Морфемный разбор:памятка для начал.школы (Эмма Матекина, Эмма Матёкина)
нет в наличии
В наличии в 63 магазинах. Смотреть на карте
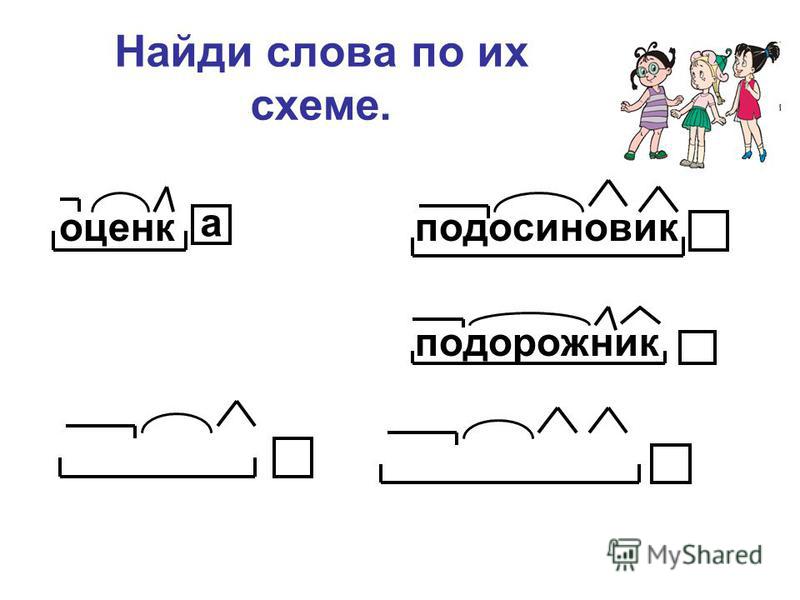
В данной памятке представлен разбор слов по составу (морфемный разбор) в разделе программы школьного курса по русскому языку, предусмотренный программой начальной школы. В памятке даны определения важнейших понятий, а также приведены основные правила и методические рекомендации по выполнению заданий, которые помогут учащимся правильно в устной и письменной форме производить разбор слов по составу. Пособие может быть использовано в следующих случаях: для объяснения, закрепления и обобщения пройденного материала; для восполнения пробелов в знаниях; в качестве дополнительного материала; для подготовки домашних заданий. . .Справочник предназначен для учеников начальных классов, учителей, родителей.
Описание
Характеристики
В данной памятке представлен разбор слов по составу (морфемный разбор) в разделе программы школьного курса по русскому языку, предусмотренный программой начальной школы.
Феникс
На товар пока нет отзывов
Поделитесь своим мнением раньше всех
Как получить бонусы за отзыв о товаре
1
Сделайте заказ в интернет-магазине
2
Напишите развёрнутый отзыв от 300 символов только на то, что вы купили
3 Дождитесь, пока отзыв опубликуют.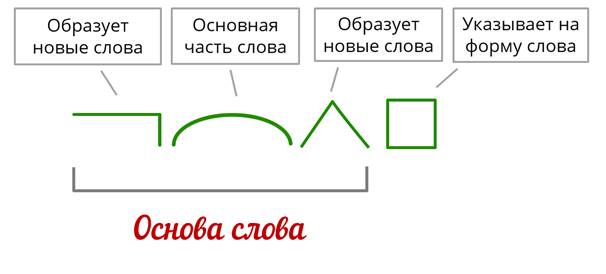
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусов
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусов
Морфемный разбор:памятка для начал.школы
Эмма Матекина, Эмма Матёкина
Нет оценок
нет в наличии
Книга «Морфемный разбор:памятка для начал.школы» есть в наличии в интернет-магазине «Читай-город» по привлекательной цене. Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом
другом регионе России, вы можете оформить заказ на книгу
Эмма Матекина, Эмма Матёкина
«Морфемный разбор:памятка для начал.школы» и выбрать удобный способ его получения: самовывоз, доставка курьером или отправка
почтой. Чтобы покупать книги вам было ещё приятнее, мы регулярно проводим акции и конкурсы.
Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом
другом регионе России, вы можете оформить заказ на книгу
Эмма Матекина, Эмма Матёкина
«Морфемный разбор:памятка для начал.школы» и выбрать удобный способ его получения: самовывоз, доставка курьером или отправка
почтой. Чтобы покупать книги вам было ещё приятнее, мы регулярно проводим акции и конкурсы.
