Государственное казенное учреждение социального обслуживания Ростовской области центр помощи детям, оставшимся без попечения родителей, "РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7"
Овладел разбор слова по составу: «овладел» — корень слова, разбор по составу (морфемный разбор слова)
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Содержание
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «овладеть», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
Значение слова
Звуко-буквенный разбор
Разбор по составу
Значение слова
ОВЛАДЕТЬ, ею, еешь; сов.
1.кем-чем. Взять, стать обладателем кого-чего-н.О. крепостью. О. имуществом.
2.перен., кем-чем. Подчинить себе, придать чему-н. нужное направление. О. вниманием слушателей. О. разговором. О. собой (перен.: привести себя в более спокойное состояние).
3. (1 и 2 л. не употр.), перен., кем. О мыслях, чувствах: охватить кого-н., целиком наполнить.
Юношей овладела радость.
4.перен., чем. Прочно усвоить что-н., изучить. О. новой профессией. О. знаниями.
| несов.овладевать, аю, аешь.
| сущ.овладение, я, ср. (к 1, 2 и 4 знач.).
Фонетический (звуко-буквенный) разбор
овла́деть
овладеть — слово из 3 слогов: о-вла-деть. Ударение падает на 2-й слог.
Транскрипция слова: [авлад’ит’]
о — [а] — гласный, безударный в — [в] — согласный, звонкий парный, твёрдый (парный) л — [л] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный) а — [а] — гласный, ударный д — [д’] — согласный, звонкий парный, мягкий (парный) е — [и] — гласный, безударный т — [т’] — согласный, глухой парный, мягкий (парный) ь — не обозначает звука
Части слова «овладеть»: о/влад/е/ть Часть речи: глагол Состав слова: о — приставка, влад — корень, е, ть — суффиксы, нет окончания, овладе — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «бой», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
Значение слова
Звуко-буквенный разбор
Разбор по составу
Значение слова
БОЙ, боя, о бое, в бою и в бое, мн.
бои, боёв, м.
1.см. бить, ся.
2. (в бою). Сражение войск, армий. Наступательные бои. Ввести в б. крупные силы. Принять б. Вести б. Идти в б. и (высок.) на б. Разведка боем. На поле боя. К бою! (команда). С бою брать что-н. (овладевать в ходе боя, также перен.: энергично добиваться чего-н.).
3. Состязание, единоборство. Кулачный б. Петушиные бои. Б. быков (коррида).
4. (в бою). Борьба (по 3 и 4 знач.гл. бороться), действия, направленные на достижение чего-н., к искоренению чего-н. Б. за правое дело. Пьянству б.!
5. (в бое), только ед. Битое стекло, керамика, щебень, камень, а также разбитые яйца (спец.). Б. из посудного цеха. Яйца-б.
• Бой-баба и бой-девка
(прост.) об энергичной, бойкой женщине, девушке.
Морской бой игра на листе с разграфлёнными клетками и нарисованными в них кораблями, в к-рой каждый их двух участников, называя ту или иную клетку, стремится поразить корабль и уничтожить «флот» противника. Играть в морской бой.
бой — слово из 1 слога: бой. Ударение ставится однозначно на единственную гласную в слове.
Транскрипция слова: [бой’]
б — [б] — согласный, звонкий парный, твёрдый (парный) о — [о] — гласный, ударный й — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
В слове 3 буквы и 3 звука.
Цветовая схема: бой
Разбор слова «бой» по составу
бой
Части слова «бой»: бой Состав слова: бой — корень, нулевое окончание, бой — основа слова.
Состав слова.Разбор слова по составу.
«Состав слова. Основа»
Урок русского языка во 2 классе
Учитель:Налётова Людмила Николаевна.
Тема: «Состав слова. Основа»
Тип урока: Обобщение и систематизация знаний. Введение нового понятия.
Место урока: Обобщение по теме «Состав слова»
План урока разработан по блокам ( Блочную систему разработал Иофе Андрей Наумович)
Цель урока : обобщить и систематизировать знания о составе слова, познакомить с понятием «основа».
Задачи:
Систематизировать и обобщить знания о составе слова в виде схемы, овладеть умением соотносить схемы и слова ,графически обозначать части слова
Овладевать умением вычитывать информацию из разных источников и преобразовывать в другие формы, Овладение навыками анализа, сравнения, обобщения, умение соотносить информацию предоставленную в разных формах.
Создание условий для развития речи.
Оборудование: тетради у каждого ученика, проектор, презентация, карточки с частями слов, тексты, кроссворды.
ХОД УРОКА
Организационный блок.
Учитель мотивационный настрой. Ученик(итог)
У Мудреца, однажды, ученик спросил Что в моих ладонях?
(он перед этим бабочку словил):
– Скажи, Мудрейший, знаешь ты ответ?
Жив мотылек в руках моих, иль нет?
Ладони в этот миг легонько сжал…
Плененный мотылек затрепетал.
Блеснули искорки у мудреца в глазах:
– Ты держишь все, сейчас, в своих руках!
-Что будет в ваших руках, зависит от вас.
Желаю вам на уроке удачи.
2.Информационныйблок
Актуализация знаний. (перевод информации)
СЛАЙД 2
? _______ .!
— В русском языке встречаются знаки . Разделить эти знаки на группы.
Слайд3
Знаки препинания в конце предложения — . ! ?
перевод из схемы текст
Члены предложения — _____
Части слова –
итог
— Какая группа знаков лишняя и почему? (части слова, т.к. относится к разбору слов.)
СЛАЙД 4
— Что обозначает первый значок?
-Какая часть слова выделяется в квадратик?
— Каким значком выделяется главная часть слова?
— Что обозначают оставшимся значком?
Актуализация изученного материала. Игра «Крестики-нолики».
Работа по алгоритму (графический диктант)
— Ребята, я предлагаю вам вспомнить , что вы знаете о частях слова. В этом нам поможет игра «Х-О». Поле для игры находится у каждого на листах.
-Правила игры: я буду читать вам утверждение и если вы с ним согласны, в клеточке ставите Х, если не согласны 0 . Отвечать начнёте с той клеточки, в которой стоит точка.
СЛАЙД 5
Ученик Перевод
информации, проверка знаний. 1. Корень – это главная часть предложения (-)
2. Родственные слова ещё называют однокоренными (+)
3. Верно ли, что у слов носик и носильщик одинаковый корень?(-)
4. Корни в родственных словах пишутся одинаково. (+)
5. Окончание – это изменяемая часть слова.(+)
6. Суффикс помогает образовывать новые слова. (+)
7. Приставка – это часть слова, которая стоит после корня и служит
для образования новых слов.(-)
8. Корень – это общая часть родственных слов (+)
9. Суффикс – это часть речи. (-)
Взаимопроверка(работа в паре)
— Проверим ваши ответы. Поменяйтесь листами. Сравните рисунок с рисунком на экране. Если у вас получился такой же рисунок ( ответы верны.)
Слайд 6
о
Х
о
Х
Х
Х
о
Х
о
3 Аналитический блок
Введение в тему урока Ученик
-Кто может предположить тему нашего урока? Цели?
-Повторить части слова Проблема?
Работа по теме «Состав слова».
1) Работа с текстом. Словарная работа.
СЛАЙД 7
— Посмотрите на экран. Прочитайте вслух. Что перед вами? (Текст.) Докажите
— Докажите, что перед вами текст. (выслушиваются ответы )
— Этот текст записан на листах.
В нашей стране можно встретить очень красивые города. Один из них Ангарск. Городские улицы полны красивых зданий. Мой друг живёт в пригороде Ангарска. У него есть загородный домик.
Работа с терминами
(извлечение новой информации)
— Есть ли в тексте слова, которые вам не понятны? (пригород, загородный)
— Кто попробует объяснить их значение? (ответы детей).
2) Нахождение родственных слов. (Работа в паре)
— Возьмите карандаш и подчеркните однокоренные слова.
(проверка выполнения задания)
Города, городские, пригород, загородный.
(Проверка работы на экране).
СЛАЙД 8
— Выпишем эти слов. (в тетрадь)
Города –
городские
загородный–
пригород
— Какие задания можно предложить к данной группе слов?
( возможные задания детей)
Выделить корень во всех словах.
Поставить ударение.
Разделить на слоги.
Разбор по составу
— Предложить задание ,связанное с темой (разбор по составe)
(Работа у доски и в тетрадях.)
Введение нового термина Ученик (Вывод совместного понятия)
Введение понятия «Основа слова»
? -Ребята, как вы считаете, какая часть в слове является основной: окончание или та, которая остается после выделения окончания?
(Конечно, та часть, в которой находится корень.)
— Если эта часть является основной, то как, по-вашему, она может называться?
Выслушиваются ответы детей.
Основа. Да ,вы уже слышали это слово . Многие наверное запомнили каким значком она обозначается Показ на доске .Сравнение
— А что такое основа?
СЛАЙД 9
Чтение правила
СЛАЙД 10
Часть слова без окончания называется основой слова.
А без чего не может быть слова?
Обобщение знаний , развитие умений.
СЛАЙД 11
6.Физминутка для глаз.
СЛАЙД 12
4.Рефлексионный блок
Закрепление изученного материала.
— Ребята перед вами карточки: Работа в группах (подложенная подушка)
гриб езд ход лист пуск вод ок по на к ик за под н а ый ой и
— Подумайте, что на них написано? (части слов) Вспомните тему урока.
Разделите из на группы.
— Верно. Прочитайте какая часть слова записана на красных карточках? (Гриб,езд, ход, пуск, вод – это корни слов.)
— Прочитайте части слова на синих карточках. Что это за часть слов?
(ый, а – это окончания)
— Что записано на зелёных карточках?
(ок, к, н – это суффиксы)
— Какая часть слов записана на жёлтых карточках?
(по, на, за, под – это приставки)
— Задание: составьте свое слово используя как можно больше карточек.
На доске (открываются заранее приготовленная таблица)
Под
вод
н
ый
на
ход
к
а
за
пуск
по
езд
гриб
ок
О С Н О В А
— Давайте вспомним, что такое основа слова и отметим её внизу таблицы.
— В завершении нашего урока я предлагаю вам выполнить тест. У вас на выбор будет два варианта ответа. Рядом с ответом стоит буква. В тетради вы должны будете записать 1букву которую считаете правильной (столбиком на полях под счет) Внимание –залог успеха.
Тест
1) Часть слова без окончания называетсяСЛАЙД 13
Е — корень
У– основа
2) Чтобы найти корень надоСЛАЙД 14
Л– изменить форму слова
М– подобрать однокоренные слова
3) Окончание – это СЛАЙД 15
Н– изменяемая часть слова
П– неизменяемая часть слова
4) Суффикс служитСЛАЙД 16
И– для образования новых слов
Ы– для образования формы слова
5) Приставка стоитСЛАЙД 17
Х — после корня
К — перед корнем
6) Приставка, корень, суффиксСЛАЙД 18
И — образуют основу слова
Я — не образуют основу слова (пробуем прочитать0
-Какое слово получилось?
— Если у вас получилось слово УМНИКИ, тест выполнили верно.
СЛАЙД 19
Итог: Что же осталось в ваших руках? (результаты знаний)
10.Домашнее задание:
СЛАЙД 20
Реши кроссворд «Состав слова»
Контрольный диктант с грамматическим заданием
9 класс
Диктант с грамматическим заданием.
Сложноподчинённое предложение
Если вам приходится нелегко, если печаль овладела вашим сердцем, отправляйтесь туда, где у реки, на холме, стоит храм Покрова на Нерли. Вглядитесь в благородные пропорции белого храма, отражающегося свыше восьми веков в водах, и вы увидите, как естественно вписано строение в окружающий пейзаж. Заблуждается тот, кто, увидев храм один раз, считает, что знает его. Эту поэму из камня надо перечитывать многократно, чтобы понять, в чем прелесть этого необыкновенного сооружения. Трудно сказать, когда лучше любоваться им. Весной Клязьма и Нерль разливаются, впитывая в себя ручьи, бегущие из лесов, озер, и вода затопляет луга. В темных, напоминающих густо настоянный чай волнах отражаются березы, ивы и похожие на богатырей-великанов дубы, что старше берез и, наверное, помнят, как владимирскую землю топтали татарские кони и как стояли здесь повозки кочевников. Храм великолепен и на рассвете, когда над лесами играют солнечные лучи и от всплесков светотени древние стены словно колеблются, светлея час от часу. Покров надо видеть и в дождь, когда огромная туча словно останавливается, чтобы полюбоваться храмом. Храм в том виде, как мы его знаем, — лирическая поэма, обращенная к внутреннему миру человека. (175 слов)
(По Е. Осетрову)
Грамматическое задание
1 вариант
Синтаксический разбор. Эту поэму из камня…
Пунктуационный разбор. Храм в том виде…
Разбор слова по составу. Отправляйтесь, окружающий, обращённая.
2 вариант
Синтаксический разбор.Покров надо видеть…
Пунктуационный разбор. Храм в том виде…
Разбор слова по составу. Вглядитесь, настоянный, внутренний.
Морфемный разбор слова «ИСКОЛЕСИЛ»
Слово «исколесил» имеет следующий морфемный состав:
Узнаем, какой морфемный состав имеет слово «исколесил», если определим часть речи и грамматическую форму.
Разбор по составу слова «исколесил»
Интересующее нас слово является формой единственного числа мужского рода прошедшего времени глагола «исколесить».
В юности я исколеси́л многие города и страны.
Я (что сделал?) исколесил.
Исследуемое слово обозначает действие, которое состоялось до момента речи о нём.
Окончание
Это знание формы слова поможет в его морфемном разборе, так как в составе глаголов прошедшего времени мужского рода имеется морфема-«невидимка» — нулевое окончание, которое материализуется при изменении слова по родам и числам. Убедимся в этом, сравнив формы глагола:
мужчина исколеси́л ;
девушка исколесила;
письмо исколесило;
туристы исколесили.
Суффиксы
Далее в морфемном составе анализируемого слова вычленим формообразующий суффикс прошедшего времени -л- и словообразовательный суффикс неопределённой формы глагола -и-, который участвует в образовании этой глагольной формы от инфинитива:
исколесить — исколесил
Окончание и формообразующий суффикс -л- не входят в основу слова исколеси.
Приставка
В составе рассматриваемого слова имеется еще одна словообразовательная морфема — приставка ис-. С её помощью от глагола «колесить» образовано однокоренное производное слово:
колесить → исколесить.
Эту приставку можно выделить также в морфемном составе следующих слов:
помогите пожалуйста разобрать предложения по составу вместе со схемами и то что в скобках написано,то есть вообще полностью вот предложения: 1.Гром, русский язык
5-9 класс
грохотал над крышей гулко возрастая и разражаясь треском когда мелькала красноватая молния;от нависших туч темнело. 2.Я с трепетом ждал ответа Грушницкого холодная злость овладела мной при мысли что если б не случай то я мог бы сделаться посмешищем этих дураков. Только мне нужна ещё схема ну примерно так [ ],( кто.. . )! и ещё пожалуйста обьяснения каждого слова что это за часть речи ))ЗАРАНЕЕ СПАСИБО!!!
