2.Красит, подбирает, раскрывает Разобрать по составу
помогите пожалуйста дам лучший ответ
3. Послушай чтение одноклассников. Определи тему текстов.Звёзды это огромные раскалённые газовыешары. Самые горячие звёзды голубого цвета, а менеегоря … чие – красного. Звёзды бывают маленькие, боль-шие и гигантские.Однажды я попытался сосчитать все звёзды нанебе, но быстро сбился. В книге я прочитал, что безвсяких приборов можно разглядеть около шести тысячзвёзд, а с помощью телескопа – почти два миллиарда!На небе в ясную погоду мы видим маленькиемерцающие точки звёзды. Звёзды кажутся наммаленькими, потому что они от нас находятся оченьдалеко и свет от далёких звёзд приходит на Землюспустя сотни и даже тысячи лет.(Атлас Земли. ЭКСМО, 2012)Сравни тексты с помощью таблицы. Определи тип текстов.Текст- рассказывают,повествование сообщают о чём-либоТекст- описывают предметы,описание событиячто? Где?когда? как?какой? какая?какое? какие?Текст-рассуждениеобъясняют что-либо,рассуждают о причинахпочему?• Спиши текст-рассуждение. Подчеркни в первом предложенийграмматическую основу. Обозначь, какими частями речи вы-ражены подлежащее и сказуемое. У подлежащего определипадеж.
Помогите пж, с заданием в онлайн мектеп. Прочитай предложение. Заполни таблицуПод кустом черемухи звонко журчит говорливый ручей.
Звёзды — это огромные раскалённые газовыешары. Самые горячие звёзды голубого цвета, а менеегорячие — Красного. Звёзды бывают маленькие, большие и гига
… нтскиеОднажды я попытался сосчитать все звёзды нанебе, но быстро сбился, в книге я прочитал, что безвсяких приборов можно разглядеть около шести тысячзасал, а с помощью телескопа — почти два миллиарааНа небе в ясную погоду мы видим маленькиемерцающие точки — звёзды, звезды кажутся наммаленькими, потому что они от нас находятся оченьдалеко и свет от далёких звёзд приходит на Земліоспустя сотни и даже тысячи лет.(Атлас Земли, Эксмо, 2012)Сравни тексты с помощью таблицы, определи тип текстовТекстрассказывают,Что? Где?повествование | сообщајот о чём-либо когда? как?Текст описываlог предметы,какой? какая?описание событиякакое? какие? ?Текст объясняют что-либо,почему?рассуждение рассуждатото причинах• Спиши текст рассуждение.
посмотрите видеосюжета Маншук Маметовой почтили в западном казахстане. При его просмотре ведите записи чтобы ответить на вопросы
какова основная мысль видеосюжета? Совпали ли ваши предположения? Запишите ответы на вопросы в двухчастном дневнике. Память Маншук Маметовой
5. Найдите в тексте два слова с приставкой, оканчивающейся на с. Объясните их правописание. 6. Скажите, какие части письма отсутствуют. Допишите их.
4. Запиши пословицы вставляя наречия антонимы
СОРИ СРОЧНО ЗА 20 МИНУТЗадание ниже 3 КЛАСС ДАМ 15 БАЛЛОВПОПРОШАЙКАМ БАН!!!!!!!!
пожалуйста очень нужно
5 класс. Русский язык. Способы словообразования — Состав слова.
Комментарии преподавателя1. Морфемика – это раздел языкознания, в котором изучается система морфем языка и морфемная структура слов.
Морфема – это минимальная значимая часть слова.
Морфемы: корень, суффикс, приставка, окончание.
Рис. 1. Морфемы.
2.Корень – это обязательная часть слова.
Только из корня состоят служебные слова (но, для, если), междометия (ах, алло), многие наречия (очень, весьма), неизменяемые существительные (алоэ, кенгуру) и прилагательные (беж, макси).
Корни, которые могут употребляться только в сочетании с приставками или суффиксами, называются связанными (об-у-ть, раз-у-ть; о-де-ть, раз- де-ть).
3.Приставка — словообразовательная морфема, стоящая перед корнем или другой приставкой (пере-делать, пре-хорошенький, при-морье, кое-где, пере—о-деть).
Рис.2. Приставка.
4.Суффикс — словообразовательная морфема, стоящая после корня (стол-ик, красн-е-ть).
Рис. 3. Суффикс.
В лингвистике наряду с суффиксом выделяют также постфикс — словообразовательную морфему, стоящую после окончания или формообразующего суффикса (умы-ть-ся, к-ого-
5.Окончание — формообразующая морфема, выражающая грамматические значения рода, лица, числа и падежа (хотя бы одно из них!) и служащая для связи слов в словосочетании и предложении,
Окончание есть только у изменяемых слов. Нет окончаний у служебных слов, наречий, неизменяемых существительных и прилагательных, деепричастий, инфинитива.
У некоторых сложных существительных и числительных несколько окончаний.
Сравните: тр-и-ст-а, тр-ех-сот-□, диван□-кровать□, диван-а-кроват-и.
Нулевая морфема – это значимое отсутствие морфемы.
Стола – Р.п.
Стол□ – И.п. или В.п.
Нулевой суффикс мы выделяем, например, в форме прошедшего времени нёс
(сравните: нес-л-а) или форме повелительного наклонения читай.План морфемного разбора слова:
1. Выделяем окончание и основу слова.
2. Выделяем корень слова, подбирая однокоренные слова.
3. Выделяем приставки и суффиксы.
Образец морфемного разбора:
Двухэтажный (окончания –ух, -ый, основа … (такая основа называется прерывистой), корни дв-, этаж-, суффикс –н-).
Переулок (окончание нулевое, основа переулок, корень –ул-, приставка пере-, суффикс –ок).
Словообразование – это процесс образования производных слов и раздел языкознания, изучающий этот процесс.
Способы словообразования:
Приставочный: делать – переделать
Суффиксальный: синий – син
Приставочно-суффиксальный: стакан – подстаканник
Усечение: заместитель – зам
Сложение: лес+степь – лесостепь
Сращение: вечнозеленый
Аббревиация: Московский государственный университет – МГУ, сберегательный банк – сбербанк
Субстантивация (переход прилагательного или причастия в существительное): столовая
Смешанные способы словообразования: орден+носить = орденоносец (сложение и суффиксация)
План словообразовательного разбора слова:
1. Поставить слово в начальную форму.
2. Определить слово, от которого оно образовано. Например, обновление – обновить (а не новый).
3. Объяснить значение исследуемого слова через значение слова, от которого оно образовано (например, слушатель – тот, кто слушает
).4. Выделить основу, от которой образовано исследуемое слово.
5. Указать средство словообразования.
6. Указать способ словообразования.
Образец словообразовательного разбора:
1. Под-окон-ник – окно
Основа окн-
Средства словообразования: приставка под- и суффикс –ник. Способ словообразования: приставочно-суффиксальный
2. Мир(о)твор-ец – мир+творить
Основы, от которых образовано слово, — мир- и твор-
Средства словообразования: сложение основ и суффикс –ец.
Способ словообразования: сложение и суффиксация
10. Домашнее задание
Домашнее задание
Упражнения №
Задание №1. Даны слова: петь, учить, одеть, знал, столик, верхом, рано, волчонок, новее, ворча.
Задание №2. Даны слова: обучить, приходила, узнали, подоконник, треугольник, встряска, настольный, излишне, снова. Для каких слов из перечисленных годится следующий морфемный разбор:
ИСТОЧНИКИ
http://www.youtube.com/watch?v=AeX6EALboR8
http://doc4web.ru/russkiy-yazik/konspekt-uroka-dlya-klassa-sostav-slova-i-slovoobrazovanie.html
http://nsportal.ru/shkola/russkiy-yazyk/library/2014/10/28/konspekt-uroka-sostav-slova-5-klass
http://nsportal.ru/shkola/russkiy-yazyk/library/2012/12/01/konspekt-uroka-russkogo-yazyka-v-5-klasse-po-temezakreplenie
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Открытый урок по теме «Словообразование. Обобщающее повторение темы»
Цель: обобщить знания учащихся по изученной теме.
Задачи:
Образовательные:
- вспомнить основные способы образования слов;
- закрепить умение отличать морфемный разбор от словообразовательного;
- повторить приставки пре- и при-;
- повторить чередующиеся гласные в корне;
- *СЗ — запятые в СП и ПП с однородными членами.
Развивающие:
- развить логическое мышление;
- развить монологическую речь.
Воспитывающие:
- привить любовь к русскому языку
Ход урока
I. ОМ.
Готовность к уроку: учебник, тетрадь, ручка, карандаш.
Оснащение урока: учебник, карточки с индивидуальными заданиями, кроссворды
II. Целеполагание
Объявление темы урока, его цели и задач.
III. Актуализация знаний.
1. Повторение теории по теме: «Словообразование»
— Что такое словообразование?
-Что такое морфемика?
— Какие нам известны значимые части слова?
— Что такое окончание?
— Что такое основа слова?
— Что такое корень?
— Что такое приставка?
— Что такое суффикс?
— Какие нам известны способы образования слов? (перечислить и записать на доске в столбик)
2. Распределительный диктант.
Распределительный диктант.
- Приставочный: бесполезный, поднести
- Приставочно-суффиксальный: опилки, наездник, ошейник
- Суффиксальный: сосновый, мячик, ленточки
- Бессуфиксальный: отход, заплыв, перелет
- Сложение основ(): листопад , сталевар
- Сложение части слова и целого слова: стенгазета, медпункт
- Сложение целых слов: кресло-качалка, город-герой
- Сложносокращенные слова: комбат, ВВЦ
- Переход одной части речи в другую: кондитерская, ученый
Проверка распределительного диктанта. *+карточки с индивидуальными заданиями
3. Морфемный и словообразовательный разбор слова(по вариантам I-II)
а) разберите по составу слова:
Вывод: Чем отличается морфемный разбор от словообразовательного?
Ответ учащихся: Морфемный разбор-это разбор слова по составу, а словообразовательный- это от чего и с помощью чего образовано слово.
4. Повторение приставок пре- и при-
— Назовите четыре значения приставки при-
— Назовите два значения приставки пре-
— Приведите примеры словосочетаний на приставки пре- и при-
(Устно и письменно в тетрадях) *+карточки с индивидуальными заданиями
— Решение кроссвордов (с опорой на доске).
1. Какое значение приставки при- «спряталось» в этом слове? (13 клеток)
(Присоединение)
2. Какое значение приставки пре- «спряталось» в этом слове?(5 клеток)
(Очень)
3. Какие два слова с приставками пре- и при- пересеклись в точке «Е»?
(Приключение-преодоление)
5. Повторение чередующейся гласной в корне слова.
а) Прослушайте стишок и сформулируйте правило о чередовании гласных в корне слова.
Корень -кос- спросил Всезнайку
«Ты скажи мне без утайки,
Почему подружка –Кас-
Возгордилася у нас?»
И ответил тут Всезнайка
Абсолютно без утайки,
Что подружку нашу -Кас-
Защищает суффикс –а-
Ответ учащихся: если после корня следует -а- , то в корне пишется –кас-
Например: касаться, но коснуться
б) Прослушайте стишок, сформулируйте правило о чередовании гласных в корне слова.
-Раст- и –рос- пришли с прогулки,
Не сидели ни минутки:
Всем хотели рассказать,
Как их правильно писать.
Если в корне буква Т,
То пиши растение, ну а если подросло,
То напишем букву О.
Что ж тут долго рассуждать-
Нужно просто это знать.
Ответ учащихся: если корень оканчивается на согласный звук Т, то в корне пишется А, если на С, то – О
— Есть ли исключение из правила?
Ответ: есть: росток, Ростов, отрасль
Например: вырастить цветы, водоросли в озере
Но: маленький росток, отрасль промышленности
в) Прослушайте стишок и сформулируйте правило о чередовании гласных в корне слова.
Гар- и гор- друг с дружкой дружат,
Им пожар совсем не нужен,
Заключили соглашенье:
Гар- писать под удареньем.
Гор- не будет ударяться
Будет просто –гор- писаться.
Согласитесь ради дела,
Что загар и загорелый-
Очень просто для примера.
Ответ учащихся: в корнях гар-, гор- под ударением пишется А, без ударения – О
Например: угар, загар, огарок, но загорелый, горелки, подгореть(искл. : выгарки)
* + карточки с индивидуальными заданиями
*СЗ 6. Сопутствующее повторение: запятая в СП и ПП с однородными членами
В лесу мы собирали растения, подбирали причудливые корни деревьев, не пренебрегали шишками, перышками, потому что это пригодится нам для игрушек на елку. (запись предложения на доске и в тетрадях)
1 ученик:
1. Характеристика предложения.
Повествовательное, невосклицательное, распространенное, двусоставное, сложное, полное.
2. Подчеркнуть грамматические основы предложения
3. Дать его схему
2 ученик:
4.
Разобрать предложение по членам.
 Разобрать предложение по членам.
Разобрать предложение по членам.3 ученик:
5. Разобрать по составу слова: перышками, игрушек, причудливые.
4 ученик:
6. Отработать слова с чередующейся гласной в корне слова:
Собирали (подбирали), растения.
5 ученик:
7. Отработать орфограмму: приставки пре- и при-:
причудливые, пригодится, пренебрегаем (неясное значение→запоминаем)
6 ученик:
8. Чем осложнено предложение?
9. Схемы однородных членов предложения
10. Собирали, подбирали, пренебрегали
11. Шишками, перышками
Ответ: однородными сказуемыми и однородными дополнениями
Резервное задание:
Соприкосновение с природой всегда прекрасно.
- Подчеркнуть грамматическую основу
- Отработать графически изученные орфограммы
IV. Подведение итогов урока.
- Что мы сегодня повторили? (см.задачи урока)
- Что было особенно интересно?
- Что вызвало затруднения?
- Оценка урока учителем.
100 ballov.kz образовательный портал для подготовки к ЕНТ и КТА
В 2021 году казахстанские школьники будут сдавать по-новому Единое национальное тестирование. Помимо того, что главный школьный экзамен будет проходить электронно, выпускникам предоставят возможность испытать свою удачу дважды. Корреспондент zakon.kz побеседовал с вице-министром образования и науки Мирасом Дауленовым и узнал, к чему готовиться будущим абитуриентам.
— О переводе ЕНТ на электронный формат говорилось не раз. И вот, с 2021 года тестирование начнут проводить по-новому. Мирас Мухтарович, расскажите, как это будет?
— По содержанию все остается по-прежнему, но меняется формат. Если раньше школьник садился за парту и ему выдавали бумажный вариант книжки и лист ответа, то теперь тест будут сдавать за компьютером в электронном формате. У каждого выпускника будет свое место, огороженное оргстеклом.
Если раньше школьник садился за парту и ему выдавали бумажный вариант книжки и лист ответа, то теперь тест будут сдавать за компьютером в электронном формате. У каждого выпускника будет свое место, огороженное оргстеклом.
Зарегистрироваться можно будет электронно на сайте Национального центра тестирования. Но, удобство в том, что школьник сам сможет выбрать дату, время и место сдачи тестирования.
Кроме того, в этом году ЕНТ для претендующих на грант будет длиться три месяца, и в течение 100 дней сдать его можно будет два раза.
— Расскажите поподробнее?
— В марте пройдет тестирование для желающих поступить на платной основе, а для претендующих на грант мы ввели новые правила. Школьник, чтобы поступить на грант, по желанию может сдать ЕНТ два раза в апреле, мае или в июне, а наилучший результат отправить на конкурс. Но есть ограничение — два раза в один день сдавать тест нельзя. К примеру, если ты сдал ЕНТ в апреле, то потом повторно можно пересдать его через несколько дней или в мае, июне. Мы рекомендуем все-таки брать небольшой перерыв, чтобы еще лучше подготовиться. Но в любом случае это выбор школьника.
— Система оценивания останется прежней?
— Количество предметов остается прежним — три обязательных предмета и два на выбор. Если в бумажном формате закрашенный вариант ответа уже нельзя было исправить, то в электронном формате школьник сможет вернуться к вопросу и поменять ответ, но до того, как завершил тест.
Самое главное — результаты теста можно будет получить сразу же после нажатия кнопки «завершить тестирование». Раньше уходило очень много времени на проверку ответов, дети и родители переживали, ждали вечера, чтобы узнать результат. Сейчас мы все автоматизировали и набранное количество баллов будет выведено на экран сразу же после завершения тестирования.
Максимальное количество баллов остается прежним — 140.
— А апелляция?
— Если сдающий не будет согласен с какими-то вопросами, посчитает их некорректными, то он сразу же на месте сможет подать заявку на апелляцию. Не нужно будет ждать следующего дня, идти в центр тестирования, вуз или школу, все это будет электронно.
Не нужно будет ждать следующего дня, идти в центр тестирования, вуз или школу, все это будет электронно.
— С учетом того, что школьникам не придется вручную закрашивать листы ответов, будет ли изменено время сдачи тестирования?
— Мы решили оставить прежнее время — 240 минут. Но теперь, как вы отметили, школьникам не нужно будет тратить час на то, чтобы правильно закрасить лист ответов, они спокойно смогут использовать это время на решение задач.
— Не секрет, что в некоторых селах и отдаленных населенных пунктах не хватает компьютеров. Как сельские школьники будут сдавать ЕНТ по новому формату?
