Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: лотецв сейчас в п о н с е сейчас дробьле составить слова сейчас рушагмл сейчас пооаршм сейчас прссоыь сейчас а з и м у т сейчас косунлч сейчас уоницка сейчас няскиаитл сейчас рюталав сейчас иарвнв сейчас уакбмб сейчас компас 1 секунда назад а к у л т ш 1 секунда назад
Морфологический разбор слова «начала»
Слово можно разобрать в 2 вариантах, в зависимости от того, в каком контексте оно используется.
1 вариант разбора
Часть речи: Существительное
НАЧАЛА — неодушевленное
Начальная форма слова: «НАЧАЛО»
| Слово | Морфологические признаки |
|---|---|
| НАЧАЛА |
|
| НАЧАЛА |
|
| НАЧАЛА |
|
Все формы слова НАЧАЛА
НАЧАЛО, НАЧАЛА, НАЧАЛУ, НАЧАЛОМ, НАЧАЛЕ, НАЧАЛ, НАЧАЛАМ, НАЧАЛАМИ, НАЧАЛАХ
2 вариант разбора
Часть речи: Глагол в личной форме
НАЧАЛА — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «НАЧАТЬ»
| Слово | Морфологические признаки |
|---|---|
| НАЧАЛА |
|
Все формы слова НАЧАЛА
НАЧАТЬ, НАЧАЛ, НАЧАЛА, НАЧАЛО, НАЧАЛИ, НАЧНУ, НАЧНЕМ, НАЧНЕШЬ, НАЧНЕТЕ, НАЧНЕТ, НАЧНУТ, НАЧАВ, НАЧАВШИ, НАЧНЕМТЕ, НАЧНИ, НАЧНИТЕ, НАЧАВШИЙ, НАЧАВШЕГО, НАЧАВШЕМУ, НАЧАВШИМ, НАЧАВШЕМ, НАЧАВШАЯ, НАЧАВШЕЙ, НАЧАВШУЮ, НАЧАВШЕЮ, НАЧАВШЕЕ, НАЧАВШИЕ, НАЧАВШИХ, НАЧАВШИМИ, НАЧАТЫЙ, НАЧАТОГО, НАЧАТОМУ, НАЧАТЫМ, НАЧАТОМ, НАЧАТ, НАЧАТАЯ, НАЧАТОЙ, НАЧАТУЮ, НАЧАТОЮ, НАЧАТА, НАЧАТОЕ, НАЧАТО, НАЧАТЫЕ, НАЧАТЫХ, НАЧАТЫМИ, НАЧАТЫ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «НАЧАЛА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «начала»
Примеры предложений со словом «начала»
1
Горького – реальная картина начала жизни писателя, начала очень трудного.
Детство, Максим Горький, 1913г.
2
Я постепенно начала свыкаться с этой мыслью, которая мне очень нравилась с самого начала.
Дикие лошади. У любой истории есть начало, Джаннетт Уоллс, 2009г.
3
Бронвен считала оставшиеся до начала школьных занятий дни свободы – двадцать один, – а я начала прощупывать возможность найти работу фотографа.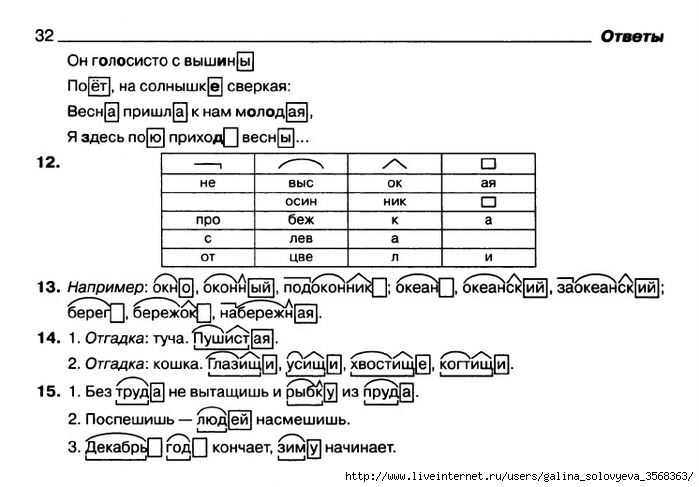
Тайны Торнвуда, Анна Ромеро, 2013г.
4
Начала, начала уже, – погрозила ей пальцем Лида.
Я вернулась, Господи! (сборник), Надежда Смирнова, 2014г.
5
С начала девяностых годов он решил стать сельским предпринимателем и для начала взялся копить деньги на грузовой автомобиль.
Игра света (сборник), Альберт Карышев, 2012г.
Найти еще примеры предложений со словом НАЧАЛА
Curiosity Archives — Страница 4 из 8
Время и место
Терренс
21 сентября 2015 г. Совсем недавно появились циферблаты Fathom Watch Faces для Android Wear. Эта работа вдохновила меня отслеживать все места, где я был, и то, как я перемещался между ними, с помощью приложения Moves.
Этот проект был отличным способом применить на практике мои предварительные знания о D3.js. Я бы также рекомендовал книгу Скотта Мюррея Interactive Data Visualization for the Web , которая помогла понять основы D3.js.
Ознакомьтесь с проектом здесь. 17 августа 2015 г. Многие из нас в Fathom очарованы географией и тонкими странностями вокруг нас, поэтому казалось вполне естественным, что мы создаем Place Poetry. Веселое мобильное приложение позволяет людям составлять стихи из городов со странными названиями, одновременно отмечая местоположение и расстояние своего путешествия.
