ГДЗ по русскому языку 2 класс учебник Канакина, Горецкий 2 часть
- Тип: ГДЗ, Решебник.
- Автор: В. П. Канакина, В. Г. Горецкий.
- Год: 2021.
- Серия: Школа России.
- Издательство: Просвещение.
Подготовили готовое домашнее задание к упражнениям на 127 странице по предмету русский язык за 2 класс. Ответы на задания: 218, 219, 220 и 221.
Учебник 2 часть — Страница 127.
Ответы 2021 года.
Номер 218.
- Выберите любое задание и выполните его:
1. Выполните звуко-буквенный разбор любого слова.
2. Выпишите буквы из выделенного слова в алфавитном порядке.
3. Найдите слово, в котором букв меньше, чем звуков. Запишите это слово.
Ответ:
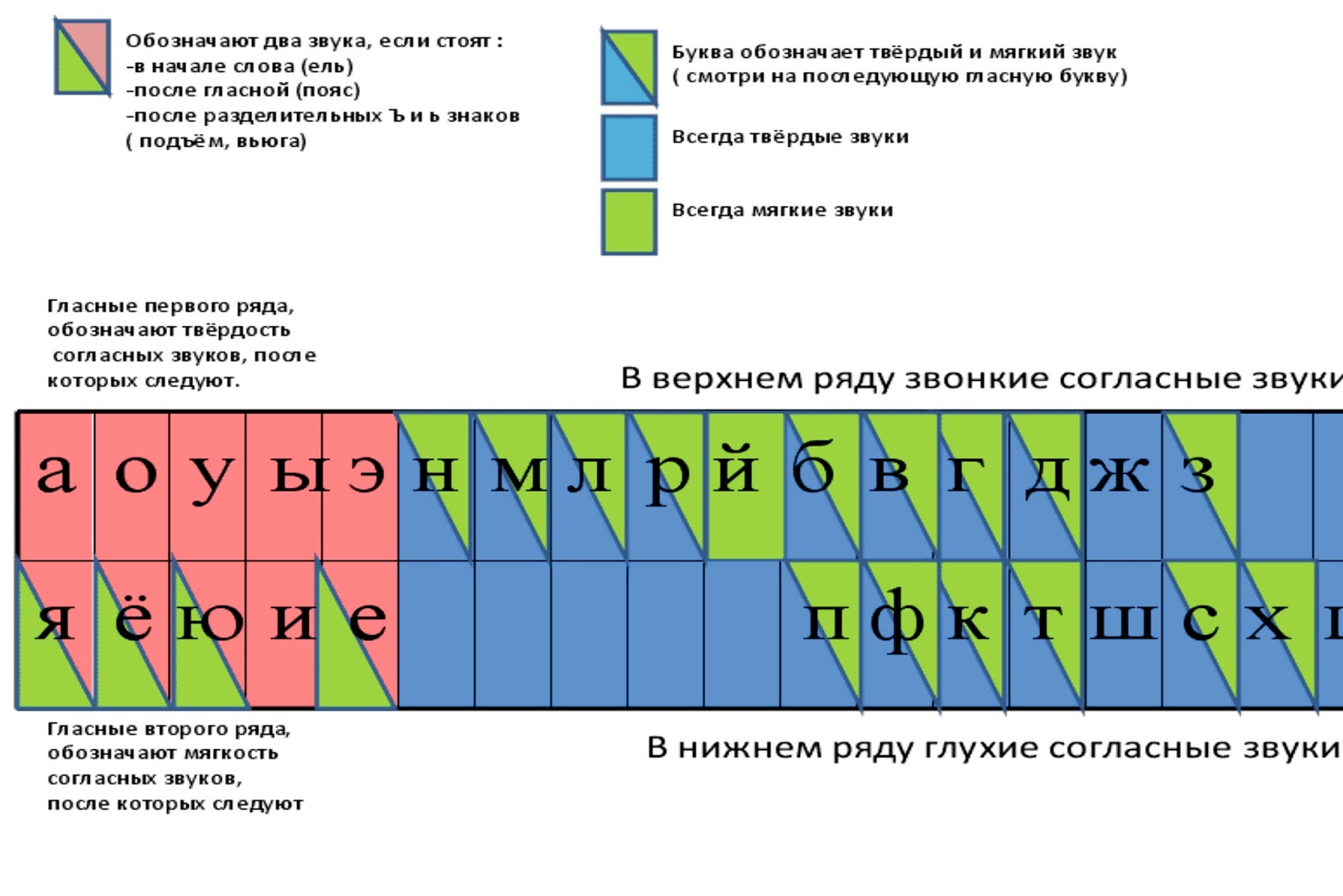
1. Звуко-буквенный разбор (см. Памятку 1, с. 130).
