Морфемный разбор — SСHOOLSTARS
Рассказываем, как выполнить морфемный разбор (разобрать слово по составу). Представлен план, образец и примеры разбора.
1 Морфемный разбор: разбор слова по составу
1.1 Морфемы (основные и другие) и основа слова
1.2 Основные морфемы: корень, приставка, суффикс, окончание
2 Как сделать морфемный разбор (разобрать слово по составу)?
2.1 План морфемного разбора (разбора слова по составу)
2.2 Примеры планов морфемного разбора по учебникам (книгам)
2.3 Образец устного морфемного разбора (разбора слова по составу)
3 Примеры морфемного разбора (разбора слова по составу)
Морфемный разбор: разбор слова по составу
Морфемы (основные и другие) и основа слова
Разобрать слово по составу — значит сделать его морфемный разбор, то есть указать, из каких морфем оно состоит.
Морфема
Морфема — это минимальная значимая часть слова, главная из которых — корень.
В корне заключено общее для всех однокоренных слов значение, например, игра, игрушечный, играть, игровая, игрушечка.

Другие морфемы
Кроме корня, в состав слова могут входить и другие морфемы. В русском языке есть ряд слов, в состав которых входят так называемые уникальные элементы — унификсы, не встречающиеся больше ни в каких других словах (они выделяются как суффиксы, поскольку стоят после корня и перед окончанием): в словах: аплодисменты, детвора, маскарад, попадья, стекалярус и некоторые другие. Как суффиксы выделяются и постфиксы — частицы -ся и -сь в возвратных глаголах: спрятаться, купаюсь. Кроме того, в состав слова может входить интерфикс — в русском языке это соединительная гласная о (снегопад) или е (птицелов).
Другие морфемы:
- Унификс
- Аффикс (постфикс, префикс)
- Интерфикс
Основа слова
Традиционное определение основы слова (это часть слова без окончания) не совсем точно поскольку кроме окончания в основу не входят формообразующие суффиксы глаголов -ть, -ти – показатели неопределённой формы (плыть, расти) и -л- – показатель прошедшего времени (убежал, убежала, убежало, убежали).
Основные морфемы: корень, приставка, суффикс, окончание
Корень
Корень — это главная и незаменимая часть слова, для нахождения которой необходимо подобрать родственные слова. Эта часть обозначается дугой вверху разбираемого слова.
Разберем на примере: Ветерок — в слове ветерок — ветер — корень, проверочное однокоренное слово — ветер.
В русском языке существуют слова, состоящие из корней:
- только из него: кот, лес, сад, пол;
- Из трех: электроаппаратостроение, хромолитограф, биогеохимический.
- Из четырех: биомагнитогидродинамика.
Суффикс
Суффикс — морфема, стоящая сразу за корнем, являющаяся словообразовательной частью. Она присутствует не во всех словах.
Эта часть обозначается крышечкой вверху слова.
 Эта часть обозначается крышечкой вверху слова.
Эта часть обозначается крышечкой вверху слова.Разберем на примере: журнальчик — в слове журнальчик — чик является уменьшительно-ласкательным суффиксом.
Существуют случаи, когда в слове присутствуют несколько суффиксов:
- Один: чемоданчик, футлярчик, портфельчик;
- Два: сыроватость, брезгливость, высказывание;
- Три: бесхитростность, хранилище, сеялка.
Приставка
Приставка — Морфема, находящаяся до корня, являющаяся словообразовательной частью. Она присутствует не во всех словах. Эта часть обозначается лежащей буквой «Г» вверху слова.
Разберем на примере: выход — в слове выход — вы является приставкой, образующей значение обратного слова от слова ход.
В русском языке существуют слова, состоящие из приставки:
- Одной: выходит, подходит, исходит:
- Двух: беспеременный, беспрогонный, безнаборный;
- Трех: поуспокоиться, незаприходованный, неприсоединившийся.

Окончание
Окончание —
Морфема связующая слова в речи благодаря своей изменчивости. Эта часть обозначается рамкой, окружающей окончание.