 Другие были названы в честь влиятельных лидеров – королей и президентов, местных мэров, а часто – в честь самих основателей. Многие топонимы в Соединенных Штатах – это пережитки местных культур, искорененных или перемещенных во время колонизации. Города также были названы в честь природы, цветов, погоды, известных авторов и относительной географии. Тем не менее, со всеми этими общими темами некоторые основатели городов пошли дальше и дальше.
Другие были названы в честь влиятельных лидеров – королей и президентов, местных мэров, а часто – в честь самих основателей. Многие топонимы в Соединенных Штатах – это пережитки местных культур, искорененных или перемещенных во время колонизации. Города также были названы в честь природы, цветов, погоды, известных авторов и относительной географии. Тем не менее, со всеми этими общими темами некоторые основатели городов пошли дальше и дальше. Когда Бен создавал свой оригинальный проект zipdecode, он работал со списком всех городов с уникальными названиями в Соединенных Штатах. Этот список содержит 19 053 имени и послужил основой для Place Poetry. Многие имена в списке очень изобретательны. Одни имена искушают судьбу ( Waterproof, Smackover, Tornado ), другие пропитаны тщеславием ( Superior, Radiant, Cashtown ). Некоторые места отражают пренебрежительное отношение основателя к городу ( Blowing Rock, Hurdle Mills, Idiotville ) и другие заставляют задуматься, как такое имя вошло в обиход ( Кусачий , Своеобразный , Вырезать и стрелять , Продолговатый ).
Мы сузили исходный список имен до избранного набора избранных и отсортировали их по тематическим категориям. По мере того, как эти слова перетаскиваются из разных корзин в пространство композиции, местоположение города наносится на карту. Когда стихотворение готово, автор может увидеть, сколько миль длится его или ее стихотворение, а также может поделиться им в социальных сетях или по электронной почте. Посмотрите, поделитесь стихотворением, и пусть ваш внутренний поэт извергает необычные ароматы.
Примечание. Place Poetry создан для мобильных устройств, поэтому посетите сайт placepoetry.us со своего телефона или планшета!
Написание кода
Мелани
7 августа 2015 г.
Я нашел Fathom на курсе визуализации данных в колледже, который вел профессор статистики, поэтому мое первое знакомство с информационным дизайном произошло через призму статистического анализа. Я провел большую часть своего времени в этом классе, следя за тем, чтобы данные не были искажены, и работая с особенно сложными фрагментами кода. Чем сложнее анализ или код, тем лучше я относился к проекту, и я хотел, чтобы эта сложность отображалась в моем конечном продукте. Если код работал и делал что-то классное, то я был счастлив.
Чем сложнее анализ или код, тем лучше я относился к проекту, и я хотел, чтобы эта сложность отображалась в моем конечном продукте. Если код работал и делал что-то классное, то я был счастлив.
Вопреки утверждениям Твиттера, этим летом я узнал больше, чем просто как пользоваться перфоратором. Пару недель назад я показал Джеймсу несколько слайдов с презентации моей работы этим летом. Одним из его первых комментариев было: «Это требует любви к дизайну». Я как бы знал это, но это не казалось мне приоритетом. Я просто пытался четко представить необходимый контент. Для Джеймса дизайн — неотъемлемая часть любой работы. Как новичок в дизайн-мышлении, это был один из моментов, который начал менять мою оценку своей работы.
Сравнение моего слайда справа с более элегантной версией Джеймса слева. Когда я начал работать в Fathom в июне, меня сразу же поразило, насколько рабочий процесс отличается от среды, к которой я привык. Вместо того, чтобы сосредоточиться на технической или аналитической стороне информационного дизайна, большие вопросы всегда касались дизайна: кто является аудиторией? Что их больше всего интересует? Как этот инструмент может быть более интуитивно понятным для них? И самое главное, что за история в данных? Раньше я никогда не думал о передаче данных как о сторителлинге. Обработка данных всегда была для меня довольно черно-белой; вы ищете ответ в виде доказательств, чтобы доказать, что ваша гипотеза верна или ложна. Информационный дизайн в Fathom не такой. Очевидно, что этот процесс по-прежнему включает в себя тщательное исследование и анализ данных, но он направлен на то, чтобы люди могли с легкостью перемещаться по данным.
Обработка данных всегда была для меня довольно черно-белой; вы ищете ответ в виде доказательств, чтобы доказать, что ваша гипотеза верна или ложна. Информационный дизайн в Fathom не такой. Очевидно, что этот процесс по-прежнему включает в себя тщательное исследование и анализ данных, но он направлен на то, чтобы люди могли с легкостью перемещаться по данным.
