Фонетика. Графика. Орфоэпия. Фонетический анализ слова
Слайд 1
Описание слайда:
Фонетика. Графика. Орфоэпия Фонетический анализ слова
Слайд 2
Описание слайда:
Запишите высказывание К.Паустовского. Вставьте буквы и знаки препинания. Слова то ш…лестят как трава то б…рмочут как родники то пер…свистываются как птицы то п…званивают как первый лед.
Слайд 3
Описание слайда:
Проверяем Слова то шелестят, как травы, то бормочут, как родники, то пересвистываются, как птицы, то, перезваниваются, как первый лед.
Слайд 4
Описание слайда:
В название какого раздела науки о языке входит часть слов телефон, магнитофон, микрофон?
Слайд 5
Описание слайда:
Что изучает фонетика?
Слайд 6
Описание слайда:
Звуки, при образовании которых воздушная струя проходит через рот без препятствий.
Слайд 7
Описание слайда:
При образовании этих звуков воздушная струя проходит через рот, преодолевая различные препятствия.
Слайд 8
Описание слайда:
Сколько гласных звуков в русском языке?
Слайд 9
Описание слайда:
Гласные делятся на…. Ударные Безударные
Слайд 10
Описание слайда:
Сколько согласных звуков в русском языке?
Слайд 11
Описание слайда:
Согласные звуки делятся на… Глухие Звонкие
Слайд 12
Описание слайда:
Слайд 13
Описание слайда:
Слайд 14
Описание слайда:
Какие буквы называют йотированными?
Слайд 15
Описание слайда:
Потренируемся
Слайд 16
Описание слайда:
Какими звуками и буквами различаются следующие пары слов? Вол – вёл, плоты – плоды, супы – зубы, лук – люк, мол – мель
Слайд 17
Описание слайда:
Запишите слова, которые образуются, если прочитать в обратном порядке транскрипцию следующих слов.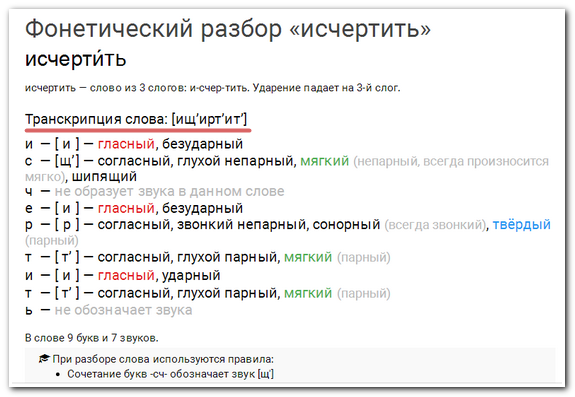 Лён, лей, люк, ток, шёл, шей
Лён, лей, люк, ток, шёл, шей
Слайд 18
Описание слайда:
Фонетические процессы
В потоке речи звуки влияют друг на друга, что приводит к их изменению. Эти изменения звуков называются фонетическими процессами.
Основные фонетические процессы, связанные с согласными звуками.
1. Оглушение звонких парных на конце слова: Род [ рот ], флаг [ флак ].
2. Оглушение звонких парных перед глухими: Селедка [ селетка ], в траву [ фтраву].
3. Озвончение глухих парных перед звонкими (кроме сонорных и [ в ], [ в` ]: Косьба [каз`ба], к дереву [ гд`эр`иву ].
4. Расподобление звуков – усиление различий между звуками для облегчения произношения. НАПРИМЕР, в слове легкий вместо звуков [гк` ] произносим сочетание [ хк` ], что облегчает произношение слова.
5. Упрощение групп согласных происходит в словах, где есть непроизносимые согласные: в сочетании из трех согласных один не произносится:
снт – [ сн ]: устный – у[ сн ]ый;
здн – [ зн ]: поздний – по[ зн]ий;
лнц – [ нц ]: солнце – со[ нц ]е;
рдц – [ рц ]: сердце – се[ рц ]е.
Слайд 19
Описание слайда:
Задание. Определите, какой согласный звук (глухой или звонкий) обозначен подчеркнутой буквой. Какие фонетические процессы наблюдаются в приведенных словах? Забастовка, сдаться, от дома, любовь, что, указка, честный, счастливый, рябь, мороз, расчет, к берегу.
Слайд 20
Описание слайда:
Орфоэпия — наука (раздел фонетики), занимающаяся нормами произношения, их обоснованием и установлением.
Слайд 21
Описание слайда:
Произношение сочетаний ЧН, ЧТ
В современном языке слова с сочетанием ЧН можно разделить на три группы:
1. те, в который чт произносится как [шн]: конечно, скучно, яичница, двоечник, прачечная, девичник, а также женские отчества на –чна: Ильинична, Кузьминична и др.
Слайд 22
Описание слайда:
Упражнение. Прочитайте данные слова обращая внимание на произношение ЧН. Потому что, Кузьминична, табачный, молочный, нечто, булочная, девичник, очечник, нарочно, яичница, шуточный, троечник, Фоминична, подсолнечник, бесконечный, двоечник, скучно, конечный.
Описание слайда:
Произношение согласных перед Е в заимствованных словах Сравните: Тень, дерево, песок, месяц, век, мелочь, академия, бассейн. Бизнес, Шопен, безе, мате, латте, рейтинг.
Слайд 24
Описание слайда:
Ударение
В русском языке ударение свободное. Роль ударения:
Различает разные слова (мУка – мукА)
Различает некоторые формы разных слов (ношУ – нОшу, крУжки – кружкИ)
различает формы одного слова (снЕга – снегА)
Роль ударения:
Различает разные слова (мУка – мукА)
Различает некоторые формы разных слов (ношУ – нОшу, крУжки – кружкИ)
различает формы одного слова (снЕга – снегА)
Слайд 25
Описание слайда:
План фонетического разбора 1 Орфографическая запись слова. 2 Деление слова на слоги и место ударения. 3 Фонетическая транскрипция слова. 4 Характеристика всех звуков по порядку: а) согласный – звонкий – глухой (парный – непарный), твёрдый – мягкий (парный – непарный), какой буквой обозначен; б) гласный: ударный – безударный. 5 Количество звуков и букв.
Слайд 26
Описание слайда:
Сделайте фонетический анализ слов Сеять, настроение, образ, вправо, низкий, скучный, ёжиться.
Слайд 27
Описание слайда:
Домашнее задание
Фонетический разбор слов:
сеять, яичница, ложь. Выписать все формы указанных глаголов прошедшего времени (м.р, ж.р., ср. р.) и расставить в них ударение:
Начать, брать, сеять, класть, винить.
Выписать все формы указанных глаголов прошедшего времени (м.р, ж.р., ср. р.) и расставить в них ударение:
Начать, брать, сеять, класть, винить.
Фонетика. Фонетический анализ слова — презентация онлайн
Фонетика.
Фонетический анализ слова
Запишите высказывание К.
Паустовского.
Вставьте буквы и знаки препинания.
Слова то ш…лестят как трава то
б…рмочут как родники то
пер…свистываются как птицы то
п…званивают как первый лед.
Словарная работа
Сертифика̀т – документ, удостоверяющий права
на что-либо (документ, удостоверяющий качество товара).
Толера̀нтность – терпение к чужому мнению,
культуре, религии.
Что изучает фонетика?
Звуки, при образовании
которых воздушная
струя проходит через рот
без препятствий.
При образовании этих звуков воздушная
струя проходит через рот, преодолевая
различные препятствия.
Сколько гласных звуков
в русском языке?
Сколько гласных звуков
в русском языке?
Гласные делятся на….
Ударные
Безударные
Буквы Е,Ё,Ю,Я обозначают
Один звук
После согласного
лёд – Ё = [ о]
мячик – Я = [а]
пюре – Ю = [у]
Два звука
В остальных случаях
( в начале слова,
после Ь и Ъ,
после согласных)
ёжик –Ё = [й᾿о]
маячить –Я = [й᾿а]
вьюга –Ю = [ й᾿у]
Сколько согласных
звуков в русском языке?
Сколько согласных
звуков в русском языке?
Согласные звуки делятся на…
Глухие
Звонкие
Всегда твердыми являются согласные
звуки:
•[Ж]
•[Ш]
•[Ц]
Исключение:жюри -[ж᾿]ури
Всегда мягкими являются согласные звуки:
•[Й᾿]
•[Ч᾿]
•[Щ᾿]
Исключения:
помощник-помо[ш]ник,
всенощная- всено[ш]ная
Буквы Е,Ё,Ю,Я,И,Ь
•Показывают на письме
мягкость предшествующего
согласного:
певунья, мягкими
Буквы Ь и Ъ
НЕ обозначают звуков!
Потренируемся
Какими звуками и буквами различаются
следующие пары слов?
Вол – вёл, плоты – плоды,
супы – зубы, лук – люк,
мол – мель
Запишите слова, которые образуются, если
прочитать в обратном порядке
транскрипцию следующих слов.
Лён, лей, люк, ток, шёл, шей.
Фонетические процессы
1. Редукция
2. Оглушение
3. Озвончение
4. Выпадение
5. Смягчение
6. Стяжение
Фонетические процессы
В потоке речи звуки влияют друг на друга, что приводит к их изменению. Эти
изменения звуков называются фонетическими процессами.
Основные фонетические процессы, связанные с согласными звуками.
1. Оглушение звонких парных на конце слова: Род [ рот ], флаг [ флак ].
2. Оглушение звонких парных перед глухими: Селедка [ селетка ], в траву [
фтраву].
3. Озвончение глухих парных перед звонкими (кроме сонорных и [ в ], [ в` ]:
Косьба [каз`ба], к дереву [ гд`эр`иву ].
4. Расподобление звуков – усиление различий между звуками для облегчения
произношения. НАПРИМЕР, в слове легкий вместо звуков [гк` ] произносим
сочетание [ хк` ], что облегчает произношение слова.
5. Упрощение групп согласных происходит в словах, где есть
непроизносимые согласные: в сочетании из трех согласных один не
произносится:
снт – [ сн ]: устный – у[ сн ]ый;
здн – [ зн ]: поздний – по[ зн]ий;
лнц – [ нц ]: солнце – со[ нц ]е;
рдц – [ рц ]: сердце – се[ рц ]е.
Задание. Определите, какой согласный
звук (глухой или звонкий) обозначен
подчеркнутой буквой. Какие
фонетические процессы наблюдаются в
приведенных словах?
Забастовка, сдаться, от дома,
любовь, что, указка, честный,
счастливый, рябь, мороз, расчет,
к берегу.
Какие фонетические процессы
происходят в словах?
Молодёжь, просьба,
вестник, кость, учиться,
сожалеть, сочувствовать,
робкий, молотьба, сугроб,
расчёт.
Вставьте пропущенные буквы
Полезный тру…, дальнее
ро…ство, высший
пилота…, издер…ки
производства,
неожиданная развя…ка,
настоятельная про…ьба
Вставьте пропущенные буквы
Аген…ство, доблес…ный,
я…ственный, ярос…ный,
сверс…ник;
ровес…ник, чудес…ный,
ужас…ный;
праз…ник, чу…ство,
я…ства.
План фонетического разбора
1
2
3
4
Орфографическая запись слова.
Деление слова на слоги и место ударения.
Фонетическая транскрипция слова.
Характеристика всех звуков по порядку:
•а) согласный – звонкий – глухой (парный –
непарный), твёрдый – мягкий (парный –
непарный), какой буквой обозначен;
•б) гласный: ударный – безударный.
5
Количество звуков и букв.
Сделайте фонетический анализ слов
Сеять, настроение, образ,
вправо, низкий, скучный,
ёжиться.
ВЫПОЛНИТЕ ТЕСТ
1. В каком ряду во всех словах пропущена безударная
проверяемая гласная корня?
1
встр…чать, в…рховный, уд…влённый
2
апл…дисменты, укр…тить, совм…щать
3
изл…жение, пров…нциальный, р…дколесье
4
д…ректор, зад…рать, нап…дающий
2. В каком ряду во всех словах пропущена безударная
проверяемая гласная корня?
1
п…лисадник, насл…ждение, просл…влять
2
пр…зидиум, пр…вилегии, беспр…кословно
3
ог…рчение, побл…дневший, в…риант
4
сат…рический, перекл…каться, л…гичность
3. В каком ряду во всех словах пропущена безударная
проверяемая гласная корня?
1
покл…нение, ст…пендия, предпол…жение
2
пер…одический, амн…стировать, умн…жение
3
д…агноз, происх…дить, пож…лать
4
подг…рел, сп…сать, в…стибюль
4. В каком ряду во всех словах пропущена безударная
проверяемая гласная корня?
1
г…ниальный, п…ссимист, трад…ционный
2
соб…раться, зам…нить, ап…лляция
3
просв…щение, асф…льтированный, нак…рмить
4
м…гистраль, м…теринский, опров…ргать
5. В каком ряду во всех словах пропущена чередующаяся
В каком ряду во всех словах пропущена чередующаяся
безударная гласная в корне?
