What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.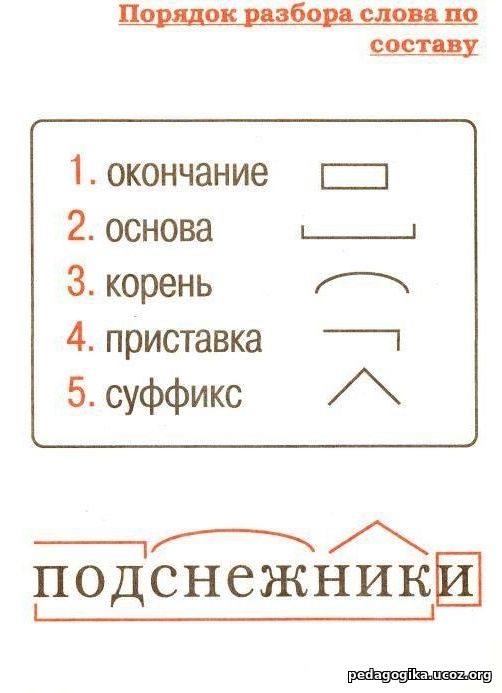
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор слова «пищевые»
Часть речи: Прилагательное
ПИЩЕВЫЕ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «ПИЩЕВОЙ»
| Слово | Морфологические признаки |
|---|---|
| ПИЩЕВЫЕ |
|
| ПИЩЕВЫЕ |
|
Все формы слова ПИЩЕВЫЕ
ПИЩЕВОЙ, ПИЩЕВОГО, ПИЩЕВОМУ, ПИЩЕВЫМ, ПИЩЕВОМ, ПИЩЕВАЯ, ПИЩЕВУЮ, ПИЩЕВОЮ, ПИЩЕВОЕ, ПИЩЕВЫЕ, ПИЩЕВЫХ, ПИЩЕВЫМИ, ПИЩЕВЕЕ, ПИЩЕВЕЙ, ПОПИЩЕВЕЕ, ПОПИЩЕВЕЙ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ПИЩЕВЫЕ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «пищевые»
1
Капуста устроилась работать на пищевой комбинат и собиралась поступать в пищевой же техникум.
Нелегальный рассказ о любви (Сборник), Игорь Сахновский, 2009г.2
И началось все с пищевой поваренной соли, она являлась первой пищевой добавкой.
Записки санитара, Павел Рупасов3
На манер пищевой цепочки животных, человек – одно из основных звеньев пищевой цепочки системы.
4
Сразу несколько их одноклассников поступили учиться в Пищевой Институт, и на Раушской собрались и школьные приятели и новые друзья из Пищевого.
5
Вдобавок нередко значительная часть содержимого упаковок – не что иное, как пищевые добавки.
Напиток вечной бодрости, Ахмет Мырадович ПенджиевНайти еще примеры предложений со словом ПИЩЕВЫЕ
состав, факторы размещения предприятий, основные районы и центры.
 Проблемы и перспективы развития.
Проблемы и перспективы развития.Лёгкая и пищевая промышленности составляют третье звено агропромышленного комплекса. Лёгкая включает текстильную, швейную, меховую, трикотажную и кожевенно-обувную промышленности. Главная отрасль текстильная. Она включает — первичную обработку сырья (хлопка, шелка, шерсти, льна), прядильное производство, а также ткачество и отделку тканей (окраску, нанесение рисунка). Сырьё для текстильной промышленности невыгодно возить на большие расстояния, поэтому предприятия по первичной обработке сырья удобнее размещать у его источников: шерсти (Северный Кавказ), льна (Нечерноземье). Текстильная промышленность требует много квалифицированных трудовых ресурсов (в основном женских), продукцию её невыгодно перевозить на большие расстояния, поэтому для её размещения важными являются трудовой и потребительский фактор. Главными текстильными районами страны, уже долгое время остаётся — Центральная Россия (Ивановская, Костромская, Московская области).
Единственное натуральное волокно, которое выращивается в России, — лен. Поэтому все предприятия по производству льняных тканей возникли именно там, где выращивался лен, в Центральном районе. Именно сюда для переработки стали привозить в середине XIX в. хлопок из Америки, а затем и из Средней Азии. Таким образом, оказалось, что Центральный район сконцентрировал у себя почти все мощности по производству хлопчатобумажных тканей, даже в советское время в Центральном районе производилось почти 2/3 всех тканей (Иваново, Подмосковье). Уже в послевоенные годы стали размещать хлопчатобумажные комбинаты в районах потребления тканей или в тех местах, где наблюдалась диспропорция между занятостью мужчин и женщин. В период максимального развития текстильной отрасли шелковая и шерстяная промышленности также концентрировались в Центральном экономическом районе, в то же время как сырье для шерстяной отрасли завозилось с Северного Кавказа. Завершающие (отделочные) стадии текстильной промышленности тяготеют к центрам высокой художественной культуры, обладающим высококвалифицированными кадрами художников (Москва, С.
Поэтому все предприятия по производству льняных тканей возникли именно там, где выращивался лен, в Центральном районе. Именно сюда для переработки стали привозить в середине XIX в. хлопок из Америки, а затем и из Средней Азии. Таким образом, оказалось, что Центральный район сконцентрировал у себя почти все мощности по производству хлопчатобумажных тканей, даже в советское время в Центральном районе производилось почти 2/3 всех тканей (Иваново, Подмосковье). Уже в послевоенные годы стали размещать хлопчатобумажные комбинаты в районах потребления тканей или в тех местах, где наблюдалась диспропорция между занятостью мужчин и женщин. В период максимального развития текстильной отрасли шелковая и шерстяная промышленности также концентрировались в Центральном экономическом районе, в то же время как сырье для шерстяной отрасли завозилось с Северного Кавказа. Завершающие (отделочные) стадии текстильной промышленности тяготеют к центрам высокой художественной культуры, обладающим высококвалифицированными кадрами художников (Москва, С.
Пищевая промышленность производит продукты питания для людей. Она больше, чем другие отрасли, связана с сельским хозяйством, так как получает от него сырье. Развитие и размещение предприятий пищевой промышленности определяется размещением потребителей продукции, специализацией сельского хозяйства и условиями транспортировки продукции.
По характеру используемого сырья входящие в её состав отрасли можно разделить на две группы:
- отрасли, использующие необработанное сырьё, это рыбная, маслодельная, крупяная, консервная, сахарная;
- отрасли, использующие сырьё, прошедшее переработку, это макаронная, хлебопекарная, кондитерская и т.
 д.
д.
Производства первой группы размещены в основном в районах производства соответствующего сырья: сахарная — в Центрально–Чернозёмном районе, маслобойная — на Северном Кавказе. Для производства второй группы основным факторам размещения является — потребительский, так как продукция этих отраслей либо скоропортящаяся, либо перевозка её обходится дороже перевозки сырья. Эти производства размещены в основном в густонаселенных районах, в крупных городах. И только мясо — молочная промышленность, может размещаться как в районах потребления (молоко, кисломолочные продукты, колбаса), так и в районах сырья (консервированные продукты).
Пищевая и легкая промышленность — старейшие отрасли, но в своем развитии они значительно отстают от многих других промышленных отраслей. Кризис, последовавший за распадом СССР, наиболее сильно ударил по легкой промышленности. Очень остро стала сказываться нехватка сырья, значительная часть которого поступала из союзных республик. Российская легкая и пищевая промышленность находится в состоянии жесткой конкуренции с зарубежными производителями, и главная задача этих отраслей — повышение качества продукции и снижение её себестоимости.
Анализ использования соевого белка в пищевой промышленности Текст научной статьи по специальности «Прочие технологии»
УДК 577.112:582.739:663/664
А.В. Смагина, М.В. Сытова
Всероссийский научно-исследовательский институт рыбного хозяйства и океанографии, 107140, г. Москва, ул. В. Красносельская, 17
АНАЛИЗ ИСПОЛЬЗОВАНИЯ СОЕВОГО БЕЛКА В ПИЩЕВОЙ ПРОМЫШЛЕННОСТИ
В настоящее время проблема обеспечения населения полноценным пищевым белком сохраняет свою актуальность, основным резервом белкового питания населения в мире признана соя. Использование продуктов переработки сои в пищевой промышленности ставит задачу разработки современных методов или модификации существующей методологии качественного и количественного определения содержания сои в пищевых продуктах.
Ключевые слова: соя, белок, пищевые продукты.
A.V. Smagina, M.V. Sytova THE ANALYSIS OF USE OF SOYA FIBER IN THE FOOD-PROCESSING INDUSTRY
Now the problem of maintenance of the population high-grade food fiber keeps the urgency, the basic reserve of an albuminous food of the population in the world recognises a soya. Use ofproducts of processing of a soya in the food-processing industry puts a problem of working out of modern methods or updating of existing methodology of qualitative and quantitative definition of the maintenance of a soya in foodstuff.
Keywords: а soya, fiber, foodstuff.
Проблема обеспечения населения продовольствием, в частности полноценным пищевым белком, сохраняет свою актуальность в настоящее время. Специалисты продовольственной и сельскохозяйственной организации ООН (FAO) считают, для того чтобы предотвратить масштабный голод и гарантировать продовольственную безопасность, до 2050 г. мировое производство сельхозкультур должно возрасти вдвое. К тому времени население планеты увеличится до 9,1 млрд человек [1].
мировое производство сельхозкультур должно возрасти вдвое. К тому времени население планеты увеличится до 9,1 млрд человек [1].
Общепризнанным путем в ликвидации дефицита белка, устранения его качественной неполноценности и улучшения пищевой ценности продуктов питания является использование новых его источников. Среди всех сельскохозяйственных культур в общей массе белка соя занимает второе место (62,7 млн т) после пшеницы (71 млн т). Однако пшеничный белок для пищевых целей используется на 74 %, а соевый белок, по оценкам ФАО, не более чем на 10 %, поэтому основным резервом белкового питания населения в мире признана соя [2].
Соевые белки отличаются уникальным аминокислотным составом, практически не уступающим белкам животного происхождения, что отмечено в документах Всемирной организации здравоохранения [2].
Пищевое использование сои высокими темпами растет во всех ведущих странах мира и составляет по 5-8 % в год. Ежегодно 85 % от урожая семян сои перерабатывается для получения двух основных продуктов: соевого масла и соевого шрота. В условиях повышенного интереса общества к вопросам питательности пищевых продуктов белок сои получает все большее признание как высокопитательный, функциональный и рентабельный пищевой ингредиент, позволяющий дополнять и улучшать пищевую ценность готовой продукции, одновременно снизить ее себестоимость. По данным специалистов Института питания РАМН, недостаточное поступление легкоусвояемых
Ежегодно 85 % от урожая семян сои перерабатывается для получения двух основных продуктов: соевого масла и соевого шрота. В условиях повышенного интереса общества к вопросам питательности пищевых продуктов белок сои получает все большее признание как высокопитательный, функциональный и рентабельный пищевой ингредиент, позволяющий дополнять и улучшать пищевую ценность готовой продукции, одновременно снизить ее себестоимость. По данным специалистов Института питания РАМН, недостаточное поступление легкоусвояемых
форм белка в рационах питания приводит к нарушению иммунной устойчивости организма.
В настоящее время соевый рынок также активно развивается и в России. Однако объемы отечественного производства семян сои явно недостаточны для удовлетворения растущих потребностей промышленности и населения в продуктах их переработки.
Также необходимо отметить, что соя еще недостаточно используется как непременный белковый компонент для многих производств в пищевой промышленности — от консервной, рыбной, мясной, овощной до хлебопекарной и кондитерской. Применение соевых белковых продуктов в пищевой промышленности России распространяется в основном на производство мясных и молочных продуктов (по данным консалтингового агентства Market Advice, 85 % соевого белкового сырья), и только 15 % приходится на другие отрасли пищевой промышленности (хлебопекарную, кондитерскую) [3, 4].
Применение соевых белковых продуктов в пищевой промышленности России распространяется в основном на производство мясных и молочных продуктов (по данным консалтингового агентства Market Advice, 85 % соевого белкового сырья), и только 15 % приходится на другие отрасли пищевой промышленности (хлебопекарную, кондитерскую) [3, 4].
В свете этого актуальной является проблема обогащения соевым белком других категорий пищевых продуктов и повышения эффективности использования соевого сырья, в первую очередь, соевой муки, которая является вторичным продуктом производства соевого масла, содержит в своем составе до 50 % полноценного белка и которая гораздо дешевле, чем соевые белковые изоляты и концентраты [2].
Проблемы со здоровьем чаще всего возникают в результате неправильного питания. Всемирная организация здравоохранения предложила программу изменения структуры питания, которая предусматривает уменьшение потребления насыщенных жиров и холестерина при равноценном обеспечении организма человека растительным белком. Поэтому центральное место в этой программе отводится сое. Она является ценным продуктом здорового, диетического и лечебного питания и одним из пищевых факторов, обуславливающих долголетие человека.
Поэтому центральное место в этой программе отводится сое. Она является ценным продуктом здорового, диетического и лечебного питания и одним из пищевых факторов, обуславливающих долголетие человека.
В настоящее время соя находит применение в основном в двух направлениях. Первое из них связано с тем, что соевые продукты используются как базовые при изготовлении различной продукции. Второе направление более перспективно, но менее развито и заключается в использовании соевых продуктов как универсальной добавки. В этом случае производители пищевых полуфабрикатов видят в применении соевых продуктов источник снижения себестоимости готовых изделий.
Предпочтительность сои для использования в качестве источника белка для питания людей описана в ряде литературных материалов, анализ которых показал перспективу использования белков сои и других растительных белков в производстве диетических продуктов [5, 6]. Установлено, что основной пищевой добавкой при производстве функциональных продуктов в будущем останутся растительные белки, в том числе полученные из сои [7].
Установлено, что основной пищевой добавкой при производстве функциональных продуктов в будущем останутся растительные белки, в том числе полученные из сои [7].
Отмечается, что низкое содержание крахмала или даже его отсутствие в сое придает ей диетические свойства. Углеводы сои ценны тем, что большая их часть хорошо растворима в воде. Минеральная часть, богатая калием и фосфором, имеет щелочную реакцию, в то время как зола злаковых — кислую. Этим объясняется значительное накопление человеческим организмом азота при питании соевым белком. Соевый глицерин, являющийся основным компонентом соевого белка, способствует понижению содержания холестерина в крови. Следовательно, соя является универсальной пищевой добавкой. Ее можно использовать при изготовлении ряда видов продукции: масла, маргарина, печенья, бисквитов, конфет, молока, творога и др. Соя является ценным источником витаминов, особенно витаминов группы В, Д и Е, микро- и макроэлементов, среди которых особенно важно наличие находящегося в усвояемом виде железа, кальция, калия и фосфора и уникального комплекса других важнейших биологически активных компонентов. Поэтому регулярное употребление продуктов на основе сои
Поэтому регулярное употребление продуктов на основе сои
делает их необходимейшим компонентом диеты при железодефицитных анемичных состояниях [8, 9].
Соевые белки являются поистине уникальными для растительных протеинов, так как состав их незаменимых аминокислот почти идентичен составу белков животного происхождения. Именно поэтому во всем мире соя и продукты из нее используются в качестве ингредиентов или полных заменителей грудного женского молока и включаются в состав других специализированных продуктов детского питания. Соевый белок по своей биологической ценности приравнен к белку мяса. Это значит, что суммарное содержание аминокислот в нем достаточно, чтобы обеспечить все метаболические циклы в организме человека. В текстурированных соевых продуктах содержание белка достигает 70 %, а в изолятах — до 92 %. Соевый белок хорошо усваиваются организмом (перевариваемость достигает 95 %) и, в отличие от животных белков, не способствует образованию мочевой кислоты [1, 5, 9].
В сое содержатся жирные полиненасыщенные кислоты, которые незаменимы для человеческого организма. Одна из выполняемых ими функций — связывание и выведение холестерина, что особенно актуально при употреблении значительных количеств животной пищи. Сама соя холестерина не содержит, и это усиливает защитное действие на стенки кровеносных сосудов. Благодаря идеальному соотношению жирных полиненасыщенных кислот, а также отсутствию холестерина продукты из сои являются продуктами лечебно-профилактического назначения. Но они также уникальны и по достаточно высокому содержанию лецитина — фосфолипида особой структуры, играющего чрезвычайно важную роль в функционировании биологических мембран. Наличие лецитина, который принимает важное участие в обмене жиров и холестерина в организме, оказывает активное липотропное действие, уменьшает накопление жиров в печени и способствует их сгоранию, уменьшает синтез холестерина, регулирует правильный обмен и всасывание жиров, обладает желчегонным действием.
Вследствие того, что натуральные продукты из сои не содержат лактозу и холестерин, их предназначение распространяется на специальное и диетическое питание, особенно для детей и людей пожилого возраста. Они незаменимы в диете лиц, страдающих пищевой аллергией на животные белки и, в частности, непереносимостью молока, лиц, страдающих сердечно-сосудистыми заболеваниями, являются уникальным диетотерапевтическим средством для больных диабетом и, безусловно, должны быть включены в рацион людей, страдающих ожирением, а также широко использоваться в профилактике этих распространенных в современном обществе недугов.
Немаловажно также и то, что соевые продукты являются источником пищевой диетической клетчатки, которой также обеднен рацион современного человека на постсоветском регионе. Правда, ее содержание в продуктах из сои не позволяет восполнить необходимую суточную потребность взрослого человека, но позволяет снизить ее дефицит в рационе и даже при имеющемся уровне содержания проявить сорбционные, детоксифицирующие свойства интенсифицировать обменные процессы в организме [5, 3].
Использование соевых бобов объясняется не только исключительно высоким естественным уровнем в них белка высокой биологической ценности, но и набольшим его выходом с единицы сельскохозяйственной площади. В последние годы соя стала в ряде стран одной из ведущих культур. Так, в США по площадям посева (24 %) она занимает третье место после пшеницы (28 %) и кукурузы (28 %). Мировой сбор соевых бобов в 2001 г. составил 164,6 млн т. Для сравнения, Россия собрала в этом же году, по ориентировочным данным, лишь около 0,2 млн т, или 0,12 % от мирового урожая [1].
Основная масса соевых бобов подвергается переработке с получением трех фракций: сырого соевого масла (18 %), обезжиренного шрота (80 %) и оболочечного с зародышем продукта (2 %). Лишь 5-10 % обезжиренного соевого шрота подвергаются переработке для получения пищевых форм соевых белковых продуктов. Таким образом, для
производства пищевой продукции имеется огромный сырьевой потенциал, а с учетом постоянного увеличения сбора сои это не отразится на кормопроизводстве [1].
Предшествующий тысячелетний опыт получения пищевых продуктов из соевых бобов и 40-летний новейший период промышленного внедрения современных технологий по их переработке доказали возможность производства широкой гаммы соевых белковых продуктов, используемых как непосредственно в питании человека, так и в составе большого ассортимента пищевой продукции. Изменение стереотипа питания происходит благодаря высоким пищевым достоинствам соевых белковых продуктов (белки со сбалансированным аминокислотным составом, отсутствием холестерина, сниженное содержание ненасыщенных жирных кислот) и наличию в них биологически активных веществ, имеющих выраженное профилактическое и лечебное действие [10, 11].
В пищевой промышленности существует два принципиально различных подхода к использованию соевых белков. В первом случае они применяются ради их технологических свойств (жиро- и влагосвязывание, стабилизирующая, эмульгирующая способность и др. ) наряду со многими другими конкурентными функциональными ингредиентами. Во втором случае соевые белки не имеют альтернативы, так как их используют из-за уникальных, только им присущих свойств. Промышленное производство продуктов с заданными химическим составом и функциональными свойствами создало основу для получения массовой пищевой продукции с улучшенной пищевой ценностью и в более широком ассортименте, а также продуктов детского, диетического и специализированного питания, направленного лечебно-профилактического действия. При этом соевые белковые продукты нельзя рассматривать лишь в качестве продуктов питания для людей с низкими доходами, поскольку особенности их химического состава и свойств способствуют рационализации питания и оздоровлению всех слоев населения [12, 1].
) наряду со многими другими конкурентными функциональными ингредиентами. Во втором случае соевые белки не имеют альтернативы, так как их используют из-за уникальных, только им присущих свойств. Промышленное производство продуктов с заданными химическим составом и функциональными свойствами создало основу для получения массовой пищевой продукции с улучшенной пищевой ценностью и в более широком ассортименте, а также продуктов детского, диетического и специализированного питания, направленного лечебно-профилактического действия. При этом соевые белковые продукты нельзя рассматривать лишь в качестве продуктов питания для людей с низкими доходами, поскольку особенности их химического состава и свойств способствуют рационализации питания и оздоровлению всех слоев населения [12, 1].
Необходимо отметить, что соя является одной из сельскохозяйственных культур, над которыми в настоящее время производятся генетические изменения. Генномодифицированная (трансгенная, биотехнологическая, клонированная) соя получает широкое распространение в мире. В 1995 г. фирма «Монсанто» (США) выпустила на рынок генетически измененную сою с новым признаком Roundup Ready (далее — RR). RR -торговая марка гербицида, называющегося глифосат, который был изобретён в 1970-х гг. RR-растения содержат полную копию гена EPSP synthase из почвенной бактерии Agrobacterium sp. Strain CP4, перенесенную в геном сои, что делает сою устойчивой к глифосату, применяемому для борьбы с сорной растительностью. С агрономической точки зрения это весьма полезно, так как урожайность сои сильно зависит от наличия сорняков, которые затеняют эту светолюбивую культуру.
Генномодифицированная (трансгенная, биотехнологическая, клонированная) соя получает широкое распространение в мире. В 1995 г. фирма «Монсанто» (США) выпустила на рынок генетически измененную сою с новым признаком Roundup Ready (далее — RR). RR -торговая марка гербицида, называющегося глифосат, который был изобретён в 1970-х гг. RR-растения содержат полную копию гена EPSP synthase из почвенной бактерии Agrobacterium sp. Strain CP4, перенесенную в геном сои, что делает сою устойчивой к глифосату, применяемому для борьбы с сорной растительностью. С агрономической точки зрения это весьма полезно, так как урожайность сои сильно зависит от наличия сорняков, которые затеняют эту светолюбивую культуру.
Привлекательность RR-сои для сельскохозяйственных товаропроизводителей заключается в том, что ее легче и дешевле возделывать, поскольку можно намного эффективнее бороться с сорной растительностью. Вместе с тем употребление в пищу продуктов, содержащих транс-жиры, увеличивает риск сердечно-сосудистых заболеваний. Тем не менее в настоящее время RR-соя выращивается практически на 100 % всех посевных площадей в США, засеянных этой культурой [7].
Применение модифицированной сои при производстве пищевых продуктов должно быть указано в маркировке, для того чтобы покупатель мог сделать выбор в пользу того или иного продукта.
Продукты из сои, такие, как обезжиренная соевая мука, концентраты, изоляты и их текстурированные формы, находят всё более широкое применение в различных отраслях пищевых производств и, прежде всего, в мясоперерабатывающей промышленности. Последнее объясняется тем, что, обладая высокими функциональными свойствами, указанные соевые белковые продукты, заменяя часть более дорогого мясного сырья, не только не изменяют органолептические характеристики конечного изделия, но и снижают
содержание жира и улучшают структуру и внешний вид этих комбинированных продуктов, особенно при использовании низкосортного мясного сырья. При этом подобная замена не отражается на суммарной биологической ценности конечного изделия, так как соевые изоляты и концентраты не уступают мясному белку по этому показателю. Разработаны технологии по включению данных соевых продуктов в рецептуры молочных, хлебобулочных, масложировых и других изделий [13].
Анализируя современное положение в области выращивания и потребления сои, можно сделать вывод, что производство соевых продуктов продолжает расширяться, увеличивается ассортимент таких продуктов, как изоляты, концентраты и текстурированные концентраты соевого белка, а также пищевой полножирной, полужирной, маложирной, обезжиренной и текстурированной соевой муки, которые нашли широкое применение во многих отраслях пищевой промышленности и непосредственно в питании населения. Наряду с этим в Японии, Китае и странах ЮгоВосточной Азии исторически сложилась технология переработки цельных соевых бобовых для получения традиционных в этом регионе продуктов питания, в частности, соевого напитка (так называемое «соевое молоко»), окары, тофу и ряда других, которые используются в системе общественного питания и домашних условиях не только в этих странах.
С одной стороны, Россия занимает одно из последних мест в мире по культивированию сои, что, несомненно, становится в настоящее время серьезной проблемой, а с другой — неблагоприятная структура белкового питания населения свидетельствует о необходимости увеличения использования соевых белковых продуктов как непосредственно в питании человека, так и в пищевых производствах.
Таким образом, роль соевых белковых продуктов трудно переоценить. Их следует рассматривать в качестве обычных, а не экзотических продуктов, характеризующихся присущей им пищевой ценностью, особенности которой, несомненно, будут способствовать улучшению сбалансированности рационов питания.