Пчё│лы – 2 слога, 5 звуков, 5 букв.
[п] – согласный, глухой, твёрдый;
[ч’] – согласный, глухой, мягкий;
[о́] – гласный, ударный;
[ы] – гласный, безударный.

Можно оформить так:
Пчё|лы [п ч’ о́ л ы] – 2 слога, 5 звуков, 5 букв.
п [п] – согласный, глухой парный [п-б], твёрдый парный [п-п’], буква «пэ»;
ч [ч’] – согласный, глухой непарный, мягкий непарный, буква «чэ»;
ё [о́] – гласный, ударный;
л [л] – согласный, звонкий непарный, твёрдый парный [л-л’], буква «эль»;
ы [ы] – гласный, безударный.
2. И, К, П, Р, С, Т, Я.
3. Поют – 4 б, 5 зв. [п а й’ у т].
Номер 219.
Кто правильно назовёт все буквы русского алфавита?
- Запишите по памяти все буквы в алфавитном порядке.
Ответ:
Правила правописания
Номер 220.
Вспомните, какие буквы в корнях слов надо проверять. Когда их надо проверять?
Ответ:
В корнях нужно проверять гласные и согласные буквы, которые стоят в слабой позиции.
- Используя форзац учебника, вспомните правила правописания слов, которые вы уже изучили.


Ответ:
Правила:
1. Гласные после шипящих: жи-ши, ча-ща, чу-щу.
2. Парные по глухости – звонкости согласные (чтобы проверить парный по глухости-звонкости согласный звук, нужно изменить форму слова или подобрать однокоренное слово так, чтобы после этого согласного стоял гласный или непарный звонкий согласный).
3. Безударная гласная (чтобы проверить безударный согласный в корне слова, нужно изменить форму слова или подобрать однокоренное слово так, чтобы этот гласный стал ударным).
- Для чего надо знать правила орфографии?
Ответ:
Правила орфографии нужно знать, чтобы правильно писать, быть грамотным человеком.
Номер 221.
Прочитайте. Объясните правописание выделенных орфограмм.
Москва, дожди, сугроб, стакан, Алёша, пчела, мороз, ученик, Россия, синичка, ручьи, ночной, больница, сказка, чаща, лыжи, сладкий, бежать, шина, чудо, ищу, Волга.
Ответ:
Безударная гласная в корне слова, проверяемая ударением: дожди́ – дождь, пчела́ – пчёлы, больни́ца – боль, бежа́ть – бег.
Безударная гласная в корне слова, непроверяемая ударением: Москва, стакан, мороз, ученик, синичка.
Мягкий разделительный знак: ручьи.
Парный согласный: сугроб – сугробы, мороз – морозы, сказка – ска зать, сладкий – сладость.
Буквосочетание чк, чн пишется без мягкого знака: ночной, синичка.
Гласные после шипящих: чаща, лыжи, шина, чудо, ищу.
Имена собственные: Алёша, Волга.
Удвоенная согласная: Россия.
- Запишите 3-4 слова на разные правила. Каждое слово пишите с новой строки, а рядом с ним – 2–3 слова на это же правило. Подчеркните в словах орфограммы.
Ответ:
Дожди, столы, стволы, ряды
Москва, квартира, город, дежурный
Ручьи, воробьи, колья, колье
Сугроб, укроп, стог, серп
Синичка, сестричка, ручной, крючки
Чаща, малыши, мыши, чучело
Алёша, Марина, Егор, Наташа
- Составьте с одним из слов предложение. Запишите. Подчеркните в нём грамматическую основу.
 Запишите. Подчеркните в нём грамматическую основу.
Запишите. Подчеркните в нём грамматическую основу.Ответ:
Алёша выпил стакан чая с лимоном.
