинная аудитория настоящей работы студентов может исходить из классного сообщества.
Эффективный опыт обучения всегда был индивидуальным
В статье Edutopia под названием «The Original Makerspace» учительница английского языка в средней школе Лаура Брэдли отметила, что ее класс письма мало чем отличается от makerspaces, возникающих в школах.
«Хотя письменный класс может и не выглядеть как творческое пространство, принципы, лежащие в основе творческого проекта, также можно увидеть на семинаре по письму, ориентированному на студентов», - сказала она.«Создатели и писатели работают через процессы, которые включают в себя мозговой штурм, создание черновиков, поиск отзывов (или тестирование) для внесения улучшений и, в конечном итоге, создание конечного продукта».
Учебный опыт, учитывающий голос и выбор учащихся, дает учащимся соответствующий уровень сложности и обеспечивает подлинную аудиторию для реальной работы. Это не новые концепции. Они существуют с начала формального школьного обучения без больших затрат. Позитивные отношения развиваются, потому что каждый поддерживает друг друга в личных делах.Технологии используются тогда, когда это необходимо, а не только тогда, когда это приятно. Учителя, привлекающие учеников к этому типу обучения, индивидуальны, потому что ученику дается право учиться, как и всем остальным.
Мэтт семнадцатый год учится в системе государственного образования. Он начал работать учителем 5-6 классов в сельской школе за пределами Висконсин-Рэпидс, штат Висконсин. После семи лет преподавания он работал деканом в средней школе, которая превратилась в помощника директора и, в конечном итоге, директора в начальной школе.Теперь, будучи директором начальной школы Объединенного школьного округа Mineral Point, Мэтт наслаждается учебной программой, инструкциями и оценкой образования. Вы также можете связаться с Мэттом в Twitter на @ReadByExample и на его веб-сайте mattrenwick.com.
Индикаторы рынка парсинга- Cresset
Любой, кто смотрел на фондовый рынок в течение последних двух месяцев, не подозревал, что мировая экономика находится в приостановленном состоянии, поскольку страны борются с глобальной пандемией.Вопреки основным вызовам Америки, индекс S&P 500 вырос на 36% от своего дна 23 марта (примерно через неделю после начала блокады в США) до мая, в результате чего индекс голубых фишек упал до 5% за год. Расхождение вызывает вопрос: имеет ли смысл владеть акциями сейчас?
Cresset оценивает фондовые рынки с нескольких точек зрения. Во-первых, конечно, это оценка . Рынок дешевый или дорогой? Хотя оценка - не лучший инструмент выбора времени, мы знаем, что дешевые рынки со временем имеют тенденцию превосходить по эффективности дорогие.Во-вторых, это экономический фон : если фондовые рынки - это рыба в аквариуме, то учитывайте температуру воды. Способствует ли экономическая среда принятию риска и получению прибыли? В-третьих, ликвидность , наличие денег для займов, расходов и инвестиций. Обильная ликвидность способствует принятию риска; рыночные распродажи, такие как 28-процентное падение в период с 20 февраля по 22 марта, подпитываются мировым стремлением к наличным деньгам. В-четвертых, психология - важная краткосрочная противоположная метрика, особенно в точках крайнего оптимизма или широко распространенного страха.Пятое - импульс : дешевый рынок, подтвержденный покупками, исторически был открытым приглашением к инвестированию и получению прибыли.
Давайте оценим состояние фондовых рынков сегодня на основе этих показателей:
Оценка: C. Рынки акций занимают нейтральную позицию с точки зрения оценки, хотя, учитывая падение оценок прибыли на 2020 год, мы вынуждены использовать скользящую и текущую статистику. Рыночная капитализация как доля от ВВП, мера, которую предпочитает Уоррен Баффет, является макро-метрикой, которая исторически использовалась.Эта точка зрения показывает, что рынок немного переоценен, примерно на 10% выше, чем его долгосрочная медиана.
Соотношение стоимости предприятия к EBITDA (EV / EBITDA) - один из наших любимых показателей, поскольку он рассматривает акции как предприятия, генерирующие денежные потоки, после корректировки с учетом остатков денежных средств и долга. Исходя из этого, акции с малой капитализацией, представленные Russell 2000, являются самой дорогой основной категорией акций, торгуются с более чем 18-кратным денежным потоком или доходностью около 5,2%. На этот счет S&P 500 предлагает доходность около 6 денежных потоков.3 процента. Международные развитые и развивающиеся рынки предлагают доходность денежных потоков 10,5% и 11,1% соответственно.
Циклически скорректированное соотношение цены и прибыли (CAPE) было одним из наиболее полезных инструментов рыночной оценки. Популяризованный профессором Йельского университета Робертом Шиллером, CAPE использует реальную прибыль на акцию (EPS) за 10-летний период для сглаживания колебаний корпоративной прибыли, которые происходят в разные периоды экономического цикла. Исторически сложилось так, что коэффициент CAPE был хорошим предиктором последующих 10-летних показателей рынка.Это неотъемлемый компонент долгосрочных предположений Cresset о рынке капитала. На основе CAPE S&P 500 в настоящее время 21, что предполагает 10-летнюю доходность в годовом исчислении на уровне 6+ процентов, исходя из исторических данных.
Наши оценочные показатели предполагают, что держатели акций будут придерживаться курса, несмотря на недавний рост фондового рынка перед лицом тревожных экономических условий.
