Урок русского языка «Морфемный разбор слов»
#5 класс #Русский язык #ФГОС #Методические разработки #Урок #Учитель-предметник #Школьное образование #УМК Л. М. Рыбченковой
Как превратить в ?
Тема? Морфемный разбор слова
Терминологический диктант
Любая значимая часть слова
То, что отличается от другого только окончанием
Единственная изменяемая часть слова
Единственная часть слова, которая не является морфемой
Не выраженное в данной форме окончание
-Л- и -ТЬ- — это суффиксы, которые не входят в основу, потому что они…
Общая часть родственных слов
Значимая часть слова, стоящая перед корнем
Значимая часть слова, стоящая за корнем
Часть слова, стоящая после всех морфем
Ответы:
1. Морфема
2. Форма слова
3. Окончание
4. Основа
5. Нулевое
6. Формообразующие
7. Корень
8. Приставка
9. Суффикс
10. Постфикс
Приставка
9. Суффикс
10. Постфикс
Порядок морфемного разбора 2 1. Определяю часть речи (зачем?) Помню, что есть неизменяемые слова! 2. Подбираю и записываю формы слова (как?) Изменяю слова по РЧП или лицам!
Порядок морфемного разбора 2 3. Выделяю окончание Помню, что есть неизменяемые слова! 4. Обозначаю основу Помню, что есть формообразующие суффиксы!
Порядок морфемного разбора 2 5. Подбираю и записываю однокоренные слова, выделяю корень Помню, что есть чередования! 6. Выделяю приставку и суффикс Доказываю, что они встречаются и в других словах!
Образец морфемного разбора 2 Переехали 2 1. глагол, изменяется 2. переехал , переехала 3. поезд, ехавший, еду зд // х // д
Образец морфемного разбора
2
Переехали
2
4. ПЕРЕшёл, ПЕРЕдумал
5. отдАть, поддаЛ
ПЕРЕшёл, ПЕРЕдумал
5. отдАть, поддаЛ
Произведите морфемный разбор слов: 2 Припекло солнышко, появились проталинки, показались подснежники. 2 2 2 2 2 2
Проталина* — место, где растаял снег и открылась земля.
Морфемный разбор 2 Припекло 2 1. глагол, изменяется 2. припекла , припекли 3. печь, печной, выпекать к // ч 4. пришёл, принёс 5. шёл, дал
Морфемный разбор 2 солнышко 2 1. сущ., изменяется 2. солнышк а , солнышк и 3. солнце, солнечный 4. перышко, судёнышко
Морфемный разбор
2
появились
2
1. глагол, изменяется
2. появил а сь, появился
3. явка, новоявленный
4. поселились
в // вл
глагол, изменяется
2. появил а сь, появился
3. явка, новоявленный
4. поселились
в // вл
Морфемный разбор 2 проталинки 2 1. сущ., изменяется 2. проталинк а , проталинк у 3. талый, тает 4. проталина, морщинка л // ?
Морфемный разбор 2 показались 2 1. глагол, изменяется 2. показал а сь, показался 3. указ, кажется 4. поселились к // ж
Морфемный разбор 2 подснежники 2 1. сущ., изменяется 2. подснежник а , подснежник у 3. снег, снежный 4. снежный, ключик г // ж
Чем будет отличаться
морфемный разбор
выделенных слов?
На душе сразу стало
весело и радостно. Захотелось смеяться и петь.
2
2
Захотелось смеяться и петь.
2
2
Морфемный разбор 2 сразу 2 1. наречие, не изменяется 3. раз, разом 4. снова, снову 2.
Морфемный разбор 2 петь 2 1. Инфинитив, не изменяется 3. пение, пою 4. жить, лить 2. е // о
Самостоятельно разберите слова РАДОСТНО (1В) и СМЕЯТЬСЯ (2В) На душе сразу стало весело и радостно. Захотелось смеяться и петь.
Закончи фразу… 1. Цифра 2 над словом обозначает… 2. Его нужно начинать с определения… 3. Чтобы выделить окончание, напишу… 4. Чтобы найти корень, подберу… 5. Чтобы превратить 2 в «5», ???
1. морфемный разбор
2. части речи
3. формы слова
4. однокоренные слова
5. выучу порядок разбора
Ответы
однокоренные слова
5. выучу порядок разбора
Ответы
Домашнее задание: Разбери слова и получи «5» 1 балл за слова: угловой, грустно, вызову, перемена, столовая 2 балла — подберезовик, подкупил, засветло 3 балла — озорничать, неприглядно 4 балла — рассмеяться 5 баллов — водонепроницаемый
«Собери слово» 1. Приставка, как в слове ПОДНОС, корень, как в слове ДАРИТЬ, суффикс, как в слове ДРУЖОК 2. Корень, как в слове ПОБЕЛИЛ, суффикс, как в слове МАЛЕНЬКИЙ, окончание, как в слове СИНИЙ
Морфемный разбор и его особенности :: SYL.ru
Правда ли, что при общении с новыми знакомыми нужно много говорить
Как универсальный способ успокоить младенца: для начала — укачивать 5 минут
Модная техника окрашивая сомбре: как сохранить летний образ осенью
Запасаемся шиповником на зиму: правила и способы сушки и использования плодов
«Нарастить» линию роста волос: 10 способов визуально уменьшить крупный лоб
Тенденции и модные вариации тупого боба на осень — любимой стрижки звезд
Предотвратить появления морщин: зачем наносить вазелин на кожу вокруг глаз
Подсветка лица с помощью окрашивания волос: что представляет собой новый тренд
Шляпа «федора» — самый трендовый аксессуар осени: как ее вписать в образ
Автор Ольга Иванова
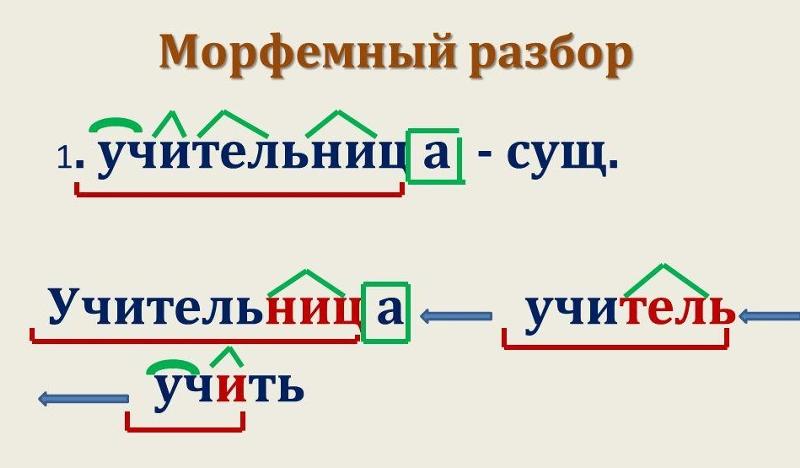
Морфема — это неделимая часть слова. В число морфем входят корень, приставка, суффикс и окончание. В сложных словах, где два корня, есть ещё и соединительная гласная -о или -е, которая называется интерфикс.
В число морфем входят корень, приставка, суффикс и окончание. В сложных словах, где два корня, есть ещё и соединительная гласная -о или -е, которая называется интерфикс.
Уметь определять морфемы в слове, видеть его структуру — путь к грамотности, поскольку многие морфемы строятся по одинаковым правилам. Иначе то, чем сейчас придётся заниматься, называется более привычными словами — разбор слов по составу. На первый взгляд, всё тут просто, в этом разборе, тем более — в школе это основной вид работы на уроках русского языка. Однако язык наш настолько богат, что и состав, и количество морфем часто оказываются разными. И совсем не безразлично, каким образом разделяется слово на морфемы. Почему-то всегда хочется первым делом найти корень слова как самую главную и самую понятную его часть. А потом наверняка само пойдёт: слева — приставка, справа — суффикс, за ним — окончание. Не тут-то было. Этот подход ошибочен, и дело в том самом корне, с которого нельзя начинать.
Морфемный анализ слова — начало
Возьмём какое-нибудь красивое и не короткое слово. Например — переплетение. Определите, что за часть речи мы собираемся исследовать. Существительное. Что ещё можно сказать по этому поводу? Единственное число. Именительный падеж. Определим основу слова: переплетения, переплетению, о переплетении. Основа переплетени-. Окончание тоже нашли: -е. А теперь постарайтесь ответить, изменяемое ли слово перед нами? Неизменяемые слова на то и неизменяемые, что держат форму, да и окончаний у них нет. А вот изменяемые имеют право на множество форм, каждая из которых может иметь и окончание, и формообразующий суффикс, и всё вместе. Но вот незадача: формообразование не входит в основу слова, ведь эта часть всегда остаётся неизменной. Потоэму первым делом нужно определить окончания и, конечно же, формообразующие суффиксы.
Теперь приставки и суффиксы
Продолжаем морфемный разбор. И всё ещё рано определять корень слова. Посмотрим, сколько у нас приставок и суффиксов. Их часто бывает несколько: понаехали тут, понавыстраивали словечек… Вот тут нужна словообразовательная цепочка, а не куча-мала родственных слов, которые должны были бы приходить стройными рядами. Правильно будет так: переплетение-плетение-плетень-плету-плеть. Неправильно: переплетение-плеть-плетень-плету-плетение.
И всё ещё рано определять корень слова. Посмотрим, сколько у нас приставок и суффиксов. Их часто бывает несколько: понаехали тут, понавыстраивали словечек… Вот тут нужна словообразовательная цепочка, а не куча-мала родственных слов, которые должны были бы приходить стройными рядами. Правильно будет так: переплетение-плетение-плетень-плету-плеть. Неправильно: переплетение-плеть-плетень-плету-плетение.
Во втором случае категорически непонятен суффикс. Вполне может получиться морфемный разбор с ошибками. По первому построению сразу ясно, что в этом слове суффикс -ени. Если найдём другие слова с этим суффиксом, значит, тут он один. Вдохновение, воскресение, преломление. Теперь пора вычленить и приставку. Прежде всего определите, существует ли это слово отдельно от неё. Конечно, да — плетение. Существует ли эта приставка в других словах? Тоже — да. Перенесение, переживание, переодевание — много их. Что это значит? Что здесь словообразовательная приставка пере-, вот мы её и нашли. Разрастается наш морфемный разбор немыслимыми узорами — ух какое красивое дерево мы уже вырастили и подобрались к самым корням его, и дело подходит к концу.
Перенесение, переживание, переодевание — много их. Что это значит? Что здесь словообразовательная приставка пере-, вот мы её и нашли. Разрастается наш морфемный разбор немыслимыми узорами — ух какое красивое дерево мы уже вырастили и подобрались к самым корням его, и дело подходит к концу.
А вот теперь — корень!
Когда в основе стали видны и понятны все словообразовательные части, можно приступать к раскопкам корня. А что ж, морфемный разбор слов — дело многотрудное. Выкопали корень? Ну, конечно, —плет-. Теперь возьмём разноцветные скрепочки и составим единое цветное слово, с которым в процессе разбора мы уже успели сродниться.
Похожие статьи
- Местоимение «его»: разряд, падеж, морфологический разбор. Предложение с местоимением «его»
- Что такое словообразовательная цепочка?
- Морфологический разбор причастия: методика выполнения
- Краткая характеристика и морфологический разбор глагола
- Грамматические признаки существительного.
 Существительное как часть речи
Существительное как часть речи - Давайте разберемся, как пишется «не» с причастиями
- Что такое молния? Сколько значений имеет слово?
 Существительное как часть речи
Существительное как часть речиТакже читайте
Морфемный и словообразовательный разбор слова
Сегодня мы найдём ответы на такие вопросы:
· Как выполняется морфемный разбор слова?
· Как выполняется словообразовательный разбор слова?
· Что нужно знать, чтобы правильно выполнять морфемный и словообразовательный разборы?
Наша речь состоит из слов, и с самыми
разными словами нам приходится сталкиваться постоянно. Так что неудивительно,
что нам интересно, из чего состоят слова. И на предыдущих уроках мы уже дали
ответ на этот вопрос.
Слова состоят из морфем. Морфемы – это значимые части слова. И значит, нам интересно – какие именно морфемы присутствуют в этом конкретном слове. То есть, какой у слова состав.
Состав слова нам помогает прояснить морфемный разбор. В чём мы разбираемся и что будем разбирать? Разбирать мы будем слово. Наша задача при морфемном разборе – увидеть, из каких морфем состоит слово.
Итак, морфемный разбор – это выделение морфем (значимых частей), из которых состоит слово.
Но ведь нам нужно знать, что именно мы хотим найти в слове. Из каких частей может состоять слово? Мы можем выделить корень, приставку, суффикс, окончание. Это и есть морфемы.
А что мы знаем обо всех этих морфемах?
Корень – это основная часть слова, благодаря корню образуются однокоренные
слова. При помощи приставок и суффиксов часто образуются новые слова. А
окончание указывает на грамматическую форму слова. Часть слова без окончания
называется основой слова. Основу в слове мы тоже выделяем. Окончание в
основу не входит.
Часть слова без окончания
называется основой слова. Основу в слове мы тоже выделяем. Окончание в
основу не входит.
И теперь мы можем приступить к морфемному разбору слова! Возьмём слово подсказка. И составим небольшую инструкцию по разбору этого слова.
С чего нам начать? Конечно, с самого простого – с окончания. Достаточно изменить слово, чтобы увидеть, какое у него окончание. Подсказки, подсказке. Вот какая часть меняется. У нашего слова – окончание -а.
Запишем в инструкцию первый пункт – выделить окончание.
Сразу же после окончания можно выделять основу – ведь в неё не входит только окончание.
И наш второй пункт – обозначить основу слова.
А теперь нужно выделить самую важную часть! Для этого подберём однокоренные слова. Подсказать, рассказать… видно, что общая часть у однокоренных слов — -сказ- Это и есть наш корень.
Третий пункт инструкции – выделить
корень.
Ну, а теперь можно выделять и всё остальное! Часть слова перед корнем – это приставка под-. А морфема между корнем и окончанием – это суффикс -к.
