Сделайте синтаксический разбор выделенного предложения.
Определите тип текста, объясните свой выбор.
Вставьте пропущенные буквы и расставьте знаки препинания.
Разберите по составу подчёркнутые слова.
Объясните значение слова горизонт.
Текст 8
Лет двести тому (на)зад ветер-сеятель пр..нёс два семечка в Блудово болото: семя сосны и семя ели. Оба семечка л..гли в одну ямку возле больш..го плоского камня. С тех пор уже лет двести эти ель и сосна вместе р..стут. Дерев..я разных пород ужасно боролись между собой корнями за питание, суч..ями — за воздух и свет. Поднимаясь всё выше они вп..вались сухими суч..ями в ж..вые ств..лы и местами насквозь прокололи друг друга. Злой ветер устроив дерев..ям таую (не)счастную жизнь прил..тел сюда иногда пок..чать их. И тогда дерев..я ст..нали и выли на всё Блудово болото, как живые существа.
(М. М. Пришвин.
Сказка-быль «Кладовая солнца»)
М. Пришвин.
Сказка-быль «Кладовая солнца»)
Выполните следующие задания:
Определите стиль текста, объясните свой выбор.
Вставьте пропущенные буквы, раскройте скобки и расставьте недостающие знаки препинания.
Разберите по составу слово поднимаясь.
Укажите количество букв и звуков в слове: сучьями.
Произведите морфологический разбор слова устроив.
Текст № 9
Золотая осень.
Вот и наступил первый месяц осени. Ра(с,сс)ыпал золото и багрянец по рощам и дубравам.
Осень то порадует
погожими и ясными днями, то засв..стит
ветер и пойдёт скучный и долгий дождь. Осень од..рила все деревья разными
нарядами. Например, дуб стоит как грозный
богатырь, одетый в ж..лтую одежду, а
берёзка, в белом платьице, как девушка.
Только ёлочка (не)меняет свой наряд, она
вечно зелёная. В солнечную погоду листья
кажутся з.
Выполните следующие задания:
1. Выразительно прочитайте текст.
2. Определите стиль текста, объясните свой выбор.
3. Вставьте пропущенные буквы и раскройте скобки.
4. Разберите по составу слово (по)разному.
Текст № 10
Осе(н,нн)яя роза.
Осыпал лес свои в..ршины,
Са.. обнажил своё чело,
Дохнул сентябрь, и георгины
Дыханьем ночи обожгло.
Но в дуновении м..роза
Между п..гибшими одна
Лишь ты одна, царица – роза,
Бл..гоуханна и пышна.
Назло ж..стоким испытаньям
Ты очертаньем и дыханьем
В..сною ве..шь на меня.
(А.Фет.)
Выполните следующие задания:
Выразительно прочитайте текст.

Определите его тему, основную мысль.
Объясните смысл выделенных слов.
Вставьте пропущенные буквы, объясните графически вставленные орфограммы.
Выпишите все служебные части речи (предлоги, союзы, частицы).
Текст № 11
Пятый день несло (не)проглядной в..югой. В белом от снега и холодном хуторском доме стоял бледный сумрак. Было больше горе: был т..жело болен ребёнок. И в жару в бреду он часто плакал и просил дать ему какие(то) красные лапти. И мать не отходившая от постели то(же) плакала горькими слезами.
Нефёд пр..нёс соломы на топку свалил её на пол отдуваясь дыша холодом приотворил дверь заглянул:
— Ну что барыня как? Не полегчало?
— Куда там Нефёдушка! Верно, и не выживет! Всё какие (то) красные лапти просит…
_ Лапти? Что за лапти такие?
— А Господь его
знает. Бредит, весь огнём горит…
Бредит, весь огнём горит…
Мотнул шапкой задумался. И вдруг твёрдо:
— Значит, надо добывать. Значит, душа желает.
(И.А. Бунин. «Лапти»)
Выполните следующие задания
Канакина. 3 класс. Учебник №1. Проверь себя с. 100
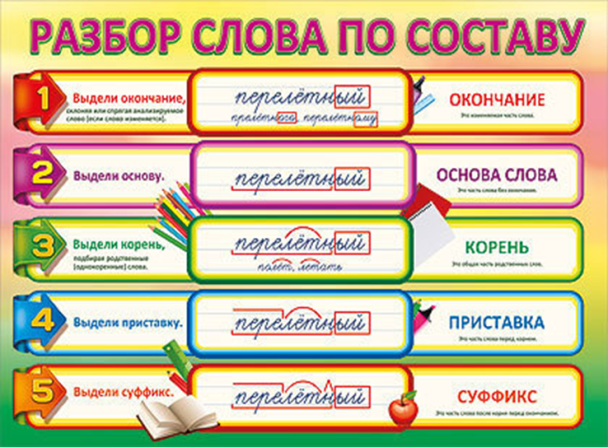
1. Объясните, как найти в словах указанные части слова:
Снежок (корень).