морфем · PyPI
морфем
Практичная библиотека Python для определения морфем в английском языке.
Сообщить об ошибке · Функция запроса
Содержание- О проекте
- Построен с
- Начиная
- Предпосылки
- Установка
- Использование
- Дорожная карта
- Содействие
- Лицензия
- Контакт
- Благодарности
О проекте
Простое и практичное решение для получения информации о морфемах
на слово. Большая часть логики использует простую стратегию поиска
на основе MorphoLex-en
проект. Неизвестный т.е. имена людей и мест считаются за 1 морфему.
Большая часть логики использует простую стратегию поиска
на основе MorphoLex-en
проект. Неизвестный т.е. имена людей и мест считаются за 1 морфему.
Это неконтекстное решение, предназначенное для подачи более сложной логики для НЛП.
(наверх)
Встроено с
- MorphoLex-en
- крошечная БД
- панды
(наверх)
Начало работы
Пользоваться этой библиотекой довольно просто и рутинно. Будет добавлено больше деталей в этот раздел, когда мы приближаемся к первому выпуску.
Предварительные условия
Этот проект был разработан с использованием Python 3.9 других версий Python 3 должен работать .
Установка
pip install морфемы
(наверх)
Использование
из импорта морфем Морфемы
путь = "./данные"
m = Морфемы (путь)
print(m.parse("организационно"))
Вывод:
{
"слово": "организационно",
"статус": "FOUND_IN_DATABASE",
"количество_морфем": 5,
"дерево": [
{
"дети": [
{
"текст": "орган",
"тип": "корень"
},
{
"текст": "из",
"тип": "связанный"
}
],
"тип": "бесплатно"
},
{
"текст": "ион",
"тип": "связанный"
},
{
"текст": "аль",
"тип": "связанный"
},
{
"текст": "лы",
"тип": "связанный"
}
]
}
Определение типов:
- корень: значение корня слова (некоторые морфемы могут иметь несколько корней (пример: молочный коктейль)
- bound: добавляет к корню морфемы.
 Не вносит смысла сам по себе.
Не вносит смысла сам по себе. - бесплатно: слово, которое можно использовать отдельно. В одной морфеме может быть несколько свободных типов (пример: молочный коктейль)
 Не вносит смысла сам по себе.
Не вносит смысла сам по себе. Ненайденные слова помечаются статусом NOT_FOUND и по умолчанию
до 1 морфемы. Это будет улучшено в будущих выпусках.
ПРИМЕЧАНИЕ. Указанный путь data — это место, где будет храниться библиотека морфем.
хранить базу данных, содержащую морфемы из MorphoLex-ru
наряду с другими поисками, чтобы помочь правильно обнаружить морфемы.
(наверх)
Дорожная карта
- Обнаружение морфем известных слов
- Обработка общеупотребительных имен и мест (учитывается как 1 морфема)
- Обработка неизвестных слов
Полный список открытых вопросов см. предлагаемые функции (и известные проблемы).
(наверх)
Участие
Участие — это то, что делает сообщество открытого исходного кода таким замечательным
место, чтобы учиться, вдохновлять и творить. Любой ваш вклад большое спасибо .
Любой ваш вклад большое спасибо .
Вы хотите поддерживать другие языки? Вы свободно говорите на язык вы хотите? Помогите внести свой вклад и развить этот проект до более универсальное морфемное решение!
Если у вас есть предложение, которое могло бы сделать это лучше, разветвите репозиторий. и создайте запрос на включение. Вы также можете просто открыть задачу с тегом «улучшение». Не забудьте поставить звезду проекту! Еще раз спасибо!
- Форк проекта
- Создайте свою ветку Feature (
git checkout -b feature/AmazingFeature) - Зафиксируйте свои изменения (
git commit -m 'Добавить удивительную функцию') - Push to the Branch (
git push origin feature/AmazingFeature) - Открыть запрос на вытягивание
(наверх)
Лицензия
Распространяется по лицензии MIT. См. LICENSE.txt для получения дополнительной информации.