Экономичный фон Класс: D . Не нужно быть экономистом, чтобы знать, что экономика ужасна. Почти 30 миллионов американцев остались без работы, и ожидается, что в этом квартале реальный ВВП упадет на 34% в годовом исчислении.Падение рынка труда в 2020 году - доля рабочей силы, теряющей работу, - является самым резким и глубоким спадом на рынке труда в современной экономической истории. В соответствии с прогнозами экономистов Еженедельный экономический индекс ФРС Нью-Йорка, который измеряет реальную экономическую активность с еженедельной периодичностью, является лучшим способом оставаться в курсе последних прогнозов квартального роста в годовом исчислении. Согласно последним данным, экономика во втором квартале 20-го квартала будет на 10% меньше, чем во 2-м квартале 19-го. Мы надеемся, что расходы будут постепенно расти по мере возобновления работы штатов.Тем временем американское производство и производство находятся в упадке.
Уровень ликвидности: A. Финансовый кризис 2008-2009 годов был, оглядываясь назад, всего лишь на учение против пандемии COVID-19, и Федеральная резервная система извлекла уроки из этого опыта - она проделала большую работу в своей роли кредитора в крайнем случае. Мы были впечатлены, когда ФРС Бернанке увеличила свой баланс с 900 миллиардов долларов до 2 триллионов долларов в течение 18 месяцев. Мы были по-настоящему впечатлены, когда ФРС Пауэлла за несколько недель увеличила объем покупок облигаций на 3 триллиона долларов.Перспектива остановки мировой экономики спровоцировала бегство на рынки капитала, поскольку инвесторы привлекали деньги. Действия ФРС - вливания ликвидности составили 30 процентов ВВП - подавили панические продажи и стабилизировали рынки акций и облигаций. Благодаря этим усилиям, а также усилиям Конгресса по передаче чеков в руки частных лиц и владельцев малого бизнеса, меры по обеспечению ликвидности Cresset являются надежными. Только волатильность фондового рынка остается в самом узком квинтиле своего исторического диапазона.
Психология Класс: B. Психология инвестора - это противоположный индикатор, в котором рынок в краткосрочной перспективе представляет собой пересечение реальности и ожиданий. История показала, что в реальности намного легче превзойти плохие ожидания медвежьих инвесторов, чем воспрепятствовать бурным ожиданиям слишком оптимистичных инвесторов. Плохие новости и плохие рынки влияют на настроения инвесторов, делая цены более привлекательными. Исторические данные показывают, что доходность S&P 500 более чем в два раза в следующем году на основе широко распространенного медвежьего настроения, согласно опросу Американской ассоциации индивидуальных инвесторов (AAII).Последнее исследование AAII показывает, что инвесторы, хотя и пессимистичны, не так уж сильно настроены, что свидетельствует в пользу нейтральной позиции по акциям. Пессимизм среди международных инвесторов достиг своего пика со времен финансового кризиса, что позволяет предположить, что в краткосрочной перспективе могут появиться возможности инвестирования за рубежом.
Momentum Оценка: B +. В то время как экономисты спорят о V-образном восстановлении экономики, инвесторы в акции столкнулись с резким V-образным отскоком рынка в течение трех месяцев.Относительная доходность S&P 500 по отношению к трехмесячным казначейским векселям благоприятствует S&P 500 после кратковременного падения. Широта рынка, доля компаний, участвующих в митинге, не получила такого же энтузиазма, что свидетельствует о некоторой слабости. Только четверть акций NYSE в настоящее время торгуются выше своих 200-дневных скользящих средних. Индекс умных денег (SMI), технический показатель, который анализирует торговлю в первые полчаса («тупой» = розничная торговля), меняет знак и добавляет в последние полчаса («умный» = институциональный).Это говорит о том, что дно рынка осталось позади. Во время финансового кризиса SMI достигла дна в октябре 2008 года, за пять месяцев до более широкого разворота рынка. В этом году индекс умных денег достиг дна в конце февраля.
Сложив все вместе, мы пришли к выводу, что те, кто инвестировал в акции, должны оставаться инвесторами. Международные и развивающиеся рынки находятся в наилучшем положении с точки зрения оценки, но импульс является мощной силой, а импульс в настоящее время благоприятствует акциям с высокой капитализацией, ориентированным на рост.Мы будем искать импульсы со стороны международных и развивающихся рынков в качестве индикаторов для перемещения капитала в этих направлениях.
Разбор строки в Swift | Swift by Sundell
Практически каждая программа на планете так или иначе имеет дело со строками, поскольку текст играет фундаментальную роль в том, как мы общаемся и представляем различные формы данных. Но обработка и анализ строк одновременно надежным и эффективным способом может иногда быть действительно трудным. Хотя некоторые строки имеют очень строгий и удобный для компьютера формат, например JSON или XML, другие строки могут быть гораздо более хаотичными .
На этой неделе давайте рассмотрим различные способы синтаксического анализа и извлечения информации из таких строк, а также то, как разные методы и API приведут к разному набору компромиссов.
Масштабное создание мобильных приложений: Эта бесплатная 200-страничная книга, основанная на опыте масштабирования разработки приложения Uber за четыре года, поможет вам преодолеть 39 наиболее часто встречающихся проблем при создании больших приложений для iOS. Книгу можно бесплатно скачать в течение ограниченного времени, так что возьмите копию прямо сейчас.
В некотором смысле Swift заработал репутацию человека, с которым немного сложно работать, когда дело доходит до синтаксического анализа строк. Хотя это правда, что реализация Swift String не предлагает такого же удобства , как многие другие языки (например, вы не можете просто произвольно получить доступ к заданному символу, используя целое число, например string [7] ), это упрощает написание правильного кода синтаксического анализа строки .
