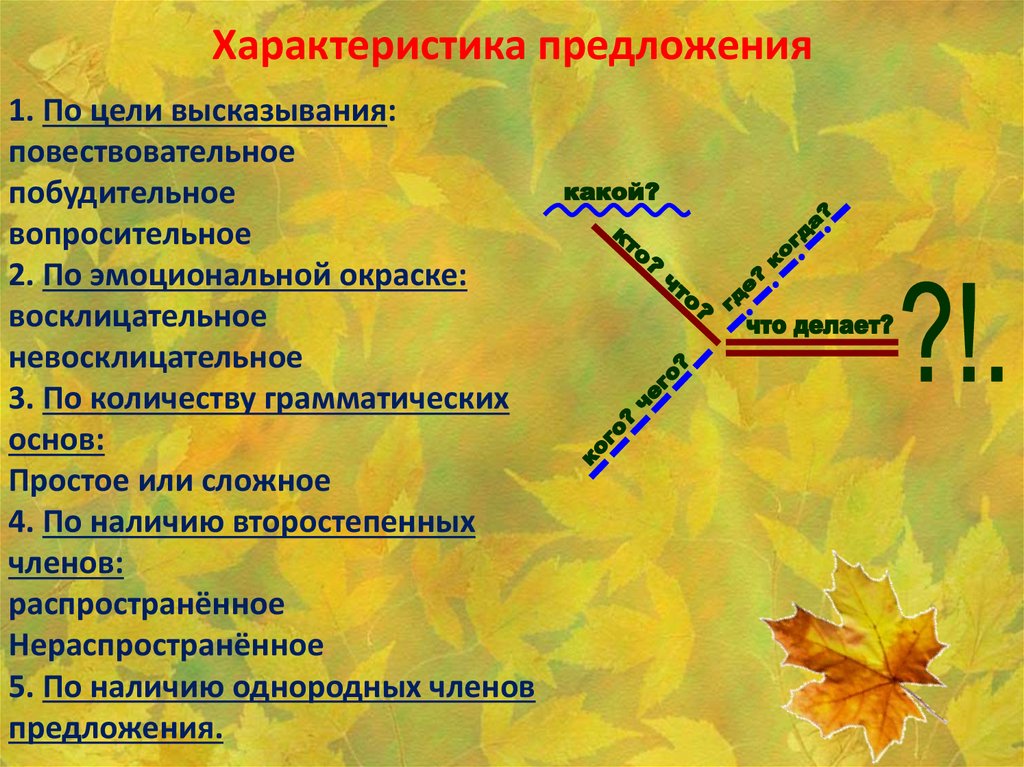
Синтаксический ⭐ разбор односоставного и двусоставного предложения: отличия, примеры упражнений
Односоставные и двусоставные предложения в русском языке
Односоставные предложения имеют один главный член (подлежащее или сказуемое), двусоставные — оба главных члена (и подлежащее, и сказуемое).
Особенности и отличия друг от друга
В односоставном предложении главный член создает его предикативность, так как называет действие, явление или предмет и выражает их отношение к действительности. В двусоставном — субъект и предикат логического суждения имеют разное грамматическое выражение.
ОпределениеПредикативность — способность предложения сообщать, описывать ситуацию. Отдельно взятое слово такой способностью не обладает.
Данные предложения имеют общий порядок синтаксического разбора, но только при разборе односоставного предложения дополнительно указывается его вид.
| Вид односоставного предложения | Чем выражен главный член предложения | Пример |
Определенно-личное (бесподлежащное; в форме глагола содержится указание на определенное лицо). | Глаголом 1 или 2 лица настоящего или будущего времени. | Хотите чай? |
| Неопределенно-личное (бесподлежащное; действие совершается неопределенными лицами). |
| Вдалеке громко поют. Где-то спорили о том, кто выйдет из этой войны победителем. Заметили бы его раньше — успели бы отреагировать. |
| Обобщенно-личное (бесподлежащное; подразумевается, что действие может совершить любой, каждый). |
| Семь раз отмерь — один отрежь. Всегда охотно даем советы. |
Безличное (бесподлежащное; сказуемое не выражает значения лица). |
| Уже давно рассвело. Ей было лень. |
| Инфинитивное (бесподлежащное; сказуемое — глагол в неопределенной форме). | Инфинитивом. | Не зацвести цветам в этом году. |
| Номинативное (главный член — подлежащее). |
| Вот мой дом. Три ряда удивительных фигур вдалеке. |
Односоставное предложение нужно отличать от неполного. Смысл отдельно взятого неполного предложения будет непонятен, а полное односоставное мы сможем понять без контекста. Например, смысл неполного предложения «Там, за перелеском» будет ясен, когда мы прочитаем предыдущее предложение.
«—Подскажете, где тут деревня Огарево?
— А там, за перелеском».
В односоставном назывном предложении «Погода изумительная!» недостающее сказуемое мысленно легко восстановить.
Анализ синтаксического разбора предложения можно представить следующим образом:
Источник: infourok.ru
Рассмотрим варианты синтаксического разбора односоставных и двусоставных предложений на примере простых предложений.
Правила синтаксического разбора односоставных предложений
Источник: znanija.com
Синтаксический разбор двусоставных предложений
Источник: znanija.com
Примеры упражнений
Упражнение 1Определите виды односоставных предложений, укажите грамматическую основу.
1) Внезапно у меня помутнело в глазах. 2) Отчего тебе не спится? 3) Приказали убрать все комнаты и перемыть посуду. 4) Начинаю понемногу привыкать к твоей навязчивости. 5) А мне все думалось. 6) Раз уж сделано, надо это принять как должное. 7) Хватит чаи распивать! 8) Глупому в поле не давай воли.
Укажите лицо, время и наклонение глагольного сказуемого. Постройте схемы предложений.
1) Одевайтесь скорее и поспешите к ней! 2) Давайте поговорим о Павлике, о его поведении. 3) Считаю это неприемлемым для Вас. 4) Умчалось вдаль и не воротишь. 5) Я даже не смог бы подумать о том, что мы с вами сойдемся в этом вопросе. 6) Любить меня сложно, но возможно. 7) Как же глупо мы с вами расстались. 8) Подумай о том, как ответить себе на этот вопрос.
Упражнение 3Выполните синтаксический разбор предложения.
На темно-синем небе изредка вспыхивало красивой, яркой, извилистой лентой, освещая округу.
Ответы
Упражнение 1Определите виды односоставных предложений, укажите грамматическую основу.
