Разбор слова по составу — Орфография. Морфемика. Словообразование
Разберите слова по составу.
1. Ночник, выпечка, плечистый, плясун, пчелиный, робкий, садовый, свисток, больной, силач, синева, ходули, подсказка, скворушка, снежинка, хитрый, травинка, тропинка, сосновый, соринка, столовая, теплица, тростник, похвала, храбрец, хлопушка,
чернота, часовой, читка, боковой, бодрый, верхушка, веснушки, ветвистый, вечерок, винтовой, водяной, подводный, глотка, детки, заварка, загадка.
2. Золотистый, пляска, зеркальный, тростинка, травяной, желтоватый, глазёнки, медовик, восход, бессмыслица, наплечник, побег, надводный, зарубежный, безвкусица, подосиновик, подберёзовик, пододеяльник, прожилка, бестолковый, газетчик, барабанщик, извозчик, матушка, крикунья, звёздочка, дворовый, градусник, вестник, кудрявый, испарение, малинник, изюминка, шипучий, чистка.
3. Добренький, крепкий, стрелок, вольница, комариный, защитник, плясун, выдумщик, колючий, подлечить, изрезать, грузчик, парочка, заползти, свистнуть, предсказал, просидишь, протекает, задачник, счастливый, мускулистый, работник, помощница, журавлиный, ванночка, стаканчик, плачевный, дальняя, прихлопывают, братец, скрипач, синяк, контролёр, мордашка, холодец, времечко, услужливая, расспросил, извиняется, повизгиваешь, лежачий, прибежище.
4. Берёзовый, усидчивый, скользить, желтизна, задвижка, блёкнуть, братишка, рассыпчатый, запугать, задумчивый, пожарище, кожица, задвижка, впадина, решётчатый, горчинка, продуктовый, преградить, бродячий, наигрывает, добудиться, абрикосовый, трескучий, свинцовый, сучок, медвежонок, запугать, соринка, черепитчатый, пскович, морщинка, взлетает, раненый, боксёр, темечко, капитанский, распутица, расстилаться, предполагать.
Ответ:
1. Ночник (ноч — корень, ник — суффикс, нулевое окончание, ночник — основа слова), выпечка (вы — приставка, печ — корень, к — суффикс, а — окончание, выпечк — основа слова), плечистый (плеч — корень, ист — суффикс, ый — окончание, плечист — основа слова), плясун (пляс — корень, ун — суффикс, нулевое окончание, плясун — основа слова), пчелиный (пчел — корень, ин — суффикс, ый — окончание, пчелин — основа слова), робкий (робк — корень, ий — окончание, робк — основа слова), садовый (сад — корень, ов — суффикс, ый — окончание, садов — основа слова), свисток (свист — корень, ок — суффикс, нулевое окончание, свисток — основа слова), больной (боль — корень, н — суффикс, ой — окончание, больн — основа слова), силач (сил — корень, ач — суффикс, нулевое окончание, силач — основа слова), синева (син — корень, ев — суффикс, а — окончание, синев — основа слова), ходули (ход — корень, ул — суффикс, и — окончание, ходул — основа слова), подсказка (под — приставка, сказ — корень, к — суффикс, а — окончание, подсказк — основа слова), скворушка (сквор — корень, ушк — суффикс, а — окончание, скворушк — основа слова), снежинка (снеж — корень, ин, к — суффиксы, а — окончание, снежинк — основа слова), хитрый (хитр — корень, ый — окончание, хитр — основа слова), травинка (трав — корень, ин, к — суффиксы, а — окончание, травинк — основа слова), тропинка (троп — корень, инк — суффикс, а — окончание, тропинк — основа слова), сосновый (сосн — корень, ов — суффикс, ый — окончание, соснов — основа слова), соринка (сор — корень, инк — суффикс, а — окончание, соринк — основа слова), столовая (стол — корень, ов — суффикс, ая — окончание, столов — основа слова), теплица (тепл — корень, иц — суффикс, а — окончание, теплиц — основа слова), тростник (тростник — корень, нулевое окончание, тростник — основа слова), похвала (по — приставка, хвал — корень, а — окончание, похвал — основа слова), храбрец (храбр — корень, ец — суффикс, нулевое окончание, храбрец — основа слова), хлопушка (хлоп — корень, ушк — суффикс, а — окончание, хлопушк — основа слова), чернота (черн — корень, от — суффикс, а — окончание, чернот — основа слова), часовой (час — корень, ов — суффикс, ой — окончание, часов — основа слова), читка (чит — корень, к — суффикс, а — окончание, читк — основа слова), боковой (бок — корень, ов — суффикс, ой — окончание, боков — основа слова), бодрый (бодр — корень, ый — окончание, бодр — основа слова), верхушка (верх — корень, ушк — суффикс, а — окончание, верхушк — основа слова), веснушки (весн — корень, ушк — суффикс, и — окончание, веснушк — основа слова), ветвистый (ветв — корень, ист — суффикс, ый — окончание, вестивст — основа слова), вечерок (вечер — корень, ок — суффикс, нулевое окончание, вечерок — основа слова), винтовой (винт — корень, ов — суффикс, ой — окончание, винтов — основа слова), водяной (вод — корень, ян — суффикс, ой — окончание, водян — основа слова), подводный (под — приставка, вод — корень, н — суффикс, ый — окончание, подводн — основа слова), глотка (глот — корень, к — суффикс, а — окончание, глотк — основа слова), детки (дет — корень, к — суффикс, и — окончание, детк — основа слова), заварка (за — приставка, вар — корень, к — суффикс, а — окончание, заварк — основа слова), загадка (за — приставка, гад — корень, к — суффикс, а — окончание, загадк — основа слова).