Потому что, хотя приятно иметь возможность произвольного доступа к любому заданному символу в строке на основе его воспринимаемой позиции, многоязычный (или, возможно, эмодзи-язычный ?) Мир, в котором мы живем сегодня, делает такие API очень подверженными ошибкам , поскольку способ, которым символ представлен в текстовом пользовательском интерфейсе, во многих случаях сильно отличается от того, как на самом деле хранит в строковом значении.
В Swift строка состоит из набора из символов значений, сохраненных с использованием кодировки UTF-8 . Это означает, что если мы перебираем строку (например, используя цикл для ), каждый элемент будет символом , который может быть буквой, смайликом или какой-либо другой формой символа. Чтобы идентифицировать группы символов (например, буквы или цифры), мы можем использовать CharacterSet , который можно передать нескольким различным API на String и связанных с ним типах.
Допустим, мы работаем над приложением, которое позволяет нескольким различным пользователям совместно работать над документом, и что мы хотим реализовать функцию, которая позволяет пользователям упоминать других людей, используя синтаксис @mention , похожий на Twitter.
Идентификация пользователей, упомянутых в данной строке, - это задача, которая на самом деле очень похожа на то, что компилятор Swift должен делать при идентификации различных частей в строке кода - процесс, известный как lexing или tokenizing - только то, что наша реализация будет на несколько порядков проще, так как нам нужно искать только одного вида токена.
Начальная реализация может выглядеть примерно так - вычисляемое свойство на String , в котором мы разбиваем строку на @ символов, отбрасываем первый элемент (так как это будет текст перед первым @ - sign), а затем compactMap поверх результата - идентификация строк непустых буквенных символов:
extension String {
var упомянутоUsernames: [String] {
let parts = split (разделитель: "@"). dropFirst ()
пусть delimiterSet = CharacterSet.буквы. перевернутые
return parts.compactMap {часть в
let name = part.components (separatedBy: delimiterSet) [0]
вернуть name.isEmpty? ноль: имя
}
}
} Вышеупомянутая реализация довольно проста и использует некоторые действительно хорошие функции Swift, такие как изменение коллекций, использование compactMap для отбрасывания значений nil и так далее. Но у него есть одна проблема - требуется три итерации , одна для разделения строки на основе @ символов, одна для итерации по всем этим частям, а затем одна для разделения каждой части на основе небуквенных символов.
Хотя каждая итерация меньше предыдущей (поэтому сложность нашего алгоритма не совсем O (3N) ), несколько итераций чаще всего приводят к некоторой форме узких мест по мере роста входного набора данных. В нашем случае это может стать проблемой, поскольку мы планируем применить этот алгоритм к документам любого размера (возможно, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), Так что давайте посмотрим, сможем ли мы что-нибудь сделать. чтобы оптимизировать его.
Вместо того, чтобы разбивать нашу строку на компоненты, а затем повторять эти компоненты, давайте вместо этого сделаем один проход через нашу строку - путем итерации по ее символам.Хотя для этого потребуется немного больше кода ручного анализа, это позволит нам сократить наш алгоритм до одной итерации, например:
extension String {
var упомянутоUsernames: [String] {
var partialName: Строка?
var names = [String] ()
func parse (символ _: символ) {
if var name = partialName {
guard character.isLetter else {
if! name.isEmpty {
имена.добавить (имя)
}
partialName = nil
возвратный синтаксический анализ (символ)
}
name.append (символ)
partialName = имя
} else if character == "@" {
partialName = ""
}
}
forEach (синтаксический анализ)
если let lastName = partialName,! lastName.isEmpty {
names.append (фамилия)
}
вернуть имена
}
} Обратите внимание, что приведенный выше API isLetter для Character был добавлен в Swift 5.
Хотя приведенная выше реализация намного сложнее, чем наша первоначальная, она примерно в два раза быстрее (в среднем), что дает нам первый четкий компромисс : выбираем ли мы более простое решение по потенциальной цене производительности - или мы выберем более сложный, а также более эффективный алгоритм?
Обсуждение того, какой компромисс принять, становится еще более интересным по мере того, как наш список требований растет. Предположим, что после успешного развертывания функции упоминания для наших пользователей мы начали получать запросы на добавление поддержки для хэштегов, и мы решили сделать именно это.
Поскольку обнаружение имен пользователей и хэштегов - это одна и та же проблема (отличается только начальный символ - @ и # ), имеет смысл использовать одну и ту же реализацию для обнаружения обоих. Для этого давайте сначала определим тип Symbol , который мы будем использовать для представления либо упоминания, либо хэштега:
struct Symbol {
enum Kind {упоминание о регистре, хэштег}
пусть добрые: добрые
var строка: Строка
} Хотя мы, , могли бы использовать вместо перечисление со связанными строковыми значениями - поскольку и упоминания, и хэштеги имеют одну и ту же структуру, это упростит наш алгоритм, если мы будем использовать структуру.Однако, чтобы разрешить использование Symbol в стиле перечисления , мы также можем добавить некоторые статические фабричные методы, чтобы упростить создание значений с использованием точечного синтаксиса:
extension Symbol {
упоминание статической функции (_ строка: Строка) -> Символ {
символ возврата (вид: упоминание, строка: строка)
}
хэштег static func (_ строка: String) -> Symbol {
символ возврата (вид: хэштег, строка: строка)
}
} С учетом вышеизложенного, давайте обновим наш упомянутый алгоритм имен пользователей по сравнению с предыдущим, чтобы обнаруживать символы, а не только имена пользователей:
extension String {
var symbols: [Symbol] {
var partialSymbol: Символ?