Думать об информационном дизайне как о рассказывании историй было для меня огромным. Изначально меня привлекала компьютерная наука, потому что она была похожа на творческое письмо; это то же самое творение, просто написанное на другом языке. Код создает приложения так же, как предложения создают изображения. Я часто думал, что должен применять ту же строгую логику, что и при кодировании , к написанию эссе, и теперь я понимаю, что творческий подход и проницательность, связанные с письмом, должны быть перенесены и в мой код. Точно так же, как никто не хочет читать книгу с непрерывным действием и без сюжета, никто ничего не получает от яркой гистограммы.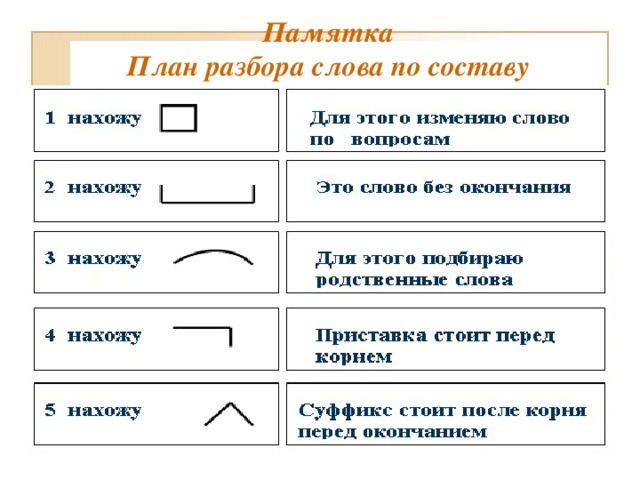
Когда я рос, мои учителя английского языка говорили мне не использовать сокращения в письме, поэтому я был удивлен, когда в прошлом семестре мой преподаватель английского языка просмотрел мой первый рассказ и сократил слова там, где это уместно. Я был ослеплен тем, что считал «правилом», когда на самом деле отсутствие сокращений звучало неестественно для персонажей и отвлекало от истории. Точно так же я понял, что мои инстинкты следовать статистическим «правилам» будут подавлять многих пользователей отвлекающей или ненужной информацией, вместо того, чтобы дать им возможность исследовать.
В школе мои уроки информатики сосредоточены на программировании. Работа, которую мы отправляем, представляет собой исходный код, и оценки основаны больше на том, как этот код написан, чем на том, что он производит. Укоренившись в исходном коде, основное внимание уделяется теории и алгоритмам. В Fathom недостаточно просто останавливаться на достигнутом. Код — это инструмент для создания, но особо крутой или сложный код не должен управлять процессом. Движущей силой является видение конечного продукта, проницательный инструмент.
Движущей силой является видение конечного продукта, проницательный инструмент.
#NoCeilings встречается с National Geographic в Kew Gardens
Оливия
7 июля 2015 г.
В промежутке между выпуском «Без потолков» и работой над «Космическими обезьянами и тигровым вином» я посетил сады Кью, где собрана самая разнообразная коллекция видов растений в мире. Читая о садах в рамках подготовки к поездке, я наткнулся на недавнюю статью четырех женщин-исследователей, посвященную гендерному разрыву в области ботаники.
- Сад камней в садах Кью
- Сад камней в садах Кью
Исследователи взяли названия всех растений из Международного индекса названий растений (IPNI) и определили пол первоначальных ботаников, которые открыли и назвали каждый вид. Результаты показали, что, хотя «примерно 20% научных авторов в период с 1900 по 2000 год были женщинами… женщины-авторы составляют 5% названий новых видов растений, опубликованных за этот период времени». Всего женщины назвали и опубликовали менее 3% видов наземных растений.
Всего женщины назвали и опубликовали менее 3% видов наземных растений.
Просмотрите этот пост на большом экране, чтобы увидеть интерактивную версию визуализации выше.
Гендерный разрыв в ботанике особенно интересен, потому что она исторически считалась «женской» наукой. Как отмечается в документе, отсутствие у женщин — или категорический отказ — в доступе к службам публикации и ресурсам, возможно, способствовало тому, что их новые публикации с именами были нечастыми. Беатрикс Поттер, например, запретили представлять свою статью «О прорастании спор Agaricineae 9».0012 , в Линнеевском обществе в 1897 году, поскольку женщины не могли посещать собрания Общества. Гендерный разрыв в ботанике все еще сохраняется, однако он стал одним из самых маленьких пробелов в науке: женщины-ботаники называют около 4 видов на каждые 5 видов, названных их коллегами-мужчинами.
Было бы здорово, если бы в этом направлении публиковалось больше исследований, которые использовались бы в качестве точки отсчета того, как сохраняется гендерный разрыв в доступе к академическим ресурсам, исследовательским возможностям, а также доступности публикации и распространения.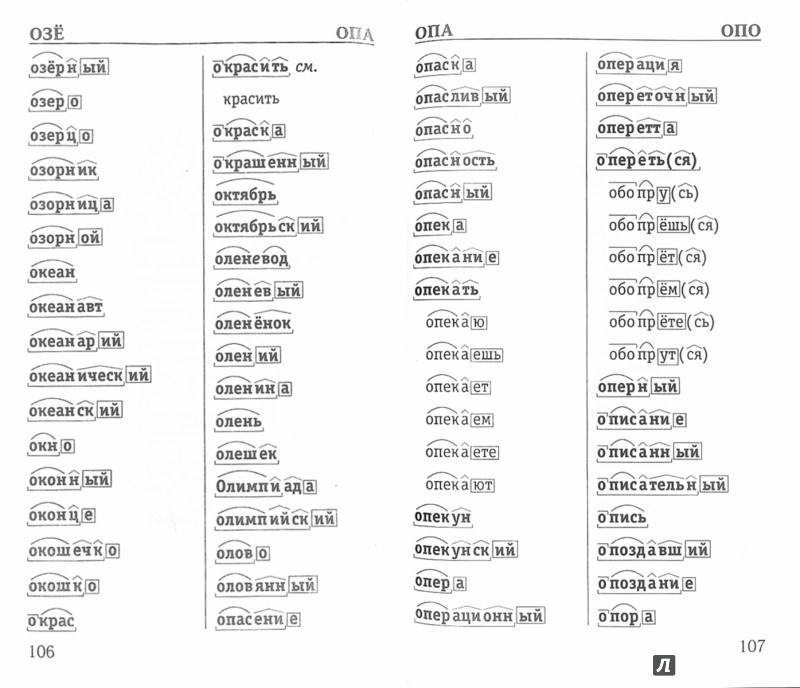
Кстати, источник данных для нашего последнего проекта National Geographic хранит записи о международной торговле растениями. В ходе наших ранних исследований в рамках проекта мы изучали как животных, так и растения и обнаружили, что подснежник Воронова ( Galanthus woronowii ), названный в честь русского ботаника Георга Воронова, был самым продаваемым растением в 2013 году. большой экран для интерактивной версии визуализации выше.