1) Внезапно у меня помутнело в глазах. (безличное; сказуемое «помутнело») 2) Отчего тебе не спится? (безличное; сказуемое «не спится») 3) Приказали убрать все комнаты и перемыть посуду. (неопределенно-личное; сказуемое «приказали убрать» и «перемыть») 4) Начинаю понемногу привыкать к твоей навязчивости. (определенно-личное; сказуемое «начинаю привыкать») 5) А мне все думалось. (безличное; сказуемое «думалось») 6) Раз уж сделано, надо это принять как должное. (безличное; сказуемые «сделано», «надо принять») 7) Хватит чаи распивать! (инфинитивное; сказуемое «хватить распивать») 8) Глупому в поле не давай воли. (обобщенно-личное; сказуемое «не давай»).
(определенно-личное; сказуемое «начинаю привыкать») 5) А мне все думалось. (безличное; сказуемое «думалось») 6) Раз уж сделано, надо это принять как должное. (безличное; сказуемые «сделано», «надо принять») 7) Хватит чаи распивать! (инфинитивное; сказуемое «хватить распивать») 8) Глупому в поле не давай воли. (обобщенно-личное; сказуемое «не давай»).
Укажите лицо, время и наклонение глагольного сказуемого. Постройте схемы предложений.
1) Одевайтесь скорее и поспешите к ней! (оба глагола во 2 лице, повелительном наклонении) 2) Давайте поговорим (1 лицо, повелительное наклонение) о Павлике, о его поведении. 3) Считаю (1 лицо, настоящее время, изъявительное наклонение) это неприемлемым для Вас. 4) Умчалось (3 лицо, прошедшее время, изъявительное наклонение) вдаль и не воротишь (2 лицо, будущее время, изъявительное наклонение). 5) Я даже не смог бы подумать (1 лицо, прошедшее время, условное наклонение) о том, что мы с вами сойдемся (1 лицо, будущее время, изъявительное наклонение) в этом вопросе. 6) Любить (неопределенная форма) меня сложно, но возможно. 7) Как же глупо мы с вами расстались (1 лицо, прошедшее время, изъявительное наклонение). 8) Подумай (2 лицо, повелительное наклонение) о том, как ответить (неопределенная форма) себе на этот вопрос.
6) Любить (неопределенная форма) меня сложно, но возможно. 7) Как же глупо мы с вами расстались (1 лицо, прошедшее время, изъявительное наклонение). 8) Подумай (2 лицо, повелительное наклонение) о том, как ответить (неопределенная форма) себе на этот вопрос.
Выполните синтаксический разбор предложения.
Синтаксис и синтаксический разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Синтаксис и синтаксический разбор
Синтаксис – это раздел науки о языке, в котором изучаются словосочетание, предложения и их строение.
Предложение может нам рассказать, какой предмет, какое действие с ним совершалось и как оно совершалось. Это возможно потому, что слова в предложениях связаны смысловыми и грамматическими связями.
Изучая этот раздел – синтаксис – мы узнаем, по каким правилам соединяются слова в словосочетания и как строятся предложения.
Синтаксис тесно связан с пунктуацией, разделом русского языка, изучающим постановку знаков препинания в предложении.
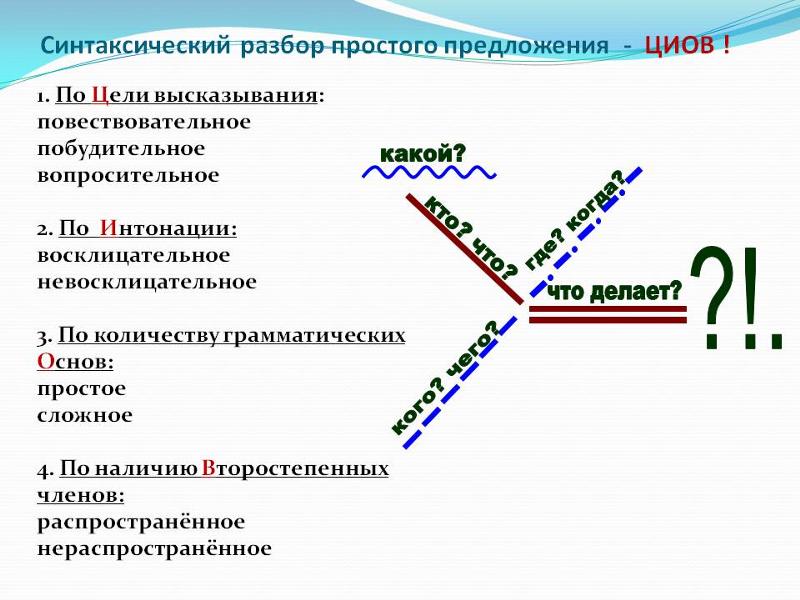
Синтаксический разбор предложения:1. Вид по цели высказывания: повествовательное, вопросительное или побудительное.
2. Вид по эмоциональной окраске (интонации): восклицательное или невосклицательное.
3. Вид по наличию второстепенных членов предложения: распространенное или нераспространенное.
4. Простое или сложное.
5. Однородные члены (какие).
6. Подчёркиваем все члены предложения (главные и второстепенные).
Например:
Мама испекла пирог. (повествовательное, невосклицательное, простое, распространенное)
Мама испекла пирог с черникой и яблоками. (повествовательное, невосклицательное, простое, распространенное, с однородными дополнениями)
Мама испекла пирог, и мы съели его на ужин. (повествовательное, невосклицательное, сложное, с союзом «и»)
Советуем посмотреть:
Словосочетание
Предложение
Правило встречается в следующих упражнениях:
3 класс
Упражнение 44, Канакина, Горецкий, Учебник, часть 1
Упражнение 61, Канакина, Горецкий, Учебник, часть 1
Упражнение 91, Канакина, Горецкий, Учебник, часть 1
Упражнение 170, Канакина, Горецкий, Учебник, часть 2
Упражнение 173, Канакина, Горецкий, Учебник, часть 2
Упражнение 207, Канакина, Горецкий, Учебник, часть 2
Упражнение 220, Канакина, Горецкий, Учебник, часть 2
Упражнение 233, Канакина, Горецкий, Учебник, часть 2
Упражнение 234, Канакина, Горецкий, Учебник, часть 2
4 класс
Упражнение 29, Канакина, Горецкий, Учебник, часть 1
Упражнение 35, Канакина, Горецкий, Учебник, часть 1
Упражнение 182, Канакина, Горецкий, Учебник, часть 1
Упражнение 266, Канакина, Горецкий, Учебник, часть 2
Упражнение 298, Канакина, Горецкий, Учебник, часть 2
Упражнение 325, Канакина, Горецкий, Учебник, часть 2
5 класс
Упражнение 506, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 2
7 класс
Упражнение 25, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 222, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 245, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 248, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 362, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 186, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 370, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 41, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник
Упражнение 60, Бархударов, Крючков, Максимов, Учебник
Упражнение 235, Бархударов, Крючков, Максимов, Учебник
Анализ данных журнала | Документация New Relic
В New Relic синтаксический анализ журнала относится к процессу извлечения атрибутов (пар ключ:значение) из неструктурированных данных журнала. Вы можете использовать эти атрибуты для поиска и запроса журналов более удобными способами, что, в свою очередь, поможет вам создавать более качественные диаграммы и оповещения.