1
з…рница, прик…саться, прор…сти
2
обл…денение, поб…дитель, кр…тиковать
3
м…рковь, ув…деть, пл…тить
4
д…рога, уд…вление, ст…ловый
6. В каком ряду во всех словах пропущена чередующаяся
безударная гласная?
1
прик…сновение, дог…нять, ед…ница
2
ап…лляция, прид…раться, экспер…мент
3
к…сательная, соск…чить, м…кать кисть в краску
4
к…ртина, опт…мизм, взб…раться
7. В каком ряду во всех словах пропущена чередующаяся
безударная гласная в корне?
1
соб…рутся, заг…релый, к…ммерсант
2
разб…рать, подж…гать, ск…чок
3
к…пошится, предв…рительный, зар…сли
4
с…туация, ср…жаться, б…седующий
8. В каком ряду во всех словах пропущена безударная
чередующаяся гласная?
1
покл…нение, прил…жение, з…мовщики
2
в…стибюль, всп…хать, уед…нение
3
р. ..внение, заг…релый, прик…сновение
..внение, заг…релый, прик…сновение
4
пож…лать, оч…рование, бл…стательный
Домашнее задание
• Фонетический разбор слов:
•сеять, яичница, ложь.
• Выписать все формы указанных глаголов прошедшего времени
(м.р, ж.р., ср. р.) и расставить в них ударение:
•Начать, брать, сеять, класть, винить.
|
Заглавная страница
КАТЕГОРИИ: Археология ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрации Техника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ? Влияние общества на человека Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. |
⇐ ПредыдущаяСтр 5 из 5 Начальная форма: АРОМАТ Часть речи: существительное Грамматика: единственное число, мужской род, неодушевленное, творительный падеж Формы: аромат, аромата, аромату, ароматом, аромате, ароматы, ароматов, ароматам, ароматами, ароматах Анализ текста Тема: наступила осень. Тип речи текста: описание Стиль текста: художественный
Билет №29 1) устное задание: 2) Практическое задание А он, мятежный, просит бури. Привлеченные светом, бабочки прилетели и кружились около фонаря. Вставить пропущенные буквы, сделать синтаксический разбор, фонетический разбор слова, морфологический разбор. Синтаксический разбор:Водой холодной обтирайся, если хочешь быть здоров. Предложение: Побудительное, невосклицательное, простое, двусоставное, распространенное. Фонетический разбор: Водой в [в] — согласный, твердый, звонкий, парный о [`о] — гласный, безударный д [д] — согласный, твердый, звонкий, парный о [а] — гласный, ударный й [й’] — согласный, мягкий, звонкий, непарный, сонорный Морфологический разбор: холодной Начальная форма: ХОЛОДНЫЙ Часть речи: прилагательное Грамматика: единственное число, женский род, качественное прилагательное, родительный падеж Формы: холодный, холодного, холодному, холодным, холодном, холодная, холодной, холодную, холодною, холодное, холодные, холодных, холодными, холоден, холодна, холодно, холодны, холоднее, холодней, похолоднее, похолодней, холоднейший, холоднейшего, холоднейшему, холоднейшим, холоднейшем, холоднейшая, холоднейшей, холоднейшую, холоднейшею, холоднейшее, холоднейшие, холоднейших, холоднейшими Анализ текста Тема: искусство как воспитание Тип речи текста: рассуждение Стиль текста: художественный.
Морфологический разбор: березе Начальная форма: БЕРЕЗА Часть речи: существительное Грамматика: дательный падеж, слово обычно не имеет множественного числа, единственное число, женский род, неодушевленное Формы: береза, березы, березе, березу, березой, березою. Анализ текста Тема текста: Россия – мать Тип речи текста: рассуждение Стиль текста: художественный
Билет №23 1) устное задание 2) практическое задание Наступила дождливая, грязная темная ночь. Длинный товарный поезд уже давно стоит на полустанке. Вставить пропущенные буквы, сделать синтаксический разбор, фонетический разбор слова, морфологический разбор. Синтаксический разбор предложения:Прямо против окна, на противоположной стороне, высился красивый барский дом. Предложение: Повествовательное, невосклицательное, простое, двусоставное, распространенное. Фонетический разбор: стороне с [с] — согласный, твердый, глухой, парный т [т] — согласный, твердый, глухой, парный о [а] — гласный, безударный р [р] — согласный, твердый, звонкий, непарный, сонорный о [а] — гласный, безударный н [н] — согласный, твердый, звонкий, непарный, сонорный е [э] — гласный, ударный. Морфологический разбор: Высился Начальная форма: ВЫСИТЬСЯ Часть речи: глагол в личной форме Грамматика: действительный залог, единственное число, мужской род, непереходный, несовершенный вид, прошедшее время Формы: выситься, вышусь, высимся, высишься, выситесь, высится, высятся, высился, высилась, высилось, высились, высясь, высившись, высься, высьтесь, высящийся, высящегося, высящемуся, высящимся, высящемся, высящаяся, высящейся, высящуюся, высящеюся, высящееся, высящиеся, высящихся, высящимися, высившийся, высившегося, высившемуся, высившимся, высившемся, высившаяся, высившейся, высившуюся, высившеюся, высившееся, высившиеся, высившихся, высившимися Анализ текста Тема текста: яблоня Определение типа речи текста: рассуждение Определение стиля: …………
Билет №24 1) устное задание: старославянизмы. Старославянизмы — слова, заимствованные из старославянского языка, языка богослужебных книг. Классификация по группам: Восходящие к общеславянскому языку Старославянизмы, имевшие восточнославянские варианты, отличавшиеся своим звучанием или аффиксальным оформлением: злато, нощь, рыбарь, ладья, врата, чреда (очередь), плен (полон) Без созвучия с русскими словами Старославянизмы без созвучных русских слов: перст, уста, ланиты (щёки), перси (грудь). Семантические. 2) практическое задание На митингах, мы, газетчики, узнавали много новостей. Лютейший бич небес, природы ужас — мор свирепствует в лесах. Вставить пропущенные буквы, сделать синтаксический разбор, фонетический разбор слова, морфологический разбор. Синтаксический разбор:Я приготовился стрелять, но птица из кустов не вылетела. Предложение: повествовательное, невосклицательное, сложное, связь союзная, ССП. Фонетический разбор: Птица Пти´ца – слово из 2 слогов, 1-й ударный п — [п] — согл., глух., тв. т — [т’] — согл., глух., мягк. и — [и´] — гл., ударн. Ц — [ц] — согл., глух. непарн., тв. непарн. а — [ъ] — гл.. безуд. Морфологический разбор: кустов Начальная форма: КУСТ Часть речи: существительное Грамматика: множественное число, мужской род, неодушевленное, родительный падеж Формы: куст, куста, кусту, кустом, кусте, кусты, кустов, кустам, кустами, кустах Анализ текста Тема: человек должен быть интеллигентным Тип речи текста: рассуждение Стиль текста: разговорный
Билет №25 1) устное задание: Диалектные слова. Слова-термины Диалектные слова — это слова, употребляемые только жителями той или иной местности. Термин — это определенное слово, обозначающее специальное понятие, которое относится к той или иной области техники, науки, искусства и т. д. (технический термин, научный термин, религиозный термин) . Термин не может иметь двойного значения. Используется в специализированной литературе, тематических беседах и т. д. 2) практическое задание Конечно, не один Евгений смятенье Тани видеть мог. Берег, как я уже сказал, был низкий песчаный. Вставить пропущенные буквы, сделать синтаксический разбор, фонетический разбор слова, морфологический разбор. Синтаксический разбор:Рядом за столиком сидела компания молодых людей, которые громко спорили о футбольном матче. Предложение: повествовательное, невосклицательное, простое, двусоставное, распространенное. Фонетический разбор: столиком с [с] — согласный, твердый, глухой, парный т [т] — согласный, твердый, глухой, парный о [`о] — гласный, ударный л [л’] — согласный, мягкий, звонкий, непарный, сонорный и [и] — гласный, безударный к [к] — согласный, твердый, глухой, парный о [`о] — гласный, безударный м [м] — согласный, твердый, звонкий, непарный, сонорный. Морфологический разбор: сидела Начальная форма: СИДЕТЬ Часть речи: глагол в личной форме Грамматика: действительный залог, единственное число, женский род, непереходный, несовершенный вид, прошедшее время Формы: сидеть, сижу, сидим, сидишь, сидите, сидит, сидят, сидел, сидела, сидело, сидели, сидя, сидев, сидевши, сиди, сидящий, сидящего, сидящему, сидящим, сидящем, сидящая, сидящей, сидящую, сидящею, сидящее, сидящие, сидящих, сидящими, сидевший, сидевшего, сидевшему, сидевшим, сидевшем, сидевшая, сидевшей, сидевшую, сидевшею, сидевшее, сидевшие, сидевших, сидевшими. Анализ текста Тема: ежедневные записи Тип речи текста: повествование Стиль текста: публицистический
Билет 1) устное задание: 2) Практическое задание На лавке у окна сидел отец. Во время сильных дождей река разливается по – весеннему, бурно и шумно, и тогда дает себя знать. Вставить пропущенные буквы, сделать синтаксический разбор, фонетический разбор слова, морфологический разбор. Синтаксический разбор:Ранние утренники, схватив листву деревьев, окрасили ее золотыми, лиловыми и пунцовыми красками. Предложение: повествовательное, невосклицательное, простое, двусоставное, распространенное. Фонетический разбор: окрасили о [а] — гласный, безударный к [г] — согласный, твердый, звонкий, парный р [р] — согласный, твердый, звонкий, непарный, сонорный а [`а] — гласный, ударный с [с’] — согласный, мягкий, глухой, парный и [и] — гласный, безударный л [л] — согласный, твердый, звонкий, непарный, сонорный и [и] — гласный, безударный ⇐ Предыдущая12345 Читайте также: Как правильно слушать собеседника Типичные ошибки при выполнении бросков в баскетболе Принятие христианства на Руси и его значение Средства массовой информации США |
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 1190; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia. |

 Определение реакций опор и моментов защемления
Определение реакций опор и моментов защемления





 Например, в русских народных говорах существуют слова «барка» (льдина), «браный» (вытканный узорами, узорчатый), «девъё» (девушки), «зыбка» (подвесная колыбель), «мряка» (сырая, тёмная погода с моросящим дождём). Речь жителей той или иной местности называют диалектом.
Например, в русских народных говорах существуют слова «барка» (льдина), «браный» (вытканный узорами, узорчатый), «девъё» (девушки), «зыбка» (подвесная колыбель), «мряка» (сырая, тёмная погода с моросящим дождём). Речь жителей той или иной местности называют диалектом.

 su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь — 176.9.44.166 (0.011 с.)
su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь — 176.9.44.166 (0.011 с.)Презентация — Фонетика — Графика — Орфоэпия
Слайд 1
Фонетика. Графика. Орфоэпия
Фонетический анализ слова
Слайд 2
Запишите высказывание К.Паустовского. Вставьте буквы и знаки препинания.
Слова то ш…лестят как трава то б…рмочут как родники то пер…свистываются как птицы то п…званивают как первый лед.
Слайд 3
Проверяем
Слова то шелестят, как травы, то бормочут, как родники, то пересвистываются, как птицы, то, перезваниваются, как первый лед.
Слайд 4
В название какого раздела науки о языке входит часть слов телефон, магнитофон, микрофон?
Фонетика
Слайд 5
Что изучает фонетика?
Звуки речи
Слайд 6
Звуки, при образовании которых воздушная струя проходит через рот без препятствий.
Гласные звуки
Слайд 7
При образовании этих звуков воздушная струя проходит через рот, преодолевая различные препятствия.
Согласные звуки
Слайд 8
Сколько гласных звуков в русском языке?
Гласных звуков шесть:
[и], [ы], [у], [э], [о], [а].
Слайд 9
Гласные делятся на….
Ударные Безударные
Слайд 10
Сколько согласных звуков в русском языке?
36
Слайд 11
Согласные звуки делятся на…
Глухие Звонкие
Слайд 12
Слайд 13
Слайд 14
Какие буквы называют йотированными?
Слайд 15
Потренируемся
Слайд 16
Какими звуками и буквами различаются следующие пары слов?
Вол – вёл, плоты – плоды,
супы – зубы, лук – люк,
мол – мель
Слайд 17
Запишите слова, которые образуются, если прочитать в обратном порядке транскрипцию следующих слов.
Лён, лей, люк, ток, шёл, шей
ноль
ель
куль
кот
ложь
ешь
Слайд 18
Фонетические процессы
В потоке речи звуки влияют друг на друга, что приводит к их изменению. Эти изменения звуков называются фонетическими процессами.
Основные фонетические процессы, связанные с согласными звуками.
1. Оглушение звонких парных на конце слова: Род [ рот ], флаг [ флак ]. 2. Оглушение звонких парных перед глухими: Селедка [ селетка ], в траву [ фтраву]. 3. Озвончение глухих парных перед звонкими (кроме сонорных и [ в ], [ в` ]: Косьба [каз`ба], к дереву [ гд`эр`иву ].
