Синтаксический и пунктуационный разбор предложений со словами, словосочетаниями и предложениями, грамматически не связанными с членами предложения
Урок по русскому языку в 8 кл.
Тема: Синтаксический и пунктуационный разбор предложений со словами, словосочетаниями и предложениями, грамматически не связанными с членами предложения
Цели урока:
Образовательные: познакомить учащихся с порядком устного и письменного синтаксического и пунктуационного разбора предложения со словами, не являющимися членами предложения, научить производить устно и письменно синтаксический и пунктуационный разбор предложения со словами, не являющимися членами предложения.
Развивающие: сформировать умение употреблять вводные слова и вставные конструкции как средство связи предложений в тексте.
Воспитательная:воспитывать интерес к предмету;воспитывать сотрудничество, доброжелательное отношение к товарищам.
Ход урока
Организационный момент
Актуализация знаний.
Первый ученик читает диалог, рассказывает о знаках препинания при междометиях, определяет текстообразующую роль междометий. Второй читает семь предложений из басен И. А. Крылова, определяет, какие чувства выражают междометия.
III. Повторение. Объяснительный диктант.
Одна из загадок природы — способность птиц определять время начала перелетов. Как птицы определяют, живя в тропиках, приближение весны у нас? По-видимому, им помогают птичьи биологические часы.
Как известно, солнце в течение дня перемещается из восточных районов небосвода в западные. Удивление вызывают наблюдения, показывающие способность птиц ориентироваться по солнцу. Для многих птиц эта способность врожденная. Птицы, как утверждают ученые, ощущают также зеленые запахи, прислушиваются к раздающимся снизу звукам, учитывают величину центробежной силы, возникающей при вращении Земли, и реагируют на изменение ее магнитного поля.
(Б. Сергеев)
IV. Объяснение нового материала.
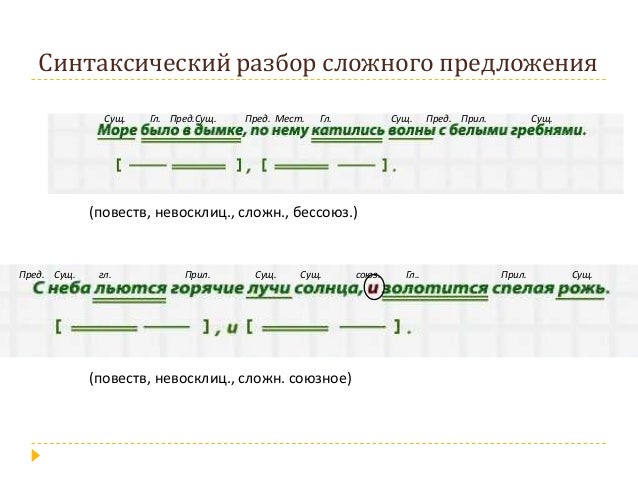
Учащиеся знакомятся с образцами устного и письменного синтаксического разбора на с. 18б—187 (§ 64), пунктуационного разбора на с. 188.
V. Закрепление материала.
1. В упр. 394 учащиеся выразительно читают стихотворные строки А. С. Пушкина. Класс следит за правильным произношением предложений с обращением, вводными и вставными конструкциями.
2. Упр. 395 выполняют самостоятельно.
3. В упр. 396 читают выразительно стихотворения, выделяя при чтении обращения интонацией восхищения родной природой. Производят устный пунктуационный разбор.
4. Самостоятельная работа по упр. 398. дополнительное задание: произведите письменный синтаксический разбор одного предложения (по выбору учащихся).
VI. Домашнее задание: § 64, выполнить упр. 397 устно ответить на контрольные вопросы на с. 189.
Адрес публикации: https://www.prodlenka.org/metodicheskie-razrabotki/127932-sintaksicheskij-i-punktuacionnyj-razbor-predl
разбор — Как написать грамматику для выражения, когда оно может иметь множество возможных форм
У меня есть несколько предложений, которые мне нужно преобразовать в код регулярного выражения, и я пытался использовать для этого Pyparsing. Предложения — это, по сути, правила поиска, говорящие нам, что искать.