Рейтинг
← Выбрать другую страницу ←
‘: г'[BCDFGHJKLMNPQRSTVWXZ]’, ‘.’: r'[BVDGJLMNRWZ]’, ‘%’: r'(?:ER|E|ES|ED|ING|EL)’, ‘&’: г'(?:[SCGZXJ]|CH|SH)’, ‘@’: r'(?:[TSRDLZNJ]|TH|CH|SH)’, }и функция для создания фрагмента регулярного выражения из этого сопоставления:
def mkregex(rule):
регулярное выражение = г""
для ch в правиле:
регулярное выражение += rule_syntax.get(ch, ch)
возвращать регулярное выражение
Я не знаю, как вы хотите обрабатывать правила с пробелами, я закомментировал правило ' /// '
Теперь мы реализуем функцию, которая преобразует синтаксис вашего правила в «интересный» кортеж:
def mkrule(ruletxt):
txt, до, после, фонема = ruletxt. split('/')
правило = г""
если раньше:
# использовать незахватывающую группу для соответствия тексту «до»
правило += r'(?:' + mkregex(before) + ')'
# создаем группу захвата для рассматриваемого текста
правило += r'(?P' + txt + ')'
если после:
# добавить шаблон просмотра вперед
правило += r'(?=' + mkregex(после) + ')'
# вернуть кортеж, содержащий
# - регулярное выражение, созданное из правила
# - строчная версия фонем между тире
# - исходное правило (для объяснения и отладки)
правило возврата, "-%s-" % phoneme.lower(), ruletxt
 split('/')
правило = г""
если раньше:
# использовать незахватывающую группу для соответствия тексту «до»
правило += r'(?:' + mkregex(before) + ')'
# создаем группу захвата для рассматриваемого текста
правило += r'(?P
split('/')
правило = г""
если раньше:
# использовать незахватывающую группу для соответствия тексту «до»
правило += r'(?:' + mkregex(before) + ')'
# создаем группу захвата для рассматриваемого текста
правило += r'(?P Подход, который мы выберем, заключается в итеративной замене совпадающих правил фонемами. Чтобы убедиться, что мы не заменяем текст, который уже был преобразован (например, фонемы), мы сделаем входную строку прописной, а фонемы — прописной. Чтобы фонемы не пересекались друг с другом, мы добавили - с каждой стороны (в конце нам придется убрать это).
Преобразование всех ваших правил в интересные кортежи:
rules = [mkrule(r) for r in [
#" /// ", # это правило создает проблемы
"А///УХ",
"АР///АХ-Р",
"АР/ /О/УХ-Р",
"АР//#/ЭХ-Р",
"КАК/^/#/АЕ-А-С",
"А//ВА/УХ",
"АВ///АВ",
. ..
]]
 ..
]]
..
]]
Почти готово, просто функция замены найденного текста из одного правила:
def match_and_replace(word, rule, phonemes):
# правило может совпасть несколько раз, найти их все
соответствует = [(m.start(), m.end()) для m в re.finditer(правило, слово)]
match.reverse() # мы заменим на месте, так что начнем сзади
chars = list(word) # преобразовать в список символов, так как строки неизменяемы
для начала, конца в совпадениях:
символы[начало:конец] = фонемы
return ''.join(chars) # преобразовать обратно в строку
Наконец, функция извлечения «фонем» из слова:
def фонемы(слово, объяснение=ложь):
# Механизмы правил всегда должны быть в состоянии объяснить свои результаты ;-)
если объяснить:
напечатать "слово:", слово
result = " %s " % word.upper() # добавьте пробел вокруг слова, чтобы правила, содержащие пробелы, могли с чем-то работать
шаг = 0
# перебираем все интересные кортежи
для правила, фонемы, правилаtxt в правилах:
# для каждого правила tmp - это строка, в которой все совпадения для `правила` заменены на `фонема`
tmp = match_and_replace(результат, правило, фонема)
если объяснить и tmp != результат:
шаг += 1
print 'шаг %d: %r ---> %r [правило: %r (%r)]' % (
шаг, результат, tmp, ruletxt, правило
)
результат = температура
# удалить артефакты
res, _count = re. subn(r'-+', '-', result.replace(' ', '').strip('-'))
если объяснить:
напечатать "результат:", рез
Распечатать
вернуть разрешение
 subn(r'-+', '-', result.replace(' ', '').strip('-'))
если объяснить:
напечатать "результат:", рез
Распечатать
вернуть разрешение
subn(r'-+', '-', result.replace(' ', '').strip('-'))
если объяснить:
напечатать "результат:", рез
Распечатать
вернуть разрешение
При этом я получаю следующие результаты:
>>> фонемы('отмена', объяснение=Истина)
слово: прервать
шаг 1: 'ПРЕРЫВАНИЕ' ---> '-ae-BORT' [правило: 'A///AE' ('(?PA)')]
шаг 2: '-ae-BORT ' ---> ' -ae--b-ORT ' [правило: 'B///B' ('(?PB)')]
шаг 3: '-ae--b-ORT ' ---> ' -ae--b--aw-r-T ' [правило: 'ИЛИ///AW-R' ('(?POR) ')]
шаг 4: '-ae--b--aw-r-T ' ---> ' -ae--b--aw-r--t- ' [правило: 'T///T' ('(?P <Найдено>Т)')]
результат: ae-b-aw-r-t
Вам нужно разумно упорядочить правила, чтобы получить желаемые результаты, или использовать более сложные алгоритмы, которые могут найти все возможные перестановки правил, которые совпадают, а затем найти лучший.