4. Расподобление звуков – усиление различий между звуками для облегчения произношения. НАПРИМЕР, в слове легкий вместо звуков [гк` ] произносим сочетание [ хк` ], что облегчает произношение слова.
5. Упрощение групп согласных происходит в словах, где есть непроизносимые согласные: в сочетании из трех согласных один не произносится:
снт – [ сн ]: устный – у[ сн ]ый; здн – [ зн ]: поздний – по[ зн]ий; лнц – [ нц ]: солнце – со[ нц ]е; рдц – [ рц ]: сердце – се[ рц ]е.
Эти изменения звуков называются фонетическими процессами.
Основные фонетические процессы, связанные с согласными звуками.
1. Оглушение звонких парных на конце слова: Род [ рот ], флаг [ флак ]. 2. Оглушение звонких парных перед глухими: Селедка [ селетка ], в траву [ фтраву]. 3. Озвончение глухих парных перед звонкими (кроме сонорных и [ в ], [ в` ]: Косьба [каз`ба], к дереву [ гд`эр`иву ].
4. Расподобление звуков – усиление различий между звуками для облегчения произношения. НАПРИМЕР, в слове легкий вместо звуков [гк` ] произносим сочетание [ хк` ], что облегчает произношение слова.
5. Упрощение групп согласных происходит в словах, где есть непроизносимые согласные: в сочетании из трех согласных один не произносится:
снт – [ сн ]: устный – у[ сн ]ый; здн – [ зн ]: поздний – по[ зн]ий; лнц – [ нц ]: солнце – со[ нц ]е; рдц – [ рц ]: сердце – се[ рц ]е.
Слайд 19
Задание. Определите, какой согласный звук (глухой или звонкий) обозначен подчеркнутой буквой. Какие фонетические процессы наблюдаются в приведенных словах?
Какие фонетические процессы наблюдаются в приведенных словах?
Забастовка, сдаться, от дома, любовь, что, указка, честный, счастливый, рябь, мороз, расчет, к берегу.
Слайд 20
Орфоэпия
— наука (раздел фонетики), занимающаяся нормами произношения, их обоснованием и установлением.
звОнит // звонИт
Слайд 21
Произношение сочетаний ЧН, ЧТ
В современном языке слова с сочетанием ЧН можно разделить на три группы:
1. те, в который чт произносится как [шн]: конечно, скучно, яичница, двоечник, прачечная, девичник, а также женские отчества на –чна: Ильинична, Кузьминична и др.
2. те, в который чн произносится как [ч’н]: точно, удачный, маскировочный и др.
3. те, в которых оба варианта считаются нормативными: подсвечник, булочная, горничная, порядочный и др.
Слайд 22
Упражнение. Прочитайте данные слова обращая внимание на произношение ЧН.
Потому что, Кузьминична, табачный, молочный, нечто, булочная, девичник, очечник, нарочно, яичница, шуточный, троечник, Фоминична, подсолнечник, бесконечный, двоечник, скучно, конечный.
Слайд 23
Произношение согласных перед Е в заимствованных словах
Сравните:
Тень, дерево, песок, месяц, век, мелочь, академия, бассейн.
Бизнес, Шопен, безе, мате, латте, рейтинг.
Слайд 24
Ударение
В русском языке ударение свободное.
Роль ударения:
Различает разные слова (мУка – мукА)
Различает некоторые формы разных слов (ношУ – нОшу, крУжки – кружкИ)
различает формы одного слова (снЕга – снегА)
Слайд 25
План фонетического разбора
1 Орфографическая запись слова.
2 Деление слова на слоги и место ударения.
3 Фонетическая транскрипция слова.
4 Характеристика всех звуков по порядку:
а) согласный – звонкий – глухой (парный – непарный), твёрдый – мягкий (парный – непарный), какой буквой обозначен;
б) гласный: ударный – безударный.
5 Количество звуков и букв.
Слайд 26
Сделайте фонетический анализ слов
Сеять, настроение, образ, вправо, низкий, скучный, ёжиться.
Слайд 27
Домашнее задание
Фонетический разбор слов:
сеять, яичница, ложь.
Выписать все формы указанных глаголов прошедшего времени (м.р, ж.р., ср. р.) и расставить в них ударение:
Начать, брать, сеять, класть, винить.
Тест «Готовимся к ГИА. Задание А4. Фонетический анализ слова»
Категория: Русский язык.
Тест «Готовимся к ГИА. Задание А4. Фонетический анализ слова»
Задание 1.
Выпишите слова, в которых произносится:
А) гласный звук [ ы]:
Прыжок, сила, специи, имя, цыган, щиплет, зажим, циркуль, наивная, перешить.
Б) гласный звук [ а]:
Площадь, часть, ясень, тяжёлый, рьяный, пояс, жалеть, вяжу, диван, тянет
В) гласный звук [ о]:
Ёлка, вода, комар, герцог, строитель, шоссе, порядок, тёмный, корабль, забота.
Г) звук [ й ‘]:
Лейка, тюльпан, объём, песня, ягода, потёмки, йогурт, чьи-то, вьюга, поезд.
Задание 2.
А) Выпишите все слова, в которых все согласные звуки твёрдые.
Честь, жизнь, биться, редко, циновка, бокал, язык, рожь, тихий, щавель, песня, борщ, царь, шлюпка, ружьё.
Б) Выпишите все слова, в которых все согласные звуки глухие.
Город, молотьба, кайма, подход, цапля, шёпот, вступить, юг, бездна, подчинить, дверца, похож, сговор.
В) Выпишите все слова, в которых звуков больше, чем букв.
Пирожное, крыльцо, пьёшь, якорь, неизвестный, юмор, отъезд, лающий, сторож, вещь, тянуть, соловьи, тёрка, поёт.
Задание 3.
Выпишите слова, в которых мягкий знак служит для обозначения мягкости предыдущего согласного.
Спрячьте, пароль, встреть, ручьи, разрежь, тень, вещь, пыльный, письменный, восемьсот, литься, шьют, ведьма, ходить, поёшь, коньки, мольба, настежь.
Реши самостоятельно тесты.
1. Укажите ошибочное суждение.
1) В слове РАДОСТНЫЙ есть буква, обозначающая непроизносимый звук.
2) В слове ПЛАТЬЕ звуков меньше, чем букв.
3) В слове ГВОЗДЬ последний звук [т’].
4) В слове РОСКОШЬ все согласные звуки твёрдые.
2. Укажите ошибочное суждение.
1) В слове АЛЛЕЯ звуков меньше, чем букв.
2) В слове СЧАСТЛИВЫЙ есть буква, обозначающая непроизносимый звук.
3) В слове МОЛОТЬБА есть звук [д’].
4) В слове МАЛЫШ все согласные звуки твёрдые.
3. Укажите ошибочное суждение.
1) В слове ЕЖЕВИКА звуков больше, чем букв.
2) В слове ЛЕСТНИЦА есть буква, обозначающая непроизносимый звук.
3) В слове ЮБКА есть звук [п].
4) В слове ОТРЕЖЬТЕ мягкость согласного [ж’] на письме обозначена буквой Ь (мягкий знак).
4. Укажите ошибочное суждение.
1) В слове ПРОГРАММА звуков меньше, чем букв.
2) В слове МЫШЬ один из согласных звуков мягкий.
3) В слове СЕРДЦЕ есть буква, обозначающая непроизносимый звук.
4) В слове СЪЕЗД последний звук – [т].
5. Укажите ошибочное суждение.
1) В слове УЧАСТНИК есть буква, обозначающая непроизносимый согласный.
2) В слове МЕСТНОСТЬ звуков меньше, чем букв.
3) В слове КОСЬБА есть звук [з’].
4) В слове ЮБИЛЯР все согласные звуки мягкие.
6. Укажите ошибочное суждение.
1) В слове ВТРОЕ первый звук – [ф].
2) В слове ВЕСТНИК есть буква, обозначающая непроизносимый звук.
3) В слове БУЛЬОН звуков меньше, чем букв.
4) В слове ПОЁШЬ есть мягкий звонкий звук [й’]
7. Укажите ошибочное суждение.
1) В слове ЧУВСТВО есть буква, обозначающая непроизносимый согласный.
2) В слове ИЗВЕСТНОСТЬ звуков меньше, чем букв.
3) В слове ПРОСЬБА есть звук [с’].
4) В слове ПИСЬМО мягкость согласного [с’] на письме обозначена буквой Ь (мягкий знак).
8. Укажите ошибочное суждение.
1) В слове ОБЪЯСНИ звуков больше, чем букв.
2) В слове ПРАЗДНИК есть буква, обозначающая непроизносимый согласный.
3) В слове СДАЧА первый звук – [з].
4) В слове ПЛЯСАТЬ мягкость согласного [л’] на письме обозначена буквой Я.
9. Укажите ошибочное суждение.
1) В слове ОБЪЯВЛЕНИЕ звуков больше, чем букв.
2) В слове ТРОСТНИК есть буква, обозначающая непроизносимый звук.
3) В слове ОТГАДАТЬ второй звук – [д].
4) В слове ПЕСНЯ все согласные звуки твёрдые.
10. Укажите ошибочное суждение.
1) В слове ЯРОСТНЫЙ есть буква, обозначающая непроизносимый согласный.
2) В слове ВЬЮГА количество звуков равно количеству букв.
3) В слове СДЕЛКА первый звук – [с].
4) В слове БОРЬБА мягкость согласного [р’] на письме обозначена буквой Ь (мягкий знак).
11. Укажите ошибочное суждение.
1) В слове ТРОСТНИК есть буква, обозначающая непроизносимый звук.
2) В слове ЕЖИХА все согласные звуки твёрдые.
3) В слове ЛЕНЬ мягкость согласного [н’] на письме обозначена буквой Ь (мягкий знак).
4) В слове ГРАД последний звук [т].
12. Укажите ошибочное суждение.
1) В слове МЫШЬ мягкость согласного [ш’] на письме обозначена буквой Ь (мягкий знак)
2) В слове МОЛОДЕЕШЬ одинаковое количество букв и звуков.
3) В слове КОСЬБА есть звук [з’].
4) В слове ПРАЗДНИК есть буква, обозначающая непроизносимый звук.
13. Укажите ошибочное суждение.
1) В слове ВСКОРЕ первый звук [ф].
2) В слове СЛУЧИТСЯ один мягкий согласный звук.
3) В слове ЮНАЯ звуков больше, чем букв.
4) В слове ЧУВСТВА есть согласный звук [в].
14. Укажите ошибочное суждение.
1) В слове ИСПОВЕДЬ последний звук [ т’].
2) В слове СТАВИТЬ все согласные звуки имеют пару по звонкости/ глухости.
3) В слове ОТЪЕЗД звуков меньше, чем букв.
4) В слове ТЕПЕРЬ все согласные мягкие.
15. Укажите ошибочное суждение.
1) В слове СЕГОДНЯ есть звук [в].
2) В слове РЕДКИЙ при произношении происходит оглушение согласного звука.
3) В слове НАРОЧНО сочетание ЧН произносится как [шн].
4) В слове ОБЪЯВИЛ звуков меньше, чем букв
16. Укажите ошибочное суждение.
1) В слове ВЛАСТНЫЙ букв больше, чем звуков.
2) В слове РЕДКО третий звук – [т].
3) В слове ОТПРАВЬТЕ мягкость согласного [в’] на письме обозначена буквой Ь (мягкий знак).
4) В слове ОБЯЗАТЕЛЬНАЯ звуков больше, чем букв.
17. Укажите ошибочное суждение.
1) В конце слова ГВОЗДЬ произносится звук [т’].
2) В слове ФУТБОЛ третий звук – [д].
3) В слове ЛОЖЬ буквой Ь (мягкий знак) на письме обозначена мягкость предыдущего согласного.
4) В слове СКОРОСТЬЮ количество букв и звуков совпадает.
18. Укажите ошибочное суждение.
1) В слове СЧИТАТЬ первый звук – [с].
2) В слове ОЩУЩЕНИЕ третий звук [у].
3) В слове МОЖЕШЬ звуков меньше, чем букв.
4) В слове ВСПЫХНУВШИЙ первый звук [ф]
19. Укажите ошибочное суждение.
1) В слове ПРЯМОЙ третий звук – [а].
2) В слове ПРОСЬБА четвёртый звук -[ з’]
3) В слове ОБЩЕСТВЕННЫЙ четвёртый звук – [э].
4) В слове ЗДОРОВЬЕ количество звуков и букв совпадает.
20. Укажите ошибочное суждение.
1) В слове ЧУВСТВО буквой В обозначен непроизносимый согласный
2) В слове СОБСТВЕННЫЙ третий звук – [п]
3) В слове СУДЬБА мягкость согласного [д’] на письме обозначена буквой Ь (мягкий знак).
4. В слове ПРИВЯЗАННОСТЬ звуков больше, чем букв.
21. Укажите ошибочное суждение.
1) В слове МЕСТНЫЙ буквой Т обозначен непроизносимый согласный.
2) В слове ПОЛОСКА второй звук – [о].
3) В слове ВОЗЬМУ мягкость согласного [з’] на письме обозначена буквой Ь (мягкий знак).
4) В слове ВЫЯСНИЛОСЬ количество звуков и букв совпадает.