Предложения — это, по сути, правила поиска, говорящие нам, что искать.
Примеры предложений —
LINE_CONTAINS это фраза— это пример правила поиска, указывающего, что строка, в которой вы ищете, должна содержать фразу, это фразаLINE_STARTSWITH Однако мы— это пример правила поиска, указывающего, что строка, которую вы ищете, должна начинаться с фразыОднако мыПравила также можно комбинировать, например-
LINE_CONTAINS фраза один ПЕРЕД {фразой2 И фразой3} И СТРОКА_STARTSWITH Однако мы
Список всех актуальных приговоров (при необходимости) можно найти здесь.
лпар ::= '{'
рпар ::= '}'
line_directive ::= LINE_CONTAINS | LINE_STARTSWITH
фраза ::= lpar(?) + (word+) + rpar(?) # означает, что если фраза заключена в скобки, она останется прежней
upto_N_words ::= lpar + 'UPTO' + число + 'WORDS' + rpar
N_words ::= lpar + num + 'WORDS' + rpar
upto_N_characters ::= lpar + 'UPTO' + число + 'CHARACTERS' + rpar
N_characters ::= lpar + num + 'СИМВОЛЫ' + rpar
JOIN_phrase ::= фраза + JOIN + фраза
AND_phrase ::= фраза (+ ПРИСОЕДИНЯЙТЕСЬ + фраза)+
OR_phrase ::= фраза (+ ИЛИ + фраза)+
BEFORE_phrase ::= фраза (+ BEFORE + фраза)+
AFTER_phrase ::= фраза (+ ПОСЛЕ + фраза)+
braced_OR_phrase ::= lpar + OR_phrase + rpar
braced_AND_phrase ::= lpar + AND_phrase + rpar
braced_BEFORE_phrase ::= lpar + BEFORE_phrase + rpar
braced_AFTER_phrase ::= lpar + AFTER_phrase + rpar
braced_JOIN_phrase ::= lpar + JOIN_phrase + rpar
правило ::= line_directive + субправило
final_expr ::= правило (+ И/ИЛИ + правило)+
Проблема заключается в субправиле , для которого (на основе имеющихся у меня эмпирических данных) мне удалось получить все следующие выражения —
субправило ::= фраза
::= ИЛИ_фраза
::= JOIN_phrase
::= BEFORE_phrase
::= AFTER_phrase
::= И_фраза
::= фраза + upto_N_words + фраза
::= braced_OR_phrase + фраза
::= фраза + braced_OR_phrase
::= фраза + braced_OR_phrase + фраза
::= фраза + upto_N_words + braced_OR_phrase
::= фраза + до_N_символов + фраза
::= braced_OR_phrase + фраза + upto_N_words + фраза
::= фраза + braced_OR_phrase + upto_N_words + фраза
Чтобы привести пример, у меня есть одно предложение: LINE_CONTAINS Целью этого исследования было {определить ИЛИ идентифицировать} гены с повышенной регуляцией
 Для этого подправило, как указано выше, имеет вид
Для этого подправило, как указано выше, имеет вид фраза + фигурная скобка_ИЛИ_фраза + фраза . Итак, мой вопрос: как мне написать простое грамматическое выражение BNF для подправила , чтобы я мог легко закодировать грамматику для него с помощью Pyparsing? Кроме того, любой вклад относительно моей нынешней техники абсолютно приветствуется.