var symbols = [Symbol] ()
func parse (символ _: символ) {
if var symbol = partialSymbol {
охранник.isLetter else {
if! symbol.string.isEmpty {
symbols.append (символ)
}
partialSymbol = nil
возвратный синтаксический анализ (символ)
}
symbol.string.append (символ)
partialSymbol = символ
} еще {
переключить символ {
кейс "@":
partialSymbol = .mention ("")
кейс "#":
partialSymbol =.хэштег("")
дефолт:
перерыв
}
}
}
forEach (синтаксический анализ)
если let lastSymbol = partialSymbol,! lastSymbol.string.isEmpty {
symbols.append (lastSymbol)
}
символы возврата
}
} С указанным выше изменением разница между нашей первоначальной реализацией на основе разделения строк и нашим последним алгоритмом становится еще больше - поскольку, если бы мы токенизировали имена пользователей и хэштеги путем разделения строк, нам потребовалось бы 6 различных итераций ( 2 раза по 3) - два из которых будут полными проходами через исходную строку.
Однако было бы неплохо, если бы мы смогли найти какую-то золотую середину между простотой нашей первоначальной реализации и мощностью нашего ручного алгоритма. Одним из способов сделать это могло бы быть введение абстракции, которая отделяет часть нашего алгоритма токенизации от логики фактического обращения с любыми найденными токенами.
Для этого давайте переместим основную часть нашего последнего алгоритма в метод tokenize , который принимает словарь обработчиков, хешированных в зависимости от того, какой символ они обрабатывают, например:
extension String {
func tokenize (с использованием обработчиков: [Character: (String) -> Void]) {
var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse (символ _: символ) {
if var data = parsingData {
охранник.isLetter else {
if! data.symbol.isEmpty {
data.handler (data.symbol)
}
parsingData = nil
возвратный синтаксический анализ (символ)
}
data.symbol.append (символ)
parsingData = данные
} еще {
guard let handler = handlers [персонаж] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
forEach (синтаксический анализ)
если пусть lastData = parsingData,! lastData.symbol.isEmpty {
lastData.handler (lastData.symbol)
}
}
} Вышеупомянутое не только немного очищает нашу реализацию, но также дает нам гораздо больше гибкости - поскольку теперь мы можем повторно использовать один и тот же алгоритм токенизации во многих различных контекстах и выбирать, как каждый токен должен обрабатываться на сайте вызова. .
Теперь мы можем сократить код разбора символов, который был раньше, до следующего:
extension String {
var symbols: [Symbol] {
var symbols = [Symbol] ()
tokenize (используя: [
"@": {символы.append (.mention ($ 0))},
"#": {symbols.append (.hashtag ($ 0))}
])
символы возврата
}
} Очень красиво и чисто! 👍 Но, как и раньше, здесь есть ряд компромиссов. Хотя абстракции - отличный способ скрыть сложную логику за гораздо более красивым API, они не бесплатны. Фактически, нашей последней версии требуется примерно на 40% больше времени для выполнения по сравнению с тем, когда алгоритм был встроен в свойство символов . Тем не менее, это примерно в два раза быстрее, чем делать то же самое при разделении строк, так что на самом деле это может быть та хорошая золотая середина, которую мы искали.
До сих пор мы в основном сравнивали итерацию вручную по символам строки с разбиением ее на компоненты, но, как и во многих других случаях, есть и другие варианты, которые следует учитывать.
Одним из таких вариантов является использование типа Foundation Scanner для непрерывного сканирования строки для идентификации искомых токенов. Как и в нашей предыдущей реализации, он позволяет нам полагаться на абстракцию (на этот раз предоставленную Apple) для обработки большей части «тяжелой работы» нашего алгоритма .Вот как может выглядеть такая реализация:
extension String {
var symbols: [Symbol] {
let scanner = Сканер (строка: self)
let symbolSet = CharacterSet (charactersIn: "@ #")
var symbols = [Symbol] ()
var symbolKind: Тип символа?
while! scanner.isAtEnd {
if let kind = symbolKind {
symbolKind = nil
var результат: NSString?
scanner.scanCharacters (от:.буквы, в: & результат)
guard let string = result else {
Продолжать
}
symbols.append (Символ (вид: вид, строка: строка как строка))
} еще {
scanner.scanUpToCharacters (из: symbolSet, в: nil)
if scanner.scanString ("@", into: nil) {
symbolKind = .mention
} else if scanner.scanString ("#", into: nil) {
symbolKind =.хэштег
}
}
}
символы возврата
}
} Хотя «Objective-C-ness» из Scanner может сделать наш код немного менее «Swifty» , это допустимый вариант для такого рода проблем - и его характеристики производительности включены -par с нашей ручной реализацией на основе итераций из прошлого. Можно также утверждать, что использование Scanner дает немного более читаемый код, поскольку его API-интерфейсы явно заявляют, что мы сканируем на заданную строку в каждой части алгоритма, но это будет очень субъективно.
Давайте рассмотрим еще одно место для оптимизации - использование ленивых коллекций . До этого момента все реализации, которые мы исследовали, имели одну общую черту - все они немедленно анализировали всю строку. Хотя это вполне нормально для сценариев использования, которые также будут использовать все результаты немедленно, мы потенциально могли бы еще оптимизировать вещи, вместо этого выполняя синтаксический анализ более ленивым способом .
Как мы рассмотрели в «Быстрые последовательности: искусство быть ленивым» , отсрочка вычисления элемента в последовательности до тех пор, пока он действительно не понадобится , иногда может дать нам повышение производительности - особенно если вызывающий будет только потреблять подмножество нашей последовательности.