— Задача в том, чтобы правильно выбрать время и дату тестирования. Центры тестирования есть во всех регионах, в Нур-Султане, Алматы и Шымкенте их несколько. Школьники, проживающие в отдаленных населенных пунктах, как и раньше смогут приехать в город, где есть эти центры, и сдать тестирование.
— На сколько процентов будет обновлена база вопросов?
— База вопросов ежегодно обновляется как минимум на 30%. В этом году мы добавили контекстные задания, то что школьники всегда просили. Мы уделили большое внимание истории Казахстана и всемирной истории — исключили практически все даты. Для нас главное не зазубривание дат, а понимание значения исторических событий. Но по каждому предмету будут контекстные вопросы.
— По вашему мнению система справится с возможными хакерскими атаками, взломами?
— Информационная безопасность — это первостепенный и приоритетный вопрос. Центральный аппарат всей системы находится в Нур-Султане. Связь с региональными центрами сдачи ЕНТ проводится по закрытому VPN-каналу. Коды правильных ответов только в Национальном центре тестирования.
Кроме того, дополнительно через ГТС КНБ (Государственная техническая служба) все тесты проходят проверку на предмет возможного вмешательства. Здесь все не просто, это специальные защищенные каналы связи.
— А что с санитарными требованиями? Нужно ли будет школьникам сдавать ПЦР-тест перед ЕНТ?
— ПЦР-тест сдавать не нужно будет. Требование по маскам будет. При необходимости Центр национального тестирования будет выдавать маски школьникам во время сдачи ЕНТ. И, конечно же, будем измерять температуру. Социальная дистанция будет соблюдаться в каждой аудитории.
— Сколько человек будет сидеть в одной аудитории?
— Участники ЕНТ не за семь дней будут сдавать тестирование, как это было раньше, а в течение трех месяцев. Поэтому по заполняемости аудитории вопросов не будет.
— Будут ли ужесточены требования по дисциплине, запрещенным предметам?
— Мы уделяем большое внимание академической честности. На входе в центры тестирования, как и в предыдущие годы, будут стоять металлоискатели. Перечень запрещенных предметов остается прежним — телефоны, шпаргалки и прочее. Но, помимо фронтальной камеры, которая будет транслировать происходящее в аудитории, над каждым столом будет установлена еще одна камера. Она же будет использоваться в качестве идентификации школьника — как Face ID. Сел, зарегистрировался и приступил к заданиям. Мы применеям систему прокторинга.
Понятно, что каждое движение абитуриента нам будет видно. Если во время сдачи ЕНТ обнаружим, что сдающий использовал телефон или шпаргалку, то тестирование автоматически будет прекращено, система отключится.
— А наблюдатели будут присутствовать во время сдачи тестирования?
— Когда в бумажном формате проводили ЕНТ, мы привлекали очень много дежурных. В одной аудитории было по 3-4 человека. При электронной сдаче такого не будет, максимум один наблюдатель, потому что все будет видно по камерам.
— По вашим наблюдениям школьники стали меньше использовать запрещенные предметы, к примеру, пользоваться телефонами?
— Практика показывает, что школьники стали ответственнее относиться к ЕНТ. Если в 2019 году на 120 тыс. школьников мы изъяли 120 тыс. запрещенных предметов, по сути у каждого сдающего был телефон. То в прошлом году мы на 120 тыс. школьников обнаружили всего 2,5 тыс. телефонов, и у всех были аннулированы результаты.
Если в 2019 году на 120 тыс. школьников мы изъяли 120 тыс. запрещенных предметов, по сути у каждого сдающего был телефон. То в прошлом году мы на 120 тыс. школьников обнаружили всего 2,5 тыс. телефонов, и у всех были аннулированы результаты.
Напомню, что в 2020 году мы также начали использовать систему искусственного интеллекта. Это анализ видеозаписей, который проводится после тестирования. Так, в прошлом году 100 абитуриентов лишились грантов за то, что во время сдачи ЕНТ использовали запрещенные предметы.
— Сколько средств выделено на проведение ЕНТ в этом году?
Если раньше на ЕНТ требовалось 1,5 млрд тенге из-за распечатки книжек и листов ответов, то сейчас расходы значительно сокращены за счет перехода на электронный формат. Они будут, но несущественные.
— Все-таки почему именно в 2021 году было принято решение проводить ЕНТ в электронном формате. Это как-то связано с пандемией?
— Это не связано с пандемией. Просто нужно переходить на качественно новый уровень. Мы апробировали данный формат на педагогах школ, вы знаете, что они сдают квалификационный тест, на магистрантах, так почему бы не использовать этот же формат при сдаче ЕНТ. Тем более, что это удобно, и для школьников теперь будет много плюсов.
Подобрать однокоренные слова онлайн — образуй, найди и запиши. Текстовод.Корень
{{ info }}
Подобрать- {{ item.word }} ({{ item.root }}) {{ item.tag }}
Этот онлайн сервис подбирает однокоренные слова.
Однокоренные слова – это такие слова, у которых одинаковый по значению корень, но разные морфемы — приставки и суффиксы. Причём, однокоренные слова могут быть как одной части речи, так и разной.
Например, лес (существительное), лесорубочный (прилагательное), обезлесить (глагол).
Слова создают целые семьи, поэтому их ещё называют родственные.
Смотрите сами: лезть — на-лезть — об-лез-лый. Всё это родственные слова.
Корень — это основная часть любого слова. Именно в нём содержится главный лексический смысл слова. И у однокоренных слов корень складывается из одних и тех же букв.
Данная программа указывает часть речи к каждому однокоренному слову.
Также, у каждого слова определяются некоторые синтаксические характеристики.
Важно помнить, что слова, имеющие одинаковый корень, не всегда являются однокоренными.
Например.
1. Снег-снегоочистительный, снегурка, снегоход, снегозадерживающий.
У всех этих слов общий корень «снег».
Значение у этой группы слов единое: вид атмосферных осадков. Значит, это однокоренные слова.
2. Вода-водитель-верховодитель. Эта группа слов имеет одинаковый корень «вод». Но смысл у этих слов разный — поэтому они не будут однокоренными.
Зачем нужен наш сервис?
Для того, чтобы быть грамотным человеком, нужно знать, как правильно писать слова.
Однокоренные слова подбирают с целью определения пропущенной буквы в корне слова.
А именно:
— Если отсутствует гласная буква в корне, то подбираются такие родственные слова, у которых искомая буква будет под ударением.
Например, слово каток. Чтобы проверить правописание буквы «а», необходимо вспомнить однокоренное слово. Например, выкатывать. Здесь ударение на первую «а». Всё сразу становится понятно.
— Если пропущена согласная в корне, то нужно найти такое однокоренное слово, у которого следом за неизвестной буквой будет стоять согласная. Когда слышишь звук, правильно определяешь искомую букву.
Когда слышишь звук, правильно определяешь искомую букву.
Слово ножка. Как правильно писать ножка или ношка? Проверочное слово — ноЖенька.
Напишите в поисковой форме ваше слово и нажмите кнопку «разобрать».
Основа слова. Разбор слова по составу
Здравствуйте, друзья мои!
Сегодня мы с вами продолжим разговор о составе слова и будем учиться разбирать слова по составу. Но прежде я хочу загадать вам загадку. Что это?
Она выражает значение слова
И называется просто – …
Вы догадались? Многие сейчас скажут: «Вообще-то, не она, а он. Ведь это – корень слова». Ну конечно, в корне заключено основное лексическое значение слова. Но ведь случается, что однокоренные слова могут иметь совершенно противоположное значение. Например, однокоренные слова открыть и закрыть, приклеить и отклеить, одеть и раздеть. В этих словах противоположное значение придают приставки. А вот, например, слова ученик и учитель. Здесь значение меняют суффиксы. Кстати, обратите внимание на то, что в этих словах не по одному, а по два суффикса.
Так что полное значение слова выражается не только в корне. Если есть суффиксы и приставки, они тоже участвуют в лексическом значении слова. И вся часть слова, в которой выражено его значение, называется его основой. В основу не входит только окончание. Как написано в одном стихотворении.
Та часть слова, что изменяется,
Окончанием называется,
Остальную же часть слова
Именуем мы основой.
Основа в слове обозначается горизонтальной квадратной скобочкой,
вертикальные линии которой показывают начало и конец основы.
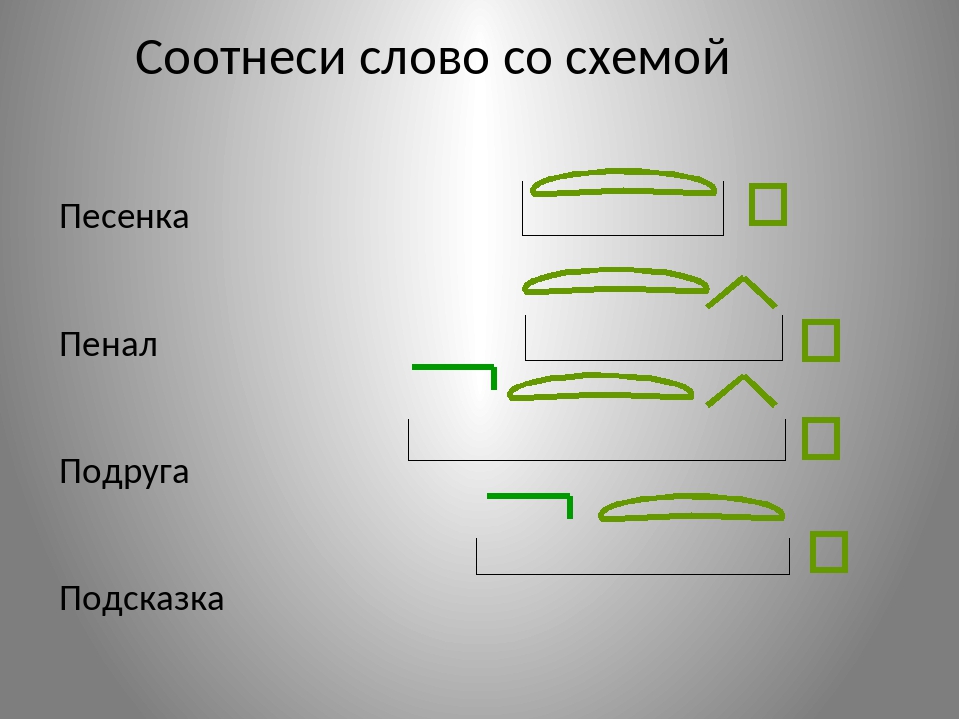
Как же найти основу в слове? Элементарно! Возьмём, например, слово посадка. Изменяем его.
Посадки, посадку, посадкой.
Выделяем окончание -а. Всё остальное – это основа.
А какая основа в слове школьник? Изменяем слово: школьника, школьнику, о школьнике. В слове школьник нулевое окончание и основа – школьник.
Друзья мои, вы поняли, насколько это просто – выделить основу слова? Изменяем его, находим окончание. И часть слова без окончания является его основой.
Сейчас вы убедитесь, что найти основу слова – это просто. Найдите сами основу в словах дорога, подсказка, настольный, глобус.
Вы готовы проверить свою работу? Я уверен, вы справились с нею.
Дорога – дорогу, дороги. Основа дорог-.
Подсказка – подсказки, подсказку. Основа подсказк-.
Настольный – настольная, настольную, настольные. Основа настольн-.
Глобус – глобуса, глобусу. Основа глобус.
Друзья мои, помните ли вы, что есть слова, которые нельзя изменять, например, такие как кино, пальто, кофе, пианино, метро, кенгуру, шоссе. Так как в этих словах нет окончаний, то их основа – это всё слово полностью.
Кстати, хочу обратить ваше внимание на слово шоссе. Шоссе – это дорога с твёрдым покрытием. Слово ШОССЕ надо запомнить. В словах дорога и шоссе первые гласные – О.
А ещё в слове шоссе удвоенное С с гласной Е.
А теперь пришло время разбирать слова по составу.
Возьмём, например, слово разведка.
Первое, что мы должны сделать, – объяснить смысл слова и определить, к
какой части речи оно относится.
Слова разведка отвечает на вопрос что?, значит, – это имя существительное. Обозначает сбор каких-либо сведений.
Слово разведка можно изменить: разведка – разведки, разведку. Таким образом, окончание в нём –а. Выделяем его прямоугольником.
Выделяем основу. Это часть слова без окончания – разведк-.
Теперь надо найти в слове корень. Для этого подбираем однокоренные слова: сведения, выведать. Общая часть этих слов – -вед-. Это и есть корень. Выделяем его дугой.
Перед корнем стоит приставка раз-.
А после корня перед окончанием – суффикс -к-.
Конечно, приставки и суффиксы есть не во всех словах, но в слове разведка они есть.
Итак, теперь можно сказать, что в слове разведка окончание -а, основа – разведк-, корень —вед-, приставка раз-, суффикс -к-.
И ещё разберём по составу слово пирог.
Находим окончание, изменив слово. Пирога, пирогу. В слове пирог нулевое окончание. А основа – пирог.
Находим корень, подбирая однокоренные слова. Пирожок, пирожковый. Чередование согласных г-ж..Корень пирог. В этом слове нет ни приставки, ни суффикса. Есть только нулевое окончание, основа пирог и корень пирог.
Кстати, слово пирог, как и слово шоссе, надо запомнить. В прежние времена ни один пир не обходился без ПИРогов. Испекли ПИРоги – будет ПИР.
Но вернёмся к разбору слов по составу. Я надеюсь, вы запомнили, как его выполнять? А для тех, у кого это ещё не совсем хорошо получается, я предлагаю известную запоминалку:
Школьник, при разборе слова
Окончанье и основу
Первым
делом находи.
После корня будет суффикс,
А приставка – впереди.
Хочу сказать вам, ребята, что иногда встречаются слова, которые трудно бывает разобрать по составу. И тогда нам на помощь могут прийти словообразовательные словари.
В таких словарях часто собраны рядом однокоренные слова, и все части слов отделены друг от друга. Например, вот так:
Ну, вот и истекает наше время. Что же вам необходимо запомнить?
Часть слова без окончания называется основой слова. Основа выражает лексическое значение слова.
Чтобы найти основу слова, нужно отделить окончание.
Как разобрать слово по составу?
* Объяснить смысл слова и определить, к какой части речи оно относится.
* Изменить слово для того, чтобы выделить в нём окончание и основу.
* Выделить в слове корень. Для этого подобрать однокоренные слова.
* Обозначить приставку (если она есть). Приставка стоит перед корнем.
* Обозначить суффикс (если он есть). Суффикс стоит после корня перед окончанием.
А ещё не забудьте, как пишутся слова ШОССЕ и ПИРОГ.
Ну а я прощаюсь с вами сегодня. До новых встреч, мои друзья!
Первые два слова в строке — sql server
Многие решения не работают для любых строк, в которых меньше 2 слов. , что все более вероятно для людей, надеющихся разобрать первые n слов.
Давайте сначала посмотрим на запрос, а затем как мы можем определить, правильно ли он вычислен.
Для этого нам нужно вложить несколько операторов CHARINDEX , которые принимают следующие параметры:
CHARINDEX ( expressionToFind , expressionToSearch [, start_location ])
Charindex вернет первый индекс , в котором найдет конкретную строку. Что мы продолжаем делать, так это пинать мяч по дороге, добавляя
Что мы продолжаем делать, так это пинать мяч по дороге, добавляя start_location , равное первому найденному экземпляру +1, чтобы он нашел 2-й, 3-й, 4-й экземпляр и т. Д. , 0, … мы можем просто использовать LEFT (@str, ... для захвата первой части строки, но в любом случае вычислить, насколько глубоко нужно зайти, трудная часть:
DECLARE @string VARCHAR (1000) = 'Один, два, три';
ВЫБРАТЬ ВЛЕВО (@string, CHARINDEX ('', @string,
CHARINDEX ('', @ строка,
CHARINDEX ('', @ строка,
CHARINDEX ('', @ строка) +1) +1) +1))
Но это приведет к ошибке , если у нас не будет минимального количества слов:
Технически, это будет просто бесконечно зацикливаться.Как только в нем закончатся места, он снова начнет индексацию с начала
Популярная викторина … к чему приведет приведенный выше запрос? Для ответа наведите указатель мыши на
ВЫБРАТЬ ВЛЕВО («Один, два, три», 3) - «Один»
В решении в разделе «Извлечение определенного количества слов из строки в sql» мы можем проверить, что последний CHARINDEX дал ненулевое значение, что означает, что он попал в пробел на этом уровне глубины.Но также, поскольку вложенный charindex является своего рода громоздким, мы можем получить эту информацию немного более непосредственно, подсчитав количество вхождений определенной подстроки в SQL varchar?
