Первые шаги — подготовительные задания / Фонетический разбор / Русский на 5
В этой статье:
Тема: Деление слов на слоги и определение ударного слога.
Научись делить слова на слоги. Сколько гласных, столько и слогов.
Затем научись определять ударный слог.
Сколько слогов в словах:
семья, шапка, шубка, моя, лапа, диван, её?Правильные ответы:
- 2
Сколько слогов в словах:
окошко, ошибка, потолок, деревня, тишина?Правильные ответы:
- 3
Одинаковое количество слогов в словах:
перекрёсток, телевизор, перестрелка?Правильные ответы:
- да
Одинаковое количество слогов в словах:
диета, дилемма, модернизм, петрушка, котёночек?Правильные ответы:
- нет
Сколько слогов в слове
филологический?Правильные ответы:
- 6
Сколько слогов в словах:
май, он, ой, ах, стол, сто, зной?- 1 или больше 1-го
Правильные ответы:
- 1
Нужно ли показывать ударение в словах:
краб, ёж, мёд, одноимённый, край, крик?Правильные ответы:
- нет
На каком слоге ударение в словах:
звонит, брала, включит, атлас (ткань)?- на первом или на втором
Правильные ответы:
- на втором
На каком слоге ударение в словах:
шарфы, банты, порты, значимость?- на первом или на втором
Правильные ответы:
- на первом
На каком слоге ударение в словах:
по рекам, по средам, партер, столяр?- на первом или на втором
Правильные ответы:
- на втором
Тема: Соотношение букв и звуков.
 Характеристика звуков.
Характеристика звуков.
-
Какой звук произносится в словах на месте выделенных букв:
съёмка, привезти, сито?- [c]- согл., глух., тв.
- [с’]- согл., глух., мягк.
-
Какой звук произносится в словах на месте выделенных букв:
шёл, что, шорох?- [ш] — согл., глух., тв. непарн.
- [ш] — согл., глух., тв.
- [ш’:] — согл., гл., мягк. непарн.
-
Какой звук произносится в словах на месте выделенных букв: о
тца, стараться, улыбается?- [ц:] — гласн.
- [ц:] — согл., глух., тв. непарн.
- [ц:] — согл., зв. непарн., тв. непарн.
- [ц:] -согл., глух. непарн.,тв. непарн.
-
Какой звук произносится в словах на месте выделенных букв: по
дпол, повод, тратить?- [т] — согл., гл., тв.
- [т’] — согл., гл., мягк.
- [д] — согл., зв., тв.
- [д’] — согл., зв., мягк.
-
Какой звук произносится в словах на месте выделенных букв:
экономия, игра, история?- [и] — гл., безуд.
- [э] — гл., безуд.
- [и] — гл. ударн.
-
Какой звук произносится в словах на месте выделенных букв:
вскоре, факт, Коровьев?- [ф] — согл., глух., тв.
- [в] — согл., вз., тв.
-
Какой звук произносится в словах на месте выделенных букв:ма
йка, строй, йод?- [й’] — согл., зв. непарн.
 , мягк. непарн.
, мягк. непарн. - [й] — согл., зв. непарный, тв.
- [й’] — согл., зв. непарн.
-
Какой звук произносится в словах на месте выделенных букв:
ем, подъезд, ездить?- Два звука: [й’] — согл., зв. непарн., мягк., непарн. и [э] — гл.ударн.
- [э] — гл. ударн.
- [й’] — согл., мягк. непарн., зв. непарн.
-
Какой звук произносится в словах на месте выделенных букв: гри
б, грипп, тулуп?- [б] — согл., зв., тв.
- [б’] -согл., зв., мягк.
- [п] — согл., гл., тв.
- [п] — согл., зв., тв.
-
Какой звук произносится в словах на месте выделенных букв: с
ыр, лыжи, шины?- [и] — гл. ударн.
- [и] -гл. безударн.
- [ы] -гл. ударн.
- [ы] — гл. безударн.
 , мягк. непарн.
, мягк. непарн.Правильные ответы:
- [с’]- согл., глух., мягк.
- [ш] — согл., глух., тв. непарн.
- [т] — согл., гл., тв.
- [и] — гл., безуд.
- [ф] — согл., глух., тв.
- [й’] — согл., зв. непарн., мягк. непарн.
- Два звука: [й’] — согл., зв. непарн., мягк., непарн. и [э] — гл.ударн.
- [п] — согл., гл., тв.
- [ы] -гл. ударн.
Тема: Транскрипция.
1. Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:
Слова:
1) [й’а], 2) [й’ий’о´], 3) [с’й’э´л’и], 4) [c’н’эк], 5) [пърас’о´нък]*,
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [парас’о´нак]*
Ответ:
1) я, 2) её, 3) съели, 4) снег, 5) поросёнок
2. Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:
Слова:
1) [фс’э], 2) [фс’о], 3) [пъзнако´м’иц:ъ]*, 4) [м’ит’э´л’], 5) [бас’э´й’н],
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [пазнако´м’иц:а]*
Ответ:
1) все, 2) всё, 3) познакомиться, 4) метель, 5) бассейн,
3.
 Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:
Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:Слова:
1) [бъгаты´р’]1, 2) [н’ит’], 3) [л’ингв’и´с’т’икъ]2, 4) [аб’й’о´м], 5) [кам’п’й’у´тър]3,
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [багаты´р’]1, [л’ингв’и´с’т’ика]2, [кам’п’й’у´тар]3
Ответ:
1) богатырь, 2) нить, 3) лингвистика, 4) объём, 5) компьютер
4. Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:
Слова:
1) [фай’л], 2) [тр’э´н’инк], 3) [с’э´рц’э], 4) [дрост], 5) [й’у´пкъ]*,
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [й’у´пка]*
Ответ:
1) файл, 2) тренинг, 3) сердце, 4) дрозд, 5) юбка
5. Прочитай транскрипцию, определи, какие слова представлены и запиши их буквами:
Слова:
1) [т’и´х’ий’], 2) [ш’:от]*, 3) [каз’о´л], 4) [зв’о´зды], 5) [лы´жы]
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [ш’от]*
Ответ:
1) тихий, 2) счёт, 3) козёл, 4) звёзды, 5)лыжи
Тема: Составление транскрипции.
1. Затранскрибируй слова:
1) пол, 2) дом, 3) курс, 4) зуб, 5) дам
Ответ:
1) [пол], 2) [дом], 3) [курс], 4) [зуп], 5) [дам]
2. Затранскрибируй слова:
1) мать, лёд, лгать, знать, тень
Ответ:
[мат’], [л’от], [лгат’], [знат’], [т’эн’]
3. Затранскрибируй слова:
1) вода, 2) дома, 3) сама, 4) окно, 5) возил
Ответ:
1) [вада´], 2) [дама´], 3) [сама´], 4) [акно´], 5) [ваз’и´л]
4. Затранскрибируй слова:
1) носил, 2) водил, 3) носы, 4) душа, 5) лыжи
Ответ:
1) [нас’и´л], 2) [вад’и´л], 3) [насы´], 4) [душа´], 5) [лы´жы]
5.
 Затранскрибируй слова:
Затранскрибируй слова:1) мяч, 2) меч, 3) мячом, 4) мечом, 5)речь
Ответ:
1) [м’ач’], 2) [м’эч’], 3) [м’ич’о´м], 4) [м’ич’о´м], 5) [р’эч’]
6. Затранскрибируй слова:
1) течь, 2) течёт, 3) тенью, 4) речью, 5) север
Ответ:
1) [т’эч’], 2) [т’ич’о´т], 3) [т’э´н’й’у], 4) [р’э´ч’й’у], 5) [c’э´в’ьр]*
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [c’э´в’ир]*
7. Затранскрибируй слова:
1) хорошо, 2) холодно, 3) запад, 4) карандаш, 5)колбаса
Ответ:
1) [хърашо´]1, 2) [хо´лъднъ]2, 3) [за´път]3, 4) [къранда´ш]4, 5) [кълбаса´]5
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции:
[харашо´]1, [хо´ладна]2, [за´пат]3, [каранда´ш]4, [калбаса´]5
8. Затранскрибируй слова:
1) самовар, 2) радость, 3) садовый, 4) прогулка, 5) парашют
Ответ:
1) [съмава´р]1, 2) [ра´дъс’т’]2, 3) [садо´вый’], 4) [прагу´лкъ]3, 5) [пърашу´т]4
Внимание! Упрощённый вариант транскрипции:
[самава´р]1, [ра´дас’т’]
9. Затранскрибируй слова:
1) экран, 2) этаж, 3) этикет, 4) эстетика, 5) экономика
Ответ:
[эыкра´н], [эыта´ш], [эыт’ик’э´т], [эыстэ´т’икъ]1, [эыкано´м’икъ]2
Примечание:
Э в безударных слогах в начале слова может произноситься по-разному: 1) как [эы] и 2) как [э].
Вариант [и] характерен для разговорной речи:
1) [икра´н], 2) [ита´ш], 3) [ит’ик’э´т], 4) [истэ´т’икъ]1, 5) [икано´м’икъ]2
Вариант с прояснённым [э] встречается в речи дикторов, актёров и людей со старомосковским произношением. Этому варианту соответствует транскрипция:
Этому варианту соответствует транскрипция:
1) [экра´н], 2) [эта´ш], 3) [эт’ик’э´т], 4) [эстэ´т’икъ]1, 5) [экано´м’икъ]2
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [истэ´т’ика] 1, [икано´м’ика]2 , т.е. с [а] в заударных слогах.
10. Затранскрибируй слова:
1) оса, 2) автобус, 3) остановка, 4) аквариум, 5) осторожность
Ответ:
1) [аса´], 2) [афто´бус], 3) [астано´фка]1, 3) [аква´р’иум], 4) [астаро´жнас’т’]2
Внимание! Упрощённый вариант транскрипции, широко принятый в школьной традиции: [астано´фка]1, [астаро´жнас’т’]2
11. Затранскрибируй слова:
1) я, 2) ёж, 3) её, 4) июль, 5) юла
Ответ:
1) [й’a], 2) [й’ош], 3) [й’ий’о´], 4) [ий’у´л’], 5) [й’ула´]
Для желающих потренироваться в фонетическом разборе на более широком материале рекомендуем наш справочный ресурс: Фонетический словарь.
Смотрите также
— Понравилась статья?:)Мой мир
Одноклассники
Google+
Особенности фонетического разбора / Фонетический разбор / Русский на 5
Данный вид разбора вызывает множество затруднений. Мало кому удаётся избежать в нём ошибок. Почему?
Дело в том, что для его выполнения нужны знания и предельное внимание: мелочей в фонетике не бывает.
Необходимо знать правила транскрипции, уметь её писать. Нужно понимать, что делать и в какой последовательности.
В учебниках примеров транскрипции и образцов фонетического разбора слов почти не встречается. Поэтому здесь приводится много примеров. Я вижу свою задачу в том, чтобы с максимальной наглядностью показать, что от тебя требуется.
На сайте открыт «Фонетический словарь». Он учит выполнять фонетический анализ слова на частотных примерах. Можно попросить добавить в словарь желаемое слово.
Для фонетического разбора нужно уметь:
- различать звуки и буквы,
- замечать неточные соответствия и несоответствия между звуковым и буквенным составами слов,
- обозначать произношение звуков транскрипцией,
- определять гласные и согласные,
- отличать ударные гласные от безударных,
- отличать глухие согласные от звонких, а твёрдые от мягких,
- знать, какие согласные непарные по глухости-звонкости, а какие — по твёрдости-мягкости,
- знать, какие позиции сильные, а какие слабые и что происходит в слабой позиции.
Если ты не знаешь базовых понятий фонетики, не понимаешь различия между буквами и звуками, не умеешь определять гласные и согласные, отличать глухие от звонких, твёрдые от мягких и т.п., то тебе лучше начать с рубрики Русская грамматика. Раздел 2. Фонетика.
Помни:
Приступать к фонетическому разбору без знаний — только терять время. Ошибок в этом случае не избежать. Чтобы сэкономить время, советую сначала ликвидировать пробелы в знаниях.
Порядок разбора
- Запиши слово, обозначая деление на слоги, сосчитай количество слогов.
- Определи ударный слог, поставь ударение.
- Запиши слово в столбик буквами и транскрипцией. Обрати внимание на соотношение букв и звуков. Подсчитай количество букв и звуков. Запиши эти данные.
- Дай характеристику звукам: гласным и согласным.
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
Первые шаги — подготовительные задания. Фонетический, звуко-буквенный разбор слова ящерица: схема, транскрипция слова на русском языке.
 сколько слогов, букв, звуков, куда падает ударение в слове ящерица
сколько слогов, букв, звуков, куда падает ударение в слове ящерицаДля быстрого деления слов на слоги в режиме онлайн воспользуйтесь формой ниже. В текстовое поле можно вводить несколько слов через пробел или запятую. При нажатии кнопки «Разделить на слоги» результат будет показан мгновенно в текстовом поле. Форма предназначена для выделения слогов только в русских словах, набранных русскими буквами.
Форма удобна для случаев, в которых требуется разбить много слов на слоги без деталей и справочной информации. Если нужно узнать, сколько и какие слоги есть в словах, какие есть варианты переноса, то воспользуйтесь формой поиска или подберите слова по количеству слогов в них:
Примечание.
1. Не используйте результат деления слов на слоги для определения мест переноса слов. Деление на слоги и выделение мест переноса слов не всегда одно и то же. На нашем сайте подробно объясняется разница (пункты 4-5 из правил деления на слоги).
2. Деление на слоги производится с учётом правил школьной программы. Некоторые правила могут отличаться от правил институтской программы и школ с углублённым изучением русского языка. По этой причине в отдельных случаях слоги могут быть выделены не в соответствии с вашими знаниями о правилах деления слов на слоги.
Слог
Слогом называется один гласный звук или сочетание одного гласного с одним или несколькими согласными. Другими словами: гласные звуки образуют слоги, согласные звуки только в соединении с гласным образуют слог. Для запоминания может помочь небольшая шпаргалка: гласные — «гласят», согласные — «согласуются». Например: в слове собака выделяют три слога со-ба-ка (гласные: о, а, а, согласные: с, б, к), слове Азия — три слога А-зи-я (гласные: а, и, я, согласный: з).
Слоги, состоящие из двух и более звуков, бывают открытые и закрытые. Открытые слоги оканчиваются на гласный звук: во-да, тра-ва, ро-ди-на. Закрытые слоги оканчиваются на согласный: ком-байн, кор-ка, жел-теть.
Выделяют прикрытые слоги, начинающиеся с согласного, и неприкрытые, начинающиеся с гласного. Примеры: ко-ра (оба слога прикрытых), я-бло-ко (один неприкрытый, два прикрытых).
Примеры: ко-ра (оба слога прикрытых), я-бло-ко (один неприкрытый, два прикрытых).
Сколько слогов в слове?
Слова состоят из слогов. Исходя из определения слога, количество слогов в слове определяется количеством гласных звуков. Школьные учителя русского языка часто говорят: «Сколько гласных — столько слогов».
Пример: сне г — один слог, чи та ть — два слога, ра бо та — три слога, дли но шеее — пять слогов.
Еще примеры слогов:
- вода — слоги во и да ;
- читала — слоги чи , та , ла ;
- я — слог я ;
- вешние — слоги ве , шни , е ;
- стул — слог стул , в слове один слог, состоящий из одного гласного и трёх согласных звуков.
Слог является минимальной частью слова при произнесении, если не учитывать вырожденные случаи, когда требуется произносить слово по буквам. Отсюда известные выражения: читать по слогам, произносить по слогам. Слог, как звук и ударение, относится к разделу фонетики.
В русском языке есть слова без слогов, то есть состоящие только из согласных. Ярким примером таких слов служат звукоподражательные слова. Например: хм, т-с-с-с, тр-тр-тр.
Казалось бы, для любого человека, научившегося читать, нет ничего проще, чем разделить слова на слоги. На практике же оказывается, что это не такая уж и легкая задача, более того, чтобы правильно выполнить это задание, нужно знать некоторые нюансы. Если вдуматься, далеко не каждый сможет даже дать четкий ответ на простой вопрос: «Что такое слог?»
Так что же это такое — слог?
Как известно, каждое слово состоит из слогов, которые, в свою очередь, состоят из букв. Однако, чтобы сочетание букв было слогом, в нем обязательно должна присутствовать одна гласная, которая уже сама по себе может составлять слог. Принято считать, что слог — это самая меньшая произносимая единица речи или, проще говоря, звук/звукосочетание, произносимое за один выдох. Например, слово «я-бло-ко». Чтобы его произнести, необходимо трижды выдохнуть, а значит, это слово состоит из трех слогов.