Учитывая постепенно нарастающую тенденцию к замещению в питании населения России белков животного происхождения на белки зерновых и крупяных культур и картофеля, характеризующихся значительно более низкой биологической ценностью, увеличение использования в пищевых целях соевых белковых продуктов приведет к значительному повышению качества суммарно потребляемого белка.
Использование продуктов переработки сои в пищевой промышленности, в том числе в мясоперерабатывающей, ставит перед исследователями задачу разработки современных методов или модификации существующей методологии качественного и количественного определения содержания сои в пищевых продуктах для информирования потребителей. Это обусловлено действующим российским законодательством в сфере технического регулирования и требованиями мирового рынка.
Список литературы
1. Елисеев А.С. Соя в России и в мире: история культуры и особенности её возделывания [Текст] / А.С. Елисеев // Аграрное обозрение. — 2010. — № 3 (19). — С. 69.
2. Подобедов А.В. Уникальные свойства сои [Текст] / А.В. Подобедов // Достижения науки и техники АПК. — 2002. — № 6. — С. 42-45.
3. Годон Б.С. Растительный белок [Текст] / Б.С. Годон; [пер. с фр. В.Г. Долгополова / под ред. Т.П. Микулович]. — М.: Агропромиздат, 1991. — 684 с.
4. Скрипко О.В. Рыбные продукты функционального назначения с использованием сои [Текст] / О.В. Скрипко // Пищ. пром-сть. — 2008. — № 9. — С. 70-72.
5. Зобкова З.С. Продукты на основе соевых компонентов для профилактики и диетического питания [Текст] / З.С. Зобкова // Молоч. пром-сть. — 199В. — № 5. — С. 15-16.
6. Гаврилова Н.Б. Производство диетических комбинированных молочных продуктов [Текст] / Н.Б. Гаврилова, Л.В. Скрипникова. -Семипалатинск, 1994. — 18 с.
7. Лошкова Е.Н. Изучение функциональных свойств соевых белковых препаратов, полученных из генномодифицированных источников [Текст] / Е.Н. Лошкова // Пища. Экология. Человек: материалы V Междунар. науч. -техн. конф. — М., 2003. — С. 86-В7.
В. Львов В.О. Возможность использования сои в производстве комбинированных молочных продуктов [Текст] / В.О. Львов // Maisto chemija ir technologija. Konferencijos pranesim4 medziaga. Kaunas. — 2QQ1. — C. 3В.
9. Мендельсон Г.И. Значение соевых белковых продуктов в питании
человека [Текст] / Г.И. Мендельсон // Пищ. пром-сть. — 2QQ4. — № 6. — С. 90-91.
1Q. Малина И.Л. Практические аспекты технологий производства
комбинированных молочных продуктов [Текст] / И.Л. Малина, А.А. Мухин // Пищ. пром-сть. — 2QQ1. — № 2. — С. 22-23.
11. Шестобитов В.В. К вопросу о соевом молоке [Текст] / В.В. Шестобитов // Молоч. пром-сть. — 2QQ3. — № 1. — С. 53-54.
12. Павлов В.А. Производство и использование соевого белка в молочной промышленности [Текст] / В.А. Павлов, А.М. Колодкин, Л.И. Линецкая. — М.: АгроНИИТЭИММП, 1988. — 32 с.
13. Сулимина О.Г. Международный семинар по производству соевых продуктов [Текст] / О.Г. Сулимина // Пищ. пром-сть. — 2QQ1. — № 4. — С. 14-15.
Сведения об авторах: Смагина Анна Владимировна, инженер, e-mail: [email protected];
Сытова Марина Владимировна, кандидат технических наук, доцент, e-mail: [email protected].
Что россияне часто ищут на iHerb — и насколько эти средства полезны и безопасны
Издание Reminder изучило самые популярные запросы на iHerb.
57 549 просмотров
Россия стала особенным рынком для американского маркетплейса iHerb. По данным сервиса Similarweb, почти 21,5% посетителей сайта в декабре 2019 года — из нашей страны. Доля Соединенных Штатов, для сравнения, всего 12%.
Что привлекает россиян на iHerb? Недорогие пищевые добавки, суперфуды и косметика, в описании которых часто встречаются слова «органический» и «натуральный».
Правоохранительные органы не раз пытались запретить iHerb, поскольку там продаются незарегистрированные в России и «небезопасные биологически активные добавки к пище».
Но пока маркетплейс не сдается: в конце прошлого года компания открыла в Москве официальное подразделение и зарегистрировала юрлицо. В планах: заключить партнёрство с местными ритейлерами Ozon и Wildberries, что сократит сроки доставки заказов до пары дней. Кто победит в этой битве, пока неясно.
Reminder изучил список самых популярных поисковых запросов россиян на iHerb и рассказывает, насколько искомые товары полезны и безопасны.
Омега-3
По запросу «омега 3» на ru.iherb.com можно найти 1161 товар. Подавляющее большинство — пищевые добавки, изготовленные из рыбьего жира, одного из источников омега-3.
Омега-3 — это общее название одной из групп особых органических соединений, полиненасыщенных жирных кислот. В результате химических реакций они превращаются в фосфолипиды (соединения фосфора и жиров).
Из них строятся мембраны всех клеток нашего организма, которые поддерживают их целостность, защищают от внешних воздействий и отвечают за клеточный обмен веществ. Кроме того, они способны бороться с воспалением сосудов и их сужением сосудов из-за холестериновых бляшек.
Синтезировать самостоятельно кислоты омега-3 наш организм не умеет. Поэтому мы должны получать их из внешних источников — то есть из пищи. Особенно богаты омега-3: рыба жирных сортов, морепродукты, орехи, семена некоторых растений (например, льна или конопли).
Полноценно и разнообразно питаясь (например, два-три раза в неделю съедая по 120 г рыбы), человек может полностью покрыть свою потребность в этих веществах.
Необходимость в приеме препаратов омега-3 может возникнуть при аллергиях, не позволяющих употреблять продукты, содержащие полиненасыщенные кислоты. Или из-за пищевых предпочтений, например, нелюбви к рыбе. Но в любом случае, решение о назначении конкретных средств должен принимать врач.
В остальные случаях, если человек здоров, дополнительные дозы омега-3 в виде пищевых добавок, скорее всего, не дадут особого эффекта.
Так, крупное исследование VITAL, участники которого в течение 5,3 лет принимали добавки по 1 г полиненасыщенных жирных кислот, показало, что это вещества не способны предотвращать серьезные сердечно-сосудистые заболевания. Также их прием не снижает проявления депрессии. И даже не лечит синдром сухого глаза.
Витамин D
По запросу «витамин D» сайт ru.iherb.com выдает 4247 товаров. Это также пищевые добавки, содержащие холекальциферол — D3 или эргокальциферол — D2. И то, и другое — биологически активные вещества, входящие в группу под общим названием «витамин D».
Основная задача витамина D — обеспечивать усвоение фосфора и кальция, главных строительных элементов для наших костей. При их дефиците может развиться остеомаляция. Это заболевание, при котором уменьшается минерализация костей из-за чего они становятся патологически гибкими и деформируются.
В пожилом возрасте недостаток витамина D способен вызвать остеопороз — еще одно заболевание, характеризующееся снижением плотности костей. Витамин необходим и для множества других процессов — например, для успешного функционирования механизма нервной проводимости, для работы иммунной системы.
Организм человека получает витамин D весьма специфичным способом. D3 синтезируется в коже под воздействием солнечных лучей. Кроме того, в не очень больших количествах, он содержится в пище (а D2 мы получаем только из нее). Например, в той же рыбе, яичных желтках, сливочном масле или грибах лисичках.
Именно поэтому, предполагается, что добрать необходимую организму дозу витамина D непросто, особенно в странах с низкой инсоляцией (Россия к ним относится). Что может приводить к той самой опасной хронической недостаточности этого вещества, а впоследствии и к его дефициту.
Эти состояния диагностируется с помощью анализа, определяющего концентрацию одной из форм витамина D — 25(OH)D (25-гидроксивитамин D или кальцидиол) в плазме крови. Она измеряется в нанограммах на моль.
По российским клиническим рекомендациям 2015 года, менее 20 нг/мл кальцидиола в плазме указывает на дефицит, менее 30 нг/мл — на недостаточность этого вещества. И то, и другое медицинские организации советуют корректировать с помощью лекарственных препаратов, содержащих D3 или D2. Назначать их и выбирать схему приема должен врач.
Тем не менее в последнее время в медицинском сообществе спорят, нужно ли в действительности бороться с недостатком витамина D. Тем более, что многочисленные исследования показывают, что прием добавок с витамином D не снижают частоту возникновения рака и сердечно-сосудистых заболеваний, как считалась раньше.
Коллаген
Результов по запросу «коллаген» на ru.iherb.com — 856.
По большей части это тоже пищевые добавки, содержащие коллаген различного, как утверждают производители, происхождения: животного (например, из кожи и костей свиней и коров), растительного (производят из аминокислот, добытых из водорослей и пшеницы) или так называемого морского (получают из кожных покровов рыб).
Коллаген — самый распространенный белок в нашем организме, составляющий основу соединительной ткани. Он обеспечивает эластичность кожи и костно-мышечной системы: суставов, сухожилий, хрящей.
Хорошая новость: наш организм синтезирует весь нужный ему коллаген сам из аминокислот, витаминов С и А и меди. Этот процесс идет постоянно. Однако с возрастом, он замедляется: после 20 лет человек начинает терять примерно 1,5% своего коллагена ежегодно.
Как настаивают производители пищевых добавок, если принимать коллаген дополнительно — можно улучшить состояние суставов, омолодить кожу, укрепить волосы и ногти. Но с точки зрения физиологии, процесс кажется сомнительным.
Попадая в организм коллаген из пищевой добавки не сможет напрямую поступить в нашу кожу или волосы и сразу же укрепить их. Он пройдет тот же путь что и любая другая пища: расщепится в пищеварительном тракте на свои составляющие — собственно аминокислоты.
Они всасываются и в дальнейшем действительно используются организмом для создания в том числе и эндогенного коллагена. Хитрость в том, что точно такие же аминокислоты мы получаем, например, выпивая молоко или съедая котлету.
Впрочем, в базах научных работ есть исследования — правда, небольшие и не особенно убедительные — подтверждающие, что добавки с этим белком работают. Например, одно из них доказывает, что прием гидролизованного коллагена способен повысить эластичность кожи. Но в нем принимали участие всего 18 женщин.
Авторы другой работы утверждают, что прием одной конкретной биодобавки Pure Gold Collagen с коллагеном и другими веществами, способен минимизировать видимые признаки старения кожи. Другие препараты в работе не рассматривались.
Магний
По запросу «магний» на ru.iherb.com можно найти 5996 товаров. Это, по преимуществу, биодобавки, содержащие магний в различных формах, а также в комбинации с другими веществами, которые должны, по утверждению производителей, повышать его всасываемость.
Магний — еще один критически важный для нормального функционирования человеческого организма микроэлемент. Он участвует во множестве реакций и процессов, например, в синтезе белка, создании ДНК и формировании костей, регуляции уровня глюкозы в крови, контроле работы нервной системы и в сокращении мышц при движении.
Дефицит магния встречается не часто. Спровоцировать его могут: алкоголизм, заболевания желудочно-кишечного тракта, мешающие всасыванию магния, диабет второго типа, и другие патологические состояния.
А вот недостаточность магния, даже в развитых странах, обнаруживается не редко. Так, примерно 50% американцев потребляет меньше магния, чем требуется организму. Главная причина этого: неправильный — в основном, однообразный — рацион питания.
Весь магний мы получаем, опять же, с пищей: он есть и в продуктах животного происхождения (лососе и молоке, например), и в продуктах растительного происхождения (фруктах, овощах, зерновых, бобовых, орехах — арахисе, миндале, кешью). Лучший источник — листовые овощи: особенно хорош для пополнения запасов магния шпинат.
Здоровым, полноценно питающимся людям нет никакой необходимости принимать пищевые добавки с магнием. Тем более, что дополнительными чудодейственными эффектами они, вероятно, не обладают.
Например, нет качественных научных данных, что препараты с магнием способны уменьшить симптомы депрессии. Но установлено, что они точно не справляются с послеродовой депрессией и тревожностью.
Кроме того, есть только одна научная работа, подтверждающая, что магний помогает организму снижать стресс от высокой физической нагрузки во время интенсивных занятий спортом. Правда, опубликована она была в далеком 1998 году, и с тех пор её результаты не перепроверялись.
Витамин C
По запросу «Витамин С» на ru.iherb.com можно найти 359 товаров. Большая часть — пищевые добавки в виде капсул или таблеток (детский вариант — жевательные конфеты), содержащие аскорбиновую кислоту («официальное» название витамина С) в различных дозировках.
С — один из наиболее изученных витаминов. Он участвует в обменных процессах и в формировании того же коллагена. Является антиоксидантом, то есть защищает организм от свободных радикалов, которые приводят к старению клеток. Повышает усвоение негемового железа — той формы этого вещества, которая содержится в растениях.
Дефицит витамина С логичным образом может привести, например, к снижению синтеза коллагена (в особо запущенных формах — к цинге, болезни, в ходе которой теряется прочность соединительной ткани) и анемии (снижению гемоглобина в крови, одной из причин которого может быть недостаточное поступление железа).
Но в современных развитых странах, большинство населения которых имеет доступ к основным группам продуктов, дефицит витамина С встречается редко. Лучшие источники аскорбинки — овощи и фрукты. Например, сладкий перец, цитрусовые (особенно апельсины и грейпфруты), киви, клубника и брокколи.
Серьезных научных доказательств, что повышенные дозы витамина С приносят организму пользу, практически нет. Например, учеными давно опровергнут миф о том, что регулярный прием аскорбинки помогает бороться с простудами: реже болеть ими, а если уж не повезло — легче выздоравливать.
Кроме того, до сих пор точно не установлено, обладают ли высокие дозы витамина С противораковым эффектом и минимизируют ли они последствия химической терапии, как было принято считать еще недавно.
При этом, принимать большое количество аскорбинки небезопасно (верхний допустимый уровень потребления — 2000 мг/сут). Высокие дозы провоцируют желудочные колики, тошноту и диарею. И могут привести к более серьезным последствиям, например, к мочекаменной болезни.
Омега-3 для детей
Результов по запросу «омега-3 для детей» на ru.iherb.com — 153. Это также пищевые добавки — часто с ароматизаторами — в жидком виде, а также в виде капсул, жевательных конфет. Многие произведены из натурального рыбьего жира.
Младенцы обычно получают омега-3 с грудным молоком, дети постарше — с пищей. И если ребенок питается полноценно, дефицита этих кислот у него обычно не возникает.
Польза от приема детьми добавок с омега-3 без показаний не очевидна. Например, считалось, что они способны улучшить когнитивные способности ребенка — память и способность к обучению.
Но результаты опубликованного в 2018 году исследования, проведенного командой ученых из университетов Бирмингема и Оксфорда, опровергают это.
Под их наблюдением 376 школьников 7–9 лет были разделены на две группы. До начала эксперимента были протестированы их навыки чтения и работа кратковременной памяти. После чего дети, попавшие в первую группу, начали ежедневно принимать по 600 мг омега-3. Вторая группа получала плацебо.
Спустя 16 недель дети прошли повторное тестирование, и никакой существенной разницы в результатах обеих групп обнаружено не было.
Впрочем, у ученых есть некоторые основания полагать, что прием омега-3 снижает интенсивность симптомов расстройств аутического спектра у детей. Но механизм работы пищевых добавок в этом случае пока не ясен.
Витамин D для детей
По запросу «витамин Д для детей» на ru.iherb.com обнаруживается 539 результатов. Это пищевые добавки — тоже часто с ароматизаторами — в виде капсул, жевательных конфет, а также различные продукты (каши, хлопья, снеки), обогащенные витамином D.
Ситуация с этим микроэлементом особая: ВОЗ, а вслед за ней и официальные медицинские организации большинства стран (например, США и Великобритании) советуют с рождения давать ребенку содержащие витамин D пищевые добавки.
Дело в том, что в первые месяцы жизни дети редко бывают на открытом солнце. Поэтому витамин D они получают, как и все прочие питательные вещества, в основном, с грудным молоком. Состав которого напрямую зависит от того, что ест мама и от особенностей её организма.
Если уровень витамина D у неё невысок, значит, его будет мало и в молоке. Из-за чего у ребенка может развиться дефицит. Это может привести к серьезным последствиям: рахиту (костным деформациям, которые остаются во взрослом возрасте), судорогам и затрудненному дыханию у грудничков.
В 2016 году Всемирный консенсус по профилактике и лечению нутритивного рахита рекомендовал назначать детям в возрасте до 12 месяцев витамин D в количестве 400 МЕ в сутки, а после 12 месяцев — 600 МЕ в сутки.
Принимать препараты требуется без перерывов круглый год. При этом педиатры настаивают, что лучше использовать не биологически активные добавки, а зарегистрированные лекарственные — так называемые «аптечные» — препараты, производство и состав которых контролируются.
Кокосовое масло
Поиск по запросу «кокосовое масло» на ru.iherb.com позволяет найти 2293 товара. В основном, это натуральное кокосовое масло и различные косметические средства из него.
Кокосовое масло получают из белой мякоти зрелых кокосов. Его давно используют жители Индии, Малайзии и других стран Юго-Восточной Азии. На Запад оно попало в XIX веке, и что любопытно, до 1950-х широко использовали для приготовления пищи.
Потом интерес к этому продукту стал спадать — из-за исследваний, в которых ставилась под сомнение его польза. Но в середине 2000-х кокосовое масло на Западе вновь стало популярным.
Современные адепты этого продукта успели придумать десятки вариантов его применения. В том числе самых экзотических: маслом советуют чистить ванную, натирать деревянную мебель (якобы это дезинфицирует и защищает от пересыхания), смазывать подушечки лап котам и собакам, разжигать костер.
Но чаще всего кокосовое масло употребляют в пищу (готовят на нем) и используют его для ухода за кожей и волосами. И то, и другое вызывает некоторые вопросы. Дело в том, что кокосовое масло более чем на 82% состоит из насыщенных жиров. Их связывают с повышенным риском сердечно-сосудистых заболеваний.
Поэтому потребление насыщенных жиров рекомендуется снижать: в рационе человека они должны составлять менее 10% от общего потребления энергии.
Для наружного применения — увлажнения кожи в частности, — кокосовое масло также, вероятно, средство не идеальное. Дело в том, что оно обладает довольно высоким уровнем комедогенности. То есть, способно привести к закупориванию и загрязнению пор кожи, и как следствие, вызывать акне.
Статья подготовлена онлайн-изданием Reminder, которое посвящено здоровью, психологии и практической философии. Больше полезной информации можно найти на наших страницах в Facebook, Telegram или в рассылке.
Другие материалы на Reminder:
Закодированная еда: безвредные и опасные добавки с индексом «Е»
Добавки – лучшие помощницы пищепрома: они дарят маргарину гладкую текстуру, увеличивают срок хранения салатов, придают аппетитный цвет колбасам и сосискам. Однако многие потребители скептически относятся к пищевым добавкам и воспринимают наличие «Е» на этикетке как сигнал опасности. Мы спросили у эксперта, стоит ли так категорично относиться ко всем «Е-шкам»?
Владимир Бессонов
Кандидат химических наук, доктор биологических наук, заведующий лабораторией химии пищевых продуктов ФГБУН «ФИЦ питания и биотехнологии»
– Само слово «добавка» практически стало синонимом слову «вред», и совершенно напрасно. Пищевые добавки (прошу не путать их с вкусоароматическими веществами, ароматизаторами, которые не являются пищевыми добавками) ежегодно рассматриваются на совещаниях Комитета Комиссии «Кодекс Алиментариус» по пищевым добавкам (CCFA), в которых принимают участие эксперты всех стран. Россию в комитете представляет Институт питания и биотехнологии Российской академии медицинских наук.
Как на самом деле производят вкусоароматические вещества и ароматизаторы, смотрите ЗДЕСЬ.
CCFA подчиняется как Всемирной организации здравоохранения (ВОЗ), так и Продовольственной и сельскохозяйственной организации ООН (FAO). На заседаниях CCFA эксперты делятся новыми данными о рисках использования пищевых добавок и принимают решение об изменении норм их использования, сокращении их списка. Они также рассматривают данные о новых добавках и оценивают необходимость их использования в производстве пищевых продуктов.
Почему «Е» и что стоит за трехзначными номерами?
Потребители часто спрашивают, откуда взялась эта самая буква «Е». Буква «Е» – от первой буквы в слове «Europa», потому что в странах Европейского сообщества в 1953 году была создана система цифровой идентификации. А еще от слов essbar/edible, что в переводе с немецкого/английского означает «съедобный».
Классификация пищевых добавок
Е100 – Е199 – красители пищевые (окрашивают).
Е200 – Е299 – консерванты (помогают сохранять продукт, увеличивают срок годности).
Е300 – Е399 – антиоксиданты (замедляют процесс окисления).
Е400 – Е499 – стабилизаторы (придают продуктам желаемую форму и текстуру).
Е500 – Е599 – эмульгаторы (придают продуктам желаемую консистенцию).
Е600 – Е699 – усилители вкуса и аромата.
Е700 – Е899 – зарезервированные номера для другой возможной информации.
– Трехзначный индекс «Е», присвоенный добавке, говорит о том, что она проверена на качество и безопасность. Разрешенные добавки не должны настораживать покупателей, однако решение об их употреблении каждый принимает сам, – подчеркивает Владимир Бессонов.
СПРАВОЧНО
Применение пищевых добавок регламентируется «Санитарно-эпидемиологическими правилами и нормативами СанПиН 2.3.2.1293-03 «Гигиенические требования по применению пищевых добавок» и техническим регламентом Таможенного союза (ТР ТС) 029/2012 «Требования безопасности пищевых добавок, ароматизаторов и технологических вспомогательных средств». Список пищевых добавок, разрешенных в России, утверждает Минздрав РФ, а государственный контроль их качества осуществляют органы Роспотребнадзора.
Каких добавок не стоит бояться?
Человек давно и успешно использует разные «пищевые добавки». Самыми известными консервантами являются, например, соль и сахар, а красителями – сок свеклы и моркови. С введением индекса «Е» многие известные продукты стали обозначать в маркировке под определенными цифрами. Например, яблочному пектину – Е440, лимонной кислоте – Е330, аскорбиновой – Е300 и т. д. В маркировке эти обозначения не расшифровывают, и поэтому большинству потребителей непонятно, что это за «шифры».
– Из-за неосведомленности потребителей стали появляться статьи, в которых «знатоки» утверждают, что все «Е» могут быть опасны для человека. Да, любая из перечисленных добавок действительно может нанести вред здоровью, если употребить большое количество в чистом виде, но это противоречит здравому смыслу. К тому же, следуя этой логике, можно надорвать организм любыми полезными продуктами, например яблоками, поедая их без меры, – уточняет Владимир Бессонов.
В ряде продуктов использование некоторых добавок оправдано соображениями безопасности. Например, известный консервант нитрит натрия (Е250) чаще всего используется при производстве вареных, сырокопченых, солено-копченых и вяленых мясных продуктов, так как он является фиксатором окраски колбас. Кроме этого, Е250 обладает антибактериальными свойствами и даже защищает продукт от бактерий ботулизма.
Нитрит натрия Е250: для чего используется этот консервант, в каких продуктах его можно встретить и сколько можно съесть продукта, содержащего эту добавку, читайте ЗДЕСЬ.
Слухи о вреде сильно преувеличены
Обычного покупателя пугают любые ингредиенты, названия которых ему неизвестны или напоминают урок химии. Например, бензойная кислота (пищевые добавки Е210 – Е213). В клюкве есть бензойная кислота, она предохраняет ягоды от порчи, повышает срок хранения. Это ее свойство выделили, охарактеризовали и начали использовать. В зрелых сырах тоже есть бензойная кислота, она образуется при действии культур закваски, благодаря этому зрелый сыр не портится.
Бензойную кислоту можно получить и путем химического синтеза, но с точки зрения аналитической химии она неотличима от бензойной кислоты, выделенной из плодов растений.
Тем не менее содержание бензойной кислоты как внесенной пищевой добавки нормируется соответствующим техническим регламентом ТР ТС 029/2012. Поскольку технические регламенты устанавливают требования к безопасности продукции, то превышение содержания данной пищевой добавки может представлять потенциальный риск для здоровья человека. Допустимая безопасная суточная доза для человека – 5 мг/кг массы тела.
Среди потребительских опасений существует и страх о том, что производители пичкают продукты глутаматом натрия, чтобы сделать более насыщенными вкус и аромат. Наш эксперт считает, что слухи о вреде глутамата натрия (Е621) сильно преувеличены.
– Любой белок содержит глутаминовую кислоту – это одна из 20 аминокислот, входящих в состав любого белка, – объясняет Владимир Бессонов. – Пищевая добавка глутамат натрия получается в результате растворения этой кислоты. Следовательно, во всех белковых продуктах можно найти глутамат натрия или его следы – и в тех, куда его добавили специально, и в тех, куда не добавляли. Е621 работает на наши вкусовые рецепторы, делая продукты более аппетитными, привлекательными. В списке аллергенов Е621 не значится. Сведения о вреде Е621 отсылают нас к опыту, когда-то проведенному на мышах, который показал, что глутамат натрия оказывает негативное влияние, но при сверхувеличенной дозе – более 10 г усилителя на 1 кг массы тела. Для взрослого человека это приблизительно 700 г в сутки сухой чистой пищевой добавки. Кроме того, если в пищу положить предельно допустимую дозу, то мы не сможем есть такой продукт, потому что он будет невкусным.