РЕДАКТИРОВАТЬ: После применения принципов, изложенных @Paul в его ответе, вот версия кода MCVE . Он принимает список предложений для анализа hrrsents , анализирует каждое предложение, преобразует его в соответствующее регулярное выражение и возвращает список строк регулярных выражений —
из pyparsing import *
импортировать повторно
def parse_hrr (hrrsents):
ДО, И, ИЛИ, СЛОВА, СИМВОЛОВ = карта (Литерал, "ДО И ИЛИ СЛОВА СИМВОЛОВ".split())
LBRACE,RBRACE = карта (подавить, "{}")
целое число = pyparsing_common.integer()
LINE_CONTAINS, PARA_STARTSWITH, LINE_ENDSWITH = карта (буквальное,
"""LINE_CONTAINS PARA_STARTSWITH LINE_ENDSWITH""". split()) # опцион пут для LINE_ENDSWITH. Пользователи могут использовать, я в настоящее время не
ДО, ПОСЛЕ, ПРИСОЕДИНЯЙТЕСЬ = map (буквально, "ДО ПОСЛЕ ПРИСОЕДИНЕНИЯ".split())
ключевое слово = ДО | СЛОВА | И | ИЛИ | ДО | ПОСЛЕ | ПРИСОЕДИНЯЙТЕСЬ | LINE_CONTAINS | PARA_STARTSWITH
узел класса (объект):
def __init__(я, токены):
self.tokens = токены
деф сгенерировать (сам):
проходить
класс LiteralNode (узел):
деф сгенерировать (сам):
return "(%s)" %(re.escape(''.join(self.tokens[0]))) # здесь объединил элементы, так что re.escape не нужно делать escape для всего списка
класс ConsecutivePhrases (узел):
деф сгенерировать (сам):
присоединиться к_этим=[]
токены = self.tokens[0]
для t в токенах:
tg = t.генерировать ()
join_these.append(tg)
последовательность = []
для слова в join_these[:-1]:
if (r"(([\w]+\s*)" в слове) или (r"((\w){0," в слове): #или если первая часть регулярного выражения в слове:
seq.
split()) # опцион пут для LINE_ENDSWITH. Пользователи могут использовать, я в настоящее время не
ДО, ПОСЛЕ, ПРИСОЕДИНЯЙТЕСЬ = map (буквально, "ДО ПОСЛЕ ПРИСОЕДИНЕНИЯ".split())
ключевое слово = ДО | СЛОВА | И | ИЛИ | ДО | ПОСЛЕ | ПРИСОЕДИНЯЙТЕСЬ | LINE_CONTAINS | PARA_STARTSWITH
узел класса (объект):
def __init__(я, токены):
self.tokens = токены
деф сгенерировать (сам):
проходить
класс LiteralNode (узел):
деф сгенерировать (сам):
return "(%s)" %(re.escape(''.join(self.tokens[0]))) # здесь объединил элементы, так что re.escape не нужно делать escape для всего списка
класс ConsecutivePhrases (узел):
деф сгенерировать (сам):
присоединиться к_этим=[]
токены = self.tokens[0]
для t в токенах:
tg = t.генерировать ()
join_these.append(tg)
последовательность = []
для слова в join_these[:-1]:
if (r"(([\w]+\s*)" в слове) или (r"((\w){0," в слове): #или если первая часть регулярного выражения в слове:
seq. append (слово + "")
еще:
seq.append(слово + "\s+")
seq.append(join_these[-1])
результат = "".присоединиться(последовательность)
вернуть результат
класс AndNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
присоединиться к_этим=[]
для t в токенах[::2]:
tg = t.генерировать ()
tg_mod = tg[0]+r'?=.*\b'+tg[1:][:-1]+r'\b)' # чтобы разместить команды регулярного выражения в нужном месте
join_these.append(tg_mod)
присоединился = ''.join(ele для ele в join_these)
полный = '('+ присоединился+')'
вернуться полный
класс OrNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
join = '|'.join(t.generate() для t в токенах[::2])
полный = '('+ присоединился+')'
вернуться полный
класс LineTermNode (узел):
деф сгенерировать (сам):
токены = self. " + a + r"(?=[\W_]|$))458")}
для line_dir, phr_term в zip(токены[0::2], токены[1::2]):
ret = dir_phr_map[line_dir](phr_term.generate())
вернуться обратно
класс LineAndNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
вернуть '&&&'.join(t.generate() для t в токенах[::2])
класс LineOrNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
return '@@@'.join(t.generate() для t в токенах[::2])
класс UpToWordsNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
word_re = r"([\w]+\s*)"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "(%s{0,%d})" % (word_re, op)
вернуться обратно
класс UpToCharactersNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
char_re = г"\ш"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "((%s){0,%d})" % (char_re, op)
вернуться обратно
класс BeforeAfterJoinNode (узел):
деф сгенерировать (сам):
токены = self.
