Слова «порог» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «порог» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «порог» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «порог».
Содержимое:
- 1 Слоги в слове «порог» деление на слоги
- 2 Как перенести слово «порог»
- 3 Морфологический разбор слова «порог»
- 4 Разбор слова «порог» по составу
- 5 Сходные по морфемному строению слова «порог»
- 6 Синонимы слова «порог»
- 7 Ударение в слове «порог»
- 8 Фонетическая транскрипция слова «порог»
- 9 Фонетический разбор слова «порог» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «порог»
- 11 Сочетаемость слова «порог»
- 12 Значение слова «порог»
- 13 Склонение слова «порог» по подежам
- 14 Как правильно пишется слово «порог»
- 15 Ассоциации к слову «порог»
Слоги в слове «порог» деление на слоги
Количество слогов: 2
По слогам: по-рог
Как перенести слово «порог»
по—рог
Морфологический разбор слова «порог»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: мужской;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
порог
Разбор слова «порог» по составу
| порог | корень |
| ø | нулевое окончание |
порог
Сходные по морфемному строению слова «порог»
Сходные по морфемному строению слова
Синонимы слова «порог»
1. флютбет
флютбет
2. король
3. боровик
4. фахбаум
5. порожек
6. падун
7. преддверие
8. граница
9. возвышение
10. ригель
11. предел
12. предельная возможность
13. перепад
14. водоскат
15. дальше некуда
16. водопад
Ударение в слове «порог»
поро́г — ударение падает на 2-й слог
Фонетическая транскрипция слова «порог»
[пар`ок]
Фонетический разбор слова «порог» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| п | [п] | согласный, глухой парный, твёрдый, шумный | п |
| о | [а] | гласный, безударный | о |
| р | [р] | согласный, звонкий непарный (сонорный), твёрдый | р |
| о | [`о] | гласный, ударный | о |
| г | [к] | согласный, глухой парный, твёрдый, шумный | г |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 5 букв и 5 звуков.
Буквы: 2 гласных буквы, 3 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «порог»
Едва мы переступили её порог, спичка в руке у моего друга погасла, но он тут же без малейшего звука зажёг другую.
Источник: Уильям Хорнунг, Первое дело Раффлза (сборник).
После чего добротная дубовая дверь разлетелась мелкой щепой, а на пороге появился чёрт…
Источник: Е. А. Самойлова, Чужой трон, 2005.
Тут-то и появилась она — тихо и незаметно возникла на пороге моего кабинета, словно давно там стояла.
Источник: Светлана Алешина, Бальзам на душу, 2003.
Сочетаемость слова «порог»
1. болевой порог
2. высокий порог
3. днепровские пороги
4.
5. порог квартиры
6. порог комнаты
7. страж порога
8. через мгновение на пороге
9. через минуту на пороге
10. переступить порог
11. стоять на пороге
12. остановиться на пороге
13. (полная таблица сочетаемости)
Значение слова «порог»
ПОРО́Г , -а, м. 1. Брус на полу под дверью (обычно деревянный). (Малый академический словарь, МАС)
Склонение слова «порог» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | порог | пороги |
| РодительныйРод. | чего? | порога | порогов |
| ДательныйДат. | чему? | порогу | порогам |
| ВинительныйВин. | что? | порог | пороги |
| ТворительныйТв. | чем? | порогом | порогами |
ПредложныйПред. | о чём? | пороге | порогах |
Как правильно пишется слово «порог»
Орфография слова «порог»Правильно слово пишется: поро́г
Нумерация букв в слове
Номера букв в слове «порог» в прямом и обратном порядке:
- 5
п
1 - 4
о
2 - 3
р
3 - 2
о
4 - 1
г
5
Ассоциации к слову «порог»
Косяк
Опочивальня
Жилища
Замер
Сени
Дверь
Чувствительность
Зрелость
Ливрея
Нерешительность
Горница
Хижина
Прихожая
Коврик
Дворецкий
Халатик
Избушка
Спальня
Щеколда
Кабинет
Передник
Гостиная
Скрип
Детина
Фартук
Водопад
Изба
Зала
Засов
Юрт
Половица
Хата
Полушубок
Халат
Болевой
Заспанный
Застылый
Стоялый
Постоялый
Дверной
Дородный
Входной
Нерешительный
Широкоплечий
Давешний
Седовласый
Заплаканный
Стоящий
Невысокий
Коренастый
Махровый
Переступить
Перешагнуть
Переступать
Отвориться
Распахнуться
Ступить
Шагнуть
Топтаться
Споткнуться
Замешкаться
Отворить
Появиться
Возникнуть
Открыться
Задержаться
Вкопать
Приостановиться
Переминаться
Распахнуть
Скрипнуть
Замереть
Помедлить
Всклокочить
Остановиться
Приоткрыться
Затворить
Запыхаться
Пускать
Пустить
Сгорбить
Застынуть
Постучаться
Перетащить
Обернуться
Захлопнуть
Проесть
Постучать
Закутать
Вышвырнуть
Отпереть
Стучаться
Превысить
- Материализоваться
Остолбенеть
Пениться
Захлопнуться
Стоя
Настежь
Дома
КИМы на целый учебный год по русскому языку для 4 класса.

Контрольные работы по русскому языку 4-й класс .
Административный контрольный диктант по теме «Повторение изученного в 3-м классе» (входная работа)
1 четверть 15.09.2016
«Клюква»
Кислая и очень полезная для здоровья ягода клюква растет летом, а собирают её поздно осенью. Самая сладкая клюква бывает весной, когда пролежит всю зиму в снегу.
В начале апреля дети отправились на болото. Сначала дорога была широкая. Потом она превратилась в узкую тропку. Вдоль тропы стояли сухие травы. Можно долго ходить по болоту и не понять, что под ногами клюква. Ягоды прячутся в болотных кочках и не видны. Наклонился взять одну ягодку, а вытянул длинную зелёную ниточку со многими клюквинками.
По М. Пришвину
Слова для справок: растёт, бывает, превратилась.
Грамматические задания:
1. Выпишите по одному слову с орфограммами корня: парными согласными, безударными гласными, непроизносимыми согласными. Подберите проверочные слова, обозначьте орфограммы.
Подберите проверочные слова, обозначьте орфограммы.
2. Выполните звуко – буквенный разбор слова: 1 вариант – ягода, 2 вариант – поздно.
3. Обозначьте грамматическую основу: 1 вариант – в третьем предложении, 2 вариант – в шестом предложении.
Контрольные работы по русскому языку 4-й класс
1 четверть
Обучающее изложение «Кот – ворюга».
Кот – ворюга.
К нам повадился какой – то кот. Мы не знали, как его поймать. Он так ловко прятался, что никто из нас его толком не видел.
Только через неделю удалось установить, что у кота разорвано ухо и отрублен кусок грязного хвоста. Это был кот, потерявший всякую совесть, кот – бродяга и бандит. Звали его за глаза Ворюгой. Он воровал всё: рыбу, мясо, сметану и хлеб.
Один раз нам удалось поймать кота. Это оказался тощий кот – беспризорник. Сначала мы хотели его как следует проучить. Потом решили накормить его.
Потом решили накормить его.
Втащили кото в чулан и дали жаренную свинину, заливное из окуней. Творожники, сметану.
Кот ел больше часа. Он вышел из чулана, сел на порог и принялся умываться, а потом растянулся у печки.
С этого дня он у нас прижился и перестал воровать.
Контрольные работы по русскому языку 4-й класс
1 четверть
Контрольная работа «Проверь себя» №1 по разделу «Повторяем – узнаём новое» (Учебник, стр.34)
1.Ответьте на вопросы (устно).
— Какие цели могут быть у собеседника в речевом общении?
— Каковы основные правила успешного общения?
— Что такое диалог и что такое монолог?
— Каковы основные признаки текста?
2. Проверьте своё умение расставлять в предложениях недостающие запятые. Что они выделяют в данных предложениях?
1. Что ты рано в гости осень к нам пришла? (А. Плещеев.)
2. Выйди радуга – дуга на зелёные луга.
Выйди радуга – дуга на зелёные луга.
3. До свидания старый год! Грустно расставаться. (Р. Заславский.)
3. Спишите рассказ А. Бачай. Определите его тему. Озаглавьте текст.
Живём мы вместе с котом Клёпой и кошкой Мартой. Однажды накормила их на ночь и пошла спать.
Разбудил меня стук, вроде кто – то в доме в футбол играет. Встала и увидела такую сцену. Клёпа прыгает по полу с банкой на голове, в которой осталось молоко.
Вынесла Клёпу из дома во двор, разбила аккуратно камнем банку и освободила его. Кот прыгнул на меня и стал лизать лицо и руки в знак благодарности. Вот такая история.
Контрольные работы по русскому языку 4-й класс
1 четверть
Контрольный диктант «Осень» по разделу «Повторяем – узнаём новое» по теме «Текст как речевое произведение».
Осень
Ранняя осень. Красив и печален русский лес в эти чудесные дни. Гущу золотой листвы прорезают объятые огнём клёны. Медленно летят с лёгкие пяточки листьев. Между деревьями блещут серебром тонкие нитки паутины Краснеет поздний гриб. В лесу тишина. Только грустно шелестит под ногами мягкий ковёр листвы.
Медленно летят с лёгкие пяточки листьев. Между деревьями блещут серебром тонкие нитки паутины Краснеет поздний гриб. В лесу тишина. Только грустно шелестит под ногами мягкий ковёр листвы.
Воздух свежий и прозрачный. Вода в лесных ручьях чистая и холодная. Ещё зелёный стоит дуб. Но вершины берёз уже оголились.
По И. Соколову — Микитову
Слова для справок: медленно.
Грамматические задания:
1. Напишите, к какому типу относится этот текст. Выпишите словосочетания, доказывающие это.
2. Выполните звуко – буквенный разбор слова:
1 вариант – грустно,
2 вариант – листья.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
1 четверть 07.10. 2016
Контрольный диктант «Гроза» по разделу «Язык как средство общения» по теме «Средства общения»
Гроза.
Надвигалась летняя гроза. Гигантская лиловая туча медленно поднималась над лесом. Низкие ракиты шелестели и лепетали. Резкий ветер загудел в вышине. Деревья забушевали. Большие капли дождя яростно застучали по листьям. Слепящая длинная молния полосой пересекла мрачное небо. Раздался оглушительный треск. Загрохотал гром. Дождь полил ручьями.
Гигантская лиловая туча медленно поднималась над лесом. Низкие ракиты шелестели и лепетали. Резкий ветер загудел в вышине. Деревья забушевали. Большие капли дождя яростно застучали по листьям. Слепящая длинная молния полосой пересекла мрачное небо. Раздался оглушительный треск. Загрохотал гром. Дождь полил ручьями.
Но вот опять весело засияло яркое солнце. Воздух стал свежим и лёгким. Как всё радостно блестит после дождя! Как чудесно пахнут душистая земляника и грибы!
По И. Тургеневу.
Грамматические задания:
1. Выпишите три слова с проверяемыми безударными гласными, подберите проверочные слова, обозначьте орфограмму.
2. Выполните звуко – буквенный разбор слова: 1 вариант – дождь, 2 вариант – яростно.
3. Обозначьте грамматическую основу: 1 вариант – в четвёртом предложении, 2 вариант – в третьем предложении.
4. Обозначьте ударение в словах.
Хвоя, банты, щавель, торты, звонит, понял, задали, инструменты, свёкла, шофёр.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
1 четверть 08.10. 2016
Контрольная работа «Проверь себя» №2 по разделу «Язык как средство общения» по теме «Средства общения» (Учебник, стр.51)
1.Закончите предложение. Запишите его.
Самое главное средство общения — …
2. Укажите количество звуков и букв в данных словах.
Одуванчик, мяч, речь, ель, ёжик, бурьян.
3. Разделите слова сначала на слоги, а потом на части для переноса. Все ли слова можно разделить для переноса?
Майка, встретил, ябеда, акация, мою.
4. Сделайте звуко – буквенный разбор каждого слова. Подчеркните буквы, обозначающие два звука.
Люлька, жирный, ёлка, вьюн, объявит.
5. Запишите текст, раскрывая скобки и вставляя пропущенные буквы, где это необходимо.
(В)солнеч..ный день осен..ю (на)опушке елового леса собрались м..лодые в..сёлые берё..ки, как будто там, в еловом л. .су, им стало хол..дно, скуч..ной стала их ж..знь. Они (за)хотели (по)греться на открытом м..стеч..ке. Так в д..ревнях ст..рики выходят (на)солнышко и с..дят (на)скамееч..ках возле своих д..мов.
.су, им стало хол..дно, скуч..ной стала их ж..знь. Они (за)хотели (по)греться на открытом м..стеч..ке. Так в д..ревнях ст..рики выходят (на)солнышко и с..дят (на)скамееч..ках возле своих д..мов.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
1 четверть 18.10. 2016.
Контрольное списывание «Мама» по разделу «Язык как средство общения» по теме «Главные и второстепенные члены предложения»
Мама
Ты всегда будешь помнить мамин голос, мамины глаза, мамины руки. Мама научила тебя ходить, говорить. Мама прочла тебе первую книгу. От мамы ты узнал имена птиц – воробей, ласточка, синица. Узнал, что у каждого цветка есть имя – ромашка, василёк, иван – да- марья. Мама всегда рядом с тобой. Всё, что ты видел, как бы начиналось с мамы. И любовь к Родине начинается с любви к маме.
По Ю. Яковлеву.
Примечание. Обратить внимание детей на написание подчёркнутых слов.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
1 четверть 27.10. 2016
Обучающее изложение «Первый снег».
Первый снег
Таня посмотрела в окно. Небо было полно снежинок. Снежинки летали, кружились и падали. Они ложились на деревенские крыши, чёрствую грязь на дороге, замёрзшие лужицы, голые ветки деревьев.
Таня вышла во двор и стала разглядывать снежинки. В воздухе они похожи на лёгкий пух. А поближе – звёздочки. Все разные. У одной лучики были широкие, а у другой они торчали, как острые стрелки.
После обеда Таня не узнала свою деревню. Вся она стала белая. И крыши, и дороги, и огороды были белые.
Выглянуло солнышко, снег заблестел и заискрился. Зима пришла.
По Л. Воронковой
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
1 четверть 29.10. 2016
Контрольный диктант «Трусиха» по разделу «Язык как средство общения» по теме «Предложение»
Трусиха
Ребята играли в войну. Валю с братом Андрюшей в игру не принимали. Валя была трусихой. А Андрюша умел только ползать.
Валю с братом Андрюшей в игру не принимали. Валя была трусихой. А Андрюша умел только ползать.
Вдруг ребята услышали крики. Пёс Лохмач сорвался с цепи. Дети бросились врассыпную, только Андрюша остался на улице.
Валя кинулась к брату. Огромный пёс нёсся прямо на девочку. Она заслонила Андрюшу, бросила в собаку игрушку и громко закричала.
Наперерез Лохмачу бежал сторож. Он схватил пса за ошейник и увёл.
Ребята выходили из своих убежищ. Счастливый Андрюша уже улыбался, а Валя плакала навзрыд. Она очень испугалась.
По Н. Артюховой
Слова для справок: наперерез, навзрыд, врассыпную.
Грамматические задания:
1.Выпишите предложения к схемам.
1вариант О,О, и О
2вариант О и О
2. Выпишите словосочетания, графически обозначьте главное и зависимое слова:
1вариант – из второго предложения третьего абзаца.
2вариант – из первого предложения последнего абзаца.
3. Выполните звуко – буквенный разбор слов:
1 вариант – вдруг,
2 вариант – очень.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 1 четверть 30.10. 2016
Контрольная работа№3 по разделу «Язык как средство общения» для обобщения знаний по темам «Предложение» и «Словосочетание» (Учебник, стр.80)
1.Закончите предложение. Запишите их.
Предложения по цели высказывания бывают: … .