Разберем на примере: правило — в слове правило окончание — буква о, изменяющаяся в зависимости от числа и падежа слова. Чтобы его найти необходимо изменить слово, и меняющаяся часть на его конце и есть окончание.
Слово может быть с окончанием:
- Без него— К этим словам относятся: деепричастие, заимствованные несклоняемые слова, наречие, несклоняемые прилагательные. Разберем на примере: сделав, по-моему, гороно, цвет.
- Нулевым— В таком случае слово имеет окончание в измененных формах, но в именительном падеже его нет: кот, рот, глаз, паз;
- Одним: кошка, лисица, лампа, свеча;
- Двумя: тремястами, шестьюстами.

Как сделать морфемный разбор (разобрать слово по составу)?
План морфемного разбора (разбора слова по составу)
- Часть речи. Определяем, к какой части речи относится анализируемое слово.
- Окончание и основа слова. Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой.
- Корень. Выделяем корень. Для определения корня подбираем однокоренные слова.
- Приставка и суффикс. Определяем, входит ли в основу слова кроме корня также приставка и суффикс.
- Выделяем приставку. Для этого подбираем слова с такой же приставкой.
- Выделяем суффикс. Для этого подбираем слова с таким же суффиксом.
- Графическое обозначение.Обозначаем части слова с помощью графических обозначений.

Примеры планов морфемного разбора по учебникам (книгам)
Образец устного морфемного разбора (разбора слова по составу)
Выполним разбор слова по составу: ПОДЕЛКА.
- Часть речи. Поделка – имя существительное.
- Окончание и основа слова. Выделяем окончание и основу. Для этого изменим слово: поделка, поделки, поделке → окончание –а. Выделим основу: поделк-.
- Корень. Выделяем корень. Для определения корня подбираем однокоренные слова: делаем, выделка, передел → корень –дел-.
- Приставка и суффикс. Определяем, входит ли в основу слова кроме корня также приставка и суффикс.
- Выделяем приставку. Для этого подбираем слова с такой же приставкой: поход, полетел, повозка → приставка по-.
- Выделяем суффикс. Для этого подбираем слова с таким же суффиксом: повозка, привычка, прожилка → суффикс –к-.
- Графическое обозначение. Обозначаем части слова с помощью графических обозначений.
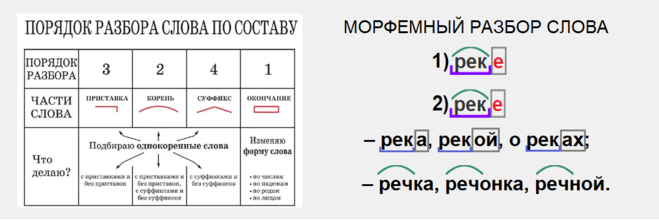
ПОДЕЛКА
Примеры морфемного разбора (разбора слова по составу)
ЗЕРКАЛЬНЫЙ
ПОЗОЛОТА
ЛОВЕЦ
ЗАМАЗКА
ИГРИВЫЙ
ИГРУШКА
НОСИШКО
КОТЁНОК
КРАСИВЫЙ
Морфемика. Морфемный разбор — презентация онлайн
Похожие презентации:
Научный стиль речи
Проект по русскому языку — Рассказ о слове Звезда
ЕГЭ-2019 по русскому языку. Задание 9
Технология В.А. Илюхиной «Письмо с открытыми правилами» для учащихся начальных классов
Язык и профессии. Культура речи
Изложение по рассказу В. Бочарникова «Мал, да удал»
Роль русского языка в многонациональной России
ЕГЭ-2019 по русскому языку. Задание 10
Новое в сочинении на ЕГЭ. Комментарий
Художественный стиль речи
Памятка по русскому языку
Морфемика
Морфемный разбор (*2)
Тема «Морфемика. Морфемный разбор»
Морфемный разбор»
Цель: систематизация изученного по теме
«Морфемика», повторение и обобщение
пройденного, направленное на выполнение
морфемного разбора (разбора по частям
слова)
Работа по теме
Морфемика –
раздел науки о языке,
изучающий морфемы, части
слова.
Работа по теме
Морфема,
или часть слова –
значимая часть слова.
