Слова «последовательность» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «последовательность» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «последовательность» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «последовательность».
Содержимое:
- 1 Слоги в слове «последовательность» деление на слоги
- 2 Как перенести слово «последовательность»
- 3 Морфологический разбор слова «последовательность»
- 4 Разбор слова «последовательность» по составу
- 5 Синонимы слова «последовательность»
- 6 Антонимы слова «последовательность»
- 7 Ударение в слове «последовательность»
- 8 Фонетическая транскрипция слова «последовательность»
- 9 Фонетический разбор слова «последовательность» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «последовательность»
- 11 Сочетаемость слова «последовательность»
- 12 Значение слова «последовательность»
- 13 Как правильно пишется слово «последовательность»
- 14 Ассоциации к слову «последовательность»
Слоги в слове «последовательность» деление на слоги
Количество слогов: 6
По слогам: по-сле-до-ва-тель-ность
По правилам школьной программы слово «последовательность» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
пос-ле-до-ва-тель-ность
По программе института слоги выделяются на основе восходящей звучности:
по-сле-до-ва-тель-ность
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
с примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
ь всегда примыкает к предшествующей согласной, смягчая её
Как перенести слово «последовательность»
по—следовательность
пос—ледовательность
после—довательность
последо—вательность
последова—тельность
последовате—льность
последователь—ность
Морфологический разбор слова «последовательность»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: женский;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
последовательность
Разбор слова «последовательность» по составу
| по | приставка |
| след | корень |
| ова | суффикс |
| тельн | суффикс |
| ость | суффикс |
| ø | нулевое окончание |
последовательность
Синонимы слова «последовательность»
1. выдержанность
выдержанность
2. логичность
3. подпоследовательность
4. градация
5. методичность
6. набор
7. обоснованность
8. расстановка
9. ступенчатость
10. упорность
11. упорство
12. ряд
13. стройность
14. связность
15. связь
16. очередь
17. порядок
18. очередность
19. ортодоксальность
20. черед
21. череда
22. хронология
23. правоверность
24. градационность
Антонимы слова «последовательность»
1. непоследовательность
2. непостоянство
3. параллельность
Ударение в слове «последовательность»
после́довательность — ударение падает на 2-й слог
Фонетическая транскрипция слова «последовательность»
[пасл’`эдават’ил’наст’]
Фонетический разбор слова «последовательность» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| п | [п] | согласный, глухой парный, твёрдый, шумный | п |
| о | [а] | гласный, безударный | о |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| е | [`э] | гласный, ударный | е |
| д | [д] | согласный, звонкий парный, твёрдый, шумный | д |
| о | [а] | гласный, безударный | о |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| а | [а] | гласный, безударный | а |
| т | [т’] | согласный, глухой парный, мягкий, шумный | т |
| е | [и] | гласный, безударный | е |
| л | [л’] | согласный, звонкий непарный (сонорный), мягкий | л |
| ь | — | не обозначает звука | ь |
| н | [н] | согласный, звонкий непарный (сонорный), твёрдый | н |
| о | [а] | гласный, безударный | о |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| т | [т’] | согласный, глухой парный, мягкий, шумный | т |
| ь | — | не обозначает звука | ь |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 18 букв и 16 звуков.
Буквы: 6 гласных букв, 10 согласных букв, 2 буквы не означают звуков.
Звуки: 6 гласных звуков, 10 согласных звуков.
Предложения со словом «последовательность»
Действительно, создать полную картину последовательности событий никак не удавалось.
Источник: Д. Р. Кунц, Вторжение, 2004.
Это люди, которые создают оптимальные условия для работы и показывают подопечным наиболее эффективную для них последовательность действий.
Источник: Валерий Михайлов, Медитация. Книга заблудшей овцы.
Лишь пройдя такой курс, учитель проводил повторение изученного в систематической и хронологической последовательности.
Источник: М. Т. Студеникин, Методика преподавания истории в русской школе XIX – начала ХХ в., 2016.
Сочетаемость слова «последовательность»
1.
2. в нужной последовательности
3. логическая последовательность
4. последовательность событий
5. последовательность действий
6. последовательность движений
7. принцип последовательности
8. в порядке последовательности
9. закон последовательности
10. восстановить последовательность событий
11. соблюдать последовательность
12. запомнить последовательность
13. (полная таблица сочетаемости)
Значение слова «последовательность»
ПОСЛЕ́ДОВАТЕЛЬНОСТЬ , -и, ж. Свойство по знач. прил. последовательный. Последовательность событий. Политическая последовательность коммунистов. Последовательность в рассуждениях. (Малый академический словарь, МАС)
Как правильно пишется слово «последовательность»
Орфография слова «последовательность»Правильно слово пишется: после́довательность
Гласные: о, е, о, а, е, о;
Согласные: п, с, л, д, в, т, л, н, с, т;
Нумерация букв в слове
Номера букв в слове «последовательность» в прямом и обратном порядке:
- 18
п
1 - 17
о
2 - 16
с
3 - 15
л
4 - 14
е
5 - 13
д
6 - 12
о
7 - 11
в
8 - 10
а
9 - 9
т
10 - 8
е
11 - 7
л
12 - 6
ь
13 - 5
н
14 - 4
о
15 - 3
с
16 - 2
т
17 - 1
ь
18
Ассоциации к слову «последовательность»
Днк
Диаграмма
Алгоритм
Бит
Изложение
Домен
Белок
Ген
Молекула
Мутация
Нажатие
Кода
Теорема
Гена
Хронология
Событие
Закономерность
Вычисление
Цифра
Белка
Синтез
Отрезка
Сдвиг
Регистр
Алфавит
Интервал
Сборка
Матрица
Элемент
Отрезок
Преобразование
Символ
Совокупность
Расшифровка
Нуль
Клавиатура
Построение
Образующая
Импульс
Логик
Конфигурация
Повествование
Фрагмент
Карлик
Перечисление
Трансляция
Компонент
Вектор
Функция
Эволюция
Логический
Произвольный
Кодовый
Эволюционный
Определённый
Последовательный
Линейный
Идентичный
Молекулярный
Знаковый
Генетический
Заданный
Исходный
Структурный
Функциональный
Нулевой
Закономерный
Цифровой
Пространственный
Случайный
Частичный
Оптимальный
Временной
Первичный
Единичный
Кадровый
Непрерывный
Множественный
Карликовый
Динамический
Выстраивать
Упорядочить
Чередоваться
Выстраиваться
Повторяться
Убывать
Выполняться
Сходиться
Строгать
Зашифровать
Соблюдаться
Воспроизводить
Взаимодействовать
Нарушаться
Сменять
Формировать
Воспроизвести
Запоминать
Обозначаться
Значение слов в словарях
wordmap
Сложность и многогранность русского языка порой удивляют даже его носителей. Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Особенность заключается в отсутствии структурности. Ведь очень много вольностей допускается не только при построении предложений. Использование некоторых словоформ тоже имеет несколько вариаций.
Сложности и особенности работы со словом
В русском языке огромное количество допущений, которые нельзя встретить в других культурах. Ведь в речи часто используются не только литературные слова, которых свыше 150 тысяч. Но еще и диалектизмы. Так как в России много народов и культур, их более 250 тысяч. Неудивительно, что даже носителям языка иногда необходимо отыскать точные значения слов. Сделать это можно с помощью толковых словарей или специального сервиса WordMap.
Чем удобна такая площадка? Это понятный и простой словарь значений слов, использовать который предлагается в режиме онлайн. Сервис позволяет:
- узнать точное значение слова или идиомы;
- определить его корректное написание;
- понять, как правильно в нем ставить ударение.


Площадка предлагает ознакомиться с историей возникновения слова. Тут рассказывается, из какого языка или культуры оно пришло, когда и кем использовалось в речи.
Осуществляя поиск значения слов в словаре, важно понимать его суть. Ведь звуковая составляющая каждой лексической единицы в языке неразрывно связана с определенными предметами или явлениями. Вот почему при использовании сервиса не стоит ставить знак равенства между значением искомого слова и его понятием. Они связаны между собой, но не являются единым целым. К примеру, понятие слова «центр» можно определить как середину чего-либо. Однако конкретные значения могут указывать на внутреннюю часть комнаты, города, геометрической фигуры и т. д. Иногда речь идет о медицинской организации, математике или машиностроении. В многозначности и заключается сложность русского языка.
Поиск значений через WordMap
Для того, чтобы узнать, что значит слово, была проведена кропотливая работа. Ведь разные пособия и сборники могут давать разные значения одних и тех же лексических конструкций.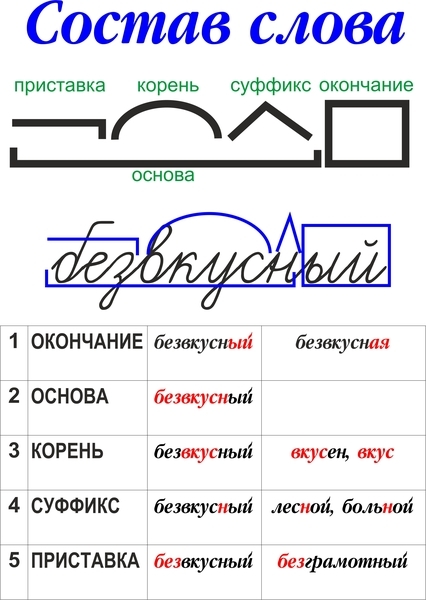 Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
Чтобы получить максимально полное представление о слове, стоит обратиться к сервису WordMap. В системе есть значения из наиболее популярных и авторитетных источников, включая словари:
- Ожегова;
- Даля;
- медицинского;
- городов;
- жаргонов;
- БСЭ и т. д.
Благодаря этому можно узнать не только все книжные, но и переносные значения лексической конструкции.
Только что искали:
граданфл 3 секунды назад
мухобойка 3 секунды назад
молоб 4 секунды назад
нежинский 4 секунды назад
подпёкший 5 секунд назад
доимпериалистическое 6 секунд назад
ркоуг 6 секунд назад
найти косметичку 7 секунд назад
новоселенгинск 13 секунд назад
бусс 13 секунд назад
перебрызгаем 24 секунды назад
ветхая одежда 24 секунды назад
овсянка садовая 27 секунд назад
емелечкин 28 секунд назад
кусс 29 секунд назад
Ваша оценка
Закрыть
Спасибо за вашу оценку!
Закрыть
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Время | Откуда |
|---|---|---|---|---|
| Игрок 1 | подметальщик | 111 слов | 9 часов назад | 95. 29.166.185 29.166.185 |
| Игрок 2 | можжевельник | 46 слов | 9 часов назад | 95.29.166.185 |
| Игрок 3 | аристократ | 85 слов | 10 часов назад | 95.29.166.185 |
| Игрок 4 | атлантида | 20 слов | 10 часов назад | 95.29.166.185 |
| Игрок 5 | аеиобдклмнпстф | 0 слов | 14 часов назад | 89.179.43.231 |
| Игрок 6 | взвинчивание | 0 слов | 1 день назад | 176.59.107.114 |
| Игрок 7 | контрабасист | 157 слов | 1 день назад | 95.29.167.68 |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | кумыс | 46:47 | 14 минут назад | 95. 57.104.201 57.104.201 |
| Игрок 2 | мамка | 0:0 | 15 минут назад | 188.124.237.52 |
| Игрок 3 | папка | 50:51 | 3 часа назад | 178.75.76.83 |
| Игрок 4 | папка | 0:0 | 3 часа назад | 178.75.76.83 |
| Игрок 5 | папка | 0:0 | 3 часа назад | 178.75.76.83 |
| Игрок 6 | обкат | 47:49 | 6 часов назад | 176.59.103.180 |
| Игрок 7 | оплыв | 45:42 | 6 часов назад | 176.59.103.180 |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| PL000040247703 | На одного | 20 вопросов | 7 часов назад | 37. 225.54.147 225.54.147 |
| Амина | На одного | 20 вопросов | 1 день назад | 89.144.196.148 |
| Гулнара | На двоих | 10 вопросов | 1 день назад | 45.132.254.2 |
| Ог | На одного | 10 вопросов | 1 день назад | 188.162.12.108 |
| Света | На одного | 5 вопросов | 1 день назад | 80.95.44.43 |
| Е | На одного | 10 вопросов | 1 день назад | 95.222.118.165 |
| Гл | На одного | 10 вопросов | 2 дня назад | 176.93.241.73 |
| Играть в Чепуху! | ||||
Морфемный разбор слова по составу
А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я
Как правильно разобрать слово по составу
Морфемный разбор – это такой вид разбора, когда в слове выделяют следующие значимые части:
— окончание;
— основу;
— приставку;
— суффикс;
— корень;
— постфикс;
— префикс.
Основным принципом русского правописания признан именно морфемный разбор. Перед тем, как определить правило, согласно которому следует писать ту или иную букву, необходимо понять, с какой частью слова оно связано. Например, мы не знаем, «е» или « и» написать во втором слоге слова «ключик». Разбираем его по составу, обнаруживаем, что орфограмма пропущена в суффиксе -чик-. Находим правило, согласно которому «и» в данном суффиксе пишется в том случае, если при изменении формы слова с именительного падежа на родительный (нет чего? ключика) гласный «не выпадает». Если бы гласный при переходе слова в родительный падеж «выпал», как в примере «замочек – замочка», в суффиксе следовало бы писать «е». Иногда определить часть слова с пропущенной орфограммой бывает непросто. Сейчас вы можете узнать в онлайн как разобрать любое слово по составу.
Порядок морфемного разбора слова по составу
Как и при других видах разбора, при обнаружении морфем в составе слова необходимо соблюдать строгую последовательность действий.
Пошаговые этапы:
- Ищем окончание. Для этого слово нужно изменить так, чтобы выявить, есть ли у него изменяющаяся часть. «Город – города – городу». Окончания – а, у, основа – город. Начинать разбор с поиска корня — неверно, так как корень не всегда легко определить (снять, подъем, сжать), либо его нет совсем (изъ — я — ть). Чтобы не ошибиться в спорных ситуациях, разбор по составу рационально провести на нашем ресурсе в режиме онлайн. Полезно также обращаться к специализированному морфемному словарю.
- Определяем основу. Когда окончание найдено и обозначено, основой будет считаться вся остальная часть слова: город – основа «город»: город-а, город-у, о город-е. Обратите внимание: в слове «город» тоже есть окончание — нулевое. В неизменяемых словах (наречиях и деепричастиях), основой считается всё слово: глухо, навсегда, спеша.
Необходимо учесть, что в лингвистике существует несколько научных школ, внутри которых сложились различные подходы к границам морфем. Одни учёные считают, что -ть на конце глаголов неопределённой формы (спать, играть, сидеть) является окончанием. Другие полагают, что это суффикс.
При обращении к морфемному словарю важно учитывать уровень подготовки пользователя. Ученику школы достаточно традиционной точки зрения, а студент обязан смотреть глубже, изучать происхождение слова. При разборе по составу прилагательного «червонный» обнаруживаем, что оно находится в родстве не только со словом «червлёный», но и с существительным «червь». Происходит историческое чередование морфем в/вл в корнях слов.
- Выделяем суффиксы, сначала — формообразующие: разбираемое слово со составу сравнивается с другими его формами – суффикс -л- прошедшего времени глагола (обеща-л, обеща-ю). Затем выделяем словообразовательные суффиксы (в нашем примере это суффикс –а-). Выстраиваем цепочку, которая поможет проследить, от какого слова образовалось разбираемое слово: «спаса – тель» – от слова «спасать» с помощью суффикса –тель.
- Обнаруживаем приставки. Попробуйте заменить предполагаемую приставку на другую, подберите примеры с такой же приставкой.
- Находим корень. Чтобы правильно выделить главную часть слова, подберём однокоренные слова (травяной – трава, травинка).
 Другие полагают, что это суффикс.
При обращении к морфемному словарю важно учитывать уровень подготовки пользователя. Ученику школы достаточно традиционной точки зрения, а студент обязан смотреть глубже, изучать происхождение слова. При разборе по составу прилагательного «червонный» обнаруживаем, что оно находится в родстве не только со словом «червлёный», но и с существительным «червь». Происходит историческое чередование морфем в/вл в корнях слов.
Другие полагают, что это суффикс.
При обращении к морфемному словарю важно учитывать уровень подготовки пользователя. Ученику школы достаточно традиционной точки зрения, а студент обязан смотреть глубже, изучать происхождение слова. При разборе по составу прилагательного «червонный» обнаруживаем, что оно находится в родстве не только со словом «червлёный», но и с существительным «червь». Происходит историческое чередование морфем в/вл в корнях слов.
Завершающий этап морфемного разбора
После завершения разбора проверьте, правильно ли выделены морфемы графически. Не забывайте выделять нулевое окончание, если не находите его в составе слова. В неизменяемых словах (наречиях, деепричастиях) окончание отсутствует.
Последний этап работы потребует обращения к вашему личному словарному запасу или справочному материалу. Подберите 2-3 слова с подобным составом, чтобы убедиться, что такая словообразовательная модель приемлема для русского языка.
Наш сервис даёт доступ к словарю морфем русского языка, который поможет вам с лёгкостью разобрать любое слово по составу в онлайн-режиме.
Подготовка к ЕГЭ, ОГЭ и решебники
ЕГЭ 2019. Математика. Базовый и профильный уровни. 4000 задач с ответами — Под ред. Ященко И.В.
ЕГЭ 2019. Русский язык. Типовые тестовые задания. 49 вариантов — Васильевых И.П., Гостева Ю.Н.
Русский язык. Типовые тестовые задания. 49 вариантов — Васильевых И.П., Гостева Ю.Н.
ОГЭ 2019. Математика. Тематические тестовые задания — Минаева С.С., Мельникова Н.Б.