По интонации предложения могут быть … .
Главные члены предложения – это … .
Кроме главных членов, в предложении также могут быть … .
2. Выберите верный ответ.
а) Однородные члены предложения являются одним и тем же членом предложения, отвечают на один и тот же вопрос. Относятся к одному и тому же слову в предложении.
б) Запятая между однородными членами ставится в том случае, если они соединяются с помощью союзов а, но или с помощью интонации перечисления (без союзов).
в) Запятая между однородными членами не ставится, если они соединяются с помощью союзов а, но или с помощью интонации перечисления (без союзов).
г) Запятая перед союзом и при однородных членах предложения ставится, если этот союз употребляется один раз.
3. Ответьте на вопросы.
а) Какое предложение называется сложным?
б) Какие знаки препинания ставятся в сложном предложении?
в) Что такое словосочетание?
г) Как связаны слова в словосочетании?
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
2 четверть 14.11. 2016.
Контрольная работа № 4 по разделу «Язык как средство общения» по теме «Слово и его значение»
(Учебник, стр.93)
1.Выберите верный ответ.
Слово имеет только звуко – буквенную форму.
У слова есть лексическое значение и звуко – буквенная форма.
2. Распределите слова в пять синонимических групп.
Сообщение, забавно, храбрый, весть, потешно, отважный, известие, добрый, глаза. Комично, смелый, сердечный, очи, мужественный, неустрашимый, душевный, новость.
3. Подберите к каждому из данных слов синоним и антоним.
Тихий – … .
Тонкий – … .
Радость – … .
Правда – … .
Смеяться – … .
Прибежать – … .
4. Приведите свои примеры слов – омонимов.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
2 четверть 25.11. 2016
Контрольный диктант «Кукушка» по теме «Правописание предлогов и приставок»
Кукушка
Все птицы вьют гнёзда и высиживают птенцов. Но у кукушки другие повадки. Улетит пеночка от гнезда за кормом. Оставит яйца без присмотра. Тут кукушка и подкинет своё яйцо птичке в гнездо.
Вот высидят пеночки кукушонка. Подрос он и пеночкиных птенчиков из гнезда выкинул на землю. Остался у птиц один большой взъерошенный птенец.
Целый день носят пеночки в клювах гусениц, личинок, жуков. А кукушонок съест корм, разевает широко рот и снова пищит. А мать его беззаботно летает по лесу.
Слова для справок: беззаботно, снова.
Грамматические задания:
1. Спишите стихотворение – шутку, раскрывая скобки. Обозначьте сверху существительное с предлогом и глагол.
Я, не жалея мыла,
Нос терпеливо мыла.
Зависело б (от)мыла,
Веснушки б я (от)мыла.
Я. Козловский
2. Выпишите по одному слову с разделительным твёрдым и разделительным мягким знаками, графически объясните орфограммы.
3. Выпишите по одному слову с орфограммой – гласным и с орфограммой – согласным в приставке. Обозначьте орфограммы.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
2 четверть 05.12. 2016
Обучающее изложение «Горькая вода»
Горькая вода
Толя с Витей возвращались домой из леса.
По дороге шла старушка с ведром воды. Видно было, что ей тяжело.
Витя побежал помогать старушке, а Толя прошёл мимо. Старушка от всего сердца благодарила мальчика.
Однажды Толя шёл с прогулки. Он захотел пить. Постучал в одну избу. Дверь открыла знакомая старушка. Она приветливо встретила Толю, дала воды. Мальчик покраснел. Он торопливо выпил воды и выбежал на улицу. Вода показалась ему горькой.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 2 четверть 15.12. 2016
Контрольная работа № 5 по разделу «Язык как средство общения» по теме «Состав слова» (Учебник, стр.111)
1.Разберите по составу данные слова.
Перекрёсток, впадина, старенькая, уедем.
2. Распределите слова в группы по значению корня. Корень в словах каждой группы выделите.
Слепой, ослепнуть, слипнуться, прилипнуть, липкий, ослепительный.
3. Прочитайте утверждения и выберите верные ответы.
а) Разделительный твёрдый знак пишется только после приставки, оканчивающейся на согласную букву, перед корнем, который начинается с одной из гласных букв: е, ё, ю, я.
б) Разделительный твёрдый знак пишется только после приставки, оканчивающейся на согласную букву, перед корнем, который начинается с одной из гласных букв: е, ё, ю, я, и.
в) Сложными называют слова, в которых два корня.
4. Закончите предложения.
Корень слова – это … .
Корень выражает … значение слова.
Основа слова – это … .
5. Запишите, раскрывая скобки и вставляя, где нужно, пропущенные буквы в слова.
(Под)кинуть (под)дерево, (за)вернуть (за)угол.
Раз..ехаться, за..ехать, з..говорить, пр..дполагать, д..говориться.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
2 четверть 16.12. 2016
Контрольный диктант «Беда» по разделу «Язык как средство общения» по теме «Состав слова».
Беда
Был ясный день. Ярко светило весеннее солнце. В ельнике было жарко. Подул лёгкий ветерочек. В воздухе чувствовался резкий запах дыма. Туристы не затушили костёр. Загорелась сухая трава. Это большая опасность для леса. Огонь подобрался к старой ели. Занялись нижние ветки. Вот узкие языки пламени стали лизать муравейник.
В воздухе чувствовался резкий запах дыма. Туристы не затушили костёр. Загорелась сухая трава. Это большая опасность для леса. Огонь подобрался к старой ели. Занялись нижние ветки. Вот узкие языки пламени стали лизать муравейник.
Мы отломили тяжёлые еловые лапы и стали тушить пожар. От муравейника тонкой струйкой шёл дымок. Выносливые муравьи прожили морозную и голодную зиму. Но от лесного пожара не спаслись.
Поникли молодые деревья. Птицы перестали петь. На поляне остались чёрные отметины. Природа долго будет зализывать раны. Берегите лес!
Слова для справок: муравейник, загорелась.
Грамматические задания:
1.Выпишите любую группу однокоренных слов, разберите их по составу.
2. Образуйте от слов 2 – 3 однокоренных слов при помощи суффиксов — ик -, — ёнок -, — их -, — ок -, — ат -, — ят -.
1 вариант – слон
2 вариант – волк
3.Выпишите три глагола с приставками, выделите приставки.
Уровень повышенной сложности.
4.Запишите слова, подчеркните то, в котором нет суффикса.
Точка, внучка, кочка.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
2 четверть 24.12. 2016Контрольная работа № 6 по разделу «Язык как средство общения» по теме «Слово как часть речи»
(Учебник, стр.119)
1.Выберите верный ответ.
а) Части речи – это имя существительное, имя прилагательное, местоимение, глагол, предлог, союз.
б) Части речи – это приставка, корень, суффикс, окончание, основа.
2.Распределите слова по группам (частям речи).
Хороший, похорошеть, синева, синенький, синеть, далёкий, даль, удалить, ласка, ласковый, ласкать.
3.Укажите, к какой части речи относится каждое из выделенных слов.
Мы построили скворечню для весёлого скворца.
(Е. Тараховская)
4.Образуйте с каждым из данных корней одно имя существительное, одно имя прилагательное и один глагол.
Весел — , чёрн — , син — .
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 2 четверть 25.12. 2016.
Контрольный диктант «В тундре» по разделу «Язык как средство общения» по теме «Слово как часть речи».
В тундре
Ползёт по тундре трактор. Летом местные болота иначе не пройти. Шипы стальных гусениц срывают зелёный покров тундры. А под ним сплошная жидкая грязь. Другая машина по старому следу не пойдёт. Можно завязнуть. Водители ищут новую дорогу.
Ужасная картина предстаёт взору с самолёта. Вся тундра будто ножом изрезана. След гусениц заживёт через десятки лет. Ведь северные мхи растут медленнее деревьев! А без мха тяжело прожить северным оленям и другим животным тундры.
Грамматические задания:
1.Подчеркните главные члены предложения и определите части речи:
1 вариант – в первом предложении;
2 вариант – в восьмом предложении.
2. Разберите слова как части речи.
1 вариант – (по) тундре, местные, срывают.
2 вариант – гусениц, ползёт, ужасная.
3. Укажите части речи и разберите слова по составу.
1 вариант – ползёт, зелёный, северные.
2 вариант – стальных, заживёт, покров.
Уровень повышенной сложности.
Разберите слова по составу, найдите лишнее слово.
Рыбак, чужак, дурак, простак, пятак.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
3 четверть 12.02. 2016
Контрольный диктант «Лес» по разделу «Слово как часть речи» по теме «Имя существительное»
Лес
Лес – это большой город с тысячами жителей. Разными жилищами застроен этот гигант. В глубоких норках, тёплых гнёздах, просторных берлогах, крошечных хибарках поселились лесные обитатели. Жители лесов – звери, птицы, насекомые. Весь день они хлопочут по хозяйству.
С утра до вечера снуют птицы меж стволов деревьев, кустов, веток. Поймают жуков, гусениц – несут своим птенчикам. Не сидят без дела работящие муравьи. Они поедают вредителей леса. Охраняют лес от болезней хищники – лесные санитары.
Поймают жуков, гусениц – несут своим птенчикам. Не сидят без дела работящие муравьи. Они поедают вредителей леса. Охраняют лес от болезней хищники – лесные санитары.
Леса наши – это кладезь богатств. Берегите деревья, кусты, травы. Не разоряйте птичьих гнёзд. Не разрушайте муравейники. Будьте природе друзьями и рачительными хозяевами.
Слова для справок: хибарки, кладезь, рачительные.
Грамматические задания:
1. Выпишите по три словосочетания с именами существительными во множественном числе, определите падеж и склонение.
2.Спишите предложения. Имена существительные, данные в скобках, запишите в форме родительного падежа множественного падежа.
Сок (апельсины) и (мандарины) содержит много (витамины). Бабушка сварила варенье из (вишня) и (абрикосы)
3. Выполните разбор имён существительных как части речи:
1 вариант – вредителей,
2 вариант – гусениц.
4. Запишите противоположные по значению фразеологизмы парами.
Семи пядей во лбу, ворон считать, держать ухо востро, без царя в голове.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
3 четверть 03.03.2017.
Контрольный диктант «Зимний день» по разделу «Слово как часть речи» по теме «Имя прилагательное»
Зимний день
Стоит чудесный зимний день. Над нами ясное голубое небо. Всё вокруг покрыто пушистым снежным ковром. Яркий свет слепит глаза. Мы въехали в лес. Деревья стоят словно в сказке. На стволе высокой сосны мы заметили пёстрого дятла. Он ловко долбит шишку. Синички и воробьи дружно подбирают сосновые семена. Рыжая белка быстро мелькнула среди деревьев.
Под сосной видны следы. Это заяц – беляк пробежал по нетронутому снегу.
Хорошо в лесу! Легко дышать свежим морозным воздухом.
Грамматические задания:
1. Выпишите из текста три словосочетания «прилагательное + существительное». Выделите в именах прилагательных окончания, определите падеж.
Выделите в именах прилагательных окончания, определите падеж.
2. Составьте словосочетания по схемам.
«прилагательное + существительное, м.р., Т.п.»
«прилагательное + существительное, ср.р., Д.п.»
«прилагательное + существительное, ж.р., П.п.»
3. Спишите, вставляя подходящие по смыслу имена прилагательные.
В …, …, … убору стоит осенний лес.
На …, … загорелись яркие звёзды.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
3 четверть 12.03. 2017..
Контрольный диктант «Лесной голосок» по разделу «Слово как часть речи» по теме «Местоимение»
Лесной голосок
В солнечный день я бродил в берёзовом перелеске. Вдали послышался знакомый лесной голосок. Это куковала кукушка. Я её слышал много раз. Но никогда не видел. Какая она из себя?
Увидеть её оказалось совсем непросто. Я иду к ней на голосок, а она – от меня. В прятки со мной играет. Решил наоборот играть: я спрячусь, а ты поищи. Залез в куст орешника и кукукнул один раз. Кукушка замолкла. И вдруг неподалёку послышался её крик. Я молчок: поищи получше. А она уже совсем близко кукует.
В прятки со мной играет. Решил наоборот играть: я спрячусь, а ты поищи. Залез в куст орешника и кукукнул один раз. Кукушка замолкла. И вдруг неподалёку послышался её крик. Я молчок: поищи получше. А она уже совсем близко кукует.
Гляжу – через поляну летит птица. Хвост у неё длинный. Сама серая, грудка в тёмных пестринках. Может это ястребёнок? А птица подлетела к соседнему дереву, села на сучок и закуковала. Вот она какая – кукушка!
Грамматические задания:
1.Выпишите из текста местоимения. Определите их лицо, число и падеж.
2. Спишите слова, разделяя их на две группы.
Для, он, по, её, от, за, вы, нам, у тебя.
3. Вставьте в текст подходящие по смыслу местоимения.
В субботу … пошли в парк. Деревья стояли в пёстром наряде. На … были красные, жёлтые, оранжевые листья.
… встал под деревом. На … посыпались осенние листья.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
4 четверть 21. 04. 2017..
04. 2017..
Контрольный диктант «Весеннее утро» по разделу «Слово как часть речи» по теме «Глагол»
Весеннее утро
Как хорошо весеннее утро! Из – за синей полоски леса показалось солнце. В его лучах краснеют вершины гигантских сосен. Над рекой золотистым дымком клубится туман. Вот туман пропадает в прозрачном воздухе и открывает синюю гладь реки. В зеркальной поверхности реки видишь голубое небо и облака. На яркой зелени сверкает роса. Лёгкий ветерок покачивает ивовые серёжки. Дрозд на еловой верхушке высвистывает песенку. Свистит и слушает. А в ответ ему удивительная тишина.
Грамматические задания:
1.Выпишите два глагола, разберите их как часть речи.
2. Разберите по составу глагол высвистывает.
3.Найдите по два глагола I и II спряжения и выделите в них окончания, укажите спряжение.
4. Образуйте от глагола покачивает глагол женского рода в прошедшем времени.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
4 четверть 04. 05. 2017.
05. 2017.
Контрольный диктант «Предсказатели погоды» по разделу «Слово как часть речи» по темам «Имя числительное» и «Наречие».
Предсказатели погоды
Птицы чудесно предсказывают погоду. Они постоянно в воздухе и обладают чувствительностью даже к небольшим изменениям в природе. Перед ненастной погодой резко падает давление воздуха. Низко летают насекомые. Ласточки и стрижи в охоте за ними тоже снижают свой полёт. Слабеет солнечная освещённость. Эту перемену птицы и насекомые чувствуют заранее. Замолкают голоса пернатых. Не порхают бабочки и стрекозы.
Резкие крики галок и ворон – первый признак дождя летом или осенью. Все вороны сидят рядком головой в одну сторону – жди ветра.
Грамматические задания:
1.Выпишите из текста пять наречий. Поставьте к ним вопросы.
2. Подберите к глаголам подходящие по смыслу наречия, запишите словосочетания.
Кричать, прыгать, бегать, писать, спать.
3. дайте характеристику имён числительных по разряду и составу.
дайте характеристику имён числительных по разряду и составу.
Тысяча, пятьсот, девяносто девятый.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 4 четверть 18.05. 2017..
Контрольное списывание «Лесные пожары»
Лесные пожары
Лесные пожары возникают от небрежного обращения с огнём. Бросят горящую спичку, оставят тлеющие угли костра.
Набежал ветерок, раздул пламя. Синий огонёк зажёг сухую ветку и побежал по высохшей траве, прошлогодним листьям. Бушует пламя, густой дым ползёт в небо.
Начался лесной пожар.
Сколько деревьев уничтожит он! Сколько погибнет лесных обитателей!
Мечутся по лесу белки, зайцы и лоси. Против огня они бессильны.
А какое жуткое, тоскливое зрелище – выгоревшие участки леса! Чёрная земля, чёрные стволы упавших деревьев. Много лет пройдёт, пока снова вырастет живой лес.