Кроме глутамата существуют и другие усилители вкуса – Е626 – Е629 (гуанилаты) и Е630 – 639 (инозинаты). Подробнее о них читайте ЗДЕСЬ.
Еще один консервант, который часто используют в пищевой промышленности, – диоксид серы Е220. Это разрешенная добавка, которая, во-первых, предотвращает размножение бактерий и грибов. Во-вторых, тормозит ферментативное потемнение фруктов и овощей и, в-третьих, увеличивает срок годности продуктов.
СПРАВОЧНО
Следует иметь в виду, что диоксид серы является аллергеном (таким же, как, например, арахис, орехи, молоко и продукты его переработки). Следовательно, согласно ТР ТС 022/2011 «Пищевая продукция в части ее маркировки», производитель обязан выносить на этикетку Е220, если содержание этой добавки в продукте более 10 мг/кг. Если на этикетке не указан диоксид серы, то его там должно быть меньше.
Диоксид серы активно применяют и в производстве вин. Подробнее о том, как используют этот консервант виноделы и стоит ли опасаться данной добавки, читайте ЗДЕСЬ.Какие Е-добавки разрешены при производстве вареной колбасы, читайте ЗДЕСЬ.
Изгои среди добавок
Тем не менее в разное время какие-то добавки запрещались в России, значит, на это были причины. Эксперт комментирует такие случаи.
– У нас были запрещены некоторые парабены и краситель «красный 2G» (Е128), но не потому, что они были ядовитыми или токсичными, а потому, что во время исследования было выявлено, что они могут спровоцировать «возможные неблагоприятные эффекты от их использования». Показательно, что для объявления добавки с индексом «Е» вне закона достаточно подозрения в том, что добавка может быть потенциально опасной для здоровья человека. Таким образом, реализуется принцип минимизации рисков для здоровья человека. Малейшее сомнение трактуется как запрет, – уточняет Владимир Бессонов.
При этом процедура введения пищевой добавки в список разрешенных невероятно трудоемкая и длительная.
Представитель какого-либо государства с подачи внутреннего производителя обращается в Комитет Комиссии «Кодекс Алиментариус» по пищевым добавкам (CCFA) с просьбой рассмотреть предложение о введении добавки. Затем начинается обсуждение необходимости ее введения, что требует доказательств. Если принято положительное решение, создается международная рабочая группа, которая тщательно изучает все известные документы о предложенной добавке, ее эффектах. Дальнейшее рассмотрение предполагает восемь стадий. Так как комитет собирается один раз в год, добавка будет обсуждаться в лучшем случае восемь последующих лет. Есть вероятность отката на год назад, если у членов комитета возникнут сомнения. За это время накапливаются необходимые сведения о возможных особенностях использования добавки. Нередко этот процесс затягивается на 20 лет.
Список неразрешенных добавок в РФ
Е103 – алканин (краситель).
Е121 – «цитрусовый красный 2» (краситель).
Е123 – «красный амарант» (краситель).
Е128 – «красный 2G» (краситель).
Е216 – пара-гидроксибензойной кислоты пропиловый эфир, группа парабенов (консервант).
Е217 – пара-гидроксибензойной кислоты пропилового эфира натриевая соль (консервант).
Е240 – формальдегид (консервант).
Доказано, что применение таких добавок может нанести вред организму. (По данным Роспотребнадзора.)
Благодарим за то, что дочитали этот текст до конца. Следите за новостями, подписывайтесь на рассылку.
При цитировании данного материала активная ссылка на источник обязательна.
Пищевая биотехнология
CHOOSING A PROPIONIX — FOOD BIOTECHNOLOGY
БИОТЕХНОЛОГИЯБИОТЕХНОЛОГИЯ — производственное использование биологических агентов (в частности микроорганизмов) для получения полезных продуктов и осуществления целевых превращений. В биотехнологических процессах также используются такие биологические макромолекулы как белки — чаще всего ферменты, рибонуклеиновые кислоты.
Биотехнология — это наука об использовании биологических процессов в технике и промышленном производстве. Название ее происходит от греческих слов bios — жизнь, teken — искусство, logos — слово, учение, наука. В соответствии с определением Европейской федерации биотехнологов (ЕФБ, 1984) биотехнология базируется на интегральном использовании биохимии, микробиологии и инженерных наук в целях промышленной реализации способностей микроорганизмов, культур клеток тканей и их частей. Уже в самом определении предмета отражено его местоположение как пограничного, благодаря чему результаты фундаментальных исследований в области биологических, химических и технических дисциплин приобретают выраженное прикладное значение.
Биотехнология – междисциплинарная область знания, и в XXI в. она займет ключевые позиции в цикле естественных наук. Исходя из определения, данного выше, современным биотехнологам необходимо хорошо знать не только биологию, но и молекулярную генетику и цитологию, генетику и молекулярную медицину, вирусологию, микробиологию и биохимию, технологию производства ферментных препаратов и других биотехнологических производственных процессов. С биоинформатикой и системной биологией тесно связаны компьютерные и информационные технологии. Поэтому неудивительно, что до сих пор не существует кратких и содержательных учебных пособий по биотехнологии, которые охватывали бы эту дисциплину во всем ее многообразии. В дополнительном материале в кратком описательном перечне указаны некоторые популярные направления (+ необходимые знания) из большого многообразия задач научно-прикладной дисциплины XXI века.
Основным направлением компании ООО «Пропионикс» является пищевая биотехнология
ПИЩЕВАЯ БИОТЕХНОЛОГИЯБиотехнология пищевая (пищевая биоиндустрия) — раздел биотехнологии, занимающийся разработкой теории и практики создания пищевых продуктов общего, лечебно-профилактического назначения и специальной ориентации.
История биотехнологии. Использование в промышленном производстве микроорганизмов или их ферментов, обеспечивающих технологический процесс, известно издревле, однако систематизированные научные исследования позволили существенно расширить арсенал методов и средств биотехнологии. Люди выступали в роли биотехнологов с незапамятных времен: занимались хлебопечением и сыроделием, производили другие кисломолочные продукты и варили пиво, используя различные микроорганизмы даже не подозревая об их существовании. Сам термин «биотехнология» появился в нашем языке недавно, ранее его заменяли словами «промышленная микробиология» или «техническая биохимия». Впервые термин «биотехнология» применил венгерский инженер Карл Эреки в 1917 году.
По видимому, древнейшим биотехнологическим процессом было брожение. Об этом свидетельствует описание способа приготовления пива, обнаруженное на дощечке, найденной при раскопках Вавилона, которая датируется 6-м тысячелетием до н. э. Известно, что в третьем тысячелетии до н. э. шумеры могли изготовлять уже около двадцати сортов пива. Не менее древними являются и такие процессы, как виноделие, получение кисломолочных продуктов и выпекание хлеба. Иными словами, биотехнология — это наука о методах и технологиях производства различных веществ и продуктов с использованием природных биологических объектов и процессов. И это есть ее традиционное, классическое понимание…
Несведущий в микробиологии видит практическое значение микроорганизмов в первую очередь во вреде, который они причиняют человеку, животным и растениям. Этими болезнетворными (патогенными) микроорганизмами и их специфическими особенностями занимаются такие науки, как медицинская и ветеринарная микробиология, а также фитопатология. Хотя микроорганизмы и в других сферах природы, и в промышленности выступают иногда в роли вредителей, их роль как полезных организмов существенно преобладает. Они уже давно завоевали себе прочное место в домашнем хозяйстве, а в промышленности они совершенно необходимы. Их используют в самых различных отраслях от первичной переработки сельскохозяйственных продуктов до катализа сложнейших этапов химических синтезов.
*Применительно к направлению деятельности ООО «Пропионикс» см. также:
Глобальные технологические тренды — Биотехнологии – Еда как источник здоровья (Трендлеттер НИУ ВШЭ # 15 • 2015)
Классические микробиологические производства: Как было уже отмечено выше, на примере пивоварения и виноделия с использованием различных дрожжей, выпечки хлеба и приготовления молочных продуктов с помощью молочнокислых бактерий, а также получения пищевого уксуса при участии уксуснокислых бактерий становится очевидным, что микроорганизмы относятся к старейшим культурным «растениям».
В Японии и Индонезии соевые бобы издавна перерабатываются с помощью мицелиальных грибов, дрожжей и молочнокислых бактерий. Если не считать получения этанола, в промышленном производстве индивидуальных веществ микроорганизмы начали использовать лишь в последние шестьдесят лет.
Уже в период первой мировой войны с помощью управляемого дрожжевого брожения получали глицерин. Молочная и лимонная кислоты, в больших количествах необходимые для пищевой промышленности, производятся с помощью молочнокислых бактерий и гриба Aspergillus niger соответственно. Из дешевых, богатых углеводами отходов путем брожения, осуществляемого клостридиями и бациллами, можно получать ацетон, бутанол, 2-пропанол, бутандиол и другие важные химические соединения.
Новые микробные производства
Классические виды брожения дополняются новыми применениями микробов в химических производствах. Из грибов получают каротиноиды и стероиды. Когда выяснилось, что Corynebacterium glutamicum из сахара и соли аммония с большим выходом синтезирует глутаминовую кислоту, были выделены бактерии и разработаны методы, с помощью которых можно в больших масштабах производить многие аминокислоты, нуклеотиды и реактивы для биохимических исследований.
Микроорганизмы используются химиками в качестве катализаторов для осуществления некоторых этапов в длинной цепи реакций синтеза; микробиологические процессы по своей химической специфичности и по выходу продукта превосходят химические реакции; ферменты, применяемые в промышленности, — амилазы для гидролиза крахмала, протеиназы для обработки кож, пектиназы для осветления фруктовых соков и другие — получают также из культур микроорганизмов. Все это и многое другое показывает огромный потенциал т.н. прикладной микробиологии и биохимии.
Пищевая и сельскохозяйственная биотехнологииПрименительно к профилю компании ООО «Пропионикс» следует отметить два важных направления биотехнологии: пищевую и сельскохозяйственную. Данные направления хорошо раскрыты в комплексной программе развития биотехнологий в Российской Федерации на период до 2020 года (утв. Правительством РФ от 24 апреля 2012 г. N 1853п-П8)
Стратегической целью Программы является выход России на лидирующие позиции в области разработки биотехнологий, в том числе по отдельным направлениям биомедицины, агробиотехнологий, промышленной биотехнологии и биоэнергетики, и создание глобально конкурентоспособного сектора биоэкономики, который наряду с наноиндустрией и информационными технологиями должен стать основой модернизации и построения постиндустриальной экономики.
Долгосрочной целью реализации Программы является выход в 2020 году на объем биоэкономики в России в размере около 1% ВВП и в 2030 году — не менее 3% ВВП
В программе выделены основные приоритетные направления развития биотехнологий в России. К ним относятся:
1. Биофармацевтика
2. Биомедицина
3. Промышленная биотехнология
4. Биоэнергетика
5. Сельскохозяйственная биотехнология
6. Пищевая биотехнология
7. Лесная биотехнология
8. Природоохранная (экологическая) биотехнология
9. Морская биотехнология
6. Пищевая биотехнологияСовременная пищевая биотехнология представляет собой индустрию пищевых ингредиентов — вспомогательных технологических добавок, вводимых в пищевые продукты в процессе их изготовления для повышения их полезных свойств.
Огромное количество пищевых ингредиентов в настоящее время импортируется, в связи с чем организация их производства в России является актуальной, социально востребованной задачей.
6.1. «Пищевой белок»
Человек традиционно получает белки, жиры и углеводы (основные компоненты пищи) из животных и растительных источников. Уже сегодня эти источники не покрывают все увеличивающиеся потребности человечества.
Современные методы биотехнологий в сочетании с применением ультра- и нанофильтрационных систем делают экономически обоснованным извлечение пищевого белка из широкого класса сырьевых продуктов и отходов пищевой промышленности. Таким образом, комплекс мероприятий направлен на распространение технологий, превращающих малоценные отходы в белковые продукты и компоненты с высокой добавленной стоимостью.
6.2. «Ферментные препараты»
Ферменты, применяемые в пищевых производствах, являются продуктами с высокой добавленной стоимостью, в России практически не производятся. Развитие данного направления позволит создать компактный по масштабам, но высокоэффективный сектор, являющийся с одной стороны базой развития всех направлений пищевой отрасли, направленных на глубокую переработку сырья, с другой стороны, производство пищевых ферментов обладает высоким экспортным потенциалом.
6.3. «Пребиотики, пробиотики, синбиотики»
Развитие производства и пищевого инжиниринга продуктов данной группы является необходимым элементом для формирования в России рынка здорового питания. Задачей данного комплекса мероприятий является создание пробиотических продуктов, расширение исследований и практики внедрения в ассортимент предприятий новых продуктов и комплексных решений.
6.4. «Функциональные пищевые продукты, включая лечебные, профилактические и детские»
К функционально пищевым продуктам относят пищевые продукты систематического употребления, сохраняющие и улучшающие здоровье и снижающие риск развития заболеваний благодаря наличию в их составе функциональных ингредиентов. Они не являются лекарственными средствами, но препятствуют возникновению отдельных болезней, способствуют росту и развитию детей, тормозят старение организма. В соответствии с мировой практикой продукт считается функциональным, если регламентируемое содержание микронутриентов в нем достаточно для удовлетворения (при обычном уровне потребления) 25 — 50% от среднесуточной потребности в этих компонентах. Развитие направления является важной социальной задачей, снижающей нагрузку на сектор медицины и социально-экономический ущерб от болезней.
6.5. «Пищевые ингредиенты, включая витамины и функциональные смеси»
Пищевые ингредиенты используются для повышения питательной ценности, удлинения срока хранения, изменения консистенции и усиления вкуса и аромата продуктов. Используемые производителями пищевые ингредиенты, как правило, имеют растительное или бактериальное происхождение. Многие аминокислотные добавки, усилители вкуса и витамины, добавляемые в пищевые продукты, производятся с помощью бактериальной ферментации. В результате реализации комплекса мероприятий биотехнология должна обеспечить производителям пищевых продуктов возможность синтеза большого количества пищевых добавок, которые в настоящее время слишком дороги либо малодоступны из-за ограниченности природных источников этих соединений.
6.6. «Глубокая переработка пищевого сырья»
Биотехнология предоставляет множество возможностей усовершенствования методов переработки сырья в конечные продукты: натуральные ароматизаторы и красители; новые технологические добавки, в том числе ферменты и эмульгаторы; заквасочные культуры; новые средства для утилизации отходов; экологически чистые производственные процессы; новые средства для обеспечения сохранения безопасности продуктов в процессе изготовления.
Современные технологии глубокой переработки пищевого сырья строятся на принципах безотходного производства: продукты переработки либо возвращаются в производственный цикл, либо используются в других отраслях (прежде всего в производстве парфюмерно-косметических средств, фармацевтике, сельскохозяйственном производстве). Внедрение таких технологических схем в значительной степени обусловлено достижениями современной биотехнологии, сделавшей доступным и экономически обоснованным извлечение из пищевого сырья широкой гаммы новых продуктов. В рамках комплекса мероприятий будут созданы условия для распространения технологий глубокой переработки пищевого сырья и радикального снижения отходов пищевой промышленности. В результате реализации Программы в России будет развернуто производство широкой гаммы пищевых ингредиентов, включая витамины и функциональные смеси, достигнуты высокие показатели переработки продовольственного сырья, обеспечено импортозамещение по большинству импортируемых в настоящее время ингредиентов для производства пищевых продуктов.
Ответственный за разработку и реализацию комплекса мер по направлению — Минсельхоз России.
5. Сельскохозяйственная биотехнология
Примечание от PROPIONIIX: Здесь актуальным для ООО «Пропионикс» являются направления Сельскохозяйственной биотехнологии, отмеченные в программе под пп 5.7. и 5.9 (кормовой белок и биологические компоненты кормов и премиксов):
«Кормовой белок»
Согласно терминологии указанной программы, кормовой микробиологический белок (кормовые дрожжи)* — это сухая концентрированная биомасса дрожжевых клеток, специально выращиваемая на корм сельскохозяйственным животным, птице, пушным зверям, рыбе. Добавление кормового белка в корма резко улучшает их качество и способствует повышению производительности в животноводстве. Комплексом мероприятий будет предусмотрено развитие производства кормового белка в России и создание новых научно-технических заделов, совершенствующих технологии его производства и виды использования.
Примечание от PROPIONIX: Однако здесь следует отметить, что использование бактерий в качестве продуцента белкового корма является более эффективным, так как бактерии образуют до 75% белка по массе, в то время как дрожжи — не более 60%. Например, использование различных штаммов пропионовокислых бактерий (Propionibacterium freudenreichii subsp. shermanii), позволяет получать кормовой белок со значительными технологическими и качественными преимуществами.
«Биологические компоненты кормов и премиксов»
Современный уровень технологий кормления сельскохозяйственных животных опирается на широкое применение биологичских компонентов (ферменты, аминокислоты, БВК, пробиотики и другие). В результате развития животноводства в России, которое в основном опирается на импорт технологий и поголовья, сформировался емкий рынок этих продуктов биотехнологии. Однако формирование рынка не привело пока к развитию производственной и технологической базы, появлению новых продуктов, созданных на основе научных достижений российских ученых.
В 2010 году в животноводстве в качестве кормов было использовано 45 млн. т зерна, что говорит о крайне низкой эффективности кормопроизводства в стране. Доля зерна в комбикормах составляет 70% (в странах Европейского Союза — 40-45%), кроме того, в непереработанном виде было использовано более половины из общего количества зерна предназначенного для кормов.
Важно отметить, что производство комбикормов и премиксов в значительной степени ведется без использования биопрепаратов (ферментов, ветеринарных и кормовых антибиотиков, пробиотиков и так далее). При таком кормлении конверсия корма в получение животноводческой продукции существенно отстает от мировых показателей, что снижает конкурентоспособность российского животноводства. Комплексом мероприятий будут созданы условия для развития производственной и технологической базы биотехнологических компонентов кормов и премиксов.
Реализация указанных комплексов мероприятий позволит решить вопросы создания высокоэффективного сельского хозяйства и обеспечения населения полноценным сбалансированным питанием.
Некоторые направления в пищевой биотехнологии:
Ферментация в пищевой промышленностиВВЕДЕНИЕ. Процессы ферментации с использованием микроорганизмов нашли широкое применение в производстве пищевых продуктов. Реакции, осуществляемые микроорганизмами, используются при консервировании, рН среды понижается в результате молочнокислого брожения (в квашеной капусте), после частичного гидролиза в присутствии микроорганизмов (хлебная закваска, колбасные изделия, темпех) продукты лучше усваиваются организмом, для улучшения вкуса (кисломолочные продукты), а также для получения соусов (соевый соус, мисо из риса). В развитых странах примерно треть всех продуктов питания получают путем ферментации, осуществляемой определенными штаммами микроорганизмов.
СТАРТОВЫЕ КУЛЬТУРЫ. В пищевой промышленности используются самые разнообразные микроорганизмы. Они служат в качестве стартовых культур при приготовлении кисломолочных продуктов, различных сортов хлеба (закваски), выпечки (пекарские дрожжи), в пивоварении (пивные дрожжи) и виноделии. Стартовая культура может содержать только один штамм микроорганизмов, различные микроорганизмы одного вида и смешанные культуры. Наиболее важным критерием качества культуры является высокая скорость ферментации и получение желаемого продукта, например обладающего устойчивостью к антибиотикам или фаговой инфекции. Объем рынка стартовых культур в мире составляет сотни миллионов долларов США.
ПРОИЗВОДСТВО КОЛБАС. Сырокопченые колбасы (они могут храниться вне холодильной камеры) готовят со стартовой культурой стафилококковых бактерий (Staphylococcus carnosus) и лактобактерий, а также бактерий рода Penicillium. Гликоген мышечной ткани перерабатывается микроорганизмами с образованием молочной кислоты, это позволяет снизить уровень рН ниже 5 и предотвратить рост многих других микроорганизмов. В кислой среде белок мышечной ткани (изоэлектрическая точка 5,3) переходит в желеобразное состояние. Продукты ферментативных превращений жиров и белков обеспечивают специфический вкус колбасного изделия. При изготовлении соленых колбас (поваренная соль, нитраты и нитриты в качестве консервантов) используют стафилококковые бактерии или лактобактерии, устойчивые к повышенному содержанию соли.
СЫРОВАРЕНИЕ. В 1994 г. мировое производство сыра достигло 14,6 млн т в год, при этом около 6 млн т сыра было произведено в странах Европейского союза (ЕС). В Европе производится более 1000 сортов сыра. Чтобы приготовить сыр, молоко сбраживают, добавляя в него сычужный фермент или рекомбинантный химозин. Спровоцированная стартовыми культурами ферментация приводит к образованию молочнокислого сгустка, из которого вызревает сыр. В производстве сыров используют самые разные микроорганизмы, чаще всего Penicillum (камамбер, рокфор), Streptococcus, Propionibacterium freudenreichii (эмменталь) и Lactococcus (гарцер). Разнообразие сортов сыра объясняется различным происхождением молока (коровье, козье или овечье), технологией производства (аэробные, анаэробные или смешанные условия роста бактериальной культуры), а также методами введения стартовых культур (поверхностное нанесение или внутреннее впрыскивание).
ФЕРМЕНТИРОВАННЫЕ ПРОДУКТЫ ИЗ НЕ ЕВРОПЕЙСКИХ СТРАН. В китайской кухнетрадиционно используется так называемый красныйрис (ang-kak). Его получают, добавляя к влажному рису споры Monascus purpureus. Благодаря антимикробным свойствам красный рис получил широкое распространение в качестве приправы, его также применяют при нарушениях пищеварения. В восточной кухне готовят кишк (kishk), для этого набухшиезерна пшеницы подвергают ферментации бактериями, обитающими в кислом молоке. Японская приправа мисо получается в результате добавления к пропаренному рису грибов Aspergillus oryzae. По очень древнему рецепту китайской кухни до сих пор готовятсоевый соус – белковый гидролизат, обладающийсильным ароматом. Для этого в смесь соевой муки пшеничных отрубей впрыскивают культуры грибов Aspergillus oryzae; в условиях повышенной влажностипри температуре 35°С образуется поверхностнаякультура. После добавления равного объема водногораствора соли смесь подвергают ферментации молочнокислыми бактериями или дрожжами в течениегода при комнатной температуре. Путем ферментации соевых бобов или пропаренного риса под действием грибов Rhizopus oligosporus готовят темпех (tempeh) – основную пищу населения Индонезии и Малайзии.
Пищевые продукты и молочнокислое брожениеВВЕДЕНИЕ. История использования человеком процессов молочнокислого брожения молока (кисломолочные продукты), овощей (квашеная капуста) и кормов для скота (силос) насчитывает сотни, а для некоторых процессов и тысячи лет. Луи Пастер, впервые выделивший молочнокислые бактерии в 1856 г., заложил основы для понимания биохимии этого важного процесса. Продукты, получаемые в результате молочнокислого брожения, обладают хорошими вкусовыми качествами и долго хранятся, так как снижение pH, происходящее в процессе брожения, препятствует развитию других микроорганизмов.
МОЛОЧНОКИСЛЫЕ БАКТЕРИИ. Группа молочнокислых бактерий весьма гетерогенна по морфологии клеток, однако физиология ее представителей описана достаточно однозначно: все молочнокислые бактерии окрашиваются по методу Грама и являются облигатными аэробами, т. е. они не синтезируют гемсодержащие белки (каталазы), однако могут расти в присутствии кислорода. Молочнокислые бактерии расщепляют лактозу до глюкозы и галактозы, а затем превращают их в лактат. При «гомоферментативном» молочнокислом брожении (также называемом гликолизом), которое осуществляют Streptococcus pyogenes, Lactobacillus casei и Lactococcus lactis, из 1 моль глюкозы образуется 2 моль лактата, а при «гетероферментативном» брожении, осуществляемом Leuconostoc mesenteroides и Lactobacillus brevis, – только 1 моль лактата. От наличия лактатрацемазы в клетках бактерий зависит образуется ли L-(+)-молочная кислота (обычно выход 50–90%), D-(–)-молочная кислота или их рацемат. Физиологическую ценность кисломолочных продуктов трудно переоценить: в них нет лактозы и они содержат белки, уже подвергшиеся мягкому гидролизу.