(наверх)
Контактное лицо
ECSC, ltd – [email protected]
Ссылка на проект: https://github.com/ecscstatsconsulting/morphemes
(наверх)
Благодарности Энкеледа Куко
(наверх)
Производительность синтаксического анализатора планирования и грамматики
Производительность синтаксического анализатора планирования и грамматикиДалее: Восстановление после неудачных анализов Up: Синтаксический анализ Предыдущий: Синтаксический анализ
Самые быстрые алгоритмы разбора контекстно-свободных грамматик делают
использование предсказания на основе левого контекста для ограничения количества узлов
и ребра, которые парсер должен вставить в диаграмму. Однако, если
устойчивость перед лицом возможно неграмотного ввода или неадекватного
желательно грамматическое покрытие, такие алгоритмы неуместны.
Синтаксический анализ снизу вверх предпочтительнее из-за его надежности, и эта надежность
вытекает из того факта, что восходящий синтаксический анализатор будет создавать узлы и
ребра на диаграмме, которые парсер с прогнозированием сверху вниз не сделал бы.
Очевидная проблема заключается в том, что эти дополнительные узлы не обходятся без
сопутствующие расходы. Мур и Даудинг (1991) наблюдал девятикратное
увеличение времени, необходимого для разбора предложений с простым
Синтаксический анализатор CKY в отличие от парсера с уменьшением сдвига.
Мы решили эту проблему, добавив механизм повестки дня в
восходящий парсер, основанный на Kaplan (1973), как описано у Винограда
(1983). Цель повестки — позволить нам заказывать узлы
(полные составляющие) и ребра (неполные составляющие) в
график для дальнейшей обработки. По мере построения узлов и ребер они
оцениваются в соответствии с различными критериями того, насколько вероятно, что они фигурируют
в правильном разборе. Это позволяет нам запланировать, какие составляющие
работать с первым, чтобы мы могли следовать только наиболее вероятным путям в
пространство поиска и найти синтаксический анализ, не перебирая все
возможности. Алгоритм планирования прост: изучите
разветвления компонентов с наивысшим баллом в первую очередь.
Кроме того, есть возможность сократить пространство поиска. пользователь может установить ограничения на количество разрешенных узлов и ребер для сохранения в графике. Узлы индексируются по их атомарным грамматическая категория (т. е. за исключением признаков) и строка позиции, с которой они начинаются. Ребра индексируются по их атомарным грамматическая категория и позиция строки, где они заканчиваются. Алгоритм обрезки прост: выбросить все, кроме n составляющие с наивысшим баллом для каждой пары категория/строка-позиция.
Часто указывалось, что различные стандартные стратегии синтаксического анализа
соответствуют различным стратегиям планирования в синтаксическом анализаторе на основе повестки дня.
Однако при практическом анализе необходима стратегия планирования.
что позволяет нам следовать только наиболее вероятным путям в поиске
пространства и найти правильный синтаксический анализ, не перебирая все
возможности. Литература не была столь освещена в этом
проблема.
Мы разработали наш синтаксический анализатор для оценки каждого узла и ребра на основе три критерии:
- Длина подстроки, натянутой компонентом.
- Является ли компонент узлом или ребром, т.е. компонент является полным или нет.
- Оценки, полученные на основе эвристики предпочтения, закодированные в DIALOGIC на протяжении многих лет, описанные и систематизированные в Хоббс и Медведь (1990).
Однако, после длительных экспериментов с различными весами, мы пришли к выводу, что факторы длины и полноты не улучшить производительность в широком диапазоне предложений. Имеющиеся данные свидетельствуют о том, что оценка, основанная только на факторе предпочтения дает наилучшие результаты. Причина правильная или почти правильная синтаксический анализ встречается так часто с помощью этого метода, что эти предпочтения эвристики очень эффективны.
В Сообщении 99 из 11 предложений, признанных релевантными, только
Предложение 14 не разобрал. Это произошло из-за ошибки в предложении
само по себе использование «по крайней мере» вместо «по крайней мере». Из 10
предложений, которые были проанализированы, 5 были полностью правильными, в том числе
самое длинное, предложение 7 (27 слов за 77 секунд). Было три
ошибки (предложения 3, 4 и 9), в которых предпочтительное многословие
смысл фраз «перед» и «сияющий путь» утратил смысл.