Например, слово «я-бло-ко». Чтобы его произнести, необходимо трижды выдохнуть, а значит, это слово состоит из трех слогов.
В нашем языке один слог не может содержать более одной гласной. Поэтому сколько гласных в слове — столько и слогов. Гласные являются слоговыми звуками (создают слог), в тоже время согласные — неслоговыми (не могут образовать слог).
Теории слога
Существует целых четыре теории, пытающиеся объяснить, что такое слог.
- Теория выдоха. Одна из самых древних. Согласно ей, количество слогов в слове равно количеству выдохов, делающихся при его произношении.
- Акустическая теория. Она подразумевает, что слог — это сочетание звуков с большой и меньшей громкостью. Гласный — более громкий, поэтому он способен как самостоятельно формировать слог, так и притягивать к себе согласные, как менее громкие звуки.
- Артикуляторная теория. В этой теории слог преподносится как результат мышечного напряжения, которое возрастает к гласному и спадает по направлению к согласному.
- Динамическая теория. Объясняет слог как комплексное явление, на которое влияет ряд факторов, перечисленных в предыдущих теориях.
Стоит отметить, что каждая из вышеизложенных теорий имеет свои недостатки, впрочем, как и достоинства, и ни одна из них полностью так и не смогла охарактеризовать природу понятия «слог».
Виды слогов
Слово может состоять из разного количества слогов — от одного и более. Все зависит от гласных, например: «сон» — один слог, «сно-ви-де-ни-е» — пять. По этой категории они делятся на односложные и многосложные.
Если в составе слова — более одного слога, то на один из них падает ударение, и он называется ударным (при произношении выделяется длиной и силой звучания), а все прочие — безударными.
В зависимости от того, на какой звук оканчивается слог, они бывают открытыми (на гласный) и закрытыми (на согласный). Например слово «за-вод». В данном случае первый слог является открытым, так как заканчивается на гласную «а», второй же является закрытым из-за окончания на согласную «д».
Как правильно разделять слова по слогам?
Прежде всего, стоит уточнить, что не всегда разделение слов на фонетические слоги совпадает с разделением для переноса. Так, согласно правилам переноса, одну букву нельзя отделять, даже если она гласная и является слогом. Однако если слово разделить на слоги, согласно правилам деления, то гласная, не окруженная согласными, будет составлять один полноценный слог. Для примера: в слове «ю-ла» фонетически два слога, но при переносе это слово разделяться не будет.
Как и уточнялось выше, в слове ровно столько слогов, сколько и гласных. Один гласный звук может выступать в качестве слога, но если в нем более одного звука, то начинаться такой слог будет обязательно с согласного. Выше приведенный пример — слово «ю-ла» — делится именно таким образом, а не «юл-а». Данный пример демонстрирует, как второй гласный «а» притягивает «л» к себе.
Если в средине слова попадаются несколько согласных подряд, они относятся к следующему слогу. Данное правило распространяется и на случаи с одинаковыми согласными, и на случаи с разными неслоговыми звуками. Слово «о-тча-я-нный» иллюстрирует оба варианта. Буква «а» во втором слоге притянула к себе сочетание из разных согласных букв — «тч», а «ы» — двойное «нн». Из этого правила есть одно исключение — для непарных неслоговых звуков. Если первым в буквосочетании стоит звонкий согласный (й, ль, л, мь, м, нь, н, рь, р), то он отделяется вместе с предыдущим гласным. В слове «склян-ка» буква «н» относится к первому слогу, так как является непарным звонким согласным. А в предыдущем примере — «о-тча-я-нный» — «н» отошла к началу следующего слога, согласно общему правилу, так как была парным сонорным.
Иногда буквосочетания согласных на письме означают несколько букв, но звучат как один звук. В таких случаях деление слова по слогам и деление для переноса будут отличаться. Поскольку сочетание означает один звук, то и разъединять эти буквы не следует при разделе на слоги. Однако при переносе такие буквосочетания разделяются. К примеру, в слове «и-зжо-га» три слога, однако при переносе это слово будет делиться как «изжо-га». Кроме буквосочетания «зж», произносимого как один длинный звук [ж:], это правило распространяется и на сочетания «тся»/«ться», в которых «тс»/ «тьс» звучат как [ц]. Например, правильно делить «у-чи-ться» не разрывая «тс», но при переносе будет «учить-ся».
К примеру, в слове «и-зжо-га» три слога, однако при переносе это слово будет делиться как «изжо-га». Кроме буквосочетания «зж», произносимого как один длинный звук [ж:], это правило распространяется и на сочетания «тся»/«ться», в которых «тс»/ «тьс» звучат как [ц]. Например, правильно делить «у-чи-ться» не разрывая «тс», но при переносе будет «учить-ся».
Как уже было отмечено в предыдущем разделе, слог бывает открытым и закрытым. В русском языке закрытых слогов значительно меньше. Как правило, они находятся лишь в конце слова: «ха-кер». В редких случаях закрытые слоги могут оказаться в средине слова, при условии, что слог заканчивается на непарный сонорный: «сум-ка», но «бу-дка».
Как правильно разделять слова для переноса
Разобравшись с вопросом, что такое слог, какие бывают их виды, и как делить на них, стоит обратить снимание на правила переноса слов. Ведь при внешней похожести эти два процесса далеко не всегда приводят к одинаковому результату.
При разделении слова для переноса используются те же принципы, что и при обычном делении на слоги, но стоит обратить внимание на ряд нюансов.
Категорически запрещено отрывать одну букву от слова, даже если это образующая слог гласная. Этот запрет распространяется и на перенос группы согласных без гласной, с мягким знаком или й. К примеру, на слоги «а-ни-ме» делится так, а вот переносить его можно только таким образом: «ани-ме». В результате при переносе выходит два слога, хотя в действительности их три.
Если две и более согласных находятся рядом, их можно делить по своему усмотрению: «те-ксту-ра» или «тек-сту-ра».
При парных согласных, находящихся между гласными, их разделяют, кроме случаев, когда эти буквы являются частью корня на стыке с суффиксом или префиксом: «клас-сы», но «класс-ный». Тот же принцип касается согласной в конце корня слова перед суффиксом — от корня отрывать буквы при переносе, конечно, можно, но нежелательно: «киев-ский». Аналогично — в отношении приставки: последнюю согласную, входящую в ее состав, отрывать нельзя: «под-ползти». Если же корень начинается с гласной, можно либо все так же отделить саму приставку, либо вместе с ней перенести два слога корня: «без-аварийный», «безава-рийный».
Если же корень начинается с гласной, можно либо все так же отделить саму приставку, либо вместе с ней перенести два слога корня: «без-аварийный», «безава-рийный».
Аббревиатуры переносить нельзя, а вот сложносокращенные слова можно, но только по составным.
Азбука по слогам
Слог имеет огромное практическое значение при обучении детей чтению. С самого начала ученики изучают буквы и слоги, которые из них можно комбинировать. А впоследствии из слогов дети учатся постепенно строить слова. Сначала детей обучают читать слова из простых открытых слогов — «ма», «мо», «му» и подобных, а вскоре задачу усложняют. Большинство букварей и методических пособий, посвященных данному вопросу, построены именно по этой методике.
Более того, специально для развития умения читать по слогам некоторые детские книжки выпускают с текстами, разделенными на слоги. Это облегчает процесс чтения и способствует доведению умения распознавать слоги до автоматизма.
Само по себе понятие «слог» является еще не до конца изученным предметом лингвистики. При этом его практическое значение сложно переоценить. Ведь эта маленькая частичка слова помогает не только обучиться чтению и правилам письма, но и помогает понять многие грамматические правила. Не стоит также забывать, что, благодаря слогу, существует поэзия. Ведь основные системы создания рифм основываются как раз на свойствах этой крошечной фонетико-фонологической единицы. И хотя существует масса теорий и исследований, посвященных ему, вопрос о том, что такое слог, остается открытым.
Б о л ь ш о й
б оль — ш о й Этот скрипт позволяет делить слова на слоги. Помните, что правила разделения слов на слоги и правила переноса — это разные правила.
1. В русском языке есть разные по слышимости звуки: гласные звуки являются более звучными по сравнению с согласными звуками.
Именно гласные звуки образуют слоги, являются слогообразующими. Слог — это один звук или несколько звуков, произносимых одним выдыхательным толчком воздуха: во-да, на-у-ка.
В слове столько слогов, сколько гласных звуков.
Согласные звуки являются неслоговыми. При произношении слова согласные звуки «тянутся» к гласным, образуя вместе с гласными слог.
2. Слог может состоять из одного звука (и тогда это обязательно гласный) или нескольких звуков (в этом случае в слоге, кроме гласного, есть согласный или группа согласных): ободок — о-бо-док; страна — стра-на; ночник — но-чник; миниатюра — ми-ни-а-тю-ра. Если слог состоит из двух и более звуков, то начинается он обязательно с согласного.
3. Слоги бывают открытыми и закрытыми.
Открытый слог оканчивается на гласный звук: во-да, стра-на.
Закрытый слог оканчивается на согласный звук: сон, лай-нер.
Открытых слогов в русском языке больше. Закрытые слоги обычно наблюдаются в конце слова: но-чник (первый слог открытый, второй — закрытый), о-бо-док (первые два слога открытые, третий — закрытый).
В середине слова слог, как правило, оканчивается на гласный звук, а согласный или группа согласных, стоящих после гласного, обычно отходят к последующему слогу: но-чник, ди-ктор.
В середине слова закрытые слоги могут образовывать лишь непарные звонкие согласные [й], [р], [р’], [л], [л’], [м], [м’], [н], [н’] (сонорные): май-ка, Сонь-ка, со-лом-ка.
4. Иногда в слове могут писаться два согласных, а звучать один, например: изжить [иж:ыт’]. Поэтому в данном случае выделяются два слога: и-зжить . Деление на части из-жить соответствует правилам переноса слова, а не делению на слоги.
То же самое можно проследить на примере глагола уезжать, в котором сочетание согласных зж звучит как один звук [ж:]; поэтому деление на слоги будет — у-е-зжать , а деление слова для переноса — уез-жать .
Особенно часто ошибки наблюдаются при выделении слогов у форм глаголов, оканчивающихся на -тся, -ться.
Деление вить-ся, жмёт-ся является делением на части для переноса, а не делением на слоги, поскольку в таких формах сочетание букв тс, тьс звучит как один звук [ц].
При делении на слоги сочетания букв тс, тьс целиком отходят к последующему слогу: ви-ться, жмё-тся.
5. При сочетании нескольких согласных в середине слова: два одинаковых согласных обязательно отходят к последующему слогу: о-ттечь, да-нный; два и более согласных обычно отходят к последующему слогу: ша-пка, ра-вный. Исключение составляют сочетания согласных, в которых первым является непарный звонкий (сонорный): буквы р, рь, л, ль, м, мь, н, нь, й: мар-ка, зорь-ка, бул-ка, стель-ка, дам-ка, бан-ка, бань-ка, лай-ка.
В этой статье вы найдете информацию о том, как сделать фонетический разбор слова — ЯЩЕРИЦА.
Не все знают, что такое фонетический разбор слова. В русской грамматике под этим понятием имеют в виду характеристику звуковой составляющей. Причем слово надо разбить не просто на буквы, а на звуки. Звуков гораздо больше, чем букв. Ведь некоторые буквы обозначают два звука. Давайте далее узнаем, как разобрать слово — ЯЩЕРИЦА на звуки в подробностях.
Сколько слогов, букв, звуков, звука А в слове ЯЩЕРИЦА: схема, транскрипция слова на русском языке
Как уже упоминалось выше, между буквами и звуками существует большая разница. Прежде, чем осуществить фонетический разбор, рассмотрим немного теорию вопроса.
Что представляют собой буквы? Это символы, которые употребляют в письме. С помощью букв формируют слова в тексте. Они применяются для визуального изложения слов, человек воспринимает написанное глазами. Эти символы можно читать. А когда чтение происходит вслух, то вот тут уже образуются звуки. Точнее буквы сливаются в слоги, а слоги в слова. Всего в русском языке насчитывается тридцать три буквы в алфавите. Принято русский алфавит называть — кириллицей. Даже первоклассники знают, в какой последовательности расположены буквы в алфавите благодаря урокам русского языка.
В алфавите русской грамматики имеются гласные и согласные буквы. Точнее — десять гласных и двадцать одна согласная буква. Еще в его состав входят мягкий знак и твердый знак. С их помощью подчеркивают мягкость или твердость согласного звука.
С их помощью подчеркивают мягкость или твердость согласного звука.
Вот и подобрались ближе к понятию — звуки. Они представляют собой голосовую речь. Благодаря им формируются слова воедино. Звуки, как и буквы бывают гласными, согласными. Когда делают фонетический разбор слова, анализируют именно их.
Некоторые буквы состоят из двух звуков. В частности:
- Буква Е состоит из звука Й и звука Э
- Буква Ё состоит из звука Й и звука О
- Буква Ю состоит из звука Й и звука У
- Буква Я состоит из звука Й и звука А
Очень интересно, что если гласная безударная, то такие буквы, как Е и Я имеют звук Й и звук И записывают их как: [ЙИ]
Звуки необходимо слышать, ведь их произносят не так, как пишут. Пример такого свойства:
- Слово — детские. Согласные буквы Т, С, как правило, сливаются в один звук Ц.
Теперь разберем слово ЯЩЕРИЦА
Транскрипция данного слова выглядит следующим образом:
[Й’АЩ’ИР’ИЦА]
Буква Я — имеет два звука мягкий [Й’
] — сонорный согласный, звонкий, непарный и мягкий звук[А] (гласный, ударный).
Буква Щ
— [Щ’
] — шипящий согласный, глухой и мягкий, непарный.
Буква Е — [И] гласный и безударный
Буква Р — [Р’
] — сонорные согласный звук, непарный звонкий и мягкий
Буква И — один звук [И] (гласный ибезударный)
Буква Ц — [Ц] один звук согласный, непарный глухой и твердый
Буква А — [А] гласный и безударный.
Как видите в слове имеется семь букв, восемь звуков.
ВАЖНО : Гласная буква (Я, Ю, Е, Ё) вначале слова всегда дает два звука, так как она является йотированной. В слове ящерица применялось это правило.
Куда падает ударение в слове ЯЩЕРИЦА?
В данном слове ударение падает на Я — на первый слог . Всего в слове — четыре слога. Главной фонетической составляющей является правильное и четкое проговаривание гласных звуков в тех слогах, на которые падает ударение. Их, как правило, выделяют именно продолжительным звучанием и неискаженностью. Благодаря этому четко можно услышать, какую букву писать в этом слове, к примеру: Е или И. Легче и делать фонетический разбор ударного слога. В грамматике такое положение гласной называется сильной позицией. Остальные гласные в слове имеют слабую позицию.
Их, как правило, выделяют именно продолжительным звучанием и неискаженностью. Благодаря этому четко можно услышать, какую букву писать в этом слове, к примеру: Е или И. Легче и делать фонетический разбор ударного слога. В грамматике такое положение гласной называется сильной позицией. Остальные гласные в слове имеют слабую позицию.
При звуковом анализе :
- гласный слог, на который падает ударение (сильная позиция) проговаривается четко с более длительным звучанием.
- безударный слог с гласной буквой (слабая позиция) читается без определенной интонации, звучит не так четко, как ударный.
Ящерица — фонетический разбор
Как видите, сделать фонетический разбор слова не так уж и сложно. Главное знать некоторые правила русской грамматики и все звуки, которых 42 в русском языке.
Видео: фонетический разбор слова
Слова делятся на слоги. Слог — это один звук или несколько звуков, произносимых одним выдыха-тельным толчком воздуха.
Ср.: во-да, на-у-ка.
1. В русском языке есть разные по слышимости звуки: гласные звуки являются более звучными по сравнению с согласными звуками.
Именно гласные звуки образуют слоги, являются слогообразующими.
Согласные звуки являются неслоговыми. При произношении слова согласные звуки «тянутся» к гласным, образуя вместе с гласными слог.
2. Слог может состоять из одного звука (и тогда это обязательно гласный!) или нескольких звуков (в этом случае в слоге кроме гласного есть согласный или группа согласных).
Ободок — о-бо-док; страна — стра-на; ночник — но-чник; миниатюра — ми-ни-а-тю-ра.
3. Слоги бывают открытыми и закрытыми.
Открытый слог оканчивается на гласный звук.
Во-да, стра-на.
Закрытый слог оканчивается на согласный звук.
Сон, лай-нер.
Открытых слогов в русском языке больше. Закрытые слоги обычно наблюдаются в конце слова.
Закрытые слоги обычно наблюдаются в конце слова.
Ср.: но-чник (первый слог открытый, второй — закрытый), о-бо-док (первые два слога открытые, третий — закрытый).