Вот и следующие пункты инструкции. Выделить суффикс. Выделить приставку.
Кажется, что морфемный разбор – это совсем несложно, верно ведь?
Но на самом деле у нас может возникнуть проблема, и не одна. На пути к правильному морфемному разбору подстерегает немало трудностей!
Например, мы можем сделать ошибку в разборе из-за того, что у слова может быть нулевое окончание или не быть окончания вообще.
Вот слова день, яблок, учил. В этих словах – нулевое окончание. А вот слова везде, когда, метро. В этих словах окончаний вообще нет. Это слова неизменяемые.
Нужно помнить об этом. И самое главное
– нельзя путать нулевое окончание и отсутствие окончания! Мы уже сказали
самое важное: нет окончаний только у неизменяемых слов. Значит, нулевое
окончание может быть только у изменяемого слова!
Значит, нулевое
окончание может быть только у изменяемого слова!
Вот слово дел. Изменим его – дело. Слово изменяется, значит, у слова – нулевое окончание.
А вот слово давно. Попытаемся его изменить. Слово не изменяется. Значит, у слова нет окончания.
Если определение окончания вызывает трудности – нужно просто попробовать изменить слово.
Второй трудностью может стать то, что иногда нам хочется выделить слишком мало морфем.
Вот слово задача. У него окончание -а. Но как же с остальными морфемами? Нам так и хочется выделить корень задач-. Ведь есть же такие слова, как задачник, многозадачный… наверное, у них тот же корень?
На эти уловки морфемики лучше не попадаться.
Посмотрим на слово задача. Нет
ли какого-нибудь слова, к которому оно было бы близко по значению? Задачу можно
задать. В этом однокоренном слове уже нет суффикса –ч-, поэтому мы
выделяем его в слове задача. А слово задать явно произошло от
слова дать. Значит, у него и у слова задача – есть приставка за-. А
теперь можно выделить и корень – это корень -да-. Мы правильно разобрали это
слово, потому что подумали, от чего оно может быть образовано.
А слово задать явно произошло от
слова дать. Значит, у него и у слова задача – есть приставка за-. А
теперь можно выделить и корень – это корень -да-. Мы правильно разобрали это
слово, потому что подумали, от чего оно может быть образовано.
Но с образованием слов нужно быть осторожнее. Потому что иногда мы слишком увлекаемся мыслями, от чего произошло слово. И выделяем слишком много морфем.
Посмотрим на слово рябина. У него окончание а-. Но как же остальные морфемы? Как же нам хочется выделить корень -ряб- и суффикс -ин-! Ведь действительно есть такой суффикс и есть такой корень! Но не все так просто.
Слово рябина действительно
образовалось от слова рябой. Но какое отношение сейчас рябой цвет имеет
к рябине? Рябина – это такая ягода, а рябой сейчас обозначает – «покрытый
рябью, пёстрый, в точечки». Совершенно никакого сходства! Значит, эти слова
разошлись по значению, и теперь у слова рябина корень рябин-. Выходит,
нам нужно обращать внимание ещё и на значение слов!
Выходит,
нам нужно обращать внимание ещё и на значение слов!
Мы уже заметили, что иногда нам требуется узнать, от чего и как образовалось слово.
Ведь мы можем назвать своих родителей и перечислить имена бабушек и дедушек, часто мы можем сказать даже – чем мы похожи на своих предков! А можно ли такое проделать со словами?
Понять, как образовалось слово, нам помогает словообразовательный разбор. При словообразовательном разборе мы как бы вынуждаем слово рассказать нам, как оно получилось и какие слова были его предками.
Итак, словообразовательный разбор слова – это выяснение того, каким образом образовалось данное слово.
И мы уже говорили о том, что слова могут образовываться самыми разными способами. Например, мы можем прибавить к слову какую-то морфему или даже несколько морфем – и у нас получится новое слово!
Такие способы словообразования
называются морфемными. Это приставочный, суффиксальный,
приставочно-суффиксальный и бессуфиксный способы.
Это приставочный, суффиксальный,
приставочно-суффиксальный и бессуфиксный способы.
С другой стороны, мы можем обойтись и без добавления морфем.
Есть неморфемные способы образования слов. Это сложение основ, сложение слов, переход слова в другую часть речи.
Давайте приступим к словообразовательному разбору слова! Возьмём слово бесшумный. И составим на его примере инструкцию по разбору слова.
Сначала нужно понять, что слово обозначает. Ведь мы уже говорили, как важно следить за значением слова.
Бесшумный значит «не издающий шума, не шумный». Мы можем записать пункт первый нашего разбора – дать толкование значению слова.
А теперь можно найти слово, которое
ближе всего по значению, при этом однокоренное. Для нашего слова
это прилагательное «шумный». И сразу же мы видим, что слово бесшумный
образовалось при помощи приставки бес-. Значит, это приставочный способ
словообразования.
Второй пункт разбора – подобрать ближайшее однокоренное слово и определить, при помощи чего слово образовано.
А теперь осталось только отметить, от какой основы образовалось наше слово. В слове шумный обозначим основу шумн-. Разбор окончен. Добавим последний пункт: найти основу, от которой образовалось слово.
Вот интересно – а слово шумный ведь тоже от чего-то образовалось? Да. Легко увидеть, что оно образовалось от слова шум при помощи суффикса -н-. Суффиксальным способом. Основу в слове шум тоже несложно выделить. И получается, что теперь мы дошли до самого первого слова, с которого началось образование всех остальных.
Значит, при желании мы можем проследить все изменения при образовании слов.
При этом образуется словообразовательная цепочка.
Словообразовательная цепочка позволяет
увидеть весь путь, который проходит слово. Построим цепочку для слова устаревший. Это слово образовалось от глагола устареть при помощи суффикса -вш-. Основа, от которой слово образовалось – устаре-. Глагол устареть образовался от глагола стареть
при помощи приставки у-. Основа, от которой теперь образовалось слово – старе-. Наконец, слово стареть образовалось от
основы прилагательного старый при помощи суффикса -е-.
Это слово образовалось от глагола устареть при помощи суффикса -вш-. Основа, от которой слово образовалось – устаре-. Глагол устареть образовался от глагола стареть
при помощи приставки у-. Основа, от которой теперь образовалось слово – старе-. Наконец, слово стареть образовалось от
основы прилагательного старый при помощи суффикса -е-.
Вот такая у нас образовалась цепочка при помощи которой мы дошли до самого первого, неделимого элемента, с которого все начиналось.
Мы уже поняли, что самое главное в словообразовательном разборе – это подобрать близкое слово. И вот тут-то нам предстоит опять столкнуться с проблемами!
Конечно, при выполнении словообразовательного разбора нас тоже подстерегают всяческие трудности.
Во-первых, нам бывает очень трудно определить бессуффиксный способ образования слов.
Возьмём такое неприятное слово, как прогул. Что нам мешает сказать, что оно образовано от глагола гулять при помощи приставки? Ведь кажется, что это самое близкое слово!
Не будем поддаваться искушению! Вместо
этого поразмыслим.
В глаголе есть суффикс –я-, а в существительном он куда-то пропадает. Получается, что чтобы образовать существительное нам надо и убрать суффикс, и добавить приставку. Но ведь есть слово, от которого нужно просто отнять суффикс! Это слово – прогулять. Слово прогул образовалось от него бессуффиксным способом.
С этим же способом связана и ещё одна похожая проблема. Вот слово глубь. Мы видим его, и нам хочется сказать: оно ни от чего не образовалось! Наоборот, слово глубокий может образоваться от слова глубь, ведь в прилагательном больше морфем!
Но мы-то знаем, что очень часто как раз существительные образуются от глаголов и прилагательных! И можно посмотреть на значение существительного: глубь – это нечто глубокое. Поэтому именно существительное глубь образуется от прилагательного глубокий бессуффиксным способом.
Нужно помнить, что главное – это всё
же значение, а не количество морфем.
Во-вторых, иногда мы путаем приставочный и суффиксальный способы образования слов с приставочно-суффиксальным.
Вот слово пригородный. Наверное, оно образовалось от слова город при помощи приставки и суффикса? Этот способ выглядит правильным, ведь слова так близки по значению!
Но есть слово, которое ещё ближе к слову пригородный. Это слово пригород. Прилагательное пригородный образуется от его основы при помощи суффикса -эн- — то есть, это суффиксальный способ.
Мы должны помнить, что подбирать нужно ближайшее слово.
А вот слово прибрежный. Варианты —брежный— или –прибреж— нам не подходят, потому что таких слов нет. Значит, это прилагательное образовалось от существительного берег при помощи приставки и суффикса. Это приставочно-суффиксальный способ.
Если от слова нельзя отбросить только
приставку или только суффикс, то перед нами слово, образованное
приставочно-суффиксальным способом. Нужно быть внимательными при определении
способа образования слова.
Нужно быть внимательными при определении
способа образования слова.
Морфемный и словообразовательный разборы тесно связаны. Но их всё же нужно различать.
При морфемном разборе мы выясняем, из каких морфем состоит слово. То есть, разбираем слово по составу. При этом мы обозначаем все морфемы.
А при словообразовательном разборе мы выясняем, от какого слова и каким образом образовалось данное слово. И обозначаем только то, при помощи чего образовалось слово.
Нужно запомнить порядок выполнения этих разборов.
Урок по русскому языку для 5 класса по теме «Морфемика. Морфемный разбор слова» | План-конспект урока по русскому языку (5 класс) на тему:
Урок по русскому языку для 5 класса по теме
«Морфемика. Морфемный разбор слова».
Задачи урока:
Образовательные:
- обобщение знаний о морфемах слова;
- совершенствование навыка морфемного разбора слова;
- научиться различать однокоренные слова и формы одного и того же слова;
Развивающие:
- развивать умения планировать, контролировать, регулировать и анализировать собственную учебную деятельность;
- развивать речь учащихся, обогащать словарный запас детей;
- развивать умение работать с текстом;
- развивать сообразительность, мышление, память.

Воспитательные:
- создавать у учащихся положительную мотивацию к уроку русского языка путём вовлечения каждого в активную деятельность;
- воспитывать потребность оценивать свою деятельность.
- воспитывать культуру речи, любовь к слову;
- воспитывать внимание, доброе отношение друг к другу.
- Оборудование:
- Листы с рабочими материалами для учащихся.
- Вид работы: групповая.
- Тип урока: урок совершенствования знаний, умений и навыков.
Оформление доски:
1. Тракторист Велосипед Соломенная Аптека Программа Карикатура Медальон Перрон | Классная работа. Морфемика. Морфемный разбор слова. | |
Хозяйство Спортсмен Деревня Лекарство Компьютер Карандаш Память Вокзал | 2. 3. стекло – сущ. стекло – глаг. | |

Ход урока:
І. Создание психологически благоприятного настроя в классе
— Здравствуйте! Уверена, что сегодня поработаем очень плодотворно. Запишите сразу число и тему урока.
Начать сегодняшний урок я хочу стихотворением Сергея Острового:
К словам привыкаешь день ото дня,
А они первородного смысла полны…
И когда я слышу:
— Извини меня! —
Это значит:
— Исключи меня из вины!
У слова цвет своего огня.
Свое пространство. Свои рубежи.
И когда я слышу:
— Береги меня!
Это значит:
— Берегами меня окружи!
У слова есть корни. И есть родня.
Оно не подкидыш под сирым кустом.
И когда я слышу:
— Защити меня! —
Это значит:
— Спрячь меня за своим щитом!
Вслушайся. Вникни. Не позабудь.
У слова свой норов. Свое нутро.
И если ты в эту проникнешь суть —
Слово тебе сотворит добро.
-Что хочет нам сказать автор?
Если вы будете внимательно прислушиваться и присматриваться к словам, то проникните в их суть и «слово тебе сотворит добро»: откроет свои тайны, и вы будете более грамотными и более богатыми духовно, потому что осознаете красоту и глубину родного языка. И если к людям хорошо относиться, то и к вам будет такое же отношение. Почаще в своей речи употребляйте «волшебные» слова: извини, спасибо, пожалуйста и т.д. Помните: Слово тебе сотворит добро! А мы с вами сейчас как раз изучаем слова. Какой раздел языкознания изучает словарный состав языка? Кстати, что изучали вчера?
II. Фронтальный опрос.
Что такое словообразовательный разбор, что он показывает?
Какие морфемы участвуют в образовании новых слов?
Назовите способы образования слов.
III. Целеполагание.
Тема сегодняшнего урока – «Морфемный разбор слова».
Что значит «морфемный»?
— Что общего у приставки и суффикса? (Служат для образования новых слов)
— Чем отличается окончание от приставки и суффикса? (Окончание не образует новые слова, а образует только формы одного и того же слова и служит для связи слов в предложении).
— Какая морфема в слове самая главная? Почему? (Корень слова, так как содержит в себе лексическое значение слова)
— Что нужно узнать на этом уроке?
-Чему нужно научиться?
А может, и учиться нечему, и вы уже всё знаете? Возможно. Как вы думаете, есть ли какой-нибудь порядок разбора слова по составу или всё равно, в каком порядке выделять морфемы? Давайте исследуем этот вопрос!
IV. Решение проблемной задачи.
Посмотрите на доску:
-Как вы думаете, одинаковы ли по морфемному составу выделенные слова? Разберите их. Можно советоваться с соседом по парте.
Доска: окно – ровно дышать; движение быстро – быстро оделся.
А теперь разберите слово хлопок. (хлОпок, хлопОк имеют разный состав)
Проверяем.
Делаем вывод: можно ли просто по внешнему облику судить о морфемном составе слова?
-Итак, наша задача – составить алгоритм (план) морфемного разбора слова, а потом уже мы вместе научимся выполнять этот разбор.
V. Работа в группах: составить план морфемного разбора.
Проверка, выработка общего плана: 1. Определить часть речи. 2. Определить лексическое слово. 3. Выделить окончание (если оно есть) и основу слова. 4. Выделить корень. 5. Выделить приставки и суффиксы, если они есть.