Итак, окончательное решение должно выглядеть так, чтобы захватить первые
4 слова : DECLARE @string VARCHAR (1000) = «Один, два, три, четыре, пять, шесть»;
ВЫБЕРИТЕ СЛУЧАЙ, КОГДА LEN (@string) -LEN (REPLACE (@string, '', '')) <4
ТОГДА @string
ИНАЧЕ СЛЕВА (@string, CHARINDEX ('', @string,
CHARINDEX ('', @ строка,
CHARINDEX ('', @ строка,
CHARINDEX ('', @ строка) +1) +1) +1))
КОНЕЦ
Если пробелов меньше 4, мы просто вернем всю строку. Для более чем четырех мы найдем позицию 4-го пробела и вернем левую часть строки полностью в эту позицию
Для более чем четырех мы найдем позицию 4-го пробела и вернем левую часть строки полностью в эту позицию
Как написать эссе с определениями
Эссе с определениями может быть обманчиво сложным для написания. Этот тип бумаги требует, чтобы вы написали личное, но академическое определение одного конкретного слова. Определение должно быть подробным и длинным. Важно, чтобы вы выбрали слово, которое даст вам о чем писать, и есть несколько стандартных тактик, которые вы можете использовать, чтобы уточнить этот термин.Вот несколько рекомендаций, которые следует учитывать при написании эссе с определениями.
Часть 1 из 3: Выбор правильного слова
1: Выберите абстрактное слово со сложным значением. [1]Простое слово, относящееся к конкретному слову, не даст вам много смысла писать, но сложное слово, относящееся к абстрактному понятию, дает больше материала для изучения.
- Обычно существительные, относящиеся к человеку, месту или предмету, слишком просты для эссе с определением.Однако существительные, относящиеся к идее, работают лучше, как и большинство прилагательных.
- Например, слово «дом» довольно простое, и сочинение вокруг него может быть скучным. Однако переключившись на что-то более абстрактное, например «дом», вы можете больше поиграть с определением. «Дом» - это концепция, и в его создание входит множество элементов. Для сравнения, «дом» - это просто строение.
Помимо сложности, это слово также должно относиться к чему-то, что может означать разные вещи для разных людей.
- Эссе с определением является несколько субъективным по своей природе, поскольку требует от вас анализа и определения слова с вашей собственной точки зрения. Если после анализа слова вы получите тот же ответ, что и любой другой, может показаться, что вашему эссе не хватает глубины.

Словарные определения могут сказать вам не так много. Поскольку вам нужно уточнить слово, которое вы выбираете для определения, вам потребуется собственная база знаний или опыт работы с выбранной вами концепцией.
- Например, если вы никогда не слышали термин «педантичный», ваше понимание этого слова будет ограниченным. Вы можете представить себе слово для своего эссе, но без предварительного понимания концепции вы не узнаете, действительно ли описываемое вами определение подходит.
Хотя вы не будете полностью полагаться на словарное определение в своем эссе, ознакомление с официальным определением позволит вам сравнить свое собственное понимание концепции с самым простым и академическим ее объяснением.
- Например, одно определение «друга» - это «человек, привязанный к другому из-за чувства привязанности или личного уважения». [2] Ваши собственные идеи или убеждения о том, кем на самом деле является «друг», вероятно, содержат гораздо больше информации, но это базовое определение может дать вам хорошую отправную точку для формирования вашего собственного.
5:
Изучите происхождение слова.Найдите выбранное вами слово в Oxford English Dictionary или в другом словаре этимологии. [3]
- Эти источники могут рассказать вам историю, стоящую за словом, что может дать дальнейшее понимание общего определения, а также информацию о том, как слово стало означать то, что оно означает сегодня.
Часть 2 из 3: Возможные элементы эффективного определения
1: Напишите анализ. [4]Разделите слово на разные части. Проанализируйте и определите каждую часть в отдельном абзаце.
- Вы можете разделить «возврат» на «повторно» и «повернуть». Слово «дружба» можно разделить на «друг» и «корабль».
- Чтобы проанализировать каждую часть слова, вам все равно придется использовать дополнительные тактики определения, такие как отрицание и классификация.
- Обратите внимание, что эта тактика работает только для слов, состоящих из нескольких частей. Слово «любовь», например, не может быть далее разбито.Однако, определяя «платоническую любовь», вы могли бы определить и «платоническую», и «любовь» отдельно в своем эссе.

2:
Классифицируйте термин.Укажите, к каким классам и частям речи принадлежит слово в соответствии со стандартным словарным определением.
- Хотя эта информация очень проста и суха, она может предоставить полезный контекст о том, как используется данное слово.
Незнакомое или необычное понятие можно объяснить с помощью понятий, более доступных среднему человеку.
- Многие люди никогда не слышали, например, слова «собратья». Одно из основных определений - «член одной профессии, братства и т. Д.» Таким образом, вы можете сравнить «собраться» с «коллегой», что является похожим, но более знакомым понятием. [5]
4:
Укажите традиционные подробности этого термина.Объясните любые физические характеристики или традиционные мысли, используемые для описания выбранного вами термина.
- Термин «дом» часто физически визуализируется как дом или квартира. Говоря более абстрактно, «дом» традиционно считается теплой, уютной и безопасной средой. Вы можете включить все эти особенности в эссе с определением «дома».
Люди часто связываются с историями и яркими образами, поэтому использование подходящего рассказа или изображения, относящегося к данному термину, может быть использовано для разъяснения абстрактной, бесформенной концепции.
- В эссе с определением «доброты», например, вы можете написать о поступке доброты, свидетелем которого вы недавно стали. Тот, кто подстригает лужайку у пожилого соседа, может быть хорошим примером, так же как и тот, кто дал вам ободряющее слово, когда вы чувствуете себя подавленным.

Если термин часто используется неправильно или неправильно, упоминание того, чем он не является, является эффективным способом привлечь внимание к концепции.
- Типичным примером может служить термин «смелость». Этот термин часто ассоциируется с отсутствием страха, но многие будут утверждать, что «смелость» более точно описывается как действие вопреки страху.
Вот когда вам пригодится ваше исследование этимологии слова. Объясните, откуда возник этот термин и как он стал означать то, что означает в настоящее время.
Часть 3 из 3: Определение структуры эссе
1: Введите стандартное разрешение.Во вводном абзаце необходимо четко указать, какое у вас слово, а также его традиционное или словарное определение.
- Открывая словарное определение вашего термина, вы создаете контекст и базовый уровень знаний о слове. Это позволит вам представить и развить собственное определение.
- Это особенно важно, когда традиционное определение вашего термина заметно отличается от вашего собственного.
В вашем фактическом тезисе термин должен быть определен своими словами.
- Держите определение в своей диссертации кратким и основным. Вы подробнее остановитесь на этом в основной части статьи.
- Избегайте использования пассивных фраз, содержащих слово «есть», при определении вашего термина. Фразы «это где» и «когда» особенно неуклюжи. [6]
- Не повторяйте часть определенного термина в своем определении.
3:
Отдельные части определения в отдельные параграфы. Каждую тактику или метод, используемый для определения вашего термина, следует изучить в отдельном абзаце.
- Обратите внимание, что вам не нужно использовать все возможные методы определения термина в своем эссе. Вы должны использовать множество различных методов, чтобы создать полную, всестороннюю картину термина, но некоторые тактики отлично работают с одними терминами, но не с другими.
Кратко изложите свои основные мысли в начале заключительного абзаца.
- Это краткое изложение не нуждается в подробном описании. Обычно просмотр тематического предложения каждого основного абзаца - хороший способ составить простой список ваших основных моментов.
- Вы также можете завершить эссе, сославшись на фразы или образы, упомянутые во введении.
Если определяемый вами термин играет определенную роль в вашей жизни и опыте, ваши заключительные замечания - хорошее место, чтобы вкратце упомянуть о роли, которую он играет.
- Свяжите свой опыт с этим термином с определением, которое вы дали ему в своей диссертации. Не делитесь опытом, который связан с этим термином, но противоречит всему, что вы написали в своем эссе.
Источники и ссылки
- http://www.roanestate.edu/owl/Definition.HTML
- http://dictionary.reference.com/browse/friend?s=t
- http://www.etymonline.com/
- http://leo.stcloudstate.edu/acadwrite/definition.html
- http://dictionary.reference.com/browse/confrere?s=t
- http://grammar.ccc.commnet.edu/grammar/composition/definition.htm
Последние достижения в области машинного обучения
Рекомендации для читателей
Что это за страница? На этой странице слева показаны таблицы, извлеченные из документов arXiv. Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Какие цветные прямоугольники справа? Здесь показаны результаты, извлеченные из бумаги и связанные с таблицами слева. Результат состоит из значения метрики, имени модели, имени набора данных и имени задачи.
Что означают цвета? Зеленый означает, что результат одобрен и показан на сайте. Желтый - результат того, что вы добавили, но еще не сохранили.Синий - это результат ссылки, полученный из другой бумаги.
Откуда берутся предлагаемые результаты? У нас есть модель машинного обучения, работающая в фоновом режиме, которая дает рекомендации по статьям.
Откуда берутся ссылочные результаты? Если мы находим в таблице результаты со ссылками на другие статьи, мы показываем проанализированный справочный блок, который редакторы могут использовать для аннотирования, чтобы получить эти дополнительные результаты из других статей.
Рекомендации редактора
Я впервые редактирую и боюсь ошибиться.Помощь! Не волнуйтесь! Если вы сделаете ошибки, мы можем исправить их: все версионировано! Так что просто сообщите нам на канале Slack, если вы что-то случайно удалили (и так далее) - это вообще не проблема, так что дерзайте!
Как добавить новый результат из таблицы? Щелкните ячейку в таблице слева, откуда берется результат. Затем выберите одно из 5 лучших предложений. Вы можете вручную отредактировать неправильные или отсутствующие поля. Затем выберите задачу, набор данных и название метрики из таксономии «Документы с кодом».Вы должны проверить, существует ли уже эталонный тест, чтобы предотвратить дублирование; если его не существует, вы можете создать новый набор данных. Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Каковы соглашения об именах моделей? Название модели должно быть простым, как указано в документе. Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Другие советы и рекомендации
- Если эталонный тест для введенной пары набор данных / задача уже существует, вы увидите ссылку.
- Если эталонный тест не существует, появится значок «новый», обозначающий новый рейтинг.
- Если вам повезет, Cmd + щелкните ячейку в таблице, чтобы автоматически получить первый результат.
- При редактировании нескольких результатов из одной и той же таблицы вы можете нажать кнопку «Изменить все», чтобы скопировать текущее значение во все другие записи из этой таблицы.
Как добавить результаты, на которые имеются ссылки? Если в таблице есть ссылки, вы можете использовать функцию синтаксического анализа ссылок, чтобы получить больше результатов из других документов. Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты. Ниже вы можете увидеть пример.
Таблица сравнения извлечена из статьи Универсальная языковая модель «Тонкая настройка для классификации текста» (Howard and Ruder, 2018) с проанализированными ссылками.Как сохранить изменения? Когда вы будете довольны своим изменением, нажмите «Сохранить», и предложенные вами изменения станут зелеными!
Как написать идеальное синтезированное эссе для экзамена по языку AP
Если вы планируете сдавать экзамен AP Language (или AP Lang), вы, возможно, уже знаете, что 55% вашей общей оценки за экзамен будет основано на трех эссе. Первое из трех эссе, которое вам нужно будет написать на экзамене AP Language, называется «обобщающим эссе»."Если вы хотите заработать полные баллы на этой части экзамена AP Lang, вам необходимо знать, что такое обобщающее эссе и какие навыки оцениваются в обобщающем эссе AP Lang.
В этой статье мы объясним различные аспекты синтезирующего эссе AP Lang, , включая то, какие навыки вам необходимо продемонстрировать в своем ответе на синтезирующее эссе, чтобы получить хороший балл. Мы также дадим вам полный анализ реальной подсказки AP Lang Synthesis Essay, предоставим анализ примера синтезирующего эссе AP Lang и дадим вам четыре совета по написанию синтезирующего эссе.
Давайте начнем с более подробного рассмотрения того, как работает синтезное эссе AP Lang!
2021 AP Test Changes из-за COVID-19
В связи с продолжающейся пандемией коронавируса COVID-19 тесты AP теперь будут проводиться в течение трех разных сессий с мая по июнь. Даты ваших экзаменов, а также то, будут ли они проводиться онлайн или в бумажной форме, будут зависеть от вашей школы. Чтобы узнать больше о том, как все это будет работать, а также получить самую свежую информацию о датах испытаний, онлайн-обзоре AP и о том, что эти изменения значат для вас, обязательно ознакомьтесь с нашей статьей часто задаваемых вопросов о AP COVID-19 на 2021 год.
Синтез Эссе А. П. Лэнг: что это такое и как работает
Обобщающее эссе AP Lang - первое из трех эссе, включенных в раздел «Свободный ответ» экзамена AP Lang.
Эссе, посвященное синтезу AP Lang, в разделе «Свободный ответ» длится 1 час . Этот час состоит из рекомендованного 15-минутного периода чтения и 40-минутного периода письма. Имейте в виду, что эти временные рамки являются просто рекомендациями, и что экзаменуемые могут анализировать отведенные 60 минут для завершения обобщающего эссе по своему усмотрению.
А вот как выглядит структура синтезирующего эссе А. П. Ланга. Экзамен представляет от шести до семи источников, которые организованы по определенной теме (например, альтернативная энергия или выдающаяся область, которые являются прошлыми темами сводного экзамена).
Из этих шести-семи источников как минимум два являются визуальными , включая как минимум один количественный источник (например, график или круговую диаграмму). Остальные четыре-пять источников основаны на печатном тексте, и каждый из них содержит примерно 500 слов.
В дополнение к шести-семи источникам экзамен AP Lang предоставляет письменные подсказки, состоящие из трех абзацев. В подсказке будет кратко объяснена тема эссе, а затем представлено утверждение, на которое студенты ответят в сочинении, которое синтезирует материал как минимум из трех из предоставленных источников.
Вот пример подсказки, предоставленной Советом колледжа:
Указания : Следующий запрос основан на шести сопутствующих источниках.
Этот вопрос требует, чтобы вы объединили различные источники в связное, хорошо написанное эссе. Обратитесь к источникам, чтобы поддержать вашу позицию; избегайте простого пересказа или резюме. Ваш аргумент должен быть центральным; источники должны поддержать этот аргумент .
Не забудьте указать как прямые, так и косвенные ссылки.
Введение
Телевидение оказало влияние на президентские выборы в США с 1960-х годов. Но что это за влияние и как оно повлияло на избранных? Сделал ли он выборы более справедливыми и доступными, или он переместил кандидатов от преследования проблем к преследованию имиджа?
Переуступка
Внимательно прочтите следующие источники (включая любую вводную информацию). Затем в эссе, объединяющем по крайней мере три источника поддержки, займите позицию, которая защищает, оспаривает или квалифицирует утверждение о том, что телевидение оказало положительное влияние на президентские выборы.
Источники называются «Источник A», «Источник B» и т. Д .; заголовки включены для вашего удобства.
Источник A (Кэмпбелл)
Источник B (Харт и Трис)
Источник C (Менанд)
Источник D (диаграмма)
Источник E (Ранни)
Источник F (Коппел)
Как мы упоминали ранее, в этом приглашении приводится тема, которая в нем кратко объясняется, а затем предлагается занять позицию. В этом случае вам придется выбрать позицию относительно того, положительно или отрицательно повлияло телевидение на выборы в США. Вам также дается шесть источников для оценки и использования в своем ответе. Теперь, когда у вас есть все необходимое, ваша задача - написать потрясающее обобщающее эссе.
В этом случае вам придется выбрать позицию относительно того, положительно или отрицательно повлияло телевидение на выборы в США. Вам также дается шесть источников для оценки и использования в своем ответе. Теперь, когда у вас есть все необходимое, ваша задача - написать потрясающее обобщающее эссе.
Но что именно означает «синтезировать»? Согласно CollegeBoard, когда в подсказке к эссе вас просят синтезировать, это означает, что вы должны «комбинировать различные точки зрения из источников, чтобы сформировать поддержку последовательной позиции» в письменной форме.Другими словами, сводное эссе просит вас изложить свое утверждение по теме, а затем выделить связи между несколькими источниками, которые поддерживают ваше утверждение по этой теме. Кроме того, вам нужно будет привести конкретные свидетельства из ваших источников, чтобы подтвердить свою точку зрения.
За обобщающее эссе вы набираете шесть из общих баллов на экзамене AP Lang . Студенты могут получить 0–1 балл за написание тезиса в эссе, 0–4 балла за включение доказательств и комментариев и 0–1 балл за сложность мысли и продемонстрированное сложное понимание темы.
Ваша оценка будет основана на том, насколько эффективно вы выполните следующие задачи в своем эссе по синтезу AP Lang:
Напишите диссертацию, которая отвечает на приглашение экзамена с защитной позицией
Предоставьте конкретные доказательства, подтверждающие все утверждения в вашей аргументации из как минимум трех из предоставленных источников, и четко и последовательно объясните, как доказательства, которые вы включаете, подтверждают вашу аргументацию
Продемонстрировать изощренность мышления, либо придумав продуманный аргумент, поместив аргумент в более широкий контекст, объяснив ограничения аргумента
Делайте риторический выбор, укрепляющий ваши аргументы, и / или используйте яркий и убедительный стиль в своем эссе.

Если ваше синтетическое эссе соответствует критериям, указанным выше, , то есть хорошие шансы, что вы получите хорошие баллы по этой части экзамена AP Lang!
Если вы ищете еще больше информации о выставлении оценок, совет колледжей разместил на своем веб-сайте рубрику оценки AP Lang Free Response. (Вы можете найти его здесь.) Мы рекомендуем внимательно изучить его, так как он включает дополнительные сведения о выставлении оценок за синтез эссе.
Не бойтесь.... мы собираемся научить вас, как разобрать даже сложнейшую подсказку для сочинения по синтезу AP.