Подснежники вообще ( Galanthus spp.) содержат вещество галантамин, которое можно использовать при лечении болезни Альцгеймера. Хотя я пропустил сезон их цветения, мне удалось найти подснежник обыкновенный ( Galanthus nivalis ) в саду камней Kew Gardens.
Обыкновенный подснежник можно найти в Саду камней в Садах Кью.Большая часть нашей работы связана с одной областью знаний, поэтому удивительно, когда мы можем найти точки их пересечения. Кто знает, может, в следующий раз наш интерес к еде соединится с любовью к телевидению…
Jawsography
Джеймс
23 июня 2015 г.
В честь 40-летия и специального переиздания знаменитого фильма, из-за которого мы боялись плавать в океане, мы представляем Jawsography, интерактивное приложение для анализа кинематография фильма 1975 года «Челюсти».
Меня всегда восхищали художественное оформление и операторская работа в классическом фильме Спилберга. Несмотря на то, что на протяжении всего фильма он применяет множество удивительных приемов кинопроизводства, сильные композиционные сдвиги слева, в центре и справа в каждом кадре поразительны.
Я хотел проверить, были ли настоящие композиционные сдвиги такими же сильными, как мои первоначальные воспоминания о просмотре фильма, поэтому мы создали инструмент, который позволял нам просматривать все кадры фильма. Мы начали с просмотра 1 кадра за 10 секунд фильма, но в итоге получили слишком много переходных кадров. Последнее приложение тянет 1 кадр в минуту фильма.
Челюсти со скоростью 1 кадр в минуту Композиционные паттерны начали проявляться довольно четко. Мы создали еще один инструмент, который позволял нам быстро просматривать кадры и отмечать, какие из них имеют левый, центральный или правый визуальный вес. В свое время мы начали описывать позиционирование с морской номенклатуры: левый и правый борт.
Мы создали еще один инструмент, который позволял нам быстро просматривать кадры и отмечать, какие из них имеют левый, центральный или правый визуальный вес. В свое время мы начали описывать позиционирование с морской номенклатуры: левый и правый борт.
- Порт
- Мидель
- Правый борт
Мне было так весело пролистывать кадры и определять, какой композиционный вес был самым сильным, что мне удалось превратить большую часть офиса в очередную бесполезную работу. Я был полон решимости воплотить это приложение в жизнь. Вскоре родилась челюсть. Взгляните на свое мобильное устройство (или ноутбук), чтобы увидеть кинематографию «Челюстей» совершенно по-новому. Нырнуть в!
CSE230 Wi13 — монадический анализ
CSE230 Wi13 — монадический анализHome оценка Лекции Задания Ссылки Пьяцца
> импорт Data.Char
> импорт Data.Functor
> импорт Control.Monad
 Char
Char Прежде чем мы продолжим, слово от наших спонсоров:
**Не бойтесь монад**
Это просто (чрезвычайно универсальная) абстракция, например map или fold .
Синтаксический анализатор — это часть программного обеспечения, которая принимает необработанные Строка (или последовательность байтов) и возвращает какой-либо структурированный объект, например, список опций, XML-дерево или объект JSON, Абстрактное синтаксическое дерево программы и так далее. Синтаксический анализ является одной из самых основных вычислительных задач. Каждая серьезная программная система имеет парсер, спрятанный где-то внутри, например
- Сценарии оболочки (параметры командной строки)
- Веб-браузеры (да!)
- Игры (дескрипторы уровней)
- Маршрутизаторы (пакеты)
- и т. д.
(Действительно, я бросаю вам вызов, чтобы найти какую-либо серьезную систему, в которой не где-нибудь выполнял бы какой-то синтаксический анализ!)
Самый простой и точный способ представить синтаксический анализатор как функцию
тип Parser = String -> StructuredObject
Составление синтаксических анализаторов
Обычный способ создания синтаксического анализатора заключается в указании грамматики и использовании генератора синтаксического анализа (например, yacc, bison, antlr) для создания фактической функции синтаксического анализа. Несмотря на элегантность, одним из основных ограничений подхода, основанного на грамматике, является отсутствие модульности. Например, предположим, что у меня есть два вида примитивных значений
Несмотря на элегантность, одним из основных ограничений подхода, основанного на грамматике, является отсутствие модульности. Например, предположим, что у меня есть два вида примитивных значений Thingy и Whatsit .
Thingy: правило {действие}
; Whatsit: правило {действие}
;
Если вам нужен синтаксический анализатор для последовательностей Thingy и Whatsit , мы должны тщательно продублировать правила как
Thingies : Thingy Thingies { ... }
EmptyThingy { ... }
; Whatsits: Whatsit Whatsits {...}
EmptyWhatsit {...}
;
Это затрудняет повторное использование подпарсеров. Далее мы увидим, как создать мини-парсеров для подзначений, чтобы получить большие парсеры для сложных значений.