Дополнительное задание
Дополните текст призывами и советами бережно относиться к лесу.
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 4 четверть 20.05. 2017..
Итоговый контрольный диктант «Последние денёчки»
Последние денёчки
Ранним мартовским утром проснулось солнце. Отдёрнуло оно лёгкую кисею облаков и взглянуло на землю. А там за ночь зима да мороз свои порядки навели. Около берёзки свежий снежок бросили, холмы молочным туманом укрыли. А в лесочке ледяные сосульки на соснах развесили. Радостно ребятишки бегут по последнему снежку.
Поглядело светило на эти проказы и стало землю пригревать. Лёд и снег сразу потускнел. По лесной ложбинке побежал весёлый говорливый ручеёк. Он бежал и пел свою песенку о весне.
Грамматические задания:
1.В последнем предложении выделите основу, выпишите из него словосочетания. Над каждым словом надпишите части речи.
2. Разберите слова как части речи.
Укрыли, молочным, за ночь.
3. Выполните звуко – буквенный разбор слова ледяные
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год
4 четверть 27. 05. 2017..
05. 2017..
Контрольное изложение «Кто хозяин?».
Кто хозяин?
Большой чёрный бродячий пёс отзывался на кличку Жук. У Жука были больная лапа. Илья и Ваня стали ухаживать за несчастным псом. Каждый из них хотел быть хозяином Жука.
Однажды осенью мальчики с собакой гуляли по лесу. Вдруг раздался яростный лай. Из кустов малинника выскочили две овчарки и повалили Жука.
Ваня мгновенно влез на дерево. Илья схватил длинную палку, бросился защищать Жука. Прибежал местный лесник и прогнал озверевших овчарок.
Лесник поинтересовался хозяином Жука. Илья сказал, что это его собака. Ваня промолчал.
По В. Осеевой
Контрольные работы по русскому языку 4-й класс 2016-2017 учебный год 4 четверть 29.05. 2017..
Итоговая контрольная работа за 4 класс.
РУССКИЙ ЯЗЫК
Школа ___________________________________________Класс 4 «в»
Фамилия, имя ________________________________________________
ИНСТРУКЦИЯ ДЛЯ УЧАЩИХСЯ
На выполнение работы отводится 45 минут.
В работе тебе встретятся разные задания. В некоторых заданиях тебе нужно будет выбрать ответ из нескольких предложенных и обвести цифру, которая стоит рядом с ответом, который ты считаешь верным. Обрати внимание: иногда в заданиях с выбором ответа правильный ответ только один, а иногда правильных ответов несколько. Внимательно читай задания! В некоторых заданиях тебе нужно будет записать несколько слов, иногда тебе нужно будет написать небольшие тексты.
Одни задания покажутся тебе лёгкими, другие — трудными. Рядом с номерами некоторых заданий стоит звёздочка (*) — так отмечены более трудные задания. Если ты не знаешь, как выполнить задание, пропусти его и переходи к следующему. Если останется время, ты можешь ещё раз попробовать выполнить пропущенные задания.
Если ты ошибся и хочешь исправить свой ответ, то зачеркни его и обведи или запиши тот ответ, который считаешь верным.
Желаем успеха!
1. Обведи номер ряда, в котором фамилии стоят в алфавитном порядке.
1) Груздев, Дунаев, Редькин, Москвин
2) Клюев, Пирогов, Тихонов, Федин
3) Борисов, Рожков, Никулин, Щепкин
4) Аристов, Волгин, Журов, Дятлов
2. Обведи номер верного утверждения о слове чайки.
1) В слове чайки все согласные мягкие.
2) В слове чайки три слога.
3) В слове чайки букв больше, чем звуков.
4) В слове чайки нет глухих согласных.
3*. Прочитай названия столбцов и строчек таблицы. Запиши данные ниже слова в нужную часть таблицы. Обрати внимание: первое слово уже записано.
Зелень, весёлый, решишь, чаща, метели килька,
В слове два слога | В слове три слога | В слове все согласные звуки мягкие | В слове НЕ все согласные звуки мягкие |
килька |
4. Обведи номер ряда, в который включены родственные слова и среди них нет формы одного из слов.
Обведи номер ряда, в который включены родственные слова и среди них нет формы одного из слов.
1) город, городской, города, городок
2) снег, снежный, снежок, снежная
3) ветер, ветрище, ветерок, ветреный
4) лист, листок, листопад, листком
5. Обведи номер слова, которое соответствует схеме:
1) покраска
2) повязка
3) погода
4) полоска
6*. Объедини в группы словá, которые имеют одинаковый состав слóва. Запиши каждую группу на отдельной строчке.
Голова, малиновый, ключик, журнал, приморский, заморозки
7. Запиши в каждый столбик таблицы по 2 слова из данных предложений.
Перед рассветом над лесом кружит прохладный ветерок. Медленно появляется на небе солнце. Поздней осенью вода в ручьях бывает чистая и прозрачная.
Имена существительные | Имена прилагательные | Глаголы |
1) . | 1) ……………………………….. | 1) ……………………………….. |
2) ………………………………. | 2) ………………………………. | 2) ………………………………. |
 ……………………………….
……………………………….8. Обведи номер словосочетания, в котором есть имя существительное 3-го склонения в единственном числе, в дательном падеже.
1) засыпать от усталости
2) повернуться к кроватке
3) подойти к сирени
4) размышлять о жизни
9. Обведи номер словосочетания, в котором есть имя прилагательное мужского рода в творительном падеже.
1) яркому солнцу
2) новому фильму
3) душистому мылу
4) сладким горошком
10. Прочитай предложение.
В это солнечное утро лес был наполнен необыкновенной радостью.
Определи, в какой форме употреблено в предложении выделенное имя прилагательное. Обведи номер ответа.
Обведи номер ответа.
1) в форме м. р., ед. ч., И. п.
2) в форме м. р., ед. ч., В. п.
3) в форме ср. р., ед. ч., В. п.
4) в форме ср. р., ед. ч., И. п.
11. Обведи номер предложения, в котором выделенное слово является глаголом.
1) Это был такой протяжный вой, что мы замерли.
2) Альма, не вой так громко, нас услышат.
3) Это был даже не вой, а очень грустная песня.
4) Волчий вой всегда очень пугал меня.
12. Обведи номер предложения, в котором есть глагол в форме настоящего времени, ед. числа, 3 лица.
1) Город улыбается тебе цветами на клумбах.
2) Летом на юге звёзды сияют очень ярко.
3) Ты идёшь сегодня на спектакль?
4) Рано утром вода в лужах замёрзла.
13*. Учительница задала два вопроса, ответы Кати и Гены приведены ниже. Отметь, кто из ребят дал правильный ответ. Подтверди выбранный ответ двумя примерами. Если правильного ответа нет, напиши свой и подтверди его двумя примерами.
Вопрос 1. У всех ли имён существительных есть окончания?
Катя: Да, у всех.
Гена: Нет, не у всех.
Правильного ответа нет.
Мой ответ: _________________________
Вопрос 2. Все ли имена существительные изменяются по числам?
Катя: Не все имена существительные изменяются по числам.
Гена: Все имена существительные изменяются по числам.
Правильного ответа нет.
Мой ответ:__________________________
14. Прочитай предложение. Подчеркни подлежащее и сказуемое.
Солнечный луч упал на снег под елью.
15. Найди и отметь предложение с однородными сказуемыми, соединенными союзом и.
1) Мы шли по тропинке, прислушивались к звукам.
2) В доме у бабушки жили ѐжик и кошка.
3) Заяц заметил нас и поскакал в лес.
4) Наступил вечер, скоро на небе зажгутся звѐзды.
16. Прочитай варианты проверки слов. Найди верное утверждение. Обведи его номер.
1) Слово …гурец можно проверить словом овощ.
2) Слово п…левой можно проверить словом поле.
3) Слово с… лонка можно проверить словом солнечный.
4) Слово стр…ла можно проверить словом стрелять.
17*. Объедини в группы слова, в которых есть одна и та же орфограмма в корне. Запиши каждую группу на отдельной строчке.
Гибкий, устный, поздний, рыбка, зимовье, сердце, пятно, редкий, полезный
18. Прочитай запись телефонного разговора.
Федя позвонил своему другу Гене. К телефону подошёл папа Гены, Игорь Семёнович.
1) — А Генка дома? — Добрый день, Федя! Нет, он ещё не вернулся из школы. 2) — А скажите ему, чтобы он мне позвонил! — Договорились, Федя! Я ему передам. До свидания.
3) — Хорошо.
Запиши слова, которые ты считаешь необходимым вставить в реплики Феди.
Реплика 1 ______________________________________________________
Реплика 2 ______________________________________________________
Реплика 3 ______________________________________________________
ПРОЧИТАЙ РАССКАЗ И ВЫПОЛНИ ЗАДАНИЯ 19-20.
У меня на даче стояла бочка с водой. Рядом на дереве сидели бок о бок два молодых воробья, совсем ещё молодых, с пушком, сквозящим из-за перьев.
Вот один воробей бойко и уверенно перепорхнул на край бочки и стал пить. Пил, и всё поглядывал на другого, и перекликался с ним на звенящем своём языке. Другой — чуть поменьше — с серьёзным видом сидел на ветке и опасливо косился на бочку. А пить-то хотелось — клюв был разинут от жары.
И вдруг я ясно увидел: тот, первый, — он уже давно напился и просто примером своим ободряет другого, показывает, что ничего тут нет страшного. Он прыгал по краю бочки, опускал клюв, захватывал воду и тотчас ронял её из клюва, и поглядывал на брата, и звал его.
Братишка на ветке решился, слетел к бочке. Но только коснулся лапками сырого, позеленевшего края, — и сейчас же испуганно порхнул назад, на дерево.
А тот опять стал его звать. И добился наконец: братишка перелетел на бочку, неуверенно сел, всё время трепыхал крылышками, и напился. Оба улетели.
Оба улетели.
(по В. В. Вересаеву)
19. Допиши пропущенные пункты плана.
1. Два воробья на ветке.
2. Пить хочется!
3. _________________.
4. _________________.
5. Удачная попытка
20*. Как ты считаешь, о чѐм этот рассказ? В чѐм его основная мысль? Напиши об этом. В твоей записи должно быть 2-3 предложения, и это обязательно должен быть связный текст.
32
Помогите ,пожалуйста с фонетическим разбором . Слова крас… -reshimne.ru
Новые вопросы
Ответы
красивее-(крас»ив»эй»э)-8 букв,9звуков,4 слога;
легче-(л»эгч»э)-5 букв,5 звуков,2 слога.
Похожие вопросы
Помогите пожалуйста умоляю
1. Определите слово, в котором пропущена безударная проверяемая гласная корня. Выпишите это слово, вставив пропущенную букву.
прил.
 .гающийся
.гающийсяан..мальный
обм..кнуть
пож..леть
р..сток
2. Определите слово, в котором пропущена безударная проверяемая гласная корня. Выпишите это слово, вставив пр…
Найдите в предложениях цельные словосочетания и подчеркните их как члены предложения: Дети хотели купить маме с папой подарок. Входят семь богатырей. Я пришёл к другу за двумя тетрадями….
Марфологические признаки формы прилагательных 4класс русский язык…
Подберите к именам существительным синонимы. Определите их склонение…
Как подчёркиваются предложения (слова):
Учившийся в Киевской бурсе и приехавших у отцу;ещё смотревшим изподлобья;выпущенные семинаристы;привыкшая уже;прибиравшие комнаты;носивший оружие.
Если есть причастные обороты, то обозначить главное и зависимое слово, задать вопрос
Подскажите очень надо!
Спасибо!…
Математика
Литература
Алгебра
Русский язык
Геометрия
Английский язык
Физика
Биология
Другие предметы
История
Обществознание
Окружающий мир
География
Українська мова
Українська література
Қазақ тiлi
Беларуская мова
Информатика
Экономика
Музыка
Французский язык
Немецкий язык
МХК
ОБЖ
Психология
python — добавить синтаксический анализ функций к простому pyparsing с нечисловыми аргументами
Я пытаюсь добавить функции к выражениям с возможностью принимать нечисловые аргументы. После добавления синтаксического анализа функций к простой грамматике арифметики pyparsing и https://pyparsing.wikispaces.com/file/view/fourFn.py я мог управлять функциями с числовыми входными данными. Однако не удалось обновить их для нечисловых входов. Вот мой тестовый код, пытающийся передать ident вместе с expr на ввод функции:
После добавления синтаксического анализа функций к простой грамматике арифметики pyparsing и https://pyparsing.wikispaces.com/file/view/fourFn.py я мог управлять функциями с числовыми входными данными. Однако не удалось обновить их для нечисловых входов. Вот мой тестовый код, пытающийся передать ident вместе с expr на ввод функции:
# FourFn.py
#
# Демонстрация модуля pyparsing, реализующего простой синтаксический анализатор выражений с 4 функциями,
# с поддержкой экспоненциального представления и символов для e и pi.
# Расширено для добавления возведения в степень и простых встроенных функций.
# Расширенные тестовые примеры, упрощенный метод pushFirst.
#
# Copyright 2003-2006 Пол Макгуайр
#
из pyparsing import Literal,CaselessLiteral,Word,Combine,Group,Optional,\
ZeroOrMore, Forward, nums, alphas, delimitedList
импортировать математику
оператор импорта
импорт pprint
стек выражений = []
def pushFirst(strg, loc, toks):
exprStack.append( toks[0] )
def pushUMinus(strg, loc, toks):
если токс и токс[0]=='-':
exprStack. ":
op2 = оценить стек (ы)
op1 = оценить стек (ы)
вернуть opn[op]( op1, op2 )
Элиф оп == "ПИ":
вернуть math.pi # 3.1415926535
Элиф оп == "Е":
вернуть math.e # 2.718281828
Элиф Оп в ФН:
вернуть fn[op](оценитьStack(s))
Элиф op[0].isalpha():
вернуть 0
еще:
возврат с плавающей запятой (оп)
если __name__ == "__main__":
стек выражений = []
res= BNF().parseString("asw(aa)").asList()
напечатайте «рез =», рез
val = оценить стек ( exprStack [:] )
распечатать значение
":
op2 = оценить стек (ы)
op1 = оценить стек (ы)
вернуть opn[op]( op1, op2 )
Элиф оп == "ПИ":
вернуть math.pi # 3.1415926535
Элиф оп == "Е":
вернуть math.e # 2.718281828
Элиф Оп в ФН:
вернуть fn[op](оценитьStack(s))
Элиф op[0].isalpha():
вернуть 0
еще:
возврат с плавающей запятой (оп)
если __name__ == "__main__":
стек выражений = []
res= BNF().parseString("asw(aa)").asList()
напечатайте «рез =», рез
val = оценить стек ( exprStack [:] )
распечатать значение
 ":
op2 = оценить стек (ы)
op1 = оценить стек (ы)
вернуть opn[op]( op1, op2 )
Элиф оп == "ПИ":
вернуть math.pi # 3.1415926535
Элиф оп == "Е":
вернуть math.e # 2.718281828
Элиф Оп в ФН:
вернуть fn[op](оценитьStack(s))
Элиф op[0].isalpha():
вернуть 0
еще:
возврат с плавающей запятой (оп)
если __name__ == "__main__":
стек выражений = []
res= BNF().parseString("asw(aa)").asList()
напечатайте «рез =», рез
val = оценить стек ( exprStack [:] )
распечатать значение
":
op2 = оценить стек (ы)
op1 = оценить стек (ы)
вернуть opn[op]( op1, op2 )
Элиф оп == "ПИ":
вернуть math.pi # 3.1415926535
Элиф оп == "Е":
вернуть math.e # 2.718281828
Элиф Оп в ФН:
вернуть fn[op](оценитьStack(s))
Элиф op[0].isalpha():
вернуть 0
еще:
возврат с плавающей запятой (оп)
если __name__ == "__main__":
стек выражений = []
res= BNF().parseString("asw(aa)").asList()
напечатайте «рез =», рез
val = оценить стек ( exprStack [:] )
распечатать значение
Результат числового ввода:
C:\temp>python test.py res= ['asw', '11'] с = ['11', 'аш'] op= asw <тип 'str'> с = ['11'] op= 11 <тип 'str'> Х равно 11,0 1 9": TypeError: 'in' в качестве левого операнда требуется строка, а не ParseResults
Где я ошибаюсь? Очень новичок в pyparsing и все еще пытаюсь понять это.