3) со значением предмета или лица, имеющего отношение к действию (производящего его, являющегося его результатом и др.), образованные от глагола (накипь-Ø— ← накипеть) или двух производящих основ — основы существительного и основы глагола: пароход-Ø-¤ ← пар + ходить, бракодел-Ø-¤ ← брак + делать. Альтернативные суффиксы — —ник-, -ец-: теплообмен—ник ← тепло + обменивать, земледел-ец ← земля + делать; прилагательные: 1) от глаголов: вхож-Ø-ий ← входить. Альтернативный суффикс — —н-: рез-н-ой ← резать; 2) от существительных: будн-Ø-ий ← будни. Альтернативный суффикс — —н-: лес-н-ой ← лес. Есть и другие случаи нулевой словообразующей суффиксации, но они менее распространены. В комплексе 1 способ образования подобных слов называется бессуффиксным, в комплексе 2 слова такого рода вовсе не рассматриваются. Морфемный разбор (разбор слова по составу) При морфемном разборе слова (разборе слова по составу) сначала в слове выделяется окончание и формообразующий суффикс (если они есть), подчёркивается основа. После этого основа слова разбивается на морфемы. Как мы уже говорили, возможны два противоположных подхода к морфемному членению основы: формально-структурный и формально-смысловой. Суть формально-структурного морфемного разбора состоит в том, что в основе в первую очередь выделяется корень как общая часть родственных слов. Затем то, что идёт до корня, учеником должно быть осознано как приставка (приставки) в соответствии с представлениями ученика о том, встречались ли ему подобные элементы в других словах. Аналогично с суффиксами. Иначе говоря, главным при разборе становится эффект узнаваемости учеником морфем, внешнее сходство каких-то частей разных слов. Ошибки в определении корня слова связаны с неразличением синхронного морфемного и исторического (этимологического) состава слова. Причём комплекс 2 неразличение современного и исторического морфемного состава слов берёт за установку, помогающую иногда в определении правильности написания, что вполне соответствует общей орфографико-пунктуационной направленности курса и учебника в целом. Так, в учебнике по теории в качестве иллюстративного материала приведён такой пример морфемного разбора слова искусство (ис-кус-ств-о). Очевидно, что такой подход не может способствовать корректному выделению корня в современной структуре слова и приводит к выделению в основе незначимых сегментов. Ошибки в выделении приставок и суффиксов связаны с алгоритмом морфемного членения — с представлением большинства учащихся о слове как о веренице морфем, которые должны быть «опознаны» как уже встречавшиеся в других словах. Формально-структурный подход к морфемному членению слова не является исключительно принадлежностью школьной практики. Аналогичный подход осуществлён в ряде научных изданий, например в «Словаре морфем русского языка» А. И. Кузнецовой и Т. Ф. Ефремовой, где утверждается, что «морфемный анализ мало зависит от словообразовательного, так как обычно при членении слова используется сопоставительный метод, при котором практически не учитывается, что от чего образуется». Формально-структурному подходу противопоставлен подход формально-смысловой (формально-семантический). Подход учебных комплексов к вопросу о принципах и алгоритме морфемного членения различен: учебные комплексы 1 и 3 предлагают формально-смысловой подход к морфемному членению слова (комплекс 3 в большей степени, чем комплекс 1), комплекс 2 — формально-структурный. Алгоритм морфемного разбора основы состоит в построении словообразовательной цепочки «наоборот»: со слова как бы «снимаются» приставки и суффиксы, корень же выделяется в последнюю очередь. При разборе постоянно необходимо соотнесение значения производного и значения его производящего; производящая основа в современном русском языке — основа мотивирующая. Если между значением производного и значением производящего (в нашем представлении) слова нет отношения мотивированности, производящее выбрано неверно. Таким образом, порядок разбора слова по составу таков: 1) выделить окончание, формообразующий суффикс (если они есть в слове), 2) выделить основу слова — часть слова без окончаний и формообразующих суффиксов, 3) выделить в основе слова приставку и / или суффикс через построение словообразовательной цепочки, 4) выделить в слове корень. Примеры: 1) плотничал Образец рассуждения: плотничал — форма глагола плотничать; глагол стоит в форме прошедшего времени изъявительного наклонения, что выражено формообразующим суффиксом —л—, мужского рода единственного числа, что выражено нулевым кончанием (сравним: плотничал-и). Основа — плотнича—. Глагол плотничать образован от существительного плотник, мотивируется через него: плотничать — «быть плотником»; разница между основой плотнича и плотник — суффикс —а—, в основах представлено чередование к / ч. Существительное плотник в современном языке непроизводно, так как не может быть мотивировано через слово плот. Следовательно, плотник / плотнич — корень. Таким образом, словоформа плотничал имеет нулевое окончание со значением мужского рода единственного числа, формообразующий суффикс —л— со значением прошедшего времени изъявительного наклонения, словообразующий суффикс —а— со значением являться тем, что названо в мотивирующей основе, корень плотнич. Основа слова плотнича-. Образец письменного оформления: 2) одевание Образец рассуждения: Одевание — существительное, окончание —е (именно этот сегмент слова изменяется при его склонении: одевани-е, одевани-я, одевани-ю). На стыке окончания и основы во всех формах произносится звук [й’], который «спрятан» в букве е, стоящей после гласной. Следовательно, этот звук принадлежит к основе, закрывает её. Слово одевание производно от глагола одевать: одевание — ‘процесс, когда одевают, то же, что одевать’. Разница между основой одеваний и глагольной основой одева — сегмент —ни[й’]-, являющийся словообразующим суффиксом. Глагол одевать производен от глагола одеть и имеет значение несовершенного вида. Средство словообразования — суффикс —ва—. Глагол одеть непроизводен, но в языке есть глаголы раз-деть, пере-одеть с тем же корнем, но другими приставками, следовательно, мы имеем дело со связанным корнем —де— и приставкой о—. |

 И это способно привести к массовым ошибкам, причина которых — игнорирование того факта, что морфема является значимой языковой единицей. Отсутствие работы по определению значения морфем приводит в ошибкам двух типов, имеющих разную природу:
И это способно привести к массовым ошибкам, причина которых — игнорирование того факта, что морфема является значимой языковой единицей. Отсутствие работы по определению значения морфем приводит в ошибкам двух типов, имеющих разную природу: Крайнее выражение разборов такого рода — случаи типа клю-чик (ср.: лёт-чик), я-щик (обой-щик). Но и при правильно определённом корне очень часто приходится сталкиваться с неправильным определением количества и состава приставок и суффиксов, если этих морфем в слове больше двух. Это связано, во-первых, с алгоритмом морфемного членения и, во-вторых, с тем, что в учебниках слова, имеющие более одной приставки и/или суффикса, практически не приводятся.
Крайнее выражение разборов такого рода — случаи типа клю-чик (ср.: лёт-чик), я-щик (обой-щик). Но и при правильно определённом корне очень часто приходится сталкиваться с неправильным определением количества и состава приставок и суффиксов, если этих морфем в слове больше двух. Это связано, во-первых, с алгоритмом морфемного членения и, во-вторых, с тем, что в учебниках слова, имеющие более одной приставки и/или суффикса, практически не приводятся. Главная установка данного подхода и алгоритм морфемного разбора выходят из трудов Г. О. Винокура и состоят в неразрывности морфемного членения и словообразовательного разбора. О том, что этот подход является целесообразным и даже единственно возможным, писали многие учёные и методисты на протяжении многих десятилетий.
Главная установка данного подхода и алгоритм морфемного разбора выходят из трудов Г. О. Винокура и состоят в неразрывности морфемного членения и словообразовательного разбора. О том, что этот подход является целесообразным и даже единственно возможным, писали многие учёные и методисты на протяжении многих десятилетий.

 Основа слова — одевани[й’].
Основа слова — одевани[й’].Кластеризация метагеномных последовательностей на основе состава | by Vijini Mallawaarachchi
Кластеризация метагеномных последовательностей на основе состава олигонуклеотидов
Кластеризация — это задача группировки точек данных таким образом, чтобы сходные точки группировались близко друг к другу, а разные — дальше друг от друга. Кластеризация применяется в анализе последовательностей, особенно в области метагеномики (подробнее о метагеномике можно прочитать из моей предыдущей статьи здесь). Метагеномные образцы могут содержать последовательности тысяч видов, и мы должны сгруппировать эти последовательности, представляющие разные таксономические уровни, для поддержки последующего анализа. Этот процесс группировки называется метагеномный биннинг . В этой статье я объясню, как мы можем группировать метагеномные последовательности на основе их олигонуклеотидного состава.
Кластеризация применяется в анализе последовательностей, особенно в области метагеномики (подробнее о метагеномике можно прочитать из моей предыдущей статьи здесь). Метагеномные образцы могут содержать последовательности тысяч видов, и мы должны сгруппировать эти последовательности, представляющие разные таксономические уровни, для поддержки последующего анализа. Этот процесс группировки называется метагеномный биннинг . В этой статье я объясню, как мы можем группировать метагеномные последовательности на основе их олигонуклеотидного состава.
Олигонуклеотид считается непрерывной последовательностью небольшого числа нуклеотидов. С точки зрения вычислений мы определяем олигонуклеотиды как k-меров (слова размера k ). Состав олигонуклеотидов считается консервативным в пределах микробных видов и варьируется между видами [1][2]. Обычно это справедливо для олигонуклеотидов размером от 2 ( динуклеотидов/2-меры ) до 8 ( октануклеотидов/8-меры ) [2]. Частота олигонуклеотидов определенного размера в последовательности дает нам геномную сигнатуру этой конкретной последовательности. Эти сигнатуры генома могут варьироваться от вида к виду из-за влияния таких факторов, как
Частота олигонуклеотидов определенного размера в последовательности дает нам геномную сигнатуру этой конкретной последовательности. Эти сигнатуры генома могут варьироваться от вида к виду из-за влияния таких факторов, как
- структура ДНК
- процессы репликации и репарации
- эволюционное давление
В этом сравнении я рассмотрел 3-меры (также известные как тримеры или тринуклеотиды ) и их состав ( тринуклеотидная композиция ). Есть 32 (4³/2) различных 3-меров , когда мы объединяем обратные комплименты. Мы получаем нормированные частоты каждого отдельного тринуклеотида, подсчитывая количество вхождений этого тринуклеотида и разделив его на общее количество тринуклеотидов. Обычно мы используем нормализованную частоту олигонуклеотидов во избежание неравномерности, вызванной разной длиной последовательностей.
Нормализованная частота kᵢ
= Количество вхождений kᵢ / общее количество k-меров
(где kᵢ — iᵗʰ k-мер)
Вы можете узнать больше о том, как получить эти k-меров частотных векторов для последовательности из статьи под названием «Векторизация последовательностей ДНК».
Векторизация последовательностей ДНК
Эффективное преобразование последовательностей ACGT в частотные векторы k-mer
medium.com
Эталонные геномы, которые я использовал в следующих примерах, были получены из Nanopore GridION и PromethION Mock Microbial Community Data Community Edition из ZymoBIOMICS Microbial Community Standards .
Геномные сигнатуры двух геномов Рассмотрим простой пример, где у нас есть два генома Pseudomonas aeruginosa и Staphylococcus aureus . Мы можем получить нормализованные векторы частот тринуклеотидов для каждого генома. Я использовал метод, представленный в статье Векторизация последовательностей ДНК. Вы можете посмотреть и даже попробовать разные k значений. В этой статье я использовал k=3 .
Я использовал метод, представленный в статье Векторизация последовательностей ДНК. Вы можете посмотреть и даже попробовать разные k значений. В этой статье я использовал k=3 .
Если мы нанесем нормализованные частоты тринуклеотидов для этих двух геномов, это будет выглядеть так, как показано на рисунке 1. между профилями тринуклеотидного состава двух геномов. Мы можем использовать эту функцию для разделения последовательностей.
Кластеризация смеси последовательностей из двух геномов
Давайте рассмотрим образец набора данных, который я смоделировал, используя 100 прочтений длиной 10 000 п.н. для каждого из видов Pseudomonas aeruginosa и Staphylococcus aureus . Я использовал инструмент под названием SimLoRD для имитации чтения. Ниже приведен пример команды, которую я использовал.
simlord --read-reference--fixed-readlength 10000 --num-reads 100
После того, как мы получили нормализованные векторы частот тринуклеотидов для всех прочтений, мы можем получить график PCA (рис. 2) и график TSNE (рис. 3) следующим образом.
2) и график TSNE (рис. 3) следующим образом.
Мы видим четкое разделение последовательностей двух видов.
Другим простым примером, который мы можем рассмотреть, является наличие трех геномов: Pseudomonas aeruginosa , Staphylococcus aureus и Escherichia Coil . Эти три генома также имеют различные геномные подписи. Если мы построим нормализованные векторы тринуклеотидных частот прочтений, смоделированных из этих трех геномов, графики будут выглядеть следующим образом.
Рис. 4. PCA-график нормализованных частотных векторов тринуклеотидов для 100 прочтений длиной 10 000 п.н. для каждого вида Pseudomonas aeruginosa, Staphylococcus aureus и Escherichia Coil от каждого из видов Pseudomonas aeruginosa, Staphylococcus aureus и Escherichia Coil Как и на предыдущих рисунках, здесь также видно четкое разделение последовательностей трех видов. Следовательно, мы можем применить множество методов кластеризации и машинного обучения, чтобы разделить эти последовательности.
Следовательно, мы можем применить множество методов кластеризации и машинного обучения, чтобы разделить эти последовательности.
- MaxBin использует частоты тетрануклеотидов вместе с алгоритмом максимизации ожидания и вероятностным подходом к контигам бинов.
- MrGBP использует олигонуклеотидную композицию (может иметь немного другое представление) с DBSCAN для группировки контигов.
- LikelyBin использует пентануклеотидные частоты с подходом Монте-Карло цепи Маркова.
Могут быть случаи, когда даже если у нас есть два разных вида, они могут иметь одинаковые образцы состава олигонуклеотидов. Например, рассмотрим два генома Enterococcus faecalis и Listeria monocytogenes . Если мы нанесем нормализованные частоты тринуклеотидов для этих двух геномов, это будет выглядеть так, как показано на рисунке 6.
Рис. из этих двух геномов графики будут выглядеть следующим образом. Рис. 7. PCA-график нормализованных векторов частот тринуклеотидов 100 прочтений длиной 10 000 п.н. для каждого из видов Enterococcus faecalis и Listeria monocytogenes трудно найти четкое разделение между двумя видами. Следовательно, мы должны использовать дополнительную информацию, такую как численность видов, для кластеризации последовательностей в таких сценариях.
Рис. 7. PCA-график нормализованных векторов частот тринуклеотидов 100 прочтений длиной 10 000 п.н. для каждого из видов Enterococcus faecalis и Listeria monocytogenes трудно найти четкое разделение между двумя видами. Следовательно, мы должны использовать дополнительную информацию, такую как численность видов, для кластеризации последовательностей в таких сценариях.Надеюсь, вы получили общее представление о том, как мы можем кластеризовать метагеномные последовательности, используя методы биннинга на основе состава. Я надеюсь, что это поможет вам в учебе и не стесняйтесь использовать информацию и методы в своих исследовательских проектах. Я приложил блокнот с кодом, чтобы вы могли поиграть с другими геномами.
Вы также можете прочитать больше о метагеномике и связанных с ней анализах, которые я провел, из моих предыдущих статей, перечисленных ниже.
Метагеномика — Кто там и чем занимается?
Получение информации о данных микробных сообществ
в направлении datascience. com
com
Насколько COVID-19 похож на ранее обнаруженные коронавирусы
Простое сравнение профилей состава геномов различных коронавирусов
в направлении datascience.com
Спасибо за прочтение!
Ура!
[1] Карлин, С. и др. . Композиционные предубеждения бактериальных геномов и эволюционные последствия. Journal of Bacteriology , 179(12), 3899–3913 (1997).
[2] Dick, G. J. et al. Анализ сигнатур последовательностей микробного генома в масштабах всего сообщества. Биология генома , 10(8), R85 (2009).
Оценка точности высокопроизводительного секвенирования региона ITS1 Neocallimastigomycota для анализа состава сообщества
Введение
Neocallimastigomycota представляют собой важный класс строго анаэробных грибов, которые обычно встречаются в экосистемах кишечника травоядных, особенно крупных млекопитающих. Анаэробные грибы наиболее тщательно изучались на жвачных животных, где они могут увеличивать расщепление клетчатки и потребление корма на 7–9% и до 40% соответственно (Gordon and Phillips, 2005). Анаэробные грибы также представляют большой биотехнологический интерес благодаря своим мощным ферментам, разрушающим волокна (Solomon et al., 2016). В настоящее время охарактеризовано одиннадцать родов анаэробных грибов (Edwards et al., 2017; Hanafy et al., 2018; Joshi et al., 2018), при этом доказательства существования большего количества родов получены в результате независимого анализа образцов окружающей среды (Liggenstoffer et al. , 2010; Николсон и др., 2010; Киттельманн и др., 2012, 2013). Используя область ITS1 анаэробных грибов, была разработана таксономическая структура и соответствующая курируемая база данных, которая классифицирует последовательности ITS1 по охарактеризованным родам и еще некультивируемым кладам на уровне рода или вида (Koetschan et al., 2014). Это ценный ресурс для анализа последовательностей, полученных из образцов окружающей среды, особенно при использовании HTS ампликонов со штрих-кодом, который стал методом выбора для определения состава сообщества анаэробных грибов (Liggenstoffer et al.
Анаэробные грибы также представляют большой биотехнологический интерес благодаря своим мощным ферментам, разрушающим волокна (Solomon et al., 2016). В настоящее время охарактеризовано одиннадцать родов анаэробных грибов (Edwards et al., 2017; Hanafy et al., 2018; Joshi et al., 2018), при этом доказательства существования большего количества родов получены в результате независимого анализа образцов окружающей среды (Liggenstoffer et al. , 2010; Николсон и др., 2010; Киттельманн и др., 2012, 2013). Используя область ITS1 анаэробных грибов, была разработана таксономическая структура и соответствующая курируемая база данных, которая классифицирует последовательности ITS1 по охарактеризованным родам и еще некультивируемым кладам на уровне рода или вида (Koetschan et al., 2014). Это ценный ресурс для анализа последовательностей, полученных из образцов окружающей среды, особенно при использовании HTS ампликонов со штрих-кодом, который стал методом выбора для определения состава сообщества анаэробных грибов (Liggenstoffer et al. , 2010; Kittelmann et al., 2012). , 2013). Однако с тех пор было признано, что используемый сайт прямого праймера, основанный на области ITS1 (праймер MN100F), сохраняется не у всех анаэробных грибов (Kittelmann et al., 2013; Callaghan et al., 2015).
, 2010; Kittelmann et al., 2012). , 2013). Однако с тех пор было признано, что используемый сайт прямого праймера, основанный на области ITS1 (праймер MN100F), сохраняется не у всех анаэробных грибов (Kittelmann et al., 2013; Callaghan et al., 2015).
Из-за отсутствия консервативных сайтов праймирования в области ITS1 для специфичной для анаэробных грибов амплификации рекомендуются праймеры, нацеленные на более консервативные фланкирующие области гена 18S и 5.8S рРНК. Таким примером являются праймеры, ранее разработанные для специфического для анаэробных грибов автоматизированного анализа рибосомных межгенных спейсеров (ARISA), которые генерируют ампликон длиной ~350–440 п.н. (Edwards et al., 2008). На основе полноразмерных последовательностей в базе данных Koetschan et al. (2014), размер области ITS1 варьируется от 192–282 базы. Хотя этот полиморфизм размера ITS1 ценен для ARISA, он проблематичен для создания стабильной филогении ITS1, если только выравнивание последовательностей не будет улучшено с использованием информации о вторичной структуре (Edwards et al. , 2017).
, 2017).
Неоднородность размеров внутреннего транскрибируемого спейсера 1 существует не только между чистыми культурами анаэробных грибов, но и внутри них (Edwards et al., 2008). Таким образом, возможно, неудивительно, что в одной культуре множественные клонированные последовательности ITS1 могут различаться на целых 13% между повторами ITS1 (Callaghan et al., 2015). Однако значение, которое это имеет для интерпретации данных высокопроизводительного секвенирования, полученных из чистых культур и образцов окружающей среды, неизвестно. Таким образом, целью данного исследования была оценка точности HTS области ITS1 анаэробных грибов на основе ранее опубликованных праймеров ARISA (Edwards et al., 2008) с использованием чистых культур анаэробных грибов и определенных фиктивных сообществ различного состава. и сложность. Это важно не только с точки зрения контроля качества данных, но и для выявления проблем, связанных с полиморфизмом и неоднородностью в пределах области ITS1. После текущих дебатов о ценности области ITS1 для анализа анаэробных грибов (Edwards et al. , 2017) результаты этого исследования предоставят четкую доказательную базу в отношении сильных сторон и ограничений его использования в качестве таксономического маркера анаэробных грибов.