22. Укажите ошибочное суждение.
1) В слове СНЕГ последний звук – [к].
2) В слове ЖЁСТКИЙ второй звук [о].
3) В слове НАДПИСЬ мягкость согласного [с’] на письме обозначена буквой Ь (мягкий знак).
4) В слове СТРИЧЬСЯ мягкость согласного [ч’] на письме обозначена буквой Ь (мягкий знак).
23. Укажите ошибочное суждение.
1) В слове КОЕК звуков больше, чем букв.
2) В слове ПОВЯЗКА происходит оглушение согласного звука.
3) В слове ЧИСТЕНЬКИЙ все согласные звуки глухие.
4) В слове УЮТНЫЙ три слога.
ОТВЕТЫ.
Задание 1.
А) прыжок, специи, цыган, зажим, циркуль, перешить;
Б) часть, ясень, рьяный, диван, тянет;
В) ёлка, тёмный, забота;
Г) лейка, объём, ягода, йогурт, чьи-то, вьюга, поезд;
Задание 2
А) циновка, бокал, рожь;
Б) подход, шёпот, вступить, похож;
В) пирожное, юмор, лающий, поёт;
Задание 3.
Пароль, встреть, тень, пыльный, письменный, ведьма, ходить, коньки, мольба.
ТЕСТЫ.
1) 2
2) 1
3) 4
4) 2
5) 4
6) 3
7) 3
8) 1
9) 4
10) 3
11) 2
12) 1
13) 4
14) 3
15) 4
16) 4
17) 3
18) 1
19) 1
20) 4
21) 2
22) 4
23) 3
Метки: Русский язык
Фонетика — обзор | Темы ScienceDirect
SciencendirectRegistersign в
Plusadd To Mendeley, связанные с имплантатами, осложнения и неудачи
Michael G. Newman DDS, FACD, в Newman и Carranza’s Clinical Poeriorontology, 2019
Newman DDS, FACD, в Newman и Carranza’s Clinical Poeriorontology, 2019
Phonetices Prodestontology, 2019
Phonetitics. изготовленные с необычными небными контурами (т. е. с ограниченным или узким небным пространством) или имеющие пространства под и вокруг супраструктуры, могут создавать фонетические проблемы для пациента. Это особенно проблематично, когда для пациентов с тяжелой атрофией верхней челюсти изготавливаются несъемные реставрации с опорой на имплантаты. Горизонтальная потеря кости в предчелюстной кости часто приводит к небному расположению зубных имплантатов, в результате чего протез закрывает область резцового сосочка. Поскольку некоторые звуки образуются, когда кончик языка слегка касается неба в области резцового сосочка, прикрытие этой области может мешать правильному произношению. Полные реставрации с титановым каркасом позволяют использовать более тонкий материал в этой области и могут свести к минимуму фонетические осложнения.

Эти осложнения усугубляются при использовании немедленной несъемной временной реставрации. Фонетические проблемы могут быть распространены в случаях полного съемного протеза. Тем не менее, с зубными протезами клиницист может определить многие проблемы речи в воске до окончательной реставрации, что упрощает фокусировку на конкретной проблемной области. Чтобы свести к минимуму фонетические проблемы, необходима идеальная установка зубов и многочисленные корректировки. Этим пациентам, вероятно, лучше всего подходят съемные протезы верхней челюсти с опорой на имплантаты, потому что их конструкция облегчает замену отсутствующей альвеолярной структуры и позволяет избежать образования пространств, которые позволяют воздуху выходить во время речи.
См. главу ClinicalKey
P. Case, B. Tuller, в Encyclopedia of Human Behavior (Second Edition), 2012 г.
Abstract
Фонетика — это изучение звуков речи. Он включает в себя описание возможных звуков языков мира, исследование того, как человеческий речевой тракт производит эти звуки, и попытку понять, как такие звуки воспринимаются. За кратким историческим обзором следует сначала обзор анатомии и физиологии органов речи, основ акустики, аппаратуры и методов, используемых для описания и анализа речи, а затем обзор схем артикуляционной и акустической классификации, просодии и надсегментов. , признаки и обнаружение признаков, коартикуляция и экспериментальная фонетика.
За кратким историческим обзором следует сначала обзор анатомии и физиологии органов речи, основ акустики, аппаратуры и методов, используемых для описания и анализа речи, а затем обзор схем артикуляционной и акустической классификации, просодии и надсегментов. , признаки и обнаружение признаков, коартикуляция и экспериментальная фонетика.
Просмотреть главуКнига покупок
Прочитать всю главу
URL: https://www.sciencedirect.com/science/article/pii/B9780123750006002780
M. Ashby, в Encyclopedia of Language & Linguistics (издание M. Ashby), in Encyclopedia of Language & Linguistics 2006
Фонетическая классификация — это система категорий и меток, лежащая в основе описательной фонетики и Международного фонетического алфавита. Это зависит от сегментации речи на последовательность звуков. Для согласных классификация определяет используемый механизм воздушного потока, активность гортани, а также место и тип артикуляционного сужения. Для гласных используется смешанная система слуховых и артикуляционных сравнений с относительно фиксированными качествами гласных. Общепринятый взгляд на классификацию остался практически неизменным, несмотря на различные новые предложения. Глубокие вопросы фонетического анализа остаются нерешенными, но в настоящее время представляются немодными областями для исследований.
Для гласных используется смешанная система слуховых и артикуляционных сравнений с относительно фиксированными качествами гласных. Общепринятый взгляд на классификацию остался практически неизменным, несмотря на различные новые предложения. Глубокие вопросы фонетического анализа остаются нерешенными, но в настоящее время представляются немодными областями для исследований.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B0080448542000122
J.C. Wells, in Secon0 Edition 60 Language & Linguistics.
Введение
Фонетическая транскрипция — это использование фонетических символов для представления звуков речи. В идеале каждый звук в произнесенном высказывании представлен письменным фонетическим символом, чтобы обеспечить запись, достаточную для точной реконструкции высказывания. Система транскрипции в целом будет отражать фонетический анализ, наложенный транскрибером на материал. В частности, выбор набора символов будет иметь тенденцию отражать решения о (1) сегментации языковых данных и (2) их фонематизации или фонологической обработке. На практике один и тот же набор данных может быть транскрибирован более чем одним способом. Различные системы транскрипции могут быть подходящими для различных целей. Такие цели могут включать описательную фонетику, теоретическую фонологию, языковую педагогику, лексикографию, речевую и языковую терапию, компьютеризированное распознавание речи и синтез речи. Каждый из них имеет определенные требования.
В частности, выбор набора символов будет иметь тенденцию отражать решения о (1) сегментации языковых данных и (2) их фонематизации или фонологической обработке. На практике один и тот же набор данных может быть транскрибирован более чем одним способом. Различные системы транскрипции могут быть подходящими для различных целей. Такие цели могут включать описательную фонетику, теоретическую фонологию, языковую педагогику, лексикографию, речевую и языковую терапию, компьютеризированное распознавание речи и синтез речи. Каждый из них имеет определенные требования.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B0080448542000146
J.J. Охала, в Энциклопедии языка и лингвистики (второе издание), 2006 г.
Фонетика — это изучение произношения. Другие обозначения этой области исследования включают «науку о речи» или «фонетические науки» (множественное число важно) и «фонологию». 0073 фонология для изучения более абстрактных, более функциональных или более психологических аспектов основ речи и применять фонетику только к физическим, в том числе физиологическим, аспектам речи. На самом деле границы размыты, и некоторые настаивают на том, что присвоение ярлыков различным областям исследования менее важно, чем поиск ответов на вопросы.
0073 фонология для изучения более абстрактных, более функциональных или более психологических аспектов основ речи и применять фонетику только к физическим, в том числе физиологическим, аспектам речи. На самом деле границы размыты, и некоторые настаивают на том, что присвоение ярлыков различным областям исследования менее важно, чем поиск ответов на вопросы.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B008044854200016X
И. Вишер, Энциклопедия языка и лингвистики (второе издание), 2006 г.
Фонетическое истощение
Фонетическое истощение является результатом максимизации экономии говорящим в устной беседе. Это особенно влияет на языковые элементы, которые подверглись грамматикализации. В силу своего довольно абстрактного значения они имеют меньшую информативность, чем лексические слова, что часто отражается в более слабой фонологической форме. Оказалось, что при расщеплении лексической формы на два употребления (см. «Дивергенция» ниже) лексическая единица сохраняет свою полную фонетическую форму, а функционализированная единица подвергается фонетической редукции, как в один против a(n), собирается против собирается . Фонетическое истощение может, наконец, способствовать возобновлению цикла грамматикализации. Это, очевидно, произошло с древнегерманским отрицателем предикации ne , который полностью исчез в германских языках и был заменен другими отрицателями, такими как английский , а не , или немецкий nicht .
Оказалось, что при расщеплении лексической формы на два употребления (см. «Дивергенция» ниже) лексическая единица сохраняет свою полную фонетическую форму, а функционализированная единица подвергается фонетической редукции, как в один против a(n), собирается против собирается . Фонетическое истощение может, наконец, способствовать возобновлению цикла грамматикализации. Это, очевидно, произошло с древнегерманским отрицателем предикации ne , который полностью исчез в германских языках и был заменен другими отрицателями, такими как английский , а не , или немецкий nicht .
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B0080448542001929
М. Гордон, Энциклопедия языка и лингвистики (второе издание), 2006 г.
Фонетические исследования дали важные сведения о явлениях гармонии. Одна точка зрения состоит в том, что гармония возникает из-за эффектов коартикуляции низкого уровня, которые слушатели не могут проанализировать из сигнала. Другой более телеологический подход рассматривает гармонию как максимизацию перцептивной значимости распространяющегося свойства. Факторы производства речи, наблюдаемые в детском языке, и данные об ошибках речи также, по-видимому, играют роль в некоторых системах гармонии согласных. Фонетические исследования также исследовали, действительно ли очевидные случаи нелокальной гармонии являются дальними, или же распространяющийся признак влияет на сегменты, промежуточные между триггером и целью гармонии.
Одна точка зрения состоит в том, что гармония возникает из-за эффектов коартикуляции низкого уровня, которые слушатели не могут проанализировать из сигнала. Другой более телеологический подход рассматривает гармонию как максимизацию перцептивной значимости распространяющегося свойства. Факторы производства речи, наблюдаемые в детском языке, и данные об ошибках речи также, по-видимому, играют роль в некоторых системах гармонии согласных. Фонетические исследования также исследовали, действительно ли очевидные случаи нелокальной гармонии являются дальними, или же распространяющийся признак влияет на сегменты, промежуточные между триггером и целью гармонии.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B008044854200033X
J. Kingston, in Encyclopedia of Language & Linguistics (второе издание). 2006
Лаборатория фонетики использует инструменты и программное обеспечение для экспериментального измерения многих аспектов артикуляции, акустики или восприятия звуков речи. В этой статье описываются методы, которые широко используются для выполнения этих измерений. В нем также перечислены многие центральные нерешенные проблемы фонетики, а также методы и методы, разработанные фонетиками для их решения. Запись завершается обсуждением двух недавних нововведений в лабораторной фонетике: более широкое использование более естественной речи в исследованиях как артикуляции, так и восприятия и все более широкое использование экспериментов и количественных измерений в исследованиях фонологии; это второе нововведение известно как «лабораторная фонология».
В этой статье описываются методы, которые широко используются для выполнения этих измерений. В нем также перечислены многие центральные нерешенные проблемы фонетики, а также методы и методы, разработанные фонетиками для их решения. Запись завершается обсуждением двух недавних нововведений в лабораторной фонетике: более широкое использование более естественной речи в исследованиях как артикуляции, так и восприятия и все более широкое использование экспериментов и количественных измерений в исследованиях фонологии; это второе нововведение известно как «лабораторная фонология».
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B0080448542000080
D.S. Race, A.B. Hillis, in Brain Mapping, 2015
Моторный выход
Фонетическая обработка включает в себя моторное планирование и работу мышц, используемых для речи (например, артикуляторов). Фонетическая обработка наиболее тесно связана с нижней лобной извилиной (особенно с областью Брока), участками островковой извилины, дополнительной корой и премоторной корой. Повреждение этих областей связано с дефицитом речевой практики или оркестровки двигательных планов губ, языка, челюсти, неба, голосовых складок и дыхательных мышц для членораздельной речи (Ash et al., 2009).; Дэвис и др., 2008 г.; Трупе и др., 2013). Обратите внимание, что проблемы с речевой практикой отличаются от нарушений силы, тона, скорости, диапазона или координации артикуляционных мышц, известных как дизартрия.
Фонетическая обработка наиболее тесно связана с нижней лобной извилиной (особенно с областью Брока), участками островковой извилины, дополнительной корой и премоторной корой. Повреждение этих областей связано с дефицитом речевой практики или оркестровки двигательных планов губ, языка, челюсти, неба, голосовых складок и дыхательных мышц для членораздельной речи (Ash et al., 2009).; Дэвис и др., 2008 г.; Трупе и др., 2013). Обратите внимание, что проблемы с речевой практикой отличаются от нарушений силы, тона, скорости, диапазона или координации артикуляционных мышц, известных как дизартрия.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B9780123970251002670
H.G.