Вы можете использовать эти атрибуты для поиска и запроса журналов более удобными способами, что, в свою очередь, поможет вам создавать более качественные диаграммы и оповещения.
New Relic автоматически анализирует данные журнала в соответствии с определенными правилами анализа. В этом документе вы узнаете, как работает синтаксический анализ журналов и как создавать собственные настраиваемые правила синтаксического анализа.
Вы также можете создавать, запрашивать и управлять правилами анализа журналов с помощью NerdGraph, нашего API GraphQL, по адресу api.newrelic.com/graphiql. Для получения дополнительной информации см. наш учебник NerdGraph по разбору.
Вот 5-минутное видео об анализе журнала:
Пример анализа
Хорошим примером является стандартный журнал доступа NGINX, содержащий неструктурированный текст. Это полезно для поиска, но не более того. Вот пример типичной строки:
Это полезно для поиска, но не более того. Вот пример типичной строки:
127.180.71.3 - - [10/May/1997:08:05:32 +0000] "GET /downloads/product_1 HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
В неанализируемом формате, вам нужно будет выполнить полнотекстовый поиск, чтобы ответить на большинство вопросов. После синтаксического анализа журнал организован в атрибуты, такие как код ответа и URL запроса :
"remote_addr":"93.180.71.3",
"время":"1586514731",
"метод": "GET",
"путь":"/downloads/product_1",
"версия": "HTTP/1.1",
"ответ": "304",
"bytesSent": 0,
"user_agent": "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21) )"
Синтаксический анализ упрощает создание пользовательских запросов, учитывающих эти значения. Это поможет вам понять распределение кодов ответов по URL-адресам запросов и быстро найти проблемные страницы.
Как работает синтаксический анализ журналов
Вот обзор того, как New Relic реализует синтаксический анализ журналов:
Анализ журнала | Как это работает |
|---|---|
Что |
|
Когда |
|
Как |
|
 По умолчанию используется поле
По умолчанию используется поле 
Атрибуты синтаксического анализа с использованием Grok
Шаблоны синтаксического анализа задаются с использованием Grok, отраслевого стандарта для анализа сообщений журнала. Любой входящий журнал с полем logtype будет проверен на соответствие нашим встроенным правилам синтаксического анализа, и, если возможно, к журналу будет применен соответствующий шаблон Grok.
Grok — это расширенный набор регулярных выражений, который добавляет встроенные именованные шаблоны для использования вместо буквальных сложных регулярных выражений. Например, вместо того, чтобы помнить, что целое число может быть сопоставлено с регулярным выражением (?:[+-]?(?:[0-9]+)) , вы можете просто написать %{INT} использовать шаблон Grok INT , который представляет то же самое регулярное выражение.
Шаблоны Grok имеют синтаксис:
%{ИМЯ_ШАБЛОНА[:ДОПОЛНИТЕЛЬНЫЙ_ЭКСТРАКТИРОВАННЫЙ_АТРИБУТ_ИМЯ[:ДОПОЛНИТЕЛЬНЫЙ_ТИП]]}
Где:
-
PATTERN_NAME— один из поддерживаемых шаблонов Grok. Имя шаблона — это просто удобное для пользователя имя, представляющее регулярное выражение. Они в точности равны соответствующему регулярному выражению. -
OPTIONAL_EXTRACTED_ATTRIBUTE_NAME, если указано, это имя атрибута, которое будет добавлено в ваше сообщение журнала со значением, соответствующим имени шаблона. Это эквивалентно использованию именованной группы захвата с использованием регулярных выражений. Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением.
Это эквивалентно использованию именованной группы захвата с использованием регулярных выражений. Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением. -
OPTIONAL_TYPEопределяет тип значения атрибута для извлечения. Если он опущен, значения извлекаются как строки. Например, чтобы извлечь значение123из"Размер файла: 123"в виде числа в атрибутразмер_файла, используйте значение: %{INT:file_size:int}.
 Это эквивалентно использованию именованной группы захвата с использованием регулярных выражений. Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением.
Это эквивалентно использованию именованной группы захвата с использованием регулярных выражений. Если это не предусмотрено, то правило синтаксического анализа будет просто соответствовать области вашей строки, но не будет извлекать атрибут с его значением.Вы также можете использовать сочетание регулярных выражений и имен шаблонов Grok в вашей соответствующей строке.
Щелкните эту ссылку, чтобы просмотреть список поддерживаемых шаблонов Grok, и здесь, чтобы просмотреть список поддерживаемых типов Grok.
Обратите внимание, что имена переменных должны быть заданы явно и должны быть строчными, например %{URI:uri} . Такие выражения, как
Такие выражения, как %{URI} или %{URI:URI} , не будут работать.
Запись журнала может выглядеть примерно так:
"сообщение": "54.3.120.2 2048 0"
Эта информация является точной, но не совсем понятно, что она означает. Шаблоны Grok помогают извлекать и понимать нужные данные телеметрии. Например, такая запись в журнале гораздо проще в использовании:
"host_ip": "43.3.120.2",
"bytes_received": 2048,
"bytes_sent": 0
Для этого создайте шаблон Grok, который извлекает эти три поля; например:
%{IP:host_ip} %{INT:bytes_received} %{INT:bytes_sent}
После обработки ваша запись журнала будет включать поля host_ip , bytes_received и 90 023 байта_отправлено . Теперь вы можете использовать эти поля в New Relic для фильтрации, фасетирования и выполнения статистических операций с данными журнала. Дополнительные сведения о том, как анализировать журналы с помощью шаблонов Grok в New Relic, см. в нашем блоге.
в нашем блоге.