Работа по теме
2 – МОРФЕМНЫЙ РАЗБОР (РАЗБОР СЛОВА
ПО СОСТАВУ)
1.
Определить часть речи
2.
Окончание (у слов, которые изменяются:
сущ., прил., гл.)
3.
Основа (часть слова без окончания,
без суффиксов -ть, -ти у начальной формы глагола,
без суффикса -л- у глагола прошедшего времени)
4.
Корень (наименьшая общая часть
родственных слов)
Приставки, суффиксы
Работа по теме
Окончание –
изменяемая часть слова,
которая служит для связи
слов в предложении
Работа по теме
Основа –
часть слова без окончания
Работа по теме
Окончание –
изменяемая часть слова, которая
служит для связи слов в
предложении
*Надо помнить:
об изменяемых и неизменяемых
частях речи;
о нулевом окончании изменяемых
частей речи (оно появляется в другой
форме слова)
Работа по теме
Изменяемые части речи:
Имя сущ.
 (изм. по падежам)
(изм. по падежам)Имя прил.
Причастие (изм. по падежам)
Глагол (изм. по числам, родам или лицам –
зависит от времени глагола)
Числит.
Местоим.
Работа по теме
Неизменяемые части речи и формы слов:
Наречие
Деепричастие
Имя прил. в простой сравнительной
степени сравнения
Работа по теме
Корень –
наименьшая общая часть
родственных слов, в которой
заключено общее лексическое
значение.
Работа по теме
Приставка –
часть слова, которая стоит
перед корнем и служит для
образования новых слов.
Работа по теме
Суффикс –
часть слова, которая стоит
после корня и служит для
образования новых слов.
Работа по теме
Каменный — прил.
Окончание — -ый: каменного, каменному;
Основа – каменн-;
Корень – камен-: камень, окаменеть;
Суффикс — -н-.
Работа по теме
Убежать – глагол в нач. форме
Окончания нет (н.ф. -неизменяемая форма)
Основа – убежа- (-ть и -ти в основу не
входят)
Корень — -беж-: бежать, бег (г//ж)
Приставка – у-;
Суффиксы — -а , -ть.

Работа по теме
Зацвести – глагол в начальной форме
Окончания нет(н.ф. – неизменяемая форма)
Основа – зацвеc- (-ти в основу не входит)
Корень – цвес-: цветок, цвет; (с//т)
Приставка – за-;
Суффикс — -ти.
Работа по теме
Проходил — глагол в прош.времени
Окончание – нулевое (так как при
изменении слова по родам и числам
окончание появляется: проходила,
проходили)
Основа – проходи- (-л у гл. в прош. времени в
основу не входит)
Корень — -ход-: ходит, выход
Приставка – про-;
Суффиксы — -и, -л.
Работа по теме
Заново – наречие;
Неизменяемая часть речи,
окончания нет;
Основа — всё слово;
Корень — -нов-: новый, обновить;
Приставка – за-;
Суффикс — -о.
Вернёмся к цели
Мы повторили основной
теоретический материал по теме
«Морфемика», составили образец
морфемного разбора слова.
Домашнее задание
Выучите правила, которые мы повторили в
разделе «Морфемика»
Выполните морфемный разбор
Перепрыгивать
Пролетает
Отползти
Подосиновик
Черника
Глубокая
Метро
Свысока
English Русский Правила
Компьютерная лингвистика
Компьютерная лингвистикаЛингвистика 581
Преобразователи морфологии и конечных состояний
Морфологический анализ: поиск морфологических составляющих
- сердито = злой + лукавый
- доказано = доказать + en
- * убежище = иметь + ан
- утки = утка + мн. ч.
- утки = утка + 3rdsg
- земля = земля (N, sg)
- шлифовка = шлифовка + pst
- неопровержимость = неопровержимо + отрицаю + способно + ит
 ч.
ч.Часть речи: класс слов, которые имеют много общих свойств. (подробнее позже). Примеры: существительные, глаголы.