В середине слова слог, как правило, оканчивается на гласный звук, а согласный или группа согласных, стоящих после гласного, обычно отходят к последующему слогу!
Но-чник, по-ддать, ди-ктор.
Обратите внимание!
Иногда в слове могут писаться два согласных, а звучать один, например: изж
ить [иж:ы́т’]. Поэтому в данном случае выделяются два слога: и-зжить .
Деление на части из-жить соответствует правилам переноса слова, а не делению на слоги!
То же самое можно проследить на примере глагола уезж ать , в котором сочетание согласных зж звучит как один звук [ж:] ; поэтому деление на слоги будет — у-е-зжать , а деление на части для переноса — уез-жать .
Особенно часто ошибки наблюдаются при выделении слогов у форм глаголов, оканчивающихся на -тся, -ться .
- Деление вить-ся, жмёт-ся является делением на части для переноса, а не делением на слоги, поскольку в таких формах сочетание букв тс, тьс звучит как один звук [ц] .
- При делении на слоги сочетания букв тс, тьс целиком отходят к последующему слогу: ви-ться, жмё-тся .
В середине слова закрытые слоги могут образовывать лишь непарные звонкие согласные: [ j ], [р], [р’], [л], [л’], [м], [м’], [н], [н’].
Май -ка, Сонь -ка, со-лом -ка.
Обратите внимание!
При сочетании нескольких согласных в середине слова:
1) Два одинаковых согласных обязательно отходят к последующему слогу.
О-тт ечь, да-нн ый.
2) Два и более согласных обычно отходят к последующему слогу.
Ша-пк а, ра-вн ый.
Исключение составляют сочетания согласных, в которых первым является непарный звонкий (буквы р, рь, л, ль, м, мь, н, нь, й
).
Мар-ка, зорь-ка, бул-ка, стель-ка, дам-ка, бан-ка, бань-ка, лай-ка.
4. Деление на слоги часто не совпадает с делением на части слова (приставка, корень, суффикс, окончание) и с делением слова на части при переносе.
Например, слово рассчитанный
делится на морфемы рас-счит-а-нн-ый (рас — приставка, счит — корень; а, нн — суффиксы; ый — окончание).
Это же слово при переносе членится следующим образом: рас-счи-тан-ный .
На слоги слово делится так: ра-ссчи-та-нный .
| Правила переноса слов | Примеры |
|---|---|
| 1. Как правило, слова переносятся по слогам. Буквы ъ, ь, й от предыдущих букв не отделяются. | Разъ -езд, синь -ка, мой -ка. |
| 2. Нельзя переносить или оставлять на cтроке одну букву, даже если она обозначает слог. | О бо-док ; слова осень, имя нельзя разделить для переноса. |
| 3. При переносе нельзя отрывать от приставки конечную согласную букву. | От -течь, раз -лить. |
| 4. При переносе нельзя отрывать от корня первую согласную букву. | По-к ропить, при-к репить. |
| 5. При переносе слов с двойными согласными одна буква остаётся на строке, а другая переносится. | Ран-н ий, тер-р ор, ван-н а. |
| 6. Букву ы после приставки нельзя отрывать от корня, но не следует переносить часть слова, начинающуюся с буквы ы . | Разы -скать. |
как пережили первые две недели дистанционного обучения школьники Владивостока (ОПРОС) – Новости Владивостока на VL.ru
Уже две недели школьники Владивостока находятся на онлайн-обучении. И если в гимназиях и престижных школах уроки проходят в полноценном видеоформате, то в некоторых учреждениях обучение ограничивается фотографиями заданий и редкой перепиской в мессенджерах. VL.ru поговорил с родителями школьников и учителем о том, как в Приморье в сжатые сроки было организовано онлайн-обучение в условиях самоизоляции.
VL.ru поговорил с родителями школьников и учителем о том, как в Приморье в сжатые сроки было организовано онлайн-обучение в условиях самоизоляции.
Корреспондент VL.ru поговорил с десятком родителей, и рассказ каждого был не похож на другой. Все называли разные приложения и сайты, которые используют для дистанционного обучения в классах: «Сетевой город», «Учи.ру», «Яндекс.Учебник», Google, а также Zoom и Skype в качестве сервисов для видеозвонков, а кому-то фотографии заданий присылают в WhatsApp. Единых распоряжений для образовательных учреждений региона не было. А онлайн-видеоуроки проходят далеко не везде – в основном лишь в престижных образовательных учреждениях.
На прошедшей неделе громкое обсуждение онлайн-обучения в одном из местных сообществ в Facebook инициировал отец пятиклассника Тимур Балакирев. Он пожаловался: видеоуроков у его сына вообще нет, всё ограничивается лишь домашними заданиями. Мужчина назвал процесс обучения в их школе № 47 «полной профанацией», а сервис «Сетевой город» – «ожившим кошмаром».
«На портале «Сетевой город» есть электронный дневник – учителя пишут домашнее задание, и всё мы должны выполнять в письменном виде, потом фотографировать и отправлять, – рассказал Тимур корреспонденту VL.ru. – Сервис кошмарный, всю прошлую неделю не работал из-за большой нагрузки. Ребёнок делает домашнее задание на 4-5 страниц, каждая отдельно фотографируется, затем заливается – тоже по отдельности, сервис не позволяет всё сразу выделять и добавлять. Тратишь на это каждый раз от 10 до 30 минут, пока всё заливаешь».
Ещё один сервис, который предложили в школе, где учится ребёнок Тимура, – портал «Учи.ру». В рамках бесплатного доступа можно выполнить до 20 заданий в совокупности по всем предметам. Видеоуроки для ребёнка отец сам ищет в интернете.
«Это не дистанционное обучение, это самообучение, тогда вопрос – почему за него оценки ставятся? – недоумевает Тимур. – Ребёнок в этом возрасте уже привык к определённой схеме обучения: проходят тему, решают по ней примеры. .. Когда это всё валится без сопровождения и учебного процесса – стало намного сложнее. Почему-то нельзя было разработать и спустить на школы готовую систему. Получается, на уровне города и края всё скинули на школы, а те выкручиваются в рамках своих компетенций. В нашей школе, видимо, с технологиями всё очень плохо».
.. Когда это всё валится без сопровождения и учебного процесса – стало намного сложнее. Почему-то нельзя было разработать и спустить на школы готовую систему. Получается, на уровне города и края всё скинули на школы, а те выкручиваются в рамках своих компетенций. В нашей школе, видимо, с технологиями всё очень плохо».
Мать шестиклассника Светлана Червень жалуется на похожие проблемы. Онлайн-занятия проводят лишь два учителя – по русскому языку и математике, всё остальное остаётся фактически на самообучении: «При этом ссылку из интернета на видеоуроки прислала только учитель английского языка, остальные высылают задания и выставляют оценки в электронный журнал. По физкультуре выдали задание написать за четверть три реферата по две страницы каждый… Первую неделю с учёбой просиживали с 10 утра до 10 вечера. На этой неделе уже научились укладываться до 15:00. Сами ищем видеоуроки подходящие».
А второкласснице Соне из школы № 58 по физкультуре задали написать режим дня. Правда, и реальные упражнения тоже надо делать, а затем присылать фото и видеоотчёты. Видеоуроков в формате онлайн нет, но зато присутствует какое-то подобие программы и системы обучения: задают задания по «Яндекс.Учебнику» и по учебнику обыкновенному – просят фотографировать и присылать результат.
«Задание утром по WhatsApp присылает учитель, – рассказывает Соня. – Мы сначала делаем эти задания – проходим урок по учебнику, а потом в «Яндексе» отвечаем на вопросы, повторяем. На домашнем обучении лучше, потому что никто не получил даже ни одной четвёрки!»
Про своего сына-первоклассника, который тоже учится в школе № 58, рассказала жительница Владивостока Софья. По её словам, сначала детям предложили онлайн-видеоуроки, но против высказались родители – мамам первоклашек показался слишком сложным новый формат.
«Уроки должны были проходить в 10 утра, два урока по 30 минут – математика и русский, а остальное на домашнем, самостоятельном обучении, – рассказывает Софья. – И в первый день выявилось много технических несостыковок, вопросы со звуком. Лично меня такой формат более чем устраивал, я понимала, что всё наладится. Но у нас поднялась волна: ничего не понимаем, не знаем, не смогли подключиться и со звуком плохо. Говорили, что в других классах всё по-человечески, дают небольшой список заданий, а у нас, мол, решили онлайн-обучение сделать. Кто-то нажаловались директору, и учительница сказала: не хотите – не будем, меня это даже больше устраивает».
– И в первый день выявилось много технических несостыковок, вопросы со звуком. Лично меня такой формат более чем устраивал, я понимала, что всё наладится. Но у нас поднялась волна: ничего не понимаем, не знаем, не смогли подключиться и со звуком плохо. Говорили, что в других классах всё по-человечески, дают небольшой список заданий, а у нас, мол, решили онлайн-обучение сделать. Кто-то нажаловались директору, и учительница сказала: не хотите – не будем, меня это даже больше устраивает».
Ребёнку Софьи присылают скан-копии страниц из учебников, задания, ссылки на видеоуроки и презентации. Есть и «Яндекс.Учебник», где первоклашки проходят тестовые задания. Утром, с 10 до 12 часов, учительница выделила время, когда родители могут в чате обратиться с любым вопросом по поводу уроков.
При этом девушка отмечает, процесс такого обучения проходит не так уж легко: «Первоклашка не может самостоятельно воспринимать эти материалы. Если сложная задача – сразу же ко мне бежит. Это вызывает боль, стресс и переживания. Я окончила школу энное количество лет назад, не помню фонетический разбор слова, правила не помню, лезу в интернет, смотрю инструкции, заново ребёнку объясняю. Тяжело сочетать это всё и с работой. Вечное переживание, что не можешь уделить внимание ребёнку и заниматься уроками».
У преподавателя, завкафедрой политологии ДВФУ Натальи Коломейцевой четверо детей. Все работают и учатся онлайн, поэтому интернета порой не хватает. Двое дочек – в гимназии № 1, уроки со второй недели проходят каждый день через приложение для видеозвонков Zoom. Бальными танцами, математикой и французским занимаются также, в формате онлайн.
«Первая неделя прошла сумбурно, но давали все задания, а вторая прошла уже лучше, подключили дополнительные ресурсы, дети могут слушать уроки онлайн, – рассказывает Наталья. – Не говорю, что всем нужно переходить на онлайн-школу, но дети стали больше успевать. Между уроками, если они идут не подряд, успевают что-то делать, появилась возможность дополнительно заниматься математикой. И мы не тратим свободное время на дорогу. Да ещё и папа разрешил работать на компьютере – это явно их гармоничный формат, в онлайне готовы заниматься давно, живут этим, совершенно спокойно справляются. Учителям бывает сложно, а дети помогают разобраться».
И мы не тратим свободное время на дорогу. Да ещё и папа разрешил работать на компьютере – это явно их гармоничный формат, в онлайне готовы заниматься давно, живут этим, совершенно спокойно справляются. Учителям бывает сложно, а дети помогают разобраться».
Учитель Ксения Меленчук, которая ведёт Telegram-канал «Идеальная училка» и преподаёт английский у 5-х и 8-х классов в Международной лингвистической школе во Владивостоке, с детьми занимается онлайн при помощи платформ Google, которые позволяют по ходу занятия иллюстрировать детям предмет разговора, показывать презентации и давать тесты.
«Единой системы нет, но есть рекомендации, которые выдало министерство. И школы перешли на дистанционное образование по-разному, – отмечает Ксения. – Кто-то, насколько я знаю, просто высылает задания – не у всех наработан навык подобной работы. Мы формат работы в сети начали пробовать с осени: просила учеников домашнее задание онлайн присылать – мол, ребята, век высоких технологий, попробуйте. Сейчас наша школа перешла в формат видеоконференций на Google-сервисах. Есть возможность записывать уроки, и, если ребёнок отсутствует, я могу этот урок ему переслать, ученик ничего не потеряет. Я стала по-другому относиться к подготовке к уроку, уделять больше времени презентациям: чтобы, пока я говорила, ребёнку на экране был написан вопрос, были иллюстрации, относящиеся к теме. Здесь приходится продумывать каждый вдох, и подготовка выросла по времени сильно. Стараюсь, чтобы всё было продумано, время не пропало зря».
Несмотря на то, что нынешние пятиклассники и восьмиклассники буквально рождаются с телефоном в руках, создание текстового документа для них оказалось новым опытом. Ксения рассказывает: учила ставить точку, запятую и апостроф на английской клавиатуре. Много времени для учителя при подготовке занимает создание инструкций – как выполнить то или иное задание.
По ходу урока Ксения разрешает ребёнку выключить камеру и звук, но во время ответа ученика должно быть видно. Отдельно пришлось проговорить правила интернет-этикета: «Прошу не забывать, что чат видно всем, нужно быть уважительными, воспитанными. Ничего против демонстрации котов и собак не имею, кто-то игрушки ставит перед камерой. У учеников всё индивидуально: кому-то не нравится работа с компьютером, не хватает физического восприятия, зависит от индивидуальных качеств детей. И ещё: я понимаю, что у наших детей есть все технические возможности, но у большого количества школьников в городе их нет: когда один компьютер на несколько детей, например. Немного непродуманно. Дистанционное образование – это замечательно, но сейчас это немного не то, к чему надо стремиться. Нужно полученный опыт использовать и переформатировать».
Отдельно пришлось проговорить правила интернет-этикета: «Прошу не забывать, что чат видно всем, нужно быть уважительными, воспитанными. Ничего против демонстрации котов и собак не имею, кто-то игрушки ставит перед камерой. У учеников всё индивидуально: кому-то не нравится работа с компьютером, не хватает физического восприятия, зависит от индивидуальных качеств детей. И ещё: я понимаю, что у наших детей есть все технические возможности, но у большого количества школьников в городе их нет: когда один компьютер на несколько детей, например. Немного непродуманно. Дистанционное образование – это замечательно, но сейчас это немного не то, к чему надо стремиться. Нужно полученный опыт использовать и переформатировать».
Напомним, в первый же день перехода на онлайн-обучение образовательные платформы не выдержали наплыва посетителей. Родители школьников не могли открыть электронный дневник «Сетевой город Приморье», а образовательные порталы «Яндекса», платформа «Учи.ру» и сервис для видеоконференций Zoom тоже работали с перебоями. После этого работа худо-бедно наладилась. Планируется, что школьники Приморья будут учиться онлайн как минимум до конца апреля.
Урок 1: Основы фонетической транскрипции
Упражнение 1.1
Прочитайте и перепишите в транскрипции:
Мáмочка, бáбушка, молокó, хорошó, соснá, хóлодно, сторонá, крокодил, шоколáд, сорóка, хохотáть, гóрод, молодóй, говорить, поговóрка, машина, домовóй, дóговор, шкóла, сковорóдка, открытка, останóвка, аромáт, автомобиль.
Дéрево, колéно, берёза, дéвочка, веснá, деловóй, лесовóз, перевóд, телефóн, телевизор, ревизóр, режиссёр, сериáл, мéбель, чердáк, чемодáн, человéк, дядя, тётя, зарядка, нянечка, вязáть, тяжёлая, мяснáя, лягýшка, рядовóй, синяя.
Яблоко, янтáрь, Япóния, Яна, Ярослáв, язык, яма, ягода, явлéние, янвáрь, ясная, Еврóпа, Елéна, Éва, Египет, европéйский, éдем, едá, ёжик, ёлочка, ель, Егóр, éли, юбка, южный, юлá, Юрмала, юноша, юный, югозáпад, Югослáвия, ювелир.
Семья, дерéвья, моя, зелёная, Татьяна, запятáя, дьякон, Дáрья, Мария, лéтняя, польёт, моё, синее, ненáстье, счáстье, здорóвье, съéхать, въéхать, поéхать, твою, синюю, дéлаю, свою, Раиса, Зинаида, мои, свои, оперáции, лаборатóрии.
Катáться, занимáться, купáться, одевáться, учиться, умывáться, договориться, он улыбáется, она стесняется, они катáются, он учился, она рáдовалась, я обиделся.
Ключ
Русский язык. Фонетический разбор. Р/т младшего школьника /Код 2194
Серия:
Р/т младшего школьника.Автор:
Е.П. БахуроваХудожник:
Н. Александрова, А. Артюх, О. Вовикова, Т. Володина, А. Воробьёв, Е. Немирова, К. Павлова, К. Поповян, М. Рюмина, Т. ЧижковаКоличество страниц:
32Год издания:
2019Возрастные ограничения:
0+Оплата банковским переводом (напр., через Сбербанк РФ или иной удобный для Вас банк)
Данный способ оплаты предполагает, что вы предварительно оплачиваете 100% стоимости заказа (вместе с доставкой) переводом на наш расчетный счет. После оформления заказа перед Вами отображается уже заполненная счет-квитанция для оплаты через Сбербанк РФ или иной удобный для Вас банк, Вы можете ее распечатать или переписать реквизиты, а затем отнести квитанцию в ближайшей отделение банк и произвести оплату по реквизитам через кассу отделения выбранного Вами банка.