, 2017) результаты этого исследования предоставят четкую доказательную базу в отношении сильных сторон и ограничений его использования в качестве таксономического маркера анаэробных грибов.
Материалы и методы.
Чистые культуры и ДНК. были получены, как описано ранее (Dollhofer et al., 2016).
Neocallimastix frontalis штамм RE1 и Orpinomyces sp. SR2 (также известный как Orpinomyces sp. OUS1) был выделен из рубца барана (Stewart and Richardson, 19).89; Брукман и др., 2000). Анаэромицеты sp. 28xy был выделен из фекалий хайлендской коровы (Callaghan, 2014). Пиромицеты зр. CaDo16a был выделен из шлама варочного котла баварской биогазовой установки (Dollhofer et al., 2017). Caecomyces sp. CaDo13a был выделен из рубцовой жидкости дикой альпийской козы (личное сообщение, Callaghan and Dollhofer). Доступные данные о последовательности участка ITS одной из пяти чистых культур, Piromyces sp. CaDo16a присвоен код гипотезы вида Sh2571620. 08FU в базе данных UNITE (Nilsson et al., 2018).
08FU в базе данных UNITE (Nilsson et al., 2018).Секвенирование чистых культур на основе библиотеки клонов
Для каждой из пяти чистых культур был создан эталонный набор данных ITS1 с использованием подхода библиотеки клонов. Ампликон ПЦР, содержащий неполный ген 18S рРНК (~310 п.н.), полную область ITS1 и неполный ген 5,8S рРНК (116 п.н.), амплифицировали с использованием прямого праймера 5′-CAT CCT TGA TCG GRA GGT CC-3′ (т.е., обратный праймер AF-SSU, предложенный Dollhofer et al. (2017) в прямой ориентации), и обратный праймер Neo QPCR Rev (5′-GTG CAA TAT GCG TTC GAA GAT T-3′, Edwards et al., 2008). ПЦР проводили в трех повторностях для каждой культуры с использованием 50 мкл реакционных растворов, содержащих 1 × буфер HF (Finnzymes, Вантаа, Финляндия), 1 мкл dNTP Mix (10 мМ; Promega, Лейден, Нидерланды), 2 ЕД Phusion 9.0253® Высокоточная ДНК-полимераза Hot Start II (Finnzymes), 500 нМ каждого праймера и 2 нг ДНК. Условия циклирования включали начальную денатурацию при 98°С в течение 3 мин, затем 40 циклов при 98°С в течение 10 с, 50°С в течение 30 с и 72°С в течение 30 с и конечное удлинение при 72°С. в течение 6 мин. Успешная амплификация была подтверждена электрофорезом в агарозном геле на 2% (масса/объем) агарозном геле, содержащем 1 × SYBR ® Safe (Invitrogen, Карлсбад, Калифорния, США). Также была проведена реакция NTC, но продукт ПЦР не был получен. Объединенный продукт ПЦР для каждой из пяти чистых культур очищали с использованием HighPrep 9.0253 TM (MagBio Europe Ltd., Кент, Соединенное Королевство) и количественно определяли с использованием флуорометра Qubit в сочетании с набором для анализа BR dsDNA (Invitrogen). Затем продукты ПЦР снабжали А-хвостом и клонировали с использованием векторной системы pGEM-T easy (Promega). С помощью сине-белого скрининга были случайным образом отобраны трансформированные белые клоны (19–20 на чистую культуру) и отправлены на секвенирование по Сэнгеру с использованием как сайтов праймирования M13F, так и M13R в векторе (GATC-Biotech, Кельн, Германия). Качество прочтений проверяли вручную, и для каждого клона готовили консенсусные прочтения.
в течение 6 мин. Успешная амплификация была подтверждена электрофорезом в агарозном геле на 2% (масса/объем) агарозном геле, содержащем 1 × SYBR ® Safe (Invitrogen, Карлсбад, Калифорния, США). Также была проведена реакция NTC, но продукт ПЦР не был получен. Объединенный продукт ПЦР для каждой из пяти чистых культур очищали с использованием HighPrep 9.0253 TM (MagBio Europe Ltd., Кент, Соединенное Королевство) и количественно определяли с использованием флуорометра Qubit в сочетании с набором для анализа BR dsDNA (Invitrogen). Затем продукты ПЦР снабжали А-хвостом и клонировали с использованием векторной системы pGEM-T easy (Promega). С помощью сине-белого скрининга были случайным образом отобраны трансформированные белые клоны (19–20 на чистую культуру) и отправлены на секвенирование по Сэнгеру с использованием как сайтов праймирования M13F, так и M13R в векторе (GATC-Biotech, Кельн, Германия). Качество прочтений проверяли вручную, и для каждого клона готовили консенсусные прочтения.
Подготовка шаблонной ДНК фиктивного сообщества
Четыре различных фиктивных сообщества (от Mock_1 до Mock_4) были приготовлены путем объединения очищенных и количественно определенных ПЦР-ампликонов, использованных для подготовки библиотеки клонов. Использовали ПЦР-ампликоны, а не геномную ДНК, поскольку число копий оперона rrn используемых культур было неизвестно. Ампликоны для ПЦР объединяли в зависимости от количества ДНК, что в сумме дало 500 нг в объеме 50 мкл. Mock_1 состоял из 250 нг обоих N. frontalis RE1 и Anaeromyces sp. 28xy. Mock_2 состоял из 100 нг каждой из пяти чистых культур. Mock_3 состоял из 250 нг N. frontalis RE1, 100 нг Orpinomyces sp. SR2, 75 нг Piromyces sp. CaDo16a, 50 нг Caecomyces sp. CaDo13a и 25 нг Anaeromyces sp. 28xy. Mock_4 состоял из 88,89 нг N. frontalis RE1, 10 нг Caecomyces sp. CaDo13a, 1 нг пиромицетов сп. CaDo16a, 0,1 нг Orpinomyces sp. SR2 и 0,01 нг Anaeromyces sp. 28xy. Каждое фиктивное сообщество готовили в двух экземплярах, а затем объединяли, чтобы свести к минимуму вариации, связанные с пипетированием. Затем определяли теоретический состав каждого фиктивного сообщества с учетом молярности ампликона ПЦР каждой культуры в фиктивном сообществе. Это было сделано путем расчета количества ампликонов ПЦР в количестве ДНК из каждой культуры, присутствующей в макете, с использованием количества добавленной ДНК (как указано выше) и среднего размера клонов из соответствующей библиотеки клонов. Затем по этим значениям для каждого фиктивного сообщества рассчитывали относительную численность в процентах.
SR2 и 0,01 нг Anaeromyces sp. 28xy. Каждое фиктивное сообщество готовили в двух экземплярах, а затем объединяли, чтобы свести к минимуму вариации, связанные с пипетированием. Затем определяли теоретический состав каждого фиктивного сообщества с учетом молярности ампликона ПЦР каждой культуры в фиктивном сообществе. Это было сделано путем расчета количества ампликонов ПЦР в количестве ДНК из каждой культуры, присутствующей в макете, с использованием количества добавленной ДНК (как указано выше) и среднего размера клонов из соответствующей библиотеки клонов. Затем по этим значениям для каждого фиктивного сообщества рассчитывали относительную численность в процентах.
Высокопроизводительное секвенирование Illumina
Ампликоны со штрих-кодом, содержащие частичный ген 18S рРНК (∼130 п.н.), полную область ITS1 и частичный ген 5.8S рРНК (~31 п.н.), были созданы для пяти чистых культур и четырех имитационных сообществ с использованием двухэтапная стратегия ПЦР с Labcycler (SensoQuest, Геттинген, Германия). Эту подготовку повторяли трижды, так как все образцы независимо запускались в трех разных библиотеках (A, B и C). Кроме того, фиктивные образцы сообщества также были секвенированы в двух экземплярах в одной библиотеке A (т.е. A1 и A2).
Эту подготовку повторяли трижды, так как все образцы независимо запускались в трех разных библиотеках (A, B и C). Кроме того, фиктивные образцы сообщества также были секвенированы в двух экземплярах в одной библиотеке A (т.е. A1 и A2).
Первую стадию ПЦР проводили с использованием ранее опубликованных праймеров ARISA (Edwards et al., 2008) с добавлением адаптеров UniTag (подчеркнуты): Neo 18S For 5′- GAGCCGTAGCCAGTCTGC AATCCTTCGGATTGGCT-3′ и Neo 5.8S Rev 5′- GCCGTGACCGTGACATCG CGAGAACC AAGAGATCCA-3′. ПЦР проводили в общем объеме 25 мкл, содержащем 1 × HF-буфер, 1 мкл dNTP Mix (10 мМ), 1 ед. Phusion ® Hot Start II High-Fidelity DNA полимеразы, 500 нМ каждого праймера и 2 нг чистой культуры или фиктивной ДНК сообщества. Условия циклирования состояли из начальной денатурации при 98°С в течение 3 мин, затем 40 циклов 98°С в течение 10 с, 58°С в течение 30 с, 72°С в течение 30 с и окончательное удлинение при 72°С в течение 6 мин. Для каждого образца готовили тройные реакции ПЦР, а также реакции NTC. Наличие продуктов ПЦР в образцах и их отсутствие в NTC подтверждали электрофорезом в агарозном геле с концентрацией 2% (вес/объем), содержащем 1 × SYBR ® Safe. Объединенные тройные реакции, а также отрицательные индивидуальные реакции NTC затем очищали с использованием HighPrep 9.0253 ТМ . Реакции NTC были дополнительно обработаны и секвенированы таким же образом, как и образцы, так что любая OTU (Blaxter et al., 2005), явно связанная с любой из реакций NTC, могла быть удалена вручную во время обработки полученных данных последовательности.
Наличие продуктов ПЦР в образцах и их отсутствие в NTC подтверждали электрофорезом в агарозном геле с концентрацией 2% (вес/объем), содержащем 1 × SYBR ® Safe. Объединенные тройные реакции, а также отрицательные индивидуальные реакции NTC затем очищали с использованием HighPrep 9.0253 ТМ . Реакции NTC были дополнительно обработаны и секвенированы таким же образом, как и образцы, так что любая OTU (Blaxter et al., 2005), явно связанная с любой из реакций NTC, могла быть удалена вручную во время обработки полученных данных последовательности.
Затем был использован второй этап ПЦР для добавления восьминуклеотидного штрих-кода, специфичного для образца, к 5′- и 3′-концу продуктов ПЦР, как описано ранее (van Lingen et al., 2017). Каждая реакция ПЦР с конечным объемом 100 мкл содержала 5 мкл очищенного продукта первой стадии ПЦР, по 5 мкл прямого и обратного праймеров со штрих-кодом (10 мкМ), 2 мкл смеси dNTP (10 мМ), 2 ед. Phusion. ® Высокоточная ДНК-полимераза Hot Start II и 1 × буфер HF. Амплификация состояла из начальной денатурации при 98°С в течение 30 с, затем пяти циклов 98°С в течение 10 с, 52°С в течение 20 с, 72°С в течение 20 с и конечного удлинения при 72°С в течение 10 с. мин. Затем продукты ПЦР со штрих-кодом очищали с использованием HighPrep TM и количественно определяли с использованием Qubit в сочетании с набором для анализа BR dsDNA. Очищенные продукты ПЦР образца затем объединяли в эквимолярных количествах, за исключением очищенных продуктов ПЦР NTC, которые были включены на основании максимального объема очищенного продукта ПЦР образца, использованного в эквимолярном пуле. Затем пулы подвергали лигированию адаптера с последующим секвенированием на платформе Illumina HiSeq с использованием химии 300 PE (GATC-Biotech, Констанц, Германия, теперь часть Eurofins Genomics Germany GmbH).
Амплификация состояла из начальной денатурации при 98°С в течение 30 с, затем пяти циклов 98°С в течение 10 с, 52°С в течение 20 с, 72°С в течение 20 с и конечного удлинения при 72°С в течение 10 с. мин. Затем продукты ПЦР со штрих-кодом очищали с использованием HighPrep TM и количественно определяли с использованием Qubit в сочетании с набором для анализа BR dsDNA. Очищенные продукты ПЦР образца затем объединяли в эквимолярных количествах, за исключением очищенных продуктов ПЦР NTC, которые были включены на основании максимального объема очищенного продукта ПЦР образца, использованного в эквимолярном пуле. Затем пулы подвергали лигированию адаптера с последующим секвенированием на платформе Illumina HiSeq с использованием химии 300 PE (GATC-Biotech, Констанц, Германия, теперь часть Eurofins Genomics Germany GmbH).
Теоретические файлы последовательности фиктивных сообществ
Теоретические файлы fastq (прямой и обратный) для каждого фиктивного сообщества (от T_Mock_1 до T_Mock_4) были созданы на основе справочных данных библиотеки клонов. Эти файлы служили нескольким целям. Оптимальные параметры для биоинформатической обработки данных HTS анаэробных грибов были определены с использованием этого эталонного набора данных (дополнительная фигура S1). Кроме того, сравнение теоретических фиктивных сообществ с фактически секвенированными фиктивными сообществами (от Mock_1 до Mock_4) позволило определить, связаны ли какие-либо обнаруженные предубеждения с генерацией самих данных HTS или их последующей биоинформатической обработкой. Файлы были подготовлены следующим образом. Для каждой культуры все клонированные последовательности из эталонного набора данных сначала выравнивали с использованием ClustalW версии 2.1 (Larkin et al., 2007), а затем обрезали in silico для создания концов, которые соответствовали праймерам ПЦР, используемым для HTS, с использованием GeneDoc версии 2.6 (Nicholas and Ncholas, 1997). Используя знание теоретического состава каждого фиктивного сообщества (см. выше), обрезанные последовательности для чистых культур затем объединяли в соответствующих пропорциях для создания прямых и обратных файлов fastq, каждый из которых содержал в общей сложности 200 000 прочтений.
Эти файлы служили нескольким целям. Оптимальные параметры для биоинформатической обработки данных HTS анаэробных грибов были определены с использованием этого эталонного набора данных (дополнительная фигура S1). Кроме того, сравнение теоретических фиктивных сообществ с фактически секвенированными фиктивными сообществами (от Mock_1 до Mock_4) позволило определить, связаны ли какие-либо обнаруженные предубеждения с генерацией самих данных HTS или их последующей биоинформатической обработкой. Файлы были подготовлены следующим образом. Для каждой культуры все клонированные последовательности из эталонного набора данных сначала выравнивали с использованием ClustalW версии 2.1 (Larkin et al., 2007), а затем обрезали in silico для создания концов, которые соответствовали праймерам ПЦР, используемым для HTS, с использованием GeneDoc версии 2.6 (Nicholas and Ncholas, 1997). Используя знание теоретического состава каждого фиктивного сообщества (см. выше), обрезанные последовательности для чистых культур затем объединяли в соответствующих пропорциях для создания прямых и обратных файлов fastq, каждый из которых содержал в общей сложности 200 000 прочтений. Затем к каждому теоретическому фиктивному сообществу были добавлены различные уникальные штрих-коды, что позволило обрабатывать соответствующие файлы fastq точно так же, как секвенированные образцы фиктивного сообщества во время обработки биоинформатики. Никакая таксономическая информация не была включена в файлы, так как они обрабатывались точно так же, как образцы во время анализа данных. Сценарий, использованный для создания файлов fastq теоретических фиктивных сообществ, а также связанные с ними данные теоретических фиктивных сообществ, использованные в этом исследовании, доступны по адресу https://gitlab.com/wurssb/gen_fake_mocks.
Затем к каждому теоретическому фиктивному сообществу были добавлены различные уникальные штрих-коды, что позволило обрабатывать соответствующие файлы fastq точно так же, как секвенированные образцы фиктивного сообщества во время обработки биоинформатики. Никакая таксономическая информация не была включена в файлы, так как они обрабатывались точно так же, как образцы во время анализа данных. Сценарий, использованный для создания файлов fastq теоретических фиктивных сообществ, а также связанные с ними данные теоретических фиктивных сообществ, использованные в этом исследовании, доступны по адресу https://gitlab.com/wurssb/gen_fake_mocks.
Анализ высокопроизводительных данных о последовательностях
Необработанные данные о последовательностях Illumina и теоретические макеты файлов fastq сообщества были обработаны с использованием NG-Tax (версия NGTax-2.jar 1 ). Используя открытый эталонный подход, NG-Tax определяет OTU как уникальные последовательности, которые превышают заданный пользователем минимальный порог численности (Ramiro-Garcia et al. , 2016). NG-Tax фильтрует библиотеки PE, чтобы содержать только прочитанные пары с идеально совпадающими штрих-кодами, а подробности образцов штрих-кодов и файлов библиотек, использованных в этом исследовании, представлены в дополнительной таблице S1. NG-Tax был выполнен со следующими параметрами: длина чтения PE 150 оснований (поскольку за пределами этой длины средние показатели качества чтения ухудшались), отношение численности OTU 2,0, минимальный порог численности был установлен на уровне 0,6% (дополнительный рисунок S1), уровень идентичности 100 % и исправление 1 несоответствия (99,33%). Поскольку используемые праймеры ампликонов ПЦР не входили в базу данных AF-ITS1 (версия 3.3 2 ), используемую для аннотации OTU (что является требованием для аннотации NG-Tax), пустой файл базы данных (emptydb.fasta.gz 3 ), а затем OTU аннотировались вручную.
, 2016). NG-Tax фильтрует библиотеки PE, чтобы содержать только прочитанные пары с идеально совпадающими штрих-кодами, а подробности образцов штрих-кодов и файлов библиотек, использованных в этом исследовании, представлены в дополнительной таблице S1. NG-Tax был выполнен со следующими параметрами: длина чтения PE 150 оснований (поскольку за пределами этой длины средние показатели качества чтения ухудшались), отношение численности OTU 2,0, минимальный порог численности был установлен на уровне 0,6% (дополнительный рисунок S1), уровень идентичности 100 % и исправление 1 несоответствия (99,33%). Поскольку используемые праймеры ампликонов ПЦР не входили в базу данных AF-ITS1 (версия 3.3 2 ), используемую для аннотации OTU (что является требованием для аннотации NG-Tax), пустой файл базы данных (emptydb.fasta.gz 3 ), а затем OTU аннотировались вручную.