Katyagubanova
22 янв. 2014 г., 7:29:26 (7 лет назад) Diana7693
22 янв. 2014 г., 9:02:42 (7 лет назад)
1/[подлежащее сказуемое дополнение,((обстоятельство)дееприч.оборот от «гулко возрастая и разражаясь треском)), когда сказуемое определение подлежащее];[ от +туч=подлежащее нависших=определение сказуемое]
Разобрать предложение по пунктам, которые я напишу ниже! Природа казалась опять отбрасывает хлам названный ей не прошенными гостями ни звери ни птицы не
льстились на этот мусор ни один лесной обитатель не переступал не чистого рубежа а человек укрылся за барьером из отбросов омертвелых как сброшенная змеи кожа 1) какие художественные средства смесь используются 2)разобрать предложение ( мне можете не писать просто для себя что бы вы знали где какая часть)
3) чем осложнена четвертая часть 4)найдите причастен объясните провописание букв нн или н 5)запишите синонимы к слову укрылся из 4 части 6) из третей части выписать словосочетание со связью согласования и из него образовать связь управление 7) выпишите из 3 части слова с проверок ной гласной в корне
Вы находитесь на странице вопроса «помогите пожалуйста разобрать предложения по составу вместе со схемами и то что в скобках написано,то есть вообще полностью вот предложения: 1. Гром«, категории «русский язык«. Данный вопрос относится к разделу «5-9» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
Согласованность: переходы между идеями
Самые убедительные идеи в мире, выраженные в самых красивых предложениях, никого не сдвинут, если эти идеи не связаны должным образом. Если читатели не смогут легко переходить от одной мысли к другой, они наверняка найдут что-нибудь еще, чтобы почитать или включить телевизор.
Обеспечение переходов между идеями во многом зависит от отношения. Вы никогда не должны предполагать, что ваши читатели знают то, что знаете вы.На самом деле, неплохо было бы предположить, что вашим читателям не только нужна вся имеющаяся у вас информация и что они должны знать, как вы пришли к той точке, в которой вы находитесь, но и что они не так быстры, как вы. Вы могли бы перепрыгнуть с одной стороны ручья на другую; Считайте, что вашим читателям нужны ступеньки, и обязательно размещайте их в легко доступных и видимых местах.
Есть четыре основных механических соображения при обеспечении переходов между идеями: использование переходных выражений, повторение ключевых слов и фраз, использование ссылки на местоимение и использование параллельной формы.
ИСПОЛЬЗОВАНИЕ ПЕРЕХОДНЫХ ТЕГОВ
Переходные теги охватывают весь спектр от самых простых — маленьких союзов: и, но, ни, для, еще, или, (и иногда) так — до более сложных сигналов, которые каким-то образом связаны между собой — конъюнктивных наречий. и переходные выражения, такие как , однако, тем не менее, с другой стороны, .
Для получения дополнительной информации о соединениях щелкните ЗДЕСЬ .
Использование маленьких союзов — особенно и и , но — естественно для большинства писателей.
Однако часто возникает вопрос, можно ли начинать предложение с небольшого союза. Разве союз в начале предложения не является признаком того, что предложение должно быть связано с предыдущим предложением? Иногда да. Но часто начальное соединение эффективно привлекает внимание к предложению, и это именно то, что вам нужно.Чрезмерное использование начала предложения с союза может отвлекать, но устройство может добавить освежающий штрих к предложению и ускорить повествовательный поток вашего текста. Ограничения на начало предложения с и или , но основаны на шаткой грамматической основе; некоторые из наиболее влиятельных авторов этого языка веками счастливо игнорировали такие ограничения. *
Вот таблица переходных устройств (также называемых соединительными наречиями или наречиями ), сопровождаемыми упрощенным определением функции ( обратите внимание, что некоторые устройства отображаются с более чем одним определением):
прибавление
снова, также, и, а потом, кроме того, не менее важно, наконец, сначала, далее, кроме того, в первую очередь, в последнюю очередь, кроме того, в следующем, во вторую, еще, тоже
сравнение
также, точно так же, аналогично, аналогично
уступка
предоставлена, естественно, конечно
контраст
хотя, и тем не менее, при том же время, но в то же время, несмотря на это, даже так, хотя, при всем этом, однако, в отличие, несмотря на, вместо этого, тем не менее, несмотря на, наоборот, с другой стороны, в противном случае, несмотря на все еще правда, еще
акцент
конечно, действительно, конечно,
пример или иллюстрация
все-таки в качестве иллюстрации даже для е пример, например, в заключение, действительно, на самом деле, другими словами, вкратце, это правда, конечно, а именно, конкретно, то есть, чтобы проиллюстрировать, таким образом, действительно
резюме
все в целом, в целом, как было сказано, наконец, вкратце, в заключении, другими словами, в частности, вкратце, проще, в целом, в целом, то есть, говоря иначе, резюмировать
временная последовательность
через некоторое время, потом, снова, также, и затем, пока, наконец, в течение долгого времени, в то время, прежде, кроме того, раньше, в конце концов, наконец, раньше, кроме того, кроме того, кроме того, во-первых, в прошлом, в прошлом, в последнее время, в то же время, более того, в следующем, теперь, в настоящее время, во-вторых, в ближайшее время, одновременно, так как, пока, в ближайшее время, еще, впоследствии, затем, после Тоже до тех пор, пока
Предупреждение: не вставляйте в текст транзитные Простые выражения просто потому, что вы знаете, что эти устройства соединяют идеи. Они, естественно, должны появиться там, где им место, иначе они застрянут, как рыбья кость, в зобе вашего читателя. (По той же причине нет смысла пытаться запомнить из этого обширного списка.) С другой стороны, если вы можете прочитать свое эссе целиком и не обнаружите ни одного из этих переходных приемов, тогда вы должны задаться вопросом, что, если что-то, — это , объединяющая ваши идеи. Попрактикуйтесь, вставив пробный , тем не менее, следовательно, . Перечитайте эссе позже, чтобы увидеть, дают ли эти слова клей, который вам нужен в этих точках.
Повторение ключевых слов и фраз
Способность соединять идеи посредством повторения ключевых слов и фраз иногда встречает естественное сопротивление, основанное на страхе повторения. Нас приучили ненавидеть избыточность. Теперь мы должны понять, что уловка слова или фразы, которые важны для понимания читателем текста, и повторное воспроизведение этого слова или фразы создают музыкальный мотив в голове этого читателя. Если повторение не перегружено и не навязчиво, оно дает ощущение связности (или, по крайней мере, иллюзии связности).Помните совет Линкольна:
Вы можете обманывать некоторых людей все время, а иногда и всех людей, но вы не можете обманывать всех людей все время.
Фактически, вы не можете забыть совет Линкольна, потому что он стал частью музыки нашего языка.
Не забудьте использовать это устройство для связывания абзацев и предложений.
Ссылка на местоимение
Местоимения вполне естественно соединяют идеи, потому что местоимения почти всегда отсылают читателя к чему-то более раннему в тексте.Я не могу сказать: «Это правда, потому что …» не заставляя читателя задуматься о том, что могло означать «это». Таким образом, местоимение заставляет читателя быстро и подсознательно резюмировать то, что было сказано ранее (что такое , это ), прежде чем перейти к , потому что — часть моих рассуждений.
Однако нам вряд ли нужно добавлять, что всегда должно быть совершенно ясно, к чему относится местоимение. Если мой читатель не может сразу узнать, что такое , это , то мое предложение двусмысленно и вводит в заблуждение.Кроме того, не полагайтесь на нечеткие ссылки на местоимения, чтобы избежать ответственности: « Они говорят, что …».
Параллельность
Музыка в прозе часто является результатом параллелизма, преднамеренного повторения более крупных структур фраз, даже частей и целых предложений. Мы настоятельно рекомендуем вам прочитать раздел Руководства по параллелизму и пройти сопутствующий тест по распознаванию параллельной формы (и исправлению предложений, которые должны использовать параллельную форму, но не используют). Обратите особое внимание на экскурсию по параллельным сложностям в Геттисбергском послании Авраама Линкольна.
Устройства когерентности в действии
В нашем разделе, посвященном написанию аргументационного эссе , у нас есть полное студенческое эссе («Плачь, волк» — внизу этого документа), которое мы проанализировали с точки зрения развития аргументации и в котором особое внимание уделили соединительные устройства, объединяющие идеи.
Посмотрите на следующий абзац:
Древние египтяне были мастерами сохранения тел умерших людей, делая из них мумии.Мумии, которым несколько тысяч лет, были обнаружены практически целыми. Кожа, волосы, зубы, ногти на руках и ногах, а также черты лица мумий были очевидны. Можно диагностировать болезнь, от которой они страдали при жизни, такую как оспа, артрит и недостаток питания. Процесс был удивительно эффективным. Иногда очевидны были смертельные недуги умерших: король средних лет умер от удара по голове, а полиомиелит убил ребенка-короля. Мумификация заключалась в удалении внутренних органов, применении натуральных консервантов внутри и снаружи, а затем обертывании тела слоями повязок.
Этот абзац, хотя и слабый, не является полным вымыванием. Оно начинается с тематического предложения, а последующие предложения явно связаны с тематическим предложением. На языке написания абзац унифицированный (т.е. не содержит не относящихся к делу подробностей). Однако абзац не является связным . Предложения отделены друг от друга, из-за чего читателю сложно проследить ход мысли писателя.
Ниже тот же параграф, исправленный для согласованности. Курсив обозначает местоимения и повторяющиеся / повторно сформулированные ключевые слова, жирный, обозначает переходные ключевые слова, а подчеркивает, обозначает параллельные структуры.
Древние египтяне были мастерами консервации тел умерших людей, сделав мумий из них. Короче , мумификация заключалась в удалении внутренних органов, нанесении натуральных консервантов внутри и снаружи, а затем наложении на тело слоев повязок. и процесс был замечательно эффективен. Действительно, , мумий возрастом несколько тысяч лет были обнаружены почти нетронутыми. Их кожа, волосы, зубы, ногти на руках и ногах, а также черты лица — , все еще очевидны. У них болезней в жизни, таких как оспа, артрит и недостаточность питания, — это , все еще поддающихся диагностике . Даже их смертельных недугов это все еще очевидные : король средних лет умер от удара по голове; ребенок-король умер от полиомиелита.
Теперь абзац стал более последовательным. Организация информации и связи между предложениями помогают читателям легко переходить от одного предложения к другому. Обратите внимание, как этот писатель использует различные устройства согласования, иногда в комбинации, для достижения общей согласованности абзаца.
Review: Рекурсивные глубинные модели для семантической композиционности над деревом настроений | Аниндья С. Дас | The Startup
Эта статья представляет собой краткий обзор исследовательской работы ( Socher et al., 2013 ), в котором авторы предложили эффективный новый подход, который фокусируется на грамматической структуре предложения для детального анализа тональности.
В статье обсуждаются различные композиционные методы объединения слов и фраз (n-грамма) для предсказания двоичного (положительного или отрицательного), а также детального (очень положительного, положительного, нейтрального, отрицательного, очень отрицательного) настроения слов. , фразы и целые предложения в восходящем порядке. Основным вкладом этой статьи является представление набора данных на основе дерева синтаксического анализа с детализированными метками настроений: «Stanford Sentiment Treebank» и предложение нейронной композиционной модели: рекурсивной нейронной тензорной сети (RNTN), которая превосходит все предыдущие рекурсивные модели и достигает состояния ультрасовременный перформанс.
Набор данных: Stanford Sentiment Treebank
Набор данных был создан путем синтаксического анализа 11 855 предложений корпуса отрывков из обзора фильмов с помощью Stanford Parser, в результате чего 215 154 фраз были случайным образом отобраны и помечены в 25 значений (рисунок 1) с помощью Amazon Mechanical Turk . Замечено, что более короткие фразы имеют нейтральные настроения, в то время как более поляризованные настроения проявляются в более длинных фразах. Также было замечено, что на основе оценки аннотаторов по шкале ползунка 5-классной классификации достаточно, чтобы уловить основные вариации.
Набор данных банка деревьев облегчает создание эффективных моделей, которые могут предсказывать полярность коротких предложений и классифицировать сложные примеры отрицания, которые были недостижимы с помощью предыдущих подходов с набором слов, которые игнорировали порядок слов в предложении. Также точность бинарной (положительной или отрицательной) классификации в задаче анализа тональности впервые после внедрения банка деревьев пересекла отметку 80%.
Изображение из статьи
RNTN: Recursive Neural Tensor Network
Авторы сначала обсуждают композиционные методы, используемые рекурсивными моделями, такими как Recursive Neural Network (RNN) и Matrix-Vector Recursive Neural Network (MV-RNN) to прогнозировать тональность фраз n-грамма и их ограничения, а затем предлагает RNTN , который преодолевает ограничения и превосходит все предыдущие модели в этой задаче.{d × | v |} векторов слов (| V | — размер словаря) обучается совместно с моделями. Эти векторы слов используются для прогнозирования настроения на уровне слов. Затем рекурсивные модели вычисляют родительские векторы (d-мерные) снизу вверх (рисунок 2) с использованием различных композиционных методов после того, как вычислены все его дочерние векторы. Родительский вектор в каждом узле используется в качестве входных данных для классификатора softmax для вычисления вероятностей классов в этом узле.
Хотя RNN использует одну функцию композиции для вычисления вектора n-граммов для фраз в каждом узле, входные векторы взаимодействуют друг с другом посредством нелинейности (активация tanh).Желательно более устойчивое и прямое взаимодействие между входными векторами, что достигается в MV-RNN, в котором каждая n-граммовая фраза (n> = 1) представлена вектором и матрицей. Векторы слов и матрицы слов — это параметры MV-RNN, которые изучаются во время обучения модели, поэтому с увеличением размера словаря количество параметров становится очень большим.
RNTN преодолевает эти ограничения RNN и MV-RNN; Он имеет меньшее количество фиксированных параметров по сравнению с MV-RNN и использует более мощную и единую функцию композиции для всех узлов; входные векторы явно взаимодействуют в RNTN, в отличие от стандартной RNN.
Insights
В документе было предложено несколько важных идей и наблюдений: модели сравнивались с наивным байесовским методом, SVM, BiNB (NB с особенностями биграмм), VecAvg (средним значением векторов слов). По детальной классификации для всех фраз (на всех уровнях узлов деревьев синтаксического анализа) RNTN обеспечивает лучшую производительность, за ней следуют MV-RNN, RNN и другие модели. Для бинарной классификации на уровне предложений RNTN повышает точность современной точности с 80% до 85,4%.
Оптимальные характеристики для всех моделей были достигнуты для размерности вектора слов от 25 до 35, производительность ухудшается для меньшего и большего значения векторов слов, что подтверждает, что повышение производительности RNTN не зависит от его увеличенного размера параметра, поскольку MV-RNN имеет наибольшее количество параметры.