Давайте обновим нашу последнюю реализацию на основе Scanner , чтобы она выполнялась лениво. Для этого мы обернем наш алгоритм в AnySequence и AnyIterator , что позволит нам формировать ленивые последовательности, не требуя от нас реализации нового типа с нуля:
extension String {
символы var: AnySequence {
let symbolSet = CharacterSet (charactersIn: "@ #")
вернуть AnySequence {() -> AnyIterator в
let scanner = Сканер (строка: self)
var symbolKind: Символ.Добрый?
func iterate () -> Символ? {
guard! scanner.isAtEnd else {
вернуть ноль
}
guard let kind = symbolKind else {
scanner.scanUpToCharacters (из: symbolSet, в: nil)
if scanner.scanString ("@", into: nil) {
symbolKind = .mention
} else if scanner.scanString ("#", into: nil) {
symbolKind = .hashtag
}
вернуть итерацию ()
}
symbolKind = nil
var результат: NSString?
сканер.scanCharacters (из: букв в: & результат)
guard let string = result else {
вернуть итерацию ()
}
символ возврата (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (итерация)
}
}
} С указанным выше изменением мы теперь получаем довольно значительный прирост производительности для такого кода, который выполняет итерацию только через нашу последовательность из символов до заданной точки:
let firstHashtag = string.symbols.first {$ 0.kind == .hashtag} И это дает нам последний компромисс для этой статьи - готовы ли мы принять дополнительную сложность (и, возможно, немного более сложную отладку), чтобы сделать более короткие итерации более производительными?
Масштабное создание мобильных приложений: Эта бесплатная 200-страничная книга, основанная на опыте масштабирования разработки приложения Uber за четыре года, поможет вам преодолеть 39 наиболее часто встречающихся проблем при создании больших приложений для iOS.Книгу можно бесплатно скачать в течение ограниченного времени, так что возьмите копию прямо сейчас.
Как и при написании любых алгоритмов, какая именно реализация будет наиболее подходящей, в значительной степени зависит как от того, с какой проблемой мы имеем дело, насколько велики наборы данных, на которых мы планируем ее запускать, так и от того, как результат будет израсходован.
Есть, конечно, также много других способов синтаксического анализа строк в Swift, которые эта статья не охватывала - например, использование регулярных выражений или погружение в анализ вещей на базовом уровне Unicode - но, надеюсь, это дало вам обзор некоторых инструментов и методов, которые находятся в нашем распоряжении, и различных компромиссов, с которыми все они приходят.
Мой личный подход почти всегда заключается в том, чтобы начинать с простейшей возможной реализации и, постоянно измеряя результаты и характеристики производительности моих алгоритмов, увеличивать масштаб по мере необходимости - точно так же, как в этой статье. В следующей статье мы также подробнее рассмотрим, как точно измерить наш код по различным типам показателей производительности.
Как вы думаете? У вас есть любимый способ синтаксического анализа строк в Swift, или вы попробуете один из методов из этой статьи в следующий раз, когда столкнетесь с подобной проблемой? Дайте мне знать - вместе со своими вопросами, комментариями и отзывами - в Twitter @johnsundell или связавшись со мной.
Спасибо за чтение! 🚀
Изучение исполняемого нейросемантического анализатора | Вычислительная лингвистика
Когда для прогнозирования токенов уделяется пристальное внимание, цель ℒ a остается той же, но ℒ y отличается. Это связано с тем, что уровень внимания не является дифференцируемым, чтобы ошибки могли распространяться обратно. Мы используем альтернативный алгоритм в стиле REINFORCE (Williams, 1992) для обратного распространения ошибки. В этом сценарии нейронный уровень внимания используется в качестве предиктора политики для выбора выбора внимания, в то время как последующие нейронные слои используются в качестве функции значения для вычисления вознаграждения - нижней границы журнала правдоподобия p ( y | x , a ).Пусть u t обозначает выбор скрытого внимания 2 на каждом временном шаге t ; мы максимизируем ожидаемую логарифмическую вероятность токена логической формы с учетом общего выбора внимания для всех примеров, что согласно неравенству Дженсена является нижней границей журнала правдоподобия журнала p ( y | x , a ):Ly = ∑ (x, l) ∈T∑up (u | x, a) logp (y | u, x, a) ≤∑ (x, l) ∈Tlog∑up (u | x, a) p ( y | u, x, a) = ∑ (x, l) ∈Tlogp (y | x, a)
(47) Градиент ℒ y относительно параметров модели θ равен∂Ly∂ θ = ∑ (x, l) ∈T∑up (u | x, a) ∂logp (y | u, x, a) ∂θ + logp (y | u, x, a) ∂p (u | x, а) ∂θ = ∑ (x, l) ∈T∑up (u | x, a) ∂logp (y | u, x, a) ∂θ + logp (y | u, x, a) ∂logp (u | x, a) ∂θp (u | x, a) = ∑ (x, l) ∈T∑up (u | x, a) ∂logp (y | u, x, a) ∂θ + logp (y | u, x, a) ∂logp (u | x, a) ∂θ≈∑ (x, l) ∈T1N∑k = 1K∂logp (y | uk, x, a) ∂θ + logp (y | uk, x, a) ∂logp (uk | x, a) ∂θ
(48), которое оценивается методом Монте-Карло с K выборками.Этот оценщик градиента имеет высокую дисперсию, потому что логарифм вознаграждения p ( y | u k , x , a ) зависит от образцов u k . Базовая линия , зависящая от ввода, используется для уменьшения дисперсии, которая регулирует обновление градиента как∂Ly∂θ = ∑ (x, l) ∈T1N∑k = 1K∂logp (y | uk, x, a) ∂ θ + (logp (y | uk, x, a) −b) ∂logp (uk | x, a) ∂θ
(49) В качестве базовой линии мы используем предиктор маркера мягкого внимания, описанный ранее.Эффект состоит в том, чтобы поощрять образцы внимания, которые возвращают более высокую награду, чем стандартное мягкое внимание, в то же время препятствуя тем, которые приводят к более низкому вознаграждению. Для каждого обучающего случая мы аппроксимируем ожидаемый градиент с помощью одной выборки u k .Разбор документов, содержащих таблицы | Документация Cloud Document AI
В этом примере показано, как использовать процесс метод запроса обработки небольшого документа (<= 5 страниц, <20 МБ).В
пример использует доступ
токен для учетной записи службы, настроенной для проекта с помощью Cloud SDK. Для
инструкция по установке Cloud SDK, настройке проекта с сервисом
аккаунт и получение токена доступа см.