КИСЛОМОЛОЧНЫЕ ПРОДУКТЫ. Среди кисломолочных продуктов в Европе наиболее распространены простокваша, сметана, йогурт, кефир и пахта (<1% жира). Эти продукты получаются при бактериальном заражении сырого молока в естественных условиях хранения. В йогурте содержание L-(+)-молочной кислоты более 95%. Этот продукт производят, используя Lactobacillus acidophilus или облигатно анаэробный штамм L. bifidus, обнаруженный в кишечной флоре грудных младенцев. Йогурты особенно хорошо усваиваются организмом и оказывают стимулирующее действие на иммунную систему. В результате реакций, осуществляемых бактериальными протеазами и липазами, кисломолочные продукты приобретают своеобразный вкус. Наиболее важными микроорганизмами для производства молочных продуктов являются стрептококки, лактобактерии, Leuconostoc и дрожжи.
ЗАКВАШИВАНИЕ ОВОЩЕЙ И ОВОЩНЫХ СОКОВ. В Германии особой популярностью пользуются квашеная капуста и соленые огурцы (заготавливаются иреализуются через торговую сеть около 200 000 т в год). Для заквашивания обычно используют белокочанную капусту, которую помещают в бочки вместимостью до 100 т. Как правило, процесс брожения осуществляется разнообразными микроорганизмами(бактериями, дрожжами и грибами) в результатеспонтанного заражения, однако в некоторых случаях брожение инициируют добавлением закваски (стартовых культур). В качестве других примеров использования в пищу овощей, подвергшихся молочнокислому брожению, можно привести квашеную свеклу(Польша и Россия) и кимчи (кислая китайская капуста или редька, Корея). Овощные соки, подвергшиесяферментации молочнокислыми бактериями, особенно богаты витаминами и минеральными веществами,хорошо усваиваются организмом и хранятся продолжительное время (например, морковный и томатныйсоки).
ЗАКВАСКА. В отличие от пшеничной муки, используемой для приготовления дрожжевого теста, ржаная мука закисает при рН<4,3; это позволяет получать своеобразную корочку при выпекании хлеба из ржаной муки. В закваске для теста при рН 4,2 наряду с молочнокислыми бактериями содержатся дрожжи.
СИЛОСОВАНИЕ – распространенный способ заготовки сочных кормов, в частности, кормовой свеклы. Силосную культуру измельчают, а затем помещают в специальные хранилища с ограниченным доступом воздуха. В таких условиях осуществляется процесс молочнокислого брожения. Если молочная кислота образуется в недостаточных количествах, силос может оказаться зараженным маслянокислыми бактериями, в том числе представителями клостридий. В этом случае бактерии могут попасть в молоко коров, которые питались зараженным силосом. Как правило, в силосе присутствует психотрофный патоген Listeria monocytоgenes, который в случае несоблюдения правил пастеризации может активно размножаться на пищевых продуктах (в мягких сырах, мясном фарше и зеленом салате) при длительном хранении в холодильнике.
Приведем упрощенный перечень необходимых областей знаний и наиболее востребованных направлений деятельности в прикладной биотехнологии:
Биотехнологическое производство пищевых продуктов Алкогольные напитки Пивоварение Ферментация в пищевой промышленности Пищевые продукты и молочнокислое брожение Спирты, кислоты и аминокислоты Этиловый спирт 1-Бутанол, ацетон Уксусная кислота Лимонная кислота Молочная и глюконовая кислоты Аминокислоты L-Глутаминовая кислота D,L-Метионин, L-лизин и L-треонин Аспартам, L-фенилаланин и L-аспарагиновая кислота Получение L-аминокислот в процессе ферментативной трансформации Антибиотики Антибиотики: источники, применение и механизмы действия Антибиотики: получение. Устойчивость к антибиотикам β-Лактамные антибиотики: структура, биосинтез и механизм действия β-Лактамные антибиотики: промышленное получение Пептидные антибиотики и антибиотики – производные аминокислот Гликопептидные, полиэфирные и нуклеозидные антибиотики Аминогликозидные антибиотики Тетрациклины, хиноны, хинолоны и другие ароматические антибиотики Поликетидные антибиотики Получение новых антибиотиков Специальные продукты Витамины Нуклеозиды и нуклеотиды Биодетергенты и биокосметика Микробные полисахариды Биоматериалы Биотрансформация Биотрансформация стероидов Ферменты Ферменты Ферментативный катализ Ферменты в клинических анализах Тесты с помощью ферментов Применение ферментов в промышленных технологиях Ферменты в производстве моющих средств Ферменты, расщепляющие крахмал Ферментативное расщепление крахмала в промышленности Ферментативное превращение сахаров Утилизация целлюлозы и полиозы Использование ферментов в целлюлозно-бумажной промышленности Пектиназы Ферменты в производстве молочных продуктов Использование ферментов в хлебобулочной и мясоперерабатывающей промышленности Ферменты в кожевенной и текстильной промышленности Перспективы получения ферментов для промышленных технологий Белковая инженерия Пекарские и кормовые дрожжи Пекарские и кормовые дрожжи Белки и жиры из одноклеточных организмов Биотехнология в медицине Инсулин Гормон роста и другие гормоны Гемоглобин, сывороточный альбумин и лактоферрин Факторы свертывания крови Антикоагулянты и тромболитики Ингибиторы ферментов Иммунная система Стволовые клетки Тканевая инженерия Интерфероны Интерлейкины Эритропоэтин и другие факторы роста Другие белки, имеющие медицинское значение Вакцины Рекомбинантные вакцины Антитела Моноклональные антитела Рекомбинантные и каталитические антитела Методы иммуноанализа Биосенсоры | Биотехнология и окружающая среда Аэробная очистка сточных вод Анаэробная очистка сточных вод и переработка ила Биологическая очистка газовых выбросов Биологическая очистка почв Микробиологическое выщелачивание руд и биокоррозия Биотехнология в сельском хозяйстве Животноводство Перенос эмбрионов и клонирование животных Картирование генов Трансгенные животные Генетическая ферма и ксенотрансплантация Растениеводство Культивирование растительных клеток: поверхностные культуры Культивирование растительных клеток: суспензионные культуры Трансгенные растения: методы получения Трансгенные растения: устойчивость к неблагоприятным воздействиям Трансгенные растения Основы микробиологии Вирусы Бактериофаги Микроорганизмы Бактерии Некоторые бактерии, важные для биотехнологии Грибы Дрожжи Микроорганизмы: выделение и хранение штамма. Техника безопасности Усовершенствование штаммов микроорганизмов Основы биотехнологических методов Микроорганизмы: рост в искусственных условиях Кинетика образования продуктов метаболизма и биомассы в культуре микроорганизмов Периодическая ферментация с добавлением субстрата и непрерывная ферментация Технология ферментации Промышленные процессы ферментации Культивирование животных клеток Биореакторы для культивирования животных клеток Биореакторы с иммобилизованными ферментами и клетками Очистка биотехнологических продуктов Очистка биотехнологических продуктов: хроматографические методы Экономические аспекты биотехнологического производства Методы генетической инженерии Структура ДНК Функции ДНК Эксперимент в генетической инженерии Методы выделения ДНК Ферменты, модифицирующие ДНК ПЦР: метод и его практическое применение ПЦР: лабораторная практика ДНК: химический синтез и определение размера молекул Секвенирование ДНК Введение ДНК в живые клетки (трансформация) Идентификация и клонирование генов Экспрессия генов Выключение генов РНК Геномные библиотеки и картирование генома Геном прокариот Геном эукариот Геном человека Функциональный анализ генома человека ДНК-анализ Белковые и ДНК-чипы Маркерные группы Тенденции развития Генная терапия Поиск биологически активных веществ Протеомика Биоинформатика Обмен веществ Метаболомика и метаболическая инженерия Системная биология «Белая» биотехнология Техника безопасности, этические и экономические аспекты Техника безопасности при проведении генно-инженерных манипуляций Сертификация биотехнологической продукции Этические аспекты генетической инженерии Патентование в биотехнологии
|
Дополнительно см.:
- 1. Микроорганизмы: рост в искусственных условиях
- 2. Кинетика образования продуктов метаболизма и биомассы в культуре микроорганизмов
- 3. Периодическая ферментация с добавлением субстрата и непрерывная ферментация
- 4. Технология ферментации
- 5. Промышленные процессы ферментации
- 6. Биореакторы с иммобилизованными ферментами и клетками
- 7. Очистка биотехнологических продуктов
К разделу: Закваски промышленные
ОСНОВНЫЕ ПОДРАЗДЕЛЫ
(PDF) Модель разбора семантических кадров RNN на основе двух моделей для обнаружения намерений и заполнения слотов
Зепп Хохрайтер и J¨
urgen Schmidhuber. 1997.
Долговременная кратковременная память. Нейронные вычисления
9 (8): 1735–1780.
Дидерик Кингма и Джимми Ба. 2014. Адам: Метод
для стохастической оптимизации. Препринт arXiv
arXiv: 1412.6980.
Гакуто Курата, Бинг Сян, Боуэн Чжоу и Мо Ю.
2016. Использование информации на уровне предложений с кодировщиком
lstm для заполнения семантических интервалов.In Proceed-
ings конференции 2016 года по эмпирическим методам
в обработке естественного языка. страницы 2077–2083.
Бинг Лю и Ян Лейн. 2015. Рекуррентная нейронная сеть —
прогнозирование структурированного вывода для разговорного языка —
понимание языка. В Proc. Семинар NIPS
по машинному обучению для людей с недостаточным уровнем разговорной речи
, положение и взаимодействие.
Бинг Лю и Ян Лейн. 2016a. Основанные на внимании повторяющиеся модели нейронных сетей
аренды для совместного обнаружения намерений
и заполнения слотов.Interspeech 2016, страницы 685–689.
Бинг Лю и Ян Лейн. 2016b. Совместное использование разговорного онлайн-языка
и моделирование языка с
рекуррентных нейронных сетей. На 17-м ежегодном собрании
Специальной группы по дискурсу и Dia-
logue. стр. 22.
Gr´
egoire Mesnil, Yann Dauphin, Kaisheng Yao,
Yoshua Bengio, Li Deng, Dilek Hakkani-Tur, Xi-
aodong He, Larry Heck, Gokhan Tur, Dong Yu и др.
2015. Использование рекуррентных нейронных сетей для заполнения слотов
в понимании разговорной речи. IEEE / ACM
Транзакции по аудио, речи и языку. Обработка
(TASLP) 23 (3): 530–539.
Родерик Мюррей-Смит и Т. Йохансен. 1997. Mul-
Типовые подходы к нелинейному моделированию и
управления. CRC Press.
Кумпати С. Нарендра, Ю Ван и Вэй Чен. 2014.
Проблемы стабильности, надежности и производительности при адаптации второго уровня
.В Американской конференции по контролю —
ence (ACC), 2014. IEEE, страницы 2377–2382.
Кумпати С. Нарендра, Ю Ван и Вэй Чен. 2015.
Расширение адаптации второго уровня с использованием нескольких моделей
для систем siso. В документе American Control Con-
ference (ACC), 2015. IEEE, страницы 171–176.
Кумпати С. Нарендра, Ю Ван и Снехасис
Мукхопадхай. 2016. Быстрое обучение с подкреплением
с использованием нескольких моделей. In Decision and Control
(CDC), 55-я конференция IEEE 2016 г.IEEE, страницы
7183–7188.
Цзицюань Нгиам, Адитья Хосла, Мингью Ким, Джухан
Нам, Хонглак Ли и Эндрю И Нг. 2011. Multi-
модальное глубокое обучение. В материалах 28-й международной конференции по машинному обучению
(ICML-
11). страницы 689–696.
Баолинь Пэн и Кайшэн Яо. 2015. Рекуррентные нейронные сети
с внешней памятью для языкового понимания
стоя. Препринт arXiv arXiv: 1506.00195.
Рухи Сарикая, Джеффри Э. Хинтон и Бхувана Рам —
абхадран. 2011. Сети глубокого убеждения для естественного языка
маршрутизации вызовов. In Acoustics, Speech and Sig-
nal Processing (ICASSP), 2011 IEEE International
Conference on. IEEE, страницы 5680–5683.
Нитиш Шривастава и Руслан Р Салахутдинов. 2012.
Мультимодальное обучение с глубокой маской Больцмана
скулов. Успехи в области нейронных информационных процессов —
систем.страницы 2222–2230.
Илья Суцкевер, Ориол Виньялс и Куок В Ле. 2014.
Последовательность для последовательного обучения с нейронной сетью —
работает. Успехи в области нейронных информационных процессов —
систем. страницы 3104–3112.
Гохан Тур, Дилек Хаккани-Т ¨
ur и Ларри Хек.
2010. Что еще предстоит понять в atis? В Spo-
ken Language Technology Workshop (SLT), 2010
IEEE. IEEE, страницы 19–24.
Ю Ван.2017. Новая концепция с использованием нейронной сети lstm-
работает для динамической идентификации систем. В Amer-
ican Control Conference (ACC), 2017. IEEE, pages
5324–5329.
Ю Ван и Хунся Цзинь. 2018. Основанный на ускорении алгоритм
глубоких нейронных сетей для обучения с подкреплением
. В Американской конференции по контролю (ACC),
2018. IEEE.
Пуян Сюй и Рухи Сарикая. 2013. Треугольный crf на основе сверточной нейронной сети
для совместного обнаружения
палатки и заполнения слотов.In Automatic Speech
Recognition and Understanding (ASRU), 2013 IEEE
Workshop on. IEEE, страницы 78–83.
Пуян Сюй и Рухи Сарикая. 2014. Контекстная до-
основная классификация в понимании разговорного языка-
систем с использованием рекуррентной нейронной сети. В
Акустика, обработка речи и сигналов (ICASSP),
Международная конференция IEEE 2014 г. IEEE,
, страницы 136–140.
Кайшэн Яо, Баолинь Пэн, Юй Чжан, Донг Ю, Ge-
офрей Цвейг и Янъян Ши.2014. Разговорный язык —
понимание языка с использованием долговременной краткосрочной памяти
нейронных сетей. В Speken Language Technology
Workshop (SLT), 2014 IEEE. IEEE, страницы 189–194.
Сяодун Чжан и Хоуфэн Ван. 2016. Совместная модель
определения намерений и заполнения слотов для понимания устной речи
. В материалах
Двадцать пятой международной совместной конференции
по искусственному интеллекту. AAAI Press, страницы 2993–
2999.
Анализ доменных имен, составленных из случайных букв, для подтверждения киберсквоттинга
Крик боли ответчика в деле AXA SA против Whois Privacy Protection Service, Inc. / Ugurcan Bulut, axathemes, D2016-1483 (WIPO 12 декабря 2016 г.) «[Что вы хотите от меня, люди? Я уже удалил все файлы из этого домена, а он пуст. Что еще вы хотите, чтобы я сделал ??? » вызывает несколько интересных вопросов. «A», «x» и «a» — это необычная строка букв, но в отличие от других знаковых строк, таких как, например, «u», «b» и «s», «i», «b» и «m». которые начали свою жизнь как первые буквы трехсловных брендов. AXA не является аббревиатурой.Будь то придуманные строки или аббревиатуры, знаковые строки — это не , а просто случайных букв. Объединение их со словарными словами (независимо от того, предполагает ли связь с бизнесом истцов), по сути, делает вывод о киберсквоттинге.
Добавление «тем» к AXA, особенно когда AXA также владеет AXA THEMA, «денег» для UBS, когда UBS занимается денежным бизнесом, или «еды» для IBM (даже если еда не имеет прямого отношения к бизнесу IBM) подрывает доверие к этим респондентам. даже если они появляются и спорят о незнании намерений; что они «имели в виду» совершенно другой проект без ссылки на товарные знаки.Невинность — это, по сути, позиция Ответчика в AXA. Он изобразил негодование, но у него не было никаких объяснений по поводу включения товарного знака в доменное имя: «Откуда вы можете знать, [он говорит], что [доменное имя] относится [к] AXA THEMES, может быть, это AXAT HEMES или AXATH EMES. »
А почему бы не? Возможно, регистрант мог бы использовать вымышленные фразы для создания бизнеса, используя любую из двух альтернативных возможностей, но для этого ему нужно было бы предоставить убедительные доказательства существования или формирования такого бизнеса.В отсутствие доказательств Панели сделают вывод о киберсквоттинге. Истцы имеют преимущество, когда Респонденты не могут объяснить, что делает товарный знак в доменном имени, даже если добавленное слово не связано с товарным знаком; Например,
Что, если случайные буквы, заявленные как товарный знак, появятся в доменном имени, которое соответствует словарному слову? Насколько далеко право владельца товарного знака распространяется на случайные буквы? Например, может ли AXA SA претендовать на
В «Обзоре ВОИС» в качестве примера предлагается «театр», в котором владелец знака HEAT начинает судебное разбирательство на основании сбивающего с толку сходства, поскольку имя домена включает буквы «h», «e», «a,» и т.«Проблемы возникли на самом деле в деле« Филипп Плейн против Кимберли Уэбб », D2014-0778 (WIPO 30 июля 2014 г.), в котором Заявитель увидел, что его товарный знак встроен в
[A] Следствием аргумента истца является то, что любой товарный знак, присутствующий в доменном имени, будет удовлетворять запутывающему тесту на сходство на том основании, что он будет распознаваться в доменном имени поисковыми системами … Этот результат изменяет текущее понимание сбивающего с толку сходство, и предполагает, что даже если путаница, вызванная технологическим эффектом, была принята, визуальные или звуковые характеристики нельзя полностью игнорировать … Недостаточно, чтобы товарный знак был видим только тогда, когда зрителю сказали, что он определенно присутствует.
Однако «пленочный» случай — экзотика; пока единственный в своем роде. Как правило, чтобы быть похожим до степени смешения, товарный знак должен быть виден объективному наблюдателю. Строка букв в более крупной строке похожа до степени смешения, только если она объявляет о себе, как это было в деле Zino Davidoff SA v. Guan Rang Guang, D2016-1027 (WIPO 5 июля 2016 г.) (
В каждом из этих споров есть общее молчание респондентов либо по умолчанию по внешнему виду, либо для аргументации неоправданных позиций, проверяющих доверчивость; таким образом, если в записи ничего не говорится о причине регистрации доменного имени или причина неубедительна, подразумевается намерение. Вот почему доменные имена, содержащие товарные знаки в сочетании с другими буквами или словами, предполагающими связь, ассоциацию или спонсорство с истцом, обычно считаются нарушающими авторские права.Там, где нет других записей, кроме заявителя, или если молчание, естественно, прибегнуть к умозаключениям, которые, как правило, в пользу заявителя.
В абстракции «m», «s» и «n» могут проходить как случайные буквы, безопасные для компании Mediterranean Shipping Company (в том смысле, что буквы в качестве аббревиатуры могут быть привлекательными для многих предприятий), за исключением того, что ответчик добавил «груз», «транспорт». , «и» доставка «, которые описывают деятельность Истца. MSC Mediterranean Shipping Company Holding S.A. против Whoisguard Protected, Whoisguard, Inc./ HOSTER NODE, D2016-21059 (WIPO 7 декабря 2016 г.). В том же духе «m», «w», «e» также кажутся безопасными, особенно с расширением dot pub, но добавление «.pub» вносит вероятную путаницу, поскольку истец предлагает широкий спектр юридических публикаций. » McDermott Will & Emery LLP против Ван Вэй, FA1610001699686 (Форум 28 ноября 2016 г.) ((
Что касается респондентов, то в Advanced Analytical Technologies, Inc.v. Hare, Myles / URL Enterprises Ltd., FA1611001701430 (Forum 1 января 2017 г.) Истец назвал указанную строку, нарушающую авторские права, «неотличимым четырехбуквенным доменным именем», которое Ответчик был очень рад признать (фактически, колеса телеги, я думаю, это выражение!) Комиссия из трех членов постановила, что «спорное доменное имя
Другой пример — тройка А, которая имеет устоявшееся значение, не связанное с товарным знаком. В деле Американская автомобильная ассоциация, Inc. против Адама Купера — AAA Locksmith, D2015-0683 (WIPO 3 июля 2015 г.) (
убедил, что ссылка на слесаря «AAA» в доменном имени относится к «рангу по алфавитной шкале оценок» и не имеет ничего общего с Американской автомобильной ассоциацией. Кроме того, хотя Ответчик утверждает в контексте первого элемента, что отличие его веб-страниц от веб-страниц Истца предотвращает любую путаницу, Комиссия принимает к сведению тот факт, что значительные различия между веб-страницами Ответчика и Истца приводят к выводу, что Ответчик не был пытается имитировать веб-сайт Заявителя или иным образом недобросовестно использовать доменное имя.
Вопрос в том, есть ли какие-либо доказательства того, что при выборе трехбуквенной строки Ответчик имел какое-либо намерение воспользоваться товарным знаком Истца. Быстрая проверка базы данных показывает, что 99% случаев со строкой AAA заканчиваются отменой или передачей доменных имен — к ним относятся
Владелец этого доменного имени, Parmamagoo Media, LLC, утверждает, что он готовится использовать домен для предоставления услуг обмена в индустрии таймшеров.Хотя Заявитель использует свой знак AAA в индустрии туризма, Группа считает, что слова «обменная сеть» сами по себе не указывают на какую-либо конкретную услугу или отрасль. Комиссия не считает, что Истец может контролировать каждое возможное использование своих знаков; он ограничен классовыми ограничениями при регистрации. Следовательно, Parmamagoo может иметь законный интерес в доменном имени.
На этом обсуждение не заканчивается, потому что о нарушении свидетельствуют не только строки произвольных букв.В деле L-com, Inc. против Resolution Services / Resolution Services Ltd., FA161100 1703364 (Форум 21 декабря 2016 г.)
Однако, поскольку Ответчик не ответил, Комиссия должна принять любое разумное утверждение Истца как истинное.Поскольку это явно не является необоснованным утверждением, Комиссия принимает этот аргумент как возможный, хотя и не принимает идею о том, что Ответчик может быть «принужден» к совершению мошенничества. По крайней мере, по совокупности проверок обстоятельств, Комиссия считает, что Ответчик недобросовестно использовал и регистрировал оспариваемое доменное имя.
Спекуляция о мошенничестве не совсем надуманная. Например, в деле Arla Foods Amba против Майкла Гатри, M. Guthrie Building Solutions, D2016-2213 (WIPO 16 декабря 2016 г.) (
Пищевая химия, объединяющая продукты
Зная, как разные комбинации Пища реагирует в организме и по вкусу.
Узнайте, как максимально увеличить здоровье и энергия без еды более. Узнайте о химическом составе пищи и о том, насколько точно продукты, которые съеденные вместе могут принести вам пользу, а также то, как другие съеденные продукты вместе могут действительно свести к минимуму пользу от этих продуктов. В время Когда вы должны есть определенные продукты, также важно. Как если ты ешь хлеб перед основным приемом пищи вы можете Поднимите уровень сахара в крови и увеличьте ваш аппетит.Но если ты ешь хлеб после ужина ты замедлишься замедлить процесс превращения углеводов в сахар. Еда комбинации также влияют на аромат и вкус. Можно есть то же самое здоровую пищу каждый день, но есть некоторые продукты, которые нельзя есть все время каждый день. Важно разнообразить свой рацион, чтобы что вы покрываете все свои потребности в питании, и что вы нет получать слишком много какой-либо одной пищи, потому что некоторые продукты могут быть вредными для определенных людей, и вы также могли бы развить непереносимость.Вы также должны знать какие витамины следует принимать вместе для максимального эффекта, и знать, какие добавки это не следует принимать вместе.
Пищевая химия это изучение химических процессов и взаимодействия всех биологические и небиологические компоненты пищевых продуктов.
Присадки — Аллергия — Вкус — Запах
Ингредиент является компонентом смесь или сложный. Аннотация часть чего-то. Пища, входящая в состав смеси Готовка.
Отвар — любые пищевые продукты, производимые сочетание разных ингредиентов. Возникновение необычной смеси. В изобретение схемы или рассказа для какой-то цели. Акт создания что-то такое, как лекарство, напиток или суп, путем смешивания или смешивания разнообразие компонентов.
Лекарства Лекарства и Взаимодействие с едой — что вы едите и пьете может повлиять на то, как ваш лекарства работают.
Еда Физическая Химия считается отраслью пищевой химии. с изучением как физических, так и химических взаимодействий в пищевых продуктах в термины физических и химических принципов, применяемых к пищевые системы, а также как приложения физических / химических методов и приборов для изучения продуктов.
Приправа — Готовка — Добавки — Этикетки для пищевых продуктов
Наука о еде прикладная наука, посвященная изучению продуктов питания. В Институт пищевых технологий определяет науку о пищевых продуктах как «дисциплину в которые инженерные, биологические и физические науки используются для изучения характер продуктов, причины порчи, принципы лежащая в основе обработки пищевых продуктов, и улучшение продуктов питания для потребителя общественные.
Еда Инженерное дело это мультидисциплинарная область прикладных физических наук, которая объединяет наука, микробиология и инженерное образование для продуктов питания и связанных отрасли. Пищевая инженерия включает, но не ограничивается, применение агротехники, машиностроения и принципы химической инженерии к пищевым материалам. Пищевые инженеры обеспечивают передача технологических знаний, необходимых для рентабельной производство и реализация продуктов питания и услуг.Физика, химия и математика имеют фундаментальное значение для понимания и машиностроительная продукция и операции в пищевой промышленности.