Для этого мы немного обобщим приведенный выше тип синтаксического анализатора, отметив, что (суб-)парсеру не нужно (действительно, не будет) потреблять все его входных данных, и поэтому мы можем просто иметь синтаксический анализатор вернуть неиспользованный ввод
тип Parser = String -> (StructuredObject, String)
Конечно, было бы глупо иметь разные типы парсеров для разных типов объектов, поэтому мы можем сделать его параметризованным типом
тип Parser a = String -> (a, String)
Последнее обобщение: синтаксический анализатор может возвращать несколько результатов, например, мы можем захотеть проанализировать строку
.
"2 - 3 - 4"
либо как
Минус (Минус 2 3) 4
или как
Минус 2 (Минус 3 4)
Итак, мы можем заставить наши синтаксические анализаторы возвращать список возможных результатов (где пустой список соответствует сбою синтаксического анализа.)
> Парсер нового типа a = P (String -> [(a, String)])
Вышеупомянутое просто синтаксический анализатор ( кашель действие) фактический синтаксический анализ выполняется
> doParse (P p) s = p s
Давайте создадим несколько парсеров!
Вот очень простой анализатор символов, который возвращает первый символ из списка, если он существует
> oneChar :: Parser Char
> oneChar = P (\cs -> case cs of
> c:cs' -> [(c, cs')]
> _ -> [])
> twoChar0 = P (\cs -> case cs of
> c1:c2:cs' -> [((c1,c2), cs')]
> _ -> [])
Запускаем анализатор
ghci> doParse oneChar "Эй!"
[('ч',"эй!")]ghci> doParse oneChar ""
[]
Парсер Состав
Мы можем написать комбинатор, который принимает два парсера и возвращает новый парсер, который возвращает пару значений
параP :: Анализатор a -> Анализатор b -> Анализатор (a,b)
пара P p1 p2 = P (\cs ->
[((x,y), cs'') | (x, cs' ) <- doParse p1 cs,
(y, cs'') <- doParse p2 cs ']
)
Теперь мы можем написать еще один синтаксический анализатор, который получает пару значений Char
twoChar :: Parser (Char, Char)
twoChar = P (\cs -> случай cs из
c1:c2:cs' -> [((c1, c2), cs')]
_ -> [])
или более элегантно, как
> twoChar = параP oneChar oneChar
, который будет работать так
ghci> doParse twoChar "эй!"
[(('h','e'), "y!")]ghci> doParse twoChar ""
[]
Теперь мы могли бы продолжать это делать, но часто, чтобы двигаться вперед, полезно сделать шаг назад и взглянуть на более широкую картину.
Вот тип парсера
Парсер нового типа a = P (String -> [(a, String)])
это должно напоминать тебе о чем-то другом, помнишь это?
тип ST a = состояние -> (a, состояние)
Действительно, синтаксический анализатор, как и преобразователь состояний, является монадой! если правильно прищуриться. Нам нужно определить функции return и >>= .
Первый очень простой, мы можем позволить типам вести нас
:тип returnP
returnP :: a -> Parser a
, что означает, что мы должны игнорировать входную строку и просто вернуть элемент ввода
.> returnP x = P (\cs -> [(x, cs)])
Привязка немного сложнее, но опять же, давайте опираться на типы
:type bindP
bindP :: Анализатор a -> (a -> Анализатор b) -> Анализатор b
, поэтому нам нужно высосать значения и из первого синтаксического анализатора и вызвать второй синтаксический анализатор с ними для оставшейся части строки.
> p1 `bindP` fp2 = P (\cs ->
> [(y, cs'') | (x, cs') <- doParse p1 cs
> , (y, cs'') <- doParse ( fp2 x) cs'])
Вооружившись ими, мы можем официально называть парсеры монадами
> экземпляр Monad Parser, где
> (>>=) = bindP
> return = returnP
Поскольку синтаксические анализаторы являются монадами, мы можем написать кучу высокоуровневых комбинаторов для объединения меньших синтаксических анализаторов в более крупные.
Например, мы можем использовать нашу любимую нотацию до , чтобы переписать пару P как
> параP px py = do x <- px
> y <- py
> возврат (x, y)
шокирующе, точь-в-точь как 9Отсюда функционируют 0163 пары .
Теперь давайте разомнем наши монадические мышцы синтаксического анализа и напишем несколько новых синтаксических анализаторов. Будет полезно иметь синтаксический анализатор сбоев , который всегда сгорает, то есть возвращает [] — нет успешных синтаксических анализов.
> сбойP = P $ const []
Кажется немного глупым писать вышеизложенное, но полезно создать более богатые синтаксические анализаторы, подобные следующему, который анализирует Char , если удовлетворяет предикату р
> satP :: (Char -> Bool) -> Parser Char
> satP p = do
> c <- oneChar
> если pc, то вернуть c, иначе failP
мы можем написать несколько простых парсеров для определенных символов
> нижний регистрP = satP isAsciiLower
ghci> doParse (satP ('h' ==)) "mugatu"
[]
ghci> doParse (satP ('h' ==)) "hello"
[('h',"ello")] Следующий алфавит и числовые символы разбора соответственно
> alphaChar = satP isAlpha
> digitChar = satP isDigit
, и этот малыш возвращает первую цифру строки как Int
> digitInt = do
> c <- digitChar
> return ((read [c]) :: Int)
который работает так
ghci> doParse digitInt "92"
[(9,"2")]ghci> doParse digitInt "cat"
[]
Наконец, этот синтаксический анализатор будет анализировать только определенный Char передано как ввод
> char c = satP (== c)
Комбинатор недетерминированного выбора
Теперь давайте напишем комбинатор, который принимает два подпарсера и недетерминированно выбирает между ними.