Полный текст настоящего предложения для эссе по синтезу языка AP
В этом разделе, мы научим вас, как анализировать и отвечать на напоминания о синтезе эссе за пять простых шагов, включая рекомендуемые временные рамки для каждого шага процесса.
Шаг 1. Проанализируйте подсказку
Самое первое, что нужно сделать, когда часы начнут работать, - это прочитать и проанализировать подсказку. Чтобы продемонстрировать, как это сделать, мы рассмотрим образец подсказки для эссе по синтезу AP Lang ниже. Это сообщение пришло прямо из экзамена AP Lang 2018:
.Известный домен - это власть, которой обладают правительства для приобретения собственности у частных владельцев для общественного пользования. Обоснование выдающихся владений состоит в том, что правительства обладают большей юридической властью над землями в пределах их владений, чем частные собственники. Известная область была учреждена так или иначе во всем мире на протяжении сотен лет.
Внимательно прочтите следующие шесть источников, включая вводную информацию по каждому источнику. Затем синтезируйте материал по крайней мере из трех источников и включите его в связное, хорошо разработанное эссе, которое защищает, оспаривает или уточняет представление о том, что выдающаяся область является продуктивной и полезной.
Ваш аргумент должен быть в центре вашего эссе. Используйте источники, чтобы развить свой аргумент и объяснить его обоснование. Избегайте простого суммирования источников.Четко укажите, из каких источников вы черпаете, с помощью прямой цитаты, перефразирования или резюме. Вы можете цитировать источники как Источник A, Источник B и т. Д. Или используя описания в круглых скобках.
При первом чтении вы можете нервничать по поводу того, как ответить на этот запрос ... особенно если вы не знаете, что такое выдающийся домен! Но если вы разделите подсказку на части, вы сможете сразу понять, что подсказка просит вас сделать.
Чтобы получить полное представление о том, что вам нужно сделать в этом запросе, вам необходимо указать наиболее важные детали в этом запросе, абзац за абзацем. Вот что просит вас сделать каждый абзац:
- Параграф 1: Приглашение представляет и кратко объясняет тему , по которой вы будете писать свое эссе для синтеза. Эта тема - концепция выдающейся области.
- Параграф 2: Приглашение представляет конкретное утверждение о концепции выдающейся области в этом абзаце: Выдающаяся область является продуктивной и выгодной. Этот абзац инструктирует вас решить, хотите ли вы защитить, оспорить или квалифицировать это утверждение в своем обобщающем эссе , и использовать для этого материалы как минимум из трех из предоставленных источников.
- Параграф 3: В последнем параграфе подсказки экзамен дает вам четкие инструкции о том, как подойти к написанию синтетического эссе . Во-первых, сделайте ваши аргументы в центре эссе. Во-вторых, используйте материал как минимум из трех источников для развития и объяснения своих аргументов. В-третьих, предоставьте комментарии к включенному вами материалу и предоставьте надлежащие цитаты, когда вы включаете цитаты, пересказы или резюме из предоставленных источников.
Итак, вам придется согласиться, не согласиться с заявлением, изложенным в подсказке, или уточнить его, а затем использовать как минимум три источника для обоснования своего ответа. Поскольку вы, вероятно, мало что знаете о выдающемся домене, вы, вероятно, определитесь с вашей позицией после того, как вы прочитали предоставленные источники.
Чтобы эффективно использовать свое время на экзамене , вам следует потратить около 2 минут на чтение подсказки и запоминание того, что вас просят сделать.У вас будет достаточно времени, чтобы прочитать предоставленные источники, что станет следующим шагом к написанию обобщающего эссе.
Шаг 2. Внимательно прочтите исходный код
После того, как вы внимательно прочитали подсказку и отметили наиболее важные детали, вам необходимо прочитать все предоставленных источников. Заманчиво пропустить один или два источника, чтобы сэкономить время, но мы не рекомендуем этого делать. Это потому, что вам необходимо доскональное понимание темы, прежде чем вы сможете точно ответить на запрос!
Для примера приглашения к экзамену, приведенного выше, предоставлено шесть источников.Мы не собираемся включать все источники в эту статью, но вы можете просмотреть шесть источников из этого вопроса на экзамене AP Lang 2018 здесь. Источники включают пять источников печатного текста и один визуальный источник - мультфильм.
Читая исходники, важно читать быстро и внимательно. Не торопитесь! Держите карандаш в руке, чтобы быстро отметить важные отрывки, которые вы, возможно, захотите использовать в качестве доказательства в своем синтезе. Пока вы читаете источники и отмечаете отрывки, вы хотите подумать о том, как информация, которую вы читаете, влияет на вашу позицию по проблеме (в данном случае - на выдающуюся область).
Когда вы закончите чтение, потребуется несколько секунд, чтобы резюмировать во фразе или предложении, защищает ли источник, оспаривает или квалифицирует, является ли выдающийся домен выгодным (что является заявлением в приглашении) . Хотя может показаться, что у вас нет на это времени, важно дать себе эти заметки о каждом источнике, чтобы вы знали , как вы можете использовать каждый из них в качестве доказательства в своем эссе.
Хотя может показаться, что у вас нет на это времени, важно дать себе эти заметки о каждом источнике, чтобы вы знали , как вы можете использовать каждый из них в качестве доказательства в своем эссе.
Вот что мы имеем в виду: допустим, вы хотите оспорить идею о том, что выдающаяся область полезна.Если вы записали заметки о каждом источнике и о том, что в нем говорится, вам будет легче включить соответствующую информацию в свой план и свое эссе.
Итак, сколько времени вам следует потратить на чтение предоставленных источников? Экзамен AP Lang рекомендует уделить 15 минут чтению источников. . Если вы потратите около двух из этих минут на чтение и разбиение подсказки для эссе, имеет смысл потратить оставшиеся 13 минут на чтение и аннотирование источников.
Если вы закончите читать и комментируете раньше, вы всегда можете перейти к составлению сводного эссе.Но убедитесь, что вы не торопитесь и внимательно читаете! Лучше потратить немного больше времени на чтение и понимание источников сейчас, чтобы вам не пришлось возвращаться и перечитывать источники позже.
Сильный тезис сделает много тяжелой работы в вашем эссе. (Видите, что мы там делали?)
Шаг 3. Напишите сильный тезис
После того, как вы проанализировали подсказку и внимательно прочитали источники, следующее, что вам нужно сделать, чтобы написать хорошее синтезирующее эссе, - это написать сильное тезисное изложение .
Хорошая новость о написании тезиса для этого обобщающего эссе заключается в том, что у вас есть все необходимые инструменты для этого под рукой. Все, что вам нужно сделать, чтобы написать свой тезис, - это решить, ваша позиция относится к указанной теме.
В приведенном ранее примере подсказки вам, по сути, дается три варианта оформления вашего тезисного утверждения: вы можете защитить, оспорить или квалифицировать претензию, предоставленную подсказкой, , что выдающийся домен является продуктивным и Благородный .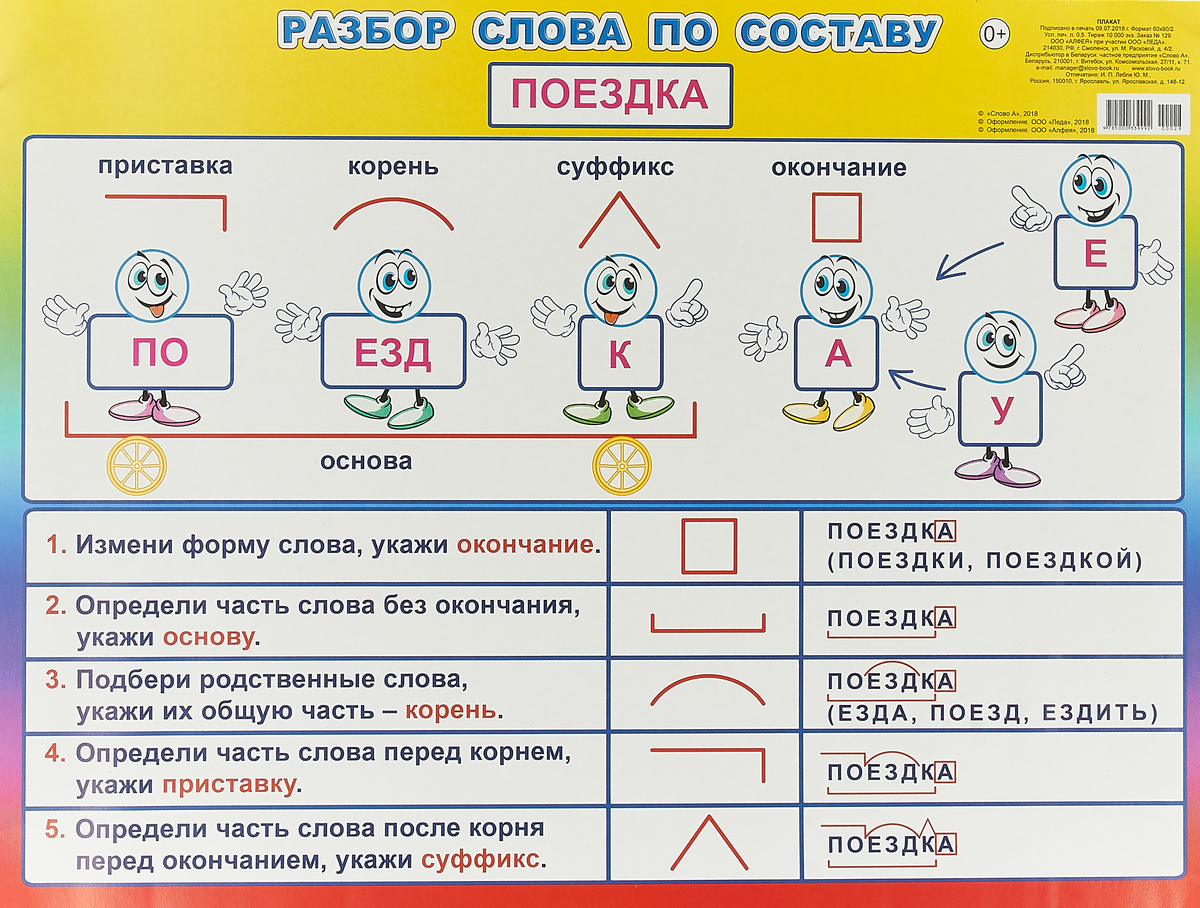 Вот что это означает для каждого варианта:
Вот что это означает для каждого варианта:
Если вы решите отстаивать претензию, ваша задача будет заключаться в том, чтобы доказать, что претензия верна. . В этом случае вам нужно будет показать, что выдающийся домен - это хорошо.
Если вы решите оспорить претензию, вы будете утверждать, что претензия неверна. Другими словами, вы будете утверждать, что выдающийся домен бесполезен. или выгодны.
Если вы решите соответствовать требованиям, это означает, что вы согласны с частью претензии, но не согласны с другой частью претензии. Например, вы можете утверждать, что выдающийся домен может быть продуктивным инструментом для правительств, но не выгоден для владельцев собственности. Или, может быть, вы утверждаете, что выдающаяся область полезна в определенных обстоятельствах, но не в других.
Когда вы решаете, хотите ли вы, чтобы ваше обобщающее эссе защищало, оспаривало или уточняло это утверждение, вам необходимо четко выразить эту позицию в своем тезисе. Вы не хотите просто повторять утверждение, представленное в подсказке, резюмировать проблему без последовательного утверждения или писать тезис, не отвечающий на подсказку.
Вот пример тезиса, получившего полные баллы за выдающееся эссе по синтезу предметной области:
Хотя выдающиеся владения могут быть неправомерно использованы в личных интересах за счет граждан, они являются жизненно важным инструментом любого правительства, которое намеревается иметь какое-либо влияние на землю, которой оно управляет, помимо письменного закона.
Этот тезис получил полные баллы, потому что он излагает оправданную позицию и устанавливает линию рассуждений по вопросу о выдающейся области. В нем излагается позиция автора (что некоторые части выдающейся области хороши, а другие плохи), а затем объясняется , почему автор так думает (это хорошо, потому что позволяет правительству выполнять свою работу, но это плохо потому что правительство может злоупотреблять своей властью.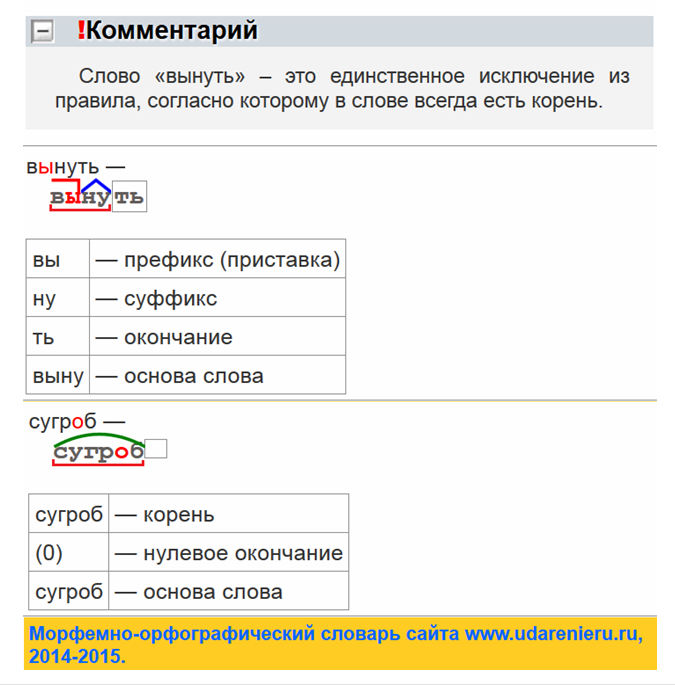 )
)
Поскольку в этом примере тезиса излагается обоснованная позиция и устанавливается линия рассуждений, его можно развить в основной части эссе с помощью дополнительных утверждений, подтверждающих доказательств и комментариев.И веский аргумент является ключом к получению шести баллов за ваше обобщающее эссе для AP Lang!
Ищете помощь в подготовке к экзамену AP?
Наши индивидуальные онлайн-услуги по обучению AP могут помочь вам подготовиться к экзаменам AP. Найдите лучшего репетитора, получившего высокие баллы на экзамене, на который вы готовитесь!
Шаг 4: Создайте набросок эссе для обнаженных костей
После того, как вы составили проект тезисов, у вас есть основа, необходимая для разработки краткого плана вашего синтезирующего эссе.Разработка плана может показаться пустой тратой вашего драгоценного времени, но , если вы хорошо разработаете план, на самом деле сэкономит ваше время, когда вы начнете писать свое эссе.
Имея это в виду, мы рекомендуем потратить от 5 до 10 минут на написание своего синтезирующего эссе . Если вы используете краткую схему, подобную приведенной ниже, помечая каждый фрагмент содержания, который вам необходимо включить в черновик эссе, вы сможете разработать наиболее важные фрагменты синтеза еще до того, как начнете составлять собственно эссе.
Чтобы помочь вам увидеть, как это может работать в день тестирования, мы создали для вас образец схемы. Вы даже можете запомнить этот план, чтобы помочь вам в тестовый день! В схеме ниже вы найдете места для заполнения тезисов, тематические предложения основного абзаца, доказательства из предоставленных источников и комментарий :
- Введение
- Представьте контекст, окружающий тему эссе, в двух предложениях (это хорошее место, чтобы использовать то, что вы узнали об основных мнениях или разногласиях по этой теме, прочитав свои источники).
- Напишите прямое, ясное и краткое изложение тезиса, в котором изложена ваша позиция по теме.
- Представьте контекст, окружающий тему эссе, в двух предложениях (это хорошее место, чтобы использовать то, что вы узнали об основных мнениях или разногласиях по этой теме, прочитав свои источники).
- Кузов
- Основной абзац №1
- Тематическое предложение, представляющее первую опорную точку или пункт формулы
- Свидетельство № 1
- Комментарий к показаниям № 1
- Доказательство № 2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац # 2
- Тематическое предложение, представляющее вторую опорную точку или пункт формулы
- Свидетельство № 1
- Комментарий к показаниям № 1
- Доказательство № 2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац № 3
- Тематическое предложение, представляющее три опорных пункта или претензию
- Свидетельство № 1
- Комментарий к показаниям № 1
- Доказательство № 2 (при необходимости)
- Комментарий к доказательству № 2 (при необходимости)
- Основной абзац №1
- Заключительный абзац
- Обобщает основную линию рассуждений, которую вы развили и отстаивали на протяжении всего эссе.
- Повторяет тезис

Потратив время на разработку этих важнейших частей синтеза в виде скроенного наброска, вы получите карту для вашего последнего эссе.Если у вас есть карта, писать сочинение будет намного проще.
Шаг 5. Составьте ответ на эссе
Самое замечательное в том, чтобы потратить несколько минут на разработку плана, состоит в том, что вы можете развить его в свой черновик эссе. После того, как вы потратите от 5 до 10 минут на набросок вашего сводного эссе, , вы можете использовать оставшиеся 30-35 минут, чтобы составить свое сочинение и просмотреть его.
Поскольку вы набросаете эссе до того, как начнете писать, написание эссе должно быть довольно простым. Вы уже будете знать, сколько абзацев вы собираетесь написать, какова будет тема каждого абзаца и какие цитаты, пересказы или резюме вы собираетесь включить в каждый абзац из предоставленных источников. Вам просто нужно будет заполнить одну из самых важных частей вашего синтеза - ваш комментарий.