2. Золотистый (золот — корень, ист — суффикс, ый — окончание, золотист — основа слова), пляска (пляс — корень, к — суффикс, а — окончание, пляск — основа слова), зеркальный (зеркаль — корень, н — суффикс, ый — окончание, зеркальн — основа слова), тростинка (трост — корень, ин, к — суффиксы, а — окончание, тростинк — основа слова), травяной (трав — корень, ян — суффикс, ой — окончание, травян — основа слова), желтоватый (желт — корень, оват — суффикс, ый — окончание, желтоват — основа слова), глазёнки (глаз — корень, ёнк — суффикс, и — окончание, глазёнк — основа слова), медовик (мед — корень, ов, ик — суффикс, нулевое окончание, медовик — основа слова), восход (вос — приставка, ход — корень, нулевое окончание, восход — основа слова), бессмыслица (бес, с — приставки, мысл — корень, иц — суффикс, а — окончание, бессмыслиц — основа слова), наплечник (на — приставка, плеч — корень, ник — суффикс, нулевое окончание, наплечник — основа слова), побег (по — приставка, бег — корень, нулевое окончание, побег — основа слова), надводный (над — приставка, вод — корень, н — суффикс, ый — окончание, надводн — основа слова), зарубежный (за — приставка, рубеж — корень, н — суффикс, ый — окончание, зарубежн — основа слова), безвкусица (без — приставка, вкус — корень, иц — суффикс, а — окончание, безвкусиц — основа слова), подосиновик (под — приставка, осин — корень, ов, ик — суффиксы, нулевое окончание, подосиновик — основа слова), подберёзовик (под — приставка, берёз — корень, ов, ик — суффиксы, нулевое окончание, подберёзовик — основа слова), пододеяльник (под — приставка, одеяль — корень, ник — суффикс, нулевое окончание, пододеяльник — основа слова), прожилка (про — приставка, жил — корень, к — суффикс, а — окончание, прожилк — основа слова), бестолковый (бес — приставка, толк — корень, ов — суффикс, ый — окончание, бестолков — основа слова), газетчик (газет — корень, чик — суффикс, нулевое окончание, газетчик — основа слова), барабанщик (барабан — корень, щик — суффикс, нулевое окончание, барабанщик — основа слова), извозчик (из — приставка, воз — корень, чик — суффикс, нулевое окончание, извозчик — основа слова), матушка (мат — корень, ушк — суффикс, а — окончание, матушк — основа слова), крикунья (крик — корень, унь — суффикс, я — окончание, крикунь — основа слова), звёздочка (звёзд — корень, очк — суффикс, а — окончание, звёздочк — основа слова), дворовый (двор — корень, ов — суффикс, ый — окончание, дворов — основа слова), градусник (градус — корень, ник — суффикс, нулевое окончание, градусник — основа слова), вестник (вест — корень, ник — суффикс, нулевое окончание, вестник — основа слова), кудрявый (кудр — корень, яв — суффикс, ый — окончание, кудряв — основа слова), испарение (ис — приставка, пар — корень, ени — суффикс, е — окончание, испарени — основа слова), малинник (малин — корень, ник — суффикс, нулевое окончание, малинник — основа слова), изюминка (изюм — корень, инк — суффикс, а — окончание, изюминк — основа слова), шипучий (шип — корень, уч — суффикс, ий — окончание, шипуч — основа слова), чистка (чист — корень, к — суффикс, а — окончание, чистк — основа слова).
3. Добренький (добр — корень, еньк — суффикс, ий — окончание, добреньк — основа слова), крепкий (крепк — корень, ий — окончание, крепк — основа слова), стрелок (стрел — корень, ок — суффикс, нулевое окончание, стрелок — основа слова), вольница (воль — корень, н, иц — суффиксы, а — окончание, вольниц — основа слова), комариный (комар — корень, ин — суффикс, ый — окончание, комарин — основа слова), защитник (защит — корень, ник — суффикс, нулевое окончание, защитник — основа слова), плясун (пляс — корень, ун — суффикс, нулевое окончание, плясун — основа слова), выдумщик (вы — приставка, дум — корень, щик — суффикс, нулевое окончание, выдумщик — основа слова), колючий (кол — корень, юч — суффикс, ий — окончание, колюч — основа слова), подлечить (под — приставка, леч — корень, и, ть — суффиксы, нет окончания, подлечи — основа слова), изрезать (из — приставка, рез — корень, а, ть — суффиксы, нет окончания, изреза — основа слова), грузчик (груз — корень, чик — суффикс, нулевое окончание, грузчик — основа слова), парочка (пар — корень, очк — суффикс, а — окончание, парочк — основа слова), заползти (за — приставка, полз — корень, ти — суффикс, нет окончания, заполз — основа слова), свистнуть (свист — корень, ну, ть — суффиксы, нет окончания, свистну — основа слова), предсказал (пред — приставка, сказ — корень, а, л — суффиксы, нулевое окончание, предсказа — основа слова), просидишь (про — приставка, сид — корень, ишь — окончание, просид — основа слова), протекает (про — приставка, тек — корень, а — суффикс, ет — окончание, протека — основа слова), задачник (за — приставка, да — корень, ч, ник — суффиксы, нулевое окончание, задачник — основа слова), счастливый (счаст — корень, лив — суффикс, ый — окончание, счастлив основа слова), мускулистый (мускул — корень, ист — суффикс, ый — окончание, мускулист — основа слова), работник (работ — корень, ник — суффикс, нулевое окончание, работник — основа слова), помощница (по — приставка, мощ — корень, ниц — суффикс, а — окончание, помощниц — основа слова), журавлиный (журавл — корень, ин — суффикс, ый — окончание, журавлин — основа слова), ванночка (ванн — корень, очк — суффикс, а — окончание, ванночк — основа слова), стаканчик (стакан — корень, чик — суффикс, нулевое окончание, стаканчик — основа слова), плачевный (плач — корень, ев, н — суффиксы, ый — окончание, плачевн — основа слова), дальняя (даль — корень, н — суффикс, яя — окончание, дальн — основа слова), прихлопывают (при — приставка, хлоп — корень, ыва — суффикс, ют — окончание, прихлопыва — основа слова), братец (брат — корень, ец — суффикс, нулевое окончание, братец — основа слова), скрипач (скрип — корень, ач — суффикс, нулевое окончание, скрипач — основа слова), синяк (син — корень, як — суффикс, нулевое окончание, синяк — основа слова), контролёр (контрол — корень, ёр — суффикс, нулевое окончание, контролёр — основа слова), мордашка (морд — корень, ашк — суффикс, а — окончание, мордашк — основа слова), холодец (холод — корень, ец — суффикс, нулевое окончание, холодец — основа слова), времечко (врем — корень, ечк — суффикс, о — окончание, времечк — основа слова), услужливая (у — приставка, служ — корень, лив — суффикс, ая — окончание, услужлив — основа слова), расспросил (рас — приставка, спрос — корень, и — суффикс, л — постфикс, расспроси — основа слова), извиняется (из — приставка, вин — корень, я — суффикс, ет — окончание, ся — постфикс, извиня — основа слова), повизгиваешь (по — приставка, визг — корень, ива — суффикс, ешь — окончание, повизгива — основа слова), лежачий (леж — корень, ач, ий — суффиксы, нулевое окончание, лежачий — основа слова), прибежище (при — приставка, беж — корень, ищ — суффикс, е — окончание, прибежищ — основа слова).