Чтобы найти корень, надо подобрать однокоренные слова и выделить в них общую часть: снеж/
Позвонит (приставка).
Чтобы найти приставку в слове, надо подобрать однокоренное слово без приставки или с другой приставкой. Часть слова, которая стоит перед корнем, и будет приставкой: по/звонит — звонит, пере/звонит, за/звонит.
Медвежонок (суффикс).
Чтобы найти в слове суффикс, надо подобрать однокоренные слова без суффикса или с другими суффиксами. Часть слова, которая стоит после корня перед окончанием, и будет суффиксом: межвеж/онок — медведь, медвеж/ата.
Часть слова, которая стоит после корня перед окончанием, и будет суффиксом: межвеж/онок — медведь, медвеж/ата.
Гроза (окончание).
Чтобы найти окончание в слове, надо изменить форму слова: гроз/а
2. Докажите, что слова вязать и вязкий не являются однокоренными.
Слова вязать и вязкий не являются однокоренными, потому что у них разное лексическое значение.
Вязать — изготовлять ткань или предметы одежды путём сравнительно неплотного переплетения нитей.
Вязать — вязание, завязать.
Вязкий — тягучий, липкий, клейкий.
Вязкий — вязкость.
3. Найдите лишнее слово в каждой группе слов. Объясните свой ответ.
Берег, берега, береговой, побережье.
Лишнее слово: берега (форма слова), остальные слова — однокоренные.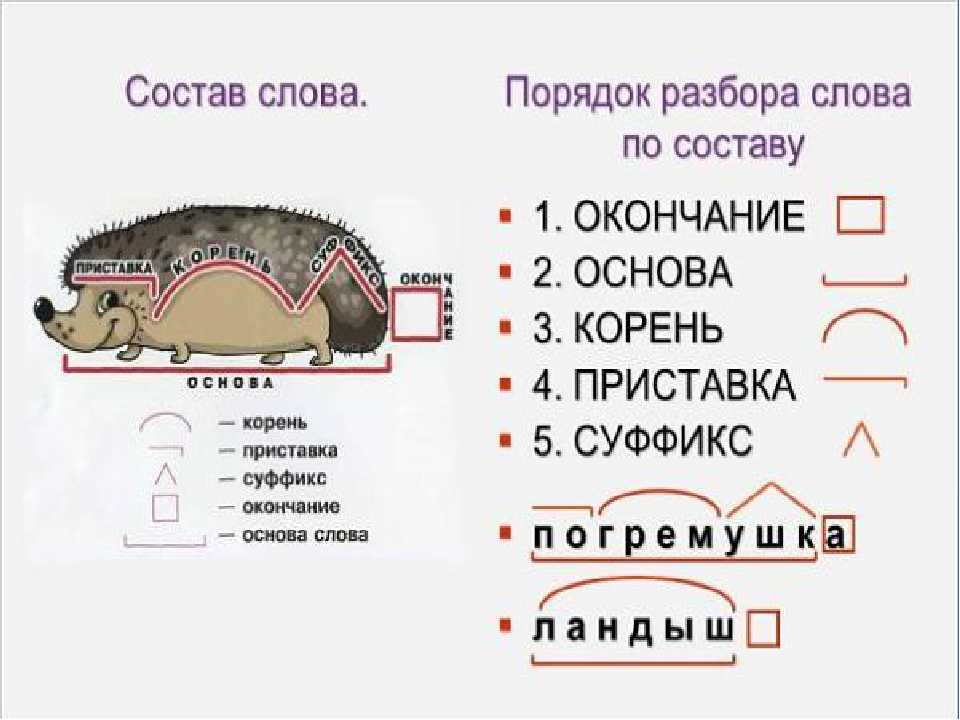
Дальний, синий, зимний, соседний.
Лишнее слово: синий
Солнце, пальто, облако, весна.
Лишнее слово: пальто (употребляются только в одной форме).
4. В какие группы по составу можно объединить данные слова? Назовите часть слов, которая их объединяет.
Белый, побелеть, белизна, голубенький, покраснеть, желтизна, беленький, жёлтый.
белый, жёлтый
белизна, желтизна, голубенький, беленький
побелеть, покраснеть
- Нарисуйте схему состава выделенного слова и подберите другое слово с таким же составом.