их разложения. Было две ошибки при подключении. В предложении
3 относительное предложение было неправильно присоединено к «front» вместо
«посольство», а в предложении 8 слово «в Перу» было добавлено к
«нападение» вместо «интересов». Все эти ошибки были
безвредный. Кроме того, в предложении 5 «и уничтожил два
транспортных средств» было сгруппировано с «Полиция сказала» вместо «
бомба разбила окна»; эта ошибка не безобидна. В каждом случае
грамматика предпочитает правильное чтение. Мы считаем, что ошибки были вызваны
к проблеме в анализаторе расписания, которую мы обнаружили на неделе
оценка, но чувствовала себя слишком глубокой и далеко идущей, чтобы пытаться
исправить в этом месте.
Это произошло из-за ошибки в предложении
само по себе использование «по крайней мере» вместо «по крайней мере». Из 10
предложений, которые были проанализированы, 5 были полностью правильными, в том числе
самое длинное, предложение 7 (27 слов за 77 секунд). Было три
ошибки (предложения 3, 4 и 9), в которых предпочтительное многословие
смысл фраз «перед» и «сияющий путь» утратил смысл.
их разложения. Было две ошибки при подключении. В предложении
3 относительное предложение было неправильно присоединено к «front» вместо
«посольство», а в предложении 8 слово «в Перу» было добавлено к
«нападение» вместо «интересов». Все эти ошибки были
безвредный. Кроме того, в предложении 5 «и уничтожил два
транспортных средств» было сгруппировано с «Полиция сказала» вместо «
бомба разбила окна»; эта ошибка не безобидна. В каждом случае
грамматика предпочитает правильное чтение. Мы считаем, что ошибки были вызваны
к проблеме в анализаторе расписания, которую мы обнаружили на неделе
оценка, но чувствовала себя слишком глубокой и далеко идущей, чтобы пытаться
исправить в этом месте.
В первых 20 сообщениях тестовой выборки было дано 131 предложение. синтаксический анализатор планирования после статистической фильтрации релевантности. Анализ был произведен для 81 из 131 предложения, или 62%. Из этих, 43 (или 33%) ответили полностью правильно, а еще 30 ответили тремя и менее словами. ошибки. Таким образом, 56% предложений были разобраны правильно или почти правильно.
Эти результаты, естественно, варьируются в зависимости от длины предложений. В 64 предложениях было менее 30 морфем (где слово «морфема» мы имеем в виду основу слова или флективный аффикс). Из них 37 (58%) имели полностью правильные синтаксические анализы, а 48 (75%) имели три или меньше ошибок. Напротив, синтаксический анализатор планирования попытался только 8 предложений более более 50 морфем, и только две из них проанализированы, ни одна из них даже почти правильно.
Из 44 предложений, которые не удалось разобрать, девять были вызваны проблемами в
лексические статьи. Восемнадцать были из-за недостатков в грамматике,
в основном включает наречное размещение и менее чем общий
трактовка союзов и сравнительных выражений. Шесть были из-за искажения
текст. Причины одиннадцати сбоев при синтаксическом анализе не установлены.
определенный. Эти ошибки равномерно распределены по всему предложению.
длины. Кроме того, в список попали семь предложений, содержащих более 30 морфем.
ограничение по времени, которое мы установили, и синтаксический анализ терминальной подстроки, как описано
ниже, был вызван.
Шесть были из-за искажения
текст. Причины одиннадцати сбоев при синтаксическом анализе не установлены.
определенный. Эти ошибки равномерно распределены по всему предложению.
длины. Кроме того, в список попали семь предложений, содержащих более 30 морфем.
ограничение по времени, которое мы установили, и синтаксический анализ терминальной подстроки, как описано
ниже, был вызван.
Большинство ошибок при синтаксическом анализе можно отнести к пяти-шести причины. Двумя основными причинами являются тенденция планирования синтаксический анализатор, чтобы потерять избранные близкие вложения конъюнктов и дополнений ближе к концу длинных предложений и склонность неправильно анализировать нить
[[Существительное Существительное] Глагол NP]
в качестве
[Существительное] [Существительное Глагол () NP],
снова вопреки эвристике предпочтения грамматики. Мы верим
что большинство этих проблем связано с тем, что работа
синтаксический анализатор расписания недостаточно равномерно распределен по
разные части предложения, и мы ожидаем, что эта трудность
может быть решена с относительно небольшими усилиями.