Миксолог — это человек, создающий коктейли; бармен. Миксология — это искусство комбинирования различных ингредиентов для приготовления коктейлей. Итак, мы можем научить Химия и получить В то же время пьяный, круто. В научными терминами это будет исследование воздействия алкоголя на человека разум и тело. И не все студенты будут пить, потому что вам понадобится студенты должны быть трезвыми исследователями и не подвергаться воздействию химических веществ субстанция, так что их суждение, познание, сознание, память, концентрация, функция, производительность, способность, емкость, зрение, слух и подвижность никоим образом не нарушается.
Аромат и Баланс, наверное, самые важные составляющие качество коктейля, но все зависит от температуры, текстуры, аромата, крепости и презентация, которая делает напиток хорошо сбалансированным. Некоторые дескрипторы текстур для коктейлей и спиртных напитков: густые, сиропный, недостаточно разбавлен. Тонкий, слабый, не интегрированный, перетряхнутый. Шелковистый. Свет. Шипучий, шипучий. Дубильный, вяжущий. Мягкая, мягкая, пенистый, пенистый. Слякотный, вязкий, жевательный. Хрустящий. (хрустящий, твердый, сухой и ломкий).Густой, коренастый (кусочки вещество, смешанное с чем-нибудь более кремовым).
Текстура еды Влияет на воспринимаемый вкус еды. Вязкость — Пудинг (wiki) — водянистый или сливочный? Холодная или теплая?
Сливочный — это еда или напитки, в которых есть богатые вкус или густая гладкая текстура.
Реология — это изучение течения вещества, в первую очередь в жидкости. состоянии, но также как «мягкие твердые вещества» или твердые вещества в условиях, в которых они реагировать пластическим потоком, а не упруго деформироваться в ответ на приложенная сила.Это раздел физики, который занимается деформация и течение материалов, как твердых, так и жидких. Ньютоновские жидкости можно охарактеризовать одним коэффициентом Вязкость для определенной температуры. Хотя эта вязкость меняется с температурой, она не меняется. со скоростью деформации. Только небольшая группа жидкостей демонстрирует такую постоянную вязкость. Большой класс жидкостей, вязкость которых изменяется в зависимости от Скорость деформации (относительная скорость потока) называют неньютоновскими жидкостями.
Инфузия — это процесс извлечения химических соединений или ароматизаторы из растительного материала в растворителе, таком как воду, масло или спирт, позволяя материалу оставаться во взвешенном состоянии в растворитель с течением времени (процесс, часто называемый замачиванием). Настой тоже название полученной жидкости. Процесс настаивания отчетливый из обоих отваров — метод экстракции, включающий кипячение растения материал — и перколяция, при которой вода проходит через материал (как в кофеварке).
точность Кулинария: включение новых текстур и вкусов | Лекция 2 (2011) (youtube, 1:52) — Научный центр Гарвардского университета.
Дистилляция (изготовление спирт) — Кипячение — Температура и вкус
«Для нашего мозга« вкус »- это на самом деле сочетание вкуса еды, понюхать и прикоснуться к единственное ощущение. Текстура и запах играют не менее важную роль, чем вкусовые рецепторы. испытать то, что мы едим ».
Значения на этикетках продуктов питания — Обработанный Пища — Кислые продукты и PH
Scio — это карманный молекулярный датчик, который сообщает вам, что на самом деле еда как калорий, сахара и жира.
Молекулярный Гастрономия это раздел науки о продуктах питания, который стремится исследовать физические и химические превращения ингредиентов, происходящие при приготовлении пищи. Его программа включает три оси, так как приготовление пищи признано компоненты, которые являются социальными, художественными и техническими. Молекулярная кухня — это современный стиль приготовления пищи, в котором используются многие технические инновации из научных дисциплин.
Органический Синтез — это особая отрасль химического синтеза. с построением органических соединений посредством органических реакций.Органический молекулы часто содержат более высокий уровень сложности, чем чисто неорганические соединений, так что синтез органических соединений развился в один из важнейших разделов органической химии.
Пищевая синергия
Таблица матрицы продуктов питания
(изображение)
Еда Комбинирование, также известное как трофология, — это термин, обозначающий пищевой подход, который отстаивает определенные сочетания продуктов питания как основополагающие здоровье и потеря веса (например, не смешивать продукты, богатые углеводами и продукты, богатые белком, в одном приёме пищи).
Композиция для вкусовых добавок
Сомелье или винный стюард, опытный и знающий вино профессионал, обычно работающий в хороших ресторанах, специализирующийся на всех аспекты винного сервиса, а также вина и еды спаривание. Роль в изысканной кухне сегодня гораздо более специализированная и информировано, чем у винного официанта.
Fusion Кухня — это кухня, сочетающая в себе элементы разных Кулинария Традиции.
Кулинария
Воздействие на еду —
Знания о питании — Intercropping
Антинутриенты — это природные или синтетические соединения, которые мешают
поглощение или
питательные вещества.Исследования питания сосредоточены на тех
антинутриенты, обычно содержащиеся в пищевых продуктах и напитках. Протеаза
ингибиторы — это вещества, подавляющие действие трипсина, пепсина и
другие протеазы в кишечнике, препятствующие пищеварению и последующему
всасывание протеина. Например, ингибитор трипсина Боумена-Бирка содержится в соевых бобах.
Примеры: протеаза
ингибиторы — это вещества,
подавляют действие трипсина, пепсина и других протеаз в кишечнике,
предотвращение переваривания и последующего всасывания белка.Для
Например, ингибитор трипсина Боумена-Бирка содержится в соевых бобах. Липаза
ингибиторы взаимодействуют с ферментами, такими как липаза поджелудочной железы человека, которые
катализируют гидролиз некоторых липидов, в том числе жиров. Например,
лекарство от ожирения орлистат заставляет процент жира проходить через
непереваренный пищеварительный тракт.
Амилаза
ингибиторы предотвращают действие ферментов, разрушающих гликозидные связи
крахмала и других сложных углеводов, предотвращающих высвобождение
простые сахара и усвоение организмом.Ингибиторы амилазы, такие как липаза
ингибиторы, использовались в качестве диетической помощи и лечения ожирения. Амилаза
ингибиторы присутствуют во многих видах бобов; в продаже
Ингибиторы амилазы извлекаются из белой фасоли.
Фитик
кислота имеет сильное связывающее сродство с минералами, такими как кальций,
магний, железо, медь и цинк. Это приводит к выпадению осадков, в результате чего
минералы, недоступные для всасывания в кишечнике. Фитиновые кислоты
распространены в скорлупе орехов, семян и зерен.Щавелевая
кислота и оксалаты присутствуют во многих растениях, особенно в членах
семейства шпинатных. Оксалаты связываются с кальцием и препятствуют его усвоению.
в теле человека. Глюкозинолаты предотвращают поглощение йода, влияя на функцию
щитовидной железы и, таким образом, считаются гойтрогенами. Они находятся в
брокколи, брюссельская капуста, капуста и цветная капуста. Чрезмерное потребление
Необходимые питательные вещества также могут оказывать антипитательное действие.
Чрезмерное потребление клетчатки может сократить время прохождения через
кишечник до такой степени, что другие питательные вещества не могут всасываться.Поскольку кальций, железо, цинк и магний используют один и тот же транспортер
в кишечнике чрезмерное потребление одного из этих минералов может
привести к насыщению транспортной системы и снижению поглощения
другие минералы. Некоторые белки также могут быть антинутриентами, например,
ингибиторы трипсина и лектины, содержащиеся в бобовых. Эти ингибиторы ферментов
мешают пищеварению. Еще одна особенно распространенная форма
антинутриенты — это флавоноиды, которые представляют собой группу полифенольных
соединения, в состав которых входят дубильные вещества.Эти соединения хелатируют металлы, такие как
железо и цинк и уменьшают усвоение этих питательных веществ, но они также
подавляют пищеварительные ферменты, а также могут осаждать белки. Сапонины в
растения могут служить в качестве антикормовых средств.
Питательные вещества —
Питание.
Советы по питанию
Вы получите больше растительного железа из черных бобов, если будете есть их с что-то богатое витамином С, например красный перец.
Влияние потребления яиц на всасывание каротиноидов из совместно потребляемых, сырой овощи.
Хумус, сделанный из семена кунжута (в тахини), намазанные на цельнозерновой хлеб, дают вам все аминокислоты, чтобы сформировать полноценный белок.
Фитаты — а вид кислоты — в таких вещах, как чай и кофе, может уменьшиться абсорбция железа и цинка.
Комбинация куркумы и черного перца дает куркумин, пигмент куркумы, который имеет противовоспалительные и противоопухолевые свойства, легче усваиваются организмом доступ.
Влияние Пиперин о фармакокинетике куркумина.
Фармакокинетика это раздел фармакологии, посвященный определение судьбы веществ, вводимых в живой организм.
Освобождение это процесс высвобождения лекарства из фармацевтического формулировка. Смотрите также IVIVC.
Поглощение это процесс вещество, попадающее в кровообращение. Растворимый.
Распределение это дисперсия или распространение веществ по всему жидкости и ткани тело.
Метаболизация или биотрансформация, или инактивация, это распознавание организмом присутствия инородного вещества и необратимое превращение родительских соединений в дочерние метаболиты.
Экскреция это выведение веществ из организма. В редких случаях некоторые лекарства необратимо накапливаются в тканях организма.
Пища переваривается с разной скоростью: подождите 2 часа после еды фруктов, 3 часа
после употребления крахмалов, через 4 часа после употребления белка.
Кофе
Принимая витамины одновременно с чашкой кофе или чай может мешать усвоению организмом многих необходимых питательные вещества. Это наверное лучше употреблять кофеин между приемами пищи, а не непосредственно перед или просто после. Кофеин также мягкий мочегонное средство, что увеличивает мочеиспускание. Обезвоживание. Итак, водорастворимые витамины, такие как Витамины группы B могут быть истощены в результате потери жидкости. Вода витамины: витамин С, биотин и семь витаминов группы В — тиамин (B-1), рибофлавин (B-2), ниацин (B-3), пантотеновая кислота (B-5), пиридоксин (B-6), фолиевая кислота (B-9) и кобаламин (B-12).Жирорастворимые витамины: A, D, E или K. Кофе также увеличивает выведение минералы магний, калий, натрий и фосфат. А также есть доказательства того, что кофеин препятствует действию витамина А. Нефильтрованный кофе — важный источник кафестол а также кахвеол дитерпены, которые, как было установлено, повышают общий уровень сыворотки и ЛПНП концентрация холестерина в организме человека. Исследование кофе штата Орегон — Преимущества для мозга от Кофе — Чай.
кофеин вызывает вывод кальция с мочой и кал.На каждые 150 мг кофеин проглочен, примерно столько же, сколько содержится в одной чашке кофе, 5 мг кальция потерян. Кофеин подавляет рецепторы витамина D, которые ограничивают его количество. что будет поглощено. Так как витамин D важен для усвоения и использование кальция в строительстве костей, это также может уменьшить минеральные вещества в костях. плотность, что приводит к повышенному риску остеопороза. Кофеин препятствует усвоению организмом железа, необходимого для красный производство клеток крови.Кофеин может снизить всасывание марганец, цинк и медь. Так что не принимайте витамины с кофе, подождите Пару часов. Кофеин самый популярный в мире психоактивный препарат. Стимулятор центральной нервной системы класса метилксантинов. Наиболее заметным является то, что он обратимо блокирует действие аденозина на его рецептор и, следовательно, предотвращает начало сонливость, вызванная аденозином. Кофеин также стимулирует определенные порции вегетативной нервной системы.Кофе стимулирует надпочечники железы, вызывая выброс кортизол, гормон стресса, поэтому уровень тревожности может быть высоким в утро. Если вы перестанете пить кофе, у вас могут возникнуть головные боли. из-за отмены кофеина, но это должно исчезнуть через несколько дней.
Завод: Существует около 70 видов кофе. цветущее растение и два основных типа: Coffea Arabica (бобы арабики) и Coffea canephora var. Робуста (бобы Робуста). Производство кофе — Часто задаваемые вопросы о кофе — История кофе.
Кофе — это заваренный напиток, приготовленный из обжаренных кофейных зерен,
которые представляют собой семена ягод из
Кофе
растение, представляющее собой род цветковых растений, семена которых, называемые кофе
бобы, используются для приготовления различных кофейных напитков и продуктов. Это
член семейства Rubiaceae. Это кусты или небольшие деревья, произрастающие в
тропическая и южная Африка и тропическая Азия. Кофе содержит много
фитохимические вещества, антиоксиданты и
другие питательные вещества
это исследование показало, что оно полезно для нашего организма.
Обжарка: Фасоль запекается при температуре от 180 до 250 градусов Цельсия.
где-то от 2 до 25 минут. Во время ожога сахара и жиры
разлагаются, аминокислоты и сахара реагируют друг с другом, и разложение
продукты искровой цепной реакции. завершается формированием десятков
ароматических соединений, составляющих этот соблазнительный кофейный букет.
Кофе
Обжарка —
Реакция Майяра
— Опасность высокой температуры.
Соединения: Соединения включают альдегиды, кетоны,
фураны, пиразины, пиридины, фенольные соединения, индолы, лактоны,
сложные эфиры и бензотиазины.Но для хлорогеновых кислот больше обжарки приводит
к меньшему количеству этих полезных фенолов.
Хлорогеновые кислоты: около 45 из них
фенольные соединения были обнаружены в кофейной кислоте кофе,
противовоспалительные и антибактериальные свойства.
Тригонеллин: Это
горький алкалоид защищает мозг от повреждений,
блокирование движения раковых клеток, борьба с бактериями и снижение
уровень сахара в крови и общий холестерин. Кахвеол и кафестол: эти дитерпены,
которые способствуют горькому вкусу кофе, были связаны с
предотвращение и борьба с раковыми клетками.Но они также были связаны с
повышение холестерина.
Шлифовка: Стандартный дом
болгарка за 42 секунды по сравнению с 5 секундами удвоила количество
кофеин выжатый из 37-граммовой порции. Ручная кофемолка Rok — Система измельчения кофе RAFINO.
Пивоварение: Методы пивоварения также имеют решающее значение для того, чтобы выжать
бобы. На выбор есть несколько способов: Кратковременное кипячение.
(Турецкий), замачивание (французская пресса), фильтрация (капельный кофе) и
под давлением (эспрессо).Эспрессо-машины, которые нагревают до 91-96 градусов тепла.
Цельсия) воду под давлением (~ 9 бар) равномерно по тонкому, хорошо упакованному кофе
измельчает, производит напитки с наиболее концентрированными дозами кофеина.
Холодное заваривание Кофе на 67 процентов меньше кислее, чем горячего заваривания. Также снижает привкус пригорания и горечь, которые вы получаете от горячего заваривания. кофе. Холодный чай.
Мир
Brewers Cup — это соревнование, демонстрирующее мастерство и мастерство
заваривать кофе вручную.Аэропресс.
Jolt — Brew Coffee & Tea in the Palm of Your Hand — портативный кофе
и заварщик чая, который можно заваривать в любой точке мира, используя аккумуляторные
батареи.
Oomph
Портативная кофеварка, быстрая ручная портативная кофеварка и
чашка путешествия!
Джина Кофейный Пивовар — kickstarter
В рано утром наши тела производят высокий уровень кортизола, гормон стресса, который нам помогает стать более бдительными. Наполнение организма кофеином первым делом Утро сигнализирует организму о необходимости вырабатывать меньше кортизола, а это означает, что организм будет Чтобы проснуться, начните полагаться на кофе, а не на его естественные функции.Так подождать пару часов после пробуждения, чтобы выпить кофе, принесут вам больше пользы.
Питье кофе Инфо-график (изображение) — Кофе Потребление по странам (изображение)
Кофе I
Нравится: Seattles Best Post Alley 5 Dark Roast, Gevalia Kaffe Majestic
жаркое, органика собственного производства Newmans, специальная смесь средней обжарки, щука из старбакс
место обжарки, кофе lavazza italy, килиманджаро одного происхождения, lavazza italy
кофе классико средней обжарки, lavazza italy coffee gran aroma medium
обжарка, зеленый кофе резерва эфиопия яргачеф темная обжарка, брионис
здоровое утро средней обжарки.
Если вам не нравится какой-то конкретный кофе, смешайте его
с кофе, который тебе нравится. Пока это что-то хорошо для вас, тогда это помогает
смешивайте то, что вам нравится, с тем, что вам не нравится, потому что это всегда
сделайте вещи, которые вам не нравятся, немного более терпимыми.
Остаток средств.
Приправа.
Если вам что-то не нравится само по себе, смешайте это с тем, что вы делаете.
нравиться. Если что-то еще хорошо и хорошо для вас, то нет причин
выбросить. Пищевые отходы.Смешивание удовольствия с
Обязанность.
Улучшение кофейной гущи компост. Кофейная гуща улучшается компост двумя способами. Они обычно содержат около 2% азота (столько же, сколько и навоз), который питает микроорганизмы, переваривающие растительные остатки, и превращает их в компост. Во-вторых, по мере разложения кофейная гуща может подавить обычную грибковую гниль и уменьшить рост кишечной палочки и Staphylococcus spp., По данным исследование, опубликованное Университетом штата Вашингтон.Для оптимального компоста подавление болезней, от 10 до 20 процентов кофейной гущи от общего количества объем компоста. Дождевые черви тоже любят кофейную гущу. Оставив миску Использованная гуща в холодильнике на ночь избавит вашу морозильную камеру от неприятного запаха.
Четыре сигматика Грибной кофе с львиной гривой и чагой для концентрации + внимания, Веганский, Палео, 0,09 унции (10 штук). Растворимый грибной кофе обычный молотый кофе с порошками из лекарственные грибы. Он не похож на грибы, он такой же, как обычный кофе, за исключением с кордицепсом, повышающим выносливость, успокаивающей чагой и грибом с львиной гривой экстракты, которые, как считается, обладают улучшающими когнитивные способности свойствами.противовоспалительное, противовирусное, благоприятное для кишечника, содержат большое количество антиоксиданты (больше, чем асаи, черника и какао) и поддерживают наши печень при вымывании токсинов.
Кофе влияет на ваш метаболизм множеством других способов, помимо пробуждения вы вверх, включая ваш метаболизм нейротрансмиттеров, обычно связанных с каннабис. Нейромедиаторы, относящиеся к эндоканнабиноидная система — те же, на которые влияет каннабис — уменьшились выпив от четырех до восьми чашек кофе в день.Это наоборот о том, что происходит после того, как кто-то употребляет каннабис. Исследование также дает возможность понимание причины закусок. Кофе также может увеличить выведение стероидов.
Теанин является аминокислотным аналогом протеиногенных аминокислот L-глутамата и L-глутамин и содержится в основном в определенных видах растений и грибов. Он был обнаружен в составе зеленого чая в 1949 году, а в 1950 году был обнаружен. изолированные из листьев гёкуро. Теанин дает уникальный бульон или пикантный (умами) ароматизатор для настоев зеленого чая.
Во всем мире люди выпивают около трех миллиардов чашек кофе каждый день. Умеренное употребление кофе в большинстве случаев безопасно. Но привычное потребление кофе или чрезмерное употребление кофе может увеличить риск трех заболеваний: остеоартрит, артропатия и ожирение, которые могут вызывать сильную боль и страдания людей с этими состояниями. может привести к повышенный риск некоторых заболеваний.
Вещи
это может повлиять на уровень кофеина в кофе.Кофеин — это
чрезвычайно стабильна в процессе обжарки. Если вы измеряете свой кофе
ложками легкого обжаренного кофе будет
больше кофеина. Так как фасоль более плотная, чем у более темной обжарки. Однако если
вы взвешиваете мерные ложки, темное жаркое будет содержать больше кофеина, потому что
меньше масса. Фасоль для фасоли, светлая обжарка по сравнению с темной обжаркой, каждый
будет иметь относительно такой же уровень кофеина. Может быть изменение
кофеин в зависимости от того, как вы отмеряли свой кофе.Существует примерно девяносто бобов разницы между фунтом темного и
кофе светлой обжарки, причем темная обжарка побеждает. В течение
В процессе обжарки бобы теряют массу. Плотность фасоли меняется;
бобы, которые прожариваются дольше, менее плотные. Вот почему у вас больше
фасоль массой темной обжарки. Когда кофе обжаривается, зерна теряют
примерно 90% их содержания воды. Если вы измеряете
кофе ложками, кофе легкой обжарки будет больше
кофеин.Кофеин — репеллент от насекомых, поэтому очень
на малых высотах больше кофеина в
кофейные зерна, потому что насекомых больше, а на очень большой высоте
насекомых гораздо меньше, поэтому и кофеина меньше. Большая высота
кофе также имеет тенденцию содержать больше полифенолов благодаря богатой питательными веществами почве.
Чем меньше размер помола, тем больше
площадь поверхности, обеспечивающая максимальную экстракцию. Разный кофе
методы заваривания требуют разного помола
размеры. Температура воды — еще один фактор,
более высокие температуры приводят к более высокой экстракции.Техника перелива
высшие экстракции. Обычно вам нужно использовать немного больший помол.
размера, чем вы делаете с техникой погружения. Если вы используете очень и очень
мелкий помол в заливке, он просто впитывает всю воду и ничего
проходит через. вы все еще можете извлечь немного кофеина из
В этом методе используется средний и мелкий помол. Использование большего количества кофейной гущи
принесет вам больше кофеина, а использование большего количества воды разбавит напиток.
Турецкий кофе сочетает в себе ультратонкий помол и кипяток с
без фильтрации.Этот кофе может быть довольно горьким из-за чрезмерной экстракции.
Французская пресса не получит высоких извлечений. Холодное пиво — это
метод недостаточной экстракции и обычно извлекают от 75 до 80 процентов того, что
попадаешь в горячее варево. Бренд кофе с наибольшим содержанием кофеина
— это кофе Biohazard, содержащий 928 мг кофеина на 12 унций.
Перколяция относится к движению и фильтрации жидкостей через
пористые материалы. Это описывается законом Дарси. Более широкие приложения
с тех пор были разработаны, которые охватывают возможность подключения многих смоделированных систем
как решетки или графы, аналогично связности компонентов решетки в
проблема фильтрации, которая модулирует способность к просачиванию.
Содержание
Отвар — это метод экстракции путем отваривания трав или растений. материал для растворения химикатов материала, который может включать стебли, корни, кора и корневища. Отвар включает сначала затирание растительный материал для максимального растворения, а затем кипячение в воде для извлечения масел, летучих органических соединений и других различных химических веществ вещества. Отвар можно использовать для приготовления тизана, настойки и тому подобного. решения. Из отваров и настоев могут выделяться жидкости с разными характеристиками. химические свойства, так как температура и / или разница в приготовлении могут в результате в отварах будет больше маслорастворимых химикатов, чем в настоях.В процесс также может применяться к мясу и овощам для приготовления бульона или бульон, хотя этот термин обычно используется только для описания вареного растения экстракты, как правило, для медицинских или научных целей. Отвар тоже название получившейся жидкости. Хотя этот метод добычи отличается от настаивания и перколяции, образующиеся жидкости иногда могут быть похожими по своему действию или общему виду и вкусу.
Заваривание замачивание твердого вещества в жидкости (обычно в воде), обычно для того, чтобы извлекать ароматизаторы или смягчать его.Специфика процесса приготовления чая подготовлены для питья, оставив листья в нагретой воде, чтобы высвободить аромат и питательные вещества известен как замачивание. Травяные чаи могут быть приготовлены отвар, настой или мацерация. Некоторые твердые частицы замачивают, чтобы удалить ингредиент, такой как соль, где растворенное вещество не является желаемым продуктом.
Белок
Сочетание белков диетическая стратегия белкового питания с использованием дополнительных источников для оптимизации биологической ценности и повышения качества протеина.Белковая комплементация — Белки (знания)
Старайтесь не смешивать продукты, богатые углеводами, и продукты, богатые белком, в одном приеме пищи.
PH
Разделение еды на три группы: щелочные, кислые и нейтральные Кислые продукты богаты белком, такие как мясо, рыба, молочные продукты и т. д. Щелочные продукты богаты углеводами, такие как рис, зерна и картофель. Сенная диета — Щелочная диета — PHСочетание продуктов для усиления вкуса
Вкус — это сенсорный впечатление от еды или другое вещество, и определяется в первую очередь химический чувства вкуса и запаха.«Чувства тройничного нерва», которые обнаруживают химические раздражители во рту и горла, а также температура и текстура также важны для общий гештальт вкусового восприятия. Вкус еды как таковой может быть заменены натуральными или искусственными ароматизаторами, которые влияют на эти чувства. Сочетание вкусов.
Сочетание еды это метод определения того, какие продукты подходят друг другу. Метод основан на том принципе, что продукты хорошо сочетаются друг с другом, когда они поделиться ключевыми вкусовыми составляющими.Пищевое спаривание — относительно новый метод, часто путают с сочетанием вина и еды. Напротив, в foodpairing ВЭЖХ, газовая хроматография и другие лабораторные методы анализа пищевых продуктов и найти общие химические компоненты.