После оформления заказа перед Вами отображается уже заполненная счет-квитанция для оплаты через Сбербанк РФ или иной удобный для Вас банк, Вы можете ее распечатать или переписать реквизиты, а затем отнести квитанцию в ближайшей отделение банк и произвести оплату по реквизитам через кассу отделения выбранного Вами банка.
Оплата банковской картой Visa, MasterСard, Maestro, Visa Electron, МИР
Данным способом Вы можете оплатить заказ непосредственно после оформления заказа (предполагается 100 % оплата Товара).
*Данный способ оплаты можно использовать только при оформлении заказа на физическое лицо. Для юридических лиц и индивидуальных предпринимателей данный способ оплаты недоступен.
**к сожалению, не все банковские карты пригодны для оплаты через интернет. Однако некоторые банки начали выпуск специальных карт «электрон» этого типа, имеющих коды CVC2 и CVV2, которые могут быть использованы для оплаты заказов через интернет. Код CVV2/CVC2 — это контрольный номер, состоящий из трех цифр, который напечатан на обратной стороне банковской карты. Этот номер, обычно, напечатан в верхнем правом углу специальной полосы для подписи. Ввод номера необходим, чтобы убедиться, что карта используется настоящим владельцем.
При оформлении заказа просим Вас указывать реальный адрес электронный почты, на него после совершения платежа будет автоматически направлен кассовый чек, подтверждающий оплату Товара.
Внимание! До поступления денежных средств за заказанный Товар интернет – магазин Стрекоза не резервирует Товары на складе и не приступает к формированию заказа.
Формирование заказа осуществляется только после подтверждения оплаты или поступления денежных средств на расчетный счет интернет – магазина Стрекоза (срок зачисления денежных средств на расчетный счет интернет – магазина обычно составляет от 1 до 3 рабочих дней). Вы можете ускорить формирование и отправку заказа, прислав нам копию банковской квитанции на адрес электронной почты td@strecoza. ru или воспользовавшись на сайте вкладкой для обратной связи. Обратите внимание, что в разных банках могут взиматься комиссионные сборы при совершении платежей.
ru или воспользовавшись на сайте вкладкой для обратной связи. Обратите внимание, что в разных банках могут взиматься комиссионные сборы при совершении платежей.
Какие платежи НЕ принимаются:
- Для заказов, оформленных физическими лицами НЕ допускается оплата заказа юридическими лицами или индивидуальными предпринимателями.
Возврат денежных средств покупателю по безналичному расчету
Возврат денежных средств осуществляется на банковскую карту, с которой происходила оплата заказа. Срок перечисления средств занимает до 10- ти рабочих дней. Сроки окончательного зачисления средств на банковскую карту зависят от платежных систем MC и VISA, а также от Вашего банка и могут составлять до 30 рабочих дней.
При оформлении возврата денежных средств Вам необходимо предоставить требование, о возврате направив его на адрес электронной почты [email protected] или воспользовавшись на сайте интернет – магазина вкладкой обратная связь, приложить к нему копию паспорта или иной документ удостоверяющий личность покупателя, кассовый чек.
ЗАЯВЛЕНИЕ НА ВОЗВРАТ ДЕНЕЖНЫХ СРЕДСТВ
«Любовь» фонетический звуко-буквенный разбор слова
Хорошо осуществленный фонетический разбор слова «любовь» будет предполагаться в том, чтобы найти все буквы и звуки в нем. После чего нас ожидает звуко-буквенный разбор слова «любовь» и определение всех характеристик. Начинаем дальше.
Фонетический разбор
Первый пункт в нашем разборе будет посвящен тому, сколько звуков и букв в слове «любовь». Остановимся на этом далее.
- Выделим слоги в нашем существительном: лю-бовь, видим здесь 2 слога
- Увидим все звуки и буквы в существительном «любовь». Перед нами есть шесть букв, из которых две – это гласные и три согласных. Также в слове находится мягкий знак. Со звуками дела обстоят по-другому. Их на один меньше. Всего два гласных и три согласных.
- Определим букву под ударением. (любОвь), вторая гласная.
- Перенос существительного «любовь» возможен, стоит его делать по слогам.

Транскрипция слова
Она будет выглядеть так [л’убоф’]
Увидим звуко-буквенный разбор
Сейчас пришло время представить характеристику каждому звуку.
- л – [л’] – мягкий, характеризующийся как согласный и сонорный. Он звонкий непарный.
- ю – [у] – звук не под ударением. Он гласный.
- б – [б] – твердый звук, характеризующийся как согласный. Он звонкий парный.
- о – [о] – звук под ударением. Он гласный.
- в – [ф’] – мягкий, характеризующийся как согласный. Он глухой парный.
- ь – [ ] – не будет в нашем примере звуком.
Проверь себя: «Мальчик» фонетический разбор слова
И в конце предлагаю разобрать места, где возникают трудности.
У гласных.
Первая гласная без ударения, и мы слышим ее как [у]. Ударная бука чудесно прослушивается.
У согласных.
Последняя согласная оглушается и слышна как [ф’]. Первые две в слове «любовь» – без сложностей.
лингвист Buffalo: Что универсального в фонетике?
Как полевой исследователь, я часто поражаюсь тому, сколько лингвистических паттернов я заметил, которые просто «не должны» возникать. Лингвистика часто продвигается как область, утверждая слишком сильные и слишком близорукие теории. Считается, что сначала следует принять универсальность, а затем соответствующим образом приспособиться (или, к сожалению, игнорировать исключения и продолжать). В фонетике понятие универсализма имеет долгую историю.Якобсон, Фант и Галле (1961) предположили, что для характеристики межъязыковых различий нужны только отличительные черты. После того, как вы определили функции, вы можете просто предположить, что у всех говорящих было одинаковое отображение функций на артикуляцию. Эта идея сохранялась до 1970-х годов (по крайней мере, среди фонологов), но начала рушиться в 1980-х — 1990-х годах с работой Пэта Китинга по озвучиванию (1984), обсуждением коартикуляции Дугом Уэленом (1990) и дискуссией Кингстона и Дила об «автоматическом «и» управляемая «фонетика (1994).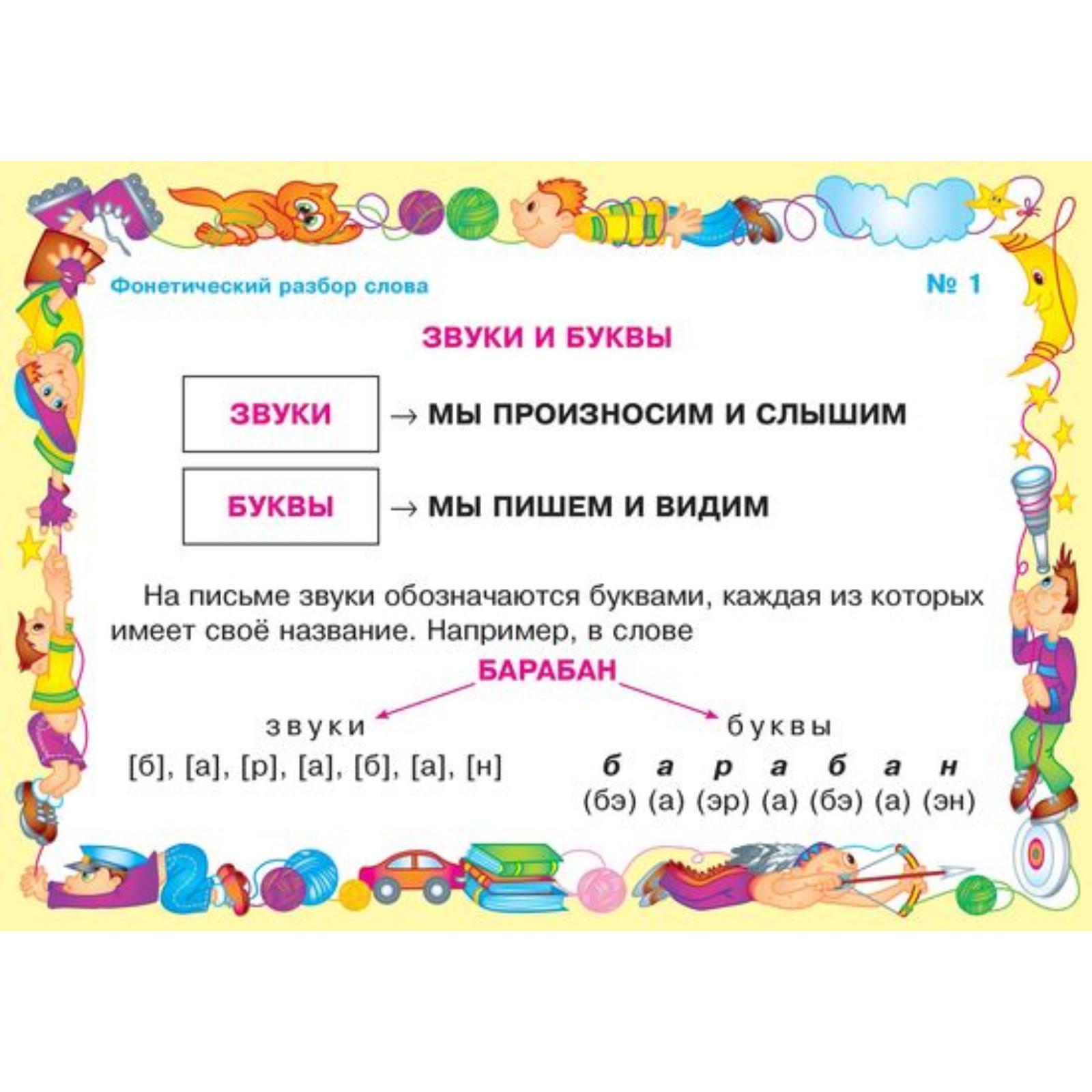 В результате этой более ранней работы и в результате эволюции лабораторной фонологии возник консенсус в том, что фонетические паттерны строго контролируются говорящими, и многие паттерны зависят от языка.
В результате этой более ранней работы и в результате эволюции лабораторной фонологии возник консенсус в том, что фонетические паттерны строго контролируются говорящими, и многие паттерны зависят от языка.
Книга Лэдда (2014) дает хороший обзор многих из этих идей — в частности, мнение о том, что «Фонологи хотят, чтобы их описания учитывали фонетические детали высказываний. Однако большинство из них неохотно рассматривают использование формализмов, включающих непрерывную математику и количественные данные. переменные, и без таких формализмов вряд ли какая-либо теория может адекватно рассматривать все аспекты лингвистического использования звука.» (стр.51)
Если мы перенесемся в наши дни, фонетика и фонология сильно отличаются от того, что было раньше. Я думаю, что большинство лабораторных фонологов (а большинство фонологов в настоящее время являются лабораторными фонологами) согласятся с тем, что репрезентации каким-то образом отражают распределение произведений и что статистические и артикуляционные детали могут варьироваться градиентным образом в зависимости от языка.С учетом этого, что осталось от фонетических универсалий? Несомненно, есть несколько универсалий относительно фонологической инвентаризации, которые можно обсудить (см. Недавнюю книгу Гордона 2016 года по этой теме).Но как быть с фонетическими паттернами, которые лучше всего уловить количественно? Что такое универсалии и почти универсалии? Я подумал, что начну собирать их здесь, чтобы систематизировать свои мысли и подвергнуть сомнению свои предположения. Я приглашаю всех предлагать и здесь дополнительные вещи.
1. Спинные остановки (почти всегда) имеют более продолжительное время VOT (время начала голоса), чем корональные или губные остановки. той же категории гортани (звонкие, безголосые, безголосые с аспирацией) спинные остановки будут иметь более длительную VOT, чем корональные или губные остановки.Более свежий анализ этого вопроса можно найти у Chodroff et al. (2019), где авторы рассмотрели более 100 различных языков. Из выбранных языков 95% имели дорсальный> коронарный узор. Это открытие, вероятно, связано с механическим ограничением движения тыльной стороны языка. Так как спинка имеет большую массу, для высвобождения требуется больше времени (Stevens 2000). При прочих равных, большие артикуляторы обычно движутся медленнее, чем маленькие — общий принцип физиологии и движения.Эта более длинная часть высвобождения задерживает вентилирование надларингеальной полости, что в конечном итоге способствует аэродинамическим условиям для голоса.
Из выбранных языков 95% имели дорсальный> коронарный узор. Это открытие, вероятно, связано с механическим ограничением движения тыльной стороны языка. Так как спинка имеет большую массу, для высвобождения требуется больше времени (Stevens 2000). При прочих равных, большие артикуляторы обычно движутся медленнее, чем маленькие — общий принцип физиологии и движения.Эта более длинная часть высвобождения задерживает вентилирование надларингеальной полости, что в конечном итоге способствует аэродинамическим условиям для голоса.
2. Все языки имеют окончательное удлинение произношения.
Хотя языки, как правило, различаются по степени удлинения слов в заключительной фразе или заключительной позиции высказывания, похоже, что это было обнаружено во всех языках, где это было исследовано (Fletcher 2010, White et al.2020) . Даже языки, в которых отсутствуют фонологические единицы, используемые в интонационных системах (граничные тона, высшие акценты), по-видимому, имеют удлинение в конце произнесения (DiCanio and Hatcher, 2018, DiCanio et al.2018, в печати).
Вероятно, существует биомеханическое объяснение удлинения конечного высказывания, основанного на артикуляционном замедлении в конце произнесения. По мере того как говорящие заканчивают свое высказывание, их артикуляторы постепенно начинают двигаться медленнее (Byrd & Saltzman 2003). Масштаб этого эффекта варьируется в зависимости от языка, и пока неясно, затронуты ли одни типы слогов больше, чем другие, например, закрытые слоги или слоги с короткими гласными могут подвергаться меньшему окончательному удлинению.
3.Языки оптимизируют расстояние между гласными в артикуляции / акустике.
Я пока оставлю открытым вопрос, относится ли это только к артикуляционной дисперсии или акустической дисперсии (конечно, по этому поводу ведутся споры), но похоже, что большинство языков пытается оптимизировать высоту и обратную сторону гласных. В языках с асимметричными системами гласных, например / i, e, a, o /, или / i, e, ɛ, a, o, u /, гласные заднего ряда будут иметь значения F1, которые часто находятся между значениями соответствующих гласных переднего ряда (Becker-Kristal 2010 ).Becker-Kristal изучила акустику более чем 100 различных языков и обнаружила, что это общая закономерность. Противоположная картина якобы верна, но в большинстве языков контрастов передних гласных больше, чем контрастов задних.
*** Отредактировано для включения новых вещей — спасибо Элеоноре Чодрофф, Дэвиду Камхольцу, Джозефу Касильясу, Рори Тернбулл, Клэр Бауэрн, Карлосу Вагнеру и другим в Твиттере, чьи личности / имена неясны. ***
4. Внутренняя F0 высоких гласных
Существует некоторое обсуждение этого эффекта, но кажется, что, при прочих равных, высокие гласные будут иметь более высокий F0, чем низкие гласные (Whalen & Levitt 1995).На всех языках, где это было исследовано, исследователи нашли этому положительные доказательства. Whalen и Levitt отмечают, что объяснение здесь связано с повышенным субглоточным давлением и большей активностью перстнещитовидной железы (CT) при образовании высоких гласных по сравнению с низкими гласными. Якобы, когда язык поднят, он оказывает давление на гортань через подъязычно-подъязычные и подъязычные мышцы. Это поднимает щитовидный хрящ и, таким образом, оказывает давление на перстнещитовидный желез (повышая F0). В этом случае потребуется большее субглоточное давление, чтобы превысить импеданс из-за большего напряжения голосовых связок.
Однако существует тенденция не наблюдать эффекта в контекстах с низким F0, в частности, для низких тонов в языках тонов. Я лично задавался вопросом об этом в языках Mixtec и Triqui, хотя обычно довольно сложно контролировать глоттализацию, тон и качество гласных одновременно на этих языках, чтобы исследовать этот вопрос. Почему эффект не проявляется на низких тонах? Одна возможность состоит в том, что управление F0 существенно отличается в контексте низкого F0. Согласно модели вибрации голосовых связок Титце (1994), тиреоаритиеноидные (ТА) мышцы более ответственны за вибрацию голосовых складок, когда F0 низкий.Возможно, поднятие языка оказывает меньшее усилие на TA, чем на CT.