Вы уже будете знать, сколько абзацев вы собираетесь написать, какова будет тема каждого абзаца и какие цитаты, пересказы или резюме вы собираетесь включить в каждый абзац из предоставленных источников. Вам просто нужно будет заполнить одну из самых важных частей вашего синтеза - ваш комментарий.
Комментарии - это ваше объяснение того, почему ваши доказательства подтверждают аргумент, который вы изложили в своей диссертации. Ваш комментарий - это то место, где вы на самом деле приводите свои аргументы, поэтому это такая важная часть вашего синтезирующего эссе.
Обдумывая, что сказать в своем комментарии, помните одну вещь, которую указывает напоминание AP Lang к синтезу эссе: не просто резюмируйте источники. Вместо этого, когда вы комментируете доказательства, которые вы включаете, , вам необходимо объяснить, как эти доказательства поддерживают или опровергают ваш тезис . Вы должны включить комментарий, который предлагает вдумчивый или новый взгляд на доказательства из ваших источников, чтобы развить вашу аргументацию.
Одна очень важная вещь, которую следует помнить при составлении эссе, - это цитировать свои источники.В приглашении к синтезу экзамена AP Lang указано, что вы можете использовать общие ярлыки для предоставленных источников (например, «Источник 1», «Источник 2», «Источник 3» и т. Д.). В приглашении к экзамену будет указано, какая метка соответствует какому источнику, поэтому вам необходимо внимательно процитировать источники. Вы можете процитировать свои источники в предложении, в котором вы вводите цитату, резюме или перефразирование, или вы можете использовать цитату в скобках. Цитирование ваших источников влияет на вашу оценку синтезируемого эссе, поэтому важно помнить об этом.
Одна из самых важных частей вашего заявления в колледж - это то, какие уроки вы выбираете в старшей школе (в сочетании с тем, насколько хорошо вы успеваете в этих классах). Наша команда экспертов по поступлению в PrepScholar объединила свои знания в это единственное руководство по планированию расписания вашего школьного курса. Мы посоветуем вам, как сбалансировать ваше расписание между обычными курсами и курсами с отличием / AP / IB, как выбрать дополнительные занятия и какие классы вы не можете позволить себе не посещать.
Мы посоветуем вам, как сбалансировать ваше расписание между обычными курсами и курсами с отличием / AP / IB, как выбрать дополнительные занятия и какие классы вы не можете позволить себе не посещать.
Продолжайте читать, чтобы увидеть реальный пример отличного ответа на эссе по синтезу AP!
Реальный пример синтеза AP и анализ
Если вам все еще интересно, как написать обобщающее эссе, примеры реальных эссе из прошлых экзаменов AP Lang могут прояснить ситуацию. Эти ответы на реферативное эссе для учащихся могут помочь вам понять, как написать обобщающее эссе, которое сбьет с толку учащихся.
Хотя в Интернете есть несколько примеров сочинений, мы выбрали один, чтобы рассмотреть его поближе. Мы собираемся дать вам краткий анализ одного из этих примеров обобщающих эссе студентов из экзамена AP Lang 2019 ниже!
Пример эссе синтеза Ответ А.П. Ланга
Для начала давайте посмотрим на официальную подсказку к синтезу эссе 2019 года:
В ответ на растущий спрос нашего общества на энергию, крупномасштабная ветроэнергетика привлекла внимание правительств и потребителей как потенциальная альтернатива традиционным материалам, которые питают наши электрические сети, таким как уголь, нефть, природный газ, вода или даже более новые. источники, такие как ядерная или солнечная энергия.Тем не менее, создание крупномасштабных ветряных электростанций коммерческого класса часто является предметом споров по разным причинам.
Внимательно прочтите шесть источников, найденных на экзамене AP по английскому языку и композиции 2019 (вопрос 1), включая вводную информацию по каждому источнику. Напишите эссе, которое синтезирует материал как минимум из трех источников и развивает вашу позицию по наиболее важным факторам, которые человек или агентство должны учитывать при принятии решения о создании ветряной электростанции.
Источник A (фотография)
Источник B (Лейтон)
Источник C (Селтенрих)
Источник D (коричневый)
Источник E (Правило)
Источник F (Molla)
В своем ответе вы должны сделать следующее:
- Ответьте на запрос с тезисом, представляющим оправданную позицию.
- Выберите и используйте доказательства как минимум из 3 из предоставленных источников для подтверждения своей аргументации. Четко укажите использованные источники с помощью прямой цитаты, перефразирования или резюме. Источники могут упоминаться как Источник A, Источник B и т. Д., или используя описание в круглых скобках.
- Объясните, как доказательства подтверждают вашу линию рассуждений.
- Используйте правильную грамматику и пунктуацию в своих аргументах.

Теперь, когда вы точно знаете, что подсказка просила студентов сделать в синтезирующем эссе AP Lang 2019 года, вот пример синтезирующего эссе AP Lang, написанный настоящим студентом на экзамене AP Lang в 2019 году:
[1] Ситуация была известна в течение многих лет, и все еще очень мало делается: альтернативная энергия - единственный способ надежно обеспечить энергией меняющийся мир.Энергия, поступающая от промышленности и частной жизни, является подавляющим источником невозобновляемых источников энергии, и в связи с сокращением запасов ископаемого топлива прекращение эксплуатации угольных и газовых топливных электростанций является лишь вопросом времени. Итак, одна из жизнеспособных альтернатив - энергия ветра. Но, как и во всем, есть свои плюсы и минусы. Основными факторами, которые должны учитывать энергетические компании при строительстве ветряных электростанций, являются экологические, эстетические и экономические факторы.
[2] Экологические преимущества использования энергии ветра хорошо известны и доказаны.Ветровая энергия, согласно оценке источника B, несомненно, чистая и возобновляемая. От того, что для их производства требуется очень мало опасных материалов, до недостатка топлива, помимо того, что происходит естественным образом, энергия ветра на сегодняшний день является одним из наименее вредных для окружающей среды доступных источников энергии. Кроме того, энергия ветра посредством коробки передач и современных материалов лопастей имеет самый высокий процент удержания энергии. Согласно источнику F, энергия ветра сохраняет 1164% энергии, вложенной в систему, что означает, что она увеличивает энергию, преобразованную из топлива (ветра) в электричество, в 10 раз! Ни один другой метод производства электроэнергии не эффективен даже наполовину.Важно учитывать эффективность и экологичность ветровой энергии, особенно потому, что они вносят экономический вклад в энергетические компании.
Согласно источнику F, энергия ветра сохраняет 1164% энергии, вложенной в систему, что означает, что она увеличивает энергию, преобразованную из топлива (ветра) в электричество, в 10 раз! Ни один другой метод производства электроэнергии не эффективен даже наполовину.Важно учитывать эффективность и экологичность ветровой энергии, особенно потому, что они вносят экономический вклад в энергетические компании.
[3] С экономической точки зрения энергия ветра является одновременно благом и костью для электрических компаний и других пользователей. Для потребителей энергия ветра очень дешевая, что приводит к более низким счетам, чем из любого другого источника. Потребители также получают косвенное возмещение в виде налогов (источник D). В одном техасском городке Маккейми налоговые поступления увеличились на 30% за счет строительства ветряной электростанции.Это помогает финансировать улучшения города. Но нет сомнений, что ветроэнергетика наносит ущерб и энергетическим компаниям. Хотя с точки зрения возобновляемой энергии ветер невероятно дешев, он все же значительно дороже ископаемого топлива. Таким образом, хотя он помогает сократить выбросы, он обходится электроэнергетическим компаниям дороже, чем традиционные заводы, работающие на ископаемом топливе. Хотя общая экономическая тенденция является положительной, есть некоторые препятствия, которые необходимо преодолеть, прежде чем энергия ветра станет действительно более эффективной, чем ископаемое топливо.
[4] Эстетика может стать самым большим препятствием для энергетических компаний. Хотя энергия ветра может принести значительную экономическую и экологическую выгоду, люди всегда будут бороться за сохранение чистой, нетронутой земли. К сожалению, для улучшения внешнего вида турбин мало что можно сделать. Белая краска - самый распространенный выбор, потому что она «ассоциируется с чистотой». (Источник E). Но это может сделать его заметным, как больной большой палец, и сделать гигантские машины более неуместными. Сайт также не может быть изменен, потому что это влияет на генерирующую мощность. Звук вызывает еще большее беспокойство, потому что он нарушает личную продуктивность, нарушая режим сна людей. Энергетическим компаниям следует подумать о том, чтобы работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку.
Сайт также не может быть изменен, потому что это влияет на генерирующую мощность. Звук вызывает еще большее беспокойство, потому что он нарушает личную продуктивность, нарушая режим сна людей. Энергетическим компаниям следует подумать о том, чтобы работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку.
[5] Как и в большинстве случаев, у ветроэнергетики нет простого ответа. Компании, создающие их, обязаны взвесить преимущества и последствия.Но, уравновешивая экономику, эффективность и эстетику, энергетические компании могут создать решение, которое уравновешивает влияние человека с сохранением окружающей среды.
И это полный пример сочинения по синтезу AP Lang, написанного в ответ на настоящее приглашение к экзамену AP Lang! Важно помнить, что подсказки к синтезу эссе на экзамене AP Lang всегда одинаково структурированы и сформулированы, и студенты часто отвечают примерно в том же количестве абзацев, что и в приведенном выше примере ответа на эссе.
Далее, давайте проанализируем это эссе в качестве примера и поговорим о том, что в нем эффективно, что можно улучшить и какие баллы ему присуждали прошлые экзаменаторы.
Анализ
Чтобы начать анализ образца эссе синтеза, давайте посмотрим на оценочный комментарий, предоставленный Советом колледжей:
- За разработку дипломной работы реферат получил 1 из 1 возможных баллов
- За доказательства и комментарии эссе получило 4 из 4 возможных баллов
- За изощренность мысли эссе получило 0 баллов из 1 возможных.
Это означает, что окончательная оценка за этот пример эссе составила 5 из 6 возможных баллов . Давайте более внимательно посмотрим на содержание эссе-примера, чтобы выяснить, почему оно получило такую разбивку баллов.
Разработка диссертации
Тезисы - одна из трех основных категорий, которые принимаются во внимание , когда вам присуждаются баллы на этой части экзамена. Это примерное эссе получило 1 балл из 1.
Это примерное эссе получило 1 балл из 1.
И вот почему: тезис ясно и кратко излагает позицию по теме, представленной в подсказке - альтернативная энергия и энергия ветра - и определяет наиболее важные факторы, которые энергетические компании должны учитывать при принятии решения о создании ветряной электростанции. .
Доказательства и комментарии
Вторая ключевая категория, принимаемая во внимание при оценке сводных экзаменов, - это включение доказательств и комментариев. Этот образец получил 4 из 4 возможных баллов за эту часть обобщающего эссе.Как минимум, этот образец эссе соответствует упомянутому в приглашении требованию о том, чтобы автор использовал доказательства как минимум из трех из предоставленных источников.
Вдобавок к этому, автор хорошо справляется со связью включенных доказательств с утверждением, сделанным в тезисе, посредством эффективных комментариев. Комментарий в этом образце эссе эффективен, потому что он выходит за рамки простого резюмирования того, что говорят предоставленные источники. Вместо этого он объясняет и анализирует доказательства, представленные в отобранных источниках, и связывает их с подтверждающими пунктами, которые автор делает в каждом основном абзаце.
Наконец, автор эссе также получил баллы за доказательства и комментарии, потому что автор разработал и поддержал последовательную линию рассуждений на протяжении всего эссе . Эта линия рассуждений резюмируется в четвертом абзаце в следующем предложении: «Энергетическим компаниям следует учесть одну вещь - работать с производством турбин, чтобы сделать машины менее эстетичными, чтобы получить большую общественную поддержку».
Поскольку автор проделал хорошую работу, последовательно развивая свои аргументы и объединяя доказательства, они получили полные оценки в этой категории.Все идет нормально!
Утонченность мысли
Итак, мы знаем, что это эссе получило 5 баллов из 6, а место, где писатель потерял балл, было связано с утонченностью мышления, за которое автор получил 0 баллов из 1. Это потому, что в этом образце эссе делается несколько обобщений и расплывчатых утверждений, вместо которых можно было бы сделать конкретные утверждения , которые поддерживают более сбалансированный аргумент.
Это потому, что в этом образце эссе делается несколько обобщений и расплывчатых утверждений, вместо которых можно было бы сделать конкретные утверждения , которые поддерживают более сбалансированный аргумент.
Например, в следующем предложении из 5-го абзаца типового эссе автор упускает возможность указать конкретные возможности, которые энергетические компании должны учитывать в отношении энергии ветра .Вместо этого автор двусмысленно и уклончиво говорит: «Как и на большинство вещей, ветроэнергетика не имеет простого ответа. Компании, создающие их, должны взвесить выгоды и последствия».
Если автор этого эссе был заинтересован в том, чтобы попытаться получить этот 6-й балл в ответе на обобщающее эссе, он мог бы подумать о более конкретных утверждениях. Например, они могут указать конкретные преимущества и последствия для , которые энергетические компании должны учитывать при принятии решения о создании ветряной электростанции.Сюда могут входить такие вещи, как воздействие на окружающую среду, экономические последствия или даже плотность населения!
Несмотря на потерю одного балла в последней категории, это эссе-пример синтеза является сильным. Он хорошо разработан, продуманно написан и развивает аргументы по теме экзамена, используя доказательства и поддержку.
4 совета по написанию синтезирующего эссе
AP Lang - это экзамен с ограничением по времени, поэтому вам нужно выбрать то, на чем вы хотите сосредоточиться, в то ограниченное время, которое вам дается на написание обобщающего эссе.Продолжайте читать, чтобы получить совет наших экспертов о том, на чем вам следует сосредоточиться во время экзамена.
Совет 1. Прочтите сначала подсказку
Это может показаться очевидным, но когда у вас мало времени, легко растеряться. Просто помните: , когда придет время писать сводное эссе, сначала прочтите подсказку !
Почему так важно прочитать подсказку перед чтением исходных текстов? Потому что, когда вы знаете, на какой вопрос вы пытаетесь ответить, вы сможете читать источники более стратегически. Подсказка поможет вам понять, какие утверждения, моменты, факты или мнения следует искать при чтении источников.
Подсказка поможет вам понять, какие утверждения, моменты, факты или мнения следует искать при чтении источников.
Чтение источников, не прочитав сначала подсказку, похоже на попытку водить машину с завязанными глазами: вы, вероятно, сможете это сделать, но, скорее всего, это плохо закончится!
Совет 2: делайте заметки во время чтения
В течение 15-минутного периода чтения в начале обобщающего эссе вы будете читать источники как можно быстрее.В конце концов, вам, вероятно, не терпится начать писать!
Хотя определенно важно эффективно использовать свое время, также важно читать достаточно внимательно, чтобы понимать свои источники. Внимательное чтение позволит вам определить части источников, которые также помогут вам поддержать ваше тезисное изложение в вашем эссе.
Читая источники, подумайте о том, чтобы пометить полезные отрывки звездочкой или галочкой на полях экзамена , чтобы вы знали, какие части текста нужно быстро перечитывать при составлении сводного эссе.Вы также можете подумать о суммировании ключевых моментов или положения каждого источника в предложении или нескольких словах, когда вы закончите читать каждый источник во время периода чтения. Это поможет вам узнать позицию каждого источника по данной теме и выбрать три (или больше!), Которые поддержат ваш аргумент о синтезе.
Совет 3: начните с тезиса
Если вы не начнете свое сочинение-синтез с сильного тезисного утверждения, будет сложно написать эффективное сочинение-синтез. Как только вы закончите читать и комментировать предоставленные источники, вам нужно сделать следующее - написать сильное тезисное заявление.
Согласно руководству CollegeBoard по оценке синтезируемого эссе AP Lang, сильное тезисное изложение будет отвечать на запрос - , а не , переформулируйте или перефразируйте подсказку. Хорошая диссертация займет четкую, обоснованную позицию по теме, изложенной в подсказке и источниках.
Другими словами, чтобы написать твердое тезисное изложение, которым будет руководствоваться остальная часть вашего синтезирующего эссе, вам нужно подумать о вашей позиции по рассматриваемой теме, а затем заявить о ней на основе вашего должность. Эта позиция будет либо защищать, либо оспаривать, либо квалифицировать утверждение, сделанное в подсказке к эссе.
Обоснованная позиция, которую вы заняли в своем тезисе, будет определять вашу аргументацию в остальной части эссе, поэтому важно сначала сделать это . Когда у вас будет сильное тезисное изложение, вы можете приступить к наброску своего эссе.
Совет 4. Сосредоточьтесь на своем комментарии
Написание вдумчивых, оригинальных комментариев, объясняющих ваши аргументы и источники, очень важно.Фактически, если вы сделаете это хорошо, вы получите четыре очка (из шести)!
AP Lang предоставляет вам от шести до семи источников на экзамене, и вы должны будете включить цитаты, перефразирование или резюме по крайней мере из трех из этих источников в свое обобщающее эссе и интерпретировать эти доказательства для читателя.