Файлы Fasta OTU из созданного NG-Tax файла биома 4 были извлечены с помощью скрипта otuseq_export. py 5 . OTU были аннотированы с помощью поиска BLASTN в базе данных AF-ITS1 с использованием настроек по умолчанию с «-num_alignments 10» (версия BLAST 2.4.0). Для OTU, которые не могли быть аннотированы базой данных AF-ITS1, поиск BLASTN выполнялся в базе данных NCBI. Пороговые уровни для аннотаций OTU были определены на основе среднего процентного сходства полноразмерных последовательностей в базе данных AF-ITS1 внутри клады и внутри рода. Эти пороговые уровни были >98% для клады и> 95% для рода. На основании исследования Koetschan et al. (2014), термин клада определяется как известный вид или некультивируемая подгруппа в пределах монофилетической линии, которая была идентифицирована с помощью анализа данных о последовательности участка ITS1, основанного на вторичной структуре. Как ранее отмечалось Koetschan et al. (2014), неизвестно, представляют ли некоторые из некультивируемых подгрупп новые виды или потенциально новые роды. Файл биома, сгенерированный NG-Tax, был преобразован в таблицу с разделителями табуляцией, чтобы можно было добавлять аннотации OTU.
py 5 . OTU были аннотированы с помощью поиска BLASTN в базе данных AF-ITS1 с использованием настроек по умолчанию с «-num_alignments 10» (версия BLAST 2.4.0). Для OTU, которые не могли быть аннотированы базой данных AF-ITS1, поиск BLASTN выполнялся в базе данных NCBI. Пороговые уровни для аннотаций OTU были определены на основе среднего процентного сходства полноразмерных последовательностей в базе данных AF-ITS1 внутри клады и внутри рода. Эти пороговые уровни были >98% для клады и> 95% для рода. На основании исследования Koetschan et al. (2014), термин клада определяется как известный вид или некультивируемая подгруппа в пределах монофилетической линии, которая была идентифицирована с помощью анализа данных о последовательности участка ITS1, основанного на вторичной структуре. Как ранее отмечалось Koetschan et al. (2014), неизвестно, представляют ли некоторые из некультивируемых подгрупп новые виды или потенциально новые роды. Файл биома, сгенерированный NG-Tax, был преобразован в таблицу с разделителями табуляцией, чтобы можно было добавлять аннотации OTU. OTU, которые были явно связаны с образцами NTC, также были вручную удалены из таблицы с разделителями табуляцией на этом этапе. Полученная таблица с разделителями табуляции затем была преобразована обратно в файл биома 9.0253 6 .
OTU, которые были явно связаны с образцами NTC, также были вручную удалены из таблицы с разделителями табуляцией на этом этапе. Полученная таблица с разделителями табуляции затем была преобразована обратно в файл биома 9.0253 6 .
Графики были созданы с помощью ggplot2 (Wickham, 2009) в R версии 3.4.0. Точность секвенирования фиктивных сообществ определялась путем расчета значений корреляции Пирсона (Pearson, 1909) и попарно взвешенных расстояний UniFrac (Lozupone et al., 2011) между секвенированными фиктивными сообществами и соответствующим теоретическим фиктивным сообществом. Чтобы проверить различия в точности между фиктивными сообществами, данные (как описано выше) для всех фиктивных сообществ были проанализированы с помощью ANOVA и Тьюки 9.Выполнен тест 0235 post hoc (Genstat, 19-е издание, VSN International Ltd.). Значения вероятности <0,05 считались значимыми.
Доступность данных
Данные библиотеки секвенированных клонов по Сэнгеру депонированы в NCBI под следующими регистрационными номерами: N. frontalis RE1 (MK036660-MK036676), Orpinomyces sp. SR2 (MK036677-MK036695), Piromyces sp. CaDo16a (MK036696-MK036714), Caecomyces sp. CaDo13a (MK036715-MK036728) и Анаэромицеты зр. 28xy (MK036729-MK036744). Данные HTS депонированы в Европейском архиве нуклеотидов под регистрационным номером исследования PRJEB29131.
frontalis RE1 (MK036660-MK036676), Orpinomyces sp. SR2 (MK036677-MK036695), Piromyces sp. CaDo16a (MK036696-MK036714), Caecomyces sp. CaDo13a (MK036715-MK036728) и Анаэромицеты зр. 28xy (MK036729-MK036744). Данные HTS депонированы в Европейском архиве нуклеотидов под регистрационным номером исследования PRJEB29131.
Результаты и обсуждение
Анализ таксономии чистых культур анаэробных грибов и полиморфизма размеров ITS1 на основе библиотеки клонов
Чистые культуры пяти морфологически различных родов анаэробных грибов использовались для создания эталонного набора данных ITS1 с использованием клонирования и секвенирования по Сэнгеру. Пять анаэробных грибов были N. frontalis RE1, Anaeromyces sp. 28xy, Orpinomyces sp. SR2, Piromyces sp. CaDo16a и Caecomyces sp. CaDo13a. Все пять чистых культур генерировали фрагменты рибосомных оперонов (часть гена 18S рРНК, полную область ITS1 и часть гена 5. 8S рРНК), размер которых различался как внутри, так и между культурами (табл. 1). Это согласуется с ранее опубликованным анализом ARISA чистых культур анаэробных грибов (Edwards et al., 2008).
8S рРНК), размер которых различался как внутри, так и между культурами (табл. 1). Это согласуется с ранее опубликованным анализом ARISA чистых культур анаэробных грибов (Edwards et al., 2008).
Таблица 1. Размер последовательности и таксономия клонированных последовательностей (частичный ген 18S рРНК – полная область ITS1 – частичный ген 5.8S рРНК), полученных из чистых культур анаэробных грибов.
Результаты аннотирования на основе BLAST полной области ITS1 клонированных последовательностей в сравнении с базой данных AF-ITS1 показали, что полная и непротиворечивая аннотация на уровне клады для всех клонов имела место только для N. frontalis RE1 (клада Неокаллимастикс 1 ). С Анаэромицеты зр. 28xy, только семь из 16 клонов могли быть надежно аннотированы на уровне клады ( Anaeromyces 1 ). Для Orpinomyces sp. SR2, 18 из 19 клонов были аннотированы как клада Orpinomyces 1a , тогда как одна последовательность была аннотирована как ветвь Orpinomyces 1b . Это поднимает вопрос относительно достоверности подразделения клады Orpinomyces 1 (Koetschan et al., 2014).
Это поднимает вопрос относительно достоверности подразделения клады Orpinomyces 1 (Koetschan et al., 2014).
Ни один из Пиромицетов сп. Клоны CaDo16a можно аннотировать на уровне клады или рода с использованием базы данных AF-ITS1 из-за того, что они имеют <90,5% идентичности. Следовательно, в этом исследовании последовательности, соответствующие Piromyces sp. CaDo16a были аннотированы как «CaDo16a; Н.А.». Низкая идентичность Piromyces sp. CaDo16a к другим последовательностям Piromyces в базе данных AF-ITS1 не является полностью неожиданным, поскольку недавно было высказано предположение, что этот штамм представляет новую кладу в этом роде на основании филогенетического анализа его гена 28S рРНК (Dollhofer et al., 2017) . С Caecomyces sp. CaDo13a, 11 из 14 клонов были аннотированы как клада Caecomyces 1 , тогда как два клона могли быть аннотированы только на уровне рода. Интересно, что один из 14 клонов был аннотирован на уровне рода как Cyllamyces . Это добавляет веса текущим предположениям о том, являются ли Cyllamyces и Caecomyces (Ozkose et al., 2001; Paul et al., 2018) или нет (Callaghan et al., 2015; Wang et al., 2017). ) отдельные роды.
Это добавляет веса текущим предположениям о том, являются ли Cyllamyces и Caecomyces (Ozkose et al., 2001; Paul et al., 2018) или нет (Callaghan et al., 2015; Wang et al., 2017). ) отдельные роды.
В чистых культурах клонированные последовательности, которые были аннотированы по-разному, различались по размеру по сравнению с другими клонами (таблица 1). Поскольку фланкирующие области генов 18S рРНК и 5.8S рРНК были одинаковыми по размеру, изменение размера ампликона было связано только с областью ITS1. Однако у N. frontalis RE1 большой диапазон размеров ITS1 не привел к различным аннотациям. Это, вероятно, является отражением различий в размерах клонов N. frontalis RE1 из-за вставок, а не делеций в области ITS1. Эти результаты подчеркивают необходимость секвенирования нескольких клонов из отдельных чистых культур для дальнейшего уточнения существующих таксономических структур на основе ITS1 для анаэробных грибов (Koetschan et al., 2014; Paul et al. , 2018). Например, основываясь на полноразмерных последовательностях ITS1 в библиотеках клонов, 98% порог идентичности для клады (это исследование) или эквивалента вида (Paul et al., 2018) кажется разумным, исходя из среднего значения идентичности в каждой библиотеке клонов (дополнительная таблица S2). Однако если учитывать минимальную идентичность в каждой библиотеке клонов, то это пороговое значение действительно только для одной из пяти чистых культур ( Piromyces sp. CaDo16a). Это ограничение использования ITS1 в качестве таксономического маркера, которое нелегко обойти, особенно при интерпретации данных о последовательности, полученных в результате независимого от культивирования анализа образцов окружающей среды.
, 2018). Например, основываясь на полноразмерных последовательностях ITS1 в библиотеках клонов, 98% порог идентичности для клады (это исследование) или эквивалента вида (Paul et al., 2018) кажется разумным, исходя из среднего значения идентичности в каждой библиотеке клонов (дополнительная таблица S2). Однако если учитывать минимальную идентичность в каждой библиотеке клонов, то это пороговое значение действительно только для одной из пяти чистых культур ( Piromyces sp. CaDo16a). Это ограничение использования ITS1 в качестве таксономического маркера, которое нелегко обойти, особенно при интерпретации данных о последовательности, полученных в результате независимого от культивирования анализа образцов окружающей среды.
Все клонированные последовательности полностью соответствовали праймерам, использованным для HTS. Данные о последовательности библиотеки клонов использовались для прогнозирования размеров ампликонов, которые теоретически могут быть получены с использованием HTS (рис. 1). Диапазон размеров области ITS1 чистых культур (200–279 оснований) был репрезентативным для диапазона размеров последовательностей полноразмерной области ITS1, присутствующих в базе данных AF-ITS1 (192–282 основания).
1). Диапазон размеров области ITS1 чистых культур (200–279 оснований) был репрезентативным для диапазона размеров последовательностей полноразмерной области ITS1, присутствующих в базе данных AF-ITS1 (192–282 основания).
Рис. 1. Предсказание размеров ампликона со штрих-кодом. Последовательности библиотеки клонов (см. Таблицу 1) использовали для предсказания in silico размер ампликона (исключая адаптеры UniTag и штрих-коды), который будет получен с помощью праймеров ампликонов со штрих-кодом для каждой из чистых культур: N. frontalis RE1 ( n = 17), Orpinomyces sp. SR2 ( n = 19), Piromyces sp. CaDo16a ( n = 19), Caecomyces sp. CaDo13a ( n = 14) и Anaeromyces sp. 28xy ( н = 16).
Высокопроизводительный анализ последовательности области ITS1 чистых культур анаэробных грибов с точки зрения OTU и их таксономии
После обработки данных Illumina HiSeq по анаэробным грибкам среднее количество прочтений на образец чистой культуры составило 391 807 (SD 149 721) (дополнительная таблица S1). Анализ данных HTS чистой культуры показал, что количество обнаруженных OTU в целом было одинаковым среди повторных образцов ( n = 3), но сильно различалось между культурами: Anaeromyces sp. 28xy (28–29 OTU), Orpinomyces sp. SR2 (14–15 OTU), N. frontalis RE1 (12 OTU), Пиромицеты зр. CaDo16a (3–7 OTU) и Caecomyces sp. CaDo13a (3–5 OTU). Количество OTU в основном было выше (например, Anaeromyces sp. 28xy, Orpinomyces sp. SR2, N. frontalis RE1 и Piromyces sp. CaDo16a), но в одном случае ниже ( Caecomyces sp. .CaDo13a), чем количество уникальных последовательностей, обнаруженных в библиотеках клонов (таблица 1). Ожидалось, что будет обнаружено больше OTU из-за увеличения глубины секвенирования (> 10 4 × большее покрытие на чистую культуру) метода HTS по сравнению с библиотеками клонов. Однако обнаружение меньшего количества OTU было неожиданным. Причиной этого, происходящего с Caecomyces sp.
Анализ данных HTS чистой культуры показал, что количество обнаруженных OTU в целом было одинаковым среди повторных образцов ( n = 3), но сильно различалось между культурами: Anaeromyces sp. 28xy (28–29 OTU), Orpinomyces sp. SR2 (14–15 OTU), N. frontalis RE1 (12 OTU), Пиромицеты зр. CaDo16a (3–7 OTU) и Caecomyces sp. CaDo13a (3–5 OTU). Количество OTU в основном было выше (например, Anaeromyces sp. 28xy, Orpinomyces sp. SR2, N. frontalis RE1 и Piromyces sp. CaDo16a), но в одном случае ниже ( Caecomyces sp. .CaDo13a), чем количество уникальных последовательностей, обнаруженных в библиотеках клонов (таблица 1). Ожидалось, что будет обнаружено больше OTU из-за увеличения глубины секвенирования (> 10 4 × большее покрытие на чистую культуру) метода HTS по сравнению с библиотеками клонов. Однако обнаружение меньшего количества OTU было неожиданным. Причиной этого, происходящего с Caecomyces sp. CaDo13a заключалась в том, что SNP присутствовал в частичном гене 5.8S рРНК в области, которая не была включена в ампликон со штрих-кодом. Из-за этого два разных типа последовательностей нельзя было различить с помощью секвенирования ампликонов, что привело к меньшему количеству OTU по сравнению с библиотекой клонов.
CaDo13a заключалась в том, что SNP присутствовал в частичном гене 5.8S рРНК в области, которая не была включена в ампликон со штрих-кодом. Из-за этого два разных типа последовательностей нельзя было различить с помощью секвенирования ампликонов, что привело к меньшему количеству OTU по сравнению с библиотекой клонов.
При суммировании на уровне клады аннотация OTU на основе BLAST не всегда соответствовала предсказанию из соответствующих библиотек клонов (рис. 2). В двух чистых культурах N. frontalis RE1 и Orpinomyces sp. SR2 меньшее количество OTU можно было надежно отнести к уровню клады по сравнению с библиотеками клонов. В обеих этих культурах было обнаружено больше OTU по сравнению с количеством уникальных последовательностей в соответствующих библиотеках клонов. В Анаэромицеты зр. 28xy, противоположное наблюдалось с большей долей OTU, которые можно было надежно отнести к уровню клады, по сравнению с библиотекой клонов. Противоположные различия в реакции между этими родами, вероятно, связаны с различиями в том, где вариации между копиями ITS1 расположены в области ITS1, поскольку область ITS1 была лишь частично секвенирована в ампликонах со штрих-кодом по сравнению с полностью секвенированной в клоне.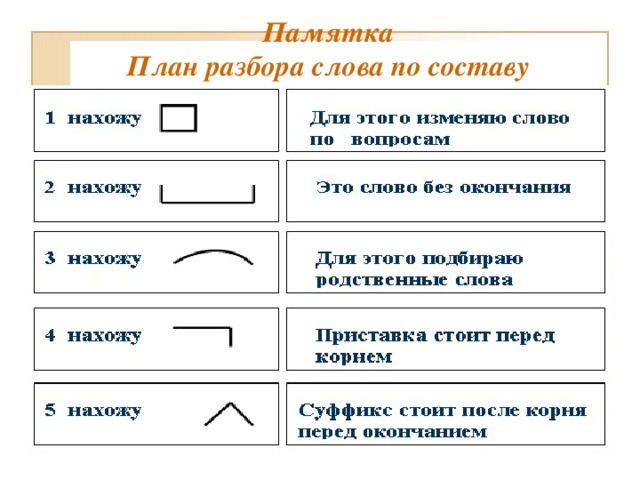 библиотеки. Однако во всех культурах аннотация на уровне рода соответствовала таковой в библиотеках клонов. С Caecomyces sp. CaDo13a относительная численность аннотаций рода Caecomyces и Cyllamyces отличалась от определенной для библиотек клонов. Причиной этого, вероятно, является более высокая глубина секвенирования с помощью метода HTS, поскольку изменение относительной численности противоположно тому, что можно было бы ожидать, если бы предпочтительно амплифицировали OTU Cyllamyces меньшего размера (рис. 1 и таблица 1).
библиотеки. Однако во всех культурах аннотация на уровне рода соответствовала таковой в библиотеках клонов. С Caecomyces sp. CaDo13a относительная численность аннотаций рода Caecomyces и Cyllamyces отличалась от определенной для библиотек клонов. Причиной этого, вероятно, является более высокая глубина секвенирования с помощью метода HTS, поскольку изменение относительной численности противоположно тому, что можно было бы ожидать, если бы предпочтительно амплифицировали OTU Cyllamyces меньшего размера (рис. 1 и таблица 1).
Рисунок 2. Таксономическая аннотация чистых культур анаэробных грибов на основе высокопроизводительного секвенирования. Пять различных чистых культур (обозначенных названием штамма), реплицированных библиотекой (A, B и C), показаны в сравнении с теоретической относительной численностью (T), которая была определена на основе данных соответствующей библиотеки клонов (см. Таблицу 1). Аннотации указаны как для рода, так и для некультивируемой клады на уровне рода или вида. NA означает, что уровень клады или рода не может быть аннотирован в пределах семейства Неокаллимастиговые .
NA означает, что уровень клады или рода не может быть аннотирован в пределах семейства Неокаллимастиговые .
Оценка точности высокопроизводительного секвенирования области ITS1 анаэробных грибов с использованием фиктивных сообществ
Были подготовлены четыре фиктивных сообщества (Mock_1–Mock_4), которые различались по составу. В целом, эти имитационные сообщества были репрезентативными для состава сообщества анаэробных грибов, о котором ранее сообщалось в кишечнике травоядных (Liggenstoffer et al., 2010). Mock_1 и Mock_2 были приготовлены с использованием одинаковых количеств ампликонов ПЦР из двух или пяти чистых культур соответственно. Mock_3 и Mock_4 состояли из ДНК всех пяти чистых культур, но в других пропорциях по сравнению с Mock_2. Mock_3 имел ступенчатые пропорции каждой из пяти чистых культур, тогда как Mock_4 имел несколько чистых культур с низким содержанием (т.е. 1, 0,1 и 0,01%). Эти четыре имитационных сообщества затем использовались для HTS, чтобы оценить точность метода применительно к образцам, различающимся по сложности и разнообразию.
После обработки данных среднее количество прочтений на образец фиктивного сообщества составило 211 817 (SD 58 041) (дополнительная таблица S1). Все повторы ( n = 4) секвенированных фиктивных сообществ генерировали аналогичные профили (рис. 3). Mock_1 и Mock_4 хорошо сравнимы с теоретическим составом соответствующего фиктивного сообщества (рис. 4). Однако в Mock_4 не было OTU, связанного с CaDo16a ; нет данных или Caecomyces ; NA обнаружен, несмотря на то, что он присутствует на уровне 1,1 и 1,5% соответственно в теоретическом фиктивном сообществе (таблица 2). Кажется, это противоречит обнаружению Циламицеты ; NA, которая присутствовала на уровне 0,8% в теоретическом фиктивном сообществе (таблица 2). Эти наблюдения показывают, что предел обнаружения таксона методом не является «жестким» и зависит от чего-то другого, кроме минимального порога численности 0,6%, используемого при обработке данных. Большое количество циклов ПЦР, использованных для получения ампликона со штрих-кодом, как и в других исследованиях (Liggenstoffer et al. , 2010; Kittelmann et al., 2013), может дать потенциальное объяснение этому. В этих условиях второстепенные таксоны могут быть недопредставлены, если происходит предпочтительная амплификация или другие шаблоны более многочисленны.