4. Берёзовый (берёз — корень, ов — суффикс, ый — окончание, берёзов — основа слова), усидчивый (у — приставка, сид — корень, чив — суффикс, ый — окончание, усидчив — основа слова), скользить (скольз — корень, и, ть — суффиксы, нет окончания, скользи — основа слова), желтизна (желт — корень, изн — суффикс, а — окончание, желтизн — основа слова), задвижка (за — приставка, движ — корень, к — суффикс, а — окончание, задвижк — основа слова), блёкнуть (блёк — корень, ну, ть — суффиксы, нет окончания, блёкну — основа слова), братишка (брат — корень, ишк — суффикс, а — окончание, братишк — основа слова), рассыпчатый (рас — приставка, сып — корень, чат — суффикс, ый — окончание, рассыпчат — основа слова), запугать (за — приставка, пуг — корень, а, ть — суффиксы, нет окончания, запуга — основа слова), задумчивый (за — приставка, дум — корень, чив — суффикс, ый — окончание, задумчив — основа слова), пожарище (пожар — корень, ищ — суффикс, е — окончание, пожарищ — основа слова), кожица (кож — корень, иц — суффикс, а — окончание, кожиц — основа слова), задвижка (за — приставка, движ — корень, к — суффикс, а — окончание, задвижк — основа слова), впадина (в — приставка, пад — корень, ин — суффикс, а — окончание, впадин — основа слова), решётчатый (решётч — корень, ат — суффикс, ый — окончание, решётчат — основа слова), горчинка (горч — корень, инк — суффикс, а — окончание, горчинк — основа слова), продуктовый (продукт — корень, ов — суффикс, ый — окончание, продуктов — основа слова), преградить (преград — корень, и, ть — суффиксы, нет окончания, прегради — основа слова), бродячий (брод — корень, яч — суффикс, ий — окончание, бродяч — основа слова), наигрывает (на — приставка, игр — корень, ыва — суффикс, ет — окончание, наигрыва — основа слова), добудиться (до — приставка, буд — корень, и, ть, ся — суффиксы, нет окончания, добуди + ся — основа слова), абрикосовый (абрикос — корень, ов — суффикс, ый — окончание, абрикосов — основа слова), трескучий (треск — корень, уч — суффикс, ий — окончание, трескуч — основа слова), свинцовый (свинц — корень, ов — суффикс, ый — окончание, свинцов — основа слова), сучок (суч — корень, ок — суффикс, нулевое окончание, сучок — основа слова), медвежонок (медвеж — корень, онок — суффикс, нулевое окончание, медвежонок — основа слова), запугать (за — приставка, пуг — корень, а, ть — суффиксы, нет окончания, запуга — основа слова), соринка (сор — корень, инк — суффикс, а — окончание, соринк — основа слова), черепитчатый (черепит — корень, чат — суффикс, ый — окончание, черепитчат — основа слова), пскович (псков — корень, ич — суффикс, нулевое окончание, пскович — основа слова), морщинка (морщ — корень, ин, к — суффиксы, а — окончание, морщинк — основа слова), взлетает (вз — приставка, лет — корень, а — суффик, ет — окончание, взлета — основа слова), раненый (ран — корень, ен — суффикс, ый — окончание, ранен — основа слова), боксёр (бокс — корень, ёр — суффикс, нулевое окончание, боксёр — основа слова), темечко (тем — корень, ечк — суффикс, о — окончание, темечк — основа слова), капитанский (капитан — корень, ск — суффикс, ий — окончание, капитанск — основа слова), распутица (рас — приставка, пут — корень, иц — суффикс, а — окончание, распутниц — основа слова), расстилаться (рас — приставка, стил — корень, а — суффикс, ть — окончание, ся — постфикс, расстила + ся — основа слова), предполагать (предполаг — корень, а, ть — суффиксы, ть — окончание, предполага — основа слова).
CSE230 Wi13 — монадический анализ
CSE230 Wi13 — монадический анализГлавная оценка Лекции Задания Ссылки Пьяцца
> импорт Data.Char
> импорт Data.Functor
> импорт Control.Monad
Прежде чем мы продолжим, слово от наших спонсоров:
**Не бойтесь монад**
Это просто (чрезвычайно универсальная) абстракция, например map или fold .
Синтаксический анализатор — это часть программного обеспечения, которая принимает необработанные Строка (или последовательность байтов) и возвращает некоторый структурированный объект, например, список опций, XML-дерево или объект JSON, Абстрактное синтаксическое дерево программы и так далее. Синтаксический анализ является одной из самых основных вычислительных задач. Каждая серьезная программная система имеет парсер, спрятанный где-то внутри, например
- Сценарии оболочки (параметры командной строки)
- Веб-браузеры (да!)
- Игры (дескрипторы уровней)
- Маршрутизаторы (пакеты)
- и т.
 д.
д.
 д.