Токенизация и синтаксический анализ в Elixir с помощью yecc и leex – Андреа Леопарди
Лексический анализ (токенизация) и синтаксический анализ являются очень важными понятиями в информатике и программировании. За этими концепциями стоит много теории, но я не буду говорить об этом здесь, потому что, ну, это много . Кроме того, мне кажется, что подход к этим темам с «научной» точки зрения делает их немного пугающими; однако их использование на практике оказывается довольно простым. Если вы хотите узнать больше о теории, зайдите в Википедию (лексический анализ и синтаксический анализ) или прочитайте удивительную книгу о драконах (которую я рекомендую всем программистам, она фантастическая).
За этими концепциями стоит много теории, но я не буду говорить об этом здесь, потому что, ну, это много . Кроме того, мне кажется, что подход к этим темам с «научной» точки зрения делает их немного пугающими; однако их использование на практике оказывается довольно простым. Если вы хотите узнать больше о теории, зайдите в Википедию (лексический анализ и синтаксический анализ) или прочитайте удивительную книгу о драконах (которую я рекомендую всем программистам, она фантастическая).
Обычно люди избегают использования лексеров и синтаксических анализаторов в пользу ручной обработки строк и регулярных выражений . Я думаю, что это может произойти из-за присущей этим инструментам сложности. В этом посте мы постараемся избавиться от этой сложности!
Во-первых, лексеры и синтаксические анализаторы обычно используются вместе, но они не обязательно должны быть . Вы можете использовать лексер, чтобы преобразовать некоторую строку в плоский список токенов, и вы можете использовать синтаксический анализатор, чтобы понять грамматику чего угодно.
Небольшое замечание, прежде чем мы начнем. Я сказал, что люди часто выбирают регулярные выражения для «разбора» и понимания текста. Хотя это нормально для очень простых задач синтаксического анализа, в большинстве случаев это приводит к загадочному и хрупкому коду. Кроме того, регулярные выражения ограничены в том, какие типы грамматики они могут анализировать (попробуйте анализировать HTML с помощью регулярных выражений), поэтому иногда вы будете нужно что-то помощнее.
Erlang предоставляет два модуля, которые значительно упрощают задачу написания лексеров и парсеров: leex и yecc . Модуль leex представляет собой генератор lexer : он читает файл, написанный с использованием специального синтаксиса, и выдает модуль Erlang (в файле .erl ), который вы можете скомпилировать и использовать для фактической токенизации. yecc ведет себя так же, за исключением того, что он генерирует синтаксические анализаторы вместо лексеров.
Поскольку эти модули доступны в стандартном дистрибутиве Erlang (в группе приложений «Инструменты синтаксического анализа»), я думаю, что их использование практически не имеет недостатков, когда есть проблема, которую они могут помочь решить.
Каждый пост, объясняющий что-то, нуждается в одном из этих примеров, так что давайте составим наш: мы собираемся токенизировать и анализировать списки Elixir атомов и целых чисел, выведенных в виде строк. Конечная цель будет заключаться в том, чтобы иметь возможность читать список Эликсира, выраженный в виде строки, и преобразовывать его обратно в строку Эликсира, например:0003
iex> ListParser.parse("[1, 2, [:foo, [:bar]]]")
[1, 2, [:foo, [:bar]]]
Это маленькое, надуманное и нереалистичное, так что мы должны идти.
Первое, что нам нужно сделать, это токенизировать строку: токенизация просто означает превращение строки в список токенов, которые представляют собой вещи, немного более структурированные, чем плоский список символов.
Например, один маркер может быть целым числом, например 4917 : целое число 4917 имеет «больше структуры», чем список символов [?4, ?9, ?1, ?7] , потому что мы можем рассматривать его как единое целое.
Разметка наших списков проста: мы размечаем только скобки (слева [ и справа ] ), запятые, целые числа и атомы. Мы собираемся токенизировать только простые атомы, такие как :foo или :foo_bar , игнорируя атомы, которые должны использовать двойные или одинарные кавычки, например :'foo bar' или :"hello world!" .