Food Pairing откройте для себя новое комбинации вкусов за секунды. Продукты, меняющие вкус.
Комбинации продуктов — Комбинации вкусов — Food Combos
Расстройства пищевого поведения
Эффект Дорито — это когда еда нам лжет.В природе, вкус и питание идут рука об руку.
Если Flavorist’s из Компании по производству ароматизаторов действительно заботились о людях, которых они использовали бы, чтобы сделать здоровыми еда вкусная, а не вредная. Зарабатывать деньги за счет других здоровье людей безумно и преступно. Наука о еде.
Институт пищевых технологий
Сенсорная Анализ это научная дисциплина, которая применяет принципы экспериментального дизайна и статистический анализ использования человеческих органов чувств (зрение, обоняние, вкус, осязание и слух) для оценки потребительских товаров.
Лексическая вкусовая синестезия это редкая форма синестезия, в которой устная и письменная речь (а также некоторые цвета и эмоции) заставляет людей испытывать автоматические и очень устойчивый вкус / запах.
Как пищевой краситель меняет восприятие вкуса
Сочетание чая и еды
Почему Вкусно или хорошо Вкус не всегда значит Здоровый?
Знания о еде — Знания о физическом здоровье
Фотографии еды — Что едят люди — Школьные обеды
Smart Gastronomy Lab
3D-печать Еда — NASA 3D Food — Гладкая еда — Пюре из блюд — Поколение W
Natural Machines Видео (youtube)
6 Sensor Labs Портативный датчик аллергенов.
Тройничный нерв — это нерв, отвечающий за ощущения на лице и двигательные функции, такие как кусание и жевание.
Вкус — Чувство вкуса — Сладкий — Соленый — Кислый — Горький
Вкус один из пяти традиционных чувства, которые принадлежат вкусовая система. Вкус — это ощущение, возникающее при вещество в ротовая полость химически реагирует с клетками вкусовых рецепторов, расположенными на вкусе бутоны в ротовой полости, в основном на язык.Вкус вместе с Запах (обоняние) и стимуляция тройничного нерва (регистрация текстуры, боли, и температура), определяет вкус пищи или других веществ. Люди есть вкусовые рецепторы на вкусовых сосочках (вкусовые чашечки) и других областях включая верхнюю поверхность языка и надгортанник. Каждый ароматизатор — это химическое соединение.
Умами, который является пятым вкусом, который является загадочным, но интересным, приятным пикантным вкус.
Sweet имеет характерный вкус сахар, который нравится чувства и радость уму.Что-нибудь не соленое, кислое или горькое. Сладость обычно считается приятным ощущением, вызывается присутствием сахаров и несколько других веществ. Сладость часто связана с альдегидами и кетонами, которые содержат карбонильная группа. Сладость определяется различными G-белками, связанными с рецепторы, связанные с G-белком густдуцином, обнаруженные на вкусовых рецепторах. В как минимум два разных варианта «рецепторов сладости» должны быть активируется, чтобы мозг регистрировал сладость.Соединяет чувства мозга как сладкие, таким образом, соединения, которые могут связываться с различной прочностью связи с два разных рецептора сладости. Эти рецепторы — T1R2 + 3. (гетеродимер) и T1R3 (гомодимер), которые объясняют все сладкое ощущение у люди и животные. Пороги определения вкуса сладких веществ оценивается по сравнению с сахарозой, которая имеет индекс 1. Средний человек порог обнаружения сахарозы составляет 10 миллимолей на литр. Для лактозы это составляет 30 миллимолей на литр, с индексом сладости 0.3 и 5-нитро-2-пропоксианилин 0,002 миллимоля на литр. «Натуральные» подсластители, такие как сахариды активируйте GPCR, который высвобождает густдуцин. Затем густдуцин активирует молекула аденилатциклазы, которая катализирует выработку молекула цАМФ, или аденозин-3 ‘, 5’-циклический монофосфат. Эта молекула закрывает ионные каналы калия, что приводит к деполяризации и высвобождение нейротрансмиттера. Синтетические подсластители, такие как сахарин, активируют различных GPCR и вызывают деполяризацию вкусовых рецепторов альтернативный путь.Sweet Tooth — это когда человек имеет сильную тягу к сладкому еда.
Соленость — простейший рецептор, обнаруженный в рот, который является рецептор хлорида натрия (соли). Соленость — это вкус, производимый в первую очередь наличием ионов натрия. Другие ионы группы щелочных металлов также вкус соленый, но чем дальше от натрия, тем менее соленое ощущение. Канал натрия в стенке вкусовых клеток позволяет катионам натрия проникать в клетка. Это само по себе деполяризует ячейку и размыкает в зависимости от напряжения. кальциевые каналы, наводняющие клетку положительными ионами кальция и ведущие к высвобождению нейромедиаторов.Этот натриевый канал известен как эпителиальный натриевый канал (ENaC) и состоит из трех субъединиц. ENaC может быть блокируется препаратом амилорид у многих млекопитающих, особенно у крыс. В однако чувствительность соленого вкуса к амилориду у людей значительно менее выражен, что позволяет предположить, что могут быть дополнительные рецепторные белки, помимо ENaC, предстоит открыть. Размер лития и ионы калия наиболее похожи на ионы натрия, и, таким образом, соленость наиболее похожа.Напротив, ионы рубидия и цезия далеки от крупнее, поэтому их соленый вкус соответственно различается. Соленость веществ оценивается относительно хлорида натрия (NaCl), который имеет индекс из 1. Калий, как хлорид калия (KCl), является основным ингредиентом в заменителях соли и имеет индекс солености 0,6. Другой моновалентный катионы, например аммоний (Nh5 +) и двухвалентные катионы щелочноземельных металлов группа металлов периодической таблицы, например кальций (Ca2 +), ионы обычно вызывают скорее горький, чем соленый вкус, даже если они тоже могут пройти непосредственно через ионные каналы в языке, вызывая действие потенциал.Но хлорид кальция более соленый и менее горький, чем хлорид калия и обычно используется в рассоле для рассола вместо KCl.
Кислый вкус — это вкус, определяющий кислотность. Кислотность веществ оценивается по отношению к разбавленной соляной кислоте, имеющей индекс кислотности из 1. Для сравнения: винная кислота имеет индекс кислинки 0,7, лимонная кислоты с индексом 0,46 и угольной кислоты с индексом 0,06. Кислый вкус обнаруживается небольшим подмножеством клеток, которые распределены по всем вкусам бутоны на языке.Клетки кислого вкуса можно определить по выражению белок PKD2L1, хотя этот ген не требуется для кислых реакций. Есть свидетельства того, что протоны, содержащиеся в кислых веществах, может напрямую проникать в клетки кислого вкуса через апикально расположенный ион каналы. Эта передача положительного заряда в ячейку может сама по себе вызвать электрический отклик. Также было высказано предположение, что слабые кислоты например, уксусная кислота, которая не полностью диссоциирует при физиологическом pH ценностей, может проникать в вкусовые клетки и тем самым вызывать электрический отклик.По этому механизму внутриклеточные ионы водорода ингибируют калиевые каналы, которые обычно функционируют для гиперполяризации клетки. От комбинация прямого поступления ионов водорода (который сам деполяризует клетка) и угнетение гиперполяризационного канала, кислинка заставляет вкусовую клетку запускать потенциалы действия и высвобождать нейромедиатор. Наиболее распространенная группа продуктов, содержащая натурально кислые продукты. продукты — это фрукты, такие как лимон, виноград, апельсин, тамаринд, а иногда дыня.Вино также обычно имеет кислый оттенок вкуса, и если его не хранить правильно молоко может испортиться и стать кислым. Дети в США и Великобритания демонстрирует большее удовольствие от кислого вкуса, чем взрослые, и кислые конфеты популярны в Северной Америке, включая Cry Babies, Warheads, Lemon drops, Shock Tarts и кислые версии Skittles и Starburst. Многие из этих конфеты содержат лимонную кислоту или яблочную кислоту. Sweet Tarts — это кисло-сладкие конфеты, изобретенные Джеффом Соузой в 1962 году. Конфеты были созданы по тому же базовому рецепту, что и уже популярные Продукты Pixy Stix и Lik-M-Aid.Пирог это что-то кислое, как лимон.
Используется международная шкала единиц горечи или просто шкала IBU. приблизительно для определения горечи пива. Эта шкала не измеряется по воспринимаемой горечи пива, а скорее по количеству изо-альфа-кислоты. Изогумулон — это химические соединения, которые придают горький вкус. пива и относятся к классу соединений, известных как изо-альфа-кислоты. Они содержатся в хмеле. В пивоварне не любят сладкое, у них есть хмелевые зубы.Измерения Пива включать горечь, разнообразие вкусов, присутствующих в напитке, а также с их интенсивностью, содержанием алкоголя и цветом. Стандарты этих характеристик позволяют более объективное и единообразное определение в целом качества любого пива.
Горечь — самый чувствительный вкус, и многие ее воспринимают. неприятным, резким или неприятным, но иногда желательно и намеренно добавлен через различные горькие вещества.Общие горькие продукты и напитки включают кофе, несладкое какао, южноамериканский мате, биттер тыква, оливки, кожура цитрусовых, многие растения семейства Brassicaceae, зелень одуванчика, дикий цикорий и эскарол. Этанол в спиртовой напитки горькие на вкус, как и дополнительные горькие ингредиенты, содержащиеся в некоторые алкогольные напитки, включая хмель в пиве и апельсин в биттерах. Хинин также известен своим горьким вкусом и содержится в тонизирующей воде. Горечь интересна тем, кто изучает эволюцию, а также различные исследователей в области здравоохранения, поскольку большое количество природных горьких соединений известно, что он токсичен.Способность обнаруживать горькие токсичные соединения при низких порогах считается важным защитным функция. Листья растений часто содержат токсичные соединения, но даже среди приматы-листоеды, есть тенденция отдавать предпочтение незрелым листьям, которые как правило, содержат больше белка и меньше клетчатки и ядов, чем зрелые листья. Среди людей используются различные методы обработки пищевых продуктов. во всем мире, чтобы детоксифицировать несъедобные продукты и сделать их вкусными.Кроме того, использование огня, изменение диеты и избегание токсинов имеет привело к нейтральной эволюции горькой чувствительности человека. Это позволило несколько мутаций потери функции, которые привели к снижению сенсорной способность к горечи у людей по сравнению с другими видами. В порог стимуляции горького вкуса хинином в среднем составляет концентрация 8 мкМ (8 мкмоль). Пороги вкуса другого биттера вещества оцениваются относительно хинина, поэтому на него дается ссылка индекс 1.Например, бруцин имеет индекс 11, поэтому воспринимается как более горький, чем хинин, и обнаруживается при гораздо более низких порог решения. Самым горьким из известных веществ является синтетический химический денатоний, имеющий индекс 1000. Он используется как аверсивный агент (горькое средство), который добавляется к токсичным веществам для предотвращения случайное проглатывание. Он был обнаружен в 1958 году при исследовании лигнокаин, местный анестетик, Макфарлан Смит из Горджи, Эдинбург, Шотландия.Исследования показали, что TAS2R (вкусовые рецепторы, тип 2, также известные как T2R), такие как TAS2R38, связанный с G-белком густдуцином, являются отвечает за способность человека воспринимать горькие вещества. Они есть определяется не только их способностью ощущать на вкус определенную «горькую» лиганды, но также и морфологией самого рецептора (поверхностно-связанный, мономерный). Считается, что семейство TAS2R у человека включает около 25 различные вкусовые рецепторы, некоторые из которых могут распознавать самые разные горькие на вкус соединения.Было проведено более 670 горьких вкусовых добавок. идентифицированы в горькой базе данных, из которых более 200 были назначены один или несколько специфических рецепторов. В последнее время высказываются предположения, что селективные ограничения на семейство TAS2R были ослаблены из-за относительно высокая скорость мутации и псевдогенизации. Исследователи используют два синтетические вещества, фенилтиокарбамид (PTC) и 6-н-пропилтиоурацил (ПРОП) изучить генетику горького восприятия. Эти два вещества для одних горький вкус, для других — практически безвкусный.Среди дегустаторами, некоторые из них являются так называемыми «супер-дегустаторами», для которых PTC и PROP чрезвычайно горький. Разница в чувствительности определяется двумя общими аллели в локусе TAS2R38. Эта генетическая вариация способности к вкус вещества был источником большого интереса для тех, кто изучает генетика. Густдуцин состоит из трех субъединиц. Когда он активируется GPCR, его субъединицы распадаются и активируют фосфодиэстеразу, соседнюю фермент, который, в свою очередь, превращает предшественник в клетке в вторичный мессенджер, закрывающий ионные каналы калия.Кроме того, это вторичный мессенджер может стимулировать эндоплазматический ретикулум для высвобождения Ca2 + что способствует деполяризации. Это приводит к накоплению калия. ионы в клетке, деполяризация и высвобождение нейромедиаторов. Это также возможно, что некоторые вещества, имеющие горький вкус, напрямую взаимодействуют с G-белком, из-за структурного сходства с соответствующим GPCR.
Вкус и острота — это аппетитный вкус и иногда описывается своим японским названием умами или мясным.Его можно попробовать в сыре и соевый соус, а также содержится во многих других ферментированных и выдержанных продуктах. Этот вкус также присутствует в помидорах, зернах и бобах. Заимствование от По-японски означает «хороший вкус» или «хороший вкус», умами считается фундамент многих восточных кухонь; и другие кухни давно работали по принципам, которые стремились объединить продукты для производства пикантных ароматы, такие как акцент на телячьи бульон Огюста Эскофье, выдающийся шеф-повар французской кухни 19 века, а в римской сознательное употребление кисломолочного рыбного соуса.Однако это было совсем недавно. признанный в современной науке основным вкусом; хорошо после другого основного вкусы были признаны учеными, отчасти из-за их соответствие четырем вкусам древнегреческой философии. Умами, или «Восхитительность», впервые была изучена научным методом и идентифицированный Кикунаэ Икеда, который начал анализировать комбу в 1907 году, пытаясь изолировать его вкус даси. Он выделил вещество, которое назвал адзиномото, по-японски «источник аромата».Его Ajinomoto Co., Inc. в настоящее время работает более 32 000 человек. Позже Аджиномото был идентифицирован как химический глутамат натрия (MSG), который все чаще используется независимо как пищевая добавка, это натриевая соль, которая производит сильный пикантный вкус, особенно в сочетании с продуктами, богатыми нуклеотидами такие как мясо, рыба, орехи и грибы. Некоторые пикантные вкусовые рецепторы отзываются специально для глутамата так же, как «сладкие» реагируют на сахар. Глутамат связывается с вариантом глутамата, связанного с G-белком. рецепторы.Считается, что аминокислота L-глутамат связывается с типом GPCR, известного как метаботропный рецептор глутамата (mGluR4). Это вызывает комплекс G-протеина для активации вторичного рецептора, который в конечном итоге приводит к высвобождению нейромедиатора. Промежуточные этапы неизвестны. (См. Страницы TAS1R1 и TAS1R3 для дальнейшего объяснения аминокислоты вкусовый рецептор).
Кислая пища ощущается в нижняя челюсть и шея, потому что ваши слюнные железы усиленно работают. Слюна 99.5 процентов воды, но он также содержит определенные вещества, которые поможет вам жевать, попробовать на вкус и проглотить, а также защитит зубы. Твое тело производит от 2 до 4 пинт слюны каждый день, и большая ее часть вырабатывается в Поздний вечер. Однако ваши вкусовые рецепторы играют важную роль в том, как вы выделяете много слюны. Острая пища, сладкая пища и кислая, кислая на вкус продукты могут вызвать слюнные железы, расположенные ниже язык, под челюстью и под ушами — для выработки большего количества слюны.А также иногда можно почувствовать работу желез, особенно больших околоушные железы, расположенные между челюстью и ушами.
Экзокринные слюнные железы Железы, вырабатывающие слюну через систему протоков. У людей есть три парные большие слюнные железы (околоушная, подчелюстная и подъязычный), а также сотни малых слюнных желез. Слюнные железы можно разделить на серозные, слизистые или серозно-слизистые (смешанные). В серозном секреции, основным типом секретируемого белка является альфа-амилаза, фермент который расщепляет крахмал на мальтозу и глюкозу, а в слизистых секреции основной секретируемый белок — муцин, который действует как смазка.У человека ежедневно вырабатывается от 0,5 до 1,5 литров слюны. Секреция слюны (слюноотделение) опосредуется парасимпатической стимуляция; ацетилхолин является активным нейромедиатором и связывается с мускариновые рецепторы в железах, что приводит к увеличению слюноотделение.
Небо это нёбо у людей и других млекопитающих. Он отделяет полость рта из полости носа. Вкус делится на две части, переднее костлявое твердое небо и заднее мясистое мягкое небо (или велум).
Очищающее средство для вкуса, как правило, представляет собой элемент с нейтральным вкусом в пище, позволяет очистить вкус от одного аромата к другому чтобы вы могли точно попробовать еду, не имея других вещи, которые вы съели, влияют или влияют на ваш вкус восприятие. В культурах, где разнообразие вкусов в блюдах принято, средство для очищения вкуса считается незаменимым компаньоном для закусок.
Вкусовые качества — это гедонистическая награда (т. е. удовольствие) от пищи или жидкости, которые подходят для «вкус», который часто меняется в зависимости от гомеостатического удовлетворения потребности в питании, воде или энергии.Вкусовые качества пищи или жидкости, в отличие от аромата или вкуса, варьируется в зависимости от состояния человека: это ниже после потребления и выше при лишении. Вкусовые качества продуктов, однако можно узнать. Все больше осознается, что это может вызвать гедонический голод, не зависящий от гомеостатических потребностей.
Язык это мышечный орган во рту большинства позвоночных, который управляет пищей для жевания и используется при глотании. Это важно в пищеварительной системе и является основным органом вкуса во вкусовых ощущениях. система.Верхняя поверхность языка (спинка) покрыта вкусовыми сосочками. расположен в многочисленных язычных сосочках. Он чувствительный и остается влажным благодаря слюна и богато снабжена нервами и кровеносными сосудами. Язык также служит естественным средством чистки зубов. Основная функция язык — это возможность говорить у людей и вокализовать у других животные.
Вкус Почки содержат клетки вкусовых рецепторов, которые также известны как вкусовые клетки. Вкусовые рецепторы расположены вокруг небольшого структуры, известные как сосочки, обнаруженные на верхней поверхности языка, мягкое небо, верхний отдел пищевода, щека и надгортанник.Эти структуры участвуют в обнаружении пяти элементов вкусового восприятия: соленого, кислый, горький, сладкий и умами; через комбинацию этих элементов мы обнаруживаем «ароматы». Популярный миф приписывает эти разные вкусы разные области языка; на самом деле эти вкусы можно обнаружить любой областью языка. Через небольшие отверстия в эпителии языка, так называемые вкусовые поры, части пищи, растворенные в слюне, попадают в контакт со вкусовыми рецепторами.Они расположены на вершине вкуса рецепторные клетки, составляющие вкусовые рецепторы. Клетки вкусовых рецепторов отправлять информацию, обнаруженную кластерами различных рецепторов и ионов каналы к вкусовым зонам мозга через седьмой, девятый и десятые черепные нервы. В среднем человеческий язык имеет 2–8 000 вкусовых качеств. бутоны.
Рецептор вкуса это тип рецептора, который способствует ощущение вкуса. Когда еда или другие вещества попадают в рот, молекулы взаимодействуют со слюной и связаны со вкусовыми рецепторами в полости рта и других местах.Молекулы, дающие ощущение вкуса, считаются «живыми». Вкус рецепторы делятся на два семейства: Тип 1, сладкий, первый в 2001 году охарактеризован: TAS1R2 — TAS1R3. Тип 2, горький, первый охарактеризованные в 2000 году: TAS2R1 — TAS2R50 и TAS2R60. Комбинации эти рецепторы в димерах или других комплексах вносят вклад в различные восприятие вкуса. Визуальный, обонятельный, «сапиктивный» (восприятие вкусов), тройничного нерва (горячий, прохладный), механический, все способствуют восприятие вкуса.Из них временный рецепторный потенциальный катионный канал ваниллоидные рецепторы члена 1 подсемейства V (TRPV1) ответственны за восприятие тепла от некоторых молекул, таких как капсаицин, и CMR1 рецептор отвечает за восприятие холода такими молекулами, как ментол, эвкалиптол и ицилин.
TAS2R38 представляет собой белок, который у человека кодируется геном TAS2R38. TAS2R38 — это рецептор горького вкуса.
Рецептор арилуглеводородов — это белок, который у человека кодируется ген AHR.Арилуглеводородный рецептор представляет собой активируемый лигандом фактор транскрипции, участвующий в регуляции биологических ответов на планарные ароматические (арил) углеводороды. Было показано, что этот рецептор регулируют ферменты, метаболизирующие ксенобиотики, такие как цитохром P450. Фенотип.
Горечь — это естественная система предупреждения, которая защищает нас от вредных вещества. Но теперь мы знаем, что горечь — лишь один из факторов, определяет, безопасно или опасно что-то есть.Найдено исследование люди, чувствительные к горькому привкусу хинина и ПРОП, синтетического вкус, связанный с соединениями, содержащимися в овощах семейства крестоцветных, избегайте кофе. Для алкоголя более высокая чувствительность к горечи PROP привела к снижение потребления алкоголя, особенно красного вина. Связь количества сосочков с интенсивностью горечи хинина и PROP внутри и между людьми. Испытуемых попросили оценить горечь одного 6-н-пропил-2-тиоурацила (PROP) и двух хинина HCl (QHCl) концентрации представлены через фильтровальную бумагу различных размеров.Количество вкусовые сосочки, стимулированные этой фильтровальной бумагой, подсчитывались в каждом физическое лицо. Чувствительность всего рта к PROP определялась в отдельном сеанс. В поддержку других демонстраций пространственного суммирования эти данные показали, что интенсивность воспринимаемой горечи увеличивалась как функция области стимуляции внутри предметов. Между предметами был значительная тенденция к увеличению воспринимаемой горечи PROP с увеличением язычная плотность грибовидных сосочков, хотя эта тенденция была очень переменная и была продемонстрирована только среди тех, кто показал хотя бы умеренная чувствительность к ПРОП.С другой стороны, количество стимулированных грибовидные сосочки не могли объяснить индивидуальные различия в воспринимается горечь QHCl.
Дисгевзия искажение вкусовых ощущений. Дисгевзия также часто ассоциируется с агевзией, что означает полное отсутствие вкуса, и гипогевзией, которая происходит снижение вкусовой чувствительности. Расстройства вкуса.
Наш вкус бутоны и обоняние легко формируются нашими предубеждениями и ожидания.Можете ли вы доверять своим вкусовым рецепторам? (ВИННЫЙ ВЫЗОВ) (YouTube) — 150 ароматов и вкусов, которые можно попробовать в винах.
Супертастер человек, который испытывает чувство вкуса с гораздо большей интенсивностью чем в среднем, а некоторые исследования показывают повышенную чувствительность к горький вкус. Причина этого повышенного отклика неизвестно, хотя считается, что это связано с наличием TAS2R38 гена, способность ощущать вкус PROP и PTC, и, по крайней мере частично, благодаря повышенное количество грибовидных сосочков.Любое эволюционное преимущество супер дегустация непонятна. В некоторых средах повышенный вкусовой отклик, особенно горечи, представляет собой важное преимущество в избегать потенциально токсичных алкалоидов растений. В других средах, повышенная реакция на горечь могла ограничить диапазон вкусовых качеств. продукты.
Стать тестером вкуса (wkihow) — Как попробовать
Вкус — Факты о вкусе — Ароматизатор Комплекты — Дегустация науки
Вкус и оральные ощущения у людей различаются.
Обновленная система вкусовых ощущений показывает, как ароматы переходят от языка к мозгу.
Мозг воспринимает вкус всеми органами чувств, показывают исследования.
Ассоциативное обучение меняет кросс-модальные представления во вкусовых ощущениях. кора.
Вкусовые рецепторы действительно везде, в том числе двоеточие. И если он получит подверженный слишком большой горечи, он вызывает выброс ионов, которые в в свою очередь, вода попадает в кишечник через осмос, и тело испытывает понос.
Вы также можете оплачивать себя. И люди, которые заболели от определенной пищи, также будут воспринимать эту пищу по-другому. Люди также могут по-разному воспринимать определенные продукты, когда: имея Гиперчувствительность или пониженная чувствительность ниже нормы чувствительность к чужеродному агенту, например аллергену, при котором реакция необычно задерживается или уменьшается по степени. Также называется гипоэргией. Ваш восприятие вкуса также может измениться, когда смешано слишком много продуктов все вместе, Кроссмодальный.
Я не позволяю вкусу сказать мне что есть. Хотя важно, чтобы мы понимали, что вкус мой быть признаком того, что некоторая пища может быть небезопасной для нас, мы не можем пусть вкус мешает нам есть пищу, которая, как мы знаем, полезна для нас.