д.(Действительно, я бросаю вам вызов, чтобы найти какую-либо серьезную систему, которая не где-то занимается синтаксическим анализом!)
Самый простой и точный способ представить синтаксический анализатор как функцию
тип Parser = String -> StructuredObject
Составление парсеров
Обычный способ создания синтаксического анализатора заключается в указании грамматики и использовании генератора синтаксического анализа (например, yacc, bison, antlr) для создания фактической функции синтаксического анализа. Несмотря на элегантность, одним из основных ограничений подхода, основанного на грамматике, является отсутствие модульности. Например, предположим, что у меня есть два вида примитивных значений Thingy и Whatsit .
Thingy : правило { действие }
; Whatsit: правило {действие}
;
Если вам нужен синтаксический анализатор для последовательностей Thingy и Whatsit , мы должны тщательно продублировать правила как
Thingies : Thingy Thingies { . .. }
EmptyThingy { ... }
; Whatsits: Whatsit Whatsits {...}
EmptyWhatsit {...}
;
 .. }
.. } Это затрудняет повторное использование подпарсеров. Далее мы увидим, как составить мини-парсера для подзначений, чтобы получить большие парсеры для сложных значений.
Для этого мы немного обобщим приведенный выше тип синтаксического анализатора, отметив, что (суб-)парсеру не нужно (действительно, не будет) потреблять все его входных данных, и поэтому мы можем просто иметь синтаксический анализатор вернуть неиспользованный ввод
тип Parser = String -> (StructuredObject, String)
Конечно, было бы глупо иметь разные типы парсеров для разных типов объектов, поэтому мы можем сделать его параметризованным типом
тип Parser a = String -> (a, String)
Последнее обобщение: синтаксический анализатор может возвращать несколько результатов, например, мы можем захотеть проанализировать строку
."2 - 3 - 4"
либо как
Минус (Минус 2 3) 4
или как
Минус 2 (Минус 3 4)
Таким образом, мы можем заставить наши синтаксические анализаторы возвращать список возможных результатов (где пустой список соответствует сбою синтаксического анализа.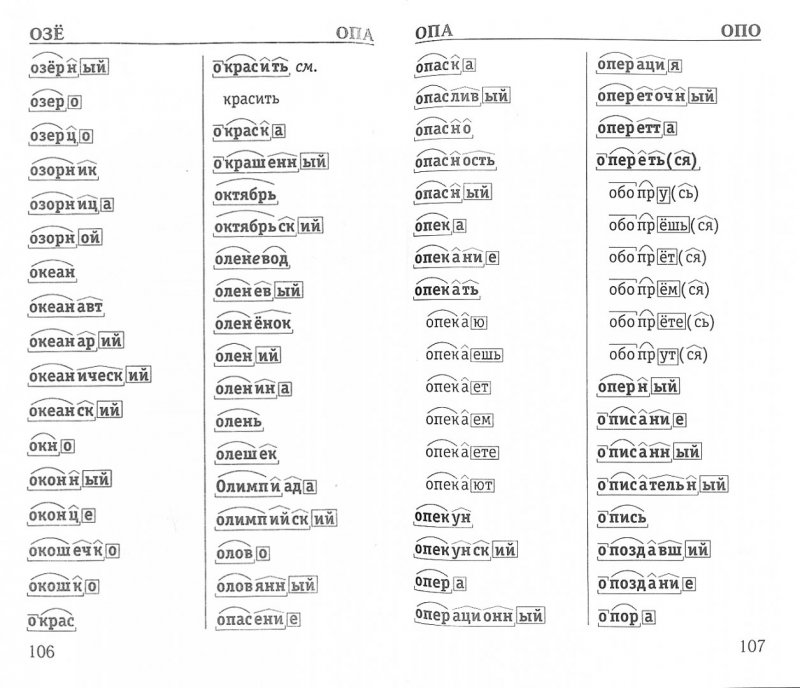 )
)
> Парсер нового типа a = P (String -> [(a, String)])
Вышеупомянутое просто синтаксический анализатор ( кашель действие) фактический синтаксический анализ выполняется
> doParse (P p) s = p s
Давайте создадим несколько парсеров!
Вот очень простой анализатор символов, который возвращает первый Char из списка, если он существует
> oneChar :: Parser Char
> oneChar = P (\cs -> case cs of
> c:cs' -> [(c, cs')]
> _ -> [])
> twoChar0 = P (\cs -> случай cs из
> c1:c2:cs' -> [((c1,c2), cs')]
> _ -> [])
Запускаем анализатор
ghci> doParse oneChar "эй!"
[('ч',"эй!")]ghci> doParse oneChar ""
[]
Парсер Состав
Мы можем написать комбинатор, который принимает два парсера и возвращает новый парсер, который возвращает пару значений
парыP :: Анализатор a -> Анализатор b -> Анализатор (a,b)
пара P p1 p2 = P (\cs ->
[((x,y), cs'') | (x, cs' ) <- doParse p1 cs,
(y, cs'') <- doParse p2 cs ']
)
Теперь мы можем написать еще один анализатор, который получает пару значений Char
twoChar :: Parser (Char, Char)
twoChar = P (\cs -> case cs of
c1:c2:cs' -> [((c1, c2), cs')]
_ -> [])
или более элегантно, как
> twoChar = параP oneChar oneChar
, который будет работать так
ghci> doParse twoChar "эй!"
[(('h','e'), "y!")]ghci> doParse twoChar ""
[]
Теперь мы могли бы продолжать это делать, но часто, чтобы двигаться вперед, полезно сделать шаг назад и взглянуть на более широкую картину.
Вот тип парсера
Парсер нового типа a = P (String -> [(a, String)])
это должно напоминать тебе о чем-то другом, помнишь это?
тип ST a = состояние -> (a, состояние)
Действительно, синтаксический анализатор, как и преобразователь состояний, является монадой! если правильно прищуриться. Нам нужно определить функции return и >>= .