tokens[0]
operator_opn_map = {'ДО': лямбда a,b: a + '.*?' + b, 'ПОСЛЕ': лямбда a,b: b + '.*?' + a, 'JOIN': лямбда a,b: a + '[-]?' + б}
рет = токены[0].генерировать()
для оператора, операнд в zip(токены[1::2], токены[2::2]):
ret = operator_opn_map[operator](ret, operand.generate()) # по сути, это вызов элемента dict, и для каждого такого элемента требуются 2 переменные (a&b), поэтому их нужно предоставить как ret и op.generate
вернуться обратно
## ГРАММАТИКА
слово = ~ключевое слово + слово (альфа, буквенное обозначение+'-_+/()')
uptowords_expr = Group(LBRACE + UPTO + integer("число слов") + WORDS + RBRACE).setParseAction(UpToWordsNode)
uptochars_expr = Group(LBRACE + UPTO + integer("numberofchars") + CHARACTERS + RBRACE).setParseAction(UpToCharactersNode)
некоторые_слова = OneOrMore(слово).setParseAction(' '.join, LiteralNode)
фраза_элемент = некоторые_слова | uptowords_expr | uptochars_expr
фраза_выражение = infixNotation(фраза_элемент,
[
((BEFORE | AFTER | JOIN), 2, opAssoc. LEFT, BeforeAfterJoinNode), # ранее не работало, потому что BEFORE и т. д. не были ключевыми словами и, следовательно, анализировались как слова
(Нет, 2, opAssoc.LEFT, ConsecutivePhrases),
(И, 2, opAssoc.LEFT, AndNode),
(OR, 2, opAssoc.LEFT, OrNode),
],
lpar=Подавить('{'), rpar=Подавить('}')
) # структура отдельной фразы с ее операторами
line_term = Группа((LINE_CONTAINS|PARA_STARTSWITH)("line_directive") +
(phrase_expr)("phrases")) # в основном придание структуры одному подправилу, имеющему строчный термин и фразу
#
line_contents_expr = infixNotation(line_term.setParseAction(LineTermNode),
[(И, 2, opAssoc.LEFT, LineAndNode),
(OR, 2, opAssoc.LEFT, LineOrNode),
]
) # грамматика для всего правила/предложения
#######################################
мррлист=[]
для t в часах:
т = т. /$] вокруг 'гена'
mrrlist.append(final_regexes3)
возврат (мррлист)
 split()) # опцион пут для LINE_ENDSWITH. Пользователи могут использовать, я в настоящее время не
ДО, ПОСЛЕ, ПРИСОЕДИНЯЙТЕСЬ = map (буквально, "ДО ПОСЛЕ ПРИСОЕДИНЕНИЯ".split())
ключевое слово = ДО | СЛОВА | И | ИЛИ | ДО | ПОСЛЕ | ПРИСОЕДИНЯЙТЕСЬ | LINE_CONTAINS | PARA_STARTSWITH
узел класса (объект):
def __init__(я, токены):
self.tokens = токены
деф сгенерировать (сам):
проходить
класс LiteralNode (узел):
деф сгенерировать (сам):
return "(%s)" %(re.escape(''.join(self.tokens[0]))) # здесь объединил элементы, так что re.escape не нужно делать escape для всего списка
класс ConsecutivePhrases (узел):
деф сгенерировать (сам):
присоединиться к_этим=[]
токены = self.tokens[0]
для t в токенах:
tg = t.генерировать ()
join_these.append(tg)
последовательность = []
для слова в join_these[:-1]:
if (r"(([\w]+\s*)" в слове) или (r"((\w){0," в слове): #или если первая часть регулярного выражения в слове:
seq.