Я лично задавался вопросом об этом в языках Mixtec и Triqui, хотя обычно довольно сложно контролировать глоттализацию, тон и качество гласных одновременно на этих языках, чтобы исследовать этот вопрос. Почему эффект не проявляется на низких тонах? Одна возможность состоит в том, что управление F0 существенно отличается в контексте низкого F0. Согласно модели вибрации голосовых связок Титце (1994), тиреоаритиеноидные (ТА) мышцы более ответственны за вибрацию голосовых складок, когда F0 низкий.Возможно, поднятие языка оказывает меньшее усилие на TA, чем на CT.
5. Озвученные остановки короче по продолжительности, чем беззвучные
Трудно поддерживать голос, когда есть какое-либо сужение в надгортанной полости. Предполагая, что вентиляция небно-глоточного порта отсутствует, закрытие надларингеального орального упора вызовет повышение давления над голосовой щелью, которое будет препятствовать необходимому перепаду давления в голосовой щели, необходимому для продолжения голоса — аэродинамическое ограничение голоса (Ohala, 1983).Таким образом, стопы относительно быстро перестанут звучать во время закрытия. Точно так же для звонких фрикативов необходимость поддерживать узкое сужение для трения и более высокое внутриротовое давление воздуха по сравнению с атмосферным давлением воздуха противоречит одновременной необходимости поддерживать большее субглоточное давление по сравнению с внутриротовым (надгортальным) давлением воздуха для продолжительного озвучивание. Таким образом, звонкие фрикативы часто лишают или де-фрикативизируют (и производятся как продолженные).
Следствием аэродинамического ограничения озвучивания в остановках является то, что продолжительность озвучивания остановок ограничена, и поэтому оказывается, что озвученные остановки короче, чем глухие.Это наблюдалось со времен ранней работы Лискера (1957) (также см. Лискер 1986). Вроде бы фонетический универсал. А как насчет фрикативов? Звонкие фрикативы обычно короче глухих? Я думаю, что по этому поводу еще нет жюри. Хотя трудно поддерживать одновременное озвучивание и трение для озвученных фрикативов, временные ограничения не так ясны, как с остановками. Тем не менее, звонкие фрикативы почти всегда короче глухих.
Хотя трудно поддерживать одновременное озвучивание и трение для озвученных фрикативов, временные ограничения не так ясны, как с остановками. Тем не менее, звонкие фрикативы почти всегда короче глухих.
Размышляя о мнимых фонетических универсалиях, я поражаюсь множеству паттернов, которые не кажутся такими универсальными, как когда-то считалось.Я больше всего знаком с теми, кто участвовал в исследованиях, которые я провел.
6. Не универсальный — слово-начальное усиление
Распространенный кросс-лингвистический образец состоит в том, что согласные в начале слова будут воспроизводиться с большей продолжительностью и / или с более сильной артикуляцией (больше контакта, более высокая скорость). Fougeron & Keating (1997) представляет собой основополагающую статью, в которой наблюдают эту закономерность у англоговорящих. Он был изучен на разных языках — совсем недавно в работе Katz & Fricke (2018) и White et al.(2020). Хотя Fougeron и Keating (1997) и последующие работы Keating et al. (2003) не утверждают, что этот паттерн универсален, White et al. (2020) заявляют (в своих выводах) следующее:
«Мы предполагаем, однако, что первоначальное удлинение согласных, вероятно, будет поддерживать универсальную структурную функцию из-за критической важности начала слов для связанных процессов сегментации речи и распознавания слов».
Должен признаться, я работаю над статьей, в которой это утверждение рассматривается вместе с некоторыми из моих исследований Yoloxóchitl Mixtec, отомангского языка в Мексике.Язык префиксальный и имеет заключительное ударение. Начальные согласные слова всегда короче срединных и (по крайней мере, в статье, над которой я сейчас работаю) подвергаются большему смягчению. Вы не должны верить мне на слово, основываясь на том, что еще не опубликовано. Результаты исследования продолжительности повторяются как у DiCanio et al. (2018) и DiCanio et al. (появиться). Итак, три разных издания с разными спикерами нашли эффект. (Я просто упомяну здесь, потому что это блог, а не публикация, что такая же закономерность, похоже, сохраняется в Itunyoso Triqui — другом языке Mixtecan с заключительным ударением и префиксом.Это еще одна газета этим летом.)
(Я просто упомяну здесь, потому что это блог, а не публикация, что такая же закономерность, похоже, сохраняется в Itunyoso Triqui — другом языке Mixtecan с заключительным ударением и префиксом.Это еще одна газета этим летом.)
«Наши результаты показывают, что в процессе распознавания устного слова слушатели держатся ближе к поверхностной форме, пока другие звуки не приведут к интерпретации, что поверхностная форма является результатом морфофонологического изменения мутации.« (Уссишкин и др., 2017, с.30)
Хотя это исследование не рассматривает усиление начального слова, оно предполагает, что в префиксальных языках есть что-то иное с точки зрения распознавания слов. Если целью усиления начального слова слова является усиление сигналов к сегментации слов, то логично предположить, что усиление начального слова слова может не произойти в языках с большим количеством префиксов. По крайней мере, данные Mixtec показывают, что удлинение согласных в начале слова действительно не универсально. 7. Не универсальный — носители тонального языка лучше воспринимают высоту тона, чем носители нетональных языков.
Знаю, знаю, тебе хочется верить, что это правда. Все слушатели тонального языка должны обладать сверхспособностями, когда дело доходит до восприятия звука, верно? Оказывается, свидетельства здесь довольно неоднозначны, и в конечном итоге роль музыкального опыта играет большую роль. Существуют статьи, в которых были обнаружены доказательства того, что владение языком тонов дает определенные преимущества в различении высоты тона, когда слушатели должны различать как тональные категории, так и внутри них (Burnham et al. 1996, Hallé et al. 2004, Peng et al. 2010). Однако есть и другие статьи, не показывающие никаких преимуществ (Stagray & Downs 1993, DiCanio 2012, So & Best 2010). Обычно речь идет о музыкальном прошлом слушателей. В Stagray & Downs (1993) авторы выбрали только говорящих на китайском языке, у которых не было музыкального опыта, а в DiCanio (2012) ни один из слушателей Triqui не имел музыкального опыта. В So & Best (2010) авторы отобрали 300 гонконгских кантонских слушателей и выбрали только тех, кто (а) не знает мандаринского языка и (б) не имеет формального музыкального образования.Только 30/300 квалифицированных! Многие другие исследования, в которых обнаруживается преимущество слушателей языка тонов, не учитывают музыкальный фон.
1996, Hallé et al. 2004, Peng et al. 2010). Однако есть и другие статьи, не показывающие никаких преимуществ (Stagray & Downs 1993, DiCanio 2012, So & Best 2010). Обычно речь идет о музыкальном прошлом слушателей. В Stagray & Downs (1993) авторы выбрали только говорящих на китайском языке, у которых не было музыкального опыта, а в DiCanio (2012) ни один из слушателей Triqui не имел музыкального опыта. В So & Best (2010) авторы отобрали 300 гонконгских кантонских слушателей и выбрали только тех, кто (а) не знает мандаринского языка и (б) не имеет формального музыкального образования.Только 30/300 квалифицированных! Многие другие исследования, в которых обнаруживается преимущество слушателей языка тонов, не учитывают музыкальный фон.
Итак, насколько музыкальные способности играют роль в тональном различении? Я могу привести пример из некоторых данных из моей статьи 2012 года (хотя в самой статье это не обсуждалось). Triqui — сильно тональный, с девятью лексическими тонами (/ 1, 2, 3, 4, 45, 13, 43, 32, 31 /) и обширной тональной морфофонологией (DiCanio 2016). Можно представить, что при предъявлении стимулов в континууме между двумя тональными категориями, например.грамм. падающие тона 32 и 31, они могут быть очень осторожны при восприятии небольших различий. Оказывается, они лучше воспринимают различия между категориями (шаги 2-4, 3-5, 4-6, 5-7), чем различия внутри категорий (шаги 1-3, 6-8).
| Точность различения тональных континуумов для Triqui и французских слушателей. Данные DiCanio (2012). Ни у одного говорящего на Triqui нет музыкального образования, но есть небольшая часть (13/20) франкоговорящих.Дискриминация лучше, чем предполагалось в конце континуума, потому что слушатели сравнивали ресинтезированную естественную речь с несинтезированной речью. |
 Это довольно удивительно, но как только мы разделим говорящих на французском языке по их музыкальному фону, мы обнаружим, что не-музыканты группы были хуже в тональной дискриминации между категориями, чем слушатели Triqui (но лучше в дискриминации внутри категории).Наличие некоторого музыкального образования (по крайней мере, 2-3 года) значительно улучшит ваши способности различать высоту звука. Говоря на языке тонов, вы можете хорошо различать два определенных тона вашего языка на категориальной границе между ними, но, по-видимому, это не делает вас волшебным образом лучше в различении высоты тона.
Это довольно удивительно, но как только мы разделим говорящих на французском языке по их музыкальному фону, мы обнаружим, что не-музыканты группы были хуже в тональной дискриминации между категориями, чем слушатели Triqui (но лучше в дискриминации внутри категории).Наличие некоторого музыкального образования (по крайней мере, 2-3 года) значительно улучшит ваши способности различать высоту звука. Говоря на языке тонов, вы можете хорошо различать два определенных тона вашего языка на категориальной границе между ними, но, по-видимому, это не делает вас волшебным образом лучше в различении высоты тона.——
Несомненно, есть много других вещей, которые можно было бы добавить сюда как для универсалов, так и для , но уже не для универсалов. Я, конечно, очень пристрастен здесь как человек, работающий над просодией.(Меня больше интересуют просодические паттерны.) Это постоянно обновляемый список вещей, которые как для моей личной памяти, так и для других, чтобы внести свой вклад (или спорить). Так что любые мысли о том, что можно добавить, приветствуются.
_____________
1. Здесь есть много других источников, которые мне, вероятно, не хватает. Я был бы рад добавить все, что вам предложат.
Артикул:
Беккер-Кристал Р. (2010). Акустическая типология инвентаря гласных и теория дисперсии: выводы из большого кросс-лингвистического корпуса. Кандидатская диссертация, Калифорнийский университет в Лос-Анджелесе.Бернем, Д., Фрэнсис, Э., Вебстер, Д., Луксанианавин, С., Аттапайбоун, К., Ласерда, Ф., и Келлер, П. (1996). Восприятие лексического тона в разных языках: свидетельство лингвистического способа обработки. В Труды 4-й Международной конференции по обработке разговорной речи , том 4, страницы 2514–2517.
Берд Д. и Зальцман Э. (2003). Упругая фраза: моделирование динамики приграничного удлинения. Фонетический журнал, 31: 149–180.
Чо Т. и Ладефогед П. (1999). Вариации и универсалии в VOT: данные с 18 языков. Фонетический журнал , 27: 207–229.
Фонетический журнал , 27: 207–229.
Chodroff, E., Golden, A., and Wilson, C. (2019). Ковариация времени начала остановки голоса в разных языках: свидетельство универсального ограничения фонетической реализации. Журнал Американского акустического общества, экспресс-письма , 145 (1): EL109 – EL115.
ДиКанио, К. Т. (2012). Кросс-лингвистическое восприятие тона Itunyoso Trique. Фонетический журнал, 40: 672–688.
ДиКанио, К. Т. (2016). Абстрактные и конкретные тональные классы в морфологии личности Itunyoso Trique. В Palancar, E. и Léonard, J.-L., редакторах, Tone and Inflection: New Facts and New Perspectives , volume 296 of Trends in Linguistics Studies and Monographs, chapter 10, pages 225–266. Мутон де Грюйтер.
ДиКанио, К., Бенн, Дж., И Кастильо Гарсия, Р. (2018). Фонетика информационной структуры в Yoloxóchitl Mixtec. Фонетический журнал, 68: 50–68.
ДиКанио, К., Бенн, Дж. И Кастильо Гарсия, Р. (в печати). Выявление влияния положения и отклонения на уровне произнесения на производство тона. Language and Speech , в печати. Препринт доступен здесь.
ДиКанио, К. и Хэтчер, Р. (2018). О неуниверсальности интонации: свидетельство Triqui. Журнал акустического общества Америки , 144: 1941.
ДиКанио, К., Чжан, К., Уэлен, Д.Х., и Кастильо Гарсия, Р. (2019). Фонетическая структура согласных Yoloxóchitl Mixtec. Журнал Международной фонетической ассоциации , https://doi.org/10.1017/S0025100318000294.Флетчер, Дж. (2010). Просодия речи: хронометраж и ритм. В «Справочник фонетических наук», стр. 521–602. Wiley-Blackwell, 2-е издание.
Фужерон К. и Китинг П. А. (1997). Артикуляционное усиление по краям просодических доменов. Журнал акустического общества Америки, 101 (6): 3728–3740.
Гордон, М. К. (2016). Фонологическая типология . Издательство Оксфордского университета.
Халле, П. А., Чанг, Ю. К., и Бест, К. Т. (2004). Идентификация и различение тонов китайского мандаринского диалекта китайскими и французскими слушателями. Фонетический журнал , 32 (3): 395–421.
Т. (2004). Идентификация и различение тонов китайского мандаринского диалекта китайскими и французскими слушателями. Фонетический журнал , 32 (3): 395–421.
Якобсон Р., Фант К. Г. М. и Галле М. (1961). Предварительные сведения к анализу речи: отличительные черты и их корреляты . MIT Press.
Кац, Дж.и Фрике, М. (2018). Нарушение слуха улучшает сегментацию слов: функциональную основу феномена лениции. Glossa, 3 (1): 1–25.
Китинг П. (1984). Фонетическое и фонологическое представление озвучивания стоп-согласных. Язык , 60: 286–319.
Китинг, П., Чо, Т., Фужерон, К., и Сюй, К.-С. (2003). Усиление артикуляционной составляющей предметной области на четырех языках. In Local, Дж., Огден, Р. и Темпл, Р., редакторы, Фонетическая интерпретация: документы по лабораторной фонологии VI , страницы 145–163.Издательство Кембриджского университета, Кембридж, Великобритания.Кингстон, Дж. И Дил, Р. Л. (1994). Фонетические знания. Language, 70 (3): 419–454.
Ladd, D. R. (2014). Синхронная структура в фонологии. Oxford University Press.
Лискер Л. (1957). Продолжительность закрытия и различие между голосом и голосом на английском языке. Язык , 33: 42–49.
Лискер Л. (1986). Озвучивание на английском языке: каталог акустических характеристик, сигнализирующих / b / по сравнению с / p / в хореях. Язык и речь, 29 (3): 3–11.
Мунхалл, К. Г. и Лёфквист, А. (1992). Жестовая агрегация в речи: гортанные жесты. Фонетический журнал , 20: 93–110.
Охала, Дж. (1983). Происхождение звуковых паттернов в ограничениях голосового тракта. В MacNeilage, P. F., редактор, Производство речи , страницы 189–216. Спрингер, Нью-Йорк.
Peng, G., Zheng, H.-Y., Gong, T., Yang, R.-X., Kong, J.-P., and Wang, W.S.-Y. (2010). Влияние языкового опыта на категориальное восприятие контуров высоты звука. Фонетический журнал , 38: 616–624.
Так, К. К. и Бест, К. Т. (2010). Межъязыковое восприятие неродных тональных контрастов: эффекты фонологических и фонетических влияний неродных. Язык и речь , 53 (2): 273–293.
К. и Бест, К. Т. (2010). Межъязыковое восприятие неродных тональных контрастов: эффекты фонологических и фонетических влияний неродных. Язык и речь , 53 (2): 273–293.
Стэгрей, Дж. И Даунс, Д. (1993). Различная чувствительность к частоте среди носителей тонального и нетонального языка. Журнал китайской лингвистики , 21: 143–163.
Стивенс, К. Н. (2000). Акустическая фонетика .MIT Press, первое издание.
Титце И. Р. (1994). Принципы голосового производства. Прентис-Холл, Энглвуд Клиффс, Нью-Джерси.
Уссишкин А., Уорнер Н., Клейтон И., Бреннер Д., Карни А., Хаммонд М. и Фишер М. (2017). Лексическое представление и обработка морфологических изменений начального слова: шотландская гэльская мутация. Журнал лабораторной фонологии, 8 (1): 1–34.Уэлен Д. Х. (1990). Коартикуляция в значительной степени запланирована. Фонетический журнал, 18 (1): 3–35.
Уэлен Д. Х. и Левитт А. Г. (1995). Универсальность внутреннего f0 гласных. Фонетический журнал , 23: 349–366.