> selectP :: Парсер a -> Парсер a -> Парсер a
Как нам закодировать выбор в наших парсерах? Что ж, мы хотим вернуть успешный синтаксический анализ, если или синтаксический анализатор успешен. Поскольку наши синтаксические анализаторы возвращают несколько значений,
> p1 `выбрать P` p2 = P (\cs -> doParse p1 cs ++ doParse p2 cs)
Мы можем использовать приведенный выше комбинатор для создания синтаксического анализатора, который возвращает либо алфавит, либо числовой символ
> alphaNumChar = alphaChar `выберитеP` digitChar
Когда мы запускаем это выше, мы получаем довольно интересные результаты
ghci> doParse alphaNumChar "cat"
[('c',"at")]
ghci> doParse alphaNumChar "2cat"
[('2',"cat")]
ghci> doParse alphaNumChar "2at"
[('2',"в")]
Что еще лучше, так это то, что если оба анализатора завершатся успешно, вы получите все результаты. Например, вот синтаксический анализатор, который берет n символов из ввода

> захватить :: Int -> Строка синтаксического анализатора
> захватить n | n <= 0 = вернуть ""
> | в противном случае = do c <- oneChar
> cs <- grabn (n-1)
> return (c:cs)
ДЕЛАТЬ В КЛАССЕ Как бы вы уничтожили неприятную рекурсию выше?
Теперь мы можем использовать наш комбинатор выбора
> захват2или4 = захват 2 `выбратьP` захват 4
и сейчас, мы вернем оба результата если возможно
ghci> doParse grab2or4 "mickeymouse"
[("mi","ckeymouse"),("mick","eymouse")]
и только один результат, если это возможно
ghci> doParse grab2or4 "микрофон"
[("mi","c")]ghci> doParse grab2or4 "m"
[]
Даже имея в своем распоряжении рудиментарные синтаксические анализаторы, мы можем начать делать некоторые довольно интересные вещи. Например, вот небольшой калькулятор. Сначала разбираем операцию
> intOp = плюс `chooseP` минус `chooseP` умножить на `chooseP` разделить
> где плюс = char '+' >> возврат (+)
> минус = char '-' >> возврат (-)
> раз = char '*' >> вернуть (*)
> разделить = char '/' >> вернуть div
DO IN CLASS Можете ли вы угадать тип анализатора выше?
Далее мы можем разобрать выражение
> calc = do x <- digitInt
> op <- intOp
> y <- digitInt
> return $ x `op` y
, который при запуске будет анализировать и вычислять
ghci> doParse calc "8/2"
[(4,"")]ghci> doParse calc "8+2cat"
[(10,"cat")]ghci> doParse calc "8/2cat"
[(4,"cat")]ghci> doParse calc "8-2cat"
[(6,"cat")]ghci> doParse calc "8*2cat"
[(16,"cat" )]
Рекурсивный анализ
Чтобы начать парсить интересные вещи, нам нужно добавить рекурсию в наши комбинаторы. Например, очень хорошо анализировать отдельные символы (как в
Например, очень хорошо анализировать отдельные символы (как в char выше), но было бы намного больше, если бы мы могли получить определенные токены String .
Попробуем написать!
> строка :: строка -> строка анализатора
string "" = return ""
string (c:cs) = do char c
string cs
return $ c:cs
ДЕЛАТЬ В КЛАССЕ Фу-у-у! Это явная рекурсия?! Давайте попробуем еще раз (можете найти закономерность)
> string = undefined -- введите
Гораздо лучше!
ghci> doParse (строка "микрофон") "mickeyMouse"
[("микрофон","keyMouse")]ghci> doParse (строка "микрофон") "дональд дак"
[]
Хорошо, я думаю, тогда это было не совсем рекурсивно!
Давайте попробуем еще раз.
Давайте напишем комбинатор, который принимает синтаксический анализатор p , который возвращает и , и возвращает синтаксический анализатор, который возвращает много значений и . То есть он продолжает захватывать как можно больше значений
То есть он продолжает захватывать как можно больше значений a и возвращает их как [a] .
> manyP :: Parser a -> Parser [a]
> manyP p = many1 `chooseP` many0
> где many0 = return []
> many1 = do x <- p
> xs <- manyP p
> return (x:xs)
Но будьте осторожны! Вышеупомянутое может дать много результатов
ghci> doParse (manyP digitInt) "123a"
[([], "123a"), ([1], "23a"), ([1, 2], "3a"), ([1, 2, 3], "а")]
, который просто представляет собой все возможные способы извлечения последовательностей целых чисел из входной строки.
Детерминированный максимальный анализ
Часто нам нужен один результат, а не набор результатов. Например, более интуитивное поведение много будет возвращать максимальную последовательность элементов, а не все префиксы.