беленький зёрн/ышк/о
5. Объясните, в каком порядке вы разберёте по составу слова записка и подоконник.
1. Определяем, что слова изменяются, находим окончание (записк/а — окончание -а, подоконник — нулевое).
2. Выделяем в словах основу — часть без окончания (записк-, подоконник-).
3. Находим корень слова, для этого подбираем однокоренные слова (за/пис/ка — пис/ать, под/пис/ать, пере/пис/ать; под/окон/ник — окн/а, окон/ная).
4. Находим приставку. Для этого подбираем однокоренные слова без приставки или с другой приставкой. Часть слова, которая стоит перед корнем, и будет приставкой: за/писка, под/оконник.
5. Находим в слове суффикс. Для этого подбираем однокоренные слова без суффикса или с другими суффиксами. Часть слова, которая стоит после корня перед окончанием, и будет суффиксом: запис/к/а, подокон/ник/.
6. Образуйте от слова дорога слова со следующими значениями:
а) «маленькая узкая дорога»;
дорожка
б) «тот, кто строит дороги»;
дорожник
в) прилагательное к слову дорога;
дорожный
г) «трава, растущая вдоль дороги».
подорожник
7. Назовите слово.
Приставка, суффикс и окончание те же, что и в слове подберёзовик, корень — как в слове осинник.
подосиновик
Ответы по русскому языку. 3 класс. Учебник. Часть 1. Канакина В. П.
Ответы по русскому языку. 3 класс
языков программирования: синтаксический анализ
языков программирования: синтаксический анализАбстрактный синтаксис
Абстрактный синтаксис — это представление программы, которая:
- абстрагирует ненужные детали конкретного синтаксиса;
- сохраняет только достаточно информации, чтобы мы могли назначить значение (семантика) терминов; и
- соответствует структуре BNF языка.

Разбор означает интерпретацию входного потока как термов на подручном языке. Напомним, что мы рассматриваем язык синтаксиса как состоящего из трех слоев: лексических элементов, контекстно-свободного синтаксиса, и контекстно-зависимый синтаксис. Следовательно, мы будем анализировать язык рассматривая эти три слоя по отдельности.
Лексический анализатор или токенизатор принимает входной поток символов и разбивает его на токены. Для этого курса мы будем использовать Scheme tokenizer, чтобы сделать это за нас.
Синтаксический анализатор берет поток токенов, созданный лексическим анализатором, и строит представление абстрактного синтаксиса программы, называемое
Вернемся к примеру запроса. Запрос:
запрос ::= слово
| НЕ запрашивать
| (запрос И запрос)
Чтобы разобрать запросы, мы должны исправить представление для токенов. и представление для запросов, т.е. для реферата
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
и представление для запросов, т.е. для реферата
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
Слово - символ
НЕ НЕ
И И
(-"("
) - ")"
Предположим, что у нас есть функция tokenize : ввод -> список токенов
который преобразует входной поток в список таких токенов.
Мы возьмем на себя функции сделай-Слово, сделай-Не и сделай-И
построить соответствующие представления запросов.Теперь мы можем написать функцию parse для разбора запросов. Эта функция примет список токенов в качестве входных данных и вернет пара абстрактного запроса и оставшаяся часть ввода.
(определить синтаксический анализ
(лямбда (вход)
(cond ((равно? 'НЕ (автомобильный ввод))
(let* ((r (анализ (ввод cdr)))
(q (автомобиль г))
(остальное (cdr r)))
(минусы(сделать-не д) остальное)))
((символ? (ввод автомобиля))
(минусы (сделать-Word (ввод автомобиля)) (ввод cdr)))
((равно? "(" (автомобильный ввод))
(let* ((r1 (анализ (ввод cdr)))
(q1 (автомобиль r1))
(остаток1 (cdr r1))
(остаток2 (cdr остаток1)); пропустить "И"
(r2 (разбор остальных2))
(q2 (автомобиль r2))
(остальное3 (cdr r2))
(остальное4 (cdr оставшееся3))) ; пропускать ")"
(минусы(сделать-И д1 д2)остальные4)))
(иначе (ошибка "Неверный ввод")))))
Это довольно просто, потому что грамматика для запросов — LL0. Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
секс-выражение ::= #t | #f | номер | символ | символ | () | нить
| (половое выражение . половое выражение) | #(sexp*) | (секс*)
S-выражение вида (sexp .sexp) это пара; s-выражение вида #(sexp*) вектор; и (sexp*) — это список. Списки
представлено с помощью пар и нуля. S-выражения построены
на читается и (цитата sexp) ,
который может быть сокращен 'sexp .Если мы теперь немного изменим синтаксис запросов, чтобы запросы являются подмножеством s-выражений, мы можем использовать s-выражение parser, чтобы сделать часть синтаксического анализа для нас. Давайте переопределим запросы следующим образом:
д ::= слово | (НЕ д) | (И q q)Обратите внимание на круглые скобки, которые теперь требуются вокруг запроса NOT.
 Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
(определить синтаксический анализ
(лямбда (sexp)
(cond ((символ? sexp) (make-Word sexp))
((пара? секс)
(состояние ((равно? 'НЕ (автомобильное выражение))
(сделать-не (разобрать (кадр sexp))))
((равно? 'И (автомобильное секс-выражение))
(make-And (parse (caddr sexp)) (parse (caddr sexp))))
(иначе (ошибка "Неверный ввод"))))
(иначе (ошибка "Неверный ввод")))))
Давайте теперь создадим синтаксический анализатор для подмножества Scheme. мы рассмотрим следующее подмножество:
е ::= #t | #f | () | номер | ...
| Икс
| (лямбда (х*) е)
| (если е е е)
| (cond (e e)* [(else e)])
| (э э*)
Мы будем представлять токены точно так же, как Scheme представляет их в
s-выражения. Мы используем определить-запись средство для создания представлений абстрактного синтаксиса:(определить запись Const (значение)) (определить запись Var (имя)) (определить-записать Лам (формальное тело)) (определить-записать, если (проверить, а затем еще)) (определение-запись Cond (предложения еще)) (определить запись Ap (забавные аргументы))Каждое выражение
(define-record Foo (field1 . .. fieldN)) строит следующие процедуры:  .. fieldN))
.. fieldN)) мейк-фу , Фу? и Foo->field1 через Foo->fieldN .
Они называются конструктором, предикатом и селекторами (или средствами доступа).
для данных типа Foo .
Следующие тождества будут иметь место:(Foo? (make-Foo v1 ... vN)) = #t (Foo->fieldM (make-Foo v1 ... vN)) = vMдля значений
v1 ... vN .
Теперь давайте разберем Схему.
(определить синтаксический анализ
(лямбда (sexp)
(cond ((член sexp '(#t #f ()))
(сделать-константное секс-выражение))
((или (число? секс-выражение) (строка? секс-выражение) (символ? секс-выражение))
(сделать-константное секс-выражение))
((символ? секс-выражение)
(сделать-Var секс))
((пара? секс)
(cond ((равно? 'лямбда (автомобильное выражение))
(сделать-лам (кадр sexp) (разобрать (каддр sexp))))
((равно? 'если (автомобильное выражение))
(make-If (кадр sexp) (каддр sexp) (каддр sexp)))
((равно? 'cond (автомобиль секс))
. .. ...)
(еще
(make-Ap (parse (car seexp)) (map parse (cdr sexp)))))))))
 .. ...)
(еще
(make-Ap (parse (car seexp)) (map parse (cdr sexp)))))))))
.. ...)
(еще
(make-Ap (parse (car seexp)) (map parse (cdr sexp)))))))))
Чтение
- Опытный интриган, главы 11, 12, 13
- EOPL Глава 2
Что такое анализ данных? — Определение парсера данных
Спасибо! Ваша заявка принята!
Ой! Что-то пошло не так при отправке формы.
Синтаксический анализ данных используется для сканирования информации из больших наборов данных и ее структурирования в понятном для человека виде. Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь.
Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь.
Синтаксический анализ данных — это процесс преобразования строки данных из одного формата в другой. Если вы читаете данные в необработанном HTML, анализатор данных поможет вам преобразовать их в более читаемый формат, например, в обычный текст. Не вся информация преобразуется в процессе синтаксического анализа, и программы имеют свои собственные наборы правил, когда речь идет о синтаксическом анализе информации.
Короче говоря, программа анализа данных используется для преобразования неструктурированных данных в JSON, CSV и другие форматы файлов и добавляет структуру к указанной информации.
Определение синтаксического анализа В области компьютерного программирования синтаксический анализ определяется как анализ строки символов, специальных символов и структур данных с использованием обработки естественного языка (NLP). Когда вы определяете извлечение при синтаксическом анализе, это относится к структурированию информации из наборов данных и приданию ей значения путем ее организации на основе определенных пользователем правил.
Когда вы определяете извлечение при синтаксическом анализе, это относится к структурированию информации из наборов данных и приданию ей значения путем ее организации на основе определенных пользователем правил.