- Запишите предложение (один ученик пишет на доске):
Я весь день стирала, мыла и порядок наводила, но вот только для себя не хватило мыла.
— Какое слово встречается в предложении дважды?
— Одинаков ли морфемный состав слова «мыла»? Разберите их по составу, используя алгоритм.
- Итак, чему мы научились? Откликнулись слова добром, приоткрыли свои тайны? (Учились составлять план работы, учились слушать друг друга, утвердили алгоритм морфемного разбора) Теперь осталось проверить алгоритм в действии и потренироваться в разборе слов.
VI. Самостоятельная работа. Выполните задания на листочках. (2-3 минуты)
VII. Повторение словарных слов.
(На доске записаны два столбика словарных слов)
— Прочитайте слова парами и установите между ними смысловую зависимость. (Дети читают вслух по одной паре слов)
— Еще раз прочитайте про себя и запомните слова в столбиках. (Затем учитель закрывает слова первого столбика)
— Глядя на слова второго столбика, запишите по памяти слова первого столбика. (Дети пишут)
— Кто запомнил все 8 слов? (Один ученик вызывается к доске и читает записанные слова орфографически.).
– Найдите среди записанных слов те, которые соответствуют схеме (схема изображена на доске под № 2). Выпишите эти слова и выделите в них морфемы. — Какие слова вы выписали? Докажите, что они соответствуют схеме. («тракторист» и «соломенная»).
VIII. Связь морфемики с орфографией.
-Так для чего же нужны знания по морфемике? Зачем нужно уметь выполнять морфемный разбор? -Вспомните, правописание каких орфограмм зависит от того, в какой морфеме она находится? Приведите примеры.
(ПРАВОПИСАНИЕ ПРИСТАВОК:
СДЕЛАТЬ, ОТБРОСИТЬ, НАДПИСАТЬ, ПОДДЕЛЬНЫЙ
О-Ё-Е ПОСЛЕ ШИПЯЩИХ:
ЧЁРНЫЙ, ШЁПОТ, ШОРОХ, ЧАЩОБА, ВРАЧОМ, ТУЧЕЙ, ХОРОШО, ТЯЖЁЛЫЙ, ШОКОЛАД, НОЖОМ, КАЛАЧОМ)
От умения правильно выделять морфемы зависит умение грамотно писать.
IX. Творческое задание.
— Придумайте предложения или мини-текст со словами
стекло — существительное
стекло — глагол
(Учитель открывает запись этих слов на доске)
— Прочитайте свои работы. (Заслушиваются несколько учащихся)
Жидкое стекло в форму стекло.
Я сегодня мыла стекло и мыло по стеклу стекло.
За окном дождь. Я сижу у окна и смотрю на улицу через стекло. Вот несколько капель стекло.
X. Подведение итогов урока.
— Что изучает морфемика? Что такое морфема? Как правильно выполнять морфемный разбор? (Учитель оценивает работу учащихся на уроке и выставляет отметки)
— Где можно применить новые знания?
— Оцените свою работу на уроке. Работу класса.
ГДЗ учебник по русскому языку 7 класс Ладыженская. §37. Морфологический разбор наречия Упражнение 238
- 7 класс
- Русский язык 👍
- Ладыженская
- №238
авторы: Ладыженская, Баранов.
издательство: Просвещение
Раздел:
- Предыдущее
- Следующее
Прочитайте текст А. Алексина. Сделайте морфологический разбор выделенных наречий письменно и устно. • Выпишите слова с пропусками и со скобками. Обозначьте условия выбора слитных и раздельных написаний.
Всюду ребята люб..т пр(е, и)дум..вать прозвища. Но у нас в школе это, как говорили учителя, «стало опаснейшей эп..демией».
А что тут опас(?)ного? Мне кажет(?)ся, прозвище говорит о человек. . гораздо больше, чем имя. Имя вообще ни(о)чём определён, нн)..м (не)говорит. Ведь прозвище пр(е, и)дум..вают в зависимост.. от характера. А имя дают тогда, когда у человека ещё вообще нет (ни)какого характера. Вот если меня назовут просто по им..ни, — Алик! — что (обо)мне можно будет узнать? А если по прозвищу— Детектив! — сразу стан..т понятно, (на)кого я похож(?).
Жаль только, что (не)которые ребята путают и вместо «Детектив» кр..чат «Дефектив». Но я в таких случаях (не)откл..каюсь.
reshalka.com
Решение
Яркие футболки в нашем магазине reshalkashop.ru
Любят (любить, 2 спр.), придумывать (приставка при− = доведение
действия до конца; придумываю), опасного (опасен), кажется (что
делает?), о человеке (2−е скл., пр. п.), ни о чём (предлог о), определённом (суффикс −н− после основы на н; каком?), не говорит (не с глаголами), придумывают (приставка при− = доведение действия до конца;
придумываю), в зависимости (3−е скл. , пр. п.), никакого (отриц. местоим.), по имени (разноскл., дат. п.), что обо мне (предлог обо), станет (1 спр., 3−е л., ед. ч.), на кого (предлог + местоим.), похож (кр. прил. на шипящ. без ь), некоторые (неопред. местоим.), кричат (крик), не откликаюсь (не с глаг.; кликнуть).
Всюду — наречие.
Во−первых, оно обозначает признак действия: любят придумывать (где?) всюду.
Во−вторых, это неизменяемое слово.
В−третьих, в предложении является обстоятельством.
Письменный разбор
Всюду — наречие.
I. Любят придумывать (где?) всюду; признак действия
II. Неизм.
III. Любят придумывать (где?) всюду.
Вообще — наречие.
Во−первых, оно обозначает признак действия: не говорит (как?) вообще.
Во−вторых, это неизменяемое слово.
В−третьих, в предложении является обстоятельством.
Письменный разбор
Вообще — наречие.
I. Не говорит (как?) вообще, признак действия.
II. Неизм.
III. Не говорит (как?) вообще.
Тогда — наречие.
Во−первых, оно обозначает признак действия: дают (когда?) тогда.
Во−вторых, это неизменяемое слово.
В−третьих, в предложении является обстоятельством.
Письменный разбор
Тогда — наречие.
I. Дают (когда?) тогда, признак действия.
II. Неизм.
III. Дают (когда?) тогда.
Прозвища — существительное.
I. Придумывать (что?) прозвища.
II. Н. ф. − прозвище. Пост. признаки − нариц., неодуш., ср. р., 2−е скл.;
непост. признаки − вин. п., мн. ч.
III. Придумывать (что?) прозвища.
(В) зависимости — существительное.
I. (В чем?) в зависимости.
II. Н. ф. — зависимость. Пост. признаки − нариц. , неодуш., ж. р., 3−е скл.;
непост. признаки − и. и., ед. ч.
III. (В чем?) в зависимости,
Дают − [дай’ут]− два слога.
[д] — согласный, звонкий, твердый;
[а] — гласный, безударный;
[й’] — согласный, звонкий, мягкий;
[у] — гласный, ударный;
[т] — согласный, глухой, твердый.
Букв 4. Звуков 5
- Предыдущее
- Следующее
Нашли ошибку?
Если Вы нашли ошибку, неточность или просто не согласны с ответом, пожалуйста сообщите нам об этом
Морфологический разбор частей речи. Часть 2
Похожие презентации:
Разбор. Фонетический, морфемный, морфологический, синтаксический и словообразовательный разбор
Система частей речи
Система частей речи
Морфологический разбор частей речи. Часть 1
Морфология. Морфологический разбор
Система частей речи
Морфология. Система частей речи
Классификация частей речи
Морфологический разбор частей речи. Синтаксический разбор предложения
Служебные части речи
Морфологический
разбор частей речи
Часть 2
Сегодня мы…
1.
Упорядочим знания о морфологическом
разборе.
2.
Выполним морфологический разбор
неизменяемых частей речи.
3.
Узнаем о трудностях, с которыми мы
можем столкнуться при разборе
неизменяемых частей речи.
Вспомним…
Схема морфологического разбора
1
Общее значение
Вопрос
Начальная форма
2
Морфологические признаки
Постоянные
Непостоянные
3
Функция в предложении
Части речи
Что общего у
этих частей
речи?
Изменяемые
части речи
У всех этих частей
речи есть
непостоянные
признаки.
Неизменяемые части речи
Непостоянных
признаков у
этих частей
речи не будет.
Схема морфологического разбора
1
Общее значение
Вопрос
Начальная форма
2
Морфологические признаки
Постоянные
Непостоянные
3
Функция в предложении
Разбор сразу стал
проще!
Деепричастие
Общее значение
Дополнительное действие
Вопрос
что делая? что сделав?
Признаки
Вид, неизменяемость
Функция
Обстоятельство
Разберём деепричастие!
Вздохнув, ученик открыл очередной учебник.
Вздохнув – дееприч.
I. (Что сделав?) вздохнув.
От глаг. вздохнуть.
II. Неизмен., сов. вид.
III. Открыл (как?) вздохнув.
Наречие
Общее значение
Признак действия или признака
Вопрос
где? когда? как? зачем? с какой целью?
Признаки
Определительное или обстоятельственное,
разряд по значению
Функция
Обстоятельство, определение
Разберём наречие!
Нам постоянно приходится учить тексты наизусть.
Наизусть – наречие.
I. (Как?) наизусть.
II. Определит., образа действия.
III. Учить (как?) наизусть.
Неизменяемые части речи
А чем
отличается
разбор этих
частей речи?
Просто больше
признаков.
Схема морфологического разбора
1
Общее значение
2
Морфологические признаки
3
Функция в предложении
Предлог
Общее значение Соединение слов в словосочетании
Простой/сложный/составной,
Признаки
непроизводный/производный
(отымённый, отглагольный, наречный).
Разберём предлог!
Мы продолжали двигаться, несмотря на холод.
Несмотря на – предлог.
В. п.
I. Продолжали несмотря на холод.
II. Составной, производный, отглагольный.
Союз
Общее значение
Признаки
Соединение однородных членов
или частей сложного предложения
Простой/составной,
непроизводный/производный,
одиночный/повторяющийся,
сочинительный/подчинительный,
разряд по значению
Разберём союз!
Они так и не узнали, где будет проходить концерт.
Где – союз.
I. [ ], (где…).
II. Простой, произв, один., подчин., места.
Частица
Выражение дополнительных
Общее значение оттенков значения или
образование формы
Смыслообразующие/формообразующие,
Признаки
непроизводная/производная
Разберём частицу!
Эта кисточка используется только для гуаши.
Только – частица.
I. Доп. знач. ограничения.
II. Производная, смыслообр.
Неизменяемые части речи
Но ведь
междометие
не служебная
часть речи!
Но разбираем
мы его всё так
же!
Междометие
Общее значение
Выражение чувств и эмоций
Производное/непроизводное
Признаки
Эмоциональное/императивное/
этикетное
Разберём междометие!
Жуть, какой ужасный поступок!
Жуть– междометие.
I. Чувство ужаса и возмущения.
II. Производное, эмоциональное.
Обратите внимание!
предлог
наречие
деепричастие
Как это всё
различить?!
союз
частица
Различаем части речи!
Куда?
Они увидели, как их друг идёт навстречу.
предлог
Вместе они отправились навстречу судьбе.
К наречию можно
поставить конкретный
собственный вопрос!
наречие
Различаем части речи!
Благодаря чему?
Благодаря знаниям он сдал экзамен.
предлог
деепричастие
Они отчаянно заикались, благодаря за помощь.
Предлог входит в
поставленный вопрос.
Как?
Различаем части речи!
наречие
Он попал точно в цель.
союз
Капли в траве сверкали, точно маленькие алмазы.
Мы точно собираемся в поход?
частица
Частицу легко
выбросить из текста.
Запомним…
Общие правила морфологического разбора
Мы берём слово в составе
предложения.
Устный разбор отличается от
письменного.
Запомним…
Схема морфологического разбора
Если часть
речи
изменяется.
1
Общее значение
Вопрос
Начальная форма
2
Морфологические признаки
Постоянные
Непостоянные
3
Функция в предложении
Запомним…
Схема морфологического разбора
Если часть
речи не
изменяется.
1
Общее значение
Вопрос
2
Морфологические признаки
Постоянные
3
Функция в предложении
Запомним…
Схема морфологического разбора
Если часть
речи
служебная.
1
Общее значение
(= роль в предложении)
2
Морфологические признаки
До встречи
на уроках
русского языка!
English Русский Правила
3.2 Морфологический разбор
Целью морфологического разбора является выяснить, из каких морфем состоит данное слово. Например, морфологический синтаксический анализатор должен быть в состоянии сказать нам, что слово кошки является формой множественного числа основы существительного кошка , а слово мыши является формой множественного числа основы существительного мышь . Таким образом, при вводе строки кошки морфологический анализатор должен выдать результат, похожий на 9.0003 кат N ПЛ . Here are some more examples:
mouse | mouse N SG |
mice | mouse N PL |
foxes | fox N PL |
Морфологический анализ дает информацию, полезную во многих приложениях НЛП. Например, при синтаксическом анализе полезно знать признаки согласования слов. Точно так же средства проверки грамматики должны знать информацию о соглашении, чтобы обнаруживать такие ошибки. Но морфологическая информация также помогает программам проверки орфографии решить, является ли что-то возможным словом или нет, а в информационном поиске она используется для поиска не только cat , если это ввод пользователя, но также и для cat .
Чтобы перейти от поверхностной формы слова к его морфологическому анализу, мы проделаем два шага. Во-первых, мы собираемся разделить слова на возможные компоненты. Итак, мы составим cat + s из cat , используя + для обозначения границ морфем. На этом этапе мы также примем во внимание правила правописания, так что есть два возможных способа разделения 9.0003 лисы , а именно лиса + с и лиса + с . Первый предполагает, что foxe — это основа, а s — суффикс, тогда как второй предполагает, что основа — это fox , а e введено из-за правила правописания, которое мы видели выше.