Первый очень простой, мы можем позволить типам вести нас
:тип returnP
returnP :: a -> Parser a
, что означает, что мы должны игнорировать входную строку и просто вернуть элемент ввода
.> returnP x = P (\cs -> [(x, cs)])
Привязка немного сложнее, но опять же, давайте опираться на типы
:type bindP
bindP :: Анализатор a -> (a -> Анализатор b) -> Анализатор b
, поэтому нам нужно высосать значения и из первого синтаксического анализатора и вызвать второй синтаксический анализатор с ними для оставшейся части строки.
> p1 `bindP` fp2 = P (\cs ->
> [(y, cs'') | (x, cs') <- doParse p1 cs
> , (y, cs'') <- doParse ( fp2 x) cs'])
Вооружившись ими, мы можем официально называть парсеры монадами
> экземпляр Monad Parser, где
> (>>=) = bindP
> return = returnP
Поскольку синтаксические анализаторы являются монадами, мы можем написать кучу высокоуровневых комбинаторов для объединения меньших синтаксических анализаторов в более крупные.
Например, мы можем использовать нашу любимую нотацию do , чтобы переписать пару P как
> параP px py = do x <- px
> y <- py
> возврат (x, y)
шокирующе, точь-в-точь как пар функционируют отсюда.
Теперь давайте разомнем наши монадические мускулы и напишем несколько новых парсеров. Будет полезно иметь синтаксический анализатор сбой , который всегда сгорает, то есть возвращает [] — нет успешных синтаксических анализов.
> сбойP = P $ const []
Кажется немного глупым писать вышеизложенное, но полезно создать более богатые синтаксические анализаторы, подобные следующему, который анализирует Char , если удовлетворяет предикату р
> satP :: (Char -> Bool) -> Parser Char
> satP p = do
> c <- oneChar
> если pc, то вернуть c, иначе failP
мы можем написать несколько простых парсеров для определенных символов
> нижний регистрP = satP isAsciiLower
ghci> doParse (satP ('h' ==)) "mugatu"
[]
ghci> doParse (satP ('h' ==)) "hello"
[('h',"ello")] Следующий алфавит и числовые символы разбора соответственно
> alphaChar = satP isAlpha
> digitChar = satP isDigit
и этот малыш возвращает первую цифру строки как Int
> digitInt = do
> c <- digitChar
> return ((read [c]) :: Int)
который работает так
ghci> doParse digitInt "92"
[(9,"2")]ghci> doParse digitInt "cat"
[]
Наконец, этот синтаксический анализатор будет анализировать только определенный Char передано как ввод
> char c = satP (== c)
Комбинатор недетерминированного выбора
Теперь давайте напишем комбинатор, который принимает два подпарсера и недетерминированно выбирает между ними.
> selectP :: Парсер a -> Парсер a -> Парсер a
Как бы мы закодировали выбор в наших парсерах? Итак, мы хотим вернуть успешный синтаксический анализ, если или синтаксический анализатор успешен. Поскольку наши синтаксические анализаторы возвращают несколько значений,
> p1 `выбрать P` p2 = P (\cs -> doParse p1 cs ++ doParse p2 cs)
Мы можем использовать приведенный выше комбинатор для создания синтаксического анализатора, который возвращает либо алфавит, либо числовой символ
> alphaNumChar = alphaChar `выберитеP` digitChar
Когда мы запускаем это выше, мы получаем довольно интересные результаты
ghci> doParse alphaNumChar "cat"
[('c',"at")]
ghci> doParse alphaNumChar "2cat"
[('2',"cat")]
ghci> doParse alphaNumChar "2at"
[('2',"в")]
Что еще лучше, так это то, что если оба синтаксических анализатора завершатся успешно, вы получите все результаты. Например, вот синтаксический анализатор, который берет
Например, вот синтаксический анализатор, который берет n символов из ввода
> захватить :: Int -> Строка синтаксического анализатора
> захватить n | n <= 0 = возврат ""
> | иначе = do c <- oneChar
> cs <-grabbn (n-1)
> return (c:cs)
ДЕЛАТЬ В КЛАССЕ Как бы вы уничтожили неприятную рекурсию из вышеприведенного?
Теперь мы можем использовать наш комбинатор выбора
> захват2или4 = захват 2 `выбратьP` захват 4
и сейчас, мы вернем оба результата если возможно
ghci> doParse grab2or4 "mickeymouse"
[("mi","ckeymouse"),("mick","eymouse")]
и только один результат, если это возможно
ghci> doParse grab2or4 "микрофон"
[("mi","c")]ghci> doParse grab2or4 "m"
[]
Даже имея в своем распоряжении рудиментарные синтаксические анализаторы, мы можем начать делать некоторые довольно интересные вещи. Например, вот небольшой калькулятор.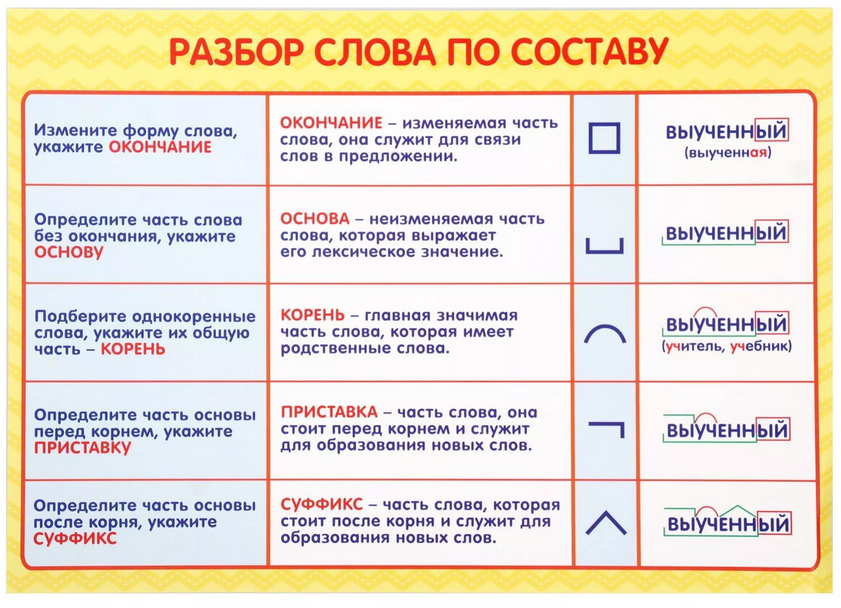 Сначала разбираем операцию
Сначала разбираем операцию
> intOp = плюс `chooseP` минус `chooseP` умножить на `chooseP` разделить
> где плюс = char '+' >> возврат (+)
> минус = char '-' >> возврат (-)
> раз = char '*' >> вернуть (*)
> разделить = char '/' >> вернуть div
DO IN CLASS Можете ли вы угадать тип вышеприведенного синтаксического анализатора?