Прежде чем вы начнете.
Образец
тело запроса
содержит обязательные поля ( inputConfig ) и дополнительные поля, некоторые
для обработки конкретных таблиц
( tableExtractionParams ).
Обратите внимание, что поведение по умолчанию включает извлечение таблицы и автоматическую таблицу
определение местоположения, даже если tableExtractionParams не
указано.
Если запрос выполнен успешно, сервер возвращает код состояния HTTP 200 OK и
ответ в формате JSON. Тело ответа содержит экземпляр
Документ в стандартном формате.
Ответ
{
"ури": "",
" текст ": "Groove \ nStep \ nH. \ NMajor \ nAA / TT \ n1.23 \ n0.64 \ n5.41 \ n3.80 \ n2.21 \ n1.18 \ n
AC / GT \ n2.71 \ n1.09 \ n2.90 \ n1.21 \ n4.14 \ n1.03 \ nAG / CT \ n1.72 \ n1.92 \ n2.54 \ n3.21 \ n2. 92 \ n
1.48 \ nATIAT \ n2.32 \ n0.65 \ n4.95 \ n1.85 \ n2.55 \ n2.10 \ nCA / TG \ n1.35 \ n0.26 \ n2.58 \ n0.56 \ n3.40 \ n
1,50 \ nCC / GG \ n3.66 \ n1.09 \ n1.49 \ n1.00 \ n4.17 \ n0.77 \ nCG / CG \ n1.90 \ n1.78 \ n0.46 \ n2.08 \ n5.36 \ n
1.10 \ nGA / TC \ n2.58 \ n2.83 \ n1.03 \ n0.80 \ n5.14 \ n0.38 \ nGC / GC \ n2.34 \ n3.03 \ n1.32 \ n1.08 \ n5.03 \ n
0.70 \ nTA / TA \ n2.26 \ n0.00 \ n6.48 \ n4.72 \ n0.72 \ n3.19 \ nMinor \ nAA / TT \ n1.28 \ n1.32 \ n0.45 \ n0. 42 \ n
8.15 \ n0.00 \ nAC / GT \ n1.92 \ n1.97 \ n0.00 \ n0.94 \ n3.53 \ n3.17 \ nAG / CT \ n0.00 \ n0.63 \ n2.64 \ n1.86 \ n
3.00 \ n1.79 \ nATIAT \ n0.52 \ n1.51 \ n2.66 \ n0.30 \ n3.75 \ n2.38 \ nCA / TG \ n0.00 \ n1.13 \ n1.38 \ n1. 33 \ n
5.79 \ n1.80 \ nCC / GG \ n1.91 \ n1.80 \ n2.35 \ n1.49 \ n3.39 \ n2.27 \ nCG / CG \ n0.00 \ n2.19 \ n2.41 \ n2.73 \ n
2.25 \ n2.38 \ nGA / TC \ n0.00 \ n1.26 \ n0.75 \ n2.38 \ n3.62 \ n0.00 \ nGC / GC \ n0.00 \ n2.56 \ n1.35 \ n1.92 \ n
2.67 \ n1.23 \ nTA / TA \ n0.00 \ n3.88 \ n0.00 \ n0.00 \ n4.94 \ n3.65 \ nR. \ NПервая степень \ n родственные связи \ n
внук 8 лет \ nи \ nОбразование \ nМиграция \ nактивность \ nВозраст \ nВозраст \ nРынок \ nЗдоровье \ nМедицина \ n
Резиденция \ nПол \ n (лет) категория \ nУровень \ Интеграция, специализация предприятия \ n
Домохозяйство 1 Хуасапампа \ n26 \ nмужчин \ nпервоначальный \ nсезонный \ nнизкий \ n37 \ nмолодой \ nнет \ nбрат \ n
из 2 \ nДомохозяйство 2 Huasapampa \ n25 \ nмолодая невестка 1 начальной школы \ nсезонная \ n
низкий \ n36 \ nнет \ nДомашнее хозяйство 3 Huasapampa \ n21 \ nМолодая дочь 5-ти лет \ nвысокая \ nlow \ n
57 \ nнет \ nнет \ nДомашнее хозяйство 4 Huasapampa \ n49 \ nСредний мужчина \ nпервоначальный \ nсезонный \ nвысокий \ n22 \ n
нет \ nДомохозяйство 5 Huasapampa \ n52 \ nСредняя женщина \ nДругие 3 \ nпервоначальные \ nсезонные \ nсезонные \ n
99 \ nнет \ nДомашнее хозяйство 6 Huasapampa \ n45 \ nСредняя женщина \ nосновная \ nсезонная \ nсезонная \ n50 \ nнет \ n
Домохозяйство 7 Хуасапампа \ n44 \ nСредний мужчина \ nпервоначальный \ nсезонный \ nнизкий \ n медицинский работник \ n12 \ n
дедушка 1 \ nи брат 9 \ nДомохозяйство 8 Huasapampa \ n63 \ nстарый \ nмужской \ nпервоначальный \ n
сезонный \ nнизкий \ nАндийский лекарь \ n82 \ nДомашний дом 9 Huasapampa \ n76 \ nстарый \ nмужчин \ nбрат из 8 \ n
первичный \ nсезонный \ nнизкий \ nпостоянный лекарь \ n44 \ nполупостоянный медицинский работник средней степени тяжести \ n
вторичный полупостоянный \ nДомашний дом 10 Huasapampa \ n62 \ nстарый \ nмужской \ n52 \ nДомашний дом 11 Huito \ n