Перегиб против происхождения
- утка против утки, кошка против кошки, бык против быка: Все существительные имеют форму множественного числа (почти?: оборудование, аппарат, мебель, пехота)
- ходьба или ходьба, разговоры и разговоры, курение и курение: все существительные имеют -ing формы (герундий, причастие настоящего времени)
- Испанский глагол amare («любить»)
- ходить = ходить + ing
Форма = основа + суффикс
Звуковая система против правописания
- английские согласные
- английских гласных
Алломорфия: множественное число с
- fox: лисы, /fa aak s/ + /ax z/
- собака: собаки, /d ao g/ + /z/
- утка: утки, /d uh k/ + /s/
- лилли: лилии, /l ih l i/ + /z/
В этой главе мы занимаемся орфографией. Это означает, что мы
касаются правил правописания вместо фонологические правила для алломорфии. Мы оперируем орфографическими представлениями
не фонетические представления.
Это означает, что мы
касаются правил правописания вместо фонологические правила для алломорфии. Мы оперируем орфографическими представлениями
не фонетические представления.
| Орфографическое единственное число | Фонология | Орфографическое множественное число |
| вигвам | /t iy p iy/ + /z/ | вигвам |
| лилли | /l ih l iy/ + /z/ | лилии |
Продуктивное окончание: [s] (морфема s, с его фонологически предсказуемые алломорфы) по сравнению с неправильными формами. Обратите внимание, что многие неправильные формы не образованы аффиксацией.
| Обычный | Нерегулярный |
|
|
- Морфологический анализ слова:
Основа плюс различные морфологический особенности слова, независимо от того, они сигнализируются аффиксацией.

Мы предполагаем, что категория является морфологическим признаком.
Анализ и распознавание
Морфологическое распознавание: Принимает и отклоняет формы:
- Принять: гуси
Отклонить: гуси
Морфологический анализ производит морфологический анализ (сначала корень, за которым следует категория основы, за которой следуют все аффиксы):
- гуси: гусь + N + PL
гусь: гусь + N + SG, гусь +V +3SG
молотый: молотый +N +SG, молотый +V +PPart
- Соприкасающаяся поверхность и «лежащая в основе»
формы
Морфотактическое распознавание
Морфотактика синтаксис морфем: в каком порядке они
зайдите, какие единицы они делают.
Базовый морфотактический факт об аффиксах в том, где они присоединяются к по отношению к стволу.
- Префикс* + основа + суффикс*
Аффикс — это либо префикс, либо суффикс (английский)
- выполнимость = сделать + способность + ity
* doityable = сделать + ity + способность
Использование FSA для распознавания
- Автомат класса Word: морфотактика
- Лексикон принят для распознавания
- Все основы с прикрепленной информацией о классе слов
- лиса, вино: обр.-существительное
- гуси, рыба, штаны: irreg-pl-существительное
- гусь, рыба, оборудование, растопка: irreg-sg-существительное
- Все аффиксы
- Все основы с прикрепленной информацией о классе слов
- Слово-автомат: распознаватель
- Распознает «морфотактические цепочки», а не поверхностные цепочки
Английский («лисы», а не «лисы»). Отсутствующий вид
информация.
- Нам нужен реализационный правила, которые говорят нам: fox + s => foxes.
- В фонологических представлениях это будут
правила алломорфии. О графических изображениях
это правила правописания.
 Отсутствующий вид
информация.
Отсутствующий вид
информация.Датчики конечных состояний
Мы представляем Преобразователи конечного состояния , увеличение FSA, в которых есть две ленты
- Автомат двухленточный,
верхняя лента — лента «основного представления», а нижняя
«поверхностное представление»
Основная идея: FST — это то же самое, что FSA, на котором расположены дуги. помечен парами символов, базовый символ и символ поверхности. Дугу и можно взять на всякий случай текущий символ сверху лента соответствует основному символу представления на и и текущий символ на нижней ленте соответствует символу представления поверхности на a .
- Переход с маркировкой a:e означает «а», поскольку базовое представление соответствует «e» как представление поверхности
- Переход «а» (без двоеточия) является аббревиатурой
для «a: a», что означает «a» как базовое представление
соответствует «а» как представлению поверхности.
Преобразователи с конечным числом состояний (FST) дайте нам технологию сделать разбор.