Далее мы можем разобрать выражение
> calc = do x <- digitInt
> op <- intOp
> y <- digitInt
> return $ x `op` y
, который при запуске будет анализировать и вычислять
ghci> doParse calc "8/2"
[(4,"")]ghci> doParse calc "8+2cat"
[(10,"cat")]ghci> doParse calc "8/2cat"
[(4,"cat")]ghci> doParse calc "8-2cat"
[(6,"cat")]ghci> doParse calc "8*2cat"
[(16,"cat" )]
Рекурсивный анализ
Чтобы начать парсить интересные вещи, нам нужно добавить рекурсию в наши комбинаторы. Например, очень хорошо анализировать отдельные символы (как в
Например, очень хорошо анализировать отдельные символы (как в char выше), но было бы намного больше, если бы мы могли получить определенные токены String .
Попробуем написать!
> строка :: строка -> строка анализатора
string "" = return ""
string (c:cs) = do char c
string cs
return $ c:cs
ДЕЛАТЬ В КЛАССЕ Фу-у-у! Это явная рекурсия?! Давайте попробуем еще раз (можете найти закономерность)
> string = undefined -- введите
Гораздо лучше!
ghci> doParse (строка "микрофон") "mickeyMouse"
[("микрофон","keyMouse")]ghci> doParse (строка "микрофон") "дональд дак"
[]
Хорошо, я думаю, тогда это было не совсем рекурсивно!
Давайте попробуем еще раз.
Давайте напишем комбинатор, который принимает синтаксический анализатор p , который возвращает и , и возвращает синтаксический анализатор, который возвращает много значений и .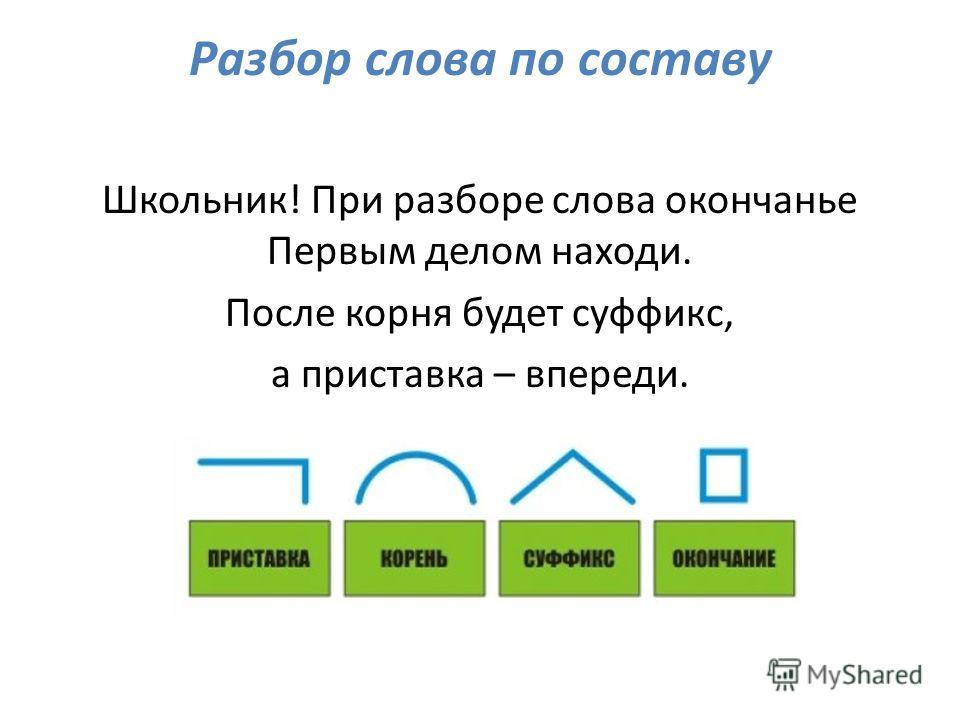 То есть он продолжает захватывать как можно больше значений
То есть он продолжает захватывать как можно больше значений a и возвращает их как [a] .
> manyP :: Parser a -> Parser [a]
> manyP p = many1 `chooseP` many0
> где many0 = return []
> many1 = do x <- p
> xs <- manyP p
> return (x:xs)
Но будьте осторожны! Вышеприведенное может дать много результатов
ghci> doParse (manyP digitInt) "123a"
[([], "123a"), ([1], "23a"), ([1, 2], "3a"), ([1, 2, 3], "а")]
, который просто представляет собой все возможные способы извлечения последовательностей целых чисел из входной строки.
Детерминированный максимальный анализ
Часто нам нужен один результат, а не набор результатов. Например, более интуитивное поведение много будет возвращать максимальную последовательность элементов, а не все префиксы.