Для этого нам понадобится детерминированный комбинатор выбора
> (<|>) :: Парсер a -> Парсер a -> Парсер a
> p1 <|> p2 = P $ \cs -> case doParse (p1 `chooseP` p2) cs of
> [] -> []
> х:_ -> [х]
>
Приведенный выше синтаксический анализатор запускает выбор, но возвращает только первый результат. Теперь мы можем вернуться к
Теперь мы можем вернуться к комбинатор manyP и убедитесь, что он возвращает одну максимальную последовательность
> mmanyP :: Parser a -> Parser [a]
> mmanyP p = mmany1 <|> mmany0
> где mmany0 = return []
> mmany1 = do x <- p
> xs <- mmanyP p
> return (х:хс)
ДЕЛАТЬ В КЛАССЕ Подождите! В чем именно разница между вышеперечисленным и оригинальным manyP ? Как вы это объясните:
ghci> doParse (manyP digitInt) "123a"
[([1,2,3],"a"),([1,2],"3a"),([1],"23a"),( [],"123a")]ghci> doParse (mmanyP digitInt) "123a"
[([1,2,3],"a")]
Давайте воспользуемся этим, чтобы написать синтаксический анализатор, который будет возвращать целое число (а не только одну цифру).
oneInt :: Parser Integer
oneInt = do xs <- mmanyP digitChar
return $ ((read xs) :: Integer)
Помимо , можете ли вы найти шаблон выше? Взяли парсер mmanyP digitChar и просто преобразовал его вывод, используя функцию чтения . Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
Это повторяющаяся тема, и тип того, что мы сделали, дает нам подсказку
(a -> b) -> парсер a -> парсер b
Ага! очень похоже на карту . Действительно, существует обобщенная версия map , которую мы видели ранее ( lift1 ), и мы ограничиваем шаблон, объявляя Parser экземпляром Functor класса типов 9.0003
> instance Functor Parser, где
> fmap f p = do x <- p
> return (f x)
после чего мы можем переписать
> oneInt :: Parser Int
> oneInt = прочитать `fmap` mmanyP digitChar
Давай попробуем
ghci> doParse oneInt "123a"
[(123, "a")]
Давайте воспользуемся вышеизложенным для создания небольшого калькулятора, который анализирует и вычисляет арифметические выражения. По сути, выражение представляет собой либо двоичный операнд, применяемый к двум подвыражениям, либо целое число. Мы можем сформулировать это как
> calc0 :: Parser Int
> calc0 = binExp <|> oneInt
> где binExp = do x <- oneInt
> o <- intOp
> y <- calc0
> return $ x `o` y
Это работает очень хорошо!
ghci> doParse calc0 "1+2+33"
[(36,"")]ghci> doParse calc0 "11+22-33"
[(0,"")]
, но с минусом
все становится немного странно.
ghci> doParse calc0 "11+22-33+45"
[(-45,"")]
А? Что ж, если вы снова посмотрите на код, вы поймете, что приведенное выше было проанализировано как
.11 + ( 22 - (33 + 45))
, потому что в каждом binExp мы требуем, чтобы левый операнд был целым числом. Другими словами, мы предполагаем, что каждый оператор является правой ассоциативностью , отсюда и полученный выше результат.
Интересно, можем ли мы попытаться это исправить, просто перевернув заказ
> calc1 :: Parser Int
> calc1 = binExp <|> oneInt
> где binExp = do x <- calc1
> o <- intOp
> y <- oneInt
> return $ x `o` y
ДЕЛАТЬ В КЛАССЕ Но здесь есть ошибка… Вы можете это понять? (Подсказка: что вернет следующее?)
ghci> doParse calc1 "2+2"
Хуже того, у нас нет приоритета, и поэтому
ghci> doParse calc0 "10*2+100"
[(1020,"")]
, так как строка анализируется как
10*(2+100)
$> calc2 = oneInt >>= захватить $> где захватить x = кг x <|> вернуть x $> кг x = сделать o <- intOp $> y <- oneInt $> захватить $ x o y
Приоритет
Мы можем добавить и ассоциативность, и приоритет обычным способом, расслоив парсер на разные уровни.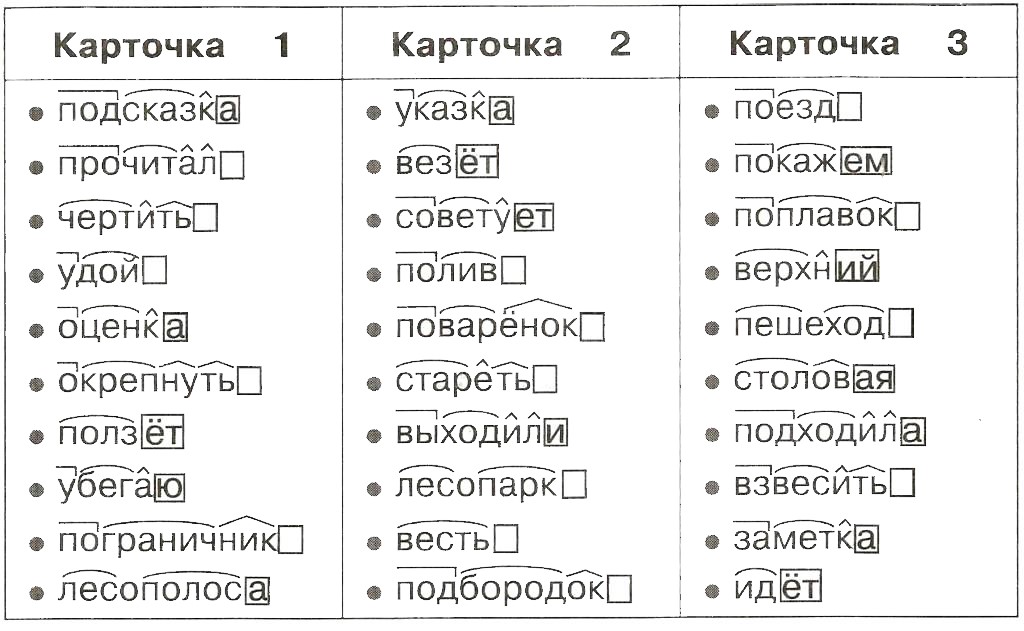 Здесь давайте разделим наши операции на приоритет сложения и умножения.