Как описать грамматику языка
EBNF: Как описать грамматику языкаИнструмент
Веб-сайт tomassetti. me изменился: теперь он является частью strumenta.com. Вы по-прежнему будете находить все новости в обычном качестве, но в новом оформлении.
me изменился: теперь он является частью strumenta.com. Вы по-прежнему будете находить все новости в обычном качестве, но в новом оформлении.
в парсинге
EBNF является наиболее часто используемым формализмом для описания структуры языков.
В этой статье мы увидим:
- Что такое EBNF
- Примеры грамматик, определенных с помощью EBNF
- Как мы можем определить грамматику с помощью EBNF
- Несколько вещей, которые следует учитывать при использовании EBNF
- Как использовать EBNF на практике сегодня
- Резюме с некоторыми заключительными мыслями
Похоже ли это на план?
Синтаксический анализ: инструменты и библиотеки
Получите руководство по электронной почте, чтобы прочитать его на всех своих устройствах, когда у вас будет время. Узнайте о синтаксическом анализе в Java, Python, C# и JavaScript
.Имя
Адрес электронной почты
Мы используем это поле для обнаружения спам-ботов. Если вы заполните это, вы будете отмечены как спамер.
Если вы заполните это, вы будете отмечены как спамер.
Что такое EBNF?
EBNF — это способ определения грамматики формального языка. Его можно считать метаязыком, потому что это язык для описания других языков.
Формальный язык — это язык с точной структурой, такой как языки программирования, языки данных или предметно-ориентированные языки (DSL). Java, XML и CSS — все это примеры формальных языков.
Грамматика может использоваться для определения двух противоположных вещей:
- как распознавать разные части фрагмента кода, написанного на формальном языке
- возможные способы создания корректного фрагмента кода на формальном языке
Например, простая грамматика может сказать нам, что документ на нашем языке состоит из списка объявлений, а объявления определяются последовательностью ключевого слова Xyz и имя.
Исходя из этого, мы могли бы:
- распознать в кодовых последовательностях ключевого слова Xyz и имя как экземпляры этих объявлений, которые мы рассмотрели
- , мы могли бы генерировать действительные документы на нашем языке, написав список объявлений, каждый раз вставляя ключевое слово Xyz и имя
Хотя есть два возможных использования грамматики, нас обычно интересует только первый: распознавание того, является ли фрагмент кода допустимым для данного языка, и идентификация различных структуры, типичные для языка (например, функции, методы, классы и т. д.).
д.).
Что означает EBNF?
Хорошо, но что означает EBNF? EBNF расшифровывается как Расширенная форма Бэкуса-Наура . Вас не удивит, что это расширенная версия формы Бэкуса-Наура (БНФ).
Существует по крайней мере еще один формат, производный от BNF, который называется ABNF, для формы Augment Backus-Naur . Основной целью ABNF является описание протоколов двунаправленной связи. EBNF — наиболее часто используемый вариант формата.
Несмотря на то, что существует стандарт для EBNF, обычно используются разные расширения или немного отличающийся синтаксис. В оставшейся части статьи мы добавим больше комментариев при рассмотрении конкретных частей EBNF.
Почему BNF недостаточно?
EBNF был изобретен для преодоления ограничений базового формата. Основной из них является несуществующая поддержка для простого определения повторений. Это означает, что общие шаблоны BNF, такие как определение серии повторяющихся элементов, громоздки и зависят от нелогичной логической математики.
Например, чтобы определить список слов, разделенных запятой (например, джон, кофе, логика), вы хотели бы сказать что-то вроде «список — это одно слово, за которым следует множество пар запятых и слов». Вы можете сказать то же самое с EBNF. Вместо этого в базовом формате BNF нет эквивалента «много». Таким образом, чтобы описать то же самое, вам нужно было бы сказать что-то вроде «список — это одно слово или список, за которым следует пара запятой и слова». Это работает, но сложно, поскольку определяет не один список, а серию вложенных списков.
По сути, предыдущий пример будет таким: «Джон, кофе, логика — это список из , Джон, и , , за которым следует список из , кофе, и , и , логика ».
Примеры грамматик EBNF
Мы увидим несколько примеров грамматик, взятых из списка, доступного на github. Позже мы могли бы ссылаться на них при объяснении правил.
Также обратите внимание, что для каждого языка могут быть разные эквивалентные грамматики. Таким образом, для одних и тех же языков вы можете найти грамматики, которые не совсем одинаковы, но в любом случае они правильны.
Таким образом, для одних и тех же языков вы можете найти грамматики, которые не совсем одинаковы, но в любом случае они правильны.
Грамматика EBNF для HTML
htmlDocument
: (скриптлет | SEA_WS)* xml? (скриптлет | SEA_WS)* dtd? (скриптлет | SEA_WS)* htmlЭлементы*
;
htmlЭлементы
: htmlРазное* htmlЭлемент htmlРазное*
;
htmlЭлемент
: TAG_OPEN htmlИмя тега htmlАтрибут* TAG_CLOSE htmlКонтент TAG_OPEN TAG_SLASH htmlИмя тега TAG_CLOSE
| TAG_OPEN htmlИмя тега htmlАтрибут* TAG_SLASH_CLOSE
| TAG_OPEN htmlИмя тега htmlАтрибут* TAG_CLOSE
| скриптлет
| сценарий
| стиль
;
htmlКонтент
: htmlChardata? ((htmlElement | xhtmlCDATA | htmlComment) htmlChardata?)*
;
htmlАтрибут
: htmlAttributeName TAG_EQUALS htmlAttributeValue
| htmlАтрибутИмя
;
htmlАтрибутИмя
: НАЗВАНИЕ ТЭГА
;
htmlAttributeValue
: ATTVALUE_VALUE
;
htmlTagName
: НАЗВАНИЕ ТЭГА
;
htmlChardata
: HTML_TEXT
| SEA_WS
;
htmlРазное
: htmlКомментарий
| SEA_WS
;
htmlКомментарий
: HTML_КОММЕНТАРИЙ
| HTML_CONDITIONAL_COMMENT
;
xhtmlCDATA
: КДАННЫЕ
;
дтд
: DTD
;
XML
: XML_DECLARATION
;
скриптлет
: СКРИПТЛЕТ
;
сценарий
: SCRIPT_OPEN (SCRIPT_BODY | SCRIPT_SHORT_BODY)
;
стиль
: STYLE_OPEN (STYLE_BODY | STYLE_SHORT_BODY)
; Грамматика EBNF для TinyC
TinyC — это упрощенная версия C. Мы выбрали ее, потому что грамматика для обычного языка программирования была бы слишком сложной, чтобы служить примером. Обычно мы рассматриваем грамматики длиннее 1000 строк.
Мы выбрали ее, потому что грамматика для обычного языка программирования была бы слишком сложной, чтобы служить примером. Обычно мы рассматриваем грамматики длиннее 1000 строк.
программа
: заявление+
;
утверждение
: оператор paren_expr 'if'
| 'if' оператор paren_expr оператор 'else'
| 'пока' оператор paren_expr
| оператор 'do', 'пока' paren_expr ';'
| '{' утверждение* '}'
| выражение ';'
| ';'
;
paren_expr
: '('выражение')'
;
выражение
: тест
| идентификатор '=' выражение
;
тест
: сумма
| сумма '<' сумма
;
сумма
: срок
| сумма '+' термин
| сумма '-' член
;
срок
: я бы
| целое число
| paren_expr
;
я бы
: НИТЬ
;
целое число
: INT
;
НИТЬ
: [а-я]+
;
INT
: [0-9]+
;
WS
: [rnt] -> пропустить
; Как мы обычно определяем грамматику, используя EBNF?
Мы определяем грамматику, указывая, как объединять отдельные элементы в значимые структуры. В первом приближении мы можем рассматривать отдельные слова как элементы. Структуры соответствуют предложениям, точкам, абзацам, главам и целым документам.
В первом приближении мы можем рассматривать отдельные слова как элементы. Структуры соответствуют предложениям, точкам, абзацам, главам и целым документам.
Грамматика говорит нам, как правильно соединять отдельные слова для получения предложений, и как мы можем продвигаться вперед, объединяя предложения в точки, точки в абзацы и так далее, пока не получим весь документ.
РБНФ: Терминалы и нетерминалыТерминалы и нетерминалы
В используемом нами приближении отдельные слова соответствуют терминалам , а все структуры, построенные над ними (предложения, периоды, абзацы, главы и целые документы) соответствуют нетерминалам .
Как выглядят терминалы
Иногда терминалы также называют жетонами. Это наименьший блок, который мы рассматриваем в наших грамматиках EBNF.
Терминал может быть:
- литерал в кавычках
- регулярное выражение
- имя, относящееся к терминальному определению. Эта опция не является частью стандарта EBNF, но используется очень часто. Обычно для этих терминальных определений используются имена в верхнем регистре, чтобы отличить их от нетерминальных определений. Эти последние определения являются правильными продукционными правилами
 Обычно для этих терминальных определений используются имена в верхнем регистре, чтобы отличить их от нетерминальных определений. Эти последние определения являются правильными продукционными правилами
Обычно для этих терминальных определений используются имена в верхнем регистре, чтобы отличить их от нетерминальных определений. Эти последние определения являются правильными продукционными правилами Например, в грамматике вы можете использовать "когда" для указания именно этой строки. Также используются регулярные выражения, например /[a-z]+/ . Наконец, мы могли бы где-нибудь сгруппировать определения терминалов, а затем использовать их имена для ссылки на них. Преимущество использования определений в том, что они позволяют повторно использовать их несколько раз.
Давайте посмотрим на некоторые типичные терминалы:
- идентификаторы: это имена, используемые для переменных, классов, функций, методов и так далее. Обычно большинство языков используют разные соглашения для разных имен. Например, в Java имена классов начинаются с заглавной буквы, статические константы записываются с использованием всех заглавных букв, а имена методов и переменных начинаются со строчной буквы. Однако это всего лишь лучшие практики: в Java есть только один тип идентификатора, который можно использовать везде. Это относится не ко всем языкам. В таких языках, как Haskell, идентификаторы, используемые для типов, должны начинаться с заглавной буквы. Еще одна вещь, которую следует учитывать, это то, что определение идентификаторов обычно пересекается с определениями ключевых слов. Последние должны иметь приоритет. То есть, если токен может быть либо идентификатором, либо ключевым словом, то он должен быть распознан как ключевое слово.
- ключевые слова: почти каждый язык использует ключевые слова. Это точные строки, которые используются для обозначения начала определения (например,
classв Java илиdefв Python), модификатора (public,private,static,finalи т. д.). .) или структуры потока управления (while,для,дои т. д.) - литералы: они позволяют определять значения на наших языках. У нас могут быть строковые литералы, числовые литералы, символьные литералы, логические литералы (но мы также можем рассматривать их как ключевые слова), литералы массивов, литералы карт и многое другое, в зависимости от языка
- разделители и ограничители: такие как двоеточия, точки с запятой, запятые, круглые скобки, скобки, фигурные скобки
- пробелы: пробелы, табуляции, новые строки. Как правило, они не имеют смысла, и их можно использовать везде в коде. Некоторые языки могут иметь более структурированные формы комментариев к документации
 Однако это всего лишь лучшие практики: в Java есть только один тип идентификатора, который можно использовать везде. Это относится не ко всем языкам. В таких языках, как Haskell, идентификаторы, используемые для типов, должны начинаться с заглавной буквы. Еще одна вещь, которую следует учитывать, это то, что определение идентификаторов обычно пересекается с определениями ключевых слов. Последние должны иметь приоритет. То есть, если токен может быть либо идентификатором, либо ключевым словом, то он должен быть распознан как ключевое слово.
Однако это всего лишь лучшие практики: в Java есть только один тип идентификатора, который можно использовать везде. Это относится не ко всем языкам. В таких языках, как Haskell, идентификаторы, используемые для типов, должны начинаться с заглавной буквы. Еще одна вещь, которую следует учитывать, это то, что определение идентификаторов обычно пересекается с определениями ключевых слов. Последние должны иметь приоритет. То есть, если токен может быть либо идентификатором, либо ключевым словом, то он должен быть распознан как ключевое слово. У нас могут быть строковые литералы, числовые литералы, символьные литералы, логические литералы (но мы также можем рассматривать их как ключевые слова), литералы массивов, литералы карт и многое другое, в зависимости от языка
У нас могут быть строковые литералы, числовые литералы, символьные литералы, логические литералы (но мы также можем рассматривать их как ключевые слова), литералы массивов, литералы карт и многое другое, в зависимости от языкаПробелы и комментарии обычно игнорируются в грамматиках EBNF. Это потому, что обычно они могут использоваться везде в языке, поэтому о них следует сообщать по всей грамматике. Некоторые инструменты имеют специальные параметры для пометки некоторых терминалов как терминалов, которые следует игнорировать.
Как определяются терминалы
Терминалы определяются с помощью строковых констант или регулярных выражений. Давайте посмотрим на некоторые типичные определения.
Давайте посмотрим на некоторые типичные определения.
| Category | Terminal | Definition | Note |
| Identifier | Java identifier | /[a-zA-Z$_][a -zA-Z0-9$_]*/ | Это упрощение, поскольку технически возможно также использовать управляющие последовательности UTF в идентификаторах Java |
| Идентификатор типа Haskell | /[A-Z][a-zA-Z0-9$_’]*/ | ||
| Идентификатор значения Haskell | /[a-za-z0][a-za-z0][a-za-z0][a-za-z0][a-zA-Z0-9$_’]*/ 9_’]*/ | ||
| Ключевое слово | Некоторые ключевые слова Java | «abstract», «assert», «boolean», «break», «byte», «case», «catch», «char », «класс», «константа»… | «константа» — это ключевое слово в Java, даже если оно не используется ни в одной конструкции. Это зарезервированное ключевое слово для использования в будущем (то же самое относится и к «goto») 9.0229 Это зарезервированное ключевое слово для использования в будущем (то же самое относится и к «goto») 9.0229 |
| Некоторые ключевые слова Python 3/td> | «def», «return», «raise», «from», «import», «as», «global», «nonlocal», «assert»… | ||
| Литерал | Строковый литерал Java | /'»‘ (~[«] | ” [\b\t\n\f\r»‘])* ‘»‘/ | Это упрощение. Мы игнорируем восьмеричные escape-последовательности и escape-последовательности Unicode |
| Символьный литерал Java | /”’ (~[‘] |” [\b\t\n\f\r”‘]) »’ | ||
| Целочисленный литерал Java | /[«0»-«9»](([«0»-«9″,»_»])*[«0»-«9»])?/ | Целочисленный литерал Java может быть выражен в десятичном, шестнадцатеричном, восьмеричном или двоичном формате. Мы просто рассматриваем десятичный формат здесь. Это верно и для длинных литералов Java | |
| “9”])?(‘l’|’L’) | |||
| Литерал с плавающей запятой Java | /[“0”-“9”](([“0”-“9″,”_”])*[“0”-“9”])?’. ‘([“0”-“9”](([“0”- «9″»,_»])*[«0»-«9»])?)?(‘f’|’F’) ‘([“0”-“9”](([“0”- «9″»,_»])*[«0»-«9»])?)?(‘f’|’F’) | Литерал с плавающей запятой Java может быть выражен в десятичном или шестнадцатеричном формате. Мы просто рассматриваем десятичный формат здесь. We are also ignoring the possibility of specifying the exponent | |
| Java boolean literal | /”true”|”false”/ | ||
| Separator/Delimiter | Some Java separators and delimiters | “( “, “)”, “{“, “}”, “”, “;”… | |
| Некоторые рубиновые сепараторы и разделители | «», «;»… | ||
| Whitespace | 9 29226. \ 292929 292929 29292929292929292929292929. \ raves | . | |
| Рубиновый пробел | /(‘ ‘|’\t’)+/ | ||
| Комментарий | Комментарий к строке Java | 9\r/026 /’/2] ~||
| Комментарий блока Java | /’\/*’ . *? ‘*\/’/ *? ‘*\/’/ | ||
| Комментарий строки Python | /’#’ ~[\r\n\f]*/ |
Как выглядят нетерминалы
Нетерминалы получаются с помощью группировки нетерминалы в иерархии. В конце концов, наша цель — получить абстрактное синтаксическое дерево, которое представляет собой дерево . Наше дерево будет иметь корень: один нетерминал, представляющий весь наш документ. Корень будет содержать другие нетерминалы, которые будут содержать другие нетерминалы и так далее.