Почему некоторые продукты плохо пахнут, но имеют прекрасный вкус? Вещи, которые хорошо пахнут и имеют неприятный вкус, обычно имеют сильный запах. горький компонент в их вкусе, который вы можете попробовать языком, но не запах. В то время как ваш нос и ваш язык используют химические вещества рецепторы, они не реагируют на одни и те же химические вещества.Сыры могут пахнуть как грязные носки, но приятный на вкус. Ферментированный рыбный соус может пахнуть свежезагрязненный подгузник, но он будет очень вкусным.
Обонятельный белый — это запах состоит из множества одинаково сильных, но разнообразных запахов, возможно, более 30. Смеси разных запахов в диапазоне восприятия имеют тенденцию запах очень похож на человеческий, несмотря на то, что он состоит из разных компонентов. Концепция похожа на все разные спектральные цвета объединяются в белый цвет. Обонятельный белый цвет не является ни приятным, ни неприятным.
Во вкусовых сосочках обнаружен новый тип вкусовых клеток. Исследование на мышах
определяет вкусовую клетку, которая распознает любой вкус, кроме соли. Они обнаружили
ранее неизвестное подмножество клеток типа III, которые были «широко
отзывчивый «и может сообщать о кислых раздражителях с помощью одного сигнального пути,
и сладкие, горькие и умами раздражители с использованием другого. Вкусовые рецепторы используют три
типы вкусовых клеток: клетки типа I действуют как опорные клетки; Клетки типа II
распознавать горький, сладкий и умами вкусы; и клетки типа III обнаруживают кислые и
соленые вкусы.
Температура влияет на вкус
Почему температура пищи влияет на вкус? Потому что эффект температура неоднородна по соединений, можно ожидать, что вкусовой «профиль» пищи будет изменяется при изменении его температуры. Если все остальное равно, при горячем Температура: горький и сладкий вкус должен преобладать соленый и кислый. Почему теплая еда отличается на вкус, когда она холодная? Некоторые продукты имеют другой вкус, горячие или Холодный.Большинство людей предпочитают холодную газировку и их кофе горячий, и новое исследование показывает, что это могло быть потому, что изменения температура продуктов и напитков влияет на вкус интенсивность кислого, горького и вяжущего.
Почему
еда вкуснее, когда она теплая? Согласно
исследователи, реакция TRPM5 на наши вкусовые рецепторы намного больше
интенсивный, когда температура пищи или жидкости повышается, вызывая
более сильный электрический сигнал в мозг, что приводит к усилению
вкус.«Самый яркий пример сладкого вкуса — мороженое.
Влияет ли холод на вкусовые рецепторы? Так холодно
просто блокирует наш нос и обоняние, но вместе с этим и наши
способность вкушать пищу просто бросается в глаза. Лихорадка меняет наш вкус
еда. Вы избегаете еды, потому что она безвкусная и безвкусная, потому что
что простуда сделала с вашими вкусовыми рецепторами.
Приготовление и температура влияют на
Бактерии и питание.
Форма стакана может повлиять на вкус
Почему Форма стакана влияет на вкус? Бокал для вина, который наклоняется внутрь по направлению к ободу концентрирует спиртовые ароматы вокруг обода.Это значит, что когда мы направляем ваш нос к центру стакана, резкость газообразный этанол или алкоголь восстанавливается, делая вино ароматы более отчетливые. И в зависимости от формы вашего стакана, когда ты пьешь ты по-другому наклоняешь голову, эти разные позы меняются скорость попадания вина в ваш язык, а также место его попадания, и если жидкость попадает на заднюю часть языка, это может вызвать другой вкус ощущение, чем если бы он попал спереди или по бокам.Температура также может влиять на аромат тоже. Типы стаканов для питья (изображение).Наши Восприятие еды также может влиять на вкус. Известно, что людям нравится вина больше, когда им сказали, что оно дорогое.
Прихлебывание помогает улучшить ваши вкусовые качества. Шумное потребление методы действительно могут повлиять на опыт дегустации.
Горячее обжигающее вещество
Капсаицин — активный компонент чили перец, который относится к роду Capsicum.Это раздражает млекопитающих, в том числе человека, и вызывает ощущение жжения в любой ткани с с которым он вступает в контакт. Капсаицин и некоторые родственные соединения являются называются капсаициноидами и производятся в виде вторичных метаболитов перцем чили. перец, вероятно, как средство отпугивания некоторых млекопитающих и грибов. Чистый капсаицин — гидрофобный, бесцветный, очень острый, кристаллический или воскообразный твердое соединение.Шогаол острые составляющие имбиря, сходные по химической структуре с гингерол.Самым распространенным из группы является (6) -шогаол. Как и зингерон, это производится при сушке или приготовлении имбиря. Более того, шогаол (и гингерол) превращаются в другие составляющие при нагревании время, поэтому имбирь теряет свою остроту при приготовлении.
Гингерол химическое соединение, обнаруженное в свежем имбирь. По химическому составу гингерол является родственником капсаицина и пиперина, соединения, которые дают перец чили и чернить перец их соответствующей пряностью.Обычно встречается как острый желтое масло, но также может образовывать легкоплавкое кристаллическое твердое вещество.
Некоторые считают Зингерон ключевым компонентом остроты имбирь, но придает «сладкий» привкус приготовленного имбиря. Zingerone — это кристаллическое твердое вещество, плохо растворимое в воде и растворимое в эфире. При синтезе и дегустации не имеет остроты, что позволяет предположить, что это более вероятно, что зингерон является продуктом разложения, а не прямой источник, острота имбиря.Зингерон похож по химическому составу структура к другим ароматизирующим химическим веществам, таким как ванилин и эвгенол. это используется в качестве ароматизирующей добавки в пряных маслах и в парфюмерии для введения пряные ароматы. Свежий имбирь не содержит зингерона, но его производят путем варки или сушки корня имбиря, что вызывает обратную альдольную реакцию на имбирь.
Запахи — Запахи — Запахи
Сила обоняния — Человеческий нос может различать не менее 1 триллиона различных запахов.
Обоняние это обоняние. Это чувство опосредовано специализированными сенсорные клетки носовой полости позвоночных, что можно считать аналогом сенсорные клетки усиков беспозвоночных. У людей обоняние возникает, когда молекулы одоранта связываются с определенными участками обонятельного рецепторы. Эти рецепторы используются для обнаружения запаха. Они собираются вместе в клубочках, структуре, которая передает сигналы к обонятельная луковица (структура мозга непосредственно над носовой полостью и ниже лобной доли).Черепные нервы.
Обонятельная система это часть сенсорного система, используемая для обоняния (обоняния). Большинство млекопитающих и рептилий имеют основная обонятельная система и дополнительная обонятельная система. Главный обонятельная система обнаруживает находящиеся в воздухе вещества, а вспомогательная система чувствует раздражители жидкой фазы. Чувства запаха и вкуса (вкусовые система) часто называют хемосенсорной системой, потому что они оба дают мозгу информацию о химическом составе объекты через процесс, называемый трансдукцией.
Датчики, обнаруживающие запахи в носу, тоже присутствуют во вкусе человека. на языке обнаружены клетки.
Обоняние — это Химическое чутье, которое стимулируется такими веществами, как раздражающие растворы или пары, способные возбуждать рецепторы слизистой оболочки оболочки носа, рта, глаз и дыхательных путей. Ваша способность запах исходит от специализированных сенсорных клеток, называемых обонятельными сенсорными нейроны, которые находятся в небольшом участке ткани высоко внутри носа.Эти клетки напрямую связаны с мозгом. Каждый обонятельный нейрон имеет один рецептор запаха. Как только нейроны обнаруживают молекулы, они отправляют сообщения в ваш мозг, который распознает запах. Больше запахов в среды, чем есть рецепторы, и любая данная молекула может стимулировать комбинация рецепторов, создающая уникальное представление в мозгу. Эти представления регистрируются мозгом как особый запах. Запахи достигают обонятельных сенсорных нейронов двумя путями.Первое путь проходит через ноздри. Второй путь — через канал который соединяет верхнюю часть горла с носом. Выпускает жевательную пищу ароматы, которые получают доступ к обонянию сенсорные нейроны через второй канал. Если канал заблокирован, например, когда ваш нос из-за простуды или гриппа запахи не достигают сенсорных клеток, стимулируется запахами. В результате вы теряете большую часть своей способности получать удовольствие вкус еды. Таким образом, ваше обоняние и вкус тесно взаимодействуют. все вместе.Без обонятельных сенсорных нейронов, знакомые вкусы, такие как шоколад или апельсин, будет трудно различать. Без запаха продукты, как правило, имеют мягкий вкус и мало или без аромата. Некоторые люди, которые идут к врачу, потому что думают, что потеряли чувство вкуса, удивляются, узнав, что потеряли вместо этого обоняние. На ваше обоняние также влияют то, что называется здравым химическим смыслом. В этом смысле задействованы тысячи нервных окончаний, особенно на влажных поверхностях глаз, носа, рот и горло.Эти нервные окончания помогают вам чувствовать раздражение. вещества, такие как слезоточивость лука или освежающие прохлада ментола.
Обонятельные рецепторы действуют как чувствительные химические сенсоры и находятся в другие части тела, а не только наш нос. Больше наших ДНК посвящена генам для разных обонятельных рецепторов, чем для любого другого типа белок. Искусственный Интеллектуальные датчики.
Гиперосмия — это повышенная острота обоняния или обострение чувствительности. запах, который обычно вызван более низким порогом запаха.Этот перцептивный расстройство возникает, когда в любой момент появляется аномально повышенный сигнал между обонятельными рецепторами и обонятельной корой. Причины гиперосмии могут быть генетическими, гормональными, экологическими или результатом бензодиазепиновый абстинентный синдром. Когда одоранты попадают в носовую полость, они связываются с рецепторами запахов в основании обонятельного эпителия. Эти рецепторы представляют собой биполярные нейроны, которые соединяются с гломерулярным слоем. обонятельной луковицы, проходящей через решетчатую пластинку.На гломерулярный слой, аксоны от нейронов обонятельного рецептора перемешиваются с дендритами из внутренних нейронов обонятельной луковицы: митриальные / тафтинговые клетки и дофаминергические перигломерулярные клетки. Из обонятельной луковицы, митральные / тафтинговые клетки посылают аксоны через латеральный обонятельный тракт ( черепной нерв I) с обонятельной корой, которая включает грушевидную кора головного мозга, энторинальная кора и части миндалины. Из энторинала коры аксоны доходят до медиального дорсального ядра таламуса, которое затем переходят к орбитофронтальной коре.
Гиперосмический человек, «супер-нюхач», который может обнаружить болезнь Паркинсона. Заболевание только по запаху.
Движущиеся гены помогают Носу разбираться в запахах. Человеческий нос может различить один триллион разных ароматов — исключительный подвиг, который требует 10 миллионов специализированных нервных клеток, или нейроны в носу и семья из других более 400 выделенных генов. Но именно то, как эти гены и нейроны работают вместе, чтобы выбрать Особый запах давно озадачил ученых.Это по большей части потому что активность генов внутри каждого нейрона — где каждый из этих 10 миллиона нейронов выбирают активацию только одного из этих сотен выделенные гены — казались слишком простыми, чтобы учесть их огромное количество запахов, которые должен уловить нос.
Ученые расшифровывают, как мозг воспринимает запах. Прошлые исследования показали молекулы в воздухе, связанные с запахами, запускают рецепторные клетки, выстилающие нос, чтобы посылать электрические сигналы к пучкам нервных окончаний в лампочке, называемой клубочки, а затем и клетки головного мозга (нейроны).Сроки и порядок проведения Известно, что активация клубочков уникальна для каждого запаха с сигналами затем передается в кору головного мозга, которая контролирует, как животное воспринимает запах, реагирует на него и запоминает. Но потому что ароматы могут быть разными со временем и смешиваясь с другими, ученые до сих пор изо всех сил пытались точно отслеживать единую сигнатуру запаха по нескольким типам нейронов.
Как запахи превращаются в долговременные воспоминания. Нейробиологи исследовали, какая область мозга отвечает за хранение запахов как долговременные воспоминания.Некоторые запахи могут вызвать воспоминания об опыте лет назад. Новое исследование показывает, что грушевидная кора, входящая в состав обонятельный мозг участвует в процессе сохранения этих воспоминаний; в механизм, однако, работает только во взаимодействии с другими областями мозга.
Почему запахи вызывают сильные воспоминания. Запах путешествует по автостраде в гиппокамп в головном мозге.
Вы почувствуете запах позже: воздействие запахов в раннем младенчестве может изменять поведение взрослых. Ученые исследуют, как «запечатлеть» некоторые запахи новорожденные мыши влияют на социальное поведение взрослых.Запахи новорожденных мышей подвержены влиянию на многие виды социального поведения в более позднем возрасте, но как это случается до сих пор загадка. Ученые открыли молекулы необходимо для печати.
Грибные тела, как известно, играют роль в обонятельном обучении и памяти.
Обонятельная память связана с восприятием запахов.
Почему мы любим запах осени?
Пириформ Кора — это область головного мозга, часть носового мозга, расположенная в головном мозге.Функция грушевидная кора относится к обоняние.
Европейская обоняющая фабрика Heritage Project и Sensory Mining находят ключ ароматы, ароматные пространства и обонятельные практики, которые сформировали наши культур? Как извлечь сенсорные данные из цифрового текста большого размера и коллекции изображений? Как мы можем представить запах во всех его аспектах в база данных? Как нам сохранить обонятельное наследие? И — зачем мы? Добыча сенсорных данных.
Анализ данных сенсорной оценки знаний — сложный процесс из-за к крайней редкости данных и большому разбросу ответов от различные члены (называемые экспертами) комиссии. Основные цели интеллектуальный анализ в сенсорных науках понимает зависимость оценка воспринимаемой симпатии по уровням концентрации вкусовых добавок. ингредиенты, определение ингредиентов, которые вызывают симпатию, сегментирование разделить на группы со схожими предпочтениями и оптимизацией вкусов. чтобы увеличить симпатию к группе.В нашем подходе используется (1) генетическое программирование. (символическая регрессия) и ансамблевые методы для создания множества разнообразных объяснения предпочтений оценщика с достоверной информацией; (2) статистические методы экстраполяции полученных ансамблей на ненаблюдаемые области вкусового пространства, и сегментируйте оценщиков на группы, которые либо имеют одинаковую склонность к вкусам, либо управляемый теми же ингредиентами; и (3) оптимизация роя с двумя целями. для определения вкусов, которые неизменно нравятся избранным сегмент оценщиков.
Сенсорная наука это мультидисциплинарная область, включающая измерения, интерпретацию и понимание человеческих реакций на свойства продукта, как они воспринимаются такие чувства, как зрение, обоняние, вкус, осязание и слух.
Влияние запаха на полезность крыс. Несмотря на свою репутацию, крысы удивительно общительны и регулярно выручают друг друга. Исследователи показали, что крыса просто должна почувствовать запах другой крысы, которая занимается полезное поведение для увеличения собственной полезности.Это первая исследование, чтобы показать, что одного запаха сотрудничающей крысы достаточно, чтобы вызвать полезный ответ.
Чувство акулы кровь в воде на расстоянии 0,5 км или 1/3 мили. Акула может почувствуйте запах крови в воде и вернитесь по тропе к источнику. Может обнаруживают одну часть экстракта рыбы в 25 миллионах частей морской воды, эквивалент десяти капель крови в городском плавании среднего размера бассейн.
Обонятельная морфология и физиология эластожаберных жабер.Эластожаберный Считается, что рыбы обладают большей обонятельной чувствительностью, чем костистые рыб отчасти из-за большой площади эпителиальной поверхности, которая состоит из их органов обоняния; однако прямые доказательства корреляции Размер обонятельного органа для обонятельной чувствительности отсутствует. Этот исследование изучило обонятельную морфологию и физиологию пяти удаленных родственные виды пластиножаберных. В частности, мы количественно оценили количество ламелей и пластинчатой поверхности (как если бы это был плоский лист, а не учитывая вторичные ламели), составляющие их органы обоняния.Мы также рассчитаны обонятельные пороги и относительная эффективность аминокислотные отдушки для каждого вида. Органы обоняния различались у обоих количество ламелей и площадь ламеллярной поверхности, которая может быть связана с их общая среда обитания, но ни одна из них не коррелирует с обонятельным порогом. Пороговые значения запахов аминокислот, основных обонятельных раздражителей всех рыб, варьировала от 10–9,0 до 10–6,9 моль л – 1, что свидетельствует о том, что эти виды пластиножаберных демонстрируют сравнимые пороги с костистыми.В Кроме того, относительная эффективность аминокислотных стимулов к обонятельный орган эластожаберцев аналогичен описанному ранее в костистых костях с нейтральными аминокислотами, вызывающими значительно больший ответы, чем другие. В совокупности эти результаты указывают на параллели в обонятельная физиология между этими двумя группами рыб.
Функция двусторонних различий во времени прихода запаха в обонятельные органы. Ориентация акул. Направление источника сигнала запаха может быть оценивается по двусторонним различиям в интенсивности и / или приходе сигнала время.Наиболее известные примеры использования разницы во времени прибытия: в акустической ориентации. Считается, что для хеморецепции животные ориентироваться, сравнивая двусторонние различия в концентрации запаха, поворачивая в сторону более высоких концентраций [2, 3, 4]. Однако разница во времени должна нельзя игнорировать, потому что шлейфы запаха демонстрируют хаотическую перемежаемость с дисперсия концентрации на несколько порядков больше, чем среднее значение концентрации (например,). Мы представили небольшой вид акул Mustelus. canis, с тщательно рассчитанными по времени и измеренными импульсами запаха прямо в их ноздри.Они повернулись в сторону стимулированной первой, даже с задержкой. импульсы более высокой концентрации. Это первое неопровержимое доказательство того, что в полуестественных условиях и без тренировки, двустороннее время различия преобладают над различиями в концентрации запаха. Этот ответ каждый раз направлять акулу в пятно запаха и тем самым усиливать ее контакт со шлейфом, т. е. с потоком пятен. Животные с большим количеством широко расставленные ноздри могли бы разрешить меньшие углы атаки при более высокая скорость плавания, функция, которая, возможно, способствовала эволюция акул-молотов.Это представляет собой новое рулевое управление. алгоритм отслеживания запаховых шлейфов.
Нервная система нематод характеризуется: заднее нервное кольцо вокруг области глотки (область глубоко внутри ротовой полости) и две пары продольных нервных тяжей, идущих вниз по тело. Также существуют спинные (спинные) и вентральные (брюшные) нервные тяжи. как набор боковых нервных тяжей по всему телу.
Теория квантового обоняния предполагает, что эффект квантовой физики, известный как туннелирование действительно происходит, и рецепторы в носу фактически идентифицируя молекулы по их различным молекулярным колебаниям а не их формы.
Вибрационная теория обоняния или вибрационная теория запаха предполагает, что характер запаха молекулы обусловлен ее частота колебаний в инфракрасном диапазоне диапазон. Эта противоречивая теория является альтернативой более широко распространенной принятая док-теория обоняния (ранее называвшаяся теорией формы ольфакция), который предполагает, что характер запаха молекулы обусловлен диапазон слабых нековалентных взаимодействий между его пахучим белком рецептор (обнаруженный в эпителии носа), такой как электростатический и Ван дер-ваальсовыми взаимодействиями, а также водородными связями, дипольным притяжением, пи-стекинг, ион металла, взаимодействие катион-пи и гидрофобные эффекты, в дополнение к конформации молекулы.
Ошибки запаха
Нарушения обоняния. Люди, у которых есть Нарушения обоняния либо снижают их способность обонять, либо меняют их. по способу восприятия запахов.
Гипосмия [high-POSE-mee-ah] — это пониженная способность обнаруживать запахи.
Аносмия [ах-НОС-ми-ах] — это полный неспособность обнаруживать запахи. В редких случаях кто-то может родиться без обоняние, состояние, называемое врожденной аносмией. Аносмия это неспособность воспринимать запах или отсутствие функционального обоняния — потеря обоняния.Аносмия может быть временной, но есть аносмия. (включая травматическую аносмию) могут быть постоянными. Аносмия возникает из-за ряда факторов, в том числе воспаление слизистой оболочки носа, закупорка носовые ходы или разрушение одной височной доли. Воспаление из-за к хроническим изменениям слизистой оболочки придаточных пазух носа и средней и верхние носовые раковины.
Паросмия [pahr-OZE-mee-ah] — это изменение в нормальное восприятие запахов, например, когда запах чего-то знакомое искажено, или когда что-то, что обычно приятно пахнет сейчас пахнет отвратительно.Паросмия обонятельная дисфункция, которая характеризуется неспособностью мозг, чтобы правильно определить «естественный» запах запаха. Что происходит вместо этого естественный запах транскрибируется в то, что чаще всего описывается как неприятный аромат, обычно «пригоревший», «гниющий» «фекальный» или «химический» запах ». запахи. Более конкретно это называется эуосмией (греч.).
Обонятельная усталость — это временная нормальная неспособность различить особый запах после продолжительного воздействия этого вещества, находящегося в воздухе.Для Например, при входе в ресторан вначале запах еды часто воспринимается как очень сильный, но со временем осознание запаха обычно исчезает до такой степени, что запах становится незаметным или слишком сильным. слабее. После выхода из зоны сильного запаха чувствительность восстанавливается. с течением времени. Это одна из причин, почему мы не можем сказать, насколько плохо мы пахнем. потому что мы очень быстро приспосабливаемся к запахам.
Фантосмия [фан-ТОЕС-ми-ах] это ощущение запаха, которого нет.Фантосмия — это обонятельная галлюцинация запаха, который не на самом деле там. Это может произойти в одной или обеих ноздрях. Неприятный фантомия, какосмия, встречается чаще и часто описывается как обоняние что-то сгоревшее, испорченное, испорченное или гнилое. Испытывая случайные фантомные запахи являются нормальным явлением и обычно проходят сами по себе в время. Когда галлюцинации этого типа не проходят или когда они продолжайте возвращаться, это может очень расстроить и нарушить индивидуальный качество жизни.Фантомные запахи встречаются у каждого пятнадцатого американца. Синестезия — Звуковое восприятие.
Маскировка запаха означает нейтрализацию вызывает определенные запахи, используя другие вещи, которые поглощают запах или скрыть запах. Шумоподавление.
Обоняние может имеют большое влияние на аппетит, пищевые предпочтения и способность нюхать сигналы опасности, такие как пожар, утечка газа и испорченная пища.
Чувство запах уменьшается в пожилом возрасте. Снижается производство обонятельных нейронов. с преклонным возрастом.
Оториноларингология — это хирургическая специальность в медицине, которая занимается заболеваниями уха, носа и горла (ЛОР) и связанными с ними структуры головы и шеи. Врачи, специализирующиеся в этой области: вызвали оториноларингологов, отоларингологи, ЛОР-врачи, ЛОР-хирурги или хирурги головы и шеи. Пациенты обращаются за помощью к оториноларингологу по поводу заболеваний ухо, нос, горло, основание черепа, а также для хирургического лечения раковые и доброкачественные опухоли головы и шеи.
Без запаха — это то, что не имеет запаха, и его нельзя нюхать или заметил. Газ без запаха.
Запах Порог обнаружения — это самая низкая концентрация определенного запаха. соединение, воспринимаемое человеком обоняние. В порог химического соединения частично определяется его формой, полярность, частичные заряды и молекулярная масса. Обонятельные механизмы отвечает за другой порог обнаружения соединения, не очень хорошо понял.Таким образом, невозможно точно предсказать пороговые значения запаха. Скорее, они должны быть измерены с помощью обширных тестов с участием людей. в лабораторных условиях. Оптические изомеры могут иметь различное детектирование. пороговые значения, потому что их конформации могут привести к тому, что они будут меньше воспринимаемый человеческим носом. Лишь в последние годы такие соединения были разделены на газовые хроматографы, которые используются в аналитическая химия для разделения и анализа соединений, которые могут испаряться без разложения.
Слоеные сумматоры химически замаскированы так что их трудно обнаружить по запаху. Слоеные гадюки так сложно обнаруживать по запаху, что обученные собаки-змеи могут ходить по живому сумматор, не замечая. У них также есть узоры, которые их маскируют. визуально.
Ученые находят новый способ понять запахи. Математическая модель показывает карту запахов из окружающей среды. Ученые открыл новый способ организации молекул запаха в зависимости от того, как часто они встречаются вместе в природе, и сопоставить эти данные, чтобы обнаружить области запаха комбинации, которые люди находят наиболее приятными.