32 \ nмолодой \ nмужчин \ nнизкий \ nнет \ n28 \ nмолодой \ nмолодой мужчина \ nДомашнее хозяйство 12 Huito \ nlow \ n
вторичный \ nвторичный полупостоянный \ nпервичный \ n24 \ nнет \ nнет \ n47 \ nДомашний 13 Huito \ n38 \ n
высокий \ n53 \ nнет \ nДомашнее хозяйство 14 Huito \ n43 \ nсредняя женщина \ nсезонный \ nнизкий \ nнет \ n50 \ n
Домохозяйство 15 Huito \ n42 \ nМолодой \ nмужчина \ nпостоянный медицинский работник средней степени тяжести \ n53 \ n
Домохозяйство 16 Huito \ n47 \ nСредний мужской \ nвторичный полупостоянный средний \ n46 \ nнет \ n
Дом 17 Huito \ n68 \ nстарый \ nмужской \ nнет \ nсезонный \ nнизкий \ nнет \ n29 \ nДомашний 18 Huito \ n
65 \ nстарый \ n женский \ nнет \ nнет \ nнизкий \ nнет \ n47 \ n2c \ nАкарицид \ nLC50 (мг-мл) ª 95% ДИ \ n
Наклон (± SE) \ nScopoletin \ n540 \ n0.938 (0,576 ~ 2,292) \ n1,314 (± 0,15) \ n6.321 \ n0,097 \ nDFB \ n540 \ n
0,477 (0,118 ~ 0,902) \ n2,254 (+0,24) \ n5,939 \ n0,051 \ nªLC50: средняя летальная концентрация.
ДИ: 95% доверительный интервал. Линейность проверки хи-квадрат, альфа = 0,05. \ NКатегория \ n
Земля \ nРезультат \ nКатегория \ nЖивотные \ nРезультат \ nCl: Без изменений \ nC2: Временный переход в клан \ n
C3: Постоянный переход в клан \ nL1: Без изменений \ nL2: Временный переход в клан (до мужчин = 18 \ n
лет) \ nL3: Постоянная смена клана \ n% 3D \ nC4: Разделите 25% до 75% самой старой женщине; отдых \ n
в дом клана \ nP1: Без изменений \ nP2: Все переходят в дом клана - временно \ n
(до мужчины = 18 лет) \ nP3: Все для клановой семьи - навсегда \ nP4: Все для других
домохозяйство (жена) \ nЛюди \ nНовый \ nh2: "Сын \" (следующий старший мужчина) \ nдомохозяйство h3: "Клан \"
- временное новое домашнее хозяйство \ nh4: "Клан \" - постоянное \ nh5: "Старшая жена \" (самая старшая женщина)
- постоянный \ nH5: "Старшая жена \" - временный (до мужчины = \ n18 лет) \ nГолова \ nГруппы \ n
Лечение \ nКонтрольная группа \ nОбычные мыши, не получавшие лечения \ nМыши получали 0.1 мл 25% CCI,
растворяют в оливковом масле путем повторной \ nинтраперитонеальной инъекции два раза в неделю до 10
недель \ nCCl, группа \ nМышам вводили TSA (1 мг / кг, 30 мкл, начало на неделе 1 в течение \ n
одновременное вмешательство) внутрибрюшинной инъекцией после CCl, инъекции \ nCCl, плюс
Группа, принимавшая TSA \ nМышам вводили TSA (1 мг / кг, 30 мкл, начало на 6 неделе.
для \ n позднего вмешательства) внутрибрюшинной инъекцией после CCl, инъекции \ nCCI, плюс TSA
- поздняя группа \ nМышам вводили ДМСО (30 мкл) внутрибрюшинной инъекцией \ n
после CCl, инъекция \ nCCl, плюс группа ДМСО \ n ",
« страниц »: [
{
"pageNumber": 1 ,
"измерение": {
«ширина»: 2035 г.,
«высота»: 1965 г.,
«единица»: «пиксели»
},
"макет": {
"textAnchor": {
"textSegments": [
{
«endIndex»: «750»
}
]
},
«уверенность»: 0.82,
"boundingPoly": {
"вершины": [
{},
{
«х»: 2035
},
{
«x»: 2035,
"y": 1965
},
{
"y": 1965
}
],
"normalizedVertices": [
{},
{
«х»: 1
},
{
«x»: 1,
«у»: 1
},
{
«у»: 1
}
]
},
"ориентация": "PAGE_UP"
},
"detectLanguages": [
{
"languageCode": "en",
«уверенность»: 0.09
},
{
"languageCode": "ro",
«уверенность»: 0,05
},
{
"languageCode": "vi",
«уверенность»: 0,02
}
],
« блоков »: [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "7"
}
]
},
"boundingPoly": {
"normalizedVertices": [
{
«х»: 0.036363635, г.