На рисунке ниже показано, как мы можем перейти от потока токенов (или терминалов) к AST, который группирует терминалы в иерархию нетерминалов.
EBNF — от потока токенов к ASTВ грамматике мы определим правила парсера, которые определяют, как строится AST.
Мы видели, что нетерминалы представляют структуры на разных уровнях. Примеры нетерминалов:
- программа/документ : представляет весь файл
- модуль/классы: сгруппировать несколько объявлений вместе
- функции/методы: сгруппировать операторы вместе
- операторы: это отдельные инструкции. Некоторые из них могут содержать другие утверждения. Например, циклы имеют тело, которое представляет собой список других операторов
- выражения: обычно используются в операторах и могут быть составлены различными способами
 Некоторые из них могут содержать другие утверждения. Например, циклы имеют тело, которое представляет собой список других операторов
Некоторые из них могут содержать другие утверждения. Например, циклы имеют тело, которое представляет собой список других операторовКак определяются нетерминалы? Мы увидим это в следующем разделе.
Определение производственных правил
Грамматика РБНФ по существу представляет собой список производственных правил. Каждое производственное правило говорит нам, как можно составить нетерминал. Теперь мы увидим различные элементы, которые мы можем использовать в таких правилах.
Терминал
Мы видели, что терминал может быть определен в строке, задав строку или регулярное выражение, или может быть определен в другом месте и просто указан в правиле. Последний метод технически не является частью EBNF, но широко используется.
выражение : тест | id '=' expr // '=' это терминал ; я бы : STRING // STRING — это терминал, в верхнем регистре ;
Обратитесь к нетерминалу
Подобно ссылкам на терминалы, мы также можем ссылаться на нетерминалы. Однако это может привести к леворекурсивным правилам, которые обычно запрещены. Подробнее см. параграф о рекурсии в грамматиках.
Однако это может привести к леворекурсивным правилам, которые обычно запрещены. Подробнее см. параграф о рекурсии в грамматиках.
выражение : тест | id '=' expr // id является нетерминалом, на который ссылается производственное правило expr ; я бы : НИТЬ ;
Последовательность
Последовательность просто представляется путем указания двух элементов один за другим.
// htmlAttribute можно создать двумя способами. Первый требует
// последовательность. Сначала нам нужно найти htmlAttributeName, затем
// TAG_EQUALS и, наконец, htmlAttributeValue
htmlАтрибут
: htmlAttributeName TAG_EQUALS htmlAttributeValue
| htmlАтрибутИмя
; Это также называется конкатенацией, и в стандарте EBNF запятые используются между элементами, в то время как обычно вы просто используете пробелы для разделения элементов последовательности.
Альтернатива
Существуют некоторые конструкции или части конструкций, которые можно определить по-разному. Для представления этого случая мы используем альтернативы. Различные варианты разделены вертикальной чертой (« | »)
// Существуют разные способы создания заявления
утверждение
: оператор 'if' paren_expr // 1-й вариант
| 'if' оператор paren_expr 'else' оператор // 2-й вариант
| Оператор 'while' paren_expr // 3-й вариант
| оператор 'do', 'пока' paren_expr ';' // 4-й вариант
| '{' оператор* '}' // 5-й вариант
| выражение ';' // 6-й вариант
| ';' // 7-й вариант
;
// Альтернативы обычно используются на верхнем уровне продукционных правил
// но это не всегда так. В htmlDocument они используются внутри
// последовательность
htmlДокумент
: (скриптлет | SEA_WS)* xml? (скриптлет | SEA_WS)* dtd? (скриптлет | SEA_WS)* htmlЭлементы*
;
Необязательный (ноль или один раз)
Элемент может появляться ноль или один раз. Другими словами, это может быть необязательным.
Другими словами, это может быть необязательным.
// оба вхождения htmlChardata являются необязательными
htmlКонтент
: htmlChardata? ((htmlElement | xhtmlCDATA | htmlComment) htmlChardata?)*
; В стандарте EBNF необязательные элементы представлены в квадратных скобках. Однако чаще всего они представлены знаком вопроса после необязательного элемента.
Ноль или больше раз
Элемент может появляться ноль или более раз (нет верхнего предела).
// В трех из этих вариантов может появиться htmlAttribute
// столько раз, сколько мы хотим.
htmlЭлемент
: TAG_OPEN htmlИмя тега htmlАтрибут* TAG_CLOSE htmlКонтент TAG_OPEN TAG_SLASH htmlИмя тега TAG_CLOSE
| TAG_OPEN htmlИмя тега htmlАтрибут* TAG_SLASH_CLOSE
| TAG_OPEN htmlИмя тега htmlАтрибут* TAG_CLOSE
| скриптлет
| сценарий
| стиль
; В стандартном РБНФ необязательные элементы представлены внутри фигурных скобок. Однако чаще всего они представлены звездочкой, следующей за повторяющимся элементом.
Однако чаще всего они представлены звездочкой, следующей за повторяющимся элементом.
Один или несколько раз
Элемент может появляться один или несколько раз (без верхнего предела).
// Нам нужен хотя бы один оператор. У нас может быть только один или несколько программа : заявление+ ;
В этом примере мы говорим, что в программе должен быть хотя бы один оператор.
Этого нет в стандартном EBNF, однако это эквивалентно последовательности, в которой одни и те же элементы присутствуют дважды, а во второй раз за ними следует звездочка, так что один и тот же элемент фактически всегда присутствует хотя бы один раз.
Группировка
Мы можем сгруппировать несколько элементов, используя круглые скобки. Обычно это используется, потому что модификатор (необязательный, ноль или более, один или более) должен применяться к набору элементов. Его также можно использовать для управления приоритетом операторов.
Его также можно использовать для управления приоритетом операторов.
// скрипт определяется как последовательность терминала SCRIPT_OPEN
// и группа ( SCRIPT_BODY | SCRIPT_SHORT_BODY)
сценарий
: SCRIPT_OPEN (SCRIPT_BODY | SCRIPT_SHORT_BODY)
; Без использования группировки у нас была бы альтернатива между последовательностью SCRIPT_OPEN SCRIPT_BODY (первый вариант) и SCRIPT_SHORT_BODY (второй вариант).
Несколько моментов для размышления
Мы увидели, какие конструкции можно использовать для определения правил производства. Теперь давайте углубимся в некоторые аспекты, которые мы должны учитывать при написании грамматик.
Рекурсия в грамматике: влево или вправо?
EBNF позволяет нам определять повторяющиеся грамматики. Повторяющиеся грамматики — это грамматики с повторяющимися продукционными правилами, т. е. продукционными правилами, которые ссылаются на самих себя, и они делают это в начале продукционного правила (9).0527 повторяющихся слева грамматик) или в конце ( повторяющихся справа грамматик).
Повторяющиеся грамматики — это грамматики с повторяющимися продукционными правилами, т. е. продукционными правилами, которые ссылаются на самих себя, и они делают это в начале продукционного правила (9).0527 повторяющихся слева грамматик) или в конце ( повторяющихся справа грамматик).
Левоповторяющиеся грамматики более распространены. Рассмотрим этот пример:
выражение: INT
| выражение ПЛЮС выражение
; Это производственное правило остается повторяющимся, поскольку выражение может начинаться с… выражения .
Дело в том, что многие инструменты, обрабатывающие грамматики EBNF, не могут с этим справиться, потому что рискуют зациклиться. Существуют способы рефакторинга левых повторяющихся правил, однако они приводят к менее четким грамматикам. Итак, если вы можете, просто используйте современные инструменты, которые имеют дело с лево- и правоповторяющимися грамматиками.
Итак, если вы можете, просто используйте современные инструменты, которые имеют дело с лево- и правоповторяющимися грамматиками.
Приоритет
Приоритет может относиться к двум вещам: приоритет в грамматике EBNF (т. е. порядок применения операторов в грамматиках) и приоритет в языках, определенных EBNF.
Это очень важно, потому что позволит правильно интерпретировать такие выражения, как:
1 + 2 * 3
В этом случае мы все знаем, что умножение имеет приоритет над сложением. В языках, которые мы собираемся определить, у нас может быть много разных правил, и нам нужно определить определенный порядок их рассмотрения.
Давайте поговорим о втором.
Традиционным способом управления приоритетом является определение списка различных правил, которые ссылаются друг на друга. На верхнем уровне у нас будут более абстрактные правила, такие как
На верхнем уровне у нас будут более абстрактные правила, такие как выражение , на нижнем уровне у нас будут правила, представляющие наименьшие компоненты, такие как один терм . Типичный пример показан в TinyC:
expr : тест | идентификатор '=' выражение ; тест : сумма | сумма '<' сумма ; сумма : срок | сумма '+' термин | сумма '-' член ; срок : я бы | целое число | paren_expr ;
Грамматика в том виде, в каком она определена, заставляет сначала анализировать отдельные термины (идентификатор, целое число или выражения в скобках). Позже это можно комбинировать, используя знак плюс или минус. Затем можно использовать оператор меньше, чем, и это может быть частью выражения, рассматриваемого правила верхнего уровня.
Это относительно простой пример, но в более богатых языках у нас могло бы быть 7-12 промежуточных правил, таких как проверка и сумма, для представления различных групп операторов с одинаковым приоритетом. К слову об умножении, делении, степени, операторах сравнения, логических операторах, доступе к массиву и т.д. Существует много возможных способов построения выражений, и вам необходимо определить порядок приоритета.
Теперь некоторые современные инструменты используют именно тот порядок, в котором определены альтернативы, для получения правил приоритета. Например, в ANTLR вы можете написать предыдущий пример так:
expr : идентификатор '=' выражение | выражение '<' выражение | выражение '+' выражение | выражение '-' выражение | я бы | целое число | paren_expr ;
Типичный шаблон: определение списков
Обычно мы хотим определить в грамматике EBNF список.
У нас есть список параметров, список переменных, всевозможные списки.
Обычно у нас есть разделитель между элементами (например, ЗАПЯТАЯ ). У нас могут быть списки, в которых должен быть хотя бы один элемент, и списки, в которых может не быть элементов. Давайте посмотрим, как мы можем реализовать оба:
myListOfAtLeastOneElement:
элемент (элемент COMMA)*
;
myListOfOfPotentiallyZeroElements:
(элемент (элемент ЗАПЯТАЯ)*)?
; Синтаксическая и семантическая валидность
Мы видели, что РБНФ можно использовать для определения грамматики, мы должны учитывать, что грамматика определяет, что такое синтаксически допустимо , но ничего не говорит нам о том, что такое семантически правильно .
Что это значит? Рассмотрим следующие примеры:
- документ, содержащий несколько объявлений элементов с одинаковыми именами
- сумма двух переменных: целочисленная и логическая
- ссылка на переменную, которая не была объявлена ранее
Мы можем представить язык, где все эти примеры синтаксически правильны, т. е. построены согласно грамматике языка. Однако все они семантически неверны, поскольку не учитывают дополнительных ограничений на использование языка. Эти семантические ограничения используются в дополнение к грамматике после того, как структуры языка были распознаны. В грамматике мы можем сказать что-то вроде объявление должно состоять из определенного ключевого слова и имени , с семантическими ограничениями мы можем сказать два объявления не должны иметь одинаковое имя . Комбинируя синтаксические и семантические правила, мы можем выразить то, что допустимо в нашем языке.
е. построены согласно грамматике языка. Однако все они семантически неверны, поскольку не учитывают дополнительных ограничений на использование языка. Эти семантические ограничения используются в дополнение к грамматике после того, как структуры языка были распознаны. В грамматике мы можем сказать что-то вроде объявление должно состоять из определенного ключевого слова и имени , с семантическими ограничениями мы можем сказать два объявления не должны иметь одинаковое имя . Комбинируя синтаксические и семантические правила, мы можем выразить то, что допустимо в нашем языке.
Как вы определяете семантические правила? Написав код, который работает на AST. Вы не можете сделать это в грамматике EBNF.
Куда идти дальше?
Грамматика EBNF полезна для обсуждения и общения с другими разработчиками языка. Как правило, вы можете захотеть сделать с ним больше: вы хотите создать настоящие синтаксические анализаторы и инструменты для обработки языков из ваших грамматик EBNF. Лично мне нравится работать с ANTLR. Я предлагаю взглянуть на мегаучебник ANTLR.
Лично мне нравится работать с ANTLR. Я предлагаю взглянуть на мегаучебник ANTLR.
Возможно, вам будет интересно узнать больше о синтаксическом анализе. Мы подготовили различные статьи, объясняющие, как действовать в зависимости от языка, с которым вы предпочитаете работать:
- Синтаксический анализ на Java
- Синтаксический анализ на C#
- Синтаксический анализ на Python
- Синтаксический анализ на JavaScript
И если вы заблудились и не уверены о том, как двигаться вперед, просто дайте нам знать.
Резюме
В этой статье мы стремились быть практичными: мы обсудили, что делается на практике и что вам нужно, чтобы начать писать грамматики с использованием EBNF. Мы обсудили различия между типичными обычаями и стандартом и попытались дать полную и правильную картину.
Есть вещи, которые мы не обсуждали: например, история, которая привела к созданию EBNF или его корни в работах Хомского и других ученых. Мы не обсуждали, что такое контекстно-свободная грамматика. Теория говорит нам, что EBNF нельзя использовать для описания всех возможных форм грамматик. Тем не менее, он достаточно мощный, чтобы описать все формальные языки, в которых вы хотели бы писать.
Теория говорит нам, что EBNF нельзя использовать для описания всех возможных форм грамматик. Тем не менее, он достаточно мощный, чтобы описать все формальные языки, в которых вы хотели бы писать.
В остальной части этого веб-сайта вы должны найти статьи о следующих шагах, таких как создание компилятора или редактора для вашего языка. Итак, получайте удовольствие!
Категории
Подробнее об анализе
Сопоставление регулярных выражений в дикой природе
Сопоставление регулярных выражений в дикой природеРасс Кокс
[email protected]
март 2010 г.
Введение
Первые две статьи из этой серии,
«Сопоставление регулярных выражений может быть простым и быстрым»
и «Сопоставление регулярных выражений: подход виртуальной машины».
представил основу сопоставления регулярных выражений на основе DFA и NFA.
Оба были основаны на игрушечных реализациях, оптимизированных для обучения основным идеям. Эта статья основана на производственной реализации.
Эта статья основана на производственной реализации.
Я провел лето 2006 года, создавая Code Search, который позволяет программистам искать исходный код с помощью регулярных выражений. То есть он позволяет вам grep через мировой общедоступный исходный код. Изначально мы планировали использовать PCRE для поиска по регулярным выражениям, пока мы не поняли, что он использует алгоритм поиска с возвратом, это означает, что поиск занимает экспоненциальное время или произвольная глубина стека. Поскольку Code Search принимает регулярные выражения от любого пользователя в Интернете, использование PCRE оставило бы его открытым для простых атак типа «отказ в обслуживании». В качестве альтернативы PCRE я написал новый, тщательно переработанный парсер регулярных выражений. обернутый Grep Кена Томпсона с открытым исходным кодом реализация, которая использует быстрый DFA.