Хотя включение доказательств очень важно, чтобы получить дополнительный балл за «сложность мысли» в синтезирующем эссе, важно потратить больше времени на обдумывание вашего комментария к доказательствам, которые вы решили включить.Комментарий - это ваш шанс продемонстрировать оригинальное мышление, сильные риторические навыки и ясно объяснить , как приведенные вами доказательства подтверждают позицию, изложенную вами в своем тезисе.
Чтобы заработать 6-й возможный балл за сводное эссе, убедитесь, что ваш комментарий демонстрирует тонкое понимание исходного материала, объясняет это тонкое понимание и помещает доказательства, взятые из источников, в беседу друг с другом.Для этого старайтесь избегать неопределенных формулировок. По возможности будьте конкретны и всегда связывайте свой комментарий с тезисом!
Что дальше?
Экзамен по языку AP - это гораздо больше, чем просто сводное эссе. Обязательно ознакомьтесь с нашим экспертным руководством по всему экзамену, а затем узнайте больше о сложном разделе с несколькими вариантами ответов.
Сложен ли экзамен AP Lang ... или это легко? Посмотрите, как он сочетается с другими тестами AP в нашем списке самых сложных экзаменов AP.
Знаете ли вы, что технически существует два экзамена AP по английскому языку? В этой статье вы можете узнать больше о втором тесте AP по английскому языку, литературном экзамене AP. И если вы не уверены, следует ли вам проходить тест AP Lang или AP Lit, мы также можем помочь вам принять это решение.
Хотите улучшить свой результат SAT на 160 баллов или ваш результат ACT на 4 балла? Мы написали руководство для каждого теста о 5 лучших стратегиях, которые вы должны использовать, чтобы улучшить свой результат.Скачать бесплатно сейчас:
Комбинаторы монадического синтаксического анализатора на C #
Концепция синтаксического анализа всегда казалась мне очень сложной. Я думал, что для работы в этой области нужно иметь доступ к некоторым секретным знаниям, принесенным инопланетной расой или кем-то в этом роде.
Некоторое время назад мне пришлось реализовать надлежащий разбор уценки в DiscordChatExporter, чтобы я мог заменить неэффективные регулярные выражения, которые я использовал.Я понятия не имел, как подойти к этой проблеме, поэтому потратил несколько дней на изучение этого вопроса, в конце концов узнав о комбинаторах парсеров. Эта концепция познакомила меня с совершенно новой парадигмой написания синтаксических анализаторов, которая на самом деле делает его увлекательным и приятным занятием.
В этой статье я постараюсь дать краткий общий обзор того, что такое синтаксический анализатор и что составляет формальный язык, а затем перейду к комбинаторам синтаксического анализатора, чтобы показать, насколько легко с его помощью создавать синтаксические анализаторы. Мы также напишем в качестве упражнения рабочий JSON-процессор.
Что такое парсер
Я уверен, что для большинства людей слово «синтаксический анализатор» не ново. В конце концов, мы все время «анализируем» вещи либо напрямую через такие, как int.Parse и XElement.Parse , либо косвенно при десериализации HTTP-ответов, чтении настроек приложения и т. Д.
А что такое парсер в общем смысле этого слова?
Как люди, мы наделены множеством врожденных способностей, одна из которых - способность подсознательно разбирать текст на логические компоненты.Это очень важный навык, потому что он позволяет нам обнаруживать закономерности, анализировать семантику и сравнивать различные фрагменты текста друг с другом.
Например, видите ли вы какую-то логическую структуру, когда смотрите на 123 456.97 ? Вы легко можете сказать, что это номер, состоящий из нескольких компонентов:
- Цифры (
123) - Разделитель тысяч (пробел)
- Цифры (
456) - Десятичный разделитель (
.) - Цифры (
97)
По очевидным причинам компьютер не может обнаруживать подобные закономерности. В конце концов, он видит только кажущуюся случайной последовательность байтов: 31 32 33 20 34 35 36 2E 39 37 .
Поскольку мы имеем дело с текстом, нам нужен способ его анализировать. Для этого нам необходимо программно создать тот же набор синтаксических компонентов, который мы можем видеть естественным образом:
новые SyntacticComponents []
{
новый NumericLiteralComponent (123),
новый компонент ThousandsSeparatorComponent (""),
новый NumericLiteralComponent (456),
новый DecimalSeparatorComponent ("."),
новый NumericLiteralComponent (97)
} Это то, что делают парсеры. Они принимают ввод, обычно в виде текста, и формализуют его с помощью объектов предметной области. В случае неверного ввода парсер отклоняет его с информативным сообщением об ошибке.
[Ввод] ------ (Парсер)
/ \
✓ / \ X
/ \
[Объекты домена] [Сообщение об ошибке] Конечно, это довольно простой пример, существуют гораздо более сложные языки и вводы.Но в целом можно сказать, что синтаксический анализатор - это часть кода, которая может помочь построить синтаксическую структуру входного текста, эффективно помогая компьютеру «понять» его.
Считается ли ввод действительным или нет, решается набором грамматических правил, которые эффективно определяют структуру языка.
Формальная грамматика
Анализ чисел- это не ракетостроение, и вы бы не стали читать эту статью, если бы это было то, что вам нужно. Каждый может написать быстрое регулярное выражение для разделения такого текста на синтаксические компоненты.
Говоря о регулярных выражениях, знаете ли вы, почему они называются регулярными ?
В информатике есть область под названием , теория формального языка , которая конкретно занимается языками. По сути, это набор абстракций, которые помогают нам понимать языки с более формальной точки зрения.
Сам формальный язык основан в основном на концепции грамматики, которая представляет собой набор правил, которые диктуют, как создавать допустимые символы на данном языке.Когда мы говорим о допустимом и недопустимом вводе, мы имеем в виду грамматику.
В зависимости от сложности этих правил грамматики делятся на разные типы в соответствии с иерархией Хомского. На самом нижнем уровне вы найдете два наиболее распространенных типа грамматики: обычных и контекстно-свободных грамматик.
+ --------------------------------- +
| |
| БЕСКОНТЕКСТОВЫЕ ГРАММАТИКИ |
| |
| |
| + -------------------- + |
| | | |
| | ОБЫЧНЫЕ ГРАММАТИКИ | |
| | | |
| + -------------------- + |
+ --------------------------------- + Основное различие между ними состоит в том, что правила обычной грамматики, в отличие от контекстно-свободных, не могут быть рекурсивными.Рекурсивное грамматическое правило - это правило, которое создает символ, который может быть вычислен с помощью того же правила.
HTML - хороший пример контекстно-свободного языка, потому что элемент в HTML может содержать другие элементы, которые, в свою очередь, могут содержать другие элементы, и так далее. По этой же причине его невозможно проанализировать с помощью регулярных выражений.
В результате, в то время как входные данные, которые придерживаются обычной грамматики, могут быть представлены с использованием последовательности синтаксических компонентов, контекстно-свободная грамматика представлена с использованием структуры более высокого уровня - синтаксического дерева:
[документ HTML]
| \
| \
/ \ \
<основной> <нижний колонтитул> \
/ | \
</code> </pre><p> Итак, если мы не можем использовать регулярные выражения для построения этих синтаксических деревьев, что нам делать?</p><h3><span class="ez-toc-section" id="%D0%9A%D0%BE%D0%BC%D0%B1%D0%B8%D0%BD%D0%B0%D1%82%D0%BE%D1%80%D1%8B_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80%D0%B0"></span> Комбинаторы синтаксического анализатора <span class="ez-toc-section-end"></span></h3><p> Есть много подходов к написанию синтаксических анализаторов для контекстно-свободных языков.Большинство известных вам языковых инструментов построено либо на ручных синтаксических анализаторах стека циклов, либо на структурах генератора синтаксического анализа, либо на комбинаторах синтаксического анализатора.</p><p> Комбинаторы синтаксического анализатора, как концепция, вращаются вокруг представления каждого синтаксического анализатора как модульной функции, которая принимает некоторый ввод и выдает либо успешный результат, либо ошибку:</p><pre> <code> f (ввод) -> (результат, inputRemainder) | (ошибка) </code> </pre><p> Эти синтаксические анализаторы можно преобразовать или объединить в более сложные синтаксические анализаторы, заключив функцию в другую функцию.Вообще говоря, комбинаторы - это просто еще один класс функций, которые берут на себя другие функции синтаксического анализатора и создают более сложные.</p><p> Идея состоит в том, чтобы начать с написания синтаксических анализаторов для простейших грамматических правил вашего языка, а затем постепенно продвигаться вверх по иерархии, используя различные комбинаторы. Поднимаясь уровень за уровнем, вы в конечном итоге должны достичь самого верхнего узла, который представляет так называемый начальный символ.</p><p> Это может быть слишком абстрактным для понимания, так как насчет практического примера?</p><h3><span class="ez-toc-section" id="%D0%9F%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80_JSON_%D1%81_%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5%D0%BC_%D0%BA%D0%BE%D0%BC%D0%B1%D0%B8%D0%BD%D0%B0%D1%82%D0%BE%D1%80%D0%BE%D0%B2_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B3%D0%BE_%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%82%D0%BE%D1%80%D0%B0"></span> Процессор JSON с использованием комбинаторов синтаксического анализатора <span class="ez-toc-section-end"></span></h3><p> Чтобы лучше понять этот подход, давайте напишем функциональный парсер JSON с использованием C # и библиотеки Sprache.Эта библиотека предоставляет набор базовых низкоуровневых синтаксических анализаторов и методов для их объединения, которые по сути являются строительными блоками, которые мы можем использовать для создания наших собственных сложных синтаксических анализаторов.</p><p> Для начала я создал проект и определил классы, которые представляют различные сущности в грамматике JSON, всего 6 из них:</p><ul><li> <code> JsonObject </code></li><li> <code> JsonArray </code></li><li> <code> JsonString </code></li><li> <code> JsonNumber </code></li><li> <code> JsonBoolean </code></li><li> <code> JsonNull </code></li></ul><p> Вот соответствующий код для них, для краткости сжатый в один фрагмент:</p><pre> <code>
общедоступный абстрактный класс JsonEntity
{
общедоступный виртуальный JsonEntity this [имя строки] =>
выбросить новое исключение InvalidOperationException ($ "{GetType ().Name} не поддерживает эту операцию. ");
общедоступный виртуальный JsonEntity this [int index] =>
throw new InvalidOperationException ($ "{GetType (). Name} не поддерживает эту операцию.");
общедоступный виртуальный T GetValue <T> () =>
throw new InvalidOperationException ($ "{GetType (). Name} не поддерживает эту операцию.");
общедоступный статический анализ JsonEntity (строка json) =>
throw new NotImplementedException («Еще не реализовано!»);
}
открытый класс JsonObject: JsonEntity
{
общедоступный IReadOnlyDictionary <строка, JsonEntity> Свойства {получить; }
общедоступный JsonObject (свойства IReadOnlyDictionary <string, JsonEntity>)
{
Свойства = свойства;
}
общедоступное переопределение JsonEntity this [имя строки] =>
Характеристики.TryGetValue (имя, результат var)? результат: ноль;
}
открытый класс JsonArray: JsonEntity
{
public IReadOnlyList <JsonEntity> Дети {получить; }
общедоступный JsonArray (дети IReadOnlyList <JsonEntity>)
{
Дети = дети;
}
публичное переопределение JsonEntity this [int index] => Children.ElementAtOrDefault (index);
}
общедоступный абстрактный класс JsonLiteral <TValue>: JsonEntity
{
общественное значение TValue {получить; }
защищенный JsonLiteral (значение TValue)
{
Значение = значение;
}
публичное переопределение T GetValue <T> () => (T) Convert.ChangeType (Значение, typeof (T));
}
открытый класс JsonString: JsonLiteral <string>
{
public JsonString (строковое значение): base (значение)
{
}
}
открытый класс JsonNumber: JsonLiteral <double>
{
public JsonNumber (двойное значение): base (значение)
{
}
}
открытый класс JsonBoolean: JsonLiteral <bool>
{
общедоступный JsonBoolean (значение типа bool): base (значение)
{
}
}
открытый класс JsonNull: JsonLiteral <объект>
{
public JsonNull (): base (null)
{
}
} </code> </pre><p> Вы можете видеть, что все наши типы JSON наследуются от класса <code> JsonEntity </code>, который определяет несколько виртуальных методов.Эти методы вызывают исключение по умолчанию, но они переопределяются правильной реализацией для типов, которые их поддерживают.</p><p> Используя <code> JsonEntity.Parse </code>, вы можете преобразовать фрагмент текста JSON в объекты нашего домена и пройти всю иерархию с помощью индексаторов:</p><pre> <code> var price = JsonEntity.Parse (json) ["заказ"] ["предметы"] [0] ["цена"]. GetValue <double> (); </code> </pre><p> Конечно, это пока не сработает, потому что наш метод <code> Parse </code> не реализован.Давай исправим это.</p><p> Начните с загрузки библиотеки Sprache из NuGet, затем создайте новый внутренний статический класс с именем <code> JsonGrammar </code>. Здесь мы определим грамматику для нашего языка:</p><pre> <code> внутренний статический класс JsonGrammar
{
} </code> </pre><p> Как я объяснил выше, этот подход заключается в построении сначала простых независимых синтаксических анализаторов и постепенного продвижения вверх по иерархии. По этой причине имеет смысл начать с самой простой сущности - <code> JsonNull </code>, которая может иметь только одно значение:</p>.<pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <JsonNull> JsonNull =
Разобрать.Строка ("ноль"). Возврат (новый JsonNull ());
} </code> </pre><p> Давайте быстро рассмотрим то, что мы здесь только что написали.</p><p> Справа от знака равенства мы вызываем <code> Parse.String </code>, чтобы создать базовый синтаксический анализатор, который будет искать последовательность символов, составляющих строку «null». Этот метод создает делегат типа <code> Parser <IEnumerable <char>> </code>, но, поскольку нас не особо интересует сама последовательность символов, мы связываем ее с методом расширения <code> Return </code>, который позволяет нам указать конкретный объект для возврата. вместо.Это также изменяет тип делегата на <code> Parser <JsonNull> </code>.</p><p> Стоит отметить, что пока мы пишем это, синтаксический анализ еще не происходит. Мы только создаем делегат, который позже можно будет вызвать для анализа определенного ввода.</p><p> Если мы вызовем <code> JsonNull.Parse ("null") </code>, он вернет объект типа <code> JsonNull </code>. Если мы попытаемся вызвать его на любом другом входе, он выдаст исключение с подробной ошибкой.</p><p> Это круто, но пока не особо полезно.</p><p> Перейдем к <code> JsonBoolean </code>. Этот тип, в отличие от <code> JsonNull </code>, на самом деле имеет два потенциальных состояния: <code> истинный </code> и <code> ложный </code>. Мы можем обрабатывать их с помощью двух отдельных парсеров:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <JsonBoolean> TrueJsonBoolean =
Parse.String ("true"). Return (new JsonBoolean (true));
частный статический только для чтения Parser <JsonBoolean> FalseJsonBoolean =
Разобрать.String ("false"). Return (new JsonBoolean (false));
} </code> </pre><p> Это работает очень похоже на предыдущий синтаксический анализатор, который мы написали, за исключением того, что теперь у нас есть два разных синтаксических анализатора для одной сущности.</p><p> Как вы, наверное, догадались, именно здесь в игру вступают комбинаторы. Мы можем объединить эти два парсера в один, используя комбинатор <code> или </code> следующим образом:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <JsonBoolean> TrueJsonBoolean =
Разобрать.Строка ("истина"). Возврат (новый JsonBoolean (истина));
частный статический только для чтения Parser <JsonBoolean> FalseJsonBoolean =
Parse.String ("false"). Return (new JsonBoolean (false));
частный статический только для чтения Parser <JsonBoolean> JsonBoolean =
TrueJsonBoolean.Or (FalseJsonBoolean);
} </code> </pre><p> Комбинатор <code> или </code> - это метод расширения, который принимает два синтаксических анализатора одного типа и создает новый синтаксический анализатор, который завершается успешно, если один из них завершается успешно. Это означает, что если мы попытаемся вызвать <code> JsonBoolean.Анализируя ("истина") </code>, мы получим <code> JsonBoolean </code>, у которого <code> Value </code> равно <code> true </code>. Точно так же, если мы вызовем <code> JsonBoolean.Parse ("false") </code>, мы получим <code> JsonBoolean </code>, значение <code> которого </code> равно <code> false </code>. И, конечно же, любой неожиданный ввод приведет к ошибке.</p><p> Одна из самых крутых особенностей использования комбинаторов синтаксического анализатора - это то, насколько выразителен ваш код. На самом деле это можно прочитать буквально:</p><pre> <code> JsonBoolean имеет значение TrueJsonBoolean или FalseJsonBoolean.TrueJsonBoolean - это строка «true», которая производит JsonBoolean, значение которого равно «true».