На втором этапе мы будем использовать лексикон основ и аффиксов для поиска категорий основ и значения аффиксов. Таким образом, cat + s будут сопоставлены с cat NP PL и fox + s до fox N PL . Теперь мы также узнаем, что foxe не является легальной основой. Это говорит нам о том, что разделение лисиц на лис + s на самом деле было неправильным способом разделения лисиц , который следует отбросить. Но обратите внимание, что для слова дома правильно разделить его на дома + s .
Вот картинка, иллюстрирующая два шага нашего морфологического парсера с некоторыми примерами.
Теперь мы создадим два преобразователя: один для преобразования поверхностной формы в промежуточную форму, а другой — для преобразования промежуточной формы в основную форму.
3.2.1 От поверхности к промежуточной форме
Для проведения морфологического разбора этот преобразователь должен преобразовать поверхностную форму в промежуточную форму. Сейчас мы просто хотим охватить случаи английских существительных в единственном и множественном числе, которые мы видели выше. Это означает, что преобразователь может вставлять или не вставлять границу морфемы, если слово заканчивается на 9.0003 с . Могут быть слова в единственном числе, оканчивающиеся на s (например, поцелуй ). Вот почему мы не хотим делать вставку границы морфемы обязательной. Если слово заканчивается на ses , xes или zes , оно может, кроме того, удалить e при введении границы морфемы. Вот преобразователь, который делает это. Дуга «другие» в этом преобразователе обозначает переход, который отображает все символы, кроме s, z, x , на себя.
Давайте посмотрим, как этот преобразователь работает с некоторыми из наших примеров. На следующих графиках показаны возможные последовательности состояний, через которые может пройти преобразователь, при условии, что поверхность формирует кошек и лисиц в качестве входных данных.
3.2.2 От промежуточной формы к морфологической структуре
Теперь мы хотим взять промежуточную форму, созданную в предыдущем разделе, и сопоставить ее с базовой формой. Вход, который должен принимать этот преобразователь, имеет одну из следующих форм:
основа регулярного существительного, напр.
кошка основа основного существительного + s, напр. cat + s
единственное число неправильная основа существительного, напр. мышь
множественное число неправильная основа существительного, напр. мыши
В первом случае преобразователь должен сопоставить все символы стебля с собой, а затем выдать N и SG . Во втором случае он отображает все символы основы на себя, но затем выводит N и заменяет PL на s . В третьем случае делается то же самое, что и в первом. Наконец, в четвертом случае преобразователь должен сопоставить неправильную основу существительного множественного числа с соответствующей основой единственного числа (например, мыши в мышь ), а затем добавить N и PL . Итак, общая структура этого преобразователя выглядит так:
Что еще нужно указать, так это то, как именно выглядят части между состоянием 1 и состояниями 2,3 и 4 соответственно. Здесь нам нужно распознать основы существительных и решить, являются ли они правильными или нет. Мы делаем это, кодируя лексикон следующим образом. Часть преобразователя, которая распознает cat , например, выглядит так:
А сопоставление частей преобразователя мыши на мышь можно указать следующим образом: этот ввод имеет правильную форму и добавляет информацию о категории и числе.
3.2.3 Объединение двух преобразователей
Если теперь два преобразователя для преобразования поверхности в промежуточную форму и для отображения из промежуточного состояния в нижележащую форму будут работать в каскаде (т. е. мы позволим второму преобразователю работать на вывод первого), мы можем сделать морфологический анализ (некоторых) английских словосочетаний. Однако мы также можем использовать этот преобразователь для создания поверхностной формы из основной формы. Помните, что мы можем изменить направление трансляции при использовании преобразователя в режиме трансляции.
Теперь рассмотрим ввод ягод . Что из этого сделают наши каскадные преобразователи? Первый вернет два возможных разбиения, ягоды и ягоды + s , но тот, который нам нужен, ягоды + s , не является одним из них. Причина этого в том, что здесь действует еще одно правило правописания, которое мы вообще не учли. Это правило гласит, что « y меняется на , т.е. до s «. Таким образом, на первом этапе может быть несколько правил правописания, и все они должны быть применены.
В основном есть два способа справиться с этим. Во-первых, мы можем сформулировать преобразователи для каждого из правил таким образом, чтобы их можно было запускать каскадно. Другая возможность состоит в том, чтобы определить преобразователи таким образом, чтобы их можно было применять параллельно.
Существуют алгоритмы объединения нескольких каскадных преобразователей или нескольких преобразователей, которые предполагается применять параллельно, в один преобразователь. Однако эти алгоритмы работают только в том случае, если отдельные преобразователи подчиняются некоторым ограничениям, так что мы должны проявлять осторожность при их определении.
3.2.4 Помещение в Пролог
Если вы хотите реализовать небольшой морфологический синтаксический анализатор, который мы видели в предыдущем разделе, все, что вам действительно нужно сделать, это перевести спецификации преобразователя в формат Пролога, который мы использовали в последняя лекция. Затем вы можете использовать программу преобразователя последней лекции, чтобы запустить их.
Мы не будем подробно показывать, как выглядят преобразователи в Прологе, но мы хотим быстро взглянуть на вставной преобразователь e , потому что у него есть одна интересная особенность; а именно 9′):- !.
дуга(6,1,X:X) :- !.
Чтение вслух на основе морфем: свидетельства дислексиков и опытных итальянских читателей
. 2008 г., июль; 108 (1): 243–62.
doi: 10.1016/j.cognition.2007.12.010. Epub 2008, 8 февраля.
Кристина Бурани 1 , Стефания Марколини, Мария Де Лука, Пьерлуиджи Зокколотти
принадлежность
- 1 Институт когнитивных наук и технологий, ISTC-CNR, Via S. Martino della Battaglia 44, 00185 Рим, Италия. [email protected]
- PMID: 18262178
- DOI: 10.1016/j.cognition.2007.12.010
Кристина Бурани и др. Познание. 2008 июль
. 2008 г., июль; 108 (1): 243–62.
doi: 10.1016/j.cognition.2007.12.010. Epub 2008, 8 февраля.
Авторы
Кристина Бурани 1 , Стефания Марколини, Мария Де Лука, Пьерлуиджи Зокколотти
принадлежность
- 1 Институт когнитивных наук и технологий, ISTC-CNR, Via S. Martino della Battaglia 44, 00185 Рим, Италия. [email protected]
- PMID: 18262178
- DOI: 10.1016/j.cognition.2007.12.010
Абстрактный
Роль морфологии в чтении вслух была исследована путем измерения латентности называния псевдослов и слов, состоящих из морфем (корней и словообразовательных суффиксов) и соответствующих им простых псевдослов и слов. В исследовании приняли участие три группы итальянских детей разного возраста и способностей к чтению, включая детей с дислексией, а также одна группа взрослых читателей. Все четыре группы читали псевдослова, состоящие из корня и суффикса, быстрее и точнее, чем простые псевдослова (опыт 1). В отличие от опытных молодых и взрослых читателей, как дислексики, так и дети младшего возраста извлекли пользу из морфологической структуры также при чтении слов вслух (Эксперимент 2). Предполагается, что морфема представляет собой единицу промежуточного размера, которая оказывается полезной при обработке всех языковых стимулов, включая слова, у лиц с ограниченными способностями к чтению (дислектики и младшие читатели), которые не полностью освоили обработку всего слова. Для опытных читателей морфемный анализ полезен для чтения тех стимулов (то есть псевдослов, состоящих из морфем), для которых не существует лексической единицы, состоящей из целого слова; там, где такие лексические единицы, состоящие из целых слов, действительно существуют, опытным читателям не нужно полагаться на морфологический анализ, поскольку они могут полагаться на лексическую (целое слово) единицу чтения, которая больше, чем морфема.
Похожие статьи
Эффект длины при чтении и лексическом решении: данные опытных читателей и участника с дислексией, связанной с развитием.
Джуфард А., Карбоннел С., Вальдуа С. Джуфард А. и др. Познание мозга 2004 г., июль; 55 (2): 332-40. doi: 10.1016/j.bandc.2004.02.035. Познание мозга 2004. PMID: 15177808 Клиническое испытание.
Чтение и правописание на основе морфем у итальянских детей с дислексией развития и дисортографией.
Анджелелли П., Маринелли К.В., Де Сальваторе М., Бурани К. Анджелелли П. и др. Дислексия. 2017 ноябрь;23(4):387-405. doi: 10.1002/dys.1554. Epub 2017 8 февраля. Дислексия. 2017. PMID: 28177182
Чтение производных слов итальянскими детьми с дислексией и без нее: влияние длины корня.
Бурани С., Марколини С., Трафиканте Д., Зокколотти П. Бурани С. и др. Фронт Псих. 2018 8 мая; 9:647. doi: 10.3389/fpsyg.2018.00647. Электронная коллекция 2018. Фронт Псих. 2018. PMID: 29867633 Бесплатная статья ЧВК.
Обращая внимание на чтение: нейробиология чтения и дислексии.
Shaywitz SE, Shaywitz BA. Shaywitz SE и др. Дев психопат. 2008 г. Осень; 20 (4): 1329-49. дои: 10.1017/S0
00631. Дев психопат. 2008. PMID: 18838044 Обзор.Овладение чтением, дислексия развития и умелое чтение на разных языках: психолингвистическая теория размера зерна.
Зиглер Дж. К., Госвами У. Ziegler JC и соавт. Психологический бык. 2005 г., январь; 131 (1): 3–29. doi: 10.
1037/0033-2909.131.1.3.
Психологический бык. 2005.
PMID: 15631549
Обзор.
Посмотреть все похожие статьи
Цитируется
Морфосинтаксические навыки влияют на точность письменного декодирования итальянских детей с дислексией развития и без нее.
Казани Э., Вулчанова М., Кардиналетти А. Казани Э. и др. Фронт Псих. 2022 27 апр;13:841638. doi: 10.3389/fpsyg.2022.841638. Электронная коллекция 2022. Фронт Псих. 2022. PMID: 35572334 Бесплатная статья ЧВК.
Модулирует ли морфологическая структура доступ к встроенному значению слова у детей, читающих?
Hasenäcker J, Solaja O, Crepaldi D. Hasenäcker J, et al. Мем Когнит. 2021 окт;49(7):1334-1347.
doi: 10.3758/s13421-021-01164-3. Epub 2021 22 марта.
Мем Когнит. 2021.
PMID: 33754308
Бесплатная статья ЧВК.Кодирование положения морфемы в развитии чтения, изученное с помощью задачи поиска букв.
Хазенакер Дж., Котори М., Крепальди Д. Hasenäcker J, et al. Дж Когн. 2021 17 февраля; 4(1):16. doi: 10.5334/joc.153. Дж Когн. 2021. PMID: 33634233 Бесплатная статья ЧВК.
Ранняя чувствительность к морфологии у начинающих читателей арабского языка.
Эль Акики С, Содержание А. Эль Акики С. и др. Фронт Псих. 2020 23 сент.; 11:552315. doi: 10.3389/fpsyg.2020.552315. Электронная коллекция 2020. Фронт Псих. 2020. PMID: 33071873 Бесплатная статья ЧВК.
Морфологическая декомпозиция помогает распознавать низкочастотные слова у типично развивающихся испаноговорящих детей.
Д’Алессио М.Дж., Уилсон М.А., Джайченко В. Д’Алессио М.Дж. и соавт. J Психолингвист Res. 2019 дек.;48(6):1407-1428. doi: 10.1007/s10936-019-09665-8. J Психолингвист Res. 2019. PMID: 314
Просмотреть все статьи «Цитируется по»
Типы публикаций
термины MeSH
Электронный текстовый корпус шумерских царских надписей
Содержание
I. Фраза существительного
1. Шаблон
2. Морфемные соответствия
- 2-й именной слот
- 3-й номинальный слот
- 4-й номинальный слот
- 5-й номинальный слот
- 6-й номинальный слот
II. Конечный глагол
1. Шаблон
2. Морфемные соответствия
- 1-й глагольный слот
- 2-й словесный слот
- 3-й словесный слот
- 4-й словесный слот
- 5-й словесный слот
- 6-й словесный слот
- 7-й словесный слот
- 8-й словесный слот
- 9-й словесный слот
- 10-й словесный слот
- 11-й словесный слот
- 12-й словесный слот
- 13-й словесный слот
- 14-й словесный слот
- 15-й словесный слот
III. Неопределенный глагол
1. Шаблон
2. Морфемные соответствия
- 1-й неконечный глагольный слот
- 2-й неконечный словесный слот
- 3-й неконечный словесный слот
- 4-й неконечный словесный слот
Аббревиатуры
- CF = форма цитирования
- df = форма по умолчанию (выделена жирным шрифтом и курсивом)
- M1 = морфемное представление
- M2 = морфемное глянцевое представление
- N = номинальный слот
- NV = слот неконечной глагольной формы
- p-tag = тег положения
- V = глагольный слот
I. Шаблонная фраза
7
7 1. Шаблон фразы
7
N1 (Слот 1 именной фразы) = Голова
N2 = Модификатор
N3 = Владелец (именная фраза или притяжательная энклитика)
N4 = Маркер множественного числа или суффикс порядкового номера
N5 = Маркер корпуса
N6 = связка
| N1 | N2 | N3 | N4 | N5 | N6 |
|---|---|---|---|---|---|
и | № | enee | ø | мужчины | |
в девичестве | по | камак | и | утра | |
Ани | кама | ра | Менден | ||
би | от | Мензен | |||
я | та | сетка | |||
зуненее | и | няня | |||
аненее | |||||
ак | |||||
джин | |||||
ne | |||||
или |
2. Морфемные соответствия
2-й именной слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
и | N2 | ДЕМ | указательное местоимение |
в девичестве | N2 | DEM3 | указательное местоимение |
3-й номинальный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
№ | N3 | 1-SG-ПОСС | Притяжательная энклитика 1-го лица единственного числа |
по | N3 | 2-SG-ПОСС | Притяжательная энклитика 2-го лица единственного числа |
Ани | N3 | 3-SG-H-ПОСС | 3-е лицо единственного числа человеческая притяжательная энклитика |
би | N3 | 3-SG-NH-ПОСС | 3-е лицо единственного числа нечеловеческое притяжательное энклитическое |
би | N3 | DEM2 | указательное местоимение |
я | N3 | 1-PL-ПОСС | Притяжательная энклитика 1-го лица множественного числа |
зунене | N3 | 2-PL-ПОСС | Притяжательная энклитика 2-го лица множественного числа |
аненее | N3 | 3-PL-POSS | Притяжательная энклитика 3-го лица множественного числа |
Примечание 1: Двойные гласные обозначают долгую гласную
4-й номинальный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
enee | N4 | PL | множественный маркер |
камак | N4 | ЗАКАЗ | Суффикс порядкового номера |
кама | N4 | ЗАКАЗ | более поздняя форма суффикса порядкового номера |
5-й номинальный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
ø | N5 | АБС | абсолютный маркер |
и | N5 | ЭРГ | эргативный падеж-маркер (df) |
ра | N5 | ДАТ-Х | человеческий дательный падеж-маркер (df) |
и | N5 | ДАТ-НХ | нечеловеческий дательный падеж-маркер |
от | N5 | КОМ | маркер для деликатесов |
та | N5 | АБЛ | Маркер для абляционного корпуса |
N5 | СРОК | конечный маркер корпуса | |
‘а | N5 | L1 | локатив1 регистр-маркер (df) |
ра | N5 | L2-H | человеческий локатив2 маркер случая |
N5 | Л2-НХ | нечеловеческий локативный2 маркер случая | |
ра | N5 | L3-H | человеческая локация3 маркер случая |
и | N5 | L3-NH | нечеловеческий локатив3 маркер случая |
ак | N5 | ГЕН | Маркер родительного падежа |
джин | N5 | ЭКВ | эквивалентный маркер |
нет | N5 | Л4 | локатив4 маркер корпуса |
или | N5 | АДВ | суффикс наречия |
Примечание 1: L4 считается архаичным локативным регистром-маркером (возможно, соответствующим глагольному префиксу L1 /ni/), используемому только в формах, подобных nu2-a-zu-ne (ср. Krecher 1993)
Примечание 2: Систему падежей, используемую ETCSRI, см. Золиоми 2007b и 2010.