Для этого нам понадобится детерминированный комбинатор выбора
> (<|>) :: Парсер a -> Парсер a -> Парсер a
> p1 <|> p2 = P $ \cs -> case doParse (p1 `chooseP` p2) cs of
> [] -> []
> х:_ -> [х]
>
Приведенный выше синтаксический анализатор запускает выбор, но возвращает только первый результат. Теперь мы можем вернуться к
Теперь мы можем вернуться к комбинатор manyP и убедитесь, что он возвращает одну максимальную последовательность
> mmanyP :: Parser a -> Parser [a]
> mmanyP p = mmany1 <|> mmany0
> где mmany0 = return []
> mmany1 = do x <- p
> xs <- mmanyP p
> return (х:хс)
ДЕЛАТЬ В КЛАССЕ Подожди! В чем именно разница между вышеперечисленным и оригинальным manyP ? Как вы это объясните:
ghci> doParse (manyP digitInt) "123a"
[([1,2,3],"a"),([1,2],"3a"),([1],"23a"),( [],"123a")]ghci> doParse (mmanyP digitInt) "123a"
[([1,2,3],"a")]
Давайте воспользуемся этим, чтобы написать синтаксический анализатор, который будет возвращать целое число (а не только одну цифру).
oneInt :: Parser Integer
oneInt = do xs <- mmanyP digitChar
return $ ((read xs) :: Integer)
Помимо , можете ли вы найти шаблон выше? Взяли парсер mmanyP digitChar и просто преобразовал его вывод, используя функцию чтения .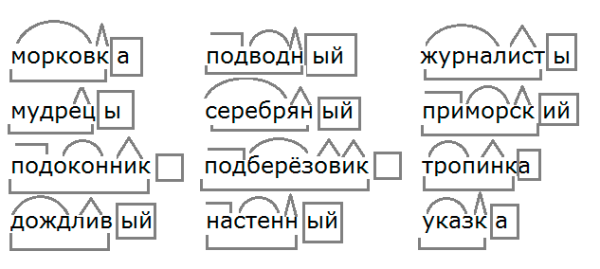 Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
(a -> b) -> Парсер a -> Парсер b
Ага! очень похоже на карту . Действительно, существует обобщенная версия map , которую мы видели ранее ( lift1 ), и мы ограничиваем шаблон, объявляя Parser экземпляром Functor класса типов 9.0003
> экземпляр Functor Parser, где
> fmap f p = do x <- p
> return (f x)
после чего мы можем переписать
> oneInt :: Parser Int
> oneInt = прочитать `fmap` mmanyP digitChar
Давай попробуем
ghci> doParse oneInt "123a"
[(123, "a")]
Давайте воспользуемся вышеизложенным для создания небольшого калькулятора, который анализирует и вычисляет арифметические выражения. По сути, выражение представляет собой либо двоичный операнд, применяемый к двум подвыражениям, либо целое число. Мы можем сформулировать это как
> calc0 :: Parser Int
> calc0 = binExp <|> oneInt
> где binExp = do x <- oneInt
> o <- intOp
> y <- calc0
> return $ x `o` y
Это работает очень хорошо!
ghci> doParse calc0 "1+2+33"
[(36,"")]ghci> doParse calc0 "11+22-33"
[(0,"")]
, но с минусом
все становится немного странно.
ghci> doParse calc0 "11+22-33+45"
[(-45,"")]
А? Что ж, если вы снова посмотрите на код, вы поймете, что приведенное выше было проанализировано как
.11 + ( 22 - (33 + 45))
, потому что в каждом binExp мы требуем, чтобы левый операнд был целым числом. Другими словами, мы предполагаем, что каждый оператор является правой ассоциативностью , отсюда и полученный выше результат.
Интересно, можем ли мы попытаться это исправить, просто перевернув заказ
> calc1 :: Parser Int
> calc1 = binExp <|> oneInt
> где binExp = do x <- calc1
> o <- intOp
> y <- oneInt
> return $ x `o` y
ДЕЛАТЬ В КЛАССЕ Но здесь есть ошибка… Вы можете это понять? (Подсказка: что вернет следующее?)
ghci> doParse calc1 "2+2"
Хуже того, у нас нет приоритета, и поэтому
ghci> doParse calc0 "10*2+100"
[(1020,"")]
, так как строка анализируется как
10*(2+100)
$> calc2 = oneInt >>= захватить $> где захватить x = кг x <|> вернуть x $> кг x = сделать o <- intOp $> y <- oneInt $> захватить $ x o y
Приоритет
Мы можем добавить и ассоциативность, и приоритет обычным способом, расслоив парсер на разные уровни. Здесь давайте разделим наши операции на приоритет сложения и умножения.
Здесь давайте разделим наши операции на приоритет сложения и умножения.
> addOp = плюс `chooseP` минус
> где плюс = char '+' >> return (+)
> минус = char '-' >> возврат (-)
>
> mulOp = умножить `chooseP` разделить
> где раз = char '*' >> вернуть (*)
> разделить = char '/' >> возврат div
Теперь мы можем разделить наш язык на (взаимно рекурсивные) подъязыки, где каждое выражение верхнего уровня анализируется как сумма произведений
> sumE = addE <|> prodE
> где addE = do x <- prodE
> o <- addOp
> y <- sumE
> return $ x `o` y
>
> prodE = mulE <|> factorE
> где mulE = do x <- factorE
> o <- mulOp
> y <- prodE
> return $ x `o` y
>
> factorE = parenE <|> oneInt
> где parenE = do char '('
> n <- sumE
> char ')'
> вернуть номер
Мы можем запустить это
ghci> doParse sumE "10*2+100"
[(120,"")]ghci> doParse sumE "10*(2+100)"
[(1020,"")]
Вы понимаете, почему первый синтаксический анализ вернул 120 ? Что произойдет, если мы поменяем местами порядок prodE и sumE в теле addE (или factorE и prodE в теле prodE )? Почему?
Шаблон синтаксического анализа: Цепочка
Нет особого смысла злорадствовать по поводу комбинаторов, если мы собираемся писать код, подобный приведенному выше — корпуса sumE и prodE практически идентичны!