Уайт, Л., Бенавидес-Варела, С., и Мади, К. (2020). Является ли удлинение начальной согласной и конечной гласной универсальными признаками сегментации слов? Фонетический журнал , 81: 1–14.
фонетических — есть ли язык, письмо которого на 100% фонематическое?
100% совпадение было бы чрезвычайно сложно — каждый язык содержит исключения из обычных правил произношения (не только из заимствованных слов и часто используемых иностранных слов), поэтому многие тонкие нюансы могут появиться только в нескольких словах (часто из-за того, что их трудно произносить «правильно» из-за окружающих букв и остановок).
Не говоря уже о том, что многие различия в произношении зависят от ситуации и обычно не записываются в словах — например, повышение тональности в вопросе.
Хорошая фонематическая / фонетическая система письма должна в основном включать весь IPA, а затем еще несколько для случаев, когда даже лингвисты не уверены, что также означает много повторяющихся букв и очень сложную для изучения систему письма. И со всеми напряжениями, высотой тона, вариациями длины и т. Д., Это все равно будет звучать механически, если мы подадим его на синтезатор речи, и все равно будут ошибки, когда компьютер записывает речь, даже с самым лучшим оборудованием и в лабораторных условиях условия.
И со всеми напряжениями, высотой тона, вариациями длины и т. Д., Это все равно будет звучать механически, если мы подадим его на синтезатор речи, и все равно будут ошибки, когда компьютер записывает речь, даже с самым лучшим оборудованием и в лабораторных условиях условия.
Фонематическая система письма, которая работает с тем, как местные жители произносят свои слова и иностранные слова, немного снизит сложность, но за счет невозможности правильно произносить иностранные слова. Даже этот сокращенный набор будет довольно большим (математически выражается: половина бесконечности — это все еще бесконечность).
В порядке упрощения. Вещи, которые могут изменить написание слова для произвольного произношения, часто не учитываются.В западных языках мы обычно можем опустить высоту звука, в то время как тональный язык нуждается в этом, поскольку есть много слов, в которых тон имеет значение буквально. В других языках, вероятно, есть и другие вещи, которые мы можем делать с пунктуацией и т. Д. Или которые обычно понятны из контекста.
Кроме того, упрощение звуков, которые местные жители обычно не различают четко или где могут быть небольшие различия в зависимости от региона, может сделать систему письма более полезной.
В некоторых языках часто нет разницы между озвученными и глухими версиями звука — например, в немецком с s, o и некоторыми другими.Когда правила языка дают понять, где какую версию использовать, даже это должно быть нормально.
Для более значительных различий в произношении я бы лично предпочел разные буквы, но некоторые лингвисты, кажется, считают более важным, чтобы слова были написаны одинаково даже при незначительных различиях в регионах. Iirc, в какой-то стране была введена буква в кириллицу, которая позволяла использовать два разных произношения одних и тех же слов, где было общее различие в произношении части и, следовательно, непоследовательное написание этих слов.
Носители английского языка, кажется, считают более важным придерживаться корней слов и игнорировать фактическое произношение в их написании. Схож с французским, хотя и немного по-другому. Я лично предпочел бы добавлять новые слова там, где разница в произношении стала слишком большой. Так что я бы добавил «таф», «ню», «тейбел» и многие другие … 🙂
Схож с французским, хотя и немного по-другому. Я лично предпочел бы добавлять новые слова там, где разница в произношении стала слишком большой. Так что я бы добавил «таф», «ню», «тейбел» и многие другие … 🙂
jakewvincent / R-syllable-parser: синтаксический анализатор слогов, который разбирает фонетические транскрипции слов на слоги, используя принципы, которым обучаются студенты по фонологии 1
Этот README находится в разработке
Этот набор скриптов определяет несколько функций (главная из которых — syllabify () ), которые вместе могут формировать слоги в фонетической транскрипции, используя принципы, которым обучают студентов в Фонологии 1.Некоторые из предоставленных функций (а именно, transcribe () ) взаимодействуют с локальной копией словаря произношения Университета Карнеги-Меллона (CMU), который обеспечивает фонетическую транскрипцию (с использованием последовательностей ARPABET) для более 134 000 слов в английском лексиконе. Также предоставляются скрипты, которые проверяют словарь на наличие обновлений, загружают самую последнюю версию с веб-сайта словаря и форматируют ее, включая преобразование кодов ARPABET в символы международного фонетического алфавита (IPA).
Синтаксический анализатор в основном использует стратегию, которой обучают студентов-фонологов, когда они учатся определять слоговую форму слова:
- Определите ядра слогов по гласным. Если есть две соседние гласные, проверьте, являются ли эти гласные вместе известным дифтонгом в языке. Если да, считайте их частью ядра одного слога. Отдельные гласные считаются ядром своего слога.
- Определите начало слога (это происходит до шага 3 в соответствии с принципом начала).Автоматический синтаксический анализ согласных, предшествующих первой гласной, в первый слог. Разберите согласный, непосредственно предшествующий любой из других гласных, в слог этой гласной. Если какие-либо оставшиеся неразборчивые согласные находятся не после последней гласной в слове и имеют согласную после них, проверьте, являются ли эти согласные и следующие за ними допустимым началом в языке (определяемым как группа согласных, которая может встречаться в начале слова. , если это слово не является заимствованием). Если это законное начало, разберите этот согласный на слог согласного, следующего за ним.Если это не законное начало, оставьте этот согласный без разбора.
- Идентифицируйте слоговые коды , разбирая все оставшиеся неразборчивые согласные на предшествующие им слоги.
 , если это слово не является заимствованием). Если это законное начало, разберите этот согласный на слог согласного, следующего за ним.Если это не законное начало, оставьте этот согласный без разбора.
, если это слово не является заимствованием). Если это законное начало, разберите этот согласный на слог согласного, следующего за ним.Если это не законное начало, оставьте этот согласный без разбора.Начало работы
Предварительные требования
- Среда языка программирования R
- Следующие пакеты R:
- Дополнительные пакеты:
- RCurl (требуется для проверки версии словаря и загрузки обновлений)
- pbapply (требуется программой форматирования словаря)
Установка
Использование Git
- Клонируйте этот репозиторий в каталог по вашему выбору:
git clone https: // github.com / jakewvincent / R-syllable-parser.git - Откройте терминал R и установите в качестве рабочего каталога каталог, в который вы клонировали этот репозиторий.
- Источник
master.R, запустивsource (file = "master.R")в вашем терминале R.
Скачав файл .zip
- Загрузите этот репозиторий в виде zip-файла и распакуйте его в каталог по вашему выбору.
- Откройте терминал R и установите в качестве рабочего каталога каталог, в который вы распаковали заархивированный файл репозитория.
- Источник
master.R, запустивsource (file = "master.R")в вашем терминале R.
Использование парсера (раздел в стадии разработки)
После получения master.R , как указано выше, все функции, определенные этими сценариями, становятся доступными для использования. Некоторые из этих функций (а именно, cvify () и sonority () ) в основном используются для внутренних целей. Вот описание каждой функции:
syllabify () расшифровать () cvify () звучность () random_word () Кодирование, декодирование и сбор данных: изучение рецептивной фонетической / фонологической системы Экспериментальные методы и конструкции для исследования фонологического кодирования разговорной речи Измерение фонетического восприятия у взрослых Движение глаз как зависимая мера в исследованиях разговорной речи Нейрофизиологические методы в лабораторной фонологии
Джессика Мэй Джессика Мэй — преподаватель кафедры лингвистики Северо-Западного университета. Ее исследовательские интересы включают восприятие речи взрослыми и младенцами, раннее овладение языком и языковую обработку двуязычными.
Ее исследовательские интересы включают восприятие речи взрослыми и младенцами, раннее овладение языком и языковую обработку двуязычными.
Нильс О. Шиллер — профессор психо- и нейролингвистики Лейденского университета и член правления Лейденского института мозга и познания (LIBC). Его исследовательские интересы включают кодирование словоформ, чтение вслух и фонетические аспекты речевого образования.
Пол АйверсонПол Айверсон — преподаватель речи в Университетском колледже Лондона.Его основное внимание в исследованиях уделяется пластичности восприятия речи, особенно в усвоении первого и второго языка, адаптации акцента и фонетически ухудшенных условиях (например, шум и нарушение слуха).
Шари Р. СпирШари Р. Спир — профессор лингвистики и директор лабораторий психолингвистики в Университете штата Огайо. Ее основной исследовательский интерес — влияние просодической структуры, особенно интонации, на производство, понимание и усвоение разговорных языков.
Уильям ИдсардиУильям Идсарди — профессор и заведующий кафедрой лингвистики в Университете Мэриленда. Его исследования сосредоточены на архитектуре фонологии и ее связи с другими компонентами грамматики. В своей работе он использует различные методы, включая грамматический анализ фонологических паттернов, компьютерное моделирование, поведенческие эксперименты и нейронные меры обработки речи.
Дэвид ПоппельДэвид Поппель — профессор психологии и неврологии Нью-Йоркского университета.Его исследование направлено на раскрытие мозговых основ восприятия речи, лексического представления и лексической обработки как с лингвистической, так и с нейробиологической точек зрения.
Для доступа к полному контенту Oxford Handbooks Online требуется подписка или покупка. Общедоступные пользователи могут искать на сайте и просматривать аннотации и ключевые слова для каждой книги и главы без подписки.
Пожалуйста, подпишитесь или войдите, чтобы получить доступ к полному тексту.
Если вы приобрели печатное издание, содержащее токен доступа, просмотрите этот токен для получения информации о том, как зарегистрировать свой код.
По вопросам доступа или устранения неполадок, пожалуйста, ознакомьтесь с нашими часто задаваемыми вопросами, а если вы не можете найти там ответ, свяжитесь с нами.
просодик · PyPI
Prosodic — метрико-фонологический синтаксический анализатор, написанный на Python. В настоящее время он может анализировать английский и финский текст, но добавить дополнительные языки легко с помощью словаря произношения или пользовательской функции Python.Prosodic был построен Райаном Хойзером, Джошем Фальком и Арто Анттила, начиная с лета 2010 года. Джош также поддерживает еще один репозиторий, в котором он переписал часть этого проекта, которая выполняет фонетическую транскрипцию для английского и финского языков. Сэм Боуман также внес свой вклад в базу кода, добавив несколько новых метрических ограничений.
О Prosodic
Prosodic выполняет две основные функции. Сначала он токенизирует текст в слова, а затем преобразует каждое слово в ударную, слоговую, фонетическую транскрипцию.Во-вторых, при желании он находит наилучший доступный метрический синтаксический анализ для каждой строки текста. В стиле теории оптимальности предпринимаются (почти) все логически возможные синтаксические анализы, но наилучшими являются те, которые в наименьшей степени нарушают набор определяемых пользователем ограничений. Метрические ограничения по умолчанию предложены Кипарски и Хэнсоном в их статье «Параметрическая теория поэтического метра» (Language, 1996). См. Ниже, как реализованы эти и другие ограничения.
Пример метрического анализа
Вот пример действия метрического синтаксического анализатора в первом сонете Шекспира.
[текст] [синтаксический анализ]
из самых прекрасных существ, которых мы желаем увеличить с | FAI | rest | CREA | tures | WE | de | SIRE | in | CREASE
что таким образом роза красоты может никогда не умереть, что | ТАМ | by | BEAU | ty's | ROSE | might | NEV | er | DIE
но как созревший должен со временем умереть, но | КАК | RI | на | ДОЛЖЕН | на | ВРЕМЯ | де | ПРЕКРАТИТЬ
его нежный наследник может носить его память его | ДЕСЯТЬ | дер | НАСЛЕДНИК | могущество | МЕДВЕДЬ | его | MEM | o | RY
но ты обратился к своим собственным ярким глазам, но | THOU | con | TRACT | ed | TO | thine | OWN | bright | EYES
питай пламя твоего света самодостаточным топливом, питайся своим пламенем СВЕТА. с | SELF | sub | STAN | tial | FU | el
устраивая голод там, где лежит изобилие MAK | ing.a | FA | mine | WHERE | ab | UN | dance | LIES
ты враг твоему сладкому я слишком жесток твой | СЕБЯ | твое | ВОПРОС | к себе | СЛАДКОЕ СЕБЯ | тоже | CRU | el
ты, что теперь свежий орнамент мира ты | ЭТО | искусство | ТЕПЕРЬ | МИР | свежий | ИЛИ | на | Мент
и только вестник яркой весны и | ON | ly | HER | ald | TO | the | GAU | dy | Spring
в своем собственном бутоне закопайте свое содержимое с помощью | IN | thine | OWN | bud | BU | ri | EST | thy | CON | палатка
и нежный churl mak'st отходы в скупости и | TEN | der | CHURL | mak'st | WASTE | in | NIG | gard | ING
пожалей мир, а то обжора будет милой.| МИР | или | ИНАЧЕ | это | GLUT | тонна | БЫТЬ
съесть причитающееся миру у могилы, и ты, чтобы | ЕСТЬ | | МИРА | должное | ПО | МОГИЛЫ | и | ТЕБЯ
 с | SELF | sub | STAN | tial | FU | el
устраивая голод там, где лежит изобилие MAK | ing.a | FA | mine | WHERE | ab | UN | dance | LIES
ты враг твоему сладкому я слишком жесток твой | СЕБЯ | твое | ВОПРОС | к себе | СЛАДКОЕ СЕБЯ | тоже | CRU | el
ты, что теперь свежий орнамент мира ты | ЭТО | искусство | ТЕПЕРЬ | МИР | свежий | ИЛИ | на | Мент
и только вестник яркой весны и | ON | ly | HER | ald | TO | the | GAU | dy | Spring
в своем собственном бутоне закопайте свое содержимое с помощью | IN | thine | OWN | bud | BU | ri | EST | thy | CON | палатка
и нежный churl mak'st отходы в скупости и | TEN | der | CHURL | mak'st | WASTE | in | NIG | gard | ING
пожалей мир, а то обжора будет милой.| МИР | или | ИНАЧЕ | это | GLUT | тонна | БЫТЬ
съесть причитающееся миру у могилы, и ты, чтобы | ЕСТЬ | | МИРА | должное | ПО | МОГИЛЫ | и | ТЕБЯ
с | SELF | sub | STAN | tial | FU | el
устраивая голод там, где лежит изобилие MAK | ing.a | FA | mine | WHERE | ab | UN | dance | LIES
ты враг твоему сладкому я слишком жесток твой | СЕБЯ | твое | ВОПРОС | к себе | СЛАДКОЕ СЕБЯ | тоже | CRU | el
ты, что теперь свежий орнамент мира ты | ЭТО | искусство | ТЕПЕРЬ | МИР | свежий | ИЛИ | на | Мент
и только вестник яркой весны и | ON | ly | HER | ald | TO | the | GAU | dy | Spring
в своем собственном бутоне закопайте свое содержимое с помощью | IN | thine | OWN | bud | BU | ri | EST | thy | CON | палатка
и нежный churl mak'st отходы в скупости и | TEN | der | CHURL | mak'st | WASTE | in | NIG | gard | ING
пожалей мир, а то обжора будет милой.| МИР | или | ИНАЧЕ | это | GLUT | тонна | БЫТЬ
съесть причитающееся миру у могилы, и ты, чтобы | ЕСТЬ | | МИРА | должное | ПО | МОГИЛЫ | и | ТЕБЯ
Неплохо, правда? Просодика отражает не только общий размер ямба сонета, но и некоторые его вариации. Он точно фиксирует перевороты хореи в линиях « Mak ing a fam ine , где a bun dance лежит » и « Pi ty the world or else this glut ton быть .«Кроме того, в зависимости от ограничений, он также захватывает удвоенный сильный удар, который часто может следовать за двойным слабым ударом в строке« Твое я твой враг твоему сладкому я тоже жестокий »(см. , для этого метрического паттерна, обзор Брюса Хейса на книгу Дерека Аттриджа The Rhythms of English Poetry in Language 60.1, 1984). Он также ошибается в некоторых строках: например, в его интерпретации «питай пламя твоего света». . Но насколько он точен в среднем?
Вывод метрических примечаний
См. Здесь для быстрого ознакомления с тремя файлами выходной статистики, созданными в процессе метрической аннотации.
Точность метрического парсера
В предварительных тестах мы запустили Prosodic на выборке из 1800 проанализированных вручную строк ямбического, хореального, анапестического и дактильного стихов (включительно). Например, вот строка и то, как она была проанализирована человеком, Просодик, и «голый шаблон» метра его стихотворения (ямб).
Например, вот строка и то, как она была проанализирована человеком, Просодик, и «голый шаблон» метра его стихотворения (ямб).