Если у вас есть правильные разрешения, вы можете создать правила синтаксического анализа в нашем пользовательском интерфейсе, чтобы создавать, тестировать и включать синтаксический анализ Grok. Например, чтобы получить определенный тип сообщения об ошибке для одной из ваших микрослужб, называемой Inventory Services, вы должны создать правило синтаксического анализа Grok, которое ищет определенное сообщение об ошибке и продукт. Для этого:
Дайте правилу имя; например,
Ошибка анализа служб инвентаризации.Выберите существующее поле для анализа (по умолчанию =
сообщение) или введите новое имя поля.Определите предложение NRQL
WHERE, которое действует как предварительный фильтр для входящих журналов; например,entity.name='Inventory Service'. Этот предварительный фильтр сужает количество журналов, которые должны быть обработаны вашим правилом, удаляя ненужную обработку.Выберите соответствующий журнал, если он существует, или щелкните вкладку Вставить журнал, чтобы вставить образец журнала.
Добавить правило разбора Grok; например:
Ошибка инвентаризации: %{DATA:error_message} для продукта %{INT:product_id}
Где:

-
Ошибка инвентаризации: Имя правила синтаксического анализа -
error_message: Сообщение об ошибке, которое вы хотите для выбора -
product_id: идентификатор продукта для службы инвентаризации
Включите и сохраните правило синтаксического анализа.
Вскоре вы увидите, что ваши журналы Inventory Service пополнились двумя новыми полями:
error_messageиproduct_id. Отсюда вы можете запрашивать эти поля, создавать диаграммы и информационные панели, устанавливать оповещения и т. д.Для получения полной информации см.
нашу документацию по добавлению настраиваемых правил синтаксического анализа в пользовательском интерфейсе.
 нашу документацию по добавлению настраиваемых правил синтаксического анализа в пользовательском интерфейсе.
нашу документацию по добавлению настраиваемых правил синтаксического анализа в пользовательском интерфейсе. Поле OPTIONAL_TYPE определяет тип значения атрибута для извлечения. Если он опущен, значения извлекаются как строки.
Поддерживаемые типы:
Тип указан в Grok | Тип хранится в базе данных New Relic |
|---|---|
| |
| 9000 2 длинный |
| |
| |
| |
| ISO 8601 время как |
| |
| ISO 8601 время как |
| Структурированные данные JSON. |
| Данные CSV. Дополнительные сведения см. в разделе Анализ CSV. |
| Географическое положение по IP-адресам. Дополнительную информацию см. в разделе Геолокация IP-адресов. |
 Дополнительные сведения см. в разделе Анализ JSON, смешанного с обычным текстом.
Дополнительные сведения см. в разделе Анализ JSON, смешанного с обычным текстом. Конвейер журналов New Relic по умолчанию анализирует сообщения журнала JSON, но иногда у вас есть сообщения журнала JSON, смешанные с обычным текстом. В этой ситуации вы можете захотеть проанализировать их, а затем иметь возможность фильтровать с помощью атрибутов JSON.
Если это так, вы можете использовать json тип grok, который будет анализировать JSON, захваченный шаблоном grok. Этот формат состоит из трех основных частей: синтаксиса grok, префикса, который вы хотели бы присвоить анализируемым атрибутам json, и типа json grok. Используя тип json grok, вы можете извлекать и анализировать JSON из неправильно отформатированных журналов; например, если ваши журналы имеют префикс строки даты/времени:
2015-05-13T23:39:43.
 945958Z {"event": "TestRequest", "status": 200, "response": {"headers ": {"X-Custom": "foo"}}, "request": {"headers": {"X-Custom": "bar"}}}
945958Z {"event": "TestRequest", "status": 200, "response": {"headers ": {"X-Custom": "foo"}}, "request": {"headers": {"X-Custom": "bar"}}} Чтобы извлечь и проанализировать данные JSON из этого формата журнала, создайте следующее выражение Grok:
%{TIMESTAMP_ISO8601:containerTimestamp} %{GREEDYDATA:my_attribute_prefix:json}
Полученный журнал это:
containerTimestamp: "2015-05-13T23:39:43.945958Z"
my_attribute_prefix.event: "TestRequest"
my_attribute_prefix.status: 200
my_attribute_prefix.response .headers.X-Custom: "foo"
my_attribute_prefix.request.headers.X-Custom: "bar"
Вы также можете настроить тип json Grok, используя :json(_CONFIG_) :
-
json( {"dropOriginal": правда}): удалить фрагмент JSON, который использовался при синтаксическом анализе. Если установлено значениеtrue(значение по умолчанию), правило синтаксического анализа удалит исходный фрагмент JSON. Обратите внимание, что атрибуты JSON останутся в поле сообщения. -
json({"dropOriginal": false}): это покажет извлеченную полезную нагрузку JSON. При установке наfalse, полная полезная нагрузка только в формате JSON будет отображаться под атрибутом, названным вmy_attribute_prefixвыше. Обратите внимание, что атрибуты JSON останутся здесь в поле сообщения, а также предоставят пользователю 3 разных представления данных JSON. Если вас беспокоит хранение всех трех версий, рекомендуется использовать значение по умолчаниюtrue. -
json({"depth": 62}): Уровни глубины, которые вы хотите проанализировать значение JSON (по умолчанию 62).
 Обратите внимание, что атрибуты JSON останутся в поле сообщения.
Обратите внимание, что атрибуты JSON останутся в поле сообщения. Если ваша система отправляет журналы со значениями, разделенными запятыми (CSV), и вам необходимо проанализировать их в New Relic, вы можете использовать csv Тип Grok, который анализирует CSV, захваченный шаблоном Grok.
Этот формат состоит из трех основных частей: синтаксиса Grok, префикса, который вы хотели бы присвоить анализируемым атрибутам CSV, и типа Grok csv . Используя тип
Используя тип csv Grok, вы можете извлекать и анализировать CSV из журналов.
В качестве примера приведена следующая строка журнала CSV:
"2015-05-13T23:39:43.945958Z,202,POST,/shopcart/checkout,142,10"
И правило анализа со следующим форма:
%{GREEDYDATA:log:csv({"столбцы": ["отметка времени", "статус", "метод", "url", "время", "байты"]})}
Проанализирует ваш log следующим образом:
log.timestamp: "2015-05-13T23:39:43.945958Z"
log.status: "202"
log.method: "POST"
log.url: "/shopcar т /checkout"
log.time: "142"
log.bytes: "10"
Если вам нужно опустить префикс «log», вы можете включить в конфигурацию "noPrefix": true .
%{GREEDYDATA:log:csv({"столбцы": ["отметка времени", "статус", "метод", "url", "время", "байты"], "noPrefix": true})}
Конфигурация столбцов:
- Необходимо указать столбцы в конфигурации типа CSV Grok (которая должна быть допустимым JSON).