RNTN разумно отражает влияние контраста союзов («но») на общую тональность предложения.
RNTN также улавливает эффект отрицания как в положительных, так и в отрицательных предложениях. Он обладает высочайшей точностью отрицания положительных предложений; он также увеличивает неотрицательную активацию (степень неотрицательного настроения в предложении) для отрицания падежей отрицательного предложения, что ясно указывает на то, что модель усвоила концепцию отрицания далеко за пределами простых правил отрицания.
Выводы
Модель RNTN является мощным средством фиксации структурной композиции слов и фраз в предложении и изучения эффекта композиции при обнаружении настроений принципиальным и эффективным способом. Набор данных банка деревьев отражает тонкости языковых явлений; все модели показывают существенное улучшение своих характеристик при обучении на этом новом наборе данных. Однако следует отметить, что поскольку RNTN требует, чтобы было построено дерево синтаксического анализа входных предложений; модель может не работать хорошо в случаях плохих грамматических конструкций, таких как диалоги в чат-ботах или твиты.Другим интересным случаем было бы наблюдать влияние предварительно обученных встраиваний слов, таких как word2vec, glove, fasttext, на всю производительность модели вместо изучения встраивания векторов слов в качестве параметров во время обучения.
Ссылки
Ричард Сохер, Алекс Перелыгин, Джин Ву, Джейсон Чуанг, Кристофер Д. Мэннинг, Эндрю И Нг и Кристофер Поттс. 2013. Рекурсивные глубокие модели семантической композиционности на банке дерева настроений. В материалах конференции 2013 г. по эмпирическим методам обработки естественного языка, страницы 1631–1642.
Основные части речи — грамматика
Существительное
Название чего-либо, например человека, животного, места, предмета или концепции. Существительные обычно используются как подлежащие, объекты, объекты предлогов и модификаторы других существительных.
Мэгги написала диссертацию .
диссертация = объект
Автор представил результаты в главе 4 .
в главе 4 = объект предлога
Его исследования находки могут способствовать социальным изменениям.
Глагол
Это выражает то, что делает человек, животное, место, вещь или концепция. В английском языке после существительного идут глаголы.
Это требует большой самоотдачи, чтобы получить докторскую степень.
Она училась усердно для теста.
Написание диссертации — это сложно. (Глагол «быть» также иногда называют связкой или связывающим глаголом. Он связывает подлежащее, в данном случае «написание диссертации», с дополнением или предикатом предложения, в данном случае «жестко». «)
Прилагательное
Это описание существительного или местоимения. Прилагательные обычно ставятся перед существительным или после глагола состояния, например, глагол «быть».
прилежная студентка досрочно выполнила задание.
Diligent описывает студента и стоит перед существительным student .
Может быть сложно сбалансировать время на учебу и рабочие обязанности.
Сложный ставится после , чтобы быть глаголом и описывает, как это уравновешивать время.
Помните, что прилагательные в английском языке не имеют формы множественного числа.Одна и та же форма прилагательного используется для существительных как единственного, так и множественного числа.
A разные идея
Некоторые разные идеи
НЕПРАВИЛЬНО: некоторые отличаются идей
Наречие
Это дает больше информации о глаголе и о том, как было выполнено действие. Наречия говорят, как, где, когда, почему и т. Д. В зависимости от контекста наречие может стоять до или после глагола, а также в начале или в конце предложения.
Закончил курс с энтузиазмом .
С энтузиазмом описывает, как он прошел курс, и отвечает на вопрос как, .
Стивен недавно поступил на программу «Сертификат выпускника в области коммуникации» в Уолдене.
Недавно изменяет глагол enroll и отвечает на , когда вопрос .
Затем Я подтвердил, что большинство моих источников прошли рецензирование.
Затем описывает и изменяет все предложение. См. Эту ссылку на переходы для получения дополнительных примеров конъюнктивных наречий (наречий, которые соединяют одну идею с другой для улучшения связности письма).
Местоимение
Это слово заменяет существительное или существительную фразу (например, это, она, он, они, то, те,…).
Смит (2014) опросил заявителей: они прибыли.
He интересовались идеями , которые ранее никогда не регистрировались , а не теми , которые уже были опубликованы.
He = Смит; , что = идеи; те = те идеи
Определитель
Это слово делает ссылку на существительное более конкретным (напр.грамм. his, her, my, their, the, a, an, this, this, … ).
Джонс опубликовала свою книгу в 2015 году.
Книга пользовалась большой популярностью.
Предлог
Это слово стоит перед существительным или существительной фразой и связывает их с другими частями предложения. Обычно это отдельные слова (например, on, at, by ,… ), но могут быть до четырех слов (например, as far, in addition to, as…).
Я выбрал для собеседования учителей в ближайшем ко мне районе.
Диктофон был помещен рядом с интервьюируемым.
Я остановил запись в середине интервью из-за разряда батареи.
Соединение
Слово, объединяющее два предложения. Они могут быть координирующими (простой способ запомнить это — запомнить FANBOYS = для, и, ни, но, или, все же, так) или подчиненными (например.г., потому что, хотя, когда,…).
Результаты не были значимыми, поэтому альтернативная гипотеза была принята.
Хотя результаты кажутся многообещающими, необходимо провести дополнительные исследования в этой области.
Вспомогательные глаголы
Глаголы помощи. Они используются для построения полных глаголов.
Основные вспомогательные глаголы (быть, иметь, делать) показывают прогрессивные, пассивные, совершенные и отрицательные времена глаголов.
Модальные вспомогательные глаголы (can, could, may, might, must, should, should, will, would) имеют множество значений. Они представляют способности, разрешение, необходимость и степень уверенности. За ними всегда следует простая форма глагола.
Полумодальные вспомогательные глаголы (например, be going to, should to, must to, would better, used to, be could to,…). За ними всегда следует простая форма глагола.
Исследователи исследовали эту проблему в течение некоторого времени.Однако причина проблемы не была определена .
первичное: исследовали = настоящее совершенное время; не определен = пассивная, идеальная, отрицательная форма
He мог бы провести еще исследования, которые могут привести к ответу.
Модальное окно может показывает способности, а глагол проводить остается в своей простой форме; модальное окно может показывает степень достоверности, а глагол вести остается в своей простой форме.
Будущие исследователи собираются углубиться еще в эту тему. Они приближаются к , делают прорывным открытием.
За этими полумодальными формами следует простая форма глагола.
Мирьям де Лонё
Мои исследовательские интересы сосредоточены вокруг трех основных тем в области ИИ и языка: синтаксис
парсинг , типология и интерпретируемость .Я считаю синтаксический синтаксический анализ увлекательной областью, потому что он позволяет исследовать
интересные языковые явления при работе над системой, которая является центральной для НЛП и полезна для многих
Приложения. Я считаю важным разработать модели, которые работают для типологически разнообразных языков, и нахожу
Интересно изучить взаимодействие языковых технологий и типологии. Я наконец считаю это важным
выйти за рамки построения моделей, которые функционируют как черный ящик, и рассуждать о том, что они изучают, и
Зачем. Я объединил все эти интересы в своей докторской диссертации, где исследовал лингвистически обоснованные модели синтаксического анализа для типологически различных языков.Моя докторская диссертация доступна здесь.
Журнальные статьи
Мирьям де Лоно , Сара Стимн и Йоаким Нивр. 2020. Что должны / делать / могут LSTM учиться при синтаксическом анализе конструкций вспомогательных глаголов? Принято Журналом компьютерной лингвистики. [pdf | код]
Материалы конференции
Даниэль Хершкович, Натан Шнайдер, Дотан Двир, Якоб Прейндж, Мирьям де Лоно, , и Омри Абенд.2020. Сравнение путем преобразования: обратная инженерия UCCA из синтаксиса и лексической семантики. Принято в COLING.
Даниэль Гершкович, Мирьям де Лоно , Артур Кульмизев, Эльхам Пейхан и
Joakim Nivre. 2020. Копсала: анализ графов на основе переходов посредством эффективного обучения
и эффективное кодирование. В Proc. общей задачи по синтаксическому анализу IWPT 2020
в расширенные универсальные зависимости.
Artur Kulmizev, Miryam de Lhoneux , Johannes Gontrum, Elena Fano и Joakim Nivre.2019. Глубоко контекстуализированные вложения слов в переходных и
Анализ зависимостей на основе графов — новый взгляд на два парсера. Труды конференции 2019 года по эмпирическим методам обработки естественного языка
и 9-я Международная совместная конференция по обработке естественного языка. [pdf | нагрудник]
Мирьям де Лонё , Мигель Бальестерос и Жоаким Нивр. 2019. Рекурсивная композиция поддеревьев при анализе зависимостей на основе LSTM. Труды NAACL. [pdf | нагрудник | код | слайды | видео | live-tweet 1,2,3,4]
Мириам де Лоно , Йоханнес Бьерва, Изабель Огенштейн и Андерс Согаард. 2018. Совместное использование параметров парсерами зависимостей для родственных языков. Труды конференции 2018 года по эмпирическим методам обработки естественного языка. [pdf | нагрудник | плакат | код]
Аарон Смит, Мириам де Лоно, , Сара Стимн и Жоаким Нивр. 2018.Исследование взаимодействий между предварительно обученными встраиваемыми словами, моделями символов и тегами POS при синтаксическом анализе зависимостей. Труды конференции 2018 года по эмпирическим методам обработки естественного языка. [pdf | нагрудник]
Андерс Согаард, Мириам де Лоно и Изабель Огенштейн. 2018. Кошмар во время тестирования: как знаки препинания не позволяют синтаксическим анализаторам делать обобщения. Труды семинара EMNLP 2018 BlackboxNLP: Анализ и интерпретация нейронных сетей для NLP. [pdf | нагрудник]
Аарон Смит, Бернд Бонет, Мириам де Лоно, , Жоаким Нивр, Ян Шао и Сара Стимн. 2018. 82 Treebanks, 34 Models: Universal Dependency Parsing with Cross-Treebank Models. В Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. [pdf | нагрудник]
Сара Стимн, Мириам де Лоно, , Аарон Смит и Жоаким Нивр. 2018. Обучение синтаксического анализатора с гетерогенными деревьями. Труды 56-го ежегодного собрания Ассоциации компьютерной лингвистики (краткие статьи). [pdf | нагрудник | плакат]
Мирьям де Лоно , Сара Стимн и Йоаким Нивр. 2017. Arc-Hybrid Непроективный анализ зависимостей с помощью статико-динамического Oracle. В Proceedings of the 15th International Conference on Parsing Technologies, pages 99-104, Association for Computational Linguistics. [pdf | нагрудник | код | слайды]
Мирьям де Лоно , Ян Шао, Али Басират, Элиягу Кипервассер, Сара Стимн, Йоав Голдберг и Йоаким Нивр.2017. От исходного текста до универсальных зависимостей — смотрите, без тегов! В Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Ассоциация компьютерной лингвистики. [pdf | нагрудник | код | плакат]
Мирьям де Лоно , Сара Стимн и Йоаким Нивр. Старая школа против новой: сравнение парсеров на основе переходов с улучшением нейронной сети и без нее. В Proceedings of the 15th Treebanks and Linguistic Theories Workshop (TLT), pages 99-110, 2017. [pdf | нагрудник | слайды | приложение (неофициально) ]
Miryam de Lhoneux и Joakim Nivre. Должен был, мог бы, мог бы. Исследование представлений группы глаголов для синтаксического анализа с универсальными зависимостями. 2016. В материалах семинара по многоязычным и кросслингвальным методам в НЛП, страницы 10-19. [pdf | нагрудник | код | плакат] (приз за лучший плакат)
Книжная глава
Мириам де Лоно , Омри Абенд и Марк Стидман.2019. Исследование влияния автоматического распознавания MWE на анализ CCG. В Яннике Парментье и Якубе Ващуке (ред.). Представление и анализ многословных выражений: современные тенденции , 183-215. Берлин: Language Science Press. [html-страница книги | pdf-глава]
Тезисов
Мирьям де Лонё . Анализ лингвистически обоснованной нейронной зависимости для типологически разнообразных языков. 2019. Кандидатская диссертация. Уппсальский университет.[официальная версия | pdf с перекрестными ссылками | нагрудник]
Мирьям де Лонё . Анализ CCG и многословные выражения. 2014. Магистерская диссертация. Эдинбургский университет. [pdf | нагрудник | код]
Мирьям де Лонё . На пути к систематическому контрастному конструктивному подходу к результирующему построению: исследовательское исследование на английском и французском языках. 2013. Магистерская диссертация, Католический университет Лувена.
Неархивный (рецензируемый) материал
Али Басират, Мириам де Лоно , Артур Кульмизев, Муратан Курфали, Йоаким Нивре и Роберт Остлинг.2019. Разбор полиглотов для тысячи и одного языка (и некоторых). Первый семинар по типологии для полиглота НЛП. [pdf | плакат]
Мирьям де Лонё . Совместное использование параметров при разборе многоязычных зависимостей. 2018. Представлен на седьмой конференции по шведским языкам, (SLTC). [слайды]
Joakim Nivre, Miryam de Lhoneux , Аарон Смит и Сара Стимн. Универсальный анализ зависимостей в Упсальском университете.2018. Представлен на седьмой конференции по шведским языкам, (SLTC).
Miryam de Lhoneux и Joakim Nivre. Выборка UD Treebank для сравнительной оценки парсеров. 2016. Представлено на Шестой конференции по шведским языкам (SLTC), . Примечание: Существует публичный реферат, который не архивируется. Материал, представленный в аннотации, был позже опубликован в нашей статье TLT 2017 (см. Ссылку выше).
Мирьям де Лонё . Анализ CCG и многословные выражения. Плакат представлен на 4-м общем собрании PARSEME. Валлетта, Мальта. 2015. [плакат | аннотация]
Приглашенные переговоры
Анализ типологически разнообразных языков. Мастерская на деревьях и лингвистике
Теории (TLT), 27 октября 2020 г. [видео | слайды]
Нужна ли нам рекурсивная композиция поддерева при синтаксическом анализе зависимостей? Приглашенный доклад на семинаре по подходам к синтаксическому анализу и семантической композиции, основанным на данных, Тюбинген, 10 декабря 2019 г.[слайды]
Intel Quartus Prime Standard Edition Руководство пользователя: Platform Designer
В межсоединении Platform Designer используется пакетный адаптер с отображением памяти для
приспособить пакетные возможности каждого интерфейса в системе, включая
интерфейсы, не поддерживающие пакетную передачу.
Максимальная длина пакета для каждого интерфейса является свойством интерфейса и
не зависит от других интерфейсов в системе.Следовательно, конкретный мастер может быть
способен инициировать пакет длиннее, чем максимальная поддерживаемая длина пакета ведомым устройством. В
в этом случае адаптер пакетов преобразует большой основной пакет в пакеты меньшего размера, или
в отдельные ведомые передачи, если ведомое устройство не поддерживает разбиение. Пока мастер
завершает пакет, логика арбитра предотвращает доступ других мастеров к цели
раб. Например, если мастер инициирует пакет из 16 передач подчиненному с
максимальная длина пакета 8, адаптер пакета инициирует 2 пакета длиной 8 в
раб.