В течение следующих трех лет я реализовал несколько новых бэкендов, которые
коллективно заменили код grep и расширили
функциональность, выходящая за рамки того, что необходимо для POSIX grep. Результат, RE2, обеспечивает большую часть функциональности PCRE.
с использованием интерфейса C++, очень близкого к PCRE, но гарантирующего линейное время
выполнение и фиксированный размер стека.
RE2 теперь широко используется в Google, как в поиске кода,
и во внутренних системах, таких как Sawzall
и БигТейбл.
Результат, RE2, обеспечивает большую часть функциональности PCRE.
с использованием интерфейса C++, очень близкого к PCRE, но гарантирующего линейное время
выполнение и фиксированный размер стека.
RE2 теперь широко используется в Google, как в поиске кода,
и во внутренних системах, таких как Sawzall
и БигТейбл.
По состоянию на март 2010 года RE2 является проектом с открытым исходным кодом.
при этом все разработки ведутся публично.
Эта статья представляет собой экскурсию по исходному коду RE2, показывающую, как
методы, описанные в первых двух статьях, применяются в производственной реализации.
9 и $.
Сегодня программистов ожидает какофония наворотов.
Работа современного синтаксического анализатора регулярных выражений состоит в том, чтобы разобраться в шуме.
и перегнать его обратно в исходные фундаментальные концепции.
Парсер RE2 создает структуру данных Regexp , определенную в регулярное выражение.h .
Он очень близок к исходному синтаксису egrep, за исключением нескольких особых случаев:
- Литеральные строки представлены
узлами kRegexpLiteralString, которые занимают меньше память, чем конкатенация отдельныхkRegexpLiteralузлов. - Подсчитанное повторение представлено
узлами kRegexpRepeat, хотя это представление не может быть реализовано напрямую; мы увидим, как они компилируются позже. - Классы символов представлены не в виде простого списка диапазонов или в виде растрового изображения а как сбалансированное бинарное дерево диапазонов. Это представление является более сложным чем простой список, но имеет решающее значение для обработки больших классов символов Unicode.
- Класс символов «любой символ» получает специальный тип узла, как и оператор «любой байт». Есть разница между двумя при сопоставлении входного текста UTF-8 режим работы RE2 по умолчанию.
- При сопоставлении без учета регистра используется специальный флаг и специальный регистр для
Диапазон ASCII, а не двухэлементные классы символов:
(?i)abcпревращается вabcбез учета регистра. бит вместо[Aa][Bb][Cc]. RE2 изначально использовал последний, но это было слишком интенсивно для памяти, особенно с древовидными классами символов.


Парсер RE2 находится в parse.cc .
Это написанный от руки синтаксический анализатор, позволяющий избежать зависимости от конкретного генератора синтаксических анализаторов.
и потому, что современный синтаксис регулярных выражений достаточно нерегулярен, чтобы требовать особого внимания.
Парсер не использует рекурсивный спуск, потому что глубина рекурсии была бы
потенциально неограничен и может переполнить стек,
особенно в многопоточной среде.
Вместо этого синтаксический анализатор поддерживает явный стек синтаксического анализа, как это сделал бы сгенерированный синтаксический анализатор LR(1).
Что меня удивило, так это разнообразие способов
реальные пользователи пишут одно и то же регулярное выражение.
Например, часто можно увидеть, как используются одноэлементные классы символов.
вместо экранирования — [.] вместо \. —или варианты
вместо классов символов — a|b|c|d вместо [a-d] .
Синтаксический анализатор уделяет особое внимание тому, чтобы использовать для них наиболее эффективную форму. так что
так что [.] по-прежнему является одним литералом, а a|b|c|d по-прежнему является классом символов.
Он применяет эти упрощения во время синтаксического анализа, а не во втором проходе.
чтобы избежать большего, чем необходимо, промежуточного объема памяти.
Прогулка по регулярному выражению
После анализа регулярного выражения пришло время его обработки.
Разобранная форма представляет собой стандартное дерево, что предполагает его обработку с помощью
стандартные рекурсивные обходы. К сожалению, мы не можем предположить, что существует
достаточно стека, чтобы сделать это. Какой-нибудь коварный пользователь может представить нам
регулярное выражение типа (((((((((((а*)*)*)*)*)*)*)*)*)*)* (но больше) и вызвать переполнение стека.
Вместо этого обход регулярного выражения должен использовать
явный стек. Шаблон Walker скрывает управление стеком, что делает это ограничение
немного вкуснее.
Оглядываясь назад, я думаю, что форма дерева и Уокер могло быть ошибкой. Если рекурсия не разрешена (как в данном случае),
может быть лучше полностью избегать рекурсивного представления,
вместо этого сохранение проанализированного регулярного выражения в обратной польской нотации
как у Томпсона 1968 бумаги и этот пример кода.
Если форма RPN записывала максимальную глубину стека, используемую в выражении,
обход выделил бы стек именно такого размера и
затем пролистайте представление за одно линейное сканирование.
Если рекурсия не разрешена (как в данном случае),
может быть лучше полностью избегать рекурсивного представления,
вместо этого сохранение проанализированного регулярного выражения в обратной польской нотации
как у Томпсона 1968 бумаги и этот пример кода.
Если форма RPN записывала максимальную глубину стека, используемую в выражении,
обход выделил бы стек именно такого размера и
затем пролистайте представление за одно линейное сканирование.
Шаг 2: Упростите
Следующий этап обработки — упрощение,
который переписывает сложные операторы в более простые
чтобы облегчить последующую обработку.
Со временем большая часть кода в проходе упрощения RE2 переместилась в синтаксический анализатор,
потому что упрощение жадно снижает объем промежуточной памяти.
Сегодня у упрощенца осталась только одна задача:
расширение подсчитанных повторений как х{2,5} в
последовательность основных операций типа xx(x(x(x)?)?)? .
Шаг 3. Скомпилируйте
После того, как регулярное выражение использует только основные операции
описанный в первой статье, его можно скомпилировать с помощью изложенных там приемов. Должно быть легко увидеть переписку.
Должно быть легко увидеть переписку.
У компилятора RE2 есть одна интересная особенность, которую я узнал из группы Томпсона. Он компилирует классы символов UTF-8. вплоть до автомата, который считывает ввод по одному байту за раз. Другими словами, декодирование UTF-8 встроено в автомат. Например, для соответствия любой кодовой точке Unicode от 0000 до FFFF (шестнадцатеричный), автомат принимает любую из следующих последовательностей байтов:
[00-7F] // кодовые точки 0000-007F [C2-DF][80-BF] // кодовые точки 0080-07FF [E0][A0-BF][80-BF] // кодовые точки 0800-0FFF [E1-EF][80-BF][80-BF] // кодовые точки 1000-FFFF
Составленная форма - это не просто чередование
эти последовательности: общие суффиксы, такие как [80-BF] можно вынести за скобки. Фактическая скомпилированная форма для этого примера:
Пример выше имеет то преимущество, что довольно регулярно. Вот полный диапазон Unicode, 000000-10FFFF:
Крупнее, но все равно обычный. Настоящие нарушения возникают из-за классов персонажей, которые
развивались в течение истории Unicode.
Например, вот
Настоящие нарушения возникают из-за классов персонажей, которые
развивались в течение истории Unicode.
Например, вот \p{Sc} , кодовые точки символа валюты:
Символы валют настолько сложны, насколько это возможно в этой статье,
но другие классы намного сложнее; например, посмотрите на \p{Greek} (греческий шрифт) или на \p{Lu} (прописные буквы).
Результатом компиляции является граф инструкций, как и в последних двух статьях. Представление ближе к графику в первом, но при печати выглядит как ВМ программы во втором.
Компиляция UTF-8 делает компилятор немного сложнее, но делает механизмы сопоставления намного быстрее: они могут обрабатывать по одному байту за раз в узких циклах. Кроме того, оказывается, что есть много совпадений; наличие только одной копии обработки UTF-8 помогает сохранить код правильным.
Шаг 4: Сопоставьте
Все описанное до сих пор происходит в конструкторе RE2. После создания объекта его можно использовать в последовательности операций сопоставления.
С точки зрения пользователя есть только две функции сопоставления:
После создания объекта его можно использовать в последовательности операций сопоставления.
С точки зрения пользователя есть только две функции сопоставления: RE2::PartialMatch , который находит первое совпадение во входном тексте,
и RE2::FullMatch , для которого требуется, чтобы совпадение покрывало все входные данные.
Однако, с точки зрения RE2, есть много разных вопросов, которые
можно задать с их помощью, и реализация адаптируется к вопросу.
RE2 различает четыре основных проблемы сопоставления регулярных выражений: 9re$")
RE2::PartialMatch(s, "re")
RE2::PartialMatch(s, "(re)", &match)
RE2::PartialMatch(s, "(r+)(e+)", &m1, &m2)
Ясно, что каждое из них является частным случаем следующего. С точки зрения пользователя имеет смысл предоставить только четвертый,
но реализация отличает их, потому что она может реализовать
более ранние вопросы намного эффективнее, чем более поздние.
9re$")
С точки зрения пользователя имеет смысл предоставить только четвертый,
но реализация отличает их, потому что она может реализовать
более ранние вопросы намного эффективнее, чем более поздние.
9re$")
Именно этот вопрос мы рассмотрели в первой статье. В этой статье мы увидели, что простой DFA, построенный на лету, превзошел все, кроме другие реализации DFA. RE2 также использует DFA для этого вопроса, но DFA более эффективен с точки зрения памяти и более удобен для потоков. Он использует два важных уточнения.
Иметь возможность очищать кеш DFA. Тщательно подобранное регулярное выражение и вводимый текст могут
заставить DFA создавать новое состояние для каждого байта ввода.
На больших входных данных эти состояния быстро накапливаются.
RE2 DFA рассматривает свои состояния как кеш; если кеш заполняется,
DFA освобождает их всех и начинает сначала.
Это позволяет DFA работать с фиксированным объемом памяти.
несмотря на рассмотрение произвольного числа состояний во время
ход матча.
Не сохранять состояние в скомпилированной программе. DFA в первой статье использовал простой
поле порядкового номера в скомпилированной программе для отслеживания
от того, появилось ли государство в конкретном списке
( s->lastlist и listid ).
Это отслеживание позволило выполнять вставку списка с помощью
удаление дубликатов за постоянное время.
В многопоточной программе было бы удобно разделить
один объект RE2 среди нескольких потоков, что исключает
метод порядкового номера.
Но мы определенно хотим вставку списка с дубликатом
устранение за постоянное время.
К счастью, существует структура данных, разработанная точно
для этой ситуации: разреженные наборы.
RE2 реализует их в шаблоне SparseArray.
(Обзор этой идеи см. в разделе «Использование неинициализированной памяти для развлечения и получения прибыли».)
Соответствует ли регулярное выражение подстроке строки?
RE2::PartialMatch(s, "re")
Последний вопрос спрашивал, соответствует ли регулярное выражение
вся строка; этот спрашивает, соответствует ли он
в любом месте строки. Мы могли бы свести этот вопрос к последнему, если
переписывая
Мы могли бы свести этот вопрос к последнему, если
переписывая re в .*re.* ,
но мы можем добиться большего успеха, переписав его в .*re и обработка задней части отдельно.
Поиск буквального первого байта. DFA или форму скомпилированной программы можно проанализировать, чтобы
определить, начинается ли каждое возможное совпадение с одного и того же первого байта,
как при поиске (исследование|случайное) .
В этом случае, когда DFA хочет начать новый матч,
он может избежать общего цикла DFA и искать
первый байт с использованием memchr ,
который часто реализуется с помощью специальных аппаратных инструкций.
Выручайте раньше. Если задается вопрос, есть ли частичное совпадение
(например, есть ли совпадение для аб+ в ccccabbbddd ?),
DFA может остановиться раньше,
как только он находит ab . Путем изменения цикла DFA
проверять совпадение после каждого байта, он может остановиться, как только
есть любой матч, даже если он не самый длинный. Помните, что вызывающему абоненту важно только наличие совпадения.
не то, что есть, поэтому DFA может не искать самый длинный.
Помните, что вызывающему абоненту важно только наличие совпадения.
не то, что есть, поэтому DFA может не искать самый длинный.
Это звучит как DFA, немного отличающийся от
один используется для последнего вопроса, и это. Код ДФА
написан как единый обобщенный цикл, который смотрит на флаги, управляющие
его поведение, например, есть ли буквальное первое
байт искать или остановить как можно раньше.
В 2008 году, когда я писал код DFA, он был слишком медленным, чтобы
проверьте флаги во внутреннем цикле. Вместо этого Встроенный цикл поиска функция принимает три логических флага, а затем
специализированный, вызывая его из восьми различных функций
используя все комбинации.
Когда необходимо сделать звонок, он должен быть сделан в один из восьми
специализированные функции, а не оригинал.
В 2008 году этот трюк создал восемь разных копий.
поисковой петли, каждая с тугой внутренней петлей
оптимизирован для своего конкретного случая.
Я недавно заметил, что последняя версия g++ отказывается
встроенный InlinedSearchLoop , потому что он такой
большая функция, так что больше нет восьми разных
копии в программе.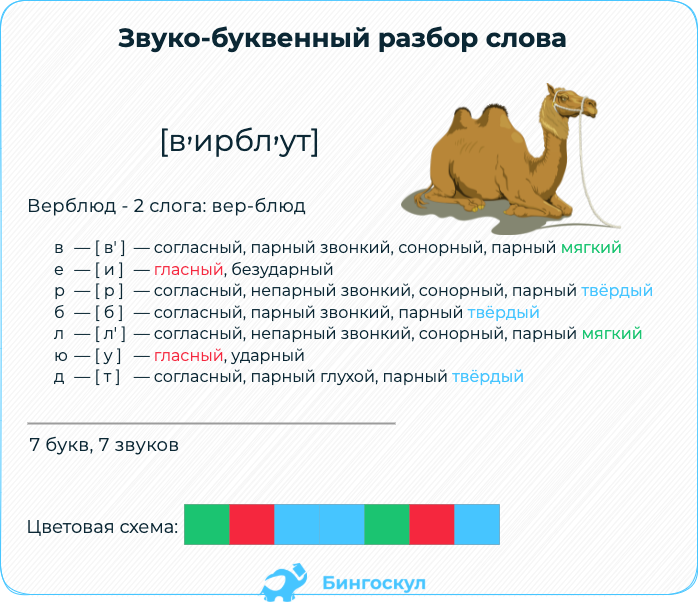 Можно было бы снова ввести
восемь копий, сделав
Можно было бы снова ввести
восемь копий, сделав Встроенный цикл поиска шаблонная функция, но, похоже, это уже не имеет значения:
Я попробовал это, и специализированный код не был быстрее.
Соответствует ли регулярное выражение подстроке строки? Если да, то где?
RE2::PartialMatch(s, "(re)", &match)
Звонящий становится более требовательным. Теперь он хочет знать, где совпадение, но все еще не заботиться о границах подсовпадений. Мы могли бы вернуться к прямому моделированию NFA, но это влечет за собой значительное снижение скорости по сравнению к НФА. Вместо этого, приложив немного больше усилий, мы можем выжать эту информацию из DFA.
Найти точную конечную точку. Стандартные представления DFA рассматривают каждое состояние как
представляющий неупорядоченный набор состояний NFA.
Если вместо этого мы рассматриваем состояние DFA как частично упорядоченный набор состояний NFA,
мы можем отслеживать, какие возможности имеют приоритет над другими,
так что DFA может определить точное место, где матч останавливается.