Создать собственный токенизатор для этого базового синтаксиса было бы несложно, но leex значительно упрощает работу, позволяя нам написать лексер с очень простым синтаксисом. По сути, вы идентифицируете токены с помощью регулярных выражений и связываете выражение Erlang с каждым регулярным выражением, чтобы создать токен. Я упоминал ранее, что регулярные выражения не подходят для этой работы: ну, они не лучший инструмент для синтаксического анализа из-за рекурсивного характера задачи, но они отлично подходят для разделения элементов в плоской структуре.
Я упоминал ранее, что регулярные выражения не подходят для этой работы: ну, они не лучший инструмент для синтаксического анализа из-за рекурсивного характера задачи, но они отлично подходят для разделения элементов в плоской структуре.
Синтаксис правила leex таков:
Регулярное выражение: код Erlang.
В «коде Erlang» мы должны вернуть кортеж {:token, value} , если мы хотим, чтобы лексер вернул нам этот токен (фактически, кортеж {token, Value} , поскольку мы должны используйте синтаксис Erlang, а не Elixir).
Наш лексер прост:
Правила.
[0-9]+ : {токен, {целое, TokenLine, TokenChars}}.
:[a-z_]+ : {токен, {атом, TokenLine, TokenChars}}.
\[ : {токен, {'[', TokenLine}}.
\] : {токен, {']', TokenLine}}.
, : {токен, {',', TokenLine}}.
Мы возвращаем {:token, value} , чтобы сообщить leex , что нас интересует соответствующий токен (поэтому первый элемент кортежа — :token ) и мы хотим включить его в вывод лексического анализа.
TokenLine и TokenChars — это переменные, которые leex делают доступными в выражении Erlang после каждого регулярного выражения. Эти переменные содержат строку соответствующего токена и содержимое соответствующего токена (в виде списка символов).
Мы всегда используем двух- или трехэлементные кортежи в качестве значений токенов, потому что это формат yecc . Как видите, иногда нас интересует значение токена, поэтому мы возвращаем трехэлементный кортеж, но иногда сам токен является его значением (например, запятая), поэтому двухэлементного кортежа достаточно. Строка маркера является обязательной, чтобы yecc мог выдавать точные сообщения об ошибках.
Нам не обязательно хранить все найденные жетоны: мы можем их сбросить, вернув атом :skip_token вместо кортежа {:token, value} . Обычный вариант использования — пропуск пробелов:
[\s\t\n\r]+ : skip_token.
Регулярные выражения могут быстро стать неприятными, но мы можем извлечь их в определений в форме ALIAS = REGEX . Мы помещаем определения вверху файла перед списком правил. Чтобы использовать эти определения в регулярных выражениях, мы должны заключить их в фигурные скобки.
Мы помещаем определения вверху файла перед списком правил. Чтобы использовать эти определения в регулярных выражениях, мы должны заключить их в фигурные скобки.
Определения.
ЦЕЛОЕ = [0-9]+
АТОМ = :[a-z_]+
ПРОБЕЛ = [\s\t\n\r]
Правила.
{INT} : {токен, {int, TokenLine, TokenChars}}.
{ATOM}: {токен, {атом, TokenLine, TokenChars}}.
\[ : {токен, {'[', TokenLine}}.
\] : {токен, {']', TokenLine}}.
, : {токен, {',', TokenLine}}.
{WHITESPACE}+ : skip_token.
Мы готовы опробовать наш лексер. Во-первых, мы должны записать его в файл с расширением .xrl . Затем мы можем превратить файл .xrl в .erl файл с :leex.file/1 . Наконец, мы можем скомпилировать только что сгенерированный модуль Erlang. Помните, что большинство модулей Erlang принимают списки символов вместо двоичных, поэтому мы должны заключать их в одинарные кавычки, а не в двойные. (Примечание: Erlang использует одинарные кавычки для выражения сложных атомов, таких как , но вы это помните, верно?)
iex> :leex.
 file(' list_lexer.xrl')
iex> c("list_lexer.erl")
iex> {:ok, токены, _} = :list_lexer.string('[1, [:foo]]')
iex> токены
{:"[", 1}, {:int, 1, '1'}, {:",", 1}, {:"[", 1}, {:atom, 1, ':foo'}, {:"]", 1}, {:"]", 1}]
file(' list_lexer.xrl')
iex> c("list_lexer.erl")
iex> {:ok, токены, _} = :list_lexer.string('[1, [:foo]]')
iex> токены
{:"[", 1}, {:int, 1, '1'}, {:",", 1}, {:"[", 1}, {:atom, 1, ':foo'}, {:"]", 1}, {:"]", 1}]
Отлично! leex также предоставляет возможность определить некоторый код Erlang, связанный с лексером: это делается в коде Erlang. Раздел внизу файла .xrl . Мы могли бы воспользоваться этим, чтобы преобразовать токены атома в атомы:
...