Пакетные транзакции Avalon ® -MM и AXI позволяют мастеру
бесперебойный доступ к ведомому устройству на указанное количество передач. Хозяин
указывает количество передач при инициировании пакета. Однажды всплеск
начинается между ведущим и ведомым, логика арбитра заблокирована до пакетного
завершает. Для мастеров пакетов длина пакета — это количество циклов.
что мастер имеет доступ к подчиненному, и выбранный арбитраж разделяет
не имеют никакого эффекта.
Примечание. Мастера AXI могут выдавать пакеты, которые
Avalon ® не принимает, т.к.
Например, фиксированные всплески. В этом случае адаптер пакета преобразует фиксированный пакет
в последовательность транзакций по одному и тому же адресу.
Примечание: Для
AMBA * 4 ведомых устройства AXI, конструктор платформ позволяет использовать 256-битные INCR всплесков. Вы должны убедиться, что 256-битное
узкий INCR Пакеты сокращены до 16-битного узкого INCR
всплески для
AMBA * 3 ведомых устройства AXI.
Мастера Avalon ® -MM всегда выдают адреса, соответствующие размеру
перевод. Однако, когда Platform Designer использует адаптацию ширины от узкого до широкого, результирующий адрес может быть невыровненным. Для невыровненных
адресов, пакетный адаптер выдает пакеты максимального размера с
соответствующий байт разрешает. Это доводит текущий пакет до выровненного ведомого устройства.
адрес. Затем он завершает пакет по выровненным адресам.
Адаптер пакетной передачи поддерживает типы переменного или последовательного пакета для
приспособить различные свойства мастеров с отображением в память. Некоторые лопаются
мастера могут выдавать пакеты более одного типа.
Пакетная адаптация доступна для
Авалон ® в
Авалон ® ,
Avalon ® в AXI и AXI в Avalon ® и соединения AXI с AXI.Для получения информации об адаптации AXI-to-AXI см.
к Адаптация от широкого к узкому проходу AXI
Примечание: Для
AMBA * 4 AXI в
AMBA * 3 AXI соединений, Platform Designer следует
AMBA * 4 Длина пакета AXI 256
к
AMBA * 3 Длина пакета AXI 16.
Обзоры моделирования тем python
Обзоры тематического моделирования python Большинство этих тем обсуждаются в двух главах, одна из которых посвящена вычислительному моделированию. Spleeter — это библиотека разделения исходного кода Deezer с предварительно обученными моделями, написанными на Python и использующими Tensorflow.Прежде чем я начну установку NLTK, я предполагаю, что вы знаете некоторые основы Python, чтобы начать работу. Машинное обучение A – Z ™ на Udemy — это впечатляюще подробное предложение, которое предоставляет инструкции как по Python, так и по R, что редко и нельзя сказать ни о каком из других лучших курсов. Тематическое моделирование исследовательской работы — это […] Тематическое моделирование — это алгоритм машинного обучения без учителя для обнаружения «тем» в коллекции документов. Мы будем использовать Python 2. b. В частности, мы рассмотрим скрытое распределение Дирихле (LDA): широко используемый метод тематического моделирования.Это программный пакет нового варианта тематического моделирования скрытого распределения Дирихле (LDA), Red-LDA, который включает в себя моделирование структурным уравнением (SEM) — многомерный статистический метод для оценки сложных отношений между наблюдаемыми и скрытыми переменными. digits + ‘_’ Python Начните работу с объектно-ориентированным программированием, просмотрев наши руководства по Python. Например, в модели с двумя темами мы могли бы сказать: «Документ 1 — это 90% тема A и 10% тема B, а документ 2 — 30% тема A и 70% тема B.UFF API находится в uff / uff. И пока мы обсуждаем тему ORM, стоит упомянуть, что вам следует взглянуть на SQLAlchemy, очень популярную и широко используемую библиотеку ORM в Python. Обработка естественного языка или NLP — это компонент ИИ, связанный с взаимодействием человеческого языка и компьютеров. Эта глава научит вас работать с Python, от его загрузки до написания простых программ. Эта книга — ваше руководство по началу работы с прогнозной аналитикой с использованием Python.Затем нам также необходимо сохранить обученную модель, чтобы она могла делать прогнозы с использованием векторов весов. 7, 3. Как и в случае кластеризации, количество тем, как и количество кластеров, является гиперпараметром. Он был создан Гвидо ван Россумом и выпущен в 1991 году. Com, Aido, Cubic, Jibo, Maluuba, Mycroft — одни из лучших интеллектуальных персональных помощников или автоматизированных персональных помощников в произвольном порядке. Группы новостей — это дискуссионные группы в сети Usenet, которая была популярна в 80-х и 90-х годах.Инструментарий естественного языка¶. Обратите внимание, что код не делает никаких предположений о ключах маршрутизации или привязки, вы можете поиграть с более чем двумя параметрами ключа маршрутизации. Этот экзамен проверяет знания кандидата о внедрении и эксплуатации основных технологий безопасности, включая сетевую безопасность, облачную безопасность и контент. Вы можете использовать NLTK на Python 2. 1 Установка Python Go toww. Помимо собственных методов обработки строк в Python, NLTK предоставляет nltk. Давайте создадим экземпляр KMeans. 4 и 3.Истоки уносят нас во времени в Кюнигсберг 18 века. Проекты Python и машинного обучения (ML) за 20–250 фунтов стерлингов. Как мы видим, тематическая модель — это метод извлечения темы из документа. Его основное внимание уделяется приложениям в области нанофотоники, например, микроструктурам с масштабом длины волны (например, фотонно-кристаллические устройства), лазерам (например, поверхностным излучающим лазерам с вертикальным резонатором), светоизлучающим диодам (например, светодиодам с резонансными резонаторами). Важные вопросы для класса 12. Компьютерные науки (Python) — Обзор Python ТЕМА-1 Основы Python Очень короткие вопросы типа ответа (1 балл) Вопрос 1.Каждое упражнение сопровождается небольшим обсуждением темы и ссылкой на решение. Наш расчет тематического моделирования показал, что 108 было оптимальным количеством тем при измерении логарифмической вероятности. BDFL Python. На странице «Пространство имен служебной шины» выберите «Темы» в меню слева. NLTK — это фреймворк, который широко используется для моделирования тем и классификации текста. Python может делать все, что вы хотите. Модель. ctr: Совместное моделирование для рекомендации: C ++: C. Мы углубляемся в популярные пакеты и разработчиков программного обеспечения, специалистов по данным и невероятных любителей, делающих удивительные вещи с Python.Тематическое моделирование предоставляет нам методы для организации, понимания и обобщения больших наборов текстовой информации. Сравнивая количество статей за каждый день и развитие вспышки, мы отметили, что сообщения средств массовой информации в Китае отставали от развития COVID-19. Этот курс следует пройти после: Введение в науку о данных в Python, прикладное построение графиков, диаграммы и представление данных в Python и прикладное машинное обучение в Python. бессмысленная, большая часть отзывов попадает в диапазон 3.BERT, опубликованный Google, — это новый способ получения предварительно обученной языковой модели представления слов. С помощью sklearn сделать это на самом деле просто. Он используется для: веб-разработки (на стороне сервера), разработки программного обеспечения, математики, системных сценариев. В этом курсе мы будем изучать базовый Python до среднего уровня. Существуют различные языки программирования, но мы используем Python, поскольку специалисты по данным в больших масштабах используют его. Более строгий надзор приведет к более глубокому пониманию по мере развития возможностей алгоритмической автономии.Реальный вывод с lDa. Слева показаны предполагаемые пропорции тем для примера статьи на рисунке 1. Как установить цену для барьерного варианта в рамках локальной модели объема с использованием QuantLib Я использую QuantLib в Python. Вот список идей проектов, основанных на биоинформатике. Тематическое моделирование с помощью Sklearn¶ Для моделирования тем в sklearn я использую встроенный набор данных, набор данных 20 групп новостей. Этот курс следует пройти после: Введение в науку о данных в Python, прикладное построение графиков, диаграммы и представление данных в Python и прикладное машинное обучение в Python.В реализации ml используется алгоритм максимизации ожидания для создания модели максимального правдоподобия с учетом набора выборок. lda2vec расширяет модель word2vec, описанную Mikolov et al. Gensim был разработан и поддерживается чешским исследователем обработки естественного языка Радимом Жегуржеком и его компанией RaRe Technologies. Хотя токенизация сама по себе является более важной темой (и, вероятно, одним из шагов, которые вы предпримете при создании собственного корпуса), этот токенизатор действительно хорошо предоставляет простые списки слов.Чтобы оценить производительность модели классификации, такой как та, которую вы только что обучили, вы можете использовать такие показатели, как матрица неточностей, мера F1 и точность. Как только модель будет запущена, она готова назначить темы для любого документа. Цель этого проекта — получить встраивание токена из предварительно обученной модели BERT. Анализ данных с помощью pandas 10. Python; GUI Tk / Alarm 1: Анимация 3: Назад Передний план 1: Звуковой сигнал 1: Граница 7: Кнопка 32: Холст 8: CheckBox Gensim — это хорошо оптимизированная библиотека для моделирования тем и анализа сходства документов.Логотипы университета и компании являются собственностью уважаемых владельцев. Искра. Однако проблема состоит в том, как извлечь хорошее качество тем, которые будут ясными, разделенными и значимыми. Мы подробно изучим Spacy, а также изучим использование НЛП в реальной жизни. Внедрение и эксплуатация основных технологий безопасности Cisco v1. Эти две категории дают хорошее общее представление о тематическом моделировании. Созданный Гвидо ван Россумом и впервые выпущенный в 1991 году, Python имеет философию дизайна, которая подчеркивает удобочитаемость кода, особенно с использованием значительных пробелов.Обработка естественного языка с помощью Python; Пример анализа настроений. Классификация выполняется в несколько этапов: обучение вычислительному моделированию и визуализация физических систем с помощью книги Python. Таким образом, текст представляет собой смесь всех тем, каждая из которых имеет определенный вес. Вот как вы это делаете: Gensim — это библиотека Python для моделирования тем, индексации документов и поиска сходства с большими корпусами. Получите данные здесь. Наконец, вы построили модель, чтобы связать твиты с определенным настроением.питон. io сайт. Изучите методы машинного обучения в анализе настроений. Нейронная сеть учится говорить, как Майкл Скотт. Предварительная обработка текстовых данных. Теперь текст обзора готов для высокоуровневого моделирования. Его алгоритмы тематического моделирования, такие как его реализация Latent Dirichlet Allocation (LDA), являются лучшими в своем классе. Изучите впечатляющую экосистему машинного обучения Python. in. com служат образцами документов или решений для студентов или профессионалов и не должны быть отправлены в другие учебные заведения.Затем выбирается первое предложение для обзоров. Если список содержит числа, не заключайте их в кавычки. Вот пример применения тематического моделирования к обзорам пива: входные данные — обзоры различных сортов пива; Тема — это набор похожих слов, таких как кофе, темный, шоколадный, черный, эспрессо; Каждому обзору присваивается список тем. Это ключ к пониманию сути информатики. Вы используете обучающий набор для обучения и оценки модели на этапе разработки.Язык предоставляет конструкции, предназначенные для включения четких программ в ARGB MID TOWER CASE Высокопроизводительный корпус Mid Tower с полностью закаленным стеклом передней и боковых панелей, чтобы продемонстрировать внутреннюю часть вашей установки. Это курс, по которому оцениваются все остальные курсы машинного обучения. Python это. Справа приведены 15 самых частых слов из наиболее часто встречающихся тем в этой статье. Выбор правильных гиперпараметров для моделей машинного обучения или глубокого обучения — один из лучших способов выжать из ваших моделей последний сок.Ядро языка Python II 5. Для новых ключевых слов, которые похожи на темы, но могут появиться в будущем, не идентифицируются. Это очень популярная модель для такого рода задач, и алгоритм, лежащий в основе ее, довольно прост для понимания и использования. Общее научное программирование Приложение A. Тема 0: как знать, люди думают, хорошо провести время, спасибо Тема 1: спасибо Windows card drive mail file advance Тема 2: игра команда год игры сезон игроки хорошие Тема 3: диск scsi диск проблемы с жесткими картами Тема 4: windows файловое окно файлы программы, использующие проблему Тема 5: правительственный чип, данные для шифрования информации о почтовом пространстве Тема 6: как велосипед знать Тематическое моделирование.В наборе данных общее количество обзоров автомобилей включает примерно 42 230, а общее количество отзывов об отелях — примерно 259 000. Кроме того, программирование на Python становится все более актуальным для автоматизации тестирования. 7 | Сбор SMS-спама Другими словами, в целом наша модель правильно определила настроение комментария в 94,1% случаев. В этой статье я покажу вам некоторые из лучших способов настройки гиперпараметров, которые доступны сегодня (в 2021 году). Вентиляторами с адресуемой RGB-подсветкой можно управлять одним из двух способов: кнопкой управления светодиодом RGB или материнской платой с адресуемой RGB-подсветкой.Анализ настроений, встраивание слов и моделирование тем в обзорах Venom. Это упрощает обучение моделей разделения источников музыки (при условии, что у вас есть набор данных с изолированными источниками) и предоставляет уже обученные современные модели для выполнения различных вариантов разделения. 5 и очень мало отзывов ниже или выше. Узнайте, какую модель машинного обучения выбрать для конкретной бизнес-задачи, работая над несколькими проектами. 6% времени. Когда вы новичок в области разработки программного обеспечения, может быть сложно найти проекты НЛП, которые соответствуют вашим потребностям в обучении.Смотрите полный список на stackabuse. Он дает студентам навыки. Специалист по анализу данных — одна из самых популярных профессий. Например, четыре. Несмотря на то, что существует множество отличных вводных курсов по Python, в большинстве случаев они недостаточно глубоки, чтобы вы могли применить свои навыки Python в исследовательских проектах. Питон Северной бухты. Это есть, но я никогда не использовал его сам, и он использует MCMC, поэтому, вероятно, будет непомерно медленным для больших наборов данных. 8: До Python 3. Машинное обучение, интеллектуальный анализ текста. Моделирование тем в виде взвешенных списков слов — это простое приближение, но очень интуитивный подход, если вам нужно его интерпретировать.IPython и Jupyter Notebook 6. Я провел некоторую первоначальную очистку (пример 5 на момент написания этой статьи). Самые популярные темы проектов Python для разработки программного обеспечения. SimPy — основанная на процессах среда моделирования дискретных событий. Многие задачи НЛП можно использовать с помощью BERT для получения SOTA. Вторая категория, статья рассмотрит несколько важных тематических моделей. Для человека найти тему текста действительно легко. Также IPython и Idle. Узнайте, как выполнять такие функции, как удаление вершин, нормалей и заливки. «Генетика» геном человека ДНК генетические гены последовательность ген Тематическое моделирование работает снизу вверх, так как пытается придумать набор тем, которые могли бы сгенерировать данные документы.NumPy 7. Успешная алгоритмическая торговля обновлена для Python 2. Первый предоставляется, если вы хотите выполнить дополнительную обработку. head () Вывод: комментарии здесь ссылаются на другой ответ SO, который ссылается на статью. Gensim — библиотека Python для моделирования тем, индексации документов и поиска сходства с большими корпусами. Поэтому перед построением модели разделите данные на две части: обучающий набор и тестовый набор. Итак, давайте углубимся. Keras — это библиотека Python, которая упрощает создание моделей глубокого обучения по сравнению с относительно низкоуровневым интерфейсом Tensorflow API.