Здесь давайте разделим наши операции на приоритет сложения и умножения.
> addOp = плюс `chooseP` минус
> где плюс = char '+' >> return (+)
> минус = char '-' >> возврат (-)
>
> mulOp = умножить `chooseP` разделить
> где раз = char '*' >> вернуть (*)
> разделить = char '/' >> возврат div
Теперь мы можем разделить наш язык на (взаимно рекурсивные) подъязыки, где каждое выражение верхнего уровня анализируется как сумма произведений
> sumE = addE <|> prodE
> где addE = do x <- prodE
> o <- addOp
> y <- sumE
> return $ x `o` y
>
> prodE = mulE <|> factorE
> где mulE = do x <- factorE
> o <- mulOp
> y <- prodE
> return $ x `o` y
>
> factorE = parenE <|> oneInt
> где parenE = do char '('
> n <- sumE
> char ')'
> вернуть номер
Мы можем запустить это
ghci> doParse sumE "10*2+100"
[(120,"")]ghci> doParse sumE "10*(2+100)"
[(1020,"")]
Вы понимаете, почему первый синтаксический анализ вернул 120 ? Что произойдет, если мы поменяем местами порядок prodE и sumE в теле addE (или factorE и prodE в теле prodE )? Почему?
Шаблон синтаксического анализа: Цепочка
Нет особого смысла злорадствовать по поводу комбинаторов, если мы собираемся писать код, подобный приведенному выше — корпуса sumE и prodE практически идентичны!
Давайте посмотрим на них поближе. В сущности,
В сущности, sumE имеет форму
prodE + < prodE + < prodE + ... < prodE >>>
, то есть мы продолжаем связывать вместе значения prodE и добавлять их столько, сколько сможем. Аналогично prodE имеет форму
фактор E * < фактор E * < фактор E * ... < фактор E >>>
, где мы продолжаем связывать значения factorE и умножать их столько, сколько сможем. В вышесказанном есть что-то неприятное: операторы сложения правоассоциативны
ghci> doParse sumE "10-1-1"
[(10,"")]
Ух! Надеюсь, вы понимаете, почему: это потому, что приведенное выше было проанализировано как 10 - (1 - 1) (правоассоциативный), а не (10 - 1) - 1 (левый ассоциативный). У вас может возникнуть соблазн исправить это, просто поменяв местами prodE и sumE
sumE = addE <|> prodE
где addE = do x <- sumE
o <- addOp
y <- prodE
return $ x `o` y
, но это было бы катастрофой. Вы видите, почему? Парсер для
Вы видите, почему? Парсер для sumE напрямую (рекурсивно) вызывает сам себя без каких-либо входных данных! Таким образом, он уходит в глубокий конец и никогда не возвращается. Вместо этого мы хотим убедиться, что продолжаем потреблять prodE значений и суммирование их (скорее как сложение), так что мы могли бы сделать
> sumE1 = prodE1 >>= addE1
> где addE1 x = захватить x <|> return x
> захватить x = сделать о <- addOp
> y <- prodE1
> addE1 $ x `o` y
>
> prodE1 = factorE1 >>= mulE1
> где mulE1 x = захватить x <|> вернуть x
> захватить x = сделать о <- mulOp
> y <- factorE1
> mulE1 $ x `o` y
>
> factorE1 = parenE <|> oneInt
> где parenE = do char '('
> n <- sumE1
> char ')'
> return n
Легко проверить, что приведенное выше действительно ассоциативно слева.
ghci> doParse sumE1 "10-1-1"
[(8,"")]
, а также очень легко обнаружить и заблокировать шаблон цепных вычислений: единственное отличие состоит в том, что base парсер ( prodE1 против factorE1 ) и бинарная операция ( addOp против mulOp ). Мы просто вносим эти параметры в наш комбинатор
Мы просто вносим эти параметры в наш комбинатор
> p `chainl` pop = p >>= rest
> где rest x = схватить x <|> return x
> схватить x = do o <- pop
> y <- p
> rest $ x `o` г
Точно так же нам часто нужно анализировать выражения в квадратных скобках, поэтому мы можем написать комбинатор
> parenP l p r = do char l
> x <- p
> char r
> return x
после чего мы можем переписать грамматику в три строки
> sumE2 = prodE2 `chainl` addOp
> prodE2 = factorE2 `chainl` mulOp
> factorE2 = parenP '('sumE2 ')' <|> oneInt
ghci> doParse sumE2 "10-1-1"
[(8,"")]ghci> doParse sumE2 "10*2+1"
[(21,"")]ghci> doParse sumE2 "10+2*1"
[(12,"")]
На этом мы завершаем наше (в классе) изучение монадического синтаксического анализа. Это всего лишь верхушка айсберга. Хотя синтаксический анализ — очень старая проблема, и ее изучали на заре вычислительной техники, мы увидели, как монады привносят свежий взгляд, который недавно был перенесен из Haskell во многие другие языки.