- Вы можете игнорировать любой столбец, установив «_» (подчеркивание) в качестве имени столбца, чтобы удалить его из результирующего объекта.

Дополнительные параметры конфигурации:
Хотя конфигурация «столбцы» является обязательной, можно изменить синтаксический анализ CSV со следующими настройками.
- dropOriginal : (по умолчанию
true) Удалите фрагмент CSV, используемый при анализе. Если установлено значениеtrue(значение по умолчанию), правило синтаксического анализа удаляет исходное поле. - noPrefix : (по умолчанию
false) Не включает имя поля Grok в качестве префикса результирующего объекта. - разделитель : (по умолчанию
,) Определяет символ/строку, разделяющую каждый столбец.- Другим распространенным сценарием являются значения, разделенные табуляцией (TSV), для этого необходимо указать
\tв качестве разделителя, напр. %{GREEDYDATA:log:csv({"столбцы": ["отметка времени", "статус", "метод", "url", "время", "байты"], "разделитель": "\t"})
- Другим распространенным сценарием являются значения, разделенные табуляцией (TSV), для этого необходимо указать
- quoteChar : (по умолчанию
") Определяет символ, который может окружать содержимое столбца.

в указанные атрибуты.Вы можете использовать geo Тип Grok, который находит положение IP-адреса, захваченного шаблоном Grok. Этот формат можно настроить для возврата одного или нескольких полей, связанных с адресом, таких как город, страна и широта/долгота IP.
В качестве примера приведена следующая строка журнала:
2015-05-13T23:39:43.945958Z 146.190.212.184
И правило синтаксического анализа следующего вида:
900 18%{TIMESTAMP_ISO8601:containerTimestamp} %{ GREEDYDATA:ip:geo({«lookup»:[«город»,»регион»,»код страны», «широта»,»долгота»]})}
Мы проанализируем ваш журнал следующим образом:
ip: 146.190.212.
ip.city: North Bergen
ip.countryCode: US
ip.country Имя: США
ip.широта: 40.793
ip.longitude: -74.0247
ip.postalCode: 07047
ip.region: NJ
ip.regionName: New Jersey
containerTimestamp:2015-05-13T2 3:39:43.945958Z
ISO8601_TIMEZONE:Z
 184
184 Конфигурация поиска:
Необходимо указать нужные поля поиска , возвращаемые действием geo . Требуется хотя бы один элемент из следующих вариантов.
- город : название города
- код страны : сокращение страны
- название страны : название страны
- широта : Широта
- Долгота : Долгота
- Почтовый индекс : Почтовый индекс , почтовый индекс или аналогичный
- регион : Аббревиатура штата, провинции или территории
- regionName : Название штата, провинции или территории
Организация по типу журнала
Конвейер приема журналов New Relic может анализировать данные путем сопоставления события журнала с правило, описывающее, как следует анализировать журнал. Существует два способа анализа событий журнала:
Существует два способа анализа событий журнала:
- Используйте встроенное правило.
- Определите пользовательское правило.
Правила представляют собой комбинацию логики сопоставления и логики синтаксического анализа. Сопоставление выполняется путем определения соответствия запроса атрибуту журналов. Правила не применяются задним числом. Журналы, собранные до создания правила, не анализируются этим правилом.
Самый простой способ упорядочить журналы и способы их анализа — включить поле logtype в событие журнала. Это сообщает New Relic, какое встроенное правило следует применять к журналам.
Важно
Когда правило синтаксического анализа становится активным, данные, проанализированные этим правилом, постоянно изменяются. Это не может быть отменено.
Ограничения
Синтаксический анализ требует больших вычислительных ресурсов, что сопряжено с риском. Анализ выполняется для пользовательских правил, определенных в учетной записи, и для сопоставления шаблонов с журналом.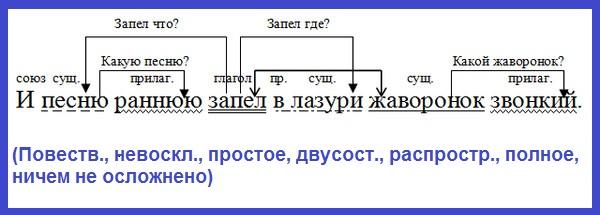 Большое количество шаблонов или плохо определенные пользовательские правила потребляют огромное количество памяти и ресурсов ЦП, а также требуют очень много времени для выполнения.
Большое количество шаблонов или плохо определенные пользовательские правила потребляют огромное количество памяти и ресурсов ЦП, а также требуют очень много времени для выполнения.
Чтобы предотвратить проблемы, мы применяем два ограничения на синтаксический анализ: на сообщение, на правило и на учетную запись.
Ограничение | Описание |
|---|---|
На сообщение на правило 9 0005 | Ограничение на количество сообщений на правило не позволяет сократить время, затрачиваемое на синтаксический анализ любого отдельного сообщения. более 100 мс. Если этот предел достигнут, система прекратит попытки проанализировать сообщение журнала с помощью этого правила. Конвейер приема попытается запустить любое другое применимое к этому сообщению сообщение, и сообщение все равно будет передано через конвейер приема и сохранено в NRDB. Сообщение журнала будет в исходном, неанализированном формате. |
На учетную запись | Ограничение на учетную запись существует для предотвращения использования учетными записями ресурсов, превышающих их справедливую долю. Лимит учитывает общее время, затрачиваемое на обработку всех сообщений журнала для учетной записи в минуту. Предел не является фиксированным значением; он масштабируется вверх или вниз пропорционально объему данных, ежедневно хранимых учетной записью, и размеру среды, которая впоследствии выделяется для поддержки этого клиента. |

Подсказка
Чтобы легко проверить, достигнуты ли ограничения скорости, перейдите в свою систему. Ограничивает страницу в пользовательском интерфейсе New Relic.
Встроенные правила синтаксического анализа
Для распространенных форматов журналов уже созданы хорошо зарекомендовавшие себя правила синтаксического анализа. Чтобы воспользоваться преимуществами встроенных правил синтаксического анализа, добавьте атрибут logtype при пересылке журналов. Установите значение, указанное в следующей таблице, и правила для этого типа журнала будут применяться автоматически.
Установите значение, указанное в следующей таблице, и правила для этого типа журнала будут применяться автоматически.
Список встроенных правил
Следующие значения атрибутов logtype сопоставляются с предопределенным правилом синтаксического анализа. Например, чтобы запросить Application Load Balancer:
- В пользовательском интерфейсе New Relic используйте формат
logtype:"alb". - Из NerdGraph используйте формат
logtype = 'alb'.