- Мы представляем, что начинаем с
лента представления поверхности, содержащая
поверхностное слово в качестве входных данных. Наша задача – заполнить
базовое представительство, лицензированное FST.
Или, в неоднозначных случаях, заполнить ВСЕ нижележащие
представительства, лицензированные FST.
Преобразователи с конечным числом состояний дают нам технологию для работы создание поверхностных форм
- Мы представляем, что начинаем с
основная лента представления, содержащая
базовое представление в качестве входных данных. Этот
может состоять из последовательности аффиксов и основ
и морфологические признаки взяты из лексикона:
- могу ли я
Для этого примера есть
нет, но для- сделать в состоянии ит
Мы свяжем поверхность с нижележащими формами через «промежуточное» морфотактическое представление. Для этого потребуются два отдельных FST, один из которых связан с Furface. к промежуточным представлениям, относящимся промежуточные по отношению к базовым представлениям.
Относительно лежащего в основе промежуточного (морфотактического) представления:
- Морфологический лексикон просто большой
FST связывает основы с морфологическими классами слов
- Основы, связанные с информацией о классе слов
- лиса, вино; регулярное существительное
- гуси, рыба, штаны; нерег-пл-существительное
- рыба, оборудование, растопка; нерег-sg-существительное
- Осложнение — неправильное множественное число, связанное с
непредсказуемое единственное число:
g   o:e   o:e   s   e нерег-пл-существительное
m   o:i   u:eps   s:c   e нерег-пл-существительное
- Основы, связанные с информацией о классе слов
- FST, который фиксирует эту информацию
- Нам также необходимо связать информацию о классе слов к морфологическому Особенности и морфотактическая информация: преобразователь словесного класса
- «Состав» этих двух преобразователей
- Лингвистически картинка приятная:
- Преобразователь от основного к промежуточному сам состоит из
из двух преобразователей, большой из которых фиксирует морфологические классы слов
для стеблей и маленький, который фиксирует морфотактику
из классов слов.

 Для этого примера есть
нет, но для
Для этого примера есть
нет, но для
Отношение промежуточного (морфотактического) представления к поверхности (орфография правила).
Проблема
- попрошайничество + инг = попрошайничество: удвоение согласных
- mak + ing = изготовление: e-удаление 9, нет #.
- Эта машина предназначена для того, чтобы оставлять каждое слово, которое правило НЕ относится к неизменным.
- Состояние 0 является нерелевантным состоянием ввода. Мы остаемся в состояние 0, пока мы не увидим что-то важное. Состояние 0 является конечным состоянием.
- Состояние 1 означает, что мы нашли {s,x,z}. Состояние 2 означает, что мы нашли границу морфемы.
- Состояние 2 — это состояние готовности к правилу . мы видели морфема заканчивается на {s,x,z}. 9:eps переход из состояния 5 в состояние 2.
- Переход {z,s,x} от 5 к 1. Это упражнение 3.10.
- Правило требует электронной вставки только перед
окончание слова с.
 ) в порядке. И видя
граница морфемы, мы возвращаемся к состоянию
2, потому что это состояние готовности к правилу, подходящее
когда мы видели морфему, оканчивающуюся на s.
) в порядке. И видя
граница морфемы, мы возвращаемся к состоянию
2, потому что это состояние готовности к правилу, подходящее
когда мы видели морфему, оканчивающуюся на s.Использование правила электронной вставки при разборе:
- Правильный анализ
Underlying                Государственный Поверхность a s s e s s # Базовый a s s e s s # eps с Состояние 0 1 1 2 3 4 отказ 9007Поверхность a s s eps e s s # #
Смитсоновский проект истории синтеза речи (dk_773.