Линия: Напрасная тревога в поисках дальнего этажа
Человек: ТРЕВОГАЕТСЯ НАЙТИ ДИСТАНЦИОННЫЙ ПОЛ.
s w w s w s w s w s
Просодич: Тревога в ВОЙНЕ, чтобы НАЙТИ ДИСТАНЦИОННЫЙ ЭТАЖ
s w w s w s w s w s
Шаблон: AnXIOUS in VAIN, чтобы НАЙТИ ДИСТАНЦИОННЫЙ ЭТАЖ
w s w s w s w s w s
* *
Мы видим, что Просодич правильно понимает эту строку; в шаблоне все верно, не хватает только хореической инверсии.Пропустив все строки таким образом (используя команду / eval Prosodic [см. Ниже]), мы можем увидеть, какой процент слогов и Prosodic, и шаблон «правильно» захватывают — где «правильно» означает согласие с человеческий разбор.
| % Слоги правильно проанализированы | ||||
|---|---|---|---|---|
| Другой человек | Просодик | Базовый шаблон (для этого счетчика) | Базовый шаблон (ямбический метр) | |
| Ямбические линии | 93.7% | 92,6% | 89,0% | 89,0% |
| Хрохаические линии | 98,8% | 94,5% | 95,3% | 4,5% |
| Анапестические линии | 97,2% | 84,7% | 66,1% | 52,9% |
| Дактильные линии | 95,8% | 83,8% | 75,6% | 49,7% |
Степень, в которой два человека-метщика (оба англ. Литературы Ph.D. студенты) согласны с тем, что это находится в первом столбце: учитывая, что метрическое сканирование неизбежно меняется от человека к человеку, это может быть принято как верхний порог того, что мы могли бы ожидать от Просодика. Но Prosodic не так уж и далек, особенно для двоичных измерителей (ямб и хорея). С тройными счетчиками сложнее: они чаще отклоняются от своих метрических шаблонов, как это видно в третьем столбце. Но третий столбец метрических шаблонов предполагает, что мы уже знаем размер стихотворения (что мы и знаем в этом оценочном примере).Неудивительно, что если мы еще не знаем размер и просто применяем темплейт ямба к каждому стихотворению, тогда он хорошо работает для ямбических стихов, но совсем не подходит для стихов других размеров, как можно увидеть в четвертой колонке. Это означает, что, для анализа стихов, размер которых неизвестен , или для анализа стихотворений вольного стиха или даже прозы, Prosodic особенно полезен. Разбирая строки индивидуально и независимо от размера «стихотворения», Просодик, тем не менее, способен обнаружить основные контуры метрических узоров в строках.В другом исследовательском проекте, проводимом Стэнфордской литературной лабораторией, синтаксический анализ Просодика позволил предсказать общий размер в 200 стихотворениях с точностью около 98%.
Приведенные выше данные были получены, когда измеритель был определен как следующие ограничения и веса: [* Strength.s => - u / 3.0] [* Strength.w => - p / 3.0] [* stress.s => -u / 2.0] [* stress.w => - p / 2.0] [* footmin-none / 1.0] [* footmin-no-s-except-previous-by-ww / 10.0] [* posthoc-no-final -ww / 2.0] [* posthoc-standardize-weakpos / 1.0] [* word-elision / 1.0] . Эти и другие ограничения упомянуты ниже, но лучше всего задокументированы в их файле конфигурации, config.py .
[И последнее замечание: эти человеческие аннотации сделаны доктором литературных наук. студенты — воплощают определенные предположения о метре, которые распространены в литературных, но не лингвистических кругах. Например, представление хохаической инверсии как буквального переворачивания ступней, «swws», — это не то, как Кипарский представлял бы ее; для него переворот хореи — это просто условное допустимое нарушение ямбического метра.Однако Prosodic не обязательно придерживается одной из этих теорий или подходов: синтаксический анализ, соответствующий любой теории, может быть сгенерирован с использованием различных наборов ограничений.]
Установка
Быстрый старт
Для установки Prosodic лучше всего использовать pip. В терминале введите:
pip install git + git: //github.com/quadrismegistus/prosodic.git
После установки у вас должен быть доступ к исполняемому файлу «prosodic».Просто запустите:
просодический
, чтобы открыть интерактивный интерфейс терминала.
Быстрый запуск (в Python)
Prosodic также можно использовать в качестве модуля Python в ваших собственных приложениях:
импорт просодика как p
text = p.Text («Могу я сравнить тебя с летним днем?»)
text.parse ()
Инструкции по использованию Prosodic в интерактивном режиме и в качестве модуля Python приведены ниже.
Использование
Существует два основных способа использования Prosodic: в интерактивном режиме и, для более продвинутых пользователей Python, в качестве модуля Python.
Интерактивный режим
Вы можете войти в интерактивный режим просодики, запустив prosodic . Это приведет вас к такому интерфейсу:
##################################################################################
## добро пожаловать в просодик! v1.3 ##
#############################################
[введите строку текста или введите одну из следующих команд:]
/ text загрузить текст
/ corpus загрузить папку с текстами
/ paste введите многострочный текст
/ eval сравнивает этот измеритель с образцом, помеченным вручную
/ mute скрыть вывод с экрана
/ save сохранить предыдущий вывод в файл
/ выход выход
>> [0.0s] prosodic: en $
Загрузка текста
Первое, что нужно сделать при использовании Prosodic, — это дать ему текст для работы. Есть несколько способов сделать это. Самый простой способ — просто набрать строку по одному. Вы также можете ввести / вставить , а затем ввести или скопировать / вставить несколько строк за раз. Вы также можете ввести / text , чтобы загрузить текст, или / corpus , чтобы загрузить папку с текстовыми файлами. Если вы это сделаете, вам будут предоставлены инструкции о том, как указать относительный путь из папки корпуса Prosodic или абсолютный путь к другому файлу или папке на вашем диске.Вы также можете определить текст, с которым хотите работать, в качестве аргумента для команды, которую вы используете для загрузки Prosodic: prosodic /path/to/my/file.txt .
Проверка фонетических / фонологических аннотаций
Еще до метрического анализа загруженного текста (см. Ниже) вы можете запустить несколько команд, чтобы проверить, как Prosodic интерпретировал текст с точки зрения его фонетики и фонологии. Команда / show покажет фонетическую транскрипцию и профили ударения и веса для каждого слова:
000001 из P: ʌv S: U W: L
000002 мужчин P: 'mænz S: P W: H
000003 первый P: 'fɛːst S: P W: H
000004 неповиновение P: `dɪ.sə.'biː.diː.əns S: SUPUU W: LLHHH
000005 и P: ænd S: U W: L
000006 P: ðə S: U W: L
000007 фруктовый P: 'фруктовый S: P W: H
Команда / tree показывает иерархическое описание фонологии каждого слова, поскольку оно встроено в иерархическую организацию текста. Например, начало вывода / tree для этой строки будет:
----- | (S1) <Станца>
|
| ----- | (S1.L1) <Строка> [первого непослушания человека и плода]
|
| ----- | (S1.L1.W1) <Слово> из <ʌv>
| [+ функциональное слово]
| [numSyll = 1]
|
| ----- | (S1.L1.W1.S1) <Слог> [ʌv]
| [prom.stress = 0,0]
|
| ----- | (S1.L1.W1.S1.SB1) [ʌv]
| [shape = VC]
| [-prom.vheight]
| [-prom.weight]
|
| ----- | (S1.L1.W1.S1.SB1.O1) <Установка>
|
| ----- | (S1.L1.W1.S1.SB1.R2) <рим>
|
| ----- | (S1.L1.W1.S1.SB1.R2.N1) <Ядро>
| [-prom.vheight]
|
| ----- | (S1.L1.W1.S1.SB1.R2.N1.P1) <Телефон> [ʌ]
|
| ----- | (S1.L1.W1.S1.SB1.R2.C2)
|
| ----- | (S1.L1.W1.S1.SB1.R2.C2.P1) <Телефон> [v]
|
| ----- | (S1.L1.W2) <Слово> мужчина <'mænz>
| [numSyll = 1]
|
| ----- | (S1.L1.W2.S1) <Слог> ['mænz]
| [prom.stress = 1.0]
| [prom.kalevala = 1.0]
|
| ----- | (S1.L1.W2.S1.SB1) [mænz]
| [shape = CVCC]
| [-выпускной вечер.vheight]
| [+ выпускной вес]
|
| ----- | (S1.L1.W2.S1.SB1.O1) <Установка>
|
| ----- | (S1.L1.W2.S1.SB1.O1.P1) <Телефон> [м]
|
| ----- | (S1.L1.W2.S1.SB1.R2) <рим>
|
| ----- | (S1.L1.W2.S1.SB1.R2.N1) <Ядро>
| [-prom.vheight]
|
| ----- | (S1.L1.W2.S1.SB1.R2.N1.P1) <Телефон> [æ]
|
| ----- | (S1.L1.W2.S1.SB1.R2.C2)
|
| ----- | (S1.L1.W2.S1.SB1.R2.C2.P1) <Телефон> [n]
|
| ----- | (S1.L1.W2.S1.SB1.R2.C2.P2) <Телефон> [z]
Наконец, команда / query позволяет запрашивать эти фонологические аннотации. После ввода / запроса запускается синтаксический анализатор языка запросов (введите / для выхода или нажмите Ctrl + D ). Какие ударные слоги в тексте? (слог: [+ prom.stress]) . Какие все звонкие фонемы? (Фонема: [+ голос]) . Какие все слоги с звонкими началами и кодами? (Слог: (Начало: [+ voice]) (Coda: [+ voice])) .И т. Д.
Метрический анализ текста
Команда / parse будет метрически анализировать любой текст, загруженный в Prosodic в данный момент. После анализа текста становятся возможными дальнейшие команды, каждая из которых либо просматривает, либо сохраняет данные, полученные от анализатора.
Команда / scan выводит лучший синтаксический анализ для каждой строки вместе со статистикой, какие ограничения были нарушены. [Этот вывод, как и любой другой вывод, можно сохранить на диск (а затем открыть в Excel) с помощью команды / save .] Например, вот первые четыре строки Paradise Lost с использованием команды / scan :
синтаксический анализ текста #pars #viol meter [* footmin-none] [* strong.s => - u] [* strong.w => - p] [* stress.s => - u] [* stress.w => - p]
первого непослушания человека и плод | MANS | first | DI | so | BE | di | ENCE | and.the | FRUIT 3 5 wswswswswws 0 0 2 2 1
этого запретного дерева, чей смертельный вкус | ТО | для | ЗАЯВКИ | den | TREE | которого | MOR | tal | TAST 1 0 wswswswsws 0 0 0 0 0
принесли смерть в мир, и все наши беды принесли | СМЕРТЬ | в | В | МИР | и | ВСЕ | наши | WOE 1 2 wswswswsws 0 0 0 2 0
с потерей рая до одного великого человека с | ПОТЕРЬ | из | ED | en | TILL | one | GRE | ater | MAN 1 2 wswswswsws 0 0 2 0 0
Команда / report — это более подробная версия команды / scan , печатающая все возможные (т.е.е. негармонически-ограниченный) синтаксический анализ для каждой строки. Например, для каждой строки выводится такой результат:
==============================
[строка №1 из 4]: о первом непослушании человека и его плодах
--------------------
[анализ №3 из 3]: ошибки 8.0
1 нед.
2 с МАН
Сначала 3 нед [* stress.w => - p]
4 с DI
5 нед так
6 с BE
7 Вт ди
8 с ENCE [* stress.s => - u]
9 нед и
10 с [* stress.s => - u]
11 w фрукты [* стресс.w => - p]
[* stress.s => - u]: 4.0 [* stress.w => - p]: 4.0
--------------------
--------------------
[синтаксический анализ № 2 из 3]: ошибки 5.0
1 нед.
2 с МАН
Сначала 3 нед [* stress.w => - p]
4 с DI
5 нед так
6 с BE
7 w di ence [* footmin-none]
8 с И [* stress.s => - u]
9 нед.
10 с ФРУКТЫ
[* footmin-none]: 1.0 [* stress.s => - u]: 2.0 [* stress.w => - p]: 2.0
--------------------
--------------------
[синтаксический анализ № 1 из 3]: ошибки 5.0
1 нед.
2 с МАН
3 нед [* стресс.w => - p]
4 с DI
5 нед так
6 с BE
7 Вт ди
8 с ENCE [* stress.s => - u]
9 w и [* footmin-none]
10 с ФРУКТЫ
[* footmin-none]: 1.0 [* stress.s => - u]: 2.0 [* stress.w => - p]: 2.0
--------------------
==============================
Наконец, вы также можете сохранить различную статистику из метрического синтаксического анализатора в форме, разделенной табуляцией, выполнив команду / stats .
Оценка измерителя по разобранному вручную образцу
Насколько хорошо Prosodic справляется, когда его метрические синтаксические разборы сравниваются с теми, которые аннотировал человеческий читатель? Приведенная выше статистика в разделе «Точность метрического синтаксического анализатора» была сгенерирована с помощью команды оценки: / eval .Оттуда вы можете выбрать электронную таблицу (текстовый файл с разделителями табуляции или документ Excel), сохраненную в папке tagged_samples / , чтобы использовать ее в качестве «основной истины», синтаксического анализа, аннотированного человеком. Команда / eval спросит, какие столбцы в файле соответствуют строке («Первое неповиновение человека и плод»), синтаксическому анализу («wswswswwsws») и (необязательно) метру строки («ямб» ). Затем Prosodic проанализирует строки под столбцом «строка» (как всегда, используя текущую конфигурацию метрических ограничений в файле config.py ) и сохранять статистику в ту же папку в форме, разделенной табуляцией. Электронная таблица, используемая в приведенной выше таблице точности, предоставлена поэтическим проектом Стэнфордской литературной лаборатории в 2014 и 2016 годах.
Варианты конфигурации
Вся настройка Prosodic происходит в config.py в вашей папке с просодическими данными, которая по умолчанию является папкой prosodic_data в вашей домашней папке. (Если там только config_default.py , скопируйте его в файл config.py .) Этот файл довольно хорошо документирован и является лучшим источником документации по его использованию. (Лучше всего редактировать этот файл в текстовом редакторе, который выделяет синтаксис Python, чтобы вы могли визуально видеть, какие настройки деактивированы «закомментированными», то есть наличием символа «#» в начале их строк.) Вот список того, что вы там найдете.
- Технические параметры работы Prosodic:
- Пути, используемые для корпусов, результатов и помеченных образцов
- Используемый язык (в настоящее время английский или финский)
- Какой механизм преобразования текста в речь, если таковой имеется, используется для анализа неизвестных английских слов?
- Выводить ли вывод на экран
- Параметры метрического синтаксического анализа:
- Минимальный и максимальный размер метрических позиций (от мора до двух и более слогов)
- Ограничения, используемые в метрическом синтаксическом анализе, некоторые из которых:
- Ограничения, предложенные Кипарским и Хэнсоном в «Параметрической теории поэтического метра» ( Language , 1996):
- Сила : Слабый / сильный слог не должен находиться в сильной / слабой метрической позиции.
- Ударение : Безударный / ударный слог не должен занимать сильную / слабую метрическую позицию.
- Вес : легкий / тяжелый слог не должен находиться в сильной / слабой метрической позиции.
- Минимальная ступня : двусложная метрическая позиция не должна содержать более минимальной ступни (только если слоги являются легкими-тяжелыми или легкие-легкие допустимы двусложные положения).
- Другие ограничения, регулирующие двусложные метрические позиции
- Ограничения, позволяющие начальным частям линий быть экстраметрическими
- Ограничения, регулирующие исключения слов (например,грамм. «Плутон-и-ан» становится «Плутон-иан»)
- Ограничения, предложенные Кипарским и Хэнсоном в «Параметрической теории поэтического метра» ( Language , 1996):
- Что передать метрическому синтаксическому анализатору: строку в текстовом файле, строку между знаками препинания и т. Д.
- Параметры слов и токенизации:
- Регулярное выражение, используемое для токенизации слов
- Для слов с несколькими профилями напряжения (например, «INto» и «inTO»): разрешить ли метрическому синтаксическому анализатору выбирать профиль напряжения на основе того, что метрически лучше всего работает в строке.
- Разрешить ли пропускаемое произношение (e.грамм. «Plu-ton-ian» вместо «Plu-ton-i-an») также в качестве метрических возможностей
- Как отображать фонетический вывод для слов (IPA, орфография, обозначение CMU)
Опять же, дополнительную информацию см. В документации в файле config.py .
Запуск Prosodic как модуля Python
Prosodic также можно запускать в других приложениях Python.