Чтобы узнать, какие поля анализируются для каждого правила, см. нашу документацию о встроенных правилах анализа.
| Источник журнала | Пример сопоставления запроса | |
|---|---|---|---|
| Журналы доступа Apache | | |
| Логи ошибок Apache | Журналы балансировщика нагрузки приложений | |
| Журналы Cassandra | | 90 063|
| CloudFront (стандартные веб-журналы) | | |
| CloudFront (веб-журналы в режиме реального времени) | | |
| Журналы Elastic Load Balancer 9007 0 | | |
| Журналы HAProxy | | |
| KTranslate журналы работоспособности контейнера | | |
| |||
| сообщения Linux | | |
| Журналы сервера Microsoft IIS - формат W3C | | |
| Журналы MongoDB 9007 0 | | |
| Журналы Monit | 9000 2 logtype:"monit" | |
| Ошибка MySQL журналы | | |
| 9000 2 журнала доступа NGINX | | |
| Журналы ошибок NGINX | | |
| Журналы Postgresql | | |
| Журналы Rabbitmq | 90 067||
| Журналы Redis | | |
| Журнал маршрута 53 | | |
| Системные журналы в формате RFC5424 90 070 | |
Добавьте атрибут
типа журнала При объединении журналов важно предоставлять метаданные, которые упрощают организацию, поиск и анализ этих журналов. Один простой способ сделать это — добавить атрибут
Один простой способ сделать это — добавить атрибут тип журнала к сообщениям журнала при их отправке. Встроенные правила синтаксического анализа применяются по умолчанию к определенным значениям logtype .
Подсказка
Поля logType , logtype и LOGTYPE поддерживаются для встроенных правил. Для простоты поиска мы рекомендуем использовать единый синтаксис в вашей организации.
Вот несколько примеров того, как добавить тип журнала в журналы, отправляемые некоторыми из наших поддерживаемых способов доставки.
Добавить тип журнала в качестве атрибута . Вы должны установить тип журнала для каждого именованного источника.
- имя: файл-простой
файл: /путь/к/файлу
атрибуты:
тип журнала: fileRaw
- имя: nginx-example
файл: /var/log/nginx.log
атрибуты:
тип журнала: nginx
Добавить блок фильтра в . , который использует  conf файл
conf файл record_transformer для добавления нового поля. В этом примере мы используем тип журнала из nginx для запуска встроенного правила разбора NGINX. Ознакомьтесь с другими примерами Fluentd.
<контейнеры фильтров>
@type record_transformer
enable_ruby true
#Добавить тип журнала для срабатывания встроенного правила синтаксического анализа для журналов доступа nginx 2 метки времени записи[ "time"]
#Добавить поля имени хоста и тега ко всем записям Добавить фильтрующий блок на
.conf, который используетrecord_modifierдля добавления нового поля. В этом примере мы используем тип журналаизnginxдля запуска встроенного правила разбора NGINX. Ознакомьтесь с другими примерами Fluent Bit.[FILTER]
Name record_modifier
Match *
Record logtype nginx
Record hostname ${HOSTNAME}
Record service_name Sample-App-Name
Добавьте блок фильтра в конфигурацию Logstash, которая использует
add_fieldизменить фильтр, чтобы добавить новое поле.изnginxдля запуска встроенного правила разбора NGINX. Ознакомьтесь с другими примерами Logstash.filter {
mutate {
add_field => {
"logtype" => "nginx"
"service_name" => "myservicename"
"hostname" => "%{ хост}"
Вы можете добавить атрибуты в запрос JSON, отправляемый в New Relic. В этом примере мы добавляем
logtypeатрибут со значениемnginxдля запуска встроенного правила синтаксического анализа NGINX. Узнайте больше об использовании Logs API.POST /log/v1 HTTP/1.1
Host: log-api.newrelic.com
Content-Type: application/json
X-License-Key: YOUR_LICENSE_KEY
Accept: */* 9 0005
Содержание -Длина: 133
"отметка времени": TIMESTAMP_IN_UNIX_EPOCH,
"сообщение": "Пользователь xyz вошел в систему",
"тип журнала": "nginx",
"service": "login-service",
"hostname": "login.
Создание и просмотр пользовательских правил синтаксического анализа
Многие журналы имеют уникальный формат или структуру. Для их анализа необходимо построить и применить пользовательскую логику.
В левой навигационной панели пользовательского интерфейса журналов выберите Анализ , затем создайте собственное правило анализа с допустимым предложением NRQL
WHEREи шаблоном Grok.Для создания собственных настраиваемых правил синтаксического анализа и управления ими:
- Перейдите по адресу one.newrelic.com > Журналы .
- В меню Управление данными в левой навигационной панели пользовательского интерфейса журналов щелкните Анализ , затем щелкните Создать правило анализа .
- Введите имя нового правила синтаксического анализа.
- Выберите существующее поле для анализа (по умолчанию =
сообщение) или введите новое имя поля.- Введите действительное предложение NRQL
WHERE, соответствующее журналам, которые вы хотите проанализировать.- Выберите соответствующий журнал, если он существует, или щелкните значок Вставка журнала вкладка для вставки образца журнала.
- Введите правило синтаксического анализа и убедитесь, что оно работает, просмотрев результаты в разделе Вывод . Чтобы узнать о Grok и пользовательских правилах синтаксического анализа, прочитайте запись в нашем блоге о том, как анализировать журналы с помощью шаблонов Grok.
- Включите и сохраните пользовательское правило синтаксического анализа.
Чтобы просмотреть существующие правила синтаксического анализа:
- Перейдите по адресу one.newrelic.com > Журналы .
- Из Управление данными в левой навигационной панели пользовательского интерфейса журналов нажмите Разбор .
Устранение неполадок
Если синтаксический анализ не работает должным образом, это может быть связано с:
 В этом примере мы используем тип журнала
В этом примере мы используем тип журнала  example.com"
example.com" 
- Логика: Логика сопоставления правил синтаксического анализа не соответствует нужным журналам.
- Время: Если ваше правило сопоставления синтаксического анализа нацелено на значение, которого еще не существует, оно завершится ошибкой. Это может произойти, если значение добавляется позже в конвейере как часть процесса обогащения.
- Ограничения: Каждую минуту выделяется фиксированное количество времени для обработки журналов с помощью синтаксического анализа, шаблонов, фильтров удаления и т. д. Если было потрачено максимальное количество времени, синтаксический анализ будет пропущен для дополнительных записей событий журнала.