 htm)
htm)времени с помощью морфологической декомпозиции, запутанных ситуаций когда поверхностная форма не содержала молчаливого «е» (задыхаться -> задыхаться + ing), имело место удвоение согласных (опущено -> опущено + ed) или последний «y» был изменен (города -> город + s). Джонатан Аллен и Дебора Финкель расширила эти методы, увеличив морфему словарь до 12 000 наименований (Allen и др. ., 1979; Allen и др. ., 1987). Морфемы были выбраны путем интерактивного изучения примерно 50 000 уникальных слов в корпусе Брауна, выборка из один миллион слов текста (Кусера и Фрэнсис, 1967).13 Аллен и др. . (1979) также разработали правила рассмотрения случаев, когда
слово имеет несколько разборов (например, « дефицит » =
« дефицит + ити » или « шрам + город «). Одно из правил, проиллюстрированное этим примером, состоит в том, что проставление
скорее, чем компаундирование. Ни одно из этих указаний не является абсолютным,
поэтому, сравнивая два альтернативных морфемных разложения, авторы
вызвал набор эвристических процедур оценки, посредством которых данный
морфемное деление влечет за собой штраф в зависимости от того, что было
произошло до сих пор. Некоторые морфемы произносятся по-разному
в зависимости от ударения в слове и характера
присутствуют другие морфемы (обратите внимание на вторую « o » из « фото » есть
фонематически реализуется как
в
« фото «, « фото «, « фото » соответственно).
Группа MITalk разработала
правила для обработки некоторых из этих случаев, и просто добавил целые
полиморфные слова в лексикон, если правило было слишком
сложным или недостаточно продуктивным. Одним из преимуществ словаря морфем, помимо способности правильно делить сложные слова, состоит в том, что набор из 12 000 морфем может представлять более 100 000 английских слов. Таким образом, очень большой словарный запас достигается при умеренных затратах на хранение. Однако самый большой Преимуществом словаря морфем может оказаться его способность передавать информацию о частях речи синтаксическому анализатору, чтобы для улучшения просодии предложений см. ниже. Недавняя работа в Bell Laboratories (Coker, 1985) расширила этот
подход путем увеличения лексикона морфем до 43 000 морфем, и
добавление к правилам анализа суффиксов и префиксов и ударения
переназначение суффиксов, меняющих ударение. 4. Имена собственные Имена собственные представляют собой особую проблему, поскольку правила их
произношение часто зависит от того, какой язык считается
лежащее в основе происхождения написания (Либерман, 1979). Коммерческий
система, которая лучше всего подходит для произношения имен собственных, новейшая
Плата Speech Plus Calltext по-прежнему имеет уровень ошибок около 20% в
свой компонент правил при столкновении со случайными именами собственными (Райт и др. , 1986). Черч (1985) недавно предложил решение
эта проблема, которая включает в себя статистику частоты возникновения
трехбуквенных последовательностей на каждом из нескольких языков. Первый
шаг должен использовать эту статистику, чтобы оценить языковую семью
неизвестное слово. Для слов средней длины он находит, что
часто та или иная буквенная тройка в слове по существу правил
все, кроме правильного языка. C. Синтаксический анализ Наложение соответствующего просодического контура на предложение требует
хотя бы частичный синтаксический анализ. Кроме того, некоторые
двусмысленность произношения может быть разрешена с помощью синтаксической информации. Хотя существуют мощные стратегии синтаксического анализа (см., например, Woods, 1970; Aho
и Ульман, 19 лет72; Маркус, 1980 год; Каплан и Бреснан, 1982), они склонны
производить множество альтернативных синтаксических анализов даже для предложений, которые кажутся
просто и однозначно. Например, «Время летит, как стрела».
умножить неоднозначность на синтаксическом уровне ; система синтаксического анализа
потребует огромного запаса знаний о мире (семантика/
прагматика) вести себя так, как мы, и сосредоточиться сразу на единственном
разумная структурная интерпретация предложения. |
 Этот алгоритм подсчета очков выбирает правильный
разложение для «формально» из множества (форма+все+у,
for+mall+y, form+ally, form+al+ly). Если после всего этого
вычисления, слово оказалось исключением из разбора
эвристика (например, « был «не произносится»
как « быть » + « -en «), весь
слово было добавлено в лексикон морфем в неразборном
form.14 Ан
альтернативный метод работы с флективными суффиксами,
деривационные аффиксы и составление обсуждается в церкви
(1985, стр. 251).