split()) # опцион пут для LINE_ENDSWITH. Пользователи могут использовать, я в настоящее время не
ДО, ПОСЛЕ, ПРИСОЕДИНЯЙТЕСЬ = map (буквально, "ДО ПОСЛЕ ПРИСОЕДИНЕНИЯ".split())
ключевое слово = ДО | СЛОВА | И | ИЛИ | ДО | ПОСЛЕ | ПРИСОЕДИНЯЙТЕСЬ | LINE_CONTAINS | PARA_STARTSWITH
узел класса (объект):
def __init__(я, токены):
self.tokens = токены
деф сгенерировать (сам):
проходить
класс LiteralNode (узел):
деф сгенерировать (сам):
return "(%s)" %(re.escape(''.join(self.tokens[0]))) # здесь объединил элементы, так что re.escape не нужно делать escape для всего списка
класс ConsecutivePhrases (узел):
деф сгенерировать (сам):
присоединиться к_этим=[]
токены = self.tokens[0]
для t в токенах:
tg = t.генерировать ()
join_these.append(tg)
последовательность = []
для слова в join_these[:-1]:
if (r"(([\w]+\s*)" в слове) или (r"((\w){0," в слове): #или если первая часть регулярного выражения в слове:
seq.
 " + a + r"(?=[\W_]|$))458")}
для line_dir, phr_term в zip(токены[0::2], токены[1::2]):
ret = dir_phr_map[line_dir](phr_term.generate())
вернуться обратно
класс LineAndNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
вернуть '&&&'.join(t.generate() для t в токенах[::2])
класс LineOrNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
return '@@@'.join(t.generate() для t в токенах[::2])
класс UpToWordsNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
word_re = r"([\w]+\s*)"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "(%s{0,%d})" % (word_re, op)
вернуться обратно
класс UpToCharactersNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
char_re = г"\ш"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "((%s){0,%d})" % (char_re, op)
вернуться обратно
класс BeforeAfterJoinNode (узел):
деф сгенерировать (сам):
токены = self.
" + a + r"(?=[\W_]|$))458")}
для line_dir, phr_term в zip(токены[0::2], токены[1::2]):
ret = dir_phr_map[line_dir](phr_term.generate())
вернуться обратно
класс LineAndNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
вернуть '&&&'.join(t.generate() для t в токенах[::2])
класс LineOrNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
return '@@@'.join(t.generate() для t в токенах[::2])
класс UpToWordsNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
word_re = r"([\w]+\s*)"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "(%s{0,%d})" % (word_re, op)
вернуться обратно
класс UpToCharactersNode (узел):
деф сгенерировать (сам):
токены = self.tokens[0]
рет = ''
char_re = г"\ш"
для op, операнд в zip(токены[1::2], токены[2::2]):
# op содержит проанализированное выражение "upto"
ret += "((%s){0,%d})" % (char_re, op)
вернуться обратно
класс BeforeAfterJoinNode (узел):
деф сгенерировать (сам):
токены = self.

 /$] вокруг 'гена'
mrrlist.append(final_regexes3)
возврат (мррлист)
/$] вокруг 'гена'
mrrlist.append(final_regexes3)
возврат (мррлист)
Attempto Controlled English
Attempto Controlled English — это формально определенный недвусмысленный язык, который является подмножеством английского языка. Это очень мило.
Я знал об этом некоторое время, но я никогда не возился с этим, потому что стандартная настройка реализации довольно сложная. Я хотел хороший, простой пакет на Haskell, который определял бы только парсер и принтер, как это делает haskell-src-exts. Таким образом, я могу использовать ACE для разбора простого английского языка для самых разных целей 1 с простым знакомым API, который я могу просмотреть на Hackage. Отчасти это также хороший опыт обучения.