Чтобы устранить эти проблемы, создайте или настройте собственные правила синтаксического анализа.
Если вы еще этого не сделали, создайте бесплатную учетную запись New Relic ниже, чтобы начать отслеживать свои данные сегодня.
Глава 20 Правила синтаксического анализа
Глава 20 Правила синтаксического анализаВ этой главе вы узнаете о: HideВ этой главе вы узнаете о: Show
- О правилах синтаксического анализа
- Необходимость добавления правил синтаксического анализа в отчет Flex
- Использование токенов в EventTracker
- Часто задаваемые вопросы: если я привяжу новое значение токена к правилу синтаксического анализа, будут ли эти значения токена постоянно сохраняться в базе данных?
- Предыдущие знания
- Компоненты правил синтаксического анализа
- Токен
- Вхождения правил синтаксического анализа
- Отображаемое имя
- Разделитель
- Терминатор
- Просмотр правил синтаксического анализа
- Добавить группы значений токена
- Добавить правило
- Мастер значения токена
- Использовать шаблон по умолчанию
- Создать новый шаблон
- Создать отчет Flex
О правилах синтаксического анализа
Правила синтаксического анализа — это маркеры, определяемые пользователем. Помимо стандартного формата определения отчета, модуль отчетов EventTracker предоставляет простой, но мощный журнал Flex Reports, средство создания отчетов.
Помимо стандартного формата определения отчета, модуль отчетов EventTracker предоставляет простой, но мощный журнал Flex Reports, средство создания отчетов.
Это помогает анализировать и включать части засоренного системного журнала, такие как сообщения и описания событий Windows, в виде столбцов в отчеты.
Правило синтаксического анализапомогает вам определять новые токены, связывать их с шаблонами динамических отчетов и создавать гибкие отчеты. EventTracker отображает проанализированные данные под теми токенами, которые вы определили.
При настройке отчетов Flex вы также можете выбрать интересующие вас столбцы отчета, применить фильтры, отсортировать столбцы отчета и изменить порядок столбцов, которые должны отображаться в отчетах.
В двух словах Правила синтаксического анализа помогает манипулировать данными и создавать понятные отчеты.
Необходимость добавления правил синтаксического анализа в отчет Flex
Проверка компонентов данных журнала занимает много времени. Данные содержат фрагменты информации.
Данные содержат фрагменты информации.
Поскольку ценная информация содержится в описании журнала, должен быть способ разбить и проанализировать данные и превратить их в ценную бизнес-информацию.
Кроме того, не существует стандартизированного формата сообщений, поскольку разные поставщики систем NIX придерживаются разных соглашений.
Например, значения, разделенные запятыми, текст фиксированной ширины и текст произвольной формы используются администратором для расшифровки сообщений системного журнала.
Использование токенов в EventTracker
Общие вопросы, которые возникают,
· 'Недостаточно ли создать отчеты Flex с помощью шаблонов, предоставляемых EventTracker?'
· Достаточно ли гибок EventTracker для добавления токенов?
· Если да, не предоставляет ли EventTracker какие-либо предопределенные токены для упрощения моей работы?
· Можно ли определить собственные токены?
Если вас волнуют эти вопросы, расслабьтесь!
EventTracker поставляется вместе с точно определенным набором токенов для вашего удобства. Если вы хотите добавить токены, если эти предопределенные токены не соответствуют вашим требованиям, EventTracker предоставляет соответствующие возможности для добавления, изменения и удаления токенов. В противном случае достаточно токенов по умолчанию.
Если вы хотите добавить токены, если эти предопределенные токены не соответствуют вашим требованиям, EventTracker предоставляет соответствующие возможности для добавления, изменения и удаления токенов. В противном случае достаточно токенов по умолчанию.
Часто задаваемые вопросы: если я привяжу новое значение токена к правилу синтаксического анализа, будут ли эти значения токена постоянно сохраняться в базе данных?
На ваше усмотрение. При определении нового Token-Value у вас есть возможность постоянно сохранять Token-Values в базе данных или привязывать Token-Value только для одного экземпляра генерации отчета.
Предыдущие знания
Важно хорошо знать и понимать форматы сообщений системного журнала для различных версий систем NIX. Хотя основные принципы настаивают на простоте, создатели системного журнала пишут сообщения в соответствии со своей прихотью и капризом. Так что приспособьтесь к среде, в которой вы работаете, чтобы понять синтаксис и семантику сообщений системного журнала.
Компоненты правил синтаксического анализа
Компоненты Правила синтаксического анализа — это основные элементы, необходимые для формирования ваших запросов для извлечения необходимых данных из сообщений журнала.
Жетон
Токен— это «ключ», который механизм создания отчетов рассматривает как точку отсчета и рассматривает строку, которая прошла успешно для синтаксического анализа. Предоставление токена необязательно и может содержать:
· Символы (a, b, c…)
· Числа (1, 2, 3…)
· Специальные символы (#, $, %), пробел…
· или комбинация всех трех (a1#)
Возникновение правила синтаксического анализа
Если в описании есть несколько вхождений токена, механизм создания отчетов рассматривает только первое вхождение в качестве контрольной точки. Итак, будьте конкретны, когда формулируете свой запрос.
Отображаемое имя
Отображаемое имя — это временно предполагаемое имя (псевдоним) для запрошенной строки. Это имя будет отображаться как «токен» в отчете. Обязательно указывать отображаемое имя, оно должно быть уникальным во всем отчете. Вы можете выбрать любое имя и может содержать:
Это имя будет отображаться как «токен» в отчете. Обязательно указывать отображаемое имя, оно должно быть уникальным во всем отчете. Вы можете выбрать любое имя и может содержать:
· символов
· номера
· или комбинация этих двух
· специальные символы не принимаются
Сепаратор
Разделитель — это символ или слово, разделяющее ключ и значение в описании. Необязательно предоставлять разделитель и может содержать:
· символов
· номера
· специальные символы
· или комбинация всех трех
Терминатор
Терминатор — это символ или слово, определяющее конец пары ключ-значение в описании. Запрошенная строка извлекается до первого появления терминатора. Необязательно предоставлять терминатор и может содержать:
· Символов
· Номера
· Специальные символы
· или комбинация всех трех
Таким образом, правило синтаксического анализа обеспечивает гибкость настройки:
· Выбор данных
· Сортировка последовательностей
Просмотр правил синтаксического анализа
1 Чтобы просмотреть правила синтаксического анализа, выберите раскрывающийся список Admin , а затем выберите Правила синтаксического анализа .