Фонетика как академическая дисциплина современной науки о речи расширилась во второй половине девятнадцатого века. Она началась с систематического внедрения метода непосредственного наблюдения. Визуальное обследование артикуляционных процессов звукообразования единичной речи привело к «звуковой физиологии», которая позволила систематически и однозначно определить категории всех существующих речевых звуков. Когда в последнее десятилетие этого века фонетики стали пользоваться приборами для записи артикуляционных движений и акустических речевых сигналов, центральным вопросом фонетических исследований стало открытие большой вариативности в реализации категориальных звуков речи как графически изображаемых функций времени. Это положило начало развитию широкой экспериментальной работы в первой половине ХХ века, связанной с изменением звуков речи и фонетической формы слов в результате коартикуляции и просодических влияний.
Визуальное обследование артикуляционных процессов звукообразования единичной речи привело к «звуковой физиологии», которая позволила систематически и однозначно определить категории всех существующих речевых звуков. Когда в последнее десятилетие этого века фонетики стали пользоваться приборами для записи артикуляционных движений и акустических речевых сигналов, центральным вопросом фонетических исследований стало открытие большой вариативности в реализации категориальных звуков речи как графически изображаемых функций времени. Это положило начало развитию широкой экспериментальной работы в первой половине ХХ века, связанной с изменением звуков речи и фонетической формы слов в результате коартикуляции и просодических влияний.
Просмотреть главуКнига покупок
Прочитать главу полностью
URL: https://www.sciencedirect.com/science/article/pii/B0080448542000031
» Что такое плохая фонематическая осведомленность?
» Что такое плохая фонематическая осведомленность?Изучение строительных блоков слов – звуков, их написания и частей слова
1 ответ
Многие, а возможно, и большинство тех, кто испытывает затруднения при чтении и правописании, имеют проблемы с распознаванием идентичности, порядка и/или количества звуков в произносимых словах.
В оценочных отчетах это часто называют плохой фонематической осведомленностью, а иногда и плохой фонологической осведомленностью.
«Фонематика» говорит об отдельных звуках. «Фонологический» — более общий термин, включающий слоги и рифму.
Звуковая идентификация
Рот — это маленькое, мягкое, быстро движущееся место, и многие звуки, которые он издает, очень похожи.
Звуки «к» и «т» легко спутать, потому что они оба производятся путем остановки потока воздуха с помощью языка на нёбе, а затем выпускают его с небольшим выбросом воздуха.
Основное различие между этими двумя звуками заключается в том, что один из них производится в передней части рта, а другой — в задней. Разница обычно не видна, если только вы не преувеличиваете. Дошкольники часто путают эти звуки. Моя маленькая соседка Натали обычно сидела на скамейке в моем питомнике и помогала мне с игрушками, а также вставляла ремни в столбик, такая прелесть.
Попробуйте поменять местами звуки «к» и «т» в предложении и посмотрите, заметит ли это ваш слушатель. Например, спросите кого-нибудь из соседней комнаты, выключил ли он свой томпьютер. Вам, вероятно, придется сначала немного попрактиковаться в ложном подходе, чтобы переопределить ваши хорошо отработанные двигательные паттерны для слов «повернулся» и «компьютер». Если говорить в обычном темпе и не преувеличивать ложность, вряд ли это даже заметят. Ошибка будет просто статической, которую нам нужно все время сглаживать, чтобы понять других людей, например, фоновый шум, икота и различные акценты.
Например, спросите кого-нибудь из соседней комнаты, выключил ли он свой томпьютер. Вам, вероятно, придется сначала немного попрактиковаться в ложном подходе, чтобы переопределить ваши хорошо отработанные двигательные паттерны для слов «повернулся» и «компьютер». Если говорить в обычном темпе и не преувеличивать ложность, вряд ли это даже заметят. Ошибка будет просто статической, которую нам нужно все время сглаживать, чтобы понять других людей, например, фоновый шум, икота и различные акценты.
Запоминающиеся цитаты преподобного Спунера замещают совсем другие звуки, чтобы их было легче заметить – отчитывание студентов за то, что они дрались с лжецами в подсобке, за то, что они попробовали всего червяка, и т. д. Звуки «ф» и «л» сильно различаются в способ их воспроизведения (фрикативный или жидкий звук), их расположение (зубы на губе или кончик языка за зубами) и звучание (глухой или звонкий). То же самое для «t» и «w». Нет смысла шутить, если люди не слышат.
Некоторые звуки английской речи, которые легко спутать, включают:
- d и g (отличаются только расположением), поэтому дошкольники называют клыков «додами», а det drubby в darden.

- п и б, т и д, к и г (отличаются только звонкостью), а в некоторых языках между этими звуками нет разницы. Подростки, говорящие на сомалийском языке, с которыми я работаю, вечно просят бенчил поострее и ходят в столовую, чтобы перекусить.
- m и n, n и ng (отличаются только местоположением), поэтому моя племянница подарила своей маме чудесные средства для купания на Рождество с небольшой запиской, в которой говорилось, что это заставит ее «шлепать и спамить» на Новый год.
- th и f или v (отличаются только местом). На самом деле, если вы внимательно прислушаетесь, то увидите, что многие взрослые говорят, что им не по себе.
- f и v (отличаются только озвучиванием), что помогает объяснить f in of и v у Чехова и Рахманинова.
- s и z (отличаются только озвучиванием), что помогает объяснить s в словах is, as, has, Does и Was, а также z в словах pretzel, Fitzroy и blintz.
- s и sh (отличаются только расположением), чтобы маленькие дети шли мокрые и не ложились спать.
- ш и ч, и ж (как в видении) и дж, потому что на самом деле есть звук ш в ч и звук ж в j (ч = т + ш, и дж = д + ж).
- a как в кошке и u как в разрезе. Эта путаница усугубляется тем, как детей учат произносить слово «а» при запоминании Золотых слов (если честно, мне жаль, что я не могу бросить Золотые слова в море).
- е как в подоле и я как в нем. Попробуйте произнести эти звуки один за другим и почувствуйте, насколько тонка разница между ними.
- Много других гласных, например. Раньше у нас был мэр, который обычно приветствовал всех на собрании City Cancel.


Так, например, я работал с маленьким парнем, который перепутал все звуки трения, не различая и не производя различий между:
- «s/z» и «f/v», например. он сказал, что ему было несколько лет, и он взял кота в зане на зет.
- «с/з» и «ш/ж», и «ц/дз» и «ч/ж» напр. он сеял мне пиратский трезур, катал футбольный мяч и прыгал по лужам.
- «f/v» и «th» например. он боролся, что может пойти с мамой в Вух Фитре. Это довольно стандартно для годовалых и даже шестилетних детей.
 он боролся, что может пойти с мамой в Вух Фитре. Это довольно стандартно для годовалых и даже шестилетних детей.
он боролся, что может пойти с мамой в Вух Фитре. Это довольно стандартно для годовалых и даже шестилетних детей.Для детей школьного возраста важно научиться различать и правильно произносить звуки речи в первые несколько лет обучения в школе, потому что чем дольше вы практикуете артикуляционную ошибку, тем труднее ее сместить и тем труднее возникают ассоциированные звуково-буквенные отношения. учиться. Мы знаем, что дети с нарушениями речи чаще испытывают трудности с грамотностью, чем их одноклассники.
Звуковой порядок
Любой, кто преподавал английский как второй язык, знает, что учащиеся часто путают «kitchen» и «chicken», потому что эти два слова содержат одинаковые звуки, но в другом порядке. Чтобы усложнить ситуацию, написание «ч» может представлять как звук «к», как в слове «школа», так и звук «ч», как в слове «курица».
В английском языке потеряно, упс, много слов, состоящих из одинаковых звуков в разном порядке. Наиболее запутанные из них меняют местами звуки в трудноразличимых частях слова:
- Tap-pan-apt и top-pot-opt легко различить, потому что каждое слово имеет разный первый звук, а первые звуки в словах различить проще всего.
- Cusp-cups, best-bets и west-wets немного сложнее, потому что замененные звуки находятся в конце, что не так легко услышать, как в начале. Также звуки «с» и «т» очень похожи. Попробуйте долго произносить «т», и вы обнаружите, что звук расплывается в «с», так как оба звука произносятся кончиком языка за зубами, но «т» останавливает воздух, а затем выпускает его, тогда как «с» выдавливает воздух через узкое пространство.
- Blot-bolt, cold-comd, bulb-blub поменялись местами звуки внутри слова, а не в начале или конце слова, которые легче услышать. Однако звук «л» после гласного несколько меняет произношение гласного, потому что «л» — это согласный звук, похожий на гласный (много воздуха выходит по бокам языка, так что это довольно открытый звук, как гласный звук). Это делает эти пары слов немного легче различать.
- Split-spilt и silts-slits снова сложнее, потому что эти пары слов содержат одни и те же пять звуков, а также одни и те же первый и последний звуки. Разница лишь в том, что два из трех звуков внутри слов меняются местами.

 Разница лишь в том, что два из трех звуков внутри слов меняются местами.
Разница лишь в том, что два из трех звуков внутри слов меняются местами.Поскольку взрослые, как правило, сосредотачиваются на буквах и понимают их больше, чем звуки речи, орфографические ошибки, связанные с неразличением порядка звуков в слове, часто ошибочно интерпретируются как зрительные ошибки.
Номер звука
Большинство людей знают, что маленькие дети часто упрощают трудные для произнесения слова, опуская один или два звука. Они говорят «тейн» для «поезда», «хан» для «руки», «соп» для «остановки» и «тинг» для «струны».
Соединить два согласных звука вместе довольно сложно, потому что это быстрые, четко артикулированные звуки. Спросите любого говорящего по-японски, пытающегося выучить английский язык. В японском согласные всегда отделяются гласными, поэтому японские посетители говорят, что австралийцы фухриэнухдухлы, и спрашивают о здоровье вашей гухранухдухмы.
Точно так же отдельные звуки в сочетаниях согласных относительно трудно различить, но когда ребенок пишет «назад» вместо «черный», это часто рассматривается как визуальная или словарная ошибка, а не как ошибка, связанная со слухом. все звуки.
все звуки.
Другая проблема заключается в том, что маленькие дети и дети старшего возраста с более слабой рабочей памятью не могут удерживать в голове сразу много звуков. Если вы попросите их разбить слово, содержащее пять звуков, например «штамп», есть вероятность, что один из звуков выпадет. В качестве альтернативы они могут предлагать группы звуков, таких как «st» или «amp», и не иметь возможности детализировать их до отдельных звуков и одновременно удерживать их все в рабочей памяти.
Изучение комков, таких как сочетания согласных и рифмы, кажется решением этой проблемы, пока вы не поймете, сколько возможных сочетаний согласных и рифм существует в английском языке. Наш мозг просто не может запомнить их все, даже если бы у нас было на это время.
Графика: http://btezcan.edublogs.org
Неправильное произношение – красный флаг проблем с правописанием/чтением
Некоторые неправильные произношения — это просто оговорки, например, называние гороха и моркови «ключами и попугаями» (хорошо, это, вероятно, преднамеренный спунеризм), но другие могут указывать на проблемы с различением звуков и, следовательно, с изучением и различением слов.
Подумайте о подростках и взрослых, которые говорят «акс» вместо «спросить» и регулярно используют такие слова НКР, как «антарктический», «побег», «либари», «озорной», «ядерный», «явно», «перогативный», «произношение», «шерберт» и «зоология», или, скажем, у их виноградного деда была проблема с ниц. У меня есть красно-черный наряд с немного испанским оттенком, который на днях назвали моим нарядом «фламинго».
Частые неправильные произношения и неправильное использование слов, подобные этим, говорят о том, что человек не очень хорошо усвоил звук и написание. Официально на это обычно не обращают особого внимания, потому что они все еще понятны, и официально никто не слишком заботится о правописании в эпоху проверки орфографии.
Однако неправильное произношение и орфографические ошибки могут быть истолкованы как означающие, что человек не очень умен, осторожен или хорошо образован. В Интернете полно статей с такими заголовками, как «10 слов, которые вы произносите неправильно, из-за чего люди думают, что вы идиот». Заявления о приеме на работу, содержащие орфографические ошибки, обычно попадают в круглую картотеку.
Заявления о приеме на работу, содержащие орфографические ошибки, обычно попадают в круглую картотеку.
Опытные читатели и специалисты по правописанию имеют инструменты, необходимые им для того, чтобы без особых усилий распаковать структуру нового слова — слоги, звуки и их варианты написания, аффиксы и основы — и затем собрать их обратно в своей голове. Хорошая фонематическая осведомленность является одним из основных инструментов, и она тесно связана со знанием орфографических моделей и подкрепляется ими.
Когда опытные читатели и орфографы слышат новое слово, такое как незнакомое имя, они часто спрашивают, как оно пишется, и выполняют мысленное упражнение «сопоставление звуков буквам», которое помогает им запомнить более подробное представление о структуре слова. как устные, так и письменные.