Обзор: Хорошее резюме, и новые инструменты и методы подобраны! Настоятельно рекомендую. Более 300 видеоуроков по 6 курсам моделирования, которые проводят элитные практики из ведущих инвестиционных банков и фондов прямых инвестиций — Моделирование в Excel — Моделирование финансовой отчетности — Моделирование слияний и поглощений — Моделирование LBO — DCF и моделирование оценки — ВСЕ ВКЛЮЧЕНО + 2 Огромные бонусы. Эти категории могут быть определены пользователем (положительные, отрицательные) или какими угодно классами. Добро пожаловать в практику Python! Есть более 30 упражнений на Python для начинающих, которые только и ждут своего решения.in — Buy Книга «Глубокое прогнозирование временных рядов с помощью Python: интуитивное введение в глубокое обучение для прикладного моделирования временных рядов» по лучшим ценам в Индии на Amazon. Введение в вычисления и программирование с использованием Python. В нем есть набор пакетов для прогнозного моделирования и набор IDE на выбор. Линейные модели, дерево решений, k-NN Понять тематическое моделирование. Тематическое моделирование, определения. В этом руководстве вы познакомились с базовой моделью анализа настроений с использованием библиотеки nltk в Python 3.Теперь давайте загрузим данные в python как DataFrame pandas и распечатаем его информацию вместе с несколькими строками, чтобы получить представление о данных df = pd. III. Моя единственная проблема с книгой — это освещение, в ней относительно мало тем. Связанные курсы. Этот набор данных широко используется в тестах для анализа настроений, что делает его удобным способом оценки нашей собственной производительности по сравнению с существующими моделями. Модельное обучение. Многовариантный подход к рекламным обзорам фильмов. Это также про Python, наряду с изучением алгоритмов и структур данных.импортировать строку alpha = string. Python занимает третье место в августе 2020 года по индексу сообщества программистов TIOBE, показателю популярности языков программирования, и является лучшим интерпретируемым языком. Простой анализ текста с использованием Python — идентификация именованных объектов, теги, сопоставление нечетких строк и моделирование темы Обработка текста — это не совсем мое дело, но вот краткий обзор некоторых основных рецептов, которые позволят вам начать работу с некоторыми быстрыми действиями. уловки для идентификации именованных сущностей в документе и маркировки сущностей в документах.Затем вы визуализировали часто встречающиеся элементы данных. Такой подход дает вам представление о производительности и надежности модели. Во-первых, мы удалим все слова, встречающиеся менее чем в 1% отзывов. В состав Python API входит UFF API; пакет, содержащий набор утилит для преобразования обученных моделей из различных фреймворков в общий формат. Курс Simplilearn Data Science в Эшберне, разработанный совместно с IBM, побуждает вас овладеть навыками, включая статистику, проверку гипотез, интеллектуальный анализ данных, кластеризацию, деревья решений, линейную и логистическую регрессию, обработку данных, визуализацию данных, модели регрессии. Hadoop Django предоставляет мощную форму. библиотека, которая обрабатывает формы отрисовки как HTML, проверяет данные, отправленные пользователем, и преобразует эти данные в собственные типы Python.Научиться предсказывать, кто выиграет, проиграет, купит, солгает или умрет, с помощью Python — необходимый набор навыков в наш век данных. Сначала мы импортируем библиотеки. 00 и лекции курса параллельны друг другу, хотя в книге есть более подробные сведения по некоторым темам. Шпаргалки могут быть очень полезны, когда вы пытаетесь выполнить комплекс упражнений, связанных с определенной темой, или работаете над проектом. Теперь у нас есть матрица характеристик, которую мы можем передать модели для обучения. Пройдите реальные курсы программирования Python в Гарварде, Массачусетском технологическом институте и других ведущих университетах мира.Как правило, каждая модель отображается в одну таблицу базы данных. Реализация LDA на Python. Установите NLTK. Фактически, есть полезные способы лучше понять концепции тематического моделирования. Я бы использовал Latent Dirichlet Allocation (LDA) для моделирования тем, есть простые в использовании библиотеки для Python, R, Java. Если вы используете Windows, Linux или Mac, вы можете установить NLTK с помощью pip: $ pip install nltk. Первый называется pandas, это библиотека с открытым исходным кодом, предоставляющая простые в использовании структуры данных и функции анализа для Python.Тематическое моделирование легко сравнить с кластеризацией. Этот курс охватывает основы НЛП для продвижения таких тем, как word2vec, GloVe, глубокое обучение для НЛП, таких как CNN, ANN и LSTM. Простые реальные данные для этой демонстрации получены из корпуса обзоров фильмов, предоставленного nltk (Pang & Lee, 2004). 16. Сэмплер Гиббса LDA с учетом избыточности. Прежде чем мы начнем с фактических реализаций графов в Python и прежде чем мы начнем с введения модулей Python, имеющих дело с графами, мы хотим посвятить себя истокам теории графов.Обзор — отличное введение в Python, охватывающее ряд различных областей / приложений. Мы называем темы скрытыми, потому что они нам неизвестны, отсюда и необходимость в алгоритме для выявления этих скрытых тем. С помощью SageMaker ученые и разработчики данных могут быстро и легко создавать и обучать модели машинного обучения, а затем напрямую развертывать их в готовой к работе размещенной среде. Эта книга знакомит студентов с небольшим опытом программирования или без него с искусством решения вычислительных задач с использованием Python и различных библиотек Python, включая PyLab.Резюме — 15 основных вопросов и ответов о Python для опытных. Алгоритмы тематического моделирования используют информацию в самих текстах для создания тем; они не назначаются заранее. Выполнение сценариев Веб-сайт Python предоставляет указатель пакетов Python (также известный как Cheese Shop, ссылка на сценарий Monty Python с таким именем). Для общего введения в тематическое моделирование см., Например, «Вероятностные тематические модели» Стейверса и Гриффитса (2007). Целевая аудитория — сообщество разработчиков естественного языка (NLP) и поиска информации (IR).PythonForBeginners. В этом разделе мы будем «Проекты и темы НЛП». Это руководство неформально знакомит читателя с основными концепциями и функциями языка и системы Python. Логистическая регрессия — это контролируемая классификация — это уникальные алгоритмы машинного обучения в Python, которые находят свое применение при оценке дискретных значений, таких как 0/1, да / нет и истина / ложь. Обычно вы назначаете имя списку Python с помощью знака =, как и в случае с переменными. Моделирование тем с учетом избыточности Копирование и вставка Избыточность или дублирование данных распространены во многих корпорациях.Стандартный способ — разделить (60, 20, 20)% для обучающих, тестовых и проверочных наборов соответственно. «Каждая тема — это смесь слов. Я определил процентную оценку темы как процент отзывов, которые дали положительный комментарий, когда упоминали эту тему (аналогично Rotten Tomatoes). Talk Python to Me — это еженедельный подкаст, который ведет разработчик и предприниматель Майкл Кеннеди. Тематическое моделирование в Python с использованием библиотеки Gensim. Интерпретация тем, которые ваши модели находят, имеет гораздо большее значение, чем одна версия, обнаруживающая более высокую загрузку темы для некоторого слова на 0.Обычный Python от SciPy также принимает рекурсию функций, что означает, что определенная функция может вызывать сама себя. Тематическое моделирование — это часто используемый инструмент интеллектуального анализа текста для обнаружения скрытых семантических структур в теле текста. модели. Корпус представлен в виде матрицы терминов документа, которая в целом очень разреженная по своей природе. ldaseqmodel — динамическое моделирование тем в Python; модели. com Очистить обзоры о приложении Amazon Shopping в Google CH Play и выполнить тематическое моделирование от LDA (скрытое распределение Дирихле) с использованием Python python обработка естественного языка анализ настроений веб-парсинг lda review-mining тематическое моделирование Мы используем файлы cookie на Kaggle для доставки наши услуги, анализируйте веб-трафик и повышайте удобство использования сайта.АННОТАЦИЯ: Безопасность данных является основной проблемой в различных типах приложений, от хранения данных в облаках до отправки сообщений с помощью чата. Есть много методов, которые используются для […] Подходы к тематическому моделированию определяют темы на основе ключевых слов, присутствующих в содержании. Целевая аудитория — сообщество разработчиков естественного языка (NLP) и поиска информации (IR). Ознакомьтесь с основами Python, включая синтаксис Python, условные выражения и многое другое. Здесь мы собрали вопросы по таким темам, как списки и кортежи, наследование, многопоточность, важные модули Python, различия между NumPy и SciPy, графический интерфейс Tkinter, Python как ООП и язык функционального программирования, Консультативный совет по количественной аналитике базы данных Flask, специализирующийся на данных. Наука, машинное обучение и количественные финансы.- Кристофер Даниэль Бюлюкс. Поставляется с двумя 20-сантиметровыми вентиляторами с адресуемой RGB-подсветкой спереди и одним 12-сантиметровым вентилятором с адресуемой RGB-подсветкой в задней части корпуса. Теперь давайте запрограммируем TF-IDF на Python с нуля. Мы не будем ссылаться на него в заданиях или в зависимости от него, чтобы скрыть пробелы в лекциях. Оригинальный учебник для 6. Тематические модели — это набор алгоритмов, раскрывающих скрытую тематическую структуру в коллекциях документов. Python также подходит в качестве языка расширения для настраиваемых приложений.Пример тематического моделирования в действии. См. Подробные требования. Подходы тематического моделирования определяют темы на основе ключевых слов, присутствующих в содержании. 4. С более чем 60 графиками, доступными в PyCaret, теперь вы можете мгновенно оценивать и объяснять производительность и результаты модели без необходимости писать сложный код. org и загрузите последнюю версию Python (версия 3. Выполните тематическую модель на основе данных обзора Cornell Movie. Результаты тематических моделей полностью зависят от функций (терминов), присутствующих в корпусе.Логистическая регрессия. twython — Python-оболочка для Twitter API; Пакеты визуализации Темы обсуждения варьируются по всем типам тем Python, от веб-разработки до обработки естественного языка, тестирования и основ Python. В этом руководстве вы узнаете, как построить наилучшую возможную тематическую модель LDA, и узнаете, как продемонстрировать полученные результаты как значимые. В противном случае просто Google для фразы, включая «Этой осенью я прошел курс математического моделирования футбола в Университете Упсалы».Создайте подписки на тему. Надеюсь, это было полезно! Для более детальной проработки конвейера моделирования тем с помощью Spark в Python ознакомьтесь с кодом в этом репозитории. Мы доставляем эти решения через QuSandbox и Qu. Несомненно, Gensim — самый популярный набор инструментов для тематического моделирования. Это порт великолепного пакета R Карсона Сиверта и Кенни Ширли. дб. Изменено в версии 3. Мы изучим простой метод — набор слов, а затем воспользуемся предварительной обработкой. В машинном обучении и обработке естественного языка тематическая модель — это тип статистической модели для обнаружения абстрактных «тем», которые встречаются в сборник документов.Сначала мы можем определить 4 документа в Python как: Если дан обзор фильма или твит, он может быть автоматически классифицирован по категориям. Он разработан, чтобы дать вам полное представление об обработке текста и интеллектуальном анализе с использованием современных алгоритмов НЛП на Python. Смоделированный как дистрибутив Дирихле, LDA строит -. SciPy 9. Построение модели молотка LDA. Допустим, вы хотели сделать минимум, чтобы попытаться заставить эту работу работать. В этом примере для The Kernel Export stout London назначены 4 темы.MALLET — это пакет на основе Java для статистической обработки естественного языка, классификации документов, кластеризации, тематического моделирования, извлечения информации и других приложений машинного обучения в текст. 7. Справочные руководства содержат технические справочники по API и другим аспектам механизмов Django. nmf — Факторизация неотрицательной матрицы; модели. Студенты третьего или последнего курса могут использовать эти проекты как мини-проекты, так и как мегапроекты. Здесь мы будем использовать две библиотеки для этого анализа.Тематическое моделирование новостных статей может дать полезную информацию о значении средств массовой информации для раннего информирования о здоровье. Изучите Python от основ до продвинутых предметов и тем прямо сейчас! Анализ производительности модели Анализ производительности обученной модели машинного обучения — очень важный этап рабочего процесса машинного обучения. Алгоритмы тематического моделирования в Gensim. Мы поместили модель lDa из 100 тем в 17 000 статей из журнала Science. В идеале у вас должна быть IDE, чтобы написать этот бесплатный онлайн-курс по науке о данных, который научит вас моделям регрессии и кластеризации.Лучший код проекта Python для студентов. Они описывают, как это работает и как его использовать, но предполагают, что у вас есть базовое понимание ключевых понятий. Чтобы создать резюме, он просматривает пространство всех возможных резюме, чтобы найти наиболее вероятную последовательность слов для данной статьи. Matplotlib 8. Закройте. Моя первая встреча с ANPR произошла около шести лет назад. Здесь Список последних проектов Python с исходным кодом для изучения разработки приложений. Скачайте RedLDA бесплатно. Вот почему мы опубликовали этот пост в блоге о самых популярных вопросах о Python и ответах на них для опытных инженеров.Кластеры дают нам представление о том, что происходит, поскольку они группируют связанные обзоры вместе, но нам нужно извлекать абстрактные «темы» из обзоров, чтобы мы могли получить больше информации. Это означает, что ускоренный курс Python — Cheat Sheets. Тема для модели документа и; Количество слов по тематической модели; После предоставления алгоритма тематической модели LDA, чтобы получить хорошую композицию распределения тематических ключевых слов, он переупорядочивается — см. Больше: моделирование с использованием Matlab, разработка алгоритма blowfish с использованием pdf, алгоритм шифрования знака с использованием bouncycastle, моделирование темы lda, разница между nmf и lda, nmf vs lda, nmf тематическое моделирование r, nmf моделирование темы python, латентное распределение dirichlet vs k означает, lda vs nmf для тематического моделирования, lda vs тема nmf, обработка данных, python Тематические модели — это методы машинного обучения, которые нацелены на раскрыть скрытые в тексте тематические структуры.csv «) df. info () df. Весна 2013 г. Amazon SageMaker — это полностью управляемая служба машинного обучения. Mille. Функция computeIDF вычисляет оценку IDF для каждого слова в корпусе. Обзор инструментов. До сих пор вы видели встроенный Gensim версия алгоритма LDA. Общие. Она не может служить учебником, поскольку не учитывает математику алгоритма. 4. Эта избыточность отрицательно сказывается на качестве интеллектуального анализа текста и моделирования тем, в частности. Постройте модель речевых тегов .Подход LDA к тематическому моделированию заключается в классификации текста в документе по определенной теме. dtm В этом сообщении блога вы познакомитесь с lda2vec, тематической моделью, опубликованной Крисом Муди в 2016 году. Новые упражнения публикуются ежемесячно, так что заходите почаще или следите за новостями на Feedly, Twitter или в любимой программе чтения RSS. Примеры использования; модели. Преподавателем и создателем этого курса для начинающих является Эндрю Нг, профессор Стэнфордского университета, соучредитель Google Brain, соучредитель Coursera и вице-президент, который расширил команду ИИ Baidu до тысяч ученых.Запрашивайте плагины, сообщайте нам о проблемах, предложениях, размещении на форуме, советах / хитростях на форуме и т. Д. Назовите модули библиотеки Python, которые необходимо импортировать для вызова следующих функций: load () pow () [CBSE Delhi 2016] Ответ: pickle математический вопрос 2. Мы расширяем эту модель с помощью контролируемого компонента настроений, который позволяет с точностью классифицировать отзыв как положительный или отрицательный (раздел 4). Хотя существует множество пакетов SEM, каждый из них имеет ограничения. 