{INT} : {токен, {int, TokenLine, list_to_integer(TokenChars)}}.
{ATOM}: {токен, {атом, TokenLine, to_atom(TokenChars)}}.
...
Эрланг-код.
to_atom([$:|Символы]) ->
list_to_atom (Символы).
to_atom/1 просто удаляет первый символ токена атома (который представляет собой двоеточие, $: в языке Erlang) и преобразует остальные в атом. Мы также использовали list_to_integer/1 для преобразования целочисленных токенов в целые числа.
Наш полный лексер выглядит так:
Определения.
 ЦЕЛОЕ = [0-9]+
АТОМ = :[a-z_]+
ПРОБЕЛ = [\s\t\n\r]
Правила.
{INT} : {токен, {int, TokenLine, list_to_integer(TokenChars)}}.
{ATOM}: {токен, {атом, TokenLine, to_atom(TokenChars)}}.
\[ : {токен, {'[', TokenLine}}.
\] : {токен, {']', TokenLine}}.
, : {токен, {',', TokenLine}}.
{WHITESPACE}+ : skip_token.
Эрланг-код.
to_atom([$:|Символы]) ->
list_to_atom (Символы).
ЦЕЛОЕ = [0-9]+
АТОМ = :[a-z_]+
ПРОБЕЛ = [\s\t\n\r]
Правила.
{INT} : {токен, {int, TokenLine, list_to_integer(TokenChars)}}.
{ATOM}: {токен, {атом, TokenLine, to_atom(TokenChars)}}.
\[ : {токен, {'[', TokenLine}}.
\] : {токен, {']', TokenLine}}.
, : {токен, {',', TokenLine}}.
{WHITESPACE}+ : skip_token.
Эрланг-код.
to_atom([$:|Символы]) ->
list_to_atom (Символы).
Работает так, как мы и ожидали:
iex> {:ok, tokens, _} = :list_lexer.string('[1, :foo]')
iex> токены
[{:"[", 1}, {:int, 1, 1}, {:",", 1}, {:atom, 1, :foo}, {:"]", 1}]
Теперь у нас есть плоский список токенов. Мы хотим структурировать эти токены и превратить их в списки Эликсира: нам нужно разобрать список токенов. Анализатор работает на основе грамматики , которая представляет собой набор правил, описывающих структуру токенов.
Несмотря на то, что мы могли бы вручную создать собственный анализатор (что немного сложнее, чем развертывание собственного лексера), его легко использовать yecc : он позволяет писать очень декларативные грамматики и так же прост в использовании, как leex .
Небольшое примечание: на данный момент вы можете подумать, что эти имена не имеют смысла. Делают (более или менее). Оба они основаны на двух очень известных программах: генераторе лексеров lex и генераторе парсеров yacc . Оказывается, эти люди из Эрланга не просто сумасшедшие, а?
Назад к нам. Центральным элементом синтаксиса yecc является цифра 9.0049 правило , которое имеет вид:
Левая сторона -> Правая сторона : выражения Эрланга.
Слева находится категория токенов , а справа — категория или список категорий токенов. Категории токенов могут быть двух типов: терминал и нетерминал . Терминалы — это просто токены, которые не распространяются на другие категории; нетерминалы — это категории, которые рекурсивно расширяются до других категорий.
Например, :"[" или {атом, атом} токены являются терминалами. Список может быть представлен списком нетерминалом:
список -> '[' ']'.
 % или...
список -> '['элементы']'.
% Кстати, '%' используется для комментариев так же, как и в Erlang.
% или...
список -> '['элементы']'.
% Кстати, '%' используется для комментариев так же, как и в Erlang.
Как видите, мы можем определить несколько «предложений» для каждой категории: категория может принимать любое значение из этих предложений (думайте о них как об «или»).
elems сам по себе нетерминал. Мы можем определить его как отдельный элемент или элемент, запятую и список элементов:
элементы -> элемент. элементы -> элементы ',' элементы.
Категория elems может быть elem , elem , elem и так далее.
elem сам по себе нетерминал: он представляет целое число, атом или список. Обратите внимание, как элегантно мы можем представить тот факт, что элемент списка сам может быть списком:
elem -> int. элемент -> атом. элемент -> список.
Красиво!
Все нетерминалы должны в какой-то момент расширяться до терминалов: у вас не может быть нетерминала, который ни во что не расширяется.
yecc также требует, чтобы вы указали, какие категории являются терминалами, а какие не являются терминалами в верхней части файла:
Терминалы '[' ']' ',' int atom. Элементы списка нетерминалов elem.