В правилах POSIX состояния, соответствующие началу совпадений
более ранние на входе имеют приоритет над состояниями, соответствующими
к более позднему началу.
Например, вместо состояния DFA, представляющего пять состояний NFA {1,2,3,4,5} может представлять {1,4}{2,3,5} :
совпадение, возникающее из состояний 1 или 4 , является
предпочтительнее совпадения из штата 2 , 3 или 5 .
Это заботится о «крайней левой» части «самого левого самого длинного».
Чтобы реализовать «самое длинное» требование, каждый раз
совпадение найдено в определенном состоянии, DFA записывает его и продолжает
выполнение только тех состояний, которые имеют равный или более высокий приоритет.
Как только в DFA заканчиваются состояния, последней записанной позицией совпадения является конец.
самого левого самого длинного совпадения.
В правилах в стиле Perl самая левая семантика
обрабатываются одинаково, но Perl не занимает больше всего времени
самые левые совпадения. Вместо этого госсписки упорядочены полностью: нет двух
состояния имеют равный приоритет. В чередовании
Вместо этого госсписки упорядочены полностью: нет двух
состояния имеют равный приоритет. В чередовании a|b штаты, изучающие и , имеют более высокий приоритет, чем
штаты, изучающие b .
Повторение x* похоже на циклическое чередование, которое
продолжает выбирать между поиском другого x и
соответствует остальной части выражения.
Каждое чередование дает более высокий приоритет поиску еще х .
Графически оба представляют собой 90 108 узлов Split 90 109, как в первой статье:
Разделение дает более высокий приоритет пути, выходящему за пределы вершины. Нежадное повторение — это просто жадное повторение с приоритеты поменялись местами.
Чтобы найти конец совпадения Perl, каждый раз, когда совпадение найдено
в определенном состоянии DFA записывает его, но продолжает выполнять
только те состояния, которые имеют более высокий приоритет. Как только у него закончатся состояния,
последняя записанная позиция обязательно является концом
совпадение с наивысшим приоритетом.
Отлично: теперь мы знаем, чем закончится матч. Но вызывающий абонент также хочет знать, где начинается матч. Как мы это делаем?
Запустите DFA в обратном направлении, чтобы найти начало. При изучении регулярных выражений в теории вычислений
класс, стандартное упражнение состоит в том, чтобы доказать, что если
вы берете регулярное выражение и обращаете все конкатенации
(например, [Gg]oo+gle становится elgo+o[Gg] )
то вы получите регулярное выражение, которое соответствует
обращение любой строки, совпавшей с оригиналом.
На таких занятиях не так много упражнений, связанных
регулярные выражения и автоматы имеют практическое значение,
но этот делает!
DFA сообщает только о том, где заканчивается совпадение, но если мы запустим DFA
назад по тексту, то, что DFA видит как конец
матча фактически будет началом.
Поскольку мы обращаем ввод, мы должны обратить
регулярное выражение тоже, обратив все конкатенации
во время компиляции.
После компиляции обратного регулярного выражения
мы запускаем DFA в обратном направлении от конечной точки
найдено при прямом сканировании, рассматривая все состояния как эквивалентные по приоритету
и ищем максимально длинную конечную точку. Это самая левая точка в строке, где
могло начаться, и поскольку мы были осторожны на предыдущем шаге
чтобы выбрать конец крайнего левого совпадения, это начало.
Это самая левая точка в строке, где
могло начаться, и поскольку мы были осторожны на предыдущем шаге
чтобы выбрать конец крайнего левого совпадения, это начало.
Соответствует ли это регулярное выражение этой строке? Если да, то где? Где подматчи?
RE2::PartialMatch(s, "(r+)(e+)", &m1, &m2)
Это самый сложный вопрос, который может задать звонящий.
Запустите DFA, чтобы ответить на первые две части. DFA работает быстро, но может ответить только на первые две части. Для ответа на третью часть необходимо прямое моделирование NFA. Тем не менее, DFA достаточно быстр, поэтому имеет смысл его вызывать. для первых двух. Использование DFA для поиска общего совпадения сокращает количество текста, который должен обработать NFA, что помогает при поиске больших тексты для мелких целей, а также полностью избегает NFA, когда ответ на вопрос первый вопрос «нет», очень распространенный случай.
Как только DFA находит место совпадения,
пора вызывать NFA для поиска границ подсовпадений. NFA асимптотически эффективна (линейна по размеру
регулярное выражение и линейное по размеру вводимого текста),
но поскольку он должен копировать граничные наборы подсовпадений,
в обычных случаях он может быть медленнее, чем бэктрекер, такой как PCRE.
В обмен на гарантированную производительность в худшем случае,
средний корпус страдает немного.
(Подробнее см. в разделе «Сопоставление регулярных выражений: подход виртуальной машины».)
NFA асимптотически эффективна (линейна по размеру
регулярное выражение и линейное по размеру вводимого текста),
но поскольку он должен копировать граничные наборы подсовпадений,
в обычных случаях он может быть медленнее, чем бэктрекер, такой как PCRE.
В обмен на гарантированную производительность в худшем случае,
средний корпус страдает немного.
(Подробнее см. в разделе «Сопоставление регулярных выражений: подход виртуальной машины».)
Несколько важных общих случаев не требуют полный механизм NFA, чтобы гарантировать эффективное выполнение. Их можно обработать с помощью пользовательского кода, прежде чем они упадут. вернемся к НФА.
По возможности используйте однопроходный NFA. NFA тратит свое время на отслеживание нескольких
наборы границ подсовпадения (в частности, их копирование), но можно идентифицировать
большой класс регулярных выражений, для которых NFA
никогда не нужно сохранять более одного набора граничных положений,
независимо от того, какой ввод.
Давайте определим «однопроходное регулярное выражение»
быть регулярным выражением со свойством, которое
на каждый входной байт во время привязанного совпадения есть только
одна альтернатива, которая имеет смысл для данного входного байта.
Например, x*yx* является однопроходным: вы читаете x до y , затем вы читаете y , затем вы продолжаете читать x .
Ни в коем случае вам не нужно гадать, что делать или делать резервную копию
и попробуйте другое предположение.
С другой стороны, 9x]*)x(.*) — однопроходный; (.*)x(.*) не является. (\d+)-(\d+) — однопроходный; (\d+).(\d+) не является.
Простая интуиция для определения однопроходных регулярных выражений
заключается в том, что всегда сразу видно, когда повторение заканчивается.
Также должно быть сразу видно, какая ветвь | взять: x(y|z) является однопроходным, а (xy|xz) — нет.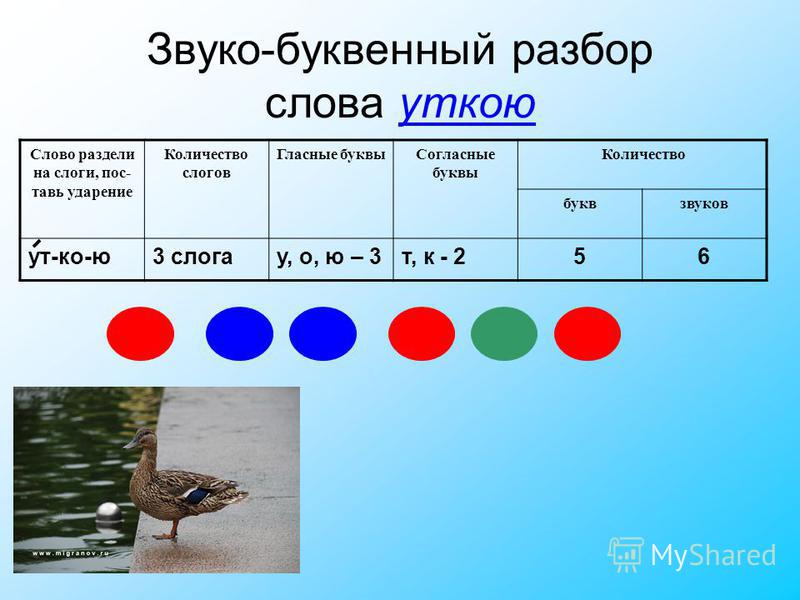
Поскольку есть только один возможный следующий выбор, однопроходная реализация NFA никогда не требует создания копии граничного набора подсовпадений. Одноходовой двигатель выполняется из двух половин. Во время компиляции однопроходный код анализирует скомпилированную форму программы, чтобы определить, он однопроходный. Если это так, движок вычисляет структуру данных, записывая, что делать. для каждого возможного состояния и входного байта. Тогда при выполнении однопроходный двигатель может пролететь через струну, найти совпадение (или нет) за один проход.
По возможности используйте средство возврата битового состояния. Бэктрекеры, такие как PCRE, избегают копирования наборов подсовпадений:
они имеют единый набор и перезаписывают и восстанавливают его в течение
рекурсия. Для корректности такой подход должен быть готов
чтобы повторно посетить одну и ту же часть строки несколько раз, по крайней мере, один раз
на штат NFA.
Однако это все равно будет только линейное сканирование времени: экспоненциальное время
часть PCRE заключается в повторном просмотре одной и той же части строки много раз
для состояния NFA, потому что алгоритм не помнит, что
раньше он шел по определенному пути.
Средство поиска с возвратом по битовому состоянию выполняет стандартный поиск с возвратом. алгоритм, реализованный с помощью ручного стека, и добавляет отслеживание растрового изображения, которое (состояние, позиция строки) связывает уже посетили. Для небольших совпавших регулярных выражений против небольших строк выделение и очистка растрового изображения значительно дешевле, чем копирование штатов NFA. RE2 использует возврат битового состояния, когда размер растрового изображения не превышает 32 килобайт.
Если ничего не помогает , используйте стандартный NFA.
Анализ
RE2 запрещает функции PCRE, которые невозможно реализовать
эффективно использовать автоматы. (Самая заметная такая функция — обратные ссылки.)
В обмен на отказ от этих сложных в реализации (и часто неправильно используемых)
функции, RE2 может достоверно анализировать регулярные выражения или
автоматы.
Мы уже видели примеры анализа для использования в самой RE2,
в использовании DFA memchr и в анализе
является ли регулярное выражение однопроходным. RE2 также может выполнять анализ, который позволяет приложениям более высокого уровня
скоростные поиски.
RE2 также может выполнять анализ, который позволяет приложениям более высокого уровня
скоростные поиски.
Диапазоны соответствия .
Bigtable хранит записи
в порядке хранения по имени строки, что позволяет эффективно сканировать все строки с именами
в заданном диапазоне. Bigtable также позволяет клиентам указывать фильтр регулярного выражения:
сканирование пропускает строки с именами, которые не являются точным совпадением с регулярным выражением.
Некоторым клиентам удобно использовать только фильтр регулярных выражений
и не беспокойтесь об установке диапазона строк. Эти клиенты могут улучшить
эффективность такого сканирования, попросив RE2 вычислить
диапазон строк, которые могут соответствовать регулярному выражению
а затем ограничить сканирование только этим диапазоном.
Например, для (привет|мир)+ , RE2::PossibleMatchRange может определить, что все возможные совпадения находятся в диапазоне [ hello , worldworle ]. Он работает, исследуя график DFA из начального состояния,
поиск пути с наименьшими возможными значениями байтов
и путь с максимально возможными значениями байтов.
Он работает, исследуя график DFA из начального состояния,
поиск пути с наименьшими возможными значениями байтов
и путь с максимально возможными значениями байтов. и в конце worldworle не опечатка: мирмирмир < мирмир но не мирмир : PossibleMatchRange часто должен усекать используемые строки
чтобы указать диапазон, и когда он это делает, он должен округлить верхнюю границу вверх.
Требуемые подстроки .
Предположим, у вас есть эффективный способ проверить, какая из строк списка
отображаться как подстроки в большом тексте (например, возможно, вы реализовали
алгоритм Ахо-Корасика),
но теперь ваши пользователи также хотят иметь возможность эффективно выполнять поиск по регулярным выражениям.
Регулярные выражения часто содержат большие литеральные строки; если бы это могло быть
идентифицированы, их можно было ввести в поисковик строк, а затем результаты
поисковик строк можно использовать для фильтрации набора поисковых запросов по регулярным выражениям
которые необходимы.
Класс FilteredRE2 реализует этот анализ. Имея список регулярных выражений, он проходит обычный
выражения для вычисления логического выражения, включающего литеральные строки
а затем возвращает список строк.
Например, FilteredRE2 преобразует (hello|hi)world[az]+foo в логическое выражение
«( helloworld ИЛИ hiworld ) И foo »
и возвращает эти три строки.
Учитывая несколько регулярных выражений, FilteredRE2 преобразует
каждый в логическое выражение и возвращает все задействованные строки.
Затем, после того, как ему сказали, какая из строк присутствует, FilteredRE2 может оценивать каждое выражение
для определения набора регулярных выражений, которые могут присутствовать.
Эта фильтрация может значительно сократить количество фактических поисков с использованием регулярных выражений.
Осуществимость этих анализов в решающей степени зависит от простоты
их ввода. Первый использует форму DFA, а второй использует проанализированный
регулярное выражение ( Регулярное выражение* ). Такие анализы будут более сложными.
(может быть, даже невозможно)
если бы RE2 допускал нерегулярные функции в своих регулярных выражениях.
Такие анализы будут более сложными.
(может быть, даже невозможно)
если бы RE2 допускал нерегулярные функции в своих регулярных выражениях.
Интернационализация
RE2 рассматривает регулярные выражения как описания последовательностей Unicode.
и может искать текст, закодированный в UTF-8 или Latin-1.
Подобно PCRE и другим реализациям регулярных выражений,
именованные группы, такие как [[:digit:]] и \d содержат только ASCII, но группы свойств Unicode, такие как \p{Nd} содержать полный Unicode.
Задача для RE2 состоит в том, чтобы реализовать большой
Набор символов Unicode эффективно и компактно.
Мы видели выше, что класс символов представлен
как сбалансированное бинарное дерево, но также важно
сохраняйте размер библиотеки небольшим, что означает
жесткая кодировка необходимых таблиц Unicode.
Для интернационализированных классов символов RE2 реализует
свойство Unicode 5.2 General Category
(например, \pN или \p{Lu} )
а также свойство Unicode Script
(например, \p {греч. ).
Их следует использовать всякий раз, когда совпадения не предназначены
быть ограниченным символами ASCII
(например,  }
} \pN или \p{Nd} вместо [[:digit:]] или \d ).
RE2 не реализует другие свойства Unicode.
(см. Технический стандарт Unicode № 18: Регулярные выражения Unicode).
Таблица групп Unicode сопоставляет имя группы с массивом
диапазоны кодов, определяющие группу.
Для таблиц Unicode 5.2 требуется 4258 диапазонов кодов.
Поскольку Unicode содержит более 65 536 кодовых точек, каждый диапазон
обычно требуется два 32-битных числа (начало и конец),
или всего 34 килобайта.
Однако, поскольку подавляющее большинство диапазонов включает только
кодовых точек меньше 65 536, имеет смысл разделить каждую
сгруппировать в набор 16-битных диапазонов и набор 32-битных диапазонов,
сокращение размера таблицы до 18 килобайт.
RE2 реализует совпадения без учета регистра (включено (?i) ) в соответствии с
спецификация Unicode 5. 2:
он складывается
2:
он складывается А с а , Á с а ,
и даже K с K (Кельвины) и S с ſ (длинные с).
Имеется 2061 символ для конкретного случая.
Таблица RE2 сопоставляет каждую кодовую точку Unicode со следующей
самая большая точка, которую следует рассматривать как одну и ту же.
Например, таблица карт Б 9от 0109 до б и б до б .
В большинстве этих циклов участвуют только два символа, но есть
несколько длиннее: например,
карты таблицы К от до к , к от до К (символ Кельвина),
и К обратно в К .
Эта таблица очень повторяющаяся: A сопоставляется с a , B сопоставляется с b и так далее.