Этот алгоритм подсчета очков выбирает правильный
разложение для «формально» из множества (форма+все+у,
for+mall+y, form+ally, form+al+ly). Если после всего этого
вычисления, слово оказалось исключением из разбора
эвристика (например, « был «не произносится»
как « быть » + « -en «), весь
слово было добавлено в лексикон морфем в неразборном
form.14 Ан
альтернативный метод работы с флективными суффиксами,
деривационные аффиксы и составление обсуждается в церкви
(1985, стр. 251). Разложение по морфемам
Алгоритм способен анализировать около 98%
слов в типичном тексте и должен иметь большую точность
чем правила преобразования букв в фонемы. Точная точность MITalk
алгоритм декомпозиции морфем никогда не измерялся,
хотя беглый взгляд на текст из трех абзацев
(Аллен и др. ., 1987, стр. 89-92) указывает на несколько (легко
исправимых) ошибок, а процент правильных слов составляет всего около 95%.
Разложение по морфемам
Алгоритм способен анализировать около 98%
слов в типичном тексте и должен иметь большую точность
чем правила преобразования букв в фонемы. Точная точность MITalk
алгоритм декомпозиции морфем никогда не измерялся,
хотя беглый взгляд на текст из трех абзацев
(Аллен и др. ., 1987, стр. 89-92) указывает на несколько (легко
исправимых) ошибок, а процент правильных слов составляет всего около 95%. Алгоритм и
лексикон морфем занимает около 900 кбайт в режиме реального времени.
доска для преобразования текста в речь (Олив и Либерман, 1985).
Алгоритм и
лексикон морфем занимает около 900 кбайт в режиме реального времени.
доска для преобразования текста в речь (Олив и Либерман, 1985). Второй шаг – применение стресса.
и правила преобразования букв в фонемы для рассматриваемого языка. Производительность
утверждается, что она намного превосходит любую систему, ограниченную
единый набор правил для всех имен собственных. Важность выполнения
имена собственные по правилу выявляются статистическим анализом, показывающим
что словари с большими именами не решают проблему. Исключения
словарь, содержащий 2000 имен собственных, покроет около 50%
имена в случайном телефонном справочнике, и 6000 имен собственных будут
охватывают около 60%. Однако добавление в словарь исключений за пределы
6000 имён по существу бесплодны в том смысле, что одно не может получить
вне асимптоты около 62% имен в одном телефоне
каталог, независимо от того, сколько имен получено из другого
справочник (Церковная, 1985).
Второй шаг – применение стресса.
и правила преобразования букв в фонемы для рассматриваемого языка. Производительность
утверждается, что она намного превосходит любую систему, ограниченную
единый набор правил для всех имен собственных. Важность выполнения
имена собственные по правилу выявляются статистическим анализом, показывающим
что словари с большими именами не решают проблему. Исключения
словарь, содержащий 2000 имен собственных, покроет около 50%
имена в случайном телефонном справочнике, и 6000 имен собственных будут
охватывают около 60%. Однако добавление в словарь исключений за пределы
6000 имён по существу бесплодны в том смысле, что одно не может получить
вне асимптоты около 62% имен в одном телефоне
каталог, независимо от того, сколько имен получено из другого
справочник (Церковная, 1985). Например, существует более 50 многозначных слов существительного/глагола, таких как
как « разрешение «, которые произносятся с ударением на первый слог
если существительное, и с ударением на втором слоге, если глагол (см.
Приложение D в Конрой и др. ., 1986). Единственный способ произнести эти
слова правильно, чтобы выяснить синтаксическую структуру ввода
предложение, включая расположение глаголов. Правильная формулировка
умеренно длинные предложения также требуют знания местонахождения
границы фраз. Таким образом, было бы весьма желательно включить
парсер в системе преобразования текста в речь.
Например, существует более 50 многозначных слов существительного/глагола, таких как
как « разрешение «, которые произносятся с ударением на первый слог
если существительное, и с ударением на втором слоге, если глагол (см.
Приложение D в Конрой и др. ., 1986). Единственный способ произнести эти
слова правильно, чтобы выяснить синтаксическую структуру ввода
предложение, включая расположение глаголов. Правильная формулировка
умеренно длинные предложения также требуют знания местонахождения
границы фраз. Таким образом, было бы весьма желательно включить
парсер в системе преобразования текста в речь.