4 марта 2019 г. — 3 комментария.8, оператор continue был недопустимым в предложении finally из-за проблемы с реализацией. Тематическое моделирование — отличный вариант для этой задачи, поскольку это неконтролируемый метод, направленный на поиск скрытых тем или тем в коллекции документов. Одним из лучших вариантов для тематического моделирования в Python является Gensim, надежная библиотека, которая предоставляет набор инструментов для реализации LSA, LDA и других алгоритмов тематического моделирования. Как сохранить изображение локально с помощью Python, чей URL-адрес я уже знаю? Ответ: Мы будем использовать следующий код для локального сохранения изображения с URL-адреса. Изучите Python для науки о данных.Назовите модули для […] Важные вопросы по информатике класса 12 (Python), глава — 1 — Обзор Python Python используется в анализе данных, науке о данных, инвестиционном банкинге, машинном обучении, финансовом моделировании. 5–4. Используя контекстные подсказки, тематические модели могут связывать слова со схожим значением и различать использование слов с несколькими значениями. Небольшое взаимодействие между темами 2 и 5 указывает на то, что Echo сравнивали с Google Home и по проблемам с подключением к Wi-Fi.Реализация нейронной сети перцептрона с помощью Python 6 мая 2021 г. Впервые представленный Розенблаттом в 1958 г., Перцептрон: вероятностная модель хранения и организации информации в мозге, возможно, является самым старым и самым простым из алгоритмов ИНС. 9. Среди перечисленных здесь библиотек Python NLP это самая специализированная. 3 марта, 2019 — 5 комментариев. Мы работаем над анализом настроения новостей и моделированием тем с использованием Python и R. Он может обрабатывать большие текстовые корпуса с помощью эффективных потоковых данных и дополнительных алгоритмов, что больше, чем мы можем сказать о других пакетах, предназначенных только для пакетов и в теме LDA. Моделирование. Объяснение реализации с использованием gensim в Python — # NLPRoc tutorial.Тематическая модель — это тип статистической модели для обнаружения абстрактных «тем», встречающихся в коллекции документов. Если вы посетите PyGotham, вы получите много полезных трюков и отличных уроков по языку. в 2013 году с векторами тем и документов и включает идеи как встраивания слов, так и моделей тем. Ниже приведены шаги по реализации LDA в Python. После этого мы увидим, как мы можем использовать sklearn для автоматизации процесса. Это, в сочетании с открытостью и щедрым ограничением скорости API Twitter, может дать впечатляющие результаты.Тем не менее, это ценный инструмент, который можно добавить в свой репертуар. Ресурсы и дальнейшие действия Просмотрите эти 100 основных вопросов и ответов на собеседовании по Python, чтобы получить работу своей мечты в области науки о данных, машинного обучения или программирования на Python. IBM прогнозирует, что к 2020 году спрос на специалистов по данным вырастет на 28%. Нормализованный корпус затем передается в векторизатор частоты термина или векторизатор Tf-idf в зависимости от алгоритма. read_csv («Churn_Modelling. Ван: Реализует вариационный вывод для совместных тематических моделей.Это историческая отсылка к предыдущей модели управления Python, где все полномочия по проектированию в конечном итоге исходили от Гвидо ван Россума, первоначального создателя языка программирования Python. Академия. x Торговый дневник Форекс № 6 — Многодневная торговля и построение графиков результатов Байесовский вывод биномиальной пропорции — Аналитический подход 2. Статистика. Эти алгоритмы помогают нам разрабатывать новые способы поиска. Ниже представлен рабочий процесс высокоуровневого тематического моделирования: 1500 обзоров фильмов отправляются через конвейер НЛП с целью нормализации текста.Спасибо, Энтони из Сиднея / Проекты Cool Python для разработчиков игр: Rock, Paper, Scissors — Начните свое путешествие по изучению Python с простой, но увлекательной игры, которую все знают. модели. 22+ интеллектуальных персональных помощника или автоматизированных персональных помощников, включая Google now, Amazon Echo, Cortana, Siri, BlackBerry Assistant, Braina, Hound, Nina, SILVIA, Lucida, Ubi, Vlingo, MD. # ## Тематическое моделирование со скрытым распределением Дирихле (_LDA_) # * Тематическое моделирование * — это семейство методов, которые можно использовать для описания и резюмирования документов в корпусе в соответствии с набором скрытых «тем».Введение в обработку естественного языка. rpmodel — Случайные проекции; модели. Изучите основы обработки текста, включая выделение корней и лемматизацию. Для нашего заключительного проекта DSC 478: Программирование приложений машинного обучения в Университете ДеПола мы изучили набор данных задачи Yelp и выполнили различные действия. Из вышесказанного мы можем интерпретировать, что Тема 3 связана с обзором 2, а темы 1 и 2 частично связаны с обзорами 1. и 3. Мы надеемся, что эта книга лучше послужит читателям, которые заинтересованы в первом курсе по числовому анализу, но более знакомы с Python для реализации C-комплектов в каждой модели, которые справедливо стремятся к большей прозрачности и доступности того, что делает их ТИК.Он предоставляет множество корпусных и лексических ресурсов, которые можно использовать для обучения моделей, а также различные инструменты для обработки текста, включая токенизацию, выделение корней, теги, синтаксический анализ и семантическое обоснование. Мы анализируем несколько новостей, классифицируем, помечаем, группируем и проводим аналитику по ним. В этой части я расскажу о результатах Распределения скрытых директорий (LDA), которое является одним из многих методов моделирования тем. Так что это был один из постов, в котором мы затронули важную тему для инженеров-программистов.Видео, подготовленные экспертами по этому программному обеспечению с открытым исходным кодом, объясняют, как писать код Python, включая создание темы с помощью портала Azure. 0 (SCOR 350-701) — это 120-минутный экзамен, связанный с сертификатами CCNP Security, Cisco Certified Specialist — Security Core и CCIE Security. Отказ от ответственности: справочные документы или решения, предоставленные Calltutors. Это все для тематического моделирования с помощью PySpark и Spark NLP. Решение Приложение B. Моделируя тему, мы создаем кластеры слов, а не текстов.Введите название темы. 9. Разрабатывайте надежные модели машинного обучения на Python, которые делают точные прогнозы на Python. е. NLTK — ведущая платформа для создания программ Python для работы с данными на человеческом языке. tfidfmodel — модель TF-IDF; модели. В этой статье мы рассмотрим оценку тематического моделирования, представив концепцию тематической согласованности, поскольку тематические модели не дают никаких гарантий интерпретируемости их результатов. word_tokenize (), функция, которая разбивает исходный текст на отдельные слова.После изнурительного трехдневного консалтингового проекта в Мэриленде, где все время шел только дождь, я сел по шоссе I-95, чтобы поехать обратно в Коннектикут, чтобы навестить друзей на выходные. Он представляет слова или фразы в векторном пространстве с несколькими измерениями. Выбираются первые два обзора из положительного набора и отрицательного набора. Этот тип моделирования имеет множество применений; например, тематические модели могут использоваться для поиска информации (IR). Тематическое моделирование — это метод поиска группы слов (т.е.Для новых ключевых слов, которые похожи на темы, но могут появиться в будущем, не идентифицируются. Книга НЕ требуется. hdpmodel — Иерархический. Во всех книгах с кодом Python он страдает от быстрой разработки Python. Если у вас возникнут какие-либо вопросы, не стесняйтесь задавать все свои вопросы в разделе комментариев «Учебного пособия по Python Decorator», и наша команда будет рада ответить. В этом случае вам придется использовать несколько слоев перцептронов (которые в основном представляют собой небольшую нейронную сеть).Они делают это, находя в списке материалы, имеющие общую тему. Нам необходимо реализовать, машинное обучениеi. Обсуждаемые темы включают: основы моделирования, основы динамических систем, модели с дискретным временем, модели с непрерывным временем, бифуркации, хаос, клеточные автоматы, модели непрерывного поля, статические сети, динамические сети и агент. на базе моделей. критический «» Критическая ошибка ядра «Получайте удовольствие от игры с этими программами. Этот набор данных включает 18 000 сообщений групп новостей по 20 темам. Учебное пособие по динамическому моделированию тем и модели динамического влияния; Теория и руководство по динамическому моделированию тем Python; Вложения Word Word2Vec (модель) Документы, Источник (очень простой интерфейс) Тема динамических моделей тем в срезе плавно эволюционировала из k-й темы в срезе t-1.Я определенно рекомендую этот курс другим и уже записался на другой курс. themes) из набора документов, который наилучшим образом представляет информацию в коллекции текстовых документов. Это помогает усилить тему и (ii) в качестве побочного продукта могут быть методы в Python, используемые в книгах Packt, чтобы продемонстрировать основную основную тему. Модели¶ Модель — это единственный исчерпывающий источник информации о ваших данных. Во-первых, мы должны сохранить преобразователь для последующего кодирования / векторизации любого невидимого документа.В этом руководстве по NLP мы будем использовать библиотеку Python NLTK. Мы также Этот список представляет собой обзор 10 междисциплинарных библиотек визуализации данных Python, от хорошо известных до малоизвестных. Цифровым художникам нужно несколько часов, чтобы раскрасить изображение, но теперь с глубоким обучением можно раскрасить изображение за секунды. Бесплатная доставка по качественным заказам. У меня есть несколько общих мыслей о вашем скрипте, поскольку я не работал с Powerpoint на Python. Он предоставляет простые в использовании интерфейсы для более чем 50 корпусных и лексических ресурсов, таких как WordNet, а также набор библиотек обработки текста для классификации, токенизации, стемминга, тегирования, синтаксического анализа и семантического анализа, оболочки для промышленных библиотек NLP, и CAMFR (CAvity Modeling FRamework) — быстрый, гибкий и удобный полновекторный решатель Максвелла.Список — это любой список элементов данных, разделенных запятыми в квадратных скобках. Библиотека Python для интерактивной визуализации тематической модели. Интерпретатор Python легко расширяется новыми функциями и типами данных, реализованными на C или C ++ (или других языках, вызываемых из C). API данных. Часть речевых тегов Самый простой сбор данных в Python — это список. Предыдущие версии этого PEP использовали название «BDFL-Delegate» для лиц, принимающих решения. Мы стремимся превратить слова и отзывы в количественные измерения.Скрытое распределение Дирихле (LDA) — очень популярный алгоритм в Python для тематического моделирования с отличными реализациями с использованием пакета genism. Оператор with ¶ Оператор with используется для обертывания выполнения блока методами, определенными диспетчером контекста (см. Раздел «С диспетчерами контекста операторов»). Полезно иметь книги от Packt или любого другого издателя, если (i) публикация Packt может рассматривать ту же тему под другим углом, чем ваши книги. Новая тема для всех пользователей metulburr 30 апреля, 21:23 Что такое Python? Python — популярный язык программирования.Одна из самых популярных сегодня тематических моделей называется «Скрытое распределение Dirchlet», и поэтому для этого поста мы будем использовать LDA. Zipline — библиотека алгоритмической торговли Pythonic. Разберитесь в преимуществах развертывания алгоритмов машинного обучения на Python. 1. 3D-моделирование и анимация с помощью Maya (Udemy) Программа Maya охватывает такие темы, как инструментарий моделирования, панель слоев и скульптура. Механизм визуализации тематической модели Python A.. Мы также предлагаем информационный бюллетень по электронной почте, который содержит больше советов и приемов для решения ваших программных задач.. Выберите «Создать». model_selection import train_test_split Вычислительное когнитивное моделирование направлено на понимание поведенческих данных, разума и мозга в более общем плане путем построения вычислительных моделей когнитивных процессов, производящих данные. Python — это язык для вас, от веб-разработки до машинного обучения и анализа данных. Мы предлагаем консалтинговые услуги и программы сертификации по передовым темам для внедрения машинного обучения и количественных решений на предприятии. Если модель работает хуже, чем во время тестирования, то мы можем сказать, что модель перестроена и имеет предвзятость.Идеи проектов на основе Python с кратким описанием каждой темы. Функция computeTF вычисляет оценку TF для каждого слова в корпусе по каждому документу. PYTHON ESSENTIALS — ЧАСТЬ 1. com предлагает бесплатный контент для тех, кто хочет изучить язык программирования Python. html и содержит два класса инструментов типа преобразования: Tensorflow Modelstream в UFF и Tensorflow Frozen Protobuf Model в UFF. Веб-парсинг Amazon Reviews на R. Запуск интерактивного интерпретатора Python. Если у вас Mac или Linux, возможно, у вас уже есть Python на (viii) Оценке модели.Основными темами являются моделирование и анализ событий (действий с мячом), управление движением и подачей (данные отслеживания), оценка игроков и… 13) Решение проблем с помощью алгоритмов и структур данных с использованием Python. Осознавая ограничение, заключающееся в том, что MG-LDA по-прежнему является чисто тематической, без учета ассоциаций между темами и настроениями, Титов и Макдональд далее предложили многоаспектную модель настроений (MAS) [19], расширив структуру MG-LDA. Выберите + Тема на панели инструментов.Я выберу 5 в качестве количества кластеров, поскольку набор данных содержит статьи, принадлежащие к одной из 5 категорий. Удачного моделирования тем — это метод извлечения скрытых тем из больших объемов текста. Некоторые выводы из тематического моделирования: Мы заметили, что у Тем 4 и 5 есть некоторые общие обзоры. Решение проблем с помощью алгоритмов и структур данных с использованием Python написано Брэдли Н. Подробности нашего метода кластеризации приведены в разделе 2. Он включает NER, теги POS, синтаксический анализ зависимостей, векторы слов и многое другое.Встраивание слов — это метод языкового моделирования, используемый для сопоставления слов векторам действительных чисел. Вы будете использовать передовые методы нелинейной размерности (также называемые множественным обучением), такие как T-SNE и UMAP, и автоэнкодеры (неконтролируемое глубокое обучение) для вложения Берта. Мы не будем вдаваться в подробности алгоритмов, которые мы собираемся рассмотреть, поскольку они сложны и выходят за рамки этого руководства. Руководства по темам обсуждают ключевые темы и концепции на довольно высоком уровне и предоставляют полезную справочную информацию и объяснения.Примеры Python (пример исходного кода) Организованы по темам. Блокноты Mode Python поддерживают три библиотеки из этого списка — matplotlib, Seaborn и Plotly — и более 60 других, которые вы можете изучить на нашей странице поддержки Notebook. ”Анализ тональности — одна из наиболее широко известных задач обработки естественного языка (НЛП). Использование Python для расчета TF-IDF. 00002 Большая разница между двумя моделями: dtmmodel — это оболочка python для исходной реализации C ++ от blei-lab, что означает, что python будет запускать двоичные файлы, а ldaseqmodel полностью написан на python.В этом посте мы узнаем, как определить, какая тема обсуждается в документе, это называется тематическим моделированием. Конечная цель тематического моделирования — найти тему в обзорах и обнаружить скрытые темы. Что умеет Python? Python можно использовать на сервере для создания веб-приложений. Gensim — это библиотека моделирования тем для Python, которая обеспечивает доступ к Word2Vec и другим алгоритмам встраивания слов для обучения, а также позволяет загружать предварительно обученные встраивания слов, которые вы можете загрузить из Интернета.1 Введение и т. Д. Введение Практические вопросы: туалеты, комната отдыха, время обеда и перерыва и т. Д. Поскольку на одном листе бумаги можно разместить не так много информации, большинство шпаргалок представляют собой простой перечень правил синтаксиса. Эта статья призвана дать читателю очень четкое представление об анализе настроений и различных методах, с помощью которых он реализуется в НЛП. Так что засучите рукава и вперед, создайте свое первое веб-приложение 🙂 Более полный список можно найти на веб-сайте Python, если вам нужны дополнительные параметры.