Давайте посмотрим на них поближе. В сущности,
В сущности, sumE имеет форму
prodE + < prodE + < prodE + ... < prodE >>>
, то есть мы продолжаем связывать значений prodE и добавлять их столько, сколько сможем. Аналогично prodE имеет форму
фактор E * < фактор E * < фактор E * ... < фактор E >>>
, где мы продолжаем связывать значений factorE и умножать их столько, сколько сможем. В вышесказанном есть что-то неприятное: операторы сложения правоассоциативны
ghci> doParse sumE "10-1-1"
[(10,"")]
Ух! Надеюсь, вы понимаете, почему: это потому, что приведенное выше было проанализировано как 10 - (1 - 1) (правоассоциативный), а не (10 - 1) - 1 (левый ассоциативный). У вас может возникнуть соблазн исправить это, просто поменяв местами prodE и sumE
sumE = addE <|> prodE
где addE = do x <- sumE
o <- addOp
y <- prodE
return $ x `o` y
, но это было бы катастрофой. Вы видите, почему? Парсер для
Вы видите, почему? Парсер для sumE напрямую (рекурсивно) вызывает себя без каких-либо входных данных! Таким образом, он уходит в глубокий конец и никогда не возвращается. Вместо этого мы хотим убедиться, что продолжаем потреблять prodE значений и складывание их (скорее как сложение), так что мы можем сделать
> sumE1 = prodE1 >>= addE1
> где addE1 x = захватить x <|> return x
> захватить x = сделать о <- addOp
> y <- prodE1
> addE1 $ x `o` y
>
> prodE1 = factorE1 >>= mulE1
> где mulE1 x = захватить x <|> вернуть x
> захватить x = сделать о <- mulOp
> y <- factorE1
> mulE1 $ x `o` y
>
> factorE1 = parenE <|> oneInt
> где parenE = do char '('
> n <- sumE1
> char ')'
> return n
Легко проверить, что приведенное выше действительно ассоциативно слева.
ghci> doParse sumE1 "10-1-1"
[(8,"")]
, а также очень легко обнаружить и заблокировать шаблон цепных вычислений: единственное отличие состоит в том, что базовый синтаксический анализатор ( prodE1 против factorE1 ) и бинарная операция ( addOp против mulOp ). Мы просто вносим эти параметры в наш комбинатор
Мы просто вносим эти параметры в наш комбинатор
> p `chainl` pop = p >>= rest
> где rest x = схватить x <|> return x
> схватить x = do o <- pop
> y <- p
> rest $ x `o` г
Точно так же нам часто нужно анализировать выражения в квадратных скобках, поэтому мы можем написать комбинатор
> parenP l p r = do char l
> x <- p
> char r
> return x
после чего мы можем переписать грамматику в три строки
> sumE2 = prodE2 `chainl` addOp
> prodE2 = factorE2 `chainl` mulOp
> factorE2 = parenP '('sumE2 ')' <|> oneInt
ghci> doParse sumE2 "10-1-1"
[(8,"")]ghci> doParse sumE2 "10*2+1"
[(21,"")]ghci> doParse sumE2 "10+2*1"
[(12,"")]
На этом мы завершаем наше (в классе) изучение монадического синтаксического анализа. Это всего лишь верхушка айсберга. Хотя синтаксический анализ — очень старая проблема, и ее изучали на заре вычислительной техники, мы увидели, как монады привносят свежий взгляд, который недавно был перенесен из Haskell во многие другие языки. Недавно было опубликовано несколько захватывающих статей на эту тему, которые вы можете изучить самостоятельно. Наконец, Haskell поставляется с несколькими библиотеками комбинаторов синтаксических анализаторов, включая Parsec, с которым вы поэкспериментируете в HW3.
Недавно было опубликовано несколько захватывающих статей на эту тему, которые вы можете изучить самостоятельно. Наконец, Haskell поставляется с несколькими библиотеками комбинаторов синтаксических анализаторов, включая Parsec, с которым вы поэкспериментируете в HW3.
Совместный жадный анализ и составление слов на основе RNN: Жоэль Легран: Бесплатная загрузка, заимствование и потоковая передача: Интернет-архив
Предварительный просмотр элемента
Предварительный просмотр этого элемента недоступен
Похоже, этот элемент не содержит файлов, которые можно найти на Archive.org.
Пожалуйста, загрузите файлы в этом элементе, чтобы взаимодействовать с ними на вашем компьютере.
Показать все файлы
EMBED (для блогов, размещенных на wordpress. com, и тегов
com, и тегов
Хотите больше? Дополнительные сведения о встраивании, примеры и помощь!
текстов
- по
- Жоэль Легран; Ронан Коллоберт
- Дата публикации
- 2014-12-22
- Применение
- http://arxiv.org/licenses/nonexclusive-distrib/1.0/
- Темы
- Нейронные и эволюционные вычисления, репозиторий компьютерных исследований, вычисления и язык, обучение
- Издатель
- arXiv.org
- Коллекция
- архив; журналы
- Участник
- Интернет-архив
В этой статье представлен жадный синтаксический анализатор, основанный на нейронных сетях, в котором используется новое композиционное представление поддерева. Жадный парсер и композиционная процедура обучаются совместно и тесно зависят друг от друга. Процедура композиции выводит векторное представление, которое суммирует синтаксически (анализ тегов) и семантически (слова) поддеревья. Композиция и тегирование достигаются с помощью непрерывных представлений (слов или тегов) и рекуррентных нейронных сетей. Мы достигаем производительности F1 наравне с известными существующими парсерами, имея при этом преимущество в скорости благодаря жадности парсера. Мы предоставляем полнофункциональную реализацию метода, описанного в этой статье.
Жадный парсер и композиционная процедура обучаются совместно и тесно зависят друг от друга. Процедура композиции выводит векторное представление, которое суммирует синтаксически (анализ тегов) и семантически (слова) поддеревья. Композиция и тегирование достигаются с помощью непрерывных представлений (слов или тегов) и рекуррентных нейронных сетей. Мы достигаем производительности F1 наравне с известными существующими парсерами, имея при этом преимущество в скорости благодаря жадности парсера. Мы предоставляем полнофункциональную реализацию метода, описанного в этой статье.
Примечания
Опубликовано в качестве доклада на конференции ICLR 2015
- Дата добавления
- 30.06.2018 10:33:12
- Внешний идентификатор
- урна:arXiv:1412.7028
- Идентификатор
- архив-1412.7028
- Сканер
- Библиотека Python для Интернет-архива 1.