, 2010; Kittelmann et al., 2013), может дать потенциальное объяснение этому. В этих условиях второстепенные таксоны могут быть недопредставлены, если происходит предпочтительная амплификация или другие шаблоны более многочисленны.
Рисунок 3. Таксономическая аннотация четырех определенных имитационных сообществ анаэробных грибов (от Mock_1 до Mock_4) на основе высокопроизводительного секвенирования. Репликаты секвенировали в трех разных библиотеках (А, В и С), а также готовили дубликаты для одной библиотеки (А1 и А2). Результаты повторных проб сравнивали с относительной численностью теоретических фиктивных сообществ (T). Цветовой ключ для таксономических аннотаций такой же, как на рисунке 2.
Рисунок 4. Значения корреляции Пирсона между секвенированными фиктивными сообществами (от Mock_1 до Mock_4) и соответствующими теоретическими фиктивными сообществами. Значение 1 указывает на идеальное совпадение с соответствующим теоретическим фиктивным сообществом. Имитационные сообщества с разными буквами значительно отличаются друг от друга по значениям корреляции Пирсона ( P < 0,001).
Имитационные сообщества с разными буквами значительно отличаются друг от друга по значениям корреляции Пирсона ( P < 0,001).
Таблица 2. Сравнение процентного отклонения и секвенированных фиктивных сообществ ( n = 4) по отношению к теоретическим макетным сообществам.
Значения корреляции Пирсона между секвенированными и теоретическими макетными сообществами были значительно выше для Mock_1 и Mock_4 по сравнению с Mock_2 и Mock_3 ( P <0,001) (рис. 4). Значения корреляции Пирсона для Mock_3 также были значительно выше, чем для Mock_2 ( P <0,001) (рис. 4). Значительная разница между Mock_2 и Mock_3 по сравнению с Mock_1 и Mock_4 ( P <0,001) также было обнаружено с использованием взвешенных расстояний UniFrac (дополнительный рисунок S2). Как в Mock_2, так и в Mock_3 относительная численность Orpinomyces ; Orpinomyces 1a , Orpinomyces ; Orpinomyces 1b и Cylamyces ; NA были намного выше, чем ожидалось (Рисунок 3 и Таблица 2). Эти три таксона представляют собой наименьшие из ампликонов со штрих-кодом, предсказанных на основе данных библиотеки клонов (рис. 1 и таблица 1). Поэтому предполагается, что их более высокая относительная численность может быть связана с предпочтительной амплификации этих меньших ампликонов во время ПЦР. Анализ размера региона ITS1 в базе данных AF-ITS1 показал, что пять из 32 названных кладов были того же размера или меньше, чем 9.0235 Orpinomyces 1b (рис. 5). Ранее сообщалось о дискриминации более длинных продуктов ПЦР, когда для всей области ITS использовались универсальные грибковые праймеры (Ihrmark et al., 2012). В другом исследовании не было обнаружено никаких доказательств предвзятости размера в области ITS1 при анализе ложного сообщества с использованием универсальных грибковых праймеров, однако не было указано, какой диапазон размеров ITS1 представляет ложное сообщество (Tedersoo et al., 2015).
Эти три таксона представляют собой наименьшие из ампликонов со штрих-кодом, предсказанных на основе данных библиотеки клонов (рис. 1 и таблица 1). Поэтому предполагается, что их более высокая относительная численность может быть связана с предпочтительной амплификации этих меньших ампликонов во время ПЦР. Анализ размера региона ITS1 в базе данных AF-ITS1 показал, что пять из 32 названных кладов были того же размера или меньше, чем 9.0235 Orpinomyces 1b (рис. 5). Ранее сообщалось о дискриминации более длинных продуктов ПЦР, когда для всей области ITS использовались универсальные грибковые праймеры (Ihrmark et al., 2012). В другом исследовании не было обнаружено никаких доказательств предвзятости размера в области ITS1 при анализе ложного сообщества с использованием универсальных грибковых праймеров, однако не было указано, какой диапазон размеров ITS1 представляет ложное сообщество (Tedersoo et al., 2015).
Рис. 5. Распределение размеров области ITS1 анаэробных грибов. Блочная диаграмма распределения размеров полноразмерных последовательностей области ITS1, присутствующих в базе данных ITS1 анаэробных грибов (версия 3.3), которые связаны с названными кладами. Пунктирная линия указывает размер, начиная с которого наблюдалась преимущественная амплификация в фиктивных сообществах (т. е. 211 оснований — это длина области ITS1 для Орпиномицеты зр. Клон SR2, который был аннотирован как Orpinomyces 1b).
Блочная диаграмма распределения размеров полноразмерных последовательностей области ITS1, присутствующих в базе данных ITS1 анаэробных грибов (версия 3.3), которые связаны с названными кладами. Пунктирная линия указывает размер, начиная с которого наблюдалась преимущественная амплификация в фиктивных сообществах (т. е. 211 оснований — это длина области ITS1 для Орпиномицеты зр. Клон SR2, который был аннотирован как Orpinomyces 1b).
Поскольку данные секвенирования ампликонов по своей сути являются композиционными, измерения отдельных таксонов не являются независимыми (Gloor et al., 2017). Следовательно, если относительная численность некоторых таксонов выше ожидаемой, относительная численность других ниже. Это явно имело место для Mock_2 и Mock_3. В Mock_2 таксоны, принадлежащие к Neocallimastix , Anaeromyces и CaDo16a, были в 0,6–0,8 раза ниже, чем ожидалось. В Mock_3, 9Таксоны 0235 Neocallimastix и CaDo16a были в 0,4–0,8 раза ниже, чем ожидалось, а Anaeromyces вообще не были обнаружены, несмотря на то, что они составляли 4,9% теоретического фиктивного сообщества.
Из плохого совпадения Mock_2 и Mock_3 с теоретическими макетами по сравнению с Mock_1 и Mock_4 можно сделать вывод, что на точность метода влияет состав выборки сообщества. Следовательно, необходимо разработать альтернативный таксономический маркер для анаэробных грибов и связанную с ним курируемую базу данных для обеспечения точного анализа проб окружающей среды. В целом сообщалось, что область ITS2 аналогична (Blaalid et al., 2013) или лучше (Yang et al., 2018), чем область ITS1, как таксономический маркер царства грибов. Таквелл и др. (2005) также показали, что подгруппы анаэробных грибов, идентифицированные с помощью ITS2, были в целом такими же, как подгруппы, идентифицированные с помощью ITS1. Однако в некоторых случаях Tuckwell et al. (2005) обнаружили для отдельных культур различия в последовательностях в области ITS1, но не в области ITS2, и наоборот. Вследствие этого, а также ограниченного количества данных о последовательностях ITS2, доступных для анаэробных грибов, неудивительно, что сообщество исследователей анаэробных грибов сосредоточило свое внимание на гене 28S рРНК как на альтернативе ITS1 (Edwards et al. , 2017).
, 2017).
Для анаэробных грибов область D1/D2 гена 28S рРНК, по-видимому, имеет таксономическое разрешение, сходное с областью ITS1 (Wang et al., 2017). Таким образом, он может создать более стабильную филогенетическую основу для анаэробных грибов, чем ITS1, из-за его более консервативного размера и, следовательно, более ограниченной гетерогенности в отдельных культурах. Были разработаны праймеры, специфичные для анаэробных грибов, нацеленные на область D1/D2 гена 28S рРНК (Dollhofer et al., 2016), которые также использовались в сочетании с библиотеками клонов для изучения состава сообщества анаэробных грибов в образцах окружающей среды (Dollhofer et al. , 2017). Однако эталонные последовательности этой области для ранее охарактеризованных таксонов в настоящее время ограничены (Wang et al., 2017). Также существует проблема с точки зрения того, как связать последовательности гена 28S рРНК с некультивируемыми кладами уровня рода или вида, которые на сегодняшний день были охарактеризованы только на основе последовательностей области ITS1, полученных из окружающей среды. Кроме того, недавно были получены противоречивые результаты, когда библиотеки клонов генов ITS1 и 28S рРНК использовались для анализа анаэробных грибов в образце окружающей среды (Mura et al., 2018). Поэтому, по крайней мере на данный момент, вполне вероятно, что ITS1 будет по-прежнему использоваться для оценки разнообразия анаэробных грибов и структуры сообщества в пробах окружающей среды до тех пор, пока не будет разработан альтернативный таксономический маркер и связанная с ним таксономическая схема и база данных (аналогичные тем, которые в настоящее время доступны для ITS1). были разработаны и оценены.
Кроме того, недавно были получены противоречивые результаты, когда библиотеки клонов генов ITS1 и 28S рРНК использовались для анализа анаэробных грибов в образце окружающей среды (Mura et al., 2018). Поэтому, по крайней мере на данный момент, вполне вероятно, что ITS1 будет по-прежнему использоваться для оценки разнообразия анаэробных грибов и структуры сообщества в пробах окружающей среды до тех пор, пока не будет разработан альтернативный таксономический маркер и связанная с ним таксономическая схема и база данных (аналогичные тем, которые в настоящее время доступны для ITS1). были разработаны и оценены.
Заключение
Результаты этого исследования показывают, что, хотя HTS области ITS1 анаэробных грибов можно использовать для анализа проб окружающей среды, например, для выявления различий между видами хозяев, диетами, группами лечения и т. д., точность метода зависит от состава выборки сообщества. Кроме того, неоднозначность аннотации последовательностей в чистых культурах из-за гетерогенности ITS1 усиливает ограничения области ITS1 для таксономического отнесения анаэробных грибов. Чтобы преодолеть эти проблемы, необходимо разработать альтернативный таксономический маркер для анаэробных грибов.
Чтобы преодолеть эти проблемы, необходимо разработать альтернативный таксономический маркер для анаэробных грибов.
Заявление о доступности данных
Наборы данных, созданные для этого исследования, можно найти в базе данных NCBI (MK036660-MK036676, MK036677-MK036695, MK036696-MK036714, MK036715-MK036728 и MK036715-MK036728 и MK036724-MK036) .
Вклад автора
Компания JE инициировала исследование, участвовала в его разработке, провела лабораторную работу, проанализировала и интерпретировала данные, подготовила рукопись и получила финансирование. GH и HS участвовали в разработке дизайна исследования, интерпретации данных и составлении рукописи. Б.Н. и С.К. участвовали в анализе и интерпретации данных, а также в составлении рукописи. Все авторы прочитали и одобрили окончательный вариант рукописи.
Финансирование
Компания JE получила финансирование от исследовательской и инновационной программы Horizon 2020 Европейского Союза в рамках соглашения о гранте Марии Склодовской-Кюри № 706899. Авторы также признают финансирование проекта UNLOCK, финансируемого Нидерландской организацией научных исследований (NRGWI.obrug.2018.005). ).
Авторы также признают финансирование проекта UNLOCK, финансируемого Нидерландской организацией научных исследований (NRGWI.obrug.2018.005). ).
Конфликт интересов
С.К. был сотрудником Wilmar International Limited.
Остальные авторы заявляют, что исследование проводилось в отсутствие каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Выражаем благодарность д-ру Тони М. Каллагану и Веронике Доллхофер за предоставление геномной ДНК анаэробных грибов, использованных в этом исследовании. Джесси ван Дам и Васин Пончивин выражают благодарность за помощь в реализации NG-Tax для анализа данных HTS без использования справочной базы данных. JE благодарит Рут Экспозито Гомес за то, что она побудила написать эту работу в виде рукописи.
Дополнительный материал
Дополнительный материал к этой статье можно найти в Интернете по адресу: https://www.frontiersin. org/articles/10.3389 https://gitlab.com/wurssb/gen_fake_mocks/tree/master/paper_data/TestMock_150_06_TAX_FINAL_hdf5.biom
org/articles/10.3389 https://gitlab.com/wurssb/gen_fake_mocks/tree/master/paper_data/TestMock_150_06_TAX_FINAL_hdf5.biom
Ссылки
Блаалид Р., Кумар С., Нильссон Р. Х., Абаренков К., Кирк П. М. и Каусеруд Х. (2013). ITS1 против ITS2 как меташтрих-коды ДНК для грибов. Мол. Экол. Ресурс. 13, 218–224. doi: 10.1111/1755-0998.12065
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Blaxter, M., Mann, J., Chapman, T., Thomas, F., Whitton, C., Floyd, R., et al. (2005). Определение операционных таксономических единиц с использованием данных штрих-кода ДНК. Филос Транс. Р. Соц. Б биологических наук. 360, 1935–1943 гг. doi: 10.1098/rstb.2005.1725
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Брукман Дж. Л., Менним Г., Тринчи А. П. Дж., Теодору М. К. и Таквелл Д. С. (2000). Идентификация и характеристика анаэробных кишечных грибов с использованием молекулярных методологий, основанных на рибосомной ITS1 и 18S рРНК. Микробиология 246, 393–403. doi: 10.1099/00221287-146-2-393
Микробиология 246, 393–403. doi: 10.1099/00221287-146-2-393
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Каллаган, Т. М. (2014). Разработка инструментов для идентификации и таксономического размещения неокаллимастиг. к.т.н. Диссертация, Пенглайс, Университет Аберистуита.
Google Scholar
Каллаган Т. М., Подмирсег С. М., Хольвек Д., Эдвардс Дж. Э., Пуния А. К., Дагар С. С. и др. (2015). Buwchfawromyces eastonii род. ноябрь, сп. nov.: новый анаэробный грибок ( Neocallimastigomycota ), выделенный из фекалий буйвола. MycoKeys 9, 11–28. doi: 10.3897/mycokeys.9.9032
Полный текст CrossRef | Google Scholar
Доллхофер В., Каллаган Т. М., Дорн-Ин С., Бауэр Дж. и Лебун М. (2016). Разработка трех конкретных инструментов на основе ПЦР для определения количества, целлюлозолитической транскрипционной активности и филогении анаэробных грибов. J. Microbiol. Методы. 127, 28–40. doi: 10.1016/j. mimet.2016.05.017
mimet.2016.05.017
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Доллхофер В., Каллаган Т. М., Гриффит Г. В., Лебун М. и Бауэр Дж. (2017). Присутствие и транскрипционная активность анаэробных грибов в сельскохозяйственных биогазовых установках. Биоресурс. Технол. 235, 131–139. doi: 10.1016/j.biortech.2017.03.116
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Эдвардс Дж. Э., Форстер Р. Дж., Каллаган Т. М., Доллхофер В., Дагар С. С., Ченг Ю. и др. (2017). Методы ПЦР и омики для изучения разнообразия, экологии и биологии анаэробных грибов: понимание, проблемы и возможности. Перед. микробиол. 8:1657. doi: 10.3389/fmicb.2017.01657
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Эдвардс, Дж. Э., Кингстон-Смит, А. Х., Хименес, Х. Р., Хьюс, С. А., Скот, К. П., Гриффит, Г. В., и др. (2008). Динамика начальной колонизации неконсервируемого райграса пастбищного анаэробными грибами в рубце крупного рогатого скота. FEMS микробиол. Экол. 66, 537–545. doi: 10.1111/j.1574-6941.2008.00563.x
FEMS микробиол. Экол. 66, 537–545. doi: 10.1111/j.1574-6941.2008.00563.x
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Глор, Г. Б., Маклейм, Дж. М., Павловски-Глан, В., и Эгоскью, Дж. Дж. (2017). Наборы данных микробиома являются композиционными: и это необязательно. Фронт. микробиол. 6:2224. doi: 10.3389/fmicb.2017.02224
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Gordon, GLR, and Phillips, MW (2005). Роль анаэробных кишечных грибов у жвачных животных. Нутр. Рез. Ред. 11, 133–168. doi: 10.1079/nrr19980009
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ханафи, Р. А., Эльшахед, М. С., и Юссеф, Н. Х. (2018). Feramyces austinii, род. ноябрь, сп. nov., анаэробный кишечный гриб из образцов рубца и фекалий диких варварских баранов и ланей. Микология 110, 513–525. doi: 10.1080/00275514.2018.1466610
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ihrmark, K. , Bödeker, I.T.M., Cruz-Martinez, K., Friberg, H., Kubartova, A., Schenck, J., et al. (2012). Новые праймеры для амплификации грибкового региона ITS2 — оценка путем 454-секвенирования искусственных и естественных сообществ. FEMS микробиол. Экол. 82, 666–677. doi: 10.1111/j.1574-6941.2012.01437.x
, Bödeker, I.T.M., Cruz-Martinez, K., Friberg, H., Kubartova, A., Schenck, J., et al. (2012). Новые праймеры для амплификации грибкового региона ITS2 — оценка путем 454-секвенирования искусственных и естественных сообществ. FEMS микробиол. Экол. 82, 666–677. doi: 10.1111/j.1574-6941.2012.01437.x
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Джоши, А., Ланджекар, В.Б., Дакепхалкар, П.К., Каллаган, Т.М., Гриффит, Г.В., и Дагар, С.С. (2018). Liebetanzomyces polymorphus род. и др. nov., новый анаэробный гриб ( Neocallimastigomycota ), выделенный из рубца козы. MycoKeys 40, 89–110. doi: 10.3897/mycokeys.40.28337
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Киттельманн С., Нейлор Г. Э., Кулаард Дж. П. и Янссен П. Х. (2012). Предлагаемая таксономия анаэробных грибов (класс Neocallimastigomycetes), подходящая для крупномасштабного анализа структуры сообщества на основе последовательностей. PLoS One 7:e36866. doi: 10.1371/journal.pone.0036866
PLoS One 7:e36866. doi: 10.1371/journal.pone.0036866
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Киттельманн С., Зеедорф Х., Уолтерс В. А., Клементе Дж. К., Найт Р., Гордон Дж. И. и др. (2013). Одновременное секвенирование ампликонов для изучения моделей совместного присутствия бактериальных, архейных и эукариотических микроорганизмов в микробных сообществах рубца. PLoS One 8:e47879. doi: 10.1371/journal.pone.0047879
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Koetschan, C., Kittelmann, S., Lu, J., Al-Halbouni, D., Jarvis, G. N., Müller, T., et al. (2014). Анализ вторичной структуры внутреннего расшифрованного спейсера 1 выявил общее ядро для всех анаэробных грибов ( Neocallimastigomycota ). PLoS One 9:e91928. doi: 10.1371/journal.pone.0091928
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ларкин М. А., Блэкшилдс Г., Браун Н. П. , Ченна Р., Макгеттиган П. А., Маквильям Х. и др. (2007). Clustal W и Clustal X версии 2.0. Биоинформатика 23, 2947–2948. doi: 10.1093/bioinformatics/btm404
, Ченна Р., Макгеттиган П. А., Маквильям Х. и др. (2007). Clustal W и Clustal X версии 2.0. Биоинформатика 23, 2947–2948. doi: 10.1093/bioinformatics/btm404
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лиггенштоффер А.С., Юссеф Н.Х., Кугер М.Б. и Эльшахед М.С. (2010). Филогенетическое разнообразие и структура сообщества анаэробных кишечных грибов (филум Neocallimastigomycota) у жвачных и нежвачных травоядных. ISME J. 4, 1225–1235. doi: 10.1038/ismej.2010.49
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Лозупоне, К., Лладсер, М.Е., Найтс, Д., Стомбо, Дж., и Найт, Р. (2011). UniFrac: эффективная метрика расстояния для сравнения микробного сообщества. ISME J. 5, 169–172. doi: 10.1038/ismej.2010.133
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Mura, E., Edwards, J., Kittelmann, S., Kaerger, K., Voigt, K., Mrázek, J., et al. (2018). Сообщества анаэробных грибов различаются по пищеварительному тракту лошади. Грибковый биол. 123, 240–246. doi: 10.1016/j.funbio.2018.12.004
Грибковый биол. 123, 240–246. doi: 10.1016/j.funbio.2018.12.004
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Николас, К.Б., и Нколас, Х.Б. (1997). GeneDoc: инструмент для редактирования и аннотирования нескольких выравниваний последовательностей. Версия 1.1.004, распространяемая Автором.