FalseJsonBoolean - это строка «false», которая создает `JsonBoolean`, значение которого -` false`. </code> </pre><p> Чтение подобного кода позволяет легко определить структуру текста, который мы пытаемся разобрать.</p><p> Давайте обработаем наш следующий тип данных, <code> JsonNumber </code>:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический анализатор только для чтения <JsonNumber> JsonNumber =
Разобрать.ДесятичныйИнвариант
.Select (s => double.Parse (s, CultureInfo.InvariantCulture))
.Select (v => новый номер JsonNumber (v));
} </code> </pre><p> Как видите, Sprache уже предоставляет <code> Parse.DecimalInvariant </code> из коробки, которую мы можем использовать для сопоставления числа. Поскольку это возвращает <code> Parser <string> </code>, когда он анализирует текст, представляющий число, нам нужно сначала преобразовать его в <code> double </code>, а затем в наш объект <code> JsonNumber </code>.</p><p> Метод <code> Select </code> здесь работает аналогично методу <code> Select </code> LINQ - он лениво преобразует базовое значение контейнера в другую форму.Это позволяет отображать необработанные последовательности символов в более сложные объекты предметной области более высокого уровня.</p><p> Между прочим, типы, которые имеют операцию <code> Select </code> (или, в просторечии, операцию «сопоставление»), называются «функторами». Как видите, они не ограничиваются коллекциями (например, <code> IEnumerable<T> </code>), но также могут быть контейнерами с одним значением, как наш <code> Parser<T> </code> здесь.</p><p> Разобравшись с этим, перейдем к <code> JsonString </code>:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический анализатор только для чтения <JsonString> JsonString =
из открытого в Parse.Char ('"')
от значения в Parse.CharExcept ('"'). Many (). Text ()
из закрытия в Parse.Char ('"')
выберите новый JsonString (значение);
} </code> </pre><p> Здесь вы можете увидеть, как мы объединили три последовательных синтаксических анализатора в один с использованием синтаксиса понимания LINQ. Вы, наверное, знакомы с этим синтаксисом по работе с коллекциями, но здесь он немного другой.</p><p> Каждая строка, начинающаяся с <code> от </code>, представляет отдельный синтаксический анализатор, который производит значение. Мы указываем имя для значения слева и определяем фактический синтаксический анализатор справа.Чтобы свести параметры к одному результату, мы заканчиваем оператором <code> select </code>, который конструирует объект, который нам нужен.</p><p> Это работает, потому что соединение <code> с операторами </code> внутренне вызывает метод расширения <code> SelectMany </code>, который автор этой библиотеки определил для работы с <code> Parser<T> </code>.</p><p> Да, и типы, которые позволяют делать это с помощью <code> SelectMany </code> (также известного как «плоская карта»), - это то, что мы называем «монадами».</p><p> Только что написанный синтаксический анализатор попытается сопоставить двойную кавычку, за которой следует (возможно, пустая) последовательность символов, не содержащая двойных кавычек, завершенная другой двойной кавычкой, в конечном итоге возвращая объект <code> JsonString </code> с текстом внутри .</p><p> Переходим к нашему первому непримитивному типу, <code> JsonArray </code>:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <JsonArray> JsonArray =
из открытого в Parse.Char ('[')
от детей в JsonEntity.Token (). DelimitedBy (Parse.Char (','))
из закрытия в Parse.Char (']')
выберите новый JsonArray (children.ToArray ());
} </code> </pre><p> Структурно массив JSON представляет собой просто последовательность сущностей, разделенных запятыми, заключенных в пару квадратных скобок.Мы можем определить это, используя комбинатор <code> DelimitedBy </code>, который пытается сопоставить первый синтаксический анализатор, многократно разделенный вторым.</p><p> Обратите внимание, что этот комбинатор принимает <code> Parse.Char (',') </code> вместо просто <code> ',' </code>. На самом деле мы могли бы использовать вместо него более сложный синтаксический анализатор, который даже не возвращает <code> char </code> или <code> string </code>. В этом сила комбинаторов синтаксического анализа - по мере того, как мы постепенно продвигаемся вверх по структуре наших данных, мы работаем с синтаксическими анализаторами все более высокого порядка.</p><p> Если вы внимательно следовали приведенным здесь инструкциям, вы, вероятно, заметили, что приведенный выше код на самом деле не компилируется. Это потому, что мы ссылаемся на <code> JsonEntity </code>, который является синтаксическим анализатором, который мы еще не определили. Это потому, что это правило грамматики является рекурсивным - массив может содержать любую сущность, которая может быть, помимо прочего, массивом, который может содержать любую сущность, которая может быть массивом, что… вы понимаете.</p><p> В качестве временного решения мы можем определить фиктивный объект вместо <code> JsonEntity </code>, просто чтобы он скомпилировался:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <JsonArray> JsonArray =
из открытого в Parse.Char ('[')
от детей в JsonEntity.Token (). DelimitedBy (Parse.Char (','))
из закрытия в Parse.Char (']')
выберите новый JsonArray (children.ToArray ());
общедоступный статический только для чтения Parser <JsonEntity> JsonEntity = null;
} </code> </pre><p> Также обратите внимание на метод расширения <code> Token () </code>? Это превращает наш синтаксический анализатор в синтаксический анализатор более высокого порядка, который сразу же использует все пробелы вокруг нашего ввода. Как мы знаем, JSON игнорирует пробелы, если они не заключены в двойные кавычки, поэтому нам необходимо это учитывать.Если мы этого не сделаем, наш синтаксический анализатор выдаст ошибку при обнаружении пробелов.</p><p> Анализ <code> JsonObject </code> очень похож, за исключением того, что он содержит свойства вместо необработанных сущностей. Итак, сначала нам нужно начать с парсера:</p><pre> <code> внутренний статический класс JsonGrammar
{
частный статический только для чтения Parser <KeyValuePair <string, JsonEntity >> JsonProperty =
от имени в JsonString.Select (s => s.Value)
из двоеточия в Parse.Char (':').Токен ()
от значения в JsonEntity
выберите новый KeyValuePair <строка, JsonEntity> (имя, значение);
частный статический только для чтения Parser <JsonObject> JsonObject =
из открытого в Parse.Char ('{')
из свойств в JsonProperty.Token (). DelimitedBy (Parse.Char (','))
из закрытия в Parse.Char ('}')
выберите новый JsonObject (properties.ToDictionary (p => p.Key, p => p.Value));
} </code> </pre><p> Поскольку наша модель реализует <code> JsonObject </code> с использованием словаря, отдельное свойство выражается с помощью <code> KeyValuePair <string, JsonEntity> </code>, то есть имени свойства (<code> строка </code>) и его значения (<code> JsonEntity </code>).</p><p> Как видите, мы снова использовали синтаксис понимания LINQ для объединения последовательных синтаксических анализаторов. <code> JsonProperty </code> состоит из <code> JsonString </code> для имени, двоеточия и <code> JsonEntity </code>, обозначающего его значение. Мы используем <code> Select () </code> на <code> JsonString </code> для ленивого извлечения только необработанного значения <code> string </code>, поскольку нас не интересует сам объект.</p><p> Для парсера <code> JsonObject </code> мы практически написали тот же код, что и для <code> JsonArray </code>, заменив квадратные скобки фигурными скобками и <code> JsonEntity </code> на <code> JsonProperty </code>.</p><p> Наконец, завершив работу с каждым отдельным типом сущности, мы можем правильно определить <code> JsonEntity </code>, объединив синтаксические анализаторы, которые мы написали ранее:</p><pre> <code> внутренний статический класс JsonGrammar
{
общедоступный статический только для чтения Parser <JsonEntity> JsonEntity =
JsonObject
.Или <JsonEntity> (JsonArray)
.Or (JsonString)
.Or (JsonNumber)
.Или (JsonBoolean)
.Or (JsonNull);
} </code> </pre><p> И обновите статический метод, который у нас есть в самом классе <code> JsonEntity </code>, чтобы он вызывал соответствующий парсер:</p><pre> <code> публичный абстрактный класс JsonEntity
{
общедоступный статический анализ JsonEntity (строка json) => JsonGrammar.JsonEntity.Parse (json);
} </code> </pre><p> Вот и все, JSON-процессор у нас рабочий! Теперь мы можем вызвать <code> JsonEntity.Parse </code> для любого допустимого текста JSON и преобразовать его в наш домен, то есть в дерево из <code> JsonEntity </code> объектов.</p><h3><span class="ez-toc-section" id="%D0%97%D0%B0%D0%B2%D0%B5%D1%80%D1%88%D0%B5%D0%BD%D0%B8%D0%B5"></span> Завершение <span class="ez-toc-section-end"></span></h3> Разбор<p> не должен быть сложной и недоступной задачей. Функциональное программирование помогает нам моделировать сложную грамматику как композицию более мелких функций, о которых довольно легко рассуждать. И, к счастью, мы можем сделать это и на C #!</p><p> Если вы все еще жаждете знаний и хотите увидеть немного более сложный пример, ознакомьтесь с LtGt, процессором HTML (с селекторами CSS!), Который я изначально написал с использованием Sprache.</p><p> Если вы хотите узнать больше о синтаксическом анализе в целом, я рекомендую прочитать статью Габриэле Томассетти «Анализ в C #».</p><p> Есть также другие библиотеки комбинаторов монадического синтаксического анализатора в .NET, которые вы можете проверить, в первую очередь Superpower, Pidgin, Parsley и FParsec (F #).</p><p> Эта статья в значительной степени основана на моем выступлении с .NET Fest 2019 «Комбинаторы монадического синтаксического анализатора в C #». Здесь вы можете найти исходную презентацию и полный исходный код парсера JSON.</p><h2><span class="ez-toc-section" id="ch07_indd"></span> ch07.indd <span class="ez-toc-section-end"></span></h2><p>% PDF-1.6
%
699 0 объект
/ M (D: 20110125145506-06'00 ') / Имя (ARE Acrobat Product v8.0 P23 0002337) / ByteRange [0 116 9650 2583256] / Ссылка [> / Data 699 0 R / TransformMethod / UR3 / Type / SigRef> >] / Prop_Build> / App> / PubSec >>> / Type / Sig >>>> / Metadata 778 0 R / AcroForm 774 0 R / Pages 689 0 R / Type / Catalog / PageLabels 687 0 R >>
эндобдж
700 0 объект
>
эндобдж
778 0 объект
> поток
PScript5.dll версии 5.2.22011-01-25T14: 55: 06-06: 002011-01-25T08: 23: 13-08: 002011-01-25T14: 55: 06-06: 00application / pdf<li xml:lang="x-default"> ch07.indd</li><li> пользователь</li> Acrobat Distiller 8.1.0 (Windows) uuid: fff082e9-29c8-4cc8-abf3-538c9d05b7efuuid: ed82956f-4e87-4a9c-96a4-46a3710a0004 конечный поток
эндобдж
774 0 объект
> / Кодировка >>> / SigFlags 2 >>
эндобдж
689 0 объект
>
эндобдж
687 0 объект
>
эндобдж
688 0 объект
>
эндобдж
690 0 объект
>
эндобдж
691 0 объект
>
эндобдж
692 0 объект
>
эндобдж
693 0 объект
>
эндобдж
694 0 объект
>
эндобдж
695 0 объект
>
эндобдж
534 0 объект
>
эндобдж
541 0 объект
>
эндобдж
547 0 объект
>
эндобдж
552 0 объект
>
эндобдж
559 0 объект
>
эндобдж
566 0 объект
>
эндобдж
568 0 объект
> поток
h ބ Vn6} ẈTh% E) @C "* tq,> / u1" p̙3_ "A
E2igh9gT] I} ^ D: ($ q | L * I & Vkhq j
(uZ1) NP: g ## b9ZF3Vgw> (3d? T8t? OȨpi $ m
0CxMa3xh¼} W -> - jefr /
2PUN% Q) ILq ܪ ev # b2 {b</p><p> IJ [uƭ # -
ɋ! X8pxMQ3
.XμL9Π9DЮyhWCpcj> T 猈 uH (܇` X72KA.Vş> 4 ~ $ BKilsy ه (gM @ TT8dOe> Ś2Drs ~ vL_m [> {ԝp! B: + w5: WÉz'u \>; iSwTR5 ') T2
S'Otevq W _ :! ԕ5 # U! FjuUVX [jmЧ% 9Dyo06) q`fjZ</p><h2><span class="ez-toc-section" id="CODE_128_%D0%B8_GS1128_%EF%BD%9C_%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B_%D1%88%D1%82%D1%80%D0%B8%D1%85%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%EF%BD%9C_%D0%A1%D0%BF%D1%80%D0%B0%D0%B2%D0%BE%D1%87%D0%BD%D1%8B%D0%B9_%D1%81%D0%B0%D0%B9%D1%82_%D0%BF%D0%BE_%D1%81%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D0%B0%D0%BC_%D1%88%D1%82%D1%80%D0%B8%D1%85%D0%BA%D0%BE%D0%B4%D0%BE%D0%B2_%D0%B8_%D0%BD%D0%BE%D1%83%D1%85%D0%B0%D1%83_%D1%87%D1%82%D0%B5%D0%BD%D0%B8%D1%8F"></span> CODE 128 и GS1-128 | Основы штрих-кодов | Справочный сайт по стандартам штрих-кодов и ноу-хау чтения <span class="ez-toc-section-end"></span></h2><hr/><p> В мире доступно около 100 типов штрих-кодов. Ниже приводится введение в штрих-коды CODE128 и GS1-128.</p><p> Единственное руководство, которое вам нужно, чтобы узнать все о <strong> штрих-кодах </strong>!</p><p> Это руководство предоставляет легкое для понимания объяснение структур и стандартов одномерных кодов, таких как EAN, CODE39 и CODE128.</p><p> Скачать</p><h3><span class="ez-toc-section" id="%D0%9A%D0%9E%D0%94_128"></span> КОД 128 <span class="ez-toc-section-end"></span></h3><p> CODE 128 - штрих-код, разработанный Computer Identics Corporation (США) в 1981 году. <br/> CODE 128 может представлять все 128 символов кода ASCII (числа, прописные / строчные буквы, символы и управляющие коды). Поскольку он может представлять все символы (кроме японских кандзи, хираганы и катаканы), которые могут использоваться на клавиатуре компьютера, это удобный для компьютера штрих-код.</p><h4></h4><i/> КОД 128 Состав</h4><p> Базовый состав следующий:</p><p></p><ul><li> ・ Существует 4 типа размеров стержней.</li><li> ・ Один символ представлен 3 полосами и 3 пробелами (всего шесть элементов).</li><li> ・ Начальный персонаж бывает трех типов; «КОД-А», «КОД-В» и «КОД-С». Тип начального символа определяет символьный состав последующих символов. (См. Таблицу состава символов на странице 41. Например, когда CODE A используется в качестве начального символа, символы в столбце CODE-A могут быть представлены.)</li></ul><p></p><ul><li> ・ При использовании CODE-C двухзначные числа могут быть представлены одним типом штрихового рисунка.Это обеспечивает очень высокую плотность данных.</li><li> ・ Когда используются символы кодового набора (CODE-A, CODE-B и CODE-C), штрих-код, начинающийся с начального символа CODE-A, может быть изменен для использования символов в столбце CODE-B или CODE-C в процессе обработки штрих-кода.</li><li> ・ Когда используется «SHIFT», только один символ рядом с SHIFT может быть изменен на символ в следующем столбце (A на B, B на C, C на A). (Аналогично нажатию клавиши SHIFT на клавиатуре компьютера)</li><li> ・ «Модуль 103» используется как контрольная цифра.</li></ul><p> Скачать</p><hr/><h4></h4><i/> КОД 128 Состав символов</h4><p> Скачать</p><h4></h4><i/> КОД 128 Характеристики</h4><ul><li> ・ Штрих-код CODE 128 может включать все 128 символов кода ASCII (включая управляющие коды, такие как [ESC], [STX], [ETX], [CR] и [LF]).</li><li> ・ Когда CODE-C используется в качестве начального символа, одна полоса может представлять 2-значные числа.Это позволяет очень эффективно составлять штрих-код. Если данные штрих-кода содержат 12 или более цифр, CODE 128 обеспечивает меньший размер, чем ITF.</li><li> ・ Поскольку CODE 128 использует 4 типа размера полосок, требуются принтеры с высоким качеством печати. CODE 128 не подходит для печати на матричных принтерах и струйных принтерах FA, а также для флексографской печати на гофрированном картоне.</li></ul><p> Скачать</p><h4></h4><i/> КОД 128 Приложения</h4><p> Использование CODE-C в качестве стартового кода позволяет CODE 128 предоставлять штрих-код с очень высокой плотностью данных, если обрабатываются только числа.<br/> GS1-128 использует характеристики CODE 128 и в настоящее время используется во многих промышленных приложениях. В GS1-128 штрих-код включает различные данные, такие как дата изготовления продукта, дата открытия, вес, размер, номер партии, место назначения, счет клиента и т. Д. <br/></p><p> CODE 128 используется в следующих отраслях : <br/> ・ Швейная промышленность США <br/> ・ Пищевая промышленность США <br/> ・ Производство лекарств и медицинского оборудования в США <br/> ・ Пищевая промышленность Австралии и Новой Зеландии <br/> ・ Европейская промышленность по производству лекарственных средств и медицинских инструментов</p><p> Скачать</p><hr/><h3><span class="ez-toc-section" id="GS1128"></span> GS1-128 <span class="ez-toc-section-end"></span></h3><h4></h4><i/> Что такое GS1-128?</h4><p> GS1-128 - это штрих-код, который предоставляет различные данные, включая данные о распределении и бизнес-транзакциях, в дополнение к данным, предоставляемым кодом JAN и стандартным кодом распространения (ITF), доступным в настоящее время.</p><p> В штрих-код GS1-128 могут быть включены следующие данные:</p><p> ・ Номер пакета <br/> ・ Количество в упаковке <br/> ・ Масса, вместимость и кубатура <br/> ・ Дата изготовления и годность качества</p><p> ・ Номер лота <br/> ・ Номер локации (пункт назначения) <br/> ・ Код счета клиента <br/> ・ Номер заказа клиента</p><p> Необходимые данные используются для формирования этикетки со штрих-кодом для различных приложений.