Более слабые читатели и орфографы, как правило, не могут этого сделать, поэтому их мысленные представления слов менее точны и полны.
Детей можно систематически учить тому, как различать идентичность, количество и порядок звуков в словах (мои рабочие тетради — лишь один из способов сделать это), чтобы формировать их фонематический слух. Почему это обычно не происходит в школах, остается загадкой.
Почему это обычно не происходит в школах, остается загадкой.
« Прозрение одного учителя ранней грамотности
От полуконтролируемого до почти неконтролируемого распознавания речи с очень малыми ресурсами за счет совместного изучения фонетических структур из аудио и текстовых вложений
1 Введение
Автоматическое распознавание речи (ASR) достигло значительных успехов во многих приложениях [1, 2, 3] . Однако при существующих технологиях машинам приходится учиться на огромном количестве аннотированных данных для достижения приемлемой точности, что затрудняет разработку таких технологий для новых языков с небольшими ресурсами. Сбор большого количества речевых данных стоит дорого, не говоря уже о аннотировании данных. Это остается верным, по крайней мере, для 95% языков во всем мире.
Сообщалось о значительных усилиях по полуконтролируемому ASR [4, 5, 6, 7, 8, 9, 10, 11] .
Однако в большинстве случаев по-прежнему требовалось большое количество речевых данных, включая значительную часть аннотированных. Таким образом, обучение систем ASR с относительно небольшим объемом данных, большая часть которых не аннотирована, остается важной, но нерешенной проблемой.
Распознавание речи в таких условиях «очень низкого» ресурса является целевой задачей данной статьи.
Таким образом, обучение систем ASR с относительно небольшим объемом данных, большая часть которых не аннотирована, остается важной, но нерешенной проблемой.
Распознавание речи в таких условиях «очень низкого» ресурса является целевой задачей данной статьи.
Мы заметили, что человеческие младенцы начинают изучать язык по звукам небольшого количества слов-образцов, не слыша большого количества данных. Они более или менее узнают эти слова по тому, «как они звучат», или по фонетической структуре слов. Эти образцовые слова и их фонетические структуры затем, кажется, «обобщаются» на другие слова и предложения, которые они изучают позже. Конечно, очень желательно, чтобы машины тоже могли это делать. В данной статье мы начинаем некоторую предварительную работу в этом направлении.
Audio Word2Vec был предложен для преобразования произносимых слов (сегменты сигналов для слов без знания основных слов, которые они представляют) в векторы фиксированной размерности
[12] , несущие информацию о фонетических структурах произнесенных слов. Сегментное аудио Word2Vec также было предложено для совместного сегментирования высказывания в последовательность произнесенных слов и преобразования их в последовательность векторов [13] .
Были предприняты значительные усилия, чтобы попытаться согласовать такие вложения аудио с вложениями слов 9.0007 [14] , который был одним из способов научить машины запоминать слова вместе с их звуками или фонетической структурой.
Недавно сообщалось о подходах полууправляемого сквозного распознавания речи в аналогичных направлениях [10, 11] .
Но во всех этих работах по-прежнему использовался относительно большой объем обучающих данных.
С другой стороны, неконтролируемое распознавание фонем и почти неконтролируемое распознавание слов недавно было достигнуто в некоторой степени с использованием аудио- и текстовых данных, выровненных с нулевым или близким к нулю [15, 9] , в первую очередь путем сопоставления аудио вложений с текстовыми токенами, чья установка «очень низкого» ресурса является целью этой статьи.
Сегментное аудио Word2Vec также было предложено для совместного сегментирования высказывания в последовательность произнесенных слов и преобразования их в последовательность векторов [13] .
Были предприняты значительные усилия, чтобы попытаться согласовать такие вложения аудио с вложениями слов 9.0007 [14] , который был одним из способов научить машины запоминать слова вместе с их звуками или фонетической структурой.
Недавно сообщалось о подходах полууправляемого сквозного распознавания речи в аналогичных направлениях [10, 11] .
Но во всех этих работах по-прежнему использовался относительно большой объем обучающих данных.
С другой стороны, неконтролируемое распознавание фонем и почти неконтролируемое распознавание слов недавно было достигнуто в некоторой степени с использованием аудио- и текстовых данных, выровненных с нулевым или близким к нулю [15, 9] , в первую очередь путем сопоставления аудио вложений с текстовыми токенами, чья установка «очень низкого» ресурса является целью этой статьи.
В этой работе мы позволяем машинам изучать фонетические структуры слов из пространств вложений соответствующих устных и текстовых слов, а также отношения между ними. Все это можно выучить вместе или отдельно для устных и текстовых слов, а затем изучить отношения между ними. Было обнаружено, что первое лучше, и разумное распознавание речи было достижимо с очень низким ресурсом. В первоначальных экспериментах с набором данных TIMIT только 2,1 часа общих речевых данных (в которых 2500 произнесенных слов были аннотированы, а остальные не маркированы) дали уровень ошибок в словах 44,6%, и это число может быть уменьшено до 34,2%, если 4,1 часа речевых данных (в которых аннотировано 20000 произнесенных слов). Эти результаты не являются удовлетворительными, но являются хорошей отправной точкой.
Рисунок 1. Архитектура предлагаемого подхода. Рисунок 2. Встраивание выравнивания (красный пунктирный блок в середине рисунка 1), реализованное путем преобразования между двумя скрытыми пространствами.
2 Предлагаемый подход
Для ясности мы обозначаем речевой корпус как X={xi}Mi=1, который состоит из M произносимых слов, каждое из которых представлено как xi=(xi1,xi2,…,xiT), где xit — вектор акустических признаков. в момент времени t и T — длина произнесенного слова. Каждое произносимое слово xi соответствует текстовому слову в W={wk}Nk=1, где N — количество различных текстовых слов в корпусе. Мы можем представить каждое текстовое слово как последовательность единиц подслова, таких как фонемы или символы, и обозначить его как yi=(yi1,yi2,…,yiL), где yil — однократный вектор для l -е -е подслово, а L — количество подслов в слове. Небольшой набор известных парных данных обозначается как Z={(xj,yj)}, где (xj,yj) соответствует одному и тому же текстовому слову.
В начальной работе здесь мы сосредоточились на совместном изучении слов в звуковой и текстовой формах, поэтому мы предполагаем, что все обучающие произносимые слова были должным образом сегментированы с хорошими границами. Многие существующие подходы могут быть использованы для автоматического разделения высказываний на произносимые слова [16, 17, 18, 19, 20, 21, 22, 23, 24] , включая Segmental Audio Word2Vec [13] , упомянутый выше.
Расширение ввода всего высказывания без сегментации оставлено для будущей работы.
Многие существующие подходы могут быть использованы для автоматического разделения высказываний на произносимые слова [16, 17, 18, 19, 20, 21, 22, 23, 24] , включая Segmental Audio Word2Vec [13] , упомянутый выше.
Расширение ввода всего высказывания без сегментации оставлено для будущей работы.
Текстовое слово соответствует множеству различных произносимых слов с различными акустическими факторами, такими как характеристики динамика или микрофона и шум. Ниже для простоты мы будем называть все такие акустические факторы характеристиками громкоговорителей.
2.1 Внутридоменная неконтролируемая архитектура автоэнкодера
В архитектуре предлагаемого подхода на рисунке 1 есть три кодера и два декодера.
Мы используем два кодировщика Ep и Es для кодирования фонетических структур и характеристик говорящего произносимого слова xi в аудиофонетический вектор vpa и вектор говорящего vs соответственно.
Между тем, мы используем другой кодировщик Et для кодирования фонетической структуры текстового слова yi в текстовый фонетический вектор vpt, где текстовые слова yi представлены в виде последовательностей однократных векторов для подслов.
Аудиодекодер Da принимает пару (vpa, vs) в качестве входных данных и реконструирует исходные характеристики произнесенного слова x′i. Декодер текста Dt принимает vpt в качестве входных данных и реконструирует исходные признаки текстового слова y′i. Для неконтролируемого обучения используются две внутридоменные потери:
Внутридоменная потеря реконструкции звука, которая представляет собой среднеквадратичную ошибку между исходным звуком и реконструированными функциями:
Лин_а_р =∑i∥xi−Da(Ep(xi),Es(xi))∥22. (1) Потеря реконструкции текста внутри домена, которая является отрицательной логарифмической вероятностью для последовательностей текстового вектора, подлежащих реконструкции:
Лин_т_р =-∑ilogPr(yi|Dt(Et(yi))). (2)
2.
 2 Междоменная реконструкция с парными данными
2 Междоменная реконструкция с парными даннымиКогда скрытые пространства для фонетических структур для произносимых слов xi и текстовых слов yi изучаются индивидуально на основе потерь внутридоменной реконструкции (1)(2), они могут быть очень разными, поскольку первые представляют собой непрерывные сигналы различной длины. и поведение, а последние представляют собой последовательности дискретных символов заданной длины. Поэтому здесь мы пытаемся выучить их совместно, используя относительно небольшое количество известных пар произносимых слов xj и соответствующих им текстовых слов yj, Z={(xj,yj)}. Будем надеяться, что два скрытых пространства можно каким-то образом скрутить и получить одно общее скрытое пространство, в котором оба фонетических вектора для аудио и текста, vpa и vpt, могут быть правильно представлены. Таким образом, используются две междоменные потери ниже:
Потеря междоменной аудиореконструкции:
Lcr_a_r =∑(xj,yj)∈Z∥xj−Da(Et(yj),Es(xj))∥22. (3) Потеря междоменной реконструкции текста:
Lcr_t_r =−∑(xj,yj)∈ZlogPr(yj|Dt(Ep(xj))). (4)

Минимизируя потери при реконструкции для аудио/текстовых признаков, полученных с помощью фонетических векторов, вычисленных из входных последовательностей в другой области, как в (3)(4), фонетические векторы устных и текстовых слов можно каким-то образом выровнять, чтобы нести некоторые непротиворечивая информация о фонетических структурах.
2.3 Междоменное выравнивание фонетических векторов с парными данными
Помимо потерь междоменной реконструкции (3)(4), два скрытых пространства могут быть дополнительно выровнены за счет потери шарнира для всех известных пар устных и текстовых слов (xj,yj):
Потеря междоменного внедрения:
Lcr_emb =∑(xj,yj)∈Z∥Ep(xj)−Et(yj)∥22 (5) +∑(xi,yj)∉Zmax(0,λ−∥Ep(xi)−Et(yj)∥22).

Во втором члене (5) для каждого текстового слова yj мы случайным образом выбираем xi так, что (xi,yj)∉Z служит отрицательной выборкой. Таким образом, фонетические векторы, соответствующие разным текстовым словам, могут находиться достаточно далеко друг от друга. Здесь в (3)(4)(5) небольшое количество парных устных и текстовых слов {(xj, yj)}∈Z служит лишь небольшим количеством образцовых слов и их звуков, когда человеческие младенцы начинают изучать язык. Реконструкция и выравнивание в этих двух пространствах должны каким-то образом попытаться «обобщить» фонетические структуры этих слов-образцов на другие слова языка, как это делают человеческие младенцы.
2.4 Совместное обучение и вывод
Функция общих потерь
L, которую необходимо минимизировать во время обучения, представляет собой взвешенную сумму пяти вышеуказанных потерь:
| л | =α1Lin_a_r+α2Lin_t_r | (6) | ||
| +α3Lcr_a_r+α4Lcr_t_r+α5Lcr_emb |
Во время вывода для каждого отдельного текстового слова wk в обучающих данных мы вычисляем его текстовый фонетический вектор (vpt)k, k = 1, …, N. Затем для каждого произносимого слова xi в тестовых данных мы применяем softmax к отрицательному расстоянию между его звуковым фонетическим вектором vpa и каждым текстовым фонетическим вектором (vpt)k
Затем для каждого произносимого слова xi в тестовых данных мы применяем softmax к отрицательному расстоянию между его звуковым фонетическим вектором vpa и каждым текстовым фонетическим вектором (vpt)k
, чтобы получить апостериорную вероятность для каждого слова текста
Pra(wk|xi):
| Пра(нед|xi) | =exp(−∥Ep(xi)−(vpt)k∥22)∑Nj=1exp(−∥Ep(xi)−(vpt)j∥22). | (7) |
Когда доступно большое количество непарных текстовых данных, языковая модель может быть обучена и интегрирована в вывод. Предположим, произнесенное слово xi является t-м произнесенным словом в высказывании u, а соответствующее ему текстовое слово — ut. Тогда логарифмическая вероятность распознавания равна:
| logPr(ut=wk|xi) | =logPra(нед|xi) | (8) | ||
| +βlogPrLM(ут=нед), |
, где первый член такой же, как в (7), а PrLM(⋅) — оценка языковой модели. Все αi и β
Все αi и β
выше являются гиперпараметрами.
2.5 Регуляризация согласованности циклов
Далее мы можем добавить к исходной функции потерь (6) потерю согласованности циклов:
| лцикл | =∑(xj,yj)∈Z∥xj−Da(Et(Dt(Ep(xj))),Es(xj))∥22 | (9) | ||
| +∥yj−Dt(Ep(Da(Et(yj),Es(xj))))∥22. |
Часть первого члена показана пунктирным фиолетовым кругом справа на рисунке 1, а часть второго члена показана пунктирным синим кругом в левой части рисунка.