Вместо того, чтобы перечислять каждый символ, мы можем перечислить диапазоны и дельты: A через Z сопоставляется со значением плюс 32, a через j сопоставить со значением минус 32, k отображается в K (снова символ Кельвина) и так далее. Существует особый случай для диапазонов с сериями старших/младших пар и
нижняя/верхняя пары.
Эта кодировка сокращает таблицу с 2061 записи, занимающей 16 килобайт, до
279 записей, занимающих 3 килобайта.
Существует особый случай для диапазонов с сериями старших/младших пар и
нижняя/верхняя пары.
Эта кодировка сокращает таблицу с 2061 записи, занимающей 16 килобайт, до
279 записей, занимающих 3 килобайта.
RE2 не реализует именованные символы, как в Python u"\N{LATIN SMALL LETTER X}" как псевдоним для "x" .
Даже не обращая внимания на очевидные проблемы с пользовательским интерфейсом, необходимая таблица будет занимать около 150 килобайт.
Тестирование
Откуда мы знаем, что код RE2 правильный?
Тестирование реализации регулярных выражений — сложная задача,
особенно когда реализация имеет столько же различных путей кода, сколько и RE2.
Другие библиотеки, такие как Boost,
ПКРЕ и
Перл,
со временем создали большие наборы тестов, поддерживаемые вручную.
В RE2 есть небольшое количество написанных от руки тестов для проверки основных
функциональность, но быстро выяснилось, что рукописный
одни только тесты потребовали бы слишком много усилий для создания и поддержки
если бы они хорошо освещали RE2. Вместо этого основная часть тестирования выполняется путем создания
и механическая проверка тестовых случаев.
Вместо этого основная часть тестирования выполняется путем создания
и механическая проверка тестовых случаев.
Учитывая список небольших регулярных выражений и операторов,
класс RegexpGenerator генерирует все возможные выражения, используя те
операторы до заданного размера. Затем StringGenerator генерирует все возможные
строки по заданному алфавиту до заданного размера.
Затем для каждого регулярного выражения и каждой входной строки тесты RE2 проверяют, что
вывод четырех разных движков регулярных выражений
соглашаются друг с другом, и с тривиальным отступлением
реализация написана только для тестирования,
и (обычно) с самим PCRE.
RE2 не во всех случаях соответствует PCRE, поэтому тестер включает
анализ для проверки случаев
в отношении которых RE2 и PCRE расходятся во мнениях, как указано в разделе «Предостережения» ниже.
За исключением случаев, когда регулярное выражение включает эти граничные случаи,
тестер требует согласия RE2 и PCRE
на исход матча.
Исчерпывающие тесты должны ограничиваться небольшими регулярными выражениями.
и небольшие входные строки, но большинство ошибок можно обнаружить с помощью небольших тестовых случаев.
Перечисление всех небольших тестовых случаев выявляет почти все ошибки, которые не замечаются.
несколько рукописных тестов.
Тем не менее, RE2 также включает рандомизированный тестер, варианты RegexpGenerator и StringGenerator которые генерируют более крупные случайные экземпляры.
Случайное тестирование редко что-то улавливает
что меньшее исчерпывающее тестирование пропустило,
но это все еще хорошая уверенность в том, что большие выражения и тексты
продолжать работать корректно.
Производительность
RE2 конкурентоспособен с PCRE при небольших запросах и быстрее при больших.
Производительность для небольших поисков сообщается в микросекундах,
так как время поиска в основном не зависит от фактического размера текста
(около 10 байт в этих примерах). Производительность при больших объемах поиска указывается в МБ/с.
поскольку время поиска обычно линейно зависит от фактического размера текста.
Представленные тесты выполняются re2/testing/regexp_benchmark.cc . Каталог re2/source/browse/benchlog содержит накопленные результаты.
(Все тесты выполняются с PCRE 8.01, последней версией на момент написания.)
Сборник. RE2 компилирует регулярные выражения примерно в 3-4 раза медленнее, чем PCRE:
| ||||||||||||||||||
| Время составить простое регулярное выражение. | ||||||||||||||||||
Разница составляет около 5-10 микросекунд на регулярное выражение. Эти тайминги включают время, потраченное на освобождение регулярного выражения после синтаксического анализа. и компиляция. Мы ожидаем, что общий случай состоит в том, что регулярные выражения кэшируются между совпадениями, когда скорость критична, делая время компиляции не слишком важным.
Скомпилированная форма RE2 больше, чем форма объекта PCRE,
несколько килобайт против нескольких сотен байт для типичного небольшого регулярного выражения.
RE2 выполняет дополнительный анализ регулярного выражения во время компиляции.
и хранит более богатую форму, чем PCRE.
RE2 также сохраняет состояние (частично построенный DFA) при вызовах:
после запуска нескольких матчей простой RE2 может использовать 10 КБ,
но большее количество совпадений обычно не увеличивает занимаемую площадь. RE2 ограничивает общее использование пространства до указанного пользователем максимума.
(по умолчанию 1 МБ).
Полное совпадение, информация о подсовпадении отсутствует .
Выше мы видели, что некоторые поиски сложнее, чем другие.
и что RE2 использует разные реализации для разных видов поиска.
Этот тест ищет .*$ в случайно сгенерированном входном тексте заданного размера.
Это дает ощущение полной скорости поиска.
Скорость поиска .*$ в случайном тексте. (Mac Pro) |
RE2 использует DFA для запуска поиска.
Полное совпадение, однопроходное регулярное выражение, информация о частичном совпадении, крошечные строки .
Этот тест ищет ([0-9]+)-([0-9]+)-([0-9]+) в строке 650-253-0001 , запрашивая расположение трех подсовпадений:
| ||||||||||||||||||
Время совпадения ([0-9]+)-([0-9]+)-([0-9]+) в 650-253-0001 . | ||||||||||||||||||
RE2 использует механизм сопоставления OnePass для запуска поиска, избегая накладных расходов на полный НФА.
Полное совпадение, неоднозначное регулярное выражение, информация о частичном совпадении, крошечные строки .
Если регулярное выражение неоднозначно, RE2 не может использовать движок OnePass,
но если и регулярное выражение, и строка малы, RE2 может использовать механизм BitState.
Этот тест ищет [0-9]+.(.*) в 650-253-0001 :
| ||||||||||||||||||
Время совпадения [0-9]+.(.*) в 650-253-0001 . | ||||||||||||||||||
Здесь RE2 заметно медленнее, чем PCRE, потому что регулярное выражение не
однозначный: никогда не ясно, должна ли дополнительная цифра
быть добавлен к [0-9]+ или использоваться для соответствия ‘ . ’.
PCRE оптимизирован для матчей; при представлении строк
которые не совпадают, его время выполнения может расти экспоненциально в
в худшем случае и заметно медленнее даже в обычных случаях.
Напротив, RE2 движется с линейной скоростью независимо от
совпадает ли текст. Конкретная скорость зависит от размера текста и регулярного выражения.
В небольших случаях, подобных этому, RE2 использует BitState; в более крупных случаях,
он должен вернуться к NFA.
Частичное совпадение, фактического совпадения нет . Поиск частичного (непривязанного) совпадения требует, чтобы сопоставление движок считает совпадения, начинающиеся с каждого байта в строке. PCRE реализует это как цикл, который пытается начать с каждого байта. в строке, в то время как реализации RE2 могут запускать все эти в параллели. Реализации RE2 анализируют регулярное выражение более тщательно, чем это делает PCRE, что приводит к потенциальному ускорению.
Этот тест ищет ABCDEFGHIJKLMNOPQRSTUVWXYZ$ в случайно сгенерированном тексте.
Скорость поиска ABCDEFGHIJKLMNOPQRSTUVWXYZ$ в случайном тексте. (Mac Pro) |
RE2 DFA тратит большую часть своего времени
в мемчр ищу ведущий А . PCRE также замечает ведущий A , хотя он
кажется, не так много преимуществ.
Подозреваю, что PCRE больше не использует memchr после нахождения первого A .
Следующий бенчмарк немного сложнее, так как нет
ведущий символ в memchr for.
Он ищет [XYZ]ABCDEFGHIJKLMNOPQRSTUVWXYZ$ .
Скорость поиска [XYZ]ABCDEFGHIJKLMNOPQRSTUVWXYZ$ в случайном тексте. (Mac Pro) |
PCRE прибегает к гораздо более медленной обработке, чтобы справиться с этим, в то время как DFA RE2 выполняет свой быстрый цикл байт за раз.
Следующий бенчмарк довольно сложный для PCRE.
Он ищет [ -~]*ABCDEFGHIJKLMNOPQRSTUVWXYZ$ .
Текст не соответствует этому выражению, но PCRE сканирует
вся строка в каждой позиции соответствует [ -~]* прежде чем понять, что там нет совпадения. Это заканчивается тем, что для сопоставления требуется время O(text 2 ).
DFA RE2 делает один линейный проход.
Скорость поиска [-~]*ABCDEFGHIJKLMNOPQRSTUVWXYZ$ случайным текстом. (Mac Pro) |
Обратите внимание, что PCRE останавливается на текстах длиной 4 КБ.
Поиск и разбор .
Другим типичным использованием RE является поиск и разбор определенной строки.
в тексте. Этот тест генерирует случайный текст с (650) 253-0001 в конце, а затем делает
непривязанный поиск (\d{3}-|\(\d{3}\)\s+)(\d{3}-\d{4}) ,
извлечение кода города отдельно из 7-значного номера телефона.
Скорость поиска и сопоставления (\d{3}-|\(\d{3}\\)\s+)(\d{3}-\d{4}) случайным текстом, заканчивающимся на (650) 253-0001 . (Mac Pro) |
Более быстрый поиск DFA в RE2 отвечает за улучшенную скорость.
Резюме . RE2 требует около 10 КБ на регулярное выражение, в отличие от половины КБ в PCRE или около того. В обмен на дополнительное пространство RE2 гарантирует производительность с линейным временем. хотя постоянная линейного времени зависит от ситуации.
RE2 работает примерно с той же скоростью, что и PCRE, для запросов,
строка совпадает, но не запрашивать информацию о частичном совпадении
(например, RE2::FullMatch или RE2::PartialMatch без дополнительных аргументов).
При использовании регулярных выражений для анализа текста RE2 работает примерно с той же скоростью.
как PCRE для однозначных регулярных выражений.
Он работает примерно вдвое быстрее для неоднозначных регулярных выражений с небольшими совпадениями,
и значительно медленнее для неоднозначных регулярных выражений с большими совпадениями.
Объемы данных, используемые в этих случаях, обычно
достаточно мала, чтобы разница во времени выполнения не была узким местом. (Например, любая потеря производительности при синтаксическом анализе имени файла исчезает.
по сравнению со временем, необходимым для открытия файла.)
RE2 отлично справляется с поиском больших объемов текста. Он может находить совпадения намного быстрее, чем PCRE, особенно если поиск требует возврата PCRE.
Эти тесты сравниваются с PCRE, потому что это самое прямое сравнение: C/C++ против C/C++ с почти идентичным интерфейс. Важно подчеркнуть, что бенчмарки интересны тем, что в первую очередь сравнивают алгоритмы, не настройка производительности. Выбор алгоритма PCRE, по крайней мере, в общем случае, вынуждается попыткой быть полностью совместимым с Perl и его друзьями.
Предостережения
RE2 явно не пытается обрабатывать каждое расширение, которое
Перл представил.
Поддерживаемые расширения Perl:
нежадное повторение; классы символов, такие как \d ; а также
пустые утверждения, такие как \A , \b , \B и \z . RE2 не поддерживает произвольные утверждения вперед или назад,
он также не поддерживает обратные ссылки.
Он поддерживает подсчитываемое повторение, но реализуется
фактическое повторение ( \d{3} становится \d\d\d ),
поэтому большое количество повторений неразумно.
RE2 поддерживает именованные захваты в стиле Python (?P ,
но не альтернативные синтаксисы (? и (?'name'expr) используется .NET и Perl.
RE2 не всегда соответствует поведению PCRE. Есть несколько известных случаи, когда RE2 намеренно отличается:
- Если регулярное выражение содержит повторение пустой строки,
как
(а*)+, тогда PCRE будет обрабатывать репликацию последовательность заканчивается пустой строкой, а RE2 — нет. В частности, при сопоставлении(a*)+сaaa, PCRE запускает+дважды, один раз для соответствияaaaи второй раз, чтобы соответствовать пустой строке. RE2 работает на +только один раз, чтобы соответствоватьaaa. Поскольку скобки захватывают самый правый текст, с которым они совпали, для PCRE$1будет пустой строкой, а для RE2$1будетааа. При необходимости поведение PCRE можно было бы засунуть в RE2. - Perl и PCRE различаются значением регулярного выражения
\v. В Perl он соответствует только символу вертикальной табуляции (VT, 0x0B), в то время как в PCRE он соответствует как вертикальной вкладке, так и новой строке. RE2 выбирает сторону Perl. - В однострочном режиме, если вводимый текст заканчивается символом новой строки,
Perl и PCRE позволяют
$сопоставляться либо до, либо после этот последний перевод строки. RE2 требует, чтобы он совпадал после, в самом конце текста. 9[:alpha:]] оба означают любой Unicode символ, которого нет в[[:alpha:]].
В Perl и PCRE есть несколько малоизвестных особенностей. которые RE2 предпочитает не реализовывать. Это:
- «Расширенные» регулярные выражения традиционно
следовал правилу, согласно которому словесные символы означают
сами, если не сбежали, в то время как
знаки препинания могут быть специальными, если они не экранированы.
Таким образом,
\qдолжно означать что-то особенное и\#должны соответствовать литералу#. Perl и PCRE принимают экранированные буквы как литералы если буква (пока) не имеет значения. Таким образом, в Perl\qсоответствует литералуq, по крайней мере, пока не будет введено другое значение. RE2 отклоняет неизвестные экранированные буквы, а не молча рассматривая их как литералы. Это также помогает диагностировать использование последовательностей, которые RE2 не поддерживает, например,\cx(см. ниже). - RE2 не распознает
\cxкак символ Control-X. Вставьте литеральный управляющий символ, используя синтаксис строки C++ или восьмеричное или шестнадцатеричное escape-последовательность. - В POSIX
\bозначает возврат. В Perl это означает границу слова, кроме как внутри класса символов, когда это означает возврат ([\b]). RE2 пытается избежать путаницы, никогда не распознавая\bкак backspace. RE2 отклоняет\bв режиме POSIX, распознает его как границу слова в режиме Perl, и всегда отклоняет его в классах персонажей. Чтобы соответствовать символу возврата, вставьте символ возврата или напишите\010. - RE2 не распознает атомарные операторы группировки
(?>...)и++. Они используются в основном в качестве вспомогательного средства при возврате. RE2 предоставляет более полное решение. - RE2 не распознает
\C,\Gили\X. - RE2 не распознает
условные подшаблоны
(?(...)...), комментарии(?#...), ссылки на шаблоны(?R)(?1)(?P>foo), или выноски C(?C.. ..)
По умолчанию RE2 применяет максимум 1 МБ (на объект RE2).
для двух Prog и их DFA s.
Этого достаточно для большинства выражений, но очень большие выражения
или паттерны с большим числом повторений могут превышать
эти пределы.
Нехватка памяти во время компиляции
заставляет re.ok() возвращать false,
с объяснением в re.error() .
RE2 не может исчерпать память во время текстового поиска:
он удалит кэшированный DFA и запустит новый DFA.
используя восстановленную память.
Если ему придется сбрасывать DFA слишком часто, он вернется
в поиске NFA.
Резюме
RE2 демонстрирует, что можно использовать теорию автоматов для
реализовать почти все возможности современного поиска с возвратом
библиотека регулярных выражений, такая как PCRE. Потому что он уходит своими корнями в
теоретическая основа автоматов, RE2 обеспечивает более сильную
гарантирует время выполнения, чем и позволяет проводить высокоуровневый анализ
это было бы сложно или невозможно при реализации ad hoc.