Как COVID-19 вызывает потерю запаха. Обонятельные опорные клетки, а не нейроны,
уязвимы для новой коронавирусной инфекции. Потеря обоняния или аносмия,
является одним из самых ранних и наиболее часто регистрируемых симптомов COVID-19. А
новое исследование определяет типы обонятельных клеток, наиболее уязвимые к инфекции
новым коронавирусом. Удивительно, но сенсорные нейроны, отвечающие за обоняние
не входят в число уязвимых типов клеток. Отчетность о достижениях науки
24 июля исследовательская группа обнаружила, что обонятельные сенсорные нейроны не
экспрессируют ген, кодирующий белок рецептора ACE2, который SARS-CoV-2
используется для проникновения в клетки человека.Вместо этого ACE2 экспрессируется в клетках, которые
обеспечивают метаболическую и структурную поддержку обонятельных сенсорных нейронов, так как
а также определенные популяции стволовых клеток и клеток кровеносных сосудов. В
результаты показывают, что инфекция ненейрональных типов клеток может быть
ответственны за аносмию у пациентов с COVID-19 и помогают информировать усилия по
лучше понять прогрессирование болезни. Команда сосредоточилась на
ген ACE2, широко встречающийся в клетках дыхательных путей человека, который
кодирует основной рецепторный белок, на который нацелен SARS-CoV-2, чтобы получить доступ
в клетки человека.Они также изучили другой ген, TMPRSS2, который кодирует
фермент, который считается важным для проникновения SARS-CoV-2 в клетку. В
анализы показали, что и ACE2, и TMPRSS2 экспрессируются клетками в
обонятельный эпителий — специализированная ткань в верхней части носа.
полость, отвечающая за обнаружение запаха, в которой находятся обонятельные сенсорные
нейроны и множество поддерживающих клеток. Однако ни один из генов не был
экспрессируется обонятельными сенсорными нейронами. Напротив, эти нейроны
экспрессировать гены, связанные со способностью других коронавирусов проникать
клетки.Исследователи обнаружили, что два конкретных типа клеток обонятельной
эпителий экспрессировал ACE2 на уровне, аналогичном тому, который наблюдался в
клетки нижних дыхательных путей, наиболее частые мишени
SARS-CoV-2, предполагающий уязвимость к инфекции. К ним относятся
сустентакулярные клетки, которые окружают сенсорные нейроны и, как считается,
обеспечивают структурную и метаболическую поддержку, а базальные клетки действуют как
стволовые клетки, регенерирующие обонятельный эпителий после повреждения.В
присутствие белков, кодируемых обоими генами в этих клетках, было подтверждено
иммуноокрашивание. В дополнительных экспериментах исследователи обнаружили, что
Стволовые клетки обонятельного эпителия экспрессировали белок ACE2 на более высоких уровнях
после искусственно вызванного повреждения по сравнению с покоящимися стволовыми клетками. Этот
может указывать на дополнительную уязвимость SARS-CoV-2, но это остается неясным
важно ли это для клинического течения аносмии у
По словам авторов, пациенты с COVID-19.Датта и его коллеги также
проанализировали экспрессию генов в почти 50 000 отдельных клетках мыши.
обонятельная луковица, структура в переднем мозге, которая получает сигналы от
обонятельные сенсорные нейроны и отвечают за первичную обработку запаха.
Нейроны обонятельной луковицы не экспрессируют ACE2. Ген и
связанный белок присутствовал только в клетках кровеносных сосудов, в частности
перициты, которые участвуют в регуляции артериального давления, кровь-мозг
поддержание барьера и воспалительные реакции.Нет типов ячеек в
обонятельная луковица экспрессирует ген TMPRSS2. Ключ к разгадке потери запаха. Все вместе,
Эти данные предполагают, что аносмия, связанная с COVID-19, может возникать в результате
временная потеря функции опорных клеток обоняния
эпителий, который косвенно вызывает изменения обонятельных сенсорных нейронов,
сказали авторы.
Запахи — Ароматы
Запах вызывается одним или несколькими летучими химическими соединениями, обычно очень низкая концентрация, которую люди или другие животные воспринимают с помощью органов чувств обоняния.Запахи также обычно называют запахами, которые могут относиться к как приятные, так и неприятные запахи.
Аромат характерный приятный запах. Любое свойство, обнаруженное обонятельная система. Запах, оставленный при прохождении мимо человека или животного, может проследить. Уловить запах; почуять. Туалетные принадлежности, излучающие и распространяет ароматный запах. Причина запаха или запаха. Применять духи к. Ароматические продукты — Янки ароматы — Ароматические масла.
Аромат химическое соединение, которое имеет запах или запах.Химическое соединение имеет запаха или запаха, когда он достаточно летучий для транспортировки в обонятельная система в верхней части носа.
Ароматерапия — Сила запаха.
Аромат кофе, кажется, повышает производительность в математике. Запах кофейный аромат, в котором нет кофеина, создает у студентов ожидание, что они будут лучше успевать тесты.
Воспоминаний больше всего эмоционально, когда они запущен по запаху, а не по виду, звуку или чему-то еще.
Попурри представляет собой смесь высушенного, естественно ароматного растительного материала, используемого для обеспечения нежный естественный запах внутри зданий, чаще всего в жилых настройки. Его обычно помещают в декоративную (часто деревянную) миску, или завязаны в небольшом саше из прозрачной ткани.
Сделать попурри из сушеных цветов
Магазин парфюмерии — The Scent Wizard
Цифровой аромат — Отправить открытки Postagram от ваш iPhone или Android
Феромон — это секретируемый или выделяемый химический фактор, который вызывает Социальное ответ у представителей одного и того же вида.Феромоны — это химические вещества, способные действия вне тела секретирующего человека, чтобы повлиять на поведение принимающих лиц. Окситоцин.
Тристрам Вятт: Человеческий феромон (видео)
Этот запах — Lynyrd
Skynyrd (песня на YouTube) Ооооо, этот запах, запах смерти окружает
ты.
Почему вам трудно
Запах
Себя точно, Вони. Наша неспособность
запах наш собственный запах изо рта проистекает из некоторой эволюционной адаптации.После
все, некоторые запахи просто не нужно обнаруживать все время, поэтому
разум Отфильтровывает подавляющее большинство химических ароматов, которые
окружают нас. Тот же принцип применим и к вашему дыханию. Ваш нос и
связаны между собой рот, ощущения вкуса и запаха. Из-за
эта взаимосвязанность, эта система должна игнорировать наличие определенных
постоянные запахи, один из которых плохой
дыхание. Вы когда-нибудь задумывались, почему не чувствуете запаха изнутри
нос? Причина довольно проста — если бы вы могли, было бы труднее
понюхайте все остальное.
Неприятный запах изо рта — это симптом, при котором присутствует заметно неприятный запах изо рта. Около 85% случаев происходят изо рта по разным причинам. (также известный как галитоз). Зубы
Обонятельный эталонный синдром — это психическое заболевание, при котором стойкое ложное убеждение и озабоченность идеей испускания необычный запах тела, который пациент считает отвратительным и неприятным другим лицам.
Запах тела — Пот — Гигиена
Почему мне нравится запах собственного пердежа? Там вероятно, нет ни одного человека на планете Земля, который наслаждается запахом пукает другого человека.А как насчет наших? Оказывается, когда дело доходит до из-за метеоризма мы на самом деле не терпим запаха. Другими словами, мы вроде как на самом деле нравится нюхать собственные гудки. Наши пердуны совершенно уникальный для нас. Это связано с уникальным в своем роде бактериальный отвар каждый из нас находится в нашем пищеварительном и кишечном трактах. Газ образуется, когда эти бактерии воздействуют на то, что мы ели или пили, и когда все смешано вместе, что ж, это дает нам особый отпечаток пальца пердения, если вы будут.Вам не нравится метеоризм других людей, потому что ваш мозг обнаруживает это как то, что пытается навредить вашему телу. На самом деле пукает может распространяют болезнь, поэтому они действительно могут убить. Так что в следующий раз, когда вы с другом будете в машине, окна будут подняты, и ты пукаешься, когда твой друг говорит: «Чувак, ты убиваешь меня этими пукает «, этот человек может говорить правду. Тотализатор, где делаются ставки на смерть знаменитостей Раньше был Гей — Гриффины (YouTube).
Запах пищи контролирует переработку клеток и влияет на жизнь ожидание.Запах пищи влияет на физиологию и старение, Согласно исследованиям, проведенным на модельном организме, аскариды. Удивительно, но эти отношения связаны с одной парой обонятельных нейроны. Запах пищи вызывает различные физиологические процессы в организме. наше тело. Таким образом, производство слюны и пищеварительных ферментов снижается. стимулировали перед фактическим приемом пищи, чтобы приготовить желудочно-кишечный тракт на предстоящий пищеварительный процесс. В в здоровом организме эта координация зависит от динамического баланса между образование и деградация белков (протеостаз).Это играет важную роль в переработке клеток и в процессе старения. Два из 358 нейронов, образующих нервную систему нематод, являются частью обонятельная система, и поэтому важна для восприятия запаха. Влияние запахов на клеточном уровне — это малоизученная область.
Учимся готовить — Фотографии еды
Дикие и одомашненные Moringa oleifera различаются по вкусу, составу глюкозинолатов и антиоксидантному потенциалу, но не по активности мирозиназы или содержанию белка
Гепц П. Сохранение и использование генетических ресурсов растений. Наука о растениеводстве. 46 (5), 2278–92 (2006).
Артикул Google Scholar
Брозинска М., Фуртадо А. и Генри Р. Дж. Геномика диких родственников сельскохозяйственных культур: расширение генофонда для улучшения сельскохозяйственных культур. Plant Biotechnol J. 14 (4), 1070–85 (2016).
Артикул PubMed CAS Google Scholar
Мигиковски, З. и Майлс, С. Использование диких родственников для селекции многолетних культур с помощью геномики. Компания Frontiers Plant Sci . 8 (2017).
Китинг, Дж. Д. Х., Эберт, А. В., Хьюз, Дж. А., Янг, Р. Ю. и Кураба, Дж. Стремление к достижению Цели 2 устойчивого развития ООН во всем мире: важная роль Moringa oleifera. Acta Hortic. 1158 , 1–10 (2017).
Артикул Google Scholar
Олсон, М. Э. Moringaceae: Семейство палочек. Стр. 167–169 в Редакционном комитете «Флора Северной Америки», редакторы 1993+. Флора Северной Америки К северу от Мексики. 15+ тт. Нью-Йорк и Оксфорд. Vol. 7 (2010).
Olson, M. E. et al. . Концентрация протеинов и минералов в листьях представителей рода Moringa «Miracle Tree». Plos One 11 (7), e0159782 (2016).
Артикул PubMed PubMed Central CAS Google Scholar
Амагло, Н. К. и др. . Профилирование выбранных фитохимических и питательных веществ в различных тканях многоцелевого дерева Moringa oleifera L., выращенного в Гане. Food Chem. 122 , 1047–1054 (2010).
Артикул CAS Google Scholar
Amagloh, FK, Atuna, RA, McBride, R., Carey, EE & Christides, T. Содержание питательных веществ и общее содержание полифенолов в темно-зеленых листовых овощах и оценка их биодоступности железа с использованием in vitro пищеварение / модель клеток Caco-2. Foods 6 (7), 54, https://doi.org/10.3390/foods6070054 (2017).
Артикул PubMed Central Google Scholar
Санчес-Мачадо, Д. И., Нуньес-Гастелум, Дж. А., Рейес-Морена, К., Рамирес-Вонг, Б. и Лопес-Сервантес, Дж. Пищевая ценность съедобных частей Moringa oleifera . Food Anal. Meth. 3 , 175–180 (2010).
Артикул Google Scholar
Тумер Т. Б., Рохас-Сильва П., Пулев А., Раскин И. и Уотерман С. Прямая и косвенная антиоксидантная активность обогащенных полифенолами и изотиоцианатом фракций из Moringa oleifera . J. Agric. Food Chem. 63 (5), 1505–1513 (2015).
Артикул PubMed CAS Google Scholar
Galuppo, M. et al. . Антибактериальная активность глюкоморинга, биоактивированного мирозиназой, в отношении двух важных патогенных микроорганизмов, влияющих на здоровье пациентов в больницах на длительный срок. Молекулы 8 , 14340–14348 (2013).
Артикул CAS Google Scholar
Харистой, X., Фэи, Дж. У., Шолтус, И. и Лозневски, А. Оценка антимикробного действия некоторых изотиоцианатов на Helicobacter pylori . Planta Med. 71 , 326–330 (2005).
Артикул PubMed CAS Google Scholar
Chuang, P.-H. и др. . Противогрибковая активность сырых экстрактов и эфирного масла Moringa oleifera Lam. Biresource Technol. 98 , 232–236 (2007).
ADS Статья CAS Google Scholar
Гупта Р. и др. . Оценка противодиабетической и антиоксидантной активности Moringa oleifera при экспериментальном диабете. Дж . Диабет 4 , 164–171 (2012).
Артикул Google Scholar
John, S. & Chellappa, A.R. Гипогликемический эффект листьев Moringa oleifera (голень) на людей с диабетом и крыс-альбиносов. Индийский J. Nutr. Диета. 42 (1), 22–29 (2005).
Google Scholar
Сугунабаи Дж., Джаярадж М., Карпагам Т. и Варалакшми Б. Противодиабетическая эффективность Moringa oleifera и Solanum nigrum . Внутр. J. Pharm. Pharm. Sci. 6 (S1), 40–42 (2014).
Google Scholar
Duangjai, A., Ingkaninan, K. & Limpeanchob, N. Возможные механизмы гипохолестеринемического эффекта тайских специй / диетических экстрактов. Нат. Prod. Res. 25 (4), 341–352 (2011).
Артикул PubMed CAS Google Scholar
Намбиар В. С., Гуин П., Парнами С. и Даниэль М. Влияние антиоксидантов из листьев голени на липидный профиль гиперлипидемий. J. Herb. Med. 4 (1), 165–172 (2010).
Google Scholar
Debnath, S., Biswas, D., Ray, K. & Guha, D. Moringa oleifera индуцировала потенцирование высвобождения серотонина рецепторами 5-HT3 в экспериментальной модели язвы. Фитомедицина 18 , 91–95 (2011).
Артикул PubMed CAS Google Scholar
Данги С. Ю., Джолли С. И. и Нараянан С. Антигипертензивная активность общих алкалоидов из листьев Moringa oleifera . Pharm. Биол. 40 (2), 144–148 (2002).
Артикул CAS Google Scholar
Файзи, С. и др. . Гипотензивные компоненты стручков Moringa oleifera . Planta Med. 64 , 225–228 (1998).
Артикул PubMed CAS Google Scholar
Аль-Асмари, А. К. и др. . Moringa oleifera как противораковое средство против линий клеток рака груди и колоректального рака. Plos One 10 (8), e0135814 (2015).
Артикул PubMed PubMed Central CAS Google Scholar
Diab, K. A. E., Guru, S. K., Bhushan, S. & Sexena, A. K. In vitro противораковая активность Anogeissus latifolia , Terminalia bellerica , Acacia catechu и Moringa oleifera. Asian Pac. J. Cancer Prev. 16 (15), 6423–6428 (2015).
Артикул PubMed Google Scholar
Гевара А. П. и др. .Противоопухолевый промотор из Moringa oleifera Lam. Mutat. Res. 440 , 181–188 (1999).
Артикул PubMed CAS Google Scholar
Тилок, К., Фулюкдари, А. и Чутургун, А. А. Антипролиферативное действие сырого водного экстракта листьев Moringa oleifera на раковые клетки альвеолярного эпителия человека. BMC Дополнение. Альтерн. Med. 13 , 226 (2013).
Артикул PubMed PubMed Central Google Scholar
Fahey, J. W. et al. . Разнообразие хемозащитных глюкозинолатов у Moringaceae ( Moringa spp.). Sci. Отчет 8 (2018).
Jaja-Chimedza, A. et al. . Биохимическая характеристика и противовоспалительные свойства экстракта семян моринги, обогащенного изотиоцианатом ( Moringa oleifera ). Plos One 12 (8), e0182658 (2017).
Артикул PubMed PubMed Central CAS Google Scholar
Kim, Y. et al. . Обогащенный изотиоцианатом экстракт семян моринги облегчает симптомы язвенного колита у мышей. Plos One 12 (9), e0184709 (2017).
Артикул PubMed PubMed Central CAS Google Scholar
Waterman, C. и др. . Стабильные экстрагируемые водой изотиоцианаты из листьев Moringa oleifera ослабляют воспаление in vitro . Фитохимия 103 , 114–122 (2014).
Артикул PubMed PubMed Central CAS Google Scholar
Олсон, М. Э. и Фэхи, Дж. У. Moringa oleifera : многоцелевое дерево для засушливых тропиков. Revista Mexicana de Biodiversidad 82 , 1071–1082 (2011).
Google Scholar
Александер Э. и Фэхи Дж. У. Мнение: Текущие методы селекции фруктов — плодотворны или бесполезны? 19 октября -е 2015 FreshFruitPortal.com (приглашенный комментарий), http://www.freshfruitportal.com/news/2015/10/19/opinion-current-fruit-breeding-practices-fruitful-or-futile/?country = другие (2015).
Дорр, Б., Уэйд, К. Л., Стефенсон, К. К., Рид, С. Б. и Фэйи, Дж.W. Cultivar влияние на содержание глюкозинолатов Moringa oleifera и вкус: пилотное исследование. Ecol. Food Nutr. 48 , 199–211 (2009).
Артикул PubMed Google Scholar
Fahey, J. W. Moringa oleifera : обзор лекарственного потенциала. Acta Hortic. 1158 , 209–224 (2017).
Артикул Google Scholar
Фэи, Дж. У., Зальцманн, А. Т. и Талалай, П. Химическое разнообразие и распределение глюкозинолатов и изотиоцианатов среди растений. Phytochemistr y 56 , 5–51 (2001). [исправление: Фитохимия 59 , 237 (2002)].
Shikita, M., Fahey, JW, Golden, TR, Holtzclaw, WD & Talalay, P. Необычный случай «неконкурентной активации» аскорбиновой кислотой: очистка и кинетические свойства мирозиназы из Raphanus sativus саженцев. J. Biochem. 341 , 725–732 (1999).
CAS Google Scholar
Wade, K. L., Ito, Y., Ramarathnam, A., Holtzclaw, W. D. и Fahey, J. W. Очистка активной мирозиназы из растений с помощью водной двухфазной противоточной хроматографии. Phytochem. Анальный. 26 , 47–53 (2015).
Артикул PubMed CAS Google Scholar
Белл, Л., Метвен, Л., Синьор, А., Оруна-Конча, М. Дж. И Вагстафф, К. Анализ семи образцов салатной ракеты ( Eruca sativa ): взаимосвязь между сенсорными атрибутами и летучими и нелетучими соединения. Food Chem. 218 , 181–191 (2017).
Артикул PubMed PubMed Central CAS Google Scholar
Калверт, Дж. Дж. Выбор пищи западными гориллами (G.грамм. горилла) в отношении пищевой химии. Oecologia 65 (2), 236–246 (1985).
ADS Статья PubMed Google Scholar
Энгель, Э., Мартин, Н. и Иссанчу, С. Чувствительность к аллилизотиоцианату, диметилтрисульфиду, синигрину и потреблению вареной цветной капусты. Аппетит 46 (3), 263–269 (2006).
Артикул PubMed CAS Google Scholar
Такемото, Х. Фитохимическое определение выбора листовой пищи дикими шимпанзе в Гине, Босу. J. Chem. Ecol. 29 (11), 2551–2573 (2003).
Артикул PubMed CAS Google Scholar
Wieczorek, M. N., Walczak, M., Skrzypczak-Zielinska, M. & Jelen, H.H. Горький вкус овощей Brassica: роль генетических факторов, рецепторов, изотиоцианатов, глюкозинолатов и вкусового контекста. Крит. Rev. Food Sci. Nutr. 18 , 1–11 (2017).
Артикул CAS Google Scholar
Badgett, B. L. Часть I. Глюкозид горчичного масла из семян Moringa oleifera . Докторская диссертация (Хьюстон, Техас, США: Университет Райса, 1964).
Ландис, Дж. Р. и Кох, Г. Г. Измерение согласия наблюдателя для категориальных данных. Биометрия 33 (1), 159–174 (1977).
Артикул PubMed МАТЕМАТИКА CAS Google Scholar
Динкова-Костова, А. Т. и Костов, Р. В. Глюкозинолаты и изотиоцианаты в здоровье и болезнях. Trends Mol. Med. 18 (6), 337–347 (2012).
Артикул PubMed CAS Google Scholar
Динкова-Костова, А.Т., Фэхи, Дж. У., Костов, Р. В., Кенслер, Т.W. KEAP1 и готово? Нацеливание на путь NRF2 с помощью сульфорафана. Trends Food Sci . Tech ., 1–13 (2017).
Джуге, Н., Митен, Р. Ф. и Трака, М. Молекулярные основы химиопрофилактики сульфорафаном: всесторонний обзор. Cell. Мол. Life Sci. 64 (9), 1105–27 (2007).
Артикул PubMed CAS Google Scholar
Беренс, М., Ганн, Х.К., Рамос, П. С., Мейерхоф, В. и Вудинг, С. П. Генетическое, функциональное и фенотипическое разнообразие в TAS2R38-опосредованном восприятии горького вкуса. Chem. Чувства 38 (6), 475–484 (2013).
Артикул PubMed CAS Google Scholar
Jeong, Y.J. et al. . Изотиоцианаты подавляют инвазию и метастазирование опухолей, воздействуя на активность FAK / MMP-9. Oncotarget 8 (38), 63949–63962 (2017).
Артикул PubMed PubMed Central Google Scholar
Subedi, L., Venkastesan, R. & Kim, S. Y. Нейропротекторная и противовоспалительная активность аллилизотиоцианата за счет ослабления передачи сигналов JNK / NF-KB / TNF-a. Внутр. J. Mol. Sci. 18 (7), 1423, https://doi.org/10.3390/ijms18071423 (2017).
Артикул PubMed Central Google Scholar
Waterman, C. и др. . Богатый изотиоцианатом экстракт Moringa oleifera снижает прибавку в весе, резистентность к инсулину и глюконеогенез в печени у мышей. Мол. Орех. Food Res. 59 (6), 1013–1024 (2015).
Артикул CAS Google Scholar
Afuang, W., Siddhuraju, P. & Becker, K. Сравнительная оценка пищевой ценности сырых, экстрагированных метанолом остатков и метанольных экстрактов моринги ( Moringa oleifera Lam.) листьев на показатели роста и использование корма у нильской тилапии ( Oreochromis niloticus L.). Aquaculture Res. 34 , 1147–1159 (2003).
Артикул CAS Google Scholar
Маккар, Х. П. С. и Беккер, К. Питательные вещества и факторы древности в различных морфологических частях дерева Moringa oleifera . J. Agric. Sci. 128 (3), 311–322 (1997).
Артикул Google Scholar
Fahey, J. W. & Talalay, P. Антиоксидантные функции сульфорафана: мощный индуктор ферментов детоксикации фазы 2. Food Chem. Toxicol. 37 (9–10), 973–979 (1999).
Артикул PubMed CAS Google Scholar
Gao, X. & Talalay, P. Индукция генов фазы 2 с помощью сульфорафана защищает пигментные эпителиальные клетки сетчатки от фотоокислительного повреждения. Proc. Natl. Акад. Sci. США 101 , 10446–10451 (2004).
ADS Статья PubMed PubMed Central CAS Google Scholar
Гао, X., Динкова-Костова, А. Т. и Талалай, П. Мощная и продолжительная защита пигментных эпителиальных клеток сетчатки человека, кератиноцитов и лейкозных клеток мышей от окислительного повреждения: непрямые антиоксидантные эффекты сульфорафана. Proc. Natl.Акад. Sci. США 98 , 15221–15226 (2001).
ADS Статья PubMed PubMed Central CAS Google Scholar
Джоко, С. и др. . Сравнение химических структур и цитозащитных способностей прямых и непрямых антиоксидантов. J Funct. Продукты питания 35 , 245–255 (2017).
Артикул CAS Google Scholar
Talalay, P. & Fahey, J. W. Фитохимические вещества из крестоцветных растений защищают от рака, модулируя метаболизм канцерогенов. J. Nutrition 131 , 3027S – 3033S (2001).
Артикул CAS Google Scholar
Динкова-Костова А. Т., Талалай П. Прямые и косвенные антиоксидантные свойства индукторов цитопротекторных белков. Мол. Орех. Food Res. 52 , S128 – S138 (2008).
Google Scholar
Баллок, С. Климат Чамелы, Халиско, и тенденции в южном прибрежном регионе Мексики. Arch. Метеор. Geophys. B. 36 , 297–316 (1986).
Google Scholar
Smith, P. K. et al. . Измерение белка с использованием бицинхониновой кислоты. Анал. Биохим. 150 (1), 76–85 (1985).
Артикул PubMed CAS Google Scholar
Fahey, J. W., Dinkova-Kostova, A. T. & Talalay, P. Биотестирование на микротитровальных планшетах Prochaska на индукторы NQO1. Methods Enzymol. 382 (Часть B), 243–258 (2004).
Артикул PubMed CAS Google Scholar
Уэйд, К. Л., Гаррард, И. Дж. И Фэхи, Дж. У.Усовершенствованный метод хроматографии гидрофильных взаимодействий для идентификации и количественного определения глюкозинолатов. J. Chrom. А 1154 , 469–472 (2007).
Артикул CAS Google Scholar
Динкова-Костова А.Т. и др. . Акцепторы фенольной реакции Михаэля: комбинированная прямая и непрямая антиоксидантная защита от электрофилов и окислителей.