Таблица 1: Частота ошибок в словах (WER) (%) Спектр производительности для разных размеров обучающих данных и разных N (количество парных слов) при совместном обучении в (6) подраздела 2.4.2.6 Раздельное обучение, а затем преобразование
Поскольку непрерывные сигналы произносимых слов и дискретные последовательности символов текстовых слов сильно различаются, выравнивание между двумя скрытыми пробелами, как указано выше, может быть негладким. Например, при совместном обучении в (6) междоменные потери (3)(4)(5) неизбежно нарушают внутридоменные потери (1)(2) и вызывают искажения фонетических структур для отдельных звуковых и текстовые домены.
Конечно, существует и другой вариант, т. е. сначала обучение внутридоменных фонетических структур отдельно для устных и текстовых слов, а затем изучение преобразования между ними.
Например, при совместном обучении в (6) междоменные потери (3)(4)(5) неизбежно нарушают внутридоменные потери (1)(2) и вызывают искажения фонетических структур для отдельных звуковых и текстовые домены.
Конечно, существует и другой вариант, т. е. сначала обучение внутридоменных фонетических структур отдельно для устных и текстовых слов, а затем изучение преобразования между ними.
Эту концепцию можно понять, заменив блок с красными точками в центре справа на рис. 1, обозначенный как «Выравнивание встраивания», на блок, показанный на рис. 2.
Таким образом, рисунок 1 становится двумя независимыми автоэнкодерами для произносимых и текстовых слов слева и справа, соответственно обученных только с потерями внутридоменной реконструкции (1)(2), плюс набор преобразований выравнивания Mat и Mta между двумя скрытыми пространства.
Таким образом, фонетические структуры устных и текстовых слов могут быть лучше изучены отдельно в разных местах. Однако в левой части рисунка 1 показан набор 9 на основе GAN. 0007 [9, 25] критериев необходимо для распутывания характеристик говорящего от фонетических структур (не показано на рисунке 1), в то время как на исходном рисунке 1 это распутывание может быть достигнуто с помощью текстового автокодировщика слов.
для разных объемов обучающих данных (часы) и разного N (количества парных слов). Черные точки — это реальные результаты экспериментов. Контуры создаются на основе линейной интерполяции среди черных точек.
Фонетические векторы vpa и vpt, обученные отдельно, сначала нормализуются во всех измерениях и проецируются на их пространство более низких измерений с помощью PCA.
Спроецированные векторы в пространствах главных компонент соответственно обозначаются как A={ai}Mi=1 для аудио и T={ti}Ni=1 для текста.
Парные устные и текстовые слова Z={(xj,yj)} обозначаются здесь как Z={(aj,tj)}, где aj и tj соответствуют одному и тому же слову.
Затем изучается пара матриц преобразования, Mat и Mta, где Mat отображает вектор a в A в пространство T, то есть t=Mata, а Mta отображает вектор t в T в пространство A. Mat и Mta инициализируются как единичные матрицы, а затем итеративно изучаются с градиентным спуском, минимизирующим целевую функцию:
| Lt=∑(aj,tj)∈Z∥tj−Mataj∥22+∑(aj,tj)∈Z∥aj−Mtatj∥22 | (10) | ||
| +λ′∑(aj,tj)∈Z(∥aj−MtaMataj∥22+∥tj−MatMtatj∥22). |
В первых двух членах мы хотим, чтобы преобразование aj с помощью Mat было близко к tj и наоборот. Последние два члена предназначены для согласованности циклов, т. Е. После преобразования aj в пространство T с помощью Mat и последующего преобразования обратно с помощью Mta оно должно получить исходное aj, и наоборот. λ′ — гиперпараметр.
| Н | Фонема как единица подслова | чар. | |||||
| (# из | Совместное (с (6)) | Отдельный (с (10)) | Соединение | ||||
| спаренный) | Д=1 | Д=2 | Д=3 | Д=1 | Д=2 | Д=3 | Д=1 |
| 39809 | 32,9 | 31,7 | 31,3 | 68,6 | 67,0 | 65,6 | 38,6 |
| 1000 | 48,2 | 47,4 | 47,5 | 71,8 | 72,5 | 74,6 | 60,5 |
4 и раздельного обучения с последующим преобразованием (10) в подразделе 2.6 для уровней L = 1,2,3 ГРУ с использованием фонем или символов (сокращенно « Char.» в таблице) в качестве единиц подслов, с данными за 4,1 часа и N = 39.809 и 1000. Таблица 3: Исследования абляции для предлагаемого подхода к совместному обучению в (6) при удалении члена потерь в (1) (2) (3) (4) (5) с данными за 4,1 часа. Таблица 4: Вклады циклической согласованности в (9) подраздела 2.5 для данных за 4,1 часа и различных N.3 Экспериментальная установка
3.1 Набор данных
Здесь использовался набор данныхTIMIT [26] . Его тренировочный набор содержит всего 4620 высказываний (4,1 часа), всего 39809 слов или 4893 отдельных слова. Таким образом, этот набор данных близок к рассмотренному здесь параметру «очень низкий» ресурс. Мы следовали стандартному рецепту Kaldi [27]
для извлечения MFCC 39-dim с кепстральным средним значением по произнесению и нормализацией дисперсии (CMVN), применяемыми в качестве акустических признаков.
3.2 Реализация модели
Все три кодера Ep, Es и Et на рисунке 1 были Bi-GRU со скрытым размером 256 слоев. Декодеры Da и Dt были GRU с размером скрытого слоя 512 и 256 соответственно. Значение порога λ в (5) было установлено равным 0,01. Гиперпараметры (α1,α2,α3,α4,α5,β) были установлены на (0,2,1,0,0,2,1,0,5,0,0,01). Мы обучили модель языка триграмм транскрипции данных TIMIT и выполнили поиск луча с размером луча 10 во время вывода в (8), чтобы получить результаты распознавания. Адам оптимизатор 9Использовался 0007 [28] , а начальная скорость обучения составляла 10–4. Размер мини-партии был 32. При реализации выравнивания встраивания на рисунке 2 дискриминатор, использованный при встраивании звука для распутывания вектора говорящего, представлял собой двухслойную полносвязную сеть со скрытым размером 256, а функции отображения Mat и Mta представляли собой линейные матрицы, следующие настройке предыдущая работа [9] .
4 эксперимента
4.
1 Спектр производительности для разных размеров обучающих данных и разного количества парных словСначала мы хотим увидеть достижимую производительность по частоте ошибок в словах (WER) (%) по сравнению с набором тестов для подхода к совместному обучению (6) в подразделе 2.4, когда размер обучающих данных и количество парных слов (N) равны соответственно сводится к минимуму. Все кодеры и декодеры являются одноуровневыми GRU. Результаты перечислены в таблице 1 (пустой верхний левый угол, поскольку для меньшего размера данных можно пометить и объединить в пары только меньшее количество слов). Двумерное отображение этого спектра производительности показано на рисунке 3, где черные точки — это реальные результаты в таблице 1, а контуры созданы на основе линейной интерполяции среди черных точек.
Из таблицы 1 видно, что только 2,1 часа общих данных (в которых 2500 произнесенных слов были помечены, а остальные не помечены) дали WER 44,6% (красный), и это число может быть уменьшено до 34,2%, если 4,1 часа данные (в которых 20000 слов помечены) были доступны (синий). Мы также можем видеть, как менялся WER, когда общий размер данных был изменен на фиксированное значение N (например, N = 2500, горизонтальная пунктирная красная линия на рисунке 3) или N был изменен на фиксированный размер данных (например, 2,1 часа, вертикальная оранжевая линия на рис. 3).
В настоящее время эти цифры все еще относительно высоки (особенно для N≤1000 или менее 1,0 часа данных), но плавный, непрерывный спектр производительности может означать, что предлагаемый подход является хорошим направлением, и в будущем может быть достигнута более высокая производительность.
Например, выровненные фонетические структуры для N парных слов, казалось, «обобщали» на большее количество немаркированных слов.
Кроме того, можно обнаружить, что в нижней половине рисунка 3 контуры более горизонтальны, что означает, что для малых N (например, N≤600) помощь, предлагаемая большим объемом данных, может быть ограничена.
Однако в верхней половине рисунка 3 контуры идут вверх слева, что означает, что для большего N (например, N ≥ 600) больший размер данных дает более низкий WER.
4.2 Различные стратегии обучения и параметры модели
Таблица 1 и рисунок 3 относятся к стратегии совместного обучения в (6) подраздела 2.4 и одноуровневым GRU. Здесь мы хотим увидеть производительность стратегии раздельного обучения плюс последующее преобразование в (10) подраздела 2.6. Результаты представлены в левой части (совместная) и средней части (отдельная) таблицы 2 для данных за 4,1 часа и N = 39809, 1000. Также приведены результаты для 2-го и 3-го уровней ГРУ в кодерах/декодерах (L=2, 3).
Результаты в таблице 2 эмпирически показали, что совместное изучение фонетических структур из устных и текстовых слов вместе с выравниванием между ними превзошло стратегию раздельного обучения, а затем преобразования.
Весьма вероятно, что фонетические структуры последовательностей единиц подслов определенной длины сильно отличаются от структур сигнальных сегментов разной длины, поэтому их выравнивание и деформация во время совместного обучения дает более плавные отношения отображения, в то время как принудительное преобразование между двумя отдельно обученными структурами может быть слишком жестким. .
Кроме того, модель с L=2 достигла немного лучших результатов по сравнению с L=1 в случае данных за 4,1 часа, в то время как переобучение произошло с L=3, когда N было мало.
Все приведенные выше результаты относятся к фонемам, взятым в качестве единиц подслов.
В правом столбце таблицы 2 представлены результаты для персонажей с совместным обучением и L=1.
Мы видим, что символы работали намного хуже, чем фонемы.
Ясно, что последовательности фонем намного лучше описывали фонетические структуры, чем последовательности символов.
4.3 Исследования абляции и регуляризация цикличности
В таблице 3 мы провели исследования абляции для совместного обучения в (6) данных подраздела 2.4 и 4.1 часов и N = 39809 и 1000, удалив член потери в (1) (2) (3) (4) (5) в подразделах 2.1, 2.2 и 2.3.
Мы видим, что все потери при реконструкции в (1)(2)(3)(4) были полезны, но потери при реконструкции междоменного текста в (4) были особенно важны, очевидно, потому, что последовательности фонем наиболее точно описывали фонетические структуры, и междоменная реконструкция предложила хорошие отношения отображения. С другой стороны, междоменное встраивание обучения потерям из парных устных и текстовых слов в (5) внесло здесь наиболее значительный вклад.
Знания, полученные здесь из парных данных, «обобщаются» на другие немаркированные слова.
Мы также проверили согласованность циклов, упомянутую в (9) подраздела 2.5, для данных за 4,1 часа и различных значений N. Результаты в таблице 3 показали, что согласованность циклов может не помочь для больших N, но стала полезной для меньших N (например, N≤200), когда слишком малое количество таких парных слов или «опорных точек» было недостаточным для построения отношений сопоставления. Это связано с тем, что условие согласованности цикла требовало, чтобы каждое парное произносимое и текстовое слово проходило через все кодировщики и декодеры.
5 Обсуждение и заключение
В этой работе мы исследуем возможность выполнения распознавания речи с очень низким ресурсом (небольшой размер данных с небольшим количеством парных помеченных слов) путем совместного изучения фонетических структур из аудио и текстовых вложений. Был получен гладкий и непрерывный спектр производительности WER, когда размер данных и количество парных слов были соответственно уменьшены до минимума.
Достигнутые WER были все еще относительно высокими, но подразумевали хорошее направление для будущей работы.
Ссылки
- [1] Багданов Д., Чоровски Ю., Сердюк Д., Бракель П., Бенжио Ю. Сквозная распознавание речи с большим словарным запасом на основе внимания», в Acoustics, Обработка речи и сигналов (ICASSP), Международная конференция IEEE, 2016 г. на . IEEE, 2016 г., стр. 4945–4949.
- [2] Д. Амодей, С. Анантанараянан, Р. Анубхай, Дж. Бай, Э. Баттенберг, К. Кейс, Дж. Каспер, Б. Катандзаро, К. Ченг, Г. Чен и др. , «Глубокая речь 2: Сквозное распознавание речи на английском и китайском языках», в Международная конференция по машинному обучению , 2016 г., стр. 173–182.
- [3]
Ю. Чжан, В. Чан, Н. Джейтли, «Очень глубокие сверточные сети для
сквозное распознавание речи», в Акустика, речь и сигнал
Обработка (ICASSP), Международная конференция IEEE, 2017 г. , посвященная . IEEE, 2017 г., стр. 4845–4849.