В [1]: импортировать просодику как p
В [2]: t = p.Text ("corpora / shakespeare / sonnet-001.текст")
В [3]: t.parse ()
В [4]: для синтаксического анализа в t.bestParses ():
...: распечатать синтаксический анализ
...:
из | FAI | rest | CREA | tures | WE | de | SIRE | in | CREASE
что | ЗДЕСЬ | авторством | БО | ty's | ROSE | might | NEV | er | DIE
[...]
Для получения дополнительной информации см. Wiki.
Зависимости
Механизм преобразования текста в речь для анализа неизвестных английских слов
По умолчанию Prosodic использует словарь произношения CMU для определения границ слогов, образца ударения и другой информации об английских словах, необходимой для метрического синтаксического анализа.Строки со словами, которых нет в этом словаре, снова по умолчанию пропускаются при синтаксическом анализе. Однако с помощью механизма преобразования текста в речь можно «озвучивать» неизвестные английские слова в ударной слоговой форме, которая затем может быть проанализирована. Prosodic поддерживает два движка TTS: espeak (рекомендуется) и OpenMary . Я считаю, что espeak дает лучшие слоги, чем OpenMary (по крайней мере, для английского), и его проще использовать, но любой из них будет работать нормально.
Настройка espeak
Espeak — это движок TTS с открытым исходным кодом для систем Windows и Unix (включая Mac OS X).Вы можете скачать его для своей операционной системы здесь. Но если вы используете Mac OS X, еще более простой способ установить espeak — через диспетчер пакетов HomeBrew. Для этого установите homebrew, если вы этого не сделали, а затем запустите в терминале: brew install espeak . После установки espeak установите флаг «en_TTS_ENGINE» в файле config.py на «espeak». Вот и все!
Примечание: Espeak производит un -сложную транскрипцию IPA любого заданного (реального или нереального) слова.Чтобы придать им слоговое выражение, используется слоговификатор из Penn Phonetics Toolkit (P2TK). Дополнительным плюсом этого конвейера является согласованность: тот же самый слоговый указатель отвечает за границы слогов в словаре произношения CMU, из которого Просодик извлекает (если возможно), прежде чем прибегать к механизму TTS.
Настройка OpenMary
OpenMary — еще один движок TTS с открытым исходным кодом, написанный на Java и разработанный двумя немецкими исследовательскими институтами: лабораторией языковых технологий DFKI и Институтом фонетики Саарландского университета.Чтобы установить OpenMary, сначала загрузите его здесь [выберите ссылку «Run time package»]. Затем разархивируйте zip-файл, перейдите в распакованную папку и запустите OpenMary в качестве сервера. Для этого введите в терминал после распаковки: ./marytts-5.2/bin/marytts-server.sh . Чтобы использовать OpenMary в Prosodic, вам необходимо заранее убедиться, что OpenMary работает как серверный процесс; в противном случае вам придется повторить последнюю команду. Для espeak в этом шаге нет необходимости.
Зависимости модуля Python
По умолчанию Prosodic не имеет зависимостей модулей.Модули, которые он действительно использует — lexconvert, P2TK syllabify.py и Python-переносчик для слоговой орфографии английского языка — небольшие и уже включены в репозиторий. Однако есть несколько исключений, в зависимости от того, что вы хотите сделать. Чтобы установить эти модули, сначала установите pip, если вы еще этого не сделали.
- Если вы хотите использовать встроенный язык запросов (доступный в «/ query» в интерактивном режиме), вам необходимо установить pyparsing:
pip install pyparsing. - Если вы используете OpenMary, вам необходимо установить синтаксический анализатор XML Beautiful Soup 4 и модуль unicode unidecode:
pip install bs4иpip install unidecode. - Если вы хотите иметь возможность читать оценочные данные в виде электронной таблицы (* .xls, * .xlsx) (доступны в «/ eval» в интерактивном режиме), вам необходимо установить xlrd:
pip install xlrd.
Как это работает
Как работает просодик? Вот обзор двух его основных аспектов: как слова токенизируются, фонетически транскрибируются, силлабифицируются и ударяются; а затем как эта информация используется для поиска оптимального метрического синтаксического анализа в соответствии с набором ограничений.
От текста к словам, к фонетике и фонологии
Просодик впервые встречает фрагмент английского или финского текста. Он токенизирует этот текст в соответствии с определяемым пользователем токенизатором, установленным для параметра «tokenizer» в файле config.py , по умолчанию разбивая строки на слова с помощью пробелов и дефисов. В финском тексте представлена реализация финского IPA-транскрипции и слоговой записи на чистом Python, созданная Джошем Фальком. В английском процесс более сложный.Если слово найдено в словаре произношения CMU, используется его слоговая, ударная, фонетическая транскрипция. В противном случае используется механизм преобразования текста в речь, чтобы «озвучить» неизвестное слово, а затем использовать слоговой преобразователь, чтобы разбить подчеркнутую транскрипцию IPA на слоги. Подробнее об использовании механизма преобразования текста в речь и силлабификатора см. Выше «Механизм преобразования текста в речь для синтаксического анализа неизвестных английских слов».
С помощью этих фонетико-фонологических транскрипций Prosodic строит каждое слово как иерархию его составных частей.Например, английское слово «любовь» интерпретируется:
| (W1) <Слово> любовь <'l ah v>
| [numSyll = 1]
|
| ----- | (W1.S1) <Слог>
| [prom.stress = 1.0]
|
| ----- | (W1.S1.SB1)
| [shape = CVC]
| [+ выпускной вес]
|
| ----- | (W1.S1.SB1.O1) <Установка>
|
| ----- | (W1.S1.SB1.O1.P1) <Телефон> [l]
|
| ----- | (W1.S1.SB1.R2) <рим>
|
| ----- | (W1.S1.SB1.R2.N1) <Ядро>
|
| ----- | (W1.S1.SB1.R2.N1.P1) <Телефон> [ʌ]
|
| ----- | (W1.S1.SB1.R2.C2) <Код>
|
| ----- | (W1.S1.SB1.R2.C2.P1) <Телефон> [v]
Благодаря такой иерархической организации становятся возможными сложные запросы к языковым структурам в их взаимосвязях.Другими словами, поскольку иерархия определяет базовые отношения между лингвистическими структурами «дочерние» или «содержащиеся в», можно запросить, скажем, «все начала с , по крайней мере, с одним звонким согласным в ударных слогах. . » (Подробнее о включенном языке запросов см. Выше).
От фонологии к метрике
Когда эти фонетические и фонологические аннотации к словам размещены, метрический синтаксический анализ может затем использовать их, поскольку он пытается максимизировать соответствие между метрически сильными позициями и, скажем, слоговым ударением.Синтаксический анализ выполняется в духе теории оптимальности: (почти) предпринимаются попытки (почти) всех логически возможных синтаксических анализов, но наилучшими являются те, которые в наименьшей степени нарушают набор определяемых пользователем ограничений. Если общая оценка нарушения синтаксического анализа A для каждого ограничения такая же, как и оценка синтаксического анализа B, но есть хотя бы одно ограничение, при котором оценка нарушения синтаксического анализа A даже хуже, чем оценка нарушения синтаксического анализа B, то синтаксический анализ A «гармонически ограничен» синтаксическим анализом B. A никогда не бывает лучше Parse B; и по крайней мере в одном случае это хуже.Независимо от того, как взвешиваются ограничения, эти «ограниченные» синтаксические разборы категорически хуже других. Метрический синтаксический анализатор, написанный в основном Джошем Фальком, работает так же быстро, как и он, игнорируя гармонически ограниченные синтаксические разборы по мере его продвижения: таким образом, ему не нужно продвигаться дальше по синтаксическому анализу, как только он понимает, что этот синтаксический анализ уже ограничен другие разборы.
Число из неограниченных синтаксических разборов для данной строки тогда представляет некоторую метрическую сложность строки.Например, возьмем фразу Ричарда III (Шекспира): «Лошадь! Лошадь! Мое королевство вместо лошади!» Только один синтаксический анализ выживает в процессе гармонического ограничения:
[анализ № 1 из 1]: ошибки 2.0
1 нед.
2 с ЛОШАДЬ
3 нед
4 с ЛОШАДЬ
5 нед.
6 с КОРОЛЬ
7 Вт дом
8 с ДЛЯ [* stress.s => - u]
9 нед
10 сек ЛОШАДЬ
[* stress.s => - u]: 2.0
Этот синтаксический анализ нарушает только одно ограничение: он возвышает безударное слово «for» до метрически сильной позиции.Сравните эту строчку с другой строкой Шекспира, которая имеет такое же количество слогов, но более сложна в метрическом отношении: «Никогда еще яд не исходил из такого сладкого места». Здесь выживают четыре анализа:
--------------------
[синтаксический анализ №4 из 4]: 14.0 ошибок
1 w nev [* Strength.w => - p] [* stress.w => - p]
2 с ER [* Strength.s => - u] [* stress.s => - u]
Пришло 3 недели [* stress.w => - p]
4 секунды POI
5 Вт сын
6 с ОТ [* stress.s => - u]
7 нед так
8 сек СЛАДКИЙ
9 нед
10 с МЕСТО
[*сила.s => - u]: 3.0 [* Strength.w => - p]: 3.0 [* stress.s => - u]: 4.0 [* stress.w => - p]: 4.0
--------------------
--------------------
[синтаксический анализ № 3 из 4]: 13.0 ошибок
1 с NEV
2 недели
3 с ПРИШЕЛ POI [* footmin-none] [* footmin-no-s-except -preded-by-ww]
4 w сын
5 с ОТ [* stress.s => - u]
6 нед так
7 сек СЛАДКИЙ
8 нед
9 с МЕСТО
[* footmin-no-s-except-previous-by-ww]: 10.0 [* footmin-none]: 1.0 [* stress.s => - u]: 2.0
--------------------
--------------------
[синтаксический анализ №2 из 4]: 9.0 ошибок
1 с NEV
2 пришли [* stress.w => - p] [* footmin-none]
3 секунды POI
4 w сын от [* footmin-none]
5 с SO [* stress.s => - u]
6 w sweet a [* stress.w => - p] [* footmin-none]
7 с МЕСТО
[* footmin-none]: 3.0 [* stress.s => - u]: 2.0 [* stress.w => - p]: 4.0
--------------------
--------------------
[синтаксический анализ № 1 из 4]: ошибки 6.0
1 с NEV
2 пришли [* stress.w => - p] [* footmin-none]
3 секунды POI
4 w сын
5 с ОТ [* stress.s => - u]
6 нед так
7 сек СЛАДКИЙ
8 нед
9 сек МЕСТО [* posthoc-standardize-weakpos]
[* footmin-none]: 1.0 [* posthoc-standardize-weakpos]: 1.0 [* stress.s => - u]: 2.0 [* stress.w => - p]: 2.0
--------------------
Лучший синтаксический анализ (внизу) — ямб с хоровой инверсией; он нарушает ограничение на понижение ударных слогов («пришел») в метрически слабую позицию, а также ограничение, препятствующее двусложным позициям. Следующее лучшее — это дактильная интерпретация линии, но она также нарушает определенные ограничения. Третий лучший попытался втиснуть два слога в сильную позицию, а последний — традиционный ямбический синтаксический анализ — попытался изменить контур ударения слова «никогда», что нарушает ограничения, поощряющие соответствие между метром и «силой» слога в многосложных словах. .
Метрические ограничения по умолчанию предложены Кипарски и Хэнсоном в их статье «Параметрическая теория поэтического метра» (Language, 1996). См. config.py для лучшего описания этих и других ограничений.
Расширение Prosodic
Добавление языков
Есть два возможных метода, с помощью которых Просодик может понимать язык:
с использованием словаря в формате:
- {слово-токен} [табуляция] {ударение, слоговое письмо, формат IPA}
- например:
- сбивать с толку [tab] bɪ.’fə.dəl
- befuddled [tab] bɪ.’fə.dəld
- befuddles [вкладка] bɪ.’fə.dəlz
с использованием функции python, которая принимает слово-токен в качестве входных данных и ударный, слоговый формат IPA в качестве выходных данных.
В настоящее время финский язык используется вторым методом; Английский, комбинация двух, с использованием словаря для распознанных слов и функции python для нераспознанных слов.
Чтобы добавить статьи в словарь языка, просто добавьте запись в указанном выше формате в словарь [имя_языка].tsv в папке [prosodic_dir] / dicts / [language_twoletter_code] .
Чтобы полностью добавить новый язык, вы можете создать новый словарь в указанном выше формате и поместить его в папку [prosodic_dir] / dicts / [language_twoletter_code] / [language_name] .tsv . Или вы можете создать файл python под [prosodic_dir] / dicts / [language_twoletter_code] / [language_name] .py , который имеет функцию get (token, config = {}) . Эта функция должна принимать слово-токен в качестве своего единственного аргумента и параметры конфигурации Просодика в качестве необязательного аргумента ключевого слова, и она должна возвращать список кортежей в форме:
[
(
<строка Unicode ipa>,
<строка токена разделена на список строк слогов>,
{словарь необязательных аргументов ключевого слова, которые должны быть сохранены в объекте слова},
),
...
]
Например, get ("into", config = {'add_elided_pronunciations': 1}) может вернуть:
[
(u "ɪn.'tuː", ['in', 'to'], {'is_elision': False}),
u "'ɪn.tuː", [' in ',' to '], {' is_elision ': False}),
u "ɪn.tʌ", ['in', 'to'], {'is_elision': False})
]
См. Для примеров функцию get () в dicts / en / english.py или dicts / fi / finnish.py .
Вклад в кодовую базу
Пожалуйста, не стесняйтесь тянуть и возвращаться к базе кода здесь! И не стесняйтесь использовать этот код в своих проектах: он под лицензией GPLv3.
Перейти к основному содержанию ПоискПоиск
- Где угодно
Поиск Поиск
Расширенный поиск- Войти | регистр
- Подписка / продление
- Учреждения
- Индивидуальные подписки
- Индивидуальные продления
- Библиотекари 6 909 Чикагский пакет
- Полный охват и охват содержимого
- Файлы KBART и RSS-каналы
- Разрешения и перепечатки
- Инициатива развивающихся стран Чикаго
- Даты отправки и претензии
- Часто задаваемые вопросы библиотекарей
- и платежи
- О нас
- Публикуйте у нас
- Недавно приобретенные журналы tners
- Подпишитесь на уведомления eTOC
- Пресс-релизы
- СМИ
- Издательство Чикагского университета
- Распределительный центр в Чикаго
- Чикагский университет
- Положения и условия
- Заявление об издательской этике
- Уведомление о конфиденциальности
- Доступность Chicago Journals
- Доступность университета
- Следуйте за нами на facebook
- Следуйте за нами в Twitter
- Свяжитесь с нами
- Запросы СМИ и рекламы
- Открытый доступ в Чикаго
- Следуйте за нами на facebook
- Следуйте за нами в Twitter
Джеймс Таубер: Лингвистика
Меня приняли на внешнюю программу докторантуры в Университете Эссекса, но я взял отпуск, чтобы основать Эльдарион.
В 1996 году я окончил Университет Западной Австралии со степенью бакалавра наук (с отличием) по лингвистике.
Сфера моих интересов в лингвистике:
Чтобы немного повеселиться, просмотрите мои случайные лингвистические наблюдения.
Немного автобиографии
В моем детстве, примерно в возрасте двенадцати лет, произошло несколько событий, которые легли в основу моего интереса к лингвистике.
В 1985 году я учился в последнем классе начальной школы в Брунее.Уроки английского в основном включали индивидуальную работу с серией учебников, как мне кажется, Рональда Ридаута. Я был единственным в маленьком классе, кто добрался до Книги 8, и я помню, что в ней использовался более систематический подход к языку, чем в предыдущих книгах, и преподавались такие вещи, как Международный фонетический алфавит.
В том же году я получил на свой день рождения «Возвращение короля» Толкина (я был большим поклонником «Хоббита»). Не прочитав первые две части Властелина Колец, я не хотел начинать читать основной текст RotK, поэтому вместо этого потратил время на изучение приложений и, в частности, алфавита Тенгвар и его отношения к фонетике, которую я имел. учиться по моему учебнику английского языка.
В 1986 году, когда я учился на первом году обучения в средней школе заочно, я изучал латынь и увлекся ее флективной морфологией.
Примерно в то же время я играл на компьютере в приключенческие текстовые игры, в которых вы должны были указать, что вы хотите делать, с помощью простых предложений на английском языке. Это заинтересовало меня обработкой естественного языка, особенно потому, что я сразу же захотел писать свои собственные приключенческие игры. В своем исследовании того, что было задействовано, я впервые столкнулся с такими терминами, как «лексикон» и «синтаксический анализатор».
В течение нескольких лет мое внимание сместилось в сторону других аспектов компьютеров и теоретической физики. В последние годы учебы в старшей школе я вместе с лучшим другом начал изучать искусственный язык.