Google Scholar
Николсон, М. Дж., МакСвини, К. С., Маки, Р. И., Брукман, Дж. Л., и Теодору, М. К. (2010). Разнообразие популяций анаэробных кишечных грибов проанализировано с использованием рибосомных последовательностей ITS1 в фекалиях диких и домашних травоядных. Анаэробы 16, 66–73. doi: 10.1016/j.anaerobe.2009.05.003
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Нильссон Р. Х., Ларссон К.-Х., Тейлор А. Ф. С., Бенгтссон-Палме Дж., Джеппесен Т. С., Шигель Д. и др. (2018). База данных UNITE для молекулярной идентификации грибов: работа с темными таксонами и параллельные таксономические классификации. Рез. нуклеиновых кислот. 47, 259–264. doi: 10.1093/nar/gky1022
Рез. нуклеиновых кислот. 47, 259–264. doi: 10.1093/nar/gky1022
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Озкос, Э., Томас, Б.Дж., Дэвис, Д.Р., Гриффит, Г.В., и Теодору, М.К. (2001). Cyllamyces aberensis gen.nov. sp.nov., новый анаэробный кишечный гриб с разветвленными спорангиеносцами, выделенный от крупного рогатого скота. Кан. Дж. Бот. 79, 666–673. doi: 10.1139/cjb-79-6-666
Полный текст CrossRef | Google Scholar
Пол С.С., Бу Д., Сюй Дж., Хайд К.Д. и Ю З. (2018). Филогенетическая перепись глобального разнообразия кишечных анаэробных грибов и новая таксономическая структура. Грибковые водолазы. 89, 253–266. doi: 10.1007/s13225-018-0396-6
Полный текст CrossRef | Google Scholar
Пирсон, К. (1909). Определение коэффициента корреляции. Наука 30, 23–25. doi: 10.1126/science.30.757.23
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ramiro-Garcia, J. , Hermes, G.D.A., Giatsis, C., Sipkema, D., Zoetendal, E.G., Schaap, P.J., et al. (2016). NG-Tax, высокоточный и проверенный конвейер для анализа ампликонов 16S рРНК из сложных биомов. F1000Исследование 5:1791. doi: 10.12688/f1000research.9227.1
, Hermes, G.D.A., Giatsis, C., Sipkema, D., Zoetendal, E.G., Schaap, P.J., et al. (2016). NG-Tax, высокоточный и проверенный конвейер для анализа ампликонов 16S рРНК из сложных биомов. F1000Исследование 5:1791. doi: 10.12688/f1000research.9227.1
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Соломон К.В., Хайтьема С.Х., Хенске Дж.К., Гилмор С.П., Борхес-Ривера Д., Липзен А. и др. (2016). Кишечные грибы с ранним разветвлением обладают большим комплексным набором ферментов, разлагающих биомассу. Наука 351, 1192–1195. doi: 10.1126/science.aad1431
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Стюарт, К. С., и Ричардсон, А. Дж. (19 лет).89). Повышенная устойчивость анаэробных грибов рубца к ионофорам монензину и лазалоциду в присутствии метаногенных бактерий. Дж. Заявл. бактериол. 66, 85–93. doi: 10.1111/j.1365-2672.1989.tb02458.x
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Тедерсоо Л. , Анслан С., Бахрам М., Пылме С., Риит Т., Лийв И. и др. (2015). Метагеномы дробовика и несколько комбинаций пар праймеров и штрих-кодов ампликонов выявляют систематические ошибки в анализе меташтрихкодирования грибов. MycoKeys 10, 1–43. doi: 10.3897/mycokeys.10.4852
, Анслан С., Бахрам М., Пылме С., Риит Т., Лийв И. и др. (2015). Метагеномы дробовика и несколько комбинаций пар праймеров и штрих-кодов ампликонов выявляют систематические ошибки в анализе меташтрихкодирования грибов. MycoKeys 10, 1–43. doi: 10.3897/mycokeys.10.4852
Полный текст CrossRef | Google Scholar
Таквелл, Д. С., Николсон, М. Дж., МакСвини, К. С., Теодору, М. К., и Брукман, Дж. Л. (2005). Быстрое отнесение грибов рубца к предполагаемым родам с использованием вторичных структур РНК ITS1 и ITS2 для получения групповых отпечатков пальцев. Микробиология 151, 1557–1567. doi: 10.1099/mic.0.27689-0
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
ван Линген, Х. Дж., Эдвардс, Дж. Э., Вайдья, Дж. Д., ван Гастелен, С., Сакченти, Э., ван ден Богерт, Б., и др. (2017). Суточная динамика газообразных и растворенных метаболитов и состава микробиоты в рубце крупного рогатого скота. Перед. микробиол. 8:425. doi: 10. 3389/fmicb.2017.00425
3389/fmicb.2017.00425
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван X., Лю X. и Грёневальд Дж. З. (2017). Филогения анаэробных грибов (тип Neocallimastigomycota) с участием яков в Китае. Антони Ван Левенгук 110, 87–103. doi: 10.1007/s10482-016-0779-1
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Уикхэм, Х. (2009). Ggplot2: элегантная графика для анализа данных. Нью-Йорк: Springer-Verlag.
Google Scholar
Ян, Р. Х., Су, Дж. Х., Шан, Дж. Дж., Ву, Ю. Ю., Ли, Ю., Бао, Д. П., и др. (2018). Оценка внутреннего транскрибируемого спейсера (ITS) рибосомной ДНК, особенно ITS1 и ITS2, для анализа грибкового разнообразия путем глубокого секвенирования. PLoS One 13:e0206428. doi: 10.1371/journal.pone.0206428
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar. фотография. Речь идет о позиционировании персонажа, чтобы показать его отношение к другим элементам сцены.
Представьте себе доску для игры в крестики-нолики — две линии по вертикали и еще две по горизонтали.
Точки интереса лежат на пересекающихся линиях
Пока камера кадрирует кадр, держите изображение на пересекающихся линиях. Это приятнее для глаз. Но кроме того, другой кадр камеры расскажет другую историю. Это простой способ определить место персонажа в мире.
Композиция кадров и правило третей
Композиция кадра в Nightcrawler , ну, кишит этим правилом. Лу появляется сбоку кадра, вдали от мира, в котором он существует.
Использование Гилроем правила третей изолирует Лу, выделяя это как основную тему. Правило третей также можно использовать с двумя символами.
Правило третей с двумя символами
Не забудьте нарисовать эту воображаемую доску для игры в крестики-нолики. Поместите символ по обе стороны от пересекающихся линий. Гилрой также использует эту технику, чтобы показать темную сторону персонажа. Во многих сценах Лу расположен не по центру, и видна только сторона его лица.
Во многих сценах Лу расположен не по центру, и видна только сторона его лица.
Обрамление может указывать на ненадежного персонажа
Трудно доверять тому, кого мы редко видим.
Решение режиссера поставить Лу таким образом, показывая только его профиль, создает ненадежного, отстраненного персонажа.
Овладение композицией кадра и кадрированием в кино также позволяет нарушать некоторые правила композиции.
Правила композиции Баланс и симметрияПонимание правил композиции кадра является бесценным знанием для режиссеров и операторов. И поэтому знать, когда их сломать.
Съемка идеально симметричного кадра с нарушением правила третей используется по очень специфическим причинам. Гилрой помещает Лу в центр экрана, игнорируя правило третей.
Мы это чувствуем. Но почему?
Нарушение правила третей Лу в центре внимания. И это вызывает напряжение.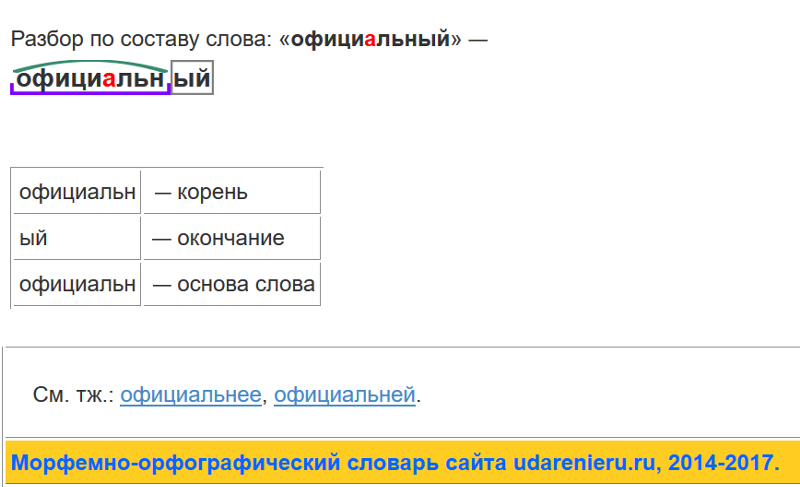
Художники используют эту технику, чтобы направить взгляд зрителя в определенное место. А наведение взгляда на центр экрана может в конечном итоге лучше представить вашу историю и вызвать больше эмоций. Прошлые фильмы сделали это хорошо. Баланс и симметрия в кадре могут быть очень эффектными.
Рассмотрим эти примеры из лучших фильмов Стэнли Кубрика.
Симметрия в цельнометаллической оболочкеОни часто раскрывают черты характера и динамику силы.
Устрашающая симметрия и баланс в фильме «2001: Космическая одиссея»Или они создают настолько идеально симметричное место, что зрители мгновенно чувствуют себя ошеломленными. Если вы что-нибудь знаете о режиссерском стиле Уэса Андерсона, вы знаете, что он любит симметричный кадр.
Уэс Андерсон использует строгую симметрию в «Королевстве полной луны» Работа в тандеме с правилами композиции, блокирования и постановки также отвечает за создание динамических кадров.
БЛОКИРОВКА ОПРЕДЕЛЕНИЕ
Что такое блокировка?Блокировка — это способ, которым режиссер перемещает актеров в сцене. Подход режиссера к блокировке зависит от желаемого результата (например, для драматического эффекта, для передачи предполагаемого сообщения или для визуализации динамики власти).
Блокировка актера в симметричном кадре может быть очень эффективным способом привести зрителя к определенному чувству или эмоции. Это видео является частью нашего мастер-класса по технике кинопроизводства, который позволяет нам визуализировать силу блокировок и постановок.
Блокировка актеров для продвижения сюжета • Получите всю серию мастер-классов
Обратите внимание, что управление взглядом зрителя должно быть вашим приоритетом в каждой сцене, которую вы создаете. Блокировка часто использует направляющие линии, чтобы контролировать то, что видит аудитория, и то, как они это видят. Это влияет на то, как они это интерпретируют.
Направляющие линии — это настоящие линии (а иногда и воображаемые) в кадре, которые направляют взгляд к ключевым элементам сцены.
Художники используют эту технику, чтобы направить взгляд зрителя, но они также используют ее, чтобы связать персонажа с важными объектами, ситуациями или второстепенными предметами. Что бы ни привлекло ваше внимание в сцене, направляющие линии, вероятно, имеют к этому какое-то отношение.
Это очень полезный тип композиции кадра, поскольку он передает основной контекст аудитории. Давайте посмотрим, как он используется в Nightcrawler. В этих стрингерных сценах используются направляющие линии, которые ведут нас к месту аварии.
Сможете ли вы их заметить?
Диагональная линия от ног Лу к задним колесам полицейской машины, помогите кадрировать кадр. Это ведущая линия, которая, что интересно, также представляет то, что его камера способна запечатлеть.
Другая ведущая линия определяется движением персонажа. Он идет на аварию с камерой, по прямой.
Диагональ и прямая линия обрамляют аварию как фокус. Что интересно, так это то, что его камера делает то же самое внутри сцены.
В то время как это правило композиции помогает нам сфокусироваться, другие техники помогают нам сфокусироваться.
Глаз для сопереживания Кадрирование на уровне глазКадрирование на уровне глаз размещает аудиторию на уровне глаз с персонажами, что создает впечатление, что мы равны с персонажем. Направляя взгляд и разум на размышления о том, как бы мы себя чувствовали, если бы были там, потому что кажется, будто мы уже здесь.
Nightcrawler использует эту технику, чтобы вызвать сочувствие к своему антигерою. Независимо от того, что персонаж Лу читал на странице, то, что мы видели на экране, было кем-то вроде нас.
Перейдите по ссылке на изображение, чтобы увидеть полную раскадровку StudioBinder ключевых моментов фильма.
Организуйте снимки с уровня глаз с помощью StudioBinder
Это чувство связи очень важно при просмотре антигероя. Это освобождает место для эмпатии. Эмоция, необходимая, чтобы оставаться на связи с очень ущербным персонажем. И так, мы остаемся для поездки.
Просто показав зрителю глаза персонажа, зритель заглянет в его душу. Возможно, это не является незыблемым правилом композиции кадра, но это эффективная техника.
Крупный план его глаз говорит о том, что в данный момент важны состояние души и внутренние переживания Лу. Это позволяет нам чувствовать то, что чувствует он. Это самый простой способ вызвать сочувствие.
Крупный план Лу на уровне глаз
Теперь давайте отодвинем кадр от камеры и посмотрим, как наш режиссер использует базовую видеокомпозицию, чтобы показать, как Лу чувствует себя в мире.
Примеры композиции Глубина резкости Чтобы понять кинематографию, нужно понять глубину резкости.
Овладение пространственной композицией в кадре — одна из отличительных черт эффективного визуального повествования. Но прежде чем мы научимся управлять глубиной в интересах нашей истории, почему бы нам сначала не определить глубину резкости.
Определение глубины резкости
Что такое глубина резкости?
Глубина резкости описывает размер области изображения, где объекты выглядят достаточно резкими. Эта область называется полем , а размер этой области равен глубине этого поля.
Глубина резкости — это, по сути, ваша зона резкости. Если вы сделаете эту зону длиннее, сфокусировав больше объектов, вы получите большую глубину резкости.
Точно так же, если вы сделаете эту зону короче или меньше, с меньшим фокусом, у вас будет малая глубина резкости. Один из способов добиться этой регулировки — использовать диафрагму объектива.
При большой глубине резкости больше объектов в фокусе Теперь, когда мы знаем немного больше об этом, мы можем управлять глубиной резкости, чтобы передать различные ощущения, тона и отношения между объектами.
Что такое реечный фокус?
Реечный фокус в кинопроизводстве меняет фокус во время кадра. Этот термин может относиться к небольшим или большим изменениям фокуса. Если фокус неглубокий, то техника становится более заметной.
Один из моих любимых способов манипулирования изображением — использование фокуса стойки. Он меняет фокус прямо в середине кадра.
Если режиссер начинает с большой глубины резкости, а в том же кадре переходит к малой, новый сфокусированный элемент становится центральным элементом сцены.
Драматизирует его, просто переключая типы фокусировки камеры, манипулируя глубиной резкости. Посмотрите видео ниже, чтобы увидеть эту технику в Casino Royale .
Управление глубиной резкости с помощью Rack FocusНо съемка элементов в фокусе — не единственный способ рассказать свою историю.
Съемка не в фокусе может быть столь же мощной. Мы увидим в Nightcrawler , как режиссер использует размытие, чтобы проиллюстрировать свои темы.
Мы увидим в Nightcrawler , как режиссер использует размытие, чтобы проиллюстрировать свои темы.
В фотографии боке (/ˈboʊkeɪ/ BOH-kay; яп.: [боке]) — это эстетическое качество размытия, возникающее в нефокусных частях изображения, создаваемого объективом. Боке определяется как «способ, которым объектив отображает точки света, находящиеся вне фокуса».
Боке — это круглое размытие изображения, полученное не в фокусе.
Основная тема в Nightcrawler — изоляция. Чтобы показать это, Гилрой хорошо использует правила композиции кадра с эффектом боке.
Типы снимка Композиция: Боке Техника, чтобы показать изоляцию Лу
Этот вид снимка помогает отдалить Лу от окружающего мира.
Подключен только к себе.
Директор также держит человек вне фокуса. Эта техника используется, чтобы больше узнать об отчуждении Лу от общества.
Держите других не в фокусе, чтобы испытать отчуждение
Все, кроме Лу, размыты. Формально они в его мире, но чувствуют себя очень далеко.
Его изоляция ощущается на протяжении всего фильма благодаря преднамеренным кадрам камеры и основным советам по композиции видео.
Правила композиции Композиция глубокого космосаПоскольку в композиции кадра так много нюансов, иногда трудно уследить за всеми этими приемами. Я счел за лучшее создать отдельный раздел для композиции дальнего космоса отдельно от глубины резкости.
Мы определим снимки дальнего космоса, а также то, что называется глубоким фокусом, и определим, как все они соотносятся друг с другом.
Затем мы рассмотрим, как они часто работают вместе, чтобы запечатлеть намеренные (и невероятные) моменты в фильме.
Состав дальнего космоса ОПРЕДЕЛЕНИЕ
Что такое состав дальнего космоса?
Кинематографисты используют глубокое пространство , когда важные элементы сцены расположены как близко, так и далеко от камеры. Эти элементы не должны быть в фокусе.
Эти элементы не должны быть в фокусе.
Отличие, глубина фокус, определяется элементами как вблизи, так и далеко от камеры в фокусе.
знаменитых сцен с глубоким фокусом, снятых Гражданином Кейном, по-прежнему являются одними из лучших примеров того, как знание правил композиции кадра может помочь вам рассказать глубоко личную историю.
В этой сцене в композиции дальнего космоса персонажи располагаются на разной глубине, при этом все четверо остаются в фокусе.
Разная глубина указывает на то, что происходит с каждым персонажем. Маленький мальчик появляется далеко, но в кадре, чтобы напомнить нам, что он скоро исчезнет из поля зрения, как только его отправят.
Deep Space and Focus Citizen Kane В то время как Citizen Kane использует технику объемной композиции, чтобы рассказать свою историю, Nightcrawler, делает то же самое, фокусируясь на отношениях между персонажами.
Когда Лу находится далеко от камеры, а Нина чуть ближе, мы видим работу глубокого космоса. Это разделение друг от друга подчеркивает их разные личности.
У человека чистые мотивы. Другой… не очень.
При большой глубине резкости мы также видим, что телевизоры засвечены и находятся в фокусе. Выявление приоритета Лу — телевидение или его работа.
Композиция фильма
Завершение правил композиции
Как мы уже говорили, правила композиции больше похожи на предложения. Они призваны направлять и помогать, а не ограничивать или запрещать. Есть много случаев, когда вы действительно должны следовать правилам композиции, а в других случаях идеально их нарушать.
Режиссер, такой как Дэн Гилрой, и такой фильм, как Nightcrawler , — отличные примеры того, как можно играть с правилами композиции. Вот что происходит, когда художник действительно знает свое дело.