Вы также должны указать корневой символ , то есть начальный нетерминал, который генерирует всю грамматику. В нашем случае это список :
Список корневых символов.
Мы почти закончили! Последнее, что нам нужно сделать, это преобразовать проанализированные списки в списки Elixir. Мы можем сделать это в коде Erlang, связанном с каждым правилом синтаксического анализа. В этих выражениях Эрланга у нас есть несколько специальных атомов: "1$" , "2$" , "3$" и так далее. yecc заменяет их значением, возвращаемым кодом Erlang, связанным с категорией по тому же индексу в правой части правила. Я только что слышал, что вы подумали « что?! «; вы правы, это намного проще понять на практике:
list -> '[' ']' : [].
 % пустой список переводится в пустой список
список ->
'['элементы']' : '$2'. % список формируется из его элементов
элементы ->
элемент : ['$1']. % одноэлементный список (и базовый вариант для рекурсии)
элементы ->
elem ',' elems : ['$1'|'$3']. % '$3' будет заменено рекурсивно
элемент -> int : extract_token('$1').
элемент -> атом: extract_token('$1').
элемент -> список: '$1'.
% Да, здесь мы также можем использовать код Erlang.
Эрланг-код.
Extract_token({_Token, _Line, Value}) -> Значение.
% пустой список переводится в пустой список
список ->
'['элементы']' : '$2'. % список формируется из его элементов
элементы ->
элемент : ['$1']. % одноэлементный список (и базовый вариант для рекурсии)
элементы ->
elem ',' elems : ['$1'|'$3']. % '$3' будет заменено рекурсивно
элемент -> int : extract_token('$1').
элемент -> атом: extract_token('$1').
элемент -> список: '$1'.
% Да, здесь мы также можем использовать код Erlang.
Эрланг-код.
Extract_token({_Token, _Line, Value}) -> Значение.
Готово! Вот как выглядит наш полный парсер:
Список нетерминалов elems elem.
Терминалы '[' ']' ',' int атом.
Список корневых символов.
список -> '[' ']' : [].
список -> '[' элементы ']' : '$2'.
элементы -> элемент : ['$1'].
elems -> elem ',' elems : ['$1'|'$3'].
элемент -> int : extract_token('$1').
элемент -> атом: extract_token('$1').
элемент -> список: '$1'.
Эрланг-код.
Extract_token({_Token, _Line, Value}) -> Значение.
Теперь мы можем создать файл Erlang из yecc файл (который имеет расширение .) точно так же, как мы сделали с  yrl
yrl leex :
iex> :yecc.file('list_parser.yrl')
iex> c("list_parser.erl")
iex> :list_parser.parse([{:"[", 1}, {:atom, 1, :foo}, {:"]", 1}])
{:хорошо, [:фу]}
Работает!
Теперь мы можем передать вывод лексера прямо в синтаксический анализатор:
iex> source = "[:foo, [1], [:bar, [2, 3]]]"
iex> {:ok, tokens, _} = source |> String.to_charlist() |> :list_lexer.string
iex> :list_parser.parse(токены)
{:ok, [:foo, [1], [:bar, [2, 3]]]}
Отлично!
Создание файлов Erlang вручную из файлов .xrl и .yrl с последующей компиляцией этих файлов Erlang может очень быстро стать утомительным. К счастью, Mix может сделать это за вас!
В Mix есть понятие «компиляторы»: это именно то, что вы о них думаете, компиляторы. Mix предоставляет компилятор для Erlang (который просто компилирует файлов .erl через установку Erlang), один для Elixir, а также компилятор :leex и :yecc 9Компилятор 0014. На самом деле они включены по умолчанию, как вы можете видеть, проверив возвращаемое значение
На самом деле они включены по умолчанию, как вы можете видеть, проверив возвращаемое значение Mix.compilers/0 внутри проекта Mix:
iex> Mix.compilers() [:yecc, :leex, :erlang, :elixir, :app]
Единственное, что вам нужно сделать, чтобы все это работало без особых усилий внутри проекта Mix, — это поместить файлы .xrl и .yrl в каталог src/ проекта. У вас будут скомпилированные модули Erlang, когда Mix скомпилирует проект.