Итак, я просмотрел статью «Синтаксис английского языка, контролируемого попытками», чтобы посмотреть, достаточно ли она полна, чтобы написать на ее основе синтаксический анализатор парсеков. Это было! Сначала я написал токенизатор с помощью Attoparsec и написал несколько тестов. Из этих токенов я создал набор комбинаторов для Parsec, а затем написал парсер. При написании синтаксического анализатора я подготовил набор тестов для каждой грамматической продукции. Наконец, я написал симпатичный принтер и написал несколько тестов, чтобы проверить, что
Из этих токенов я создал набор комбинаторов для Parsec, а затем написал парсер. При написании синтаксического анализатора я подготовил набор тестов для каждой грамматической продукции. Наконец, я написал симпатичный принтер и написал несколько тестов, чтобы проверить, что печать. разобрать . Распечатать . синтаксический анализ = идентификатор .
Новички в синтаксическом анализе Haskell могут найти интересный вариант использования, поскольку он выполняет токенизацию с помощью Attoparsec (из текста), а затем анализирует собственный тип токена (Token) с помощью Parsec. Общая трудность заключается в том, чтобы избежать синтаксического анализа строки в Parsec, который используется в большинстве учебных пособий в качестве демонстрации.
Пакет Hackage здесь. Я нахожу документацию интересной для просмотра. Я попытался включить полезные примеры для производственных правил. Вам не нужно знать теорию синтаксиса, чтобы использовать эту библиотеку.
Вот образец ACE. Мы можем разобрать предложение «a <существительное> <интранс-глагол>» следующим образом:
Мы можем разобрать предложение «a <существительное> <интранс-глагол>» следующим образом:
λ> разобрал спецификацию «a <существительное> <интранс-глагол>». Правильно (Спецификация (SentenceCoord (SentenceCoord_1 (SentenceCoord_2) (SentenceCoord_3 (TopicalizedSentenceComposite (CompositeSentence (Предложение (NPCoordUnmarked (UnmarkedNPCoord (NP (SpecifyDeterminer A)) (Н' Ничего (Н "<существительное>") Ничего Ничего Ничего)) Ничего)) (VPCoordVP (VP (V' Ничего (ComplVIV (IntransitiveV "<интранс-глагол>")) [])))))) Ничего) Ничего) Ничего) Ничего) Ничего)
Все, что связано со словарем, записывается как . Синтаксический анализатор на самом деле берет список синтаксических анализаторов, чтобы вы могли предоставить свои собственные синтаксические анализаторы для каждого типа слова. Эти слова не представляют интереса для грамматики, и ваш конкретный домен может поддерживать другие типы слов.
Если мы довольно напечатаем разобранную фразу, мы получим:
λ> fmap pretty (разобранная спецификация "a <существительное> <интранс-глагол>.
 ")
Right "a <существительное> <интранс-глагол>."
")
Right "a <существительное> <интранс-глагол>." Т.е. мы получаем обратно то, что вложили. Я также написал HTML-принтер. Более сложное предложение демонстрирует результат:
.для каждого <существительное> if a <существительное> that <транс-глагол> some <существительное> и <имя-собственное>‘s <существительное> <транс-глагол> 2 <существительное> then some <существительное> < intrans-verb> и некоторые <существительное>
a <существительное> <собственное имя>‘s <существительное> <наречие>.
Можно распечатать с помощью
fmap (renderHtml .toMarkup) . проанализированная спецификация
и вывод:
for each <существительное> if <существительное> that <транс-глагол> some <существительное> и <имя-собственное>‘s <существительное> <транс-глагол> 2 <существительное> then some <существительное>
и некоторые <существительное> a <существительное> <собственное имя>‘s <существительное> <наречие>.