Вверх Далее Основное руководство по глубине резкости Овладение глубиной резкости возможно только при полном ее понимании. Узнайте больше из этого исчерпывающего руководства, чтобы начать создавать невероятно динамичные кадры. Погрузитесь глубже с практическими примерами.
Узнайте больше из этого исчерпывающего руководства, чтобы начать создавать невероятно динамичные кадры. Погрузитесь глубже с практическими примерами.
Up Next: Руководство по глубине резкости→
Определение последовательности и сцены в написании сценария
ВВЕДЕНИЕ
«Структура сценария» признается жизненно важным компонентом успешного сценария — если вы создаете и организуете все важные элементы истории, прежде чем приступить к написанию, этот план и шаблон ускорит ваше написание и создаст часть работы со всеми ключевыми моментами сюжета и конфликтами персонажей , представленными в нужное время. ScreenWriting Sciences 19-Sequence Model поможет вам в этом.
Дэн О’Бэннон, соавтор сценариев Alien и Total Recall , , описывает структуру сценария следующим образом: ‘» В его книге «Руководство по структуре сценария» , освещаются критические моменты сюжета и конфликты персонажей в группе классических фильмов из Касабланка — Лоуренс Аравийский. Аналогично, в «История», Роберт Макки называет Структуру следующим образом: «… Подборка событий из жизненных историй персонажей, составленных в стратегическую последовательность, чтобы вызвать определенные эмоции и выразить определенное мнение. жизни.’ Далее он описывает составные части «Истории», а именно: «Событие», «Сцена», «Ритм», «Последовательность» и «Действие». структура как: ‘»….Конкретные события в фильме и их положение относительно друг друга. Правильная структура возникает, когда правильные события происходят в правильной последовательности, чтобы вызвать максимальное эмоциональное вовлечение в rtreader и аудиторию'». Он определяет контрольный список структурные требования, в том числе мотивация персонажа, конфликты, темп, предвкушение, любопытство аудитории и предвидение.
Аналогично, в «История», Роберт Макки называет Структуру следующим образом: «… Подборка событий из жизненных историй персонажей, составленных в стратегическую последовательность, чтобы вызвать определенные эмоции и выразить определенное мнение. жизни.’ Далее он описывает составные части «Истории», а именно: «Событие», «Сцена», «Ритм», «Последовательность» и «Действие». структура как: ‘»….Конкретные события в фильме и их положение относительно друг друга. Правильная структура возникает, когда правильные события происходят в правильной последовательности, чтобы вызвать максимальное эмоциональное вовлечение в rtreader и аудиторию'». Он определяет контрольный список структурные требования, в том числе мотивация персонажа, конфликты, темп, предвкушение, любопытство аудитории и предвидение.
Что делает модель из 19 последовательностей , так это создает шаблон для истории и элементов сюжета, описанных О’Бэнноном, Макки и Хауге.
ПОСЛЕДОВАТЕЛЬНОСТИ
«Последовательности » образуют шаблон для написания сценария. Сложный сюжет проще написать, когда история разбита на управляемые блоки определенного содержания. «Эпизоды», и их составные «Сцены», — это также то, как создается, редактируется и демонстрируется фильм. Модель с 8 последовательностями является одной из наиболее часто упоминаемых структур последовательности, и существует множество книг, веб-сайтов и программного обеспечения, которые могут помочь в написании сценария с использованием этой модели. 19-Sequence Model , опубликованная в Journal of Screenwriting , описывает исследование, которое продемонстрировало, что большинство из 132 проанализированных фильмов состоят из 19-Sequences, а не из восьми. Я сопоставлю эти две модели ниже, предварительно определив термины «Последовательность», и «Сцена».
КОМПОЗИТНЫЕ ОПРЕДЕЛЕНИЯ И «ПОСЛЕДОВАТЕЛЬНОСТЬ», «СЦЕНА» И «КАДР»
The Journal of Screenwriting 9В документе 0008 , в котором описывается модель с 19 последовательностями , используется тщательно аргументированное определение для «Последовательность» и «Сцена» . Однако пространство в журнале не позволяло полностью объяснить эти определения. Как отмечается в статье, заслуживающие доверия авторы используют разные определения (например, Макки, Филд, Коугил и Каретникова): «Последовательность» и «Сцена» в определенной степени являются идеосинкразическими конструкциями. Для целей анализа и разработки 19-Модель последовательности, составные определения «Последовательность» и «Сцена» были получены путем объединения формулировок определений этих авторов. Теперь для ясности я проиллюстрирую происхождение и определение Последовательность и Сцена (и Кадр ) с помощью На набережной . Как Морфеус говорит Нео в Матрица : «Ты должен увидеть это сам». Я приветствую ваши комментарии.
Как Морфеус говорит Нео в Матрица : «Ты должен увидеть это сам». Я приветствую ваши комментарии.
На набережной был написан Бадом Шульбергом, а фильм создан: режиссером Элией Казаном, монтажером Джином Милфордом, оператором Борисом Кауфманом и арт-директором-декоратором Ричардом Дэем, наряду с незабываемыми выступлениями Марлона Брандо, Евы Мари Сэйнт, Карла Молдена, Ли Дж. Кобб, Род Стайгер, Джон Гамильтон, Пэт Хеннинг и Джеймс Вестерфилд. Фильм получил замечательные восемь премий Оскар (в том числе за лучший рассказ и сценарий ).
Эпизод-Сцена-Кадр Композиция Эпизода 1 из На набережной.
1. Определение «выстрела»
Посмотрите следующий клип до отметки 0:40 мин и обратитесь к рисунку выше. На набережной открывается с дневным видом на набережную хижины Союза портовых грузчиков , расположенной на деревянной пристани, а позади пришвартован огромный океанский лайнер. Пятеро мужчин выходят из хижины (Терри Маллой, его старший брат Чарли, Джонни Френдли — коррумпированный босс Союза грузчиков и два бандита) и идут по деревянным трапам к берегу. Все эти изображения и события снимаются камерой за один непрерывный «дубль». Это составляет «Выстрел 1». Перспектива камеры переключается на мужчин, приближающихся к верхней части деревянного пандуса рядом с автомобилем. Френдли толкает Терри, который затем уходит в другом направлении с выражением покорного нежелания на лице. Очевидно, Терри посылают что-то делать. Это «Выстрел 2». Наконец, камера переключается на ночной вид, который начинается с «Кадра 3» в 0:37 мин. Эта разница между днем и ночью показывает нам, что прошло значительное количество времени с тех пор, как Терри оставил Дружелюбного на пристани. Местонахождение Терри тоже изменилось.
Пятеро мужчин выходят из хижины (Терри Маллой, его старший брат Чарли, Джонни Френдли — коррумпированный босс Союза грузчиков и два бандита) и идут по деревянным трапам к берегу. Все эти изображения и события снимаются камерой за один непрерывный «дубль». Это составляет «Выстрел 1». Перспектива камеры переключается на мужчин, приближающихся к верхней части деревянного пандуса рядом с автомобилем. Френдли толкает Терри, который затем уходит в другом направлении с выражением покорного нежелания на лице. Очевидно, Терри посылают что-то делать. Это «Выстрел 2». Наконец, камера переключается на ночной вид, который начинается с «Кадра 3» в 0:37 мин. Эта разница между днем и ночью показывает нам, что прошло значительное количество времени с тех пор, как Терри оставил Дружелюбного на пристани. Местонахождение Терри тоже изменилось.
КАДР : ‘Непрерывная съемка камерой’.
2. Определение сцены попадает туда? Нажмите кнопку «Старт» клипа выше и смотрите до конца клипа на 1:34 минуте.
Определение сцены попадает туда? Нажмите кнопку «Старт» клипа выше и смотрите до конца клипа на 1:34 минуте.
Кадр 3 — ночной вид Терри сверху, когда он идет по темному переулку. Камера показывает Терри ближе, когда он останавливается, смотрит вверх и кричит: «Джоуи» (кадр 4). С точки зрения Терри мы смотрим вверх, на многоквартирный дом, на тускло освещенное окно (Кадр 5). Крупный план: Терри снова зовет Джоуи по имени (Кадр 6). Камера смотрит вверх, в то же самое окно, когда за занавеской появляется силуэт Джоуи (Кадр 7). Джоуи открывает окно и спрашивает Терри, чего он хочет (все еще Кадр 7). На крупном плане Терри говорит, что нашел одного из голубей Джоуи и протягивает птицу (Кадр 8). Вернувшись к окну, Джоуи говорит, что потерял одного из своих голубей в последней гонке (Кадр 9).). Терри слушает, как Джоуи говорит, что хочет вернуть птицу и что ему нужно быть осторожным в эти дни (кадр 10). Терри отвечает, что встретит Джоуи в его голубятне на крыше (все еще Кадр 10). После того, как Джоуи соглашается встретиться с Терри на крыше, Джоуи закрывает окно (Кадр 11). Камера перемещается вверх от окна Джои, показывая двух мужчин, стоящих на крыше (все еще Кадр 11). Терри некоторое время продолжает смотреть вверх, затем выпускает голубя (Кадр 12). Птица взлетает вверх, когда Терри уходит (Кадр 13). Начало следующего кадра происходит позже в другом географическом месте и показывает Терри, прибывающего к бару Джонни Френдли (Кадр 14).
После того, как Джоуи соглашается встретиться с Терри на крыше, Джоуи закрывает окно (Кадр 11). Камера перемещается вверх от окна Джои, показывая двух мужчин, стоящих на крыше (все еще Кадр 11). Терри некоторое время продолжает смотреть вверх, затем выпускает голубя (Кадр 12). Птица взлетает вверх, когда Терри уходит (Кадр 13). Начало следующего кадра происходит позже в другом географическом месте и показывает Терри, прибывающего к бару Джонни Френдли (Кадр 14).
Кадры 1–2 и Кадры 3–13 — это две отдельные группы кадров, каждая из которых представляет собой важный компонент структуры фильма, а именно « СЦЕНА» . Сцена 1 изображает, как Дружелюбие заставляет Терри уйти и заняться чем-то. Сцена 2 фокусируется на взаимодействии Терри с Джоуи.
СЦЕНА: Кадр или несколько кадров, которые вместе составляют единое законченное и единое драматическое событие, действие, единицу или элемент киноповествования, либо блок (сегмент) повествования. Конец сцены обозначается целенаправленным изменением времени, изменением статуса персонажа, фокусом действия и/или местом.
Конец сцены обозначается целенаправленным изменением времени, изменением статуса персонажа, фокусом действия и/или местом.
Сцена 3.
После того, как Терри выходит из бара Джонни Френдли, он объявляет своему брату Чарли и двум головорезам, что Джоуи находится на крыше (Кадр 14). Затем Джоуи плачет, падая (после того, как его столкнули) с крыши (Кадр 15) и через веревку для стирки одежды (Кадр 16). Один бандит говорит, что кто-то упал с крыши (Кадр 17). Камера переключается на включение света в многоквартирном доме, из окон которого появляются люди (Кадр 18). Один головорез говорит, что Джоуи «думал, что будет петь для Комиссии по расследованию преступлений» (Кадр 19).). Терри выражает шок от того, что Джоуи был убит, а не просто велел «придумать», и отклоняет приглашение присоединиться к Чарли в баре Johnny Friendly’s Bar (все еще Shot 19). Далее следует изображение тела Джоуи, лежащего на земле в окружении разных людей (начало кадра 20). Кадр 19 — конец Сцены 3.
Кадр 19 — конец Сцены 3.
Мы многому учимся в Сцене 3. Ни секунды впустую. Это пишет в лучшем виде.
- Джоуи планирует дать показания в «Криминальной комиссии».
- Джоуи создает проблемы для Джонни Френдли.
- Джои не отреагировала на запугивание людей Дружелюбия.
- Дружелюбный, безжалостно решает проблемы.
- Головорезы Дружелюбия и Чарли проявляют бессердечное равнодушие.
- Терри удивлен, сбит с толку и шокирован тем, что Джоуи был убит.
Сцена 4.
Следующая сцена снята в переулке под квартирой Джоуи и, кажется, находится вне поля зрения Терри, который стоит возле бара Johnny Friendly’s в одиночестве.
В тот момент, когда отец Бэрри прибывает, чтобы отдать Джоуи последний обряд, полицейский встает и говорит женщине, что ее муж был убит пять лет назад (Кадр 20). На крупном плане полицейский слышит, как Поп Дойл (Pop Doyle) говорит, что не знает, толкнул Джоуи или упал, а женщина говорит, что Джоуи был единственным, с кем хватило смелости поговорить: «Эти следователи».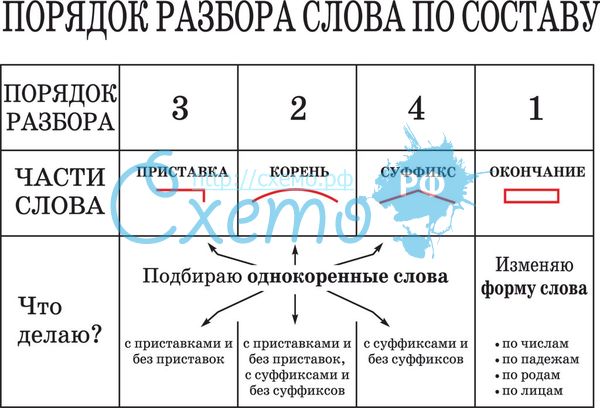 (Кадр 21). Отец Барри читает Джои последние обряды. Кто-то на заднем плане говорит: «Ничего не говори. Молчи. Ты проживешь дольше». (Кадр 22). Поп Дойл слушает, как кто-то говорит, что люди, которые говорят, в конечном итоге умирают, как Джоуи (Кадр 23). Когда отец Барри поднимает Эди с тела Джоуи, она спрашивает, кто хотел убить Джоуи (Кадр 24). Полицейский накрывает тело Джоуи газетой, но Эди бежит к телу Джоуи и срывает газету. На крупном плане отец Барри призывает Эди иметь «Время и Веру» и что он будет в церкви, если он ей понадобится (Кадр 25). Но Эди отчитывает его, говоря: «Вы когда-нибудь слышали о святом, скрывающемся в церкви?» (Кадр 26). Эди смотрит в сторону и плачет; «Я хочу знать, кто убил моего брата» (Кадр 27). Наконец, мы видим, как Биг Мак проходит мимо Терри, все еще стоящего возле бара Johnny Friendly’s Bar (Кадр 28). Терри делает паузу, затем следует за Биг Маком в бар (5:58 на DVD).
(Кадр 21). Отец Барри читает Джои последние обряды. Кто-то на заднем плане говорит: «Ничего не говори. Молчи. Ты проживешь дольше». (Кадр 22). Поп Дойл слушает, как кто-то говорит, что люди, которые говорят, в конечном итоге умирают, как Джоуи (Кадр 23). Когда отец Барри поднимает Эди с тела Джоуи, она спрашивает, кто хотел убить Джоуи (Кадр 24). Полицейский накрывает тело Джоуи газетой, но Эди бежит к телу Джоуи и срывает газету. На крупном плане отец Барри призывает Эди иметь «Время и Веру» и что он будет в церкви, если он ей понадобится (Кадр 25). Но Эди отчитывает его, говоря: «Вы когда-нибудь слышали о святом, скрывающемся в церкви?» (Кадр 26). Эди смотрит в сторону и плачет; «Я хочу знать, кто убил моего брата» (Кадр 27). Наконец, мы видим, как Биг Мак проходит мимо Терри, все еще стоящего возле бара Johnny Friendly’s Bar (Кадр 28). Терри делает паузу, затем следует за Биг Маком в бар (5:58 на DVD).
- Кадры 1–2 составляют сцену 1.
- Кадры 3–13 составляют сцену 2.
- Кадры 14–19 составляют сцену 3.
- Кадры 20–27 составляют сцену 4. Сцена 5.

Теперь мы готовы определить «Последовательность».
3. Определение «эпизода»
Если вы продолжите смотреть « На набережной » до отметки 11:00 на DVD, вы увидите, что Кадр 28 переносит нас в Сцену 5, которая конкретно вот что происходит в баре «Дружелюбие» и вдали от места убийства. Это совершенно другая составляющая истории. Сцены с 1 по 4 посвящены роли Терри в убийстве Джоуи и реакции ключевых свидетелей (Эди, отца Барри и Попа Дойла). Напротив, Сцена 5 фокусируется на Джонни Френдли и его мире; Убийство Джоуи почти не признается и, конечно, не движет действием. Таким образом, Сцены с 1 по 4 составляют основной структурный элемент структуры сценария, а именно 9 сцен.0007 ‘Последовательность’ . Сцена 5 — это начало следующей последовательности.
ПОСЛЕДОВАТЕЛЬНОСТЬ: Последовательность — это Сцена или ряд связанных Сцен, которые представляют собой последовательность связанных событий или идей, составляющих и продвигающих отдельный компонент повествования, сюжета и/или развития персонажа».
С этими определениями «Последовательности» и «Сцены» я затем посмотрел 132 фильма, чтобы определить, где Последовательности были очерчены в каждом фильме. Именно этот анализ представлен в Журнал сценарного мастерства Бумага.
КОНТРАСТЫ МЕЖДУ МОДЕЛЯМИ 19 И 8 ПОСЛЕДОВАТЕЛЬНОСТЕЙ
«Модель восьми последовательностей»
. Согласно записи в Википедии о «Сценарном мастерстве»:
«Структура из восьми последовательностей» — это система, разработанная Фрэнком Дэниелом, когда он был главой Программы написания сценариев для выпускников Университета Южной Калифорнии. Отчасти это основано на том факте, что на заре кинематографа технические вопросы вынуждали сценаристов делить свои истории на последовательности, каждая длиной в ролик (около десяти минут) (Gulino, 2005). Последовательный подход имитирует этот ранний стиль. История разбита на восемь эпизодов по 10-15 минут. Эпизоды служат «мини-фильмами», каждый со своей собственной сжатой трехактной структурой. Первые две последовательности объединяются, чтобы сформировать первый акт фильма. Следующие четыре составляют второй акт фильма. Последние две последовательности завершают развязку и развязку истории. Разрешение каждой последовательности создает ситуацию, которая устанавливает следующую последовательность».
Эпизоды служат «мини-фильмами», каждый со своей собственной сжатой трехактной структурой. Первые две последовательности объединяются, чтобы сформировать первый акт фильма. Следующие четыре составляют второй акт фильма. Последние две последовательности завершают развязку и развязку истории. Разрешение каждой последовательности создает ситуацию, которая устанавливает следующую последовательность».
Модель восьмисерийной структуры, таким образом, основана на практическом требовании многолетней давности о том, что фильмы должны быть разделены на 10-15-минутные сегменты из-за размера катушки с пленкой. Таким образом, длина и содержание последовательности кажутся произвольными. Предположение, по-видимому, состоит в том, что современные сценаристы «знают» о временном ограничении этой структуры киноленты и по-прежнему либо по своей природе, либо намеренно ей следуют. Однако вывод из результатов моего исследования состоит в том, что сценаристы этого не делают. Например, полезно сравнить модель восьми последовательностей с моделью девяти последовательностей. 0018 19-серийная модель ScreenWriting Science с примером из книги Пола Гулино: ‘Screenwriting: The Sequence Approach’ (2005):
0018 19-серийная модель ScreenWriting Science с примером из книги Пола Гулино: ‘Screenwriting: The Sequence Approach’ (2005):
Double Indemnity была написана для Билли Уайлдера и была номинирована на премию Seven Награды Академии. Вот три акта Двойная компенсация в восьмипоследовательной модели :
Акт I:
A: Вступительное признание Нефф и Филлис, оставляющая сообщение для Нефф.