Отображаются группы Token-Value по умолчанию. EventTracker предоставляет предопределенные правила синтаксического анализа.
2 Для поиска по значениям токенов щелкните раскрывающийся список Token-Value и выберите нужный вариант.
3 Введите критерии поиска в поле поиска, а затем щелкните значок Search .
Пример. Чтобы найти значение токена «политика аудита», введите слово «политика аудита» в поле поиска, а затем щелкните значок поиска. Отображается соответствующая информация.
4 Чтобы очистить критерии поиска, выберите значок Очистить все .
Добавить группы значений токена
Группы значения токена по умолчанию доступны на панели значения токена.
1 Чтобы добавить новую группу, щелкните значок.
2 Введите соответствующее имя группы, описание и нажмите OK .
Создана новая группа значений токена.
Добавить правило
1 Чтобы добавить новое правило, нажмите кнопку Добавить правило .
2 Введите соответствующие данные и нажмите Добавить .
· Пример. Следующие пары "ключ-значение" можно добавить следующим образом.
· Отображаемое имя: Сводка журналов
· Токен: время регистрации
· Разделитель ‘:’
· Терминатор: \n
· Новое правило отображается на панели Token-Value.
| г. 2 ПРИМЕЧАНИЕ |
Может быть более одного Token-Value с одним и тем же отображаемым именем, но один из токенов, разделитель или терминатор должен быть другим/уникальным. Пример: отображаемое имя такое же, как на снимке экрана, приведенном ниже, но разделитель отличается.
|

3 Чтобы изменить значение токена, нажмите кнопку Изменить , внесите необходимые изменения и нажмите Сохранить .
2 ПРИМЕЧАНИЕ |
Одновременно можно редактировать только одно значение токена. |
4 Чтобы удалить значение токена, нажмите кнопку Удалить .
5 Чтобы значение маркера в другую группу, нажмите Переместить в группу.
2 ПРИМЕЧАНИЕ |
Вы можете перейти в другую группу, если помимо выбранной существуют другие группы Token-Value. |

Мастер значения токена
1 Чтобы просмотреть Мастер значения токена , выберите Администратор , выберите Правила синтаксического анализа .
По умолчанию отображаются группы Token-Value .
2 Нажмите кнопку Мастера значения токена .
Мастер Token-Value Wizard отображает окно Sample Logs.
3 Нажмите любой из значков Извлечь пары значений токена .
Отображается вкладка Create Token-Value с дополнительными данными.
4 Выберите список значений токенов и нажмите кнопку Добавить >> .
Пример: Выберите Имя клиента в списке значений токенов, а затем нажмите Добавить .
Отображение сведений о значении токена.
Вы можете изменить отображаемые значения по умолчанию.
5 Нажмите Подтвердить, , а затем нажмите Сохранить.
Использовать шаблон по умолчанию
1 Выберите Admin , а затем выберите Parsing Rules .
Отображаются группы Token-Value по умолчанию. EventTracker предоставляет предопределенные правила синтаксического анализа.
2 Выберите вкладку Template .
Группа Шаблоны отображается на левой панели, а Шаблоны отображаются на правой панели.
3 Чтобы выполнить поиск по имени группы, введите имя в поле Поиск и щелкните значок поиска.
4 Чтобы экспортировать или импортировать конфигурацию, используйте значок экспорта или значок импорта.
Создать новый шаблон
1. В мастере значения токена выберите вкладку Создать значение токена ,
. 2. Добавьте описание и нажмите Создать шаблон.
На следующей странице отображается:
3. Внесите необходимые изменения в параметр Token Value и Token .
4. Введите имя шаблона .
5. Чтобы отфильтровать значения, щелкните значок .
EventTracker: отображается окно «Определенный шаблон».
6. Введите соответствующие данные и нажмите Добавить .
Пример: введите имя токена (т. е. новый токен), выходное значение (т. е. параметр).
Вы можете выбрать регулярное выражение или разделитель. Регулярное выражение используется для поиска определенного шаблона.
· Выберите разделитель «-». Это может быть пробел, знак равенства «=» и т. д.
· Выберите порядковые значения (например, числовые), чтобы еще больше разделить правила.
7. Нажмите Добавить в столбец шаблона .
Нажмите Добавить в столбец шаблона .
8. Нажмите кнопку Сохранить .
Теперь в окне «Определить правила синтаксического анализа» созданный новый шаблон отображается в Шаблоне 9.1540 таб.
Создание отчетов Flex
1 Войдите в EventTracker Enterprise, щелкните значок Reports и выберите Dashboard или Configuration .
2 Нажмите кнопку New в Dashboard/Configuration .
3 Выберите любую вкладку Compliance / Security / Operations / Flex reports / Alphabetical .
4 Расширить узел дерева отчетов и выберите любой отчет. Выберите Тип отчета как По запросу . Щелкните Далее.
Например: на вкладке Flex Reports выберите Logs , а затем выберите Summary .
Тип отчета выбран как По запросу.
EventTracker отображает мастер отчетов.
5 Нажмите Далее >>.
6 Выберите необходимые параметры (например, Сайты , Группа, Системы, Показать все сайты, Все системы ).
7 Выберите Realtime или File Transfer , а затем нажмите Next>>.
8 Выберите требуемый параметр Interval и Limit to time Range.
9 Выберите требуемый тип экспорта (например, файл PDF, документ Word, файл HTML, быстрый просмотр (не сохраняется на жестком диске )).
10 Выберите нужный Вариант формата .
---------------------------------------------------------------- --------------------------------------------------
Пример:
а. Если вы выберете опцию Parsing Rule . Щелкните Далее>>.
Сводка журналов отображается для выбора правила синтаксического анализа.
б. Нажмите Выберите правило синтаксического анализа гиперссылка.
Отображается окно правила синтаксического анализа поиска.
в. Выберите необходимые параметры и нажмите кнопку ОК.
Отображается сводка журналов (т. е. шаг 5).
д. Выберите любой параметр Сводка ; выберите соответствующий параметр в раскрывающемся списке Сортировать по .
эл. Выберите токенов сопоставления с одинаковым «тегом» в один столбец , если требуется.
(ИЛИ)
ф. Если вы выбрали Token Template , нажмите Next>>.
г. Выберите шаблон. (т.е. введите имя шаблона, которое вы ранее настроили в правилах синтаксического анализа — Мастер значения токена)
ч. Выберите/введите необходимые параметры и нажмите Далее>>.
-------------------------------------------------- ------------------------------------
11 Нажмите кнопку Далее>> .