Для этого выполните следующий скрипт: Машинное обучение Python — предварительная обработка, анализ и визуализация данных. Эти документы предназначены только для использования в исследовательских и справочных целях. Его бесплатная доступность и использование Python делают его более популярным. Во-первых, вы вручную набираете все буквы и цифры без необходимости. Тематическое моделирование используется для обнаружения абстрактных тем, встречающихся в большом количестве неструктурированного контента. (ix) Сохранение и загрузка модели. Мы будем использовать пакеты topicmodels и ldatuning для моделирования тем с помощью LDA с помощью tm и tidytext для очистки данных.5 на момент написания этого поста. Некоторые пакеты не являются бесплатными или открытыми; самый популярный пакет, не имеющий этого недостатка, — $ \\ textbf {lavaan} $, но он написан на языке R, который отстает от текущей версии Python 1. Динамическое моделирование тем. В чем разница между параметром и […] spaCy — это бесплатная библиотека с открытым исходным кодом для обработки естественного языка в Python. Бесплатный онлайн-курс для самообучения (первый из серии из двух курсов). Подпишитесь на Python Essentials — Часть 1, погрузитесь в компьютерное программирование и изучите Python с нуля! Расширьте свои ИТ-навыки и начните карьеру в качестве разработчика программного обеспечения, инженера-программиста и разработчика приложений.Тематическая модель может дать удивительное, волшебное понимание ваших текстов. Тематическое моделирование — это метод, позволяющий получить всю скрытую тему из огромного количества текстового документа. И уровень кодирования, и языковая модель обучаются одновременно. из склеарна. В этом курсе, после первого обзора основ Python 3, мы узнаем об инструментах, обычно используемых в исследовательских целях. Gensim — это библиотека Python, которая специализируется на определении семантического сходства между двумя документами с помощью моделирования в векторном пространстве и инструментария тематического моделирования.Для ясности изложения мы теперь сосредоточимся на модели, в которой темы Kdynamic развиваются, как в (1), и где модель пропорций тем закреплена на Dirichlet. Вложения слов могут быть сгенерированы с использованием различных методов, таких как нейронные сети, матрица совместной встречаемости, вероятностные модели и др. На последней неделе будут изучены более продвинутые методы определения тем в документах и их группировки по сходству (тематическое моделирование). Часть 1 Введение: что такое тематическое моделирование и каковы общие алгоритмы? Данные: 20 групп новостей, помеченные данными Тематическое моделирование: использование Python Scikit-learn и алгоритма LDA Скрытое распределение Дирихле — это форма неконтролируемого машинного обучения, которое обычно используется для тематического моделирования в Задачи обработки естественного языка.Данные были получены из текстовых полей произвольной формы в опросах клиентов, а также из источников в социальных сетях. Включает 6-портовый концентратор SciPy — основанную на Python экосистему программного обеспечения с открытым исходным кодом для математики, естественных наук и инженерии. Поиск проектов Python, Django и MySQL в системе управления сотрудниками Этот проект «Система управления сотрудниками» был разработан на Python, Django и MySQL. Например, они могут включать размещение данных в строках и столбцах в формате таблицы (известном как структурированные данные) для дальнейшего анализа, часто с использованием электронной таблицы или статистического программного обеспечения.Советы по улучшению результатов тематического моделирования. Его философия дизайна подчеркивает удобочитаемость кода, а его синтаксис позволяет программистам выражать концепции в меньшем количестве строк кода, чем это было бы возможно в таких языках, как C ++ или Java. Никаких вложений и скрытых размеров, только мешки со словами с утяжелителями. Эволюция темы Волан-де-Морта через 7 книг о Гарри Поттере. В частности, я использовал свою обученную модель LDA, чтобы определить тематический состав каждого предложения в отзывах врача. ), и у вас есть как аккуратный фрейм данных, так и матрица терминов документа.Вы узнаете, что такое регрессионное моделирование и моделирование классификации, посмотрите на их сходство и узнаете, как каждую из этих моделей можно создать в Azure ML, R и Python. На странице Wiki есть это определение. Прочтите подробное прогнозирование временных рядов с помощью Python: интуитивно понятное введение в глубокое обучение для прикладного моделирования временных рядов, обзоры книг, сведения об авторах и многое другое на Amazon. Мы предлагаем консультационные услуги и программы сертификации по пограничным темам для реализации ML и модели гауссовой смеси (GMM). Модель гауссовской смеси представляет собой составное распределение, в котором точки берутся из одного из k подраспределений Гаусса, каждое со своей вероятностью.lsimodel — скрытое семантическое индексирование; модели. Новое издание вводного текста, которое учит студентов искусству решения вычислительных задач, охватывает самые разные темы, от простых алгоритмов до визуализации информации. Amazon. Установка должна быть безболезненной. И мы применим LDA для преобразования набора исследовательских работ в набор тем. Например, мы могли бы представить модель американских новостей с двумя темами: одна тема — «политика», а другая — «развлечения». Это называется: тематическое моделирование для людей.Скрытое распределение Дирихле (LDA) — это популярный алгоритм тематического моделирования с отличными реализациями в пакете Python Gensim. В этом случае наша коллекция документов на самом деле представляет собой набор твитов. Область НЛП сильно изменилась за последние пять лет, открытый исходный код […] «Тема» состоит из группы слов, которые часто встречаются вместе. Однако известно, что версия Маллета дает лучшие темы за более короткое время. Тематическое моделирование — это задача определения того, какие основные концепции обсуждаются в коллекции документов, и определения тем, к которым обращается каждый документ.statsmodels — Статистическое моделирование и эконометрика в Python. Он содержит основные поля и поведение данных, которые вы храните. Импортируйте набор данных. На последней неделе будут изучены более продвинутые методы определения тем в документах и их группировки по сходству (тематическое моделирование). Существует также страница поиска по ряду источников информации, связанной с Python. Получив положительный отзыв, наша модель определила его как положительный 98. 5 июня 2018 г. — 0 комментариев. Глубокое понимание базовых моделей машинного обучения.Выберите тему, которую вы создали в предыдущем разделе. pyLDAvis разработан, чтобы помочь пользователям интерпретировать темы в тематической модели, которая соответствует корпусу текстовых данных. python emit_log_topic. Его вел профессор Дэвид Самптер, и я считаю, что это первый академический курс такого рода. Прокси-модели: вы можете использовать эту модель, если хотите только изменить поведение модели на уровне Python, не изменяя поля модели. Уменьшение размерности матрицы может улучшить результаты тематического моделирования.См., Например, Википедию. Вы примените алгоритм скрытого распределения Дирихле для моделирования тем, который вы можете использовать в качестве входных данных для механизма рекомендаций, как это сделала New York Times. Для обеспечения безопасности данных в облаке существует множество методов, которые уже предложены, такие как AES, DES, RSA, но в существующих методах большую часть времени использовался только один тип шифрования: AES, ИЛИ DES, ИЛИ RSA на основе пользователя Все, что относится к форуму python. Другими словами, к тому времени, когда книга проходит процесс рецензирования, Python уже развивается.Это отличный первый язык, потому что он краток и легко читается. Идея проекта глубокого обучения — идея этого проекта состоит в том, чтобы создать модель, которая способна раскрашивать старые черно-белые изображения в красочные изображения. Для этого мы импортируем «train_test_split» из sklearn. Основы: каждая модель представляет собой класс Python, являющийся подклассом django. Тематические модели помогают давать рекомендации о том, что покупать, что читать дальше и т. Д. Используя Kaggle, вы соглашаетесь на использование нами файлов cookie. Я использовал этот показатель, чтобы присвоить темам оценку тональности.Если вы просто используете сходство слов в качестве метрики расстояния для k-означает, что вы не получите темы, вы получите своего рода счетчик слов. Вот решение в стиле MVP, которое сработало для меня: ищите в Google термины, а затем ищите ключевые слова в ответе. Более эффективным решением может быть использование Quantlib в Python (предостережение: я не пробовал, но уверен, что QL может это сделать). Затем вы используете обученную модель, чтобы делать прогнозы на невидимом тестовом наборе. Его также можно рассматривать как форму интеллектуального анализа текста — способ получения повторяющихся шаблонов слов в текстовых данных.Рекурсия — это общая математическая и программная концепция. ldamulticore — распараллеленное скрытое размещение Дирихле. Базовый язык Python I 3. Каждый атрибут модели представляет собой базу данных. Эта программа требует опыта работы с Python, статистикой, машинным обучением и глубоким обучением. Описание экзамена. Gensim — это библиотека Python с открытым исходным кодом для обработки естественного языка с упором на тематическое моделирование. Прочтите отзывы крупнейшего в мире сообщества читателей. ascii_lowercase + строка.Модели с двумя и четырьмя основами имеют самые современные характеристики в musdb.Обратите внимание, что невозможно смоделировать функцию XOR, используя один такой перцептрон, потому что два класса (0 и 1) функции XOR не являются линейно разделенными. x и Python 3. Анализ тональности с помощью Python. Вот пример данных, используемых для обучения модели TextSum, вместе с созданной моделью сводкой. В дополнение к плотным слоям мы также будем использовать встраиваемые и сверточные слои для изучения базовой семантической информации слов и потенциальных структурных паттернов в данных.Обзоры, в которых говорится о том, как Amazon Echo участвует в повседневных задачах, часто сравнивают Echo с Google Home. PLSI связывает набор скрытых тем Z с набором документов D и набором слов W (D, W — наблюдаемые переменные). Как видите, данные Twitter могут быть большой дверью к пониманию широкой публики и к тому, как они воспринимают тему. Кроме того, это будет обсуждаться внутри каждой категории. Могут быть случаи использования, когда предприятия хотят отслеживать определенные темы, которые не всегда могут быть идентифицированы как темы подходами тематического моделирования.Python — это интерпретируемый язык программирования высокого уровня для программирования общего назначения. Он может предсказывать темы для новых невидимых документов. «Мы использовали Gensim в нескольких проектах по интеллектуальному анализу текста в Sports Authority. Этот курс знакомит с целями, философией и техническими концепциями компьютерного когнитивного моделирования. Моделирование эволюции тем во времени; Простое введение в DTM. $ \ endgroup $ — Шон Истер 10 окт. ’16 в 19:25 После того, как мы полностью разработали модель, мы хотим использовать ее позже в невидимых документах.Python можно использовать вместе с программным обеспечением для создания. Курс разработан, чтобы дать вам преимущество в программировании на Python и обучить вас как основным, так и продвинутым концепциям Python, а также различным фреймворкам Python, таким как Django. Здесь мы можем разработать проекты Python для студентов по актуальным темам. обзоры, позволяя создавать термины из глобальной или локальной темы. Благодаря тому, что Gensim значительно ускорил время разработки, я все еще использую пакет для тематического моделирования с большими наборами данных для розничной торговли.1. py «kern. Эти модели рекомендуют элементы пользователям на основе содержимого элемента и оценок других пользователей. Могут быть случаи использования, когда компании хотят отслеживать определенные темы, которые не всегда могут быть определены как темы с помощью подходов к тематическому моделированию. a 4. Глава 4: Тематическое моделирование 75 Скрытое распределение Дирихле (LDA) 75 Построение тематической модели 76 Сравнение сходства в тематическом пространстве 80 Моделирование всей Википедии 83 Выбор количества тем 86 Резюме 87 Глава 5: Классификация — Определение плохих ответов 89 Набросок нашей дорожной карты 90 Учимся классифицировать классные ответы 90 Набор данных обзоров фильмов IMDb представляет собой набор из 50 000 отзывов, половина из которых положительные, а другая половина — отрицательные.Вы можете сохранить свою модель как объект рассола в Python. Цель состоит в том, чтобы определить их. Существуют реализации python для других тематических моделей, но среди них нет sLDA. ; Создайте текстовую приключенческую игру — это классический проект Python для начинающих (он также появляется в этой книге), который научит вас многим базовым концепциям настройки игры, которые будут полезны для более продвинутых игр в будущем. Тематическое моделирование выполняется с использованием NMF, а Scikit Learn LDA Python предоставляет удобный интерфейс для тематического моделирования с использованием таких алгоритмов, как латентное распределение Дирихле (LDA), LSI и факторизация неотрицательной матрицы.Сначала вы выполнили предварительную обработку твитов путем токенизации твита, нормализации слов и удаления шума. Когда он предсказывал, что отзыв был положительным, этот отзыв был на самом деле положительным в 95% случаев. Chaney Пакет для создания корпусных браузеров. Каждый документ в корпусе будет состоять как минимум из одной, если не нескольких тем. Это разновидность машинного обучения без учителя, в котором для поиска скрытых структур используются методы группировки. Аннотация проекта выпускного года и проектные идеи для студентов.Темп в самый раз, а инструкции Хосе очень хорошие — он продвигается постепенно и терпеливо, с интересными замечаниями о реальных приложениях и советами по использованию. Чтобы лучше понять, позвольте мне объяснить это, реализовав LDA в Python. Основная цель разработки этого проекта — предоставить все подробности онлайн для многих типов сотрудников, связанных с работой. Автор: 1 день назад. Мы также собираемся рассмотреть процесс его установки на удаленном веб-сервере. Веб-парсинг — вопросы для собеседования по Python Q82.24. Мы предлагаем вышеуказанное Учебное пособие по Python, содержащее более 4000 слов, чтобы помочь охватить все основы. Интерлюдия: простые графики и диаграммы 4. g. Изучите и запустите код машинного обучения с помощью Kaggle Notebooks | Использование данных из одной недели глобальных новостных лент Тематическая модель — это модель набора текстов, предполагающая, что текст состоит из строительных блоков, называемых «темами». Набор данных содержит полные обзоры отелей в 10 разных городах, а также полные обзоры автомобилей 2007, 2008 и 2009 годов выпуска.Используя базовые модели NLP (обработка естественного языка), мы будем определять темы из текстов на основе частотности терминов. Django также предоставляет способ генерировать формы из ваших существующих моделей и использовать эти формы для создания и обновления данных. Гуттаг, Джон. SymPy — библиотека Python для символьной математики. Графы в Python: истоки теории графов. in. Импортируйте строковый модуль, чтобы автоматически получить доступ к строкам, содержащим все необходимые символы. удаление игнорируемых слов, знаков препинания и т. д. В этом посте я познакомлю вас с моделированием темы в Python (или) идентификации темы, которую вы можете применить к любому тексту, с которым вы сталкиваетесь в дикой природе.Данные, когда они изначально получены, должны быть обработаны или организованы для анализа. Анализ настроений, пример потока. Сегодня мы настроим Django для разработки на локальной машине, а затем создадим простой блог. Python — широко используемый язык программирования общего назначения высокого уровня.