B: Второй визит Неффа к Филлис и согласие убить мужа Филлис.
Акт II:
К: Неффу и Филлис мешает сломанная нога мистера Дитрихсона.
D: Нефф и Филлис убивают мистера Дитрихсона.
Э: Сначала Киз приходит к выводу, что смерть была несчастным случаем, а затем вызывает подозрения.
Ж: Нефф узнает, что Филлис замешана в предыдущем убийстве мужа; Нефф становится подозрительным
Акт III:
G: Нефф терпит откровения о Сачетти и приходит к выводу, что его единственная надежда — устранить ее. Он идет к ней домой и убивает ее.
Он идет к ней домой и убивает ее.
H: Нефф отправляет Сачетти обратно к Лоле, затем лично сталкивается с Кизом, пытается совершить последний побег, но терпит неудачу.
Разбивка ScreenWriting Science на , однако, отличается. Я сосредоточусь на Act III для сравнения.
Акт III, в том виде, в котором он представлен. Краткий обзор сценария «Двойная компенсация» фактически состоит из пяти эпизодов, а не из двух, каждый из которых преследует разные цели в повествовании. А именно:
Кульминация
ПОСЛЕДОВАТЕЛЬНОСТЬ 1 : После того, как Лола говорит Нефф, что подозревает, что у Зачетти и Филлис роман, и убила ее отца, Нефф узнает, что Киз тоже считает Зачетти сообщником Филлис и не подозревает Нефф.
ПОСЛЕДОВАТЕЛЬНОСТЬ 2 : В следующих двух клипах Нефф входит в дом Филлис с намерением убить Филлис за ее предательство и прикрыть свою причастность, инсценировав убийство Филлис Зачетти.
Но Филлис стреляет в Неффа первой, хотя после того, как она говорит, что любит его. Нефф убивает Филлис.
ПОСЛЕДОВАТЕЛЬНОСТЬ 3 : Возле дома Филлис Нефф решает не подставлять Зачетти. Он говорит Закетти, что Филлис солгала ему и что Лола действительно любит его.
ПОСЛЕДОВАТЕЛЬНОСТЬ 4 : В кабинете Неффа в здании страхового офиса. Киз подслушивает признание Неффа. Киз говорит Неффу, что он слишком ранен, чтобы сбежать.
Резолюция
ПОСЛЕДОВАТЕЛЬНОСТЬ 5 : У входа в здание страхового офиса. Нефф пытается сбежать, но падает. Киз вызывает скорую помощь. Они оба признают свою дружбу.
Различия в двух подходах четко видны между последовательностью G модели восьми последовательностей и последовательностями 3, 4 и 5 модели Screenwriting Science. Модель 19 последовательностей фокусируется на разделении сюжета на определяемые сюжетные единицы на основе сюжетных моментов и эмоционального воздействия.
Преимущество 19-серийной модели и резюме сценария для написания сценария
Наука сценарного мастерства использовала эвристический и объективный подход для определения структуры последовательностей сценариев и получения общего, единообразного шаблона. Каждое резюме сценария использует этот шаблон для представления структуры «Последовательность-сцена» успешных фильмов, чтобы вы могли использовать фильмы, похожие на тот, который вы пишете, в качестве модели.
Особое преимущество представления Резюме сценария в виде компонентов Последовательности заключается в том, что после того, как вы спланировали свой сценарий в соответствии с форматом Последовательности Науки о написании сценариев, становится намного проще писать определенные разделы для конкретных целей повествования. Модель ScreenWriting Science особенно полезна во втором акте, где определяются важные вехи. В каждом обзоре сценария у вас, по сути, есть план сценария! Комбинируя сценарии, подобные тому, который вы пишете, «Сводки сценариев» упростят создание вашего сюжета и написание реального сценария.
Модель ScreenWriting Science особенно полезна во втором акте, где определяются важные вехи. В каждом обзоре сценария у вас, по сути, есть план сценария! Комбинируя сценарии, подобные тому, который вы пишете, «Сводки сценариев» упростят создание вашего сюжета и написание реального сценария.
Сравнение последовательности с кластерным анализом молекулярных свойств и состава белков семейства глутатионпероксидазы
Исследовательская статья в Американском журнале биотехнологии и биоинформатики состав белков семейства глутатионпероксидазы
Shailesh Kumar1*, Sumit Govil2, Vikram Kumar1
ICMR-Национальный институт холеры и кишечных заболеваний, Индийский совет медицинских исследований, P 33 CIT Road, Scheme XM< Beliaghata, Kolkata 700010, West Bengal, India
Глутатионпероксидаза (GPx) — очень важный белок помогает в уничтожении экзогенных материалов из тела человека, которые, как сообщается, выполняют ту же работу в других организмах. Аминокислота селеноцистеин вносит вклад в структуру этого белка. Здесь проводится сравнительное исследование методов, основанных на последовательностях, и методов, основанных на свойствах, для всех выбранных последовательностей глутатионпероксидазы для человека. Была изучена база данных Swiss Prot, и было получено только 65 белков семейства GPx, из которых 18 отобранных последовательностей были использованы для дальнейшего анализа. Метод расстояний на основе последовательности анализа множественных последовательностей используется для поиска похожих групп. Затем все 18 последовательностей были изучены для анализа количества сайтов расщепления с последующей иерархической кластеризацией, которая представляет сайты расщепления на основе сходных групп. Кроме того, эти последовательности были вычислены для определения аминокислотного состава и различных свойств, таких как теоретический PI, индекс нестабильности, алифатический индекс и гидропатия, с последующей иерархической кластеризацией. Интересным фактом, полученным в этом исследовании, является то, что по сравнению с сайтами расщепления, основанными на кластеризации, и аминокислотным составом со свойствами, основанными на кластеризации, группы имеют сходный тип.
Аминокислота селеноцистеин вносит вклад в структуру этого белка. Здесь проводится сравнительное исследование методов, основанных на последовательностях, и методов, основанных на свойствах, для всех выбранных последовательностей глутатионпероксидазы для человека. Была изучена база данных Swiss Prot, и было получено только 65 белков семейства GPx, из которых 18 отобранных последовательностей были использованы для дальнейшего анализа. Метод расстояний на основе последовательности анализа множественных последовательностей используется для поиска похожих групп. Затем все 18 последовательностей были изучены для анализа количества сайтов расщепления с последующей иерархической кластеризацией, которая представляет сайты расщепления на основе сходных групп. Кроме того, эти последовательности были вычислены для определения аминокислотного состава и различных свойств, таких как теоретический PI, индекс нестабильности, алифатический индекс и гидропатия, с последующей иерархической кластеризацией. Интересным фактом, полученным в этом исследовании, является то, что по сравнению с сайтами расщепления, основанными на кластеризации, и аминокислотным составом со свойствами, основанными на кластеризации, группы имеют сходный тип. Эти похожие группы не имеют групп методов, основанных на последовательности отношений. Следовательно, мы заключаем, что для нахождения функционального сходства между различными последовательностями кластеризация методов, основанных на свойствах, более надежна по сравнению с методами, основанными на последовательностях, филогенетическими методами.
Эти похожие группы не имеют групп методов, основанных на последовательности отношений. Следовательно, мы заключаем, что для нахождения функционального сходства между различными последовательностями кластеризация методов, основанных на свойствах, более надежна по сравнению с методами, основанными на последовательностях, филогенетическими методами.
Ключевые слова: Глутатионпероксидаза; вычислительный анализ; иерархическая кластеризация; куратор; гидропатия.
Бесплатный полнотекстовый PDF
Как цитировать эту статью:
Шайлеш Кумар, Сумит Говил и Викрам Кумар. Сравнение последовательности с кластерным анализом молекулярных свойств и состава белков семейства глутатионпероксидазы. Американский журнал биотехнологии и биоинформатики, 2018 г.; 2:6 . DOI: 10.28933/ajobb-2018-01-0401
Ссылки:
1 Дж. Р. Артур, «Глутатионпероксидазы». Клеточные и молекулярные науки о жизни CMLS, 2001, 57. 13-14, 1825-1835.
13-14, 1825-1835.
2 Гордон С. Миллс, «Катаболизм гемоглобина I. Глутатионпероксидаза, фермент эритроцитов, защищающий гемоглобин от окислительного распада». Журнал биологической химии 1957, 1, 229, 89-197.
3 Акиб Икбал и др. «Восстановление гидропероксида тиоредоксин-специфическими изоферментами глутатионпероксидазы Arabidopsis thaliana». Журнал ФЭБС 2006, 273.24, 5589-5597.
4 Л. Ю., С. Венкатараман, М. К. Коулман, Д. Р. Шпиц, П. В. Верц, Ф. Э. Доманн. Глутатионпероксидаза-1 ингибирует индуцированную УФА экспрессию АР-2альфа в кератиноцитах человека. Biochem Biophys Res Commun. 2006, 4, 35, 1066-71.
5 S. Blankenberg, H. J. Rupprecht, C. Bickel, M. Torzewski, G. Hafner, L. Tiret, M. Smieja, F. Cambien, J. Meyer, K. J. Lackner, Активность глутатионпероксидазы 1 и сердечно-сосудистые события у пациентов с ишемической болезнью сердца. Н. англ. J. Med., 2003, 349, 1605-1613.
6 K Faucher, H Rabinovitch-Chable, J Cook-Moreau, G Barriere, F Sturtz, M Rigaud, Сверхэкспрессия GPX1 человека изменяет апоптотическое соотношение Bax и Bcl-2 в эндотелиальных клетках человека. Мол. Клетка. Биохим, 2005, 277, 81-87.
Мол. Клетка. Биохим, 2005, 277, 81-87.
7 С. Кумар, К. Бхадхадхара, С. Говил, Н. Матхур, А. Н. Патхак, исследования In-Silico для сравнительного анализа изоферментов пероксидов глутатиона у человека разумного. International Journal of Pharma and Bio Sciences, 2014, 4(B), 5, 352 – 363.
8 Консорциум UniProt – Деятельность Universal Protein Resource (UniProt) Nucleic Acids Res. 2014, 42: Д191-Д198.
9 Педро Ромеро и др. «Сложность последовательности неупорядоченного белка». Белки: структура, функция и биоинформатика, 200, 1, 42, 38-48.
10 Дж. А. Тенрейро Мачадо, Энтропийный анализ Шеннона геномного кода. «Математические проблемы в технике», 2012.
11 К. Тамура, Г. Стечер, Д. Петерсон, А. Филипски и С. Кумар, MEGA6: молекулярно-эволюционный генетический анализ, версия 6.0. Молекулярная биология и эволюция, 2013, 12, 30, 2725-2729.
12 Уильям Дж. Бруно, Д. Соччи Николас и Л. Халперн Аарон, «Взвешенное объединение соседей: основанный на правдоподобии подход к реконструкции филогении на основе расстояния». Молекулярная биология и эволюция, 2000, 1, 17, 189.-197.
Молекулярная биология и эволюция, 2000, 1, 17, 189.-197.
13 Инструмент ExPASy PeptideCutter: Gasteiger E., Hoogland C., Gattiker A., Duvaud S., Wilkins M.R., Appel R.D., Bairoch A.;Инструменты идентификации и анализа белков на сервере ExPASy;(In) John M. Walker ( изд.): Справочник по протоколам протеомики, Humana Press (2005).
14 Берхин Павел. «Обзор методов кластеризации интеллектуального анализа данных». Группировка многомерных данных. Springer Berlin Heidelberg, 2006. 25–71.
15 Gasteiger E., Hoogland C., Gattiker A., Duvaud S., Wilkins M.R., Appel R.D., Bairoch A.;Инструменты идентификации и анализа белков на сервере ExPASy;(In) John M. Walker (ed): The Справочник по протоколам протеомики, Humana Press (2005) — (ProtParam).
Условия использования/Политика конфиденциальности/Отказ от ответственности/Другие политики:
Вы соглашаетесь с тем, что, используя наш сайт/услуги, вы прочитали, поняли и согласились соблюдать все наши условия использования/политику конфиденциальности / заявление об отказе от ответственности / другие правила (нажмите здесь, чтобы узнать подробности).
CC BY 4.0
Эта работа и ее PDF-файл(ы) находятся под лицензией Creative Commons Attribution 4.0 International License.
Аминокислотный состав — Протеопедия, жизнь в 3D
Материал из Proteopedia
Перейти к: навигация, поиск
Состав аминокислот белка относится к процентному содержанию каждой аминокислоты в последовательности этого белка. Процент, иногда называемый мольным процентом, рассчитывается для каждой из 22 стандартных аминокислот как количество этой аминокислоты, деленное на общее количество аминокислот в белковой цепи или молекуле.
Содержимое
|
Пример
В качестве примера приведен аминокислотный состав ацетилхолинэстеразы Torpedo californica (тихоокеанский электрический скат), структура которого 2ace. Последовательность канонической изоформы имеет длину 586. В зрелой форме сигнальный пептид удаляется с амино-конца, а пропептид удаляется с карбокси-конца, оставляя зрелую длину 537 с таким составом:
Последовательность канонической изоформы имеет длину 586. В зрелой форме сигнальный пептид удаляется с амино-конца, а пропептид удаляется с карбокси-конца, оставляя зрелую длину 537 с таким составом:
| Эта гистограмма состава была создана с помощью калькулятора состава/молекулярного веса Protein Information Resource (PIR). Белковые последовательности легко получить на UniProt.Org или просмотреть запись PDB в FirstGlance в Jmol и щелкнуть последовательности. Вы можете выровнять геномную полноразмерную последовательность из UniProt с экспериментально кристаллизованной последовательностью. Вот инструкции. |
Средние составы
Средние составы были рассчитаны для большого количества белков из различных таксонов. Они сведены в таблицу, которую можно загрузить с помощью таблицы amino-acid-composition.xlsx.zip. Обнадеживает согласие между таблицами, составленными в 1993, 1998 и 2008 годах (цитаты приведены в электронной таблице).
Вышеупомянутые проценты были определены для нескольких тысяч последовательностей различных белков длиной 200 остатков, с идентичностью последовательностей менее 50% [1] . Эти данные включены в приведенную выше электронную таблицу.
Детерминанты аминокислотного состава
GC-содержание генома организма является сильнейшим детерминантом аминокислотного состава на уровне генома. [2] [3] [4] .
Другие, более слабые воздействия:
- Температуры роста (мезофилия/термофилия/гипертермофилия). У термофилов больше глутаминовой кислоты (с уменьшением глутамина), а также больше лизина и аргинина [2] . Вероятно, это связано с большим количеством солевых мостиков в белках термофилов, которые, как полагают, способствуют термостабильности [5] .
- Длина цепи . Белки термофилов в среднем короче, чем у мезофилов. Средние длины 283 и 340 соответственно [2] . Исследование около 550 000 белков длиной 50-200 аминокислот [1] пришло к выводу:
- Увеличиваются по длине, достигают плато: Ala, Asp, Glu, Gly, Pro, Val; меньшее увеличение для Gln и Thr.
- Уменьшаются с длиной: Cys, Phe, His, Ile, Lys, Met, Asn, Ser.
- Leu и Tyr самые высокие в коротких и длинных цепях и реже в белках среднего размера.
- Пики Arg в белках среднего размера.
- Trp постоянна и составляет около 1,4% для длин 75-200.
- Линкеры по сравнению с доменами : Линкеры между доменами имеют больше полярных остатков, тогда как компактные домены имеют больше гидрофобных остатков [3] .
- Среда обитания : Окружающая среда, в которой живет организм, оказывает незначительное влияние на средний состав его белков [4] .
- Композиционная изменчивость ранжирует археи > бактериофаги > эукариоты [3] .
 Исследование около 550 000 белков длиной 50-200 аминокислот [1] пришло к выводу:
Исследование около 550 000 белков длиной 50-200 аминокислот [1] пришло к выводу:Калькуляторы состава
- Калькулятор состава/молекулярного веса Protein Information Resource (PIR) создает очень полезную гистограмму (см. пример выше), но не предоставляет готовую таблицу.
 пример выше), но не предоставляет готовую таблицу.
пример выше), но не предоставляет готовую таблицу.- EMBOSS-PepStats EMBL-EBI создает таблицу, которую легко импортировать в электронную таблицу. В таблице есть однобуквенные и трехбуквенные сокращения аминокислот, , отсортированные по однобуквенным кодам .
| Импорт данных композиции в Excel: Скопируйте только столбцы данных, вставьте в текстовый редактор и сохраните в обычный текстовый файл. В Excel в существующей (возможно, пустой) электронной таблице Файл, Импорт, Текст. Отметьте 3 параметра разделителя: Tab, Space, рассматривать последовательные разделители как один. Приступить к импорту. |
- ProtParam ExPASy создает таблицу, которую легко импортировать в электронную таблицу. В таблице есть как однобуквенные, так и трехбуквенные сокращения аминокислот, , отсортированные по трехбуквенным кодам . Он также предлагает вывод CSV, альтернативный формат, понятный электронным таблицам.
Ссылки
- ↑ 1,0 1,1 Каруго О. Аминокислотный состав и размер белка. Белковая наука. 2008 Декабрь; 17 (12): 2187-91. doi: 10.1110/ps.037762.108. Epub 2008, 9 сентября. PMID: 18780815 doi: http://dx.doi.org/10.1110/ps.037762.108
- ↑ 2.0 2.1 2.2 Текая Ф., Ерамян Э., Дуджон Б. Аминокислотный состав геномов, образ жизни организмов и эволюционные тенденции: глобальная картина с анализом соответствия. Ген. 2002 4 сентября; 297(1-2):51-60. doi: 10.1016/s0378-1119(02)00871-5. PMID: 12384285 doi: http://dx.doi.org/10.1016/s0378-1119(02)00871-5
- ↑ 3,0 3,1 3,2 Брюн Д., Андраде-Наварро М.А., Миер П. Сравнение аминокислотного состава доменов и линкеров в масштабах всего протеома. Примечания BMC Res. 2018 9 февраля; 11 (1): 117. doi: 10.1186/s13104-018-3221-0. PMID: 29426365 doi: http://dx.doi.org/10.1186/s13104-018-3221-0
- ↑ 4.0 4.1 Moura A, Savageau MA, Alves R. Признаки относительного аминокислотного состава организмов и окружающей среды.
 Аминокислотный состав и размер белка. Белковая наука. 2008 Декабрь; 17 (12): 2187-91. doi: 10.1110/ps.037762.108. Epub 2008, 9 сентября. PMID: 18780815 doi: http://dx.doi.org/10.1110/ps.037762.108
Аминокислотный состав и размер белка. Белковая наука. 2008 Декабрь; 17 (12): 2187-91. doi: 10.1110/ps.037762.108. Epub 2008, 9 сентября. PMID: 18780815 doi: http://dx.doi.org/10.1110/ps.037762.108