Примечание 3: ADV на самом деле является производной морфемой.
6-й номинальный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
мужчины | N6 | КС-1-SG | форма первого лица единственного числа энклитической связки (df) |
мужчины | N6 | КС-2-SG | форма второго лица единственного числа энклитической связки |
утра | N6 | КС-3-SG | форма энклитической связки от третьего лица единственного числа |
Менден | N6 | КС-1-PL | форма множественного числа от первого лица энклитической связки |
Мензен | N6 | КС-2-PL | форма второго лица множественного числа энклитической связки |
сетка | Н6 | КС-3-PL | форма множественного числа от третьего лица энклитической связки |
нанна | N6 | КРОМЕ | частица, относящаяся к исключению из отрицательного утверждения |
Примечание 1: Для /нанна/ ср. Эдзард 2003: 158 и Винкер и Джонсон 2009: 361–362.
II. Конечный глагол
1. Шаблон
Слот 1 | модальный префикс ha-, отрицательный префикс nu-, префикс предшествования |
Слот 2 | Модальный префиксы, отличные от ha-, префиксы конечных маркеров |
Слот 3 | Префикс координатора |
Слот 4 | Вентивный (цислокативный) префикс |
Слот 5 | Средний префикс или 3-й местоименный префикс (с указанием лица, рода и числа первого в последовательности размерных префиксов) |
Слот 6 | Начальный местоименный префикс (с указанием лица, рода и числа первого в последовательности размерных префиксов) x |
Слот 7 | Размер I: префикс дательного падежа |
Слот 8 | Размерность II: комитативный префикс |
Слот 9 | Размер III: префикс аблатива или терминатора |
Слот 10 | Размер IV: префикс locative1, locative2 или locative3 |
Слот 11 | Префикс конечного местоимения (относится к A или P, в зависимости от времени) |
Слот 12 | шток |
Слот 13 | маркер настоящего-будущего (в непереходных глаголах) |
Слот 14 | местоименный суффикс (относится к A, S или P в зависимости от времени) |
Слот 15 | Подчиненный |
| В1 | В2 | В3 | В4 | V5 | V6 | В7 | V8 | В9 | В10 | В11 | V12 | В13 | В14 | В15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
нет | и | нга | м | ба | 1 | и | от | та | нет | 1 | ШТОК | изд | и | |
га | и | мю | б | р | Ши | нет | и | STEM-PF | и | ø | ||||
и | и | и | и | нет | STEM-PL | и | ||||||||
ШТОК | II | нн | и | б | STEM-RDP | энден | ||||||||
STEM-PL | мее | ø | КС | энзен | ||||||||||
STEM-RDP | га | или | ||||||||||||
нан | enee | |||||||||||||
бар | ||||||||||||||
нуш | ||||||||||||||
Ши | ||||||||||||||
н/д |
Примечание 1: В повелительных глагольных формах STEM(-PL/RDP) занимает V1, а V12 пуст.
2. Соответствия морфем
1-й глагольный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
нет | В1 | НЕГ | отрицательный префикс |
га | В1 | МОД1 | модальный1 префикс |
и | В1 | Муравейник | префикс старшинства |
ЦФ | В1 | ШТОК | словесный ствол |
ЦФ | В1 | STEM-PL | глагольная основа множественного числа |
ЦФ | В1 | STEM-RDP | дублированная словесная основа |
2-й словесный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
га | В1 | МОД2 | префикс modal2 |
нан | В1 | МОД3 | модальный3 префикс |
бар | В1 | МОД4 | модальный4 префикс |
нуш | В1 | МОД5 | модальный5 префикс |
Ши | В1 | МОД6 | модальный6 префикс |
н/д | В1 | МОД7 | модальный7 префикс |
и | В2 | ФИН | конечный маркер |
II | В2 | ФИН-ЛИ | удлиненный конечный маркер, сигнализирующий о синкопировании гласной префикса L1 |
II | В2 | FIN-L2 | удлиненный конечный маркер, сигнализирующий о синкопировании гласной префикса L2 |
и | В2 | ФИН | конечный маркер |
аа | В2 | FIN-L2 | удлиненный конечный маркер, сигнализирующий о синкопировании гласной префикса L2 |
все | В2 | ФИН | конечный маркер |
Примечание 1: компенсирующее удлинение конечного маркера происходит, когда префикс L2 в V10 (которому предшествует местоименный префикс в V5 или V6) или гласная префикса L1 становится синкопированной. В этих глагольных формах удлинение FIN рассматривается и интерпретируется как маркер L2. (См. Jagersma 2006)
3-й словесный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
нга | V3 | КООР | префикс координатора |
4-й словесный слот
| M1 | р-тег | М2 | описание |
|---|---|---|---|
м | В4 | ВЕН | Вентивный (цислокативный) префикс |
мю | В4 | ВЕН | Вентивный (цислокативный) префикс |
5-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
ба | В5 | СРЕДНИЙ | средний префикс |
б | В5 | 3-НХ | Нечеловеческий начальный местоименный префикс от третьего лица единственного числа |
6-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
1 | V6 | 1-SG | Начальный местоименный префикс от первого лица единственного числа (= IPP) |
р | V6 | 2-SG | второе лицо единственного числа IPP |
и | V6 | 2-SG | второе лицо единственного числа IPP |
нн | V6 | 3-SG-H | человеческое IPP от третьего лица единственного числа |
и | V6 | 1-PL | первое лицо множественного числа IPP |
V6 | 3-PL | третье лицо множественного числа IPP |
7-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
и | В7 | ДАТ | префикс дательного падежа |
8-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
да | V8 | СОМ | комитативный префикс |
9-й словесный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
та | В9 | АБЛ | префикс аблатива |
Ши | В9 | СРОК | Завершающий префикс |
В9 | СРОК | завершающий префикс |
10-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
ни | В10 | L1 | местный1 префикс |
нет | В10 | ЛОК-ОБ | локативный префикс, используемый в качестве каузативного маркера в текстах OB |
нет | В10 | L1-СИН | префикс синкопированного местного падежа1 |
и | В10 | L2 | местный2 префикс |
и | В10 | L2 | местный2 префикс |
ø | В10 | L2-СИН | префикс синкопированного местного падежа2 |
и | В10 | L3 | местный3 префикс |
Примечание 1: Таким образом, форма, подобная i₃-ib₂-ĝal₂, будет анализироваться как
. M1: V1=ii.V5=b.V10=ø.V12=øal.V14=ø
M2: V1=FIN-L2.V5=3-NH.V10=L2-SYN.V12=STEM.V14=3-SG-S
11-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
1 | В11 | 1-SG-A | окончательная местоименная приставка от первого лица единственного числа (= FPP), истолкованная агентом |
е | В11 | 2-SG-A | второе лицо единственного числа FPP, истолкованный агентом |
нет | В11 | 3-SG-H-A | FPP человека от третьего лица единственного числа, истолкованный с агентом (df) |
нет | В11 | 3-SG-H-P | FPP человека от третьего лица единственного числа, истолкованный с пациентом |
n | В11 | 3-SG-H-L3 | FPP человека от третьего лица единственного числа, истолкованный с участником L3 |
n | В11 | 1-SG-A-OB | От первого лица единственного числа FPP, истолкованный агентом в текстах OB |
b | В11 | 3-SG-NH-A | от третьего лица единственного числа нечеловеческий FPP, истолкованный с агентом |
b | В11 | 3-SG-NH-P | от третьего лица единственного числа нечеловеческого FPP, истолкованного с пациентом (df) |
b | В11 | 3-SG-NH-L3 | третье лицо, единственное число, нечеловеческий FPP, истолкованный с участником L3 |
nnee | В11 | 3-PL-H-P | третье лицо, множественное число, человеческий FPP, истолкованный с пациентом |
Примечание 1: Для конечных местоименных префиксов, истолковываемых с участником в L3, ср. Zólyomi 1999: 221, fn 13 (с другой терминологией) и Jagersma 2006.
12-й словесный слот
| M1 | р-тег | М2 | описание |
|---|---|---|---|
ЦФ | V12 | ШТОК | словесная основа (df) |
CF | V12 | STEM-PF | глагольная основа настоящего-будущего |
CF | V12 | STEM-PL | глагольная основа множественного числа |
CF | V12 | STEM-RDP | дублированная глагольная основа |
CF | V12 | КС | независимая связка |
Примечание 1: они могут быть объединены, например, sub2 является STEM-PF-PL , т. Порядок квалификационных толкований должен следовать этой таблице (поэтому подпункт 2 может быть глоссирован только как раньше, но не как STEM-PL-PF).
Примечание 2: В отличие от The Penn Parsed Corpus of Sumerian [http://psd.museum.upenn.edu/ppcs/MorphologyTable.html], ETCSRI не будет иметь специального шаблона со специальными слотами для повелительных глагольных форм: в императивных глагольных формах предполагается, что глагольная основа занимает V1.
13-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
изд | В13 | ПФ | маркер настоящего-будущего |
en | В13 | ПЛЭН | глагольный суффикс, обозначающий множественность S или P |
Примечание: PLEN засвидетельствован очень редко (ср. Krecher 1965 и 1987).
14-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
и | В14 | 1-SG-A | Суффикс агента первого лица единственного числа (df) |
en | В14 | 1-СГ-С | Суффикс подлежащего от первого лица единственного числа |
en | В14 | 1-СГ-П | Суффикс пациента от первого лица единственного числа |
en | В14 | 2-SG-A | Суффикс второго лица единственного числа |
en | В14 | 2-СГ-С | суффикс подлежащего второго лица единственного числа |
и | В14 | 2-СГ-П | Суффикс пациента второго лица единственного числа |
ø | В14 | 3-СГ-С | суффикс субъекта от третьего лица единственного числа человека или не человека |
ø | В14 | 3-СГ-П | суффикс подлежащего от третьего лица единственного числа человека или не человека (df) |
e | В14 | 3-SG-A | суффикс человеческого или нечеловеческого агента от третьего лица единственного числа |
e | В14 | 3-СГ-С-ОБ | Суффикс субъекта от третьего лица единственного числа человека или не человека в текстах OB |
enden | В14 | 1-ПЛ-А | Суффикс агента от первого лица множественного числа |
enden | В14 | 1-ПЛ-С | Суффикс подлежащего от первого лица множественного числа (df) |
enden | В14 | 1-PL | Суффикс первого лица множественного числа в переходных претеритных глагольных формах множественного числа |
enzen | В14 | 2-ПЛ-А | Суффикс второго лица множественного числа |
enzen | В14 | 2-ПЛ-С | Суффикс подлежащего во множественном числе второго лица (df) |
enzen | В14 | 2-PL | Суффикс второго лица множественного числа в переходных претеритных глагольных формах множественного числа |
или | В14 | 3-PL-S | Суффикс подлежащего во множественном числе во втором лице |
eš | В14 | 3-ПЛ-П | Суффикс пациента множественного числа во втором лице (df) |
eš | В14 | 3-PL | суффикс третьего лица множественного числа в переходных претеритных глагольных формах множественного числа (df) |
enee | В14 | 3-PL-A | Суффикс третьего лица множественного числа в глагольных формах настоящего и будущего |
Примечание 1: В переходных претеритных формах агенты множественного числа имеют перекрестную ссылку с перифрастической конструкцией, включающей использование двух аффиксов: форма единственного числа FPP в V11 и форма множественного числа местоименного суффикса в V14, то есть FPP в V11. согласуется по роду и лицу, в то время как суффикс в V14 согласуется по числу и лицу с агентом. В этих формах суффикс в V14 будет обозначаться как 1-PL, 2-PL или 3-PL, то есть без указания его синтаксической функции, например: …-3-SG-H-A-основа-3-PL
15-й словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
В15 | SUB | подчиненный |
III. Неопределенный глагол
1. Шаблон
| НВ11 | НВ2 | НВ3 | НВ4 |
|---|---|---|---|
нет | ШТОК | изд | |
STEM-PF | |||
STEM-RDP |
Примечание 1: Неконечная глагольная форма может занимать либо N1, либо N2. В первом случае оно действует как существительное, а во втором — как модификатор. Так называемые прилагательные считаются неличными глагольными формами.