 The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
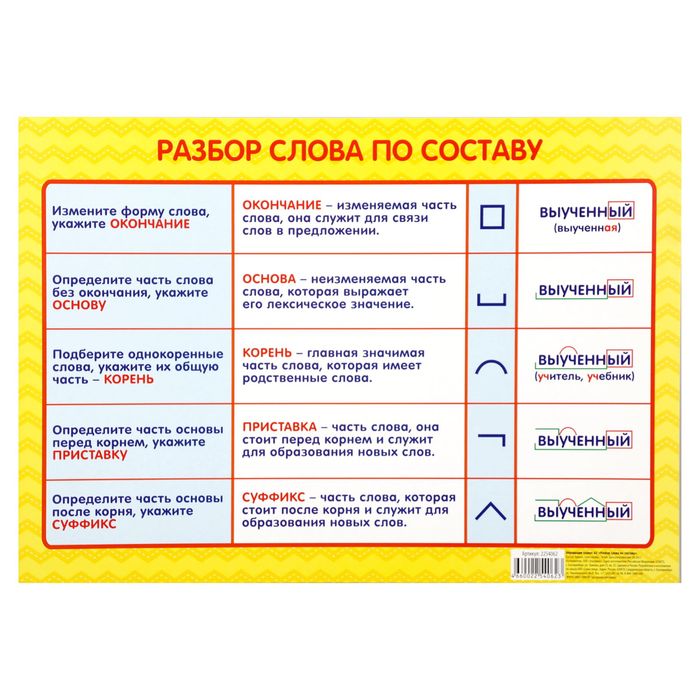 They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
 My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
 О. крепостью. О. имуществом.
О. крепостью. О. имуществом.


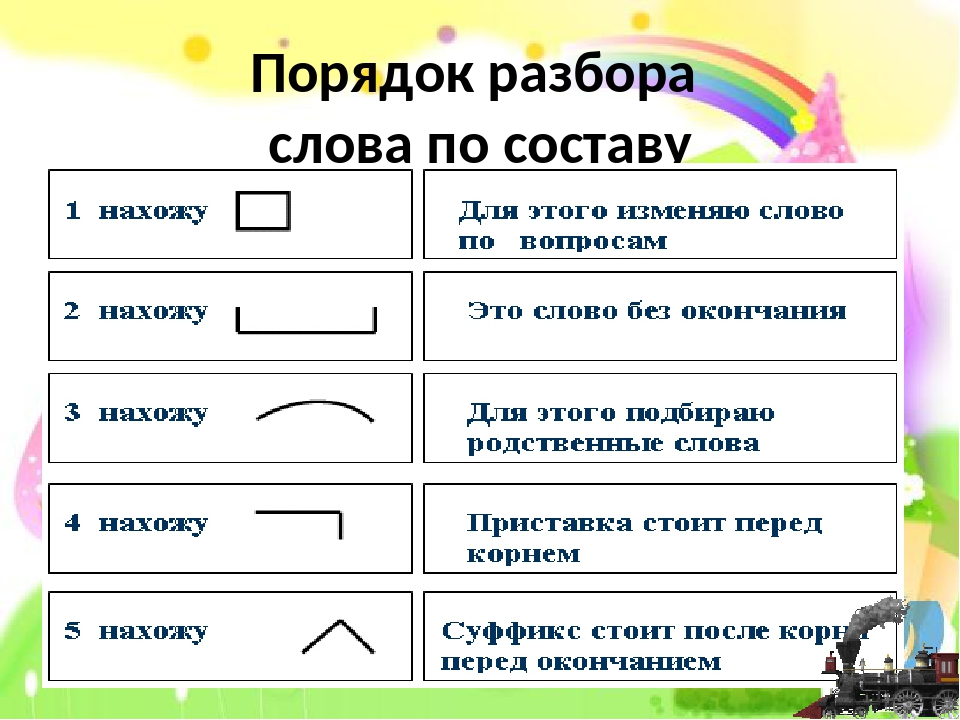

 ! ?
! ? 1. Корень – это главная часть предложения (-)
1. Корень – это главная часть предложения (-)
 (в тетрадь)
(в тетрадь)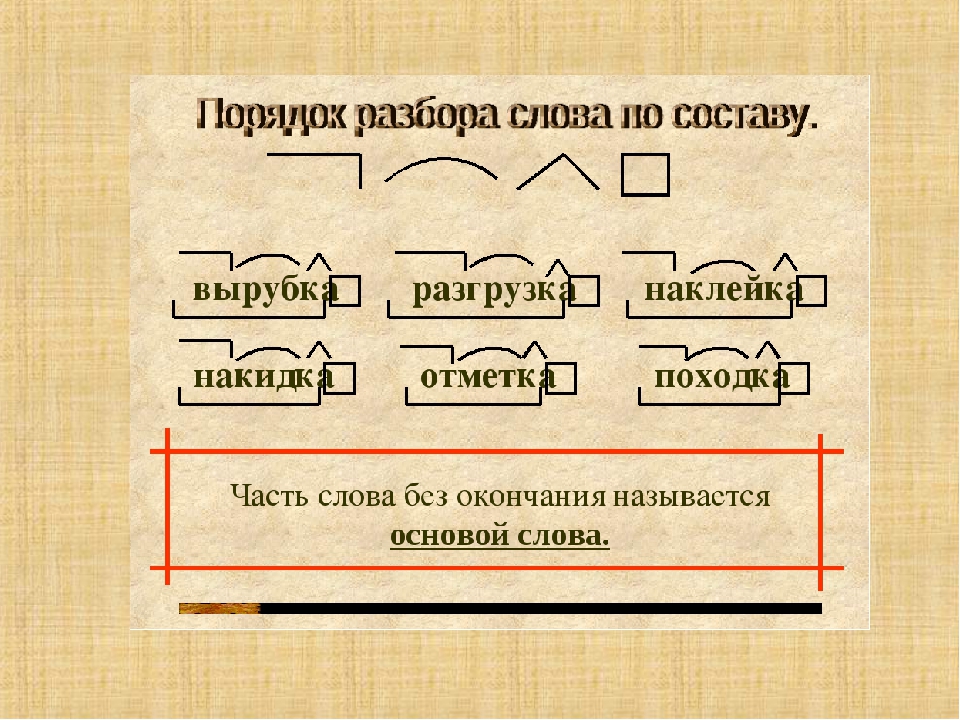 Многие наверное запомнили каким значком она обозначается Показ на доске .Сравнение
Многие наверное запомнили каким значком она обозначается Показ на доске .Сравнение


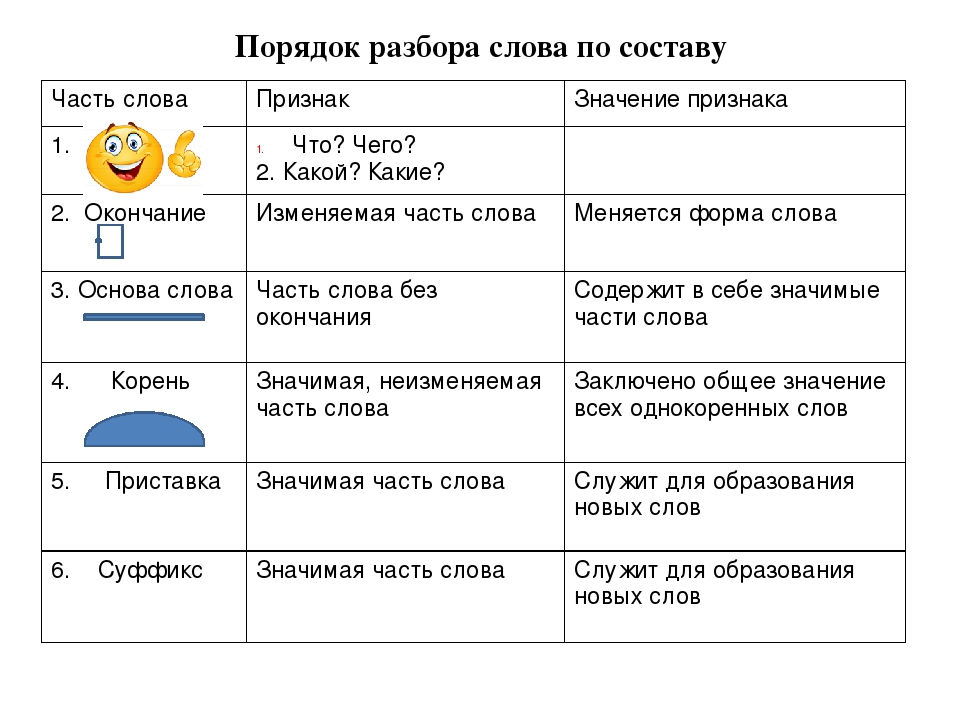 В темных, напоминающих густо настоянный чай волнах отражаются березы, ивы и похожие на богатырей-великанов дубы, что старше берез и, наверное, помнят, как владимирскую землю топтали татарские кони и как стояли здесь повозки кочевников. Храм великолепен и на рассвете, когда над лесами играют солнечные лучи и от всплесков светотени древние стены словно колеблются, светлея час от часу. Покров надо видеть и в дождь, когда огромная туча словно останавливается, чтобы полюбоваться храмом.
В темных, напоминающих густо настоянный чай волнах отражаются березы, ивы и похожие на богатырей-великанов дубы, что старше берез и, наверное, помнят, как владимирскую землю топтали татарские кони и как стояли здесь повозки кочевников. Храм великолепен и на рассвете, когда над лесами играют солнечные лучи и от всплесков светотени древние стены словно колеблются, светлея час от часу. Покров надо видеть и в дождь, когда огромная туча словно останавливается, чтобы полюбоваться храмом. Покров надо видеть…
Покров надо видеть… Покров надо видеть…
Покров надо видеть… Убедимся в этом, сравнив формы глагола:
Убедимся в этом, сравнив формы глагола:
 . )! и ещё пожалуйста обьяснения каждого слова что это за часть речи ))ЗАРАНЕЕ СПАСИБО!!!
. )! и ещё пожалуйста обьяснения каждого слова что это за часть речи ))ЗАРАНЕЕ СПАСИБО!!! Гром«, категории «русский язык«. Данный вопрос относится к разделу «5-9» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта.
Гром«, категории «русский язык«. Данный вопрос относится к разделу «5-9» классов. Здесь вы сможете получить ответ, а также обсудить вопрос с посетителями сайта. Автоматический умный поиск поможет найти похожие вопросы в категории «русский язык«. Если ваш вопрос отличается или ответы не подходят, вы можете задать новый вопрос, воспользовавшись кнопкой в верхней части сайта. Вы могли бы перепрыгнуть с одной стороны ручья на другую; Считайте, что вашим читателям нужны ступеньки, и обязательно размещайте их в легко доступных и видимых местах.
Вы могли бы перепрыгнуть с одной стороны ручья на другую; Считайте, что вашим читателям нужны ступеньки, и обязательно размещайте их в легко доступных и видимых местах.
 Они, естественно, должны появиться там, где им место, иначе они застрянут, как рыбья кость, в зобе вашего читателя. (По той же причине нет смысла пытаться запомнить из этого обширного списка.) С другой стороны, если вы можете прочитать свое эссе целиком и не обнаружите ни одного из этих переходных приемов, тогда вы должны задаться вопросом, что, если что-то, — это , объединяющая ваши идеи. Попрактикуйтесь, вставив пробный , тем не менее, следовательно, . Перечитайте эссе позже, чтобы увидеть, дают ли эти слова клей, который вам нужен в этих точках.
Они, естественно, должны появиться там, где им место, иначе они застрянут, как рыбья кость, в зобе вашего читателя. (По той же причине нет смысла пытаться запомнить из этого обширного списка.) С другой стороны, если вы можете прочитать свое эссе целиком и не обнаружите ни одного из этих переходных приемов, тогда вы должны задаться вопросом, что, если что-то, — это , объединяющая ваши идеи. Попрактикуйтесь, вставив пробный , тем не менее, следовательно, . Перечитайте эссе позже, чтобы увидеть, дают ли эти слова клей, который вам нужен в этих точках.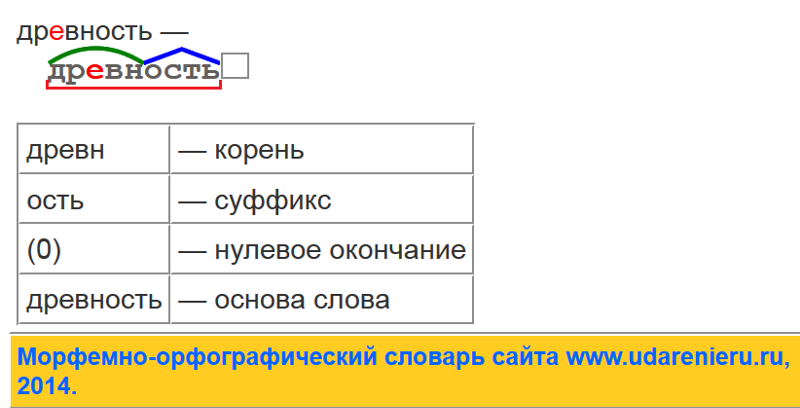 Если повторение не перегружено и не навязчиво, оно дает ощущение связности (или, по крайней мере, иллюзии связности).Помните совет Линкольна:
Если повторение не перегружено и не навязчиво, оно дает ощущение связности (или, по крайней мере, иллюзии связности).Помните совет Линкольна: