Морфологический разбор слова «научиться»
Часть речи: Инфинитив
НАУЧИТЬСЯ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАУЧИТЬСЯ»
| Слово | Морфологические признаки |
|---|---|
| НАУЧИТЬСЯ |
|
Все формы слова НАУЧИТЬСЯ
НАУЧИТЬСЯ, НАУЧИЛСЯ, НАУЧИЛАСЬ, НАУЧИЛОСЬ, НАУЧИЛИСЬ, НАУЧУСЬ, НАУЧИМСЯ, НАУЧИШЬСЯ, НАУЧИТЕСЬ, НАУЧИТСЯ, НАУЧАТСЯ, НАУЧАСЬ, НАУЧИВШИСЬ, НАУЧИМТЕСЬ, НАУЧИСЬ, НАУЧИВШИЙСЯ, НАУЧИВШЕГОСЯ, НАУЧИВШЕМУСЯ, НАУЧИВШИМСЯ, НАУЧИВШЕМСЯ, НАУЧИВШАЯСЯ, НАУЧИВШЕЙСЯ, НАУЧИВШУЮСЯ, НАУЧИВШЕЮСЯ, НАУЧИВШЕЕСЯ, НАУЧИВШИЕСЯ, НАУЧИВШИХСЯ, НАУЧИВШИМИСЯ
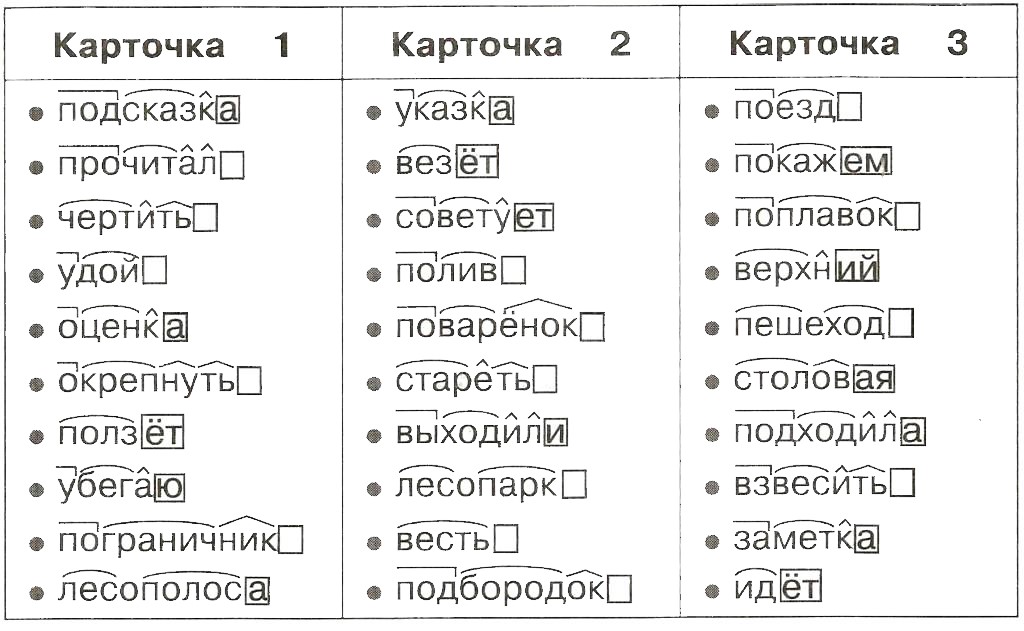
Разбор слова по составу научиться
научи
ться
| Основа слова | научи |
|---|---|
| Приставка | на |
| Корень | уч |
| Суффикс | и |
| Глагольное окончание | ть |
| Постфикс | ся |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАУЧИТЬСЯ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «научиться»
1
И при этом не давать им чему-то научиться, воевать научиться
Каратели, Алесь Адамович, 1979г.
2
Научиться сидеть на ней верхом – все равно что научиться тому, как покорить Грузию.
Орхан, Роберт Ирвин, 1997г.
3
А если я могу научиться петь, то разве я не могу научиться и многому другому?
Баллада о Максе и Амели, Давид Сафир, 2018г.
4
Но, прежде чем научиться читать на этом языке, надо было научиться различать его буквы.
Даниэль Штайн, переводчик, Людмила Улицкая, 2006г.
5
Максимум, чего он мог достичь, – научиться галлюцинациям, а точнее – научиться управлять ими.
Пустые коридоры, Константин Шеметов, 2015г.
Найти еще примеры предложений со словом НАУЧИТЬСЯ
[PDF] Обучение распределенному словесному представлению для анализа межъязыковых зависимостей title={Распределенное обучение представлению слов для анализа межъязыковых зависимостей}, автор={Минь Сяо и Юйхун Го}, название книги={CoNLL}, год = {2014} }
- Мин Сяо, Юхун Го
- Опубликовано в CoNLL 1 июня 2014 г.
- Информатика, лингвистика
В этой статье предлагается изучить языконезависимые представления слов для решения межъязыкового синтаксического анализа зависимостей, целью которого является прогнозирование деревьев синтаксического анализа зависимостей для предложений на целевом языке путем обучения синтаксического анализатора зависимостей помеченными предложениями из исходного языка.
Представление в ACL
cis-linux1.temple.eduАнализ межъязыковых зависимостей на основе распределенных представлений
- Jiang Guo, Wanxiang Che, David Yarowsky, Haifeng Wang, Ting Liu
ACL 9 Информатика, лингвистика
- 2015
В этой статье представлены два алгоритма для создания межъязыковых распределенных представлений слов, которые отображают словари из двух разных языков в общее векторное пространство и устраняют разрыв в лексических признаках с помощью распределенных представлений признаков и их композиции.
Аннотационные проекции Обучение репрезентации для межсового анализа зависимости
- Min Xiao, Yuhong Guo
Компьютерная наука, лингвистика
Conll
- 2015
для синтаксического анализа межъязыковых зависимостей путем создания скрытых представлений межъязыковых данных посредством завершения матрицы и проекций аннотаций на большое количество немаркированных параллельных предложений.
Основанная на распределенных представлениях структура для анализа межъязыкового переноса
- Jiang Guo, Wanxiang Che, David Yarowsky, Haifeng Wang, Ting Liu
Информатика, лингвистика
J. Artif. Интел. Рез.
- 2016
В этой статье представлены два алгоритма для создания межъязыковых распределенных представлений слов, которые отображают словари из двух разных языков в общее векторное пространство и значительно превосходят современные делексикализованные модели, дополненные спроецированным кластером. функции на идентичных данных.
Целевой язык с ограниченным ограниченным языком для перекрестного анализа зависимости
- Tao Meng, Nanyun Peng, Kai-Wei Chang
Компьютерная наука, лингвистика
EMNLP
- 2019 9000
It Is Supe. лингвистических знаний для целевых языков может существенно улучшить межъязыковой анализатор зависимостей на основе графа и предложить новые алгоритмы, которые адаптируют два метода, лагранжеву релаксацию и апостериорную регуляризацию, для проведения вывода с ограничениями корпусной статистики.
перекрестная передача для неконтролируемого диапазона зависимости без параллельных данных
- Long Duong, Trevor Cohn, Steven Bird, Paul Cook
Компьютерная наука, лингвистика
СМОРТИЧЕСКИЙ СОВЕРИНС. которые обобщают синтаксические контексты двуязычного словаря и включают их в синтаксический анализатор нейронной сети, а также демонстрируют эмпирические улучшения по сравнению с базовым делексикализованным синтаксическим анализатором в наборах данных CoNLL и Universal Dependency Treebank.
Неконтролируемое перекрестное встроение слов с помощью многоязычных моделей нейронного языка
- Takashi Wada, Tomoharu Iwata
Компьютерная наука, Linguistic
Arxiv
- 2018 9007
- Васи Уддин Ахмад, Чжисон Чжан, Сюэже Ма, Э. Хови, Кай-Вей Чанг, Нанюн Пэн
Информатика, лингвистика
NAACL
- 2019
- Wasi Uddin Ahmad, Zhisong Zhang, Xuezhe MA, Kai-Wei Chang, Nanyun Peng
Компьютерная наука, лингвистика
Conll
20119
- 111111111111111111118 2011 2011 2011 2011 2011 2011 2011 2011 г.
 2011 года. исследует состязательное обучение для изучения контекстных кодировщиков, которые создают инвариантные представления для разных языков, чтобы облегчить межъязыковую передачу, и предлагает использовать неаннотированные предложения из вспомогательных языков, чтобы помочь в изучении языково-независимых представлений.
2011 года. исследует состязательное обучение для изучения контекстных кодировщиков, которые создают инвариантные представления для разных языков, чтобы облегчить межъязыковую передачу, и предлагает использовать неаннотированные предложения из вспомогательных языков, чтобы помочь в изучении языково-независимых представлений.Неконтролируемая перекрестная адаптация адаптации диапазонов зависимости с использованием CRF AutoEncoders
- Z. Li, Kewei TU
Компьютерная наука
Результаты
- 2020
фреймворк для задачи межъязыковой адаптации парсеров зависимостей без аннотированных целевых корпусов и параллельных корпусов.
Двуязычные вложения слов на основе зависимостей без выравнивания слов
- Taghreed Alqaisi, Alexandros Komninos, Simon E. M. O’Keefe
Компьютерная наука, лингвистика
2020 Международная совместная конференция по нейронным сетям (IJCNN)
- 2020
.
выравнивания (BilBOWA) с использованием линейных контекстов Bag-of-words и контекстов на основе зависимостей, чтобы предоставить доказательства того, что использование функций зависимости в двуязычных встраиваниях слов имеет различный эффект, основанный на синтаксическом сходстве и сходстве структуры предложения языковой пары.с показателем 1-10 из 46 ссылок
Sort Byrelevancemost, под влиянием PapersRecency
Селективное совместное использование для многоязычного парирования зависимости
- Tahira Naseem, R. Barzilay, A. Globersing
Computer Science, Linguiste, R. Barzilay, A. Globerson
, Computer Science, Linguiste, R. Barzilay, A. Globerson
, Computer Science, Linguiste, R. Barzilay, A. Globerson
.
Мы представляем новый алгоритм анализа многоязычных зависимостей, который использует аннотации из различных наборов исходных языков для анализа нового языка без аннотаций.
Наша мотивация – расширить…Адаптация и проекция анализатора с квази-синхронной грамматикой
- Дэвид А. Смит, Джейсон Эйснер
Компьютерная наука
EMNLP
- 2009
We Connect Two Scendaries in Structure Learning. одного корпуса в другой стиль аннотаций и проецирование синтаксических аннотаций с одного языка на другой. Мы предлагаем…
Индукция грамматики зависимостей через ограничения проекции битекста
- Кузман Ганчев, Дженнифер Гилленуотер, Б. Таскар
Информатика
ACL
- 2009
ограничивает пространство возможных целевых деревьев и оценивает подход к данным общих задач CoNLL в Болгарии и Испании и показывает, что он последовательно превосходит неконтролируемые методы и может превзойти контролируемое обучение для ограниченных обучающих данных.
Анализ межъязыковых зависимостей с использованием двуязычного лексикона
- Чжао Хай, Ян Сонг, К. Кит, Годун Чжоу
Информатика
ACL
- 2009
Межъязыковые кластеры слов для прямого переноса лингвистической структуры
- Оскар Тэкстрем, Райан Т. Макдональд, Якоб Ушкорайт
Информатика, Лингвистика
NAACL
- 2012
Показано, что при дополнении систем прямого переноса межъязыковыми кластерными функциями относительная погрешность делексикализованных синтаксических анализаторов зависимостей, обученных на английских банках деревьев и переведенных на иностранные языки, может быть снижен до 13%.