смешать новый list_parser mkdir list_parser/src mv ./list_parser.yrl ./list_lexer.xrl ./list_parser/src/
Теперь внутри list_parser/lib/list_parser.ex :
defmodule ListParser do
@spec разбор (двоичный) :: список
def parse(str) сделать
{:хорошо, токены, _} = str |> to_charlist() |> :list_lexer.string()
{:хорошо, список} = :list_parser.parse(токены)
список
конец
конец
Все это может звучать очень абстрактно, но уверяю вас, что leex и yecc имеют множество практических применений.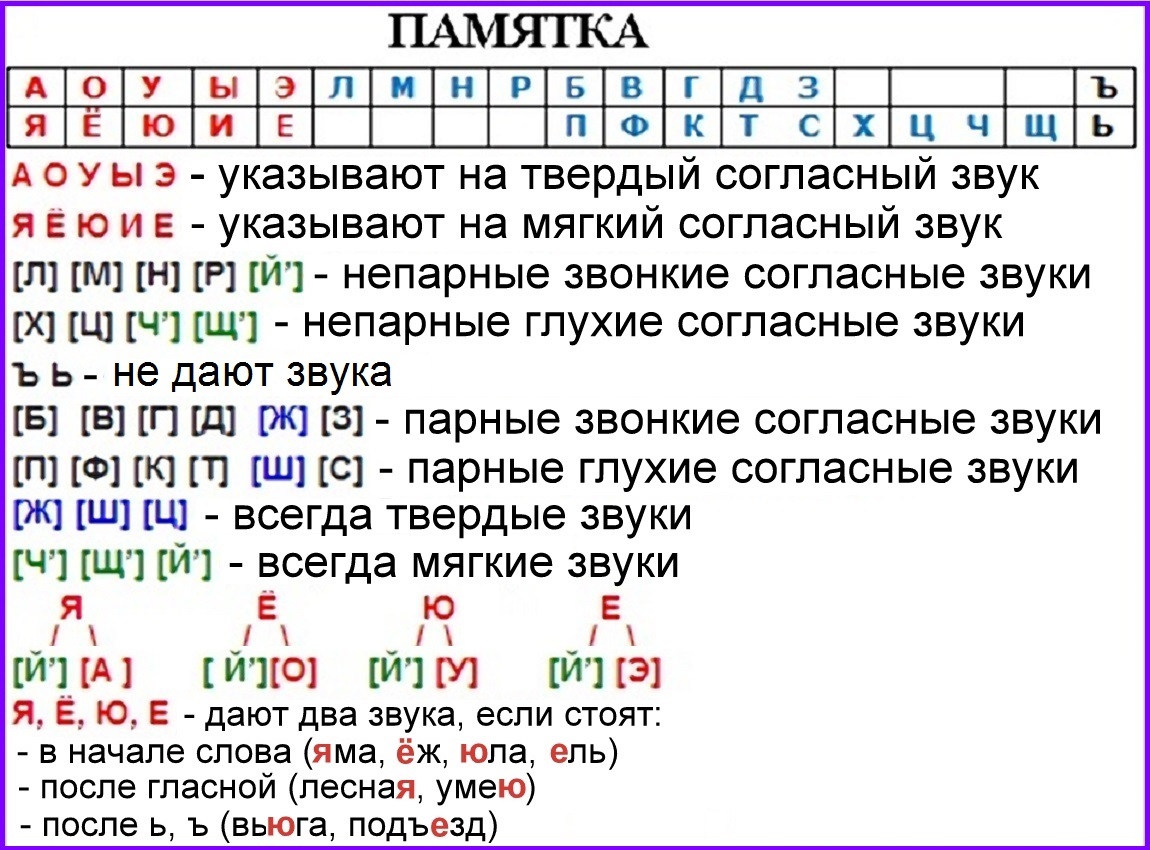 Например, недавно мне пришлось написать парсер для файлов PO в контексте написания привязки Elixir к GNU gettext. Что ж, я использовал
Например, недавно мне пришлось написать парсер для файлов PO в контексте написания привязки Elixir к GNU gettext. Что ж, я использовал yecc для написания синтаксического анализатора: в результате получилась очень декларативная, чистая и простая для понимания грамматика (вы можете увидеть ее здесь), и я очень доволен ею. Мы не использовали leex в Gettext, а решили использовать собственный лексер, но только потому, что токенизация была очень простой, а leex , возможно, было немного излишним.
Хотите еще один пример из Real-World™? Подождите, кажется, у меня есть такой: вы когда-нибудь слышали о языке программирования Elixir? Это хороший язык, построенный на основе виртуального сопоставления Erlang, ориентированный на параллелизм, отказ от… Ну, он анализируется yecc !
Мы создали лексер и парсер для преобразования строк, представляющих списки Elixir, в настоящие списки Elixir. Мы использовали модуль Erlang leex для генерации лексера и модуль yecc для генерации парсера.