Примечание 2: Как и нефинитные глагольные формы, количественные числительные могут использоваться как модификаторы, так и существительные, поэтому они будут вставлены в нефинитный глагольный шаблон.
2. Морфемные соответствия
1-й неконечный глагольный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
нет | НВ1 | НЕГ | отрицательный префикс |
2-й неконечный глагольный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
ЦФ | НВ2 | ШТОК | словесная основа |
CF | НВ2 | STEM-PF | глагольная основа настоящего-будущего |
CF | НВ2 | STEM-PL | глагольная основа множественного числа |
CF | НВ2 | STEM-RDP | дублированная глагольная основа |
3-й неконечный глагольный слот
| М1 | р-тег | M2 | описание |
|---|---|---|---|
изд | НВ3 | ПФ | Маркер настоящего будущего |
4-й неконечный словесный слот
| M1 | р-тег | M2 | описание |
|---|---|---|---|
НВ4 | SUB | подчиненный |
Примечание 1: В основном у нас есть 3 + 1 фактических форм, которые должны быть сгенерированы: LAL, LAL-ed, LAL-a и LAL-ed-a. Четвертая маргинальная форма встречается только в так называемом «местоименном спряжении», например, STEM-ed-a-ĝu-ne. (Аргументы Keetman [2008] в пользу иного анализа этих форм оказались неубедительными.)
Ссылки
Эдзард, Дитц Отто (2003), Шумерская грамматика (Справочник по востоковедению, раздел I, 71). Лейден — Бостон: Брилл, 2003.
.
Джагерсма, Брэм (2006). «Конечные лица-префиксы и пассив», НАБУ ., вып. 93.
Китман, Ян (2008 г.), «Der auf / -e (d) / gebildete Stamm des sumerischen Verbums», Revue d’Assyriologie 102, 9–16.
Крехер, Иоахим (1965), «Zur sumerischen Grammatik», Zeitschrift für Assyriologie 57, 12–30.
Крехер, Иоахим (1987), «DU = ku₄(-r)» eintreten, «hineinbringen», Zeitschrift für Assyriologie 77, 7–21.
Крехер, Иоахим (1993), «Суффикс определения -/a/», Acta Sumerologica 15, 81–93.
Винкер, Рональд — Дж. Кейл Джонсон (2009 г.), «Апелляционный процесс в судебном протоколе {di til-la} из Ура III Уммы», AoF 36, 349–364.
Золёми, Габор (1999), «Инфикс директивы и наклонный объект в шумерском языке: отчет об истории их взаимоотношений», Orientalia NS 68 (1999), 215–253.
Золиоми, Габор (2007b), «Sumerisch», в Michael Streck, Hrsg., Schriften und Sprachen des Alten Orients . 3., überarb. Ауфляж. Дармштадт: Wissenschaftliche Buchgesellschaft, 11–43.
Золиоми, Габор (2010), «Дело о шумерских делах», Леонид Коган и др., Ред. Материалы 53e Rencontre Assyriologique Internationale , Том. 1: Язык Древнего Ближнего Востока (2 части) (Вавилон и Бибель, 4A-B). Озеро Вайнона, Индиана: Eisenbrauns, 577–590.
Дата последнего изменения: 19 сентября 2021 г.
Язык в Индии
1. ВВЕДЕНИЕ
При машинном переводе санскритских предложений основной задачей перевода является морфологический анализ санскритских слов. Поскольку слова представляют собой комбинацию более чем одного основного слова, они должны быть подразделены, а разделенные слова должны быть проанализированы. Морфологический анализ дает нам полную информацию о классе, к которому принадлежат разделенные слова. Морфологический синтаксический анализатор состоит из набора преобразователей, которые преобразуют данный ввод в набор допустимых и вероятных слов, формируя морфологический словарь. Они также дают разбор этих слов. Вторая часть синтаксического анализатора — это модуль Vichcheda, который разбивает ввод на основные слова санскрита. Наконец, компаратор сравнивает слова в словаре и выходные данные модуля Vichcheda и делает вывод, распознано ли сгенерированное слово/слова. Разбор санскритских слов необходим, потому что анализируемый ввод определяет, какие фразы заменят санскритский текст при его переводе на любой другой язык.
Настоящий материал состоит из шести разделов, озаглавленных «Морфологический разбор», «Сандхи Виччеда на санскрите», «Разбор слов, основанных на сандхи», «Заключительные замечания» и «Приложение». Первые два раздела дают основу для понимания статьи. Раздел «Морфологический анализ» дает общее введение в морфологический анализ и иллюстрирует его с помощью примеров. Представление о том, как сандхи исполняется на санскрите, дается в следующем разделе под названием «Сандхи виччеда на санскрите». Раздел, озаглавленный «Разбор слов, основанных на Сандхи», составляет основу настоящей статьи. Он дает архитектуру предлагаемой идеи синтаксического анализатора и обсуждает каждую из его частей, приводя примеры там, где это необходимо. Критический взгляд на настоящий материал дан в разделе «Заключительные замечания». В этом разделе также рассматриваются преимущества и возможные будущие усовершенствования. В разделе «Ссылки» перечислены различные книги и материалы, на которые ссылались в процессе разработки этого материала. В последнем разделе даны деванагри-эквиваленты римского письма, используемые в этой статье для представления санскритского текста.
2. МОРФОЛОГИЧЕСКИЙ РАЗБОР
Морфологический анализ слов, принадлежащих к естественным языкам, включает предоставление структуры данных входных данных с указанием различных морфем, составляющих входные данные, и того, как они связаны друг с другом. Морфемы — это меньшие по смыслу несущие единицы слов. Эти морфемы можно разделить на основы и аффиксы, которые могут быть префиксами, суффиксами, инфиксами или циркумфиксами. В то время как префиксы — это те морфемы, которые могут стоять перед основой, а постфиксы — это те, которые применяются к концу основы, циркумфиксы — это те морфемы, которые могут применяться с обеих сторон основы. Морфемы, отнесенные к категории инфиксов, — это те, которые появляются внутри основы.
Любой морфологический синтаксический анализатор должен состоять из частей, действующих как лексикон, дающий исчерпывающий список всех морфем, присутствующих в языке, морфотактические правила, определяющие положение одной морфемы по отношению к другой, и набор орфографических правил, определяющий, как две заданные морфемы комбинировать. Лексикон в сочетании с морфотактикой может быть смоделирован с помощью конечного автомата. Конечный автомат может быть каким-то преобразователем. Орфографические правила могут быть использованы на этапе, когда необходимо, чтобы морфемы были объединены вместе, чтобы дать поверхностное слово.
Пример 1
В таком слове, как «книги» — «книга» и «-с» — две морфемы. Когда слово «книги» анализируется, проанализированный вывод говорит нам, что слово было образовано, потому что существительное с названием «книга» использовалось во множественном числе, то есть вывод может быть примерно таким- (книга, существительное, множественное число). Эта информация впоследствии может быть использована для перевода слова «книги» на другие языки.
3. САНДИ ВИЧЧЕДА НА САНСКРИТЕ
Входными данными для синтаксического анализатора являются слова, которые также могут представлять собой слияние более чем одного санскритского слова. Такое систематическое сочетание слов называется сандхи. Санскритское слово сандхи означает «соединяться». Сандхи — это слияние двух букв, находящихся в непосредственном контакте друг с другом. Когда два слова находятся рядом друг с другом, последняя буква одного слова и первая буква следующего слова вступают в непосредственный контакт, что может привести к объединению двух слов в более крупное слово. Это объединение происходит по правилам сандхи. Практически слово, образованное по правилам сандхи, может содержать любое количество меньших слов.
В широком смысле типы сандхи можно классифицировать как сварасандхи и халсандхи. Сварасандхи имеет дело с сочетаниями гласных, а Халсандхи — с сочетаниями согласных.
Пример 2
а) а+I=E как в sva+IraH=svEraH (Тот, кто действует умышленно)
б) a+A=A как в rAmeNAnIwaH=rAmeNa+AnIwaH (принесено Рамой)
4. РАЗБОР СЛОВ НА ОСНОВЕ САНДХИ
При анализе слов, образованных с использованием орфографических правил сандхи, необходимо сгенерировать весь набор подслов, содержащихся в каждом входном слове, вместе с проанализированным выводом каждого такого подслова. Модель, которая помогает нам достичь этой цели, представлена на рисунке 1 ниже.
Модуль синтаксического анализатора/генератора использует часть входных данных и генерирует возможные результаты разделения, которые могут возникнуть. Эта информация хранится в морфологическом словаре, который действует как временный буфер. Другая строка, которая также генерируется синтаксическим анализатором/генератором, используется модулем Vichcheda. Затем модуль Vichcheda преобразует это в соответствующую строку, которая соответствует правилам sandhi. Он также добавляет строку в начало оставшейся строки, полученной после разделения. Этот модуль отправляет измененные строки компаратору. Компаратор сопоставляет входные данные, которые он получает из Морфологического словаря, с первой строкой, полученной из модуля Виччеда. Следующая строка возвращается системе в качестве входных данных. Этот процесс повторяется до тех пор, пока входное слово не будет полностью проанализировано.
Различные блоки на рисунке 1 описаны под:
Модуль парсера/генератора:
Этот модуль представляет собой набор датчиков, как описано выше. Преобразователи представляют собой машины Мура с несколькими выходами. Преобразователи определяются как:
- Конечное множество состояний s0, s1, s2, где s0 — начальное состояние.
- Алфавит A= ({буквы деванагри} U null), для входных строк и двух наборов выходных строк.
- Выходной алфавит O C (P {часть речи, падеж, число, род, времена, } U ноль).
- Выходная таблица, содержащая три набора выходных данных.
- Графическое представление, представляющее переходы между состояниями. Общее представление показано на рисунке 2 ниже.
Все преобразователи объединены в системный модуль морфологического анализа, который называется Анализатор/Генератор. Конструкция этого набора преобразователей показана на рис. 3, где каждый преобразователь относится к типу, показанному на рис. 2. Для каждого слова имеется один преобразователь, который, если применимо, заботится о его склонении. Часть склонения обрабатывается путем добавления соответствующих суффиксов (полученных из знания санскритских таблиц склонения) к основе. Эту работу выполняет преобразователь. Вход в модуль направлен на преобразователи. Преобразователи разбирают входную букву за буквой. Когда прочитано достаточно входных букв, указывающих на некоторую возможную грамматическую характеристику, это указывается в выводе ‘parse string’. В каждом состоянии вывод, соответствующий строке, т. е. «частичный корень», сохраняется в выходной таблице. Это отправляется в модуль Виччеда. Кроме того, строка «вероятное подслово» генерируется различными преобразователями и сохраняется в Морфологическом словаре.
Пример 3
Санскритское слово rAmasyAcAryah (Ачарья Рамы) представляет собой слияние слов «rAmasya» (богов) и «Acharyah» (Ачарья или учитель). Преобразователь сначала проанализирует «rAmasya», а затем на следующем ходу проанализирует «Acharyah». Преобразователь для «rAma» показан в качестве примера на рис. 4.
Модуль Виччеда
Этот модуль состоит из трех частей, а именно. Создатель слов, Генератор разделения и Правило Сандхи. Модуль принимает «частичный корень» и следующую за ним входную букву/буквы в качестве входных данных. Если таких входных букв/букв нет, то модуль производителя Word просто передает «частичный корень» компаратору, в противном случае генератор разделения генерирует возможные разделенные выходные данные, соответствующие прочитанной входной букве/буквам. Он определяет разделенные выходные данные, которые должны быть сгенерированы в соответствии с правилами Сандхи, найденными в блоке правил Сандхи модуля Vichcheda. Word Producer объединяет «частичный корень» со всеми первыми частями пары выходных данных, сгенерированных модулем Split Generator. Он отправляет эти соединенные слова вместе со вторыми частями пары выходов в компаратор. Некоторые правила модуля «Правило Сандхи» приведены ниже:
А-> а, а | а, а | А,а |А,А
я -> я, я | я, я | я, я | я, я
У-> у, у | у, у | У, у | У, У
е-> а, я | А, я | а, я | А, я | е, а | а, е
Е-> а, е | А, е | а, е | А,Е
о->а,у | А, у | а, у | А,У | о, а | а,о
О -> а, о | А, о | а, о | А, О
г-> а, д | А, д |
у-> я, (гласная) | я, (гласная) v-> u, (гласная) | У (гласная) ай-> е, (гласная) av-> о, (гласная) Ау-> Е, (гласная) Av-> O, (гласная) Где (гласная)={a,A,i,I,u,U,e,E,o,O}
Морфологический словарь
Набор «вероятных подслов», сгенерированных Парсером/Генератором, временно сохраняется в Морфологическом словаре. Словарь изменчив в том смысле, что он очищается после каждой успешной генерации подслова ввода. Эти слова, присутствующие в настоящее время, сравниваются в компараторе. В меньшей области Морфологический словарь содержит очень мало слов или всего одно слово. Но по мере увеличения количества слов Морфологический словарь может оказать большую помощь в отслеживании нужного слова.
Компаратор
Четыре входа, а именно. две строки из Word Producer, ввод из Морфологического словаря и правильный анализ каждого такого ввода попадают в Comparator. Этот модуль сравнивает список слов, присутствующих в словаре, с первой выходной строкой пары выходных данных Word Producer. Если компаратор находит точное совпадение строки в словаре, он отправляет эту строку вместе с соответствующим синтаксическим анализом в качестве вывода. Он также отправляет вторую строку, полученную от Word Producer, обратно в качестве входных данных для всей системы морфологического синтаксического анализа. Если вторая строка отсутствует, а существование первой строки подтверждено, то компаратор указывает, что ввод был распознан. На любом этапе, если компаратор не может найти совпадение, это означает, что ввод не распознан.
6. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
При машинном переводе санскритских слов нам нужно выполнить сандхи виччеда введенных нам данных. Таким образом, уже на первом этапе морфологического разбора нам необходимо рассмотреть расщепление слов. Таким образом, представленная статья помогает удовлетворить одну из самых основных потребностей переводчика санскрита. Система была обобщена для обработки любого количества возможных подслов для конкретного ввода. Описанная система может быть расширена, чтобы учитывать все возможные типы Сандхи, путем разработки правил, данных для правила Сандхи. Есть много вопросов, которые необходимо учитывать для системы синтаксического анализа этого типа. Одним из них может быть рассмотрение возможной двусмысленности, возникающей, когда одно и то же слово (пример — «rAmAByam» на рис. 4) встречается в двух разных случаях. Решение этой проблемы должно включать в себя возможность выбора одного разбора из заданных вариантов для каждого вхождения слова. Это может быть реализовано на более поздних этапах перевода.
ССЫЛКИ
1. «Обработка речи и языка — введение в обработку естественного языка» Дэниела Джурафски и Джеймса Мартина, переиздание 2000 г.
2. «Обработка естественного языка» Акшара Бхарати, Винита Чайтаньи, Раджива Сангала.
3. «Введение в теорию компьютеров» — второе издание Даниэля И.А.Коэна
4. «Высшая санскритская грамматика» М. Р. Кале
5. «Сандхи Вивека» А. Варадараджа.
С. Апарна
[email protected]
М. Ингл
[email protected]
НАРУШЕНИЕ ЯЗЫКА ПРИ АУТИЗМЕ | О ПРЕПОДАВАНИИ ПОЭЗИИ В ИНДИЙСКИХ КОНТЕКСТАХ — Некоторые наблюдения и предложения | АПОДДХААРАПАДАРТА — ПРИНЦИП ИНТЕЛЛЕКТУАЛЬНОЙ АБСТРАКЦИИ | МОРФОЛОГИЧЕСКИЙ РАЗБОР СЛОВ НА ОСНОВЕ ‘САНДХИ’ В САНСКРИТСКОМ ТЕКСТЕ | КИТАЙСКИЕ ЯЗЫКИ: НОВАЯ ЛЕКСИКОГРАФИЧЕСКАЯ ПЕРСПЕКТИВА ИЗ ГОНКОНГА | ЯЗЫКИ, НАХОДЯЩИЕСЯ НА ИСЧЕЗНОВЕНИИ – УНИКАЛЬНЫЙ ПРОЕКТ ПО ИХ СПАСЕНИЮ, доклад Школы востоковедения и африканистики | ГЛАВНАЯ СТРАНИЦА | КОНТАКТЫ С РЕДАКТОРОМ
Заросший морфемный анализ.
«заросший» — морфемный анализ слова, разбор по составу (корневой суффикс, приставка, окончание)Схема разбора по составу заросший:
поросенок с ней
Разбор слов по составу.
Conjugation of the word «overgrown»:
Connecting vowel: is absent
Postfix : is absent
Morphemes — parts of the word overgrown
overgrown
Detailed analysis of the word overgrown по составу. Корень слова, префикс, суффикс и окончание слова. Морфемный анализ слова орос, его схема и части слова (морфемы).
- Морфемная схема: порос/в/ее
- Структура слова по морфемам: корень/суффикс/окончание
- Схема (построение) слова орос по составу: корень порос + суффикс ш + его окончание
- Список морфем в слове заросший:
- порос — корень
- ш — суффикс
- гер — окончание
- Типы морфем и их количество в слове заросший:
- префикс: отсутствует — 0
- root: pig — 1
- connecting vowel: is absent — 0
- cyffix: sh — 1
- postfix: is absent — 0
- end: her — 1
Всего морфем в слове: 3.
Деривационный анализ слова заросший
- Базовое слово: заросший ;
- Производные аффиксы: префикс отсутствует , суффикс ш , постфикс отсутствует ;
- Словообразование: ○ суффикс ;
- Способ обучения: производный, так как образован 1 (одним) способом .
См. также другие словари:
Ударение в слове заросший: на какой слог ударение и как… Слово «заросший» правильно пишется как… Ударение в слове заросшее
Морфемный разбор слова overgrown
Морфемным разбором слова обычно называют разбор слова по составу — это поиск и анализ морфем (частей слова), входящих в данное слово.
Морфемный анализ слова заросший делается очень просто. Для этого достаточно соблюдать все правила и порядок разбора.
Сделаем разбор морфем правильно, а для этого пройдем всего 5 шагов:
- определение части речи слова — первый шаг;
- второе — окончание выделяем: у словоизменяемых слов спрягаем или склоняем, у неизменяемых (гербов, наречий, некоторых существительных и прилагательных, служебных частей речи) — окончаний нет;
- Далее ищем базу. Это самая легкая часть, потому что для определения основы нужно просто отрезать окончание. Это будет основой слова;
- Следующим шагом является поиск корня слова. Подбираем родственные слова к переросшим (их еще называют однокоренными), тогда корень слова будет очевиден;
- Остальные морфемы находим, подбирая другие слова, образованные таким же образом.
Как видите, морфемный разбор делается просто. Теперь давайте определим основные морфемы слова и проанализируем его.
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по их месту в слове и установление значения каждой из них. Его еще называют в школьной программе. морфемный разбор . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, герундий, наречие, числительное.
План: Как разобрать слово по составу?
При проведении морфемного анализа соблюдайте определенную последовательность выделения знаменательных частей. Начните с того, чтобы «снять» морфемы с конца, методом «зачистки корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к разбору сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи оно относится. Вспомните признаки слов, принадлежащих к этой части речи:
- изменяемый (имеет окончание) или неизменяемый (не имеет окончания)
- имеет ли он формообразующий суффикс?
- Найдите концовку. Для этого склоняем по падежам, меняем число, род или лицо, спрягаем — переменная часть будет окончанием. Помните об изменении слов с нулевым окончанием, обязательно укажите, если они есть: сон (), друг (), слышимость (), благодарность (), съел ().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найдите корень в базе. Для этого сравните ряд родственных слов. Их общей частью является корень. Помните об однокоренных словах с чередующимися корнями.
- Если слово имеет два (и более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить анализ и выделить все значимые части значками
В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать слова с одним корнем и потом найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5–9 классах для общеобразовательных школ. У разных авторов подход к морфемному анализу по составу отличается. Чтобы избежать проблем при выполнении домашнего задания, сравните приведенный ниже порядок подведения итогов с вашим учебником.
Порядок полного морфемного анализа по составу
Во избежание ошибок желательно связать морфемный разбор с деривационным разбором. Такой анализ называется формально-семантическим.
- Установите часть речи и выполните графический морфемный анализ слова, то есть обозначьте все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы, образующие словоформу (если есть)
- Запишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пис-а-т → за-пис-а-т → за-пис-ыва-т», «сух (ой) → сух-ар () → сух-ар-ниц -(а)». Для слов со связными корнями подберите односоставные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспал»:
- окончание «а» указывает на форму глагола женского рода единственного числа прошедшего времени, ср.: проспал-и;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением потери, невыгоды, ср.: просчитаться, потерять, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Основы слов: сон, засыпание, сонливость, недосыпание, бессонница.
Разбор слова по составу один из видов лингвистического исследования, целью которого является определение структуры или состава слова, классификация морфем по их месту в слове и установление значения каждой из них. Его еще называют в школьной программе. морфемный разбор . Сайт-инструкция поможет правильно разобрать любую часть речи онлайн: существительное, прилагательное, глагол, местоимение, причастие, герундий, наречие, числительное.
План: Как разобрать слово по составу?
При проведении морфемного анализа соблюдайте определенную последовательность выделения знаменательных частей. Начните с того, чтобы «снять» морфемы с конца, методом «зачистки корня». Подходите к анализу осмысленно, избегайте бездумного деления. Определите значения морфем и выберите однокоренные слова, чтобы подтвердить правильность анализа.
- Напишите слово в той же форме, что и в домашнем задании. Прежде чем приступить к разбору сочинения, выясните его лексическое значение (значение).
- Определите из контекста, к какой части речи оно относится. Вспомните признаки слов, принадлежащих к этой части речи:
- изменяемый (имеет окончание) или неизменяемый (не имеет окончания)
- имеет ли он формообразующий суффикс?
- Найдите концовку. Для этого склоняем по падежам, меняем число, род или лицо, спрягаем — переменная часть будет окончанием. Помните об изменении слов с нулевым окончанием, обязательно укажите, если они есть: сон (), друг (), слышимость (), благодарность (), съел ().
- Выделить основу слова — это часть без окончания (и формообразующего суффикса).
- Обозначить префикс в базе (если есть). Для этого сравните однокоренные слова с префиксами и без них.
- Определите суффикс (если есть). Для проверки подберите слова с разными корнями и с одинаковым суффиксом, чтобы они выражали одинаковое значение.
- Найдите корень в базе. Для этого сравните ряд родственных слов. Их общей частью является корень. Помните об однокоренных словах с чередующимися корнями.
- Если слово имеет два (и более) корня, укажите соединительную гласную (если есть): листопад, звездолет, садовник, пешеход.
- Пометить формообразующие суффиксы и постфиксы (если есть)
- Перепроверить анализ и выделить все значимые части значками
В начальных классах разобрать слово — значит выделить окончание и основу, затем обозначить приставку суффиксом, подобрать слова с одним корнем и потом найти их общую часть: корень, и все.
* Примечание: Министерство образования Российской Федерации рекомендует три учебных комплекса по русскому языку в 5–9 классах для общеобразовательных школ. У разных авторов подход к морфемному анализу по составу отличается. Чтобы избежать проблем при выполнении домашнего задания, сравните приведенный ниже порядок подведения итогов с вашим учебником.
Порядок полного морфемного анализа по составу
Во избежание ошибок желательно связать морфемный разбор с деривационным разбором. Такой анализ называется формально-семантическим.
- Установите часть речи и выполните графический морфемный анализ слова, то есть обозначьте все имеющиеся морфемы.
- Выпишите окончание, определите его грамматическое значение. Укажите суффиксы, образующие словоформу (если есть)
- Запишите основу слова (без формообразующих морфем: окончания и формообразующие суффиксы)
- Найдите морфемы. Выпишите суффиксы и приставки, обоснуйте их выбор, объясните их значение
- Корень: свободный или связанный. Для слов со свободными корнями составьте словообразовательную цепочку: «пис-а-т → за-пис-а-т → за-пис-ыва-т», «сух (ой) → сух-ар () → сух-ар-ниц -(а)». Для слов со связными корнями подберите односоставные слова: «одеть-раздеть-переодеться».
- Запишите корень, подберите однокоренные слова, отметьте возможные варианты, чередование гласных или согласных в корнях.
Как найти морфему в слове?
Пример полного морфемного разбора глагола «проспал»:
- окончание «а» указывает на форму глагола женского рода единственного числа прошедшего времени, ср.: проспал-и;
- основание гандикапа «проспал»;
- два суффикса: «а» — суффикс основы глагола, «л» — этот суффикс, образует глаголы прошедшего времени,
- приставка «про» — действие со значением потери, невыгоды, ср.: просчитаться, потерять, упустить;
- словообразовательная цепочка: сон — проспал — проспал;
- корень «сп» — в родственных словах возможны чередования сп//сн//сон//сып. Основы слов: сон, засыпание, сонливость, недосыпание, бессонница.
Кафедра лингвистики | Ресурсы
Условные обозначения для подстрочного поморфемного толкования
pdf версия
О правилах
Лейпцигские правила глоссирования были разработаны совместно кафедрой
лингвистики Института эволюционной антропологии им. Макса Планка
(Бернард Комри, Мартин Хаспельмат) и кафедрой лингвистики
Лейпцигского университета (Бальтазар Бикель). Они состоят из десяти правил для
«синтаксиса» и «семантики» подстрочных толкований и приложения с предлагаемым
«лексиконом» сокращенных меток категорий. Правила охватывают большую часть
потребности лингвистов в глянцевании текстов, но большинство авторов сочтут необходимым добавить (или изменить) определенные соглашения (особенно метки категорий). Тем не менее, будет полезно иметь стандартный набор соглашений, на который могут ссылаться лингвисты, и
Лейпцигские правила предлагаются как таковые сообществу лингвистов. Правила
предназначены для отражения общего использования, и предлагается очень мало (в основном необязательных) нововведений
.
Мы намерены время от времени обновлять Лейпцигские правила глянцевания, поэтому отзывы
приветствую.
Лейпциг, последнее изменение: 31 мая 2015 г.
Дальнейшими обновлениями будет заниматься Комитет редакторов лингвистических журналов.
Важные ссылки:
Леманн, Кристиан. 1982. «Указания по подстрочным морфемным переводам».
Folia Linguistica 16: 199-224.
Крофт, Уильям. 2003. Типология и универсалии . 2-е изд. Кембридж: Cambridge
University Press, стр. xix-xxv.
Правила
(пересмотренная версия от февраля 2008 г.)
Преамбула
Подстрочные поморфемные глоссы дают информацию о
значениях и грамматических свойствах отдельных слов и частей
слов. Лингвисты в целом соблюдают определенные условные обозначения при глоссировании
, и основная цель этого документа — сделать явными наиболее широко используемые
соглашения.
В зависимости от целей автора и предполагаемого уровня
знаний читателей будут выбраны различные степени детализации. Таким образом, текущие правила
допускают некоторую гибкость в различных отношениях, и иногда упоминаются альтернативные варианты
.
Основной целью, которая предполагается здесь, является представление примера в исследовательской статье или книге
. Когда тегируется весь корпус, могут применяться несколько иные соображения
(например, может потребоваться добавить информацию о более крупных
единиц, таких как слова или фразы; правила здесь допускают только информацию
о морфемах).
Следует также отметить, что часто существует несколько способов анализа
морфологических паттернов языка. Соглашения о глоссировании не помогают
лингвистам выбирать между ними, а просто обеспечивают стандартные способы сокращения возможных описаний. Кроме того, глоссирование редко является полным морфологическим описанием, и следует иметь в виду, что его назначение —
. 0244 не для проведения анализа, а для предоставления дополнительной информации
о структуре текста или примера, помимо идиоматического перевода.
Замечание по трактовке глоссов в данных, цитируемых из других источников: глоссы
являются частью анализа, а не частью данных. При цитировании примера из опубликованного источника
толкование может быть изменено автором, если он предпочитает другую терминологию, другой стиль или другой анализ.
Правило 1: Пословное выравнивание
Подстрочные глоссы выравниваются по левому краю вертикально, слово за словом, с примером. Например.
(1) Индонезийский (Sneddon 1996:237)
- Мерека
- ди
- Джакарта
- секаранг.
- Они
- в
- Джакарта
- сейчас
«Сейчас они в Джакарте».
Топ
Правило 2: Поморфемное соответствие
Сегментируемые морфемы разделяются дефисами, как в примере, так и
в толковании. В примере
и в глянце должно быть ровно одинаковое количество дефисов. Например.
(2) лезгин (Haspelmath 1993:207)
- Гила
- абур-у-н
- ферма
- хамишалуй
- гунна
- амук’-да-ч.
- сейчас
- они-OBL-GEN
- ферма
- навсегда
- позади
- остаться-FUT-NEG
‘Теперь их ферма не останется навсегда.’
Поскольку дефисы и вертикальное выравнивание делают текст необычным, авторы
могут захотеть добавить в начало еще одну строку, содержащую неизмененный текст
, или прибегнуть к варианту, описанному в правиле 4 (и особенно 4C).
Границы клитики отмечены знаком равенства, как в объекте
язык и в глянце.
(3) Западно-Гренландский (Fortescue 1984:127)
- palasi=lu
- niuirtur=lu
- священник=и
- лавочник=и
‘и священник, и лавочник’
Правило 2А. (Необязательно)
Если морфологически связанные элементы составляют отдельные просодические или
фонологические слова, дефис и один пробел могут использоваться вместе в
объектный язык (но не в глянце).
(4) Хаха Лай
- a-nii-laay
- 3SG-смех-FUT
‘он/она будет смеяться’
Правило 3: Метки грамматических категорий
Грамматические морфемы обычно представляются сокращенными грамматическими
метками категорий, напечатанными прописными буквами (обычно прописными). Список из
стандартных аббревиатур (которые широко известны среди лингвистов) приведены в
конце этого документа.
Конечно, могут потребоваться отклонения от этих стандартных сокращений
в особых случаях, например. если категория очень часто встречается в языке, так что более короткое сокращение
более удобно, например. CPL (вместо COMPL) для
«полный», PF (вместо PRF) для «совершенный» и т. д. Если категория очень редкая,
может быть проще вообще не сокращать ее метку.
Во многих случаях допускается либо
метка категории, либо слово из метаязыка. Таким образом, оба
(5) Русский
- Мой
- с
- Марко
- поэкса-л-и
- автобус-ом
- в
- Переделкино.
- 1PL
- КОМ
- Марко
- го-ПСТ-ПЛ
- автобус-ИНС
- Все
- Переделкино.
- мы
- с
- Марко
- Go-PST-PL
- автобус-по от
- до
- Переделкино.
‘Мы с Марко поехали в Перделкино на автобусе’.
Правило 4. Соответствия «один ко многим»
Когда один элемент объектного языка воспроизводится несколькими элементами метаязыка
(словами или сокращениями), они разделяются точками. Например.
(6) Турецкий
- чик-мак
- выход-INF
‘выйти’
(7) Латинский
- полость рта
- остров-GEN.PL
«островов»
(8) Французский
- доп.
- шево
- по .АРТ.PL
- лошад.PL
‘к лошадям’
(9) немецкий
- безсер-н
- Ветер-н
- наш-DAT.PL
- отец.PL-DAT.PL
‘отцам нашим’
(10) хеттский (Lehmann 1982:211)
- н=ан
- апедани
- мехуни
- эссанду.
- СОЕДИНИТЕЛЬ=он
- т.дат.SG
- время.DAT.SG
- .есть.они.должны
‘Они будут чествовать его в этот день.’ (CONN = соединительный)
(11) Яминджунг (Шультце-Берндт 2000:92)
- нангаян
- гуны-би-ярлуга?
- кто
- 2DU. A.3SG.P-FUT-тычок
‘Кого вы двое хотите пронзить копьем?’
Порядок расположения двух элементов метаязыка может быть определен
различными принципами, которые нелегко обобщить, поэтому для этого не будет
какого-либо правила.
Существуют различные причины соответствия «один ко многим» между элементами объектного языка
и элементами глянца. Они объединены
единообразным использованием периода. Если кто-то хочет провести различие между ними, он может
следовать Правилам 4А-Е.
Топ
Правило 4А. (Необязательно)
Если элемент объектного языка не является ни формально, ни семантически сегментируемым, и только в метаязыке отсутствует однословный эквивалент, вместо точки может использоваться подчеркивание.
(12) Турецкий (ср. 6)
- чик-мак
- come_out-INF
‘выйти’
Правило 4В. (Необязательно)
Если элемент объектного языка формально не поддается сегментации, но имеет два четко различимых значения или грамматических свойства, можно использовать точку с запятой. Например.
(13) Латинский (ср. 7)
- полость рта
- остров-GEN;PL
«островов»
(14) Французский
- доп.
- шево
- по;ART;PL
- лошадь;PL
‘к лошадям’
Правило 4С. (Необязательно)
Если элемент объектного языка формально и семантически сегментирован, но автор не хочет показывать формальную сегментацию (потому что это не имеет значения и/или чтобы сохранить текст нетронутым), можно использовать двоеточие. Например.
(15) хеттский (Lehmann 1982:211) (ср. 10)
- н=ан
- апедани
- мехуни
- эссанду.
- СОЕДИНИТЕЛЬ=он
- что:DAT;SG
- время:DAT;SG
- есть:они:должны
‘Они будут чествовать его в этот день. ‘
Правило 4D. (Необязательно)
Если о грамматическом свойстве объектного языка сигнализирует
морфофонологическое изменение (аблаут, мутация, чередование тонов и т. д.), то
0244 обратная косая черта используется для разделения метки категории и остальной части глянца.
(16) немецкий (ср. 9)
- безсер-н
- Ветер-н
- наш-DAT.PL
- отец.PL-DAT.PL
‘отцам нашим’ (ср. единственное число Фатер)
(17) Ирландский
- бхрис-ис
- PST\перерыв-2SG
‘вы сломались’ (ср. nonpast bris-)
(18) Киньяруанда
- му-кора
- SBJV\1PL-рабочий
‘что мы работаем’ (ср. ориентировочное mù-kòrà)
Правило 4Е. (Необязательно)
Если в языке есть аффиксы числа лица, которые одновременно выражают агентоподобный и
пациентоподобный аргумент переходного глагола, то в толковании может использоваться символ «>», чтобы указать, что первый является агентоподобным. аргумент и
секунда — это терпеливый аргумент.
(19) Jaminjung (Schultze-Berndt 2000:92) (ср. 11)
- нангаян
- гуны-би-ярлуга?
- кто
- 2DU>3SG-FUT-тычок
‘Кого вы двое хотите пронзить копьем?’
Топ
Правило 5: Таблички с лицами и номерами
Лицо и число не разделяются точкой, если они расположены в этом порядке. Например.
(20) итальянский
- и-ямо
- go-PRS.1PL (не: go-PRS.1.PL)
‘мы идем’
Правило 5А. (Необязательно)
Маркеры чисел и рода очень часто встречаются в некоторых языках, особенно
в сочетании с лицом. Поэтому некоторые авторы используют сокращенные аббревиатуры
без заглавной буквы без точки. Если этот вариант принят, то в (21) используется глянец
секунды.
(21) Белхаре
- ne-e
- а-хим-чи
- н-юННа
- DEM-LOC
- т. дат.SG
- 3NSG-be.NPST
- DEM-LOC
- 1sPOSS-дом-PL
- 3нс-бе.НПСТ
‘Вот мои дома»
Правило 6: Неявные элементы
Если поморфемное толкование содержит элемент, который не соответствует
явному элементу в примере, он может быть заключен в квадратные скобки
. Очевидная альтернатива состоит в том, чтобы включить явный «Ø» в текст объектного языка
, который отделяется дефисом, как явный элемент.
(22) Латинский
- пуэр
- или:
- пуэр-Ø
- мальчик[NOM.SG]
- мальчик-НОМ.SG
- «мальчик»
- ‘мальчик’
Топ
Правило 7: Неотъемлемые категории
Неотъемлемые, неявные категории, такие как пол, могут быть указаны в толковании, но используется специальный граничный символ
, круглая скобка. Например.
(23) Хунзиб (ван ден Берг 1995:46)
- унция#-ди-г
- xxe
- м-ук’э-р
- мальчик-ОБЛ-АД
- дерево(G4)
- G4-изгиб-PRET
‘Из-за мальчика дерево согнулось’. (G4 = 4-й род, AD = адессив, PRET = претерит)
Правило 8: Двудольные элементы
Грамматические или лексические элементы, состоящие из двух частей, которые рассматриваются как
различных морфологических объекта (например, двудольные основы, такие как Lakhota na-xʔu̧ ‘слышать’) можно рассматривать двумя разными способами:
(i) Глянец может быть просто повторен:
(24) Лахота
- на-вичха-ва-ксʔу̧
- услышать-3PL.UND-1SG. ACT-слушать
«Я слышу их» (UND = претерпевший, ACT = актер)
(i) Глянец может быть просто повторен:
(25) Лахота
- на-вичха-ва-ксʔу̧
- услышать-3PL.UND-1SG.ACT-STEM
«Я слышу их»
Циркумфиксы являются «двудольными аффиксами» и могут обрабатываться таким же образом, например.
(26) Немецкий
- гэ-сэх-ан
- или:
- ge-seh-en
- PTCP-см. PTCP
- PTCP-см.-CIRC
- «увидел»
- «увидел»
Правило 9: Инфиксы
Инфиксы заключены в угловые скобки, как и аналог объектного языка
в толковании.
(27) Тагальский
- б<ум>или (основа: били)
-
купить
«купить»
(28) Латинский
- reli
qu-ere (ствол: reliqu-)
- оставить
-INF
‘уйти’
Инфиксы, как правило, легко идентифицировать как лево-периферические (как в 27) или как право-периферийные (как в 28), и это определяет положение глянца
, соответствующего инфиксу, по отношению к глянцу основы. Если инфикс
не является явно периферийным, какое-то другое основание для линеаризации глянца должно быть
найдено.
Топ
Правило 10: Дублирование
Редупликация обрабатывается аналогично аффиксации, но с тильдой (вместо обычного дефиса
), соединяющей копируемый элемент с основой.
(29) Иврит
- ерак~рак-им
- зеленый~ATT-M.PL
‘зеленоватые’ (АТТ= ослабление)
(30) Тагальский
- би~били
- ИПФВ~купить
‘покупает’
(31) Тагальский
- б<ум>и~били
-
IPFV~купить
«покупает» (ACTFOC = фокус на актера)
Приложение: Список стандартных сокращений
| 1 | от первого лица |
| 2 | второе лицо |
| 3 | третье лицо |
| А | агентоподобный аргумент канонического переходного глагола |
| АБЛ | аблатив |
| АБС | абсолютный |
| АКК | винительный падеж |
| АДЖ | прилагательное |
| АДВ | наречие (иал) |
| СМА | соглашение |
| ВСЕ | общий |
| АНТИП | антипассивный |
| ПРИЛОЖЕНИЕ | прикладной |
| АРТ | артикул |
| ДОПОЛНИТЕЛЬНЫЙ | вспомогательный |
| БЕН | благотворительный |
| КАУС | возбудитель |
| CLF | классификатор |
| СОМ | комбинированный |
| КОМП | дополняющее устройство |
| КОМПЛЕКТ | полный |
| СОСТОЯНИЕ | условно |
| КС | связка |
| КВБ | глагол |
| ДАТ | дательный |
| ДЕКЛ | декларативный |
| ДЭФ | определенный |
| ДЕМ | демонстративный |
| ДЭТ | определитель |
| РАССТОЯНИЕ | дистальный |
| РАЙОН | дистрибутив |
| ДУ | двойной |
| ПРОДОЛЖИТЕЛЬНОСТЬ | прочный |
| ЭРГ | эргативный |
| ИСКЛ | эксклюзивный |
| Ф | женский |
| ВОК | фокус |
| ФУТ | будущее |
| ГЕН | родительный падеж |
| ИМП | императив |
| ВКЛ. | включительно |
| ИНД | ориентировочно |
| Индивидуальный номер | неопределенный |
| ИНФ | инфинитив |
| ИНС | инструментальный |
| ИНТР | непереходный |
| ИПФВ | несовершенный |
| IRR | ирреалис |
| LOC | местный |
| М | мужской род |
| Н | средний |
| Н- | не- (например, NSG не в единственном числе, NPST не в прошлом) |
| НЕГ | отрицание, отрицательное |
| НМЛЗ | номинализатор/номинализация |
| НОМ | именительный |
| ОБЖ | объект |
| ОБЛ | косой |
| Р | терпеливый аргумент канонического переходного глагола |
| ПРОПУСК | пассивный |
| ПФВ | совершенный |
| PL | во множественном числе |
| ПОС | притяжательный |
| ПРЕД | предикатив |
| ПРФ | идеальный |
| ПС | подарок |
| ПРОГ | прогрессивный |
| ПРОХ | запретительный |
| ПРОКС | ближний/ближний |
| PST | прошлое |
| ПТСР | причастие |
| ПУРП | целенаправленный |
| В | частица вопроса/маркер |
| КОЛИЧЕСТВО | кавычка |
| РЭЦП | взаимный |
| REFL | рефлекторный |
| РЕЛ | относительный |
| РЭС | результирующий |
| С | одиночный аргумент канонического непереходного глагола |
| СБЖ | тема |
| СБЖВ | сослагательное наклонение |
| СГ | единственное число |
| ВЕРХ | тема |
| ТУ | переходный |
| ЛОС | звательный |
Топ
Ссылки
Фортескью, Майкл.