«y»: 0,03562341
},
{
«x»: 0,13808353,
«y»: 0,036132317
},
{
«x»: 0,13808353,
«y»: 0,06005089
},
{
«x»: 0,036363635,
«y»: 0,059541985
}
]
},
"ориентация": "PAGE_UP"
},
"detectLanguages": [
{
"languageCode": "en",
«уверенность»: 1
}
]
},
...
{
"макет": {
...
}
}
],
« абзацев »: [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "7"
}
]
},
"boundingPoly": {
"normalizedVertices": [
{
«x»: 0,036363635,
«y»: 0,03562341
},
{
«х»: 0.13808353, г.
«y»: 0,036132317
},
{
«x»: 0,13808353,
«y»: 0,06005089
},
{
«x»: 0,036363635,
«y»: 0,059541985
}
]
},
"ориентация": "PAGE_UP"
},
"detectLanguages": [
{
"languageCode": "en",
«уверенность»: 1
}
]
},
...
{
"макет": {
...
}
}
],
« строк »: [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "7"
}
]
},
«уверенность»: 0,85,
"boundingPoly": {
"normalizedVertices": [
{
«x»: 0,036363635,
«y»: 0,03562341
},
{
«х»: 0.13808353, г.
«y»: 0,03562341
},
{
«x»: 0,13808353,
«y»: 0,06005089
},
{
«x»: 0,036363635,
«y»: 0,06005089
}
]
},
"ориентация": "PAGE_UP"
}
},
...
{
"макет": {
"textAnchor": {
"textSegments": [
{
"startIndex": "747",
«endIndex»: «750»
}
]
},
«уверенность»: 0.56,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0,8142506,
«y»: 0,037150126
},
{
«x»: 0,83685505,
«y»: 0,037150126
},
{
«x»: 0,83685505,
«y»: 0,064631045
},
{
"x": 0,8142506,
«y»: 0,064631045
}
]
},
"ориентация": "PAGE_UP"
}
}
],
« токенов »: [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "7"
}
]
},
«уверенность»: 0.85,
"boundingPoly": {
"normalizedVertices": [
{
«x»: 0,036363635,
«y»: 0,03562341
},
{
«x»: 0,13808353,
«y»: 0,036132317
},
{
«x»: 0,13808353,
«y»: 0,06005089
},
{
«x»: 0,036363635,
«y»: 0,059541985
}
]
},
"ориентация": "PAGE_UP"
},
"detectBreak": {
"тип": "WIDE_SPACE"
},
"detectLanguages": [
{
"languageCode": "en"
}
]
},
...
{
"макет": {
...
},
"detectBreak": {
"тип": "WIDE_SPACE"
}
}
],
« столов »: [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "15"
},
{
"startIndex": "747",
«endIndex»: «750»
},
{
"startIndex": "15",
"endIndex": "63"
},
...
{
"startIndex": "742",
"endIndex": "747"
}
]
},
«уверенность»: 1,
"boundingPoly": {
"normalizedVertices": [
{},
{
«х»: 1
},
{
«x»: 1,
«у»: 1
},
{
«у»: 1
}
]
},
"ориентация": "PAGE_UP"
},
"headerRows": [
{
"клетки": [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"endIndex": "7"
}
]
},
"boundingPoly": {
"normalizedVertices": [
{},
{
«х»: 0.18179365
},
{
"x": 0,18179365,
«y»: 0,096692115
},
{
«y»: 0,096692115
}
]
},
"ориентация": "PAGE_UP"
},
"rowSpan": 1,
«colSpan»: 1
},
...
{
"макет": {
...
},
"rowSpan": 1,
«colSpan»: 1
}
]
}
],
"bodyRows": [
{
"клетки": [
{
"макет": {
"textAnchor": {
"textSegments": [
{
"startIndex": "15",
"endIndex": "21"
}
]
},
"boundingPoly": {
"normalizedVertices": [
{
«у»: 0.096692115
},
{
"x": 0,18179365,
«y»: 0,096692115
},
{
"x": 0,18179365,
«y»: 0,16504733
},
{
«y»: 0,16504733
}
]
},
"ориентация": "PAGE_UP"
},
"rowSpan": 1,
«colSpan»: 1
},
...
{
"макет": {
...
},
"rowSpan": 1,
«colSpan»: 1
}
]
},
...
{
"клетки": [
...
]
}
]
}
],
« formFields »: [
...
]
},
{
"pageNumber": 2 ,
"измерение": {
...
},
"макет": {
...
},
"detectLanguages": [
...
],
"блоки": [
...
],
"параграфы": [
...
],
"строки": [
...
],
"токены": [
...
],
"столы": [
{
"макет": {
...
},
"headerRows": [
...
],
"bodyRows": [
...
]
}
],
"formFields": [
...
]
},
{
«pageNumber»: 3 ,
"измерение": {
...
},
"макет": {
...
},
"detectLanguages": [
...
],
"блоки": [
...
],
"параграфы": [
...
],
"строки": [
...
],
"токены": [
...
],
"столы": [
...
],
"formFields": [
...
]
},
{
«pageNumber»: 4 ,
...
},
{
"pageNumber": 5 ,
...
}
]
}
Разбор Python XML с помощью ElementTree не возвращает None
Я пытаюсь разобрать эту XML-строку с помощью ElementTree в Python,
данные, хранящиеся в виде строки,
xml = '' ' <Студент> 1 Авель Не входит [email protected] 7 <Студент> 2 Джозеф Не входит <Электронная почта> joseph @ hisschool.