- [4]
К. Весели, М. Ханнеманн и Л. Бургет, «Полуконтролируемая тренировка глубоких нейронные сети», в
Автоматическое распознавание и понимание речи (ASRU), 2013 Семинар IEEE по . IEEE, 2013, стр. 267–272. - [5] Э. Дикичи и М. Сарачлар, «Частично контролируемые и неконтролируемые обучение дискриминационной языковой модели для автоматического распознавания речи», Речевое общение , vol. 83, стр. 54–63, 2016.
- [6] С. Томас, М. Л. Зельцер, К. Черч и Х. Германский, «Глубокая нейронная сеть функции и полуконтролируемое обучение распознаванию речи с низкими ресурсами», в Акустика, обработка речи и сигналов (ICASSP), IEEE 2013 г. Международная конференция . IEEE, 2013, стр. 6704–6708.
- [7]
Ф. Грезль и М. Карафиат, «Сочетание многоязычного и
полуконтролируемое обучение языкам с ограниченными ресурсами», в Пятнадцатом
Ежегодная конференция Международной ассоциации речевой коммуникации ,
2014.
- [8] К. Весело, Л. Бургет и Дж. Чернок, «Полуконтролируемое обучение днн с выбором слов для аср». в INTERSPEECH , 2017, стр. 3687–3691.
- [9] Ю.-К. Чен, К.-Х. Шен, С.-Ф. Хуанг, Х.-ю. Ли и Л.-с. Ли, «Почти неконтролируемое распознавание речи с близким к нулю ресурсом на основе фонетические структуры, извлеченные из очень маленьких непарных речевых и текстовых данных». Препринт arXiv arXiv:1810.12566 , 2018 г.
- [10] С. Карита, С. Ватанабэ, Т. Ивата, А. Огава и М. Делькруа, «Полуконтролируемая сквозное распознавание речи», Proc. Интерспич 2018 , стр. 2–6, 2018.
- [11] Дж. Дрекслер и Дж. Гласс, «Сочетание сквозного и состязательного обучения для распознавание речи с низким уровнем ресурсов», в IEEE Spoken Language 2018 г. Технологический семинар (SLT) . IEEE, 2018. С. 361–368.
- [12]
Ю. Чанг, К. Ву, К. Шен, Х. Ли и Л. Ли, «Аудио word2vec: без присмотра изучение представлений аудиосегментов с использованием последовательности к последовательности автоэнкодер», в
Interspeech 2016, 17-я ежегодная конференция Международная ассоциация речевой коммуникации, Сан-Франциско, Калифорния, США, 8-12 сентября 2016 г. , 2016 г., стр. 765–769. [Онлайн]. Доступный:
https://doi.org/10.21437/Interspeech.2016-82 - [13] Ю.-Х. Ван, Х.-Ю. Ли и Л.-С. Ли, «Сегментное аудио Word2Vec: Представление высказываний в виде последовательностей векторов с приложениями в разговорной речи. определение термина», в ICASSP , 2017.
- [14] Ю.-А. Чанг, В.-Х. Венг, С. Тонг и Дж. Гласс, «Неконтролируемые кросс-модальные выравнивание пространства для встраивания речи и текста», в Достижения в нейронной сети Системы обработки информации , 2018, стр. 7365–7375.
- [15] Д. Лю, К. Чен, Х. Ли и Л. Ли, «Полностью неконтролируемая фонема распознавание путем состязательного изучения взаимосвязей сопоставления по аудио эмбеддинги», в Interspeech 2018, 19th Annual Conference of the Международная ассоциация речевой коммуникации, Хайдарабад, Индия, 2-6 Сентябрь 2018 г. , 2018 г., стр. 3748–3752. [Онлайн]. Доступный: https://doi.org/10.21437/Interspeech.2018-1800
- [16]
Т. Тран, С. Тошнивал, М. Бансал, К. Гимпель, К. Ливеску и М. Остендорф,
«Разбор речи: нейронный подход к интеграции лексических и
акустико-просодическая информация», в Материалах конференции 2018 г.
Североамериканского отделения Ассоциации вычислительных
Лингвистика: технологии человеческого языка, NAACL-HLT 2018, Новый Орлеан,
Луизиана, США, 1–6 июня 2018 г., том 1 (Длинные статьи) , 2018 г., стр. 69–81.
[Онлайн]. Доступно: https://aclanthology.info/papers/N18-1007/n18-1007
- [17] Х. Танг, Л. Лу, Л. Конг, К. Гимпель, К. Ливеску, К. Дайер, Н. А. Смит и С. Реналс, «Сквозные нейронные сегментарные модели для распознавания речи». Дж. Сел. Темы Обработка сигналов , том. 11, нет. 8, стр. 1254–1264, 2017. [Онлайн]. Доступно: https://doi.org/10.1109/JSTSP.2017.2752462.
- [18]
Х. Кампер, К. Ливеску и С. Голдуотер, «Встроенная сегментная модель k-средних для неконтролируемой сегментации и кластеризации речи», в
Автоматический Семинар по распознаванию и пониманию речи (ASRU), 2017 г. IEEE . IEEE, 2017 г., стр. 719–726. - [19] Х. Кампер, А. Янсен и С. Голдуотер, «Сегментная структура для полностью неконтролируемое распознавание речи с большим словарным запасом», Компьютер Речь и язык , том. 46, стр. 154–174, 2017.
- [20] К. Левин, А. Янсен и Б. Ван Дурме, “Сегментное акустическое индексирование для нулевого поиск по ключевому слову ресурса», в ICASSP , 2015.
- [21] С. Бенжио и Г. Хейгольд, «Внедрение слов для распознавания речи», в ИНТЕРСПИЧ , 2014.
- [22]
Г. Чен, К. Парада и Т. Н. Сайнат, «Выявление ключевых слов по запросам с использованием сетей долговременной кратковременной памяти», в
ICASSP , 2015. - [23] С. Сеттл, К. Левин, Х. Кампер и К. Ливеску, «Поиск по примеру с дискриминационное нейронное акустическое встраивание слов», INTERSPEECH , 2017.
- [24]
А. Янсен, М. Плакал, Р. Пандья, Д. Эллис, С. Херши, Дж. Лю, К. Мур и
Р. А. Зарус, «На пути к изучению семантических звуковых репрезентаций из
неразмеченные данные», в Семинар NIPS по машинному обучению для аудиосигнала
Обработка (ML4Audio) , 2017.
- [25] И. Гулраджани, Ф. Ахмед, М. Аржовски, В. Дюмулен и А. Курвиль, «Улучшенный обучение вассерштейновских GAN», в NIPS , 2017.
- [26] Дж. С. Гарофоло, Л. Ф. Ламель, В. М. Фишер, Дж. Г. Фискус и Д. С. Паллетт, «Darpa представляет собой компакт-диск с акустико-фонетическим корпусом непрерывной речи. первая речь диск 1-1.1», Технический отчет NASA STI/Recon n , vol. 93, 1993.
- [27] Д. Пови, А. Гошал, Г. Булианн, Л. Бергет, О. Глембек, Н. Гоэль, М. Ханнеманн, П. Мотличек, Ю. Цянь, П. Шварц и др. , «Калди набор инструментов для распознавания речи», на семинаре IEEE 2011 по автоматической речи. узнавание и понимание , нет. EPFL-CONF-192584. Общество обработки сигналов IEEE, 2011 г.
- [28] Д. П. Кингма, Дж. Ба, «Адам: метод стохастической оптимизации», сб. 3-я Международная конференция по образовательным представительствам, ICLR 2015,
Сан-Диего, Калифорния, США, 7-9 мая, 2015 г., Материалы конференции , 2015 г. [Онлайн]. Доступно: http://arxiv.org/abs/1412.6980
Фонологическая и фонематическая осведомленность | Чтение ракет
Фонологическая осведомленность — это широкий навык, который включает в себя идентификацию единиц устной речи и манипулирование ими — такими частями, как слова, слоги, начала и рифмы. Дети, обладающие фонологическим слухом, способны определять и составлять устные рифмы, могут выстукивать количество слогов в слове и могут распознавать слова с одинаковыми начальными звуками, такие как «деньги» и «мама».
Фонематическая осведомленность относится к особой способности сосредотачиваться на отдельных звуках (фонемах) в произносимых словах и манипулировать ими. Фонемы – это мельчайшие единицы, из которых состоит разговорная речь. Фонемы объединяются, образуя слоги и слова. Например, слово «мат» имеет три фонемы: /м/ /а/ /т/. В английском языке 44 фонемы, включая звуки, представленные буквосочетаниями, такими как /th/. Приобретение фонематического восприятия важно, потому что оно является основой для навыков правописания и распознавания слов. Фонематическая осведомленность является одним из лучших показателей того, насколько хорошо дети научатся читать в течение первых двух лет обучения в школе.
Учащиеся, подверженные риску затруднений при чтении, часто имеют более низкий уровень фонологической и фонематической осведомленности, чем их одноклассники. Хорошая новость заключается в том, что фонематическое и фонологическое восприятие можно развить с помощью ряда упражнений. Читайте ниже для получения дополнительной информации.
Как выглядит проблема
Точка зрения ребенка: как это выглядит для меня
Дети обычно выражают свое разочарование и трудности в общих чертах, например: «Я ненавижу читать!» или «Это глупо!». Но если бы они могли, вот как дети могли бы описать, как трудности с фонологическим или фонематическим восприятием влияют на их чтение:
- Я не знаю слов, которые рифмуются с кот .
- Что вы имеете в виду, когда говорите: «Какие звуки в слове кисть ?»
- Я не знаю, сколько слогов в моем имени.
- Я не знаю, какие звуки совпадают в , бит и , хит .
Взгляд родителя: что я вижу дома
Вот несколько подсказок для родителей о том, что у ребенка могут быть проблемы с фонологическим или фонематическим восприятием:
- Ей трудно придумать рифму для простого слова, такого как кошка (например, крыса или летучая мышь).
- Она не проявляет интереса к языковым играм, словесным играм или рифмовке.
Взгляд учителя: то, что я вижу в классе
Вот несколько подсказок для учителей о том, что у учащегося могут быть проблемы с фонологическим или фонематическим восприятием:
- Она неправильно выполняет действия по смешиванию; например, сложите звуки /k/ /i/ /ck/, чтобы получилось слово удар .
- Он неправильно выполняет действия по замене фонемы; например, измените /m/ в mate на /cr/, чтобы сделать crate .
- Ему трудно сказать, сколько слогов в слове бумага .
- У него проблемы с рифмовкой, слогами или написанием нового слова по его звучанию.
Как помочь
С помощью родителей и учителей дети могут научиться стратегиям преодоления фонологических и/или фонематических проблем, влияющих на чтение. Ниже приведены некоторые советы и конкретные действия.
Что дети могут сделать, чтобы помочь себе
- Будьте готовы играть в словесные и звуковые игры с родителями или учителями.
- Будьте терпеливы при изучении новой информации, связанной со словами и звуками. Давать ушам тренировку сложно!
- Тренируйтесь слышать отдельные звуки в словах. Может помочь использование пластиковой фишки в качестве счетчика каждого звука, который вы слышите в слове.
- Будьте готовы практиковаться в письме. Это даст вам возможность сопоставить звуки с буквами.
Что родители могут сделать, чтобы помочь дома
- Уточните у учителя или директора вашего ребенка, чтобы убедиться, что школьная программа чтения обучает фонологическим, фонематическим навыкам и фоническим навыкам.
- Если ваш ребенок уже достиг возраста, в котором фонематический слух и фонологические навыки обучаются в рамках всего класса (обычно от детского сада до первого или второго класса), убедитесь, что он или она обучаются этим навыкам индивидуально или в небольшой группе.
- Выполняйте действия, которые помогут вашему ребенку развить звуковые навыки (убедитесь, что они короткие и веселые; не позволяйте ребенку расстраиваться):
- Помогите ребенку придумать несколько слов, которые начинаются со звука /м/ или /ч/ или других начальных звуков.
- Составьте глупые предложения со словами, начинающимися с одного и того же звука, например: «Никто не был добр к соседке Нэнси».
- Играйте с ребенком в простые игры на рифмование или смешивание, например, по очереди придумывайте рифмующиеся слова ( go – no ) или смешивайте простые слова (/d/, /o/, /g/ = собака ).
- Читать книги со стихами. Научите ребенка стишкам, коротким стихотворениям и песням.
- Упражняйтесь в азбуке, указывая буквы везде, где вы их видите, и читая алфавитные книги.
- Рассмотрите возможность использования компьютерного программного обеспечения, направленного на развитие фонологических и фонематических навыков. Многие из этих программ используют красочную графику и анимацию, которые привлекают и мотивируют маленьких детей.
Что учителя могут сделать, чтобы помочь в школе
- Узнайте все о фонемах (существует более 40 звуков речи, которые могут быть неочевидны для бегло читающих и говорящих).
- Убедитесь, что школьная программа по чтению и другие материалы включают развитие фонемных навыков, особенно в детском саду и в первом классе (эти навыки не приходят сами собой, но им необходимо учить).
- Если дети достигли возраста, в котором необходимо развивать фонематическую осведомленность и формирование фонологических навыков (обычно от детского сада до первого или второго класса), занимайтесь этими навыками один на один или в небольшой группе.