Синтаксический анализ имеет разные определения для лингвистов и программистов, но общее мнение состоит в том, что он используется для анализа предложений и отображения семантических отношений между ними. Другими словами, вы определяете извлечение информации из файлов и их фильтрацию как синтаксический анализ.
Типы анализа данныхАнализ данных использует два подхода, когда речь идет о семантическом анализе анализа данных, управляемого текстовой грамматикой, и анализа данных, управляемого данными. Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.
Вот как работают эти два подхода:
1. Анализ данных на основе грамматики Анализ данных на основе грамматики означает, что анализатор использует набор правил формальной грамматики для процесса анализа. Это работает так: предложения из неструктурированных данных фрагментируются и преобразуются в структурированный формат. Проблема анализа данных на основе грамматики заключается в том, что моделям не хватает надежности. Это преодолевается путем ослабления грамматических ограничений, так что предложения, выходящие за рамки правил грамматики, могут быть исключены для последующего анализа. Синтаксический анализ текста является подмножеством анализа грамматики и назначает ряд анализов для данной строки. Он также решает проблемы устранения неоднозначности, с которыми сталкиваются традиционные методы синтаксического анализа.
Анализ данных на основе данных использует вероятностную модель и обходит дедуктивные подходы к анализу текста, которые часто используются в моделях на основе грамматики. В этом типе синтаксического анализа программа синтаксического анализа применяет методы, основанные на правилах, семантические уравнения и обработку естественного языка (NLP) для структурирования и анализа предложений. В отличие от синтаксического анализа на основе грамматики, синтаксический анализ данных на основе данных использует статистические синтаксические анализаторы и современные банки деревьев для получения широкого охвата языков. Анализ разговорных языков и предложений, требующих точности, с немаркированными данными, относящимися к предметной области, подпадает под область анализа данных на основе данных.
Что делает парсер? Он извлекает данные из документов, структурирует их и фильтрует детали.
Синтаксический анализ данных используется различными отраслевыми вертикалями для преобразования информации в электронные форматы из документов. Ниже приведены наиболее популярные варианты использования синтаксического анализа в отраслях:
1. Оптимизация бизнес-процессов Парсеры данных используются компаниями для структурирования неструктурированных наборов данных в полезную информацию. Предприятия используют синтаксический анализ данных для оптимизации своих рабочих процессов, связанных с извлечением данных. Синтаксический анализ используется в области инвестиционного анализа, маркетинга, управления социальными сетями и других бизнес-приложений.
Банки и NBFC используют анализ данных для очистки миллиардов данных о клиентах и извлечения ключевой информации из приложений. Анализ данных используется для анализа кредитных отчетов, инвестиционных портфелей, проверки доходов и получения более полных сведений о клиентах. Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.
3. Доставка и логистика Предприятия, предоставляющие товары/услуги в режиме онлайн, используют анализаторы данных для получения сведений о счетах и доставке. Парсеры используются для упорядочивания отгрузочных этикеток и обеспечения правильного форматирования данных.
Данные о потенциальных клиентах извлекаются из электронных писем владельцев недвижимости и строителей. Технологии парсинга используются для извлечения данных для платформ CRM и обработки документации для передачи агентам по недвижимости. Благодаря контактным данным, адресам собственности, данным о денежных потоках и источникам потенциальных клиентов, парсеры очень полезны для компаний, занимающихся недвижимостью, когда речь идет о покупках, аренде и продажах.
Стоит ли создавать собственный парсер?Распространенный вопрос, который постоянно возникает при обработке документов в организациях, заключается в том, следует ли создавать собственный анализатор данных. Специальное программное обеспечение для синтаксического анализа текста, созданное для внутренних команд, определенно создано с учетом конкретных требований к синтаксическому анализу в организациях.
Однако недостатком является то, что весь персонал должен быть обучен тому, как им пользоваться. Затраты на создание пользовательской программы синтаксического анализа могут быть высокими, поскольку требуется больше времени и ресурсов. Кроме того, эти решения требуют тщательного планирования и собственных выделенных серверов для более быстрого анализа. Если вы переносите системы, они могут быть несовместимы с новыми технологиями и потребуют обновления.
Идеальным сценарием является использование анализатора данных, совместимого с устаревшими системами и предназначенного для различных вариантов использования. Парсер данных Docsumo дает вам полный контроль над извлечением данных и предназначен для работы со всеми типами предприятий, будь то стартапы, предприятия или крупные организации.
Заключение Анализ данных делает информацию доступной для организаций и упрощает ее чтение. Преобразованные данные могут быть эффективно переданы клиентам, а синтаксические анализаторы предназначены для обеспечения гибкости и масштабируемости бизнес-операций по своей природе.