</p><p> Например, онлайн-покупка / заказ с использованием EDI (система обмена электронными данными между компаниями), управление датой открытия продуктов питания, управление сроком действия лекарств, упрощение работы по проверке поступающих продуктов, сортировка пакетов для каждого пункта назначения и т. Д. .. (Следующая этикетка представляет собой образец от производителя продуктов питания.)</p><p></p><p> Скачать</p><h4></h4><i/> История создания GS1-128</h4> Код JAN<p> и стандартный код распределения (ITF) - это штрих-коды для обозначения самого продукта и его количества, а не для таких данных, как дата производства, номер упаковки, срок действия качества и номер заказа.<br/> Хотя CODE 39 позволяет включать такие данные в штрих-код, обмен такими данными между компаниями не разрешен, поскольку определение и количество цифр данных различаются. <br/> GS1-128 признан всемирным универсальным штрих-кодом для общего использования, при этом элементы и количество цифр данных, а также тип штрих-кода стандартизированы.</p><p> Скачать</p><h4></h4><i/> GS1-128 Состав</h4><p> Базовый состав GS1-128 выглядит следующим образом:</p><ul><li> ・ Код 128 используется в качестве штрих-кода.</li><li> ・ Чтобы разделить требуемые данные, такие как вес и открытые данные, добавляется «идентификатор приложения (AI)», за которым следуют данные. Если представлено несколько данных, все данные должны быть связаны.</li></ul><p></p><ul><li> Хотя идентификаторы приложений заключены в скобки, скобки не включены в данные штрих-кода. Они используются только для презентации.</li></ul><p> В приведенном выше примере после идентификатора приложения "01" назначается 14-значный код для идентификации доставочного контейнера (минимальная единица упаковки для ящиков из гофрированного картона).После идентификатора приложения «15» данные, представляющие достоверность качества (допустимость потребления или валидность лекарственного средства), приведены для отображения 27 августа 1995 года. После последнего идентификатора приложения «30» данные, представляющие количество поставки, приведены для отображения 3 штук. <br/> Идентификаторов приложений около 100, кроме вышеперечисленных. Необходимые данные выбираются и включаются в штрих-коды пользователями.</p><p> GS1-128 не предназначен для представления фиксированных данных, но данные выбираются пользователем.Следовательно, для последовательного использования GS1-128 среди компаний стандарты для системы штрих-кодов с доступными данными должны быть подготовлены соответствующей отраслью и группами вовлеченных компаний.</p><ul><li> ・ Чтобы отличить GS1-128 от CODE 128, необходимо указать [FNC 1] (функция 1) после стартового кода (CODE-A – C).</li><li> ・ Даже если количество цифр для данных, следующих за идентификатором приложения, является переменной длиной, [FNC 1] дается для разделения данных.</li></ul><p></p><ul><li> ・ При добавлении GS1-128 к коду EAN и стандартному коду распределения (ITF) его можно использовать в качестве кода для добавления дополнительных данных.</li></ul><p> GS1-128 предназначен для представления идентификаторов приложений и относящихся к продуктам данных или данных транзакций компаний, использующих КОД 128. <br/> Другими словами, GS1-128 - это стандарт приложений для представления различных данных.CODE 128 является стандартом только для самого штрих-кода. Разница между GS1-128 и CODE 128 заключается в том, представляет ли он приложение или нет. <br/> Поскольку GS1-128 использует состав штрих-кода CODE 128, любой считыватель штрих-кода, который может считывать CODE 128, может использоваться для чтения данных GS1-128.</p><p> Скачать</p><h4></h4><i/> Идентификатор приложения</h4><h5></h5><i/> Идентификатор приложения</h5><p> Существует 100 типов идентификаторов приложений, которые можно классифицировать следующим образом.Некоторые данные, следующие за каждым идентификатором приложения, содержат фиксированное количество цифр (стандартный идентификатор коробки, дата и единица измерения), а другие - неопределенное количество цифр (номер партии, серийный номер, количество в упаковке, количество и номер заказа. ).</p><table><tr><th> Классификация</th><th> Контент</th><th> Идентификатор приложения</th></tr><tr><th> Стиль упаковки</th><td> ・ Номера картонных коробок указаны на коробке из гофрированного картона, в которой находятся смешанные продукты.<br/> ・ Номера картонных коробок указаны на всех ящиках из гофрированного картона, штабелированных на поддонах. <br/> ・ Для использования ASN (Advanced Shipment Notice) с указанием на этикетке SCM (см. Стр. 51)</td><td> 00 "ID стандартной коробки"</td></tr><tr><th rowspan="5"> Управление продуктами</th><td> ・ Коробка из гофрированного картона соответствует требованиям к доставке, и на ней нет стандартного символа распределения ITF.</td><td> 01 «Код контейнера доставки»</td></tr><tr><td> • Восстановленные и модифицированные продукты</td><td> 20</td></tr><tr><td> • Указаны даты изделий (дата изготовления, дата упаковки и гарантийный срок).</td><td> 11 ~ 17</td></tr><tr><td> • Номер лота</td><td> 10</td></tr><tr><td> • Серийный номер продукта</td><td> 21</td></tr><tr><th> Измерение <br/> индикация</th><td> • Указаны вес, кубатура и объем.
на коробке из гофрированного картона, содержащей
мерные продукты (продукты и свежая рыба).</td><td> 310 ~ 369</td></tr><tr><th rowspan="4"> Администрация</th><td> • Номер заказа клиента</td><td> 400</td></tr><tr><td> • Номер товарной партии</td><td> 401</td></tr><tr><td> • Номер местонахождения (компании, офисы и
мест)</td><td> 410 ~ 421</td></tr><tr><td> • Внутреннее использование и любые данные, установленные компаниями</td><td> 90 ~ 99</td></tr></table><h5></h5><i/> Типовые идентификаторы приложений</h5><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Количество цифр в данных</th></tr><tr><th> 00</th><td> Стандартная упаковка ID</td><td> 18 цифр</td></tr></table><p> «00» - это идентификатор, который дает порядковый номер упаковки каждой коробке из гофрированного картона и поддону для доставки.Поэтому для каждой доставки дается свой номер. <br/> Данные состоят из 18 цифр следующего состава:</p><table><tr><td> Тип корпуса</td><td> 1 цифра</td></tr><tr><td> Универсальный код компании</td><td> 7 цифр</td></tr><tr><td> Серийный номер упаковки для каждой поставки</td><td> 9 цифр</td></tr><tr><td> Контрольная цифра (модуль упругости 10/3 веса)</td><td> 1 цифра</td></tr></table><p> «Тип упаковки» выглядит следующим образом:</p><table><tr><th colspan="2"> Тип корпуса</th></tr><tr><th> 0</th><td> Ящик или картон</td></tr><tr><th> 1</th><td> Поддон (больше ящика и коробки)</td></tr><tr><th> 2</th><td> Контейнер (больше поддона)</td></tr><tr><th> 3</th><td> Любой тип упаковки, кроме вышеуказанного</td></tr><tr><th> 4</th><td> По внутренним требованиям (для внутреннего пользования)</td></tr><tr><th> 5</th><td> По взаимным требованиям заинтересованных компаний</td></tr><tr><th> 6 ~ 9</th><td> Использование запрещено</td></tr></table><p></p><p> «Универсальная балансовая единица» обозначается как «код страны» + «код производителя» для компаний, которые
зарегистрировано ЯНВАРЬ.Для компаний, которые не регистрировали JAN, необходимо получить универсальный бизнес
код счета.</p><p> «Стандартный идентификатор коробки» в Европе и Америке называется SSCC-18 (серийный код транспортной тары).</p><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Количество цифр в данных</th></tr><tr><th> 01</th><td> Код контейнера доставки</td><td> 14 цифр</td></tr></table><p> Такой же состав стандартного кода распределения (ITF) обычно применяется к "01".Он состоит из кода EAN упакованного продукта и индикатора упаковки, который указывает количество продукта.</p><table><tr><td> Индикатор упаковки</td><td> 1 цифра</td></tr><tr><td> Код EAN</td><td> 12 цифр</td></tr><tr><td> Контрольная цифра (модуль упругости 10/3 веса)</td><td> 1 цифра</td></tr></table><p> «Показатель упаковки» выглядит следующим образом:</p><table><tr><th colspan="2"> Индикатор упаковки</th></tr><tr><th> 0</th><td> Ящики из гофрированного картона, содержащие смешанные продукты</td></tr><tr><th> 1 ~ 8</th><td> Ящик из гофрированного картона для штучных изделий в таком же количестве.Диапазон настройки от 1 до 8. Во многих случаях устанавливается 1.</td></tr><tr><th> 9</th><td> Коробка из гофрокартона, в которой разное количество для одной единицы</td></tr></table><p> Поскольку «код доставки контейнера» имеет тот же состав данных, что и код EAN и стандартный код распространения, его можно использовать только при условии, что коды EAN и стандартные коды распространения не напечатаны на ящиках из гофрированного картона.</p><p> «Код доставки контейнера» в Европе и Америке называется SCC-14 (Код транспортировочного контейнера).</p><p></p><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Формат</th></tr><tr><th> 10</th><td> Номер партии или номер партии</td><td> До 20 буквенно-цифровых символов</td></tr></table><p> «10» - это идентификатор приложения, обозначающий номер партии и номер партии продукта.Доступно 20 буквенно-цифровых символов (переменной длины) или меньше.</p><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Формат</th></tr><tr><th> 11</th><td> Дата изготовления (ГГММДД)</td><td> 6-значный номер</td></tr><tr><th> 13</th><td> Дата упаковки (ГГММДД)</td><td> 6-значный номер</td></tr><tr><th> 15</th><td> Срок действия качества (ГГММДД)</td><td> 6-значный номер</td></tr><tr><th> 17</th><td> Срок действия на продажу (ГГММДД)</td><td> 6-значный номер</td></tr></table><p> Указаны данные за разные даты.<br/> Для достоверности качества указаны важные данные, необходимые для управления. Например, «открытая дата» продуктов и «годность лекарств».</p><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Формат</th></tr><tr><th> 400</th><td> Административный номер (номер заказа клиента)</td><td> До 30 буквенно-цифровых символов</td></tr><tr><th> 411</th><td> Номер местонахождения (код счета клиента)</td><td> 13-значный номер</td></tr></table><p> Это идентификаторы приложений для указания административных данных, таких как «номер заказа» клиентов и «код счета клиента».</p><table><tr><th> Идентификатор приложения</th><th> Контент</th><th> Формат</th></tr><tr><th> 410</th><td> Номер местоположения (код направления)</td><td> 13-значный номер</td></tr><tr><th> 420</th><td> Номер местонахождения (почтовый индекс пункта назначения)</td><td> В пределах 9 буквенно-цифровых символов</td></tr></table><p> Используются для сортировки товаров по направлениям.</div><footer class="entry-footer"><div id="author_box" class="row no-gutters"><div class="author_avatar col-2"> <img alt='' src="//xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif" data-lazy-type="image" data-src='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=96&d=mm&r=g' srcset="" data-srcset='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=192&d=mm&r=g 2x' class='lazy lazy-hidden avatar avatar-96 photo' height='96' width='96' decoding='async'/><noscript><img alt='' src='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=96&d=mm&r=g' srcset='https://secure.gravatar.com/avatar/b142b184aa8663e4da31fb1a71be88cc?s=192&d=mm&r=g 2x' class='avatar avatar-96 photo' height='96' width='96' decoding='async'/></noscript></div><div class="author_info col-10"><h4 class="author_name title-font"> admin</h4><div class="author_bio"></div></div></div></footer></article><nav class="navigation post-navigation" aria-label="Записи"><h2 class="screen-reader-text">Навигация по записям</h2><div class="nav-links"><div class="nav-previous"><a href="https://xn--7-dtbea5camjj.xn--p1ai/raznoe/temno-sinij-czvet-komu-idet-temno-sinij-czvet-v-odezhde-sochetanie-i-foto-2021.html" rel="prev"><span class="nav-title title-font">Темно синий цвет кому идет: ТЕМНО-СИНИЙ цвет в одежде — сочетание и фото, 2021</span></a></div><div class="nav-next"><a href="https://xn--7-dtbea5camjj.xn--p1ai/raznoe/prostye-detskie-fokusy-fokusy-dlya-detej-v-domashnih-usloviyah.html" rel="next"><span class="nav-title title-font">Простые детские фокусы: Фокусы для детей в домашних условиях</span></a></div></div></nav><div id="comments" class="comments-area"><div id="respond" class="comment-respond"><h3 id="reply-title" class="comment-reply-title">Добавить комментарий <small><a rel="nofollow" id="cancel-comment-reply-link" href="/raznoe/podbirayut-razbor-slova-po-sostavu-stranicza-ne-najdena.html#respond" style="display:none;">Отменить ответ</a></small></h3><form action="https://xn--7-dtbea5camjj.xn--p1ai/wp-comments-post.php" method="post" id="commentform" class="comment-form" novalidate><p class="comment-notes"><span id="email-notes">Ваш адрес email не будет опубликован.</span> <span class="required-field-message">Обязательные поля помечены <span class="required">*</span></span></p><p class="comment-form-comment"><label for="comment">Комментарий <span class="required">*</span></label><textarea id="comment" name="comment" cols="45" rows="8" maxlength="65525" required></textarea></p><p class="comment-form-author"><label for="author">Имя <span class="required">*</span></label> <input id="author" name="author" type="text" value="" size="30" maxlength="245" autocomplete="name" required /></p><p class="comment-form-email"><label for="email">Email <span class="required">*</span></label> <input id="email" name="email" type="email" value="" size="30" maxlength="100" aria-describedby="email-notes" autocomplete="email" required /></p><p class="comment-form-url"><label for="url">Сайт</label> <input id="url" name="url" type="url" value="" size="30" maxlength="200" autocomplete="url" /></p><p class="form-submit"><input name="submit" type="submit" id="submit" class="submit" value="Отправить комментарий" /> <input type='hidden' name='comment_post_ID' value='22801' id='comment_post_ID' /> <input type='hidden' name='comment_parent' id='comment_parent' value='0' /></p></form></div></div></main><aside id="secondary" class="widget-area order-2"><section id="categories-47" class="widget widget_categories"><h3 class="widget-title title-font"><span>Рубрики</span></h3><ul><li class="cat-item cat-item-10"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/vospityvat">Воспитывать</a></li><li class="cat-item cat-item-11"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/deti">Дети</a></li><li class="cat-item cat-item-13"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/podrostok">Подросток</a></li><li class="cat-item cat-item-9"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/pravilno">Правильно</a></li><li class="cat-item cat-item-8"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/raznoe">Разное</a></li><li class="cat-item cat-item-12"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/rekomendaczii">Рекомендации</a></li><li class="cat-item cat-item-1"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/sovety">Советы</a></li></ul></section></aside></div></div><div id="footer-sidebar" class="widget-area"><div class="container"><div class="row"></div></div></div><footer id="colophon" class="site-footer"><div class="site-info"> 2025 © Все права защищены.</div></footer></div><nav id="menu" class="panel" role="navigation"> <button class="go-to-bottom"></button> <button id="close-menu" class="menu-link"><i class="fa fa-times"></i></button><ul id="mobile-menu" class="menu"><li id="menu-item-26342" class="menu-item menu-item-type-taxonomy menu-item-object-category current-post-ancestor current-menu-parent current-post-parent mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/raznoe"></i>Семейные советы</a></li><li id="menu-item-26343" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/pravilno"></i>Как правильно ?</a></li><li id="menu-item-26344" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/deti"></i>Дети</a></li><li id="menu-item-26345" class="menu-item menu-item-type-taxonomy menu-item-object-category mdl-list__item"><a href="https://xn--7-dtbea5camjj.xn--p1ai/category/vospityvat"></i>Воспитание</a></li></ul> <button class="go-to-top"></button></nav> <noscript><style>.lazyload{display:none}</style></noscript><script data-noptimize="1">window.lazySizesConfig=window.lazySizesConfig||{};window.lazySizesConfig.loadMode=1;</script><script async data-noptimize="1" src='https://xn--7-dtbea5camjj.xn--p1ai/wp-content/plugins/autoptimize/classes/external/js/lazysizes.min.js'></script> <!-- noptimize -->
<style>iframe,object{width:100%;height:480px}img{max-width:100%}</style><script>new Image().src="//counter.yadro.ru/hit?r"+escape(document.referrer)+((typeof(screen)=="undefined")?"":";s"+screen.width+"*"+screen.height+"*"+(screen.colorDepth?screen.colorDepth:screen.pixelDepth))+";u"+escape(document.URL)+";h"+escape(document.title.substring(0,150))+";"+Math.random();</script>
<!-- /noptimize --> <script defer src="https://xn--7-dtbea5camjj.xn--p1ai/wp-content/cache/autoptimize/js/autoptimize_1ef490c9359ea65f37b76aed46105dbe.js"></script></body></html><script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="da9f11daf2c53264ae418923-|49" defer></script>