Адаптация к целевому языку анализаторов различительного перевода
- Оскар Тэкстрем, Райан Т. Макдональд, Йоаким Нивре
Информатика
NAACL
- 2013
В этой работе показано, как последние идеи по выборочному совместному использованию параметров могут быть применены к дискриминационному синтаксическому анализатору путем тщательной декомпозиции функций его модели, а также показано, как синтаксический анализатор можно повторно лексизировать и адаптировать с помощью немаркированного целевого объекта.
языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.Передача из нескольких источников делексикализованных синтаксических анализаторов зависимостей
- Райан Т. Макдональд, Слав Петров, Кит Б. Холл
Информатика
EMNLP
- 2011
Эта работа демонстрирует, что парсеры, производящие делексикализованные парсеры, могут быть значительно выше, чем парсеры, производящие делексикализованные парсеры, могут быть напрямую переданы между языками, делексикализованными парсерами и показывает, что простые методы введения нескольких исходных языков могут значительно улучшить общее качество результирующих синтаксических анализаторов.
Общая задача CoNLL-X по анализу многоязычных зависимостей
- S. Buchholz, E. Marsi
Информатика
CoNLL
- 2006
Описано, как деревья деревьев для 13 языков были преобразованы в один и тот же общий формат зависимостей и как анализ производительности был преобразован в один и тот же общий формат зависимостей -языковой разбор.
Парсеры начальной загрузки посредством синтаксической проекции на параллельные тексты
- Р. Хва, П. Резник, А. Вайнберг, Клара И. Кабезас, О. Колак
Лингвистика, информатика
Инженерия естественного языка
- 2005
Использование параллельного текста для решения проблемы создания синтаксических аннотаций на других языках путем аннотирования английской стороны параллельного корпуса, перенос анализа на второй язык , и обучить стохастический анализатор на полученных зашумленных аннотациях.
Кросслингвальная индукция смысловых ролей
- Иван Титов, А. Клементьев
Информатика
ACL
- 2012
В этой работе рассматривается неконтролируемая индукция семантических ролей из предложений, аннотированных автоматически прогнозируемыми представлениями синтаксической зависимости, и для этого используется современная генеративная байесовская непараметрическая модель.
так.разбор — Является ли слово «лексер» синонимом слова «парсер»?
спросил
Изменено 11 лет, 6 месяцев назад
Просмотрено 647 раз
В заголовке вопрос: Слова «лексер» и «парсер» синонимы или разные? Похоже, что в Википедии эти слова взаимозаменяемы, но английский не мой родной язык, поэтому я не уверен.
- синтаксический анализ
- язык-агностик
- лексер
- синоним
2
Лексер используется для разделения входных данных на токены, тогда как синтаксический анализатор используется для построения абстрактного синтаксического дерева из этой последовательности токенов.
Теперь вы можете просто сказать, что токены — это просто символы и напрямую использовать синтаксический анализатор, но часто бывает удобно иметь синтаксический анализатор, которому нужно только просмотреть один токен, чтобы определить, что он собирается делать дальше.
Лексер обычно описывается с помощью простых правил регулярных выражений, которые проверяются по порядку. Существуют такие инструменты, как
lex, которые могут автоматически генерировать лексеры из такого описания.[0-9]+ Номер [A-Z]+ Идентификатор + Плюс
Анализатор, с другой стороны, обычно описывается путем указания грамматики . Опять же, существуют инструменты, такие как
yacc, которые могут генерировать синтаксические анализаторы из такого описания.выражение ::= выражение Плюс выражение | Число | ИдентификаторНет. Лексер разбивает входной поток на «слова»; парсер обнаруживает синтаксическую структуру между такими «словами». Например, при вводе:
скорость = путь/время;
вывод лексера:
скорость (идентификатор) = (оператор присваивания) путь (идентификатор) / (бинарный оператор) время (идентификатор) ; (разделитель операторов)
и тогда синтаксический анализатор может установить следующую структуру:
= (назначить) lvalue: скорость rvalue: результат / (разделение) дивиденд: содержимое переменной "путь" делитель: содержимое переменной "время"Нет.
Лексер разбивает исходный текст на лексемы, тогда как синтаксический анализатор соответствующим образом интерпретирует последовательность лексем.Они разные.
Лексер принимает поток входных символов в качестве входных данных и создает токены (также известные как «лексемы») в качестве выходных данных.
Синтаксический анализатор принимает токены (лексемы) в качестве входных данных и создает (например) абстрактное синтаксическое дерево, представляющее операторы.
Однако они достаточно похожи, поэтому многие люди (особенно те, кто никогда не писал ничего похожего на компилятор или интерпретатор) рассматривают их как одно и то же или (чаще) используют «анализатор», когда они действительно имеют в виду это «лексер».
Насколько мне известно, лексер и парсер близки по значению, но не являются точными синонимами. Хотя многие источники используют их как аналогичные, лексер (аббревиатура от лексического анализатора) идентифицирует токены, относящиеся к языку, из входных данных; в то время как синтаксические анализаторы определяют, соответствует ли поток токенов грамматике рассматриваемого языка.
. обратные языковые модели, и эти сети являются общими для всех языков, так что встраивания слов каждого языка отображаются в общее скрытое пространство, что позволяет измерять сходство слов в нескольких языках.
О трудностях межъязыкового переноса с разницей в порядке: пример разбора зависимостей
Исследование межъязыкового переноса и утверждение о том, что модель, не зависящая от порядка, будет работать лучше при переносе на далекие иностранные языки, показывает, что архитектуры на основе RNN хорошо переносятся на языки, близкие к английскому, в то время как модели с самостоятельным вниманием лучшую общую межъязыковую переносимость и особенно хорошо работают на далеких языках.
Проповедник по межзобной зависимости с нематборенными вспомогательными языками

 2011 года. исследует состязательное обучение для изучения контекстных кодировщиков, которые создают инвариантные представления для разных языков, чтобы облегчить межъязыковую передачу, и предлагает использовать неаннотированные предложения из вспомогательных языков, чтобы помочь в изучении языково-независимых представлений.
2011 года. исследует состязательное обучение для изучения контекстных кодировщиков, которые создают инвариантные представления для разных языков, чтобы облегчить межъязыковую передачу, и предлагает использовать неаннотированные предложения из вспомогательных языков, чтобы помочь в изучении языково-независимых представлений. выравнивания (BilBOWA) с использованием линейных контекстов Bag-of-words и контекстов на основе зависимостей, чтобы предоставить доказательства того, что использование функций зависимости в двуязычных встраиваниях слов имеет различный эффект, основанный на синтаксическом сходстве и сходстве структуры предложения языковой пары.
выравнивания (BilBOWA) с использованием линейных контекстов Bag-of-words и контекстов на основе зависимостей, чтобы предоставить доказательства того, что использование функций зависимости в двуязычных встраиваниях слов имеет различный эффект, основанный на синтаксическом сходстве и сходстве структуры предложения языковой пары. Наша мотивация – расширить…
Наша мотивация – расширить… Кит, Годун Чжоу
Кит, Годун Чжоу языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.
языковые данные и метод обучения, который может включать различные источники знаний с помощью неоднозначных обозначений.
 так.
так.
 Лексер разбивает исходный текст на лексемы, тогда как синтаксический анализатор соответствующим образом интерпретирует последовательность лексем.
Лексер разбивает исходный текст на лексемы, тогда как синтаксический анализатор соответствующим образом интерпретирует последовательность лексем.